Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
هناك اختلاف كبير بين تصميم المواقع من حيث الخلفية front end أو برمجة المواقع back end ودمج الاثنين سويا هو ما يسمي full stack وبالتفصيل كالتالي: تصميم المواقع والذي يهتم بشكل الموقع وألوانه وكل ذلك يتم باستخدام لغات التصميم وهي HTML و CSS و JavaScript . برمجة المواقع وهي تفاصيل أداء المواقع والذي يرتبط بقواعد البيانات ويؤدي مهمات الموقع وهكذا، وهذا يحتاج لغات برمجة مثل php و python. وفي مجال برمجة المواقع، تعتبر php هي اللغة الأكثر استخداما في هذا المجال لأنها ببساطة مصممة لذل، لذا تعلمها سيكون مطلوبا بشدة وستلقي دعما واسعا لذا هي المفضلة. كذلك استخدام بايثون أصبح سهلا وذلك لأن طريقة كتابتها سهلة، الا انها لم تلق الدعم الازم حتى الان في هذا المجال بينما تمتاز بايثون بعلوم البيانات. لذا كلتا اللغتين مفضلتان الا أن php تكون مطلوبة أكثر.
-
عوضا عن اضافة القيم بشكل يدوي وهو ما لم يتم استخدامه عادة في التطبيقات العملية، يمكنك كذلك اظهار قيمة كل خلية بشكل تلقائي كالتالي: import seaborn as sns import pandas as pd import numpy as np # قاعدة البيانات df = pd.DataFrame(np.random.random((10,10)), columns=["a","b","c","d","e","f","g","h","i","j"]) # رسم الخريطة sns.heatmap(df, annot=True, annot_kws={"size": 7}) وتظهر كالتالي: بعدذلك تستطيع دمجها مع أي رموز أخرى كما في الإجابة السابقة.
.png.9e69a1b271f29d42ed6bea5a835671c7.png)
-
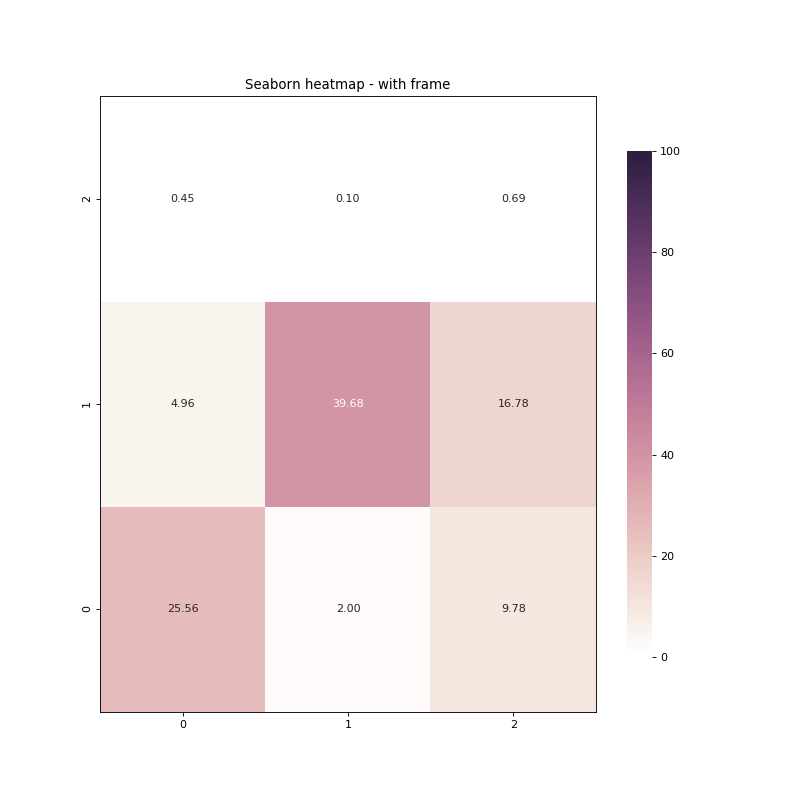
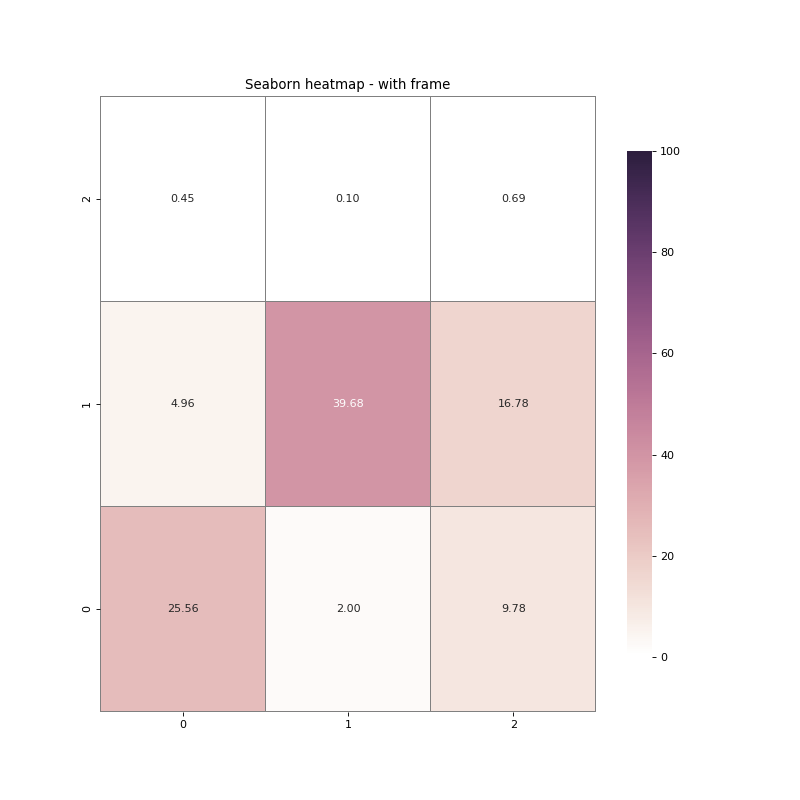
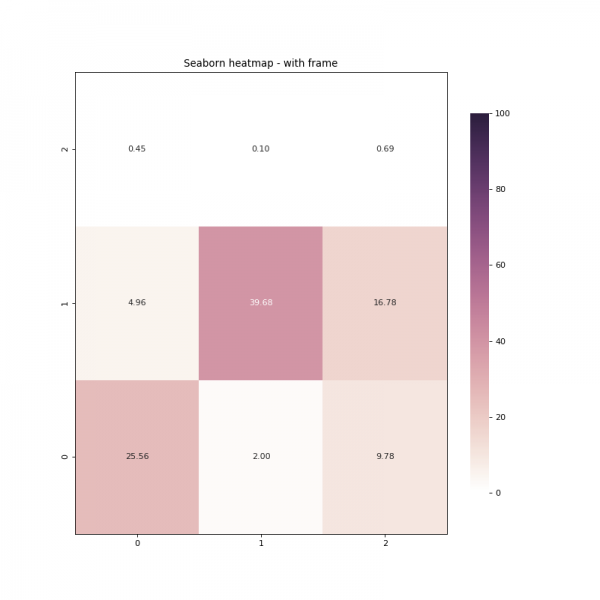
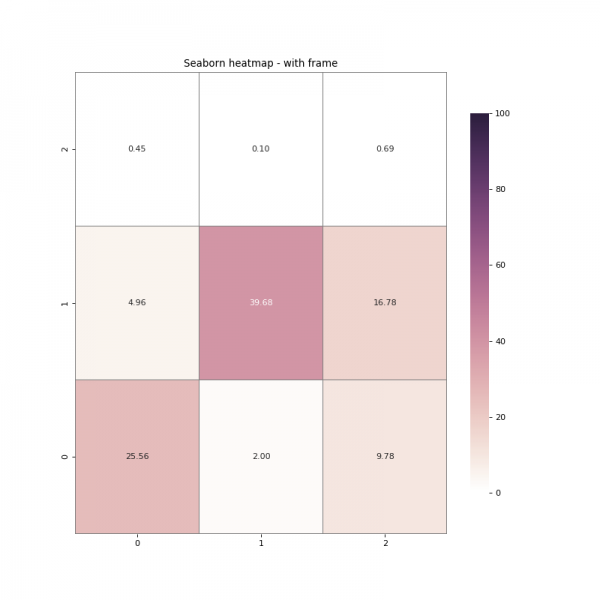
بالاضافة للطريقة السابقة يمكنك استخدام ايضا الطريقة التالية: for _, spine in res.spines.items(): spine.set_visible(True) المثال التالي يوضح كيف نضيف اطاراً حول الأربع أركان: import seaborn as sns import numpy as np import pandas as pd import matplotlib.pyplot as plt data = np.array([[25.55535942, 1.99598017, 9.78107706], [ 4.95758736, 39.68268716, 16.78109873], [ 0.45401194, 0.10003128, 0.6921669 ]]) df = pd.DataFrame(data=data) fig = plt.figure(num=None, figsize=(10, 10), dpi=80, facecolor='w', edgecolor='k') cmap = sns.cubehelix_palette(light=1, as_cmap=True) res = sns.heatmap(df, annot=True, vmin=0.0, vmax=100.0, fmt='.2f', cmap=cmap, cbar_kws={"shrink": .82}) res.invert_yaxis() #اظهار الاطار for _, spine in res.spines.items(): spine.set_visible(True) plt.title('Seaborn heatmap - with frame') plt.savefig('seaborn_heatmap_with_frame_01.png') plt.show() ويظهر الاطار كالتالي: بالإضافة لهذا يمكننا وضع إطار حول كل خليه داخل الرسمة كذلك بنفس الطريقة كالتالي: import seaborn as sns import numpy as np import pandas as pd import matplotlib.pyplot as plt data = np.array([[25.55535942, 1.99598017, 9.78107706], [ 4.95758736, 39.68268716, 16.78109873], [ 0.45401194, 0.10003128, 0.6921669 ]]) df = pd.DataFrame(data=data) fig = plt.figure(num=None, figsize=(10, 10), dpi=80, facecolor='w', edgecolor='k') cmap = sns.cubehelix_palette(light=1, as_cmap=True) res = sns.heatmap(df, annot=True, vmin=0.0, vmax=100.0, fmt='.2f', cmap=cmap, cbar_kws={"shrink": .82}, linewidths=0.1, linecolor='gray') #اظهار الاطار res.invert_yaxis() plt.title('Seaborn heatmap - with frame') plt.savefig('seaborn_heatmap_with_frame_and_cell_border_01.png') plt.show() وتظهر كالتالي: لاحظ اننا يمكننا تغيير لون الإطار كذلك باستخدام الألوان المتاحة في المكتبة، وكذلك عرضة وحجمه.
-
بناء على التوضيح في الإجابة السابقة دعنا نأخذ مثالا على كيفية تطبيق هذا في الرسم: # استدعاء المكتبات import seaborn as sns import matplotlib.pyplot as plt # استخدام اللون الرمادي كخلفية) sns.set(style="darkgrid") df = sns.load_dataset('iris') #ضبط اللون الخاص بكل رسمة my_pal = {"versicolor": "g", "setosa": "b", "virginica":"m"} sns.boxplot(x=df["species"], y=df["sepal_length"], palette=my_pal) plt.show() وتكون شكل الرسمة كالتالي: لاحظ أننا نستطيع تغيير سواء الوان الرسمة أو الخلفية باستخدام اختصارات الألوان التي تم شرحها مسبقا.
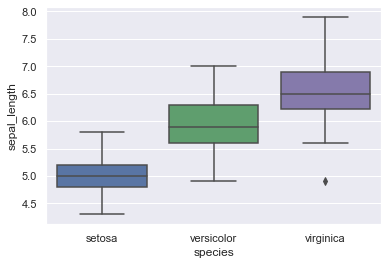
-
يمكنك كذلك استخدام cbar_ax لوضع مكان شريط الألوان كما تريد، وبالتالي يمكنك تغيير أبعاده وكذلك مكانه في الصورة كالتالي: import seaborn as sns import pandas as pd import numpy as np import matplotlib.pylab as plt uniform_data = np.random.rand(10, 12) fig, ax = plt.subplots(1, 1) #مكان وحجم ال colorbar cbar_ax = fig.add_axes([.905, .3, .05, .3]) sns.heatmap(uniform_data, ax=ax, cbar_ax = cbar_ax, cbar=True) plt.show() وتظهر كالتالي:
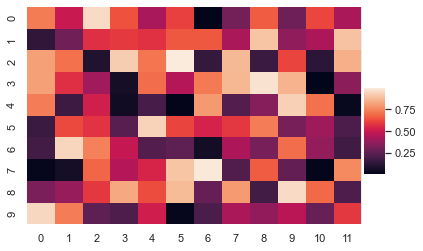
-
يمكنك كذلك استخدام الدالة facet.set مع استخدام المعامل axis_bgcolor وذلك لظبط ألوان الخلفية كالتالي: import seaborn as sns import matplotlib.pyplot as plt # loading dataset data = sns.load_dataset("iris") # draw lineplot facet = sns.lineplot(x="sepal_length", y="sepal_width", data=data) facet.set(axis_bgcolor='k') plt.show() أو استخدام الدالة sns.set(style = color) لضبط لون الخلفية بسهولة كالتالي: import seaborn as sns import matplotlib.pyplot as plt # loading dataset data = sns.load_dataset("iris") # ضبط اللون sns.set(style = "darkgrid") facet = sns.lineplot(x="sepal_length", y="sepal_width", data=data) plt.show() وتظهر كالتالي:
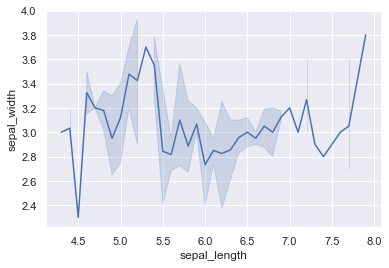
-
بالإضافة للإجابة السابقة، يمكنك تحيك ال legend ليكون خارج الصورة في الناحية التي تريد عن طريق استخدام bbox_to_anchor() كالتالي: import seaborn as sns import matplotlib.pyplot as plt sns.set(style="whitegrid") titanic = sns.load_dataset("titanic") g = sns.factorplot("class", "survived", "sex", data=titanic, kind="bar", size=6, palette="muted", legend=False) g.despine(left=True) plt.legend(bbox_to_anchor=(1.02, 1),loc='upper left') # أعلى يسار الصور لكن خارجها g.set_ylabels("survival probability") ويكون الخرج:
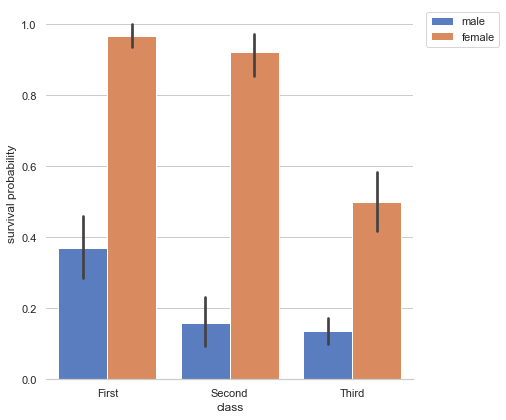
-
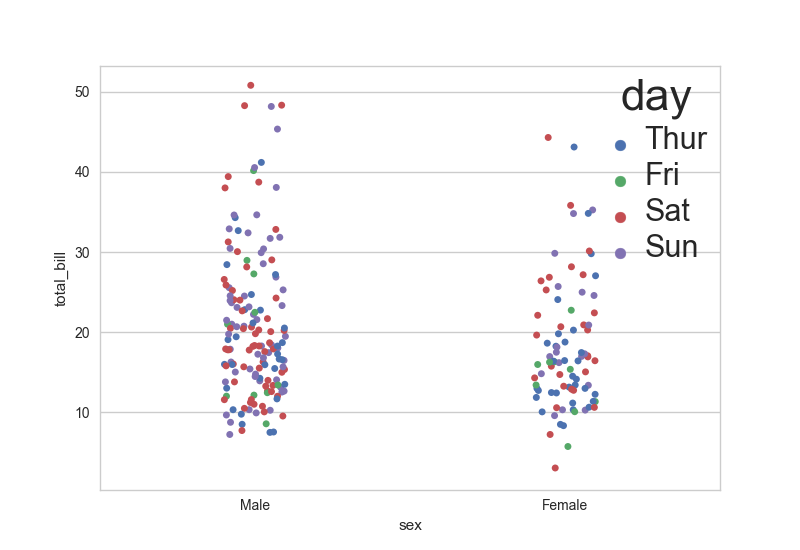
يمكنك تعديل حجم الخط في ال legend عن طريق استخدام setp كالتالي: import seaborn as sns import matplotlib.pylab as plt sns.set_style("whitegrid") tips = sns.load_dataset("tips") ax = sns.stripplot(x="sex", y="total_bill", hue="day", data=tips, jitter=True) plt.setp(ax.get_legend().get_texts(), fontsize='22') # لنص legend plt.setp(ax.get_legend().get_title(), fontsize='32') # لعنوان legend ax.set_title("Title", fontsize = 40) # تحديد حجم العنوان plt.show() وتظهر كالتالي: ويمكنك تحديد مكان ال legend كذلك اذا أردتها في الجانب.
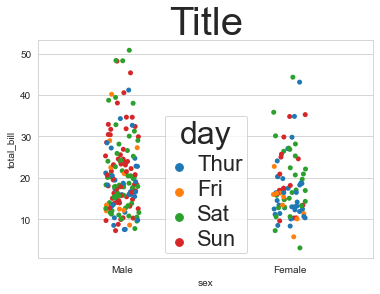
-
بجانب الحل السابق يمكنك كذلك استخدام حلقة تكرارية بسيطة وذلك عوضا عن كتابة كل سطر لكل رسمة بشكل مفصل ، المثال التالي يوضح ذلك: import numpy as np # البيانات المراد رسمها df = pd.DataFrame({'a' :['one','one','two','two','one','two','one','one','one','two'], 'b': np.random.randint(1,8,10), 'c': np.random.randint(1,8,10), 'd': np.random.randint(1,8,10), 'e': np.random.randint(1,8,10)}) names = df.columns.drop('a') ncols = len(names) fig, axes = plt.subplots(1,ncols) #حلقة تكرارية للرسم for name, ax in zip(names, axes.flatten()): sns.boxplot(y=name, x= "a", data=df, orient='v', ax=ax) plt.tight_layout() ويكون الناتج كالتالي: لاحظ اننا هنا ثبتنا اسماء الرسومات كلها، لكنك يمكنك تحديد اسم أو رقم لكل رسمة بحيث يكون مميزا لها كذلك.
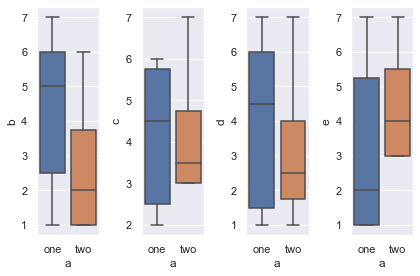
-
كما قال أستاذ محمد عن الخوارزمية فإن طريقة كتابتها سهلة للغاية هكذا: #عرف متغير يبدأ بالصفر sum = 0 #قم بعمل تكرار من 0 وحتى 101، وذلك لان أخر قيمة ستكون 100 for i in range (0,101): sum = sum + i #قم بجمع كل قيمة جديدة مع ما سبق #أطبع القيمة النهائية لحاصل الجمع print(sum) #الخرج >>> 5050
- 2 اجابة
-
- 1
-

-
اذا كنت تستخدم نسخة بعد 0.11 فالكود التالي قد يحل المشكلة: import seaborn as sns import numpy as np data = np.random.normal(size=100) path = "/path/to/img/plot.png" plot = sns.displot(data) plot.fig.savefig(path) plot.fig.clf() #أكمل رسمتك الخاصة واذا كنت تحب التكرار فيمكنك استخدام for وذلك عوضا عن وضع كل رسمة أسفل الثانية ثم وضع الفاصل وهكذا: import seaborn as sns import numpy as np for i in range(3): data = np.random.normal(size=100) path = "/path/to/img/plot2_{0:01d}.png".format(i) plot = sns.displot(data) plot.fig.savefig(path) plot.fig.clf() اما اذا كانت النسخة قبل ذلك فيجب تعديل طريقة كتابته قليلا هكذا: import seaborn as sns import numpy as np data = np.random.normal(size=100) path = "/path/to/img/plot.png" plot = sns.distplot(data) plot.get_figure().savefig(path) plot.get_figure().clf() #لاحظ اختلاف شكل الدالة المستخدمه
-
الكود التالي يوضح كيفية تسمية كل شئ على الخريطة الحرارية heatmap، حيث يمكنك وضع عنوان رئيسي بجانب تسمة المحاور مع وضع تسمية للتدريج الحراري في الجانب هكذا: import pandas as pd import seaborn as sns from matplotlib import pyplot as plt df = pd.DataFrame({'A':(10,20,30,40), 'B':(10,20,30,40), 'C':(90,110,130,200)}) ax = sns.heatmap(df.pivot_table(index='B', columns='A', values='C'), cbar_kws={'label': 'Your Title'})#عنوان التدريج الحراري plt.title('Title', fontsize = 20) # عنوان مع خط 20 plt.xlabel('X axis', fontsize = 15) # عنوان المحور السيني مع خط 15 plt.ylabel('Y axis', fontsize = 15) # عنوان المحور الصادي مع خط 15 plt.show() وكذلك تستطيع التحكم في حجم الخطوط وألوانها وغير ذلك. ويكون الناتج كالتالي:
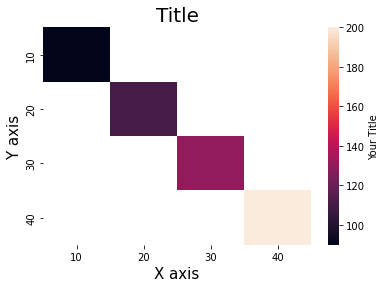
-
في الاجابة السابقة يمكنك استخدام plt.ylim و plt.xlim كدوال من matplot لضبط قيم المحاور، وبنفس الطريقة يمكنك كذلك استخدام ()ax.set مع استخدام ylim للمحور الصادر و xlim للمحور السيني كالتالي: from matplotlib import pyplot as plt import seaborn as sns plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True sns.set_style("whitegrid") tips = sns.load_dataset("tips") ax = sns.boxplot(x="day", y="total_bill", data=tips) ax.set(ylim=(0, 40))#بداية ونهاية قيم المحور الصادى plt.show() والناتج هكذا:
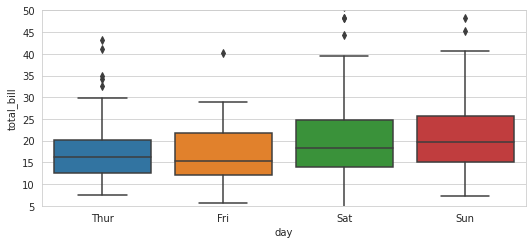
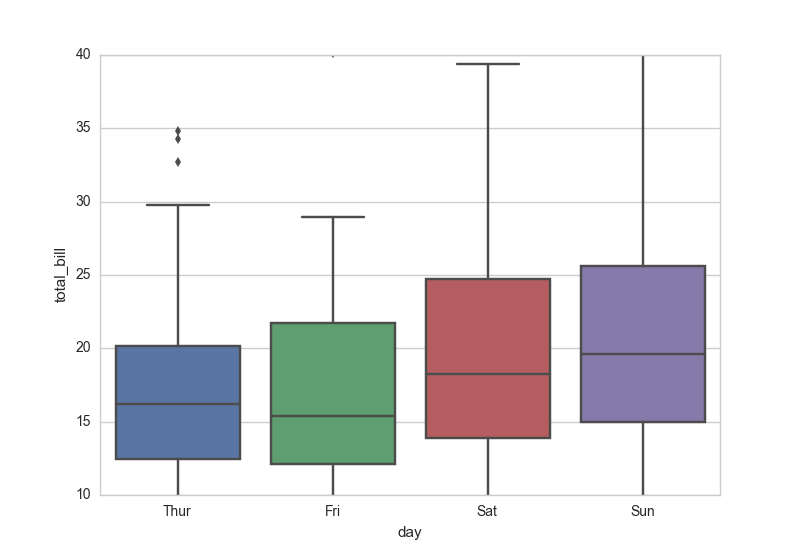
-
يمكنك كذلك استخدام اساليب تغيير الحجم في matplot نفسها داخل seaborn كالتالي: from matplotlib import pyplot import seaborn import mylib a4_dims = (11.7, 8.27) df = mylib.load_data() fig, ax = pyplot.subplots(figsize=a4_dims) seaborn.violinplot(ax=ax, data=df, **violin_options) أو استخدام catplot داخل seaborn كالتالي: sns.catplot(data=df, x='xvar', y='yvar', hue='hue_bar', height=8.27, aspect=11.7/8.27)
-
يمكنك تنجنب الخطأ الناتج عن استخدام set_axis_labels عن طريق استخدام matplotlib.pyplot.xlabel و matplotlib.pyplot.ylabel وذلك لان محاور seaborn لها نفس صيغة matplot لذا يصلح استخدام تلك الطريقة معها. كمثال لاستخدامها على الكود السابق: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt fake = pd.DataFrame({'cat': ['red', 'green', 'blue'], 'val': [1, 2, 3]}) fig = sns.barplot(x = 'val', y = 'cat', data = fake, color = 'black') plt.xlabel("Colors") plt.ylabel("Values") plt.title("Colors vs Values") # يمكنك الغاء هذا السطر اذا لم تكن تختاج الى عنوان plt.show(fig) ويكون الناتج:
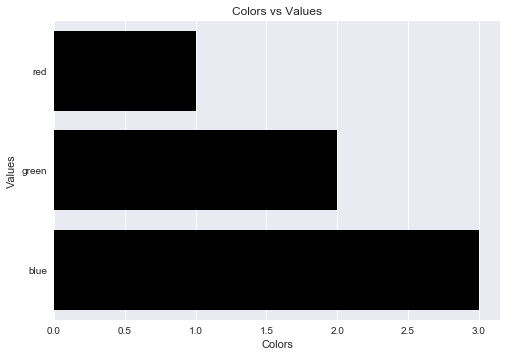
-
بالاضافة للطرق السابقة يمكنك استخدام الدالة setp من matplot وذلك لان seaborn تقوم بارجاع المحاور بنفس صيغة matplot وبالتالي يمكن استخدامها كالتالي: plt.setp(labels, rotation=45) حيث تقوم باخذ عناوين المحاور مع درجة تدويرها. كمثال الكود التالي: import pandas as pd import matplotlib.pyplot as plt import seaborn as sns df = pd.DataFrame({"Date": ['01012019','01022019','01032019','01042019', '01052019','01062019','01072019','01082019'], "Price": [77,76,68,70,78,79,74,75]}) df["Date"] = pd.to_datetime(df["Date"], format = "%d%m%Y") plt.figure(figsize = (15,8)) ax = sns.barplot(x = 'Date', y = 'Price',data = df) locs, labels = plt.xticks() plt.setp(labels, rotation=45) حينها تظهر الارقام السفلي بميل قيمته 45 درجة كالتالي:
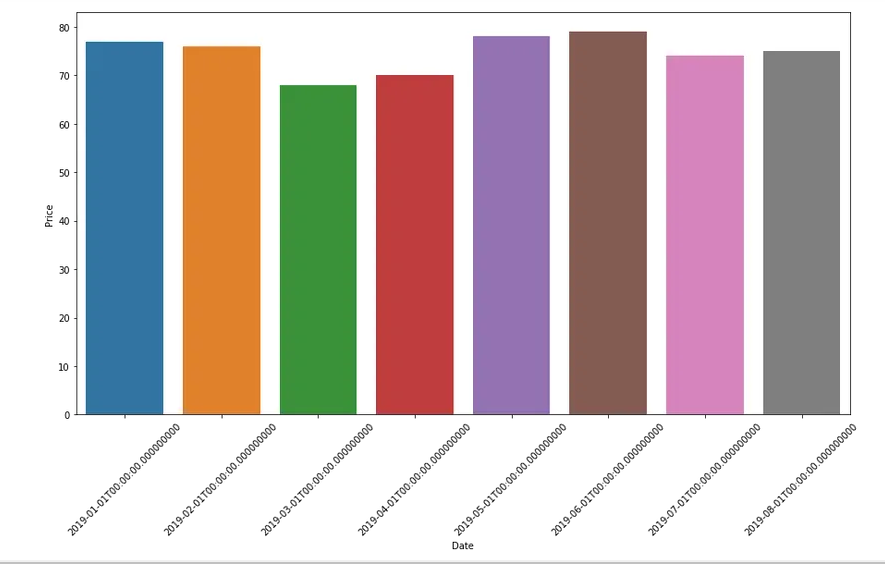
-
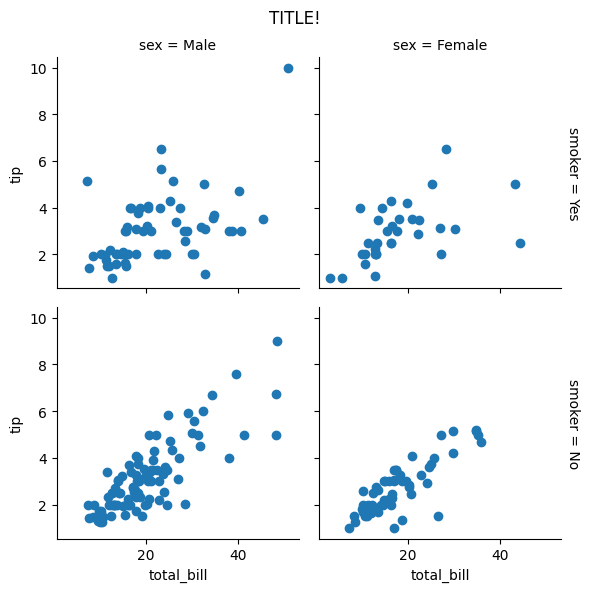
بالاضافة للاجابة السابقة، اذا كنت تستخدم FacetGrid لتنظيم عرض الصور ، فهي بشكل تلقائي تقوم بوضع تسمية كل صف وعمود بجانبه بشكل منظم وحينها تستطيع استخدام suptitle لعرض عنوان أساسي كالتالي: from matplotlib.pyplot import scatter as plt_scatter g = sns.FacetGrid(tips, col='sex', row='smoker', margin_titles=True) g.map(plt_scatter, 'total_bill', 'tip') g.fig.subplots_adjust(top=0.9) g.fig.suptitle('TITLE!') ويكون خرج الكود السابق كالتالي: لاحظ عرض عنوان كل رسمة (في الصف والعمود الخاص بها) بجانبها بحيث تكون أكثر وضوحا.
-
يمكنك إزالة n\ ببساطة بعدما نقوم بتحليل النص كالتالي: text = '''\n Apple has quietly hired Dr. Rajiv B. Kumar, a pediatric endocrinologist \n. He will continue working at the hospital part time \n ''' tokenized_sent_before_remove_n = nltk.sent_tokenize(text) >>> ['\n Apple has quietly hired Dr. Rajiv B. Kumar, a pediatric endocrinologist \n.', 'He will continue working at the hospital part time'] tokenized_sent_after_remove_n = [x.replace('\n','') for x in tokenized_sent] >>> [' Apple has quietly hired Dr. Rajiv B. Kumar, a pediatric endocrinologist .', 'He will continue working at the hospital part time'] وبنفس الطريقة تستطيع إزالة t\ كما استخدمناها لإزالة n\.
-
لو أن عندنا مجموعة كبيرة من الكلمات الإنجليزية، ونريد أن نقوم بتصفيتها كالتالي: word_list = "Nick likes to play football, however he is not too fond of tennis." الكود التالي يوضح ببساطة كيفية القيام بذلك: filtered_word_list = word_list[:] #عمل نسخة من الكلمات for word in word_list: # نقوم بالبحث في كل كلمة if word in stopwords.words('english'): filtered_word_list.remove(word) # ازالة أي كلمة عبارة عن stop word ويكون الناتج: ['Nick', 'likes', 'play', 'football', ',', 'however', 'fond', 'tennis', '.']
-
يمكنك عمل Tokinaization ببساطة اذا كان النص بسيط من خلال split والتي تمكنا من فصل الكلمات عن بعضها البعض كالتالي: text = """Founded in 2002, SpaceX’s mission is to enable humans to become a spacefaring civilization and a multi-planet species by building a self-sustaining city on Mars. In 2008, SpaceX’s Falcon 1 became the first privately developed liquid-fuel launch vehicle to orbit the Earth.""" # فصلها من عند المسافة text.split() أو باستخدام NLTK كالتالي: from nltk.tokenize import word_tokenize text = """Founded in 2002, SpaceX’s mission is to enable humans to become a spacefaring civilization and a multi planet species by building a self-sustaining city on Mars. In 2008, SpaceX’s Falcon 1 became the first privately developed liquid-fuel launch vehicle to orbit the Earth.""" word_tokenize(text) ويكون الناتج في الحالتين كالتالي: Output : ['Founded', 'in', '2002,', 'SpaceX’s', 'mission', 'is', 'to', 'enable', 'humans', 'to', 'become', 'a', 'spacefaring', 'civilization', 'and', 'a', 'multi-planet', 'species', 'by', 'building', 'a', 'self-sustaining', 'city', 'on', 'Mars.', 'In', '2008,', 'SpaceX’s', 'Falcon', '1', 'became', 'the', 'first', 'privately', 'developed', 'liquid-fuel', 'launch', 'vehicle', 'to', 'orbit', 'the', 'Earth.']
-
يمكنك كذلك استخدام lemma_names ، الكود التالي يوضح كيفية ايجاد المترادفات بسهولة: for ss in wn.synsets('small'): print(ss.name(), ss.lemma_names()) ويكون الخرج عبارة عن مجموعة من ال sets تمثل المترادفات المتقاربة كالتالي: small.n.01 ['small'] small.n.02 ['small'] small.a.01 ['small', 'little'] minor.s.10 ['minor', 'modest', 'small', 'small-scale', 'pocket-size', 'pocket-sized'] little.s.03 ['little', 'small'] small.s.04 ['small'] humble.s.01 ['humble', 'low', 'lowly', 'modest', 'small'] ... وتستطيع كذلك التأكد من مدى قرب كلمتين من بعضهما بنفس الدالة ببساطة كالتالي: #استدعاء المكتبات import nltk from nltk.corpus import wordnet first_word = wordnet.synset("Travel.v.01") second_word = wordnet.synset("Walk.v.01") print('Similarity: ' + str(first_word.wup_similarity(second_word))) first_word = wordnet.synset("Good.n.01") second_word = wordnet.synset("zebra.n.01") print('Similarity: ' + str(first_word.wup_similarity(second_word))) ويكون الخرج كالتالي: Similarity: 0.6666666666666666 Similarity: 0.09090909090909091 لاحظ أن الأرقام السابقة تكون نسب مئوية (اذا قمت بضربها *100) لمدي تقارب كلمتين من بعضهما، وقد تحتاج لتلك الخطوة للتأكد من جودة المترادفات التي حصلت عليها سابقا.
-
كما أوضح علي فإن NLTK توفر امكانية ايجاد العلامات النحوية بسهولة خاصة باللغة الإنجليزية، المثال التالي يوضح كيفية القيام بهذا بشكل مفصل، لاحظ أولا فصل الجملة بعد ذلك معرفة القواعد الخاصة بكل كلمة ثم تجميع الكلمات المتشابهة سويا: #استدعاء المكتبات from nltk import pos_tag from nltk import RegexpParser #فصل الجملة الى كلمات text ="learn php from hsoub and make study easy".split() print("After Split:",text) tokens_tag = pos_tag(text) print("After Token:",tokens_tag) patterns= """mychunk:{<NN.?>*<VBD.?>*<JJ.?>*<CC>?}""" chunker = RegexpParser(patterns) print("After Regex:",chunker) #الخرج النهائي output = chunker.parse(tokens_tag) print("After Chunking",output) ويكون شكل الخرج هكذا: After Split: ['learn', 'php', 'from', 'hsoub', 'and', 'make', 'study', 'easy'] After Token: [('learn', 'JJ'), ('php', 'NN'), ('from', 'IN'), ('hsoub', 'NN'), ('and', 'CC'), ('make', 'VB'), ('study', 'NN'), ('easy', 'JJ')] After Regex: chunk.RegexpParser with 1 stages: RegexpChunkParser with 1 rules: <ChunkRule: '<NN.?>*<VBD.?>*<JJ.?>*<CC>?'> After Chunking (S (mychunk learn/JJ) (mychunk php/NN) from/IN (mychunk hsoub/NN and/CC) make/VB (mychunk study/NN easy/JJ))
-
يمكنك كذلك استخدام tokenize لتقسيم الجمل بشكل تلقائي كالتالي: #تحميل المكتبة import nltk.data #تحميل ملف النص tokenizer = nltk.data.load('tokenizers/punkt/english.pickle') fp = open("test.txt") data = fp.read() #فصل الملف الى جمل print ('\n-----\n'.join(tokenizer.tokenize(data)))
-
يمكنك استخدام driver.page_source للحصول على كود المصدر كالتالي: # استدعاء المكتبة from selenium import webdriver # استخدام chrome driver = webdriver.Chrome() # الموقع url = "https://academy.hsoub.com/" # فتح ال URL driver.get(url) # الحصول على كود المصدر get_source = driver.page_source # طباعة كود المصدر print(get_source) الناتج: https://academy.hsoub.com/
-
بجانب الكود السابق يمكنك كذلك استخدام chrome options كالتالي: chrome_options = Options() chrome_options.add_argument("user-data-dir=selenium") driver = webdriver.Chrome(chrome_options=chrome_options) driver.get("www.google.com") حيث يمكنك متابعة النشاط الذي يقوم به وحفظ ملفات تعريف الارتباط الناتجة عنها وبعد ذلك في كل مرة تستخدام Webdriver تقوم بفتح المكان وتجد كل الcookies هناك. وفي المرة الثانية التي تقوم بتشغيل Webdriver تجد كل الملفات هنا: from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument("user-data-dir=selenium") driver = webdriver.Chrome(chrome_options=chrome_options) driver.get("www.google.com") # هنا تجد كل ملفات تعريف الارتباطوالاعدادات وغيرها الموجوده في السيشن السابقة