Mustafa Suleiman
-
المساهمات
20334 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
494
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
ذلك متاح من خلال منصة GitHub، اضغطي على المجلد، وسيتم عرض محتواه، ستجدي أعلى اليمين ثلاث نقاط ... اضغطي عليهم ثم اختاري delete directory. ثم اضغطي على commit changes. لكن الطريقة الصحيحة هي حذف المجلد على حاسوبك في المستودع المحلي ثم دفع التغييرات إلى GitHub من خلال الأوامر: git add . git commit -m "deleted GitTutorProject/img" git push -u origin main وسيتم تحديث المستودع البعيد على github وحذف المجلد. ولتجنب إدخال نفسك في متاهة مفرغة، أرجو إنشاء مجلد للدورة ثم بداخله قم بإنشاء عدّة مجلدات حيث مجلد لكل مسار في الدورة. وبداخل كل مجلد قم بوضع التطبيقات العملية التي قمنا بها في ذلك المسار. ثم رفع المجلد الرئيسي بالكامل بما يحتويه من مجلدات على مستودع GitHub وتوفير الرابط الخاص به عند التقدم للإختبار. وفي حال وجود مشروع به الكثير من الملفات والمجلدات ويحتاج إلى مجلد خاص به مثل مشروع "تخصيص نموذج لغة باستخدام LangChain و OpenAI" هنا تقوم برفع المشروع على مستودع GitHub منفصل خاص به.
- 2 اجابة
-
- 1
-

-
 الجزء الخاص بالـ details سبب المشكلة، لاحظ: قم بوضع التنسيق التالي له: section.details { overflow: hidden; }
الجزء الخاص بالـ details سبب المشكلة، لاحظ: قم بوضع التنسيق التالي له: section.details { overflow: hidden; }
-
في ملف Scripts.js قمت بتهيئة الـ Carousel، ثم مرة أخرى في ملف HTML من خلال السمة data-bs-ride="carousel" في العنصر <div id="testimonialCarousel"> والتي تخبر Bootstrap ببدء تشغيل الـ Carousel تلقائيًا عند تحميل الصفحة. لذا قم بحذف الكود الذي في ملف Scripts.js وسيتم حل المشكلة. ولديك أخطاء أخرى، حيث قمت بتضمين JQuery ولا حاجة إلى ذلك مع الإصدار 5 من بوتستراب فهو لا يعتمد على تلك المكتبة بل جافاسكريبت فقط، وكذلك قمت بتضمين bootstrap.rtl.min.css يجب حذفه وإبقاء bootstrap.min.css فقط لتجنب التعارض.
- 1 جواب
-
- 1
-

-
لا مشكلة الأمر طبيعي وهو الطريقة الصحيحة في HTML5، فلا تحتاج أبداً لإضافة الشرطة المائلة / بنفسك، حيث توجد عناصر تُسمى العناصر الفارغة Void Elements، وهي لا تحتوي على محتوى بداخلها مثل نص أو عناصر أخرى، وبالتالي لا تحتاج إلى وسم إغلاق. كالتالي: <meta charset="UTF-8"> <link rel="stylesheet" href="style.css"> <img src="image.png" alt=""> <input type="text"> لكن في العناصر التي بها وسم إغلاق فيجب كتابة الشرطة المائلة بشكل صحيح في وسم الإغلاق.
- 3 اجابة
-
- 1
-
-
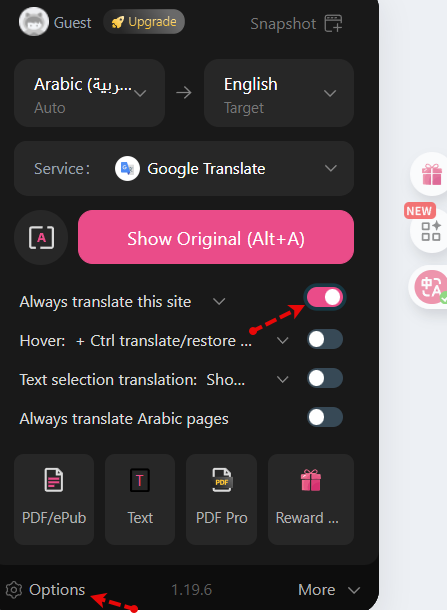
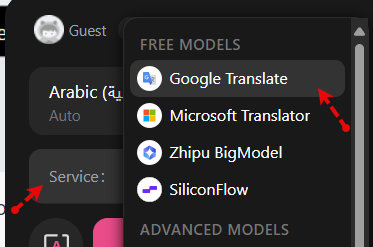
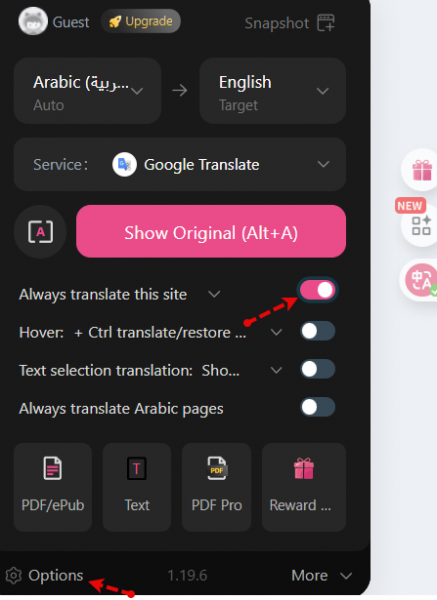
المنصة موجه للناطقين بالعربية، لذا النسخة الإنجليزية غير متاحة، لكن تستطيع الحصول على ذلك من خلال تثبيت إضافة: Immersive Translate بعد التثبيت قم بتحديث الصفحة وستجد أيقونات جانبية قد ظهرت، فاضغط على أيقونة الإضافة ثم اختر الإعدادات settings: ثم قم بإختيار ترجمة google: ثم قم بتفعيل خيار always translate this site: ثم اضغط على options وقم بتعديل translation mode إلى only translation: عد للموقع وأعد تحديث الصفحة وستجد اللغة بالإنجليزية.


-
للتوضيح أولاً، Prompt Engineering يعني آلية لصياغة الأوامر بشكل دقيق وفعال للتواصل مع نماذج الذكاء الاصطناعي، بهدف الحصول على أفضل النتائج الممكنة وأكثرها دقة وفائدة. ويعتبر فن وعلم في نفس الوقت، أي هناك مجال للإبداع به وليس قواعد جامدة فقط، وتلك القواعد أن تكون واضح ومحدد قدر الإمكان ولا تترك مجالاً للتخمين، بمعنى التفصيل وليس كتابة prompt مُبهم. كذلك توفير السياق اللازم، لمنح النموذج معلومات تساعده على فهم طلبك بشكل أعمق، وأيضًا اطلب من النموذج أن يتقمص دور معين، فذلك يغير من أسلوبه ونبرته وتركيزه، كأن تطلب منه أن يتقمص دور خبير في مجال معين أو الشرح بأسلوب معين وهكذا. و تحديد التنسيق بطلب أن تكون المخرجات بالشكل الذي تريده، مع توفير مثال أو اثنين للنموذج لتوضيح ما تريده تمامًا، وذلك يسمى Few-Shot Prompting. ونادرًا ما ستحصل على النتيجة المثالية من المحاولة الأولى، فالـ prompt الجيد هو نتيجة لسلسلة من التحسينات، ستجد تفصيل هنا:
- 5 اجابة
-
- 1
-
-
أداة التصميم المُعتمدة والإحترافية حاليًا هي Figma، لكن الأداة بمفردها ليست كافية لتصميم واجهة مستخدم جيدة، ستحتاج إلى دراسة الأساسيات الخاصة بالتصميم، كذلك يوجد أدوات أخرى مساعدة، ثم نأتي لخطوة استلهام التصميم، والتي تتطلب تغذية بصرية لإختيار أشكال الأقسام في موقعك من عدة تصاميم مختلفة أي تجميع التصميم من خلال عدة تصاميم، وقد تصادف تصميم مناسب للفكرة التي تريد تنفيذها ولا مشكلة في ذلك لكن حاول التعديل عليه وليس نسخه كما هو أي تستلهم منه، أو اذكر أنك لم تقم بتصميم الجزء الخاص بالـ UI/UX بل كتبت الكود فقط لحفظ الحقوق، وستجد مواقع كثيرة لاستلهام التصميم. وستجد تفصيل هنا بخصوص ما سبق: وبالطبع ستحتاج إلى دراسة أساسيات برنامج Photoshop من أجل التعديلات الغير مُعقدة الخاصة بالصور، أي لن تقوم بالتصميم بل التعديل، فأنت لست مُصمم بل مُطور واجهات مستخدم، فهناك فرق بين مطور الـ Fron-End وبين مُصمم UI\UX.
-
الدورة بالأكاديمية تختص بمجال البرمجة بشكل خاص مثل دورة بايثون وجافاسكريبت وهكذا، وما حوله من مفاهيم بشكل عام مثل دورة إدارة المنتجات، كما تمتلك الأكاديمية كذلك خطة طموحة للتوسع مستقبلاً لإنتاج دورات في مجالات أخرى مثل التسويق وخدمة العملاء والتصميم. لذا في حال الدورات لديك خارج نطاق ما سبق، فليس متاح نشرها بالأكاديمية، عدا ذلك يجب توافر شروط معينة للعمل كمدرب (مُحاضر) ستجد تفصيل هنا: درّب معنا
-
آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
-
ليس شرطًا في نهاية المسار، المقصود التطبيقات العملية الخاصة بالمسار، وستجد بجانبها "تطبيق عملي" وفي مسارات أخرى لا يوجد تطبيقات عملية، بل تمارين نقوم بتفيذها خلال الدروس، هنا ستقوم بتنفيذ تلك التمارين كما بالشرح ثم وضعها داخل مجلد ورفعه. والأسهل لك لتجنب التشتت، أرجو إنشاء مجلد للدورة ثم بداخله قم بإنشاء عدّة مجلدات حيث مجلد لكل مسار في الدورة. وبداخل كل مجلد قم بوضع التطبيقات العملية التي قمنا بها في ذلك المسار، ثم رفع المجلد الرئيسي بالكامل بما يحتويه من مجلدات على مستودع GitHub وتوفير الرابط الخاص به عند التقدم للإختبار. لكن في دورات أخرى يوجد مشاريع عملية كاملة أي بها ملفات ومجلدات كثيرة، هنا ستقوم بإنشاء مجلد خاص للمشروع ثم رفعه على مستودع GitHub خاص به، مثل مشروع "تخصيص نموذج لغة باستخدام LangChain و OpenAI" في دورة الذكاء الاصطناعي.
-
ما هي قاعدة البيانات التي تريدين استخدامها؟ الأسهل هي sqlite من خلال تحميل الخادم: https://www.sqlite.org/2025/sqlite-dll-win-x64-3500300.zip وإضافة مسار المجلد لمتغيرات البيئة في النظام، وبعد ذلك ستتعاملين مع قاعدة البيانات من خلال ملف عن طريق برنامج مثل DB Browser (SQLite). وهناك قواعد بيانات أخرى، بالطبع الأشهر هو الخادم الخاص بقاعدة البيانات MySQL، وتستطيعي تحميله من هنا: MySQL Community Server ثم ستحتاجين إلى تثبيت PhpMyAdmin لإدارة قاعدة البيانات من خلال واجهة رسومية، أو تثبيت MySQL Workbench. والأمر بحاجة إلى خبرة تقنية نسبيًا لإعداد ما سبق بشكل صحيح، ويوجد طريقة أسهل من خلال تحميل وتثبيت بيئة تطوير جاهزة للاستخدام بشكل مباشر، والأفضل بيئة Laragon فهي أحدث وأسهل من بيئة XAMPP القديمة. https://github.com/leokhoa/laragon/releases/download/6.0.0/laragon-wamp.exe وسيتم تثبيت وتهيئة Sqlite و mysql وغيرهم.
-
ليس المطلوب منك رفع التطبيقات العملية البسيطة، بل المشاريع العملية الكاملة، أي التطبيق بجانبها "تطبيق عملي" أو مشروع عملي كامل يستغرق وبه ملفات ومجلدات وليس بسيط. لكن في حال المسار ليس به تطبيق عملي، وستقوم بدراسة 4 مسارات فقط، إذن أرجو إنشاء مجلد للدورة ثم بداخله قم بإنشاء عدّة مجلدات حيث مجلد لكل مسار في الدورة. وبداخل كل مجلد قم بوضع التطبيقات العملية التي قمنا بها في ذلك المسار. ثم رفع المجلد الرئيسي بالكامل بما يحتويه من مجلدات على مستودع GitHub وتوفير الرابط الخاص به عند التقدم للإختبار. وفي حال وجود مشروع به الكثير من الملفات والمجلدات ويحتاج إلى مجلد خاص به مثل مشروع هنا تقوم برفع المشروع على مستودع GitHub منفصل خاص به.
-
ستجد هنا قائمة بالمصطلحات الإنجليزية والعربية التي يتم استخدامها في الدورات البرمجية: الفكرة أنّ محتوى الدورة موجه للناطقين بالعربية بشكل خاص، وفي التحديثات الأخيرة تم الإنتباه لتلك النقطة وشرح المصطلحات بالإنجليزية والعربية معًا. بالنسبة للشهادة، طالما أنك درست المحتوى الخاص بالمسارات من قبل، فقم بتنفيذ المشاريع العملية الموجود في تلك المسارات ثم التقدم للإختبار والحصول على الشهادة، والحد الأدنى للتقدم للإختبار هو إنهاء 4 مسارات على الأقل.
-
في مجال البرمجة الشهادات البرمجية غير مؤثرة، هي دليل على أنكِ أنهيتي محتوى دراسي معين، لكن لا تدل على مستوى المهارة أو الخبرة، فأغلب الشهادات البرمجية عبارة عن شهادات إتمام للدورة بمجرد مشاهدتها للنهاية تحصلين على الشهادة. لكن منصات قليلة توفر الشهادة بعد إجتياز إختبار عملي لقياس مدى استيعابك لما تم شرحه، ومنها أكاديمية حسوب. وفي الواقع العملي لا يتم الإنتباه لأي شهادة، بل التركيز ينصب على معرض الأعمال وما قمتي بتنفيذه، فذلك هو الإثبات الوحيد على مستوى مهاراتك، لكنه غير كافٍ أيضًا، فهناك مقابلات تقنية لقياس مستواكي التقني ومشاريع عملية أيضًا، فمعرض الأعمال قد يكون نسخ ولصق لمشاريع على الإنترنت، لذا في حال وجود مشاريع فريدة توضح مستوى الخبرة، فستكون تلك نقطة تميز لك. الشهادات التي تتطلب تحضير ودراسة ودفع مبلغ مالي، كالتالي توفرها مايكروسوفت أو أمازون، فتلك لها أهمية بالطبع وتتطلب مستوى خبرة معين للحصول عليها.
-
لا مشكلة، ما تحتاجه في النهاية هو خوارزمية للمرور على بيانات المنتجات وإرجاع المطابقات، سواء كانت البيانات مخزنة في مصفوفة ثابتة، ملف JSON محلي، أو قاعدة بيانات تستعلم منها عبر الـ API. كالتالي: HTML <input id="searchBox" placeholder="ابحث عن منتج..." /> <ul id="results"></ul> جافاسكريبت: const products = [ { id: 1, name: "حذاء رياضي", price: 40 }, { id: 2, name: "تي-شيرت قطني", price: 15 }, { id: 3, name: "ساعة ذكية", price: 120 } ]; function searchProducts(query) { const q = query.trim().toLowerCase(); return products.filter(p => p.name.toLowerCase().includes(q)); } const box = document.getElementById("searchBox"); const results = document.getElementById("results"); box.addEventListener("input", () => { const matches = searchProducts(box.value); results.innerHTML = matches .map(p => `<li>${p.name} – $${p.price}</li>`) .join("") || "<li>لا توجد نتائج</li>"; }); وبإمكانك استبدال الـArray بملف products.json وتحميله بــ fetch() إن أردت إبقاء البيانات مفصولة عن الكود. وذلك مناسب في حال عدد المنتجات محدود أي بضع مئات ولا حاجة إلى ميزات بحث متقدمة، لكن في الواقع العملي وجود API وقاعدة بيانات أمر ضروري لأي متجر إلكتروني لمعالجة طلبات الشراء والأمور المتعلقة بها من إدارة المخزون، تسجيل دخول المستخدمين، والمدفوعات، وكذلك التعديل على المنتجات وخلافه، فمن غير العملي التعديل على المنتج من خلال تعديل الكود. أيضًا عربة الشراء، حيث يجب ربط العربة بالمستخدم أو بالجلسة وأحيانًا مزامنتها بين الأجهزة، وبالطبع تستطيع الاحتفاظ بالعربة في localStorage لكن ذلك للتجارب البسيطة، ولن تعمل لو انتقل المستخدم إلى جهاز آخر أو مسح بيانات المتصفح أو فتح الموقع من متصفح آخر. قم بتجربة استخدام منصة Supabase أو firebase لإنشاء واجهة خلفية للمتجر بشكل سهل.
-
بجانب دورة تطوير واجهات المستخدم، ستقوم بدراسة المسارات التالية من دورة جافاسكريبت: أساسيات لغة JavaScript أساسيات React.js تطبيق دردشة يشبه WhatsApp (جزء react فقط أي تطبيق الويب). أساسيات TypeScript تطبيقات الويب التقدمية PWA بعدها تستطيع العمل كمطور واجهة أمامية باستخدام React، والتقدم للمشاريع على مواقع العمل الحر، لكن بشرط بناء مشاريع أخرى بجانب التي في الدورة لتحسين مهاراتك. والفترة التي بعدها قم بتعلم Node.js و Next.js
-
صحيح، ستتعلم MERN Stack وتلك مجموعة من التقنيات المستخدمة لتطوير تطبيقات الويب بشكل كامل أي Full-Stack باستخدام JavaScript، وتتكون من أربع تقنيات رئيسية: MongoDB قاعدة بيانات غير علائقية تخزن البيانات بتنسيق (BSON) مشابه لـ JSON، لتخزين البيانات بشكل مرن وسريع. Express.js: إطار عمل لتطوير تطبيقات الخادم أي الـ Backend بواسطة Node.js، وذلك لإنشاء APIs وإدارة الطلبات. React: مكتبة جافاسكريبت لتطوير واجهات المستخدم أي الـ Frontend بشكل ديناميكي وتفاعلي، تعتمد على مفهوم المكونات. Node.js: بيئة تشغيل جافاسكريبت على الخادم، نستخدمها لتنفيذ الكود خارج المتصفح وإدارة العمليات الخاصة بالواجهة الخلفية. بجانب أيضًا أنك ستتعلم Next.js وهو إطار Full-stack أيضًا يعتمد على React و Node.js ومطلوب بشدة في سوق العمل.
- 10 اجابة
-
- 1
-
-
في حال تفهمت ما تقصدين، وهو أنكِ تريدين رفع التطبيقات العملية لكن وضعها بداخل مجلد، حيث مجلد لكل مسار، صحيح؟ ستقومين بإنشاء مجلد رئيسي للدورة، ثم تقسيمه إلى مجلدات وداخل كل مجلد يتم تقسيمه إلى مجلدات خاصة بكل قسم، ثم تضعين التطبيقات العملية الخاصة بالدروس في كل قسم. ثم رفع المجلد الرئيسي بالكامل بما يحتويه من مجلدات على مستودع GitHub وتوفير الرابط الخاص به عند التقدم للإختبار. ولرفعه، ستحتاجين إلى إنشاء مستودع GIT بداخله من خلال الأمر: git init ثم تنفيذ باقي خطوات رفع المشروع هنا: https://academy.hsoub.com/questions/12523-رفع-الواجبات-على-github/#findComment-34318 وفي حال وجود مشروع به الكثير من الملفات والمجلدات ويحتاج إلى مجلد خاص به مثل مشروع "تخصيص نموذج لغة باستخدام LangChain و OpenAI" هنا تقوم برفع المشروع على مستودع GitHub منفصل خاص به.
- 1 جواب
-
- 1
-
-
لا مشكلة تستطيعي رفع ملفات إلى المستودع بشكل مباشر، لكن تلك ليست الطريقة الصحيحة لاستخدام GIT، لأنّ الرفع بشكل مباشر يعني استبدال الملفات القديمة التي بنفس الاسم، و بالطبع تستطيعي الرجوع للنسخة القديمة من الملف، لكن الأمر غير عملي لأنكِ ستضطرين إلى رفع الملفات بشكل يدوي ولكل مجلد أيضًا. لذا الأسهل لكِ هو من خلال التيرمنال، حيث ستقومين بتنفيذ أوامر بسيطة وسيتم دفع التغييرات التي تمت على المشروع إلى مستودع GitHub. وفي حال تواجهين صعوبة في استخدام التيرمنال، والأمر طبيعي في البداية ستحتاجين إلى بعض الوقت والممارسة فقط، فهناك واجهة رسومية تستطيعين استخدامها للتعامل مع GitHub: https://desktop.github.com/download
- 9 اجابة
-
- 1
-
-
ما المقصود بحفظ بياناتك؟ لحفظ الكود في ملف ستقوم بإنشاء ملف على سطح المكتب بالضغط في أي مكان فارغ بزر الفأرة الأيمن ثم اختر new ثم text document ثم أعد تسمية ذلك الملف بالضغط عليه بزر الفأرة الأيمن ثم اختر rename وأعد تسميته إلى app.py المهم هو صيغة الملف py. ولا مشكلة في اختيار أي اسم. بعد ذلك افتح الملف في محرر الأكواد vscode وقم بكتابة الكود الذي تريده واضغط على CTRL + S لحفظ الكود في الملف وسيبقى به وتستطيع العودة إليه في أي وقت.
-
سيتم بها تطوير مشاريع ويب، وبالتالي استخدام لغات الويب الأساسية وهم HTML, CSS, JS ولا تستطيع بناء مشروع ويب بدون تلك اللغات، لذا ستحتاج أولاً إلى دراسة HTM, CSS من خلال المسار الأول من دورة تطوير واجهات المستخدم فهو مجاني لك كحال باقي المسارات الأولى من جميع الدورات.
-
اللغات المتاحة هي: بايثون جافاسكريبت و HTML, CSS PHP Ruby Godot script وتستطيع تفقد الدورات المتاحة هنا: دورات تعليمية
-
تقصد في جافاسكريبت بدون React؟ تستطيع ذلك لا مشكلة، نعم، ولكن ليس مباشرة على عناصر DOM لأنها ليست arrays بشكل افتراضي بل كائنات تشبه المصفوفات، حيث يجب أولاً تحويل مجموعة عناصر DOM وهم NodeList أو HTMLCollection إلى مصفوفة. بمعنى بعد قيامك بإختيار مجموعة من العناصر المحددة باستخدام querySelectorAll الذي يعيد NodeList، فتستطيع تحويلها إلى مصفوفة من خلال Array.from const items = document.querySelectorAll('.item'); const texts = Array.from(items).map(item => item.textContent); console.log(texts); أو معامل النشر spread (...) const items = document.querySelectorAll('.item'); const texts = [...items].map(item => item.textContent); console.log(texts) وللعلم في المتصفحات الحديثة، NodeList تدعم بعض دوال المصفوفات مثل forEach، ولكن ليس map.
-
ستجد تفصيل هنا:
-
الإختبار شفهي في البداية لقياس مدى استيعابك لما تم شرحه في الدورة، ثم يتم اسناد مشروع لتنفيذه، آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.