


Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
يمكننا أن نقوم بازالتها بسهولة باستخدام بعض العمليات المنطاقة. تستخدم الدالة isnan لتقوم بفحص كل عنصر في المصفوفة اذا كان قيمته nan ام لا، وتقوم بارجاع قيمه True او False كناتج بحث لكل عنصر حيث تعني True ان قيمه العنصر nan. لذا اذا كنا نريد ازالة العناصر التي قيمتها nan ، يجب أن نقوم بعكس المنطق المستخدم هنا، اي نقوم بعكس كل True الي False حتى نستطيع ازالته، ومن هنا سنستخدم دالة العكس not. لذا يكون الكود المستخدم كالتالي: new_array = new_array[numpy.logical_not(numpy.isnan(new_array))] واذا قمنا بتشغيلة على المصفوفة الخاصة بك تكون النتيجة كالتالي: array([1400., 1500., 1600., 1700.]) يمكنك كذلك انشاء مصفوفة اخري ونقل اليها كل القيم التي لا تساوي nan، لكن هذة الطريقة لن تعدل على المصفوفة الاصلية وانما تخلق مصفوفة جديدة وتحتاج مساحة أكبر لذلك.
-
في البداية دعنا نتذكر دالة التنشيط tanh أو sigmoid والتي تقوم باخراج أحتمال الخرج فقط اذا كان ثنائي (0 او 1) تقوم softmax بتوسيع تلك الفكرة لانها تستطيع اخراج أكثر من صنف multi class وذلك عندما يكون الخرج الخاص بنا متعدد (قطة أو كلب أو أسد ...الخ) أي أن Softmax تقوم بتعيين احتمالات عشرية لكل فئة في تصنيف ال Multi class . يجب ان يكون مجموع تلك الاحتمالات = 1.0. يساعد هذا في التدريب حيث يجعله يتعلم بسرعة أكبر مما لو كان الأمر خلاف ذلك. الشكل التالي يوضح هذة الفكرة: حيث تمثل تلك المعادلة ال softmax بحيث يقوم بادخال كل قيمه ووضعها في دالة اسية e ثم حساب قيمتها مقسومه على مجموع كل القيم مرفوع للدالة الاسية e. وتتميز تلك الدوال بقدرتها على تصنيف متعدد من الفئات عكس معظم الدوال التنشيطية الاخرى، لكن على صعيد أخر فانها أبطا نسبية من منافسيها نظرا لاحتياجها لحساب عمليات اسيه تاخذ وقتا. اما عن استخدامها في keras فهي سهلة كالتالي: tf.keras.layers.Softmax(axis=-1, **kwargs) كمثال: >>> inp = np.asarray([1., 2., 1.]) >>> layer = tf.keras.layers.Softmax() >>> layer(inp).numpy() array([0.21194157, 0.5761169 , 0.21194157], dtype=float32) >>> mask = np.asarray([True, False, True], dtype=bool) >>> layer(inp, mask).numpy() array([0.5, 0. , 0.5], dtype=float32) وفي الموديل، عادة ما تستخدم في أخر طبقة فقط من التعلم كالتالي: model.add(layers.Dense(46, activation='softmax')) # الطبقة الاخيرة من التعلم model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
-
فعليا، لا فرق بينهما اطلاقا، ف numpy.array هو فقط مجرد دالة مريحة في استخدامها لانشاء ndarray، لكنها ليست فئة مختلفة بذاتها او class مختلف. يمكنك كذلك انشاء مصفوفة عن طريق استخدام numpy.ndarray، لكنها ليست طريقة محببة باي حال يمكنكن ملاحظة الفرق من الكود التالي: from numpy import array M = array([ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]) # أظهار المصفوفة print(M) # ما هو نوع المصفوفة المنشأه؟ print(type(M)) # طباعة شكل الموديول print(type(M).__module__) وعند تشغيل الكود يظهر التالي: [[1 2 3] [4 5 6] [7 8 9]] <class 'numpy.ndarray'> numpy لذا اذا لاحظت، لا يوجد فرق فعلي، فقط اختلاف تسميات.
-
هناك طريقتين شهيرتين في numpy تستخدمان لملئ مصفوفة بنفس الرقم وهما: np.empty : وتستخدم في ملئ مصفوفة بنفس القيمة كالتالي: a = np.empty(100) a.fill(9) np.full: وتستخدم في الاصدارات الحديثة من numpy كالتالي: np.full(100, 9) ثم لاعادة تشكيل المصفوفة بالابعاد التي تريد يمكنك استخدم np.reshape كالتالي: a.reshape(5,5) وستقوم بتحويلها لمصفوفة ذات ابعاد 5*5
-
الدالة BinaryAccuracy هي احدى الطرق التى يمكن حساب دقة النموذج Accuracy. وتعتمد على قياس نسبة المرات الصحيحة التي استطاع النموذج ان يتنبأها بدلالة العلامات labels الصحيحة للداتا. على سبيل المثال، لو أن العلامات الصحيحة هي [1, 1, 0, 0]، وما تنبأ به النموذج هو [0.98, 1, 0, 0.6]، لذلك فإن نسبة التوقع هي 75%، ولو أن الاوزان كانت [1, 0, 0, 1]، حينها فإن binary accuracy ستكون 50% هذا المقياس يقوم بتكوين متغيرين وهما total و count، تستخدم total في ايجاد عدد العلامات labels في الداتا كلها ، اماcount تستخدم لحساب عدد المرات التي تكون القيم المتوقعة فيها هي القيم الصحيحة، ويتم ارجاع المعدل عن طريق قسمة count على total في شكل معيار احادي binary accuracy. اما عن استخدامها في keras فهي كالتالي: tf.keras.metrics.BinaryAccuracy( name="binary_accuracy", dtype=None, threshold=0.5 ) حيث: name: هو اسم المعيار وهو اختياري dtype: وهو نوع البيانات في الخرج وهو ايضا اختياري. threshold: هو القيمة التي تفصل بين حساب اذا كان التوقع صحيح أم خطأ، وتمون قيمته من 0 ل 1، هذه القيمة يتم حسابها بطرقة تطبيقة عن طريق تجربة عدة ارقام واختيار الافضل. وفي استخدامها لتدريب النموذج، تستخدم ف اخر طبقة كالتالي: model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['BinaryAccuracy'])
- 2 اجابة
-
- 1
-

-
نقوم باستخدام هياكل البيانات في كثير من الاشياء في تطوير المواقع منها: التعامل مع قواعد البيانات والتى هي شئ ضرورى في برمجة المواقع، تحتاج فيها الي دراسة متعمقة في هياكل البيانات حتى تحدد وتصمم شكل قاعدة البيانات التي تكون الانسب لشكل البيانات الخاصة بجد، والتى تجعلها سهلة في التخزين والاسترجاع والسرعة. كذلك نحتاجها في تصميم خوارزميات الموقع، مثل الشكل الذي نخزن به بيانات العملاء لنجعل عملية البحث اسرع ما يمكن أو اذا كنت تستخدم خرائط فيجب عليك معرفة نظريات الاشكال الهندسية graph theroy للتعامل معها.
-
بشكل عام، لا تقبل النماذج التدريب على قيم سالبة، لان الترميز يجب أن يبدأ من 0 وحتي ما لا نهاية، وذلك لان له أساس في الرياضيات، حيث يتم تحويل كل تلك القيم في النهاية الي متجهات بحيث ترتبط كل قيمة بترميز معين، وبما انه لا يوجد معني لمتجهات سالبة القيمة، اذا لا يمكن أن تتضمن الترميزات قيما سالبة. أما في طبقة ال dense حيث يتم تحويل كل المصفوفات الناتجة الى متجاهات احادية البعد 1-D فتكون قيم الترميزات بين 0 و 1 فقط. يمكنك تخيلها مثل قاموس بحيث تنتمي كل قيمة فيه الي فئة محددة. ولان الترميز عندك قد ظهر فيه قيم سالبة، فهذا يعني أن استخدامك للتضمين غير صحيح، ولتجنب هذة المشكلة عليك استخدام one-hot encoder لجعل كل القيم أرقاما صحيحية. كذلك يمكنك تعديل شكل البيانات المخدلة عن طريق np.reshape وهذا لتجعلها موحدة في كل خطوات التدريب، قد يلغي هذا تلك المشكلة ايضا.
-
نعم أنت بالفعل كذلك، فقط قم بالبدء في مشاريع كبيرة وكاملة حتى تطبق ما تعلمته بشكل فعلي، يمكنك التجربة على مشاريع عبر الانترنت ثم الدخول الى مستقل وتطبيق ما تعلمته في مشاريع حقيقة ومربحة.
- 3 اجابة
-
- 1
-
-
ظهر هذا الخطأ لانه evaluate تقوم بحساب الخطأ loss و ال metrics، بينما انت في النموذج الذي قمت بتحميله، لم تقم بتعريف ال loss أو metrics لهذا يحدث هذا الخطأ. على صعيد أخر فان predict يقوم بتمريم البيانات التي تريد أن تظهر نواتجها الى داخل النموذج المدرب ومن ثم تخرج على الناتج دون أي عمليات اضافية. لذا لا تظهر فيه أي مشكلة. وفيه اثناء عملية التدريب ، تحتاج كذلك الى تعريف ال loss ، ولذلك يجب ان تقوم بعمل compile للنموذج، حتى وان كان هذا سيغير قيم الاوزان. و تعتمد مخرجات النموذج على تعريفه بالأوزان، و هذا يتم بشكل تلقائي ويمكنك التنبؤ به من أي نموذج ،حتى بدون أي تدريب. وذلك لان كل نموذج في Keras لديه بالفعل بأوزان (إما تمت تهيئتها بواسطتك أو تمت تهيئتها عشوائيًا). عندما تقوم بإدخال بيانات شيء ما ، يقوم النموذج بحساب الناتج. وهذا هو كل ما يهم. النموذج الجيد تكون له أوزان مناسبة ويخرج النواتج بشكل صحيح. ولكن قبل الوصول إلى هذه الغاية ، يجب تدريب نموذجك. يمكن تدريب النموذج وحفظ الاوزان لاعادة استخدامها كالتالي: اولا قم بناء النموذج: def create_model(): model = tf.keras.Sequential([ tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[IMG_SIZE,IMG_SIZE, 3]), tf.keras.layers.Conv2D(kernel_size=3, filters=64, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(pool_size=2), tf.keras.layers.Conv2D(kernel_size=3, filters=128, padding='same', activation='relu'), tf.keras.layers.Conv2D(kernel_size=1, filters=256, padding='same', activation='relu'), tf.keras.layers.GlobalAveragePooling2D(), tf.keras.layers.Dense(10,'softmax')]) model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]) return model ثم قم بحفظ الاوزان بعد كل دورة: model=create_model() model_checkpoint=tf.keras.callbacks.ModelCheckpoint('CIFAR10{epoch:02d}.h5',period=3,save_weights_only=True) history = model.fit(x_train[:2000], y_train[:2000], batch_size=BATCH_SIZE, epochs=6, callbacks=[model_checkpoint], validation_data=(x_val[:100], y_val[:100]), shuffle=True) قم بتحميل الموديل الذذي قمت بحفظه ثم اختبره مجددا: new_model=create_model() new_model.evaluate(x_val,y_val) new_model.load_weights('CIFAR1006.h5') new_model.evaluate(x_val,y_val) هذا سوف يعطيك ناتج التوقع على البيانات المدخلة بشكل صحيح.
-
الدالة concatenate تستخدم لدمج أكثر من مصفوفة سوية، وتستخدم على الشكل التالي: numpy.concatenate((a1, a2, ...), axis=0) حيث أن axis هو الاتجاة الذي نريد الدمج عليه، فاذا كان = 0 فهذا معناه اننا نريد دمج الصفوف سويا أما ان كان axis =1 فاننا نريد دمج الاعمدة سويا. المشكلة أنه يحاول ربط المصفوفات بالفهرس الخاص بكل عنصر index وليس بقيمه العناصر، وسبب ذلك الاساسي هو شكل استخدامك للدالة حيث قمت بتمرير المصفوفات كالتالي: np.concatenate(a, b) وفي numpy ، يكون الاساس هو الترميز بالفهرسه index لكل عنصر ، الا اذا لم توضع الاقواس [ ]قبل المصفوفة،أو باضافة اقواس ( ) اضافية: لذلك فان التعديل الذي يجب صنعه كالتالي: >>> import numpy as np >>> a = np.array([1, 2, 3]) >>> b = np.array([4, 5]) >>> np.concatenate([a, b]) #النعديل >>> np.concatenate((a, b)) #خيار اخر للتعديل
-
تقوم الدالة flatten دائما بعمل نسخة من المصفوفة المراد تعديلها، وذلك للحفاظ على المصفوفة الاصلية، لكن ذلك يحتاج الى مساحة أكبر لتخزين كلا المصفوفتين.كذلك فانها كائن ndarray وبالتالي لا يمكن استدعاؤها إلا لمصفوفات عددية حقيقية أي تنتمي فقط ل Numpy. اما الدالة ravel فتقوم بارجاع المصفوفة الاصلية متى كان ذلك قابلا للعرض، اما اذا لم تكن قابلة للعرض فانها قد تقوم بتعديل المصفوفة باكملها. لذلك عادة ما تكون أسرع من flatten لانها لا تحتاج الى عمل نسخ للمصفوفة.هي وظيفة على مستوى المكتبة وبالتالي يمكن استدعاؤها على أي كائن يمكنلا يشترط أن تكون من نوعيه ndarray. مثال على الفرق في استخدام الدالتين: import numpy as np # Create a numpy array a = np.array([(1,2,3,4),(3,1,4,2)]) # Let's print the array a print ("Original array:\n ") print(a) print ("Dimension of array-> " , (a.ndim)) print("\nOutput for RAVEL \n") # Convert nd array to 1D array b = a.ravel() print(b) b[0]=1000 print(b) print(a) print ("Dimension of array->" ,(b.ndim)) print("\nOutput for FLATTEN \n") # Convert nd array to 1D array c = a.flatten() # Flatten تقوم باعطاء نسخه من c print(c) c[0]=0 print(c) # a لن ينتج عنه تعديل في c هنا التعديل في print(a) print ("Dimension of array-> " , (c.ndim)) ويكون الخرج كالتالي: Original array: [[1 2 3 4] [3 1 4 2]] Dimension of array-> 2 Output for RAVEL [1 2 3 4 3 1 4 2] [1000 2 3 4 3 1 4 2] [[1000 2 3 4] [ 3 1 4 2]] Dimension of array-> 1 Output for FLATTEN [1000 2 3 4 3 1 4 2] [0 2 3 4 3 1 4 2] [[1000 2 3 4] [ 3 1 4 2]] Dimension of array-> 1 يمكنك أن تلاحظ الفرق بين أشكال المصفوفات الخارجه من كلتا الطريقتين وكذلك أن flatten تاخذ نسخه من الدالة الاصلية فقط.
-
هناك الكثير من المكتبات التي تسمح بتحويل الصور الي بيكسل وكذلك تحويل البيكسل الي صور، وتسمح كذلك باستقبالها سواء الوان RGB او ابيض واسود grey. أشهر المكتبات للتعامل مع الصور: opencv نستطيع باستخدامها ان نقوم اما بقراءه الصور كالتالي: # Python code to read image import cv2 img = cv2.imread("example.png", cv2.IMREAD_COLOR) cv2.imshow("Cute Kitens", img) cv2.waitKey(0) cv2.destroyAllWindows() ويمكن تبديل cv2.IMREAD_COLOR ب 0 في حالة أردنا قرائتها بالابيض والاسود. أما عن حفظ الصور فيمكن استخدامها كالتالي: # importing cv2 import cv2 # path path = r'example.png' # Using cv2.imread() method # Using 0 to read image in grayscale mode img = cv2.imread(path, 0) # Displaying the image cv2.imshow('image', img) مكتبة PIL يمكن استخدامها من أجل قراءة وكتابة الصور كالتالي: from PIL import Image import PIL # creating a image object (main image) im1 = Image.open(r"C:\Users\System-Pc\Desktop\flower1.jpg") # save a image using extension im1 = im1.save("example.jpg")
-
خوارزميّة التحسين آدم adam optimization هي امتداد لخوارزميّة انحدار المُشتقّ العشوائيّ (SGD=Stochastic Gradien Descent)، وتستخدم مؤخراً على نطاق واسع في تطبيقات التعلّم العميق وخاصّةً الرؤية الحاسوبيِّة ومهام معالجة اللّغة الطبيعيّة. وهي خوارزميّة تحسين من الدّرجة الأولى يمكن أن تحلَّ محل عمليّة انحدار المشتق العشوائي التقليدية SGD “حيث تقوم عملية انحدار المشتق العشوائيّ بالإنطلاق من نقطة عشوائيّة وتعمل على الانتقال بخطوات ثابتة للوصول إلى لحظة التّدرُّب ولكنّ ذلك يتطلّب عدداً كبيراً من التكرارات بسبب العشوائيّة”، ويمكنها تحديث أوزان الشبكة العصبونية بشكل متكرّر بناءاً على بيانات التدريب. مزايا خوارزميّة التحسين آدم ذاكرة أقل. حسابات فعّالة. ثبات التدرّج من خلال عملية تصحيح mt و vt لجعل القيم متقاربة “تم ذِكر عمليّة التصحيح في تهيئة الخوارزميّة”. مناسبة لحل مشاكل التحسين مع البيانات والمُعاملات واسعة النطاق. مناسبة للأهداف الثابتة (أي بيانات التعلّم ثابتة ولا يتم تحديثها ضمن عمليّة التعلّم، مثلاً: عمليّة تصنيف الصور). ختلف خوارزميّة آدم عن انحدار المُشتقّ العشوائيّ SGD، حيث يُحافِظ الأخير على مُعامل تعلّم واحد (ألفا α) لتحديث جميع الأوزان، ولا يتغيّر معدّل التعلّم أثناء عمليّة التدريب. وفي الجّهة المقابلة تقوم آدم بحساب معدّلات التعلّم التكيّفيّة المستقلّة للمعاملات المختلفة عن طريق حساب تقديرات اللحظة الأولى والثانية للتدرج “حسابات خاصّة لهذه الخوارزميّة”. أما عن استخدامها في keras فهو سهل وتوجد على هيئة دالة ويمكن ظبطها كالتالي: keras.optimizers.Adam( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=False, name="Adam", **kwargs ) في معظم الاحيان، لا تهتم فقط الا ب learning_rate وهو معدل التعلم، يمكنك محاولة تعديلها بالتجربة حتى تعطيك افضل ناتج واحسن سرعة بالنسبة للنموذج الخاص بك. وفي استخدامها للتعلم، يمكن ظبطها في أخر خطوة كالتالي: model.compile(optimizer=keras.optimizers.Adam( learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-07, amsgrad=True, name="Adam", ) , loss='binary_crossentropy', metrics=['acc'])
-
تفيدك في الكثير من الاشياء. منها مثلا اختيار الشكل الانسب لتخزين البيانات لسهولة استرجاعها وتوفير المساحة.
-
بالتأكيد تحتاج الى تعلم هياكل البيانات أو data structure، والاصح في الترتيب هو أن تتعلم data structure اولا ثم تتعلم الخارزميات لانها ستسهلها عليك. كذلك فان تصميم الخوارزميات يتطلب معرفة مسبقة ب data structure وذلك لانك بالتاكيد تحتاجها في التصميم، كمثال اذا اردت تصميم خوارزمية تعتمد على المصفوفات فيجب أن تعرف ماهية المصفوصة وكيف تخزن فيها البيانات وذلك لتتحكم في امكانياتها، وهكذا في كل أنواع البيانات. عندما تكمل تعلمها بدقة سترى الفرق في كيف أن تصميم الخوارزميات أصبح اسهل و أوضح.
- 4 اجابة
-
- 1
-
-
req: يحتوي هذا على شكل الطلب http الذي تقوم بارسالة اثناء التطبيق.ومن أجل استقبال الرد من الطلب السابق، تستخدم res والذي تحتوي على اجابة طلب ال http. يمكن اعادة تسمية هذه المتغيرات الي اي اسم تريده كما نرى في الكود التالي: app.get('/user/:id', function(request, response){ response.send('user ' + request.params.id); }); اما عن استخدامها داخل app.get فهو فقط بتمريرهم داخل الطلب كما نري في الكود التالي: app.get('/people.json', function(request, response) { // هنا توضح شكل المحتوى حتي يستطيع المتصفح فهمه // هذا هو شكل المحتوى على الشكل json response.contentType('application/json'); //في الطبيعي، يكون العائد من قاعدة بيانات، لكن هنا يمكننا ان نضعها بشكل يدوى حتى نوضح الفكرة var people = [ { name: 'Ahmed', location: 'Egypt' }, { name: 'Mohammed', location: 'Jordan' }, { name: 'mostafa', location: 'Sodan' } ]; // حيث أن الطلب المرسل على صيغه json // للتعامل مع البيانات القادمة JSON.stringify() يمكن أن نستخدم الدالة الداخلية var peopleJSON = JSON.stringify(people); // هنا يمكننا ارسال النتائج التي عادت الينا الي المتصفح لعرضها response.send(peopleJSON); });
-
كأساليب لتعلم الخوارزميات، تعتبر pseudo code و Flowchart هما أهم الطرق لتعلمها وتطبيقها خاصه pseudo code، ولكن هذا ليس كافيا للتعلم والتمكن، فهذة فقط مجرد أدوات. اذا أتممت تعلم تلك الطريقتين فأنت الان تستطيع كتابة وتصميم الخوارزمية، أما عن تطبيقها وهو الجزء الأهم، فيجب عليك أن تعتاد وتتدرب عليها. حاول أن تختار أي لغة برمجة تشاء،مثل بايثون أو c وطبق عليها فعليا الخوارزميات التي تقوم بتصميمها، وبذلك تكون قد حولت ال pseudo code الي كود فعلي. هناك الكثير من المواقع التي توفر تدريبا على الخوارزميات منها hacker rank وهو الاشهر على الاطلاق، قم بالتدريب كثيرا فهذا أفضل من استمرار التعلم فقط.
- 3 اجابة
-
- 1
-
-
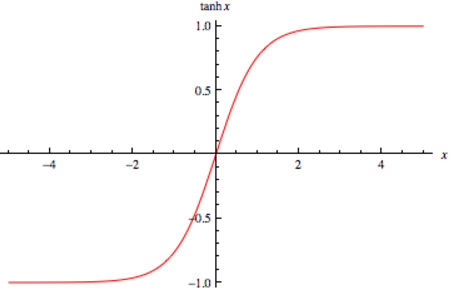
تعتبر دالة tanh دالة غير خطية، وهي تتشابه في هذا مع دالة ال sigmoid ، غير أن دالة ال sigmoid تتراوح قيمة الخرج من 0 ل 1 بينما دالة tanh تتراوح قيمة الخرج من -1 ل 1 كما هو موضح في الصورة التالية: هنا ، يمكنك الملاحظة من الرسم البياني ، أن tanh تستطيع ربط المدخلات بالمخرجات جيدًا. يتم تطبيق ذلك بحيث أن المدخلات الإيجابية بشدة (الصحيحة) يتم تعيينها بالقرب من 1 ، بينما يتم تعيين المدخلات السلبية بشدة (الخاطئة) بالقرب من -1. وتعتبر الصيغة الرياضية للدالة tanh كالتالي: f(x) = tanh(x) = (e^(2x) - 1) / (e^(2x) + 1) يمكنك استخدام بايثون لرسم الدالة نفسها بالكود التالي: import numpy as np import matplotlib.pyplot as plt def tanh(x): return np.tanh(x) def generate_sample_data(start, end, step): return np.linspace(start, end, step) x = generate_sample_data(-5, 5, 10) y = tanh(x) # Now plot plt.xlabel("x") plt.ylabel("tanh(x)") plt.plot(x, y) plt.show() ومن أهم ميزاتها انها سريعة في الاستخدام كما أن مشتقتها تشمل المجال كاملا لذلك فأنه لا يمكن أن يحدث أي أخطاء أثناء التدريب. على الرغم أن tanh تحتوي على الكثير من الخصائص الجيدة لبناء الموديل ، يجب على المرء دائمًا توخي الحذر عند استخدامه. لا تزال هذه الدالة دالة تنشيط غير خطية ، مما يعني أنها يمكن أن تكون عرضة لمشكلة عدم الاستقرار في التدريب. مشكلة عدم الاستقرار في التدريب هي الحالة التي تصبح فيها المشتقات تساوى 0 حتى مع حدوث تغيير كبير في المدخلات. أما عن استخدامها في keras بالطريقة الأتية: >>> a = tf.constant([-3.0,-1.0, 0.0,1.0,3.0], dtype = tf.float32) >>> b = tf.keras.activations.tanh(a) >>> b.numpy() array([-0.9950547, -0.7615942, 0., 0.7615942, 0.9950547], dtype=float32) وفي بناء الموديل يمكن أستخدامها كالتالي: model.add(Dense(12, input_shape=(8,), activation='tanh')) model.add(Dense(8, activation='tanh'))
-
في بداية بناء أي نموذج، عليك أن تقوم بتحديد شكل المدخلات للنموذج في أول طبقة وذلك حتى يستطيع أن يتعامل مع شكل البيانات المدخلة. في باقي الطبقات بعد الطبقة الاولى، لست بحاجة الى تعريف شكل المدخلات بنفسك، وذلك لانه يقوم بتمرير البيانات من طبقة الى الاخرى دون الاحتياج الى اى تدخل خارجي. لتعريف المدخلات للنموذج، نقوم بتمرير ال parameter التالي: input_shape(input-shape) حيث يوضع بين الاقواس شكل البيانات المدخلة، وهذا يتم فقط في أول طبقة من النموذج. يجب عليك أن تنظر الي شكل البيانات المدخلة والتي تكون محكومة بشكل ال dataset، هنا أنت تستخدم imdb dataset ، لو تفحصت في شكلها، سجد أن حجم ال feature الذي تحتوية هو 2494، يمكنك أدخالهم مره واحدة لكن هذا قد يسبب بطئ في النموذج، لذلك سنقوم بتقسيمها الي 50. لذلك للتغلب على المشكلة الظاهرة، يمكننها تعديلها في الكود لتصبح كالتالي from keras.datasets import imdb from keras import preprocessing max_features = 1000 datalength = 50 #حجم البيانات المدخلة (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train,datalength=datalength) x_test = preprocessing.sequence.pad_sequences(x_test, datalength=datalength) from keras.models import Sequential from keras.layers import Flatten, Dense,Embedding model = Sequential() model.add(Embedding(1000, 8, input_length=datalength)) #تعريف حجم البيانات المدخلة model.add(Flatten()) model.add(Dense(64, activation='tanh')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=3, batch_size=64, validation_split=0.2) :
-
بوجة عام، ظهور رسالة name 'something' is not defined يعني أنك قمت باستخدام متغير أو دالة دون تعريفها مسبقا سواء باستدعائها او بتعريف بالمتغير. هنا ظهور الرسالة: name 'Dense' is not defined لانك قمت باستخدام الدالة dense دون استدعائها مسبقا، كل ما عليك هو استدعائها ببساطه كالتالي: from keras.datasets import imdb from keras import preprocessing from keras.layers import Dense # استدعاء Dense max_features = 1000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train,maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) from keras.models import Sequential from keras.layers import Flatten,Embedding model = Sequential() model =Sequential() model.add(Dense(16, activation='relu',input_shape=(20,))) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) history = model.fit(x_train, y_train, epochs=3, batch_size=64, validation_split=0.2
-
يتم تخزين صفائف numpy في كتل متجاورة من الذاكرة. إذا كنت ترغب في إضافة صفوف أو أعمدة إلى array موجودة، يجب نسخ array بأكملها إلى كتلة جديدة من الذاكرة، وإنشاء فجوات للعناصر الجديدة التي سيتم تخزينها. هذا غير فعال للغاية إذا فعلت مرارا وتكرارا بناء صفيف. في حالة إضافة الصفوف، فإن أفضل رهان الخاص بك هو إنشاء مجموعة كبيرة حيث ستكون مجموعة البيانات الخاصة بك في نهاية المطاف، ثم قم بتعيين البيانات إليها في الصف عبر الصف أنظر المثال التالي: >>> import numpy >>> a = numpy.zeros(shape=(5,2)) >>> a array([[ 0., 0.], [ 0., 0.], [ 0., 0.], [ 0., 0.], [ 0., 0.]]) >>> a[0] = [1,2] >>> a[1] = [2,3] >>> a array([[ 1., 2.], [ 2., 3.], [ 0., 0.], [ 0., 0.], [ 0., 0.]]) وهذه افضل طريقة يمكنك أستخدام المساحة المؤقتة memory بحيث تضمن اداء المهمة وتكون سريعة كذلك.
-
توجد الاختلافات بشكل أساسي عند إرجاع المدخلات دون تغيير، بدلا من إنشاء مجموعة جديدة كنسخة. بمعني أوضح أن الاختلاف الاساسي يكمن في استخدام الذاكرة المؤقتة memory حيث أن: array: تقوم بعمل نسخة من المصوفة التي تحتويها. asarray: تستخدم المساحة الاصلية الخاصة بالمصفوفة. asanyarray : تستخدم المساحة الاصلية الخاصة بالمصفوفة، asanyarray سوف تعيد مصفوفة على النوع ndarray أنظر المثال التالي: a= np.array([1,2,3]) b=np.array(a) # Open up a new space, make a copy c=np.asarray(a) # Still use the original space d=np.asanyarray(a) # Still use the original space a[1]=0 print("a:",a) print("b:",b) print("c:",c) print("d:",d) >>> a: [1 0 3] b: [1 2 3] c: [1 0 3] d: [1 0 3] أنظر كذلك المثال القادم لتوضيح الفرق في انواع المصفوفات: دعنا ننشئ مصفوفة كالتالي: >>> A = numpy.matrix(numpy.ones((3,3))) >>> A matrix([[ 1., 1., 1.], [ 1., 1., 1.], [ 1., 1., 1.]]) أستخدم numpy.array لتعديل A. لن يعمل ذلك لأنك تعدل نسخة: >>> numpy.array(A)[2]=2 >>> A matrix([[ 1., 1., 1.], [ 1., 1., 1.], [ 1., 1., 1.]]) الان استخدم numpy.asarray لتعديل A، هذا سوف يعمل لانك تقوم بتعديل A نفسها: >>> numpy.asarray(A)[2]=2 >>> A matrix([[ 1., 1., 1.], [ 1., 1., 1.], [ 2., 2., 2.]]) كذلك array() يقدم مجموعة واسعة من الخيارات أوسع من الدوال الاخرى.
-
تستخدم الدالة tolist من اجل تحويل المصفوفة في هيئة numpy الي list، انظر المثال التالي لتحويل مصفوفة احادية الي list: a = np.uint32([1, 2]) a_list = list(a) a_list >>[1, 2] type(a_list[0]) >><class 'numpy.uint32'> a_tolist = a.tolist() a_tolist >>[1, 2] type(a_tolist[0]) >><class 'int'> كذلك تستخدم tolist لتحويل مصفوفات ثناية الأبعاد مثل المثال التالي: a = np.array([[1, 2], [3, 4]]) list(a) >> [array([1, 2]), array([3, 4])] a.tolist() >> [[1, 2], [3, 4]]
- 3 اجابة
-
- 1
-
-
تعرف ال matrix والتي جمعها matrices على انها المصفوفة ثنائية الأبعاد، والتي التي تحتوي على صفوف وأعمدة فقط، أنظر المثال التالي: >>> import numpy as np >>> a = np.array([[2,3], [4,5]]) >>> >>> y = np.asmatrix(a) >>> >>> a[0,0] = 5 >>> >>> y matrix([[5, 3], [4, 5]]) أما عن np.array فهي شكل اكثر شمولا عن np.mat، حيث أنها لا تقف فقط عند المصفوفات ثنائية الأبعاد وانما تدعم كل ألابعاد N-dimensional. np.array([[1, 2], [3, 4]]) array([[1, 2], [3, 4]]) كما انها أسهل في التعامل وتوفر أمكانيات اكثر للتعامل مع المصفوفات، في الكود التالي بعض العمليات التي توفرها numpy.array import numpy # Two matrices are initialized by value x = numpy.array([[1, 2], [4, 5]]) y = numpy.array([[7, 8], [9, 10]]) # جمع مصفوفتين print ("Addition of two matrices: ") print (numpy.add(x,y)) # subtract()طرح مصفوفتين print ("Subtraction of two matrices : ") print (numpy.subtract(x,y)) # divide()قسمة مصفوفتين print ("Matrix Division : ") print (numpy.divide(x,y)) print ("Multiplication of two matrices: ") print (numpy.multiply(x,y)) print ("The product of two matrices : ") print (numpy.dot(x,y)) print ("square root is : ") print (numpy.sqrt(x)) print ("The summation of elements : ") print (numpy.sum(y)) print ("The column wise summation : ") print (numpy.sum(y,axis=0)) print ("The row wise summation: ") print (numpy.sum(y,axis=1)) # using "T" عكس المصفوفة print ("Matrix transposition : ") print (x.T) ويكون الخرج كالتالي: Addition of two matrices: [[ 8 10] [13 15]] Subtraction of two matrices : [[-6 -6] [-5 -5]] Matrix Division : [[0.14285714 0.25 ] [0.44444444 0.5 ]] Multiplication of two matrices: [[ 7 16] [36 50]] The product of two matrices : [[25 28] [73 82]] square root is : [[1. 1.41421356] [2. 2.23606798]] The summation of elements : 34 The column wise summation : [16 18] The row wise summation: [15 19] Matrix transposition : [[1 4] [2 5]]
- 3 اجابة
-
- 1
-
-
بالنسبة لسؤالك فإنه ينقسم الي جزئين أساسين: اذا أردت طباعة المصفوفة بدون فواصل، فهناك حلان: الاول أن تقوم فقط باستخدام أمر print دون أي شئ أخر، وذلك لانه هناك اختلاف بين شكل المصفوفة المخزنه في الذاكرة والتي تظهر عند استدعائها باستخدام كتابة اسمها كما في المثال التالي: a = np.random.random(10) >>> a array([0.71244268, 0.65202232, 0.45514279, 0.12868502, 0.86755307, 0.54365432, 0.76884071, 0.37287693, 0.10350725, 0.66008725]) وذلك لانه يقوم بطباعتها بالشكل المخزن في الذاكرة،أما اذا اردت طباعتها من دون فواصل، فقط أستخدم print كالتالي: a = np.random.random(10) >>> print(a) array([0.71244268 0.65202232 0.45514279 0.12868502 0.86755307 0.54365432 0.76884071 0.37287693 0.10350725 0.66008725]) الطريقة الثانية هي استخدام الامر print مع اعطاءه بعض الخصائص الاضافية كالتالي: print(*data, sep='') حيث أن sep يوضع بعدها الشكل الذي تريد أن تقوم بفصل العناصر به، فهنا وضعنا علامات تنصيص بينها فارغ أي أنه الفواصل بين عناصر المصفوفة هي الفراغ space. بالنسبة للتحكم بدقة الاخراج أو الدقة، فيمكنك تحديد عدد الارقام العشرية التي تريد ظهورها عن طريق: np.set_printoptions(precision=2) حيث أن الرقم بعد precision يوضح عددالاربام العشرية التي تريد ظهورها في النواتج.
- 3 اجابة
-
- 1
-