Mustafa Suleiman
-
المساهمات
20358 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
يقوم بطباعة أفضل مجموعة من المعلمات التي تم العثور عليها بواسطة GridSearchCV بعد تجربة جميع التركيبات المحددة في param_grid وتقييمها باستخدام التحقق المتقاطع Cross-Validation مع cv=5.
- 7 اجابة
-
- 1
-

-
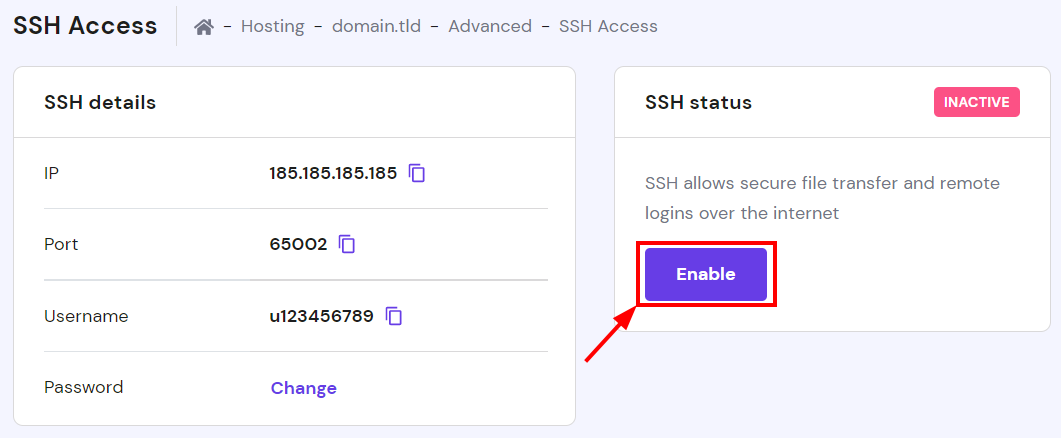
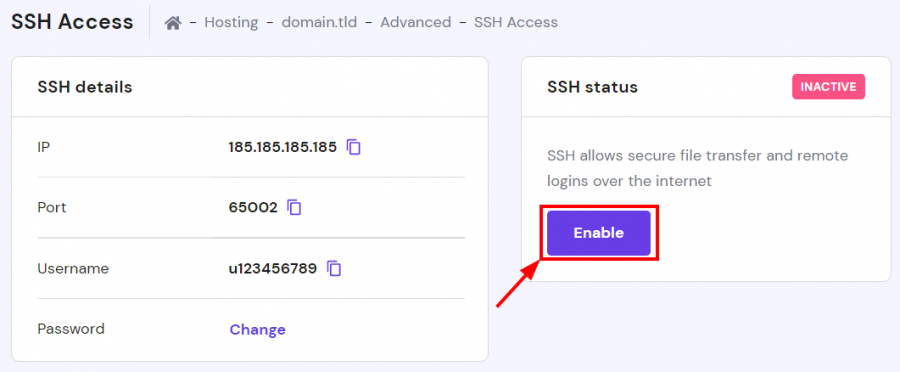
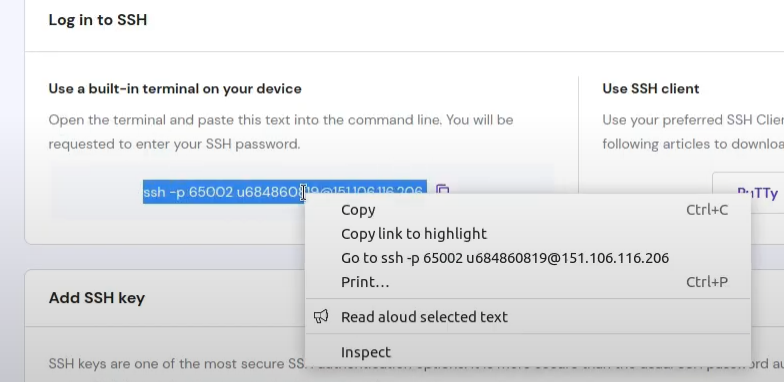
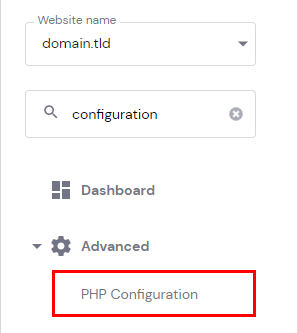
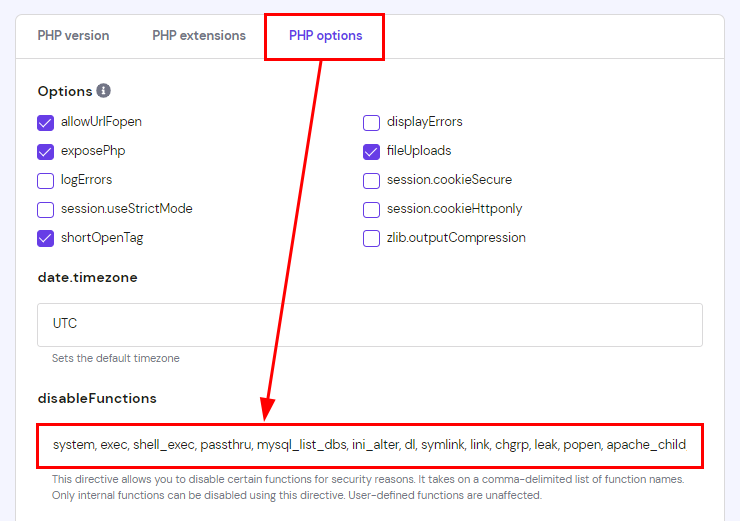
 أولاً عليك تفعيل وظيفة symlink على الاستضافة من خلال التوجه إلى: https://hpanel.hostinger.com/websites ثم manage وستجد PHP Configuration: اضغط على تبويب PHP options وستجد أسفل disableFunctions كلمة symlink قم بحذف الكلمة وحذف الفاصلة , الخاصة بها. الآن ستحتاج إلى استخدام SSH من أجل تنفيذ أوامر من خلال التيرمنال، أولاً توجه إلى: https://hpanel.hostinger.com/websites وستجد الخيار SSH Access: ثم ستجد قسم باسم SSH status أسفله يوجد زر Enable اضغط عليه: وتستطيع الإتصال من خلال نسخ أمر الإتصال بالأسفل في نفس الصفحة. على حاسوبك افتح التيرمنال ثم ألصق الأمر وسيتم الإتصال لكن سيطلب من الباسورد، تستطيع تغييره من نفس الصفحة بالضغط على CHANGE بجانب password ثم حدد كلمة مرور وتذكرها جيدًا. الآن قم بتنفيذ أمر ls -la لتفقد المجلدات والملفات التي في المسار الحالي ثم التنقل وتنفيذ الأوامر التي تريدها.
أولاً عليك تفعيل وظيفة symlink على الاستضافة من خلال التوجه إلى: https://hpanel.hostinger.com/websites ثم manage وستجد PHP Configuration: اضغط على تبويب PHP options وستجد أسفل disableFunctions كلمة symlink قم بحذف الكلمة وحذف الفاصلة , الخاصة بها. الآن ستحتاج إلى استخدام SSH من أجل تنفيذ أوامر من خلال التيرمنال، أولاً توجه إلى: https://hpanel.hostinger.com/websites وستجد الخيار SSH Access: ثم ستجد قسم باسم SSH status أسفله يوجد زر Enable اضغط عليه: وتستطيع الإتصال من خلال نسخ أمر الإتصال بالأسفل في نفس الصفحة. على حاسوبك افتح التيرمنال ثم ألصق الأمر وسيتم الإتصال لكن سيطلب من الباسورد، تستطيع تغييره من نفس الصفحة بالضغط على CHANGE بجانب password ثم حدد كلمة مرور وتذكرها جيدًا. الآن قم بتنفيذ أمر ls -la لتفقد المجلدات والملفات التي في المسار الحالي ثم التنقل وتنفيذ الأوامر التي تريدها.
-
بايثون ليست مناسبة لتطبيقات سطح المكتب، فلا يوجد إطار قوي خاص بها لتطوير تطبيقات لأنظمة سطح المكتب وليس من السهل تصدير تطبيقات سطح مكتب قابلة للتشغيل من خلالها أقصد مثل ملفات exe، على عكس جافاسكريبت فلديها Electron.js. لكن لو أردت التخصص في تطوير برامج سطح المكتب فستحتاج إلى تعلم لغة قوية وهي C# للتطوير من خلال .NET وستتمكن من تطوير تطبيق لمختلف أنظمة التشغيل المكتبية.
- 3 اجابة
-
- 1
-
-
ذلك هو المناسب بجانب دورة الذكاء الاصطناعي التي درستها بالفعل، الدورات الباقية خاصة بتطوير مواقع الويب وأمور أخرى.
-
دورة علوم الحاسوب ودورة تطوير التطبيقات باستخدام لغة Python
-
تقصد في أكاديمية حسوب؟ أرجو التوضيح لمساعدتك بشكل أفضل.
-
ذلك ما ذكرته، في التعليق السابق.
-
هل ستتخصص في كلاهما؟ الأفضل اختيار مجال واحد، عامًة لو أردت كلاهما، فمن حيث الأهمية ستحتاج إلى دراسة الإحصاء والرياضيات التطبيقية، لتتمكن من فهم البيانات، تحليل النتائج، وتجنب الأخطاء الشائعة كالانحياز أو سوء تفسير الارتباطات. أساسيات الإحصاء Descriptive & Inferential Statistics. تصميم التجارب Experimental Design واختبار A/B. الاحتمالات Probability Theory. تحليل السلاسل الزمنية Time Series Analysis. الرياضيات للذكاء الاصطناعي Linear Algebra, Calculus. ثم هندسة البيانات Data Engineering لأن 80% من وقت عالم البيانات يُستهلك في جمع البيانات، تنظيفها، وتحويلها، وستحتاج إلى تعلم: Advanced SQL for Data Analysis تصميم قواعد البيانات Database Design أدوات ETL مثل Apache Airflow. أدوات معالجة البيانات الضخمة: Hadoop, Spark. لكن لتمييز نفسك في سوق العمل عليك التخصص، فمثلاً بخصوص تعلم الآلة يوجد تخصصات: Computer Vision. Natural Language Processing (NLP). Reinforcement Learning.
-
لا مشكلة، لكن مع بعض الخطوات الإضافية المطلوبة لجعل النموذج متوافقًا مع واجهة scikit-learn، حيث توفر Keras واجهة جاهزة KerasClassifier أو KerasRegressor لدمج النماذج مع أدوات scikit-learn مثل GridSearchCV. وتستطيع تحديد أي عدد من القيم لكل معامل فائق ليس فقط 3 أو 4، لكن تذكر أن زيادة عدد القيم يزيد الوقت الحسابي بشكل كبير، واستخدم GridSearchCV كما تفعل مع أي نموذج في scikit-learn.
- 7 اجابة
-
- 1
-
-
ذلك أسلوب مُنظم لضبط المعاملات الفائقة Hyperparameters في نماذج التعلم الآلي للعثور على أفضل مجموعة من المعاملات الفائقة التي تُحسّن أداء النموذج كالدقة، السرعة وغيرهم بمعنى تُحدد المعاملات الفائقة التي تريد ضبطها كمُعدل التعلم learning rate وعدد الأشجار في Random Forest والمعاملات الأخرى، وتُحدد القيم المُحتملة لكل معامل كالتالي learning_rate = [0.01, 0.1, 1]. ويُنشئ Grid Search جميع التركيبات الممكنة من القيم المُحددة، أي لو لديك معاملين عدد الأشجار = [50, 100] والعمق الأقصى = [3, 5]، فالشبكة ستكون (50,3), (50,5), (100,3), (100,5). ولكل تركيبة، يُدرّب النموذج ويُقيّم أداؤه باستخدام تقنية مثل k-fold cross-validation، وتُختار التركيبة التي تعطي أفضل أداء بناءًا على مقياس مثل الدقة أو الـF1-score. from sklearn.model_selection import GridSearchCV from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() param_grid = { 'n_estimators': [50, 100, 200], 'max_depth': [None, 10, 20], 'min_samples_split': [2, 5] } grid_search = GridSearchCV(model, param_grid, cv=5) grid_search.fit(X_train, y_train) print(grid_search.best_params_) لكن ذلك غير فعّال في حال بعض المعاملات غير مؤثرة.
- 7 اجابة
-
- 1
-
-
ستحتاج إلى رأس Content-Disposition لفرض التحميل، وإرسال محتوى الملف مباشرةً إلى المتصفح ثم حذف الملف من الخادم بعد التحميل لو أردت وذلك اختياري. <?php $host = 'localhost'; $user = 'root'; $pass = ''; $dbname = 'database_name'; // اسم الملف المؤقت على الخادم $backupFile = 'backup_' . $dbname . '_' . date('Y-m-d_H-i-s') . '.sql'; $command = "mysqldump -h $host -u $user"; if (!empty($pass)) { $command .= " -p$pass"; } $command .= " $dbname > $backupFile"; $returnValue = system($command, $output, $returnCode); if ($returnCode === 0 && file_exists($backupFile)) { header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename="' . basename($backupFile) . '"'); header('Content-Length: ' . filesize($backupFile)); readfile($backupFile); unlink($backupFile); exit; } else { echo "<b>حدث خطأ أثناء عمل النسخة الاحتياطية:</b><br><br>"; echo "<b>قيمة الخروج من الأمر (Return Code):</b> " . $returnCode . "<br><br>"; if (!empty($output)) { echo "<b>رسائل الخطأ (إن وجدت):</b><pre>"; foreach ($output as $line) { echo htmlspecialchars($line) . "<br>"; } echo "</pre>"; } else { echo "<b>لم يتم الحصول على أي رسائل خطأ تفصيلية من الأمر.</b><br>"; } } ?> unlink($backupFile) لحذف الملف المؤقت $backupFile من الخادم، وكما أشرت إجراء اختياري، ومن الأفضل فعل ذلك حيث لا داعي للاحتفاظ بنسخة احتياطية على الخادم بعد تحميلها للحفاظ على أمن قاعدة البيانات.
-
في الجهاز الأول الذي تشارك منه عليك السماح لحركة مرور Samba في جدار الحماية: sudo ufw allow samba sudo ufw reload حاول مرة أخرى إلغاء مشاركة المجلد الحالي، ثم أعد مشاركته بنفس الطريقة، ثم أعد تشغيل samba: sudo systemctl restart smbd بخصوص كلمة المرور، هل قمت بالإتصال عن طريق الضغط على registered user وليس anonymous.
-
عليك التفكير في هيكل البيانات المناسب للمشكلة قبل الحل، فكتابة الكود هي أخر خطوة، لو استخدمت الكائنات سيؤدي إلى فقدان الأرقام المكررة لأن المفاتيح في الكائنات يجب أن تكون فريدة، استخدم مصفوفة لتخزين كل رقم مع وزنه. وحساب الوزن باستخدام reduce، لحساب مجموع الأرقام لكل عدد بطريقة أكثر كفاءة، ثم الترتيب باستخدام الوزن والترتيب الأبجدي أي عند تساوي الوزن، نقارن الأرقام كسلاسل نصية باستخدام ميثود localeCompare. وعليك معالجة الفراغات من خلال ميثودز trim() و split(/\s+/) للتأكد من التعامل مع الفراغات الزائدة بشكل صحيح. function orderWeight(strng) { const numbers = strng.trim().split(/\s+/).filter(n => n !== ''); if (numbers.length === 0) return ''; return numbers .map(num => ({ num, weight: num.split('').reduce((sum, digit) => sum + parseInt(digit, 10), 0) })) .sort((a, b) => { if (a.weight === b.weight) { return a.num.localeCompare(b.num); } return a.weight - b.weight; }) .map(entry => entry.num) .join(' '); } console.log(orderWeight("56 65 74 100 99 68 86 180 90")); ما قمت به هو تقسيم السلسلة المدخلة إلى مصفوفة من الأرقام مع تجاهل الفراغات الزائدة، وحساب الوزن لكل عدد: بحساب مجموع أرقامه بمعنى 100 هي 1+0+0 = 1. ثم نرتب المصفوفة حسب الوزن، وفي حالة التساوي نرتب أبجديًا، ثم إعادة تجميع النتيجة باستخراج الأرقام المرتبة ونضمّنها في سلسلة واحدة.
-
الشخص الذي يستأجر العقار لفترة زمنية محددة هو المُستأجر، وذلك بموجب عقد إيجار يبرم مع مالك العقار وهو المؤجر، وحقوق المستأجر مستمدة بشكل أساسي من عقد الإيجار والقوانين المنظمة للعلاقة الإيجارية في بلدك. وتلك الحقوق هي الحق في الانتفاع بالعقار، السكن الهادئ والآمن، صيانة العقار، الخصوصية، تجديد عقد الإيجار في بعض الحالات وبشروط معينة، الحماية من الإخلاء التعسفي، الحصول على نسخة من عقد الإيجار والحقوق الأخرى المنصوص عليها في عقد الإيجار والقوانين المحلية، أي له حقوق مؤقتة بالإنتفاع بالعقار لفترة محددة بموجب العقد. أما المستفيد من العقار فهو الشخص الذي يستفيد من العقار بشكل أو بآخر، ولكن ليس بالضرورة أن يكون هو المستأجر أو المالك المباشر، أي المستفيد مصطلح أوسع وأشمل، يشمل المستفيد من الوقف الخيري أو الأهلي، المستفيد من الوصية أو الميراث، المستفيد من حق الانتفاع والمستفيد من عقد التأمين على العقار، ونطاق الحقوق واسع ومتنوع ويعتمد بشكل كبير على نوع الاستفادة الممنوحة وظروفها وتتراوح بين مؤقتة ودائمة.
-
الدورة بمثابة تأهيل لدخول مجال البرمجة، وستتعلم بها الأساسيات اللازمة لإختيار المجال البرمجي المناسب الذي تريده والذي يتم إختياره حسب المطلوب في سوق العمل المراد العمل به أي الذي تستهدفه. ستتعلم بها ما يلي: أساسيات البرمجة بتعلم المنطق البرمجي أولاً من خلال سكراتش ثم تعلم كتابة الكود من خلال لغة برمجية وهي بايثون وجافاسكريبت ثم تعلم الخوارزميات وهياكل البيانات ثم تعلم مفاهيم أخرى خاصة بعلوم الحاسوب، ستجد تفصيل هنا:
-
ستحتاجين إلى الإتصال بقاعدة البيانات من خلال PDO، ثم استعلام SQL لترتيب النتائج حسب التخصص مع ORDER BY specialty لضمان ترتيب النتائج حسب التخصص. ثم إنشاء مصفوفة جديدة $groupedStudents وتكرار خلال جميع الطلاب وتجميعهم حسب التخصص. ولكل تخصص يتم إنشاء جدول منفصل، مع استخدام حلقتين متداخلتين الأولى للتخصصات والثانية لعرض بيانات الطلاب داخل كل تخصص. كالتالي: <?php $host = 'localhost'; $dbname = 'اسم_قاعدة_البيانات'; $username = 'اسم_المستخدم'; $password = 'كلمة_المرور'; try { $conn = new PDO("mysql:host=$host;dbname=$dbname", $username, $password); $conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); $stmt = $conn->prepare("SELECT * FROM students ORDER BY specialty"); $stmt->execute(); $students = $stmt->fetchAll(PDO::FETCH_ASSOC); $groupedStudents = []; foreach ($students as $student) { $specialty = $student['specialty']; if (!isset($groupedStudents[$specialty])) { $groupedStudents[$specialty] = []; } $groupedStudents[$specialty][] = $student; } if (!empty($groupedStudents)) { foreach ($groupedStudents as $specialty => $students) { echo "<h2>تخصص: $specialty</h2>"; echo "<table border='1'>"; echo "<tr><th>ID</th><th>الاسم</th><th>البريد الإلكتروني</th><th>التاريخ</th></tr>"; foreach ($students as $student) { echo "<tr>"; echo "<td>{$student['id']}</td>"; echo "<td>{$student['name']}</td>"; echo "<td>{$student['email']}</td>"; echo "<td>{$student['date']}</td>"; echo "</tr>"; } echo "</table><br>"; } } else { echo "لا توجد بيانات لعرضها"; } } catch(PDOException $e) { echo "خطأ في الاتصال: " . $e->getMessage(); } $conn = null; ?> بالطبع عليكِ تعديل أسماء الجدول والحقول لتتناسب مع قاعدة البيانات لديكِ.
-
من الأفضل دراسة المسارات كما هي بالترتيب، فالدورات في الأكاديمية ممنهجة والمسارات مرتبة بشكل متدرج، ولن يؤثر ذلك على الدراسة فالمسارات في البداية هي تطبيقات بسيطة ومقدمة للمسارات المتقدمة الأخرى بدءًا من مسار تعلم الآلة Machine Learning، أي لن تحتاج إلى استيعاب لمكتبة pandas في البداية. عامًة الترتيب الذي ذكرته لا مشكلة به وتستطيع الدراسة من خلاله كما يحلو لك.
- 2 اجابة
-
- 1
-
-
لا نستخدم ذلك بشكل مباشر هنا، لأن النموذج الحالي مبني باستخدام طبقات بسيطة Dense, BatchNormalization بدون ميزات skip connections في ResNet أو التوصيلات الكثيفة dense blocks في DenseNet. لو أردت دمج مفاهيم ResNet أو DenseNet في النموذج، يجب تعديل بنية الطبقات كالتالي، أولاً تُضاف Residual Connections بين الطبقات، حيث يُضاف إخراج طبقة سابقة إلى إخراج طبقة لاحقة. وستقوم بتعديل جزء من الكود باستخدام Functional API لأن Sequential لا يدعم التوصيلات المتفرعة Residual Connections. from tensorflow.keras.layers import Add input_layer = keras.layers.Input(shape=(input_shape,)) x = keras.layers.Dense(8)(input_layer) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) residual = x x = keras.layers.Dense(128)(x) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) x = Add()([x, residual]) # إضافة الوصلة المتبقية هنا from tensorflow.keras.layers import Add input_layer = keras.layers.Input(shape=(input_shape,)) x = keras.layers.Dense(8)(input_layer) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) residual = x x = keras.layers.Dense(128)(x) x = keras.layers.BatchNormalization()(x) x = keras.layers.Activation('tanh')(x) x = Add()([x, residual]) # إضافة الوصلة المتبقية هنا # باقي الطبقات ثم تُضاف Dense Connections حيث يُوصَل إخراج كل طبقة سابقة كمدخل لجميع الطبقات اللاحقة في الـblock. from tensorflow.keras.layers import Concatenate def dense_block(x): x1 = keras.layers.Dense(128)(x) x1 = keras.layers.BatchNormalization()(x1) x1 = keras.layers.Activation('tanh')(x1) x = Concatenate()([x, x1]) # دمج الإخراج مع المدخلات الأصلية x2 = keras.layers.Dense(64)(x) x2 = keras.layers.BatchNormalization()(x2) x2 = keras.layers.Activation('tanh')(x2) x = Concatenate()([x, x2]) return x input_layer = keras.layers.Input(shape=(input_shape,)) x = dense_block(input_layer) وللحفاظ على بنية Sequential، الأفضل استخدام حزم جاهزة مثل tensorflow.keras.applications.ResNet50، لكن ذلك غير عملي للشبكات الصغيرة.
- 5 اجابة
-
- 1
-
-
الأمر يعتمد على طبيعة البيانات والخوارزمية المستخدمة، فالحالات التي يُمكن فيها تحسين TP وTN معًا هي عند تحسين عام في النموذج أي لو قمت بتحسين جودة النموذج بشكل عام مثل استخدام خوارزمية أكثر تعقيدًا، تحسين الميزات، أو معالجة البيانات بشكل أفضل، فقد يزيد كل من TP وTN معًا. بمعنى استخدام نموذج مثل Gradient Boosting بدلًا من Logistic Regression في حال البيانات غير خطية، ومعالجة البيانات المفقودة أو إزالة الضوضاء. الحالة الأخرى هي تحسين توازن الفئات في البيانات غير المتوازنة، باستخدام تقنيات مثل Oversampling كـ SMOTE للفئة الأقل، وClass weighting في الخوارزميات كزيادة وزن الفئة النادرة. او تحسين مساحة الميزات من خلال تقنيات مثل PCA أو Feature Engineering لفصل الفئتين بشكل أفضل. ستفاضل بينهم في حالات معينة، وهي عند تغيير عتبة التصنيف Threshold فسيتم زيادة TN أي تصنيف سلبي أكثر دقة، وانخفاض TP فبعض الإيجابيات الحقيقية تُصنف خطأً كسلبية، وتخفيض العتبة Threshold يؤدي إلى العكس أيضًا. وفي البيانات المتداخلة، فلو هناك تداخل كبير بين توزيعات الفئتين، فتحسين TP يتطلب تخفيض TN والعكس صحيح. ولتحسين كلاهما، تفقد الدقة Accuracy، فلو تحسنت سيتحسن TP و/أو TN مع تقليل الأخطاء FP وFN. أيضًا منحنى ROC-AUC، والذي يقيس الأداء العام بغض النظر عن العتبة، تحسنه يعني قدرة النموذج على التمييز بين الفئتين بشكل أفضل، وذلك يعزز كل من TP وTN معًا. وتأكد من أن النموذج لا ينحاز لفئة معينة، مع استخدام مقياس مثل F1-Score (يجمع بين Precision وRecall) أو G-Mean، بالإضافة إلى Grid Search أو Bayesian Optimization لتحسين معلمات النموذج.
- 2 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
ربما بسبب الـ Overfitting، ويحدث التدريب الزائد أو فرط التخصص في حال تعلم النموذج بيانات التدريب بشكل جيد جدًا، لدرجة أنه يبدأ في حفظ الضوضاء أو التفاصيل غير المهمة في بيانات التدريب، بالتالي يصبح النموذج جيدًا جدًا في التنبؤ ببيانات التدريب، ولكنه لا يؤدي أداءً جيدًا على البيانات الجديدة التي لم يرها من قبل أي بيانات التحقق، وارتفاع دقة التدريب مع ثبات دقة التحقق يعني مشكلة تدريب زائد. أو ربما مشكلة في بيانات التحقق ففي حال صغيرة جدًا، لن تكون ممثلة بشكل جيد للبيانات الحقيقية، وذلك يجعل دقة التحقق غير مستقرة أو لا تعكس الأداء الحقيقي للنموذج، وأيضًا لو مختلفة بشكل كبير عن بيانات التدريب من حيث التوزيع أو الخصائص، فلن يكون النموذج قادرًا على التعميم بشكل جيد عليها. أو معدل التعلم غير المناسب Learning Rate فعند إرتفاعه بشكل كبير مرتفعًا فسيتجاوز النموذج الحد الأمثل ولا يتمكن من الاستقرار على حل جيد لبيانات التحقق، ولو منخفضًا جدًا، فسيستغرق النموذج وقتًا طويلاً للتعلم على بيانات التحقق، أو لا يتعلم بشكل فعال على الإطلاق.
- 2 اجابة
-
- 1
-
-
آلية الإختبار هي كالتالي: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتُطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
- 5 اجابة
-
- 1
-

-
بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة.
- 5 اجابة
-
- 1
-