ياسر مسكين
-
المساهمات
2906 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
6
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو ياسر مسكين
-
 السلام عليكم ورحمة الله، بداية فإن محرر الأكواد NetBeans لا يرتبط مباشرة بتطوير تطبيقات أندرويد بنفس مستوى التكامل الذي توفره بيئة Android Studio، فهو في الأصل مخصّص لتطوير تطبيقات جافا العامة ويمكن إضافة دعم أندرويد له عبر إضافات مثل NBAndroid لكن هذه الإضافات تبقى أقل ثباتا وتكاملا مقارنة بأدوات وأطر العمل المدمجة في Android Studio.
السلام عليكم ورحمة الله، بداية فإن محرر الأكواد NetBeans لا يرتبط مباشرة بتطوير تطبيقات أندرويد بنفس مستوى التكامل الذي توفره بيئة Android Studio، فهو في الأصل مخصّص لتطوير تطبيقات جافا العامة ويمكن إضافة دعم أندرويد له عبر إضافات مثل NBAndroid لكن هذه الإضافات تبقى أقل ثباتا وتكاملا مقارنة بأدوات وأطر العمل المدمجة في Android Studio.- 4 اجابة
-
- 1
-

-
وعليكم السلام ورحمة الله تعالى وبركاته، مصطلح ال Vibe Coding يطلق على نمط برمجة جديد يعتمد على الذكاء الاصطناعي، وبالتحديد على النماذج اللغوية الكبيرة (LLMs)، حيث يقوم الشخص بوصف المشكلة بشكل غير رسمي أو موجز على شكل (prompt) ويترك مهمة كتابة الكود للنموذج الذكي بمفرده. ويتولى الذكاء الاصطناعي إنشاء الكود، تصحيح الأخطاء، وتحسين الأداء من تلقاء نفسه. لكن بالرغم من ذلك فلا أنصح بالاعتماد عليه في فترة التعلم ولا حتى وسائل وأدوات الذكاء الاصطناعي الأخرى كونها لا تعلّم المنطق البرمجي لذا يجب التدرج في التعلم ولا ضرر في استعمالها عند التمكن من البرمجة لأغراض تسهيل المهام وأتمتتها والإنجاز بسرعة فهي بذلك تتيح للمبرمجين والمهندسين التركيز على التوجيه العام والمراجعة بدلا من كتابة كل سطر كود بأنفسهم.
- 5 اجابة
-
- 1
-
-
بما أنك قد حققت شرط إتمام أربعة مسارات تعليمية على الأقل. يمكنك التقدم إلى امتحان الدورة، من خلال التواصل مع مركز مساعدة أكاديمية حسوب، مع مراعاة الشروط التالية: - التطبيق العملي مع المدرب، والاحتفاظ بالمشاريع العملية الناتجة لإرسالها للمراجعة. - رفع المشاريع على حسابك على GitHub أولا بأول لمشاركتها معنا. وفي الإختبار سيتم اختبارك فقط في المسارات التي قمت بدراستها ويوجد تفاصيل أكثر حول الإختبار من صفحة [الامتحان والحصول على الشهادة]
-
من خلال رسالة الخطأ فهي تشير إلى أنّ لديك أخطاء توافق في مكتبات Flutter فمثلا مكتبة country_code_picker تستخدم خاصية button المهملة، ومكتبة modal_bottom_sheet تحتوي على مشاكل متعددة لحل المشكلة أولا نقوم تحديث المكتبات في ملف pubspec.yaml: dependencies: country_code_picker: ^3.0.0 modal_bottom_sheet: ^3.0.0 ثم نفذ: flutter pub get
-
نعم فقد تم إضافة مسار جديد تحت اسم التعلم المعزز. وهذا التحديث يشمل 44 درسًا بمدة 8 ساعات ونصف. والتعلم المعزز هو نوع من أنواع التعلم الآلي، يتعلم فيه الذكاء الاصطناعي من خلال التجربة والخطأ، تمامًا كما يتعلم الإنسان إذ يضع النظام نفسه في بيئة ويتخذ قرارات، وإذا كانت قراراته جيدة يحصل على مكافأة، وإذا كانت سيئة يتلقى عقوبة. وبمرور الوقت، يتعلم اختيار التصرفات التي تحقق له أفضل النتائج. وقبل أسابيع تمت إضافة مسار تطبيقات عملية باستخدام المحولات وهذا ما يجعل عدد المسارات 12:
- 4 اجابة
-
- 1
-
-
هل تقصد أنك أنهيت دورة إدارة تطوير المنتجات؟ إن كان كذلك فعمل ممتاز أحسنت. يمكنك التقدم إلى امتحان الدورة، من خلال التواصل مع مركز مساعدة أكاديمية حسوب، مع مراعاة الشروط التالية: - إتمام أربعة مسارات تعليمية على الأقل. - التطبيق العملي مع المدرب، والاحتفاظ بالمشاريع العملية الناتجة لإرسالها للمراجعة. - رفع المشاريع على حسابك على GitHub أولا بأول لمشاركتها معنا. وفي الإختبار سيتم اختبارك فقط في المسارات التي قمت بدراستها ويوجد تفاصيل أكثر حول الإختبار من صفحة [الامتحان والحصول على الشهادة] أما إن كنت قد تقصد المشروع النهائي الذي قدمه لك المدرب، فأرجو التواصل مع مركز المساعدة والمتابعة معهم بخصوصه.
-
الأكاديمية تهتم بتعليم الطالب المهارات المطلوبة في سوق العمل، فالطالب يدرس المادة العلمية ويتعلم مهارات حل المشكلات التي تواجهه في حياته العملية وبالنسبة لاسترداد الاستثمار فهو أكيد حقيقي، وما دام قد تم وضعه ضمن ميزات الدورة فالأكاديمية تضمن ذلك. بعد الانتهاء من أي دورة من دورات أكاديميّة حسوب سيتم إرشادك وتوجيهك أثناء فترة بحثك عن عمل، فبعد إتمامك للدورة سيتم الإطّلاع على سيرتك الذاتية من قبل المختصّين لدينا وتقديم ارشادات مخصّصة لك لتحسينها وكذلك على ملفّك الشخصي في مواقع العمل الحر. بخصوص التفاصيل أرجو التواصل مع مركز مساعدة أكاديمية حسوب.
- 4 اجابة
-
- 1
-
-
للأسف، هذا الأمر غير ممكن حاليا، ويمكنك مراجعة توصيات أكاديمية حسوب وحقوق الملكية إذ تقول: الدروس متاحة للطلاب المشتركين فقط ويمكن الوصول لها من خلال حساب الطالب عبر الانترنت في أي وقت لذا إن كان لديك مشكلة في مشاهدة الدروس حاول تثبيت الدقة على 540 فهي حل وسط حسب سرعة الانترنت أو يمكنك تحسين نوعية اشتراك الانترنت و زيادة سرعة الوصول كما يمكنك تصفح سبب ذلك من خلال مراجعة الأجوبة التالية: ومن هنا:
-
بعد الانتهاء من أي دورة من دورات أكاديميّة حسوب سيتم إرشادك وتوجيهك أثناء فترة بحثك عن عمل، فبعد إتمامك للدورة سيتم الإطّلاع على سيرتك الذاتية من قبل المختصّين لدينا وتقديم ارشادات مخصّصة لك لتحسينها وكذلك على ملفّك الشخصي في مواقع العمل الحر. بخصوص التفاصيل أرجو التواصل مع مركز مساعدة أكاديمية حسوب.
- 3 اجابة
-
- 1
-
-
يمكنك التقدم إلى امتحان الدورة، من خلال التواصل مع مركز مساعدة أكاديمية حسوب، مع مراعاة الشروط التالية: إتمام أربعة مسارات تعليمية على الأقل. التطبيق العملي مع المدرب، والاحتفاظ بالمشاريع العملية الناتجة لإرسالها للمراجعة. رفع المشاريع على حسابك على GitHub أولًا بأول لمشاركتها معنا. وفي الإختبار سيتم اختبارك فقط في المسارات التي قمت بدراستها ويوجد تفاصيل أكثر حول الإختبار من صفحة: الحصول على الشهادة
- 2 اجابة
-
- 1
-
-
المشكلة تظهر في استيراد ملف الصورة logo.png في مكون TopHeader.tsx والخطأ يشير إلى أن TypeScript لا يستطيع العثور على الملف في المسار التالي: ../../img/logo.png وهذا يعني أن المسار غير صحيح لاحظ أنك في هذا المسار: src/components/header/TopHeader.tsx والمسار الحالي ../../img/logo.png سيؤدي إلى البحث عن الصورة في: src/img/logo.png لذا أرجو التأكد من أن مجلد img موجود داخل src في حال لم يكن كذلك عدل المسار. وفي حال كان السؤال متعلقا بإحدى الدورات التي قمت بالاشتراك فيها، أرجو منك الانتقال إلى قسم "دوراتي" ثم أسفل الدرس الذي واجهت فيه المشكلة، ستجد صندوقا للتعليقات مثل الذي هنا: ثم قم بإضافة سؤالك هناك، وهذا لمساعدتك بشكل أفضل. بالتوفيق إن شاء الله.
- 2 اجابة
-
- 1
-
-
إن كنت تقصد الملفات المصدرية الخاصة بالدورة، فيتم وضعها في بداية المسار في أسفل درس المدخل أو المقدمة كالتالي:

-
وعليكم السلام ورحمة الله تعالى وبركاته، كل دالة مصممة للتعامل مع صورة واحدة هذا يسمح بدمجها بطرق متعددة وتطبيق هذه العمليات بشكل متكرر على مجموعات بيانات كبيرة، سواء كانت تحتوي على الآلاف أو حتى المليارات من الصور وتتيح هذه الوحدة استخدام تقنيات المعالجة المتوازية مثل تعدد الخيوط أو تسريع GPU، بالإضافة إلى إمكانية التكامل مع أدوات أخرى، مما يساعدك على إدارة وتحليل كميات ضخمة من البيانات البصرية بكفاءة في المشاريع الواقعية. شروحات أكثر يمكنك إيجادها من هنا:
- 3 اجابة
-
- 1
-
-
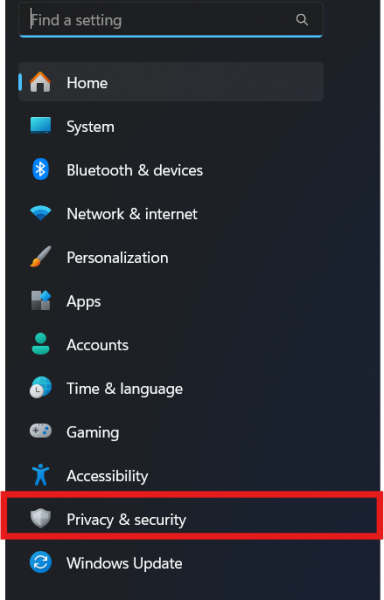
وعليكم السلام ورحمة الله تعالى وبركاته، بداية انقر على View من القائمة، ثم اختر "إظهار الأجهزة المخفية (Show hidden devices)" وانظر إن ظهرت لك أم لا: جرب أيضا البحث عن تغييرات الأجهزة من خلال النقر بزر الفأرة الأيمن على اسم جهازك في الأعلى، ثم اختر "البحث عن تغييرات الأجهزة (Scan for hardware changes): في حال لم تظهر لك تحت فئة "Imaging devices" أو تحت "Cameras" يمكنك أن تبحث في قائمة Start عن Settings ثم Privacy & Security: ثم Camera: هناك قم بتفعيل الوصول للكاميرا على الجهاز.


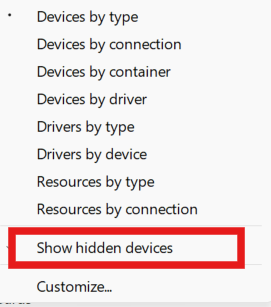
-
وعليكم السلام ورحمة الله تعالى وبركاته، COLMAP هو في الأساس خط أنابيب مستقل أو ما يعرف بال pipeline مكتوب بلغة C++، ويحتوي على واجهة مستخدم رسومية وأدوات سطر أوامر لإعادة بناء الهيكل من الحركة (SfM) والإستريو متعدد الرؤى (MVS). لذا فهو ليس مكتبة بايثون أصلية ولكن بالرغم من ذلك هناك روابط بايثون والمعروفة باسم PyCOLMAP التي تتيح لنا استخدام معظم وظائف COLMAP في بيئة بايثون، مما يمكّن من كتابة سكريبتات وأتمتة مهام إعادة البناء ضمن مشاريع بايثون. يمكنك التعرف أكثر عليه من التوثيق الرسمي من هنا: COLMAP ومن هنا: pycolmap
- 2 اجابة
-
- 1
-
-
عمل ممتاز إذ أنّك أنهيت أول مسار من الدورة، والخطوة القادمة هي متابعة الدروس درسا بدرس، ومسارا بمسار حتى إتمام جميع مسارات الدورة. ترتيب الدروس والمسارات مدروس ولم يتم عمله بشكل عشوائي لذا لا داعي للقلق أو التسرع فهذا المجال يحتاج إلى تركيز وتريّث وصبر أثناء التعلم. بالنسبة للمثال الذي ذكرت فهو مثال تمهيدي للدخول في المسار الثاني من الدورة "أساسيات البرمجة" وبعد إتمامك لهذا المسار يمكنك التطبيق العملي سواء مع التمارين التي يعدّها المدرب في الدرس، أو من خلال طلبها منا في التعليقات أسفل الدرس الذي تريد التطبيق عليه، أو من خلال منصات معروفة ك LeetCode مثلا.
- 3 اجابة
-
- 1
-
-
يستخدم تحليل المكونات الرئيسية (PCA) لتقليل الأبعاد في مجموعات البيانات الكبيرة والمعقدة، مما يُسهّل تحليلها وتصورها. يقوم PCA بتحويل الميزات الأصلية إلى مجموعة جديدة من المكونات الرئيسية التي تحتفظ بأكبر قدر ممكن من التباين في البيانات، مما يساعد في تبسيط النماذج وتقليل التعقيد الحسابي. وليس من الضروري دائما استخدام PCA مع الشبكات العصبية في بعض الحالات يمكن أن يساعد PCA في تقليل الأبعاد وبالتالي تقليل عدد المعلمات في الشبكة، مما قد يقلل من خطر التعميم الزائد (overfitting) ويحسن أداء النموذج. ومع ذلك قد يؤدي تقليل الأبعاد أيضا إلى فقدان بعض المعلومات المهمة، مما قد يؤثر سلبا على أداء الشبكة. لذلك يفضل تقييم تأثير PCA على أداء الشبكة العصبية في سياق المشكلة المحددة. ويستخدم PCA بشكل شائع مع خوارزميات تعلم الآلة الأخرى كخطوة تمهيدية لتقليل الأبعاد والتعامل مع التعدد الخطي بين الميزات هذا يمكن أن يحسن أداء بعض الخوارزميات ويقلل من التعقيد الحسابي ولكن يجب تقييم تأثير PCA على كل خوارزمية بشكل منفصل، حيث قد لا يكون له دائمًا تأثير إيجابي. ويكون استخدام PCA مناسبا عندما يكون لديك مجموعة بيانات ذات عدد كبير من الميزات، خاصة إذا كانت هذه الميزات مرتبطة ببعضها البعض. في هذه الحالات يمكن أن يساعد PCA في تقليل الأبعاد مع الاحتفاظ بأكبر قدر ممكن من المعلومات، مما يسهل عملية التحليل ويقلل من التعقيد الحسابي ومع ذلك يجب الحذر عند استخدام PCA، حيث قد يؤدي إلى فقدان بعض المعلومات المهمة، خاصة إذا تم تقليل عدد الأبعاد بشكل كبير.
- 4 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله تعالى وبركاته، StandardScaler وPCA هي عمليتان من خطوات معالجة البيانات المهمة قبل تطبيق نماذج التعلم الآلي، لكن كل واحدة منهما تخدم غرضا مختلفا. بحيث يقوم StandardScaler بتوحيد كل ميزة من خلال طرح المتوسط وقسمة القيم على الانحراف المعياري، بحيث يتحول كل عمود من البيانات ليصبح متوسطه صفر وانحرافه معياري واحد. هذا التوحيد يساعد في ضمان أن تكون جميع الميزات على نفس النطاق، مما يمنع ميزة ذات قيم أكبر من غيرها من التأثير المفرط على النموذج. في حين تستخدم تقنية PCA (تحليل المكونات الرئيسية) لتقليل الأبعاد عن طريق إيجاد محاور جديدة تدعى المكونات الرئيسية، والتي تلتقط أكبر قدر ممكن من التباين الموجود في البيانات. يقوم PCA بتحويل الميزات الأصلية إلى مكونات جديدة يمكن تمثيل البيانات بها بأبعاد أقل، مما يبسط عملية التحليل دون فقدان المعلومات المهمة. ومن المهم جدا تطبيق StandardScaler قبل استخدام PCA، لأن PCA يعتمد على قياس التباين في البيانات فإذا كانت الميزات غير موحدة، فقد تهيمن الميزات ذات النطاق الأكبر على النتائج، مما يؤدي إلى مكونات رئيسية غير متوازنة.
- 2 اجابة
-
- 1
-
-
أولا تأكد من تشغيل خادم XAMPP بشكل صحيح قم بفتح لوحة تحكم XAMPP ثم تحقق من أن Apache قيد التشغيل: ثم اضغط على Explorer وقم بحفظ كل ملفات المشروع داخل مجلد htdocs وتأكد من وجود كل من: index.html script.php داخل هذا المجلد بعدها افتح المتصفح واكتب: http://localhost:8080/your_project واستبدل your_project باسم مجلد المشروع الذي حفظته في htdocs اذا استمرت المشكلة أرسل مجلد المشروع.
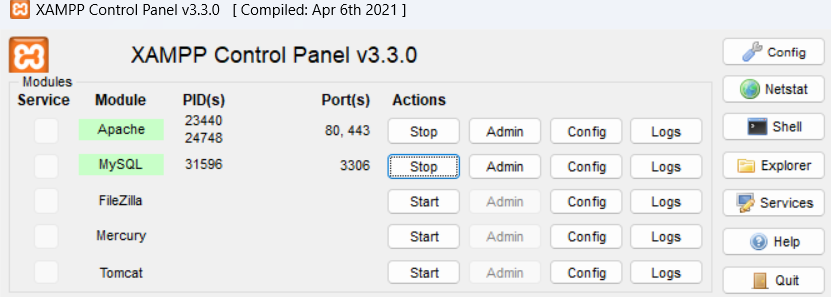
-
قم بالضغط على مفتاحي (Win + R) لفتح نافذة التشغيل ثم اكتب الأمر التالي: diskmgmt.msc واضغط Enter ستفتح لك نافذة "إدارة الأقراص" التي تعرض الأقسام المختلفة على القرص قم بالبحث عن قسم آخر (مثل D أو E) يحتوي على مساحة غير مستخدمة كافية قم انقر بزر الفأرة الأيمن على القسم الذي يحتوي على مساحة زائدة مثلا D واختر "تصغير الحجم" (Shrink Volume) سيحسب النظام الحجم القابل للتصغير بعدها أدخل القيمة (بالميجابايت) التي تريد تحريرها على سبيل المثال إذا كنت تحتاج إلى 40 جيجابايت، أدخل 40000 ثم اضغط على "تصغير" لإنشاء مساحة غير مخصصة بجانب القسم. لكن انتبه لأنه يجب أن تكون المساحة غير المخصصة موجودة مباشرة بعد القسم C إذا لم تكن كذلك مثلا إذا كانت موجودة بعد قسم آخر، فقد تحتاج إلى استخدام برنامج إدارة أقسام خارجي. بعدها انقر بزر الفأرة الأيمن على القسم C ثم اختر "توسيع الحجم" (Extend Volume) سيظهر معالج التوسيع، اضغط "التالي". ثم تأكد من تحديد المساحة غير المخصصة التي قمت بإنشائها، ثم اضغط "التالي" وبعدها "إنهاء". سيقوم النظام بإضافة المساحة غير المخصصة إلى القسم C. إذا لم تستطع إدارة الأقراص في ويندوز نقل المساحة غير المُخصصة بحيث تكون بجوار القسم C، يمكنك استخدام برامج مثل: EaseUS Partition Master MiniTool Partition Wizard هذه البرامج تتيح لك نقل الأقسام وإعادة ترتيبها بطريقة تجعل المساحة غير المخصصة مجاورة للقسم C، ومن ثم توسيعه. بعد الانتهاء من العمليات، يفضل إعادة تشغيل الكمبيوتر للتأكد من تطبيق التغييرات بنجاح.
- 3 اجابة
-
- 1
-
-
دورة علوم الحاسوب أعدّت خصيصا لتعليم المبادئ الأساسية في البرمجة أي أنك بعد دراستها ستحتاج إلى دراسة مجال برمجي تخصصي يكون مطلوبا في سوق العمل، ومن خلال إتمامك لهذه الدورة ستتمكن من إختيار المجال الذي تريده لأنك ستكون قد اطلعت على أغلب مجالات البرمجة خلال الدورة وأصبحت لديك دراية بالمفاهيم البرمجية ومختلف الوظائف الممكنة. يمكنك الاطلاع على الإجابة التالية التي تشرح الهدف من الدورة: كما أنه من الجيد أخذ فكرة عن البرمجة من هنا: وعن مجالات البرمجة من هنا: يمكنك أيضا التعرف أكثر حول وظائف البرمجة الأكثر طلبا من هنا: أما الرواتب فهي تختلف وتعتمد على العديد من العوامل، لذا أول خطوة بعد إتمامك للدورة هي البدء باختيار مجال والتخصص فيه وعمل مشاريع وبناء معرض أعمال خاص بك، ثم سيتم توجيهك لبناء سيرة ذاتية جيدة والتقدم لعروض العمل المختلفة، لكن أهم شيء أن لا تتوقف عن التعلم لأنّ دورة علوم الحاسوب هي أول خطوة نحو التخصص في المجال.
-
وعليكم السلام ورحمة الله تعالى وبركاته، أسماء الملفات قد تكون حساسة لحالة الأحرف في بعض السياقات كما أن المسافات الإضافية أو الأخطاء الإملائية قد تسبب مشاكل لذا يمكنك تعديل اسم الملف ليكون training.csv بدلا من Copy of excel for training csv.csv ثم أعد المحاولة مرة أخرى. في حال استمرت المشكلة حاول استخدام الخط المائل للأمام / حيث يعمل على جميع الأنظمة الأساسية كالتالي: pd.read_csv("C:/Users/User/Documents/training.csv") وأرجو في حال كان سؤالك متعلقا بإحدى الدورات التي قمت بالاشتراك فيها، أرجو منك الانتقال إلى قسم "دوراتي" ثم أسفل الدرس الذي واجهت فيه المشكلة، قم بإضافة سؤالك هناك، وهذا لمساعدتك بشكل أفضل.
-
وعليكم السلام ورحمة الله تعالى وبركاته، Structure-from-Motion (SfM) و Neural Radiance Fields (NeRF) هما تقنيتان لإنشاء تمثيلات ثلاثية الأبعاد من صور ثنائية الأبعاد. SfM هي تقنية في رؤية الكمبيوتر، تعيد بناء البنية ثلاثية الأبعاد لمشهد ومواقع الكاميرات من خلال اكتشاف الميزات، تقدير وضع الكاميرا، التقاطع، وتعديل الحزمة، مما ينتج سحابة نقاط ويستخدم في النمذجة ثلاثية الأبعاد والروبوتات، بينما تعتمد NeRF على التعلم العميق لتمثيل المشهد كدالة مستمرة باستخدام إحداثيات ثلاثية الأبعاد واتجاه الرؤية، مع عرض الحجم والتدريب على صور لتوليد مناظر واقعية مفصلة، وهي مثالية للواقع الافتراضي لكنها تتطلب موارد أكبر. أيضا نجد أن SfM تعتمد على الطرق الهندسية وتناسب إعادة البناء المتفرق بصور أقل، بينما تتفوق NeRF في التفاصيل والإضاءة المعقدة، مما يجعل كل تقنية مناسبة لتطبيقات مختلفة.
- 2 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله تعالى وبركاته، لا يوجد اختصار مدمج في VS Code يقوم بتجميد الكود بشكل مباشر أعتقد أنك تقصد ميزة "التوقف عند نقطة التوقف" (Breakpoint) التي توقف تنفيذ الكود أثناء عملية debugging إن كان هذا ما تقصده يمكنك عمل ذلك من خلال الاختصار التالي: Shift + F9 أو إذا كنت تقصد تعليق الأسطر البرمجية بحيث لا تصبح وظيفية وجعلها تعليقات، يمكنك ذلك من خلال الضغط على: Ctrl + /
- 4 اجابة
-
- 1
-
-
أرجو إرفاق المشروع لتصفح المشكلة عن كثب.