

تُعَد مستندات بي دي إف PDF ومستندات وورد Word ملفات ثنائية، مما يجعلها أكثر تعقيدًا من الملفات النصية العادية، إذ تخزِّن الكثير من المعلومات المتعلقة بالخطوط والألوان وتخطيط الصفحات بالإضافة إلى النصوص. إذا أدرتَ أن تقرأ برامجك أو تكتبها في ملفات PDF أو مستندات وورد، فستحتاج إلى تطبيق أكثر من مجرد تمرير أسماء الملفات إلى الدالة open()، لذا توجد وحدات بايثون Python التي تسهّل عليك التفاعل مع ملفات PDF ومستندات وورد مثل الوحدتين PyPDF2 و Python-Docx اللتين سنوضّحهما في هذا المقال.
مستندات PDF
يرمز الاختصار PDF إلى صيغة المستندات المنقولة Portable Document Format التي تستخدم امتداد الملف .pdf. تدعم ملفات PDF العديد من الميزات، ولكن سنركز في هذا المقال على المهمتين اللتين ستفعلهما باستخدام هذه الملفات في أغلب الأحيان وهما: قراءة محتوى النصوص من ملفات PDF وإنشاء ملفات PDF جديدة من مستندات موجودة مسبقًا.
سنستخدم الوحدة PyPDF2 ذات الإصدار 1.26.0 للعمل مع ملفات PDF، لذا من المهم أن تثبّت هذا الإصدار لأن الإصدارات اللاحقة من وحدة PyPDF2 قد تكون غير متوافقة مع شيفرتنا البرمجية، إذًا شغّل الأمر pip install --user PyPDF2==1.26.0 من سطر الأوامر لتثبيت هذه الوحدة، ولاحظ أن اسم الوحدة حساس لحالة الحروف، لذا تأكد من أن الحرف y صغير والحروف الأخرى كبيرة. اتبع الإرشادات الخاصة بتثبيت الوحدات الخارجية التي سنوضّحها في مقال لاحق من هذه السلسلة. إذا جرى تثبيت هذه الوحدة بصورة صحيحة، فيُفترض ألّا يؤدي تشغيل الأمر import PyPDF2 في الصدفة التفاعلية Interactive Shell إلى عرض أيّ أخطاء.
ملاحظة: تُعَد ملفات PDF رائعة لتجهيز النصوص بحيث تسهل طباعتها وقراءتها، ولكن ليس من السهل على البرمجيات تحليلها إلى نصوص عادية، لذلك قد ترتكب الوحدة PyPDF2 أخطاءً عند استخراج النص من ملف PDF، وقد لا تتمكّن من فتح بعض ملفات PDF، ولا يوجد الكثير لفعله لحل هذه المشكلة، إذ قد تكون وحدة PyPDF2 ببساطة غير قادرة على العمل مع بعض ملفات PDF، ولكننا لم نجد بعد أيّ ملفات PDF لا يمكن فتحها باستخدام وحدة PyPDF2.
استخراج النص من ملفات PDF
لا تمتلك وحدة PyPDF2 طريقةً لاستخراج الصور أو المخططات أو الوسائط الأخرى من مستندات PDF، ولكن يمكنها استخراج النص وإعادته بوصفه سلسلة بايثون. سنستخدم في مثالنا مستند PDF الموضّح في الشكل التالي للبدء في تعلم كيفية عمل وحدة PyPDF2:

صفحة PDF التي سنستخرج النص منها
نزّل ملف PDF الموضّح في الشكل السابق وأدخِل ما يلي في الصدفة التفاعلية:
>>> import PyPDF2 >>> pdfFileObj = open('meetingminutes.pdf', 'rb') >>> pdfReader = PyPDF2.PdfFileReader(pdfFileObj) ➊ >>> pdfReader.numPages 19 ➋ >>> pageObj = pdfReader.getPage(0) ➌ >>> pageObj.extractText() 'OOFFFFIICCIIAALL BBOOAARRDD MMIINNUUTTEESS Meeting of March 7, 2015 \n The Board of Elementary and Secondary Education shall provide leadership and create policies for education that expand opportunities for children, empower families and communities, and advance Louisiana in an increasingly competitive global market. BOARD of ELEMENTARY and SECONDARY EDUCATION ' >>> pdfFileObj.close()
نستورد أولًا وحدة PyPDF2، ثم نفتح الملف meetingminutes.pdf للقراءة في الوضع الثنائي ونخزّنه في المتغير pdfFileObj. يمكن الحصول على كائن PdfFileReader الذي يمثل ملف PDF من خلال استدعاء الدالة PyPDF2.PdfFileReader() وتمرير المتغير pdfFileObj إليها، ثم خزّن هذا الكائن في المتغير pdfReader.
يُخزَّن إجمالي عدد صفحات المستند في السمة Attribute التي هي numPages الخاصة بالكائن PdfFileReader ➊، ويحتوي ملف PDF في مثالنا على 19 صفحة، ولكن نريد استخراج النص من الصفحة الأولى فقط من خلال الحصول على كائن Page من كائن PdfFileReader، حيث يمثل كائن Page صفحة واحدة من ملف PDF. يمكنك الحصول على كائن Page من خلال استدعاء التابع getPage() ➋ الخاص بكائن PdfFileReader وتمرير رقم الصفحة التي تريدها إليه، ورقم الصفحة هو 0 في مثالنا.
تستخدم الوحدة PyPDF2 فهرسًا مستنِدًا إلى القيمة 0 للحصول على الصفحات، فالصفحة الأولى هي الصفحة 0، والصفحة الثانية هي الصفحة 1 وإلخ، إذ تُستخدَم هذه الطريقة دائمًا حتى لو كانت الصفحات مرقَّمة بطريقة مختلفة في المستند. لنفترض مثلًا أن لديك ملف PDF يمثّل مقطعًا من تقرير أطول، ويتألف هذا المقطع من ثلاث صفحات، وأرقام الصفحات هي 42 و 43 و 44. يمكن الحصول على الصفحة الأولى من هذا المستند من خلال استدعاء التابع pdfReader.getPage(0) وليس من خلال استدعاء getPage(42) أو getPage(1).
نحصل على كائن Page، ثم نستدعي التابع extractText() الخاص بهذا الكائن لإعادة سلسلة نصية تمثل النص الموجود في الصفحة ➌. لاحظ أن استخراج النص ليس مثاليًا، فالنص "Charles E. “Chas” Roemer, President" من ملف PDF غير موجود في السلسلة النصية التي يعيدها التابع extractText()، وتكون المسافات غير مفعّلة في بعض الأحيان، ولكن قد يكون هذا المحتوى التقريبي لنص ملف PDF كافيًا لبرنامجك.
فك تشفير ملفات PDF
تحتوي بعض مستندات PDF على ميزة تشفير تمنع قراءتها حتى يضع الشخص الذي يفتح المستند كلمة المرور. لندخِل ما يلي في الصدفة التفاعلية مع ملف PDF الذي نزلته، وهذا الملف مُشفَّر باستخدام كلمة المرور rosebud:
>>> import PyPDF2 >>> pdfReader = PyPDF2.PdfFileReader(open('encrypted.pdf', 'rb')) ➊ >>> pdfReader.isEncrypted True >>> pdfReader.getPage(0) ➋ Traceback (most recent call last): File "<pyshell#173>", line 1, in <module> pdfReader.getPage() --snip-- File "C:\Python34\lib\site-packages\PyPDF2\pdf.py", line 1173, in getObject raise utils.PdfReadError("file has not been decrypted") PyPDF2.utils.PdfReadError: file has not been decrypted >>> pdfReader = PyPDF2.PdfFileReader(open('encrypted.pdf', 'rb')) ➌ >>> pdfReader.decrypt('rosebud') 1 >>> pageObj = pdfReader.getPage(0)
تحتوي جميع كائنات PdfFileReader على السمة isEncrypted التي تكون قيمتها True إذا كان ملف PDF مُشفرًا، وتكون قيمتها False إن لم يكن ملف PDF مُشفَّرًا ➊، وستؤدي أيّ محاولة لاستدعاء دالةٍ تقرأ الملف قبل فك تشفيره باستخدام كلمة المرور الصحيحة إلى حدوث خطأ ➋.
ملاحظة: يوجد خطأٌ في الإصدار 1.26.0 من وحدة PyPDF2، حيث يؤدي استدعاء التابع getPage() لملف PDF مشفَّر قبل استدعاء الدالة decrypt() لهذا الملف إلى فشل استدعاءات التابع getPage() المستقبلية مع ظهور الخطأ IndexError: list index out of range، ولذلك أعاد المثال السابق فتح الملف باستخدام كائن PdfFileReader جديد.
يمكن قراءة ملف PDF مشفَّر من خلال استدعاء الدالة decrypt() وتمرير كلمة المرور بوصفها سلسلة نصية إليه ➌، وسترى أن استدعاء التابع getPage() لم يعُد يسبّب خطأً بعد استدعاء الدالة decrypt() مع كلمة المرور الصحيحة، بينما إذا أعطيتَ كلمة مرور خطأ، فستعيد الدالة decrypt() القيمة 0 وسيفشل التابع getPage(). لاحظ أن التابع decrypt() يفك تشفير الكائن PdfFileReader فقط وليس ملف PDF الفعلي، إذ يبقى الملف الموجود على قرص حاسوبك الصلب مشفَّرًا بعد انتهاء البرنامج، وبالتالي يجب أن يستدعي برنامجُك التابعَ decrypt() عند تشغيله مرة أخرى.
إنشاء ملفات PDF
يمكن للكائن PdfFileWriter الخاص بالوحدة PyPDF2 إنشاء ملفات PDF جديدة، ولكن لا تستطيع وحدة PyPDF2 كتابة نص عشوائي في ملف PDF كما تفعل شيفرة بايثون مع ملفات النصوص العادية، لذا تقتصر إمكانات كتابة ملفات PDF في وحدة PyPDF2 على نسخ الصفحات من ملفات PDF الأخرى وتدوير الصفحات ودمجها وتشفير الملفات.
لا تسمح وحدة PyPDF2 بتعديل ملف PDF مباشرةً، لذا يجب إنشاء ملف PDF جديد ثم نسخ المحتوى من مستند موجود مسبقًا. ستتبع الأمثلة الواردة في هذا القسم النهج العام التالي:
-
فتح ملفٍ أو أكثر من ملفات PDF الموجودة مسبقًا (ملفات PDF المصدر) في كائنات
PdfFileReader. -
إنشاء كائن
PdfFileWriterجديد. -
نسخ الصفحات من كائنات
PdfFileReaderإلى كائنPdfFileWriter. -
استخدام كائن
PdfFileWriterلكتابة ملف PDF الناتج.
يؤدي إنشاء كائن PdfFileWriter إلى إنشاء قيمةٍ تمثّل مستند PDF في شيفرة بايثون فقط دون إنشاء ملف PDF الفعلي، ولذلك يجب استدعاء التابع write() الخاص بهذا الكائن. يأخذ هذا التابع كائن File عادي مفتوح في وضع الكتابة الثنائي، حيث يمكنك الحصول على كائن File من خلال استدعاء الدالة open() الخاصة بلغة بايثون مع وسيطين هما: السلسلة النصية التي تريد أن تمثّل اسم ملف PDF والوسيط 'wb' الذي يشير إلى أنه يجب فتح الملف في وضع الكتابة الثنائي. لا تقلق إذا كان ذلك مربكًا بعض الشيء، حيث سنرى كيفية ذلك في الأمثلة البرمجية التالية.
نسخ الصفحات
يمكنك استخدام وحدة PyPDF2 لنسخ الصفحات من مستند PDF إلى آخر، مما يتيح لك دمج ملفات PDF متعددة أو قص الصفحات غير المرغوب فيها أو إعادة ترتيب الصفحات.
نزّل الملفين meetingminutes.pdf و meetingminutes2.pdf وضعهما في مجلد العمل الحالي، ثم أدخِل ما يلي في الصدفة التفاعلية:
>>> import PyPDF2 >>> pdf1File = open('meetingminutes.pdf', 'rb') >>> pdf2File = open('meetingminutes2.pdf', 'rb') ➊ >>> pdf1Reader = PyPDF2.PdfFileReader(pdf1File) ➋ >>> pdf2Reader = PyPDF2.PdfFileReader(pdf2File) ➌ >>> pdfWriter = PyPDF2.PdfFileWriter() >>> for pageNum in range(pdf1Reader.numPages): ➍ pageObj = pdf1Reader.getPage(pageNum) ➎ pdfWriter.addPage(pageObj) >>> for pageNum in range(pdf2Reader.numPages): ➍ pageObj = pdf2Reader.getPage(pageNum) ➎ pdfWriter.addPage(pageObj) ➏ >>> pdfOutputFile = open('combinedminutes.pdf', 'wb') >>> pdfWriter.write(pdfOutputFile) >>> pdfOutputFile.close() >>> pdf1File.close() >>> pdf2File.close()
افتح ملفي PDF في وضع القراءة الثنائي وخزّن كائني File الناتجين في المتغيرين pdf1File و pdf2File، ثم استدعِ الدالة PyPDF2.PdfFileReader() ومرّر المتغير pdf1File إليها للحصول على كائن PdfFileReader للملف meetingminutes.pdf ➊، ثم استدعيها مرةً أخرى ومرّر المتغير pdf2File إليها للحصول على كائن PdfFileReader للملف meetingminutes2.pdf ➋، ثم أنشئ كائن PdfFileWriter جديد، والذي يمثل مستند PDF فارغ ➌.
انسخ بعد ذلك جميع الصفحات من ملفي PDF المصدر وأضِفها إلى كائن PdfFileWriter، واحصل على كائن Page من خلال استدعاء التابع getPage() لكائن PdfFileReader ➍، ثم مرّر كائن Page إلى التابع addPage() الخاص بالكائن PdfFileReader ➎. نفّذ هذه الخطوات أولًا للمتغير pdf1Reader ثم للمتغير pdf2Reader مرة أخرى، ثم اكتب ملف PDF جديد اسمه combinedminutes.pdf عند الانتهاء من نسخ الصفحات من خلال تمرير كائن File إلى التابع write() الخاص بالكائن PdfFileWriter ➏.
ملاحظة: لا يمكن لوحدة PyPDF2 إدراج صفحات في منتصف كائن PdfFileWriter، إذ يضيف التابع addPage() الصفحات إلى نهاية الملف فقط.
أنشأنا ملف PDF جديد يدمج صفحاتٍ من الملفين meetingminutes.pdf وmeetingminutes2.pdf في مستند واحد. تذكّر أنه يجب فتح كائن File الذي مرّرناه إلى الدالة PyPDF2.PdfFileReader() في وضع القراءة الثنائي من خلال تمرير الوسيط 'rb' بوصفه وسيطًا ثانيًا للدالة open()، ويجب فتح كائن File الذي مرّرناه إلى الدالة PyPDF2.PdfFileReader() في وضع الكتابة الثنائي باستخدام الوسيط 'wb'.
تدوير الصفحات
يمكن تدوير صفحات ملف PDF بمقدار مضاعفات 90 درجة باستخدام التوابع rotateClockwise() و rotateCounterClockwise(). لنمرّر أحد الأعداد الصحيحة 90 أو 180 أو 270 إلى هذه التوابع، ولندخِل ما يلي في الصدفة التفاعلية مع ملف meetingminutes.pdf الموجود في مجلد العمل الحالي:
>>> import PyPDF2 >>> minutesFile = open('meetingminutes.pdf', 'rb') >>> pdfReader = PyPDF2.PdfFileReader(minutesFile) ➊ >>> page = pdfReader.getPage(0) ➋ >>> page.rotateClockwise(90) {'/Contents': [IndirectObject(961, 0), IndirectObject(962, 0), --snip-- } >>> pdfWriter = PyPDF2.PdfFileWriter() >>> pdfWriter.addPage(page) ➌ >>> resultPdfFile = open('rotatedPage.pdf', 'wb') >>> pdfWriter.write(resultPdfFile) >>> resultPdfFile.close() >>> minutesFile.close()
استخدمنا التابع getPage(0) لتحديد الصفحة الأولى من ملف PDF ➊، ثم استدعينا التابع rotateClockwise(90) لتلك الصفحة ➋، ثم كتبنا ملف PDF جديد مع الصفحة التي دوّرناها وحفظناه بالاسم rotatedPage.pdf ➌.
سيحتوي ملف PDF الناتج على صفحة واحدة مع تدويرها بمقدار 90 درجة باتجاه عقارب الساعة كما هو موضّح في الشكل التالي، وتحتوي القيم المُعادة من التابعين rotateClockwise() و rotateCounterClockwise() على الكثير من المعلومات التي يمكنك تجاهلها.

ملف rotatedPage.pdf مع تدوير الصفحة بمقدار 90 درجة باتجاه عقارب الساعة
دمج الصفحات
يمكن لوحدة PyPDF2 أن تدمج محتويات صفحة مع صفحة أخرى، ويُعَد ذلك مفيدًا لإضافة شعار أو علامة زمنية أو مائية إلى الصفحة، إذ تسهّل لغة بايثون إضافة علامات مائية إلى ملفات متعددة وعلى الصفحات التي يحدّدها برنامجك فقط.
نزّل الملف watermark.pdf، ثم ضعه في مجلد العمل الحالي مع الملف meetingminutes.pdf، ثم أدخِل ما يلي في الصدفة التفاعلية:
>>> import PyPDF2 >>> minutesFile = open('meetingminutes.pdf', 'rb') ➊ >>> pdfReader = PyPDF2.PdfFileReader(minutesFile) ➋ >>> minutesFirstPage = pdfReader.getPage(0) ➌ >>> pdfWatermarkReader = PyPDF2.PdfFileReader(open('watermark.pdf', 'rb')) ➍ >>> minutesFirstPage.mergePage(pdfWatermarkReader.getPage(0)) ➎ >>> pdfWriter = PyPDF2.PdfFileWriter() ➏ >>> pdfWriter.addPage(minutesFirstPage) ➐ >>> for pageNum in range(1, pdfReader.numPages): pageObj = pdfReader.getPage(pageNum) pdfWriter.addPage(pageObj) >>> resultPdfFile = open('watermarkedCover.pdf', 'wb') >>> pdfWriter.write(resultPdfFile) >>> minutesFile.close() >>> resultPdfFile.close()
أنشأنا في المثال السابق كائن PdfFileReader للملف meetingminutes.pdf ➊، واستدعينا التابع getPage(0) للحصول على كائن Page للصفحة الأولى وتخزين هذا الكائن في المتغير minutesFirstPage ➋. أنشأنا بعد ذلك كائن PdfFileReader للملف watermark.pdf ➌، واستدعينا التابع mergePage() للمتغير minutesFirstPage ➍، فالوسيط الذي نمرّره إلى التابع mergePage() هو كائن Page للصفحة الأولى من الملف watermark.pdf.
استدعينا التابع mergePage() للمتغير minutesFirstPage، وبالتالي أصبح هذا المتغير يمثّل الصفحة الأولى التي وضعنا عليها علامة مائية، ثم أنشأنا كائن PdfFileWriter ➎ وأضفنا الصفحة الأولى التي وضعنا عليها علامة مائية ➏، ثم مررنا بحلقة على بقية الصفحات الموجودة في الملف meetingminutes.pdf، وأضفناها إلى الكائن PdfFileWriter ➐. أخيرًا، فتحنا ملف PDF جديد اسمه watermarkedCover.pdf، وكتبنا محتويات الكائن PdfFileWriter فيه.
يبين الشكل التالي النتائج، حيث يحتوي ملف PDF الجديد watermarkedCover.pdf على جميع محتويات الملف meetingminutes.pdf، وتحمل الصفحة الأولى فيه علامة مائية:

ملف PDF الأصلي (على اليسار) وملف PDF للعلامة مائية (في الوسط) وملف PDF لدمج الملفين (على اليمين)
تشفير ملفات PDF
يمكن لكائن PdfFileWriter أيضًا إضافة تشفيرٍ إلى مستند PDF. إذًا لندخِل ما يلي في الصدفة التفاعلية:
>>> import PyPDF2 >>> pdfFile = open('meetingminutes.pdf', 'rb') >>> pdfReader = PyPDF2.PdfFileReader(pdfFile) >>> pdfWriter = PyPDF2.PdfFileWriter() >>> for pageNum in range(pdfReader.numPages): pdfWriter.addPage(pdfReader.getPage(pageNum)) ➊ >>> pdfWriter.encrypt('swordfish') >>> resultPdf = open('encryptedminutes.pdf', 'wb') >>> pdfWriter.write(resultPdf) >>> resultPdf.close()
استدعِ التابع encrypt() ومرّر إليه سلسلة كلمة المرور ➊ قبل استدعاء التابع write() للحفظ في الملف. يمكن أن تحتوي ملفات PDF على كلمة مرور المستخدم user password التي تسمح لك بعرض ملف PDF وكلمة مرور المالك owner password التي تسمح لك بضبط أذونات للطباعة والتعليق واستخراج النص وميزات أخرى، حيث تُعَد كلمة مرور المستخدم وكلمة مرور المالك الوسيطين الأول والثاني للتابع encrypt() على التوالي. إذا مرّرنا سلسلة نصية واحدة فقط كوسيط إلى التابع encrypt()، فسنستخدمها لكلمتي المرور.
نسخنا في المثال السابق صفحات الملف meetingminutes.pdf إلى كائن PdfFileWriter الذي شفّرناه بكلمة المرور swordfish، وفتحنا ملف PDF جديد بالاسم encryptedminutes.pdf، وكتبنا محتويات الكائن PdfFileWriter في ملف PDF الجديد، ويجب إدخال كلمة المرور قبل التمكّن من عرض الملف encryptedminutes.pdf. قد ترغب في حذف الملف meetingminutes.pdf الأصلي غير المُشفَّر بعد التأكد من تشفير نسخته بصورة صحيحة.
تطبيق عملي: دمج صفحات مختارة من عدة ملفات PDF
لنفترض أن لديك مهمة مملة تتمثل في دمج عشرات من مستندات PDF في ملف PDF واحد، ويحتوي كل مستند على ورقة غلاف في الصفحة الأولى، ولكنك لا تريد تكرار ورقة الغلاف في النتيجة النهائية، إذ توجد الكثير من البرامج المجانية لدمج ملفات PDF، ولكن تدمج الكثير منها الملفات بأكملها مع بعضها البعض ببساطة. إذًا لنكتب برنامج بايثون لتخصيص الصفحات التي تريدها في ملف PDF الناتج عن دمج عدة مستندات PDF.
إليك الخطوات العامة التي سيطبّقها برنامجك:
- البحث عن جميع ملفات PDF الموجودة في مجلد العمل الحالي.
- فرز أسماء الملفات بحيث تُضاف ملفات PDF بالترتيب.
- كتابة جميع الصفحات باستثناء الصفحة الأولى من كل ملف PDF في الملف الناتج.
ولكن ستحتاج شيفرتك البرمجية إلى تطبيق الخطوات التالية من ناحية التنفيذ:
-
استدعاء التابع
os.listdir()للعثور على كافة الملفات الموجودة في مجلد العمل وإزالة الملفات التي ليست ملفات PDF. -
استدعاء تابع فرز القائمة
sort()الخاصة بلغة بايثون لترتيب أسماء الملفات أبجديًا. -
إنشاء كائن
PdfFileWriterلملف PDF الناتج. -
التكرار ضمن حلقة على كل ملف PDF لإنشاء كائن
PdfFileReaderله. - التكرار ضمن حلقة على كل صفحة (ما عدا الصفحة الأولى) في كل ملف PDF.
- إضافة الصفحات إلى ملف PDF الناتج.
- كتابة ملف PDF الناتج في ملفٍ اسمه allminutes.pdf.
افتح تبويبًا جديدًا لإنشاء ملفٍ جديد في محرّرك واحفظه بالاسم combinePdfs.py.
الخطوة الأولى: البحث عن جميع ملفات PDF
أولًا، يجب أن يحصل برنامجك على قائمةٍ بجميع الملفات التي لها الامتداد .pdf الموجودة في مجلد العمل الحالي وفرزها، لذا يجب أن تكون شيفرتك البرمجية تبدو كما يلي:
#! python3 # combinePdfs.py - دمج جميع ملفات PDF الموجودة في مجلد العمل الحالي في ملف PDF واحد ➊ import PyPDF2, os # الحصول على جميع أسماء ملفات PDF pdfFiles = [] for filename in os.listdir('.'): if filename.endswith('.pdf'): ➋ pdfFiles.append(filename) ➌ pdfFiles.sort(key = str.lower) ➍ pdfWriter = PyPDF2.PdfFileWriter() # التكرار ضمن حلقة على جميع ملفات PDF # التكرار ضمن حلقة على جميع الصفحات (باستثناء الصفحة الأولى) وإضافتها # حفظ ملف PDF الناتج في ملف
السطر الأول في الشيفرة البرمجية السابقة هو سطر Shebang (سطر يبدأ بالسلسلة النصية "#!")، والسطر الثاني هو التعليق الوصفي لما يفعله البرنامج، ثم تستورد الشيفرة البرمجية وحدات os و PyPDF2 ➊. يعيد استدعاء التابع os.listdir('.') قائمةً بالملفات الموجودة في مجلد العمل الحالي، حيث تتكرر الشيفرة البرمجية ضمن حلقة على هذه القائمة وتضيف الملفات التي لها الامتداد .pdf فقط إلى القائمة pdfFiles ➋. تُفرَز بعد ذلك هذه القائمة وفق الترتيب الأبجدي باستخدام وسيط الكلمة المفتاحية Keyword Argument الذي هو key = str.lower الخاص بالتابع sort() ➌، ويُنشَأ كائن PdfFileWriter للاحتفاظ بصفحات PDF المدموجة ➍. أخيرًا، توجد بعض التعليقات التي توضّح ما تبقى من البرنامج.
الخطوة الثانية: فتح ملفات PDF
يجب الآن أن يقرأ البرنامج كلّ ملف PDF موجودٍ في القائمة pdfFiles، لذا أضِف ما يلي إلى برنامجك:
#! python3 # combinePdfs.py - دمج جميع ملفات PDF الموجودة في مجلد العمل الحالي في ملف PDF واحد import PyPDF2, os # الحصول على جميع أسماء ملفات PDF pdfFiles = [] --snip-- # التكرار ضمن حلقة على جميع ملفات PDF for filename in pdfFiles: pdfFileObj = open(filename, 'rb') pdfReader = PyPDF2.PdfFileReader(pdfFileObj) # التكرار ضمن حلقة على جميع الصفحات (باستثناء الصفحة الأولى) وإضافتها # حفظ ملف PDF الناتج في ملف
تفتح الحلقة اسم ملف لكل ملف PDF في وضع القراءة الثنائي من خلال استدعاء الدالة open() مع الوسيط الثاني 'rb'، حيث يعيد استدعاء الدالة open() كائن File المُمرَّر إلى الدالة PyPDF2.PdfFileReader() لإنشاء كائن PdfFileReader لملف PDF.
الخطوة الثالثة: إضافة الصفحات
يجب التكرار ضمن حلقة على كل صفحة من كل ملف PDF باستثناء الصفحة الأولى. إذًا أضِف الشيفرة البرمجية التالية إلى برنامجك:
#! python3 # combinePdfs.py - دمج جميع ملفات PDF الموجودة في مجلد العمل الحالي في ملف PDF واحد import PyPDF2, os --snip-- # التكرار ضمن حلقة على جميع ملفات PDF for filename in pdfFiles: --snip-- # التكرار ضمن حلقة على جميع الصفحات (باستثناء الصفحة الأولى) وإضافتها ➊ for pageNum in range(1, pdfReader.numPages): pageObj = pdfReader.getPage(pageNum) pdfWriter.addPage(pageObj) # حفظ ملف PDF الناتج في ملف
تنسخ الشيفرة البرمجية الموجودة داخل حلقة for كل كائن Page إلى كائن PdfFileWriter، ولكن تذكّر أنك تريد تخطي الصفحة الأولى. يجب أن تبدأ حلقتك من القيمة 1 ➊ لأن وحدة PyPDF2 تَعُدّ القيمة 0 هي الصفحة الأولى، ثم تصل إلى العدد الصحيح الموجود في pdfReader.numPages دون تضمينه في الحلقة.
الخطوة الرابعة: حفظ النتائج
سيحتوي المتغير pdfWriter على كائن PdfFileWriter مع الصفحات الخاصة بجميع ملفات PDF المدموجة بعد الانتهاء من حلقات for المتداخلة، والخطوة الأخيرة هي كتابة هذا المحتوى في ملفٍ على القرص الصلب، لذا أضِف الشيفرة البرمجية التالية إلى برنامجك:
#! python3 # combinePdfs.py - دمج جميع ملفات PDF الموجودة في مجلد العمل الحالي في ملف PDF واحد import PyPDF2, os --snip-- # التكرار ضمن حلقة على جميع الملفات PDF for filename in pdfFiles: --snip-- # التكرار ضمن حلقة على جميع الصفحات (باستثناء الصفحة الأولى) وإضافتها for pageNum in range(1, pdfReader.numPages): --snip-- # حفظ ملف PDF الناتج في ملف pdfOutput = open('allminutes.pdf', 'wb') pdfWriter.write(pdfOutput) pdfOutput.close()
يؤدي تمرير 'wb' إلى الدالة open() إلى فتح ملف PDF الناتج allminutes.pdf في وضع الكتابة الثنائي، وبالتالي يؤدي تمرير كائن File الناتج إلى التابع write() إلى إنشاء ملف PDF الفعلي، ويؤدي استدعاء التابع close() إلى إنهاء البرنامج.
أفكار لبرامج مماثلة
تتيح لك القدرة على إنشاء ملفات PDF من صفحات ملفات PDF الأخرى إنشاءَ برامج يمكنها تطبيق ما يلي:
- قص صفحات محددة من ملفات PDF.
- إعادة ترتيب الصفحات في ملف PDF.
-
إنشاء ملف PDF من الصفحات التي تحتوي على بعض النصوص التي يحدّدها التابع
extractText().
مستندات وورد Word
يمكن للغة بايثون إنشاء وتعديل مستندات وورد التي لها امتداد الملفات .docx باستخدام الوحدة docx التي يمكنك تثبيتها من خلال تشغيل الأمر pip install --user -U python-docx==0.8.10. اتبع الإرشادات الخاصة بتثبيت الوحدات الخارجية التي سنوضّحها في [مقالٍ لاحق](رابط مقال سنترجمه لاحقًا https://automatetheboringstuff.com/2e/appendixa/).
ملاحظة: إذا استخدمتَ الأداة pip لتثبيت وحدة Python-Docx لأول مرة، فتأكد من تثبيت python-docx وليس docx، فاسم الحزمة docx مُخصَّص لوحدةٍ مختلفة لن نتحدّث عنها في هذا المقال، ولكن ستحتاج إلى تشغيل الأمر import docx وليس import python-docx عندما تريد استيراد الوحدة من حزمة python-docx.
إن لم يكن لديك تطبيق وورد، فيمكنك استخدام ليبر أوفيس رايتر LibreOffice Writer وأوبن أوفيس رايتر OpenOffice Writer، وهما تطبيقان بديلان مجانيان لأنظمة ويندوز Windows وماك macOS ولينكس Linux، ويٌستخدمان لفتح ملفات .docx، حيث يمكنك تنزيلهما من موقعهما الرسمي، ويوجد التوثيق الكامل لوحدة Python-Docx على موقعها الرسمي. سنركّز في هذا المقال على وورد في نظام تشغيل ويندوز بالرغم من وجود إصدار من وورد على نظام تشغيل ماك macOS.
تحتوي ملفات .docx على هياكل متعددة مقارنةً بالنصوص العادية، ويُمثَّل كلّ هيكلٍ منها بثلاثة أنواع مختلفة من البيانات في الوحدة Python-Docx، حيث يمثِّل كائن Document المستند بأكمله، ويحتوي كائن Document على قائمةٍ من كائنات Paragraph للفقرات الموجودة في المستند، إذ تبدأ فقرة جديدة عندما يضغط المستخدم على زر ENTER أو RETURN أثناء الكتابة في مستند وورد، ويحتوي كل كائن من كائنات Paragraph على قائمة تضم كائن Run واحدًا أو أكثر. تحتوي الفقرة المكونة من جملة واحدة في الشكل التالي على أربعة كائنات Run:
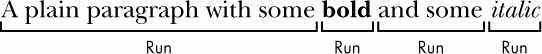
كائنات Run الموجودة ضمن كائن Paragraph
يُعَد النص الموجود في مستند وورد أكثرَ من مجرد سلسلة نصية، فلهذا النص نوع خطٍ وحجم ولون ومعلومات تنسيقٍ أخرى مرتبطةٌ به، حيث يمثل النمط Style في وورد مجموعةً من هذه السمات. يمثّل الكائن Run التشغيل المتجاور للنصوص التي لها النمط نفسه، إذ يجب أن يكون هناك كائن Run جديد كلما تغيّر نمط النص.
قراءة مستندات وورد
لنختبر الآن وحدة docx، لذا نزّل الملف demo.docx واحفظه في مجلد العمل، ثم أدخِل ما يلي في الصدفة التفاعلية:
>>> import docx ➊ >>> doc = docx.Document('demo.docx') ➋ >>> len(doc.paragraphs) 7 ➌ >>> doc.paragraphs[0].text 'Document Title' ➍ >>> doc.paragraphs[1].text 'A plain paragraph with some bold and some italic' ➎ >>> len(doc.paragraphs[1].runs) 4 ➏ >>> doc.paragraphs[1].runs[0].text 'A plain paragraph with some ' ➐ >>> doc.paragraphs[1].runs[1].text 'bold' ➑ >>> doc.paragraphs[1].runs[2].text ' and some ' ➒ >>> doc.paragraphs[1].runs[3].text 'italic'
نفتح ملف .docx في بايثون ونستدعي الدالة docx.Document() ونمرّر إليها اسم الملف demo.docx ➊، مما يؤدي إلى إعادة كائن Document الذي يحتوي على السمة paragraphs التي تمثل قائمةً من كائنات Paragraph. إذا استدعينا الدالة len() للسمة doc.paragraphs، فستعيد القيمة 7، مما يخبرنا بوجود سبعة كائنات Paragraph في هذا المستند ➋. يمتلك كل كائن من كائنات Paragraph السمةَ text التي تحتوي على سلسلة نصية من النص الموجود في تلك الفقرة (بدون معلومات النمط). تحتوي السمة text الأولى في مثالنا على النص 'DocumentTitle' ➌، وتحتوي السمة text الثانية على النص 'A plain paragraph with some bold and some italic' ➍.
يمتلك كل كائن Paragraph أيضًا على السمة runs التي تمثل قائمةً من كائنات Run التي تمتلك أيضًا السمة text التي تحتوي على نص كائن Run الخاص بها. لنلقِ نظرةً على سمات text في كائن Paragraph الثاني، والتي تمثّل النص 'A plain paragraph with some bold and some italic'، حيث يعطي استدعاء الدالة len() لهذا الكائن القيمةَ 4، والتي تمثل وجود أربعة كائنات Run ➎. يحتوي كائن Run الأول على النص 'A plain paragraph with some ' ➏، ثم يتغير النص إلى نمط خط عريض، وبالتالي يبدأ النص 'bold' كائن Run جديد ➐، ثم يعود النص إلى نمط خطٍ غير عريض، مما يعطي كائن Run ثالث، وهو النص ' and some ' ➑. أخيرًا، يحتوي كائن Run الرابع والأخير على النص 'italic' بنمط خطٍ مائل ➒.
ستتمكن برامج بايثون الآن باستخدام الوحدة Python-Docx من قراءة النص من ملف .docx واستخدامه مثل أيّ قيمة سلسلة نصية أخرى.
الحصول على النص الكامل من ملف امتداده .docx
إذا كان اهتمامك بالنص فقط دون الاهتمام بمعلومات التنسيق في مستند وورد، فيمكنك استخدام الدالة getText() التي تأخذ اسم ملف .docx وتعيد قيمة سلسلة نصية واحدة تمثّل النص الخاص بهذا الملف. افتح تبويبًا جديدًا لإنشاء ملف جديد في محرّرك، وأدخِل الشيفرة البرمجية التالية، واحفظ الملف بالاسم readDocx.py:
#! python3 import docx def getText(filename): doc = docx.Document(filename) fullText = [] for para in doc.paragraphs: fullText.append(para.text) return '\n'.join(fullText)
تفتح الدالة getText() مستند وورد، وتتكرر ضمن حلقة على كافة كائنات Paragraph الموجودة في القائمة paragraphs، ثم تلحِق النص الخاص بها بالقائمة الموجودة في المتغير fullText. تُضَم السلاسل النصية الموجودة في المتغير fullText بعد انتهاء الحلقة مع محارف السطر الجديد.
يمكن استيراد برنامج readDocx.py مثل أي وحدة أخرى، وإذا أردتَ النص فقط من مستند وورد، فيمكنك إدخال ما يلي:
>>> import readDocx >>> print(readDocx.getText('demo.docx')) Document Title A plain paragraph with some bold and some italic Heading, level 1 Intense quote first item in unordered list first item in ordered list
يمكنك أيضًا ضبط الدالة getText() لتعديل السلسلة النصية قبل إعادتها، فمثلًا يمكننا وضع مسافة بادئة لكل فقرة من خلال تعديل استدعاء التابع append() في الملف readDocx.py كما يلي:
fullText.append(' ' + para.text)
يمكننا إضافة مسافة مزدوجة بين الفقرات من خلال تغيير شيفرة استدعاء التابع join() إلى ما يلي:
return '\n\n'.join(fullText)
لاحظ أنك لا تحتاج سوى بضعة أسطر من الشيفرة البرمجية لكتابة الدوال التي تقرأ ملف .docx وتعيد سلسلة نصية من محتوى هذا الملف حسب رغبتك.
تنسيق كائنات Paragraph وكائنات Run
يمكنك رؤية الأنماط في وورد ضمن نظام ويندوز بالضغط على المفاتيح Ctrl-Alt-Shift-S لعرض لوحة الأنماط Styles التي تشبه الشكل التالي، بينما يمكنك عرض لوحة الأنماط في نظام تشغيل ماك macOS بالنقر على عنصر قائمة العرض View ثم الأنماط Styles.
عرض لوحة الأنماط بالضغط على المفاتيح CTRL-ALT-SHIFT-S في نظام ويندوز
يستخدم برنامج وورد ومعالجات النصوص الأخرى أنماطًا للحفاظ على تناسق العرض المرئي لأنواع النصوص المتشابهة وسهولة تغييره، فمثلًا قد ترغب في ضبط فقرات النص لتكون بخطٍ من النوع Times New Roman وحجمه 11 نقطة ومتحاذٍ من جهة اليسار وغير مضبوط من جهة اليمين، حيث يمكنك إنشاء نمط باستخدام هذه الإعدادات وإسناده لجميع فقرات النص، وإذا أردتَ لاحقًا تغيير طريقة عرض جميع فقرات النص في المستند، فيمكنك تغيير النمط فقط، وستُحدَّث جميع تلك الفقرات تلقائيًا.
هناك ثلاثة أنواع من الأنماط بالنسبة لمستندات وورد وهي: أنماط الفقرة Paragraph Styles التي يمكن تطبيقها على كائنات Paragraph، وأنماط المحارف Character Styles التي يمكن تطبيقها على كائنات Run، والأنماط المرتبطة Linked Styles التي يمكن تطبيقها على كلا النوعين من الكائنات. يمكنك إعطاء كائنات Paragraph وكائنات Run أنماطٍ من خلال ضبط السمة style الخاصة بها على سلسلةٍ نصية تمثّل اسم النمط، وإذا كانت هذه السمة مضبوطةً على القيمة None، فلن يكون هناك نمط مرتبط بكائن Paragraph أو كائن Run.
إليك قيم السلاسل النصية لأنماط وورد الافتراضية:
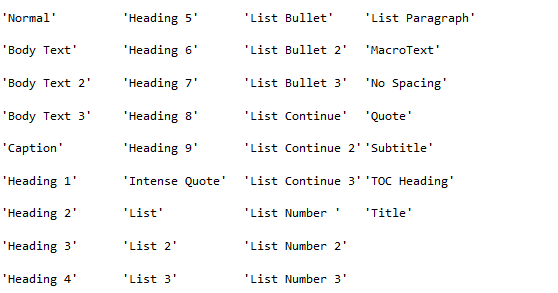
يجب إضافة ' Char' إلى نهاية اسم النمط عند استخدام نمط مرتبط بكائن Run، فمثلًا يمكنك ضبط النمط المرتبط Quote لكائن Paragraph من خلال استخدام paragraphObj.style = 'Quote'، ولكنك ستستخدم runObj.style = 'Quote Char' بالنسبة لكائن Run.
الأنماط الوحيدة التي يمكن استخدامها في الإصدار 0.8.10 من وحدة Python-Docx هي أنماط وورد الافتراضية والأنماط الموجودة في ملف .docx المفتوح، ولا يمكن إنشاء أنماط جديدة، بالرغم من أن ذلك قد تغيّر في الإصدارات اللاحقة من وحدة Python-Docx.
إنشاء مستندات وورد مع أنماط غير افتراضية
إذا أردتَ إنشاء مستندات وورد تستخدم أنماطٍ مختلفة عن الأنماط الافتراضية، فيجب فتح وورد على مستند فارغ وإنشاء الأنماط بنفسك من خلال النقر على زر "نمط جديد New Style" الموجود أسفل لوحة الأنماط كما هو موضح في الشكل التالي على نظام ويندوز:
زر نمط جديد New Style (على اليسار) ونافذة إنشاء نمط جديد من التنسيق Create New Style from Formatting (على اليمين).
سيؤدي الضغط على زر نمط جديد إلى فتح نافذة "إنشاء نمط جديد من التنسيق Create New Style from Formatting" حيث يمكنك إدخال النمط الجديد. ارجع بعد ذلك إلى الصدفة التفاعلية وافتح هذا المستند الفارغ باستخدام الدالة docx.Document()، واستخدمه كأساسٍ لمستند وورد الخاص بك. سيكون الاسم الذي أعطيته لهذا النمط متاحًا الآن للاستخدام مع وحدة Python-Docx.
سمات الكائن Run
يمكن تنسيق كائنات Run باستخدام سمات text، حيث يمكن ضبط كل سمة على قيمة من ثلاث قيم هي: القيمة True (تكون السمة مُفعَّلةً دائمًا بغض النظر عن الأنماط الأخرى المُطبَّقة على الكائن Run)، أو القيمة False (تكون السمة مُعطَّلة دائمًا)، أو القيمة None (الإعداد الافتراضي لأيّ نمطٍ مضبوط للكائن Run).
يوضّح الجدول التالي السمات text التي يمكن ضبطها لكائنات Run:
| السمة | وصفها |
|---|---|
السمة bold
|
يظهر النص بخط عريض |
السمة italic
|
يظهر النص بخط مائل |
السمة underline
|
يوضَع خط تحت النص |
السمة strike
|
يظهر النص مع خطٍ في وسطه |
السمة double_strike
|
يظهر النص مع خط مزدوج في وسطه |
السمة all_caps
|
يظهر النص بحروف كبيرة |
السمة small_caps
|
يظهر النص بحروف كبيرة، وتكون الحروف الصغيرة أصغر بنقطتين |
السمة shadow
|
يظهر النص مع ظل |
السمة outline
|
يظهر النص مُحدَّدًا وليس ممتلئًا |
السمة rtl
|
النص مكتوب من اليمين إلى اليسار |
السمة imprint
|
يظهر النص مضغوطًا إلى داخل الصفحة |
السمة emboss
|
يبدو النص مرتفعًا عن الصفحة ارتفاعًا بارزًا |
أدخِل مثلًا ما يلي في الصدفة التفاعلية لتغيير أنماط الملف demo.docx:
>>> import docx >>> doc = docx.Document('demo.docx') >>> doc.paragraphs[0].text 'Document Title' >>> doc.paragraphs[0].style # The exact id may be different: _ParagraphStyle('Title') id: 3095631007984 >>> doc.paragraphs[0].style = 'Normal' >>> doc.paragraphs[1].text 'A plain paragraph with some bold and some italic' >>> (doc.paragraphs[1].runs[0].text, doc.paragraphs[1].runs[1].text, doc. paragraphs[1].runs[2].text, doc.paragraphs[1].runs[3].text) ('A plain paragraph with some ', 'bold', ' and some ', 'italic') >>> doc.paragraphs[1].runs[0].style = 'QuoteChar' >>> doc.paragraphs[1].runs[1].underline = True >>> doc.paragraphs[1].runs[3].underline = True >>> doc.save('restyled.docx')
استخدمنا في المثال السابق سمات text و style لرؤية ما هو موجود في الفقرات ضمن المستند بسهولة، إذ يمكننا أن نرى أنه من السهل تقسيم الفقرة إلى كائنات Run والوصول إلى كلٍّ منها على حدة، لذلك يمكننا الحصول على كائنات Run الأولى والثانية والرابعة في الفقرة الثانية، وتنسيق كلِّ منها، وحفظ النتائج في مستند جديد.
ستكون للكلمات Document Title الموجودة في أعلى المستند restyled.docx النمط العادي Normal بدلًا من نمط العنوان Title، وسيكون لكائن Run الخاص بالنص A plain paragraph with some النمط QuoteChar، وسيكون لكائني Run الخاصين بالكلمتين bold و italic سمات underline المضبوطة على القيمة True. يوضح الشكل التالي كيف تبدو أنماط الفقرات وكائنات Run في المستند restyled.docx:

ملف restyled.docx
كتابة مستندات وورد
لندخِل ما يلي في الصدفة التفاعلية:
>>> import docx >>> doc = docx.Document() >>> doc.add_paragraph('Hello, world!') <docx.text.Paragraph object at 0x0000000003B56F60> >>> doc.save('helloworld.docx')
يمكننا إنشاء ملف .docx من خلال استدعاء الدالة docx.Document() لإعادة كائن مستند Document وورد جديد وفارغ، ويضيف التابع add_paragraph() الخاص بالمستند فقرةً نصية جديدة إلى المستند ويعيد مرجعًا إلى كائن Paragraph المُضاف. نمرّر سلسلةً نصية تمثّل اسم الملف إلى التابع save() الخاص بالمستند عند الانتهاء من إضافة النص لحفظ الكائن Document في ملف. تؤدي الشيفرة البرمجية السابقة إلى إنشاء ملف بالاسم helloworld.docx في مجلد العمل الحالي والذي يبدو عند فتحه كما يلي:
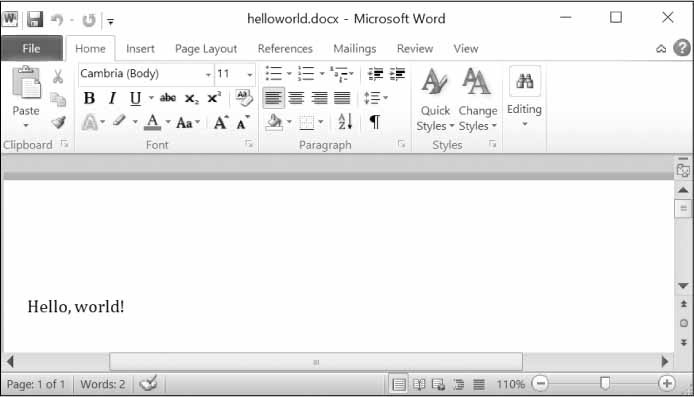
مستند وورد الذي أنشأناه باستخدام الاستدعاء add_paragraph('Hello, world!')
يمكنك إضافة فقرات من خلال استدعاء التابع add_paragraph() مرةً أخرى مع نص الفقرة الجديدة، أو يمكنك استدعاء التابع add_run() الخاص بالفقرة وتمرير سلسلة نصية إليه لإضافة نص إلى نهاية فقرة موجودة مسبقًا. إذًا لندخِل ما يلي في الصدفة التفاعلية:
>>> import docx >>> doc = docx.Document() >>> doc.add_paragraph('Hello world!') <docx.text.Paragraph object at 0x000000000366AD30> >>> paraObj1 = doc.add_paragraph('This is a second paragraph.') >>> paraObj2 = doc.add_paragraph('This is a yet another paragraph.') >>> paraObj1.add_run(' This text is being added to the second paragraph.') <docx.text.Run object at 0x0000000003A2C860> >>> doc.save('multipleParagraphs.docx')
لاحظ أن النص "This text is being added to the second paragraph." أضيف إلى كائن Paragraph في المتغير paraObj1، وهو الفقرة الثانية المُضافة إلى المتغير doc. تعيد الدالتان add_paragraph() و add_run() كائنات Paragraph و Run على التوالي بحيث توفّر عليك عناء استخراجها في خطوة منفصلة. ضع في بالك أنه يمكن إضافة كائنات Paragraph الجديدة إلى نهاية المستند فقط، ويمكن إضافة كائنات Run الجديدة إلى نهاية كائن Paragraph فقط، وذلك اعتبارًا من الإصدار 0.8.10 من وحدة Python-Docx. أخيرًا، يمكن استدعاء التابع save() مرة أخرى لحفظ التغييرات الإضافية التي أجريتها.
سيبدو المستند الناتج مثل المستند الموضّح في الشكل التالي:
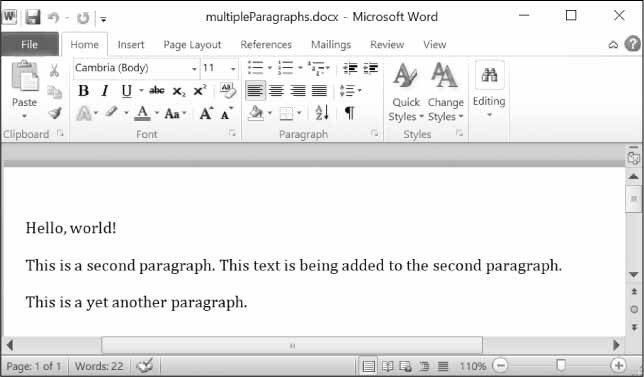
المستند الذي يحتوي على كائنات Paragraph و Run المتعددة المُضافة
تأخذ كلّ من الدالتين add_paragraph() و add_run() وسيطًا ثانيًا اختياريًا، وهو سلسلة نصية من نمط الكائن Paragraph أو Run كما في المثال التالي:
>>> doc.add_paragraph('Hello, world!', 'Title')
يضيف السطر السابق فقرةً تحتوي على النص "Hello, world!" من نمط العنوان Title Style.
إضافة العناوين Headings
يؤدي استدعاء الدالة add_heading() إلى إضافة فقرة تحتوي على أحد أنماط العناوين. لندخِل ما يلي في الصدفة التفاعلية:
>>> doc = docx.Document() >>> doc.add_heading('Header 0', 0) <docx.text.Paragraph object at 0x00000000036CB3C8> >>> doc.add_heading('Header 1', 1) <docx.text.Paragraph object at 0x00000000036CB630> >>> doc.add_heading('Header 2', 2) <docx.text.Paragraph object at 0x00000000036CB828> >>> doc.add_heading('Header 3', 3) <docx.text.Paragraph object at 0x00000000036CB2E8> >>> doc.add_heading('Header 4', 4) <docx.text.Paragraph object at 0x00000000036CB3C8> >>> doc.save('headings.docx')
وسطاء الدالة add_heading() هي سلسلة نصية تمثّل نص العنوان وعدد صحيح قيمته من 0 إلى 4، حيث يجعل العدد الصحيح 0 العنوان من النمط Title style، والذي يُستخدَم في الجزء العلوي من المستند، والأعداد الصحيحة من 1 إلى 4 مُخصَّصة لمستويات العناوين المختلفة، حيث يكون العدد 1 هو العنوان الرئيسي والعدد 4 هو العنوان الفرعي الأدنى. تعيد الدالة add_heading() كائن Paragraph لتوفّر عليك إجراء خطوة استخراجه من كائن Document في خطوة منفصلة.
سيبدو ملف headings.docx الناتج مثل المستند الموضّح في الشكل التالي:
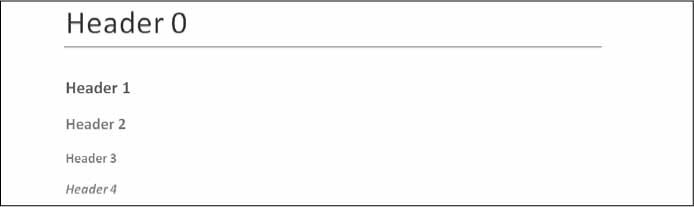
مستند headings.docx الذي يحتوي على العناوين من 0 إلى 4
إضافة فواصل الأسطر والصفحات
يمكن إضافة فاصل أسطر بدلًا من بدء فقرة جديدة بالكامل من خلال استدعاء التابع add_break() لكائن Run الذي تريد ظهور الفاصل بعده، وإذا أردتَ إضافة فاصل صفحات، فيجب تمرير القيمة docx.enum.text.WD_BREAK.PAGE بوصفها وسيطًا وحيدًا للتابع add_break() كما في السطر ➊ من المثال التالي:
>>> doc = docx.Document() >>> doc.add_paragraph('This is on the first page!') <docx.text.Paragraph object at 0x0000000003785518> ➊ >>> doc.paragraphs[0].runs[0].add_break(docx.enum.text.WD_BREAK.PAGE) >>> doc.add_paragraph('This is on the second page!') <docx.text.Paragraph object at 0x00000000037855F8> >>> doc.save('twoPage.docx')
تؤدي الشيفرة البرمجية السابقة إلى إنشاء مستند وورد مؤلف من صفحتين مع وجود النص "This is on the first page!" في الصفحة الأولى والنص "This is on the second page!" في الصفحة الثانية. لا يزال هناك مساحة كبيرة في الصفحة الأولى بعد النص "This is on the first page!"، ولكننا أجبرنا الفقرة التالية على البدء في صفحة جديدة من خلال إدراج فاصل صفحات بعد كائن Run الأول للفقرة الأولى ➊.
إضافة الصور
تحتوي كائنات Document على التابع add_picture() الذي يتيح إضافة صورةٍ إلى نهاية المستند. لنفترض أن لديك ملفًا اسمه zophie.png مثلًا في مجلد العمل الحالي، حيث يمكنك إضافة الصورة zophie.png إلى نهاية مستندك بعرض 1 بوصة وارتفاع 4 سنتيمترات من خلال إدخال ما يلي (يستخدم برنامج وورد الوحدات الإنجليزية والمترية):
>>> doc.add_picture('zophie.png', width=docx.shared.Inches(1), height=docx.shared.Cm(4)) <docx.shape.InlineShape object at 0x00000000036C7D30>
الوسيط الأول للتابع add_picture() هو سلسلة نصية تمثّل اسم ملف الصورة، وتضبط وسطاء الكلمات المفتاحية width و height الاختيارية عرض الصورة وارتفاعها في المستند، وإذا تُرِكا دون ضبط، فسيكون العرض والارتفاع الافتراضي هو الحجم الطبيعي للصورة.
قد تفضّل تحديد ارتفاع الصورة وعرضها بوحدات مألوفة مثل وحدات البوصة والسنتيمتر، لذا يمكنك استخدام الدالتين docx.shared.Inches() و docx.shared.Cm() عندما تحدّد وسطاء الكلمات المفتاحية width و height.
إنشاء ملفات PDF من مستندات وورد
لا تسمح لك وحدة PyPDF2 بإنشاء مستندات PDF مباشرةً، ولكن توجد طريقة لإنشاء ملفات PDF باستخدام بايثون إذا كنت تستخدم نظام ويندوز مع وجود مايكروسوفت وورد مثبَّتًا عليه، لذا ستحتاج إلى تثبيت الحزمة Pywin32 من خلال تشغيل الأمر pip install --user -U pywin32==224. إذا استخدمتَ هذه الحزمة مع وحدة docx، فيمكنك إنشاء مستندات وورد ثم تحويلها إلى ملفات PDF باستخدام السكربت التالي، لذا افتح تبويبًا جديدًا لإنشاء ملف جديد في محرّرك، وأدخِل الشيفرة البرمجية التالية، واحفظها بالاسم convertWordToPDF.py:
# يعمل هذا السكربت على نظام ويندوز فقط، ويجب أن يكون وورد مثبتًا عليه import win32com.client # install with "pip install pywin32==224" import docx wordFilename = 'your_word_document.docx' pdfFilename = 'your_pdf_filename.pdf' doc = docx.Document() # ضع شيفرة إنشاء مستند وورد هنا doc.save(wordFilename) wdFormatPDF = 17 # Word's numeric code for PDFs. wordObj = win32com.client.Dispatch('Word.Application') docObj = wordObj.Documents.Open(wordFilename) docObj.SaveAs(pdfFilename, FileFormat=wdFormatPDF) docObj.Close() wordObj.Quit()
يمكنك كتابة برنامج ينتج عنه ملفات PDF مع المحتوى الخاص بك من خلال استخدام وحدة docx لإنشاء مستند وورد، ثم استخدام وحدة win32com.client الخاصة بحزمة Pywin32 لتحويله إلى ملف PDF. ضع استدعاءات دوال الوحدة docx مكان التعليق # ضع شيفرة إنشاء مستند وورد هنا لإنشاء المحتوى الخاص بك لملف PDF في مستند وورد.
قد تبدو هذه الطريقة لإنتاج ملفات PDF معقدة، ولكن تكون الحلول البرمجية الاحترافية معقدةً في أغلب الأحيان.
مشاريع للتدريب
حاول كتابة البرامج التي تؤدي المهام التي سنوضّحها فيما يلي لكسب خبرة عملية أكبر.
برنامج للتأكد من تشفير ملفات PDF
استخدم الدالة os.walk() لكتابة سكربتٍ يمر على كل ملف PDF في المجلد ومجلداته الفرعية، وشفّر ملفات PDF باستخدام كلمة المرور المتوفرة في سطر الأوامر، واحفظ كل ملف PDF مشفّر مع إضافة اللاحقة _encrypted.pdf إلى اسم الملف الأصلي، ثم اطلب من البرنامج محاولة قراءة الملف وفك تشفيره للتأكد من تشفيره بصورة صحيحة قبل حذف الملف الأصلي.
اكتب بعد ذلك برنامجًا يبحث عن جميع ملفات PDF المشفرة في المجلد ومجلداته الفرعية، وينشئ نسخة مشفَّرة من ملف PDF باستخدام كلمة المرور المتوفرة. إذا كانت كلمة المرور غير صحيحة، فيجب على البرنامج طباعة رسالة للمستخدم والانتقال إلى ملف PDF التالي.
برنامج لإنشاء دعوات مخصصة في مستندات وورد
لنفترض أن لديك ملفًا نصيًا بأسماء الضيوف، حيث يحتوي الملف guests.txt على اسم شخص واحد في كل سطر كما يلي:
Prof. Plum Miss Scarlet Col. Mustard Al Sweigart RoboCop
اكتب برنامجًا ينشئ مستند وورد يحتوي على دعوات مخصصة كما يلي:
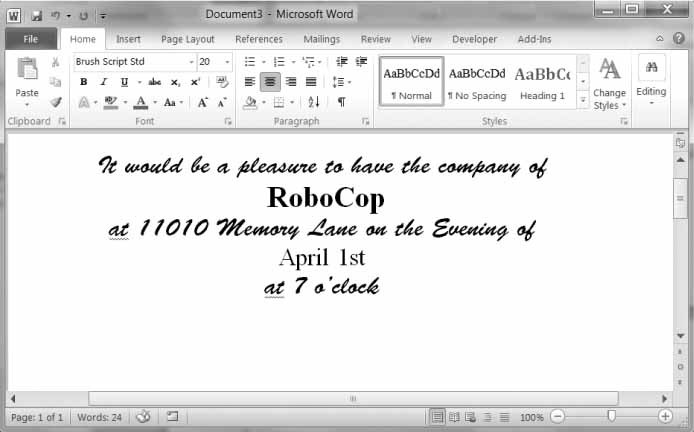
مستند وورد الذي أنشأناه باستخدام سكربت الدعوات المخصصة
يمكن للوحدة Python-Docx استخدام الأنماط الموجودة مسبقًا في مستند وورد فقط، لذا يجب أولًا إضافة هذه الأنماط إلى ملف وورد فارغ ثم فتح هذا الملف باستخدام وحدة Python-Docx. يجب أن تكون هناك دعوة واحدة لكل صفحة في مستند وورد الناتج، لذا استدعِ التابع add_break() لإضافة فاصل صفحة بعد الفقرة الأخيرة من كل دعوة، وبالتالي يجب فتح مستند وورد واحد فقط لطباعة كافة الدعوات دفعةً واحدة.
ملاحظة: يمكنك أيضًا تنزيل نموذج الملف guests.txt.
برنامج لاستخدام هجوم القوة الغاشمة لكسر كلمة مرور ملفات PDF
لنفترض أن لديك ملف PDF مشفَّرًا نسيت كلمة مروره، ولكنك تتذكر أنه كان كلمة إنجليزية واحدة، وتُعَد محاولة تخمين كلمة المرور التي نسيتها مهمةً مملة جدًا، لذا يمكنك كتابة برنامج يفك تشفير ملف PDF من خلال تجربة جميع الكلمات الإنجليزية الممكنة حتى يجد الكلمة الصحيحة، ويسمى ذلك هجوم القوة الغاشمة لإيجاد كلمة المرور. نزّل الملف النصي dictionary.txt الذي يحتوي على أكثر من 44000 كلمة إنجليزية بحيث توجد كلمة واحدة في كل سطر.
استخدم مهارات قراءة الملفات التي تعلمتها سابقًا لإنشاء قائمةٍ بالسلاسل النصية التي تمثّل الكلمات من خلال قراءة الملف dictionary.txt، ثم المرور على كل كلمة في هذه القائمة، وتمريرها إلى التابع decrypt(). إذا أعاد هذا التابع العدد الصحيح 0، فستكون كلمة المرور خاطئة ويجب أن ينتقل برنامجك إلى كلمة المرور التالية، وإذا أعاد التابع decrypt() القيمة 1، فيجب أن يخرج برنامجك من الحلقة ويطبع كلمة المرور المُخترقة، ويجب عليك أيضًا تجربة كلٍّ من الحروف الكبيرة والصغيرة لكل كلمة. يستغرق استعراض جميع الكلمات الكبيرة والصغيرة البالغ عددها 88000 كلمة من ملف القاموس بضع دقائق، ولذلك يجب عدم استخدام كلمة إنجليزية بسيطة لكلمات المرور الخاصة بك.
الخلاصة
لا تُعد المعلومات النصية مُخصَّصة للملفات النصية العادية فقط، إذ يُحتمَل أن تتعامل مع ملفات PDF ومستندات وورد في كثير من الأحيان، حيث يمكنك استخدام وحدة PyPDF2 لقراءة وكتابة مستندات PDF، ولكن قد لا تؤدي قراءة النص من مستندات PDF دائمًا إلى ترجمة مثالية للسلاسل النصية بسبب تنسيق ملف PDF المعقد، وقد لا تكون بعض ملفات PDF قابلة للقراءة على الإطلاق، وبالتالي لن يحالفك الحظ في هذه الحالات إن لم تدعم التحديثات المستقبلية لوحدة PyPDF2 ميزات إضافية لملفات PDF.
تُعَد مستندات وورد أكثر موثوقية، ويمكنك قراءتها باستخدام وحدة docx الخاصة بحزمة python-docx. يمكنك معالجة النصوص في مستندات وورد باستخدام كائنات Paragraph و Run، ويمكن أيضًا إعطاء هذه الكائنات أنماطًا، بالرغم من أن هذه الأنماط يجب أن تكون من مجموعة الأنماط الافتراضية أو الأنماط الموجودة في المستند مسبقًا. يمكنك إضافة فقرات وعناوين وفواصل وصور جديدة إلى المستند في نهايته فقط.
ترجِع العديد من قيود التعامل مع ملفات PDF ومستندات وورد إلى أن هذه التنسيقات تهدف إلى عرضها بصورة جيدة للقرّاء، عوضًا عن سهولة تحليلها من طرف البرمجيات، لذا سنوضّح في المقال التالي تنسيقين شائعين آخرين لتخزين المعلومات هما: ملفات JSON و CSV المُصمَّمة لتستخدمها الحواسيب، وسترى أن لغة بايثون يمكنها العمل مع هذه التنسيقات بسهولة أكبر.
ترجمة -وبتصرُّف- للمقال Working with PDF and Word documents لصاحبه Al Sweigart.









أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.