

نناقش في مقال اليوم طريقة استخدام توابع PEFT أو ما يعرف باسم توابع المعاملات الفعالة لصقل النماذج Parameter-Efficient Fine Tuning methods، وهي نوعٌ خاص من التوابع يُلغي أو يجمًد فعالية المعاملات الأصلية للنماذج المُدَرَّبة مسبقًا أثناء التدريب، ويستبدلها بمجموعة أصغر من المعاملات الخاصة بالمُكيّفات adapters ليجري تدريبها على المهمة المطلوبة بدلًا من تدريب النموذج كاملًا.
توفر هذه الطريقة استخدام الذاكرة والموارد الحاسوبية المختلفة بشكل كبير لأن المكيّفات adapters المُدَرَّبة باستعمال توابع PEFT صغيرة الحجم مقارنة بالنماذج الكاملة، وهذا يجعلها أسهل في التحميل والتخزين والمشاركة، وهي تعطي النتائج نفسها التي نحصل عليها بتدريب كامل النموذج.
ما هي المكيفات Adapters؟
المكيفات adapters هي بدائل خفيفة الوزن لتحسين نماذج الذكاء الاصطناعي المدربة مسبقًا pre-trained والمصقولة fine-tuned، فبدلاً من ضبط النموذج بالكامل، تُضاف المكيفات adapters بهيئة تعديلات صغيرة بين طبقات النموذج بعد مراحل معينة، وعند التدريب تُجَمَّدْ جميع أوزان النموذج وتُحدَّث أوزان المكيفات فقط وهو ما يؤدي إلى توفير كبير في الموارد الحاسوبية وتسريع التدريب وتحسين الأداء.
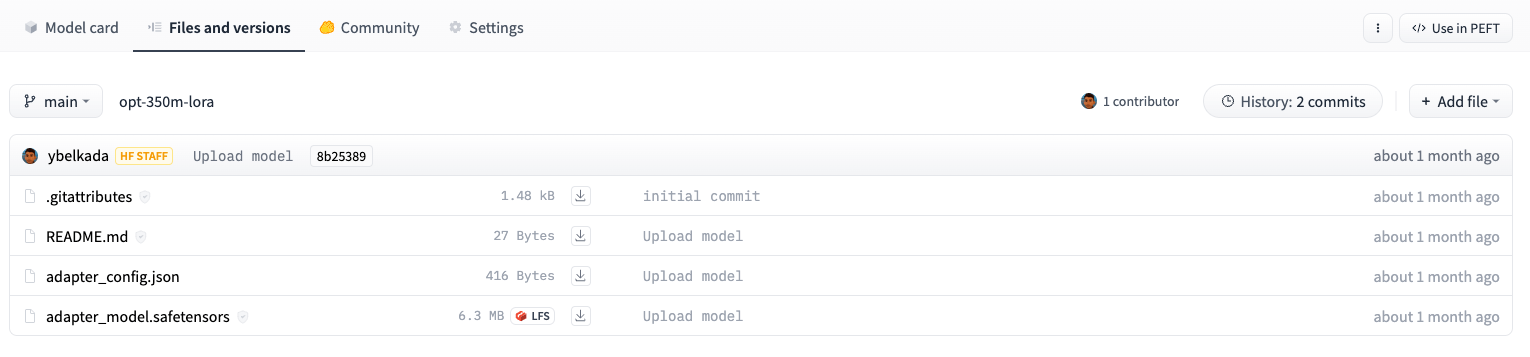
ألقِ نظرة على الصورة التالية مثلًا فهي مأخوذة من مستودع النماذج، ولاحظ الفرق بين حجم مكيف النموذج OPTForCausalLM وبين حجم النموذج نفسه، إذ يبلغ حجم المكيف adapter حوالي 6 ميجا بايت بينما يصل حجم النموذج الأساسي إلى 700 ميجا.
كما سيفيدك الاطلاع على PEFT إذا كنت مهتمًا بمعرفة المزيد من التفاصيل عنها.
إعداد بيئة العمل
ابدأ بتثبيت المكتبة PEFT من خلال الأمر التالي:
pip install peft
وإذا رغبت باستثمار مزاياها الحديثة أولًا بأول ثَبِّتها من المصدر الأساسي كما يلي:
pip install git+https://github.com/huggingface/peft.git
توافق نماذج PEFT مع مكتبة المحوّلات Transformers
تدعم مكتبة المحوّلات Transformers عددًا من توابع PEFT تلقائيًا، فيمكنك تحميل أوزانها weights بسهولة سواء كانت مخزنة محليًّا أو في مستودع النماذج، ويمكن تدريبها وتشغيلها ببضع أسطر برمجية فقط، وهذه أبرزها:
أما إذا رغبت باستخدام توابع أخرى مع مكتبة المحولات Transformers مثل: Prompt Learning و Prompt tuning فراجع توثيقات PEFT.
تحميل PEFT Adapter
يساعدك الصنف AutoModelFor وأصناف أخرى مشابهة على تحميل نماذج PEFT adapter من مكتبة المحوّلات Transformers واستخدامها في مشروعك، لكن تأكد من وجود الملف adapter_config.json وأوزان adapter في مجلدك المحلي أو المستودع البعيد Hub كما هو موضوح في الصورة السابقة.
على سبيل المثال يمكنك تحميل نموذج PEFT adapter لمهمة النمذجة اللغوية السببية causal language modeling التي تمكنك من التنبؤ بالكلمة التالية في سلسلة نصية معينة بناءً على الكلمات السابقة باتباع التالي:
-
حدد المُعَرِّف الخاص بنموذج PEFT الذي تريده (أي PEFT model id).
-
مَرِّرْ هذا المُعَرِّف إلى الصنف AutoModelForCausalLM.
from transformers import AutoModelForCausalLM, AutoTokenizer peft_model_id = "ybelkada/opt-350m-lora" model = AutoModelForCausalLM.from_pretrained(peft_model_id)
يمكنك تحميل PEFT adapter أيضًا باستخدام الصنف AutoModelFor والصنف OPTForCausalLM والصنف LlamaForCausalLM كما يمكنك تحميله أيضًا بواسطة التابع load_adapter كما يلي:
from transformers import AutoModelForCausalLM, AutoTokenizer model_id = "facebook/opt-350m" peft_model_id = "ybelkada/opt-350m-lora" model = AutoModelForCausalLM.from_pretrained(model_id) model.load_adapter(peft_model_id)
التحميل بصيغة 8 بت أو 4 بت
يمكنك الاستفادة من مكتبة bitsandbytes لتقليل استهلاك الذاكرة عن طريق تحميل النماذج باستخدام أنواع بيانات 8 بت و 4 بت، يساعدك هذا على توفير الذاكرة وتسريع تحميل النماذج الكبيرة، حيث يمكنك استخدام المعامل الذي تريده سواء كان load_in_8bit أو load_in_4bit ضمن محددات الدالة from_pretrained() لتختار طبيعة تحميل نموذجك، ويمكنك أيضًا ضبط المعامل device_map="auto" لتوزيع حمل النموذج بكفاءة على الموارد الحاسوبية المتاحة لك، وذلك وفق التالي:
from transformers import AutoModelForCausalLM, AutoTokenizer peft_model_id = "ybelkada/opt-350m-lora" model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
تحميل adapter جديد
يمكنك تعزيز إمكانيات نموذج الذكاء الاصطناعي من خلال تحميل مُكيَّف adapter إضافي لأي نموذج يحتوي على مُكيَّف adapter سابق لكن يشترط أن يكون من نفس نوع المُكيَّف الحالي الموجود مسبقًا في النموذج، كأن يكونا كلاهما من النوع LoRA مثلًا، وتُنجز ذلك باستخدام ~peft.PeftModel.add_adapter كما في المثال التالي:
هذه الشيفرة الأصلية لتحميل مُكيَّف LoRA adapter لنموذج الذكاء الاصطناعي:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer from peft import LoraConfig model_id = "facebook/opt-350m" model = AutoModelForCausalLM.from_pretrained(model_id) lora_config = LoraConfig( target_modules=["q_proj", "k_proj"], init_lora_weights=False ) model.add_adapter(lora_config, adapter_name="adapter_1")
والآن سنضيف إليها السطر التالي لتحميل مُكيَّف LoRA adapter إضافي:
# إضافة adapter جديد بنفس الإعدادات تمامًا model.add_adapter(lora_config, adapter_name="adapter_2")
ثم سنستخدم ~peft.PeftModel.set_adapter لنُحدد أي adapter هو المعتمد في النموذج:
# استخدام adapter_1 model.set_adapter("adapter_1") output = model.generate(**inputs) print(tokenizer.decode(output_disabled[0], skip_special_tokens=True)) # استخدام adapter_2 model.set_adapter("adapter_2") output_enabled = model.generate(**inputs) print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
طريقة تفعيل adapter معين أو إلغاء تفعيله
يبين المثال التالي طريقة تفعيل adapter module:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer from peft import PeftConfig model_id = "facebook/opt-350m" adapter_model_id = "ybelkada/opt-350m-lora" tokenizer = AutoTokenizer.from_pretrained(model_id) text = "Hello" inputs = tokenizer(text, return_tensors="pt") model = AutoModelForCausalLM.from_pretrained(model_id) peft_config = PeftConfig.from_pretrained(adapter_model_id) # تهيئة الأوزان العشوائية peft_config.init_lora_weights = False model.add_adapter(peft_config) model.enable_adapters() output = model.generate(**inputs)
وهذه طريقة إلغاء التفعيل:
model.disable_adapters() output = model.generate(**inputs)
تدريب PEFT adapter
يمكنك تدريب PEFT adapters على المهمة التي تريدها باستخدام صنف المُدَرِّب Trainer ببضع أوامر برمجية فقط، ألقِ نظرة على المثال التالي لتدريب LoRA adapter:
اقتباسراجع مقال صقل fine-tune نموذج ذكاء اصطناعي مُدَرَّبْ مُسبقًا من هذه السلسلة على أكاديمية حسوب لمعرفة المزيد عن طريقة تدريب النماذج باستخدام صنف المُدَرّب وصقلها على بيانات محددة.
-
1. حدد ضمن إعدادات adapter المهمة التي تود تدريبه عليها، والمعاملات الفائقة hyperparameters الخاصة به وفق التالي، (يمكنك التَعرُّف على المعاملات الفائقة للنوع LoRA adapter واستخداماتها باستعراض تفاصيل
~peft.LoraConfig😞
from peft import LoraConfig peft_config = LoraConfig( lora_alpha=16, lora_dropout=0.1, r=64, bias="none", task_type="CAUSAL_LM", )
- 2. أضِفْ adapter إلى النموذج:
model.add_adapter(peft_config)
- 3. مَرِّرْ النموذج إلى المُدَرِّب:
trainer = Trainer(model=model, ...) trainer.train()
وفي النهاية احفظ adapter بعد التدريب وحَمِّله مجددًا كما يلي:
model.save_pretrained(save_dir) model = AutoModelForCausalLM.from_pretrained(save_dir)
زيادة طبقات إضافية قابلة للتدريب إلى PEFT adapter
مَرِّرْ modules_to_save ضمن إعدادات PEFT لصقل fine-tune أي مُكيَّفات تود إضافتها إلى نموذجك الذي يحتوي في الأساس على adapters أخرى، كما في المثال التالي الذي يبين طريقة صقل lm_head فوق نموذج يحتوي في الأساس على LoRA adapter:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer from peft import LoraConfig model_id = "facebook/opt-350m" model = AutoModelForCausalLM.from_pretrained(model_id) lora_config = LoraConfig( target_modules=["q_proj", "k_proj"], modules_to_save=["lm_head"], ) model.add_adapter(lora_config)
الخلاصة
تعرفنا في هذا المقال على المكيفات adapters وهي وحدات صغيرة تعوض عن تدريب نماذج الذكاء الاصطناعي الكاملة فتُحسِّن الأداء، وتعلمنا كيفية تحميل PEFT Adapters وإضافتها إلى نماذج مكتبة المحولات Transformers وتدريبها، وأيضًا تعرفنا على طريقة إضافة أكثر من مكيف adapter إلى النموذج لتحسين كفاءته بشرط أن تكون جميعها من نوعٍ واحد، مع إمكانية تفعيلها أو إلغاء تفعيلها حسب الحاجة.
ترجمة -وبتصرف- لقسم Load adapters with PEFT من توثيقات Hugging Face.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.