

الخوارزمية الشرهة هي كل خوارزمية تسعى إلى حل مشكلةٍ عبر البحث عن أفضل خيار في كل مرحلة جزئية من أجل إيجاد الحل الشامل والمثالي، ولهذا تُسمّى شرهة، إذ تحاول أن تبحث عن أفضل الخيارات في كل مرحلة ممكنة، ولا تأخذ بالضرورة كل المراحل بالحسبان، ولذلك لا تعطي الحل المثالي دائمًا لكامل المشكلة، وإنّما تعطي حلًا مؤلفًا من حلول جزئية مثالية، والتي تكون عادةً قريبةً إلى حدّ ما من الحل الشامل المثالي في مدة زمنية معقولة.
ترميز هوفمان Human Coding
ترميز هوفمان هو نوع خاص من الترميز المُحسّن optimal prefix code الذي يُستخدم في الضغط المحافظ على البيانات lossless data compression، إذ تضغط هذه الخوارزمية البيانات بفعالية كبيرة، بحيث يمكن أن تختزل من 20٪ إلى 90٪ من مساحة الذاكرة تبعًا لخصائص البيانات المضغوطة.
ونحن ننظر إلى البيانات التي سنعمل عليها على أنها سلاسل من الحروف، تبدأ خوارزمية هوفمان الشرهة Huffman's greedy algorithm بإنشاء جدول يحدّد عدد مرات ظهور كل حرف (أي تردّده)، وبناءً على ذلك تنشئ الترميز المثالي لتمثيل كل حرف على هيئة سلسلة من القيم الثنائية (0 و 1). وقد اقتُرِحت هذه الخوارزمية على يد ديفيد هوفمان في عام 1951.
لنفترض أنّ لدينا ملفًّا يحتوي بيانات مؤلفة من 100000 محرف، ونود ضغطها في أقل مساحة ممكنة. سنفترض أنّ هناك 6 أحرف مختلفة فقط في الملف. وأنّ تردّد الأحرف هو كالتالي:
+---------------------------------+-----+-----+-----+-----+-----+-----+ | Character | a | b | c | d | e | f | +---------------------------------+-----+-----+-----+-----+-----+-----+ |Frequency (in thousands) | 45 | 13 | 12 | 16 | 9 | 5 | +---------------------------------+-----+-----+-----+-----+-----+-----+
لدينا عدة خيارات لتمثيل هذه البيانات، وسنحاول فيما يلي تصميم ترميز ثنائي للمحارف Binary Character Code، بحيث نمثّل كلّ حرف بسلسلة ثنائية فريدة سنسميها codeword أو الكلمة الرمزية.
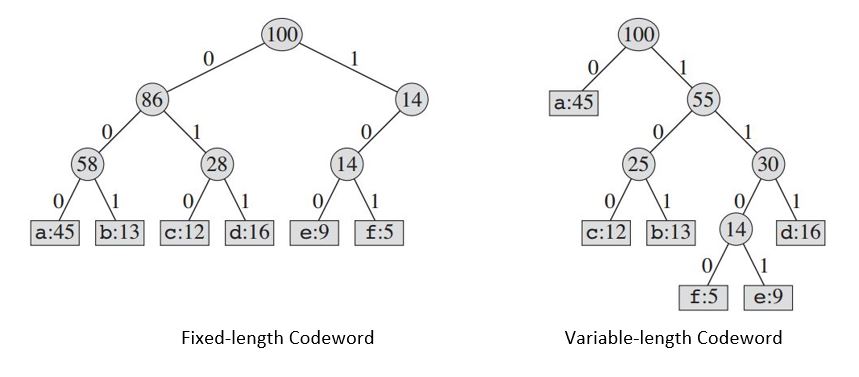
هذان الترميزان مشتقّان من الشجرة أعلاه:
+----------------------------------+-----+-----+-----+-----+------+------+ | Character | a | b | c | d | e | f | +----------------------------------+-----+-----+-----+-----+------+------+ | Fixed-length Codeword | 000 | 001 | 010 | 011 | 100 | 101 | +----------------------------------+-----+-----+-----+-----+------+------+ |Variable-length Codeword | 0 | 101 | 100 | 111 | 1101 | 1100 | +----------------------------------+-----+-----+-----+-----+------+------+
إذا أردنا استخدام ترميز ثابت الطول فسنحتاج إلى ثلاث بتّات bit لتمثيل الأحرف الستة. تتطلّب هذه الطريقة 300000 بتّة لتخزين الملف بأكمله. والسؤال الآن، هل هذا أفضل ترميز ممكن؟
هناك نوع آخر من الترميز، وهو ترميز متغيّر الطول، أي أنّ الشيفرات التي تمثّل الحروف قد تكون من أطوال مختلفة، قد يكون أفضل بكثير من الترميز ثابت الطول، إذ أنّه يُرشِّد المساحة المُستخدمة لتخزين البيانات عبر إعطاء الأحرف الكثيرة التكرار/التردد شيفرات قصيرة، فيما يترك الشيفرات الطويلة للأحرف قليلة التردّد.
ويتطلب هذا الترميز الآتي:
(45 X 1 + 13 X 3 + 12 X 3 + 16 X 3 + 9 X 4 + 5 X 4) X 1000 = 224000
بتّةً لتمثيل الملف، أي أنّه يقتص على حوالي 25% من مساحة الذاكرة موازنة بالتمثيل ثابت الطول.
اقتباستنبيه: لا نأخذ بالحسبان الترميزات التي تكون فيها كلمة رمزية codeword لحرف معيّن سابقةً prefix لكلمة رمزية أخرى، والتي يُطلق عليها ترميزات سابقة prefix codes. فمثلًا، في الترميز متغير الطول، سنرمّز السلسة النصية الثلاثية
abcبالترميز 0.101.100 = 0101100، حيث تمثّل النقطة.عمليّة الضمّ concatenation.
تبسّط ترميزات السوابق Prefix codes عمليّة فك الترميز decoding، فما دام من غير الممكن أن يكون أيّ ترميز كلميّ سابقة لترميز كلميّ آخر، فإنّ الترميز الكلميّ الذي يبدأ ترميز الملف لن يكون فيه أيّ لبس، لهذا يمكننا بسهولة تحديد الترميز الكلميّ الأولي، ثمّ ترجمته إلى الحرف الأصلي الذي يرمز له، ثمّ تكرار عملية فك الترميز على بقية الملف المُرمّز. على سبيل المثال، هناك طريقة واحدة فقط لفك ترميز 001011101، وهي 0.0.101.1101، لتي تُترجم إلى aabe.
باختصار، ستكون جميع توليف التمثيلات الثنائية مختلفةً عن بعضها، فإذا رمزنا لحرف ما بالترميز الكلمي 110 مثلًا، فلا يمكن ترميز أيّ حرف آخر بترميز كلمي يبدأ بالترميز السابق، مثل 1101 أو 1100. وهذا لمنع اللبس أثناء فك الترميز، وتجنّب أيّ ارتباك حول ما إذا كان علينا اختيار 110 أو الاستمرار في تحليل التسلسل البتّي.
تقنيات الضغط
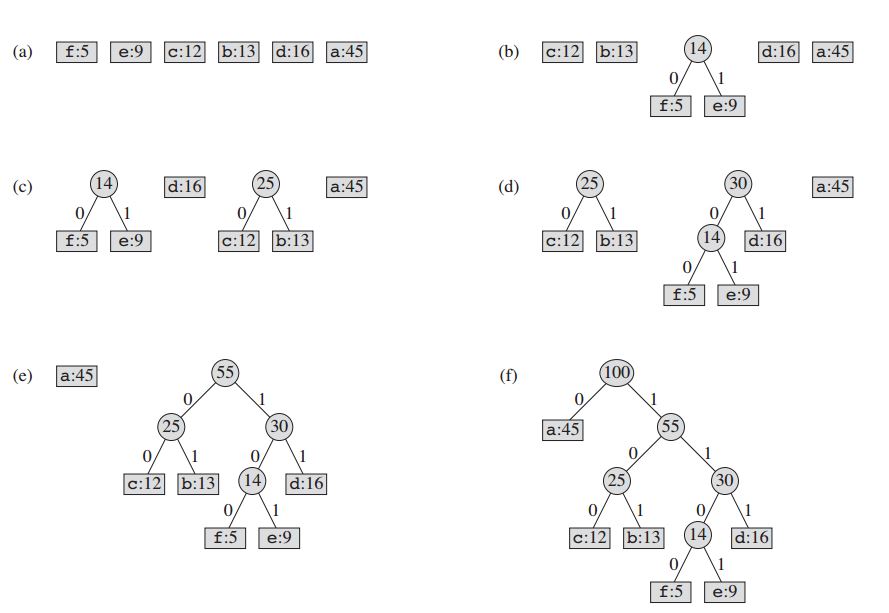
تعمل تقنية الضغط عبر إنشاء شجرة ثنائية من العقد، يمكن تخزينها في مصفوفة عادية حجمها (n) يساوي عدد الرموز، وكل عقدة يمكن أن تكون إما ورقة leaf أو عقدة داخلية internal node.
وتكون جميع العقد في البداية عبارة عن أوراق، تحتوي كل ورقة الرمز المراد تمثيله إلى جانب تردّده، ورابطًا اختياريًا يشير إلى ابنيها child nodes. ونصطلح في العادة على تمثيل الابن الأيسر بالبتّة '0'، فيما تمثّل البتة '1' الابن الأيمن، وتُخزّن العقد في رتل أو طابور، وعند استخراج قيمة منه، يعيد العقدة ذات التردد الأقل.
وهذه هي خطوات العملية:
- أنشئ ورقةً لكلّ رمز، ثمّ أضفه إلى رتل الأولويات.
- طالما يحتوي الطابور أكثر من عقدة واحدة:
- انزع العقدتين ذواتي أكبر أولوية من الطابور.
- أنشئ عقدةً داخليةً جديدة، مع جعل العُقدتين اللتان استخرجتَهما من الطابور أبناءً لها، بحيث يساوي التردّد مجموع تردّدي العقدتين.
- أضف العقدة الجديدة إلى الطابور.
- العقدة المتبقية هي العقدة الجذرية، وبهذا نكون قد أكملنا شجرة هوفمان.
انظر إلى الأمثلة التالية:
ستبدو الشيفرة التوضيحية pseudo-code كالتالي، حيث أن C هي مجموعة المحارف والمعلومات ذات الصلة:
Procedure Huffman(C): n = C.size Q = priority_queue() for i = 1 to n n = node(C[i]) Q.push(n) end for while Q.size() is not equal to 1 Z = new node() Z.left = x = Q.pop Z.right = y = Q.pop Z.frequency = x.frequency + y.frequency Q.push(Z) end while Return Q
يتطلب استخدام الخوارزمية في الحالات العامة إجراء عملية ترتيب مسبق للمصفوفة المُدخلة. ويمثّل n عدد الرموز في الأبجدية، ويكون عادةً صغيرًا جدًّا (موازنةً بطول الرسالة المراد ترميزها)، لذا فإنّ تعقيد الوقت ليس مهمًا جدًا في اختيار هذه الخوارزمية.
تقنيات فك الضغط Decompression
فك الضغط هو عملية ترجمة تدفق من ترميزات السوابق prefix codes إلى بايتات فردية، وعادةً عن طريق تسلّق الشجرة عقدة بعقدة مع قراءة كل بتّة من المدخلات. يؤدّي الوصول إلى ورقة إلى إنهاء البحث عن قيمة البايت المضغوط، حيث تمثل قيمة الورقة الحرفَ المطلوب.
وعادةً ما تُنشأ شجرة هوفمان باستخدام بيانات معدّلة إحصائيًا في كل دورة ضغط، وعليه فإنّ إعادة البناء بسيطة إلى حدّ ما؛ أما خلاف ذلك، فيجب إرسال المعلومات اللازمة لإعادة بناء الشجرة بشكل منفصل. انظر الشيفرة التوضيحية التالية، تمثل root جذر شجرة هوفمان، بينما تمثل S تدفق البتات المراد ضغطه:
Procedure HuffmanDecompression(root, S): n := S.length for i := 1 to n current = root while current.left != NULL and current.right != NULL if S[i] is equal to '0' current := current.left else current := current.right endif i := i+1 endwhile print current.symbol endfor
يحسب ترميز هوفمان تردّد كل محرف ويخزّنه على هيئة سلسلة ثنائية، وتتمثل فكرة الخوارزمية هنا في تعيين ترميزات متغيرة الأطوال للمحارف المُدخلة، بحيث يستند طول الترميزات على تردّدات الأحرف المقابلة، وذلك عبر إنشاء شجرة ثنائية والعمل عليها تصاعديًا حتى يكون الحرفان الأقل ترددًا بعيدين قدر الإمكان عن الجذر. وبهذه الطريقة سيحصل الحرف الأكثر تردّدًا على أقصر ترميز، بينما يحصل الحرف الأقل تردّدًا على أطول ترميز.
مشكلة اختيار الأنشطة Activity Selection Problem
لنفترض أنّ لديك مجموعةً من المهام التي عليك إنجازها (أنشطة)، بحيث لكل نشاط وقت بداية ووقت نهاية. ولا يُسمح لك بأداء أكثر من نشاط واحد في كلّ مرّة. السؤال الآن هو كيف تعثر على طريقة لأداء أقصى عدد ممكن من الأنشطة.
على سبيل المثال، لنفترض أنّ لديك مجموعةً من الأقسام الدراسية للاختيار من بينها.
| النشاط رقم | وقت البداية | وقت النهاية |
|---|---|---|
| 1 | 10.20 صباحا | 11.00 صباحا |
| 2 | 10.30 صباحا | 11.30 صباحا |
| 3 | 11.00 صباحا | 12.00 صباحا |
| 4 | 10.00 صباحا | 11.30 صباحا |
| 5 | 9.00 صباحا | 11.00 صباحا |
تذكّر أنه لا يمكنك أخذ فصلين دراسيين متداخلين، وهذا يعني أنه لا يمكنك أخذ الفصل 1 و2، لأنهما يتشاركان في الفترة من 10:30 صباحًا إلى 11.00 صباحًا. بالمقابل، يجوز لك أخذ الفصلين 1 و3، لأنهما لا يتشاركان أيّ وقت.
عليك الآن أن تختار الفصول بطريقة تتيح لك أخذ أكبر عدد ممكن من الفصول دون أي تداخل، لكن كيف تفعل هذا؟
تحليل الجدول الزمني للفصول
هذه بعض الطرق الممكنة لحل المشكلة:
- ترتيب الأنشطة بحسب وقت البداية: هذا يعني أنّنا سنأخذ النشاطات التي تبدأ أولًا، ثم نأخذ النشاطات من القائمة المُرتّبة من النشاط الأوّل إلى الأخير، ونتحقق ممّا إذا كان كل نشاط يتداخل مع النشاط الذي اخترناه سابقًا أم لا. إذا لم يكن هناك تداخل بين النشاطين، فسننفّذ النشاط، وإلا لن ننفّذه. تُعَد هذه الطريقة صالحةً لبعض الحالات، كما في المثال التالي:
| النشاط رقم | وقت البداية | وقت النهاية |
|---|---|---|
| 1 | 11.00 صباحا | 1.30 مساء |
| 2 | 11.30 صباحا | 12.00 ظهرًا |
| 3 | 1.30 مساء | 2.00 مساء |
| 4 | 10.00 صباحا | 11.00 صباحا |
سنحصل على هذا الترتيب 4 -> 1 -> 2 -> 3، وسننفّذ الأنشطة 4 -> 1 -> 3، ونتخطّى النشاط 2. وهذا يعني أننا سننفّذ 3 نشاطات، وهو الحد الأقصى الممكن. بهذا تكون طريقتنا قد نجحت إذًا في هذه الحالة، لكن هذا لا يعني أنّها ستنجح دائمًا، إذ هناك حالات يمكن أن تفشل فيها. كما يبيّن المثال التالي:
| النشاط رقم | وقت البداية | وقت النهاية |
|---|---|---|
| 1 | 11.00 صباحا | 1.30 مساء |
| 2 | 11.30 صباحا | 12.00 ظهرًا |
| 3 | 1.30 مساء | 2.00 مساء |
| 4 | 10.00 صباحا | 3.00 صباحا |
سنحصل على الترتيب التالي: 4 -> 1 -> 2 -> 3، ولن يُنفّذ إلا النشاط 4، أي نشاط واحد وحسب، لكنّنا نعلم أنّ الإجابة الأمثل هي 1 -> 3 أو 2- -> 3، وذلك لأنه في كلا الحالتين سنحضر فصلين دراسيين، وهذا يبيّن أنّ طريقتنا لم تنجح في الحالة المذكورة أعلاه، وذلك لنجرّب طريقةً أخرى.
- ترتيب الأنشطة بحسب مددها الزمنية: هذا يعني تنفيذ أقصر الأنشطة أولًا. ستحل هذه الطريقة المشكلة السابقة، لكنها ليست كاملةً أيضًا، فلا تزال هناك بعض الحالات التي لا يمكن أن تحلها. ولنطبق الطريقة على الحالة التالية:
| النشاط رقم | وقت البداية | وقت النهاية |
|---|---|---|
| 1 | 6.00 صباحا | 11.40 صباحا |
| 2 | 11.30 صباحا | 12.00 ظهرًا |
| 3 | 11.40 صباحا | 2.00 مساء |
إذا رتّبنا الأنشطة بحسب مددها الزمنية فسنحصل على الترتيب 2 -> 3 -> 1، لكن إن نفّذنا النشاط رقم 2 أولاً، فلن نستطيع تنفيذ أيّ نشاط آخر. الجواب المثالي هو تنفيذ النشاط 1 ثم 3، لذا لا يمكن أن يكون هذا حلًا لهذه المشكلة.
لنجرّب طريقةً أخرى:
-
ترتيب الأنشطة بحسب وقت الإنتهاء: هذا يعني أنّ الأنشطة التي تنتهي أولا توضع أولًا. انظر الخوارزمية:
- ترتيب الأنشطة بحسب أوقات نهايتها.
- إذا لم يتقاسم النشاط المراد تنفيذه وقتًا مشتركًا مع الأنشطة المُنفّذة سابقًا، فسننفّذه.
لنحلّل المثال الأول:
| النشاط رقم | وقت البداية | وقت النهاية |
|---|---|---|
| 1 | 10.20 صباحا | 11.00 صباحا |
| 2 | 10.30 صباحا | 11.30 صباحا |
| 3 | 11.00 صباحا | 12.00 صباحا |
| 4 | 10.00 صباحا | 11.30 صباحا |
| 5 | 9.00 صباحا | 11.00 صباحا |
نرتب الأنشطة بحسب أوقات نهاياتها لنحصل على الترتيب 1 -> 5 -> 2 -> 4 -> 3، والجواب الصحيح هو 1 -> 3، أي أنّنا سننفّذ النشاطين 1 و3. وهو الجواب الصحيح:
- ترتيب الأنشطة.
- نفّذ أول نشاط في قائمة الأنشطة المرتبة.
- عيّن قيمة النشاط الأول إلى النشاط الحالي Current_activity := first activity.
- عين end_time := t، حيث t يمثل وقت إنهاء النشاط الحالي
- اذهب إلى النشاط الموالي إن كان موجودًا، خلاف ذلك أنهِ الخوارزمية.
- إن كان وقت البداية الخاص بالنشاط الحالي أكبر من end_time، نفّذ النشاط وعد إلى المرحلة 4.
- خلاف ذلك اذهب إلى المرحلة 5.
مشكلة الصرف Change-making problem
لنفترض أنّ لديك مبلغًا معينًا في نظام نقدي ما، هل يمكن إيجاد الحد الأدنى من القطع والأوراق النقدية المقابلة لذلك المبلغ.
حسب الأنظمة المالية الأساسية، إذا افترضنا في بعض النظم المالية -مثل التي نستخدمها الآن- أنّ العملات النقدية الممكنة هي 1 و2 و5 و10، فالحل البديهي هو أن نبدأ بأعلى قطعة أو ورقة نقدية، ثمّ نكرّر هذا الإجراء إلى أن نستكمل المبلغ. فمثلا، إن كان المبلغ هو 28 درهمًا، فيمكننا تصريفه إلى 10 + 10 + 5 + 2 + 1 = 28، وهكذا سيكون الحدّ الأدنى هو 5، وهو الحل الصحيح.
نستطيع فعل هذا بشكل تكراري في لغة OCaml كما يلي:
(* نفترض أنّ النظام النقدي مُرتب ترتيبًا تنازليًا *) let change_make money_system amount = let rec loop given amount = if amount = 0 then given else (* القيمة الأولى أصغر أو تساوي باقي المبلغ *) let coin = List.find ((>=) amount) money_system in loop (coin::given) (amount - coin) in loop [] amount
هذه الخوارزمية ليست صالحةً دائمًا، فلو كان المبلغ يساوي 99 وكانت القطع والأوراق النقدية الممكنة هي 10 و7 و5، فإنّ الحل السابق لن يعمل، إذ لو أخذنا أكبر القطع النقدية 10، وجمعناه إلى أن نصل إلى 90، فستبقى لنا 9، وهو مبلغ لا يمكن تكوينه من القطعتين 5 و7.
ثم إنّه لا توجد ضمانة لوجود حلّ أصلًا، وهذه المشكلة في الواقع صعبة للغاية، لكن توجد بعض الحلول الصالحة التي تجمع بين الشره greediness والتذكر memoization، وتقوم على استكشاف جميع الإمكانات، واختيار تلك التي تتألف من أقل عدد من القطع النقدية.
لنفترض أنّ لدينا مبلغًا X> 0، وقد اخترنا قطعة نقدية P من النظام المالي، سيكون المبلغ المتبقي إذن هو X-P. نحلّ الآن مشكلة تصريف المبلغ X-P إلى أقل عدد ممكن من القطع النقدية، ونجرّب هذا مع جميع القطع النقدية في النظام. لاحظ أنّه في كل مرة نختار قطعة نقدية P فإنّنا نجعل المشكلة أصغر (أي X-P). ويكون الحل النهائي -إذا كان موجودًا- هو أصغر مسار من المسارات التي اتبعناها وأدّت إلى المبلغ 0.
انظر فيما يلي دالة OCaml تكرارية لحل هذه المشكلة، تعيد هذه الدالة None في حال لم يكن هناك حل:
(* option utilities *) let optmin x y = match x,y with | None,a | a,None -> a | Some x, Some y-> Some (min x y) let optsucc = function | Some x -> Some (x+1) | None -> None (* مشكلة الصرف*) let change_make money_system amount = let rec loop n = let onepiece acc piece = match n - piece with | 0 -> (*problem solved with one coin*) Some 1 | x -> if x < 0 then (* نتجاهل هذا الحل إن لم نصل إلى 0*) None else (*من القطع النقدية الباقية None نبحث عن أقصر مسار يخالف*) optmin (optsucc (loop x)) acc in (*على جميع القطع النقدية onepiece نستدعي*) List.fold_left onepiece None money_system in loop amount
اقتباسملاحظة: يمكن أن تحسب هذه الخوارزمية مجموعة الصرف الخاصة بالقيمة نفسها عدة مرات، وهنا يمكن أن يكون التذكير memoization مفيدًا جدّا في تجنّب التكرار وتسريع النتائج.
خوارزمية كروسكال Kruskal's Algorithm
خوارزمية كروسكال هي خوارزمية تهدف إلى إيجاد المسار الأقصر (الأقل كلفة)، وهي من الخوارزميات الشرهة Greedy Algorithm التي تُستخدَم بكثرة في نظرية المخططات.
استخدام المجموعات التوزيعية
هناك شيئان يمكننا القيام بهما لتحسين مجموعة الخوارزميات الفرعية للمجموعات التوزيعية المُحسّنة sub-optimal disjoint-set subalgorithms، وهما:
-
مقاييس بحثية لضغط المسار Path compression heuristic: لن تحتاج الدالة
findSet(انظر الشيفرة أدناه) إلى التكرار على شجرة ارتفاعها أطول من2، وإلا فيمكنها ربط العقد السفلية مباشرة بالجذر، مما يحسّن عمليات العبور traversals المستقبلية:
subalgo findSet(v: a node): if v.parent != v v.parent = findSet(v.parent) return v.parent
- المقاييس البحثية القائمة على الارتفاع Height-based merging heuristic: خزّن ارتفاع الشجيرة subtree الخاصة بكل عقدة، واجعل الشجرة الأطول أبًا parent للشجرة الأصغر عند الدمج، وذلك دون زيادة ارتفاع أيّ شجرة:
subalgo unionSet(u, v: nodes): vRoot = findSet(v) uRoot = findSet(u) if vRoot == uRoot: return if vRoot.height < uRoot.height: vRoot.parent = uRoot else if vRoot.height > uRoot.height: uRoot.parent = vRoot else: uRoot.parent = vRoot uRoot.height = uRoot.height + 1
يستغرق هذا مدة O(alpha(n)) لكلّ عملية، حيث تمثّل alpha مقلوب inverse دالة أكرمان Ackermann المعروفة بسرعة نموها، وهذا يعني أنّ alpha ستكون بطيئة جدًا، ويمكن عدّ تعقيدها عمليًا ثابتًا (O(1))، ما يعني أنّ تعقيد خوارزمية Kruskal سيساوي O(m log m + m) = O(m log m) أخذًا بالحسبان الترتيبَ الأولي.
اقتباسملاحظة: قد يقلّل ضغط المسار Path compression ارتفاع الشجرة، وعليه فإنّ موازنة ارتفاعات الأشجار في خضمّ عملية الاتحاد union operation ليس مهمةً سهلة.
ولتجنّب تعقيد تخزين وحساب ارتفاعات الأشجار، يمكن اختيار الشجرة الأب parent عشوائيًا:
subalgo unionSet(u, v: nodes): vRoot = findSet(v) uRoot = findSet(u) if vRoot == uRoot: return if random() % 2 == 0: vRoot.parent = uRoot else: uRoot.parent = vRoot
عمليًا، ينتج عن هذه الخوارزمية العشوائية مرفوقة بعملية ضغط المسار في الدالة findSet، تحسّن كبير في الأداء رغم أنّها أكثر بساطة.
تطبيق مفصل implementation
من أجل رصد الدورات cycle detection بفعالية، سنعُدّ كل عقدة جزءًا من شجرة، ونتحقّق عند إضافة ضلع ممّا إذا كانت عقدَتاه جزءًا من شجرتين منفصلتين. في البداية، تشكّل كلّ عقدة شجرةً مؤلفةً من عقدة واحدة وحسب:
algorithm kruskalMST(G: a graph) sort Gs edges by their value // بحسب القيم G ترتيب MST = a forest of trees, initially each tree is a node in the graph // غابة من الأشجار، حيث تمثل كل شجرة عقدة من الشعبة for each edge e in G: if the root of the tree that e.first belongs to is not the same as the root of the tree that e.second belongs to: connect one of the roots to the other, thus merging two trees
إذا كان جذر الشجرة التي ينتمي إليها e.first يساوي جذر الشجرة التي ينتمي إليها e.second، فاربط أحد الجذرين بالآخر، وهكذا تُدمَج الشجرتان.
return MST, which now a single-tree forest // أصبحت الآن غابة من شجرة واحدة MST
يقوم منظور الغابات forest -مجموعة من الأشجار غير المتصلة بالضرورة- المذكور أعلاه على استخدام المجموعات التوزيعية disjoint-set data structure، وينطوي على ثلاث عمليات رئيسية:
subalgo makeSet(v: a node):
v.parent = v <- make a new tree rooted at v
subalgo findSet(v: a node):
if v.parent == v:
return v
return findSet(v.parent)
subalgo unionSet(v, u: nodes):
vRoot = findSet(v)
uRoot = findSet(u)
uRoot.parent = vRoot
algorithm kruskalMST(G: a graph):
sort Gs edges by their value
for each node n in G:
makeSet(n)
for each edge e in G:
if findSet(e.first) != findSet(e.second):
unionSet(e.first, e.second)
يستغرق هذا التطبيق حوالي O(n log n) لإدارة المجموعات التوزيعية، وهكذا يصبح التعقيد الزمني الإجمالي لخوارزمية كروسكال O(m*n log n ).
في الأخير، نستعرض تطبيقًا آخر عالي المستوى للخوارزمية، حيث نرتّب الأضلاع بحسب القيم، ثمّ نضيف كلّ واحد منها إلى شجرة الامتداد الأدنى MST بالترتيب ما لم ينجم عن ذلك دورة.
algorithm kruskalMST(G: a graph) sort Gs edges by their value MST = an empty graph for each edge e in G: if adding e to MST does not create a cycle: add e to MST return MST
ترجمة -بتصرّف- للفصلين 16 و17 من كتاب Algorithms Notes for Professionals.









أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.