


Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
الفرق فهو ترتيب الألوان الذي تقرأه matplot ، فهي تقرأ BGR في حين أن معظم الصور RGB، لذا ببساطة شديدة كل ما علينا هو تغيير ترتيب الألون كالتالي: plt.imshow(lena[:,:,::-1]) # RGB-> BGR وتستطيع كتابتها بطريقة مختلفة كالتالي: plt.imshow(lena[...,::-1]) وستظهر بالشكل الصحيح هكذا:

-
يمكنك استخدام اما الطريقة اليدوية واما طريقة سريعة باستخدام opencv لايجاد عدد الاطارات داخل فيديو، الكود التالي يوضح الطريقيتين والفرق في السرعة بينهما: def frame_count(video_path, manual=False): def manual_count(handler): frames = 0 while True: status, frame = handler.read() if not status: break frames += 1 return frames cap = cv2.VideoCapture(video_path) # بطيئة لكنها دقيقة 100% if manual: frames = manual_count(cap) #سريعة لكن ليس بدقة الأولي else: try: frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) except: frames = manual_count(cap) cap.release() return frames اذا قمنا بتشغيل الكود وطباعة الوقت الذي تستغرقه كل طريقه منهما بجانب عدد الاطارات تكون كالتالي: #الطريقة الأولى frames: 3671 0.018054921 (s) #الطريقة الثانية frames: 3521 9.447095287 (s) لاحظ الاختلاف في الوقت المستغرق من كل منها وكذلك عدد الإطارات، الطريقة الأولى أبطأ لكنها دقيقة 100% أما الثانية فهي سريعة للغاية لكن بطيئة.
-
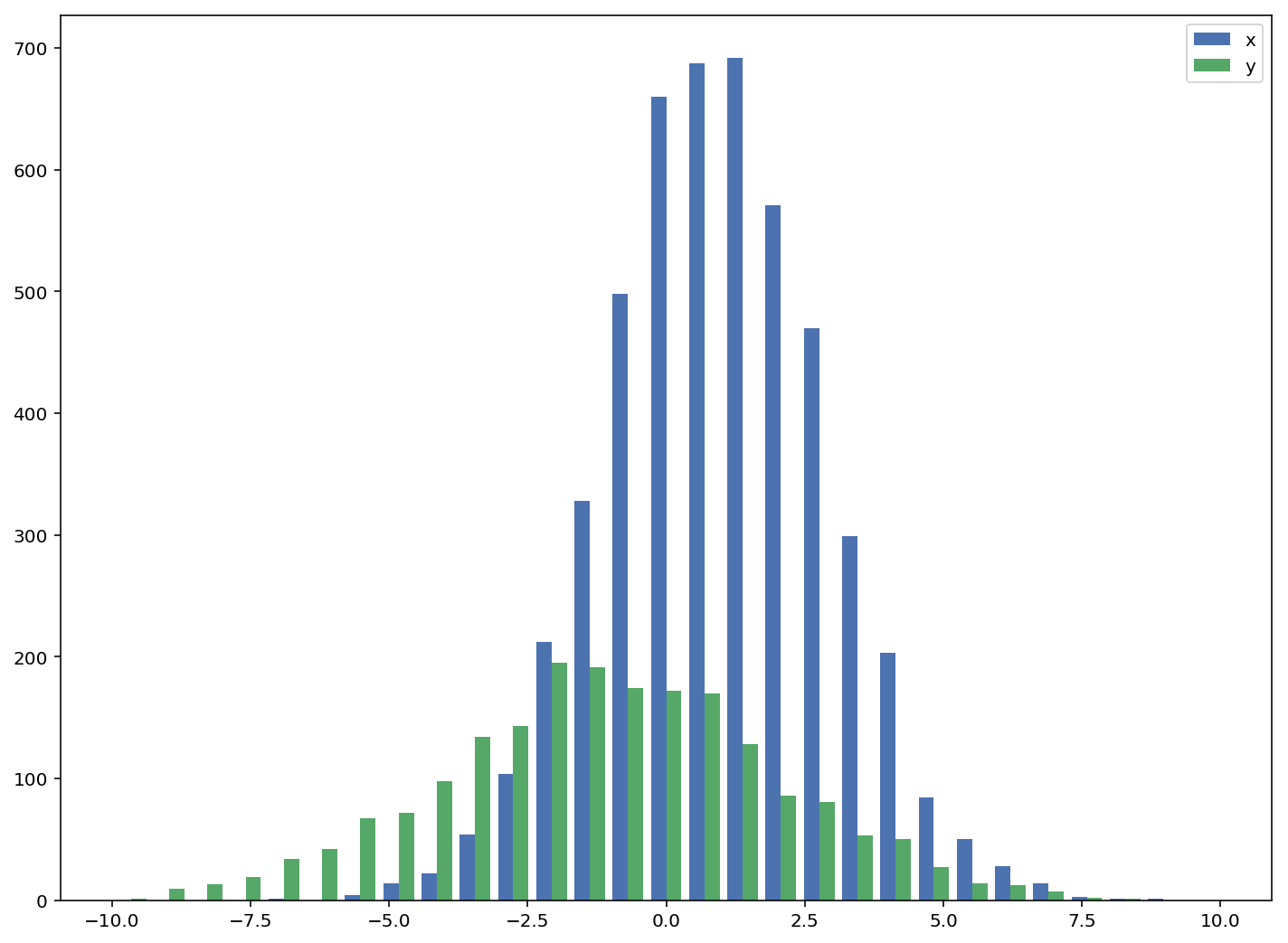
الموضوع بسيط حيث يمكنك فقط رسم كل هيستوغرام بمفردة واعطاءهما اسماً ومن ثم وضعهم في نفس الرسمة وسيكونون مختلفين، أنظر المثال التالي للتوضيح: #استدعاء المكتبات import random import numpy from matplotlib import pyplot #تخمين أرقام عشوائية x = [random.gauss(3,1) for _ in range(400)] y = [random.gauss(4,2) for _ in range(400)] bins = numpy.linspace(-10, 10, 100) #رسم الشكلين pyplot.hist(x, bins, alpha=0.5, label='x') pyplot.hist(y, bins, alpha=0.5, label='y') pyplot.legend(loc='upper right') pyplot.show() وسيظهروا ببساطة كالتالي: اما اذا لم ترد الرسومات متداخلة وأردتهم بجوار بعضهم البعض يمكنك التعديل قليلا على نفس الكود ليصبح هكذا: import numpy as np import matplotlib.pyplot as plt plt.style.use('seaborn-deep') x = np.random.normal(1, 2, 5000) y = np.random.normal(-1, 3, 2000) bins = np.linspace(-10, 10, 30) #لاحظ التغيير هنا plt.hist([x, y], bins, label=['x', 'y']) plt.legend(loc='upper right') plt.show() وستظهر الرسومات بجانب بعضها:
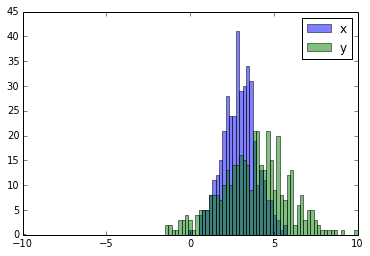
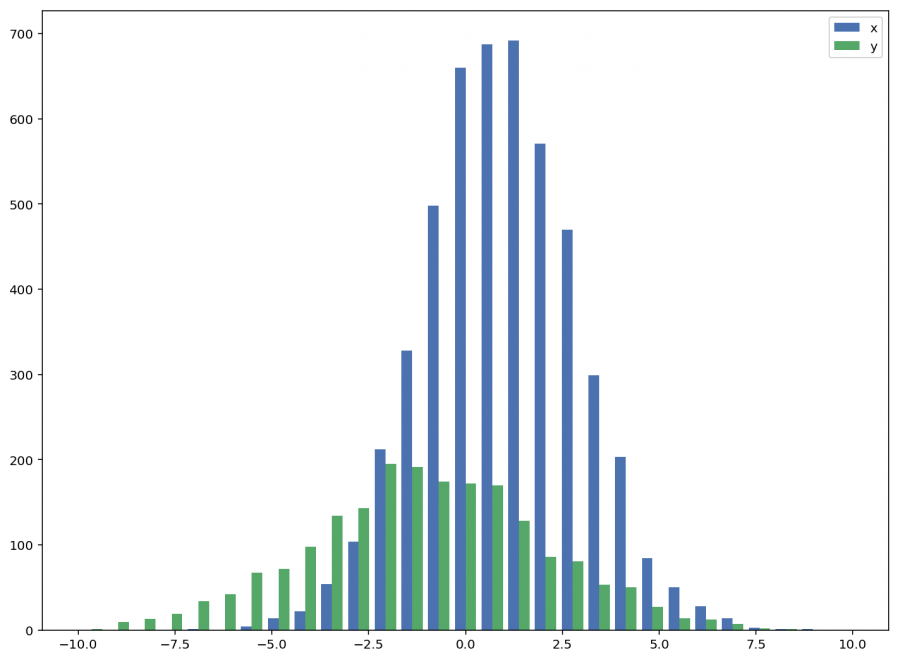
-
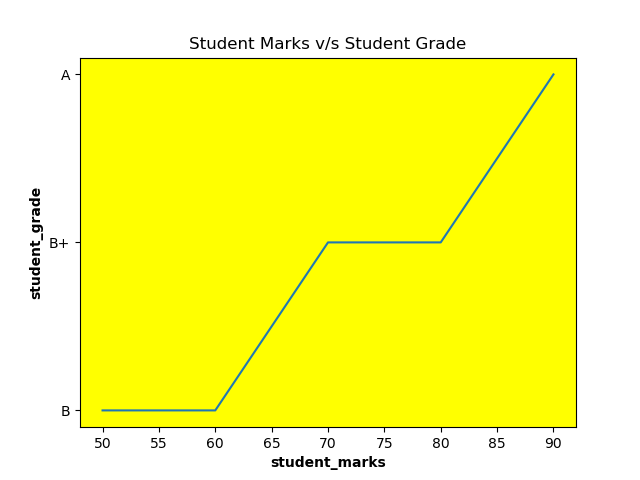
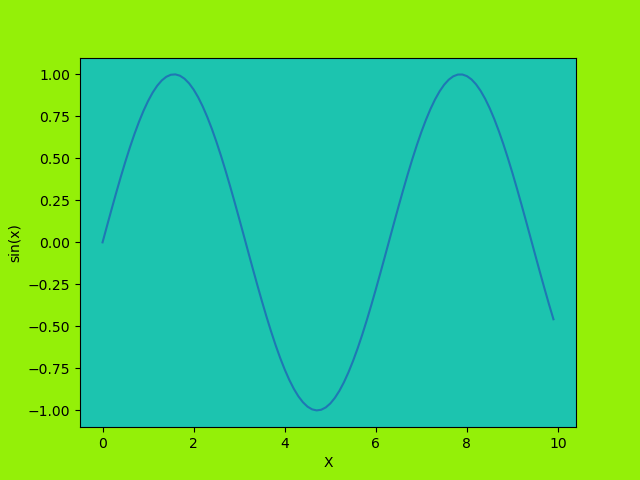
يمكنك استخدام ax.set_facecolor والذي يمكنك بالتحكم بالوان الرسومات بشكل كبير ابتداء من تغيير الخلفية وحتى تغيير الوان بداخل بعضها كما سنري في الامثلة التالية. الولا دعنا ننشئ رسم بشكل بسيط: # استدعاء الدالة import matplotlib.pyplot as plt # اعطاء قيم student_marks = [50, 60, 70, 80, 90] student_grade = ['B', 'B', 'B+', 'B+', 'A'] plt.plot(student_marks, student_grade) # اعطاء اسماء للمحاور plt.xlabel("student_marks", fontweight='bold') plt.ylabel("student_grade", fontweight='bold') # اعطاء اسم للرسم plt.title("Student Marks v/s Student Grade") # عرض الرسم plt.show() تظهر كأي رسم اعتيادي كالتالي: ويمكننا تغيير لون الخلفية للون الأصفر بسهولة كالتالي: #نفس السابق import matplotlib.pyplot as plt student_marks = [50, 60, 70, 80, 90] student_grade = ['B', 'B', 'B+', 'B+', 'A'] plt.plot(student_marks, student_grade) plt.xlabel("student_marks", fontweight='bold') ax = plt.axes() # تغيير لون الخلفية للاصفر ax.set_facecolor("yellow") plt.ylabel("student_grade", fontweight='bold') plt.title("Student Marks v/s Student Grade") plt.show() وتظهر هكذا: يمكنك كذلك تغيير اللون الداخلى والخارجي للرسم بسهولة: # استدعاء المكتبات import matplotlib.pyplot as plt import numpy as np # اعطاء قيم x = np.arange(0, 10, .1) y = np.sin(x) # ضبط لون الخلفية الخارجي plt.figure(facecolor='#94F008') # الرسم plt.plot(x, y) # اعطاء اسماء للمحاور plt.xlabel("X") ax = plt.axes() # ضبط لون الخلفية الداخلية ax.set_facecolor("#1CC4AF") plt.ylabel('sin(x)') # اظهار الرسم plt.show() وتظهر هكذا: لاحظ امكانية كتابة اللون اما باسمه اذا كان متوافرا أو بالكود الخاص به.
.thumb.png.5cc3e3f26286ac8714b24f051c493614.png)
-
تستطيع استخدام selectROI لتحديد الأماكن التي تهتم بها ورسم الخطوط والمستطيلات حولها، وتتميز بسهولة استخدامها كما انها تمكنك من تحديد مكان أو أكثر في الصورة، المثال التالي يوضح كيفية استخدامها لاستخراج وجة شخص واحد: import cv2 import numpy as np #مكان الصورة img_path="image.jpeg" #قراءة الصورة img_raw = cv2.imread(img_path) #استخدام الدالة roi = cv2.selectROI(img_raw) #اظهار المكان print(roi) #قص المنطقة التي تم تحديدها roi_cropped = img_raw[int(roi[1]):int(roi[1]+roi[3]), int(roi[0]):int(roi[0]+roi[2])] #اظهار الصورةالمقصوصة cv2.imshow("ROI", roi_cropped) #حفظ الصورة المقصوصة cv2.imwrite("crop.jpeg",roi_cropped) cv2.waitKey(0) وتظهر كالتالي: يمكنك كذلك استخدامها لقص عدة أماكن مرة واحدة كالتالي: import cv2 import numpy as np img_path="image.jpeg" img_raw = cv2.imread(img_path) ROIs = cv2.selectROIs("Select Rois",img_raw) print(ROIs) crop_number=0 #تحديد الأماكن المراد قصها for rect in ROIs: x1=rect[0] y1=rect[1] x2=rect[2] y2=rect[3] #قص الأماكن img_crop=img_raw[y1:y1+y2,x1:x1+x2] cv2.imshow("crop"+str(crop_number),img_crop) cv2.imwrite("crop"+str(crop_number)+".jpeg",img_crop) crop_number+=1 cv2.waitKey(0) وتظهر هنا كالتالي:


-
تستخدم الدالة cv2.waitKey كأنها مؤقت ، بحيث تقوم بادخال الوقت الذي تريد أن تنتظره الدالة (بالمللي ثانية) بحيث يقوم البرنامج خلال تلك المدة بعمله على الصور او الفيديوهات ثم بعد انتهاء الوقت يقوم بعمل شئ أخر، الكود التالي مثال على هذا: import cv2 import time img = cv2.imread("flowers.jpg") cv2.imshow("Flowers",img) initial_time = time.time() cv2.waitKey(3000) final_time = time.time() print("Window is closed after",(final_time-initial_time)) ويكون الخرج تلك الصورة مع الوقت الذي أخذته الصوره وهي 3 ثوان: Window is closed after 3.0099525451660156 يمكن أيضا استخدامها بحيث لا تنتظر وقتا محددا وانما حدث، كالضغط على زر، المثال التالي يوضح إستخدامها بحيث تظل الصورة معروضة حتى يقوم المستخدم بالضغط على أي زر فتختفي: #استدعاء الدالة import cv2 as cv #قراءة الصورة imageread = cv.imread('C:/Users/admin/Desktop/images/test.jpg') #انتظار الحدث cv.imshow('Image', imageread) cv.waitKey(0) cv.destroyAllWindows()

-
يمكنك استخدام الدالة cv2.vconcat للدمج بشكل vertical أي رأسي والدالة cv2.hconcat للدمج بشكل horizontal أي أفقي. المثال التالي يوضح كيفية دمج صورتين بشكل رأسي ولهم نفس الأبعاد: import cv2 import numpy as np #قراءة الصور im1 = cv2.imread('data/src/lena.jpg') im2 = cv2.imread('data/src/rocket.jpg') #دمج الصور وعرضها im_v = cv2.vconcat([im1, im1]) cv2.imwrite('data/dst/opencv_vconcat.jpg', im_v) وتظهر كالتالي: يمكنك كذلك دمج الصور التي ليس لها أبعاد متساوية كالتالي: def vconcat_resize_min(im_list, interpolation=cv2.INTER_CUBIC): w_min = min(im.shape[1] for im in im_list) im_list_resize = [cv2.resize(im, (w_min, int(im.shape[0] * w_min / im.shape[1])), interpolation=interpolation) for im in im_list] return cv2.vconcat(im_list_resize) im_v_resize = vconcat_resize_min([im1, im2, im1]) cv2.imwrite('data/dst/opencv_vconcat_resize.jpg', im_v_resize) وتظهر كالتالي بعد تعديل أبعادهم سويا: ويمكن استخدام نفس الطرق في دمج الصور أفقيا


-
يمكنك ببساطة استخدام الدالة puttext لوضع الكلام على الصور وهي كالتالي: cv2.putText(image, text, org, font, fontScale, color, thickness, lineType, bottomLeftOrigin) حيث تقوم بأخذ الصورة سواء بتحميلها او صنعها ووضع الكلام الذي تريده بتنسيقاته مثل اللون سمك الخط وكذلك مكان الكلام ، المثال التالي يوضح كيفية وضع الكلام على صوره صنعناها: import numpy as np import cv2 #اختيار نوع الخط font = cv2.FONT_HERSHEY_SIMPLEX # صنع صورة سوداء img = np.zeros((512,512,3), np.uint8) #كتابة الكلام على الصورة cv2.putText(img,'Hack Projects',(10,500), font, 1,(255,255,255),2) #عرض الصورة cv2.imshow("img",img) cv2.waitKey(0) يمكنك كذلك استخدامها بشكل مستمر داخل while بحيث تقوم بتغيير الكلام او ايقافه كالتالي: import cv2 path = "C:/Users//Desktop/test.jpg" img = cv2.imread(path) font = cv2.FONT_HERSHEY_SIMPLEX i = 10 while(1): cv2.imshow('img',img) k = cv2.waitKey(33) if k==27: # Esc اضغط للخروج break elif k==-1: # في العادي -1 ترجع لذا نكمل continue else: print (k) # غير ذلك اطبع القيمة على الصورة cv2.putText(img, chr(k), (i, 50), font, 1, (0, 255, 0), 1, cv2.LINE_AA) i+=15 cv2.waitKey(0) cv2.destroyAllWindows()
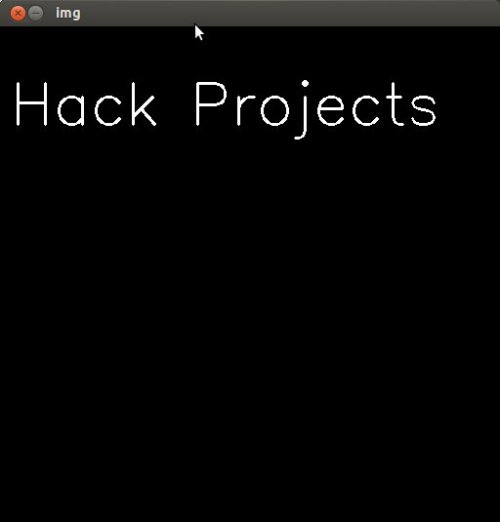
-
يمكن استخدام الدالة axcline لتحديد اتجاه العمود الذي تريد رسمه بسهولة وهي كالتالي: matplotlib.pyplot.axhline(y=0, xmin=0, xmax=1, hold=None, **kwargs) بحيث تقوم بتحديد المكان على المحور السيني x ومكان بدء الخط العمودي y ومكان نهايته. المثال التالي يوضح كيفية استخدامها بسهوله داخل رسمه: from matplotlib import pyplot as plt xdata = list(range(10)) ydata = [_*2 for _ in xdata] plt.plot(xdata, ydata, 'b') plt.axvline(x=5, ymin=0.1, ymax=0.9) plt.grid() plt.show() ويمكنك كذلك رسم عدة خطوط سويا في نفس الرسمة كالتالي: from matplotlib import pyplot as plt xdata = list(range(10)) ydata = [_*2 for _ in xdata] plt.plot(xdata, ydata, 'b') plt.hlines(y=5, xmin=0, xmax=10) plt.vlines(x=5, ymin=0, ymax=20) plt.grid() plt.show()
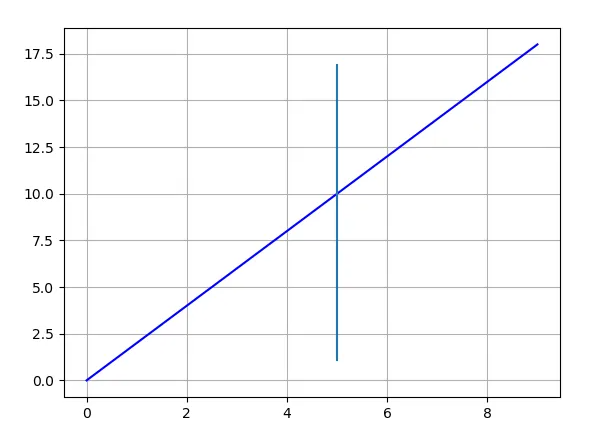
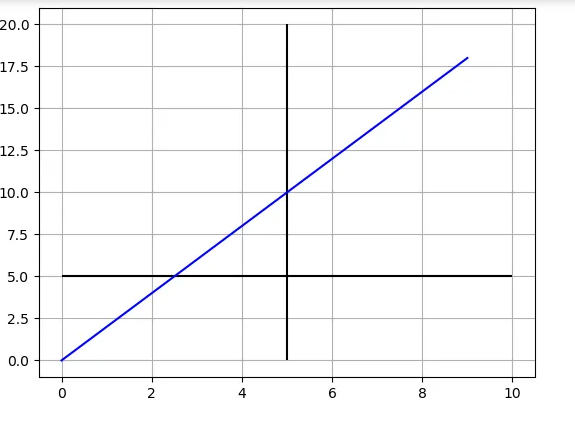
-
ببساطة يعتبر التعتيم البسيط هي طريقة لفصل بعض عناصر الصورة عن بعضها الاخر، بحيث يتم وضع قيمة يكون ما قبلها مثلا 0 أي أسود وما بعدها يكون 255 أي ابيض كالكود التالي: If f (x, y) < T then f (x, y) = 0 else f (x, y) = 255 where f (x, y) = Coordinate Pixel Value T = Threshold Value. وتوجد منها الكثير من الأنواع التي تختلف في طريقة عملها وهي كالتالي: cv2.THRESH_BINARY #تكون القيم أما 0 أو 1 cv2.THRESH_BINARY_INV # نفس طريقة عمل السابقة لكن ما يكون أبيض هناك هو أسود هنا والعكس cv2.THRESH_TRUNC # تضع الحد الأقصي لقيمة البيكسل وما أكبر منها تجعله يساويها cv2.THRESH_TOZERO # تقوم بوضع كل كثافة بيكسل أقل من القيمة الموضوعه ل 0 cv2.THRESH_TOZERO_INV # عكس السابقه بحيث كل كثافة بيكسل أقل من القيمة الموضوعه ب 255 وكمثال لطريقة عمل كل منهم أنظر الكود التالي حيث نقوم بتحميل صورة وتطبيق كل الطرق عليها لملاحظة الفرق: import cv2 import numpy as np from matplotlib import pyplot as plt img = cv2.imread('gradient.png',0) ret,thresh1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY) ret,thresh2 = cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV) ret,thresh3 = cv2.threshold(img,127,255,cv2.THRESH_TRUNC) ret,thresh4 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO) ret,thresh5 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV) titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV'] images = [img, thresh1, thresh2, thresh3, thresh4, thresh5] for i in xrange(6): plt.subplot(2,3,i+1),plt.imshow(images[i],'gray') plt.title(titles[i]) plt.xticks([]),plt.yticks([]) plt.show() تكون الفروقات واضحة كالتالي:

-
يمكنك كذلك استخدام الدالة ax.set_title() لاضافة عناوين للرسومات كالتالي: import matplotlib.pyplot as plt import numpy as np x = np.array([0, 1, 2, 3]) y = np.array([3, 8, 1, 10]) plt.subplot(1, 2, 1) ax = plt.plot(x,y) ax.set_title("first plot") x = np.array([0, 1, 2, 3]) y = np.array([10, 20, 30, 40]) plt.subplot(1, 2, 2) ax = plt.plot(x,y) ax.set_title("second plot") plt.show() ويقوم بوضع العناوين فوق الرسومات كالشكل التالي:

-
بجانب طريقة علي، يمكنك استخدام pyplot.text ايضا لفعل هذا، أنظر هذا الكود لشرح الفكرة: def plot_embeddings(M_reduced, word2Ind, words): for word in words: x, y = M_reduced[word2Ind[word]] plt.scatter(x, y, marker='x', color='red') plt.text(x+.03, y+.03, word, fontsize=9) plt.show() #وضع النقاط M_reduced_plot_test = np.array([[1, 1], [-1, -1], [1, -1], [-1, 1], [0, 0]]) word2Ind_plot_test = {'test1': 0, 'test2': 1, 'test3': 2, 'test4': 3, 'test5': 4} #الكلمات المراد وضعها words = ['test1', 'test2', 'test3', 'test4', 'test5'] plot_embeddings(M_reduced_plot_test, word2Ind_plot_test, words) ويكون الشكل كالتالي: اما اذا أردت تطبيقه على حالتك يمكنك استبدال الكلمات بالشكل الذي تريد والنقاط بنقاطك التي تريد رسمها فقط.
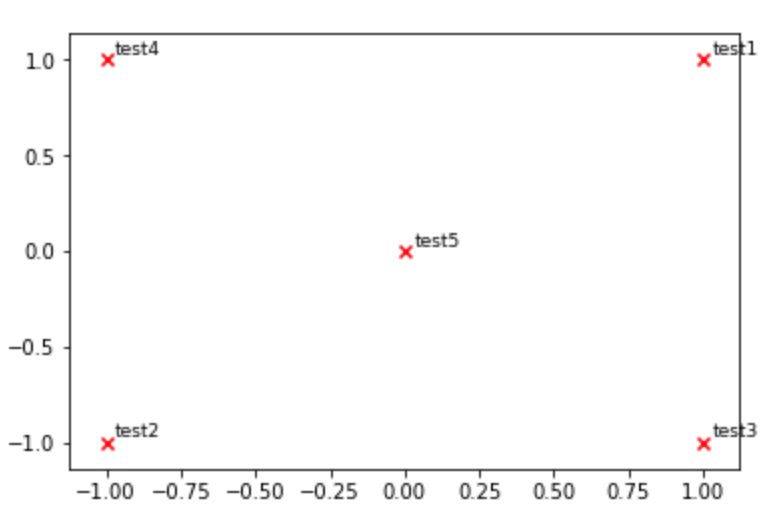
-
يمكنك استخدام الدالة cv2.getTickCount() لقياس الوقت الذي يستغرقه الكود عن طريق بدء العد قبل بداية تنفيذ الكود ثم وقفه في نهاية الكود وحساب فرق الوقت بين البداية والنهاية ويكون هو الوقت الذي استغرقه الكود كالتالي: e1 = cv2.getTickCount() # البداية ret, frame = cap.read() cv2.imshow("cam",frame) e2 = cv2.getTickCount() # النهاية كذلك يمكنك استخدام الدالة time ، أنظر المقارنة بين الطريقيتين واستخدامهم: t_start=time.time() # البداية time1=0 while True: e1 = cv2.getTickCount() ret, frame = cap.read() cv2.imshow("cam",frame) e2 = cv2.getTickCount() time1 = (e2 - e1)/ cv2.getTickFrequency() + time1 elapsedTime= time.time()-t_start # النهاية ولتحسين الأداء يمكننا استخدام cv2.setUseOptimized كالتالي: # التأكد من تشغيله In [5]: cv.useOptimized() Out[5]: True In [6]: %timeit res = cv.medianBlur(img,49) 10 loops, best of 3: 34.9 ms per loop # وقفه In [7]: cv.setUseOptimized(False) In [8]: cv.useOptimized() Out[8]: False In [9]: %timeit res = cv.medianBlur(img,49) 10 loops, best of 3: 64.1 ms per loop
-
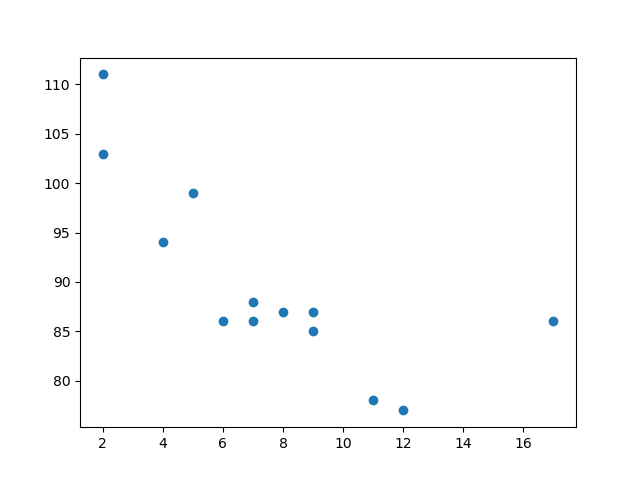
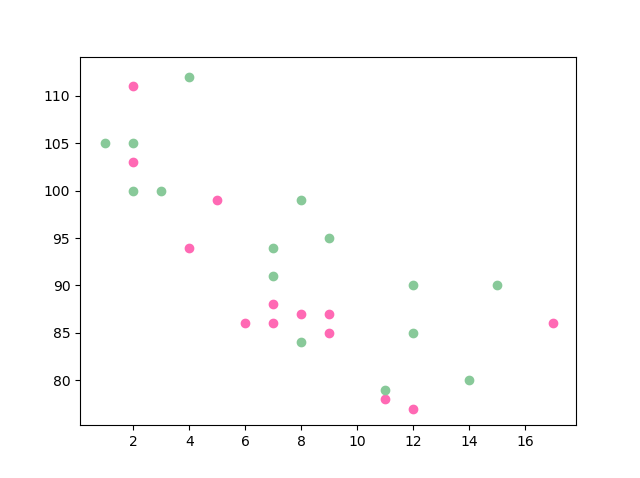
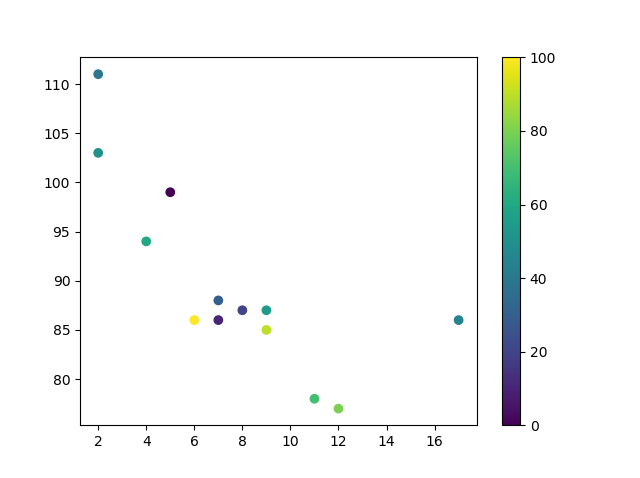
تعتبر دالة scatter احدى أسهل وأهم دوال الرسم، وتوجد في matplot كالتالي: matplotlib.pyplot.scatter(x_axis_data, y_axis_data, s=None, c=None, marker=None, cmap=None,alpha=None, linewidths=None, edgecolors=None) وأكثر ما يهمنا في استخدامها هما المعامل الأول الذي يمثل محور السينات x_axis والمعامل الثاني والذي يمثل محور الصادات y_axis، سأقوم بتوضيح بعض ما يمكن للدالة أن تفعله. أولا الرسم البسيط كالتالي: import matplotlib.pyplot as plt import numpy as np x = np.array([5,7,8,7,2,17,2,9,4,11,12,9,6]) y = np.array([99,86,87,88,111,86,103,87,94,78,77,85,86]) plt.scatter(x, y) plt.show() وتقوم برسم النقاط بلون موحد كالتالي: كذلك يمكنك رسم أكثر من دالة للمقارنة بينهم باألوان مختلفة مع تحديد اللون الذي تريد كالتالي: import matplotlib.pyplot as plt import numpy as np x = np.array([5,7,8,7,2,17,2,9,4,11,12,9,6]) y = np.array([99,86,87,88,111,86,103,87,94,78,77,85,86]) plt.scatter(x, y, color = 'hotpink') x = np.array([2,2,8,1,15,8,12,9,7,3,11,4,7,14,12]) y = np.array([100,105,84,105,90,99,90,95,94,100,79,112,91,80,85]) plt.scatter(x, y, color = '#88c999') plt.show() أو استخدام ال heatmap لتمثيل كل نقطة بقيمة كالتالي: import matplotlib.pyplot as plt import numpy as np x = np.array([5,7,8,7,2,17,2,9,4,11,12,9,6]) y = np.array([99,86,87,88,111,86,103,87,94,78,77,85,86]) colors = np.array([0, 10, 20, 30, 40, 45, 50, 55, 60, 70, 80, 90, 100]) plt.scatter(x, y, c=colors, cmap='viridis') plt.colorbar() plt.show() والكثير من المميزات الأخرى.
-
اذا كنت تقصد تغيير في شكل النتيجة، فلا، join العادية لا تؤثر في شكل الخرج حيث أن : Table1 JOIN Table 2 = Table2 JOIN Table1 ونفس الوضع بالنسبة ل INNER JOIN و NATURAL JOIN . لكن على صعيد الأداء، فبالتاكيد هناك فرق، حيث أن JOIN تقوم بدمج عناصر الجدول الأول مع الجدول الثاني، وذلك فان عدد عناصر كل جدول يفرق في الاداء وبالتالي ترتيبيهم حيث يبدا بايجاد العمود الأول والبحث عن تطابق بين كل عنصر فيه وكل الجدول الثاني. أما بالنسبة ل LEFT JOIN , RIGHT JOIN , فالترتيب يفرق حتى في شكل الخرج وذلك لانه يهتم بترتيب الجداول، وقد يجد تطابق اذا كان Table1 اولا لكنه لا يجد اذا كان Table1 ثانيا وهكذا.
-
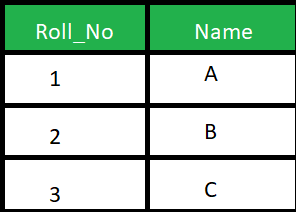
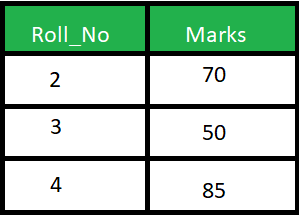
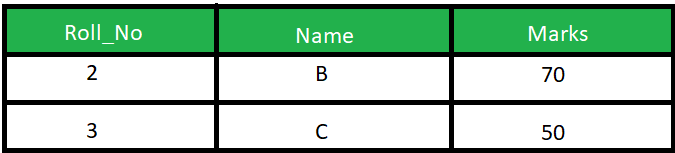
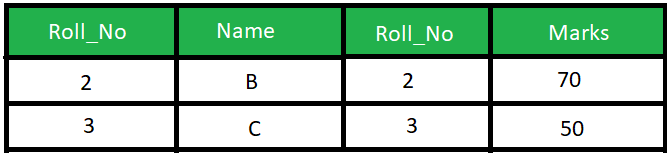
هناك فروق كثيرة بين الطريقتين، لكن بشكل أساسي، فان الفرق يتمثل فيه كيفية عمل كل منهما: Natural Join : تقوم باختيار الأعمدة بناء على التطابق في محتوى عمود مشترك بين الجداول التي يتم الاختيار بينها، بمعني انه يبحث عن عمود مشترك ويقوم باظهار كل الخصائص بدمج الأعمدة المراد دمجها بناء على تطابق هذا العمود المشترك، أنظر المثال التالي: تخيل أن هناك جدول للطلاب كالتالي: وجدول أخر للدرجات كالتالي: لاحظ وجود عمود مشترك Roll_No وبه أشخاص متطابقون في كلا الجدولين (2 و 3)، اذا قمنا بتشغيل هذا الأمر: SELECT * FROM Student NATURAL JOIN Marks; فسيقوم باختيار الأشخاص المشتركون في كلا الجدولين بناء على العمود Roll_No كالتالي: Inner Join : يقوم باختيار العناصر المتشابهة تمام مثلا Natural Join لكن يقوم بارجاع العمود المشترك مرة عن كل جدول، بمعني أخر أنه يقوم بوضع كل جدول بجانب الأخر بعد بحث التطابق بين الجدولين، في المثال السابق ، لو قمنا بتشغيل الأمر: SELECT * FROM student S INNER JOIN Marks M ON S.Roll_No = M.Roll_No; يكون الخرج على الشكل التالي:
- 2 اجابة
-
- 1
-

-
ببساطة يمثل هذا المعامل شكل الخرج الذي تريده، بحيث يمثل اول رقمين ابعاد ال grid الذي تريد انشاؤه، فمثلا 11 يعني صف واحد وعمود واحد أي أنها رسمة واحدة فقط، بينما 22 تمثل مربعا به عمودين وصفين أي 4 رسمات وهكذا. بينما يمثل الرقم الثالث مكان الرسمة داخل هذا ال grid، ف 1 هو المكان الاول في الصف الاول يسارا، و 2 العمود الثاني الصف الاول وهكذا. بحيث يكون العد من اليسار الي اليمين ثم بالصف. المثال التالي يوضح معني الشرح: fig = plt.figure() fig.add_subplot(1, 2, 1) #أعلى وأسفل يسارا fig.add_subplot(2, 2, 2) #أعلى اليمين fig.add_subplot(2, 2, 4) #أسفل اليمين plt.show()
-
بالاضافة لاجابة علي، اذا كنت تستخدم tensorflow 2 فهناك طريقة أبسط وأسرع من استخدام generator عن طريق التعامل مع Tensor مباشرة كالتالي: t = [[[4,2]], [[3,4,5]]] rt=tf.ragged.constant(t) dataset = tf.data.Dataset.from_tensor_slices(rt) for x in dataset: print(x) >>> <tf.RaggedTensor [[4, 2]]> >>> <tf.RaggedTensor [[3, 4, 5]]> والنسخ الأحدث تستطيع تحويلها ببساطة كالتالي: dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3]) for element in dataset: print(element) >>> tf.tensor( 1 ,shape=(), dtype=int32) >>> tf.tensor( 2 ,shape=(), dtype=int32) >>> tf.tensor( 3 ,shape=(), dtype=int32)
-
يمكنك استخدام call_command بسهولة لتنفيذ الاوامر من داخل الكود الخاص بك بسهوله كالتالي: from django.core.management import call_command call_command('my_command', 'foo', bar='baz') حيث my_command هو اسم الأمر الذي تريد تنفيذه. وكأمثله لاحظ الأكواد التاليه: from django.core.management import call_command call_command('test', 'myapp', verbosity=3, interactive=False) حيث تنفذ تلك الأوامر تماما مثلما تستطيع تنفيذها بالطريقة التقليدية من ال terminal: $ ./manage.py migrate myapp --noinput -v 3 كذلك عوضا عن أن تقوم بعمل call_command يمكنك تشغيل manage.py من داخل الكود ببساطة كالتالي: from myapp.management.commands import my_management_task cmd = my_management_task.Command() opts = {} cmd.handle_noargs(**opts)
- 3 اجابة
-
- 1
-
-
استخدام order_by('?') سيقوم بايقاف الخادم لمدة ثانتين تقريبا خلال وقت عمله، هناك طريقة أفضل باستخدام المكتبة random المشهورة في بايثون ، الكود التالي يوضح كيفية استخدامها لاداء الغرض المطلوب: from django.db.models.aggregates import Count from random import randint class PaintingManager(models.Manager): def random(self): count = self.aggregate(count=Count('id'))['count'] random_index = randint(0, count - 1) return self.all()[random_index] أو بشكل أبسط: from random import randint count = Model.objects.count() random_object = Model.objects.all()[randint(0, count - 1)] #عينة واحدة عشوائية
- 4 اجابة
-
- 1
-
-
بالاضافة للحلول السابقة، قد تكون المشكلة في Meta subclass of models.. قد يكون لديك تعريف كالتالي سواء في apps.py أو models.py أو views.py : label = <app name> اذا كان هناك أي إحتمال بحيث أن meta class لا يحمل نفس العنوان label الخاص بالتطبيق خاصتك app ، قد لا يتم رصد أي تغيرات تحدث، ببساطة لانه لا يجد توافق بين ما تقوم بتغييره وما هو معرف عنده. لذا قد تحتاج الى تعديلها كالتالي: class ModelClassName(models.Model): class Meta: app_label = '<app name>' # <-- هذا ما يجب ضبطه باسم تطبيقك. field_name = models.FloatField() ...
- 4 اجابة
-
- 1
-
-
توجد trainable و non-trainable parameters في عملية أعداة التعليم او transfer learning، وتعرف كالتالي: non-trainable parameters : هي التي لم يتم تدريبها باستخدام gradient descent أو بمعني أخر هي الأوزان التي لم يتم تحسينها أثناء عملية ال backpropagation بينما على النقيض trainable parameters: هي الأوزان التي تم تدريبها سابقا وتحسينها وجاهزة للاستخدام مباشرة. ويمكنك التعرف عليها عن طريق بناء النموذج وعمل model.summary: from keras.layers import * from keras.models import * model = Sequential() model.add(Dense(10, trainable=False, input_shape=(100,))) model.summary() تظهر كالتالي هنا لاننا لم نقم بتدريب النموذج حتى الأن: _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 10) 1010 ================================================================= Total params: 1,010 Trainable params: 0 Non-trainable params: 1,010 ويمكننا التغيير بين اذا كانت الأوزان قابلة لاعادة التدريب ام لا كالتالي: model.layers[0].trainable = True _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 10) 1010 ================================================================= Total params: 1,010 Trainable params: 1,010 Non-trainable params: 0 _________________________________________________________________ وعندما تريد أعادة بناء النموذج أو تدريبه مجددا ، يجب التركيز على تلك الأوزان التي لم يتم تدريبها بعد لتقوم بتدريبها على النموذج الخاص بك لتحسين النواتج.
-
الدالة compile هي المسئولة عن تعريف: دالة الفقد Loss : مثل Binary_cross_Entropy أو Categorical Crossentropy وهما الأكثر شهرة واستخداماً. المحسن Optimizer: مثل Adam و rmsprop مقياس الدقة الذي تستخدمه metrics: مثل Accuracy أو F1-score أو precision غيرها تبعا لحالة البيانات. كما هو موضح في تعريفها التالي: Model.compile( optimizer="rmsprop", loss=None, metrics=None, weighted_metrics=None, steps_per_execution=None, **kwargs ) ويمكنك استخدامها ببساطة بعد أن تقوم ببناء طبقات التعلم التي تريد ثم وضعها في النهاية مع تحديد ال parameter التي شرحناها سابقا بما يناسب عملية التعلم خاصتك كالتالي: inputs = tf.keras.layers.Input(shape=(3,)) outputs = tf.keras.layers.Dense(2)(inputs) model = tf.keras.models.Model(inputs=inputs, outputs=outputs) model.compile(optimizer="Adam", loss="mse", metrics=["mae"]) model.metrics_names
-
يمكن أن يظهر هذا الخطأ نتيجة تمريرك ال token كالتالي: token = RefreshToken(access_token) بينما يجب عليك أن تقوم بتمريره في refresh token.. يمكنك كذلك تجربة عل blacklist لل tokens كالتالي: #urls.py path('/api/logout', views.BlacklistRefreshView.as_view(), name="logout"), #view.py from rest_framework_simplejwt.tokens import RefreshToken class BlacklistRefreshView(APIView): def post(self, request) token = RefreshToken(request.data.get('refresh')) token.blacklist() return Response("Success")
- 2 اجابة
-
- 1
-
-
في البداية عليك أن تتأكد من أن كل البيانات على شكل datetime لان غير ذلك قد يسبب أخطاءا عن البحث: import datetime date_from = datetime.datetime.strptime(request.GET['q1'], '%Y-%m-%d') date_to = datetime.datetime.strptime(request.GET['q2'], '%Y-%m-%d') بعد ذلك تقوم بالبحث عن التواريخ التى تريد الحصول عليها ببساطة باستخدام الكود التالي: datetime = User.objects.filter(created__range=(date_from, date_to))
- 4 اجابة
-
- 1
-
.png.fb86d6e77df81269f1e2deb8a0b271cb.png)


