

يوجه النقد لنماذج تعلّم الآلة غالبًا بأنها صناديق سوداء نُدخَل فيها البيانات من جهة للحصول على أجوبة دقيقة في أغلب الأحيان، ومن جهة أخرى دون أي تفسير واضح لكيفية الحصول على الجواب.
نعاين في هذا الجزء الثالث من بناء نموذج تعلّم آلة في بايثون نموذج التعلّم المطوّر لمحاولة فهم كيفية وصوله للتنبؤ الدقيق، وما يُمكن تعلمه حول مسألتنا المطروحة (التنبؤ بمعامل نجمة الطاقة) من هذا النموذج. وسنختم بمناقشة جزءٍ مهمٍ في مشاريع تعلّم الآلة وهو توثيق العمل وعرض النتائج بوضوح.
عرضنا في الجزء الأول مسألة تنظيف البيانات وتحليلها الاستكشافي، ومن ثم آليات هندسة الميزات لاختيار المناسب منها؛ أما في الجزء الثاني فشرحنا آلية احتساب القيم الناقصة وعرضنا الشيفرة اللازمة لإنشاء نماذج تعلّم، كما وازنا بين عدة نماذج تعلّم ممكنة وصولًا إلى اختيار النموذج الأمثل لمسألتنا. وبهدف تحسين أداء النموذج المختار عالجنا مسألة معايرة المعاملات الفائقة للنموذج باستخدام البحث العشوائي مع التقويم المتقاطع. وفي النهاية حسبنا أداء النموذج مع بيانات الاختبار. ننصح الجميع بتحميل الشيفرة ومعاينتها ومشاركتها، فهي متاحة للعموم.
نُذكّر بأننا نعمل على تطوير نموذج تعلّم آلة من نمط موجه عبر الانحدار، وذلك باستخدام بيانات الطاقة لمباني نيويورك المتاحة للعموم بهدف التنبؤ بمعامل نجمة الطاقة للمبنى، ووصلنا في النهاية إلى بناء نموذج تعلّم من نمط الانحدار المعزز بالتدرج مع متوسط خطأ مطلق يساوي إلى 9.1 نقطة، بحيث يتراوح معامل نجمة الطاقة بين 1 و100 نقطة.
تفسير وفهم النموذج
يُعدّ الانحدار المعزز بالتدرج من النماذج المعقدة، إلا أنه يتموضع في منتصف مقياس إمكانية تفسير النموذج نظرًا لاحتوائه على أشجار القرار القابلة للشرح والتفسير.
سننظر في الطرق الثلاثة التالية لمحاولة فهم آلية التنبؤ:
- أهمية الميزات.
- معاينة شجرة قرار واحدة.
- التفسيرات المحلية المحايدة للنموذج.
تختص الطريقة الأولى والثانية بأشجار القرار؛ أما الطريقة الثالثة فهي طريقة عامة يُمكن استخدامها مع أي نموذج، وهي حزمة برمجية جديدة وخطوة مهمة نحو فهم آلية التنبؤ في مسائل تعلّم الآلة.
أهمية الميزات
تُحسب أهمية ميزة ما بمدى تأثيرها في الوصول إلى القيمة الهدف. وهنا لن نخوض في حسابات الأهمية المعقدة مثل حساب متوسط الانخفاض في عدم النقاء أو حساب انخفاض الخطأ عند تضمين الميزة، إذ توفر مكتبات Scikit-Learn إمكانية حساب أهمية كل ميزة لأي نموذج متعلّم يعتمد على الأشجار.
تحسب الشيفرة التالية أهمية الميزات باستخدام model.feature_importances، حيث model هو النموذج المطور، ثم نضع الأهميات المحسوبة في إطار بيانات بهدف رسم العشر الأوائل الأكثر أهمية:
import pandas as pd # model النموذج المطور importances = model.feature_importances_ # train_features إطار بيانات المزايا feature_list = list(train_features.columns) # وضع أهميات المزايا في إطار بيانات feature_results = pd.DataFrame({'feature': feature_list, 'importance': importances}) # إظهار الميزات العشر الأكثر أهمية feature_results = feature_results.sort_values('importance', ascending = False).reset_index(drop=True) feature_results.head(10)
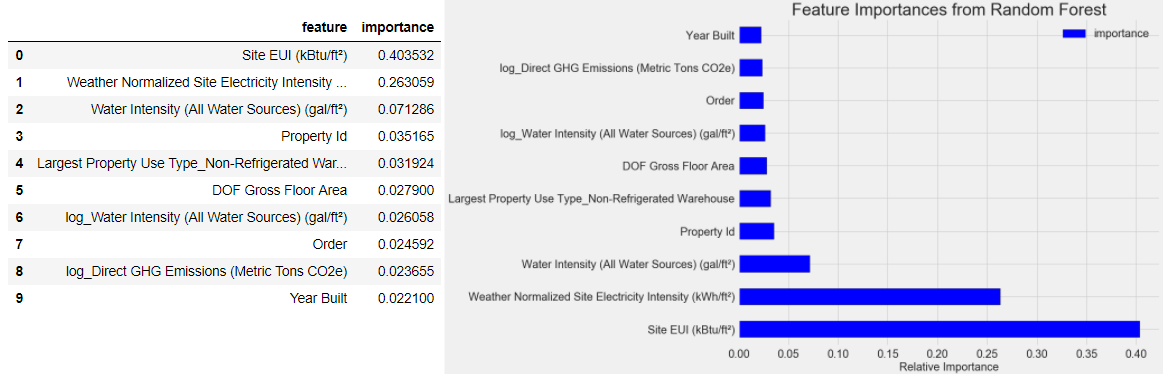
يُظهِر الشكل بوضوح أن أهم ميزتين (تُشكّلان لوحدهما حوالي 66% من الأهمية الكلية هما كثافة استخدام الطاقة Site EUI Energy Use Intensity، وكثافة الكهرباء وفق الطقس Weather Normalized Site Electricity Intensity.
تنخفض أهمية الميزات الأخرى بعد هاتين الميزتين مما يعني أننا لسنا مضطرين لاستخدام كل الميزات في النموذج (64 ميزة) للوصول إلى دقة كبيرة، وقد اخترنا عمليًا على سبيل التجريب عشر ميزات فقط وقمنا بإعادة بناء النموذج إلا أن دقته لم تكن جيدةً. وبهذا تعرّفنا السريع عن أهم الميزات المؤثرة في معامل نجمة الطاقة دون الاضطرار للغوص كثيرًا في الخلفية النظرية لهذا الموضوع.
معاينة شجرة قرار وحيدة
تُعَد أشجار القرار من أبسط الأشياء القابلة للفهم بخلاف الانحدار المعزز بالتدرج، حيث نستخدم في الشيفرة التالية التابع export_graphviz من Scikit-Learn لمعاينة أي شجرة من غابة الأشجار، إذ نستخرج أولًا شجرةً من غابة الأشجار ثم نحفظها في ملف نقطي dot.
from sklearn import tree # استخراج الشجرة (105) single_tree = model.estimators_[105][0] # حفظ الشجرة في ملف نقطي tree.export_graphviz(single_tree, out_file = 'images/tree.dot', feature_names = feature_list)
نستخدم برمجية المعاينة من Graphviz لحفظ الصورة بصيغة png وذلك باستخدام التعليمة cmd التالية:
dot -Tpng images/tree.dot -o images/tree.png
ويكون الناتج عبارة عن شجرة كاملة:

لا يُمكن تفحص الشجرة السابقة جيدًا على الرغم من أن عمقها 6 فقط لذا سنعيد توليد الشجرة بعمق 2 عن طريق تعديل معامل العمق للتابع export_graphviz:
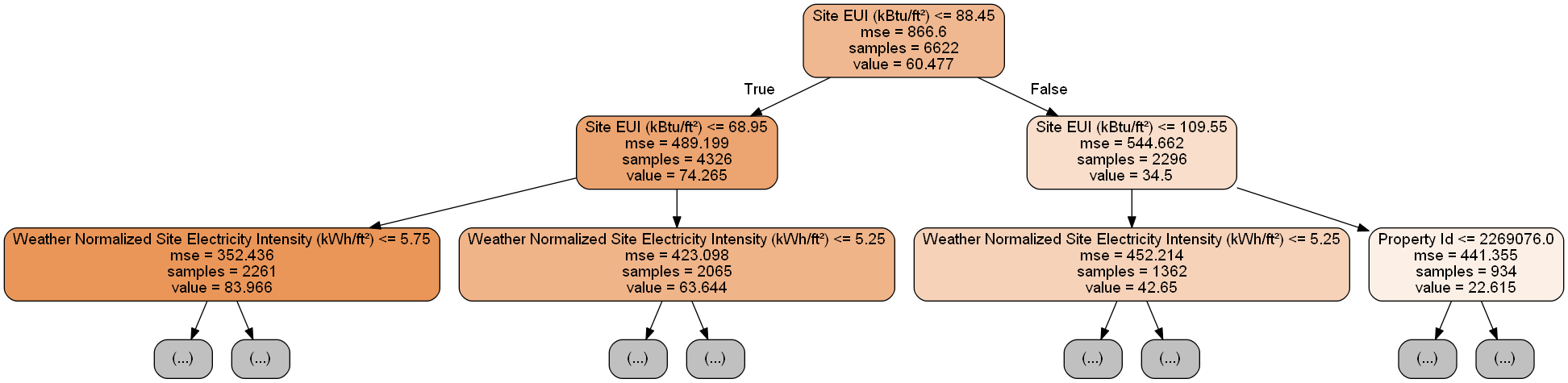
تحوي كل عقدة من الشجرة المعلومات التالية:
- اختبار منطقي لقيمة ميزة ما، حيث تُحدّد نتيجة هذا الاختبار المنطقي الاتجاه التالي في الشجرة نزولًا يمينًا أو يسارًا.
-
mseقياس الخطأ في العقدة. -
samplesعدد الأمثلة في العقدة. -
valueتقدير القيمة الهدف عند هذه العقدة.
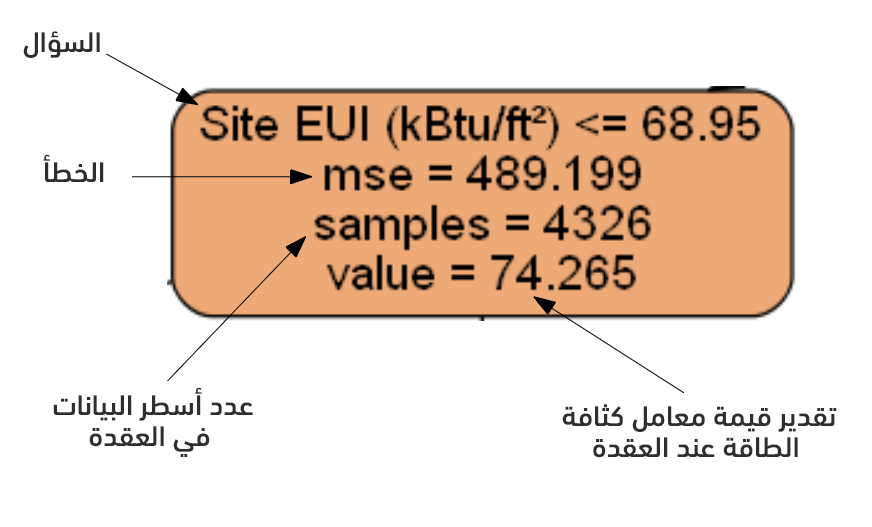
بالطبع لن يكون في أوراق الشجرة إلا الخطأ وتقدير القيمة الهدف.
تتنبأ شجرة القرار بالنتيجة كما يلي: تبدأ من العقدة الأولى (الجذر) وتتحرك نحو الأسفل حتى تصل لورقة من أوراق الشجرة، ويُحدّد الاختبار المنطقي نعم/لا في كل عقدة اتجاه الحركة يمينًا أو يسارًا. فمثلًا، تسأل عقدة الشكل السابق عما إذا كانت قيمة ميزة كثافة الطاقة EUI أقل من 68.95 أم لا؟ فإذا كان الاختبار صحيحًا ينتقل للعقدة الأدنى اليسرى، وإلا للعقدة الأدنى اليمنى، وهكذا حتى الوصول لورقة فتكون القيمة فيها هي قيمة التنبؤ النهائي. وإذا حوت الورقة على عدد من الأمثلة فسيكون لهم جميعًا نفس قيمة التنبؤ.
وبالطبع فكلما نزلنا في الشجرة ينقص الخطأ المرتكب في التنبؤ لأننا ننعم عمليًا الأمثلة أكثر فأكثر، إلا أن زيادة العمق قد توقعنا في مشكلة فرط التخصيص ولن تتمكن الشجرة عندها من تعميم الأمثلة.
عايرنا المعاملات الفائقة للنموذج في المقالة السابقة والتي تتحكم في شجرة القرار الناتجة، مثل العمق الأعظم للشجرة وعدد الأمثلة الأصغر المطلوب في ورقة، وهما معاملان يلعبان دورًا كبيرًا في المقايضة الملائمة/عدم الملائمة الفائضة.
تسمح معاينة شجرة القرار لنا بفهم تأثير هذه المعاملات الفائقة عمليًا، وعلى الرغم من أن معاينة جميع الأشجار أمرًا صعبًا، إلا أنه يكفي لنا معاينة شجرة واحدة فقط لنتمكن من فهم آلية التنبؤ التي ينجزها النموذج. وتبدو هذه الطريقة المعتمدة على مخطط انسيابي مشابهةً لما يفعله الإنسان عند اتخاذ قراراته بالإجابة على سؤال حول قيمة معينة في كل مرة.
تراكب أشجار القرار المعتمدة على مجموعات يبَيّن تنبؤات العديد من أشجار القرار الفردية من أجل إنشاء نموذج أكثر دقة مع تباين أقل، وتميل مجموعات الأشجار عامةً إلى أن تكون دقيقةً للغاية، كما أنها سهلة الشرح.
التفسيرات المحلية المحايدة للنموذج LIME
تهدف هذه الأداة الجديدة إلى شرح تنبؤ وحيد لأي نموذج، وذلك بإنشاء تقريب محلي للنموذج يكون قريبًا من المثال المدروس باستخدام نموذج بسيط مثل الانحدار الخطي (للحصول على تفاصيل أكثر يُمكن مراجعة الملف).
سنستخدم LIME لتفحص تنبؤ خاطئ ينجزه نموذجنا المطور، وللحصول على تنبؤ خاطئ نستخرج المثال الذي يكون معامل الخطأ المطلق له أكبر ما يُمكن:
from sklearn.ensemble import GradientBoostingRegressor # إنشاء النموذج مع المعاملات الفائقة الأمثل model = GradientBoostingRegressor(loss='lad', max_depth=5, max_features=None, min_samples_leaf=6, min_samples_split=6, n_estimators=800, random_state=42) # ملائمة واختبار النموذج model.fit(X, y) model_pred = model.predict(X_test) # إيجاد الأخطاء residuals = abs(model_pred - y_test) # استخراج أكثر تنبؤ خاطئ wrong = X_test[np.argmax(residuals), :] print('Prediction: %0.4f' % np.argmax(residuals)) print('Actual Value: %0.4f' % y_test[np.argmax(residuals)])
يكون الناتج:
Prediction: 12.8615 Actual Value: 100.0000
تُنشئ الشيفرة التالية كائن شرح مع تمرير المعاملات التالية له: بيانات التدريب والنمط وعناوين بيانات التدريب وأسماء الميزات.
import lime # إنشاء كائن شرح explainer = lime.lime_tabular.LimeTabularExplainer(training_data = X, mode = 'regression', training_labels = y, feature_names = feature_list) # شرح أسوء تنبؤ exp = explainer.explain_instance(data_row = wrong, predict_fn = model.predict) # رسم شرح التنبؤ exp.as_pyplot_figure();
ويكون الناتج ما يلي:
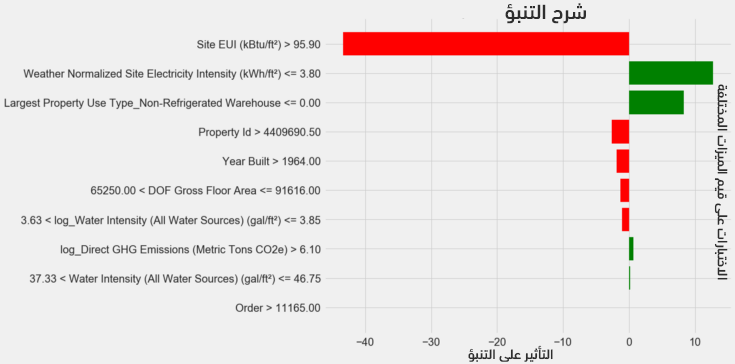
يُمكن تفسير الشكل كما يلي: يُظهِر المحور y الميزات التي أوصلت للنتيجة مع شريط أخضر في حال كانت قيمة الميزة تؤثر إيجابًا على القيمة الهدف؛ أما إذا كان تأثير قيمة الميزة سلبًيا فيكون لون الشريط أحمر. مثلًا: تؤدي قيمة الميزة الأولى والتي هي أكبر من 95.90 إلى طرح حوالي 40 من القيمة الهدف؛ أما الميزة الثانية والتي قيمتها أقل من 3.80 فتجمع 10 للتنبؤ، حيث تكون قيمة التنبؤ النهائية حاصل جمع كل هذه القيم الموجبة والسالبة.
يُمكن الحصول على نظرة أخرى لنفس المعلومات باستخدام الطريقة show_in_notebook:
# إظهار الشروحات exp.show_in_notebook()

يُبين الشكل آلية المحاكمة التي ينجزها النموذج وصولًا للهدف من خلال عرض تأثير كل ميزة على التنبؤ (يسار الشكل)، وعرض القيم الفعلية (يمين الشكل).
للأسف، يُظهر المثال تنبؤ النموذج للقيمة الهدف بحوالي 12 بينما القيمة الفعلية هي 100؛ إلا أنه بتفحص قيم الميزات يتبين أن قيمة معامل كثافة الطاقة مرتفعة نسبيًا، مما يعني أن معامل نجمة الطاقة يجب أن يكون منخفضًا لأن الارتباط بين كثافة الطاقة ومعامل نجمة الطاقة هو ارتباط سلبي كما عرضنا سابقًا. في مثل هذه الحالة يجب البحث عن سبب إعطاء المبنى معاملًا مرتفعًا على الرغم من أن كثافة الطاقة مرتفعة. وهنا قد تبدو أدوات الشرح المتوفرة غير كاملة، إلا أنها وفي جميع الأحوال ساعدتنا على فهم النموذج المتعلّم، مما يسمح لنا باتخاذ قرارات أفضل.
توثيق العمل وإعداد تقارير النتائج
يغفل الكثيرون في المشاريع التقنية عن ضرورة توثيق العمل وعرض النتائج بوضوح، حيث يُمكن أن يُهمَل عملنا ولو كان رائعًا في حال لم نعرض النتائج بطريقة مناسبة.
يهدف التوثيق إلى وضع جميع الشروحات والتعليقات التي تُمكّن الآخرين من قراءة الشيفرة المكتوبة وفهمها وإعادة بنائها بسرعة عند الحاجة، إذ يُعدّ استخدام أدوات مثل Jupyter Notebooks والتي تسمح بوضع الشروحات المطلوبة أمرًا أساسيًا كي نتمكن نحن أولًا، ومن ثم الآخرين بمراجعة الشيفرة وتعديلها إن لزم ولو بعد أشهر من كتابتها. تسمح بعض الإضافات للأداة السابقة بإخفاء الشيفرة في التقرير النهائي، إذ قد لا يرغب البعض بمشاهدة قطع بايثون في كل فقرة.
يجد كاتب المقال الأصلي صعوبةً في تلخيص العمل المنجز وإخفاء التفاصيل، إلا أنه يوجز العمل كله في النقطتين التاليتين:
- يُمكن بناء نموذج تعلّم للتنبؤ بمعامل نجمة الطاقة بالاعتماد على بيانات الطاقة لمدينة نيويورك مع خطأ ممكن بحوالي 9.1 نقطة.
- تلعب الميزتان التاليتان الدور الأكبر في تحديد معامل نجمة الطاقة: كثافة استخدام الطاقة Site EUI' Energy Use Intensity` وكثافة الكهرباء وفق الطقس Weather Normalized Site Electricity Intensity.
أُنجز هذا المشروع بصفة اختبار لكاتب المقال لقبوله في وظيفة في شركة ناشئة، كما طُلب منه عرضُ عمله واستنتاجاته في النهاية، ولذا فقد طور ملفًا من النمط Jupyter Notebook لتسليمه للشركة، وعوضًا عن تحويل الملف إلى pdf فورًا استخدم Latex لتحويله إلى ملف من النمط tex، ومن ثم تحريره باستخدام texStudio قبل توليد الملف النهائي بصيغة pdf. علمًا أنه يُمكن توليد الصيغة pdf من Jupyter مباشرةً وتحريرها لإجراء بعض التحسينات عليها.
وفي نهاية المطاف تلعب مهارة عرض النتائج دورًا أساسيًا في إبراز أهمية العمل ونتائجه التي يُمكن أن تُبنى القرارات وفقها.
النتائج
استعرضنا في هذه السلسلة من المقالات الثلاثة خطوات بناء مشروع تعلّم آلة كامل من البداية إلى النهاية، حيث بدأنا بتنظيف البيانات ثم انتقلنا إلى بناء النموذج ومن ثم لمحاولة فهم نموذج التعلّم.
نُعيد التذكير أخيًرا بخطوات بناء نموذج تعلّم الآلة:
- تنظيف البيانات وتنسيقها.
- تحليل البيانات الاستكشافي.
- هندسة الميزات والاختيار منها.
- موازنة نماذج تعلّم الآلة باستخدام مقياس للأداء.
- معايرة المعاملات الفائقة لنموذج التعلّم.
- تقويم النموذج الأمثل مع بيانات الاختبار.
- تفسير نتائج النموذج إلى أقصى حد ممكن.
- استخلاص النتائج وتوثيق العمل.
قد تختلف هذه الخطوات وفق المسألة المطروحة طبعًا، وغالبًا ما يكون العمل في مسائل تعلّم الآلة تكراريًا وليس تسلسليًا، أي يُمكن أن نعود لخطوات سابقة دومًا.
نأمل أن توفر لك هذه السلسلة من المقالات الثلاثة دليلًا جيدًا يُساعدك أثناء معالجتك لمشاريع تعلّم الآلة المستقبلية، كما نتمنى أن تكون هذه السلسلة قد منحتك الثقة لتكون قادرًا على تنفيذ مشاريع تعلّم الآلة الخاصة بك. وتذكر بأن أحدًا لا يعمل بمفرده وأنه يوجد الكثير من المجموعات الداعمة والتي يُمكن طلب المساعدة منها. ننصحك بالرجوع إلى كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة من أكاديمية حسوب.
ترجمة -وبتصرف- للمقال A Complete Machine Learning Project Walk-Through in Python: Part Three لكاتبه Will Koehrsen.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.