

الرسم التخطيطي أو المخطط هو مجموعة من النقاط والخطوط التي ترتبط ببعضها (يمكن أن تكون فارغة)، وتسمى نقاط المخطط رؤوسًا vertices أو عقدًا nodes، بينما تسمى الخطوط التي تربط رؤوس المخطط أضلاعًا edges أو أقواسًا أو خطوطًا.
يعرَّف مخطط G مثلًا كزوْج (V، E)، حيث تمثّل V مجموعة من الحروف، وتمثّل E مجموعة الأضلاع التي تربط تلك الحروف، انظر:
E ⊆ {(u,v) | u, v ∈ V}
تخزين المخططات
هناك طريقتان شائعتان لتخزين المخططات، وهما:
- مصفوفة التجاور Adjacency Matrix.
- قائمة التجاور.
مصفوفة التجاور
مصفوفة التجاور هي مصفوفة تُستخدم لتمثيل مخطط محدود finite graph، وتشير عناصر المصفوفة إلى ما إذا كانت أزواج الرؤوس متجاورة (مترابطة) في المخطط أم لا.
وفي نظرية المخططات، نقول أنّ العقدة B مجاورة للعقدة A إذا كنا نستطيع الذهاب من العقدة A إلى العقدة B، وسنتعلم الآن كيفية تخزين العُقد المتجاورة عبر مصفوفة التجاور Adjacency Matrix ثنائية الأبعاد، هذا يعني أننا سنمثل العقد التي تتشارك الأضلاع فيما بينها.

نرى في الشكل الموضح أعلاه جدولًا إلى جانب المخطط، ويمثّل هذا الجدول مصفوفة التجاور الخاصة بالمخطط المجاور له، وتمثل Matrix[i][j] = 1 هنا وجود ضلع بين i و j. بالمقابل، سنكتب Matrix[i][j] = 0 إذا لم يكن هناك أيّ ضلع يربطهما.
نستطيع وزن تلك الأضلاع، أي إلحاق رقم بكل ضلع -قد يمثل هذا الرقم المسافة بين مدينتين مثلًا-، وهنا نضع الوزن في الموضع Matrix[i][j] بدلًا من 1.
والمخطط الموضح أعلاه ثنائي الاتجاه Bidirectional، أو غير موجّه Undirected، أي أنّه إذا كان بإمكاننا الانتقال من العقدة 2 إلى العقدة 1 فيمكننا أيضًا الانتقال من العقدة 1 إلى العقدة 2. إن لم تتحقّق هذه الخاصية نقول أنّ المخطط موجّه Directed. وتوضع أسهم بدل الخطوط إذا كان المخطط موجَّهًا، كما يمكن استخدام مصفوفات التجاور لتمثيل هذا النوع من المخططات.
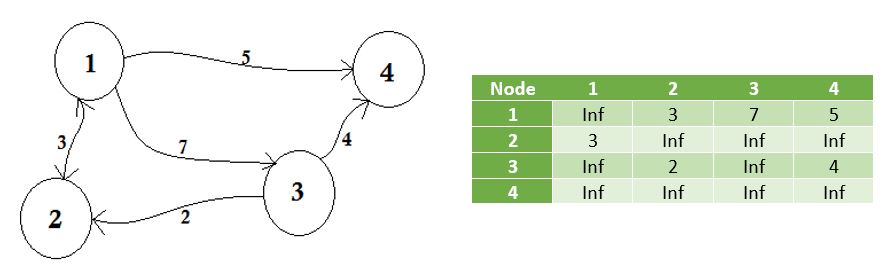
لكن على خلاف المخططات غير الموجّهة، فإن العقد التي لا تشترك في أيّ ضلع تُمثَّل باللانهاية inf في المخططات الموجّهة كما يبيّن الرسم أعلاه. هناك أمر آخر ينبغي الانتباه له، وهو أنّ مصفوفة التجاور الخاصة بمخطط غير موجّه تكون دائما غير متماثلة.
انظر الشيفرة التوضيحية pseudo-code التالية لإنشاء مصفوفة التجاور، حيث يمثل N عدد العُقد:
Procedure AdjacencyMatrix(N): Matrix[N][N] for i from 1 to N for j from 1 to N Take input -> Matrix[i][j] endfor endfor
فيما يلي طريقة أخرى لتعبئة المصفوفة، يمثل N فيها عدد العُقَد بينما يمثل E عدد الأضلاع:
Procedure AdjacencyMatrix(N, E): Matrix[N][E] for i from 1 to E input -> n1, n2, cost Matrix[n1][n2] = cost Matrix[n2][n1] = cost endfor
يمكنك إزالة السطر
Matrix[n2][n1] = cost
من الشيفرة في المخططات الموجّهة.
عيوب استخدام مصفوفة التجاور
إحدى المشاكل التي تنجم عن استخدام مصفوفات التجاور هو أنّها تستهلك مقدارا كبيرًا من الذاكرة، فمهما كان عدد أضلاع المخطط، سنحتاج دائمًا إلى مصفوفة بحجم N*N، حيث يمثّل N عدد العُقد. أما إذا كانت هناك 10000 عقدة في المخطط فسنحتاج مصفوفة بحجم 4 * 10000 * 10000، أي حوالي 381 ميغابايت، وهذا مضيعة للذاكرة، علمًا أنّ الكثير من المخططات لا تحتوي إلا القليل من الأضلاع.
وبفرض أنّنا نريد أن نعرف العقد التي يمكننا الوصول إليها انطلاقًا من العقدة u، فسنحتاج إلى التحقق من الصفّ الخاص بـ u في المصفوفة بالكامل، وهذا سيكلفنا الكثير من الوقت.
والفائدة الوحيدة لمصفوفة التجاور هي أنها تمكّننا من العثور بسهولة على مسار بين عقدتين مثل u-v، وكذلك تكلفة cost ذلك المسار، أي مجموع أوزان الأضلاع التي تؤلف المسار.
شيفرة جافا التالية تطبق الشيفرة العامّة أعلاه:
import java.util.Scanner; public class Represent_Graph_Adjacency_Matrix { private final int vertices; private int[][] adjacency_matrix; public Represent_Graph_Adjacency_Matrix(int v) { vertices = v; adjacency_matrix = new int[vertices + 1][vertices + 1]; } public void makeEdge(int to, int from, int edge) { try { adjacency_matrix[to][from] = edge; } catch (ArrayIndexOutOfBoundsException index) { System.out.println("The vertices does not exists"); } } public int getEdge(int to, int from) { try { return adjacency_matrix[to][from]; } catch (ArrayIndexOutOfBoundsException index) { System.out.println("The vertices does not exists"); } return -1; } public static void main(String args[]) { int v, e, count = 1, to = 0, from = 0; Scanner sc = new Scanner(System.in); Represent_Graph_Adjacency_Matrix graph; try { System.out.println("Enter the number of vertices: "); v = sc.nextInt(); System.out.println("Enter the number of edges: "); e = sc.nextInt(); graph = new Represent_Graph_Adjacency_Matrix(v); System.out.println("Enter the edges: <to> <from>"); while (count <= e) { to = sc.nextInt(); from = sc.nextInt(); graph.makeEdge(to, from, 1); count++; } System.out.println("The adjacency matrix for the given graph is: "); System.out.print(" "); for (int i = 1; i <= v; i++) System.out.print(i + " "); System.out.println(); for (int i = 1; i <= v; i++) { System.out.print(i + " "); for (int j = 1; j <= v; j++) System.out.print(graph.getEdge(i, j) + " "); System.out.println(); } } catch (Exception E) { System.out.println("Something went wrong"); } sc.close(); } }
لتشغيل الشيفرة أعلاه، احفظ الملف، ثم صرّف compile الشيفرة باستخدام التعليمة الآتية:
javac Represent_Graph_Adjacency_Matrix.java
انظر المثال التالي الذي يوضح هذا:
$ java Represent_Graph_Adjacency_Matrix Enter the number of vertices: 4 Enter the number of edges: 6 Enter the edges: 1 1 3 4 2 3 1 4 2 4 1 2 The adjacency matrix for the given graph is: 1 2 3 4 1 1 1 0 1 2 0 0 1 1 3 0 0 0 1 4 0 0 0 0
تخزين المخططات (قوائم التجاور)
قائمة التجاور هي مجموعة من القوائم غير المرتبة تُستخدم لتمثيل المخططات المحدودة finite graphs، وتصف كل قائمة في المجموعة جيرانَ كلّ حرف من حروف المخطط. وميزة قوائم التجاور أنّها تحتاج مساحة ذاكرة أقل لتخزين المخططات.
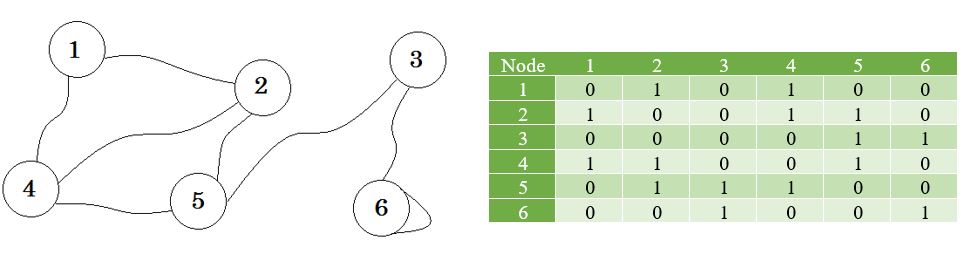
انظر المثال التالي عن مخططٍ ومصفوفة التجاور الخاصة به:
وهذه قائمة التجاور الخاصة بالمخطط أعلاه:
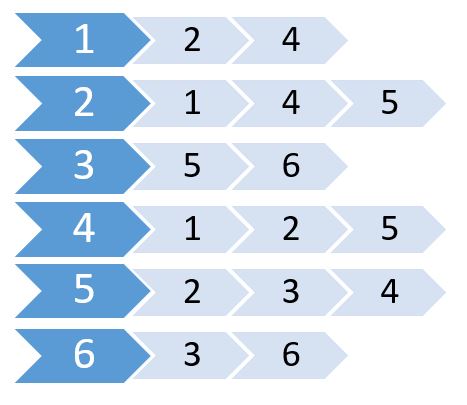
تسمى هذه القائمة قائمةَ التجاور adjacency list، وتوضّح الروابط بين العقد. نستطيع إن شئنا تخزين هذه المعلومات باستخدام مصفوفة ثنائية الأبعاد، لكن هذا سيكلفنا نفس مقدار الذاكرة الذي يتطلّبه تخزين مصفوفة التجاور. بدلاً من ذلك، سنستخدم الذاكرة المخصّصة ديناميكيًا لتخزين هذه القيم.
تدعم العديد من لغات البرمجة نوعي البيانات المتجهات Vector والقوائم List ، والتي يمكننا استخدامها لتخزين قائمة التجاور، وهكذا لن يكون علينا تحديد حجم القائمة إذ يكفي أن نحدّد الحد الأقصى لعدد العقد. انظر الشيفرة العامة لذلك، حيث يمثل maxN الحد الأقصى للعُقد، بينما يمثل E عدد الأضلاع، ويشير التعبير x, y إلى وجود ضلع يربط بين x وy:
Procedure Adjacency-List(maxN, E): edge[maxN] = Vector() for i from 1 to E input -> x, y edge[x].push(y) edge[y].push(x) end for Return edge
وبما أنّ هذا المخطط غير موجّه فإنّ وجود ضلع من x إلى y يستلزم وجود ضلع معاكس، أي ضلعٍ من y إلى x، ولن تتحقق هذه الخاصية في المخططات غير الموجّهة.
أما بالنسبة للمخططات الموزونة فسنحتاج إلى تخزين التكلفة (الوزن) أيضًا، من خلال إنشاء متجه أو قائمة أخرى باسم cost[] لتخزينها، انظر الشيفرة العامة لذلك:
Procedure Adjacency-List(maxN, E): edge[maxN] = Vector() cost[maxN] = Vector() for i from 1 to E input -> x, y, w edge[x].push(y) cost[x].push(w) end for Return edge, cost
يمكننا الآن أن نعثر بسهولة على العقد المتصلة بعقدة ما وعددها أيضًا، وسنحتاج وقتًا أقل مقارنة بمصفوفة التجاور. بالمقابل، ستكون مصفوفة التجاور أكثر كفاءة إن احتجنا إلى معرفة ما إذا كان هناك ضلع بين u وv.
مقدمة إلى نظرية الرسوم التخطيطية
نظرية المخططات أو الرسوم التخطيطية Graph Theory هي فرع من فروع الرياضيات يهتم بدراسة الرسوم التخطيطية، وهي كائنات رياضية تُستخدم لنمذجة العلاقات الزوجية بين الكائنات.
طُوِّرت نظرية المخططات من قبل اختراع الحاسوب، إذ كتب ليونهارت أويلر Leonhard Euler ورقة حول جسور كونيجسبرج السبعة Seven Bridges of Königsberg والتي تُعدّ أوّل ورقة علمية عن نظرية المخططات، وأدرك الناس منذ ذلك الحين أنه إذا أمكننا تحويل المشاكل إلى مسائل من نوع مدينة-طريق City-Road، فيمكننا حلها بسهولة باستخدام نظرية المخططات. وهناك تطبيقات عديدة لهذه النظرية، لعل أشهرها هو العثور على أقصر مسافة بين مدينتين.
فمثلا، ينبغي أن تمرّ عبر العديد من المُوجّهات routers عندما تدخل موقعًا إلكترونيا، انطلاقًا من الخادم، لكي تصل محتويات الموقع إلى حاسوبك. تساهم نظرية المخططات هنا في العثور على الموجّهات التي ينبغي المرور عبرها للوصول إلى حاسوبك في أسرع وقت. كما تُستخدم خلال الحروب لتحديد الطريق الذي يجب قصفه لقطع العاصمة عن المدن الأخرى. وسنتعلم فيما يلي بعض الأساسيات لهذه النظرية.
إليك تعاريف من المهم الاطلاع عليها ومعرفتها:
- المخططات: لنقل أنّ لدينا 6 مدن، نرقّم هذه المدن من 1 إلى 6. سننشئ الآن مخططًا يمثّل هذه المدن، حيث تمثل الرؤوسُ المدن، مع ربط المدن التي تربطها طرق فيما بينها بأضلاع.
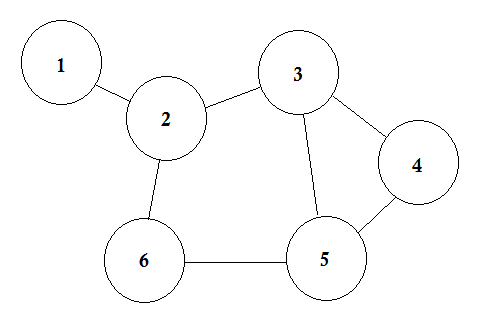
هذا مخطط بسيط لتمثيل المدن والطرق الرابطة بينها، ونسمي هذه المدن في نظرية المخططات عقدًا Nodes أو حروفًا Vertex فيما نسمّي الطرق أضلاعًا Edge.
يمكن أن تمثل العقدة أشياءً كثيرة، إذ قد تمثّل مدنًا أو مطارات أو مربّعات على رقعة الشطرنج. بالمقابل، تمثل الأضلاع العلاقات بين تلك العقد. مثلًا، يمكن أن تمثّل هذه العلاقات الوقت اللازم للانتقال من مطار إلى آخر، أو نقلة الفارس من مربّع إلى المربعات الأخرى على رقعة الشطرنج، وغير ذلك.
تمثيل لمسار الفارس على رقعة الشطرنج
وببساطة، تمثّل العقدة أيّ نوع من الكائنات، وتمثّل الأضلاع العلاقات بين تلك الكائنات.
-
العقدة المتجاورة Adjacent Node: تكون B مجاورة لـ A إذا اشتركت عقدة A مع عقدة أخرى B في ضلع واحد، أي نقول أنّ العقدتين متجاورتان إذا اتصلت عقدتان اتصالًا مباشرًا، ويمكن لكل عقدة أن يكون لها عدة عقد مجاورة.
-
المخططات الموجّهة وغير الموجّهة Directed and Undirected Graph: توضع علامات توجيهية (مثل الأسهم) على الأضلاع في المخططات الموجّهة للدلالة على أنّ الضلع أحادي الاتجاه. من ناحية أخرى، تحتوي أضلاع المخططات غير الموجّهة على علامات اتجاه على كلا الجانبين، للدلالة على أنها ثنائية الاتجاه. لكن تُحذف علامات التوجيه تلك في الغالب من المخططات غير الموجّهة، وتمثّل حينها الأضلاع كخطوط وحسب.
وإذا افترضنا وجود حفلٍ في مكان ما، فسنمثّل الأشخاص الحاضرين بالعُقد، وسنرسم خطًا بين شخصين إذا تصافحا. لا شك أن هذه المخططات غير موجّهة هنا، لأنّه إذا صافح عمرو زيدًا فهذا يعني أنّ زيدًا صافح عَمرًا كذلك، فهي عملية ثنائية. بالمقابل، إذا رسمنا ضلعًا من عمرو إلى زيد إن كان زيد يقدّر عَمرًا ويحترمه فإنّ هذه المخططات ستكون موجّهة، ذلك أن الإعجاب لا يشترط أن يكون متبادلًا.
يُطلق على النوع الأول مخططات غير موجّهة undirected graphs، وتسمّى الأضلاع أضلاعًا غير موجّهة undirected edges، بالمقابل، يسمّى النوع الثاني مخططات موجّهة directed graph وتسمّى الأضلاع أضلاعًا موجّهة directed edges.
- المخططات الموزونة وغير الموزونة Weighted and Unweighted Graph: المخطط الموزون هو مخطط يكون لكلّ ضلع من أضلاعه رقم (وزن)، يمكن أن تمثّل هذه الأوزان التكاليف أو الأطوال أو السعات وغير ذلك، وذلك اعتمادًا على المشكلة المطروحة.
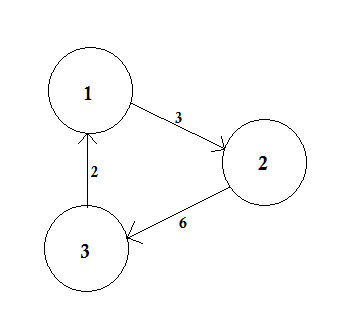
بالمقابل، المخططات غير الموزونة هي مخططات نفترض أنّ أوزان جميع أضلاعها متساوية (تساوي1 افتراضيًا ).
- المسارات: يمثّل المسار طريقًا للانتقال من عقدة إلى أخرى ويتألّف من سلسلة من الأضلاع، ولا شيء يمنع وجود عدة مسارات بين عقدتين.
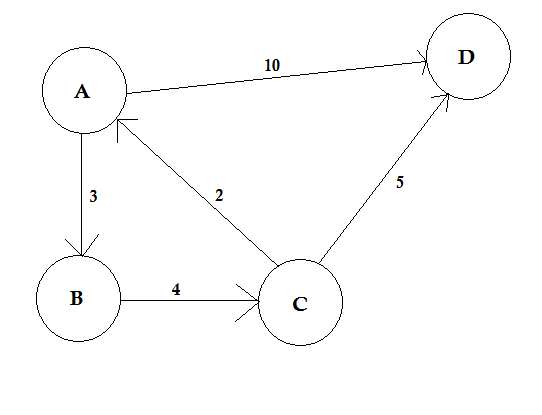
في المثال أعلاه، هناك مساران من A إلى D، الأول هو A-> B ،B-> C ،C-> D ، وكلفته (مجموع أوزان الأضلاع التي تؤلّفه) هي 3 + 4 + 2 = 9، أما المسار الآخر فهو A-> D، وكلفته 10. يقال أن المسار الذي يكلّف أدنى قدر هو المسار الأقصر.
- الدرجة degree: درجة الحرف degree of a vertex هي عدد الأضلاع المرتبطة به، فإذا كان هناك ضلع يرتبط بالحرف في كلا الطرفين (حلقة loop)، فسيُحسب مرتين.
يكون للعُقد في المخططات الموجّهة نوعان مختلفان من الدرجات:
- الدرجة الداخلية In-degree: عدد الأضلاع التي تشير إلى العقدة.
- الدرجة الخارجية Out-degree: عدد الأضلاع التي تنطلق من العقدة الحالية وتشير إلى العقد الأخرى. بالنسبة للمخططات غير الموجّهة، يكون هناك نوع واحد طبعا، ويُسمّى درجة الحرف.
بعض الخوارزميات المتعلقة بنظرية المخططات:
- خوارزمية بلمان فورد Bellman–Ford
- خوارزمية ديكسترا Dijkstra
- خوارزمية فورد فولكرسون Ford–Fulkerson
- خوارزمية كروسكال Kruskal.
- خوارزمية الجار الأقرب Nearest neighbour algorithm.
- خوارزمية بْرِم Prim.
- خوارزمية البحث العميق أولا Depth-first search.
- خوارزمية البحث العريض أولًا Breadth-first search.
سوف نستعرضُ بعض هذه الخوارزميات لاحقًا.
الترتيب الطوبولوجي Topological Sort
يرتّب الترتيب الطوبولوجي حروف مخطط موجّه ترتيبًا خطيًا، إذ يضعها في قائمة مُرتّبة حسب الأضلاع الموجّهة التي تربط تلك الحروف. وليكون هذا الترتيب ممكنا، يجب ألّا يحتوي المخطط على دورة موجّهة directed cycle، فإن كان لدينا مخطط G = (V, E)، فالترتيب الخطي رياضيًا هو ترتيب متوافق مع المخطط، أي يحقّق ما يلي:
-
إن كانت
Gتحتوي الضلع(u, v) ∈ Eالذي ينتمي إلى E وينطلق من الحرف u إلى v، فستكون u أصغر من v وفق هذا الترتيب.
وهنا من المهم ملاحظة أنّ كلّ مخطط موجّه غير دوري directed acyclic graph، أو DAG اختصارًا له ترتيب طوبولوجي واحد على الأقل، وهناك عدد من الخوارزميات التي تمكّننا من إنشاء ترتيب طوبولوجي لمخطط موجّه غير دوري في وقتٍ خطي، هذا مثال عام على إحداها:
-
استدع دالة
depth_first_search(G)لحساب أوقات الإنتهاء finishing times بـv.fلكل حرفv - عقب الانتهاء من حرف ما، أدرِجه في مقدّمة قائمة مرتبطة linked list.
- يُحدَّد الترتيب الطوبولوجي بقائمة الحروف المرتبطة التي نتجت من الخطوتين السابقتين.
يمكن إجراء ترتيب طوبولوجي في مدة V + E، لأنّ "خوارزمية البحث العميق أولًا depth-first search" تستغرق مدّة (V + E) ـ كما ستستغرق Ω(1) (وقت ثابت) لإدراج كل الحروف |V| في مقدمة القائمة المرتبطة.
تستخدم العديدُ من التطبيقات المخططاتَ الموجّهة الدورية directed acyclic graphs لتمثيل الأسبقية بين الأحداث، إذ يُستخدم الترتيب الطوبولوجي للحصول على الترتيب الصحيح لمعالجة كل حرف من حروف المخطط. وقد تمثّل حروف المخططُ المهامَ التي يتعيّن إنجازها، فيما تمثل الأضلاع أسبقية تنفيذ تلك المهام، وهكذا يمثّل الترتيب الطوبولوجي التسلسل المناسب لأداء مجموعة المهام الموضّحة في V.
مثال
ليكن v حرفًا يمثّل مهمّة Task(hours_to_complete: int)، بحيث يمثّل الوسيط hours_to_complete الوقت المُستغرَق لتنفيذ المهمة. فمثلًا، تمثّل Task(4) مهمّة تستغرق 4 ساعات لإكمالها.
من جهة أخرى، يمثّل ضلع e قيمة Cooldown(hours: int)، والتي تمثّل المدة الزمنية التي تنقضي قبل استئناف المهمة التالية (أي التي يشير إليها الضلع) بعد الانتهاء من المهمة الحالية (التي ينطلق منها الضلع). فإن كان هناك ضلع Cooldown(3) يربط بين مهمّتين أ و ب، فذلك يعني أنه بعد الانتهاء من المهمة أ، ستحتاج أن تنتظر 3 ساعات حتى تستطيع تنفيذ المهمة ب (مثلا ليبرد المحرّك).
فيما يلي، المخطط غير الدوري والموجّه dag يحتوي 5 رؤوس:
A <- dag.add_vertex(Task(4));
B <- dag.add_vertex(Task(5));
C <- dag.add_vertex(Task(3));
D <- dag.add_vertex(Task(2));
E <- dag.add_vertex(Task(7));
نربط الحروف عبر أضلاع موجّهة بحيث يكون المخططات غير دوري، انظر:
// A ---> C -----+ // | | | // v v v // B ---> D ---> E dag.add_edge(A, B, Cooldown(2)); dag.add_edge(A, C, Cooldown(2)); dag.add_edge(B, D, Cooldown(1)); dag.add_edge(C, D, Cooldown(1)); dag.add_edge(C, E, Cooldown(1)); dag.add_edge(D, E, Cooldown(3));
ستكون هناك ثلاثة تراتيب طوبولوجية ممكنة بين A وE:
- A -> B -> D -> E
- A -> C -> D -> E
- A -> C -> E
رصد الدورات في المخططات الموجهة باستخدام الاجتياز العميق أولا Depth First Traversal
إذا نتج عن الاجتياز العميق أولًا ضلعٌ خلفي back edge، فذلك يعني أنّ المخطط الموجّه يحتوي دورة cycle. والضلع الخلفي هو ضلع ينطلق من عقدة ويعود إليها أو إلى إحدى أسلافها في شجرة بحث عميق أولًا Depth-first search اختصارًا DFS.
بالنسبة لمخطط غير متصل disconnected graph، سنحصل على غابة بحث عميق أولا أو غابة DFS وهي اختصار لـ DFS forest، لذلك سيكون عليك التكرار على جميع الحروف في المخطط لإيجاد أشجار البحث العميق أولًا والمنفصلة disjoint DFS trees.
فيما يلي تنفيذ بلغة C++:
#include <iostream> #include <list> using namespace std; #define NUM_V 4 bool helper(list<int> *graph, int u, bool* visited, bool* recStack) { visited[u]=true; recStack[u]=true; list<int>::iterator i; for(i = graph[u].begin();i!=graph[u].end();++i) { if(recStack[*i])
شرح السطر السابق في الشيفرة: عند إيجاد حرف v في مكدس التكرارية الخاص باجتياز DFS، أعِد true، تابع المثال الآتي:
return true; else if(*i==u) // في حال كان هناك ضلع من الحرف إلى نفسه return true; else if(!visited[*i]) { if(helper(graph, *i, visited, recStack)) return true; } } recStack[u]=false; return false; }
هنا تستدعي دالة التغليف الدالةَ helper على كل حرف لم يُزَر بعد، وتعيد دالة helper القيمة true عند رصد ضلع خلفي في الشجيرة، وإلا فإنها تعيد false، تابع المثال الآتي:
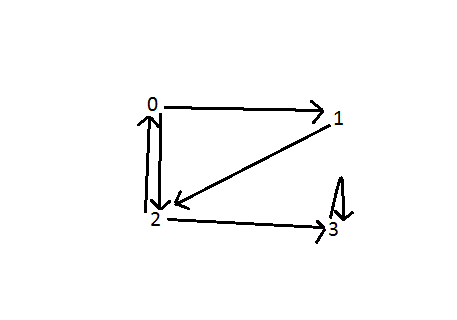
bool isCyclic(list<int> *graph, int V) { bool visited[V]; // مصفوفة لتتبع الأحرف المُزارة سلفا bool recStack[V]; // مصفوفة لتتبع الأحرف في المكدس التكراري للاجتياز for(int i = 0;i<V;i++) visited[i]=false, recStack[i]=false; // تهيئة جميع الأحرف على أنها غير مُزارة تكراريًا for(int u = 0; u < V; u++) // التحقق اليدوي مما إذا كانت كل الأحرف مُزارة { if(visited[u]==false) { if(helper(graph, u, visited, recStack)) // التحقق مما إذا كانت شجرةُ “بحثٍ عميقٍ أولًا” تحتوي دورة. return true; } } return false; } /* Driver function */ int main() { list<int>* graph = new list<int>[NUM_V]; graph[0].push_back(1); graph[0].push_back(2); graph[1].push_back(2); graph[2].push_back(0); graph[2].push_back(3); graph[3].push_back(3); bool res = isCyclic(graph, NUM_V); cout<<res<<endl; }
تكون النتيجة كما هو موضّح أدناه، أن هناك ثلاثة أضلاع خلفية في المخططات، واحد بين الحرفين 0 و 2؛ وآخر بين الحروف 0 و1 و2؛ والحرف 3. والتعقيد الزمني للبحث يساوي O (V + E)، حيث يمثّل V عدد الحروف، وE يمثّل عدد الأضلاع.
خوارزمية Thorup
كيف يمكن العثور على أقصر مسار من حرف (مصدر) معيّن إلى أيّ حرف آخر في مخطط غير موجّهة؟ قدّم "ميكيل توغوب Mikkel Thorup" -نُطْقُ اسمه من الدانماركية- أول خوارزمية تحل هذه المشكلة. يساوي التعقيد الزمني لهذه الخوارزمية O (m).
وفيما يلي الأفكارُ الأساسية التي تعتمد عليها الخوارزمية:
- هناك عدّة طرق للعثور على الشجرة المتفرّعة spanning tree في مدة O (m) (لن نذكر هذه الطرق هنا)، سيكون عليك إنشاء الشجرة المتفرّعة من الضلع الأقصر إلى الأطول، وسينتج عن ذلك غابة (مجموعة من الأشجار غير المتصلة بالضرورة) تحتوي العديد من المكوّنات المتصلة قبل أن تنمو كاملةً.
- اختر عددًا صحيحًا b (b> = 2)، ولا تأخذ بالحسبان إلّا الغابات المتفرّعة ذات الطول الأقصى b ^ k، ثم ادمج المكونات المتشابهة في كل شيء ولكن تختلف في قيمة k. سنسمّى أصغر قيم k مستوى المكوّن level of the component. ثم ضع المكوّنات بعد هذا في الشجرة في المكان المناسب بحيث يكون الحرف u أبًا للحرف v إذ كان u هي أصغر مكوّن مختلف عن v ويحتوي v بشكل كامل. الجذر سيكون المخطط بأكمله، أمّا الأوراق فهي الحروف المفردة single vertices في المخطط الأصلي (مستواها يساوي سالب ما لا نهاية). ستحتوي الشجرة على O (n) عقدة.
- حافظ على المسافة بين كل مكوّن وبين المصدر كما هو الحال في خوارزمية Dijkstra، تساوي مسافة مكوّن يحتوي أكثر من حرفٍ المسافةَ الأقل بين أبنائها غير الموسَّعين unexpanded children. اجعل مسافة الحرف الأصلي source vertex على 0، ثمّ حدّث الأسلاف وفقًا لذلك.
- احسب المسافات بنظام العدّ من الأساس b أو base b، وعند زيارة عقدة في المستوى k للمرة الأولى، ضع أبناءها في مجموعات أو سلَّات buckets مشتركة بين جميع العقد من المستوى k. وخذ بالحسبان أوّل b سلّة وحسب في كل مرة تزور فيها عقدة، وَزُر كلّ واحدة منها ثمّ أزلها، ثمّ حدّث مسافة العقدة الحالية، وَأعِد ربط العقدة الحالية بأصلها باستخدام المسافة الجديدة وانتظر الزيارة القادمة للسلات التالية.
- عند زيارة ورقة leaf، تكون المسافة الحالية هي المسافة النهائية للحرف. وسِّع جميع الأضلاع المنطلقة منه في المخطط الأصلي، ثمّ حدّث المسافات وفقًا لذلك.
- زر العقدة الجذرية (المخطط كاملًا) بشكل متكرر إلى أن تصل إلى الوجهة المقصودة.
تعتمد هذه الخوارزمية على حقيقة أنّه لا يمكن أن يوجد ضلع ذا طول أقل من l بين مكوّنيْن متصليْن في غابة متفرّعة ذات حدّ طولي يساوي length limitation، لذلك، يمكنك حصر تركيزك على مكوّن واحد متصل بدءًا من مسافة x إلى أن تصل إلى المسافة x + l. ستزور بعض الحروف في الطريق قبل زيارة جميع الحروف ذات المسافة الأقصر، لكن ذلك لا يهم بما أنّنا نعلم أنّه لن يكون هناك مسار أقصر إلى هنا من تلك الحروف.
اجتياز المخططات Graph Traversals
هناك العديد من الخوارزميات للبحث في المخططات، سنستعرض إحداها فيما يلي، وهي خوارزمية البحث العميق أولا.
تنفذ الشيفرة التالية هذه الخوارزمية، إذ تنشئ دالة تأخذ فهرس العقدة الحالي كوسيط، وقائمة التجاور (مخزّنة في متجهة من المتجهات)، ومتجهة منطقية vector of boolean لتعقّب العقدة التي تمت زيارتها، انظر:
void dfs(int node, vector<vector<int>>* graph, vector<bool>* visited) { // التحقّق مما إذا كانت العقدة مُزارة سلفا if((*visited)[node]) return; // set as visited to avoid visiting the same node twice (*visited)[node] = true; // نفّذ بعض الإجراءات هنا cout << node; // اجتياز العقد المتجاورة عبر البحث العميق أولا for(int i = 0; i < (*graph)[node].size(); ++i) dfs((*graph)[node][i], graph, visited); }
ترجمة -بتصرّف- للفصلين 9 و10 من كتاب Algorithms Notes for Professionals
اقرأ أيضًا
- المقالة السابقة: الأشجار Trees في الخوازرميات
- مدخل إلى الخوارزميات
- دليل شامل عن تحليل تعقيد الخوارزمية
- النسخة الكاملة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة









أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.