Ahmed Sharshar
-
المساهمات
348 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ahmed Sharshar
-
يعاني تعلم الألة والتعلم العميق من كثرة ال parameters أو المتغيرات التي يتم ظبطها خلال عملية التعلم، وتؤدي كثرتها الى شيئين رئيسين، أولهما البطئ في عملية التعلم، الثانية هي ال overfitting أو الضبط الزائد وهو أن يتعلم الموديل فقط بناء على البيانات التى ليده ولا يستطيع التعميم. من أجل حل تلك المشكلة ، نلجأ الي عدة طرق لتقليل عدد المتغيرات التي نقوم بتدريبها، احدى هذه الطرق هو ال droupout. .ما يسبب ال overfitting، أن الشبكة تعتمد غالبًا على مجموعات محددة جدًا من الوزن ، نوع من "مؤامرة" الأوزان. كونها محددة للغاية ، فإنها تميل إلى أن تكون هشة: أزل واحدة وتنهار المؤامرة. هذه هي الفكرة من وراء التسرب. لتفكيك هذه المؤامرات ، نتخلى بشكل عشوائي عن جزء من وحدات إدخال الطبقة في كل خطوة من التدريب ، مما يجعل من الصعب على الشبكة تعلم تلك الأنماط الزائفة في بيانات التدريب. بدلاً من ذلك ، يجب أن تبحث عن أنماط عامة وواسعة ، والتي تميل أنماط وزنها إلى أن تكون أكثر قوة.يمكنك أيضًا التفكير في التسرب على أنه إنشاء نوع من مجموعة الشبكات. لن يتم إجراء التنبؤات من قبل شبكة واحدة كبيرة ، ولكن بدلاً من ذلك من قبل لجنة من الشبكات الأصغر. في الشكل التفاعلي الأتي، نري أنه يتم أختيا اثنين فقط من الأربع طبقات من أجل اكمال عملية التعلم بينما يتم التخلي عن اثنين أخرين، لذا هنا فإن ال dropout = 0.5: ملحوظه مهمه: يتم اختيار الطبقات التي تكمل او تسقط من عملية التعلم عشوائيا تماما. اما عن تطبيقها في keras فهي سهلة للغاية، هناك طبقة تسمي dropout يتم اعطاءها قيمة هي عبارة عن النسبة المراد التخلي عنها كما في المثال الأتي: keras.Sequential([ # ... layers.Dropout(rate=0.3), # يتم الاستغناء عن 30% من الطبقات في المرحلة التالية layers.Dense(16), # ... ]) لذلك فإنه اذا كنت تعاني من ال Overfitting بشكل كبير، يمكنك اختيا تلك القيمه بحيث تكون أكبر من 0.5 اما اذا كان ال overfitting قليل، ضع تلك القيمة صغيره بحيث لا تؤثر عن دقة النموذج، يمكنك اختيار تلك القيمه بحيث تكون أقل من 0.5
-
تظهر المشكلة نتيجة اختلاف كل البيانات في كل مرحلة، وذلك لأن شكل البيانات الخارجة من أول مرحلة هي (1,1,1) بينما المرحلة الثانية تتطلب بيانات ذات شكل (9,1,1) وحل هذا يكون بحل كل خطوة على حده. بالنسبة للمرلحلة الأولي يجب تعديل حجم ال batch_size الذي يدخل لعملية التعلم، هنا أنت تستخدم كل البيانات في التعلم وهذا ليس صوابا وأنما يجب تغييرها لتكون 1 وذلك حتي يتم توقع كل خطوة في التسلسل خطوة تلو خطوة، والتعديل الذي يجب أن يتم على الكود كالتالي: n_batch = 1 طريقة أخري عن طريق عمل تعديل بسيط في المرحلة الثانية من التدريب، وهي عن طريق استخدام أحجام دفعات مختلفة للتدريب، وذلك بنسخ القيم التي تم تعلمها من الشبكة التي تم تدريبها سابقا وإنشاء شبكة جديدة باستخدام القيم التي تم نسخها، ويكون التعديل كالتالي: #sequence إنشاء تسلسل length = 10 s= [i/float(length) for i in range(length)] # إنشاء أزواج x/y df = DataFrame(s) df = concat([df, df.shift(1)], axis=1) df.dropna(inplace=True) val = df.values data = val[:, 0] label=val[:, 1] data = data.reshape(len(data), 1, 1) # القسم 0 # إعادة تعيين حجم الدفعة n_batch = 1 # إعادة تعريف النموذج new_model = Sequential() new_model.add(LSTM(n_neurons, batch_input_shape=(n_batch, X.shape[1], X.shape[2]), stateful=True)) new_model.add(Dense(1)) old_weights = model.get_weights() new_model.set_weights(old_weights) model.compile(loss='mse', optimizer='rmsprop') # القسم 1 for i in range(n_epoch): model.fit(data, label, epochs=1, batch_size=n_batch, verbose=1, shuffle=False) model.reset_states() # القسم 2 for i in range(len(data)): testX, testy = data[i], label[i] testX = testX.reshape(1, 1, 1) yhat = new_model.predict(testX, batch_size=n_batch) print('>Expected=%.1f, Predicted=%.1f' % (testy, yhat))
-
تستخدم ال batch_size من أجل تحديد كمية الداتا التي ستدخل الي الموديل في كل مرة يقوم فيها الموديل بالتدريب. بمعني أنه يقوم بتقسيم الداتا كلها إلى كميات متساوية من البيانات بحيث تدخل تباعا الي الموديل. فمثلا لو أن الداتا تحتوي على 100 صف من البيانات، فيقوم تقسيمها الي 10 أقسام كل واحدة تحتوي على 10 صفوف من البيانات. لكن ماذا يحدث إذا قمنا بتقسيم البيانات بأكثر مما تحتويه الداتا كلها، بمعني أن نحاول تقسيم 5 صفووف الي 10 اقسام؟، حيناها ستظهر رسالة الخطأ التي ظهرت لك والتي تعني أن حجم ال batch_size أكبر من الحجم الكلي للبيانات. ولعلاج تلك المشكلة ما عليك سوى تقليل حجم ال batch_size حتي يستطيع الموديل أن يقسم البيانات كالتالي: model.Fit(with_noise, no_noise,epochs: 10,batch_size: 32,steps_per_epoch:2,validation_split: validation_split); هنا قمنا بتصغير حجم ال batch_size من 140 في الموديل الخاص بك الى 32، جرب هذا وستختفي رسالة الخطأ
-
يؤدي حساب تكرارات قيمة في مصفوفة NumPy إلى إرجاع تكرار القيمة في المصفوفة. على سبيل المثال ، في [1 ، 2 ، 3 ، 2 ، 1 ، 2] ، فإن 2 تظهر ثلاث مرات. استخدم ()np.count_nonzero لحساب عدد المرات التي تظهر بها قيمة معينة. ويمكن استدعائها كالتالي: np.count_nonzero(array == value) حيث تضع value بالرقم الذي تريد أن تبحث عن عدد مرات تكراره. كمثال يمكن انشاء المصفوفة التالية: arr = numpy.array([0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1]) ثم نستدعى الدالة كالتالي: occurrences = np.count_nonzero(arr == 1) print(occurrences) يكون الناتج = 4. يمكنك كذلك البحث في مصفوفة من صفوف وأعمدة بأستخدام نفس الدالة كالتالي: np.count_nonzero(array == value, axis=n) حيث أن axis هو اما الصف أو العمود الذي نريد البحث فيه، فمثلا لو n=1 فسيقوم بحساب تكرارات القيمة في كل صف. واذا كانت n=0 فسيقوم بحساب تكرارات القيمة في كل عمود. مثال، دعنا ننشأ المصفوفة التالية: arr = numpy.array( [1, 2, 3, 2, 1, 2]) ثم نكتب الكود التالي: row_occurrences = np.count_nonzero(an_array == 2, axis=1) print(row_occurrences) ويكون الخرج من تشغيله كالتالي: [1 2]
- 4 اجابة
-
- 1
-

-
لإيجاد الفهرس الخاص بقيمة معينه في numpy: نستطيع استخدام الدلة: numpy.where(boolArr) نستطيع أن نضع boolArr بالشرط الذي نريد تحقيقه، ففي المثال التالي نبحث عن الفهرس الخاص بالقيمة 15، ويقوم بارجاع list فيها كل الفهرس الخاص بكل مرة ظهرت فيها القيمة 15، ولايجاد أول مره كل ما عليك هو أختيار أول عنصر في الlist التي بها الفهرس: import numpy as np # أنشاء list بها عدة ارقام arr = np.array([11, 12, 13, 14, 15, 16, 17, 15, 11, 12, 14, 15, 16, 17]) # نطبع كل الفهرس الخاص بالرقم 15 result = np.where(arr == 15) print('Tuple of arrays returned : ', result) print("Elements with value 15 exists at following indices", result[0], sep='\n') ويكون الخرج كالتالي: Tuple of arrays returned : (array([ 4, 7, 11], dtype=int32),) Elements with value 15 exists at following indices [ 4 7 11] ولاختيار أول مره تظهر ظهر فيها الرقم 15: x_index = result[0]
- 4 اجابة
-
- 1
-
-
ستحتاج إلى عرض المصفوفة الخاصة بك كمصفوفة بها حقول (مصفوفة منظمة). وتصبح الطريقة "الصحيحة" قبيحة تمامًا إذا لم تحدد في البداية المصفوفة بالحقول كمثال سريع ، لترتيبها وإرجاع نسخة منها: In [1]: import numpy as np In [2]: a = np.array([[1,2,3],[4,5,6],[0,0,1]]) In [3]: np.sort(a.view('i8,i8,i8'), order=['f1'], axis=0).view(np.int) Out[3]: array([[0, 0, 1], [1, 2, 3], [4, 5, 6]]) اما لترتيبها في نفس مكانها: In [6]: a.view('i8,i8,i8').sort(order=['f1'], axis=0) In [7]: a Out[7]: array([[0, 0, 1], [1, 2, 3], [4, 5, 6]]) الميزة الوحيدة لهذه الطريقة هي أن طريقة "الترتيب" هي قائمة بالحقول لترتيب البحث. على سبيل المثال ، يمكنك الفرز حسب العمود الثاني ، ثم العمود الثالث ، ثم العمود الأول من خلال تقديم الترتيب = ['f1' ، 'f2' ، 'f0'].
- 3 اجابة
-
- 1
-
-
دعنا نفهم ما هي case لنعرف كيف تعمل أولا: case تشبة if في بعض اللغات، وما بداخلها هو الكود الذي يتم تنفيذة اذا حدث الشرط الذي يوضع بجوار case. لذلك فانها تعتبر حلقة مغلقة ، واذا اردت تعريف متغير أكثر من مرة بداخله، عليك أن تكرره أكثر من مرة. لذلك أبسط حل هو أن تقوم بتعريف الأربع متغيرات الذي تريد استخدامهم في ال global ، خارج أي case منهم، فتقوم بوضع الكود التالي قبل اول case: $colorSelect = $_POST['colorSelect']; $colorNumber = $_POST['colorNumber']; $countPiece = $_POST['countPiece']; $total = $_POST['total']; وبما انه تم تعريفهم في ال global فلا داعي لاعادة تعرفيهم داخل أي case منهم، كمثال: $colorSelect = $_POST['colorSelect']; $colorNumber = $_POST['colorNumber']; $countPiece = $_POST['countPiece']; $total = $_POST['total']; case 'add_buttons': // var_dump($_POST);exit; $order = $_POST['order']; $buttons = $_POST['buttons']; // $result = $conn->query("DELETE FROM order_buttons WHERE order_id='$order'"); for ($i =0; $i < count($buttons); $i++){ try { $result = $conn->query("INSERT INTO order_buttons(order_id, button_id, color_select, colorNumber_input, countPiece , total ) VALUES('$order','$buttons[$i]','$colorSelect[$i]' ,'$colorNumber[$i]','$countPiece[$i]','$total[$i]')"); } catch (Exception $e) { var_dump($e->getTrace()); // or to get the full error info, just var_dump($e); } هذا يسهل ويقلل من حجم الكود ويجعله أسرع ُأثناء تشغيله.
- 2 اجابة
-
- 1
-
-
الإجابة على هذا السؤال نسبية للغاية لكن سأجاوبك من وجهة نظري كخريج من كلية الهندسة قسم حاسبات. بالنسبة لكلية حاسبات ومعلومات فهي تركز أكثر على تعلم البرمجة بشكل بحت، وهي جيده للغاية لمن أراد أن يتدرب بشكل مستمر خصوصا في المجالات التي لا تتطلب معرفة قوية باساسيات العلوم مثل برمجة مواقع الأنترنت وبرمجة تطبيقات الهواتف. كذلك فإن دراستها لا تركز بشكل قوي على العلوم الاساسية والنظريات وانما تركز أكثر على البرمجة الفعلية وكثرة العمل على مشاريع، لذلك فان طلابها يكونون جيدين للغاية في البرمجة التقليدية لكن ليس لكل المشاكل الصعبة تحديدا. أما كلية الهندسة فهي لا تركز بشكل أساسي على البرمجة في بدايتها، ولذلك لان اول سنة تكون عامة بين كل اقسام الكلية، فتدرس رياضيات وفيزياء و رسم وكيمياء وكهرباء وهكذا. بداية من السنة التي تليها تدخل في التخصص، وبداخل التخصص ذاته تعاود أخذ أساسيات العلوم، فهناك أكثر من مادة للرياضيات ستدرسها وكذلك الاحتمال وغيره. وتتميز كلية الهندسة انها تجعلك أقوي من الناحية النظرية، فتستطيع حل مشكلات أصعب، لكن عليك العمل مع نفسك لتنمية مهارات البرمجة، وكذلك تدرس فيها الهاردووير وهو ما لا يتواجد في كلية الحاسبات والمعلومات.
-
هناك العديد من الدوال التي تساعد على معرفة أماكن الملفات وتوصيلها ببعض منها: realpath() : تستخدم للحصول على مسار الملف المطلوب ، عن طريق تمرير أسم الملف المراد البحث عنه داخل الاقواس. dirname( ) : تستخدم للحصول على أسماء المجلدات وتستخدم بالذات الطريقة السابقة. أما اذا أرد ربط ملف التنسيقات style بأسهل طريقة فهناك دالة include تسخدم تحديد لهذا الغرض ، وطريقه استخدامه بسيطة كالتالي: <?php include ('style.css') ?> وهنا يجب أن تضع مكان ملف ال style بالنسبة لمكان ملف ال php، أي أن لو ملف style في نفس ملجد php تضع اسمه مباشرة، أما اذا كان في ملف أخل فعليك كتابة ./ ثم المسار الخاص بملف style.
-
من أجل تثبيت السكريبت chocolaty ، يحث الكتاب على عرض السكريبت ذاته أولا قبل محاولة تثبيته للتاكد من سلامته. لذلك قام باستخدام .net من أجل عرض السكريبت، عن طريق انشاء كائنا متغيرا أسماه script ، يمكنك أن تقوم بتسميته أي شئ أخر حسب رغبتك ففهي النهاية هو متغير، لكن يجب أن تبدأ بالعلامه $ قبل أي اسم تختاره، ثم بعد ذلك قام بتعيين القيمة له عن طريق الكود التالي: $script = New-Object Net.WebClient حيث أن: New-Object تستخدم لانشاء كائن جديد وهي كلمه مثبتة. WebClient حتي يقوم بربط الكائن المنشأ من المتصفح Internet Explorer. بعد ذلك بدأ بالبحث في الخيارات المتاحة أمامه بعد تعيين المتغير script، لكن ليفعل ذلك عليه توصيل الكائن الذي تم انشاءه مع WebClient عن طريق الكود التالي: $script | Get-Member بعد ذلك يمكنك تصفح المتغير script وترى ماذا يمكن أن تفعل به.
-
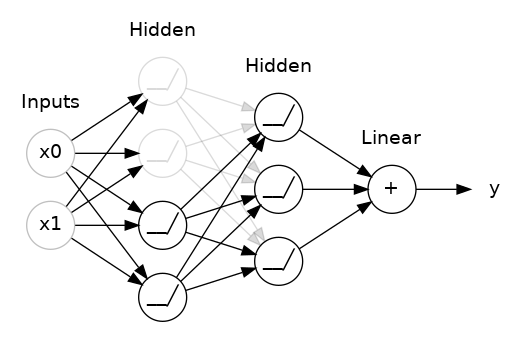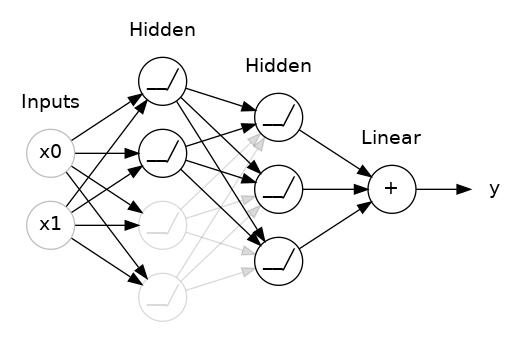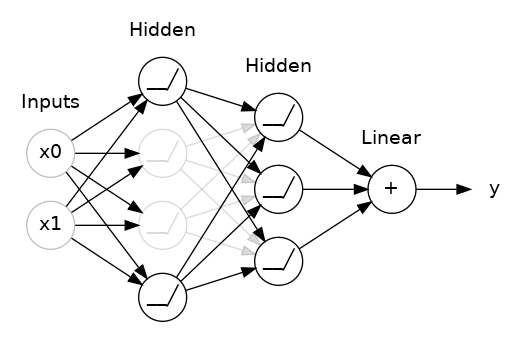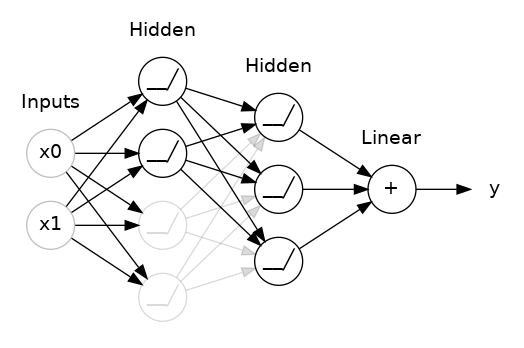
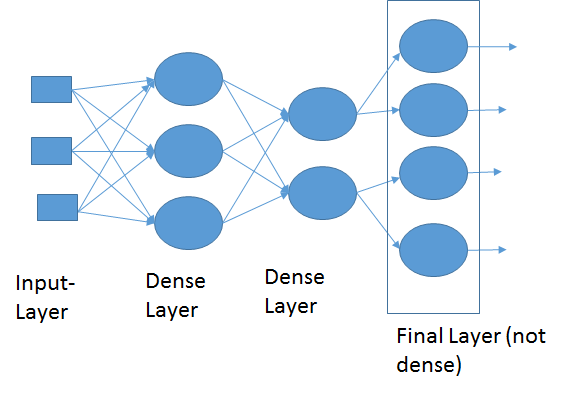
تعبر رسالة المشكلة عن خطأ في عدد التصنيفات التي تريدها، بمعني أخر فان قاعدة البيانات التي تستخدمها dataset تحتوي على 46 صنفا من المخرجات (أي انها 46 نوعا مختلفا من البيانات) ، وأنت هنا وضعت فقط الخرج على انه صنفين: model.add(layers.Dense(1, activation='softmax')) الطبقة الأخيرة دائما، وهي أخر طبقة توضع في عملية التعلم مثل المثال السابق، يجب ان تحتوي على عدد المخرجات التي تريدها والتي يجب أن تتطابق مع طبيعه ال dataset، لان تلك الطبقة تقوم بعمل flatten او تسطيح للداتا بحيث أن كل نقطة تمثل خرجا ما، وبما أنك تحتاج الى استخراج 46 نوعا مختلفا، يجب أن يكون هناك 46 نقطة في أخر طبقة. مثال، الصورة التالية توضح نموذجا بسيطا بحيث أن اخر طبقة تحتوي على 4 نقاط، لذا فأن الخرج هنا هو 4 أصناف مختلفة: لذلك فإن حل مشكلتك بسيط: فقط قم بتعديل أخر طبقة لتكون 46 بدلا من 1 كالتالي: model.add(layers.Dense(46, activation='softmax'))
-
لتنزيل أي برنامج عبر اللينكس يوجد طريقتين: الأول باستخدام الترمينال terminal وهذة هي الطريقة الأكثر اتباعا عبر كتابة التالي: sudo apt install <اسم البرنامج> أو تقوم بتنزيله بامتداد .tar وتثبيته بالطريقة المعتاده مثل ويندوز. أما عن استخدام البرنامج بعد ذلك فلا حاجة لاعادة تنزيله في كل مره، فقط اذهب الى "show applications" أسفل يسار الصفحة، ثم تبحث في خانة البحث عن اسم البرنامج وسوف تجده وتفتحه بالطريقة العادية عن طريق الضغط عليه مرتين.
- 2 اجابة
-
- 1
-
-
حل السؤال بسيط، الارقام المثالية هي الارقام التي فيها مجموع مكوناتها يساوى الرقم ذاته. أي أن الرقم 6 عناصرة 2 ،3،1 ، لان 2*3 = 6 و 1*6 =6 واذا جمعنا 1+2+3 =6 لذلك هو رقم مثالي. سنكتب برنامج يقوم بالمرور عبر كل رقم من 1 ل 1000 عن طريق حركة تكرارية، ويقوم باستخراج عناصره، ثم يجمعهم، اذا كان جمعهم يساوى الرقم نفسه يطبعه ثم يكمل لباقي الارقام. فيما يلي الكود الذي يقوم بالتالي: #include <stdio.h> int main(){ int sum; for(int number = 1;number <= 1000; number++){ sum = 0; for (int i = 1; i <= number/2; i++){ if (number % i == 0){ sum += i; } } if (sum == number){ printf("%d is perfect\n", number); } } return 0; } ناتج الكود سيكون التالي: 6 is perfect 28 is perfect 496 is perfect
- 1 جواب
-
- 1
-
-
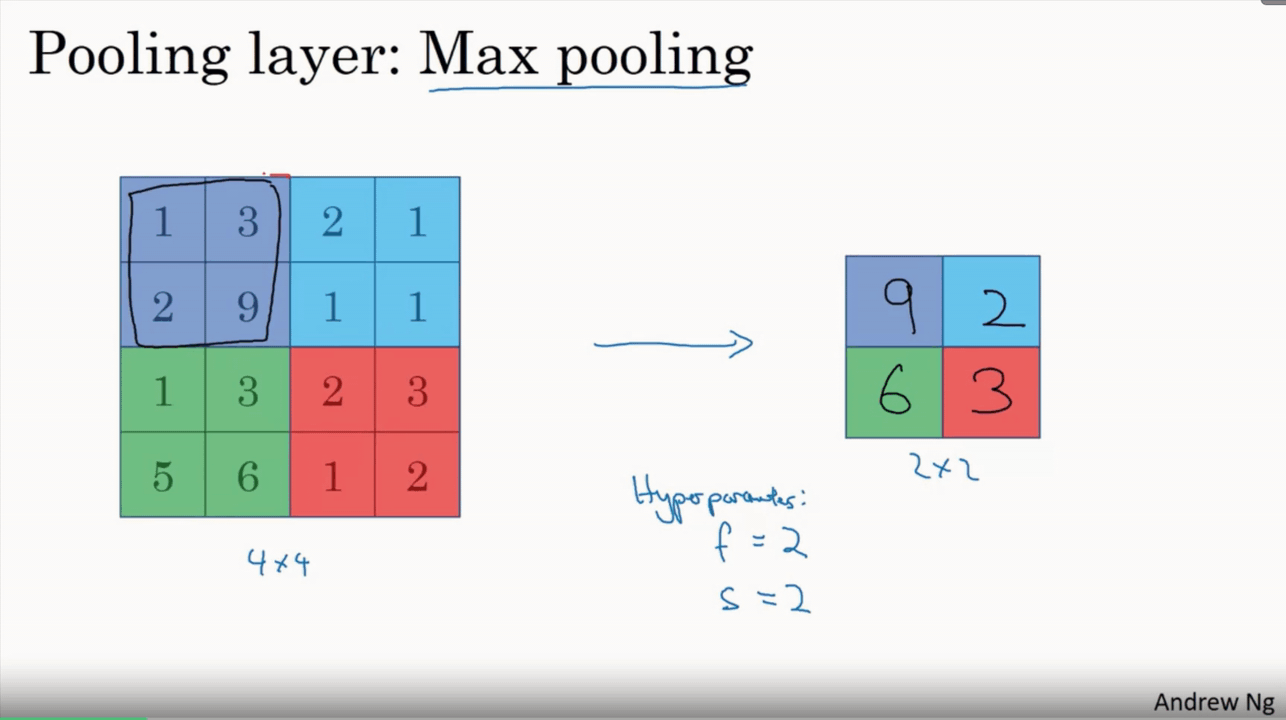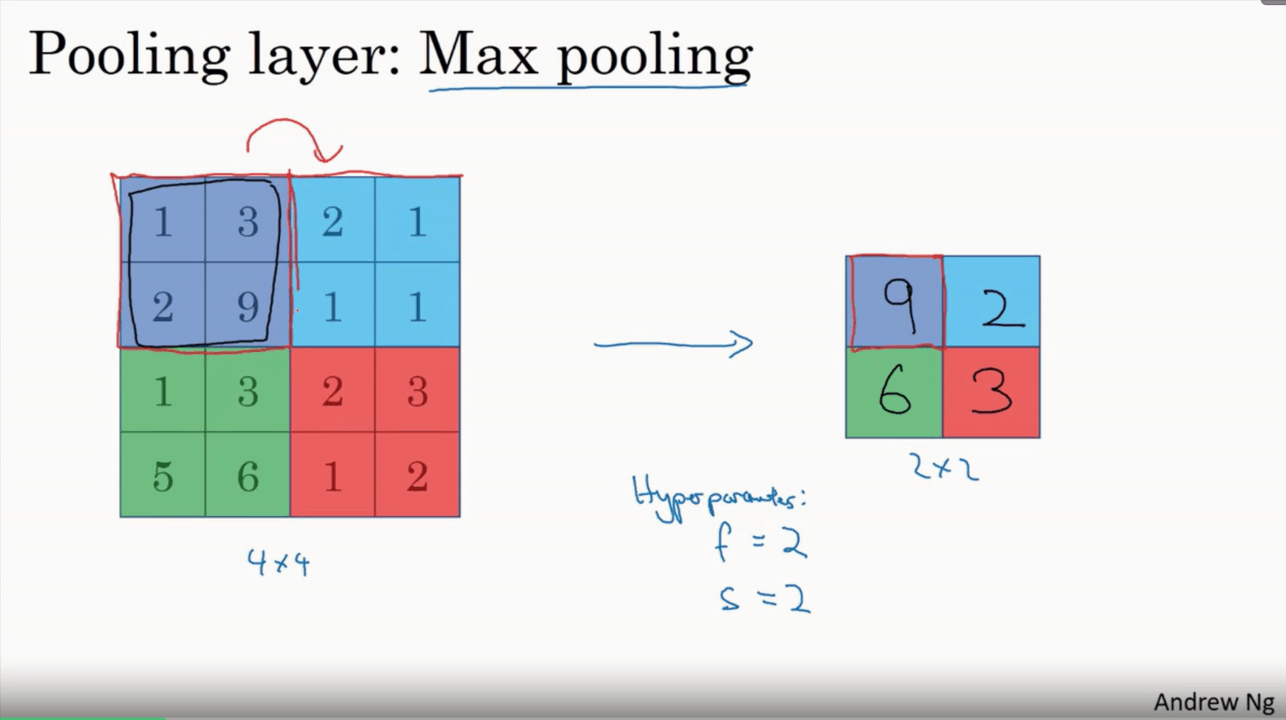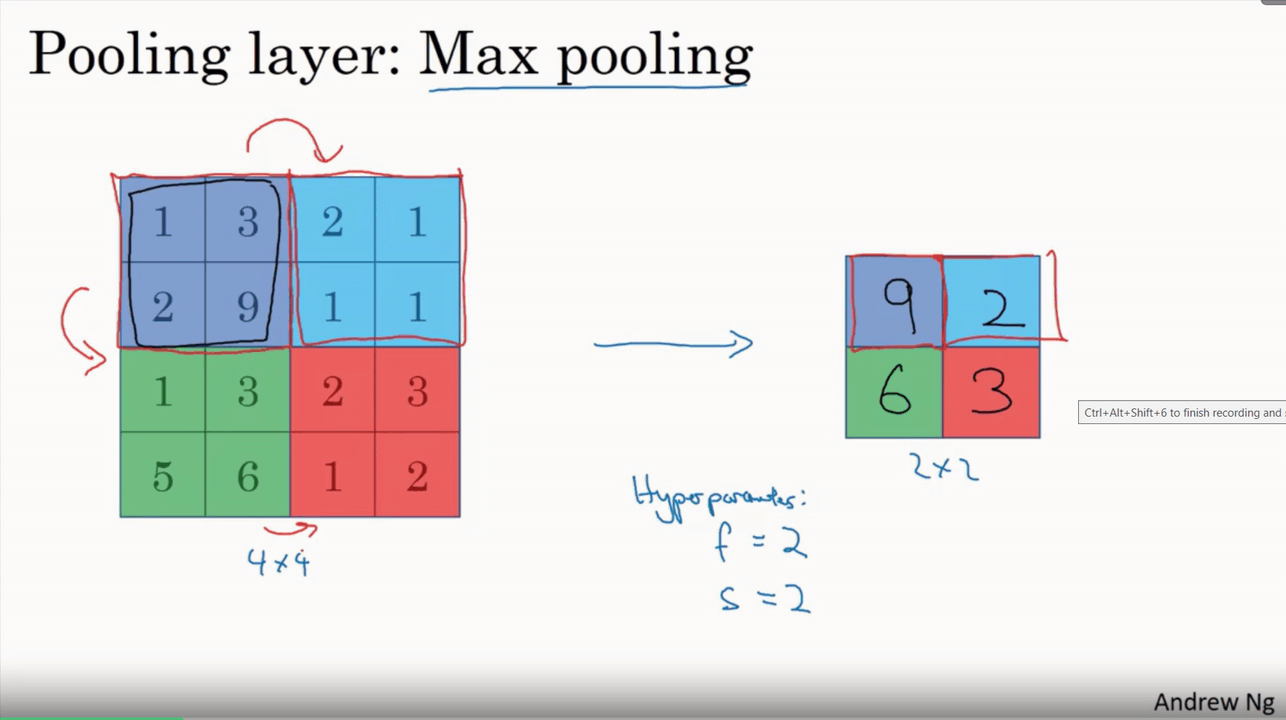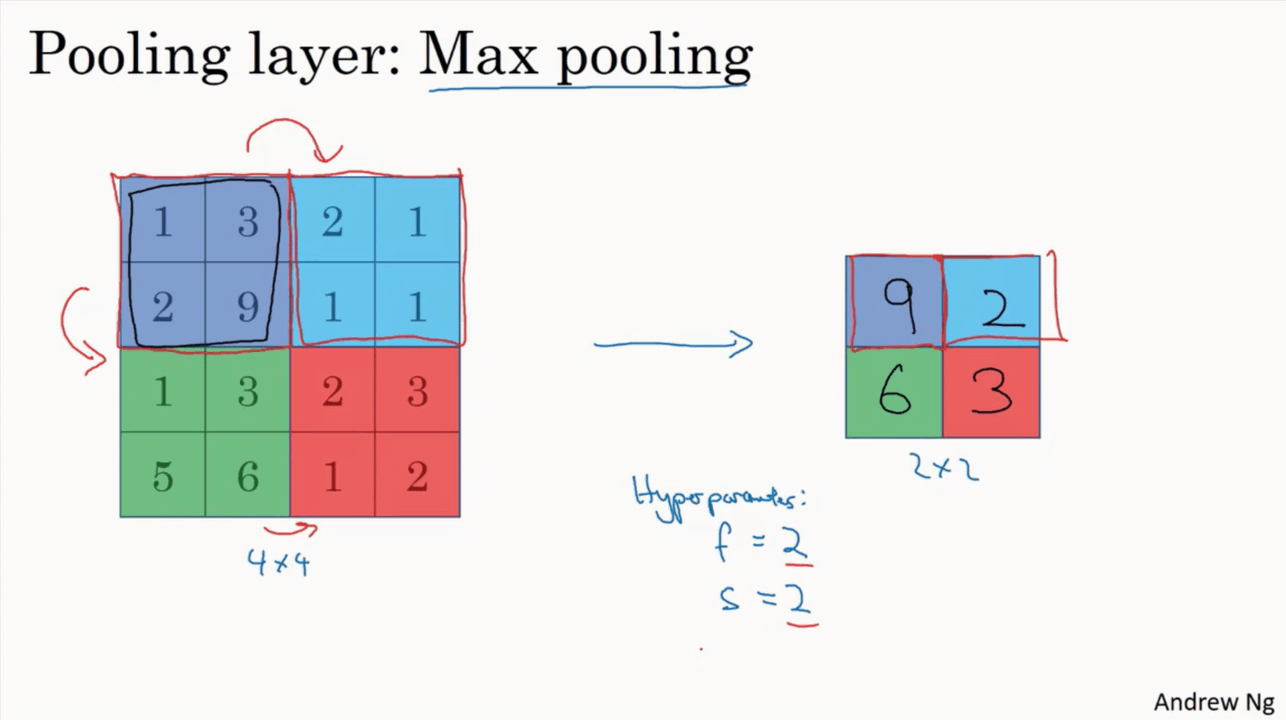
يعاني تعلم الالة من كمية المعلومات الكثيرة التي يجب علي الموديل أن يتعلمها ، وذلك لان كمية البيانات التي تدخل الى النظام كبيره للغاية، وهذا قد يستغرق اسابيع وربما شهور لو تركنا حجم البيانات الأصلية كما هي، بالاضافة الى أن معظم هذة البيانات تكون غير هامة وتركها قد يسبب نتائج سيئة، لذلك لجأ العلماء الي طرق كثيرة لتخفيض حجم البيانات وترك المهم منها فقط. التجميع المكاني أو كما يعرف ايضا ب اخذ عينات فرعية subsampling أو الاختزال downsampling يقوم بتقليص الأبعاد لكل خريطة خصائص مع اعتبار الإبقاء على المعلومات المهمة. التجميع المكاني له عدة انواع مثل: Max (اعلى قيمة)، Average (حساب المتوسط)، Sum (المجموع) . في حالة التجميع باستخدام اعلى قيمة Max Pooling فإننا نقوم بتحديد المنطقة المكانية المتجاورة (نافذة بحجم ٢x٢ على سبيل المثال) ونقوم باستخراج العنصر (البكسل) صاحب اعلى قيمة في النافذة المحددة من خريطة الخصائص المصححة. وبنفس الطريقة لو استخدمنا المتوسط Average فسنقوم بحساب متوسط الاعداد في تلك النافذة فقط او مجموعهم في حال Sum. بشكل عام فإن التجميع باستخدام اعلى قيمة Max Pooling قد اظهر اداء افضل. الشكل البياني التفاعلي الأتي يستعرض مثال لاستخدام التجميع باستخدام اعلى قيمة Max Pooling على خريطة الخصائص المصححة المستخرجة بعد عملية الالتفاف convolution بالاضافة لعملية الريلو ReLU باستخدام نافذة ذات حجم ٢x٢ وتستخدم ال maxpooling في تقليص حجم البيانات باستخراج الاكبر منها كقيمه عددية، وتستخدم بشده مع الشبكات العصبية التلاففية CNN وتستطيع تحديد حجم النافذة والحركات التي تقوم بها بسهولة في بايثون. اما عن maxpooling في keras فهي كالتالي: tf.keras.layers.MaxPooling2D( pool_size=(2, 2), strides=None, padding="valid", data_format=None ) pool_size: وهي حجم النافذة التي تقوم بتحديد أبعادها لأختيار القيمة الأكبر منها، كما هو موضح في الكود السابق وكذلك الشكل التفاعلي بالاعلى، فان حجم النافذة هنا 2*2، أي يقوم باختيار مربع به 4 عناصر ويختار فقط القيمة الأعلى بينهم ويهمل الباقي. strides: هي حجم الخطوة التي تتحركها النافذة من قيمه لأخرى، أي لو كانت =1 ، فانه سيتحرك خطوة واحده لليمين في كل خطوة ويرسم المربع ذاته بنفس الأبعاد ويختار أكبر قيمة وهكذا. القيمة الافتراضية لها none ويمكن وضعها بأي رقم صحيح. padding: هي الطبقة الصفرية التي يمكن أن تحيط بالصورة، أي عند أستخدامها فانها تضيف اطارا عباره عن صف او عمود في كل حد من حدود الصورة وذلك ليحافظ على اول قيمة تأخذ اطلاقا من ال maxpooling .الوضع الافتراضي لها هو valid أي موجودة. الكود التالي يوضح كيف يمكن أستخدامها داخل موديل باستخدام keras. import keras from keras.models import Sequential from keras.layers import Activation from keras.layers.core import Dense, Flatten from keras.layers.convolutional import * from keras.layers.pooling import * model_valid = Sequential([ Dense(16, input_shape=(20,20,3), activation='relu'), Conv2D(32, kernel_size=(3,3), activation='relu', padding='same'), MaxPooling2D(pool_size=(2, 2), strides=2, padding='valid'), #هنا نستخدم maxpooling Conv2D(64, kernel_size=(5,5), activation='relu', padding='same'), Flatten(), Dense(2, activation='softmax') ]) وتكون نتيجة تشغيل الكود اذا اردنا استخراج ابعاد الصوره بعد كل عملية كاتالي: > model_valid.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_2 (Dense) (None, 20, 20, 16) 64 _________________________________________________________________ conv2d_1 (Conv2D) (None, 20, 20, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 10, 10, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 10, 10, 64) 51264 _________________________________________________________________ flatten_1 (Flatten) (None, 6400) 0 _________________________________________________________________ dense_2 (Dense) (None, 2) 12802 ================================================================= Total params: 68,770 Trainable params: 68,770 Non-trainable params: 0 _________________________ يمكننا أن نلاحظ من خلال الخرج output_shape أن حجم الصورة قد قل للنصف بعد استخدام ال maxpooling، وذلك لاننا وضعنا حجم النافذة (2,2) وكذلك حجم الخطوة stride =2، حيناها ساخذ قيمه واحده من كل مربع به عنصرين فتقل حجم الصورة للنصف.
- 2 اجابة
-
- 1
-
-
تعتبر الميزة الفعلية لاستخدام phpStorm هو انه بيئة عمل IDE وليس مجرد محرر أكواد، وهذا ما يجعله بطيئا أثناء التحميل ونسبيا معقد عن محرر الأكواد Notepad+. ان الـIDE هو أكثر من مجرد محرر نصوص بسيط. على الرغم من أن برامج تحرير النصوص التي تتمحور حول الأكواد مثل Notepad+ تقدم العديد من الميزات المريحة مثل تمييز بناء الجملة والواجهات القابلة للتخصيص وأدوات التنقل الشاملة ، فإنها تتيح لك فقط كتابة الأكواد البرمجية. لجعل التطبيقات تعمل ، على الأقل تحتاج إلى مترجم وDebugger. يتضمن الـIDE كل هذه المميزات وأكثر. تأتي بعض الـIDEs مع أدوات إضافية للAutomation، كما قد تحتوي على أدوات لاختبار عملية التطوير وتصورها. يعني مصطلح "بيئة التطوير المتكاملة" أن لديك كل ما تحتاجه لتحويل الكود إلى تطبيقات وبرامج فعّالة. ويمكن ذكر بعض مميزات ال IDE كالتالي: إبراز بناء الجملة إكمال الكود التحكم في الاصدار مثل استخدام git التصحيح ومتابعة الأخطاء (debugging) بسبب كل هذه المميزات، يلجأ العديد من مبرمجي php لاستخدام phpStorm ، ويرجع البطئ النسبي في إستخدامه لانه يحتوى على مميزات أكثر بكثير من محرر الأكواد.
-
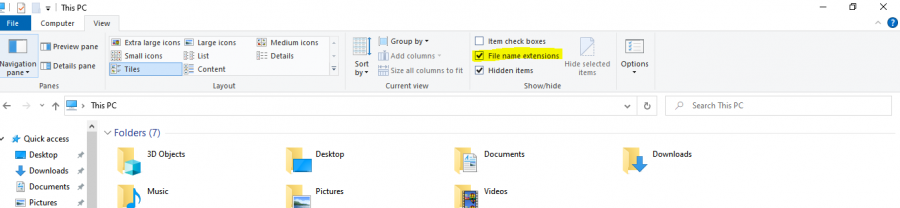
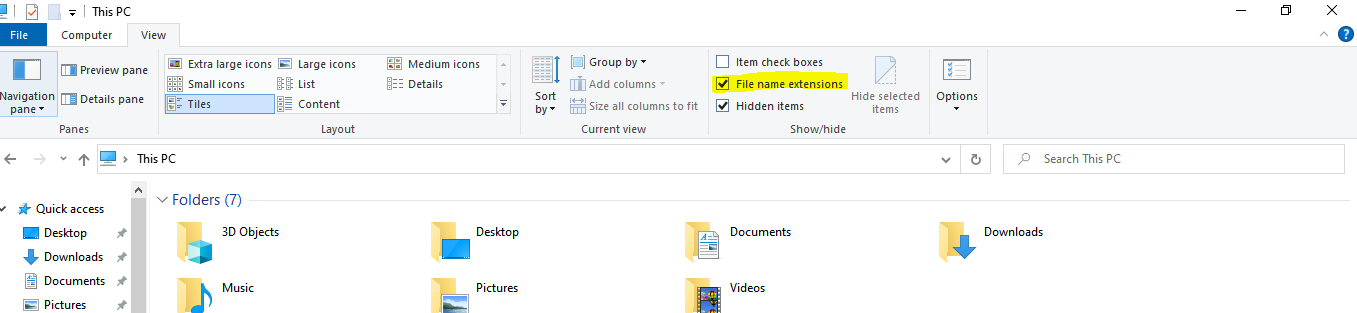
يمكنك تغيير هذا الإمتداد بأكثر من طريقة سأوضح لك أثنتين منهما: يمكن عمل ذلك بطريقه يدوية عن طريق بالتعديل على امتدادات الملفات : أذهب الي this pc في الويندوز ، من أعلى قم بأختيار view وعمل علامة صح على ال view file extension، كما هو موضح بالصورة الأتية: بعد ذلك إذهب الي الملف المراد تعديله وقم بعمل إعادة تسمية له، إحذف كل الأسم متضمنا الامتداد وقم بتسميته من جديد بالامتداد الذى تريد مع مراعاة وضح علامة نقطة "." قبل الامتداد كما هو موضح بالصورة التالية: بعد ذلك سيقوم ويندوز باظهار رسالة تأكيد إذا كنت تريد فعلا تغيير الملف، قم بإختيار "yes" وسيتم تغيير الملف الي ملف .js . الطريقة الثانية هي بفتح أي محرر أكواد مثل visual studio code ثم عمل "open" لملف ..txt المراد تغيير، بعد ذلك قم بعمل save as واختار الامتداد .js على الرغم من أن كلا الطريقيتين تعملان، الا أن الطريقة الاولى أسهل وأيضا مفيدة بشكل عام لتغيير إمتداد أي ملف في المستقبل.
.thumb.png.d11ca48ff74f89cd8ce10ab94c6bcb3e.png)
- 2 اجابة
-
- 1
-
-
عند ظهور الرسالة "no changes added to commit" فهذا يعني التالي: يحتوي Git على "منطقة انتقالية" حيث يلزم إضافة الملفات قبل عمل commit. في الكود الخاص بك يمكنك كتابة التالي: git commit -am "اكتب الرسالة الذي تريد رفعها هنا" لاحظ اضافة a. يمكن كتابتها أيضًا كالتالي وتؤدي نفس النتيجة: git commit -a -m "message"
-
مزايا استخدام TypeScript عن JavaScript: يشير TypeScript دائمًا إلى أخطاء الترجمة في وقت كتابة الكود. بسبب هذا في وقت التشغيل ، فإن فرصة حدوث أخطاء أقل بكثير بينما JavaScript هي تظهر الاخطاء فقط بعمل تشغيل الكود. يحتوي TypeScript على ميزة مكتوبة بقوة أو تدعم الكتابة الثابتة. هذا يعني أن الكتابة الثابتة تسمح بالتحقق من صحة النوع في وقت الترجمة. هذا غير متوفر فيJavaScript. يدعم TypeScript مكتبات JS ووثائق API لا يعد TypeScript سوى JavaScript مع اضافة بعض الميزات الإضافية مثل ميزات ES6. قد لا يكون مدعومًا في المستعرض الخاص بك ولكن يمكن لمجمع TypeScript تجميع ملفات .ts في ES3 و ES4 و ES5 أيضًا. يسمح بدعم أفضل لأداة وقت التطوير. عيوب استخدام TypeScript على JavaScript بشكل عام ، يستغرق TypeScript وقتًا لتشغيل الكود كما انه يتطلب كتابة عدد أكبر من الاكواد.
- 2 اجابة
-
- 2
-
-
اذا أردت ان تبني قاعدة قوية من المعرفة قبل بدأ أي شئ أولا، عليك بتكوين بعض المعرفة العلمية بجانب قدرتك عن البرمجة، لذا اقترح أن تبدأ بأخذ كورس data structure وبعده كورس algorithms. اما عن بايثون يمكنك أن تفعل بها الكثير فمثلا: يمكنك أن تقوم بتعمله من أجل برمجة المواقع باستخدام django وكذلك flask. أو تقوم بعمل تطبيقات لسطح المكتب وهو ما تعتبر بايثون قوي فيه بشدة. تستخدم بايثون بشدة في مجال علم البيانات سواء بتحليل البيانات أو الذكاء الاصطناعي، لكن قبل الدخول في هذا المجال أنصح بأخذ كورس احصاء وكورس رياضيات. تستخدم بايثون في مجال برمجة الالعاب. يمكن أستخدام بايثون في عمل تطبيقات للهاتف لكنها ليست بالقوة الازمة في هذا المجال.
-
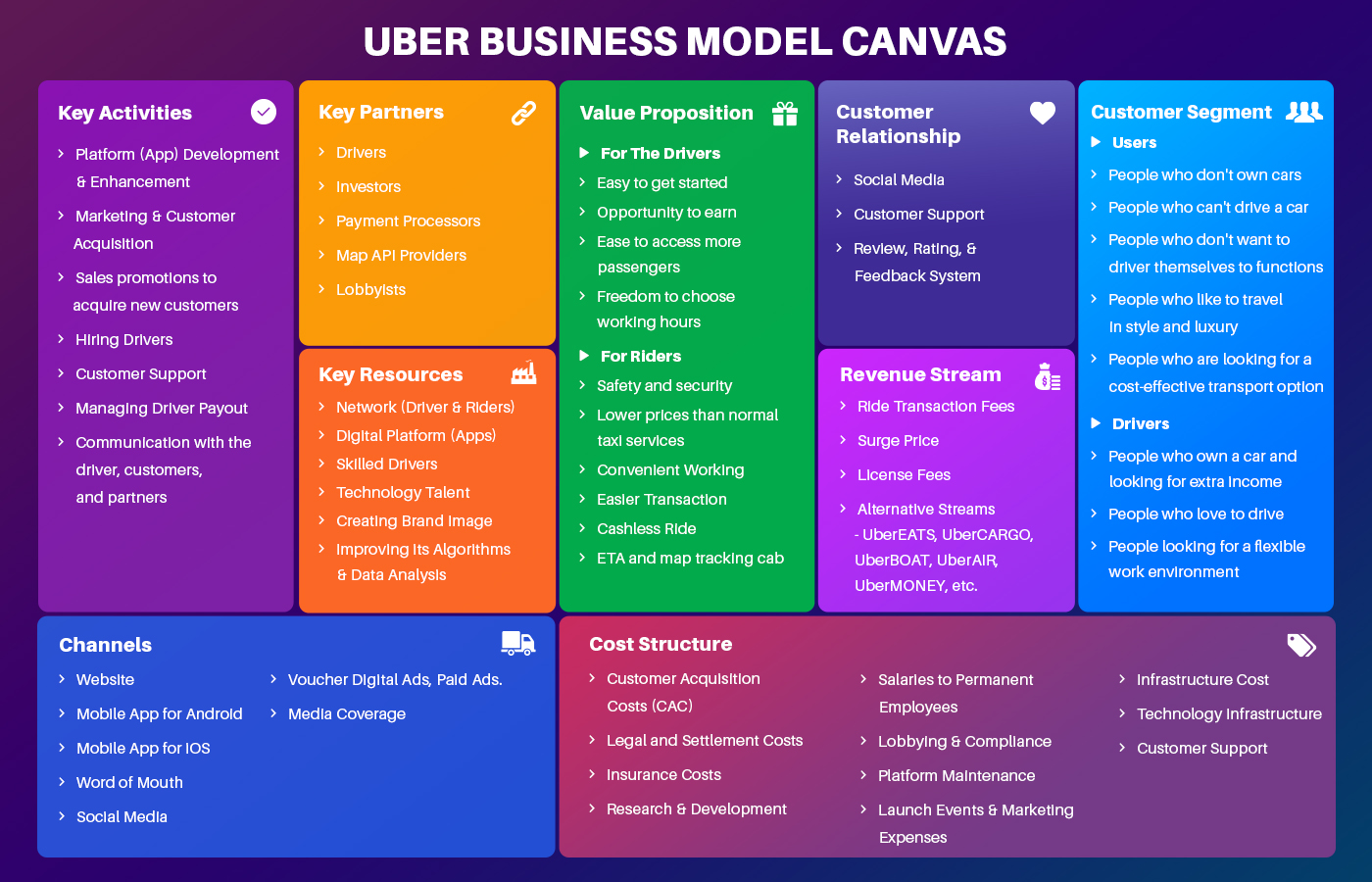
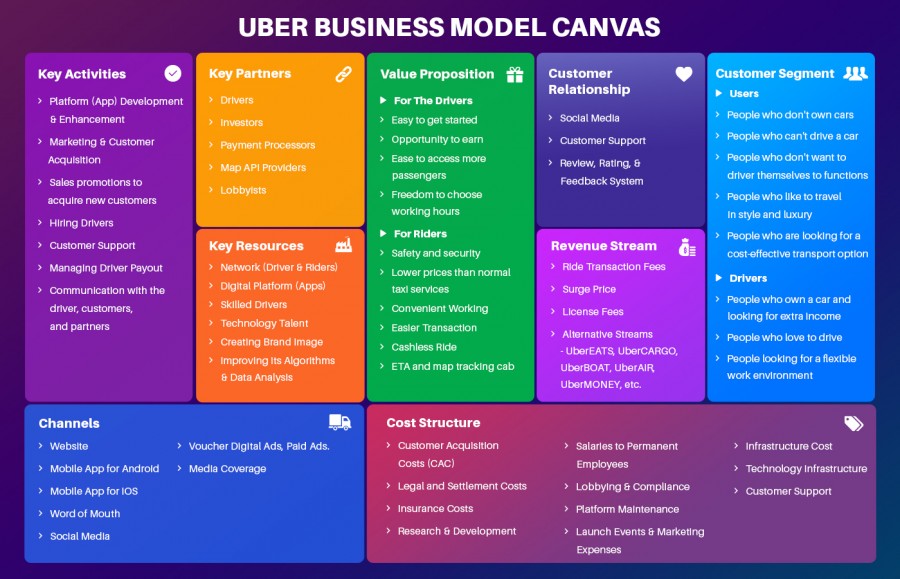
يعتبر مخطط نموذج العمل التجاري "business model canvas" الطريقة المباشرة لمعرفة توجهات أي شركة بشكل مختصر، الصورة التالية توضح مخطط نموذج العمل التجاري لشركة أوبر: اذا نظرت على قسم "customer relationship" أو العلاقة مع العميل، فانها توضح كيف تقوم الشركة باجتذاب زبائنها وهو ما تقوم عليه في عملية التوسع، لاجتذاب عملاء جدد تقوم أوبر بزيادة الدعم الفني وكذلك الاعتماد على أراء العملاء في تحسين الخدمة. تلك العلاقة ،مع البحث عن طبيعة الدولة المستهدفة، توضح للشركة اذا ما كان المكان الجديد المستهدف يصلح للاستثمار ام لا. ودائما ما تعمل مثل هذة الشركات الكبرى على جعل سياستها واحدة في مختلف الفروع مع تغيير سعر الخدمة طبقا لحالة البلد، كذلك تقوم الشركات بعمل دراسة جدوى من حيث قابلية البلد لاستضافة خدامتها وكذلك الحالة الاقتصاية ونظام الضرائب وهكذا.
.thumb.jpg.ec0afe30d3f65a679cdcc58f396eb7cf.jpg)
- 3 اجابة
-
- 1
-
-
لمعرفة كيف تقوم أي شركة بالمكسب، عليك أن تبحث عن مخطط نموذج العمل التجاري"business model canvas" الخاص بها. شركة حالا تعتمد على مخطط نموذج العمل التجاري مشابة تماما لشركة أوبر، الصورة التالية توضح مخطط نموذج العمل التجاري الخاصة بشركة أوبر: اذا نظرت الي قسم "Revenue stream" أي العوائد، والذي يوضح من أين تكسب الشركة المال،تجد أنها تعتمد على اقتطاع نسبة من تكلفة الرحلة وكذلك بيع تراخيصها او استخدام علامتها التجارية والاعلانات. ونظرا لكثرة عدد الرحلات التي تقوم بها يوميا، فان اقتطاع نسبة صغيرة في مثل هذا العدد الكبير يحقق دخل كبير وهو ما تعتمد عليه الشركة بشكل اساسي بجانب بعض المصادر الثانوية.
- 3 اجابة
-
- 1
-
-
تعتبر مواصفات اختيار الشريك التقني متغيرة للغاية وتعتمد على اولويات صاحب العمل بشكل كبير، ولكن هناك بعض الصفات التي ينصح بها أغلب الخبراء منها: مهارات التواصل لديه حتى يستطيع أن يعمل في مجموعات. الخبرة الشفافية التزام التسعير، وهو مرتب الشريك أو النسبة التي سيحصل عليها الشهادات - التوصيات وللتأكد من تلك الصفات، عليك أن تقوم بالسؤال عنه في محل عمله السابق وكذلك أن تطلب منه أن يقدم ما لديه من شهادات أخيرا يمكنك أن تقوم بعمل أختبار صغير له في المجال الذي تحتاجه فيه لتستطيع تقييم اداءه العملي. ملحوظة: قد تحتاج لشخص متخصص في الموارد البشرية أثناء عملية الأختيار لان لهم نظرة خاصة ويستطيعون تحديد شخصية الفرد بناء على اجاباته على اسئله معينه يقومون بسؤاله اياها.
-
مرحبا أخي الكريم بالنسبة لتجديد بطاقتك فإنه لن يطلب منك شهادات خبرة حتى تستطيع كتابة تخصصك في البرمجة في البطاقة،لكنه قد يطلب اثبات قيد تابع لاحد النقابات الخاصة بالبرمجة في مصر وهي "حاسبات ومعلومات" أو "هندسة". وبشكل عام اذا اردت استخراج شهادة خبرة كل ما عليك هو التوجة للشركة التي تعمل بها وتطلب شهادة خبرة من قسم الموارد البشرية HR اما اذا كنت تعمل عمل حر فلن تستطيع استخراج شهادة خبرة.
-
حاول أن تقوم بحذف الكوكيز الخاصة بالموقعين وسوف يعملان جيدا
-
لتحديد المهمام التي يجب ان يقوم بها الشريك التقني، علينا في البداية أن نعرف ما هو الشريك التقني. الشريك التقني هو الشخص المسئول عن الاعمال التقنية في المشروع، سواء كان مصدر خارجي مثل التعاقد مع شركة اخرى لتقوم بتلك الأعمال او تعيين موظفين في الشركة لأداء تلك المهام اذا كان حجم التقنيات أكبر قليلا، وفي بعض الاحيان قد يدخل حتى كشريك اذا كانت الشركة قائمة على الأعمال التقنية. بالنسبة لمهامه فإنه يكون ملتزما بكل الجانب التقني في المشروع، ابتداءا من برمجة التطبيق والعمل على تحسينه المستمر وكذلك تعديل الأخطاء التي يقوم العملاء بالشكوى منها، بمعنى أخر هو ملتزم بكل ما يخص الاكواد داخل التطبيق. أما عن الجانب القانوني فإن مصدر الاكواد (source code) يكون من حق الشركة وبالطبع فإن فكرة التطبيق يجب أن تكون محفوظه لضمان عمل تطبيق مشابه.

.png.12c0aa683b3eb7980d5135648e65486f.png)
.jpg.538f3a78b0215adc890e8a821c847f76.jpg)