

يمكننا تخزين المعلومات في المتغيرات في برنامجنا وستبقى موجودة طالما استمر تشغيل البرنامج، لكنا ماذا لو أردنا الحفاظ على البيانات بعد انتهاء تنفيذ البرنامج؟ سنحتاج إلى حفظها إلى ملف؛ وسنتعلم في هذا المقال كيفية استخدام بايثون لإنشاء وقراءة وكتابة الملفات في حاسوبنا.
الملفات ومساراتها
يملك كل ملف خاصيتان أساسيتان: اسم الملف ومساره. يحدد مسار الملف أين سيظهر في حاسوبك، فمثلًا هنالك ملف في حاسوبي الذي يعمل بنظام ويندوز موجود اسمه project.docx في المسار C:\Users\Al\Documents.
الجزء الذي يلي اسم الملف ويأتي بعد النقطة يسمى بامتداد الملف file extension ويخبرنا ما هو نوع الملف، فمثلًا الملف project.docx هو مستند وورد؛ بينما تشير Users و Al و Documents إلى مجلدات.
يمكن أن تحتوي المجلدات على ملفات ومجلدات أخرى، فمثلًا الملف project.docx موجود في المجلد Documents الذي بدوره موجود في المجلد Al الموجود في المجلد Users. يوضح الشكل الآتي هذه البنية.
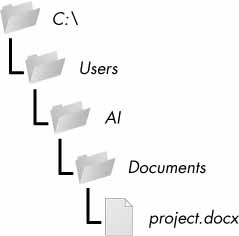
الشكل 1: ملف موجود في مجلد
الجزءC:\ من المسار يسمى بالمجلد الجذر root، أي يحتوي على جميع المجلدات الأخرى. وهو المجلد C:\ في نظام ويندوز أو يسمى القرص C:؛ أما في ماك أو لينكس فيكون المجلد الجذر هو /. سنستعمل في هذه السلسلة نمط مسارات ويندوز لأنها أكثر شيوعًا، لكن إن كنت تستعمل ماك أو لينكس فاستعمل بنية المسارات المناسبة لنظامك.
تظهر أجهزة التخزين الأخرى مثل أقراص DVD أو وسائط تخزين USB بطرائق مختلف حسب نظام التشغيل، ففي ويندوز ستظهر على شكل قرص جديد له حرف مختلف مثل D:/ أو E:/. بينما في ماك فستظهر كمجلد جديد في المجلد /Volumes، وفي لينكس ستظهر كمجلدات جديدة في المجلد /mnt (أو /media حسب التوزيعة عندك).
من المهم أن تلاحظ أن أسماء الملفات والمجلدات غير حساسة لحالة الأحرف في ويندوز وماك، لكنها حساسة لحالة الأحرف في لينكس.
ملاحظة: من المؤكد أن بنية المجلدات وأسماء الملفات في حاسوبك ونظام تشغيلك تختلف عمّا هو عندي، لذا لن تستطيع اتباع أمثلة هذه السلسلة حرفيًا. لكن جرب المتابعة على الملفات والمجلدات الموجودة عندك.
الخط المائل الخلفي \ في ويندوز والخط المائل الأمامي / في ماك ولينكس
تستعمل مسارات الملفات في أنظمة ويندوز الخط المائل الخلفي \ الذي يفصل بين أسماء المجلدات؛ أما في ماك ولينكس فيستعمل الخط المائل الأمامي / فاصلًا بين المجلدات؛ ولو أردت أن تعمل برامجك التي تكتبها على جميع الأنظمة (وهذا أمر مهم أنصحك به) فعليك أن تتعامل مع كلا الحالتين.
لحسن الحظ هنالك دالة في الوحدة pathlib باسم Path()، التي نمرر إليها سلاسل نصية بأسماء المجلدات والملف المطلوب، وستعيد الدالة Path() سلسلةً نصيةً لمسار الملف يستعمل الفاصل الصحيح بين المجلدات وفقًا لنظام التشغيل:
>>> from pathlib import Path >>> Path('spam', 'olive', 'eggs') WindowsPath('spam/olive/eggs') >>> str(Path('spam', 'olive', 'eggs')) 'spam\\olive\\eggs'
لاحظ أن من الشائع حين استيراد pathlib أن نكتب from pathlib import Path وإلا فسنحتاج إلى كتابة pathlib.Path في كل مرة نريد استعمال Path فيها.
سأشغل أمثلة هذا المقال على نظام ويندوز، لذا ستعيد الدالة Path('spam', 'olive', 'eggs') الكائن WindowsPath للمسار النهائي WindowsPath('spam/olive/eggs')؛ وصحيحٌ أن ويندوز يستعمل الخط المائل الخلفي في المسارات، لكن تمثيل الكائن WindowsPath في الطرفية التفاعلية يستعمل الخط المائل الأمامي، هذا لأن مطوري البرمجيات مفتوحة المصدر يفضلون نظام لينكس ويستعملون العادات الخاصة به أثناء التطوير.
إذا أردنا الحصول على سلسلة نصية من المسار، فيمكننا تمرير الكائن WindowsPath إلى الدالة str() التي ستعيد في مثالنا السلسلة النصية 'spam\\olive\\eggs'، لاحظ أن الخطوط المائلة الخلفية مضاعفة لأن كل خط مائل خلفي يحتاج إلى خطٍ مائل خلفي آخر لتهريبه.
إذا استخدمنا الدالة السابقة في نظام لينكس فستعيد كائن PosixPath، الذي حين تمريره إلى الدالة str() فسيعيد السلسلة النصية 'spam/olive/eggs' (كلمة POSIX تشير إلى مجموعة من المعايير الحاكمة للأنظمة الشبيهة بيونكس Unix-like مثل لينكس، إذا لم تجرب لينكس من قبل فأنصحك وبشدة أن تجربه).
يمكن تمرير كائنات Path (سواءً كانت WindowsPath أو PosixPath اعتمادًا على نظام تشغيلك) إلى دوال أخرى متعلقة بالتعامل مع الملفات والتي سنشرحها خلال هذا المقال.
المثال الآتي يولد مجموعة من مسارات الملفات في أحد المجلدات:
>>> from pathlib import Path >>> myFiles = ['accounts.txt', 'details.csv', 'invite.docx'] >>> for filename in myFiles: print(Path(r'C:\Users\Al', filename)) C:\Users\Al\accounts.txt C:\Users\Al\details.csv C:\Users\Al\invite.docx
يفصل الخط المائل الخلفي بين المجلدات في ويندوز، لذا لا يمكنك استخدامه في أسماء الملفات، لكنك تستطيع استخدام الخطوط المائلة الخلفية \ في ماك ولينكس، فبينما يشير المسار Path(r'spam\eggs') إلى مجلدين مختلفين (أو الملف eggs في المجلد spam) في ويندوز، لكنه يشير إلى مجلد أو ملف باسم spam\eggs في ماك ولينكس. لهذا السبب من المستحسن استخدام الخطوط المائلة الأمامية / في شيفرات بايثون دومًا، وسنفعل المثل في أمثلة المقال، وستضمن لنا الوحدة pathlib أن المسارات التي نستخدمها تعمل على جميع أنظمة التشغيل.
لاحظ أن الوحدة pathlib جديدة في بايثون 3.4 وأتت لتستبدل دوال os.path القديمة؛ وتدعمها دوال المكتبة القياسية في بايثون بدءًا من الإصدار 3.6. إذا كنت تعمل مع سكربتات مكتوبة بإصدار بايثون 2 فأنصحك أن تستعمل الوحدة pathlib2 التي توفر إمكانية pathlib في بايثون 2.7. يشرح المقال 1 خطوات تثبيت pathlib2 باستخدام pip.
سأوضح أي اختلافات واستخدامات للوحدة os حين الحاجة، فقد تستفيد منها حين قراءة السكربتات القديمة أو التي كتبها غيرك.
استخدام العامل / لجمع المسارات
نستخدم العامل + عادةً لجمع عددين كما في التعبير 2 + 2، الذي ينتج القيمة العددية 4، لكن يمكننا أيضًا استخدام العامل + لجمع سلسلتين نصيتين كما في التعبير 'Hello' + 'World' الذي ينتج السلسلة النصية 'HelloWorld'. وبشكل مشابه يستعمل العامل / للقسمة لكن يمكنه أيضًا أن يجمع بين كائنات Path والسلاسل النصية، وهو يفيد في التعامل مع كائنات Path التي أنشأناها سابقًا عبر الدالة Path():
>>> from pathlib import Path >>> Path('spam') / 'olive' / 'eggs' WindowsPath('spam/olive/eggs') >>> Path('spam') / Path('olive/eggs') WindowsPath('spam/olive/eggs') >>> Path('spam') / Path('olive', 'eggs') WindowsPath('spam/olive/eggs')
يسهل استخدام العامل / مع كائنات Path عملية جمع المسارات مع بعضها كما لو كانت سلاسل نصية بسيطة، واستخدامه أكثر أمانًا من إجراء عملية جمع للسلاسل النصية يدويًا أو عبر التابع join() كما في المثال الآتي:
>>> homeFolder = r'C:\Users\Al' >>> subFolder = 'spam' >>> homeFolder + '\\' + subFolder 'C:\\Users\\Al\\spam' >>> '\\'.join([homeFolder, subFolder]) 'C:\\Users\\Al\\spam'
الشيفرة السابقة ليست آمنة لأن الخطوط المائلة الخلفية لا تعمل إلا على ويندوز كما ناقشنا في الأقسام السابقة. يمكنك أن تضيف عبارةً شرطيةً if للتحقق من sys.platform (الذي يحتوي على سلسلة نصية تصف نظام التشغيل المستعمل) لتحديد ما هو نوع الخط المائل الذي نريد استخدامه. لكن استخدام هذه الشيفرة في كل مكان تريد التعامل مع مسارات الملفات فيه هو أمر متعب وغير متناسق ومن المرجح أن يسبب علل برمجية.
تحل الوحدة pathlib هذه المشاكل بإعادة استخدام معامل القسمة / ليجمع بين المسارات دون مشاكل بغض النظر عن نظام التشغيل المستعمل. يوضح المثال الآتي آلية استخدامه:
>>> homeFolder = Path('C:/Users/Al') >>> subFolder = Path('spam') >>> homeFolder / subFolder WindowsPath('C:/Users/Al/spam') >>> str(homeFolder / subFolder) 'C:\\Users\\Al\\spam'
أمر واحد مهم يجب أن نبقيه في ذهننا أثناء استخدام العامل / لجمع المسارات هو أن إحدى أول قيمتين من المسارات التي يجب جمعها يجب أن تكون كائن Path، وإلا فستظهر لك بايثون رسالة خطأ:
>>> 'spam' / 'olive' / 'eggs' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for /: 'str' and 'str'
تقيّم بايثون التعبير البرمجي الذي يستعمل العامل / من اليسار إلى اليمين إلى كائن Path، لهذا يجب أن يكون أول أو ثاني قيمة من اليسار من النوع Path لكي تستطيع إنتاج كائن Path من التعبير البرمجي. هذه هي آلية العمل التي تتبعها بايثون للحصول على كائن Path النهائي:
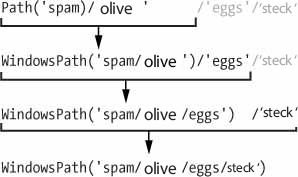
الشكل 2: آلية تفسير المسارات مع العامل /
إذا ظهرت رسالة الخطأ TypeError: unsupported operand type(s) for /: 'str' and 'str' فهذا يعني أن علينا وضع الكائن Path في الطرف الأيسر من التعبير البرمجي.
يستبدل العامل / الدالةَ os.path.join() التي يمكنك معرفة المزيد عنها من التوثيق الرسمي https://docs.python.org/3/library/os.path.html#os.path.join.
مجلد العمل الحالي
يملك كل برنامج تشغله على حاسوب ما يسمى «مجلد العمل الحالي» current working directory أو اختصارًا cwd؛ تفترض بايثون أن أي ملفات أو مسارات لا تبدأ بالمجلد الجذر هي موجودة في مجلد العمل الحالي.
ملاحظة: صحيح أننا نقول «مجلد» ترجمةً لكلمة directory التي تعني «موجِّه»، لكنها شائعة بين المستخدمين العرب أكثر؛ ولا أحد يقول current working folder. أغلبية الاصطلاحات البرمجية تستعمل directory بدلًا من folder، لذا ستجد هذه الكلمة مستعملةً في أسماء الدوال المشروحة تاليًا.
يمكننا الحصول على سلسلة نصية تمثل مجلد العمل الحالي باستخدام Path.cwd()، ويمكن تغييرها باستخدام os.chdir():
>>> from pathlib import Path >>> import os >>> Path.cwd() WindowsPath('C:/Users/Al/AppData/Local/Programs/Python/Python37')' >>> os.chdir('C:\\Windows\\System32') >>> Path.cwd() WindowsPath('C:/Windows/System32')
لاحظ أن مجلد العمل الحالي هو C:\Users\Al\AppData\Local\Programs\Python\Python37 لذا إذا استعملنا اسم الملف project.docx فإنه سيشير إلى المسار C:\Users\Al\AppData\Local\Programs\Python\Python37\project.docx. حينما بدلنا مجلد العمل الحالي إلى C:\Windows\System32 فسيفسر project.docx إلى المسار C:\Windows\System32\project.docx.
ستظهر بايثون رسالة خطأ حين محاولة تغيير مجلد العمل الحالي إلى مجلد غير موجود:
>>> os.chdir('C:/ThisFolderDoesNotExist') Traceback (most recent call last): File "<stdin>", line 1, in <module> FileNotFoundError: [WinError 2] The system cannot find the file specified: 'C:/ThisFolderDoesNotExist'
لا توجد دالة في pathlib لتغيير مجلد العمل الحالي، لأن تغييره أثناء تشغيل البرنامج قد يسبب علل برمجية نحن في غنى عنها.
الدالة os.getcwd() هي الطريقة القديمة للحصول على سلسلة نصية تمثل مجلد العمل الحالي.
مجلد المنزل
يمتلك جميع المستخدمون مجلدًا خاصًا بهم يسمى مجلد المنزل home directory، ويمكننا الحصول على كائن Path لمجلد المنزل باستدعاء Path.home():
>>> Path.home() WindowsPath('C:/Users/Al')
توجد مجلدات المنزل عادةً في مكان محدد يختلف حسب نظام تشغيلك:
-
في ويندوز تكون في
C:\Users. -
في ماك تكون في
/Users. -
في لينكس تكون في
/home.
من شبه المؤكد أن سكربتات بايثون التي تكتبها ستمتلك أذونات القراءة والكتابة في مجلد المنزل، لذا من المستحسن أن تضع الملفات التي ستعالجها عبر بايثون فيه.
المسارات النسبية والمسارات المطلقة
هنالك طريقتان لتحديد مسار ملف:
- مسار مطلق absolute path، الذي يبدأ من المجلد الجذر.
- مسار نسبي relative path، الذي يبدأ من مجلد العمل الحالي للبرنامج.
هنالك النقطة . والنقطتان .. حين التعامل مع المسارات، وهي ليست مجلدات حقيقة ولكنها أسماء خاصة، إذا تمثل النقطة . المجلد الحالي، بينما النقطتان .. تمثل المجلد الأب.
يوضح الشكل 3 بعض الملفات والمجلدات ويكون مجلد العمل الحالي فيه هو C:\olive، وفيه مسارات الملفات والمجلدات كلها المطلقة والنسبية.

الشكل 3: المسارات المطلقة والنسبية
لاحظ أن .\ في بداية المسارات النسبية اختيارية، إذ يشير .\spam.txt و spam.txt إلى نفس الملف.
إنشاء مجلدات جديدة باستخدام الدالة os.makedires()
يمكن لبرامجك إنشاء مجلدات جديدة باستخدام الدالة os.makedires():
>>> import os >>> os.makedirs('C:\\delicious\\walnut\\waffles')
سينتشئ المثال السابق المجلد C:\delicious وبداخله المجلد walnut وبداخله المجلد waffles. فالدالة os.makedires() ستنشِئ أي مجلدات لازمة غير موجودة مسبقًا.
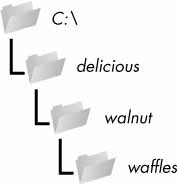
الشكل 4: ناتج تنفيذ os.makedirs('C:\delicious\walnut\waffles')
لإنشاء مجلد من كائن Path فيمكننا استدعاء التابع mkdir()، فمثلًا سأنشِئ المجلد spam في مجلد المنزل في حاسوبي:
>>> from pathlib import Path >>> Path(r'C:\Users\Al\spam').mkdir()
لاحظ أن التابع mkdir() يستطيع إنشاء مجلد واحد فقط، ولن ينشِئ مجلدات فرعية كما في الدالة os.makedirs().
التعامل مع المسارات النسبية والمطلقة
توفر الوحدة pathlib توابع للتحقق إن كان أحد المسارات نسبيًا أو مطلقًا، وتستطيع إعادة المسار المطلق من مسارٍ نسبي.
سيعيد استدعاء التابع is_absolute() على كائن Path القيمة True إذا كان يمثل مسارًا مطلقًا أو False إذا كان يمثل مسارًا نسبيًا. تذكر أن تستعمل مسارات موجودة في حاسوبك في الأمثلة القادمة:
>>> Path.cwd() WindowsPath('C:/Users/Al/AppData/Local/Programs/Python/Python37') >>> Path.cwd().is_absolute() True >>> Path('spam/olive/eggs').is_absolute() False
للحصول على مسار مطلق من مسار نسبي يمكننا وضع Path.cwd() / قبل كائن Path، فحينما نقول «مسار نسبي» فهذا يعني أن المسار منسوب إلى مجلد العمل الحالي:
>>> Path('my/relative/path') WindowsPath('my/relative/path') >>> Path.cwd() / Path('my/relative/path') WindowsPath('C:/Users/Al/AppData/Local/Programs/Python/Python37/my/relative/ path')
أما إذا كان المسار النسبي منسوب إلى مسار مختلف عن مجلد العمل الحالي، فعلينا تبديل Path.cwd() إلى ذاك المسار، ففي المثال الآتي سنحصل على المسار النسبي نسبةً إلى مجلد المنزل الخاص بنا بدلًا من مجلد العمل الحالي:
>>> Path('my/relative/path') WindowsPath('my/relative/path') >>> Path.home() / Path('my/relative/path') WindowsPath('C:/Users/Al/my/relative/path')
تمتلك الوحدة os.path عددًا من الدوال المفيدة المتعلقة بالمسارات النسبية والمطلقة:
-
ستعيد
os.path.abspath(path)سلسلةً نصية فيها المسار المطلق للوسيط الممرر إليها، وهذه أسهل طريقة لتحويل مسار نسبي إلى مسار مطلق. -
ستعيد
os.path.isabs(path)القيمةTrueإن كان الوسيط الممرر مسارًا مطلقًا وFalseإذا كان مسارًا نسبيًا. -
ستعيد os.path.relpath(path, start)
سلسلةً نصيةً للمسار النسبي للمسارpathبدءًا من المسارstart.إذا لم نوفر المعاملstartفسيستعمل مجلد العمل الحالي بدلًا منه.
لنجرب الدوال السابقة:
>>> os.path.abspath('.') 'C:\\Users\\Al\\AppData\\Local\\Programs\\Python\\Python37' >>> os.path.abspath('.\\Scripts') 'C:\\Users\\Al\\AppData\\Local\\Programs\\Python\\Python37\\Scripts' >>> os.path.isabs('.') False >>> os.path.isabs(os.path.abspath('.')) True
ولمّا كان المسار C:\Users\Al\AppData\Local\Programs\Python\Python37 هو مجلد العمل الحالي حين استدعاء الدالة os.path.abspath()، فسيكون المجلد . (نقطة واحدة) هو المسار المطلق لمجلد العمل الحالي 'C:\\Users\\Al\\AppData\\Local\\Programs\\Python\\Python37'.
لنجرب الدالة os.path.relpath() في الصدفة التفاعلية:
>>> os.path.relpath('C:\\Windows', 'C:\\') 'Windows' >>> os.path.relpath('C:\\Windows', 'C:\\spam\\eggs') '..\\..\\Windows'
إذا امتلك المسار النسبي نفس الأب لمجلد العمل الحالي كما في 'C:\\Windows' و 'C:\\spam\\eggs' فيمكن استخدام النقطتين .. للوصول إلى المجلد الأب.
الحصول على أقسام المسار
يمكننا استخلاص مختلف أقسام المسار عبر خاصيات الكائن Path، وهذا يفيدنا في حال أردنا إنشاء مسار جديد اعتمادًا على مسار ملف موجود مسبقًا. الشكل التالي يوضح هذه الخاصيات:
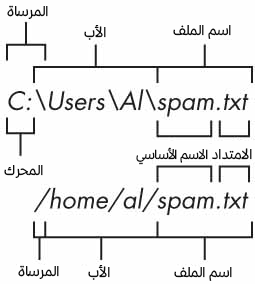
الشكل 5: أجزاء المسار (ويندوز في الأعلى، ولينكس أو ماك في الأسفل)
تتألف مسارات الملفات من الأقسام الآتية:
- المرساة anchor وهي المجلد الجذر root directory في نظام الملفات.
- المحرك drive في ويندوز وهو حرف واحد يشير إلى القرص المستخدم.
- الأب parent وهو مسار المجلد الذي يحتوي على الملف.
- اسم الملف name وهو يتألف من الاسم الأساسي stem والامتداد أو اللاحقة suffix.
لاحظ أن كائنات Path تمتلك الخاصية drive في ويندوز، لكنها غير موجودة في ماك أو لينكس. لاحظ أيضًا أن الخاصية drive لا تتضمن أول خط مائل خلفي.
لنجرب هذه الخاصيات على أحد المسارات:
>>> p = Path('C:/Users/Al/spam.txt') >>> p.anchor 'C:\\' >>> p.parent # لن يعيد سلسلة نصية بل كائن Path WindowsPath('C:/Users/Al') >>> p.name 'spam.txt' >>> p.stem 'spam' >>> p.suffix '.txt' >>> p.drive 'C:'
ستعيد هذه الخاصيات سلاسل نصية باستثناء الخاصية parent التي ستعيد كائن Path آخر.
تمنحنا الخاصية parents (التي تختلف عن الخاصية parent السابقة) وصولًا إلى كائنات Path للمجلدات الأب مع فهرس رقمي:
>>> Path.cwd() WindowsPath('C:/Users/Al/AppData/Local/Programs/Python/Python37') >>> Path.cwd().parents[0] WindowsPath('C:/Users/Al/AppData/Local/Programs/Python') >>> Path.cwd().parents[1] WindowsPath('C:/Users/Al/AppData/Local/Programs') >>> Path.cwd().parents[2] WindowsPath('C:/Users/Al/AppData/Local') >>> Path.cwd().parents[3] WindowsPath('C:/Users/Al/AppData') >>> Path.cwd().parents[4] WindowsPath('C:/Users/Al') >>> Path.cwd().parents[5] WindowsPath('C:/Users') >>> Path.cwd().parents[6] WindowsPath('C:/')
تمتلك الوحدة os.path القديمة دوال مشابهة لما سبق للحصول على مختلف أقسام المسارات كسلسلة نصية.
ستعيد الدالة os.path.dirname(path) سلسلةً نصيةً فيها كل ما يسبق آخر خط مائل في المعامل path، بينما ستعيد os.path.basename(path) سلسلةً نصيةً فيها كل ما يلي آخر خط مائل في المعامل path. الشكل 6 يوضح مخرجات الدالتين السابقتين:
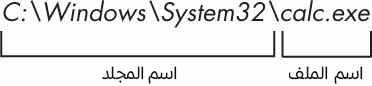
الشكل 6: اسم المجلد dirname واسم الملف basename في الوحدة os.path
لنجربها عمليًا في الطرفية التفاعلية:
>>> calcFilePath = 'C:\\Windows\\System32\\calc.exe' >>> os.path.basename(calcFilePath) 'calc.exe' >>> os.path.dirname(calcFilePath) 'C:\\Windows\\System32'
إذا احتجت إلى اسم المجلد واسم الملف معًا، فيمكنك استدعاء الدالة os.path.split() للحصول على صف فيه سلسلتين نصيتين كما يلي:
>>> calcFilePath = 'C:\\Windows\\System32\\calc.exe' >>> os.path.split(calcFilePath) ('C:\\Windows\\System32', 'calc.exe')
لاحظ أنك تستطيع إنشاء نفس الصف السابق باستدعاء الدالتين os.path.dirname() و os.path.basename() بنفسك:
>>> (os.path.dirname(calcFilePath), os.path.basename(calcFilePath)) ('C:\\Windows\\System32', 'calc.exe')
لكن استخدام os.path.split() سيوفر عليك بعض الوقت أحيانًا.
لاحظ أن الدالة os.path.split() لا تأخذ مسار أحد الملفات وتعيد قائمةً من السلاسل النصية تمثل كل مجلد، وإنما علينا استخدام الدالة split() الخاصة بالسلاسل النصية وتقسيم المسار عند كل فاصل os.sep (لاحظ أن الفاصل sep موجود في os وليس os.path). يتمثل المتغير os.sep الفاصل بين المجلدات في نظام التشغيل المستخدم، وهو '\\' في ويندوز و '/' في ماك ولينكس:
>>> calcFilePath.split(os.sep) ['C:', 'Windows', 'System32', 'calc.exe']
سعيد المثال السابق جميع أقسام المسار كقائمة من السلاسل النصية.
سيكون أول عنصر في القائمة المعادة في أنظمة ماك ولينكس هو سلسلة نصية فارغة:
>>> '/usr/bin'.split(os. sep) ['', 'usr', 'bin']
الحصول على حجم ملف ومحتويات مجلد
بعد أن تعلمنا كيف نتعامل مع مسارات الملفات والمجلدات، يمكننا أن نبدأ بجمع المعلومات حولها. توفر الوحدة os.path ما يلزم لمعرفة الحجم التخزيني لملفٍ ما بالبايت، أو للملفات والمجلدات الموجودة في مجلد معين.
-
استدعاء
os.path.getsize(path)سيعيد الحجم التخزيني للملف الموجود في المسارpathبالبايت. -
استدعاء
os.listdir(path)سيعيد قائمة list فيها أسماء كل الملفات الموجودة في المسارpath، لاحظ أننا استعملنا هنا الوحدةosوليسos.path.
لنجرب هذه الدوال في الطرفية التفاعلية:
>>> os.path.getsize('C:\\Windows\\System32\\calc.exe') 27648 >>> os.listdir('C:\\Windows\\System32') ['0409', '12520437.cpx', '12520850.cpx', '5U877.ax', 'aaclient.dll', --snip-- 'xwtpdui.dll', 'xwtpw32.dll', 'zh-CN', 'zh-HK', 'zh-TW', 'zipfldr.dll']
كما هو واضح، حجم الملف calc.exe في حاسوبي هو 27,648 بايت، ولدي الكثير من الملفات في المسار C:\Windows\system32، وإذا أردت الحصول على الحجم التخزيني لكل الملفات في هذا المجلد فسأستخدم os.path.getsize() و os.listdir() معًا.
>>> totalSize = 0 >>> for filename in os.listdir('C:\\Windows\\System32'): totalSize = totalSize + os.path.getsize(os.path.join('C:\\Windows\\System32', filename)) >>> print(totalSize) 2559970473
سأمر بحلقة التكرار على كل ملف موجود في المجلد C:\Windows\System32 وسأزيد قيمة المتغير totalSize بمقدار الحجم التخزيني لكل ملف، لاحظ أنه حين استدعاء os.path.getsize() فنستخدم os.path.join() لإضافة اسم المجلد إلى اسم الملف الحالي.
ستضاف القيمة العددية المعادة من os.path.getsize() إلى قيمة totalSize، وبعد إنهاء المرور على جميع الملفات فسنطبع قيمة totalSize لمعرفة حجم المجلد C:\Windows\System32 التخزيني.
الحصول على قائمة من الملفات التي تطابق نمطًا معينًا باستخدام glob()
إذا أردت العمل على ملفات محددة فمن الأسهل استخدام التابع glob() بدلًا من listdir()، إذ تملك كائنات Path التابع glob() للحصول على قائمة الملفات الموجودة داخل مجلد وفقًا لنمط يسمى Glob pattern، والتي تعرف أيضًا بالمحارف البديلة wildcard characters وهي نسخة مبسطة من التعابير النمطية التي يشيع استخدامها في سطر الأوامر (وتسمى هناك بالتوسعات expansion).
يعيد التابع glob() كائنًا مولدًا generator object (وهو خارج عن سياق هذا الكتاب)، الذي يمكننا تمريره إلى الدالة list() لتسهيل التعامل معه:
>>> p = Path('C:/Users/Al/Desktop') >>> p.glob('*') <generator object Path.glob at 0x000002A6E389DED0> >>> list(p.glob('*')) [WindowsPath('C:/Users/Al/Desktop/1.png'), WindowsPath('C:/Users/Al/ Desktop/22-ap.pdf'), WindowsPath('C:/Users/Al/Desktop/cat.jpg'), --snip-- WindowsPath('C:/Users/Al/Desktop/zzz.txt')]
رمز النجمة * يعني "مجموعة من أي نوع من المحارف"، وبالتالي سيعيد p.glob('*') مولدًا فيه جميع الملفات الموجودة في المسار المخزن في p. وكما في التعابير النمطية، يمكننا كتابة أنماط معقدة بعض الشيء:
>>> list(p.glob('*.txt') # قائمة بكل الملفات النصية [WindowsPath('C:/Users/Al/Desktop/foo.txt'), --snip-- WindowsPath('C:/Users/Al/Desktop/zzz.txt')]
سيعيد النمط '*.txt' كل الملفات التي تبدأ بأي مجموعة من المحارف طالما أنها تنتهي بالسلسلة النصية '.txt'، وهو عادةً امتداد الملفات النصية. أما رمز إشارة الاستفهام ? فيعني أي محرف واحد:
>>> list(p.glob('project?.docx') [WindowsPath('C:/Users/Al/Desktop/project1.docx'), WindowsPath('C:/Users/Al/ Desktop/project2.docx'), --snip-- WindowsPath('C:/Users/Al/Desktop/project9.docx')]
التعبير 'project?.docx' سيعيد 'project1.docx' أو 'project5.docx'، لكنه لن يطابق 'project10.docx' لأن رمز علامة الاستفهام ? سيطابق محرفًا واحدًا فقط، لذا لن يستطيع مطابقة محرفين '10'.
يمكنك أن تستعمل رمز النجمة وعلامة الاستفهام معًا لإنشاء تعابير مخصصة مثل:
>>> list(p.glob('*.?x?') [WindowsPath('C:/Users/Al/Desktop/calc.exe'), WindowsPath('C:/Users/Al/ Desktop/foo.txt'), --snip-- WindowsPath('C:/Users/Al/Desktop/zzz.txt')]
التعبير '*.?x?' سيعيد جميع الملفات التي لها أي اسم لكنها تنتهي بلاحقة تتألف من 3 محارف، والمحرف الوسط بينها هو 'x'.
يسهل علينا التابع glob() تحديد الملفات التي نريدها باختيار الملفات التي يطابق اسمها نمطًا معينًا. سنستخدم هنا الحلقة for للمرور على المولد generator المولد من التابع glob():
>>> p = Path('C:/Users/Al/Desktop') >>> for textFilePathObj in p.glob('*.txt'): ... print(textFilePathObj) # طباعة كائن Path كسلسلة نصية ... # معالجة الملف النصي ... C:\Users\Al\Desktop\foo.txt C:\Users\Al\Desktop\spam.txt C:\Users\Al\Desktop\zzz.txt
إذا أردت إجراء نفس العملية على جميع الملفات الموجودة في المجلد، فيمكنك أن تستعمل حينها os.listdir(p) أو p.glob('*').
التأكد من المسارات
ستفشل أغلبية دوال بايثون التي تتعامل مع الملفات إذا أعطيناها مسارًا غير موجود، لكن لحسن الحظ هنالك توابع لكائنات Path للتحقق أن المسار المعطى موجود فعلًا، وهل هو ملف أم مجلد. فعلى فرض أن المتغير p يشير إلى كائن Path، فبالتالي سيعيد استدعاء:
-
p.exists() القيمة
Trueإذا كان المسار موجودًا، أوFalseإن لم يكن موجودًا. -
p.is_file() القيمة
Trueإن كان المسار موجودًا ويشير إلى ملف، أوFalseخلاف ذلك. -
p.is_dir() القيمة
Trueإذا كان المسار موجودًا ويشير إلى مجلد، أوFalseخلاف ذلك.
دعني أجرب هذه التوابع على حاسوبي الشخصي:
>>> winDir = Path('C:/Windows') >>> notExistsDir = Path('C:/This/Folder/Does/Not/Exist') >>> calcFile = Path('C:/Windows /System32/calc.exe') >>> winDir.exists() True >>> winDir.is_dir() True >>> notExistsDir.exists() False >>> calcFile.is_file() True >>> calcFile.is_dir() False
إذا كنت تستعمل ويندوز فيمكنك أن تتحقق إن كان قرص التخزين المؤقت («الفلاشة») موصولًا إلى الحاسوب عبر التابع exists()، فمثلًا لو أردت التحقق أن القرص المسمى D:`` موجود على حاسوبي:
>>> dDrive = Path('D:/') >>> dDrive.exists() False
يبدو أنني نسيت وصل القرص إلى الحاسوب.
الوحدة القديمة os.path تستطيع إنجاز نفس المهمة باستخدام os.path.exists(path) و os.path.isfile(path) و os.path.isdir(path)، التي تعمل ملف مكافأتها في كائنات Path. وبدءًا من الإصدار بايثون 3.6 أصبحت تقبل هذه التوابع كائنات Path إضافةً إلى سلاسل نصية تحتوي على مسارات الملفات.
عملية قراءة الملفات والكتابة إليها
بعد أن تصبح مرتاحًا بالتعامل مع المجلدات والمسارات النسبية، فستتمكن من تحديد موقع الملفات التي تريد قراءتها أو الكتابة إليها.
الدوال التي سنشرحها في الأقسام الآتية تعمل على الملفات النصية البسيطة، التي هي ملفات تحتوي على محارف نصية دون أن تحتوي على معلومات التنسيقات مثل الخطوط أو الألوان أو خلاف ذلك، ومن الأمثلة على الملفات النصية البسيطة هي ملفات txt أو py التي تحتوي على شيفرات بايثون. يمكن فتح هذه الملفات باستخدام المفكرة Notepad في ويندوز، أو TextEdit في ماك، أو Kate أو Gedit في لينكس. وتستطيع أن تفتح هذه الملفات في برامجك وتعاملها كسلاسل نصية عادية.
الملفات الثنائية هي نوع آخر من الملفات، مثل الملفات التي تنتجها برامج إنشاء العروض التقديمية أو ملفات PDF أو الصور أو الملفات التنفيدية …إلخ. وإذا فتحتها بالمفكرة مثلًا فستجد أنها مجموعة من الرموز غير المفهومة:
الشكل 7: برنامج calc.exe مفتوح في المفكرة
ولأن كل نوع من الملفات الثنائية يجري التعامل معه بطريقة مختلفة، فلن ندخل بتفاصيل تعديل الملفات الثانية مباشرةً في هذا الكتاب؛ وهنالك وحدات تسهل التعامل معها مثل الوحدة shelve التي ستتعامل معها لاحقًا في هذا المقال.
التابع read_text() في الوحدة pathlib تعيد سلسلةً نصية فيها كل محتويات الملف النصي، بينما يكتب التابع write_text() ما يمرر إليه إلى ملف نصي جديد (أو يعيد الكتابة فوق ملف موجود مسبقًا):
>>> from pathlib import Path >>> p = Path('spam.txt') >>> p.write_text('Hello, world!') 13 >>> p.read_text() 'Hello, world!'
سننشئ ملفًا باسم spam.txt فيه المحتويات 'Hello, world!'، لاحظ أن التابع write_text() قد أعاد الرقم 13 الذي يشير إلى عدد المحارف التي كتبت إلى الملف (ونتجاهل تخزين هذا الرقم عادةً)، ويقرأ التابع read_text() محتويات الملف الجديد ويعيدها على شكل سلسلة نصية.
تذكر أن توابع الكائن Path توفر الأمور الأساسية في التعامل مع الملفات؛ والطريقة الأشيع لقراءة الملفات تكون عبر الدالة open() والكائن File. هنالك خطوات ثلاث لقراءة أو كتابة الملفات في بايثون:
-
استدعاء الدالة
open()لإعادة الكائنFile. -
استدعاء التابع
read()أوwrite()على الكائنFile. -
إغلاق الملف باستدعاء التابع
close()على الكائنFile.
سنشرح هذه الخطوات في الأقسام الآتية.
فتح الملفات عبر الدالة open()
لفتح ملف باستخدام الدالة open() فنمرر سلسلة نصية تحتوي على مسار الملف الذي نريد فتحه؛ والذي يكون إما مسارًا مطلقًا absolute أو نسبيًا relative. ستعيد الدالة open() كائنًا من النوع File.
لنجربها بإنشاء ملف نصي بسيط اسمه hello.txt باستخدام المفكرة أو أي محرر نصوص، وكتابة Hello, World! داخلها وحفظه في مجلد المنزل، ثم كتابة ما يلي في الطرفية التفاعلية:
>>> helloFile = open(Path.home() / 'hello.txt')
تقبل الدالة open() السلاسل النصية أيضًا، فإذا كنت تستخدم ويندوز فاكتب:
>>> helloFile = open('C:\\Users\\your_home_folder\\hello.txt')
أما إذا كان نظامك ماك:
>>> helloFile = open('/Users/your_home_folder/hello.txt')
تذكر أن تبدل الكلمة yourhomefolder باسم المستخدم في حاسوبك، فلو كان hsoub مثلًا فستدخل 'C:\\Users\\hsoub\\hello.txt' في ويندوز؛ لاحظ أن الدالة open() أصبحت تقبل كائنات Path بدءًا من إصدار بايثون 3.6، وكان عليك استخدام السلاسل النصية فقط فيما سبق.
ستفتح هذه الأوامر الملف في وضع "قراءة الملفات النصية" أو اختصارًا "وضع القراءة"، وحينما يفتح الملف في وضع القراءة فتسمح لنا بايثون بقراءة الملفات من الملف فقط، ولا يمكنك أن تكتب عليه أو تعدله بأي شكل. لكن إذا أردت أن تحدد أنك تريد فتح الملف بوضع القراءة بوضوح فمرر القيمة 'r' كثاني وسيط إلى الدالة open()، أي أن open('/Users/Al/hello.txt', 'r') و open('/Users/Al/hello.txt') متكافئتان تمامًا.
سيعيد استدعاء الدالة open() كائن File، ويمثل كائن File ملفًا على حاسوبك، وهو نوع مختلف من القيم في بايثون مثله كمثل القوائم أو القواميس التي تعرفت عليها مسبقًا.
خزنّا في المثال السابق كائن File في المتغير helloFile، ويمكنك أن تستسخدمه لأي عمليات قراءة أو كتابة مستقبلًا باستدعاء التوابع المناسبة على الكائن File المخزن في المتغير helloFile.
قراءة محتويات الملفات
أصبح لدينا الآن كائن File، ويمكننا أن نبدأ بقراءة كامل محتويات الملف كسلسلة نصية، وذلك عبر التابع read()، لنكمل مثالنا السابق الذي فيه المتغير helloFile بكتابة ما يلي:
>>> helloContent = helloFile.read() >>> helloContent 'Hello, world!'
لو تخيلت أن جميع محتويات الملف هي سلسلة نصية كبيرة، فإن التابع read() يعيد تلك السلسلة النصية.
بدلًا من ذلك، يمكنك استخدام التابع readlines() للحصول على قائمة list فيها سلاسل نصية من الملف، وكل سلسلة نصية تمثل سطرًا فيه، فمثلًا لو كان لدينا ملف اسمه sonnet29.txt في نفس المجلد الذي فيه الملف hello.txt وكتبنا فيه النص الآتي:
When, in disgrace with fortune and men's eyes, I all alone beweep my outcast state, And trouble deaf heaven with my bootless cries, And look upon myself and curse my fate,
تأكد أنك قد فصلت بين الأسطر الأربعة السابقة كلٌ في سطر مختلف، ثم أدخل ما يلي في الطرفية التفاعلية:
>>> sonnetFile = open(Path.home() / 'sonnet29.txt') >>> sonnetFile.readlines() [When, in disgrace with fortune and men's eyes,\n', ' I all alone beweep my outcast state,\n', And trouble deaf heaven with my bootless cries,\n', And look upon myself and curse my fate,']
لاحظ أن كل عنصر من عناصر القائمة (باستثناء آخر واحد) هو سلسلة نصية تنتهي بمحرف السطر الجديد \n.
يكون في العادة من الأسهل التعامل مع قائمة من السلاسل النصية بدل سلسلة نصية واحدة كبيرة.
الكتابة إلى الملفات
تسمح لنا بايثون بكتابة محتوى إلى الملفات بشكل يشبه "كتابة" الدالة print() للسلاسل النصية إلى الشاشة.
لا يمكنك أن تكتب إلى ملف قد فتحته بوضع القراءة، لذا عليك أن تفتحه بوضع "الكتابة على الملفات النصية" أو "الإضافة إلى الملفات النصية" واختصارًا وضع الكتابة أو وضع الإضافة.
وضع الكتابة سيعيد الكتابة فوق ملف موجود ويبدأ من الصفر، كما لو أعدنا إسناد قيمة جديدة إلى متغير. يمكنك فتحت الملف بوضع الكتابة بتمرير 'w' كثاني وسيط إلى الدالة open().
أما وضع الإضافة فسيضيف النص إلى نهاية ملف موجود مسبقًا، كما لو أضفنا عنصرًا إلى قائمة موجودة في متغير بدلًا من إعادة الكتابة. مرر 'a' كثاني وسيط إلى الدالة open() لفتح الملف في وضع الإضافة.
إذا لم يكن الملف الممرر إلى الدالة open() موجودًا فسينشأ ملف جديد في وضع الكتابة والإسناد. لا تنسَ أن تستدعي الدالة close() قبل إعادة فتح الملف مجددًا.
لنجرب هذه المفاهيم معًا بكتابة:
>>> oliveFile = open('olive.txt', 'w') >>> oliveFile.write('Hello, world!\n') 13 >>> oliveFile.close() >>> oliveFile = open('olive.txt', 'a') >>> oliveFile.write('Olive is not a vegetable.') 25 >>> oliveFile.close() >>> oliveFile = open('olive.txt') >>> content = oliveFile.read() >>> oliveFile.close() >>> print(content) Hello, world! Olive is not a vegetable.
في البداية فتحنا الملف becon.txt بوضع الكتابة، ولعدم وجود الملف becon.txt بعد فإن بايثون تنشئه لنا، واستدعاء التابع write() وتمرير السلسلة النصية 'Hello, world! /n' سيؤدي إلى كتابتها إلى الملف وإعادة عدد المحارف المكتوبة بما فيها محرف السطر الجديد. ثم أغلقنا في النهاية الملف.
لإضافة نص إلى المحتويات الموجودة لملف بدلًا من استبداله، فسنفتح الملف في وضع الإضافة، وأضفنا السلسلة النصية 'Olive is not a vegetable.' إلى الملف وأغلقناه.
في النهاية نريد أن نطبع محتويات الملف فاستخدمنا الدالة open() لفتح الملف في الوضع الافتراضي وهو وضع القراءة، وخزنّا محتويات الملف في المتغير content ثم أغلقنا الملف وطبعنا محتوياته.
لاحظ أن التابع write() لا يضيف محرف السطر الجديد إلى نهاية السلسلة النصية مثلما تفعل الدالة print() لذا عليك أن تضيفه بنفسك. تذكر أنك تستطيع تمرير كائن Path إلى الدالة open() بدلًا من سلسلة نصية بسيطة بدءًا من إصدار بايثون 3.6.
حفظ المتغيرات باستخدام الوحدة shelve
يمكنك أن تحفظ المتغيرات الموجودة في برامجك إلى ملفات ثنائية باستخدام الوحدة shelve، وبالتالي يمكنك أن تستعيد البيانات إلى المتغيرات من ملف مخزن على حاسوبك.
تسمح لك الوحدة shelve بحفظ واستعادة البيانات إلى برنامجك، فلو ضبطتَ مثلًا بعض المتغيرات في برنامجك، يمكنك أن تحفظ تلك البيانات على الرف (shelf، ومن هنا أتى اسم الوحدة) ثم تستعيد تلك القيم حينما تشغل برنامجك مجددًا.
>>> import shelve >>> shelfFile = shelve.open('mydata') >>> cats = ['Zophie', 'Pooka', 'Simon'] >>> shelfFile['cats'] = cats >>> shelfFile.close()
لقراءة وكتابة البيانات باستخدام الوحدة shelve عليك أن تستوردها أولًا، ثم تستدعي shelve.open() وتمرر إليها اسم الملف ثم تخزن القيم. لاحظ أنك تستطيع التعامل مع القيم كما لو أنها قاموس. بعد أن تنتهي لا تنسَ استدعاء close().
أنشأنا في المثال السابق القائمة cats وكتبنا shelfFile['cats'] = cats لتخزين القائمة في shelfFile كقيمة مرتبطة مع المفتاح 'cat' (كما في مفاتيح القواميس). ثم استدعينا close() على shelfFile، لاحظ أنه بدءًا من إصدار بايثون 3.7 سيكون عليك تمرير أسماء الملفات إلى open() كسلاسل نصية، ولا يمكنك تمرير كائن Path.
بعد تشغيل الشيفرة السابقة في ويندوز، ستجد ثلاثة ملفات جديدة في المجلد وهي mydata.bak و mydata.dat و mydata.dir؛ أما على ماك فسينشَأ ملف واحد باسم mydata.db.
تحتوي هذه الملفات الثنائية على البيانات التي خزنتها «على الرف»؛ ولا تهمك صيغة هذه الملفات الثانية، فكل ما تحتاج إلى معرفته هو ما تفعله الوحدة shelve وليس كيف تفعل ذلك. وهذه الوحدة تريح رأسك من القلق حول كيفية تخزين البرنامج للبيانات.
يمكن لبرامجك استخدام الوحدة shelve لإعادة فتح الملف والحصول على البيانات، ولا حاجة إلى تحديد إن كنت تريد قراءة البيانات أم كتابتها، ففتح الملف يسمح بكلي العمليتين.
>>> shelfFile = shelve.open('mydata') >>> type(shelfFile) <class 'shelve.DbfilenameShelf'> >>> shelfFile['cats'] ['Zophie', 'Pooka', 'Simon'] >>> shelfFile.close()
فتحنا في المثال السابق الملف الذي وضعنا فيه البيانات، وتأكدنا أن التخزين سليم إذ أعاد shelfFile['cats'] نفس القائمة التي خزناها سابقًا، وفي النهاية أغلقنا الملف close().
هنالك تابعان اسمهما keys() و values() تشبه تلك الموجودة في القواميس التي تعيد قيمةً شبيهة بالقوائم list-like للمفاتيح والقيم الموجودة في الرف. ولأن هذه التوابع تعيد قيمًا شبيهة بالقوائم وليست قوائم حقيقية فيجب عليك تمريرها إلى الدالة list() للحصول على قائمة حقيقية تتعامل معها.
>>> shelfFile = shelve.open('mydata') >>> list(shelfFile.keys()) ['cats'] >>> list(shelfFile.values()) [['Zophie', 'Pooka', 'Simon']] >>> shelfFile.close()
الخلاصة أن الملفات النصية البسيطة مفيدة لتخزين البيانات النصية الأساسية، أما لو أردت حفظ بيانات من برنامج بايثون الذي كتبته، فيمكنك أن تستفيد من الوحدة shelve.
حفظ المتغيرات مع الدالة pprint.pformat()
إذا كنت تذكر في قسم «تجميل الطباعة» أن الدالة pprint.pprint() تطبع محتويات قائمة أو قاموس بتنسيق مخصص، بينما الدالة pprint.pformat() تنسق النص وتعيده بدلًا من طباعته مباشرةً.
وصحيحٌ أن النص المعاد من هذه الدالة سيكون منسقًا تنسيقًا جميلًا لتسهيل قراءته، لكنه في الواقع منسق كما لو أنه شفيرة بايثون.
لنقل مثلًا أن لديك قاموسًا مخزنًا في متغير وأردت حفظ هذا المتغير ومحتوياته للاستخدام مستقبلًا، فيمكنك أن تستفيد من الدالة pprint.pformat() لإعادة سلسلة نصية تكتبها إلى ملف .py ويمكنك أن تستورد هذا الملف في أي مرة تريد استخدام المتغير المخزن فيه.
>>> import pprint >>> cats = [{'name': 'Zophie', 'desc': 'chubby'}, {'name': 'Pooka', 'desc': 'fluffy'}] >>> pprint.pformat(cats) "[{'desc': 'chubby', 'name': 'Zophie'}, {'desc': 'fluffy', 'name': 'Pooka'}]" >>> fileObj = open('myCats.py', 'w') >>> fileObj.write('cats = ' + pprint.pformat(cats) + '\n') 83 >>> fileObj.close()
استوردنا في هذا المثال الوحدة pprint لكي نستطيع استخدام الدالة pprint.pformat()، ولدينا متغير cats فيه قائمة من القواميس؛ ولكي نحتفظ بالقائمة الموجودة في المتغير cats حتى بعد أن نغلق الصدفة التفاعلية فيمكننا استخدام الدالة pprint.pformat() لإعادته كسلسلة نصية، ثم بعد حصولنا على السلسلة النصية يمكننا كتابتها إلى ملف وليكن اسمه myCats.py.
تذكر أن الوحدات التي تستوردها العبارة import هي سكربتات بايثون عادية؛ وعندما نحفظ السلسلة النصية المأخوذة من pprint.pformat() إلى ملف .py فيمكن اعتبار هذا الملف على أنه وحدة يمكن استيرادها مثل أي وحدات بايثون الأخرى.
ولأن سكربتات بايثون هي ملفات نصية بسيط امتدادها .py فيمكن لبرامجك أن تولد برامج بايثون أخرى، ويمكنك استيراد تلك البرامج داخل برامجك:
>>> import myCats >>> myCats.cats [{'name': 'Zophie', 'desc': 'chubby'}, {'name': 'Pooka', 'desc': 'fluffy'}] >>> myCats.cats[0] {'name': 'Zophie', 'desc': 'chubby'} >>> myCats.cats[0]['name'] 'Zophie'
الفائدة من إنشاء ملف .py بسيط بدلًا من حفظ المتغيرات مع الوحدة shelve هو أن الناتج ملف نصي يمكن قراءته وتعديله من أي شخص بمحرر نصي بسيط.
لكن لأغلبية حالات الاستخدام يكون من المناسب حفظ البيانات باستخدام الوحدة shelve، إذا لا يمكن كتابة القيم إلى ملفات نصية بسيطة إلا إذا كانت قيمًا بسيطة مثل الأعداد والسلاسل النصية والقوائم والقواميس، بينما لا تستطيع تخزين الكائنات مثل File أو غيره كنص بسيط.
مشروع: توليد ملفات اختبارات عشوائية
لنفترض أنك أستاذ مادة الجغرافية ولديك 35 طالبًا في صفحك، وتريد إجراء اختبار لعواصم الولايات الأمريكية؛ وأنت تعرف طلابك حق المعرفة وتدرك أن بعضهم سيحاول أن يغش، لذا تريد أن تغيّر ترتيب الأسئلة في كل اختبار لكي تكون فريدة مما يجعل من الصعب جدًا نقل الإجابات من طالب آخر. عمل هذه النماذج يدويًا يأخذ وقتًا وجهدًا وسيكون أمرًا مملًا، لكن ستساعدك مهاراتك في بايثون هنا.
هذه هي وظيفة البرنامج:
- إنشاء 35 اختبار مختلف
- إنشاء 50 سؤال اختيار من إجابات متعددة لكل اختبار، بترتيب عشوائي
- توفير الإجابة الصحيحة وثلاث إجابات خطأ لكل سؤال مرتبة ترتيبًا عشوائيًا
- كتابة الاختبارات إلى 35 ملف نصي
- كتابة مفاتيح الإجابات الصحيحة إلى 35 ملف نصي
هذا يعني أن الشيفرة عليها أن:
- تخزن أسماء الولايات في أمريكا وأسماء عواصمها في قاموس
-
تستدعي
open()و write()و close()لكل ملف اختبار وإجابات -
تستخدم random.shuffle()
لترتيب الأسئلة والإجابات ترتيبًا عشوائيًا
الخطوة 1: تخزين بيانات الاختبار في قاموس
أول خطوة هي إنشاء بينة السكربت الأساسية وكتابة بيانات الاختبار. أنشِئ ملفًا باسم randomQuizGenerator.py وضع فيه المحتوى الآتي:
#! python3 # randomQuizGenerator.py - إنشاء اختبارات مع أسئلة وإجابات عشوائية # مع تخزين مفتاح الحل. ➊ import random # بيانات الاختبار: أسماء الولايات الأمريكية وعواصمها. ➋ capitals = {'Alabama': 'Montgomery', 'Alaska': 'Juneau', 'Arizona': 'Phoenix', 'Arkansas': 'Little Rock', 'California': 'Sacramento', 'Colorado': 'Denver', 'Connecticut': 'Hartford', 'Delaware': 'Dover', 'Florida': 'Tallahassee', 'Georgia': 'Atlanta', 'Hawaii': 'Honolulu', 'Idaho': 'Boise', 'Illinois': 'Springfield', 'Indiana': 'Indianapolis', 'Iowa': 'Des Moines', 'Kansas': 'Topeka', 'Kentucky': 'Frankfort', 'Louisiana': 'Baton Rouge', 'Maine': 'Augusta', 'Maryland': 'Annapolis', 'Massachusetts': 'Boston', 'Michigan': 'Lansing', 'Minnesota': 'Saint Paul', 'Mississippi': 'Jackson', 'Missouri': 'Jefferson City', 'Montana': 'Helena', 'Nebraska': 'Lincoln', 'Nevada': 'Carson City', 'New Hampshire': 'Concord', 'New Jersey': 'Trenton', 'New Mexico': 'Santa Fe', 'New York': 'Albany', 'North Carolina': 'Raleigh', 'North Dakota': 'Bismarck', 'Ohio': 'Columbus', 'Oklahoma': 'Oklahoma City', 'Oregon': 'Salem', 'Pennsylvania': 'Harrisburg', 'Rhode Island': 'Providence', 'South Carolina': 'Columbia', 'South Dakota': 'Pierre', 'Tennessee': 'Nashville', 'Texas': 'Austin', 'Utah': 'Salt Lake City', 'Vermont': 'Montpelier', 'Virginia': 'Richmond', 'Washington': 'Olympia', 'West Virginia': 'Charleston', 'Wisconsin': 'Madison', 'Wyoming': 'Cheyenne'} # توليد 35 اختبار عشوائي. ➌ for quizNum in range(35): # TODO: إنشاء ملفات الاختبار والإجابات. # TODO: كتابة ترويسة الاختبار. # TODO: تغيير ترتيب الولايات. # TODO: المرور على 50 سؤال وتوليد إجابات عشوائية.
لما كان هذا البرنامج يرتب الأسئلة والإجابات عشوائيًا، فعلينا استيراد الوحدة random ➊ لكي نستطيع استخدام الدوال الخاصة بها. يحتوي المتغير capitals ➋ على قاموس فيه أسماء الولايات الأمريكية كمفتاح وعاصمتها كقيمة. ولأننا نريد كتابة الشيفرة التي تولد ملفات الاختبار والإجابات (أضفناها على أنها TODO حاليًا) فسندخل إلى حلقة التكرار for بعدد 35 مرة ➌، ويمكننا تغيير الرقم وفق متطلبات البرنامج.
الخطوة 2: إنشاء ملف الاختبار وتغيير ترتيب الأسئلة عشوائيا
حان الوقت لبدء العمل على مهام TODO.
ستكرر الشيفرة الموجودة داخل حلقة for بعدد 35 مرة، مرة لكل اختبار، فعلينا أن نفكر بكيفية إنشاء اختبار واحدة وسيكرر الأمر على البقية.
بدايةً سنحتاج إلى إنشاء ملف الاختبار، ويجب أن يكون له اسم فريد، ويجب أن يحتوي على ترويسة قياسية فيها معلومات الاختبار ومكان ليضع الطالب اسمه وصفه وتاريخ اليوم. ثم ستكون هنالك قائمة الولايات بترتيب عشوائي، التي يمكن استخدامها لاحقًا لإنشاء الأسئلة والإجابات لكل اختبار.
أضف الأسطر الآتية إلى ملف randomQuizGenerator.py:
#! python3 # randomQuizGenerator.py - إنشاء اختبارات مع أسئلة وإجابات عشوائية # مع تخزين مفتاح الحل. --snip-- # توليد 35 اختبار عشوائي. for quizNum in range(35): # إنشاء ملف الاختبارات والإجابات ➊ quizFile = open(f'capitalsquiz{quizNum + 1}.txt', 'w') ➋ answerKeyFile = open(f'capitalsquiz_answers{quizNum + 1}.txt', 'w') # كتابة الترويسة ➌ quizFile.write('Name:\n\nDate:\n\nPeriod:\n\n') quizFile.write((' ' * 20) + f'State Capitals Quiz (Form{quizNum + 1})') quizFile.write('\n\n') # تغيير ترتيب الولايات states = list(capitals.keys()) ➍ random.shuffle(states) # TODO: المرور على 50 سؤال وتوليد إجابات عشوائية.
ستكون أسماء ملفات الاختبارات على الشكل capitalsquiz<N>.txt حيث <N> هو رقم فريد لكل اختبار يأتي من quizNum الذي هو عدّاد حلقة for. سيخزن ملف مفاتيح الإجابات للاختبار capitalsquiz<N>.txt في ملف باسم capitalsquiz_answers<N>.txt.
في كل دورة في حلقة for ستبدل قيمة {quizNum + 1} في f'capitalsquiz{quizNum + 1}.txt' و f'capitalsquiz_answers{quizNum + 1}.txt' برقم فريد، وستكون أسماء الملفات لأول مرور باسم capitalsquiz1.txt و capitalsquiz_answers1.txt. ستنشأ هذه الملفات حين استدعاء الدالة open() في السطرين ➊ و ➋ حين تمرير الوسيط الثاني 'w' لفتح الملفات في وضع الكتابة.
العبارات write() في القسم ➌ تكتب ترويسة الاختبار التي يجب على الطالب أن يملأها؛ ثم سننشِئ قائمة عشوائية فيها أسماء الولايات الأمريكية باستخدام الدالة random.shuffle() في السطر ➍، التي تغير ترتيب القيم في أي قائمة تمرر إليها.
الخطوة 3: إنشاء خيارات الإجابة
علينا الآن توليد خيارات إجابات كل سؤال، والتي ستكون اختيار من متعدد من A إلى D، أي أننا سنحتاج إلى إنشاء حلقة for أخرى لتوليد محتوى لكل سؤال من الأسئلة الخميس. ثم ستكون هنالك حلقة for ثالثة داخلها لتوليد الإجابات المحتملة لكل سؤال.
#! python3 # randomQuizGenerator.py - إنشاء اختبارات مع أسئلة وإجابات عشوائية # مع تخزين مفتاح الحل. --snip-- # المرور على الولايات الخمسين وتوليد سؤال لكل منها. for questionNum in range(50): # الحصول على الإجابات الصحيحة والخطأ. ➊ correctAnswer = capitals[states[questionNum]] ➋ wrongAnswers = list(capitals.values()) ➌ del wrongAnswers[wrongAnswers.index(correctAnswer)] ➍ wrongAnswers = random.sample(wrongAnswers, 3) ➎ answerOptions = wrongAnswers + [correctAnswer] ➏ random.shuffle(answerOptions) # TODO: كتابة السؤال والإجابات إلى ملف الاختبار # TODO: كتابة مفتاح الحل إلى ملف الحلول.
من السهل الحصول على الجواب الصحيحة، فهو القيمة المخزنة في القاموس capitals ➊. ستمر حلقة التكرار على جميع الولايات الموجودة ضمن قائمة states المرتبة عشوائيًا، من states[0] حتى states[49]، ويجد كل ولاية في capitals ثم يخزن الجواب الصحيح في المتغير correctAnswer.
عملية إنشاء قائمة بالإجابات الخطأ أصعب بقليل، عليك أولًا أن تنسخ جميع القيم في قاموس capitals ➋، ثم تحذف الجواب الصحيح ➌، ثم تأخذ ثلاث قيم عشوائية من القائمة ➍؛ وتسهل علينا الدالة random.sample() ذلك، وتأخذ وسيطين: الأول هو القائمة التي تريد الاختيار منها، والثاني هو عدد القيم التي تريدها.
ستكون القائمة النهائية هي الإضافة الصحيحة إضافةً إلى إجابات خطأ ثلاثة ➎، ثم علينا جعل الإجابات عشوائية ➏ كيلا تكون الإجابة D هي الإجابة الصحيحة دومًا.
الخطوة 4: كتابة المحتوى إلى ملفات الاختبارات والإجابات الصحيحة
كل ما بقي فعله هو كتابة السؤال إلى ملف الاختبار، وكتابة الإجابة إلى ملف الإجابات الصحيحة.
#! python3 # randomQuizGenerator.py - إنشاء اختبارات مع أسئلة وإجابات عشوائية # مع تخزين مفتاح الحل. --snip-- # المرور على الولايات الخمسين وتوليد سؤال لكل منها. for questionNum in range(50): --snip-- # كتابة السؤال والإجابات إلى ملف الاختبار. quizFile.write(f'{questionNum + 1}. What is the capital of {states[questionNum]}?\n') ➊ for i in range(4): ➋ quizFile.write(f" {'ABCD'[i]}. { answerOptions[i]}\n") quizFile.write('\n') # كتابة مفتاح الحل إلى ملف الحلول. ➌ answerKeyFile.write(f"{questionNum + 1}. {'ABCD'[answerOptions.index(correctAnswer)]}") quizFile.close() answerKeyFile.close()
تمر حلقة for على الأعداد 0 إلى 3 وتكتب الجواب في القائمة answerOptions ➊، أما التعبير 'ABCD'[i] في ➋ أن السلسلة النصية 'ABCD' ستعامل كمصفوفة وستكون قيمها هي 'A' ثم 'B' ثم 'C' ثم 'D' وفقًا لدورة حلقة التكرار.
في السطر الأخير ➌ سيعثر التعبير answerOptions.index(correctAnswer) على فهرس الإجابة الصحيحة في قائمة الإجابات المعشوائية، ثم ستكون نتيجة التعبير البرمجي 'ABCD'[answerOptions.index(correctAnswer)] هي حرف الجواب الصحيح الذي سيكتب في ملف الإجابات.
بعد أن تشغل البرنامج فسيبدو الملف capitalsquiz1.txt كما يلي، مع الانتباه إلى أن الناتج سيكون مختلفًا عما عندك لأننا نأخذ القيم عشوائيًا:
Name: Date: Period: State Capitals Quiz (Form 1) 1. What is the capital of West Virginia? A. Hartford B. Santa Fe C. Harrisburg D. Charleston 2. What is the capital of Colorado? A. Raleigh B. Harrisburg C. Denver D. Lincoln --snip--
وسيبدو ملف capitalsquiz_answers1.txt كما يلي:
1. D 2. C 3. A 4. C --snip--
مشروع: تحديث لمشروع الحافظة
لنعد كتابة مشروع الحافظة من المقال السابع من هذه السلسلة حول كيفية معالجة النصوص، لنستعمل الوحدة shelve، إذ سيتمكن المستخدم من حفظ سلاسل نصية جديدة وتحميلها إلى الحافظة دون تعديل الشيفرة المصدرية للتطبيق.
سنسمي مشروعنا mcb.pyw، فاختصار mcb هو multi-clipboard أي الحافظة المتعددة، والامتداد .pyw يعني أن بايثون لن تظهر نافذة الطرفية حين تشغيل البرنامج (راجع المقال الأول من السلسلة لمزيد من التفاصيل).
سيحفظ البرنامج المحتويات النصية للحافظة تحت كلمة مفتاحية معينة، فمثلًا لو شغلت py mcb.pyw save spam فستحفظ المحتويات الحالية للحافظة مع الكلمة المفتاحية spam، ويمكن إعادة تحميل النص إلى الحافظة مجددًا بتشغيل py mcb.pyw spam، وإذا نسي المستخدم ما الكلمات المفتاحية التي استخدمها فيمكنه تشغيل py mcb.pyw list لنسخ قائمة فيها جميع الكلمات المفتاحية إلى الحافظة.
هذه هي آلية عمل المشروع:
- التحقق من الوسيط الممرر عبر سطر الأوامر
- إذا كان save فستحفظ محتويات الحافظة إلى الكلمة المفتاحية المرسلة
- إذا كان list فستنسخ جميع الكلمات المفتاحية إلى الحافظة
- خلاف ذلك، سينسخ النص المرتبط بالكلمة المفتاحية إلى الحافظة.
هذا يعني أن على البرنامج:
-
قراءة وسائط سطر الأوامر من
sys.argv. - القراءة والكتابة إلى الحافظة.
-
حفظ وتحميل ملف
shelf.
إذا كنت تستخدم ويندوز، فيمكنك ببساطة تشغيل السكربت من نافذة Run بإنشاء ملف mcb.bat فيه المحتوى الآتي:
@pyw.exe C:\Python34\mcb.pyw %*
الخطوة 1: البنية الأساسية وضبط عملية الحفظ والتحميل
لنبدأ بكتابة الهيكل الأساسي للسكربت مع بعض التعليقات وضبط أساسي لعملية الحفظ والتحميل:
#! python3 # mcb.pyw - حفظ وتحميل نصوص إلى الحافظة. ➊ # Usage: py.exe mcb.pyw save <keyword> - حفظ الحاوية إلى keyword. # py.exe mcb.pyw <keyword> -تحميل محتويات keyword إلى الحاوية. # py.exe mcb.pyw list - تحميل كل الكلمات المفتاحية إلى الحاوية. ➋ import shelve, pyperclip, sys ➌ mcbShelf = shelve.open('mcb') # TODO: حفظ محتويات الحاوية. # TODO: إظهار كل الكلمات المفتاحية والمحتوى.
من الشائع أن نضع معلومات الاستخدام في تعليقات في أول الملف ➊، ففي حال نسيت طريقة تشغيل البرنامج فيمكنك أن تلقي نظرة سريعة على هذه التعليقات لتتذكر طريقة الاستخدام، ثم استوردنا الوحدات اللازمة ➋ فعملية النسخ واللصق إلى الحاوية تحتاج إلى الوحدة pyperclip، وقراءة وسائط سطر الأوامر تحتاج إلى الوحدة sys، وستفيدنا الوحدة shelve: فكل مرة يحفظ فيها المستخدم محتويات الحافظة فسنكتبها إلى ملف، وحينما يريد تحميل نص إلى الحافظة فسنفتح الملف ونقرأه منه، وسنسمي هذا الملف باسم mcb.
الخطوة 2: حفظ محتويات الحافظة مع كلمة مفتاحية
يسلك البرنامج سلوكًا مختلفًا اعتمادًا على ما يريده المستخدم: حفظ محتويات الحاوية مع كلمة مفتاحية، أو تحميل نص إلى الحاوية، أو عرض جميع الكلمات المفتاحية. لنعالج الآن أول حالة:
#! python3 # mcb.pyw - حفظ وتحميل نصوص إلى الحافظة. --snip-- # حفظ محتوى الحافظة. ➊ if len(sys.argv) == 3 and sys.argv[1].lower() == 'save': ➋ mcbShelf[sys.argv[2]] = pyperclip.paste() elif len(sys.argv) == 2: ➌ # TODO: تحميل المحتوى وعرض الكلمات المفتاحية. mcbShelf.close()
إذا كان أول وسيط من وسائط سطر الأوامر (الذي يكون دومًا بالفهرس 1 من قائمة sys.argv) هو 'save' ➊ فإن الوسيط الثاني هو الكلمة المفتاحية التي يجب حفظ محتويات الحافظة إليها، والتي ستستخدم كمفتاح مع mvbShelf، وستكون قيمة هذا المفتاح هي محتويات الحافظة الحالية ➋.
أما إذا كان هنالك وسيط واحد ممرر من سطر الأوامر فهذا يعني أنه إما 'list' أو كلمة مفتاحية نريد تحميل المحتوى النصي المرتبط بها إلى الحافظة. اترك تعليقًا الآن وسنكتب الشيفرة لاحقًا ➌.
الخطوة 3: تحميل الكلمات المفتاحية أو محتوى إحدى الكلمات
لنكتب الآن الشيفرة المناسبة للحالتين الباقيتين: تحميل النص المرتبط بإحدى الكلمات المفتاحية إلى الحافظة، أو نسخ قائمة بجميع الكلمات المفتاحية إلى الحافظة:
#! python3 # mcb.pyw - حفظ وتحميل نصوص إلى الحافظة. --snip-- # حفظ محتوى الحافظة. if len(sys.argv) == 3 and sys.argv[1].lower() == 'save': mcbShelf[sys.argv[2]] = pyperclip.paste() elif len(sys.argv) == 2: # تحميل المحتوى وعرض الكلمات المفتاحية. ➊ if sys.argv[1].lower() == 'list': ➋ pyperclip.copy(str(list(mcbShelf.keys()))) elif sys.argv[1] in mcbShelf: ➌ pyperclip.copy(mcbShelf[sys.argv[1]]) mcbShelf.close()
إذا كان هنالك وسيط واحد في سطر الأوامر، فلنتأكد إن كان 'list' ➊، فإذا كان كذلك فستنسخ سلسلة نصية تمثل قائمةً من الكلمات المفتاحية إلى الحافظة ➋، ويمكن للمستخدم أن يلصقها في أي محرر نصي أمامه ليقرأها.
فيما عدا ذلك فسنفترض أن الوسيط الممرر من سطر الأوامر هو كلمة مفتاحية، وإذا كانت الكلمة المفتاحية موجودة في mcbShelf فسنحمل القيمة إلى الحافظة ➌.
هذا كل ما يلزم لتطوير البرنامج! قد تختلف خطوات التشغيل اعتمادًا على نظام التشغيل الذي تستعمله، راجع المقال 1 لتفاصيل.
من غير المنطقي أن تغير الشيفرة المصدرية لبرنامجك كلما احتجت إلى تحديث البيانات، لأن المستخدم العادي لا يرتاح لتعديل الشيفرات البرمجية؛ وكل مرة تعدل فيها البرنامج فأنت تخاطر بحدوث مشاكل جديدة وعلل لم تنتبه إليها. لذا من المهم فصل البيانات اللازمة لتشغيل التطبيق عن التطبيق نفسه، مما يجعل برامجك سهلة الاستخدام من الآخرين وتقلل احتمال حدوث مشاكل فيها.
الخلاصة
تنظم الملفات في مجلدات (التي تسمى في بعض أنظمة التشغيل directory أي دليل)، ويصف مسارُ موقعَ الملف، ولكل برنامج يعمل في حاسوبك ما يسمى بمجلد العمل الحالي، مما يسمح بتحديد مسارات نسبية تبدأ من المجلد الحالي بدلًا من كتابة المسار الكامل للملف الذي يسمى أيضًا بالمسار المطلق. توفر الوحدتان pathlib و os.path عددًا من الدوال لإجراء عمليات على مسارات الملفات.
يمكن أن تتفاعل برامجك مباشرةً مع محتويات الملفات النصية، فالدالة open() تفتح الملفات للقراءة، وتستطيع أن تحصل على محتواها كسلسلة نصية واحدة كبيرة عبر التابع read() أو كقائمة من السلاسل النصية عبر التابع readlines(). يمكن أن تستخدم الدالة open() لفتح الملفات في وضع الكتابة أو الإضافة لإنشاء ملفات نصية جديدة أو الإضافة على ملفات موجودة مسبقًا، على التوالي.
تعلمنا في المقالات السابقة من هذه السلسلة كيفية استخدام الحافظة لتخزين وتحميل كمية كبيرة من النصوص إلى برامجنا بدل من كتابتها يدويًا، لكننا الآن قادرون على جعل برامجنا تقرأ الملفات من ذاكرة التخزين أو الكتابة إليها، وهذا تحسين كبير عما سبق، وتكون وسيطة التخزين أكثر استقرارًا من الحافظة. سنتعلم في المقال القادم كيفية التعامل مع الملفات نفسها، عبر نسخها وحذفها وإعادة تسميتها ونقلها …إلخ.
مشاريع تدريبية
لكي تتدرب، اكتب برامج لتنفيذ المهام الآتية.
توسعة تطبيق الحافظة
وسِّع تطبيق الحافظة الذي أنشأناه في هذا المقال وأضف إليه الأمر delete الذي يحذف كلمة مفتاحية ومحتوياتها من «الرف». ثم أضف الأمر delete دون أي وسائط إضافية الذي سيؤدي إلى حذف جميع الكلمات المفتاحية.
لعبة Mad Libs
أنشِئ لعبة Mad Libs التي تقرأ ملفًا نصية وتسمح للمستخدم بإضافة النص الذي يريده في أي مكان تظهر فيه الكلمات المفتاحية ADJECTIVE و NOUN و ADVERB و VERB في الملف النصي. فمثلًا سيبدو الملف النصي كما يلي:
The ADJECTIVE panda walked to the NOUN and then VERB. A nearby NOUN was unaffected by these events.
سيقرأ البرنامج هذا الملف، ويبحث عن تلك الكلمات، ويطلب من المستخدم أن يدخل بديلًا عنها:
Enter an adjective: silly Enter a noun: chandelier Enter a verb: screamed Enter a noun: pickup truck
وستكون نتيجة البرنامج هي:
The silly panda walked to the chandelier and then screamed. A nearby pickup truck was unaffected by these events.
ويجب أن تطبع هذه النتيجة على الشاشة وتحفظ في ملف نصي جديد باسم مناسب.
البحث عبر التعابير النمطية
اكتب برنامجًا يفتح جميع ملفات txt النصية في مجلد، ويبحث فيها عن أي سطر يحتوي على مطابقة لتعبير نمطي ضبطه المستخدم. يجب أن تعرض النتائج على الشاشة.
ترجمة -بتصرف- للمقال Reading And Writing Files من كتاب Automate the Boring Stuff with Python.












أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.