Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
تستطيع انشاء الشكل الخاص بك view دون الحاجة لاي اشكال مصنوعة مسبقا، الكود التالي يوضح كيفية انشاء token: from rest_framework import serializers, viewsets, status class SignInSerializer(serializers.Serializer): username = serializers.CharField(max_length=255, required=True) password = serializers.CharField(max_length=255, required=True, write_only=True) هناك حل أخر أطول قليلا هو أن تستدعي userview set ثم بتقوم بالكتابة على create method، بعدها تقوم بالحصول على المستخدم user ثم انشاء JWT tokens، الكود التالي يوضح تلك العملية: from rest_framework import status from djoser.views import UserViewSet from djoser import signals from djoser.compat import get_user_email from rest_framework_simplejwt.tokens import RefreshToken class CustomRegistrationView(UserViewSet): def perform_create(self, serializer): user = serializer.save() signals.user_registered.send( sender=self.__class__, user=user, request=self.request ) context = {"user": user} to = [get_user_email(user)] if settings.SEND_ACTIVATION_EMAIL: settings.EMAIL.activation(self.request, context).send(to) elif settings.SEND_CONFIRMATION_EMAIL: settings.EMAIL.confirmation(self.request, context).send(to) def create(self, request, *args, **kwargs): serializer = self.get_serializer(data=request.data) serializer.is_valid(raise_exception=True) self.perform_create(serializer) headers = self.get_success_headers(serializer.data) response_data = serializer.data user = User.objects.get(username = response_data['username']) refresh = RefreshToken.for_user(user) response_data['refresh'] = str(refresh) response_data['access'] = str(refresh.access_token) return Response(response_data, status=status.HTTP_201_CREATED, headers=headers)
- 2 اجابة
-
- 1
-

-
يمكنك استخدام دالة: target_model.set_weights(model.get_weights()) لنسخ الأوزان من الطبقات، كذلك يمكنك تحديد طبقة معينة لنسخ الاوزان منها كالتالي: model_1.layers[0].set_weights(source_model.layers[0].get_weights()) model_2.layers[0].set_weights(source_model.layers[0].get_weights()) يمكنك التأكد من نقي الأوزان عن طريق بناء نموذج بسيط والتأكد منها كالتالي: model1 = Sequential() model1.add(Dense(10, input_dim=2)) model2 = Sequential() model2.add(Dense(10, input_dim=2)) model1.compile(loss='mse', optimizer='adam') model2.compile(loss='mse', optimizer='adam') ويمكنك التأكد من الأوزان التي نقلتها كالتالي: >>> model1.layers[0].get_weights() [array([[-0.42853734, 0.18648076, -0.47137827, 0.1792168 , 0.0373047 , 0.2765705 , 0.38383502, 0.09664273, -0.4971757 , 0.41548246], [ 0.0403192 , -0.01309097, 0.6656211 , -0.0536288 , 0.58677703, 0.21625364, 0.26447064, -0.42619988, 0.17218047, -0.39748642]], dtype=float32), array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)] >>> model2.layers[0].get_weights() [array([[-0.30062824, -0.3740575 , -0.3502644 , 0.28050178, -0.68631136, 0.1596322 , 0.08288956, -0.20988202, 0.34323698, 0.2893324 ], [-0.29182747, -0.2754455 , -0.64082885, 0.29160154, 0.04342002, -0.4996035 , 0.6608283 , 0.10293472, 0.11375248, -0.43438092]], dtype=float32), array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)] >>> model2.layers[0].set_weights(model1.layers[0].get_weights()) >>> model2.layers[0].get_weights() [array([[-0.42853734, 0.18648076, -0.47137827, 0.1792168 , 0.0373047 , 0.2765705 , 0.38383502, 0.09664273, -0.4971757 , 0.41548246], [ 0.0403192 , -0.01309097, 0.6656211 , -0.0536288 , 0.58677703, 0.21625364, 0.26447064, -0.42619988, 0.17218047, -0.39748642]], dtype=float32), array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)] >>> id(model1.layers[0].get_weights()[0]) 140494823634144 >>> id(model2.layers[0].get_weights()[0]) 140494823635664
-
يمكنك استخدام الدالة model._meta.get_all_field_names() #استخدام الكود التالي عوضا اذا كنت تستخدم نسخه 1.9 model._meta.get_fields() لعرض اسماء الحقول في النموذج. كذلك يمكنك استخدام: model._meta.get_field() لتستطيع التعامل مع اسماء verbose. ويمكنك استخدام: etattr(model_instance, 'field_name') للتعامل مع قيم الحقول
- 4 اجابة
-
- 1
-
-
دعنا نشرحها في هيئة خطوات بسيطة: تقوم باستخراج معلومات النموذج الذي تم تحميله: model_config = model.get_config() تبديل الطبقة التي تريد تغييرها: input_layer_name = model_config['layers'][0]['name'] model_config['layers'][0] = { 'name': 'new_input', 'class_name': 'InputLayer', 'config': { 'batch_input_shape': (None, 300, 300), 'dtype': 'float32', 'sparse': False, 'name': 'new_input' }, 'inbound_nodes': [] } model_config['layers'][1]['inbound_nodes'] = [[['new_input', 0, 0, {}]]] model_config['input_layers'] = [['new_input', 0, 0]] ثم تقوم بانشاء النموذج الجديد: new_model = model.__class__.from_config(model_config, custom_objects={}) ثم نسخ الأوزان من النموذج القديم للجديد: # iterate over all the layers that we want to get weights from weights = [layer.get_weights() for layer in model.layers[1:]] for layer, weight in zip(new_model.layers[1:], weights): layer.set_weights(weight) بعد ذلك اضافة الطبقات التي تريد: from kerassurgeon.operations import delete_layer, insert_layer model = delete_layer(model, layer_1) # insert new_layer_1 before layer_2 in a model model = insert_layer(model, layer_2, new_layer_3) الكود التالي يمثل كذلك طريقة مختلفة وسهلة لفعل ما تريد: import keras import numpy as np def get_model(): old_input_shape = (20, 20, 3) model = keras.models.Sequential() model.add(keras.layers.Conv2D(9, (3, 3), padding="same", input_shape=old_input_shape)) model.add(keras.layers.MaxPooling2D((2, 2))) model.add(keras.layers.Flatten()) model.add(keras.layers.Dense(1, activation="sigmoid")) model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.Adam(lr=0.0001), metrics=['acc'], ) model.summary() return model def change_model(model, new_input_shape=(None, 40, 40, 3)): # تغيير شكل الدخل لاول طبقة model._layers[1].batch_input_shape = new_input_shape #استبدال وتعديل الطبقات التي تريد model._layers[2].pool_size = (8, 8) model._layers[2].strides = (8, 8) # اعادة بناء شكل النموذج new_model = keras.models.model_from_json(model.to_json()) new_model.summary() # نسخ الأوزان for layer in new_model.layers: try: layer.set_weights(model.get_layer(name=layer.name).get_weights()) except: print("Could not transfer weights for layer {}".format(layer.name)) # تجربة النموذج الجديد X = np.random.rand(10, 40, 40, 3) y_pred = new_model.predict(X) print(y_pred) return new_model if __name__ == '__main__': model = get_model() new_model = change_model(model)
-
يمكنك استخدام bulk_update بسهولة لفعل ذلك. في البداية عليك تنزيلها كالتالي: pip install django-bulk-update بعد ذلك يمكنك استخدامها بسهوله كما المثال التالي: from bulk_update.helper import bulk_update random_names = ['Walter', 'The Dude', 'Donny', 'Jesus'] people = Person.objects.all() for person in people: r = random.randrange(4) person.name = random_names[r] bulk_update(people) # تحديث كل الأعمدة من قاعدة البيانات وفي حالتك يمكنك تنفيذها في سطر واحد كالتالي: ModelClass.objects.filter(name='bar').update(name="foo")
- 2 اجابة
-
- 1
-
-
بالاضافة لطريقة سامح، يمكننا كذلك تفحص حالة self._state حيث انه اذا كانت: self._state.adding is True فهذا يعني انه تم انشاؤه created اما اذا كانت الحالة: self._state.adding is False فهذا يعني انه تم تحديثه updated وبطريقه اخرى يمكنك اضافة تاريخ انشاؤه كالتالي: date_created = models.DateTimeField(auto_now_add=True) والتأكد من وجود التاريخ من عدمه حيث انه اذا لم يوجد تاريخ للانشاء فهذا يعني انه تم تحديثه updated: created = self.date_created is None
- 4 اجابة
-
- 1
-
-
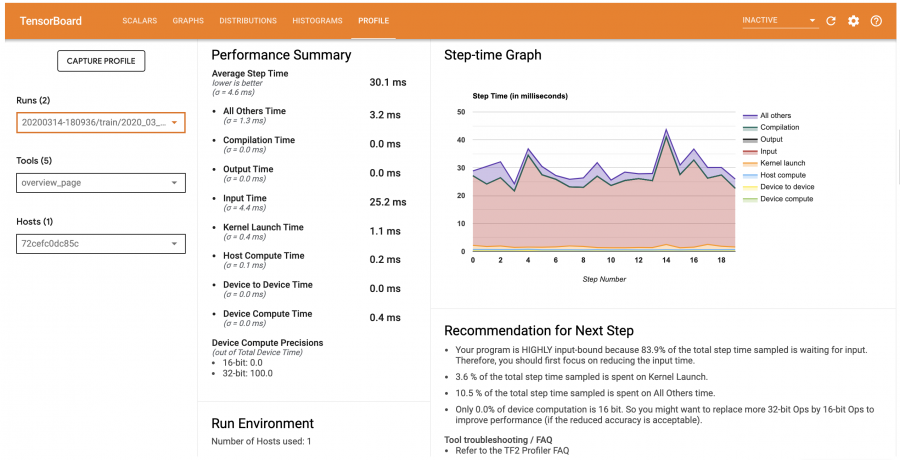
يمكنك ببساطة بناء نموذج بحيث يتم تدريبه مع حفظ بيانات التدريب في ملف لنستخدمه بعد ذلك في رسم الشكل البياني للتدريب كالتالي: #استدعاء البينات وتقسيمها import tensorflow_datasets as tfds tfds.disable_progress_bar() (ds_train, ds_test), ds_info = tfds.load( 'mnist', split=['train', 'test'], shuffle_files=True, as_supervised=True, with_info=True, ) #بناء النموذج def normalize_img(image, label): """Normalizes images: `uint8` -> `float32`.""" return tf.cast(image, tf.float32) / 255., label ds_train = ds_train.map(normalize_img) ds_train = ds_train.batch(128) ds_test = ds_test.map(normalize_img) ds_test = ds_test.batch(128) model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128,activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) model.compile( loss='sparse_categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(0.001), metrics=['accuracy'] ) # حفظ بيانات التدريب وبدء التدريب logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S") tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs, histogram_freq = 1, profile_batch = '500,520') model.fit(ds_train, epochs=2, validation_data=ds_test, callbacks = [tboard_callback]) بعد ذلك يقوم ببداء عملية التدريب، عقب النتهاء منها يمكننا استدعاء TensorBoard notebook extension كالتالي: %load_ext tensorboard ثم بدء عرض احصائيات التدريب هكذا: %tensorboard --logdir=logs ستظهر لك الإحصائيات على الشاشة هكذا:
- 2 اجابة
-
- 1
-
-
هناك طريقتين بسيطتين: الطريقة الأولي باستخدام الكود التالي مباشرة: from django.core.urlresolvers import reverse def url_to_edit_object(obj): url = reverse('admin:%s_%s_change' % (obj._meta.app_label, obj._meta.model_name), args=[obj.id] ) return u'<a href="%s">Edit %s</a>' % (url, obj.__unicode__()) الطريقة الثانية باستخدام URL reverse مباشرة كالتالي: {% url 'admin:index' %} {% url 'admin:polls_choice_add' %} {% url 'admin:polls_choice_change' choice.id %} {% url 'admin:polls_choice_changelist' %} في بعض الأحيان قد ينتج بعض الخطاء اذا كنت تستخدم شكل قديم ل URL الخاص بلوحة تحكم الأدمن، فاذا وجدت السطر : (r'^admin/(.*)', admin.site.root), يجب تغييره للصورة الجديدة ليصبح هكذا: (r'^admin/', include(admin.site.urls) ),
- 3 اجابة
-
- 1
-
-
كما أوضح علي فان تعريف ال callback في tensorflow كالتالي: tf.keras.callbacks.LambdaCallback( on_epoch_begin=None, on_epoch_end=None, on_batch_begin=None, on_batch_end=None, on_train_begin=None, on_train_end=None, **kwargs ) سأكمل على شرح علي بتوضيح بعض الأمثلة عن كيفية استخدامها، انظر المثال التالي لتري كيف يمكن استخدامها في سطر واحد مع استخدام الشروط كذلك from keras.callbacks import LambdaCallback call = LambdaCallback(on_epoch_end= lambda epochs, logs: (model.stop_training:=True) if logs.get('acc')>0.99 else None) المثال التالي يوضح استخدامها كاملا داخل دالة: def get_callbacks(self, X): sample_output_callback = LambdaCallback(on_epoch_end = lambda epoch, logs:\ logging.debug(pformat(self.sample_labels(self.model.predict(X))))) checkpoint = ModelCheckpoint(os.path.join(self.model_dir, "weights.hdf5"), verbose = 1, save_best_only = False) return [sample_output_callback, checkpoint]
-
هناك حل أخر بالاضافة لحل على قد يكون مختصرا، جرب الكود التالي مع تغيير اسماء واماكن الملفات بملفاتك: python freeze_graph.py --input_graph=/path/to/graph.pbtxt --input_checkpoint=/path/to/model.ckpt-22480 --input_binary=false --output_graph=/path/to/frozen_graph.pb --output_node_names="ما تريد اخراجه من ال graph كمثال InceptionV3/Predictions/Reshape_1 for Inception V3 " كذلك يمكنك استخدام الكود التالي ببساطة مع تغيير اسماء الملفات كذلك بما يناشبك: python -u /tfPath/models/object_detection/export_inference_graph.py \ --input_type=image_tensor \ --pipeline_config_path=/your/config/path/ssd_mobilenet_v1_pets.config \ --trained_checkpoint_prefix=/your/checkpoint/path/model.ckpt-50000 \ --output_directory=/output/path
-
يمكنك ببساطة اختيار الحدود التي تريد أن تختار منها كطريقة أخرى لعمل filter كالتالي: filter(gender='MALE', profile__level=(10, 50)) أو اختيار الطريقة التي أوضحها سامح لاختيار الحدود التي تريد عمل filter عليها كالتالي: User.objects.filter(gender='MALE', profile__level__gte = 10, profile__level__lte = 50).count()
- 2 اجابة
-
- 1
-
-
كما أوضح علي في الإجابة، فان المعادلات تلخص كل شئ، حيث أنه لحساب f1-score يجب حساب precision وكذلك recall لذا فانه تمثل الموازنه بين الطريقتين ، وهي مناسبة للغاية اذا كنت تريد اختيار النموذج بناء على التوازن بين الحسابتين. وتتميز f1-score بانها تحقق التوازن بين نسبة القيم الصحية التي تم توقعها بالنسبة للعدد الايجابي الكلى precision وهي دقة النموذج و نسبة القيم الصحيحة التي تم توقعها بالنسبة للقيم الصحيحة كلها وهي recall تعبر عن مدى اكتمال النموذح، لذلك فهي تعتبر طريقة مهمة للقياس. وهي تتواجد في tensorflow مباشرة كالتالي: tfa.metrics.F1Score( num_classes: tfa.types.FloatTensorLike, average: str = None, threshold: Optional[FloatTensorLike] = None, name: str = 'f1_score', dtype: tfa.types.AcceptableDTypes = None ) مثال لكيفية استخدامها كالتالي: metric = tfa.metrics.F1Score(num_classes=3, threshold=0.5) y_true = np.array([[1, 1, 1], [1, 0, 0], [1, 1, 0]], np.int32) y_pred = np.array([[0.2, 0.6, 0.7], [0.2, 0.6, 0.6], [0.6, 0.8, 0.0]], np.float32) metric.update_state(y_true, y_pred) result = metric.result() result.numpy() >>> [ 0.5 , 0.8 , 0.66666667 ] وبداخل النموذج يمكنك استخدامها كالتالي: pred = multilayer_perceptron(x, weights, biases) correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) with tf.Session() as sess: init = tf.initialize_all_variables() sess.run(init) for epoch in xrange(150): for i in xrange(total_batch): train_step.run(feed_dict = {x: train_arrays, y: train_labels}) avg_cost += sess.run(cost, feed_dict={x: train_arrays, y: train_labels})/total_batch if epoch % display_step == 0: print "Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost) #metrics y_p = tf.argmax(pred, 1) val_accuracy, y_pred = sess.run([accuracy, y_p], feed_dict={x:test_arrays, y:test_label}) print "validation accuracy:", val_accuracy y_true = np.argmax(test_label,1) print "Precision", sk.metrics.precision_score(y_true, y_pred) print "Recall", sk.metrics.recall_score(y_true, y_pred) print "f1_score", sk.metrics.f1_score(y_true, y_pred) print "confusion_matrix" print sk.metrics.confusion_matrix(y_true, y_pred) fpr, tpr, tresholds = sk.metrics.roc_curve(y_true, y_pred)
-
في النسخ الحديث من django،يمكنك فعل هذا ببساطة باعادة تسمية الحقل دون احداث اي تغيير في قاعدة البيانات كالتالي: operations = [ migrations.AlterField( model_name='mymodel', name='name', field=models.BooleanField(default=False, db_column=b'name'), ), migrations.RenameField( model_name='mymodel', old_name='name', new_name='full_name', ), حل أخر ببساطة عن طريق تسمية الحقل: class Foo(models.Model): name = models.CharField() الى اسم جديد: class Foo(models.Model): full_name = models.CharField() ثم قم بتشغيل الكود التالي: python manage.py makemigrations هذا سوف يقوم بحذف القديم وعمل حقل جديد. الان اذهب وقم بتعديل التالي: operations = [ migrations.RenameField( model_name='foo', old_name='name', new_name='full_name') ] ثم قم بتشغيل الكود التالي لنقل البيانات للحقل الجديد دون فقدان اي بيانات: python manage.py migrate
-
تحويل الصور الملونة RGB الي صور رمادية هو حل سهل ومطروح دائما لكنه ليس أفضل خيار اطلاقا لانه سينتج عنه نواتج تعليم سيئة للغاية، يمكنك كذلك تحميل تلك الاوزان في أول طبقة تعليمة ثم تعديلها بناء على بياناتك الجدية لكن هذا سيقلل من دقة النموذج الخاصة بك. للقيام بذلك ، سيتعين عليك إضافة بعض الاكواد حيث يتم تحميل الأوزان مسبقة التدريب. في إطار العمل الذي تختاره ، تحتاج إلى معرفة كيفية دمج على أوزان الطبقة التلافيفية الأولى في شبكتك وتعديلها قبل بدء عملية التعلم على نموذجك الجديد، بعد ذلك تضيف طبقات جديدة تقوم بتعليمها على بياناتك الجديدة. الكود التالي يوضح ببساطة كيفية القيام بتلك العملية from keras.models import Model from keras.layers import Input resnet = Resnet50(weights='imagenet',include_top= 'TRUE') input_tensor = Input(shape=(IMG_SIZE,IMG_SIZE,1) ) x = Conv2D(3,(3,3),padding='same')(input_tensor) out = resnet (x) model = Model(inputs=input_tensor,outputs=out)
-
هناك طريقة أخرى لفعل هذا عن طريق تجربة الكود التالي: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'finance', 'USER': 'django', 'PASSWORD': 'mydb123', 'HOST': '127.0.0.1', 'PORT': '', 'TEST': { 'NAME': 'test_finance', }, } } ثم بعد ذلك تقوم ببدء ال SQL خاصتك كالتالي: mysql -u root -p ثم اعط كل الصلاحيات للكود كالتالي: GRANT ALL PRIVILEGES ON test_finance.* TO 'django'@'localhost'; وسوف يقوم django بعمل الاختبار دون اي مشاكل.
-
ببساطة فإن model.evaluate تقوم بتوقع الخرج للبيانات التي تدخل للنموذج ومن ثم تقوم بحساب الدالة التي تحسب الدقة بأي طريقة كانت والتي نقوم بتحديدها في model.compile وهذا بناء على y_true و y_pred ثم يقوم بارجاع قيمة حساب دالة الدقة كمقياس. أما model.predict فانها فقط تقوم بارجاع y_pred. لذلك اذا استخدمت model.predict ثم قمت بحساب الدقة بنفسك على النتائج التي ترجع من تلك الدالة فانه من المفترض انتظهر لك نفس الارقام تماما اذا استخدمت model.evaluate مباشرة. المثال التالي يوضح كيف تستخدم model.predict: pred = model.predict(x_test) pred = np.argmax(pred, axis = 1)[:5] label = np.argmax(y_test,axis = 1)[:5] print(pred) >>> [7 2 1 0 4] print(label) >>>[7 2 1 0 2] لاحظ أنه قام بارجاع ما تم توقعه بناء على التعلم الذي حصل عليه النموذج، اذا قمت بمقارنه ما توقعه البرنامج بالترميز الصحيح لها ينتج لك دقة 80% (حيث انه قام بتوقع 4 صواب من أصل 5) وهو تماما ما تقوم بارجاعه لك دالة model.evaluate
-
بالاضافة للطريقة التي أوضحها علي، فيمكنك أن تقوم بالتحويل ببساطة بالكود التالي: from keras import backend backend.set_image_data_format('channels_last') أو كذلك يمكنك استخدام الكود التالي للتحويل الي NHWC أو NCHW: out_nchw = conv2d(image_nchw, filters, 'NCHW') out_nhwc = conv2d(image_nhwc, perm(filters), 'NHWC') assert np.allclose(out_nhwc == np.transpose(out_nchw, (0,2,3,1)))
-
الخطأ فقط أنك تقوم باستدعاء دالة يجب ادخال بها المعامل delete لكنك لم تقم بادخالها، أنظر المثال التالي للتوضيح أولا: class SomeModel(models.Model): field=models.ForeignKey(default=1, on_delete='CASCADE', to='main.Category') وهذا استخدام خاطئ ينتج عنه نفس المشكلة التى تظهر لك، لذلك حلها كان كالتالي: class SomeModel(models.Model): field=models.ForeignKey(default=1, on_delete=models.CASCADE, to='main.Category') لذلك فان حل المشكلة خاصتك بنفس الطريقة بسيطة، فقط مرر الكائن model مع اختيار DO_NOTHING عوضا عن None كالتالي: user = models.ForeignKey(User, on_delete=models.DO_NOTHING)
- 2 اجابة
-
- 1
-
-
values تقوم باعادة QuerySet والتى تقوم باعادة مجموعة من القواميس dictionaries. values_list تقوم باعادة QuerySet والتى تقوم بارجاع tubles المثال التالي يوضح الفرق بين الطريقيتين: >>> list(Article.objects.values_list('id', flat=True)) # flat=True تقوم بتحويل ال tubles الى list [1, 2, 3, 4, 5, 6] >>> list(Article.objects.values('id')) [{'id':1}, {'id':2}, {'id':3}, {'id':4}, {'id':5}, {'id':6}]
- 2 اجابة
-
- 1
-
-
في البداية قمت بتغيير مكان الملف من /shop/shop_name/base.html الى /shop_name/shop/base.html ثم قمت بتجربة الكود التالي: {% extends shop_name|add:"/shop/base.html"%} طريقة أخرى : في الاصدارات الأقدم من django يمكنك استخدام التالي: {{ "Mary had a little"|stringformat:"s lamb." }} ويمكنك كذلك تجربة هذا الكود للاصدارات الأجدد: {{ "Mary had a little"|add:" lamb." }} والنتيجة تكون كالتالي: "Mary had a little lamb."
- 2 اجابة
-
- 1
-
-
يمكنك استخدام الطريقة get بحيث حيث انها الطريقة الاساسية لجلب قيمة، ويمكنك استخدامها كالتالي: is_published = request.POST.get('is_published', False) وبشكل عام يمكنك استخدامها هكذا: my_var = dict.get(<key>, <default>) يمكنك كذلك تجربة الطريقة التالية: is_published = 'is_published' in request.POST وهذه ايضا تؤدي نفس النتيجة: is_published = 'is_published' in request.POST and request.POST['is_published']
- 2 اجابة
-
- 1
-
-
اذا كنت تستخدم Tensor وتنادي بها t.eval ، فهو تماما كأن تستخدم tf.get_default_session().run(t) تعتبر t.evel هي اختصار ل sess.run(t) بحيث أن sess هي ال session الحالية، النموذجين التاليين يؤديان نفس المهمة تماما sess = tf.Session() c = tf.constant(5.0) print sess.run(c) c = tf.constant(5.0) with tf.Session(): print c.eval() لو أن الكود الخاص بك تعامل مع عدة رسومات بيانية والكثير من الجلسات sessions فيفضل استخدام Session.run()
-
طريقة على توضح كيف تقوم بتعيين القيم بشكل يدوي للتحكم بالمعدل كما تشاء، بالاضافة لهذا يوفر tensorflow طريقة تلقائية لضبط قيم التعلم ذاتيا باستخدام tf.train.exponential_decay يمكنك استخدامها في النموذج الخاص بك كالتالي: # Optimizer: هو الذي يتحكم بمعدل التعلم بحيث يقوم بانقاص قيمته في كل دورة batch = tf.Variable(0) learning_rate = tf.train.exponential_decay( 0.01, # معدل التعلم الاساسي. batch * BATCH_SIZE, train_size, 0.95, # معدل التناقص. staircase=True) # نستخدم simple momentum من أجل التحسين optimizer = tf.train.MomentumOptimizer(learning_rate, 0.9).minimize(loss, global_step=batch)
-
الخطأ يظهر نتيجة الإصدار الذي تستخدمه من django والذي غالبا يكون أحدث من الاصدار 2.0 حيث تم تعديل اسم المكتبة في الاصدارات الحديثة، ، والحل الأبسط هو : أن تقوم بتغيير الإستدعاء القديم لديك من from django.core.urlresolvers import reverse الى from django.urls import reverse اذا كان المشروع كبيرا يمكنك تغيير كل الاستدعاءات بسهوله باستخدام find and replace كما هو موضح بالصورة:

- 2 اجابة
-
- 1
-
-
يعتمد الترتيب بشكل أساسي على رغبتك حسب المجال الذي تريده، ولوأخذناها بالترتيب السليم بانه يمكن أن يكون كالتالي: دورة علوم الحاسوب: وفي تلك الدورة تعرف أكثر عن الحاسوب نفسه، مكوناته وأنظمه التشغيل وكل الأساسيات في عالم البرمجة، وهي المقدمة المناسبة لأي دورة تعليمية خاصة بالبرمجة. دورة تطوير واجهات المستخدم: لان هذة هي المدخل المناسب والأساسي لبدء برمجة المواقع وواجهات تطبياقت الهواتف كذلك، وهي البناء الأولي لأي موقع وبه كذلك شرح لمدخل تطوير مواقع الويب. دورة تطوير التطبيقات باستخدام لغة JavaScript: حيث انها اللغة التي تعطي الموقع الحيوية والحركة، وتأتي دائما بعدما نقوم بتأسيس الموقع باستخدام HTML و CSS ويمكنك استخدامها سواء في تطوير المواقع وكذلك تبيقات الهاتف وأشياء أخرى كثيرة. لكن في بعض الأحيان يمكن الأستغناء عنها في حالة تطوير مواقع الويب، لكن لو توافر لديك الوقت يفضل أخذها. دورة تطوير تطبيقات الويب باستخدام لغة PHP: وهي تمثل البرمجة الخلفية للموقع، وهي الخطوة الأخيرة في برمجة المواقع، وتدرس كذلك مع قواعد البيانات لخلق موقع متكامل يؤدي وظائفه بشكل سلس وسليم.
- 2 اجابة
-
- 1
-