Mustafa Suleiman
-
المساهمات
20346 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
494
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
لا مشكلة في البيانات الاصطناعية كبداية، ويجب أن تكون منطقية تشبه البيانات التي تتوقع جمعها مستقبلاً قدر الإمكان، وبالطبع للتجربة ولن تعتمد على أرقام الدقة لاتخاذ قرارات نهائية، لأنك بنيت البيانات على افتراضاتك الخاصة، فالهدف منها هو فقط بناء النظام، وعندما تجمع بيانات حقيقية كافية، ستقوم بإعادة تدريب النموذج عليها. عامًة الـ Synthetic Data مفيدة لأنها تسمح ببناء وتجربة pipeline كامل للتعلم الآلي، من معالجة البيانات، إلى التدريب، إلى التكامل مع التطبيق، أيضًا تكتشف المشاكل التقنية في وقت مبكر. أول خطوة هي تحديد الـ features بالتفكير في العوامل التي تؤثر على المسافة التي يقطعها المستخدم، وهي: معلومات المستخدم: العمر، نوع الوظيفة (مندوب مبيعات، موظف مكتبي، يعمل من المنزل)، هل لديه عائلة. معلومات السيارة: سنة الصنع، نوع السيارة (صغيرة، SUV)، كفاءة الوقود. معلومات زمنية: يوم الأسبوع (1-7)، هل هو عطلة نهاية أسبوع (نعم/لا)، الشهر. معلومات سلوكية إن أمكن: مثل متوسط المسافة في الأسابيع السابقة، وتلك ميزة لها ثقل. ثم إنشاء صيغة وهمية لحساب المسافة، ولا يجب أن تكون مثالية، بل فقط لإنشاء بيانات ذات هيكل، ولتكن: distance = base_distance + job_effect + weekend_effect + previous_dist_effect + noise حيث base_distance هي مسافة أساسية يومية، مثلاً 20 كم، وjob_effect تعني تأثير نوع الوظيف، فمندوب مبيعات سيقطع 50كم أو يزيد، وموظف مكتبي +15 كم، يعمل من المنزل -10 كم. والـ weekend_effect خاص بالعطلة، حيث ستزيد المسافة للرحلات أو تقل لعدم الذهاب للعمل -15 كم. والـ noise خاصة بإضافة قيمة عشوائية صغيرة لتبدو البيانات واقعية أكثر. ثم توظيف ما سبق في الكود كالتالي: import pandas as pd import numpy as np num_samples = 5000 job_types = ['sales', 'office', 'remote', 'student'] data = { 'age': np.random.randint(18, 65, num_samples), 'car_model_year': np.random.randint(2010, 2024, num_samples), 'job_type': np.random.choice(job_types, num_samples), 'is_weekend': np.random.choice([0, 1], num_samples, p=[0.71, 0.29]), 'previous_week_distance': np.random.normal(loc=150, scale=50, size=num_samples) } df = pd.DataFrame(data) def calculate_distance(row): base_distance = 20 if row['job_type'] == 'sales': job_effect = 40 elif row['job_type'] == 'office': job_effect = 15 else: job_effect = -10 weekend_effect = -15 if not row['is_weekend'] else 5 previous_dist_effect = row['previous_week_distance'] * 0.5 noise = np.random.normal(0, 10) distance = base_distance + job_effect + weekend_effect + previous_dist_effect + noise return max(0, distance) df['weekly_distance'] = df.apply(calculate_distance, axis=1) print(df.head()) df.to_csv('synthetic_car_data.csv', index=False) وبخصوص: الخوارزمية لا بأس بها كنقطة بداية، لكونها سهلة الفهم والتنفيذ، والتدريب من خلال لا يتطلب موارد كبيرة، وبسهولة تستطيع معرفة كيف تؤثر كل ميزة مثل العمر على التنبؤ. بالتالي سرعة في التأكد من أن كل شيء يعمل من تدفق البيانات إلى التكامل قبل الانتقال إلى نماذج معقدة أكثر. وبالطبع على المدى الطويل ستحتاج إلى خوارزميات أفضل، فسلوك القيادة في الواقع أكثر تعقيدًا من علاقة خطية بسيطة، لوجود تفاعلات بين الميزات وعلاقات غير خطية. فتأثير العمر ربما لا يكون خطيًا، فقد يقود الشباب وكبار السن لمسافات أقل من الأشخاص في منتصف العمر، ومندوب المبيعات في عطلة نهاية الأسبوع ربما يقود مسافة مختلفة تمامًا عن مندوب المبيعات خلال أيام العمل. لذا ستحتاج إلى LightGBM أو XGBoost أو Random Forest، وذلك عند توفر بيانات عدة آلاف من المستخدمين على مدى بضعة أشهر، ثم قارن النتائج. لكن لو التنبؤ يعتمد بشكل كبير على تسلسل المسافات السابقة، أي التنبؤ بمسافة الأسبوع الحالي بناءًا على آخر 10 أسابيع، فستحتاج إلى LSTM. من خلال TensorFlow Lite، وهناك طريقتين الأولى لو استخدمت scikit-learn، ستحتاج إلى أداة لتحويله إلى صيغة متوافقة مثل ONNX ثم إلى TFLite أو إعادة تدريب النموذج باستخدام TensorFlow أو Keras وهو الأسهل. ثم أنشئ مجلد assets في مجلد app/src/main/ في مشروع أندرويد ستوديو، وانسخ ملف model.tflite إلى المجلد، وفي ملف build.gradle (Module: app)، أضف مكتبة TensorFlow Lite. وستحتاج إلى تحميل النموذج من مجلد assets واستخدام Interpreter لتشغيله، من خلال كتابة كود Java أو Kotlin
- 1 جواب
-
- 1
-

-
تعلم أي لغة برمجة يجعل من عملية تعلم أي لغة برمجة أخرى أسهل بمراحل، فدائمًا اللغة البرمجية الأولى هي الأصعب، لكن هناك فارق كبير بين لغة جافاسكريبت ولغة C++، فالأولى لغة عالية المستوى وبها الكثير من التجريد أي أمور مخفية عنك تحدث في الخلفية وأنت تستخدم دوال جاهزة، بينما C++ لغة متوسطة المستوى، وبإختصار هناك الكثير من الأمور التي ستقوم بها بشكل يدوي. وستجد تفصيل هنا: لغة C++ ليست موجهة للجميع، أي يُصعب استيعابها إلا من قبل فئة قليلة، لذا في دورة علوم الحاسوب تم إعتماد بايثون وجافاسكريبت للشرح، يوجد مقالات ودروس حولها هنا بالأكاديمية ستجدها هنا: دروس C++ عدا ذلك ستحتاج إلى الدراسة من على اليوتيوب أو دورات مدفوعة من مصدر آخر.
-
السؤال غير واضح، هل ذلك خاص بأحد الدروس؟ أرجو وضع السؤال أسفله إذن لمساعدتك بشكل أفضل، في حال سؤال عام فهو بحاجة إلى توضيح، أعتقد أنك تتساءل عن تجاوبية الصفحة، ستحتاج إلى معالجة ذلك عن طريق media query، ستجد تفصيل هنا:
-
ذلك أحد العناصر التي نستخدمها بداخل عنصر النموذج في HTML وهو form، فكما تعلم النموذج يتكون من حقول، ولإنشاء الحقول نستخدم عنصر input. ويوجد أنواع من عنصر input نفسه، أي حقل للنصوص، حقل لكلمة المرور، حقل للبحث، حقل للبريد وهكذا، ويتم تحديد ذلك عن طريق سمة type التي نكتبها بداخل عنصر input، وتلك هي الأنواع: <input type="button"> <input type="checkbox"> <input type="color"> <input type="date"> <input type="datetime-local"> <input type="email"> <input type="file"> <input type="hidden"> <input type="image"> <input type="month"> <input type="number"> <input type="password"> <input type="radio"> <input type="range"> <input type="reset"> <input type="search"> <input type="submit"> <input type="tel"> <input type="text"> <input type="time"> <input type="url"> <input type="week"> حيث type="password" لإنشاء حقل كلمة مرور ويُظهر النص كنقاط أو نجوم. و type="email" لإنشاء حقل بريد إلكتروني حيث يتحقق المتصفح من وجود علامة @ و type="number" هو لإنشاء حقل أرقام فقط، أي لا يقبل حروف. بينما سمة id و name ستجد تفصيل لهم هنا:
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
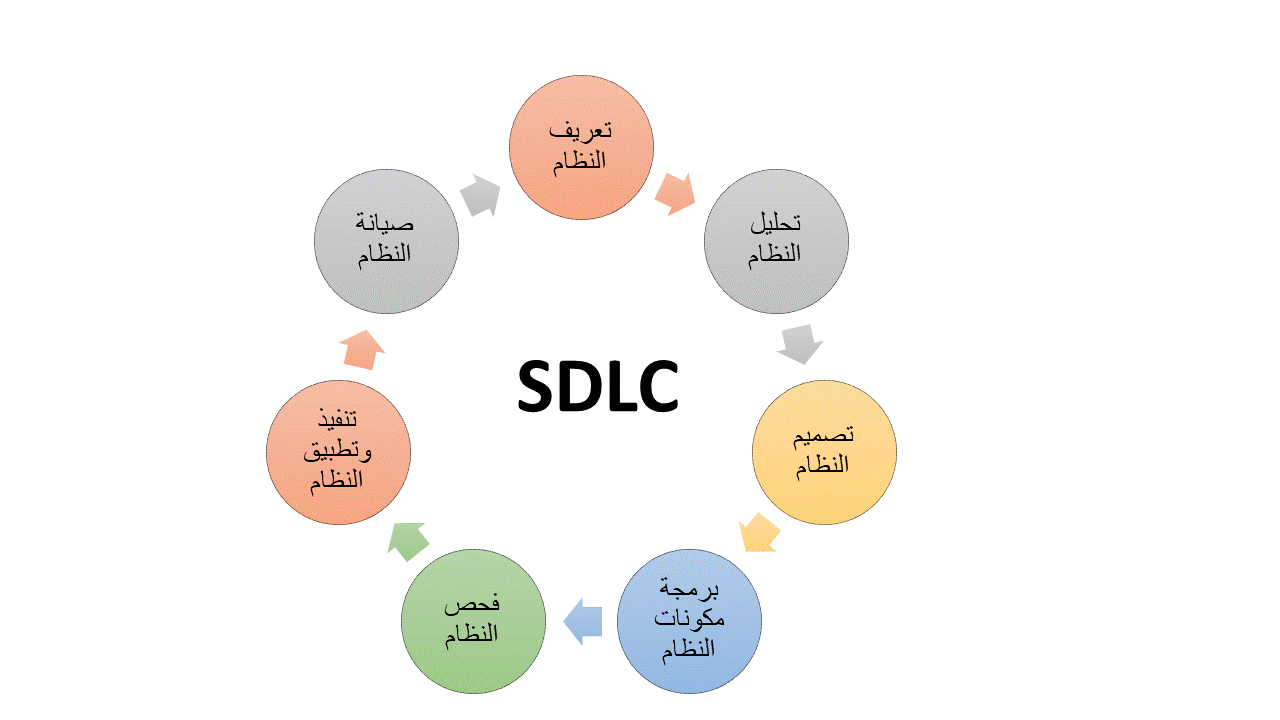
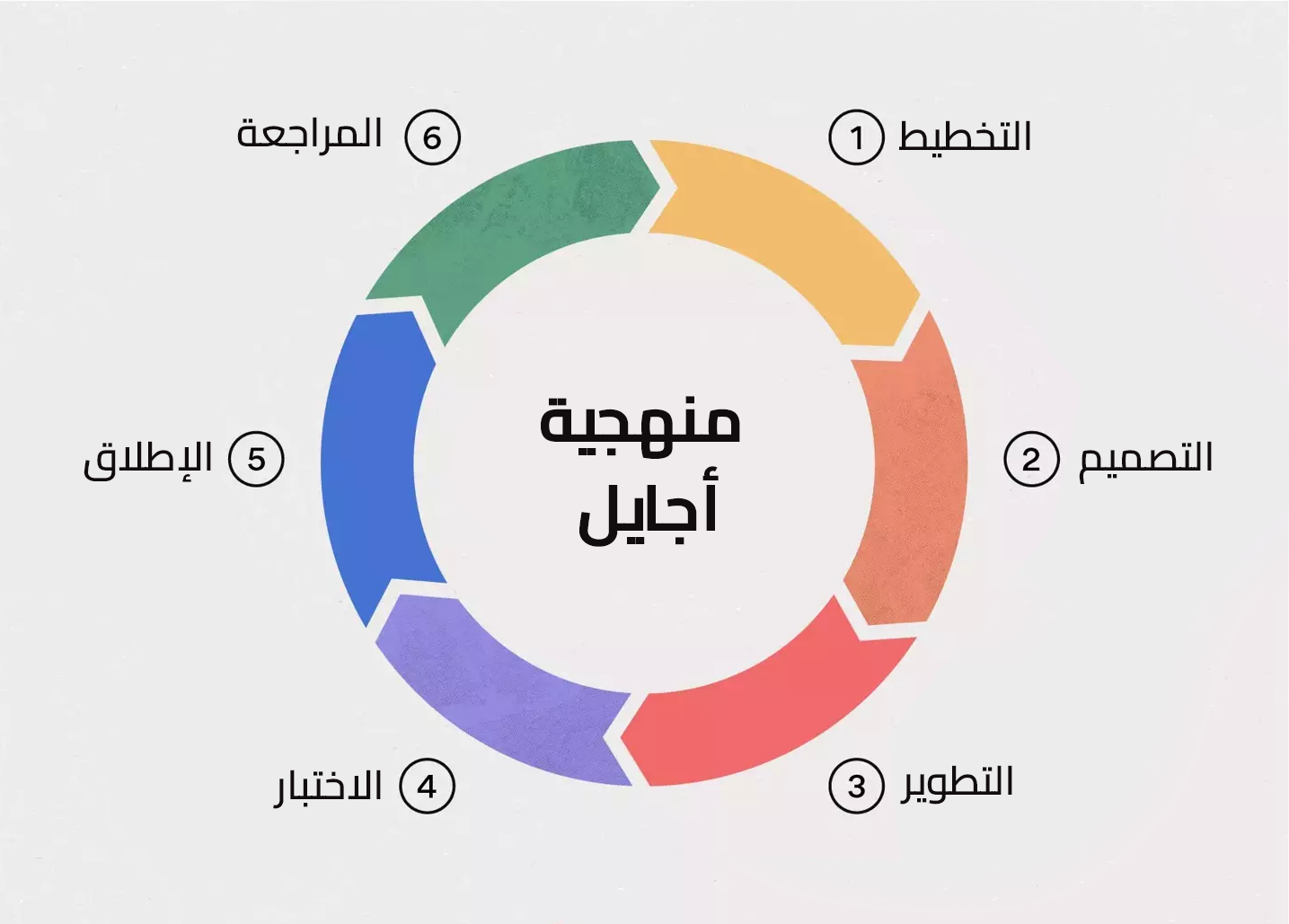
 لن تحتاجها في بداية مسيرتك، أي لو هدفك هو أن تصبح مُبرمج والعمل على تنفيذ مشاريع برمجية، فمحتواها ليس موجه لك، ما تحتاجه فعلاً هو تعلم مفهوم دورة حياة تطوير البرمجيات SDLC، وذلك متاح في دورة علوم الحاسوب، لذا هي الأنسب لك. وفيما بعد تستطيع، عند اكتساب سنوات خبرة وتريد تعلم الجانب الإداري لمجال البرمجة، فستحتاج إلى تعلم منهجيات تطوير البرمجيات ومنها الـ Agile: وسيتم دراسة ذلك في دورة إدارة تطوير المنتجات، بجانب مفاهيم أخرى. وهي مناسبة أيضًا في حال تريد العمل في التخصص الإدارة لمجال البرمجة، تحت مسمى وظيفي Product Manager، أو في حال أنك صاحب مشروع برمجي وتريد الإشراف عليه وإدارة فريق العمل بطريقة صحيحة.
لن تحتاجها في بداية مسيرتك، أي لو هدفك هو أن تصبح مُبرمج والعمل على تنفيذ مشاريع برمجية، فمحتواها ليس موجه لك، ما تحتاجه فعلاً هو تعلم مفهوم دورة حياة تطوير البرمجيات SDLC، وذلك متاح في دورة علوم الحاسوب، لذا هي الأنسب لك. وفيما بعد تستطيع، عند اكتساب سنوات خبرة وتريد تعلم الجانب الإداري لمجال البرمجة، فستحتاج إلى تعلم منهجيات تطوير البرمجيات ومنها الـ Agile: وسيتم دراسة ذلك في دورة إدارة تطوير المنتجات، بجانب مفاهيم أخرى. وهي مناسبة أيضًا في حال تريد العمل في التخصص الإدارة لمجال البرمجة، تحت مسمى وظيفي Product Manager، أو في حال أنك صاحب مشروع برمجي وتريد الإشراف عليه وإدارة فريق العمل بطريقة صحيحة.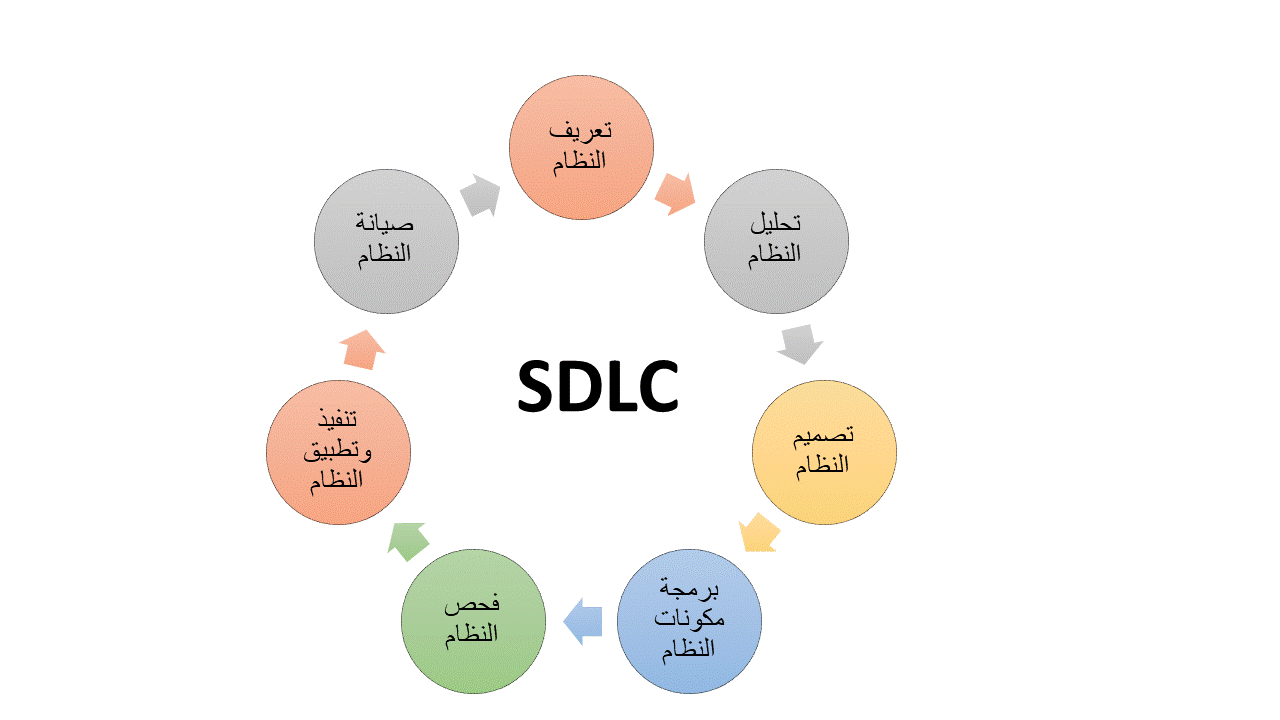
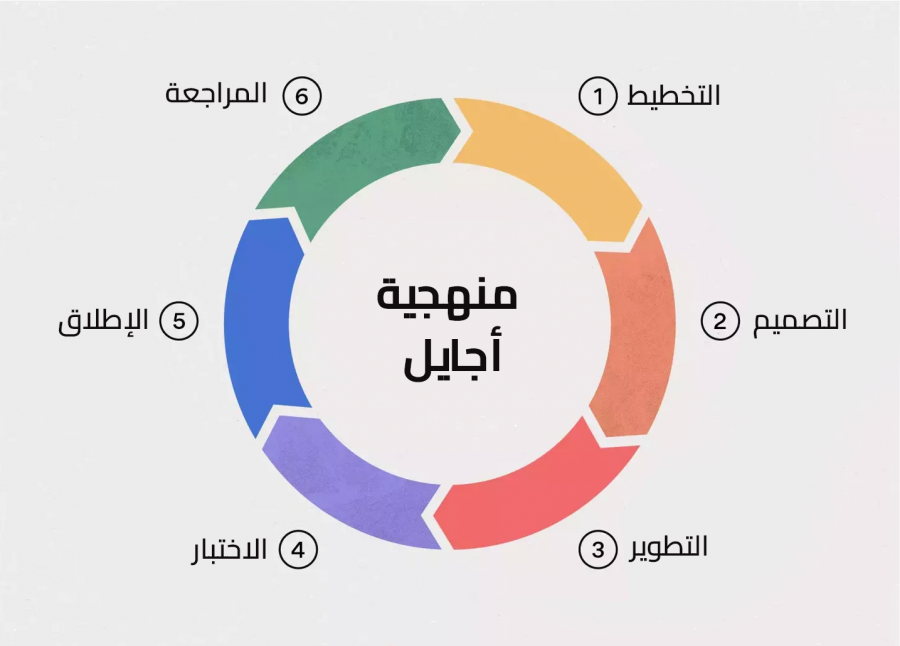
-
قبل أي نصيحة، يجب وجود هدف من دراسة الدورة، وبدونه ستفشل في الإلتزام بالدراسة، مجال البرمجة ليس بالسهل ويحتاج إلى مجهود وصبر واستمرارية، حدد هدف وذكر نفسك به دائمًا وعواقب عدم تحقيقه. بعدها ضع خطة لدراسة الدورة خلال فترة زمنية محددة وواقعية بالنسبة لظروفك، عامًة دورة متخصصة في البرمجة مثل بايثون أو جافاسكريبت، يُفترض ألا تقل المدة عن 3 أشهر، بجانب 3 أشهر أخرى للتعمق وتطوير مستواك. ثم الإلتزام بالدراسة بشكل شبه يومي، وتجنب بتاتًا الإنقطاع لفترة تزيد عن 3 أيام، فهناك مفهوم يسمى منحنى النسيان، وبمرور الوقت ستنسى المعلومات التي درستها وستضطر إلى البدء من جديد، الاستمرارية في البداية هامة جدًا لتثبيت ما تعلمته. وأثناء الدراسة عليك بتخصيص نسبة أكبر للجانب العملي وليس الدراسة بشكل نظري أو المشاهدة فقط، البرمجة أساسها الممارسة العملية. ستجد هنا تفصيل بخصوص باقي النقاط:
-
لا يوجد حل تقني 100% يمنع مطور محترف من الاحتفاظ بنسخة إذا أراد ذلك، الأمر يعتمد على مزيج بين الثقة وإتخاذ الإجراءات اللازمة، بمعنى لو أراد المطور سرقة الكود أو تنفيذ شيء خبيث فهو يستطيع ذلك، لذا ابحث عن مطور أمين وذو تقييمات جيدة من عملاء سابقين في حال ستعتمد على منصات العمل الحر. ولا تتعامل مع مطور يعرض أسعار رخيصة جدًا مقارنة بالسوق، أو رفض توقيع NDA أو طلب دفعة كبيرة كمقدم للعمل، أو يتواصل بشكل غير احترافي. في حال لست واثق، قم بتجزئة المشروع إلى مراحل، وأسند إليه مرحلة أو اثنان لتقييمه. وللعلم عقد NDA، صعب الإلتزام به عند العمل عن بُعد، لكونك تتعامل مع أفراد، خاصًة لو في بلد آخر غير بلدك، بينما لو في بلدك فالأمر مُلزم له خاصًة لو هناك قانون رادع، وبالنسبة للتعامل مع الشركات فالأمر مختلف بالطبع هناك إلتزام بالعقود.
-
1- في مرحلة التخطيط في البداية، لا تحاول أن تجعل البوت يفعل كل شيء، بل ابدأ بحالات استخدام محددة وذات قيمة عالية، كالإجابة على الأسئلة الشائعة، تتبع الطلبات، أو حجز المواعيد. كلما كان النطاق أضيق في البداية، كان من الأسهل الوصول للهدف المطلوب، وعليك استكشاف من هم عملاؤك، وما هي اللغة التي يستخدمونها رسمية أم عامية)؟ وما هي أكثر المشاكل التي يواجهونها؟ فما سبق يساهم في تصميم شخصية البوت ونبرة الحوار. ثم ارسم خرائط تدفق للمحادثات المحتملة، أي ماذا سيحدث لو سأل المستخدم عن شيء؟ ماذا لو لم يفهم البوت؟ كيف ينتقل الحوار من نقطة إلى أخرى؟ حيث يجب أن يكون الحوار طبيعي وموجه نحو حل مشكلة المستخدم بأسرع وقت. 2- ثم تنتقل إلى مرحلة إعداد البيانات، استخدم هنا سجلات المحادثات الحقيقية مع خدمة العملاء، قوائم الأسئلة الشائعة، ورسائل البريد الإلكتروني، وكلما كانت بيانات التدريب أكثر واقعية وتنوع، كان أداء البوت أفضل. بالنسبة للأسئلة المتكررة، لا تعتمد فقط على النموذج لفهمها، بل قم ببناء قاعدة بيانات منظمة FAQs يمكن للبوت البحث فيها للعثور على إجابات دقيقة ومحدثة. والعمل على تحديد النوايا Intents، وهي هدف المستخدم، بمعنى إنشاء دوال تختص بـ check_order_status أو ask_about_shipping_cost والتي يتم تحديدها بناءًا على تحليل جملة المستخدم. وأيضًا تحديد الكيانات Entities، وهي المعلومات المهمة داخل جملة المستخدم، ففي جملة ما هي حالة الطلب رقم 12345؟، النية هنا هي check_order_status والكيان هو order_number وقيمته 12345. فالتصميم الجيد للنوايا والكيانات هو أساس استيعاب البوت لطلب المستخدم. 3- بناء منطق الحوار، والذي هو عقل البوت الذي يقرر ماذا سيقول ومتى، فبناءًا على النية والكيانات التي تم استخلاصها، يتم بتنفيذ الإجراء المناسب، فلو النية هي check_order_status وكان كيان order_number موجود، فمنطق الحوار يستدعي الـ API الخاص بتتبع الطلبات، ولو الكيان مفقود، فسيقوم البوت بالرد "بالتأكيد يمكنني المساعدة ما هو رقم طلبك؟" وتوفير خيارات بديلة في حال لم يستوعب النموذج السؤال، أو اطلب إعادة صياغة للسؤال، والتعامل مع الإنقطاعات سواء طرح المستخدم استفسار آخر بينما يجيب البوت على سؤال سابق، أو قام المستخدم بتغيير الموضوع فجأة، أو قام بتصحيح خطأ للبوت. أيضًا قوة البوت الحقيقية تكمن في قدرته على تنفيذ مهام فعلية، وذلك يتطلب ربطه بالأنظمة الأخرى: نظام إدارة علاقات العملاء CRM لسحب بيانات العميل أو تسجيل المحادثة. قواعد البيانات للبحث عن المنتجات أو التحقق من المخزون. APIs للتكامل مع خدمات الشحن، بوابات الدفع، أو أنظمة حجز المواعيد. 4- مطور الـ API يجب أن يعمل على آلية التسليم لموظف خدمة العملاء، عندما يطلب المستخدم ذلك، أو عندما يفشل البوت في حل المشكلة، والأهم هو نقل سياق المحادثة بالكامل حتى لا يضطر العميل لتكرار نفسه. الأفضل البدء بنموذج مدرب مسبقًا مثل GPT أو BERT العربي، ثم الضبط الدقيق على البيانات التي لديك، مع تنفيذ نظام تحديث دوري شهري أو ربع سنوي، وراقب الأداء باستمرار عبر مؤشرات منها معدل الدقة في تصنيف النوايا، رضا العملاء ومعدل التحويل لموظف خدمة العملاء.
- 1 جواب
-
- 1
-

-
لا أنصحك بالإعتماد على التدوين الورقي، فلن تستطيع العثور على المعلومات بسهولة عند تدوين الكثير من الملاحظات، اعتمد على أدوات رقمية مثل Notion أو google tasks. بالنسبة للدروس النظرية لا تقم بتدوين كل شيء، النقاط الهامة فقط والتي تظن أنك بحاجة إلى تدوينها، فقم بذلك واكتب الأمر بنفسك بشكل مختصر وواضح في نفس الوقت أي ليس مبهم لكي تتمكن من استيعابه فيما بعد. أما الدروس العملية بمعنى الأكواد، فلا حاجة إلى تدوين أي شيء هنا، فقط استخدم التعليقات على الأكواد أثناء كتابتك للكود، لتوضيح الأمر لك عند العودة والمراجعة أو تريد تذكر شيء ما وكيف قمت به. وفي حال هناك أمر يحتاج إلى خطوات كثيرة وثابتة، ابحث عن مقال يشرحه ثم قم بحفظ رابط ذلك المقال باستخدام الأدوات السابق ذكرها، وفي حال لم تجد قم بإنشاء شرح لنفسك، لتسهيل الأمر على نفسك عند الحاجة إلي تنفيذه مرة أخرى في مشروع مختلف. وعامًة البرمجة تعتمد على الممارسة العملية بشكل كبير، أي ركز على التعلم من خلال كتابة الأكواد وتنفيذ المشاريع وليس التركيز على التدوين بنسبة أكبر. ومع الوقت وأثناء التعلم ستتحسن مهاراتك في التدوين وستقوم بتدوين الأمور الهامة فعلاً، لذا لا تشغل بالك كثيرًا في البداية، الأمر يتضح بمرور الوقت.
- 3 اجابة
-
- 1
-
-
ملف app.py غير موجود، قم بإعادة فتحه في vscode والتجربة مرة أخرى، لاحظ علامة الشطب على اسم الملف
-
هل قمت بتثبيت إضافة python؟ https://marketplace.visualstudio.com/items?itemName=ms-python.python بعد تثبيتها قم بالتجربة مرة أخرى بالضغط على زر التشغيل أعلى اليسار <، لو استمرت المشكلة اضغط على السهم الذي بجانب أيقونة التشغيل واختر run python file in dedicated terminal
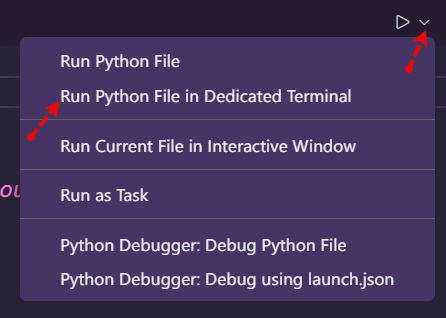
-
الأمر غير مرتبط، إلا في حال أنك تقوم بتقديم خدمات متعلقة بالذكاء الاصطناعي، فبدراسة الدورة ستتعلم المهارات اللازمة لتصبح مطور ذكاء اصطناعي محترف، والأمر سينعكس على مستوى الجودة التي توفرها من خلال خدماتك وبالتالي زيادة الطلب على خدماتك. لكن إنهاء الدورة لمجرد إنهائها لن يعود عليك بالنفع، يجب التأني في دراستها والتعمق قليلاً في المفاهيم والتطبيق بشكل عملي وعدم الإكتفاء بما يتم شرحه فقط.
- 2 اجابة
-
- 1
-
-
بالطبع لا، ما يتم رفعه على GitHub هو الكود المصدري ليس أكثر، أي الكود الذي يتم رفعه هو المنطق الخاص باستخدام أو تدريب النموذج والذي يتم استخدامه لتحديث بيانات النموذج أو استخدامه. الصحيح هو تصدير هيكل قاعدة البيانات فقط، أي تصدير هيكل الجداول فقط بدون البيانات من خلال ملف باسم schema.sql يحتوي على أوامر CREATE TABLE التي تنشئ الجداول والعلاقات بينها، وهو آمن للمشاركة وصغير الحجم. ولو أردت تسهيل الأمر أكثر، قم بإنشاء بيانات وهمية من خلال إنشاء ملف SQL آخر seeds.sql مثلاً يحتوي على بعض البيانات الوهمية غير الحساسة وهي منتج تجريبي ومستخدم تجريبي واحد، حتى يتمكن الشخص من رؤية الموقع يعمل ببيانات مبدئية. ولكن بما أنّ قاعدة البيانات غير حساسة أو مهمة، تستطيع تصديرها ورفعها بالكامل. بالنسبة للطريقة، افتح phpMyAdmin واذهب إلى تبويب Export ثم اختر طريقة التصدير Custom - display all possible options واختر صيغة التصدير SQL. ثم في قسم Format-specific options ستجد قائمة منسدلة بجانب الجداول، فقم بتغيير الخيار من Structure and data هيكل وبيانات إلى Structure only هيكل فقط، وانزل إلى أسفل الصفحة واضغط على زر Export وسيقوم المتصفح بتحميل ملف بامتداد.sql فقم بإعادة تسميته إلى schema.sql
- 5 اجابة
-
- 1
-
-
مفهوم Bias value أساسي وموجود في العديد من نماذج تعلم الآلة، وجزء لا يتجزأ من معظم النماذج الخطيةوغيرها ومنهاالإنحدار الخطي وللوجستي وآلات المتجهات الداعمة SVM، وبأبسط شكل ممكن هو عبارة عن معادلة الخط المستقيم التي درستها في المدرسة: y = mx + b حيث m هو الميل Slope الذي يحدد مدى انحدار الخط، وفي تعلم الآلة ذلك يمثل الوزن، و b هو القاطع الذي يحدد النقطة التي يقطع فيها الخط المحور الرأسي، وذلك هو الـ Bias، أي وظيفته تحريك الخط بأكمله للأعلى أو للأسفل دون تغيير ميله. بالتالي يمنح النموذج مرونة أكبر وبدونه، سيكون أي خط أو أي دالة قرار مجبرة على المرور بنقطة الأصل (0,0)، الأمر الذي يحد بشدة من قدرة النموذج على تمثيل البيانات الحقيقية. وللعلم بعض نماذج تعلم الآلة لا تحتوي على Bias بنفس المفهوم الحسابي، فنماذج الشجرة كأشجار القرار والغابات العشوائية تعمل عن طريق تقسيم البيانات بناءًا على شروط، مثل هل العمر أكبر من 30؟، ولا تستخدم معادلة خطية بداخلها، وبالتالي لا يوجد بها مفهوم Bias. وأيضًا خوارزمية أقرب جار KNN تعتمد على المسافة بين النقاط، وهي خوارزمية غير بارامترية ولا تتعلم أوزان أو تحيز.
- 3 اجابة
-
- 1
-
-
ليس بتلك البساطة، هي مزعجة في البداية، فتعريف الأنواع Types تحتاج إلى كتابة كود إضافي لتحديد نوع كل متغير، وكل معامل في الدالة، وما ستعيده الدالة، وذلك يبطئ عملية الكتابة. وخطوة التحويل، بحيث لا يمكنك تشغيل كود تايب سكريبت مباشرة في المتصفح بل يجب أولاً تحويله إلى جافا سكريبت، وتلك خطوة إضافية في عملية التطوير، أيضًا تمنعك تايب سكريبت من تنفيذ منطق الكود بمرونة في جافا سكريبت. لكن فور الإعتياد عليها ورؤية المشاكل والصعوبات التي تجنبك إياها، فلن تعود لكتابة كود جافاسكريبت عادي، وهناك أسباب لإعتماد الشركات على تايب سكريبت في المشاريع في الواقع العملي وليس جافاسكريبت، أي للعمل كمطور جافاسكريبت يجب تعلم تايب سكريبت لا محالة. بالطبع في المشاريع البسيطة لا حاجة إلى استخدام تايب سكريبت، فذلك تعقيد لا داعي له، وأيضًا عند تعلم الأساسيات للغة جافاسكريبت والتعمق بها، تجنب تشتيت نفسك بلغة تايب سكريبت، تعلمها في النهاية كتحسين لمهاراتك. أي الشعور بالإزعاج هو في الحقيقة الثمن الذي تدفعه مقابل الحصول على مميزات قوية جدًا على المدى الطويل، ومنها اكتشاف الأخطاء مبكرًا، فمعظم الأخطاء التي تكتشفها في جافا سكريبت أثناء تشغيل التطبيق مثل undefined is not a function، تكتشفها تايب سكريبت وأنت تكتب الكود في المحرر، الأمر الذي يوفر ساعات طويلة من تصحيح الأخطاء. وسهولة تنفيذ الـ Refactoring، بحيث لو قررت تغيير اسم خاصية في كائن ما، ستقوم تايب سكريبت بتنبيهك في كل مكان آخر في الكود يستخدم الخاصية بشكل خاطئ، وتصبح عملية تطوير وتحديث المشاريع الكبيرة آمنة أكثر.
- 3 اجابة
-
- 1
-
-
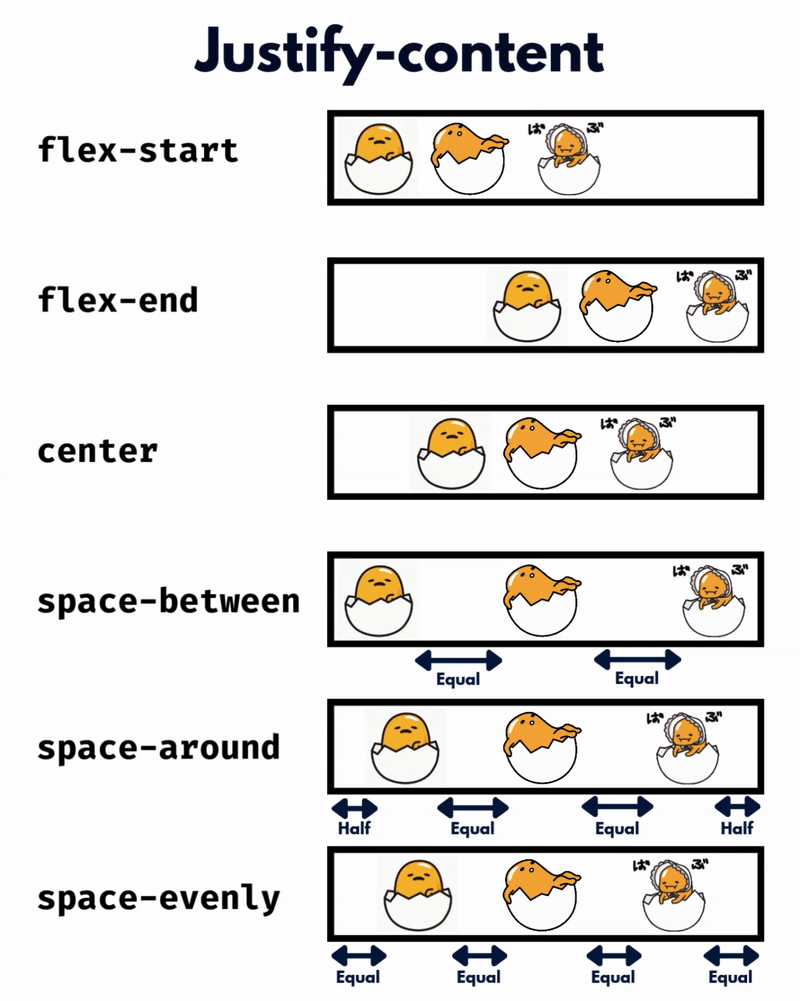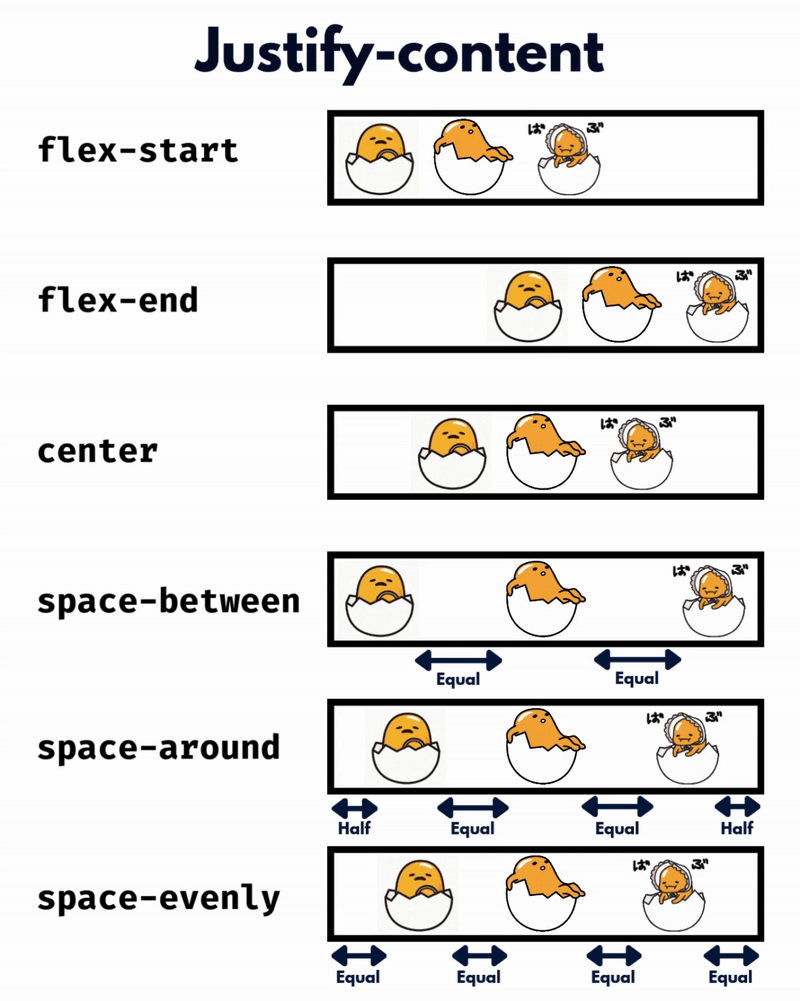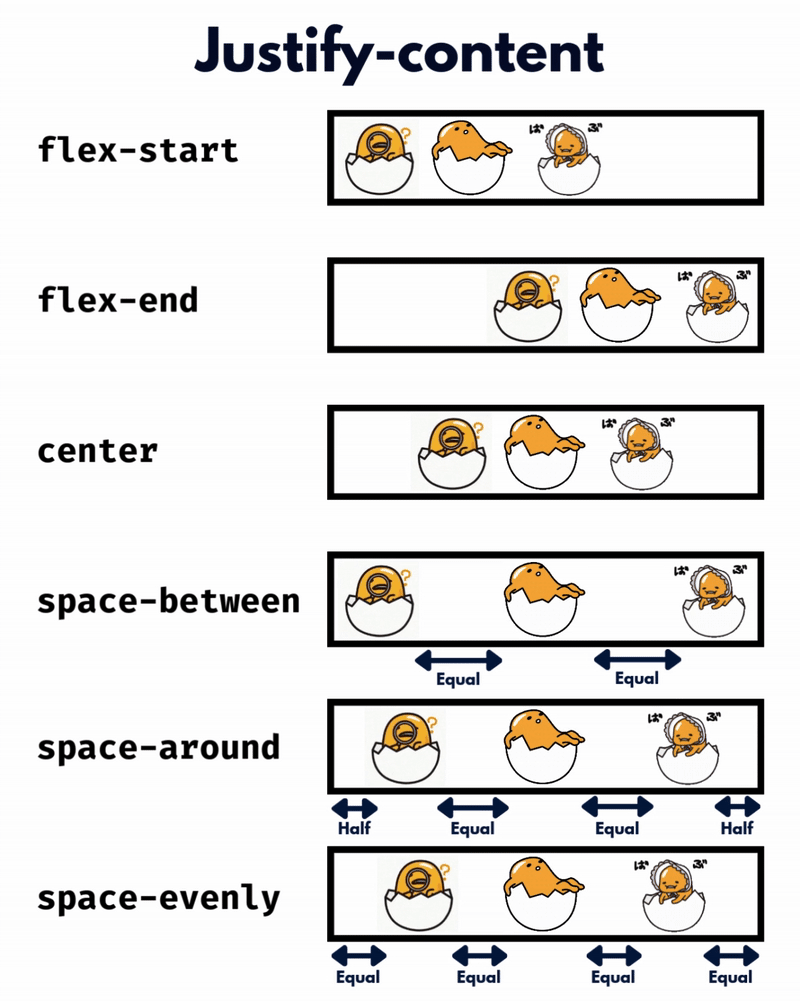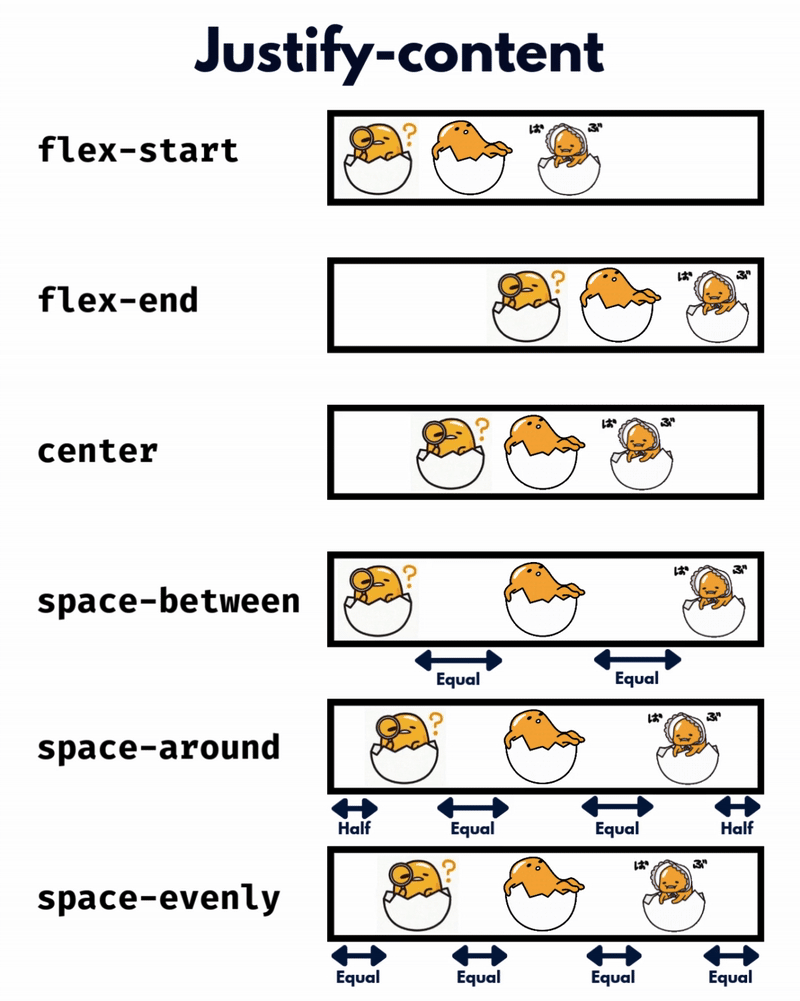
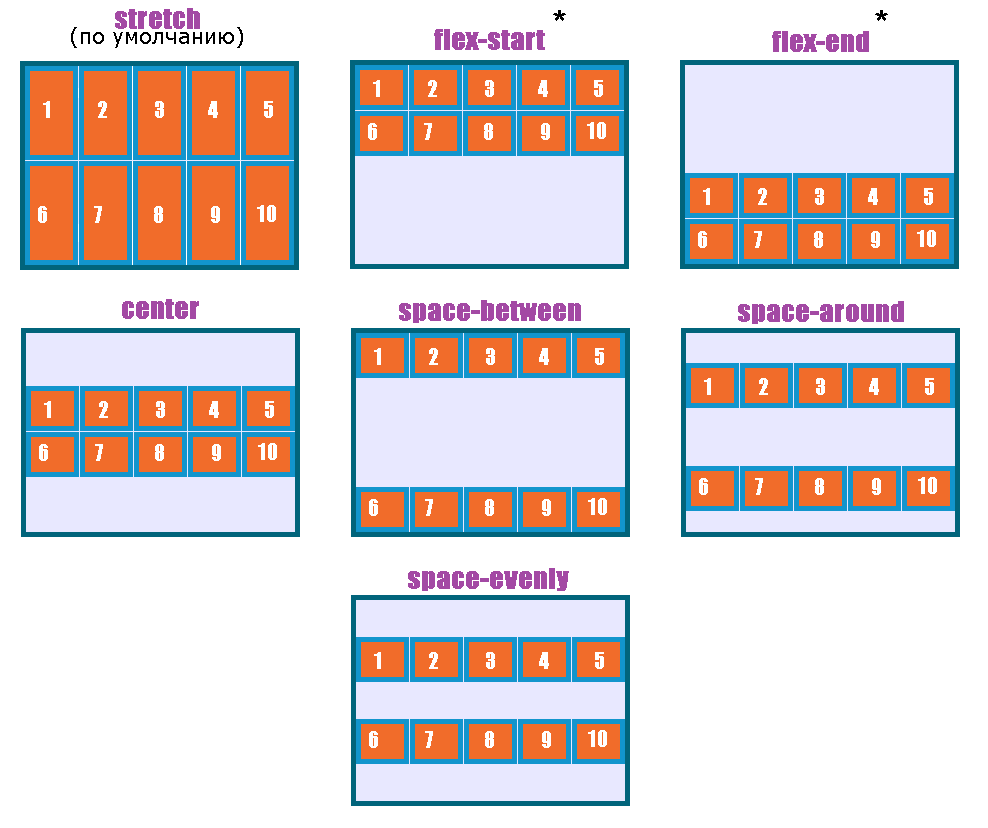
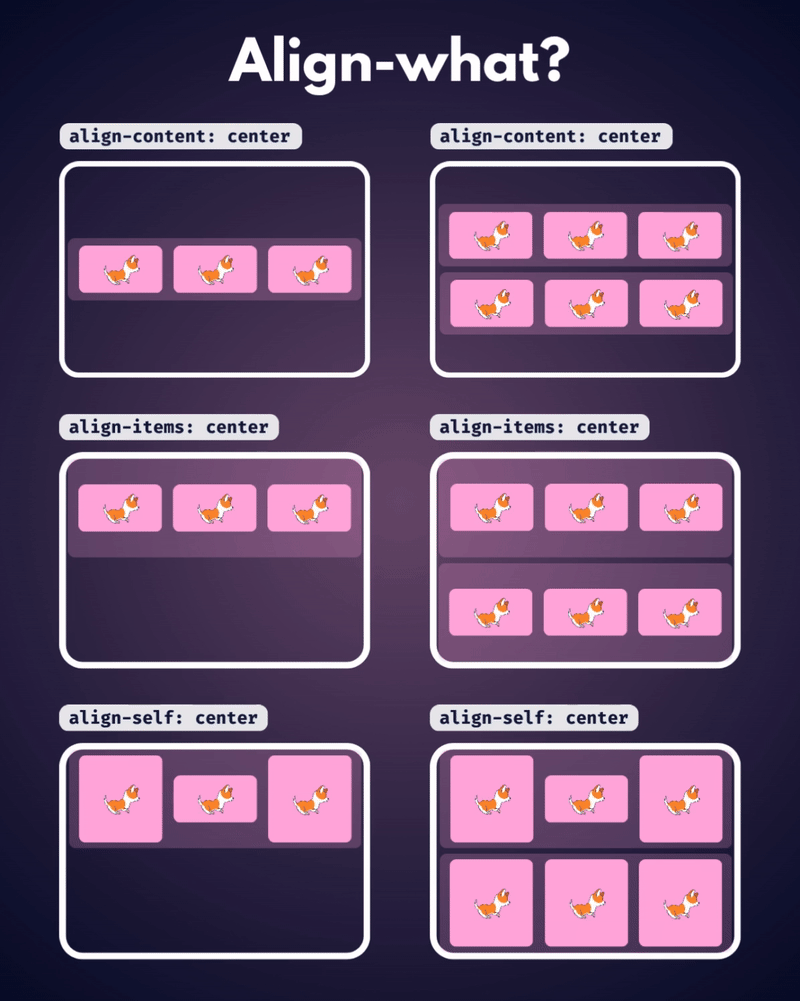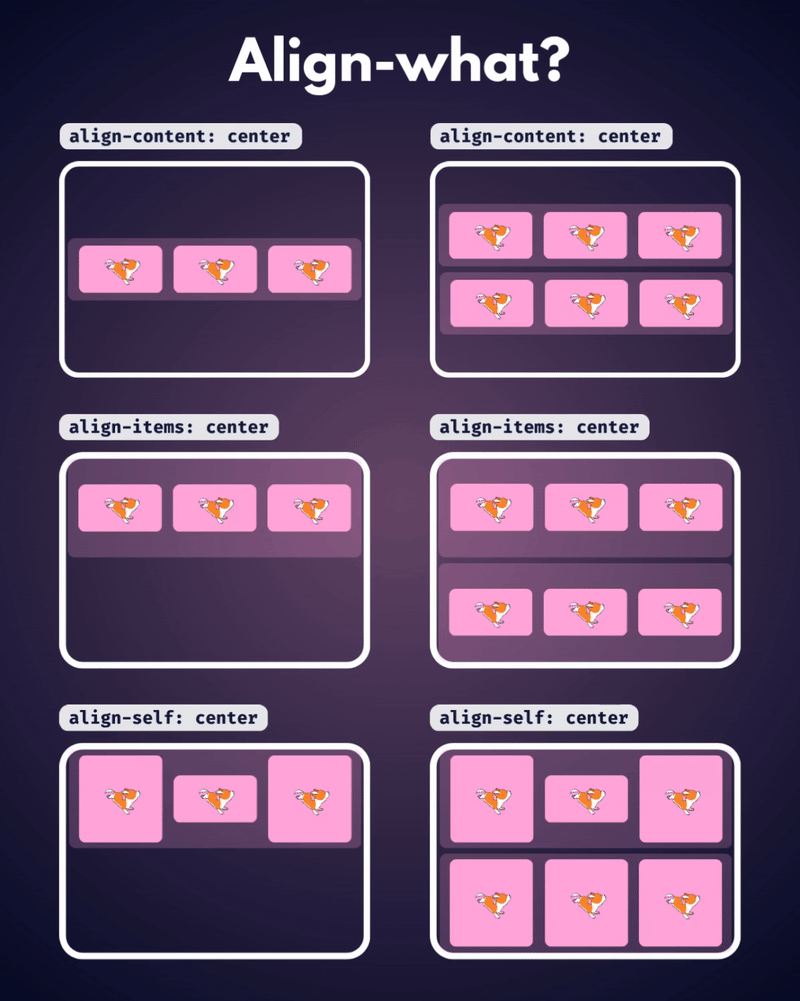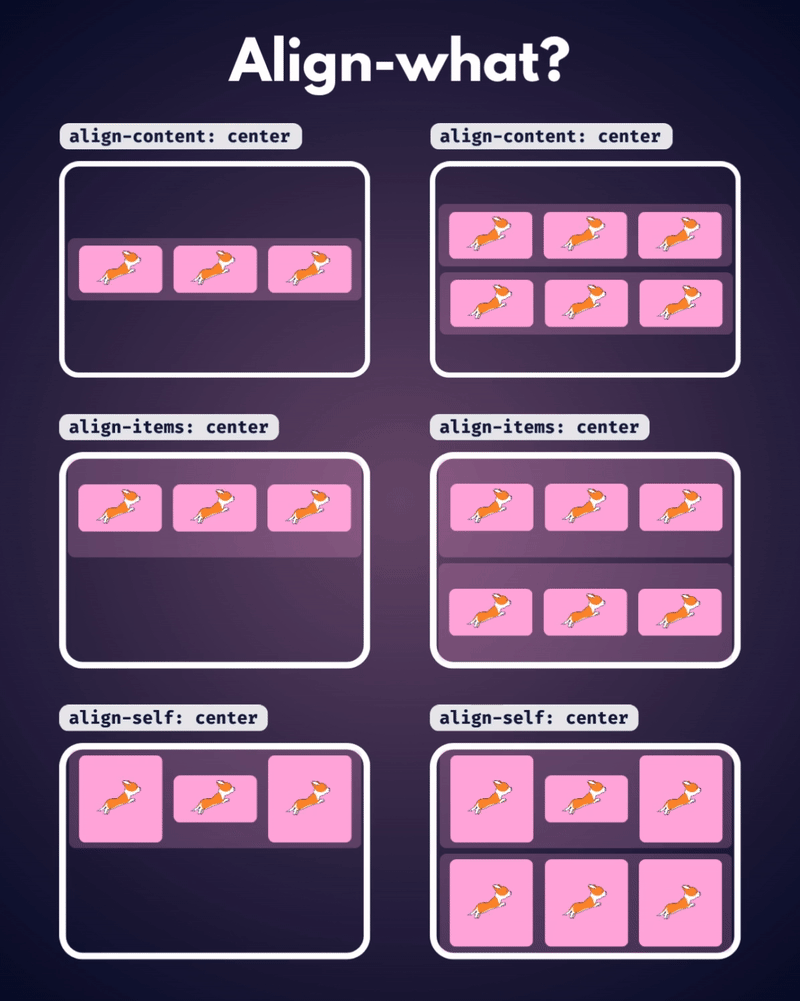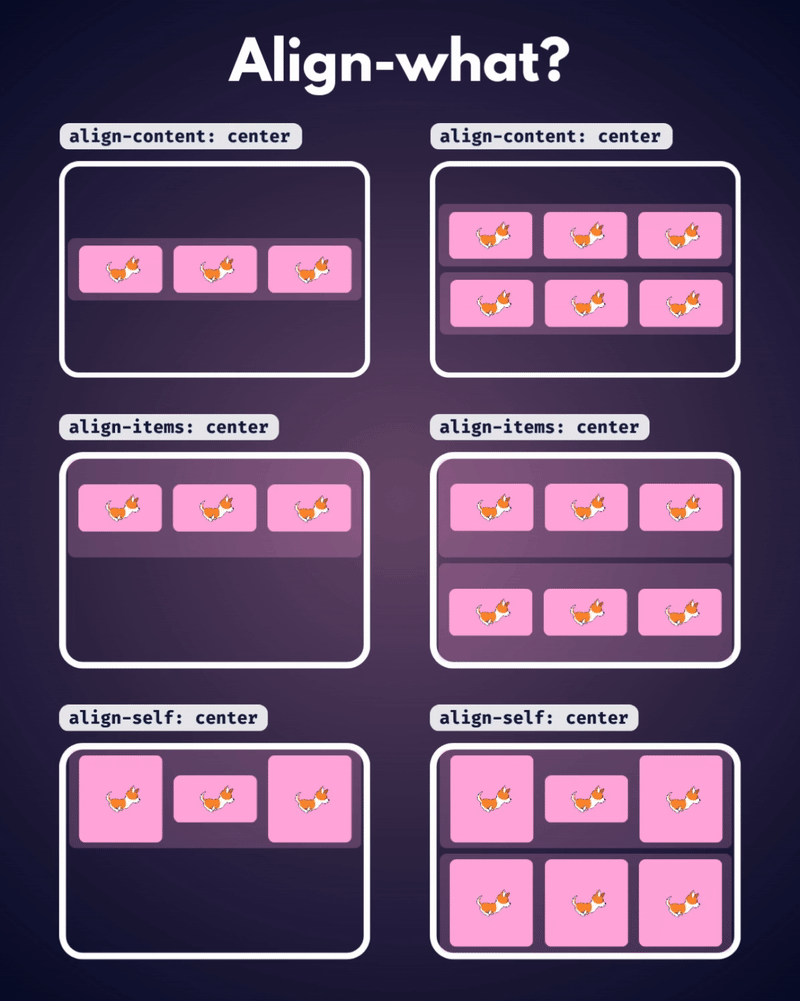
الإتجاه الإفتراضي للعناصر في CSS Flexbox هو المحور الأفقي، بمعنى يتم تموضع العناصر بشكل أفقي على هيئة صفوف، لذا سأوضح على هذا الأساس، حيث أنّ الأمر مختلف في حال تم تغيير القيمة الإفتراضية إلى المحور الرأسي flex-direction: column خاصية justify-content تعمل على محاذاة العناصر مًعا ككتلة واحدة على طول المحور الأفقي وتوزع المساحات الفارغة بينها، بمعنى justify-content: center تعمل على تجميع كل العناصر في منتصف الحاوية أفقيًا وأي مساحة فارغة ستكون موزعة بالتساوي على اليمين واليسار. بينما خاصية align-content هي عكس الخاصية السابقة، حيث تحاذي العناصر ككتلة واحدة على المحور الرأسي أي عموديًا، لذا align-content: center لو يوجد سطران أو أكثر من العناصر، ستقوم الخاصية بتجميع كل الأسطر معًا ككتلة واحدة ووضعها في منتصف الحاوية عموديًا. لكن لن الخاصية إلا في حال لديك أسطر متعددة من العناصر، وذلك يحدث لو قمت بتعيين خاصية flex-wrap: wrap وتكون العناصر أكثر من أن تتسع في سطر واحد، أي لو هناك سطر واحد فقط، فلن يكون لخاصية align-content أي تأثير. وخاصية . align-items هي لمحاذاة العناصر الفردية داخل الحاوية على المحور الرأسي (العمودي)، أي للتحكم في محاذاة الأسطر أو الصفوف داخل حاوية flexbox، وهي تعمل حتى لو يوجد سطر واحد فقط من العناصر. ولو العناصر أطول من بعضها، فستتم محاذاتها جميعًا في المنتصف بالنسبة لبعضها البعض، لاحظ الفرق:
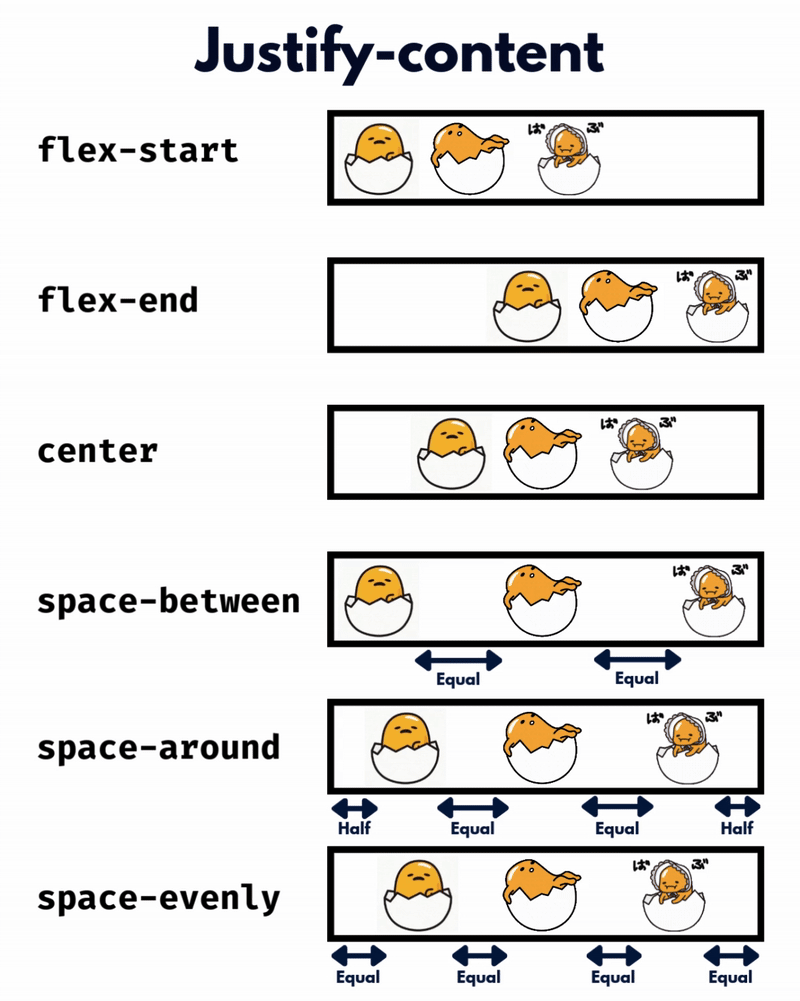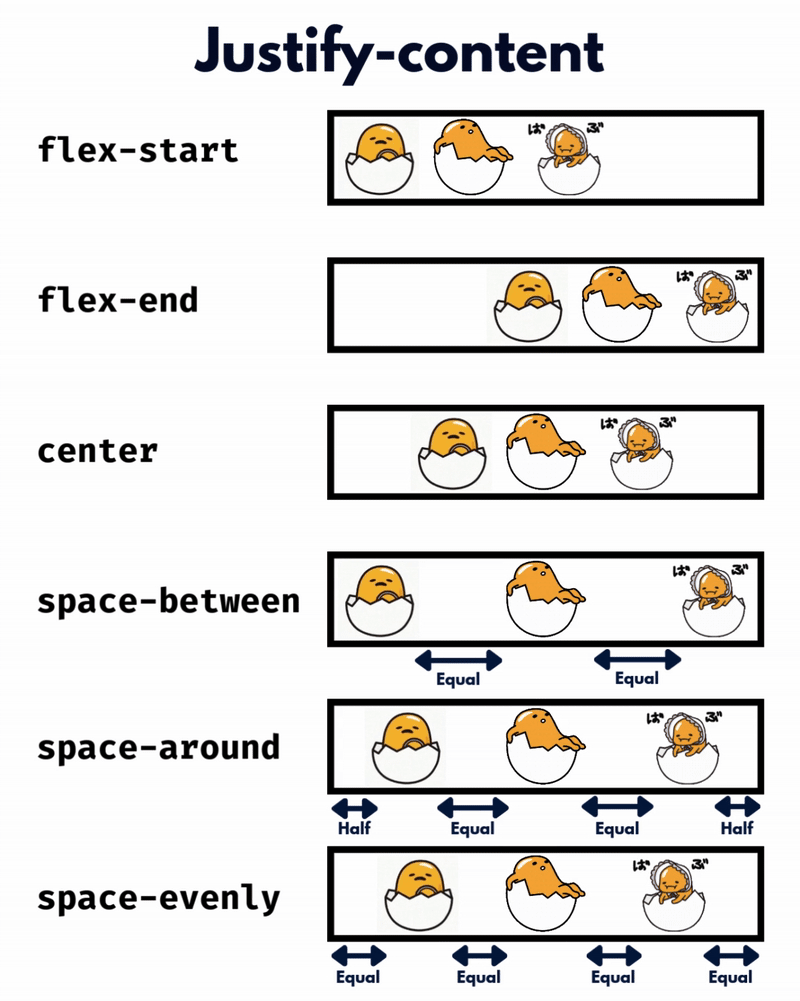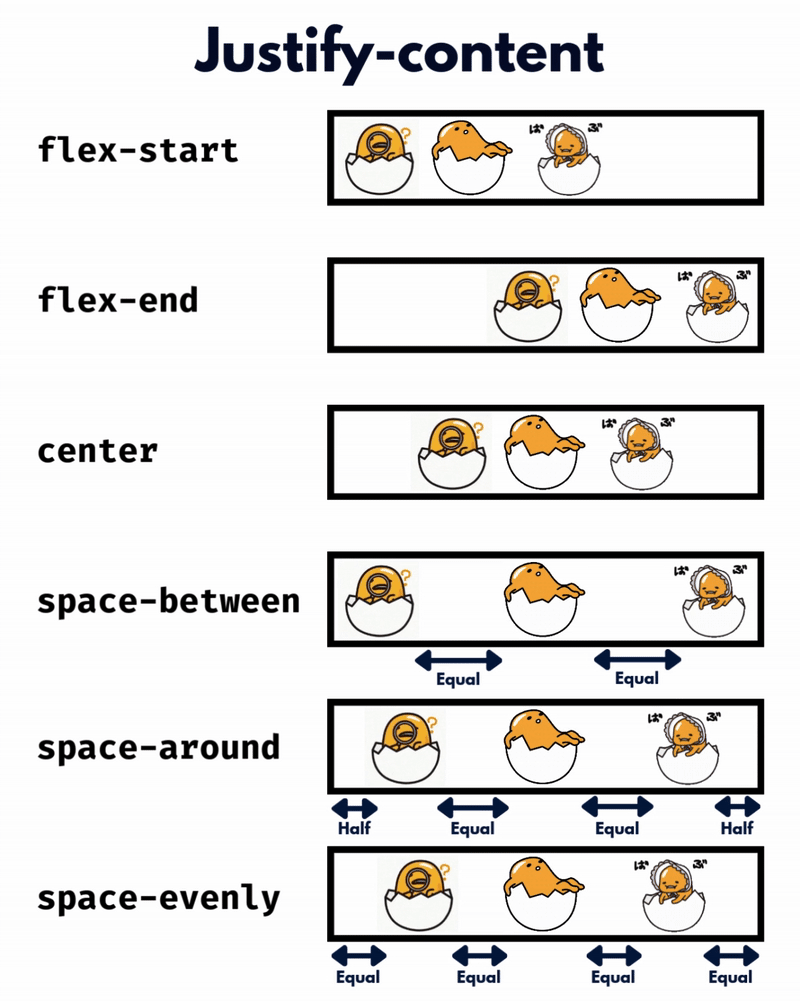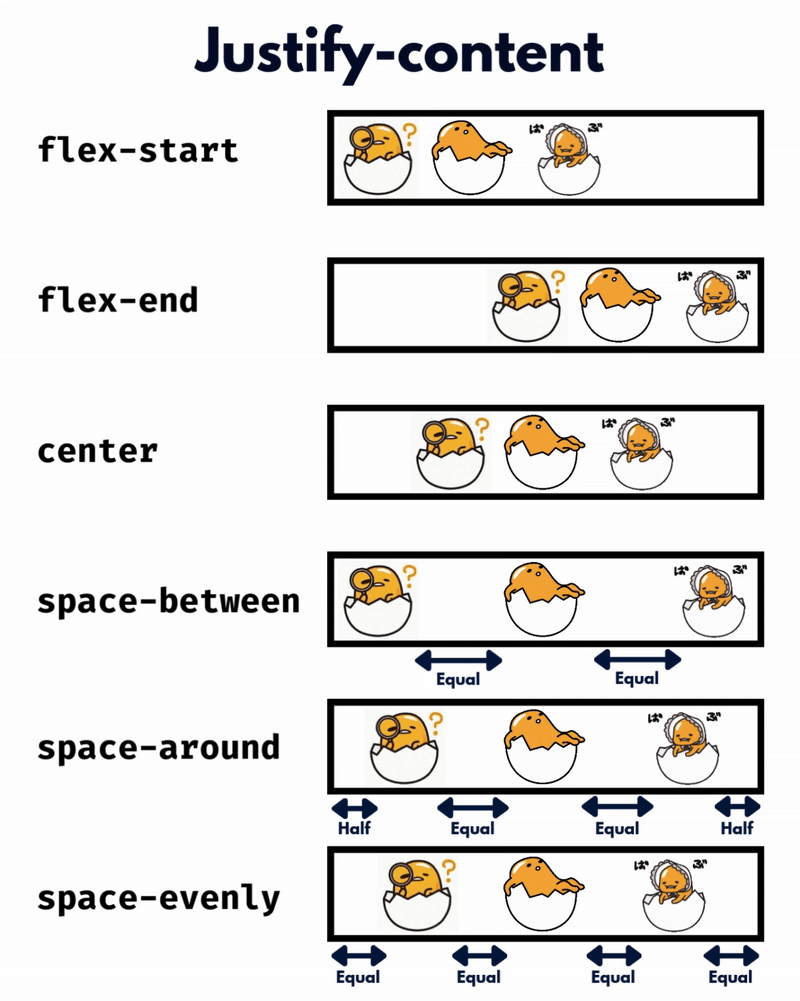
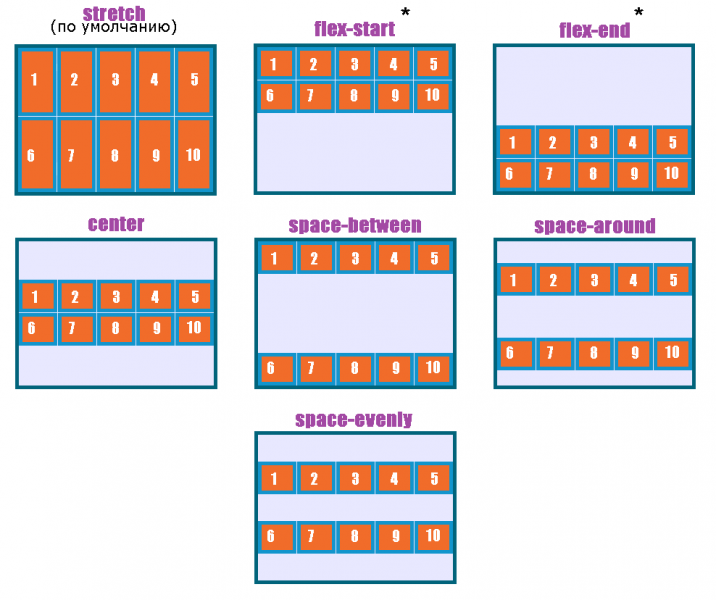
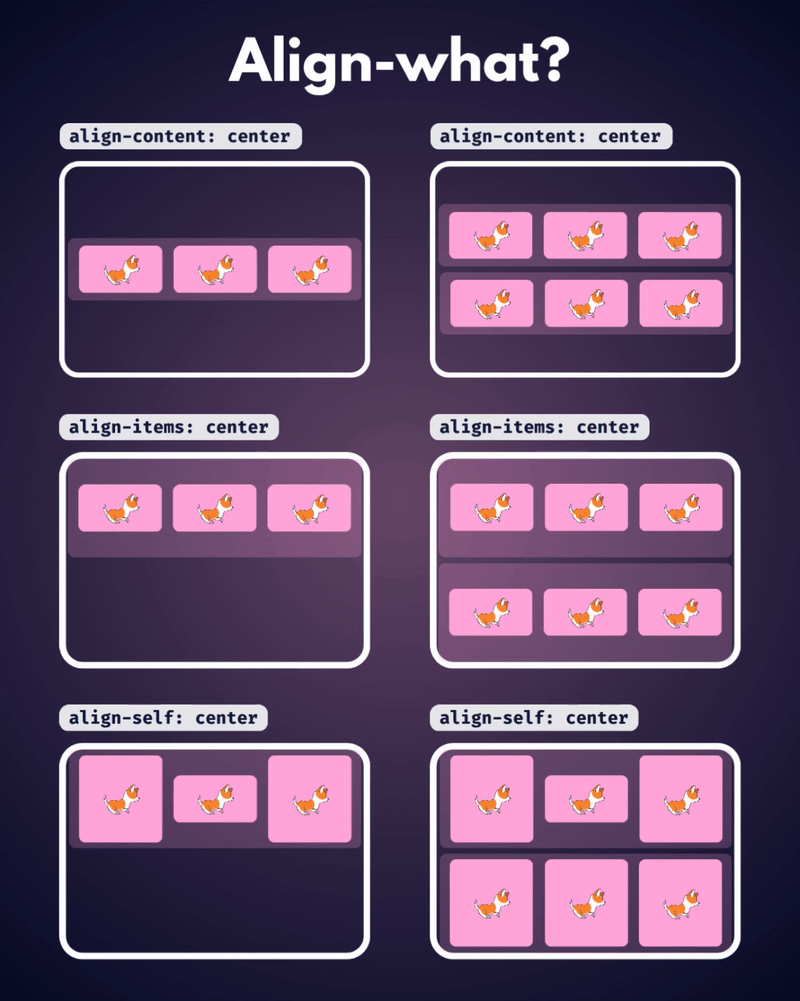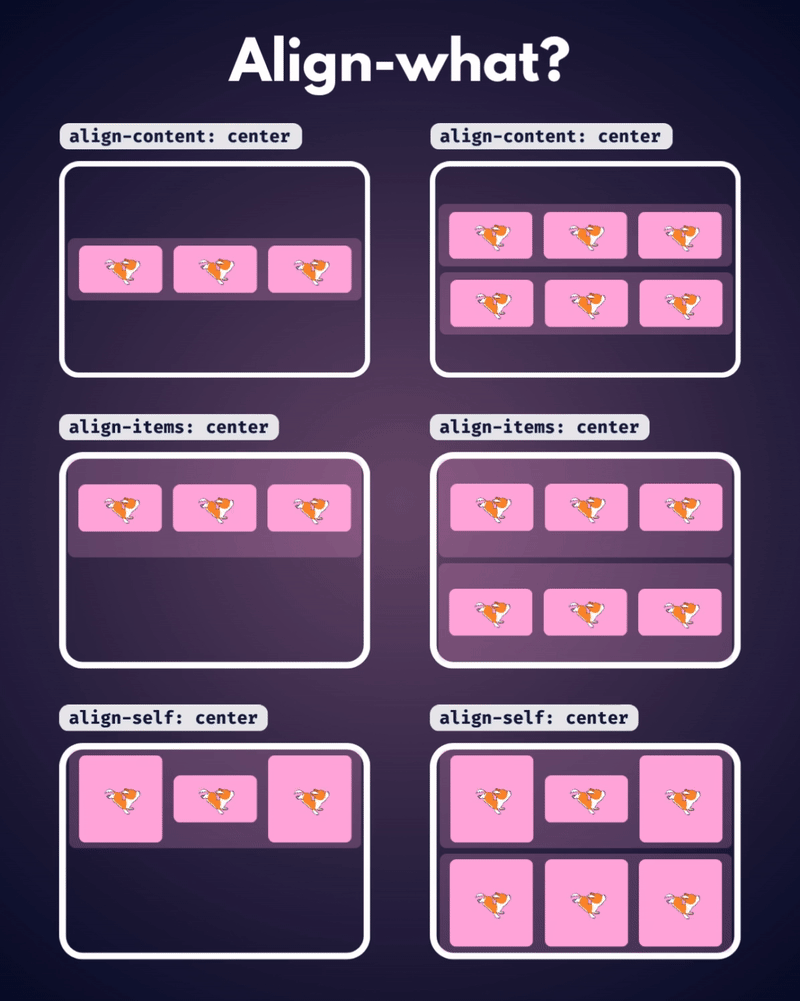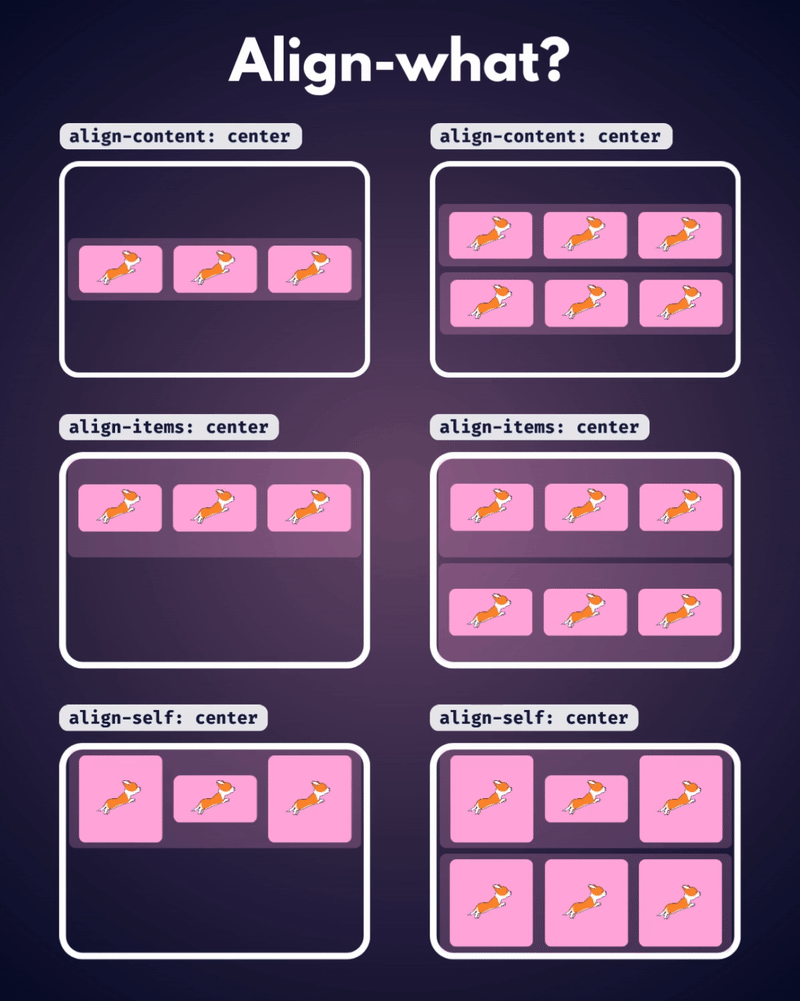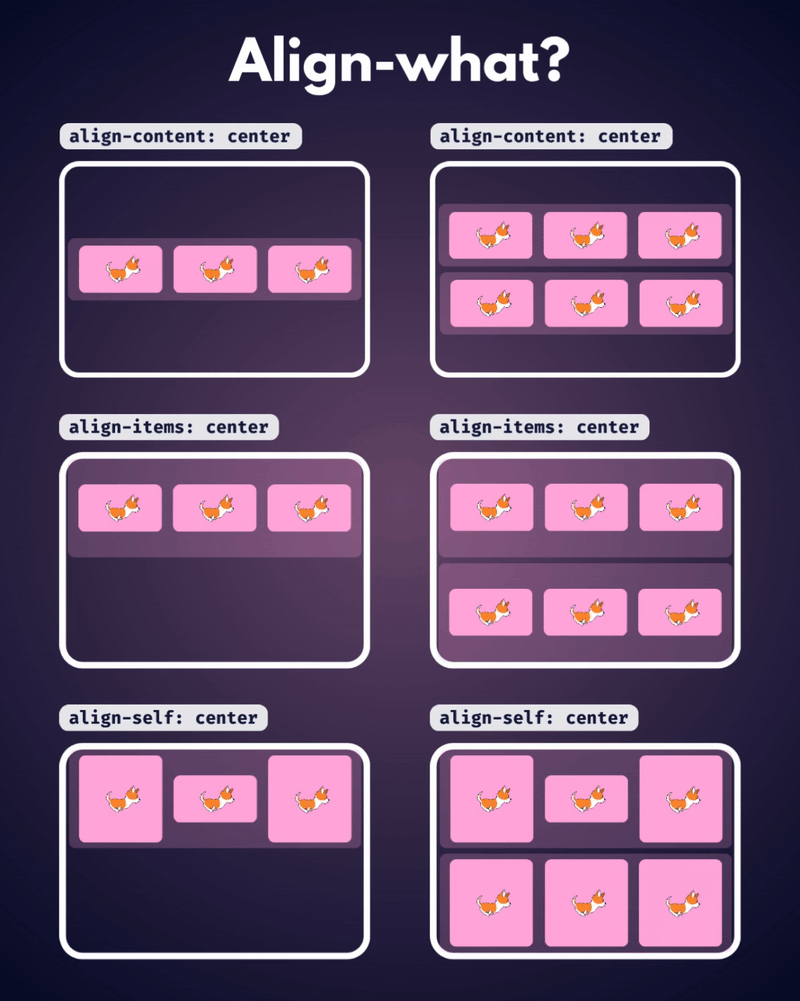
-
بجانب اسم كل درس في المسارات بالدورة ستجد دائرة زرقاء وعند مشاهدة الدرس تختفي تلك الدائرة، لكن في حال الإنقطاع لمدة تزيد عن أسبوع أو شهر، سيُصعب عليك تتبع أين توقفت، لذا أرجو تدوين أخر درس توقفت عنده في مدونة خاصة بك ولتكن google tasks. أو يمكنك استخدام قالب الدراسة التالي لتخطيط دراستك للدورة، في حال تُفضل استخدام Notion: https://www.notion.com/templates/course-planner-schedule-and-learning-progress ومن خلاله تستطيع قياس مدى تقدمك بالدورة. أما بالنسبة للمدة المناسبة لدراسة الدورة، فالأمر راجع لمجهودك ومدى تفرغك وأيضًا خبراتك السابقة في حال كان لديك دراية بالبرمجة من قبل، ستحتاج إلى 3 أشهر على الأقل وقد تصل إلى 6 أشهر وفي رأي الحد الأدنى هو 6 أشهر في حال دورة متخصصة مثل دورة بايثون أو جافاكسريبت، بينما دورة علوم الحاسوب فيكفي 3 أشهر، والأمر المهم هو تحديد الوقت اليومي للدراسة والتطبيق، وليس من الضروري أن تنهي عددًا محددًا من الفيديوهات يوميًا، بل من الأفضل تخصيص عدد معين من الساعات يوميًا للدراسة بتركيز وتطبيق المفاهيم التي تعلمتها، ولا تعتمد على ذاكرتك فقط بل قم بكتابة الكود بنفسك لتثبيت المعرفة. ولا تنسى أن الاستيعاب والتطبيق يتطلبان وقتًا إضافيًا، وستحتاج إلى مراجعة المحتوى والبحث عن تفاصيل إضافية لفهمه بشكل كامل، بمعنى 4 إلى 5 أضعاف وقت الدورة لتتمكن من استيعاب المعلومات وتطبيقها بشكل جيد. وتحديد وقت للانتهاء من الدورة يساعدك على الالتزام وتقييم تقدمك، ولو تركت الأمر بدون جدولة، فستستغرق وقتًا طويلاً لإكمال الدورة بسبب الانشغالات الأخرى. وعندما ترى فيديو بمدة 30 دقيقة، فالوقت الفعلي الذي ستحتاجه لاستيعاب محتواه وتطبيقه يكون أكثر بكثير من ذلك، وليس كل النصائح والمعلومات تقدم بشكل سهل وقابل للفهم فورًا، فستحتاج إلى وقت إضافي لفهم المفاهيم وتطبيقها في البرمجة، بالتالي يجب احتساب وقت إضافي للمراجعة والتطبيق العملي، وحتى البحث عن توضيحات إضافية إن لزم الأمر. وفي حال كنت مبتدئًا في البرمجة، فبلا شك يوجد وقت إضافي لفهم المفاهيم الأساسية. أخيرًا، لا تنسى أن التطبيق العملي هو الأهم وليس المشاهدة النظرية، عليك التطبيق على المفاهيم التي تعلمتها بنفسك وحاول تغيير الكود لتفهمه بشكل أفضل، واستمر في التطوير وكن صبورًا.
- 3 اجابة
-
- 1
-
-
بالضبط التعمق في بايثون في البداية، سيجنبك الكثير من الصعوبات لاحقًا. بالنسبة للتواصل، تستطيع طرح طلب (سؤال) في قسم أسئلة البرمجة للتواصل مع الآخرين حيث سيتم رؤية سؤالك من قبل الآخرين، أيضًا مجتمع https://io.hsoub.com تابع لشركة حسوب ومخصص للتواصل.
-
ما تبحث عن هو Templates أي قوالب، في البداية إن كان ذلك بغرض التعلم فهو أمر جيد لتفحص الكود وإنشاء مثله، لكن إن ما كنت في مرحلة التعلم فلا أنصحك أبدًا بفعل ذلك فأنت بحاجة إلى الممارسة لا إختصار الوقت. إنشاء موقع أو اثنان ليس بالأمر الكافي، ويجب إنشاء أكثر من موقع بأفكار وتصاميم مختلفة لتوظيف ما تعلمته. عامًة المستودع التالي ستجد به القوالب التي تبحث عنها: https://github.com/bradtraversy/design-resources-for-developers#html--css-templates الأفضل استلهام التصميم وتطويره بنفسك، والأمر متاح وبوفرة، كل ما عليك هو إعتماد 3 مواقع تُفضلها من ضمن مواقع كثيرة تقدم تصميمات لتستلهم منها، الأسهل هو الإعتماد على موقع Pinterest وهو بمثابة محرك Google ولكن للصور والأفكار الإبداعية، أي بدلاً من البحث عن معلومات، أنت تبحث عن إلهام بصري. ابحث مثلاً عن Restaurant Website Landing Page أو Minimalist Cafe UI Design، الفكرة هي البحث باسم نوعية التصميم التي تريدها، حيث Minimalist يعني البساطة، عامًة مع الوقت سيتضح لك الأمر وستكتشف العديد من المواقع عن طريقه. لديك أيضًا المواقع التالية: Dribbble Awwwards Behance onepagelove collectui
-
لا يوجد أي متطلبات لبدء دراسة الدورة، ستجد كل ما تحتاجه بدءًا من أساسيات بايثون وحتى دراسة التعلم العميق. ولو أردت التعمق أكثر في بايثون وهو ما أنصحك به، تستطيع دراسة المسار الأول من دورة بايثون والذي به تفصيل أكبر، والمسارات الأولى من جميع الدورات متاحة لك بشكل مجاني عند الإشتراك بأي دورة. بالنسبة للنصائح، ستجد تفصيل هنا بخصوص دراسة الدورة بشكل فعال:
- 5 اجابة
-
- 1
-
-
أرجو توضيح ما هي الدورة المقصودة؟ عامًة يوجد في بعض المسارات مشروع عملي للتطبيق على ما قمنا بدراسته، أو تطبيقات عملية، في حال تريد تمارين حول دروس معينة أرجو طرح سؤال أسفل الدرس وسيتم توفير تمارين عملية لك. لكن الدروس النظرية لا يوجد تطبيقات عليها بطبيعة الحال، لذا في حال أنك في دورة علوم الحاسوب، فهناك الكثير من الدروس النظرية والتي لا يوجد تطبيق عملي عليها.
-
ابحث عن javascript projects for beginners وقم بتفعيل خيار الترجمة لاستيعاب الشرح، أو لو أردت باللغة العربية، ابحث عن مشاريع جافاسكريبت للمبتدئين.
-
على أرض الواقع لا يتم استخدام أحدث التقنيات في جميع المشاريع، فغالب الحال ستعمل على مشاريع تم تطويرها بالفعل منذ مدة، بالتالي ستجد أنّ JQuery مستخدمة بها بالرغم من أنّها عفا عليها الزمن ولم تعد تُستخدم بكثرة حاليًا كما كانت من قبل، وذلك بسبب تطور جافاسكريبت. بالتالي ليس شرط تعلم jQuery وتستطيع تعلم React مباشرًة وذلك يكفي، ثم تستطيع تعلم jQuery وقتما تحتاج إلى ذلك، ولو أردت رأي تعلم أساسيات jQuery ثم التطبيق على مشروع بسيط لا أكثر، وفي حال احتجتها تستطيع التعمق بها. بالنسبة لجافاسكريبت، فحاليًا قمت بإنهاء مسار الأساسيات، يجب إذن التطبيق على ما درسته، ابحث على اليوتيوب عن مشاريع جافاسكريبت للمبتدئين وقم بتنفيذ مشروعين على الأقل، ثم تستطيع متابعة دورة تطوير واجهات المستخدم.
- 5 اجابة
-
- 1
-