

لدى أقسام علوم الحاسوب هوس غير طبيعي بخوارزميات الترتيب، فبناءً على الوقت الذي يمضيه طلبة علوم الحاسوب في دراسة هذا الموضوع، قد تظن أن الاختيار ما بين خوارزميات الترتيب هو حجر الزاوية في هندسة البرمجيات الحديثة. واقع الأمر هو أن مطوري البرمجيات قد يقضون سنوات قد تصل إلى مسارهم المهني بأكمله دون التفكير في طريقة حدوث عملية الترتيب، فهم يَستخدِمون في كل التطبيقات تقريبًا الخوارزمية متعددة الأغراض التي توفِّرها اللغة أو المكتبة التي يستخدمونها، والتي تكون كافيةً في معظم الحالات.
لذلك لو تجاهلت هذه المقالة ولم تتعلم أي شيء عن خوارزميات الترتيب، فما يزال بإمكانك أن تصبح مُطوِّر برمجيات جيدًا، ومع ذلك، هناك عدة أسباب قد تدفعك لقراءته:
- على الرغم من وجود خوارزميات متعددة الأغراض يُمكِنها العمل بشكل جيد في غالبية التطبيقات، هنالك خوارزميّتان مُتخصّصتان قد تحتاج إلى معرفة القليل عنهما: الترتيب بالجذر radix sort والترتيب بالكومة المقيدّة bounded heap sort.
- تُعدّ خوارزمية الترتيب بالدمج merge sort المثال التعليميّ الأمثل، فهي تُوضِّح استراتيجية "قسِّم واغزُ divide and conquer" المهمة والمفيدة في تصميم الخوارزميات. بالإضافة إلى ذلك، ستتعلم عن ترتيب نمو order of growth لم تَرَهُ من قبل، هو ترتيب النمو "الخطي-اللوغاريتمي linearithmic". ومن الجدير بالذكر أن غالبية الخوارزميات الشهيرة تكون عادةً خوارزميّاتٍ هجينةً وتستخدم بشكلٍ أو بآخر فكرة الترتيب بالدمج.
- أحد الأسباب الأخرى التي قد تدفعك إلى تعلم خوارزميات الترتيب هي مقابلات العمل التقنية، فعادةً ما تُسأل خلالها عن تلك الخوارزميات. إذا كنت تريد الحصول على وظيفة، فسيُساعدك إظهار اطلاعك على أبجديات علوم الحاسوب.
سنُحلِّل في هذا الفصل خوارزمية الترتيب بالإدراج insertion sort، وسننفِّذ خوارزمية الترتيب بالدمج، وأخيرًا، سنشرح خوارزمية الترتيب بالجذر، وسنكتب نسخةً بسيطةً من خوارزمية الترتيب بالكومة المُقيّدة.
الترتيب بالإدراج Insertion sort
سنبدأ بخوارزمية الترتيب بالإدراج، لأنها بسيطة ومهمة. على الرغم من أنها ليست الخوارزمية الأكفأ إلا أنها تملك بعض الميزات المتعلقة بتحرير الذاكرة كما سنرى لاحقًا.
لن نشرح هذه الخوارزمية هنا، ولكن يُفضّلُ لو قرأت مقالة ويكيبيديا عن الترتيب بالإدراج Insertion Sort، فهي تحتوي على شيفرة وهمية وأمثلة متحركة. وبعدما تفهم فكرتها العامة يمكنك متابعة القراءة هنا.
تَعرِض الشيفرة التالية تنفيذًا بلغة جافا لخوارزمية الترتيب بالإدراج:
public class ListSorter<T> { public void insertionSort(List<T> list, Comparator<T> comparator) { for (int i=1; i < list.size(); i++) { T elt_i = list.get(i); int j = i; while (j > 0) { T elt_j = list.get(j-1); if (comparator.compare(elt_i, elt_j) >= 0) { break; } list.set(j, elt_j); j--; } list.set(j, elt_i); } } }
عرَّفنا الصنف ListSorter ليَعمَل كحاوٍ لخوارزميات الترتيب. نظرًا لأننا استخدمنا معامل نوع type parameter، اسمه T، ستتمكَّن التوابع التي سنكتبها من العمل مع قوائم تحتوي على أي نوع من الكائنات.
يستقبل التابع insertionSort معاملين: الأول عبارة عن قائمة من أي نوع ممتدّ من الواجهة List والثاني عبارة عن كائن من النوع Comparator بإمكانه موازنة كائنات النوع T. يُرتِّب هذا التابع القائمة في نفس المكان أي أنه يُعدِّل القائمة الموجودة ولا يحتاج إلى حجز مساحة إضافية جديدة.
تَستدعِي الشيفرة التالية هذا التابع مع قائمة من النوع List تحتوي على كائنات من النوع Integer:
List<Integer> list = new ArrayList<Integer>( Arrays.asList(3, 5, 1, 4, 2)); Comparator<Integer> comparator = new Comparator<Integer>() { @Override public int compare(Integer elt1, Integer elt2) { return elt1.compareTo(elt2); } }; ListSorter<Integer> sorter = new ListSorter<Integer>(); sorter.insertionSort(list, comparator); System.out.println(list);
يحتوي التابع insertionSort على حلقتين متداخلتين nested loops، ولذلك، قد تظن أن زمن تنفيذه تربيعي، وهذا صحيحٌ في تلك الحالة، ولكن قبل أن تتوصل إلى تلك النتيجة، عليك أولًا أن تتأكّد من أن عدد مرات تنفيذِ كل حلقةٍ يتناسب مع حجم المصفوفة n.
تتكرر الحلقة الخارجية من 1 إلى list.size()، ولذلك تُعدّ خطيّةً بالنسبة لحجم القائمة n، بينما تتكرر الحلقة الداخلية من i إلى صفر، لذلك هي أيضًا خطيّة بالنسبة لقيمة n. بناءً على ذلك، يكون عدد مرات تنفيذ الحلقة الداخلية تربيعيًّا.
إذا لم تكن متأكّدًا من ذلك، انظر إلى البرهان التالي:
-
في المرة الأولى، قيمة
iتساوي 1، وتتكرر الحلقة الداخليّة مرةً واحدةً على الأكثر. -
في المرة الثانية، قيمة
iتساوي 2، وتتكرر الحلقة الداخليّة مرتين على الأكثر. -
في المرة الأخيرة، قيمة
iتساوي n-1، وتتكرر الحلقة الداخليّة عددًا قدره n-1 من المرات على الأكثر.
وبالتالي، يكون عدد مرات تنفيذ الحلقة الداخلية هو مجموع المتتالية 1، 2، … حتى n-1، وهو ما يُساوِي n(n-1)/2. لاحِظ أن القيمة الأساسية (ذات الأس الأكبر) بهذا التعبير هي n2.
يُعدّ الترتيب بالإدراج تربيعيًا في أسوأ حالة، ومع ذلك:
- إذا كانت العناصر مُرتَّبةً أو شبه مُرتَّبةٍ بالفعل، فإن الترتيب بالإدراج يكون خطّيًّا. بالتحديد، إذا لم يكن كل عنصرٍ أبعدَ من موضعه الصحيح مسافةً أكبرَ من k، فإن الحلقة الداخلية لن تُنفَّذ أكثر من عددٍ قدره k من المرات، ويكون زمن التنفيذ الكلي هو O(kn).
- نظرًا لأن تنفيذ تلك الخوارزمية بسيط، فإن تكلفته منخفضة، أي على الرغم من أن زمن التنفيذ يساوي a n2، إلا أن المعامل a قد يكون صغيرًا.
ولذلك، إذا عرفنا أن المصفوفة شبه مُرتَّبة أو إذا لم تكن كبيرةً جدًا، فقد يكون الترتيب بالإدراج خيارًا جيدًا، ولكن بالنسبة للمصفوفات الكبيرة، فهنالك خيارات أفضل بكثير.
تمرين 14
تُعدّ خوارزمية الترتيب بالدمج merge sort واحدةً من ضمن مجموعةٍ من الخوارزميات التي يتفوق زمن تنفيذها على الزمن التربيعيّ. ننصحك قبل المتابعة بقراءة مقالة ويكيبيديا عن الترتيب بالدمج merge sort. بعد أن تفهم الفكرة العامة للخوارزمية، يُمكِنك العودة لاختبار فهمك بكتابة تنفيذٍ لها.
ستجد ملفات الشيفرة التالية الخاصة بالتمرين في مستودع الكتاب:
نفِّذ الأمر ant build لتصريف ملفات الشيفرة ثم نفِّذ الأمر ant ListSorterTest. سيفشل الاختبار كالعادة لأن ما يزال عليك إكمال بعض الشيفرة.
ستجد ضمن الملف ListSorter.java شيفرةً مبدئيّةً للتابعين mergeSortInPlace و mergeSort:
public void mergeSortInPlace(List<T> list, Comparator<T> comparator) { List<T> sorted = mergeSortHelper(list, comparator); list.clear(); list.addAll(sorted); } private List<T> mergeSort(List<T> list, Comparator<T> comparator) { // TODO: fill this in! return null; }
يقوم التابعان بنفس الشيء، ولكنهما يوفران واجهاتٍ مختلفة. يَستقبِل التابع mergeSort قائمةً ويعيد قائمةً جديدةً تحتوي على نفس العناصر بعد ترتيبها ترتيبًا تصاعديًا. في المقابل، يُعدِّل التابع mergeSortInPlace القائمة ذاتها ولا يعيد أيّة قيمة.
عليك إكمال التابع mergeSort. ويمكنك بدلًا من كتابة نسخة تعاودية recursive بالكامل، أن تتبع الطريقة التالية:
- قسِّم القائمة إلى نصفين.
-
رتِّب النصفين باستخدام التابع
Collections.sortأو التابعinsertionSort. - ادمج النصفين المُرتَّبين إلى قائمة واحدة مُرتَّبة.
سيعطيك هذا التمرين الفرصة لتنقيح شيفرة الدمج دون التعامل مع تعقيدات التوابع التعاودية.
والآن أضف حالة أساسية base case. إذا كان لديك قائمة تحتوي على عنصر واحد فقط، يُمكِنك أن تعيدها مباشرةً لأنها نوعًا ما مُرتَّبة بالفعل، وإذا كان طول القائمة أقل من قيمة معينة، يُمكِنك أن تُرتِّبها باستخدام التابع Collections.sort أو التابع insertionSort. اختبر الحالة الأساسية قبل إكمال القراءة.
أخيرًا، عدِّل الحل واجعله يُنفِّذ استدعاءين تعاوديّين لترتيب نصفي المصفوفة. إذا عدلته بالشكل الصحيح، ينبغي أن ينجح الاختباران testMergeSort و testMergeSortInPlace.
تحليل أداء خوارزمية الترتيب بالدمج
لكي نصنف زمن تنفيذ خوارزمية الترتيب بالدمج، علينا أن نفكر بمستويات التعاود وبكمية العمل المطلوب في كل مستوى. لنفترض أننا سنبدأ بقائمةٍ تحتوي على عددٍ قدره n من العناصر. وفيما يلي خطوات الخوارزمية:
- نُنشِئ مصفوفتين وننسخ نصف العناصر إليهما.
- نُرتِّب النصفين.
- ندمج النصفين.
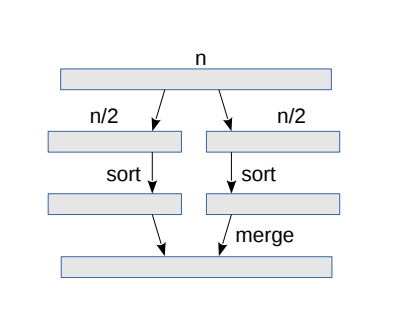
تنسخ الخطوة الأولى كل عنصر مرةً واحدةً، أي أنها خطّيّة. بالمثل، تنسخ الخطوة الثالثة كل عنصر مرةً واحدةً فقط، أي أنها خطّيّة كذلك. علينا الآن أن نُحدِّد تعقيد الخطوة الثانية. ستساعدنا على ذلك الصورة التالية التي تَعرِض مستويات التعاود.
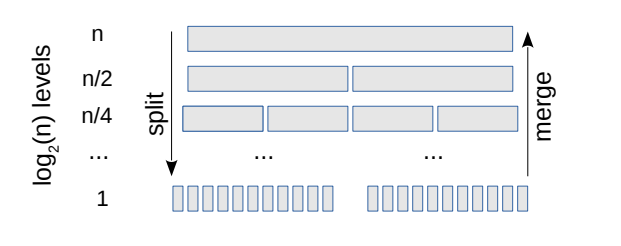
في المستوى الأعلى، سيكون لدينا قائمة واحدة مُكوَّنة من عددٍ قدره n من العناصر. للتبسيط، سنفترض أن n عبارة عن قيمة مرفوعة للأس 2، وبالتالي، سيكون لدينا في المستوى التالي قائمتان تحتويان على عدد n/2 من العناصر. ثمّ في المستوى التالي، سيكون لدينا 4 قوائم تحتوي على عدد قدره n/4 من العناصر، وهكذا حتى نصل إلى عدد n من القوائم تحتوي جميعها على عنصر واحد فقط.
لدينا إذًا عدد قدره n من العناصر في كل مستوى. أثناء نزولنا في المستويات، قسّمنا المصفوفات في كل مستوى إلى نصفين، وهو ما يستغرق زمنًا يتناسب مع n في كل مستوى، وأثناء صعودنا للأعلى، علينا أن ندمج عددًا من العناصر مجموعه n وهو ما يستغرق زمنًا خطيًا أيضًا.
إذا كان عدد المستويات يساوي h، فإن العمل الإجمالي المطلوب يساوي O(nh)، والآن، كم هو عدد المستويات؟ يُمكِننا أن نفكر في ذلك بطريقتين:
- كم عدد المرات التي سنضطر خلالها لتقسيم n إلى نصفين حتى نصل إلى 1.
- أو كم عدد المرات التي سنضطرّ خلالها لمضاعفة العدد 1 قبل أن نصل إلى n.
يُمكِننا طرح السؤال الثاني بطريقة أخرى: "ما هي قيمة الأس المرفوع للعدد 2 لكي نحصل على n؟".
بحساب لوغاريتم أساس 2 لكلا الطرفين، نحصل على التالي:
أي أن الزمن الكلي يساوي O(n log(n)). لاحظ أننا تجاهلنا قيمة أساس اللوغاريتم لأن اختلاف أساس اللوغاريتم يؤثر فقط بعامل ثابت، أي أن جميع اللوغاريتمات لها نفس ترتيب النمو order of growth.
يُطلَق أحيانًا على الخوارزميات التي تنتمي إلى O(n log(n)) اسم "خطي-لوغاريتمي linearithmic"، ولكن في العادة نقول "n log n".
في الواقع، يُعدّ O(n log(n)) الحد الأدنى من الناحية النظرية لخوارزميات الترتيب التي تَعتمد على موازنة العناصر مع بعضها البعض. يعني ذلك أنه لا توجد خوارزمية ترتيب بالموازنة ذات ترتيب نموٍّ أفضلَ من n log n.
ولكن كما سنرى في القسم التالي، هناك خوارزميات ترتيبٍ لا تعتمد على الموازنة وتستغرق زمنًا خطيًا.
خوارزمية الترتيب بالجذر Radix sort
أثناء الحملة الرئاسية في الولايات المتحدة الأمريكية لعام 2008، طُلِبَ من المرشح باراك أوباما Barack Obama تحليل أداء خوارزمية impromptu أثناء زيارته لمؤسسة جوجل Google. سأله الرئيس التنفيذي إريك شميدت Eric Schmidt مازحًا عن أكفأ طريقة لترتيب مليون عدد صحيح من نوع 32 بت. بدا أن أوباما كان قد اُخبرَ بذلك قبل اللقاء لأنه أجاب سريعًا "لا أظن أن خوارزمية ترتيب الفقاعات bubble sort ستكون الطريقة الأفضل". يُمكِنك مشاهدة فيديو لقاء أوباما مع إريك شميدت لو أردت.
كان أوباما على حق، فخوارزمية ترتيب الفقاعات bubble sort صحيحٌ أنها بسيطة وسهلة الفهم، لكنّها تستغرق زمنًا تربيعيًا، كما أن أداءها ليس جيدًا بالموازنة مع خوارزميات الترتيب التربيعية الأخرى.
ربما خوارزمية الترتيب بالجذر radix sort هي الإجابة التي كان ينتظرها شميدت، فهي خوارزمية ترتيب غير مبنيّة على الموازنة، كما أنها تَعمَل بنجاح عندما يكون حجم العناصر مقيّدًا كعدد صحيح من نوع 32 بت أو سلسلة نصية مُكوَّنة من 20 محرفًا.
لكي نفهم طريقة عملها، لنتخيل أن لدينا مكدّسًا stack من البطاقات، وكل واحدة منها تحتوي على كلمة مُكوَّنة من ثلاثة أحرف. ها هي الطريقة التي يُمكِن أن نرتب بها تلك البطاقات:
-
مرّ عبر البطاقات وقسمها إلى مجموعات بناءً على الحرف الأول، أي ينبغي أن تكون الكلمات البادئة بالحرف
aضمن مجموعة واحدة، يليها الكلمات التي تبدأ بحرفb، وهكذا. -
قسِّم كل مجموعة مرة أخرى بناءً على الحرف الثاني، بحيث تصبح الكلمات البادئة بالحرفين
aaمعًا، يليها الكلمات التي تبدأ بالحرفينab، وهكذا. لن تكون كل المجموعات مملوءةً بالتأكيد، ولكن لا بأس بذلك. - قسِّم كل مجموعة مرة أخرى بحسب الحرف الثالث.
والآن، أصبحت كل مجموعة مُكوَّنة من عنصر واحد فقط، كما أصبحت المجموعات مُرتَّبةً ترتيبًا تصاعديًا. تَعرِض الصورة التالية مثالًا عن الكلمات المكوَّنة من ثلاثة أحرف.

يَعرِض الصف الأول الكلمات غير المُرتَّبة، بينما يَعرِض الصف الثاني شكل المجموعات بعد اجتيازها للمرة الأولى. تبدأ كلمات كل مجموعة بنفس الحرف.
بعد اجتياز الكلمات للمرة الثانية، تبدأ كلمات كل مجموعة بنفس الحرفين الأوليين، وبعد اجتيازها للمرة الثالثة، سيكون هنالك كلمة واحدة فقط في كل مجموعة، وستكون المجموعات مُرتَّبة.
أثناء كل اجتياز، نمرّ عبر العناصر ونضيفها إلى المجموعات. يُعدّ كل اجتياز منها خطيًا طالما كانت تلك المجموعات تَسمَح بإضافة العناصر إليها بزمن خطي.
تعتمد عدد مرات الاجتياز -التي سنطلق عليها w- على عرض الكلمات، ولكنه لا يعتمد على عدد الكلمات n، وبالتالي، يكون ترتيب النمو O(wn) وهو خطي بالنسبة لقيمة n.
تتوفَّر نسخ أخرى من خوارزمية الترتيب بالجذر، ويُمكِن تنفيذ كُلٍّ منها بطرق كثيرة. يُمكِنك قراءة المزيد عن خوارزمية الترتيب بالجذر، كما يُمكِنك أن تحاول كتابة تنفيذ لها.
خوارزمية الترتيب بالكومة Heap sort
إلى جانب خوارزمية الترتيب بالجذر التي تُطبَّق عندما يكون حجم الأشياء المطلوب ترتيبها مقيّدًا، هنالك خوارزمية مُخصَّصة أخرى هي خوارزمية الترتيب بالكومة المُقيّدة، والتي تُطبَّق عندما نعمل مع بياناتٍ ضخمةٍ جدًا ونحتاج إلى معرفة أكبر 10 أو أكبر عدد k حيث k قيمة أصغر بكثير من n.
لنفترض مثلًا أننا نراقب خدمةً عبر الإنترنت تتعامل مع بلايين المعاملات يوميًا، وأننا نريد في نهاية كل يوم معرفة أكبر k من المعاملات (أو أبطأ أو أي معيار آخر). يُمكِننا مثلًا أن نُخزِّن جميع المعاملات، ثم نُرتِّبها في نهاية اليوم، ونختار أول k من المعاملات. سيستغرق ذلك زمنًا يتناسب مع n log n، وسيكون بطيئًا جدًا لأننا من المحتمل ألا نتمكَّن من ملاءمة بلايين المعاملات داخل ذاكرة برنامج واحد، وبالتالي، قد نضطرّ لاستخدام خوارزمية ترتيب بذاكرة خارجية (خارج النواة).
يُمكِننا بدلًا من ذلك أن نَستخدِم كومة مُقيدّة heap. إليك ما سنفعله في ما تبقى من هذه المقالة:
- سنشرح خوارزمية الترتيب بالكومة (غير المقيدة).
- ستنفذ الخوارزمية.
- سنشرح خوارزمية الترتيب بالكومة المُقيدة ونُحلِّلها.
لكي تفهم ما يعنيه الترتيب بالكومة، عليك أولًا فهم ماهية الكومة. الكومة ببساطة عبارة عن هيكل بياني data structure مشابه لشجرة البحث الثنائية binary search tree. تتلخص الفروق بينهما في النقاط التالية:
-
تتمتع أي عقدة
xبشجرة البحث الثنائية بـ"خاصية BST" أي تكون جميع عقد الشجرة الفرعية subtree الموجود على يسار العقدةxأصغر منxكما تكون جميع عقد الشجرة الفرعية الموجودة على يمينها أكبر منx. -
تتمتع أي عقدة
xضمن الكومة بـ"خاصية الكومة" أي تكون جميع عقد الشجرتين الفرعيتين للعقدةxأكبر منx. - تتشابه الكومة مع أشجار البحث الثنائية المتزنة من جهة أنه عندما تضيف العناصر إليها أو تحذفها منها، فإنها قد تقوم ببعض العمل الإضافي لضمان استمرارية اتزان الشجرة، وبالتالي، يُمكِن تنفيذها بكفاءة باستخدام مصفوفة من العناصر.
دائمًا ما يكون جذر الكومة هو العنصر الأصغر، وبالتالي، يُمكِننا أن نعثر عليه بزمن ثابت. تستغرق إضافة العناصر وحذفها من الكومة زمنًا يتناسب مع طول الشجرة h، ولأن الكومة دائمًا ما تكون متزنة، فإن h يتناسب مع log n. يُمكِنك قراءة المزيد عن الكومة لو أردت.
تُنفِّذ جافا الصنف PriorityQueue باستخدام كومة. يحتوي ذلك الصنف على التوابع المُعرَّفة في الواجهة Queue ومن بينها التابعان offer و poll اللّذان نلخص عملهما فيما يلي:
-
offer: يضيف عنصرًا إلى الرتل queue، ويُحدِّث الكومة بحيث يَضمَن استيفاء "خاصية الكومة" لجميع العقد. لاحِظ أنه يستغرق زمنًا يتناسب مع log n. -
poll: يَحذِف أصغر عنصر من الرتل من الجذر ويُحدِّث الكومة. يستغرق أيضًا زمنًا يتناسب مع log n.
إذا كان لديك كائن من النوع PriorityQueue، تستطيع بسهولة ترتيب تجميعة عناصر طولها n على النحو التالي:
-
أضف جميع عناصر التجميعة إلى كائن الصنف
PriorityQueueباستخدام التابعoffer. -
احذف العناصر من الرتل باستخدام التابع
pollوأضفها إلى قائمة من النوعList.
نظرًا لأن التابع poll يعيد أصغر عنصر مُتبقٍّ في الرتل، فإن العناصر تُضاف إلى القائمة مُرتَّبةً تصاعديًّا. يُطلَق على هذا النوع من الترتيب اسم الترتيب بالكومة.
تستغرق إضافة عددٍ قدره n من العناصر إلى رتلٍ زمنًا يتناسب مع n log n، ونفس الأمر ينطبق على حذف عددٍ قدره n من العناصر منه، وبالتالي، تنتمي خوارزمية الترتيب بالكومة إلى المجموعة O(n log(n)).
ستجد ضمن الملف ListSorter.java تعريفًا مبدئيًا لتابع اسمه heapSort. أكمله ونفِّذ الأمر ant ListSorterTest لكي تتأكّد من أنه يَعمَل بشكل صحيح.
الكومة المُقيدّة Bounded heap
تَعمَل الكومة المقيدة كأي كومة عادية، ولكنها تكون مقيدة بعدد k من العناصر. إذا كان لديك عدد n من العناصر، يُمكِنك أن تحتفظ فقط بأكبر عدد k من العناصر باتباع التالي:
ستكون الكومة فارغة مبدئيًا، وعليك أن تُنفِّذ التالي لكل عنصر x:
-
التفريع الأول: إذا لم تكن الكومة ممتلئةً، أضف
xإلى الكومة. -
التفريع الثاني: إذا كانت الكومة ممتلئةً، وازن قيمة
xمع أصغر عنصر في الكومة. إذا كانت قيمةxأصغر، فلا يُمكِن أن تكون ضمن أكبر عدد k من العناصر، ولذلك، يُمكِنك أن تتجاهلها. -
التفريع الثالث: إذا كانت الكومة ممتلئةً، وكانت قيمة
xأكبر من قيمة أصغر عنصر بالكومة، احذف أصغر عنصر، وأضفxمكانه.
بوجود أصغر عنصر أعلى الكومة، يُمكِننا الاحتفاظ بأكبر عدد k من العناصر. لنحلل الآن أداء هذه الخوارزمية. إننا ننفِّذ ما يلي لكل عنصر:
- التفريع الأول: تستغرق إضافة عنصر إلى الكومة زمنًا يتناسب مع O(log k).
- التفريع الثاني: يستغرق العثور على أصغر عنصر بالكومة زمنًا يتناسب مع O(1).
-
التفريع الثالث: يستغرق حذف أصغر عنصر زمنًا يتناسب مع O(log k)، كما أن إضافة
xتستغرق نفس مقدار الزمن.
في الحالة الأسوأ، تكون العناصر مُرتَّبة تصاعديًا، وبالتالي، نُنفِّذ التفريع الثالث دائمًا، ويكون الزمن الإجمالي لمعالجة عدد n من العناصر هو O(n log K) أي خطّيّ مع n.
ستجد في الملف ListSorter.java تعريفًا مبدئيًا لتابع اسمه topK. يَستقبِل هذا التابع قائمةً من النوع List وكائنًا من النوع Comparator وعددًا صحيحًا k، ويعيد أكبر عدد k من عناصر القائمة بترتيب تصاعدي. أكمل متن التابع ثم نفِّذ الأمر ant ListSorterTest لكي تتأكّد من أنه يَعمَل بشكل صحيح.
تعقيد المساحة Space complexity
تحدثنا حتى الآن عن تحليل زمن التنفيذ فقط، ولكن بالنسبة لكثير من الخوارزميات، ينبغي أن نُولِي للمساحة التي تتطلّبها الخوارزمية بعض الاهتمام. على سبيل المثال، تحتاج خوارزمية الترتيب بالدمج merge sort إلى إنشاء نسخ من البيانات، وقد كانت مساحة الذاكرة الإجمالية التي تطلّبها تنفيذنا لتلك الخوارزمية هو O(n log n). في الواقع، يُمكِننا أن نُخفِّض ذلك إلى O(n) إذا نفذنا نفس الخوارزمية بطريقة أفضل.
في المقابل، لا تنسخ خوارزمية الترتيب بالإدراج insertion sort البيانات لأنها تُرتِّب العناصر في أماكنها، وتَستخدِم متغيراتٍ مؤقتةً لموازنة عنصرين في كل مرة، كما تَستخدِم عددًا قليلًا من المتغيرات المحلية local الأخرى، ولكن المساحة التي تتطلبها لا تعتمد على n.
تُنشِئ نسختنا من خوارزمية الترتيب بالكومة كائنًا جديدًا من النوع PriorityQueue، وتُخزِّن فيه العناصر، أي أن المساحة المطلوبة تنتمي إلى المجموعة O(n)، وإذا سمحنا بترتيب عناصر القائمة في نفس المكان، يُمكِننا أن نُخفِّض المساحة المطلوبة لتنفيذ خوارزمية الترتيب بالكومة إلى المجموعة O(1).
من مميزات النسخة التي نفَّذناها من تلك الخوارزمية هي أنها تحتاج فقط إلى مساحة تتناسب مع k (أي عدد العناصر المطلوب الاحتفاظ بها)، وعادةً ما تكون k أصغر بكثير من قيمة n.
يميل مطورو البرمجيات إلى التركيز على زمن التشغيل وإهمال حيز الذاكرة المطلوب، وهذا في الحقيقة، مناسب لكثير من التطبيقات، ولكن عند التعامل مع بيانات ضخمة، تكون المساحة المطلوبة بنفس القدر من الأهمية إن لم تكن أهم، كما في الحالات التالية مثلًا:
- إذا لم تكن مساحة ذاكرة البرنامج ملائمةً للبيانات، عادةً ما يزداد زمن التشغيل إلى حد كبير وقد لا يَعمَل البرنامج من الأساس. إذا اخترت خوارزمية تتطلّب حيزًا أقل من الذاكرة، وتَسمَح بملائمة المعالجة ضمن الذاكرة، فقد يَعمَل البرنامج بسرعةٍ أعلى بكثير. بالإضافة إلى ذلك، تَستغِل البرامج التي تتطلَّب مساحة ذاكرة أقل الذاكرة المؤقتة لوحدة المعالجة المركزية CPU caches بشكل أفضل وتَعمَل بسرعة أكبر.
- في الخوادم التي تُشغِّل برامج كثيرة في الوقت نفسه، إذا أمكنك تقليل المساحة التي يتطلبها كل برنامج، فقد تتمكّن من تشغيل برامج أكثر على نفس الخادم، مما يُقلل من تكلفة الطاقة والعتاد المطلوبة.
كانت هذه بعض الأسباب التي توضح أهمية الاطلاع على متطلبات الخوارزميات المتعلقة بالذاكرة.
يمكنك التوسع أكثر في الموضوع بقراءة توثيق خوارزميات الترتيب في توثيق موسوعة حسوب.
ترجمة -بتصرّف- للفصل Chapter 17: Sorting من كتاب Think Data Structures: Algorithms and Information Retrieval in Java.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.