
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 11/08/15 في كل الموقع
-
 هناك العديد من المرشّحات أو ما نُطلق عليه عادة نحن معشر المصمّمين اسم الفلاتر Filters وهي أدوات مساعدة تقوم بمهام رائعة وهناك فلاتر أساسية توجد بطبيعة الحال ضمن قائمة Filters في البرنامج، كما أنه هناك فلاتر يمكن تحميلها من الإنترنت وإضافتها على البرنامج. سنقوم في هذا الدرس باستخدام أكثر من فلتر لنشكّل تأثير تموّج لانعكاس شعار أكاديمية حسوب على أمواج الماء. نبدأ أولاً بفتح ملف جديد في الفوتوشوب وقد اخترت الحجم 1024×683 لهذا الدرس. سنقوم باستخدام أداة سطل الدهان Paint Bucket Tool أو نضغط على مفتاح G ثم نلوّن الصورة باللون الأسود. والآن سنستخدم صورة الأمواج المائية وقد اخترت هنا الصورة التالية الرائعة التي التقطتها MALIZ ONG وسنقوم بإدراجها ضمن الملف وتعديل حجمها لتتناسب مع حجم العمل. بعد ذلك سنذهب الى القائمة: Layer > New Adjustment Layer > Hue and Saturation وسندخل القيم التالية: Hue = 0Saturation = -71Lightness = 0 Layer > New Adjustment Layer > Levels أدخل القيم: 0 - 0.5 - 255. Layer > New Adjustment Layer > Brightness and Contrast أدخل القيم: Brightness = 0Contrast = -35 والآن نحفظ الملف باسم "Hsoub-Water.PSD" وانتبه يجب أن تكون صيغة الملف PSD. والآن سنقوم بإدراج الشعار. Filter > Distort > Displace أدخل القيم وتأكد من اختيار جميع الخيارات الموجودة تماماً كما في الصورة: وعند الضغط على OK سيفتح نافذة لاختيار ملف وهنا نختار الملف الذي حفظناه قبل قليل "Hsoub-Water.PSD". والآن انسخ طبقة الشعار نسخة ثانية ثم طبق الفلتر على طبقة الشعار الأصلية وليس المنسوخة من القائمة: Filter > Blur > Gaussian Blur وضع القيمة 3. وستكون النتيجة كما في الصورة: والآن أدمج طبقتي الشعار معاً بتحديد الأولى ثم اضغط على Shift وحدد الثانية ثم اضغط Ctrl+E. ثم طبق خصائص المزج لطبقة الشعار Overlay. ثم ننقر مرتين على طبقة الشعار لتفتح نافذة التأثيرات ونطبّق التأثير Color Overlay وندخل القيمة 70% مع المحافظة على خصائص المزج داخل النافذة كما هي Normal. والآن نفتح طبقة جديدة فوق كل الطبقات ونلونها بالكامل باللون الأسود ثم ننقر مرتين على الطبقة لأجل التأثيرات ونضع الإعدادات كما في الصور: لتكون النتيجة حتى اللحظة: وأخيراً نضيف طبقة جديدة فوق كل الطبقات ونلونها بالكامل باللون الأزرق بحسب القيم في الصورة: ثم نغير خصائص المزج للطبقة إلى Overlay. والنتيجة النهائية هي: بإمكانكم تجربة الأمر مع شعاراتكم الخاصة وتجربة تغيير الإعدادات كما تشاؤون واستمتعوا بالنتائج المذهلة.2 نقاط
هناك العديد من المرشّحات أو ما نُطلق عليه عادة نحن معشر المصمّمين اسم الفلاتر Filters وهي أدوات مساعدة تقوم بمهام رائعة وهناك فلاتر أساسية توجد بطبيعة الحال ضمن قائمة Filters في البرنامج، كما أنه هناك فلاتر يمكن تحميلها من الإنترنت وإضافتها على البرنامج. سنقوم في هذا الدرس باستخدام أكثر من فلتر لنشكّل تأثير تموّج لانعكاس شعار أكاديمية حسوب على أمواج الماء. نبدأ أولاً بفتح ملف جديد في الفوتوشوب وقد اخترت الحجم 1024×683 لهذا الدرس. سنقوم باستخدام أداة سطل الدهان Paint Bucket Tool أو نضغط على مفتاح G ثم نلوّن الصورة باللون الأسود. والآن سنستخدم صورة الأمواج المائية وقد اخترت هنا الصورة التالية الرائعة التي التقطتها MALIZ ONG وسنقوم بإدراجها ضمن الملف وتعديل حجمها لتتناسب مع حجم العمل. بعد ذلك سنذهب الى القائمة: Layer > New Adjustment Layer > Hue and Saturation وسندخل القيم التالية: Hue = 0Saturation = -71Lightness = 0 Layer > New Adjustment Layer > Levels أدخل القيم: 0 - 0.5 - 255. Layer > New Adjustment Layer > Brightness and Contrast أدخل القيم: Brightness = 0Contrast = -35 والآن نحفظ الملف باسم "Hsoub-Water.PSD" وانتبه يجب أن تكون صيغة الملف PSD. والآن سنقوم بإدراج الشعار. Filter > Distort > Displace أدخل القيم وتأكد من اختيار جميع الخيارات الموجودة تماماً كما في الصورة: وعند الضغط على OK سيفتح نافذة لاختيار ملف وهنا نختار الملف الذي حفظناه قبل قليل "Hsoub-Water.PSD". والآن انسخ طبقة الشعار نسخة ثانية ثم طبق الفلتر على طبقة الشعار الأصلية وليس المنسوخة من القائمة: Filter > Blur > Gaussian Blur وضع القيمة 3. وستكون النتيجة كما في الصورة: والآن أدمج طبقتي الشعار معاً بتحديد الأولى ثم اضغط على Shift وحدد الثانية ثم اضغط Ctrl+E. ثم طبق خصائص المزج لطبقة الشعار Overlay. ثم ننقر مرتين على طبقة الشعار لتفتح نافذة التأثيرات ونطبّق التأثير Color Overlay وندخل القيمة 70% مع المحافظة على خصائص المزج داخل النافذة كما هي Normal. والآن نفتح طبقة جديدة فوق كل الطبقات ونلونها بالكامل باللون الأسود ثم ننقر مرتين على الطبقة لأجل التأثيرات ونضع الإعدادات كما في الصور: لتكون النتيجة حتى اللحظة: وأخيراً نضيف طبقة جديدة فوق كل الطبقات ونلونها بالكامل باللون الأزرق بحسب القيم في الصورة: ثم نغير خصائص المزج للطبقة إلى Overlay. والنتيجة النهائية هي: بإمكانكم تجربة الأمر مع شعاراتكم الخاصة وتجربة تغيير الإعدادات كما تشاؤون واستمتعوا بالنتائج المذهلة.2 نقاط -
.png.277c8af39ed5b9d67faf0e2c20da6e7e.png) تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الأول في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث سيتناول الجزء الثاني منها موضوع المخططات البيانية الإحصائية، أما الجزء الثالث فسيتحدث عن كيفية إجراء بعض الاختبارات الإحصائية بلغة R، فيما نختم السلسلة بجزء رابع يتحدث عن بعض التقنيات المتقدمة في هذه اللغة. يمكنك تحميل لغة R من الموقع الرسمي لها على الشابكة والموجود على العنوان http://www.r-project.org حيث توجد إصدارات منها لمعظم أنظمة التشغيل الشائعة ومنها Windows و Linux وحتى Apple. إن عملية التنصيب سهلة وتخلو من التعقيدات، وعند الانتهاء منها يمكنك تشغيل بيئة عمل لغة R بالنقر على الأيقونة الخاصة بالبرنامج سواء تلك الموجودة على سطح المكتب أو من خلال قائمة البرامج، وحينها ستظهر لك شاشة سطر الأوامر الخاصة بلغة R وهو المكان المعتاد لكتابة الأوامر الخاصة بهذه اللغة كما هو ملاحظ في الشكل التالي: وبما أننا ذكرنا أن هذه اللغة واسعة الانتشار في مجال النشر العلمي، لذا دعونا نطلع على تعليمتنا الأولى وهي تعليمة ()citation والتي تعرض الطريقة الرسمية للإشارة إلى لغة R كمرجع ضمن لائحة المراجع المستخدمة في أي ورقة علمية كما هو موضح بالشكل التالي: في لغة R تستخدم الفاصلة المنقوطة للفصل فيما بين كل أمر من أوامر اللغة الموجودة على سطر واحد (فيما لاحاجة لتلك الفواصل المنقوطة إن كانت كل تعليمة ترد ضمن سطر مستقل بها)، كما ترى فإن خرج تنفيذ أي أمر أو دالة بلغة R يظهر بعدها مباشرة، وهكذا تتكون جلسة العمل الاعتيادية من تنفيذ لتتالي من الأوامر والتعليمات وصولا إلى إنجاز العمل أو التحليل المطلوب، ويمكنك باستخدام أزرار الأسهم إلى الأعلى وإلى الأسفل من التنقل عبر مجموعة الأوامر التي تم تنفيذها خلال جلسة العمل الحالية جيئة وذهابا، كذلك يمكنك استعراض آخر 15 أمر على سبيل المثال من خلال الدالة (history(15، هذا عدى عن إمكانية حفظ وتخزين أرشيف أوامر الجلسة الحالية في ملف باستخدام الدالة ("savehistory("myfile ومن ثم استعادة ذلك الأرشيف في جلسة عمل جديدة منفصلة باستخدام الدالة "("loadhistory("myfile، هناك اختصار آخر مفيد حينما ترى أن نافذة سطر الأوامر لديك أصبحت مزدحمة بالنتائج وتريد تنظيفها، فكل ما عليك القيام به هو النقر على الاختصار Ctrl+L (مع ملاحظة أن ذلك لن يحذف أي من البيانات التي تم تحميلها إلى البرنامج والمحفوظة بالتالي في الذاكرة، بل يقوم فقط بتنظيف الشاشة المعروضة أمامك). قبل الانطلاق قدما في استعراض ما في هذه اللغة من دوال وكيفية استخدام كل منها، دعونا بداية نتعرف على طريقة الحصول على المساعدة فيها، إذ يتدرج الأمر من طلب الحصول على المساعدة الخاصة بأمر محدد أو دالة بعينها، وذلك بذكر اسم الأمر أو الدالة عقب علامة الاستفهام ومن ثم النقر على زر الإدخال، فمثلا يقوم الأمر read.table? بعرض الصفحة الخاصة بتوثيق التعليمة read.table ضمن ملفات المساعدة الخاصة بلغة R. أما إن أردت البحث عن مفهوم معين أو كلمة مفتاحية ما دون أن تعلم تماما أي الدوال هي التي تتعامل معها في لغة R، فيمكنك استخدام الأمر ("help.search("data input لتعرض عليك بعدها مجموعة من الأوامر ذات الصلة بهذا المفهوم، وتستطيع حينها الحصول على شرح أو مساعدة تفصيلية لأي من تلك الدوال بالطريقة التي أشرنا إليها سابقا. هناك وسيلة مساعدة أخرى متوفرة في لغة R موجهة إلى فئة المبرمجين الذين يفضلون رؤية الأمثلة وهي تعمل على أن يقرؤوا العشرات من أسطر ملفات المساعدة، وهؤلاء يمكنهم استخدام الأمر example بعد أن تمرر له اسم الدالة المراد الحصول على أمثلة عملية عن طريق استخدامها، فعلى سبيل المثال يمكنك تجربة الأمر (example(mean. وطالما أننا نتحدث عن وسائل وأساليب الحصول على المساعدة، أجد أنه من المفيد ذكر طريقة إضافة التعليقات في لغة R، وهو أسلوب لا تخفى ضرورته على أي مبرمج محترف، ففي لغة R التعليقات هي كل نص يتلو الرمز # سواء ظهر من بداية السطر أو جاء بعد تعليمة ما، لكن الغريب أن لغة R تفتقر إلى طريقة لجعل مقطع كامل يعامل معاملة التعليقات (كما هو حال استخدام أسلوب التأطير /* ... */ في العديد من لغات البرمجة الأخرى). الخطوة التالية التي يجب تعلمها الآن هي آلية استيراد البيانات وقراءتها من مصادرها وإن تعددت تنسيقات وصيغ تلك المصادر، فعلى سبيل المثال يمكنك القراءة من جداول البيانات المحفوظة بتنسيق csv باستخدام الأمر التالي: data <- read.csv("d:/mydir/myfile.csv", header=TRUE, sep=”;”)كما هو واضح فقد أشرنا إلى أن السطر الأول من محتويات الملف المستورد هو عبارة عن تسميات الأعمدة من خلال الخاصية header=TRUE، كذلك تم تحديد الفاصل ما بين عمود وآخر من البيانات على أنه الفاصلة المنقوطة من خلال الخاصية ";"=sep. وقد استخدمنا في هذا المثال الاسم الكامل للملف بما فيه المسار، أما إن ذكرت اسم الملف دون تحديد المسار فسيتم البحث عنه ضمن ما يدعى بمجلد العمل، ولمعرفة أين يشير مجلد العمل الحالي لديك يمكنك استخدام الأمر ()getwd، أو يمكنك تحديد مجلد عمل مختلف باستخدام الأمر ("setwd("d:/mydir ، من جهة أخرى يمكنك الاستعاضة عن كل ذلك باستخدام الأمر ()file.choose عوضا عن ذكر اسم الملف ومساره، حيث ستحصل عند التنفيذ على صندوق حوار يتيح للمستخدم استعراض ما على حاسوبه من مجلدات وملفات وصولا إلى اختيار الملف المطلوب. كما سبق وأن رأينا فإن عملية الإسناد في لغة R يشار إليها بالرمز <- وهي الطريقة الأكثر شيوعا مقارنة برمز المساواة = والذي يصح استخدامه على الرغم من عدم شيوعه بين معشر المبرمجين بلغة R، إن البيانات المقروءة سيتم حفظها ضمن إطار بيانات (dataframe) أسميناه في حالة مثالنا السابق data، ويمكنك استعراض محتويات إطار البيانات ذلك بمجرد كتابة اسمه ومن ثم النقر على زر الإدخال ضمن سطر الأوامر، أما إن كانت كمية البيانات ضخمة فمن المفيد استخدام أي من الأمرين (head(data والذي يعرض مجموعة من الأسطر مقتطعة من بداية كتلة البيانات، أو الأمر (tail(data والذي يعرض مجموعة أخرى من الأسطر مقتطعة من نهاية كتلة البيانات ذاتها. كذلك تستطيع استخدام الأمر التالي: data <- edit(data)لعرض تلك البيانات ضمن نافذة جدول بسيط يتيح للمستخدم تنقيحها ومن ثم إعادتها إلى ذات إطار البيانات الأصلي كما هو موضح من الأمر السابق. إن كانت البيانات مخزنة في ملف نصي يستخدم رمز الجدولة للفصل ما بين أعمدته (أي text tab delimated)، فعليك حينها استخدام الأمر read.data عوضا عن الأمر read.csv الموضح في المثال السابق، وهناك حالة خاصة عندما تكون البيانات المراد استيرادها موجودة فعليا ضمن الحافظة، وحينها عليك الاستعاضة عن ذكر اسم الملف بالعبارة “clipboard”. لدى لغة R أيضا المزيد من تعليمات الاستيراد التي تختص كل منها بتنسيق مختلف، فعلى سبيل المثال لا الحصر نذكر الأوامر التالية: read.spss و read.systat و read.mtp و read.xport. نستطيع الوصول بكل سهولة إلى أي جزئية في إطار البيانات الحالي من خلال المرونة التي تتيحها لنا لغة R، فلو كان لدينا إطار عمل يدعى data على سبيل المثال، فإن التعبير [data[i,j سيشير إلى العنصر أو القيمة الموجودة في السطر i والعمود j، أما التعبير [,data[i فيشير إلى كامل السطر i في حين أن التعبير [data[,n:m فيشير بدوره إلى مجموعة الأعمدة بدءا من n حتى m، من جهة أخرى فإن التعبير [,data[-i فيشير إلى كامل البيانات ضمن data فيما عدى السطر i، وأخيرا فإن التعبير [,(data[c(n,m فهو يشير إلى السطرين n و m تحديدا دون غيرهما من أسطر البيانات في data. تأتي لغة R محزومة مع إطار بيانات افتراضي يدعى mtcars يتضمن بيانات مأخوذة من مجلة Motor Trend لعام 1974 تقارن فيها عشر من مواصفات التصميم والأداء لأكثر من ثلاثين سيارة منتجة في العام 1973، وسنستخدم من بيانات تلك المواصفات في مقالتنا هذه كل من mpg ويقصد بها عدد الأميال المقطوعة بغالون البنزين الواحد، و cyl الذي يمثل عدد الإسطوانات في محرك السيارة، و wt وهو الوزن بآلاف الليبرات (الليبرة تقريبا نصف كيلوغرام)، وكذلك qsec وهو التسارع مقاسا بالزمن اللازم لقطع مسافة ربع ميل (لمزيد من المعلومات والتفاصيل يمكنك طلب المساعدة باستخدام التعليمة ?mtcars). سنستخدم هذه البيانات في استعراض مجموعة من الأمثلة حول ما سيتلو ذكره من دوال وتقنيات إحصائية. بمجرد استيراد بياناتك يمكنك الوصول إلى القيم الموجودة في أي من أعمدة جدولك باستخدام الصيغة mtcars$mpg على سبيل المثال حيث mpg يشير إلى اسم العمود، أما إن أردت أسلوبا أكثر سهولة واختصارا يقتصر على ذكر اسم العمود فقط دون الحاجة إلى ذكر اسم إطار البيانات المأخوذ منه في كل مرة، فعليك بداية استخدام الأمر (attach(mtcars عقب استيرادك للبيانات، وحينها يكفي ذكر الاسم mpg للدلالة على ذات العمود من البيانات. وتستطيع استعراض ما تحويه ذاكرة الجلسة الحالية من بيانات في لغة R باستخدام الأمر ()ls ، إضافة إلى ذلك يمكنك حذف أي من كتل البيانات تلك من ذاكرة الجلسة الحالية باستخدام الأمر (rm(x حيث يشير الرمز x إلى اسم كتلة البيانات سواء كانت عمود (أي شعاع من القيم) أو مصفوفة أو إطار بيانات كامل، حتى أنك تستطيع حذف كل ما يوجد الآن في ذاكرة الجلسة الحالية من بيانات سبق وأن تم تحميلها وذلك باستخدام الأمر (()rm(list=ls. عند قيامك بتحميل بياناتك إلى ذاكرة الجلسة الحالية، تصبح مستعدا للبدء في العمل عليها لتطبيق تحليلاتك المختلفة. ومن الأوامر الأساسية المتاحة نذكر على سبيل المثال الدالة (max(mpg والتي تعيد القيمة العظمى ضمن العمود mpg (أي شعاع القيم mpg)، أما الدالة (min(mpg فهي على عكس سابقتها تعيد القيمة الصغرى، في حين أن الدالة (mean(mpg تعيد المتوسط الحسابي للقيم الواردة في mpg، والدالة (median(mpg تعيد قيمة الوسيط (الوسيط هو القيمة التي تقع في المنتصف عند ترتيب قيم mpg تصاعديا، وبالتالي تكون نصف قيم mpg تزيد عن قيمة هذا الوسيط فيما النصف الآخر يقل عنها، وعادة ما يستخدم الوسيط للدلالة على مركز المجموعة حينما تكون هناك قيم متطرفة زيادة أو نقصانا بحيث تؤثر على المتوسط الحسابي وتؤدي إلى انحيازه). من جهة أخرى هناك دوال تستخدم لوصف مدى تشتت قراءات وقيم mpg حول النقطة المركزية الممثلة بالمتوسط، ومنها الدالة (var(mpg والتي تحسب مقدار التباين، والدالة (sd(mpg والتي تعيد قيمة الانحراف المعياري. يحسب التباين من خلال العلاقة التالية أي أننا نراكم مجموع فروقات كل واحدة من قراءاتنا عن قيمة المتوسط بعد أن نربّع هذا الفرق، حيث تخدم عملية التربيع في جعل الناتج موجبا دوما (كون الأخطاء أو الفروقات موجودة سواء كانت بالزيادة أو النقصان، وإن لم نفعل ذلك لحصلنا دوما على الناتج 0 كمحصلة لعملية الجمع تلك)، الخدمة الثانية التي نحصل عليها من هذا التربيع هي تقليل أثر الفروقات الصغيرة على حساب تعظيم ومضاعفة تأثير الفروقات الكبيرة (فتربيع الأرقام الصغيرة لايضاعفها بقدر ما يفعل مع الأرقام الكبيرة، ولولا ذلك لاكتفينا بالقيمة المطلقة للفروقات المحسوبة عن المتوسط عند حساب مقدار التباين). من جهة ثانية فإن الانحراف المعياري يقوم بتقييس معيار التباين وذلك للتعبير عن التشتت بصيغة مستقلة عن عدد العينات أو القراءات التي لدينا (والتي تؤثر على قيمة التباين كونه حساب تراكمي يزداد بازدياد عدد القراءات)، وتتم عملية التقييس تلك من خلال تقسيم مقدار التباين الناتج على (n-1) وهو عدد العينات منقوصا منه واحد، وبعد عملية القسمة تلك نحسب الجذر التربيعي الناتج وذلك حتى يعود المقدار المحسوب إلى ذات فضاء القيم الموجودة لدينا بدلا من كونه في حالة التباين من مرتبة مربّع تلك الأرقام، فيعود من السهل علينا مقارنته مباشرة مع قيمنا أو المتوسط الخاص بتلك القيم. أما الدالة (summary(mpg فهي عامة الاستخدام ويختلف سلوكها وخرجها بحسب الكائن الممرر إليها، ففي حالة تمرير شعاع من القيم العددية فسيكون ناتج تنفيذها هو ملخص لتلك القيم والذي يشمل كل من المتوسط والوسيط إضافة إلى القيمتين العظمى والصغرى والربعين الأول والثالث (ويعرفان بشكل مشابه للوسيط، إذ يشير الربع الأول إلى القيمة التي تقل عنها ربع قراءاتك بعد ترتيبها تصاعديا، فيما الربع الثالث كما هو واضح من اسمه فهو القيمة التي تقل عنها ثلاثة أرباع قيم mpg المرتبة تصاعديا، وهما قيمتان تساعدان في فهم كيفية توزع بياناتك). كذلك تمتلك لغة R مجموعة واسعة من الدوال الرياضياتية مثل (abs(x والتي تعيد القيمة المطلقة (الإيجابية الإشارة دوما) للقيمة أو شعاع القيم المدخل لها، والدالة (sqrt(x التي تحسب الجذر التربيعي والتي نستطيع الحصول على نفس وظيفتها من خلال عملية الرفع إلى أس مقداره نصف أي x^0.5 ، كذلك لدينا الدوال المثلثية المختلفة مثل (sin(x و (cos(x وغيرهما، هذا بالإضافة إلى طيف من دوال التقريب المختلفة مثل (floor(2.718 والتي ستعيد القيمة 2 كأكبر عدد صحيح أصغر من القيمة المعطاة، وكذلك الدالة (ceiling(3.142 والتي ستعيد القيمة 4 كأصغر عدد صحيح أكبر من القيمة المعطاة، أما الدالة (round(2.718, digits=2 فستعيد القيمة 2.72 حيث تقوم هذه الدالة بعملية التقريب الحسابية المعتادة مع إمكانية تحديد عدد الخانات العشرية بعد الفاصلة والتي تريد الاحتفاظ بها. لدينا أيضا دوال التحويل مثل (log(x التي تحسب اللوغاريتم الطبيعي للمقدار x، فيما تحسب الدالة (log10(x اللوغاريتم العشري لذات المقدار x، مع هذا يمكنك استخدام الصيغة الأكثر مرونة وهي (log(x,n والتي تحسب اللوغاريتم لأي أساس يحدده المبرمج من خلال المقدار n، فمثلا يمكنك حساب اللوغاريتم الثنائي للمقدار x باستخدام التعليمة (log(x,2. هذه هي نهاية الجزء الأول من سلسلة المقالات التي تتحدث عن لغة R، سنتحدث في الجزء الثاني عن المخططات البيانية الإحصائية. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة
تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الأول في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث سيتناول الجزء الثاني منها موضوع المخططات البيانية الإحصائية، أما الجزء الثالث فسيتحدث عن كيفية إجراء بعض الاختبارات الإحصائية بلغة R، فيما نختم السلسلة بجزء رابع يتحدث عن بعض التقنيات المتقدمة في هذه اللغة. يمكنك تحميل لغة R من الموقع الرسمي لها على الشابكة والموجود على العنوان http://www.r-project.org حيث توجد إصدارات منها لمعظم أنظمة التشغيل الشائعة ومنها Windows و Linux وحتى Apple. إن عملية التنصيب سهلة وتخلو من التعقيدات، وعند الانتهاء منها يمكنك تشغيل بيئة عمل لغة R بالنقر على الأيقونة الخاصة بالبرنامج سواء تلك الموجودة على سطح المكتب أو من خلال قائمة البرامج، وحينها ستظهر لك شاشة سطر الأوامر الخاصة بلغة R وهو المكان المعتاد لكتابة الأوامر الخاصة بهذه اللغة كما هو ملاحظ في الشكل التالي: وبما أننا ذكرنا أن هذه اللغة واسعة الانتشار في مجال النشر العلمي، لذا دعونا نطلع على تعليمتنا الأولى وهي تعليمة ()citation والتي تعرض الطريقة الرسمية للإشارة إلى لغة R كمرجع ضمن لائحة المراجع المستخدمة في أي ورقة علمية كما هو موضح بالشكل التالي: في لغة R تستخدم الفاصلة المنقوطة للفصل فيما بين كل أمر من أوامر اللغة الموجودة على سطر واحد (فيما لاحاجة لتلك الفواصل المنقوطة إن كانت كل تعليمة ترد ضمن سطر مستقل بها)، كما ترى فإن خرج تنفيذ أي أمر أو دالة بلغة R يظهر بعدها مباشرة، وهكذا تتكون جلسة العمل الاعتيادية من تنفيذ لتتالي من الأوامر والتعليمات وصولا إلى إنجاز العمل أو التحليل المطلوب، ويمكنك باستخدام أزرار الأسهم إلى الأعلى وإلى الأسفل من التنقل عبر مجموعة الأوامر التي تم تنفيذها خلال جلسة العمل الحالية جيئة وذهابا، كذلك يمكنك استعراض آخر 15 أمر على سبيل المثال من خلال الدالة (history(15، هذا عدى عن إمكانية حفظ وتخزين أرشيف أوامر الجلسة الحالية في ملف باستخدام الدالة ("savehistory("myfile ومن ثم استعادة ذلك الأرشيف في جلسة عمل جديدة منفصلة باستخدام الدالة "("loadhistory("myfile، هناك اختصار آخر مفيد حينما ترى أن نافذة سطر الأوامر لديك أصبحت مزدحمة بالنتائج وتريد تنظيفها، فكل ما عليك القيام به هو النقر على الاختصار Ctrl+L (مع ملاحظة أن ذلك لن يحذف أي من البيانات التي تم تحميلها إلى البرنامج والمحفوظة بالتالي في الذاكرة، بل يقوم فقط بتنظيف الشاشة المعروضة أمامك). قبل الانطلاق قدما في استعراض ما في هذه اللغة من دوال وكيفية استخدام كل منها، دعونا بداية نتعرف على طريقة الحصول على المساعدة فيها، إذ يتدرج الأمر من طلب الحصول على المساعدة الخاصة بأمر محدد أو دالة بعينها، وذلك بذكر اسم الأمر أو الدالة عقب علامة الاستفهام ومن ثم النقر على زر الإدخال، فمثلا يقوم الأمر read.table? بعرض الصفحة الخاصة بتوثيق التعليمة read.table ضمن ملفات المساعدة الخاصة بلغة R. أما إن أردت البحث عن مفهوم معين أو كلمة مفتاحية ما دون أن تعلم تماما أي الدوال هي التي تتعامل معها في لغة R، فيمكنك استخدام الأمر ("help.search("data input لتعرض عليك بعدها مجموعة من الأوامر ذات الصلة بهذا المفهوم، وتستطيع حينها الحصول على شرح أو مساعدة تفصيلية لأي من تلك الدوال بالطريقة التي أشرنا إليها سابقا. هناك وسيلة مساعدة أخرى متوفرة في لغة R موجهة إلى فئة المبرمجين الذين يفضلون رؤية الأمثلة وهي تعمل على أن يقرؤوا العشرات من أسطر ملفات المساعدة، وهؤلاء يمكنهم استخدام الأمر example بعد أن تمرر له اسم الدالة المراد الحصول على أمثلة عملية عن طريق استخدامها، فعلى سبيل المثال يمكنك تجربة الأمر (example(mean. وطالما أننا نتحدث عن وسائل وأساليب الحصول على المساعدة، أجد أنه من المفيد ذكر طريقة إضافة التعليقات في لغة R، وهو أسلوب لا تخفى ضرورته على أي مبرمج محترف، ففي لغة R التعليقات هي كل نص يتلو الرمز # سواء ظهر من بداية السطر أو جاء بعد تعليمة ما، لكن الغريب أن لغة R تفتقر إلى طريقة لجعل مقطع كامل يعامل معاملة التعليقات (كما هو حال استخدام أسلوب التأطير /* ... */ في العديد من لغات البرمجة الأخرى). الخطوة التالية التي يجب تعلمها الآن هي آلية استيراد البيانات وقراءتها من مصادرها وإن تعددت تنسيقات وصيغ تلك المصادر، فعلى سبيل المثال يمكنك القراءة من جداول البيانات المحفوظة بتنسيق csv باستخدام الأمر التالي: data <- read.csv("d:/mydir/myfile.csv", header=TRUE, sep=”;”)كما هو واضح فقد أشرنا إلى أن السطر الأول من محتويات الملف المستورد هو عبارة عن تسميات الأعمدة من خلال الخاصية header=TRUE، كذلك تم تحديد الفاصل ما بين عمود وآخر من البيانات على أنه الفاصلة المنقوطة من خلال الخاصية ";"=sep. وقد استخدمنا في هذا المثال الاسم الكامل للملف بما فيه المسار، أما إن ذكرت اسم الملف دون تحديد المسار فسيتم البحث عنه ضمن ما يدعى بمجلد العمل، ولمعرفة أين يشير مجلد العمل الحالي لديك يمكنك استخدام الأمر ()getwd، أو يمكنك تحديد مجلد عمل مختلف باستخدام الأمر ("setwd("d:/mydir ، من جهة أخرى يمكنك الاستعاضة عن كل ذلك باستخدام الأمر ()file.choose عوضا عن ذكر اسم الملف ومساره، حيث ستحصل عند التنفيذ على صندوق حوار يتيح للمستخدم استعراض ما على حاسوبه من مجلدات وملفات وصولا إلى اختيار الملف المطلوب. كما سبق وأن رأينا فإن عملية الإسناد في لغة R يشار إليها بالرمز <- وهي الطريقة الأكثر شيوعا مقارنة برمز المساواة = والذي يصح استخدامه على الرغم من عدم شيوعه بين معشر المبرمجين بلغة R، إن البيانات المقروءة سيتم حفظها ضمن إطار بيانات (dataframe) أسميناه في حالة مثالنا السابق data، ويمكنك استعراض محتويات إطار البيانات ذلك بمجرد كتابة اسمه ومن ثم النقر على زر الإدخال ضمن سطر الأوامر، أما إن كانت كمية البيانات ضخمة فمن المفيد استخدام أي من الأمرين (head(data والذي يعرض مجموعة من الأسطر مقتطعة من بداية كتلة البيانات، أو الأمر (tail(data والذي يعرض مجموعة أخرى من الأسطر مقتطعة من نهاية كتلة البيانات ذاتها. كذلك تستطيع استخدام الأمر التالي: data <- edit(data)لعرض تلك البيانات ضمن نافذة جدول بسيط يتيح للمستخدم تنقيحها ومن ثم إعادتها إلى ذات إطار البيانات الأصلي كما هو موضح من الأمر السابق. إن كانت البيانات مخزنة في ملف نصي يستخدم رمز الجدولة للفصل ما بين أعمدته (أي text tab delimated)، فعليك حينها استخدام الأمر read.data عوضا عن الأمر read.csv الموضح في المثال السابق، وهناك حالة خاصة عندما تكون البيانات المراد استيرادها موجودة فعليا ضمن الحافظة، وحينها عليك الاستعاضة عن ذكر اسم الملف بالعبارة “clipboard”. لدى لغة R أيضا المزيد من تعليمات الاستيراد التي تختص كل منها بتنسيق مختلف، فعلى سبيل المثال لا الحصر نذكر الأوامر التالية: read.spss و read.systat و read.mtp و read.xport. نستطيع الوصول بكل سهولة إلى أي جزئية في إطار البيانات الحالي من خلال المرونة التي تتيحها لنا لغة R، فلو كان لدينا إطار عمل يدعى data على سبيل المثال، فإن التعبير [data[i,j سيشير إلى العنصر أو القيمة الموجودة في السطر i والعمود j، أما التعبير [,data[i فيشير إلى كامل السطر i في حين أن التعبير [data[,n:m فيشير بدوره إلى مجموعة الأعمدة بدءا من n حتى m، من جهة أخرى فإن التعبير [,data[-i فيشير إلى كامل البيانات ضمن data فيما عدى السطر i، وأخيرا فإن التعبير [,(data[c(n,m فهو يشير إلى السطرين n و m تحديدا دون غيرهما من أسطر البيانات في data. تأتي لغة R محزومة مع إطار بيانات افتراضي يدعى mtcars يتضمن بيانات مأخوذة من مجلة Motor Trend لعام 1974 تقارن فيها عشر من مواصفات التصميم والأداء لأكثر من ثلاثين سيارة منتجة في العام 1973، وسنستخدم من بيانات تلك المواصفات في مقالتنا هذه كل من mpg ويقصد بها عدد الأميال المقطوعة بغالون البنزين الواحد، و cyl الذي يمثل عدد الإسطوانات في محرك السيارة، و wt وهو الوزن بآلاف الليبرات (الليبرة تقريبا نصف كيلوغرام)، وكذلك qsec وهو التسارع مقاسا بالزمن اللازم لقطع مسافة ربع ميل (لمزيد من المعلومات والتفاصيل يمكنك طلب المساعدة باستخدام التعليمة ?mtcars). سنستخدم هذه البيانات في استعراض مجموعة من الأمثلة حول ما سيتلو ذكره من دوال وتقنيات إحصائية. بمجرد استيراد بياناتك يمكنك الوصول إلى القيم الموجودة في أي من أعمدة جدولك باستخدام الصيغة mtcars$mpg على سبيل المثال حيث mpg يشير إلى اسم العمود، أما إن أردت أسلوبا أكثر سهولة واختصارا يقتصر على ذكر اسم العمود فقط دون الحاجة إلى ذكر اسم إطار البيانات المأخوذ منه في كل مرة، فعليك بداية استخدام الأمر (attach(mtcars عقب استيرادك للبيانات، وحينها يكفي ذكر الاسم mpg للدلالة على ذات العمود من البيانات. وتستطيع استعراض ما تحويه ذاكرة الجلسة الحالية من بيانات في لغة R باستخدام الأمر ()ls ، إضافة إلى ذلك يمكنك حذف أي من كتل البيانات تلك من ذاكرة الجلسة الحالية باستخدام الأمر (rm(x حيث يشير الرمز x إلى اسم كتلة البيانات سواء كانت عمود (أي شعاع من القيم) أو مصفوفة أو إطار بيانات كامل، حتى أنك تستطيع حذف كل ما يوجد الآن في ذاكرة الجلسة الحالية من بيانات سبق وأن تم تحميلها وذلك باستخدام الأمر (()rm(list=ls. عند قيامك بتحميل بياناتك إلى ذاكرة الجلسة الحالية، تصبح مستعدا للبدء في العمل عليها لتطبيق تحليلاتك المختلفة. ومن الأوامر الأساسية المتاحة نذكر على سبيل المثال الدالة (max(mpg والتي تعيد القيمة العظمى ضمن العمود mpg (أي شعاع القيم mpg)، أما الدالة (min(mpg فهي على عكس سابقتها تعيد القيمة الصغرى، في حين أن الدالة (mean(mpg تعيد المتوسط الحسابي للقيم الواردة في mpg، والدالة (median(mpg تعيد قيمة الوسيط (الوسيط هو القيمة التي تقع في المنتصف عند ترتيب قيم mpg تصاعديا، وبالتالي تكون نصف قيم mpg تزيد عن قيمة هذا الوسيط فيما النصف الآخر يقل عنها، وعادة ما يستخدم الوسيط للدلالة على مركز المجموعة حينما تكون هناك قيم متطرفة زيادة أو نقصانا بحيث تؤثر على المتوسط الحسابي وتؤدي إلى انحيازه). من جهة أخرى هناك دوال تستخدم لوصف مدى تشتت قراءات وقيم mpg حول النقطة المركزية الممثلة بالمتوسط، ومنها الدالة (var(mpg والتي تحسب مقدار التباين، والدالة (sd(mpg والتي تعيد قيمة الانحراف المعياري. يحسب التباين من خلال العلاقة التالية أي أننا نراكم مجموع فروقات كل واحدة من قراءاتنا عن قيمة المتوسط بعد أن نربّع هذا الفرق، حيث تخدم عملية التربيع في جعل الناتج موجبا دوما (كون الأخطاء أو الفروقات موجودة سواء كانت بالزيادة أو النقصان، وإن لم نفعل ذلك لحصلنا دوما على الناتج 0 كمحصلة لعملية الجمع تلك)، الخدمة الثانية التي نحصل عليها من هذا التربيع هي تقليل أثر الفروقات الصغيرة على حساب تعظيم ومضاعفة تأثير الفروقات الكبيرة (فتربيع الأرقام الصغيرة لايضاعفها بقدر ما يفعل مع الأرقام الكبيرة، ولولا ذلك لاكتفينا بالقيمة المطلقة للفروقات المحسوبة عن المتوسط عند حساب مقدار التباين). من جهة ثانية فإن الانحراف المعياري يقوم بتقييس معيار التباين وذلك للتعبير عن التشتت بصيغة مستقلة عن عدد العينات أو القراءات التي لدينا (والتي تؤثر على قيمة التباين كونه حساب تراكمي يزداد بازدياد عدد القراءات)، وتتم عملية التقييس تلك من خلال تقسيم مقدار التباين الناتج على (n-1) وهو عدد العينات منقوصا منه واحد، وبعد عملية القسمة تلك نحسب الجذر التربيعي الناتج وذلك حتى يعود المقدار المحسوب إلى ذات فضاء القيم الموجودة لدينا بدلا من كونه في حالة التباين من مرتبة مربّع تلك الأرقام، فيعود من السهل علينا مقارنته مباشرة مع قيمنا أو المتوسط الخاص بتلك القيم. أما الدالة (summary(mpg فهي عامة الاستخدام ويختلف سلوكها وخرجها بحسب الكائن الممرر إليها، ففي حالة تمرير شعاع من القيم العددية فسيكون ناتج تنفيذها هو ملخص لتلك القيم والذي يشمل كل من المتوسط والوسيط إضافة إلى القيمتين العظمى والصغرى والربعين الأول والثالث (ويعرفان بشكل مشابه للوسيط، إذ يشير الربع الأول إلى القيمة التي تقل عنها ربع قراءاتك بعد ترتيبها تصاعديا، فيما الربع الثالث كما هو واضح من اسمه فهو القيمة التي تقل عنها ثلاثة أرباع قيم mpg المرتبة تصاعديا، وهما قيمتان تساعدان في فهم كيفية توزع بياناتك). كذلك تمتلك لغة R مجموعة واسعة من الدوال الرياضياتية مثل (abs(x والتي تعيد القيمة المطلقة (الإيجابية الإشارة دوما) للقيمة أو شعاع القيم المدخل لها، والدالة (sqrt(x التي تحسب الجذر التربيعي والتي نستطيع الحصول على نفس وظيفتها من خلال عملية الرفع إلى أس مقداره نصف أي x^0.5 ، كذلك لدينا الدوال المثلثية المختلفة مثل (sin(x و (cos(x وغيرهما، هذا بالإضافة إلى طيف من دوال التقريب المختلفة مثل (floor(2.718 والتي ستعيد القيمة 2 كأكبر عدد صحيح أصغر من القيمة المعطاة، وكذلك الدالة (ceiling(3.142 والتي ستعيد القيمة 4 كأصغر عدد صحيح أكبر من القيمة المعطاة، أما الدالة (round(2.718, digits=2 فستعيد القيمة 2.72 حيث تقوم هذه الدالة بعملية التقريب الحسابية المعتادة مع إمكانية تحديد عدد الخانات العشرية بعد الفاصلة والتي تريد الاحتفاظ بها. لدينا أيضا دوال التحويل مثل (log(x التي تحسب اللوغاريتم الطبيعي للمقدار x، فيما تحسب الدالة (log10(x اللوغاريتم العشري لذات المقدار x، مع هذا يمكنك استخدام الصيغة الأكثر مرونة وهي (log(x,n والتي تحسب اللوغاريتم لأي أساس يحدده المبرمج من خلال المقدار n، فمثلا يمكنك حساب اللوغاريتم الثنائي للمقدار x باستخدام التعليمة (log(x,2. هذه هي نهاية الجزء الأول من سلسلة المقالات التي تتحدث عن لغة R، سنتحدث في الجزء الثاني عن المخططات البيانية الإحصائية. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة -
 تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الثاني في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث قدم الجزء الأول مدخل عام إلى هذه اللغة بما فيها الإحصائيات الوصفية، أما الجزء الثالث فسيتحدث عن كيفية إجراء بعض الاختبارات الإحصائية بلغة R، فيما نختم السلسلة بجزء رابع يتحدث عن بعض التقنيات المتقدمة في هذه اللغة. للتذكير فقط، تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتبة، وكل مانكتبه تاليا يكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر mtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد. تبدأ أول خطوة من أي تحليل إحصائي باستكشاف ما لدينا من بيانات وذلك من خلال إلقاء نظرة سريعة على بعض المخططات البيانية والرسوم التوضيحية ذات الصبغة الإحصائية والتي عليها أن تقوم بتنفيذ تلك المهمة على أتم وجه، وسنمر في مقالتنا هذه على مجموعة من أهم وأشهر تلك المخططات البيانية الإحصائية محاولين تقديم شرح مختصر عن كل منها يصف طريقة توليده ويوضح ما يتم عرضه وطبيعة الفائدة منه. لدى لغة R تعليمة بسيطة بالصيغة لكنها في ذات الوقت تقدم خدمة عظيمة في إطار عرض ما لدينا من بيانات وتوضيح ما فيها من علاقات محتملة، تدعى هذه التعليمة pairs وتقبل كدخل لها إسم إطار البيانات الذي لدينا كاملا، لتقوم بعدها برسم مصفوفة من المخططات البيانية لكل زوج ممكن من هذه البيانات على شكل مخطط مبعثر (scatter plot) بحيث يظهر كل زوج في مخططين بيانيين يتبادلان فيه مكان التمثيل على المحورين x و y، يظهر الشكل التالي مثالا عن ناتج تنفيذ هذه التعليمة عند تطبيقها على إطار mtcars للبيانات: pairs(mtcars); هنالك ملاحظة أود ذكرها طالما أننا نتحدث عن الرسوم البيانية، فمعشر الإحصائيين لا يفضلون استخدام مخطط القطاعات الدائرية على عكس ما هو شائع في عالم المال والأعمال، ويفضلون بديلا عنها الخطوط البيانية أو حتى التمثيل بالأعمدة وذلك لأن الناس يستطيعون الحكم على الأطوال بشكل أكثر دقة من الأحجام، خصوصا عندما تكون القيم متقاربة. أما لرسم مخطط مبعثر (scatter) بين أي عمودين من البيانات نستطيع استخدام الدالة plot العامة الأغراض، فمثلا (plot(wt, mpg والتي يمكن كتابتها أيضا بالصيغة (plot(mpg~wt حيث سيمثل وزن السيارات بقيم wt على محور x فيما المسافة المقطوعة بغالون البنزين الواحد والتي تعطى بقيم mpg ستمثل على المحور y ليظهر لدينا المخطط البياني كما هو موضح في الشكل التالي: في بعض الأحيان قد لا يكون هذا النوع من المخططات البيانية هو الطريقة الأمثل لعرض ما لدينا من معلومات، خصوصا عندما تكون بيانات أحد طرفي العلاقة عبارة عن قيم محددة بعينها وليست قراءات تتوزع على طيف المحور المسندة إليه كما في حالة المخطط البياني الذي تولده التعليمة (plot(cyl, mpg حيث cyl تمثل عدد إسطوانات المحرك، حينها سيكون الشكل الناتج غريبا قليلا وأقل فائدة في التعبير عن ما يربط بين المقادير المرسومة كما هو موضح أدناه: لحسن الحظ فإن سلوك الدالة plot يتعدل بشكل آلي تبعا لطبيعة ونوع البيانات التي تمرر إليها، وما سنقوم به الآن هو تحويل نوع cyl إلى معاملة وذلك باستخدام الأمر (cyl <- factor(cyl، بمعنى أن لهذا المقدار قيم محددة لايستطيع أن يأخذ غيرها، وسنلاحظ طبيعة هذا التغير في طريقة تعامل توابع لغة R المختلفة مع هذا المقدار الجديد بعد تغيير توصيفه (يمكن لك أن تجرب معه الدالة summary لترى أن ماتحصل عليه من ناتج يختلف عما سبق وأن رأيت، فعوضا عن القيمة الصغرى والعظمى والمتوسط والوسيط الخ... وهي المقادير التي توصف بها عادة أي مجموعة قيم عددية، أصبحنا نرى الآن عدد القيم المحددة التي يمتلكها هذا المعامل مقدار تكرار ظهور كل من تلك القيم). ليس هذا فحسب بل إن سلوك الدالة plot سوف يتغير كذلك، فإن حاولت الآن إعادة تنفيذ ذات الأمر السابق (plot(cyl, mpg فسوف تحصل على المخطط البياني التالي: وما يظهر لنا في هذا الشكل هو مجموعة من المخططات الصندوقية لكل قيمة أو مستوى من عدد إسطوانات المحرك في cyl (سنأتي بعد قليل على شرح هذا النوع من المخططات الصندوقية بشيء من التفصيل، فقليلا من الصبر إن كنت غير عارف بها). هناك مخطط بياني آخر ذي طبيعة استخدام إحصائية موجود في جعبتنا ألا وهو المدرج التكراري (Histogram)، وهو يبين طبيعة توزع ما لدينا من قيم على المجال المحصور ما بين الحد الأدنى والأقصى، ففي بعض الأحيان لا يكون تلخيص البيانات بمساعدة الحد الأدنى والأقصى والمتوسط كافيا، حينها نلجأ إلى هذا المخطط البياني والذي يقسم فيه المجال الكلي ما بين الحد الأدنى والحد الأقصى إلى فئات أو مجموعات، ومن ثم نرسم أعمدة بيانية توضح عدد مرات تكرار ظهور القيم ضمن كل واحدة من هذه الفئات أو المجموعات. فعلى سبيل المثال تستطيع تجربة الأمر التالي ("hist(qsec, col="gray لتوضيح توزع معدل التسارع بين السيارات المدروسة حيث تشير القيم في qsec إلى الزمن اللازم لقطع مسافة ربع ميل مقاسا بالثواني، لاحظ أننا اخترنا اللون الرمادي الذي سترسم به الأعمدة وذلك من خلال تحديد قيمة الوسيط col. لدينا نوع آخر من المخططات البيانية ذات الصبغة الإحصائية متاح لنا وهو المخطط الصندوقي آنف الذكر، ويمكن طلب عرض بياناتنا من خلاله باستخدام الدالة ("boxplot(qsec, col="gray حيث سنحصل بالنتيجة على الشكل التالي: حيث يوضح الخطين الأفقيين على طرفي الرسم في الأعلى والأسفل كل من القيمة الصغرى (في الأسفل) والعظمى (في الأعلى)، أما الصندوق الموجود بينهما فتوضح بدايته من الأسفل ما ندعوه بحد الربع الأول (وهو ما كان يظهر ضمن خرج الدالة summary تحت التسمية Q1)، وبالتالي يكون المجال المحدد ما بين القيمة الصغرى وطرف هذا الصندوق يتضمن ربع ما لدينا من قيم، أما المجال المحدد ما بين طرفي الصندوق الأسفل والأعلى فيتضمن بالضبط نصف ما لدينا من قيم حيث أن الحد الأعلى للصندوق هو الربع الثالث أي Q3، أما الخط الذي يقطع ذلك الصندوق بالعرض فهو الوسيط (وليس المتوسط الحسابي)، وهو يدل على الحد الذي يقسم كتلة البيانات التي لدينا إلى مجموعتين متساويتين في العدد إحداهما تتضمن القيم التي تعلو خط الوسيط والأخرى فيها القيم التي تقع أسفل خط هذا الوسيط. في بعض الأحيان قد نرى دوائر أو نقاط تتجاوز حد القيمة العظمى أو تقل عن حد القيمة الصغرى، وهي في واقع الأمر من بياناتنا أيضا لكنها تعامل معاملة القيم الشاذة أو الغريبة وذلك حينما يتجاوز بعدها عن المتوسط ضعفي الإنحراف المعياري (standard deviation) لمجموعة البيانات التي لدينا. إن حجر الزاوية في تصميم أي تجربة علمية على أساس إحصائي سليم يبدأ من توليد التوزيع العشوائي لمعاملاتها حتى لايكون هناك أي تفضيل أو إنحياز لأي منها، كذلك علينا تكرار كل واحدة من تلك المعاملات لأكثر من مرة حتى تكون الاستجابة المدروسة ليست مجرد مصادفة بل تمت المصادقة عليها من خلال إعادتها وتكرارها، إن مجموعة الأوامر التالية تعطي مثالا على طريقة تصميم تجربة بمعاملة لها 12 قيمة مختلفة في 3 مكررات (وهو ما يطلق عليه عادة في التجارب العلمية بتصميم القطاعات العشوائية الكاملة RCBD أي Randomised Complete Block Design): x <- 1:12; RCBD <- replicate(3, sample(x));حيث يشير التركيب 1:12 إلى تسلسل الأرقام من 1 وحتى 12 على التوالي، فيما تقوم الدالة sample ببعثرة عناصر الشعاع x بشكل عشوائي، في حين أن دور الدالة replicate في هذا التركيب هو تكرار ناتج تنفيذ الدالة sample لثلاث مرات، لعرض محتويات التصميم الناتج أكتب RCBD ضمن سطر الأوامر في لغة R ومن ثم إنقر على زر الإدخال (إنتبه إلى أن الأسماء في لغة R حساسة لحالة الأحرف). تجدر الإشارة إلى أنه بإمكانك حفظ مجموعة التعليمات التي تود تنفيذها ضمن ملف نصي، وعادة ما تستخدم اللاحقة R لمثل تلك الملفات (على سبيل المثال script.R)، ومن ثم تستطيع استدعاء ذلك الملف ليتم تنفيذ محتواه من تعليمات وأوامر دفعة واحدة وذلك باستخدام التعليمة ("source("script.R أو حتى من خلال الخيار Source R code في قائمة File. هذه هي نهاية الجزء الثاني من سلسلة المقالات التي تتحدث عن لغة R، في الجزء الثالث سنتناول موضوع الاختبارات الإحصائية. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة
تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الثاني في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث قدم الجزء الأول مدخل عام إلى هذه اللغة بما فيها الإحصائيات الوصفية، أما الجزء الثالث فسيتحدث عن كيفية إجراء بعض الاختبارات الإحصائية بلغة R، فيما نختم السلسلة بجزء رابع يتحدث عن بعض التقنيات المتقدمة في هذه اللغة. للتذكير فقط، تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتبة، وكل مانكتبه تاليا يكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر mtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد. تبدأ أول خطوة من أي تحليل إحصائي باستكشاف ما لدينا من بيانات وذلك من خلال إلقاء نظرة سريعة على بعض المخططات البيانية والرسوم التوضيحية ذات الصبغة الإحصائية والتي عليها أن تقوم بتنفيذ تلك المهمة على أتم وجه، وسنمر في مقالتنا هذه على مجموعة من أهم وأشهر تلك المخططات البيانية الإحصائية محاولين تقديم شرح مختصر عن كل منها يصف طريقة توليده ويوضح ما يتم عرضه وطبيعة الفائدة منه. لدى لغة R تعليمة بسيطة بالصيغة لكنها في ذات الوقت تقدم خدمة عظيمة في إطار عرض ما لدينا من بيانات وتوضيح ما فيها من علاقات محتملة، تدعى هذه التعليمة pairs وتقبل كدخل لها إسم إطار البيانات الذي لدينا كاملا، لتقوم بعدها برسم مصفوفة من المخططات البيانية لكل زوج ممكن من هذه البيانات على شكل مخطط مبعثر (scatter plot) بحيث يظهر كل زوج في مخططين بيانيين يتبادلان فيه مكان التمثيل على المحورين x و y، يظهر الشكل التالي مثالا عن ناتج تنفيذ هذه التعليمة عند تطبيقها على إطار mtcars للبيانات: pairs(mtcars); هنالك ملاحظة أود ذكرها طالما أننا نتحدث عن الرسوم البيانية، فمعشر الإحصائيين لا يفضلون استخدام مخطط القطاعات الدائرية على عكس ما هو شائع في عالم المال والأعمال، ويفضلون بديلا عنها الخطوط البيانية أو حتى التمثيل بالأعمدة وذلك لأن الناس يستطيعون الحكم على الأطوال بشكل أكثر دقة من الأحجام، خصوصا عندما تكون القيم متقاربة. أما لرسم مخطط مبعثر (scatter) بين أي عمودين من البيانات نستطيع استخدام الدالة plot العامة الأغراض، فمثلا (plot(wt, mpg والتي يمكن كتابتها أيضا بالصيغة (plot(mpg~wt حيث سيمثل وزن السيارات بقيم wt على محور x فيما المسافة المقطوعة بغالون البنزين الواحد والتي تعطى بقيم mpg ستمثل على المحور y ليظهر لدينا المخطط البياني كما هو موضح في الشكل التالي: في بعض الأحيان قد لا يكون هذا النوع من المخططات البيانية هو الطريقة الأمثل لعرض ما لدينا من معلومات، خصوصا عندما تكون بيانات أحد طرفي العلاقة عبارة عن قيم محددة بعينها وليست قراءات تتوزع على طيف المحور المسندة إليه كما في حالة المخطط البياني الذي تولده التعليمة (plot(cyl, mpg حيث cyl تمثل عدد إسطوانات المحرك، حينها سيكون الشكل الناتج غريبا قليلا وأقل فائدة في التعبير عن ما يربط بين المقادير المرسومة كما هو موضح أدناه: لحسن الحظ فإن سلوك الدالة plot يتعدل بشكل آلي تبعا لطبيعة ونوع البيانات التي تمرر إليها، وما سنقوم به الآن هو تحويل نوع cyl إلى معاملة وذلك باستخدام الأمر (cyl <- factor(cyl، بمعنى أن لهذا المقدار قيم محددة لايستطيع أن يأخذ غيرها، وسنلاحظ طبيعة هذا التغير في طريقة تعامل توابع لغة R المختلفة مع هذا المقدار الجديد بعد تغيير توصيفه (يمكن لك أن تجرب معه الدالة summary لترى أن ماتحصل عليه من ناتج يختلف عما سبق وأن رأيت، فعوضا عن القيمة الصغرى والعظمى والمتوسط والوسيط الخ... وهي المقادير التي توصف بها عادة أي مجموعة قيم عددية، أصبحنا نرى الآن عدد القيم المحددة التي يمتلكها هذا المعامل مقدار تكرار ظهور كل من تلك القيم). ليس هذا فحسب بل إن سلوك الدالة plot سوف يتغير كذلك، فإن حاولت الآن إعادة تنفيذ ذات الأمر السابق (plot(cyl, mpg فسوف تحصل على المخطط البياني التالي: وما يظهر لنا في هذا الشكل هو مجموعة من المخططات الصندوقية لكل قيمة أو مستوى من عدد إسطوانات المحرك في cyl (سنأتي بعد قليل على شرح هذا النوع من المخططات الصندوقية بشيء من التفصيل، فقليلا من الصبر إن كنت غير عارف بها). هناك مخطط بياني آخر ذي طبيعة استخدام إحصائية موجود في جعبتنا ألا وهو المدرج التكراري (Histogram)، وهو يبين طبيعة توزع ما لدينا من قيم على المجال المحصور ما بين الحد الأدنى والأقصى، ففي بعض الأحيان لا يكون تلخيص البيانات بمساعدة الحد الأدنى والأقصى والمتوسط كافيا، حينها نلجأ إلى هذا المخطط البياني والذي يقسم فيه المجال الكلي ما بين الحد الأدنى والحد الأقصى إلى فئات أو مجموعات، ومن ثم نرسم أعمدة بيانية توضح عدد مرات تكرار ظهور القيم ضمن كل واحدة من هذه الفئات أو المجموعات. فعلى سبيل المثال تستطيع تجربة الأمر التالي ("hist(qsec, col="gray لتوضيح توزع معدل التسارع بين السيارات المدروسة حيث تشير القيم في qsec إلى الزمن اللازم لقطع مسافة ربع ميل مقاسا بالثواني، لاحظ أننا اخترنا اللون الرمادي الذي سترسم به الأعمدة وذلك من خلال تحديد قيمة الوسيط col. لدينا نوع آخر من المخططات البيانية ذات الصبغة الإحصائية متاح لنا وهو المخطط الصندوقي آنف الذكر، ويمكن طلب عرض بياناتنا من خلاله باستخدام الدالة ("boxplot(qsec, col="gray حيث سنحصل بالنتيجة على الشكل التالي: حيث يوضح الخطين الأفقيين على طرفي الرسم في الأعلى والأسفل كل من القيمة الصغرى (في الأسفل) والعظمى (في الأعلى)، أما الصندوق الموجود بينهما فتوضح بدايته من الأسفل ما ندعوه بحد الربع الأول (وهو ما كان يظهر ضمن خرج الدالة summary تحت التسمية Q1)، وبالتالي يكون المجال المحدد ما بين القيمة الصغرى وطرف هذا الصندوق يتضمن ربع ما لدينا من قيم، أما المجال المحدد ما بين طرفي الصندوق الأسفل والأعلى فيتضمن بالضبط نصف ما لدينا من قيم حيث أن الحد الأعلى للصندوق هو الربع الثالث أي Q3، أما الخط الذي يقطع ذلك الصندوق بالعرض فهو الوسيط (وليس المتوسط الحسابي)، وهو يدل على الحد الذي يقسم كتلة البيانات التي لدينا إلى مجموعتين متساويتين في العدد إحداهما تتضمن القيم التي تعلو خط الوسيط والأخرى فيها القيم التي تقع أسفل خط هذا الوسيط. في بعض الأحيان قد نرى دوائر أو نقاط تتجاوز حد القيمة العظمى أو تقل عن حد القيمة الصغرى، وهي في واقع الأمر من بياناتنا أيضا لكنها تعامل معاملة القيم الشاذة أو الغريبة وذلك حينما يتجاوز بعدها عن المتوسط ضعفي الإنحراف المعياري (standard deviation) لمجموعة البيانات التي لدينا. إن حجر الزاوية في تصميم أي تجربة علمية على أساس إحصائي سليم يبدأ من توليد التوزيع العشوائي لمعاملاتها حتى لايكون هناك أي تفضيل أو إنحياز لأي منها، كذلك علينا تكرار كل واحدة من تلك المعاملات لأكثر من مرة حتى تكون الاستجابة المدروسة ليست مجرد مصادفة بل تمت المصادقة عليها من خلال إعادتها وتكرارها، إن مجموعة الأوامر التالية تعطي مثالا على طريقة تصميم تجربة بمعاملة لها 12 قيمة مختلفة في 3 مكررات (وهو ما يطلق عليه عادة في التجارب العلمية بتصميم القطاعات العشوائية الكاملة RCBD أي Randomised Complete Block Design): x <- 1:12; RCBD <- replicate(3, sample(x));حيث يشير التركيب 1:12 إلى تسلسل الأرقام من 1 وحتى 12 على التوالي، فيما تقوم الدالة sample ببعثرة عناصر الشعاع x بشكل عشوائي، في حين أن دور الدالة replicate في هذا التركيب هو تكرار ناتج تنفيذ الدالة sample لثلاث مرات، لعرض محتويات التصميم الناتج أكتب RCBD ضمن سطر الأوامر في لغة R ومن ثم إنقر على زر الإدخال (إنتبه إلى أن الأسماء في لغة R حساسة لحالة الأحرف). تجدر الإشارة إلى أنه بإمكانك حفظ مجموعة التعليمات التي تود تنفيذها ضمن ملف نصي، وعادة ما تستخدم اللاحقة R لمثل تلك الملفات (على سبيل المثال script.R)، ومن ثم تستطيع استدعاء ذلك الملف ليتم تنفيذ محتواه من تعليمات وأوامر دفعة واحدة وذلك باستخدام التعليمة ("source("script.R أو حتى من خلال الخيار Source R code في قائمة File. هذه هي نهاية الجزء الثاني من سلسلة المقالات التي تتحدث عن لغة R، في الجزء الثالث سنتناول موضوع الاختبارات الإحصائية. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة -
 تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الأخير في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث قدم الجزء الأول مدخل عام إلى هذه اللغة بما فيها الإحصائيات الوصفية، أما الجزء الثاني فتحدث عن كيفية توليد بعض المخططات البيانية الإحصائية بلغة R، أما الجزء الثالث فتحدثنا فيه عن طريقة إجراء بعض التحاليل الإحصائية باستخدام هذه اللغة. للتذكير فقط، تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتبة، وكل مانكتبه تاليا يكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر mtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد. عندما لا تكون المقادير المراد إختبارها كميّة متدرجة كما سبق وأن شاهدنا في تحاليل سابقة مثل إختبار t، بل هي قيم نوعية كحالة أنواع محركات السيارات من حيث عدد الإسطوانات cyl وارتباطها بنوع ناقل الحركة am هل هو أوتوماتيكي أم عادي، طبعا الغاية هي معرفة هل هناك فروق معنوية ما بين الفئات المختلفة للحركات من حيث عدد إسطواناتها، لمثل هكذا حالات عليك استخدام اختبار إحصائي يدعى باختبار chi-squared والمثال التالي يوضح كيفية تحضير بياناتك لهذا النوع من التحليل مستخدمين الدالة table حيث عرضنا في التعليمة التالية كيف سيظهر ناتج تنفيذ تلك الدالة على بياناتنا فقط لتوضيح شكل الجدول المطلوب تمريره للدالة chisq.test التالي والذي يقوم بتنفيذ الاختبار المقصود. كما جرت العادة فإن ما يهمنا من هذا الخرج هو قيمة p-value والتي تشير إلى إحتمال المصادفة (بمعنى أنه لاتوجد فروقات معنوية ما بين الفئات المختلفة وما يظهر لدينا من فروقات هي في هامش خطأ التجربة)، في المثال السابق قيمة p-value هي 0.01265 أي ضمن الحد المسموح به عادة للقبول بوجود فروق معنوية وهو 5% (أي 0.05)، وبالتالي فالفروق الملاحظة معنوية وموجودة، بمعنى أن نسبة السيارات ذات ناقل الحركة الأوتوماتيكي am=1 هي أكبر في حالة السيارات ذات عدد الإسطوانات الكبير مقارنة بتلك التي لديها محركات تحتوي على أربع اسطوانات فقط. ولمعرفة كم سيكون عدد السيارات ذات علبة التروس اليدوية أو الأوتوماتيكية في كل فئة من فئات المحركات الثلاث المصنفة بحسب عدد الإسطوانات وذلك في حال كان التوزع متساويا والفروقات غير موجودة نستخدم الدالة التالية: chisq.test(myTable)$expectedلننتقل إلى أداة أخرى تتيح لنا استكشاف جملة البيانات التي بين أيدينا وما فيها من علاقات وارتباطات وذلك من خلال شكل واحد يتضمن خريطة حرارية مضاف لها شجرتي عنقدة هرمية لكل من أعمدة البيانات التي لدينا (الصفات المدروسة مثل الوزن wt وعدد إسطوانات المحرك cyl وعدد الأميال المقطوعة بغالون البنزين الواحد mpg) وأسطر البيانات (وهي في حالتنا تمثل أنواع السيارات المدروسة مثل Toyota Corona و Honda Civic وغيرهما)، إن التعليمة التي نتحدث عنها هنا هي تعليمة heatmap لكن العقبة التي تقف في طريقنا هي نوع بيانات الدخل لهذه التعليمة، فهي لا تقبل إطار البيانات إنما هي بحاجة إلى بيانات محزومة على شكل مصفوفة! لا تقلق من هكذا عقبة، فهناك طيف كامل من التعليمات بلغة R مهمتها التحويل فيما بين صيغ وتنسيقات البيانات المختلفة، ولجميعها الصيغة التالية: y <- as.*(x)حيث x هي البيانات بتنسيقها الأصلي و y هي ذات البيانات بعد تحويلها إلى التنسيق المطلوب حيث يستعاض عن رمز النجمة * (في الصيغة الموضحة أعلاه) بالتنسيق الهدف والمطلوب التحويل إليه، فمثلا نجد مجموعة التعليمات التالية: (as.null(x و (as.numeric(x و (as.character(x و (as.factor(x الخ... وفق ذات الأسلوب، لدينا طقم آخر من التعليمات غايته التحقق إن كانت صيغة متحول ما تتبع تنسيقا بعينه أم لا، وتلك التعليمات تعيد القيمة المنطقية true إن كان المتحول يطابق التنسيق الخاص بالتعليمة فيما تعيد القيمة المنطقية false في بقية الحالات، حيث تجد على سبيل المثال مجموعة التعليمات التالية متاحة لك للاستخدام وهي: (is.null(x و(is.numeric(x و(is.character(x و (is.factor(x الخ... حسنا، لكن كيف سنستفيد من كل هذه المعلومات في حالة مثالنا المتعلق باستخدام تعليمة heatmap والتي تحتاج كدخل لها بيانات بتنسيق matrix وليس data.frame كما سبق وأن ذكرنا، للقيام بذلك سنستخدم التعليمة التالية لتحويل إطار بيانات mtcars الذي نستخدمه في مثالنا إلى تنسيق المصفوفة ونحفظه ضمن متحول جديد أسميناه للسهولة x وبعدها مررنا تلك المصفوفة x إلى تعليمة heatmap لنحصل على النتيجة الموضحة في الشكل التالي: x <- as.matrix(mtcars); heatmap(x, scale=”column”); من البديهي في الخريطة الحرارية الاستنتاج بأن النقاط التي تتقارب ألوانها في هذا المخطط تعود إلى قراءات متقاربة في القيمة ضمن البيانات التي استخدمت في توليد ذلك المخطط، كذلك فإن الأغصان التي تتلاقى مبكرا ضمن كل من شجرتي العنقدة الهرمية سواء للصفات (أعلى الرسم) أو السيارات (على يسار الرسم) تشير إلى تشابه أكبر من تلك التي تتلاقى في أماكن أبعد. نستطيع في لغة R كما في أي لغة برمجة أخرى أن نعرف توابعنا الخاصة ومن ثم نستدعيها، والمثال التالي يوضح حالة نموذجية بسيطة سنشرحها سطرا بسطر وبشكل مقتضب، حيث سنقوم بتعريف تابع جديد سندعوه SEM لحساب الخطأ المعياري المرتكب في حساب قيمة المتوسط، وهو للمصادفة الغريبة تابع غير موجود ضمن مجموعة توابع لغة R الأساسية! إن حساب تلك القيمة الإحصائية بسيط نسبيا فهي ناتج تقسيم الإنحراف المعياري على جذر عدد القراءات منقوصا منه واحد، لنلقي نظرة الآن على الشيفرة البرمجية التي نقوم من خلالها بتعريف هذا التابع: SEM <- function(x, na.rm = TRUE) { if (na.rm == TRUE) VAR <- x[!is.na(x)] else VAR <- x; SD <- sd(VAR); N <- length(VAR); SE <- SD/sqrt(N - 1); return(SE); }كما نلاحظ في السطر الأول فقد قمنا بتحديد اسم التابع قبل رمز الإسناد، أما ما يتلو رمز الإسناد فهو تصريح بأن ما نقوم بتعريفه هنا ما هو إلا تابع له وسيطين دعونا الأول x والذي يفترض به أن يتضمن شعاع القيم التي نرغب بحساب الخطأ المعياري المرتكب في حساب متوسطها، أما الثاني فدعوناه na.rm وهو وسيط اختياري بحسب الصيغة الموضحة أعلاه وقيمته الافتراضية هي TRUE وسنستخدمه لمعرفة إن كان المستخدم يريد تضمين أم حذف القيم غير المحددة أي القيم المفقودة، ومن ثم نرى القوس الكبير قد فتح ليقوم بحزم مجموعة التعليمات التي تنتمي إلى هذا التابع. السطر التالي مباشرة يتأكد من اختيار المستخدم بالنسبة لطريقة التعامل مع القيم المفقودة، فإن كان يرغب بحذفها نقلنا إلى المتحول الداخلي VAR فقط تلك القيم من x والتي ليست غير محددة أو مفقودة، وإلا فإن قيمة المتحول الداخلي VAR ستتضمن كامل قيم الشعاع x (وضعنا الأمر بهذه الصيغة لتوضيح آلية استخدام العبارات الشرطية والوسطاء ذات القيم الاختيارية، لكن الصواب في هذه الحالة بالذات هو أننا نقوم دوما باستثناء القيم الغير محددة فحساب قيمتنا غير ممكن بوجودها). بعد ذلك نقوم بحساب الانحراف المعياري للقيم التي باتت موجودة الآن في المتحول VAR وذلك من خلال استخدامنا للتابع sd ونحفظ الجواب الناتج بمتحول جديد ندعوه SD (تذكر أن لغة R حساسة لحالة الأحرف كبيرة كانت أم صغيرة بمعنى أنها تميز فيما بينها). أما في السطر التالي فنقوم بإيجاد عدد العناصر الموجودة بشعاع القيم VAR ومن ثم نحفظ ذلك العدد ضمن متحول جديد ندعوه N. وهكذا أصبحنا جاهزين لحساب قيمة الخطأ المعياري المرتكب في حساب متوسط مجموعة القيم هذه وذلك من خلال إجراء عملية القسمة لقيمة الانحراف المعياري على الجذر التربيعي لعدد القراءات بعد أن أنقصناه بمقدار 1، حينها نحفظ الجواب الناتج في متحول جديد دعوناه في مثالنا SE، لتأتي بعدها الخطوة الأخيرة باستخدامنا للأمر return ليعيد الجواب الناتج إلى من استدعى هذا التابع، ونختم أخيرا بإغلاق القوس الكبير الذي استخدم لحزم مجموعة التعليمات هذه رابطا إياها باسم التابع الذي صرحنا عنها بداية في السطر الأول. إن لغة R هي لغة مفتوحة المصدر إلى حد بعيد، فأي تابع تقوم بتعريفه مثل تابعنا الذي دعوناه SEM الوارد أعلاه، يستطيع المستخدم الاطلاع على شيفرته المصدرية كاملة بمجرد كتابة اسمه دون أي زيادة أو إضافات ومن ثم النقر على زر الإدخال، ليس هذا فحسب، بل حتى أنك تستطيع الإطلاع على كيفية كتابة التوابع الخاصة بلغة R نفسها دون كثير عناء، فعلى سبيل المثال إن كان لديك فضول لمعرفة طبيعة وتفاصيل الخوارزمية التي استخدمت في التابع cor لحساب قيمة معامل الارتباط أو التابع lm لحساب علاقة الانحدار وسواهما من التوابع الأخرى، فكل ما عليك القيام به هو كتابة اسم ذلك التابع دون أي إضافات أخرى ومن ثم النقر على زر الإدخال، لتقوم لغة R بعرض الشيفرة المصدرية الداخلية لذلك التابع كاملة أمامك. إن إحدى نقاط قوة لغة R هي سهولة توسعتها من خلال مجموعة الإضافات الهائلة المتاحة لها والتي قام بتطويرها الآلاف من الجامعات والمراكز العلمية وحتى الباحثين المستقلين وطلاب الدراسات العليا، يعينهم في ذلك السهولة النسبية في آلية بناء مثل تلك المكتبات أو الإضافة الجديدة لهذه اللغة، فهي لاتحتاج في أغلب الحالات إلى أي خبرات أو معارف خارج نطاق لغة R نفسها وهو أمر ممتع ومميز بحق، للإطلاع على لائحة الإضافات الرسمية المنشورة على موقع لغة R نفسها يمكنكم التحقق من هذا الرابط (ملاحظة: لقد اخترنا مخدم موجود في روسيا الاتحادية لضمان الوصول إليه بسهولة دون أي حجب!): أما لمن لديه فضول التعرف على آلية بناء مكتبته أو إضافته الخاصة فأحيله إلى هذا المرجع السهل والمميز. من الإضافات المميزة التي أنصحك قارئي العزيز بالإطلاع عليها هناك الإضافة ggplot2 والتي تفتح أمام مستخدمي لغة R آفاقا واسعة لتحسين وإثراء نوعية المخططات البيانية التي يمكن توليدها والحصول عليها، وهذه الإضافة هي إضافة ذائعة الصيت حتى أن هنالك كتب كاملة تتحدث عنها وعن مزاياها وإمكانياتها، كذلك نذكر الإضافة doSMP على سبيل المثال والتي قد تكون واحدة من الإضافات الأولى التي ترغب بالتعرف عليها إن كنت تطمح لقرع باب الحوسبة التفرعية، فهي أداة بسيطة تستطيع من خلالها تحويل بنى الحلقات البسيطة إلى نسخة تفرعية تستثمر كامل طاقة نوى المعالج أو المعالجات التي لديك (حيث أن المعالجات الثنائية والرباعية النوى أصبحت شائعة في الأسواق هذه الأيام، والتوجه العام هو نحو زيادة عدد النوى المتاحة على شريحة معالج واحد). أخيرا وليس آخرا، تجدر الإشارة إلى أداة مميزة أخرى تدعى RExcel والتي تسمح للغة R أن تعمل بالتكامل مع تطبيق Microsoft Excel ذائع الصيت وواسع الانتشار للجداول الممتدة، فهي تمكن المستخدم من نقل البيانات من برنامج Excel إلى لغة R وبالعكس، هذا عدى عن تمكين مستخدمي برنامج Excel من استدعاء توابع لغة R المختلفة وتنفيذها على ما لديهم من بيانات مباشرة كما لو كان التعامل يتم مع أي تابع معتاد ضمن برنامج Excel، حيث سيتم تنفيذ التحليل باستخدام لغة R ومن ثم إعادة النتيجة إلي برنامج Excel بشكل مباشر وشفاف ليتم عرضها في إحدى الخلايا دون كثير عناء من قبل المستخدم. لا يخلو تنصيب هذه الأداة يدويا من بعض التعقيد لكثرة ما فيها من مكونات وما تحتاج إليه من ضبط وإعداد، لكن أسهل طريقة للحصول عليها جاهزة للعمل هي من خلال تنصيب RAndFriendsSetup والتي تستطيع الحصول عليها من خلال هذا الرابط: http://rcom.univie.ac.at. في ختام هذه السلسلة من المقالات، نحن نعي تماما أن ما قمنا به لا يتجاوز خدشنا لسطح المعرفة العميق بهذا المجال من العلوم سواء على صعيد الإحصاء أو لغة R ذاتها، لكنها مقدمة متواضعة نضعها بين أيدي المهتمين لينطلقوا منها ويبنوا عليها وصولا إلى نضج أعمق وإغناء أفضل لهذا الموضوع، وقد تجاوزنا في هذه السلسلة من المقالات عن تناول بعض المواضيع الشيقة التي ترتبط بهذا السياق وذلك سعيا منا وراء التبسيط والسهولة نظرا لأن هدفنا الأصلي كان تقديم مجموعة من المقالات التي تمثل مدخلا للغة R، وبالتالي فإن مناقشة أي موضوع يتسم بالتعقيد قد يضر بهذا الهدف والغاية، لكني قد أعود لاحقا للكتابة عن بعضها وأخص بالذكر هنا مناقشة موضوع تحليل التباين ANOVA شائع الصيت بين كل من خاض بمزيد من التفصيل في علم التحليل الإحصائي، لذا ترقبوا منا كل جديد. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة
تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الأخير في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث قدم الجزء الأول مدخل عام إلى هذه اللغة بما فيها الإحصائيات الوصفية، أما الجزء الثاني فتحدث عن كيفية توليد بعض المخططات البيانية الإحصائية بلغة R، أما الجزء الثالث فتحدثنا فيه عن طريقة إجراء بعض التحاليل الإحصائية باستخدام هذه اللغة. للتذكير فقط، تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتبة، وكل مانكتبه تاليا يكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر mtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد. عندما لا تكون المقادير المراد إختبارها كميّة متدرجة كما سبق وأن شاهدنا في تحاليل سابقة مثل إختبار t، بل هي قيم نوعية كحالة أنواع محركات السيارات من حيث عدد الإسطوانات cyl وارتباطها بنوع ناقل الحركة am هل هو أوتوماتيكي أم عادي، طبعا الغاية هي معرفة هل هناك فروق معنوية ما بين الفئات المختلفة للحركات من حيث عدد إسطواناتها، لمثل هكذا حالات عليك استخدام اختبار إحصائي يدعى باختبار chi-squared والمثال التالي يوضح كيفية تحضير بياناتك لهذا النوع من التحليل مستخدمين الدالة table حيث عرضنا في التعليمة التالية كيف سيظهر ناتج تنفيذ تلك الدالة على بياناتنا فقط لتوضيح شكل الجدول المطلوب تمريره للدالة chisq.test التالي والذي يقوم بتنفيذ الاختبار المقصود. كما جرت العادة فإن ما يهمنا من هذا الخرج هو قيمة p-value والتي تشير إلى إحتمال المصادفة (بمعنى أنه لاتوجد فروقات معنوية ما بين الفئات المختلفة وما يظهر لدينا من فروقات هي في هامش خطأ التجربة)، في المثال السابق قيمة p-value هي 0.01265 أي ضمن الحد المسموح به عادة للقبول بوجود فروق معنوية وهو 5% (أي 0.05)، وبالتالي فالفروق الملاحظة معنوية وموجودة، بمعنى أن نسبة السيارات ذات ناقل الحركة الأوتوماتيكي am=1 هي أكبر في حالة السيارات ذات عدد الإسطوانات الكبير مقارنة بتلك التي لديها محركات تحتوي على أربع اسطوانات فقط. ولمعرفة كم سيكون عدد السيارات ذات علبة التروس اليدوية أو الأوتوماتيكية في كل فئة من فئات المحركات الثلاث المصنفة بحسب عدد الإسطوانات وذلك في حال كان التوزع متساويا والفروقات غير موجودة نستخدم الدالة التالية: chisq.test(myTable)$expectedلننتقل إلى أداة أخرى تتيح لنا استكشاف جملة البيانات التي بين أيدينا وما فيها من علاقات وارتباطات وذلك من خلال شكل واحد يتضمن خريطة حرارية مضاف لها شجرتي عنقدة هرمية لكل من أعمدة البيانات التي لدينا (الصفات المدروسة مثل الوزن wt وعدد إسطوانات المحرك cyl وعدد الأميال المقطوعة بغالون البنزين الواحد mpg) وأسطر البيانات (وهي في حالتنا تمثل أنواع السيارات المدروسة مثل Toyota Corona و Honda Civic وغيرهما)، إن التعليمة التي نتحدث عنها هنا هي تعليمة heatmap لكن العقبة التي تقف في طريقنا هي نوع بيانات الدخل لهذه التعليمة، فهي لا تقبل إطار البيانات إنما هي بحاجة إلى بيانات محزومة على شكل مصفوفة! لا تقلق من هكذا عقبة، فهناك طيف كامل من التعليمات بلغة R مهمتها التحويل فيما بين صيغ وتنسيقات البيانات المختلفة، ولجميعها الصيغة التالية: y <- as.*(x)حيث x هي البيانات بتنسيقها الأصلي و y هي ذات البيانات بعد تحويلها إلى التنسيق المطلوب حيث يستعاض عن رمز النجمة * (في الصيغة الموضحة أعلاه) بالتنسيق الهدف والمطلوب التحويل إليه، فمثلا نجد مجموعة التعليمات التالية: (as.null(x و (as.numeric(x و (as.character(x و (as.factor(x الخ... وفق ذات الأسلوب، لدينا طقم آخر من التعليمات غايته التحقق إن كانت صيغة متحول ما تتبع تنسيقا بعينه أم لا، وتلك التعليمات تعيد القيمة المنطقية true إن كان المتحول يطابق التنسيق الخاص بالتعليمة فيما تعيد القيمة المنطقية false في بقية الحالات، حيث تجد على سبيل المثال مجموعة التعليمات التالية متاحة لك للاستخدام وهي: (is.null(x و(is.numeric(x و(is.character(x و (is.factor(x الخ... حسنا، لكن كيف سنستفيد من كل هذه المعلومات في حالة مثالنا المتعلق باستخدام تعليمة heatmap والتي تحتاج كدخل لها بيانات بتنسيق matrix وليس data.frame كما سبق وأن ذكرنا، للقيام بذلك سنستخدم التعليمة التالية لتحويل إطار بيانات mtcars الذي نستخدمه في مثالنا إلى تنسيق المصفوفة ونحفظه ضمن متحول جديد أسميناه للسهولة x وبعدها مررنا تلك المصفوفة x إلى تعليمة heatmap لنحصل على النتيجة الموضحة في الشكل التالي: x <- as.matrix(mtcars); heatmap(x, scale=”column”); من البديهي في الخريطة الحرارية الاستنتاج بأن النقاط التي تتقارب ألوانها في هذا المخطط تعود إلى قراءات متقاربة في القيمة ضمن البيانات التي استخدمت في توليد ذلك المخطط، كذلك فإن الأغصان التي تتلاقى مبكرا ضمن كل من شجرتي العنقدة الهرمية سواء للصفات (أعلى الرسم) أو السيارات (على يسار الرسم) تشير إلى تشابه أكبر من تلك التي تتلاقى في أماكن أبعد. نستطيع في لغة R كما في أي لغة برمجة أخرى أن نعرف توابعنا الخاصة ومن ثم نستدعيها، والمثال التالي يوضح حالة نموذجية بسيطة سنشرحها سطرا بسطر وبشكل مقتضب، حيث سنقوم بتعريف تابع جديد سندعوه SEM لحساب الخطأ المعياري المرتكب في حساب قيمة المتوسط، وهو للمصادفة الغريبة تابع غير موجود ضمن مجموعة توابع لغة R الأساسية! إن حساب تلك القيمة الإحصائية بسيط نسبيا فهي ناتج تقسيم الإنحراف المعياري على جذر عدد القراءات منقوصا منه واحد، لنلقي نظرة الآن على الشيفرة البرمجية التي نقوم من خلالها بتعريف هذا التابع: SEM <- function(x, na.rm = TRUE) { if (na.rm == TRUE) VAR <- x[!is.na(x)] else VAR <- x; SD <- sd(VAR); N <- length(VAR); SE <- SD/sqrt(N - 1); return(SE); }كما نلاحظ في السطر الأول فقد قمنا بتحديد اسم التابع قبل رمز الإسناد، أما ما يتلو رمز الإسناد فهو تصريح بأن ما نقوم بتعريفه هنا ما هو إلا تابع له وسيطين دعونا الأول x والذي يفترض به أن يتضمن شعاع القيم التي نرغب بحساب الخطأ المعياري المرتكب في حساب متوسطها، أما الثاني فدعوناه na.rm وهو وسيط اختياري بحسب الصيغة الموضحة أعلاه وقيمته الافتراضية هي TRUE وسنستخدمه لمعرفة إن كان المستخدم يريد تضمين أم حذف القيم غير المحددة أي القيم المفقودة، ومن ثم نرى القوس الكبير قد فتح ليقوم بحزم مجموعة التعليمات التي تنتمي إلى هذا التابع. السطر التالي مباشرة يتأكد من اختيار المستخدم بالنسبة لطريقة التعامل مع القيم المفقودة، فإن كان يرغب بحذفها نقلنا إلى المتحول الداخلي VAR فقط تلك القيم من x والتي ليست غير محددة أو مفقودة، وإلا فإن قيمة المتحول الداخلي VAR ستتضمن كامل قيم الشعاع x (وضعنا الأمر بهذه الصيغة لتوضيح آلية استخدام العبارات الشرطية والوسطاء ذات القيم الاختيارية، لكن الصواب في هذه الحالة بالذات هو أننا نقوم دوما باستثناء القيم الغير محددة فحساب قيمتنا غير ممكن بوجودها). بعد ذلك نقوم بحساب الانحراف المعياري للقيم التي باتت موجودة الآن في المتحول VAR وذلك من خلال استخدامنا للتابع sd ونحفظ الجواب الناتج بمتحول جديد ندعوه SD (تذكر أن لغة R حساسة لحالة الأحرف كبيرة كانت أم صغيرة بمعنى أنها تميز فيما بينها). أما في السطر التالي فنقوم بإيجاد عدد العناصر الموجودة بشعاع القيم VAR ومن ثم نحفظ ذلك العدد ضمن متحول جديد ندعوه N. وهكذا أصبحنا جاهزين لحساب قيمة الخطأ المعياري المرتكب في حساب متوسط مجموعة القيم هذه وذلك من خلال إجراء عملية القسمة لقيمة الانحراف المعياري على الجذر التربيعي لعدد القراءات بعد أن أنقصناه بمقدار 1، حينها نحفظ الجواب الناتج في متحول جديد دعوناه في مثالنا SE، لتأتي بعدها الخطوة الأخيرة باستخدامنا للأمر return ليعيد الجواب الناتج إلى من استدعى هذا التابع، ونختم أخيرا بإغلاق القوس الكبير الذي استخدم لحزم مجموعة التعليمات هذه رابطا إياها باسم التابع الذي صرحنا عنها بداية في السطر الأول. إن لغة R هي لغة مفتوحة المصدر إلى حد بعيد، فأي تابع تقوم بتعريفه مثل تابعنا الذي دعوناه SEM الوارد أعلاه، يستطيع المستخدم الاطلاع على شيفرته المصدرية كاملة بمجرد كتابة اسمه دون أي زيادة أو إضافات ومن ثم النقر على زر الإدخال، ليس هذا فحسب، بل حتى أنك تستطيع الإطلاع على كيفية كتابة التوابع الخاصة بلغة R نفسها دون كثير عناء، فعلى سبيل المثال إن كان لديك فضول لمعرفة طبيعة وتفاصيل الخوارزمية التي استخدمت في التابع cor لحساب قيمة معامل الارتباط أو التابع lm لحساب علاقة الانحدار وسواهما من التوابع الأخرى، فكل ما عليك القيام به هو كتابة اسم ذلك التابع دون أي إضافات أخرى ومن ثم النقر على زر الإدخال، لتقوم لغة R بعرض الشيفرة المصدرية الداخلية لذلك التابع كاملة أمامك. إن إحدى نقاط قوة لغة R هي سهولة توسعتها من خلال مجموعة الإضافات الهائلة المتاحة لها والتي قام بتطويرها الآلاف من الجامعات والمراكز العلمية وحتى الباحثين المستقلين وطلاب الدراسات العليا، يعينهم في ذلك السهولة النسبية في آلية بناء مثل تلك المكتبات أو الإضافة الجديدة لهذه اللغة، فهي لاتحتاج في أغلب الحالات إلى أي خبرات أو معارف خارج نطاق لغة R نفسها وهو أمر ممتع ومميز بحق، للإطلاع على لائحة الإضافات الرسمية المنشورة على موقع لغة R نفسها يمكنكم التحقق من هذا الرابط (ملاحظة: لقد اخترنا مخدم موجود في روسيا الاتحادية لضمان الوصول إليه بسهولة دون أي حجب!): أما لمن لديه فضول التعرف على آلية بناء مكتبته أو إضافته الخاصة فأحيله إلى هذا المرجع السهل والمميز. من الإضافات المميزة التي أنصحك قارئي العزيز بالإطلاع عليها هناك الإضافة ggplot2 والتي تفتح أمام مستخدمي لغة R آفاقا واسعة لتحسين وإثراء نوعية المخططات البيانية التي يمكن توليدها والحصول عليها، وهذه الإضافة هي إضافة ذائعة الصيت حتى أن هنالك كتب كاملة تتحدث عنها وعن مزاياها وإمكانياتها، كذلك نذكر الإضافة doSMP على سبيل المثال والتي قد تكون واحدة من الإضافات الأولى التي ترغب بالتعرف عليها إن كنت تطمح لقرع باب الحوسبة التفرعية، فهي أداة بسيطة تستطيع من خلالها تحويل بنى الحلقات البسيطة إلى نسخة تفرعية تستثمر كامل طاقة نوى المعالج أو المعالجات التي لديك (حيث أن المعالجات الثنائية والرباعية النوى أصبحت شائعة في الأسواق هذه الأيام، والتوجه العام هو نحو زيادة عدد النوى المتاحة على شريحة معالج واحد). أخيرا وليس آخرا، تجدر الإشارة إلى أداة مميزة أخرى تدعى RExcel والتي تسمح للغة R أن تعمل بالتكامل مع تطبيق Microsoft Excel ذائع الصيت وواسع الانتشار للجداول الممتدة، فهي تمكن المستخدم من نقل البيانات من برنامج Excel إلى لغة R وبالعكس، هذا عدى عن تمكين مستخدمي برنامج Excel من استدعاء توابع لغة R المختلفة وتنفيذها على ما لديهم من بيانات مباشرة كما لو كان التعامل يتم مع أي تابع معتاد ضمن برنامج Excel، حيث سيتم تنفيذ التحليل باستخدام لغة R ومن ثم إعادة النتيجة إلي برنامج Excel بشكل مباشر وشفاف ليتم عرضها في إحدى الخلايا دون كثير عناء من قبل المستخدم. لا يخلو تنصيب هذه الأداة يدويا من بعض التعقيد لكثرة ما فيها من مكونات وما تحتاج إليه من ضبط وإعداد، لكن أسهل طريقة للحصول عليها جاهزة للعمل هي من خلال تنصيب RAndFriendsSetup والتي تستطيع الحصول عليها من خلال هذا الرابط: http://rcom.univie.ac.at. في ختام هذه السلسلة من المقالات، نحن نعي تماما أن ما قمنا به لا يتجاوز خدشنا لسطح المعرفة العميق بهذا المجال من العلوم سواء على صعيد الإحصاء أو لغة R ذاتها، لكنها مقدمة متواضعة نضعها بين أيدي المهتمين لينطلقوا منها ويبنوا عليها وصولا إلى نضج أعمق وإغناء أفضل لهذا الموضوع، وقد تجاوزنا في هذه السلسلة من المقالات عن تناول بعض المواضيع الشيقة التي ترتبط بهذا السياق وذلك سعيا منا وراء التبسيط والسهولة نظرا لأن هدفنا الأصلي كان تقديم مجموعة من المقالات التي تمثل مدخلا للغة R، وبالتالي فإن مناقشة أي موضوع يتسم بالتعقيد قد يضر بهذا الهدف والغاية، لكني قد أعود لاحقا للكتابة عن بعضها وأخص بالذكر هنا مناقشة موضوع تحليل التباين ANOVA شائع الصيت بين كل من خاض بمزيد من التفصيل في علم التحليل الإحصائي، لذا ترقبوا منا كل جديد. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة -
 كلّما تحدّثتُ إلى ريادي أعمال مرّ على إطلاق شركته النّاشئة ثمانية أو تسعة أشهر فإنني دائمًا ما أودّ معرفة الشيء نفسه في البداية: إذا افترضنا أن النفقات ستبقى ثابتة خلال الأشهر القادمة، والدّخل سيبقى بنفس المُستوى الذي كان عليه خلال الأشهر القليلة الماضية، فهل ستتمكّن الشّركة من الوصول إلى حد التّربّح اعتمادًا على المال المُتبقّي لديها فقط؟ أو بعبارة أخرى، هل الشّركة النّاشئة حيّة أم في طريقها نحو الموت؟ من المرّوع معرفة أن غالبية الرياديين لا يملكون جوابًا على هذا السؤال. نصف المؤسّسين الذين تحدّثتُ معهم لا يعرفون إن كانت شركاتهم النّاشئة حيّة أم في طريقها نحو موت مُحتمّ إذا كنتَ واحدًا من هؤلاء فيمكنك حينها الاستعانة بالآلة الحاسبة التي صنعها Trevor Blackwell لمعرفة الجواب. السبب وراء أهميّة معرفتك الجواب؛ تعود إلى أن بقية حديثي مع هذا الرّيادي تعتمد على وضع شركته الناشئة، فإذا كانت الشركة تتجه نحو الربح؛ حينها سنتحدث عن القيام بأشياء جديدة وطموحة. أما إذا كانت الشركة تتجه نحو الإفلاس فسنهتمّ وقتها بالكيفية التي ستحافظ بها على الشركة، وكيف يمكن تغيير المسار الحالي والذي يقودنا نحو نهايات سيئة. لماذا لا يعرف سوى عدد قليل جدًا من المؤسسين فيما إذا كانت شركاتهم تتّجه نحو الربح أو الإفلاس؟ أعتقد أن السبب الرئيسي لذلك هو أنهم لم يعتادوا على طرح هذا السؤال على أنفسهم. إذ ليس من المنطقي أن تطرح سؤالًا كهذا في وقتٍ مُبكرٍ جدًا، إنك تبدو كما لو كنتَ تسأل طفلًا ذا ثلاث أعوام عن خططه المُستقبلية. لكن ومع نمو الشركات الناشئة مع الوقت فإن هذا الطرح يتحول من سؤالٍ لا معنىً له إلى آخر مصيريّ، والمشكلة أن مثل هذه التحولات غالبًا ما تحدث على حين غرّة. لذا أقترح الحل التالي: اطرح هذا السؤال على نفسك في وقتٍ مبكرٍ جدًا بدلًا من طرحه في وقتٍ متأخر جدًا. فمن الصعوبة بمكان التنبؤ بشكل دقيق متى سيتحول هذا السؤال من كونه بلا معنى إلى كونه سؤالًا مصيريًا، إلا أنني أرجح عدم حصول مشاكل في حال بدأت القلق على توجه الشركة نحو الإفلاس مبكرًا، بينما سيكون هناك خطرٌ كبيرٌ بالتأكيد في حال تنبّهت إلى ذلك في وقت متأخرٍ جدًا. يعود السبب في ذلك إلى ظاهرة أسميها القرصة المُميتة The fatal pinch التي كتبتُ عنها مُسبقًا، وتعني توجّه الشركة الناشئة نحو الإفلاس مع النموّ البطيء في ظل عدم وجود وقت كافٍ لإصلاح ذلك. ينتهي مؤسسو الشركات الناشئة إلى هذا المصير بسبب عدم إدراكهم منذ البداية إلى أين هم متجهون. هناك سبب آخر لعدم طرح المؤسسين هذا السؤال على أنفسهم، وهو افتراضهم أنه من السهل الحصول على التمويل. إلا أنّه كثيرًا ما يثبت خطأ هذا الاعتقاد، والأسوأ من ذلك أنه كلما اعتمدت على هذه الفرضية بشكل أكبر كلما أصبح احتمال خطأها أكبر. قد يساعدك في ذلك أن تفصل ما بين الحقائق والآمال، فبدلاً من التفكير في المستقبل بتفاؤلٍ غامض، افصل العناصر عن بعضها بشكل واضح. قُل: "نحن نتجه للإفلاس ولكنّنا نعوّل على المستثمرين لإنقاذنا"، سيجعلك هذا تدق ناقوس الخطر ويضعك في حالة أكثر تنبهًا ووعيًا، وكلما كان ذلك مبكرًا كلما كنت قادرًا على تجنب القرصة المُميتة Fatal pinch. إنه لمن دواعي الأمان أن تتمكّن من الاعتماد على المستثمرين لإنقاذك من الإفلاس بطبيعة الحال. وكقاعدة عامّة فإن ما يهم المستثمرين هو نمو شركتك، فإذا كان لديك إيرادات ذات نموٍ عالٍ، ولتكن ستّة أضعاف في العام، فإنه سيمكنك حينها البدء في الاعتماد على المستثمرين المهتمين حتى لو لم تكن شركتك قد وصلت إلى مستوى التّربّح. [1] رغم ذلك يبقى المستثمرون متقلبي المزاج للغاية ولا يمكنك الاعتماد عليهم كثيرًا. لأنك لا تدري كيف ومتى يُثار قلقهم أحيانًا تجاه وضع شركتك؛ حتى مع معدّل نموٍ عظيم. وفي العموم فإنه لا يمكنك الحصول على استثمار بشكل آمن عندما تستخدم خطّة واحدة، لذا يجب أن تمتلك دائمًا خطة بديلة، وأن تعرف بالضبط ما الذي تحتاجه للاستمرار إذا لم تحصل على تمويل أكثر، كما يجب أن تعرف بدقة متى يجب أن تنتقل إلى الخطة البديلة إذا لم تعمل خطتك الأساسية. على أية حال، يفترض الكثير من المؤسسين أنهم أمام حالتين فقط: إما النمو السريع أو الحفاظ على تكاليف التشغيل منخفضة بحيث لا يمكن الجمع بينهما. وفي الحقيقة هناك رابط ضعيف بين إنفاق الشركة الناشئة وسرعة النمو؛ فعندما يكون نمو الشركة الناشئة سريعًا فهذا يعود إلى أن المنتج يلبي حاجة كبيرة وملحّة بشكل مباشر، أو بعبارة أخرى؛ إنه يضرب على الوتر الحساس. وفي المقابل عندما تنفق الشركة الناشئة بشكل كبير فهذا يرجع غالبًا إلى أن تطوير المنتج أو بيعه يكلف الكثير، أو ربما ببساطة لأنهم مبذّرون . عليك ألا تسأل فقط عن كيفية تجنب الأزمة الخانقة (أو القرصة المُميتة) وإنما أيضًا عن كيفية تجنب التوجه نحو الإفلاس. والجواب سهل: لا تتسرع في توظيف أشخاص جدد، لأن هذا هو أكبر قاتل للشركات الناشئة التي تبحث عن التمويل.[2] يقول مؤسسو الشركات الناشئة أنهم بحاجة إلى توظيف أشخاص إضافيين لتحقيق النمو، ولكن يخطئ معظمهم في المبالغة بتقدير هذه الحاجة بدلًا من تقليل قيمتها. لماذا؟ هناك عدة أسباب لذلك، أحدها وجود الكثير مما ينبغي القيام به، فيظن المؤسسون المبتدئون أن توظيف عدد كافٍ من الأشخاص شرطٌ لازم لإتمام العمل. سببٌ آخر، وهو أن الشركات الناشئة الناجحة اليوم لديها الكثير من الموظفين، فيبدو الأمر وكأن هذا ما يجب القيام به للنجاح. في الواقع إن فرق العمل الكبيرة في الشركات الناشئة الناجحة هي غالبًا ما تكون نتيجةً للنمو وليست سببًا له. سببٌ ثالث وهو أن المؤسسين لا يرغبون في مواجهة السبب الحقيقي لبطء النمو، أي أن المنتج غير مرغوب به بشكل كافٍ. أضف إلى أن المؤسسين الذين يحصلون على التمويل غالبًا ما يفرطون في التوظيف overhire بتشجيع شركات رأس المال المخاطر التي تمولهم. إن استراتيجية الكيّ أو العلاج Kill-or-cure تُعتبر مثالية بالنسبة لشركات رأس المال المخاطر التي تحمي نفسها عن طريق تأثير المحفظة Portfolio Effect. ولهذا ترغب شركات رأس المال المُخاطر أن يحدث انفجار في شركتك (سواء كان يعني ذلك حدوث نمو كبير جدًّا أو موت الشّركة) ، لكنك كمؤسس تملك دوافع مختلفة، وما يهمك هو الاستمرار قبل أيّ شيء.[3] (تأثير المحفظة The Portfolio Effect هو مصطلح استثماري. يشير إلى أن إضافة المزيد من التنوّع على محفظة الاستثمار الخاصة بك سيُقلّل من تأثير المخاطر عليك. هذا يشبه ببساطة المثل الإنكليزي بأن لا تضع البيض في سلّة واحدة). هناك طريقة أخرى شائعة لموت المشاريع الناشئة؛ حيث تصنع الشركة منتجًا جذابًا لكنه ليس جذّابًا بما فيه الكفاية ويكون معدّل النمو الابتدائي جيدًا. يحصل المؤسسون على جولتهم الاستثمارية الأولى بسهولة لأنهم يبدون أذكياء وأصحاب فكرة معقولة. لكن بحكم أن المُنتج ليس جذّابا بما فيه الكفاية والنمو يكون "عاديًا" وليس عظيمًا يُقنع المؤسسون أنفسهم أن توظيف مجموعة من الأشخاص هي الطريقة الأنسب لتعزيز النمو ويوافق ممولوهم. ولكن بما أن المنتج جذاب "بعض الشيء" فقط فإن النمو لن يزداد أبدًا. يأمل المؤسسون الآن بالحصول على المزيد من الاستثمارات لإنقاذهم، ولكنهم أصبحوا غير جذابين للمستثمرين بسبب النفقات العالية والنمو البطيء، وهكذا تموت الشركة بسبب عدم قدرتها على تحصيل المزيد من التمويل. ما ينبغي أن تقوم به الشركة هنا هو معالجة المشكلة الأساسية، أي كون المنتج جذابًا "بعض الشيء" فقط. ونادرًا ما يكون توظيف المزيد من الناس هو طريقة لإصلاح ذلك. في الحقيقة هذا ما يجعل الأمور أكثر صعوبة غالب الأحيان. بينما تحتاج المنتجات في هذه المرحلة المبكرة إلى التطوير التدريجي وفقًا لمتطلبات المستخدمين للوصول إلى الصيغة الأفضل بدل الاعتماد على الصيغة المحددة لها بشكل مسبق، وعادةً ما يكون هذا الأمر أسهل بوجود عدد أقل من الأشخاص.[4] باختصار فإن سؤال إذا ما كنتَ تتجه للربح أو للإفلاس يحميك من ذلك، ربما تتصدى التّحذيرات من إمكانية موت مشروعك لرغبات الإفراط في التوظيف، وستكون حينها مضطرًا للبحث عن طرق أخرى لزيادة النمو. على سبيل المثال: عن طريق القيام بالأشياء التي لا يمكن القيام بها على نطاق واسع، أو إعادة تصميم المنتج بطريقة لا يمكن القيام بها إلا من طرف المؤسسين. بالنسبة للعديد من الشركات الناشئة إن لم نقل معظمها، فإن هذه الطرق في النمو هي التي تحقّق النتائج في نهاية المطاف. انتظر Airbnb على سبيل المثال أربعة أشهر بعد تخرّجهم من YC قبل أن يوظفّوا أول موظّف. وفي تلك الفترة أجهد المؤسسون أنفسهم بشكل كبير في سبيل التطوير التدريجي للموقع كي يصل إلى النجاح المذهل الذي هو عليه الآن. هوامش:[1] النمو العالي للاستخدام يهم المستثمرين أيضًا، حيث ستكون الإيرادات في النهاية من مضاعفات الاستخدام بشكل ثابت، وبالتالي كل X% من نمو الاستخدام يتوقع أن تحقّق X% من نمو الإيرادات. لكن في الحقيقة يقلل المستثمرون من قيمة الإيرادات المتوقعة، لذا إذا كنت تقيس نسبة استخدام منتجك فإنك ستحتاج إلى نسبة نمو مرتفعة للفت أنظار المستثمرين. [2] تكون الشركات الناشئة التي لا تبحث عن تمويل في مأمن من الوقوع في مشكلة التوظيف السريع للغاية، لأنه لا يمكنها تحمل نفقات ذلك. لكن هذا لا يعني أنه عليك تجنب الحصول على تمويل لعدم الوقوع في هذه المشكلة. إن الطريقة الوحيدة لتجنب ذلك هي الامتناع الكلي عن التوظيف. [3] من المُتوقّع أن يكون ميل شركات رأس المال المخاطر إلى دفع المؤسسين نحو الإفراط في التوظيف لا يخدم مصالحها هي أيضًا، فهم لا يعرفون كم من الشركات قد فشلت بسبب الإسراف في النفقات حيث كان من الممكن أن تبلي جيدًا لو كتبت لها الفرصة في النجاة. ومن المُتوقّع أن يكون عددها كبيرًا. [4] كتب Sam Altman بعد قراءته مسودة المقال: ويضيف Paul Buchheit: (يتضمن التوسع Scaling الحصول على المزيد من الموظفين، طلب المزيد من رأس المال، أو إنفاق المزيد على التسويق، وعادةً ما يصاحب ذلك زيادة في المبيعات). ترجمة -وبتصرّف- للمقال Default Alive or Default Dead لصاحبه بول جراهام (Paul Graham). حقوق الصورة البارزة: Designed by Freepik.1 نقطة
كلّما تحدّثتُ إلى ريادي أعمال مرّ على إطلاق شركته النّاشئة ثمانية أو تسعة أشهر فإنني دائمًا ما أودّ معرفة الشيء نفسه في البداية: إذا افترضنا أن النفقات ستبقى ثابتة خلال الأشهر القادمة، والدّخل سيبقى بنفس المُستوى الذي كان عليه خلال الأشهر القليلة الماضية، فهل ستتمكّن الشّركة من الوصول إلى حد التّربّح اعتمادًا على المال المُتبقّي لديها فقط؟ أو بعبارة أخرى، هل الشّركة النّاشئة حيّة أم في طريقها نحو الموت؟ من المرّوع معرفة أن غالبية الرياديين لا يملكون جوابًا على هذا السؤال. نصف المؤسّسين الذين تحدّثتُ معهم لا يعرفون إن كانت شركاتهم النّاشئة حيّة أم في طريقها نحو موت مُحتمّ إذا كنتَ واحدًا من هؤلاء فيمكنك حينها الاستعانة بالآلة الحاسبة التي صنعها Trevor Blackwell لمعرفة الجواب. السبب وراء أهميّة معرفتك الجواب؛ تعود إلى أن بقية حديثي مع هذا الرّيادي تعتمد على وضع شركته الناشئة، فإذا كانت الشركة تتجه نحو الربح؛ حينها سنتحدث عن القيام بأشياء جديدة وطموحة. أما إذا كانت الشركة تتجه نحو الإفلاس فسنهتمّ وقتها بالكيفية التي ستحافظ بها على الشركة، وكيف يمكن تغيير المسار الحالي والذي يقودنا نحو نهايات سيئة. لماذا لا يعرف سوى عدد قليل جدًا من المؤسسين فيما إذا كانت شركاتهم تتّجه نحو الربح أو الإفلاس؟ أعتقد أن السبب الرئيسي لذلك هو أنهم لم يعتادوا على طرح هذا السؤال على أنفسهم. إذ ليس من المنطقي أن تطرح سؤالًا كهذا في وقتٍ مُبكرٍ جدًا، إنك تبدو كما لو كنتَ تسأل طفلًا ذا ثلاث أعوام عن خططه المُستقبلية. لكن ومع نمو الشركات الناشئة مع الوقت فإن هذا الطرح يتحول من سؤالٍ لا معنىً له إلى آخر مصيريّ، والمشكلة أن مثل هذه التحولات غالبًا ما تحدث على حين غرّة. لذا أقترح الحل التالي: اطرح هذا السؤال على نفسك في وقتٍ مبكرٍ جدًا بدلًا من طرحه في وقتٍ متأخر جدًا. فمن الصعوبة بمكان التنبؤ بشكل دقيق متى سيتحول هذا السؤال من كونه بلا معنى إلى كونه سؤالًا مصيريًا، إلا أنني أرجح عدم حصول مشاكل في حال بدأت القلق على توجه الشركة نحو الإفلاس مبكرًا، بينما سيكون هناك خطرٌ كبيرٌ بالتأكيد في حال تنبّهت إلى ذلك في وقت متأخرٍ جدًا. يعود السبب في ذلك إلى ظاهرة أسميها القرصة المُميتة The fatal pinch التي كتبتُ عنها مُسبقًا، وتعني توجّه الشركة الناشئة نحو الإفلاس مع النموّ البطيء في ظل عدم وجود وقت كافٍ لإصلاح ذلك. ينتهي مؤسسو الشركات الناشئة إلى هذا المصير بسبب عدم إدراكهم منذ البداية إلى أين هم متجهون. هناك سبب آخر لعدم طرح المؤسسين هذا السؤال على أنفسهم، وهو افتراضهم أنه من السهل الحصول على التمويل. إلا أنّه كثيرًا ما يثبت خطأ هذا الاعتقاد، والأسوأ من ذلك أنه كلما اعتمدت على هذه الفرضية بشكل أكبر كلما أصبح احتمال خطأها أكبر. قد يساعدك في ذلك أن تفصل ما بين الحقائق والآمال، فبدلاً من التفكير في المستقبل بتفاؤلٍ غامض، افصل العناصر عن بعضها بشكل واضح. قُل: "نحن نتجه للإفلاس ولكنّنا نعوّل على المستثمرين لإنقاذنا"، سيجعلك هذا تدق ناقوس الخطر ويضعك في حالة أكثر تنبهًا ووعيًا، وكلما كان ذلك مبكرًا كلما كنت قادرًا على تجنب القرصة المُميتة Fatal pinch. إنه لمن دواعي الأمان أن تتمكّن من الاعتماد على المستثمرين لإنقاذك من الإفلاس بطبيعة الحال. وكقاعدة عامّة فإن ما يهم المستثمرين هو نمو شركتك، فإذا كان لديك إيرادات ذات نموٍ عالٍ، ولتكن ستّة أضعاف في العام، فإنه سيمكنك حينها البدء في الاعتماد على المستثمرين المهتمين حتى لو لم تكن شركتك قد وصلت إلى مستوى التّربّح. [1] رغم ذلك يبقى المستثمرون متقلبي المزاج للغاية ولا يمكنك الاعتماد عليهم كثيرًا. لأنك لا تدري كيف ومتى يُثار قلقهم أحيانًا تجاه وضع شركتك؛ حتى مع معدّل نموٍ عظيم. وفي العموم فإنه لا يمكنك الحصول على استثمار بشكل آمن عندما تستخدم خطّة واحدة، لذا يجب أن تمتلك دائمًا خطة بديلة، وأن تعرف بالضبط ما الذي تحتاجه للاستمرار إذا لم تحصل على تمويل أكثر، كما يجب أن تعرف بدقة متى يجب أن تنتقل إلى الخطة البديلة إذا لم تعمل خطتك الأساسية. على أية حال، يفترض الكثير من المؤسسين أنهم أمام حالتين فقط: إما النمو السريع أو الحفاظ على تكاليف التشغيل منخفضة بحيث لا يمكن الجمع بينهما. وفي الحقيقة هناك رابط ضعيف بين إنفاق الشركة الناشئة وسرعة النمو؛ فعندما يكون نمو الشركة الناشئة سريعًا فهذا يعود إلى أن المنتج يلبي حاجة كبيرة وملحّة بشكل مباشر، أو بعبارة أخرى؛ إنه يضرب على الوتر الحساس. وفي المقابل عندما تنفق الشركة الناشئة بشكل كبير فهذا يرجع غالبًا إلى أن تطوير المنتج أو بيعه يكلف الكثير، أو ربما ببساطة لأنهم مبذّرون . عليك ألا تسأل فقط عن كيفية تجنب الأزمة الخانقة (أو القرصة المُميتة) وإنما أيضًا عن كيفية تجنب التوجه نحو الإفلاس. والجواب سهل: لا تتسرع في توظيف أشخاص جدد، لأن هذا هو أكبر قاتل للشركات الناشئة التي تبحث عن التمويل.[2] يقول مؤسسو الشركات الناشئة أنهم بحاجة إلى توظيف أشخاص إضافيين لتحقيق النمو، ولكن يخطئ معظمهم في المبالغة بتقدير هذه الحاجة بدلًا من تقليل قيمتها. لماذا؟ هناك عدة أسباب لذلك، أحدها وجود الكثير مما ينبغي القيام به، فيظن المؤسسون المبتدئون أن توظيف عدد كافٍ من الأشخاص شرطٌ لازم لإتمام العمل. سببٌ آخر، وهو أن الشركات الناشئة الناجحة اليوم لديها الكثير من الموظفين، فيبدو الأمر وكأن هذا ما يجب القيام به للنجاح. في الواقع إن فرق العمل الكبيرة في الشركات الناشئة الناجحة هي غالبًا ما تكون نتيجةً للنمو وليست سببًا له. سببٌ ثالث وهو أن المؤسسين لا يرغبون في مواجهة السبب الحقيقي لبطء النمو، أي أن المنتج غير مرغوب به بشكل كافٍ. أضف إلى أن المؤسسين الذين يحصلون على التمويل غالبًا ما يفرطون في التوظيف overhire بتشجيع شركات رأس المال المخاطر التي تمولهم. إن استراتيجية الكيّ أو العلاج Kill-or-cure تُعتبر مثالية بالنسبة لشركات رأس المال المخاطر التي تحمي نفسها عن طريق تأثير المحفظة Portfolio Effect. ولهذا ترغب شركات رأس المال المُخاطر أن يحدث انفجار في شركتك (سواء كان يعني ذلك حدوث نمو كبير جدًّا أو موت الشّركة) ، لكنك كمؤسس تملك دوافع مختلفة، وما يهمك هو الاستمرار قبل أيّ شيء.[3] (تأثير المحفظة The Portfolio Effect هو مصطلح استثماري. يشير إلى أن إضافة المزيد من التنوّع على محفظة الاستثمار الخاصة بك سيُقلّل من تأثير المخاطر عليك. هذا يشبه ببساطة المثل الإنكليزي بأن لا تضع البيض في سلّة واحدة). هناك طريقة أخرى شائعة لموت المشاريع الناشئة؛ حيث تصنع الشركة منتجًا جذابًا لكنه ليس جذّابًا بما فيه الكفاية ويكون معدّل النمو الابتدائي جيدًا. يحصل المؤسسون على جولتهم الاستثمارية الأولى بسهولة لأنهم يبدون أذكياء وأصحاب فكرة معقولة. لكن بحكم أن المُنتج ليس جذّابا بما فيه الكفاية والنمو يكون "عاديًا" وليس عظيمًا يُقنع المؤسسون أنفسهم أن توظيف مجموعة من الأشخاص هي الطريقة الأنسب لتعزيز النمو ويوافق ممولوهم. ولكن بما أن المنتج جذاب "بعض الشيء" فقط فإن النمو لن يزداد أبدًا. يأمل المؤسسون الآن بالحصول على المزيد من الاستثمارات لإنقاذهم، ولكنهم أصبحوا غير جذابين للمستثمرين بسبب النفقات العالية والنمو البطيء، وهكذا تموت الشركة بسبب عدم قدرتها على تحصيل المزيد من التمويل. ما ينبغي أن تقوم به الشركة هنا هو معالجة المشكلة الأساسية، أي كون المنتج جذابًا "بعض الشيء" فقط. ونادرًا ما يكون توظيف المزيد من الناس هو طريقة لإصلاح ذلك. في الحقيقة هذا ما يجعل الأمور أكثر صعوبة غالب الأحيان. بينما تحتاج المنتجات في هذه المرحلة المبكرة إلى التطوير التدريجي وفقًا لمتطلبات المستخدمين للوصول إلى الصيغة الأفضل بدل الاعتماد على الصيغة المحددة لها بشكل مسبق، وعادةً ما يكون هذا الأمر أسهل بوجود عدد أقل من الأشخاص.[4] باختصار فإن سؤال إذا ما كنتَ تتجه للربح أو للإفلاس يحميك من ذلك، ربما تتصدى التّحذيرات من إمكانية موت مشروعك لرغبات الإفراط في التوظيف، وستكون حينها مضطرًا للبحث عن طرق أخرى لزيادة النمو. على سبيل المثال: عن طريق القيام بالأشياء التي لا يمكن القيام بها على نطاق واسع، أو إعادة تصميم المنتج بطريقة لا يمكن القيام بها إلا من طرف المؤسسين. بالنسبة للعديد من الشركات الناشئة إن لم نقل معظمها، فإن هذه الطرق في النمو هي التي تحقّق النتائج في نهاية المطاف. انتظر Airbnb على سبيل المثال أربعة أشهر بعد تخرّجهم من YC قبل أن يوظفّوا أول موظّف. وفي تلك الفترة أجهد المؤسسون أنفسهم بشكل كبير في سبيل التطوير التدريجي للموقع كي يصل إلى النجاح المذهل الذي هو عليه الآن. هوامش:[1] النمو العالي للاستخدام يهم المستثمرين أيضًا، حيث ستكون الإيرادات في النهاية من مضاعفات الاستخدام بشكل ثابت، وبالتالي كل X% من نمو الاستخدام يتوقع أن تحقّق X% من نمو الإيرادات. لكن في الحقيقة يقلل المستثمرون من قيمة الإيرادات المتوقعة، لذا إذا كنت تقيس نسبة استخدام منتجك فإنك ستحتاج إلى نسبة نمو مرتفعة للفت أنظار المستثمرين. [2] تكون الشركات الناشئة التي لا تبحث عن تمويل في مأمن من الوقوع في مشكلة التوظيف السريع للغاية، لأنه لا يمكنها تحمل نفقات ذلك. لكن هذا لا يعني أنه عليك تجنب الحصول على تمويل لعدم الوقوع في هذه المشكلة. إن الطريقة الوحيدة لتجنب ذلك هي الامتناع الكلي عن التوظيف. [3] من المُتوقّع أن يكون ميل شركات رأس المال المخاطر إلى دفع المؤسسين نحو الإفراط في التوظيف لا يخدم مصالحها هي أيضًا، فهم لا يعرفون كم من الشركات قد فشلت بسبب الإسراف في النفقات حيث كان من الممكن أن تبلي جيدًا لو كتبت لها الفرصة في النجاة. ومن المُتوقّع أن يكون عددها كبيرًا. [4] كتب Sam Altman بعد قراءته مسودة المقال: ويضيف Paul Buchheit: (يتضمن التوسع Scaling الحصول على المزيد من الموظفين، طلب المزيد من رأس المال، أو إنفاق المزيد على التسويق، وعادةً ما يصاحب ذلك زيادة في المبيعات). ترجمة -وبتصرّف- للمقال Default Alive or Default Dead لصاحبه بول جراهام (Paul Graham). حقوق الصورة البارزة: Designed by Freepik.1 نقطة -
 سيضفي الحصول على أي مشروع مهما كان في مستهل مشوارك في العمل الحرّ بظلاله على نفسك بلا شك، ولكن قد ينتهي بك الأمر إلى العمل على مشاريع لا تحبّذ العمل عليها لسبب أو لآخر. وأفضل سبيل لتحاشي العمل مع هذا النوع من المشاريع هو الحرص على عدم الموافقة على عرض العميل في المقام الأول، لكن كيف كان لك أن تتبين هذا النوع من العملاء؟ وعلى فرض أنك عرفت، كيف لك أن ترفض العرض بأفضل أسلوب ممكن؟ فيما يلي بضعة أفكار يمكن لك الاستعانة بها لاكتشاف فيما إذا كان العميل مناسب لك أو لا وكيف لك أن تقول: ‹‹لا››. غربل العملاء بناء على تفضيلاتك الخاصةخذ بعين الاعتبار اختياراتك الشخصية، فبالنسبة لي لا أستلم مشاريع مرتبطة بالمُسكرات أو بشركات التبغ أو المواقع المخلّة بالآداب العامة، ولا مواقع القمار وما شابهها، وهي خطوط حمراء بالنسبة لي، لذا أنصحك بتحديد خطوطك الحمراء، والتي قد تختلف عن الحدود التي رسمتها لنفسي. مهما كانت أسبابك ودوافعك في الرفض أو القبول، يجب عليك دائمًا أنت تدرك ما لك وما عليك، وما يمكن لك التغاضي عنه وما لا يقبل النقاش، وسيساعدك التفكير بهذا المنطق على اتخاذ القرار الحكيم والصائب في اللحظة التي يدق بابك فيها عميلٌ بحفنة عارمة من النقود. استقصي عن العميللا أقصد أن تبحث عنه في فيس بوك وتتعدّى على خصوصيته أو شيء من هذا القبيل، ما أعنيه هو البحث عن تجارته ومنتجاته لا أكثر، فمثلًا: هل أعماله تتماشى مع معتقداتك؟ هل هي شرعية/قانونية؟ هل منتجه/مشروعه/موقعه يٌقدّم الجودة التي يَعد أن يٌقدّمها؟ تيقظ من العلامات المنذرةهل يقدّم العميل المعلومات والتفاصيل التي تسأله عنها؟ هل يقدّر وقتك ويحترمه؟ هل قرأ المعلومات التي قدّمتها له؟ ماذا عن أسلوبه في التواصل، هل هو صريح وسريع في الرد. سألني مرة من المرات أحد العملاء عن توضيحٍ ما كنت بالفعل قد أرسلته له بجانب توفّره على موقعي وبالخط العريض، وهذه واحدة من العلامات المُنذرة بالنسبة لي. كيفية رفض طلبات العملاء غير الملائمينالزبدة والخلاصة التي توصلت إليها للتعامل الأفضل مع هذا النوع من العملاء هي ثلاث نقاط: تقديم سبب مقنع، الودية والدماثة في الرد، وعدم ترك أي مجال للتفاوض. نموذج لرسالة لرفض طلب العميل لأسباب شخصيةإليك نموذج رسالة يمكن لك أن تستخدمها من أجل عميل لا ترغب العمل معه لأسباب شخصية: النزاهة والصدق في التعامل أمر أساسي دائمًا وأبدًا، وعليه يجب مراعاة ذلك عند تقديم أعذارك للعميل. بالنسبة لي عادةً ما أخبر العميل بأن تجارته/أعماله تُصنّف من الأصناف الأربعة من المشاريع التي لا أقبل العمل عليها نظرًا لأسباب شخصية. بالمجمل لا يستاء أحد من ذلك، خاصة إن أشرت لهم بمستقل آخر كفء وعلى استعداد على إتمام مشروعهم، ودائمًا ما تؤول الأمور إلى رضى جميع الأطراف. رسالة لرفض مشروع عميل أظهر علامة منذرة: بهذا الأسلوب بدون زيادة أو نقصان فخير الكلام ما قلّ ودلّ. رفض مشروع عميل بعد الشروع في العمل ليتبين لك فيما بعد عدم ملائمته لمعاييركتعتبر هذه الحالة بلا شك أصعب من الحالتين السابقتين، على كلٍ أسلوب الرفض هو ما سيساعد على تسهيل المهمة. تذكر دائمًا استخدام الأسلوب الودي واحترام العميل مهما كانت أسباب الرفض. خاتمةبطريقة أو بأخرى، رفض عروض العُملاء ليس بتلك المشكلة الكبيرة لا بل إن لها إيجابيات إذا نظرت إلى الجزء المملوء من الكأس؛ تعزيز شخصيتك كمستقل واكتساب الخبرة اللازمة في التعامل مع المواقف المحرجة. ترجمة -وبتصرف- للمقال: Client not a good fit? Here’s how to say no to them. لصاحبه: Samar Owais. حقوق الصورة البارزة: Designed by Freepik.1 نقطة
سيضفي الحصول على أي مشروع مهما كان في مستهل مشوارك في العمل الحرّ بظلاله على نفسك بلا شك، ولكن قد ينتهي بك الأمر إلى العمل على مشاريع لا تحبّذ العمل عليها لسبب أو لآخر. وأفضل سبيل لتحاشي العمل مع هذا النوع من المشاريع هو الحرص على عدم الموافقة على عرض العميل في المقام الأول، لكن كيف كان لك أن تتبين هذا النوع من العملاء؟ وعلى فرض أنك عرفت، كيف لك أن ترفض العرض بأفضل أسلوب ممكن؟ فيما يلي بضعة أفكار يمكن لك الاستعانة بها لاكتشاف فيما إذا كان العميل مناسب لك أو لا وكيف لك أن تقول: ‹‹لا››. غربل العملاء بناء على تفضيلاتك الخاصةخذ بعين الاعتبار اختياراتك الشخصية، فبالنسبة لي لا أستلم مشاريع مرتبطة بالمُسكرات أو بشركات التبغ أو المواقع المخلّة بالآداب العامة، ولا مواقع القمار وما شابهها، وهي خطوط حمراء بالنسبة لي، لذا أنصحك بتحديد خطوطك الحمراء، والتي قد تختلف عن الحدود التي رسمتها لنفسي. مهما كانت أسبابك ودوافعك في الرفض أو القبول، يجب عليك دائمًا أنت تدرك ما لك وما عليك، وما يمكن لك التغاضي عنه وما لا يقبل النقاش، وسيساعدك التفكير بهذا المنطق على اتخاذ القرار الحكيم والصائب في اللحظة التي يدق بابك فيها عميلٌ بحفنة عارمة من النقود. استقصي عن العميللا أقصد أن تبحث عنه في فيس بوك وتتعدّى على خصوصيته أو شيء من هذا القبيل، ما أعنيه هو البحث عن تجارته ومنتجاته لا أكثر، فمثلًا: هل أعماله تتماشى مع معتقداتك؟ هل هي شرعية/قانونية؟ هل منتجه/مشروعه/موقعه يٌقدّم الجودة التي يَعد أن يٌقدّمها؟ تيقظ من العلامات المنذرةهل يقدّم العميل المعلومات والتفاصيل التي تسأله عنها؟ هل يقدّر وقتك ويحترمه؟ هل قرأ المعلومات التي قدّمتها له؟ ماذا عن أسلوبه في التواصل، هل هو صريح وسريع في الرد. سألني مرة من المرات أحد العملاء عن توضيحٍ ما كنت بالفعل قد أرسلته له بجانب توفّره على موقعي وبالخط العريض، وهذه واحدة من العلامات المُنذرة بالنسبة لي. كيفية رفض طلبات العملاء غير الملائمينالزبدة والخلاصة التي توصلت إليها للتعامل الأفضل مع هذا النوع من العملاء هي ثلاث نقاط: تقديم سبب مقنع، الودية والدماثة في الرد، وعدم ترك أي مجال للتفاوض. نموذج لرسالة لرفض طلب العميل لأسباب شخصيةإليك نموذج رسالة يمكن لك أن تستخدمها من أجل عميل لا ترغب العمل معه لأسباب شخصية: النزاهة والصدق في التعامل أمر أساسي دائمًا وأبدًا، وعليه يجب مراعاة ذلك عند تقديم أعذارك للعميل. بالنسبة لي عادةً ما أخبر العميل بأن تجارته/أعماله تُصنّف من الأصناف الأربعة من المشاريع التي لا أقبل العمل عليها نظرًا لأسباب شخصية. بالمجمل لا يستاء أحد من ذلك، خاصة إن أشرت لهم بمستقل آخر كفء وعلى استعداد على إتمام مشروعهم، ودائمًا ما تؤول الأمور إلى رضى جميع الأطراف. رسالة لرفض مشروع عميل أظهر علامة منذرة: بهذا الأسلوب بدون زيادة أو نقصان فخير الكلام ما قلّ ودلّ. رفض مشروع عميل بعد الشروع في العمل ليتبين لك فيما بعد عدم ملائمته لمعاييركتعتبر هذه الحالة بلا شك أصعب من الحالتين السابقتين، على كلٍ أسلوب الرفض هو ما سيساعد على تسهيل المهمة. تذكر دائمًا استخدام الأسلوب الودي واحترام العميل مهما كانت أسباب الرفض. خاتمةبطريقة أو بأخرى، رفض عروض العُملاء ليس بتلك المشكلة الكبيرة لا بل إن لها إيجابيات إذا نظرت إلى الجزء المملوء من الكأس؛ تعزيز شخصيتك كمستقل واكتساب الخبرة اللازمة في التعامل مع المواقف المحرجة. ترجمة -وبتصرف- للمقال: Client not a good fit? Here’s how to say no to them. لصاحبه: Samar Owais. حقوق الصورة البارزة: Designed by Freepik.1 نقطة -
 تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الثالث في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث قدم الجزء الأول مدخل عام إلى هذه اللغة بما فيها الإحصائيات الوصفية، أما الجزء الثاني فتحدث عن كيفية توليد بعض المخططات البيانية الإحصائية بلغة R، فيما سنختم السلسلة بجزء رابع يتحدث عن بعض التقنيات المتقدمة في هذه اللغة. للتذكير فقط، تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتبة، وكل مانكتبه تاليا يكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر mtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد. كل ما سبق ذكره من دوال يندرج تحت مظلة ما يدعى بالإحصائيات الوصفية العامة والتي تتعلق بشعاع معين من القيم، أما الدالة cor(x, y) فهي تحسب مقدار معامل الارتباط بين شعاعين من القيم هما في هذه الحالة x و y (أو بين عمودين في حالة البيانات المستوردة من ملف ما)، حيث تتدرج قيمة معامل الارتباط من -1 حتى +1 وتشير القيم الموجبة إلى وجود إرتباط طردي يزداد وضوحا كلما اقترب من +1، أي أنه كلما زادت قيمة x رافقها زيادة في قيمة y، فيما تشير القيمة السالبة لمعامل الارتباط إلى وجود ارتباط أيضا لكنه في هذه الحالة عكسي ويزداد وضوحا كلما اقترب من -1، أي أن قيمة x تزداد بتناقص y والعكس صحيح، في حين تشير قيمة معامل الارتباط التي تقترب من الصفر إلى أن تغير قيمة x لا يظهر أي علاقة بتغير قيمة y المقابلة. مع ذلك عليك كباحث أن تجد علاقة سببية بين x و y قبل أن تلجئ إلى حساب معامل الارتباط واعتماد ما تحصل عليه من نتائج، فإن كانت x تشير على سبيل المثال إلى عدد سكان مدينة دمشق خلال السنوات العشرين الماضية، فيما تشير yإلى عدد السيارات في مدينة حلب خلال نفس الفترة الزمنية، فإن قيمة معامل الارتباط إن تم حسابه سوف تشير إلى وجود ارتباط إيجابي طردي واضح، وهو شيء طبيعي! فعدد سكان دمشق في ازدياد وكذلك عدد السيارات في مدينة حلب، لكن هل لهذا الارتباط الطردي المحسوب هنا أي معنى سببي؟ من الواضح أن الجواب هو لا، لذا عليك توخي الحذر عند استخدام الأساليب والطرق الإحصائية. لننتقل الآن إلى استعراض مجموعة من الاختبارات الإحصائية وكيفية تنفيذها باستخدام لغة R. دعونا نبدأ باختبار معامل الارتباط والذي سبق وأن رأينا دالة cor البسيطة التي تحسب قيمته، لكنها تبقينا في التباس إحصائي، فإن حصلنا على سبيل المثال على الناتج 0.3 فهل سنقول بأن هناك إرتباط لكنه ضعيف؟ أم ننفي وجود مثل هذا الارتباط ونقبل أن مقدار معامل الارتباط قريب إلى 0 وبالتالي فهو غير معنوي أي غير موجود؟ في حقيقة الأمر هناك اختبار يحسب مدى إحتمالية الحصول على مقدار ما لمعامل الارتباط عن طريق المصادفة البحتة دون أن يكون هناك إرتباط حقيقي أو فعلي، وعادة ما يقبل في مجال الإحصاء إعتبار الحد 0.05 (أي 5%) هو الحد الأقصى المسموح به من الشك، فإن كان احتمال المصادفة أقل من 0.05 رفضنا فرضية المصادفة وبالتالي فالارتباط موجود ومعنوي (أي أننا نعمل هنا بأسلوب نقض الفرض)، وإلا فإننا لا نستطيع إثبات ذلك كون الشكوك في إحتمال المصادفة أكبر من أن يتم إهمالها أو التغاضي عنها. لتجريب ذلك دعونا بداية نختبر حساب معامل الارتباط ما بين وزن السيارة من جهة والمسافة التي تقطعها بالأميال لكل غالون من البنزين، ويتم ذلك مباشرة من خلال الأمر (cor(wt, mpg وسيكون الناتج في هذه الحالة هو -0.87 أي أن طبيعة تلك العلاقة هي عكسية واضحة. أما لتنفيذ الاختبار المفصل لمعامل الارتباط، فعلينا حينها استخدام الأمر البديل التالي (cor.test(wt, mpg ليظهر الناتج كما هو موضح في الشكل التالي والذي يتضمن أيضا إختبار وجود أي إرتباط ما بين وزن السيارة من جهة والزمن اللازم لقطع مسافة ربع ميل. لتفسير ما حصلنا عليه من نتائج علينا مراقبة القيمة المحسوبة للمقدار p-value والتي تشير إلى احتمال كون قيمة معامل الارتباط التي لدينا قد ظهرت بالمصادفة وأن هذا الارتباط الذي نتحدث عنه غير موجود أصلا، ففي الحالة الأولى قيمة هذا الاحتمال صغيرة جدا إذ تبلغ 1.294e-10 (وهي معروضة بصيغة التمثيل العلمي للأرقام الكبيرة أو الصغيرة، وفي حالتنا هذه يساوي 1.294 x 10^-10 أو 1.294 مقسوما على عشرة بالأس عشرة). أما في الحالة الثانية، فعلى الرغم من أن قيمة معامل الإرتباط هي -0.175 إلا أن احتمال المصادفة في الحصول على هذه القيمة لمعامل الارتباط بالنسبة لمجموعة البيانات المدروسة (أي p-value) هو 0.3389 أي تقريبا %34 وهو هامش شك كبير يصعب تجاهله، لذا من وجهة النظر الإحصائية لا يعد ذلك الارتباط معنويا أو موجودا أصلا. يمكننا أيضا تطبيق دالة الارتباط على كامل إطار البيانات بكل ما فيه من أعمدة بحيث تحفظ النتائج ضمن مصفوفة تعرض فيها قيم معامل الارتباط ما بين كل زوجين ممكنين من الأعمدة مثنى مثنى بشكل مشابه لما نحصل عليه في النسخة الرسومية من تلك الأزواج والتي تنتج عند تطبيق الدالة pairs، وللقيام بذلك يمكنك تنفيذ الأمر التالي: (cor(mtcars. هناك إختبار إحصائي آخر مفيد وبسيط هو إختبار t يستخدم عادة لتحديد ما إذا كانت مجموعتان من العينات أو القراءات تنتميان لذات المجتمع الإحصائي، بمعنى أنهما تمتلكان ذات الصفات والمقومات الإحصائية، وبالتالي لا دليل إحصائي يمكنه التمييز فيما بينهما، أي أنه يختبر الفروق الظاهرة بين المجموعتين هل هي معنوية لدرجة يمكننا معها التفريق بينهما أم لا، إن ناتج هذا الاختبار كما هو حال الإختبار السابق والعديد غيرها من الإختبارات الإحصائية يعطى على شكل قيمة تمثل مقدار احتمال ما يدعى بفرضية العدم، وفي حالتنا هذه تنص فرضية العدم على نفي وجود فروق معنوية ما بين مجموعتي العينات أو القراءات قيد الدراسة، فإن كانت قيمة هذا الإحتمال 0.05 فما دون، رفضنا نظرية العدم وقبلنا بأن ما نراه من فروقات ليس مجرد مصادفة بل هو دليل على أن الفروقات ما بين هاتين المجموعتين من البيانات معنوية في هامش خطأ لا يتجاوز 5% وهي العتبة الإحصائية المقبولة عادة (في بعض الدراسات كالحالات المخبرية أو الطبية قد يجري التشدد أكثر فلا نقبل بأكثر من 1% كهامش للخطأ أو ما هو دون ذلك). سنقوم بداية بتقسيم بيانات الزمن اللازم لقطع مسافة ربع ميل والتي لدينا في إطار البيانات mtcars إلى ثلاث مجموعات على أساس عدد اسطوانات المحرك cyl (المجموعة a للسيارات ذات 4 اسطوانات، والمجموعة b للسيارات ذات 6 اسطوانات، وأخيرا المجموعة c للسيارات ذات 8 اسطوانات) وذلك بمعونة مجموعة التعليمات التالية بلغة R: a <- qsec[cyl == 4]; b <- qsec[cyl == 6]; c <- qsec[cyl == 8];يوضح المثالين التاليين إختبار t للمقارنة بين سيارات المجموعة a والمجموعة b من ناحية التسارع، ونلاحظ أن الفروقات بينهما غير معنوية! حيث أن احتمال المصادفة p-value هو %18 تقريبا (أي أنه يتجاوز حد %5 المعتمد عادة)، فمتوسط الزمن اللازم لقطع ربع ميل في الفئة الأولى هو تقريبا 19 ثانية، أما في المجموعة الثانية فهو 18 ثانية تقريبا. بعد ذلك قمنا بالمقارنة ما بين المجموعتين a و c لنجد أن الفروقات بينهما تصنف على أنها معنوية وذلك بحسب نتائج إختبار t حيث أن قيمة p-value هي تقريبا %0.1 مع متوسط زمن 19 ثانية للمجموعة الأولى و 16.75 ثانية للمجموعة الثانية. من جهة أخرى وبمجرد تحديد وجود ارتباط معنوي ما بين أي مقدارين، علينا عندها توصيف ذلك الارتباط بشكل كمي بعد أن حددنا وجوده بشكل وصفي، وهذا ما يتم توصيفه من خلال علاقة الانحدار (Regression) ومثالها العلاقة الخطية البسيطة والتي يعبر عنها بمعادلة خط مستقيم من الشكل y = a + b x حيث a هو الثابت الذي يمثل قيمة y حينما تكون قيمة x = 0 في حين أن b تمثل ميل ذلك الخط المستقيم (أو نسبة تغير المقدار y من أجل تغير قيمة x بمقدار 1)، وتحسب هذه المقادير بحيث يمر الخط المستقيم من بين مجموعة النقاط (x, y) بشكل يجعل مقدار الخطأ أقل ما يمكن، حيث أن قيمة الخطأ في كل نقطة x مقاسة هي عبارة عن الفرق ما بين قيمة y الفعلية المقابلة وبين قيمة y المحسوبة من خلال علاقة الخط المستقيم التي حصلنا عليها في علاقة الإنحدار. إن أشكال علاقات الإنحدار يمكن لها أن تتدرج من البساطة (حيث قيمة y تحسب بدلالة متحول وحيد x1) إلى أشكال أكثر تعقيدا نستخدم فيها أكثر من متحول x لحساب قيمة y ( مثلا y = a + b x1 + c x2 + d x3)، كما أن علاقة الإنحدار تلك يمكن أن لا تكون خطية فحسب (وفيها تظهر x من الدرجة الأولى فقط) بل يمكن لها أن تتعدى إلى صيغ تربيعية أو تكعيبية أو سواها (مثلا y = a + b x + c x2 + d x3)، وللقيام بحساب تابع الإنحدار الخطي البسيط بلغة R نستخدم التعليمة التالية (fit <- lm(y ~ x، فمثلا في حال الرغبة في إيجاد تابع الإنحدار الخطي البسيط الذي يحسب المسافة المقطوعة بغالون البنزين الواحد بدلالة وزن السيارة نستخدم الأمر التالي: fit <- lm(mpg ~ wt);ويمكن عرض تفاصيل نتائج هذا الحساب الذي أجريناه للتو باستخدام الدالة summary العامة الأغراض بعد تمرير النموذج الذي تم حسابه باستخدام الدالة ()lm سابقة الذكر، وسيكون الناتج كما هو موضح أدناه: كذلك نستطيع عرض علاقة الإنحدار الخطي البسيطة هذه بشكل رسومي أيضا وذلك من خلال التعليمتين التاليتين: plot(wt, mpg); abline(fit);حيث تقوم دالة ()plot برسم المخطط البياني الذي يمثل وزن السيارات wt على محور السينات x فيما المسافة المقطوعة بغالون البنزين الواحد mpg يتم تمثيلها على محور العينات y، من جهة أخرى تقوم الدالة ()abline بإضافة ورسم الخط المستقيم الذي يوضح علاقة الإنحدار التي لدينا، وهي علاقة خطية بسيطة. بإمكانك تحسين ما يعرضه الشكل السابق من خلال إظهار أسماء موديلات السيارات لبعض النقاط المختارة من ذلك المخطط البياني من خلال استدعاء الدالة التالية: identify(wt, mpg, labels=rownames(mtcars));حيث يشير الوسيطين الأول والثاني إلى المقادير الممثلة على كل من محور السينات x ومحور العينات y على التوالي، فيما وظيفة الوسيط الثالث هي تحديد القيمة المراد عرضها لكل نقطة يتم اختيارها من نقاط المخطط البياني الظاهر أمامنا (حيث سيتغير شكل مشيرة الفأرة، وعند النقر على أي نقطة من نقاط المخطط البياني يتم إضافة تسمية قربها، ويستمر هذا السلوك إلى أن تنقر على زر Esc من لوحة المفاتيح)، وفي حالتنا هذه سنستخدم أسماء موديلات السيارات المتوافرة أصلا في إطار mtcars للبيانات على شكل تسميات للأسطر، وما تقوم به دالة rownames هنا هو استرجاع تلك الأسماء وتمريرها للوسيط labels في الدالة identify حتى تستخدمها. إن طريقة كتابة العلاقة في الدالة lm تحدد نوع تابع الإنحدار الذي يجري نمذجته، وما رأيناه في مثالنا السابق هو علاقة إنحدار خطية بسيطة حيث أن ترميز العلاقة المستخدم كان من الشكل y~x وهو يكافئ العلاقة الرياضية y=a+bx، قد نحتاج إلى بناء نموذج فيه تابع الإنحدار خطي بسيط لكن بدون الثابت (أي أن a=0 بمعنى أن y لا تمتلك قيمة عندما x=0)، في تلك الحالة نستخدم الترميز التالي للعلاقة في الدالة lm وهو y~x-1 والمكافئ الرياضي لهذه العلاقة هو y=bx، أما إن كانت علاقة الإنحدار خطية لكن ليست بسيطة، بمعنى أنه لدينا أكثر من متحول أو قيمة تؤثر في حساب y عندها نستخدم الترميز التالي y~x1+x2 وفي تلك الحالة يكون المكافئ الرياضي هو y=a+bx1+cx2، من جهة أخرى إن أردنا نمذجة علاقة إنحدار بسيطة لكن غير خطية فعلينا حينها استخدام الترميز التالي في الوسيط الذي سيتم تمريره للدالة lm وهو (y~x+I(x^2 وأعتقد أنك تستطيع تخمين المكافئ الرياضي لعلاقة الانحدار البسيطة غير الخطية هذه وهو y=a+bx+cx^2 بمجرد حساب علاقة الإنحدار، يمكننا استخدام النموذج الناتج لتوقع قيمة y بدلالة قيمة x المعطاة، فماذا ستكون المسافة المتوقع قطعها بغالون البنزين الواحد إن علمنا أن وزن السيارة هو 4.5 ألف ليبرة؟ لحساب ذلك نستخدم الدالة ()predict كما يلي (وسيكون الناتج هو 13.235 ميل تقريبا): predict(fit, list(wt = 4.5)); هذه هي نهاية الجزء الثالث من سلسلة المقالات التي تتحدث عن لغة R، انتظروا الجزء الرابع والذي سنتناول فيه بعض التطبيقات المتقدمة لهذه اللغة فإلى لقاء قريب. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة
تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوفر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاع البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS خصوصا في مجال توافر الجديد من الطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها ارتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة. سنحاول في هذه المقالة أن نقدم مدخلا مبسطا ومختصرا لأساسيات هذه اللغة ونستكشف بعضا من إمكانياتها واستخداماتها، والتي أتمنى أن أراها تدرّس في جامعاتنا يوما ما، بحيث تستخدم كأداة للاختبار والتجربة والتطوير ضمن الجلسات العملية لبعض المقررات العلمية في الكليات ذات الاختصاص. هذا هو الجزء الثالث في سلسة مؤلفة من أربع مقالات تهدف إلى التعريف بلغة R حيث قدم الجزء الأول مدخل عام إلى هذه اللغة بما فيها الإحصائيات الوصفية، أما الجزء الثاني فتحدث عن كيفية توليد بعض المخططات البيانية الإحصائية بلغة R، فيما سنختم السلسلة بجزء رابع يتحدث عن بعض التقنيات المتقدمة في هذه اللغة. للتذكير فقط، تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتبة، وكل مانكتبه تاليا يكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر mtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد. كل ما سبق ذكره من دوال يندرج تحت مظلة ما يدعى بالإحصائيات الوصفية العامة والتي تتعلق بشعاع معين من القيم، أما الدالة cor(x, y) فهي تحسب مقدار معامل الارتباط بين شعاعين من القيم هما في هذه الحالة x و y (أو بين عمودين في حالة البيانات المستوردة من ملف ما)، حيث تتدرج قيمة معامل الارتباط من -1 حتى +1 وتشير القيم الموجبة إلى وجود إرتباط طردي يزداد وضوحا كلما اقترب من +1، أي أنه كلما زادت قيمة x رافقها زيادة في قيمة y، فيما تشير القيمة السالبة لمعامل الارتباط إلى وجود ارتباط أيضا لكنه في هذه الحالة عكسي ويزداد وضوحا كلما اقترب من -1، أي أن قيمة x تزداد بتناقص y والعكس صحيح، في حين تشير قيمة معامل الارتباط التي تقترب من الصفر إلى أن تغير قيمة x لا يظهر أي علاقة بتغير قيمة y المقابلة. مع ذلك عليك كباحث أن تجد علاقة سببية بين x و y قبل أن تلجئ إلى حساب معامل الارتباط واعتماد ما تحصل عليه من نتائج، فإن كانت x تشير على سبيل المثال إلى عدد سكان مدينة دمشق خلال السنوات العشرين الماضية، فيما تشير yإلى عدد السيارات في مدينة حلب خلال نفس الفترة الزمنية، فإن قيمة معامل الارتباط إن تم حسابه سوف تشير إلى وجود ارتباط إيجابي طردي واضح، وهو شيء طبيعي! فعدد سكان دمشق في ازدياد وكذلك عدد السيارات في مدينة حلب، لكن هل لهذا الارتباط الطردي المحسوب هنا أي معنى سببي؟ من الواضح أن الجواب هو لا، لذا عليك توخي الحذر عند استخدام الأساليب والطرق الإحصائية. لننتقل الآن إلى استعراض مجموعة من الاختبارات الإحصائية وكيفية تنفيذها باستخدام لغة R. دعونا نبدأ باختبار معامل الارتباط والذي سبق وأن رأينا دالة cor البسيطة التي تحسب قيمته، لكنها تبقينا في التباس إحصائي، فإن حصلنا على سبيل المثال على الناتج 0.3 فهل سنقول بأن هناك إرتباط لكنه ضعيف؟ أم ننفي وجود مثل هذا الارتباط ونقبل أن مقدار معامل الارتباط قريب إلى 0 وبالتالي فهو غير معنوي أي غير موجود؟ في حقيقة الأمر هناك اختبار يحسب مدى إحتمالية الحصول على مقدار ما لمعامل الارتباط عن طريق المصادفة البحتة دون أن يكون هناك إرتباط حقيقي أو فعلي، وعادة ما يقبل في مجال الإحصاء إعتبار الحد 0.05 (أي 5%) هو الحد الأقصى المسموح به من الشك، فإن كان احتمال المصادفة أقل من 0.05 رفضنا فرضية المصادفة وبالتالي فالارتباط موجود ومعنوي (أي أننا نعمل هنا بأسلوب نقض الفرض)، وإلا فإننا لا نستطيع إثبات ذلك كون الشكوك في إحتمال المصادفة أكبر من أن يتم إهمالها أو التغاضي عنها. لتجريب ذلك دعونا بداية نختبر حساب معامل الارتباط ما بين وزن السيارة من جهة والمسافة التي تقطعها بالأميال لكل غالون من البنزين، ويتم ذلك مباشرة من خلال الأمر (cor(wt, mpg وسيكون الناتج في هذه الحالة هو -0.87 أي أن طبيعة تلك العلاقة هي عكسية واضحة. أما لتنفيذ الاختبار المفصل لمعامل الارتباط، فعلينا حينها استخدام الأمر البديل التالي (cor.test(wt, mpg ليظهر الناتج كما هو موضح في الشكل التالي والذي يتضمن أيضا إختبار وجود أي إرتباط ما بين وزن السيارة من جهة والزمن اللازم لقطع مسافة ربع ميل. لتفسير ما حصلنا عليه من نتائج علينا مراقبة القيمة المحسوبة للمقدار p-value والتي تشير إلى احتمال كون قيمة معامل الارتباط التي لدينا قد ظهرت بالمصادفة وأن هذا الارتباط الذي نتحدث عنه غير موجود أصلا، ففي الحالة الأولى قيمة هذا الاحتمال صغيرة جدا إذ تبلغ 1.294e-10 (وهي معروضة بصيغة التمثيل العلمي للأرقام الكبيرة أو الصغيرة، وفي حالتنا هذه يساوي 1.294 x 10^-10 أو 1.294 مقسوما على عشرة بالأس عشرة). أما في الحالة الثانية، فعلى الرغم من أن قيمة معامل الإرتباط هي -0.175 إلا أن احتمال المصادفة في الحصول على هذه القيمة لمعامل الارتباط بالنسبة لمجموعة البيانات المدروسة (أي p-value) هو 0.3389 أي تقريبا %34 وهو هامش شك كبير يصعب تجاهله، لذا من وجهة النظر الإحصائية لا يعد ذلك الارتباط معنويا أو موجودا أصلا. يمكننا أيضا تطبيق دالة الارتباط على كامل إطار البيانات بكل ما فيه من أعمدة بحيث تحفظ النتائج ضمن مصفوفة تعرض فيها قيم معامل الارتباط ما بين كل زوجين ممكنين من الأعمدة مثنى مثنى بشكل مشابه لما نحصل عليه في النسخة الرسومية من تلك الأزواج والتي تنتج عند تطبيق الدالة pairs، وللقيام بذلك يمكنك تنفيذ الأمر التالي: (cor(mtcars. هناك إختبار إحصائي آخر مفيد وبسيط هو إختبار t يستخدم عادة لتحديد ما إذا كانت مجموعتان من العينات أو القراءات تنتميان لذات المجتمع الإحصائي، بمعنى أنهما تمتلكان ذات الصفات والمقومات الإحصائية، وبالتالي لا دليل إحصائي يمكنه التمييز فيما بينهما، أي أنه يختبر الفروق الظاهرة بين المجموعتين هل هي معنوية لدرجة يمكننا معها التفريق بينهما أم لا، إن ناتج هذا الاختبار كما هو حال الإختبار السابق والعديد غيرها من الإختبارات الإحصائية يعطى على شكل قيمة تمثل مقدار احتمال ما يدعى بفرضية العدم، وفي حالتنا هذه تنص فرضية العدم على نفي وجود فروق معنوية ما بين مجموعتي العينات أو القراءات قيد الدراسة، فإن كانت قيمة هذا الإحتمال 0.05 فما دون، رفضنا نظرية العدم وقبلنا بأن ما نراه من فروقات ليس مجرد مصادفة بل هو دليل على أن الفروقات ما بين هاتين المجموعتين من البيانات معنوية في هامش خطأ لا يتجاوز 5% وهي العتبة الإحصائية المقبولة عادة (في بعض الدراسات كالحالات المخبرية أو الطبية قد يجري التشدد أكثر فلا نقبل بأكثر من 1% كهامش للخطأ أو ما هو دون ذلك). سنقوم بداية بتقسيم بيانات الزمن اللازم لقطع مسافة ربع ميل والتي لدينا في إطار البيانات mtcars إلى ثلاث مجموعات على أساس عدد اسطوانات المحرك cyl (المجموعة a للسيارات ذات 4 اسطوانات، والمجموعة b للسيارات ذات 6 اسطوانات، وأخيرا المجموعة c للسيارات ذات 8 اسطوانات) وذلك بمعونة مجموعة التعليمات التالية بلغة R: a <- qsec[cyl == 4]; b <- qsec[cyl == 6]; c <- qsec[cyl == 8];يوضح المثالين التاليين إختبار t للمقارنة بين سيارات المجموعة a والمجموعة b من ناحية التسارع، ونلاحظ أن الفروقات بينهما غير معنوية! حيث أن احتمال المصادفة p-value هو %18 تقريبا (أي أنه يتجاوز حد %5 المعتمد عادة)، فمتوسط الزمن اللازم لقطع ربع ميل في الفئة الأولى هو تقريبا 19 ثانية، أما في المجموعة الثانية فهو 18 ثانية تقريبا. بعد ذلك قمنا بالمقارنة ما بين المجموعتين a و c لنجد أن الفروقات بينهما تصنف على أنها معنوية وذلك بحسب نتائج إختبار t حيث أن قيمة p-value هي تقريبا %0.1 مع متوسط زمن 19 ثانية للمجموعة الأولى و 16.75 ثانية للمجموعة الثانية. من جهة أخرى وبمجرد تحديد وجود ارتباط معنوي ما بين أي مقدارين، علينا عندها توصيف ذلك الارتباط بشكل كمي بعد أن حددنا وجوده بشكل وصفي، وهذا ما يتم توصيفه من خلال علاقة الانحدار (Regression) ومثالها العلاقة الخطية البسيطة والتي يعبر عنها بمعادلة خط مستقيم من الشكل y = a + b x حيث a هو الثابت الذي يمثل قيمة y حينما تكون قيمة x = 0 في حين أن b تمثل ميل ذلك الخط المستقيم (أو نسبة تغير المقدار y من أجل تغير قيمة x بمقدار 1)، وتحسب هذه المقادير بحيث يمر الخط المستقيم من بين مجموعة النقاط (x, y) بشكل يجعل مقدار الخطأ أقل ما يمكن، حيث أن قيمة الخطأ في كل نقطة x مقاسة هي عبارة عن الفرق ما بين قيمة y الفعلية المقابلة وبين قيمة y المحسوبة من خلال علاقة الخط المستقيم التي حصلنا عليها في علاقة الإنحدار. إن أشكال علاقات الإنحدار يمكن لها أن تتدرج من البساطة (حيث قيمة y تحسب بدلالة متحول وحيد x1) إلى أشكال أكثر تعقيدا نستخدم فيها أكثر من متحول x لحساب قيمة y ( مثلا y = a + b x1 + c x2 + d x3)، كما أن علاقة الإنحدار تلك يمكن أن لا تكون خطية فحسب (وفيها تظهر x من الدرجة الأولى فقط) بل يمكن لها أن تتعدى إلى صيغ تربيعية أو تكعيبية أو سواها (مثلا y = a + b x + c x2 + d x3)، وللقيام بحساب تابع الإنحدار الخطي البسيط بلغة R نستخدم التعليمة التالية (fit <- lm(y ~ x، فمثلا في حال الرغبة في إيجاد تابع الإنحدار الخطي البسيط الذي يحسب المسافة المقطوعة بغالون البنزين الواحد بدلالة وزن السيارة نستخدم الأمر التالي: fit <- lm(mpg ~ wt);ويمكن عرض تفاصيل نتائج هذا الحساب الذي أجريناه للتو باستخدام الدالة summary العامة الأغراض بعد تمرير النموذج الذي تم حسابه باستخدام الدالة ()lm سابقة الذكر، وسيكون الناتج كما هو موضح أدناه: كذلك نستطيع عرض علاقة الإنحدار الخطي البسيطة هذه بشكل رسومي أيضا وذلك من خلال التعليمتين التاليتين: plot(wt, mpg); abline(fit);حيث تقوم دالة ()plot برسم المخطط البياني الذي يمثل وزن السيارات wt على محور السينات x فيما المسافة المقطوعة بغالون البنزين الواحد mpg يتم تمثيلها على محور العينات y، من جهة أخرى تقوم الدالة ()abline بإضافة ورسم الخط المستقيم الذي يوضح علاقة الإنحدار التي لدينا، وهي علاقة خطية بسيطة. بإمكانك تحسين ما يعرضه الشكل السابق من خلال إظهار أسماء موديلات السيارات لبعض النقاط المختارة من ذلك المخطط البياني من خلال استدعاء الدالة التالية: identify(wt, mpg, labels=rownames(mtcars));حيث يشير الوسيطين الأول والثاني إلى المقادير الممثلة على كل من محور السينات x ومحور العينات y على التوالي، فيما وظيفة الوسيط الثالث هي تحديد القيمة المراد عرضها لكل نقطة يتم اختيارها من نقاط المخطط البياني الظاهر أمامنا (حيث سيتغير شكل مشيرة الفأرة، وعند النقر على أي نقطة من نقاط المخطط البياني يتم إضافة تسمية قربها، ويستمر هذا السلوك إلى أن تنقر على زر Esc من لوحة المفاتيح)، وفي حالتنا هذه سنستخدم أسماء موديلات السيارات المتوافرة أصلا في إطار mtcars للبيانات على شكل تسميات للأسطر، وما تقوم به دالة rownames هنا هو استرجاع تلك الأسماء وتمريرها للوسيط labels في الدالة identify حتى تستخدمها. إن طريقة كتابة العلاقة في الدالة lm تحدد نوع تابع الإنحدار الذي يجري نمذجته، وما رأيناه في مثالنا السابق هو علاقة إنحدار خطية بسيطة حيث أن ترميز العلاقة المستخدم كان من الشكل y~x وهو يكافئ العلاقة الرياضية y=a+bx، قد نحتاج إلى بناء نموذج فيه تابع الإنحدار خطي بسيط لكن بدون الثابت (أي أن a=0 بمعنى أن y لا تمتلك قيمة عندما x=0)، في تلك الحالة نستخدم الترميز التالي للعلاقة في الدالة lm وهو y~x-1 والمكافئ الرياضي لهذه العلاقة هو y=bx، أما إن كانت علاقة الإنحدار خطية لكن ليست بسيطة، بمعنى أنه لدينا أكثر من متحول أو قيمة تؤثر في حساب y عندها نستخدم الترميز التالي y~x1+x2 وفي تلك الحالة يكون المكافئ الرياضي هو y=a+bx1+cx2، من جهة أخرى إن أردنا نمذجة علاقة إنحدار بسيطة لكن غير خطية فعلينا حينها استخدام الترميز التالي في الوسيط الذي سيتم تمريره للدالة lm وهو (y~x+I(x^2 وأعتقد أنك تستطيع تخمين المكافئ الرياضي لعلاقة الانحدار البسيطة غير الخطية هذه وهو y=a+bx+cx^2 بمجرد حساب علاقة الإنحدار، يمكننا استخدام النموذج الناتج لتوقع قيمة y بدلالة قيمة x المعطاة، فماذا ستكون المسافة المتوقع قطعها بغالون البنزين الواحد إن علمنا أن وزن السيارة هو 4.5 ألف ليبرة؟ لحساب ذلك نستخدم الدالة ()predict كما يلي (وسيكون الناتج هو 13.235 ميل تقريبا): predict(fit, list(wt = 4.5)); هذه هي نهاية الجزء الثالث من سلسلة المقالات التي تتحدث عن لغة R، انتظروا الجزء الرابع والذي سنتناول فيه بعض التطبيقات المتقدمة لهذه اللغة فإلى لقاء قريب. لائحة المراجع: http://www.r-project.orghttp://www.statmethods.nethttp://www.r-tutor.com1 نقطة -
 سنتعلم في هذا الدرس طريقة تصميم سمكة المهرج Clownfish في برنامج Illustrator باستخدام الأشكال الأساسية، سيكون الدرس ملائمًا جدًّا للمبتدئين، وستساعد الأشكال الأساسيّة كذلك في إضفاء لمسة كارتونيّة على هذه الشخصيّة المحبوبة، وعلى أي حال فلا شكّ في أنّ من شاهد فيلم البحث عن نيمو يعرف أنّ سمكة المهرّج رفيق ممتع ولطيف. هذه هي سمكة المهرج التي سنقوم بتصميمها في هذا الدرس، لاحظ كيف تضفي الظلال والتفاصيل الإضافية على الزعانف بعضًا من الحيوية على هذه الشخصية المرحة. افتح ملفًّا جديدًا في Illustrator وابدأ برسم دائرة بقياس 130px ستمثّل جسم سمكتنا، ثمّ ارسم شكلًا بيضويًّا بقياس 20px في 60px واجعله يتوسّط أعلى الدائرة باستخدام لوحة المحاذاة Align palette، ثم اسحبه للأعلى بمقدار 40px تقريبًا. اسحب نقطة الإرساء اليسرى للشكل البيضويّ بواسطة أداة التحديد المباشر Direct Selection Tool بمقدار 5px إلى اليسار، وبهذا نكون قد صنعنا الزعنفة الظهريّة. لصنع الزعنفة الصدريّة ارسم دائرة بقياس 15px واسحب نقطة إرسائها اليسرى إلى اليسار بمقدار 3px، واسحب نقطة إرسائها السفلى بمقدار 3px إلى الأسفل. حدد كلًّا من الجسم والشكل الجديد ثم انقر مع الضغط على مفتاح ALT على جسم السمكة لجعله العنصر الأساسيّ للمحاذاة (سيظهر خط أزرق سميك حول الشكل). حاذِ الشكل الجديد وسطيًا وباتجاه يسار الجسم ثم اسحبه إلى اليسار بمقدار 10px تقريبًا. انسخ والصق الشكل في نفس المكان بالضغط على CTRL+C ثم CTRL+F (أو CMD+C ثم CMD+F في نظام الماك) ثم اعكس الشكل عموديًّا عن طريق الضغط بالزرّ الأيمن من الفأرة واختيار Transform>Reflect من القائمة المنسدلة، ثم حاذه إلى يمين جسم السمكة. الزعانف الجانبية صغيرة أليس كذلك؟ لا تقلق، لم ننتهِ منها بعد، ارسم شكلًا بيضويًّا بقياس 50px في 60px، ثم ادفع نقطة الإرساء اليمنى إلى الجهة اليمنى بمقدار 10px، واسحب نقطة الإرساء اليسرى إلى إلى اليسار بمقدار 5px. حاذِ الشكل وسطيًّا وباتجاه يسار جسم السمكة قبل سحبه إلى اليسار بمقدار 45px تقريبًا، انقر على الشكل بزرّ الفأرة الأيمن ثم اختر Arrange > Send to Back من القائمة المنسدلة ليكون الشكل أسفل بقية الأشكال. انسخ والصق ثم اعكس الزعنفة وانقلها إلى الجهة اليمنى من جسم السمكة. تمتاز سمكة المهرّج بالأشرطة البيضاء على جسمها، ولن تكتمل سمكتنا دون وجود هذا الشريط، ارسم شكل بيضويًّا بقياس 110px في 140px ثم اذهب إلى القائمة: Object > Path > Offset Path أدخل القيمة -10px في مربع Offset ثم اضغط OK. حدد الدائرتين ثم اضغط على أيقونة Minus Front من لوحة Pathfinder للحصول على الشكل المطلوب. حاذِ شكل الشريط وسطيًّا وبالاتجاه العلوي لجسم السمكة ثم اسحبه إلى الأسفل بمقدار 10px. انسخ شكل جسم السمكة ثم حدد معه شكل الشريط واضغط على أيقونة Intersect في لوحة Pathfinder، الصق الآن شكل الجسم في المكان ثمّ أعد ترتيب طبقات الأشكال. لصنع وجه السمكة، ارسم دائرتين بمقاس 15px من أجل العينين، افصل الدائرتين عن بعضهما البعض بمقدار 20px تقريبًا، اجمع العينين بالضغط على (CTRL+G) ثم حاذهما إلى منتصف شكل الجسم، يمكن الاستفادة من عملية جعل الجسم العنصر الأساس في المحاذاة وذلك بالضغط على ALT مع النقر على شكل الجسم بعد تحديد كل من الجسم والعيون معًا. ارسم دائرة أخرى بمقاس 15px لتمثل فم السمكة وضعها تحت العيون بمسافة 5px، ثم استخدم أداة التحديد المباشر لحذف نقطة الإرساء العلوية. لقد حصلت على سمكة مهرج باسمة. تمتلك أسماك المهرج كذلك أطرافًا سوداء في زعانفها بالإضافة إلى الأشرطة البيضاء، ولصنع الأطراف السوداء للزعانف الظهرية انسخ شكل الزعنفة والصقها إلى الخلف في نفس المكان، ثم اسحبها إلى الأسفل بمقدار 10px. حدد الزعفنتين الأصليّة والمستنسخة ثم اضغط على أيقونة Minus Front من لوحة Pathfinder، لتحصل على طرف الزعنفة فقط. الصق الشكل الأصلي مرة أخرى في نفس المكان ثم غير ترتيبه عن طريق إرساله إلى الخلف بالضغط على (Ctrl+[) لأكثر من مرّة إلى أن يصل الشكل إلى المكان الصحيح. كرّر هذه الخطوات لصناعة أطراف الزعانف الصدريّة، ولكن اسحب نسخة شكل الزعنفة اليسرى باتجاه اليمين بمقدار 10px ثمّ اضغط على أيقونة Minus Front، واسحب كذلك نسخة الزعنفة اليمنى باتجاه اليسار بمقدار 10px. سنحتاج إلى حركة أخرى لنحصل على الشكل النهائي لسمكة لننتقل بعدها إلى عملية التلوين. حدّد جسم السمكة، والزعانف الظهريّة والدوائر الصغيرة التي تربط الزعانف الصدريّة بالجسم، ثم اضغط على أيقونة Unite من لوحة Pathfinder لدمج الأشكال الأربعة. أعد ترتيب الأشكال فوق بعضها البعض بإرسال الزعانف الظهريّة إلى الخلف، وإرسال الشريط وأطراف الزعانف والوجه إلى الإمام. يمكننا الآن إضافة الألوان إلى الشكل، وقد اخترت اللون البني للحدّ الخارجي Stroke، واللون البرتقالي للتعبئة الداخليّة Fill، واللون البني الغامق لأطراف الزعانف. لا زالت السمكة تبدو مسطّحة قليلًا؛ لذا سنضيف إليها بعض الظلال لإعطاءها بعض الأبعاد. سنستخدم نفس الخطوات التي اتبعناها في إنشاء أطراف الزعانف، لذا انسخ جسم السمكة والصقه في نفس المكان ثم اسحبه إلى الأعلى بمقدار 10px، بعدها قُصَّه من الشكل الأصلي بالضغط على أيقونة Minus Front. الصق نسخة أخرى من الجسم ثمّ أعد ترتيب الأشكال حسب الحاجة. حدّد الظلّ، ثم أزل حدّه الخارجي Stroke، وباستخدام لوحة Transparency غيّر نمط المزج لهذا الشكل إلى Multiply والشفافيّة إلى 25%. كرّر هذه الخطوات مع الزعانف الصدريّة ولكن اسحبها إلى الأعلى بمقدار 30px قبل الضغط على أيقونة Minus Front. لإضافة المزيد من التفاصيل إلى الزعانف الصدريّة، ارسم دائرة بقياس 5px ثم باستخدام أداة نقطة الإرساء (Anchor Point Tool (SHIFT+C اضغط على نقطة الإرساء اليمنى للدائرة لتتحول إلى نقطة حادّة. اسحب هذه النقطة إلى اليمن بمقدار 20px ثم اصنع نسختين أخريين من الشكل الناتج، رتّب هذه الأشكال فوق بعضها البعض وافصل بينها بمسافة قدرها 5px. دوّر الشكل العلوي بمقدار -15 درجة والشكل السفلي بمقدار 15 درجة ثم اضغط (CTRL+G) لتجميع الأشكال الثلاثة. ضع الأشكال الثلاثة في منتصف الزعنفة الصدرية اليسرى ثم لوّنها باللون البرتقاليّ الذي استخدمته في تلوين جسم السمكة دون إضافة حد خارجيّ. باستخدام لوحة Transparency غيّر نمط المزج إلى Multiply والشفافية إلى 35%. انسخ والصق واعكس الأشكال الثلاثة ثم ضعها في منتصف الزعنفة الصدريّة اليمنى. بقي أن نعدّل سماكة الحد الخارجي لإضافة إحساس بالعمق إلى الشكل، وللقيام بذلك حدّد الجسم والزعانف الصدريّة والفم ثم أضف إليها حدًّا خارجيًا بمقدار 2px. أزل الحدّ الخارجي حول أطراف الزعانف البنّية إن وجدت. اصنع نسخة من جسم السمكة والزعانف الصدريّة ثم الصقها في نفس المكان، ثم ادمج هذه الأشكال مع بعضها البعض بالضغط على أيقونة Unite في لوحة Pathfinder. أرسل الأشكال المندمجة إلى الخلف بالضغط على (SHIFT+CTRL+[) ثم اذهب إلى القائمة: Object > Path > Offset Path أضف القيمة 3px إلى مربع Offset واختر Round من قائمة Joins ثم اضغط OK. لوّن الشكل الناتج باللّون البني مع إزالة الحدّ الخارجي، وها قد انتهينا. لم لا تضع سمكتك فوق خلفية زرقاء مع بعض الفقاعات لتبدو وكأنّها في موطنها؟ ترجمة ـوبتصرّفـ للمقال Create a Clownfish in Illustrator Using Basic Shape لصاحبته Liz Canning.1 نقطة
سنتعلم في هذا الدرس طريقة تصميم سمكة المهرج Clownfish في برنامج Illustrator باستخدام الأشكال الأساسية، سيكون الدرس ملائمًا جدًّا للمبتدئين، وستساعد الأشكال الأساسيّة كذلك في إضفاء لمسة كارتونيّة على هذه الشخصيّة المحبوبة، وعلى أي حال فلا شكّ في أنّ من شاهد فيلم البحث عن نيمو يعرف أنّ سمكة المهرّج رفيق ممتع ولطيف. هذه هي سمكة المهرج التي سنقوم بتصميمها في هذا الدرس، لاحظ كيف تضفي الظلال والتفاصيل الإضافية على الزعانف بعضًا من الحيوية على هذه الشخصية المرحة. افتح ملفًّا جديدًا في Illustrator وابدأ برسم دائرة بقياس 130px ستمثّل جسم سمكتنا، ثمّ ارسم شكلًا بيضويًّا بقياس 20px في 60px واجعله يتوسّط أعلى الدائرة باستخدام لوحة المحاذاة Align palette، ثم اسحبه للأعلى بمقدار 40px تقريبًا. اسحب نقطة الإرساء اليسرى للشكل البيضويّ بواسطة أداة التحديد المباشر Direct Selection Tool بمقدار 5px إلى اليسار، وبهذا نكون قد صنعنا الزعنفة الظهريّة. لصنع الزعنفة الصدريّة ارسم دائرة بقياس 15px واسحب نقطة إرسائها اليسرى إلى اليسار بمقدار 3px، واسحب نقطة إرسائها السفلى بمقدار 3px إلى الأسفل. حدد كلًّا من الجسم والشكل الجديد ثم انقر مع الضغط على مفتاح ALT على جسم السمكة لجعله العنصر الأساسيّ للمحاذاة (سيظهر خط أزرق سميك حول الشكل). حاذِ الشكل الجديد وسطيًا وباتجاه يسار الجسم ثم اسحبه إلى اليسار بمقدار 10px تقريبًا. انسخ والصق الشكل في نفس المكان بالضغط على CTRL+C ثم CTRL+F (أو CMD+C ثم CMD+F في نظام الماك) ثم اعكس الشكل عموديًّا عن طريق الضغط بالزرّ الأيمن من الفأرة واختيار Transform>Reflect من القائمة المنسدلة، ثم حاذه إلى يمين جسم السمكة. الزعانف الجانبية صغيرة أليس كذلك؟ لا تقلق، لم ننتهِ منها بعد، ارسم شكلًا بيضويًّا بقياس 50px في 60px، ثم ادفع نقطة الإرساء اليمنى إلى الجهة اليمنى بمقدار 10px، واسحب نقطة الإرساء اليسرى إلى إلى اليسار بمقدار 5px. حاذِ الشكل وسطيًّا وباتجاه يسار جسم السمكة قبل سحبه إلى اليسار بمقدار 45px تقريبًا، انقر على الشكل بزرّ الفأرة الأيمن ثم اختر Arrange > Send to Back من القائمة المنسدلة ليكون الشكل أسفل بقية الأشكال. انسخ والصق ثم اعكس الزعنفة وانقلها إلى الجهة اليمنى من جسم السمكة. تمتاز سمكة المهرّج بالأشرطة البيضاء على جسمها، ولن تكتمل سمكتنا دون وجود هذا الشريط، ارسم شكل بيضويًّا بقياس 110px في 140px ثم اذهب إلى القائمة: Object > Path > Offset Path أدخل القيمة -10px في مربع Offset ثم اضغط OK. حدد الدائرتين ثم اضغط على أيقونة Minus Front من لوحة Pathfinder للحصول على الشكل المطلوب. حاذِ شكل الشريط وسطيًّا وبالاتجاه العلوي لجسم السمكة ثم اسحبه إلى الأسفل بمقدار 10px. انسخ شكل جسم السمكة ثم حدد معه شكل الشريط واضغط على أيقونة Intersect في لوحة Pathfinder، الصق الآن شكل الجسم في المكان ثمّ أعد ترتيب طبقات الأشكال. لصنع وجه السمكة، ارسم دائرتين بمقاس 15px من أجل العينين، افصل الدائرتين عن بعضهما البعض بمقدار 20px تقريبًا، اجمع العينين بالضغط على (CTRL+G) ثم حاذهما إلى منتصف شكل الجسم، يمكن الاستفادة من عملية جعل الجسم العنصر الأساس في المحاذاة وذلك بالضغط على ALT مع النقر على شكل الجسم بعد تحديد كل من الجسم والعيون معًا. ارسم دائرة أخرى بمقاس 15px لتمثل فم السمكة وضعها تحت العيون بمسافة 5px، ثم استخدم أداة التحديد المباشر لحذف نقطة الإرساء العلوية. لقد حصلت على سمكة مهرج باسمة. تمتلك أسماك المهرج كذلك أطرافًا سوداء في زعانفها بالإضافة إلى الأشرطة البيضاء، ولصنع الأطراف السوداء للزعانف الظهرية انسخ شكل الزعنفة والصقها إلى الخلف في نفس المكان، ثم اسحبها إلى الأسفل بمقدار 10px. حدد الزعفنتين الأصليّة والمستنسخة ثم اضغط على أيقونة Minus Front من لوحة Pathfinder، لتحصل على طرف الزعنفة فقط. الصق الشكل الأصلي مرة أخرى في نفس المكان ثم غير ترتيبه عن طريق إرساله إلى الخلف بالضغط على (Ctrl+[) لأكثر من مرّة إلى أن يصل الشكل إلى المكان الصحيح. كرّر هذه الخطوات لصناعة أطراف الزعانف الصدريّة، ولكن اسحب نسخة شكل الزعنفة اليسرى باتجاه اليمين بمقدار 10px ثمّ اضغط على أيقونة Minus Front، واسحب كذلك نسخة الزعنفة اليمنى باتجاه اليسار بمقدار 10px. سنحتاج إلى حركة أخرى لنحصل على الشكل النهائي لسمكة لننتقل بعدها إلى عملية التلوين. حدّد جسم السمكة، والزعانف الظهريّة والدوائر الصغيرة التي تربط الزعانف الصدريّة بالجسم، ثم اضغط على أيقونة Unite من لوحة Pathfinder لدمج الأشكال الأربعة. أعد ترتيب الأشكال فوق بعضها البعض بإرسال الزعانف الظهريّة إلى الخلف، وإرسال الشريط وأطراف الزعانف والوجه إلى الإمام. يمكننا الآن إضافة الألوان إلى الشكل، وقد اخترت اللون البني للحدّ الخارجي Stroke، واللون البرتقالي للتعبئة الداخليّة Fill، واللون البني الغامق لأطراف الزعانف. لا زالت السمكة تبدو مسطّحة قليلًا؛ لذا سنضيف إليها بعض الظلال لإعطاءها بعض الأبعاد. سنستخدم نفس الخطوات التي اتبعناها في إنشاء أطراف الزعانف، لذا انسخ جسم السمكة والصقه في نفس المكان ثم اسحبه إلى الأعلى بمقدار 10px، بعدها قُصَّه من الشكل الأصلي بالضغط على أيقونة Minus Front. الصق نسخة أخرى من الجسم ثمّ أعد ترتيب الأشكال حسب الحاجة. حدّد الظلّ، ثم أزل حدّه الخارجي Stroke، وباستخدام لوحة Transparency غيّر نمط المزج لهذا الشكل إلى Multiply والشفافيّة إلى 25%. كرّر هذه الخطوات مع الزعانف الصدريّة ولكن اسحبها إلى الأعلى بمقدار 30px قبل الضغط على أيقونة Minus Front. لإضافة المزيد من التفاصيل إلى الزعانف الصدريّة، ارسم دائرة بقياس 5px ثم باستخدام أداة نقطة الإرساء (Anchor Point Tool (SHIFT+C اضغط على نقطة الإرساء اليمنى للدائرة لتتحول إلى نقطة حادّة. اسحب هذه النقطة إلى اليمن بمقدار 20px ثم اصنع نسختين أخريين من الشكل الناتج، رتّب هذه الأشكال فوق بعضها البعض وافصل بينها بمسافة قدرها 5px. دوّر الشكل العلوي بمقدار -15 درجة والشكل السفلي بمقدار 15 درجة ثم اضغط (CTRL+G) لتجميع الأشكال الثلاثة. ضع الأشكال الثلاثة في منتصف الزعنفة الصدرية اليسرى ثم لوّنها باللون البرتقاليّ الذي استخدمته في تلوين جسم السمكة دون إضافة حد خارجيّ. باستخدام لوحة Transparency غيّر نمط المزج إلى Multiply والشفافية إلى 35%. انسخ والصق واعكس الأشكال الثلاثة ثم ضعها في منتصف الزعنفة الصدريّة اليمنى. بقي أن نعدّل سماكة الحد الخارجي لإضافة إحساس بالعمق إلى الشكل، وللقيام بذلك حدّد الجسم والزعانف الصدريّة والفم ثم أضف إليها حدًّا خارجيًا بمقدار 2px. أزل الحدّ الخارجي حول أطراف الزعانف البنّية إن وجدت. اصنع نسخة من جسم السمكة والزعانف الصدريّة ثم الصقها في نفس المكان، ثم ادمج هذه الأشكال مع بعضها البعض بالضغط على أيقونة Unite في لوحة Pathfinder. أرسل الأشكال المندمجة إلى الخلف بالضغط على (SHIFT+CTRL+[) ثم اذهب إلى القائمة: Object > Path > Offset Path أضف القيمة 3px إلى مربع Offset واختر Round من قائمة Joins ثم اضغط OK. لوّن الشكل الناتج باللّون البني مع إزالة الحدّ الخارجي، وها قد انتهينا. لم لا تضع سمكتك فوق خلفية زرقاء مع بعض الفقاعات لتبدو وكأنّها في موطنها؟ ترجمة ـوبتصرّفـ للمقال Create a Clownfish in Illustrator Using Basic Shape لصاحبته Liz Canning.1 نقطة -
نسخ المحتوى يعتبر من بين مشاكل العمل على الإنترنت، باعتباره سرقة مجهود الآخرين، أريد من خلال هذا السؤال معرفة متى نكون أمام حالة نسخ محتوى، وماهي أهم أنواعه؟ وهل يوجد نسخ مباح ؟1 نقطة
-
يتنوع نسخ المحتوى ما بين : - النسخ المباشر من أي تعديل ولا ذكر للمصدر وهذا سرقة فاضحة للمحتوى. - النسخ المعدل وهذا النوع من السرقة الذكية بحيث يتم تعديل بعض فقرات النص لكن مع إبقاء قالبه الأصلي. - النسخ مع ذكر المصدر، وهذا نسخ مباح ليس فيه أي ضرر في ذلك بل قد يفيد صاحب الموقع بما أنه اشهر برابط مقالته. - النسخ من عدة مصادر أي نسخ عدة فقرات وخياطتها في محتوى واحد، لكن مع ذلك يبقى سرقة إن لم يتم ذكر المصادر.1 نقطة
-
لكي ينجح رائد الأعمال في لفت انتباه موظفيه يجب عليه أن يتحلى ببعض الصفات التي تمكنه من جلبهم إليه، سأتعرض لبعض منها في شكل نقاط: - يجب عليه أولا أن يفهم كيف يفكر الموظف، يجب عليه أن يراعي شعوره فهو إنسان قبل كل شئ وليس آلة، الموظف يعمل غالبا ثمان ساعات أو أكثر ولذلك توجب أن نفهم ظروفه وطريقة تفكيره. - بناءا على النقطة الأولى سيكون حريا بنا أن نبتعد في حديثنا مع الموظف عن كل أساليب الانتقاد التي ينتهجها الكثير من المدراء في حق موظفيهم، ولقد ثبت علميا أنه لو تنتقد موظفيك فإنك ستخسرهم لأن ذلك سيولد شحنة وبغضاء بين الطرفين وهو ما لا يعد بتاتا في صالح الشركة، وعليه يتوجب الحديث مع موظفيك بطريقة غير مباشرة توصل بها الرسالة وتحفظ بها شعور الموظف. - أحيانا قد يمل الموظف أو ربما ظروف ما تجعله كسولا أو يفقد الرغبة، لذلك سيكون من الضروري أن تعمل على تحفيزهم سواءا بالحديث الحماسي، أو حتى بالمكافآت المالية، حاول أن تمزج بين الطريقتين، فالهدايا والكلام الحلو يقرب بينك وبين موظفيك ويجعلهم يحسون بقيمة أكبر.1 نقطة
-
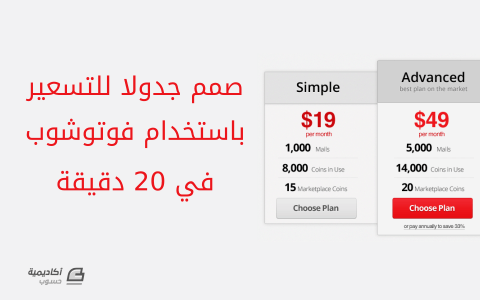 اعتاد المصمّمون على عرض البيانات بطرق مختلفة، إذ يمكن عرضها على شكل تصميم، أو واجهة معيّنة، أو ربّما على شكل جداول، كلّ ذلك تيسيرًا لفهم هذه البيانات. وقد كانت جداول الأسعار ولا زالت مستخدمة من قبل العديد من الشّركات والأفراد على حدٍّ سواء لعرض خطط التّسعير المتوفرة لديهم. إن كنت تملك خططاً متعدّدة للتسعير فعرضها على هيئة جدول للتّسعير سيكون أمرًا مفيدًا وجذّابًا في نفس الوقت. سنستخدم برنامج Adobe Photoshop لتصميم جدول للتّسعير وسيستغرق العمل حوالي 20 إلى 30 دقيقة. جدول التسعير الخطوة 1أنشئ ملفًّا جديدًا بالأبعاد 1200px في 600px. ستكون أبعاد جدول التّسعير 1000px في 340px ولكنّنا سنحتاج إلى بعض المساحة الّتي ستحيط بالجدول، لذا ستكون أبعاد الملفّ أكبر قليلًا من أبعاد الجدول. الخطوة 2بواسطة أداة المستطيل ذو الأطراف المدوّرة (Rounded Rectangle Tool (U، ارسم مستطيلًا بالأبعاد التّالية: 1000px في 340px، ثمّ أضف إليه بريقًا خارجيًا خفيفًا Outer Glow بواسطة أنماط الطبقات Layer Styles بالإضافة إلى حدّ خارجيّ Stroke بسماكة 1px، كذلك أعط الحدّ الخارجيّ لونًا أغمق بقليل من لون المستطيل. الخطوة 3سنقسّم جدول التّسعير إلى ثلاثة أقسام. التّرويسة، المحتوى ومساحة لزرّ الإجراء. سيحتوي قسم التّرويسة على اسم الخطّة فقط. باستخدام أداة المستطيل (Rectangle Tool (U، ارسم شكلاً بعرض 1000px وارتفاع 70px. لوّن المستطيل باللّون (#e0e3e3) وأضف إليه ظلًّا للحصول على نفس التّأثير الذي ينتج من تطبيق (البريق الخارجيّ Outer Glow) باستثناء إمكانية تحديد اتّجاه الظّلّ (بتغيير مقدار الزّاوية). الخطوة 4سيحتوي جدول التّسعير على 4 خطط يمكن التّسجيل في الموقع من خلالها، ومن الشّائع أن تقوم بتمييز إحدى الخطط وتسميتها بـ (الخطة الأفضل) أو ما شابه ذلك. استخدم أداة المستطيل ذي الحوافّ المدوّرة (U) وارسم شكلاً بالأبعاد 250px في 290px، ثم طبّق نفس التأثيرات الّتي طبّقتها على الطّبقة الأساسيّة. الخطوة 5كرّر الخطوة 3، باستثناء تلوين التّرويسة بلون رماديّ غامق (#d1d1d1). الخطوة 6سنستخدم نوعين من الخطوط في جدول التّسعير، (Open Sans) و (Helvetica)، استخدم الوزن متوسّط السّماكة لخط (Open Sans) في اسم الخطّة في قسم التّرويسة. الخطوة 7استخدم الخط (Helvetica) في قائمة الأسعار لكلّ خطّة، وبما أنّنا نرغب في تمييز (الخطة المتقدّمة)، سنعطي وسم السّعر لونًا أحمر برّاقًا. الخطوة 8ننتقل الآن إلى قسم (المحتوى)، والّذي سيحتوي على ثلاث مزايا ستقدّمها لزبائنك، وسيكون ذا بنية جميلة وبسيطة. سنستخدم خطّ (Open Sans)، سيكون خطّ الأرقام بحجم 24pt سميك، أما خطّ النّصوص سيكون بحجم 14pt عاديّ. ستكون المزايا مفصولة عن بعضها البعض بخطوط منقّطة، ويمكن استبدالها بكلّ سهولة بخطّ بسيط. الخطوة 9يجب أن تحتوي كل خطّة على زرّ يمكن للزّبون ومن خلال الضّغط عليه أن يتّخذ إجراءً تجاه الخطّة، سواء كان هذا الإجراء هو الحصول على معلومات أوسع عن هذه الخطّة، الاستئناف أو الدفع. باستخدام أداة المستطيل ذي الحوافّ المدوّرة (U)، ارسم مستطيلاً رماديّ اللّون، وأضف إليه تأثير الظلّ بلون رماديّ غامق. الخطوة 10طبّق تأثير التدرّج اللوني Gradient Overlay واختر نمط المزج Soft Light، والشّفافية بمقدار 40%. الخطوة 11أضف إلى الزرّ حدًّا خارجيًّا من النّوع المتدرّج Gradient. الخطوة 12مستخدمًا الخطّ (Open Sans Bold) وبحجم 24pt، أضف بعض الكلمات إلى الزرّ، سنضيف عبارة (Choose Plan). ضاعف قسمي (المحتوى) و(وزرّ الإجراء) مرّتين، وضعهما في المكان المخصّص لكلّ منهما. يمكنك الرجوع إلى الشّكل النهائيّ لمعرفة الأماكن المخصّصة لهذين القسمين. الخطوة 13لا تختلف (الخطّة المتقدمة) عن الخطط الأخرى سوى أنّ لون وسم السّعر وزرّ الإجراء أكثر بريقًا. زرّ الإجراء الأحمر مشابه بشكل كبير للأزرار الرماديّة، ولكنّه يختلف عنها بلونه الأساسيّ #ed161c، ولون الحدّ الخارجيّ المبيّن في الصّورة أدناه. الخطوة 14أخيرًا، غيّر ألوان الحدّ الخارجيّ من الألوان الرماديّة إلى الألوان الحمراء التّالية. النتيجة النهائية ترجمة -وبتصرف- للدرس Create a Pricing Table Using Photoshop in bout 20 Minutes لصاحبه Dainis Graveris.1 نقطة
اعتاد المصمّمون على عرض البيانات بطرق مختلفة، إذ يمكن عرضها على شكل تصميم، أو واجهة معيّنة، أو ربّما على شكل جداول، كلّ ذلك تيسيرًا لفهم هذه البيانات. وقد كانت جداول الأسعار ولا زالت مستخدمة من قبل العديد من الشّركات والأفراد على حدٍّ سواء لعرض خطط التّسعير المتوفرة لديهم. إن كنت تملك خططاً متعدّدة للتسعير فعرضها على هيئة جدول للتّسعير سيكون أمرًا مفيدًا وجذّابًا في نفس الوقت. سنستخدم برنامج Adobe Photoshop لتصميم جدول للتّسعير وسيستغرق العمل حوالي 20 إلى 30 دقيقة. جدول التسعير الخطوة 1أنشئ ملفًّا جديدًا بالأبعاد 1200px في 600px. ستكون أبعاد جدول التّسعير 1000px في 340px ولكنّنا سنحتاج إلى بعض المساحة الّتي ستحيط بالجدول، لذا ستكون أبعاد الملفّ أكبر قليلًا من أبعاد الجدول. الخطوة 2بواسطة أداة المستطيل ذو الأطراف المدوّرة (Rounded Rectangle Tool (U، ارسم مستطيلًا بالأبعاد التّالية: 1000px في 340px، ثمّ أضف إليه بريقًا خارجيًا خفيفًا Outer Glow بواسطة أنماط الطبقات Layer Styles بالإضافة إلى حدّ خارجيّ Stroke بسماكة 1px، كذلك أعط الحدّ الخارجيّ لونًا أغمق بقليل من لون المستطيل. الخطوة 3سنقسّم جدول التّسعير إلى ثلاثة أقسام. التّرويسة، المحتوى ومساحة لزرّ الإجراء. سيحتوي قسم التّرويسة على اسم الخطّة فقط. باستخدام أداة المستطيل (Rectangle Tool (U، ارسم شكلاً بعرض 1000px وارتفاع 70px. لوّن المستطيل باللّون (#e0e3e3) وأضف إليه ظلًّا للحصول على نفس التّأثير الذي ينتج من تطبيق (البريق الخارجيّ Outer Glow) باستثناء إمكانية تحديد اتّجاه الظّلّ (بتغيير مقدار الزّاوية). الخطوة 4سيحتوي جدول التّسعير على 4 خطط يمكن التّسجيل في الموقع من خلالها، ومن الشّائع أن تقوم بتمييز إحدى الخطط وتسميتها بـ (الخطة الأفضل) أو ما شابه ذلك. استخدم أداة المستطيل ذي الحوافّ المدوّرة (U) وارسم شكلاً بالأبعاد 250px في 290px، ثم طبّق نفس التأثيرات الّتي طبّقتها على الطّبقة الأساسيّة. الخطوة 5كرّر الخطوة 3، باستثناء تلوين التّرويسة بلون رماديّ غامق (#d1d1d1). الخطوة 6سنستخدم نوعين من الخطوط في جدول التّسعير، (Open Sans) و (Helvetica)، استخدم الوزن متوسّط السّماكة لخط (Open Sans) في اسم الخطّة في قسم التّرويسة. الخطوة 7استخدم الخط (Helvetica) في قائمة الأسعار لكلّ خطّة، وبما أنّنا نرغب في تمييز (الخطة المتقدّمة)، سنعطي وسم السّعر لونًا أحمر برّاقًا. الخطوة 8ننتقل الآن إلى قسم (المحتوى)، والّذي سيحتوي على ثلاث مزايا ستقدّمها لزبائنك، وسيكون ذا بنية جميلة وبسيطة. سنستخدم خطّ (Open Sans)، سيكون خطّ الأرقام بحجم 24pt سميك، أما خطّ النّصوص سيكون بحجم 14pt عاديّ. ستكون المزايا مفصولة عن بعضها البعض بخطوط منقّطة، ويمكن استبدالها بكلّ سهولة بخطّ بسيط. الخطوة 9يجب أن تحتوي كل خطّة على زرّ يمكن للزّبون ومن خلال الضّغط عليه أن يتّخذ إجراءً تجاه الخطّة، سواء كان هذا الإجراء هو الحصول على معلومات أوسع عن هذه الخطّة، الاستئناف أو الدفع. باستخدام أداة المستطيل ذي الحوافّ المدوّرة (U)، ارسم مستطيلاً رماديّ اللّون، وأضف إليه تأثير الظلّ بلون رماديّ غامق. الخطوة 10طبّق تأثير التدرّج اللوني Gradient Overlay واختر نمط المزج Soft Light، والشّفافية بمقدار 40%. الخطوة 11أضف إلى الزرّ حدًّا خارجيًّا من النّوع المتدرّج Gradient. الخطوة 12مستخدمًا الخطّ (Open Sans Bold) وبحجم 24pt، أضف بعض الكلمات إلى الزرّ، سنضيف عبارة (Choose Plan). ضاعف قسمي (المحتوى) و(وزرّ الإجراء) مرّتين، وضعهما في المكان المخصّص لكلّ منهما. يمكنك الرجوع إلى الشّكل النهائيّ لمعرفة الأماكن المخصّصة لهذين القسمين. الخطوة 13لا تختلف (الخطّة المتقدمة) عن الخطط الأخرى سوى أنّ لون وسم السّعر وزرّ الإجراء أكثر بريقًا. زرّ الإجراء الأحمر مشابه بشكل كبير للأزرار الرماديّة، ولكنّه يختلف عنها بلونه الأساسيّ #ed161c، ولون الحدّ الخارجيّ المبيّن في الصّورة أدناه. الخطوة 14أخيرًا، غيّر ألوان الحدّ الخارجيّ من الألوان الرماديّة إلى الألوان الحمراء التّالية. النتيجة النهائية ترجمة -وبتصرف- للدرس Create a Pricing Table Using Photoshop in bout 20 Minutes لصاحبه Dainis Graveris.1 نقطة


