


Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
يمكنك استخدام الدالة numpy.insert ، انظر المثال التالي للتوضيح: a = np.array([[1, 1], [2, 2], [3, 3]]) a >>> array([[1, 1], [2, 2], [3, 3]]) np.insert(a, 1, 5) >>> array([1, 5, 1, ..., 2, 3, 3]) لاحظ ان الدالة تقوم بأخذ ثلاث قيم، اولا المصفوفة التي تريد الاضافة اليها، ثم موقع العنصر الذي تريد اضافته ، في المثال السابق مثلا كان موقع العنصر هو 1 لذا قام باضافته في المكان الثاني لانه يبدأ العد من 0، واخيرا ياخذ قيمة العنصر الذي تريد اضافته وفي المثال السابق كان 5. لاحظ انه يمكنك اضافته في اي مكان سواءكان صفا او عمود، انظر المثال التالي: a = np.array([[1, 1], [2, 2], [3, 3]]) np.insert(a, 1, 5, axis=1) array([[1, 5, 1], [2, 5, 2], [3, 5, 3]]) لاحظ ان وضع axis=1 يقوم باضفة العنصر في مكانه بالاعمدة وليس الصفوف، اما axis=0 وهي القيمه الافتراضيه يقوم باعتبار المصفوفة كانها صف ويقوم بتحديد مكان العنصر المراد اضافته على هذا الاساس
- 4 اجابة
-
- 1
-

-
نعم يمكنك ذلك، انظر المثال التالي، دعنا ننشأ المصفوفة التاليه: array = np.array([7, 5, 3, 2, 6, 1, 4]) بعد ذلك يمكننا ترتيبها تصاعديا كالتالي: # ترتيب تصاعدي sorted_array = np.sort(array) # [1, 2, 3, 4, 5, 6, 7] او ترتيبها تنازليا كالتالي: # ترتيب تنازلي reverse_array = sorted_array[::-1] # [7, 6, 5, 4, 3, 2, 1] وبشكل عام تستخدم np.sort(array)[::-1] لترتيب المصفوفة بشكل تنازلي. طريقة اخرى مختلفه هي ان تقوم بعمل مصفوفة أخرى وتقوم باضافة العناصر المرتبه تصاعدي في المصفوفة الاولى بشكل معكوس في المصفوفة الثانية، لكن تلك الطريقة تسلتزم مجهودا اكثر وكذلك تاخذ مساحة اكبر لكنها تحافظ لنا على المصفوفة القديمة كما هي.
- 4 اجابة
-
- 1
-
-
دعنا نقوم بانشاء مصفوفة بشكل عشوائي كالتالي: import numpy as np x = np.random.randint(0, 10, 30) print(x) output >>> [9 8 3 8 6 0 8 0 9 5 1 2 9 3 4 4 9 4 5 8 6 6 6 6 9 4 8 6 2 0] يمكننا استخدام الدالة bincount( ).argmax( ) والتي تعطينا اكثر رقم تكرر في هذة المصفوفة كالتالي: print(np.bincount(x).argmax()) output >>> 6 هنا قام بارجاع الرقم 6 لانه الاكثر تكرارا في المصفوفة التي انشأناها. كذلك يمكننا استخدام الدالة counter وذلك لاعطاءنا كل رقم في المصفوفة وعدد مرات تكراره على شكل tuple مرتبة تنازليا كالتالي: from collections import Counter b = Counter(x) print (b.most_common()) output >>> [(6, 6), (9, 5), (8, 5), (4, 4), (0, 3), (3, 2), (5, 2), (2, 2), (1, 1)] هنا قامت الدالة بارجاع كل رقم في المصفوفة وبجواره عدد مرات تكراره، فمثلا الرقم 9 تم تكراره 5 مرات وهكذا.
- 4 اجابة
-
- 1
-
-
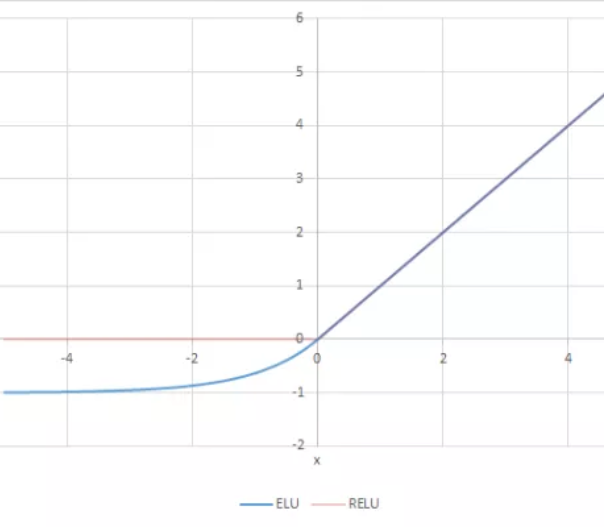
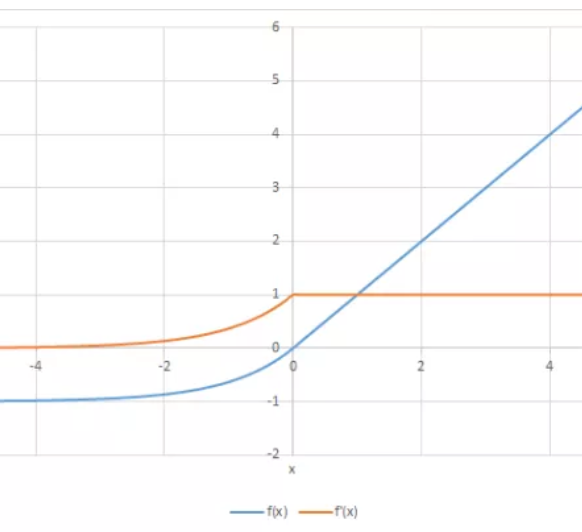
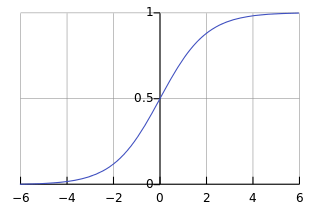
ELU هو اختصار ل Exponential Linear Unit وتعني الوحدة الاسية الخطية، اي انها تدمج كلا من خصائص الدوال الاسية والخطية. يمكنك ملاحظة هذا من خلال تعريفها الرياضي التالي: R(z)={z z>0 α.(e^z–1) z<=0} ويمكن رسمها بالشكل التالي: تستطيع ان تلاحظ من الرسم تصرف الدالة، وهي تأخذ شكلا اسيا في القيم الاقل من الصفر بينما تتحول لتصبح خطية في القيم الاكبر من الصفر. اما مشتقتها فتعرف كالتالي: R′(z)={1 z>0 α.e^z z<0} ويتم رسمها على النحو التالي: مميزاتها: تصبح ELU سلسسه ببطء حتى يكون الخرج مساويًا لـ -α بينما ينعدم RELU بشكل سريع في هذه الحالة. ELU هو بديل قوي لـ ReLU. على عكس ReLU ، يمكن أن ينتج ELU مخرجات سلبية. عيوبها: في القيم الموجبة الاكبر من 0،تاخذ القيم الهخارجة تصاعدا بشكل كبير ويمكن ان تتراوح من 0 الي مالانهاية. اما عن استعمالها في keras فهي توجد في الصورة التالية: tf.keras.layers.ELU(alpha=1.0, **kwargs) ويمكن استخدامها كالتالي: >>> import tensorflow as tf >>> model = tf.keras.Sequential() >>> model.add(tf.keras.layers.Conv2D(32, (3, 3), activation='elu', ... input_shape=(28, 28, 1))) >>> model.add(tf.keras.layers.MaxPooling2D((2, 2))) >>> model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='elu')) >>> model.add(tf.keras.layers.MaxPooling2D((2, 2))) >>> model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='elu'))
-
لو قمت بكتابة dense1 = Dense(10, activation='relu')(input_x) فان dense1 ليست طبقة وانما هي الخرج، اما اذا اردت تعريف طبقة معينة تكتبها هكذا: Dense(10, activation='relu') لذا هذا ما يبدو انك تحاول تحقيقه: dense1 = Dense(10, activation='relu') y = dense1(input_x) ويكون الكود الصحيح كالتالي: import tensorflow as tf from tensorflow.contrib.keras import layers input_x = tf.placeholder(tf.float32, [None, 10], name='input_x') dense1 = layers.Dense(10, activation='relu') y = dense1(input_x) weights = dense1.get_weights()
-
المشكلة تكمن في شكل ترميز البيانات وعدم استخدامك لدالة loss مناسبة لحسابها، وهذا الاختلاف ما بين sparse_categorical_crossentropy و categorical_crossentropy حيث ان categorical_crossentropy تتوقع ان الترميز بين 0 و 1، وهو الشكل الذي قمت بالترميز اليه سابقا. لذلك كل ما عليك هو تعديل loss='sparse_categorical_crossentropy' لتصبح: loss='categorical_crossentropy' ويكون الكود السليم كالتالي: K.set_image_dim_ordering('th') numpy.random.seed(7) from keras.datasets import mnist # تحميل البيانات (X_train, y_train), (X_test, y_test) = mnist.load_data() # تحضير البيانات X_train = X_train.reshape(X_train.shape[0], 1, 28, 28) X_test = X_test.reshape(X_test.shape[0], 1, 28, 28) X_train=X_train.astype('float32')/ 255.0 X_test=X_test.astype('float32')/ 255.0 #label ترميز ال y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) model = Sequential() model.add(Convolution2D(32, 3, 3, input_shape=(1, 28, 28), activation='tanh')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Convolution2D(16, 3, 3, activation='tanh')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(100, activation='tanh')) model.add(Dense(y_test.shape[1], activation='softmax')) # تجميع المعلومات model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['acc']) # بناء النموذج model = larger_model() # تدريبه model.fit(X_train, y_train, epochs=12, batch_size=128,validation_data=(X_test, y_test)) # تقييم النموذج scores = model.evaluate(X_test, y_test) print("Baseline Error: %.2f%%" % (100-scores[1]*100)) # حفظه model_json = model.to_json() with open('mnist_model.json', 'w') as f: f.write(model_json) model.save_weights("mnist_weights.h5") # تحميله with open('mnist_model.json') as f: model_json = f.read() model = model_from_json(model_json) model.load_weights('mnist_weights.h5') # تجميع المعلومات model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['acc']) scores = model.evaluate(X_test, y_test) print("Baseline Error: %.2f%%" % (100-scores[1]*100))
-
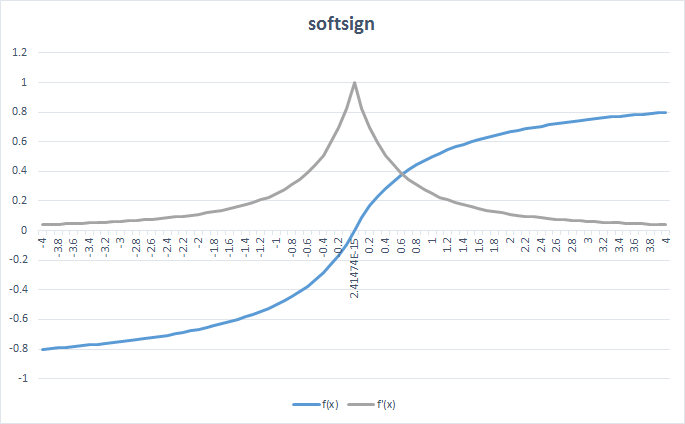
دالة Softsign هي دالة تنشيط تقوم بإعادة تعيين القيم بين -1 و 1 من خلال تطبيق عتبة threshold تمامًا مثل دالة sigmoid. الميزة فيها أن قيمة softsign هي صفر في مركزها ، اي ان نقطة الاصل لديها هي 0 مما يساعد الطبقة العصبية التالية أثناء عملية propagating. وتعبر عنها رياضيا بالصيغة التالية: f(x) = x / (1 + |x|) وتمثل مشتقتها بالصيغة التالية: dy/dx = 1 / (1 + |x|)^2 ويمكن تمثيل الدالة ومشتقتها كما هو موضح في الشكل التالي: ويمكنك اختبارها بالكود كالتالي: import tensorflow as tf input_tensor = tf.constant([-1.5, 9.0, 11.0], dtype = tf.float32) gen_output = tf.keras.activations.softsign(input_tensor) gen_output.numpy() output >>> array([-0.6 , 0.9 , 0.9166667] , dtype=float32) على الرغم من التشابة الملحوظ بينها وبين دالة tanh ، الا ان هناك اختلاف بينهما، الاختلاف الأساسي هو أن وظيفةالدالة tanh تتقارب أسيًا، اي تشبة الدوال الاسية. في حالة الدالة Softsign ، فإنها تتقارب مع دوال كثيرة الحدود. وهذا الخط الرفيع بين الدالتين يخلق فرقًا كبيرًا بين الحالتين وحالات الاستخدام الخاصة بكل منهما بهما. ورغم ذلك فان دالة relu تعد افضل واكثر استخداما من softsign لانها ابسط وتاخذ وقتا اقل في الحسابات منهاوايضا تعد افضل في الحسابات المعقدة التي توجد في طبقات التعلم العميق. ويمكنك استخدامها في keras تماما مثل اي دالة تنشيط اخري كالتالي: from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='softsign')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
-
يحدث هذا الخطأ بسبب وجود نسخه قديمة من dask. الحل ان تقوم بتحديث dask الي نسخه 0.15 او احدث. في نافذه البحث في ويندوز قم بالبحث عن cmd، بعد ذلك اكتب بداخله: conda update dask سيقوم بعمل تحديث له. بعد الانتهاء قم بكتابه السطر التالي: pip show dask يجب ان يظهر لك السطر التالي: Name: dask Version: 0.15.0 Summary: Parallel PyData with Task Scheduling Home-page: http://github.com/dask/dask/ Author: Matthew Rocklin Author-email: mrocklin@gmail.com License: BSD Location: c:\anaconda3\lib\site-packages Requires: قد تختلف الاصدارات قليلا عن 0.15.0 لكن لن تحدث فرقا طالما هي 0.15.0 او احدث
-
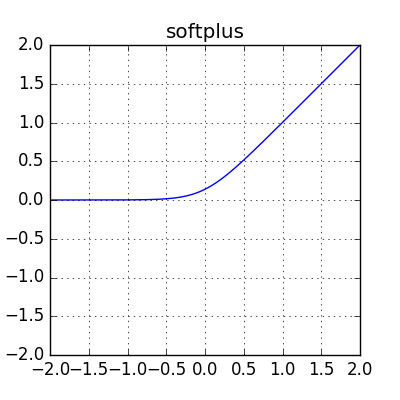
softplus هي دالة تنشيط تتميز بسهولة اجراء عملية التفاضل الخاصة بها، وهي على الصيغة الرياضية التالي: f(x) = ln(1+e^x) وتمثل بيانيا بالشكل التالي: ويتضح منها ان المجال الخاص بها هو 0 الى موجب ما لانهاية ، فهي تجعل القيم الاقل من الصفر = 0 بينما القيم الاكبر من الصفر تتصاعد بشكل مستقيم. وبالنسبة لتفاضلها فهو على الشكل التالي: e^x / (1+e^x) أو 1 / (1 + e^-x) وتاخذ الشكل البياني التالي: ويمكنك ان تلاحظ ان مشتقة تلك الدالة هي نفسها مشتقة الدالة sigmoid ، في النهاية هما نفس الدالة لكن بصيغ مختلفة في البداية، لهذا فهي ليست مستخدمة بشدة نظرا لاستخدام sigmoid والتي تؤدي نفس المهمة، لقراءه المزيد عن sigmoid يمكنك قراءه الاجابات في السؤال التالي: يمكنك استخدامها في keras كالمثال التالي: >>> a = tf.constant([-20, -1.0, 0.0, 1.0, 20], dtype = tf.float32) >>> b = tf.keras.activations.softplus(a) >>> b.numpy() array([2.0611537e-09, 3.1326166e-01, 6.9314718e-01, 1.3132616e+00, 2.0000000e+01], dtype=float32) وفي بناء النماذج، يمكنك استخدامها كالتالي: from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='softplus')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
-
هذه المشكلة تحدث بسبب شكل المصفوفات التي تريد ضربهما، دعنا نفهم كيف تتم ضرب المصفوفات. لضرب مصفوفتين يجب ان يكون عدد الاعمدة في المصفوفة الاولى يساوى عدد صفوف المصفوفة الثانية، حيث ان ترتيب الضرب يهم، كمثال لضرب مصفوفة ذات ابعاد (5,3) * (4,5) تنتج مصفوفة ذات ابعاد (4,3) حيث تمثل اول قيمه عدد الصفوف وهي هنا =4 والقيمة الثانية عدد الاعمدة وهي هنا 3. اما بالنسبة للمشكلة هنا تحديدا فهي بسبب استخدام الشكل * ، وهي تقوم بعملية ضرب المصفوفات فقط في حالة انها علي شكل numpy.matrix وبشكل عام تقوم العلامة * بعمل ضرب القيم سويا او ما يسمي element wise multiplication وهذا يجعل عملية الضرب المطلوبة غير ملاءمة لانة يجب ان تكون كلتا المصفوفتين من نفس الشكل تماما. لكن المطورين ابتعدوا عن هذا الشكل وعوضا عنها استخدموا العلامة . والتي تمثل dot product . فيمكنك هنا اما تحويل المصفوفتين الي Numpy.matrix وضربهما او استخدام x.y للضرب مباشرة. يمكنك كذلك استخدام numpy.dot، والتي تقوم بعملية الضرب المعتادة للمصفوفات، انظر المثال التالي: In [1]: import numpy In [2]: numpy.dot(numpy.ones([97, 2]), numpy.ones([2, 1])).shape Out[2]: (97, 1)
- 3 اجابة
-
- 1
-
-
يمكنك استخدام الدالة numpy.reshape لتشكيل اي مصفوفة بالشكل التي تريد، وهي بالشكل التالي: numpy.reshape(arr, newshape, order='C') انظر المثال التالي للتوضيح. # نقوم بانشاء مصفوفة احادية الابعاد 1 arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) print('1D Numpy array:') print(arr) لتحويلها نكتب الكود التالي،حيث أن (2,5) هي شكل المصفوفة الجديدة بحيث ان 2 هو عدد الصفوف و 5 عدد الاعمدة. import numpy as np arr = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # تحويل المصفوفة للشكل ثنائي الابعاد arr_2d = np.reshape(arr, (2, 5)) print(arr_2d) ويكون شكل الخرج كالتالي: [[0 1 2 3 4] [5 6 7 8 9]]
-
يمكنك حلها بالدالة التالية ببساطة: import numpy as np import scipy.stats def mean_confidence_interval(data, confidence=0.95): a = 1.0 * np.array(data) n = len(a) m, se = np.mean(a), scipy.stats.sem(a) h = se * scipy.stats.t.ppf((1 + confidence) / 2., n-1) return m, m-h, m+h كذلك هناك دالة داخلية يمكنك استعمالها كالتالي: import numpy as np, scipy.stats as st st.t.interval(0.95, len(a)-1, loc=np.mean(a), scale=st.sem(a)) حيث ان 0.95 تمثل نسبة ال Confidence Interval التى تريدها. هنا بعض الامثلة التي قد توضح تبين الفكرة: In [9]: a = range(10,14) In [10]: mean_confidence_interval(a) Out[10]: (11.5, 9.4457397432391215, 13.554260256760879) In [11]: st.t.interval(0.95, len(a)-1, loc=np.mean(a), scale=st.sem(a)) Out[11]: (9.4457397432391215, 13.554260256760879) لاحظ ان قيم ال Confidence Interval في كلتا الطريقتين واحدة
- 2 اجابة
-
- 1
-
-
يمكن ان تكون هذه المشكلة ناتجة من سوء تثبيت ل tensorflow 2 لذلك يجب ان نبدأ بالتاكد من سلامة التثبيت، شغل الاكواد التالية في terminal من windows pip install --upgrade pip pip install tensorflow==2.0.0-alpha0 pip install keras pip install numpy==1.16.2 اذا تم هذا التنزيل بشكل سليم يمكنك ان تشغل الكود : tf.compat.v1.Session() بدلا من tf.Session() وهذا بسبب تحديث tensorflow 2 بدلا من tensorflow 1 وبشكل عام اذا كان لديلك اكواد تعمل علي tensorflow 1 وتريد تشغيلها على tensorflow 2 يمكنك كتابة الكود التالي لجعلها متطابقة معها: import tensorflow.compat.v1 as tf tf.disable_v2_behavior()
- 2 اجابة
-
- 1
-
-
هناك طريقة سهلة وهي فقط باستخدام .numpy() لتحويل tensor الي numpy array كالتالي: import tensorflow as tf a = tf.constant([[1, 2], [3, 4]]) b = tf.add(a, 1) a.numpy() # array([[1, 2], # [3, 4]], dtype=int32) b.numpy() # array([[2, 3], # [4, 5]], dtype=int32) tf.multiply(a, b).numpy() # array([[ 2, 6], # [12, 20]], dtype=int32) اذا لم تعمل هذة الطريقة يمكنك حينها استخدام الدالة التالية: tf.compat.v1.Session المثال التالي يوضح الطريقة: a = tf.constant([[1, 2], [3, 4]]) b = tf.add(a, 1) out = tf.multiply(a, b) out.eval(session=tf.compat.v1.Session()) # array([[ 2, 6], # [12, 20]], dtype=int32)
-
من أجل تشغيل الموديل الخاص بك، يجب ان تقوم بعمل compile وهي الدالة التي تقوم بتجميع وتشغيل كل ما تم بناءه في الخطوات السابقة كلها. وتكون الدالة compile على الشكل التالي: Model.compile( optimizer="rmsprop", loss=None, metrics=None, loss_weights=None, weighted_metrics=None, run_eagerly=None, steps_per_execution=None, **kwargs ) بشكل عام نهتم بأول 3 متغيرات فقط لتعديلها: optimizer: وهو المحسن الذي نريد استخدامه loss: وهي دالة الفقد التي نريد استخدامها metrics: وهي المعيار الذي نريد حساب الكفاءه منه كل ما نريد تعديله في الكود الخاص بك هو تعديل فقط اخر جزء بزيادة الدالة compile لها لتكون كالتالي: model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc']) history = model.fit(partial_x_train, partial_y_train, epochs=6, batch_size=512, validation_data=(x_val, y_val))
-
يستطيع keras الان التقسيم بين الصور الخاصة ب tarining وكذلك testing حتى اذا كانوا في نفس المسار كالتالي: لاحظ ان train_data_dir هو المسار الذي توجد به الصور الخاصة بك train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, validation_split=0.2) # تقسم نسبة ال validation train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_height, img_width), batch_size=batch_size, class_mode='binary', subset='training') # نضع بعض الصور في ال training validation_generator = train_datagen.flow_from_directory( train_data_dir, # نفس المسار الذي توجد به الصور الخاصة ب training target_size=(img_height, img_width), batch_size=batch_size, class_mode='binary', subset='validation') # نضع تلك الصور ك validation model.fit_generator( train_generator, steps_per_epoch = train_generator.samples // batch_size, validation_data = validation_generator, validation_steps = validation_generator.samples // batch_size, epochs = nb_epochs)
-
تعد Batch Normalization مجرد طبقة ، لذا يمكنك استخدامها على النحو لإنشاء بنية الشبكة التي تريدها. حالة الاستخدام العامة هي استخدام Batch Normalization بين الطبقات الخطية وغير الخطية في الموديل الخاص بك ، لأنها تقوم بعمل Normalize للدخل إلى دالة التنشيط ، بحيث تكون متمركزًا في القسم الخطي لدالة التنشيط (مثل Sigmoid). وتقوم بشكل اساسي على تحويل بحيث يصبح متوسط الخرج قريبا من 0 والانحراف قريبا من 1. استخدم Batch Normalization بين الطبقات التلافيفية convolutional layers وغير الخطية ، مثل طبقات ReLU ، لتسريع تدريب الشبكات العصبية التلافيفية وتقليل تاثر الموديل بالقيم الابتدائية له والتي يتم تعيينها بشكل عشوائي. يمكنك استخدامها كطبقة من طبقات التعلم كالتالي: from keras.layers.normalization import BatchNormalization model = Sequential() model.add(Dense(64, input_dim=14, init='uniform')) model.add(BatchNormalization()) model.add(Activation('tanh')) model.add(Dropout(0.5)) model.add(Dense(64, init='uniform')) model.add(BatchNormalization()) model.add(Activation('tanh')) model.add(Dropout(0.5)) model.add(Dense(2, init='uniform')) model.add(BatchNormalization()) model.add(Activation('softmax')) sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='binary_crossentropy', optimizer=sgd) model.fit(X_train, y_train, nb_epoch=20, batch_size=16, show_accuracy=True, validation_split=0.2, verbose = 2)
-
نعم يمكنك استخدام keras على ال GPU حيث انها تدعم كلا من CPU و GPU، لكن هناك بعض اشياء يجب التحقق منها اولا: يجب أن يحتوى جهازك على كارت شاشة GPU ( يجب ان يكون من نوع nvidia وليس amd حيث انه يدعم nvidia فقط) يجب أن تقوم بتحميل ال driver الخاص بكارت الشاشة الخاص بك من tensorflow يجب ان تقوم بتحميل cuda ، يمكنك تحميله من هنا يجب أن تتاكد ان tensorflow يعمل على ال gpu الخاص بك عنك طريق تشغيل الكود الاتي: sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) هذا سيجعل tensorflow يبدأ العمل على الجهاز. يمكنك كذلك تشغيل الكود التالي لتفعيله والتأكد: from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) والخرج يجب أن يكون كالتالي: [ name: "/cpu:0"device_type: "CPU", name: "/gpu:0"device_type: "GPU" ] اذا ظهر كذلك فان كل شئ يعمل بشكل جيد. يمكنك بعد ذلك تفعيل keras بالكود التالي: from keras import backend as K K.tensorflow_backend._get_available_gpus() الان يمكنك استعمال keras للتدريب على ال gpu بدل ال cpu.
- 1 جواب
-
- 1
-
-
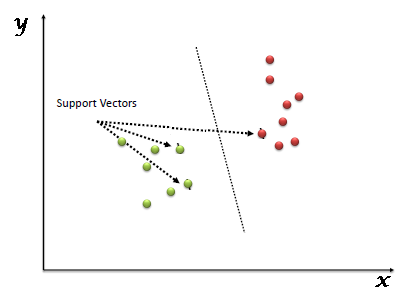
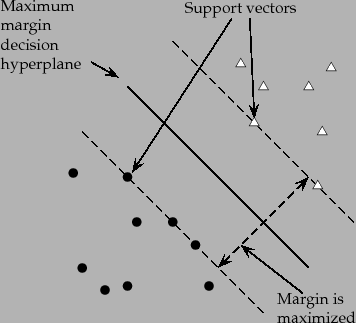
SVM هي خوارزمية تعلم تستخدم بشدة في تعلم الالة وتستعمل في بشكل اساسي في عمليات التصنيف التصنيف. SVM مبنية على فكرة إيجاد مستوي hyperplane والذي يقوم بتقسيم البيانات الى عدة اجزاء منفصلة بحيث يمثل كل جزء منهم class او تصنيف معين من البيانات.وتعتبر أقرب نقطتين للمستوي الفائق الذي تقوم برسمه ال SVM هي المتجهات الداعمة او support vector كما هو موضح في الصورة التالية: المتجهات الداعمة أو support vector المتجهات الداعمة هي النقاط الأقرب للمستوي الفائق hyperplane وهي النقاط التي اذا قمنا بإزالتها من البيانات ستغير من موقع المستوي الفائق والذي سيغير من شكل البيانات المفصولة. لذلك يمكن اعتبار هذه النقاط أنها العناصر الاهم في البيانات. تحديد المستوي الفائق الانسب: نقوم بتحديد المستوى الفائق الانسب عن طريق اختيار اكثر مستوى نستطيع ان نقسم به البيانات بشكل سليم. ويكون ذلك عن طريق اختيار مستوى يجعل المسافة بينه وبين أقرب نقطة في كل مجوعة من البيانات اكبر ما يمكن. تسمي المسافة بين المستوي الفائق و أقرب نقطة من كل مجموعات البيانات بالهامش (margin). والهدف من هذا هو زيادة احتمالية التصنيف الصحيح للبيانات الجديدة. أنظر الي الشكل التالي للتوضيح. إيجابيات و سلبيات آلة المتجهات الداعمة الإيجابيات الدقة والنتائج المرتفعة تعمل جيداً على مجموعات البيانات الصغيرة. تظل فعالة في الحالات التي يكون فيها عدد الأبعاد أكبر من عدد العينات. السلبيات لا تصلح لمجموعات البيانات الكبيرة حيث أن المدة اللازمة لتدريبها عالية تعتبر أقل فعّالية مع البيانات الأكثر غير المفصولة جيدا والتي يكون فيها تداخلا بين ال classes. تستعمل SVM في مهام تصنيف النصوص مثل تصنيف المواضيع وتمييز الرسائل المزعجة وتحليل المشاعر تستعمل في التعرف على الصور. تستعمل في مجالات تمييز الأرقام المكتوبة يدوياً.
- 1 جواب
-
- 1
-
-
الشبكة العصبية المتكررة (RNN) هي نوع من الشبكات العصبية حيث يتم تغذية الإخراج من الخطوة السابقة كمدخل إلى الخطوة الحالية. في الشبكات العصبية التقليدية ، تكون جميع المدخلات والمخرجات مستقلة عن بعضها البعض ، ولكن في حالات مثل عندما يكون مطلوبًا للتنبؤ بالكلمة التالية من الجملة ، تكون الكلمات السابقة مطلوبة وبالتالي هناك حاجة لتذكر الكلمات السابقة. وهكذا ظهرت RNN إلى حيز الوجود ، والتي حلت هذه المشكلة بمساعدة الطبقة المخفية. الميزة الرئيسية والأكثر أهمية لـ RNN هي Hidden state ، والتي تتذكر بعض المعلومات حول تسلسل البيانات. تمتلك RNN "ذاكرة" تتذكر جميع المعلومات حول ما تم حسابه. يستخدم نفس الاوزان لكل إدخال لأنه يؤدي نفس المهمة على جميع المدخلات أو الطبقات المخفية لإنتاج المخرجات. هذا يقلل من تعقيد الاوزان وحجمها ، على عكس الشبكات العصبية الأخرى. تدريب RNN يتم توفير خطوة زمنية واحدة للإدخال للشبكة. ثم احسب حالتها الحالية باستخدام مجموعة من المدخلات الحالية والحالة السابقة. يتم ادخال الحالة الجديدة كمدخل للحالة التالية. بمجرد اكتمال جميع الخطوات الزمنية ، يتم استخدام الحالة الحالية النهائية لحساب الإخراج. ثم تتم مقارنة المخرجات بالمخرجات الفعلية ، أي الناتج المستهدف ويتم حساب الخطأ. ثم يتم إعادة نشر الخطأ إلى الشبكة لتحديث الأوزان وبالتالي يتم تدريب الشبكة (RNN). مزايا الشبكة العصبية المتكررة RNN تتذكر RNN كل المعلومات طول فترة التدريب وهذا مفيد في توقع السلاسل الزمنية فقط بسبب ميزة تذكر المدخلات السابقة أيضًا. وهذا ما يسمى بالذاكرة طويلة المدى. لذلك تستخدم في تحليل اللغات الطبيعية. عيوب الشبكة العصبية المتكررة RNN تدريب RNN صعبة للغاية وتاخذ وقتا طويلا. لا يمكن معالجة التسلسلات الطويلة جدًا إذا كنت تستخدم tanh أو relu كدالة تنشيط.
-
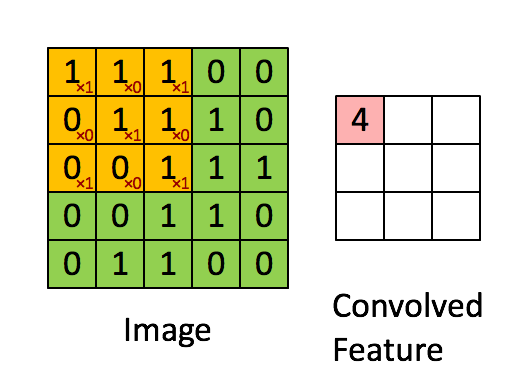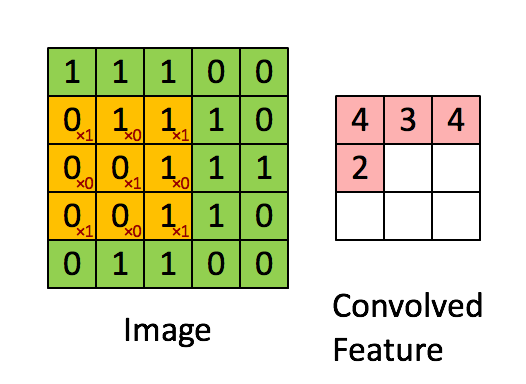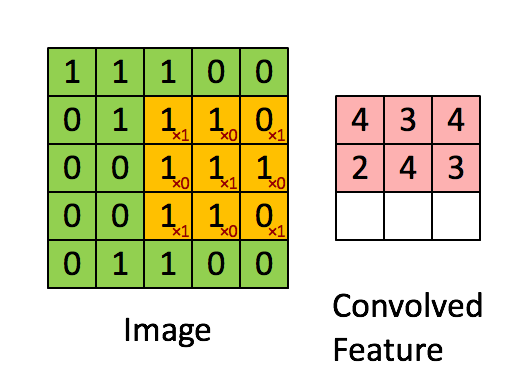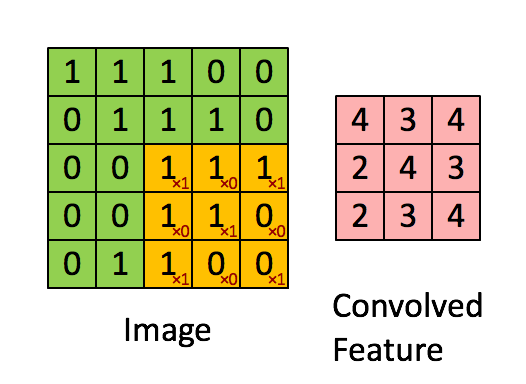
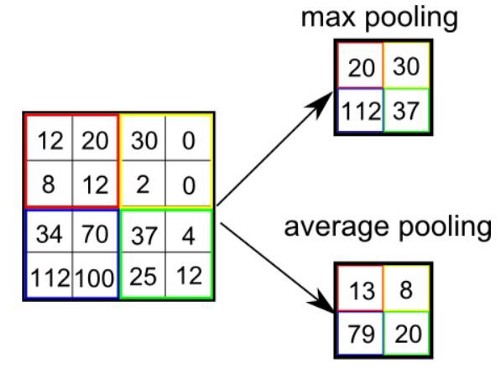
الشبكة العصبونية التلافيفية CNN هي طريقة من طرق التعلم العميق والتي تستخدم بشكل اساسي في تصنيف الصور وتستخدم احيانا في الاشارات signals. تقوم ال cnn على عدد من العمليات المتتابعة وهي كالتالي: عملية استخلاص الخصائص عبر عملية الالتفاف convolution: حيث نقوم بعمل filter يقوم بمسح الصورة خطوة بخطوة واستخلاص العناصر المميزة فيها ، يمكن تكرار تلك الخطوة اكثر من مره وفي كل مره نغير من حجم ال filter، انظر الgif التالي للتوضيح: الخطوة الثانية هي طبقة ال pooling : والتي نقوم فيها باختيار عناصر محددة من المصفوفات التي قمنا باستخراجها من الخطوة السابقة، وذلك من أجل السرعة والحجم وكذلك الدقة. وهنا نقوم باختيار اما اكبر العناصر في حجم مصفوفة معين max_pooling او ناخذ المتوسط average_pooling. انظر الصورة التالي للتوضيح: الطبقة الاخيرة وهي طبقة التواصل الكلي dense layer والتي نقوم فيها بجمعكل الخصائص التي قمن باستخلاصها من المراحل السابقة للقيام بعملية الاختيار classification، انظر الصورة التالية:
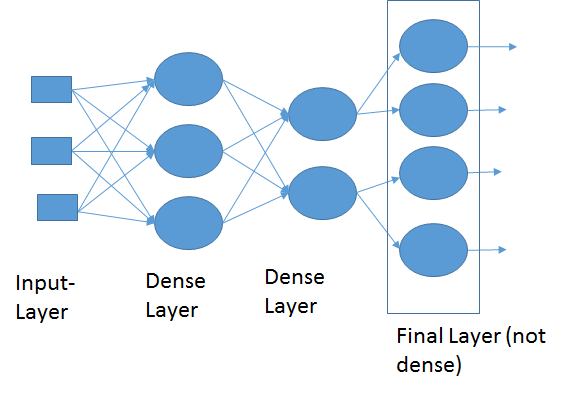
- 1 جواب
-
- 1
-
-
التعلم العميق هو فقط مصطلح منتشر في المجتمع العلمي والتطبيقي ليدل على مستويات اعمق من التعلم عكس تعلم الالة العادي. وتعتبر الميزة الاساسية فية هو امكانية استخلاصة للعناصر المميزة للبيانات feature extraction بشكل تلقائي دون الحاجة الي استخدام طرق أخرى لذلك كما نفعل في تعلم الألة التطبيقي. كذلك فهو يتميز بالطبقات المتعددة للتعلم، فعلى عكس التعلم التقليدي الذي يقوم على طبقة واحدة فقط، التعلم الميق يمر بعدة مراحل منها : تحديد شكل البيانات عملية التعلم على مراحل كل مرحلة تقوم باستخلاص ميزة معينة عملية التعلم العادي والتي تدمج كل الخصائص سويا ثم عملية تحديد نوع الخرج ويشمل مصطلح التعلم العميق كثر من المجالات منها ما يتعلق بالصور مثل CNN ومنها ما يتعلق بالصوت وتحليل اللغات الطبيعية مثل LSTM وصولا لتقنيات التزييف العميق deep fake.
- 1 جواب
-
- 1
-
-
دورات حسوب تكون مسجلة ولذلك لتمكنك من الوصول للفيديوهات في اي وقت تريد دون تقييد. لكن ذلك لا يعني عدم التواصل، فرغم انها مسجلة، الا ان هناك مجتمع من المتعلمين حاضرين دائما من أجل المساعدة سواء كان لديك سؤال او اردت مشاركة شئ او المساعدة في جواب شئ ما وهناك ايضا متابعة مستمرة من فريق عمل الدورة. يمكنك الوصول الي المعلومات عن الدورات بالضغط عليها من هنا
-
MeanAbsolutePercentageError هي دالة تكلفة تستخدم لحساب نسبة الخطأ كنسبة مئوية بين القيم الحقيقية y_true والقيم المتوقعة y_pred من النموذج واعطاءه كنسبة مئوية ويتم حسابها كالتالي: loss = ((y_true - y_pred) / y_true)* 100 وفي keras توجد الدالة على الصورة الاتيه: tf.keras.losses.MeanAbsolutePercentageError( reduction=losses_utils.ReductionV2.AUTO, name='mean_absolute_percentage_error' ) حيث توجد ضمن دوال التكلفة tf.keras.losses، ويمكنك استخدامها كالتالي: >>> y_true = [[0., 1.], [0., 0.]] >>> y_pred = [[1., 1.], [1., 0.]] >>> # Using 'auto'/'sum_over_batch_size' reduction type. >>> mse = tf.keras.losses.MeanSquaredError() >>> mse(y_true, y_pred).numpy() 0.5 0.5 تعني هنا ان نص ما توقعنا به جاء مطابقا للقيم الحقيقية. ويمكنك استخدامها اثناء تدريب النموذج باضافتها في اخر سطر للتدريب كالتالي: model.compile(optimizer='adam', loss="MeanAbsolutePercentageError", metrics=['mae']
-
يمكنك رسم خريطه حرارية او ما عرف باسم heatmap بكثير ممن الطرق، دعنا نرى بعض اشهر تلك الطرق: يمكنك استخدام الكود التالي: import matplotlib.pyplot as plt import numpy as np # generate 2 2d grids for the x & y bounds y, x = np.meshgrid(np.linspace(-3, 3, 100), np.linspace(-3, 3, 100)) z = (1 - x / 2. + x ** 5 + y ** 3) * np.exp(-x ** 2 - y ** 2) # x and y are bounds, so z should be the value *inside* those bounds. # Therefore, remove the last value from the z array. z = z[:-1, :-1] z_min, z_max = -np.abs(z).max(), np.abs(z).max() fig, ax = plt.subplots() c = ax.pcolormesh(x, y, z, cmap='RdBu', vmin=z_min, vmax=z_max) ax.set_title('pcolormesh') # set the limits of the plot to the limits of the data ax.axis([x.min(), x.max(), y.min(), y.max()]) fig.colorbar(c, ax=ax) plt.show() سيكون الخرج الخاص به كالتالي: وهي خريطه حرارية تمثل النقط الاغمق فيها اماكن النقاط الاكثر تكرارا: هناك طريقة أخرى متقدمه تستخدم في اعطاء معلومات اكثر تحديدا ووضوحا، عن طريق اعطاء النسب كارقام وكذلك الوان وليست الوان فقط وبالتالي هي اكثر تحديدا ووضوحا، انظر الكود التالي: import numpy as np import matplotlib import matplotlib.pyplot as plt vegetables = ["cucumber", "tomato", "lettuce", "asparagus", "potato", "wheat", "barley"] farmers = ["Farmer Joe", "Upland Bros.", "Smith Gardening", "Agrifun", "Organiculture", "BioGoods Ltd.", "Cornylee Corp."] harvest = np.array([[0.8, 2.4, 2.5, 3.9, 0.0, 4.0, 0.0], [2.4, 0.0, 4.0, 1.0, 2.7, 0.0, 0.0], [1.1, 2.4, 0.8, 4.3, 1.9, 4.4, 0.0], [0.6, 0.0, 0.3, 0.0, 3.1, 0.0, 0.0], [0.7, 1.7, 0.6, 2.6, 2.2, 6.2, 0.0], [1.3, 1.2, 0.0, 0.0, 0.0, 3.2, 5.1], [0.1, 2.0, 0.0, 1.4, 0.0, 1.9, 6.3]]) fig, ax = plt.subplots() im = ax.imshow(harvest) # We want to show all ticks... ax.set_xticks(np.arange(len(farmers))) ax.set_yticks(np.arange(len(vegetables))) # ... and label them with the respective list entries ax.set_xticklabels(farmers) ax.set_yticklabels(vegetables) # Rotate the tick labels and set their alignment. plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor") # Loop over data dimensions and create text annotations. for i in range(len(vegetables)): for j in range(len(farmers)): text = ax.text(j, i, harvest[i, j], ha="center", va="center", color="w") ax.set_title("Harvest of local farmers (in tons/year)") fig.tight_layout() plt.show() وتكون الخرج كالتالي: وبالطبع تستطيع تغيير الالوان والعناوين سواء الافقية او الرأسية، وتمثل الارقام الظاهرة داخل كل مربع عدد المرات التي ظهرت فيها القيم المشتركه بين العمود والصف المتقاطعين في ذلك المربع.
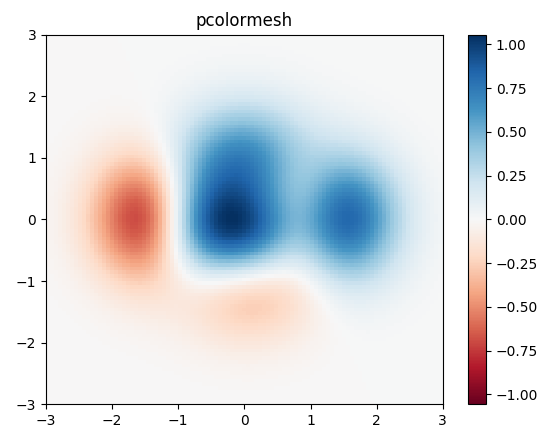
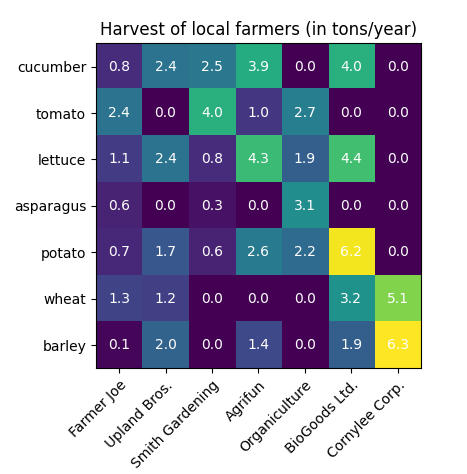
- 2 اجابة
-
- 1
-