

يُعد فلاسك إطار عمل يستخدم لغة البرمجة بايثون Python لبناء تطبيقات الويب، أما SQLite فهو محرّك قواعد بيانات يستخدم لغة البرمجة بايثون لتخزين بيانات تطبيق الويب. سنعمل في هذا المقال على تعديل تطبيق ويب مبني باستخدام فلاسك و SQLite من خلال إضافة علاقة من نوع متعدد-إلى-متعدد إليه.
يمكنك البدء بقراءة هذا المقال مباشرةً، إلّا أنّه متابعةٌ للمقال السابق، لذلك من الأفضل قراءة المقال السابق بدايةً، إذ بيّنا فيه طريقة إدارة قاعدة بيانات متعدّدة الجداول ذات علاقة واحد-إلى-متعدد من خلال إنشاء تطبيق لإدارة المهام، ويمكِّن هذا التطبيق مستخدميه من إضافة عناصر مهام جديدة وتصنيفها ضمن قوائم مختلفة مع إمكانية تعديل العناصر.
تُعرَّف علاقة قاعدة البيانات متعدّد-إلى-متعدّد على أنها علاقةٌ بين جدولين، إذ يمكن لأي سجلٍ من الجدولين الارتباط مع عدّة سجلات من الآخر، فمثلًا في تطبيق مدونة يمكن لجدول التدوينات posts أن يرتبط بعلاقة من نوع متعدد-إلى-متعدّد مع جدول أسماء المؤلفين (كُتَّاب التدوينات)، بمعنى أن كل تدوينة قد ترتبط بعدّة أسماء مؤلفين، وأيضًا قد يرتبط كل اسم مؤلف بعدّة تدوينات، وبالتالي فإنّ العلاقة ما بين التدوينات وأسماء المؤلفين هي علاقة متعدّد-إلى-متعدّد. أيُّ تطبيقٍ آخر من تطبيقات التواصل الاجتماعي هو مثالٌ آخر، إذ أن كل منشور قد يحتوي عدّة إشارات مرجعية، وكل إشارة مرجعية قد تتضمّن عدة منشورات.
ومع اتباع الخطوات الواردة في هذا المقال، سنضيف على تطبيق إدارة المهام المُنشأ سابقًا ميزة تخصيص عناصر المهام لمستخدمين مختلفين، وسندعو المستخدمين الذين خُصَّصت لهم مهام بالمُخَصَّصين؛ فبفرض لدينا عنصر مهام من قائمة المهام المنزلية وهو "تنظيف المطبخ"، والتي من الممكن تخصيصها لشخصين مُختلفين وليكونا مثلًا أحمد ومحمّد، فكل مهمّة يمكن أن تملك عدّة مُخَصَّصين وهم في مثالنا أحمد ومحمّد، وبالمقابل يمكن تخصيص عدّة مهام للمستخدم الواحد، فمن الممكن مثلًا تخصيص عدّة مهام لأحمد، وبذلك نجد أنّ العلاقة ما بين عناصر المهام والمُخَصَّصين هي فعليًا من نوع متعدّد-إلى-متعدّد.
سيُضاف إلى التطبيق مع نهاية هذا المقال وسم مُخصّص إلى Assigned to مع قائمة بأسماء المُخَصَّصين.
مستلزمات العمل
قبل المتابعة في هذا المقال لا بدّ من:
- توفُّر بيئة برمجة بايثون 3 محلية، وسنستدعي في مقالنا مجلد المشروع flask_todo المُنشأ مُسبقًا من الخطوات في المقال السابق.
- توفّر تطبيق إدارة المهام المُنجز في المقال السابق، وفي الخطوة الأولى من هذا المقال سيكون لديك الخيار إما باستنساخ التطبيق مُباشرةً دون إعداده من قبلك، أو اتباع الخطوات التفصيلية في المقال السابق لبناء التطبيق ومن ثمّ الإكمال في هذا المقال، كما يمكنك الحصول على الشيفرة الكاملة للتطبيق.
- يجب فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite.
الخطوة الأولى - إعداد تطبيق الويب الخاص بإدارة المهام سنُعدّ في هذه الخطوة تطبيق الويب الخاص بإدارة المهام ليكون جاهزاً لإجراء التعديلات عليه، ولكن إذا كنت قد اتبعت الخطوات الواردة في المقال السابق (المذكور ضمن فقرة مستلزمات العمل من مقالنا هذا)، فستكون لديك شيفرة التطبيق إضافةً إلى البيئة الافتراضية مُفعلّةً على حاسوبك، وبإمكانك تجاوز هذه الخطوة مباشرةً.
سنستخدم لشرح آلية إضافة علاقة من النوع متعدّد-إلى-متعدّد لتطبيق ويب مبني باستخدام فلاسك شيفرة تطبيق إدارة المهام الذي أنشأناه سابقًا (راجع فقرة مستلزمات العمل) والمبني باستخدام فلاسك و SQLite وإطار العمل بوتستراب Bootstrap، إذ يمكِّن هذا التطبيق مستخدميه من إنشاء مهام جديدة وتعديلها وحذفها وتمييزها على أنها "مُنجزة".
بدايةً، استخدم الأمر Git لاستنساخ شيفرة تطبيق إدارة المهام المُنشأ سابقًا:
$ git clone https://github.com/do-community/flask-todo
بالانتقال إلى المجلد flask-todo:
$ cd flask_todo
سننشئ بيئة عمل افتراضية جديدة:
$ python -m venv env
ثمّ سنفعِّلها كما يلي:
$ source env/bin/activate
الآن، سنحمّل إطار فلاسك ونثبته باستخدام الأمر:
$ pip install Flask
ثمّ سنهيء قاعدة البيانات باستخدام البرنامج الموجود في الملف init_db.py:
(env)user@localhost:$ python init_db.py
بعد ذلك، سنسند القيم اللازمة إلى متغيرات بيئة فلاسك على النحو التالي:
(env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development
إذ يشير متغير البيئة FLASK_APP إلى تطبيق الويب الخاص بإدارة المهام الذي نطوّره في هذا المقال، والموجود في الملف app.py في حالتنا؛ بينما يشير المتغير FLASK_ENV إلى وضع بيئة العمل، وهنا أُسندت القيمة development للعمل بوضع تطوير التطبيق، ما يتيح تشغيل منقّح الأخطاء، ومن المهم تذكّر عدم استخدام هذا الوضع في مرحلة التشغيل الفعلي للتطبيق أي في بيئة الإنتاج.
سنشغّل خادم التطوير:
(env)user@localhost:$ flask run
يمكننا الآن الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح للوصول إلى التطبيق. ولإيقاف خادم التطوير، نستخدم الاختصار "CTRL + C".
أمّا الآن فسنطّلع على ملف تخطيط قاعدة البيانات لفهم بنية قاعدة البيانات الحالية والعلاقات ما بين الجداول فيها. إذا كنت قد اطلعت مُسبقًا من المقال السابق على الملف schema.sql وأصبح مألوفًا بالنسبة لك، فبإمكانك تجاوز هذه الخطوة.
سنفتح الملف schema.sql:
(env)user@localhost:$ nano schema.sql
فتظهر محتويات الملف على النحو التالي:
DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) );
وفيه جدولين، الأول lists لتخزين القوائم، مثل قائمة المهام المنزلية Home أو قائمة المهام الدراسية study، والثاني items لتخزين عناصر المهام، مثل مهمّة غسل الأطباق Do the dishes أو مهمّة تعلّم فلاسك Learn Flask.
ويحتوي جدول القوائم lists على الأعمدة التالية:
- "id": ويحتوي على معرّف ID القائمة.
- "created": يحتوي على تاريخ ووقت إنشاء قائمة المهام.
- "title": عنوان قائمة المهام.
أمّا جدول عناصر المهام، فيحتوي على الأعمدة التالية:
- "id": يحتوي على معرّف ID العنصر.
- "list_id": يحتوي على معرّف القائمة التي ينتمي إليها العنصر.
- "created": يحتوي تاريخ إنشاء العنصر.
- "content": محتوى العنصر.
- "done": يحدّد حالة عنصر المهام من حيث الإنجاز، إذ تدل القيمة "0" على أنّ المهمّة لم تُنجز بعد، أمّا القيمة "1" فتعني أنّ المهمّة قد أُنجزت.
ويتضمّن جدول العناصر items مفتاحًا أجنبيًا foreign key، إذ يشير العمود list_id إلى العمود id من جدول القوائم lists الأب، وهذا ما يمثّل علاقةً من النوع واحد-إلى-متعدّد one-to-many ما بين العناصر والقوائم، بمعنى أنّ القائمة الواحدة يمكن أن تضم عدّة عناصر في حين ينتمي كل عنصر لقائمة واحدة:
FOREIGN KEY (list_id) REFERENCES lists (id)
سنستخدم في الخطوة التالية العلاقة من نوع متعدّد-إلى-متعدّد للربط بين جدولين في قاعدة البيانات.
الخطوة الثانية - إضافة جدول المخصصين
سنستعرض في هذه الخطوة كيفية تطبيق علاقة من نوع متعدّد-إلى-متعدّد وكيفية دمج الجداول، ومن ثمّ سنضيف جدولًا جديدًا إلى قاعدة البيانات لتخزين المُخَصَّصين.
العلاقة من نوع متعدّد-إلى-متعدّد هي طريقةٌ لربط جدولين، بحيث يكون لكل عنصر من أحدهما عدّة علاقات مع عدّة عناصر من الجدول الآخر.
بفرض لدينا جدولٌ بسيط لعناصر المهام على النحو التالي:
Items +----+-------------------+ | id | content | +----+-------------------+ | 1 | Buy eggs | | 2 | Fix lighting | | 3 | Paint the bedroom | +----+-------------------+
وجدول للمُخَصَّصين على النحو التالي:
assignees +----+------+ | id | name | +----+------+ | 1 | Ahmad| | 2 | Mohammad | +----+------+
وعلى فرض أنّنا نريد تخصيص مهمّة إصلاح المصباح Fix lighting لكلٍ من أحمد ومحمّد، فمن الممكن إنجاز ذلك بإضافة صفٍ جديد لجدول العناصر كما يلي:
items +----+-------------------+-----------+ | id | content | assignees | +----+-------------------+-----------+ | 1 | Buy eggs | | | 2 | Fix lighting | 1, 2 | | 3 | Paint the bedroom | | +----+-------------------+-----------+
ولكن وبما أنّ كل عمود ينبغي أن يحتوي على قيمةٍ واحدة لضمان سلاسة العمليات، نجد أنّ المنهجية أعلاه خاطئة؛ فعند إسناد قيم متعدّدة للسجل الواحد في العمود، ستغدو العمليات الأساسية البسيطة، مثل إضافة، أو تحديث البيانات معقّدةً وبطيئة، والحل يكون باستخدام جدول ثالث يحوي أعمدةً تشير إلى المفاتيح الأساسية للجداول ذات الصلة، وهو ما ندعوه عادةً جدول الدمج join table، وهو يخزّن المعرّفات لكل عنصر في كل جدول.
وفيما يلي مثالٌ لجدول دمج يربط بين جدولي العناصر والمُخَصَّصين:
item_assignees +----+---------+-------------+ | id | item_id | assignee_id | +----+---------+-------------+ | 1 | 2 | 1 | | 2 | 2 | 2 | +----+---------+-------------+
ففي السطر الأوّل من جدول الدمج أعلاه، يرتبط العنصّر ذو المعرّف 2، الذي يمثّل مهمّة إصلاح المصباح Fix lighting مع المُخّصَّص ذو المعرّف 1 (أحمد)، أمّا في السطر الثاني فإنّ عنصر المهام نفسه يرتبط مع المُخّصَّص ذو المعرّف 2 (محمّد)، ما يعني أنّ عنصر المهام قد خُصِّص لكل من أحمد ومحمّد، ويمكننا تخصيص عدّة عناصر مهام على نحوٍ مشابه لشخص مُخَصَّص واحد.
سنعمل الآن على تعديل قاعدة بيانات تطبيق المهام لإضافة الجدول الذي يخزّن المُخَصَّصين.
لذا بدايةً، سنفتح ملف تخطيط قاعدة البيانات schema.sql لإضافة جدولٍ جديد باسم assignees:
(env)user@localhost:$ nano schema.sql
وسنضيف سطرًا برمجيًا لحذف أي جداول موجودة أصلًا في قاعدة البيانات باسم assignees، وهذا ما يجنبنا أي تضاربات قد تحصل مُستقبلًا نتيجة وجود جدولين بنفس الاسم وبأعمدة مُختلفة في قاعدة البيانات، والذي قد يؤدي لتوقف تنفيذ الشيفرة نتيجة عدم توافق الجدول الموجود مع تخطيط قاعدة البيانات.
الآن، سنضيف شيفرة SQL اللازمة للجدول الجديد:
DROP TABLE IF EXISTS assignees; DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); CREATE TABLE assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL );
اِحفظ الملف وأغلقه.
يحتوي جدول المُخَصَّصين assignees الجديد على الأعمدة التالية:
- "id": ويحتوي على معرّف ID المُخَصَّص.
- "name": يحتوي على اسم المُخَصَّص.
الآن، سنعدّل ملف تهيئة قاعدة البيانات init_db.py بغية إضافة بعض المُخَصَّصين إلى قاعدة البيانات:
(env)user@localhost:$ nano init_db.py
عدّل الملف ليصبح كما يلي:
import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Ahmad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Mohammad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('sami',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Yousef',)) connection.commit() connection.close()
اِحفظ الملف وأغلقه.
استخدمنا في الشيفرة السابقة كائن المؤشّر cursor لتنفيذ تعليمة INSERT في SQL اللازمة لإدخال أربعة أسماء إلى جدول المُخّصَّصين assignees، كما استخدمنا الموضع المؤقت ? في الدالة ()execute ومرّرنا له السجل الحاوي على اسم المُخَصًّص بما يضمن إدخال البيانات في قاعدة البيانات بأمان، ثمّ حفظنا التغييرات باستخدام الدالة ()connection.commit، وأُغلق الاتصال مع قاعدة البيانات باستخدام الدالة ()connection.close.
وبذلك سيُضاف أربعة مُخّصَّصين إلى قاعدة البيانات، أسماؤهم أحمد ومحمّد وسامي ويوسف.
الآن سنعيد تهيئة قاعدة البيانات بتشغيل البرنامج init_db.py:
(env)user@localhost:$ python init_db.py
وبذلك يصبح لدينا جدول لتخزين المُخّصَّصين في قاعدة البيانات. فيما يلي سنضيف جدول الدمج بهدف إنشاء علاقةٍ من نوع متعدّد-إلى-متعدّد بين عناصر المهام والمُخّصَّصين.
الخطوة الثالثة - إضافة جدول دمج ذو علاقة متعدد-إلى-متعدد
سنستخدم في هذه الخطوة جدول دمج لربط عناصر المهام بالمُخَصَّصين، لذا بدايةً سنعدّل ملف تخطيط قاعدة البيانات بغية إضافة جدول دمج جديد، كما سنعدّل ملف تهيئة قاعدة البيانات لإضافة بعض التخصيصات، أي تخصيص بعض عناصر المهام لبعض المُخَصَّصين، ثمّ سنستعرض المُخَصَّصين لكل مهمّة باستخدام برنامج تجريبي لفهم التغييرات الحاصلة في قاعدة البيانات.
سنفتح بدايةً ملف تخطيط قاعدة البيانات schema.sql لإضافة جدول جديد:
(env)user@localhost:$ nano schema.sql
وبما أنّ هذا الجدول يدمج العناصر مع المُخَصَّصين فسنسميه جدول عناصر مُخَصَّصين item_assignees، وسنضيف سطرًا برمجيًا لحذف أي جداول موجودة أصلًا في قاعدة البيانات بنفس الاسم، ومن ثمّ سنضيف شيفرة SQL اللازمة لهذا الجدول:
DROP TABLE IF EXISTS assignees; DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; DROP TABLE IF EXISTS item_assignees; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); CREATE TABLE assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL ); CREATE TABLE item_assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, item_id INTEGER, assignee_id INTEGER, FOREIGN KEY(item_id) REFERENCES items(id), FOREIGN KEY(assignee_id) REFERENCES assignees(id) );
اِحفظ الملف وأغلقه.
يحتوي جدول عناصر مُخَصَّصين item_assignees الجديد على الأعمدة التالية:
- "id": ويحتوي على معرّف ID المُدخَل والدال على العلاقة ما بين مهمّة ومُخَصَّص، إذ يمثّل كل سطر من هذا الجدول علاقةً ما بين مهمّة ومُخَصَّص.
- "item_id": ويحتوي على معرّف ID لعنصر المهام المُسند للمُخَصَّص ذا المعرّف "assignee_id" الموافق.
- "assignee_id": ويحتوي على معرّف ID للمُخَصَّص المُسند إليه عنصر المهام ذا المعرّف "item_id" الموافق.
ويملك الجدول item_assignees مفتاحين أجنبيين، الأول يربط عمود معرّف العنصر item_id في هذا الجدول مع عمود المعرّف id من جدول العناصر items، والثاني يربط عمود معرّف المُخَصَّص من هذا الجدول مع عمود المعرّف id من جدول المُخَصَّصين assignees.
والآن سنفتح ملف تهيئة قاعدة البيانات لإضافة بعض التخصيصات، أي إسناد مهام لمُخَصَّصين:
(env)user@localhost:$ nano init_db.py
وسنعدّل الملف ليصبح كما يلي:
import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) cur.execute("INSERT INTO assignees (name) VALUES (?)", (Ahmad,)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Mohammad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Sami',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Yousef',)) # Assign "Morning meeting" to "Ahmad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 1)) # Assign "Morning meeting" to "Mohammad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 2)) # Assign "Morning meeting" to "Yousef" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 4)) # Assign "Buy fruit" to "Ahmad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (2, 1)) connection.commit() connection.close()
يُخصِّص الجزء الجديد المُضاف إلى الشيفرة السابقة عناصر مهام إلى مُخَصَّصين وذلك بإدخال كل منهما في جدول الدمج item_assignees، بحيث نُدخل معرّف قائمة المهام item_id المُراد تخصيصها (إسنادها) مع معرّف الشخص (المُخَصَّص) الموافق assignee_id. فمثلًا، أسندنا في الشيفرة أعلاه مهمّة الاجتماع الصباحي Morning meeting ذات المعرّف 1 إلى المُخَصَّص Ahmad ذو المعرّف 1، وأكملنا الأسطر التالية وفق النمط ذاته، ومجدّدًا استخدمنا الموضع المؤقت ? لتمرير القيم المراد إدخالها على هيئة مجموعة إلى التابع ()cur.execute بأمان.
اِحفظ الملف وأغلقه.
الآن سنعيد تهيئة قاعدة البيانات مجدّدًا بتشغيل البرنامج في الملف init_db.py كما يلي:
(env)user@localhost:$ python init_db.py
ثم سنشغّل البرنامج التجريبي list_example.py، الذي يعرض عناصر المهام الموجودة في قاعدة البيانات:
(env)user@localhost:$ python list_example.py
ويكون الخرج على النحو التالي:
Home Buy fruit | id: 2 | done: 0 Cook dinner | id: 3 | done: 0 Study Learn Flask | id: 4 | done: 0 Learn SQLite | id: 5 | done: 0 Work Morning meeting | id: 1 | done: 0
نلاحظ من الخرج أنه يعرض كل عناصر المهام تحت القائمة التي يتبع لها، إضافةً لعرض معرّف وحالة كل عنصر (مُنجز / غير مُنجز)، إذ تدل القيمة 0 على عدم إنجازه بعد، أمّا القيمة 1 فتعني أنّه مُنجز.
الآن، سنعمل على عرض المُخَصَّصين لكل عنصر مهام، لذلك سنفتح الملف list_example.py:
(env)user@localhost:$ nano list_example.py
ونعدله بحيث يعرض المُخَصَّصين لكل عنصر مهام كما يلي:
from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): # Create an empty list for items items = [] # Go through each to-do item row in the groupby() grouper object for item in g: # Get the assignees of the current to-do item assignees = conn.execute('SELECT a.id, a.name FROM assignees a \ JOIN item_assignees i_a \ ON a.id = i_a.assignee_id \ WHERE i_a.item_id = ?', (item['id'],)).fetchall() # Convert the item row into a dictionary to add assignees item = dict(item) item['assignees'] = assignees items.append(item) # Build the list of dictionaries # the list's name (ex: Home/Study/Work) as the key # and a list of dictionaries of to-do items # belonging to that list as the value lists[k] = list(items) for list_, items in lists.items(): print(list_) for item in items: assignee_names = ', '.join(a['name'] for a in item['assignees']) print(' ', item['content'], '| id:', item['id'], '| done:', item['done'], '| assignees:', assignee_names)
اِحفظ الملف وأغلقه.
استخدمنا في الشيفرة السابقة دالة الفرز ()groupby لفرز عناصر المهام بحسب عناوين القوائم التي ينتمي لها كل عنصر (لمزيد من التفاصيل حول هذه النقطة يمكنك الاطلاع على الخطوة الثانية من مقال استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد، وخلال إجراء عملية الفرز السابقة، أنشأنا قائمةً فارغةً باسم items، وهي ستحتوي كافّة بيانات عناصر المهام، من معرّف العنصر ومحتواه والمُخَصَّص
ومن ثمّ نمر ضمن حلقة for المُخصّصة للعناصر وخلال g دورة (تكرار) على كافّة عناصر المهام لجلب المُخَصَّص لكل عنصر وحفظه ضمن المتغير assignees، الذي سيخزّن نتائج الاستعلام SELECT في SQL؛ إذ يجلب هذا الاستعلام معرّف المُخَصَّص a.id واسمه a.name من جدول المُخَصَّصين assignees (وقد رمزنا لهذا الجدول بالحرف a بهدف اختصار الاستعلام)، ثمّ يدمج معرّف واسم المُخَصَّص item_assignees المرتبط بالقائمة المطلوبة في جدول الدمج (رمزه المُختصَر i_a) وذلك من خلال تحقيق شرط كون معرّف المُخَصّص المأخوذ من جدول المُخَصَّصين مساويًا للمعرّف في جدول الدمج a.id = i_a.assignee_id وذلك عند كون قيمة معرّف عنصر المهام i_a.item_id في جدول الدمج مساويةً لقيمة معرّف العنصر الحالي ['item['id'، ومن ثمّ نحصل على نتائج الاستعلام ضمن قائمة باستخدام التابع()fetchall.
وبما أنّ كائن sqlite3.Row العادي لا يدعم مبدأ الإسناد، أضفنا السطر البرمجي التالي:
item = dict(item)
لتحويل العناصر إلى قواميس بايثون، والتي سنستخدمها لإضافة المُخَصَّصين إلى العناصر، ثمّ أضفنا مفتاحًا جديدًا وهو assignees إلى قاموس العناصر item باستخدام السطر البرمجي التالي:
item['assignees'] = assignees
وذلك بهدف الوصول إلى مُخَصَّصي العناصر مباشرةً من قاموس العناصر، ثمّ أضفنا العنصر المعدّل هذا إلى قائمة العناصر items، ثم بنينا قائمة القواميس المحتوية لكامل البيانات، فكل مفتاح ضمن القاموس يمثّل عنوان قائمة المهام وقيمة هذا المفتاح تضم كافّة العناصر التابعة لهذه القائمة.
أما لطباعة النتائج استُخدمت الحلقة:
for list_, items in lists.items()
للمرور على كافّة عناوين قوائم المهام والعناصر التابعة لكل منها، بحيث يُطبَع عنوان القائمة _list، ثمّ نمر باستخدام حلقة على كافّة العناصر التابعة لها؛ كما أُضيف متغيّرٌ باسم assignee_names، بحيث تستخدم قيمته دالة الدمج ()join لدمج العناصر الناتجة عن تعليمة البناء generator expression التالية، التي تجلب اسم المُخَصَّص ['a['name:
a['name'] for a in item['assignees']
مع بيانات هذا المُخَصَّص من القائمة ['item['assignees، وهذا ما يضمن إضافة أسماء المُخَصَّصين، ونهايةً تُطبع باقي بيانات عناصر المهام باستخدام الدالة ()print.
نشغِّل الآن البرنامج التجريبي list_example.py:
(env)user@localhost:$ python list_example.py
فيكون الخرج على النحو التالي:
Home Buy fruit | id: 2 | done: 0 | assignees: Ahmad Cook dinner | id: 3 | done: 0 | assignees: Study Learn Flask | id: 4 | done: 0 | assignees: Learn SQLite | id: 5 | done: 0 | assignees: Work Morning meeting | id: 1 | done: 0 | assignees: Ahmad, Mohammad, Yousef
وبذلك أصبح بالإمكان عرض المُخَصَّصين لكل عنصر مهام لكامل البيانات.
ومع نهاية هذه الخطوة، نكزن قد عرضنا أسماء المُخَصَّصين لكل عنصر مهام. سنستخدم هذه الشيفرة في الخطوة التالية لعرض أسماء المُخَصَّصين تحت كل عنصر مهام وذلك في الصفحة الرئيسية للتطبيق.
الخطوة الرابعة - عرض المخصصين في الصفحة الرئيسية للتطبيق سنعدّل في هذه الخطوة الصفحة الرئيسية لتطبيق إدارة المهام، بحيث تعرض المُخَصَّصين لكل عنصر مهام. سنعدّل بدايةً الملف app.py، الذي يحتوي على شيفرة تطبيق فلاسك، ثمّ سنعدّل القالب index.html لعرض المُخَصَّصين تحت كل عنصر مهام في الصفحة الرئيسية.
لذا، سنفتح الملف app.py لتعديل دالة فلاسك ()index:
(env)user@localhost:$ nano app.py
وسنعدّل الدالة لتصبح كما يلي:
@app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): # Create an empty list for items items = [] # Go through each to-do item row in the groupby() grouper object for item in g: # Get the assignees of the current to-do item assignees = conn.execute('SELECT a.id, a.name FROM assignees a \ JOIN item_assignees i_a \ ON a.id = i_a.assignee_id \ WHERE i_a.item_id = ?', (item['id'],)).fetchall() # Convert the item row into a dictionary to add assignees item = dict(item) item['assignees'] = assignees items.append(item) # Build the list of dictionaries # the list's name (ex: Home/Study/Work) as the key # and a list of dictionaries of to-do items # belonging to that list as the value lists[k] = list(items) conn.close() return render_template('index.html', lists=lists)
اِحفظ الملف وأغلقه.
الشيفرة السابقة مماثلةٌ لتلك المُستخدمة في البرنامج التجريبي list_example.py في الخطوة الثالثة، وباستخدامنا لها سيحتوي المتغير lists على كافّة البيانات التي نحتاج بما فيها بيانات المُخَصًّصين التي سنستخدمها في القالب index.html للوصول إلى أسمائهم.
لذا سنفتح الملف index.html:
(env)user@localhost:$ nano templates/index.html
ثم نعدّله بهدف إضافة أسماء المُخَصًّصين بعد كل عنصر ليصبح كما يلي:
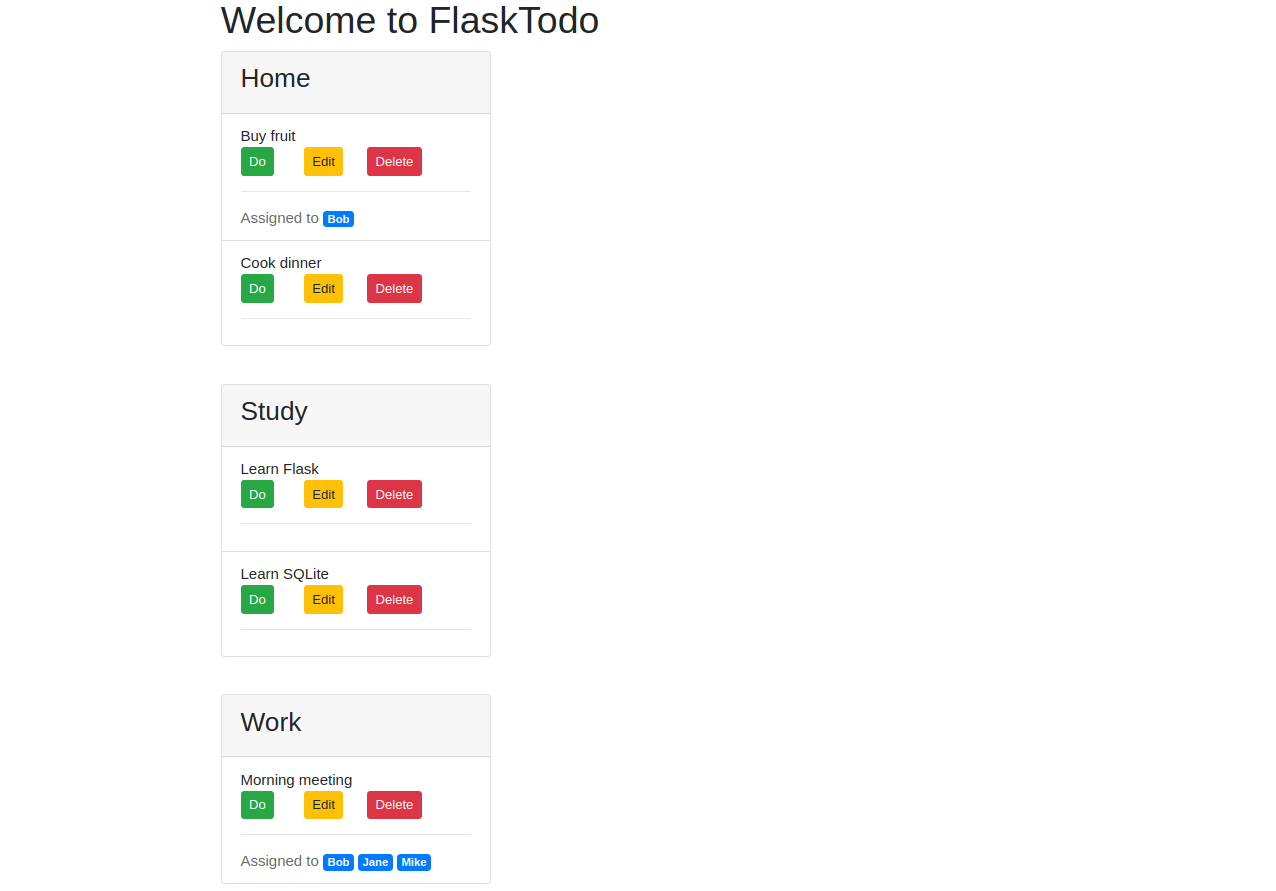
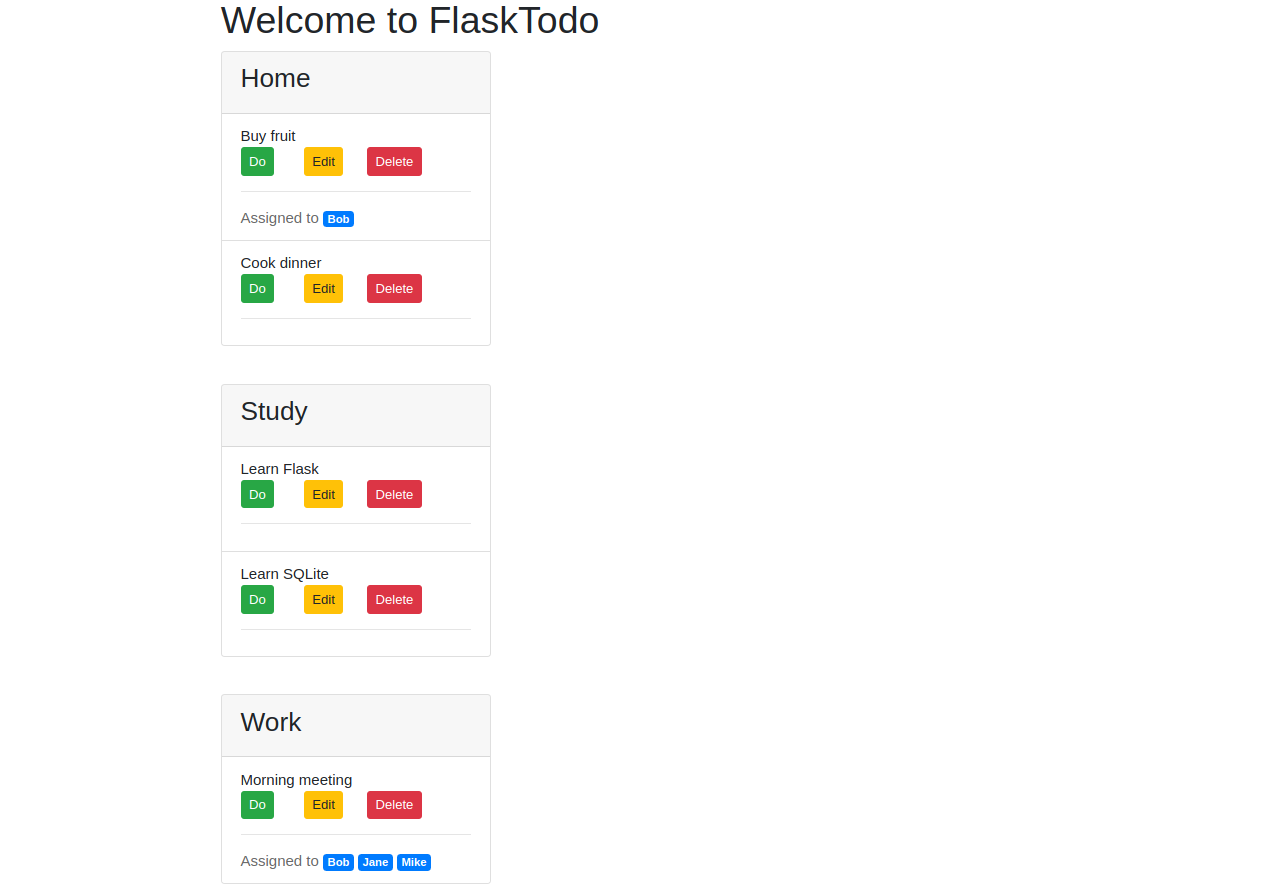
{% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item" {% if item['done'] %} style="text-decoration: line-through;" {% endif %} >{{ item['content'] }} {% if not item ['done'] %} {% set URL = 'do' %} {% set BUTTON = 'Do' %} {% else %} {% set URL = 'undo' %} {% set BUTTON = 'Undo' %} {% endif %} <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> <div class="col-12 col-md-3"> <form action="{{ url_for('delete', id=item['id']) }}" method="POST"> <input type="submit" value="Delete" class="btn btn-danger btn-sm"> </form> </div> </div> <hr> {% if item['assignees'] %} <span style="color: #6a6a6a">Assigned to</span> {% for assignee in item['assignees'] %} <span class="badge badge-primary"> {{ assignee['name'] }} </span> {% endfor %} {% endif %} </li> {% endfor %} </ul> </div> {% endfor %} {% endblock %}
اِحفظ الملف وأغلقه.
وبهذه التعديلات أعلاه نكون قد أضفنا فاصل أسطر تحت كل عنصر باستخدام وسم الفاصل الأفقي <hr>، وبالتالي في حال أُسندت مهامٌ معينة إلى مُخَصَّصين بواسطة التعليمة:
if item['assignees']
ستظهر عبارة Assigned to وإلى جانبها أسماء المُخَصَّصين ['assignee['name الموافقين من القائمة ['item['assignees
الآن، نشغِّل خادم التطوير:
(env)user@localhost:$ flask run
ونصل إلى الصفحة الرئيسية index للتطبيق من خلال الذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح.
وبذلك أصبح من الممكن إسناد المهمّة الواحدة إلى عدّة مُخَصَّصين وإسناد عدّة مهام للمُخَصًّص الواحد.
يمكنك الاطلاع على شيفرة التطبيق كاملةً.
الخاتمة
تعرفّنا في هذا المقال على علاقة قاعدة البيانات من نوع متعدّد-إلى-متعدّد، وكيفية استخدامها في تطبيق ويب مبني باستخدام فلاسك و SQLite، وكيفية دمج جدولين وفرز وتصنيف البيانات المترابطة باستخدام بايثون.
ومع نهاية هذا المقال نكون قد أنجزنا تطبيق إدارة المهام كاملًا، والذي يمكّن مستخدميه من إنشاء عناصر مهام جديدة، وتمييز المُنجز منها، مع إمكانية تعديل أو حذف المهام الموجودة أصلًا، وإنشاء قوائم جديدة، بحيث من الممكن تخصيص كل عنصر مهام إلى عدّة مُخَصَّصين.
ترجمة -وبتصرف- للمقال How To Use Many-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.