ياسر مسكين
-
المساهمات
2907 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
6
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو ياسر مسكين
-
Kadane's Algorithm هي خوارزمية خطية تستخدم لإيجاد أكبر مجموع لمصفوفة فرعية في مصفوفة معينة تعرف المصفوفة الفرعية بأنها مجموعة متصلة من العناصر داخل المصفوفة وتتعامل الخوارزمية بفاعلية مع الأرقام الموجبة والسالبة، مما يجعلها أداة متعددة الاستخدامات لحل العديد من المشكلات المتعلقة بالمصفوفات الفرعية. تعتمد الخوارزمية على منهج البرمجة الديناميكية من خلال حساب أكبر مجموع متصل ينتهي عند كل عنصر في المصفوفة والفكرة الأساسية هي مقارنة العنصر الحالي بأكبر مجموع متصل سابق، وتحديث القيم بناء على ذلك ولتنفيذها نقوم بالتالي أولا نقوم بتهيئة متغيرين: max_so_far: أكبر مجموع متصل تم العثور عليه حتى الآن. max_ending_here: المجموع المتصل الحالي. ثم نمرر على كل عنصر في المصفوفة من خلال إضافة العنصر الحالي إلى max_ending_here فإذا كان max_ending_here أقل من الصفر، نقوم بإعادة ضبطه إلى صفر، ونقوم بتحديث max_so_far إذا كان max_ending_here أكبر منه. وعند الانتهاء من المرور على المصفوفة، سيحتوي max_so_far على أكبر مجموع متصل على هذا النحو: public class KadaneAlgorithm { public static int maxSubarraySum(int[] arr) { int max_so_far = Integer.MIN_VALUE; int max_ending_here = 0; for (int i = 0; i < arr.length; i++) { max_ending_here += arr[i]; if (max_ending_here < 0) { max_ending_here = 0; } if (max_so_far < max_ending_here) { max_so_far = max_ending_here; } } return max_so_far; } public static void main(String[] args) { int[] arr = {-2, 1, -3, 4, -1, 2, 1, -5, 4}; int maxSum = maxSubarraySum(arr); System.out.println("أكبر مجموع متصل هو: " + maxSum); } } ثم الإخراج سيكون: أكبر مجموع متصل هو: 6 وهو ناتج جمع [4, -1, 2, 1]. أما بالنسبة للتعقيد الزمني لهذه الخوارزنية فهو O(n) حيث n هو عدد عناصر المصفوفة.
- 3 اجابة
-
- 1
-

-
 وعليكم السلام ورحمة الله تعالى وبركاته، ال Convolutional Neural Networks ليست مقتصرة على الرؤية الحاسوبية فقط على الرغم من أنها أصبحت مشهورة بنجاحها في المهام المتعلقة بالصور مثل التصنيف والكشف والتجزئة، إلا أنه يتم الآن تطبيقها في العديد من المجالات الأخرى. على سبيل المثال تستخدم في معالجة اللغة الطبيعية لمهام مثل تصنيف النصوص وتحليل المشاعر، وفي معالجة الصوت والتعرف على الكلام، وحتى في مجالات مثل المعلوماتية الحيوية وتحليل السلاسل الزمنية. كما أنّ قدرتها على تعلم الميزات الهرمية تلقائيا من البيانات تجعلها متعددة الاستخدامات للعديد من أنواع المدخلات المنظمة والمتسلسلة. كما أنها وسيلة لتعلم الأنماط الموجودة في البيانات بحيث يمكن أن تكون البيانات بأي شكل مثل ثنائي الأبعاد أو ثلاثي الأبعاد أو أكثر وغالبا ما تستخدم الصور في الشروحات لأنها تجعل من السهل فهم كيفية تطبيق الشبكة على البيانات. وأيضا تم استخدامها في المجال الطبي لتحليل البيانات التسلسلية مثل إشارات تخطيط القلب الكهربائي (ECG) لذا فإن مرونتها في التعامل مع أنواع مختلفة من البيانات المنظمة ضمن شبكة (grid) تجعلها مفيدة في مجالات متنوعة، ولا تقتصر فقط على مهام الإدراك البصري.
وعليكم السلام ورحمة الله تعالى وبركاته، ال Convolutional Neural Networks ليست مقتصرة على الرؤية الحاسوبية فقط على الرغم من أنها أصبحت مشهورة بنجاحها في المهام المتعلقة بالصور مثل التصنيف والكشف والتجزئة، إلا أنه يتم الآن تطبيقها في العديد من المجالات الأخرى. على سبيل المثال تستخدم في معالجة اللغة الطبيعية لمهام مثل تصنيف النصوص وتحليل المشاعر، وفي معالجة الصوت والتعرف على الكلام، وحتى في مجالات مثل المعلوماتية الحيوية وتحليل السلاسل الزمنية. كما أنّ قدرتها على تعلم الميزات الهرمية تلقائيا من البيانات تجعلها متعددة الاستخدامات للعديد من أنواع المدخلات المنظمة والمتسلسلة. كما أنها وسيلة لتعلم الأنماط الموجودة في البيانات بحيث يمكن أن تكون البيانات بأي شكل مثل ثنائي الأبعاد أو ثلاثي الأبعاد أو أكثر وغالبا ما تستخدم الصور في الشروحات لأنها تجعل من السهل فهم كيفية تطبيق الشبكة على البيانات. وأيضا تم استخدامها في المجال الطبي لتحليل البيانات التسلسلية مثل إشارات تخطيط القلب الكهربائي (ECG) لذا فإن مرونتها في التعامل مع أنواع مختلفة من البيانات المنظمة ضمن شبكة (grid) تجعلها مفيدة في مجالات متنوعة، ولا تقتصر فقط على مهام الإدراك البصري.- 4 اجابة
-
- 1
-
-
أولا أقترح عليك هذه المقالة التي تشرح كيف يتم ذلك نظريا وعمليا من هنا: وبالنسبة لخطوات التحويل فيجب بدءا تثبيت مكتبة PyInstaller من خلال فتح نافذة الأوامر أو الطرفية ثم نقوم بالتثبيت باستخدام pip: pip install pyinstaller بعدها انتقل إلى مجلد السكريبت الخاص بك من خلال تغيير المسار في الطرفية باستخدام الكلمة المفتاحية cd متبوعة بمسار المجلد، ثم شغّل PyInstaller مع خيار --onefile لجمع كل الملفات في ملف تنفيذي واحد: pyinstaller --onefile script.py يمكنك دوما مراجعة التوثيق الرسمي للمكتبة من هنا: PyInstaller في حال أردت إضافة إعدادات إضافية للأمر. أو يمكنك متابعة الخطوات من خلال هذه الإجابة:
- 2 اجابة
-
- 1
-
-
مرحبا بك، بما أنك مشترك في كلا الدورتين، فمن الأفضل إكمال دورة علوم الحاسوب أولا قبل الانتقال إلى دورة الذكاء الاصطناعي. صحيح أنّ بعض الدروس والمسارات في دورة علوم الحاسوب مثل أنظمة التشغيل، وهياكل البيانات، وقواعد البيانات قد لا تبدو مرتبطة مباشرة بالذكاء الاصطناعي لكنها مع ذلك ستكسبك فهما عميقا لكيفية عمل الحاسوب والبرامج عموما وينصح بمن لا يمتلك خلفية عامة حول مجال علم الحاسوب أن يبدأ بهذه الدورة فهي صمّمت خصّيصا لهذا الغرض ولكي يجد الطالب نفسه مرتاحا عند التطرق لمواضيع أكثر تعقيدا في الدورات الأخرى كما أن فهم تلك المحاور سيكون مفيدا عند البدء في تطوير وتحسين نماذج الذكاء الاصطناعي عند التطبيق العملي. لكن في حال رأيت نفسك متمكنا من دروس الدورة ومساراتها يمكنك مراجعتها مراجعة خفيفة لمعرفة إن كنت قد استوعبت الدورة أم لا، وليكن بعلمك أنك لن تتمكن من الحصول على شهادة دورة علوم الحاسوب إلا إن أكملت أربع مسارات كاملة منها وقمت برفع المشاريع فهذا شرط أساسي لكل دورة. لذا يحبّذ إتمامها أولا، وفي حال أردت البدء في الدورة يمكنك دراسة مسارات البرمجة الكائنية، الخوارزميات وبنى المعطيات لكونها أساسية ثم ابدأ في دورة الذكاء الاصطناعي. ثم يمكنك العودة إليها فيما بعد وإتمامها حينما تكون مستعدا لذلك.
- 2 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله تعالى وبركاته، الأمر ليس ثابتا أو ينطبق على الجميع فهو يعتمد على أهدافك وخلفيتك بالنسبة للعديد من المتعلمين فهم يعتبرون لغة بايثون مناسبة تماما لفهم وتطبيق هياكل البيانات والخوارزميات لأن تركيبها الواضح والمختصر يتيح التركيز على المفاهيم الأساسية بسهولة بدلا من التفاصيل ذات المستوى المنخفض مثل إدارة الذاكرة وهذا يمكن أن يكون مفيدا بشكل خاص عندما تكون في بدايات تعلمك أو إذا كان هدفك الرئيسي هو تطوير التفكير الخوارزمي ومهارات حل المشكلات. من ناحية أخرى إذا كنت ترغب في فهم أعمق لما يحدث تحت الغطاء على سبيل المثال كيف تنفذ هياكل البيانات على مستوى الذاكرة، وكيف تعمل المؤشرات، وكيف تؤثر إدارة الذاكرة اليدوية على الأداء فإن تعلمها بلغة منخفضة المستوى مثل C ينصح به بشكل كبير وهذا ما كان يتم اعتماده في الجامعات التعليمية فهذه اللغة تجبرك على التعامل مع هذه التفاصيل، مما يرسخ فهمك لكيفية عمل الخوارزميات على مستوى أكثر أساسية لكن قد يكون التعقيد الإضافي في التعامل مع إدارة الذاكرة والمؤشرات مصدر تشتيت إذا كان تركيزك الأساسي هو تعلم المفاهيم الخوارزمية المجردة لذا يرجع الأمر في الأخير إليك.
- 3 اجابة
-
- 1
-
-
يمكنك إيجاد الإجابة المناسبة لاستفسارك من خلال هذا الرابط: في الأكاديمية وسائل الدفع المتاحة هي إما عن طريق البطاقة الإئتمانية أو PayPal، ولكن بطاقة الدفع يجب أن تكون من نوع Debit أو Credit وليس Prepaid أي ليست مسبقة الدفع، أو تستطيع ربط أي بطاقة بباي بال ثم الدفع عن طريق باي بال مباشرة. كما تُوفّر أكاديمية حسوب لزوارها إمكانية شراء بطاقة هدية ومشاركتها، ليتمكن متلقّي الهدية من استخدامها في التسجيل بالدورات المتوفرة في الأكاديمية يمكنك الاطلاع أكثر من هنا: https://support.academy.hsoub.com/how-to-buy-gift-card
-
إذا كنت تميل إلى إتقان مجال واحد وتريد أن تصبح خبيرا فيه، فقد يكون التخصص هو الخيار المناسب ومع ذلك إذا كنت تستمتع بالتعلم بشكل واسع وترغب في العمل على مشاريع تجمع بين تقنيات الذكاء الاصطناعي المتعددة، فقد يكون تنمية المهارات في كلا المجالين أمرا جيدا. في الأغلب الكثير من المحترفين في هذا المجال يجدون أنفسهم يميلون إلى البدء بالتركيز على مجال معين ثم توسيع خبراتهم تدريجيا وهذا هو النهج الأفضل مع مرور الوقت وتوضيح اهتماماتهم المهنية، لذا يمكنك اختيار مجال محدد والتخصص فيه وهذا لا يعني أن لا تتطرق إلى مجالات أخرى، ففي رحلة تعلمك ستجد عدة مجالات تتقاطع مع مجالك التخصصي، ومن الجيد أن تكون لديك فكرة حولها، وحتى أن تكون ملما بها.
- 4 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله وبركاته، DeepLearning.AI هي شركة تكنولوجيا تعليمية متخصصة في مجال الذكاء الاصطناعي وتعلم الآلة بحيث تقدم الشركة دورات تعليمية عبر الإنترنت وتخصصات وموارد، مثل برنامج التخصص الرائد في التعلم العميق والدورة غير التقنية "الذكاء الاصطناعي للجميع"، وذلك بشكل أساسي من خلال منصات مثل Coursera.
- 4 اجابة
-
- 1
-
-
بالنسبة للكود الأول: data.drop(columns=data.loc[:, 'x_2':'z_40'].columns, inplace=True) فهو يحدد الأعمدة من 'x_2' إلى 'z_40' ثم يمرر قائمة أسماء الأعمدة الناتجة إلى دالة drop باستخدام معامل columns المخصص أما أما الكود الثاني: data.drop(data.loc[:, 'x_2':'z_40'], axis=1, inplace=True) فهو يمرر الجزء الفرعي من DataFrame وليس مجرد تسميات الأعمدة إلى دالة drop في Pandas تتوقع دالة drop أن يكون أول معامل لها هو التسمية أو قائمة التسميات وليس DataFrame على الرغم من أن Pandas قد يتسامح أحيانا مع الكائنات الشبيهة بالقوائم، فإن تمرير DataFrame بدلا من قائمة الأعمدة يكون أقل وضحا وقد يؤدي إلى أخطاء أو سلوك غير متوقع في بعض الحالات. من ناحية الأداء فكلاهما يؤديان نفس الوظيفة إلا أنّ الطريقة الأولى تعتبر أكثر كفاءة قليلا لأنها تستخرج قائمة أسماء الأعمدة الضرورية فقط بدلا من DataFrame فرعي كامل.
- 3 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله وبركاته، قم بفتح نافذة التشغيل من خلال الأمر Win + R ثم اكتب "cmd" واضغط Enter وستفتح لك نافذة موجه الأوامر، بعدها اكتب الأمر التالي: powercfg /batteryreport وستظهر لك رسالة تبدأ ب "Battery life report......." وستظهر أيضا مسارا للملف، انسخ مسار الملف والصقه في المتصفح وسيتم فتح تقرير البطارية، ابحث عن "DESIGN CAPACITY" و "FULL CHARGE CAPACITY" والفرق بينهما سيعطيك فكرة عن حالة البطارية. DESIGN CAPACITY: هي سعة البطارية عندما قمت بتشغيل اللاب توب لأول مرة، وهي السعة الكاملة التي تم تصميم البطارية لها. FULL CHARGE CAPACITY: هي السعة الحالية التي يمكن للبطارية الاحتفاظ بها بعد الشحن الكامل في الوقت الحالي، إذا كانت بطاريتك ضعيفة أو تالفة، فسيكون هذا الرقم منخفضا جدا الآن. وكحل كحل محتمل، قم بإيقاف تشغيل اللاب توب وافصل كابل الشحن عنه، ثم قم بإزالة البطارية واتركها خارجا لمدة لا تقل عن 5 دقائق خلال هذه الفترة، افتح اللاب توب واضغط مع الاستمرار على زر الطاقة لمدة 10 ثوان وهذا الإجراء سيزيل أي شحنات كهربائية متبقية في مكونات اللاب توب. بعد ذلك أعد تركيب البطارية، وصل كابل الشحن، ثم قم بتشغيل اللاب توب وتحقق مما إذا كان يشحن بشكل طبيعي واتركه ليشحن لبعض الوقت، ثم افصل كابل الشحن وتأكد مما إذا كان اللاب توب يبقى قيد التشغيل أو إذا كان لا يزال ينطفئ. فإذا انطفأ اللاب توب مباشرة بعد فصل الشاحن، فهذا يعني أن البطارية لا تعمل وغالبا ما تكون البطارية قد وصلت إلى نهاية عمرها الافتراضي ولم تعد تحتفظ بالشحن. أحيانا تتوقف بطاريات اللاب توب عن العمل بشكل مفاجئ بسبب حدوث دائرة كهربائية قصيرة داخل مكوناتها ورغم أن معظم البطاريات تكون متينة، إلا أن الحرارة الشديدة أو البرودة، أو ملامسة السوائل، أو التعرض لصدمة حادة نتيجة الاصطدام أو السقوط، يمكن أن تتسبب في تلف البطارية. هناك احتمال آخر وهو أن يكون موصل البطارية داخل اللاب توب تالفا يمكن أن يحدث ذلك لنفس الأسباب التي قد تتسبب في تلف البطارية نفسها. إذا لم تعد البطارية تحتفظ بالشحن وكان اللاب توب لا يزال ضمن فترة الضمان، يُفضل التواصل مع الشركة المصنعة والمطالبة بتصليح الضمان. أما إذا كان الضمان منتهيًا، فقد تحتاج إلى شراء بطارية بديلة.
- 3 اجابة
-
- 1
-
-
استخدام cv2.imwrite() هو المفضل عادة عندما تحتاج إلى الحفاظ على القيم الدقيقة للبكسل وجودة الصورة الأصلية، لأنه يكتب بيانات الصورة الخام مباشرة إلى الملف دون أي معالجة إضافية أو تنسيق، بينما plt.savefig() مصمّم لحفظ الأشكال الكاملة غالبا مع المحاور والعناوين وعناصر الرسم الأخرى وقد يدخل تعديلات مثل تغيير مقياس DPI، وإضافة الهوامش، أو حتى ظهور آثار ضغط خفيفة يمكن أن تؤثر على الجودة والدقة.
- 5 اجابة
-
- 1
-
-
إذا كان تطبيقك يتطلب سلوك خادم مخصص للغاية أو إذا كنت تدمج مع نظام Express قائم، فإن استخدام Express مع Next.js يمكن أن يكون مفيدا وبالنسبة للعديد من المشاريع الجديدة، فإن القدرات المدمجة في Next.js قوية بما يكفي للتعامل مع منطق الواجهة الأمامية والخلفية دون الحاجة إلى تعقيد إضافي لخادم خارجي. وباختصار إذا أردت استخدام Express مع Next.js يمكن ذلك إذا كنت بحاجة إلى وسائط متقدمة أو توجيه مخصص يتجاوز ما يقدمه Next.js أو إذا كنت تقوم بتكييف بنية خلفية تعتمد على Express أو تدمج مع خدمات Node.js أخرى. كما يمكنك الاكتفاء بالخادم المدمج في Next.js إذا كانت احتياجات تطبيقك تتم تلبيتها من خلال مسارات API وميزات SSR في Next.js، خاصة مع التحسينات الأخيرة فالنسخ الأحدث من Next.js قد حسنت مسارات API، وإمكانيات الوسائط، ودعم الخدمات بدون خادم (serverless) وبالنسبة للعديد من المشاريع، تعني هذه التحسينات أن الخادم المدمج كاف، مما يلغي الحاجة إلى إعداد خادم خارجي إلا إذا كانت المتطلبات محددة للغاية. يمكنك المراجعة أكثر من خلال موسوعة حسوب: Next.js أو من خلال المقالات والإجابات التالية:
-
وعليكم السلام ورحمة الله وبركاته، ترتيب المسارات وحتى الدروس لم يتم وضعه عشوائيا فهذا الترتيب مهم لترابط الدروس ببعضها البعض، ولوجود مسارات للتطبيقات العملية ولأهميتها في ترسيخ المفاهيم الأولية بالنسبة للمبتدئين في المجال. فالانتقال من المسار الثالث إلى المسار الثامن مباشرة قد يتسبب في بعض اللبس في حال كان المتعلم مبتدئا ولا يملك خلفية عامة حول هذا المجال خاصة فيما يخص بكيفية التعامل مع البيانات، وتحليلها وتعلم الآلة فهي ضرروية لفهم دروس التعلم العميق. يمكنك تجاوز مسار التعامل مع البيانات وتحليل البيانات وتعلم الآلة في حال كانت لديك خلفية حولهما ثم الرجوع إليهما في وقت لاحق.
- 3 اجابة
-
- 1
-

-
المشكلة تظهر من مكتبة seaborn وهذه التحذيرات تتعلق باستخدام خاصية use_inf_as_na التي أصبحت مهجورة (deprecated) في pandas وستتم إزالتها في إصدارات مستقبلية. والخاصية use_inf_as_na تعامل القيم اللانهائية (Infinity) كقيم مفقودة (NaN) أي عندما تستخدم seaborn للرسم البياني، فإنه يستخدم هذه الخاصية داخليا، مما يسبب ظهور هذه التحذيرات. لإزالة هذه التحذيرات وضمان استقرار الكود في المستقبل، قم بإضافة السطرين التاليين في بداية الكود قبل عملية الرسم البياني: import numpy as np data = data.replace([np.inf, -np.inf], np.nan) ليصبح الكود النهائي كالتالي: import matplotlib.pyplot as plt import seaborn as sns import numpy as np import pandas as pd data = data.replace([np.inf, -np.inf], np.nan) plt.figure(figsize=(12, 6)) plt.subplot(1, 3, 1) sns.histplot(data['x_1'], kde=True) plt.title('Distribution of x_1') plt.subplot(1, 3, 2) sns.histplot(data['y_1'], kde=True) plt.title('Distribution of y_1') plt.subplot(1, 3, 3) sns.histplot(data['z_1'], kde=True) plt.title('Distribution of z_1') # Adjusts the layout to prevent overlapping of plots plt.tight_layout() # Display all plots plt.show()
- 9 اجابة
-
- 1
-
-
يمكنك حل المشكلة بطريقة مختلفة تجنب تعديل ملفات ال vendor مباشرة، وذلك عبر إنشاء ملف مساعد (helper) خاص بك يحتوي على تعريف الدالة ثم تضمينه ضمن autoload الخاص بالمشروع وبهذه الطريقة تعرف الدالة قبل أن يحتاج إليها كود Laravel دون تعديل أي ملف من ملفات الvendor. أولا أنشئ ملفا تحت مجلد المشروع مثلا داخل app/Helpers/ وليكن اسمه helpers.php وفي هذا الملف عرف دالة join_paths في النطاق (namespace) المناسب بحيث تحاكي تعريفها المطلوب. ثم قم بتحرير ملف composer.json وأضف مسار الملف ضمن القسم "autoload" تحت المفتاح "files" وهذا يضمن تحميل الملف تلقائيا عند بدء تشغيل التطبيق وبعد حفظ التغييرات، نفّذ الأمر: composer dump-autoload وهذا حتى يتم تحديث نظام autoload وتطبيق التعريف الجديد. ثم أعد تشغيل التطبيق وتأكد من أن الخطأ لم يعد يظهر، مما يعني أن الدالة أصبحت معرفة بشكل صحيح قبل استخدامها في كود Laravel.
-
كما تمت الإشارة في التعليق الأول، يمكنك الوصول إلى المسارات الأولى من خلال الضغط على تبويبة "دوراتي" أعلى الصفحة: أو يمكنك الوصول إليها من خلال الضغط على هذا الرابط مباشرة: دوراتي. وستلاحظ أنّ المسارات الأولى هي كالتالي، كما يمكنك التوجه إليها من هنا مباشرة وهذا لتسهيل عملية الوصول : أساسيات بايثون أساسيات إدارة تطوير المنتجات مدخل إلى علوم الحاسوب أساسيات تطوير الويب أساسيات لغة بايثون Python أساسيات لغة JavaScript أساسيات لغة PHP أساسيات لغة روبي أساسيات تطوير الألعاب
-
كما تم التطرق في الإجابات السابقة، فإنّ تقنية ال Face Recognition تعني التعرف على الوجه وهو عملية تحديد هوية شخص من خلال صورة أو فيديو عن طريق مقارنة الوجه المدخل بقاعدة بيانات كبيرة تحتوي على وجوه معروفة. تكون العملية عادة مقارنة من واحد إلى متعدد 1:N حيث يسأل النظام: "من هذا الشخص؟" على سبيل المثال قد تستخدم الجهات الأمنية التعرف على الوجه لتحديد مشتبه به في حشد من الأشخاص عبر مقارنة صورته مع قاعدة بيانات لصور المجرمين وهذا أمر مفيد للغاية بحيث يتم على هذا النحو: يكتشف النظام وجود وجه في الصورة (الكشف عن الوجه). يستخرج النظام المميزات الفريدة مثل المسافة بين العينين وشكل الفك وغيرها. ثم يقوم بمقارنة هذه المميزات مع قاعدة بيانات من القوالب المخزنة لإيجاد تطابق. بينما Face Verification هو تقنية التحقق من الوجه من خلال عملية مقارنة من واحد إلى واحد 1:1 أين تستخدم لتأكيد أن الشخص هو بالفعل من يدعي أنه هو بدلا من البحث في عدة صور، يتم مقارنة وجه حي بصورة مسجلة مسبقا نفس الفكرة عند فتح هاتفك باستخدام خاصية Face ID حيث تتم مقارنة وجهك مع الصورة المخزنة للتحقق من هويتك كالتالي: يلتقط النظام صورة للشخص. يستخرج قالبا بيومتريا من الصورة. يقوم بمقارنة هذا القالب مباشرة مع القالب المخزن أثناء عملية التسجيل. إذا كان القالبان متطابقين بدرجة كافية، يتم تأكيد هوية الشخص.
- 6 اجابة
-
- 1
-
-
نعم من الممكن تخزين بيانات المتجر الإلكتروني محليا على جهاز اللابتوب الخاص بك والفكرة الأساسية هي تشغيل نظام إدارة قواعد البيانات (DBMS) على جهازك بحيث تخزن كل بيانات التطبيق بشكل دائم على القرص الصلب. يمكنك تحميل وتثبيت خادم MySQL وأثناء عملية التثبيت ستلاحظين أن MySQL يقوم بإعداد مسار معين لتخزين كافة قواعد البيانات والجداول كملفات على القرص الصلب. كما يمكنك استخدام SQLite وهو محرك قاعدة بيانات مدمج لا يحتاج إلى تشغيل خادم منفصل، حيث تخزن قاعدة البيانات بأكملها في ملف واحد على القرص الصلب كما أنه لا يتطلب استخدامه إعداد خادم معقد مما يجعله خيارا ممتازا للتطبيقات الصغيرة أو أثناء التطوير والعديد من لغات البرمجة والأطر تدعم SQLite بشكل مدمج ويمكنك ببساطة الإشارة إلى مسار الملف الذي يحتوي على قاعدة البيانات في إعدادات التطبيق.
-
في لغة بايثون القائمة المعرفة كالتالي: array = [1, 2, 3, 4, 5] ليست مصفوفة ثابتة بل هي مصفوفة ديناميكية مما يعني أنه بعد إنشاء القائمة يمكنك إضافة أو إزالة أو تعديل عناصرها دون الحاجة لتحديد حجم ثابت مسبقا على سبيل المثال يمكنك إضافة عنصر باستخدام array.append(6) فتصبح القائمة: array = [1, 2, 3, 4, 5, 6] أو إزالة عنصر باستخدام array.pop(). وفي لغات أخرى مثل C أو Java تكون المصفوفات الثابتة ذات حجم محدد عند إنشائها ولا يمكن تغييره دون إنشاء مصفوفة جديدة على سبيل المثال في لغة C يمكنك تعريف مصفوفة كالتالي: int array[5]، حيث لا يمكن تغيير حجمها لاحقا. لا تحتوي بايثون على نوع مدمج للمصفوفة الثابتة، إذ أن القوائم مصممة لتكون أكثر مرونة وإذا كنت بحاجة إلى تسلسل غير قابل للتعديل من العناصر، يمكنك استخدام ال tuple، والذي يتم تعريفه بالشكل التالي: tuple_array = (1, 2, 3, 4, 5) لاحظ استخدمنا الأقواس ( ) بدلا من [ ].
- 5 اجابة
-
- 1
-
-
المشكلة تكمن في الدالة someCode(). هذه ليست دالة موجودة أصلا في لغة جافاسكربت فجافاسكربت لديها دوال مدمجة كثيرة مثل parseInt()، console.log()، إلخ لكن someCode() ليست واحدة منها. عندما يظهر خطأ يقول "someCode is not defined" فهذا يعني أن جافاسكربت تبحث عن دالة بهذا الاسم ولم تجدها. ربما الكتاب يقصد أن تقوم أنت بكتابة هذه الدالة من الممكن أن يكون هذا تمرين في الكتاب، حيث يطلب منك كتابة دالة تسمى someCode() تأخذ تاريخ الميلاد وتحسب العمر لذلك يمكنك المحاولة في إنشاء هذه الدالة ثم اختبار الكود الخاص بك.
-
من الأفضل أن تبدأ في دراسة أنماط التصميم (design patterns) بعد أن تتقن أساسيات البرمجة الكائنية (OOP) فدراسة أنماط التصميم ستساعدك في كتابة كود نظيف ومنظم مما يسهل صيانته وتحديثه ومنه حل المشكلات البرمجية بطرق مجربة حيث أنها تقدم حلولا متكررة للمشاكل الشائعة إضافة إلى تحسين فرصك المهنية فهي مهارة مطلوبة في العديد من الشركات، خاصة في تطوير التطبيقات الكبيرة والمعقدة. كما يمكنك أيضا تطبيق بعض هذه الأنماط في مشاريع الذكاء الاصطناعي التي تعمل عليها، مما سيساعدك على الربط بين المفاهيم النظرية والعملية. بالتدريج ومع زيادة خبرتك، ستجد أن فهم أنماط التصميم يعزز من قدرتك على تصميم وتطوير برمجيات متكاملة وأكثر كفاءة يمكنك دراستها من هنا: أنماط التصميم
-
أرجو منك مراسلة مركز مساعدة أكاديمية حسوب فهو الوحيد المخول في دراسة الشؤون المالية الخاصة بالطلبة، يمكنك مراسلتهم وسيساعدونك أو يقترحون عليك حلولا لمشكلتك، إلى حين ذلك أرجو مراجعة هذه الإجابة:
-
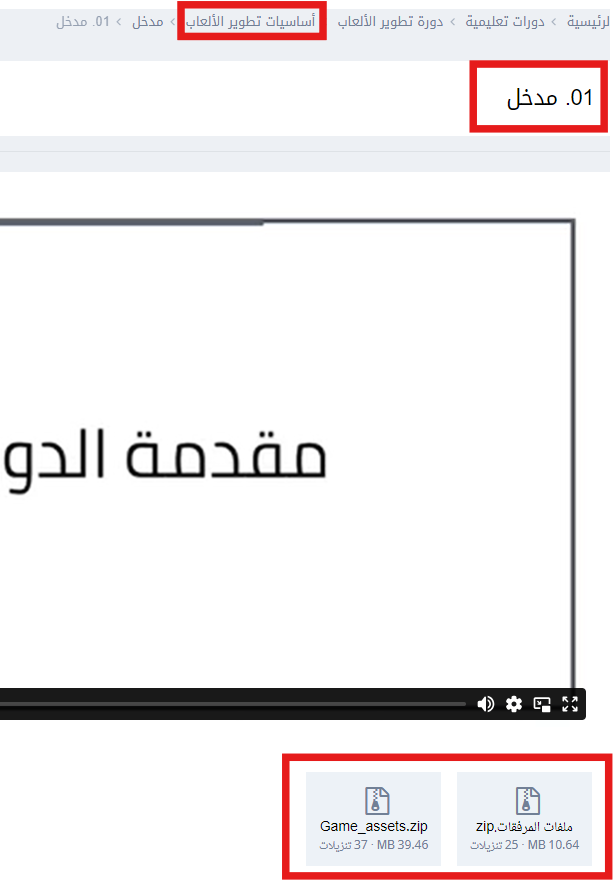
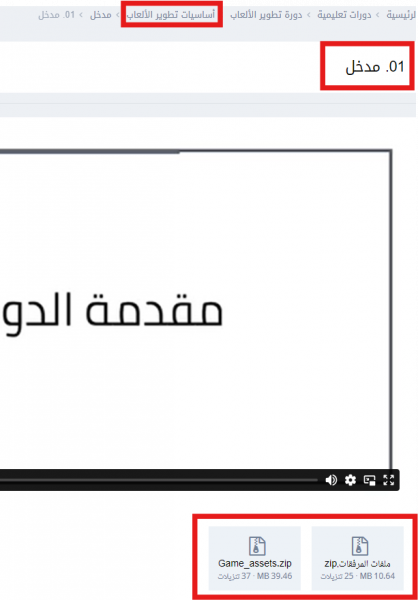
هل تقصد الملفات المصدرية والمرفقات التي يعمل بها المدرّب؟ إن كان كذلك فيمكنك الوصول إليها من خلال درس المقدمة عند مدخل كلّ مسار أين ستجد رابطا مباشرا لتحميل الملفات أو رابطا مباشرا نحو مستودع المشروع الخاص بالدورة التي اشتركت فيها، في حال لم تجده فهذا يعني أنّ المسار أو الدرس الذي أنت فيه ليس بحاجة إلى ملفات مصدرية ويجب التركيز فقط على محتوى الدرس والتطبيق المباشر مع المدرب. يمكنك الوصول إليها وتحميلها مثلما هو موضح في هذه الصورة: بخصوص الملخصات فالأكاديمية لا توفرها وهذا لدفع الطالب إلى عمل ملخصاته بنفسه لكي يسهُل عليه الرجوع إليها وتترسّخ في ذهنه أكثر، فأفضل الملخصات هي التي يعملها الإنسان بنفسه وأنصحك بمراجعة الأجوبة على نفس التساؤل من هنا:
-
ينبغي أولا معرفة شروط التقدم للامتحان النهائي لأي دورة تشترك فيها وهي كالآتي: إتمام أربعة مسارات تعليمية على الأقل (لا يهم الترتيب) التطبيق العملي مع المدرب، والاحتفاظ بالمشاريع العملية الناتجة لإرسالها للمراجعة رفع المشاريع على حسابك على GitHub أولًا بأول لمشاركتها معنا يمكنك التقدم إلى امتحان الدورة، من خلال التواصل مع مركز مساعدة أكاديمية حسوب. ولو تركز على النقطة الثانية وهي توضح لنا أنّ التطبيق العملي شرط أساسي للتعلم في الدورة، ستجد في العديد من المسارات تطبيقات عملية مختلفة ستصادفها في مختلف الدروس، يمكنك القيام بها ومشاركتها معنا مباشرة لنصححها لك. كما توجد مسارات خاصة تُعنى بالتطبيق العملي من خلال إنشاء التطبيقات مباشرة، وهذا يعتمد على نوع الدورة التي اشتركت فيها.
-
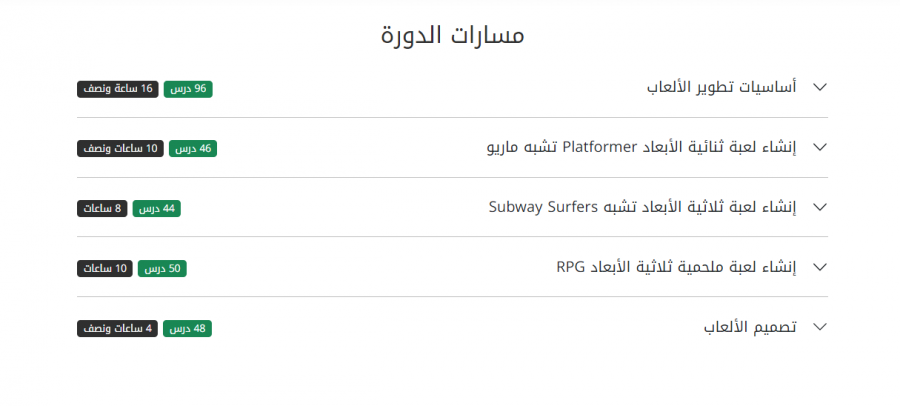
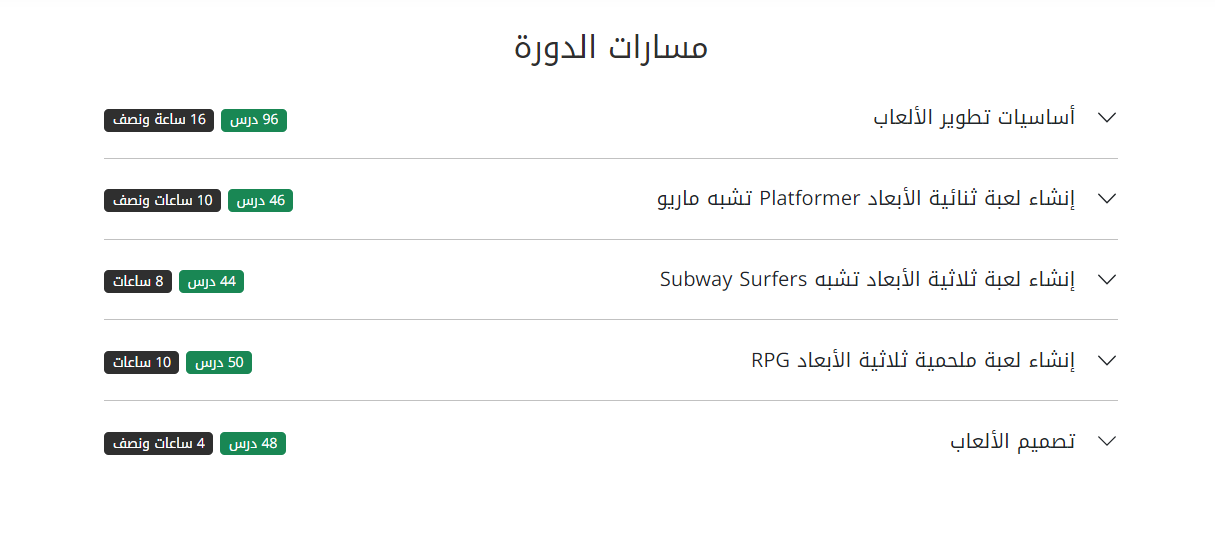
من خلال هذه الصفحة يمكنك التطرق إلى جميع محاور ومسارات الدورة وميزاتها وما يمكنك تعلمه وعمله من خلالها: https://academy.hsoub.com/learn/game-development/ وكما تلاحظ فإنّ مسار نشر الألعاب لم يتم إضافته بعد في الدورة، لكن هذا لا يعني عدم إضافته مستقبلا، يمكن أن يتم تحديث الدورة في أي لحظة ومن ميزات الدورة أنها تتيح لك وصولا مدى الحياة لها، وستحصل على تنبيه لحظة حدوث تحديث للدورة: يمكنك التعرف على مزايا دورات حسوب من هنا: فضلا عن العديد من المقالات التي تتناول هذا المجال: https://academy.hsoub.com/programming/game-development/ يمكنك البحث عن أي شيئ تريد من خلال شريط البحث: وعلى كلّ فإنه لنشر اللعبة على منصات متعددة، يجب اتباع إجراءات محددة تختلف من منصة لأخرى ففي حالة Android، تحتاج أولا إلى إنشاء حساب مطور عبر Google Play Console، ثم توليد ملف APK أو App Bundle واختباره باستخدام الأجهزة الحقيقية أو المحاكيات، وبعد التأكد من خلوه من الأخطاء، يتم رفعه للمراجعة أولا من قبل جوجل للنشر في المتجر. أما على iOS فالأمر يبدأ بالاشتراك في برنامج Apple Developer، ومن ثم إعداد اللعبة باستخدام Xcode مع توقيعها رقميا، يلي ذلك إجراء اختبارات دقيقة على الأجهزة الفعلية أو المحاكيات، ومن ثم رفع التطبيق عبر App Store Connect حيث تتم مراجعته من قبل آبل قبل النشر. وفيما يتعلق بأجهزة Sony مثل PS4 و PS5، يجب التسجيل كمطور عبر منصة PlayStation Partners والحصول على أدوات التطوير الخاصة بسوني، مع ضرورة تعديل اللعبة بما يتوافق مع معايير الجودة والأداء الخاصة بالمنصة، ثم تقديمها للمراجعة الفنية قبل الحصول على الموافقة النهائية للنشر.