ياسر مسكين
-
المساهمات
2780 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
6
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو ياسر مسكين
-
كما تم التطرق في الإجابات السابقة، فإنّ تقنية ال Face Recognition تعني التعرف على الوجه وهو عملية تحديد هوية شخص من خلال صورة أو فيديو عن طريق مقارنة الوجه المدخل بقاعدة بيانات كبيرة تحتوي على وجوه معروفة. تكون العملية عادة مقارنة من واحد إلى متعدد 1:N حيث يسأل النظام: "من هذا الشخص؟" على سبيل المثال قد تستخدم الجهات الأمنية التعرف على الوجه لتحديد مشتبه به في حشد من الأشخاص عبر مقارنة صورته مع قاعدة بيانات لصور المجرمين وهذا أمر مفيد للغاية بحيث يتم على هذا النحو: يكتشف النظام وجود وجه في الصورة (الكشف عن الوجه). يستخرج النظام المميزات الفريدة مثل المسافة بين العينين وشكل الفك وغيرها. ثم يقوم بمقارنة هذه المميزات مع قاعدة بيانات من القوالب المخزنة لإيجاد تطابق. بينما Face Verification هو تقنية التحقق من الوجه من خلال عملية مقارنة من واحد إلى واحد 1:1 أين تستخدم لتأكيد أن الشخص هو بالفعل من يدعي أنه هو بدلا من البحث في عدة صور، يتم مقارنة وجه حي بصورة مسجلة مسبقا نفس الفكرة عند فتح هاتفك باستخدام خاصية Face ID حيث تتم مقارنة وجهك مع الصورة المخزنة للتحقق من هويتك كالتالي: يلتقط النظام صورة للشخص. يستخرج قالبا بيومتريا من الصورة. يقوم بمقارنة هذا القالب مباشرة مع القالب المخزن أثناء عملية التسجيل. إذا كان القالبان متطابقين بدرجة كافية، يتم تأكيد هوية الشخص.
- 6 اجابة
-
- 1
-

-
نعم من الممكن تخزين بيانات المتجر الإلكتروني محليا على جهاز اللابتوب الخاص بك والفكرة الأساسية هي تشغيل نظام إدارة قواعد البيانات (DBMS) على جهازك بحيث تخزن كل بيانات التطبيق بشكل دائم على القرص الصلب. يمكنك تحميل وتثبيت خادم MySQL وأثناء عملية التثبيت ستلاحظين أن MySQL يقوم بإعداد مسار معين لتخزين كافة قواعد البيانات والجداول كملفات على القرص الصلب. كما يمكنك استخدام SQLite وهو محرك قاعدة بيانات مدمج لا يحتاج إلى تشغيل خادم منفصل، حيث تخزن قاعدة البيانات بأكملها في ملف واحد على القرص الصلب كما أنه لا يتطلب استخدامه إعداد خادم معقد مما يجعله خيارا ممتازا للتطبيقات الصغيرة أو أثناء التطوير والعديد من لغات البرمجة والأطر تدعم SQLite بشكل مدمج ويمكنك ببساطة الإشارة إلى مسار الملف الذي يحتوي على قاعدة البيانات في إعدادات التطبيق.
-
في لغة بايثون القائمة المعرفة كالتالي: array = [1, 2, 3, 4, 5] ليست مصفوفة ثابتة بل هي مصفوفة ديناميكية مما يعني أنه بعد إنشاء القائمة يمكنك إضافة أو إزالة أو تعديل عناصرها دون الحاجة لتحديد حجم ثابت مسبقا على سبيل المثال يمكنك إضافة عنصر باستخدام array.append(6) فتصبح القائمة: array = [1, 2, 3, 4, 5, 6] أو إزالة عنصر باستخدام array.pop(). وفي لغات أخرى مثل C أو Java تكون المصفوفات الثابتة ذات حجم محدد عند إنشائها ولا يمكن تغييره دون إنشاء مصفوفة جديدة على سبيل المثال في لغة C يمكنك تعريف مصفوفة كالتالي: int array[5]، حيث لا يمكن تغيير حجمها لاحقا. لا تحتوي بايثون على نوع مدمج للمصفوفة الثابتة، إذ أن القوائم مصممة لتكون أكثر مرونة وإذا كنت بحاجة إلى تسلسل غير قابل للتعديل من العناصر، يمكنك استخدام ال tuple، والذي يتم تعريفه بالشكل التالي: tuple_array = (1, 2, 3, 4, 5) لاحظ استخدمنا الأقواس ( ) بدلا من [ ].
- 5 اجابة
-
- 1
-
-
المشكلة تكمن في الدالة someCode(). هذه ليست دالة موجودة أصلا في لغة جافاسكربت فجافاسكربت لديها دوال مدمجة كثيرة مثل parseInt()، console.log()، إلخ لكن someCode() ليست واحدة منها. عندما يظهر خطأ يقول "someCode is not defined" فهذا يعني أن جافاسكربت تبحث عن دالة بهذا الاسم ولم تجدها. ربما الكتاب يقصد أن تقوم أنت بكتابة هذه الدالة من الممكن أن يكون هذا تمرين في الكتاب، حيث يطلب منك كتابة دالة تسمى someCode() تأخذ تاريخ الميلاد وتحسب العمر لذلك يمكنك المحاولة في إنشاء هذه الدالة ثم اختبار الكود الخاص بك.
-
من الأفضل أن تبدأ في دراسة أنماط التصميم (design patterns) بعد أن تتقن أساسيات البرمجة الكائنية (OOP) فدراسة أنماط التصميم ستساعدك في كتابة كود نظيف ومنظم مما يسهل صيانته وتحديثه ومنه حل المشكلات البرمجية بطرق مجربة حيث أنها تقدم حلولا متكررة للمشاكل الشائعة إضافة إلى تحسين فرصك المهنية فهي مهارة مطلوبة في العديد من الشركات، خاصة في تطوير التطبيقات الكبيرة والمعقدة. كما يمكنك أيضا تطبيق بعض هذه الأنماط في مشاريع الذكاء الاصطناعي التي تعمل عليها، مما سيساعدك على الربط بين المفاهيم النظرية والعملية. بالتدريج ومع زيادة خبرتك، ستجد أن فهم أنماط التصميم يعزز من قدرتك على تصميم وتطوير برمجيات متكاملة وأكثر كفاءة يمكنك دراستها من هنا: أنماط التصميم
-
أرجو منك مراسلة مركز مساعدة أكاديمية حسوب فهو الوحيد المخول في دراسة الشؤون المالية الخاصة بالطلبة، يمكنك مراسلتهم وسيساعدونك أو يقترحون عليك حلولا لمشكلتك، إلى حين ذلك أرجو مراجعة هذه الإجابة:
-
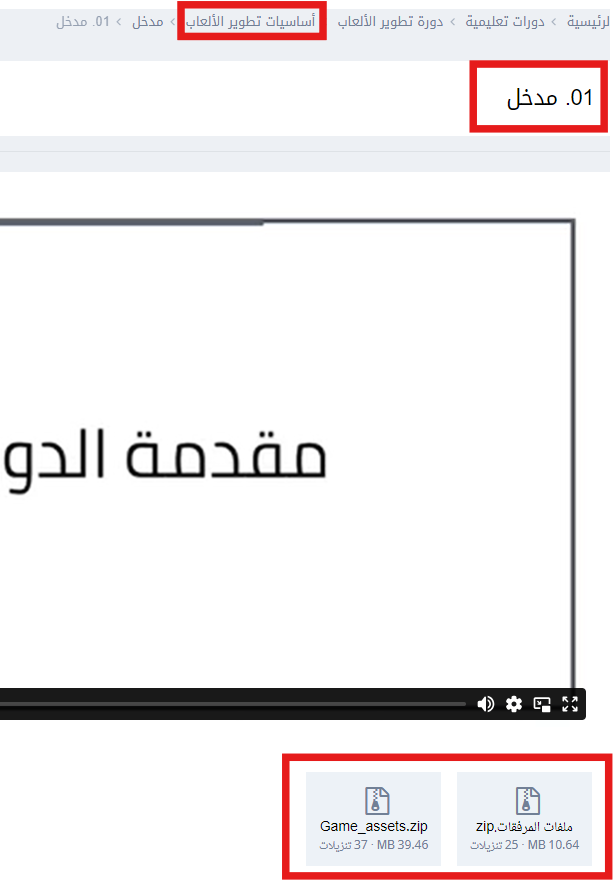
هل تقصد الملفات المصدرية والمرفقات التي يعمل بها المدرّب؟ إن كان كذلك فيمكنك الوصول إليها من خلال درس المقدمة عند مدخل كلّ مسار أين ستجد رابطا مباشرا لتحميل الملفات أو رابطا مباشرا نحو مستودع المشروع الخاص بالدورة التي اشتركت فيها، في حال لم تجده فهذا يعني أنّ المسار أو الدرس الذي أنت فيه ليس بحاجة إلى ملفات مصدرية ويجب التركيز فقط على محتوى الدرس والتطبيق المباشر مع المدرب. يمكنك الوصول إليها وتحميلها مثلما هو موضح في هذه الصورة: بخصوص الملخصات فالأكاديمية لا توفرها وهذا لدفع الطالب إلى عمل ملخصاته بنفسه لكي يسهُل عليه الرجوع إليها وتترسّخ في ذهنه أكثر، فأفضل الملخصات هي التي يعملها الإنسان بنفسه وأنصحك بمراجعة الأجوبة على نفس التساؤل من هنا:
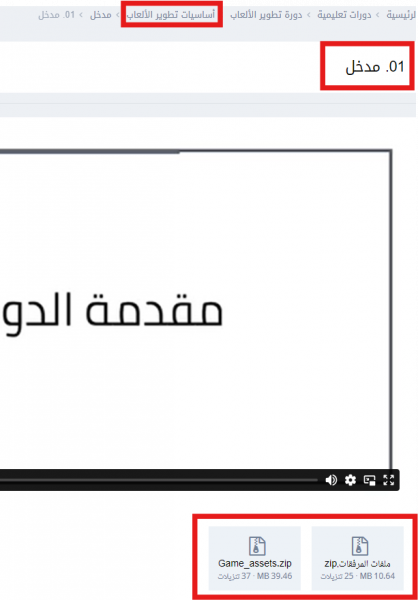
-
ينبغي أولا معرفة شروط التقدم للامتحان النهائي لأي دورة تشترك فيها وهي كالآتي: إتمام أربعة مسارات تعليمية على الأقل (لا يهم الترتيب) التطبيق العملي مع المدرب، والاحتفاظ بالمشاريع العملية الناتجة لإرسالها للمراجعة رفع المشاريع على حسابك على GitHub أولًا بأول لمشاركتها معنا يمكنك التقدم إلى امتحان الدورة، من خلال التواصل مع مركز مساعدة أكاديمية حسوب. ولو تركز على النقطة الثانية وهي توضح لنا أنّ التطبيق العملي شرط أساسي للتعلم في الدورة، ستجد في العديد من المسارات تطبيقات عملية مختلفة ستصادفها في مختلف الدروس، يمكنك القيام بها ومشاركتها معنا مباشرة لنصححها لك. كما توجد مسارات خاصة تُعنى بالتطبيق العملي من خلال إنشاء التطبيقات مباشرة، وهذا يعتمد على نوع الدورة التي اشتركت فيها.
-
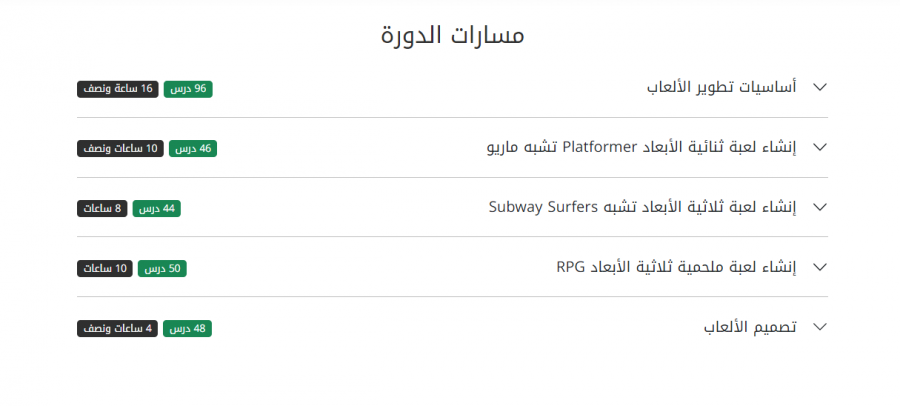
من خلال هذه الصفحة يمكنك التطرق إلى جميع محاور ومسارات الدورة وميزاتها وما يمكنك تعلمه وعمله من خلالها: https://academy.hsoub.com/learn/game-development/ وكما تلاحظ فإنّ مسار نشر الألعاب لم يتم إضافته بعد في الدورة، لكن هذا لا يعني عدم إضافته مستقبلا، يمكن أن يتم تحديث الدورة في أي لحظة ومن ميزات الدورة أنها تتيح لك وصولا مدى الحياة لها، وستحصل على تنبيه لحظة حدوث تحديث للدورة: يمكنك التعرف على مزايا دورات حسوب من هنا: فضلا عن العديد من المقالات التي تتناول هذا المجال: https://academy.hsoub.com/programming/game-development/ يمكنك البحث عن أي شيئ تريد من خلال شريط البحث: وعلى كلّ فإنه لنشر اللعبة على منصات متعددة، يجب اتباع إجراءات محددة تختلف من منصة لأخرى ففي حالة Android، تحتاج أولا إلى إنشاء حساب مطور عبر Google Play Console، ثم توليد ملف APK أو App Bundle واختباره باستخدام الأجهزة الحقيقية أو المحاكيات، وبعد التأكد من خلوه من الأخطاء، يتم رفعه للمراجعة أولا من قبل جوجل للنشر في المتجر. أما على iOS فالأمر يبدأ بالاشتراك في برنامج Apple Developer، ومن ثم إعداد اللعبة باستخدام Xcode مع توقيعها رقميا، يلي ذلك إجراء اختبارات دقيقة على الأجهزة الفعلية أو المحاكيات، ومن ثم رفع التطبيق عبر App Store Connect حيث تتم مراجعته من قبل آبل قبل النشر. وفيما يتعلق بأجهزة Sony مثل PS4 و PS5، يجب التسجيل كمطور عبر منصة PlayStation Partners والحصول على أدوات التطوير الخاصة بسوني، مع ضرورة تعديل اللعبة بما يتوافق مع معايير الجودة والأداء الخاصة بالمنصة، ثم تقديمها للمراجعة الفنية قبل الحصول على الموافقة النهائية للنشر.
-
 ليس هنالك شرط للتعلم بالترتيب بالنسبة لهذين المجالين، يمكنك تعلمهما كلاهما، سواء بدأت بنماذج اللغة الكبيرة أو بالرؤية الحاسوبية وكلّ ذلك يعتمد على رغبتك وعلى أهدافك من عملية التعلم، فإذا كنت مهتما بمعالجة اللغة والتفاعل مع النصوص يمكنك البدء بتعلم نماذج اللغة الكبيرة (LLMs) وتقنيات معالجة اللغة الطبيعية (NLP) هنا ستتعلم كيف يمكن للذكاء الاصطناعي فهم النصوص وكيف يتم إنشاء المحتوى وكيف يتم تحليل المعاني. أما إذا كنت تميل إلى العمل مع الصور والفيديوهات فأعتقد أنه يفضل البدء بتعلم الرؤية الحاسوبية (CV)، حيث ستتعرف على كيفية تحليل الصور والتعرف على الأشياء، وتطبيقات الواقع المعزز والذكاء الاصطناعي في المجالات البصرية. في الأخير إذا كنت مهتما بالتطبيقات المتعددة الوسائط يمكنك بعد الحصول على الأساسيات في أحد المجالين البدء بالتعرف على النماذج متعددة الوسائط (MLLMs) التي تدمج بين معالجة اللغة والرؤية معا. وفي حال كنت مشتركا في دورة الذكاء الاصطناعي فمؤخرا قد تمّ إضافة مسار خاص بالتطبيقات العملية باستخدام الرؤية الحاسوبية يمكنك تعلمها من هناك: هذه المقالة مفيدة أيضا:
ليس هنالك شرط للتعلم بالترتيب بالنسبة لهذين المجالين، يمكنك تعلمهما كلاهما، سواء بدأت بنماذج اللغة الكبيرة أو بالرؤية الحاسوبية وكلّ ذلك يعتمد على رغبتك وعلى أهدافك من عملية التعلم، فإذا كنت مهتما بمعالجة اللغة والتفاعل مع النصوص يمكنك البدء بتعلم نماذج اللغة الكبيرة (LLMs) وتقنيات معالجة اللغة الطبيعية (NLP) هنا ستتعلم كيف يمكن للذكاء الاصطناعي فهم النصوص وكيف يتم إنشاء المحتوى وكيف يتم تحليل المعاني. أما إذا كنت تميل إلى العمل مع الصور والفيديوهات فأعتقد أنه يفضل البدء بتعلم الرؤية الحاسوبية (CV)، حيث ستتعرف على كيفية تحليل الصور والتعرف على الأشياء، وتطبيقات الواقع المعزز والذكاء الاصطناعي في المجالات البصرية. في الأخير إذا كنت مهتما بالتطبيقات المتعددة الوسائط يمكنك بعد الحصول على الأساسيات في أحد المجالين البدء بالتعرف على النماذج متعددة الوسائط (MLLMs) التي تدمج بين معالجة اللغة والرؤية معا. وفي حال كنت مشتركا في دورة الذكاء الاصطناعي فمؤخرا قد تمّ إضافة مسار خاص بالتطبيقات العملية باستخدام الرؤية الحاسوبية يمكنك تعلمها من هناك: هذه المقالة مفيدة أيضا: -
وعليكم السلام ورحمة الله وبركاته، Figma هو أداة تستخدم لتصميم الواجهات البصرية للمواقع، حيث تقوم بإنشاء نماذج توضيحية (UI) تظهر شكل الموقع بدون تحويلها إلى كود. ولجعل الموقع يعمل فعليا على الإنترنت، يجب أولا تحويل هذا التصميم إلى شفرة برمجية باستخدام HTML وCSS وJavaScript. إذا كان الموقع يعرض محتوى ثابت فقط، فيمكن الاعتماد على تحويل التصميم إلى صفحات ويب وأما إذا كان يتطلب تفاعلا مع المستخدمين أو إدارة بيانات عبر قاعدة بيانات، فستحتاج إلى تطوير جزء خلفي (backend) للتعامل مع هذه المتطلبات. بعد الانتهاء من تحويل التصميم إلى كود وبرمجته يتم رفع الملفات إلى خدمة استضافة مناسبة سواء كانت مجانية أو مدفوعة.
-
توجد مقالة تشرح الفرق بينهما بشكل مفصل أنصحك وأقترح عليك مراجعتها من هنا: يمكنك إيجاد مقالات أخرى تتحدث عن Mongodb من هنا: https://academy.hsoub.com/devops/servers/databases/mongodb/
-
كما تمّ التوضيح في التعليقات السابقة، فدورة علوم الحاسوب أُعدّت خصيصا لهكذا حالات، وما دمت لا تمتلك أيّ خبرة مسبقة بعد فالبدء مباشرة في الدورة لن يشكّل أيّ عائق للتعلم. كما أنّ هنالك ثلّة من المدربين سيحرصون على التواجد على مدار الساعة من أجل الردّ على استفساراتك وانشغالاتك. في حال لم تفهم مرحلة ما أو درسا بعينه، كلّ ما عليك فعله هو التوجه أسفل الدرس أين سيكون هنالك صندوق للتعليقات مشابه لهذا يمكنك طرح انشغالك هناك في أيّ وقت وحين. https://academy.hsoub.com/learn/computer-science/
-
مشكلة النسيان مشكلة عادية وأيّ شخص معرّض لها، لا داعي للقلق أو الشعور بالتوتر من هذا الأمر، في البرمجة أنت لست مطالبا بالحفظ المهم أن تفهم المفاهيم التي يتم تدريسها وتطبق مع المدرب، وفي حال نسيت أمرا ما يمكنك طرح سؤالك أو البحث من خلال موسوعة حسوب أو من خلال تصفح التوثيقات الرسمية للمكتبات والتكنولوجيات وحتى لغات البرمجة وأطر العمل المختلفة، ولقد تمّت الإجابة عن تساؤلات مشابهة وسأرفق لك مجموعة من الإجابات يمكنك الاطلاع عليها:
-
يمكنك حساب تاريخ الانتهاء المتوقع بإضافة عدد الأيام إلى تاريخ اليوم فرضا نستخدم لغة بايثون سيكون الأمر كالتالي: import datetime days_to_add = 15 today = datetime.date.today() expected_end_date = today + datetime.timedelta(days=days_to_add) print("تاريخ الانتهاء المتوقع:", expected_end_date) بحيث نستخدم دالة datetime.date.today() للحصول على تاريخ اليوم ونقوم بإنشاء فرق زمني باستخدام هذه العبارة: datetime.timedelta(days=days_to_add). ثم يتم جمعهما للحصول على التاريخ المتوقع للانتهاء.
-
هذه فترة طويلة نوعا ما، لذا في حالة عدم وجود ظروف قاهرة فمن الأفضل عدم تجاوز فترة الأسبوعين دون دراسة أو برمجة. لكن لا بأس، بما أنك قلت أنك درست الخوارزميات ووصلت إليها فهذا يعني أنك كنت تقريبا في منتصف الدورة، يمكنك الرجوع من بداية الدورة وتسريع الفيديو بهذه الطريقة: أي تسريع الجزئيات التي ترى نفسك أنك قد استوعبتها وتتذكرها، يمكنك تجاوز أيضا التمارين والتطبيقات التي أنجزتها من قبل في حال كنت قد فهمتها. وفي حال وجدت نفسك قد نسيت الكثير من الأمور في المسار يرجى إعادة مشاهدته وطرح سؤالك في أسفل الدرس أين سنساعدك.
-
هل تقوم بتصفح الهاتف أثناء متابعة الدروس؟ في حال كان كذلك أرجو منك الابتعاد عن أيّ مشتّتات أثناء التعلم والمتابعة مع المدرب وهذا لتحقيق أقصى استفادة ممكنة من الدورات، فعوامل التشتت كثيرة وفي كثير من الأحيان هي التي تسبّب فقدان التركيز ومنه نسيان الكثير من المفاهيم الأساسية. إضافة إلى ذلك، قلة التطبيق وعدم الاستمرارية وترك فراغ زمني كبير قد يصل لثلاثة أسابيع وحتى شهر دون مراجعة أو تطبيق برمجي فالطالب هنا حتما سينسى ما تلقّاه من معارف. أما بالنسبة للنسيان قصير المدى مثلا وأنت تتعلم قد تنسى أمورا معينة، ففي هذه الحالة لا تخف فهذا الأمر طبيعي، ونحن في البرمجة لسنا مطالبين بالحفظ بل بالفهم، وتوجد مواقع خاصة بالتوثيقات الرسمية والمكتبات ويمكنك الرجوع إليها متى احتجت إلى ذلك. ومع الاستمرارية والتركيز والابتعاد عن المشتتات ستجد نفسك تبرمج وتتذكر كيفية عمل الأكواد وقد تحفظ الكثير من الأمور تلقائيا من خلال الممارسة. لتحقيق أقصى استفادة من الدروس أنصحك بمراجعة الأجوبة من هنا:
-
وعليكم السلام ورحمة الله، هذا سلوك طبيعي ففي بعض الأحيان عند اختيار GPU مثل P100 سيتم استخدامه لحسابات التدريب الأساسية للنموذج، لكن الكثير من العمليات مثل تحميل البيانات، التحويلات، وتحضيرات أخرى تظل تعمل على ال CPU. لذلك من الممكن جدا أن يظهر استهلاك ال CPU مرتفعا باللون الأحمر حتى وإن كنت تستخدم GPU للتدريب. لكن يجب التأكد من أن الكود الخاص بك يقوم بنقل النموذج والبيانات إلى ال GPU باستخدام .to('cuda') في PyTorch كالتالي: import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = MyModel().to(device)
- 8 اجابة
-
- 1
-
-
مرحبا زياد، في حال كان سؤالك متعلقا بإحدى الدورات التي قمت بالاشتراك فيها، أرجو منك الانتقال إلى قسم "دوراتي" ثم أسفل الدرس الذي واجهت فيه المشكلة، قم بإضافة سؤالك هناك، وهذا لمساعدتك بشكل أفضل. بالتوفيق إن شاء الله.
-
وعليكم السلام ورحمة الله، تبدأ المصفوفات بالفهرس 0 بدلا من 1 في معظم لغات البرمجة فمن الناحية التقنية يمثل فهرس المصفوفة إزاحة من عنوان الذاكرة الأساسي هنا العنصر الأول ليس له إزاحة (0)، والعنصر الثاني مزاح بمقدار حجم عنصر واحد وهكذا. في الرياضيات غالبا ما تستخدم النطاقات فترات نصف مفتوحة مثل [0,n) بمعنى "0 إلى n-1 ضمنا" هذا يجعل الحسابات أنظف إذا كان لدينا مثلا مصفوفة بطول n، فإن الفهارس الصالحة هي من 0 إلى n-1. وعندما نخزن مصفوفة أو مجموعة من العناصر فإن الكمبيوتر يحتاج إلى طريقة للوصول إلى كل عنصر والطريقة التي يعمل بها هي أنه يحفظ عنوان البداية للمصفوفة في الذاكرة أي أين تبدأ المصفوفة ولكي يصل إلى أي عنصر يستخدم هذه المعادلة البسيطة: موقع العنصر = عنوان البداية + (الفهرس × حجم العنصر) للعنصر الأول لا نحتاج إلى أي إزاحة عن نقطة البداية، لذلك تكون الإزاحة 0، وهكذا يكون الفهرس 0. يمكنك تخيل أن المصفوفة مثل صف من المنازل على شارع، المنزل الأول هو على بعد 0 متر من بداية الشارع، والمنزل الثاني على بعد 10 أمتار، والثالث على بعد 20 مترا وهكذا لذلك نشير إلى المنازل باستخدام المسافة المنزل في المسافة 0، المنزل في المسافة 10 وهكذا.
- 6 اجابة
-
- 1
-
-
مرحبا، عندما نكتب CSS نستخدم قاعدة الهوامش بهذا الشكل: margin: 3px 30px 2px 5px; وهذه القيم تعني: 3px: هامش من الأعلى 30px: هامش من اليمين 2px: هامش من الأسفل 5px: هامش من اليسار لكن في اللغة العربية أو أي لغة تكتب من اليمين إلى اليسار سيتم عرض الصفحة بالعكس لكن قيم CSS لا تتغير تلقائيا ففي اللغة الإنجليزية سيظهر الهامش الأيمن (30px) على يمين العنصر بينما في اللغة العربية سيظهر نفس الهامش (30px) لكن على يسار العنصر (لأن الاتجاه انعكس). لحل هذه المشكلة يمكنك استخدام خصائص CSS الحديثة التي تتكيف مع اتجاه اللغة: margin-block-start: 3px; margin-inline-end: 30px; margin-block-end: 2px; margin-inline-start: 5px; وفي حال كان سؤالك متعلقا بإحدى الدورات التي قمت بالاشتراك فيها، أرجو منك الانتقال إلى قسم "دوراتي" ثم أسفل الدرس الذي واجهت فيه المشكلة، قم بإضافة سؤالك هناك، وهذا لمساعدتك بشكل أفضل. بالتوفيق إن شاء الله.
- 1 جواب
-
- 1
-
-
الفرق الرئيسي بين Google Colab وJupyter Notebook يكمن في المنصة وطريقة الاستخدام فمثلا نجد أنّ Google Colab يعتمد على السحابة الإلكترونية أو الاستضافة السحابية من جوجل ولا يحتاج إلى تثبيت مسبق كما أنه يوفر وصولا مجانيا لفترات محدودة إلى وحدات معالجة الرسومات (GPU) أو وحدات المعالجة التنسورية (TPU)، مما يجعله مثاليا لمهام التعلم الآلي والتعاون الفوري عبر Google Drive. أما Jupyter Notebook فهو أداة مفتوحة المصدر تثبّت محليا على جهازنا مما يمنح تحكما كاملا في التخصيص والمكتبات والموارد، لكنه يعتمد على إمكانيات جهازك الشخصي أقترح عليك هاتين المقالتين للاستفاضة أكثر:
-
كلاهما لديه غرض مختلف فالعامل scoring يحدد كيفية تقييم أداء النموذج أثناء التحقق المتقاطع يمكنك تعيينه كسلسلة مثلا 'accuracy' أو 'f1' أو كدالة مخصصة وهنا يخبر GridSearchCV بالمقياس الذي يجب استخدامه لمقارنة تركيبات المعاملات المختلفة. في حين أنّ refit يتحكم فيما إذا كان سيتم إعادة تدريب ال estimator على مجموعة البيانات الكاملة بعد إيجاد أفضل المعاملات فعند تعيينه إلى True يقوم GridSearchCV بعد التحقق المتقاطع بإعادة تدريب النموذج باستخدام أفضل المعاملات التي تم العثور عليها على كامل بيانات التدريب، ويصبح النموذج النهائي متاحا عبر best_estimator_. إذا استخدمت عدة مقاييس عن طريق تمرير قاموس إلى scoring، يمكنك تعيين refit إلى مفتاح محدد للدلالة على المقياس الذي يجب استخدامه لاختيار أفضل نموذج. أما إذا تم تعيين refit إلى False، فلن يتم تدريب النموذج النهائي على مجموعة البيانات الكاملة، وستقتصر النتائج على نتائج التحقق المتقاطع أي أنّ scoring يتعلق بكيفية قياس أداء النموذج أثناء البحث، بينما يتعلق refit بما يجب القيام به بعد تحديد أفضل المعاملات.
- 6 اجابة
-
- 1
-
-
لا يؤدي استخدام PredefinedSplit إلى تسريع تدريب النموذج بطبيعته بل يغير فقط كيفية تقسيم البيانات أثناء ضبط المعلمات الفائقة أين يتم تحديد إجمالي وقت التدريب في GridSearchCV أو RandomizedSearchCV إلى حد كبير من خلال عدد مجموعات المعلمات وعدد التقسيمات التي تقيمها لكل مجموعة. إذا كنت تستخدم مثلا تقسيما واحدا (train/validation) بدلا من استخدام تقنيات التقسيم المتعددة (مثل 5-fold cross-validation)، فإن عدد مرات تدريب النموذج لكل تركيبة من معلمات النموذج سينخفض (من خمس مرات إلى مرة واحدة) وهذا قد يؤدي إلى تقليل الزمن الإجمالي للتدريب. بينما يقلل استخدام تقسيم واحد من زمن التدريب فإنه قد يؤثر على قوة التقييم والموثوقية لأن التقييم يعتمد على تقسيم واحد فقط بدلا من تقييم أكثر شمولا باستخدام عدة تقسيمات وإذا كنت تستخدم بالفعل تقسيما واحدا للتدريب والتحقق، فلن يكون هناك فرق كبير في زمن التدريب عند استخدام PredefinedSplit.
- 4 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله، بالنسبة لمكتبة pickle فهي مكتبة قياسية في بايثون لتخزين الكائنات وتحميلها لكنها لا تدعم ضغط البيانات أو التحسين للتخزين الفعال يمكنك مراجعتها من خلال المصدر التالي: الوحدة pickle في بايثون أما مكتبة joblib فهي جزء من حزمة scikit-learn وهي مصممة خصيصا لتحسين تخزين الكائنات التي تحتوي على مصفوفات NumPy كبيرة وهي شائعة في نماذج التعلم الآلي كما أنها تدعم ضغط البيانات مثل zlib، lz4 لتقليل حجم الملفات وتستخدم غالبا لحفظ وتحميل نماذج التعلم الآلي مثل sklearn بكفاءة، يمكنك مراجعة استخدامها من هنا: وباختصار فإن joblib هي اختيار أفضل لبيئات التعلم الآلي والبيانات الكبيرة بفضل تحسيناتها، بينما pickle مناسبة للاستخدام العام مع كائنات بايثون العادية.
- 5 اجابة
-
- 1
-