

نناقش في مقال اليوم النماذج اللغوية الكبيرة LLMs وهي صاحبة الدور الرئيسي في توليد النصوص، فهي تتكون من نماذج ذكاء اصطناعي كبيرة من نوع المحولات transformer، ومُدَرَّبة مُسبقًا على مهمة التنبؤ بالكلمة التالية أو token التالي من أي مُوجه يعطى لها، فهي إذًا تتنبأ بكلمات فردية بمقدار كلمة واحدة في كل مرة، لذا فإن توليد الجمل الكاملة سيحتاج تقنيةً أوسع تسمى توليد الانحدار الذاتي autoregressive generation.
ويُعرَّف توليد الانحدار الذاتي بأنه إجراءٌ استدلالي متكرر مع الزمن، يستدعي نموذج LLM مراتٍ متكررة وفي كل مرة يُمرر له المخرجات التي وَلَّدها في المرة السابقة كمدخلات وهكذا، وبطبيعة الحالة يحتاح إلى مدخلات ابتدائية نقدمها له ليستخدمها في الاستدعاء الأول للنموذج، وتوفر مكتبة المحولات Transformers تابعًا خاصًا لهذا الغرض هو generate()، يعمل جميع النماذج ذات الإمكانات التوليدية generative.
نسعى في هذا المقال لتحقيق ثلاثة أهداف رئيسية:
- شرح كيفية توليد نص باستخدام نموذج لغوي كبير LLM
- الإضاءة على بعض المخاطر الشائعة لتتجنبها
- اقتراح بعض المصادر التي ستساعدك على تحقيق أقصى استفادة ممكنة من نماذج LLMs
تأكد في البداية من تثبيت المكتبات الضرورية للعمل قبل أن نبدأ بالتفاصيل، وذلك وفق التالي:
pip install transformers bitsandbytes>=0.39.0 -q
توليد النص
يأخذ النموذج اللغوي المُدَرَّب على النمذجة اللغوية السببية سلسلة من الرموز النصية كمدخلات inputs ويرجع بناءً عليها التوزع الاحتمالي للرمز التالي المتوقع، ألقِ نظرة على الصورة التوضيحية التالية:
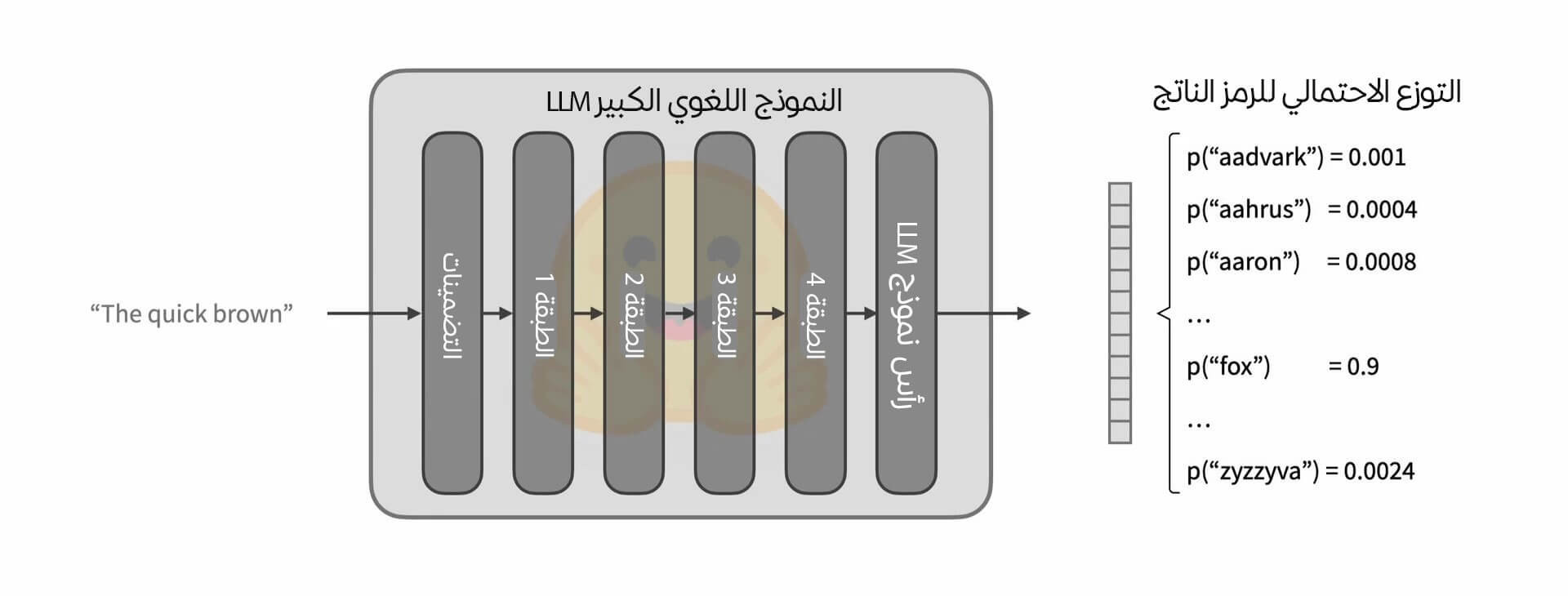
أما عن كيفية اختيار الرمز التالي من هذا التوزع الاحتمالي الناتج، فهي تختلف حسب الحالة، فقد تكون بسيطةً تتمثل بانتقاء الرمز الأكثر احتمالية من ضمن رموز التوزع الاحتمالي، أو معقدة لدرجة نحتاج معها لتطبيق عشرات التحويلات قبل الاختيار، وبصرف النظر عن طريقة الاختيار فإننا سنحصل بعد هذه المرحلة على رمز جديد نستخدمه في التكرار التالي أو الاستدعاء التالي للنموذج كما هو موضح في الصورة التالية لتوليد الانحدار الذاتي:
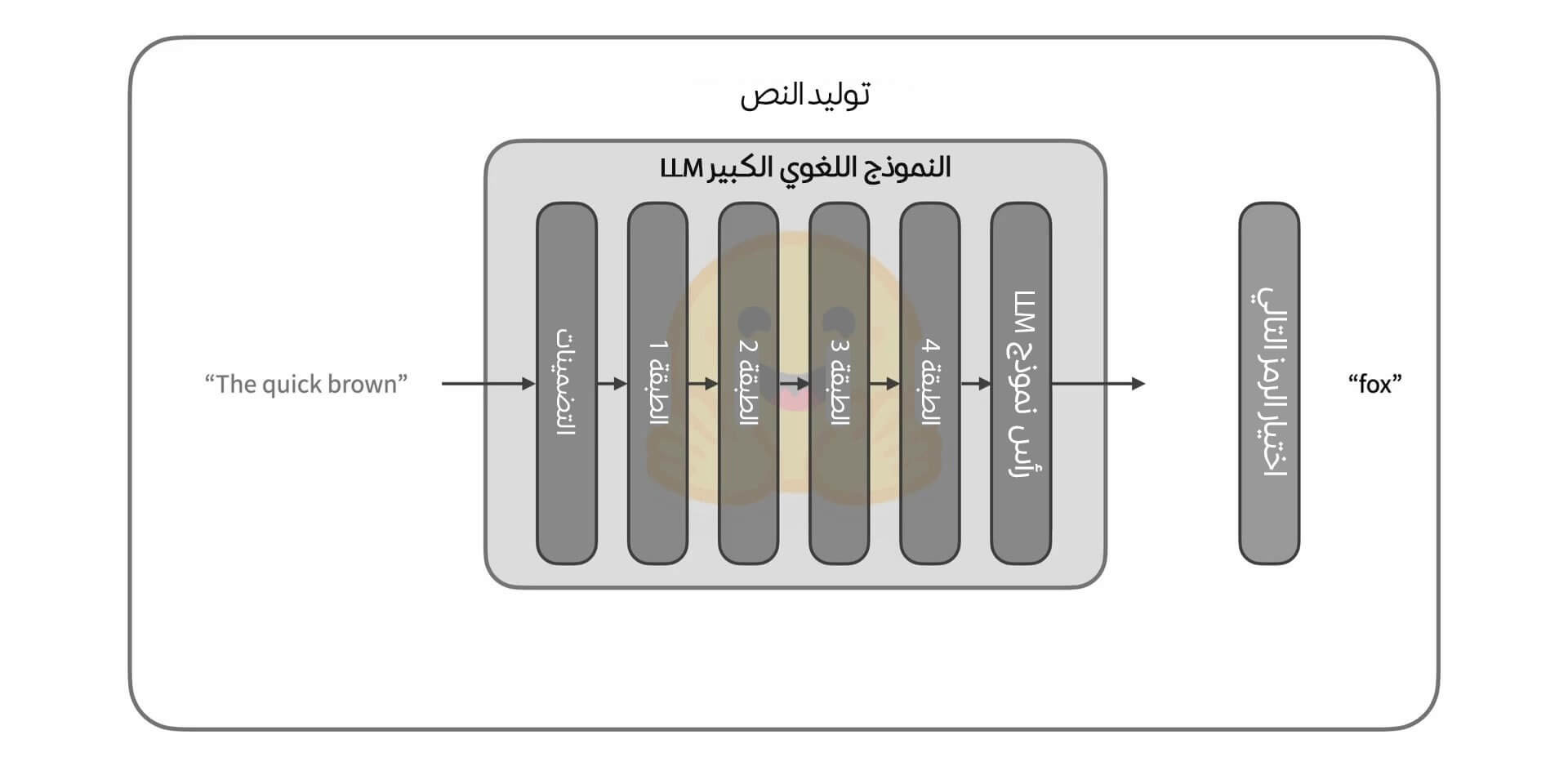
تستمر عملية توليد الكلمات حتى نصل إلى أحد شروط التوقف التي يُحددها النموذج، ويتعلم النموذج متى ينبغي أن يرجع رمز نهاية السلسلة (EOS) الذي يُعدّ الإنهاء المثالي لعملية توليد النص، وفي حال لم يرجع النموذج هذا الرمز فسيظل العمل مستمرًا لحين الوصول إلى الحد الأقصى المسموح به من الرموز.
إذًا فلديك أمرين مهمين ينبغي أن تهتم بهما ليعمل نموذجك التوليدي بالطريقة المرجوة، الأمر الأول هو كيفية اختيار الرمز التالي من بين رموز التوزع الاحتمالي، والأمر الثاني هو تحديد شرط إنهاء التوليد، تُضبط هذه الإعدادات في ملف إعدادات التوليد GenerationConfig الخاص بكل نموذج توليدي، يُحَمَّل هذا الملف مع النموذج وهو يتضنت معاملاتٍ افتراضية مناسبة له.
اقتباستنويه: تُعدّ واجهة خط الأنابيب Pipeline بدايةً جيدة لمن يرغب باستخدام أساسيات النماذج اللغوية الكبيرة (LLM)، لكنها لن تفي تمامًا بالغرض إذا رغبت باستخدام ميزات متقدمة مثل التكميم quantization والتحكم الدقيق بخطوة اختيار الرمز التالي وغيرها، فستحتاج عندها لاستخدام التابع
generate()فهو الأنسب، وتجدر الإشارة أيضًا إلى نماذج LLMs المعتمدة على توليد الانحدار الذاتي تستهلك كثيرًا من الموارد الحاسوبية لذا ينبغي تشغيلها على وحدة معالجة الرسوميات (GPU) للحصول على إنتاجية مقبولة.
لنبدأ الآن بالتطبيق العملي، حَمِّل أولًا النموذج كما يلي:
>>> from transformers import AutoModelForCausalLM >>> model = AutoModelForCausalLM.from_pretrained( "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True )
استخدمنا في الاستدعاء from_pretrained السابق معاملين device_map و load_in_4bit:
-
يضمن المعامل
device_mapأن حمل النموذج سيتوزع تلقائيًا على وحدات GPU المتاحة. -
يساعد المعامل
load_in_4bitعلى تقليل استخدام الموارد الحاسوبية إلى أقصى حد ممكن عبر تطبيق التكميم الديناميكي 4 بت.
توجد طرق أخرى عديدة لتهيئة نموذج LLM عند تحميله، عرضنا إحداها في الأمر السابق، وهي أساسية وبسيطة.
نحتاج الآن لمعالجة النص معالجةً مسبقة قبل إدخاله للنموذج وذلك باستخدام المُرَمِّز Tokenizer وهو نوع المعالجة المناسب للنصوص كما تعلمنا في مقال المعالجة المُسبقة للبيانات قبل تمريرها لنماذج الذكاء الاصطناعي:
>>> from transformers import AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left") >>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
سيُخَزَّن خرج المُرَمِّز (وهو عبارة عن النص المُرَمَّز وقناع الانتباه attention mask) في المتغير model_inputs، ويوصى عادةً بتمرير بيانات قناع الانتباه ما أمكن ذلك للحصول على أفضل النتائج، رغم أن التابع generate() سيسعى لتخمين قيمة قناع الانتباه عند عدم تمريره.
ملاحظة: قناع الانتباه attention mask هو أداة تساعد النموذج اللغوي على معرفة الأجزاء المهمة في النص الذي يعالجه وتجاهل الأجزاء غير المهمة كرموز الحشو التي تُضاف لجعل طول النصوص موحدًا. يوجه هذا القناع النموذج ليركز فقط على الكلمات الفعلية في النص ويهمل الرموز لا تعني شيئًا للحصول على نتائج دقيقة.
بعد انتهاء الترميز يُستدعى التابع generate() الذي سيُرجع الرموز tokens المتنبأ بها، والتي ستتحول إلى نص قبل إظهارها في خرج النموذج.
>>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A list of colors: red, blue, green, yellow, orange, purple, pink,'
ننوه أخيرًا إلى أنك لست مضطرًا لتمرير مدخلاتك إلى النموذج على شكل جمل مفردة، جملة واحدة في كل مرة، إذ يمكنك تجميع أكثر من جملة وتمريرها بهيئة دفعات batches مع استخدام الحشو padding لجعلها متساوية الطول، كما في المثال التالي، يزيد هذا الأسلوب من إنتاجية النموذج ويقلل الزمن والذاكرة المستهلكين:
>>> tokenizer.pad_token = tokenizer.eos_token # لا تملك معظم النماذج اللغوية الكبيرة رمزًا للحشو افتراضيًا >>> model_inputs = tokenizer( ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True) ['A list of colors: red, blue, green, yellow, orange, purple, pink,', 'Portugal is a country in southwestern Europe, on the Iber']
إذًا ببضع أسطر برمجية فقط استفدنا من أحد النماذج اللغوية الكبيرة LLM واستطعنا توليد نصوص مكلمة للجمل التي أعطيناها للنموذج.
بعض المشكلات المحتمل وقوعها
لا تناسب القيم الافتراضية لمعاملات النماذج التوليدية جميع المهام فلكل مشروع خصوصيته، والاعتماد عليها قد لا يعطينا نتائج مرضية في العديد من حالات الاستخدام، سنعرض لك أشهرها مع طرق تجنبها:
لنبدأ أولًا بتحميل النموذج والمُرَمِّز ثم نتابع بقية أجزاء الشيفرة ضمن الأمثلة تباعًا:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1") >>> tokenizer.pad_token = tokenizer.eos_token # لا تمتلك معظم النماذج اللغوية الكبيرة رمزًا للحشو افتراضيًا >>> model = AutoModelForCausalLM.from_pretrained( "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True )
توليد خرج أطول أو أقصر من اللازم
يُرجع التابع generate عشرين tokens كحد أقصى افتراضيًا، طالما أننا لم نحدد ما يخالف ذلك في ملف إعدادات التوليد Generation-config، ولكن ما ينبغي الانتباه له أن نماذج LLMs وخاصة النماذج من نوع decoder models مثل GPT و CTRL تُرجع مُوجَّه الدخل input prompt أيضًا مع كل خرج تعطيه، لذا ننصحك بتحديد الحد الأقصى لعدد الـ tokens الناتجة يدويًا، وعدم الاعتماد على الحد الافتراضي، وذلك ضمن المتغير max_new_tokens المرافق لاستدعاء generate، ألقِ نظرة على المثال التالي ولاحظ الفرق في الخرج بين الحالتين، الحالة الافتراضية، وحالة تحديد العدد الأقصى للرموز الناتجة:
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], >>> return_tensors="pt").to("cuda") # الحالة الافتراضية الحد الأقصى لعدد الرموز الناتجة هو 20 رمز >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A sequence of numbers: 1, 2, 3, 4, 5' # عند ضبط قيمة المتغير الذي سيحدد العدد الأقصى للرموز الناتجة >>> generated_ids = model.generate(**model_inputs, max_new_tokens=50) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
نمط توليد غير مناسب
افتراضيًا يختار التابع generate الرمز الأكثر احتمالية من بين الرموز الناتجة في كل تكرار ما لم نحدد طريقة مغايرة للاختيار في ملف إعدادات التوليد GenerationConfig، يسمى هذا الأسلوب الافتراضي فك التشفير الشره greedy decoding، وهو لا يناسب المهام الإبداعية التي تستفيد من بعض العينات، مثل: بناء روبوت دردشة لمحادثة العملاء أو كتابة مقال متخصص، لكنه من ناحية أخرى يعمل جيدًا مع المهام المستندة إلى المدخلات، نحو: التفريغ الصوتي والترجمة وغيره، لذا اضبط المتغير على القيمة do_sample=True في المهام الإبداعية، كما يبين المثال التالي الذي يتضمن ثلاث حالات:
>>> # استخدم هذا السطر إذا رغبت بالتكرار الكامل >>> from transformers import set_seed >>> set_seed(42) >>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda") >>> # LLM + فك التشفير الشره = مخرجات متكررة ومملة >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'I am a cat. I am a cat. I am a cat. I am a cat' >>> # مع تفعيل أخذ العينات، تصبح المخرجات أكثر إبداعًا >>> generated_ids = model.generate(**model_inputs, do_sample=True) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] 'I am a cat. Specifically, I am an indoor-only cat. I'
الحشو في الجانب الخاطئ
ذكرنا سابقًا أنك عندما تقوم بإدخال جمل أو نصوص ذات أطوال مختلفة للنموذج، فقد تحتاج إلى جعل هذه المدخلات بطول موحد ليتمكن النموذج من معالجتها بشكل صحيح من خلال إضافة رموز الحشو (padding tokens) التي تجعل جميع المدخلات بطول متساوٍ.
لكن النماذج اللغوية الكبيرة LLMs هي بنى لفك التشفير فقط decoder-only فهي تكرر الإجراءات نفسها على مدخلاتك، لكنها غير مُدَرَّبة على الاستمرار بالتكرار على رموز الحشو، لذا عندما تكون مدخلاتك مختلفة الأطوال وتحتاج للحشو لتصبح بطول موحد، فاحرص على إضافة رموز الحشو على الجانب الأيسر left-padded (أي قبل بداية النص الحقيقي) ليعمل التوليد بطريقة سليمة، وتأكد من تمرير قناع الانتباه attention mask للتابع generate حتى لا تترك الأمر للتخمين:
>>> # المُرَمِّز المستخدم هنا يحشو الرموز على الجانب الأيمن افتراضيًا، والسلسلة النصية الأولى هي >>> # السلسلة الأقصر والتي تحتاج لحشو، وعند حشوها على الجانب الأيمن سيفشل النموذج التوليدي في التنبؤ بمنطقية >>> model_inputs = tokenizer( ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt" ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] '1, 2, 33333333333' >>> # لاحظ الفرق عند تعديل الحشو ليصبح على الجانب الأيسر >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left") >>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default >>> model_inputs = tokenizer( ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt" ).to("cuda") >>> generated_ids = model.generate(**model_inputs) >>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] '1, 2, 3, 4, 5, 6,'
مُوجَّهات خاطئة
يتراجع أداء بعض النماذج عندما لا نمرر لها مُوجَّهات input prompt بالتنسيق الصحيح الذي يناسبها، يمكنك الحصول على مزيد من المعلومات عن طبيعة الدخل المتوقع للنماذج مع كل مهمة بالاطلاع على دليل المُوجَّهات في نماذج LLMs على منصة Hugging Face، ألقِ نظرة على المثال التالي الذي عن استخدام نموذج LLM للدردشة باستخدام قوالب الدردشة:
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha") >>> model = AutoModelForCausalLM.from_pretrained( "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True ) >>> set_seed(0) >>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug.""" >>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda") >>> input_length = model_inputs.input_ids.shape[1] >>> generated_ids = model.generate(**model_inputs, max_new_tokens=20) >>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0]) "I'm not a thug, but i can tell you that a human cannot eat" >>> # لم يتبع النموذج تعليماتنا هنا فهو لم يرد على السؤال كما ينبغي أن يرد أي شخص عنيف >>> # سنقدم الآن دخلًا أفضل يناسب النموذج باستخدام قوالب الدردشة، ونرى الفرق النتيجة >>> set_seed(0) >>> messages = [ { "role": "system", "content": "You are a friendly chatbot who always responds in the style of a thug", }, {"role": "user", "content": "How many helicopters can a human eat in one sitting?"}, ] >>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda") >>> input_length = model_inputs.shape[1] >>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20) >>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0]) 'None, you thug. How bout you try to focus on more useful questions?' >>> # كما تلاحظ فقد تغير أسلوب الرد واتبع تعليماتنا بطريقة أفضل فكان رده أقرب للأسلوب المطلوب
مصادر مفيدة للاستفادة من نماذج LLMs
ستحتاج لتعميق معرفتك بالنماذج اللغوية الكبيرة (LLMs) إذا رغبت بتحقيق أقصى استفادة منها، وإليك بعض الأدلة المفيدة من منصة Hugging Face المتخصصة في المجال:
أدلة الاستخدام المتقدم للتوليد Generating
- دليل استراتيجيات توليد النصوص باستخدام الذكاء الاصطناعي الذي يساعدك في تعلم كيفية التحكم بتوابع توليد مختلفة، وضبط مخرجاتها، وملفات الإعدادات الخاصة بها.
- دليل لاستخدام قوالب الدردشة مع نماذج LLMs.
- دليل LLM prompting يتضمن الأساسيات وأفضل الممارسات في كتابة المُوجَّهات.
- توثيقات واجهة برمجة التطبيقات API لكل من ملف إعدادات التوليد GenerationConfig و التابع ()generate و الأصناف clasess المرتبطة مع المعالجة المسبقة والعديد من الأمثلة التوضيحية.
أشهر نماذج LLMs
- النماذج مفتوحة المصدر التي تُركِّز على الجودة Open LLM Leaderboard.
- النماذج التي تهتم بالإنتاجية Open LLM-Perf Leaderboard.
أدلة حول تحسين السرعة والإنتاجية وتقليل استخدام الذاكرة
- دليل تحسين السرعة والذاكرة في نماذج LLMs.
- دليل التكميم Quantization باستخدام تقنيات مثل bitsandbytes و autogptq، لتخفيض متطلبات استخدام الذواكر.
مكتبات مرتبطة بالنماذج اللغوية الكبيرة
-
المكتبة
text-generation-inference، وهي بمثابة خادم إنتاج جاهز للعمل مع نماذج LLMs. -
المكتبة
optimum، وهي امتداد لمكتبة المحوّلات Transformers تساعدك في تحسين استخدام مكونات الحاسوب وموارده.
كما تساعدك دورة الذكاء الاصطناعي من أكاديمية حسوب في فهم طريقة التعامل مع النماذج اللغوية الكبيرة LLMs وربط الذكاء الاصطناعي مع تطبيقاتك المختلفة، كما يمكنك الحصول على معلومات مفيدة من دروس ومقالات قسم الذكاء الاصطناعي على أكاديمية حسوب.
الخلاصة
وصلنا إلى ختام المقال وقد عرضنا فيه طريقة استخدام النماذج اللغوية الكبيرة LLMs لتوليد النصوص الطويلة تلقائيًا من نص بسيط مُدخل، مع بيان بعض المخاطر الشائعة التي تعترض مستخدميها وكيفية تجنبها، بالإضافة لتعداد أشهر نماذج LLM، وبعض المصادر الموثوقة لمن يريد تعلمها بتعمقٍ أكبر.
ترجمة -وبتصرف- لقسم Generation with LLMs من توثيقات Hugging Face.
اقرأ أيضًا
- المقال السابق: استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي
- تدريب المًكيَّفات PEFT Adapters بدل تدريب نماذج الذكاء الاصطناعي بالكامل
- بناء تطبيق بايثون يجيب على أسئلة ملف PDF باستخدام الذكاء الاصطناعي
- تطوير تطبيق 'اختبرني' باستخدام ChatGPT ولغة جافاسكربت مع Node.js
- مصطلحات الذكاء الاصطناعي للمبتدئين









أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.