


حسام أحمد3
-
المساهمات
1 -
تاريخ الانضمام
-
تاريخ آخر زيارة
3 متابعين



آخر الزوار
971 زيارة للملف الشخصي





إنجازات حسام أحمد3
عضو مساهم (2/3)
17
السمعة بالموقع
-

 تعرفنا في المقال السابق على خوارزمية أقرب الجيران K-Nearest Neighbors، ووضحنا كيفية استخدامها عمليًا من خلال تمارين وتطبيقات متنوعة، وسنشرح اليوم خوارزمية أساسية من خوارزميات الذكاء الاصطناعي وهي خوارزمية الانحدار اللوجيستي Logistic Regression مع تطبيقات عملية باستخدام مكتبة ساي كيت ليرن ومجموعة بيانات أزهار آيرس Iris dataset. سنمر في البداية على جميع الخطوات التي تدربنا عليها في الأجزاء السابقة بإيجاز، ثم سنشرح آلية عمل خوارزمية الانحدار اللوجيستي المستخدمة بشكل أساسي في مهام التصنيف الثنائي binary classification، كما سنتطرق لبعض الطرق التي تسمح لنا باستخدام هذه الخوارزمية مع مهام التصنيف المتعدد multi classification. مفهوم الانحدار اللوجيستي تحليل الانحدار regression analysis هو أداة إحصائية مفيدة لفهم العلاقة بين متغيرات مختلفة، يساعدنا على تخمين أو توقع كيف يؤثر شيء ما يسمى المتغير المستقل independent variable على شيء آخر يسمى المتغير المعتمد dependent variable. مثلًا يمكننا معرفة كيف يؤثر عدد ساعات الدراسة على درجات الطلاب في الامتحان من خلال تحليل الانحدار واكتشاف العلاقة بين هذين المتغيرين وتحديد إن كان عدد الساعات يؤثر فعلاً في الدرجات أم لا، وفي مجموعة بيانات أزهار آيرس يمكننا استخدامه لاستكشاف العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width على سبيل المثال. هناك نوع خاص من الانحدار يطلق عليه اسم الانحدار اللوجيستي Logistic Regression نستخدمه عندما نريد التنبؤ بنتيجة تصنيف ثنائي binary classification نتيجته إما نعم أو لا، حيث تستخدم خوارزمية الانحدار اللوجيستي logistic regression دالة سينية sigmoid function تسمى بالدالة اللوجيستية logistic function والتي تحوّل المدخلات إلى قيم تقع بين الصفر والواحد مما يجعلها مناسبة لمهام التصنيف الثنائي. يمكننا أن ننظر إلى طريقة عمل خوارزمية الانحدار اللوجيستي على أنها خوارزمية تتكون من خطوتين الأولى هي إيجاد أفضل معادلة خطية تربط بين المدخلات أو المتغيرات المستقلة وبين المخرجات أي المتغيرات المعتمدة، بحيث نوجد أفضل خط يساير fitting البيانات، كما في خوارزمية توقع الانحدار الخطي. الخطوة الثانية هي تحويل القيمة المستمرة الخارجة من خوارزمية توقع الانحدار الخطي إلى احتمالية بين الصفر والواحد باستخدام الدالة اللوجيستية logistic function، والتصنيف ذو الاحتمال الأكبر هو توقع النموذج. يمكننا كذلك استخدام خوارزمية الانحدار اللوجيستي مع مشكلات التصنيف المتعدد multi classification باستخدام خدعة بسيطة تسمى واحد ضد الجميع One Vs All والتي تعرف اختصارًا OVA، حيث نعمل على تدريب عدد من المصنفات الثنائية binary classifiers يساوي عدد التصنيفات classes الموجودة في البيانات، وتكون مهمة كل مصنف classifier التمييز بين تصنيف محدد ونرمز له رقميًا بواحد 1 وما دون ذلك من التصنيفات نرمز لها جميعًا بصفر 0. يمكننا في مكتبة scikit-learn، استخدام خوارزمية الانحدار اللوجستي لمهام التصنيف المتعدد باستخدام الدالة softmax التي تحدد احتمالية انتماء كل عينة إلى إحدى التصنيفات المتعددة، بحيث يكون مجموع الاحتمالات لجميع التصنيفات classes مساويًا لواحد، بينما نستخدم الدالة sigmoid في مهام التصنيف الثنائي فقط. استكشاف مجموعة البيانات Data Exploring سنكتب برنامج بايثون لعرض المعلومات الإحصائية الأساسية لفصائل أزهار آيرس المختلفة Iris-setosa و Iris-versicolor و Iris-virginica على النحو التالي: import pandas as pd iris = pd.read_csv("iris.csv") # قائمة بجميع الفصائل SpeciesList = iris.Species.value_counts().index # حلقة تكرارية لحساب الإحصائيات لكل فصيلة for s in SpeciesList: print(f"Statistics about {s}") # حساب الإحصائيات لشريحة البيانات التي تنتمي للفصيلة الحالية print(iris[iris.Species == s].describe()) يعمل الكود السابق على توليد إحصائيات وصفية لكل فصيلة من فصائل الأزهار الموجودة في المجموعة. حيث يسمح لنا الشرط [iris[iris.Species == s باختيار العينات التي تحقق هذا الشرط، أي أننا سنختار في كل تكرار للحلقة العينات التي تنتمي للفصيلة s ثم سنستخدام التابع data.describe() للحصول على معلومات إحصائية تخص هذه العينات، مثل أكبر وأصغر قيمة في البيانات والمتوسط الحسابي للقيم والانحراف المعياري. عند تنفيذ الكود سنحصل على الخرج التالي: Statistics about Iris-setosa Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 25.50000 5.00600 3.418000 1.464000 0.24400 std 14.57738 0.35249 0.381024 0.173511 0.10721 min 1.00000 4.30000 2.300000 1.000000 0.10000 25% 13.25000 4.80000 3.125000 1.400000 0.20000 50% 25.50000 5.00000 3.400000 1.500000 0.20000 75% 37.75000 5.20000 3.675000 1.575000 0.30000 max 50.00000 5.80000 4.400000 1.900000 0.60000 Statistics about Iris-versicolor Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.000000 50.000000 50.000000 50.000000 mean 75.50000 5.936000 2.770000 4.260000 1.326000 std 14.57738 0.516171 0.313798 0.469911 0.197753 min 51.00000 4.900000 2.000000 3.000000 1.000000 25% 63.25000 5.600000 2.525000 4.000000 1.200000 50% 75.50000 5.900000 2.800000 4.350000 1.300000 75% 87.75000 6.300000 3.000000 4.600000 1.500000 max 100.00000 7.000000 3.400000 5.100000 1.800000 Statistics about Iris-virginica Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 125.50000 6.58800 2.974000 5.552000 2.02600 std 14.57738 0.63588 0.322497 0.551895 0.27465 min 101.00000 4.90000 2.200000 4.500000 1.40000 25% 113.25000 6.22500 2.800000 5.100000 1.80000 50% 125.50000 6.50000 3.000000 5.550000 2.00000 75% 137.75000 6.90000 3.175000 5.875000 2.30000 max 150.00000 7.90000 3.800000 6.900000 2.50000 Index(['Id', 'SepalLengthCm', 'SepalWidth عرض العلاقة بين البيانات باستخدام التمثيل المرئي Data Visualization سننشئ الآن رسم بياني نقطي Scatter plot لعرض العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width، لنحقق ذلك نكتب الكود التالي: import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(7,7), dpi=150) sns.scatterplot(data=iris, x="SepalLengthCm", y="PetalWidthCm", hue="Species") plt.show() استوردنا في هذا الكود مكتبة matplotlib لضبط إعدادات الرسم البياني من أبعاد الشكل ودقة الصورة الناتجة، كما استوردنا مكتبة seaborn التي توفر واجهة استخدام سهلة ومرنة للرسم. بعدها مررنا للدالة sns.scatterplot المعامل data لتحديد مجموعة البيانات التي سنعمل عليها، وحددنا بأن المحور الأفقي سيكون طول السبلات، وأن المحور العمودي سيكون عرض البتلات، ستمثل كل زهرة بنقطة في الشكل الناتج وتلون كل نقطة وفقًا لانتمائها لأحد الفصائل الثلاثة في مجموعة بيانات أزهار آيرس. عند تنفيذ الكود سنحصل على الرسم البياني التالي: تصنيف فصائل الأزهار باستخدام خوارزمية الانحدار اللوجستي سنكتب الآن برنامج بايثون لتدريب نموذج الانحدار اللوجيستي Logistic Regression على مجموعة بيانات أزهار آيرس التي تحتوي على ثلاثة فصائل من الأزهار للتمييز فيما بينها، ثم نقيم أداء النموذج على مجموعة الاختبار. import pandas as pd from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.linear_model import LogisticRegression iris = pd.read_csv("iris.csv") # Id احذف عمود # لعدم أهميته في عملية التعلم iris = iris.drop('Id',axis=1) # خواص الأزهار X = iris.iloc[:, :-1].values # وسم الأزهار y = iris.iloc[:, 4].values # تقسيم مجموعة البيانات إلى مجموعة بيانات تدريب ومجموعة بيانات اختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # إنشاء نموذج model = LogisticRegression(random_state=0, multi_class='multinomial') model.fit(X_train,y_train) prediction=model.predict(X_test) print('The accuracy of the Logistic Regression is', metrics.accuracy_score(prediction,y_test)) استوردنا في البداية عددًا من الدوال والمكتبات التي ستساعدنا في تدريب وتقييم النموذج، واستدعينا الدالة train_test_split لتقسم خاصيات مجموعة البيانات dataset features ووسوم البيانات dataset labels إلى مجموعتي تدريب واختبار كل منها يمتلك جزءًا من خاصيات مجموعة البيانات والوسوم المقابلة للعينات المختارة، وحددنا نسبة التقسيم باستخدام التعليمة test_size=0.20 لجعل عشرين بالمائة من مجموعة البيانات مجموعة اختبار، والنسبة الباقية للتدريب، ستُقسَم البيانات بشكل عشوائي في كل مرة نشغل بها الكود، ثم عرفنا كائن model يطبق خوارزمية الانحدار اللوجيستي ومررنا له المتغير random_state=0 لنضمن ثبات نتيجة تدريب النموذج عند تشغيل الكود أكثر من مرة، وحددنا نوع المشكلة بأنه تصنيف متعدد بضبط قيمة المعامل multi_class إلى multinomial. بعد أن هيئنا إعدادات النموذج سندربه على مجموعة بيانات التدريب باستخدام الدالة model.fit(X_train,y_train)، وبعد تدريب النموذج يمكننا استخدامه في تخمين الوسوم لمجموعة الاختبار باستخدام الدالة model.predict(X_test). نخزن الناتج في القائمة prediction التي تحتوي محاولة النموذج لتوقع قيم y_test، ولتقييم دقة النموذج في هذه المحاولة نستخدم الدالة metrics.accuracy_score(prediction,y_test) التي تحصي نسبة القيم التي توقعها النموذج بشكل صحيح إلى إجمالي جميع القيم. عند تنفيذ الكود سنحصل على الخرج التالي: The accuracy of the Logistic Regression is 0.9333333333333333 تعني النتيجة التي حصلنا عليها أن النموذج جيد جدًا في التنبؤ، لأنه أصاب في أكثر من 93% من الحالات فهذه النسبة تمثل نسبة العينات التي صنفها النموذج بشكل صحيح وتعرف باسم دقة النموذج، لكن الدقة ليست دائمًا المقياس الوحيد الكافي، خصوصًا في المشكلات التي يكون فيها عدد العينات في كل فئة غير متوازن لذا قد نحتاج لمقاييس إضافية لتقييم النموذج بشكل عادل. الخاتمة تعرفنا في هذه المقالة على خوارزمية الانحدار اللوجيستي Logistic Regression وكيف تعمل، وطبقناها باستخدام مكتبة ساي كيت ليرن على مجموعة بيانات أزهار إيرس، وقيمنا دقة النموذج على مجموعة بيانات اختبارية، يمكن مواصلة التدريب على مجموعات بيانات مختلفة أكبر في الحجم وتحتاج للمزيد من المعالجة، حيث تتوفر الكثير من مجموعات البيانات مفتوحة المصدر على موقع Kaggle. اقرأ أيضًا المقال السابق: استخدام خوارزمية أقرب الجيران k-Nearest Neighbors في Scikit-Learn تعرف على مكتبة Scikit learn وأهم خوارزمياتها الانحدار الإحصائي regression ودوره في ملاءمة النماذج المختلفة مع أنواع البيانات المتاحة العلاقات بين المتغيرات الإحصائية وكيفية تنفيذها في بايثون
تعرفنا في المقال السابق على خوارزمية أقرب الجيران K-Nearest Neighbors، ووضحنا كيفية استخدامها عمليًا من خلال تمارين وتطبيقات متنوعة، وسنشرح اليوم خوارزمية أساسية من خوارزميات الذكاء الاصطناعي وهي خوارزمية الانحدار اللوجيستي Logistic Regression مع تطبيقات عملية باستخدام مكتبة ساي كيت ليرن ومجموعة بيانات أزهار آيرس Iris dataset. سنمر في البداية على جميع الخطوات التي تدربنا عليها في الأجزاء السابقة بإيجاز، ثم سنشرح آلية عمل خوارزمية الانحدار اللوجيستي المستخدمة بشكل أساسي في مهام التصنيف الثنائي binary classification، كما سنتطرق لبعض الطرق التي تسمح لنا باستخدام هذه الخوارزمية مع مهام التصنيف المتعدد multi classification. مفهوم الانحدار اللوجيستي تحليل الانحدار regression analysis هو أداة إحصائية مفيدة لفهم العلاقة بين متغيرات مختلفة، يساعدنا على تخمين أو توقع كيف يؤثر شيء ما يسمى المتغير المستقل independent variable على شيء آخر يسمى المتغير المعتمد dependent variable. مثلًا يمكننا معرفة كيف يؤثر عدد ساعات الدراسة على درجات الطلاب في الامتحان من خلال تحليل الانحدار واكتشاف العلاقة بين هذين المتغيرين وتحديد إن كان عدد الساعات يؤثر فعلاً في الدرجات أم لا، وفي مجموعة بيانات أزهار آيرس يمكننا استخدامه لاستكشاف العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width على سبيل المثال. هناك نوع خاص من الانحدار يطلق عليه اسم الانحدار اللوجيستي Logistic Regression نستخدمه عندما نريد التنبؤ بنتيجة تصنيف ثنائي binary classification نتيجته إما نعم أو لا، حيث تستخدم خوارزمية الانحدار اللوجيستي logistic regression دالة سينية sigmoid function تسمى بالدالة اللوجيستية logistic function والتي تحوّل المدخلات إلى قيم تقع بين الصفر والواحد مما يجعلها مناسبة لمهام التصنيف الثنائي. يمكننا أن ننظر إلى طريقة عمل خوارزمية الانحدار اللوجيستي على أنها خوارزمية تتكون من خطوتين الأولى هي إيجاد أفضل معادلة خطية تربط بين المدخلات أو المتغيرات المستقلة وبين المخرجات أي المتغيرات المعتمدة، بحيث نوجد أفضل خط يساير fitting البيانات، كما في خوارزمية توقع الانحدار الخطي. الخطوة الثانية هي تحويل القيمة المستمرة الخارجة من خوارزمية توقع الانحدار الخطي إلى احتمالية بين الصفر والواحد باستخدام الدالة اللوجيستية logistic function، والتصنيف ذو الاحتمال الأكبر هو توقع النموذج. يمكننا كذلك استخدام خوارزمية الانحدار اللوجيستي مع مشكلات التصنيف المتعدد multi classification باستخدام خدعة بسيطة تسمى واحد ضد الجميع One Vs All والتي تعرف اختصارًا OVA، حيث نعمل على تدريب عدد من المصنفات الثنائية binary classifiers يساوي عدد التصنيفات classes الموجودة في البيانات، وتكون مهمة كل مصنف classifier التمييز بين تصنيف محدد ونرمز له رقميًا بواحد 1 وما دون ذلك من التصنيفات نرمز لها جميعًا بصفر 0. يمكننا في مكتبة scikit-learn، استخدام خوارزمية الانحدار اللوجستي لمهام التصنيف المتعدد باستخدام الدالة softmax التي تحدد احتمالية انتماء كل عينة إلى إحدى التصنيفات المتعددة، بحيث يكون مجموع الاحتمالات لجميع التصنيفات classes مساويًا لواحد، بينما نستخدم الدالة sigmoid في مهام التصنيف الثنائي فقط. استكشاف مجموعة البيانات Data Exploring سنكتب برنامج بايثون لعرض المعلومات الإحصائية الأساسية لفصائل أزهار آيرس المختلفة Iris-setosa و Iris-versicolor و Iris-virginica على النحو التالي: import pandas as pd iris = pd.read_csv("iris.csv") # قائمة بجميع الفصائل SpeciesList = iris.Species.value_counts().index # حلقة تكرارية لحساب الإحصائيات لكل فصيلة for s in SpeciesList: print(f"Statistics about {s}") # حساب الإحصائيات لشريحة البيانات التي تنتمي للفصيلة الحالية print(iris[iris.Species == s].describe()) يعمل الكود السابق على توليد إحصائيات وصفية لكل فصيلة من فصائل الأزهار الموجودة في المجموعة. حيث يسمح لنا الشرط [iris[iris.Species == s باختيار العينات التي تحقق هذا الشرط، أي أننا سنختار في كل تكرار للحلقة العينات التي تنتمي للفصيلة s ثم سنستخدام التابع data.describe() للحصول على معلومات إحصائية تخص هذه العينات، مثل أكبر وأصغر قيمة في البيانات والمتوسط الحسابي للقيم والانحراف المعياري. عند تنفيذ الكود سنحصل على الخرج التالي: Statistics about Iris-setosa Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 25.50000 5.00600 3.418000 1.464000 0.24400 std 14.57738 0.35249 0.381024 0.173511 0.10721 min 1.00000 4.30000 2.300000 1.000000 0.10000 25% 13.25000 4.80000 3.125000 1.400000 0.20000 50% 25.50000 5.00000 3.400000 1.500000 0.20000 75% 37.75000 5.20000 3.675000 1.575000 0.30000 max 50.00000 5.80000 4.400000 1.900000 0.60000 Statistics about Iris-versicolor Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.000000 50.000000 50.000000 50.000000 mean 75.50000 5.936000 2.770000 4.260000 1.326000 std 14.57738 0.516171 0.313798 0.469911 0.197753 min 51.00000 4.900000 2.000000 3.000000 1.000000 25% 63.25000 5.600000 2.525000 4.000000 1.200000 50% 75.50000 5.900000 2.800000 4.350000 1.300000 75% 87.75000 6.300000 3.000000 4.600000 1.500000 max 100.00000 7.000000 3.400000 5.100000 1.800000 Statistics about Iris-virginica Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 50.00000 50.00000 50.000000 50.000000 50.00000 mean 125.50000 6.58800 2.974000 5.552000 2.02600 std 14.57738 0.63588 0.322497 0.551895 0.27465 min 101.00000 4.90000 2.200000 4.500000 1.40000 25% 113.25000 6.22500 2.800000 5.100000 1.80000 50% 125.50000 6.50000 3.000000 5.550000 2.00000 75% 137.75000 6.90000 3.175000 5.875000 2.30000 max 150.00000 7.90000 3.800000 6.900000 2.50000 Index(['Id', 'SepalLengthCm', 'SepalWidth عرض العلاقة بين البيانات باستخدام التمثيل المرئي Data Visualization سننشئ الآن رسم بياني نقطي Scatter plot لعرض العلاقة بين طول السبلة Sepal length وعرض البتلة Petal width، لنحقق ذلك نكتب الكود التالي: import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(7,7), dpi=150) sns.scatterplot(data=iris, x="SepalLengthCm", y="PetalWidthCm", hue="Species") plt.show() استوردنا في هذا الكود مكتبة matplotlib لضبط إعدادات الرسم البياني من أبعاد الشكل ودقة الصورة الناتجة، كما استوردنا مكتبة seaborn التي توفر واجهة استخدام سهلة ومرنة للرسم. بعدها مررنا للدالة sns.scatterplot المعامل data لتحديد مجموعة البيانات التي سنعمل عليها، وحددنا بأن المحور الأفقي سيكون طول السبلات، وأن المحور العمودي سيكون عرض البتلات، ستمثل كل زهرة بنقطة في الشكل الناتج وتلون كل نقطة وفقًا لانتمائها لأحد الفصائل الثلاثة في مجموعة بيانات أزهار آيرس. عند تنفيذ الكود سنحصل على الرسم البياني التالي: تصنيف فصائل الأزهار باستخدام خوارزمية الانحدار اللوجستي سنكتب الآن برنامج بايثون لتدريب نموذج الانحدار اللوجيستي Logistic Regression على مجموعة بيانات أزهار آيرس التي تحتوي على ثلاثة فصائل من الأزهار للتمييز فيما بينها، ثم نقيم أداء النموذج على مجموعة الاختبار. import pandas as pd from sklearn.model_selection import train_test_split from sklearn import metrics from sklearn.linear_model import LogisticRegression iris = pd.read_csv("iris.csv") # Id احذف عمود # لعدم أهميته في عملية التعلم iris = iris.drop('Id',axis=1) # خواص الأزهار X = iris.iloc[:, :-1].values # وسم الأزهار y = iris.iloc[:, 4].values # تقسيم مجموعة البيانات إلى مجموعة بيانات تدريب ومجموعة بيانات اختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # إنشاء نموذج model = LogisticRegression(random_state=0, multi_class='multinomial') model.fit(X_train,y_train) prediction=model.predict(X_test) print('The accuracy of the Logistic Regression is', metrics.accuracy_score(prediction,y_test)) استوردنا في البداية عددًا من الدوال والمكتبات التي ستساعدنا في تدريب وتقييم النموذج، واستدعينا الدالة train_test_split لتقسم خاصيات مجموعة البيانات dataset features ووسوم البيانات dataset labels إلى مجموعتي تدريب واختبار كل منها يمتلك جزءًا من خاصيات مجموعة البيانات والوسوم المقابلة للعينات المختارة، وحددنا نسبة التقسيم باستخدام التعليمة test_size=0.20 لجعل عشرين بالمائة من مجموعة البيانات مجموعة اختبار، والنسبة الباقية للتدريب، ستُقسَم البيانات بشكل عشوائي في كل مرة نشغل بها الكود، ثم عرفنا كائن model يطبق خوارزمية الانحدار اللوجيستي ومررنا له المتغير random_state=0 لنضمن ثبات نتيجة تدريب النموذج عند تشغيل الكود أكثر من مرة، وحددنا نوع المشكلة بأنه تصنيف متعدد بضبط قيمة المعامل multi_class إلى multinomial. بعد أن هيئنا إعدادات النموذج سندربه على مجموعة بيانات التدريب باستخدام الدالة model.fit(X_train,y_train)، وبعد تدريب النموذج يمكننا استخدامه في تخمين الوسوم لمجموعة الاختبار باستخدام الدالة model.predict(X_test). نخزن الناتج في القائمة prediction التي تحتوي محاولة النموذج لتوقع قيم y_test، ولتقييم دقة النموذج في هذه المحاولة نستخدم الدالة metrics.accuracy_score(prediction,y_test) التي تحصي نسبة القيم التي توقعها النموذج بشكل صحيح إلى إجمالي جميع القيم. عند تنفيذ الكود سنحصل على الخرج التالي: The accuracy of the Logistic Regression is 0.9333333333333333 تعني النتيجة التي حصلنا عليها أن النموذج جيد جدًا في التنبؤ، لأنه أصاب في أكثر من 93% من الحالات فهذه النسبة تمثل نسبة العينات التي صنفها النموذج بشكل صحيح وتعرف باسم دقة النموذج، لكن الدقة ليست دائمًا المقياس الوحيد الكافي، خصوصًا في المشكلات التي يكون فيها عدد العينات في كل فئة غير متوازن لذا قد نحتاج لمقاييس إضافية لتقييم النموذج بشكل عادل. الخاتمة تعرفنا في هذه المقالة على خوارزمية الانحدار اللوجيستي Logistic Regression وكيف تعمل، وطبقناها باستخدام مكتبة ساي كيت ليرن على مجموعة بيانات أزهار إيرس، وقيمنا دقة النموذج على مجموعة بيانات اختبارية، يمكن مواصلة التدريب على مجموعات بيانات مختلفة أكبر في الحجم وتحتاج للمزيد من المعالجة، حيث تتوفر الكثير من مجموعات البيانات مفتوحة المصدر على موقع Kaggle. اقرأ أيضًا المقال السابق: استخدام خوارزمية أقرب الجيران k-Nearest Neighbors في Scikit-Learn تعرف على مكتبة Scikit learn وأهم خوارزمياتها الانحدار الإحصائي regression ودوره في ملاءمة النماذج المختلفة مع أنواع البيانات المتاحة العلاقات بين المتغيرات الإحصائية وكيفية تنفيذها في بايثون -
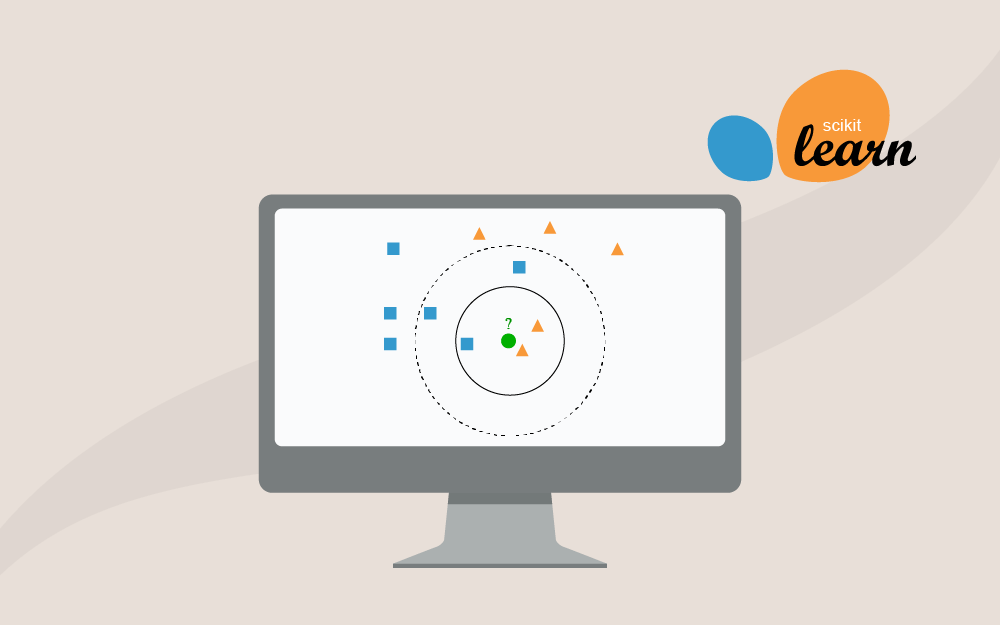 في هذا المقال من سلسلة تطبيقات عملية على استخدام مكتبة ساي كيت ليرن سنستعرض خطوة بخطوة كيفية تطبيق واحدة من أشهر خوارزميات تعلم الآلة وهي خوارزمية أقرب الجيران k-Nearest Neighbors -أو KNN اختصارًا- لتصنيف الأنواع المختلفة من الأزهار الموجودة ضمن مجموعة بيانات آيرس Iris dataset إحدى أكثر مجموعات البيانات استخدامًا في مجال تعلم الآلة والتي تعرفنا عليها في مقال سابق بعنوان أساسيات تحليل البيانات باستخدام Scikit-Learn. آلية عمل خوارزمية k-Nearest Neighbors يمكننا تعريف خوارزمية أقرب جار K-Nearest Neighbors على أنها خوارزمية لا معاملية non-parametric بمعنى أنها لا تملك أوزان أو معاملات تحاول تحسينها كما تتبع خوارزميات ذكاء اصطناعي أخرى، فهي تستخدم في مهام التصنيف Classification وتوقع الانحدار Regression، وفي كلا الحالتين تعتمد على المعلومات المتاحة لدى أقرب k من النقاط المجاورة لمجموعة بيانات التدريب، وتختلف طريقة حساب المخرجات حسب مهمة التعلم. في حالة التصنيف Classification يكون خرج النموذج أحد التصنيفات المحددة، ونقرره بناءً على تصويت الأغلبية من عدد k نقطة مجاورة لها حق التصويت أي يسمح لها بالمشاركة في اتخاذ القرار بشأن تصنيف نقطة معينة، ويكون هذا العدد المحدد k من النقاط المجاورة عددًا صحيحًا موجبًا ويفضل أن يكون فرديًا لمنع أي حالات تعادل في التصويت. من المهم اختيار قيمة k مناسبة في خوارزمية الجار الأقرب، ويفضل أن تكون قيمة صغيرة نسبيًا، فعندما نحدد عدد النقاط المجاورة k=1 سيتأثر قرار النموذج بالضجيج noise في البيانات والنقاط الخارجة outliers وغير المألوفة بشكل كبير، مما يحدث حالة إفراط في التخصيص Overfitting ويضعف قدرته على التعميم لبيانات جديدة، بينما عندما نحدد عدد النقاط المجاورة برقم كبير n يساوي عدد العينات بمجموعة بيانات التدريب سيصبح النموذج أبسط من اللازم وتحدث لديه حالة إفراط في التبسيط Underfitting بالتالي لن يكون قادر على التعبير عن العلاقات المعقدة الموجودة في البيانات وسيأخذ قرارات اعتمادًا على نقاط بعيدة جدًا ولا تؤثر على نقطة الاستفسار الحالية. في حالة توقع الانحدار Regression يكون خرج النموذج عدد مستمر ناتج عن أخذ متوسط القيم من عدد محدد k من النقاط المجاورة لتقرير قيمة نقطة الاستفسار الحالية. تعرض الصورة السابقة مثالًا على خوارزمية KNN لمهمة التصنيف، وتمثل النقطة الخضراء نقطة الاستفسار الحالية query point والتي نريد تصنيفها إما لصنف المربعات الزرقاء أو المثلثات الحمراء، فإذا قررنا أن عدد النقاط المجاورة k=3 تصبح النقاط الداخلة في القرار هي النقاط المحاطة بالدائرة المتصلة، وكما نرى فالأغلبية في هذا النطاق للمثلثات الحمراء 2 بينما الأقلية هي المربعات الزرقاء 1، بالتالي يمكننا تصنيف نقطة الاستفسار query point بأنها مثلث أحمر، بينما عند زيادة k لتصبح 5 ننظر للنقاط المحاطة بالدائرة المنقطة فنجد أن الأغلبية صارت للمربعات الزرقاء 3 مقابل 2 من المثلثات الحمراء، بالتالي يصبح التصنيف لنقطة الاستفسار مربع أزرق. بعد أن تعرفنا على آلية عمل الخوارزمية، لنستعرض مجموعة من التدريبات العملية التي تساعدنا على فهم كيفية استخدام هذه الخوارزمية بشكل فعّال باستخدام مكتبة scikit-learn. فصل مجموعة البيانات من أولى خطوات التحضير لبناء أي نموذج تعلم آلة هي فصل الخصائص Features وهي البيانات التي نستخدمها لتوقع شيء ما عن الوسوم Labels وهي القيم التي نحاول التنبؤ بها، لنكتب برنامج بايثون لتقسيم مجموعة بيانات أزهار آيرس إلى خصائصها كطول و عرض بتلة الزهرة وسبلتها والتي سنخزنها في متغير X ، والوسوم التي سنخزنها في متغير Y. سيحتوي المتغير X أول أربعة أعمدة بينما يحتوي المتغير Y وسم كل زهرة بفصيلتها مثل Setosa أو Versicolor أو Virginica. import pandas as pd iris = pd.read_csv("iris.csv") # Idاحذف عمود iris = iris.drop('Id',axis=1) # iloc : تسمح باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values print("الخصائص:") print(X) print("\nالوسوم:") print(y) كما نلاحظ فقد حذفنا في هذه الخطوة عمود المعرف Id من مجموعة البيانات، كونه لا يحمل أي معنى يتعلق بخصائص الأزهار، واستخدامه قد يؤدي لنموذج متحيز وغير دقيق. واستخدمنا التابع iloc لتحديد الخصائص X، والوسوم Y وأخيرًا، طبعنا كلًا من X و Y للتأكد من صحة التقسيم. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] ... [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] تقسيم مجموعة البيانات لمجموعة تدريب ومجموعة اختبار نحتاج لتقسيم البيانات إلى بيانات تدريب training وبيانات اختبار testing حتى نتمكن من معرفة فيما إذا كان النموذج يعمل جيدًا على بيانات جديدة لم يرها من قبل، سنكتب كود لتقسيم مجموعة بيانات آيرس إلى مجموعة تدريب تحتوي 80% من البيانات ومجموعة اختبار تحتوي 20%، بحيث يكون عدد العينات المستخدمة في التدريب هو 120 عينة والمستخدمة في الاختبار 30 عينة، ونطبع كلا المجموعتين. import pandas as pd from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") # Id احذف العمود iris = iris.drop('Id',axis=1) # iloc : تسمح لنا باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسم هذه الدالة مجموعة البيانات عشوائيًا وفقًا للنسب المحددة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n70% train data:") print(X_train) print(y_train) print("\n30% test data:") print(X_test) print(y_test) فصلنا في البداية مجموعة البيانات إلى خاصيات X ووسوم Y كما في فعلنا في التطبيق السابق، ثم استدعينا الدالة train_test_split التي تقسم خاصيات ووسوم المجموعة إلى مجموعة تدريب ومجموعة اختبار، وحددنا نسبة التقسيم باستخدام test_size=0.20 لجعل 20% من مجموعة البيانات مخصصة للاختبار، بينما 80% منها للتدريب، سيجري تقسيم البيانات عشوائيًا في كل مرة نشغل بها الكود. عند تنفيذ الكود السابق سنحصل على خرج مشابه لما يلي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [4.8 3. 1.4 0.1] [6. 2.7 5.1 1.6] [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] ترقيم الفصائل النصية الأن سنعمل على تطبيق يحوّل فصائل الأزهار في مجموعة بيانات آيرس من أسماء نصية إلى قيم رقمية، ولنفعل ذلك سنحتاج لتحويل كل قيمة إلى رقم ثابت لهذه القيمة، فمثلًا نجعل Iris-setosa:0 و Iris-versicolor:1 و Iris-virginica:2، ثم نطبع مجموعة بيانات التدريب ومجموعة بيانات الاختبار. import pandas as pd from sklearn.model_selection import train_test_split # LabelEncoder استدعي # والذي سوف نستخدمه لتحويل الفصائل من قيم نصية إلى أرقام ثابته لكل فصيلة from sklearn.preprocessing import LabelEncoder iris = pd.read_csv("iris.csv") # labelEncoder نهيئ الصنف البرمجي le = LabelEncoder() # labelEncoder نستخدم الصنف البرمجي # لتحويل التصنيفات النصية إلى أرقم iris.Species = le.fit_transform(iris.Species) # Id نحذف العمود # حيث لا يحتوي معلومات مهمة للتعلم iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # نقسم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار # كل منهما له خصائص ووسوم منفصلة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n80% train data:") print(X_train) print(y_train) print("\n20% test data:") print(X_test) print(y_test) استخدمناLabelEncoder() لنهيئ الكائن le والذي سنستخدمه لتحويل الفصائل النصية categorical classes لأرقام، حيث نرمز لكل صنف أو اسم برقم ثابت لهذا الصنف، ونستدعي هذا الكائن ليطبّق على البيانات باستخدام le.fit_transform(iris.Species) حيث تتعرف هذه الدالة في البداية على الأصناف في عمود Species وتحدد القيم التي ستعطى لكل فصيل category وتسمى هذه العملية fit ويمكن تنفيذها بشكل مستقل، ومن ثم يتم تحويل القيم النصية القديمة إلى الأرقام المقابلة عند تنفيذ عملية transform التي يمكن فصلها لكي تنفّذ بعد عملية fit على أكثر من مجموعة من البيانات التي تتضمن نفس الفصائل، ولكن في كثير من الأحيان نستخدم الدالة التي تدمج الخطوتين معًا. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] 80% train data: [[7.7 2.8 6.7 2. ] [6.7 3.1 5.6 2.4] [5.7 2.6 3.5 1. ] [6.3 2.8 5.1 1.5] [4.9 3.1 1.5 0.1] … [4.8 3. 1.4 0.3] [6.4 2.9 4.3 1.3] [4.8 3. 1.4 0.1] [5.5 2.6 4.4 1.2] [6.3 2.3 4.4 1.3]] [2 2 1 2 0 0 0 2 2 2 2 2 0 0 2 2 1 2 1 0 1 2 0 1 2 0 1 2 2 0 1 1 1 2 0 1 0 1 0 2 2 2 0 2 1 1 0 2 1 2 1 0 0 1 1 2 0 0 2 1 1 2 0 1 1 0 0 2 0 0 1 1 2 1 0 1 2 2 0 1 0 0 2 0 0 2 0 1 1 2 2 0 0 1 2 0 1 1 1 0 0 1 0 2 2 0 0 0 2 2 0 2 2 0 2 0 1 0 1 1] 20% test data: [[6.8 3.2 5.9 2.3] [5.4 3. 4.5 1.5] [4.3 3. 1.1 0.1] [5.6 3. 4.1 1.3] [6.7 3. 5. 1.7] … [5.8 2.7 3.9 1.2] [6.3 2.5 5. 1.9] [6.3 3.3 4.7 1.6] [5.1 3.7 1.5 0.4] [6.9 3.2 5.7 2.3]] [2 1 0 1 1 0 2 2 2 1 0 2 1 1 1 1 1 2 1 1 1 0 2 0 0 1 2 1 0 2] بناء نموذج K-Nearest Neighbors باستخدام ساي كيت ليرن Scikit-Learn لنكتب كود برمجي لجعل نسبة تقسيم مجموعات البيانات 70% لمجموعة التدريب و30% لمجموعة الاختبار، حيث يصبح عدد العينات المستخدمة في التدريب 105 عينة وعدد عينات الاختبار 45، ثم نتوقع باستخدام نموذج KNN تصنيفات الفصائل لمجموعة الاختبار مع تحديد عدد النقاط المجاورة ليكون 5. import pandas as pd from sklearn.model_selection import train_test_split # نستدعي المُصنف من مكتبة ساي كيت ليرن from sklearn.neighbors import KNeighborsClassifier iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم مجموعات البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # KNN Classifier استدعي # القيمة الافتراضية لعدد النقاط المجاورة التي لها حق التصويت هي 5 knn = KNeighborsClassifier(n_neighbors=5) # درب النموذج باستخدام مجموعة بيانات التدريب # في عملية التدريب الخاضع للإشراف يستطيع النموذج أن يستخدم وسم البيانات knn.fit(X_train, y_train) # استخدم النموذج المدرب لتوقع مجموعة بيانات الاختبار print("Response for test dataset:") y_pred = knn.predict(X_test) print(y_pred) استخدمنا دالة knn.fit(X_train, y_train) لتدريب الكائن الذي يُطبق خوارزمية KNN في مكتبة ساي كيت ليرن، ولتدريب النموذج استخدمنا مجموعة خاصيات التدريب X_train والوسوم المقابلة لها y_train، وأثناء تهيئة الكائن عرفنا بعض الإعدادات والمعاملات مثل عدد النقاط المجاورة n_neighbors، وبعد تدريب النموذج استخدمناه لتوقع وسوم خاصيات مجموعة الاختبار X_test. عند تنفيذ الكود سنحصل على الخرج التالي: Response for test dataset: ['Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica'] نلاحظ أن النموذج استطاع التعامل مع القيم النصية لتصنيفات الفصائل بشكل مباشر، وهذا ليس السائد في نماذج تعلم الآلة حيث أغلبها يتوقع فقط قيمًا رقمية حيث أن أغلب الخوارزميات تقوم بعمليات رياضية، ولكن كما ذكرنا من قبل فإن خوارزمية KNN لا معاملية non-parametric ولا تقوم بأي عمليات رياضية معقدة، فقط عملية التصويت في حالة التصنيف. نلاحظ أيضًا أن هذا يعمل فقط مع القيم النصية للوسوم وليس للخاصيات أو الأعمدة الأخرى المستخدمة في التدريب، حيث يحتاج النموذج لحساب المسافة بين نقطة الاستفسار query points وبين جميع النقاط في مجموعة التدريب المخزنة في الذاكرة ليستطيع تقرير أقرب k من النقاط المجاورة مسافةً. اختبار تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN سنكتب تطبيق لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب دقة النموذج لكل قيمة. import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) print("For k = %d accuracy is"%k,knn.score(X_test,y_test)) أنشأنا حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها. عند تنفيذ الكود سنحصل على الخرج التالي: For k = 1 accuracy is 0.9666666666666667 For k = 2 accuracy is 0.9666666666666667 For k = 3 accuracy is 0.9666666666666667 For k = 4 accuracy is 0.9333333333333333 For k = 5 accuracy is 0.9666666666666667 For k = 6 accuracy is 0.9666666666666667 For k = 7 accuracy is 0.9666666666666667 For k = 8 accuracy is 0.9333333333333333 For k = 9 accuracy is 0.9666666666666667 رسم بياني لدراسة تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN لنقسم الآن مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=10) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score = knn.score(X_test,y_test) acc.append(score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], acc) plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.show() أنشانا في الكود السابق حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها، وقد حفظنا دقة النموذج عند كل نقطة k في القائمة acc لنستخدمها في الرسم البياني، ويمكن أن نلاحظ أننا استخدمنا random_state=10 لتثبيت تقسيم البيانات العشوائي وجعل الكود يخرج نفس الرسم البياني في كل مرة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: مقارنة أداء النموذج بين مجموعة بيانات التدريب ومجموعة بيانات الاختبار سنكتب برنامج لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم درب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، وكذلك دقته في توقع وسوم مجموعة التدريب، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k، سنستخدم هذا الرسم البياني للمقارنة بين أداء النموذج على مجموعة التدريب أمام أدائه على مجموعة الاختبار. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=21) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة test_acc = [] train_acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) test_score = knn.score(X_test,y_test) train_score = knn.score(X_train, y_train) test_acc.append(test_score) train_acc.append(train_score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], test_acc, label=get_display(reshape("دقة النموذج على بيانات الاختبار")), color='salmon') plt.plot([k for k in range(1, 10)], train_acc, label=get_display(reshape("دقة النموذج على بيانات التدريب")), color="skyblue") plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.legend() plt.show() يختلف هذا التدريب عن السابق في أنه يحسب الدقة على مجموعة التدريب ومجموعة الاختبار وهي استراتيجية شائعة تستخدم لاختبار مدى قدرة النموذج على التعميم generalization، حيث لا ينبغي أن يكون الفرق المطلق بين أداء النموذج على مجموعة التدريب ومجموعة الاختبار كبيرًا، فأن كان أداء النموذج جيد جدًا في مجموعة التدريب وسيئ للغاية فهذا النموذج ليس قابلًا للاستخدام في العالم الحقيقي على البيانات التي لم يرها من قبل، يمكن تشبيه هذه الحالة بالطالب الذي حفظ أسئلة الاختبار وعند تخرجه ليواجه المشاكل الحقيقية فشل فشلًا ذريعًا لأنه في واقع الأمر حفظ البيانات ولم يتعلم منها وتعرف هذه الحالة بالمسايرة المفرطة أو فرط التخصيص overfitting، وفي الحالة التي يكون أداء النموذج سئيًا على كل من مجموعة بيانات الاختبار والتدريب فتعرف هذه الحالة بقلة التخصيص underfitting وهي بساطة النموذج لدرجة تمنعه من تعلم الأنماط المعقدة الموجودة في مجموعة البيانات. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخاتمة تناولنا في المقال الثالث من سلسلة تطبيقات ساي كيت ليرن مجموعة تدريبات على خوارزمية أقرب الجيران K-Nearest Neighbors واستخدمناها لتصنيف فصائل أزهار آيرس، ودرسنا كيفية تقسيم البيانات لمجموعة تدريب ومجموعة اختبار مع تقييم النموذج وحساب دقة التوقعات،كما تعرفنا على تأثير عدد النقاط المجاورة في هذه الخوارزمية، سنتدرب في المقال القادم على استخدام خوارزمية الانحدار اللوجيستي Logistic Regression وهي أيضًا خوارزمية أساسية من خوازرميات التصنيف Classification وتستخدم في مهام عديدة مثل تشخيص الأمراض وتصنيف رسائل البريد. اقرأ أيضًا المقال السابق: التمثيل المرئي للبيانات باستخدام Scikit-Learn مع Matplotlib و Seaborn تقييم واختيار نماذج تعلم الآلة مصطلحات الذكاء الاصطناعي للمبتدئين بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون واستخدام Scikit-Learn
في هذا المقال من سلسلة تطبيقات عملية على استخدام مكتبة ساي كيت ليرن سنستعرض خطوة بخطوة كيفية تطبيق واحدة من أشهر خوارزميات تعلم الآلة وهي خوارزمية أقرب الجيران k-Nearest Neighbors -أو KNN اختصارًا- لتصنيف الأنواع المختلفة من الأزهار الموجودة ضمن مجموعة بيانات آيرس Iris dataset إحدى أكثر مجموعات البيانات استخدامًا في مجال تعلم الآلة والتي تعرفنا عليها في مقال سابق بعنوان أساسيات تحليل البيانات باستخدام Scikit-Learn. آلية عمل خوارزمية k-Nearest Neighbors يمكننا تعريف خوارزمية أقرب جار K-Nearest Neighbors على أنها خوارزمية لا معاملية non-parametric بمعنى أنها لا تملك أوزان أو معاملات تحاول تحسينها كما تتبع خوارزميات ذكاء اصطناعي أخرى، فهي تستخدم في مهام التصنيف Classification وتوقع الانحدار Regression، وفي كلا الحالتين تعتمد على المعلومات المتاحة لدى أقرب k من النقاط المجاورة لمجموعة بيانات التدريب، وتختلف طريقة حساب المخرجات حسب مهمة التعلم. في حالة التصنيف Classification يكون خرج النموذج أحد التصنيفات المحددة، ونقرره بناءً على تصويت الأغلبية من عدد k نقطة مجاورة لها حق التصويت أي يسمح لها بالمشاركة في اتخاذ القرار بشأن تصنيف نقطة معينة، ويكون هذا العدد المحدد k من النقاط المجاورة عددًا صحيحًا موجبًا ويفضل أن يكون فرديًا لمنع أي حالات تعادل في التصويت. من المهم اختيار قيمة k مناسبة في خوارزمية الجار الأقرب، ويفضل أن تكون قيمة صغيرة نسبيًا، فعندما نحدد عدد النقاط المجاورة k=1 سيتأثر قرار النموذج بالضجيج noise في البيانات والنقاط الخارجة outliers وغير المألوفة بشكل كبير، مما يحدث حالة إفراط في التخصيص Overfitting ويضعف قدرته على التعميم لبيانات جديدة، بينما عندما نحدد عدد النقاط المجاورة برقم كبير n يساوي عدد العينات بمجموعة بيانات التدريب سيصبح النموذج أبسط من اللازم وتحدث لديه حالة إفراط في التبسيط Underfitting بالتالي لن يكون قادر على التعبير عن العلاقات المعقدة الموجودة في البيانات وسيأخذ قرارات اعتمادًا على نقاط بعيدة جدًا ولا تؤثر على نقطة الاستفسار الحالية. في حالة توقع الانحدار Regression يكون خرج النموذج عدد مستمر ناتج عن أخذ متوسط القيم من عدد محدد k من النقاط المجاورة لتقرير قيمة نقطة الاستفسار الحالية. تعرض الصورة السابقة مثالًا على خوارزمية KNN لمهمة التصنيف، وتمثل النقطة الخضراء نقطة الاستفسار الحالية query point والتي نريد تصنيفها إما لصنف المربعات الزرقاء أو المثلثات الحمراء، فإذا قررنا أن عدد النقاط المجاورة k=3 تصبح النقاط الداخلة في القرار هي النقاط المحاطة بالدائرة المتصلة، وكما نرى فالأغلبية في هذا النطاق للمثلثات الحمراء 2 بينما الأقلية هي المربعات الزرقاء 1، بالتالي يمكننا تصنيف نقطة الاستفسار query point بأنها مثلث أحمر، بينما عند زيادة k لتصبح 5 ننظر للنقاط المحاطة بالدائرة المنقطة فنجد أن الأغلبية صارت للمربعات الزرقاء 3 مقابل 2 من المثلثات الحمراء، بالتالي يصبح التصنيف لنقطة الاستفسار مربع أزرق. بعد أن تعرفنا على آلية عمل الخوارزمية، لنستعرض مجموعة من التدريبات العملية التي تساعدنا على فهم كيفية استخدام هذه الخوارزمية بشكل فعّال باستخدام مكتبة scikit-learn. فصل مجموعة البيانات من أولى خطوات التحضير لبناء أي نموذج تعلم آلة هي فصل الخصائص Features وهي البيانات التي نستخدمها لتوقع شيء ما عن الوسوم Labels وهي القيم التي نحاول التنبؤ بها، لنكتب برنامج بايثون لتقسيم مجموعة بيانات أزهار آيرس إلى خصائصها كطول و عرض بتلة الزهرة وسبلتها والتي سنخزنها في متغير X ، والوسوم التي سنخزنها في متغير Y. سيحتوي المتغير X أول أربعة أعمدة بينما يحتوي المتغير Y وسم كل زهرة بفصيلتها مثل Setosa أو Versicolor أو Virginica. import pandas as pd iris = pd.read_csv("iris.csv") # Idاحذف عمود iris = iris.drop('Id',axis=1) # iloc : تسمح باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values print("الخصائص:") print(X) print("\nالوسوم:") print(y) كما نلاحظ فقد حذفنا في هذه الخطوة عمود المعرف Id من مجموعة البيانات، كونه لا يحمل أي معنى يتعلق بخصائص الأزهار، واستخدامه قد يؤدي لنموذج متحيز وغير دقيق. واستخدمنا التابع iloc لتحديد الخصائص X، والوسوم Y وأخيرًا، طبعنا كلًا من X و Y للتأكد من صحة التقسيم. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] ... [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] تقسيم مجموعة البيانات لمجموعة تدريب ومجموعة اختبار نحتاج لتقسيم البيانات إلى بيانات تدريب training وبيانات اختبار testing حتى نتمكن من معرفة فيما إذا كان النموذج يعمل جيدًا على بيانات جديدة لم يرها من قبل، سنكتب كود لتقسيم مجموعة بيانات آيرس إلى مجموعة تدريب تحتوي 80% من البيانات ومجموعة اختبار تحتوي 20%، بحيث يكون عدد العينات المستخدمة في التدريب هو 120 عينة والمستخدمة في الاختبار 30 عينة، ونطبع كلا المجموعتين. import pandas as pd from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") # Id احذف العمود iris = iris.drop('Id',axis=1) # iloc : تسمح لنا باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسم هذه الدالة مجموعة البيانات عشوائيًا وفقًا للنسب المحددة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n70% train data:") print(X_train) print(y_train) print("\n30% test data:") print(X_test) print(y_test) فصلنا في البداية مجموعة البيانات إلى خاصيات X ووسوم Y كما في فعلنا في التطبيق السابق، ثم استدعينا الدالة train_test_split التي تقسم خاصيات ووسوم المجموعة إلى مجموعة تدريب ومجموعة اختبار، وحددنا نسبة التقسيم باستخدام test_size=0.20 لجعل 20% من مجموعة البيانات مخصصة للاختبار، بينما 80% منها للتدريب، سيجري تقسيم البيانات عشوائيًا في كل مرة نشغل بها الكود. عند تنفيذ الكود السابق سنحصل على خرج مشابه لما يلي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [4.8 3. 1.4 0.1] [6. 2.7 5.1 1.6] [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] ترقيم الفصائل النصية الأن سنعمل على تطبيق يحوّل فصائل الأزهار في مجموعة بيانات آيرس من أسماء نصية إلى قيم رقمية، ولنفعل ذلك سنحتاج لتحويل كل قيمة إلى رقم ثابت لهذه القيمة، فمثلًا نجعل Iris-setosa:0 و Iris-versicolor:1 و Iris-virginica:2، ثم نطبع مجموعة بيانات التدريب ومجموعة بيانات الاختبار. import pandas as pd from sklearn.model_selection import train_test_split # LabelEncoder استدعي # والذي سوف نستخدمه لتحويل الفصائل من قيم نصية إلى أرقام ثابته لكل فصيلة from sklearn.preprocessing import LabelEncoder iris = pd.read_csv("iris.csv") # labelEncoder نهيئ الصنف البرمجي le = LabelEncoder() # labelEncoder نستخدم الصنف البرمجي # لتحويل التصنيفات النصية إلى أرقم iris.Species = le.fit_transform(iris.Species) # Id نحذف العمود # حيث لا يحتوي معلومات مهمة للتعلم iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # نقسم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار # كل منهما له خصائص ووسوم منفصلة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n80% train data:") print(X_train) print(y_train) print("\n20% test data:") print(X_test) print(y_test) استخدمناLabelEncoder() لنهيئ الكائن le والذي سنستخدمه لتحويل الفصائل النصية categorical classes لأرقام، حيث نرمز لكل صنف أو اسم برقم ثابت لهذا الصنف، ونستدعي هذا الكائن ليطبّق على البيانات باستخدام le.fit_transform(iris.Species) حيث تتعرف هذه الدالة في البداية على الأصناف في عمود Species وتحدد القيم التي ستعطى لكل فصيل category وتسمى هذه العملية fit ويمكن تنفيذها بشكل مستقل، ومن ثم يتم تحويل القيم النصية القديمة إلى الأرقام المقابلة عند تنفيذ عملية transform التي يمكن فصلها لكي تنفّذ بعد عملية fit على أكثر من مجموعة من البيانات التي تتضمن نفس الفصائل، ولكن في كثير من الأحيان نستخدم الدالة التي تدمج الخطوتين معًا. عند تنفيذ الكود سنحصل على الخرج التالي: الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] 80% train data: [[7.7 2.8 6.7 2. ] [6.7 3.1 5.6 2.4] [5.7 2.6 3.5 1. ] [6.3 2.8 5.1 1.5] [4.9 3.1 1.5 0.1] … [4.8 3. 1.4 0.3] [6.4 2.9 4.3 1.3] [4.8 3. 1.4 0.1] [5.5 2.6 4.4 1.2] [6.3 2.3 4.4 1.3]] [2 2 1 2 0 0 0 2 2 2 2 2 0 0 2 2 1 2 1 0 1 2 0 1 2 0 1 2 2 0 1 1 1 2 0 1 0 1 0 2 2 2 0 2 1 1 0 2 1 2 1 0 0 1 1 2 0 0 2 1 1 2 0 1 1 0 0 2 0 0 1 1 2 1 0 1 2 2 0 1 0 0 2 0 0 2 0 1 1 2 2 0 0 1 2 0 1 1 1 0 0 1 0 2 2 0 0 0 2 2 0 2 2 0 2 0 1 0 1 1] 20% test data: [[6.8 3.2 5.9 2.3] [5.4 3. 4.5 1.5] [4.3 3. 1.1 0.1] [5.6 3. 4.1 1.3] [6.7 3. 5. 1.7] … [5.8 2.7 3.9 1.2] [6.3 2.5 5. 1.9] [6.3 3.3 4.7 1.6] [5.1 3.7 1.5 0.4] [6.9 3.2 5.7 2.3]] [2 1 0 1 1 0 2 2 2 1 0 2 1 1 1 1 1 2 1 1 1 0 2 0 0 1 2 1 0 2] بناء نموذج K-Nearest Neighbors باستخدام ساي كيت ليرن Scikit-Learn لنكتب كود برمجي لجعل نسبة تقسيم مجموعات البيانات 70% لمجموعة التدريب و30% لمجموعة الاختبار، حيث يصبح عدد العينات المستخدمة في التدريب 105 عينة وعدد عينات الاختبار 45، ثم نتوقع باستخدام نموذج KNN تصنيفات الفصائل لمجموعة الاختبار مع تحديد عدد النقاط المجاورة ليكون 5. import pandas as pd from sklearn.model_selection import train_test_split # نستدعي المُصنف من مكتبة ساي كيت ليرن from sklearn.neighbors import KNeighborsClassifier iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم مجموعات البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # KNN Classifier استدعي # القيمة الافتراضية لعدد النقاط المجاورة التي لها حق التصويت هي 5 knn = KNeighborsClassifier(n_neighbors=5) # درب النموذج باستخدام مجموعة بيانات التدريب # في عملية التدريب الخاضع للإشراف يستطيع النموذج أن يستخدم وسم البيانات knn.fit(X_train, y_train) # استخدم النموذج المدرب لتوقع مجموعة بيانات الاختبار print("Response for test dataset:") y_pred = knn.predict(X_test) print(y_pred) استخدمنا دالة knn.fit(X_train, y_train) لتدريب الكائن الذي يُطبق خوارزمية KNN في مكتبة ساي كيت ليرن، ولتدريب النموذج استخدمنا مجموعة خاصيات التدريب X_train والوسوم المقابلة لها y_train، وأثناء تهيئة الكائن عرفنا بعض الإعدادات والمعاملات مثل عدد النقاط المجاورة n_neighbors، وبعد تدريب النموذج استخدمناه لتوقع وسوم خاصيات مجموعة الاختبار X_test. عند تنفيذ الكود سنحصل على الخرج التالي: Response for test dataset: ['Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica'] نلاحظ أن النموذج استطاع التعامل مع القيم النصية لتصنيفات الفصائل بشكل مباشر، وهذا ليس السائد في نماذج تعلم الآلة حيث أغلبها يتوقع فقط قيمًا رقمية حيث أن أغلب الخوارزميات تقوم بعمليات رياضية، ولكن كما ذكرنا من قبل فإن خوارزمية KNN لا معاملية non-parametric ولا تقوم بأي عمليات رياضية معقدة، فقط عملية التصويت في حالة التصنيف. نلاحظ أيضًا أن هذا يعمل فقط مع القيم النصية للوسوم وليس للخاصيات أو الأعمدة الأخرى المستخدمة في التدريب، حيث يحتاج النموذج لحساب المسافة بين نقطة الاستفسار query points وبين جميع النقاط في مجموعة التدريب المخزنة في الذاكرة ليستطيع تقرير أقرب k من النقاط المجاورة مسافةً. اختبار تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN سنكتب تطبيق لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب دقة النموذج لكل قيمة. import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) print("For k = %d accuracy is"%k,knn.score(X_test,y_test)) أنشأنا حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها. عند تنفيذ الكود سنحصل على الخرج التالي: For k = 1 accuracy is 0.9666666666666667 For k = 2 accuracy is 0.9666666666666667 For k = 3 accuracy is 0.9666666666666667 For k = 4 accuracy is 0.9333333333333333 For k = 5 accuracy is 0.9666666666666667 For k = 6 accuracy is 0.9666666666666667 For k = 7 accuracy is 0.9666666666666667 For k = 8 accuracy is 0.9333333333333333 For k = 9 accuracy is 0.9666666666666667 رسم بياني لدراسة تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN لنقسم الآن مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=10) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score = knn.score(X_test,y_test) acc.append(score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], acc) plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.show() أنشانا في الكود السابق حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها، وقد حفظنا دقة النموذج عند كل نقطة k في القائمة acc لنستخدمها في الرسم البياني، ويمكن أن نلاحظ أننا استخدمنا random_state=10 لتثبيت تقسيم البيانات العشوائي وجعل الكود يخرج نفس الرسم البياني في كل مرة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: مقارنة أداء النموذج بين مجموعة بيانات التدريب ومجموعة بيانات الاختبار سنكتب برنامج لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم درب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، وكذلك دقته في توقع وسوم مجموعة التدريب، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k، سنستخدم هذا الرسم البياني للمقارنة بين أداء النموذج على مجموعة التدريب أمام أدائه على مجموعة الاختبار. import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=21) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة test_acc = [] train_acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) test_score = knn.score(X_test,y_test) train_score = knn.score(X_train, y_train) test_acc.append(test_score) train_acc.append(train_score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], test_acc, label=get_display(reshape("دقة النموذج على بيانات الاختبار")), color='salmon') plt.plot([k for k in range(1, 10)], train_acc, label=get_display(reshape("دقة النموذج على بيانات التدريب")), color="skyblue") plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.legend() plt.show() يختلف هذا التدريب عن السابق في أنه يحسب الدقة على مجموعة التدريب ومجموعة الاختبار وهي استراتيجية شائعة تستخدم لاختبار مدى قدرة النموذج على التعميم generalization، حيث لا ينبغي أن يكون الفرق المطلق بين أداء النموذج على مجموعة التدريب ومجموعة الاختبار كبيرًا، فأن كان أداء النموذج جيد جدًا في مجموعة التدريب وسيئ للغاية فهذا النموذج ليس قابلًا للاستخدام في العالم الحقيقي على البيانات التي لم يرها من قبل، يمكن تشبيه هذه الحالة بالطالب الذي حفظ أسئلة الاختبار وعند تخرجه ليواجه المشاكل الحقيقية فشل فشلًا ذريعًا لأنه في واقع الأمر حفظ البيانات ولم يتعلم منها وتعرف هذه الحالة بالمسايرة المفرطة أو فرط التخصيص overfitting، وفي الحالة التي يكون أداء النموذج سئيًا على كل من مجموعة بيانات الاختبار والتدريب فتعرف هذه الحالة بقلة التخصيص underfitting وهي بساطة النموذج لدرجة تمنعه من تعلم الأنماط المعقدة الموجودة في مجموعة البيانات. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخاتمة تناولنا في المقال الثالث من سلسلة تطبيقات ساي كيت ليرن مجموعة تدريبات على خوارزمية أقرب الجيران K-Nearest Neighbors واستخدمناها لتصنيف فصائل أزهار آيرس، ودرسنا كيفية تقسيم البيانات لمجموعة تدريب ومجموعة اختبار مع تقييم النموذج وحساب دقة التوقعات،كما تعرفنا على تأثير عدد النقاط المجاورة في هذه الخوارزمية، سنتدرب في المقال القادم على استخدام خوارزمية الانحدار اللوجيستي Logistic Regression وهي أيضًا خوارزمية أساسية من خوازرميات التصنيف Classification وتستخدم في مهام عديدة مثل تشخيص الأمراض وتصنيف رسائل البريد. اقرأ أيضًا المقال السابق: التمثيل المرئي للبيانات باستخدام Scikit-Learn مع Matplotlib و Seaborn تقييم واختيار نماذج تعلم الآلة مصطلحات الذكاء الاصطناعي للمبتدئين بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون واستخدام Scikit-Learn -
 نشرح في هذا المقال التمثيل المرئي لمجموعة بيانات أزهار آيرس Iris dataset باستخدام مكتبة Scikit-Learn ومجموعة من المكتبات المفيدة الأخرى بهدف ملاحظة الأنماط وفهم العلاقات بين الخاصيات المختلفة لمجموعة بيانات الأزهار من خلال عرضها على شكل رسومات بيانية. أهمية التمثيل المرئي للبيانات Data Visualization سنوفر عدة تطبيقات عملية توضح مجموعة مهمة من أنواع الرسومات البيانية plots والتي لا غنى عنها في أي عملية تحليل للبيانات أو التمثيل المرئي للبيانات والنتائج التي تسهل فهم العلاقات واكتشاف الأنماط وعرض نتائج التحليل الإحصائي وتقييم أداء نماذج تعلم الآلة، ليس فقط للمختصين في البرمجة بل للعامة، فالجميع يمكن أن يفهم الرسومات البيانية والتوضيحية التي تسرع من توصيل المعلومات. تمثيل مرئي عام للمعلومات الإحصائية سنكتب برنامج بايثون لإنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('Statistics',) plt.ylabel('Value') plt.title("General Statistics of Iris Dataset") plt.show() استوردنا في الكود السابق المكتبة pandas وهي مكتبة بايثون مفيدة لمعالجة البيانات وتحليلها، ومكتبة matplotlib والتي تتخصص في رسم الرسومات البيانية بمختلف أنواعها، وحمّلنا مجموعة البيانات في الكائن iris، ثم استخدمنا الدالةdescribe() الذي تطرقنا له في الدرس السابق لعرض الإحصائيات الهامة عن مجموعة البيانات، بعدها استدعيناplot() ومررنا له إعدادات الرسم مثل نوع الرسم البياني kind=area، وحجم الخط والألوان المستخدمة وأبعاد الرسم البياني وغيرها من الإعدادت، وأخيرًا عرضنا الرسم البياني باستخدام plt.show(). عند تنفيذ الكود السابق سنحصل على الرسم البياني التالي: رسم بياني شريطي Bar Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني شريطي لرسم توزيع ثلاث فصائل من الأزهار وبيان تكرار ها في مجموعة البيانات. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") ax=plt.subplots(1,1,figsize=(10,8)) sns.countplot(data=iris) plt.title("Iris Species Count") plt.show() أنشأنا باستخدام الدالةplt.subplots() شكلًا بيانيًا يمكنه احتواء عدد من الرسومات البيانية الجزئية، ومررنا للدالة عدد الصفوف والأعمدة التي نرغب أن يتكون منها الشكل البياني وهي في حالتنا صف واحد وعمود واحد، أي سيحتوي الشكل البياني على رسم بياني جزئي واحد فقط، ثم ضبطنا أبعاد الرسم البياني، بعدها استخدمنا الدالةsns.countplot() لإنشاء رسم شريطي Bar plot وهذه الدالة جزء من مكتبة seaborn التي تستخدم في الخلفية مكتبة matplotlib ولكنها تختصر العديد من الخطوات وتبسّطها حيث يمكن أن ننشئ العديد من الرسومات البيانية المعقدة بسطر برمجي واحد دون الدخول في تفاصيل معقدة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني دائري Pie Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني دائري يوضح توزيع فصائل الأزهار وتكرارها في مجموعة البيانات. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # ضبط أبعاد الرسم البياني plt.figure(figsize=(10,8)) labels = iris['Species'].value_counts().index # وسم كل شريحة # Index(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='object', name='Species') values = iris['Species'].value_counts().values # تكرار كل فصيلة والتي يحسب منها نسبة كل شريحة # array([50, 50, 50], dtype=int64) plt.pie(x=values, labels=labels, autopct='%1.1f%%', shadow=True, explode=[0.1, 0.1, 0.1]) plt.title("Iris Species %") plt.show() استخدمنا هنا الدالةplt.pie() لإنشاء الرسم البياني المطلوب ومررنا لها قائمة x=values تتضمن العدد في كل شريحة في الرسم البياني وقائمة أخرى labels=labels تتضمن وسم كل شريحة، وقد حصلنا على القيم ووسومها باستخدام iris['Species'].value_counts() فباستخدام التابع index نحصل على القيم الفهرسية أو المفتاحية وهي أسماء فصائل الأزهار وباستخدام التابع values نحصل على عدد كل فصيلة، بينما تحدد باقي العوامل بعض التأثيرات الجمالية مثل طريقة عرض الأرقام في الرسم البياني وإضافة ظل على الرسم، بينما القائمة الممررة للمعامل explode يعبر كل عنصر بها عن مقدار ابتعاد الشريحة عن المركز حيث تجعل القيمة 0.1 كل شريحة تبتعد عن المركز بمسافة قدرها 10% من طول نصف القطر ويمكنكم تجربة تغير هذه القيم وملاحظة التأثير الناتج. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للنقاط المبعثرة Scatter plot لسبلات الأزهار سنرسم في هذا التطبيق رسم نقطي مبعثر يوضح العلاقة بين أبعاد السبلات أي بين طولها وعرضها. import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(10,8)) # Plotting sns.scatterplot(data=iris, x="SepalLengthCm", y="SepalWidthCm", hue="Species") # Titles plt.xlabel("Sepal Length") plt.ylabel("Sepal Width") plt.title("Sepal Length VS Width") plt.show() استخدمنا الدالةsns.scatterplot() لإنشاء رسم بياني للنقاط المبعثرة بين طول السبلة SepalLengthCm وعرض السبلة SepalWidthCm مع تلوين الفصائل المختلفة للأزهار وفقًا لتصنيفها باستخدام المعامل hue وضبطنا قيمته ليلون النقاط المبعثرة اعتمادًا على الوسوم Species، ثم استخدمنا مكتبة matplotlib لضبط إعدادات الرسم والعناوين. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للمدرّج التكراري Histogram Plot سننشئ تطبيق يعرض رسم بياني من نوع Histogram ويوضح التوزيع لأبعاد كل من البتلات Petals والسبلات Sepals. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # Drop id column new_data = iris.drop('Id',axis=1) new_data.hist(edgecolor='black', linewidth=1.2) # gcf() -> get current figure fig=plt.gcf() fig.set_size_inches(12,12) plt.show() استخدمنا التابع new_data.hist لإنشاء رسم بياني للمدرّج التكراري، حيث يوضح هذا النوع تكرار القيم في كل متغير، وضبطنا لون الحواف لكل شريط في الرسم البياني ليكون باللون الأسود باستخدام edgecolor، وعرض الحواف باستخدام linewidth، واستخدامنا الدالة plt.gcf للحصول على الشكل البياني الحالي وتخزينه في الكائن fig حتى نتمكن من تعديله بحريّة. مثلًا يمكننا إعادة ضبط أبعاد الشكل البياني باستخدام الدالة fig.set_size_inches(12,12) وهي دالة تابعة للكائن fig، ثم عرضنا الرسم البياني على النحو التالي: رسم بياني مشترك Join Plot سنكتب برنامج لإنشاء رسم بياني مشترك يصف توزيع كل متغير من متغيرات الأزهار بشكل منفرد ثم بشكل مشترك في نفس الرسمة البيانية. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue') plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: ويمكننا إظهار مزيد من المعلومات باستخدام خاصية hue والتي تعطى لونًا مختلفًا لكل تصنيف. fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue', hue="Species") عند تنفيذ الكود سنحصل على الرسم البياني التالي: شبكة رسومات بيانية لأزواج من المتغيرات سنكتب برنامج بايثون لإنشاء رسم بياني يوضح العلاقة بين أزواج مختلفة من المتغيرات pairplot، وتحديد أي الفصائل يسهل تميزها عن الأخرى وفصلها. # Import necessary modules import pandas as pd import seaborn as sns iris = pd.read_csv("iris.csv") #Drop id column iris = iris.drop('Id',axis=1) sns.pairplot(iris,hue='Species') تسمح لنا الدالةsns.pairplot() برسم العلاقة بين كل المتغيرات في مجموعة البيانات، حيث تقارن كل زوج من المتغيرات برسم بياني لتشكل مصفوفة متكاملة، يمكنك من خلالها ملاحظة العلاقة بين أي زوج من المتغيرات أو الخاصيات في مجموعة البيانات، ونمرر لهذه الدالة بشكل أساسي مجموعة البيانات iris وهذا كافٍ للحصول على نتيجة ولكن يمكننا إضافة المزيد من الألوان والأبعاد في مصفوفة الرسومات البيانية باستخدام معامل hue الذي يميز بين كل تصنيف في مجموعة البيانات بلون مميز في الرسم البياني، مما يسهّل علينا اكتشاف الأنماط المتعلقة بتصنيف محدد، حيث سنلاحظ أن أغلب النقاط التي تنتمي لتصنيف واحد أي لصنف واحد من الأزهار ستتجمع حول بعضها في بعض الأماكن في الرسم البياني. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخريطة الحرارية Heat map سنكتب برنامج بايثون لإيجاد الترابط Correlation بين المتغيرات في مجموعة بيانات آيرس، باستخدام خريطة حرارية Heatmap. نوجد أولاً مصفوفة الترابط Correlation Matrix import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") corr_matrix = iris.drop(columns=["Id", "Species"]).corr() print(corr_matrix) عند تنفيذ الكود سنحصل على الخرج التالي: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm SepalLengthCm 1.000000 -0.109369 0.871754 0.817954 SepalWidthCm -0.109369 1.000000 -0.420516 -0.356544 PetalLengthCm 0.871754 -0.420516 1.000000 0.962757 PetalWidthCm 0.817954 -0.356544 0.962757 1.000000 بعدها، نرسم الخريطة الحرارية Heat Map المعبرة عن مصفوفة الترابط Correlation Matrix sns.heatmap(corr_matrix, annot=True, cmap="Blues") plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: الرسومات البيانية باللغة العربية إذا حاولنا إنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس، كما فعلنا في التطبيق الأول مع جعل العناوين باللغة العربية، سنلاحظ أن مكتبة Matplotlib لا توفر دعمًا جيدًا للغة العربية وتعرض الأحرف مبعثرة، وكذلك ستظهر كل كلمة معكوسة الاتجاه من اليسار إلى اليمين. لنلاحظ نتيجة تنفيذ الكود التالي عند محاولة عرض العناوين العربية قبل استخدام المكتبات الخارجية: iris.describe().plot(kind = "area",fontsize=15, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('الاحصائيات',) plt.ylabel('القيمة') plt.title("معلومات احصائية عامة لمجموعة بيانات آيرس") plt.show() لتصحيح هذا الخطأ سنستخدم مكتبتين خارجيتين: مكتبة arabic_reshaper لحل مشكلة عدم اتصال الحروف ببعضها مكتبة python-bidi لحل مشكلة اتجاه الحروف المعكوس والسماح بدمج مناسب لنصوص عربية مع نصوص أجنبية نستخدم الأوامر التالية لتثبيت المكتبات: pip install arabic-reshaper pip install python-bidi الآن إذا حاولنا عرض العناوين العربية بعد استخدام المكتبات الخارجية كما يلي: import pandas as pd import matplotlib.pyplot as plt from bidi.algorithm import get_display import arabic_reshaper def arabic(txt): return get_display(arabic_reshaper.reshape(txt)) iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel(arabic('الاحصائيات')) plt.ylabel(arabic('القيمة')) plt.title(arabic("معلومات احصائية عامة لمجموعة بيانات آيرس")) plt.show() الخاتمة تعرفنا في هذا المقال على كيفية تمثيل البيانات بشكل مرئي من خلال أمثلة عملية متنوعة بمكتبة Scikit-Learn والمكتبات المساعدة، وقد اكتفينا بعرض بعض أنواع فقط ونترك لكم استكشاف أنواع الرسومات المختلفة الأخرى والاستفادة منها في تمثيل البيانات وملاحظة الأنماط والعلاقات الموجودة بينها بسرعة وسهولة. ترجمة -وبتصرف- للجزء الثاني من مقال Python: Machine learning - Scikit-learn Exercises, Practice, Solution اقرأ أيضًا المقال السابق: أساسيات تحليل البيانات باستخدام Scikit-Learn مع Pandas تعرف على مكتبة Scikit learn وأهم خوارزمياتها الدليل الشامل إلى تحليل البيانات Data Analysis بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn أفضل أدوات الذكاء الاصطناعي وتعلم الآلة للمطورين المبتدئين
نشرح في هذا المقال التمثيل المرئي لمجموعة بيانات أزهار آيرس Iris dataset باستخدام مكتبة Scikit-Learn ومجموعة من المكتبات المفيدة الأخرى بهدف ملاحظة الأنماط وفهم العلاقات بين الخاصيات المختلفة لمجموعة بيانات الأزهار من خلال عرضها على شكل رسومات بيانية. أهمية التمثيل المرئي للبيانات Data Visualization سنوفر عدة تطبيقات عملية توضح مجموعة مهمة من أنواع الرسومات البيانية plots والتي لا غنى عنها في أي عملية تحليل للبيانات أو التمثيل المرئي للبيانات والنتائج التي تسهل فهم العلاقات واكتشاف الأنماط وعرض نتائج التحليل الإحصائي وتقييم أداء نماذج تعلم الآلة، ليس فقط للمختصين في البرمجة بل للعامة، فالجميع يمكن أن يفهم الرسومات البيانية والتوضيحية التي تسرع من توصيل المعلومات. تمثيل مرئي عام للمعلومات الإحصائية سنكتب برنامج بايثون لإنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('Statistics',) plt.ylabel('Value') plt.title("General Statistics of Iris Dataset") plt.show() استوردنا في الكود السابق المكتبة pandas وهي مكتبة بايثون مفيدة لمعالجة البيانات وتحليلها، ومكتبة matplotlib والتي تتخصص في رسم الرسومات البيانية بمختلف أنواعها، وحمّلنا مجموعة البيانات في الكائن iris، ثم استخدمنا الدالةdescribe() الذي تطرقنا له في الدرس السابق لعرض الإحصائيات الهامة عن مجموعة البيانات، بعدها استدعيناplot() ومررنا له إعدادات الرسم مثل نوع الرسم البياني kind=area، وحجم الخط والألوان المستخدمة وأبعاد الرسم البياني وغيرها من الإعدادت، وأخيرًا عرضنا الرسم البياني باستخدام plt.show(). عند تنفيذ الكود السابق سنحصل على الرسم البياني التالي: رسم بياني شريطي Bar Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني شريطي لرسم توزيع ثلاث فصائل من الأزهار وبيان تكرار ها في مجموعة البيانات. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") ax=plt.subplots(1,1,figsize=(10,8)) sns.countplot(data=iris) plt.title("Iris Species Count") plt.show() أنشأنا باستخدام الدالةplt.subplots() شكلًا بيانيًا يمكنه احتواء عدد من الرسومات البيانية الجزئية، ومررنا للدالة عدد الصفوف والأعمدة التي نرغب أن يتكون منها الشكل البياني وهي في حالتنا صف واحد وعمود واحد، أي سيحتوي الشكل البياني على رسم بياني جزئي واحد فقط، ثم ضبطنا أبعاد الرسم البياني، بعدها استخدمنا الدالةsns.countplot() لإنشاء رسم شريطي Bar plot وهذه الدالة جزء من مكتبة seaborn التي تستخدم في الخلفية مكتبة matplotlib ولكنها تختصر العديد من الخطوات وتبسّطها حيث يمكن أن ننشئ العديد من الرسومات البيانية المعقدة بسطر برمجي واحد دون الدخول في تفاصيل معقدة. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني دائري Pie Plot سنكتب الآن برنامج بايثون لإنشاء رسم بياني دائري يوضح توزيع فصائل الأزهار وتكرارها في مجموعة البيانات. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # ضبط أبعاد الرسم البياني plt.figure(figsize=(10,8)) labels = iris['Species'].value_counts().index # وسم كل شريحة # Index(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='object', name='Species') values = iris['Species'].value_counts().values # تكرار كل فصيلة والتي يحسب منها نسبة كل شريحة # array([50, 50, 50], dtype=int64) plt.pie(x=values, labels=labels, autopct='%1.1f%%', shadow=True, explode=[0.1, 0.1, 0.1]) plt.title("Iris Species %") plt.show() استخدمنا هنا الدالةplt.pie() لإنشاء الرسم البياني المطلوب ومررنا لها قائمة x=values تتضمن العدد في كل شريحة في الرسم البياني وقائمة أخرى labels=labels تتضمن وسم كل شريحة، وقد حصلنا على القيم ووسومها باستخدام iris['Species'].value_counts() فباستخدام التابع index نحصل على القيم الفهرسية أو المفتاحية وهي أسماء فصائل الأزهار وباستخدام التابع values نحصل على عدد كل فصيلة، بينما تحدد باقي العوامل بعض التأثيرات الجمالية مثل طريقة عرض الأرقام في الرسم البياني وإضافة ظل على الرسم، بينما القائمة الممررة للمعامل explode يعبر كل عنصر بها عن مقدار ابتعاد الشريحة عن المركز حيث تجعل القيمة 0.1 كل شريحة تبتعد عن المركز بمسافة قدرها 10% من طول نصف القطر ويمكنكم تجربة تغير هذه القيم وملاحظة التأثير الناتج. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للنقاط المبعثرة Scatter plot لسبلات الأزهار سنرسم في هذا التطبيق رسم نقطي مبعثر يوضح العلاقة بين أبعاد السبلات أي بين طولها وعرضها. import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(10,8)) # Plotting sns.scatterplot(data=iris, x="SepalLengthCm", y="SepalWidthCm", hue="Species") # Titles plt.xlabel("Sepal Length") plt.ylabel("Sepal Width") plt.title("Sepal Length VS Width") plt.show() استخدمنا الدالةsns.scatterplot() لإنشاء رسم بياني للنقاط المبعثرة بين طول السبلة SepalLengthCm وعرض السبلة SepalWidthCm مع تلوين الفصائل المختلفة للأزهار وفقًا لتصنيفها باستخدام المعامل hue وضبطنا قيمته ليلون النقاط المبعثرة اعتمادًا على الوسوم Species، ثم استخدمنا مكتبة matplotlib لضبط إعدادات الرسم والعناوين. عند تنفيذ الكود سنحصل على الرسم البياني التالي: رسم بياني للمدرّج التكراري Histogram Plot سننشئ تطبيق يعرض رسم بياني من نوع Histogram ويوضح التوزيع لأبعاد كل من البتلات Petals والسبلات Sepals. import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # Drop id column new_data = iris.drop('Id',axis=1) new_data.hist(edgecolor='black', linewidth=1.2) # gcf() -> get current figure fig=plt.gcf() fig.set_size_inches(12,12) plt.show() استخدمنا التابع new_data.hist لإنشاء رسم بياني للمدرّج التكراري، حيث يوضح هذا النوع تكرار القيم في كل متغير، وضبطنا لون الحواف لكل شريط في الرسم البياني ليكون باللون الأسود باستخدام edgecolor، وعرض الحواف باستخدام linewidth، واستخدامنا الدالة plt.gcf للحصول على الشكل البياني الحالي وتخزينه في الكائن fig حتى نتمكن من تعديله بحريّة. مثلًا يمكننا إعادة ضبط أبعاد الشكل البياني باستخدام الدالة fig.set_size_inches(12,12) وهي دالة تابعة للكائن fig، ثم عرضنا الرسم البياني على النحو التالي: رسم بياني مشترك Join Plot سنكتب برنامج لإنشاء رسم بياني مشترك يصف توزيع كل متغير من متغيرات الأزهار بشكل منفرد ثم بشكل مشترك في نفس الرسمة البيانية. import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue') plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: ويمكننا إظهار مزيد من المعلومات باستخدام خاصية hue والتي تعطى لونًا مختلفًا لكل تصنيف. fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue', hue="Species") عند تنفيذ الكود سنحصل على الرسم البياني التالي: شبكة رسومات بيانية لأزواج من المتغيرات سنكتب برنامج بايثون لإنشاء رسم بياني يوضح العلاقة بين أزواج مختلفة من المتغيرات pairplot، وتحديد أي الفصائل يسهل تميزها عن الأخرى وفصلها. # Import necessary modules import pandas as pd import seaborn as sns iris = pd.read_csv("iris.csv") #Drop id column iris = iris.drop('Id',axis=1) sns.pairplot(iris,hue='Species') تسمح لنا الدالةsns.pairplot() برسم العلاقة بين كل المتغيرات في مجموعة البيانات، حيث تقارن كل زوج من المتغيرات برسم بياني لتشكل مصفوفة متكاملة، يمكنك من خلالها ملاحظة العلاقة بين أي زوج من المتغيرات أو الخاصيات في مجموعة البيانات، ونمرر لهذه الدالة بشكل أساسي مجموعة البيانات iris وهذا كافٍ للحصول على نتيجة ولكن يمكننا إضافة المزيد من الألوان والأبعاد في مصفوفة الرسومات البيانية باستخدام معامل hue الذي يميز بين كل تصنيف في مجموعة البيانات بلون مميز في الرسم البياني، مما يسهّل علينا اكتشاف الأنماط المتعلقة بتصنيف محدد، حيث سنلاحظ أن أغلب النقاط التي تنتمي لتصنيف واحد أي لصنف واحد من الأزهار ستتجمع حول بعضها في بعض الأماكن في الرسم البياني. عند تنفيذ الكود سنحصل على الرسم البياني التالي: الخريطة الحرارية Heat map سنكتب برنامج بايثون لإيجاد الترابط Correlation بين المتغيرات في مجموعة بيانات آيرس، باستخدام خريطة حرارية Heatmap. نوجد أولاً مصفوفة الترابط Correlation Matrix import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") corr_matrix = iris.drop(columns=["Id", "Species"]).corr() print(corr_matrix) عند تنفيذ الكود سنحصل على الخرج التالي: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm SepalLengthCm 1.000000 -0.109369 0.871754 0.817954 SepalWidthCm -0.109369 1.000000 -0.420516 -0.356544 PetalLengthCm 0.871754 -0.420516 1.000000 0.962757 PetalWidthCm 0.817954 -0.356544 0.962757 1.000000 بعدها، نرسم الخريطة الحرارية Heat Map المعبرة عن مصفوفة الترابط Correlation Matrix sns.heatmap(corr_matrix, annot=True, cmap="Blues") plt.show() عند تنفيذ الكود سنحصل على الرسم البياني التالي: الرسومات البيانية باللغة العربية إذا حاولنا إنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس، كما فعلنا في التطبيق الأول مع جعل العناوين باللغة العربية، سنلاحظ أن مكتبة Matplotlib لا توفر دعمًا جيدًا للغة العربية وتعرض الأحرف مبعثرة، وكذلك ستظهر كل كلمة معكوسة الاتجاه من اليسار إلى اليمين. لنلاحظ نتيجة تنفيذ الكود التالي عند محاولة عرض العناوين العربية قبل استخدام المكتبات الخارجية: iris.describe().plot(kind = "area",fontsize=15, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('الاحصائيات',) plt.ylabel('القيمة') plt.title("معلومات احصائية عامة لمجموعة بيانات آيرس") plt.show() لتصحيح هذا الخطأ سنستخدم مكتبتين خارجيتين: مكتبة arabic_reshaper لحل مشكلة عدم اتصال الحروف ببعضها مكتبة python-bidi لحل مشكلة اتجاه الحروف المعكوس والسماح بدمج مناسب لنصوص عربية مع نصوص أجنبية نستخدم الأوامر التالية لتثبيت المكتبات: pip install arabic-reshaper pip install python-bidi الآن إذا حاولنا عرض العناوين العربية بعد استخدام المكتبات الخارجية كما يلي: import pandas as pd import matplotlib.pyplot as plt from bidi.algorithm import get_display import arabic_reshaper def arabic(txt): return get_display(arabic_reshaper.reshape(txt)) iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel(arabic('الاحصائيات')) plt.ylabel(arabic('القيمة')) plt.title(arabic("معلومات احصائية عامة لمجموعة بيانات آيرس")) plt.show() الخاتمة تعرفنا في هذا المقال على كيفية تمثيل البيانات بشكل مرئي من خلال أمثلة عملية متنوعة بمكتبة Scikit-Learn والمكتبات المساعدة، وقد اكتفينا بعرض بعض أنواع فقط ونترك لكم استكشاف أنواع الرسومات المختلفة الأخرى والاستفادة منها في تمثيل البيانات وملاحظة الأنماط والعلاقات الموجودة بينها بسرعة وسهولة. ترجمة -وبتصرف- للجزء الثاني من مقال Python: Machine learning - Scikit-learn Exercises, Practice, Solution اقرأ أيضًا المقال السابق: أساسيات تحليل البيانات باستخدام Scikit-Learn مع Pandas تعرف على مكتبة Scikit learn وأهم خوارزمياتها الدليل الشامل إلى تحليل البيانات Data Analysis بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn أفضل أدوات الذكاء الاصطناعي وتعلم الآلة للمطورين المبتدئين -
 نتناول في هذه السلسلة مجموعة متنوعة من التطبيقات العملية حول تعلم الآلة Machine Learning باستخدام إطار عمل ساي كيت ليرن Scikit-Learn الذي يوفر حزمة من الأدوات البرمجية مفتوحة المصدر تشمل خوارزميات تعلم الآلة كخوارزميات التصنيف Classification وتوقع الانحدار Regression وخوارزميات العنقدة Clustering، وقد صمم هذا الإطار ليعمل بكفاءة مع العديد من مكتبات بايثون القوية مثل NumPy و SciPy. الهدف من هذه السلسلة إرشاد المبتدئين من خلال مجموعة من التدريبات العملية المكتوبة بلغة بايثون وإطار عمل ساي كيت ليرن Scikit-Learn، فالتطبيق وحل التدريبات واحدة من أفضل طرق التعلم واكتساب المهارات لذا ننصح بمحاولة إيجاد الحل بأنفسكم قبل النظر في الأكواد المرفقة لتحقيق استفادة أفضل. ما هي مجموعة بيانات أزهار آيرس؟ سنستخدم في التطبيقات العملية مجموعة بيانات أزهار آيرس أو السوسن Iris dataset وهي مجموعة بيانات من عدة متغيرات استخدمت بواسطة عالم الإحصاء والأحياء رونالد فيشر في ورقته البحثية لعام 1936، وهي تسمى أيضًا مجموعة بيانات اندرسون نسبة للعالم الذي جمعها ليحلل التغيرات الشكلية بين الفصائل الثلاث لهذه الأزهار. تتكون مجموعة البيانات من 50 عينة لكل فصيلة من الفصائل الثلاثة للأزهار، وهي Iris setosa و Iris virginica و Iris versicolor وقيست أربعة خصائص لكل عينة وهي: طول البتلة Petal length عرض البتلة Petal width طول السبلة Sepal length عرض السبلة Sepal width وباستخدام هذه التوليفة من الخصائص استطاع فيشر تطوير نموذج تميز خطي Linear discrimination قادر على التفريق بين الفصائل وبعضها. تطبيقات أساسية باستخدام مكتبة باندا Pandas سنتعرف على مجموعة من التطبيقات التي تستخدم مكتبة باندا Pandas لتحليل واستكشاف مجموعة البيانات والتي تعد خطوة أساسية في أي مشروع لتعلم الآلة. تحميل مجموعة البيانات إلى إطار البيانات DataFrame سنكتب برنامج بلغة برمجة بايثون لتحميل مجموعة بيانات آيرس من ملف csv إلى البنية pandas التي توفرها مكتبة dataframe ونطبع شكل البيانات ونوعها وأول ثلاثة صفوف منها. import pandas as pd data = pd.read_csv("iris.csv") print("Shape of the data:") print(data.shape) print("\nData Type:") print(type(data)) print("\nFirst 3 rows:") print(data.head(3)) النمط DataFrame هو نمط توفره مكتبة pandas لتنظيم البيانات وتخزينها على هيئة جدول، وقد استوردنا في الكود السابق مكتبة pandas وقرأنا البيانات المطلوبة من الملف iris.csv وخزناها في متغير data من النمط DataFrame، ثم عرضنا عدد الأبعاد -أي عدد الصفوف والأعمدة الموجود في هذا الكائن- باستخدام التابع shape ونوع بياناته باستخدام التابع type وعرضنا أول 3 صفوف من البيانات فقط باستخدام التعليمة data.head(3). عند تنفيذ الكود، نحصل على الخرج التالي: Shape of the data: (150, 6) Data Type: <class 'pandas.core.frame.DataFrame'> First 3 rows: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa استعراض خصائص مجموعات بيانات آيرس الآن، سكتب برنامج بايثون باستخدام ساي كيت ليرن Scikit-Learn لطباعة مفاتيح الأعمدة Keys وعدد الصفوف وعدد الأعمدة وأسماء الخاصيات والوصف لمجموعة بيانات آيرس. import pandas as pd iris_data = pd.read_csv("iris.csv") print("\nKeys of Iris dataset:") print(iris_data.keys()) print("\nNumber of rows and columns of Iris dataset:") print(iris_data.shape) استخدمنا هنا أيضًا بنية DataFrame كما في المثال السابق لتخزين البيانات ضمن متغير باسم iris_data وعرضنا المفاتيح أو أسماء الأعمدة في مجموعة البيانات باستخدام الدالة iris_data.keys() والتي تمثل المتغيرات أو الخصائص المختلفة بيانات الأزهار، وعرضنا أخيرًا عدد الصفوف والأعمدة باستخدام الدالة iris_data.shape. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Keys of Iris dataset: Index(['Id', 'SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species'], dtype='object') Number of rows and columns of Iris dataset: (150, 6) عرض عدد العينات وعدد القيم المفقودة في مجموعة بيانات آيرس فيما يلي كود بايثون لمعرفة عدد العينات في مجموعة بيانات الأزهار، وعدد القيم المفقودة فيها. import pandas as pd iris = pd.read_csv("iris.csv") print(iris.info()) استوردنا مجموعة البيانات بشكل بنية جدول DataFrame وخزناها في متغير باسم iris وطبعنا المعلومات التي نحتاجها باستخدام الدالة iris.info() التي تعرض بعض المعلومات المهمة مثل عدد العينات ونوع العمود الفهرسي Index column وكذلك عدد القيم الفعلية non-null ونوع البيانات لكل عمود، بالإضافة للذاكرة RAM المستهلكة لتخزين البيانات. نحصل على الخرج التالي من تنفيذ الكود أعلاه: <class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 150 non-null int64 1 SepalLengthCm 150 non-null float64 2 SepalWidthCm 150 non-null float64 3 PetalLengthCm 150 non-null float64 4 PetalWidthCm 150 non-null float64 5 Species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB None المصفوفات المتناثرة Dense Matrices والمصفوفات عالية الكثافة Dense Matrices باستخدام NumPy و Scipy سنعمل في هذه الفقرة على إنشاء مصفوفة ثنائية الأبعاد 2D array مليئة بالواحد في كل عناصرها لواقعة على القطر الرئيسي والقيمة الصفر فيما دون ذلك، ثم نحول المصفوفة من نوع NumPy array إلى مصفوفة SciPy sparse matrix أي مصفوفة متناثرة بتنسيق CSR هو أحد تنسيقات مكتبة SciPy لتمثيل المصفوفات. وتعرف المصفوفة المتناثرة بأنها مصفوفة تحتوي في الغالب على أصفار Sparse matrix، وعلى النقيض تمامًا فإن المصفوفة الي يكون غالب عناصرها قيم لا تساوي الصفر تسمى مصفوفة عالية الكثافة Dense matrix، ويعرف معدل التناثر sparsity على أنه عدد العناصر الصفرية مقسومة على إجمالي العناصر بالمصفوفة، ويساوي أيضًا 1 مطروحًا منه معدل الكثافة Density للمصفوفة، وباستخدام هذه التعريفات يمكننا تصنيف مصفوفة بأنها متناثرة sparse إن كان معدل تناثرها Sparsity أكبر من 0.5. تكمن فائدة تحويل المصفوفة من NumPy array إلى صيغة مصفوفة متناثرة الصفوف CSR باستخدام SciPy خطوة مفيدة وفعالة وتسرع الوصول إلى العناصر ذات القيمة الفعلية غير الصفرية داخل المصفوفة، حيث تتيح صيغة CSR تخزين المصفوفة بشكل مضغوط دون الحاجة إلى تخزين الأصفار، مما يقلل من استهلاك الذاكرة ويزيد من كفاءة المعالجة. تبرز أهمية هذا التحويل بشكل خاص عند إجراء عمليات رياضية أو تحليل بيانات على مصفوفات كبيرة، حيث يسهم تجاهل الأصفار في تسريع الحسابات دون التأثير على النتائج. import numpy as np from scipy import sparse eye = np.eye(4) print("NumPy array:\n", eye) sparse_matrix = sparse.csr_matrix(eye) print("\nSciPy sparse CSR matrix:\n", sparse_matrix) بعد أن استوردنا مكتبتي NumPy و SciPy استخدمنا الدالة np.eye() لإنشاء مصفوفة ثنائية الأبعاد تتكون جميع عناصرها من أصفار فيما عدا عناصر القطر الرئيسي للمصفوفة حيث تساوي عناصره الواحد، ومررنا للدالة العدد 4 وهو عدد الصفوف، وثم خزنا الناتج في الكائن eye وطبعنا المصفوفة التي يخزنها الكائن قبل أن تحويلها، واستخدمنا الدالة sparse.csr_matrix(eye) لتحويل المصفوفة للصيغة المضغوطة CSR، وطبعنا الكائن الذي يحتوي المصفوفة الجديدة لنقارن بين الصيغتين. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: NumPy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] SciPy sparse CSR matrix: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0 نلاحظ أن صيغة CSR لا تعرض كل عناصر المصفوفة، بل تُظهر العناصر التي تحتوي على أرقام غير صفرية فقط. وبما أن المصفوفة تحتوي على 1 في كل موقع قطري سنجد تساوي دليل الصف مع دليل العمود. عرض الاحصائيات الأساسية عن مجموعة بيانات آيرس باستخدام باندا Pandas لعرض المعلومات الاحصائية الأساسية عن مجموعة البيانات مثل المتوسط والانحراف المعياري والتوزيع وغيرها من المعلومات نكتب الكود التالي: import pandas as pd data = pd.read_csv("iris.csv") print(data.describe()) استخدمنا التابع data.describe() للحصول على إحصائيات عن الكائن data من نوع DataFrame، مثل عدد القيم count والمتوسط الحسابي mean والانحراف المعياري standard deviation والتوزيع المئوي percentiles وهي إحصائية تقيس الترتيب النسبي لموقع نقطة في مجموعة البيانات، فمثلًا عند قولنا أن التوزيع المئوي 25% يساوي 38.25 فهذا يعني أن 25% من القيم الموجودة في البيانات أقل من هذا العدد، وتوجد ثلاث توزيعات مئوية أساسية هي 25% و 50% و75% تمثل الأرباع Q1 و Q2 و Q3 على الترتيب، ويعرف Q2 خاصةً بالوسيط median وهو الرقم الوسيط بين مجموعة من القيم المرتبة، وتعرض أيضًا القيمة العظمى لكل عمود، ولا تأخذ هذه الدالة في الاعتبار القيم المفقودة NAN، ولا تعمل إلا على الأعمدة الرقمية Numerical. نحصل على الخرج التالي من تنفيذ الكود أعلاه: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 150.000000 150.000000 150.000000 150.000000 150.000000 mean 75.500000 5.843333 3.054000 3.758667 1.198667 std 43.445368 0.828066 0.433594 1.764420 0.763161 min 1.000000 4.300000 2.000000 1.000000 0.100000 25% 38.250000 5.100000 2.800000 1.600000 0.300000 50% 75.500000 5.800000 3.000000 4.350000 1.300000 75% 112.750000 6.400000 3.300000 5.100000 1.800000 max 150.000000 7.900000 4.400000 6.900000 2.500000 معرفة عدد عينات كل نوع Categorical values باستخدام Pandas لنحصل على عدد عينات كل فصيلة من الفصائل في مجموعة بيانات الأزهار نكتب الكود على النحو التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Observations of each species:") print(data['Species'].value_counts()) استخدمنا الدالة value_counts() على العمود Species الذي يحتوى وسمًا لكل عينة في مجموعة البيانات، تسمح هذه الدالة بالحصول على عدد العينات في كل تصنيف، بمعنى أخر سنعرف كم عينة تنتمي لكل فصيلة من الأزهار. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Observations of each species: Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 Name: Species, dtype: int64 نلاحظ من الخرج السابق أن البيانات تحتوي على 150 زهرة موزعة بالتساوي على الفصائل الثلاثة. حذف عمود من DataFrame باستخدام Pandas لحذف عمود Id وطباعة أول خمسة صفوف حصلنا عليها بعد حذفه نكتب الكود التالي. import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) لحذف عمود من بنية DataFrame نستخدم الدالة drop() ونمرر لها اسم العمود المطلوب والمعامل axis وهو معامل يقبل قيمتين إما 0 وتعني أننا نريد حذف عمود، أو 1 والتي تعني أننا نريد حذف صف، ثم نستدعي new_data.head() لعرض أول خمسة صفوف من مجموعة البيانات الجديدة التي حصلنا عليها. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa اختيار شرائح معينة من مجموعة البيانات باستخدام Panda للوصول إلى أول أربع خلايا من كل صف في مجموعة البيانات المخزنة في بنية DataFrame واستخدم أسماء الأعمدة بالإضافة للفهرس للوصول للخلايا المحددة سنكتب كود بايثون التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) x = data.iloc[:, [1, 2, 3, 4]].values print(x) يسمح لنا التابع data.iloc[] باختيار شريحة معينة من مجموعة البيانات، حيث نحدد قبل الفاصلة الأولى الصفوف التي نريد أن تدخل في الاختيار، وبعد الفاصلة الأعمدة التي نريد أن تدخل في الاختيار، وفي حالتنا اخترنا عرض قيم جميع الصفوف باستخدام الرمز : والموجودة في أعمدة محددة [1,2,3,4]. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الخاتمة استكشفنا في هذه المجموعة من التدريبات مجموعة بيانات آيرس، وتعرفنا على خواصها والمعلومات الإحصائية الأساسية عنها، واستعرضنا تطبيقات عملية للتعامل مع بنية DataFrame لتخزين البيانات وتعديلها بطرق مختلفة، يمكن تجربة المزيد من الأكواد لاستكشاف هذه البيانات والتعرف عليها بشكل جيد قبل الانتقال للمقالة القادمة التي سنتدرب بها على إنشاء الرسومات البيانية لفهم العلاقات بين خواص مجموعة بيانات آيرس بشكلٍ مرئي. اقرأ أيضًا بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الأول خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثاني خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثالث
نتناول في هذه السلسلة مجموعة متنوعة من التطبيقات العملية حول تعلم الآلة Machine Learning باستخدام إطار عمل ساي كيت ليرن Scikit-Learn الذي يوفر حزمة من الأدوات البرمجية مفتوحة المصدر تشمل خوارزميات تعلم الآلة كخوارزميات التصنيف Classification وتوقع الانحدار Regression وخوارزميات العنقدة Clustering، وقد صمم هذا الإطار ليعمل بكفاءة مع العديد من مكتبات بايثون القوية مثل NumPy و SciPy. الهدف من هذه السلسلة إرشاد المبتدئين من خلال مجموعة من التدريبات العملية المكتوبة بلغة بايثون وإطار عمل ساي كيت ليرن Scikit-Learn، فالتطبيق وحل التدريبات واحدة من أفضل طرق التعلم واكتساب المهارات لذا ننصح بمحاولة إيجاد الحل بأنفسكم قبل النظر في الأكواد المرفقة لتحقيق استفادة أفضل. ما هي مجموعة بيانات أزهار آيرس؟ سنستخدم في التطبيقات العملية مجموعة بيانات أزهار آيرس أو السوسن Iris dataset وهي مجموعة بيانات من عدة متغيرات استخدمت بواسطة عالم الإحصاء والأحياء رونالد فيشر في ورقته البحثية لعام 1936، وهي تسمى أيضًا مجموعة بيانات اندرسون نسبة للعالم الذي جمعها ليحلل التغيرات الشكلية بين الفصائل الثلاث لهذه الأزهار. تتكون مجموعة البيانات من 50 عينة لكل فصيلة من الفصائل الثلاثة للأزهار، وهي Iris setosa و Iris virginica و Iris versicolor وقيست أربعة خصائص لكل عينة وهي: طول البتلة Petal length عرض البتلة Petal width طول السبلة Sepal length عرض السبلة Sepal width وباستخدام هذه التوليفة من الخصائص استطاع فيشر تطوير نموذج تميز خطي Linear discrimination قادر على التفريق بين الفصائل وبعضها. تطبيقات أساسية باستخدام مكتبة باندا Pandas سنتعرف على مجموعة من التطبيقات التي تستخدم مكتبة باندا Pandas لتحليل واستكشاف مجموعة البيانات والتي تعد خطوة أساسية في أي مشروع لتعلم الآلة. تحميل مجموعة البيانات إلى إطار البيانات DataFrame سنكتب برنامج بلغة برمجة بايثون لتحميل مجموعة بيانات آيرس من ملف csv إلى البنية pandas التي توفرها مكتبة dataframe ونطبع شكل البيانات ونوعها وأول ثلاثة صفوف منها. import pandas as pd data = pd.read_csv("iris.csv") print("Shape of the data:") print(data.shape) print("\nData Type:") print(type(data)) print("\nFirst 3 rows:") print(data.head(3)) النمط DataFrame هو نمط توفره مكتبة pandas لتنظيم البيانات وتخزينها على هيئة جدول، وقد استوردنا في الكود السابق مكتبة pandas وقرأنا البيانات المطلوبة من الملف iris.csv وخزناها في متغير data من النمط DataFrame، ثم عرضنا عدد الأبعاد -أي عدد الصفوف والأعمدة الموجود في هذا الكائن- باستخدام التابع shape ونوع بياناته باستخدام التابع type وعرضنا أول 3 صفوف من البيانات فقط باستخدام التعليمة data.head(3). عند تنفيذ الكود، نحصل على الخرج التالي: Shape of the data: (150, 6) Data Type: <class 'pandas.core.frame.DataFrame'> First 3 rows: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa استعراض خصائص مجموعات بيانات آيرس الآن، سكتب برنامج بايثون باستخدام ساي كيت ليرن Scikit-Learn لطباعة مفاتيح الأعمدة Keys وعدد الصفوف وعدد الأعمدة وأسماء الخاصيات والوصف لمجموعة بيانات آيرس. import pandas as pd iris_data = pd.read_csv("iris.csv") print("\nKeys of Iris dataset:") print(iris_data.keys()) print("\nNumber of rows and columns of Iris dataset:") print(iris_data.shape) استخدمنا هنا أيضًا بنية DataFrame كما في المثال السابق لتخزين البيانات ضمن متغير باسم iris_data وعرضنا المفاتيح أو أسماء الأعمدة في مجموعة البيانات باستخدام الدالة iris_data.keys() والتي تمثل المتغيرات أو الخصائص المختلفة بيانات الأزهار، وعرضنا أخيرًا عدد الصفوف والأعمدة باستخدام الدالة iris_data.shape. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Keys of Iris dataset: Index(['Id', 'SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species'], dtype='object') Number of rows and columns of Iris dataset: (150, 6) عرض عدد العينات وعدد القيم المفقودة في مجموعة بيانات آيرس فيما يلي كود بايثون لمعرفة عدد العينات في مجموعة بيانات الأزهار، وعدد القيم المفقودة فيها. import pandas as pd iris = pd.read_csv("iris.csv") print(iris.info()) استوردنا مجموعة البيانات بشكل بنية جدول DataFrame وخزناها في متغير باسم iris وطبعنا المعلومات التي نحتاجها باستخدام الدالة iris.info() التي تعرض بعض المعلومات المهمة مثل عدد العينات ونوع العمود الفهرسي Index column وكذلك عدد القيم الفعلية non-null ونوع البيانات لكل عمود، بالإضافة للذاكرة RAM المستهلكة لتخزين البيانات. نحصل على الخرج التالي من تنفيذ الكود أعلاه: <class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 150 non-null int64 1 SepalLengthCm 150 non-null float64 2 SepalWidthCm 150 non-null float64 3 PetalLengthCm 150 non-null float64 4 PetalWidthCm 150 non-null float64 5 Species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB None المصفوفات المتناثرة Dense Matrices والمصفوفات عالية الكثافة Dense Matrices باستخدام NumPy و Scipy سنعمل في هذه الفقرة على إنشاء مصفوفة ثنائية الأبعاد 2D array مليئة بالواحد في كل عناصرها لواقعة على القطر الرئيسي والقيمة الصفر فيما دون ذلك، ثم نحول المصفوفة من نوع NumPy array إلى مصفوفة SciPy sparse matrix أي مصفوفة متناثرة بتنسيق CSR هو أحد تنسيقات مكتبة SciPy لتمثيل المصفوفات. وتعرف المصفوفة المتناثرة بأنها مصفوفة تحتوي في الغالب على أصفار Sparse matrix، وعلى النقيض تمامًا فإن المصفوفة الي يكون غالب عناصرها قيم لا تساوي الصفر تسمى مصفوفة عالية الكثافة Dense matrix، ويعرف معدل التناثر sparsity على أنه عدد العناصر الصفرية مقسومة على إجمالي العناصر بالمصفوفة، ويساوي أيضًا 1 مطروحًا منه معدل الكثافة Density للمصفوفة، وباستخدام هذه التعريفات يمكننا تصنيف مصفوفة بأنها متناثرة sparse إن كان معدل تناثرها Sparsity أكبر من 0.5. تكمن فائدة تحويل المصفوفة من NumPy array إلى صيغة مصفوفة متناثرة الصفوف CSR باستخدام SciPy خطوة مفيدة وفعالة وتسرع الوصول إلى العناصر ذات القيمة الفعلية غير الصفرية داخل المصفوفة، حيث تتيح صيغة CSR تخزين المصفوفة بشكل مضغوط دون الحاجة إلى تخزين الأصفار، مما يقلل من استهلاك الذاكرة ويزيد من كفاءة المعالجة. تبرز أهمية هذا التحويل بشكل خاص عند إجراء عمليات رياضية أو تحليل بيانات على مصفوفات كبيرة، حيث يسهم تجاهل الأصفار في تسريع الحسابات دون التأثير على النتائج. import numpy as np from scipy import sparse eye = np.eye(4) print("NumPy array:\n", eye) sparse_matrix = sparse.csr_matrix(eye) print("\nSciPy sparse CSR matrix:\n", sparse_matrix) بعد أن استوردنا مكتبتي NumPy و SciPy استخدمنا الدالة np.eye() لإنشاء مصفوفة ثنائية الأبعاد تتكون جميع عناصرها من أصفار فيما عدا عناصر القطر الرئيسي للمصفوفة حيث تساوي عناصره الواحد، ومررنا للدالة العدد 4 وهو عدد الصفوف، وثم خزنا الناتج في الكائن eye وطبعنا المصفوفة التي يخزنها الكائن قبل أن تحويلها، واستخدمنا الدالة sparse.csr_matrix(eye) لتحويل المصفوفة للصيغة المضغوطة CSR، وطبعنا الكائن الذي يحتوي المصفوفة الجديدة لنقارن بين الصيغتين. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: NumPy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] SciPy sparse CSR matrix: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0 نلاحظ أن صيغة CSR لا تعرض كل عناصر المصفوفة، بل تُظهر العناصر التي تحتوي على أرقام غير صفرية فقط. وبما أن المصفوفة تحتوي على 1 في كل موقع قطري سنجد تساوي دليل الصف مع دليل العمود. عرض الاحصائيات الأساسية عن مجموعة بيانات آيرس باستخدام باندا Pandas لعرض المعلومات الاحصائية الأساسية عن مجموعة البيانات مثل المتوسط والانحراف المعياري والتوزيع وغيرها من المعلومات نكتب الكود التالي: import pandas as pd data = pd.read_csv("iris.csv") print(data.describe()) استخدمنا التابع data.describe() للحصول على إحصائيات عن الكائن data من نوع DataFrame، مثل عدد القيم count والمتوسط الحسابي mean والانحراف المعياري standard deviation والتوزيع المئوي percentiles وهي إحصائية تقيس الترتيب النسبي لموقع نقطة في مجموعة البيانات، فمثلًا عند قولنا أن التوزيع المئوي 25% يساوي 38.25 فهذا يعني أن 25% من القيم الموجودة في البيانات أقل من هذا العدد، وتوجد ثلاث توزيعات مئوية أساسية هي 25% و 50% و75% تمثل الأرباع Q1 و Q2 و Q3 على الترتيب، ويعرف Q2 خاصةً بالوسيط median وهو الرقم الوسيط بين مجموعة من القيم المرتبة، وتعرض أيضًا القيمة العظمى لكل عمود، ولا تأخذ هذه الدالة في الاعتبار القيم المفقودة NAN، ولا تعمل إلا على الأعمدة الرقمية Numerical. نحصل على الخرج التالي من تنفيذ الكود أعلاه: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 150.000000 150.000000 150.000000 150.000000 150.000000 mean 75.500000 5.843333 3.054000 3.758667 1.198667 std 43.445368 0.828066 0.433594 1.764420 0.763161 min 1.000000 4.300000 2.000000 1.000000 0.100000 25% 38.250000 5.100000 2.800000 1.600000 0.300000 50% 75.500000 5.800000 3.000000 4.350000 1.300000 75% 112.750000 6.400000 3.300000 5.100000 1.800000 max 150.000000 7.900000 4.400000 6.900000 2.500000 معرفة عدد عينات كل نوع Categorical values باستخدام Pandas لنحصل على عدد عينات كل فصيلة من الفصائل في مجموعة بيانات الأزهار نكتب الكود على النحو التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Observations of each species:") print(data['Species'].value_counts()) استخدمنا الدالة value_counts() على العمود Species الذي يحتوى وسمًا لكل عينة في مجموعة البيانات، تسمح هذه الدالة بالحصول على عدد العينات في كل تصنيف، بمعنى أخر سنعرف كم عينة تنتمي لكل فصيلة من الأزهار. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Observations of each species: Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 Name: Species, dtype: int64 نلاحظ من الخرج السابق أن البيانات تحتوي على 150 زهرة موزعة بالتساوي على الفصائل الثلاثة. حذف عمود من DataFrame باستخدام Pandas لحذف عمود Id وطباعة أول خمسة صفوف حصلنا عليها بعد حذفه نكتب الكود التالي. import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) لحذف عمود من بنية DataFrame نستخدم الدالة drop() ونمرر لها اسم العمود المطلوب والمعامل axis وهو معامل يقبل قيمتين إما 0 وتعني أننا نريد حذف عمود، أو 1 والتي تعني أننا نريد حذف صف، ثم نستدعي new_data.head() لعرض أول خمسة صفوف من مجموعة البيانات الجديدة التي حصلنا عليها. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa اختيار شرائح معينة من مجموعة البيانات باستخدام Panda للوصول إلى أول أربع خلايا من كل صف في مجموعة البيانات المخزنة في بنية DataFrame واستخدم أسماء الأعمدة بالإضافة للفهرس للوصول للخلايا المحددة سنكتب كود بايثون التالي: import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) x = data.iloc[:, [1, 2, 3, 4]].values print(x) يسمح لنا التابع data.iloc[] باختيار شريحة معينة من مجموعة البيانات، حيث نحدد قبل الفاصلة الأولى الصفوف التي نريد أن تدخل في الاختيار، وبعد الفاصلة الأعمدة التي نريد أن تدخل في الاختيار، وفي حالتنا اخترنا عرض قيم جميع الصفوف باستخدام الرمز : والموجودة في أعمدة محددة [1,2,3,4]. سنحصل على الخرج التالي من تنفيذ الكود أعلاه: Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الخاتمة استكشفنا في هذه المجموعة من التدريبات مجموعة بيانات آيرس، وتعرفنا على خواصها والمعلومات الإحصائية الأساسية عنها، واستعرضنا تطبيقات عملية للتعامل مع بنية DataFrame لتخزين البيانات وتعديلها بطرق مختلفة، يمكن تجربة المزيد من الأكواد لاستكشاف هذه البيانات والتعرف عليها بشكل جيد قبل الانتقال للمقالة القادمة التي سنتدرب بها على إنشاء الرسومات البيانية لفهم العلاقات بين خواص مجموعة بيانات آيرس بشكلٍ مرئي. اقرأ أيضًا بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الأول خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثاني خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الثالث -
 يعد باي تورش PyTorch أحد أشهر أطر عمل التعلم العميق Deep Learning، فهو الخيار الأول للباحثين في هذا المجال، وتزداد باستمرار أعداد الشركات ومراكز الأبحاث التي تتبنى استخدامه نظرًا لمرونته الكبيرة التي تساعد على تنفيذ الأفكار المختلفة. سنتعرف في هذه المقالة على مفاهيم أساسية في إطار عمل باي تورش PyTorch مثل مفهوم التفاضل التلقائي automatic differentiation، ومفهوم المخططات الرسومية الحسابية computation graphs، وكيفية تحقيق الاستفادة العظمى من المكتبات والأدوات التي يوفرها باي تورش واستخدامها لتطبيق هذه المفاهيم. المتطلبات السابقة يتطلب فهم هذه المقالة توفر الإلمام بالمواضيع التالية: معرفة بأساسيات الذكاء الاصطناعي والتعلم العميق فهم قاعدة التسلسل chain rule، وهي صيغة رياضية مستخدمة في تدريب نماذج التعلم العميق تنزيل إطار عمل باي تورش على الجهاز المحلي لتجربة الأكواد والأمثلة العملية التفاضل التلقائي Automatic Differentiation قبل مناقشة الهياكل الأساسية المستخدمة في باي تورش، سنوضح بداية مفهوم التفاضل التلقائي automatic differentiation -أو autograd اختصارًا- ودوره في التعلم العميق، فعملية حساب المشتقات أساسية في مجال التعلم العميق لدورها في تحسين أداء الشبكات العصبية. لكن تعقيدها يتزايد مع تعقيد النماذج، لذا طُورت تقنيات متقدمة مثل التفاضل التلقائي للتعامل مع هذا الأمر بكفاءة عالية. تعمل هذه التقنية -كما سنشرح لاحقًا- على إنشاء رسم بياني حسابي يتتبع العلاقات بين المتغيرات، مما يسمح بحساب المشتقات بشكل تلقائي ودقيق عبر طبقات الشبكة العصبية. حيث تحتوي الشبكات العصبية على ملايين المعاملات والأوزان التي تحتاج لتعلمها من خلال التدريب، وخلال عملية التدريب سنحتاج لحساب المشتقات Derivatives لمعرفة كيفية تحديث هذه المعاملات بما يضمن تحسين أداء النموذج. فالتفاضل التلقائي هو العمود الفقري لإطار عمل باي تورش PyTorch ولجميع مكتبات وأطر التعلم العميق، ويساعدنا محرك التفاضل التلقائي المدمج في باي تورش PyTorch والمعروف أيضًا بمحرك Autograd في فهم آلية عمل التفاضل التلقائي والأساس الذي بنيت عليه أطر عمل الذكاء الاصطناعي. تمتلك معماريات الشبكات العصبية ملايين المعاملات parameters القابلة للتعلم، وتمر عملية تدريب أي شبكة عصبية بمرحلتين وهما: مرحلة الانتشار الأمامي Forward pass التي تحسب قيمة الخسارة باستخدام دالة خسارة loss function مرحلة الانتشار الخلفي Backward pass التي يحسب قيم التدرجات gradients لتحديث المعاملات القابلة للتعلم يكون الانتشار الأمامي forward pass في غاية البساطة، فالمخرجات للطبقة الحالية هي مدخلات الطبقة التالية ويستمر هذا النمط في التكرار، ولكن الانتشار الخلفي backward pass أكثر تعقيدًا من الناحية الحسابية، فهو يتطلب استخدام قاعدة السلسلة التفاضلية chain rule من أجل حساب التدرجات بالنسبة لمعاملات دالة الخسارة loss function، بمعنى أبسط تُخبرنا التدرجات بكيفية تعديل الأوزان والمعاملات في الشبكة العصبية لتقليل الخسارة. مثال بسيط لنلقِ النظر على شبكة عصبية في غاية البساطة، تتكون من 5 عصبونات أو عقد neurons، وتعرض هذه الصورة الشبكة العصبية التي نتحدث عنها. تصف المعادلات التالية هذه الشبكة العصبية البسيطة: لنحسب التدرجات التصحيحية لكل معامل قابل للتعلم w: حُسِبَت جميع هذه التدرجات gradients باستخدام قاعدة السلسلة chain rule، ويمكن أن نلاحظ أن جميع التدرجات الفردية في الجانب الأيمن من المعادلة يمكن حسابها بشكل مباشر بما أن البسط هو دالة ضمنية لتلك الموجودة في المقام. المخططات البيانية الحسابية Computation Graphs يمكن أن نحسب التدرجات gradients لشبكتنا العصبية يدويًا لأنها شبكة بسيطة للغاية، ولكن ماذا لو أردنا إجراء حسابات لشبكة تتكون من 152 طبقة، أو شبكة تمتلك عددًا كبيرًا من التفرعات. يتطلب تصميم برنامج لبناء الشبكات العصبية الاصطناعية ANN إيجاد طريقة تمكننا من حساب التدرج التصحيحي gradient بسهولة لمختلف المعماريات التي يمكن تكونيها، فنحن لا نريد أن ينشغل المطور بالتعامل اليدوي مع عملية حساب التدرج gradient عند حدوث أي تغيير في تصميم الشبكة. يمكننا تحقيق هذا المبدأ باستخدام هيكل بيانات يسمى المخطط البياني الحسابي computation graph، وتتشابه هذه البنية في الشكل مع الرسم التوضيحي للشبكة العصبية البسيطة، مع وجود بعض الاختلافات، حيث أن العقد nodes في المخطط الحسابي هي معاملات operators وهي معاملات حسابية في أغلب الحالات كالجمع والطرح والضرب والقسمة، عدا في حالة واحدة حيث نحتاج لتعريف معامل operator يعبر عن عملية إنشاء المستخدم لمتغير مخصص. نلاحظ في الصورة التالية أننا رمزنا للمتغيرات الطرفية leaf variables بالرموز التالية a, w1, w2, w3, w4 من أجل التوضيح وسهولة التعامل، ولكنها ليست جزءًا أصيلًا من المخطط الرسومي graph، فما تمثله هو الحالة الخاصة التي ينشئ فيها المستخدم المتغيرات الخاصة به. أنشئت المتغيرات التالية b,c,d كنتيجة للعمليات الحسابية، بينما تكون المتغيرات a,w1,w2,w3,w4 معرّفة ومدخلة بواسطة المستخدم، وبما أنها ليست متغيرات ناتجة أن أي عملية حسابية، فسنرمز للعقد التي تعبر عنها باسم المتغير الذي أنشأه المستخدم. وهذا ينطبق على كل العقد الطرفية leaf nodes في المخطط الحسابي. حساب التدرجات Gradients بعد التعرف على بعض المفاهيم الأساسية، لنتعرف الآن على آلية حساب التدرجات gradients باستخدام المخطط الحسابي computation graph، يمكن اعتبار كل عقدة node في المخطط -باستثناء العقد الطرفية- دالة تستقبل مدخلات وتعالجها وتدفع بالمخرجات لتنتشر خلال المخطط. لنلقِ نظرة على العقدة التي تخرج المتغير d بعد معالجة المدخلات w4×c و w3×b، يمكننا التعبير عنها كدالة على النحو التالي: حيث تعبر d عن مخرجات الدالة f(x,y)=x+y. يمكننا الآن وببساطة حساب التدرجات gradients للدالة f بالنسبة لمدخلاتها، وفق المعادلة التالية: بعد حساب التدرجات gradients سنعمل على وسم الأسهم في الاتجاه المعاكس لها بقيمة التدرج الخاص بها، كما في الصورة التالية: توضح الصورة التالية المخطط الحسابي كاملًا بعد أن طبقنا هذه على الخطوات عند كل العقد: تاليًا، سنصف الخوارزمية التي تحسب القيمة المشتقة عند أي عقدة في المخطط الحسابي بالنسبة لدالة الخسارة L. لنقل أننا نريد حساب الاشتقاق التالي : سنتبع أولًا كل المسارات الممكنة من d إلى w4 وفي حالتنا هناك مسار واحد يصل بين المتغيرين، ثم سنضرب قيم الحواف أو الوصلات edges الواقعة على هذا المسار. يمكن أن نلاحظ أن حاصل الضرب الناتج هو نفسه الذي حصلنا عليه عند استخدام قاعدة السلسلة chain rule، وإذا كان هناك أكثر من مسار يربط المتغير بدالة الخسارة L نضرب الوصلات في كل مسار ثم نجمع حاصل الضرب من كل مسار، كما في المثال التالي: حساب التفاضل التلقائي في PyTorch Autograd بعد أن تعرفنا بشكل مفصل على ماهية المخطط الحسابي computational graph، لنستكشف الآن آلية تطبيق المخطط الحسابي في باي تورش PyTorch بشكل آلي، سنستخدم هيكل بيانات يسمى التنسور أو المُوتِر Tensor وهو أساسي في باي تورش PyTorch، حيث يشبه نوعًا ما مصفوفات مكتبة نمباي NumPy arrays، ولكن على النقيض من نمباي NumPy، فإن التنسورات tensors مصممة للاستفادة من قدرات الحوسبة الفائقة على التوزاي التي توفرها وحدات المعالجة الرسومية GPUs، ويتشابه الكود وقواعد كتابته مع تلك الموجودة في نمباي NumPy. للنشئ tensor من 3 صفوف و 5 اعمدة، ونهيأه بقيم عشوائية كما يلي: In [1]: import torch In [2]: tsr = torch.Tensor(3,5) In [3]: tsr Out[3]: tensor([[ 0.0000e+00, 0.0000e+00, 8.4452e-29, -1.0842e-19, 1.2413e-35], [ 1.4013e-45, 1.2416e-35, 1.4013e-45, 2.3331e-35, 1.4013e-45], [ 1.0108e-36, 1.4013e-45, 8.3641e-37, 1.4013e-45, 1.0040e-36]]) لنضمن قيام باي تورش PyTorch بإنشاء مخطط حسابي للموترات tensor الذي عرفناه، ينبغي علينا ضبط قيمة المتغير requires_grad إلى True، فبدون هذه الخطوة سيكون الموتر مجرد هيكل بيانات تقليدي كالذي توفره مكتبة نمباي NumPy يمكن استخدامه للعمليات الجبر الخطي السريعة. قد يكون استخدام باي تورش لإنشاء موترات أمرًا مربكًا في البداية، حيث توجد عدة طرق لإنشاء الموترات tensors، فتسمح بعض الطرق بتمرير تعريف المتغير requires_grad بشكل صريح في الدالة المُنشأة، وطرقًا أخرى تجعلنا نضبط هذا المتغير يدويًا بعد إنشاء الموتر tensor. t1 = torch.randn((3,3), requires_grad = True) t2 = torch.FloatTensor(3,3) # لا تسمح هذه الدالة بضبط هذا المتغير وقت الإنشاء # لكن يمكن ضبطه بعد الإنشاء t2.requires_grad = True تحدد الخاصية requires_grad فيما إذا كان على باي تورش تتتبع العمليات الرياضية التي تنفذ على الموتر حتى يتمكن لاحقًا من حساب التدرجات gradients أثناء الانتشار الخلفي، فإذا كانت قيمته True يجري تتبع العمليات وحساب التدرجات لاحقًا، وفي حال كانت False لن يكون هناك تتبع للعمليات، ولن تحسب التدرجات. وعند إنشاء موتر tensor كنتيجة لعملية على موتر آخر يضبط هذه الخاصية بالقيمة True فإن الموتر الناتج سيمتلكها أيضًا، فيلزم على الأقل أن يكون أحد الموترات tensors الداخلة في العملية قد فعّل هذه الخاصية أثناء إنشائه لتنتشر من خلال الموتر الناتج عن هذه العملية حتى إن لما تكن مفعلة في باقي الموترات. كما يمتلك كل موتر tensor خاصية تسمى grad_fn ، والتي تشير إلى إلى معامل رياضي operator يقوم بإنشاء المتغير، وحينما تكون خاصية requires_grad غير مفعلة False فتكون grad_fn قيمتها None. سنجد في مثال d=f(w3b,w4c)، أن دالة التدرج grad function ستكون هي عملية الجمع، حيث تجمع الدالة f المدخلات معًا، وستكون عملية الجمع عقدة في المخطط الحسابي الذي يخرج d، وفي حالة كون العقدة طرفية أي متغير معرف بواسطة المستخدم فستكون دالة التدرج الخاصة به grad_fn=None. import torch a = torch.randn((3,3), requires_grad = True) w1 = torch.randn((3,3), requires_grad = True) w2 = torch.randn((3,3), requires_grad = True) w3 = torch.randn((3,3), requires_grad = True) w4 = torch.randn((3,3), requires_grad = True) b = w1*a c = w2*a d = w3*b + w4*c L = 10 - d print("The grad fn for a is", a.grad_fn) print("The grad fn for d is", d.grad_fn) ينتج تشغيل هذا الكود الخرج التالي: The grad fn for a is None The grad fn for d is <AddBackward0 object at 0x1033afe48> دوال الصنف Autograd.Function تُنفَّذ جميع العمليات الحسابية في باي تورش PyTorch من خلال الصنف البرمجي torch.nn.Autograd.Function، الذي يشكل جزءًا أساسيًا من آلية التفاضل التلقائي. يعتمد هذا الصنف على دالتين رئيسيتين: الأولى هي دالة الانتشار الأمامي backward والتي تحسب المخرجات بناءً على المدخلات السابقة، مما يمثل العملية الحسابية التي تجريها الطبقة أثناء تمرير البيانات عبر النموذج. أما الدالة الثانية فهي دالة الانتشار الخلفي backward التي تتولى حساب التدرجات من خلال استقبالها من الطبقات التالية في الشبكة. يمكن ملاحظة أن اتجاه انتشار التدرجات gradients يكون عكسيًا، أي من المخرجات نحو المدخلات، وليس العكس. هذا يعني أن التدرجات القادمة من الدالة f تنتقل من الطبقات الأخيرة في النموذج إلى الطبقات الأولى. وتعدّل الأوزان في كل طبقة بناءً على مدى تأثيرها على الخطأ النهائي. يتم ذلك عن طريق ضرب التدرج القادم من الطبقة التالية في التدرج المحلي الخاص بتلك الطبقة، مما يساعد على حساب مقدار التغيير اللازم لكل وزن حتى تتحسن دقة النموذج. وبالتالي، تتلقى كل طبقة معلومات من الطبقة التي تليها حول كيفية تغيير أوزانها لتقليل الخطأ، ويستمر هذا التدفق العكسي حتى تصل التحديثات إلى أول طبقة في النموذج. هذا هو جوهر عملية الانتشار الخلفي التي تتيح للنموذج التعلم من الأخطاء وتحسين أدائه بمرور الوقت. مثال عملي لنفهم الأمر بمثال عملي لنفرض أن لدينا دالة حسابية بسيطة تمثل جزءًا من شبكة عصبيةd = f(w3b , w4c) d هنا هي موتر tensor، ودالة التدرج grad_fn هي <ThAddBackward> وهي عملية جميع بسيطة حيث أن الدالة التي أنشئت d تجمع المدخلات، وتتلقى دالة الانتشار الأمامي forward مدخلات دالة التدرج grad_fn حيث تتلقى w3b و w4c وتجمع المدخلات في دالة التدرج، ثم تتدفق النتيجة للأمام بعد أن تحفظ في الموتر d. وتتلقى دالة التراجع backward الخاصة بالدالة <ThAddBackward> التدرجات الداخلة incoming gradient من الطبقات التالية لها كمدخلات أي الطبقات التي على يمين الطبقة الحالية، ما نحاول حسابه هو الاشتقاق الجزئي لدالة الخسارة L بالنسبة للمتغير d والتي تتكون من كل القيم الموجودة على الوصلات edges التي تربط بين L و d، ويمكن الوصول لقيم التدرجات gradients بالنسبة للمتغير d حيث تخزن في grad وهو خاصية للموتر، فتصل لها من خلال d.grad. نحسب بعد هذا التدرجات المحلية local gradients، أي التفاضل الجزئي للمتغير d أس الدالة التي تجمع بالنسبة للمدخلات w4c ومرة أخرى بالنسبة للمدخل w3b. تُضرب التدرجات gradients القادمة من الطبقات التالية مع التدرجات المحسوبة محليًا بواسطة دالة التراجع، ومن ثم ترسل التدرجات لتنتشر تراجعيًا ناحية المدخلات محفزة تفاعلًا متسلسلًا، تشغّل فيه دالة التراجع لحساب تدرجات الدالة grad_fn المرتبطة بالمدخلات السابقة. نوضح الأمر بمثال، تقوم دالة التراجع backward المرتبطة بالدالة <ThAddBackward> الخاصة بالمتغير d بتحفيز دالة التراجع للمدخلات grad_fn والتي بدورها تحفز دالة التراجع للمدخل w4c، لاحظ أن w4c هو موتر انتقالي أي أنه مُنشَأ لحفظ ناتج العملية الوسيطة ودالة التدرجات gradient الخاصة به هي <ThMulBackward>، وحينما تستدعي هذه دالة التراجع backward لحساب عملية التدرجات gradients يمرر لها تدرج الاشتقاق الجزئي لدالة الخسارة L بالنسبة إلى المتغير d مضروبة في الاشتقاق الجزئي للمتغير d بالنسبة للمتغير w4c، وتوضح الصورة التالية المعادلة المعبرة عن هذه العملية: ويحين الدور الآن على المتغير w4c، فتصبح المعادلة المكتوبة في الأعلى هي المدخلات لهذه العقدة في عملية الانتشار التراجعي لحساب التدرجات gradients، كما كان الأمر في الخطوة الثالثة بالنسبة للمتغير d حيث كانت المدخلات هي الاشتقاق الجزئي لدالة الخسارة بالنسبة للمتغير d. لنطبق الأمر من خلال خوارزمية تحسب عملية الانتشار الخلفي باستخدام المخطط الحسابي computation graph، هذا ليس التطبيق الكامل لهذه الدالة ولكنه مثال توضيحي بسيط. def backward(self, incoming_gradients): # اضبط قيمة التدرج للموتر الحالي self.Tensor.grad = incoming_gradients # حلقة تكرارية لتنفيذ الانتشار التراجعي للتدرجات for inp in self.inputs: if inp.grad_fn is not None: # احسب التدفقات القادمة تجاه المُدخل الحالي # Compute new incoming gradients for the input new_incoming_gradients = incoming_gradients * local_grad(self.Tensor, inp) # استدعِ دالة التراجع بشكل تعاودي # Recursively call inp.grad_fn.backward(new_incoming_gradients) نجد في هذا الكود أن self.Tensor هو موتر Tensor منشئ بواسطة Autograd.Function، والتي كانت في مثالنا d، وقد شرحنا سابقًا مفهوم التدرجات القادمة incoming gradients والتدرجات المحلية local gradients. لنحسب المشتقات في الشبكة العصبية، سنحتاج لاستدعاء دالة التراجع backward وتطبيقها على Tensor الذي يمثل الخسارة loss، ونستمر في الرجوع للخلف backtrack خلال المخطط الحسابي بداية من العقدة التي تمثل دالة التدرج grad_fn الخاصة بدالة الخسارة. وشرحنا سابقًا أن دالة التراجع backward تستدعى بشكل تعاودي recursive، فأثناء تتبع أثر التفرعات خلال الشبكة الحسابية نستدعي هذه الدالة، والتي بدورها تستدعي نفسها عندما تتراجع للمستوى السابق وهكذا حتى نصل لحالة التوقف الأساسية base case وهي العقد الطرفية leaf node والتي تكون دالة التدرج grad_fn فيه عديمة القيمة None. ننبه لأن باي تورش PyTorch يعطي خطأ Error عندما نحاول استدعاء دالة التراجع backward وتطبيقها على موتر تتكون عناصره من متجهات متعددة القيم vector-valued Tensor، ويعني هذا أن دالة التراجع backward تعمل على موترات تحتوي قيمًا رقمية أحادية scalers. import torch a = torch.randn((3,3), requires_grad = True) w1 = torch.randn((3,3), requires_grad = True) w2 = torch.randn((3,3), requires_grad = True) w3 = torch.randn((3,3), requires_grad = True) w4 = torch.randn((3,3), requires_grad = True) b = w1*a c = w2*a d = w3*b + w4*c L = (10 - d) L.backward() سوف يعطي تشغيل هذا الكود الخطأ التالي: RuntimeError: grad can be implicitly created only for scalar outputs يرجع سبب هذا الخطأ لكون قيم التدرجات gradient قابلة لأن تحسب بالنسبة لقيم رقمية أحادية scalers، السبب هو طريقة تعريف التدرج gradient definition، حيث لا يمكنها أن تفاضل متجهًا بالنسبة لمتجه آخر، ولتحقيق ذلك نستخدم عملية رياضية مختلفة تسمى Jacobian وهي خارج نطاق اهتمامنا في هذا المقال. تكمن المشكلة في توقع دالة التراجع بأن تكون المخرجات قيمة واحدة أو رقم واحد وليست متجهًا. يمكننا تجاوز هذه المشكلة بطريقتين، حيث يمكننا إجراء تعديل بسيط على الكود السابق بضبط قيمة L لتكون مجموع كل الأخطاء، سوف يحل هذا مشكلتنا. import torch a = torch.randn((3,3), requires_grad = True) w1 = torch.randn((3,3), requires_grad = True) w2 = torch.randn((3,3), requires_grad = True) w3 = torch.randn((3,3), requires_grad = True) w4 = torch.randn((3,3), requires_grad = True) b = w1*a c = w2*a d = w3*b + w4*c # L = (10 - d) استبدلنا هذا # بهذا L = (10 -d).sum() L.backward() يمكننا الوصول للتدرجات الآن بكل سهولة من خلال استدعاء خاصية grad الموجودة في الموتر Tensor. لنشرح الطريقة الثانية مفترضين أننا نحتاج -لأي سبب من الأسباب- لاستخدام دالة backward على دالة متجهة vector function، يمكننا تجاوز الخطأ بتمرير موتر torch.ones للدالة بأبعاد مطابقة للموتر الذي نحاول تمريره لدالة التراجع. # L.backward() استبدل L.backward(torch.ones(L.shape)) ويمكن أن نلاحظ أننا مررنا لدالة backward التدرجات القادمة incoming gradients من مدخلاتها، وبهذا جعلنا الدالة تتلقى التدرجات gradients على هيئة موترات مليئة بالواحد Tensor of ones بنفس أبعاد L، مما يجعلها قابلة للانتشار الخلفيbackward propagation بشكل مبسط. تمكننا هذه الطريقة من الحصول على تدرجات gradients أي موتر Tensor، وتحديث الأوزان والمعاملات من خلال خوارزمية التحسين التي نفضلها. w1 = w1 - learning_rate * w1.grad أبرز الاختلافات بين باي تورش PyTorch و تنسورفلو Tensorflow المخططات الحسابية ينشئ باي تورش PyTorch مخططات حسابية ديناميكية Dynamic Computation Graph أي أنها تولد بشكل مرن تلقائيًا عند الحاجة، واستخدام دالة الانتشار الأمامي forward هو المحفز لإنشاء المتغيرات التي سنستخدمها لاحقًا في خطوة الانتشار الخلفي، وبالتالي قبل استدعاء دالة الانتشار الأمامي forward لن توجد أي عقدة تحمل موتر بخاصية دالة التدرج grad_fn. # لا يوجد أي شبكة حسابية حتى الآن، فهنا نعرف مجرد عقدة طرفية a = torch.randn((3,3), requires_grad = True) # ينطبق نفس الأمر هنا، مجرد تعريفنا لموتر w1 = torch.randn((3,3), requires_grad = True) # هنا يتم إنشاء شبكة حسابية بها دالة ضرب سيتم استخدامها لحساب التدرجات b = w1*a #Graph with node `mulBackward` is created. أنشئت الشبكة الحسابية هنا كنتيجة لتشغيل دالة الانتشار الأمامي forward الخاصة بعدة موترات tensors، وفقط عند استدعائها تُخصّص مساحات تخزينية ومتغيرات وسيطة لتحتفظ بالقيم الانتقالية التي ستستخدم في حساب التدرجات gradient لاحقًا عندما تستدعى دالة التراجع backward ، وتُحرّر المساحات التخزينية المخصصة فور الانتهاء من حساب التدرجات gradients في العقد غير الطرفية، وعندما تستدعى دالة الانتشار الأمامي forward على نفس المجموعة من الموترات Tensors، يعاد استخدام المساحات التخزينية للعقد الطرفية من التشغيل السابق للشبكة، بينما تنشأ وتخصص من جديد تلك المساحات الانتقالية أو الوسيطة عند وصول دالة الانتشار الأمامي لها. إن حاولنا استدعاء دالة التراجع backward أكثر من مرة على عقد غير طرفية non-leaf nodes، سنحصل على الخطأ التالي: RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time. يرجع هذا الخطأ لتحرير المساحات التخزينية التي أنشئت سابقًا للعقد غير الطرفية عند استدعاء دالة backward ، فلا يوجد طريق تنتشر فيه خلفيًا من خلاله عند استدعاء الدالة مرة أخرى، الأمر أشبه بعبور جسر من الحبال ثم قطع الحبال، للعبور مجددًا سنحتاج لإنشاءها من جديد، ولكن يمكنك أن نلغي هذا التأثير بضبط خاصية متاحة في دالة backward وهي retain_graph لتكون True. loss.backward(retain_graph = True) عند تفعيل هذه الخاصية سنتمكن من استخدام التراجع الخلفي backpropagation على نفس المخطط الحسابي، حيث ستتراكم التدرجات gradients، أي في المرة القادمة التي ننفذ فيها التراجع الخلفي ستضاف قيم التدرجات إلى تلك الموجودة سابقًا والمخزنة من الدورة السابقة. يناقض هذا طريقة عمل المخططات الحسابية الثابتة Static Computation Graphs التي يستخدمها تنسورفلو TensorFlow، حيث يعرف المخطط الحسابي قبل تشغيل البرنامج. ويجري تشغيله عن طريق إدخال القيم المعرفة مسبقًا. تسمح المخططات الحسابية الديناميكية dynamic graph بالتغيير في معمارية المخطط أثناء التشغيل، حيث يتم إنشاء المخطط فقط عند تشغيل جزء محدد من الكود. ويعني هذا أيضًا أن المخطط يمكن أن يعاد تعريفه أثناء تشغيل البرنامج، وكما وضحنا فهذا غير ممكن في المخطط الثابت حيث يعرف المخطط وينشأ قبل تشغيل البرنامج. ويسهل تقفي أثر الأخطاء والمشاكل التي قد تحدث مع المخططات الديناميكية المرنة حيث يمكننا معرفة مصدر الخطأ، فلن نستطيع إكمال الانتشار إن وجدنا مشكلة بجزء معين، على النقيض من المخططات الثابتة حيث يتم الانتشار في مسارات معرفة مسبقًا. وجه المقارنة مخطط حسابي ديناميكي مخطط حسابي ثابت إطار العمل باي تورش PyTorch تنسورفلو TensorFlow تعريف المخطط وقت التشغيل قبل التشغيل طريقة التشغيل يؤجل التشغيل حتى البناء الكامل للمخطط الرسومي يتم التشغيل بشكل متزامن مع بناء المخطط الرسومي المرونة مرن للغاية، يمكن تغير المعمارية وقت التشغيل أقل مرونة، فنحتاج لإعادة بناء المخطط عند كل تعديل الأداء أبطء نسبيًا، حيث تفسر كل عملية على حدة وقد يوجد تكرار أسرع حيث يتم تحسين المخطط قبل تشغيله وتفادي التكرار التحسين مساحة محدودة للتحسين، حيث تنفذ جميع العمليات فورًا مع معرفتنا بهيكل المخطط كاملًا يمكن تطبيق خوارزميات تحسن ترتيبه وطريقة تشغيله بسهولة كفاءة التخزين أقل كفاءة، فكل عملية يحجز لها مساحة مخصوصة حتى وإن كانت مكررة. أكثر كفاءة، فيعاد استخدام المتغيرات المتكررة. اكتشاف المشاكل وحل الأخطاء أسهل أصعب المعماريات المناسبة مناسب للغاية للمعماريات المرنة، مثل الشبكات العصبية التكرارية RNN، التي تتعامل مع متسلسلات من المدخلات مثل الجمل، ومرونة باي تورش تمكننا من التعامل مع حجم جمل متغير. أنسب للمعماريات الثابتة، مثل الشبكات العصبية الالتفافية CNN مجال الاستخدام المجال البحثي، وتطوير المعماريات الجديدة، ولكنه قد لا يكون محسنًا بما يكفي لبيئات التشغيل يشيع استخدامه في بيئات التشغيل وعملية الاستدلال، حيث تكون الشبكة محسنة بدرجة فائقة وقابلة للنقل والتشغيل في بيئات مختلفة. ملاحظات إضافية لنتعرف الآن على بعض الملاحظات والطرق التي يمكن أن نستخدمها لتغيير سلوك المخطط الحسابي في باي تورش PyTorch. الخاصية requires_grad تكون هذه الخاصية المتعلقة بالموترات Tensors في غاية الأهمية، عندما تريد أن تجمد بعض الطبقات في الشبكة العصبية ولا تريد أن يتم تدريبها، حيث يمكنك ببساطة أن تجعل قيمة هذه الخاصية False، وبالتالي لن تكون هذه الموترات داخلة في عملية حساب التدرجات gradients. ولن تنتشر لهم أي تدرجات gradients نتيجة لإيقاف هذه الخاصية، ولا للطبقات التي تعتمد عليها، ونلاحظ أن هذه الخاصية في الأصل قابلة للانتشار فعند تنفيذ عملية على موترات أحدها مفعل به هذه الخاصية، فسيكون الموتر الناتج يحمل هذه الخاصية مفعلة True. الخاصية torch.no_grad نحتاج أحيانًا إلى تخزين بعض المدخلات والمتغيرات الانتقالية مؤقتًا أثناء حساب التدرجات gradients، لنستخدمهم في خطوات قادمة لحساب شيء آخر، فمثلًا تدرج المتغير b=w1*a بالنسبة لمدخلاته w1 و a يساوي w1 و a فنحتاج تخزين هذه المتغيرات لاستخدامها لاحقًا في حساب التدرجات أثناء الانتشار الخلفي، ولهذا أثر ثقيل على استخدام الذاكرة. والاستدلال بحد ذاته لا يتطلب منا إعادة حساب التدرجات gradients، وبالتالي لسنا بحاجة لتخزينها بشكل دائم، في الواقع نحن لانحتاج أن ننشئ المخطط الحسابي وقت الاستدلال حيث سيؤدي هذا لهدر الذاكرة. يقدم باي تورش PyTorch حلًا لهذه المشكلة، من خلال مدير السياق context manager، المسمى torch.no_grad والذي يعطل عملية حساب التدرجات gradients في أي سياق يتطلب تحديث أوزان النموذج أو ربما تقييمه، ويوفر هذا الكثير من الذاكرة، حيث لا ننشئ المتغيرات الوسيطة ولا المخطط الحسابي. with torch.no_grad: كود الاستدلال هنا الخاتمة تعرفنا في مقال اليوم على آلية عمل التفاضل التلقائي ومحرك التفاصل المستخدم في باي تورش PyTorch والمسمى Autograd، والذي يجعل من التعامل مع باي تورش PyTorch أسهل وأبسط، بعد فهم هذه الأساسيات يمكن التعمق في فهم النماذج المعقدة، وكيف يمكن بناؤها بواسطة باي تورش. ترجمة وبتصرف لمقال PyTorch 101, Understanding Graphs, Automatic Differentiation and Autograd لصاحبه Ayoosh Kathuria اقرأ أيضًا تعرف على دوال الخسارة Loss Functions في PyTorch أفضل ممارسات هندسة المُوجِّهات Prompt Engineering: نصائح وحيل وأدوات تدريب المًكيَّفات PEFT Adapters بدل تدريب نماذج الذكاء الاصطناعي بالكامل تعرف على إطار عمل باي تورش PyTorch وأهميته لتطبيقات الذكاء الاصطناعي
يعد باي تورش PyTorch أحد أشهر أطر عمل التعلم العميق Deep Learning، فهو الخيار الأول للباحثين في هذا المجال، وتزداد باستمرار أعداد الشركات ومراكز الأبحاث التي تتبنى استخدامه نظرًا لمرونته الكبيرة التي تساعد على تنفيذ الأفكار المختلفة. سنتعرف في هذه المقالة على مفاهيم أساسية في إطار عمل باي تورش PyTorch مثل مفهوم التفاضل التلقائي automatic differentiation، ومفهوم المخططات الرسومية الحسابية computation graphs، وكيفية تحقيق الاستفادة العظمى من المكتبات والأدوات التي يوفرها باي تورش واستخدامها لتطبيق هذه المفاهيم. المتطلبات السابقة يتطلب فهم هذه المقالة توفر الإلمام بالمواضيع التالية: معرفة بأساسيات الذكاء الاصطناعي والتعلم العميق فهم قاعدة التسلسل chain rule، وهي صيغة رياضية مستخدمة في تدريب نماذج التعلم العميق تنزيل إطار عمل باي تورش على الجهاز المحلي لتجربة الأكواد والأمثلة العملية التفاضل التلقائي Automatic Differentiation قبل مناقشة الهياكل الأساسية المستخدمة في باي تورش، سنوضح بداية مفهوم التفاضل التلقائي automatic differentiation -أو autograd اختصارًا- ودوره في التعلم العميق، فعملية حساب المشتقات أساسية في مجال التعلم العميق لدورها في تحسين أداء الشبكات العصبية. لكن تعقيدها يتزايد مع تعقيد النماذج، لذا طُورت تقنيات متقدمة مثل التفاضل التلقائي للتعامل مع هذا الأمر بكفاءة عالية. تعمل هذه التقنية -كما سنشرح لاحقًا- على إنشاء رسم بياني حسابي يتتبع العلاقات بين المتغيرات، مما يسمح بحساب المشتقات بشكل تلقائي ودقيق عبر طبقات الشبكة العصبية. حيث تحتوي الشبكات العصبية على ملايين المعاملات والأوزان التي تحتاج لتعلمها من خلال التدريب، وخلال عملية التدريب سنحتاج لحساب المشتقات Derivatives لمعرفة كيفية تحديث هذه المعاملات بما يضمن تحسين أداء النموذج. فالتفاضل التلقائي هو العمود الفقري لإطار عمل باي تورش PyTorch ولجميع مكتبات وأطر التعلم العميق، ويساعدنا محرك التفاضل التلقائي المدمج في باي تورش PyTorch والمعروف أيضًا بمحرك Autograd في فهم آلية عمل التفاضل التلقائي والأساس الذي بنيت عليه أطر عمل الذكاء الاصطناعي. تمتلك معماريات الشبكات العصبية ملايين المعاملات parameters القابلة للتعلم، وتمر عملية تدريب أي شبكة عصبية بمرحلتين وهما: مرحلة الانتشار الأمامي Forward pass التي تحسب قيمة الخسارة باستخدام دالة خسارة loss function مرحلة الانتشار الخلفي Backward pass التي يحسب قيم التدرجات gradients لتحديث المعاملات القابلة للتعلم يكون الانتشار الأمامي forward pass في غاية البساطة، فالمخرجات للطبقة الحالية هي مدخلات الطبقة التالية ويستمر هذا النمط في التكرار، ولكن الانتشار الخلفي backward pass أكثر تعقيدًا من الناحية الحسابية، فهو يتطلب استخدام قاعدة السلسلة التفاضلية chain rule من أجل حساب التدرجات بالنسبة لمعاملات دالة الخسارة loss function، بمعنى أبسط تُخبرنا التدرجات بكيفية تعديل الأوزان والمعاملات في الشبكة العصبية لتقليل الخسارة. مثال بسيط لنلقِ النظر على شبكة عصبية في غاية البساطة، تتكون من 5 عصبونات أو عقد neurons، وتعرض هذه الصورة الشبكة العصبية التي نتحدث عنها. تصف المعادلات التالية هذه الشبكة العصبية البسيطة: لنحسب التدرجات التصحيحية لكل معامل قابل للتعلم w: حُسِبَت جميع هذه التدرجات gradients باستخدام قاعدة السلسلة chain rule، ويمكن أن نلاحظ أن جميع التدرجات الفردية في الجانب الأيمن من المعادلة يمكن حسابها بشكل مباشر بما أن البسط هو دالة ضمنية لتلك الموجودة في المقام. المخططات البيانية الحسابية Computation Graphs يمكن أن نحسب التدرجات gradients لشبكتنا العصبية يدويًا لأنها شبكة بسيطة للغاية، ولكن ماذا لو أردنا إجراء حسابات لشبكة تتكون من 152 طبقة، أو شبكة تمتلك عددًا كبيرًا من التفرعات. يتطلب تصميم برنامج لبناء الشبكات العصبية الاصطناعية ANN إيجاد طريقة تمكننا من حساب التدرج التصحيحي gradient بسهولة لمختلف المعماريات التي يمكن تكونيها، فنحن لا نريد أن ينشغل المطور بالتعامل اليدوي مع عملية حساب التدرج gradient عند حدوث أي تغيير في تصميم الشبكة. يمكننا تحقيق هذا المبدأ باستخدام هيكل بيانات يسمى المخطط البياني الحسابي computation graph، وتتشابه هذه البنية في الشكل مع الرسم التوضيحي للشبكة العصبية البسيطة، مع وجود بعض الاختلافات، حيث أن العقد nodes في المخطط الحسابي هي معاملات operators وهي معاملات حسابية في أغلب الحالات كالجمع والطرح والضرب والقسمة، عدا في حالة واحدة حيث نحتاج لتعريف معامل operator يعبر عن عملية إنشاء المستخدم لمتغير مخصص. نلاحظ في الصورة التالية أننا رمزنا للمتغيرات الطرفية leaf variables بالرموز التالية a, w1, w2, w3, w4 من أجل التوضيح وسهولة التعامل، ولكنها ليست جزءًا أصيلًا من المخطط الرسومي graph، فما تمثله هو الحالة الخاصة التي ينشئ فيها المستخدم المتغيرات الخاصة به. أنشئت المتغيرات التالية b,c,d كنتيجة للعمليات الحسابية، بينما تكون المتغيرات a,w1,w2,w3,w4 معرّفة ومدخلة بواسطة المستخدم، وبما أنها ليست متغيرات ناتجة أن أي عملية حسابية، فسنرمز للعقد التي تعبر عنها باسم المتغير الذي أنشأه المستخدم. وهذا ينطبق على كل العقد الطرفية leaf nodes في المخطط الحسابي. حساب التدرجات Gradients بعد التعرف على بعض المفاهيم الأساسية، لنتعرف الآن على آلية حساب التدرجات gradients باستخدام المخطط الحسابي computation graph، يمكن اعتبار كل عقدة node في المخطط -باستثناء العقد الطرفية- دالة تستقبل مدخلات وتعالجها وتدفع بالمخرجات لتنتشر خلال المخطط. لنلقِ نظرة على العقدة التي تخرج المتغير d بعد معالجة المدخلات w4×c و w3×b، يمكننا التعبير عنها كدالة على النحو التالي: حيث تعبر d عن مخرجات الدالة f(x,y)=x+y. يمكننا الآن وببساطة حساب التدرجات gradients للدالة f بالنسبة لمدخلاتها، وفق المعادلة التالية: بعد حساب التدرجات gradients سنعمل على وسم الأسهم في الاتجاه المعاكس لها بقيمة التدرج الخاص بها، كما في الصورة التالية: توضح الصورة التالية المخطط الحسابي كاملًا بعد أن طبقنا هذه على الخطوات عند كل العقد: تاليًا، سنصف الخوارزمية التي تحسب القيمة المشتقة عند أي عقدة في المخطط الحسابي بالنسبة لدالة الخسارة L. لنقل أننا نريد حساب الاشتقاق التالي : سنتبع أولًا كل المسارات الممكنة من d إلى w4 وفي حالتنا هناك مسار واحد يصل بين المتغيرين، ثم سنضرب قيم الحواف أو الوصلات edges الواقعة على هذا المسار. يمكن أن نلاحظ أن حاصل الضرب الناتج هو نفسه الذي حصلنا عليه عند استخدام قاعدة السلسلة chain rule، وإذا كان هناك أكثر من مسار يربط المتغير بدالة الخسارة L نضرب الوصلات في كل مسار ثم نجمع حاصل الضرب من كل مسار، كما في المثال التالي: حساب التفاضل التلقائي في PyTorch Autograd بعد أن تعرفنا بشكل مفصل على ماهية المخطط الحسابي computational graph، لنستكشف الآن آلية تطبيق المخطط الحسابي في باي تورش PyTorch بشكل آلي، سنستخدم هيكل بيانات يسمى التنسور أو المُوتِر Tensor وهو أساسي في باي تورش PyTorch، حيث يشبه نوعًا ما مصفوفات مكتبة نمباي NumPy arrays، ولكن على النقيض من نمباي NumPy، فإن التنسورات tensors مصممة للاستفادة من قدرات الحوسبة الفائقة على التوزاي التي توفرها وحدات المعالجة الرسومية GPUs، ويتشابه الكود وقواعد كتابته مع تلك الموجودة في نمباي NumPy. للنشئ tensor من 3 صفوف و 5 اعمدة، ونهيأه بقيم عشوائية كما يلي: In [1]: import torch In [2]: tsr = torch.Tensor(3,5) In [3]: tsr Out[3]: tensor([[ 0.0000e+00, 0.0000e+00, 8.4452e-29, -1.0842e-19, 1.2413e-35], [ 1.4013e-45, 1.2416e-35, 1.4013e-45, 2.3331e-35, 1.4013e-45], [ 1.0108e-36, 1.4013e-45, 8.3641e-37, 1.4013e-45, 1.0040e-36]]) لنضمن قيام باي تورش PyTorch بإنشاء مخطط حسابي للموترات tensor الذي عرفناه، ينبغي علينا ضبط قيمة المتغير requires_grad إلى True، فبدون هذه الخطوة سيكون الموتر مجرد هيكل بيانات تقليدي كالذي توفره مكتبة نمباي NumPy يمكن استخدامه للعمليات الجبر الخطي السريعة. قد يكون استخدام باي تورش لإنشاء موترات أمرًا مربكًا في البداية، حيث توجد عدة طرق لإنشاء الموترات tensors، فتسمح بعض الطرق بتمرير تعريف المتغير requires_grad بشكل صريح في الدالة المُنشأة، وطرقًا أخرى تجعلنا نضبط هذا المتغير يدويًا بعد إنشاء الموتر tensor. t1 = torch.randn((3,3), requires_grad = True) t2 = torch.FloatTensor(3,3) # لا تسمح هذه الدالة بضبط هذا المتغير وقت الإنشاء # لكن يمكن ضبطه بعد الإنشاء t2.requires_grad = True تحدد الخاصية requires_grad فيما إذا كان على باي تورش تتتبع العمليات الرياضية التي تنفذ على الموتر حتى يتمكن لاحقًا من حساب التدرجات gradients أثناء الانتشار الخلفي، فإذا كانت قيمته True يجري تتبع العمليات وحساب التدرجات لاحقًا، وفي حال كانت False لن يكون هناك تتبع للعمليات، ولن تحسب التدرجات. وعند إنشاء موتر tensor كنتيجة لعملية على موتر آخر يضبط هذه الخاصية بالقيمة True فإن الموتر الناتج سيمتلكها أيضًا، فيلزم على الأقل أن يكون أحد الموترات tensors الداخلة في العملية قد فعّل هذه الخاصية أثناء إنشائه لتنتشر من خلال الموتر الناتج عن هذه العملية حتى إن لما تكن مفعلة في باقي الموترات. كما يمتلك كل موتر tensor خاصية تسمى grad_fn ، والتي تشير إلى إلى معامل رياضي operator يقوم بإنشاء المتغير، وحينما تكون خاصية requires_grad غير مفعلة False فتكون grad_fn قيمتها None. سنجد في مثال d=f(w3b,w4c)، أن دالة التدرج grad function ستكون هي عملية الجمع، حيث تجمع الدالة f المدخلات معًا، وستكون عملية الجمع عقدة في المخطط الحسابي الذي يخرج d، وفي حالة كون العقدة طرفية أي متغير معرف بواسطة المستخدم فستكون دالة التدرج الخاصة به grad_fn=None. import torch a = torch.randn((3,3), requires_grad = True) w1 = torch.randn((3,3), requires_grad = True) w2 = torch.randn((3,3), requires_grad = True) w3 = torch.randn((3,3), requires_grad = True) w4 = torch.randn((3,3), requires_grad = True) b = w1*a c = w2*a d = w3*b + w4*c L = 10 - d print("The grad fn for a is", a.grad_fn) print("The grad fn for d is", d.grad_fn) ينتج تشغيل هذا الكود الخرج التالي: The grad fn for a is None The grad fn for d is <AddBackward0 object at 0x1033afe48> دوال الصنف Autograd.Function تُنفَّذ جميع العمليات الحسابية في باي تورش PyTorch من خلال الصنف البرمجي torch.nn.Autograd.Function، الذي يشكل جزءًا أساسيًا من آلية التفاضل التلقائي. يعتمد هذا الصنف على دالتين رئيسيتين: الأولى هي دالة الانتشار الأمامي backward والتي تحسب المخرجات بناءً على المدخلات السابقة، مما يمثل العملية الحسابية التي تجريها الطبقة أثناء تمرير البيانات عبر النموذج. أما الدالة الثانية فهي دالة الانتشار الخلفي backward التي تتولى حساب التدرجات من خلال استقبالها من الطبقات التالية في الشبكة. يمكن ملاحظة أن اتجاه انتشار التدرجات gradients يكون عكسيًا، أي من المخرجات نحو المدخلات، وليس العكس. هذا يعني أن التدرجات القادمة من الدالة f تنتقل من الطبقات الأخيرة في النموذج إلى الطبقات الأولى. وتعدّل الأوزان في كل طبقة بناءً على مدى تأثيرها على الخطأ النهائي. يتم ذلك عن طريق ضرب التدرج القادم من الطبقة التالية في التدرج المحلي الخاص بتلك الطبقة، مما يساعد على حساب مقدار التغيير اللازم لكل وزن حتى تتحسن دقة النموذج. وبالتالي، تتلقى كل طبقة معلومات من الطبقة التي تليها حول كيفية تغيير أوزانها لتقليل الخطأ، ويستمر هذا التدفق العكسي حتى تصل التحديثات إلى أول طبقة في النموذج. هذا هو جوهر عملية الانتشار الخلفي التي تتيح للنموذج التعلم من الأخطاء وتحسين أدائه بمرور الوقت. مثال عملي لنفهم الأمر بمثال عملي لنفرض أن لدينا دالة حسابية بسيطة تمثل جزءًا من شبكة عصبيةd = f(w3b , w4c) d هنا هي موتر tensor، ودالة التدرج grad_fn هي <ThAddBackward> وهي عملية جميع بسيطة حيث أن الدالة التي أنشئت d تجمع المدخلات، وتتلقى دالة الانتشار الأمامي forward مدخلات دالة التدرج grad_fn حيث تتلقى w3b و w4c وتجمع المدخلات في دالة التدرج، ثم تتدفق النتيجة للأمام بعد أن تحفظ في الموتر d. وتتلقى دالة التراجع backward الخاصة بالدالة <ThAddBackward> التدرجات الداخلة incoming gradient من الطبقات التالية لها كمدخلات أي الطبقات التي على يمين الطبقة الحالية، ما نحاول حسابه هو الاشتقاق الجزئي لدالة الخسارة L بالنسبة للمتغير d والتي تتكون من كل القيم الموجودة على الوصلات edges التي تربط بين L و d، ويمكن الوصول لقيم التدرجات gradients بالنسبة للمتغير d حيث تخزن في grad وهو خاصية للموتر، فتصل لها من خلال d.grad. نحسب بعد هذا التدرجات المحلية local gradients، أي التفاضل الجزئي للمتغير d أس الدالة التي تجمع بالنسبة للمدخلات w4c ومرة أخرى بالنسبة للمدخل w3b. تُضرب التدرجات gradients القادمة من الطبقات التالية مع التدرجات المحسوبة محليًا بواسطة دالة التراجع، ومن ثم ترسل التدرجات لتنتشر تراجعيًا ناحية المدخلات محفزة تفاعلًا متسلسلًا، تشغّل فيه دالة التراجع لحساب تدرجات الدالة grad_fn المرتبطة بالمدخلات السابقة. نوضح الأمر بمثال، تقوم دالة التراجع backward المرتبطة بالدالة <ThAddBackward> الخاصة بالمتغير d بتحفيز دالة التراجع للمدخلات grad_fn والتي بدورها تحفز دالة التراجع للمدخل w4c، لاحظ أن w4c هو موتر انتقالي أي أنه مُنشَأ لحفظ ناتج العملية الوسيطة ودالة التدرجات gradient الخاصة به هي <ThMulBackward>، وحينما تستدعي هذه دالة التراجع backward لحساب عملية التدرجات gradients يمرر لها تدرج الاشتقاق الجزئي لدالة الخسارة L بالنسبة إلى المتغير d مضروبة في الاشتقاق الجزئي للمتغير d بالنسبة للمتغير w4c، وتوضح الصورة التالية المعادلة المعبرة عن هذه العملية: ويحين الدور الآن على المتغير w4c، فتصبح المعادلة المكتوبة في الأعلى هي المدخلات لهذه العقدة في عملية الانتشار التراجعي لحساب التدرجات gradients، كما كان الأمر في الخطوة الثالثة بالنسبة للمتغير d حيث كانت المدخلات هي الاشتقاق الجزئي لدالة الخسارة بالنسبة للمتغير d. لنطبق الأمر من خلال خوارزمية تحسب عملية الانتشار الخلفي باستخدام المخطط الحسابي computation graph، هذا ليس التطبيق الكامل لهذه الدالة ولكنه مثال توضيحي بسيط. def backward(self, incoming_gradients): # اضبط قيمة التدرج للموتر الحالي self.Tensor.grad = incoming_gradients # حلقة تكرارية لتنفيذ الانتشار التراجعي للتدرجات for inp in self.inputs: if inp.grad_fn is not None: # احسب التدفقات القادمة تجاه المُدخل الحالي # Compute new incoming gradients for the input new_incoming_gradients = incoming_gradients * local_grad(self.Tensor, inp) # استدعِ دالة التراجع بشكل تعاودي # Recursively call inp.grad_fn.backward(new_incoming_gradients) نجد في هذا الكود أن self.Tensor هو موتر Tensor منشئ بواسطة Autograd.Function، والتي كانت في مثالنا d، وقد شرحنا سابقًا مفهوم التدرجات القادمة incoming gradients والتدرجات المحلية local gradients. لنحسب المشتقات في الشبكة العصبية، سنحتاج لاستدعاء دالة التراجع backward وتطبيقها على Tensor الذي يمثل الخسارة loss، ونستمر في الرجوع للخلف backtrack خلال المخطط الحسابي بداية من العقدة التي تمثل دالة التدرج grad_fn الخاصة بدالة الخسارة. وشرحنا سابقًا أن دالة التراجع backward تستدعى بشكل تعاودي recursive، فأثناء تتبع أثر التفرعات خلال الشبكة الحسابية نستدعي هذه الدالة، والتي بدورها تستدعي نفسها عندما تتراجع للمستوى السابق وهكذا حتى نصل لحالة التوقف الأساسية base case وهي العقد الطرفية leaf node والتي تكون دالة التدرج grad_fn فيه عديمة القيمة None. ننبه لأن باي تورش PyTorch يعطي خطأ Error عندما نحاول استدعاء دالة التراجع backward وتطبيقها على موتر تتكون عناصره من متجهات متعددة القيم vector-valued Tensor، ويعني هذا أن دالة التراجع backward تعمل على موترات تحتوي قيمًا رقمية أحادية scalers. import torch a = torch.randn((3,3), requires_grad = True) w1 = torch.randn((3,3), requires_grad = True) w2 = torch.randn((3,3), requires_grad = True) w3 = torch.randn((3,3), requires_grad = True) w4 = torch.randn((3,3), requires_grad = True) b = w1*a c = w2*a d = w3*b + w4*c L = (10 - d) L.backward() سوف يعطي تشغيل هذا الكود الخطأ التالي: RuntimeError: grad can be implicitly created only for scalar outputs يرجع سبب هذا الخطأ لكون قيم التدرجات gradient قابلة لأن تحسب بالنسبة لقيم رقمية أحادية scalers، السبب هو طريقة تعريف التدرج gradient definition، حيث لا يمكنها أن تفاضل متجهًا بالنسبة لمتجه آخر، ولتحقيق ذلك نستخدم عملية رياضية مختلفة تسمى Jacobian وهي خارج نطاق اهتمامنا في هذا المقال. تكمن المشكلة في توقع دالة التراجع بأن تكون المخرجات قيمة واحدة أو رقم واحد وليست متجهًا. يمكننا تجاوز هذه المشكلة بطريقتين، حيث يمكننا إجراء تعديل بسيط على الكود السابق بضبط قيمة L لتكون مجموع كل الأخطاء، سوف يحل هذا مشكلتنا. import torch a = torch.randn((3,3), requires_grad = True) w1 = torch.randn((3,3), requires_grad = True) w2 = torch.randn((3,3), requires_grad = True) w3 = torch.randn((3,3), requires_grad = True) w4 = torch.randn((3,3), requires_grad = True) b = w1*a c = w2*a d = w3*b + w4*c # L = (10 - d) استبدلنا هذا # بهذا L = (10 -d).sum() L.backward() يمكننا الوصول للتدرجات الآن بكل سهولة من خلال استدعاء خاصية grad الموجودة في الموتر Tensor. لنشرح الطريقة الثانية مفترضين أننا نحتاج -لأي سبب من الأسباب- لاستخدام دالة backward على دالة متجهة vector function، يمكننا تجاوز الخطأ بتمرير موتر torch.ones للدالة بأبعاد مطابقة للموتر الذي نحاول تمريره لدالة التراجع. # L.backward() استبدل L.backward(torch.ones(L.shape)) ويمكن أن نلاحظ أننا مررنا لدالة backward التدرجات القادمة incoming gradients من مدخلاتها، وبهذا جعلنا الدالة تتلقى التدرجات gradients على هيئة موترات مليئة بالواحد Tensor of ones بنفس أبعاد L، مما يجعلها قابلة للانتشار الخلفيbackward propagation بشكل مبسط. تمكننا هذه الطريقة من الحصول على تدرجات gradients أي موتر Tensor، وتحديث الأوزان والمعاملات من خلال خوارزمية التحسين التي نفضلها. w1 = w1 - learning_rate * w1.grad أبرز الاختلافات بين باي تورش PyTorch و تنسورفلو Tensorflow المخططات الحسابية ينشئ باي تورش PyTorch مخططات حسابية ديناميكية Dynamic Computation Graph أي أنها تولد بشكل مرن تلقائيًا عند الحاجة، واستخدام دالة الانتشار الأمامي forward هو المحفز لإنشاء المتغيرات التي سنستخدمها لاحقًا في خطوة الانتشار الخلفي، وبالتالي قبل استدعاء دالة الانتشار الأمامي forward لن توجد أي عقدة تحمل موتر بخاصية دالة التدرج grad_fn. # لا يوجد أي شبكة حسابية حتى الآن، فهنا نعرف مجرد عقدة طرفية a = torch.randn((3,3), requires_grad = True) # ينطبق نفس الأمر هنا، مجرد تعريفنا لموتر w1 = torch.randn((3,3), requires_grad = True) # هنا يتم إنشاء شبكة حسابية بها دالة ضرب سيتم استخدامها لحساب التدرجات b = w1*a #Graph with node `mulBackward` is created. أنشئت الشبكة الحسابية هنا كنتيجة لتشغيل دالة الانتشار الأمامي forward الخاصة بعدة موترات tensors، وفقط عند استدعائها تُخصّص مساحات تخزينية ومتغيرات وسيطة لتحتفظ بالقيم الانتقالية التي ستستخدم في حساب التدرجات gradient لاحقًا عندما تستدعى دالة التراجع backward ، وتُحرّر المساحات التخزينية المخصصة فور الانتهاء من حساب التدرجات gradients في العقد غير الطرفية، وعندما تستدعى دالة الانتشار الأمامي forward على نفس المجموعة من الموترات Tensors، يعاد استخدام المساحات التخزينية للعقد الطرفية من التشغيل السابق للشبكة، بينما تنشأ وتخصص من جديد تلك المساحات الانتقالية أو الوسيطة عند وصول دالة الانتشار الأمامي لها. إن حاولنا استدعاء دالة التراجع backward أكثر من مرة على عقد غير طرفية non-leaf nodes، سنحصل على الخطأ التالي: RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time. يرجع هذا الخطأ لتحرير المساحات التخزينية التي أنشئت سابقًا للعقد غير الطرفية عند استدعاء دالة backward ، فلا يوجد طريق تنتشر فيه خلفيًا من خلاله عند استدعاء الدالة مرة أخرى، الأمر أشبه بعبور جسر من الحبال ثم قطع الحبال، للعبور مجددًا سنحتاج لإنشاءها من جديد، ولكن يمكنك أن نلغي هذا التأثير بضبط خاصية متاحة في دالة backward وهي retain_graph لتكون True. loss.backward(retain_graph = True) عند تفعيل هذه الخاصية سنتمكن من استخدام التراجع الخلفي backpropagation على نفس المخطط الحسابي، حيث ستتراكم التدرجات gradients، أي في المرة القادمة التي ننفذ فيها التراجع الخلفي ستضاف قيم التدرجات إلى تلك الموجودة سابقًا والمخزنة من الدورة السابقة. يناقض هذا طريقة عمل المخططات الحسابية الثابتة Static Computation Graphs التي يستخدمها تنسورفلو TensorFlow، حيث يعرف المخطط الحسابي قبل تشغيل البرنامج. ويجري تشغيله عن طريق إدخال القيم المعرفة مسبقًا. تسمح المخططات الحسابية الديناميكية dynamic graph بالتغيير في معمارية المخطط أثناء التشغيل، حيث يتم إنشاء المخطط فقط عند تشغيل جزء محدد من الكود. ويعني هذا أيضًا أن المخطط يمكن أن يعاد تعريفه أثناء تشغيل البرنامج، وكما وضحنا فهذا غير ممكن في المخطط الثابت حيث يعرف المخطط وينشأ قبل تشغيل البرنامج. ويسهل تقفي أثر الأخطاء والمشاكل التي قد تحدث مع المخططات الديناميكية المرنة حيث يمكننا معرفة مصدر الخطأ، فلن نستطيع إكمال الانتشار إن وجدنا مشكلة بجزء معين، على النقيض من المخططات الثابتة حيث يتم الانتشار في مسارات معرفة مسبقًا. وجه المقارنة مخطط حسابي ديناميكي مخطط حسابي ثابت إطار العمل باي تورش PyTorch تنسورفلو TensorFlow تعريف المخطط وقت التشغيل قبل التشغيل طريقة التشغيل يؤجل التشغيل حتى البناء الكامل للمخطط الرسومي يتم التشغيل بشكل متزامن مع بناء المخطط الرسومي المرونة مرن للغاية، يمكن تغير المعمارية وقت التشغيل أقل مرونة، فنحتاج لإعادة بناء المخطط عند كل تعديل الأداء أبطء نسبيًا، حيث تفسر كل عملية على حدة وقد يوجد تكرار أسرع حيث يتم تحسين المخطط قبل تشغيله وتفادي التكرار التحسين مساحة محدودة للتحسين، حيث تنفذ جميع العمليات فورًا مع معرفتنا بهيكل المخطط كاملًا يمكن تطبيق خوارزميات تحسن ترتيبه وطريقة تشغيله بسهولة كفاءة التخزين أقل كفاءة، فكل عملية يحجز لها مساحة مخصوصة حتى وإن كانت مكررة. أكثر كفاءة، فيعاد استخدام المتغيرات المتكررة. اكتشاف المشاكل وحل الأخطاء أسهل أصعب المعماريات المناسبة مناسب للغاية للمعماريات المرنة، مثل الشبكات العصبية التكرارية RNN، التي تتعامل مع متسلسلات من المدخلات مثل الجمل، ومرونة باي تورش تمكننا من التعامل مع حجم جمل متغير. أنسب للمعماريات الثابتة، مثل الشبكات العصبية الالتفافية CNN مجال الاستخدام المجال البحثي، وتطوير المعماريات الجديدة، ولكنه قد لا يكون محسنًا بما يكفي لبيئات التشغيل يشيع استخدامه في بيئات التشغيل وعملية الاستدلال، حيث تكون الشبكة محسنة بدرجة فائقة وقابلة للنقل والتشغيل في بيئات مختلفة. ملاحظات إضافية لنتعرف الآن على بعض الملاحظات والطرق التي يمكن أن نستخدمها لتغيير سلوك المخطط الحسابي في باي تورش PyTorch. الخاصية requires_grad تكون هذه الخاصية المتعلقة بالموترات Tensors في غاية الأهمية، عندما تريد أن تجمد بعض الطبقات في الشبكة العصبية ولا تريد أن يتم تدريبها، حيث يمكنك ببساطة أن تجعل قيمة هذه الخاصية False، وبالتالي لن تكون هذه الموترات داخلة في عملية حساب التدرجات gradients. ولن تنتشر لهم أي تدرجات gradients نتيجة لإيقاف هذه الخاصية، ولا للطبقات التي تعتمد عليها، ونلاحظ أن هذه الخاصية في الأصل قابلة للانتشار فعند تنفيذ عملية على موترات أحدها مفعل به هذه الخاصية، فسيكون الموتر الناتج يحمل هذه الخاصية مفعلة True. الخاصية torch.no_grad نحتاج أحيانًا إلى تخزين بعض المدخلات والمتغيرات الانتقالية مؤقتًا أثناء حساب التدرجات gradients، لنستخدمهم في خطوات قادمة لحساب شيء آخر، فمثلًا تدرج المتغير b=w1*a بالنسبة لمدخلاته w1 و a يساوي w1 و a فنحتاج تخزين هذه المتغيرات لاستخدامها لاحقًا في حساب التدرجات أثناء الانتشار الخلفي، ولهذا أثر ثقيل على استخدام الذاكرة. والاستدلال بحد ذاته لا يتطلب منا إعادة حساب التدرجات gradients، وبالتالي لسنا بحاجة لتخزينها بشكل دائم، في الواقع نحن لانحتاج أن ننشئ المخطط الحسابي وقت الاستدلال حيث سيؤدي هذا لهدر الذاكرة. يقدم باي تورش PyTorch حلًا لهذه المشكلة، من خلال مدير السياق context manager، المسمى torch.no_grad والذي يعطل عملية حساب التدرجات gradients في أي سياق يتطلب تحديث أوزان النموذج أو ربما تقييمه، ويوفر هذا الكثير من الذاكرة، حيث لا ننشئ المتغيرات الوسيطة ولا المخطط الحسابي. with torch.no_grad: كود الاستدلال هنا الخاتمة تعرفنا في مقال اليوم على آلية عمل التفاضل التلقائي ومحرك التفاصل المستخدم في باي تورش PyTorch والمسمى Autograd، والذي يجعل من التعامل مع باي تورش PyTorch أسهل وأبسط، بعد فهم هذه الأساسيات يمكن التعمق في فهم النماذج المعقدة، وكيف يمكن بناؤها بواسطة باي تورش. ترجمة وبتصرف لمقال PyTorch 101, Understanding Graphs, Automatic Differentiation and Autograd لصاحبه Ayoosh Kathuria اقرأ أيضًا تعرف على دوال الخسارة Loss Functions في PyTorch أفضل ممارسات هندسة المُوجِّهات Prompt Engineering: نصائح وحيل وأدوات تدريب المًكيَّفات PEFT Adapters بدل تدريب نماذج الذكاء الاصطناعي بالكامل تعرف على إطار عمل باي تورش PyTorch وأهميته لتطبيقات الذكاء الاصطناعي -
 يعد مفهوم دوال الخسارة Loss Functions أساسيًا في تدريب نماذج تعلم الآلة، فلا توجد طريقة لتحفيز النموذج على التخمين بشكل صحيح بدون استخدام دالة خسارة، ويمكن أن نعرّف دالة الخسارة على أنها دالة رياضية تستخدم لقياس أداء النموذج في تنفيذ مهمة على مجموعة بيانات محددة، ومن خلال معرفة أداء النموذج على مجموعة بيانات محددة سنحصل على نظرة عامة تمكننا من اتخاذ قرارات خلال عملية التدريب كاستخدام نموذج أقوى أو حتى تغير دالة الخسارة المستخدمة لنوع آخر. سنستكشف في هذه المقالة دوال الخسارة المختلفة في باي تورش PyTorch. وكيف يتيح باي تورش للمستخدمين استخدام دوال الخسارة المطورة مسبقًا، أو بناء دالة خسارة مخصصة وأمثلة عملية توضح كيفية عملها. متطلبات المقال يتطلب فهم هذا المقال فهمًا جيدًا للشبكات العصبية الاصطناعية المكونة من طبقات متصلة تحتوي كل طبقة على عدد من العقد التي تسمى عصبون neuron. حيث تتعلم هذه الشبكات وتخمن القيم من خلال عملية التدريب training وتُضبط فيها الأوزان weights ومقدار الانحياز biases وهي معاملات تتحكم في درجة قوة التواصل بين العقد المختلفة، وهي تحاكي في طريقة عملها الخلايا العصبية الطبيعية. ولفهم الشبكات العصبية بشكل متعمق نحتاج لمعرفة أنواع الطبقات المختلفة وهي: طبقة المدخلات input layer والطبقة المخفية hidden layer وطبقة المخرجات output layer، ومعرفة بدوال التنشيط activation functions وخوارزميات التحسين optimization algorithms مثل الانحدار المتدرج gradient descent ودوال الخسارة وغيرها. كما يحتاج فهم المقال للإلمام بأساسيات لغة بايثون Python والتعامل مع إطار عمل باي تورش PyTorch لفهم الأكواد المكتوبة. ما هي دوال الخسارة Loss Functions تستخدم دوال الخسارة بشكل أساسي لتقييم أداء نموذج تعلم الآلة في تنفيذ مهمة على مجموعة بيانات محددة، فهي تحسب الفرق بين القيمة الحقيقية الصحيحة Y وبين القيمة المتوقعة ^Y، فعندما يخمن نموذج قيم قريبة جدًا من القيم الفعلية في كل من مجموعة بيانات التدريب ومجموعة بيانات الاختبار فهذا يعني أن النموذج موثوق ويُعتمد عليه. فدوال الخسارة loss functions توفر لنا معلومات مفيدة عن أداء النموذج، ولكن هذا ليس الدور الوحيد لدالة الخسارة، فهناك طرق أخرى أكثر موثوقية لتقييم النماذج مثل الصحة accuracy أو F-scores. في حين تبرز أهمية دوال الخسارة loss functions بشكل أساسي خلال عملية التدريب، وتساعدنا على دفع أوزان ومعاملات النموذج في الاتجاه الذي يقلل من الخسارة. وتقليل الخسارة يعني بالضرورة زيادة احتمالية التخمين الصحيح للقيم بواسطة نموذج تعلم الآلة، وهذا التحسن في التخمين ليس ممكنًا بدون استخدام دالة خسارة. تختلف أنواع دوال الخسارة loss functions باختلاف المشكلة التي نحاول حلها، حيث تصمم كل دالة بعناية لضمان تدفق التصحيح التدريجي gradient flow المناسب خلال عملية التدريب، ولكن من المهم معرفة دورها في عملية التدريب والتحسن المستمر. قد يصعب فهم الرموز الرياضية المعبرة عن معادلات الخسارة loss functions، حيث يتملص بعض المطورين من محاولة فهم هذه المعادلات الرياضية ويتعاملون معها على أنها صندوق أسود مجهول التفاصيل، ولكن فهم ما بداخل هذا الصندوق يعزز فهم دوال الخسارة ويساعدنا على تحديد الدالة الأفضل، سنشرح في الفقرات التالية أشهر دوال الخسارة في باي تورش، ولكن قبل هذا لنرى أين نضع هذا الصندوق، وكيف نستخدم دوال الخسارة في باي تورش؟ دوال الخسارة في باي تورش PyTorch يأتي باي تورش PyTorch معززًا بالكثير من دوال الخسارة الأساسية سهلة الاستخدام، وتُجمع كافة دوال الخسارة في وحدة برمجية واحدة باسم nn module والتي تُعدّ الوحدة الأساسية لبناء الشبكات العصبية الاصطناعية ANNs في بايتورش. يمكن إضافة دالة خسارة loss function للكود الخاص بنا بسهولة كتابة سطر برمجي واحد. لننظر معًا للمثال التالي لإضافة دالة خسارة متوسط مربع الخطأ Mean Squared Error loss function -أو MSE اختصارًا- في باي تورش PyTorch. import torch.nn as nn MSE_loss_fn = nn.MSELoss() تستخدم هذه الدالة في حساب الفرق بين قيم التخمينات والقيم الفعلية بالتنسيق التالي: #predicted_value هو التخمين القادم من الشبكة العصبية #target القيم الفعلية الموجودة في مجموعة البيانات #loss_value الخسارة بين قيمة التخمين والقيمة الفعلية Loss_value = MSE_loss_fn(predicted_value, target) بعد أن كونا فكرة أولية عن طريقة عمل دوال الخسارة في باي تورش PyTorch، لنتعمق أكثر في كواليس عمل عدد من هذه الدوال. دوال الخسارة في باي تورش PyTorch تقع معظم دوال الخسارة في باي تورش PyTorch تحت واحدة من التصنيفات الثلاثة التالية: دوال خسارة الانحدار regression loss functions دوال خسارة التصنيف classification loss functions دوال خسارة الترتيب ranking loss functions تهتم دوال خسارة الانحدار regression loss functions بالقيم والمتغيرات المستمرة continuous وهي المتغيرات التي يمكنها أن تأخذ عددًا لا نهائيًا من القيم بين رقمين، وأحد الأمثلة على هذا النوع من المتغيرات هو الأسعار، فمثلًا هل يمكن إحصاء كل الأسعار الممكنة للمنازل في منطقتنا؟ بالطبع لا ولكن يمكننا حصرها في نطاق عددي. تتعامل دوال خسارة التصنيف classification loss functions مع المتغيرات والقيم المتقطعة أو المنفصلة discrete، ومثال على هذا النوع من المهام عندما تحاول تميز كائن على أنه أحد التصنيفات المحددة ولتكن صندوق أو قلم أو زجاجة. تتوقع دوال خسارة الترتيب ranking loss functions المسافة النسبية بين القيم، وأحد التطبيقات عليها سيكون التوثيق من خلال صورة الوجه حيث نريد أن نعرف هوية صاحب الوجه بمقارنة صورته بعدد من الصور المعلومة هويتها لدينا وترتيبها حسب درجة التشابه، فالصور التي تنتمي لهذا الشخص يفترض أن تتشابه معه بنسبة كبيرة أكثر من تلك التي لأشخاص آخرين. دالة متوسط الخطأ المطلق Mean Absolute Error أو دالة الخسارة L1 تحسب دالة خسارة متوسط الخطأ المطلق MAE متوسط المجموع المطلق للفروق بين قيم التخمينات والقيم الفعلية. فتحسب أولًا الفرق بين قيمة التخمين والقيمة الفعلية عند كل عنصر في الموتر tensor، ونراكم المجموع المطلق لهذه الفروق التي حصلنا عليها في الخطوة السابقة، وفي النهاية نحسب متوسط هذا المجموع التراكمي بقسمته على العدد الكلي لتخمينات النموذج ونقارنها بالقيم الفعلية، للحصول على متوسط الخطأ المطلق MAE، وتعتبر دالة الخسارة هذه موثوقة للغاية في التعامل مع التشويش noise في البيانات. وتعرف هذه الدالة بمسمى آخر وهو دالة L1. وفيما يلي كود برمجي يُعرّف ويستخدم دالة خسارة من نوع MAE أو L1: import torch.nn as nn #size_average & reduce are deprecated # لا يوصى باستخدامهما فمن المحتمل تغيرهما في النسخ المستقبلية #reduction تحدد العملية التي ستحسب بعد حساب الفروق المطلقة لكل القيم ''' `none` tensor تعني أننا لن نقوم بأي عملية على الفروق المطلقة وسنخرجها كتنسور `sum` سنجمع جميع الفروق المطلقة لكل القيم دون أخذ المتوسط `mean` القيمة الافتراضية لهذا المعامل سنجمع جميع الفروق المطلقة ونأخذ متوسطها بقسمة المجموع على عدد العناصر في المخرجات ''' Loss_fn = nn.L1Loss(size_average=None, reduce=None, reduction='mean') input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss_fn(input, target) print(output) #tensor(0.7772, grad_fn=<L1LossBackward>) متوسط مربع الخطأ Mean Squared Error يتشابه متوسط مربع الخطأ MSE مع متوسط الخطأ المطلق MAE، لكن الفرق بينهما هو أن MSE يحسب مربع الفرق بين القيم المتوقعة والحقيقية، بينما يحسب MAE القيمة المطلقة للفرق. وبسبب وجود التربيع في MSE، تعطي هذه الدالة وزنًا أكبر للأخطاء الكبيرة، وهي أكثر حساسية للقيم الشاذة أو الضوضاء في البيانات مقارنة بالدالة MAE الأقل حساسية للقيم الشاذة لأنها لا تضخم الأخطاء الكبيرة بنفس الطريقة. ويعد متوسط مربع الخطأ المطلق المعيار الثاني Second norm أو L2 ويعرف أيضًا بالمعيار الإقليدي Euclidean norm أو المسافة الإقليدية، وهو نفس القانون المعروف لحساب المسافة بين نقطتين في الإحداثيات. فيما يلي كود برمجي يُعرّف ويستخدم دالة خسارة من نوع MSE أو L2: import torch.nn as nn loss = nn.MSELoss(size_average=None, reduce=None, reduction='mean') #ينطبق نفس الشرح السابق عن هذه المعاملات input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) print(output) #tensor(0.9823, grad_fn=<MseLossBackward>) خسارة الإنتروبيا المتقاطعة Cross-Entropy Loss تستخدم دالة خسارة الإنتروبيا المتقاطعة Cross Entropy في مسائل التصنيف classification والتي تتعامل مع تصنفيات محددة ومعدودة لقياس الفرق بين التوزيع الحقيقي للفئات والتوزيع الذي يتنبأ به النموذج. فتقيس الفرق بين توزيع الاحتماليات لكل مجموعة معطاة من المتغيرات العشوائية، ويغلب استخدام دالة softmax كطبقة المخرجات عند استخدم الإنتروبيا المتقاطعة كدالة خسارة، حيث تحوّل دالة softmax القيم الداخلة في المتجه أو التنسور tensor لتكون بين الصفر والواحد، ومجموع العناصر الخارجة ليساوي الواحد لتحقق شروط الاحتمالات، وتبقى القيمة العظمى في المتجه هي القيمة الأكبر بعد تطبيق الدالة. وبالمقارنة مع دالة hardmax التي تستخرج القيمة العظمى من متجه وتُعيّنها إلى 1، بينما تتجاهل باقي العناصر وتحواها إلى 0 فإن دالة softmax تحافظ على المعلومات النسبية لجميع القيم، مما يجعلها مناسبة أكثر لترتيب الاحتمالات فهي تعطي قيمًا احتمالية لكل تصنيف. وتتكون دالة softmax من جزأين الأول هو عدد أويلر e مرفوعًا لأس قيمة التخمين لتصنيف معين في المتجه حيث يمثل كل عنصر أحد التصنيفات المحددة. حيث أن y_i هي خرج من الشبكة العصبية الاصطناعية لتصنيف معين، وتعطينا هذه الدالة رقمًا قريبًا من الصفر ولكنه لا يكون أبدًا مساويًا للصفر، وتقترب قيمة الدالة من الواحد عندما تكون y_i قيمة كبيرة سالبة، وعندما تكون قيمة كبيرة موجبة تعطي الدالة رقمًا موجبًا كبيرًا، كما نلاحظ في المثال التالي: import numpy as np np.exp(34) #583461742527454.9 np.exp(-34) #1.713908431542013e-15 أما الجزء الثاني من الدالة فهو عملية توحيد normalization حيث تضمن هذه الخطوة أن دالة softmax تعطي دائمًا قيمة احتمالات بين الصفر والواحد. توضح الصورة التالية الخطوات التي قمنا بها: ويمكننا جمع الخطوات في معادلة واحدة تعبر عن استخدامنا لدالة softmax لتحول متجه المخرجات لاحتمالات كل تصنيف، مثلًا في مهمة التمييز بين صور القطط والكلاب قد يكون احتمال كون الصورة المدخلة للشبكة العصبية قطة هو 0.80 بينما احتمال أن تكون الصورة لكلب 0.20 مما يسهل علينا فهم التصنيفات بشكل احتمالات قابلة للترتيب. يجمع باي تورش في الوحدة nn كلًا من الإنتروبيا المتقاطعة Cross-entropy و احتمالية اللوغاريتم السالب Negative Log-Likelihood لدالة softmax في دالة خسارة واحدة. دالة خسارة احتمالية اللوغاريتم السالب تعمل دالة خسارة احتمالية اللوغاريتم السالب Negative Log-Likelihood loss -أو NLL اختصارًا- بشكل مشابه لدالة خسارة الإنتروبيا المتقاطعة Cross-Entropy، وكما ذكرنا سابقًا تجمع دالة الإنتروبيا المتقاطعة CE طبقة لوغاريتم الدالة العظمى الناعمة log-softmax مع احتمالية اللوغاريتم السالب NLL من أجل حساب قيمة خسارة الإنتوربية المتقاطعة. ويعني هذا أنه يمكننا الحصول على قيمة خسارة الإنتروبيا المتقاطعة CE باستخدام احتمالية اللوغاريتم السالب NLL بجعل الطبقة الأخيرة من الشبكة العصبية طبقة log-softmax بدلًا من دالة softmax التقليدية. وفيما يلي كود برمجي ينجز تصنيف متعدد الفئات Multi-class Classification باستخدام الدالة softmax و NLL: m = nn.LogSoftmax(dim=1) loss = nn.NLLLoss() # أبعاد المدخلات # N x C = 3 x 5 input = torch.randn(3, 5, requires_grad=True) # يجب أن تكون قيمة كل عنصر في تنسور الهدف أو القيم الفعلية أحد التصنيفات المحددة بالفعل # 0 <= value < C # C ---> يعبر عن آخر تصنيف اعتبارًا أن أول تصنيف سنرمز له بالصفر target = torch.tensor([1, 0, 4]) # المخرجات وهنا نطبق دالة لوغاريتم دالة القيمة العظمي على المدخلات # ثم نحسب مقدار الخسارة بين بينها وبين متجه الهدف أو القيم الفعلية output = loss(m(input), target) output.backward() # حساب الخسارة لتنسورات ثنائية الأبعاد يمكن على سبيل المثال أن تستخدم مع الصور N, C = 5, 4 loss = nn.NLLLoss() # أبعاد المدخلات # N x C x height x width data = torch.randn(N, 16, 10, 10) conv = nn.Conv2d(16, C, (3, 3)) m = nn.LogSoftmax(dim=1) target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C) output = loss(m(conv(data)), target) print(output) #tensor(1.4892, grad_fn=<NllLoss2DBackward>) #credit NLLLoss — PyTorch 1.9.0 documentation دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية Binary Cross-Entropy Loss دالة خسارة الإنتروبيا المتقاطعة الثنائية Binary CE هي حالة خاصة من الإنتروبيا المتقاطعة CE وتستخدم عند تصنيف البيانات لأحد تصنيفين، ولذلك تسمى ثنائية حيث نرمز لأحد التصنيفين بصفر وللآخر بواحد، ونهدف عند استخدامها لجعل النموذج يخمّن رقمًا قريبًا من الصفر عندما يكون التصنيف الفعلي هو الصفر ورقمًا قريبًا للواحد إن كان التصنيف الفعلي واحد، وتكون في الغالب الطبقة الأخيرة في الشبكة العصبية عند استخدام هذه النوع من دوال حساب الخسارة طبقة تستخدم دالة سينية Sigmoid وبالتحديد الدالة اللوجستية logistic function وهي نوع خاص من الدوال السينية sigmoid functions والتي تضمن أن المخرجات رقمًا قريبًا من الواحد أو الصفر ليحقق شروط الاحتمالات. وفيما يلي كود يحسب دالة الخسارة للانحدار اللوجستي باستخدام الدالة BCE: import torch.nn as nn m = nn.Sigmoid() loss = nn.BCELoss() input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) output = loss(m(input), target) print(output) #tensor(0.4198, grad_fn=<BinaryCrossEntropyBackward>) دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية مع لوغاريتم الفرص Binary Cross-Entropy Loss with Logits لو سألنا أحدهم ما هي فرص فوز فريقك المفضل في المباراة؟ يمكن أن يجيب باحتمال مباشر مثل 40%، ويمكن يعبر عن فرص فوز الفريق فيقول يفوز الفريق مرتين من كل خمس مرات، فهذه نفس النسبة ولكن بطريقة مختلفة. حيث يعبر الاحتمال Probability عن فرصة وقوع الحدث من إجمالي جميع الحالات الممكنة، وتعبر الفرص odds عن نسبة احتمال وقوع الحدث إلى احتمال عدم وقوعه، ويستخدم لوغاريتم الفرص Logits أو log(odds) لتحويل الاحتمالات لقيم يمكن استخدامها بسهولة في الحسابات الرياضية، ويضمن أن النتائج تتبع توزيعًا خطيًا بدلاً من أن تكون مقيدة بين الصفر والواحد. ذكرنا سابقًا أن دالة خسارة الإنتروبيا المتقاطعة الثنائية BCE تُسبق بطبقة بها الدالة السينية اللوجيستية logistic sigmoid لضمان أن المخرجات بين الواحد والصفر. وتُجمَع دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية Binary Cross-Entropy Loss مع لوغاريتم الفرص Logits الطبقتين في طبقة واحدة، ووفقًا لتوثيق باي تورش PyTorch فهذا يجعلها أكثر استقرارًا عند إجراء العمليات الحسابية حيث يمكنها الاستفادة من تحويل الضرب إلى جمع بفضل اللوغاريتم. import torch import torch.nn as nn # 64 تصنيفًا # حجم الدفعة الواحدة 10 target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10 # المخرجات التي سنجرب عليها # هذا مثال افتراضي # ولكن عندما تكون هذه المخرجات من الشبكة العصبية # قبل مرورها في الدالة اللوجستية تسمي # logit / prediction output = torch.full([10, 64], 1.5) # جميع الأوزان هنا متساوية بواحد pos_weight = torch.ones([64]) criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight) loss = criterion(output, target) # -log(sigmoid(1.5)) print(loss) #tensor(0.2014) دالة خسارة المعيار الأول المرنة Smooth L1 loss تستفيد دالة خسارة المعيار الأول Smooth L1 loss من مزايا كل من متوسط مربع الخطأ MSE ومتوسط الخطأ المطلق MAE من خلال معامل تحكم بيتا beta، وقُدم المعيار لأول مرة في الورقة البحثية Fast R-CNN . ويستخدم المعيار مربع الفرق عندما يكون الفرق المطلق بين القيم الفعلية والقيم المتوقعة أقل من بيتا beta فيصبح المعيار المستخدم MSE، ويرسم معدل الخسارة لمتوسط مربع الخطأ بشكل منحني متصل ومستمر، مما يجعل الدالة قابلة للاشتقاق عند كل القيم مما يمكننا من حساب معدل التدرج التصحيحي gradients لكل هذه القيم، ولكن عندما تصبح قيمة الخطأ عالية تظهر مشكلة تزايد التدرج بشكل خارج عن السيطرة يوصف بالإنفجاري gradient explosion حيث تصبح قيم التدرج gradients عالية وعند ضربها في الأوزان بشكل مستمر نحصل على أرقام ضخمة تؤدي في النهاية إلى عدم استيعاب المتغيرات لحجم الأرقام وعدم قدرة النظام على التعلم فيما يعرف بالفوران overflow، ولذلك عندما تبدأ هذه الظاهرة في الحدوث نستخدم معيار قيمة الخطأ المطلق MAE والذي يجعل الزيادة في قيم التدرج شبه ثابتة أي خطية عند كل القيم، ونحدد وقت التغيير بناءً على معامل التحكم بيتا beta. import torch.nn as nn loss = nn.SmoothL1Loss() input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) print(output) #tensor(0.7838, grad_fn=<SmoothL1LossBackward>) دالة الخسارة المفصلية التضمينية Hinge Embedding loss تستخدم هذه الدالة في الغالب مع مهام التعلم غير الخاضع للإشراف unsupervised learning لقياس درجة التشابه بين مُدخلين كل منهما عبارة عن تنسور tensor، يمثًل هو تنسور المدخلات input tensor والآخر تنسور الوسم labels tensor وتكون الوسوم في هذه الحالة أحد قيمتين 1 أو 1-، وتٌحلّ من خلالها المسائل التي تحتوي على تضمين غير خطي non-linear embeddings ومهام التعلم غير الخاضع للإشراف. import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) hinge_loss = nn.HingeEmbeddingLoss() output = hinge_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output) #input: tensor([[ 1.4668e+00, 2.9302e-01, -3.5806e-01, 1.8045e-01, #1.1793e+00], # [-6.9471e-05, 9.4336e-01, 8.8339e-01, -1.1010e+00, #1.5904e+00], # [-4.7971e-02, -2.7016e-01, 1.5292e+00, -6.0295e-01, #2.3883e+00]], # requires_grad=True) #target: tensor([[-0.2386, -1.2860, -0.7707, 1.2827, -0.8612], # [ 0.6747, 0.1610, 0.5223, -0.8986, 0.8069], # [ 1.0354, 0.0253, 1.0896, -1.0791, -0.0834]]) #output: tensor(1.2103, grad_fn=<MeanBackward0>) دالة خسارة الترتيب الهامشية Margin Ranking Loss تنتمي دالة الترتيب الهامشية إلى دوال خسارة الترتيب التي تهدف لقياس المسافة النسبية بين مجموعة من المدخلات في مجموعة بيانات. ويُدخل للدالة مدخلان ووسم إما 1 أو 1-، فإذا كان الوسم 1 سنفترض أن المُدخل الأول يملك ترتيبًا أعلى من المُدخل الثاني، والعكس صحيح فإذا كان الوسم 1- يكون ترتيب المٌدخل الثاني أعلى، ويمكن أن نرى هذه العلاقة في المعادلة التالية: يوضح الكود التالي حساب الخسارة بين مُدخلين input1 و input2 باستخدام الدالة MarginRankingLoss: import torch.nn as nn loss = nn.MarginRankingLoss() input1 = torch.randn(3, requires_grad=True) input2 = torch.randn(3, requires_grad=True) target = torch.randn(3).sign() output = loss(input1, input2, target) print('input1: ', input1) print('input2: ', input2) print('output: ', output) #input1: tensor([-1.1109, 0.1187, 0.9441], requires_grad=True) #input2: tensor([ 0.9284, -0.3707, -0.7504], requires_grad=True) #output: tensor(0.5648, grad_fn=<MeanBackward0>) دالة الخسارة الثلاثية الهامشية Triplet Margin loss تقيس هذه الدالة التشابه بين المُدخلات باستخدام ثلاث عينات من البيانات. فتستخدم الدالة عينة المرساة anchor sample، وعينة سالبة لا تنتمي لنفس التصنيف، وعينة إيجابية تنتمي لنفس تصنيف عينة المرساة، ونهدف إلى تعظيم المسافة بين عينة المرساة والعينة الموجبة وتقليص المسافة بين عينة المرساة والعينة السالبة بحيث لا تقل عن قيمة هامشية محددة، وباستخدام هذه الدالة الثلاثية الهامشية triplet margin نريد تخمين درجة عالية من التشابه بين المرساة anchor والعينة الموجبة، وتشابه ضعيف منخفض بين عينة المرساة anchor والعينة السالبة. يوضح الكود التالي استخدام دالة الخسارة TripletMarginLoss: import torch.nn as nn triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2) anchor = torch.randn(100, 128, requires_grad=True) positive = torch.randn(100, 128, requires_grad=True) negative = torch.randn(100, 128, requires_grad=True) output = triplet_loss(anchor, positive, negative) print(output) #tensor(1.1151, grad_fn=<MeanBackward0>) دالة خسارة تضمين جيب التمام اCosine Embedding Loss تقيس دالة خسارة تضمين جيب التمام Cosine Embedding Loss الخسارة بين اثنين من المدخلات وتنسور من الوسوم قيم عناصره إما 1 أو 1-، وتستخدم عندما نريد قياس درجة التشابه أو القرب بين مُدخلين. وتحسب الدالة درجة التشابه بحساب مسافة جيب تمام الزاوية Cosine distance بين نقطتين أو متجهين في الفضاء. حيث تتناسب مسافة جيب التمام Cosine distance مع الزاوية بين المتجهين، فكلما قلت الزاوية قلت المسافة بين المتجهين وكلما كان المتجهان أقرب كلما كانت الكائنات التي يصفانها متشابهة. يوضح الكود التالي استخدام دالة الخسارة CosineEmbeddingLoss: import torch.nn as nn loss = nn.CosineEmbeddingLoss() input1 = torch.randn(3, 6, requires_grad=True) input2 = torch.randn(3, 6, requires_grad=True) target = torch.randn(3).sign() output = loss(input1, input2, target) print('input1: ', input1) print('input2: ', input2) print('output: ', output) #input1: tensor([[ 1.2969e-01, 1.9397e+00, -1.7762e+00, -1.2793e-01, #-4.7004e-01, # -1.1736e+00], # [-3.7807e-02, 4.6385e-03, -9.5373e-01, 8.4614e-01, -1.1113e+00, # 4.0305e-01], # [-1.7561e-01, 8.8705e-01, -5.9533e-02, 1.3153e-03, -6.0306e-01, # 7.9162e-01]], requires_grad=True) #input2: tensor([[-0.6177, -0.0625, -0.7188, 0.0824, 0.3192, 1.0410], # [-0.5767, 0.0298, -0.0826, 0.5866, 1.1008, 1.6463], # [-0.9608, -0.6449, 1.4022, 1.2211, 0.8248, -1.9933]], # requires_grad=True) #output: tensor(0.0033, grad_fn=<MeanBackward0>) دالة خسارة تباعد كولباك ليبلر Kullback Leibler Divergence تستخدم هذه الدالة في تقدير الخسارة لنماذج تعلم الآلة التي تحاول تعلم توزيع احتمالات probability distribution عن طريق حساب كمية المعلومات المفقودة في عملية التقريب، ونرمز للتوزيع الفعلي الذي نحاول تعليمه للآلة بالرمز P وللتوزيع التقريبي بالرمز Q ، وتعمل هذه الدالة على قياس التشابه بين التوزيع الفعلي P والتقريبي Q وبالتالي دفع خوارزمية تعلم الآلة نحو إنتاج توزيع قريب من التوزيع الفعلي قدر الإمكان. ويلاحظ أن مقدار الخسارة في المعلومات عند استخدام التوزيع التقريبي Q لتقدير التوزيع الفعلي P ليس مساويًا للعملية العكسية التي تستخدم التوزيع الفعلي P لتقدير التوزيع التقريبي Q ولذلك يعد تباعد كولباك ليبلر KL divergence غير متماثل Not symmetric. يوضح الكود التالي استخدام الدالة KLDivLoss: import torch.nn as nn loss = nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False) input1 = torch.randn(3, 6, requires_grad=True) input2 = torch.randn(3, 6, requires_grad=True) output = loss(input1, input2) print('output: ', output) #tensor(-0.0284, grad_fn=<KlDivBackward>) بناء دالة خسارة مخصصة توجد طريقتان لبناء دالة خسارة خاصة بنا تتناسب مع المشكلة التي نحاول حلها، الأولى عن طريق تحقيقها داخل صنف class والثانية عن طريق تحقيقها كدالة مستقلة، وسنستعرض كلا الطريقتين. تُعدّ طريقة الدالة المستقلة أسهل لبناء دالة خسارة مخصصة، حيث تُمرّر المُدخلات المطلوبة للدالة وتجري بعض العمليات عليها في جسم الدالة باستخدام العوامل والدوال البرمجية الأخرى المتاحة في باي تورش PyTorch أو من أي مصدر آخر، ومن ثم تعيد قيمة تمثّل الخسارة. يوضح المثال التالي تعريف دالة مخصصة لحساب متوسط مربع الخطأ MSE: def custom_mean_square_error(y_predictions, target): square_difference = torch.square(y_predictions - target) loss_value = torch.mean(square_difference) return loss_value نمرر لهذه الدالة الخاصة تنسور التخمينات predictions tensor وتنسور الوسوم labels tensor ونستخدم بعض الدوال لحساب مربع الفرق بين التنسورين tensors ومن ثم نأخذ المتوسط ونعيده كقيمة الخسارة. y_predictions = torch.randn(3, 5, requires_grad=True); target = torch.randn(3, 5) pytorch_loss = nn.MSELoss(); p_loss = pytorch_loss(y_predictions, target) loss = custom_mean_square_error(y_predictions, target) print('custom loss: ', loss) print('pytorch loss: ', p_loss) #custom loss: tensor(2.3134, grad_fn=<MeanBackward0>) #pytorch loss: tensor(2.3134, grad_fn=<MseLossBackward>) ونقارن في هذا المقطع البرمجي بين دالتنا المخصصة والدالة المدمجة بإطار عمل باي تورش PyTorch framework ويمكنك أن تلاحظ اتفاق الدالتين في القيم النهائية مما يعني أن الدالة مبنية بشكل صحيح. بناء صنف برمجي مخصص لحساب الخسارة يوصى بهذه الطريقة لكونها الطريقة التي يستخدمها باي تورش PyTorch في الكود المصدري، ففي هذه الطريقة نعرّف دالة الخسارة داخل صنف يرث من الصنف الأساسي nn.Module وهذا يسمح لدالة الخسارة المخصصة بالعمل بطريقة مشابهة للطبقات التقليدية في باي تورش، مما يسهّل دمجها واستخدامها ضمن الشبكات العصبية الاصطناعية ANN بنفس الطريقة التي تُستخدم بها الطبقات الأخرى. class Custom_MSE(nn.Module): def __init__(self): super(Custom_MSE, self).__init__(); def forward(self, predictions, target): square_difference = torch.square(predictions - target) loss_value = torch.mean(square_difference) return loss_value def __call__(self, predictions, target): square_difference = torch.square(y_predictions - target) loss_value = torch.mean(square_difference) return loss_value الخاتمة ناقشنا في هذا المقال العديد من دوال الخسارة loss functions المتوفرة في باي تورش PyTorch وتعمقنا في آلية عمل هذه الدوال والعلاقات الرياضية المعبرة عنها، قد يكون اختيار الدالة المناسبة مهمة صعبة، ولكن بفهمك الجيد لمحتوى هذه المقالة والرجوع للتوثيق الخاص بإطار عمل باي تورش PyTorch ستتمكن من اختيار دالة الخسارة المناسبة لمشكلتك بدقة. ترجمة وبتصرف لمقالة PyTorch Loss Functions لصاحبها Henry Ansah Fordjour. اقرأ أيضًا تعرف على إطار عمل باي تورش PyTorch وأهميته لتطبيقات الذكاء الاصطناعي طريقة الصقل Fine-Tune لنموذج ذكاء اصطناعي مُدرَّب مُسبقًا تعرف على أهم كتب الذكاء الاصطناعي المجانية تعرف على مكتبة Scikit learn وأهم خوارزمياتها
يعد مفهوم دوال الخسارة Loss Functions أساسيًا في تدريب نماذج تعلم الآلة، فلا توجد طريقة لتحفيز النموذج على التخمين بشكل صحيح بدون استخدام دالة خسارة، ويمكن أن نعرّف دالة الخسارة على أنها دالة رياضية تستخدم لقياس أداء النموذج في تنفيذ مهمة على مجموعة بيانات محددة، ومن خلال معرفة أداء النموذج على مجموعة بيانات محددة سنحصل على نظرة عامة تمكننا من اتخاذ قرارات خلال عملية التدريب كاستخدام نموذج أقوى أو حتى تغير دالة الخسارة المستخدمة لنوع آخر. سنستكشف في هذه المقالة دوال الخسارة المختلفة في باي تورش PyTorch. وكيف يتيح باي تورش للمستخدمين استخدام دوال الخسارة المطورة مسبقًا، أو بناء دالة خسارة مخصصة وأمثلة عملية توضح كيفية عملها. متطلبات المقال يتطلب فهم هذا المقال فهمًا جيدًا للشبكات العصبية الاصطناعية المكونة من طبقات متصلة تحتوي كل طبقة على عدد من العقد التي تسمى عصبون neuron. حيث تتعلم هذه الشبكات وتخمن القيم من خلال عملية التدريب training وتُضبط فيها الأوزان weights ومقدار الانحياز biases وهي معاملات تتحكم في درجة قوة التواصل بين العقد المختلفة، وهي تحاكي في طريقة عملها الخلايا العصبية الطبيعية. ولفهم الشبكات العصبية بشكل متعمق نحتاج لمعرفة أنواع الطبقات المختلفة وهي: طبقة المدخلات input layer والطبقة المخفية hidden layer وطبقة المخرجات output layer، ومعرفة بدوال التنشيط activation functions وخوارزميات التحسين optimization algorithms مثل الانحدار المتدرج gradient descent ودوال الخسارة وغيرها. كما يحتاج فهم المقال للإلمام بأساسيات لغة بايثون Python والتعامل مع إطار عمل باي تورش PyTorch لفهم الأكواد المكتوبة. ما هي دوال الخسارة Loss Functions تستخدم دوال الخسارة بشكل أساسي لتقييم أداء نموذج تعلم الآلة في تنفيذ مهمة على مجموعة بيانات محددة، فهي تحسب الفرق بين القيمة الحقيقية الصحيحة Y وبين القيمة المتوقعة ^Y، فعندما يخمن نموذج قيم قريبة جدًا من القيم الفعلية في كل من مجموعة بيانات التدريب ومجموعة بيانات الاختبار فهذا يعني أن النموذج موثوق ويُعتمد عليه. فدوال الخسارة loss functions توفر لنا معلومات مفيدة عن أداء النموذج، ولكن هذا ليس الدور الوحيد لدالة الخسارة، فهناك طرق أخرى أكثر موثوقية لتقييم النماذج مثل الصحة accuracy أو F-scores. في حين تبرز أهمية دوال الخسارة loss functions بشكل أساسي خلال عملية التدريب، وتساعدنا على دفع أوزان ومعاملات النموذج في الاتجاه الذي يقلل من الخسارة. وتقليل الخسارة يعني بالضرورة زيادة احتمالية التخمين الصحيح للقيم بواسطة نموذج تعلم الآلة، وهذا التحسن في التخمين ليس ممكنًا بدون استخدام دالة خسارة. تختلف أنواع دوال الخسارة loss functions باختلاف المشكلة التي نحاول حلها، حيث تصمم كل دالة بعناية لضمان تدفق التصحيح التدريجي gradient flow المناسب خلال عملية التدريب، ولكن من المهم معرفة دورها في عملية التدريب والتحسن المستمر. قد يصعب فهم الرموز الرياضية المعبرة عن معادلات الخسارة loss functions، حيث يتملص بعض المطورين من محاولة فهم هذه المعادلات الرياضية ويتعاملون معها على أنها صندوق أسود مجهول التفاصيل، ولكن فهم ما بداخل هذا الصندوق يعزز فهم دوال الخسارة ويساعدنا على تحديد الدالة الأفضل، سنشرح في الفقرات التالية أشهر دوال الخسارة في باي تورش، ولكن قبل هذا لنرى أين نضع هذا الصندوق، وكيف نستخدم دوال الخسارة في باي تورش؟ دوال الخسارة في باي تورش PyTorch يأتي باي تورش PyTorch معززًا بالكثير من دوال الخسارة الأساسية سهلة الاستخدام، وتُجمع كافة دوال الخسارة في وحدة برمجية واحدة باسم nn module والتي تُعدّ الوحدة الأساسية لبناء الشبكات العصبية الاصطناعية ANNs في بايتورش. يمكن إضافة دالة خسارة loss function للكود الخاص بنا بسهولة كتابة سطر برمجي واحد. لننظر معًا للمثال التالي لإضافة دالة خسارة متوسط مربع الخطأ Mean Squared Error loss function -أو MSE اختصارًا- في باي تورش PyTorch. import torch.nn as nn MSE_loss_fn = nn.MSELoss() تستخدم هذه الدالة في حساب الفرق بين قيم التخمينات والقيم الفعلية بالتنسيق التالي: #predicted_value هو التخمين القادم من الشبكة العصبية #target القيم الفعلية الموجودة في مجموعة البيانات #loss_value الخسارة بين قيمة التخمين والقيمة الفعلية Loss_value = MSE_loss_fn(predicted_value, target) بعد أن كونا فكرة أولية عن طريقة عمل دوال الخسارة في باي تورش PyTorch، لنتعمق أكثر في كواليس عمل عدد من هذه الدوال. دوال الخسارة في باي تورش PyTorch تقع معظم دوال الخسارة في باي تورش PyTorch تحت واحدة من التصنيفات الثلاثة التالية: دوال خسارة الانحدار regression loss functions دوال خسارة التصنيف classification loss functions دوال خسارة الترتيب ranking loss functions تهتم دوال خسارة الانحدار regression loss functions بالقيم والمتغيرات المستمرة continuous وهي المتغيرات التي يمكنها أن تأخذ عددًا لا نهائيًا من القيم بين رقمين، وأحد الأمثلة على هذا النوع من المتغيرات هو الأسعار، فمثلًا هل يمكن إحصاء كل الأسعار الممكنة للمنازل في منطقتنا؟ بالطبع لا ولكن يمكننا حصرها في نطاق عددي. تتعامل دوال خسارة التصنيف classification loss functions مع المتغيرات والقيم المتقطعة أو المنفصلة discrete، ومثال على هذا النوع من المهام عندما تحاول تميز كائن على أنه أحد التصنيفات المحددة ولتكن صندوق أو قلم أو زجاجة. تتوقع دوال خسارة الترتيب ranking loss functions المسافة النسبية بين القيم، وأحد التطبيقات عليها سيكون التوثيق من خلال صورة الوجه حيث نريد أن نعرف هوية صاحب الوجه بمقارنة صورته بعدد من الصور المعلومة هويتها لدينا وترتيبها حسب درجة التشابه، فالصور التي تنتمي لهذا الشخص يفترض أن تتشابه معه بنسبة كبيرة أكثر من تلك التي لأشخاص آخرين. دالة متوسط الخطأ المطلق Mean Absolute Error أو دالة الخسارة L1 تحسب دالة خسارة متوسط الخطأ المطلق MAE متوسط المجموع المطلق للفروق بين قيم التخمينات والقيم الفعلية. فتحسب أولًا الفرق بين قيمة التخمين والقيمة الفعلية عند كل عنصر في الموتر tensor، ونراكم المجموع المطلق لهذه الفروق التي حصلنا عليها في الخطوة السابقة، وفي النهاية نحسب متوسط هذا المجموع التراكمي بقسمته على العدد الكلي لتخمينات النموذج ونقارنها بالقيم الفعلية، للحصول على متوسط الخطأ المطلق MAE، وتعتبر دالة الخسارة هذه موثوقة للغاية في التعامل مع التشويش noise في البيانات. وتعرف هذه الدالة بمسمى آخر وهو دالة L1. وفيما يلي كود برمجي يُعرّف ويستخدم دالة خسارة من نوع MAE أو L1: import torch.nn as nn #size_average & reduce are deprecated # لا يوصى باستخدامهما فمن المحتمل تغيرهما في النسخ المستقبلية #reduction تحدد العملية التي ستحسب بعد حساب الفروق المطلقة لكل القيم ''' `none` tensor تعني أننا لن نقوم بأي عملية على الفروق المطلقة وسنخرجها كتنسور `sum` سنجمع جميع الفروق المطلقة لكل القيم دون أخذ المتوسط `mean` القيمة الافتراضية لهذا المعامل سنجمع جميع الفروق المطلقة ونأخذ متوسطها بقسمة المجموع على عدد العناصر في المخرجات ''' Loss_fn = nn.L1Loss(size_average=None, reduce=None, reduction='mean') input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss_fn(input, target) print(output) #tensor(0.7772, grad_fn=<L1LossBackward>) متوسط مربع الخطأ Mean Squared Error يتشابه متوسط مربع الخطأ MSE مع متوسط الخطأ المطلق MAE، لكن الفرق بينهما هو أن MSE يحسب مربع الفرق بين القيم المتوقعة والحقيقية، بينما يحسب MAE القيمة المطلقة للفرق. وبسبب وجود التربيع في MSE، تعطي هذه الدالة وزنًا أكبر للأخطاء الكبيرة، وهي أكثر حساسية للقيم الشاذة أو الضوضاء في البيانات مقارنة بالدالة MAE الأقل حساسية للقيم الشاذة لأنها لا تضخم الأخطاء الكبيرة بنفس الطريقة. ويعد متوسط مربع الخطأ المطلق المعيار الثاني Second norm أو L2 ويعرف أيضًا بالمعيار الإقليدي Euclidean norm أو المسافة الإقليدية، وهو نفس القانون المعروف لحساب المسافة بين نقطتين في الإحداثيات. فيما يلي كود برمجي يُعرّف ويستخدم دالة خسارة من نوع MSE أو L2: import torch.nn as nn loss = nn.MSELoss(size_average=None, reduce=None, reduction='mean') #ينطبق نفس الشرح السابق عن هذه المعاملات input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) print(output) #tensor(0.9823, grad_fn=<MseLossBackward>) خسارة الإنتروبيا المتقاطعة Cross-Entropy Loss تستخدم دالة خسارة الإنتروبيا المتقاطعة Cross Entropy في مسائل التصنيف classification والتي تتعامل مع تصنفيات محددة ومعدودة لقياس الفرق بين التوزيع الحقيقي للفئات والتوزيع الذي يتنبأ به النموذج. فتقيس الفرق بين توزيع الاحتماليات لكل مجموعة معطاة من المتغيرات العشوائية، ويغلب استخدام دالة softmax كطبقة المخرجات عند استخدم الإنتروبيا المتقاطعة كدالة خسارة، حيث تحوّل دالة softmax القيم الداخلة في المتجه أو التنسور tensor لتكون بين الصفر والواحد، ومجموع العناصر الخارجة ليساوي الواحد لتحقق شروط الاحتمالات، وتبقى القيمة العظمى في المتجه هي القيمة الأكبر بعد تطبيق الدالة. وبالمقارنة مع دالة hardmax التي تستخرج القيمة العظمى من متجه وتُعيّنها إلى 1، بينما تتجاهل باقي العناصر وتحواها إلى 0 فإن دالة softmax تحافظ على المعلومات النسبية لجميع القيم، مما يجعلها مناسبة أكثر لترتيب الاحتمالات فهي تعطي قيمًا احتمالية لكل تصنيف. وتتكون دالة softmax من جزأين الأول هو عدد أويلر e مرفوعًا لأس قيمة التخمين لتصنيف معين في المتجه حيث يمثل كل عنصر أحد التصنيفات المحددة. حيث أن y_i هي خرج من الشبكة العصبية الاصطناعية لتصنيف معين، وتعطينا هذه الدالة رقمًا قريبًا من الصفر ولكنه لا يكون أبدًا مساويًا للصفر، وتقترب قيمة الدالة من الواحد عندما تكون y_i قيمة كبيرة سالبة، وعندما تكون قيمة كبيرة موجبة تعطي الدالة رقمًا موجبًا كبيرًا، كما نلاحظ في المثال التالي: import numpy as np np.exp(34) #583461742527454.9 np.exp(-34) #1.713908431542013e-15 أما الجزء الثاني من الدالة فهو عملية توحيد normalization حيث تضمن هذه الخطوة أن دالة softmax تعطي دائمًا قيمة احتمالات بين الصفر والواحد. توضح الصورة التالية الخطوات التي قمنا بها: ويمكننا جمع الخطوات في معادلة واحدة تعبر عن استخدامنا لدالة softmax لتحول متجه المخرجات لاحتمالات كل تصنيف، مثلًا في مهمة التمييز بين صور القطط والكلاب قد يكون احتمال كون الصورة المدخلة للشبكة العصبية قطة هو 0.80 بينما احتمال أن تكون الصورة لكلب 0.20 مما يسهل علينا فهم التصنيفات بشكل احتمالات قابلة للترتيب. يجمع باي تورش في الوحدة nn كلًا من الإنتروبيا المتقاطعة Cross-entropy و احتمالية اللوغاريتم السالب Negative Log-Likelihood لدالة softmax في دالة خسارة واحدة. دالة خسارة احتمالية اللوغاريتم السالب تعمل دالة خسارة احتمالية اللوغاريتم السالب Negative Log-Likelihood loss -أو NLL اختصارًا- بشكل مشابه لدالة خسارة الإنتروبيا المتقاطعة Cross-Entropy، وكما ذكرنا سابقًا تجمع دالة الإنتروبيا المتقاطعة CE طبقة لوغاريتم الدالة العظمى الناعمة log-softmax مع احتمالية اللوغاريتم السالب NLL من أجل حساب قيمة خسارة الإنتوربية المتقاطعة. ويعني هذا أنه يمكننا الحصول على قيمة خسارة الإنتروبيا المتقاطعة CE باستخدام احتمالية اللوغاريتم السالب NLL بجعل الطبقة الأخيرة من الشبكة العصبية طبقة log-softmax بدلًا من دالة softmax التقليدية. وفيما يلي كود برمجي ينجز تصنيف متعدد الفئات Multi-class Classification باستخدام الدالة softmax و NLL: m = nn.LogSoftmax(dim=1) loss = nn.NLLLoss() # أبعاد المدخلات # N x C = 3 x 5 input = torch.randn(3, 5, requires_grad=True) # يجب أن تكون قيمة كل عنصر في تنسور الهدف أو القيم الفعلية أحد التصنيفات المحددة بالفعل # 0 <= value < C # C ---> يعبر عن آخر تصنيف اعتبارًا أن أول تصنيف سنرمز له بالصفر target = torch.tensor([1, 0, 4]) # المخرجات وهنا نطبق دالة لوغاريتم دالة القيمة العظمي على المدخلات # ثم نحسب مقدار الخسارة بين بينها وبين متجه الهدف أو القيم الفعلية output = loss(m(input), target) output.backward() # حساب الخسارة لتنسورات ثنائية الأبعاد يمكن على سبيل المثال أن تستخدم مع الصور N, C = 5, 4 loss = nn.NLLLoss() # أبعاد المدخلات # N x C x height x width data = torch.randn(N, 16, 10, 10) conv = nn.Conv2d(16, C, (3, 3)) m = nn.LogSoftmax(dim=1) target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C) output = loss(m(conv(data)), target) print(output) #tensor(1.4892, grad_fn=<NllLoss2DBackward>) #credit NLLLoss — PyTorch 1.9.0 documentation دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية Binary Cross-Entropy Loss دالة خسارة الإنتروبيا المتقاطعة الثنائية Binary CE هي حالة خاصة من الإنتروبيا المتقاطعة CE وتستخدم عند تصنيف البيانات لأحد تصنيفين، ولذلك تسمى ثنائية حيث نرمز لأحد التصنيفين بصفر وللآخر بواحد، ونهدف عند استخدامها لجعل النموذج يخمّن رقمًا قريبًا من الصفر عندما يكون التصنيف الفعلي هو الصفر ورقمًا قريبًا للواحد إن كان التصنيف الفعلي واحد، وتكون في الغالب الطبقة الأخيرة في الشبكة العصبية عند استخدام هذه النوع من دوال حساب الخسارة طبقة تستخدم دالة سينية Sigmoid وبالتحديد الدالة اللوجستية logistic function وهي نوع خاص من الدوال السينية sigmoid functions والتي تضمن أن المخرجات رقمًا قريبًا من الواحد أو الصفر ليحقق شروط الاحتمالات. وفيما يلي كود يحسب دالة الخسارة للانحدار اللوجستي باستخدام الدالة BCE: import torch.nn as nn m = nn.Sigmoid() loss = nn.BCELoss() input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) output = loss(m(input), target) print(output) #tensor(0.4198, grad_fn=<BinaryCrossEntropyBackward>) دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية مع لوغاريتم الفرص Binary Cross-Entropy Loss with Logits لو سألنا أحدهم ما هي فرص فوز فريقك المفضل في المباراة؟ يمكن أن يجيب باحتمال مباشر مثل 40%، ويمكن يعبر عن فرص فوز الفريق فيقول يفوز الفريق مرتين من كل خمس مرات، فهذه نفس النسبة ولكن بطريقة مختلفة. حيث يعبر الاحتمال Probability عن فرصة وقوع الحدث من إجمالي جميع الحالات الممكنة، وتعبر الفرص odds عن نسبة احتمال وقوع الحدث إلى احتمال عدم وقوعه، ويستخدم لوغاريتم الفرص Logits أو log(odds) لتحويل الاحتمالات لقيم يمكن استخدامها بسهولة في الحسابات الرياضية، ويضمن أن النتائج تتبع توزيعًا خطيًا بدلاً من أن تكون مقيدة بين الصفر والواحد. ذكرنا سابقًا أن دالة خسارة الإنتروبيا المتقاطعة الثنائية BCE تُسبق بطبقة بها الدالة السينية اللوجيستية logistic sigmoid لضمان أن المخرجات بين الواحد والصفر. وتُجمَع دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية Binary Cross-Entropy Loss مع لوغاريتم الفرص Logits الطبقتين في طبقة واحدة، ووفقًا لتوثيق باي تورش PyTorch فهذا يجعلها أكثر استقرارًا عند إجراء العمليات الحسابية حيث يمكنها الاستفادة من تحويل الضرب إلى جمع بفضل اللوغاريتم. import torch import torch.nn as nn # 64 تصنيفًا # حجم الدفعة الواحدة 10 target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10 # المخرجات التي سنجرب عليها # هذا مثال افتراضي # ولكن عندما تكون هذه المخرجات من الشبكة العصبية # قبل مرورها في الدالة اللوجستية تسمي # logit / prediction output = torch.full([10, 64], 1.5) # جميع الأوزان هنا متساوية بواحد pos_weight = torch.ones([64]) criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight) loss = criterion(output, target) # -log(sigmoid(1.5)) print(loss) #tensor(0.2014) دالة خسارة المعيار الأول المرنة Smooth L1 loss تستفيد دالة خسارة المعيار الأول Smooth L1 loss من مزايا كل من متوسط مربع الخطأ MSE ومتوسط الخطأ المطلق MAE من خلال معامل تحكم بيتا beta، وقُدم المعيار لأول مرة في الورقة البحثية Fast R-CNN . ويستخدم المعيار مربع الفرق عندما يكون الفرق المطلق بين القيم الفعلية والقيم المتوقعة أقل من بيتا beta فيصبح المعيار المستخدم MSE، ويرسم معدل الخسارة لمتوسط مربع الخطأ بشكل منحني متصل ومستمر، مما يجعل الدالة قابلة للاشتقاق عند كل القيم مما يمكننا من حساب معدل التدرج التصحيحي gradients لكل هذه القيم، ولكن عندما تصبح قيمة الخطأ عالية تظهر مشكلة تزايد التدرج بشكل خارج عن السيطرة يوصف بالإنفجاري gradient explosion حيث تصبح قيم التدرج gradients عالية وعند ضربها في الأوزان بشكل مستمر نحصل على أرقام ضخمة تؤدي في النهاية إلى عدم استيعاب المتغيرات لحجم الأرقام وعدم قدرة النظام على التعلم فيما يعرف بالفوران overflow، ولذلك عندما تبدأ هذه الظاهرة في الحدوث نستخدم معيار قيمة الخطأ المطلق MAE والذي يجعل الزيادة في قيم التدرج شبه ثابتة أي خطية عند كل القيم، ونحدد وقت التغيير بناءً على معامل التحكم بيتا beta. import torch.nn as nn loss = nn.SmoothL1Loss() input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) print(output) #tensor(0.7838, grad_fn=<SmoothL1LossBackward>) دالة الخسارة المفصلية التضمينية Hinge Embedding loss تستخدم هذه الدالة في الغالب مع مهام التعلم غير الخاضع للإشراف unsupervised learning لقياس درجة التشابه بين مُدخلين كل منهما عبارة عن تنسور tensor، يمثًل هو تنسور المدخلات input tensor والآخر تنسور الوسم labels tensor وتكون الوسوم في هذه الحالة أحد قيمتين 1 أو 1-، وتٌحلّ من خلالها المسائل التي تحتوي على تضمين غير خطي non-linear embeddings ومهام التعلم غير الخاضع للإشراف. import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) hinge_loss = nn.HingeEmbeddingLoss() output = hinge_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output) #input: tensor([[ 1.4668e+00, 2.9302e-01, -3.5806e-01, 1.8045e-01, #1.1793e+00], # [-6.9471e-05, 9.4336e-01, 8.8339e-01, -1.1010e+00, #1.5904e+00], # [-4.7971e-02, -2.7016e-01, 1.5292e+00, -6.0295e-01, #2.3883e+00]], # requires_grad=True) #target: tensor([[-0.2386, -1.2860, -0.7707, 1.2827, -0.8612], # [ 0.6747, 0.1610, 0.5223, -0.8986, 0.8069], # [ 1.0354, 0.0253, 1.0896, -1.0791, -0.0834]]) #output: tensor(1.2103, grad_fn=<MeanBackward0>) دالة خسارة الترتيب الهامشية Margin Ranking Loss تنتمي دالة الترتيب الهامشية إلى دوال خسارة الترتيب التي تهدف لقياس المسافة النسبية بين مجموعة من المدخلات في مجموعة بيانات. ويُدخل للدالة مدخلان ووسم إما 1 أو 1-، فإذا كان الوسم 1 سنفترض أن المُدخل الأول يملك ترتيبًا أعلى من المُدخل الثاني، والعكس صحيح فإذا كان الوسم 1- يكون ترتيب المٌدخل الثاني أعلى، ويمكن أن نرى هذه العلاقة في المعادلة التالية: يوضح الكود التالي حساب الخسارة بين مُدخلين input1 و input2 باستخدام الدالة MarginRankingLoss: import torch.nn as nn loss = nn.MarginRankingLoss() input1 = torch.randn(3, requires_grad=True) input2 = torch.randn(3, requires_grad=True) target = torch.randn(3).sign() output = loss(input1, input2, target) print('input1: ', input1) print('input2: ', input2) print('output: ', output) #input1: tensor([-1.1109, 0.1187, 0.9441], requires_grad=True) #input2: tensor([ 0.9284, -0.3707, -0.7504], requires_grad=True) #output: tensor(0.5648, grad_fn=<MeanBackward0>) دالة الخسارة الثلاثية الهامشية Triplet Margin loss تقيس هذه الدالة التشابه بين المُدخلات باستخدام ثلاث عينات من البيانات. فتستخدم الدالة عينة المرساة anchor sample، وعينة سالبة لا تنتمي لنفس التصنيف، وعينة إيجابية تنتمي لنفس تصنيف عينة المرساة، ونهدف إلى تعظيم المسافة بين عينة المرساة والعينة الموجبة وتقليص المسافة بين عينة المرساة والعينة السالبة بحيث لا تقل عن قيمة هامشية محددة، وباستخدام هذه الدالة الثلاثية الهامشية triplet margin نريد تخمين درجة عالية من التشابه بين المرساة anchor والعينة الموجبة، وتشابه ضعيف منخفض بين عينة المرساة anchor والعينة السالبة. يوضح الكود التالي استخدام دالة الخسارة TripletMarginLoss: import torch.nn as nn triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2) anchor = torch.randn(100, 128, requires_grad=True) positive = torch.randn(100, 128, requires_grad=True) negative = torch.randn(100, 128, requires_grad=True) output = triplet_loss(anchor, positive, negative) print(output) #tensor(1.1151, grad_fn=<MeanBackward0>) دالة خسارة تضمين جيب التمام اCosine Embedding Loss تقيس دالة خسارة تضمين جيب التمام Cosine Embedding Loss الخسارة بين اثنين من المدخلات وتنسور من الوسوم قيم عناصره إما 1 أو 1-، وتستخدم عندما نريد قياس درجة التشابه أو القرب بين مُدخلين. وتحسب الدالة درجة التشابه بحساب مسافة جيب تمام الزاوية Cosine distance بين نقطتين أو متجهين في الفضاء. حيث تتناسب مسافة جيب التمام Cosine distance مع الزاوية بين المتجهين، فكلما قلت الزاوية قلت المسافة بين المتجهين وكلما كان المتجهان أقرب كلما كانت الكائنات التي يصفانها متشابهة. يوضح الكود التالي استخدام دالة الخسارة CosineEmbeddingLoss: import torch.nn as nn loss = nn.CosineEmbeddingLoss() input1 = torch.randn(3, 6, requires_grad=True) input2 = torch.randn(3, 6, requires_grad=True) target = torch.randn(3).sign() output = loss(input1, input2, target) print('input1: ', input1) print('input2: ', input2) print('output: ', output) #input1: tensor([[ 1.2969e-01, 1.9397e+00, -1.7762e+00, -1.2793e-01, #-4.7004e-01, # -1.1736e+00], # [-3.7807e-02, 4.6385e-03, -9.5373e-01, 8.4614e-01, -1.1113e+00, # 4.0305e-01], # [-1.7561e-01, 8.8705e-01, -5.9533e-02, 1.3153e-03, -6.0306e-01, # 7.9162e-01]], requires_grad=True) #input2: tensor([[-0.6177, -0.0625, -0.7188, 0.0824, 0.3192, 1.0410], # [-0.5767, 0.0298, -0.0826, 0.5866, 1.1008, 1.6463], # [-0.9608, -0.6449, 1.4022, 1.2211, 0.8248, -1.9933]], # requires_grad=True) #output: tensor(0.0033, grad_fn=<MeanBackward0>) دالة خسارة تباعد كولباك ليبلر Kullback Leibler Divergence تستخدم هذه الدالة في تقدير الخسارة لنماذج تعلم الآلة التي تحاول تعلم توزيع احتمالات probability distribution عن طريق حساب كمية المعلومات المفقودة في عملية التقريب، ونرمز للتوزيع الفعلي الذي نحاول تعليمه للآلة بالرمز P وللتوزيع التقريبي بالرمز Q ، وتعمل هذه الدالة على قياس التشابه بين التوزيع الفعلي P والتقريبي Q وبالتالي دفع خوارزمية تعلم الآلة نحو إنتاج توزيع قريب من التوزيع الفعلي قدر الإمكان. ويلاحظ أن مقدار الخسارة في المعلومات عند استخدام التوزيع التقريبي Q لتقدير التوزيع الفعلي P ليس مساويًا للعملية العكسية التي تستخدم التوزيع الفعلي P لتقدير التوزيع التقريبي Q ولذلك يعد تباعد كولباك ليبلر KL divergence غير متماثل Not symmetric. يوضح الكود التالي استخدام الدالة KLDivLoss: import torch.nn as nn loss = nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False) input1 = torch.randn(3, 6, requires_grad=True) input2 = torch.randn(3, 6, requires_grad=True) output = loss(input1, input2) print('output: ', output) #tensor(-0.0284, grad_fn=<KlDivBackward>) بناء دالة خسارة مخصصة توجد طريقتان لبناء دالة خسارة خاصة بنا تتناسب مع المشكلة التي نحاول حلها، الأولى عن طريق تحقيقها داخل صنف class والثانية عن طريق تحقيقها كدالة مستقلة، وسنستعرض كلا الطريقتين. تُعدّ طريقة الدالة المستقلة أسهل لبناء دالة خسارة مخصصة، حيث تُمرّر المُدخلات المطلوبة للدالة وتجري بعض العمليات عليها في جسم الدالة باستخدام العوامل والدوال البرمجية الأخرى المتاحة في باي تورش PyTorch أو من أي مصدر آخر، ومن ثم تعيد قيمة تمثّل الخسارة. يوضح المثال التالي تعريف دالة مخصصة لحساب متوسط مربع الخطأ MSE: def custom_mean_square_error(y_predictions, target): square_difference = torch.square(y_predictions - target) loss_value = torch.mean(square_difference) return loss_value نمرر لهذه الدالة الخاصة تنسور التخمينات predictions tensor وتنسور الوسوم labels tensor ونستخدم بعض الدوال لحساب مربع الفرق بين التنسورين tensors ومن ثم نأخذ المتوسط ونعيده كقيمة الخسارة. y_predictions = torch.randn(3, 5, requires_grad=True); target = torch.randn(3, 5) pytorch_loss = nn.MSELoss(); p_loss = pytorch_loss(y_predictions, target) loss = custom_mean_square_error(y_predictions, target) print('custom loss: ', loss) print('pytorch loss: ', p_loss) #custom loss: tensor(2.3134, grad_fn=<MeanBackward0>) #pytorch loss: tensor(2.3134, grad_fn=<MseLossBackward>) ونقارن في هذا المقطع البرمجي بين دالتنا المخصصة والدالة المدمجة بإطار عمل باي تورش PyTorch framework ويمكنك أن تلاحظ اتفاق الدالتين في القيم النهائية مما يعني أن الدالة مبنية بشكل صحيح. بناء صنف برمجي مخصص لحساب الخسارة يوصى بهذه الطريقة لكونها الطريقة التي يستخدمها باي تورش PyTorch في الكود المصدري، ففي هذه الطريقة نعرّف دالة الخسارة داخل صنف يرث من الصنف الأساسي nn.Module وهذا يسمح لدالة الخسارة المخصصة بالعمل بطريقة مشابهة للطبقات التقليدية في باي تورش، مما يسهّل دمجها واستخدامها ضمن الشبكات العصبية الاصطناعية ANN بنفس الطريقة التي تُستخدم بها الطبقات الأخرى. class Custom_MSE(nn.Module): def __init__(self): super(Custom_MSE, self).__init__(); def forward(self, predictions, target): square_difference = torch.square(predictions - target) loss_value = torch.mean(square_difference) return loss_value def __call__(self, predictions, target): square_difference = torch.square(y_predictions - target) loss_value = torch.mean(square_difference) return loss_value الخاتمة ناقشنا في هذا المقال العديد من دوال الخسارة loss functions المتوفرة في باي تورش PyTorch وتعمقنا في آلية عمل هذه الدوال والعلاقات الرياضية المعبرة عنها، قد يكون اختيار الدالة المناسبة مهمة صعبة، ولكن بفهمك الجيد لمحتوى هذه المقالة والرجوع للتوثيق الخاص بإطار عمل باي تورش PyTorch ستتمكن من اختيار دالة الخسارة المناسبة لمشكلتك بدقة. ترجمة وبتصرف لمقالة PyTorch Loss Functions لصاحبها Henry Ansah Fordjour. اقرأ أيضًا تعرف على إطار عمل باي تورش PyTorch وأهميته لتطبيقات الذكاء الاصطناعي طريقة الصقل Fine-Tune لنموذج ذكاء اصطناعي مُدرَّب مُسبقًا تعرف على أهم كتب الذكاء الاصطناعي المجانية تعرف على مكتبة Scikit learn وأهم خوارزمياتها -
 نستعرض في هذا المقال ثمانية أفكار لمشاريع ذكاء اصطناعي مميزة تناسب المبتدئين المهتمين بتعلم الذكاء الاصطناعي والتخصص فيه، فقد بدأ الذكاء الاصطناعي يغير بيئة العمل تدريجيًا، واتجهت معظم الأنشطة التجارية في الآونة الأخيرة نحو استخدام تقنيات الذكاء الاصطناعي وتعلم الآلة لتسيير أعمالها، ومن المتوقع زيادة استخدام الذكاء الاصطناعي في السنوات القادمة ما يبرز أهمية هذا المجال والطلب الكبير عليه في سوق العمل. أهمية تنفيذ مشاريع الذكاء الاصطناعي لاشك أن العمل على مشاريع عملية من أكثر الطرق فعالية لتعلم الذكاء الاصطناعي واكتساب خبرة كافية فيه، فضلًا عن كونه يوفر لنا فرصة مميزة لبناء معرض أعمال تعزز فرصتنا في الحصول على عمل. تتنوع أفكار المشاريع التي يمكن العمل عليها كتحليل المشاعر sentiment analysis ومنشورات منصات التواصل الاجتماعي، أو التعرف على أنواع النباتات من الصور وغيرها من الأفكار المتنوعة التي تحل مشكلات عملية، فتطبيق معلوماتنا على مشاريع ذكاء اصطناعي تحل مشكلات حقيقية يبرز مهاراتنا للأشخاص المهتمين بتوظيف المواهب التقنية والراغبين في التعاون معنا في مشاريع أخرى. يمكن البدء بمشاريع جانبية بسيطة كفرصة للتعلم وتطوير المهارات، بعدها يمكن العمل على تطوير مشاريع تجارية تساعد عملاء حقيقيين في تبني الذكاء الاصطناعي وقدراته في الأنشطة التجارية والمبيعات والتجارة الإلكترونية، وسنستعرض معًا ثمانية أفكار لمشاريع ممتعة في الذكاء الاصطناعي تناسب المبتدئين، وتساعدهم على بدء رحلة التعلم. خمسة نصائح قبل البدء في مشروع الذكاء الاصطناعي قد يعتقد البعض أن البدء في مشروع ذكاء اصطناعي مهمة شاقة، ولكن تقسيم أي مشروع إلى وحدات أصغر يسهل إدارتها وتطويرها سيجعل المهمة أسهل ويساعد على خروجها للنور، لذلك سنقدم في البداية بعض النصائح العملية التي تساعدنا على البدء: 1. اختيار مشروع يوافق شغفنا من الأفضل أن نبدأ بمشروع يجعلنا نشعر بالحماس والشغف حياله، ويفضل أن يرتبط بأحد اهتماماتنا أو هواياتنا، كأن يكون المشروع بناء نظام محادثة ذكي يقترح تمارين رياضية مخصصة لاحتياجات كل مستخدم، أو نظام ترشيح لاقتراح الموسيقى المناسبة لحالتك المزاجية، أو حتى مساعد مشغل بالذكاء الاصطناعي يساعد في التصميم الداخلي للمنازل من خلال عرض مظاهر مختلفة لتصميم الغرف، فاختيار فكرة توافق شغفنا سيجعلنا متحمسين دومًا وقادرين على تخطي التحديات التي نواجهها. 2. التركيز على أهداف صغيرة قابلة للتحقيق بدلًا من التركيز على حل المشاكل المعقدة مرةً واحدة، علينا التركيز على تجزئتها لأهدافٍ أصغر قابلة للتحقيق بسهولة، فمثلًا يمكن البدء بنظام تصنيف للصور image classification بدلًا من البدء مباشرةً ببناء نظام متكامل لاكتشاف الكائنات object detection، فتحقيق المكاسب الصغيرة المتراكمة يعزز ثقتنا بأنفسنا عندما نقابل تحديات جديدة مثل تجربة تقنية أو إطار عمل للمرة الأولى. 3. اختيار البنية التحتية المناسبة عندما نحاول بناء مشاريع ذكاء اصطناعي مثل نظام للتعرف على الكائنات في الوقت الحقيقي باستخدام الشبكات العصبية الالتفافية Convolutional Neural Networks أو نجرب توليد النصوص باستخدام نماذج المحولات Transformers، فنحن بحاجة لاختيار البنية التحتية المناسبة لمتطلبات مشروعنا. فتحتاج أغلب مشاريع الذكاء الاصطناعي وتعلم الآلة وحدات المعالجة الرسومية GPUs لقدراتها على المعالجة على التوازي parallel processing مما يسرِّع بشكل ملحوظ عملية تدريب نماذج الذكاء الاصطناعي واستخدامها في التنبؤ والاستدلال inference، خاصة عند التعامل مع النماذج اللغوية الضخمة LLMs. وعلينا أن نأخذ في الاعتبار بعض العوامل عند اختيارنا للمنصة التي توفر وحدات المعالجة الرسومية GPU مثل عدد وحدات كودا CUDA الموجودة في وحدة المعالجة الرسومية، وسعة تخزين ذاكرة الفيديو VRAM، وسعة مرور البيانات bandwidth من الذاكرة حيث أن لهذه المعايير تأثير في سرعة التدريب وسرعة الاستدلال وتكلفة التشغيل. ويمكننا -في حال تطوير مشروع يحتاج إلى بنية تحتية قوية- الوصول للبنية التحتية اللازمة لتدريب وتشغيل النماذج من خلال مزودي الخدمات السحابية cloud provider، ولكن في كثير من الأحيان تكون المشاريع الجانبية التي نطورها بهدف التعلم، لذا لا تكون هناك ميزانية أو جدوى من دفع مبالغ طائلة لتطوير المشروع، وفي هذه الحالة يمكن اللجوء لبدائل مجانية، أو استخدام الخطة المجانية أو الرصيد المتوفر للحسابات الجديدة على منصات مزودي الخدمات السحابية لتجربة خدماتهم، وكذلك هناك خيار استخدام كولاب collab أو كاجل Kaggle وكلاهما منصات مملوكة لجوجل وتوفران استخدامًا محدودًا ولكنهما مناسبان لأغلب المشروعات الجانبية، فمثلًا يوفر كاجل Kaggle وحدات معالجة رسومية GPUs يمكن استخدامها بسعة متجددة أسبوعية لمدة 30 ساعة شرط أن يكون الحساب موثقًا برقم هاتف، وهي فترة كافية لتجربة تدريب النماذج الصغيرة ومتوسطة الحجم أو صقل نموذج لغوي ضخم. 4. جمع البيانات المطلوبة للمشروع كي نتمكن من بناء أي مشروع ذكاء اصطناعي وتعلم آلة، سنحتاج إلى البيانات، وتوفر مواقع مثل كاجل Kaggle أو مستودع جامعة كاليفورنيا للتعلم الآلي UCI Machine Learning Repository مجموعات بيانات غنية ومجانية للاستخدام في تطوير النماذج وتحليل البيانات، ويفضل اختيار قواعد بيانات موثقة جيدًا حتى نفهم هيكلة البيانات وكيفية التعامل معها. 5. التعاون مع الآخرين لتجنب التشتت قد يكون مشروع الذكاء الاصطناعي في البداية غير واضح، وهذا قد يشتتنا من وفرة وتنوع الأدوات والطرق المتاحة لتحقيق الهدف، يمكن حل هذه المشكلة بالتعاون النشط مع الآخرين في تطوير مشاريعك مما سيجعلها تجربة ممتعة وإنتاجية أكثر. كما يمكننا الانضمام للمجتمعات التقنية المهتمة بالذكاء الاصطناعي في حال واجهنا أي مشكلة، فهي أماكن مناسبة لطرح الأسئلة ومشاركة مشاريع الذكاء الاصطناعي وإيجاد رفقاء للعمل على المشاريع، وكذلك يتيح لنا GitHub المساهمة في المشاريع مفتوحة المصدر مما يكسبنا خبرة عملية وتواصل قوي مع المطورين الخبراء في تطوير البرمجيات مفتوحة المصدر. إن التفاعل مع المجتمع ومشاريعه أو المساهمة في المناقشات الجارية بشأن الذكاء الاصطناعي يمكن أن يشكل فرصةً ثمينةً للتواصل مع مهندسي ذكاء اصطناعي خبراء يوفرون تقييمًا ومراجعةً مفيدة للغاية على مشاريع المبتدئين ويساهمون في تطوير أفكارهم وتشجيعهم على التطور المستمر والتعلم الفعال. ثمانية أفكار مشاريع ذكاء اصطناعي تناسب المبتدئين لنتعرف معًا على أبرز أفكار المشاريع المناسبة لشخص مبتدئ. 1. نظام دردشة آلي بالذكاء الاصطناعي AI Chatbot System بناء نظام دردشة آلي بالذكاء الاصطناعي هو أحد أوضح مشاريع الذكاء الاصطناعي التي يمكن البدء منها من ناحية طريقة التنفيذ وخطواتها، فباستخدام معالجة اللغات الطبيعية و خوارزميات تعلم الآلة يمكن إنشاء نظام دردشة آلي يرد على استفسارات المستخدم. وتسهّل مكتبات مثل تنسرفلو Tensorflow وباي تورش PyTorch من عملية بناء هذا النوع من الأنظمة بتوفيرها نماذج مدرّبة وأدوات سهلة الاستخدام للتعامل مع المدخلات والردود النصية. فباستخدام هذه الأدوات يمكن بناء نظام محادثة آلي chatbot بدون التعمق كثيرًا في الخوارزميات المعقدة مما يجعل هذا المشروع مناسبًا للمبتدئين. المهارات التي نحتاجها لهذا المشروع هي لغة البرمجة بايثون Python، ومعالجة اللغات الطبيعية NLP، والتعلم العميق DL، وأطر عمل الذكاء الاصطناعي مثل باي تورش PyTorch أو تنسورفلو TensorFlow، ودمج واجهة التطبيقات البرمجية API integration من الأفكار الجيدة لتطبيقات دردشة آلية بالذكاء الاصطناعي نظام محادثة آلي chatbot يستخدم النصوص المستخلصة من برامج البودكاست المفضلة، مما يسمح بالدردشة مع المستضيف والضيوف حول المواضيع التي تغطيها البرامج، أو تصميم مدرب لياقة بدنية مخصص لكل مستخدم من خلال نظام دردشة آلي يخصص التدريب بناءً على معلومات المستخدم، وأهدافه، ومؤشراته الحيوية التي تجمعها الأجهزة الذكية القابلة للارتداء، أو نظام دردشة آلي يجيب عن الأسئلة التي تخص منطقة سكننا من خلال بيانات صفحات التواصل الاجتماعي ومصادر الأخبار المحلية. 2. فلترة الرسائل المزعجة Spam Filtering يمكن تطبيق العديد من تقنيات الذكاء الاصطناعي في مشروع لفلترة الرسائل المزعجة spam filtering حيث نبني مُصنِّفًا لرسائل البريد الإلكتروني لتحديد ما إذا كانت الرسالة مزعجة أم لا. ولتحليل نص رسالة البريد الإلكتروني وتحديد الأنماط المثيرة للشك يمكن استخدام معالجة اللغات الطبيعية. وأبسط شكل للمشروع يتم من خلال مصنِّفات تحسب احتمالية كون رسالة البريد الإلكتروني مزعجة بناءً على ورود بعض الكلمات المفتاحية بها والتي وجدت من قبل في رسائل مزعجة. ويمكنك تجربة خوارزمية متجهات الدعم الآلي support vector machine من أجل تصنيف رسائل البريد الإلكتروني من خلال صفات الرسالة مثل بيانات المرسل ومحتوى الرسالة. ولنصبح أكثر تمكنًا يمكن استخدام نماذج التعلم العميق مثل الشبكات العصبية الالتفافية Convolution Neural Network أو الشبكات العصبية التكرارية Recurrent Neural Network لاكتشاف الأنماط المعقدة في النصوص أو معلومات عن البيانات المرسلة والأنماط الموجودة في الملفات المرفقة. المهارات التي نحتاجها لهذا المشروع هي: خوارزميات التعلم الآلي التصنيفية وخوارزمية متجهات الدعم الآلي SVM ولغة البرمجة بايثون Python، ومعالجة اللغات الطبيعية NLP، والتعلم العميق DL، ومعالجة البيانات Data preprocessing. 3. تطبيق ترجمة بالذكاء الاصطناعي يساعد بناء تطبيق ترجمة ذكي على تعلم بناء نماذج قادرة على التعامل مع مهام مثل تحديد اللغة language detection والترجمة وهيكلة الجمل، فيمكن استخدام معالجة اللغات الطبيعية Natural Language Processing، والترجمة الآلية العصبية Neural Maching Translation لإنشاء تطبيق لترجمة النصوص بين اللغات المختلفة. وباستخدام معمارية المحولات Transformers يمكننا تطوير نظام قادر على فهم سياق النص وتوفير ترجمة دقيقة له. للبدء في هذا المشروع سنحتاج لجمع مجموعات بيانات متعددة اللغات توفر نصوصًا وما يوازيها من ترجمة في لغات أخرى. وبمجرد تدريب نموذجنا الخاص فيمكن دمج واجهات التطبيق البرمجية مثل Google Translator أو DeepL لتحسين قدرات التطبيق في الترجمة في الوقت الحقيقي، تساعدنا هذه التطبيقات في تجنب بناء نظام ترجمة من الصفر وتجعلنا نركز على تحسين تجربة المستخدم. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: لغة البرمجة بايثون Python، ومعالجة اللغات الطبيعية NLP، والترجمة الآلية العصبية NMT، وتقنيات معمارية المحولات transformer model techniques، ودمج واجهة التطبيق البرمجية API. 4. التعرف على الأرقام المكتوبة بخط اليد ننشئ في مشروع التعرف على الأرقام المكتوبة بخط اليد نموذجًا يتعرف ويصنف آليًا الأرقام من صفر إلى تسعة الموجودة في الصور. ولبناء النموذج سنحتاج أولًا لمعالجة الصور للتأكد من أبعادها الموحدة ومن تحويلها لصور بتدرج الرمادي يمكن التعبير عنها ببيانات أقل من الصور الملونة مما يسرع من معالجة الصور ويسهل التعامل معها، وتلي هذه الخطوة استخدام الشبكات العصبية الالتفافية لتدريب نموذج يتعرف على الأنماط الموجودة في الصورة التي تميز كل رقم عن الآخر، وتعد مجموعة بيانات MNIST digit من الأشهر استخدامًا لتدريب نماذج التعرف على الأرقام العربية، وإذا أردنا التميز فيمكن تجربة مجموعات بيانات أخرى مثل MADBase وهي مجموعة بيانات للأرقام العربية الشرقية أو الهندية (۰-۹)، ويمكن التوسع أكتر في المشروع وتطبيق تقنيات التعرف البصري على الحروف Optical Charachter Recognition أو OCR اختصارًا، وهذا يتجاوز التعرف على الأرقام إلى التعرف على نصوص كاملة في تنسيقات وخطوط وأحجام مختلفة، ويستخدم في تطبيقات مثل استخراج الأرقام والحروف من لوحات السيارات أو التعرف على الكلمات المكتوبة في اللافتات الإعلانية أو غيرها. يسمح لنا هذا المشروع بتجربة تطوير أفكار لتطبيقات حقيقية مثل المعالجة الآلية للاستمارات المكتوبة بخط اليد، أو بناء نظام للتعرف على أرقام الهواتف المحمولة. المهارات التي نحتاجها لهذا المشروع: لغة البرمجة بايثون Python، والشبكات العصبية الالتفافية CNN، وخوارزميات معالجة الصور، وأطر عمل ذكاء اصطناعي مثل باي تورش PyTorch 5. تصنيف الصور Image Classification يمكن من خلال مشروع تصنيف الصور بناء نموذج يتعرف على العناصر الموجودة في الصور ويصنفها إلى أحد الأصناف المحددة مسبقًا آليًا. يبدأ المشروع بمجموعة بيانات تحتوي آلاف الصور المجمعة في أقسام مثل صور حيوانات أو مركبات أو أي من الكائنات الموجودة في حياتنا اليومية. بدايةً علينا أن نعالج الصور لجعلها موحدة الحجم والتنسيق، وبعد ذلك ندرب النموذج باستخدام شبكة عصبية التفافية CNN ليتعلم الأنماط البصرية بالصورة مثل الأشكال والألوان والخامات، ثم يمكن بعد ذلك تدريب واختبار النموذج لتصنيف صور جديدة لم يرها من قبل. وتكمن روعة هذه الفكرة في مدى إمكانية تنفيذها في العديد من التطبيقات الحياتية مثل التعرف على الوجوه، وتحليل الصور الطبية، وحتى تقنيات المركبات ذاتية القيادة. المهارات التي تحتاجها لتنفيذ هذا المشروع هي: معرفة بإطار عمل لمعالجة الصور مثل openCV، والشبكات العصبية الالتفافية CNN، وأحد أطر عمل الذكاء الاصطناعي مثل تنسورفلو TensorFlow أو باي تورش PyTorch. 6. مساعد آلي لإعادة هيكلة الكود يمكننا تطوير أداة المستخدمين في تحسين وتنقيح الأكواد الموجودة بدون تغيير وظيفتها. سنحتاج لإنشاء نموذج ذكاء اصطناعي يبحث عن المشكلات في الكود ويجد الأجزاء التي يمكن كتابتها بطرق أفضل وأكثر كفاءةً مثل مهندسي البرمجيات المحترفين. يمكن البدء بجمع أمثلة من الأكواد الفوضوية والمحسنة من مصادر مفتوحة المصدر مثل جت هاب Github، وتدريب الذكاء الاصطناعي باستخدام تقنيات تعلم الآلة للتعرف على الأنماط، ومن ثم دمجه مع محرر الأكواد أو بيئة التطوير المتكاملة IDE من أجل اقتراحات تحسينية في الزمن الحقيقي. وبمجرد التأكد من عمل الأداة بشكل صحيح يمكننا توسيع اختصاصاتها لتشمل لغات برمجة أكثر وميزات متقدمة مثل التأكد من أمان الكود وتخصيص الأسلوب. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: معالجة اللغات الطبيعية NLP، ولغة البرمجة بايثون Python، ومعرفة بطريقة تطوير إضافات لبيئة التطوير المتكاملة IDE plugin development. 7. نظام ترشيح للأفلام يسمح لنا بناء نظام لترشيح الأفلام بتخصيص تجربة اقتراح الأفلام من خلال محرك الترشيحات الذي يتوقع أي الأفلام سيستمتع بها المستخدمون بناءً على تفضيلاتهم السابقة. نحتاج للبدء بمجموعة بيانات مثل MovieLens تحتوي على تقييمات المستخدم وتفاصيل الأفلام وأنواعها. سنحلل في هذا المشروع سلوك المستخدم ونحدد الأنماط من أجل اقتراح أفلام لم يشاهدها المستخدمون من قبل ولكن من المحتمل أن يحبوها. لتحقيق هذا، يمكن استخدام تقنيات مثل الترشيح التعاوني collaborative filtering والذي يوجِد أوجه التشابه بين المستخدمين أو الأفلام بناءً على تصنيفهم وتصفية المحتوى، وتقترح هذه الطريقة الأفلام المشابهة لتلك التي أحبها المستخدم في السابق، بمجرد تمكننا من تنفيذ المشروع، سنكتسب المهارات اللازمة لتطبيق أنظمة الترشيح في سياقات مختلفة، وبالرغم من أن النظام الذي نطوره قد لا يكون قابلًا للتشغيل مع مستخدمين حقيقين إلا أنه يوفر تدريبًا جيدًا يمكّننا من بناء أنظمة مشابهة، سواءً من أجل منصات بث الأفلام والمسلسلات أو منصات التجارة الإلكترونية أو حتى منصات التواصل الاجتماعي. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: الترشيح التعاوني Collaborative filtering، والتصفية حسب المحتوى content-based filtering وتحليل مصفوفة آراء المستخدمين Matrix Factorization، ولغة البرمجة بايثون Python، وخوارزميات تعلم الآلة. 8. محلل السير الذاتية يمكن بناء مشروع محلل للسير الذاتية يستخرج المعلومات المهمة آليًا من السير الذاتية مثل الاسم ومعلومات التواصل والتعليم وخبرة العمل. سنبدأ بجمع السير الذاتية من مجموعات البيانات الموجودة في مصادر مفتوحة مثل كاجل Kaggle بتنسيقات مختلفة مثل PDF أو Word أو غيرها، وباستخدام تقنيات معالجة اللغات الطبيعية NLP سنحلل ونفصل النصوص الموجودة. بتحديدنا لأنماط محددة في التواريخ أو المسميات الوظيفية أو أسماء الشركات سنتمكن من تدريب النموذج لاكتشاف المعلومات الضرورية. ويمكن أيضًا استخدام التعرف على الكيانات المسماة Named Entity Recognition -أو NER اختصارًا- للتعرف على كيانات مثل الجامعات والدرجات العلمية والمهارات. ويمكن بمجرد تحليل البيانات تخزينها بشكل مهيكل في قاعدة بيانات تسهّل الوصول للبيانات ومقارنتها. ولتحسين هذا المشروع وتطويره يمكننا دمجه في نظام لتتبع المتقدمين على الوظائف لمساعدة فرق الموارد البشرية على التعامل مع عدد ضخم من السير الذاتية بكفاءة ودقة. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: التعرف على الكيانات المسماة NER، ولغة بايثون Python، ومعالجة اللغات الطبيعية NLP، واستخراج البيانات وتحليلها. الخلاصة تناولنا في هذه المقالة بعض أفكار مشاريع الذكاء الاصطناعي المفيدة للمهتمين بتعلم الذكاء الاصطناعي. قد نواجه أثناء تطبيق هذه المشاريع العديد من التحديات والعقبات، لكننا بالمقابل سنتعلم التعامل مع الخوارزميات والأدوات والمكتبات البرمجية بكفاءة ونصقل خبرتنا البرمجية ونبني معرض أعمال متميز. وللمهتمين بتعلم المهارات اللازمة لتنفيذ هذه المشاريع بسرعة وتطبيقها بفعالية، تقدم أكاديمية حسوب دورة الذكاء الاصطناعي المتميزة التي توفر الكثير من الوقت في تعلم الذكاء الاصطناعي من خلال دمج الجانب النظري والتطبيقي، وتحتوي العديد من التطبيقات والأمثلة العملية المفيدة بدايةً من التعامل مع البيانات وتحليلها وصولًا إلى تطبيقات متقدمة مثل النماذج اللغوية الضخمة، والتي تضمن لك بناء معرض أعمال قوي والحصول على فرصة عمل مناسبة. ترجمة وبتصرف لمقال 8 AI Side Project Ideas for Beginners لصاحبته Sujatha R. اقرأ أيضًا أمثلة على الذكاء الاصطناعي تعرف على أهم مشاريع الذكاء الاصطناعي المعالجة المُسبقة للبيانات قبل تمريرها لنماذج الذكاء الاصطناعي طريقة الصقل Fine-Tune لنموذج ذكاء اصطناعي مُدرَّب مُسبقًا
نستعرض في هذا المقال ثمانية أفكار لمشاريع ذكاء اصطناعي مميزة تناسب المبتدئين المهتمين بتعلم الذكاء الاصطناعي والتخصص فيه، فقد بدأ الذكاء الاصطناعي يغير بيئة العمل تدريجيًا، واتجهت معظم الأنشطة التجارية في الآونة الأخيرة نحو استخدام تقنيات الذكاء الاصطناعي وتعلم الآلة لتسيير أعمالها، ومن المتوقع زيادة استخدام الذكاء الاصطناعي في السنوات القادمة ما يبرز أهمية هذا المجال والطلب الكبير عليه في سوق العمل. أهمية تنفيذ مشاريع الذكاء الاصطناعي لاشك أن العمل على مشاريع عملية من أكثر الطرق فعالية لتعلم الذكاء الاصطناعي واكتساب خبرة كافية فيه، فضلًا عن كونه يوفر لنا فرصة مميزة لبناء معرض أعمال تعزز فرصتنا في الحصول على عمل. تتنوع أفكار المشاريع التي يمكن العمل عليها كتحليل المشاعر sentiment analysis ومنشورات منصات التواصل الاجتماعي، أو التعرف على أنواع النباتات من الصور وغيرها من الأفكار المتنوعة التي تحل مشكلات عملية، فتطبيق معلوماتنا على مشاريع ذكاء اصطناعي تحل مشكلات حقيقية يبرز مهاراتنا للأشخاص المهتمين بتوظيف المواهب التقنية والراغبين في التعاون معنا في مشاريع أخرى. يمكن البدء بمشاريع جانبية بسيطة كفرصة للتعلم وتطوير المهارات، بعدها يمكن العمل على تطوير مشاريع تجارية تساعد عملاء حقيقيين في تبني الذكاء الاصطناعي وقدراته في الأنشطة التجارية والمبيعات والتجارة الإلكترونية، وسنستعرض معًا ثمانية أفكار لمشاريع ممتعة في الذكاء الاصطناعي تناسب المبتدئين، وتساعدهم على بدء رحلة التعلم. خمسة نصائح قبل البدء في مشروع الذكاء الاصطناعي قد يعتقد البعض أن البدء في مشروع ذكاء اصطناعي مهمة شاقة، ولكن تقسيم أي مشروع إلى وحدات أصغر يسهل إدارتها وتطويرها سيجعل المهمة أسهل ويساعد على خروجها للنور، لذلك سنقدم في البداية بعض النصائح العملية التي تساعدنا على البدء: 1. اختيار مشروع يوافق شغفنا من الأفضل أن نبدأ بمشروع يجعلنا نشعر بالحماس والشغف حياله، ويفضل أن يرتبط بأحد اهتماماتنا أو هواياتنا، كأن يكون المشروع بناء نظام محادثة ذكي يقترح تمارين رياضية مخصصة لاحتياجات كل مستخدم، أو نظام ترشيح لاقتراح الموسيقى المناسبة لحالتك المزاجية، أو حتى مساعد مشغل بالذكاء الاصطناعي يساعد في التصميم الداخلي للمنازل من خلال عرض مظاهر مختلفة لتصميم الغرف، فاختيار فكرة توافق شغفنا سيجعلنا متحمسين دومًا وقادرين على تخطي التحديات التي نواجهها. 2. التركيز على أهداف صغيرة قابلة للتحقيق بدلًا من التركيز على حل المشاكل المعقدة مرةً واحدة، علينا التركيز على تجزئتها لأهدافٍ أصغر قابلة للتحقيق بسهولة، فمثلًا يمكن البدء بنظام تصنيف للصور image classification بدلًا من البدء مباشرةً ببناء نظام متكامل لاكتشاف الكائنات object detection، فتحقيق المكاسب الصغيرة المتراكمة يعزز ثقتنا بأنفسنا عندما نقابل تحديات جديدة مثل تجربة تقنية أو إطار عمل للمرة الأولى. 3. اختيار البنية التحتية المناسبة عندما نحاول بناء مشاريع ذكاء اصطناعي مثل نظام للتعرف على الكائنات في الوقت الحقيقي باستخدام الشبكات العصبية الالتفافية Convolutional Neural Networks أو نجرب توليد النصوص باستخدام نماذج المحولات Transformers، فنحن بحاجة لاختيار البنية التحتية المناسبة لمتطلبات مشروعنا. فتحتاج أغلب مشاريع الذكاء الاصطناعي وتعلم الآلة وحدات المعالجة الرسومية GPUs لقدراتها على المعالجة على التوازي parallel processing مما يسرِّع بشكل ملحوظ عملية تدريب نماذج الذكاء الاصطناعي واستخدامها في التنبؤ والاستدلال inference، خاصة عند التعامل مع النماذج اللغوية الضخمة LLMs. وعلينا أن نأخذ في الاعتبار بعض العوامل عند اختيارنا للمنصة التي توفر وحدات المعالجة الرسومية GPU مثل عدد وحدات كودا CUDA الموجودة في وحدة المعالجة الرسومية، وسعة تخزين ذاكرة الفيديو VRAM، وسعة مرور البيانات bandwidth من الذاكرة حيث أن لهذه المعايير تأثير في سرعة التدريب وسرعة الاستدلال وتكلفة التشغيل. ويمكننا -في حال تطوير مشروع يحتاج إلى بنية تحتية قوية- الوصول للبنية التحتية اللازمة لتدريب وتشغيل النماذج من خلال مزودي الخدمات السحابية cloud provider، ولكن في كثير من الأحيان تكون المشاريع الجانبية التي نطورها بهدف التعلم، لذا لا تكون هناك ميزانية أو جدوى من دفع مبالغ طائلة لتطوير المشروع، وفي هذه الحالة يمكن اللجوء لبدائل مجانية، أو استخدام الخطة المجانية أو الرصيد المتوفر للحسابات الجديدة على منصات مزودي الخدمات السحابية لتجربة خدماتهم، وكذلك هناك خيار استخدام كولاب collab أو كاجل Kaggle وكلاهما منصات مملوكة لجوجل وتوفران استخدامًا محدودًا ولكنهما مناسبان لأغلب المشروعات الجانبية، فمثلًا يوفر كاجل Kaggle وحدات معالجة رسومية GPUs يمكن استخدامها بسعة متجددة أسبوعية لمدة 30 ساعة شرط أن يكون الحساب موثقًا برقم هاتف، وهي فترة كافية لتجربة تدريب النماذج الصغيرة ومتوسطة الحجم أو صقل نموذج لغوي ضخم. 4. جمع البيانات المطلوبة للمشروع كي نتمكن من بناء أي مشروع ذكاء اصطناعي وتعلم آلة، سنحتاج إلى البيانات، وتوفر مواقع مثل كاجل Kaggle أو مستودع جامعة كاليفورنيا للتعلم الآلي UCI Machine Learning Repository مجموعات بيانات غنية ومجانية للاستخدام في تطوير النماذج وتحليل البيانات، ويفضل اختيار قواعد بيانات موثقة جيدًا حتى نفهم هيكلة البيانات وكيفية التعامل معها. 5. التعاون مع الآخرين لتجنب التشتت قد يكون مشروع الذكاء الاصطناعي في البداية غير واضح، وهذا قد يشتتنا من وفرة وتنوع الأدوات والطرق المتاحة لتحقيق الهدف، يمكن حل هذه المشكلة بالتعاون النشط مع الآخرين في تطوير مشاريعك مما سيجعلها تجربة ممتعة وإنتاجية أكثر. كما يمكننا الانضمام للمجتمعات التقنية المهتمة بالذكاء الاصطناعي في حال واجهنا أي مشكلة، فهي أماكن مناسبة لطرح الأسئلة ومشاركة مشاريع الذكاء الاصطناعي وإيجاد رفقاء للعمل على المشاريع، وكذلك يتيح لنا GitHub المساهمة في المشاريع مفتوحة المصدر مما يكسبنا خبرة عملية وتواصل قوي مع المطورين الخبراء في تطوير البرمجيات مفتوحة المصدر. إن التفاعل مع المجتمع ومشاريعه أو المساهمة في المناقشات الجارية بشأن الذكاء الاصطناعي يمكن أن يشكل فرصةً ثمينةً للتواصل مع مهندسي ذكاء اصطناعي خبراء يوفرون تقييمًا ومراجعةً مفيدة للغاية على مشاريع المبتدئين ويساهمون في تطوير أفكارهم وتشجيعهم على التطور المستمر والتعلم الفعال. ثمانية أفكار مشاريع ذكاء اصطناعي تناسب المبتدئين لنتعرف معًا على أبرز أفكار المشاريع المناسبة لشخص مبتدئ. 1. نظام دردشة آلي بالذكاء الاصطناعي AI Chatbot System بناء نظام دردشة آلي بالذكاء الاصطناعي هو أحد أوضح مشاريع الذكاء الاصطناعي التي يمكن البدء منها من ناحية طريقة التنفيذ وخطواتها، فباستخدام معالجة اللغات الطبيعية و خوارزميات تعلم الآلة يمكن إنشاء نظام دردشة آلي يرد على استفسارات المستخدم. وتسهّل مكتبات مثل تنسرفلو Tensorflow وباي تورش PyTorch من عملية بناء هذا النوع من الأنظمة بتوفيرها نماذج مدرّبة وأدوات سهلة الاستخدام للتعامل مع المدخلات والردود النصية. فباستخدام هذه الأدوات يمكن بناء نظام محادثة آلي chatbot بدون التعمق كثيرًا في الخوارزميات المعقدة مما يجعل هذا المشروع مناسبًا للمبتدئين. المهارات التي نحتاجها لهذا المشروع هي لغة البرمجة بايثون Python، ومعالجة اللغات الطبيعية NLP، والتعلم العميق DL، وأطر عمل الذكاء الاصطناعي مثل باي تورش PyTorch أو تنسورفلو TensorFlow، ودمج واجهة التطبيقات البرمجية API integration من الأفكار الجيدة لتطبيقات دردشة آلية بالذكاء الاصطناعي نظام محادثة آلي chatbot يستخدم النصوص المستخلصة من برامج البودكاست المفضلة، مما يسمح بالدردشة مع المستضيف والضيوف حول المواضيع التي تغطيها البرامج، أو تصميم مدرب لياقة بدنية مخصص لكل مستخدم من خلال نظام دردشة آلي يخصص التدريب بناءً على معلومات المستخدم، وأهدافه، ومؤشراته الحيوية التي تجمعها الأجهزة الذكية القابلة للارتداء، أو نظام دردشة آلي يجيب عن الأسئلة التي تخص منطقة سكننا من خلال بيانات صفحات التواصل الاجتماعي ومصادر الأخبار المحلية. 2. فلترة الرسائل المزعجة Spam Filtering يمكن تطبيق العديد من تقنيات الذكاء الاصطناعي في مشروع لفلترة الرسائل المزعجة spam filtering حيث نبني مُصنِّفًا لرسائل البريد الإلكتروني لتحديد ما إذا كانت الرسالة مزعجة أم لا. ولتحليل نص رسالة البريد الإلكتروني وتحديد الأنماط المثيرة للشك يمكن استخدام معالجة اللغات الطبيعية. وأبسط شكل للمشروع يتم من خلال مصنِّفات تحسب احتمالية كون رسالة البريد الإلكتروني مزعجة بناءً على ورود بعض الكلمات المفتاحية بها والتي وجدت من قبل في رسائل مزعجة. ويمكنك تجربة خوارزمية متجهات الدعم الآلي support vector machine من أجل تصنيف رسائل البريد الإلكتروني من خلال صفات الرسالة مثل بيانات المرسل ومحتوى الرسالة. ولنصبح أكثر تمكنًا يمكن استخدام نماذج التعلم العميق مثل الشبكات العصبية الالتفافية Convolution Neural Network أو الشبكات العصبية التكرارية Recurrent Neural Network لاكتشاف الأنماط المعقدة في النصوص أو معلومات عن البيانات المرسلة والأنماط الموجودة في الملفات المرفقة. المهارات التي نحتاجها لهذا المشروع هي: خوارزميات التعلم الآلي التصنيفية وخوارزمية متجهات الدعم الآلي SVM ولغة البرمجة بايثون Python، ومعالجة اللغات الطبيعية NLP، والتعلم العميق DL، ومعالجة البيانات Data preprocessing. 3. تطبيق ترجمة بالذكاء الاصطناعي يساعد بناء تطبيق ترجمة ذكي على تعلم بناء نماذج قادرة على التعامل مع مهام مثل تحديد اللغة language detection والترجمة وهيكلة الجمل، فيمكن استخدام معالجة اللغات الطبيعية Natural Language Processing، والترجمة الآلية العصبية Neural Maching Translation لإنشاء تطبيق لترجمة النصوص بين اللغات المختلفة. وباستخدام معمارية المحولات Transformers يمكننا تطوير نظام قادر على فهم سياق النص وتوفير ترجمة دقيقة له. للبدء في هذا المشروع سنحتاج لجمع مجموعات بيانات متعددة اللغات توفر نصوصًا وما يوازيها من ترجمة في لغات أخرى. وبمجرد تدريب نموذجنا الخاص فيمكن دمج واجهات التطبيق البرمجية مثل Google Translator أو DeepL لتحسين قدرات التطبيق في الترجمة في الوقت الحقيقي، تساعدنا هذه التطبيقات في تجنب بناء نظام ترجمة من الصفر وتجعلنا نركز على تحسين تجربة المستخدم. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: لغة البرمجة بايثون Python، ومعالجة اللغات الطبيعية NLP، والترجمة الآلية العصبية NMT، وتقنيات معمارية المحولات transformer model techniques، ودمج واجهة التطبيق البرمجية API. 4. التعرف على الأرقام المكتوبة بخط اليد ننشئ في مشروع التعرف على الأرقام المكتوبة بخط اليد نموذجًا يتعرف ويصنف آليًا الأرقام من صفر إلى تسعة الموجودة في الصور. ولبناء النموذج سنحتاج أولًا لمعالجة الصور للتأكد من أبعادها الموحدة ومن تحويلها لصور بتدرج الرمادي يمكن التعبير عنها ببيانات أقل من الصور الملونة مما يسرع من معالجة الصور ويسهل التعامل معها، وتلي هذه الخطوة استخدام الشبكات العصبية الالتفافية لتدريب نموذج يتعرف على الأنماط الموجودة في الصورة التي تميز كل رقم عن الآخر، وتعد مجموعة بيانات MNIST digit من الأشهر استخدامًا لتدريب نماذج التعرف على الأرقام العربية، وإذا أردنا التميز فيمكن تجربة مجموعات بيانات أخرى مثل MADBase وهي مجموعة بيانات للأرقام العربية الشرقية أو الهندية (۰-۹)، ويمكن التوسع أكتر في المشروع وتطبيق تقنيات التعرف البصري على الحروف Optical Charachter Recognition أو OCR اختصارًا، وهذا يتجاوز التعرف على الأرقام إلى التعرف على نصوص كاملة في تنسيقات وخطوط وأحجام مختلفة، ويستخدم في تطبيقات مثل استخراج الأرقام والحروف من لوحات السيارات أو التعرف على الكلمات المكتوبة في اللافتات الإعلانية أو غيرها. يسمح لنا هذا المشروع بتجربة تطوير أفكار لتطبيقات حقيقية مثل المعالجة الآلية للاستمارات المكتوبة بخط اليد، أو بناء نظام للتعرف على أرقام الهواتف المحمولة. المهارات التي نحتاجها لهذا المشروع: لغة البرمجة بايثون Python، والشبكات العصبية الالتفافية CNN، وخوارزميات معالجة الصور، وأطر عمل ذكاء اصطناعي مثل باي تورش PyTorch 5. تصنيف الصور Image Classification يمكن من خلال مشروع تصنيف الصور بناء نموذج يتعرف على العناصر الموجودة في الصور ويصنفها إلى أحد الأصناف المحددة مسبقًا آليًا. يبدأ المشروع بمجموعة بيانات تحتوي آلاف الصور المجمعة في أقسام مثل صور حيوانات أو مركبات أو أي من الكائنات الموجودة في حياتنا اليومية. بدايةً علينا أن نعالج الصور لجعلها موحدة الحجم والتنسيق، وبعد ذلك ندرب النموذج باستخدام شبكة عصبية التفافية CNN ليتعلم الأنماط البصرية بالصورة مثل الأشكال والألوان والخامات، ثم يمكن بعد ذلك تدريب واختبار النموذج لتصنيف صور جديدة لم يرها من قبل. وتكمن روعة هذه الفكرة في مدى إمكانية تنفيذها في العديد من التطبيقات الحياتية مثل التعرف على الوجوه، وتحليل الصور الطبية، وحتى تقنيات المركبات ذاتية القيادة. المهارات التي تحتاجها لتنفيذ هذا المشروع هي: معرفة بإطار عمل لمعالجة الصور مثل openCV، والشبكات العصبية الالتفافية CNN، وأحد أطر عمل الذكاء الاصطناعي مثل تنسورفلو TensorFlow أو باي تورش PyTorch. 6. مساعد آلي لإعادة هيكلة الكود يمكننا تطوير أداة المستخدمين في تحسين وتنقيح الأكواد الموجودة بدون تغيير وظيفتها. سنحتاج لإنشاء نموذج ذكاء اصطناعي يبحث عن المشكلات في الكود ويجد الأجزاء التي يمكن كتابتها بطرق أفضل وأكثر كفاءةً مثل مهندسي البرمجيات المحترفين. يمكن البدء بجمع أمثلة من الأكواد الفوضوية والمحسنة من مصادر مفتوحة المصدر مثل جت هاب Github، وتدريب الذكاء الاصطناعي باستخدام تقنيات تعلم الآلة للتعرف على الأنماط، ومن ثم دمجه مع محرر الأكواد أو بيئة التطوير المتكاملة IDE من أجل اقتراحات تحسينية في الزمن الحقيقي. وبمجرد التأكد من عمل الأداة بشكل صحيح يمكننا توسيع اختصاصاتها لتشمل لغات برمجة أكثر وميزات متقدمة مثل التأكد من أمان الكود وتخصيص الأسلوب. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: معالجة اللغات الطبيعية NLP، ولغة البرمجة بايثون Python، ومعرفة بطريقة تطوير إضافات لبيئة التطوير المتكاملة IDE plugin development. 7. نظام ترشيح للأفلام يسمح لنا بناء نظام لترشيح الأفلام بتخصيص تجربة اقتراح الأفلام من خلال محرك الترشيحات الذي يتوقع أي الأفلام سيستمتع بها المستخدمون بناءً على تفضيلاتهم السابقة. نحتاج للبدء بمجموعة بيانات مثل MovieLens تحتوي على تقييمات المستخدم وتفاصيل الأفلام وأنواعها. سنحلل في هذا المشروع سلوك المستخدم ونحدد الأنماط من أجل اقتراح أفلام لم يشاهدها المستخدمون من قبل ولكن من المحتمل أن يحبوها. لتحقيق هذا، يمكن استخدام تقنيات مثل الترشيح التعاوني collaborative filtering والذي يوجِد أوجه التشابه بين المستخدمين أو الأفلام بناءً على تصنيفهم وتصفية المحتوى، وتقترح هذه الطريقة الأفلام المشابهة لتلك التي أحبها المستخدم في السابق، بمجرد تمكننا من تنفيذ المشروع، سنكتسب المهارات اللازمة لتطبيق أنظمة الترشيح في سياقات مختلفة، وبالرغم من أن النظام الذي نطوره قد لا يكون قابلًا للتشغيل مع مستخدمين حقيقين إلا أنه يوفر تدريبًا جيدًا يمكّننا من بناء أنظمة مشابهة، سواءً من أجل منصات بث الأفلام والمسلسلات أو منصات التجارة الإلكترونية أو حتى منصات التواصل الاجتماعي. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: الترشيح التعاوني Collaborative filtering، والتصفية حسب المحتوى content-based filtering وتحليل مصفوفة آراء المستخدمين Matrix Factorization، ولغة البرمجة بايثون Python، وخوارزميات تعلم الآلة. 8. محلل السير الذاتية يمكن بناء مشروع محلل للسير الذاتية يستخرج المعلومات المهمة آليًا من السير الذاتية مثل الاسم ومعلومات التواصل والتعليم وخبرة العمل. سنبدأ بجمع السير الذاتية من مجموعات البيانات الموجودة في مصادر مفتوحة مثل كاجل Kaggle بتنسيقات مختلفة مثل PDF أو Word أو غيرها، وباستخدام تقنيات معالجة اللغات الطبيعية NLP سنحلل ونفصل النصوص الموجودة. بتحديدنا لأنماط محددة في التواريخ أو المسميات الوظيفية أو أسماء الشركات سنتمكن من تدريب النموذج لاكتشاف المعلومات الضرورية. ويمكن أيضًا استخدام التعرف على الكيانات المسماة Named Entity Recognition -أو NER اختصارًا- للتعرف على كيانات مثل الجامعات والدرجات العلمية والمهارات. ويمكن بمجرد تحليل البيانات تخزينها بشكل مهيكل في قاعدة بيانات تسهّل الوصول للبيانات ومقارنتها. ولتحسين هذا المشروع وتطويره يمكننا دمجه في نظام لتتبع المتقدمين على الوظائف لمساعدة فرق الموارد البشرية على التعامل مع عدد ضخم من السير الذاتية بكفاءة ودقة. المهارات التي نحتاجها لتنفيذ هذا المشروع هي: التعرف على الكيانات المسماة NER، ولغة بايثون Python، ومعالجة اللغات الطبيعية NLP، واستخراج البيانات وتحليلها. الخلاصة تناولنا في هذه المقالة بعض أفكار مشاريع الذكاء الاصطناعي المفيدة للمهتمين بتعلم الذكاء الاصطناعي. قد نواجه أثناء تطبيق هذه المشاريع العديد من التحديات والعقبات، لكننا بالمقابل سنتعلم التعامل مع الخوارزميات والأدوات والمكتبات البرمجية بكفاءة ونصقل خبرتنا البرمجية ونبني معرض أعمال متميز. وللمهتمين بتعلم المهارات اللازمة لتنفيذ هذه المشاريع بسرعة وتطبيقها بفعالية، تقدم أكاديمية حسوب دورة الذكاء الاصطناعي المتميزة التي توفر الكثير من الوقت في تعلم الذكاء الاصطناعي من خلال دمج الجانب النظري والتطبيقي، وتحتوي العديد من التطبيقات والأمثلة العملية المفيدة بدايةً من التعامل مع البيانات وتحليلها وصولًا إلى تطبيقات متقدمة مثل النماذج اللغوية الضخمة، والتي تضمن لك بناء معرض أعمال قوي والحصول على فرصة عمل مناسبة. ترجمة وبتصرف لمقال 8 AI Side Project Ideas for Beginners لصاحبته Sujatha R. اقرأ أيضًا أمثلة على الذكاء الاصطناعي تعرف على أهم مشاريع الذكاء الاصطناعي المعالجة المُسبقة للبيانات قبل تمريرها لنماذج الذكاء الاصطناعي طريقة الصقل Fine-Tune لنموذج ذكاء اصطناعي مُدرَّب مُسبقًا -
 تستعمل العديد من الشركات اليوم كلًا من وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU لتحسين أداء طيف واسع من التطبيقات بداية من مراكز البيانات Data centers وصولًا إلى الأجهزة المحمولة وغيرها من الاستخدامات المفيدة، وسنشرح في هذا المقال كل وحدة معالجة وآلية عملها ونوضح أهم أوجه التشابه والاختلاف بينهما، وحالات الاستخدام المناسبة لكل منهما، لنساعدكم على تقرير الوحدة الأفضل لمشروعكم أو نشاطكم التجاري. تطور المعالجات الحاسوبية أصبحت وحدة المعالجة المركزية Central Processing Unit -أو CPU اختصارًا- مكونًا أساسيًا في أنظمة الحواسيب منذ بداية سبعينيات القرن الماضي، فتطورت من مجرد آلات بسيطة لإجراء الحسابات والمعالجات الرياضية إلى معالجات متعددة النواة وبالغة التعقيد. فكان إصدار إنتل لمعالجها 4004 في عام 1971علامة فارقة لبداية حقبة وحدات المعالجات المركزية الحديثة ومهد الطريق للتطورات المتسارعة في قدرات المعالجة، ومع مرور الزمن أصبحت وحدات المعالجة المركزية CPUs أكثر تخصصًا وتعقيدًا حيث ظهرت ابتكارات مثل خطوط أنابيب تجزئة تنفيذ التعليمات Instruction pipelining ومتنبئ التعليمات التفرعية Branch Predictor و تقنية خيوط المعالجة الفائقة Hyper-threading وقد دفعت هذه التقنيات بحدود المعالجة الحاسوبية العامة إلى الأمام. ثم ظهرت وحدة المعالجة الرسومية Graphics Processing Unit -أو GPU اختصارًا- في بداية التسعينيات لتلبي الطلب المتزايد على المعالجة الرسومية في ألعاب الفيديو ورسوميات الحواسيب. وعلى النقيض من وحدات المعالجات المركزية CPUs التي كانت مصممة لتنفيذ التعليمات على التسلسل sequential فقد صممت المعالجات الرسومية GPUs للتعامل مع الحسابات والعمليات على التوازي parallel من أجل تنفيذ المهام الرسومية المعقدة، وكان تقديم نيفيديا لمعالجها جيفورس GeForce 256 في عام 1999 بداية حقبة جديدة للعتاد المخصص للرسوميات القادر على تخفيف الحمل الحاسوبي عن وحدات المعالجات المركزية CPUs في مهام المعالجة الرسومية. صُممت وحدات المعالجة المركزية والرسومية في البداية لأغراض مختلفة، لكن في السنوات الأخيرة بدأت قدراتهما وأدوارهما تتداخل مع بعضها البعض، فأصبحت وحدات المعالجة المركزية CPUs مدمجة مع قدرات المعالجة على التوازي، وصارت وحدات المعالجة الرسومية GPUs أكثر شمولًا وتنوعًا وظهرت لها تطبيقات أخرى غير الرسوميات مثل حل المسائل العلمية المعقدة وتطبيقات تعلم الآلة، كما حظت المعالجات الرسومية بشعبية كبيرة في السنوات الأخيرة نتيجة أدائها المبهر في أداء مهام الذكاء الاصطناعي وبالتحديد قدرتها على المعالجة المتوازية parallel computing فكانت الأداة المثالية لتدريب شبكات التعلم العميق وإجراء العمليات الحسابية على المصفوفات الضخمة التي تلعب دورًا أساسيًا في العديد من خوارزميات الذكاء الاصطناعي، مما دفع إلى اكتشافات علمية متقدمة في مجالات بحثية وتطبيقية مختلفة مثل الرؤية الحاسوبية Computer Vision ومعالجة اللغات الطبيعية Natural Language Processing والذكاء الاصطناعي التوليدي Generative AI. ما هي وحدة المعالجة المركزية CPU وحدة المعالجة المركزية CPU هي المكون الرئيسي في أجهزة الحواسيب، فهي تقوم بأغلب العمليات والمعالجة، ويشار إليها في سياقات كثيرة بعقل الحاسوب، وتنفذ وحدة المعالجة المركزية CPU التعليمات والحسابات وتنظم الأنشطة المختلفة للعتاد الحاسوبي. وتسود اليوم معالجات متعددة الأنوية multi-core processors قادرة على تنفيذ العديد من المهام في نفس الوقت مستغلة قدرات المعالجة المتوازية والمعماريات المتقدمة. وقد تحتاج بعض الشركات لاستخدام أنظمة شديدة الاعتماد على استهلاك وحدة المعالجة المركزية CPU-intensive لإجراء تحليل متقدم للبيانات، مثل معالجة مجموعات من البيانات الكبيرة الخاصة بالعملاء لاكتشاف أنماط شرائهم، وتوقع اتجاهات السوق المستقبلية. آلية عمل وحدة المعالجة المركزية CPU تعمل وحدة المعالجة المركزية CPU من خلال حلقة من العمليات معروفة باسم دورة تنفيذ التعليمات وتتكون من ثلاث خطوات وهي الجلب Fetch و فك التشفير Decode ثم التنفيذ Execute، وتكون هذه الخطوات معًا أساس جميع عمليات وحدة المعالجة المركزية CPU. والآن لنستكشف المكونات الرئيسية والخطوات المرتبطة بمعالجة التعليمات وتنفيذها لنفهم كيفية عمل وحدة المعالجة المركزية CPU: وحدة التحكم Control unit تعد وحدة التحكم بمثابة مركز القيادة الخاص بوحدة المعالجة المركزية CPU، فهي تدير وتنسق كل العمليات الخاصة بوحدة المعالجة المركزية CPU. وحدة الحساب والمنطق ALU تجري في وحدة الحساب والمنطق Arithmetic Logic Unit -أو ALU اختصارًا- كل العمليات الحسابية والمنطقية مثل الجمع والطرح والمقارنة، فهي تشكل أساس القدرات الحسابية لوحدة المعالجة المركزية CPU. السجلات Registers هي وحدات تخزين فائقة السرعة توجد بداخل شريحة وحدة المعالجة المركزية CPU، حيث تحتفظ هذه السجلات Registers بالبيانات التي تعمل عليها وحدة المعالجة المركزية CPU حاليًا، مما يسمح بسرعة الوصول لها والتعديل عليها. الذاكرة المخبئية Cache الذاكرة المخبئية Cache هي ذاكرة مؤقتة صغيرة الحجم مبنية بداخل وحدة المعالجة المركزية وهي تتميز بسرعتها وتستخدم لتخزين البيانات والتعليمات التي يُحتمل استخدامها بشكل متكرر لتسريع المعالجة، ولكنها أقل سرعة من السجلات Registers وأكبر منها في الحجم. الجلب Fetch تجلب وحدة المعالجة المركزية CPU في هذه الخطوة التعليمات من الذاكرة، ويحدد عداد البرنامج program counter موقع التعليمة الذي ستفذ حاليًا، فعداد البرنامج هو عبارة عن سجل مخصص لمتابعة وتعقب التعليمات المطلوب تنفيذها، ويحدّث نفسه تلقائيًا ليشير للتعليمة التالية. فك التشفير Decode تأتي هذه الخطوة بعد جلب fetching التعليمة حيث يجري تفسيرها بواسطة وحدة المعالجة المركزية CPU، وتعمل وحدة التحكم Control Unit على فك تشفير العمليات وتحديد ما هي العمليات التي ينبغي تنفيذها، وما هي البيانات التي تحتاجها هذه العملية. التنفيذ Execute تنفذ وحدة المعالجة المركزية CPU التعليمة، وقد يتطلب التنفيذ عمليات حسابية أو منطقية باستخدام وحدة الحساب والمنطق ALU، أو نقل بيانات خلال السجلات المختلفة، أو التفاعل مع أجزاء مختلفة من الحاسوب. التخزين Store إن كانت العملية المُنفذَّة تعيد نتيجة فسوف تحفظ هذه النتيجة في سجل register أو في الذاكرة، ويُحَدَّث عداد البرنامج program counter ليشير للتعليمة القادمة، لتبدأ نفس الحلقة في التكرار مجددًا. ما هي وحدة المعالجة الرسومية GPU تعد وحدة المعالجة الرسومية GPU دارة إلكترونية مخصصة ومصممة للتعديل على الذاكرة بسرعة، وتسريع إنشاء الصور في ذاكرة مخصصة لعرض ولإخراج المعلومات على أجهزة العرض تسمى frame buffer، وقد طُوّرت في البداية لأغراض عرض الرسوميات ثلاثية الأبعاد في ألعاب الفيديو، ثم تطورت لتصبح معالجات متوازية قووية قادرة على التعامل مع العمليات الحسابية المعقدة على التزامن. وتحتوي وحدات المعالجة الرسومية GPUs على آلاف من الأنوية cores الصغيرة وعالية الكفاءة المصممة للتعامل مع مهام متعددة على التوازي، مما يجعلها الخيار المثالي لمهام المعالجة المتوازية التي تتجاوز التطبيقات الرسومية. تستخدم الشركات اليوم قدرات وحدات المعالجة الرسومية GPUs لتطوير وتشغيل نماذج تعلم الآلة الضخمة على نطاق واسع، وهذا يتيح لها تحقيق تقدم متسارع في تخصيص وتشخيص تجربة أنظمة التوصية الخاصة بها، وتستخدم أيضًا في تطوير تقنيات المركبات ذاتية القيادة وفي خدمات الترجمة الفورية في الوقت الحقيقي وغيرها من التطبيقات الذكية. آلية عمل وحدة المعالجة الرسومية GPU تعمل وحدات المعالجة الرسومية GPUs بمبادئ مشابهة لتلك التي تتبعها وحدات المعالجة المركزية CPUs ولكنها مصممة ومحسنة لمهام المعالجة المتوازية، وهذا يجعلها الخيار الأنسب لعرض الرسوميات ولأنواع معينة من المهام. وسنشرح تاليًا آلية عمل وحدة المعالجة الرسومية GPU: المعالجات متعددة التدفق SMs تكافئ المعالجات متعددة التدفق Streaming Multiprocessors -أو SMs اختصارًا- الأنوية cores المستخدمة في وحدات المعالجة المركزية ولكن يحتوي كل معالج متعدد التدفق SM على وحدات معالجة أصغر ومتعددة ما يكسبه القدرة على التعامل مع تدفق كبير من البيانات حيث تُمكّن هذه المعمارية وحدات المعالجة الرسومية GPUs من التعامل مع العديد من المهام بنفس الوقت. أنوية كودا CUDA Cores تقع هذه الأنوية بداخل وحدات معالجة التدفق SM، وهي المسؤولة عن المعالجة بداخلها، وهي أبسط من أنوية وحدة المعالجة المركزية CPU ولكنها توجد بأعداد أكبر بكثير، حيث قد يوجد في وحدة المعالجة الرسومية GPU آلاف منها. وحدات رسم الخامة TMUs تعمل وحدة رسم الخامة Texture Mapping Unit أو TMU اختصارًا على رسم الخامة أو السطح الخارجي للنماذج ثلاثية الأبعاد بسرعة كبيرة، وهي وظيفة فريدة توجد فقط في وحدات المعالجة الرسومية GPUs وليست موجودة في وحدات المعالجة المركزية CPUs. ذاكرة الفيديو VRAM تتشابه ذاكرة الفيديو Video Memory في الوظيفة مع ذاكرة الوصول العشوائي الخاصة بوحدة المعالجة المركزية CPU، ولكنها محسنَّة لمهام المعالجة الرسومية، وهي في الغالب أسرع وتمتلك معدل نقل بيانات أكبر من الذي تملكه ذاكرة RAM. الجلب Fetch تمتلك وظيفة مماثلة لتلك الخطوة الخاصة بجلب التعليمات في وحدة المعالجة المركزية CPU، ولكنها مصممة بشكل أفضل لتنفيذ العديد من التعليمات المتشابهة على التوازي بذات الوقت. فك التشفير Decode تشابه هذه الوظيفة نظيرتها في وحدة المعالجة المركزية CPU والاختلاف بينهما هو تحسين هذه الوظيفة في GPU لتناسب مع المهام المتعلقة بمعالجة الرسوميات. التنفيذ Execute تختلف هذه الخطوة بشكلٍ جذري عن نظيرتها في وحدة المعالجة المركزية CPU، حيث تُنفِّذ وحدات المعالجة الرسومية GPUs العديد من التعليمات المتشابهة بشكل متزامن من خلال عدد كبير من أنوية كودا CUDA cores في عملية تسمى Single instruction Multiple Data -أو SIMD اختصارًا- والتي تعني إمكانية تنفيذ نفس التعليمة على عدة بيانات في نفس الوقت. التخزين Store تُحفظ النتائج عادة في ذاكرة الفيديو Video Random Access Memory -أو VRAM اختصارًا- ويسمح المستوى العالي من التوازي الذي توفره وحدات المعالجة الرسومية GPUs بتحقيق معدل نقل بيانات كبير جدًا من أجل تنفيذ المهام المتعلقة بالرسوميات. مقارنة بين وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU تعد كلتا وحدتي المعالجة المركزية والرسومية مكونات ضرورية في أنظمة الحوسبة الحديثة، وقد صُمّمت كل وحدة معالجة منهما بأولويات ومسؤوليات مختلفة وهدف تصميمي مختلف، لذا من الضروري فهم الفروقات بينهما لتحديد المناسب لنا من بينهما. الوظيفة الأساسية صُمّمت وحدات المعالجة المركزية CPUs لتكون شاملة ومتعددة الأغراض وقادرة على التعامل مع طيف واسع من المهام بكفاءة عالية، فهي تتميز في المعالجة المتسلسلة sequential processing، كما أنها مُحسّنة لاتخاذ القرارات المعقدة، وتتحكم وحدة المعالجة المركزية CPU في العتاد الحاسوبي والتنسيق بين البرامج المختلفة لتشغيلها. بنما كانت وحدات المعالجة الرسومية GPUs متخصصة في البداية في عرض الرسوميات graphics rendering، ولكنها تطورت مع الوقت لتصبح معالجات فائقة لها القدرة على المعالجة المتوازية parallel processors. وهي اليوم تشغّل التعليمات تمامًا كوحدات المعالجة المركزية CPUs ولكنها محسنة للتعامل مع الكثير من العمليات الحسابية المتزامنة. فوحدات المعالجة المركزية CPU متنوعة القدرات وشاملة المهام، في حين أن وحدات المعالجة الرسومية تتميز بالتخصص والتفوق في تنفيذ المهام القابلة للتقسيم إلى مهام كثيرة جدًا والتي تتميز بكونها مهام متشابهة ويمكن حسابها بشكل مستقل عن بعضها البعض. المعالجة تُنفِّذ وحدات المعالجة المركزية CPUs العمليات بشكل متتابع أو متسلسل، حيث تُنفِّذ التعليمات المعقدة واحدة تلو الأخرى وتستخدم تقنيات مخصصة مثل التنبؤ بالتعليمات المتفرعة أو الشرطية branch prediction أو التنفيذ غير المراعي للترتيب Out-of-Order Execution الذي يسمح بتنفيذ التعليمات بترتيب مختلف عن ترتيبها الأصلي في البرنامج لتحسين عملية المعالجة المتسلسلة، حيث تشبه وحدات المعالجة المركزية CPUs المدير المنظم فهي تنسق وتتعامل مع مهام متنوعة وتتخذ القرارات المعقدة بسرعة. من ناحية أخرى، تعالج وحدات المعالجة الرسومية GPUs المهام بالتوازي، فتنفّذ العديد من التعليمات البسيطة بشكل متزامن عبر عدد ضخم من الأنوية، وتحتوي هذه الأنوية على عدد ضخم من الخيوط threads البسيطة التي يمكنها تنفيذ عمليات بسيطة للغاية ولكن عددها الضخم يمكِّنها من معالجة كمية بيانات أكبر بنفس الوقت، فبينما تشبه وحدة المعالجة المركزية CPU المدير، تشبه وحدة المعالجة الرسومية GPU خط التجميع في المصانع حيث يوكل لكل عامل أو آلة جزء معين من العمل، وبهذا يمكن لهذه الوحدة معالجة كميات ضخمة من البيانات المتشابهة في وقت واحد. تصميم الهيكلية تمتلك وحدات المعالجة المركزية CPUs في الغالب من 2 إلى 64 نواة معقدة التركيب ومزودة بذاكرة مخبئية Caches ووحدات تحكم Control units مخصصة ومعقدة، حيث صممت هذه المكونات لتحقق أقل معدل تأخير في الاستجابة low latency، فتستطيع كل نواة التعامل مع مهام متنوعة بشكل مستقل، فتولي هذه الهيكلية أهمية للتنوع في القدرات وسرعة الاستجابة لعدد واسع ومتنوع من المهام. بينما تجمع وحدات المعالجة الرسومية GPUs مئات أو آلاف الأنوية البسيطة فيما يعرف بمعالجات متعددة التدفق streaming multiprocessors أي يمكنها معالجة عدة تدفقات من البيانات في وقت واحد، وعلى عكس وحدات المعالجة المركزية CPUs فإن أنوية وحدات المعالجة الرسومية GPUs تتشارك في وحدات التحكم والذاكرات المخبئية بداخل كل معالج متعدد، وتختلف هذه المعمارية عن وحدات المعالجة المركزية CPUs بحيث تسمع لوحدات المعالجة الرسومية GPUs بمعالجة كميات ضخمة من البيانات من خلال عمليات متشابهة عليها، فهي لا تعتمد أنوية معقدة كما في وحدات المعالجة المركزية بل تستخدم أنوية بسيطة وصغيرة تكمن قوتها وتفوقها بقدرتها في العمل على التوازي على عدد كبير من البيانات. حالات الاستخدام تبرز أهمية وحدات المعالجة المركزية CPUs في المهام التي تطلب اتخاذ قرارات معقدة، وتنفيذ عمليات متنوعة، أو تغيرات متكررة في تدفق تنفيذ العمليات. فتشغل هذه الوحدات أنظمة التشغيل والمتصفحات. وتعد الخيار الأول لمهام مثل إدارة قواعد البيانات وتشغيل برامج الإنتاجية والتنسيق بين عمليات النظام المختلفة. في حين تبرز أهمية وحدات المعالجة الرسومية GPUs في الحالات التي تتضمن إجراء العديد من العمليات الحسابية في نفس الوقت عبر عدد كبير من البيانات المتجانسة أي البيانات المتشابهة أو المتطابقة من حيث الهيكل أو النوع، فهي تتشارك مع وحدات المعالجة المركزية CPUs في القدرة على القيام بالعمليات الحسابية لكنها تتفوق بشكل جليّ في المهام التي تطلب عرض رسومات ثلاثية الأبعاد وكثيرة التفاصيل، أو في تدريب نماذج تعلم الآلة أو تنفيذ عمليات محاكاة لظواهر علمية تتطلب حسابات ضخمة، ففي كل هذه التطبيقات تتفوق وحدات المعالجة الرسومية GPUs على وحدات المعالجة المركزية CPUs عشرات المرات وربما مئات المرات من حيث الأداء، مما يعطيها دورًا لا غنى عنه في مجالات مثل رسوميات الحاسوب، والذكاء الاصطناعي والحوسبة عالية الأداء. دمج وحدة المعالجة المركزية CPU مع وحدة المعالجة الرسومية GPU تستخدم الأنظمة الحاسوبية الحديثة كلًا من وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU لتحسين التطبيقات والمهام. ويعرف هذا النهج بالحوسبة الهجينة، حيث تسمح هذه الطريقة لكل معالج بالتركيز على الأمور التي يتفوق فيهل، فتتعامل وحدات المعالجة المركزية CPUs مع المهام المعقدة المتسلسلة، وتتولى وحدات المعالجة الرسومية GPUs الحسابات المتوازية، ويعزز هذه الدمج في التقنيات أداء الأنظمة ويساعد في العديد من المجالات بداية من المحاكاة العلمية والذكاء الاصطناعي وصولًا إلى إنشاء المحتوى، ولنستعرض بعض الأمثلة على حالات يمكننا فيها دمج CPU مع GPU. لنفترض أن شركة ناشئة تطور نظامًا لاكتشاف الكائنات في الوقت الحقيقي من أجل المركبات ذاتية القيادة، فيمكن للشركة في هذه الحالة أن تستخدم وحدة المعالجة المركزية CPU في معالجة البيانات المتدفقة من المستشعرات واتخاذ قرارات سريعة، بينما تستخدم وحدة المعالجة الرسومية GPU في تشغيل نظام من الشبكات العصبية الاصطناعية Artificial Neural Networks المعقدة للتعرف على الكائنات في البيئة المحيطة بالمركبة. مثال آخر، لنفترض أن شركة تقنيات مالية تريد تطوير منصة تداول وتتوقع ورود طلبات تداول كثيرة في نفس الوقت، فيمكنها أن تستخدم وحدات المعالجة المركزية CPUs لإدارة عملية التداول وتشغيل الخوارزميات المعقدة، بينما تستفيد من وحدات المعالجة الرسومية GPUs في تحليل بيانات السوق بسرعة وتقييم المخاطر التسويقية من خلال عمليات حسابية تنفذ على التوازي. أخيرًا، لنفترض أن لدينا استوديو تطوير ألعاب ونريد صناعة لعبة عالم مفتوح متعددة الشخصيات واللاعبين، فيمكننا في هذه الحالة استخدام وحدات المعالجة المركزية CPUs في تنفيذ منطق اللعب وإضافة سلوك الذكاء الاصطناعي للعبة، بينما نعتمد على وحدات المعالجة الرسومية GPUs في عرض الرسومات المعقدة ثلاثية الأبعاد ومحاكاة الظواهر الطبيعية ومحاكاة الفيزياء لإنشاء تجربة لعب مبهرة بصريًا. ترجمة وبتصرف لمقالة ?What is the Difference Between CPU and GPU. اقرأ أيضًا تعدد المهام Multitasking في الحواسيب وحدة المعالجة المركزية تعرف على وحدة المعالجة المركزية وعملياتها في معمارية الحاسوب استكشف مصطلحات الذكاء الاصطناعي التوليدي توليد النصوص باستخدام النماذج اللغوية الكبيرة LLMs
تستعمل العديد من الشركات اليوم كلًا من وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU لتحسين أداء طيف واسع من التطبيقات بداية من مراكز البيانات Data centers وصولًا إلى الأجهزة المحمولة وغيرها من الاستخدامات المفيدة، وسنشرح في هذا المقال كل وحدة معالجة وآلية عملها ونوضح أهم أوجه التشابه والاختلاف بينهما، وحالات الاستخدام المناسبة لكل منهما، لنساعدكم على تقرير الوحدة الأفضل لمشروعكم أو نشاطكم التجاري. تطور المعالجات الحاسوبية أصبحت وحدة المعالجة المركزية Central Processing Unit -أو CPU اختصارًا- مكونًا أساسيًا في أنظمة الحواسيب منذ بداية سبعينيات القرن الماضي، فتطورت من مجرد آلات بسيطة لإجراء الحسابات والمعالجات الرياضية إلى معالجات متعددة النواة وبالغة التعقيد. فكان إصدار إنتل لمعالجها 4004 في عام 1971علامة فارقة لبداية حقبة وحدات المعالجات المركزية الحديثة ومهد الطريق للتطورات المتسارعة في قدرات المعالجة، ومع مرور الزمن أصبحت وحدات المعالجة المركزية CPUs أكثر تخصصًا وتعقيدًا حيث ظهرت ابتكارات مثل خطوط أنابيب تجزئة تنفيذ التعليمات Instruction pipelining ومتنبئ التعليمات التفرعية Branch Predictor و تقنية خيوط المعالجة الفائقة Hyper-threading وقد دفعت هذه التقنيات بحدود المعالجة الحاسوبية العامة إلى الأمام. ثم ظهرت وحدة المعالجة الرسومية Graphics Processing Unit -أو GPU اختصارًا- في بداية التسعينيات لتلبي الطلب المتزايد على المعالجة الرسومية في ألعاب الفيديو ورسوميات الحواسيب. وعلى النقيض من وحدات المعالجات المركزية CPUs التي كانت مصممة لتنفيذ التعليمات على التسلسل sequential فقد صممت المعالجات الرسومية GPUs للتعامل مع الحسابات والعمليات على التوازي parallel من أجل تنفيذ المهام الرسومية المعقدة، وكان تقديم نيفيديا لمعالجها جيفورس GeForce 256 في عام 1999 بداية حقبة جديدة للعتاد المخصص للرسوميات القادر على تخفيف الحمل الحاسوبي عن وحدات المعالجات المركزية CPUs في مهام المعالجة الرسومية. صُممت وحدات المعالجة المركزية والرسومية في البداية لأغراض مختلفة، لكن في السنوات الأخيرة بدأت قدراتهما وأدوارهما تتداخل مع بعضها البعض، فأصبحت وحدات المعالجة المركزية CPUs مدمجة مع قدرات المعالجة على التوازي، وصارت وحدات المعالجة الرسومية GPUs أكثر شمولًا وتنوعًا وظهرت لها تطبيقات أخرى غير الرسوميات مثل حل المسائل العلمية المعقدة وتطبيقات تعلم الآلة، كما حظت المعالجات الرسومية بشعبية كبيرة في السنوات الأخيرة نتيجة أدائها المبهر في أداء مهام الذكاء الاصطناعي وبالتحديد قدرتها على المعالجة المتوازية parallel computing فكانت الأداة المثالية لتدريب شبكات التعلم العميق وإجراء العمليات الحسابية على المصفوفات الضخمة التي تلعب دورًا أساسيًا في العديد من خوارزميات الذكاء الاصطناعي، مما دفع إلى اكتشافات علمية متقدمة في مجالات بحثية وتطبيقية مختلفة مثل الرؤية الحاسوبية Computer Vision ومعالجة اللغات الطبيعية Natural Language Processing والذكاء الاصطناعي التوليدي Generative AI. ما هي وحدة المعالجة المركزية CPU وحدة المعالجة المركزية CPU هي المكون الرئيسي في أجهزة الحواسيب، فهي تقوم بأغلب العمليات والمعالجة، ويشار إليها في سياقات كثيرة بعقل الحاسوب، وتنفذ وحدة المعالجة المركزية CPU التعليمات والحسابات وتنظم الأنشطة المختلفة للعتاد الحاسوبي. وتسود اليوم معالجات متعددة الأنوية multi-core processors قادرة على تنفيذ العديد من المهام في نفس الوقت مستغلة قدرات المعالجة المتوازية والمعماريات المتقدمة. وقد تحتاج بعض الشركات لاستخدام أنظمة شديدة الاعتماد على استهلاك وحدة المعالجة المركزية CPU-intensive لإجراء تحليل متقدم للبيانات، مثل معالجة مجموعات من البيانات الكبيرة الخاصة بالعملاء لاكتشاف أنماط شرائهم، وتوقع اتجاهات السوق المستقبلية. آلية عمل وحدة المعالجة المركزية CPU تعمل وحدة المعالجة المركزية CPU من خلال حلقة من العمليات معروفة باسم دورة تنفيذ التعليمات وتتكون من ثلاث خطوات وهي الجلب Fetch و فك التشفير Decode ثم التنفيذ Execute، وتكون هذه الخطوات معًا أساس جميع عمليات وحدة المعالجة المركزية CPU. والآن لنستكشف المكونات الرئيسية والخطوات المرتبطة بمعالجة التعليمات وتنفيذها لنفهم كيفية عمل وحدة المعالجة المركزية CPU: وحدة التحكم Control unit تعد وحدة التحكم بمثابة مركز القيادة الخاص بوحدة المعالجة المركزية CPU، فهي تدير وتنسق كل العمليات الخاصة بوحدة المعالجة المركزية CPU. وحدة الحساب والمنطق ALU تجري في وحدة الحساب والمنطق Arithmetic Logic Unit -أو ALU اختصارًا- كل العمليات الحسابية والمنطقية مثل الجمع والطرح والمقارنة، فهي تشكل أساس القدرات الحسابية لوحدة المعالجة المركزية CPU. السجلات Registers هي وحدات تخزين فائقة السرعة توجد بداخل شريحة وحدة المعالجة المركزية CPU، حيث تحتفظ هذه السجلات Registers بالبيانات التي تعمل عليها وحدة المعالجة المركزية CPU حاليًا، مما يسمح بسرعة الوصول لها والتعديل عليها. الذاكرة المخبئية Cache الذاكرة المخبئية Cache هي ذاكرة مؤقتة صغيرة الحجم مبنية بداخل وحدة المعالجة المركزية وهي تتميز بسرعتها وتستخدم لتخزين البيانات والتعليمات التي يُحتمل استخدامها بشكل متكرر لتسريع المعالجة، ولكنها أقل سرعة من السجلات Registers وأكبر منها في الحجم. الجلب Fetch تجلب وحدة المعالجة المركزية CPU في هذه الخطوة التعليمات من الذاكرة، ويحدد عداد البرنامج program counter موقع التعليمة الذي ستفذ حاليًا، فعداد البرنامج هو عبارة عن سجل مخصص لمتابعة وتعقب التعليمات المطلوب تنفيذها، ويحدّث نفسه تلقائيًا ليشير للتعليمة التالية. فك التشفير Decode تأتي هذه الخطوة بعد جلب fetching التعليمة حيث يجري تفسيرها بواسطة وحدة المعالجة المركزية CPU، وتعمل وحدة التحكم Control Unit على فك تشفير العمليات وتحديد ما هي العمليات التي ينبغي تنفيذها، وما هي البيانات التي تحتاجها هذه العملية. التنفيذ Execute تنفذ وحدة المعالجة المركزية CPU التعليمة، وقد يتطلب التنفيذ عمليات حسابية أو منطقية باستخدام وحدة الحساب والمنطق ALU، أو نقل بيانات خلال السجلات المختلفة، أو التفاعل مع أجزاء مختلفة من الحاسوب. التخزين Store إن كانت العملية المُنفذَّة تعيد نتيجة فسوف تحفظ هذه النتيجة في سجل register أو في الذاكرة، ويُحَدَّث عداد البرنامج program counter ليشير للتعليمة القادمة، لتبدأ نفس الحلقة في التكرار مجددًا. ما هي وحدة المعالجة الرسومية GPU تعد وحدة المعالجة الرسومية GPU دارة إلكترونية مخصصة ومصممة للتعديل على الذاكرة بسرعة، وتسريع إنشاء الصور في ذاكرة مخصصة لعرض ولإخراج المعلومات على أجهزة العرض تسمى frame buffer، وقد طُوّرت في البداية لأغراض عرض الرسوميات ثلاثية الأبعاد في ألعاب الفيديو، ثم تطورت لتصبح معالجات متوازية قووية قادرة على التعامل مع العمليات الحسابية المعقدة على التزامن. وتحتوي وحدات المعالجة الرسومية GPUs على آلاف من الأنوية cores الصغيرة وعالية الكفاءة المصممة للتعامل مع مهام متعددة على التوازي، مما يجعلها الخيار المثالي لمهام المعالجة المتوازية التي تتجاوز التطبيقات الرسومية. تستخدم الشركات اليوم قدرات وحدات المعالجة الرسومية GPUs لتطوير وتشغيل نماذج تعلم الآلة الضخمة على نطاق واسع، وهذا يتيح لها تحقيق تقدم متسارع في تخصيص وتشخيص تجربة أنظمة التوصية الخاصة بها، وتستخدم أيضًا في تطوير تقنيات المركبات ذاتية القيادة وفي خدمات الترجمة الفورية في الوقت الحقيقي وغيرها من التطبيقات الذكية. آلية عمل وحدة المعالجة الرسومية GPU تعمل وحدات المعالجة الرسومية GPUs بمبادئ مشابهة لتلك التي تتبعها وحدات المعالجة المركزية CPUs ولكنها مصممة ومحسنة لمهام المعالجة المتوازية، وهذا يجعلها الخيار الأنسب لعرض الرسوميات ولأنواع معينة من المهام. وسنشرح تاليًا آلية عمل وحدة المعالجة الرسومية GPU: المعالجات متعددة التدفق SMs تكافئ المعالجات متعددة التدفق Streaming Multiprocessors -أو SMs اختصارًا- الأنوية cores المستخدمة في وحدات المعالجة المركزية ولكن يحتوي كل معالج متعدد التدفق SM على وحدات معالجة أصغر ومتعددة ما يكسبه القدرة على التعامل مع تدفق كبير من البيانات حيث تُمكّن هذه المعمارية وحدات المعالجة الرسومية GPUs من التعامل مع العديد من المهام بنفس الوقت. أنوية كودا CUDA Cores تقع هذه الأنوية بداخل وحدات معالجة التدفق SM، وهي المسؤولة عن المعالجة بداخلها، وهي أبسط من أنوية وحدة المعالجة المركزية CPU ولكنها توجد بأعداد أكبر بكثير، حيث قد يوجد في وحدة المعالجة الرسومية GPU آلاف منها. وحدات رسم الخامة TMUs تعمل وحدة رسم الخامة Texture Mapping Unit أو TMU اختصارًا على رسم الخامة أو السطح الخارجي للنماذج ثلاثية الأبعاد بسرعة كبيرة، وهي وظيفة فريدة توجد فقط في وحدات المعالجة الرسومية GPUs وليست موجودة في وحدات المعالجة المركزية CPUs. ذاكرة الفيديو VRAM تتشابه ذاكرة الفيديو Video Memory في الوظيفة مع ذاكرة الوصول العشوائي الخاصة بوحدة المعالجة المركزية CPU، ولكنها محسنَّة لمهام المعالجة الرسومية، وهي في الغالب أسرع وتمتلك معدل نقل بيانات أكبر من الذي تملكه ذاكرة RAM. الجلب Fetch تمتلك وظيفة مماثلة لتلك الخطوة الخاصة بجلب التعليمات في وحدة المعالجة المركزية CPU، ولكنها مصممة بشكل أفضل لتنفيذ العديد من التعليمات المتشابهة على التوازي بذات الوقت. فك التشفير Decode تشابه هذه الوظيفة نظيرتها في وحدة المعالجة المركزية CPU والاختلاف بينهما هو تحسين هذه الوظيفة في GPU لتناسب مع المهام المتعلقة بمعالجة الرسوميات. التنفيذ Execute تختلف هذه الخطوة بشكلٍ جذري عن نظيرتها في وحدة المعالجة المركزية CPU، حيث تُنفِّذ وحدات المعالجة الرسومية GPUs العديد من التعليمات المتشابهة بشكل متزامن من خلال عدد كبير من أنوية كودا CUDA cores في عملية تسمى Single instruction Multiple Data -أو SIMD اختصارًا- والتي تعني إمكانية تنفيذ نفس التعليمة على عدة بيانات في نفس الوقت. التخزين Store تُحفظ النتائج عادة في ذاكرة الفيديو Video Random Access Memory -أو VRAM اختصارًا- ويسمح المستوى العالي من التوازي الذي توفره وحدات المعالجة الرسومية GPUs بتحقيق معدل نقل بيانات كبير جدًا من أجل تنفيذ المهام المتعلقة بالرسوميات. مقارنة بين وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU تعد كلتا وحدتي المعالجة المركزية والرسومية مكونات ضرورية في أنظمة الحوسبة الحديثة، وقد صُمّمت كل وحدة معالجة منهما بأولويات ومسؤوليات مختلفة وهدف تصميمي مختلف، لذا من الضروري فهم الفروقات بينهما لتحديد المناسب لنا من بينهما. الوظيفة الأساسية صُمّمت وحدات المعالجة المركزية CPUs لتكون شاملة ومتعددة الأغراض وقادرة على التعامل مع طيف واسع من المهام بكفاءة عالية، فهي تتميز في المعالجة المتسلسلة sequential processing، كما أنها مُحسّنة لاتخاذ القرارات المعقدة، وتتحكم وحدة المعالجة المركزية CPU في العتاد الحاسوبي والتنسيق بين البرامج المختلفة لتشغيلها. بنما كانت وحدات المعالجة الرسومية GPUs متخصصة في البداية في عرض الرسوميات graphics rendering، ولكنها تطورت مع الوقت لتصبح معالجات فائقة لها القدرة على المعالجة المتوازية parallel processors. وهي اليوم تشغّل التعليمات تمامًا كوحدات المعالجة المركزية CPUs ولكنها محسنة للتعامل مع الكثير من العمليات الحسابية المتزامنة. فوحدات المعالجة المركزية CPU متنوعة القدرات وشاملة المهام، في حين أن وحدات المعالجة الرسومية تتميز بالتخصص والتفوق في تنفيذ المهام القابلة للتقسيم إلى مهام كثيرة جدًا والتي تتميز بكونها مهام متشابهة ويمكن حسابها بشكل مستقل عن بعضها البعض. المعالجة تُنفِّذ وحدات المعالجة المركزية CPUs العمليات بشكل متتابع أو متسلسل، حيث تُنفِّذ التعليمات المعقدة واحدة تلو الأخرى وتستخدم تقنيات مخصصة مثل التنبؤ بالتعليمات المتفرعة أو الشرطية branch prediction أو التنفيذ غير المراعي للترتيب Out-of-Order Execution الذي يسمح بتنفيذ التعليمات بترتيب مختلف عن ترتيبها الأصلي في البرنامج لتحسين عملية المعالجة المتسلسلة، حيث تشبه وحدات المعالجة المركزية CPUs المدير المنظم فهي تنسق وتتعامل مع مهام متنوعة وتتخذ القرارات المعقدة بسرعة. من ناحية أخرى، تعالج وحدات المعالجة الرسومية GPUs المهام بالتوازي، فتنفّذ العديد من التعليمات البسيطة بشكل متزامن عبر عدد ضخم من الأنوية، وتحتوي هذه الأنوية على عدد ضخم من الخيوط threads البسيطة التي يمكنها تنفيذ عمليات بسيطة للغاية ولكن عددها الضخم يمكِّنها من معالجة كمية بيانات أكبر بنفس الوقت، فبينما تشبه وحدة المعالجة المركزية CPU المدير، تشبه وحدة المعالجة الرسومية GPU خط التجميع في المصانع حيث يوكل لكل عامل أو آلة جزء معين من العمل، وبهذا يمكن لهذه الوحدة معالجة كميات ضخمة من البيانات المتشابهة في وقت واحد. تصميم الهيكلية تمتلك وحدات المعالجة المركزية CPUs في الغالب من 2 إلى 64 نواة معقدة التركيب ومزودة بذاكرة مخبئية Caches ووحدات تحكم Control units مخصصة ومعقدة، حيث صممت هذه المكونات لتحقق أقل معدل تأخير في الاستجابة low latency، فتستطيع كل نواة التعامل مع مهام متنوعة بشكل مستقل، فتولي هذه الهيكلية أهمية للتنوع في القدرات وسرعة الاستجابة لعدد واسع ومتنوع من المهام. بينما تجمع وحدات المعالجة الرسومية GPUs مئات أو آلاف الأنوية البسيطة فيما يعرف بمعالجات متعددة التدفق streaming multiprocessors أي يمكنها معالجة عدة تدفقات من البيانات في وقت واحد، وعلى عكس وحدات المعالجة المركزية CPUs فإن أنوية وحدات المعالجة الرسومية GPUs تتشارك في وحدات التحكم والذاكرات المخبئية بداخل كل معالج متعدد، وتختلف هذه المعمارية عن وحدات المعالجة المركزية CPUs بحيث تسمع لوحدات المعالجة الرسومية GPUs بمعالجة كميات ضخمة من البيانات من خلال عمليات متشابهة عليها، فهي لا تعتمد أنوية معقدة كما في وحدات المعالجة المركزية بل تستخدم أنوية بسيطة وصغيرة تكمن قوتها وتفوقها بقدرتها في العمل على التوازي على عدد كبير من البيانات. حالات الاستخدام تبرز أهمية وحدات المعالجة المركزية CPUs في المهام التي تطلب اتخاذ قرارات معقدة، وتنفيذ عمليات متنوعة، أو تغيرات متكررة في تدفق تنفيذ العمليات. فتشغل هذه الوحدات أنظمة التشغيل والمتصفحات. وتعد الخيار الأول لمهام مثل إدارة قواعد البيانات وتشغيل برامج الإنتاجية والتنسيق بين عمليات النظام المختلفة. في حين تبرز أهمية وحدات المعالجة الرسومية GPUs في الحالات التي تتضمن إجراء العديد من العمليات الحسابية في نفس الوقت عبر عدد كبير من البيانات المتجانسة أي البيانات المتشابهة أو المتطابقة من حيث الهيكل أو النوع، فهي تتشارك مع وحدات المعالجة المركزية CPUs في القدرة على القيام بالعمليات الحسابية لكنها تتفوق بشكل جليّ في المهام التي تطلب عرض رسومات ثلاثية الأبعاد وكثيرة التفاصيل، أو في تدريب نماذج تعلم الآلة أو تنفيذ عمليات محاكاة لظواهر علمية تتطلب حسابات ضخمة، ففي كل هذه التطبيقات تتفوق وحدات المعالجة الرسومية GPUs على وحدات المعالجة المركزية CPUs عشرات المرات وربما مئات المرات من حيث الأداء، مما يعطيها دورًا لا غنى عنه في مجالات مثل رسوميات الحاسوب، والذكاء الاصطناعي والحوسبة عالية الأداء. دمج وحدة المعالجة المركزية CPU مع وحدة المعالجة الرسومية GPU تستخدم الأنظمة الحاسوبية الحديثة كلًا من وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU لتحسين التطبيقات والمهام. ويعرف هذا النهج بالحوسبة الهجينة، حيث تسمح هذه الطريقة لكل معالج بالتركيز على الأمور التي يتفوق فيهل، فتتعامل وحدات المعالجة المركزية CPUs مع المهام المعقدة المتسلسلة، وتتولى وحدات المعالجة الرسومية GPUs الحسابات المتوازية، ويعزز هذه الدمج في التقنيات أداء الأنظمة ويساعد في العديد من المجالات بداية من المحاكاة العلمية والذكاء الاصطناعي وصولًا إلى إنشاء المحتوى، ولنستعرض بعض الأمثلة على حالات يمكننا فيها دمج CPU مع GPU. لنفترض أن شركة ناشئة تطور نظامًا لاكتشاف الكائنات في الوقت الحقيقي من أجل المركبات ذاتية القيادة، فيمكن للشركة في هذه الحالة أن تستخدم وحدة المعالجة المركزية CPU في معالجة البيانات المتدفقة من المستشعرات واتخاذ قرارات سريعة، بينما تستخدم وحدة المعالجة الرسومية GPU في تشغيل نظام من الشبكات العصبية الاصطناعية Artificial Neural Networks المعقدة للتعرف على الكائنات في البيئة المحيطة بالمركبة. مثال آخر، لنفترض أن شركة تقنيات مالية تريد تطوير منصة تداول وتتوقع ورود طلبات تداول كثيرة في نفس الوقت، فيمكنها أن تستخدم وحدات المعالجة المركزية CPUs لإدارة عملية التداول وتشغيل الخوارزميات المعقدة، بينما تستفيد من وحدات المعالجة الرسومية GPUs في تحليل بيانات السوق بسرعة وتقييم المخاطر التسويقية من خلال عمليات حسابية تنفذ على التوازي. أخيرًا، لنفترض أن لدينا استوديو تطوير ألعاب ونريد صناعة لعبة عالم مفتوح متعددة الشخصيات واللاعبين، فيمكننا في هذه الحالة استخدام وحدات المعالجة المركزية CPUs في تنفيذ منطق اللعب وإضافة سلوك الذكاء الاصطناعي للعبة، بينما نعتمد على وحدات المعالجة الرسومية GPUs في عرض الرسومات المعقدة ثلاثية الأبعاد ومحاكاة الظواهر الطبيعية ومحاكاة الفيزياء لإنشاء تجربة لعب مبهرة بصريًا. ترجمة وبتصرف لمقالة ?What is the Difference Between CPU and GPU. اقرأ أيضًا تعدد المهام Multitasking في الحواسيب وحدة المعالجة المركزية تعرف على وحدة المعالجة المركزية وعملياتها في معمارية الحاسوب استكشف مصطلحات الذكاء الاصطناعي التوليدي توليد النصوص باستخدام النماذج اللغوية الكبيرة LLMs- 1 تعليق
-
- 1
-

-
 أصبحت أدوات الذكاء الاصطناعي من الأساسيات التي لا غنى عنها للمبرمجين اليوم، حيث تساعد هذه الأدوات في زيادة الإنتاجية، والتخلص من المهام التكرارية، والتفرغ لحل المشكلات البرمجية الأكثر أهمية، وقد اخترنا لكم في هذه المقالة واحدة من أدوات الذكاء الاصطناعي القوية والمفيدة لأي مبرمج وهي المساعد الذكي GitHub Copilot الذي أصبح يوفر خطة استخدام مجانية من خلال دمجه مع محرر الأكواد Visual Studio Code، حيث سنوضح أهم الميزات التي يوفرها هذا المساعد الذكي، ونوضح حالات استخدامه المختلفة لكتابة أكواد محسنة وموثقة جيدًا واكتشاف الأخطاء وحلها بكفاءة من داخل المحرر مباشرة دون الحاجة لنسخ فقرات الكود ولصقها في نماذج الذكاء الاصطناعي الخارجية. المتطلبات نحتاج قبل بدء استكشاف المساعد البرمجي GitHub Copilot إلى التأكد من تجهيز بيئة عملنا بإعداد الأمور التالية: تنزيل محرر الأكواد فيجوال ستوديو كود VS Code إنشاء حساب على منصة GitHub تنزيل إضافة GitHub Copilot و GitHub Copilot Chat لمحرر الأكواد VS Code ملاحظة: قد تكون الإضافات المطلوبة محمّلة بالفعل في محرر الأكواد، وفي هذا الحالة سنتخطى خطوة تنزيلها. خطوات ربط GitHub Copilot بمحرر أكواد VS code يمكننا من خلال محرر الأكواد VS code الاستفادة من تجربة وصول محدودة لاستخدام GitHub Copilot حيث تُمنح لنا خمسون محادثة لاستخدامها في الاستفسار من المساعد البرمجي و 2000 مرة لإكمال الكود البرمجي تجدد شهريًا، وسنتطرق في نهاية المقال لكيفية الحصول على الخطة المميزة pro بالمجان للطلبة والمعلمين والمساهمين في المشاريع مفتوحة المصدر بما يتوافق مع بعض الشروط التي تضعها منصة GitHub. بمجرد أن نفتح محرر أكواد VS code سنجد أيقونة بها شعار Github Copilot، نضغط عليها أو نفتح القائمة المنسدلة حيث سنجد خيار باسم Use AI features with Copilot for Free وباختياره تفتح نافذة جانبية ترحيبية وتطالبنا بالموافقة على الشروط والأحكام من خلال الضغط على زر Use Copilot for Free، وننصح بالاطلاع عليها قبل الموافقة. كي نتمكن من فتح نافذة الحوار مع المساعد البرمجي يمكننا استخدام الأيقونة أو اختصار الوصول السريع من لوحة المفاتيح Ctrl+ALT+I. وفي حال لم نتمكن من العثور على هذه الأيقونة أو وجدناها غير مفعلة فعلينا تسجيل الدخول إلى حساب Github الخاص بنا وربطه بمحرر الأكواد، من خلال أيقونة الحسابات Accounts الموجودة أسفل يسار الصفحة في محرر الأكواد فوق أيقونة الإعدادات، فمن خلالها نصادق على وصول محرر الأكواد VS code لحسابنا على Github والذي تحتاجه إضافة Github Copilot للعمل. اختيار نموذج الذكاء الاصطناعي يوفر Github Copilot لمستخدميه في الخطة المجانية إمكانية اختيار نموذج الذكاء الاصطناعي المشغِّل لمساعد الذكاء الاصطناعي، حيث يتاح حاليًا نموذجان فقط هما GPT 4o و Claude 3.5 sonnet. بينما تتيح الخطط المميزة المدفوعة الوصول إلى نماذج أقوى مثل OpenAI o1 و OpenAI o1-mini. ملاحظة: قد تتغير هذه النماذج بمرور الوقت وتطور إلى نماذج أخرى، من الأفضل حاليًا استخدام GPT4o أو Claude Sonnet 3.5 في تعديل ملفات الكود، بينما يفضل استخدام o1 لفهم وشرح الكود، وقد يختلف الأمر حسب حالة الاستخدام التي نتعامل معها لذا يمكن التبديل بين النماذج المتاحة ومقارنة نتائجها لنقرر الأنسب حسب كل حالة. حالات استخدام Github Copilot ضمن محرر الأكواد بعد ربط أداة الذكاء الاصطناعي بمحرر الأكواد، يمكننا الاستفادة من هذه الأداة في العديد من حالات الاستخدام العملية التي تسهل عملنا البرمجي وتزيد إنتاجيتنا. لنسعرض في الفقرات التالية أهم الحالات التي يمكننا الاستفادة منها من دمج مساعد الذكاء الاصطناعي GitHub Copilot مع محرر الأكواد. اقتراح إكمال الكود البرمجي لننشئ مجلدًا جديدًا و نفتحه في المحرر VS code، ثم ننشئ ملفًا باسم binary_search.py لنكتب خوارزمية البحث الثنائي وهي خوازرمية بحث مشهورة بكفاءتها، لنجرب أولًا كتابة تعريف دالة تستقبل مجموعة من الأرقام في مصفوفة Array، ونرى كيف سيقترح علينا المساعد البرمجي الكود المناسب للبحث ضمنها. بمجرد أن نكتب تعريف الدالة البرمجية سنلاحظ ظهور كود بلون رمادي خافت، هذا الكود هو اقتراح المساعد البرمجي ويمكننا الوقوف عليه بالمؤشر ورؤية شريط به بعض عناصر التحكم، فمثلًا قد نرى 1/2 والتي تعني أن هذا هو أحد اقتراحين، ويمكن أن نتجاهل الاقتراحات بمتابعة الكتابة أو يمكننا قبول الاقتراحات بالضغط على زر Accept أو على مفتاح Tab على لوحة المفاتيح، وكذلك يمكننا التحكم بمقدار ما نريد قبوله من الاقتراح باستمرار الضغط على زر Ctrl مع أحد أزرار الأسهم. يمكننا أيضًا كتابة تعليق يصف ما نريد وبمجرد النزول سطرًا سيقترح المساعد البرمجي كود ينفذ التعليق. تعديل عدة ملفات بأوامر مكتوبة وصوتية يتميز مساعد Github Copilot عن باقي أدوات الذكاء الاصطناعي الخارجية في وصوله للسياق البرمجي وقاعدة الأكواد التي نعمل عليها، وقدرته على التعديل على الملفات في الوقت الفعلي، ولا يقتصر الأمر على تعديل ملف واحد فيمكننا تعديل عدة ملفات بذات الوقت. لنجرب ميزة تعديل عدة ملفات معًا من خلال تطبيق خوارزميات ترتيب مشهورة سنكتبها في نفس ملف binary_sort كما في الصورة التالية: يمكننا بالطبع توليد هذه الدوال بمساعدة Github Copilot، كما نلاحظ هنا فإن اسم الملف لا يعبر عن الخوارزمية المطبقة -وهذا خطأ مقصود- لنرى كيف سيتعامل معه المساعد في خطوة لاحقة. لنفتح الآن نافذة الحوار ونكتب الموجّه prompt المناسب لطلب تعديل الملفات ويمكن استخدام أيقونة الميكروفون لتوجيه أمر صوتي. سيقترح Github Copilot التعديلات المناسبة وسيظهر لنا الاختلافات بين الملفات القديمة والتي أنشئت حديثًا، سنرى الأكواد التي حذفت مظللة بلون أحمر والتي أضيفت بلون أخضر، ولكن لن تطبق أو تضاف هذه التعديلات حتى نقبلها بالضغط على زر Accept. تحسين الكود البرمجي يمكننا مناقشة المساعد البرمجي Github Copilot في آلية كتابة كودنا البرمجي وكيفية تحسينه أو حل مشكلاته من خلال نافذة الحوار والتي تعد واحدة طرق متعددة للتواصل مع المساعد البرمجي، حيث يمكننا التواصل معه أيضًا من خلال محرر الأكواد بشكل مباشر وتفاعلي، أو من خلال سطر الأوامر أو الطرفية terminal المدمجة بمحرر أكواد VS code، أو من خلال واجهة VS code المحسنة لنجعل تجربة الاستخدام أكثر سلاسة. بملاحظة المثال السابق في تعديل الملفات سنجد عدة مشاكل واضحة، تحتاج لتصحيح بشري، ولهذا من المهم جدًا أن لاتسلم بصحة الكود المولد من أدوات الذكاء الاصطناعي دون مراجعته وتعديله، فأداة Github Copilot شأنها شأن أي أداة ذكاء اصطناعي آخرى فهي مفيدة لزيادة إنتاجيتك إن كنت بالفعل على دراية بالكود والمنطق المراد تنفيذه. تتمثل الأخطاء التي قام بها المساعد الذكي في حذف الدوال الأخرى من الملف الأول فقط، وبالتالي سنحتاج تصحيح هذا الخطأ بالإضافة لتحديث وتصحيح تسمية الملف الأول binary_sort إلى binary_seach فهو ليس خوارزمية ترتيب إنما خوارزمية بحث وهو خطأ مقصود نريد أن نختبر قدرته على اكتشافه. سنجد أن المساعد اكتشف المشكلات بالفعل ووضحها لنا في قائمة مرقمة، كما في الصورة التالية، ويمكننا أن نطلب منه تطبيقها. سيطبق المساعد الذكي هذه التعديلات، ولكن بتصفح الملفات نلاحظ أنه يقترح علينا كمُراجِع للكود code reviewing تعديل أو تصحيح بعض الأشياء، وهذه قد تكون ميزة مفيدة لاكتشاف الأخطاء أو المشاكل. يمكننا النقاش أيضًا حول تطبيق خوارزمية معينة وكيفية تحسينها كما في المثال التالي. كتبنا بداية الكود التالي بلغة بايثون والذي يتضمن تنفيذ لخوارزميتي الترتيب بالإدراج Insertion Sort والترتيب بالدمج Merge Sort من أجل ترتيب العناصر داخل قائمة وذلك قبل المناقشة والتحسين: def insertion_sort(arr): for i in range(1, len(arr)): key = arr[i] j = i - 1 while j >= 0 and arr[j] > key: arr[j+1] = arr[j] j -= 1 arr[j+1] = key def merge_sort(arr): if len(arr) > 1: mid = len(arr) // 2 left_half = arr[:mid] right_half = arr[mid:] merge_sort(left_half) merge_sort(right_half) i = j = k = 0 while i < len(left_half) and j < len(right_half): if left_half[i] < right_half[j]: arr[k] = left_half[i] i += 1 else: arr[k] = right_half[j] j += 1 k += 1 while i < len(left_half): arr[k] = left_half[i] i += 1 k += 1 while j < len(right_half): arr[k] = right_half[j] j += 1 k += 1 وفيما يلي الكود بعد التحسين واستخدام أسلوب يدمج بين خوارزميتي الترتيب لجمع ميزاتهما معًا: # This file contains implementation of merge sort algorithm. def insertion_sort(arr): for i in range(1, len(arr)): key = arr[i] j = i - 1 while j >= 0 and arr[j] > key: arr[j+1] = arr[j] j -= 1 arr[j+1] = key def merge_sort(arr, threshold=10): if len(arr) <= threshold: insertion_sort(arr) return arr if len(arr) > 1: mid = len(arr) // 2 left_half = arr[:mid] right_half = arr[mid:] merge_sort(left_half, threshold) merge_sort(right_half, threshold) i = j = k = 0 while i < len(left_half) and j < len(right_half): if left_half[i] < right_half[j]: arr[k] = left_half[i] i += 1 else: arr[k] = right_half[j] j += 1 k += 1 while i < len(left_half): arr[k] = left_half[i] i += 1 k += 1 while j < len(right_half): arr[k] = right_half[j] j += 1 k += 1 return arr # test the merge_sort function with some test cases sample = [5, 2, 9, 1, 5, 6] merge_sort(sample) print(sample) تخصيص تجربة الاستخدام قد نرغب في بعض الأحيان بأن يتبع المساعد البرمجي أسلوبًا معينًا نستخدمه في كتابة أكوادنا ولذلك نكثر في تفصيل التعليمات وتوضيحها له، ولكن هناك طريقة أفضل حيث يمكن أن نوضح للمساعد البرمجي أسلوبًا معينًا نطبقه على كامل المشروع ضمن ملف تعليمات بحيث لا نكون مضطرين لتوضيح تعليمات التخصيص في كل أمر نطلبه منه. للقيام بذلك سننشئ مجلدًا باسم github. ثم نضيف له ملفًا باسم copilot-instructions.md حيث سنكتب في هذا الملف التعليمات اللازمة والأسلوب الذي نحب كتابة الكود به كي يتبعها مساعدنا البرمجي. لاحظ المثال التالي حيث نوضح بداية كيف سيكتب لنا Github Copilot الجمل الشرطية بصيغة مختصرة تسمى العامل الثلاثي Ternary operator، ثم نوضح أسلوب توثيق الكود البرمجي الذي نرغب باستخدامه. لنختبر المخرجات بعض إضافة هذا التعديل. نلاحظ أن توثيق الكود بهذه الطريقة سيمكننا من معرفة معلومات عن الدالة عند تحديدها أو استخدامها في أي مكان آخر كما في المثال التالي. مراجعة وتدقيق الكود يمكننا استخدام Github Copilot لتدقيق ومراجعة الكود أو تلخيص التغيرات قبل طلب سحب Pull request الكود لمستودع الأكواد على Github فهذا يقلل الأخطاء البرمجية ويحسن جودة الأكواد المرفوعة. سنتبع الخطوات التالية لاستخدام هذه الميزة : نتوجه لمستودع الأكواد على Github ونطلب سحب Pull جديد أو نستخدم طلب موجود بالفعل نفتح قائمة Reviewers ونختار منها Github Copilot سيراجع المساعد الكود ويدققه لنا ثم يقدم اقتراحاته يمكننا التعامل مع التعليقات والمراجعات التي يوفرها Github Copilot كالمراجعة البشرية بقبولها أو رفضها سنجرب هذه الميزة عن طريق إنشاء مستودع أكواد Repository جديد على منصة Github ونضيف ملف بايثون math_utils.py يحتوي على دالة برمجية لقسمة رقمين، ولكن بها خطأ حيث لم نأخذ بعين الاعتبار الحالة التي يكون المقسوم عليه صفر، وسنفترض أن أحد المساهمين لاحظ هذه المشكلة وقام بطلب اشتقاق Fork لمستودع الأكواد ليصلح المشكلة، وبعد ذلك طلب سحب الملف Pull Request إلى المستودع الأصلي. في حال كنت صاحب مستودع الأكواد، فلا حاجة لاشتقاق المستودع Forking حيث يمكن إنشاء تفريعة Branch ثم طلب سحبها Pull Request. لنصحح الدالة بإضافة حالة شرطية عند كون المقسوم عليه صفرًا ونطبع رسالة الخطأ لتنبيه المستخدم. ثم نطلب سحب Pull هذا التفريع Branch الذي يحتوي التصحيح للفرع الأصلي والرئيسي. نلاحظ أنه Github Copilot قد لا يظهر لدينا في قائمة Reviewers ولكن يمكننا استخدامه لتلخيص طلب السحب Pull Request وهذا ما سنقوم به، حيث أن هذه الميزة لاتزال تجريبية وليست متاحة لدى الجميع. استخدام GitHub Copilot كخبير برمجي يتميز Github Copilot بميزة أخرى تجعله من أدوات الذكاء الاصطناعي البرمجية الفريدة، حيث يمكنه أن يعمل كخبير متخصص نستدعيه عند الوقوع في مشكلة أو عندما نرغب في معرفة آلية تنفيذ شيء ما، وهذا من خلال واجهة الحوار حيث يمكننا استدعاء الخبير من خلال رمز @ الذي يتيح قائمة من الخبراء الافتراضيين لنسألهم، مثلًا vscode@ يمكننا أن نسأله عن أي شيء يخص محرر الأكواد. نرى في هذا المثال كيف طلبنا من الخبير أن يوضح لنا كيفية تغير مظهر وتنسيق محرر الأكواد، فأخرج لنا زرًا عندما نضغط عليه يقودنا لقائمة اختيارات يمكننا من خلالها اختيار المظهر الذي نريده. @vscode how to change the Theme? لا يتوقف الأمر عند محرر الأكواد فيوجد أكثر من خبير، مثل خبير سطر الأوامر Terminal، لنفترض أننا نريد أن ننشئ في مجلد للمحاضرات Lectures، عشرة مجلدات فرعية منه وبكل منها ملف نصي فارغ برقم المحاضرة، والتي سنملؤها لاحقًا بملاحظات عن هذه المحاضرة، يمكن بالطبع محاولة فعل هذا بشكل يدوي لكن قد يستغرق الأمر وقتًا طويلًا لذا من الأفضل استخدام سطر الأوامر لتنفيذ هذه العملية بمساعدة Github Copilot. @terminal I want to create 10 folders names Lecture{i}, i the number of lecture, and for each lecture it would contain a text file named as lecture{i}_notes.txt لنفتح واجهة سطر الأوامر من خلال أحد الأزار السريعة من نافذة الحوار أو من قائمة View ثم نختار Terminal لنتمكن من وضع الأمر المولد وتشغيله، نلاحظ أن الأمر مكتوب باستخدام Powershell لأننا في حالتنا نستخدم نظام تشغيل ويندوز Windows ولكن يمكن أن نطلب استخدام Bash في حال استخدام نظام لينكس، وكما نرى فقد استطاع الأمر إنشاء الملفات التي طلبناها دون أية مشكلات، وهذه الميزة مفيدة للغاية عندما نرغب في تنفيذ بعض الأوامر من الطرفية ولكننا لا نتذكر الكلمات المفتاحية أو طريقة كتابة الأمر. حالات استخدام إضافية لمساعد Github Copilot استعرضنا في الفقرات السابقة أبرز حالات استخدام مساعد Github Copilot في محرر الأكواد، لكن في الواقع تتخطى حالات استخدام مساعد Github Copilot ملفات الكود العادية التي نتعامل معها في تخصصات البرمجة الشائعة كتطوير الواجهات الأمامية أو الخلفية، لتصل إلى البيئات المخصصة لمهندسي البيانات وتعلم الآلة المتمثلة في jupyter notebook، ولتجربة هذه الميزات سنستخدم مجموعة بيانات بسيطة وهي مجموعة بيانات لبعض ركاب سفينة تايتنك الغارقة والتي يمكنك العثور عليها في موقع كاجل Kaggle. لنعرض بضعة صفوف من مجموعة البيانات import pandas ad pd # حمل مجموعة بيانات تيتانيك titanic_df = pd.read_csv('titanic.csv') # اطبع الصفوف الأولى من البيانات titanic_df.head() باختيار زر التوليد Generate يمكننا طرح أسئلة أو توجيه أوامر بشكل كتابي أو من خلال الصوت ثم الموافقة على الاقتراح المولد أو طلب تعديله ليناسب حالة الاستخدام. فور الموافقة على الاقتراح بالضغط على قبول وتشغيل Accept & Run سنجد الرسم البياني التالي كمخرج. يوحي الرسم البياني بمعلومة هامة بخصوص نسب النجاة، فكما نرى نسبة النجاة في النساء أكبر، ونسبة الهلاك في الرجال أكبر، قد يكون هذا عائدًا بنسبة كبيرة للأولوية المعطاة للنساء والأطفال في قوارب النجاة ولكن هل يمكن للمساعد البرمجي فهم الرسومات البيانية وتلخيص الملاحظات الخاصة بها، لنختبر هذا. كما نلاحظ في السؤال الأول استطاع مساعدنا الذكي أن يستنتج ما يدل عليه الرسم البياني من نسبة نجاة أعلى للنساء، وكذلك بعد سؤاله عن سبب هذه قد استطاع توضيح السبب، وكما نلاحظ أيضًا فعند سؤاله باللغة العربية سيجيب باللغة العربية. لنوضح ميزة أخرى من خلال استخدام خلية كود يمكننا استخدام الرمز :q وطرح سؤال ثم سيجيب عنه المساعد البرمجي في نفس الخلية برمز مشابه به الإجابة :a كما في الصورة التالية. titanic_df.head(3) q: what does SibSp mean? الحصول على الخطة المميزة من Github Copilot مجانًا يمكن للطلبة أو المعلمين أو المساهمين في مشاريع مفتوحة المصدر الحصول على الخطة المميزة من Github Copilot بالمجان، فبالنسبة للطلبة يمكنهم رفع ما يثبت هذا من خلال هذه الصفحة التابعة لمنصة Github، أما المعلمون فيمكنهم من خلال هذه الرابط معرفة المميزات التي توفرها المنصة للمعلمين. يختلف الأمر قليلًا بالنسبة للمساهمين في المشاريع مفتوحة المصدر حيث ينبغي أن يصلوا لبعض الشروط التي تحددها المنصة ولا توجد طريقة للتقديم بشكل مباشر إنما ترسل إشعارات من خلال منصة Github للمساهمين الذين تجدهم مستحقين للخطة المميزة. بمجرد الحصول على الخطة المميزة كطالب برفع الإثباتات المطلوبة مثل الإيميل الجامعي وبطاقة الطالب التعريفية، سيعالج الطلب في بضعة أيام، وفي حال قبوله ستفتح ميزات متعددة لا تقتصر على الوصول لمساعد Github Copilot فقط، وإنما لمزايا أخرى يمكنك الاطلاع عليها من هنا، ولتفعيل الحساب المميز يجب تسجيل الخروج من حساب Github المحفوظ على محرر أكواد VS code وتسجيل الدخول إلى الحساب الذي جرى تفعيل الخطة المميزة عليها. للتأكد من تفعيل النسخة المميزة Pro يمكن مراجعة النماذج المتاحة للاستخدام، من خلال واجهة الحوار. الخاتمة تعرفنا في هذه المقالة عن أبرز الميزات التي توفرها أداة الذكاء الاصطناعي كوبايلوت Github Copilot للمبرمجين والمطورين عند دمجها في محرر الأكواد فيجوال ستوديو كود، حيث يمكنها مراجعة وتحسين الأكواد التي نعمل عليها، أو إكمال وتوقع الأكواد التي نريد كتابتها وغيرها من الفوائد الأخرى التي تساعدنا في توفير وقتنا وتعزيز إنتاجيتنا كمطورين، وتطرقنا في ختام المقال لكيفية الحصول على الخطة المميزة Pro بالمجان والتي تسمح لنا بالوصول لمزيد من المميزات والنماذج القوية، هل جربتم دمج هذه الأداة مع محرر الأكواد؟ شاركونا تجربتكم في التعليقات أسفل المقال. اقرأ أيضًا تعرف على منصة تنسرفلو TensorFlow للذكاء الاصطناعي فهم نظام التحكم بالإصدارات Git وأهمية استخدامه في مشاريع بايثون الإشراف على مشاريع البرمجيات مفتوحة المصدر عبر غيت هب GitHub الدليل المرجعي للعمل على نظام غيت Git
أصبحت أدوات الذكاء الاصطناعي من الأساسيات التي لا غنى عنها للمبرمجين اليوم، حيث تساعد هذه الأدوات في زيادة الإنتاجية، والتخلص من المهام التكرارية، والتفرغ لحل المشكلات البرمجية الأكثر أهمية، وقد اخترنا لكم في هذه المقالة واحدة من أدوات الذكاء الاصطناعي القوية والمفيدة لأي مبرمج وهي المساعد الذكي GitHub Copilot الذي أصبح يوفر خطة استخدام مجانية من خلال دمجه مع محرر الأكواد Visual Studio Code، حيث سنوضح أهم الميزات التي يوفرها هذا المساعد الذكي، ونوضح حالات استخدامه المختلفة لكتابة أكواد محسنة وموثقة جيدًا واكتشاف الأخطاء وحلها بكفاءة من داخل المحرر مباشرة دون الحاجة لنسخ فقرات الكود ولصقها في نماذج الذكاء الاصطناعي الخارجية. المتطلبات نحتاج قبل بدء استكشاف المساعد البرمجي GitHub Copilot إلى التأكد من تجهيز بيئة عملنا بإعداد الأمور التالية: تنزيل محرر الأكواد فيجوال ستوديو كود VS Code إنشاء حساب على منصة GitHub تنزيل إضافة GitHub Copilot و GitHub Copilot Chat لمحرر الأكواد VS Code ملاحظة: قد تكون الإضافات المطلوبة محمّلة بالفعل في محرر الأكواد، وفي هذا الحالة سنتخطى خطوة تنزيلها. خطوات ربط GitHub Copilot بمحرر أكواد VS code يمكننا من خلال محرر الأكواد VS code الاستفادة من تجربة وصول محدودة لاستخدام GitHub Copilot حيث تُمنح لنا خمسون محادثة لاستخدامها في الاستفسار من المساعد البرمجي و 2000 مرة لإكمال الكود البرمجي تجدد شهريًا، وسنتطرق في نهاية المقال لكيفية الحصول على الخطة المميزة pro بالمجان للطلبة والمعلمين والمساهمين في المشاريع مفتوحة المصدر بما يتوافق مع بعض الشروط التي تضعها منصة GitHub. بمجرد أن نفتح محرر أكواد VS code سنجد أيقونة بها شعار Github Copilot، نضغط عليها أو نفتح القائمة المنسدلة حيث سنجد خيار باسم Use AI features with Copilot for Free وباختياره تفتح نافذة جانبية ترحيبية وتطالبنا بالموافقة على الشروط والأحكام من خلال الضغط على زر Use Copilot for Free، وننصح بالاطلاع عليها قبل الموافقة. كي نتمكن من فتح نافذة الحوار مع المساعد البرمجي يمكننا استخدام الأيقونة أو اختصار الوصول السريع من لوحة المفاتيح Ctrl+ALT+I. وفي حال لم نتمكن من العثور على هذه الأيقونة أو وجدناها غير مفعلة فعلينا تسجيل الدخول إلى حساب Github الخاص بنا وربطه بمحرر الأكواد، من خلال أيقونة الحسابات Accounts الموجودة أسفل يسار الصفحة في محرر الأكواد فوق أيقونة الإعدادات، فمن خلالها نصادق على وصول محرر الأكواد VS code لحسابنا على Github والذي تحتاجه إضافة Github Copilot للعمل. اختيار نموذج الذكاء الاصطناعي يوفر Github Copilot لمستخدميه في الخطة المجانية إمكانية اختيار نموذج الذكاء الاصطناعي المشغِّل لمساعد الذكاء الاصطناعي، حيث يتاح حاليًا نموذجان فقط هما GPT 4o و Claude 3.5 sonnet. بينما تتيح الخطط المميزة المدفوعة الوصول إلى نماذج أقوى مثل OpenAI o1 و OpenAI o1-mini. ملاحظة: قد تتغير هذه النماذج بمرور الوقت وتطور إلى نماذج أخرى، من الأفضل حاليًا استخدام GPT4o أو Claude Sonnet 3.5 في تعديل ملفات الكود، بينما يفضل استخدام o1 لفهم وشرح الكود، وقد يختلف الأمر حسب حالة الاستخدام التي نتعامل معها لذا يمكن التبديل بين النماذج المتاحة ومقارنة نتائجها لنقرر الأنسب حسب كل حالة. حالات استخدام Github Copilot ضمن محرر الأكواد بعد ربط أداة الذكاء الاصطناعي بمحرر الأكواد، يمكننا الاستفادة من هذه الأداة في العديد من حالات الاستخدام العملية التي تسهل عملنا البرمجي وتزيد إنتاجيتنا. لنسعرض في الفقرات التالية أهم الحالات التي يمكننا الاستفادة منها من دمج مساعد الذكاء الاصطناعي GitHub Copilot مع محرر الأكواد. اقتراح إكمال الكود البرمجي لننشئ مجلدًا جديدًا و نفتحه في المحرر VS code، ثم ننشئ ملفًا باسم binary_search.py لنكتب خوارزمية البحث الثنائي وهي خوازرمية بحث مشهورة بكفاءتها، لنجرب أولًا كتابة تعريف دالة تستقبل مجموعة من الأرقام في مصفوفة Array، ونرى كيف سيقترح علينا المساعد البرمجي الكود المناسب للبحث ضمنها. بمجرد أن نكتب تعريف الدالة البرمجية سنلاحظ ظهور كود بلون رمادي خافت، هذا الكود هو اقتراح المساعد البرمجي ويمكننا الوقوف عليه بالمؤشر ورؤية شريط به بعض عناصر التحكم، فمثلًا قد نرى 1/2 والتي تعني أن هذا هو أحد اقتراحين، ويمكن أن نتجاهل الاقتراحات بمتابعة الكتابة أو يمكننا قبول الاقتراحات بالضغط على زر Accept أو على مفتاح Tab على لوحة المفاتيح، وكذلك يمكننا التحكم بمقدار ما نريد قبوله من الاقتراح باستمرار الضغط على زر Ctrl مع أحد أزرار الأسهم. يمكننا أيضًا كتابة تعليق يصف ما نريد وبمجرد النزول سطرًا سيقترح المساعد البرمجي كود ينفذ التعليق. تعديل عدة ملفات بأوامر مكتوبة وصوتية يتميز مساعد Github Copilot عن باقي أدوات الذكاء الاصطناعي الخارجية في وصوله للسياق البرمجي وقاعدة الأكواد التي نعمل عليها، وقدرته على التعديل على الملفات في الوقت الفعلي، ولا يقتصر الأمر على تعديل ملف واحد فيمكننا تعديل عدة ملفات بذات الوقت. لنجرب ميزة تعديل عدة ملفات معًا من خلال تطبيق خوارزميات ترتيب مشهورة سنكتبها في نفس ملف binary_sort كما في الصورة التالية: يمكننا بالطبع توليد هذه الدوال بمساعدة Github Copilot، كما نلاحظ هنا فإن اسم الملف لا يعبر عن الخوارزمية المطبقة -وهذا خطأ مقصود- لنرى كيف سيتعامل معه المساعد في خطوة لاحقة. لنفتح الآن نافذة الحوار ونكتب الموجّه prompt المناسب لطلب تعديل الملفات ويمكن استخدام أيقونة الميكروفون لتوجيه أمر صوتي. سيقترح Github Copilot التعديلات المناسبة وسيظهر لنا الاختلافات بين الملفات القديمة والتي أنشئت حديثًا، سنرى الأكواد التي حذفت مظللة بلون أحمر والتي أضيفت بلون أخضر، ولكن لن تطبق أو تضاف هذه التعديلات حتى نقبلها بالضغط على زر Accept. تحسين الكود البرمجي يمكننا مناقشة المساعد البرمجي Github Copilot في آلية كتابة كودنا البرمجي وكيفية تحسينه أو حل مشكلاته من خلال نافذة الحوار والتي تعد واحدة طرق متعددة للتواصل مع المساعد البرمجي، حيث يمكننا التواصل معه أيضًا من خلال محرر الأكواد بشكل مباشر وتفاعلي، أو من خلال سطر الأوامر أو الطرفية terminal المدمجة بمحرر أكواد VS code، أو من خلال واجهة VS code المحسنة لنجعل تجربة الاستخدام أكثر سلاسة. بملاحظة المثال السابق في تعديل الملفات سنجد عدة مشاكل واضحة، تحتاج لتصحيح بشري، ولهذا من المهم جدًا أن لاتسلم بصحة الكود المولد من أدوات الذكاء الاصطناعي دون مراجعته وتعديله، فأداة Github Copilot شأنها شأن أي أداة ذكاء اصطناعي آخرى فهي مفيدة لزيادة إنتاجيتك إن كنت بالفعل على دراية بالكود والمنطق المراد تنفيذه. تتمثل الأخطاء التي قام بها المساعد الذكي في حذف الدوال الأخرى من الملف الأول فقط، وبالتالي سنحتاج تصحيح هذا الخطأ بالإضافة لتحديث وتصحيح تسمية الملف الأول binary_sort إلى binary_seach فهو ليس خوارزمية ترتيب إنما خوارزمية بحث وهو خطأ مقصود نريد أن نختبر قدرته على اكتشافه. سنجد أن المساعد اكتشف المشكلات بالفعل ووضحها لنا في قائمة مرقمة، كما في الصورة التالية، ويمكننا أن نطلب منه تطبيقها. سيطبق المساعد الذكي هذه التعديلات، ولكن بتصفح الملفات نلاحظ أنه يقترح علينا كمُراجِع للكود code reviewing تعديل أو تصحيح بعض الأشياء، وهذه قد تكون ميزة مفيدة لاكتشاف الأخطاء أو المشاكل. يمكننا النقاش أيضًا حول تطبيق خوارزمية معينة وكيفية تحسينها كما في المثال التالي. كتبنا بداية الكود التالي بلغة بايثون والذي يتضمن تنفيذ لخوارزميتي الترتيب بالإدراج Insertion Sort والترتيب بالدمج Merge Sort من أجل ترتيب العناصر داخل قائمة وذلك قبل المناقشة والتحسين: def insertion_sort(arr): for i in range(1, len(arr)): key = arr[i] j = i - 1 while j >= 0 and arr[j] > key: arr[j+1] = arr[j] j -= 1 arr[j+1] = key def merge_sort(arr): if len(arr) > 1: mid = len(arr) // 2 left_half = arr[:mid] right_half = arr[mid:] merge_sort(left_half) merge_sort(right_half) i = j = k = 0 while i < len(left_half) and j < len(right_half): if left_half[i] < right_half[j]: arr[k] = left_half[i] i += 1 else: arr[k] = right_half[j] j += 1 k += 1 while i < len(left_half): arr[k] = left_half[i] i += 1 k += 1 while j < len(right_half): arr[k] = right_half[j] j += 1 k += 1 وفيما يلي الكود بعد التحسين واستخدام أسلوب يدمج بين خوارزميتي الترتيب لجمع ميزاتهما معًا: # This file contains implementation of merge sort algorithm. def insertion_sort(arr): for i in range(1, len(arr)): key = arr[i] j = i - 1 while j >= 0 and arr[j] > key: arr[j+1] = arr[j] j -= 1 arr[j+1] = key def merge_sort(arr, threshold=10): if len(arr) <= threshold: insertion_sort(arr) return arr if len(arr) > 1: mid = len(arr) // 2 left_half = arr[:mid] right_half = arr[mid:] merge_sort(left_half, threshold) merge_sort(right_half, threshold) i = j = k = 0 while i < len(left_half) and j < len(right_half): if left_half[i] < right_half[j]: arr[k] = left_half[i] i += 1 else: arr[k] = right_half[j] j += 1 k += 1 while i < len(left_half): arr[k] = left_half[i] i += 1 k += 1 while j < len(right_half): arr[k] = right_half[j] j += 1 k += 1 return arr # test the merge_sort function with some test cases sample = [5, 2, 9, 1, 5, 6] merge_sort(sample) print(sample) تخصيص تجربة الاستخدام قد نرغب في بعض الأحيان بأن يتبع المساعد البرمجي أسلوبًا معينًا نستخدمه في كتابة أكوادنا ولذلك نكثر في تفصيل التعليمات وتوضيحها له، ولكن هناك طريقة أفضل حيث يمكن أن نوضح للمساعد البرمجي أسلوبًا معينًا نطبقه على كامل المشروع ضمن ملف تعليمات بحيث لا نكون مضطرين لتوضيح تعليمات التخصيص في كل أمر نطلبه منه. للقيام بذلك سننشئ مجلدًا باسم github. ثم نضيف له ملفًا باسم copilot-instructions.md حيث سنكتب في هذا الملف التعليمات اللازمة والأسلوب الذي نحب كتابة الكود به كي يتبعها مساعدنا البرمجي. لاحظ المثال التالي حيث نوضح بداية كيف سيكتب لنا Github Copilot الجمل الشرطية بصيغة مختصرة تسمى العامل الثلاثي Ternary operator، ثم نوضح أسلوب توثيق الكود البرمجي الذي نرغب باستخدامه. لنختبر المخرجات بعض إضافة هذا التعديل. نلاحظ أن توثيق الكود بهذه الطريقة سيمكننا من معرفة معلومات عن الدالة عند تحديدها أو استخدامها في أي مكان آخر كما في المثال التالي. مراجعة وتدقيق الكود يمكننا استخدام Github Copilot لتدقيق ومراجعة الكود أو تلخيص التغيرات قبل طلب سحب Pull request الكود لمستودع الأكواد على Github فهذا يقلل الأخطاء البرمجية ويحسن جودة الأكواد المرفوعة. سنتبع الخطوات التالية لاستخدام هذه الميزة : نتوجه لمستودع الأكواد على Github ونطلب سحب Pull جديد أو نستخدم طلب موجود بالفعل نفتح قائمة Reviewers ونختار منها Github Copilot سيراجع المساعد الكود ويدققه لنا ثم يقدم اقتراحاته يمكننا التعامل مع التعليقات والمراجعات التي يوفرها Github Copilot كالمراجعة البشرية بقبولها أو رفضها سنجرب هذه الميزة عن طريق إنشاء مستودع أكواد Repository جديد على منصة Github ونضيف ملف بايثون math_utils.py يحتوي على دالة برمجية لقسمة رقمين، ولكن بها خطأ حيث لم نأخذ بعين الاعتبار الحالة التي يكون المقسوم عليه صفر، وسنفترض أن أحد المساهمين لاحظ هذه المشكلة وقام بطلب اشتقاق Fork لمستودع الأكواد ليصلح المشكلة، وبعد ذلك طلب سحب الملف Pull Request إلى المستودع الأصلي. في حال كنت صاحب مستودع الأكواد، فلا حاجة لاشتقاق المستودع Forking حيث يمكن إنشاء تفريعة Branch ثم طلب سحبها Pull Request. لنصحح الدالة بإضافة حالة شرطية عند كون المقسوم عليه صفرًا ونطبع رسالة الخطأ لتنبيه المستخدم. ثم نطلب سحب Pull هذا التفريع Branch الذي يحتوي التصحيح للفرع الأصلي والرئيسي. نلاحظ أنه Github Copilot قد لا يظهر لدينا في قائمة Reviewers ولكن يمكننا استخدامه لتلخيص طلب السحب Pull Request وهذا ما سنقوم به، حيث أن هذه الميزة لاتزال تجريبية وليست متاحة لدى الجميع. استخدام GitHub Copilot كخبير برمجي يتميز Github Copilot بميزة أخرى تجعله من أدوات الذكاء الاصطناعي البرمجية الفريدة، حيث يمكنه أن يعمل كخبير متخصص نستدعيه عند الوقوع في مشكلة أو عندما نرغب في معرفة آلية تنفيذ شيء ما، وهذا من خلال واجهة الحوار حيث يمكننا استدعاء الخبير من خلال رمز @ الذي يتيح قائمة من الخبراء الافتراضيين لنسألهم، مثلًا vscode@ يمكننا أن نسأله عن أي شيء يخص محرر الأكواد. نرى في هذا المثال كيف طلبنا من الخبير أن يوضح لنا كيفية تغير مظهر وتنسيق محرر الأكواد، فأخرج لنا زرًا عندما نضغط عليه يقودنا لقائمة اختيارات يمكننا من خلالها اختيار المظهر الذي نريده. @vscode how to change the Theme? لا يتوقف الأمر عند محرر الأكواد فيوجد أكثر من خبير، مثل خبير سطر الأوامر Terminal، لنفترض أننا نريد أن ننشئ في مجلد للمحاضرات Lectures، عشرة مجلدات فرعية منه وبكل منها ملف نصي فارغ برقم المحاضرة، والتي سنملؤها لاحقًا بملاحظات عن هذه المحاضرة، يمكن بالطبع محاولة فعل هذا بشكل يدوي لكن قد يستغرق الأمر وقتًا طويلًا لذا من الأفضل استخدام سطر الأوامر لتنفيذ هذه العملية بمساعدة Github Copilot. @terminal I want to create 10 folders names Lecture{i}, i the number of lecture, and for each lecture it would contain a text file named as lecture{i}_notes.txt لنفتح واجهة سطر الأوامر من خلال أحد الأزار السريعة من نافذة الحوار أو من قائمة View ثم نختار Terminal لنتمكن من وضع الأمر المولد وتشغيله، نلاحظ أن الأمر مكتوب باستخدام Powershell لأننا في حالتنا نستخدم نظام تشغيل ويندوز Windows ولكن يمكن أن نطلب استخدام Bash في حال استخدام نظام لينكس، وكما نرى فقد استطاع الأمر إنشاء الملفات التي طلبناها دون أية مشكلات، وهذه الميزة مفيدة للغاية عندما نرغب في تنفيذ بعض الأوامر من الطرفية ولكننا لا نتذكر الكلمات المفتاحية أو طريقة كتابة الأمر. حالات استخدام إضافية لمساعد Github Copilot استعرضنا في الفقرات السابقة أبرز حالات استخدام مساعد Github Copilot في محرر الأكواد، لكن في الواقع تتخطى حالات استخدام مساعد Github Copilot ملفات الكود العادية التي نتعامل معها في تخصصات البرمجة الشائعة كتطوير الواجهات الأمامية أو الخلفية، لتصل إلى البيئات المخصصة لمهندسي البيانات وتعلم الآلة المتمثلة في jupyter notebook، ولتجربة هذه الميزات سنستخدم مجموعة بيانات بسيطة وهي مجموعة بيانات لبعض ركاب سفينة تايتنك الغارقة والتي يمكنك العثور عليها في موقع كاجل Kaggle. لنعرض بضعة صفوف من مجموعة البيانات import pandas ad pd # حمل مجموعة بيانات تيتانيك titanic_df = pd.read_csv('titanic.csv') # اطبع الصفوف الأولى من البيانات titanic_df.head() باختيار زر التوليد Generate يمكننا طرح أسئلة أو توجيه أوامر بشكل كتابي أو من خلال الصوت ثم الموافقة على الاقتراح المولد أو طلب تعديله ليناسب حالة الاستخدام. فور الموافقة على الاقتراح بالضغط على قبول وتشغيل Accept & Run سنجد الرسم البياني التالي كمخرج. يوحي الرسم البياني بمعلومة هامة بخصوص نسب النجاة، فكما نرى نسبة النجاة في النساء أكبر، ونسبة الهلاك في الرجال أكبر، قد يكون هذا عائدًا بنسبة كبيرة للأولوية المعطاة للنساء والأطفال في قوارب النجاة ولكن هل يمكن للمساعد البرمجي فهم الرسومات البيانية وتلخيص الملاحظات الخاصة بها، لنختبر هذا. كما نلاحظ في السؤال الأول استطاع مساعدنا الذكي أن يستنتج ما يدل عليه الرسم البياني من نسبة نجاة أعلى للنساء، وكذلك بعد سؤاله عن سبب هذه قد استطاع توضيح السبب، وكما نلاحظ أيضًا فعند سؤاله باللغة العربية سيجيب باللغة العربية. لنوضح ميزة أخرى من خلال استخدام خلية كود يمكننا استخدام الرمز :q وطرح سؤال ثم سيجيب عنه المساعد البرمجي في نفس الخلية برمز مشابه به الإجابة :a كما في الصورة التالية. titanic_df.head(3) q: what does SibSp mean? الحصول على الخطة المميزة من Github Copilot مجانًا يمكن للطلبة أو المعلمين أو المساهمين في مشاريع مفتوحة المصدر الحصول على الخطة المميزة من Github Copilot بالمجان، فبالنسبة للطلبة يمكنهم رفع ما يثبت هذا من خلال هذه الصفحة التابعة لمنصة Github، أما المعلمون فيمكنهم من خلال هذه الرابط معرفة المميزات التي توفرها المنصة للمعلمين. يختلف الأمر قليلًا بالنسبة للمساهمين في المشاريع مفتوحة المصدر حيث ينبغي أن يصلوا لبعض الشروط التي تحددها المنصة ولا توجد طريقة للتقديم بشكل مباشر إنما ترسل إشعارات من خلال منصة Github للمساهمين الذين تجدهم مستحقين للخطة المميزة. بمجرد الحصول على الخطة المميزة كطالب برفع الإثباتات المطلوبة مثل الإيميل الجامعي وبطاقة الطالب التعريفية، سيعالج الطلب في بضعة أيام، وفي حال قبوله ستفتح ميزات متعددة لا تقتصر على الوصول لمساعد Github Copilot فقط، وإنما لمزايا أخرى يمكنك الاطلاع عليها من هنا، ولتفعيل الحساب المميز يجب تسجيل الخروج من حساب Github المحفوظ على محرر أكواد VS code وتسجيل الدخول إلى الحساب الذي جرى تفعيل الخطة المميزة عليها. للتأكد من تفعيل النسخة المميزة Pro يمكن مراجعة النماذج المتاحة للاستخدام، من خلال واجهة الحوار. الخاتمة تعرفنا في هذه المقالة عن أبرز الميزات التي توفرها أداة الذكاء الاصطناعي كوبايلوت Github Copilot للمبرمجين والمطورين عند دمجها في محرر الأكواد فيجوال ستوديو كود، حيث يمكنها مراجعة وتحسين الأكواد التي نعمل عليها، أو إكمال وتوقع الأكواد التي نريد كتابتها وغيرها من الفوائد الأخرى التي تساعدنا في توفير وقتنا وتعزيز إنتاجيتنا كمطورين، وتطرقنا في ختام المقال لكيفية الحصول على الخطة المميزة Pro بالمجان والتي تسمح لنا بالوصول لمزيد من المميزات والنماذج القوية، هل جربتم دمج هذه الأداة مع محرر الأكواد؟ شاركونا تجربتكم في التعليقات أسفل المقال. اقرأ أيضًا تعرف على منصة تنسرفلو TensorFlow للذكاء الاصطناعي فهم نظام التحكم بالإصدارات Git وأهمية استخدامه في مشاريع بايثون الإشراف على مشاريع البرمجيات مفتوحة المصدر عبر غيت هب GitHub الدليل المرجعي للعمل على نظام غيت Git -
.png.3bf48f9867a0581a369747e3592fe008.png) تعد تنسرفلو TensorFlow أحد الأدوات الأساسية في جعبة مطوري نماذج الذكاء الاصطناعي، فهي توفر بيئة متكاملة تساعد على تدريب نماذج الذكاء الاصطناعي وتشغيلها واستخدامها في الاستدلال والتنبؤ القرارات المستقبلية بمرونة وكفاءة، سنتعرف في هذه المقالة على أداة تنسرفلو TensorFlow ومميزاتها في تطوير تطبيقات الذكاء الاصطناعي وتعلم الآلة. ما هي تنسرفلو TensorFlow تنسرفلو TensorFlow هي منصة مفتوحة المصدر توفر للمطورين وعلماء البيانات الأدوات التي يحتاجونها لبناء نماذج تعلم الآلة، بداية من معالجة البيانات وتجهيزها، إلى التدريب وحتى التشغيل، وتدعم تنسرفلو العديد من لغات البرمجة عن طريق مكتبات مخصصة لكل لغة مثل بايثون و جافاسكريبت وسي و جافا وغيرها من اللغات، وإن كانت لغة بايثون هي اللغة الأكثر استخدامًا والأكثر دعمًا. طورت شركة جوجل منصة تنسرفلو TensorFlow عن طريق فريقها Google Brain في عام 2015 كي تكون بديلًا مفتوح المصدر للنظام السابق الذي كان يُستخدم في تدريب خوارزميات تعلم الآلة والمعروف باسم ديست بليف DistBelief، ومن أبرز مميزات تنسرفلو TensorFlow دعم مبدأ توزيع التدريب على عدة أجهزة لتعزيز كفاءة الأداء، وسهولة تعلمها، وكونها منصة مفتوحة المصدر مما يسمح للجميع بالمساهمة في تحسينها واستخدامها في مختلف المشاريع. كما تتميز تنسرفلو TensorFlow بقدرتها على استغلال مختلف العتاد الحاسوبي مثل وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU ومسرعات التدريب المختلفة، وهذا يجلعها تتفوق على بعض المكتبات التقليدية مثل ساي كيت ليرن Scikit learn الشهيرة التي توفر العديد من خوارزميات تعلم الآلة التقليدية ولكنها لا تدعم استخدام وحدات المعالجة الرسومية GPU، ناهيك عن التدريب الموزع، فمن غير الممكن تدريب نماذج ذكاء اصطناعي واسعة النطاق باستخدام مكتبات لا تدعم هذه الإمكانيات المتقدمة مثل التدريب الموزع أو المسرعات. معنى Tensors تُشتق تسمية تنسرفلو TensorFlow من العمليات التي تنفذها الشبكات العصبية على بيانات متعددة الأبعاد تعرف باسم تنسورات Tensors حيث تتدفق هذه البيانات Flow عبر الشبكات العصبية. لذا من الضروري توضيح معنى كلمة تنسور Tensor أو ما يعرف أيضًا باسم مُوتِّر فهو هيكل بيانات فالتنسور Tensor هو مفهوم أكثر شمولًا من المصفوفات Matrices والمتجهات Vectors وحتى القيم المفردة أو المضاعفات Scalars. المضاعف Scalar: عدد مفرد مثل العدد 5 وهو يُعد موترًا من الرتبة صفر. ونسميه مضاعف ضربه في موتر آخر سيضاعف القيم داخله المتجه Vector: مجموعة من الأرقام منظمة في صف واحد أو عمود واحد من القيم، ويُعد موترًا من الرتبة الأولى المصفوفة Matrix: مجموعة من الأرقام منظمة في صفوف وأعمدة، وتُعد المصفوفة موتر من الرتبة الثانية ويمكن للتنسورات أن تمتد إلى رتب Ranks أعلى، فكلما علت الرتبة كلما احتوى التنسور على بيانات متعددة الأبعاد تُستخدم في النماذج المعقدة على سبيل المثال يمكن استخدام تنسور Tensor من الرتبة الرابعة لتمثيل دفعة بيانات batch مكونة من مجموعة من الصور كما يلي: عدد الصورة في الدفعة: 4 صور ارتفاع الصورة: 64 بكسل عرض الصورة: 64 بكسل قنوات الألوان: ثلاثة هي الأحمر، الأخضر، الأزرق وبالتالي يمكننا التعبير عن هذه المعلومات باستخدام تنسور Tensor من 4 أبعاد، حيث يعبر البعد الأول عن ترتيب الصورة في الدفعة، ويعبر البعد الثاني عن الارتفاع، والثالث عن العرض، والرابع عن عدد قنوات الألوان كما في الصورة التالية: وبالتالي يمكن استخدام هذا التنسور Tensor لتعريف مدخلات الشبكات العصبية الالتفافية CNN التي تتعامل مع الصور، فهو يمكننا من معرفة عدد الصورة المدخلة بالدفعة وأبعادها وعدد قنوات الألوان بسهولة. استخدامات تنسرفلو TensorFlow شاع استخدام منصة تنسرفلو TensorFlow في مختلف مجالات الذكاء الاصطناعي، مثل تعلم الآلة وتحليل البيانات وتصنيف الصور والتعرف على الكائنات بالصور ومعالجة اللغات الطبيعية وتطبيقات الذكاء الاصطناعي التوليدي Generative AI. على سبيل المثال اعتمدت منصة X على تنسرفلو TensorFlow لترتيب التغريدات حسب الأهمية والصلة، فقد يتابع صاحب حساب مئات بل آلاف الأشخاص لذلك يصبح ترتيب التغريدات أمرًا محوريًا في تجربة الاستخدام، كما استخدمت باي بال PayPal خوارزميات مطورة بتنسرفلو TensorFlow لتستطيع كشف المعاملات الاحتيالية ومنعها. النظام المتكامل لتنسرفلو TensorFlow Ecosystem توفر تنسرفلو TensorFlow نظام بيئي متكامل لمطوري الذكاء الاصطناعي إو إطار شامل يوفر كل ما يلزم لتطوير نماذج الذكاء الاصطناعي وتشغيلها على مختلف الأجهزة سواء الحواسيب الشخصية أو الخوادم الخاصة أو الخوادم السحابية، إلى جانب استخدام نماذج مسبقة التدريب من خلال مكتبة متنوعة من النماذج وهو يوفر أدوات للتعامل مع كل من المراحل التالية: تدريب النموذج Training توزيع التدريب Distribution strategy التشغيل Deployment الاستدلال Inference لنشرح كل مرحلة من هذه المراحل بمزيد من التفصيل. التدريب Training تدريب النموذج هو الخطوة الأولى في بناء أي تطبيق ذكاء اصطناعي، ويتطلب الوصول لخطوة التدريب معالجة البيانات preprocessing حيث توفر تنسرفلو العديد من الأدوات لمعالجة البيانات وإعدادها لتدريب النماذج، كما توفر طريقة سهلة لبناء وتدريب الشبكات العصبية الاصطناعية Artificial Neural Networks من خلال مكتبة كيراس keras وهي مكتبة مختصة داخل الإطار الشامل لتنسرفلو TensorFlow. توزيع التدريب Distribution strategy يوفر إطار عمل تنسرفلو ميزة توزيع مهمة تدريب النموذج على عدة أجهزة من خلال الوحدة tf.distribute فبدلاً من تدريب النموذج على جهاز واحد فقط، يمكننا تقسيم عملية التدريب كي تنجز عبر معالجات متعددة. من الأفضل العمل في وضع شبكة العقد الحسابية Computational Graph mode لأنه مُصمم خصيصًا ليعمل بشكل أكثر كفاءة مع التدريب الموزع. أما إذا كنا نرغب في التجربة والتعديل للوصول إلى نموذج قابل للتطبيق على نطاق واسع، فيمكننا استخدام وضع التنفيذ الفوري Eager execution mode. هنالك العديد من التفاصيل المتقدمة التي علينا الانتباه لها عند تحديد استراتيجية توزيع التدريب، مثل كيفية مشاركة معاملات النموذج عبر الأجهزة المختلفة وكيفية توزيع المهام، ولكن من الأفضل للمبتدئين البدء بتعلم التدريب على جهاز واحد أولاً للسهولة. وبمجرد إتقان مهمة تطوير نموذج فعّال على جهاز واحد، يمكن العمل على توزيع التدريب على نطاق أوسع لتسريعه وتحسين أداءه. التشغيل Deployment يعد الانتقال من مرحلة تطوير وتدريب النموذج إلى مرحلة تشغيل النموذج وطرحه للمستخدمين تحديًا للكثيرين، فنحن بحاجة لعتاد حاسوبي يستضيف النموذج ويستقبل طلبات المستخدمين، ويمكننا توفيره من خلال موفري الخدمات السحابية Cloud provider، حيث يمكنن استئجار موارد حاسوبية لتشغيل النموذج الخاص بنا، وكما ذكرنا سابقًا فإن تنسرفلو TensorFlow هو إطار عمل متكامل لا يتوقف دوره عند تطوير النموذج فحسب، فيمكننا استخدام TensorFlow Serving لإدارة النماذج التي نحتاج لتشغيلها ونجري تحديث مستمر لها كلما توفرت لنا بيانات جديدة لتدريب النموذج عليها، وغيرها من المميزات العديدة الأخرى. الاستدلال Inference ما نعنيه باستدلال نموذج الذكاء الاصطناعي التنبؤ والتوقع المستقبلي باستخدام البيانات المعطاة، برمجيًا يمكن الاستدلال باستخدام الدالة model.predict في مكتبة Keras المدمجة ضمن TensorFlow فهذه الدالة البرمجية تأخذ البيانات كمدخلات، وتعطينا التوقع المنتظر بناء عليها، يتعرض النموذج أثناء التشغيل لآلاف أو ربما ملايين الطلبات من المستخدمين من أجل الاستدلال بناء على بعض البيانات المعطاة وينتظرون نتيجة سريعة لطلباتهم، لذا تعد سرعة استدلال النموذج عاملًا مهمًا في نجاح تشغيله. تساعدنا تنسرفلو TensorFlow في تحسين سرعة الاستدلال بعدة أدوات مثل: تحسين العمليات الحسابية باستخدام شبكة العقد الحسابية Computational graph تحسين تشغيل النماذج على مختلف أنواع العتاد كوحدات المعالجة المركزية CPUs، أو وحدات معالجة الرسومات GPUs، أو وحدات معالجة الموترات Tensor Processing Units TPUs استخدام المعالجة على التوازي Parallelism وهي طريقة لتقسيم الحسابات على أكثر من جهاز تقسيم الطلبات لدفعات Batching لتحسين استخدام سعة شبكات الانترنت Throughput فمع ملايين من الطلبات بنفس الوقت مرفقة بالبيانات قد تصبح سعة الشبكة غير قادرة على التعامل مع كل الطلبات ومعالجتها بسرعة كافية لذا علينا تقسيمها لدفعات أصغر النسخة الخفيفة من تنسرفلو TensorFlow light في بعض الحالات، قد نحتاج لتشغيل النماذج على أجهزة محدودة الإمكانيات كالأجهزة المحمولة. على سبيل المثال، تُعد تطبيقات التعرف على البصمة أو الوجه باستخدام كاميرا الهاتف نماذج ذكاء اصطناعي مخصصة للعمل على الهواتف محدودة الموارد. أو نحتاج لاستخدام نماذج الذكاء الاصطناعي غلى الشرائح الإلكترونية في مجالات إنترنت الأشياء IoT والروبوتات بهدف التعرف على الأشخاص أو التحكم في الآلات أو التنقل بشكل آلي دون الحاجة لتوجيه مباشر. لكن هذه المهام لن تكون ممكنة من دون القدرة على تشغيل النماذج على أجهزة منخفضة الموارد، وهنا يأتي دور النسخة الخفيفة من تنسرفلو TensorFlow Lite، وهي إطار عمل مفتوح المصدر للتعلم العميق يفيدنا في تقليص حجم النماذج وجعلها أسرع، دون التأثير الكبير على دقة التوقعات. كيف نستخدم TensorFlow مع مختلف لغات البرمجة تدعم تنسرفلو TensorFlow تشغيل النماذج في لغات برمجة متعددة كما ذكرنا سابقًا وتعد لغة بايثون Python هي اللغة الأساسية والأكثر استخدامًا لتطوير النماذج وبناء الحلول باستخدام تنسرفلو TensorFlow. لكن يمكننا استخدام تنسرفلو مع مختلف لغات البرمجة من خلال حفظ النموذج بصيغة موحدة تتيح التعامل معه في لغات مختلفة مثل C و Go و Java وغيرها. كما تحظى تطبيقات الويب Web Applications بدعم خاص في منصة تنسرفلو، إذ يمكننا تشغيل وتطوير نماذجنا باستخدام JavaScript، مما يتيح لنا تطوير تطبيقات الذكاء الاصطناعي وتشغيلها مباشرة على المتصفح من خلال المكتبة TensorFlow.js. مستودع النماذج مسبقة التدريب TensorFlow Hub توفر TensorFlow مكتبة واسعة من النماذج مسبقة التدريب Pre-trained عبر مستودعها TensorFlow Hub، حيث يمكننا استخدام هذه النماذج وتشغيلها مباشرة دون الحاجة لتطويرها من الصفر. تتميز هذه النماذج بتوفير ميزة الصقل fine-tuning وتخصيصها باستخدام بيانات مخصصة للمشكلة التي نسعى لحلها. وما يجعل هذه النماذج ذات قيمة كبيرة هو أنها تحتوي على معرفة مسبقة اكتسبتها من تدريبها على مجموعات بيانات ضخمة. لذا، يعد صقلها حلاً مثاليًا في العديد من التطبيقات، حيث يمكننا الحصول على نتائج دقيقة وفعالة بسرعة كبيرة بالاعتماد عليها. التمثيل المرئي للبيانات Visualization في تنسرفلو يحتاج مطور نماذج الذكاء الاصطناعي إلى مراقبة النماذج وملاحظة تطور أدائها مع مرور الوقت، لذا سيفيدهم تعزيز مشاريع الذكاء الاصطناعي برسومات بيانية لتحقيق هذا الهدف. توفر تنسرفلو TensorFlow هذه الإمكانية من خلال أداة تسمى Tensorboard توفر رسومات بيانية ومخططات توضيحية لتوضح معنى الأرقام ودلالتها، وتسهل اكتشاف الأنماط ونقاط الاهتمام. توفر Tensorboard إمكانية عرض العديد من الرسومات البيانية المفيدة مثل: رسم بياني لدقة النموذج accuracy وتغيرها بمرور الوقت رسم شبكة العٌقد الحسابية Computational graphs توفير رسومات بيانية لدراسة توزيع الأوزان والمعاملات التي تتغير مع الوقت عرض الصور والنصوص والصوتيات دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن طريقة استخدام تنسرفلو TensorFlow تحتاج منصة تنسرفلو TensorFlow إلى إجراء العديد من العمليات الحسابية على البيانات الممثلة في التنسورات Tensors. وبالتالي، تصبح مهمة تنسرفلو هي تحسين هذه العمليات الحسابية التي تتدفق إليها التنسورات، بهدف استغلال الموارد الحاسوبية المتاحة بأفضل طريقة ممكنة. فبعض الخوارزميات قد تستغرق أيامًا أو حتى أشهر لإتمام تدريبها بسبب حجم البيانات الهائل التي تتدفق خلالها في العمليات الحسابية المعقدة. لنتعرف على طريقة القيام بالتمثيل الرياضي للعمليات الحسابية التي علينا القيام بها أثناء تدريب النموذج أو استدلاله. التعامل مع شبكة العقد الحسابية Computational graph شبكة العٌقد الحسابية Computational graph هي الوسيلة التي تستخدمها تنسرفلو TensorFlow لتمثيل العمليات والخوارزميات التي تنفذها، يمكننا التفكير بها على أنها خطة مرسومة لتنفيذ الخوارزميات، إذ تتكون الشبكة من عدة عقد متصلة تتدفق خلالها التنسورات أو البيانات في اتجاه واحد، وتمثل العقدة عملية حسابية مثل الضرب أو الجمع أو غيرها من العمليات. يكتب المطور الأكواد البرمجية بلغة برمجة مثل بايثون، ثم يأتي دور تنسرفلو TensorFlow بتجهيز شبكة العٌقد الحسابية computational graph التي تتضمن جميع الخطوات لتنفيذ هذه الأكواد، ولتحسينها يجري تبسيط الخطوات المتكررة التي يمكن اختزالها، أو التخلص من الخطوات التي يمكن حذفها لتوفير الموارد الحاسوبية. كما تستخدم تنسرفلو طريقة تسمى الحساب المسبق للثوابت Constant folding، تتعامل هذه الطريقة مع المتغيرات المعلومة أو التي يمكن حساب قيمتها بشكلٍ مباشر، فتحولها إلي قيمة ثابتة أثناء بناء شبكة العٌقد الحسابية Computational graph، حيث لا نحتاج لحساب هذه القيم وقت التنفيذ. على سبيل المثال إذا كان a=2 ، b=3 و c=a+b فيمكننا إيجاد قيمة المتغير c=5 وعدم إجراء العملية الحسابية أينما وجد هذا المتغير مجددًا وقت التنفيذ، فهذا المتغير لا يعتمد سوى على ثوابت معلومة. كما تعتمد أيضًا على عملية إعادة استخدام الحدود المتكررة Common Subexpression Elimination لتبسيط شبكة العٌقد الحسابية Computational graph بحساب العمليات التي تتكرر مرة واحدة وتستخدم الناتج أينما وجد تكرار للعملية الحسابية. على سبيل المثال: إذا كان a=x+y، و b=x+y فإن a=b لذا نقوم بالعملية x+y مرة واحدة ونعوض عنها عندما نجد a أو b. أخيرًا يمكننا استخدام متغيرات أقل دقة في تنسرفلو TensorFlow كأن نستخدم متغير من نوع float16 بدلًا من float32 لتسريع الحسابات وتقليل استهلاك الموارد، ويجدر الذكر أن هذه الميزة لا تعمل إلا مع وحدات المعالجة الرسومية GPUs. لاحظ المثال التالي: import tensorflow as tf # قم بتعريف رقم عشري number = 123.456 # حدد حجم المتغير الذي تريد أن تحفظ الرقم به ليكون 32 float32 = tf.constant(number, dtype=tf.float32) # حدد حجم المتغير الذي تريد أن تحفظ الرقم به ليكون 16 float16 = tf.constant(number, dtype=tf.float16) # لنرى الاختلاف في الدقة بين الرقمين print("float32: ", float32.numpy()) print("float16: ", float16.numpy()) # حجم التخزين print("Size of float32: ", float32.numpy().nbytes, "bytes") print("Size of float16: ", float16.numpy().nbytes, "bytes") ''' output float32: 123.456 float16: 123.44 Size of float32: 4 bytes Size of float16: 2 bytes ''' قد يصل عدد المتغيرات والمعاملات في نماذج الذكاء الاصطناعي لملايين بل مليارات في بعض الأحيان، لذا من الضروري الاعتماد على تغيير دقة المتغيرات لتسريع عملية التدريب وتقليص حجم النماذج، فأداء النموذج قد يتأثر بنسبة جيدة من هذا التغير. ملاحظة: تجدر الإشارة إلى أن استخدام أسلوب تغيير دقة المتغيرات يستخدم في تقليص حجم نماذج الذكاء الاصطناعي لتعمل على الحافة on Edge أي على الأجهزة محدودة الموارد، مثل الأجهزة المحمولة أو الشرائح الحاسوبية البسيطة، التي قد لا تتسع إلا لبضعة آلاف من البايتات. استخدام شبكة العقد الحسابية لتنفيذ العمليات تفيدنا شبكة العٌقد الحسابية Computational graphs في جعل عملية تدريب النماذج أكثر مرونة وكفاءة عبر عدة منصات وأجهزة حاسوبية مختلفة، فهي محسنة لتتعامل مع العتاد الحاسوبي بشكل أفضل، كما يمكن نقل شبكة العقد الحسابية بعد تدريب النموذج ليصبح قابلًا للاستخدام على منصات وأجهزة متنوعة ولغات برمجة مختلفة فهي مجرد قالب لتنفيذ مجموعة من الأوامر التي تعطي نتيجة أو توقع في النهاية. كانت هذه الطريقة هي الوحيدة في الإصدار الأول من تنسرفلو TensorFlow 1.x ، ولكنها عانت من بعض العيوب، فقد كان علينا كمطورين كتابة الأكواد البرمجية بشكل مثالي دون أن نرى نتائج الخطوات الوسيطة، ثم ننتظر تحويل الأكواد المثالية إلي شبكة عقد حسابية محسنة، وهذا يستغرق الكثير من الوقت، بالطبع لن نحصل على النتيجة التي نرجوها من أول محاولة، فالبرمجة عملية تحسن تكرارية وتراكمية، وخاصة عند تطوير نماذج الذكاء الاصطناعي التي تحتاج إلى تجربة العديد من المعاملات حتى نجد التوليفة المناسبة من تلك المعاملات. لاحظ الكود التالي الذي يوضح كيفية تعريف دالة ConcreteFunction في تنسرفلو وكيفية تحديد المدخلات والمخرجات للعمليات الحسابية حيث سنحول العمليات البرمجية البسيطة مثل الجمع بين متغيرين إلى شبكة عُقد حسابية يمكن تنفيذها بكفاءة على أجهزة مختلفة. import tensorflow as tf @tf.function # لجعل تنسرفلو يستخدم شبكة العٌقد الحسابية def add_numbers(a, b): return a + b # نعرف ثابتين a = tf.constant(5) b = tf.constant(3) # لنقم بعملية الجمع بطريقة شبكة العٌقد الحسابية result = add_numbers(a, b) # لنحصل على الخطوات التي قام بها تنسرفلو graph_steps = add_numbers.get_concrete_function(a, b) print("الخطوات") print(graph_steps) print("الخطوات بشكل مفصـل ومبسـط") for op in graph_steps.graph.get_operations(): print(op.name) الخطــوات ConcreteFunction Input Parameters: a (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(), dtype=tf.int32, name=None) b (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(), dtype=tf.int32, name=None) Output Type: TensorSpec(shape=(), dtype=tf.int32, name=None) Captures: None الخطـوات بشكـــل مفصـل ومبسـط a b a d d I d e n t i t y تقنية التنفيذ الفوري للعمليات الحسابية Eager execution كانت عملية تطوير النماذج غير تفاعلية في الإصدار الأول من تنسرفلو TensorFlow 1.x، كما ذكرنا في الفقرة السابقة، حيث كان المطورون يكتبون الأكواد ثم ينتظرون لفترة طويلة لتحويل الأكواد إلى شبكة عُقد حسابية محسّنة، هذا جعل من الصعب اكتشاف الأخطاء وتحسين الأداء في الوقت الفعلي. لهذا السبب، وجدت طريقة التنفيذ الفوري للعمليات الحسابية Eager Execution في TensorFlow 2.x لتجعل عملية التطوير أكثر تفاعلية وسهولة. حيث يمكننا من خلال التنفيذ الفوري Eager Execution بناء العمليات الحسابية بشكل مباشر. على سبيل المثال، عندما نجمع رقمين، سنحصل على النتيجة على الفور دون الحاجة للانتظار لإكمال البرمجة أو إنشاء شبكة العُقد الحسابية. وبالتالي تسهل علينا هذه الطريقة اكتشاف الأخطاء، واختبار التعديلات، وتحسين أداء النموذج بشكل فوري وتفاعلي. لاحظ الكود التالي لاستخدام التنفيذ الفوري Eager Execution في تنسرفلو: import tensorflow as tf # Eager Mode مفعل بشكل افتراضي a = tf.constant(5) b = tf.constant(3) c = a + b print("ناتج العملية الفورية:", c.numpy()) # ناتج العملية الفورية: 8 الخاتمة وصلنا لختام مقالنا الذي شرحنا فيه بالتفصيل إطار العمل الشهير تنسرفلو TensorFlow، وأوضحنا العديد من الأدوات والتقنيات التي تُمكّن المطورين من تطوير نماذج الذكاء الاصطناعي عبر مختلف المراحل، من التدريب وحتى التشغيل. كما قمنا بتطبيق أمثلة عملية بسيطة توضح كيفية استخدام هذه الأدوات بشكل تفصيلي، بدءًا من بناء الشبكات الحسابية حتى التنفيذ الفوري للعمليات الحسابية. ننصح بتجربة هذه المنصة والاستفادة من أدواتها لتحسين وتبسيط عملية تطوير تطبيقات الذكاء الاصطناعي. اقرأ أيضًا ما هي منصة Hugging Face للذكاء الاصطناعي تعلم الذكاء الاصطناعي كل ما تود معرفته عن دراسة الذكاء الاصطناعي بناء شبكة عصبية للتعرف على الأرقام المكتوبة بخط اليد باستخدام مكتبة TensorFlow تعرف على أهم مشاريع الذكاء الاصطناعي تعرف على مكتبة المحوّلات Transformers من منصة Hugging Face
تعد تنسرفلو TensorFlow أحد الأدوات الأساسية في جعبة مطوري نماذج الذكاء الاصطناعي، فهي توفر بيئة متكاملة تساعد على تدريب نماذج الذكاء الاصطناعي وتشغيلها واستخدامها في الاستدلال والتنبؤ القرارات المستقبلية بمرونة وكفاءة، سنتعرف في هذه المقالة على أداة تنسرفلو TensorFlow ومميزاتها في تطوير تطبيقات الذكاء الاصطناعي وتعلم الآلة. ما هي تنسرفلو TensorFlow تنسرفلو TensorFlow هي منصة مفتوحة المصدر توفر للمطورين وعلماء البيانات الأدوات التي يحتاجونها لبناء نماذج تعلم الآلة، بداية من معالجة البيانات وتجهيزها، إلى التدريب وحتى التشغيل، وتدعم تنسرفلو العديد من لغات البرمجة عن طريق مكتبات مخصصة لكل لغة مثل بايثون و جافاسكريبت وسي و جافا وغيرها من اللغات، وإن كانت لغة بايثون هي اللغة الأكثر استخدامًا والأكثر دعمًا. طورت شركة جوجل منصة تنسرفلو TensorFlow عن طريق فريقها Google Brain في عام 2015 كي تكون بديلًا مفتوح المصدر للنظام السابق الذي كان يُستخدم في تدريب خوارزميات تعلم الآلة والمعروف باسم ديست بليف DistBelief، ومن أبرز مميزات تنسرفلو TensorFlow دعم مبدأ توزيع التدريب على عدة أجهزة لتعزيز كفاءة الأداء، وسهولة تعلمها، وكونها منصة مفتوحة المصدر مما يسمح للجميع بالمساهمة في تحسينها واستخدامها في مختلف المشاريع. كما تتميز تنسرفلو TensorFlow بقدرتها على استغلال مختلف العتاد الحاسوبي مثل وحدة المعالجة المركزية CPU ووحدة المعالجة الرسومية GPU ومسرعات التدريب المختلفة، وهذا يجلعها تتفوق على بعض المكتبات التقليدية مثل ساي كيت ليرن Scikit learn الشهيرة التي توفر العديد من خوارزميات تعلم الآلة التقليدية ولكنها لا تدعم استخدام وحدات المعالجة الرسومية GPU، ناهيك عن التدريب الموزع، فمن غير الممكن تدريب نماذج ذكاء اصطناعي واسعة النطاق باستخدام مكتبات لا تدعم هذه الإمكانيات المتقدمة مثل التدريب الموزع أو المسرعات. معنى Tensors تُشتق تسمية تنسرفلو TensorFlow من العمليات التي تنفذها الشبكات العصبية على بيانات متعددة الأبعاد تعرف باسم تنسورات Tensors حيث تتدفق هذه البيانات Flow عبر الشبكات العصبية. لذا من الضروري توضيح معنى كلمة تنسور Tensor أو ما يعرف أيضًا باسم مُوتِّر فهو هيكل بيانات فالتنسور Tensor هو مفهوم أكثر شمولًا من المصفوفات Matrices والمتجهات Vectors وحتى القيم المفردة أو المضاعفات Scalars. المضاعف Scalar: عدد مفرد مثل العدد 5 وهو يُعد موترًا من الرتبة صفر. ونسميه مضاعف ضربه في موتر آخر سيضاعف القيم داخله المتجه Vector: مجموعة من الأرقام منظمة في صف واحد أو عمود واحد من القيم، ويُعد موترًا من الرتبة الأولى المصفوفة Matrix: مجموعة من الأرقام منظمة في صفوف وأعمدة، وتُعد المصفوفة موتر من الرتبة الثانية ويمكن للتنسورات أن تمتد إلى رتب Ranks أعلى، فكلما علت الرتبة كلما احتوى التنسور على بيانات متعددة الأبعاد تُستخدم في النماذج المعقدة على سبيل المثال يمكن استخدام تنسور Tensor من الرتبة الرابعة لتمثيل دفعة بيانات batch مكونة من مجموعة من الصور كما يلي: عدد الصورة في الدفعة: 4 صور ارتفاع الصورة: 64 بكسل عرض الصورة: 64 بكسل قنوات الألوان: ثلاثة هي الأحمر، الأخضر، الأزرق وبالتالي يمكننا التعبير عن هذه المعلومات باستخدام تنسور Tensor من 4 أبعاد، حيث يعبر البعد الأول عن ترتيب الصورة في الدفعة، ويعبر البعد الثاني عن الارتفاع، والثالث عن العرض، والرابع عن عدد قنوات الألوان كما في الصورة التالية: وبالتالي يمكن استخدام هذا التنسور Tensor لتعريف مدخلات الشبكات العصبية الالتفافية CNN التي تتعامل مع الصور، فهو يمكننا من معرفة عدد الصورة المدخلة بالدفعة وأبعادها وعدد قنوات الألوان بسهولة. استخدامات تنسرفلو TensorFlow شاع استخدام منصة تنسرفلو TensorFlow في مختلف مجالات الذكاء الاصطناعي، مثل تعلم الآلة وتحليل البيانات وتصنيف الصور والتعرف على الكائنات بالصور ومعالجة اللغات الطبيعية وتطبيقات الذكاء الاصطناعي التوليدي Generative AI. على سبيل المثال اعتمدت منصة X على تنسرفلو TensorFlow لترتيب التغريدات حسب الأهمية والصلة، فقد يتابع صاحب حساب مئات بل آلاف الأشخاص لذلك يصبح ترتيب التغريدات أمرًا محوريًا في تجربة الاستخدام، كما استخدمت باي بال PayPal خوارزميات مطورة بتنسرفلو TensorFlow لتستطيع كشف المعاملات الاحتيالية ومنعها. النظام المتكامل لتنسرفلو TensorFlow Ecosystem توفر تنسرفلو TensorFlow نظام بيئي متكامل لمطوري الذكاء الاصطناعي إو إطار شامل يوفر كل ما يلزم لتطوير نماذج الذكاء الاصطناعي وتشغيلها على مختلف الأجهزة سواء الحواسيب الشخصية أو الخوادم الخاصة أو الخوادم السحابية، إلى جانب استخدام نماذج مسبقة التدريب من خلال مكتبة متنوعة من النماذج وهو يوفر أدوات للتعامل مع كل من المراحل التالية: تدريب النموذج Training توزيع التدريب Distribution strategy التشغيل Deployment الاستدلال Inference لنشرح كل مرحلة من هذه المراحل بمزيد من التفصيل. التدريب Training تدريب النموذج هو الخطوة الأولى في بناء أي تطبيق ذكاء اصطناعي، ويتطلب الوصول لخطوة التدريب معالجة البيانات preprocessing حيث توفر تنسرفلو العديد من الأدوات لمعالجة البيانات وإعدادها لتدريب النماذج، كما توفر طريقة سهلة لبناء وتدريب الشبكات العصبية الاصطناعية Artificial Neural Networks من خلال مكتبة كيراس keras وهي مكتبة مختصة داخل الإطار الشامل لتنسرفلو TensorFlow. توزيع التدريب Distribution strategy يوفر إطار عمل تنسرفلو ميزة توزيع مهمة تدريب النموذج على عدة أجهزة من خلال الوحدة tf.distribute فبدلاً من تدريب النموذج على جهاز واحد فقط، يمكننا تقسيم عملية التدريب كي تنجز عبر معالجات متعددة. من الأفضل العمل في وضع شبكة العقد الحسابية Computational Graph mode لأنه مُصمم خصيصًا ليعمل بشكل أكثر كفاءة مع التدريب الموزع. أما إذا كنا نرغب في التجربة والتعديل للوصول إلى نموذج قابل للتطبيق على نطاق واسع، فيمكننا استخدام وضع التنفيذ الفوري Eager execution mode. هنالك العديد من التفاصيل المتقدمة التي علينا الانتباه لها عند تحديد استراتيجية توزيع التدريب، مثل كيفية مشاركة معاملات النموذج عبر الأجهزة المختلفة وكيفية توزيع المهام، ولكن من الأفضل للمبتدئين البدء بتعلم التدريب على جهاز واحد أولاً للسهولة. وبمجرد إتقان مهمة تطوير نموذج فعّال على جهاز واحد، يمكن العمل على توزيع التدريب على نطاق أوسع لتسريعه وتحسين أداءه. التشغيل Deployment يعد الانتقال من مرحلة تطوير وتدريب النموذج إلى مرحلة تشغيل النموذج وطرحه للمستخدمين تحديًا للكثيرين، فنحن بحاجة لعتاد حاسوبي يستضيف النموذج ويستقبل طلبات المستخدمين، ويمكننا توفيره من خلال موفري الخدمات السحابية Cloud provider، حيث يمكنن استئجار موارد حاسوبية لتشغيل النموذج الخاص بنا، وكما ذكرنا سابقًا فإن تنسرفلو TensorFlow هو إطار عمل متكامل لا يتوقف دوره عند تطوير النموذج فحسب، فيمكننا استخدام TensorFlow Serving لإدارة النماذج التي نحتاج لتشغيلها ونجري تحديث مستمر لها كلما توفرت لنا بيانات جديدة لتدريب النموذج عليها، وغيرها من المميزات العديدة الأخرى. الاستدلال Inference ما نعنيه باستدلال نموذج الذكاء الاصطناعي التنبؤ والتوقع المستقبلي باستخدام البيانات المعطاة، برمجيًا يمكن الاستدلال باستخدام الدالة model.predict في مكتبة Keras المدمجة ضمن TensorFlow فهذه الدالة البرمجية تأخذ البيانات كمدخلات، وتعطينا التوقع المنتظر بناء عليها، يتعرض النموذج أثناء التشغيل لآلاف أو ربما ملايين الطلبات من المستخدمين من أجل الاستدلال بناء على بعض البيانات المعطاة وينتظرون نتيجة سريعة لطلباتهم، لذا تعد سرعة استدلال النموذج عاملًا مهمًا في نجاح تشغيله. تساعدنا تنسرفلو TensorFlow في تحسين سرعة الاستدلال بعدة أدوات مثل: تحسين العمليات الحسابية باستخدام شبكة العقد الحسابية Computational graph تحسين تشغيل النماذج على مختلف أنواع العتاد كوحدات المعالجة المركزية CPUs، أو وحدات معالجة الرسومات GPUs، أو وحدات معالجة الموترات Tensor Processing Units TPUs استخدام المعالجة على التوازي Parallelism وهي طريقة لتقسيم الحسابات على أكثر من جهاز تقسيم الطلبات لدفعات Batching لتحسين استخدام سعة شبكات الانترنت Throughput فمع ملايين من الطلبات بنفس الوقت مرفقة بالبيانات قد تصبح سعة الشبكة غير قادرة على التعامل مع كل الطلبات ومعالجتها بسرعة كافية لذا علينا تقسيمها لدفعات أصغر النسخة الخفيفة من تنسرفلو TensorFlow light في بعض الحالات، قد نحتاج لتشغيل النماذج على أجهزة محدودة الإمكانيات كالأجهزة المحمولة. على سبيل المثال، تُعد تطبيقات التعرف على البصمة أو الوجه باستخدام كاميرا الهاتف نماذج ذكاء اصطناعي مخصصة للعمل على الهواتف محدودة الموارد. أو نحتاج لاستخدام نماذج الذكاء الاصطناعي غلى الشرائح الإلكترونية في مجالات إنترنت الأشياء IoT والروبوتات بهدف التعرف على الأشخاص أو التحكم في الآلات أو التنقل بشكل آلي دون الحاجة لتوجيه مباشر. لكن هذه المهام لن تكون ممكنة من دون القدرة على تشغيل النماذج على أجهزة منخفضة الموارد، وهنا يأتي دور النسخة الخفيفة من تنسرفلو TensorFlow Lite، وهي إطار عمل مفتوح المصدر للتعلم العميق يفيدنا في تقليص حجم النماذج وجعلها أسرع، دون التأثير الكبير على دقة التوقعات. كيف نستخدم TensorFlow مع مختلف لغات البرمجة تدعم تنسرفلو TensorFlow تشغيل النماذج في لغات برمجة متعددة كما ذكرنا سابقًا وتعد لغة بايثون Python هي اللغة الأساسية والأكثر استخدامًا لتطوير النماذج وبناء الحلول باستخدام تنسرفلو TensorFlow. لكن يمكننا استخدام تنسرفلو مع مختلف لغات البرمجة من خلال حفظ النموذج بصيغة موحدة تتيح التعامل معه في لغات مختلفة مثل C و Go و Java وغيرها. كما تحظى تطبيقات الويب Web Applications بدعم خاص في منصة تنسرفلو، إذ يمكننا تشغيل وتطوير نماذجنا باستخدام JavaScript، مما يتيح لنا تطوير تطبيقات الذكاء الاصطناعي وتشغيلها مباشرة على المتصفح من خلال المكتبة TensorFlow.js. مستودع النماذج مسبقة التدريب TensorFlow Hub توفر TensorFlow مكتبة واسعة من النماذج مسبقة التدريب Pre-trained عبر مستودعها TensorFlow Hub، حيث يمكننا استخدام هذه النماذج وتشغيلها مباشرة دون الحاجة لتطويرها من الصفر. تتميز هذه النماذج بتوفير ميزة الصقل fine-tuning وتخصيصها باستخدام بيانات مخصصة للمشكلة التي نسعى لحلها. وما يجعل هذه النماذج ذات قيمة كبيرة هو أنها تحتوي على معرفة مسبقة اكتسبتها من تدريبها على مجموعات بيانات ضخمة. لذا، يعد صقلها حلاً مثاليًا في العديد من التطبيقات، حيث يمكننا الحصول على نتائج دقيقة وفعالة بسرعة كبيرة بالاعتماد عليها. التمثيل المرئي للبيانات Visualization في تنسرفلو يحتاج مطور نماذج الذكاء الاصطناعي إلى مراقبة النماذج وملاحظة تطور أدائها مع مرور الوقت، لذا سيفيدهم تعزيز مشاريع الذكاء الاصطناعي برسومات بيانية لتحقيق هذا الهدف. توفر تنسرفلو TensorFlow هذه الإمكانية من خلال أداة تسمى Tensorboard توفر رسومات بيانية ومخططات توضيحية لتوضح معنى الأرقام ودلالتها، وتسهل اكتشاف الأنماط ونقاط الاهتمام. توفر Tensorboard إمكانية عرض العديد من الرسومات البيانية المفيدة مثل: رسم بياني لدقة النموذج accuracy وتغيرها بمرور الوقت رسم شبكة العٌقد الحسابية Computational graphs توفير رسومات بيانية لدراسة توزيع الأوزان والمعاملات التي تتغير مع الوقت عرض الصور والنصوص والصوتيات دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن طريقة استخدام تنسرفلو TensorFlow تحتاج منصة تنسرفلو TensorFlow إلى إجراء العديد من العمليات الحسابية على البيانات الممثلة في التنسورات Tensors. وبالتالي، تصبح مهمة تنسرفلو هي تحسين هذه العمليات الحسابية التي تتدفق إليها التنسورات، بهدف استغلال الموارد الحاسوبية المتاحة بأفضل طريقة ممكنة. فبعض الخوارزميات قد تستغرق أيامًا أو حتى أشهر لإتمام تدريبها بسبب حجم البيانات الهائل التي تتدفق خلالها في العمليات الحسابية المعقدة. لنتعرف على طريقة القيام بالتمثيل الرياضي للعمليات الحسابية التي علينا القيام بها أثناء تدريب النموذج أو استدلاله. التعامل مع شبكة العقد الحسابية Computational graph شبكة العٌقد الحسابية Computational graph هي الوسيلة التي تستخدمها تنسرفلو TensorFlow لتمثيل العمليات والخوارزميات التي تنفذها، يمكننا التفكير بها على أنها خطة مرسومة لتنفيذ الخوارزميات، إذ تتكون الشبكة من عدة عقد متصلة تتدفق خلالها التنسورات أو البيانات في اتجاه واحد، وتمثل العقدة عملية حسابية مثل الضرب أو الجمع أو غيرها من العمليات. يكتب المطور الأكواد البرمجية بلغة برمجة مثل بايثون، ثم يأتي دور تنسرفلو TensorFlow بتجهيز شبكة العٌقد الحسابية computational graph التي تتضمن جميع الخطوات لتنفيذ هذه الأكواد، ولتحسينها يجري تبسيط الخطوات المتكررة التي يمكن اختزالها، أو التخلص من الخطوات التي يمكن حذفها لتوفير الموارد الحاسوبية. كما تستخدم تنسرفلو طريقة تسمى الحساب المسبق للثوابت Constant folding، تتعامل هذه الطريقة مع المتغيرات المعلومة أو التي يمكن حساب قيمتها بشكلٍ مباشر، فتحولها إلي قيمة ثابتة أثناء بناء شبكة العٌقد الحسابية Computational graph، حيث لا نحتاج لحساب هذه القيم وقت التنفيذ. على سبيل المثال إذا كان a=2 ، b=3 و c=a+b فيمكننا إيجاد قيمة المتغير c=5 وعدم إجراء العملية الحسابية أينما وجد هذا المتغير مجددًا وقت التنفيذ، فهذا المتغير لا يعتمد سوى على ثوابت معلومة. كما تعتمد أيضًا على عملية إعادة استخدام الحدود المتكررة Common Subexpression Elimination لتبسيط شبكة العٌقد الحسابية Computational graph بحساب العمليات التي تتكرر مرة واحدة وتستخدم الناتج أينما وجد تكرار للعملية الحسابية. على سبيل المثال: إذا كان a=x+y، و b=x+y فإن a=b لذا نقوم بالعملية x+y مرة واحدة ونعوض عنها عندما نجد a أو b. أخيرًا يمكننا استخدام متغيرات أقل دقة في تنسرفلو TensorFlow كأن نستخدم متغير من نوع float16 بدلًا من float32 لتسريع الحسابات وتقليل استهلاك الموارد، ويجدر الذكر أن هذه الميزة لا تعمل إلا مع وحدات المعالجة الرسومية GPUs. لاحظ المثال التالي: import tensorflow as tf # قم بتعريف رقم عشري number = 123.456 # حدد حجم المتغير الذي تريد أن تحفظ الرقم به ليكون 32 float32 = tf.constant(number, dtype=tf.float32) # حدد حجم المتغير الذي تريد أن تحفظ الرقم به ليكون 16 float16 = tf.constant(number, dtype=tf.float16) # لنرى الاختلاف في الدقة بين الرقمين print("float32: ", float32.numpy()) print("float16: ", float16.numpy()) # حجم التخزين print("Size of float32: ", float32.numpy().nbytes, "bytes") print("Size of float16: ", float16.numpy().nbytes, "bytes") ''' output float32: 123.456 float16: 123.44 Size of float32: 4 bytes Size of float16: 2 bytes ''' قد يصل عدد المتغيرات والمعاملات في نماذج الذكاء الاصطناعي لملايين بل مليارات في بعض الأحيان، لذا من الضروري الاعتماد على تغيير دقة المتغيرات لتسريع عملية التدريب وتقليص حجم النماذج، فأداء النموذج قد يتأثر بنسبة جيدة من هذا التغير. ملاحظة: تجدر الإشارة إلى أن استخدام أسلوب تغيير دقة المتغيرات يستخدم في تقليص حجم نماذج الذكاء الاصطناعي لتعمل على الحافة on Edge أي على الأجهزة محدودة الموارد، مثل الأجهزة المحمولة أو الشرائح الحاسوبية البسيطة، التي قد لا تتسع إلا لبضعة آلاف من البايتات. استخدام شبكة العقد الحسابية لتنفيذ العمليات تفيدنا شبكة العٌقد الحسابية Computational graphs في جعل عملية تدريب النماذج أكثر مرونة وكفاءة عبر عدة منصات وأجهزة حاسوبية مختلفة، فهي محسنة لتتعامل مع العتاد الحاسوبي بشكل أفضل، كما يمكن نقل شبكة العقد الحسابية بعد تدريب النموذج ليصبح قابلًا للاستخدام على منصات وأجهزة متنوعة ولغات برمجة مختلفة فهي مجرد قالب لتنفيذ مجموعة من الأوامر التي تعطي نتيجة أو توقع في النهاية. كانت هذه الطريقة هي الوحيدة في الإصدار الأول من تنسرفلو TensorFlow 1.x ، ولكنها عانت من بعض العيوب، فقد كان علينا كمطورين كتابة الأكواد البرمجية بشكل مثالي دون أن نرى نتائج الخطوات الوسيطة، ثم ننتظر تحويل الأكواد المثالية إلي شبكة عقد حسابية محسنة، وهذا يستغرق الكثير من الوقت، بالطبع لن نحصل على النتيجة التي نرجوها من أول محاولة، فالبرمجة عملية تحسن تكرارية وتراكمية، وخاصة عند تطوير نماذج الذكاء الاصطناعي التي تحتاج إلى تجربة العديد من المعاملات حتى نجد التوليفة المناسبة من تلك المعاملات. لاحظ الكود التالي الذي يوضح كيفية تعريف دالة ConcreteFunction في تنسرفلو وكيفية تحديد المدخلات والمخرجات للعمليات الحسابية حيث سنحول العمليات البرمجية البسيطة مثل الجمع بين متغيرين إلى شبكة عُقد حسابية يمكن تنفيذها بكفاءة على أجهزة مختلفة. import tensorflow as tf @tf.function # لجعل تنسرفلو يستخدم شبكة العٌقد الحسابية def add_numbers(a, b): return a + b # نعرف ثابتين a = tf.constant(5) b = tf.constant(3) # لنقم بعملية الجمع بطريقة شبكة العٌقد الحسابية result = add_numbers(a, b) # لنحصل على الخطوات التي قام بها تنسرفلو graph_steps = add_numbers.get_concrete_function(a, b) print("الخطوات") print(graph_steps) print("الخطوات بشكل مفصـل ومبسـط") for op in graph_steps.graph.get_operations(): print(op.name) الخطــوات ConcreteFunction Input Parameters: a (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(), dtype=tf.int32, name=None) b (POSITIONAL_OR_KEYWORD): TensorSpec(shape=(), dtype=tf.int32, name=None) Output Type: TensorSpec(shape=(), dtype=tf.int32, name=None) Captures: None الخطـوات بشكـــل مفصـل ومبسـط a b a d d I d e n t i t y تقنية التنفيذ الفوري للعمليات الحسابية Eager execution كانت عملية تطوير النماذج غير تفاعلية في الإصدار الأول من تنسرفلو TensorFlow 1.x، كما ذكرنا في الفقرة السابقة، حيث كان المطورون يكتبون الأكواد ثم ينتظرون لفترة طويلة لتحويل الأكواد إلى شبكة عُقد حسابية محسّنة، هذا جعل من الصعب اكتشاف الأخطاء وتحسين الأداء في الوقت الفعلي. لهذا السبب، وجدت طريقة التنفيذ الفوري للعمليات الحسابية Eager Execution في TensorFlow 2.x لتجعل عملية التطوير أكثر تفاعلية وسهولة. حيث يمكننا من خلال التنفيذ الفوري Eager Execution بناء العمليات الحسابية بشكل مباشر. على سبيل المثال، عندما نجمع رقمين، سنحصل على النتيجة على الفور دون الحاجة للانتظار لإكمال البرمجة أو إنشاء شبكة العُقد الحسابية. وبالتالي تسهل علينا هذه الطريقة اكتشاف الأخطاء، واختبار التعديلات، وتحسين أداء النموذج بشكل فوري وتفاعلي. لاحظ الكود التالي لاستخدام التنفيذ الفوري Eager Execution في تنسرفلو: import tensorflow as tf # Eager Mode مفعل بشكل افتراضي a = tf.constant(5) b = tf.constant(3) c = a + b print("ناتج العملية الفورية:", c.numpy()) # ناتج العملية الفورية: 8 الخاتمة وصلنا لختام مقالنا الذي شرحنا فيه بالتفصيل إطار العمل الشهير تنسرفلو TensorFlow، وأوضحنا العديد من الأدوات والتقنيات التي تُمكّن المطورين من تطوير نماذج الذكاء الاصطناعي عبر مختلف المراحل، من التدريب وحتى التشغيل. كما قمنا بتطبيق أمثلة عملية بسيطة توضح كيفية استخدام هذه الأدوات بشكل تفصيلي، بدءًا من بناء الشبكات الحسابية حتى التنفيذ الفوري للعمليات الحسابية. ننصح بتجربة هذه المنصة والاستفادة من أدواتها لتحسين وتبسيط عملية تطوير تطبيقات الذكاء الاصطناعي. اقرأ أيضًا ما هي منصة Hugging Face للذكاء الاصطناعي تعلم الذكاء الاصطناعي كل ما تود معرفته عن دراسة الذكاء الاصطناعي بناء شبكة عصبية للتعرف على الأرقام المكتوبة بخط اليد باستخدام مكتبة TensorFlow تعرف على أهم مشاريع الذكاء الاصطناعي تعرف على مكتبة المحوّلات Transformers من منصة Hugging Face -
 يمر أغلب مهندسي الذكاء الاصطناعي و تعلم الآلة أثناء تعلمهم للعديد من الخوارزميات الأساسية والتقليدية في تعلم الآلة بمكتبة ساي كيت ليرن Scikit Learn التي توفر هذه الخوارزميات وتوثيقًا جيدًا لها، في هذه المقالة سوف نستكشف هذه المكتبة القوية واستخداماتها ومميزاتها، وما الخوارزميات التي يوفرها، ونستعرض بعض الأمثلة العملية على حالات الاستخدام. ما هي مكتبة ساي كيت ليرن Scikit Learn تعد ساي كيت ليرن Scikit Learn أحد أشهر مكتبات أو أطر عمل لغة بايثون وأكثرها استعمالًا خاصة في مجالات علوم البيانات وتعلم الآلة، فهي توفر مجموعة من خوارزميات الذكاء الاصطناعي المبنية بكفاءة، وتتيح لنا استخدامها بسلاسة حيث تمتلك جميع خوارزميات التعلم المبنية بها طريقة شبه موحدة للتعامل معها، فاستخدام خوارزمية أخرى لنفس الغرض يتطلب ببساطة تغيير سطر واحد من الكود، وتوفر هذه المكتبة إمكانيات كبيرة عند بناء النماذج ومعالجة البيانات وتجهيزها، وحفظ النماذج في صيغة يمكن إعادة استخدامها لاحقًا. مميزات مكتبة ساي كيت ليرن Scikit Learn تسهل مكتبة ساي كيت ليرن Scikit Learn تطوير نماذج تعلم الآلة على المبتدئين والراغبين باختبار الأمور بسرعة، وتوفر لهم العديد من المميزات التي سنسردها ونتعرف عليها مثل: التوثيق الجيد: تتميز المكتبة بوجود توثيق مفصل وأمثلة استخدام كثيرة تساعدنا في البدء بتطوير واستخدام الخوارزميات المختلفة ومعرفة المعاملات التي يمكن ضبطها لتغير أداء النموذج وطريقة تدريبها القيم الافتراضية لمعاملات التحكم : لا داعي للقلق إن كنا نتعلم خوارزمية جديدة ونرغب في تجربتها دون الدخول في جميع التفاصيل وتأثيرات ضبط قيم معاملات التحكم أوالمعاملات الفائقة hyperparameters حيث تضبط المكتبة أغلب العوامل بقيم افتراضية مناسبة لأغلب الاستخدامات، لذا يمكننا التركيز على العوامل الأهم وفهمها بشكل أفضل أدوات للمفاضلة بين النماذج: مع تنوع الخوارزميات المبنية في المكتبة التي يمكنها القيام بنفس المهمة بطرق مختلفة يكون من الصعب على المبتدئ تقرير أي الخوارزميات هو الأفضل للمهمة التي يحاول إنجازها، لذلك توفر لنا المكتبة أدوات للمقارنة بين الخوارزميات المختلفة وعوامل التحكم المختلفة بسلاسة مكتبة غنية بالخوارزميات والأدوات: توفر المكتبة أغلب خوارزميات تعلم الآلة التقليدية، مما يغنينا عن عناء بناء هذه الخوارزميات من الصفر، إذ تتوفر عشرات الخوارزميات التي يمكن تطبيقها من خلال سطور معدودة من الكود، فيمكننا التركيز على تحسين معالجة البيانات وتحسين جودتها واختيار النموذج الأنسب للمشكلة التي لدينا التوافق مع المكتبات الأخرى: تعمل المكتبة بشكل سلس مع المكتبات الأخرى مثل باندا Pandas و نمباي NumPy التي توفر هياكل بيانات وعمليات تسهل اكتشاف أنماط البيانات وتحليلها ومعالجتها لتصبح جاهزة للنموذج الذي نحتاج لتدريبه معالجة البيانات باستخدام ساي كيت ليرن توفر ساي كيت ليرن Scikit Learn العديد من الأدوات الجيدة لمعالجة البيانات وتجهيزها لتدريب النماذج عليها، وكما نعرف تٌعد البيانات وجودتها العامل الأهم في تحسين دقة توقعات النماذج المستخدمة، لذلك هنالك بعض الخطوات التي نحتاج للقيام بها لمعالجة البيانات فمثلًا إذا كانت هناك قيم غير رقمية فنحن بحاجة لتحويلها إلى أرقام فنماذج تعلم الآلة هي نماذج رياضية ولن نستطيع القيام بعمليات حسابية على النصوص أو الصور بشكلها الأصلي. أمثلة على معالجة البيانات الترميز Encoding: هو عملية تبديل بعض البيانات بأرقام يسهل إجراء عمليات رياضية عليها، مع إمكانية إرجاعها لأصلها، يمكن ترميز البيانات في مكتبة Scikit Learn باستخدام الكود التالي: from sklearn.preprocessing import LabelEncoder # ترميز البيانات الوصفية city = ["القاهرة", "الرياض", "دمشق", "القاهرة"] # نعرف المٌرمز الذي يعوض عن اسمٍ برقم يعبر عنه encoder = LabelEncoder() # تقوم هذه الدالة بتجهيز المٌرمز # حيث سيمكننا أن نستخدمه أكثر من مرة بعد هذه الخطوة لترميز البيانات المدخلة له بناءً على أول بيانات أعطت له encoder.fit(city) # الآن يمكننا استخدامه على أي بيانات أخرى لترميزها city_encoded = encoder.transform(city) print(city_encoded) # Output: [1 0 2 1] print(encoder.transform(["الرياض"])) # Output: [0] # عكس الترميز print(encoder.inverse_transform(city_encoded)) # Output: ['القاهرة' 'الرياض' 'دمشق' 'القاهرة'] print(encoder.inverse_transform([2, 1, 0, 0, 1])) # Output: ['دمشق' 'القاهرة' 'الرياض' 'الرياض' 'القاهرة'](city_encoded) التعامل مع القيم المفقودة : قد تتضمن البيانات بعض القيم المفقودة ويمكن التعامل معها في مكتبة Scikit Learn بسهولة من خلال حذف الصفوف التي تحتوي قيمًا مفقودة إن كانت قليلة للغاية، أو التعويض عنها باستخدام المعلومات الإحصائية كالمتوسط الحسابي للقيم، أو بناء نموذج لتوقعها بحسب القيم الموجودة بالفعل. خوارزميات تعلم الآلة في مكتبة Scikit Learn تتضمن مكتبة Scikit Learn العديد من خوارزميات تعلم الآلة التي تساعدنا على تنفيذ مهام متنوعة، وفيما يلي نبذة عن أهم هذه الخوارزميات: أولًا: خوارزميات التعلم الخاضع للإشراف التعلم الخاضع للإشراف Supervised Learning هو نوع من التعلم الآلي يصف المهام التي تكون فيها البيانات المراد توقعها معلوم مخرجاتها الممكنة مسبقًا وتوجد بيانات تحتوي على ملاحظات سابقة تتضمن الوسوم Labels المراد تعليم النموذج توقعها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوارزميات توقع الانحدار Regression توقع الانحدار هو نوع من المهام التي يمكننا القيام بها باستخدام خوارزميات مضمنة في ساي كيت ليرن Scikit Learn، يتوقع هذا النوع من الخوارزميات الحصول على أمثلة سابقة يتعلم منها العلاقة بين المدخلات المعطاة والوسم المراد توقعه، والذي يكون قيمة عددية مستمرة continuous مثل توقع درجة الحرارة أو توقع أسعار المنازل. أمثلة على خوارزميات توقع الانحدار: توقع الانحدار الخطي Linear Regression توقع الانحدار بالدوال متعددة الحدود Polynomial Regression خوزارزميات التصنيف Classification يصنف البشر كل شيء حولهم من الحيوانات والجمادات إلى أنواع الأفلام والروايات، وتتوفر خوارزميات تستطيع محاكاة البشر وتتعلم تصنيف الأشياء المختلفة بإعطاء نماذج وملاحظات سابقة لتصنيفات قام بها البشر من قبل حتي تستطيع الآلة تعلم التصنيف، يمكن الاستفادة من التصنيف في أتمتة العديد من المهام المرجو فيها تصنيف عدد ضخم من العناصر في وقت قليل بالتالي توفير الوقت وزيادة الكفاءة، عملية التصنيف تخرج لنا قيمًا منفصلة discrete. من الأمثلة على استخدام هذه الخوارزميات توقع حالة الطقس هل هو مشمس أم غائم أم ماطر أم حار ...إلخ. وتصنيف الصور، وتوقع تقييمات الأفلام. أمثلة على خوارزميات التصنيف الانحدار اللوجستي Logistic Regression مٌصنّف الجار الأقرب Nearest Neighbors Classification شجرة القرار Decision Tree خوارزميات تجميع النماذج Models Ensemble تتيح لنا ساي كيت ليرن Scikit Learn القدرة على دمج أكثر من نموذج تعلم آلة ليشكلوا نموذجًا أقوى، يمكن تشبيه الأمر بلجنة أو فريق من الأصدقاء كل منهم خبير في مجال معين وعند جمع خبرتهم معًا يغطون على نقاط الضعف الخاصة بهم. يمكن تجميع النماذج باستخدام التصويت Voting حيث نجري تدريب لعدد من النماذج ثم نأخذ بتوقع الأغلبية في حالة كون المشكلة تصنيفية، أما أن كانت المشكلة توقع انحدار يمكن أن تأخذ متوسط التوقعات، لنلاحظ الكود التالي: from sklearn.ensemble import VotingClassifier # التصنيف اللوجيستي model1 = LogisticRegression() # شجرة القرارات model2 = tree.DecisionTreeClassifier() # مٌصنف أقرب الجيران model3 = KNeighborsClassifier(n_neighbors=3) # تجميع لتوقعات النماذج باستخدام التصويت model = VotingClassifier(estimators=[('lr', model1), ('dt', model2), ('knn', model3)], voting='hard') # تدريب النموذج # لاحظ أن مدخلات هذه الدالة هي الخواص المطلوب من النموذج تعلم الأنماط بها # بالإضافة إلى الوسم المٌراد توقعه # تمثل هذه المدخلات التجارب المٌراد للنموذج التعلم منها # يمكنك أن تستخدم هذه الدالة في تدريب أي نموذج في ساي كيت ليرن model.fit(X_train, y_train) # استخدام النموذج في التوقع # البيانات المدخلة للنموذج لم يرها من قبل # ولكنها تحتوي نفس الخواص والأعمدة التي تم تدريب النموذج عليها # نرغب في تدريب النموذج على التعميم لبيانات لم يرها من قبل y_pred = model.predict(X_test) جمعنا في الكود أعلاه عدد من النماذج الضعيفة ومحدودة المعرفة حيث يتدرب كل نموذج على جزء من البيانات، وجمعنا معرفتهم معًا للخروج بتوقع واحد مثال على هذا النوع هو خوارزمية الغابة العشوائية Random Forest وهي تجميع لنماذج من شجرة القرارات Decision Tree البسيطة. تقلل هذه الطريقة من فرص حفظ النموذج للبيانات وتمنحه مرونة أكثر لتعلم الأنماط الحقيقية التي تمكنه من توقع الإجابات الصحيحة عند تعرضه لبيانات جديدة عند تشغيل النموذج. خوارزميات التعلم غير الخاضع للإشراف التعلم غير الخاضع للإشراف Unsupervised Learning هو نوع من تعلم الآلة تكون فيه البيانات غير موسومة، ومهمة النموذج تعلم الأنماط بين البيانات ليكتشف الفروقات بينها، مثلًا إن كانت المدخلات صور فتكون المهمة معرفة أي الصور يمكن اعتبارها تابعة لنفس الشيء دون إعطاء وسم للبيانات في عملية التدريب، ما يعرفه النموذج هو الخواص المُراد للنموذج التعلم منها فقط للتميز بين الصور بناء عليها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوزارميات العنقدة أو التصنيف العنقودي Clustering لا نوفر للنموذج في هذه الحالة التصنيفات والوسوم المتوقع انتماء البيانات لها على غرار التصنيف العادي، ففي العنقدة Clustering على النموذج أن يكتشف هذا بنفسه من خلال تعلم الأنماط الموجودة بالبيانات للتمييز بينها. تستخدم خوزارميات العنقدة في أنظمة التوصية Recommendation systems لتقديم اقتراحات شخصية للمستخدمين تناسب اهتماماتهم، أو فصل عناصر الصورة Image segmentation من خلال تحديد البكسلات التي تنتمي لنفس العنصر Object في الصورة بالتالي تفريقها عن باقي العناصر. أمثلة على خوارزميات العنقدة: العنقدة حول عدد من نقاط التمركز k-means العنقدة الهرمية Hierarchical clustering خوارزميات اختزال البيانات نحتاج لاختزال البيانات Data Reduction في كثير من الحالات بسبب محدودية القدرة الحاسوبية وعدم تأثير كل هذه البيانات بشكل ملحوظ على أداء النموذج، ونجري اختزال البيانات عادة من خلال تقليل أبعادها بدمج بعض الأعمدة أو الخواص بدون خسارة المعلومات الهامة قدر الإمكان، فمثلًا يمكننا تقليل أبعاد الصورة مع الاحتفاظ بملامحها ودقتها قدر الإمكان، أو تقليل عدد الأعمدة من 100 إلى 10 مع احتفاظ الأعمدة العشرة بأغلبية المعلومات التي تؤثر على التوقعات. من أمثلة خوارزميات اختزال البيانات خوارزمية تحليل العنصر الأساسي Principal Component Analysis التي تمكننا من اختزال عدد الأعمدة أو الأبعاد بالبيانات مع الاحتفاظ بأكبر قدر ممكن من المعلومات. # تساعدنا هذه المكتبة على صنع هياكل بيانات مصفوفة # والقيام بالعديد من العمليات الحسابية import numpy as np # هذه الخوارزمية التي سنستخدمها لاختزال البيانات from sklearn.decomposition import PCA # في البداية لنصنع بيانات عشوائية لنقوم بالتجربة # يضمن لنا هذا السطر ثبات القيم العشوائية عند إعادة تشغيل هذا الكود np.random.seed(0) # نعرف مصفوفة عشوائية التوليد، تتكون من 10 صفوف و100 عمود X = np.random.rand(10, 100) # لنعرف الخوارزمية التي استوردناها pca = PCA(n_components=10) # نضع هنا عدد الأعمدة التي نرغب أن تصبح البيانات عليها # لنقم بتشغيل الخوارزمية على البيانات التي معنا x_pca = pca.fit_transform(X) # هذا السطر يقوم بتدريب الخوارزمية على اختزال البيانات وفي نفس الوقت يقوم باختزال البيانات المدخلة # لنرى النتائج print("حجم البيانات قبل الاختزال", X.shape) print("حجم البيانات بعد الاختزال", x_pca.shape) ''' المـــــــــخــرجـــــــــــــات ------------------------------------- حجم البيانات قبل الاختزال (10, 100) حجم البيانات بعد الاختزال (10, 10) ''' خوارزميات كشف الشذوذ كشف الشذوذ Anomaly Detection هو عملية ملاحظة الغير مألوف والخارج عن الأغلبية في البيانات. يستخدم في حالات عددية مثل اكتشاف المعاملات الاحتيالية في البنوك، واكتشاف الأنماط غير المعتادة في تدفق الشبكات مما قد يساعد على منع هجمات إغراق الشبكة بالطلبات، واكتشاف المنتجات المعيبة في خطوط الإنتاج واكتشاف الأنماط غير المعتادة للمؤشرات الحيوية لجسم الإنسان التي تستخدمها تطبيقات الساعات الذكية التي تجمع هذه المؤشرات. من الخوارزميات التي تطبق كشف الشذوذ خوارزمية غابة العزل Isolation Forest، وفيما يلي مثال على طريقة استخدامها: # استيراد نموذج كشف كشف الشذوذ from sklearn.ensemble import IsolationForest # سنستخدمها لتوليد بعض البيانات import numpy as np # نولد البيانات لتجربة النموذج X = np.array([[10, 10], [12, 12], [8, 8], [9, 9], [200, 200]]) # يمكنك ملاحظة أن النقطة الأخيرة شاذة عن باقي النقاط # لنقم بتعريف وتدريب النموذج clf = IsolationForest(contamination=0.2) # %يفترض هذا المعامل أن نسبة شذوذ 20 # لاحظ أن التدريب يتم بدون استخدام وسوم حيث أن هذا النموذج غير خاضع للإشراف clf.fit(X) # في حالة اكتشاف شذوذ سيتم وسمه بسالب واحد لتميزه predictions = clf.predict(X) print(predictions) # Output: [ 1 1 1 1 -1] خوارزميات التعلم الخاضع لإشراف جزئي يستخدم التعلم الخاضع لإشراف جزئي Semi-supervised Learning بيانات تتكون من خليط من البيانات الموسومة Labeled data والبيانات غير الموسومة Unlabeled data أثناء التدريب، يمكن أن يصبح هذا الأسلوب مفيدًا للغاية عندما يكون من الصعب الحصول على بيانات موسومة كافية أو يحتاج الحصول عليها إلى وقت ومجهود ضخم. يستخدم عادة في ترشيح المحتوى في أنظمة التوصية فبعض البيانات قد تكون متوفرة بشكل صريح مثل تقييمات المستخدم للمنتجات والتي يمكن الاستدلال بها لاقتراح المزيد من العناصر، ولكن يمكن أيضًا الاستفادة من المعلومات غير الموسومة والمعروفة ضمنية من خلال تفاعلات المستخدم. كما يستخدم في تدريب نماذج التعلم على الصور ومقاطع الفيديو حيث يمكن وسم بعض الصور أو العناصر فيها بشكل بشري لكن لا يمكن حصر جميع العناصر المختلفة التي قد تكون بداخل صورة ووسمها لذا سنستفيد من دمج الجزء الموسوم من البيانات مع الجزء غير الموسوم في توفير كمية أكبر من البيانات لتدريب نماذج أكثر دقة، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوراززميات التعلم الذاتي Self Training يمكننا استخدام التعلم الذاتي Self Training في ساي كيت ليرن Scikit Learn لتحويل أي نموذج تصنيف تقليدي إلى نموذج يمكنه التدريب على البيانات الموسومة وغير الموسومة معًا، شريطة أن يكون النموذج قادرًا على توقع التصنيفات كاحتمالات، ونحتاج لاستخدام نموذج يسمى SelfTrainingClassifier لتحويل النماذج العادية لنماذج خاضعة لإشراف جزئي، لاحظ الكود التالي: from sklearn.tree import DecisionTreeClassifier from sklearn.semi_supervised import SelfTrainingClassifier # نعرف أي مصنف ليكون نموذج الأساس base_classifier = DecisionTreeClassifier() # نقوم بإحاطة نموذج الأساس ليصبح قادرًا على التعلم الذاتي self_training_model = SelfTrainingClassifier(base_classifier) # نقوم بتدريب النموذج مثل أي نموذج تقليدي self_training_model.fit(X_train, y_train) ملاحظة: عند تجهيزنا لبيانات التدريب نحتاج لوسم البيانات غير الموسومة بقيمة 1- حيث أننا لا نستطيع أن نمرر البيانات خلال النموذج وهي غير موسومة. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن اختيار النموذج المناسب قد يبدو اختيار النموذج المناسب في مكتبة ساي كيت ليرن معقدًا، إذ يمكن استخدام أكثر من خوارزمية لحل نفس المشكلة. ولكل خوارزمية معاملات تحكم مختلفة، لذلك يجب علينا استخدام أدوات تساعدنا في مقارنة النماذج وقياس أدائها. فيما يلي بعض المعايير الرئيسية التي يمكن استخدامها: الدقة Accuracy: عدد التوقعات الصحيحة التي توقعها النموذج مقسومًا على إجمالي البيانات. كلما كانت النسبة أعلى، كان النموذج أفضل خطأ المتوسط التربيعي Mean Squared Error: الفرق بين القيمة الفعلية التي نريد التنبؤ بها والقيمة التي توقعها النموذج، ثم تربيع هذا الفرق. وهو يساعد في تحديد مدى دقة التوقعات بحث مصفوفة المعاملات GridSearch: يستخدم لاختبار عدد من المعاملات أو إعدادات النماذج المختلفة دفعة واحدة والعثور على أفضل مجموعة معاملات تحقق أفضل أداء. تستهلك هذه الطريقة وقتًا وموارد حاسوبية كبيرة خاصة إذا كانت المعاملات كثيرة جدًا مقارنة بين ساي كيت ليرن Scikit Learn و تنسورفلو TensorFlow يكمن الفرق الرئيسي بين تنسورفلو TensorFlow وبين ساي كيت ليرن Scikit Learn في تخصص الاستخدام، حيث أن ساي كيت ليرن مكتبة متخصصة بخوارزميات تعلم الآلة التقليدية Traditional Machine Learning بينما تنسورفلو TensorFlow إطار عمل شامل لتطوير وتشغيل نماذج التعلم العميق Deep Learning المبنية على الشبكات العصبية الاصطناعية. وعلى الرغم من إمكانية تدريب شبكات عصبية اصطناعية باستخدام ساي كيت ليرن فهي ليست محسنة لأجل هذا الغرض، إذ لا تستطيع المكتبة الاستفادة من وحدات المعالجة الرسومية GPUs التي تستطيع تسريع تدريب النماذج العميقة بشكل أفضل من وحدات المعالجة المركزية CPUs، بينما لا يقف دعم تنسورفلو TensorFlow عند استخدام GPU واحد، حيث يمكن توزيع التدريب على عدة أجهزة على التوازي وهو شيء صعب التحقيق باستخدام ساي كيت ليرن. الخلاصة تعرفنا في هذه المقالة على مكتبة الذكاء الاصطناعي الشهيرة ساي كيت ليرن Scikit Learn وأبرز مميزاتها ووضحنا بعض التطبيقات الواسعة لخوارزميات التعلم المبنية بها، وكذلك تعرفنا على الفرق بينها وبين إطار العمل تنسورفلو TensorFlow.ننصح بتعلم استخدام هذه المكتبة وتجربتها في بناء وتطبيق نماذج تعلم آلة مخصصة، فهي توفر أدوات قوية ومرنة تمكنكم من تنفيذ حلول مبتكرة في مختلف مجالات الذكاء الاصطناعي. اقرأ أيضًا الذكاء الاصطناعي: دليلك الشامل بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn العمل مع ملفات CSV وبيانات JSON باستخدام لغة بايثون استخدام التدريب الموزع ومكتبة Accelerate لتسريع تدريب نماذج الذكاء الاصطناعي
يمر أغلب مهندسي الذكاء الاصطناعي و تعلم الآلة أثناء تعلمهم للعديد من الخوارزميات الأساسية والتقليدية في تعلم الآلة بمكتبة ساي كيت ليرن Scikit Learn التي توفر هذه الخوارزميات وتوثيقًا جيدًا لها، في هذه المقالة سوف نستكشف هذه المكتبة القوية واستخداماتها ومميزاتها، وما الخوارزميات التي يوفرها، ونستعرض بعض الأمثلة العملية على حالات الاستخدام. ما هي مكتبة ساي كيت ليرن Scikit Learn تعد ساي كيت ليرن Scikit Learn أحد أشهر مكتبات أو أطر عمل لغة بايثون وأكثرها استعمالًا خاصة في مجالات علوم البيانات وتعلم الآلة، فهي توفر مجموعة من خوارزميات الذكاء الاصطناعي المبنية بكفاءة، وتتيح لنا استخدامها بسلاسة حيث تمتلك جميع خوارزميات التعلم المبنية بها طريقة شبه موحدة للتعامل معها، فاستخدام خوارزمية أخرى لنفس الغرض يتطلب ببساطة تغيير سطر واحد من الكود، وتوفر هذه المكتبة إمكانيات كبيرة عند بناء النماذج ومعالجة البيانات وتجهيزها، وحفظ النماذج في صيغة يمكن إعادة استخدامها لاحقًا. مميزات مكتبة ساي كيت ليرن Scikit Learn تسهل مكتبة ساي كيت ليرن Scikit Learn تطوير نماذج تعلم الآلة على المبتدئين والراغبين باختبار الأمور بسرعة، وتوفر لهم العديد من المميزات التي سنسردها ونتعرف عليها مثل: التوثيق الجيد: تتميز المكتبة بوجود توثيق مفصل وأمثلة استخدام كثيرة تساعدنا في البدء بتطوير واستخدام الخوارزميات المختلفة ومعرفة المعاملات التي يمكن ضبطها لتغير أداء النموذج وطريقة تدريبها القيم الافتراضية لمعاملات التحكم : لا داعي للقلق إن كنا نتعلم خوارزمية جديدة ونرغب في تجربتها دون الدخول في جميع التفاصيل وتأثيرات ضبط قيم معاملات التحكم أوالمعاملات الفائقة hyperparameters حيث تضبط المكتبة أغلب العوامل بقيم افتراضية مناسبة لأغلب الاستخدامات، لذا يمكننا التركيز على العوامل الأهم وفهمها بشكل أفضل أدوات للمفاضلة بين النماذج: مع تنوع الخوارزميات المبنية في المكتبة التي يمكنها القيام بنفس المهمة بطرق مختلفة يكون من الصعب على المبتدئ تقرير أي الخوارزميات هو الأفضل للمهمة التي يحاول إنجازها، لذلك توفر لنا المكتبة أدوات للمقارنة بين الخوارزميات المختلفة وعوامل التحكم المختلفة بسلاسة مكتبة غنية بالخوارزميات والأدوات: توفر المكتبة أغلب خوارزميات تعلم الآلة التقليدية، مما يغنينا عن عناء بناء هذه الخوارزميات من الصفر، إذ تتوفر عشرات الخوارزميات التي يمكن تطبيقها من خلال سطور معدودة من الكود، فيمكننا التركيز على تحسين معالجة البيانات وتحسين جودتها واختيار النموذج الأنسب للمشكلة التي لدينا التوافق مع المكتبات الأخرى: تعمل المكتبة بشكل سلس مع المكتبات الأخرى مثل باندا Pandas و نمباي NumPy التي توفر هياكل بيانات وعمليات تسهل اكتشاف أنماط البيانات وتحليلها ومعالجتها لتصبح جاهزة للنموذج الذي نحتاج لتدريبه معالجة البيانات باستخدام ساي كيت ليرن توفر ساي كيت ليرن Scikit Learn العديد من الأدوات الجيدة لمعالجة البيانات وتجهيزها لتدريب النماذج عليها، وكما نعرف تٌعد البيانات وجودتها العامل الأهم في تحسين دقة توقعات النماذج المستخدمة، لذلك هنالك بعض الخطوات التي نحتاج للقيام بها لمعالجة البيانات فمثلًا إذا كانت هناك قيم غير رقمية فنحن بحاجة لتحويلها إلى أرقام فنماذج تعلم الآلة هي نماذج رياضية ولن نستطيع القيام بعمليات حسابية على النصوص أو الصور بشكلها الأصلي. أمثلة على معالجة البيانات الترميز Encoding: هو عملية تبديل بعض البيانات بأرقام يسهل إجراء عمليات رياضية عليها، مع إمكانية إرجاعها لأصلها، يمكن ترميز البيانات في مكتبة Scikit Learn باستخدام الكود التالي: from sklearn.preprocessing import LabelEncoder # ترميز البيانات الوصفية city = ["القاهرة", "الرياض", "دمشق", "القاهرة"] # نعرف المٌرمز الذي يعوض عن اسمٍ برقم يعبر عنه encoder = LabelEncoder() # تقوم هذه الدالة بتجهيز المٌرمز # حيث سيمكننا أن نستخدمه أكثر من مرة بعد هذه الخطوة لترميز البيانات المدخلة له بناءً على أول بيانات أعطت له encoder.fit(city) # الآن يمكننا استخدامه على أي بيانات أخرى لترميزها city_encoded = encoder.transform(city) print(city_encoded) # Output: [1 0 2 1] print(encoder.transform(["الرياض"])) # Output: [0] # عكس الترميز print(encoder.inverse_transform(city_encoded)) # Output: ['القاهرة' 'الرياض' 'دمشق' 'القاهرة'] print(encoder.inverse_transform([2, 1, 0, 0, 1])) # Output: ['دمشق' 'القاهرة' 'الرياض' 'الرياض' 'القاهرة'](city_encoded) التعامل مع القيم المفقودة : قد تتضمن البيانات بعض القيم المفقودة ويمكن التعامل معها في مكتبة Scikit Learn بسهولة من خلال حذف الصفوف التي تحتوي قيمًا مفقودة إن كانت قليلة للغاية، أو التعويض عنها باستخدام المعلومات الإحصائية كالمتوسط الحسابي للقيم، أو بناء نموذج لتوقعها بحسب القيم الموجودة بالفعل. خوارزميات تعلم الآلة في مكتبة Scikit Learn تتضمن مكتبة Scikit Learn العديد من خوارزميات تعلم الآلة التي تساعدنا على تنفيذ مهام متنوعة، وفيما يلي نبذة عن أهم هذه الخوارزميات: أولًا: خوارزميات التعلم الخاضع للإشراف التعلم الخاضع للإشراف Supervised Learning هو نوع من التعلم الآلي يصف المهام التي تكون فيها البيانات المراد توقعها معلوم مخرجاتها الممكنة مسبقًا وتوجد بيانات تحتوي على ملاحظات سابقة تتضمن الوسوم Labels المراد تعليم النموذج توقعها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوارزميات توقع الانحدار Regression توقع الانحدار هو نوع من المهام التي يمكننا القيام بها باستخدام خوارزميات مضمنة في ساي كيت ليرن Scikit Learn، يتوقع هذا النوع من الخوارزميات الحصول على أمثلة سابقة يتعلم منها العلاقة بين المدخلات المعطاة والوسم المراد توقعه، والذي يكون قيمة عددية مستمرة continuous مثل توقع درجة الحرارة أو توقع أسعار المنازل. أمثلة على خوارزميات توقع الانحدار: توقع الانحدار الخطي Linear Regression توقع الانحدار بالدوال متعددة الحدود Polynomial Regression خوزارزميات التصنيف Classification يصنف البشر كل شيء حولهم من الحيوانات والجمادات إلى أنواع الأفلام والروايات، وتتوفر خوارزميات تستطيع محاكاة البشر وتتعلم تصنيف الأشياء المختلفة بإعطاء نماذج وملاحظات سابقة لتصنيفات قام بها البشر من قبل حتي تستطيع الآلة تعلم التصنيف، يمكن الاستفادة من التصنيف في أتمتة العديد من المهام المرجو فيها تصنيف عدد ضخم من العناصر في وقت قليل بالتالي توفير الوقت وزيادة الكفاءة، عملية التصنيف تخرج لنا قيمًا منفصلة discrete. من الأمثلة على استخدام هذه الخوارزميات توقع حالة الطقس هل هو مشمس أم غائم أم ماطر أم حار ...إلخ. وتصنيف الصور، وتوقع تقييمات الأفلام. أمثلة على خوارزميات التصنيف الانحدار اللوجستي Logistic Regression مٌصنّف الجار الأقرب Nearest Neighbors Classification شجرة القرار Decision Tree خوارزميات تجميع النماذج Models Ensemble تتيح لنا ساي كيت ليرن Scikit Learn القدرة على دمج أكثر من نموذج تعلم آلة ليشكلوا نموذجًا أقوى، يمكن تشبيه الأمر بلجنة أو فريق من الأصدقاء كل منهم خبير في مجال معين وعند جمع خبرتهم معًا يغطون على نقاط الضعف الخاصة بهم. يمكن تجميع النماذج باستخدام التصويت Voting حيث نجري تدريب لعدد من النماذج ثم نأخذ بتوقع الأغلبية في حالة كون المشكلة تصنيفية، أما أن كانت المشكلة توقع انحدار يمكن أن تأخذ متوسط التوقعات، لنلاحظ الكود التالي: from sklearn.ensemble import VotingClassifier # التصنيف اللوجيستي model1 = LogisticRegression() # شجرة القرارات model2 = tree.DecisionTreeClassifier() # مٌصنف أقرب الجيران model3 = KNeighborsClassifier(n_neighbors=3) # تجميع لتوقعات النماذج باستخدام التصويت model = VotingClassifier(estimators=[('lr', model1), ('dt', model2), ('knn', model3)], voting='hard') # تدريب النموذج # لاحظ أن مدخلات هذه الدالة هي الخواص المطلوب من النموذج تعلم الأنماط بها # بالإضافة إلى الوسم المٌراد توقعه # تمثل هذه المدخلات التجارب المٌراد للنموذج التعلم منها # يمكنك أن تستخدم هذه الدالة في تدريب أي نموذج في ساي كيت ليرن model.fit(X_train, y_train) # استخدام النموذج في التوقع # البيانات المدخلة للنموذج لم يرها من قبل # ولكنها تحتوي نفس الخواص والأعمدة التي تم تدريب النموذج عليها # نرغب في تدريب النموذج على التعميم لبيانات لم يرها من قبل y_pred = model.predict(X_test) جمعنا في الكود أعلاه عدد من النماذج الضعيفة ومحدودة المعرفة حيث يتدرب كل نموذج على جزء من البيانات، وجمعنا معرفتهم معًا للخروج بتوقع واحد مثال على هذا النوع هو خوارزمية الغابة العشوائية Random Forest وهي تجميع لنماذج من شجرة القرارات Decision Tree البسيطة. تقلل هذه الطريقة من فرص حفظ النموذج للبيانات وتمنحه مرونة أكثر لتعلم الأنماط الحقيقية التي تمكنه من توقع الإجابات الصحيحة عند تعرضه لبيانات جديدة عند تشغيل النموذج. خوارزميات التعلم غير الخاضع للإشراف التعلم غير الخاضع للإشراف Unsupervised Learning هو نوع من تعلم الآلة تكون فيه البيانات غير موسومة، ومهمة النموذج تعلم الأنماط بين البيانات ليكتشف الفروقات بينها، مثلًا إن كانت المدخلات صور فتكون المهمة معرفة أي الصور يمكن اعتبارها تابعة لنفس الشيء دون إعطاء وسم للبيانات في عملية التدريب، ما يعرفه النموذج هو الخواص المُراد للنموذج التعلم منها فقط للتميز بين الصور بناء عليها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوزارميات العنقدة أو التصنيف العنقودي Clustering لا نوفر للنموذج في هذه الحالة التصنيفات والوسوم المتوقع انتماء البيانات لها على غرار التصنيف العادي، ففي العنقدة Clustering على النموذج أن يكتشف هذا بنفسه من خلال تعلم الأنماط الموجودة بالبيانات للتمييز بينها. تستخدم خوزارميات العنقدة في أنظمة التوصية Recommendation systems لتقديم اقتراحات شخصية للمستخدمين تناسب اهتماماتهم، أو فصل عناصر الصورة Image segmentation من خلال تحديد البكسلات التي تنتمي لنفس العنصر Object في الصورة بالتالي تفريقها عن باقي العناصر. أمثلة على خوارزميات العنقدة: العنقدة حول عدد من نقاط التمركز k-means العنقدة الهرمية Hierarchical clustering خوارزميات اختزال البيانات نحتاج لاختزال البيانات Data Reduction في كثير من الحالات بسبب محدودية القدرة الحاسوبية وعدم تأثير كل هذه البيانات بشكل ملحوظ على أداء النموذج، ونجري اختزال البيانات عادة من خلال تقليل أبعادها بدمج بعض الأعمدة أو الخواص بدون خسارة المعلومات الهامة قدر الإمكان، فمثلًا يمكننا تقليل أبعاد الصورة مع الاحتفاظ بملامحها ودقتها قدر الإمكان، أو تقليل عدد الأعمدة من 100 إلى 10 مع احتفاظ الأعمدة العشرة بأغلبية المعلومات التي تؤثر على التوقعات. من أمثلة خوارزميات اختزال البيانات خوارزمية تحليل العنصر الأساسي Principal Component Analysis التي تمكننا من اختزال عدد الأعمدة أو الأبعاد بالبيانات مع الاحتفاظ بأكبر قدر ممكن من المعلومات. # تساعدنا هذه المكتبة على صنع هياكل بيانات مصفوفة # والقيام بالعديد من العمليات الحسابية import numpy as np # هذه الخوارزمية التي سنستخدمها لاختزال البيانات from sklearn.decomposition import PCA # في البداية لنصنع بيانات عشوائية لنقوم بالتجربة # يضمن لنا هذا السطر ثبات القيم العشوائية عند إعادة تشغيل هذا الكود np.random.seed(0) # نعرف مصفوفة عشوائية التوليد، تتكون من 10 صفوف و100 عمود X = np.random.rand(10, 100) # لنعرف الخوارزمية التي استوردناها pca = PCA(n_components=10) # نضع هنا عدد الأعمدة التي نرغب أن تصبح البيانات عليها # لنقم بتشغيل الخوارزمية على البيانات التي معنا x_pca = pca.fit_transform(X) # هذا السطر يقوم بتدريب الخوارزمية على اختزال البيانات وفي نفس الوقت يقوم باختزال البيانات المدخلة # لنرى النتائج print("حجم البيانات قبل الاختزال", X.shape) print("حجم البيانات بعد الاختزال", x_pca.shape) ''' المـــــــــخــرجـــــــــــــات ------------------------------------- حجم البيانات قبل الاختزال (10, 100) حجم البيانات بعد الاختزال (10, 10) ''' خوارزميات كشف الشذوذ كشف الشذوذ Anomaly Detection هو عملية ملاحظة الغير مألوف والخارج عن الأغلبية في البيانات. يستخدم في حالات عددية مثل اكتشاف المعاملات الاحتيالية في البنوك، واكتشاف الأنماط غير المعتادة في تدفق الشبكات مما قد يساعد على منع هجمات إغراق الشبكة بالطلبات، واكتشاف المنتجات المعيبة في خطوط الإنتاج واكتشاف الأنماط غير المعتادة للمؤشرات الحيوية لجسم الإنسان التي تستخدمها تطبيقات الساعات الذكية التي تجمع هذه المؤشرات. من الخوارزميات التي تطبق كشف الشذوذ خوارزمية غابة العزل Isolation Forest، وفيما يلي مثال على طريقة استخدامها: # استيراد نموذج كشف كشف الشذوذ from sklearn.ensemble import IsolationForest # سنستخدمها لتوليد بعض البيانات import numpy as np # نولد البيانات لتجربة النموذج X = np.array([[10, 10], [12, 12], [8, 8], [9, 9], [200, 200]]) # يمكنك ملاحظة أن النقطة الأخيرة شاذة عن باقي النقاط # لنقم بتعريف وتدريب النموذج clf = IsolationForest(contamination=0.2) # %يفترض هذا المعامل أن نسبة شذوذ 20 # لاحظ أن التدريب يتم بدون استخدام وسوم حيث أن هذا النموذج غير خاضع للإشراف clf.fit(X) # في حالة اكتشاف شذوذ سيتم وسمه بسالب واحد لتميزه predictions = clf.predict(X) print(predictions) # Output: [ 1 1 1 1 -1] خوارزميات التعلم الخاضع لإشراف جزئي يستخدم التعلم الخاضع لإشراف جزئي Semi-supervised Learning بيانات تتكون من خليط من البيانات الموسومة Labeled data والبيانات غير الموسومة Unlabeled data أثناء التدريب، يمكن أن يصبح هذا الأسلوب مفيدًا للغاية عندما يكون من الصعب الحصول على بيانات موسومة كافية أو يحتاج الحصول عليها إلى وقت ومجهود ضخم. يستخدم عادة في ترشيح المحتوى في أنظمة التوصية فبعض البيانات قد تكون متوفرة بشكل صريح مثل تقييمات المستخدم للمنتجات والتي يمكن الاستدلال بها لاقتراح المزيد من العناصر، ولكن يمكن أيضًا الاستفادة من المعلومات غير الموسومة والمعروفة ضمنية من خلال تفاعلات المستخدم. كما يستخدم في تدريب نماذج التعلم على الصور ومقاطع الفيديو حيث يمكن وسم بعض الصور أو العناصر فيها بشكل بشري لكن لا يمكن حصر جميع العناصر المختلفة التي قد تكون بداخل صورة ووسمها لذا سنستفيد من دمج الجزء الموسوم من البيانات مع الجزء غير الموسوم في توفير كمية أكبر من البيانات لتدريب نماذج أكثر دقة، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوراززميات التعلم الذاتي Self Training يمكننا استخدام التعلم الذاتي Self Training في ساي كيت ليرن Scikit Learn لتحويل أي نموذج تصنيف تقليدي إلى نموذج يمكنه التدريب على البيانات الموسومة وغير الموسومة معًا، شريطة أن يكون النموذج قادرًا على توقع التصنيفات كاحتمالات، ونحتاج لاستخدام نموذج يسمى SelfTrainingClassifier لتحويل النماذج العادية لنماذج خاضعة لإشراف جزئي، لاحظ الكود التالي: from sklearn.tree import DecisionTreeClassifier from sklearn.semi_supervised import SelfTrainingClassifier # نعرف أي مصنف ليكون نموذج الأساس base_classifier = DecisionTreeClassifier() # نقوم بإحاطة نموذج الأساس ليصبح قادرًا على التعلم الذاتي self_training_model = SelfTrainingClassifier(base_classifier) # نقوم بتدريب النموذج مثل أي نموذج تقليدي self_training_model.fit(X_train, y_train) ملاحظة: عند تجهيزنا لبيانات التدريب نحتاج لوسم البيانات غير الموسومة بقيمة 1- حيث أننا لا نستطيع أن نمرر البيانات خلال النموذج وهي غير موسومة. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن اختيار النموذج المناسب قد يبدو اختيار النموذج المناسب في مكتبة ساي كيت ليرن معقدًا، إذ يمكن استخدام أكثر من خوارزمية لحل نفس المشكلة. ولكل خوارزمية معاملات تحكم مختلفة، لذلك يجب علينا استخدام أدوات تساعدنا في مقارنة النماذج وقياس أدائها. فيما يلي بعض المعايير الرئيسية التي يمكن استخدامها: الدقة Accuracy: عدد التوقعات الصحيحة التي توقعها النموذج مقسومًا على إجمالي البيانات. كلما كانت النسبة أعلى، كان النموذج أفضل خطأ المتوسط التربيعي Mean Squared Error: الفرق بين القيمة الفعلية التي نريد التنبؤ بها والقيمة التي توقعها النموذج، ثم تربيع هذا الفرق. وهو يساعد في تحديد مدى دقة التوقعات بحث مصفوفة المعاملات GridSearch: يستخدم لاختبار عدد من المعاملات أو إعدادات النماذج المختلفة دفعة واحدة والعثور على أفضل مجموعة معاملات تحقق أفضل أداء. تستهلك هذه الطريقة وقتًا وموارد حاسوبية كبيرة خاصة إذا كانت المعاملات كثيرة جدًا مقارنة بين ساي كيت ليرن Scikit Learn و تنسورفلو TensorFlow يكمن الفرق الرئيسي بين تنسورفلو TensorFlow وبين ساي كيت ليرن Scikit Learn في تخصص الاستخدام، حيث أن ساي كيت ليرن مكتبة متخصصة بخوارزميات تعلم الآلة التقليدية Traditional Machine Learning بينما تنسورفلو TensorFlow إطار عمل شامل لتطوير وتشغيل نماذج التعلم العميق Deep Learning المبنية على الشبكات العصبية الاصطناعية. وعلى الرغم من إمكانية تدريب شبكات عصبية اصطناعية باستخدام ساي كيت ليرن فهي ليست محسنة لأجل هذا الغرض، إذ لا تستطيع المكتبة الاستفادة من وحدات المعالجة الرسومية GPUs التي تستطيع تسريع تدريب النماذج العميقة بشكل أفضل من وحدات المعالجة المركزية CPUs، بينما لا يقف دعم تنسورفلو TensorFlow عند استخدام GPU واحد، حيث يمكن توزيع التدريب على عدة أجهزة على التوازي وهو شيء صعب التحقيق باستخدام ساي كيت ليرن. الخلاصة تعرفنا في هذه المقالة على مكتبة الذكاء الاصطناعي الشهيرة ساي كيت ليرن Scikit Learn وأبرز مميزاتها ووضحنا بعض التطبيقات الواسعة لخوارزميات التعلم المبنية بها، وكذلك تعرفنا على الفرق بينها وبين إطار العمل تنسورفلو TensorFlow.ننصح بتعلم استخدام هذه المكتبة وتجربتها في بناء وتطبيق نماذج تعلم آلة مخصصة، فهي توفر أدوات قوية ومرنة تمكنكم من تنفيذ حلول مبتكرة في مختلف مجالات الذكاء الاصطناعي. اقرأ أيضًا الذكاء الاصطناعي: دليلك الشامل بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn العمل مع ملفات CSV وبيانات JSON باستخدام لغة بايثون استخدام التدريب الموزع ومكتبة Accelerate لتسريع تدريب نماذج الذكاء الاصطناعي -
 تتدرب نماذج التعلم الآلي على مجموعات من البيانات الضخمة حيث توسم نقاط الاهتمام في البيانات -أي الأجزاء المهمة في التي نريد التركيز عليها والتعلم منها- لإعطائها معنى وسياق. نتعمق في هذه المقالة في وصف طرق بناء أنظمة وسم البيانات data labeling من الصفر مركزين على تدفق البيانات في النظام وكيفية تأمينها وضمان جودتها. ما معنى وسم البيانات ينتج الذكاء المتأصل في الذكاء الاصطناعي من تعرضه لكميات من البيانات التي تتدرب عليها نماذج تعلم الآلة، ومع التقدم الحالي في النماذج اللغوية الضخمة مثل GPT-4 وجيمناي Gemini التي يمكنها معالجة تريليونات الوحدات اللغوية الصغيرة التي تسمى tokens، ولا تتكون هذه البيانات المستخدمة في التدريب من معلومات أولية مستخلصة من الإنترنت فقط فهي تتضمن أيضًا وسومًا حتى يكون التدريب فعالًا. وسم البيانات data labeling هو عملية تحويل البيانات الأولية والمعلومات غير المعالجة إلى بيانات موسومة أو بيانات معنونة لإضافة سياق ومعنى واضح لها، وتحسّن هذه العملية من دقة تدريب النموذج، فأنت توضح وتشير إلى ما ترغب للنظام أن يتعرف عليه، وتتضمن الأمثلة على وسم البيانات مهام مثل تحليل المشاعر في النصوص حيث توسم النصوص في هذه الحالة بمشاعر معينة مثل إيجابي أو سلبي أو محايد، ومهام التعرف على الكائنات في الصور إذ يوسم كل كائن في الصورة بتصنيف معين. وكذلك تستخدم في تنصيص الكلام المنطوق في الملفات الصوتية، أو وسم الأفعال في مشاهد الفيديو. تلعب جودة البيانات دورًا هائلًا في تدريب البيانات، فالمدخلات الرديئة تؤدي إلى مخرجات رديئة فلا يمكننا توقع أداء مبهر من نموذج لم يُدرّب إلا على بيانات رديئة الجودة، فالنماذج التي تتدرب على بيانات بها أخطاء وتناقض في الوسوم ستواجه صعوبة في محاولة التأقلم مع البيانات الجديدة التي لم تراها في التدريب وربما تكون متحيزة في توقعاتها مسببة أخطاء في المخرجات، ويمكن أن يؤدي تراكم البيانات الرديئة في المراحل المختلفة إلى تأثير مركب مما يؤثر على كل الخطوات والنماذج التي تعتمد عليها. يهدف هذا المقال لتوضيح طرق تعزيز جودة البيانات واكتساب أفضلية تنافسية في كافة مراحل وسم البيانات. وللسهولة سنركز على المنصات والأدوات التي تستخدم في عملية وسم البيانات ونقارن بين مميزات ومحدوديات كل تقنية وأداة، وبعد ذلك ننتقل إلى اعتبارات أخرى لا تقل أهمية مثل تقليل التحيز، وحماية الخصوصية، وزيادة دقة وسم البيانات. دور وسم البيانات في سير عمل تطبيقات تعلم الآلة يقسم تدريب نماذج تعلم الآلة إلى ثلاثة تصنيفات عامة وهي التعلم الخاضع للإشراف Supervised learning والتعلم غير الخاضع لإشراف Unsupervised learning والتعلم المعزز Reinforcement learning. يعتمد التعلم الخاضع للإشراف على البيانات الموسومة labeled training data، والتي تحتوي نقاط الاهتمام في البيانات بها على وسوم بالتوقع أو العنوان الصحيح، فيتعلم النموذج أن يربط بين خواص المدخلات والوسوم أو التسميات الصحيحة المرتبطة بها مما يعطيه القدرة على تخمين وسوم البيانات الجديدة التي لم يتدرب عليها من قبل ولا يعرف ما وسمها الحقيقي، من جهة أخرى يحلل التعلم غير الخاضع للإشراف البيانات غير الموسومة بحثًا عن الأنماط المخفية أو التجميعات الموجودة في البيانات، وأما في التعلم المعزز فتكون عملية التدريب بالتجربة والخطأ ويمكننا التدخل في مرحلة التقييم والمراجعة لتوجيه عملية التعلم. تُدرّب معظم نماذج التعلم الآلي باستخدام أسلوب التعلم الخاضع للإشراف supervised learning. ونظرًا لأهمية البيانات عالية الجودة فينبغي اعتبارها في كل خطوة من عملية التدريب لذلك يلعب وسم البيانات دورًا حيويًا في هذه العملية. إن تحضير وجمع البيانات هي العملية التي تسبق وسم البيانات، حيث تُجمع البيانات الأولية أو الخام من مصادر متنوعة مثل المستشعرات الإلكترونية sensors، وقواعد البيانات، وسجلات العمليات logs، وواجهات برمجة التطبيقات APIs، وفي الغالب لا تخضع هذه البيانات لهيكل أو تنسيق ثابت وقد تحتوي على تناقضات وشوائب مثل قيم مفقودة أو قيم شاذة outliers أي قيما غير مألوفة وتختلف بشكل كبير عن باقي البيانات، أو قيم متكررة، لذا في عملية المعالجة تُنظّف البيانات وتُنسَّق وتُحوّل لتكون جاهزة لوسمها labeling، وتستخدم استراتيجيات عديدة للتعامل مع معالجة البيانات مثل حذف الصفوف المكررة، أو حذف الصفوف التي تحتوي على قيم مفقودة أو التعويض عن هذه القيم باستخدام نماذج تخمين إحصائية، كما يمكننا إحصائيًا اكتشاف القيم الشاذة outliers ومعالجتها. تلي معالجة البيانات في الخطوات عملية وسم البيانات لتوفير المعلومات التي يحتاجها نموذج التعلم الآلي كي يتعلم، وتختلف استراتيجيات وسم البيانات باختلاف نوع هذه البيانات والغرض من النموذج، فوسم الصور يتطلب أساليب مختلفة عن وسم النصوص، وعلى الرغم من وجود أدوات وسم آلية ولكن التدخل البشري يحسن بشكل كبير من عملية الوسم خاصة عندما يتعلق الأمر بالدقة أو تفادي التحيز الذي قد يوجد في الأدوات الآلية، وبعد أن توسم البيانات تاتي مرحلة تأكيد الجودة والتي تضمن الدقة والتناسق واكتمال الوسوم، ويعمل فريق تأكيد الجودة على توظيف أسلوب الوسم المزدوج إذ يقوم أكثر من شخص بوسم عينة من البيانات بشكل مستقل ويقارنون نتائجهم لحل أي اختلاف في الآراء. الخطوة التالية هي خضوع النموذج للتدريب باستخدام البيانات الموسومة ليتعلم الأنماط والعلاقات بين المدخلات والوسوم المرتبطة بها، حيث تعدل معاملات النموذج في عملية تكرارية من التخمين وتقييم الخطأ حتى تتحسن الدقة بالنسبة للوسوم المعلومة، ولتقييم فعالية النموذج يختبر على بيانات موسومة لم يرها من قبل، وتقاس صحة تخميناته وتوقعاته باستخدام معايير رقمية مثل نسبة الصواب accuracy والدقة precision والاستذكار Recall أو الحساسية sensitivity، فإذا كان أداء النموذج ضعيفًا تُعدل بعض الأشياء قبل إعادة التدريب مثل تحسين جودة بيانات التدريب بتقليل الضوضاء بالبيانات data noise أو تقليل التحيز وتحسين عملية وسم البيانات، وفي النهاية بعد إعادة التدريب وتحسين النموذج يصبح جاهزًا للتشغيل deployment ويمكنه التفاعل مع البيانات في العالم الحقيقي. وأخيرًا من المهم مراقبة أداء النموذج لكشف وتحديد أي مشكلات قد تتطلب تحديث النموذج أو إعادة تدريبه. تحديد أنواع وطرق وسم البيانات تَسبق عملية تحديد نوع البيانات مرحلةَ تصميم وبناء معمارية وسم البيانات، حيث توجد البيانات في تنسيقات وهياكل متنوعة تشمل النصوص والصور ومقاطع الفيديو والملفات الصوتية، وكل نوع من البيانات يأتي بمجموعة من التحديات المميزة التي تتطلب طريقة خاصة في التعامل معها لتحقيق تناسق ودقة في عملية وسم البيانات، بالإضافة لذلك فبعض البرمجيات المستخدمة في وسم البيانات تتضمن أدوات مصممة للتعامل مع أنواع معينة من البيانات، وكذلك تتخصص فرق الوسم في وسم نوع محدد من البيانات، لذلك يعتمد اختيار البرمجيات والفريق المناسب بشكلٍ كبير على المشروع. على سبيل المثال، قد تطلب عملية وسم بيانات للرؤية الحاسوبية computer vision تصنيف الصور الرقمية ومقاطع الفيديو وإنشاء مستطيلات التحديد bounding boxes لعنونة الكائنات الموجودة داخلها. وتحتوي مجموعة بيانات وايمو المفتوحة waymo's open dataset مثلًا على مجموعة بيانات موسومة لمهام الرؤية الحاسوبية computer vision للسيارات ذاتية القيادة، وقد وُسمت هذه البيانات بجهود مجموعة من الأفراد عبر الإنترنت مع مساهمات واسمين فرديين. ومن التطبيقات الأخرى للرؤية الحاسوبية computer vision التصوير الطبي، والاستطلاع الجوي، والمراقبة، والتأمين، والواقع المعزز augmented reality. ويمكن وسم النصوص ومعالجتها باستخدام خوارزميات معالجة اللغات الطبيعية Natural Language processing بمجموعة متنوعة من الطرق، تشمل تحليل المشاعر sentiment analysis من النصوص مثل المشاعر الإيجابية والسلبية، واستخلاص الكلمات المفتاحية مثل العبارات ذات الصلة، وكذلك التعرف على الكيانات الموجودة في النص مثل الأشخاص والأماكن والتواريخ، يمكن أيضًا تصنيف النصوص القصيرة. على سبيل المثال، يمكن تحديد فيما إذا كانت رسالة بريد إلكتروني رسالة مزعجة spam أم لا، ويمكن التعرف على لغة النص كالعربية أو الانجليزية، وتستخدم نماذج معالجة اللغات الطبيعية في تطبيقات مثل أنظمة المحادثة chatbots والمساعدات البرمجية coding assistants والمترجمات translators ومحركات البحث search engines. كما تستخدم البيانات الصوتية في تطبيقات متنوعة تشمل تصنيف الصوتيات، والتعرف على الصوت، والتعرف على الكلام، والتحليل الصوتي، ويمكن وسم الملفات الصوتية للتعرف على كلمات معينة مثل "يا سيري" أو "Hey Siri"، وحتى تصنيف أنواع مختلفة من الأصوات، أو تحويل الكلام المنطوق إلى كلمات مكتوبة. إن العديد من نماذج التعلم الآلي هي نماذج متعددة multimodal أي أنها نماذج قادرة على تفسير والتعامل مع البيانات من مصادر مختلفة بشكل متزامن، فيمكن للسيارات ذاتية القيادة جمع معلومات بصرية مثل إشارات المرور والمارين في الطريق وتجمع بيانات صوتية مثل صوت أبواق السيارات، مما يتطلب وسمًا متعددًا multimodal labeling حيث يقوم الواسمون البشريون بجمع ووسم أنواع مختلفة من البيانات بطريقة تراعي العلاقات والتفاعلات بين تلك الأنواع. من المهم اختيار الطريقة الأنسب لوسم البيانات قبل الشروع في بناء النظام الخاص بنا، وقد كان الوسم البشري للبيانات سابقًا هو الطريقة المتبعة، ولكن مع التقدم الهائل في التعلم الآلي ازدادت إمكانيات الأتمتة مما جعل العملية أكثر كفاءة وأقل تكلفةً، ولكن تجدر الإشارة أنه وعلى الرغم من تحسن دقة أدوات الوسم الآلية فإنها لاتزال غير قادرة على مواكبة الدقة والاعتمادية التي يوفرها البشر. لذا يلجأ المختصون عادة لأسلوب مختلط يتضمن مشاركة البشر والبرامج الآلية في عملية وسم البيانات، حيث تستخدم برامج آلية لتوليد الوسوم الأولية ثم تجري مراجعتها وتدقيقها وتصحيحها بواسطة الواسم البشري، وتضاف الوسوم المصححة إلى مجموعة بيانات التدريب لتحسين دقة وأداء البرنامج الآلي، وهذا يضمن الحفاظ على مستوى جيد من الدقة والتناسق وهو أكثر الاستراتيجيات شيوعًا في وسم البيانات. اختيار مكونات نظام وسم البيانات تبدأ عملية وسم البيانات بخطوة تجميع البيانات وتخزينها، حيث تجمع البيانات إما بشكل يدوي باستخدام أساليب مثل المقابلات الشخصية والاستبيانات واستطلاعات الرأي أو بشكل آلي مثل استخلاص البيانات من الإنترنت web scraping. في حال عدم امتلاكك للموارد الكافية لجمع البيانات على نطاق واسع فيمكن الاعتمدا على مجموعات البيانات مفتوحة المصدر المتوفرة على منصات مثل كاجل Kaggle أو مستودع مجموعات البيانات الخاص بجامعة كاليفورنيا ايفرين UCI repository أو بحث جوجل لمجموعات البيانات Google dataset search أو جت هاب GitHub فكلها مصادر جيدة، بالإضافة لمصادر البيانات المصنعة باستخدام نماذج رياضية لتحاكي البيئات الحقيقة، ولتخزين هذه البيانات يمكنك تأجير مساحات تخزينية من مزودي خدمات سحابية مثل جوجل أو مايكروسوفت حتى تتوسع حسب احتياجاتك، فبشكل نظري يمكنهم توفير مساحة تخزين غير محدودة مع توفير ميزات مدمجة تزيد من التأمين، ولكن إذا كنت تعمل مع بيانات شديدة السرية وتحتاج للامتثال لقوانين وأنظمة معينة مثل مثل قانون حماية البيانات العامة GDPR فحلول التخزين المحلية هي الخيار المناسب. يمكنك أن تبدأ في وسم البيانات فور أن تنتهي من تجميعها، وتعتمد عملية الوسم بشكل رئيسي على نوع البيانات، ولكن في العموم تحدد كل نقاط الاهتمام في البيانات وتصنف باستراتيجية إبقاء الإنسان مشاركًا في العملية، وتوجد العديد من المنصات المتاحة التي تبسط هذه العملية المعقدة، وبعضها مفتوح المصدر مثل Doccano و LabelStudio و CVAT ومنصات تجارية مثل scale data engine و labelbox و Supervisely. تُراجَع الوسوم بعد إنشائها بواسطة فريق ضمان الجودة لضمان الدقة والتناسق وحل أي تناقضات موجودة في الوسوم أو اختلافات في تقرير الوسم من خلال الطرق اليدوية مثل تقرير الأغلبية أو اللجوء للمعايير أو استشارة خبراء في هذا التخصص، ويمكن تخفيف التناقضات بطرق آلية مثل استخدام نماذج إحصائية مثل Dawid-Skene لجمع الوسوم المختلفة من عدة مصادر في وسم واحد معتمد أكثر، فور الاتفاق على الوسوم بواسطة ذوي الصلة تعد الحقائق مطلقة يمكن استخدامها لتدريب نماذج التعلم الآلي، بعد التأكد من أن الوسوم دقيقة ومتسقة، تصبح هذه الوسوم حقائق ثابتة يمكن استخدامها لتدريب نماذج تعلم الآلة. هنالك أيضًا أدوات مفتوحة المصدر وأخرى تجارية تساعدنا في مراجعة الوسوم والتحقق من الجودة وتدقيق البيانات، قد تكون الأدوات التجارية أكثر تطورًا وتوفر ميزات إضافية مثل التدقيق الآلي، ونظام إدارة المراجعات، والموافقة عليها أو رفضها وأدوات تعقب لمعايير الجودة. مقارنة بين أدوات وسم البيانات تُعد الأدوات مفتوحة المصدر نقطة بداية جيدة، فعلى الرغم من محدودية وظائفها وميزاتها مقارنة بالأدوات التجارية فإن غياب رسوم الترخيص يمثل ميزة مهمة للمشاريع الصغيرة، وتقدم الأدوات التجارية وسم أولي مدعوم بالذكاء الاصطناعي ويمكن تعويض هذه الميزة في الأدوات مفتوحة المصدر عن طريق دمجها مع نموذج تعلم آلي خارجي. الاسم أنواع البيانات المدعومة إدارة سير العمل تأكيد الجودة دعم التخزين السحابي ملاحظات إضافية استديو الوسم النسخة العامة Label Studio Community Edition نصوص، صور، صوتيات، مقاطع فيديو، بيانات زمنية نعم لا التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور تحتوي النسخة المجانية على مجموعة واسعة من الميزات، ولكن النسخة المدفوعة الخاصة بالشركات أكثر احترافية سي في أيه تي CVAT صور ومقاطع فيديو نعم نعم التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور يدعم LiDAR وهو نظام لقياس المسافات ووسم المجسمات المكعبة ثلاثية الأبعاد 3D Cuboid، بالإضافة إلى وسم الأوضاع المختلفة لهيكل مبسط من نقاط مفصلية في جسد الإنسان ويمكن استخدامه لتخمين وقفته أو حركته دوكانو Doccano نصوص وصور وملفات صوتية نعم لا التخزين السحابي لجوجل مصمم لوسم النصوص ڤيا VIA (VGG Image Annotator) صور وملفات صوتية ومقاطع فيديو لا لا لا يعتمد على المتصفح ميك سينس MakeSense.AI صور لا لا لا يعتمد على المتصفح توفر المنصات مفتوحة المصدر العديد من الميزات المطلوبة لمشاريع وسم البيانات ولكن المشاريع المعقدة لتعلم الآلة تتطلب ميزات متقدمة مثل الأتمتة والقابلية للتوسع وتتاح هذه الميزات الإضافية في المنصات التجارية، بالإضافة لمزايا تأمينية والدعم الفني ومزايا مٌسّاعدة في عملية الوسم باستخدام نماذج التعلم الآلي وشاشة التقارير والرسومات البيانية التحليلية كل هذه الميزات تجعل المنصات التجارية تستحق الزيادة في التكلفة. الاسم أنواع البيانات المدعومة إدارة سير العمل تأكيد الجودة دعم التخزين السحابي ملاحظات إضافية Lablbox نصوص، صور، مقاطع فيديو، ملفات صوتية، HTML نعم نعم التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور توفر المنصة فرقًا متخصصة في الوسم وفي المجالات المرتبطة بالبيانات من خلال خدمة Boost Supervisely صور، مقاطع فيديو، بيانات ثلاثية الأبعاد مجمعة من عدة مستشعرات 3D sensor fusion، الصور الطبية بصيغة DICOM نعم نعم التخزين السحابي لجوجل، التخزين السحابي لميكروسوفت أزور بيئة متكاملة مفتوحة للدمج مع مئات التطبيقات المبنية على محرك التطبيقات الخاص بهم، يدعم LiDAR و RADAR وهي أنظمة لقياس البعد واكتشاف الأجسام بالإضافة إلى الصور الطبية متعددة الشرائح أو المستويات Scale AI Data Engine النصوص، الصور، ملفات الصوت، مقاطع الفيديو، البيانات ثلاثية الأبعاد المجمعة من عدة مستشعرات 3D sensor fusion، الخرائط نعم نعم التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور يوفر أدوات متخصصة في قطاعات وصناعات محددة SuperAnnotate النصوص، الصور، الملفات الصوتية، مقاطع الفيديو، PDF ،HTML نعم نعم التخزين السحابي لجوجل، التخزين السحابي لميكروسوفت أزور يوفر فرق وسم متعددة اللغات وخبراء متخصصين في مجالات مختلفة وإذا كنا بحاجة لميزات خاصة لا تتوفر في الأدوات المتاحة فيمكننا في هذه الحالة بناء منصة وسم محلية نقرر من خلالها ما هي البيانات التي سندعمها وما هي تنسيقاتها ونحديد أنوع الوسوم المستخدمة، كما يمكننا تصميم وبناء ميزات مثل الوسم الأولي ومراجعة الوسوم وتأكيد الجودة وأدوات لإدارة سير العمل، ولكن تكلفة بناء وتشغيل منصة تضاهي المنصات التجارية تكلفة باهظة لأغلب الشركات. يعتمد الاختيار في النهاية على عدة عوامل، مثلًا إن لم تكن الأدوات المتاحة من خلال الأطراف الخارجية تناسب متطلبات المشروع أو إذا كانت البيانات سرية فحينها سيكون بناء منصة مخصصة محليًا هو الحل الأمثل، بينما يمكن لمشاريع أخرى أن تستفيد من نظام مختلط فالمهام الأساسية للوسم تُنفَّذ بواسطة الأدوات التجارية بينما الميزات المخصصة يمكن تطويرها محليًا ودمجها مع المنصات الخارجية. ضمان الجودة والأمان في أنظمة وسم البيانات يشمل نظام وسم البيانات العديد من المكونات التي تجعله معقدًا فهو يتعامل مع كميات هائلة من البيانات ومستويات مختلفة من البنية التحتية الحاسوبية وسياسات مختلفة وأنظمة سير عمل متعددة الطبقات والمستويات، كل هذا يجعل من عملية تشغيل هذه المكونات معًا بشكل سلسل مهمة مليئة بالتحديات وقد تؤثر على جودة وسم البيانات وفعاليته بالإضافة لمخاطر الأمان والخصوصية الموجودة في كل المراحل التي تمر بها العملية. تحسين دقة وسم البيانات تسرع الأتمتة من عملية الوسم ولكن الاعتماد المفرط على الأدوات المؤتمتة لوسم البيانات يمكن أن يقلل من دقة العملية التي تتطلب وعيًا بالسياق والمجال أو قدرة على الحكم الموضوعي وهذه قدرات لا يستطيع حاليًا أي نظامٍ برمجي تقديمها، لذا من المهم وضع توجيه لعملية الوسم بشكل بشري واكتشاف الاخطاء ومعالجتها لضمان جودة وسم البيانات. كما يمكن تقليل الأخطاء في عملية الوسم بتوفير مجموعة من التوجيهات والإرشادات الشاملة، فمثلًا ينبغي أن تعرف كل التصنيفات الممكنة والتنسيقات المتعامل معها، وينبغي أن تكون هذه الإرشادات مفصلة خطوة بخطوة وتتضمن حلولًا للحالات المتطرفة أو الخاصة، كما ينبغي أن تتوفر مجموعة من الأمثلة التي توضح كيفية التعامل مع نقاط الاهتمام الواضحة وغير الواضحة في البيانات. يمكننا أيضًا تجميع آراء عدد من الواسمين المستقلين عن نفس نقطة الاهتمام في البيانات ومقارنة نتائجهم فهذا من شأنه أن يؤدي إلى درجة أعلى من الدقة. فالاتفاق بين الواسمين Inter-annotator-agreement أو ما يعرف بمعيار IAA اختصارًا هو معيار مستخدم لقياس درجة الاتفاق هذه، أي أن نقطة الاهتمام في البيانات التي تحصل على أرقام منخفضة لهذا المعيار تتطلب عملية مراجعة لتقرير الوسم الأنسب لها. كما يساهم تتبع واكتشاف الأخطاء بشكل كبير في تحسين دقة الوسوم، وكشف الأخطاء وهذا يمكن أن ينفذ آليًا باستخدام برامج مثل كلين لاب Cleanlab حيث تجري مقارنة للبيانات الموسومة باستخدام القواعد المعرفة مسبقًا لإكتشاف أي أخطاء أو اختلافات، فبالنسبة للصور يمكن اكتشاف التداخل بين مستطيلات التحديد bounding boxes آليًا، بينما في النصوص يمكن اكتشاف الوسوم المفقودة أو التنسيقات الخاطئة، وتجري مراجعة جميع الأخطاء بعد ذلك من قبل فريق ضمان الجودة، كما يمكن الاستعانة بالذكاء الاصطناعي الذي توفره العديد من المنصات التجارية لاكتشاف الأخطاء التي تحدد الأخطاء المحتملة باستخدام نماذج تعلم آلي مدربة مسبقًا على بيانات موسومة، بعد تحديد ومراجعة نقاط الاهتمام في البيانات وتقرير الوسم الأصح يضاف لبيانات التدريب الخاصة بالنموذج لتحسين دقته من خلال عملية التعلم. يوفر تتبع الأخطاء تقييمًا في غاية الأهمية ويُحسّن عملية الوسم من خلال التعلم المستمر الذي يجري بتتبع عدة معايير مفتاحية مثل دقة الوسم ودرجة الإجماع بين الواسمين، فإن كان هناك مهام معينة تكثر فيها أخطاء الواسمين فينبغي تحديد الأسباب المؤدية لهذه الأخطاء، وتوفر العديد من المنصات التجارية أدوات مبنية بها تساعد على المراقبة والتقييم من خلال الرسومات البيانية التفاعلية التي توضح سجل الوسم وتوزيع الأخطاء، ويمكن تحسين الأداء بتعديل المعايير والإرشادات لتوضيح كيفية التعامل مع الإرشادات غير الواضحة وتحسين القواعد التي تساعد في اكتشاف الأخطاء. التعامل مع التحيز وضمان العدالة تعتمد عملية وسم البيانات بشكل مكثف على الحكم والتفسير الشخصي، مما يشكل تحديًا على الواسمين ليقومو بوسم البيانات بشكل عادل وغير متحيز حتى عندما تكون البيانات غير واضحة، فمثلًا عند تصنيف النصوص يمكن أن تكون بعض العبارات والمشاعر مزاحًا أو سخرية ومن السهل أن يساء فهمها، ومثالٌ آخر في تصنيف تعابير الوجه التي يمكن أن يصنفها البعض على أنه وجه حزين والبعض الآخر يراه وجه يشعر بالملل، لذا فنسبية التصنيف أو الوسم تفتح الباب أمام التحيز أو الخطأ، ويمكن أن تكون مجموعة البيانات نفسها منحازة اعتمادًا على المصدر أو التركيب السكاني أو وجهة نظر جامعها ويمكن أن تكون غير ممثلة للمجتمع، وتدريب نماذج التعلم الآلي على بيانات منحازة يمكن أن يؤدي إلى توقعات خاطئة مثل تشخيص خاطئ للمرض بسبب تحيز البيانات الطبية المستخدمة للتدريب. لتقليل التحيز في عملية الوسم ينبغي أن يكون فريق الواسمين وفريق تأكيد الجودة من خلفيات متنوعة، فالوسم المزدوج والمتعدد يمكن أن يقلل من تأثير التحيز الناتج عن الأفراد، وعلى البيانات المستخدمة في التدريب أن تعكس العالم الحقيقي بتمثيل متوازن للتركيبة السكانية والجغرافية ويمكن جمع البيانات من مصادر واسعة التنوع وإضافة بيانات مخصوصة لمواجهة أي تحيز موجود في المصادر الأولية للبيانات، بالإضافة لذلك يمكنها أن تقلل طرق تعزيز وزيادة البيانات data augmentation مثل قلب الصور وإعادة صياغة النصوص من التحيز وتزيد تنوع البيانات بشكل مصطنع، فقلب الصورة مثلًا يُمكّن النموذج من تعلم التعرف على الكائنات بالصورة بغض النظر عن زاوية العرض مما يقلل التحيز لزاوية دوران الصورة، وإعادة صياغة النصوص تعرض النموذج لطرق أخرى للتعبير عن المعلومات مما يقلل التحيز تجاه صياغة أو كلمات معينة. كما يمكن أن تقلل الرقابة الخارجية من التحيز الموجود في عملية الوسم، وذلك من خلال دعوة فريق خارجي من المختصين بالمجال وعلماء البيانات وخبراء تعلم الآلة لتقييم سير العمل والإشراف على مراجعة وسم البيانات، وتقديم النصائح والاقتراحات التي تساعد على تحسين عملية الوسم وتقليل التحيز. خصوصية وأمان البيانات تتضمن مشروعات وسم البيانات في الغالب بيانات سرية أو خاصة لذا ينبغي أن تحتوي جميع المنصات على ميزات تضمن السرية والأمان للبيانات مثل التشفير والمصادقة المتعددة للتحكم بوصول المستخدمين. فمن أجل حماية خصوصية البيانات ينبغي أن يتم حذف البيانات الشخصية أو جعلها مجهولة الهوية، بالإضافة لذلك ينبغي تدريب كل فرد في فريق الوسم على أفضل ممارسات تأمين البيانات مثل استخدام كلمات مرور قوية وتفادي مشاركة البيانات غير المقصود. كما ينبغي أن تخضع منصات وسم البيانات للقوانين واللوائح المنظمة والتي تشمل اللائحة الشاملة لحماية البيانات GDPR وقانون كاليفورنيا لخصوصية المستخدم CCPA بالإضافة إلى قانون نقل التأمين الصحي والمساءلة HIPAA، وإخضاع المنصات التجارية للمراجعة والإشراف الخارجي والالتزام بمبادئ الثقة الخمسة وهي: الأمان والإتاحة والشفافية والموثوقية والخصوصية. مستقبل نظام وسم البيانات تحدث عملية وسم البيانات في الكواليس بالنسبة للمستخدم النهائي ولكنها ذات دور محوري في تطوير نماذج التعلم الآلي وأنظمة الذكاء الاصطناعي لذلك ينبغي أن يكون نظام الوسم قابلًا للتوسع ليواكب أي تغير في المتطلبات. تُحدَّث منصات الوسم التجارية ومفتوحة المصدر بانتظام لدعم الاحتياجات النامية لوسم البيانات، لذلك ينبغي على أنظمة الوسم المطورة محليًا أن تبني بطريقة تجعل تحديثها أمرًا سلسًا، فالتصميم المعتمد على الوحدات والمكونات القابلة للتبديل بدون التأثير على باقي النظام تٌسهّل عملية التحديث والتطوير، على سبيل المثال يمكن لتوفر ميزة دمج أنظمة وسم البيانات مع مكتبات وأطر عمل مفتوحة المصدر أن تضيف نوعًا من التكييف والتأقلم، حيث يمكن تحديثها وتطويرها باستمرار مع تطور المجال. كما توفر الحلول المبنية على خدمات الحوسبة السحابية ميزة ملحوظة للمشاريع الضخمة في وسم البيانات والتي لا يمكن أن توفرها الأنظمة المُدارة ذاتيًا، فالمنصات السحابية قابلة للتوسع آليًا في تخزينها وفي قدراتها الحاسوبية مما يقلل من الحاجة للتطويرات المكلفة في البنية التحتية. وينبغي أيضًا توسيع قدرة فريق العمل المسؤول عن وسم البيانات مع نمو حجم مجموعات البيانات، وتدريب الواسمين الجدد بسرعة على وسم البيانات بدقة وبفعالية. والتمتع بالمرونة في سد الاحتياجات في قوة العمل باستخدام خدمات الوسم المُدارة أو التعاون مع واسمين مستقلين، وينبغي أن تكون عملية التدريب والضم للفريق قابلة للتوسع في المكان واللغة وأوقات العمل. الخلاصة تعرفنا في مقال اليوم على أسس وسم البيانات لنماذج تعلم الآلة ووجدنا أن المفتاح الرئيسي لتحسين أداء ودقة نموذج التعلم الآلي هو جودة البيانات الموسومة التي ندرب النموذج عليها، وتوفير الأنظمة المختلطة التي تجمع بين البشر والأدوات المؤتمتة في وسم البيانات لتتيح للذكاء الاصطناعي تحسين الطريقة التي يعمل بها والحصول على نتائج أكثر كفاءة وفعالية. ترجمة وبتصرف لمقال Architecting Effective Data Labeling Systems for Machine Learning Pipelines لكاتبه Reza Fazeli اقرأ أيضًا معالجة الصور باستخدام لغة بايثون Python استكشف مصطلحات الذكاء الاصطناعي التوليدي تعرف على أفضل أطر عمل الذكاء الاصطناعي لمشاريع تعلم الآلة أفضل ممارسات هندسة المُوجِّهات Prompt Engineering: نصائح وحيل وأدوات
تتدرب نماذج التعلم الآلي على مجموعات من البيانات الضخمة حيث توسم نقاط الاهتمام في البيانات -أي الأجزاء المهمة في التي نريد التركيز عليها والتعلم منها- لإعطائها معنى وسياق. نتعمق في هذه المقالة في وصف طرق بناء أنظمة وسم البيانات data labeling من الصفر مركزين على تدفق البيانات في النظام وكيفية تأمينها وضمان جودتها. ما معنى وسم البيانات ينتج الذكاء المتأصل في الذكاء الاصطناعي من تعرضه لكميات من البيانات التي تتدرب عليها نماذج تعلم الآلة، ومع التقدم الحالي في النماذج اللغوية الضخمة مثل GPT-4 وجيمناي Gemini التي يمكنها معالجة تريليونات الوحدات اللغوية الصغيرة التي تسمى tokens، ولا تتكون هذه البيانات المستخدمة في التدريب من معلومات أولية مستخلصة من الإنترنت فقط فهي تتضمن أيضًا وسومًا حتى يكون التدريب فعالًا. وسم البيانات data labeling هو عملية تحويل البيانات الأولية والمعلومات غير المعالجة إلى بيانات موسومة أو بيانات معنونة لإضافة سياق ومعنى واضح لها، وتحسّن هذه العملية من دقة تدريب النموذج، فأنت توضح وتشير إلى ما ترغب للنظام أن يتعرف عليه، وتتضمن الأمثلة على وسم البيانات مهام مثل تحليل المشاعر في النصوص حيث توسم النصوص في هذه الحالة بمشاعر معينة مثل إيجابي أو سلبي أو محايد، ومهام التعرف على الكائنات في الصور إذ يوسم كل كائن في الصورة بتصنيف معين. وكذلك تستخدم في تنصيص الكلام المنطوق في الملفات الصوتية، أو وسم الأفعال في مشاهد الفيديو. تلعب جودة البيانات دورًا هائلًا في تدريب البيانات، فالمدخلات الرديئة تؤدي إلى مخرجات رديئة فلا يمكننا توقع أداء مبهر من نموذج لم يُدرّب إلا على بيانات رديئة الجودة، فالنماذج التي تتدرب على بيانات بها أخطاء وتناقض في الوسوم ستواجه صعوبة في محاولة التأقلم مع البيانات الجديدة التي لم تراها في التدريب وربما تكون متحيزة في توقعاتها مسببة أخطاء في المخرجات، ويمكن أن يؤدي تراكم البيانات الرديئة في المراحل المختلفة إلى تأثير مركب مما يؤثر على كل الخطوات والنماذج التي تعتمد عليها. يهدف هذا المقال لتوضيح طرق تعزيز جودة البيانات واكتساب أفضلية تنافسية في كافة مراحل وسم البيانات. وللسهولة سنركز على المنصات والأدوات التي تستخدم في عملية وسم البيانات ونقارن بين مميزات ومحدوديات كل تقنية وأداة، وبعد ذلك ننتقل إلى اعتبارات أخرى لا تقل أهمية مثل تقليل التحيز، وحماية الخصوصية، وزيادة دقة وسم البيانات. دور وسم البيانات في سير عمل تطبيقات تعلم الآلة يقسم تدريب نماذج تعلم الآلة إلى ثلاثة تصنيفات عامة وهي التعلم الخاضع للإشراف Supervised learning والتعلم غير الخاضع لإشراف Unsupervised learning والتعلم المعزز Reinforcement learning. يعتمد التعلم الخاضع للإشراف على البيانات الموسومة labeled training data، والتي تحتوي نقاط الاهتمام في البيانات بها على وسوم بالتوقع أو العنوان الصحيح، فيتعلم النموذج أن يربط بين خواص المدخلات والوسوم أو التسميات الصحيحة المرتبطة بها مما يعطيه القدرة على تخمين وسوم البيانات الجديدة التي لم يتدرب عليها من قبل ولا يعرف ما وسمها الحقيقي، من جهة أخرى يحلل التعلم غير الخاضع للإشراف البيانات غير الموسومة بحثًا عن الأنماط المخفية أو التجميعات الموجودة في البيانات، وأما في التعلم المعزز فتكون عملية التدريب بالتجربة والخطأ ويمكننا التدخل في مرحلة التقييم والمراجعة لتوجيه عملية التعلم. تُدرّب معظم نماذج التعلم الآلي باستخدام أسلوب التعلم الخاضع للإشراف supervised learning. ونظرًا لأهمية البيانات عالية الجودة فينبغي اعتبارها في كل خطوة من عملية التدريب لذلك يلعب وسم البيانات دورًا حيويًا في هذه العملية. إن تحضير وجمع البيانات هي العملية التي تسبق وسم البيانات، حيث تُجمع البيانات الأولية أو الخام من مصادر متنوعة مثل المستشعرات الإلكترونية sensors، وقواعد البيانات، وسجلات العمليات logs، وواجهات برمجة التطبيقات APIs، وفي الغالب لا تخضع هذه البيانات لهيكل أو تنسيق ثابت وقد تحتوي على تناقضات وشوائب مثل قيم مفقودة أو قيم شاذة outliers أي قيما غير مألوفة وتختلف بشكل كبير عن باقي البيانات، أو قيم متكررة، لذا في عملية المعالجة تُنظّف البيانات وتُنسَّق وتُحوّل لتكون جاهزة لوسمها labeling، وتستخدم استراتيجيات عديدة للتعامل مع معالجة البيانات مثل حذف الصفوف المكررة، أو حذف الصفوف التي تحتوي على قيم مفقودة أو التعويض عن هذه القيم باستخدام نماذج تخمين إحصائية، كما يمكننا إحصائيًا اكتشاف القيم الشاذة outliers ومعالجتها. تلي معالجة البيانات في الخطوات عملية وسم البيانات لتوفير المعلومات التي يحتاجها نموذج التعلم الآلي كي يتعلم، وتختلف استراتيجيات وسم البيانات باختلاف نوع هذه البيانات والغرض من النموذج، فوسم الصور يتطلب أساليب مختلفة عن وسم النصوص، وعلى الرغم من وجود أدوات وسم آلية ولكن التدخل البشري يحسن بشكل كبير من عملية الوسم خاصة عندما يتعلق الأمر بالدقة أو تفادي التحيز الذي قد يوجد في الأدوات الآلية، وبعد أن توسم البيانات تاتي مرحلة تأكيد الجودة والتي تضمن الدقة والتناسق واكتمال الوسوم، ويعمل فريق تأكيد الجودة على توظيف أسلوب الوسم المزدوج إذ يقوم أكثر من شخص بوسم عينة من البيانات بشكل مستقل ويقارنون نتائجهم لحل أي اختلاف في الآراء. الخطوة التالية هي خضوع النموذج للتدريب باستخدام البيانات الموسومة ليتعلم الأنماط والعلاقات بين المدخلات والوسوم المرتبطة بها، حيث تعدل معاملات النموذج في عملية تكرارية من التخمين وتقييم الخطأ حتى تتحسن الدقة بالنسبة للوسوم المعلومة، ولتقييم فعالية النموذج يختبر على بيانات موسومة لم يرها من قبل، وتقاس صحة تخميناته وتوقعاته باستخدام معايير رقمية مثل نسبة الصواب accuracy والدقة precision والاستذكار Recall أو الحساسية sensitivity، فإذا كان أداء النموذج ضعيفًا تُعدل بعض الأشياء قبل إعادة التدريب مثل تحسين جودة بيانات التدريب بتقليل الضوضاء بالبيانات data noise أو تقليل التحيز وتحسين عملية وسم البيانات، وفي النهاية بعد إعادة التدريب وتحسين النموذج يصبح جاهزًا للتشغيل deployment ويمكنه التفاعل مع البيانات في العالم الحقيقي. وأخيرًا من المهم مراقبة أداء النموذج لكشف وتحديد أي مشكلات قد تتطلب تحديث النموذج أو إعادة تدريبه. تحديد أنواع وطرق وسم البيانات تَسبق عملية تحديد نوع البيانات مرحلةَ تصميم وبناء معمارية وسم البيانات، حيث توجد البيانات في تنسيقات وهياكل متنوعة تشمل النصوص والصور ومقاطع الفيديو والملفات الصوتية، وكل نوع من البيانات يأتي بمجموعة من التحديات المميزة التي تتطلب طريقة خاصة في التعامل معها لتحقيق تناسق ودقة في عملية وسم البيانات، بالإضافة لذلك فبعض البرمجيات المستخدمة في وسم البيانات تتضمن أدوات مصممة للتعامل مع أنواع معينة من البيانات، وكذلك تتخصص فرق الوسم في وسم نوع محدد من البيانات، لذلك يعتمد اختيار البرمجيات والفريق المناسب بشكلٍ كبير على المشروع. على سبيل المثال، قد تطلب عملية وسم بيانات للرؤية الحاسوبية computer vision تصنيف الصور الرقمية ومقاطع الفيديو وإنشاء مستطيلات التحديد bounding boxes لعنونة الكائنات الموجودة داخلها. وتحتوي مجموعة بيانات وايمو المفتوحة waymo's open dataset مثلًا على مجموعة بيانات موسومة لمهام الرؤية الحاسوبية computer vision للسيارات ذاتية القيادة، وقد وُسمت هذه البيانات بجهود مجموعة من الأفراد عبر الإنترنت مع مساهمات واسمين فرديين. ومن التطبيقات الأخرى للرؤية الحاسوبية computer vision التصوير الطبي، والاستطلاع الجوي، والمراقبة، والتأمين، والواقع المعزز augmented reality. ويمكن وسم النصوص ومعالجتها باستخدام خوارزميات معالجة اللغات الطبيعية Natural Language processing بمجموعة متنوعة من الطرق، تشمل تحليل المشاعر sentiment analysis من النصوص مثل المشاعر الإيجابية والسلبية، واستخلاص الكلمات المفتاحية مثل العبارات ذات الصلة، وكذلك التعرف على الكيانات الموجودة في النص مثل الأشخاص والأماكن والتواريخ، يمكن أيضًا تصنيف النصوص القصيرة. على سبيل المثال، يمكن تحديد فيما إذا كانت رسالة بريد إلكتروني رسالة مزعجة spam أم لا، ويمكن التعرف على لغة النص كالعربية أو الانجليزية، وتستخدم نماذج معالجة اللغات الطبيعية في تطبيقات مثل أنظمة المحادثة chatbots والمساعدات البرمجية coding assistants والمترجمات translators ومحركات البحث search engines. كما تستخدم البيانات الصوتية في تطبيقات متنوعة تشمل تصنيف الصوتيات، والتعرف على الصوت، والتعرف على الكلام، والتحليل الصوتي، ويمكن وسم الملفات الصوتية للتعرف على كلمات معينة مثل "يا سيري" أو "Hey Siri"، وحتى تصنيف أنواع مختلفة من الأصوات، أو تحويل الكلام المنطوق إلى كلمات مكتوبة. إن العديد من نماذج التعلم الآلي هي نماذج متعددة multimodal أي أنها نماذج قادرة على تفسير والتعامل مع البيانات من مصادر مختلفة بشكل متزامن، فيمكن للسيارات ذاتية القيادة جمع معلومات بصرية مثل إشارات المرور والمارين في الطريق وتجمع بيانات صوتية مثل صوت أبواق السيارات، مما يتطلب وسمًا متعددًا multimodal labeling حيث يقوم الواسمون البشريون بجمع ووسم أنواع مختلفة من البيانات بطريقة تراعي العلاقات والتفاعلات بين تلك الأنواع. من المهم اختيار الطريقة الأنسب لوسم البيانات قبل الشروع في بناء النظام الخاص بنا، وقد كان الوسم البشري للبيانات سابقًا هو الطريقة المتبعة، ولكن مع التقدم الهائل في التعلم الآلي ازدادت إمكانيات الأتمتة مما جعل العملية أكثر كفاءة وأقل تكلفةً، ولكن تجدر الإشارة أنه وعلى الرغم من تحسن دقة أدوات الوسم الآلية فإنها لاتزال غير قادرة على مواكبة الدقة والاعتمادية التي يوفرها البشر. لذا يلجأ المختصون عادة لأسلوب مختلط يتضمن مشاركة البشر والبرامج الآلية في عملية وسم البيانات، حيث تستخدم برامج آلية لتوليد الوسوم الأولية ثم تجري مراجعتها وتدقيقها وتصحيحها بواسطة الواسم البشري، وتضاف الوسوم المصححة إلى مجموعة بيانات التدريب لتحسين دقة وأداء البرنامج الآلي، وهذا يضمن الحفاظ على مستوى جيد من الدقة والتناسق وهو أكثر الاستراتيجيات شيوعًا في وسم البيانات. اختيار مكونات نظام وسم البيانات تبدأ عملية وسم البيانات بخطوة تجميع البيانات وتخزينها، حيث تجمع البيانات إما بشكل يدوي باستخدام أساليب مثل المقابلات الشخصية والاستبيانات واستطلاعات الرأي أو بشكل آلي مثل استخلاص البيانات من الإنترنت web scraping. في حال عدم امتلاكك للموارد الكافية لجمع البيانات على نطاق واسع فيمكن الاعتمدا على مجموعات البيانات مفتوحة المصدر المتوفرة على منصات مثل كاجل Kaggle أو مستودع مجموعات البيانات الخاص بجامعة كاليفورنيا ايفرين UCI repository أو بحث جوجل لمجموعات البيانات Google dataset search أو جت هاب GitHub فكلها مصادر جيدة، بالإضافة لمصادر البيانات المصنعة باستخدام نماذج رياضية لتحاكي البيئات الحقيقة، ولتخزين هذه البيانات يمكنك تأجير مساحات تخزينية من مزودي خدمات سحابية مثل جوجل أو مايكروسوفت حتى تتوسع حسب احتياجاتك، فبشكل نظري يمكنهم توفير مساحة تخزين غير محدودة مع توفير ميزات مدمجة تزيد من التأمين، ولكن إذا كنت تعمل مع بيانات شديدة السرية وتحتاج للامتثال لقوانين وأنظمة معينة مثل مثل قانون حماية البيانات العامة GDPR فحلول التخزين المحلية هي الخيار المناسب. يمكنك أن تبدأ في وسم البيانات فور أن تنتهي من تجميعها، وتعتمد عملية الوسم بشكل رئيسي على نوع البيانات، ولكن في العموم تحدد كل نقاط الاهتمام في البيانات وتصنف باستراتيجية إبقاء الإنسان مشاركًا في العملية، وتوجد العديد من المنصات المتاحة التي تبسط هذه العملية المعقدة، وبعضها مفتوح المصدر مثل Doccano و LabelStudio و CVAT ومنصات تجارية مثل scale data engine و labelbox و Supervisely. تُراجَع الوسوم بعد إنشائها بواسطة فريق ضمان الجودة لضمان الدقة والتناسق وحل أي تناقضات موجودة في الوسوم أو اختلافات في تقرير الوسم من خلال الطرق اليدوية مثل تقرير الأغلبية أو اللجوء للمعايير أو استشارة خبراء في هذا التخصص، ويمكن تخفيف التناقضات بطرق آلية مثل استخدام نماذج إحصائية مثل Dawid-Skene لجمع الوسوم المختلفة من عدة مصادر في وسم واحد معتمد أكثر، فور الاتفاق على الوسوم بواسطة ذوي الصلة تعد الحقائق مطلقة يمكن استخدامها لتدريب نماذج التعلم الآلي، بعد التأكد من أن الوسوم دقيقة ومتسقة، تصبح هذه الوسوم حقائق ثابتة يمكن استخدامها لتدريب نماذج تعلم الآلة. هنالك أيضًا أدوات مفتوحة المصدر وأخرى تجارية تساعدنا في مراجعة الوسوم والتحقق من الجودة وتدقيق البيانات، قد تكون الأدوات التجارية أكثر تطورًا وتوفر ميزات إضافية مثل التدقيق الآلي، ونظام إدارة المراجعات، والموافقة عليها أو رفضها وأدوات تعقب لمعايير الجودة. مقارنة بين أدوات وسم البيانات تُعد الأدوات مفتوحة المصدر نقطة بداية جيدة، فعلى الرغم من محدودية وظائفها وميزاتها مقارنة بالأدوات التجارية فإن غياب رسوم الترخيص يمثل ميزة مهمة للمشاريع الصغيرة، وتقدم الأدوات التجارية وسم أولي مدعوم بالذكاء الاصطناعي ويمكن تعويض هذه الميزة في الأدوات مفتوحة المصدر عن طريق دمجها مع نموذج تعلم آلي خارجي. الاسم أنواع البيانات المدعومة إدارة سير العمل تأكيد الجودة دعم التخزين السحابي ملاحظات إضافية استديو الوسم النسخة العامة Label Studio Community Edition نصوص، صور، صوتيات، مقاطع فيديو، بيانات زمنية نعم لا التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور تحتوي النسخة المجانية على مجموعة واسعة من الميزات، ولكن النسخة المدفوعة الخاصة بالشركات أكثر احترافية سي في أيه تي CVAT صور ومقاطع فيديو نعم نعم التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور يدعم LiDAR وهو نظام لقياس المسافات ووسم المجسمات المكعبة ثلاثية الأبعاد 3D Cuboid، بالإضافة إلى وسم الأوضاع المختلفة لهيكل مبسط من نقاط مفصلية في جسد الإنسان ويمكن استخدامه لتخمين وقفته أو حركته دوكانو Doccano نصوص وصور وملفات صوتية نعم لا التخزين السحابي لجوجل مصمم لوسم النصوص ڤيا VIA (VGG Image Annotator) صور وملفات صوتية ومقاطع فيديو لا لا لا يعتمد على المتصفح ميك سينس MakeSense.AI صور لا لا لا يعتمد على المتصفح توفر المنصات مفتوحة المصدر العديد من الميزات المطلوبة لمشاريع وسم البيانات ولكن المشاريع المعقدة لتعلم الآلة تتطلب ميزات متقدمة مثل الأتمتة والقابلية للتوسع وتتاح هذه الميزات الإضافية في المنصات التجارية، بالإضافة لمزايا تأمينية والدعم الفني ومزايا مٌسّاعدة في عملية الوسم باستخدام نماذج التعلم الآلي وشاشة التقارير والرسومات البيانية التحليلية كل هذه الميزات تجعل المنصات التجارية تستحق الزيادة في التكلفة. الاسم أنواع البيانات المدعومة إدارة سير العمل تأكيد الجودة دعم التخزين السحابي ملاحظات إضافية Lablbox نصوص، صور، مقاطع فيديو، ملفات صوتية، HTML نعم نعم التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور توفر المنصة فرقًا متخصصة في الوسم وفي المجالات المرتبطة بالبيانات من خلال خدمة Boost Supervisely صور، مقاطع فيديو، بيانات ثلاثية الأبعاد مجمعة من عدة مستشعرات 3D sensor fusion، الصور الطبية بصيغة DICOM نعم نعم التخزين السحابي لجوجل، التخزين السحابي لميكروسوفت أزور بيئة متكاملة مفتوحة للدمج مع مئات التطبيقات المبنية على محرك التطبيقات الخاص بهم، يدعم LiDAR و RADAR وهي أنظمة لقياس البعد واكتشاف الأجسام بالإضافة إلى الصور الطبية متعددة الشرائح أو المستويات Scale AI Data Engine النصوص، الصور، ملفات الصوت، مقاطع الفيديو، البيانات ثلاثية الأبعاد المجمعة من عدة مستشعرات 3D sensor fusion، الخرائط نعم نعم التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور يوفر أدوات متخصصة في قطاعات وصناعات محددة SuperAnnotate النصوص، الصور، الملفات الصوتية، مقاطع الفيديو، PDF ،HTML نعم نعم التخزين السحابي لجوجل، التخزين السحابي لميكروسوفت أزور يوفر فرق وسم متعددة اللغات وخبراء متخصصين في مجالات مختلفة وإذا كنا بحاجة لميزات خاصة لا تتوفر في الأدوات المتاحة فيمكننا في هذه الحالة بناء منصة وسم محلية نقرر من خلالها ما هي البيانات التي سندعمها وما هي تنسيقاتها ونحديد أنوع الوسوم المستخدمة، كما يمكننا تصميم وبناء ميزات مثل الوسم الأولي ومراجعة الوسوم وتأكيد الجودة وأدوات لإدارة سير العمل، ولكن تكلفة بناء وتشغيل منصة تضاهي المنصات التجارية تكلفة باهظة لأغلب الشركات. يعتمد الاختيار في النهاية على عدة عوامل، مثلًا إن لم تكن الأدوات المتاحة من خلال الأطراف الخارجية تناسب متطلبات المشروع أو إذا كانت البيانات سرية فحينها سيكون بناء منصة مخصصة محليًا هو الحل الأمثل، بينما يمكن لمشاريع أخرى أن تستفيد من نظام مختلط فالمهام الأساسية للوسم تُنفَّذ بواسطة الأدوات التجارية بينما الميزات المخصصة يمكن تطويرها محليًا ودمجها مع المنصات الخارجية. ضمان الجودة والأمان في أنظمة وسم البيانات يشمل نظام وسم البيانات العديد من المكونات التي تجعله معقدًا فهو يتعامل مع كميات هائلة من البيانات ومستويات مختلفة من البنية التحتية الحاسوبية وسياسات مختلفة وأنظمة سير عمل متعددة الطبقات والمستويات، كل هذا يجعل من عملية تشغيل هذه المكونات معًا بشكل سلسل مهمة مليئة بالتحديات وقد تؤثر على جودة وسم البيانات وفعاليته بالإضافة لمخاطر الأمان والخصوصية الموجودة في كل المراحل التي تمر بها العملية. تحسين دقة وسم البيانات تسرع الأتمتة من عملية الوسم ولكن الاعتماد المفرط على الأدوات المؤتمتة لوسم البيانات يمكن أن يقلل من دقة العملية التي تتطلب وعيًا بالسياق والمجال أو قدرة على الحكم الموضوعي وهذه قدرات لا يستطيع حاليًا أي نظامٍ برمجي تقديمها، لذا من المهم وضع توجيه لعملية الوسم بشكل بشري واكتشاف الاخطاء ومعالجتها لضمان جودة وسم البيانات. كما يمكن تقليل الأخطاء في عملية الوسم بتوفير مجموعة من التوجيهات والإرشادات الشاملة، فمثلًا ينبغي أن تعرف كل التصنيفات الممكنة والتنسيقات المتعامل معها، وينبغي أن تكون هذه الإرشادات مفصلة خطوة بخطوة وتتضمن حلولًا للحالات المتطرفة أو الخاصة، كما ينبغي أن تتوفر مجموعة من الأمثلة التي توضح كيفية التعامل مع نقاط الاهتمام الواضحة وغير الواضحة في البيانات. يمكننا أيضًا تجميع آراء عدد من الواسمين المستقلين عن نفس نقطة الاهتمام في البيانات ومقارنة نتائجهم فهذا من شأنه أن يؤدي إلى درجة أعلى من الدقة. فالاتفاق بين الواسمين Inter-annotator-agreement أو ما يعرف بمعيار IAA اختصارًا هو معيار مستخدم لقياس درجة الاتفاق هذه، أي أن نقطة الاهتمام في البيانات التي تحصل على أرقام منخفضة لهذا المعيار تتطلب عملية مراجعة لتقرير الوسم الأنسب لها. كما يساهم تتبع واكتشاف الأخطاء بشكل كبير في تحسين دقة الوسوم، وكشف الأخطاء وهذا يمكن أن ينفذ آليًا باستخدام برامج مثل كلين لاب Cleanlab حيث تجري مقارنة للبيانات الموسومة باستخدام القواعد المعرفة مسبقًا لإكتشاف أي أخطاء أو اختلافات، فبالنسبة للصور يمكن اكتشاف التداخل بين مستطيلات التحديد bounding boxes آليًا، بينما في النصوص يمكن اكتشاف الوسوم المفقودة أو التنسيقات الخاطئة، وتجري مراجعة جميع الأخطاء بعد ذلك من قبل فريق ضمان الجودة، كما يمكن الاستعانة بالذكاء الاصطناعي الذي توفره العديد من المنصات التجارية لاكتشاف الأخطاء التي تحدد الأخطاء المحتملة باستخدام نماذج تعلم آلي مدربة مسبقًا على بيانات موسومة، بعد تحديد ومراجعة نقاط الاهتمام في البيانات وتقرير الوسم الأصح يضاف لبيانات التدريب الخاصة بالنموذج لتحسين دقته من خلال عملية التعلم. يوفر تتبع الأخطاء تقييمًا في غاية الأهمية ويُحسّن عملية الوسم من خلال التعلم المستمر الذي يجري بتتبع عدة معايير مفتاحية مثل دقة الوسم ودرجة الإجماع بين الواسمين، فإن كان هناك مهام معينة تكثر فيها أخطاء الواسمين فينبغي تحديد الأسباب المؤدية لهذه الأخطاء، وتوفر العديد من المنصات التجارية أدوات مبنية بها تساعد على المراقبة والتقييم من خلال الرسومات البيانية التفاعلية التي توضح سجل الوسم وتوزيع الأخطاء، ويمكن تحسين الأداء بتعديل المعايير والإرشادات لتوضيح كيفية التعامل مع الإرشادات غير الواضحة وتحسين القواعد التي تساعد في اكتشاف الأخطاء. التعامل مع التحيز وضمان العدالة تعتمد عملية وسم البيانات بشكل مكثف على الحكم والتفسير الشخصي، مما يشكل تحديًا على الواسمين ليقومو بوسم البيانات بشكل عادل وغير متحيز حتى عندما تكون البيانات غير واضحة، فمثلًا عند تصنيف النصوص يمكن أن تكون بعض العبارات والمشاعر مزاحًا أو سخرية ومن السهل أن يساء فهمها، ومثالٌ آخر في تصنيف تعابير الوجه التي يمكن أن يصنفها البعض على أنه وجه حزين والبعض الآخر يراه وجه يشعر بالملل، لذا فنسبية التصنيف أو الوسم تفتح الباب أمام التحيز أو الخطأ، ويمكن أن تكون مجموعة البيانات نفسها منحازة اعتمادًا على المصدر أو التركيب السكاني أو وجهة نظر جامعها ويمكن أن تكون غير ممثلة للمجتمع، وتدريب نماذج التعلم الآلي على بيانات منحازة يمكن أن يؤدي إلى توقعات خاطئة مثل تشخيص خاطئ للمرض بسبب تحيز البيانات الطبية المستخدمة للتدريب. لتقليل التحيز في عملية الوسم ينبغي أن يكون فريق الواسمين وفريق تأكيد الجودة من خلفيات متنوعة، فالوسم المزدوج والمتعدد يمكن أن يقلل من تأثير التحيز الناتج عن الأفراد، وعلى البيانات المستخدمة في التدريب أن تعكس العالم الحقيقي بتمثيل متوازن للتركيبة السكانية والجغرافية ويمكن جمع البيانات من مصادر واسعة التنوع وإضافة بيانات مخصوصة لمواجهة أي تحيز موجود في المصادر الأولية للبيانات، بالإضافة لذلك يمكنها أن تقلل طرق تعزيز وزيادة البيانات data augmentation مثل قلب الصور وإعادة صياغة النصوص من التحيز وتزيد تنوع البيانات بشكل مصطنع، فقلب الصورة مثلًا يُمكّن النموذج من تعلم التعرف على الكائنات بالصورة بغض النظر عن زاوية العرض مما يقلل التحيز لزاوية دوران الصورة، وإعادة صياغة النصوص تعرض النموذج لطرق أخرى للتعبير عن المعلومات مما يقلل التحيز تجاه صياغة أو كلمات معينة. كما يمكن أن تقلل الرقابة الخارجية من التحيز الموجود في عملية الوسم، وذلك من خلال دعوة فريق خارجي من المختصين بالمجال وعلماء البيانات وخبراء تعلم الآلة لتقييم سير العمل والإشراف على مراجعة وسم البيانات، وتقديم النصائح والاقتراحات التي تساعد على تحسين عملية الوسم وتقليل التحيز. خصوصية وأمان البيانات تتضمن مشروعات وسم البيانات في الغالب بيانات سرية أو خاصة لذا ينبغي أن تحتوي جميع المنصات على ميزات تضمن السرية والأمان للبيانات مثل التشفير والمصادقة المتعددة للتحكم بوصول المستخدمين. فمن أجل حماية خصوصية البيانات ينبغي أن يتم حذف البيانات الشخصية أو جعلها مجهولة الهوية، بالإضافة لذلك ينبغي تدريب كل فرد في فريق الوسم على أفضل ممارسات تأمين البيانات مثل استخدام كلمات مرور قوية وتفادي مشاركة البيانات غير المقصود. كما ينبغي أن تخضع منصات وسم البيانات للقوانين واللوائح المنظمة والتي تشمل اللائحة الشاملة لحماية البيانات GDPR وقانون كاليفورنيا لخصوصية المستخدم CCPA بالإضافة إلى قانون نقل التأمين الصحي والمساءلة HIPAA، وإخضاع المنصات التجارية للمراجعة والإشراف الخارجي والالتزام بمبادئ الثقة الخمسة وهي: الأمان والإتاحة والشفافية والموثوقية والخصوصية. مستقبل نظام وسم البيانات تحدث عملية وسم البيانات في الكواليس بالنسبة للمستخدم النهائي ولكنها ذات دور محوري في تطوير نماذج التعلم الآلي وأنظمة الذكاء الاصطناعي لذلك ينبغي أن يكون نظام الوسم قابلًا للتوسع ليواكب أي تغير في المتطلبات. تُحدَّث منصات الوسم التجارية ومفتوحة المصدر بانتظام لدعم الاحتياجات النامية لوسم البيانات، لذلك ينبغي على أنظمة الوسم المطورة محليًا أن تبني بطريقة تجعل تحديثها أمرًا سلسًا، فالتصميم المعتمد على الوحدات والمكونات القابلة للتبديل بدون التأثير على باقي النظام تٌسهّل عملية التحديث والتطوير، على سبيل المثال يمكن لتوفر ميزة دمج أنظمة وسم البيانات مع مكتبات وأطر عمل مفتوحة المصدر أن تضيف نوعًا من التكييف والتأقلم، حيث يمكن تحديثها وتطويرها باستمرار مع تطور المجال. كما توفر الحلول المبنية على خدمات الحوسبة السحابية ميزة ملحوظة للمشاريع الضخمة في وسم البيانات والتي لا يمكن أن توفرها الأنظمة المُدارة ذاتيًا، فالمنصات السحابية قابلة للتوسع آليًا في تخزينها وفي قدراتها الحاسوبية مما يقلل من الحاجة للتطويرات المكلفة في البنية التحتية. وينبغي أيضًا توسيع قدرة فريق العمل المسؤول عن وسم البيانات مع نمو حجم مجموعات البيانات، وتدريب الواسمين الجدد بسرعة على وسم البيانات بدقة وبفعالية. والتمتع بالمرونة في سد الاحتياجات في قوة العمل باستخدام خدمات الوسم المُدارة أو التعاون مع واسمين مستقلين، وينبغي أن تكون عملية التدريب والضم للفريق قابلة للتوسع في المكان واللغة وأوقات العمل. الخلاصة تعرفنا في مقال اليوم على أسس وسم البيانات لنماذج تعلم الآلة ووجدنا أن المفتاح الرئيسي لتحسين أداء ودقة نموذج التعلم الآلي هو جودة البيانات الموسومة التي ندرب النموذج عليها، وتوفير الأنظمة المختلطة التي تجمع بين البشر والأدوات المؤتمتة في وسم البيانات لتتيح للذكاء الاصطناعي تحسين الطريقة التي يعمل بها والحصول على نتائج أكثر كفاءة وفعالية. ترجمة وبتصرف لمقال Architecting Effective Data Labeling Systems for Machine Learning Pipelines لكاتبه Reza Fazeli اقرأ أيضًا معالجة الصور باستخدام لغة بايثون Python استكشف مصطلحات الذكاء الاصطناعي التوليدي تعرف على أفضل أطر عمل الذكاء الاصطناعي لمشاريع تعلم الآلة أفضل ممارسات هندسة المُوجِّهات Prompt Engineering: نصائح وحيل وأدوات -
 نوضح في هذا المقال مجموعة من النصائح المفيدة للمطورين للاستفادة المثلى من الذكاء الاصطناعي التوليدي الذي أعاد تشكيل الطريقة التي يكتب بها المطورون ومهندسو البرمجيات شيفراتهم البرمجية، واستطاعت هذه التقنية الحديثة التي غزت العالم من بضع سنوات فقط أن تنال شعبية كبيرة وتستخدم في العديد من المجالات. الذكاء الاصطناعي التوليدي ومستقبل البرمجيات كشف تقرير State of DevOps لعام 2023 أن 60% من المساهمين في الاستبيان استخدموا الذكاء الاصطناعي في تحليل البيانات وتوليد الأكواد البرمجية وتحسينها، بالإضافة لتعليم أنفسهم مهارات وتقنيات جديدة، ويكتشف المطورون طرقًا جديدة باستمرار لاستخدام هذه الأدوات التي تتطور بشكل متسارع. كما زعمت شركة Cognition Labs المتخصصة في تطوير تقنيات الذكاء الاصطناعي في ربيع عام 2024 أن منتجها يمكنه أن يستبدل المطورين ومهندسي البرمجيات في حل المشكلات البرمجية المطروحة على جت هاب Github issues بنسبة 13.86% وقد لا يبدو هذا الرقم مبهرًا للوهلة الأولى لكنه سيكون كذلك عندما تعرف أن أفضل أداء مسجل لهذه المهمة في عام 2023 لم يتجاوز نسبة حله 1.96%، ينبغي ملاحظة أن إمكانيات ديفين Devin AI تم تضخيمها لتبدو أكثر من الواقع فتحقيق النسبة المزعومة يتطلب إشراف بشري، كما ولم يستطيع تنفيذ المهام على مواقع العمل الحر، لذا حتى الآن لا يمكننا أن نعتبر ديفين Devin AI ذكاء اصطناعي يضاهي البشر في البرمجة، ولكن مع تطور الذكاء الاصطناعي يمكن أن نرى الأدوات المماثلة تتحسن. كما زعمت شركة Cognition Labs في ربيع 2024، منتجها ديفين Devin AI يمكنه أن يستبدل المطورين ومهندسي البرمجيات في حل المشكلات البرمجية المطروحة على جت هاب Github issues بنسبة 13.86% وقد لا يبدو هذا الرقم مبهرًا للوهلة الأولى لكنه سيكون كذلك عندما تعرف أن أفضل أداء مسجل لهذه المهمة في عام 2023 لم يتجاوز نسبة 1.96%، وتجدر الإشارة هنا لأن إمكانيات ديفين Devin AI لم تكن في الواقع كما زعمت الشركة فتحقيق هذه النسبة كان يتطلب إشرافًا بشريَّا، كما ولم يستطيع ديفن تنفيذ المهام على مواقع العمل الحر، لذا لا يمكننا حتى اللحظة اعتبار ديفين Devin AI ذكاء اصطناعي يضاهي البشر في البرمجة، ولكن مع تطور الذكاء الاصطناعي السريع يمكن أن يتحقق ذلك. هذا يدفعنا للتساؤل كيف يتأقلم مهندسو البرمجيات مع تقنيات وبرامج الذكاء الاصطناعي التي يمكنها كتابة برمجيات أخرى؟ ما الذي ستؤول له مسؤوليات مهندسي البرمجيات مع مرور الوقت في عالم تستحوذ فيه هذه التقنية بشكل تدريجي على كتابة الأكواد؟ هل سنستغني عن العنصر البشرية أم ستكون هناك حاجة دائمة لمهندس برمجيات متخصص يوجه السفينة؟ نناقش في الفقرات التالية كل هذه التساؤلات ونوضح آراء خبراء في المجالات التقنية المتنوعة مثل تطوير الويب وتطوير الواجهات الخلفية backend وتعلم الآلة والطريقة التي يستخدمون بها الذكاء الاصطناعي التوليدي لصقل مهاراتهم وتعزيز إنتاجيتهم في أعمالهم اليومية. ونسلط الضوء على النقاط التي يبرع بها الذكاء الاصطناعي التوليدي ونقاط الضعف التي يعاني منها، وكيف يمكن للمطورين الآخرين تحقيق الاستفادة القصوى من الذكاء الاصطناعي التوليدي في تعزيز إنتاجيتهم خلال عملية تطوير البرمجيات، وما هو مستقبل صناعة البرمجيات في ظل صعود تقنيات الذكاء الاصطناعي التوليدي. كيف يستخدم المطورون الذكاء الاصطناعي التوليدي من أشهر برامج الذكاء الاصطناعي التي يعتمد عليها المطورون في تطوير البرمجيات نذكر شات جي بي تي ChatGPT و جت هاب كوبايلوت Github Copilot، حيث يوفر شات جي بي تي ChatGPT للمستخدمين واجهة نصية تفاعلية يمكن للمستخدم من خلالها توجيه النماذج اللغوية الضخمة Large Language Model باستخدام الموجهات المناسبة فهذه النماذج لديها معرفة شاملة عن مواضيع متنوعة من بينها الأكواد البرمجية بمختلف لغات البرمجة وأطر عملها ومكتباتها، وتنبع هذه المعرفة من التدريب الذي خضعت له هذه النماذج فقد جرى تدريبها على كم هائل من البيانات مفتوحة المصدر المتوفرة على الإنترنت، ويدمج كوبايلوت Copilot مباشرة في بيئة التطوير المتكاملة IDE ليوفر للمطور قدرات متقدمة في إكمال الأكواد البرمجية واقتراح الأسطر القادمة لكتابتها، فقد تدرّب على كل الأكواد مفتوحة المصدر المتوفرة على Github، وجمع هاتين الأداتين معًا من شأنه مساعدة المطور في حل أي مشكلة تقنية يمكن أن تواجهه. الذكاء الاصطناعي في دور الخبير والمتدرب يعتمد المطورون بشكل متزايد على أدوات الذكاء الاصطناعي التوليدي لتحسين سير العمل وتبسيط العمليات البرمجية، حيث تُظهر هذه الأدوات مرونة وفعالية في تأدية دورين أساسيين الأول دور الخبير الذي يقدم الإرشاد والدعم الفني، والثاني دور المتدرب الذي ينجز المهام التكرارية والبسيطة. وفيما يلي دراسة حالة لمطورين خبراء بتخصصات مختلفة يوضح كل منهم كيف اعتمد على الذكاء الاصطناعي التوليدي لمساعدته في تأدية مهامه. الحالة الأولى مطور ويب كامل عند سؤال مطور ويب كامل full-stack web developer ومهندس ذكاء اصطناعي بخبرة تتجاوز 20 عامًا عن استخدام الذكاء الاصطناعي صرّح بما يلي: "أنا استخدم كوبايلوت copilot يوميًا، فهو يتنبأ بسطر الكود الذي أنوي كتابته أغلب المرات بدقة كبيرة. ويمكن للذكاء الاصطناعي أن يؤدي وظفتين، الأولى زميل خبير يساعد في العصف الذهني بمستوى يكافئ خبراتك وتفكيرك، والثانية كمطور مبتدئ يتولى المهام البسيطة والمتكررة في كتابة الكود". وقد وضح أنه استفاد من الواجهة البرمجية OpenAI API لما هو أبعد من مجرد التنبؤ بسطر الكود، حيث طوّر إضافة مفتوحة المصدر لتطبيق أوبسيدين Obsidian وهو تطبيق مشابه لنوشن Notion مع ميزات مختلفة، إذ تستعمل هذه الإضافة الواجهة البرمجية التي تشغل كلًا من شات جي بي تي ChatGPT و كوبايلوت Copilot، وتسمح للمستخدمين بإنشاء شخصيات مخصصة بالذكاء الاصطناعي والتفاعل معها. ويرى المطور أن مهام الذكاء الاصطناعي التوليدي الأكثر أهمية هي تلك التي تطلب وقتًا أطول لإكمالها يدويًا، ويمكن بسهولة التأكد من صحتها ودقتها في وقت قصير مثل تحويل الملف من تنسيق إلى آخر، كما يبرع جي بي تي GPT في توليد نصوص تلخص وظائف الأكواد البرمجية، مع ذلك مازلنا بحاجة لمطور خبير يمكنه فهم التفاصيل التقنية لهذا التلخيص. الحالة الثانية مطور تطبيقات iOS عند سؤال مطور تطبيقات جوال خبير عن استخدام الذكاء الاصطناعي في عمله أفاد بأنه لاحظ تحسنًا ملحوظًّا في سير عمله اليومي منذ أن دمج الذكاء الاصطناعي التوليدي به، فهو يستخدم شات جي بي تي ChatGPT وكوديوم Codeium وهو تطبيق ينافس Copilot لحل المشكلات البرمجية وصرح بما يلي: "يساعدني الذكاء الاصطناعي التوليدي في حل 80% من المشكلات البرمجية بسرعة وفي تفادي هذه المعرقلات في غضون ثواني، دون الحاجة لوقت طويل من الذهاب للبحث والعودة للتجربة من أجل إيجاد حل المشكلات المعقدة". فهو يرى أن هذه أدوات الذكاء الاصطناعي تلعب دور الخبير الموضوعي والمتدرب الذي لا يكل ولا يمل من تنفيذ المهام البسيطة والمتكررة، وتساعده في تفادي المهام المرهقة واليدوية عند كتابة الكود مثل الأنماط المتكررة في الكود أو إجراء تحسين هيكلية الكود البرمجي وإعادة تصميمه Refactoring أو هيكلة طلبات الواجهات البرمجية API بشكل صحيح، فقبل ظهور هذه الأدوات، كانت المشكلات غير المألوفة تشكل عائقًا كبيرًا أمام التقدم في المهام. ويظهر هذا التحدي بشكل خاص عند العمل على مشاريع تتطلب التعامل مع واجهات برمجية APIs أو أطر عمل غير مألوفة تحتاج لبذل جهد ذهني إضافي لفهم كيفية حل مشكلاتها. الحالة الثالثة مهندس تعلم آلة أشار مهندس تعلم آلة خبير لأهمية التأكد من صحة الأكواد المهمّة وخلوّها من الأخطاء قبل تشغيلها فهذه خطوة أساسية وضرورية جدًّا، ولن يكون من الحكمة مطلقًا نسخ الكود الذي يولده الذكاء الاصطناعي، ولصقه مباشرةً وافتراض أنه يعمل بشكل صحيح، فحتى لو تغاضينا مشكلة الهلوسة التي قد يعاني منها الذكاء الاصطناعي سيكون هناك في الغالب أسطر من الكود تحتاج للتعديل من طرف المطور البشري، فالذكاء الاصطناعي لا يمتلك السياق الكامل للمشروع ولا يدري ما هي أهدافه وتفاصيله. وأسدى نصيحة للمطورين الراغبين في تحقيق الاستفادة القصوى من الذكاء الاصطناعي التوليدي في كتابة الأكواد، بعدم إعطائه الكثير من المسؤوليات المهمة مرة واحدة، فهذه الأدوات تعمل جيدًا عندما نعطيها مهامًا محددة ومعرّفة بوضوح وتتبع أنماط الحل المتوقعة والشائعة، ففي حال أعطيناه مهام أكثر تعقيدًا أو مهام عامة غير محددة فهذا سيتسبب بجعله يعاني من الهلوسة ويعطي نتائج غير صحيحة. الذكاء الاصطناعي كمعلم شخصي وباحث يمكن استخدام الذكاء الاصطناعي التوليدي في تعلم أدوات ولغات برمجية جديدة، على سبيل المثال أشار مهندس تعلم الآلة أنه تمكن من تعلم أساسيات تيرافورم Terraform في غضون ساعة باستخدام GPT-4، وذلك من خلال كتابة موجهات لكتابة الأكواد البرمجية ثم شرحها، ثم طلب منه بعض التغيرات على الكود وتوفير العديد من المزايا والخواص والتحقق فيما إذا كانت قابلة للتطبيق، ويعقّب أنه وجد هذه الطريقة في التعلم أسرع وأكثر فعالية من محاولة اكتساب نفس القدر من المعلومات من خلال البحث في المتصفح أو قراءة الدروس التعليمية. وللتأكيد، تنجح هذه الطريقة مع المطورين الذين يمتلكون خبرة تقنية مسبقة ومعرفة بكيفية سير الأمور فقط، فهؤلاء يمكنهم اكتشاف الحالات التي يخطئ فيها النموذج. لكن ستبدأ هذه الأدوات في الفشل عندما نظن أنها ستكون دقيقة 100% لذا لا يمكننا أن نعتمد عليها بالمطلق وبثقة عمياء، وعندما نواجه مهام حساسة لا تتحمل أي نسبة خطأ فيجب علينا التحقق دومًا من صحة الكود بدمج طرق بحث المتصفح التقليدية ومخرجات الذكاء الاصطناعي للتأكد من صحة المعلومات من مصادر موثوقة. ويشدد المطورون الخبراء على ضرورة استخدام النسخ الأحدث من النماذج، فالنسخ الأحدث لها قدرة أفضل على فهم المنطق المعقد مقارنة بالنسخ القديمة فوفقًا لأوبن أيه آي OpenAI يوفر GPT-4 على سبيل المثال دقة أكبر متجاوزًا سلفه بمقدار 40%، ولذا يجب على من يرغب في استخدام أحد نماذج الذكاء الاصطناعي كمعلم شخصي أن يستخدم النسخ الأحدث فهو قادر على دعم الحقائق التي يولدها بالمصادر التي يمكنك تصفحها والتأكد منها مما يقلل من احتمال النتائج الخاطئة. يفيد استخدام الذكاء الاصطناعي التوليدي أيضًا لدراسة الواجهات البرمجية APIs الجديدة وفي العصف الذهني لإيجاد حلول للمشكلات التي تواجه المطورين، فعند استغلال قدرات النماذج اللغوية الضخمة بأقصى حد يمكن تقليل وقت البحث ليقارب الصفر بفضل نافذة السياق الضخمة لتلك النماذج. نافذة السياق Context Window هي حجم المعلومات التي يمكن للنموذج استيعابها والعمل عليها في لحظة معينة، فبينما يستطيع البشر التفكير في بضعة أمور مرتبطة بالسياق في نفس الوقت كحد أقصى، يمكن للنماذج اللغوية الضخمة معالجة عدد متزايد من الملفات المصدرية والوثائق في نفس الوقت، يمكن توضيح الفرق من خلال مثال قراءة كتاب فنحن البشر يمكننا أن نتصفح صفحتين في ذات الوقت بحد أقصى ويمكننا أن نعتبر أن هذا هو حجم نافذة السياق البشرية، ولكن بالنسبة للنماذج اللغوية الضخمة فهي تمتلك القدرة على رؤية كل صفحات الكتاب بشكل متزامن، لقد غير هذا بشكلٍ جزي طريقتنا في تحليل البيانات وإجراء البحوث. "بدأ ChatGPT بنافذة سياق تتسع 3000 كلمة، وقد وصل حاليًا باستخدام نموذج GPT-4 إلى دعم نافذة سياق تصل إلى 100 ألف كلمة، بينما يمتلك Gemini سعة استيعاب ما يصل إلى مليون كلمة، وهي سعة تجعل البحث عن كلمة أو جملة تطبيقًا فعليًا لمثال البحث عن إبرة في كومة قش، ويستطيع جيميناي التعامل مع هذه النافذة الضخمة من السياق بدقة عالية. كان بالإمكان سابقًا إعطاء النسخ الأولية من هذه الأدوات أجزاء ومقاطع من الكود كسياق من المشاريع التي تعمل عليها، وأصبح من الممكن لاحقًا إعطاؤها ملف اقرأني README مع الكود المصدري للمشروع بالكامل فأصبح إرفاق المشروع كاملًا كنافذة سياق قبل طرح الأسئلة أمرًا في غاية البساطة." نصائح لتحسين استخدام أدوات الذكاء الاصطناعي التوليدي يمكن للذكاء الاصطناعي التوليدي تعزيز إنتاجية المطورين في كتابة الأكواد والتعلم والبحث شريطة التعامل معه بشكل صحيح، فبدون سياق كافي، يصبح ChatGPT أقرب للهلوسة ولتوليد ردود غير مناسبة، وقد أظهرت دراسة تجريبية لخصائص إجابات ChatGPT على أسئلة Stack Overflow أن ردود GPT 3.5 في الأسئلة البرمجية تحتوي على معلومات خاطئة بنسبة 53%، ويمكن للسياق الخاطئ أن يكون أسوأ من عدم وجود سياق على الإطلاق، فإن قدمت حلًا ضعيفًا لمشكلة ما في الكود على أنها حل جيد سيفترض ChatGPT أن بإمكانه توليد الردود القادمة على بناء على هذا الأساس الضعيف. ولتحقيق الاستفادة القصوى من أدوات الذكاء الاصطناعي التوليدي، ينبغي أن نحدد له المهام بوضوح، ونقدم المعلومات التقنية ذات الصلة، وحدد الدور المطلوب منه والنتائج المتوقعة، كما يفيد توفير السياق للنموذج في تحسين في أداءه بشكل ملحوظ. لكن احذر من إعطاء معلومات خاصة أو حساسة للنماذج العامة، فمن الممكن أن تستخدم هذه البيانات للتدريب عليها وغالبًا ستفعل ذلك، وقد وجد الباحثون أن من الممكن استخراج مفاتيح واجهات برمجية ومعلومات خاصة باستخدام كوبايلوت Copilot و بعض النماذج الأخرى نتيجة لخطأ المطورين بتركهم تلك المعلومات والمفاتيح السرية غير مشفرة في تطبيقاتهم، ووفقًا لتقرير آي بي ام IBM عن تكلفة تسريبات البيانات فإن السبب الأكبر عالميًا لحدوث تسريبات للبيانات هي بيانات الاعتماد السرية التي تستخدم لتوثيق هوية المستخدم credentials والتي يتم تسريبها. استراتيجيات هندسة الموجهات لتوليد حلول أفضل تؤثر طرق استخدام الموجهات prompts مع الذكاء الاصطناعي التوليدي على جودة الردود المستلمة. لقد أصبحت هذه الطرق محورية للغاية لدرجة أنها أصبحت مجالًا فرعيًا للدراسة يُسمى هندسة الموجهات Prompt engineering، وهو يركز على كتابة وتحسين الموجهات بهدف توليد مخرجات عالية الجودة. تعتمد هندسة الموجهات على فكرة أن الذكاء الاصطناعي يستفيد بشكل أكبر من السياق وينتج إجابات أفضل عندما يعطى وصفًا دقيقًا ومحددًا للرد المطلوب. على سبيل المثال، بدلاً من توجيهه بطلب عام مثل "اكتب قائمة"، يمكننا كتابة مُوّجه أدق مثل: "اكتب قائمة مرقمة ورتب عناصرها حسب الأهمية". فهذه التوجيهات المحسّنة تساعد الذكاء الاصطناعي في فهم المطلوب بشكل أفضل وتوليد استجابات مفيدة. تطبق هندسة الموجهات العديد من الممارسات والحيل لتستخرج من النموذج أفضل الردود الممكنة، ومن هذه الطرق: تجربة تقنيات التعلم بصفر محاولة zero-shot وبمحاولة واحدة one-shot وببضعة محاولات few-show: فهذه لتحدد كيفية التعامل مع المهام دون تدريب مخصص أو مع تدريب محدود، فيمكنك أن لا توفر للنموذج أية أمثلة أو توفر له مثال واحد أو بضعة أمثلة للحصول على المطلوب، الفكرة هي توفير أقل سياق ممكن للنموذج مع التركيز على المعرفة المسبقة لدى النموذج وقدراته المنطقية دون الحاجة إلى تدريب مكثف توجيه النموذج من خلال تسلسل الأفكار Chain-of-thought prompting: فهذا الأسلوب يساعد الذكاء الاصطناعي في تقديم إجابات دقيقة من خلال شرح خطوات تفكيره بشكل منطقي قبل الوصول إلى الإجابة النهائية ويمكننا من فهم الكيفية التي توصل من خلالها لهذه الإجابات التوجيه التكرار وهو يعني ضرورة توجيه الذكاء الاصطناعي للمخرجات المطلوبة وتحسين نتائجه من خلال تعديل الموجهات بشكل متتابع وتكراري. التوجيه السلبي أي إخبار الذكاء الاصطناعي بما لا ينبغي عليه فعله، فمثلًا يمكننا توجيه لعدم توليد محتوى معين ومن المهم أيضًا إلى جانب ما سبق توجيه أنظمة الدردشة الآلية الذكية لجعل ردودها مختصرة فغالبية الردود التي يولدها GPT حشو لا فائدة منه، ويمكننا اختزالها عن طريق موجه prompt لتوليد ردود مختصرة، وينصح أيضاً بطلب تلخيص الموجهات والتعليمات التي طلبناها منها لتضمن أنه يدرك جيدًا ما تريده. وعند استخدام النماذج اللغوية الضخمة للمساعدة في تحسين الموجهات بنفسها من المفيد اختيار عينة لم يقم فيها النموذج بتنفيذ المطلوب كما نرغب والاستفسار منه عن سبب توليد هذا الرد، حيث يحسن هذا من صياغة الموجّهات في المرات التالية، ويمكنك في الواقع أن تطلب من النموذج اللغوي الضخم اقتراح التعديلات التي يمكن تنفيذها على الموجه للحصول على الردود التي تتوقعها. كما أن المهارات البشرية في التواصل لازالت مفيدة حتى عند التعامل مع الذكاء الاصطناعي، فالذكاء الاصطناعي يتعلم بقراءة النصوص البشرية، لذا الالتزام يمكن الالتزام ببعض القواعد المستخدمة في التواصل البشري فهي فعالة أيضًا من قبيل كن مهذبًا، أو كن واضحًا واحترافيًا. تواصل معه كأنك المدير. على سبيل المثال يمكن توجيه الذكاء الاصطناعي المتقمص لدور مراجع باستخدام نصوص الموجهات التالية الذي يوضح للذكاء الاصطناعي من هو وما المتوقع منه من خلال كتابة سلسلة الموجهات التالية: "أنت ذكاء اصطناعي يراجع الأكواد، ومصمم لتدقق وتراجع وتحسن ملفات الأكواد المصدرية، ودورك أن تتصرف كناقد يراجع الكود التي يوفرها المستخدم ويقترح التحسينات المطلوبة عليها، فأنت خبير في تحسين جودة ملف الكود بدون تغيير وظيفته. ينبغي أن تكون محترفًا في تعاملك مع المستخدم وأن تكون طريقة كلامك مهذبة ومهنية، وأن تكون مراجعتك بناءةً وتوفر شرحًا واضحًا للتحسينات المقترحة، وعليك منح أولوية للتعديلات التي تصلح الأخطاء، موضحًا أي هذه التعديلات اختياري وأيها غير اختياري. هدفك مساعدة المستخدم بتحسين جودة الكود الخاص بهم تحسينًا لا يمكنك بعده أن تجد أي شيء قابل للتطوير أبعد من ذلك، وعند وصولك لهذا المستوى وضح للمستخدم أنه لا يمكنك إيجاد شيء لتحسينه مشيرًا إلى جهوزية الكود للتشغيل أو الاستخدام. استلهم عملك من مبادئ أنماط التصميم البرمجية واعتمده كدليل أساسي في تصميم البرمجيات، عليك أن تجتهد في تطبيق ثلاثة مبادئ في الأكواد التي تراجعها وتحللها مشددًا على ضمان صحة الكود وتنسيقه الجيد وتصميمه المتقن. امنح أولوية لصحة الكود وللتحسينات، فضع دومًا التعديلات الأهم والأخطر أولًا قبل التعديلات الأقل أهمية. وقسم مراجعتك إلى ثلاثة أقسامٍ رئيسية وهي التنسيق والتصحيح والتحليل ويحتوي كل قسم على قائمة من التحسينات الممكنة تحت عنوان القسم. اتبع هذه التعليمات: ابدأ بمراجعة تنسيق الكود، مكتشفًا أي خطأ في المسافات أو محاذاة العناصر النصية للكود، فتحسن الكود من الناحية الجمالية وتجعله أسهل في القراءة تاليًا، ركز على صحة الكود وخلوه من الأخطاء النصية والوظيفية أخيرًا، أجري تحليل عالي المستوى للكود، باحثًا عن طرق لتحسين معالجة الأخطاء error handling والتعامل مع الحالات الخاصة بالإضافة لضمان جعل الكود موثقًا ويعمل بكفاءة وقابلاً للصيانة والتحديث يمكن القول أن هندسة الموجهات Prompt engineering فن أكثر من كونها علم، وهي تتطلب قدرًا معينًا من التجربة والمحاولة والخطأ للخروج بالمطلوب، إذ تفرض طبيعة تقنيات معالجة اللغات الطبيعية NLP عدم وجود حل واحد يناسب جميع المشكلات، تمامًا كما أن محادثتك مع أشخاص مختلفين تتطلب اختيارًا مختلفًا للكلمات، والموازنة بين الوضوح والتعقيد والإيجاز والإسهاب، فلكل هذا تأثير على فهم الآخرين لاحتياجاتك ولقصدك." مستقبل الذكاء الاصطناعي التوليدي في تطوير البرمجيات بعد تطور تقنيات الذكاء الاصطناعي التوليدي وأدواته ظهرت ادعاءات ومزاعم عديدة تفترض أن المهارات البرمجية ستصبح عديمة النفع، وأن الذكاء الاصطناعي سيلغي عمل المطورين ويكون قادرًا على بناء تطبيق كامل من الصفر، ولن تشكل معرفة المطورين وقدرتهم على كتابة الأكواد البرمجية أي فرق، وردًا على هذه المزاعم والافتراضات فإنه من الصعب حدوث هذا على الأقل في المدى القريب، فالذكاء الاصطناعي التوليدي لا يمكنه أن يكتب تطبيقًا مكتاملًا لنا، ولا زال يعاني من قصور في تصميم واجهات المستخدم، فلا يوجد حتى الآن أي أداة ذكاء اصطناعي حاليًا قادرة على تصميم واجهات تطبيق تتناسب مع الهوية البصرية الموجودة بالفعل. وهذا القصور ليس نتيجة لنقص المجهود في هذا المجال، فقد ظهرت منصة v0 التي تقدم خدماتها عبر السحابة كواحدة من الأدوات المتخصصة في عالم واجهات المستخدمين المولدة بالذكاء الاصطناعي، ولكنها مازالت مقتصرة على استخدام أكواد رياكت ومكوناتها الموجودة في شاد سي إن shadcn ui components، ويمكن أن تكون نتائجها النهائية مفيدة للنماذج الأولية من المشروع ولكنها تحتاج لمطور واجهة ماهر ليستطيع أن يبني واجهات تناسب الهوية البصرية، وعلى ما يبدو لازالت هذه التقنيات بحاجة لمزيد من التطوير قبل أن تنافس الخبرة البشرية. وقد أصبح تطوير البرمجيات كمنتج منتشرًا بكثرة اليوم، فالمطورون الآن مطالبون بفهم مشكلات العملاء واستخدام الأكواد لحلها بدلاً من مجرد كتابة الكود. وهذا التحول يعني أن الدور التقليدي للمطورين يتغير، ويجب عليهم التركيز على تحقيق أهداف الأعمال بدلاً من مجرد تنفيذ المهام البرمجية. وبالرغم أن هذه التحديات قد تكون صعبة للبعض، فإن تبني تقنيات مثل الذكاء الاصطناعي التوليدي يمكن أن يمنح المطورين ميزة تنافسية. الخلاصة يمكن أن نخلص من حالات الاستخدام والنقاشات الواردة في هذا المقال إلى أن الذكاء الاصطناعي سيظل بحاجة مستمرة للخبراء في توجيه واختبار مخرجاته، ولن يكون بديلاً كاملاً للمطورين المحترفين. لكن في الوقت ذاته، سيصبح أداة قوية لتعزيز إنتاجية المطورين، مما يستدعي الاستعداد لمخاطر استخدامه في تطوير البرمجيات بشكل آمن وفعال. فقد تُرك الحبل على الغارب لإنتاج الكثير من النماذج اللغوية الضخمة، ويبدو أن استخدام الذكاء الاصطناعي سيكون جزءًا أساسيًا في تطوير البرمجيات ولا يمكن تجاهله، لذا، يجب على المؤسسات المعنية تجهيز فرقها بأدوات جديدة لزيادة الإنتاجية ولتوضيح المخاطر الأمنية المرتبطة باستخدام الذكاء الاصطناعي في سير العمل. ترجمة -وبتصرف- لمقال Increase Developer Productivity With Generative AI: Tips From Leading Software Engineers لكاتبه Sam Sycamore اقرأ أيضًا مقدمة إلى الذكاء الاصطناعي التوليدي Generative AI كل ما تود معرفته عن دراسة الذكاء الاصطناعي استكشف مصطلحات الذكاء الاصطناعي التوليدي مستقبل الذكاء الاصطناعي
نوضح في هذا المقال مجموعة من النصائح المفيدة للمطورين للاستفادة المثلى من الذكاء الاصطناعي التوليدي الذي أعاد تشكيل الطريقة التي يكتب بها المطورون ومهندسو البرمجيات شيفراتهم البرمجية، واستطاعت هذه التقنية الحديثة التي غزت العالم من بضع سنوات فقط أن تنال شعبية كبيرة وتستخدم في العديد من المجالات. الذكاء الاصطناعي التوليدي ومستقبل البرمجيات كشف تقرير State of DevOps لعام 2023 أن 60% من المساهمين في الاستبيان استخدموا الذكاء الاصطناعي في تحليل البيانات وتوليد الأكواد البرمجية وتحسينها، بالإضافة لتعليم أنفسهم مهارات وتقنيات جديدة، ويكتشف المطورون طرقًا جديدة باستمرار لاستخدام هذه الأدوات التي تتطور بشكل متسارع. كما زعمت شركة Cognition Labs المتخصصة في تطوير تقنيات الذكاء الاصطناعي في ربيع عام 2024 أن منتجها يمكنه أن يستبدل المطورين ومهندسي البرمجيات في حل المشكلات البرمجية المطروحة على جت هاب Github issues بنسبة 13.86% وقد لا يبدو هذا الرقم مبهرًا للوهلة الأولى لكنه سيكون كذلك عندما تعرف أن أفضل أداء مسجل لهذه المهمة في عام 2023 لم يتجاوز نسبة حله 1.96%، ينبغي ملاحظة أن إمكانيات ديفين Devin AI تم تضخيمها لتبدو أكثر من الواقع فتحقيق النسبة المزعومة يتطلب إشراف بشري، كما ولم يستطيع تنفيذ المهام على مواقع العمل الحر، لذا حتى الآن لا يمكننا أن نعتبر ديفين Devin AI ذكاء اصطناعي يضاهي البشر في البرمجة، ولكن مع تطور الذكاء الاصطناعي يمكن أن نرى الأدوات المماثلة تتحسن. كما زعمت شركة Cognition Labs في ربيع 2024، منتجها ديفين Devin AI يمكنه أن يستبدل المطورين ومهندسي البرمجيات في حل المشكلات البرمجية المطروحة على جت هاب Github issues بنسبة 13.86% وقد لا يبدو هذا الرقم مبهرًا للوهلة الأولى لكنه سيكون كذلك عندما تعرف أن أفضل أداء مسجل لهذه المهمة في عام 2023 لم يتجاوز نسبة 1.96%، وتجدر الإشارة هنا لأن إمكانيات ديفين Devin AI لم تكن في الواقع كما زعمت الشركة فتحقيق هذه النسبة كان يتطلب إشرافًا بشريَّا، كما ولم يستطيع ديفن تنفيذ المهام على مواقع العمل الحر، لذا لا يمكننا حتى اللحظة اعتبار ديفين Devin AI ذكاء اصطناعي يضاهي البشر في البرمجة، ولكن مع تطور الذكاء الاصطناعي السريع يمكن أن يتحقق ذلك. هذا يدفعنا للتساؤل كيف يتأقلم مهندسو البرمجيات مع تقنيات وبرامج الذكاء الاصطناعي التي يمكنها كتابة برمجيات أخرى؟ ما الذي ستؤول له مسؤوليات مهندسي البرمجيات مع مرور الوقت في عالم تستحوذ فيه هذه التقنية بشكل تدريجي على كتابة الأكواد؟ هل سنستغني عن العنصر البشرية أم ستكون هناك حاجة دائمة لمهندس برمجيات متخصص يوجه السفينة؟ نناقش في الفقرات التالية كل هذه التساؤلات ونوضح آراء خبراء في المجالات التقنية المتنوعة مثل تطوير الويب وتطوير الواجهات الخلفية backend وتعلم الآلة والطريقة التي يستخدمون بها الذكاء الاصطناعي التوليدي لصقل مهاراتهم وتعزيز إنتاجيتهم في أعمالهم اليومية. ونسلط الضوء على النقاط التي يبرع بها الذكاء الاصطناعي التوليدي ونقاط الضعف التي يعاني منها، وكيف يمكن للمطورين الآخرين تحقيق الاستفادة القصوى من الذكاء الاصطناعي التوليدي في تعزيز إنتاجيتهم خلال عملية تطوير البرمجيات، وما هو مستقبل صناعة البرمجيات في ظل صعود تقنيات الذكاء الاصطناعي التوليدي. كيف يستخدم المطورون الذكاء الاصطناعي التوليدي من أشهر برامج الذكاء الاصطناعي التي يعتمد عليها المطورون في تطوير البرمجيات نذكر شات جي بي تي ChatGPT و جت هاب كوبايلوت Github Copilot، حيث يوفر شات جي بي تي ChatGPT للمستخدمين واجهة نصية تفاعلية يمكن للمستخدم من خلالها توجيه النماذج اللغوية الضخمة Large Language Model باستخدام الموجهات المناسبة فهذه النماذج لديها معرفة شاملة عن مواضيع متنوعة من بينها الأكواد البرمجية بمختلف لغات البرمجة وأطر عملها ومكتباتها، وتنبع هذه المعرفة من التدريب الذي خضعت له هذه النماذج فقد جرى تدريبها على كم هائل من البيانات مفتوحة المصدر المتوفرة على الإنترنت، ويدمج كوبايلوت Copilot مباشرة في بيئة التطوير المتكاملة IDE ليوفر للمطور قدرات متقدمة في إكمال الأكواد البرمجية واقتراح الأسطر القادمة لكتابتها، فقد تدرّب على كل الأكواد مفتوحة المصدر المتوفرة على Github، وجمع هاتين الأداتين معًا من شأنه مساعدة المطور في حل أي مشكلة تقنية يمكن أن تواجهه. الذكاء الاصطناعي في دور الخبير والمتدرب يعتمد المطورون بشكل متزايد على أدوات الذكاء الاصطناعي التوليدي لتحسين سير العمل وتبسيط العمليات البرمجية، حيث تُظهر هذه الأدوات مرونة وفعالية في تأدية دورين أساسيين الأول دور الخبير الذي يقدم الإرشاد والدعم الفني، والثاني دور المتدرب الذي ينجز المهام التكرارية والبسيطة. وفيما يلي دراسة حالة لمطورين خبراء بتخصصات مختلفة يوضح كل منهم كيف اعتمد على الذكاء الاصطناعي التوليدي لمساعدته في تأدية مهامه. الحالة الأولى مطور ويب كامل عند سؤال مطور ويب كامل full-stack web developer ومهندس ذكاء اصطناعي بخبرة تتجاوز 20 عامًا عن استخدام الذكاء الاصطناعي صرّح بما يلي: "أنا استخدم كوبايلوت copilot يوميًا، فهو يتنبأ بسطر الكود الذي أنوي كتابته أغلب المرات بدقة كبيرة. ويمكن للذكاء الاصطناعي أن يؤدي وظفتين، الأولى زميل خبير يساعد في العصف الذهني بمستوى يكافئ خبراتك وتفكيرك، والثانية كمطور مبتدئ يتولى المهام البسيطة والمتكررة في كتابة الكود". وقد وضح أنه استفاد من الواجهة البرمجية OpenAI API لما هو أبعد من مجرد التنبؤ بسطر الكود، حيث طوّر إضافة مفتوحة المصدر لتطبيق أوبسيدين Obsidian وهو تطبيق مشابه لنوشن Notion مع ميزات مختلفة، إذ تستعمل هذه الإضافة الواجهة البرمجية التي تشغل كلًا من شات جي بي تي ChatGPT و كوبايلوت Copilot، وتسمح للمستخدمين بإنشاء شخصيات مخصصة بالذكاء الاصطناعي والتفاعل معها. ويرى المطور أن مهام الذكاء الاصطناعي التوليدي الأكثر أهمية هي تلك التي تطلب وقتًا أطول لإكمالها يدويًا، ويمكن بسهولة التأكد من صحتها ودقتها في وقت قصير مثل تحويل الملف من تنسيق إلى آخر، كما يبرع جي بي تي GPT في توليد نصوص تلخص وظائف الأكواد البرمجية، مع ذلك مازلنا بحاجة لمطور خبير يمكنه فهم التفاصيل التقنية لهذا التلخيص. الحالة الثانية مطور تطبيقات iOS عند سؤال مطور تطبيقات جوال خبير عن استخدام الذكاء الاصطناعي في عمله أفاد بأنه لاحظ تحسنًا ملحوظًّا في سير عمله اليومي منذ أن دمج الذكاء الاصطناعي التوليدي به، فهو يستخدم شات جي بي تي ChatGPT وكوديوم Codeium وهو تطبيق ينافس Copilot لحل المشكلات البرمجية وصرح بما يلي: "يساعدني الذكاء الاصطناعي التوليدي في حل 80% من المشكلات البرمجية بسرعة وفي تفادي هذه المعرقلات في غضون ثواني، دون الحاجة لوقت طويل من الذهاب للبحث والعودة للتجربة من أجل إيجاد حل المشكلات المعقدة". فهو يرى أن هذه أدوات الذكاء الاصطناعي تلعب دور الخبير الموضوعي والمتدرب الذي لا يكل ولا يمل من تنفيذ المهام البسيطة والمتكررة، وتساعده في تفادي المهام المرهقة واليدوية عند كتابة الكود مثل الأنماط المتكررة في الكود أو إجراء تحسين هيكلية الكود البرمجي وإعادة تصميمه Refactoring أو هيكلة طلبات الواجهات البرمجية API بشكل صحيح، فقبل ظهور هذه الأدوات، كانت المشكلات غير المألوفة تشكل عائقًا كبيرًا أمام التقدم في المهام. ويظهر هذا التحدي بشكل خاص عند العمل على مشاريع تتطلب التعامل مع واجهات برمجية APIs أو أطر عمل غير مألوفة تحتاج لبذل جهد ذهني إضافي لفهم كيفية حل مشكلاتها. الحالة الثالثة مهندس تعلم آلة أشار مهندس تعلم آلة خبير لأهمية التأكد من صحة الأكواد المهمّة وخلوّها من الأخطاء قبل تشغيلها فهذه خطوة أساسية وضرورية جدًّا، ولن يكون من الحكمة مطلقًا نسخ الكود الذي يولده الذكاء الاصطناعي، ولصقه مباشرةً وافتراض أنه يعمل بشكل صحيح، فحتى لو تغاضينا مشكلة الهلوسة التي قد يعاني منها الذكاء الاصطناعي سيكون هناك في الغالب أسطر من الكود تحتاج للتعديل من طرف المطور البشري، فالذكاء الاصطناعي لا يمتلك السياق الكامل للمشروع ولا يدري ما هي أهدافه وتفاصيله. وأسدى نصيحة للمطورين الراغبين في تحقيق الاستفادة القصوى من الذكاء الاصطناعي التوليدي في كتابة الأكواد، بعدم إعطائه الكثير من المسؤوليات المهمة مرة واحدة، فهذه الأدوات تعمل جيدًا عندما نعطيها مهامًا محددة ومعرّفة بوضوح وتتبع أنماط الحل المتوقعة والشائعة، ففي حال أعطيناه مهام أكثر تعقيدًا أو مهام عامة غير محددة فهذا سيتسبب بجعله يعاني من الهلوسة ويعطي نتائج غير صحيحة. الذكاء الاصطناعي كمعلم شخصي وباحث يمكن استخدام الذكاء الاصطناعي التوليدي في تعلم أدوات ولغات برمجية جديدة، على سبيل المثال أشار مهندس تعلم الآلة أنه تمكن من تعلم أساسيات تيرافورم Terraform في غضون ساعة باستخدام GPT-4، وذلك من خلال كتابة موجهات لكتابة الأكواد البرمجية ثم شرحها، ثم طلب منه بعض التغيرات على الكود وتوفير العديد من المزايا والخواص والتحقق فيما إذا كانت قابلة للتطبيق، ويعقّب أنه وجد هذه الطريقة في التعلم أسرع وأكثر فعالية من محاولة اكتساب نفس القدر من المعلومات من خلال البحث في المتصفح أو قراءة الدروس التعليمية. وللتأكيد، تنجح هذه الطريقة مع المطورين الذين يمتلكون خبرة تقنية مسبقة ومعرفة بكيفية سير الأمور فقط، فهؤلاء يمكنهم اكتشاف الحالات التي يخطئ فيها النموذج. لكن ستبدأ هذه الأدوات في الفشل عندما نظن أنها ستكون دقيقة 100% لذا لا يمكننا أن نعتمد عليها بالمطلق وبثقة عمياء، وعندما نواجه مهام حساسة لا تتحمل أي نسبة خطأ فيجب علينا التحقق دومًا من صحة الكود بدمج طرق بحث المتصفح التقليدية ومخرجات الذكاء الاصطناعي للتأكد من صحة المعلومات من مصادر موثوقة. ويشدد المطورون الخبراء على ضرورة استخدام النسخ الأحدث من النماذج، فالنسخ الأحدث لها قدرة أفضل على فهم المنطق المعقد مقارنة بالنسخ القديمة فوفقًا لأوبن أيه آي OpenAI يوفر GPT-4 على سبيل المثال دقة أكبر متجاوزًا سلفه بمقدار 40%، ولذا يجب على من يرغب في استخدام أحد نماذج الذكاء الاصطناعي كمعلم شخصي أن يستخدم النسخ الأحدث فهو قادر على دعم الحقائق التي يولدها بالمصادر التي يمكنك تصفحها والتأكد منها مما يقلل من احتمال النتائج الخاطئة. يفيد استخدام الذكاء الاصطناعي التوليدي أيضًا لدراسة الواجهات البرمجية APIs الجديدة وفي العصف الذهني لإيجاد حلول للمشكلات التي تواجه المطورين، فعند استغلال قدرات النماذج اللغوية الضخمة بأقصى حد يمكن تقليل وقت البحث ليقارب الصفر بفضل نافذة السياق الضخمة لتلك النماذج. نافذة السياق Context Window هي حجم المعلومات التي يمكن للنموذج استيعابها والعمل عليها في لحظة معينة، فبينما يستطيع البشر التفكير في بضعة أمور مرتبطة بالسياق في نفس الوقت كحد أقصى، يمكن للنماذج اللغوية الضخمة معالجة عدد متزايد من الملفات المصدرية والوثائق في نفس الوقت، يمكن توضيح الفرق من خلال مثال قراءة كتاب فنحن البشر يمكننا أن نتصفح صفحتين في ذات الوقت بحد أقصى ويمكننا أن نعتبر أن هذا هو حجم نافذة السياق البشرية، ولكن بالنسبة للنماذج اللغوية الضخمة فهي تمتلك القدرة على رؤية كل صفحات الكتاب بشكل متزامن، لقد غير هذا بشكلٍ جزي طريقتنا في تحليل البيانات وإجراء البحوث. "بدأ ChatGPT بنافذة سياق تتسع 3000 كلمة، وقد وصل حاليًا باستخدام نموذج GPT-4 إلى دعم نافذة سياق تصل إلى 100 ألف كلمة، بينما يمتلك Gemini سعة استيعاب ما يصل إلى مليون كلمة، وهي سعة تجعل البحث عن كلمة أو جملة تطبيقًا فعليًا لمثال البحث عن إبرة في كومة قش، ويستطيع جيميناي التعامل مع هذه النافذة الضخمة من السياق بدقة عالية. كان بالإمكان سابقًا إعطاء النسخ الأولية من هذه الأدوات أجزاء ومقاطع من الكود كسياق من المشاريع التي تعمل عليها، وأصبح من الممكن لاحقًا إعطاؤها ملف اقرأني README مع الكود المصدري للمشروع بالكامل فأصبح إرفاق المشروع كاملًا كنافذة سياق قبل طرح الأسئلة أمرًا في غاية البساطة." نصائح لتحسين استخدام أدوات الذكاء الاصطناعي التوليدي يمكن للذكاء الاصطناعي التوليدي تعزيز إنتاجية المطورين في كتابة الأكواد والتعلم والبحث شريطة التعامل معه بشكل صحيح، فبدون سياق كافي، يصبح ChatGPT أقرب للهلوسة ولتوليد ردود غير مناسبة، وقد أظهرت دراسة تجريبية لخصائص إجابات ChatGPT على أسئلة Stack Overflow أن ردود GPT 3.5 في الأسئلة البرمجية تحتوي على معلومات خاطئة بنسبة 53%، ويمكن للسياق الخاطئ أن يكون أسوأ من عدم وجود سياق على الإطلاق، فإن قدمت حلًا ضعيفًا لمشكلة ما في الكود على أنها حل جيد سيفترض ChatGPT أن بإمكانه توليد الردود القادمة على بناء على هذا الأساس الضعيف. ولتحقيق الاستفادة القصوى من أدوات الذكاء الاصطناعي التوليدي، ينبغي أن نحدد له المهام بوضوح، ونقدم المعلومات التقنية ذات الصلة، وحدد الدور المطلوب منه والنتائج المتوقعة، كما يفيد توفير السياق للنموذج في تحسين في أداءه بشكل ملحوظ. لكن احذر من إعطاء معلومات خاصة أو حساسة للنماذج العامة، فمن الممكن أن تستخدم هذه البيانات للتدريب عليها وغالبًا ستفعل ذلك، وقد وجد الباحثون أن من الممكن استخراج مفاتيح واجهات برمجية ومعلومات خاصة باستخدام كوبايلوت Copilot و بعض النماذج الأخرى نتيجة لخطأ المطورين بتركهم تلك المعلومات والمفاتيح السرية غير مشفرة في تطبيقاتهم، ووفقًا لتقرير آي بي ام IBM عن تكلفة تسريبات البيانات فإن السبب الأكبر عالميًا لحدوث تسريبات للبيانات هي بيانات الاعتماد السرية التي تستخدم لتوثيق هوية المستخدم credentials والتي يتم تسريبها. استراتيجيات هندسة الموجهات لتوليد حلول أفضل تؤثر طرق استخدام الموجهات prompts مع الذكاء الاصطناعي التوليدي على جودة الردود المستلمة. لقد أصبحت هذه الطرق محورية للغاية لدرجة أنها أصبحت مجالًا فرعيًا للدراسة يُسمى هندسة الموجهات Prompt engineering، وهو يركز على كتابة وتحسين الموجهات بهدف توليد مخرجات عالية الجودة. تعتمد هندسة الموجهات على فكرة أن الذكاء الاصطناعي يستفيد بشكل أكبر من السياق وينتج إجابات أفضل عندما يعطى وصفًا دقيقًا ومحددًا للرد المطلوب. على سبيل المثال، بدلاً من توجيهه بطلب عام مثل "اكتب قائمة"، يمكننا كتابة مُوّجه أدق مثل: "اكتب قائمة مرقمة ورتب عناصرها حسب الأهمية". فهذه التوجيهات المحسّنة تساعد الذكاء الاصطناعي في فهم المطلوب بشكل أفضل وتوليد استجابات مفيدة. تطبق هندسة الموجهات العديد من الممارسات والحيل لتستخرج من النموذج أفضل الردود الممكنة، ومن هذه الطرق: تجربة تقنيات التعلم بصفر محاولة zero-shot وبمحاولة واحدة one-shot وببضعة محاولات few-show: فهذه لتحدد كيفية التعامل مع المهام دون تدريب مخصص أو مع تدريب محدود، فيمكنك أن لا توفر للنموذج أية أمثلة أو توفر له مثال واحد أو بضعة أمثلة للحصول على المطلوب، الفكرة هي توفير أقل سياق ممكن للنموذج مع التركيز على المعرفة المسبقة لدى النموذج وقدراته المنطقية دون الحاجة إلى تدريب مكثف توجيه النموذج من خلال تسلسل الأفكار Chain-of-thought prompting: فهذا الأسلوب يساعد الذكاء الاصطناعي في تقديم إجابات دقيقة من خلال شرح خطوات تفكيره بشكل منطقي قبل الوصول إلى الإجابة النهائية ويمكننا من فهم الكيفية التي توصل من خلالها لهذه الإجابات التوجيه التكرار وهو يعني ضرورة توجيه الذكاء الاصطناعي للمخرجات المطلوبة وتحسين نتائجه من خلال تعديل الموجهات بشكل متتابع وتكراري. التوجيه السلبي أي إخبار الذكاء الاصطناعي بما لا ينبغي عليه فعله، فمثلًا يمكننا توجيه لعدم توليد محتوى معين ومن المهم أيضًا إلى جانب ما سبق توجيه أنظمة الدردشة الآلية الذكية لجعل ردودها مختصرة فغالبية الردود التي يولدها GPT حشو لا فائدة منه، ويمكننا اختزالها عن طريق موجه prompt لتوليد ردود مختصرة، وينصح أيضاً بطلب تلخيص الموجهات والتعليمات التي طلبناها منها لتضمن أنه يدرك جيدًا ما تريده. وعند استخدام النماذج اللغوية الضخمة للمساعدة في تحسين الموجهات بنفسها من المفيد اختيار عينة لم يقم فيها النموذج بتنفيذ المطلوب كما نرغب والاستفسار منه عن سبب توليد هذا الرد، حيث يحسن هذا من صياغة الموجّهات في المرات التالية، ويمكنك في الواقع أن تطلب من النموذج اللغوي الضخم اقتراح التعديلات التي يمكن تنفيذها على الموجه للحصول على الردود التي تتوقعها. كما أن المهارات البشرية في التواصل لازالت مفيدة حتى عند التعامل مع الذكاء الاصطناعي، فالذكاء الاصطناعي يتعلم بقراءة النصوص البشرية، لذا الالتزام يمكن الالتزام ببعض القواعد المستخدمة في التواصل البشري فهي فعالة أيضًا من قبيل كن مهذبًا، أو كن واضحًا واحترافيًا. تواصل معه كأنك المدير. على سبيل المثال يمكن توجيه الذكاء الاصطناعي المتقمص لدور مراجع باستخدام نصوص الموجهات التالية الذي يوضح للذكاء الاصطناعي من هو وما المتوقع منه من خلال كتابة سلسلة الموجهات التالية: "أنت ذكاء اصطناعي يراجع الأكواد، ومصمم لتدقق وتراجع وتحسن ملفات الأكواد المصدرية، ودورك أن تتصرف كناقد يراجع الكود التي يوفرها المستخدم ويقترح التحسينات المطلوبة عليها، فأنت خبير في تحسين جودة ملف الكود بدون تغيير وظيفته. ينبغي أن تكون محترفًا في تعاملك مع المستخدم وأن تكون طريقة كلامك مهذبة ومهنية، وأن تكون مراجعتك بناءةً وتوفر شرحًا واضحًا للتحسينات المقترحة، وعليك منح أولوية للتعديلات التي تصلح الأخطاء، موضحًا أي هذه التعديلات اختياري وأيها غير اختياري. هدفك مساعدة المستخدم بتحسين جودة الكود الخاص بهم تحسينًا لا يمكنك بعده أن تجد أي شيء قابل للتطوير أبعد من ذلك، وعند وصولك لهذا المستوى وضح للمستخدم أنه لا يمكنك إيجاد شيء لتحسينه مشيرًا إلى جهوزية الكود للتشغيل أو الاستخدام. استلهم عملك من مبادئ أنماط التصميم البرمجية واعتمده كدليل أساسي في تصميم البرمجيات، عليك أن تجتهد في تطبيق ثلاثة مبادئ في الأكواد التي تراجعها وتحللها مشددًا على ضمان صحة الكود وتنسيقه الجيد وتصميمه المتقن. امنح أولوية لصحة الكود وللتحسينات، فضع دومًا التعديلات الأهم والأخطر أولًا قبل التعديلات الأقل أهمية. وقسم مراجعتك إلى ثلاثة أقسامٍ رئيسية وهي التنسيق والتصحيح والتحليل ويحتوي كل قسم على قائمة من التحسينات الممكنة تحت عنوان القسم. اتبع هذه التعليمات: ابدأ بمراجعة تنسيق الكود، مكتشفًا أي خطأ في المسافات أو محاذاة العناصر النصية للكود، فتحسن الكود من الناحية الجمالية وتجعله أسهل في القراءة تاليًا، ركز على صحة الكود وخلوه من الأخطاء النصية والوظيفية أخيرًا، أجري تحليل عالي المستوى للكود، باحثًا عن طرق لتحسين معالجة الأخطاء error handling والتعامل مع الحالات الخاصة بالإضافة لضمان جعل الكود موثقًا ويعمل بكفاءة وقابلاً للصيانة والتحديث يمكن القول أن هندسة الموجهات Prompt engineering فن أكثر من كونها علم، وهي تتطلب قدرًا معينًا من التجربة والمحاولة والخطأ للخروج بالمطلوب، إذ تفرض طبيعة تقنيات معالجة اللغات الطبيعية NLP عدم وجود حل واحد يناسب جميع المشكلات، تمامًا كما أن محادثتك مع أشخاص مختلفين تتطلب اختيارًا مختلفًا للكلمات، والموازنة بين الوضوح والتعقيد والإيجاز والإسهاب، فلكل هذا تأثير على فهم الآخرين لاحتياجاتك ولقصدك." مستقبل الذكاء الاصطناعي التوليدي في تطوير البرمجيات بعد تطور تقنيات الذكاء الاصطناعي التوليدي وأدواته ظهرت ادعاءات ومزاعم عديدة تفترض أن المهارات البرمجية ستصبح عديمة النفع، وأن الذكاء الاصطناعي سيلغي عمل المطورين ويكون قادرًا على بناء تطبيق كامل من الصفر، ولن تشكل معرفة المطورين وقدرتهم على كتابة الأكواد البرمجية أي فرق، وردًا على هذه المزاعم والافتراضات فإنه من الصعب حدوث هذا على الأقل في المدى القريب، فالذكاء الاصطناعي التوليدي لا يمكنه أن يكتب تطبيقًا مكتاملًا لنا، ولا زال يعاني من قصور في تصميم واجهات المستخدم، فلا يوجد حتى الآن أي أداة ذكاء اصطناعي حاليًا قادرة على تصميم واجهات تطبيق تتناسب مع الهوية البصرية الموجودة بالفعل. وهذا القصور ليس نتيجة لنقص المجهود في هذا المجال، فقد ظهرت منصة v0 التي تقدم خدماتها عبر السحابة كواحدة من الأدوات المتخصصة في عالم واجهات المستخدمين المولدة بالذكاء الاصطناعي، ولكنها مازالت مقتصرة على استخدام أكواد رياكت ومكوناتها الموجودة في شاد سي إن shadcn ui components، ويمكن أن تكون نتائجها النهائية مفيدة للنماذج الأولية من المشروع ولكنها تحتاج لمطور واجهة ماهر ليستطيع أن يبني واجهات تناسب الهوية البصرية، وعلى ما يبدو لازالت هذه التقنيات بحاجة لمزيد من التطوير قبل أن تنافس الخبرة البشرية. وقد أصبح تطوير البرمجيات كمنتج منتشرًا بكثرة اليوم، فالمطورون الآن مطالبون بفهم مشكلات العملاء واستخدام الأكواد لحلها بدلاً من مجرد كتابة الكود. وهذا التحول يعني أن الدور التقليدي للمطورين يتغير، ويجب عليهم التركيز على تحقيق أهداف الأعمال بدلاً من مجرد تنفيذ المهام البرمجية. وبالرغم أن هذه التحديات قد تكون صعبة للبعض، فإن تبني تقنيات مثل الذكاء الاصطناعي التوليدي يمكن أن يمنح المطورين ميزة تنافسية. الخلاصة يمكن أن نخلص من حالات الاستخدام والنقاشات الواردة في هذا المقال إلى أن الذكاء الاصطناعي سيظل بحاجة مستمرة للخبراء في توجيه واختبار مخرجاته، ولن يكون بديلاً كاملاً للمطورين المحترفين. لكن في الوقت ذاته، سيصبح أداة قوية لتعزيز إنتاجية المطورين، مما يستدعي الاستعداد لمخاطر استخدامه في تطوير البرمجيات بشكل آمن وفعال. فقد تُرك الحبل على الغارب لإنتاج الكثير من النماذج اللغوية الضخمة، ويبدو أن استخدام الذكاء الاصطناعي سيكون جزءًا أساسيًا في تطوير البرمجيات ولا يمكن تجاهله، لذا، يجب على المؤسسات المعنية تجهيز فرقها بأدوات جديدة لزيادة الإنتاجية ولتوضيح المخاطر الأمنية المرتبطة باستخدام الذكاء الاصطناعي في سير العمل. ترجمة -وبتصرف- لمقال Increase Developer Productivity With Generative AI: Tips From Leading Software Engineers لكاتبه Sam Sycamore اقرأ أيضًا مقدمة إلى الذكاء الاصطناعي التوليدي Generative AI كل ما تود معرفته عن دراسة الذكاء الاصطناعي استكشف مصطلحات الذكاء الاصطناعي التوليدي مستقبل الذكاء الاصطناعي -
 استحوذ الذكاء الاصطناعي في السنوات الأخيرة على الساحة التقنية وأثر على كل الصناعات والقطاعات، بداية من المجالات الإبداعية وصولًا إلى القطاعات المالية، مدفوعًا بالتطور متسارع الخطى للنماذج اللغوية الضخمة Large Language models أو اختصارًا LLMs مثل GPT من شركة OpenAI وجيميناي Gemini من شركة جوجل، فصارت هذه النماذج جزءًا أساسيًا من الأدوات التي يستخدمها مهندسو البرمجيات. لا يستطيع الجيل الحالي من النماذج اللغوية الضخمة استبدال مهندسي البرمجيات بالطبع، ولكنه يمكنه مساعدتهم في مهام عديدة مثل تحليل الأكواد البرمجية، واكتشاف الأخطاء وتتبعها، وإجراء المهام البسيطة الروتينية. نحاول في هذه المقالة تبسيط تعقيدات استخدام النماذج اللغوية الضخمة واستخدامها في تطبيق عملي لتوليد كود بايثون قادر على التفاعل مع تطبيق خارجي. ما هي النماذج اللغوية الضخمة Large Language Models النماذج اللغوية الضخمة هي نماذج تعلم آلي دُربت على كميات ضخمة من البيانات النصية بهدف فهم وتوليد اللغة البشرية، يبنى النموذج اللغوي الضخم عادة باستخدام المحولات transformers والمحولات هي نوع من الشبكات العصبية الاصطناعية تُستخدم بشكل أساسي في معالجة اللغات الطبيعية مثل الترجمة أو الإجابة على الأسئلة وتستخدم أيضًا في تطبيقات مثل معالجة الصور. المميز في المحولات أنها تعتمد على آلية الانتباه الذاتي، مما يجعلها قادرة على التركيز على أجزاء معينة من المدخلات، وهي تقوم على آلية تسمى الانتباه الذاتي self-attention mechanism والتي تعني أن سلسلة المدخلات تعالج بشكل متزامن بدلًا من معالجتها كلمة كلمة، وهذا يتيح للنموذج تحليل جمل كاملة، ويحسن قدرتها على فهم السياق والمعاني الضمنية للكلمات، وفعالة في توليد نصوص قريبة جدًا من الأسلوب البشري. وكلما زاد عمق الشبكة العصبية الاصطناعية كلما أمكنها تعلم معاني أدق في اللغة، ويتطلب النموذج اللغوي الضخم الحديث كمية هائلة من بيانات التدريب وقد يحتوي مليارات المعاملات parameters وهي عناصر تتغير بالتدريب على البيانات ليتأقلم النموذج على المهمة المراد تعلمها، فزيادة عمق الشبكة يؤدي إلى تحسن في المهام مثل الربط بالأسباب reasoning، على سبيل المثال من أجل تدريب GPT-3 جُمعَت بيانات من المحتوى المنشور في الكتب والإنترنت بلغ حجمها 45 تيرابايت من النصوص المضغوطة، ويحتوي النموذج ما يقارب 175 مليار معامل كي يتمكن من تحقيق هذا المستوى من المعرفة. وقد ظهرت عدة نماذج لغوية ضخمة حققت تقدمًا ملحوظًا بالإضافة إلى GPT-3 و GPT-4، نذكر منها على سبيل المثال نموذج PaLM 2 من جوجل ونموذج LLaMa 2 من ميتا. ونظرًا لاحتواء بيانات تدريب هذه النماذج على أكواد برمجية بلغات مختلفة فقد أصبحت هذه النماذج اللغوية الضخمة قادرة على توليد الأكواد البرمجية لا المحتوى النصي فحسب، إذ تستطيع النماذج اللغوية الحديثة تحويل الأوامر أو الموجهات prompts المكتوبة باللغة الطبيعية إلى كود بمختلف اللغات والتقنيات، وعلى الرغم من ذلك لن تحقق الاستفادة المرجوة من هذه الميزات القوية إذا لم تمتلك الخبرة التقنية الكافية. فوائد ومحدويات الأكواد المولدة بنماذج اللغات الضخمة يتطلب حل المشكلات والمهام المعقدة في الغالب تدخل المطورين البشريين، لكن يمكن للنماذج اللغوية الضخمة أن تعمل كمساعدات ذكية للمطورين وتكتب الأكواد لمهام أقل تعقيدًا، وتسهل التعامل مع المهام التكرارية مما يعزز الإنتاجية ويقلل وقت التطوير في مراحل هندسة البرمجيات خصوصًا في المراحل الأولى من تطوير النماذج الأولية للبرمجيات، كما يمكن أن توفر النماذج اللغوية الضخمة مساعدة كبيرة في تصحيح الكود البرمجي وتشرحه وتساعدنا على إيجاد الأخطاء التي قد يصعب علينا ملاحظتها كبشر. يجدر التوضيح أن أي أكواد مولدة باستخدام النماذج اللغوية الضخمة تعتبر نقطة للبداية وليس منتجًا نهائيًا وينبغي دائمًا مراجعة الأكواد المولدة واختبارها. والوعي بمحدوديات نماذج اللغات الضخمة، فهي تفتقد لقدرات حل المشكلات والتفكير المنطقي والإبداعي الذي يميزنا كبشر، إضافة إلى احتمال عدم تعرض النماذج للتدريب الكافي الذي يؤهلها للتعامل مع مهام متخصصة مناسبة لنوع معين من المستخدمين أو أطر العمل غير مفتوحة المصدر، وبالتالي يمكن لهذه النماذج اللغوية الضخمة أن تساعد بشكل كبير ولكن سيبقى دور المطور البشري أساسيًا في عملية التطوير بالطبع. توليد كود برمجي باستخدام نموذج لغوي ضخم: استخدام الواجهة البرمجية للطقس من أهم مميزات التطبيقات الحديثة قدرتها على التعامل مع مصادر خارجية، إذ يمكن للمطورين إرسال طلبات لهذه المصادر الخارجية من خلال واجهة برمجة التطبيقات API وهي مجموعة من التعليمات أو البروتوكولات التي توفر طريقة موحدة لتواصل التطبيقات فيما بينها. وتتطلب كتابة الكود البرمجي الذي يستخدم واجهة برمجة التطبيقات قراءة متعمقة لتوثيقات هذه الواجهة، حيث تشرح التوثيقات كافة المتطلبات والتسميات المصطلح عليها، والوظائف والعمليات التي تدعمها، وتنسيق البيانات المرسلة والمستلمة والمتطلبات الأمنية. ويمكن للنموذج اللغوي الضخم تسريع هذه العملية في حال توفرت لديه المعلومات المطلوبة. حيث يمكن للنموذج اللغوي المساعدة بتوليد الكود البرمجي اللازم لإرسال طلب لواجهة برمجة التطبيقات. وفيما يلي نوضح كيف يمكننا توجيه ChatGPT ليولد كود بلغة البرمجة بايثون لطلب بيانات الطقس من خلال الواجهة البرمجية لتطبيق للطقس OpenWeather API، وسنوضح كيف يمكننا تفادي أخطاء استخدام دوال قديمة deprecated لم تعد مدعومة، وكيف يمكننا إرسال الطلب من خلال الواجهة البرمجية OpenAI API ونختبر تأثير المعاملات على سلوك وأداء النموذج. ملاحظة: انتبه إلى تكلفة استخدام الواجهة البرمجية للطقس OpenWeather API فهي مجانية لأول 1000 طلب فقط في اليوم الواحد. تحويل موجهات تشات جي بي تي لطلبات API يتطلب المثال الذي سنطبقه عرض درجة الحرارة الحالية ووصف حالة الطقس. دعنا نوضح كيف يمكن أن يساعدنا شات جي بي تي ChatGPT في كتابة الكود، سنكتب موجهًا prompt على النحو التالي: سيولد شات جي بي تي ChatGPT هذا الكود ردًا على الموجه السابق: import requests # استبدل "YOUR_API_KEY" بمفتاح OpenWeather API الخاص بك. api_key = "YOUR_API_KEY" api_url = "http://api.openweathermap.org/data/2.5/weather" # اسم المدينة التي ترغب في الحصول على معلومات الطقس لها. city_name = "London" # المعلمات المطلوبة لإرسال الطلب إلى واجهة API. params = { 'q': city_name, # اسم المدينة 'appid': api_key, # مفتاح API 'units': 'imperial' # استخدم metric للدرجة المئوية أو imperial للفهرنهايت } try: # إرسال طلب GET إلى واجهة API. response = requests.get(api_url, params=params) # التحقق مما إذا كان الطلب ناجحًا if response.status_code == 200: # قراءة وتحليل البيانات المستلمة بصيغة JSON. weather_data = response.json() print("بيانات الطقس لمدينة:", city_name) print("درجة الحرارة:", weather_data['main']['temp'], "°F") print("الوصف:", weather_data['weather'][0]["description"]) else: # طباعة رسالة خطأ إذا لم يكن الطلب ناجحًا. print("خطأ:", response.status_code, response.text) except Exception as e: # التعامل مع أي أخطاء أثناء تنفيذ الكود. print("حدث خطأ:", e) يمكن أن تلاحظ أنه على الرغم من عدم تحديد الموقع المطلوب للواجهة البرمجية الخاصة بالطقي، فإن الكود المولد يتضمن متغير يسمى city_name وهو مضبوط على قيمة افتراضية هي لندن ويمكن تعديها حسب الطلب، ولا تنسى بالطبع استبدال YOUR_API_KEY بالمفتاح الخاص بك لواجهة برمجة التطبيق للطقس OpenWeather API. كي نتمكن من اختبار الكود المولد، نحتاج لأن يكون مفسر interpreter لغة بايثون مثبت على جهازنا، بعد تثبيته يمكن تشغيل الكود محرر أكواد مثل فيجوال ستوديو كود Visual Studio Code أو باستخدام سطر الأوامر Terminal. إليك بيانات الطقس لمدينة لندن المستلمة من الواجهة البرمجية: بيانات الطقس لمدينة: London °F درجة الحرارة: 50.4 الوصف: overcast clouds سنحتاج غالبًا لتخزين البيانات التي حصلنا عليها من الواجهة البرمجية، وبالتالي سنحتاج لتحويل البيانات إلى تنسيق محدد مثل XML أو CSV أو استخدام أوامر لغة الاستعلام البنيوية SQL لحفظ البيانات في جداول قاعدة البيانات، لذا سنطلب من النموذج اللغوي مساعدتنا في هذه المهمة عن طريق توليد الكود المناسب لكل تنسيق، فمثلا يمكننا إضافة الجملة التالية للموجه السابق: سيعيد ChatGPT نفس الكود السابق، ولكن مع إضافة بعض جمل الاستيراد وتحديث تنسيق المخرجات: # استيراد المكتبات اللازمة import requests import json from datetime import datetime # رابط الواجهة البرمجية api_url = "http://api.openweathermap.org/data/2.5/weather" # إعداد المعاملات المطلوبة للطلب params = { 'q': 'الرياض', # اسم المدينة 'appid': 'مفتاح_API_الخاص_بك', # استبدل بمفتاح API الخاص بك 'units': 'imperial' # تحديد وحدة القياس (الفهرنهايت) } try: # إرسال طلب GET إلى الواجهة البرمجية response = requests.get(api_url, params=params) # التحقق من نجاح الطلب if response.status_code == 200: # تحويل الاستجابة إلى صيغة JSON weather_data = response.json() # استخراج البيانات المهمة city = params['q'] # اسم المدينة temperature = weather_data['main']['temp'] # درجة الحرارة weather_description = weather_data['weather'][0]['description'] # وصف الطقس update_date = datetime.utcnow().strftime('%Y-%m-%d %H:%M:%S') # وقت التحديث # إنشاء أمر SQL لإدخال البيانات في قاعدة البيانات sql_command = f"INSERT INTO current_weather (city, temperature, weather_description, update_date) VALUES ('{city}', {temperature}, '{weather_description}', '{update_date}')" # طباعة أمر SQL print("أمر SQL للإدخال في قاعدة البيانات:") print(sql_command) else: # طباعة رسالة خطأ في حال فشل الطلب print("حدث خطأ في الطلب:", response.status_code, response.text) except Exception as e: # طباعة رسالة خطأ في حال حدوث استثناء print("حدث خطأ أثناء تنفيذ البرنامج:", e) وسيؤدي تنفيذ الكود السابق لتوليد الأمر التالي بلغة SQL: INSERT INTO current_weather (city, temperature, weather_description, update_date) VALUES ('London', 53.37, 'broken clouds', '2024-02-06 04:43:35') ولكن سنرى تحذيرًا ينبهنا إلى عدم استخدام الدالة ()utcnow حيث أنها مهملة deprecated ولن تكون متوفرة في إصدارات قادمة وهذا قد يتسبب في تعطل الكود الخاص بنا في التحديثات المستقبلية: DeprecationWarning: datetime.datetime.utcnow() is deprecated and scheduled for removal in a future version. Use timezone-aware objects to represent datetimes in UTC: datetime.datetime.now(datetime.UTC). وكي نمنع ChatGPT من استخدام دوال مهملة deprecated، سنضيف التوجيه التالي: بعد إضافة هذا السطر، سيبدل ChatGPT الدالة ()utcnow بدالة أخرى كما يلي: # استخدم الكائن timezone-aware لتحديث التاريخ update_date = datetime.now(timezone.utc).strftime('%Y-%m-%d %H:%M:%S') يعيد لنا هذا الكود مجددًا أمرًا بلغة SQL ويمكن اختباره في أي محرر استعلامات Query editors لنظام إدارة قواعد البيانات DBMS. وفي حال كنت تولد هذا الكود ضمن تطبيق ويب تقليدي فمن المتوقع تشغيل أمر SQL مباشرة بعد توليده من خلال الواجهة البرمجية وتحديث بيانات قاعدة البيانات في الزمن الحقيقي. استخدام الواجهة البرمجية OpenAI API بدلًا من شات ChatGPT تملك العديد من نماذج اللغات الضخمة واجهة برمجة تطبيقات API تمكّن المطور من التفاعل مع النماذج اللغوية الضخمة برمجيًا ودمجها بسلاسة داخل تطبيقاته، سنستفيد من هذه الواجهات البرمجية لإنشاء مساعد ذكي بشكل افتراضي، يوفر لنا هذا المساعد ميزات عديدة مثل إكمال الكود أو توليده من الصفر أو إعادة صياغته وتحسينه. ويمكن تحسين واجهات المستخدم وتخصيصها من خلال قوالب جاهزة من الموجهات Prompts templates، كما يتيح لنا دمج النماذج اللغوية الضخمة برمجيًا جدولة المهام أو تفعيلها عند تحقق شروط معينة ويسهل أتمتة المساعد الذكي الذي نعمل عليه. سننفذ في هذا المثال نفس المهمة السابقة وهي طلب معلومات الطقس باستخدام بايثون للتفاعل برمجيًا مع الواجهة البرمجية OpenAI API وتوليد الكود من خلال واجهة المستخدم بدلًا من كتابة موجّه في ChatGPT مباشرة. بداية علينا تثبيت الواجهة البرمجية OpenAI API باستخدام الأمر التالي: pip install openai الآن لنتمكن من استخدام الواجهة البرمجية OpenAI API نحتاج لمفتاح الواجهة API key وهو غير مجاني ويتطلب دفع رسوم. بعدها، يمكننا استيراد المكتبة openai وإرسال نفس الموجه المستخدم من قبل مع إزالة الجزء الخاص بتوليد أوامر SQL، كما نحدد النموذج المستخدم GPT-3.5 من خلال الكود التالي: import openai openai.api_key = "YOUR_API_KEY" # استبدله بمفتاح الواجهة البرمجية الخاص بك response = openai.chat.completions.create( model='gpt-3.5-turbo', max_tokens=1024, temperature=0.3, top_p=0.9, messages = [ {'role': 'system', 'content': 'أنت مساعد ذكي قائم على الذكاء الاصطناعي.'}, {'role': 'user', 'content': "اكتب كود بلغة بايثون باستخدام مكتبة requests لإرسال طلب GET إلى واجهة OpenWeather API للحصول على بيانات الطقس، وذلك عبر نقطة الوصول التالية http://api.openweathermap.org/data/2.5/weather. يجب أن يتضمن الطلب مفتاح API الخاص بك ضمن الرابط باستخدام المعامل appid. يُتوقع أن تُعيد الواجهة البيانات بتنسيق JSON، ويجب على الكود استخراج درجة الحرارة من البيانات وإعادتها بوحدة الفهرنهايت ولا يستخدم أي دوال قديمة غير مستعملة"}, ] response_message = response.choices[0].message.content print(response_message ) سيولد النموذج اللغوي الضخم كود بايثون التالي، والذي يجلب درجات الحرارة لمدينة لندن: import requests # مفتاح الواجهة البرمجية ونقطة الوصول url = "http://api.openweathermap.org/data/2.5/weather" api_key = "YOUR_API_KEY" # معاملات الاستعلام params = { 'q': 'London,uk', # مثال على المدينة ورمز الدولة. 'appid': api_key } # إرسال طلب GET. response = requests.get(url, params=params) # التحقق مما إذا كان الطلب ناجحاً. if response.status_code == 200: # تحليل استجابة JSON. data = response.json() # طباعة درجة الحرارة بالدرجة المئوية. temperature = data['main']['temp'] - 273.15 print(f"درجة الحرارة في لندن هي {temperature:.2f}°C.") else: print(f"خطأ: {response.status_code}") لاحظ أننا أزلنا التعليمات الخاصة بتحديد درجات الحرارة بالفهرنهايت لذا لم يحدد النموذج اللغوي الضخم وحدة القياس عند طلب الواجهة البرمجية للطقس، ولكنه اختار حسابها رياضيًا بتحويل الوحدة من الكلفن إلى سلسيوس عند عرض النتائج. الاستفادة من معاملات النموذج اللغوي الضخم لتحقيق أقصى استفادة يمكننا ضبط بعض المعاملات عند استخدام الواجهة البرمجية لنماذج الذكاء الاصطناعي والنماذج اللغوية الضخمة من أجل تعديل الردود المولدة منها، فهناك معاملات يمكنها تحديد مستوى العشوائية والإبداع في الردود المولدة كالمعامل Temperature، ومعاملات يمكنها التحكم بتكرار النصوص المولدة مثل Repetition Penalty، بينما تؤثر معاملات أخرى على النص اللغوي المولد مما يساعد على التحكم في جودة الكود الناتج. في الكود السابق، يمكننا ضبط قيم معاملات GPT في السطر السابع على النحو التالي: max_tokens=1024, temperature=0.3, top_p=0.9, المعامل الوصف التأثير على الكود المولد Temperature يعني درجة الحرارة إذ يتحكم هذا المعامل في عشوائية الردود المولدة، أو درجة الإبداعية في الردود، فالقيمة العالية لهذا المعامل تزيد عشوائية الردود المولدة، بينما القيمة المنخفضة تولد ردودًا واقعية، القيم الممكنة لهذا المعامل بين 0 و 2 والقيمة الافتراضية 0.7 أو 1 بحسب النموذج المستخدم. ستولد القيمة المنخفضة لهذا المعامل كودًا آمنًا يتبع الأنماط والهياكل المكتسبة خلال عملية التدريب، بينما ستولد القيمة العالية ردودًا أكثر تميزًا وغير اعتيادية مما يرفع من احتمالية الأخطاء والتناقضات البرمجية. Max token يحدد هذا المعامل الحد الأقصى لعدد الوحدات النصية tokens المولدة في الاستجابة. إذا ضبطته بقيمة صغيرة، فقد يتسبب ذلك في أن تكون الاستجابة قصيرة جدًا، بينما إذا تم ضبطته بقيمة كبيرة جدًا، قد يؤدي ذلك لاستهلاك عدد كبير من الوحدات النصية المتاحة، مما يزيد من تكلفة الاستخدام يجب أن يضبط المعامل على قيمة عالية بما يكفي لتغطية جميع الأكواد التي تحتاج إلى توليدها. ويمكنك تقليله إذا كنت ترغب في توليد الكود فقط دون توفير شرح الكود المضاف من النموذج top_p يتحكم هذا المعامل في اختيار الكلمات التالية بتقليص نطاق الخيارات المتاحة. إذا منحناه القيمة 0.1 سيقتصر على أفضل 10% من الكلمات الأكثر احتمالاً، مما يزيد الدقة. وإذا منحناه القيمة 0.5 سيوسع الاختيار ليشمل أفضل 50%، مما يعزز التنوع. ويساعد في موازنة الدقة والإبداع في الردوع. عند ضبط المعامل بقيمة منخفضة، يصبح الكود المولد أكثر توقعًا وارتباطًا بالسياق، ويجري اختيار الاحتمالات الأكثر ترجيحًا بناءً على السياق الحالي. أما عند زيادة قيمته يزداد التنوع في المخرجات، مما قد يؤدي إلى توليد كود أقل ارتباطًا بالسياق وقد يتسبب في أخطاء أو توليد كود متناقض. frequency_penalty يعني عقوبة التكرار إذ يحدّ هذا المعامل من تكرار الكلمات والعبارات في ردود النموذج اللغوي الكبير. عند ضبطه على قيمة عالية، يقلل من تكرار الكلمات أو العبارات التي استخدمها النموذج سابقًا. أما عند ضبطه على قيمة منخفضة، فيسمح للنموذج بتكرار الكلمات والعبارات. حيث تتراوح قيم هذا المعامل من 0 إلى 2. تضمن القيمة العالية لهذا المعامل تقليل التكرار في الكود المولد، مما يؤدي لتوليد أكواد أكثر تنوعًا وإبداعًا. ومع ذلك، قد يؤدي ذلك إلى اختيار عناصر أقل كفاءة أو غير صحيحة. من ناحية أخرى، عند خفض قيمته، قد لا يستكشف طرقًا متنوعة للحل. presence_penalty يعني عقوبة التواجد ويرتبط هذا المعامل بالمعامل السابق فكلاهما يشجعان على التنوع والتفرد في الكلمات المستخدمة، حيث يعاقب المعامل السابق الوحدات النصية التي استخدمت عدة مرات في النص في حين يعاقب المعامل الحالي الوحدات النصية التي ظهرت من قبل بغض النظر عن مرات التكرار، يتلخص تأثير معامل عقوبة التكرار في أنه يقلل من تكرار الكلمات بينما يركز معامل عقوبة التواجد على استخدام كلمات جديدة بالكليّة، والقيمة الصغرى لهذا المعامل هي 0 أما القيمة العظمى فهي 2. له تأثير مشابه لعقوبة التكرار، فالقيمة العالية تشجع النموذج على استكشاف حلول بديلة، ولكن قد يصبح الكود المولد أقل كفاءة ومليء بالأخطاء، بينما تسمح القيمة المنخفضة بتكرار الكود مما يؤدي إلى كود أكثر كفاءة واتساقًا، خاصةً عند وجود أنماط متكررة. stop دور هذا المعامل هو تحديد نقطة التوقف في عملية توليد النصوص. عند ضبطه مع سلسلة معينة مثل "n/"، سيتوقف النموذج عن توليد النصوص بمجرد أن يصادف هذه السلسلة مما يساعد في التحكم بدقة في نهاية الرد المولد وتحديد متى يجب أن يتوقف النموذج عن إضافة المزيد من الكلمات. يمنع هذا المعامل النموذج من توليد أجزاء من الكود لا تتناسب مع السياق أو الوظيفة المطلوبة. يجب أن تكون سلسلة التوقف نقطة منطقية وواضحة لنهاية الكود، مثل نهاية دالة أو نهاية حلقة تكرارية، لضمان توقف النموذج عن توليد المزيد من الكود بشكل مناسب. لنختبر كيفية تأثير هذه المعاملات على توليد الكود، سنجرب تعديل معاملات عقوبة التكرار frequency_penalty وعقوبة التواجد presence_penalty . عند تهيئة عقوبة التكرار frequency_penalty بقيمة مرتفعة وهي 1.5،سينتج النموذج اللغوي الضخم كودًا إضافيًا ليلاقى التوقعات محاولًا تفادي تكرار المخرجات السابقة: # ... try: # إرسال طلب GET مع المعلمات والحصول على البيانات في تنسيق JSON. response = requests.get(url, params=params) if response.status_code == 200: weather_data = response.json() # طباعة بعض المعلومات المهمة من بيانات الطقس. print("المدينة:", weather_data['name']) print("درجة الحرارة:", weather_data['main']['temp'], "K") except requests.exceptions.RequestException as e: # التعامل مع أي خطأ حدث أثناء الطلب print("خطأ:", e) عند العمل مع الكود الذي يتعامل مع واجهة برمجية API من المهم أن نلاحظ أن النتائج قد تكون غير متوقعة. ففي الكود السابق، على الرغم من أن إضافة معالجة الأخطاء مفيدة، إلا أننا لم نطلب من النموذج توليد كود يتعامل مع جميع الأخطاء المحتملة بشكل دقيق. لهذا السبب، عند إرسال نفس الطلب مرة أخرى مع نفس المعاملات، قد نحصل على نتائج مختلفة تمامًا. ولضمان استقرار الكود ومعالجته للأخطاء بشكل صحيح، يجب إضافة موجه أولي initial prompt يوجّه النموذج لتوليد الكود مع معالجة الأخطاء بشكل مناسب. بهذا الشكل، يمكن ضمان أن الكود سيكون متسقًا ويعمل كما هو متوقع في جميع الحالات. يمكننا ضبط المعامل presence_penalty بقيمة عالية ولتكن 2.0 للحصول على تأثير مشابه، حيث يتفادى النموذج تكرار المخرجات السابقة ويرسل طلب جديد للواجهة البرمجية للطقس OpenWeather API من خلال دالة ممرًا لها مفتاح الواجهة البرمجية API key كمعامل كما يلي: import requests def get_weather(api_key): url = "http://api.openweathermap.org/data/2.5/weather" params = { 'q': 'London,uk', # مثال على المدينة ورمز الدولة. 'appid': api_key } response = requests.get(url, params=params) # إضافة سطر إرسال الطلب if response.status_code == 200: data = response.json() return data else: print("خطأ:", response.status_code) # استبدل "YOUR_API_KEY" بمفتاح الواجهة البرمجية الفعلي من OpenWeather. api_key = "YOUR_API_KEY" weather_data = get_weather(api_key) print(weather_data) إن إنشاء دالة برمجية مخصصة لطلب الواجهة البرمجية لتطبيق الطقس إضافة مفيدة للكود، ولكن تمرير مفتاح الواجهة من خلال الدالة أمر غريب، فمن المعتاد في أغلب حالات الاستخدام تمرير المدينة city كمعامل للدالة، وهنا يمكننا معالجة هذه المشكلة بتعديل الموجه الأولي. يتطلب ضبط قيم معاملات نماذج اللغة الضخمة الكثير من التجربة، فبعض النتائج تكون غير متوقعة وبعض التعديلات قد تبدو عديمة التأثير، فتعديل المعاملات لا يمتلك تأثيرًا موحدًا يضمن اتباع أفضل الممارسات في توليد الكود. دمج النماذج اللغوية الضخمة في ملفات الكود المصدري بمجرد أن يصبح الكود المولد باستخدام النموذج اللغوي الضخم محسنًا وجاهزًا للعمل، ستكون الخطوة التالية هي دمج الكود الناتج مع الأكواد البرمجية السابقة. لكن قد يؤدي نسخ الكود بشكل مباشر للكود الموجود سابقًا لمشكلات في تنظيم الكود وتنسيقها مما يصعب صيانة وتعديل الكود لاحقًا. يمكننا تبسيط هذه العملية بتحويل الكود إلى أجزاء قابلة لإعادة الاستخدام مثل دوال برمجية أو كائنات وأصناف برمجية، ويمكننا تحقيق هذا أيضًا باستخدام النموذج اللغوي الضخم ما دامت التعليمات المفصلة للقيام بهذا مرفقةً في الموجه Prompt، ويجب أيضاً تحديد مدخلات هذه الدوال والمخرجات المتوقعة منها. دعنا نجعل النموذج اللغوي الضخم ينشئ الكائن البرمجي weather الذي يحوي دالة get_weather ، من خلال إضافة الأوامر التالية للموجه: عندها سنحصل على كود بايثون التالي: import requests class Weather: def __init__(self, api_key): self.api_key = api_key self.temperature = None def get_weather(self, city): url = 'http://api.openweathermap.org/data/2.5/weather' params = { 'q': city, 'appid': self.api_key, 'units': 'imperial' # طلب درجة الحرارة بالفهرنهايت. } response = requests.get(url, params=params) data = response.json() if response.status_code == 200: self.temperature = data['main']['temp'] print(f"درجة الحرارة في {city} هي {self.temperature}°F.") else: print(f"خطأ: {data['message']}") # استبدل "YOUR_API_KEY" بمفتاح الواجهة البرمجية الفعلي من OpenWeather. api_key = "YOUR_API_KEY" weather = Weather(api_key) weather.get_weather('London') يولّد النموذج دالة قابلة للتشغيل بواسطة الكائن weather، ويمكننا دمج هذا الكائن بتطبيق آخر بكل سهولة، ولكن علينا معالجة الأخطاء التي قد تقع لضمان عدم فشل عمل التطبيق وعدم عرضه لبيانات حساسة أو سرية. اختبار التطبيق ومعالجة الأخطاء إن فشل طلبات واجهة البرمجة للتطبيق API أمر شائع في التطبيقات الحقيقية، فيمكن أن تفشل الطلبات لعدة أسباب، لذا لضمان الاعتمادية ينبغي أن يتضمن الكود حالات لمعالجة الأخطاء التي يمكن أن تقع لمنع فشل التطبيق الكامل، في أغلب الأمثلة السابقة كان الكود المولد بواسطة النموذج يحوي شرطًا يختبر رمز الحالة لبروتوكول نقل النص الفائق HTTP ، فالرمز 200 يعبر عن نجاح الطلب بينما أي رمز آخر يعبر عن فشل الطلب أو وجود خطأ ينبغي التعامل معه فيقوم الكود المولد بطباعته، ولكن هذا الشرط لا يأخذ في الاعتبار حالات أخطاء شائعة أخرى مثل انتهاء وقت الطلب timeout أو أخطاء نظام أسماء النطاقات DNS. لضمان الاعتمادية ينبغي أن يحوي الكود المولد آلية لمعالجة الأخطاء، مثل استخدام try-catch عند إجراء طلب من خلال واجهة برمجة التطبيق API. لذا أضفنا النص التالي للموجه السابق: ولّد هذا التوجيه كود بايثون يحتوي كلتلة try-catch تعالج الأخطاء المحتملة: class Weather: def __init__(self, api_key): self.api_key = api_key self.temperature = None def get_weather(self, city): try: # بناء عنوان URL للواجهة البرمجية باستخدام المدينة ومفتاح API المقدم. url = "http://api.openweathermap.org/data/2.5/weather" params = {'q': city, 'appid': self.api_key, 'units': 'imperial' # الحصول على درجة الحرارة بالفهرنهايت. } # إرسال طلب GET إلى الواجهة البرمجية. response = requests.get(url, params=params) # التحقق من حالة الاستجابة if response.status_code == 200: # تحليل الاستجابة بتنسيق JSON data = response.json() # استخراج درجة الحرارة بالفهرنهايت من الاستجابة. self.temperature = data['main']['temp'] else: # عرض وصف الخطأ إذا كانت حالة الاستجابة ليست 200. print(f'خطأ: {response.status_code} - {response.json()["message"]}') except requests.exceptions.RequestException as e: # التعامل مع أي استثناءات تحدث أثناء الطلب. print(f'خطأ: {e}') يعد الكود المولد بواسطة النموذج اللغوي الضخم نقطة بداية جيدة، لكنك ستحتاج في الغالب لتعديلات إضافية لتحصيصه وزيادة الوظائف التي يقوم به، على سبيل المثال من الممكن تسجيل الأخطاء التي تحدث وتنبيه المستخدم من أخطاء الإعدادات التي قد تشمل أخطاء في استيثاق الواجهة البرمجية API authentication error ويمكن للمطورين إضافة واجهة برمجية احتياطية في حالة تعطل الواجهة الأساسية. بمجرد أن يصبح الكود قادرًا على تأدية وظيفته كما ينبغي، فالخطوة التالية مهمة للتأكد من صموده عند التشغيل الفعلي، وينبغي اختبار كل الوظائف والحالات الممكنة للخطأ، ولضمان اعتمادية قوية يمكننا أتمتة عملية الاختبارات وتقييم الأداء من خلال قياس مؤشرات الأداء المختلفة مثل وقت التشغيل واستخدام ذاكرة الوصول العشوائي واستخدام الموارد الحاسوبية، ستساعدنا هذه المؤشرات على تحديد نقاط الخلل في النظام وتحسين الموجهات prompts وصقل fine-tune معاملات النموذج اللغوي الضخم. تطور نماذج اللغات الضخمة تطورت النماذج اللغوية الضخمة لكنها لن تستبدل الخبرة البشرية حاليًا، بل سيقتصر دورها على توليد الكود البرمجي مما يسرّع ويسهّل عملية التطوير كما أنها قادرة على توليد نسخ متنوعة من الكود مما يساعد المطور على اختيار أفضل خيار من بينها، كما يمكنها تولي إنجاز المهام البسيطة والتكرارية لزيادة إنتاجية المطورين، مما يتيح للمطورين التركيز على المهام المعقدة التي تتطلب معرفة متخصصة وتفكير بشري إبداعي. ترجمة-وبتصرٌّف-للمقال Using an LLM API As an Intelligent Virtual Assistant for Python Development اقرأ أيضاً دليل استخدام ChatGPT API لتحسين خدماتك عبر الإنترنت تعرف على مكتبة المحوّلات Transformers من منصة Hugging Face تلخيص النصوص باستخدام الذكاء الاصطناعي استخدام النماذج التوليديّة Generative models لتوليد الصور
استحوذ الذكاء الاصطناعي في السنوات الأخيرة على الساحة التقنية وأثر على كل الصناعات والقطاعات، بداية من المجالات الإبداعية وصولًا إلى القطاعات المالية، مدفوعًا بالتطور متسارع الخطى للنماذج اللغوية الضخمة Large Language models أو اختصارًا LLMs مثل GPT من شركة OpenAI وجيميناي Gemini من شركة جوجل، فصارت هذه النماذج جزءًا أساسيًا من الأدوات التي يستخدمها مهندسو البرمجيات. لا يستطيع الجيل الحالي من النماذج اللغوية الضخمة استبدال مهندسي البرمجيات بالطبع، ولكنه يمكنه مساعدتهم في مهام عديدة مثل تحليل الأكواد البرمجية، واكتشاف الأخطاء وتتبعها، وإجراء المهام البسيطة الروتينية. نحاول في هذه المقالة تبسيط تعقيدات استخدام النماذج اللغوية الضخمة واستخدامها في تطبيق عملي لتوليد كود بايثون قادر على التفاعل مع تطبيق خارجي. ما هي النماذج اللغوية الضخمة Large Language Models النماذج اللغوية الضخمة هي نماذج تعلم آلي دُربت على كميات ضخمة من البيانات النصية بهدف فهم وتوليد اللغة البشرية، يبنى النموذج اللغوي الضخم عادة باستخدام المحولات transformers والمحولات هي نوع من الشبكات العصبية الاصطناعية تُستخدم بشكل أساسي في معالجة اللغات الطبيعية مثل الترجمة أو الإجابة على الأسئلة وتستخدم أيضًا في تطبيقات مثل معالجة الصور. المميز في المحولات أنها تعتمد على آلية الانتباه الذاتي، مما يجعلها قادرة على التركيز على أجزاء معينة من المدخلات، وهي تقوم على آلية تسمى الانتباه الذاتي self-attention mechanism والتي تعني أن سلسلة المدخلات تعالج بشكل متزامن بدلًا من معالجتها كلمة كلمة، وهذا يتيح للنموذج تحليل جمل كاملة، ويحسن قدرتها على فهم السياق والمعاني الضمنية للكلمات، وفعالة في توليد نصوص قريبة جدًا من الأسلوب البشري. وكلما زاد عمق الشبكة العصبية الاصطناعية كلما أمكنها تعلم معاني أدق في اللغة، ويتطلب النموذج اللغوي الضخم الحديث كمية هائلة من بيانات التدريب وقد يحتوي مليارات المعاملات parameters وهي عناصر تتغير بالتدريب على البيانات ليتأقلم النموذج على المهمة المراد تعلمها، فزيادة عمق الشبكة يؤدي إلى تحسن في المهام مثل الربط بالأسباب reasoning، على سبيل المثال من أجل تدريب GPT-3 جُمعَت بيانات من المحتوى المنشور في الكتب والإنترنت بلغ حجمها 45 تيرابايت من النصوص المضغوطة، ويحتوي النموذج ما يقارب 175 مليار معامل كي يتمكن من تحقيق هذا المستوى من المعرفة. وقد ظهرت عدة نماذج لغوية ضخمة حققت تقدمًا ملحوظًا بالإضافة إلى GPT-3 و GPT-4، نذكر منها على سبيل المثال نموذج PaLM 2 من جوجل ونموذج LLaMa 2 من ميتا. ونظرًا لاحتواء بيانات تدريب هذه النماذج على أكواد برمجية بلغات مختلفة فقد أصبحت هذه النماذج اللغوية الضخمة قادرة على توليد الأكواد البرمجية لا المحتوى النصي فحسب، إذ تستطيع النماذج اللغوية الحديثة تحويل الأوامر أو الموجهات prompts المكتوبة باللغة الطبيعية إلى كود بمختلف اللغات والتقنيات، وعلى الرغم من ذلك لن تحقق الاستفادة المرجوة من هذه الميزات القوية إذا لم تمتلك الخبرة التقنية الكافية. فوائد ومحدويات الأكواد المولدة بنماذج اللغات الضخمة يتطلب حل المشكلات والمهام المعقدة في الغالب تدخل المطورين البشريين، لكن يمكن للنماذج اللغوية الضخمة أن تعمل كمساعدات ذكية للمطورين وتكتب الأكواد لمهام أقل تعقيدًا، وتسهل التعامل مع المهام التكرارية مما يعزز الإنتاجية ويقلل وقت التطوير في مراحل هندسة البرمجيات خصوصًا في المراحل الأولى من تطوير النماذج الأولية للبرمجيات، كما يمكن أن توفر النماذج اللغوية الضخمة مساعدة كبيرة في تصحيح الكود البرمجي وتشرحه وتساعدنا على إيجاد الأخطاء التي قد يصعب علينا ملاحظتها كبشر. يجدر التوضيح أن أي أكواد مولدة باستخدام النماذج اللغوية الضخمة تعتبر نقطة للبداية وليس منتجًا نهائيًا وينبغي دائمًا مراجعة الأكواد المولدة واختبارها. والوعي بمحدوديات نماذج اللغات الضخمة، فهي تفتقد لقدرات حل المشكلات والتفكير المنطقي والإبداعي الذي يميزنا كبشر، إضافة إلى احتمال عدم تعرض النماذج للتدريب الكافي الذي يؤهلها للتعامل مع مهام متخصصة مناسبة لنوع معين من المستخدمين أو أطر العمل غير مفتوحة المصدر، وبالتالي يمكن لهذه النماذج اللغوية الضخمة أن تساعد بشكل كبير ولكن سيبقى دور المطور البشري أساسيًا في عملية التطوير بالطبع. توليد كود برمجي باستخدام نموذج لغوي ضخم: استخدام الواجهة البرمجية للطقس من أهم مميزات التطبيقات الحديثة قدرتها على التعامل مع مصادر خارجية، إذ يمكن للمطورين إرسال طلبات لهذه المصادر الخارجية من خلال واجهة برمجة التطبيقات API وهي مجموعة من التعليمات أو البروتوكولات التي توفر طريقة موحدة لتواصل التطبيقات فيما بينها. وتتطلب كتابة الكود البرمجي الذي يستخدم واجهة برمجة التطبيقات قراءة متعمقة لتوثيقات هذه الواجهة، حيث تشرح التوثيقات كافة المتطلبات والتسميات المصطلح عليها، والوظائف والعمليات التي تدعمها، وتنسيق البيانات المرسلة والمستلمة والمتطلبات الأمنية. ويمكن للنموذج اللغوي الضخم تسريع هذه العملية في حال توفرت لديه المعلومات المطلوبة. حيث يمكن للنموذج اللغوي المساعدة بتوليد الكود البرمجي اللازم لإرسال طلب لواجهة برمجة التطبيقات. وفيما يلي نوضح كيف يمكننا توجيه ChatGPT ليولد كود بلغة البرمجة بايثون لطلب بيانات الطقس من خلال الواجهة البرمجية لتطبيق للطقس OpenWeather API، وسنوضح كيف يمكننا تفادي أخطاء استخدام دوال قديمة deprecated لم تعد مدعومة، وكيف يمكننا إرسال الطلب من خلال الواجهة البرمجية OpenAI API ونختبر تأثير المعاملات على سلوك وأداء النموذج. ملاحظة: انتبه إلى تكلفة استخدام الواجهة البرمجية للطقس OpenWeather API فهي مجانية لأول 1000 طلب فقط في اليوم الواحد. تحويل موجهات تشات جي بي تي لطلبات API يتطلب المثال الذي سنطبقه عرض درجة الحرارة الحالية ووصف حالة الطقس. دعنا نوضح كيف يمكن أن يساعدنا شات جي بي تي ChatGPT في كتابة الكود، سنكتب موجهًا prompt على النحو التالي: سيولد شات جي بي تي ChatGPT هذا الكود ردًا على الموجه السابق: import requests # استبدل "YOUR_API_KEY" بمفتاح OpenWeather API الخاص بك. api_key = "YOUR_API_KEY" api_url = "http://api.openweathermap.org/data/2.5/weather" # اسم المدينة التي ترغب في الحصول على معلومات الطقس لها. city_name = "London" # المعلمات المطلوبة لإرسال الطلب إلى واجهة API. params = { 'q': city_name, # اسم المدينة 'appid': api_key, # مفتاح API 'units': 'imperial' # استخدم metric للدرجة المئوية أو imperial للفهرنهايت } try: # إرسال طلب GET إلى واجهة API. response = requests.get(api_url, params=params) # التحقق مما إذا كان الطلب ناجحًا if response.status_code == 200: # قراءة وتحليل البيانات المستلمة بصيغة JSON. weather_data = response.json() print("بيانات الطقس لمدينة:", city_name) print("درجة الحرارة:", weather_data['main']['temp'], "°F") print("الوصف:", weather_data['weather'][0]["description"]) else: # طباعة رسالة خطأ إذا لم يكن الطلب ناجحًا. print("خطأ:", response.status_code, response.text) except Exception as e: # التعامل مع أي أخطاء أثناء تنفيذ الكود. print("حدث خطأ:", e) يمكن أن تلاحظ أنه على الرغم من عدم تحديد الموقع المطلوب للواجهة البرمجية الخاصة بالطقي، فإن الكود المولد يتضمن متغير يسمى city_name وهو مضبوط على قيمة افتراضية هي لندن ويمكن تعديها حسب الطلب، ولا تنسى بالطبع استبدال YOUR_API_KEY بالمفتاح الخاص بك لواجهة برمجة التطبيق للطقس OpenWeather API. كي نتمكن من اختبار الكود المولد، نحتاج لأن يكون مفسر interpreter لغة بايثون مثبت على جهازنا، بعد تثبيته يمكن تشغيل الكود محرر أكواد مثل فيجوال ستوديو كود Visual Studio Code أو باستخدام سطر الأوامر Terminal. إليك بيانات الطقس لمدينة لندن المستلمة من الواجهة البرمجية: بيانات الطقس لمدينة: London °F درجة الحرارة: 50.4 الوصف: overcast clouds سنحتاج غالبًا لتخزين البيانات التي حصلنا عليها من الواجهة البرمجية، وبالتالي سنحتاج لتحويل البيانات إلى تنسيق محدد مثل XML أو CSV أو استخدام أوامر لغة الاستعلام البنيوية SQL لحفظ البيانات في جداول قاعدة البيانات، لذا سنطلب من النموذج اللغوي مساعدتنا في هذه المهمة عن طريق توليد الكود المناسب لكل تنسيق، فمثلا يمكننا إضافة الجملة التالية للموجه السابق: سيعيد ChatGPT نفس الكود السابق، ولكن مع إضافة بعض جمل الاستيراد وتحديث تنسيق المخرجات: # استيراد المكتبات اللازمة import requests import json from datetime import datetime # رابط الواجهة البرمجية api_url = "http://api.openweathermap.org/data/2.5/weather" # إعداد المعاملات المطلوبة للطلب params = { 'q': 'الرياض', # اسم المدينة 'appid': 'مفتاح_API_الخاص_بك', # استبدل بمفتاح API الخاص بك 'units': 'imperial' # تحديد وحدة القياس (الفهرنهايت) } try: # إرسال طلب GET إلى الواجهة البرمجية response = requests.get(api_url, params=params) # التحقق من نجاح الطلب if response.status_code == 200: # تحويل الاستجابة إلى صيغة JSON weather_data = response.json() # استخراج البيانات المهمة city = params['q'] # اسم المدينة temperature = weather_data['main']['temp'] # درجة الحرارة weather_description = weather_data['weather'][0]['description'] # وصف الطقس update_date = datetime.utcnow().strftime('%Y-%m-%d %H:%M:%S') # وقت التحديث # إنشاء أمر SQL لإدخال البيانات في قاعدة البيانات sql_command = f"INSERT INTO current_weather (city, temperature, weather_description, update_date) VALUES ('{city}', {temperature}, '{weather_description}', '{update_date}')" # طباعة أمر SQL print("أمر SQL للإدخال في قاعدة البيانات:") print(sql_command) else: # طباعة رسالة خطأ في حال فشل الطلب print("حدث خطأ في الطلب:", response.status_code, response.text) except Exception as e: # طباعة رسالة خطأ في حال حدوث استثناء print("حدث خطأ أثناء تنفيذ البرنامج:", e) وسيؤدي تنفيذ الكود السابق لتوليد الأمر التالي بلغة SQL: INSERT INTO current_weather (city, temperature, weather_description, update_date) VALUES ('London', 53.37, 'broken clouds', '2024-02-06 04:43:35') ولكن سنرى تحذيرًا ينبهنا إلى عدم استخدام الدالة ()utcnow حيث أنها مهملة deprecated ولن تكون متوفرة في إصدارات قادمة وهذا قد يتسبب في تعطل الكود الخاص بنا في التحديثات المستقبلية: DeprecationWarning: datetime.datetime.utcnow() is deprecated and scheduled for removal in a future version. Use timezone-aware objects to represent datetimes in UTC: datetime.datetime.now(datetime.UTC). وكي نمنع ChatGPT من استخدام دوال مهملة deprecated، سنضيف التوجيه التالي: بعد إضافة هذا السطر، سيبدل ChatGPT الدالة ()utcnow بدالة أخرى كما يلي: # استخدم الكائن timezone-aware لتحديث التاريخ update_date = datetime.now(timezone.utc).strftime('%Y-%m-%d %H:%M:%S') يعيد لنا هذا الكود مجددًا أمرًا بلغة SQL ويمكن اختباره في أي محرر استعلامات Query editors لنظام إدارة قواعد البيانات DBMS. وفي حال كنت تولد هذا الكود ضمن تطبيق ويب تقليدي فمن المتوقع تشغيل أمر SQL مباشرة بعد توليده من خلال الواجهة البرمجية وتحديث بيانات قاعدة البيانات في الزمن الحقيقي. استخدام الواجهة البرمجية OpenAI API بدلًا من شات ChatGPT تملك العديد من نماذج اللغات الضخمة واجهة برمجة تطبيقات API تمكّن المطور من التفاعل مع النماذج اللغوية الضخمة برمجيًا ودمجها بسلاسة داخل تطبيقاته، سنستفيد من هذه الواجهات البرمجية لإنشاء مساعد ذكي بشكل افتراضي، يوفر لنا هذا المساعد ميزات عديدة مثل إكمال الكود أو توليده من الصفر أو إعادة صياغته وتحسينه. ويمكن تحسين واجهات المستخدم وتخصيصها من خلال قوالب جاهزة من الموجهات Prompts templates، كما يتيح لنا دمج النماذج اللغوية الضخمة برمجيًا جدولة المهام أو تفعيلها عند تحقق شروط معينة ويسهل أتمتة المساعد الذكي الذي نعمل عليه. سننفذ في هذا المثال نفس المهمة السابقة وهي طلب معلومات الطقس باستخدام بايثون للتفاعل برمجيًا مع الواجهة البرمجية OpenAI API وتوليد الكود من خلال واجهة المستخدم بدلًا من كتابة موجّه في ChatGPT مباشرة. بداية علينا تثبيت الواجهة البرمجية OpenAI API باستخدام الأمر التالي: pip install openai الآن لنتمكن من استخدام الواجهة البرمجية OpenAI API نحتاج لمفتاح الواجهة API key وهو غير مجاني ويتطلب دفع رسوم. بعدها، يمكننا استيراد المكتبة openai وإرسال نفس الموجه المستخدم من قبل مع إزالة الجزء الخاص بتوليد أوامر SQL، كما نحدد النموذج المستخدم GPT-3.5 من خلال الكود التالي: import openai openai.api_key = "YOUR_API_KEY" # استبدله بمفتاح الواجهة البرمجية الخاص بك response = openai.chat.completions.create( model='gpt-3.5-turbo', max_tokens=1024, temperature=0.3, top_p=0.9, messages = [ {'role': 'system', 'content': 'أنت مساعد ذكي قائم على الذكاء الاصطناعي.'}, {'role': 'user', 'content': "اكتب كود بلغة بايثون باستخدام مكتبة requests لإرسال طلب GET إلى واجهة OpenWeather API للحصول على بيانات الطقس، وذلك عبر نقطة الوصول التالية http://api.openweathermap.org/data/2.5/weather. يجب أن يتضمن الطلب مفتاح API الخاص بك ضمن الرابط باستخدام المعامل appid. يُتوقع أن تُعيد الواجهة البيانات بتنسيق JSON، ويجب على الكود استخراج درجة الحرارة من البيانات وإعادتها بوحدة الفهرنهايت ولا يستخدم أي دوال قديمة غير مستعملة"}, ] response_message = response.choices[0].message.content print(response_message ) سيولد النموذج اللغوي الضخم كود بايثون التالي، والذي يجلب درجات الحرارة لمدينة لندن: import requests # مفتاح الواجهة البرمجية ونقطة الوصول url = "http://api.openweathermap.org/data/2.5/weather" api_key = "YOUR_API_KEY" # معاملات الاستعلام params = { 'q': 'London,uk', # مثال على المدينة ورمز الدولة. 'appid': api_key } # إرسال طلب GET. response = requests.get(url, params=params) # التحقق مما إذا كان الطلب ناجحاً. if response.status_code == 200: # تحليل استجابة JSON. data = response.json() # طباعة درجة الحرارة بالدرجة المئوية. temperature = data['main']['temp'] - 273.15 print(f"درجة الحرارة في لندن هي {temperature:.2f}°C.") else: print(f"خطأ: {response.status_code}") لاحظ أننا أزلنا التعليمات الخاصة بتحديد درجات الحرارة بالفهرنهايت لذا لم يحدد النموذج اللغوي الضخم وحدة القياس عند طلب الواجهة البرمجية للطقس، ولكنه اختار حسابها رياضيًا بتحويل الوحدة من الكلفن إلى سلسيوس عند عرض النتائج. الاستفادة من معاملات النموذج اللغوي الضخم لتحقيق أقصى استفادة يمكننا ضبط بعض المعاملات عند استخدام الواجهة البرمجية لنماذج الذكاء الاصطناعي والنماذج اللغوية الضخمة من أجل تعديل الردود المولدة منها، فهناك معاملات يمكنها تحديد مستوى العشوائية والإبداع في الردود المولدة كالمعامل Temperature، ومعاملات يمكنها التحكم بتكرار النصوص المولدة مثل Repetition Penalty، بينما تؤثر معاملات أخرى على النص اللغوي المولد مما يساعد على التحكم في جودة الكود الناتج. في الكود السابق، يمكننا ضبط قيم معاملات GPT في السطر السابع على النحو التالي: max_tokens=1024, temperature=0.3, top_p=0.9, المعامل الوصف التأثير على الكود المولد Temperature يعني درجة الحرارة إذ يتحكم هذا المعامل في عشوائية الردود المولدة، أو درجة الإبداعية في الردود، فالقيمة العالية لهذا المعامل تزيد عشوائية الردود المولدة، بينما القيمة المنخفضة تولد ردودًا واقعية، القيم الممكنة لهذا المعامل بين 0 و 2 والقيمة الافتراضية 0.7 أو 1 بحسب النموذج المستخدم. ستولد القيمة المنخفضة لهذا المعامل كودًا آمنًا يتبع الأنماط والهياكل المكتسبة خلال عملية التدريب، بينما ستولد القيمة العالية ردودًا أكثر تميزًا وغير اعتيادية مما يرفع من احتمالية الأخطاء والتناقضات البرمجية. Max token يحدد هذا المعامل الحد الأقصى لعدد الوحدات النصية tokens المولدة في الاستجابة. إذا ضبطته بقيمة صغيرة، فقد يتسبب ذلك في أن تكون الاستجابة قصيرة جدًا، بينما إذا تم ضبطته بقيمة كبيرة جدًا، قد يؤدي ذلك لاستهلاك عدد كبير من الوحدات النصية المتاحة، مما يزيد من تكلفة الاستخدام يجب أن يضبط المعامل على قيمة عالية بما يكفي لتغطية جميع الأكواد التي تحتاج إلى توليدها. ويمكنك تقليله إذا كنت ترغب في توليد الكود فقط دون توفير شرح الكود المضاف من النموذج top_p يتحكم هذا المعامل في اختيار الكلمات التالية بتقليص نطاق الخيارات المتاحة. إذا منحناه القيمة 0.1 سيقتصر على أفضل 10% من الكلمات الأكثر احتمالاً، مما يزيد الدقة. وإذا منحناه القيمة 0.5 سيوسع الاختيار ليشمل أفضل 50%، مما يعزز التنوع. ويساعد في موازنة الدقة والإبداع في الردوع. عند ضبط المعامل بقيمة منخفضة، يصبح الكود المولد أكثر توقعًا وارتباطًا بالسياق، ويجري اختيار الاحتمالات الأكثر ترجيحًا بناءً على السياق الحالي. أما عند زيادة قيمته يزداد التنوع في المخرجات، مما قد يؤدي إلى توليد كود أقل ارتباطًا بالسياق وقد يتسبب في أخطاء أو توليد كود متناقض. frequency_penalty يعني عقوبة التكرار إذ يحدّ هذا المعامل من تكرار الكلمات والعبارات في ردود النموذج اللغوي الكبير. عند ضبطه على قيمة عالية، يقلل من تكرار الكلمات أو العبارات التي استخدمها النموذج سابقًا. أما عند ضبطه على قيمة منخفضة، فيسمح للنموذج بتكرار الكلمات والعبارات. حيث تتراوح قيم هذا المعامل من 0 إلى 2. تضمن القيمة العالية لهذا المعامل تقليل التكرار في الكود المولد، مما يؤدي لتوليد أكواد أكثر تنوعًا وإبداعًا. ومع ذلك، قد يؤدي ذلك إلى اختيار عناصر أقل كفاءة أو غير صحيحة. من ناحية أخرى، عند خفض قيمته، قد لا يستكشف طرقًا متنوعة للحل. presence_penalty يعني عقوبة التواجد ويرتبط هذا المعامل بالمعامل السابق فكلاهما يشجعان على التنوع والتفرد في الكلمات المستخدمة، حيث يعاقب المعامل السابق الوحدات النصية التي استخدمت عدة مرات في النص في حين يعاقب المعامل الحالي الوحدات النصية التي ظهرت من قبل بغض النظر عن مرات التكرار، يتلخص تأثير معامل عقوبة التكرار في أنه يقلل من تكرار الكلمات بينما يركز معامل عقوبة التواجد على استخدام كلمات جديدة بالكليّة، والقيمة الصغرى لهذا المعامل هي 0 أما القيمة العظمى فهي 2. له تأثير مشابه لعقوبة التكرار، فالقيمة العالية تشجع النموذج على استكشاف حلول بديلة، ولكن قد يصبح الكود المولد أقل كفاءة ومليء بالأخطاء، بينما تسمح القيمة المنخفضة بتكرار الكود مما يؤدي إلى كود أكثر كفاءة واتساقًا، خاصةً عند وجود أنماط متكررة. stop دور هذا المعامل هو تحديد نقطة التوقف في عملية توليد النصوص. عند ضبطه مع سلسلة معينة مثل "n/"، سيتوقف النموذج عن توليد النصوص بمجرد أن يصادف هذه السلسلة مما يساعد في التحكم بدقة في نهاية الرد المولد وتحديد متى يجب أن يتوقف النموذج عن إضافة المزيد من الكلمات. يمنع هذا المعامل النموذج من توليد أجزاء من الكود لا تتناسب مع السياق أو الوظيفة المطلوبة. يجب أن تكون سلسلة التوقف نقطة منطقية وواضحة لنهاية الكود، مثل نهاية دالة أو نهاية حلقة تكرارية، لضمان توقف النموذج عن توليد المزيد من الكود بشكل مناسب. لنختبر كيفية تأثير هذه المعاملات على توليد الكود، سنجرب تعديل معاملات عقوبة التكرار frequency_penalty وعقوبة التواجد presence_penalty . عند تهيئة عقوبة التكرار frequency_penalty بقيمة مرتفعة وهي 1.5،سينتج النموذج اللغوي الضخم كودًا إضافيًا ليلاقى التوقعات محاولًا تفادي تكرار المخرجات السابقة: # ... try: # إرسال طلب GET مع المعلمات والحصول على البيانات في تنسيق JSON. response = requests.get(url, params=params) if response.status_code == 200: weather_data = response.json() # طباعة بعض المعلومات المهمة من بيانات الطقس. print("المدينة:", weather_data['name']) print("درجة الحرارة:", weather_data['main']['temp'], "K") except requests.exceptions.RequestException as e: # التعامل مع أي خطأ حدث أثناء الطلب print("خطأ:", e) عند العمل مع الكود الذي يتعامل مع واجهة برمجية API من المهم أن نلاحظ أن النتائج قد تكون غير متوقعة. ففي الكود السابق، على الرغم من أن إضافة معالجة الأخطاء مفيدة، إلا أننا لم نطلب من النموذج توليد كود يتعامل مع جميع الأخطاء المحتملة بشكل دقيق. لهذا السبب، عند إرسال نفس الطلب مرة أخرى مع نفس المعاملات، قد نحصل على نتائج مختلفة تمامًا. ولضمان استقرار الكود ومعالجته للأخطاء بشكل صحيح، يجب إضافة موجه أولي initial prompt يوجّه النموذج لتوليد الكود مع معالجة الأخطاء بشكل مناسب. بهذا الشكل، يمكن ضمان أن الكود سيكون متسقًا ويعمل كما هو متوقع في جميع الحالات. يمكننا ضبط المعامل presence_penalty بقيمة عالية ولتكن 2.0 للحصول على تأثير مشابه، حيث يتفادى النموذج تكرار المخرجات السابقة ويرسل طلب جديد للواجهة البرمجية للطقس OpenWeather API من خلال دالة ممرًا لها مفتاح الواجهة البرمجية API key كمعامل كما يلي: import requests def get_weather(api_key): url = "http://api.openweathermap.org/data/2.5/weather" params = { 'q': 'London,uk', # مثال على المدينة ورمز الدولة. 'appid': api_key } response = requests.get(url, params=params) # إضافة سطر إرسال الطلب if response.status_code == 200: data = response.json() return data else: print("خطأ:", response.status_code) # استبدل "YOUR_API_KEY" بمفتاح الواجهة البرمجية الفعلي من OpenWeather. api_key = "YOUR_API_KEY" weather_data = get_weather(api_key) print(weather_data) إن إنشاء دالة برمجية مخصصة لطلب الواجهة البرمجية لتطبيق الطقس إضافة مفيدة للكود، ولكن تمرير مفتاح الواجهة من خلال الدالة أمر غريب، فمن المعتاد في أغلب حالات الاستخدام تمرير المدينة city كمعامل للدالة، وهنا يمكننا معالجة هذه المشكلة بتعديل الموجه الأولي. يتطلب ضبط قيم معاملات نماذج اللغة الضخمة الكثير من التجربة، فبعض النتائج تكون غير متوقعة وبعض التعديلات قد تبدو عديمة التأثير، فتعديل المعاملات لا يمتلك تأثيرًا موحدًا يضمن اتباع أفضل الممارسات في توليد الكود. دمج النماذج اللغوية الضخمة في ملفات الكود المصدري بمجرد أن يصبح الكود المولد باستخدام النموذج اللغوي الضخم محسنًا وجاهزًا للعمل، ستكون الخطوة التالية هي دمج الكود الناتج مع الأكواد البرمجية السابقة. لكن قد يؤدي نسخ الكود بشكل مباشر للكود الموجود سابقًا لمشكلات في تنظيم الكود وتنسيقها مما يصعب صيانة وتعديل الكود لاحقًا. يمكننا تبسيط هذه العملية بتحويل الكود إلى أجزاء قابلة لإعادة الاستخدام مثل دوال برمجية أو كائنات وأصناف برمجية، ويمكننا تحقيق هذا أيضًا باستخدام النموذج اللغوي الضخم ما دامت التعليمات المفصلة للقيام بهذا مرفقةً في الموجه Prompt، ويجب أيضاً تحديد مدخلات هذه الدوال والمخرجات المتوقعة منها. دعنا نجعل النموذج اللغوي الضخم ينشئ الكائن البرمجي weather الذي يحوي دالة get_weather ، من خلال إضافة الأوامر التالية للموجه: عندها سنحصل على كود بايثون التالي: import requests class Weather: def __init__(self, api_key): self.api_key = api_key self.temperature = None def get_weather(self, city): url = 'http://api.openweathermap.org/data/2.5/weather' params = { 'q': city, 'appid': self.api_key, 'units': 'imperial' # طلب درجة الحرارة بالفهرنهايت. } response = requests.get(url, params=params) data = response.json() if response.status_code == 200: self.temperature = data['main']['temp'] print(f"درجة الحرارة في {city} هي {self.temperature}°F.") else: print(f"خطأ: {data['message']}") # استبدل "YOUR_API_KEY" بمفتاح الواجهة البرمجية الفعلي من OpenWeather. api_key = "YOUR_API_KEY" weather = Weather(api_key) weather.get_weather('London') يولّد النموذج دالة قابلة للتشغيل بواسطة الكائن weather، ويمكننا دمج هذا الكائن بتطبيق آخر بكل سهولة، ولكن علينا معالجة الأخطاء التي قد تقع لضمان عدم فشل عمل التطبيق وعدم عرضه لبيانات حساسة أو سرية. اختبار التطبيق ومعالجة الأخطاء إن فشل طلبات واجهة البرمجة للتطبيق API أمر شائع في التطبيقات الحقيقية، فيمكن أن تفشل الطلبات لعدة أسباب، لذا لضمان الاعتمادية ينبغي أن يتضمن الكود حالات لمعالجة الأخطاء التي يمكن أن تقع لمنع فشل التطبيق الكامل، في أغلب الأمثلة السابقة كان الكود المولد بواسطة النموذج يحوي شرطًا يختبر رمز الحالة لبروتوكول نقل النص الفائق HTTP ، فالرمز 200 يعبر عن نجاح الطلب بينما أي رمز آخر يعبر عن فشل الطلب أو وجود خطأ ينبغي التعامل معه فيقوم الكود المولد بطباعته، ولكن هذا الشرط لا يأخذ في الاعتبار حالات أخطاء شائعة أخرى مثل انتهاء وقت الطلب timeout أو أخطاء نظام أسماء النطاقات DNS. لضمان الاعتمادية ينبغي أن يحوي الكود المولد آلية لمعالجة الأخطاء، مثل استخدام try-catch عند إجراء طلب من خلال واجهة برمجة التطبيق API. لذا أضفنا النص التالي للموجه السابق: ولّد هذا التوجيه كود بايثون يحتوي كلتلة try-catch تعالج الأخطاء المحتملة: class Weather: def __init__(self, api_key): self.api_key = api_key self.temperature = None def get_weather(self, city): try: # بناء عنوان URL للواجهة البرمجية باستخدام المدينة ومفتاح API المقدم. url = "http://api.openweathermap.org/data/2.5/weather" params = {'q': city, 'appid': self.api_key, 'units': 'imperial' # الحصول على درجة الحرارة بالفهرنهايت. } # إرسال طلب GET إلى الواجهة البرمجية. response = requests.get(url, params=params) # التحقق من حالة الاستجابة if response.status_code == 200: # تحليل الاستجابة بتنسيق JSON data = response.json() # استخراج درجة الحرارة بالفهرنهايت من الاستجابة. self.temperature = data['main']['temp'] else: # عرض وصف الخطأ إذا كانت حالة الاستجابة ليست 200. print(f'خطأ: {response.status_code} - {response.json()["message"]}') except requests.exceptions.RequestException as e: # التعامل مع أي استثناءات تحدث أثناء الطلب. print(f'خطأ: {e}') يعد الكود المولد بواسطة النموذج اللغوي الضخم نقطة بداية جيدة، لكنك ستحتاج في الغالب لتعديلات إضافية لتحصيصه وزيادة الوظائف التي يقوم به، على سبيل المثال من الممكن تسجيل الأخطاء التي تحدث وتنبيه المستخدم من أخطاء الإعدادات التي قد تشمل أخطاء في استيثاق الواجهة البرمجية API authentication error ويمكن للمطورين إضافة واجهة برمجية احتياطية في حالة تعطل الواجهة الأساسية. بمجرد أن يصبح الكود قادرًا على تأدية وظيفته كما ينبغي، فالخطوة التالية مهمة للتأكد من صموده عند التشغيل الفعلي، وينبغي اختبار كل الوظائف والحالات الممكنة للخطأ، ولضمان اعتمادية قوية يمكننا أتمتة عملية الاختبارات وتقييم الأداء من خلال قياس مؤشرات الأداء المختلفة مثل وقت التشغيل واستخدام ذاكرة الوصول العشوائي واستخدام الموارد الحاسوبية، ستساعدنا هذه المؤشرات على تحديد نقاط الخلل في النظام وتحسين الموجهات prompts وصقل fine-tune معاملات النموذج اللغوي الضخم. تطور نماذج اللغات الضخمة تطورت النماذج اللغوية الضخمة لكنها لن تستبدل الخبرة البشرية حاليًا، بل سيقتصر دورها على توليد الكود البرمجي مما يسرّع ويسهّل عملية التطوير كما أنها قادرة على توليد نسخ متنوعة من الكود مما يساعد المطور على اختيار أفضل خيار من بينها، كما يمكنها تولي إنجاز المهام البسيطة والتكرارية لزيادة إنتاجية المطورين، مما يتيح للمطورين التركيز على المهام المعقدة التي تتطلب معرفة متخصصة وتفكير بشري إبداعي. ترجمة-وبتصرٌّف-للمقال Using an LLM API As an Intelligent Virtual Assistant for Python Development اقرأ أيضاً دليل استخدام ChatGPT API لتحسين خدماتك عبر الإنترنت تعرف على مكتبة المحوّلات Transformers من منصة Hugging Face تلخيص النصوص باستخدام الذكاء الاصطناعي استخدام النماذج التوليديّة Generative models لتوليد الصور- 1 تعليق
-
- 1
-
-
 نشرح في مقال اليوم الخطوات الأساسية لدمج نماذج الذكاء الاصطناعي التي توفرها شركة OpenAI في تطبيق جانغو Django، ففي الآونة الأخيرة ازادت شعبية نماذج OpenAI أو ما يعرف بنماذج GPT OpenAI بشكل كبير بفضل قدرتها على توليد محتوى نصي عالي الجودة في مختلف المجالات سواء كتابة رسائل البريد الإلكتروني والقصص، أو الإجابة على استفسارات العملاء، أو ترجمة المحتوى من لغة لأخرى. تُستخدم نماذج جي بي تي GPT models من قبل المستخدمين من خلال روبوت الدردشة تشات جي بي تي ChatGPT، وهو نظام محادثة ذكي أطلقته OpenAI، لكن يمكن للمطورين الاستفادة من هذه النماذج في تطوير تطبيقاتهم الخاصة باستعمال واجهة برمجة التطبيقات API التي وفرتها OpenAI لتوفير مرونة أكبر في التعامل مع هذه النماذج. وسنوضح في الفقرات التالية خطوات إنشاء تطبيق جانغو يستخدم هذه الواجهة البرمجية، وبالتحديد الواجهة البرمجية لنموذج إكمال المحادثة ChatCompletion API من أجل توليد قصة قصيرة ونتعرف على طريقة تخصص معاملات النموذج المختلفة، وتنسيق ردوده واستجاباته. متطلبات العمل كي نتمكن من إكمال هذه المقالة، سوف تحتاج الآتي: إطار جانغو Django مثبت على بيئة افتراضية env ضمن حاسوبنا إنشاء حساب على منصة OpenAI توليد مفتاح الواجهة البرمجية OpenAI API key من لوحة تحكم الحساب في منصة OpenAI تثبيت حزمة OpenAI Package الخاصة بلغة بايثون ضمن البيئة الافتراضية كما سنشرح في الخطوة التالية تثبيت مكتبة OpenAI في جانغو لنفترض أننا ثبَّتنا جانغو في البيئة افتراضية ضمن مجلد باسم django-apps. علينا التأكد من تفعيل البيئة الافتراضية وظهور اسمها داخل قوسين() في سطر الأوامر Terminal. إذا لم تكن البيئة الافتراضية مفعّلة فيمكننا تفعيلها يدويًا بالانتقال للمجلد django-apps في سطر الأوامر وكتابة الأمر التالي: hasoub-academy@ubuntu:$ .env/bin/activate بمجرد تفعيل البيئة الافتراضية، نشغل الأمر التالي لتنزيل حزمة OpenAI Package الخاصة بلغة بايثون: (env)hasoub-academy@ubuntu:$ pip install openai نحن الآن جاهزون للبدء بتطوير تطبيق جانغو الخاص بنا كما سنوضح في الخطوات التالية. إرسال الطلبات للواجهة البرمجية OpenAI API نحتاج بداية لإضافة مفتاح الواجهة البرمجية OpenAI API key لتطبيقنا كي نتمكن من إرسال الطلبات للواجهة البرمجية ChatCompletion API. واختبار الرد الذي نحصل عليه منها. لنكتب الأمر التالي لتشغيل بايثون داخل البيئة الافتراضية: (env)hasoub-academy@ubuntu:$ python نستورد بعدها المكتبة OpenAI ونعرًف العميل client المخصص للتفاعل مع الواجهة البرمجية كما يلي: import openai client = OpenAI(api_key="your-api-key") ملاحظة: نحتاج لاستبدالyour-api-key بمفتاح الواجهة البرمجية الخاص بنا وهو شبيه للتالي sk-abdfhghlisciodfop. بعدها نرسل طلب للواجهة البرمجية ChatCompletion API باستخدم الدالة chat.completions.create: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "عد من 1 إلى 10"} ] ) حددنا في الكود السابق النموذج الذي نحتاج لاستخدامه في تطبيقنا ليكون gpt-3.5-turbo، وأضفنا كائن رسالة واحد يحتوي على الدور مستخدم user، ومرّرنا مُوجّه prompt بسيط سنرسل لاختبار الواجهة البرمجية وهو في حالتنا طلب العد من واحد إلى عشرة. ملاحظة1: عند التفاعل مع نموذج GPT سنتعامل مع ثلاثة أدوار رئيسية وهي: دور المستخدم user الذي يطرح الأسئلة أو يطلب المساعدة من النموذج، ودور النظام system الذي يتضمن القواعد والتعليمات التي توجّه للنموذج، ودور المساعد assistance الذي يمثل نموذج الذكاء الاصطناعي نفسه والذي سنستخدمة للإجابة على أسئلة المستخدم أو تنفيذ الأوامر التي يطلبها منه. ملاحظة2: من المهم دائمًا الرجوع إلى التوثيق الرسمي لمنصة OpenAI للحصول على تعليمات دقيقة وشاملة حول كيفية استخدام نماذج GPT في تطبيقاتك، فهذه النماذج تتعدل وتتغير مع مرور الوقت. لنطبع الآن الرد المستلم من الواجهة البرمجية API والذي يتضمن عرض الأعداد من واحد إلى عشرة على شكل قائمة من خلال الأمر التالي: print(response.choices[0].message.content) سنحصل على النتيجة التالية: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 بهذا نكون قد نجحنا بإرسال طلب بسيط إلى الواجهة البرمجية، واستلمنا منها الرد، وتأكدنا أن كل شيء يسير على ما يرام. نحن جاهزون الآن لاستخدام الواجهة البرمجية لإرسال مُوجّه prompt أكثر صعوبة ونطلب من النموذج كتابة محتوى قصة قصيرة. ضبط معاملات النموذج Parameters بعد أن نجنا في إرسال طلب API بسيط إلى الواجهة البرمجية لإكمال المحادثة ChatCompletion API، لنتعرف على طريقة ضبط معاملات النموذج للتحكم بسلوك هذا النموذج. فهنالك العديد من المعاملات المتاحة للتحكم في النص المولد، سنوضح ثلاثة منها. 1. درجة الحرارة Temperature يتحكم هذا المعامل في مدى عشوائية الردود المولَّدة من قبل النموذج، ويأخذ قيمة بين الصفر والواحد، فكلما ارتفعت قيمته سنحصل على تنوع وإبداع في الردود والعكس صحيح. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. سيارة 3. كتاب 4. شمس 5. شجرة لنجرب منحه قيمة قريبة من الصفر مثل 0.1 ونرى كيف ستولد الكلمات: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. فيل 3. ضوء الشمس 4. مغامرة 5. سكون نلاحظ بالتجربة أننا عندما نطلب من النموذج أن يذكر خمس كلمات عدة مرات عند ضبط البرامتر بالقيمة 0.1 فسوف نحصل على نفس الكلمات في كل مرة، أما عندما نضبط قيمته إلى 0.8 ونجرب الطلب عدة مرات فسنلاحظ تغيّر النتائج التي نحصل عليها كل مرة: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات باللغة العربية"}], temperature=0.8 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. ضوء الشمس 3. سعادة 4. صداقة 5. تقنية 2. العدد الأقصى للوحدات النصية Max Token يسمح لنا هذا المعامل بتحديد طول النص المولد، فعند ضبطع بقيمة معينة سيضمن لنا أن الردود لن تتجاوز الرقم الذي حددناه في الوحدات النصية tokens، على سبيل المثال عندما نضبط قيمة max-token إلى 10: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=10 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاحة 2. سيارة وعندما نضبط قيمة max-token إلى 20: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=20 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاح 2. سيارة 3. موسيقى 4. محيط 5. صداقة 3. التدفق Stream يحدد هذا المعامل هل نريد أن تتدفق الردود على دفعات streams أو تعود لنا دفعة واحدة، فعند ضبطه بالقيمة True، سنستلم الرد بشكل متدفق، أي على دفعات خلال عملية توليدها. هذا يفيدنا في المحادثات الطويلة وفي تطبيقات الزمن الحقيقي التفاعلية. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], stream=True ) collected_messages = [] for chunk in response: chunk_message = chunk.choices[0].delta.content if chunk_message is not None: collected_messages.append(chunk_message) print(collected_messages) المخرجــــات ['', 'قطة', '\n', 'كتاب', '\n', 'حاسوب', '\n', 'شمس', '\n', 'ماء'] سيحتفظ المتغير chunk_message بكل جزء من الرسالة المتدفقة بشكل مؤقت أثناء استلامها من الواجهة البرمجية، بعد ذلك، ستضاف هذه الأجزاء إلى القائمة collected_messages التي تُجمع فيها كل الرسائل. يجب علينا التأكد من أن الجزء المتدفق ليس None، لأن هذه القيمة تدل على انتهاء تدفق الردود وتستخدم كشرط للخروج من الحلقة التكرارية. صياغة مُوجِّه نظام System Prompt مخصص في هذه الخطوة، سنستخدم كل ما تعلمناه من مفاهيم أساسية لكتابة مُوجِّه نظام مخصص system prompt وتوفير السياق الذي يحتاجه نموذج GPT لفهم المطلوب منه ضمن تطبيق جانغو، وسنحدد القواعد التي يجب أن يتبعها النموذج لتوليد المحتوى. ننشئ بداية وحدة بايثون تحتوي على دالة تتولى المهمة المطلوبة. لذا ننشئ ملفًا جديدًا باسم story_generator.py داخل مجلد مشروع جانغو بكتابة الأمر التالي: (env)hasoub-academy@ubuntu:$ touch ~/my_blog_app/blog/blogsite/story_generator.py ثم نضيف مفتاح الواجهة البرمجية OpenAI API key إلى متغيرات البيئة environmental variables، فلا نضيفها في ملف بايثون مباشرة لحماية المفتاح: (env)hasoub-academy@ubuntu:$ export OPENAI_KEY="your-api-key" نفتح الآن الملف story_generator.py وننشئ بداخله عميل OpenAI client ونعرف دالة باسم generate_story وظيفتها توليد محتوى قصة بناءً على مجموعة من الكلمات التي يحددها المستخدم: import os from openai import OpenAI client = OpenAI(api_key=os.environ["OPENAI_KEY"]) def generate_story(words): # استدعاء واجهة برمجة التطبيقات من OpenAI لتوليد القصة response = get_short_story(words) # تنسيق الاستجابة وإرجاعها return format_response(response) لتنظيم الكود البرمجي، سنستدعي ضمن هذه الدالة البرمجية دالة منفصلة باسم get_short_story تطلب توليد القصة من الواجهة البرمجية OpenAI API، ودالة أخرى باسم format_response تنسِّق الرد المستلم من الواجهة البرمجية. لنركز الآن على دالة توليد القصة get_short_story حيث سنضيف الكود الخاص بها في نهاية الملف story_generator.py كما يلي: def get_short_story(words): # إنشاء موجه النظام system_prompt = f"""أنت مولد قصص قصيرة. اكتب قصة قصيرة باستخدام الكلمات التالية: {words}. لا تتجاوز فقرة واحدة.""" # الاتصال بواجهة برمجة التطبيقات response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{ "role": "user", "content": system_prompt }], temperature=0.8, max_tokens=1000 ) # إرجاع استجابة الواجهة البرمجية return response كما نلاحظ فقد ضبطنا هنا مُوجِّه النظام system prompt كي يخبر النموذج ما هو، وما هي المهمة التي عليه تأديتها، وحددنا في الموجّه حجم القصة المطلوبة، ثم مررنا هذا الموجّه للواجهة البرمجية ChatCompletion API. أخيرًا نكتب كود دالة التنسيق format_response في نهاية الملف story_generator.py: def format_response(response): # استخرج القصة المولدة من الاستجابة story = response.choices[0].message.content # إزالة أي نص أو تنسيقات غير مرغوبة story = story.strip() # إرجاع القصة المنسقة return story لاختبار هذه الدوال سنستدعي الدالة generate_story ونمرر لها مجموعة كلمات كمعاملات، ثم نطبع الرد الذي تعيده لنا من خلال إضافة سطر الكود التالي للملف: print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) لنحفظ الملف ونغلقه، ونشغًله من داخل سطر الأوامر كما يلي: (env) sammy@ubuntu:$ python ~/my_blog_app/blog/blogsite/story_generator.py يجب أن نحصل على قصة تشابه القصة التالية: في زاوية مريحة من غرفة مشمسة، كانت هناك قطة ذات فرو ناعم تُدعى "مشمش"، تتمدد بكسل بجانب رف كتب شاهق. بين صفوف الكتب، كان حاسوب فضولي يهمس بهدوء. بينما كانت أشعة الشمس تتسلل عبر النافذة، مُلَقيةً ضوءًا دافئًا، لاحظت "مشمش" بقعة ماء صغيرة على الرف. مدفوعةً بالفضول، دفعت القطة الكتاب الأقرب إلى البقعة، ليُفتح الكتاب ويكشف عن مكان مخفي يحتوي على عقد ماسي متلألئ. مع اكتشاف السر، بدأت "مشمش" مغامرة غير متوقعة، حيث امتزجت أشعة الشمس، والماء، وقوة المعرفة لتنسج قصة مثيرة من الغموض والاكتشاف. بعد أن تأكدنا من عمل الدالة generate_story وتوليد القصة بشكل صحيح، لنغير طريقة تنفيذ الكود وبدلاً من طباعة القصة مباشرة في سطر الأوامر، سنستدعي الدالة من خلال عرض جانغو Django view لعرض القصة على واجهة المستخدم. print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) يمكن تجربة تعديل مُوجّه النظام system prompt بما يناسبنا لتوليد محتوى أفضل. سنلاحظ بالتجربة أن بإمكاننا دائمًا تحسين النتائج بما يتناسب مع احتياجاتنا. لننتقل إلى الخطوة التالية، حيث سندمج الوحدة التي عرفناها في ملف story_generator.py مع مشروع جانغو الخاص بنا. دمج وحدة بايثون مع جانغو في الواجهة الخلفية لدمج وحدة story_generator مع مشروع جانغو في الواجهة الخلفية، علينا تنفيذ عدة خطوات بسيطة، سنبدأ أولاً بإنشاء عرض view جديد في جانغو لاستقبال الكلمات من المستخدم، ثم سنستخدم الدالة generate_story لتوليد القصة بناءً على تلك الكلمات، وفي النهاية سنعرض النتيجة للمستخدم عبر المتصفح. نفتح ملف views.py داخل مجلد مشروع جانغو، ونستورد الوحدات والحزم البرمجية اللازمة، ثم نضيف دالة عرض view باسم generate_story_from_words ونكتب ضمنها ما يلي: from django.http import JsonResponse from .story_generator import generate_story def generate_story_from_words(request): words = request.GET.get('words') # استخراج الكلمات المتوقعة من الطلب story = generate_story(words) # استدعاء دالة generate_story باستخدام الكلمات المستخرجة return JsonResponse({'story': story}) # إرجاع القصة في استجابة JSON بعدها نحتاج لربط الدالة بمسار URL في مشروع جانغو لتمكين المستخدمين من الوصول إليها عبر المتصفح. لنفتح الملف urls.py ونضيف نمط الرابط URL pattern للدالة generate_story_from_words كما يلي: urlpatterns = [ # أنماط URL الأخرى... path('generate-story/', views.generate_story_from_words, name='generate-story'), ] الآن يمكننا إرسال الطلبات من خلال نقطة الوصول التالية/generate-story/ باستخدام المتصفح، وإرسال طلب من النوع GET لها وتمرير الكلمات المتوقعة كمعاملات للطلب، نفتح سطر الأوامر ونكتب الأمر curl بالشكل التالي: (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words=قطة,كتاب,حاسوب,شمس,ماء" علينا استبدال http://your_domain بالعنوان الفعلي الذي يستضيف مشروعنا. تمثّل الكلمات الممررة عبر هذا الرابط مثل كتاب، وماء، وحاسوب ما هي الكلمات التي نريد استخدامها لتوليد محتوى القصة. يمكن بالطبع تغيير هذه الكلمات واستخدام كلمات أخرى حسب الحاجة. بعد تشغيل أمر curl يجب أن نرى ردًا من الخادم يحتوي على القصة المولدة استنادًا إلى الكلمات التي قدمناها. (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words="قطة,كتاب,حاسوب,شمس,ماء" وسنحصل على مخرجات قريبة للتالي: { "story": "كان يا مكان، في كوخ صغير مريح يقع وسط غابة كثيفة، قطة فضولية تُدعى 'مشمش' تجلس بجانب النافذة، تستمتع بأشعة الشمس الدافئة. بينما كانت 'مشمش' تحرك ذيلها بكسل، لفت نظرها كتاب مغبر ملقى على رف قريب. بدافع الفضول، قفزت بعناية إلى الرف، مما أدى إلى سقوط مجموعة من الكتب، فتح أحدها ليكشف عن مكان مخفي. داخل هذا المكان، اكتشفت 'مشمش' حاسوبًا قديمًا، بدأ شاشته يومض عندما لمست زر الطاقة. مفتونةً بالشاشة المتوهجة، انطلقت 'مشمش' في عالم من المناظر الافتراضية، حيث تجولت بحرية، تطارد الأسماك الرقمية وتوقف للإعجاب بشلالات رائعة. ضائعة في هذه المغامرة الجديدة، اكتشفت 'مشمش' عجائب العوالم الملموسة والافتراضية معًا، مدركةً أن الاستكشاف الحقيقي لا يعرف حدودًا." } الخلاصة إلى هنا نكون قد وصلنا لنهاية هذا المقال الذي وضحنا فيه الخطوات الأساسية التي نحتاجها لدمج OpenAI modes داخل تطبيق جانغو Django باستخدام الواجهة البرمجية OpenAI API، وتعلمنا طريقة إرسال الطلبات للواجهة البرمجية ChatCompletion API والتحكم بسلوك النموذج عن طريق ضبط معاملاته المختلفة. لتحسين هذا المشروع وزيادة ميزاته، يمكننا استكشاف المزيد من مميزات الواجهة البرمجية OpenAI API وتجريب مُوجِّهات نظام system prompt مختلفة، وقيم معاملات متنوعة حتى نحصل على قصة مميزة وإبداعية. ترجمة-وبتصرٌّف-للمقال How to Integrate OpenAI GPT Models in Your Django Project اقرأ أيضًا إنشاء تطبيق جانغو وتوصيله بقاعدة بيانات مدخل إلى إطار عمل الويب جانغو Django دليلك لربط واجهة OpenAI API مع Node.js استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي
نشرح في مقال اليوم الخطوات الأساسية لدمج نماذج الذكاء الاصطناعي التي توفرها شركة OpenAI في تطبيق جانغو Django، ففي الآونة الأخيرة ازادت شعبية نماذج OpenAI أو ما يعرف بنماذج GPT OpenAI بشكل كبير بفضل قدرتها على توليد محتوى نصي عالي الجودة في مختلف المجالات سواء كتابة رسائل البريد الإلكتروني والقصص، أو الإجابة على استفسارات العملاء، أو ترجمة المحتوى من لغة لأخرى. تُستخدم نماذج جي بي تي GPT models من قبل المستخدمين من خلال روبوت الدردشة تشات جي بي تي ChatGPT، وهو نظام محادثة ذكي أطلقته OpenAI، لكن يمكن للمطورين الاستفادة من هذه النماذج في تطوير تطبيقاتهم الخاصة باستعمال واجهة برمجة التطبيقات API التي وفرتها OpenAI لتوفير مرونة أكبر في التعامل مع هذه النماذج. وسنوضح في الفقرات التالية خطوات إنشاء تطبيق جانغو يستخدم هذه الواجهة البرمجية، وبالتحديد الواجهة البرمجية لنموذج إكمال المحادثة ChatCompletion API من أجل توليد قصة قصيرة ونتعرف على طريقة تخصص معاملات النموذج المختلفة، وتنسيق ردوده واستجاباته. متطلبات العمل كي نتمكن من إكمال هذه المقالة، سوف تحتاج الآتي: إطار جانغو Django مثبت على بيئة افتراضية env ضمن حاسوبنا إنشاء حساب على منصة OpenAI توليد مفتاح الواجهة البرمجية OpenAI API key من لوحة تحكم الحساب في منصة OpenAI تثبيت حزمة OpenAI Package الخاصة بلغة بايثون ضمن البيئة الافتراضية كما سنشرح في الخطوة التالية تثبيت مكتبة OpenAI في جانغو لنفترض أننا ثبَّتنا جانغو في البيئة افتراضية ضمن مجلد باسم django-apps. علينا التأكد من تفعيل البيئة الافتراضية وظهور اسمها داخل قوسين() في سطر الأوامر Terminal. إذا لم تكن البيئة الافتراضية مفعّلة فيمكننا تفعيلها يدويًا بالانتقال للمجلد django-apps في سطر الأوامر وكتابة الأمر التالي: hasoub-academy@ubuntu:$ .env/bin/activate بمجرد تفعيل البيئة الافتراضية، نشغل الأمر التالي لتنزيل حزمة OpenAI Package الخاصة بلغة بايثون: (env)hasoub-academy@ubuntu:$ pip install openai نحن الآن جاهزون للبدء بتطوير تطبيق جانغو الخاص بنا كما سنوضح في الخطوات التالية. إرسال الطلبات للواجهة البرمجية OpenAI API نحتاج بداية لإضافة مفتاح الواجهة البرمجية OpenAI API key لتطبيقنا كي نتمكن من إرسال الطلبات للواجهة البرمجية ChatCompletion API. واختبار الرد الذي نحصل عليه منها. لنكتب الأمر التالي لتشغيل بايثون داخل البيئة الافتراضية: (env)hasoub-academy@ubuntu:$ python نستورد بعدها المكتبة OpenAI ونعرًف العميل client المخصص للتفاعل مع الواجهة البرمجية كما يلي: import openai client = OpenAI(api_key="your-api-key") ملاحظة: نحتاج لاستبدالyour-api-key بمفتاح الواجهة البرمجية الخاص بنا وهو شبيه للتالي sk-abdfhghlisciodfop. بعدها نرسل طلب للواجهة البرمجية ChatCompletion API باستخدم الدالة chat.completions.create: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "عد من 1 إلى 10"} ] ) حددنا في الكود السابق النموذج الذي نحتاج لاستخدامه في تطبيقنا ليكون gpt-3.5-turbo، وأضفنا كائن رسالة واحد يحتوي على الدور مستخدم user، ومرّرنا مُوجّه prompt بسيط سنرسل لاختبار الواجهة البرمجية وهو في حالتنا طلب العد من واحد إلى عشرة. ملاحظة1: عند التفاعل مع نموذج GPT سنتعامل مع ثلاثة أدوار رئيسية وهي: دور المستخدم user الذي يطرح الأسئلة أو يطلب المساعدة من النموذج، ودور النظام system الذي يتضمن القواعد والتعليمات التي توجّه للنموذج، ودور المساعد assistance الذي يمثل نموذج الذكاء الاصطناعي نفسه والذي سنستخدمة للإجابة على أسئلة المستخدم أو تنفيذ الأوامر التي يطلبها منه. ملاحظة2: من المهم دائمًا الرجوع إلى التوثيق الرسمي لمنصة OpenAI للحصول على تعليمات دقيقة وشاملة حول كيفية استخدام نماذج GPT في تطبيقاتك، فهذه النماذج تتعدل وتتغير مع مرور الوقت. لنطبع الآن الرد المستلم من الواجهة البرمجية API والذي يتضمن عرض الأعداد من واحد إلى عشرة على شكل قائمة من خلال الأمر التالي: print(response.choices[0].message.content) سنحصل على النتيجة التالية: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 بهذا نكون قد نجحنا بإرسال طلب بسيط إلى الواجهة البرمجية، واستلمنا منها الرد، وتأكدنا أن كل شيء يسير على ما يرام. نحن جاهزون الآن لاستخدام الواجهة البرمجية لإرسال مُوجّه prompt أكثر صعوبة ونطلب من النموذج كتابة محتوى قصة قصيرة. ضبط معاملات النموذج Parameters بعد أن نجنا في إرسال طلب API بسيط إلى الواجهة البرمجية لإكمال المحادثة ChatCompletion API، لنتعرف على طريقة ضبط معاملات النموذج للتحكم بسلوك هذا النموذج. فهنالك العديد من المعاملات المتاحة للتحكم في النص المولد، سنوضح ثلاثة منها. 1. درجة الحرارة Temperature يتحكم هذا المعامل في مدى عشوائية الردود المولَّدة من قبل النموذج، ويأخذ قيمة بين الصفر والواحد، فكلما ارتفعت قيمته سنحصل على تنوع وإبداع في الردود والعكس صحيح. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. سيارة 3. كتاب 4. شمس 5. شجرة لنجرب منحه قيمة قريبة من الصفر مثل 0.1 ونرى كيف ستولد الكلمات: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. فيل 3. ضوء الشمس 4. مغامرة 5. سكون نلاحظ بالتجربة أننا عندما نطلب من النموذج أن يذكر خمس كلمات عدة مرات عند ضبط البرامتر بالقيمة 0.1 فسوف نحصل على نفس الكلمات في كل مرة، أما عندما نضبط قيمته إلى 0.8 ونجرب الطلب عدة مرات فسنلاحظ تغيّر النتائج التي نحصل عليها كل مرة: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات باللغة العربية"}], temperature=0.8 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. ضوء الشمس 3. سعادة 4. صداقة 5. تقنية 2. العدد الأقصى للوحدات النصية Max Token يسمح لنا هذا المعامل بتحديد طول النص المولد، فعند ضبطع بقيمة معينة سيضمن لنا أن الردود لن تتجاوز الرقم الذي حددناه في الوحدات النصية tokens، على سبيل المثال عندما نضبط قيمة max-token إلى 10: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=10 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاحة 2. سيارة وعندما نضبط قيمة max-token إلى 20: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=20 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاح 2. سيارة 3. موسيقى 4. محيط 5. صداقة 3. التدفق Stream يحدد هذا المعامل هل نريد أن تتدفق الردود على دفعات streams أو تعود لنا دفعة واحدة، فعند ضبطه بالقيمة True، سنستلم الرد بشكل متدفق، أي على دفعات خلال عملية توليدها. هذا يفيدنا في المحادثات الطويلة وفي تطبيقات الزمن الحقيقي التفاعلية. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], stream=True ) collected_messages = [] for chunk in response: chunk_message = chunk.choices[0].delta.content if chunk_message is not None: collected_messages.append(chunk_message) print(collected_messages) المخرجــــات ['', 'قطة', '\n', 'كتاب', '\n', 'حاسوب', '\n', 'شمس', '\n', 'ماء'] سيحتفظ المتغير chunk_message بكل جزء من الرسالة المتدفقة بشكل مؤقت أثناء استلامها من الواجهة البرمجية، بعد ذلك، ستضاف هذه الأجزاء إلى القائمة collected_messages التي تُجمع فيها كل الرسائل. يجب علينا التأكد من أن الجزء المتدفق ليس None، لأن هذه القيمة تدل على انتهاء تدفق الردود وتستخدم كشرط للخروج من الحلقة التكرارية. صياغة مُوجِّه نظام System Prompt مخصص في هذه الخطوة، سنستخدم كل ما تعلمناه من مفاهيم أساسية لكتابة مُوجِّه نظام مخصص system prompt وتوفير السياق الذي يحتاجه نموذج GPT لفهم المطلوب منه ضمن تطبيق جانغو، وسنحدد القواعد التي يجب أن يتبعها النموذج لتوليد المحتوى. ننشئ بداية وحدة بايثون تحتوي على دالة تتولى المهمة المطلوبة. لذا ننشئ ملفًا جديدًا باسم story_generator.py داخل مجلد مشروع جانغو بكتابة الأمر التالي: (env)hasoub-academy@ubuntu:$ touch ~/my_blog_app/blog/blogsite/story_generator.py ثم نضيف مفتاح الواجهة البرمجية OpenAI API key إلى متغيرات البيئة environmental variables، فلا نضيفها في ملف بايثون مباشرة لحماية المفتاح: (env)hasoub-academy@ubuntu:$ export OPENAI_KEY="your-api-key" نفتح الآن الملف story_generator.py وننشئ بداخله عميل OpenAI client ونعرف دالة باسم generate_story وظيفتها توليد محتوى قصة بناءً على مجموعة من الكلمات التي يحددها المستخدم: import os from openai import OpenAI client = OpenAI(api_key=os.environ["OPENAI_KEY"]) def generate_story(words): # استدعاء واجهة برمجة التطبيقات من OpenAI لتوليد القصة response = get_short_story(words) # تنسيق الاستجابة وإرجاعها return format_response(response) لتنظيم الكود البرمجي، سنستدعي ضمن هذه الدالة البرمجية دالة منفصلة باسم get_short_story تطلب توليد القصة من الواجهة البرمجية OpenAI API، ودالة أخرى باسم format_response تنسِّق الرد المستلم من الواجهة البرمجية. لنركز الآن على دالة توليد القصة get_short_story حيث سنضيف الكود الخاص بها في نهاية الملف story_generator.py كما يلي: def get_short_story(words): # إنشاء موجه النظام system_prompt = f"""أنت مولد قصص قصيرة. اكتب قصة قصيرة باستخدام الكلمات التالية: {words}. لا تتجاوز فقرة واحدة.""" # الاتصال بواجهة برمجة التطبيقات response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{ "role": "user", "content": system_prompt }], temperature=0.8, max_tokens=1000 ) # إرجاع استجابة الواجهة البرمجية return response كما نلاحظ فقد ضبطنا هنا مُوجِّه النظام system prompt كي يخبر النموذج ما هو، وما هي المهمة التي عليه تأديتها، وحددنا في الموجّه حجم القصة المطلوبة، ثم مررنا هذا الموجّه للواجهة البرمجية ChatCompletion API. أخيرًا نكتب كود دالة التنسيق format_response في نهاية الملف story_generator.py: def format_response(response): # استخرج القصة المولدة من الاستجابة story = response.choices[0].message.content # إزالة أي نص أو تنسيقات غير مرغوبة story = story.strip() # إرجاع القصة المنسقة return story لاختبار هذه الدوال سنستدعي الدالة generate_story ونمرر لها مجموعة كلمات كمعاملات، ثم نطبع الرد الذي تعيده لنا من خلال إضافة سطر الكود التالي للملف: print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) لنحفظ الملف ونغلقه، ونشغًله من داخل سطر الأوامر كما يلي: (env) sammy@ubuntu:$ python ~/my_blog_app/blog/blogsite/story_generator.py يجب أن نحصل على قصة تشابه القصة التالية: في زاوية مريحة من غرفة مشمسة، كانت هناك قطة ذات فرو ناعم تُدعى "مشمش"، تتمدد بكسل بجانب رف كتب شاهق. بين صفوف الكتب، كان حاسوب فضولي يهمس بهدوء. بينما كانت أشعة الشمس تتسلل عبر النافذة، مُلَقيةً ضوءًا دافئًا، لاحظت "مشمش" بقعة ماء صغيرة على الرف. مدفوعةً بالفضول، دفعت القطة الكتاب الأقرب إلى البقعة، ليُفتح الكتاب ويكشف عن مكان مخفي يحتوي على عقد ماسي متلألئ. مع اكتشاف السر، بدأت "مشمش" مغامرة غير متوقعة، حيث امتزجت أشعة الشمس، والماء، وقوة المعرفة لتنسج قصة مثيرة من الغموض والاكتشاف. بعد أن تأكدنا من عمل الدالة generate_story وتوليد القصة بشكل صحيح، لنغير طريقة تنفيذ الكود وبدلاً من طباعة القصة مباشرة في سطر الأوامر، سنستدعي الدالة من خلال عرض جانغو Django view لعرض القصة على واجهة المستخدم. print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) يمكن تجربة تعديل مُوجّه النظام system prompt بما يناسبنا لتوليد محتوى أفضل. سنلاحظ بالتجربة أن بإمكاننا دائمًا تحسين النتائج بما يتناسب مع احتياجاتنا. لننتقل إلى الخطوة التالية، حيث سندمج الوحدة التي عرفناها في ملف story_generator.py مع مشروع جانغو الخاص بنا. دمج وحدة بايثون مع جانغو في الواجهة الخلفية لدمج وحدة story_generator مع مشروع جانغو في الواجهة الخلفية، علينا تنفيذ عدة خطوات بسيطة، سنبدأ أولاً بإنشاء عرض view جديد في جانغو لاستقبال الكلمات من المستخدم، ثم سنستخدم الدالة generate_story لتوليد القصة بناءً على تلك الكلمات، وفي النهاية سنعرض النتيجة للمستخدم عبر المتصفح. نفتح ملف views.py داخل مجلد مشروع جانغو، ونستورد الوحدات والحزم البرمجية اللازمة، ثم نضيف دالة عرض view باسم generate_story_from_words ونكتب ضمنها ما يلي: from django.http import JsonResponse from .story_generator import generate_story def generate_story_from_words(request): words = request.GET.get('words') # استخراج الكلمات المتوقعة من الطلب story = generate_story(words) # استدعاء دالة generate_story باستخدام الكلمات المستخرجة return JsonResponse({'story': story}) # إرجاع القصة في استجابة JSON بعدها نحتاج لربط الدالة بمسار URL في مشروع جانغو لتمكين المستخدمين من الوصول إليها عبر المتصفح. لنفتح الملف urls.py ونضيف نمط الرابط URL pattern للدالة generate_story_from_words كما يلي: urlpatterns = [ # أنماط URL الأخرى... path('generate-story/', views.generate_story_from_words, name='generate-story'), ] الآن يمكننا إرسال الطلبات من خلال نقطة الوصول التالية/generate-story/ باستخدام المتصفح، وإرسال طلب من النوع GET لها وتمرير الكلمات المتوقعة كمعاملات للطلب، نفتح سطر الأوامر ونكتب الأمر curl بالشكل التالي: (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words=قطة,كتاب,حاسوب,شمس,ماء" علينا استبدال http://your_domain بالعنوان الفعلي الذي يستضيف مشروعنا. تمثّل الكلمات الممررة عبر هذا الرابط مثل كتاب، وماء، وحاسوب ما هي الكلمات التي نريد استخدامها لتوليد محتوى القصة. يمكن بالطبع تغيير هذه الكلمات واستخدام كلمات أخرى حسب الحاجة. بعد تشغيل أمر curl يجب أن نرى ردًا من الخادم يحتوي على القصة المولدة استنادًا إلى الكلمات التي قدمناها. (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words="قطة,كتاب,حاسوب,شمس,ماء" وسنحصل على مخرجات قريبة للتالي: { "story": "كان يا مكان، في كوخ صغير مريح يقع وسط غابة كثيفة، قطة فضولية تُدعى 'مشمش' تجلس بجانب النافذة، تستمتع بأشعة الشمس الدافئة. بينما كانت 'مشمش' تحرك ذيلها بكسل، لفت نظرها كتاب مغبر ملقى على رف قريب. بدافع الفضول، قفزت بعناية إلى الرف، مما أدى إلى سقوط مجموعة من الكتب، فتح أحدها ليكشف عن مكان مخفي. داخل هذا المكان، اكتشفت 'مشمش' حاسوبًا قديمًا، بدأ شاشته يومض عندما لمست زر الطاقة. مفتونةً بالشاشة المتوهجة، انطلقت 'مشمش' في عالم من المناظر الافتراضية، حيث تجولت بحرية، تطارد الأسماك الرقمية وتوقف للإعجاب بشلالات رائعة. ضائعة في هذه المغامرة الجديدة، اكتشفت 'مشمش' عجائب العوالم الملموسة والافتراضية معًا، مدركةً أن الاستكشاف الحقيقي لا يعرف حدودًا." } الخلاصة إلى هنا نكون قد وصلنا لنهاية هذا المقال الذي وضحنا فيه الخطوات الأساسية التي نحتاجها لدمج OpenAI modes داخل تطبيق جانغو Django باستخدام الواجهة البرمجية OpenAI API، وتعلمنا طريقة إرسال الطلبات للواجهة البرمجية ChatCompletion API والتحكم بسلوك النموذج عن طريق ضبط معاملاته المختلفة. لتحسين هذا المشروع وزيادة ميزاته، يمكننا استكشاف المزيد من مميزات الواجهة البرمجية OpenAI API وتجريب مُوجِّهات نظام system prompt مختلفة، وقيم معاملات متنوعة حتى نحصل على قصة مميزة وإبداعية. ترجمة-وبتصرٌّف-للمقال How to Integrate OpenAI GPT Models in Your Django Project اقرأ أيضًا إنشاء تطبيق جانغو وتوصيله بقاعدة بيانات مدخل إلى إطار عمل الويب جانغو Django دليلك لربط واجهة OpenAI API مع Node.js استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي