Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
اذا كنت تستخدم نظام ال Linux يمكنك استخدام الخطوات التالية: تأكد من تحميل أخر نسخة من كروم كالتالي: chromium-browser -version اذا لم تكن لديك يمكنك تنزيله كالتالي: sudo apt-get install chromium-browser بعد ذلك قم بتحميل نسخة chrome drive من هنا: http://chromedriver.storage.googleapis.com/index.html بعد ذلك قم بفكه وضعه في المكان التالي: sudo mv chromedriver /usr/bin/ بعد ذلك يمكنك تشغيل الكود التالي وستحل المشكلة: import os from selenium import webdriver from pyvirtualdisplay import Display display = Display(visible=0, size=(800, 600)) display.start() driver = webdriver.Chrome() driver.get("http://www.google.com") print driver.page_source.encode('utf-8') driver.quit() display.stop()
-
يمكنك كذلك استعمال الكود التالي والذي يقوم باختيار ايجاد العنصر ثم اختيار القيمة التي تريد: from selenium import webdriver b = webdriver.Firefox() b.find_element_by_xpath("//select[@name='element_name']/option[text()='option_text']").click() أو استخدام الكود في الاجابة السابقة مع امكانية اختيار العناصر باستخدام موقعه Index : from selenium.webdriver.support.select import Select select_fr = Select(driver.find_element_by_id("fruits01")) select_fr.select_by_index(0)
-
يمكنك كذلك استخدام الكود التالي اذا كنت تستعمل python 2 : print(browser.current_url) و الكود في الاجابة السابقة اذا كانت النسخة python 3.
-
اذا كانت النسخ مختلفة ولمتعمل معك الإجابة السابقة، يمكنك استخدام الكود التالي وسيعمل: #استدعاء المكتبات from selenium.webdriver.firefox.options import Options as FirefoxOptions from selenium import webdriver #اختيار المتصفح options = FirefoxOptions() #الغاء ال Head options.add_argument("--headless") driver = webdriver.Firefox(options=options) driver.get("http://google.com")
-
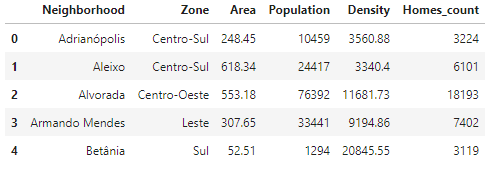
بجانب الطريقة السابقة هناك طريقة أخرى سهلة، وهي الاستفادة من أن الجداول في html يتم تعريفها بوسم table وبذلك نستطيع الحصول عليها بسهولة كالتالي: # استدعاء المكتبات import requests import pandas as pd from bs4 import BeautifulSoup # تحميل المحتوى من صفحة url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus" data = requests.get(url).text # تحويله الى html object soup = BeautifulSoup(data, 'html.parser') # طباعة الجداول print('Classes of each table:') for table in soup.find_all('table'): print(table.get('class')) ويكون الخرج كالتالي: OUTPUT: Classes of each table: ['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content'] ['wikitable', 'sortable'] ['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner'] بعد ذلك نستطيع الحصول على جدول بعينه كالتالي: # عمل قائمة بالجداول tables = soup.find_all('table') # البحث عن الجدول 'wikitable' و 'sortable' table = soup.find('table', class_='wikitable sortable') بعد ذلك نستطيع تحويل تلك الجداول الى dataframe كالتالي: # تعريف ال dataframe df = pd.DataFrame(columns=['Neighborhood', 'Zone', 'Area', 'Population', 'Density', 'Homes_count']) # تجميع البيانات for row in table.tbody.find_all('tr'): # الحصول على بيانات كل عمود columns = row.find_all('td') if(columns != []): neighborhood = columns[0].text.strip() zone = columns[1].text.strip() area = columns[2].span.contents[0].strip('&0.') population = columns[3].span.contents[0].strip('&0.') density = columns[4].span.contents[0].strip('&0.') homes_count = columns[5].span.contents[0].strip('&0.') df = df.append({'Neighborhood': neighborhood, 'Zone': zone, 'Area': area, 'Population': population, 'Density': density, 'Homes_count': homes_count}, ignore_index=True) ويكون الناتج النهائي كالتالي: df.head()
-
يمكنك كذلك استخدام طريقة مبسطة لتحميل ملفات ال pdf مباشرة كالتالي: #استدعاء المكتبات import requests from bs4 import BeautifulSoup as bs import urllib2 _URL = "url link" r = requests.get(_URL) soup = bs(r.text) urls = [] names = [] for i, link in enumerate(soup.findAll('a')): _FULLURL = _URL + link.get('href') if _FULLURL.endswith('.pdf'): urls.append(_FULLURL) names.append(soup.select('a')[i].attrs['href']) names_urls = zip(names, urls) for name, url in names_urls: print url rq = urllib2.Request(url) res = urllib2.urlopen(rq) pdf = open("pdfs/" + name, 'wb') pdf.write(res.read()) pdf.close() وكذلك يمكنك تحميل كافة ملفات ال pdf داخل صفحة بسهولة كالتالي: #استدعاء المكتبات import os import requests from urllib.parse import urljoin from bs4 import BeautifulSoup url = "url link" #عمل ملف لحفظ ما سيتم تحميله فيه folder_location = r'E:\webscraping' #خلق الملف اذا لميكن يوجد if not os.path.exists(folder_location):os.mkdir(folder_location) response = requests.get(url) soup= BeautifulSoup(response.text, "html.parser") for link in soup.select("a[href$='.pdf']"): #تسمية الملفات المحملة filename = os.path.join(folder_location,link['href'].split('/')[-1]) with open(filename, 'wb') as f: f.write(requests.get(urljoin(url,link['href'])).content)
-
بجانب استخدام xml ك parser يمكنك كذلك استخدام html مع استخدام urllib.request كبديل للمكتبة requests كالتالي: # استدعاء المكتبات import urllib.request from bs4 import BeautifulSoup # الموقع url = "https://undergrad.cs.umd.edu/what-computer-science" # قراءة الملفات من الموقع html = urllib.request.urlopen(url) # تحويلها الى html htmlParse = BeautifulSoup(html, 'html.parser') # الحصول على كل الفقرات for para in htmlParse.find_all("p"): print(para.get_text()) ويكون العائد منها كالتالي: Computer Science is the study of computers and computational systems. Unlike electrical and computer engineers, computer scientists deal mostly with software and software systems; this includes their theory, design, development, and application. Principal areas of study within Computer Science include artificial intelligence, computer systems and networks, security, database systems, human computer interaction, vision and graphics, numerical analysis, programming languages, software engineering, bioinformatics and theory of computing. Although knowing how to program is essential to the study of computer science, it is only one element of the field. Computer scientists design and analyze algorithms to solve programs and study the performance of computer hardware and software. The problems that computer scientists encounter range from the abstract-- determining what problems can be solved with computers and the complexity of the algorithms that solve them – to the tangible – designing applications that perform well on handheld devices, that are easy to use, and that uphold security measures. Graduates of University of Maryland’s Computer Science Department are lifetime learners; they are able to adapt quickly with this challenging field. Contact Our Office
-
بالاضافة للطرق السابقة يمكنك تحويل الملف الى xml ثم ايجاد القيم بسهولة باستخدام find_all كالتالي: xmlData = None with open('conf//test1.xml', 'r') as xmlFile: xmlData = xmlFile.read() xmlDecoded = xmlData xmlSoup = BeautifulSoup(xmlData, 'html.parser') repElemList = xmlSoup.find_all('repeatingelement') for repElem in repElemList: print("Processing repElem...") repElemID = repElem.get('id') repElemName = repElem.get('name') print("Attribute id = %s" % repElemID) print("Attribute name = %s" % repElemName) اما اذا أردت ايجاد قيمة عنصر معين: يمكنك كذلك استخدام find_all لجلب العناصر كالتالي: input_tag = soup.find_all(attrs={"name" : "stainfo"}) بعد ذلك تحديد العنصر الذي تريده بين كل العناصر التي تم ارجاعها: output = input_tag[0]['value'] أو استخدام find لجلب عنصر واحد فقط ثم ايجاد قيمته: input_tag = soup.find(attrs={"name": "stainfo"}) output = input_tag['value']
-
يمكنك كذلك استخدام الطرق التالية بدون الحاجة الي find_all من أجل ايجاد الوسوم: أولا اذا كان الملف لديك بالفعل يمكنك استخدام المثال التالي بسهولة: # استدعاء المكتبة from bs4 import BeautifulSoup markup = """ <!DOCTYPE> <html> <head><title>Example</title></head> <body> <div class="first"> Div with Class first </div> <p class="first"> Para with Class first </p> <div class="second"> Div with Class second </div> <span class="first"> Span with Class first </span> </body> </html> """ # تحويله الى html soup = BeautifulSoup(markup, 'html.parser') # طباعة اسماء الملفات الموجودة for i in soup.find_all(class_="first"): print(i.name) اما اذا كان لدينا رابط الصفحة فنستخدم نفس الطريقة تقريبا كالتالي: # استدعاء المكتبات from bs4 import BeautifulSoup import requests #الرابط URL = "https://academy.hsoub.com/questions/18275-%D8%A5%D9%8A%D8%AC%D8%A7%D8%AF-%D8%A7%D9%84%D9%88%D8%B3%D9%88%D9%85-tags-%D9%85%D9%86-%D8%AE%D9%84%D8%A7%D9%84-%D9%81%D8%A6%D8%A9-css-%D8%A8%D8%A7%D8%B3%D8%AA%D8%AE%D8%AF%D8%A7%D9%85-beautifulsoup-%D9%81%D9%8A-%D8%A8%D8%A7%D9%8A%D8%AB%D9%88%D9%86/" html = requests.get(URL) # تحويله الى HTML soup = BeautifulSoup(html.content, "html5lib") # طباعة اسماء ال tags for i in soup.find_all(class_="article--container_content"): print(i.name)
-
في البداية عليك البدء بتعلم كيفية استخدام نظام ال kali ,الذي يتشابه تقريبا في معظم أوامر مع بقية انظمة ال Linux، حيث أن تلك الخطوة هامة وأساسية لضمان البناء على أسس قوية. بعد ذلك يمكنك تعلم الأدوات tools الموجودة بالفعل على Linux أو تحميل الأدوات الشهيرة والتعلم باستخدامها حيث تكون أوامرها سهلة ومشتقة من الأوامر العادية لأنظمة ال Linux ,التي يفترض أنك قد تعلمتها بالفعل: حتى ان بعضها يتوافر فيه ال GUI أو واجهة المستخدم. بعد ذلك تبدأ بعمل الأدوات الخاصة بك بأكوادك الخاصة والتي حينها ستكون سهلة لأنك فهمت كيف تقوم بالأختراق وكذلك فهمت وتدربت على استخدام اللينكس. نصيحة شخصية، لا تقوم أبدا بتخطي أي خطوة من الخطوات السابقة لضمان الفهم العميق والسهل.
-
بالاضافة للطريقة السابقة التي تعتمد على ال terminal، يمكنك ايضا تثبيت الحزمة باستخدام ملف التحميل .exe أو tar في لينكس والذي تستطيع ايجاده من هنا: https://www.crummy.com/software/BeautifulSoup/bs4/download/4.0/ بعد تحميله قم بالتصفح الى مكان تحميله باستخدام cd ثم بعد ذلك اكتب السطر التالي في ال terminal كالتالي: Python setup.py install اما اذا كانت .exe تقوم بتثبيته كأي برنامج على ويندوز.
-
بالاضافة للطريقة السابقة يمكننا استخدام الكود التالي بسهولة: #استدعاء المكتبات from bs4 import BeautifulSoup import requests #العنوان الذي تريده url = "https://academy.hsoub.com/questions/18269-%D9%83%D9%8A%D9%81%D9%8A%D8%A9-%D8%A7%D8%B3%D8%AA%D8%AE%D8%B1%D8%A7%D8%AC-%D8%AC%D9%85%D9%8A%D8%B9-%D8%B9%D9%86%D8%A7%D9%88%D9%8A%D9%86-url-%D8%AF%D8%A7%D8%AE%D9%84-%D8%B5%D9%81%D8%AD%D8%A9-%D8%A7%D9%84%D9%88%D9%8A%D8%A8-%D8%A8%D8%A7%D8%B3%D8%AA%D8%AE%D8%AF%D8%A7%D9%85-%D9%85%D9%83%D8%AA%D8%A8%D8%A9%C2%A0beautifulsoup-%D9%81%D9%8A-%D8%A8%D8%A7%D9%8A%D8%AB%D9%88%D9%86/" # ارسال طلب لجلب المعلومات من الصفحة. response = requests.get(url) # الحصول على الكود من الصفحة data = response.text # تمرير ما تم الحصول عليه للمكتبة soup = BeautifulSoup(data, 'lxml') # الحصول على كل ال tags التي تبدا ب <a>. #لاحظ ان هذا يحتوى على كل ال url بداخل html tags = soup.find_all('a') # طباعة كل اللينكات for tag in tags: print(tag.get('href')) لاحظ انه هذا يقوم بارجاع كل العناوين فداخل صفحة ال html والتي تكون بداخل <a> tag ، اي كل ال links الموجودة.
-
دعنا نوضح ما فائدة تلك الخوارزمية أولا. نعلم أن أن معظم الخصائصلا تتغير حتى بعد التدوير , ولكن بالنسبة لتغيير الحجم سواء بالتكبير أو التصغير فقد لا يصح هذا، كمثال أن الزاوية لاتبقى نفسها بعد التغيير , لذلك نقول أن مكتشفات هاريس متأثرة بالحجم. ومن هنا نستخدم خوارزمية sift والتي تسمح لنا بعمل بجعل الصورة مناسبة للتكبير والتصغيير دون التأثير على خصائصها. أما كمثال على تطبيقها في opencv فهو كالتالي: في البداية علينا تحميل الصورة وبناء نموذج بسيط ل sift: #استدعاء المكتبات import cv2 import numpy as np from matplotlib import pyplot as plt %matplotlib inline #تحميل الصورة img = cv2.imread('wt.jpg') # قراءة الصورة بشكل صحيح img= cv2.cvtColor(img,cv2.COLOR_BGR2RGB) gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) # بناء النموذج sift = cv2.SIFT() kp = sift.detect(gray,None) ثم بعد ذلك نظهر الخصائص التي اكتشفها النموذج بوضع داائرة صغيرة حولها: lt.figure(figsize=(8,16)) plt.imshow(res_img) plt.xticks([]) plt.yticks([]) plt.title('Ordinary Points') plt.show() res2_img=cv2.drawKeypoints( gray,kp,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS) plt.figure(figsize=(8,16)) plt.imshow(res2_img) plt.xticks([]) plt.yticks([]) plt.title('More Clarity Points') هنا قمنا برسم دوائر صغيرة وكبيرة حول النقاط الرئيسية: ثم لحساب المواصفات يوجد عدة طرق لكن ابسطها مباشرة عن طريق ايجاد النقاط والموصفات بتابع واحد هكذا: sift = cv2.SIFT() kp, des = sift.detectAndCompute(gray,None)
.png.a85530cd959793473bad8e39714158a9.png)

-
بالاضافة للاجابة السابقة، يمكنك كذلك استخدام المكتبة base مع opencv لتحقيق ذلك: #قراءة المكتبات import cv2 import base64 cap = cv2.VideoCapture(0) #استدعاء الصورة retval, image = cap.read() #تحويل الصورة retval, buffer = cv2.imencode('.jpg', image) jpg_as_text = base64.b64encode(buffer) print(jpg_as_text) cap.release() ويمكنك التعامل مع الصورة وتحويلها الى bytes باستخدام PIL وسواء استخدمت opencv أو PIL فكلاهما يقوم بتحويل الوصرة الى bytes من نوع string كالتالي: #استدعاء المكتبات import io from PIL import Image #قراءة الصورة im = Image.open('test.jpg') #تحجيم الصورة im_resize = im.resize((500, 500)) #تحويلها الي بايتات buf = io.BytesIO() im_resize.save(buf, format='JPEG') byte_im = buf.getvalue()
-
تستطيع فصل كل قناة من قنوات الصورة الثلاث بمفردها باستخدام الدالة cv2.split كالتالي: # تحميل الصورة image = cv2.imread("image") #فصل قنوات الصورة، لاحظ هنا ترتيب القنوات مناسب لما تقوم المكتبة بقراءته وهو BGR (B, G, R) = cv2.split(image) # اظهار كل قناة بمفردها cv2.imshow("Red", R) cv2.imshow("Green", G) cv2.imshow("Blue", B) cv2.waitKey(0) وتبدو هكذا عند اظهارها: ويمكنك كذلك تمثيل كل لون ومساهته في الخلفية هكذا: # تمثيل الالوان zeros = np.zeros(image.shape[:2], dtype="uint8") cv2.imshow("Red", cv2.merge([zeros, zeros, R])) cv2.imshow("Green", cv2.merge([zeros, G, zeros])) cv2.imshow("Blue", cv2.merge([B, zeros, zeros])) cv2.waitKey(0) وهنا تظهر هكذا: ثم تستطيع اعادة دمجها مرةأخرى بأي ترتيب تريد باستخدام ال\الة cv2.merge هكذا: # دمجهم بالترتيب الصحيح merged = cv2.merge([B, G, R]) cv2.imshow("Merged", merged) cv2.waitKey(0) cv2.destroyAllWindows() وتظهر حينها ملونة هكذا:
.png.b87766919390d43e6ec9cd79ed0d9bd8.png)


-
يمكنك تحديد النقاط الحدودية سواء الداخلية أو الخاريجية للشكل ثم رسمة بالطريقة التي تعجبك كالتالي: _ret, contours, hierarchy = cv2.findContours(threshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(img,contours , -1, (255,0,0), 1) اما اذا كانت لديك النقاط الحدودية مسبقا فيمكنك رسمها مباشرة بعد تحويلها الى صيغة numpy هكذا: cv2.drawContours(image, contours, -1, (0, 255, 0), 3) حيث image هي الصورة التي تريد الرسم عليها، contours هي ال numpy التي تحوي النقاط الحدودية و -1 لتشمل كل الحدود ثم تحديد لون وسمك الخط. وتظهر بعد تشغيلها هكذا:

-
الموضوع يعتمد على المعايير، مثل وحدات قياس الوزن، فهناك الكيلوجرام وهناك الرطل وغيرها، ولكل دولة تستخدم المعيار الذي تريد، هنا نفس الفكرة، لقد قرروا استخدام BGR عوضا عن RGB والتي تعد المعيار الأساسي، ليس لشئ وانما لأهواء صانع المكتبة، فعندما سأل بالفعل عن هذا أجاب وفعليا تم اختيارها لاسباب تاريخية ليس الا، وليس هناك فرق بينهما فهما يمثلان ترتيب قنوات الالوان في الصورة والتي يمكننا ضبطها بسهولة او حتى تغييرها لنوع ثالث مثل GRB كما تشاء.
-
اذا كان الغرض من السؤال تحديد اسم الشكل فيمكنك استخدام الاجابة السابقة، اما اذا كنت تريد تحديد حدود الشكل، فبالاضافة للطريقة السابقة، يمكنك استخدام الدالة cv2.Hough والتي تمكنك من تحديد الخطوط المتصلة سويا باستخدام cv2.HoughLines والتي باستخدامها يمكننا تحديد الأشكال الهندسية ، وهناك دالة أخرى لتحديد الدوائر باستخدام cv2 HoughCircles (هناك دالة خاصة للدوائر لانها تعد خطوطا مغلقة). وتعمل عن طريق تتبع الخطوط المتصلة سويا وتقوم باظهارها بلون مختلف لتوضيحها، الكود التالي يوضح كيفية استخدامها: #استدعاء المكتبات import numpy as np import matplotlib.pyplot as plt import cv2 cap = cv2.VideoCapture(0) while True: _, image = cap.read() # التحويل للرمادي grayscale = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # تحديد حدود الاجسام edges = cv2.Canny(grayscale, 30, 100) # تحديد الخطوط lines = cv2.HoughLinesP(edges, 1, np.pi/180, 60, np.array([]), 50, 5) # توضيح الخطوط بلون مختلف for line in lines: for x1, y1, x2, y2 in line: cv2.line(image, (x1, y1), (x2, y2), (255, 0, 0), 3) cv2.line(edges, (x1, y1), (x2, y2), (255, 0, 0), 3) # عرض الصورة cv2.imshow("image", image) cv2.imshow("edges", edges) if cv2.waitKey(1) == ord("q"): break cap.release() cv2.destroyAllWindows()
-
في البداية دعنا نفهم كيف تعمل L1-NORM حتى نرى اذا كان مناسبا لما تريد أم لا. L1 تقوم بجعل قيم البيكسل للصورة بين 0 و 1 عن طريق المعادلة التالية: بينما في L2 تقوم ايضا بجعل القيم بين 0 و 1 لكن بمعادلة مختلفة وهي جذر مربع القيم كالتالي: ويمكنك تطبيق احداهما يدويا على الصور في بايثون، اما عن طريقة استخدام ال normalization في opencv فهي كالتالي: #استدعاء المكتبات import cv2 as cv import numpy as np #قراءة الصورة img = cv.imread('city.jpeg') norm_img = np.zeros((800,800)) #تعديل أبعاد الصورة باستخدام normalize final_img = cv.normalize(img, norm_img, 0, 255, cv.NORM_MINMAX) #حفظ الصورة cv.imwrite('city_normalized.jpg', final_img) cv.waitKey(0) cv.destroyAllWindows() الصورة الأصلية: بعد عمل normalization: ويمكنك استخدام cv.NORM_L1 أو cv.NORM_L2 بدلا من cv.NORM_MINMAX .
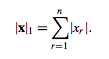
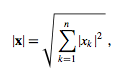


-
تستطيع تغيير درجة شفافية الرسم نفسه عن طريق استخدام alpha من دالة plot كالتالي: # استدعاء الدوال import matplotlib.pyplot as plt import numpy as np # خلق بيانات x = np.array([-2, -1, 0, 1, 2]) y1 = x*0 y2 = x*x y3 = -x*x # رسم الدالة وتغيير درجة الشفافية plt.plot(x, y2, alpha=0.2) plt.plot(x, y1, alpha=0.5) plt.plot(x, y3, alpha=1) plt.legend(["op = 0.2", "op = 0.5", "op = 1"]) plt.show() ويكون الناتج كالتالي: يمكنك كذلك جعل لون الخلفية شفافة مثل صور ال png كالتالي: import matplotlib.pyplot as plt fig = plt.figure() plt.plot(range(10)) fig.savefig('temp.png', transparent=True) يمكنك كذلك التحكم في درجة الشفافية من الدالة patch.set_alpha : import matplotlib.pyplot as plt fig = plt.figure() fig.patch.set_facecolor('blue') fig.patch.set_alpha(0.7) ax = fig.add_subplot(111) ax.plot(range(10)) #تحديد اللون ودرجة الشفافية ax.patch.set_facecolor('red') ax.patch.set_alpha(0.5) fig.savefig('temp.png', facecolor=fig.get_facecolor(), edgecolor='none') plt.show()
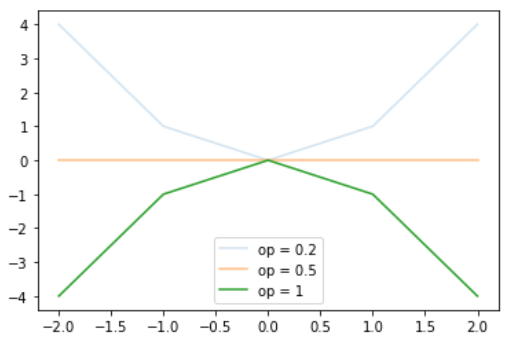
-
يمكنك كذلك استخدام ما يسمي object detection أو تحديد الكائنات والمقصود منها تحديد الأجسام أو الصور داخل صورة، ويتم ذلك عن طريق احتواء opencv على بعض النماذج المتعلمة مسبقا باستخدام التعلم العميق والتي يمكن استخدامها مباشرة، الكود التالي يوضح استخدامها بسهولة: import cv2 from matplotlib import pyplot as plt # فتح الصورة img = cv2.imread("image.jpg") # قراءة الصورة بالألوان الصحيحة img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # استدعاء النموذج المتعلم stop_data = cv2.CascadeClassifier('stop_data.xml') found = stop_data.detectMultiScale(img_gray, minSize =(20, 20)) #لا يقوم بعمل شئ لولم يوجد اشارة مرور amount_found = len(found) if amount_found != 0: # اذا كان هناك اكثر من علامة مرور for (x, y, width, height) in found: # رسم اشارة خضراء cv2.rectangle(img_rgb, (x, y), (x + height, y + width), (0, 255, 0), 5) # طباعة الصورة plt.subplot(1, 1, 1) plt.imshow(img_rgb) plt.show() والنتيجة كالتالي:
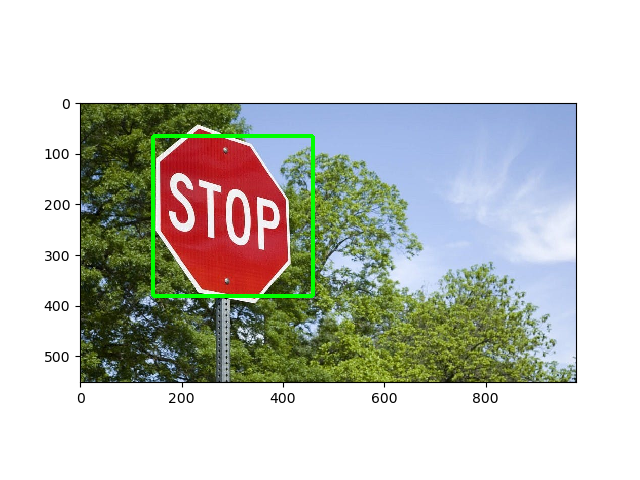
- 2 اجابة
-
- 1
-

-
الموضوع بسيط، يمكنك ايجاد منتصف الوجه ثم رسم الدائرة بابعادها التي تريدها ببساطة، الكود التالي يقوم بهذا: import cv2 #كود تحديد الوجة، قد لا تحتاجه لو لا تريد ايجاد الوقة تلقائيا face_cascade = cv2.CascadeClassifier("face.xml") cap = cv2.VideoCapture(0) while True: _, img = cap.read() gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.1, 4) for (x, y, w, h) in faces: center_coordinates = x + w // 2, y + h // 2 radius = w // 2 ايجاد نقطه المنتصف #رسم الدائرة cv2.circle(img, center_coordinates, radius, (0, 0, 100), 3) cv2.imshow('img', img) k = cv2.waitKey(30) & 0xff if k == 27: break cap.release() وتظهر كالتالي:


-
لزيادة سطوع الصورة، يمكننا اضافة ثابت على كل بيكسل ، فمثلا اذا كان عندنا صورة ذات قيم : لو أردنا زيادة سطوعها يمكننا اضافة 60 على كل بيكسل وتصبح هكذا: اما عن الكود فيمكنك استخدام cv2.add وهي ستقوم برفع الاضاءة هكذا: import cv2 import numpy as np image = cv2.imread('image.png') hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) value = 60 #القيمة التي تريد زيادتها cv2.add(hsv[:,:,2], value, hsv[:,:,2]) image = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR) cv2.imwrite('out.png', image) الدخل: والنتيجة تكون صورة أكثر سطوعا هكذا: ويمكنك زيادة السطوع أكثر بزيادة القيمة المشار لها في الكود.


-
تمنحك triggers التحكم قبل تغيير البيانات مباشرة وبعد تغيير البيانات مباشرة. هذا يسمح بـالتدقيق في صحة البيانات فمثلا انت تريد أن تقوم بإجراء معين بغض النظر عن ما تريد أن تفعل سواء كان قبل أو بعد أحد الإجراءات التالية : INSERT, UPDATE, DELETE عندها تستخدم الـ Trigger. وحينها يمكنك استخدام ال trigger حتي تنفذ تلك الأوامر دون تدخل من المبرمج. وهنا يمكنك استخدامها في حالات مشابهة للحالات التالي: عمل دالة تقوم بنقل سجلات المتابعة وتفاصيلها الى جدول الارشيف لعدم احتياجه وجدولته اسبوعيا. إضافة بيانات الى جدول التنبيهات بعد اضافة تعليق في جدول التعليقات على مقالة محددة . اما عن حالات عدم استخدامه فقد يكون بسبب صعوبة استخدامه في بعض اللغات وكذلك انه قد لا يكون واضحا للمبرمج لانه يقوم بعمله دون تدخله وبالتالي قد تحدث اشياء غير متوقعة بالنسبة للمبرمج.
-
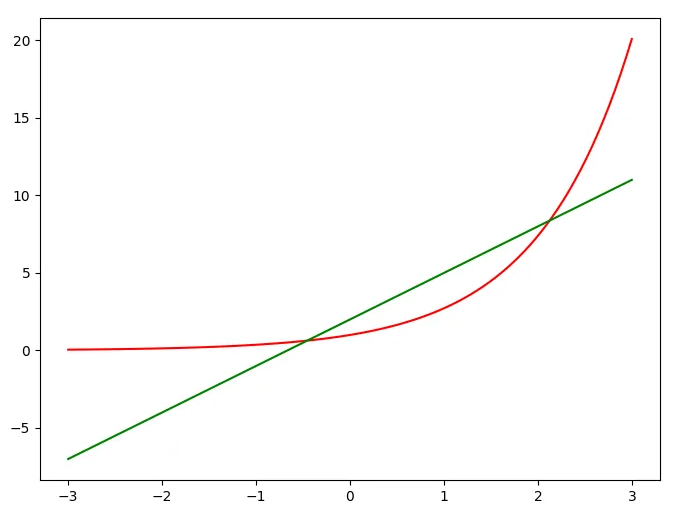
يمكنك استخدام matplotlib.axes.Axes.get_legend().set_visible() مع وضع قيمتها ب false لحذفها كالتالي: #استدعاء المكتبات import numpy as np import matplotlib.pyplot as plt #الدوال التي نريد رسمها x=np.linspace(-3,3,100) y1=np.exp(x) y2=3*x+2 #حجم الرسمة fig, ax = plt.subplots(figsize=(8,6)) #اسماء الرسومات ax.plot(x, y1, c='r', label='expoential') ax.plot(x, y2, c='g', label='Straight line') leg = plt.legend() #اخفاء ال legend ax.get_legend().set_visible(False) plt.show() أو استخدام label=_nolegend_ في matplotlib.axes.Axes.plot() كالتالي: #استدعاء الدوال import numpy as np import matplotlib.pyplot as plt x=np.linspace(-3,3,100) y1=np.exp(x) y2=3*x+2 fig, ax = plt.subplots(figsize=(8,6)) leg = plt.legend() #الرسم ax.plot(x, y1, c='r', label='_nolegend_') ax.plot(x, y2, c='g', label='_nolegend_') plt.show() أو استخدام legend_ =None كالتالي: import numpy as np import matplotlib.pyplot as plt x=np.linspace(-3,3,100) y1=np.exp(x) y2=3*x+2 fig, ax = plt.subplots(figsize=(8,6)) leg = plt.legend() ax.plot(x, y1, c='r', label='expoential') ax.plot(x, y2, c='g', label='Straight line') #حذف ال legend plt.gca.legend_ =None plt.show() وفي كل الأحوال تظهر الصورة بدون legend كالتالي: