

نتعرف في هذا الفصل إلى العرض View وتعابير الجداول الشائعة CTE التي تساهم في تحسين طريقة كتابة الاستعلامات، وذلك يجعلها أقصر وأسهل قراءةً، وسنتعلم استخدام دوال النوافذ Window Functions التي تسمح بإجراء عمليات تجميعية على مجموعة جزئية من الأسطر، كما سنتعرف على الفهارس وأهميتها في تسريع البحث ضمن البيانات.
العرض View
هو جدول منطقي يقوم بوصل أجزاء البيانات الأساسية تلقائيًا، فهو لا يقوم بتكرار البيانات ولا الاحتفاظ فيها، بل يعيد ترتيبها لعرضها فقط.
وتكمن فوائد استخدام العرض في تبسيط نموذج البيانات عند الحاجة إلى تقديمه للآخرين للعمل عليه، كما يمكن استخدامه لتبسيط العمل بالبيانات الخاصة بك.
وإذا وجدت نفسك تدمج نفس المجموعة من البيانات بشكل متكرر فيمكن للعرض تسهيل هذه العملية بدلًا من تكرارها عدة مرات.
وكذلك عند العمل مع أشخاص غير تقنيين ليسوا على دراية بلغة SQL يكون العرض هو الطريقة المُثلى لتقديم البيانات غير المنتظمة.
طريقة عمل العرض
فنلقِ نظرةً على الجداول التالية أولًا:
- جدول أقسام الشركة:
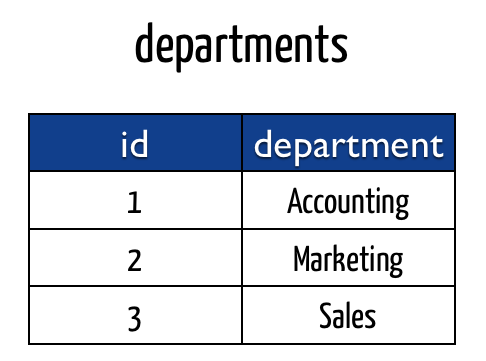
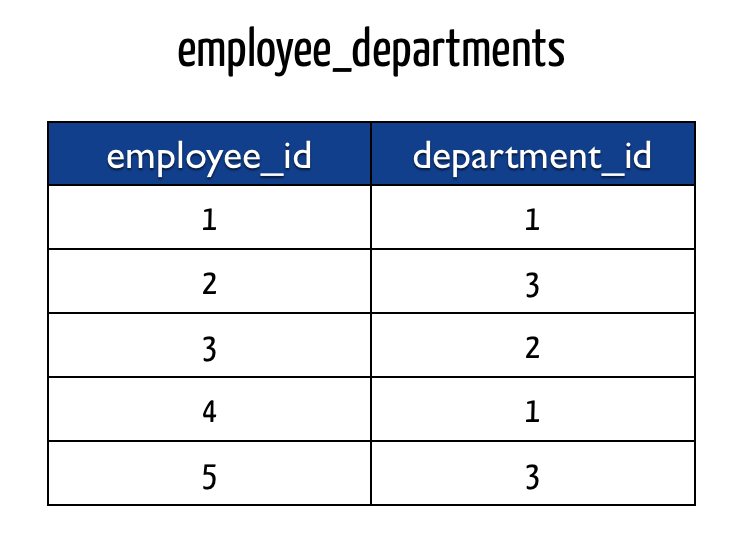
- الجدول الذي يحدد انتماء الموظف إلى قسم معين:
- جدول الموظفين:
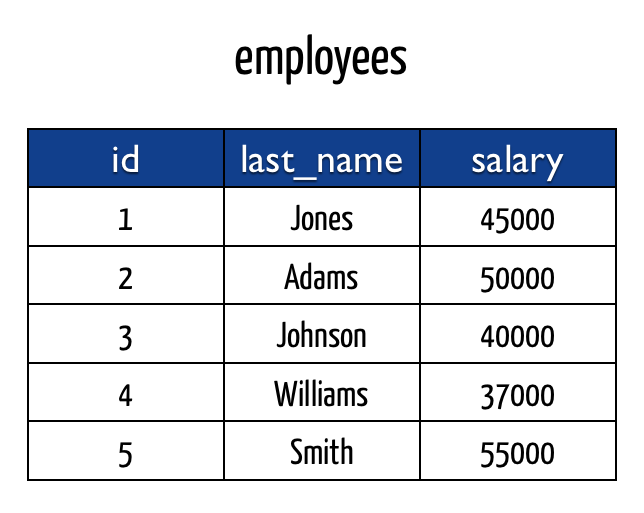
يمكنك نسخ التعليمات التالية لإنشاء الجداول وإدخال البيانات المذكورة في الصور السابقة.
CREATE TABLE departments( id serial PRIMARY KEY, department VARCHAR (50) UNIQUE NOT NULL ); INSERT INTO departments (department) VALUES ('Accounting'),('Marketing'),('Sales');
CREATE TABLE employees( id serial PRIMARY KEY, last_name VARCHAR (50) NOT NULL, salary int NOT NULL ); INSERT INTO employees (last_name,salary) VALUES ('Jones',45000),('Adams',50000),('Johnson',40000),('Williams',37000),('Smith',55000);
CREATE TABLE employee_departments( employee_id int NOT NULL, department_id int NOT NULL ); INSERT INTO employee_departments VALUES (1,1),(2,3),(3,2),(4,1),(5,3);
وللتأكد من أن الجداول أُنشئت على الوجه الصحيح وأُدخلت البيانات كما هو مخطط، فسنستعرض الجداول كما يلي:
hsoubguide=# SELECT * FROM departments; id | department ----+------------ 1 | Accounting 2 | Marketing 3 | Sales (3 rows)
hsoubguide=# SELECT * FROM employees; id | last_name | salary ----+-----------+-------- 1 | Jones | 45000 2 | Adams | 50000 3 | Johnson | 40000 4 | Williams | 37000 5 | Smith | 55000 (5 rows)
hsoubguide=# SELECT * FROM employee_departments ;
employee_id | department_id
-------------+---------------
1 | 1
2 | 3
3 | 2
4 | 1
5 | 3
(5 rows)
نهدف في المثال التالي إلى عرض أسماء الموظفين مع رواتبهم والقسم الذي ينتمون إليه، وللقيام بذلك سنكتب الاستعلام التالي:
SELECT employees.last_name, employees.salary, departments.department FROM employees, employee_departments, departments WHERE employees.id = employee_departments.employee_id AND departments.id = employee_departments.department_id;
وتكون المخرجات كما يلي:
last_name | salary | department -----------+--------+------------ Jones | 45000 | Accounting Adams | 50000 | Sales Johnson | 40000 | Marketing Williams | 37000 | Accounting Smith | 55000 | Sales (5 rows)
إذا أمعنت النظر في الجدول السابق في المخرجات، قد تتمنى لو أنه مخزّن في الذاكرة بالفعل، فبدلًا من القيام بالعديد من عمليات الربط من هذا الجدول أو ذاك، كان يمكن أن نتعامل مع هذا الجدول مباشرةً بدلًا من كتابة الاستعلام الطويل ذاك في كل مرة نريد استعراض الموظفين مع رواتبهم وأقسامهم، ولكن في الحقيقة، يمكننا إنشاء جدول وهمي عن طريق العرض View لتحقيق هذه الأمنية، كما يلي:
CREATE OR REPLACE VIEW employee_view AS SELECT employees.last_name, employees.salary, departments.department FROM employees, employee_departments, departments WHERE employees.id = employee_departments.employee_id AND departments.id = employee_departments.department_id;
يمكن الآن القيام باستعلام على الجدول الافتراضي الجديد مباشرًة:
SELECT * FROM employee_view;
وستظهر البيانات بشكل مشابه لعملية الربط التي قمنا بها سابقًأ كما يلي:
last_name | salary | department -----------+--------+------------ Jones | 45000 | Accounting Adams | 50000 | Sales Johnson | 40000 | Marketing Williams | 37000 | Accounting Smith | 55000 | Sales (5 rows)
كما يمكننا التعامل مع هذا الجدول المنطقي وكأنه جدول حقيقي، فمثلًا يمكننا الاستعلام عن أسطر هذا الجدول مع ترشيحها أو القيام بأي عملية أخرى تتم على الجداول العادية المخزنة كما في المثال التالي:
hsoubguide=# SELECT * FROM employee_view WHERE salary > 40000; last_name | salary | department -----------+--------+------------ Jones | 45000 | Accounting Adams | 50000 | Sales Smith | 55000 | Sales (3 rows)
والآن صار بالإمكان تبسيط الاستعلامات الطويلة المتكررة والمتداخلة عن طريق استخدام العرض.
عبارات الجداول الشائعة (CTE)
تشبه عبارات الجداول الشائعة CTE العرض View في بعض النواحي، فهي نتيجة مؤقتة لاستعلام سابق، يمكننا القيام بعمليات استعلام عليها مرة آخرى دون أن يكون لها وجود دائم في الذاكرة.
فهي تشكل جدولًا افتراضيًّا جديدًا ناتجًا عن الاستعلام الأول، ويمكننا القيام بعمليات على هذا الجدول، دون أن يكون له تخزين دائم في الذاكرة.
الاستخدام الأساسي لها هو تبسيط الاستعلامات المعقدة، أو الاستعلامات التي تربط عدة جداول معًا، وذلك بعمل هذا الجدول الافتراضي الوسيط أولًا، ثم القيام بالعمليات عليه بعد ذلك أو عمل جدول وسيط آخر حتى الوصول إلى النتائج المطلوبة.
سنبدأ باستعلام بسيط من الجدول products عن المنتجات التي توجد ضمن تصنيف Book أو TV كما يلي:
hsoubguide=# SELECT title,price
hsoubguide-# FROM products
hsoubguide-# WHERE tags[1]='Book' OR tags[2]='TV';
title | price
---------------+--------
Dictionary | 9.99
Python Book | 29.99
Ruby Book | 27.99
Baby Book | 7.99
Coloring Book | 5.99
42" LCD TV | 499.00
42" Plasma TV | 529.00
Python Book | 29.99
(8 rows)
والآن، لنفترض أننا لما نظرنا إلى الجدول الناتج عن الاستعلام، شعرنا بالحاجة إلى المزيد من التصفية، فأردنا مثلًا الاستعلام عن العناصر التي سعرها أكبر من 10 مع ترتيبها حسب الاسم، وإظهار 5 عناصر فقط.
عندها سنضيف العبارة التالية إلى الاستعلام السابق:
AND price>10 ORDER BY title LIMIT 5;
ليصبح الاستعلام الكامل:
hsoubguide=# SELECT title,price
hsoubguide=# FROM products
hsoubguide=# WHERE (tags[1]='Book' OR tags[2]='TV')
hsoubguide=# AND price>10
hsoubguide=# ORDER BY title
hsoubguide=# LIMIT 5;
title | price
---------------+--------
42" LCD TV | 499.00
42" Plasma TV | 529.00
Python Book | 29.99
Python Book | 29.99
Ruby Book | 27.99
(5 rows)
يمكننا تحويل الاستعلام السابق إلى مرحلتين، الأولى هي عبارة جداول شائعة CTE، والثانية هي استعلام من الجدول الناتج عن عبارة الجداول الشائعة، وذلك كما يلي:
hsoubguide=# WITH small_cte AS(
hsoubguide-# SELECT title,price
hsoubguide-# FROM products
hsoubguide-# WHERE (tags[1]='Book' OR tags[2]='TV')
hsoubguide-# )
hsoubguide-# SELECT * FROM small_cte
hsoubguide-# WHERE price>10
hsoubguide-# ORDER BY title
hsoubguide-# LIMIT 5;
title | price
---------------+--------
42" LCD TV | 499.00
42" Plasma TV | 529.00
Python Book | 29.99
Python Book | 29.99
Ruby Book | 27.99
(5 rows)
بعد أن فهمنا طريقة استخدام تعابير الجداول الشائعة، لا بد أن سؤالًا مهمًا يخطر لنا، وهو الفرق بينها وبين العرض View، والفرق بسيط، فتعابير الجداول الشائعة تُنشأ أثناء الاستعلام، بينما تُنشأ العروض مسبقًا، وتُخزّن ككائنات في قاعدة البيانات (دون تخزين الجدول الناتج عنها بالطبع كما ذكرنا من قبل) حيث يمكن استخدامها مرات عديدة، لذلك يُطلق على تعابير الجداول الشائعة أحيانًا العروض المؤقتة أو العروض الآنية.
استخدام عدة تعابير شائعة معًا
سننشئ جدولين بسيطين لتوضيح هذه الفكرة كما يلي:
hsoubguide=# CREATE TABLE test_1( hsoubguide(# id INT, hsoubguide(# value varchar(20) hsoubguide(# ); CREATE TABLE
hsoubguide=# CREATE TABLE test_2( hsoubguide(# id INT, hsoubguide(# test_1_id INT, hsoubguide(# value varchar(20) hsoubguide(# ); CREATE TABLE
في كل من الجدولين، عمود رقم معرف، وعمود للقيمة، وفي الجدول الثاني عمود فيه ربط مع أحد أسطر الجدول الأول من خلال الرقم المعرف الخاص به.
hsoubguide=# INSERT INTO test_1 hsoubguide-# VALUES(1,'aaa'),(2,'bbb'),(3,'ccc'); INSERT 0 3
hsoubguide=# INSERT INTO test_2 hsoubguide-# VALUES(1,3,'AAA'),(2,1,'BBB'),(3,3,'CCC'); INSERT 0 3
hsoubguide=# SELECT test_1.value as v1,test_2.value as v2 hsoubguide-# FROM test_1,test_2 hsoubguide-# WHERE test_1.id=test_2.test_1_id; v1 | v2 -----+----- aaa | BBB ccc | CCC ccc | AAA (3 rows)
يمكن ربط التعابير الشائعة مع بعضها كما، بحيث يكون التعبير الثاني مستخدمًا للجدول الناتج عن التعبير الأول كما في المثال التالي:
hsoubguide=# WITH cte1 AS( hsoubguide-# SELECT test_1.value AS V1,test_2.value AS v2 hsoubguide-# FROM test_1,test_2 hsoubguide-# WHERE test_1.id=test_2.test_1_id) hsoubguide-# ,cte2 AS( Hsoubguide-# SELECT * FROM cte1 hsoubguide-# WHERE v1='ccc') hsoubguide-# SELECT * FROM cte2 ORDER BY v2 DESC; v1 | v2 -----+----- ccc | CCC ccc | AAA (2 rows)
هناك الكثير مما يمكن الاستفادة منه باستخدام تعابير الجداول الشائعة عند استخدامها مع الربط أو دوال النوافذ التي سنتعرف عليها في الفقرة التالية.
دوال النوافذ
تقوم دوال النوافذ (Window Functions) بإجراء عملية حسابية على مجموعة من أسطر الجدول التي لها علاقة محددة مع السطر الحالي، وهذا يشابه إلى حد ما العمليات الحسابية التي قمنا بها باستخدام العمليات التجميعية COUNT و SUM وغيرها، إلا أن استخدام دوال النوافذ لا يسبب تجميع النتيجة في سطر واحد، بل تحافظ الأسطر على ذاتها، وخلف الكواليس تقوم دوال النوافذ بالوصول إلى الأسطر اللازمة للقيام بالعملية الحسابية.
لا بد أن الشرح السابق سيتضح أكثر مع الأمثلة على أي حال.
فلنلقِ نظرة على الجدول التالي:

للحصول على جدول مماثل للجدول السابق، يمكنك تطبيق العرض الذي استخدمناه في الفقرة السابقة:
CREATE OR REPLACE VIEW employee_view AS SELECT employees.last_name, employees.salary, departments.department FROM employees, employee_departments, departments WHERE employees.id = employee_departments.employee_id AND departments.id = employee_departments.department_id;
ثم الاستعلام عنه كما تعلمنا سابقًا:
hsoubguide=# SELECT * hsoubguide-# FROM employee_view; last_name | salary | department -----------+--------+------------ Jones | 45000 | Accounting Adams | 50000 | Sales Johnson | 40000 | Marketing Williams | 37000 | Accounting Smith | 55000 | Sales (5 rows)
في المثال التالي، سنحاول استخراج مجموع الرواتب التي تُصرف في كل قسم وذلك باستخدام دالة التجميع SUM والتوجيه GROUP BY:
SELECT department ,sum(salary) AS department_salary_sum FROM employee_view GROUP BY department;
وستكون المخرجات كما يلي:
department | department_salary_sum ------------+----------------------- Accounting | 82000 Sales | 105000 Marketing | 40000 (3 rows)
ولكن ماذا لو أردنا استعراض الجدول الأساسي هذا :
last_name | salary | department -----------+--------+------------ Jones | 45000 | Accounting Adams | 50000 | Sales Johnson | 40000 | Marketing Williams | 37000 | Accounting Smith | 55000 | Sales (5 rows)
مع إضافة عمودٍ جديد، فيه مجموع الرواتب في القسم الخاص بالموظف المذكور في ذلك السطر، هل يمكننا كتابة الاستعلام التالي:
SELECT last_name,salary,department,SUM(salary) FROM employee_view GROUP BY department;
للأسف، لا يمكننا القيام بذلك، وسيظهر الخطأ التالي:
ERROR: column "employee_view.last_name" must appear in the GROUP BY clause or be used in an aggregate function LINE 1: SELECT last_name,salary,department,SUM(salary)
ينص الخطأ على أن أي عمود غير مذكور ضمن عبارة GROUP BY أو ضمن دالة التجميع فإنه لا يمكن عرضه، وهذا منطقي، لأن دالة التجميع والعبارة GROUP BY هدفها التجميع، أي اختصار الأسطر وإظهار نتائج الاختصار.
وهنا تأتي أهمية دوال النوافذ، فالآن سنستخدم التابع SUM ولكن لن نقوم بكتابة GROUP BY، بل سنستبدلها بالعبارة OVER (PARTITION BY department) وتعني أن عملية الجمع ستتم على جزء من الجدول مقسّم حسب قيمة العمود department كما يلي :
hsoubguide2=# SELECT hsoubguide2-# last_name, hsoubguide2-# salary, hsoubguide2-# department, hsoubguide2-# SUM(salary) hsoubguide2-# OVER (PARTITION BY department) hsoubguide2-# FROM employee_view; last_name | salary | department | sum -----------+--------+------------+-------- Jones | 45000 | Accounting | 82000 Williams | 37000 | Accounting | 82000 Johnson | 40000 | Marketing | 40000 Adams | 50000 | Sales | 105000 Smith | 55000 | Sales | 105000 (5 rows)
تقوم العبارة PARTITION BY بتقسيم الجدول إلى مجموعات حسب العمود المذكور ضمن هذه العبارة، ثم يتم تنفيذ الدالة المذكورة على هذه المجموعات، وحفظ الناتج لعرضه في العمود الخاص بالدالة.
عدة دوال نوافذ في استعلام واحد
يمكننا استخدام العديد من توابع النوافذ، ولكن يجب إضافة عبارة OVERخاصة بكل استدعاء من الاستدعاءات، كما في المثال التالي:
hsoubguide2=# SELECT last_name,salary,department, hsoubguide2=# AVG(salary) OVER (PARTITION BY department), hsoubguide2=# SUM(salary) OVER (PARTITION BY salary/10000) hsoubguide2=# FROM employee_view; last_name | salary | department | avg | sum -----------+--------+------------+--------------------+-------- Jones | 45000 | Accounting | 41000.000000000000 | 82000 Williams | 37000 | Accounting | 41000.000000000000 | 82000 Johnson | 40000 | Marketing | 40000.000000000000 | 40000 Adams | 50000 | Sales | 52500.000000000000 | 105000 Smith | 55000 | Sales | 52500.000000000000 | 105000 (5 rows)
ولكن في حال كنا نرغب في استخدام نفس النافذة لتنفيذ عدة دوال عليها، فيمكننا تعريف النافذة في نهاية الاستعلام لمرة واحدة، واستخدامها عن طريق اسمٍ مستعارٍ لها، كما في المثال التالي:
hsoubguide2=# SELECT last_name,salary,department, hsoubguide2=# AVG(salary) OVER my_window, hsoubguide2=# SUM(salary) OVER my_window hsoubguide2=# FROM employee_view hsoubguide2=# WINDOW my_window AS (PARTITION BY department); last_name | salary | department | avg | sum -----------+--------+------------+--------------------+-------- Jones | 45000 | Accounting | 41000.000000000000 | 82000 Williams | 37000 | Accounting | 41000.000000000000 | 82000 Johnson | 40000 | Marketing | 40000.000000000000 | 40000 Adams | 50000 | Sales | 52500.000000000000 | 105000 Smith | 55000 | Sales | 52500.000000000000 | 105000 (5 rows)
ملاحظة: في حال أردنا إعطاء العمود الحاوي على نتائج دالة النافذة اسمًا مستعارًا باستخدام AS فيجب وضعها بعد عبارة OVER كما يلي:
hsoubguide2=# SELECT last_name,salary,department, hsoubguide2=# AVG(salary) OVER (PARTITION BY department) AS avg_department_salary, hsoubguide2=# SUM(salary) OVER (PARTITION BY department) AS sum_department_salary hsoubguide2=# FROM employee_view; last_name | salary | department | avg_department_salary | sum_department_salary -----------+--------+------------+-----------------------+----------------------- Jones | 45000 | Accounting | 41000.000000000000 | 82000 Williams | 37000 | Accounting | 41000.000000000000 | 82000 Johnson | 40000 | Marketing | 40000.000000000000 | 40000 Adams | 50000 | Sales | 52500.000000000000 | 105000 Smith | 55000 | Sales | 52500.000000000000 | 105000 (5 rows)
مثال ممتع باستخدام دوال النافذة
سنقوم في هذا المثال بإضافة عمود إلى الجدول، فيه مجموع رواتب الموظفين مجزّأة حسب الحرف الأول من أسمائهم الأخيرة.
فإذا كان هناك موظفان اسماهما الأخيرة بالحرف J سيكونان في نفس النافذة، ويتم حساب مجموع رواتبهما وإخراجه إلى جانب اسميهما.
وللقيام بذلك، سنستخدم التابع LEFT الذي يأخذ وسيطين، الأول هو اسم العمود والثاني هو عدد الحروف بدءًا من اليسار التي نريد اقتطاعها.
وستكون عبارة تجزئة النوافذ كما يلي:
OVER (PARTITION BY LEFT(last_name,1))
ولكننا نريد أيضًا أن تكون المخرجات ليست فقط مجموع رواتب الأشخاص المتشابهين في الحرف الأول من اسمهم الأخير، بل نريد إضافة هذا الحرف قبل مجموع الرواتب، كي تكون المخرجات واضحة، فبدلًا من أن يظهر لنا العدد 50000 مثلًا، نريد أن يخرج A:50000.
وللقيام بذلك، سنستخدم عملية وصل النصوص || وبدلًا من أن نطلب في الاستعلام إخراج ناتج العملية SUM(salary) سنطلب في الاستعلام العبارة التالية:
LEFT(last_name,1) || ':' || SUM(salary)
وبذلك يكون لدينا الاستعلام التالي:
hsoubguide2=# SELECT last_name,salary,department, hsoubguide2=# LEFT(last_name,1) || ':' || SUM(salary) hsoubguide2=# OVER (PARTITION BY LEFT(last_name,1)) hsoubguide2=# AS Salary_sum_by_letter hsoubguide2=# FROM employee_view; last_name | salary | department | salary_sum_by_letter -----------+--------+------------+---------------------- Adams | 50000 | Sales | A:50000 Jones | 45000 | Accounting | J:85000 Johnson | 40000 | Marketing | J:85000 Smith | 55000 | Sales | S:55000 Williams | 37000 | Accounting | W:37000 (5 rows)
دالة النافذة rank
يمكننا استخدام دالة النافذة rank لإنتاج رقم ترتيبي للأسطر ضمن التقسيم الذي قمنا به، فلو أردنا مثلًا إنتاج رقم لترتيب الموظفين حسب رواتبهم تصاعديًّا، نكتب الاستعلام التالي:
hsoubguide2=# SELECT last_name,salary,department, hsoubguide2=# rank() OVER (ORDER BY salary) hsoubguide2=# FROM employee_view; last_name | salary | department | rank -----------+--------+------------+------ Williams | 37000 | Accounting | 1 Johnson | 40000 | Marketing | 2 Jones | 45000 | Accounting | 3 Adams | 50000 | Sales | 4 Smith | 55000 | Sales | 5 (5 rows)
ويمكننا إنتاج رقم ترتيبي للموظفين حسب رواتبهم، ولكن لكل قسم على حدة، وذلك باستخدام العبارة PARTITION BY كما يلي:
hsoubguide2=# SELECT last_name,salary,department, hsoubguide2=# rank() OVER (PARTITION BY department ORDER BY salary) hsoubguide2=# FROM employee_view; last_name | salary | department | rank -----------+--------+------------+------ Williams | 37000 | Accounting | 1 Jones | 45000 | Accounting | 2 Johnson | 40000 | Marketing | 1 Adams | 50000 | Sales | 1 Smith | 55000 | Sales | 2 (5 rows)
نريد الآن إيجاد الموظفين الأعلى راتبًا في كل قسم، ولذلك سنقوم بإنشاء عرض جديد، للحفاظ على الجدول الناتج عن الاستعلام السابق ولكن سنخزّنه بترتيب معكوس، بحيث يكون الموظف الأعلى راتبًا له قيمة rank تساوي 1 كما يلي:
hsoubguide2=# CREATE OR REPLACE VIEW employee_rank AS hsoubguide2-# SELECT last_name,salary,department, hsoubguide2-# rank() OVER (PARTITION BY department ORDER BY salary DESC) hsoubguide2-# FROM employee_view; CREATE VIEW
أصبح بإمكاننا الآن تنفيذ استعلامات على الجدول الافتراضي الجديد employee_rank كما يلي:
hsoubguide2=# SELECT * FROM employee_rank WHERE rank=1; last_name | salary | department | rank -----------+--------+------------+------ Jones | 45000 | Accounting | 1 Johnson | 40000 | Marketing | 1 Smith | 55000 | Sales | 1 (3 rows)
يمكن استعراض وثائق Postgres للمزيد من التعمق في دوال النوافذ.
الفهارس Indexes
الفهرس Index هو بنية محددة تنظّم مرجعًا للبيانات مما يجعلها أسهل في البحث، وبكون الفهرس في Postgres نسخةً من العنصر المُراد فهرسته مع مرجع إلى موقع البيانات الفعلي.
تقوم Postgres عند استعلام البيانات باستخدام الفهارس إن كانت متاحة وإلا فهي تقوم بمسحٍ متتالٍ (sequential scan)، حيث يتم فيه البحث عبر جميع البيانات قبل إرجاع نتيجة.
يحقق استخدام الفهارس سرعة كبيرة في البحث والاستعلام، فإضافة عمود فهرس إلى الجدول ستسرّع غالبًا الوصول إلى البيانات، إلا أنّه بالمقابل سيؤدي إلى تبطيئ إدخال البيانات، وذلك لأن عملية الإدخال ستتضمن كتابة بيانات في مكانين مختلفين مع المحافظة على ترتيب الفهرس ضمن البيانات السابقة.
يجب الانتباه إلى نوع البيانات المستخدمة كفهرس، فالفهرسة على أساس الأرقام أو الطابع الزمني فعالة، بينما يُعدّ استخدام النصوص كفهارس غير فعّال.
لنأخذ مثالا عمليًّا بوضع فهرس للجدول employees (الذي عرضناه في بداية المقال):
CREATE INDEX idx_salary ON employees(salary);
يُمكن استخدام عدة أعمدة كفهارس في الوقت نفسه، فإن كنت تقوم بتصفية نتائج الجداول باستخدام أعمدة محددة، فيمكنك إنشاء فهارس منها كما يلي:
CREATE INDEX idx_salary ON employees(last_name, salary);
نصائح عند استخدام الفهارس
إنشاء الفهارس آنيًّا
عندما تقوم Postgres بإنشاء الفهارس (كما في أنظمة قواعد البيانات الأخرى) فإنها تقوم بقفل الجدول أثناء بناء الفهرس، وهذا يمنع إضافة المزيد من البيانات إلى الجدول. فإن كانت كمية البيانات صغيرة فإن العملية لن تستغرق الكثير من الوقت، ولكنّها ستسبب إعاقةً كبيرة للعمل على هذا الجدول إن كانت كمية البيانات كبيرة جدًا ومن ثمّ فستكون مدة قفل الجدول أطول.
وهذا يعني أنه للحصول على تحسين في كفاءة قاعدة البيانات لا بدّ من إيقاف العمل على قاعدة البيانات لمدة محددة، على الأقل للجدول الذي يتم إنشاء الفهرس له.
إلا أن Postgres تتيح إمكانية إنشاء الفهرس دون قفل الجدول، وذلك باستخدام CREATE INDEX CONCURRENTLY كما في المثال التالي:
CREATE INDEX CONCURRENTLY idx_salary ON employees(last_name, salary);
عندما يكون الفهرس أذكى منك
إن استخدام الفهرس ليس هو الحل الأسرع دومًا، فمثلًا إن كانت نتيجة الاستعلام ستعيد نسبة كبيرة من بيانات الجدول، فإن المرور على جميع بيانات الجدول أسرع في هذه الحال من استخدام الفهرس، لذا عليك الوثوق بأن Postgres ستقوم بالأمر الصحيح فيما يتعلق بسرعة الاستعلام سواء كان استخدام الفهرس أو غيره.
فهرسة النوع JSONB
إن طريقة الفهرسة الأكثر مرونة وقوة هي استخدام فهرس GIN، حيث يقوم GIN بفهرسة كل عمود ومفتاح ضمن مستند JSONB، ويمكن إضافته كما في المثال التالي:
CREATE INDEX idx_products_attributes ON products USING GIN (attributes);
المفاتيح الخارجية والفهارس
في بعض أنظمة الربط العلائقي للكائنات Object relational mapping، يؤدي إنشاء مفتاح خارجي (Foreign Key) إلى إنشاء فهرس (index) أيضًا، وننوه هنا إلى أن Postgres لا تقوم تلقائيا بإنشاء فهرس عند إنشاء مفتاح خارجي، فهي خطوة منفصلة عليك الانتباه إليها عندما لا تستخدم ORM.
الخلاصة
نجحنا في هذا الفصل بجعل استعلاماتنا أقصر وأسهل قراءةً بفضل العرض View وتعابير الجداول الشائعة CTE، كما تعرفنا على دوال النوافذ Window Functions التي تسمح بالقيام بعمليات تجميعية تحتاج إلى لغة برمجة في العادة، كما تطرقنا إلى الفهارس وكيفية إنشائها.
اقرأ أيضًا
- المقال التالي: أنواع بيانات خاصة في قواعد بيانات Postgres
- المقال السابق: استخدام أساسيات SQL في Postgres
- النسخة الكاملة لكتاب الدليل العملي إلى قواعد بيانات PostgreSQL
- كيفيّة حماية PostgreSQL من الهجمات المُؤتمتة (Automated Attacks)











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.