Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
فقط طريقة استخدامها غير صحيح ، أنت هنا تحاول أن تستخدمها في حفظ واسترجاع البيانات (على الرغم انها ليست افضل طريقة لذلك) ، لكن حلها بسيط: انظر الكود المعدل التالي: # تحميل الداتا from keras.datasets import boston_housing import keras (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # توحيد البيانات mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers # بناء النموذج def build_model(): model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss="mae", metrics=['mae']) return model # تدريب النموذج model = build_model() # قمنا بتدريب النموذج history=model.fit(train_data, train_targets,epochs=2, batch_size=64) import pickle with open('/HistoryDict', 'wb') as f: pickle.dump(history.history, f) history = pickle.load(open('/HistoryDict', "rb")) يجب ان تقوم اولا بتحميل الملف الذي قمت بقرائته عن طريق فتحه بالطريقه ذاتها التي نقوم بها في قراءه اي ملف txt، بعد ذلك تقوم باستدعاء ما قمت بتحميه باستخدام pickle.load. اما عن طرق حفظ النموذج فهذه ليست افضل طريقة حيث أن الطريقة الرائجة هي باستخدام json و h5 لحفظ هيكل النموذج والاوزان المدربة.
-
الدورات التي تقدمها حسوب تكون منظمه ومرتبة بالتسلسل الذي يجعلك تقوم بربط كل شئ سويا بشكل مرتب، كما انها تقوم بتغطية الموضوع كاملا من كافة جوانبه. فمثلا تجد في دورة جافا سكريبت، يبدأ اولا بمقدمة ثم الاساسيات ثم اهم كيفية التعامل مع المحرر وكذلك طريقة الكتابة الخاصة باللغة وهكذا . يمكنك اختيار الدورة وسيقوم بفتح صفحة بها المواضيع الاساسية مرتبة يمكنك اختيار الموضوع الذي تريد سيقوم بفتح محتواه من الفيديوهات ويمكنك فتحهم فيديو تلو الاخر. وكنصيحه الافضل هو ان تاخذهم بنفس الترتيب على الدورة لان ذلك يضمن لك فهم كل شئ بنفس طريقة شرحه وبحيث تستطيع تجميع الصورة كامله في ذهنك.
-
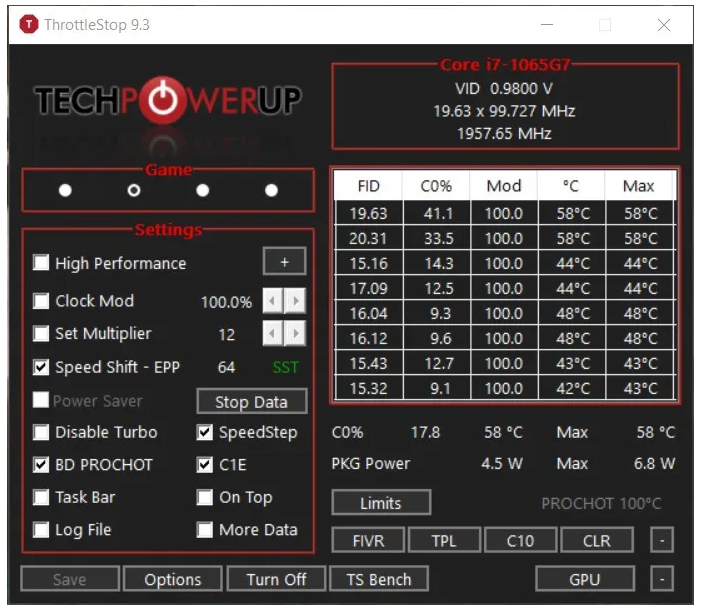
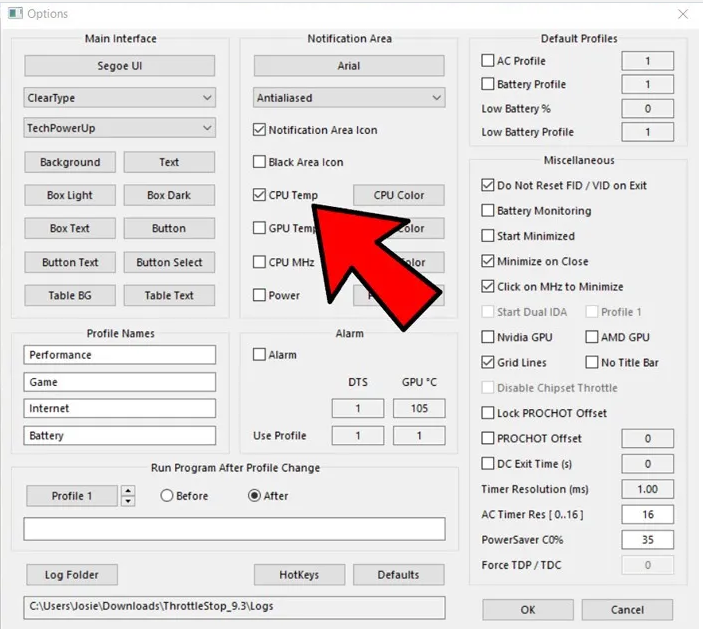
بشكل عام ، لا تقوم اجهزة الكمبيوتر بالسخونة الا وحدتين فقط وهما cpu و gpu. بالنسبة ل CPU فتقوم بالسخونه عندما تضغط على الكمبيوتر في العمل، بمعني اصح تجعله يعمل باقصي قوته في كثيره، ولان تلك الوحده تحتاج لتبريد دائما ما تجد مروحة فوقها. بالنسبة ل GPU فتقوم بالعمل فقط عندما تقوم بتشغيل اي معالجة رسوميه كالالعاب والتصميم وغيرها، يمكنك تجنب ذلك في فترات الذروة في درجات الحرارة اذا شئت. يمكنك ايضا تجنب كل ذلك ببساطه عن طريق توجية مروحه خارجية ناحية الكيسة بحيث تقوم بالمساعدة في تبريدها، ولا تضغط عليه في العمل اثناء النهار لان سخونه الاجهزة تؤدي الا اتلافها بعد فتره. اما عن الشاشة فلا تقلق من السخونه فهي لا تسخن، واذا سخنت فلا ضرر. يمكنك ايضا استخدام برنامج Throttlestop لمتابعة درجة حرارة جهازك ان كان ذلك يهمك، عندما تقوم بفتحه ستجد تلك الشاشة: قم باختيار زر options من الاسفل ، ثم اختر منها cpu: هذا سيجعل البرنامج يعرض درجة حراررة ال CPU في الشاشة الرئيسة، يمكنك كذلك اختيار GPU اذا اردت معلومات عن كارت الشاشة الخاص بك.
- 3 اجابة
-
- 1
-

-
هناك اكثر من طريقة لحفظها لكن اشهرها واكثرها استخداما هي باستخدام json لحفظ هيكل النموذج و h5 لحفظ الاوزان، انظر الكود التالي: # MLP for Pima Indians Dataset Serialize to JSON and HDF5 from keras.models import Sequential from keras.layers import Dense from keras.models import model_from_json import numpy import os # هنا نقوم ببناء النموذج الخاص بنا # fix random seed for reproducibility numpy.random.seed(7) # load pima indians dataset dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",") # split into input (X) and output (Y) variables X = dataset[:,0:8] Y = dataset[:,8] # create model model = Sequential() model.add(Dense(12, input_dim=8, activation='relu')) model.add(Dense(8, activation='relu')) model.add(Dense(1, activation='sigmoid')) # Compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # Fit the model model.fit(X, Y, epochs=150, batch_size=10, verbose=0) # evaluate the model scores = model.evaluate(X, Y, verbose=0) print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100)) # نقوم بتحويل النموذج الي json وحفظه model_json = model.to_json() with open("model.json", "w") as json_file: json_file.write(model_json) # نقوم بتحويل الاوزان الي h5 وحفظها model.save_weights("model.h5") print("Saved model to disk") # نقوم بتحميل ملف ال json عندما نحتاجه json_file = open('model.json', 'r') loaded_model_json = json_file.read() json_file.close() loaded_model = model_from_json(loaded_model_json) # نقوم بتحميل الاوزان من ملف h5 عندما نحتاجها loaded_model.load_weights("model.h5") print("Loaded model from disk") # نقوم بتجريب النموذج الذي قمنا بتحميله loaded_model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy']) score = loaded_model.evaluate(X, Y, verbose=0) print("%s: %.2f%%" % (loaded_model.metrics_names[1], score[1]*100)) يمكنك أن تري ان ملف ال json يقوم بحفظ تفاصيل شكل النموذج بداخله، اذا قمت بفتحه ستجد الشكل التالي (في الواقع معرفتك لشكله لا تهم هي فقط للمعرفه): { "class_name":"Sequential", "config":{ "name":"sequential_1", "layers":[ { "class_name":"Dense", "config":{ "name":"dense_1", "trainable":true, "batch_input_shape":[ null, 8 ], "dtype":"float32", "units":12, "activation":"relu", "use_bias":true, "kernel_initializer":{ "class_name":"VarianceScaling", "config":{ "scale":1.0, "mode":"fan_avg", "distribution":"uniform", "seed":null } }, "bias_initializer":{ "class_name":"Zeros", "config":{ } }, "kernel_regularizer":null, "bias_regularizer":null, "activity_regularizer":null, "kernel_constraint":null, "bias_constraint":null } }, { "class_name":"Dense", "config":{ "name":"dense_2", "trainable":true, "dtype":"float32", "units":8, "activation":"relu", "use_bias":true, "kernel_initializer":{ "class_name":"VarianceScaling", "config":{ "scale":1.0, "mode":"fan_avg", "distribution":"uniform", "seed":null } }, "bias_initializer":{ "class_name":"Zeros", "config":{ } }, "kernel_regularizer":null, "bias_regularizer":null, "activity_regularizer":null, "kernel_constraint":null, "bias_constraint":null } }, { "class_name":"Dense", "config":{ "name":"dense_3", "trainable":true, "dtype":"float32", "units":1, "activation":"sigmoid", "use_bias":true, "kernel_initializer":{ "class_name":"VarianceScaling", "config":{ "scale":1.0, "mode":"fan_avg", "distribution":"uniform", "seed":null } }, "bias_initializer":{ "class_name":"Zeros", "config":{ } }, "kernel_regularizer":null, "bias_regularizer":null, "activity_regularizer":null, "kernel_constraint":null, "bias_constraint":null } } ] }, "keras_version":"2.2.5", "backend":"tensorflow" }
-
اذا كانت شكل المصفوفة على هيئة numpy ، يمكنك استخدام الدالة التالية: numpy.nan_to_num(x, copy=True, nan=0.0, posinf=None, neginf=None) والتي تقوم باخذ مصفوفة بها قيم nan وتحويلها لاي قيم تريدها. اما عن تبديل القيم nan الي none فلا توجد طريقة مباشره من Numpy، فقط يجب عليك تحويلها الي dataframe وذلك لنستطيع استخدام المكتبة pandas. يمكن استخدام الدالة pandas.notnull(obj) للقيام بمثل تلك عملية التحويل، لفهم كيفية استخدامها انظر المثال التالي: >>> array = np.array([[1, np.nan, 3], [4, 5, np.nan]]) >>> array array([[ 1., nan, 3.], [ 4., 5., nan]]) >>>pd.notna(array) array([[ True, False, True], [ True, True, False]]) اما عن حالتك فيمكنك استخدام الدالة كالتالي: df1 = df.astype(object).replace(np.nan, 'None') أو استخدام الدالة التالية: >>> df1 = df.where(pd.notnull(df), None) >>> df1 0 0 1 1 None
- 3 اجابة
-
- 1
-
-
نعم، وهذة هي الغاية في النهاية، دعني أوضح لك الخطوات لاستخدام التطبيق الخاص بك في تعلم الالة: تبدأ اولا بتدريب النموذج الخاص بك. بعد ذلك تقوم بحفظ الاوزان التي تم تعلمها. تقوم برفعها على سيرفر يمكنك استئجاره من amazon او google او microsoft وغيرها بعد ذلك تحطل علي ال api الخاص بالنموذج الخاص بك الذي تم تركيبه على السيرفر عند قدوم اي دخل جديد، تقوم بارسالة عبر ال api ليدخل الى النموذج الخاص بك ليتم اختباره.
- 2 اجابة
-
- 1
-
-
نعم توجد اختلافات بينهم تجعل كل مكتبة فيهم مميزه في شئ ما، اختصارا هذة هي ممميزات كل مكتبة منهم: numpy : هي مكتبة تتعامل مع الاشكال الرياضية للمصفوفات والعمليات الحسابية عليها، لذلك فهي مهمة في عمليات الحسابات الكبيرة والتي تتضمن الكثير من الرياضيات وتكون مميزة خاصة في المصفوفات. pandas : مكتبة تعتبر تمثيلا قريبا لبرنامج excel على بايثون، حيث انها توفر اشكالا سهلة وبسيطة سواء للتعامل او للقراءه للبيانات وكذلك العمليات الرياضية البسيطة التي توضح معالجة للبيانات بشكل سهلة وواضح. كذلك فانها تعتمد على شكل dataframe والذي يجعل شكل البيانات سهلا وواضحا للقراءة، لذا فهي اكثر المكتبات استخداما في مجال تحليل البيانات. scipy: يحتوي SciPy على جميع الوظائف الجبرية التي يوجد بعضها في NumPy إلى حد ما وليس في شكل كامل. بصرف النظر عن ذلك ، هناك العديد من الخوارزميات العددية المتاحة غير الموجودة بشكل صحيح في NumPy.لذلك فهي تستخدم بشكل اكبر ليس في تنظيم البيانات وانما في العمليات الجبرية او الخوارزمية عليها، لذلك فهي تستخدم في الذكاء الاصطناعي لاحتوائها على دوال كثيرة تستخدم فيها مثل random forest.
- 2 اجابة
-
- 1
-
-
بوجة عام، لان شكل المصفوفة عندك ثنائية الابعاد، اي انها صفوف واعمدة فقط، فيمكنك استخلاص الاعمدة من 1 ل 3 كالتالي: X = data[:, [1, 3]] وبشكل عام، استخلاص اي حجم من الصفوف يتم على الشكل التالي: x = data [[#1:#last] , [#1,#last]] حيث أن اول array تمثل الصفوف التي تريد تقطيعها بينما ابثانية تمثل الاعمدة ، كذلك #1 هي اول صف او عمود تريد اخذه بينما #last هو اخر صف او عمود تريد اخذه. وتعني العلامة : الى اخذ كل الصفوف او الاعمدة على حسب المكان الذي توضع فيه.
- 3 اجابة
-
- 1
-
-
يمكنك ببساطة استخدام الدالة numpy.repeat من اجل تكرار عناصر معينة بالشكل الذي تريدة سواء كان افقيا او راسيا. انظر المثال التالي للتوضيح: >>> np.repeat(3, 4) array([3, 3, 3, 3]) >>> x = np.array([[1,2],[3,4]]) >>> np.repeat(x, 2) array([1, 1, 2, 2, 3, 3, 4, 4]) >>> np.repeat(x, 3, axis=1) array([[1, 1, 1, 2, 2, 2], [3, 3, 3, 4, 4, 4]]) >>> np.repeat(x, [1, 2], axis=0) array([[1, 2], [3, 4], [3, 4]]) حيث أن axis تمثل الاتجاة الراسي او الافقي بحيث x=0 تعني تكرارا في الاتجاة الراسي و axis =1 تعني تكرارا في الاتجاه الافقي. كذلك يمكنك استخدام طريقة ذكية كالتالي: >>> array([[1,2,3],]*3) array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) >>> array([[1,2,3],]*3).transpose() array([[1, 1, 1], [2, 2, 2], [3, 3, 3]])
- 2 اجابة
-
- 1
-
-
دورات حسوب مميزة للغاية لانها تحتوي على محتوى قوي ومباشر خال من الحشو، وذلك لانها موجهة للتاهيل من اجل العمل الحر، لذلك فان اشتراكك فيها لن يكون من اجل التعلم فقط وانما هو استثمار سيعود عليك بالارباح لاحقا. كذلك فان حسوب تضمن لك اعادة استثمارك في خلال 6 اشهر من انتهائك من الدورة، قد يضيف هذا بعض الضمانات لديك. اما عن المحتوى فهو مميز وقوي، وحتى اذا اردت مساعدة ستجد الكثير في مجتمع المساعدة لحل مشكلتك سواء في التعلم او مشكلة تقنية او ادارية. انصح بشدة باشتراكك فيها وبذل الجهد من اجل الاستفادة والربح. يمكنك الاطلاع على مزيد من التفاصيل من هنا
-
دورة علوم الحاسوب في حد ذاتها هي بداية لفروع كثيرة قد تدر عليك الالاف شهريا حتى من العمل الحر. فيعد الحصول عليها تكون قد جمعت الاساسيات لبدء البرمجة وبعدها العمل، يمكنك بعدها اختيا المجال الذي تريد سواء كان: برمجة المواقع الالكترونية برمجة تطبيقات الهاتف علوم البيانات والذكاء الاصطناعي تطبيقات سطح المكتب وغيرها من فروع البرمجىة الكثيرة. لكن لضمان العمل الحر انصح بالاكمال في تطبيقات المواقع او الهاتف لانها الاكثر طلبا في مجال العمل الحر.
-
هناك الكثير من loss functions المبنية بداخل keras بالفعل، ويمكنك استخدامها بسهولة كالتالي: model = keras.models.Sequential() model.add(Dense(100, input_shape=(1,), activation='relu')) model.add(Dense(50, activation='relu')) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam') أما اذا اردت انشاء دالة خاصة بجد يجب اتباع بعد القواعد لضمان نجاحها ومنها: يجب أن تراعي أن الدالة تاخذ فقط وسيطين فقط وهما القيم المستهدفة y_pred والقيمة الحقيقية وهي y_true وذلك لان الدالة ستقوم بعمل مقارنة بين القيم المتوقعة والقيم الحقيقية. كذلك فان الدالة يجب ان تستخدم y_pred من اجل حساب الخطأ والتي تقوم على اساسه بعمل تعديلات على القيم التي تم تعلمها بالفعل. في النهاية يمكنك تحويلها للشكل model.compile لجعلها اسهل في الاستخدام. لكن: عليك أن تاخذ حذرك من الابعاد، سواء المدخلة او المخرجة وكذلك ابعاد المدخلات في كل طبقة تعلم. كذلك يجب ان تراعي ان الدالة تقوم بارجاع متجة طوله يساوى batch_size. المثال التالي يوضح الفرق بين الدوال المبنية مسبقا وبين الدالة التي تقوم بصناعتها: هنا يوضح loss function من النوع الخطي، لاحظ ابعاد المدخلات في كل طبقة تعلم وبين الطبقة النهائية: model = keras.models.Sequential() model.add(Dense(50, input_shape=(5,), activation='relu')) model.add(Dense(20, activation='relu')) model.add(Dense(10, activation='relu')) model.add(Dense(2, activation='linear')) الكود التالي يكافؤ نفس الدالة المستخدمة مسبقا لكن تم كتابتها بشكل يدوي وهي تحقق نفس ما تحققه الدالة الجاهزة تماما، لاحظ كيف استخدمنا نفس الابعاد فيها: import keras.backend as K def custom_mse(y_true, y_pred): # calculating squared difference between target and predicted values loss = K.square(y_pred - y_true) # (batch_size, 2) # multiplying the values with weights along batch dimension loss = loss * [0.3, 0.7] # (batch_size, 2) # summing both loss values along batch dimension loss = K.sum(loss, axis=1) # (batch_size,) return loss لاحظ ان 2 تعبر عن شكل الخرج وهو 2 classes لذلك استخدمناها سواء كقيمة في الدالة المبنية مسبقا او في الدالة التي قمنا ببناءها
-
في النسخ الحديثة من keras، تم تغيير اسم المكتبة ، ويمكنك استدعائها من tensorflow كالتالي: from tensorflow.keras.utils import plot_model أو من keras مباشرة كالتالي: from keras.utils import plot_model أما عن استخدامها فهي تحتوي على التالي: tf.keras.utils.plot_model( model, to_file="model.png", show_shapes=False, show_dtype=False, show_layer_names=True, rankdir="TB", expand_nested=False, dpi=96, ) ويمكن أستخدامها في موديل التمرين كالتالي: input = tf.keras.Input(shape=(100,), dtype='int32', name='input') x = tf.keras.layers.Embedding( output_dim=512, input_dim=10000, input_length=100)(input) x = tf.keras.layers.LSTM(32)(x) x = tf.keras.layers.Dense(64, activation='relu')(x) x = tf.keras.layers.Dense(64, activation='relu')(x) x = tf.keras.layers.Dense(64, activation='relu')(x) output = tf.keras.layers.Dense(1, activation='sigmoid', name='output')(x) model = tf.keras.Model(inputs=[input], outputs=[output]) dot_img_file = '/tmp/model_1.png' tf.keras.utils.plot_model(model, to_file=dot_img_file, show_shapes=True)
-
في نسخ keras 2 او اقل، لا توجد تلك الدوال بداخل keras ، لذا اذا اردت استخدمها عليك تعريفها بنفسك كالتالي: from keras import backend as K def recall_m(y_true, y_pred): true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1))) possible_positives = K.sum(K.round(K.clip(y_true, 0, 1))) recall = true_positives / (possible_positives + K.epsilon()) return recall def precision_m(y_true, y_pred): true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1))) predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1))) precision = true_positives / (predicted_positives + K.epsilon()) return precision def f1_m(y_true, y_pred): precision = precision_m(y_true, y_pred) recall = recall_m(y_true, y_pred) return 2*((precision*recall)/(precision+recall+K.epsilon())) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc',f1_m,precision_m, recall_m]) # fit the model history = model.fit(Xtrain, ytrain, validation_split=0.3, epochs=10, verbose=0) # evaluate the model loss, accuracy, f1_score, precision, recall = model.evaluate(Xtest, ytest, verbose=0) اما في النسخ الحديثة، يمكنك استدعائها مباشرة من keras، اما باظهار كافة طرق التقييم في report كالتالي: from sklearn.metrics import classification_report y_pred = model.predict(x_test, batch_size=64, verbose=1) y_pred_bool = np.argmax(y_pred, axis=1) print(classification_report(y_test, y_pred_bool)) وتكون النتيجة كالتالي: precision recall f1-score support class 0 0.50 1.00 0.67 1 class 1 0.00 0.00 0.00 1 class 2 1.00 0.67 0.80 3 أو استخدام بعض القياسات التي تريدها فقط كالتالي: import tensorflow as tf model.compile( ... metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]) ويمكنك استخدامها اثناء التدريب كالتالي: model.compile(optimizer='rmsprop', loss="CategoricalCrossentropy", metrics=[tf.keras.metrics.Precision(), tf.keras.metrics.Recall()]) model.fit(train_x, train_y, epochs=100, batch_size=128)
-
قم بفتح مجلد المشروع الذي تريد تحميله باستخدام مستكشف الملفات أو مدير الملفات. بعد تثبيت GIT علي جهازك قم بالتوجه إلي مكان الملفات التي تود رفعها علي GitHub وإضغط علي زر الفأرة الأيمن و قم بأختيار Git Bash Here اكتب الأمر التالي لتهيئة مجلد المشروع في مستودع Git git init ثم اكتب الأمر التالي ، لإدراج الملف في منطقة الركود. git add . لأن ، سنقوم بإضافة الملفات التي نريد رفعه في المستودع الذي قمنا بأنشائه. الرجاء استبدال عنوان url في الأمر التالي بمستودع Github الذي قمت بإنشائه على Github. git remote add origin https://github.com/username/new-repo.git .سنقوم الأن برفع المجلد بداخل المستودع الذي أنشأناه. git commit -m "أسم الملف" بعد ذلك ، نقوم بإضافة أمر رفع الملفات ، عن طريق الكتابة. git push -u origin master هنا من المحتمل ان يطلب منك إدخال اسم المستخدم وكلمة المرور github. يرجى تسجيل الحساب أولاً إذا لم تقم بذلك بالفعل. في حالة وجود أخطاء عند دفع يرجى إضافة --force. وبالتالي فإن الأمر هو كالتالي git push -u origin master --force
-
اذا كانت المصفوفة فارغة empty ، فان حجمها يجب أن يكون صفرا، لذلك فان اسهل طريقة للتاكد اذا كانت فارغة ام لا هو أن تقومبالتحقق من حجمها كالتالي: import numpy as np a = np.array([]) if a.size == 0: print(empty) مثال تطبيقي: empty_array = np.array([]) is_empty = empty_array.size == 0 print(is_empty) OUTPUT True nonempty_array = np.array([1, 2, 3]) is_empty = nonempty_array.size == 0 print(is_empty) OUTPUT False
- 3 اجابة
-
- 1
-
-
هناك أكثر من طريقة لتحقيق هذا منها: الطريقة التقليدية: عن طريق تفحص كل العناصر وتبديل العناصر التي تحقق الشرط المطلوب كالتالي: shape = arr.shape result = np.zeros(shape) for x in range(0, shape[0]): for y in range(0, shape[1]): if arr[x, y] >= T: result[x, y] = 255 الطريقة السهلة: عن طريق استخدام ال fancy indexing كالتالي، الكود التالي يوضح كيفية استخدامها جميع العناصر الاكبر من 0.5 بقيمة أخرى وهي 0.5 import numpy as np x = np.array([[ 0.42436315, 0.48558583, 0.32924763], [ 0.7439979,0.58220701,0.38213418], [ 0.5097581,0.34528799,0.1563123 ]]) print("Original array:") print(x) print("Replace all elements of the said array with .5 which are greater than .5") x[x > .5] = .5 print(x) ويكون الخرج كالتالي: Original array: [[ 0.42436315 0.48558583 0.32924763] [ 0.7439979 0.58220701 0.38213418] [ 0.5097581 0.34528799 0.1563123 ]] Replace all elements of the said array with .5 which are greater than . 5 [[ 0.42436315 0.48558583 0.32924763] [ 0.5 0.5 0.38213418] [ 0.5 0.34528799 0.1563123 ]]
- 3 اجابة
-
- 1
-
-
في الاصل، تستخدم argsort في ترتيب العناصر داخل مصفوفة من النوع numpy ، استخدامها بالشكل العادي يجعل الترتيب تصاعدي ، أي من الاقل للاعلى كالتالي: avgDists = np.array([1, 8, 6, 9, 4]) ids = avgDists.argsort()[:n] أما اذا اردت استخدامها بشكل تنازلي بحيث تكون اعلى القيم في البداية يمكن استخدام العلامة - لعكس الترتيب كالتالي: avgDists = np.array([1, 8, 6, 9, 4]) ids = (-avgDists).argsort()[:n] مثال أخر، أفترض ان عندنا المصفوفة التالية [3 4 7 2] لترتيب القيم بشكل تنازلي وارجاع اماكن index اعلى 3 قيم استخدام الطريقة التالية: n = 3 largest_indices = np.argsort(-1*an_array)[:n] print(largest_indices) OUTPUT [2 1 0] هنا قام بارجاع [2,1,0] وهي تمثل أماكن أعلى العناصر بالترتيب وهى [7,4,3]
-
أنت لم تقم باستخدام أي دالة لحساب ال loss ، وهذة العملية اساسية في التعلم حيث أنها تحدد مصير استكمال عملية التعلم، وذلك لانها تقوم بحساب المشتقات ومنها تحسب الفرق بين القيم الحقيقية والقيم التي تم توقعها، وعلى هذا الاساس اما ان تكمل عملية التعلم او تتوقف. اذا بدون هذة الدالة لن يتسطيع بدأ عملية التعلم من الاساس. وهناك العديد من دوال ال loss التي يمكنك استخدامها ، منها الدالة BinaryCrossentropy() أو CategoricalCrossentropy K، والكثير من الدوال الاخرى، يمكنك البحث عن loss functions في كيراس واختيار ما يناسبك منهم. بعد التعديل يجب اضافة ال loss كما موضح في الكود التالي: from keras.layers import Embedding from keras.datasets import imdb from keras import preprocessing import keras max_features = 10000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) ###هنا model.compile(optimizer='rmsprop', loss=keras.losses.BinaryCrossentropy(), metrics=['CategoricalCrossentropy']) history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
-
توجد دالة تابعة ل numpy يمكنها حساب ال percentile، ولها نفس الاسم، حيث تقوم بنفس الحسابات الموجوده في excel وتستخدم كالتالي: # Python Program illustrating # numpy.percentile() method import numpy as np # 1D array arr = [20, 2, 7, 1, 34] print("arr : ", arr) print("50th percentile of arr : ", np.percentile(arr, 50)) print("25th percentile of arr : ", np.percentile(arr, 25)) print("75th percentile of arr : ", np.percentile(arr, 75)) كذلك يمكنك كتابة الدالة بنفسك كالتالي: import math import functools def percentile(N, percent, key=lambda x:x): """ Find the percentile of a list of values. N - is a list of values. Note N MUST BE already sorted. percent - a float value from 0.0 to 1.0. key - optional key function to compute value from each element of N. @return - the percentile of the values """ if not N: return None k = (len(N)-1) * percent f = math.floor(k) c = math.ceil(k) if f == c: return key(N[int(k)]) d0 = key(N[int(f)]) * (c-k) d1 = key(N[int(c)]) * (k-f) return d0+d1 # median is 50th percentile. median = functools.partial(percentile, percent=0.5)
-
هناك دالتين في numpy يمكنهما فعل ذلك بسهولة وهما numpy.empty() و numpy.nan() ، حيث تستخدمان سويا في انشاء المصفوفة الفارغة، عن طريق انشاء مصفوفة في البداية باستخدام ا numpy.empty() ثم ملئها بقيم nan باستخدام numpy.nan(). يمكن استخدامها عن طريق تمرير أبعاد المصفوفة المراد انشاءها بدالة numpy.empty() ثم استخدام الدالة numpy.nan() كالتالي: an_array = np.empty((4,3)) an_array[:] = np.NaN print(an_array) OUTPUT [[nan nan nan] [nan nan nan] [nan nan nan] [nan nan nan]] خيار أخر عن طريق استخدام الدالة Numpy.full وذلك لملئ المصفوفة بالقيم nan كالتالي: a = np.full([height, width], np.nan) حيث أن height هي عدد الصفوف في المصفوفة التمراد انشاءها بينما width هو عدد الاعمدة.
- 3 اجابة
-
- 1
-
-
ValueError: No gradients provided for any variable تعني أنك لم تقم باستدعاء أي دالة تكلفة loss function لتقييم النواتج، ورغم استدعاءك ل CategoricalCrossentropy الا انك لم تستدعها لتكون دالة تكلفة وانما لقياس الدقة، وهنا ظهر الخطأ، قد يكون قد حصل لديك لبس نتيجة امكانية استخدام CategoricalCrossentropy كدالة للدقة أو كدالة تكلفة. كل ما عليك فعله هو اعادة استخدامها لتصبح دالة تكلفة، أو استخدام أي دالة تكلفة أخرى تريد، كالتالي: from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) from keras.datasets import mnist import keras from tensorflow.keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) model.compile(optimizer='rmsprop', loss=keras.losses.CategoricalCrossentropy(),#هنا #أو يمكنك استبدالها بأي دالة تكلفة أخري كالتالي: # loss=keras.losses.SparseCategoricalCrossentropy() metrics=["acc"]) model.fit(train_images, train_labels, epochs=5, batch_size=64) test_loss, test_acc = model.evaluate(test_images, test_labels) # 99%
-
تكمن المشكلة في تحديدة لشكل البيانات المدخل بطريقة خاطئة هنا: model.add(Convolution2D(16, 3, 3,, W_constraint=maxnorm(3), input_shape=(3, 32, 32), border_mode='same', activation='tanh')) input_shape يمثل شكل البيانات التي تدخل الي اول طبقة في طبقات التعلم، أنت هنا قمت بتحديدها على انها (3,32,32) في حين أن شكل البيانات لديك هو (50000, 32, 32, 3)، لذا عليك ظبط شكل الدخل ليمثال شكل البيانات لديك كالتالي: model.add(Convolution2D(16, 3, 3,, W_constraint=maxnorm(3), input_shape=(50000, 32, 32, 3), border_mode='same', activation='tanh'))
-
CategoricalAccuracy تعني أنها تقوم بحساب الدقة الخاصة بالتصنيفات category لكل عنصر.بمعني أوضح أنه لو ان البيانات تحتوي على قطط وكلاب، فستقوم بحساب الدقة عن حساب عدد المرات الصائبة في تخمين صور الكلاب وعدد المرات الصائبة في تخمين صور القطط. لكن من أجل فعل ذلك، يجب أن تكون العلامات الخاصة بالصور labels أما 0 أو 1، أي يعني انه اما ان تكون كلبا او قطة، ولعمل ذلك يجب أن نستخدم one hot encoder > ولحساب النسبة فتقوم بقسمة علدد المرات الصواب على العدد الكلي للبيانات. وتوجد في keras على الصورة التالية: tf.keras.metrics.categorical_accuracy( y_true, y_pred ) ويمكن توضيح استخدامها كالتالي: y_true = [[0, 0, 1], [0, 1, 0]] y_pred = [[0.1, 0.9, 0.8], [0.05, 0.95, 0]] m = tf.keras.metrics.categorical_accuracy(y_true, y_pred) assert m.shape == (2,) m.numpy() ولاستخدامها في عملية التعلم يجب اولا تحويل شكل البيانات ل one hot from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) ثم تحديدها في اخر خطوة كالتالي: model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['CategoricalAccuracy'])
-
هناك الكثير من الطرق البسيطة التي تؤدي هذا الغرض عن طريق استخدام المكتبات مباشرة منها: استخدام numpy كاسهل واسرع طريقة كالتالي: >>> a = np.array([1, 0, 3]) >>> b = np.zeros((a.size, a.max()+1)) >>> b[np.arange(a.size),a] = 1 >>> b array([[ 0., 1., 0., 0.], [ 1., 0., 0., 0.], [ 0., 0., 0., 1.]]) أو يمكن استخدام هذة الطريقة ايضا من numpy كالتالي: >>> values = [1, 0, 3] >>> n_values = np.max(values) + 1 >>> np.eye(n_values)[values] array([[ 0., 1., 0., 0.], [ 1., 0., 0., 0.], [ 0., 0., 0., 1.]]) وطريقة ثالثة من numpy ايضا: import numpy as np num_classes = 5 targets = np.array([[2, 3, 4, 0]]).reshape(-1) one_hot_targets = np.eye(num_classes)[targets] #output array([[[ 0., 0., 1., 0., 0., 0.], [ 0., 0., 0., 1., 0., 0.], [ 0., 0., 0., 0., 1., 0.], [ 1., 0., 0., 0., 0., 0.]]]) حيث أن num_classes يمثل عدد الفئات التي تريد أن يتم ترميزها 3 class تعني قطة وكلب فأر على سبيل المثال. يمكنك أستخدام keras لعمل التحويل كالتالي: from keras.utils.np_utils import to_categorical categorical_labels = to_categorical(int_labels, num_classes=3)