
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 01/31/24 في كل الموقع
-
لماذا الكود الذي فوق الخط الاحمر يعطي false دائما عندما اقوم بعمل debug للكود , أفيدوني جزاكم الله خيرا
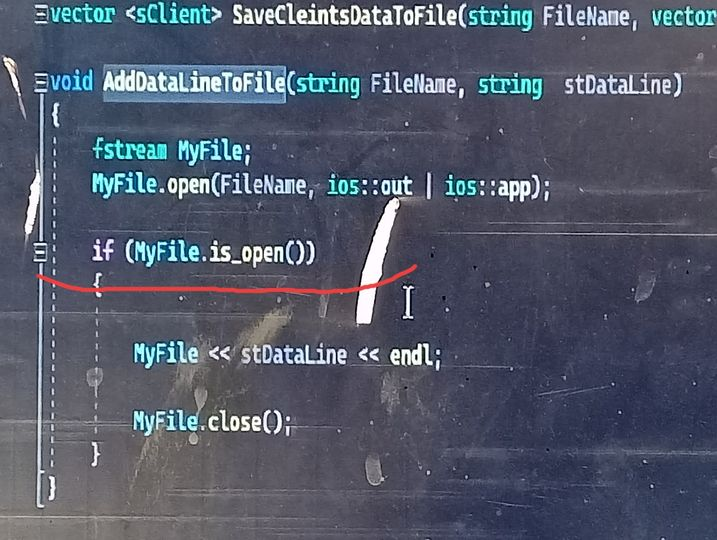 2 نقاط
2 نقاط -
اريد ان اصبح مطور ويب متكامل واكون متقن ال frontend و ال backend وافعل مواقع للشركات بحيث اجعل ذلك مصدر دخل لي لقد وجت لديكم دورة واجهة التطبيقات واللتي اظن انها فقط لل frontend وانا اريد ان اتنقن كلاً من ال frontend و ال backend اتمنى الجواب على سؤالي لأني لا اعرف ماهي الدورة المناسبة لي2 نقاط
-
السلام عليكم ورحمة الله وبركاته , لدي عدة اسئلة واتمنى من هو ذو خبرة ان يساعدني لكي اجد افضل مايمكنني ان افعله انا ادرس في جامعة سورية اسمها الجامعة الافتراضية السورية واعيش في الامارات لوجود فرع لها في الامارات ولكن هي افتراضية اي انني احضر المحاضرات اونلاين و امتحن في مكتب مستأجرونه في دبي وادرس في فرع اسمه الإجازة في الهندسة المعلوماتية التي تحتاج مني اخذ حوالي سنتين او ثلاثة لكي اختار واحدة من هذه التخصصات برمجة و ذكاء اصطناعي و اتصالات الموضوع هو انه انني اجد التعليم ليس كما كنت متوقع وسيء جدا والمحاضرات اونلاين جودتها سيئة حيث انهم يستعملون برنامج خاص بهم يعتمد على امكانيات قديمة فتظهر جودة شاشة غير واضحة و غير كاملة وصوت الدكتور الذي يشرح مشوش جدا وغير واضح وطبعا الشرح الغير مفهوم ابدا وصعوبة المنهاج ايضا و تحتاج اكثر من 6 سنين للتخرج و تعتمد على نظام الساعات , وايضا تكالفها باهضة الثمن حيث انني ادفع حوالي 300 دولار لكي اسجل على مادة واحدة واذا رسبت في مادة كي اعيدها فسوف ادفع ايضا نفس المبلغ وطبعا يجب ان اسجل على الاقل من 6-7 مواد في كل فصل دراسي وهذا صعب جدا لصعوبة المواد وتاخذ حوالي 1700 دولار كي اسجل بها واذا قررت ان اسجل اقل فهكذا سوف احتاج مالا يقل عن سبع او ثمن سنين او حتى اكثر كي اتخرج من الجامعة وعدد المواد الاجمالية للتخرج يقدر بحوالي 60 الى 70 مادة وطبعا لا اجد الوقت ابدا كي ادرس بهذا الكورس اكاديمية الحاسوب الذي سجلته والتي اجد جودة التعليم بها جيدة جيدا ولا تقارن ابدا بالجوة التعليم السيء الذي اخذه بالجامعة فأنا لا اعلم الان هل يجب علي تحمل كل هذا من اجل الشهادة الجامعية ام اخرج منها وانجز واتعلم اشياء اكثر عن البرمجة لانه كثرة الامور في هذه الجامعة لا تسمح لي بالقيام باي شيء اخر سوا دراسة موادها التي تحتاج مالا يقل عن 6 سنين للتخرج فـ الله اعلم ما كمية الاشياء التي يمكن ان انجزها في كل هذه السنين وايضا هي افتراضية وسورية ولا اعلم اذا كانت شهادتها مستحقة كل هذا واجد انه تعلمي ذاتيا للبرمجة في هذا الكورس وغيره من المصادر سيكون افضل من الجامعة . وارى انه يعطيني نتيجة افضل من الجامعة1 نقطة
-
i think laravel becomes slower as my projects get bigger, any advice to make it faster? i have 8 gigs of ram and a core i5 11th gen1 نقطة
-
السلام عليكم عند تثبيت اطار العمل TensorFlow يحدث خطاء التالي ERROR: Could not find a version that satisfies the requirement tensorflow (from versions: none) ERROR: No matching distribution found for tensorflow1 نقطة
-
على حسب فهمي ان اللغات تنقسم لنصفين اللغات المفسرة والمترجمة وفهمت ان لغة اللآلة صعبة التعلم بسبب انها تتكون من واحدات واصفار لكن سؤالي هو ان دام لغة اللآلة اسرع وتستهلك ذاكرة اقل ليه ما يكون فيه موقع او برنامج يحول الكود المكتوب باللغات المفسرة اوالمترجمة الى لغة اللآله وطبعا في حال اردنا التعديل او تطوير حاجه معينه نقدر نحول الكود مره ثانيه للغه الي نحتاجها وكذا يكون سهل علينا1 نقطة
-
السلام عليكم 1- virtualenv هي ده مكتبه زي مثل numpy 2- امتي استخدم البيئة الافتراضية 3- هل بتستخدم في الاطار العمل فقط ام المكتبة كمان وبتستخدم في المشاريع الكبير ام الضغير عادي مفيش مشكله 4- وهل في فرق بين لو ان مثل شغل ويب وعاوز اعمل البيئة الافتراضية وبين لو ان شغل فيه المجال تعلم الاله البيئة الافتراضية هل يكون في فرق في الاومر1 نقطة
-
شكرا لك اقتنعت الصراحه بجوابك واكثر شي هو ما انتبهت له ان اللغه تتكون من اصفار وواحدات وزي م قلت احتمالية الاخطاء الي ممكن تكون بتغيير احد الارقام بس وهذا ممكن انه يغير من الفكرة تماما1 نقطة
-
صحيح، اللغات المفسرة تقوم بتحويل الشيفرة المصدرية مباشرة إلى تنفيذ، في حين تستخدم اللغات المترجمة مرحلة إضافية تقوم بترجمة الشيفرة إلى رمز آلة قبل التنفيذ. بالنسبة لسؤالك حول تحويل الشيفرة من لغات مفسرة أو مترجمة إلى لغة الآلة، يمكن أن يكون هذا ممكنا من خلال استخدام برامج تعرف باسم المترجمات (Translators) أو Decompilers، إلا أنه ينبغي الإشارة إلى أن هذه الأدوات قد تكون معقدة وغير دقيقة في بعض الأحيان، خاصة عند التعامل مع تفاصيل داخل البرنامج التي قد تفقد أثناء عملية الترجمة، و كما نعرف أن لغة الآلة حساسة جدا، بتغيير رقم واحد فقط من صفر إلى واحد يتغير المعنى بأكمله، و في هذه الحالة يصعب ايجاد مكان الخطأ. فيما يخص إمكانية التعديل أو التطوير، يمكن تحويل الشيفرة المصدرية بين لغات البرمجة باستخدام أدوات تحويل اللغات (Language Converters)، ولكن يجب أن يتم ذلك بحذر، حيث قد يتسبب التحويل في فقدان بعض المعلومات أو التغييرات في البنية البرمجية.1 نقطة
-
الكود مرفق هنا ConsoleApplication1.sln بالمناسبة الكود يعمل في قراءة الملف ولا يعمل عند الكتابة والتعديل عليه1 نقطة
-
على الأغلب، لأن الملف الذي تحاول فتحه غير موجود، ففي السطر الذي قبله، تحاول فتح الملف "FileName" باستخدام وظيفة fstream::open(). إذا لم يكن الملف موجودًا، فسترجع الوظيفة false. في حال استمرت المشكلة أرفق الكود الكامل لتفقد المشكلة.1 نقطة
-
حدث الpip لأخر اصدار pip install --upgrade pip1 نقطة
-
تأكد انك مثبت python 64-bit لأن TensorFlow لا يدعم python 32-bit1 نقطة
-
ماسبب هذا الخطأ الذي يظهر لي عند رفع صور تعبر عن الخدمه التي اقدمها في موقع خمسات <html> <head><title>400 Bad Request</title></head> <body> <center><h1>400 Bad Request</h1></center> </body> </html1 نقطة
-
السلام عليكم أرجو تصحيح الخطأ بهذا الكود self.df = pd.read_excel(self.file_name,sheet_name=self.vq,header=None) self.DATA_A() self.df = pd.DataFrame.from_dict(self.dataT) self.df =self.df[['إسم الطالب', 'إسم المادة' ,'العام الدراسي' , 'نتيجة المادة' ]] self.df['نتيجة المادة'] = pd.to_numeric(self.df['نتيجة المادة'], errors='coerce') self.searjh = self.df[self.df['إسم الطالب'] == str(self.label_Title.cget("text"))] self.nT=self.searjh['نتيجة المادة'] if self.nT >= 85: self.searjh["التقدير"]="A" ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().1 نقطة
-
السلام عليكم كيف يتم تدريب نموذج تعلم الاله ان مهتم بمجال الذكاء الاصطناعي وقراة معظم المقالات الموجود علي اكادميه حسوب بس يعني مش فهم ازي النموذج ده بيتدرب يعني وبياخذ وقت اد اي وكمان اثناء النموذج بيتدرب انا قفل الكمبيوتر عادي والا اي1 نقطة
-
انا في بدايت كورس بايثون و كت اريد ان اعرف كيف ابعت الواجب هل يمكن ارسال فديو توضيحي او اي شيء و شكرا1 نقطة
-
قم برفع المشاريع على حسابك على GitHub و عند انتهائك من الدورة، ستحتاج لاجراء امتحان لتحصل على الشهادة و عندها سيتم مشاركة هذه المشاريع التي طبقتها مع فريق المختبرين ليراجعوها. و لكي تحصل على معلومات أكثر قم بقراءة المعلومات الموجودة هنا و يمكنك أيضا التواصل مع مركز المساعدة للحصول على معلومات أكثر.1 نقطة
-
هذا مكون livewire class TentComponent extends Base { use TentVaidation; public function create() { $this->newElement($this->attribute); } public function store() { $data = $this->validate(); try { Tent::create($data); $this->successOperation($this->attribute); } catch (\Throwable $th) { session()->flash('error', 'عذرا لم تتم العملية'); } } public function edit($id) { $tent = Tent::findOrFail($id); $this->tent_id = $id; $this->number = $tent->number; $this->location = $tent->location; $this->latitude = $tent->latitude; $this->longitude = $tent->longitude; $this->sacred_site_id = $tent->sacred_site_id; $this->openModal(); } public function update() { $data = $this->validate(); try { $tent = Tent::findOrFail($this->tent_id); $tent->update($data); $this->successOperation($this->attribute); } catch (\Throwable $th) { session()->flash('error', 'عذرا لم تتم العملية'); } } public function delete(Tent $tent) { return parent::destroy($tent); } public function render() { return view('livewire.tent-component', [ 'tents' => Tent::paginate(5), 'sacred_sites' => SacredSite::all(), ])->extends('dashboard.layouts.master'); } } وهذا extends from Base class Base extends Component { use WithPagination; use WithFileUploads; public $isOpen = false; public $id; public $isDeleteOpen = false; public $search = ''; public function newElement($attribute) { $this->reset($attribute); $this->openModal(); $this->resetValidation(); } public function successOperation($attribute) { session()->flash('success', 'تمت العملية بنجاح'); $this->reset($attribute); $this->closeModal(); } public function openModal() { $this->isOpen = true; } public function closeModal() { $this->isOpen = false; } public function confirmDeleteModal($id=null) { if($id) $this->id = $id; $this->isDeleteOpen = !$this->isDeleteOpen; } public function destroy($object) { try { $object->delete(); $this->successOperation($this->attribute); $this->isDeleteOpen = false; } catch (\Throwable $th) { session()->flash('error', 'عذرا لم تتم العملية'); } } } وهذا ال index والذي استدعي ال modal من خلاله @section('title') {{ $componentCollection }} @endsection @section('first-css') @endsection @section('header-content') عرض {{ $componentCollection }} @endsection <!-- row --> <div class="container-fluid"> <!--**********************************Tabs Start***********************************--> <div class="d-flex flex-wrap align-items-center mb-3 "> <button type="button" class="btn btn-primary me-1 " wire:click="create"> <i class="mdi mdi-plus-circle ms-2"></i>اضافة {{ $componentSingle }} جديد </button> </div> <!--**********************************Tabs End***********************************--> <div class="row"> <div class="col-xl-12 tab-content"> @include('dashboard.admin.tents.tables.all') </div> </div> @if ($isOpen) @include('dashboard.admin.tents.modals.tents') @endif @if ($isDeleteOpen) @include('dashboard.admin.delete') @endif @include('dashboard.layouts.massages') </div> وهذا ال Modal <div class="modal-container"> <div class="modal-bg"> </div> <div wire:ignore class="modal-boday-conent modal-content"> <div class="modal-header"> <h4 class="modal-title"> <strong>{{ $tent_id ? ' تعديل بيانات ال' . $componentSingle : ' إضافة ' . $componentSingle . ' جديد' }}</strong> </h4> <i type="reset" wire:click.prevent="$set('isOpen', false)" aria-label="Close" class="las las la-times text-danger scale5 cancel-modal"></i> </div> <div class="modal-body"> <form wire:submit.prevent="{{ $sacred_site_id ? 'update' : 'store' }}" class="row g-3 fv-plugins-bootstrap5 fv-plugins-framework needs-validation form-disable" novalidate enctype="multipart/form-data"> @csrf <div class="row"> <div class=" mb-3 col-md-6 "> <label class="form-label" for="number">رقم الخيمة </label> <input wire:model="number" type="number" id="number" name="number" class="form-control" placeholder="الرجاء ادخال رقم الخيمة "> @error('number') <div class="text-danger px-2 showValidationError "> {{ $message }} </div> @enderror </div> <div class=" mb-3 col-md-6 "> <label class="form-label" for="location">العنوان</label> <input wire:model="location" type="text" id="location" required="" value="{{ old('location') }}" name="location" class="form-control" placeholder="الرجاء إدخال العنوان"> <div class="fv-plugins-message-container invalid-feedback "> الرجاء إدخال العنوان </div> @error('location') <div class="text-danger px-2 showValidationError "> {{ $message }} </div> @enderror </div> <div class=" mb-3 col-md-12 "> <label class="form-label">الموقع </label> <div id="map" style="height: 300px;"></div> </div> <div class=" mb-3 col-md-6 "> <label class="form-label" for="latitude">خط الطول</label> <input wire:model="latitude" type="text" id="latitude" required="" value="{{ old('latitude') }}" name="latitude" class="form-control" placeholder="الرجاء إدخال خط الطول"> <div class="fv-plugins-message-container invalid-feedback "> الرجاء إدخال خط الطول </div> @error('latitude') <div class="text-danger px-2 showValidationError "> {{ $message }} </div> @enderror </div> <div class=" mb-3 col-md-6 "> <label class="form-label" for="longitude">خط العرض</label> <input wire:model="longitude" type="text" id="longitude" required="" value="{{ old('longitude') }}" name="longitude" class="form-control" placeholder="الرجاء إدخال خط العرض"> <div class="fv-plugins-message-container invalid-feedback "> الرجاء إدخال خط العرض </div> @error('longitude') <div class="text-danger px-2 showValidationError "> {{ $message }} </div> @enderror </div> <div class=" mb-3 col-md-6 "> <select wire:model="sacred_site_id" id="sacred_site_id" class="form-control" name="sacred_site_id" placeholder="الرجاء إدخال اسم المشعر المقدس"> <option disabled selected>اسم المشعر المقدس</option> @foreach ($sacred_sites as $sacred_site) <option value="{{ $sacred_site->id }}">{{ $sacred_site->name }}</option> @endforeach </select> <div class="fv-plugins-message-container invalid-feedback "> الرجاء إدخال اسم المشعر المقدس </div> @error('sacred_site_id') <div class="text-danger px-2 showValidationError "> {{ $message }} </div> @enderror </div> </div> <div class="flex justify-end"> <button type="submit" class="btn btn-primary">{{ $tent_id ? 'تحديث' : 'حفظ' }}</button> <button type="button" class="btn border-secondary" wire:click="closeModal">لغاء</button> </div> </form> </div> </div> </div> عندما أقوم بفتح ال modal أو إرسال نموذج وفشل التحقق من الصحة، يختفي جزء الخريطة. أعتقد أنه تم تقديم جافا سكريبت مرة واحدة. هل هناك أي حل للحفاظ على الخريطة (بما في ذلك التغييرات) في البث المباشر؟ شكرًا لك!1 نقطة
-
الأمر ما زال مبكرًا لتقوم بذلك، ولا تقلق في وقتها ستعرف كيف يتم الأمر، لكن في البداية يجب تعلم أساسيات بايثون والتطبيق عليها من خلال مشاريع. ثم تعلم المكتبات الخاصة بالتعامل مع البيانات ثم تعلم الجبر الخطي، ثم تعلم مفاهيم الإحتمال والإحصاء ثم تعلم أساسيات تعلم الآلة ML، وستجد تفصيل أكثر هنا: وببساطة، يتم تدريب نموذج تعلم الآلة عن طريق إعطائه مجموعة بيانات كبيرة من المدخلات والمخرجات. ويتوفر العديد من المكتبات والأدوات المستخدمة في تدريب نماذج الذكاء الاصطناعي مثل: TensorFlow PyTorch Keras Scikit-learn ثم يقوم النموذج بتحليل البيانات وتحديد الأنماط والعلاقات بينها، باستخدام تلك الأنماط، يمكن للنموذج بعد ذلك إنشاء نموذج باستطاعته استخدام تلك العلاقات لتوقع الإخراج المناسب للمدخلات الجديدة. ويختلف وقت تدريب نموذج تعلم الآلة باختلاف حجم مجموعة البيانات ونوع النموذج المستخدم، وكقاعدة: كلما زاد حجم مجموعة البيانات، كلما زاد وقت التدريب، والأنواع الأكثر تعقيدًا من النماذج تتطلب وقتًا أطول للتدريب. وبالطبع لا يجب عليك إيقاف تشغيل الكمبيوتر أثناء تدريب نموذج تعلم الآلة، فسيؤدي ذلك إلى إيقاف عملية التدريب، وستحتاج إلى إعادة تشغيلها من البداية. وعند الحاجة إلى إيقاف تشغيل الكمبيوتر لفترة قصيرة، فيجب عليك التأكد من حفظ تقدم التدريب قبل إيقاف تشغيل الكمبيوتر. وبالطبع في حالة كانت البيانات كبيرة فستحتاج إلى قوة معالجة كبيرة وهنا من الأفضل استخدام Google Colab بدلاً من حاسوبك. وستجد تفصيل أكثر هنا:1 نقطة
-
الفرق أن pip list يقوم باستعراض جميع المكتبات بما فيها مكتبات pip نفسها مثل setuptools, wheel، أما pip freeze فإنه يستعرض المكتبات التي قمنا نحن بتثبيتها (وبالطبع الاعتماديات التي تحتاجها)، وتفيدنا هذه الطريقة عندما نريد حفظ قائمة بكل المكتبات - التي قمنا بتثبيتها - في ملف، وبالتالي يمكننا استخدام هذا الملف فيما بعد لتثبيت كل المكتبات بأمر واحد، # الأمر التالي يقوم بحفظ كل المكتبات والاعتماديات في ملف نصي pip freeze > requirements.txt # الأمر التالي يقوم بتثبيت كل المكتبات الذكورة بالملف pip install -r requirements.txt وإذا فتحت الملف نفسه ستجد مسجل فيه المكتبات بشكل يشبه التالي: feedparser==5.1.3 wsgiref==0.1.2 django==1.4.21 نقطة
-
بالنسبة للسؤال الأول للمراجعة على الدروس النظرية أعدِ مراجعة ملخصات الدروس النظرية و قم بإعادة قراءة النقاط الرئيسية والمفاهيم الأساسية. مع الملاحظة أنه ليس مطلوباً الحفظ بل فهم الدروس النظرية ولو تستطيع توضيح المفاهيم وشرحها بأسلوبك الخاص، بدلاً من مجرد قراءتها. أيضاً حاول تطبيق بعض المفاهيم النظرية عملياً مثل التدريب على كتابة شفرة برنامج ما كما في مسار أساسيات البرمجة. ومع ذلك احرص على حفظ الملاحظات والنتائج بشكل منظم للرجوع إليها لاحقاً عند الضرورة. بالنسبة لسؤال الثاني أولاً أهنئك على تأهلك للنهائيات و هنا بعض النصائح والتوجيهات لإعداد جيد للمسابقة تأكد من فهمك للبنية الأساسية للغة والتعامل مع المتغيرات والتحكم في التدفق والوظائف والكائنات والمكتبات الأساسية بشكل متعمق . قم بحل التحديات والمسائل العملية بشكل منتظم ومستمر. قم بتخصيص وقت يومي لحل المشكلات وتحسين مهاراتك في البرمجة. هذا سيساعدك على تحسين سرعة ودقة حل المشكلات وتعزيز ثقتك في قدراتك.1 نقطة
-
من اين اتى المحاضر بالنافذة اللى خرجت فى الدقيقة 4:05 ؟ هل ده ملف تيكست عادى ؟ وثانيا انا معنديش امر run فى البرنامج خالص ؟1 نقطة
-
مرحبا، أنا حمزة، مهندس في علوم الحاسوب والذكاء الاصطناعي، حاصل على شهادة الماستر من جامعة جزائريّة تسمّى هواري بومدين للعلوم والتكنولوجيا، وهي تقريبا أشهر جامعة على مستوى البلد، وإن كانت ربما غير معروفة في الخارج. أتفهّم تماما مشكلتك، لأني رأيت في جامعتنا (الحقيقيّة وليس الافتراضية، والتي الدراسة فيها مجّانية تقريبا) أننا كنا ندرس تقنيات الثمانينات والتسعينات، وفي أحسن الأحوال، محتوى من 2006، في السنة الدراسيّة 2016 ! لذلك كنت أدرس البرمجة عن طريق التعلّم الذاتي في عطلة الصيف وغيرها وكنت أقوم بمشاريع صغيرة بما تعلّمته حتى أستطيع مواكبة أحدث التقنيّات ولا أبقى عالقا في المستوى المحصّل من الجامعة. في ذلك الوقت، (وربّما في الوقت الحالي أيضا) السوق في الجزائر (وربّما في غيرها من البلدان العربيّة) يشترط عموما وجود شهادة معترف بها للعمل في مجال ما. جميع الشركات تعرف أن الشهادة لوحدها لا تعني شيئا، لأن ما نحصل به على الشهادة قد لا يعني شيئا لمتطلّبات سوق العمل، لكنهم كانوا يشترطون ذلك على أية حال، ثم يقومون بمزيد من الاختبارات على المترشّح للتأكد من كفاءته. هذا الوضع ربّما بدأ يتغيّر مع السنوات الأخيرة، حيث أنني في سنة 2021 عملت في شركة فرنسية-جزائرية تحتاج مطوّري بايثون، ومع ذلك كان معنا في الفريق أشخاص من خلفيّات إلكترونيات وروبوتيكس وفيزياء، وآخرون حتى بدون شهادة جامعيّة! وكان يجمع هؤلاء جميعا أنهم متمكنون من بايثون، بغض النظر عن شهاداتهم. بخصوص ترك الجامعة، لا أستطيع أن أقرر في مكانك خاصّة أني أكملت دراستي وحصلت على الشهادة، لكن ما لاحظته في حياتي هو أنني استفدت أثناء عملي مما تعلّمته بنفسي أضعاف أضعاف ما تعلّمته في الجامعة. لكن يمكنني أن أقول من خلال خبرتي هو أن المهم أكثر هو ما تحسن فعله وليس الشهادة. فأصحاب الأعمال (خاصّة في العمل الحر) يريدون أن يروا ماذا أنجزته من مشاريع سابقة لكي يثقوا فيك ويمنحوك الفرصة لتعمل على مشاريعهم مقابل عائد مادّي.أمّا الشهادة فهي في معظم الأحيان ليست دليلا كافيا على قدرتك على العمل على مشاريعهم. لذلك إذا كنت تنوي العمل كمستقل، أو تريد إنشاء شركتك الخاصّة، أو تعرف أن السوق الذي تستهدفه لا يتطلّب شهادة، فيمكنك أن لا تهتم بمسألة الشهادة وتستثمر وقتك في تطوير مهاراتك بدلا عن ذلك.1 نقطة
-
في البداية أهنئك بما وصلت إليه وحرصك على تحصيل أعلى المراتب، في الحقيقة إجابة هذا السؤال لها عدة تفرعات، كلها تنصب في اتجاه واحد وهو الحفاظ على تركيزك وتفكيرك المنطقي، فهناك أسباب جسدية: التغذية الجيدة، وخصوصًا الفيتامينات النوم الكافي، النوم ليلًا، وعدم السهر الابتعاد عن كل ما يضر الجسم سواء من الأطعمة أو المشروبات مثل الخمور وغيرها وهناك أسباب دراسية: اكتساب مهارة برمجية على الأقل يوميًا التعرف على مجالات مختلفة في البرمجة وهناك أسباب لتنمية حل المشاكل والتفكير المنطقي: لا تتوقف أبدًا (يوميًا) عن ممارسة البرمجة تعلم الطريقة الصحيحة في حل المشاكل (وهذه أهم نقطة وسأجعلها آخر القائمة) تعرف على من هم في نفس المجال، وخصوصًا الأعلى منك خبرة حاول مساعدة الأخرين، فهذه ستجعلك تقوم بعملية البحث في موضوع محدد مما يكسبك مهارات إضافية بخصوص النقطة الأهم، وهي الطريقة الصحيحة لحل المشكلة يجب عليك فهم المطلوب جيدًا ولا تبدأ في العمل إلا لما تتأكد أن كل شيء واضح، حتى لا تضيع الوقت وتكتشف في النهاية أنه ليس المطلوبة تمرن على أساليب حل المشاكل قبل البدء في البرمجة عن طريق خرائط التدفق flowchart عند حل المشكلة لابد من تقسيمها إلى مشاكل أصغر (مشاكل أو مهام فرعية) عند حل المهمة الفرعية يكون تركيزك كله على هذه المهمة، لا تشغل بالك إطلاقًا بالمهمة التالية بعد حل المهمة الفرعية، لا تنتقل إلى التالية إلا بعد اختبارها جيدًا لا تحاول الوصول لأفضل أداء من البداية، ولكن في الأول حاول التركيز على المشكلة نفسها، وبعد ذلك قم بتحسينها مثال/ لو طُلب منك تنفيذ فاتورة تقرأ السعر والكمية وتحسب الإجمالي ثم تعرضه: تلاحظ أنها مكونة من 3 مهام: قراءة البيانات من المستخدم - إجراء الحسابات والإجمالي - عرض البيانات للمستخدم ابدأ في قراءة البيانات من المستخدم ولا تنتقل لجزئية الحسابات إلا بعد الانتهاء من المهمة الأولى واختبارها، ولا تحاول اختبار القيم الغير صالحة التي قد يدخلها المستخدم في هذه المرحلة، ولكن بعدما تتم المهمة الأساسية (الفاتورة كلها)، تبدأ في تحسينها عن طريق اختبار القيم السالبة أو ربما لا يدخل قيمًا عددية كل هذه تحسينات مطلوبة بالتأكيد وضرورية بل إجبارية، ولكن وقتها يكون بعد الانتهاء من المهمة الأساسية. هذا ملخص سريع لتنمية مستواك ومهاراتك، ويٌفضل إذا أمكن يكن معك مدرب أو شخص ذو خبرة يتابع تقدمك، ولا يمنع أن تلتحق بإحدى الشركات على سبيل التدريب ولو بدون مقابل لاكتساب مهارات فنية جديدة، إضافة إلى مهارات العمل الجماعي.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. هذه الأسئلة جيّدة جدّا لكلّ شخص يتعلّم لغة بايثون. هذه إجاباتي عليها: virtualenv أو venv اختصارا هي وحدة تمثّل جزء من المكتبة القياسيّة في بايثون (Python Standard Library) وظيفتها إنشاء بيئة افتراضية، وهذه تعني نسخة من بايثون مع بعض المكتبات الأساسيّة (مثل pip) والتي توفّر للمبرمج إمكانية تثبيت مكتبات أخرى، بحيث تكون هذه النسخة منفصلة تماما عن النسخة الأصليّة الموجودة على النظام. يتم هذا عن طريق الأمر (على ويندوز): python -m venv c:\path\to\myenv حيث المسار الموجود في النهاية هو المسار الذي تريد إنشاء البيئة الافتراضية فيه. مثلا إذا أردنا إنشاء بيئة افتراضيّة في المجلّد الحالي اسمها env فسنكتب: python -m venv env هكذا نكون قد أنشأنا بيئة افتراضية شبه فارغة. لتشغيل البيئة الافتراضيّة، يتم كتابة الأمر التالي من مجلّد المشروع الذي يحوي البيئة الافتراضية (بافتراض أن اسمها env): على ويندوز باستخدام cmd: env\Scripts\activate.bat على الأنظمة الأخرى باستخدام bash: source env/bin/activate بعد ذلك، يمكن تثبيت أيّة مكتبة مطلوبة باستخدام pip، وسيتم تثبيتها تلقائيّا داخل البيئة الافتراضية: pip install numpy وكل ملف أو مشروع بايثون يتم تشغيله داخل هذه البيئة سوف يستخدم المكتبات المثبّتة تلقائيا. لرؤية جميع المكتبات التي تم تثبيتها في البيئة الحالية (ملاحظة: هذا يتضمّن حتى المكتبات التي لم تقم بتثبيتها أنت، بل تم تثبيتها من طرف الاعتماديّات تلقائيّا): pip freeze وإذا أردت مشاركة المشروع مع غيرك، فمن المستحسن أن يكون هناك ملف يسمى requirements.txt يحوي جميع الاعتماديّات اللازمة لتشغيل المشروع. يمكن كتابة هذا الملف يدويّا، لكن أسهل طريقة لإنشاءه هي باستخدام الأمر: pip freeze > requirements.txt يمكن للشخص الآخر تثبيت الاعتماديّات بعد إنشاء بيئة افتراضيّة عنده عن طريق: pip install -r requirements.txt للخروج من البيئة الافتراضيّة، يمكن ببساطة إغلاق النافذة التي تعمل فيها، أو بطريقة أحسن باستخدام الأمر: deactivate بالنسبة لاستخدام البيئة الافتراضيّة، فمن المفروض أن يتم استخدامها في كل مشروع بايثون يتطلّب تثبيت اعتماديّات (dependencies)، لأن تثبيت الاعتماديّات بدون استخدام بيئة افتراضية يجعلها تثبّت على بيئة النظام مباشرة. كلّما كثرت المشاريع والبرامج التي تستخدم بايثون على الجهاز، وكانت جميعها تثبّت اعتماديّاتها على بيئة النظام، فهنا يزيد احتمال التضارب بين اعتماديّات تلك البرامج والمشاريع، فمثلا، قد يتطلّب أحد المشاريع استخدام آخر نسخة من Numpy، بينما لا يعمل المشروع الآخر بتلك النسخة ويتطلّب نسخة أقدم. في هذه الحالة، سيكون من المستحيل استخدام كل من المشروعين في نفس الوقت، إذ أن تثبيت اعتماديّات واحد منهما سيعطّل عمل المشروع الآخر والعكس. في مثل هذه الحالات، استخدام البيئة الافتراضيّة يصبح ضروريّا، بحيث يتم انشاء بيئة افتراضيّة لكلّ مشروع ويمكن تثبيت اعتماديّات كل مشروع على حدة. الأحسن أن تستخدم البيئة الافتراضية لكلّ المشاريع التي لديها اعتماديّات كما فصّلت في النقطة السابقة. لكن إذا كان عندك مشروع بسيط لا يستخدم سوى بايثون بدون أي مكتبة، فهنا لا حاجة إلى إنشاء بيئة افتراضيّة. استخدام البيئة الافتراضية لا علاقة له بطبيعة المشروع أو تصنيفه أو حجمه أو ماهية المكتبات المستخدمة، البيئة الافتراضيّة تعمل بنفس الطريقة مع كل المكتبات والمشاريع. نعم هناك فرق. في الواقع، خلافا لـvenv التي هي جزء من المكتبة القياسيّة في بايثون، pipenv هي مكتبة بايثون خارجيّة تقوم بنفس دور إنشاء البيئات الافتراضيّة لكنها تملك امكانيّات اضافيّة متقدّمة مقارنة بـvenv، مثل إنشاء بيئة افتراضيّة بشكل تلقائي والتحكّم بالاعتماديّات ونسخها بطريقة أكثر سهولة و مميّزات أخرى كثيرة ومفيدة لتسريع العمل. pipenv ليست المكتبة الوحيدة التي تقوم بهذه الأمور، توجد واحدة أخرى مثلا تسمى Poetry وهي التي أفضّلها شخصيّا وأستخدمها في كل مشاريعي الكبيرة. لكن بالنسبة للمبتدئين في البرمجة باستخدام بايثون (وكذلك بالنسبة لي عندما أعمل على مشاريع صغيرة) فإن استخدام venv هو الأحسن، لأن venv وإن كان ينقصها بعض الميزات إلا أنّ التعامل معها بسيط ويمكن تعلّمها في وقت قصير كما أنّها تأتي مدمجة مع بايثون ولا تحتاج إلى تثبيتها بشكل منفصل.1 نقطة
-
أولا من المفترض جزء الapi على domain وجزء الفرونت على domain أخر نبدأ نجرب بالبوست هل الapi يعمل ومظبوط ويتصل بالداتا بيز لو كان يعمل اذن نضع هذه الأكواد فى .htaccess في domain الفرونت بالتأكيد من المفترض أن يعمل بدون اى مشاكل <IfModule mod_rewrite.c> RewriteEngine On RewriteBase / RewriteRule ^index\.html$ - [L] RewriteCond %{REQUEST_FILENAME} !-f RewriteCond %{REQUEST_FILENAME} !-d RewriteCond %{REQUEST_FILENAME} !-l RewriteRule . /index.html [L] </IfModule>1 نقطة
-
اول شكراا جدا لحضرتك تاني عن انشاء بيئاء افترضيه اي الفرق بين لو كتبة virtualenv وبعد كده اسم المشروع وي pipenv وكمان venv وكمان يا أ.مصطفي لو سمحت ازي اشغل المشروع جوه البيئه الافترضيه1 نقطة
-

الإصدار 1.0.0
10292 تنزيل
تُعدّ هياكل البيانات data structures والخوارزميات algorithms واحدةً من أهم الاختراعات التي وقعت بالخمسين عامًا الأخيرة، وهي من الأدوات الأساسية التي لابُدّ أن يدرسها مهندسي البرمجيات. غالبًا ما تكون الكتب المتناولة لتلك الموضوعات -وفقًا للكاتب- ضخمةً للغاية، كما أنها عادةً ما تُركزّ على الجانب النظري، وتُقدِّم هذه المادة العلمية بدون سياق واضح وبدون أي حافز، فتَعرِض الهياكل البيانية واحدةً تلو الأخرى. هذا الكتاب مترجم عن الكتاب الشهير Think Data Structures لمؤلفه Allen B. Downey والذي يعد مرجعًا عمليًا في شرح موضوعي هياكل البيانات والخوارزميات اللذين يحتاج إلى تعلمهما كل مبرمج ومهندس برمجيات يتطلع إلى احتراف مهنته وصقل عمله ورفع مستواه. يحاول هذا الكتاب تنظيم الموضوعات نوعًا ما من خلال التركيز على برمجة تطبيق -برمجة محرك بحث-، ويَستخدِم هذا التطبيق هياكل البيانات بشكل مكثف، وهو في الواقع موضوع مهم وشيق بحد ذاته. في الحقيقة، سيدفعنا هذا التطبيق إلى دراسة بعض الموضوعات التي ربما لن تتعرَّض لها ببعض الفصول الدراسية التمهيدية الخاصة بمادة هياكل البيانات، حيث سنتعرَّض هنا مثلًا، لحفظ هياكل البيانات persistent data structure مثل ريدس Redis. يُقدِّم الكتاب أيضًا بعض الأساسيات التي تُمارَس عادةً بهندسة البرمجيات، بما في ذلك نظم التحكُّم بالإصدار version control، واختبار الوحدات unit testing. تتضمَّن غالبية فصول الكتاب تمرينًا يَسمَح للقراء بتطبيق ما تعلموه خلال الفصل، حيث يُوفِّر كل تمرين اختبارات أوتوماتيكية لفحص الحل، وبالإضافة إلى ذلك، يُوفِّر الكاتب حلًا لغالبية التمارين ببداية الفصل التالي. هذا الكتاب مُخصَّص لطلبة الجامعات بمجال علوم الحاسوب والمجالات المرتبطة به، ولمهندسي البرمجيات المحترفين، وللمتدربين بمجال هندسة البرمجيات، وكذلك للأشخاص الذين يستعدون لمقابلات العمل التقنية. ينبغي أن تكون على معرفة جيدة بلغة البرمجة جافا قبل أن تبدأ بقراءة هذا الكتاب. وبالتحديد، لابُدّ أن تَعرِف كيف تُعرِّف صنفًا class جديدًا يمتدّ extend أو يرث من صنف آخر موجود، إلى جانب إمكانية تعريف صنف يُنفِّذ واجهة interface. إذا لم تكن لديك تلك المعرفة، فيُمكِنك البدء بسلسلة مدخل إلى جافا فهي مترجمة عن كتاب شهير يشرح لغة البرمجة جافا. يمكنك قراءة الكتاب على شكل فصول منشورة على موقع أكاديمية حسوب مباشرةً إن كنت تحب القراءة على المتصفح مباشرة، وتجد الفصول مجمعة تحت وسم "هياكل البيانات 101" وإليك روابطها تاليًا: طريقة عمل الواجهات في لغة جافا مدخل إلى تحليل الخوارزميات تحليل زمن تشغيل القوائم المنفذة باستخدام مصفوفة تحليل زمن تشغيل القوائم المنفذة باستخدام قائمة مترابطة تحليل زمن تشغيل القوائم المنفذة باستخدام قائمة ازدواجية الترابط تنفيذ أسلوب البحث بالعمق أولا باستخدام طريقتي التعاود والتكرار في جافا تنفيذ أسلوب البحث بالعمق أولا باستخدام الواجهتين Iterables وIterators استخدام خريطة ومجموعة لبناء مفهرس Indexer تحليل زمن تشغيل الخرائط المنفذة باستخدام مصفوفة في جافا تنفيذ الخرائط باستخدام التعمية hashing في جافا تحسين أداء الخرائط المنفذة باستخدام التعمية HashMap في جافا تحليل زمن تشغيل الخرائط المنفذة باستخدام شجرة بحث ثنائية TreeMap في جافا استخدام أشجار البحث الثنائية والأشجار المتزنة balanced trees لتنفيذ الخرائط استخدام قاعدة بيانات Redis لحفظ البيانات فهرسة الصفحات وتحليل زمن تشغيلها باستخدام قاعدة بيانات Redis البحث الثنائي Boolean search ودمج نتائج البحث وترتيبها نظرة سريعة على بعض خوارزميات الترتيب1 نقطة -
أولاً يجب أن تعلم أن الأمر لا يتم بين ليلة وضحاها ولا حتى في غضون سنة، ربما 3 سنوات حسب خلفيتك وخبراتك السابقة. أنت بحاجة أولاً إلى تعلم أساسيات البرمجة، سواء من خلال بايثون أو من خلال C++ ولكن هي لغة ليست بالسهلة لذلك يمكنك البدء ببايثون لا مشكلة بعد المحاولة مع C++. وعلى أي حال أنت بحاجة إلى تعلم بايثون في النهاية لأن أبحاث تعلم الآلة ستجدها بشكل رئيسي تعتمد على Python، ومستخدمة بشكل شائع جدًا في مجال تعلم الآلة. بعد ذلك ستحتاج إلى تعلم أساسيات الرياضيات وهي: الجبر الخطي، والتفاضل والتكامل، وبعض مفاهيم الاحتمال والإحصاء، وركز بشكل كبير على الجبر الخطي والتفاضل والتكامل. ثم ستحتاج أن تكون على دراية بمكتبات Python المتخصصة في مجال علوم البيانات، وتشمل: Numpy: لأداء العمليات الرياضية والحسابية على البيانات بشكل فعال. Pandas: للتعامل مع البيانات بشكل هيكلي وتحليلها. Matplotlib/Seaborn: لرسم البيانات وإنشاء الرسوم البيانية. Scikit-learn (sklearn): لتنفيذ مهام التعلم الآلي وبناء نماذج. SQL Queries: للقدرة على استخدام استعلامات SQL للتفاعل مع قواعد البيانات. ثم ستحتاج إلى كورس خاص بتعلم الآلة. وستجد تفصيل أكثر هنا عن كورسات تعلم الذكاء الاصطناعي وعن الرياضيات:1 نقطة
-
وعليكم السلام، تستطيع التعرف على الذكاء الصنعي من خلال هذا المقال لتأخذ نظرة خاطفة على اهم الاحداث التي وصلت بنا إلى الذكاء الصنعي وهذا المقال للتعرف على احد افرع الذكاء الصنعي وهو التعلم الالي الذي يمكننا من بناء نماذج وتدريبها على حل مشاكل في الحياة اليومية1 نقطة
-
 حققت برامج التعلم العميق والذكاء الاصطناعي نموًا متزايدًا في الآونة الأخيرة، إذ تشير الإحصاءات إلى أن القيمة السوقية لهذه التقنيات الحديثة قد تصل إلى 930 مليون دولار بحلول العام 2025م، كما ارتفع عدد الأعمال والوظائف التي تتطلب فهم مهارات الذكاء الاصطناعي بنسبة 450 % منذ تسع سنوات مضت. فما هو التعلم العميق Deep Leaning؟ وما هي تطبيقاته الأكثر استخدامًا في العالم؟ إليك قائمة محتويات المقال: مفهوم التعلم العميق كيف يعمل التعلم العميق؟ الفرق بين تعلم الآلة والتعلم العميق تطبيقات التعلم العميق الرعاية الصحية التعلم العميق في التسويق الإلكتروني البحث الصوتي والمرئي والدردشة الآلية التعلم العميق في التعليم عالم الترفيه تقصى الحقائق وكشف الأخبار المزيفة السيارات ذاتية القيادة الأرصاد والمناخ تحديات التعلم العميق الجودة الضعيفة للبيانات خداع التعلم العميق عدم فهم السياق جيدًا ضغوط على المؤسسات قرصنة التعلم العميق مفهوم التعلم العميق التعلم العميق Deep Learning هو فئة فرعية من تعلم الآلة Machine Learning الذي يعتمد على الشبكات العصبية الاصطناعية إلى جانب التعلم التمثيلي. لذلك، فإنه عبارة عن تقنية حاسوبية تحاكي العقل البشري من خلال تصميم خوارزميات مستوحاة من بنية القشرة الدماغية ووظيفتها حتى يمكنها تقليد جميع قدرات الدماغ مثل فهم اللغة الطبيعية والأصوات ومحتوى الصور والقدرة على تنفيذ العديد من الأوامر والتعليمات كما يفعل الإنسان. ويعد التعلم العميق من العلامات الفارقة المميزة في العصر الحديث، فقد نجح العلماء في إنشاء شبكات البرسبترون العصبونية Perceptron القائمة على فكرة وظائف الشبكات العصبية Neural network، فهو يتضمن بناء شبكات عصبية قادرة على معالجة البيانات المعقدة بدرجة أكثر شمولًا وتركيزًا من تقنيات الذكاء الاصطناعي الأخرى. كيف يعمل التعلم العميق؟ استطاع العلماء دراسة العقل البشري وكيفية عمل الأدمغة التي تحتوي على مليارات الخلايا العصبية المتشابكة معًا، وذلك بهدف إنشاء نموذج محاكاة من هذه الخلايا العصبية القادرة على تصفية المعلومات وتصنيفها ومعالجتها كما يحدث في دماغ الإنسان، ومن هنا جاءت فكرة إنشاء خوارزميات التعلم العميق. ويطلق عليه التعلم العميق لأنه يستخدم الشبكة العصبية الاصطناعية العميقة. وهذه الشبكة الاصطناعية تحتوي على خلايا عصبية تضم مجموعة من الطبقات المتصلة والمتراكمة فوق بعضها بعضًا، التي تبدأ بطبقة الإدخال المستوحاة من حواس الإنسان وتستقبل إشارات البيانات والمعلومات وتنتهي بطبقة الإخراج التي تظهر النتيجة النهائية للمعلومات، وبين هاتين الطبقتين توجد طبقات مخفية تكون مسؤولة عن تحليل البيانات للوصول إلى الاستنتاجات قبل استخراجها على هيئة معلومات مفيدة. وكل طبقة في الشبكات العصبية العميقة Deep Neural Networks تكون مسؤولة عن التقاط أنماط معينة من البيانات أو معلومات محددة ومعالجتها باستخدام خوارزميات التعلم العميق. ويطلق على الخلية العصبية في هذه الشبكة اسم (عصبون) وكل خلية لها وزن يحدد أهمية كل عنصر على حدة، إضافة إلى إمكانية تعديل الأوزان أكثر من مرة لضمان الحصول على نتائج دقيقة في نهاية المطاف. وبذلك يمكن لخاصية التعلم العميق معالجة كمية هائلة من البيانات. وتعد الشبكات العصبية التلافيفية Convolutional Neural Network التي تعرف اختصارًا CNN، من أبرز الشبكات العصبية العميقة المستخدمة في التعلم العميق، فإنها تشتمل على طبقات متعددة ذات بنية استثنائية بهدف معالجة بيانات غير منظمة غالبًا مثل الصور للتنبؤ بما فيها وقراءتها ومعرفة الميزات الفريدة بها. ما الفرق بين تعلم الآلة والتعلم العميق؟ يظن الكثيرون من غير المتخصصين أن التعلم العميق وتعلم الآلة والذكاء الاصطناعي مفاهيم مترادفة وتُستخدم لتنفيذ الوظائف التقنية ذاتها، لكن الحقيقة عكس ذلك، لأن تعلم الآلة Machine Learning أحد فروع الذكاء الاصطناعي Artificial Intelligence، وأعم وأشمل من التعلم العميق Deep learning. ببساطة، يركز تعلم الآلة عمومًا على جعل الأجهزة الحاسوبية لديها القدرة على أداء المهام دون الحاجة إلى برمجة واضحة استنادًا إلى خوارزميات أكثر بساطة كتلك التي تعتمد على التوقع الخطي أو شجرة القرارات، أما التعلم العميق يستوجب إنشاء خوارزميات أكثر تعقيدًا وذات مستويات مختلفة مثل الشبكات العصبية الاصطناعية ANNs والشبكات العصبية التلافيفية CNN. كما أن خوارزميات التعلم الآلي يمكن تغذيتها ببيانات منظمة من أجل تحليلها والوصول إلى استنتاجات مفهومة، أما التعلم العميق يحتاج إلى بيانات غير منظمة وأنماط معقدة مثل النصوص المكتوبة والصور ومقاطع الفيديو والأصوات واللغات. كذلك، يتطلب التعلم العميق تدخلًا بشريًا أقل من تعلم الآلة، لكنه يحتاج إلى قوة حاسوبية وطاقة كبير للغاية من أجل المشكلات الأكثر تعقيدًا ومعالجة البيانات الضخمة باستخدام أجهزة وتقنيات معينة، على عكس تعلم الآلة الذي يتطلب كمية أقل من البيانات وقوة حاسوبية أقل أيضًا. تطبيقات التعلم العميق لا يقتصر استخدام تقنيات التعلم العميق على فهم الصور ومقاطع الفيديو فحسب، إنما يُستخدم على نطاق واسع في مجالات وقطاعات مختلفة، ونرى العديد من التطبيقات في حياتنا الراهنة خاصة مع تزايد حجم البيانات وبعدما أصبحت التكنولوجيا ميسورة التكلفة، فنلاحظ مثلًا أن النظام الأساسي في شبكة التواصل الاجتماعي "فيسبوك" لديه القدرة على معرفة أصدقائك وقراءة صورهم وتمييزها، وفيما يلي أهم تطبيقات التعلم العميق: الرعاية الصحية مع تطور الذكاء الاصطناعي، دخلت خوارزميات التعلم العميق في مجالات الطب والرعاية الصحية، ومكنت هذا القطاع من توفير القدرة على تحليل البيانات وفحصها بسرعة استثنائية، إضافة إلى دعم رعاية المرضى مع تقليل التكاليف وتحسين الكفاءات وتشخيص الأمراض. على سبيل المثال، تُستخدم أداة Aidoc في دعم الأطباء خاصة أنها تعتمد على خوارزميات تسرع تشخيص المريض وعلاجه مثل اكتشاف أماكن النزيف داخل الجمجمة والانسداد الرئوي، وغير ذلك. وبفضل خوارزميات التعلم العميق، نجح فريق بجامعة كاليفورنيا في عام 2016م، بتطوير تقنية تصور الخلايا في عينات الدم بسرعة كبيرة دون أن تؤثر سلبًا على هذه الخلايا والاستفادة منها في التحليلات المستقبلية الأخرى. كما تُستخدم الشبكات العصبية التلافيفية CNN في معرفة نتائج التصوير بالرنين المغناطيسي والأشعة السينية. وتوصلت دراسة -نُشرت نتائجها في المجلة العلمية Annals of Oncology- إلى أن خوارزميات الشبكات CNN قادرة على تحليل صور الأمراض الجلدية التي تحدد الإصابة بسرطان الجلد بدقة أكبر من الأطباء البشريين بنسبة 10%. لذلك أكد الفريق البحثي أن هذه الشبكات الاصطناعية تُعد أداة مناسبة للكشف عن سرطان الجلد. لا تقتصر تطبيقات التعلم العميق في القطاع الطبي على ذلك، بل شملت الدخول في عالم الطب الدقيق واكتشاف وتصنيع الأدوية والتنبؤ بالوفيات في المستشفيات. على سبيل المثال، طور فريق من جوجل بالتعاون مع جامعات أمريكية تقنية تعتمد على خوارزمية التعلم العميق ومعالجة اللغة الطبيعية التي حللت ما يزيد عن 46 مليار نقطة بيانات في 216 ألف سجل صحي إلكتروني عبر مستشفيين. وساعدت هذه التقنية في التنبؤ بطول فترة إقامة المرضى واحتمالات الوفاة بينهم. التعلم العميق في التسويق الإلكتروني أصبح التعلم العميق جزءًا لا يتجزأ من التسويق الإلكتروني، إذ سخرت قنوات التسويق الرقمي مثل فيسبوك قدرات التعلم العميق لتقديم أفضل تجربة للمتسوقين والمعلنين، وذلك من خلال استخدام تحليلات النص العميق Deep Text الذي يعالج اللغة بالذكاء الاصطناعي ويفهمها مثل البشر، إضافة إلى تصفية "موجز الأخبار" الخاص بالمستخدمين واكتشاف المحتوى الجديد وفهم النصوص المرغوب فيها وتجنب غيرها. وتشير الإحصائيات إلى أن أكثر من 51% من المسوقين يستثمرون تقنيات الذكاء الاصطناعي والتعلم العميق في حملات التسويق الإلكتروني للحصول على رؤى مستنيرة حول جمهورهم المستهدف في العام 2019، وفقا لما نقلته شبكة "businessinsider". بينما يرى 52% من جهات التسويق أن الذكاء الاصطناعي مهم لنجاح حملاتهم التسويقية ويؤكد 41% منهم أن تسريع نمو الإيرادات كان نتاجًا عن استخدام هذه الخوارزميات ويتوقع 80% منهم أتمتة أكثر من ربع مهامهم التسويقية خلال السنوات الخمسة المقبلة. يوجد العديد من المسوقين الذين يستخدمون تقنيات تعلم الآلة والتعلم العميق في تقديم محتوى مخصص وتحليل الفيديو والوصول إلى جمهور أكثر استهدافًا وفقًا لتفضيلاتهم أو سلوكياتهم والتفاعل معهم بفاعلية والتنبؤ برغبات العملاء والاستفادة من البيانات لأداء عروض أسعار في الوقت الفعلي. على سبيل المثال وليس الحصر، تهتم منصة "Google Cloud Video Intelligence" بإنشاء تحليلات لمقاطع الفيديو وتتيح إعداد ملخصات آلية لمستخدميها. البحث الصوتي والمرئي والدردشة الآلية هناك العديد من الشركات التي تستخدم خاصية التعلم العميق في منتجاتها الرقمية، فنجد تطبيق المساعد الصوتي Apple Siri الذي ترجم الصوت البشري إلى أوامر حاسوبية تسمح لمالكي أجهزة آيفون الحصول على المعلومات بناءً على أسئلتهم، كما أن أداة البحث الصوتي التي تستخدم خوارزميات جوجل Google Voice Search تتيح البحث بالصوت بدلًا من النصوص المكتوبة. فهي أدوات قائمة على فهم الأوامر الصوتية التي يطلبها المستخدمين. وهناك برامج سخرت التعلم العميق في البحث المرئي للجوال، مثل تطبيق "CamFind" الذي يتيح لمستخدميه التقاط صورة ما واستخدامها في إجراء عمليات البحث بدلًا من كتابة النصوص. إضافة إلى روبوتات الدردشة الآلية المستخدمة في حل مشكلات العملاء والتواصل معهم دون تدخل بشري، وهذه الروبوتات فعالة في التسويق عبر مواقع التواصل الاجتماعي والتفاعل مع العملاء وتقديم استجابات فورية لهم. التعلم العميق في التعليم يُستخدم تعلم الآلة والتعلم العميق في التعليم لمنح الطلاب تجربة تعليمية فردية وتحليل أدائهم وتعديل طرق التدريس والمناهج الدراسية استنادًا إلى البيانات التي يتم معالجتها في أثناء تجارب الطلاب، ويساعد على زيادة كفاءة المعلمين من خلال فهم إمكانات الطلاب وتقديم محتوى تعليمي ممتع يشجع المتعلمين على التعلم والمشاركة. كما يسهم في إجراء التحليلات المتقدمة والتنبؤية المتعلقة بالعملية التعليمية. ومِنْ ثَمَّ، اتخاذ القرارات والإجراءات الصحيحة الأكثر عقلانية. توجد أمثلة عديدة لاستخدام التعلم العميق والتعلم الآلي في التعليم، مثل أداة "Quizlet" التي تتيح للمتعلمين تصميم الاختبارات والبطاقات التعليمية والرسوم البيانات وتضم ما يزيد عن 50 مليون مستخدم نشط. أما منصة "SchooLinks" فإنها تمكّن الطلاب من تصميم السير الذاتية ومعرفة الدورات التدريبية التي ينبغي الحصول عليها، وغيرها من الخدمات التي تتطلب استخدام خوارزميات التعلم الآلي. وغيرها من التطبيقات والأدوات التي تستعين بخوارزميات التعلم العميق والهادفة إلى جذب الطلاب وزيادة مشاركتهم وتنوع طرق التدريس. عالم الترفيه تُستخدم تطبيقات التعلم العميق والذكاء الاصطناعي في عالم الترفيه من أجل تقديم تجربة ممتعة للعملاء، فهناك شركات عالمية عديدة مثل يوتيوب وأمازون ونتفلكس تستغل خوارزميات الذكاء الاصطناعي في عرض الأفلام والأغاني ومقاطع الفيديو المختلفة بناءً على رغبات وسلوكيات وخيارات العميل التي نفذها سابقًا. كما يمكن الاستعانة بتقنيات التعلم العميق في تحويل أصوات الممثلين إلى ترجمات نصية تلقائية أو إدراج الأصوات في الأفلام السينمائية الصامتة. وقد استخدمت بعض شركات الترفيه هذه الخوارزميات لإنشاء نمذجة التنبؤ في الوقت الفعلي اعتمادًا على الاتجاهات الحالية للعملاء التي تُجمع من مصادر البيانات، وذلك يساعد الشركات على التفاعل مع عملائهم بشكل فوري، وتوقع سلوكياتهم المستقبلية والتعرف على الأفلام ومقاطع الفيديو التي تستهلكها شرائح صغيرة من الجمهور في الوقت الحالي ومن المتوقع شهرتها مستقبلًا، فضلًا عن إمكانية إنتاج الموسيقى باستخدام نماذج قائمة على خوارزميات التعلم العميق. تقصي الحقائق وكشف الأخبار المزيفة لجأت غرف الأخبار وصالات التحرير إلى تقنيات الذكاء الاصطناعي والتعلم العميق للتحقق من المعلومات المضللة وتقصي الحقائق، فقد طور باحثون من جامعة Waterloo الكندية نظام يستخدم خوارزميات الذكاء الاصطناعي للتعلم العميق لتقييم المقالات الإخبارية تلقائيًا بهدف تحديد المعلومات المضللة. وهناك منصات عديدة لتقصي الحقائق مثل Snopes و FactCheck.org، و PolitiFact تسخر الذكاء الاصطناعي في هذه المهمة. وتعد تقنية التحليل الرقمي "InVID" من أبرز الأدوات التي تستخدم خوارزميات التعلم العميق والذكاء الاصطناعي في الكشف عن الأخبار المزيفة والمعلومات المضللة، فهي تتضمن أكثر من 15 أداة لتقصي الحقائق، فمثلًا تسمح بتجزئة الفيديو إلى صور ثابتة لإجراء بحث عكسي عليها عبر محركات البحث العملاقة مثل Google و Yandex و Baidu، إضافة إلى استخراج البيانات الوصفية للفيديوهات وتحليلها والتعرف على ما إذا كانت الصور معدلة أم أصلية، وما إلى ذلك. السيارات ذاتية القيادة واحدة من تطبيقات التعلم العميق التي أدهشت العالم، هي السيارات ذاتية القيادة التي تعتمد على الشبكات العصبية الاصطناعية في القيادة وتحديد إشارات المرور واكتشاف الأشياء التي ينبغي تجنبها في أثناء القيادة دون أي تدخل بشري، إضافة إلى التعرف على وقت ضبط السرعة وتوجيهها بطريقة آمنة في الطرقات. ففي عام 1989م، استخدمت أول سيارة ذاتية القيادة التي عرفت باسم ALVINN الشبكات العصبية لاكتشاف خطوط الممرات وتقسيم البيئة وإمكانية القيادة، وكانت النتيجة جيدة إلا أنها محدودة لعدم توافر البيانات وضعف المعالجة. والآن، أضحت هذه التجربة أفضل مما كانت عليه في الماضي، فقد استحوذت خوارزميات التعلم العميق على النواحي الفرعية للقيادة الذاتية، لا سيما في ظل توفر البيانات الضخمة والمعالجات القوية. وتعتمد القيادة الذاتية على أجهزة الاستشعار المختلفة مثل الكاميرات أو GPS لجلب البيانات من البيئة المحيطة بالسيارة ومعالجتها باستخدام خوارزميات التعلم العميق من أجل اتخاذ القرارات المناسبة والجيدة وذات الصلة بالبيئة، وهذا يتطلب توافر فحص وفهم أربعة مكونات أساسية في هذه السيارات تتمثل في التصور والإدراك perception ومعرفة الخريطة والموقع المبدئي Localization والتنبؤ بالأشياء المحيطة Prediction وصناعة القرار Decision Making. الأرصاد والمناخ ساعدت تقنيات التعلم العميق على تحليل بيانات الأرصاد الجوية والأبحاث البيولوجية والتنبؤات المناخية ومعرفة أحوال الطقس مثل احتمالات سقوط الأمطار أو وقوع الزلازل واندلاع البراكين، مما يسهم في اتخاذ الاحتياطات والإجراءات اللازمة التي تحمي الناس من مخاطر هذه الكوارث الطبيعية. على سبيل المثال، ابتكر فريق بحثي في جامعة واترلو الكندية تقنية تعتمد على خوارزميات التعلم العميق للكشف عن نقاط التحول في التغير المناخي والعمل كنظام إنذار مبكر. وإذا كنت ترغب في تطبيق هذه الخوارزميات في مشروعك أو خدماتك التقنية وتحتاج إلى بعض المساعدة، فإنه يمكنك الاستعانة بخدمات التعلم العميق التي توفرها منصة خمسات -أكبر سوق عربي لبيع وشراء الخدمات المصغرة- وتضم لفيف من الخبراء العرب والمحترفين في مجال الذكاء الاصطناعي والتعلم العميق ولديهم القدرة على تقديم الدعم لك على أكمل وجه. تحديات التعلم العميق على الرغم من الطفرة الهائلة التي أحدثتها خوارزميات التعلم العميق في مختلف القطاعات، فهو ليس حلًا سحريًا لمعالجة جميع المشكلات، لأن هناك تحديات صعبة تواجه هذه التقنيات الحديثة وتمنعها من منافسة العقل البشري. فعلى سبيل المثال، تستلزم عملية التعرف على صورة ما معالجة ملايين البيانات لتحديدها. الجودة الضعيفة للبيانات تتطلب تقنيات التعلم العميق استخدام بيانات عالية الجودة لاستخراج نتائج جيدة ودقيقة، أما البيانات الرديئة التي تحتوي على أخطاء كثيرة وقيم متطرفة وبيانات فوضوية، فلن تعمل خوارزميات التعلم العميق بصورة صحيحة. لذلك، يعكف الكثير من علماء البيانات على تنظيف البيانات وتنقيتها في أغلب أوقاتهم من خلال تجاهل القيم المتطرفة أو إصلاحها وملء البيانات المفقودة يدويًا. خداع التعلم العميق يظن البعض أن خوارزميات التعلم العميق لا يمكن خداعها، وهذا اعتقاد خاطئ تمامًا، لأنه من السهل نسبيًا استخدام الاحتيال مع هذه التقنيات. فقد أجرى باحثون في معهد ماساتشوستس للتكنولوجيا MIT في عام 2017م، دراسة حول إمكانية خداع مصنف الصور InceptionV3 التابع لجوجل، وبعد التلاعب المتعمد في صورة سلحفاة ثلاثية الأبعاد، صنفتها الشبكة العصبية الاصطناعية على أنها بندقية وليست سلحفاة، وفي تجربة أخرى حدث خلط بين طائرة الهليكوبتر والبندقية. عدم فهم السياق جيدا تحتاج خوارزميات التعلم العميق إلى بيانات كافية لتعمل بطريقة صحيحة، فهي جيدة في ربط المدخلات مع المخرجات، لكنها لا تفهم سياق البيانات التي تتعامل معها بدقة في كثير من الأحيان. فكلمة "عميق" في مصطلح التعلم العميق تركز على بنية الخوارزميات وعدد الطبقات المخفية أكثر من مستوى فهمها لما تعالجه من بيانات. وتتطلب الشبكة العصبية الاصطناعية التدريب والتأقلم حتى تفهم السياق إذا حدثت أي تغيرات في البيانات. ضغوط على المؤسسات توصلت دراسة استقصائية أجريت في عام 2017 إلى أن 80% من المؤسسات تستثمر في الذكاء الاصطناعي رغم توقعها بوجود عوائق صعبة أمامها. وهذه النتيجة تشير إلى احتمالية وجود ضغط متزايد على الشركات ومطوريها للتركيز على تقنيات التعلم العميق وحلول الذكاء الاصطناعي لزيادة الإنتاجية والوصول إلى استنتاجات مستنيرة واتخاذ قرارات صائبة تدفع هذه الشركات للأمام. قرصنة التعلم العميق هناك تخوفات من أن تصبح الشبكات العصبية عرضة للقرصنة والهجمات الإلكترونية، على سبيل المثال، من المحتمل استغلال خوارزميات التعلم العميق في السيارات ذاتية القيادة لتغيير سلوكها بطريقة مؤذية، وهذا ما فعله باحثون في تجربة نُشرت نتائجها في دورية Nature، فقد تعمدوا تضليل الشبكات العصبونية بالسيارة ذاتية القيادة من خلال وضع ملصقات معينة على كلمة "توقف" إلا أن النظام أخطأ في قراءتها واعتبرها "الحد الأقصى للسرعة 45". أخيرًا، هل يمكن القول بأن تجارب التعلم العميق محكوم عليها بالفشل؟ بالتأكيد لا، لأن تقنيات التعلم العميق تعمل بكفاءة عالية إذا ما توفرت البيانات الكافية وعالية الجودة، كما يكرس علماء البيانات والمطورون جهودهم من أجل التغلب على هذه التحديات وتحسين نماذج التعلم العميق وتطويرها وسط تخوفات من تهديد التعلم العميق النسيج الاجتماعي والاقتصادي من خلال دفع البشر إلى البطالة أو غير ذلك. المراجع والمصادر What is Deep Learning and How Does It Works [Explained] The Best Introduction to Deep Learning - A Step by Step Guide Top 10 Deep Learning Applications Used Across Industries Deep Learning Tutorial for Beginners: Neural Network Basics Difference Between Deep Learning and Machine Learning Vs AI Are There Really as Many Neurons in the Human Brain as Stars in the Milky Way? How Many Neurons Are in the Brain? ما هو التعلم العميق؟ Deep Learning vs. Machine Learning — What’s the Difference? Difference Between Machine Learning and Deep Learning Deep learning vs. machine learning – What’s the difference? The Amazing Ways Google Uses Deep Learning AI How is Machine Learning enhancing the Future of Education? Artificial intelligence may be set to reveal climate-change tipping points AI in Marketing: How brands can improve personalization, enhance ad targeting, and make their marketing teams more agile The 2021 State of Marketing AI Report MACHINE LEARNING IN EDUCATION: EXPLANATION, BENEFITS, CASE What Is Deep Learning and How Will It Change Healthcare? DEEP LEARNING IN HEALTHCARE – HOW IT’S CHANGING THE GAME Top Use Cases for AI in Media and Entertainment Deep learning won’t detect fake news, but it will give fact-checkers a boost Taking a Stance on Fake News: Towards Automatic Disinformation Assessment via Deep Bidirectional Transformer Language Models for Stance Detection Deep Learning in Self-Driving Cars Self-Driving Cars With Convolutional Neural Networks (CNN) 5 Challenges of Machine Learning! 5 Key Deep Learning/AI Challenges in 2018 The limits and challenges of deep learning Turtle or rifle? Google AI tricked by MIT students مشكلةٌ عويصة تواجه تقنيات التعلم العميق The Complete Beginner’s Guide to Deep Learning: Artificial Neural Networks كيف يمكن للذكاء الاصطناعي أن يشكل مستقبل تسويق المحتوى اقرأ أيضًا الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال تعلم الذكاء الاصطناعي1 نقطة
حققت برامج التعلم العميق والذكاء الاصطناعي نموًا متزايدًا في الآونة الأخيرة، إذ تشير الإحصاءات إلى أن القيمة السوقية لهذه التقنيات الحديثة قد تصل إلى 930 مليون دولار بحلول العام 2025م، كما ارتفع عدد الأعمال والوظائف التي تتطلب فهم مهارات الذكاء الاصطناعي بنسبة 450 % منذ تسع سنوات مضت. فما هو التعلم العميق Deep Leaning؟ وما هي تطبيقاته الأكثر استخدامًا في العالم؟ إليك قائمة محتويات المقال: مفهوم التعلم العميق كيف يعمل التعلم العميق؟ الفرق بين تعلم الآلة والتعلم العميق تطبيقات التعلم العميق الرعاية الصحية التعلم العميق في التسويق الإلكتروني البحث الصوتي والمرئي والدردشة الآلية التعلم العميق في التعليم عالم الترفيه تقصى الحقائق وكشف الأخبار المزيفة السيارات ذاتية القيادة الأرصاد والمناخ تحديات التعلم العميق الجودة الضعيفة للبيانات خداع التعلم العميق عدم فهم السياق جيدًا ضغوط على المؤسسات قرصنة التعلم العميق مفهوم التعلم العميق التعلم العميق Deep Learning هو فئة فرعية من تعلم الآلة Machine Learning الذي يعتمد على الشبكات العصبية الاصطناعية إلى جانب التعلم التمثيلي. لذلك، فإنه عبارة عن تقنية حاسوبية تحاكي العقل البشري من خلال تصميم خوارزميات مستوحاة من بنية القشرة الدماغية ووظيفتها حتى يمكنها تقليد جميع قدرات الدماغ مثل فهم اللغة الطبيعية والأصوات ومحتوى الصور والقدرة على تنفيذ العديد من الأوامر والتعليمات كما يفعل الإنسان. ويعد التعلم العميق من العلامات الفارقة المميزة في العصر الحديث، فقد نجح العلماء في إنشاء شبكات البرسبترون العصبونية Perceptron القائمة على فكرة وظائف الشبكات العصبية Neural network، فهو يتضمن بناء شبكات عصبية قادرة على معالجة البيانات المعقدة بدرجة أكثر شمولًا وتركيزًا من تقنيات الذكاء الاصطناعي الأخرى. كيف يعمل التعلم العميق؟ استطاع العلماء دراسة العقل البشري وكيفية عمل الأدمغة التي تحتوي على مليارات الخلايا العصبية المتشابكة معًا، وذلك بهدف إنشاء نموذج محاكاة من هذه الخلايا العصبية القادرة على تصفية المعلومات وتصنيفها ومعالجتها كما يحدث في دماغ الإنسان، ومن هنا جاءت فكرة إنشاء خوارزميات التعلم العميق. ويطلق عليه التعلم العميق لأنه يستخدم الشبكة العصبية الاصطناعية العميقة. وهذه الشبكة الاصطناعية تحتوي على خلايا عصبية تضم مجموعة من الطبقات المتصلة والمتراكمة فوق بعضها بعضًا، التي تبدأ بطبقة الإدخال المستوحاة من حواس الإنسان وتستقبل إشارات البيانات والمعلومات وتنتهي بطبقة الإخراج التي تظهر النتيجة النهائية للمعلومات، وبين هاتين الطبقتين توجد طبقات مخفية تكون مسؤولة عن تحليل البيانات للوصول إلى الاستنتاجات قبل استخراجها على هيئة معلومات مفيدة. وكل طبقة في الشبكات العصبية العميقة Deep Neural Networks تكون مسؤولة عن التقاط أنماط معينة من البيانات أو معلومات محددة ومعالجتها باستخدام خوارزميات التعلم العميق. ويطلق على الخلية العصبية في هذه الشبكة اسم (عصبون) وكل خلية لها وزن يحدد أهمية كل عنصر على حدة، إضافة إلى إمكانية تعديل الأوزان أكثر من مرة لضمان الحصول على نتائج دقيقة في نهاية المطاف. وبذلك يمكن لخاصية التعلم العميق معالجة كمية هائلة من البيانات. وتعد الشبكات العصبية التلافيفية Convolutional Neural Network التي تعرف اختصارًا CNN، من أبرز الشبكات العصبية العميقة المستخدمة في التعلم العميق، فإنها تشتمل على طبقات متعددة ذات بنية استثنائية بهدف معالجة بيانات غير منظمة غالبًا مثل الصور للتنبؤ بما فيها وقراءتها ومعرفة الميزات الفريدة بها. ما الفرق بين تعلم الآلة والتعلم العميق؟ يظن الكثيرون من غير المتخصصين أن التعلم العميق وتعلم الآلة والذكاء الاصطناعي مفاهيم مترادفة وتُستخدم لتنفيذ الوظائف التقنية ذاتها، لكن الحقيقة عكس ذلك، لأن تعلم الآلة Machine Learning أحد فروع الذكاء الاصطناعي Artificial Intelligence، وأعم وأشمل من التعلم العميق Deep learning. ببساطة، يركز تعلم الآلة عمومًا على جعل الأجهزة الحاسوبية لديها القدرة على أداء المهام دون الحاجة إلى برمجة واضحة استنادًا إلى خوارزميات أكثر بساطة كتلك التي تعتمد على التوقع الخطي أو شجرة القرارات، أما التعلم العميق يستوجب إنشاء خوارزميات أكثر تعقيدًا وذات مستويات مختلفة مثل الشبكات العصبية الاصطناعية ANNs والشبكات العصبية التلافيفية CNN. كما أن خوارزميات التعلم الآلي يمكن تغذيتها ببيانات منظمة من أجل تحليلها والوصول إلى استنتاجات مفهومة، أما التعلم العميق يحتاج إلى بيانات غير منظمة وأنماط معقدة مثل النصوص المكتوبة والصور ومقاطع الفيديو والأصوات واللغات. كذلك، يتطلب التعلم العميق تدخلًا بشريًا أقل من تعلم الآلة، لكنه يحتاج إلى قوة حاسوبية وطاقة كبير للغاية من أجل المشكلات الأكثر تعقيدًا ومعالجة البيانات الضخمة باستخدام أجهزة وتقنيات معينة، على عكس تعلم الآلة الذي يتطلب كمية أقل من البيانات وقوة حاسوبية أقل أيضًا. تطبيقات التعلم العميق لا يقتصر استخدام تقنيات التعلم العميق على فهم الصور ومقاطع الفيديو فحسب، إنما يُستخدم على نطاق واسع في مجالات وقطاعات مختلفة، ونرى العديد من التطبيقات في حياتنا الراهنة خاصة مع تزايد حجم البيانات وبعدما أصبحت التكنولوجيا ميسورة التكلفة، فنلاحظ مثلًا أن النظام الأساسي في شبكة التواصل الاجتماعي "فيسبوك" لديه القدرة على معرفة أصدقائك وقراءة صورهم وتمييزها، وفيما يلي أهم تطبيقات التعلم العميق: الرعاية الصحية مع تطور الذكاء الاصطناعي، دخلت خوارزميات التعلم العميق في مجالات الطب والرعاية الصحية، ومكنت هذا القطاع من توفير القدرة على تحليل البيانات وفحصها بسرعة استثنائية، إضافة إلى دعم رعاية المرضى مع تقليل التكاليف وتحسين الكفاءات وتشخيص الأمراض. على سبيل المثال، تُستخدم أداة Aidoc في دعم الأطباء خاصة أنها تعتمد على خوارزميات تسرع تشخيص المريض وعلاجه مثل اكتشاف أماكن النزيف داخل الجمجمة والانسداد الرئوي، وغير ذلك. وبفضل خوارزميات التعلم العميق، نجح فريق بجامعة كاليفورنيا في عام 2016م، بتطوير تقنية تصور الخلايا في عينات الدم بسرعة كبيرة دون أن تؤثر سلبًا على هذه الخلايا والاستفادة منها في التحليلات المستقبلية الأخرى. كما تُستخدم الشبكات العصبية التلافيفية CNN في معرفة نتائج التصوير بالرنين المغناطيسي والأشعة السينية. وتوصلت دراسة -نُشرت نتائجها في المجلة العلمية Annals of Oncology- إلى أن خوارزميات الشبكات CNN قادرة على تحليل صور الأمراض الجلدية التي تحدد الإصابة بسرطان الجلد بدقة أكبر من الأطباء البشريين بنسبة 10%. لذلك أكد الفريق البحثي أن هذه الشبكات الاصطناعية تُعد أداة مناسبة للكشف عن سرطان الجلد. لا تقتصر تطبيقات التعلم العميق في القطاع الطبي على ذلك، بل شملت الدخول في عالم الطب الدقيق واكتشاف وتصنيع الأدوية والتنبؤ بالوفيات في المستشفيات. على سبيل المثال، طور فريق من جوجل بالتعاون مع جامعات أمريكية تقنية تعتمد على خوارزمية التعلم العميق ومعالجة اللغة الطبيعية التي حللت ما يزيد عن 46 مليار نقطة بيانات في 216 ألف سجل صحي إلكتروني عبر مستشفيين. وساعدت هذه التقنية في التنبؤ بطول فترة إقامة المرضى واحتمالات الوفاة بينهم. التعلم العميق في التسويق الإلكتروني أصبح التعلم العميق جزءًا لا يتجزأ من التسويق الإلكتروني، إذ سخرت قنوات التسويق الرقمي مثل فيسبوك قدرات التعلم العميق لتقديم أفضل تجربة للمتسوقين والمعلنين، وذلك من خلال استخدام تحليلات النص العميق Deep Text الذي يعالج اللغة بالذكاء الاصطناعي ويفهمها مثل البشر، إضافة إلى تصفية "موجز الأخبار" الخاص بالمستخدمين واكتشاف المحتوى الجديد وفهم النصوص المرغوب فيها وتجنب غيرها. وتشير الإحصائيات إلى أن أكثر من 51% من المسوقين يستثمرون تقنيات الذكاء الاصطناعي والتعلم العميق في حملات التسويق الإلكتروني للحصول على رؤى مستنيرة حول جمهورهم المستهدف في العام 2019، وفقا لما نقلته شبكة "businessinsider". بينما يرى 52% من جهات التسويق أن الذكاء الاصطناعي مهم لنجاح حملاتهم التسويقية ويؤكد 41% منهم أن تسريع نمو الإيرادات كان نتاجًا عن استخدام هذه الخوارزميات ويتوقع 80% منهم أتمتة أكثر من ربع مهامهم التسويقية خلال السنوات الخمسة المقبلة. يوجد العديد من المسوقين الذين يستخدمون تقنيات تعلم الآلة والتعلم العميق في تقديم محتوى مخصص وتحليل الفيديو والوصول إلى جمهور أكثر استهدافًا وفقًا لتفضيلاتهم أو سلوكياتهم والتفاعل معهم بفاعلية والتنبؤ برغبات العملاء والاستفادة من البيانات لأداء عروض أسعار في الوقت الفعلي. على سبيل المثال وليس الحصر، تهتم منصة "Google Cloud Video Intelligence" بإنشاء تحليلات لمقاطع الفيديو وتتيح إعداد ملخصات آلية لمستخدميها. البحث الصوتي والمرئي والدردشة الآلية هناك العديد من الشركات التي تستخدم خاصية التعلم العميق في منتجاتها الرقمية، فنجد تطبيق المساعد الصوتي Apple Siri الذي ترجم الصوت البشري إلى أوامر حاسوبية تسمح لمالكي أجهزة آيفون الحصول على المعلومات بناءً على أسئلتهم، كما أن أداة البحث الصوتي التي تستخدم خوارزميات جوجل Google Voice Search تتيح البحث بالصوت بدلًا من النصوص المكتوبة. فهي أدوات قائمة على فهم الأوامر الصوتية التي يطلبها المستخدمين. وهناك برامج سخرت التعلم العميق في البحث المرئي للجوال، مثل تطبيق "CamFind" الذي يتيح لمستخدميه التقاط صورة ما واستخدامها في إجراء عمليات البحث بدلًا من كتابة النصوص. إضافة إلى روبوتات الدردشة الآلية المستخدمة في حل مشكلات العملاء والتواصل معهم دون تدخل بشري، وهذه الروبوتات فعالة في التسويق عبر مواقع التواصل الاجتماعي والتفاعل مع العملاء وتقديم استجابات فورية لهم. التعلم العميق في التعليم يُستخدم تعلم الآلة والتعلم العميق في التعليم لمنح الطلاب تجربة تعليمية فردية وتحليل أدائهم وتعديل طرق التدريس والمناهج الدراسية استنادًا إلى البيانات التي يتم معالجتها في أثناء تجارب الطلاب، ويساعد على زيادة كفاءة المعلمين من خلال فهم إمكانات الطلاب وتقديم محتوى تعليمي ممتع يشجع المتعلمين على التعلم والمشاركة. كما يسهم في إجراء التحليلات المتقدمة والتنبؤية المتعلقة بالعملية التعليمية. ومِنْ ثَمَّ، اتخاذ القرارات والإجراءات الصحيحة الأكثر عقلانية. توجد أمثلة عديدة لاستخدام التعلم العميق والتعلم الآلي في التعليم، مثل أداة "Quizlet" التي تتيح للمتعلمين تصميم الاختبارات والبطاقات التعليمية والرسوم البيانات وتضم ما يزيد عن 50 مليون مستخدم نشط. أما منصة "SchooLinks" فإنها تمكّن الطلاب من تصميم السير الذاتية ومعرفة الدورات التدريبية التي ينبغي الحصول عليها، وغيرها من الخدمات التي تتطلب استخدام خوارزميات التعلم الآلي. وغيرها من التطبيقات والأدوات التي تستعين بخوارزميات التعلم العميق والهادفة إلى جذب الطلاب وزيادة مشاركتهم وتنوع طرق التدريس. عالم الترفيه تُستخدم تطبيقات التعلم العميق والذكاء الاصطناعي في عالم الترفيه من أجل تقديم تجربة ممتعة للعملاء، فهناك شركات عالمية عديدة مثل يوتيوب وأمازون ونتفلكس تستغل خوارزميات الذكاء الاصطناعي في عرض الأفلام والأغاني ومقاطع الفيديو المختلفة بناءً على رغبات وسلوكيات وخيارات العميل التي نفذها سابقًا. كما يمكن الاستعانة بتقنيات التعلم العميق في تحويل أصوات الممثلين إلى ترجمات نصية تلقائية أو إدراج الأصوات في الأفلام السينمائية الصامتة. وقد استخدمت بعض شركات الترفيه هذه الخوارزميات لإنشاء نمذجة التنبؤ في الوقت الفعلي اعتمادًا على الاتجاهات الحالية للعملاء التي تُجمع من مصادر البيانات، وذلك يساعد الشركات على التفاعل مع عملائهم بشكل فوري، وتوقع سلوكياتهم المستقبلية والتعرف على الأفلام ومقاطع الفيديو التي تستهلكها شرائح صغيرة من الجمهور في الوقت الحالي ومن المتوقع شهرتها مستقبلًا، فضلًا عن إمكانية إنتاج الموسيقى باستخدام نماذج قائمة على خوارزميات التعلم العميق. تقصي الحقائق وكشف الأخبار المزيفة لجأت غرف الأخبار وصالات التحرير إلى تقنيات الذكاء الاصطناعي والتعلم العميق للتحقق من المعلومات المضللة وتقصي الحقائق، فقد طور باحثون من جامعة Waterloo الكندية نظام يستخدم خوارزميات الذكاء الاصطناعي للتعلم العميق لتقييم المقالات الإخبارية تلقائيًا بهدف تحديد المعلومات المضللة. وهناك منصات عديدة لتقصي الحقائق مثل Snopes و FactCheck.org، و PolitiFact تسخر الذكاء الاصطناعي في هذه المهمة. وتعد تقنية التحليل الرقمي "InVID" من أبرز الأدوات التي تستخدم خوارزميات التعلم العميق والذكاء الاصطناعي في الكشف عن الأخبار المزيفة والمعلومات المضللة، فهي تتضمن أكثر من 15 أداة لتقصي الحقائق، فمثلًا تسمح بتجزئة الفيديو إلى صور ثابتة لإجراء بحث عكسي عليها عبر محركات البحث العملاقة مثل Google و Yandex و Baidu، إضافة إلى استخراج البيانات الوصفية للفيديوهات وتحليلها والتعرف على ما إذا كانت الصور معدلة أم أصلية، وما إلى ذلك. السيارات ذاتية القيادة واحدة من تطبيقات التعلم العميق التي أدهشت العالم، هي السيارات ذاتية القيادة التي تعتمد على الشبكات العصبية الاصطناعية في القيادة وتحديد إشارات المرور واكتشاف الأشياء التي ينبغي تجنبها في أثناء القيادة دون أي تدخل بشري، إضافة إلى التعرف على وقت ضبط السرعة وتوجيهها بطريقة آمنة في الطرقات. ففي عام 1989م، استخدمت أول سيارة ذاتية القيادة التي عرفت باسم ALVINN الشبكات العصبية لاكتشاف خطوط الممرات وتقسيم البيئة وإمكانية القيادة، وكانت النتيجة جيدة إلا أنها محدودة لعدم توافر البيانات وضعف المعالجة. والآن، أضحت هذه التجربة أفضل مما كانت عليه في الماضي، فقد استحوذت خوارزميات التعلم العميق على النواحي الفرعية للقيادة الذاتية، لا سيما في ظل توفر البيانات الضخمة والمعالجات القوية. وتعتمد القيادة الذاتية على أجهزة الاستشعار المختلفة مثل الكاميرات أو GPS لجلب البيانات من البيئة المحيطة بالسيارة ومعالجتها باستخدام خوارزميات التعلم العميق من أجل اتخاذ القرارات المناسبة والجيدة وذات الصلة بالبيئة، وهذا يتطلب توافر فحص وفهم أربعة مكونات أساسية في هذه السيارات تتمثل في التصور والإدراك perception ومعرفة الخريطة والموقع المبدئي Localization والتنبؤ بالأشياء المحيطة Prediction وصناعة القرار Decision Making. الأرصاد والمناخ ساعدت تقنيات التعلم العميق على تحليل بيانات الأرصاد الجوية والأبحاث البيولوجية والتنبؤات المناخية ومعرفة أحوال الطقس مثل احتمالات سقوط الأمطار أو وقوع الزلازل واندلاع البراكين، مما يسهم في اتخاذ الاحتياطات والإجراءات اللازمة التي تحمي الناس من مخاطر هذه الكوارث الطبيعية. على سبيل المثال، ابتكر فريق بحثي في جامعة واترلو الكندية تقنية تعتمد على خوارزميات التعلم العميق للكشف عن نقاط التحول في التغير المناخي والعمل كنظام إنذار مبكر. وإذا كنت ترغب في تطبيق هذه الخوارزميات في مشروعك أو خدماتك التقنية وتحتاج إلى بعض المساعدة، فإنه يمكنك الاستعانة بخدمات التعلم العميق التي توفرها منصة خمسات -أكبر سوق عربي لبيع وشراء الخدمات المصغرة- وتضم لفيف من الخبراء العرب والمحترفين في مجال الذكاء الاصطناعي والتعلم العميق ولديهم القدرة على تقديم الدعم لك على أكمل وجه. تحديات التعلم العميق على الرغم من الطفرة الهائلة التي أحدثتها خوارزميات التعلم العميق في مختلف القطاعات، فهو ليس حلًا سحريًا لمعالجة جميع المشكلات، لأن هناك تحديات صعبة تواجه هذه التقنيات الحديثة وتمنعها من منافسة العقل البشري. فعلى سبيل المثال، تستلزم عملية التعرف على صورة ما معالجة ملايين البيانات لتحديدها. الجودة الضعيفة للبيانات تتطلب تقنيات التعلم العميق استخدام بيانات عالية الجودة لاستخراج نتائج جيدة ودقيقة، أما البيانات الرديئة التي تحتوي على أخطاء كثيرة وقيم متطرفة وبيانات فوضوية، فلن تعمل خوارزميات التعلم العميق بصورة صحيحة. لذلك، يعكف الكثير من علماء البيانات على تنظيف البيانات وتنقيتها في أغلب أوقاتهم من خلال تجاهل القيم المتطرفة أو إصلاحها وملء البيانات المفقودة يدويًا. خداع التعلم العميق يظن البعض أن خوارزميات التعلم العميق لا يمكن خداعها، وهذا اعتقاد خاطئ تمامًا، لأنه من السهل نسبيًا استخدام الاحتيال مع هذه التقنيات. فقد أجرى باحثون في معهد ماساتشوستس للتكنولوجيا MIT في عام 2017م، دراسة حول إمكانية خداع مصنف الصور InceptionV3 التابع لجوجل، وبعد التلاعب المتعمد في صورة سلحفاة ثلاثية الأبعاد، صنفتها الشبكة العصبية الاصطناعية على أنها بندقية وليست سلحفاة، وفي تجربة أخرى حدث خلط بين طائرة الهليكوبتر والبندقية. عدم فهم السياق جيدا تحتاج خوارزميات التعلم العميق إلى بيانات كافية لتعمل بطريقة صحيحة، فهي جيدة في ربط المدخلات مع المخرجات، لكنها لا تفهم سياق البيانات التي تتعامل معها بدقة في كثير من الأحيان. فكلمة "عميق" في مصطلح التعلم العميق تركز على بنية الخوارزميات وعدد الطبقات المخفية أكثر من مستوى فهمها لما تعالجه من بيانات. وتتطلب الشبكة العصبية الاصطناعية التدريب والتأقلم حتى تفهم السياق إذا حدثت أي تغيرات في البيانات. ضغوط على المؤسسات توصلت دراسة استقصائية أجريت في عام 2017 إلى أن 80% من المؤسسات تستثمر في الذكاء الاصطناعي رغم توقعها بوجود عوائق صعبة أمامها. وهذه النتيجة تشير إلى احتمالية وجود ضغط متزايد على الشركات ومطوريها للتركيز على تقنيات التعلم العميق وحلول الذكاء الاصطناعي لزيادة الإنتاجية والوصول إلى استنتاجات مستنيرة واتخاذ قرارات صائبة تدفع هذه الشركات للأمام. قرصنة التعلم العميق هناك تخوفات من أن تصبح الشبكات العصبية عرضة للقرصنة والهجمات الإلكترونية، على سبيل المثال، من المحتمل استغلال خوارزميات التعلم العميق في السيارات ذاتية القيادة لتغيير سلوكها بطريقة مؤذية، وهذا ما فعله باحثون في تجربة نُشرت نتائجها في دورية Nature، فقد تعمدوا تضليل الشبكات العصبونية بالسيارة ذاتية القيادة من خلال وضع ملصقات معينة على كلمة "توقف" إلا أن النظام أخطأ في قراءتها واعتبرها "الحد الأقصى للسرعة 45". أخيرًا، هل يمكن القول بأن تجارب التعلم العميق محكوم عليها بالفشل؟ بالتأكيد لا، لأن تقنيات التعلم العميق تعمل بكفاءة عالية إذا ما توفرت البيانات الكافية وعالية الجودة، كما يكرس علماء البيانات والمطورون جهودهم من أجل التغلب على هذه التحديات وتحسين نماذج التعلم العميق وتطويرها وسط تخوفات من تهديد التعلم العميق النسيج الاجتماعي والاقتصادي من خلال دفع البشر إلى البطالة أو غير ذلك. المراجع والمصادر What is Deep Learning and How Does It Works [Explained] The Best Introduction to Deep Learning - A Step by Step Guide Top 10 Deep Learning Applications Used Across Industries Deep Learning Tutorial for Beginners: Neural Network Basics Difference Between Deep Learning and Machine Learning Vs AI Are There Really as Many Neurons in the Human Brain as Stars in the Milky Way? How Many Neurons Are in the Brain? ما هو التعلم العميق؟ Deep Learning vs. Machine Learning — What’s the Difference? Difference Between Machine Learning and Deep Learning Deep learning vs. machine learning – What’s the difference? The Amazing Ways Google Uses Deep Learning AI How is Machine Learning enhancing the Future of Education? Artificial intelligence may be set to reveal climate-change tipping points AI in Marketing: How brands can improve personalization, enhance ad targeting, and make their marketing teams more agile The 2021 State of Marketing AI Report MACHINE LEARNING IN EDUCATION: EXPLANATION, BENEFITS, CASE What Is Deep Learning and How Will It Change Healthcare? DEEP LEARNING IN HEALTHCARE – HOW IT’S CHANGING THE GAME Top Use Cases for AI in Media and Entertainment Deep learning won’t detect fake news, but it will give fact-checkers a boost Taking a Stance on Fake News: Towards Automatic Disinformation Assessment via Deep Bidirectional Transformer Language Models for Stance Detection Deep Learning in Self-Driving Cars Self-Driving Cars With Convolutional Neural Networks (CNN) 5 Challenges of Machine Learning! 5 Key Deep Learning/AI Challenges in 2018 The limits and challenges of deep learning Turtle or rifle? Google AI tricked by MIT students مشكلةٌ عويصة تواجه تقنيات التعلم العميق The Complete Beginner’s Guide to Deep Learning: Artificial Neural Networks كيف يمكن للذكاء الاصطناعي أن يشكل مستقبل تسويق المحتوى اقرأ أيضًا الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال تعلم الذكاء الاصطناعي1 نقطة
















