

تعدّ أنظمة إدارة قواعد البيانات Relational database management system أو اختصارًا DMBS برامج حاسوبية تسمح للمستخدمين بالتفاعل مع قاعدة البيانات وتتيح لهم إمكانية التحكّم بالوصول إلى قاعدة البيانات وكتابة البيانات فيها وتنفيذ الاستعلامات Queries التي تستخلص البيانات أو تعدلها وإنجاز أي مهمّة أخرى ذات صلة بإدارة قواعد البيانات.
وبالتالي كي تتمكن من إنجاز أي من هذه المهام، يجب أن تمتلك أنظمة DMBS نموذجًا أساسيًا يُعرّف كيفية تنظيم البيانات. وإحدى منهجيات تنظيم البيانات التي لاقت استخدامًا واسعًا في برمجيات قواعد البيانات منذ ابتكارها في أواخر ستينيات القرن الماضي هي النموذج العلاقيّ أو العلائقي Relational، لدرجة أنّه وحتى وقت كتابة هذا المقال فإنّ أربعة من بين أكثر خمسة أنظمة لإدارة قواعد البيانات شيوعًا هي من النمط العلاقيّ.
يوضّح هذا المقال المفاهيمي النظري تاريخ النموذج العلاقيّ وكيفية تنظيم البيانات في قواعد البيانات العلاقيَّة وكيفية استخدامها في تطبيقاتنا المختلفة.
تاريخ النموذج العلاقي
قواعد البيانات عبارة عن مجموعات من المعلومات أو البيانات المُنظّمة منطقيًا. إذ تُعدّ أي مجموعة من البيانات كقاعدة بيانات، بغض النظر عن كيفية أو مكان تخزينها. فحتى درج الملفات المُتضمّنة لمعلومات الرواتب يُعدّ قاعدة بيانات، كذلك الأمر بالنسبة لأي مجموعة مُكدّسة من البيانات مثل نماذج المرضى في مستشفى، أو معلومات مجموعة من عملاء شركة موزعة عبر عدّة مواقع. فقبل أن تغدو عملية تخزين وإدارة البيانات باستخدام الحواسيب شائعة، كانت قواعد البيانات المادية كهذه في الأمثلة السابقة هي الوحيدة المتاحة للحكومات والمنظمات التجارية التي كانت بحاجة لتخزين المعلومات.
وفي منتصف القرن العشرين تقريبًا، شهدت علوم الحاسوب تطورات كبيرة أفضت إلى ظهور أجهزة ذات قدرة معالجة أعلى وسعات تخزين محلية وخارجية أكبر. جعلت هذه التطورات علماء الحاسوب يُدركون القدرات الهائلة لهذه الأجهزة في تخزين وإدارة كميات أكبر من البيانات.
ولكن لم تكن هناك حينها نظريات مُحدّدة حول كيفية تنظيم البيانات في الحواسيب بطرق منطقية ذات معنى فقد كان من السهل تخزين البيانات عشوائيًا على جهاز ما، لكن تصميم أنظمة قواعد البيانات سيتيح إمكانية إضافة واسترجاع وترتيب وإدارة هذه البيانات بطرق عملية وثابتة هو تحدٍ أكبر. فقد أسفرت الحاجة إلى وجود نظام منطقي لتخزين وتنظيم البيانات إلى ظهور العديد من الاقتراحات حول كيفية استخدام الحواسيب في إدارة البيانات.
ولعلّ أحد النماذج الأولية لقواعد البيانات كان النموذج الهرمي، حيث تنظم البيانات وفق هذا النموذج ضمن هيكلية أو بنية شبيهة بالشجرة بأسلوب مماثل لأنظمة الملفات. ويوضّح المثال التالي الشكل الذي قد يبدو عليه جزء من مخطط قاعدة بيانات هرمية تستخدم لتصنيف الحيوانات:
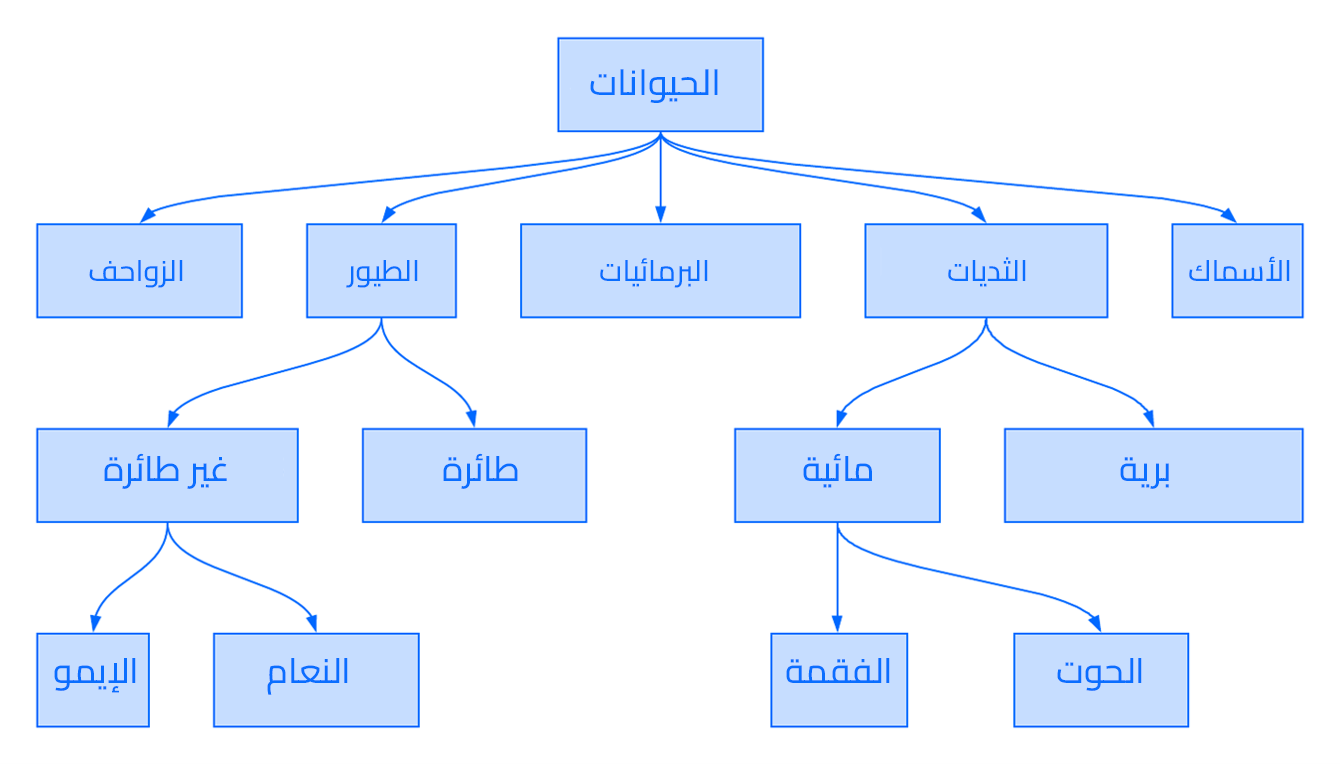
لقد طُبِّق النموذج الهرمي على نحوٍ واسع في أنظمة إدارة قواعد البيانات الأولية، لكنه أظهر بالمقابل بعض الصعوبات من حيث المرونة. ففي هذا النموذج يمكن للسجل الواحد امتلاك عدّة أبناء Children، لكن لا يمكنه أن يتبع سوى لأب Parent واحد ضمن الهيكلية الهرمية، الأمر الذي يجعل قواعد البيانات الهرمية قادرة على التعبير فقط عن علاقات من نوع "واحد-إلى-واحد (one-to-one)" و"واحد-إلى-عديد (one-to-many)" ولا يسمح بالتعبير عن العلاقات من نوع "عديد-إلى-عديد (many-to-many)"، وهذا القصور قد يفضي إلى حدوث مشاكل لدى التعامل مع نقاط بيانات تتبع لأكثر من أب.
إلى أن ابتكر عالم الحاسوب إدجار فرانك كود Edgar F. Codd والذي كان يعمل في شركة IBM النموذج العلاقيّ لإدارة قواعد البيانات وذلك في أواخر ستينيات القرن الماضي. إذ سمح نموذج Codd العلاقيّ هذا بربط السجل الواحد بأكثر من جدول، ما سمح بإمكانية التعبير عن العلاقات من نوع "عديد-إلى-عديد" بين نقاط البيانات ممكنة، بالإضافة إلى إمكانية التعبير عن العلاقات من نوع "واحد-إلى-عديد". الأمر الذي أتاح المزيد من المرونة مقارنةً بالنماذج الموجودة حينها لتصميم هياكل قواعد البيانات وأثبت قدرة أنظمة إدارة قواعد البيانات العِلاقيَّة (RDBMSs) على تلبية مجموعة أوسع بكثير من احتياجات الأعمال.
كما اقترح العالم كود Codd لغة لإدارة البيانات العلاقيَّة عُرِفت باسم ألفا (Alpha)، والتي أثّرت في تطوير لغات قواعد البيانات اللاحقة. فقد أنشأ اثنان من زملائه في IBM وهما دونالد تشامبرلين Donald Chamberlin وريمون بويس Raymond Boyce لغة مستوحاة من لغة ألفا، أطلقا عليها اسم SEQUEL اختصارًا لعبارة Structured English Query Language (لغة الاستعلام الهيكلية بالإنجليزية)، ولكن بسبب وجود علامة تجارية موجودة مسبقًا بنفس الاسم، اختصروا اسم لغتهم إلى SQL والتي يُشار إليها على نحوٍ أكثر رسمية باسم لغة الاستعلام الهيكلية Structured Query Language.
كانت قواعد البيانات العلاقيَّة الأولية بطيئة للغاية وغير عملية بسبب قيود العتاد، واحتاجت بعض الوقت حتى تنتشر، ولكن ومع حلول منتصف الثمانينات، طُبّق نموذج Codd العِلاقيّ في العديد من المنتجات التجارية لإدارة قواعد البيانات، سواء من قبل شركة IBM أو منافسيها.
إذ قام هؤلاء المُصنعّون أيضًا باتباع خطى IBM من خلال تطوير وتنفيذ لهجاتهم الخاصة من لغة SQL. وبحلول عام 1987، صادق كل من المعهد الوطني الأمريكي للمعايير American National Standards Institute والمنظمة الدولية للمعايير International Organization for Standardization على معايير لغة SQL ونشروها، ما جعل منها اللغة المعترف بها لإدارة أنظمة قواعد البيانات العلاقيَّة.
ولعلّ انتشار استخدام النموذج العلاقيّ في مجموعة متنوعة من المجالات جعل منه النموذج المعياري لإدارة البيانات. وحتى مع ظهور العديد من قواعد البيانات غير العلاقية NoSQL في السنوات الأخيرة، تبقى قواعد البيانات العلاقية هي السائدة لتخزين وتنظيم البيانات.
كيف تنظم قواعد البيانات العلاقية البيانات
الآن وبعد حصولك على فهمٍ عام لتاريخ النموذج العلاقيّ، لنلقِ نظرة أعمق على كيفية تنظيم البيانات وفق هذا النموذج.
لعلّ أهم عناصر النموذج العلاقيّ هي العلاقات Relations، والتي تُعرف لدى المستخدمين وفي أنظمة إدارة قواعد البيانات العِلاقيَّة المعاصرة بمسمى الجداول Tabels. فالعلاقة هي مجموعة من الصفوف أو السجلات في جدول، ويشترك كل صف بمجموعة من السمات أو الأعمدة (الحقول):
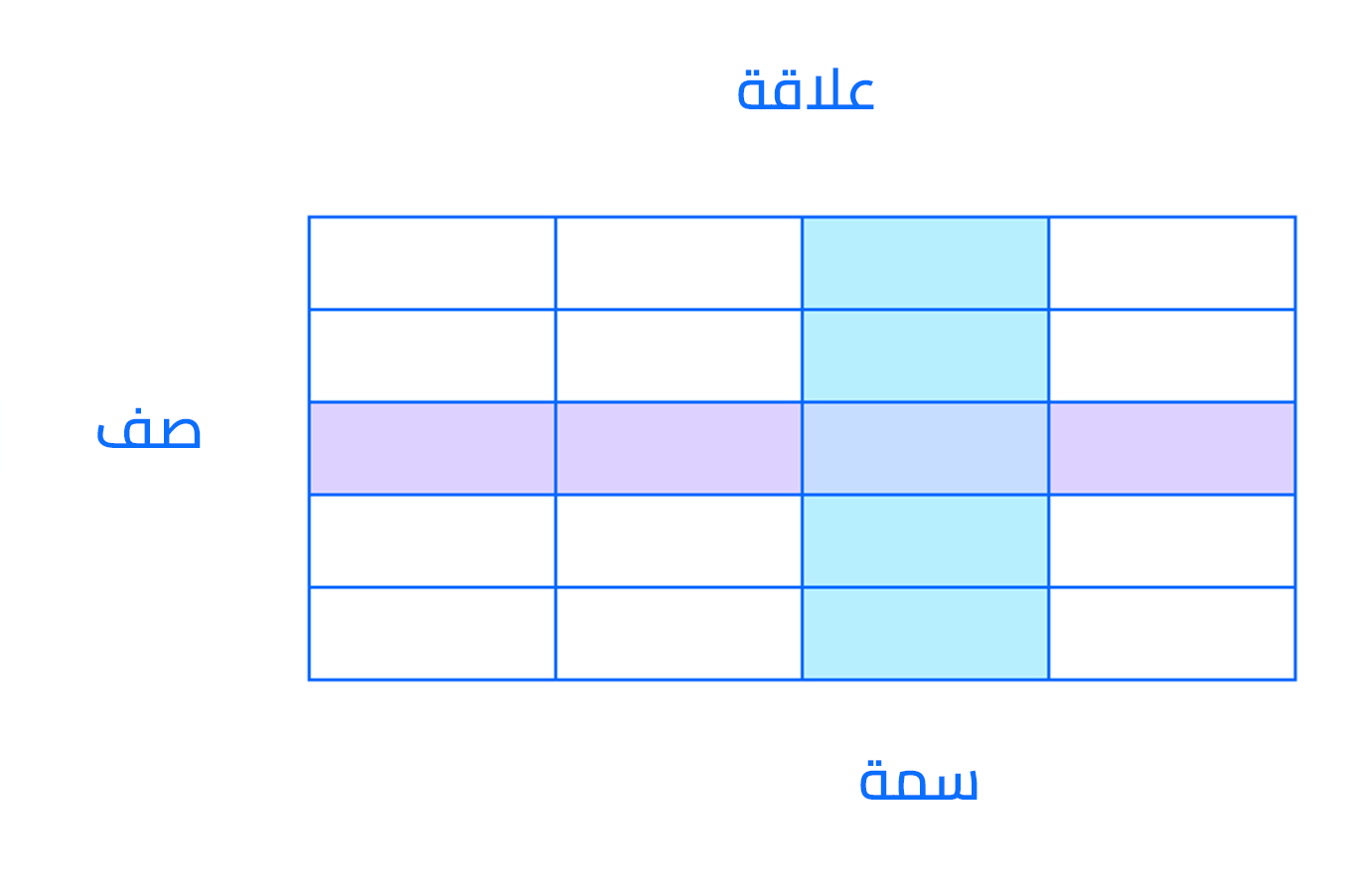
العمود هو أصغر هيكل تنظيمي في قاعدة البيانات العلاقيَّة، وهو يُمثّل الخصائص المختلفة التي تُعرّف السجلات ضمن الجدول. ولذا، تُعرف هذه الخصائص رسميًا باسم السمات. يمكن فهم كل صف على أنّه نسخة فريدة تًمثّل نوع ما من الأشخاص أو الكائنات أو الأحداث أو الروابط المحفوظة في الجدول. وقد تُمثّل هذه النسخ موظفي شركة أو مبيعات شركة تجارية عبر الإنترنت أو نتائج اختبارات مخبرية. على سبيل المثال، في جدول يحتوي على سجلات المدرسين في مدرسة ما، قد تتضمن الصفوف سمات مثل: الاسم name والمقررات الدراسية subjects وتاريخ بدء العمل start_date، وما إلى ذلك.
ولدى إنشاء الأعمدة، يتعيّن عليك تحديد نمط البيانات الخاص بكل عمود، وهو ما يُحدّد القيم التي يمكن استقبالها فيه. وعادةً ما تُقدّم أنظمة إدارة قواعد البيانات العِلاقيَّة أنماطًا فريدة خاصة بها من البيانات والتي قد لا تكون متوافقة مباشرةً مع مثيلاتها في الأنظمة الأخرى. ومن أنماط البيانات شائعة الاستخدام كل من التواريخ، والسلاسل النصية، والأعداد الصحيحة، والقيم المنطقية.
يتضمّن كل جدول في النموذج العِلاقيّ عمودًا واحدًا على الأقل يُستخدم لتمييز كل سجل على نحوٍ فريد، ويُعرف باسم المفتاح الأساسي Primary Key. وهو عمود مهم جدًا، إذ لا يحتاج المستخدمون لمعرفة مكان تخزين بياناتهم فيزيائيًا داخل الجهاز. وبدلاً من ذلك، يتولى نظام إدارة قواعد البيانات متابعة وتعقّب كل سجل واسترجاعه حسب الطلب. وبالتالي، لا يوجد ترتيب منطقي مُحدّد للسجلات، ويتمتّع المستخدمون بالحرية في استرجاع بياناتهم بالترتيب الذي يرغبون به أو باستخدام عوامل التصفية التي يختارونها.
فبفرض كان لديك جدولين وتود ربطهما ببعضهما البعض، فإحدى الطرق لإنجاز ذلك هي باستخدام المفتاح الخارجي Foreign key، وهو نسخة من المفتاح الأساسي لجدول (يُعرف بالجدول "الأب") تُدرج في عمود داخل جدول آخر (يُعرف بالجدول "الابن").
يُظهر المثال التالي العلاقة بين جدولين، الأول يُستخدم لتسجيل المعلومات حول الموظفين في شركة، والثاني لتتبع مبيعات الشركة. وفي هذا المثال، يُستخدم المفتاح الأساسي لجدول الموظفين EMPLOYEES كمفتاح أجنبي لجدول المبيعات SALES:
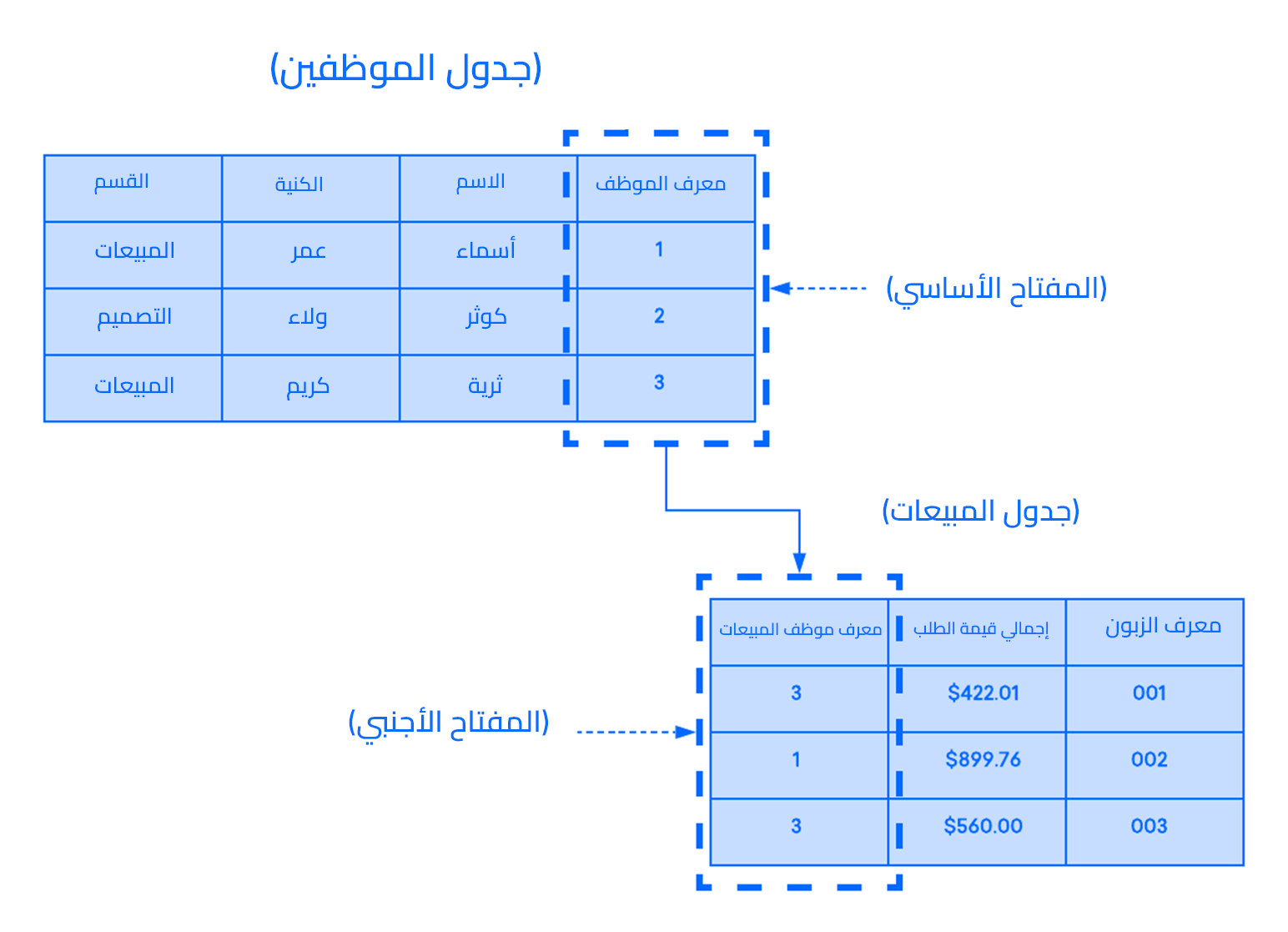
فإذا حاولت إضافة سجل إلى الجدول الابن وكانت القيمة المُدخلة في عمود المفتاح الأجنبي غير موجودة في المفتاح الأساسي للجدول الأب، فإن تعليمة الإدراج ستكون غير صالحة، وهذا يساعد في الحفاظ على صحّة مستوى العلاقة بين الجدولين (أو نزاهة العلاقة إن صح التعبير)، وبهذا ستكون السجلات في الجدولين مرتبطة على النحو الصحيح دائمًا.
لقد ساعدت عناصر النموذج العلاقيّ الهيكلية في الحفاظ على تنظيم البيانات أثناء تخزينها، ولكن تخزين البيانات لن يكون مفيدًا إلا إذا كان من الممكن استرجاعها. ولاسترجاع البيانات من RDBMS، يُمكنك إنشاء ما يُسمّى بالاستعلام query وهو عبارة عن طلب منظّم لمجموعة من المعلومات. وتستخدم معظم قواعد البيانات العِلاقيَّة لغة SQL لإدارة البيانات والاستعلام عنها كما أشرنا سابقًا. إذ تتيح لغة SQL إمكانية تصفية نتائج الاستعلام ومعالجتها باستخدام مجموعة من البنى clauses، والجمل الشرطية predicates التي تقيم كصحيح TRUE أو خاطئ FALSE أو غير معروف، والتعبيرات expressions، ما يمنحك التحكم الدقيق في البيانات التي ستظهر ضمن نتائج الاستعلام.
مزايا وقيود قواعد البيانات العلاقية
لنفكّر في بعض مزايا وعيوب قواعد البيانات العلاقيَّة بأخذ هيكلها التنظيمي الأساسي في الحسبان.
إنّ لغة SQL وقواعد البيانات التي تستخدمها في أيامنا هذه تختلف عما قدمه العالم كود Codd في نموذجه العلاقيّ الأول في عدة نواحٍ. فعلى سبيل المثال، يملي نموذج كود Codd بأنّ كل سجل في الجدول يجب أن يكون فريدًا. في حين تسمح العديد من قواعد البيانات العلاقيَّة المعاصرة بوجود سجلات مكررة. وهناك بالمقابل من يرى أن قواعد البيانات التي تستخدم لغة SQL ولا تتبع جميع مواصفات نموذج Codd لا يمكن عدها قواعد بيانات علاقيَّة حقيقية. ولكن وفي الواقع، أي نظام يستخدم SQL ويتبع نموذج Codd إلى حد معين يعدّ عادةً نظامًا لإدارة قواعد بيانات علاقيَّة.
ورغم شهرة قواعد البيانات العِلاقيَّة التي ازدادت بسرعة، إلا أنّ بعض أوجه القصور المتعلقة في النموذج العِلاقيّ بدأت بالظهور مع تزايد قيمة البيانات وتوجه الشركات لتخزين كميات أكبر منها. ومن هذه التحديات والمعوقات، صعوبة توسيع قاعدة البيانات العلاقيَّة أفقيًا. والمقصود بالتوسع الأفقي أو الخارجي عملية إضافة المزيد من الأجهزة إلى نظام حالي لتوزيع الحمولة واستيعاب حركة مرور أكبر وتحقيق معالجة أسرع. وغالبًا ما تُقارن هذه العملية بالتوسع العمودي، الذي يتضمن تحسين مواصفات الخادم الحالي من خلال توسيع ذاكرة الوصول العشوائي RAM أو وحدة المعالجة المركزية CPU.
والسبب وراء صعوبة توسيع قاعدة البيانات العلاقيَّة أفقيًا يعود إلى أنّ النموذج العلاقيّ مصمم لضمان الاتساق أو انسجام البيانات consistency، ما يعني أنّه عند استعلام العملاء ضمن قاعدة البيانات نفسها سيحصلون دائمًا على البيانات نفسها. فإذا قمت بتوسيع قاعدة البيانات العلاقيَّة أفقيًا عبر عدة أجهزة، سيصبح من الصعب ضمان هذا الاتساق، إذ قد يقوم العملاء بكتابة البيانات على عقدة معينة أو (جهاز) دون الباقي، وقد يكون هناك تأخير بين لحظة الكتابة الأولية والوقت الذي تُحدّث فيه العقد الأخرى لتعكس هذه التغييرات، ما يؤدي إلى عدم اتساق بينها.
لقد واجهت أنظمة إدارة قواعد البيانات العلاقيَّة بعض التحديات، من بينها أن النموذج العلاقيّ قد صُمّم خصيصًا للتعامل مع البيانات المهيكلة structured data، أي البيانات التي تتوافق مع نمط بيانات مُحدد مسبقًا أو على الأقل تلك المُنظمّة على نحوٍ مُحدد. لكن مع انتشار الحواسيب الشخصية وظهور الإنترنت في أوائل التسعينات، أصبحت البيانات غير المهيكلة unstructured data، كالرسائل الإلكترونية والصور والفيديوهات أكثر شيوعًا.
لا يعني كل ذلك أن قواعد البيانات العلاقيَّة باتت غير مفيدة. بل على العكس تمامًا، فالنموذج العلاقيّ ما زال هو الإطار السائد لإدارة البيانات منذ أكثر من 40 عامًا. وتدلّ شهرتها واستمراريتها على أنّ قواعد البيانات العلاقيَّة تقنية ناضجة، وهذا بحد ذاته من أبرز مزاياها.
هناك العديد من التطبيقات التي صُممت للعمل مع النموذج العِلاقيّ، بالإضافة إلى وجود العديد من مدراء قواعد البيانات المحترفين الخبراء في مجال قواعد البيانات العلاقيَّة. كما تتوفر مجموعة واسعة من الموارد المطبوعة والإلكترونية متاحة لكل من يرغب في بدء التعامل مع قواعد البيانات العِلاقيَّة.
ومن مميزات قواعد البيانات العلاقيَّة دعم معظمها لمجموعة من التعاملات transactions التي تضمن سلامة البيانات وتكاملها. والمعاملة transaction هي مجموعة من أوامر SQL التي تُنفذ وفق تسلسل معيّن كوحدة عمل مُنفصلة. إذ تعتمد المعاملات على مبدأ الكل أو لا شيء، بمعنى أنّ كل أمر في المعاملة يجب أن يكون صحيحًا، وإلا ستُلغى المعاملة بالكامل وبهذا نضمن صحّة البيانات ودقتها (نزاهة البيانات) عند التعديل على عدة سجلات أو جداول في الوقت نفسه.
وأخيرًا، تعدّ قواعد البيانات العلاقيَّة مرنة للغاية. فقد استُخدمت في تطوير مجموعة واسعة من التطبيقات المختلفة، وتستمر في العمل بكفاءة حتى مع كميات ضخمة من البيانات. كما تعدّ لغة SQL قوية جدًا، إذ تتيح لك إمكانية إضافة وتعديل البيانات على نحوٍ فوري، بالإضافة إلى تغيير هيكلية تخطيط قواعد البيانات والجداول دون التأثير على البيانات الموجودة.
الخلاصة
تعرفنا في مقال اليوم على قواعد البيانات العلاقيَّة التي لا تزال وسيلة أساسية لإدارة وتخزين البيانات بعد أكثر من خمسين عامًا على وضع التصور الأولي لها، وذلك بفضل مرونتها وتصميمها الذي يضمن صحة البيانات ودقتها. وحتى مع ظهور قواعد البيانات غير العِلاقيَّة NoSQL في السنوات الأخيرة، لا زال فهم النموذج العلاقيّ ومعرفة كيفية التعامل مع أنظمة إدارة قواعد البيانات العلاقيَّة أمر أساسي لأي شخص يرغب في بناء التطبيقات المُعتمدة على قوة البيانات.
وللتعرّف على المزيد حول بعض من أنظمة إدارة قواعد البيانات العِلاقيَّة الأشهر، وقواعد البيانات عمومًا، ننصحكم بالرجوع إلى قسم قواعد البيانات من أكاديمية حسوب.
ترجمة -وبتصرف- للمقال Understanding Relational Databases لصاحبه Mark Drake.












أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.