Mustafa Suleiman
-
المساهمات
20334 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
494
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 جميع الدورات يوجد بها تطبيقات عملية، حيث يوجد مشروع شامل في نهاية كل مسار للتطبيق على ما قمنا بدراسته، وأيضًا في بعض دروس المسار نفسه يوجد تمارين للتطبيق العملي. وبعد دراسة الأساسية، ستجد في الدورة مسارات خاصة بالمشاريع العملية الكاملة والمعقدة أكثر، ويتم التدرج في الصعوبة والأفكار. مثلاً في دورة واجهات المستخدم، يوجد مشروع بناء موقع شخصي في المسار الأول وهو أساسيات الويب. ثم في المسارات اللاحقة يوجد المشاريع التالية: بناء واجهة مستخدم تشبه موقع YouTube بناء صفحات هبوط تطوير متجر إلكتروني تطوير موقع شركة تطوير لوحة تحكم بناء مواقع ثابتة باستخدم Hugo تطوير موقع أخباري
جميع الدورات يوجد بها تطبيقات عملية، حيث يوجد مشروع شامل في نهاية كل مسار للتطبيق على ما قمنا بدراسته، وأيضًا في بعض دروس المسار نفسه يوجد تمارين للتطبيق العملي. وبعد دراسة الأساسية، ستجد في الدورة مسارات خاصة بالمشاريع العملية الكاملة والمعقدة أكثر، ويتم التدرج في الصعوبة والأفكار. مثلاً في دورة واجهات المستخدم، يوجد مشروع بناء موقع شخصي في المسار الأول وهو أساسيات الويب. ثم في المسارات اللاحقة يوجد المشاريع التالية: بناء واجهة مستخدم تشبه موقع YouTube بناء صفحات هبوط تطوير متجر إلكتروني تطوير موقع شركة تطوير لوحة تحكم بناء مواقع ثابتة باستخدم Hugo تطوير موقع أخباري -
React هي الأساس، بمعنى React Native يعتمد على React وهو إطار خاص بالهواتف وليس الويب، لذا عليك التعمق في React أولاً وتعلم Next.js بعد ذلك لأنّ Next خاصة بالويب، في حال أردت التخصص كمطور ويب شامل Full-Stack. وفيما بعد تستطيع تعلم React Native، لكن تعلم تقنيات مختلفة في نفس الوقت هو تشتيت غير مفيد. الفكرة هي أن تعلم الأساسيات لجميع تقنيات جافاسكريبت سيجعلك تظن أنك قادر على تنفيذ مشاريع، وفي الواقع أنت بحاجة إلى التعمق والتركيز على تقنيات محددة فقط لتحسين مستواك بها.
- 3 اجابة
-
- 1
-

-
اضغط على servers في pgadmin ثم اختر قاعدة البيانات postgresSQL، ولو طلب منك كلمة مرور قاعدة البيانات أدخلها لكي يسمح لك بالإتصال. ثم ستظهر لك databases وبها قواعد البيانات الخاصة بك وفي حال لم تجد بها أي شيء، فقم بالضغط عليها بزر الفأرة الأيمن اوختر create لإنشاء قاعدة بيانات.
- 3 اجابة
-
- 1
-
-
بالضغط على اسم الملف الذي صيغته exe. وها هو الرابط المباشر: https://ftp.postgresql.org/pub/pgadmin/pgadmin4/v9.7/windows/pgadmin4-9.7-x64.exe لكن لا حاجة إلى ذلك، في حال قمت بتحميل postgres من قبل، فعند تثبيتها من المفترض أن يتم ثتبيت pgadmin بشكل إفتراضي، ابحث في شريط البحث في الويندوز عن pgadmin.
-
المشكلة في سكريبت build في ملف package.json في مجلد الخادم "build": "npm install && npm install --prefix client && npm run build --prefix client", قم بحذفه ليصبح الكود: "scripts": { "dev": "node --watch index.js", "start": "node index.js" },
-
الفكرة ليست في تعلم هذا أو ذاك، بل تعلم المطلوب بالنسبة لسوق العمل الذي تستهدفه، حاليًا أنت تستهدف منصات العمل الحر ولديك خبرة بها، لذا بناءًا على المهارات المطلوبة في المشاريع المعروضة بها، تستطيع تقرير ما الذي أنت بحاجة إلى تعلمه. أي الإختيار ما بين vue.js و react.js يعتمد على ما سبق، لكن ضع في الحُسبان Angular.js في حال تريد العمل في شركات مستقبلاً، فهو الإطار المستخدم بكثرة في الشركات، بينما react.js هي الأكثر استخدامًا بشكل عام ولن تضيع وقتك إن تعلمتها وهي الخيار الأنسب في حال لا يوجد إطار عمل مُحدد للواجهة الأمامية مطلوب من في المشاريع على مواقع العمل الحر. لذا حدد وجهتك خلال سنة من الآن، وبناءًا على قرارك ستتمكن من تحديد التقنية المناسبة، ودائمًا تذكر يجب تفقد سوق العمل قبل تعلم أي تقنية.
-
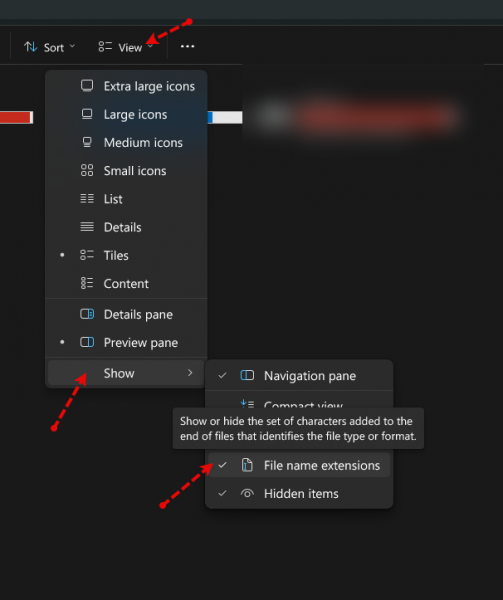
في ملف index.html قم بتضمين ملف css كالتالي: <link rel="stylesheet" href="styles.css"> ثم في مستعرض الملفات قم بتفعيل خاصية إظهار صيغ الملفات، غالبًا لديك مشكلة في صيغ الملفات:
-
أهم قطعة هي الـ GPU، والحد الأدنى هو RTX 3080 إصدار 10 جيجابايت VRAM، ثم قم بالبحث عن معالج AMD مستعمل من فئة Ryzen 9 وستحصل على صفقة جيدة قيمة مقابل سعر. وبالنسبة لباقي القطع فالأمر عائد إليك، لكن بالطبع يجب شراء هارد SSD بحجم 512 جيجابايت بحد أدنى لنظام الويندوز. وتجنب شراء كروت شاشة من AMD، لأن معظم أطر عمل تعلم الآلة مثل PyTorch وTensorFlow مُحسنة لمنصة CUDA من NVIDIA، بالتالي ستضمن أداء وتوافق أفضل، كما أن أنوية Tensor Cores من NVIDIA مصممة خصيصًا لتسريع حسابات التعلم العميق.
-
عند تغيير النص في عنصر h2 ثم الحفظ CTRL + S لا يحدث أي تغيير؟ في حال ذلك قم بتجربة إعادة تشغيل محرر vscode وتشغيل خادم live server مرة أخرى
- 5 اجابة
-
- 1
-

-
لغة HTML بسيطة فهي لغة وصفية، وعليك استيعاب المفاهيم التالية في البداية ثم استكمال باقي الدورة ولو واجهت أمر ما في مشروع تستطيع البحث عنه وتعلمه عند الحاجة، ويجب التطبيق علي ما يلي بشكل عملي وتجنب الاستيعاب بشكل نظري، وقم بالتغيير في الكود لتفهم آلية عمله: 1- يجب أن تفهم أن كل صفحة HTML لها هيكل ثابت: <!DOCTYPE html>: يُخبر المتصفح أن تلك وثيقة HTML5. <html>: العنصر الجذر الذي يلتف حول كل محتوى الصفحة. <head>: يحتوي على معلومات حول الصفحة (غير مرئية للمستخدم)، مثل العنوان والترميز. <body>: يحتوي على كل المحتوى المرئي في الصفحة (نصوص، صور، روابط، إلخ). 2- HTML تتكون من عناصر، ويتم تعريف كل عنصر باستخدام وسم للبداية ووسم للنهاية، وهناك بعض الوسوم التي لا تحتاج إلى وسم نهاية تُسمى Self-closing tags مثل <br> أو <img>. 3- السمات Attributes والتي بمثابة معلومات إضافية للعناصر، وتُكتب دائمًا في وسم البداية، href في وسم الرابط <a>، أو src في وسم الصورة <img>. 4- العناوين من عنصر <h1> للعناوين الهامة إلى <h6> الأقل أهمية، والفقرات <p> لوضع النص في فقرات منفصلة. 5- الروابط لربط الصفحات ببعضها أو بمواقع خارجية، أي العنصر <a> مع السمة href لتحديد وجهة الرابط. 6- الصور من خلال العنصر <img> مع سمتين أساسيتين وهما src لتحديد مسار (مكان) الصورة، وalt لوصف الصورة وهو مهم جدًا لإمكانية الوصول ولحالات عدم ظهور الصورة: <img src="images/my-photo.png" alt="صورة شخصية لي"> 7- القوائم <ul> وol 8- عناصر التجميع <div> و <span> حيث <div>: عنصر كتلة Block يُستخدم كحاوية لتجميع عدة عناصر معًا مثل قسم كامل في الصفحة، بينما <span> عنصر "سطري Inline لتجميع جزء صغير من النص داخل عنصر آخر لتطبيق تنسيق معين عليه لاحقًا باستخدام CSS. 9- HTML الدلالي Semantic HTML وهي استخدام وسوم لها معنى واضح بدلاً من استخدام <div> لكل شيء، لتحسين بنية الصفحة ومساعدة محركات البحث. <header>: للجزء العلوي من الصفحة (الشعار، القائمة). <nav>: لتجميع روابط التنقل الرئيسية. <main>: للمحتوى الرئيسي والفريد في الصفحة. <footer>: للجزء السفلي من الصفحة (حقوق النشر، روابط التواصل). <section>: لتقسيم الصفحة إلى أقسام منطقية. 10- Forms لجمع بيانات من المستخدم مثل نموذج تسجيل الدخول أو نموذج الاتصال: <form>: الحاوية الرئيسية للنموذج. <input>: العنصر الأساسي لإدخال البيانات (له أنواع مختلفة مثل text, password, email, submit). <label>: لربط نص وصفي بحقل الإدخال (مهم لإمكانية الوصول). <textarea>: لإدخال نصوص طويلة. <button>: لإنشاء زر. 11- الجداول: <table>: الحاوية الرئيسية للجدول. <tr>: لإنشاء صف <th>: لإنشاء خلية رأس الجدول <td>: لإنشاء خلية بيانات عادية
-
ذلك هو الكود المصدري الخاص بالمشروع، وستجد به كل الصور والأيقونات: https://github.com/mohamedelkashef15/Food-Lover/tree/main/img لاحظ اسم المستخدم mohamedelkashef15 على github موجود في الصورة التي أرفقتها، بالتالي تستطيع الوصول لحسابه على github وتفقد المشاريع الموجودة به، ومن ضمنها المشروع الذي تبحث عنه.
-
ما هو إصدار odoo الذي تستخدمه؟ عامًة ملف XML لا يتوافق مع الهيكلية الخاصة بإصدار Odoo الحديث، لأنّ طريقة تعديل واجهة نقطة البيع تغيرت، هيكل المشروع الصحيح: custom_pos_delivery/ ├── __manifest__.py ├── models/ │ ├── __init__.py │ └── pos_order.py ├── static/ │ └── src/ │ ├── js/ │ │ └── pos_delivery.js │ └── xml/ │ └── pos_delivery_templates.xml └── views/ └── pos_assets.xml والكود الخاص بملف __manifest__.py: { 'name': 'Custom POS Delivery and Pickup', 'version': '16.0.1.0.0', 'depends': ['point_of_sale'], 'data': [ 'views/pos_assets.xml', ], 'assets': { 'point_of_sale.assets': [ 'custom_pos_delivery/static/src/js/pos_delivery.js', 'custom_pos_delivery/static/src/xml/pos_delivery_templates.xml', ], }, 'installable': True, 'auto_install': False, } ثم قم بإنشاء ملف views/pos_assets.xml فارغ للتوافق: <?xml version="1.0" encoding="utf-8"?> <odoo> </odoo> ملف models/__init__.py: from . import pos_order ملف models/pos_order.py: from odoo import api, fields, models class PosOrder(models.Model): _inherit = 'pos.order' order_type = fields.Selection([ ('pickup', 'Pickup'), ('delivery', 'Delivery') ], string='Order Type', default='pickup') delivery_address = fields.Text(string='Delivery Address') delivery_person = fields.Char(string='Delivery Person') delivery_fee = fields.Float(string='Delivery Fee') @api.model def _order_fields(self, ui_order): order_fields = super(PosOrder, self)._order_fields(ui_order) order_fields['order_type'] = ui_order.get('order_type', 'pickup') order_fields['delivery_address'] = ui_order.get('delivery_address', '') order_fields['delivery_person'] = ui_order.get('delivery_person', '') order_fields['delivery_fee'] = ui_order.get('delivery_fee', 0.0) return order_fields ملف static/src/xml/pos_delivery_templates.xml: <?xml version="1.0" encoding="UTF-8"?> <templates id="template" xml:space="preserve"> <!-- إضافة أزرار نوع الطلب في شاشة المنتجات --> <t t-name="OrderTypeButtons" owl="1"> <div class="order-type-selector mt-2 p-2 bg-gray-100 rounded"> <h4 class="mb-2">نوع الطلب:</h4> <div class="d-flex gap-2"> <button class="btn btn-primary" t-on-click="selectPickup"> <i class="fa fa-shopping-bag"/> استلام من الفرع </button> <button class="btn btn-warning" t-on-click="selectDelivery"> <i class="fa fa-truck"/> توصيل للمنزل </button> </div> <div t-if="state.showDeliveryInfo" class="delivery-info mt-3"> <div class="form-group"> <label>عنوان التوصيل:</label> <textarea class="form-control" t-model="state.deliveryAddress" rows="2"/> </div> <div class="form-group"> <label>عامل التوصيل:</label> <input type="text" class="form-control" t-model="state.deliveryPerson"/> </div> <div class="form-group"> <label>رسوم التوصيل:</label> <input type="number" class="form-control" t-model="state.deliveryFee" step="0.01"/> </div> </div> </div> </t> <!-- إضافة معلومات التوصيل في الإيصال --> <t t-inherit="point_of_sale.OrderReceipt" t-inherit-mode="extension"> <xpath expr="//div[hasclass('pos-receipt-order-data')]" position="after"> <t t-if="receipt.order_type"> <div class="pos-receipt-order-type"> <div>نوع الطلب: <t t-esc="receipt.order_type === 'delivery' ? 'توصيل للمنزل' : 'استلام من الفرع'"/></div> <t t-if="receipt.order_type === 'delivery'"> <div>عنوان التوصيل: <t t-esc="receipt.delivery_address"/></div> <div>عامل التوصيل: <t t-esc="receipt.delivery_person"/></div> <div>رسوم التوصيل: <t t-esc="receipt.delivery_fee"/> <t t-esc="receipt.currency.symbol"/></div> </t> </div> <br/> </t> </xpath> </t> </templates> ملف static/src/js/pos_delivery.js: /** @odoo-module **/ import { Order } from "@point_of_sale/app/store/models"; import { ProductScreen } from "@point_of_sale/app/screens/product_screen/product_screen"; import { Component } from "@odoo/owl"; import { usePos } from "@point_of_sale/app/store/pos_hook"; import { patch } from "@web/core/utils/patch"; patch(Order.prototype, { setup() { super.setup(...arguments); this.order_type = this.order_type || 'pickup'; this.delivery_address = this.delivery_address || ''; this.delivery_person = this.delivery_person || ''; this.delivery_fee = this.delivery_fee || 0.0; }, export_as_JSON() { const json = super.export_as_JSON(...arguments); json.order_type = this.order_type; json.delivery_address = this.delivery_address; json.delivery_person = this.delivery_person; json.delivery_fee = this.delivery_fee; return json; }, export_for_printing() { const result = super.export_for_printing(...arguments); result.order_type = this.order_type; result.delivery_address = this.delivery_address; result.delivery_person = this.delivery_person; result.delivery_fee = this.delivery_fee; return result; }, set_order_type(type) { this.order_type = type; }, set_delivery_info(address, person, fee) { this.delivery_address = address; this.delivery_person = person; this.delivery_fee = parseFloat(fee) || 0.0; } }); export class OrderTypeButtons extends Component { static template = "OrderTypeButtons"; setup() { this.pos = usePos(); this.state = { showDeliveryInfo: false, deliveryAddress: '', deliveryPerson: '', deliveryFee: 0 }; } selectPickup() { const order = this.pos.get_order(); order.set_order_type('pickup'); this.state.showDeliveryInfo = false; } selectDelivery() { const order = this.pos.get_order(); order.set_order_type('delivery'); this.state.showDeliveryInfo = true; } onDeliveryInfoChange() { const order = this.pos.get_order(); order.set_delivery_info( this.state.deliveryAddress, this.state.deliveryPerson, this.state.deliveryFee ); } } patch(ProductScreen.prototype, { setup() { super.setup(...arguments); this.OrderTypeButtons = OrderTypeButtons; } }); ProductScreen.components = { ...ProductScreen.components, OrderTypeButtons, }; تحديث ملف __init__.py في المجلد الرئيسي: from . import models ثم عليك إعادة تشغيل خادم Odoo بعد إضافة الملفات وقم بتحديث قائمة التطبيقات من الإعدادات ثم تثبيت الموديول الجديد.
-
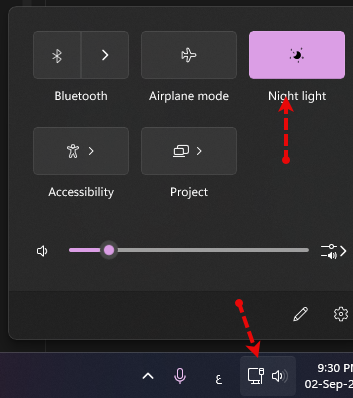
في البداية يجب تفعيل وضع الـ Night mode على حاسوبك طوال الوقت، إلا في الحالات التي تتعامل فيها مع الألوان في التصميمات فقم بتعطيله، وهي ميزة موجودة في الويندوز ولا حاجة لتثبيت برامج. لو أردت ضبط مستوى اللون الأزرق، اضغط على زر Night light بزر الفأرة الأيمن واختر Settings نفس الأمر قم بتفعيله على هاتفك، الفكرة من ذلك تقليل التعرض للضوء الأزرق قدر الإمكان. ثانيًا عليك بتوفير زجاجة مياه بجانبك دائمًا، وإلا ستصاب بالجفاف بعد فترة، الكثير يتجاهل تلك النقطة وهي غاية في الأهمية. ثالثًا، لا تستخدم الحاسوب إلا من خلال المكتب وكرسي المكتب، أي في حال لديك لابتوب فلا تستخدمه لفترات وأنت جالس على السرير مثلاً، فذلك لا يصلح للدراسة وسيؤذي رقبتك وظهرك، وأيضًا سيقلل من تركيزك، وفي حال لديك القدرة قم بشراء كرسي مكتب مُريح قدر الإمكان في حدود الميزانية المتوفرة، واختر الذي به فتحات mash للتهوية. رابعًا، قم بتثبيت تطبيق Pomodoro Timer على هاتفك ولكن اجعل جلسات الدراسة لمدة ساعتين، ثم استراحة لمدة 10 دقائق أو ربع ساعة. خامسًا، عليك تحديد ما ستقوم بتنفيذه كل يوم وتجنب الدراسة بشكل عشوائي لكي تستفيد بوقتك، أي كل يوم مساءًا قم بتحديد ما ستفعله غدًا وإلتزم به. سادسًا، الرياضة لا غنى عنها بالطبع، لكن الكثير يواجه صعوبة في الإلتزام بها، لذا بشكل واقعي، استغل أي مناسبة للخروج من المنزل للتمشية حتى لو كانت لشراء احتياجات المنزل. سابعًا، يجب البُعد عن الحاسوب لمدة يوم على الأقل تمامًا في كل أسبوع، الأجازة ستُجدد نشاطك وأيضًا لإراحة جسدك.
- 4 اجابة
-
- 1
-
-
المشاركة بحد ذاتها، حتى لو لم تحقق مركز متقدم، لها فوائد بالطبع، الأمر كله يصب في تنمية مهاراتك أنت، حيث ستنتقل من التعلم النظري أو المشاريع البسيطة إلى التعامل مع بيانات حقيقية، فوضوية، وغير مكتملة، وهي الخبرة الأقرب إلى ما ستواجهه في الواقع العملي. وملفك الشخصي على Kaggle هو بمثابة سيرة ذاتية كإثبات على أنك تستطيع تنفيذ المطلوب بالفعل، من خلال إظهار مشروع كامل استخدمت فيه تقنيات معينة التقنية، والمسؤول عن التوظيف سيتمكن من رؤية الـ Notebooks، طريقة تفكيرك، والنتائج التي حققتها. أيضًا توفر المسابقات بيانات من مجالات مختلفة جداً، منها التمويل، الطب، تحليل الصور الطبية، معالجة اللغات الطبيعية، التنبؤ بالمبيعات، وذلك من شأنه توسيع آفاقك ويوفر لك خبرة في مجالات متنوعة. و الفائزون في مسابقات Kaggle لا يستخدمون فقط الخوارزميات المعروفة، بل أحيانًا يبتكرون أو يستخدمون أحدث التقنيات والهيكليات والـ Fine-tuning وتقنيات التجميع Ensembling، بالتالي قراءة حلول الفائزين هي بحد ذاتها عملية تعلم سريعة ومكثفة. وكل مسابقة هي مشكلة فريدة تتطلب منك التفكير بعمق في كل خطوة، من فهم البيانات عن طريق منهجية EDA، إلى هندسة الميزات، واختيار النموذج الصحيح، وطريقة التحقق من صحته، وهي أهم خطوة.
- 2 اجابة
-
- 1
-
-
أرجو المتابعة أسفل نفس السؤال وليس إنشاء سؤال جديد
-
هل يمكنك مشاركة رابط المستودع الذي تستخدمه لنشر المشروع؟ أيضًا قم بتجربة حذف المشروع على render ثم إعادة إنشاء مشروع جديد واختيار المستودع الصحيح.
-
ذكرت لك الطريقة الأسهل، وبالطبع متاح ما تريده، ستحتاج إلى تعديل أمر الـ build والـ start على render لكل من الواجهة الأمامية والخلفية، بحيث تستخدم أمر cd للإنتقال للمجلد المطلوب ثم تنفيذ أمر التحزيم وأمر تشغيل المشروع، بمعنى للواجهة الأمامية أمر build: cd client && npm i && npm run build وأمر start: cd client && npm start وللواجهة الخلفية أمر build: cd server && npm i و أمر Start: cd server && npm start
-
عليك فصل مجلد الخادم عن مجلد الواجهة الأمامية، أي كل منهم في مستودع git منفصل، وكل منهم له ملف env. منفصل. ستتوجه إلى كل مجلد، ثم إنشاء مستودع من خلال: git init ثم إنشاء ملف gitignore. لكل مجلد ثم رفع المشروع إلى مستودع منفصل من خلال الأوامر التالية: git add . // ثم git commit -m "first commit" // ثم git branch -M main // ثم git remote add origin رابط المستودع // ثم git push -u origin main ثم التوجه إلى render ونشر كل مشروع من خلال رابط المستودع الخاص به، وبالطبع سيتعين عليك إنشاء متغيرات بيئة على render أثناء نشر المشروع، وهي نفس المتغيرات التي كنت تستخدمها في ملف env. وبالنسبة للواجهة الخلفية يجب إنشاء قاعدة بيانات أيضًا على render وستحصل على رابط استخدمه في متغيرات البيئة الخاصة بالواجهة الخلفية على render
-
بالضبط، يجب ذلك
-
السؤال غير واضح، في حال متعلق بأحد الدروس بالدورة، أرجو طرح السؤال أسفل الدرس، عند النزول لأسفل ستجدي صندوق تعليقات كما هنا
-
أنت تستخدم إضافة code runner وهي تعمل على تشغيل الكود وعرضه في تبويب output وليس terminal، بالتالي لن تستطيع إدخال أي قيمة. لتشغيله في الـ terminal اضغط على file بالأعلى في المحرر ثم اختر preferences ثم settings وابحث عن code runner run in terminal ثم قم بتفعيل ذلك الخيار وأعد تشغيل الكود
- 1 جواب
-
- 1
-
-
لا يتم العثور على ملف package.json لتثبيت الحزم اللازمة لتشغيل لمشروع، في حال قمت باستخدام مستودع المشروع الذي يحتوي على مجلدين client و server فذلك غير صحيح، يجب عليك رفع مجلد client على مستودع منفصل، ومجلد server في مستودع منفصل ثم نشر كلاهما على render
-
المستودع تم إنشائه في مجلد client بالتالي سيتم رفع ذلك المجلد فقط، لو أردت رفع المجلدين، ستحتاج إلى إنشاء مستودع في المجلد الرئيسي Todo ووضع gitignore. هناك وليس في المجلدات client و server حاليًا قم بحذف المستودع وإنشاء مستودع جديد، ورفع المجلد الرئيسي إليه بعد إنشاء مستودع محلي به أولاً.
-
في الإصدار 5 من express تحتاج إلى تعديل: app.get("*" , (req , res) => إلى: app.get('/{*splat}', (req, res) => حيث يجب أن يتم تسمية الـ wild card أي رمز النجمة *
- 1 جواب
-
- 1
-
-
الأفضل التوجه للتوظيف، تحتاج إلى اكتساب خبرة العمل ضمن فريق بعيدًا عن العمل الحر، وأيضًا تفهم كيف يتم إدارة المشاريع وتقسيم المهام والتواصل بين الفريق، على الأقل سنة في شركة، فالمبدأ هو "لا تستثمر فيما لا تُحسنه" والعمل الحر لن يوفر لك الخبرة الكافية. لذا ، تحتاج إلى الإنتظار قليلاً في الوقت الحالي، لاكتساب خبرة من ناحية ولاستقرار سوق البرمجيات من ناحية أخرى، فهو غير متزن حاليًا. قدم خدماتك كما أنت وتوسعتها من خلال الفريق الذي تعمل معه، بالتالي تستطيع العمل على مشاريع كبيرة، وأنت بالفعل بمثابة شركة من خلال فريقك، وفي نفس الوقت محاولة التقدم لوظائف الشركات للحصول على وظيفة مناسب.