


محمد الخضور
-
المساهمات
21 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو محمد الخضور
-
 تُعد SQLite قاعدة بيانات SQL قائمة بحد ذاتها self-contained، ومعتمدة على الملفات file-based، وهي مُضمّنة في بايثون افتراضيًا، إذ من الممكن استخدامها في أي من تطبيقات بايثون دون الحاجة لتثبيت أي برمجيات إضافية. سنتعرف في هذا المقال على الوحدة sqlite3 في بايثون 3، إذ سننشئ اتصالاً مع قاعدة بيانات SQLite، كما سنضيف جدولاً إليها، وسندخل بعض البيانات إلى هذا الجدول ونقرأها ونعدّلها. سنتعامل في هذا المقال مع مثال لتطبيق جرد مخزون أسماك في حوض مُفترض، وبالتالي لا بُدّ من التعديل في حال إضافة أو إزالة سمكة من الحوض. مستلزمات العمل لتحقيق أقصى فائدة ممكنة من هذا المقال، يُفضّل أن تكون مُطّلعًا على البرمجة بلغة بايثون وعلى أساسيات لغة SQL، وفي هذا الصدد ننصحك بقراءة المقالات التالية قبل إكمال هذا المقال: مدخل إلى لغة بايثون البرمجية. تعلم أساسيات MySQL. الخطوة الأولى – إنشاء اتصال مع قاعدة بيانات SQLite عند إنشاء اتصال مع قاعدة بيانات SQLite، فإنّنا نصل بالنتيجة إلى بيانات موجودة في ملف ما على جهاز الحاسوب، حيث تُعد محركات قواعد بيانات SQL كاملة الميزات ويمكن استخدامها لأغراض متعددة، وسنتعامل في مقالنا الحالي مع قاعدة بيانات تُعنى بتعقّب مخزون الأسماك في حوض أسماك مُفترض. يمكن الاتصال بقاعدة البيانات SQLite باستخدام الوحدة sqlite3 في بايثون على النحو التالي: import sqlite3 connection = sqlite3.connect("aquarium.db") حيث تستورد التعليمة import sqlite3 الوحدة sqlite3، مما يمنح برنامج بايثون وصولًا إلى هذه الوحدة، بينمّا تعيد الدالة ()sqlite3.connect كائن اتصال Connection والذي سنستخدمه في التخاطب مع قاعدة البيانات SQLite الموجودة في الملف aquarium.db الذي يُنشأ تلقائيًا من قبل الدالة ()sqlite3.connect في حال عدم وجود ملف بنفس الاسم أصلًا في الحاسوب. يمكن التأكد من أنّ الكائن connection قد أُنشئ بنجاح عبر تشغيل الأمر التالي: print(connection.total_changes) وبتشغيل شيفرة بايثون السابقة، سيظهر لنا الخرج التالي: 0 إذ تمثّل سمة الكائن connection.total_changes إجمالي عدد السجلات (الأسطر) التي جرى تغييرها من قبل الكائن connection، ولكننا لم ننفّذ أي تعليمات SQL حتى الآن، ما يعني أنّ العدد 0 صحيح لعدد التغييرات الإجمالي total_changes حاليًا. وفي حال رغبتك بإعادة خطوات هذا المقال من البداية في أي وقت، يمكنك حذف الملف "aquarium.db" من حاسوبك. ملاحظة: من الممكن أيضًا الاتصال بقاعدة بيانات SQLite مُتصلة بالذاكرة مُباشرةً (وليس بملف) عبر تمرير السلسة النصية الخاصّة ":memory:" إلى الدالة ()sqlite3.connect كما يلي: sqlite3.connect(":memory:") من الجدير بالملاحظة أنّ هذا النوع من قواعد البيانات سيختفي بمجرّد إنهاء برنامج بايثون، ما يجعلها مناسبة للحالات التي نحتاج فيها إلى استخدام وضع الحماية مؤقتًا (البيئة التي يمكن للمطور من خلالها العمل على مشروع قاعدة بيانات دون تعريض البيانات للخطر في حالة حدوث خطأ ما) بغية اختبار أمر ما في SQLite دون الحاجة إلى البيانات بعد إنهاء البرنامج. الخطوة الثانية – إضافة بيانات إلى قاعدة البيانات SQLite الآن وبعد أن أنشأنا الاتصال مع قاعدة بيانات SQLite المُتمثلّة بالملف "aquarium.db"، أصبح من الممكن البدء بإدخال البيانات إلى قاعدة البيانات وقراءتها منها؛ إذ تُخزّن البيانات في قواعد بيانات SQLite ضمن جداول، التي تعرّف مجموعةً من الأعمدة قد تكون خالية تمامًا، أو محتوية على سجل واحد أو أكثر، بحيث يتضمّن كل سجل بيانات موافقة للأعمدة المُعرفّة في الجدول. سننشئ جدولًا باسم "fish" يتتبع البيانات التالية: ------------------------------------------------------ | tank_number | species | name | ------------------------------------------------------ | 1 | shark | Sammy | ------------------------------------------------------ | 7 | cuttlefish | Jamie | ------------------------------------------------------ سيتتبع الجدول "fish" قيم الاسم name والنوع species ورقم الخزّان tank_number لكل سمكة في الحوض، وقد ضمّنا مثالين لسجلات الأسماك، الأول لسمكة من نوع قرش shark باسم Sammy، والآخر لسمكة من النوع حبّار cuttlefish باسم Jamie. ومن الممكن إنشاء الجدول fish في SQLite اعتمادًا على الكائن connection المُنشأ في الخطوة الأولى من هذا المقال، على النحو التالي: cursor = connection.cursor() cursor.execute("CREATE TABLE fish (name TEXT, species TEXT, tank_number INTEGER)") إذ تعيد الدالة ()connection.cursor في الشيفرة السابقة كائن مؤشّر Cursor، والذي يمكنّنا من تنفيذ تعليمات SQL على قاعدة البيانات SQLite باستخدام الدالة ()cursor.execute، أمّا السلسة النصية "... CREATE TABLE fish" فهي تعليمة SQL تُنشئ جدولًا باسم fish مُتضمنًا الأعمدة الثلاث التي أشرنا إليها سابقًا وهي الاسم name، الذي يحتوي بيانات من النوع النصي TEXT، والنوع species الذي يحتوي أيضًا بيانات من النوع النصي TEXT، ورقم الخزان tank_number، الذي يحتوي بيانات من نوع عدد صحيح INTEGER. الآن وبعدما أنشأنا الجدول، أصبح من الممكن إدخال سجلات البيانات إليه: cursor.execute("INSERT INTO fish VALUES ('Sammy', 'shark', 1)") cursor.execute("INSERT INTO fish VALUES ('Jamie', 'cuttlefish', 7)") استدعينا في الشيفرة السابقة الدالة ()cursor.execute مرتين، المرة الأولى بغية إدخال السجل الخاص بالسمكة القرش المسماة Sammy إلى الخزان رقم "1"، والثانية لإدخال سمكة الحبار المسمّاة Jamie إلى الخزان رقم "7"، أمّا السلسة النصية "... INSERT INTO fish VALUES" فهي تعليمة SQL مسؤولة عن إدخال السجلات إلى الجدول. أمّا في الخطوة التالية فسنستخدم تعليمة SELECT من تعليمات SQL بغية التحقّق من السجلات المُدخلة إلى جدول الأسماك "fish". الخطوة الثالثة – قراءة بيانات من قاعدة البيانات SQLite أضفنا في الخطوة السابقة سجلين إلى جدول الأسماك "fish" في قاعدة البيانات SQLite، ومن الممكن جلب هذه السجلات باستخدام التعليمة SELECT من تعليمات SQL على النحو التالي: rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall() print(rows) وحال تشغيل هذه الشيفرة، سيظهر الخرج التالي: [('Sammy', 'shark', 1), ('Jamie', 'cuttlefish', 7)] شغّلت الدالة ()cursor.execute -في الشيفرة السابقة- تعليمة SELECT بغية جلب قيم كل من أعمدة الاسم والنوع ورقم الخزان من جدول الأسماك "fish"، لتجلب الدالة ()fetchall كافّة نتائج التعليمة SELECT، ولدى تنفيذ التعليمة (print(rows ستظهر قائمةٌ مكونةٌ من سجلين، ولكل سجل ثلاثة مُدخلات يمثّل كل منها عمود من الأعمدة التي اخترناها من جدول الأسماك، إذ يتضمّن هذان السجلان البيانات التي أدخلناها في الخطوة الثانية، بمعنى أنّنا سنحصل على سجل لسمكة القرش "Sammy"، وسجل لسمكة الحبّار "Jamie"، وفي حال كان المطلوب جلب السجلات من جدول الأسماك التي تحقّق مجموعة من المعايير المُحدّدة، فمن الممكن استخدام العبارة WHERE على النحو التالي: target_fish_name = "Jamie" rows = cursor.execute( "SELECT name, species, tank_number FROM fish WHERE name = ?", (target_fish_name,), ).fetchall() print(rows) وعند تشغيل الشيفرة، سنحصل على الخرج التالي: [('Jamie', 'cuttlefish', 7)] تعمل التعليمة ()cursor.execute(<SQL statement>).fetchall في المثال السابق على جلب كافّة النتائج من التعليمة SELECT، بينما تعمل العبارة WHERE في التعليمة SELECT على ترشيح السجلات لتكون فقط تلك التي تكون فيها قيمة العمود name هي target_fish_name، ومن الجدير بالملاحظة أنّه من الممكن استخدام الموضع المؤقت ? بديلًا عن المتغير target_fish_name ضمن التعليمة SELECT، ومن المتوقّع في حالتنا أن يوافق سجلًا واحدًا هذا المعيار، إذ ستكون القيمة المعادة بعد الترشيح هي سجل سمكة الحبّار "Jamie". تنبيه: لا تستخدم عمليات بايثون على السلاسل النصية أبدًا في إنشاء تعليمات SQL ديناميكيًا، إذ يعرّضك استخدام هذه العمليات في تجميع السلاسل النصية لتعليمات SQL إلى خطر هجمات حقن استعلامات SQL المُستخدمة بغية سرقة أو تحريف أو تعديل البيانات المُخزّنة في قاعدة البيانات، وعوضًا عن ذلك استخدم الموضع المؤقت ? في تعليمات SQL عند رغبتك بتعويض القيم تلقائيًا من قبل برنامج بايثون، إذ نمرر مجموعةً من القيم المُجمّعة مثل وسيط ثاني في الدالة ()Cursor.execute لربط هذه القيم بتعليمات SQL، وهذا النمط من التعويض مشروح في مقالنا. الخطوة 4 – تعديل البيانات في قاعدة بيانات SQLite من الممكن تعديل السجلات في قاعدة البيانات SQLite باستخدام تعليمتي UPDATE و DELETE من تعليمات SQL. لنفترض على سبيل المثال أنّه قد نُقل القرش "Sammy" إلى الخزان رقم 2، فعندها من الممكن تعديل سجل هذه السمكة في الجدول "fish" للتعبير عن هذا التغيير على النحو التالي: new_tank_number = 2 moved_fish_name = "Sammy" cursor.execute( "UPDATE fish SET tank_number = ? WHERE name = ?", (new_tank_number, moved_fish_name) ) استخدمنا في الشيفرة السابقة تعليمة UPDATE من تعليمات SQL لتغيير رقم الخزان tank_number للسمكة Sammy إلى القيمة الجديدة "2"، إذ تضمن الجملة WHERE في التعليمة UPDATE أنّه لن تتغير قيمة رقم الخزان إلا عند تحقق شرط وهو أن يكون اسم السمكة هو Sammy أي "name = "Sammy، ومن الممكن التأكّد من تنفيذ التعديل بالشكل الصحيح من خلال تشغيل تعليمة SELECT التالية: rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall() print(rows) وبتشغيل الشيفرة السابقة سنحصل على الخرج التالي: [('Sammy', 'shark', 2), ('Jamie', 'cuttlefish', 7)] فنلاحظ أنّ السجل الخاص بالسمكة "Sammy" يملك القيمة "2" مثل رقم للخزان ضمن العمود tank_number. الآن لنفترض أنّنا حرّرنا القرش Sammy إلى الطبيعة، وبالتالي لم يعد موجودًا في الحوض، عندها يتوجّب حذف السجل الخاص به من الجدول "fish"، لذا سنستخدم التعليمة DELETE من تعليمات SQL لحذف السجل المطلوب كما يلي: released_fish_name = "Sammy" cursor.execute( "DELETE FROM fish WHERE name = ?", (released_fish_name,) ) استخدمنا في الشيفرة السابقة التعليمة DELETE من تعليمات SQL لحذف سجل السمكة Sammy من النوع shark، إذ ضمنت الجملة WHERE في التعليمة DELETE أنّه لن يُحذف السجل إلّا عند تحقق شرط كون اسم السمكة هو Sammy أي "name = "Sammy، ومن الممكن التأكّد من تنفيذ الحذف بالشكل الصحيح من خلال تشغيل تعليمة SELECT التالية: rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall() print(rows) وبتشغيل الشيفرة السابقة سنحصل على الخرج التالي: [('Jamie', 'cuttlefish', 7)] فنلاحظ أنّه قد حُذف فعلًا السجل الخاص بالسمكة Sammy من النوع shark، ولم يتبقَ سوى سجل سمكة Jamie من نوع الحبّار cuttlefish. الخطوة 5 – استخدام تعليمة with للإغلاق الآلي استخدمنا في هذا المقال كائنين رئيسين للتعامل مع قاعدة البيانات "aquarium.db" من النوع SQLite وهما: كائن اتصال باسم connection وكائن مؤشّر باسم cursor. يتوجّب إغلاق ملفات بايثون بعد الانتهاء من العمل عليها، وكذلك الأمر بالنسبة للكائنات مثل Connection و Cursor، إذ يجب إغلاقها عند الانتهاء من استخدامها، ومن الممكن استخدام العبارة with لمساعدتنا على إغلاق الكائنات Connection و Cursor تلقائيًا على النحو التالي: from contextlib import closing with closing(sqlite3.connect("aquarium.db")) as connection: with closing(connection.cursor()) as cursor: rows = cursor.execute("SELECT 1").fetchall() print(rows) تُعد الدالة closing من الدوال سهلة الاستخدام التي توفّرها الوحدة contextlib، فعند إنهاء التعليمة with، تضمن closing استدعاء الدالة ()close بغض النظر عن الكائن المُمرّر إليها، وفي مثالنا استخدمنا الدالة closing مرتين، الأولى لضمان الإغلاق التلقائي للكائن Connection المُعاد من الدالة ()sqlite3.connect، والثانية لضمان الإغلاق التلقائي للكائن Cursor المُعاد من الدالة ()connection.cursor، وبتشغيل الشيفرة السابقة سنحصل على الخرج التالي: [(1,)] وبما أنّ التعليمة "SELECT 1" هي تعليمة SQL تعيد دومًا سجلًا وحيدًا بعمود وحيد قيمتة "1"، فمن المنطقي في هذه الحالة الحصول على سجل يحتوي فقط القيمة "1" بمثابة قيمة معادة من الشيفرة. الخاتمة تمثّل الوحدة sqlite3 جزءًا فعّالًا من مكتبة بايثون المعيارية، إذ تمكنّنا من العمل مع قاعدة بيانات SQL محلية كاملة الميزات دون الحاجة لتثبيت أي برمجيات إضافية. استعرضنا في هذا المقال كيفية استخدام الوحدة sqlite3 للاتصال مع قاعدة بيانات SQLite، وكيفية إضافة البيانات إليها وقراءتها منها وتعديلها، كما نوهّنا لأخطار هجمات حقن استعلامات SQL، وبيّنا كيفية استخدام contextlib.closing لاستدعاء الدالة ()close تلقائيًا وتطبيقها على كائنات بايثون الموجودة ضمن عبارات with. ترجمة -وبتصرف- للمقال How To Use the sqlite3 Module in Python 3 لصاحبه DavidMuller. اقرأ أيضًا إضافة PHP MySQLi ونظام إدارة قواعد البيانات SQLite3 التعامل مع قواعد البيانات SQLite في تطبيقات Flask النسخةالعربية الكاملة لكتاب البرمجة بلغة بايثون
تُعد SQLite قاعدة بيانات SQL قائمة بحد ذاتها self-contained، ومعتمدة على الملفات file-based، وهي مُضمّنة في بايثون افتراضيًا، إذ من الممكن استخدامها في أي من تطبيقات بايثون دون الحاجة لتثبيت أي برمجيات إضافية. سنتعرف في هذا المقال على الوحدة sqlite3 في بايثون 3، إذ سننشئ اتصالاً مع قاعدة بيانات SQLite، كما سنضيف جدولاً إليها، وسندخل بعض البيانات إلى هذا الجدول ونقرأها ونعدّلها. سنتعامل في هذا المقال مع مثال لتطبيق جرد مخزون أسماك في حوض مُفترض، وبالتالي لا بُدّ من التعديل في حال إضافة أو إزالة سمكة من الحوض. مستلزمات العمل لتحقيق أقصى فائدة ممكنة من هذا المقال، يُفضّل أن تكون مُطّلعًا على البرمجة بلغة بايثون وعلى أساسيات لغة SQL، وفي هذا الصدد ننصحك بقراءة المقالات التالية قبل إكمال هذا المقال: مدخل إلى لغة بايثون البرمجية. تعلم أساسيات MySQL. الخطوة الأولى – إنشاء اتصال مع قاعدة بيانات SQLite عند إنشاء اتصال مع قاعدة بيانات SQLite، فإنّنا نصل بالنتيجة إلى بيانات موجودة في ملف ما على جهاز الحاسوب، حيث تُعد محركات قواعد بيانات SQL كاملة الميزات ويمكن استخدامها لأغراض متعددة، وسنتعامل في مقالنا الحالي مع قاعدة بيانات تُعنى بتعقّب مخزون الأسماك في حوض أسماك مُفترض. يمكن الاتصال بقاعدة البيانات SQLite باستخدام الوحدة sqlite3 في بايثون على النحو التالي: import sqlite3 connection = sqlite3.connect("aquarium.db") حيث تستورد التعليمة import sqlite3 الوحدة sqlite3، مما يمنح برنامج بايثون وصولًا إلى هذه الوحدة، بينمّا تعيد الدالة ()sqlite3.connect كائن اتصال Connection والذي سنستخدمه في التخاطب مع قاعدة البيانات SQLite الموجودة في الملف aquarium.db الذي يُنشأ تلقائيًا من قبل الدالة ()sqlite3.connect في حال عدم وجود ملف بنفس الاسم أصلًا في الحاسوب. يمكن التأكد من أنّ الكائن connection قد أُنشئ بنجاح عبر تشغيل الأمر التالي: print(connection.total_changes) وبتشغيل شيفرة بايثون السابقة، سيظهر لنا الخرج التالي: 0 إذ تمثّل سمة الكائن connection.total_changes إجمالي عدد السجلات (الأسطر) التي جرى تغييرها من قبل الكائن connection، ولكننا لم ننفّذ أي تعليمات SQL حتى الآن، ما يعني أنّ العدد 0 صحيح لعدد التغييرات الإجمالي total_changes حاليًا. وفي حال رغبتك بإعادة خطوات هذا المقال من البداية في أي وقت، يمكنك حذف الملف "aquarium.db" من حاسوبك. ملاحظة: من الممكن أيضًا الاتصال بقاعدة بيانات SQLite مُتصلة بالذاكرة مُباشرةً (وليس بملف) عبر تمرير السلسة النصية الخاصّة ":memory:" إلى الدالة ()sqlite3.connect كما يلي: sqlite3.connect(":memory:") من الجدير بالملاحظة أنّ هذا النوع من قواعد البيانات سيختفي بمجرّد إنهاء برنامج بايثون، ما يجعلها مناسبة للحالات التي نحتاج فيها إلى استخدام وضع الحماية مؤقتًا (البيئة التي يمكن للمطور من خلالها العمل على مشروع قاعدة بيانات دون تعريض البيانات للخطر في حالة حدوث خطأ ما) بغية اختبار أمر ما في SQLite دون الحاجة إلى البيانات بعد إنهاء البرنامج. الخطوة الثانية – إضافة بيانات إلى قاعدة البيانات SQLite الآن وبعد أن أنشأنا الاتصال مع قاعدة بيانات SQLite المُتمثلّة بالملف "aquarium.db"، أصبح من الممكن البدء بإدخال البيانات إلى قاعدة البيانات وقراءتها منها؛ إذ تُخزّن البيانات في قواعد بيانات SQLite ضمن جداول، التي تعرّف مجموعةً من الأعمدة قد تكون خالية تمامًا، أو محتوية على سجل واحد أو أكثر، بحيث يتضمّن كل سجل بيانات موافقة للأعمدة المُعرفّة في الجدول. سننشئ جدولًا باسم "fish" يتتبع البيانات التالية: ------------------------------------------------------ | tank_number | species | name | ------------------------------------------------------ | 1 | shark | Sammy | ------------------------------------------------------ | 7 | cuttlefish | Jamie | ------------------------------------------------------ سيتتبع الجدول "fish" قيم الاسم name والنوع species ورقم الخزّان tank_number لكل سمكة في الحوض، وقد ضمّنا مثالين لسجلات الأسماك، الأول لسمكة من نوع قرش shark باسم Sammy، والآخر لسمكة من النوع حبّار cuttlefish باسم Jamie. ومن الممكن إنشاء الجدول fish في SQLite اعتمادًا على الكائن connection المُنشأ في الخطوة الأولى من هذا المقال، على النحو التالي: cursor = connection.cursor() cursor.execute("CREATE TABLE fish (name TEXT, species TEXT, tank_number INTEGER)") إذ تعيد الدالة ()connection.cursor في الشيفرة السابقة كائن مؤشّر Cursor، والذي يمكنّنا من تنفيذ تعليمات SQL على قاعدة البيانات SQLite باستخدام الدالة ()cursor.execute، أمّا السلسة النصية "... CREATE TABLE fish" فهي تعليمة SQL تُنشئ جدولًا باسم fish مُتضمنًا الأعمدة الثلاث التي أشرنا إليها سابقًا وهي الاسم name، الذي يحتوي بيانات من النوع النصي TEXT، والنوع species الذي يحتوي أيضًا بيانات من النوع النصي TEXT، ورقم الخزان tank_number، الذي يحتوي بيانات من نوع عدد صحيح INTEGER. الآن وبعدما أنشأنا الجدول، أصبح من الممكن إدخال سجلات البيانات إليه: cursor.execute("INSERT INTO fish VALUES ('Sammy', 'shark', 1)") cursor.execute("INSERT INTO fish VALUES ('Jamie', 'cuttlefish', 7)") استدعينا في الشيفرة السابقة الدالة ()cursor.execute مرتين، المرة الأولى بغية إدخال السجل الخاص بالسمكة القرش المسماة Sammy إلى الخزان رقم "1"، والثانية لإدخال سمكة الحبار المسمّاة Jamie إلى الخزان رقم "7"، أمّا السلسة النصية "... INSERT INTO fish VALUES" فهي تعليمة SQL مسؤولة عن إدخال السجلات إلى الجدول. أمّا في الخطوة التالية فسنستخدم تعليمة SELECT من تعليمات SQL بغية التحقّق من السجلات المُدخلة إلى جدول الأسماك "fish". الخطوة الثالثة – قراءة بيانات من قاعدة البيانات SQLite أضفنا في الخطوة السابقة سجلين إلى جدول الأسماك "fish" في قاعدة البيانات SQLite، ومن الممكن جلب هذه السجلات باستخدام التعليمة SELECT من تعليمات SQL على النحو التالي: rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall() print(rows) وحال تشغيل هذه الشيفرة، سيظهر الخرج التالي: [('Sammy', 'shark', 1), ('Jamie', 'cuttlefish', 7)] شغّلت الدالة ()cursor.execute -في الشيفرة السابقة- تعليمة SELECT بغية جلب قيم كل من أعمدة الاسم والنوع ورقم الخزان من جدول الأسماك "fish"، لتجلب الدالة ()fetchall كافّة نتائج التعليمة SELECT، ولدى تنفيذ التعليمة (print(rows ستظهر قائمةٌ مكونةٌ من سجلين، ولكل سجل ثلاثة مُدخلات يمثّل كل منها عمود من الأعمدة التي اخترناها من جدول الأسماك، إذ يتضمّن هذان السجلان البيانات التي أدخلناها في الخطوة الثانية، بمعنى أنّنا سنحصل على سجل لسمكة القرش "Sammy"، وسجل لسمكة الحبّار "Jamie"، وفي حال كان المطلوب جلب السجلات من جدول الأسماك التي تحقّق مجموعة من المعايير المُحدّدة، فمن الممكن استخدام العبارة WHERE على النحو التالي: target_fish_name = "Jamie" rows = cursor.execute( "SELECT name, species, tank_number FROM fish WHERE name = ?", (target_fish_name,), ).fetchall() print(rows) وعند تشغيل الشيفرة، سنحصل على الخرج التالي: [('Jamie', 'cuttlefish', 7)] تعمل التعليمة ()cursor.execute(<SQL statement>).fetchall في المثال السابق على جلب كافّة النتائج من التعليمة SELECT، بينما تعمل العبارة WHERE في التعليمة SELECT على ترشيح السجلات لتكون فقط تلك التي تكون فيها قيمة العمود name هي target_fish_name، ومن الجدير بالملاحظة أنّه من الممكن استخدام الموضع المؤقت ? بديلًا عن المتغير target_fish_name ضمن التعليمة SELECT، ومن المتوقّع في حالتنا أن يوافق سجلًا واحدًا هذا المعيار، إذ ستكون القيمة المعادة بعد الترشيح هي سجل سمكة الحبّار "Jamie". تنبيه: لا تستخدم عمليات بايثون على السلاسل النصية أبدًا في إنشاء تعليمات SQL ديناميكيًا، إذ يعرّضك استخدام هذه العمليات في تجميع السلاسل النصية لتعليمات SQL إلى خطر هجمات حقن استعلامات SQL المُستخدمة بغية سرقة أو تحريف أو تعديل البيانات المُخزّنة في قاعدة البيانات، وعوضًا عن ذلك استخدم الموضع المؤقت ? في تعليمات SQL عند رغبتك بتعويض القيم تلقائيًا من قبل برنامج بايثون، إذ نمرر مجموعةً من القيم المُجمّعة مثل وسيط ثاني في الدالة ()Cursor.execute لربط هذه القيم بتعليمات SQL، وهذا النمط من التعويض مشروح في مقالنا. الخطوة 4 – تعديل البيانات في قاعدة بيانات SQLite من الممكن تعديل السجلات في قاعدة البيانات SQLite باستخدام تعليمتي UPDATE و DELETE من تعليمات SQL. لنفترض على سبيل المثال أنّه قد نُقل القرش "Sammy" إلى الخزان رقم 2، فعندها من الممكن تعديل سجل هذه السمكة في الجدول "fish" للتعبير عن هذا التغيير على النحو التالي: new_tank_number = 2 moved_fish_name = "Sammy" cursor.execute( "UPDATE fish SET tank_number = ? WHERE name = ?", (new_tank_number, moved_fish_name) ) استخدمنا في الشيفرة السابقة تعليمة UPDATE من تعليمات SQL لتغيير رقم الخزان tank_number للسمكة Sammy إلى القيمة الجديدة "2"، إذ تضمن الجملة WHERE في التعليمة UPDATE أنّه لن تتغير قيمة رقم الخزان إلا عند تحقق شرط وهو أن يكون اسم السمكة هو Sammy أي "name = "Sammy، ومن الممكن التأكّد من تنفيذ التعديل بالشكل الصحيح من خلال تشغيل تعليمة SELECT التالية: rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall() print(rows) وبتشغيل الشيفرة السابقة سنحصل على الخرج التالي: [('Sammy', 'shark', 2), ('Jamie', 'cuttlefish', 7)] فنلاحظ أنّ السجل الخاص بالسمكة "Sammy" يملك القيمة "2" مثل رقم للخزان ضمن العمود tank_number. الآن لنفترض أنّنا حرّرنا القرش Sammy إلى الطبيعة، وبالتالي لم يعد موجودًا في الحوض، عندها يتوجّب حذف السجل الخاص به من الجدول "fish"، لذا سنستخدم التعليمة DELETE من تعليمات SQL لحذف السجل المطلوب كما يلي: released_fish_name = "Sammy" cursor.execute( "DELETE FROM fish WHERE name = ?", (released_fish_name,) ) استخدمنا في الشيفرة السابقة التعليمة DELETE من تعليمات SQL لحذف سجل السمكة Sammy من النوع shark، إذ ضمنت الجملة WHERE في التعليمة DELETE أنّه لن يُحذف السجل إلّا عند تحقق شرط كون اسم السمكة هو Sammy أي "name = "Sammy، ومن الممكن التأكّد من تنفيذ الحذف بالشكل الصحيح من خلال تشغيل تعليمة SELECT التالية: rows = cursor.execute("SELECT name, species, tank_number FROM fish").fetchall() print(rows) وبتشغيل الشيفرة السابقة سنحصل على الخرج التالي: [('Jamie', 'cuttlefish', 7)] فنلاحظ أنّه قد حُذف فعلًا السجل الخاص بالسمكة Sammy من النوع shark، ولم يتبقَ سوى سجل سمكة Jamie من نوع الحبّار cuttlefish. الخطوة 5 – استخدام تعليمة with للإغلاق الآلي استخدمنا في هذا المقال كائنين رئيسين للتعامل مع قاعدة البيانات "aquarium.db" من النوع SQLite وهما: كائن اتصال باسم connection وكائن مؤشّر باسم cursor. يتوجّب إغلاق ملفات بايثون بعد الانتهاء من العمل عليها، وكذلك الأمر بالنسبة للكائنات مثل Connection و Cursor، إذ يجب إغلاقها عند الانتهاء من استخدامها، ومن الممكن استخدام العبارة with لمساعدتنا على إغلاق الكائنات Connection و Cursor تلقائيًا على النحو التالي: from contextlib import closing with closing(sqlite3.connect("aquarium.db")) as connection: with closing(connection.cursor()) as cursor: rows = cursor.execute("SELECT 1").fetchall() print(rows) تُعد الدالة closing من الدوال سهلة الاستخدام التي توفّرها الوحدة contextlib، فعند إنهاء التعليمة with، تضمن closing استدعاء الدالة ()close بغض النظر عن الكائن المُمرّر إليها، وفي مثالنا استخدمنا الدالة closing مرتين، الأولى لضمان الإغلاق التلقائي للكائن Connection المُعاد من الدالة ()sqlite3.connect، والثانية لضمان الإغلاق التلقائي للكائن Cursor المُعاد من الدالة ()connection.cursor، وبتشغيل الشيفرة السابقة سنحصل على الخرج التالي: [(1,)] وبما أنّ التعليمة "SELECT 1" هي تعليمة SQL تعيد دومًا سجلًا وحيدًا بعمود وحيد قيمتة "1"، فمن المنطقي في هذه الحالة الحصول على سجل يحتوي فقط القيمة "1" بمثابة قيمة معادة من الشيفرة. الخاتمة تمثّل الوحدة sqlite3 جزءًا فعّالًا من مكتبة بايثون المعيارية، إذ تمكنّنا من العمل مع قاعدة بيانات SQL محلية كاملة الميزات دون الحاجة لتثبيت أي برمجيات إضافية. استعرضنا في هذا المقال كيفية استخدام الوحدة sqlite3 للاتصال مع قاعدة بيانات SQLite، وكيفية إضافة البيانات إليها وقراءتها منها وتعديلها، كما نوهّنا لأخطار هجمات حقن استعلامات SQL، وبيّنا كيفية استخدام contextlib.closing لاستدعاء الدالة ()close تلقائيًا وتطبيقها على كائنات بايثون الموجودة ضمن عبارات with. ترجمة -وبتصرف- للمقال How To Use the sqlite3 Module in Python 3 لصاحبه DavidMuller. اقرأ أيضًا إضافة PHP MySQLi ونظام إدارة قواعد البيانات SQLite3 التعامل مع قواعد البيانات SQLite في تطبيقات Flask النسخةالعربية الكاملة لكتاب البرمجة بلغة بايثون -
 تمنح نماذج الويب web forms من صناديقٍ نصيّة وحقول نصوص مُتعدّدة الأسطر المستخدمين القدرة على إرسال البيانات إلى التطبيق لاستخدامها في تنفيذ أمرٍ ما، أو حتّى لإرسال محتوًى نصي كبير، فمثلًا يُمنح المستخدم في تطبيقات التواصل الاجتماعي حيزًا يمكِّنه من إضافة محتوًى جديد إلى صفحته الشخصية؛ كما يوجد أيضًا في صفحة تسجيل الدخول حقلٌ لإدراج اسم المستخدم وحقلٌ لإدراج كلمة المرور، إذ يستخدم الخادم (تطبيق فلاسك في حالتنا) هذه البيانات التي أدخلها المستخدم ليسجّل دخوله إذا كانت البيانات صحيحة أو يستجيب برسالة خطأ مثل "!Invalid credentials" لإعلام المستخدم بأن البيانات التي أدخلها خاطئة. يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدّة أدوات وميزات من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل. سننشئ في هذا المقال تطبيق ويب مُصغّر لبيان كيفيّة استخدام نماذج الويب، إذ سيتضمّن صفحةً لإظهار رسائل مُخزّنةٍ مُسبقًا ضمن قائمة باستخدام بايثون، وصفحةً أُخرى لإضافة رسائل جديدة، كما سنستخدم الرسائل الخاطفة message flashing لإبلاغ المستخدمين بوجود خطأ لدى إدخالهم لبيانات غير صحيحة. #مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات routes ودوال العرض view في فلاسك، وفي هذا الصدد يمكنك الاطلاع على المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask من لغة بايثون لفهم مبادئ فلاسك. فهم أساسيات لغة HTML. الخطوة الأولى - عرض الرسائل سننشئ في هذه الخطوة تطبيق فلاسك بصفحة رئيسية لعرض رسائل مُخزنة أصلًا في قائمة من قواميس بايثون. لذا سنفتح ملف جديد باسم "app.py" للتعديل عليه: (env)user@localhost:$ nano app.py وسنضيف الشيفرة التالية ضمنه، بغية إنشاء خادم فلاسك ذو وجهةٍ واحدة: from flask import Flask, render_template app = Flask(__name__) messages = [{'title': 'Message One', 'content': 'Message One Content'}, {'title': 'Message Two', 'content': 'Message Two Content'} ] @app.route('/') def index(): return render_template('index.html', messages=messages) ثمّ نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة كلًا من الصنف Flask الذي سنستخدمه لإنشاء نسخة من التطبيق باسم app، ودالة تصيّير القوالب ()render_template من حزمة فلاسك flask، مُمررّين المتغير الخاص __name__ اللازم لتمكين فلاسك من إعداد بعض المسارات العاملة في الخلفية؛ أمّا عن تصيير القوالب، فننصحك بقراءة المقال كيفية استخدام القوالب في تطبيقات فلاسك Flask. ثمّ أنشأنا قائمةً عامّة في بايثون باسم messages، والتي تحتوي على قواميس بايثون، وفي كل قاموس أضفنا مفتاحين أساسيين، هما: title لتخزين عنوان الرسالة، و content لتخزين مضمونها، وما هذا إلّا مثال مُبسّط لآلية تخزين البيانات، إذ نستخدم في التطبيقات العملية الواقعية قاعدة بيانات لتُخزّن هذه البيانات بصورةٍ دائم سامحةً لنا بتعديلها واسترجاعها بسهولة وفعالية. وبعد إنشاء قائمة بايثون، أنشأنا دالة العرض ()index باستخدام المُزخرف ()app.route@ الذي يحوّل دوال بايثون الاعتيادية إلى دوال عاملة في فلاسك، وفيها تكون القيمة المعادة استدعاءً للدالة ()render_template التي تُعلم فلاسك بأنّ الوجهة الحالية يجب أن تعرض في النتيحة قالب HTML باسم index.html (سننشئ ملف القالب هذا في الخطوات اللاحقة) ممررين له قيمة المتغير المُسمّى messages والذي يحتوي على قائمة الرسائل messages التي صرحنا عنها للتو مُسندين لها القيم اللازمة، وجعلناها متاحةً للاستخدام من قبل قالب HTML. ننصحك في هذا الصدد بقراءة المقال How To Create Your First Web Application Using Flask and Python 3 لفهم أعمق لدوال العرض في فلاسك. الآن، سننشئ مجلدًا للقوالب باسم "templates" ضمن المجلد "flask_app"، إذ سيبحث فلاسك ضمنه عن القوالب، وبعدها سننشئ ملف القالب الأساسي باسم "base.html" وفيه سنكتب الشيفرة الأساسية التي سترثها بقية القوالب لتجنّب تكرار الشيفرات: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html ومن ثمّ نكتب الشيفرة التالية ضمن الملف base.html لإنشاء قالب HTML الأساسي مع شريط تنقل وجزء مُخصّص للمحتوى: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> .message { padding: 10px; margin: 5px; background-color: #f3f3f3 } nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> نحفظ الملف ونغلقه. يتضمّن القالب الأساسي كافّة الشيفرات المتداولة التي سنحتاجها في القوالب الأُخرى. ستُستبدل لاحقًا كتلة العنوان title بعنوان كل صفحة وكتلة المحتوى content بمحتواها، أمّا عن شريط التصفح فسيتضمّن رابطين، الأوّل ينقل المُستخدم إلى الصفحة الرئيسية للتطبيق باستخدام الدالة المساعدة ()url_for لتحقيق الربط مع دالة العرض ()index، والآخر لصفحة المعلومات حول التطبيق في حال قررت تضمينها في تطبيقك. لذا سنفتح ملف القالب المُسمى "index.html" وهو الاسم الذي حددناه في الملف app.py: (env)user@localhost:$ nano templates/index.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Messages {% endblock %}</h1> {% for message in messages %} <div class='message'> <h3>{{ message['title'] }}</h3> <p>{{ message['content'] }}</p> </div> {% endfor %} {% endblock %} ثمّ نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة ملف القالب "base.html"، واستبدلنا محتوى كتلة المحتوى content مُستخدمين تنسيق العنوان من المستوى الأوّل <h1> الذي يفي أيضًا بالغرض لعنوان الصفحة. كما استخدما حلقة for التكرارية وهي من ضمن تعليمات محرّك القوالب جينجا Jinja وذلك في السطر البرمجي {% for message in messages %} بهدف التنقل بين الرسائل في القائمة messages (والمُخزنة ضمن المتغير المسمّى message)؛ إذ سنعرض عناوين الرسائل ضمن تنسيق عنوان من المستوى الثالث باستخدام الوسم <h3>، ومحتواها ضمن تنسيق فقرة باستخدام الوسم <p>، وكلاهما ضمن حافظة عناصر HTML باستخدام الوسم <div>. ولتشغيل تطبيق الويب الذي أنشأناه، وبعد التأكّد من وجودنا ضمن المجلد "flask_app" مع تفعيل البيئة الافتراضية، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم "app.py") وذلك باستخدام متغير بيئة فلاسك FLASK_APP: (env)user@localhost:$ export FLASK_APP=app نضبط متغير بيئة فلاسك Flask_ENV على الوضع development لتشغيل التطبيق في وضع التطوير ما يمكنّنا من استخدام مُنقّح الأخطاء كما يلي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_ENV=development بعدها، سنشغل التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نذهب إلى الرابط التالي باستخدام المتصفح: http://127.0.0.1:5000/ فتظهر الرسائل المُخزّنة أصلًا ضمن القائمة "messages" في الصفحة الرئيسية للتطبيق كما يلي: ومع نهاية هذه الخطوة نكون قد أعددنا تطبيق الويب ليعرض الرسائل المُخزنة، أمّا في الخطوة التالية سنعدّ نماذج الويب اللازمة لنسمح للمستخدمين بإضافة رسائل جديدة إلى القائمة لعرضها في الصفحة الرئيسية للتطبيق. الخطوة الثانية - إعداد نماذج الويب سننشئ في هذه الخطوة صفحةً جديدةً في التطبيق تسمح للمستخدمين بإضافة رسائل جديدة إلى قائمة الرسائل من خلال نموذج ويب. لذا سنفتح نافذة طرفية جديدة مع بقاء خادم التطوير قيد التشغيل. ومنها نفتح الملف app.py: (env)user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/create/', methods=('GET', 'POST')) def create(): return render_template('create.html') نحفظ الملف ونغلقه. تتضمّن الوجهة /create معامل طلبيات HTTP methods المتضمّن صفًا tuple هو ('GET', 'POST') للتعامل معها سواءً بطريقة GET، أو POST، إذ أن طريقة "GET" هي الطريقة الافتراضية المُستخدمة لجلب البيانات من الخادم، مثل حالة طلب عرض الصفحة الرئيسية أو صفحة المعلومات حول التطبيق؛ أمّا طريقة "POST" فتُستخدم من قبل المتصفح عند إرسال نماذج الإدخال إلى وجهةٍ مُحدّدة، الأمر الذي سيغيّر من البيانات المُخزّنة في الخادم. وفي مثالنا هذا سيُطلب عرض صفحة إنشاء رسائل جديدة "create" باستخدام طلب من النوع "GET"، إذ ستتضمّن هذه الصفحة نموذج ويب بحقول إدخال وزر إرسال، ولدى ملء النموذج من قبل المستخدم وإرساله، يُرسل طلب من النوع "POST" إلى الوجهة create/، الذي يتعامل مع الطلب من حيث التحقّق من صحة البيانات المُدخلة للتأكّد من كون المُستخدم لم يرسل نموذجًا فارغًا، لتُضاف عندها هذه البيانات إلى قائمة الرسائل "messages". تؤدي دالة فلاسك ()create حاليًا مهمةً واحدة، وهي تصيّير قالب HTML باسم "create.html" لدى استقبالها لطلب من نوع GET، لذا سننشئ الآن هذا القالب وسنعدّل الدالة ()create لتصبح قادرةً أيضًا على التعامل مع الطلبات من النوع POST اللازمة في الخطوة التالية. لذا سنفتح ملف القالب المُسمّى "create.html": (env)user@localhost:$ nano templates/create.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Add a New Message {% endblock %}</h1> <form method="post"> <label for="title">Title</label> <br> <input type="text" name="title" placeholder="Message title" value="{{ request.form['title'] }}"></input> <br> <label for="content">Message Content</label> <br> <textarea name="content" placeholder="Message content" rows="15" cols="60" >{{ request.form['content'] }}</textarea> <br> <button type="submit">Submit</button> </form> {% endblock %} ثمّ نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة قالب base.html واستبدلنا كتلة المحتوى content بكائن عنوان من المستوى الأوّل <h1> الذي سيعمل مثل عنوان للصفحة، وعيّنا في وسم كائن النموذج <form> قيمة السمة method لتكون post بمعنى أنّ بيانات النموذج ستُرسل إلى الخادم مثل طلب من نوع POST. وفي كائن النموذج أضفنا حقل إدخال نصي باسم title وهو الاسم الذي سنستخدمه في التطبيق للوصول إلى بيانات نموذج العنوان، كما أسندنا القيمة {{ request.form['title'] }} لسمة value من الوسم <input>، وهو أمرٌ مفيدٌ لتخزين البيانات التي يدخلها المستخدم مع إمكانية استعادتها في حال حدوث خطأ ما؛ فإذا نسي المستخدم مثلًا ملء الحقل النصي المُخصّص لمحتوى الرسالة content وهو حقل مطلوب، فسيُرسل طلب إلى الخادم لإرجاع رسالة خطأ في الاستجابة، ولكن البيانات في العنوان لن نفقدها لأنها محفوظة في الكائن العام request ويمكن الوصول لها من خلال القيمة ['request.from['title. أضفنا بعد حقل الإدخال المُخصّص لعنوان الرسالة، حقلًا نصيًا مُتعدّد الأسطر لمحتواها باسم content وأسندنا أيضًا القيمة {{ request.form['content'] }} لسمة value لنفس السبب آنف الذكر. ونهايةً أضفنا زر إرسال إلى نهاية النموذج. الآن وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، ننتقل إلى الوجهة الجديدة create/ باستخدام المتصفح: http://127.0.0.1:5000/create فتظهر صفحة إضافة رسالة جديدة “Add a New Message” مع حقل إدخال لعنوان الرسالة وحقل نصي مُتعدّد الأسطر لإدخال محتوى الرسالة، وزر لتقديم النموذج عند الانتهاء من إدخال البيانات. يُرسل هذا النموذج طلبًا من نوع "POST" إلى دالة فلاسك ()create، ولكن حتى الآن ما من شيفرة في الدالة للتعامل مع الطلب هذا، لذا لن يحدث شيء بعد تعبئة النموذج وإرساله> لذلك، سنكتب في الخطوة التالية الشيفرة اللازمة للتعامل مع طلب من النوع "POST" بعد إرسال النموذج، إذ سنتحقّق من صحة البيانات المرسلة (ليست فارغة)، كما سنضيف عنوان الرسالة ومحتواها إلى قائمة الرسائل "messages". الخطوة الثالثة - التعامل مع الطلبات الواردة من نماذج الويب سنتعامل في هذه الخطوة مع الطلبات الواردة من نماذج الإدخال إلى التطبيق، إذ سنعمل على الوصول إلى البيانات التي أرسلها المستخدم عبر نموذج الإدخال المُنشأ في الخطوة السابقة لإضافتها إلى قائمة الرسائل، كما سنستخدم الرسائل الخاطفة message flashing لإعلام المستخدم في حال إرسال بيانات غير صحيحة، فعندها ستظهر الرسالة لمرة واحدة وتختفي في الطلب التالي (مثل الانتقال إلى صفحة أُخرى) ومن هنا جاء سبب تسميتها بالخاطفة. لذا سنفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py لا بُد أولًا من استيراد ما يلي من إطار العمل فلاسك: الكائن request العام المسؤول عن الوصول إلى بيانات الطلب والتي ستُرسل من خلال نموذج HTML المبني في الخطوة السابقة. الدالة url_for() لتوليد عناوين الروابط. الدالة flash() لعرض رسالةٍ وامضة عند انتهاء معالجة الطلب، لإعلام المُستخدم في حال سير الأمور على نحوٍ سليم أو في حال وجود مشاكل مثل كون البيانات المُدخلة خاطئة. الدالة redirect() لإعادة توجيه المستخدم إلى موقعٍ آخر في المتصفح. سنضيف هذه الاستيرادات إلى السطر الأوّل من الملف كما يلي: from flask import Flask, render_template, request, url_for, flash, redirect # ... تخزّن الدالة flash() الرسائل في جلسة المتصفح لدى المستخدم، وهذا ما يتطلّب إعداد مفتاح أمان Secret Key، إذ سيُستخدم هذا المفتاح لجعل الجلسات آمنة، وبذلك يتمكّن فلاسك من الحفاظ على المعلومات عند الانتقال من طلبٍ إلى آخر، مثل حالة الانتقال من صفحة إنشاء رسالة جديدة إلى الصفحة الرئيسية، مع ملاحظة أن المستخدم يستطيع الوصول إلى المعلومات المُخزّنة في الجلسة، ولكنه لا يستطيع تعديلها إلّا إذا كان لديه مفتاح الأمان، وبالتالي لا يجب أن تسمح لأي أحدٍ بالوصول إلى مفتاح الأمان الخاص بك. تذكّر أنّ مفتاح الأمان يجب أن يكون سلسلةً نصيةً عشوائية بطولٍ مناسب، إذ من الممكن توليد مفتاح أمان باستخدام التابع ()os.urandom من الوحدة os، إذ يعيد هذا التابع سلسلة من البايتات العشوائية المناسبة لاستخدامات التشفير (الحصول على سلسلة نصية خاصّة أو رقم خاص). للحصول على سلسلة نصية عشوائية باستخدام هذا التابع، سنفتح نافذة طرفية جديدة ومنها نفتح صَدفة بايثون التفاعلية باستخدام الأمر التالي: (env)user@localhost:$ python وضمن صَدفة بايثون التفاعلية سنستورد الوحدة os من مكتبة بايثون المعيارية، وسنستدعي التابع ()os.urandom كما يلي: >>> import os >>> os.urandom(24).hex() فنحصل في الخرج على سلسلة مُشابهة لما يلي: 'df0331cefc6c2b9a5d0208a726a5d1c0fd37324feba25506' وبذلك يمكننا استخدام هذه السلسلة النصية مثل مفتاح أمان. ولإعداد مفتاح أمان، سنضيف ضبط SECRET_KEY إلى التطبيق من خلال الكائن app.config، الذي سنضيفه مباشرةً بعد تعريف الكائن app وقبل تعريف المتغير messages، على النحو التالي: # ... app = Flask(__name__) app.config['SECRET_KEY'] = 'your secret key' messages = [{'title': 'Message One', 'content': 'Message One Content'}, {'title': 'Message Two', 'content': 'Message Two Content'} ] # ... ومن ثمّ نعدّل دالة العرض ()create لتبدو كما يلي: # ... @app.route('/create/', methods=('GET', 'POST')) def create(): if request.method == 'POST': title = request.form['title'] content = request.form['content'] if not title: flash('Title is required!') elif not content: flash('Content is required!') else: messages.append({'title': title, 'content': content}) return redirect(url_for('index')) return render_template('create.html') تَمكَّنا باستخدام العبارة الشرطية التي توازن قيمة request.method مع القيمة POST من التحقُّق بأنّ التعليمات التالية لها لن تُنفّذ إلّا إذا كان الطلب الحالي هو فعلًا بطريقة POST، ومن ثمّ قرأنا قيم العنوان والمحتوى المرسلين من الكائن request.form الذي يمكِّننا من الوصول إلى بيانات نموذج الإدخال المُضمّنة في الطلب؛ ففي حال عدم إدخال قيمةٍ للعنوان، فسيتحقق الشرط if not title وبالتالي ستظهر رسالة للمستخدم نعلمه من خلالها بأن العنوان مطلوب وذلك باستخدام الدالة ()flash، وهذا ما يضيف هذه الرسالة إلى قائمة للرسائل الخاطفة والتي سنعرضها لاحقًا ضمن الصفحة بوصفها جزءًا من القالب الرئيسي "base.html"؛ وعلى نحوٍ مُشابه فيما يتعلّق بقسم المحتوى، ففي حال كان فارغًا، فسيتحقق الشرط elif not content وبالتالي ستظهر رسالة للمستخدم نعلمه من خلالها بأن المحتوى مطلوب، وستُضاف هذه الرسالة أيضًا إلى قائمة الرسائل الخاطفة. أمّا في حال وجود عنوان ومحتوى سليمين، فسيُضاف قاموس بايثون جديد إلى القائمة messages بالعنوان والمحتوى المدخلين من قبل المستخدم وذلك اعتمادًا على السطر البرمجي ({messages.append({'title': title, 'content': content، ومن ثمّ نعيد توجيه الطلب إلى الصفحة الرئيسية باستخدام الدالة redirect() بتمرير الرابط الناتج عن التابع url_for() الذي قد مررنا له القيمة index وسيطًا. ثمّ نحفظ الملف ونغلقه. ننتقل إلى الوجهة create/ عن طريق المتصفح كما يلي: http://127.0.0.1:5000/create وبملء النموذج بعنوان اختياري ومحتوى ما، وحالما نرسل النموذج، ستظهر الرسالة الجديدة في الصفحة الرئيسية للتطبيق. ونهايةً سنعرّض كافّة الرسائل الخاطفة ضمن الصفحة الرئيسية للتطبيق، كما سنضيف رابطًا في شريط التصفح للقالب الرئيسي base.html، للانتقال إلى صفحة إضافة رسالة جديدة مباشرةً وبسهولة، لذا سنفتح ملف القالب الرئيسي: (env)user@localhost:$ nano templates/base.html الآن، سنعدّل الملف من خلال إضافة وسم رابط <a> جديد بعد رابط تطبيق فلاسك المتوضّع في شريط التصفُّح داخل الوسم <nav>، ثمّ سنضيف حلقة تكرارية أعلى كتلة المحتوى مباشرةً لعرض الرسائل الخاطفة أسفل شريط التصفح، إذ يوفّر فلاسك هذه الرسائل من خلال دالة فلاسك الخاصة get_flashed_messages()، وسنضيف ضمن الوسم <style> السمة alert لكل رسالة مُسندين إليها بعض الخصائص من CSS كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> .message { padding: 10px; margin: 5px; background-color: #f3f3f3 } nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } .alert { padding: 20px; margin: 5px; color: #970020; background-color: #ffd5de; } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="{{ url_for('create') }}">Create</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% for message in get_flashed_messages() %} <div class="alert">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> </body> </html> ثمّ نحفظ الملف ونغلقه، وبإعادة تحميل الرابط "https://127.0.0.1:5000" في المتصفح، ستظهر الصفحة الرئيسية للتطبيق بشريط تصفُّح مُتضمّن للعنصر "Create" الذي يرتبط بالوجهة create/ الخاصّة بصفحة إنشاء رسالة جديدة. ولنرى كيفية عمل الرسائل الخاطفة، ننتقل إلى صفحة "Create" ونضغط على زر الإرسال في النموذج دون ملء أي من حقلي العنوان أوالمحتوى، فتظهر رسالة كما هو مبين بالشكل: وبالعودة إلى الصفحة الرئيسية نلاحظ أنّ الرسالة الخاطفة أسفل شريط التنقل قد اختفت، رغم عرضها على أنها جزء من القالب الأساسي، وهنا تكمن ميزتها، فلو لم تكن رسالة خاطفة لكانت ستُعرض في الصفحة الرئيسية أيضًا لأنها ترث من القالب الأساسي. ولو أرسلنا النموذج مع عنوان ومحتوى فارغ، فستظهر رسالة تفيد بأن حقل المحتوى مطلوب "!Content is required"، وبالضغط على رابط تطبيق فلاسك FlaskApp في شريط التصفُّح نعود إلى الصفحة الرئيسية للتطبيق؛ وهنا إذا ضغطنا في المُتصفّح على زر الرجوع، سنجد أن الرسالة الخاطفة المُتعلقّة بكون المحتوى فارغ لا تزال موجودة، ذلك لأنّ الطلب السابق هو المحفوظ حاليًا؛ أما لو انتقلنا إلى صفحة إنشاء رسالة جديدة من شريط التصفّح فسيُرسل طلب جديد، وبذلك تُمحى مُدخلات النموذج القديمة ومعها الرسالة الخاطفة. وبذلك نكون قد تعرّفنا على كيفية استلام مُدخلات المُستخدم والتحقّق من صحتها وإضافتها إلى مصدر البيانات (وهو قائمة بايثون في حالتنا). ملاحظة: ستختفي الرسائل المُضافة إلى الفائمة "messages" في التطبيق بمجرّد توقّف الخادم، لأنّ قوائم بايثون تُحفظ فقط في الذاكرة (المؤقتة)، أمّا لحفظ الرسائل بصورةٍ دائمة فلا بدّ من استخدام قاعدة بيانات مثل SQLite، وفي هذا الصدد ننصحك بقراءة المقال كيفية استخدام علاقة نوع واحد-إلى-متعدد one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite لمزيد من التفاصيل حول هذه الفكرة. الخاتمة أنشأنا في هذا المقال تطبيق فلاسك يتيح للمستخدمين إضافة رسائل إلى قائمة رسائل لعرضها في الصفحة الرئيسية للتطبيق. كما أنشأنا نموذج ويب وتعلمنا كيفية التعامل مع البيانات التي يرسلها المستخدم عن طريق هذا النموذج لإضافتها إلى قائمة الرسائل، كما استخدمنا الرسائل الخاطفة لإعلام المستخدم في حال إرسال بيانات غير صحيحة. ترجمة -وبتصرف- للمقال How To Use Web Forms in a Flask Application لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال السابق: كيفية التعامل مع الأخطاء في تطبيقات فلاسك Flask كيفية استخدام القوالب في تطبيقات فلاسك Flask استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا
تمنح نماذج الويب web forms من صناديقٍ نصيّة وحقول نصوص مُتعدّدة الأسطر المستخدمين القدرة على إرسال البيانات إلى التطبيق لاستخدامها في تنفيذ أمرٍ ما، أو حتّى لإرسال محتوًى نصي كبير، فمثلًا يُمنح المستخدم في تطبيقات التواصل الاجتماعي حيزًا يمكِّنه من إضافة محتوًى جديد إلى صفحته الشخصية؛ كما يوجد أيضًا في صفحة تسجيل الدخول حقلٌ لإدراج اسم المستخدم وحقلٌ لإدراج كلمة المرور، إذ يستخدم الخادم (تطبيق فلاسك في حالتنا) هذه البيانات التي أدخلها المستخدم ليسجّل دخوله إذا كانت البيانات صحيحة أو يستجيب برسالة خطأ مثل "!Invalid credentials" لإعلام المستخدم بأن البيانات التي أدخلها خاطئة. يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدّة أدوات وميزات من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل. سننشئ في هذا المقال تطبيق ويب مُصغّر لبيان كيفيّة استخدام نماذج الويب، إذ سيتضمّن صفحةً لإظهار رسائل مُخزّنةٍ مُسبقًا ضمن قائمة باستخدام بايثون، وصفحةً أُخرى لإضافة رسائل جديدة، كما سنستخدم الرسائل الخاطفة message flashing لإبلاغ المستخدمين بوجود خطأ لدى إدخالهم لبيانات غير صحيحة. #مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات routes ودوال العرض view في فلاسك، وفي هذا الصدد يمكنك الاطلاع على المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask من لغة بايثون لفهم مبادئ فلاسك. فهم أساسيات لغة HTML. الخطوة الأولى - عرض الرسائل سننشئ في هذه الخطوة تطبيق فلاسك بصفحة رئيسية لعرض رسائل مُخزنة أصلًا في قائمة من قواميس بايثون. لذا سنفتح ملف جديد باسم "app.py" للتعديل عليه: (env)user@localhost:$ nano app.py وسنضيف الشيفرة التالية ضمنه، بغية إنشاء خادم فلاسك ذو وجهةٍ واحدة: from flask import Flask, render_template app = Flask(__name__) messages = [{'title': 'Message One', 'content': 'Message One Content'}, {'title': 'Message Two', 'content': 'Message Two Content'} ] @app.route('/') def index(): return render_template('index.html', messages=messages) ثمّ نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة كلًا من الصنف Flask الذي سنستخدمه لإنشاء نسخة من التطبيق باسم app، ودالة تصيّير القوالب ()render_template من حزمة فلاسك flask، مُمررّين المتغير الخاص __name__ اللازم لتمكين فلاسك من إعداد بعض المسارات العاملة في الخلفية؛ أمّا عن تصيير القوالب، فننصحك بقراءة المقال كيفية استخدام القوالب في تطبيقات فلاسك Flask. ثمّ أنشأنا قائمةً عامّة في بايثون باسم messages، والتي تحتوي على قواميس بايثون، وفي كل قاموس أضفنا مفتاحين أساسيين، هما: title لتخزين عنوان الرسالة، و content لتخزين مضمونها، وما هذا إلّا مثال مُبسّط لآلية تخزين البيانات، إذ نستخدم في التطبيقات العملية الواقعية قاعدة بيانات لتُخزّن هذه البيانات بصورةٍ دائم سامحةً لنا بتعديلها واسترجاعها بسهولة وفعالية. وبعد إنشاء قائمة بايثون، أنشأنا دالة العرض ()index باستخدام المُزخرف ()app.route@ الذي يحوّل دوال بايثون الاعتيادية إلى دوال عاملة في فلاسك، وفيها تكون القيمة المعادة استدعاءً للدالة ()render_template التي تُعلم فلاسك بأنّ الوجهة الحالية يجب أن تعرض في النتيحة قالب HTML باسم index.html (سننشئ ملف القالب هذا في الخطوات اللاحقة) ممررين له قيمة المتغير المُسمّى messages والذي يحتوي على قائمة الرسائل messages التي صرحنا عنها للتو مُسندين لها القيم اللازمة، وجعلناها متاحةً للاستخدام من قبل قالب HTML. ننصحك في هذا الصدد بقراءة المقال How To Create Your First Web Application Using Flask and Python 3 لفهم أعمق لدوال العرض في فلاسك. الآن، سننشئ مجلدًا للقوالب باسم "templates" ضمن المجلد "flask_app"، إذ سيبحث فلاسك ضمنه عن القوالب، وبعدها سننشئ ملف القالب الأساسي باسم "base.html" وفيه سنكتب الشيفرة الأساسية التي سترثها بقية القوالب لتجنّب تكرار الشيفرات: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html ومن ثمّ نكتب الشيفرة التالية ضمن الملف base.html لإنشاء قالب HTML الأساسي مع شريط تنقل وجزء مُخصّص للمحتوى: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> .message { padding: 10px; margin: 5px; background-color: #f3f3f3 } nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> نحفظ الملف ونغلقه. يتضمّن القالب الأساسي كافّة الشيفرات المتداولة التي سنحتاجها في القوالب الأُخرى. ستُستبدل لاحقًا كتلة العنوان title بعنوان كل صفحة وكتلة المحتوى content بمحتواها، أمّا عن شريط التصفح فسيتضمّن رابطين، الأوّل ينقل المُستخدم إلى الصفحة الرئيسية للتطبيق باستخدام الدالة المساعدة ()url_for لتحقيق الربط مع دالة العرض ()index، والآخر لصفحة المعلومات حول التطبيق في حال قررت تضمينها في تطبيقك. لذا سنفتح ملف القالب المُسمى "index.html" وهو الاسم الذي حددناه في الملف app.py: (env)user@localhost:$ nano templates/index.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Messages {% endblock %}</h1> {% for message in messages %} <div class='message'> <h3>{{ message['title'] }}</h3> <p>{{ message['content'] }}</p> </div> {% endfor %} {% endblock %} ثمّ نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة ملف القالب "base.html"، واستبدلنا محتوى كتلة المحتوى content مُستخدمين تنسيق العنوان من المستوى الأوّل <h1> الذي يفي أيضًا بالغرض لعنوان الصفحة. كما استخدما حلقة for التكرارية وهي من ضمن تعليمات محرّك القوالب جينجا Jinja وذلك في السطر البرمجي {% for message in messages %} بهدف التنقل بين الرسائل في القائمة messages (والمُخزنة ضمن المتغير المسمّى message)؛ إذ سنعرض عناوين الرسائل ضمن تنسيق عنوان من المستوى الثالث باستخدام الوسم <h3>، ومحتواها ضمن تنسيق فقرة باستخدام الوسم <p>، وكلاهما ضمن حافظة عناصر HTML باستخدام الوسم <div>. ولتشغيل تطبيق الويب الذي أنشأناه، وبعد التأكّد من وجودنا ضمن المجلد "flask_app" مع تفعيل البيئة الافتراضية، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم "app.py") وذلك باستخدام متغير بيئة فلاسك FLASK_APP: (env)user@localhost:$ export FLASK_APP=app نضبط متغير بيئة فلاسك Flask_ENV على الوضع development لتشغيل التطبيق في وضع التطوير ما يمكنّنا من استخدام مُنقّح الأخطاء كما يلي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_ENV=development بعدها، سنشغل التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نذهب إلى الرابط التالي باستخدام المتصفح: http://127.0.0.1:5000/ فتظهر الرسائل المُخزّنة أصلًا ضمن القائمة "messages" في الصفحة الرئيسية للتطبيق كما يلي: ومع نهاية هذه الخطوة نكون قد أعددنا تطبيق الويب ليعرض الرسائل المُخزنة، أمّا في الخطوة التالية سنعدّ نماذج الويب اللازمة لنسمح للمستخدمين بإضافة رسائل جديدة إلى القائمة لعرضها في الصفحة الرئيسية للتطبيق. الخطوة الثانية - إعداد نماذج الويب سننشئ في هذه الخطوة صفحةً جديدةً في التطبيق تسمح للمستخدمين بإضافة رسائل جديدة إلى قائمة الرسائل من خلال نموذج ويب. لذا سنفتح نافذة طرفية جديدة مع بقاء خادم التطوير قيد التشغيل. ومنها نفتح الملف app.py: (env)user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/create/', methods=('GET', 'POST')) def create(): return render_template('create.html') نحفظ الملف ونغلقه. تتضمّن الوجهة /create معامل طلبيات HTTP methods المتضمّن صفًا tuple هو ('GET', 'POST') للتعامل معها سواءً بطريقة GET، أو POST، إذ أن طريقة "GET" هي الطريقة الافتراضية المُستخدمة لجلب البيانات من الخادم، مثل حالة طلب عرض الصفحة الرئيسية أو صفحة المعلومات حول التطبيق؛ أمّا طريقة "POST" فتُستخدم من قبل المتصفح عند إرسال نماذج الإدخال إلى وجهةٍ مُحدّدة، الأمر الذي سيغيّر من البيانات المُخزّنة في الخادم. وفي مثالنا هذا سيُطلب عرض صفحة إنشاء رسائل جديدة "create" باستخدام طلب من النوع "GET"، إذ ستتضمّن هذه الصفحة نموذج ويب بحقول إدخال وزر إرسال، ولدى ملء النموذج من قبل المستخدم وإرساله، يُرسل طلب من النوع "POST" إلى الوجهة create/، الذي يتعامل مع الطلب من حيث التحقّق من صحة البيانات المُدخلة للتأكّد من كون المُستخدم لم يرسل نموذجًا فارغًا، لتُضاف عندها هذه البيانات إلى قائمة الرسائل "messages". تؤدي دالة فلاسك ()create حاليًا مهمةً واحدة، وهي تصيّير قالب HTML باسم "create.html" لدى استقبالها لطلب من نوع GET، لذا سننشئ الآن هذا القالب وسنعدّل الدالة ()create لتصبح قادرةً أيضًا على التعامل مع الطلبات من النوع POST اللازمة في الخطوة التالية. لذا سنفتح ملف القالب المُسمّى "create.html": (env)user@localhost:$ nano templates/create.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Add a New Message {% endblock %}</h1> <form method="post"> <label for="title">Title</label> <br> <input type="text" name="title" placeholder="Message title" value="{{ request.form['title'] }}"></input> <br> <label for="content">Message Content</label> <br> <textarea name="content" placeholder="Message content" rows="15" cols="60" >{{ request.form['content'] }}</textarea> <br> <button type="submit">Submit</button> </form> {% endblock %} ثمّ نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة قالب base.html واستبدلنا كتلة المحتوى content بكائن عنوان من المستوى الأوّل <h1> الذي سيعمل مثل عنوان للصفحة، وعيّنا في وسم كائن النموذج <form> قيمة السمة method لتكون post بمعنى أنّ بيانات النموذج ستُرسل إلى الخادم مثل طلب من نوع POST. وفي كائن النموذج أضفنا حقل إدخال نصي باسم title وهو الاسم الذي سنستخدمه في التطبيق للوصول إلى بيانات نموذج العنوان، كما أسندنا القيمة {{ request.form['title'] }} لسمة value من الوسم <input>، وهو أمرٌ مفيدٌ لتخزين البيانات التي يدخلها المستخدم مع إمكانية استعادتها في حال حدوث خطأ ما؛ فإذا نسي المستخدم مثلًا ملء الحقل النصي المُخصّص لمحتوى الرسالة content وهو حقل مطلوب، فسيُرسل طلب إلى الخادم لإرجاع رسالة خطأ في الاستجابة، ولكن البيانات في العنوان لن نفقدها لأنها محفوظة في الكائن العام request ويمكن الوصول لها من خلال القيمة ['request.from['title. أضفنا بعد حقل الإدخال المُخصّص لعنوان الرسالة، حقلًا نصيًا مُتعدّد الأسطر لمحتواها باسم content وأسندنا أيضًا القيمة {{ request.form['content'] }} لسمة value لنفس السبب آنف الذكر. ونهايةً أضفنا زر إرسال إلى نهاية النموذج. الآن وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، ننتقل إلى الوجهة الجديدة create/ باستخدام المتصفح: http://127.0.0.1:5000/create فتظهر صفحة إضافة رسالة جديدة “Add a New Message” مع حقل إدخال لعنوان الرسالة وحقل نصي مُتعدّد الأسطر لإدخال محتوى الرسالة، وزر لتقديم النموذج عند الانتهاء من إدخال البيانات. يُرسل هذا النموذج طلبًا من نوع "POST" إلى دالة فلاسك ()create، ولكن حتى الآن ما من شيفرة في الدالة للتعامل مع الطلب هذا، لذا لن يحدث شيء بعد تعبئة النموذج وإرساله> لذلك، سنكتب في الخطوة التالية الشيفرة اللازمة للتعامل مع طلب من النوع "POST" بعد إرسال النموذج، إذ سنتحقّق من صحة البيانات المرسلة (ليست فارغة)، كما سنضيف عنوان الرسالة ومحتواها إلى قائمة الرسائل "messages". الخطوة الثالثة - التعامل مع الطلبات الواردة من نماذج الويب سنتعامل في هذه الخطوة مع الطلبات الواردة من نماذج الإدخال إلى التطبيق، إذ سنعمل على الوصول إلى البيانات التي أرسلها المستخدم عبر نموذج الإدخال المُنشأ في الخطوة السابقة لإضافتها إلى قائمة الرسائل، كما سنستخدم الرسائل الخاطفة message flashing لإعلام المستخدم في حال إرسال بيانات غير صحيحة، فعندها ستظهر الرسالة لمرة واحدة وتختفي في الطلب التالي (مثل الانتقال إلى صفحة أُخرى) ومن هنا جاء سبب تسميتها بالخاطفة. لذا سنفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py لا بُد أولًا من استيراد ما يلي من إطار العمل فلاسك: الكائن request العام المسؤول عن الوصول إلى بيانات الطلب والتي ستُرسل من خلال نموذج HTML المبني في الخطوة السابقة. الدالة url_for() لتوليد عناوين الروابط. الدالة flash() لعرض رسالةٍ وامضة عند انتهاء معالجة الطلب، لإعلام المُستخدم في حال سير الأمور على نحوٍ سليم أو في حال وجود مشاكل مثل كون البيانات المُدخلة خاطئة. الدالة redirect() لإعادة توجيه المستخدم إلى موقعٍ آخر في المتصفح. سنضيف هذه الاستيرادات إلى السطر الأوّل من الملف كما يلي: from flask import Flask, render_template, request, url_for, flash, redirect # ... تخزّن الدالة flash() الرسائل في جلسة المتصفح لدى المستخدم، وهذا ما يتطلّب إعداد مفتاح أمان Secret Key، إذ سيُستخدم هذا المفتاح لجعل الجلسات آمنة، وبذلك يتمكّن فلاسك من الحفاظ على المعلومات عند الانتقال من طلبٍ إلى آخر، مثل حالة الانتقال من صفحة إنشاء رسالة جديدة إلى الصفحة الرئيسية، مع ملاحظة أن المستخدم يستطيع الوصول إلى المعلومات المُخزّنة في الجلسة، ولكنه لا يستطيع تعديلها إلّا إذا كان لديه مفتاح الأمان، وبالتالي لا يجب أن تسمح لأي أحدٍ بالوصول إلى مفتاح الأمان الخاص بك. تذكّر أنّ مفتاح الأمان يجب أن يكون سلسلةً نصيةً عشوائية بطولٍ مناسب، إذ من الممكن توليد مفتاح أمان باستخدام التابع ()os.urandom من الوحدة os، إذ يعيد هذا التابع سلسلة من البايتات العشوائية المناسبة لاستخدامات التشفير (الحصول على سلسلة نصية خاصّة أو رقم خاص). للحصول على سلسلة نصية عشوائية باستخدام هذا التابع، سنفتح نافذة طرفية جديدة ومنها نفتح صَدفة بايثون التفاعلية باستخدام الأمر التالي: (env)user@localhost:$ python وضمن صَدفة بايثون التفاعلية سنستورد الوحدة os من مكتبة بايثون المعيارية، وسنستدعي التابع ()os.urandom كما يلي: >>> import os >>> os.urandom(24).hex() فنحصل في الخرج على سلسلة مُشابهة لما يلي: 'df0331cefc6c2b9a5d0208a726a5d1c0fd37324feba25506' وبذلك يمكننا استخدام هذه السلسلة النصية مثل مفتاح أمان. ولإعداد مفتاح أمان، سنضيف ضبط SECRET_KEY إلى التطبيق من خلال الكائن app.config، الذي سنضيفه مباشرةً بعد تعريف الكائن app وقبل تعريف المتغير messages، على النحو التالي: # ... app = Flask(__name__) app.config['SECRET_KEY'] = 'your secret key' messages = [{'title': 'Message One', 'content': 'Message One Content'}, {'title': 'Message Two', 'content': 'Message Two Content'} ] # ... ومن ثمّ نعدّل دالة العرض ()create لتبدو كما يلي: # ... @app.route('/create/', methods=('GET', 'POST')) def create(): if request.method == 'POST': title = request.form['title'] content = request.form['content'] if not title: flash('Title is required!') elif not content: flash('Content is required!') else: messages.append({'title': title, 'content': content}) return redirect(url_for('index')) return render_template('create.html') تَمكَّنا باستخدام العبارة الشرطية التي توازن قيمة request.method مع القيمة POST من التحقُّق بأنّ التعليمات التالية لها لن تُنفّذ إلّا إذا كان الطلب الحالي هو فعلًا بطريقة POST، ومن ثمّ قرأنا قيم العنوان والمحتوى المرسلين من الكائن request.form الذي يمكِّننا من الوصول إلى بيانات نموذج الإدخال المُضمّنة في الطلب؛ ففي حال عدم إدخال قيمةٍ للعنوان، فسيتحقق الشرط if not title وبالتالي ستظهر رسالة للمستخدم نعلمه من خلالها بأن العنوان مطلوب وذلك باستخدام الدالة ()flash، وهذا ما يضيف هذه الرسالة إلى قائمة للرسائل الخاطفة والتي سنعرضها لاحقًا ضمن الصفحة بوصفها جزءًا من القالب الرئيسي "base.html"؛ وعلى نحوٍ مُشابه فيما يتعلّق بقسم المحتوى، ففي حال كان فارغًا، فسيتحقق الشرط elif not content وبالتالي ستظهر رسالة للمستخدم نعلمه من خلالها بأن المحتوى مطلوب، وستُضاف هذه الرسالة أيضًا إلى قائمة الرسائل الخاطفة. أمّا في حال وجود عنوان ومحتوى سليمين، فسيُضاف قاموس بايثون جديد إلى القائمة messages بالعنوان والمحتوى المدخلين من قبل المستخدم وذلك اعتمادًا على السطر البرمجي ({messages.append({'title': title, 'content': content، ومن ثمّ نعيد توجيه الطلب إلى الصفحة الرئيسية باستخدام الدالة redirect() بتمرير الرابط الناتج عن التابع url_for() الذي قد مررنا له القيمة index وسيطًا. ثمّ نحفظ الملف ونغلقه. ننتقل إلى الوجهة create/ عن طريق المتصفح كما يلي: http://127.0.0.1:5000/create وبملء النموذج بعنوان اختياري ومحتوى ما، وحالما نرسل النموذج، ستظهر الرسالة الجديدة في الصفحة الرئيسية للتطبيق. ونهايةً سنعرّض كافّة الرسائل الخاطفة ضمن الصفحة الرئيسية للتطبيق، كما سنضيف رابطًا في شريط التصفح للقالب الرئيسي base.html، للانتقال إلى صفحة إضافة رسالة جديدة مباشرةً وبسهولة، لذا سنفتح ملف القالب الرئيسي: (env)user@localhost:$ nano templates/base.html الآن، سنعدّل الملف من خلال إضافة وسم رابط <a> جديد بعد رابط تطبيق فلاسك المتوضّع في شريط التصفُّح داخل الوسم <nav>، ثمّ سنضيف حلقة تكرارية أعلى كتلة المحتوى مباشرةً لعرض الرسائل الخاطفة أسفل شريط التصفح، إذ يوفّر فلاسك هذه الرسائل من خلال دالة فلاسك الخاصة get_flashed_messages()، وسنضيف ضمن الوسم <style> السمة alert لكل رسالة مُسندين إليها بعض الخصائص من CSS كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> .message { padding: 10px; margin: 5px; background-color: #f3f3f3 } nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } .alert { padding: 20px; margin: 5px; color: #970020; background-color: #ffd5de; } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="{{ url_for('create') }}">Create</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% for message in get_flashed_messages() %} <div class="alert">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> </body> </html> ثمّ نحفظ الملف ونغلقه، وبإعادة تحميل الرابط "https://127.0.0.1:5000" في المتصفح، ستظهر الصفحة الرئيسية للتطبيق بشريط تصفُّح مُتضمّن للعنصر "Create" الذي يرتبط بالوجهة create/ الخاصّة بصفحة إنشاء رسالة جديدة. ولنرى كيفية عمل الرسائل الخاطفة، ننتقل إلى صفحة "Create" ونضغط على زر الإرسال في النموذج دون ملء أي من حقلي العنوان أوالمحتوى، فتظهر رسالة كما هو مبين بالشكل: وبالعودة إلى الصفحة الرئيسية نلاحظ أنّ الرسالة الخاطفة أسفل شريط التنقل قد اختفت، رغم عرضها على أنها جزء من القالب الأساسي، وهنا تكمن ميزتها، فلو لم تكن رسالة خاطفة لكانت ستُعرض في الصفحة الرئيسية أيضًا لأنها ترث من القالب الأساسي. ولو أرسلنا النموذج مع عنوان ومحتوى فارغ، فستظهر رسالة تفيد بأن حقل المحتوى مطلوب "!Content is required"، وبالضغط على رابط تطبيق فلاسك FlaskApp في شريط التصفُّح نعود إلى الصفحة الرئيسية للتطبيق؛ وهنا إذا ضغطنا في المُتصفّح على زر الرجوع، سنجد أن الرسالة الخاطفة المُتعلقّة بكون المحتوى فارغ لا تزال موجودة، ذلك لأنّ الطلب السابق هو المحفوظ حاليًا؛ أما لو انتقلنا إلى صفحة إنشاء رسالة جديدة من شريط التصفّح فسيُرسل طلب جديد، وبذلك تُمحى مُدخلات النموذج القديمة ومعها الرسالة الخاطفة. وبذلك نكون قد تعرّفنا على كيفية استلام مُدخلات المُستخدم والتحقّق من صحتها وإضافتها إلى مصدر البيانات (وهو قائمة بايثون في حالتنا). ملاحظة: ستختفي الرسائل المُضافة إلى الفائمة "messages" في التطبيق بمجرّد توقّف الخادم، لأنّ قوائم بايثون تُحفظ فقط في الذاكرة (المؤقتة)، أمّا لحفظ الرسائل بصورةٍ دائمة فلا بدّ من استخدام قاعدة بيانات مثل SQLite، وفي هذا الصدد ننصحك بقراءة المقال كيفية استخدام علاقة نوع واحد-إلى-متعدد one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite لمزيد من التفاصيل حول هذه الفكرة. الخاتمة أنشأنا في هذا المقال تطبيق فلاسك يتيح للمستخدمين إضافة رسائل إلى قائمة رسائل لعرضها في الصفحة الرئيسية للتطبيق. كما أنشأنا نموذج ويب وتعلمنا كيفية التعامل مع البيانات التي يرسلها المستخدم عن طريق هذا النموذج لإضافتها إلى قائمة الرسائل، كما استخدمنا الرسائل الخاطفة لإعلام المستخدم في حال إرسال بيانات غير صحيحة. ترجمة -وبتصرف- للمقال How To Use Web Forms in a Flask Application لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال السابق: كيفية التعامل مع الأخطاء في تطبيقات فلاسك Flask كيفية استخدام القوالب في تطبيقات فلاسك Flask استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا -
 يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها إنشاء تطبيقات ويب في لغة بايثون. ستواجه خلال تطوير تطبيقات الويب حتمًا حالاتٍ يعطي فيها تطبيقك نتائجًا مخالفةً لتوقعاتك، وذلك بسبب أخطاء من قبيل الكتابة الخاطئة لاسم أحد المتغيرات، أو الاستخدام الخاطئ لحلقة "for" التكرارية أو بناء عبارة "if" الشرطية بطريقة خاطئة مسبّبةً وقوع أحد استثناءات بايثون، كما في حال استدعاء دالة ما قبل التصريح عنها، أو البحث عن صفحة غير موجودة أصلًا، فممّا لا شكّ فيه أنّك ستجد تطوير تطبيقات الويب باستخدام فلاسك أسهل وأكثر مرونة حال تعلمّك لكيفية التعامل مع الأخطاء والاستثناءات. سنبني في هذا المقال تطبيق ويب مُصغّر بهدف تبيان كيفيّة التعامل مع الأخطاء الشائعة التي قد تواجهك أثناء تطوير تطبيقات الويب، كما سننشئ صفحات أخطاء مُخصّصة، وسنستخدم منقّح الأخطاء في فلاسك لاستكشاف الاستثناءات في حال حدوثها وإصلاحها، كما سنستخدم سجل الأحداث logging لتتبّع الأحداث في التطبيق بحثًا عن مصادر الأخطاء. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات routes ودوال العرض view في فلاسك، وفي هذا الصدد يمكنك الاطلاع على المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask من لغة بايثون لفهم مبادئ فلاسك. فهم أساسيات لغة HTML. الخطوة الأولى - استخدام منقح الأخطاء في فلاسك سننشئ في هذا الخطوة تطبيقًا يحتوي على بضعة أخطاء بغية تشغيله دون استخدام منقّح الأخطاء، لنرى الآلية التي سيستجيب بها التطبيق، ومن ثمّ سنعيد تشغيله ولكن مع تفعيل وضع منقّح الأخطاء لنستخدمه في استكشاف أخطاء التطبيق وإصلاحها. لذلك، وبعد التأكّد من تفعيل البيئة البرمجية وتثبيت فلاسك، سننشئ ملفًا ضمن المجلد "flask_app" باسم "app.py" لتحريره: (env)user@localhost:$ nano app.py ونكتب ضمنه الشيفرة التالية: from flask import Flask app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') استوردنا في الجزء السابق من الشيفرة كائن فلاسك من حزمة falsk، ثم استخدمناه لإنشاء نسخةٍ فعليةٍ موجودةٍ في الذاكرة لتطبيق فلاسك Flask application instance باسم app، ثمّ أنشأنا دالة العرض ()index باستخدام المُزخرف ()app.route@، الذي يحوّل دوال بايثون الاعتيادية إلى دوال عرض، وفيها تكون القيمة المُعادة استدعاءً للدالة ()render_template، والتي تعرض بدورها قالب HTML المُسمى "index.html" في النتيحة. في هذه الشيفرة خطآن: الأوّل هو أنّنا لم نستورد دالة تصيّير القوالب ()render_template من حزمة فلاسك قبل استدعائها، والثاني أنّ قالب HTML المسمّى "index.html" غير موجود بعد. نحفظ الملف ونغلقه. والآن، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم app.py) وذلك باستخدام متغير بيئة فلاسك FLASK_APP على النحو التالي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_APP=app بعدها سنشغل خادم التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run فتظهر في نافذة الطرفية المعلومات التالية: * Serving Flask app 'app' (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) يحتوي الخرج السابق على عدة معلومات، مثل: اسم التطبيق المُشغَّل، وهو "app.py" في حالتنا. بيئة التشغيل الحالية التي يعمل عليها التطبيق، وهي في حالتنا بيئة الاستخدام الفعلي للتطبيق (نشر المنتج) "production"، وتُشدّد الرسالة التحذيرية هذه على كون الخادم غير مُخصّص لمرحلة نشر المنتج، وبما أنّنا نستخدمه بالواقع بغية تطوير التطبيق، فمن الممكن تجاهل الرسالة التحذيرية هذه. عبارة "Debug mode:off"، التي تشير إلى أن منقّح أخطاء فلاسك ليس قيد التشغيل، وبالتالي لن تتلقّى أي رسائل مفيدة حول الأخطاء الحاصلة في التطبيق، وهو أمرٌ طبيعي كوننا نعمل الآن في بيئة نشر المُنتج، فعرض رسائل تفصيلية بالأخطاء الحاصلة في هذه البيئة (نشر المنتج) يعرّض التطبيق لمخاطر أمنية ويعدّ ثغرة أمنية بحد ذاته. التطبيق يعمل على الرابط "/http://127.0.0.1:5000"، إذ أن "127.0.0.1" هو عنوان IP الذي يمثِّل الخادم المحلي localhost، و "5000:" هو رقم المنفذ، ولإيقاف تشغيل الخادم يمكنك الضغط على مفتاحي "CTRL+C"، ولكن لا توقفه الآن. الآن، وبالانتقال إلى الصفحة الرئيسية للتطبيق في المتصفّح عبر الرابط: http://127.0.0.1:5000/ ستظهر رسالة شبيهة بما يلي في الخرج: Internal Server Error The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application. وهو خطأ الخادم الداخلي 500 Internal Server Error، الذي يمثّل استجابةً خاطئةً للخادم تشير لكونه يواجه خطأً داخليًا في شيفرة التطبيق. وسيظهر الخرج التالي في نافذة الطرفية: [2021-09-12 15:16:56,441] ERROR in app: Exception on / [GET] Traceback (most recent call last): File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 2070, in wsgi_app response = self.full_dispatch_request() File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 1515, in full_dispatch_request rv = self.handle_user_exception(e) File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 1513, in full_dispatch_request rv = self.dispatch_request() File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 1499, in dispatch_request return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args) File "/home/abd/python/flask/series03/flask_app/app.py", line 8, in index return render_template('index.html') NameError: name 'render_template' is not defined 127.0.0.1 - - [12/Sep/2021 15:16:56] "GET / HTTP/1.1" 500 - تمرُ عملية التعقّب العكسي أعلاه على الشيفرة المُسبّبة لخطأ الخادم الداخلي، إذ يشير السطر "NameError: name 'render_template' is not defined" إلى أصل المشكلة (خطأ في الاسم)، وهو في حالتنا أنّ الدالة ()render_template غير مستوردة ما جعلها غير مُعرّفة. وهنا نلاحظ أنّه لا بدّ من الذهاب إلى نافذة الطرفية لاكتشاف الأخطاء (وليس ضمن خرج التطبيق نفسه)، والذي يُعد أمرًا غير ملائم في الاستخدام الفعلي. فمن الممكن الحصول على تجربة استكشاف أخطاء وإصلاحها بطريقة أفضل وأسهل عبر تمكين وضع تنقيح الأخطاء في خادم التطوير، ولإجراء ذلك سنوقف عمل الخادم عبر الضغط على مفتاحي "CTRL+C"، ثمّ سنضبط متغير بيئة فلاسك FLASK_ENV على الوضع development، ما يمكنّنا من تشغيل البرنامج في وضع التطوير ( الذي يُمكِّن منقّح الأخطاء) كما يلي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_ENV=development نشغّل الآن خادم التطوير: (env)user@localhost:$ flask run فيظهر في نافذة الطرفية خرجٌ مُشابه لما يلي: * Serving Flask app 'app' (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 120-484-907 ومنه نلاحظ أنّ وضع التشغيل حاليًا هو وضع التطوير، وأنّ وضع تنقيح الأخطاء قيد التشغيل وبالتالي فإنّ مُنقّح الأخطاء مُفعّل، أمّا "Debugger PIN" فيمثّل الرمز السرّي اللازم لإلغاء قفل سجل المتصفّح (لوحة المراقبة) Browser console (وهي صَدفة shell بايثون تفاعلية يمكنك الوصول إليها بالضغط على رمز الطرفية الصغير المحاط بدائرة حمراء في الصورة أدناه). وبتحديث الصفحة الرئيسية للتطبيق ضمن المتصفح، ستظهر الصفحة بالشّكل التالي: وفي هذه الحالة نرى رسالة الخطأ بصياغة وطريقة عرض أسهل للفهم، إذ يشير العنوان الأوّل فيها إلى اسم استثناء بايثون المُتسبّب بالمشكلة (وهو خطأ في الاسم "NameError" في حالتنا). أما السطر الثاني من رسالة الخطأ فيشير إلى سبب الخطأ المباشر (وهو في حالتنا أنّ الدالة ()render_template غير مُعرّفة ما يعني أنّها غير مستوردة أصلًا)، أمّا الأسطر التالية فهي نتيجة التعقّب العكسي لشيفرة فلاسك الداخلية المُنفّذة، ومن المُفضّل قراءة هذا الجزء من الأسفل إلى الأعلى، إذ يتضمّن عادةً السطر الأخير من نتيجة التعقّب العكسي أكثر المعلومات أهمية. ملاحظة: يمكنّك رمز الطرفية الصغير المحاط بدائرة حمراء في الصورة السابقة من تشغيل الشيفرة المكتوبة أصلًا بلغة بايثون ضمن المُتصفّح في أُطر عمل مُختلفة (وهنا ضمن ما يشبه صَدفة بايثون التفاعلية ولكن ضمن المتصفح نفسه)، وهذا أمرٌ مفيدٌ للتحقّق مثلًا من قيمة متغير ما بنفس الطريقة التي تؤديها صَدفة بايثون التفاعلية. عند الضغط على هذه الأيقونة يجب إدخال الرمز السري الخاص بالمنقّح Debugger PIN الذي حصلت عليه عند تشغيل الخادم في الخطوة السابقة، ولكن ضمن محاور هذا المقال لن نحتاج إلى استخدامها. الآن، لإصلاح الخطأ في الاسم "NameError" الحاصل، نترك الخادم بحالة تشغيل ونفتح نافذة طرفية جديدة، وفيها نفعّل البيئة البرمجية ومن ثمّ نفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py ونعدله ليصبح كما يلي: from flask import Flask, render_template app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة دالة تصيّير القوالب ()render_template من حزمة فلاسك flask، الأمر الذي كان ناقصًا فيما سبق مُتسبّبًا بالخطأ الحاصل. الآن وبعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، نحدّث الصفحة الرئيسية للتطبيق ضمن المتصفح، فتظهر صفحة خطأ في الخرج، تتضمّن معلومات شبيهة بما يلي: jinja2.exceptions.TemplateNotFound jinja2.exceptions.TemplateNotFound: index.html وتشير رسالة الخطأ هذه لكون القالب "index.html" غير موجود. ولإصلاح هذا الخطأ، سننشئ ملف قالب باسم "base.html" لتتمكّن القوالب الأُخرى من وراثة شيفراته بغية تجنُّب تكرار الشيفرات، كما سننشئ القالب "index.html"، الذي سيرث من القالب الرئيسي. لذا سننشئ مجلد للقوالب باسم "templates" ضمن المجلد "flask_app"، إذ سيبحث فلاسك ضمنه عن القوالب، وبعدها سنفتح ملف القالب الأساسي المُسمى "base.html" باستخدام أي محرّر نصوص (هنا سنستخدم محرّر النصوص نانو nano: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html ثمّ نكتب الشيفرة التالية ضمن الملف base.html: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> نحفظ الملف ونغلقه. يتضمّن القالب الأساسي كافّة الشيفرات المتداولة التي ستحتاجها في القوالب الأُخرى، وستُستبدل لاحقًا كتلة العنوان title بعنوان كل صفحة وكتلة المحتوى content بمحتواها، أمّا عن شريط التصفح فسيتضمّن رابطين، الأوّل ينقل المُستخدم إلى الصفحة الرئيسية للتطبيق باستخدام الدالة المساعدة ()url_for لتحقيق الربط مع دالة العرض ()index، والآخر لصفحة المعلومات حول التطبيق في حال قررت تضمينها في تطبيقك. لذا سنفتح ملف قالب index.html، الذي سيرث شيفراته من القالب الرئيسي: (env)user@localhost:$ nano templates/index.html ونكنب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Index {% endblock %}</h1> <h2>Welcome to FlaskApp!</h2> {% endblock %} ثمّ نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة ملف القالب "base.html"، متجاوزين كتلة المحتوى content، ثمّ استخدمنا كتلة العنوان title لتعيين عنوان للصفحة وعرضه ضمن تنسيق عنوان من المستوى الأوّل H1، كما كتبنا الشيفرة اللازمة لعرض رسالة ترحيب ضمن تنسيق عنوان من المستوى الثاني H2. الآن وبعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، نحدّث الصفحة الرئيسية للتطبيق ضمن المتصفح، فنجد أنّ التطبيق لا يعرض أي أخطاء وأنّ الصفحة الرئيسية للتطبيق تبدو بالشكل المطلوب. ومع نهاية هذه الخطوة نكون قد استخدمنا وضع تنقيح الأخطاء وتعرفنا على كيفية التعامل مع رسائل الخطأ، وسنعمل في الخطوة التالية على إيقاف طلب ما ليستجيب برسالة خطأ من اختيارنا، وسنتعلّم كيفية إنشاء صفحات أخطاء مُخصّصة لتظهر بمثابة استجابة لطلبات معينة. الخطوة الثانية - تخصيص صفحات أخطاء سنتعرّف في هذه الخطوة على كيفية إلغاء طلب المستخدم في حال أراد الوصول إلى بيانات غير موجودة على الخادم والاستجابة برسالة خطأ HTTP من النوع 404، كما سنتعلّم كيفية إنشاء صفحات أخطاء مُخصّصة لتظهر بمثابة استجابة لأخطاء HTTP الشائعة، مثل خطأ الخادم الداخلي "500 Internal Server Error" وخطأ عدم توفّر البيانات المطلوبة "404 Not Found". ولنبيّن كيفية إلغاء طلب والاستجابة بصفحة خطأ مُخصّصة بخطأ HTTP من نوع 404، سننشئ صفحةً مهمتها عرض عدد من الرسائل، وفي حال طلب رسالة غير موجودة، ستستجيب بخطأ من النوع 404. لذا سنفتح الملف app.py لإضافة وجهةٍ route جديدة لصفحة الرسائل: (env)user@localhost:$ nano app.py وسنضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/messages/<int:idx>') def message(idx): messages = ['Message Zero', 'Message One', 'Message Two'] return render_template('message.html', message=messages[idx]) نحفظ الملف ونغلقه. استخدمنا في الشيفرة السابقة متغيرًا يدل على رقم مؤشّر الروابط باسم idx، والمُتضمّن رقم المؤشر الذي من شأنه تحديد الرسالة المطلوب عرضها، بمعنى أنّه إذا كان الرابط هو "/messages/0"، فهذا يعني أنّ الرسالة الأولى ذات المؤشّر بالقيمة صفر هي المطلوب عرضها؛ كما استخدمنا محوّل القيم int المسؤول عن قبول قيم من النوع "عدد صحيح موجب" فقط، ذلك لأنّ متحولات العناوين تكون افتراضيًا بنمط بيانات من النوع "سلاسل نصية". تتضمّن دالة العرض message() قائمة بايثون اعتيادية باسم "messages" تحتوي على ثلاث رسائل (ولكن في الواقع العملي سيكون مصدر هذه الرسائل هو قاعدة البيانات، أو واجهة API، أو أي مصدر خارجي للبيانات، وليست مخزّنة يدويًا كما هو الحال في مثالنا التوضيحي هذا)، وفيها تكون القيمة المُعادة استدعاءً للدالة ()render_template مع وسيطين، هما: الملف "message.html" وسيطًا لملف القالب، والمتغير message الذي سيُمرّر بدوره إلى القالب، إذ تكون قيمة هذا المتغير هي أحد عناصر القائمة "messages" (أي إحدى الرسائل) وذلك تبعًا لقيمة المتغيّر idx الدال على رقم مؤشّر الرسالة المطلوبة والموجود ضمن الرابط. ومن ثمّ سننشئ ملف القالب "message.html": (env)user@localhost:$ nano templates/message.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Messages {% endblock %}</h1> <h2>{{ message }}</h2> {% endblock %} نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة ملف القالب "base.html"، متجاوزين كتلة المحتوى content، ثمّ أضفنا عنوانًا وهو "Messages" ضمن تنسيق عنوان من المستوى الأوّل H1، كما عرضنا قيمة المتغير message المُتضمّن الرسالة المطلوبة حسب الرابط ضمن تنسيق عنوان من المستوى الثاني H2. الآن، ويعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، سنزور الروابط التالية تباعًا في المتصفح: http://127.0.0.1:5000/messages/0 http://127.0.0.1:5000/messages/1 http://127.0.0.1:5000/messages/2 http://127.0.0.1:5000/messages/3 ولدى زيارة الروابط الثلاث الأولى، ستظهر النصوص "Message Zero" و "Message One" و "Message Two" على الترتيب، ضمن تنسيق عنوان من المستوى الثاني H2، في حين سيستجيب الخادم برسالة الخطأ التفصيليّة "IndexError: list index out of range" لدى زيارة الرابط الرابع (والتي تعني أنّ رقم مؤشّر الرسالة المطلوبة خارج نطاق الرسائل المتوفرّة)، لأنّنا في وضع التطوير؛ ولو كنا نعمل في بيئة نشر المنتج (التشغيل الفعلي للتطبيق) لظهر خطأ الخادم الداخلي "500 Internal Server Error"، إلّا أنّ الاستجابة الأنسب لمثل هذه الحالة بغية الإيضاح للمُستخدم ماهية الخطأ الحاصل هي الاستجابة بخطأ "404 Not Found" دلالةً على أنّ الخادم غير قادر على إيجاد رسالة برقم مؤشّر مساوٍ للرقم "3". من الممكن استخدام دالة فلاسك المساعدة ()abort للاستجابة برسالة خطأ من النوع "404"، ولتطبيق هذا الأمر، سنفتح الملف app.py: (env)user@localhost:$ nano app.py وفيه سنعدّل السطر الأوّل لنستورد دالة ()abort، ثمّ سنعدّل دالة العرض ()message بإضافة البنية "try … except" كما هو موضّح في الشيفرة التالية: from flask import Flask, render_template, abort # ... # ... @app.route('/messages/<int:idx>') def message(idx): messages = ['Message Zero', 'Message One', 'Message Two'] try: return render_template('message.html', message=messages[idx]) except IndexError: abort(404) نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة دالة ()abort المُستخدمة في إلغاء طلب ما والاستجابة برسالة خطأ مُحدّدة، كما استخدمنا البنية "try … except" في الدالة ()message بغية تغليفها، إذ نحاول بدايةً الاستجابة لطلب المستخدم بالقالب messages المتضمّن الرسالة المطلوبة وفقًا لرقم المؤشّر المطلوب في الرابط، وفي حال عدم توفّر رسالة برقم مؤشّر موافق لذلك المطلوب، سيتحقّق الاستثناء except ونستخدمه لاكتشاف الخطأ مستخدمين استدعاء الدالة (abort(404 لإلغاء هذا الطلب الخاطئ والاستجابة له بخطأ HTTP من النوع 404 "404 Not Found". الآن ويعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، وباستخدام المتصفح سنزور الرابط الذي تسبّب بظهور رسالة الخطأ IndexError في المرة الماضية (أو أي رايط برقم مؤشّر أكبر من الرقم "2"): http://127.0.0.1:5000/messages/3 فتظهر لنا الاستجابة التالية في النتيجة: Not Found The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again. وبذلك أصبح لدينا رسالة خطأ أفضل وأوضح تشير إلى عدم تمكُّن الخادم من إيجاد الرسالة المطلوبة. أمّا فيما يلي، فسنعمل على إنشاء قالب خاص بعرض صفحة بالخطأ من النوع 404 وآخر لعرض صفحة بالخطأ من النوع 500. بدايةً سنعرّف دالة باستخدام المُزخرف الخاص ()app.errorhandler مهمتها التعامل مع الخطأ من النوع 404، لذا سنفتح الملف "app.py" لتحريره: nano app.py ونعدّل الملف ليصبح كما يلي: from flask import Flask, render_template, abort app = Flask(__name__) @app.errorhandler(404) def page_not_found(error): return render_template('404.html'), 404 @app.route('/') def index(): return render_template('index.html') @app.route('/messages/<int:idx>') def message(idx): messages = ['Message Zero', 'Message One', 'Message Two'] try: return render_template('message.html', message=messages[idx]) except IndexError: abort(404) نحفظ الملف ونغلقه. استخدمنا في الشيفرة السابقة المُزخرف ()app.errorhandler@ لتعريف الدالة ()page_not_found وتخصيصها للتعامل مع نوع خطأ بحد ذاته، إذ نمرّر لها نوع الخطأ مثل وسيط، وتكون القيمة المُعادة استدعاءً للدالة ()render_template مع القالب المُسمّى "404.html" الذي سننشئه لاحقًا وسيطًا لها؛ كما من الممكن تغيير اسم القالب بالاسم الذي نريد، لتكون بدورها القيمة المعادة من الدالة ()render_template هي الرقم الصحيح 404، وهذا يدل فلاسك على أنّ رمز الخطأ في الاستجابة يجب أن يكون "404"، وفي حال عدم تحديد أي رقم لدى استدعاء الدالة، فيستجيب فلاسك افتراضيًا بالرقم "200" الدال على نجاح الطلب. الآن، سنفتح ملف القالب المُسمّى "404.html": (env)user@localhost:$ nano templates/404.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} 404 Not Found. {% endblock %}</h1> <p>OOPS! Sammy couldn't find your page; looks like it doesn't exist.</p> <p>If you entered the URL manually, please check your spelling and try again.</p> {% endblock %} نحفظ الملف ونغلقه. في الشيفرة السابقة وكما هو الحال في جميع القوالب، وسّعنا ملف القالب "base.html" واستبدلنا محتويات كتلتي المحتوى content والعنوان title، وأضفنا أي شيفرات HTML نريدها، إذ أضفنا عنوانًا مُنسقًا وفق المستوى الأوّل من العناوين باستخدام الوسم <h1>، كما استخدمنا وسم فقرة <p> لإضافة رسالة خطأ مُخصّصة تُعلم المستخدم بكون الصفحة المطلوبة غير متوفرّة، إضافةً لرسالة تفيد أولئك المستخدمين الذين قد أدخلوا الرابط المطلوب يدويًا. كما من الممكن إضافة أي شيفرات HTML و CSS وجافا سكربت JavaScript نريدها لبناء وتنسيق صفحات الأخطاء، كما هو الحال في أي قالب آخر. الآن ويعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، سننتقل مُجدّدًا إلى الرابط: http://127.0.0.1:5000/messages/3 فتظهر الصفحة بشريط تصفُّح (الموروث من القالب الرئيسي) وبرسالة الخطأ المُخصّصة التي حددناها، وسنضيف بنفس الآلية صفحة خطأ مُخصّصة لأخطاء الخادم الداخلية "500 Internal Server Error"، لذا سنفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py سنضيف الشيفرة المسؤولة عن التعامل مع الخطأ من النوع "500" أسفل تلك المسؤولة عن التعامل مع الخطأ من النوع "404"، كما يلي: # ... @app.errorhandler(404) def page_not_found(error): return render_template('404.html'), 404 @app.errorhandler(500) def internal_error(error): return render_template('500.html'), 500 # ... اعتمدنا في الشيفرة السابقة نفس الآلية المُتبعة للتعامل مع الخطأ 404، إذ استخدمنا المُزخرف ()app.errorhandler مع الرقم "500" مثل وسيط لإنشاء دالّة باسم ()internal_error للتعامل مع هذا النوع من الأخطاء. صيّر قالبًا باسم "500.html" ليستجيب برمز الخطأ ذو الرقم "500". والآن ولبيان كيفيّة عرض رسالة الخطأ المُخصّصة، سنضيف إلى نهاية الملف app.py وجهةً تستجيبُ بخطأ HTTP من النوع "500"، والذي سيعيد خطأ "500 Internal Server Error" سواءٌ كان منقّح الأخطاء قيد التشغيل أم لا: # ... @app.route('/500') def error500(): abort(500) أنشأنا في جزء الشيفرة السابق الوجهة /500 واستخدمنا الدالة abort() لإنشاء استجابة بخطأ HTTP من النوع "500". نحفظ الملف ونغلقه. ومن ثمّ سننشئ ملف القالب المُسمّى 500.html ضمن مجلد القوالب، كما يلي: (env)user@localhost:$ nano templates/500.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} 500 Internal Server Error {% endblock %}</h1> <p>OOOOPS! Something went wrong on the server.</p> <p>Sammy is currently working on this issue. Please try again later.</p> {% endblock %} ثمّ نحفظ الملف ونغلقه. اتبعنا في الشيفرة السابقة نفس الآلية المُتبعة في القالب 404.html، إذ وسّعنا ملف القالب base.html، واستبدلنا محتويات كتلة المحتوى content بعنوان ورسالتين مُخصّصتين لإعلام المستخدم حول خطأ الخادم الداخلي الحاصل. الآن، وبعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، سننتقل إلى الوجهة الجديدة التي تستجيب بالخطأ من النوع "500" عبر الرابط: http://127.0.0.1:5000/500 فستظهر صفحتنا المُخصّصة عوضًا عن صفحة الخطأ العامّة التي تظهر افتراضيًا. ومع نهاية هذه الخطوة نكون قد تعرفنا على كيفية استخدام صفحات أخطاء مُخصّصة لأخطاء HTTP في تطبيقات فلاسك. أمّا في الخطوة التالية فسنتعرّف على كيفية استخدام السجل لتتبّع الأحداث في التطبيق، والذي من شأنه تعزيز فهمنا لآلية عمل شيفرة التطبيق ما يساعد بدوره على تطوير التطبيق واكتشاف الأخطاء وإصلاحها. الخطوة الثالثة - استخدام السجل لتتبع أحداث التطبيق سنستخدم في هذه الخطوة السجل لتتّبع الأحداث الحاصلة لدى تشغيل الخادم واستخدام التطبيق، ما يساعدنا في معرفة ما يحدث لشيفرة التطبيق أثناء تنفيذها، وهذا سيسهّل بدوره اكتشاف الأخطاء وإصلاحها. لقد سبق واطلعنا على سجل الأحداث عند كل تشغيل لخادم التطوير، والذي يبدو عادةً كما يلي: 127.0.0.1 - - [21/Sep/2021 14:36:45] "GET /messages/1 HTTP/1.1" 200 - 127.0.0.1 - - [21/Sep/2021 14:36:52] "GET /messages/2 HTTP/1.1" 200 - 127.0.0.1 - - [21/Sep/2021 14:36:54] "GET /messages/3 HTTP/1.1" 404 - إذ يتضمّن سجل الأحداث السابق المعلومات التالية: "127.0.0.1": عنوان المضيف الذي يعمل ضمنه الخادم. "[21/Sep/2021 14:36:45]": وقت وتاريخ الطلب. "GET": نوع طلب HTTP وهو في هذه الحالة من النوع "GET" المُستخدم لجلب البيانات. "messages/2/": المسار الذي طلبه المُستخدم. "HTTP/1.1": إصدار بروتوكول HTTP المُستخدَم. 200 أو 404: رمز حالة الطلب. تساعد سجلات الأحداث هذه في تشخيص الأخطاء الحاصلة في التطبيق، كما من الممكن تسجيل مزيدٍ من المعلومات في سجلات الأحداث باستخدام مُسجّل الأحداث "app.logger" الذي يوفرّه فلاسك، وذلك بغية الحصول على معلومات تفصيلية حول طلباتٍ بحد ذاتها. يمكننا مع مُسجّل الأحداث هذا استخدام عدة دوال تعيد معلومات حول الأحداث باختلاف مستوياتها، إذ يدل كل مستوًى على حدثٍ ذي درجة معيّنة من الخطورة، ومن هذه الدوال: app.logger.debug(): للحصول على معلومات تفصيلية حول الحدث. app.logger.info(): للتأكّد من كون الأمور تسير على النحو السليم. app.logger.warning(): تشير لوقوع حدث غير متوقّع، مثل انخفاض مساحة القرص الصلب التخزينية، مع بقاء التطبيق يعمل على النحو السليم. app.logger.error(): تشير لوقوع خطأ في أحد أجزاء التطبيق. app.logger.critical(): يشير لوقوع خطأ حرج يعرّض كامل التطبيق للتوقف عن العمل. ولبيان كيفيّة استخدام سجّل الأحداث في فلاسك، سنفتح الملف app.py لتحريره بغية تسجيل بعض الأحداث: (env)user@localhost:$ nano app.py سنعدّل الدالة ()message لتصبح كما يلي: # ... @app.route('/messages/<int:idx>') def message(idx): app.logger.info('Building the messages list...') messages = ['Message Zero', 'Message One', 'Message Two'] try: app.logger.debug('Get message with index: {}'.format(idx)) return render_template('message.html', message=messages[idx]) except IndexError: app.logger.error('Index {} is causing an IndexError'.format(idx)) abort(404) # ... نحفظ الملف ونغلقه. سجّلنا في الشيفرة السابقة عددًا من الأحداث من مستوياتٍ مختلفة، إذ استخدمنا الدالة ()app.logger.info لتسجيل حدث يعمل بصورةٍ سليمة (أي من مستوى المعلومات INFO)؛ كما استخدمنا الدالة ()app.logger.debug لتسجيل حدث بمعلوماتٍ تفصيلية (أي من مستوى التنقيح DEBUG) مشيرين لحصول التطبيق في هذا الحدث ضمن الطلب على رقم مؤشّر رسالة؛ ثمّ استخدمنا الدالة ()app.logger.error لتسجيل حقيقة كون الاستثناء IndexError قد تحقّق بسبب ورود رقم مؤشّر خاطئ مُسبّبًا حدوث الخلل (أي حدث من مستوى الخطأ ERROR، ذلك لأنّ خطأً ما قد حدث فعلًا). الآن وبزيارة الرابط: http://127.0.0.1:5000/messages/1 نحصل في الخرج على المعلومات التالية ضمن نافذة الطرفية التي يعمل ضمنها الخادم: [2021-09-21 15:17:02,625] INFO in app: Building the messages list... [2021-09-21 15:17:02,626] DEBUG in app: Get message with index: 1 127.0.0.1 - - [21/Sep/2021 15:17:02] "GET /messages/1 HTTP/1.1" 200 - وفيه نرى رسالة المعلومات INFO المُسجلّة من قبل الدالة ()app.logger.info، ورسالة التنقيح DEBUG المُسجّلة من قبل الدالة ()app.logger.debug والتي تبيّن رقم المؤشّر المطلوب. الآن وبزيارة رابط برقم مؤشّر خارج المجال المتوفّر، مثل: http://127.0.0.1:5000/messages/3 نحصل على الخرج التالي ضمن نافذة الطرفية: [2021-09-21 15:33:43,899] INFO in app: Building the messages list... [2021-09-21 15:33:43,899] DEBUG in app: Get message with index: 3 [2021-09-21 15:33:43,900] ERROR in app: Index 3 is causing an IndexError 127.0.0.1 - - [21/Sep/2021 15:33:43] "GET /messages/3 HTTP/1.1" 404 - وهنا نلاحظ أنّنا قد حصلنا على كل من سجلات INFO و DEBUG التي حصلنا عليها المرة الماضية ولكن مع سجل جديد لحدث خطأ ERROR بسبب طلب رسالة برقم مؤشّر غير موجود وهو الرقم "3" في مثالنا. لهذه الأحداث المُسجّلة والمعلومات التفصيلية والأخطاء المُسجلة الدور المهم في المساعدة على تحديد مكان حدوث الخطأ ما يجعل اكتشافه وإصلاحه أسهل. وبذلك ومع نهاية هذه الخطوة نكون قد تعلمنا كيفية التعامل مع مُسجّل الأحداث في فلاسك. الخاتمة تعرفنا في هذا المقال على كيفية استخدام وضع التنقيح في فلاسك، واكتشاف وإصلاح بعض الأخطاء الشائعة التي قد تواجهنا خلال تطوير تطبيق ويب باستخدام فلاسك، كما تعلمنا كيفية إنشاء صفحات أخطاء مُخصّصة لأخطاء HTTP الشائعة، ونهايةً استعرضنا كيفية استخدام مسجّل الأحداث الذي يوفرّه فلاسك لتتبع الأحداث في التطبيق ما يساعد على فحص سلوك التطبيق وفهمه. ترجمة -وبتصرف- للمقال How To Handle Errors in a Flask Application لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال السابق: كيفية استخدام القوالب في تطبيقات فلاسك Flask استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا
يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها إنشاء تطبيقات ويب في لغة بايثون. ستواجه خلال تطوير تطبيقات الويب حتمًا حالاتٍ يعطي فيها تطبيقك نتائجًا مخالفةً لتوقعاتك، وذلك بسبب أخطاء من قبيل الكتابة الخاطئة لاسم أحد المتغيرات، أو الاستخدام الخاطئ لحلقة "for" التكرارية أو بناء عبارة "if" الشرطية بطريقة خاطئة مسبّبةً وقوع أحد استثناءات بايثون، كما في حال استدعاء دالة ما قبل التصريح عنها، أو البحث عن صفحة غير موجودة أصلًا، فممّا لا شكّ فيه أنّك ستجد تطوير تطبيقات الويب باستخدام فلاسك أسهل وأكثر مرونة حال تعلمّك لكيفية التعامل مع الأخطاء والاستثناءات. سنبني في هذا المقال تطبيق ويب مُصغّر بهدف تبيان كيفيّة التعامل مع الأخطاء الشائعة التي قد تواجهك أثناء تطوير تطبيقات الويب، كما سننشئ صفحات أخطاء مُخصّصة، وسنستخدم منقّح الأخطاء في فلاسك لاستكشاف الاستثناءات في حال حدوثها وإصلاحها، كما سنستخدم سجل الأحداث logging لتتبّع الأحداث في التطبيق بحثًا عن مصادر الأخطاء. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات routes ودوال العرض view في فلاسك، وفي هذا الصدد يمكنك الاطلاع على المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask من لغة بايثون لفهم مبادئ فلاسك. فهم أساسيات لغة HTML. الخطوة الأولى - استخدام منقح الأخطاء في فلاسك سننشئ في هذا الخطوة تطبيقًا يحتوي على بضعة أخطاء بغية تشغيله دون استخدام منقّح الأخطاء، لنرى الآلية التي سيستجيب بها التطبيق، ومن ثمّ سنعيد تشغيله ولكن مع تفعيل وضع منقّح الأخطاء لنستخدمه في استكشاف أخطاء التطبيق وإصلاحها. لذلك، وبعد التأكّد من تفعيل البيئة البرمجية وتثبيت فلاسك، سننشئ ملفًا ضمن المجلد "flask_app" باسم "app.py" لتحريره: (env)user@localhost:$ nano app.py ونكتب ضمنه الشيفرة التالية: from flask import Flask app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') استوردنا في الجزء السابق من الشيفرة كائن فلاسك من حزمة falsk، ثم استخدمناه لإنشاء نسخةٍ فعليةٍ موجودةٍ في الذاكرة لتطبيق فلاسك Flask application instance باسم app، ثمّ أنشأنا دالة العرض ()index باستخدام المُزخرف ()app.route@، الذي يحوّل دوال بايثون الاعتيادية إلى دوال عرض، وفيها تكون القيمة المُعادة استدعاءً للدالة ()render_template، والتي تعرض بدورها قالب HTML المُسمى "index.html" في النتيحة. في هذه الشيفرة خطآن: الأوّل هو أنّنا لم نستورد دالة تصيّير القوالب ()render_template من حزمة فلاسك قبل استدعائها، والثاني أنّ قالب HTML المسمّى "index.html" غير موجود بعد. نحفظ الملف ونغلقه. والآن، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم app.py) وذلك باستخدام متغير بيئة فلاسك FLASK_APP على النحو التالي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_APP=app بعدها سنشغل خادم التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run فتظهر في نافذة الطرفية المعلومات التالية: * Serving Flask app 'app' (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) يحتوي الخرج السابق على عدة معلومات، مثل: اسم التطبيق المُشغَّل، وهو "app.py" في حالتنا. بيئة التشغيل الحالية التي يعمل عليها التطبيق، وهي في حالتنا بيئة الاستخدام الفعلي للتطبيق (نشر المنتج) "production"، وتُشدّد الرسالة التحذيرية هذه على كون الخادم غير مُخصّص لمرحلة نشر المنتج، وبما أنّنا نستخدمه بالواقع بغية تطوير التطبيق، فمن الممكن تجاهل الرسالة التحذيرية هذه. عبارة "Debug mode:off"، التي تشير إلى أن منقّح أخطاء فلاسك ليس قيد التشغيل، وبالتالي لن تتلقّى أي رسائل مفيدة حول الأخطاء الحاصلة في التطبيق، وهو أمرٌ طبيعي كوننا نعمل الآن في بيئة نشر المُنتج، فعرض رسائل تفصيلية بالأخطاء الحاصلة في هذه البيئة (نشر المنتج) يعرّض التطبيق لمخاطر أمنية ويعدّ ثغرة أمنية بحد ذاته. التطبيق يعمل على الرابط "/http://127.0.0.1:5000"، إذ أن "127.0.0.1" هو عنوان IP الذي يمثِّل الخادم المحلي localhost، و "5000:" هو رقم المنفذ، ولإيقاف تشغيل الخادم يمكنك الضغط على مفتاحي "CTRL+C"، ولكن لا توقفه الآن. الآن، وبالانتقال إلى الصفحة الرئيسية للتطبيق في المتصفّح عبر الرابط: http://127.0.0.1:5000/ ستظهر رسالة شبيهة بما يلي في الخرج: Internal Server Error The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application. وهو خطأ الخادم الداخلي 500 Internal Server Error، الذي يمثّل استجابةً خاطئةً للخادم تشير لكونه يواجه خطأً داخليًا في شيفرة التطبيق. وسيظهر الخرج التالي في نافذة الطرفية: [2021-09-12 15:16:56,441] ERROR in app: Exception on / [GET] Traceback (most recent call last): File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 2070, in wsgi_app response = self.full_dispatch_request() File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 1515, in full_dispatch_request rv = self.handle_user_exception(e) File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 1513, in full_dispatch_request rv = self.dispatch_request() File "/home/abd/.local/lib/python3.9/site-packages/flask/app.py", line 1499, in dispatch_request return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args) File "/home/abd/python/flask/series03/flask_app/app.py", line 8, in index return render_template('index.html') NameError: name 'render_template' is not defined 127.0.0.1 - - [12/Sep/2021 15:16:56] "GET / HTTP/1.1" 500 - تمرُ عملية التعقّب العكسي أعلاه على الشيفرة المُسبّبة لخطأ الخادم الداخلي، إذ يشير السطر "NameError: name 'render_template' is not defined" إلى أصل المشكلة (خطأ في الاسم)، وهو في حالتنا أنّ الدالة ()render_template غير مستوردة ما جعلها غير مُعرّفة. وهنا نلاحظ أنّه لا بدّ من الذهاب إلى نافذة الطرفية لاكتشاف الأخطاء (وليس ضمن خرج التطبيق نفسه)، والذي يُعد أمرًا غير ملائم في الاستخدام الفعلي. فمن الممكن الحصول على تجربة استكشاف أخطاء وإصلاحها بطريقة أفضل وأسهل عبر تمكين وضع تنقيح الأخطاء في خادم التطوير، ولإجراء ذلك سنوقف عمل الخادم عبر الضغط على مفتاحي "CTRL+C"، ثمّ سنضبط متغير بيئة فلاسك FLASK_ENV على الوضع development، ما يمكنّنا من تشغيل البرنامج في وضع التطوير ( الذي يُمكِّن منقّح الأخطاء) كما يلي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_ENV=development نشغّل الآن خادم التطوير: (env)user@localhost:$ flask run فيظهر في نافذة الطرفية خرجٌ مُشابه لما يلي: * Serving Flask app 'app' (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 120-484-907 ومنه نلاحظ أنّ وضع التشغيل حاليًا هو وضع التطوير، وأنّ وضع تنقيح الأخطاء قيد التشغيل وبالتالي فإنّ مُنقّح الأخطاء مُفعّل، أمّا "Debugger PIN" فيمثّل الرمز السرّي اللازم لإلغاء قفل سجل المتصفّح (لوحة المراقبة) Browser console (وهي صَدفة shell بايثون تفاعلية يمكنك الوصول إليها بالضغط على رمز الطرفية الصغير المحاط بدائرة حمراء في الصورة أدناه). وبتحديث الصفحة الرئيسية للتطبيق ضمن المتصفح، ستظهر الصفحة بالشّكل التالي: وفي هذه الحالة نرى رسالة الخطأ بصياغة وطريقة عرض أسهل للفهم، إذ يشير العنوان الأوّل فيها إلى اسم استثناء بايثون المُتسبّب بالمشكلة (وهو خطأ في الاسم "NameError" في حالتنا). أما السطر الثاني من رسالة الخطأ فيشير إلى سبب الخطأ المباشر (وهو في حالتنا أنّ الدالة ()render_template غير مُعرّفة ما يعني أنّها غير مستوردة أصلًا)، أمّا الأسطر التالية فهي نتيجة التعقّب العكسي لشيفرة فلاسك الداخلية المُنفّذة، ومن المُفضّل قراءة هذا الجزء من الأسفل إلى الأعلى، إذ يتضمّن عادةً السطر الأخير من نتيجة التعقّب العكسي أكثر المعلومات أهمية. ملاحظة: يمكنّك رمز الطرفية الصغير المحاط بدائرة حمراء في الصورة السابقة من تشغيل الشيفرة المكتوبة أصلًا بلغة بايثون ضمن المُتصفّح في أُطر عمل مُختلفة (وهنا ضمن ما يشبه صَدفة بايثون التفاعلية ولكن ضمن المتصفح نفسه)، وهذا أمرٌ مفيدٌ للتحقّق مثلًا من قيمة متغير ما بنفس الطريقة التي تؤديها صَدفة بايثون التفاعلية. عند الضغط على هذه الأيقونة يجب إدخال الرمز السري الخاص بالمنقّح Debugger PIN الذي حصلت عليه عند تشغيل الخادم في الخطوة السابقة، ولكن ضمن محاور هذا المقال لن نحتاج إلى استخدامها. الآن، لإصلاح الخطأ في الاسم "NameError" الحاصل، نترك الخادم بحالة تشغيل ونفتح نافذة طرفية جديدة، وفيها نفعّل البيئة البرمجية ومن ثمّ نفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py ونعدله ليصبح كما يلي: from flask import Flask, render_template app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة دالة تصيّير القوالب ()render_template من حزمة فلاسك flask، الأمر الذي كان ناقصًا فيما سبق مُتسبّبًا بالخطأ الحاصل. الآن وبعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، نحدّث الصفحة الرئيسية للتطبيق ضمن المتصفح، فتظهر صفحة خطأ في الخرج، تتضمّن معلومات شبيهة بما يلي: jinja2.exceptions.TemplateNotFound jinja2.exceptions.TemplateNotFound: index.html وتشير رسالة الخطأ هذه لكون القالب "index.html" غير موجود. ولإصلاح هذا الخطأ، سننشئ ملف قالب باسم "base.html" لتتمكّن القوالب الأُخرى من وراثة شيفراته بغية تجنُّب تكرار الشيفرات، كما سننشئ القالب "index.html"، الذي سيرث من القالب الرئيسي. لذا سننشئ مجلد للقوالب باسم "templates" ضمن المجلد "flask_app"، إذ سيبحث فلاسك ضمنه عن القوالب، وبعدها سنفتح ملف القالب الأساسي المُسمى "base.html" باستخدام أي محرّر نصوص (هنا سنستخدم محرّر النصوص نانو nano: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html ثمّ نكتب الشيفرة التالية ضمن الملف base.html: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> نحفظ الملف ونغلقه. يتضمّن القالب الأساسي كافّة الشيفرات المتداولة التي ستحتاجها في القوالب الأُخرى، وستُستبدل لاحقًا كتلة العنوان title بعنوان كل صفحة وكتلة المحتوى content بمحتواها، أمّا عن شريط التصفح فسيتضمّن رابطين، الأوّل ينقل المُستخدم إلى الصفحة الرئيسية للتطبيق باستخدام الدالة المساعدة ()url_for لتحقيق الربط مع دالة العرض ()index، والآخر لصفحة المعلومات حول التطبيق في حال قررت تضمينها في تطبيقك. لذا سنفتح ملف قالب index.html، الذي سيرث شيفراته من القالب الرئيسي: (env)user@localhost:$ nano templates/index.html ونكنب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Index {% endblock %}</h1> <h2>Welcome to FlaskApp!</h2> {% endblock %} ثمّ نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة ملف القالب "base.html"، متجاوزين كتلة المحتوى content، ثمّ استخدمنا كتلة العنوان title لتعيين عنوان للصفحة وعرضه ضمن تنسيق عنوان من المستوى الأوّل H1، كما كتبنا الشيفرة اللازمة لعرض رسالة ترحيب ضمن تنسيق عنوان من المستوى الثاني H2. الآن وبعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، نحدّث الصفحة الرئيسية للتطبيق ضمن المتصفح، فنجد أنّ التطبيق لا يعرض أي أخطاء وأنّ الصفحة الرئيسية للتطبيق تبدو بالشكل المطلوب. ومع نهاية هذه الخطوة نكون قد استخدمنا وضع تنقيح الأخطاء وتعرفنا على كيفية التعامل مع رسائل الخطأ، وسنعمل في الخطوة التالية على إيقاف طلب ما ليستجيب برسالة خطأ من اختيارنا، وسنتعلّم كيفية إنشاء صفحات أخطاء مُخصّصة لتظهر بمثابة استجابة لطلبات معينة. الخطوة الثانية - تخصيص صفحات أخطاء سنتعرّف في هذه الخطوة على كيفية إلغاء طلب المستخدم في حال أراد الوصول إلى بيانات غير موجودة على الخادم والاستجابة برسالة خطأ HTTP من النوع 404، كما سنتعلّم كيفية إنشاء صفحات أخطاء مُخصّصة لتظهر بمثابة استجابة لأخطاء HTTP الشائعة، مثل خطأ الخادم الداخلي "500 Internal Server Error" وخطأ عدم توفّر البيانات المطلوبة "404 Not Found". ولنبيّن كيفية إلغاء طلب والاستجابة بصفحة خطأ مُخصّصة بخطأ HTTP من نوع 404، سننشئ صفحةً مهمتها عرض عدد من الرسائل، وفي حال طلب رسالة غير موجودة، ستستجيب بخطأ من النوع 404. لذا سنفتح الملف app.py لإضافة وجهةٍ route جديدة لصفحة الرسائل: (env)user@localhost:$ nano app.py وسنضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/messages/<int:idx>') def message(idx): messages = ['Message Zero', 'Message One', 'Message Two'] return render_template('message.html', message=messages[idx]) نحفظ الملف ونغلقه. استخدمنا في الشيفرة السابقة متغيرًا يدل على رقم مؤشّر الروابط باسم idx، والمُتضمّن رقم المؤشر الذي من شأنه تحديد الرسالة المطلوب عرضها، بمعنى أنّه إذا كان الرابط هو "/messages/0"، فهذا يعني أنّ الرسالة الأولى ذات المؤشّر بالقيمة صفر هي المطلوب عرضها؛ كما استخدمنا محوّل القيم int المسؤول عن قبول قيم من النوع "عدد صحيح موجب" فقط، ذلك لأنّ متحولات العناوين تكون افتراضيًا بنمط بيانات من النوع "سلاسل نصية". تتضمّن دالة العرض message() قائمة بايثون اعتيادية باسم "messages" تحتوي على ثلاث رسائل (ولكن في الواقع العملي سيكون مصدر هذه الرسائل هو قاعدة البيانات، أو واجهة API، أو أي مصدر خارجي للبيانات، وليست مخزّنة يدويًا كما هو الحال في مثالنا التوضيحي هذا)، وفيها تكون القيمة المُعادة استدعاءً للدالة ()render_template مع وسيطين، هما: الملف "message.html" وسيطًا لملف القالب، والمتغير message الذي سيُمرّر بدوره إلى القالب، إذ تكون قيمة هذا المتغير هي أحد عناصر القائمة "messages" (أي إحدى الرسائل) وذلك تبعًا لقيمة المتغيّر idx الدال على رقم مؤشّر الرسالة المطلوبة والموجود ضمن الرابط. ومن ثمّ سننشئ ملف القالب "message.html": (env)user@localhost:$ nano templates/message.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Messages {% endblock %}</h1> <h2>{{ message }}</h2> {% endblock %} نحفظ الملف ونغلقه. وسّعنا في الشيفرة السابقة ملف القالب "base.html"، متجاوزين كتلة المحتوى content، ثمّ أضفنا عنوانًا وهو "Messages" ضمن تنسيق عنوان من المستوى الأوّل H1، كما عرضنا قيمة المتغير message المُتضمّن الرسالة المطلوبة حسب الرابط ضمن تنسيق عنوان من المستوى الثاني H2. الآن، ويعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، سنزور الروابط التالية تباعًا في المتصفح: http://127.0.0.1:5000/messages/0 http://127.0.0.1:5000/messages/1 http://127.0.0.1:5000/messages/2 http://127.0.0.1:5000/messages/3 ولدى زيارة الروابط الثلاث الأولى، ستظهر النصوص "Message Zero" و "Message One" و "Message Two" على الترتيب، ضمن تنسيق عنوان من المستوى الثاني H2، في حين سيستجيب الخادم برسالة الخطأ التفصيليّة "IndexError: list index out of range" لدى زيارة الرابط الرابع (والتي تعني أنّ رقم مؤشّر الرسالة المطلوبة خارج نطاق الرسائل المتوفرّة)، لأنّنا في وضع التطوير؛ ولو كنا نعمل في بيئة نشر المنتج (التشغيل الفعلي للتطبيق) لظهر خطأ الخادم الداخلي "500 Internal Server Error"، إلّا أنّ الاستجابة الأنسب لمثل هذه الحالة بغية الإيضاح للمُستخدم ماهية الخطأ الحاصل هي الاستجابة بخطأ "404 Not Found" دلالةً على أنّ الخادم غير قادر على إيجاد رسالة برقم مؤشّر مساوٍ للرقم "3". من الممكن استخدام دالة فلاسك المساعدة ()abort للاستجابة برسالة خطأ من النوع "404"، ولتطبيق هذا الأمر، سنفتح الملف app.py: (env)user@localhost:$ nano app.py وفيه سنعدّل السطر الأوّل لنستورد دالة ()abort، ثمّ سنعدّل دالة العرض ()message بإضافة البنية "try … except" كما هو موضّح في الشيفرة التالية: from flask import Flask, render_template, abort # ... # ... @app.route('/messages/<int:idx>') def message(idx): messages = ['Message Zero', 'Message One', 'Message Two'] try: return render_template('message.html', message=messages[idx]) except IndexError: abort(404) نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة دالة ()abort المُستخدمة في إلغاء طلب ما والاستجابة برسالة خطأ مُحدّدة، كما استخدمنا البنية "try … except" في الدالة ()message بغية تغليفها، إذ نحاول بدايةً الاستجابة لطلب المستخدم بالقالب messages المتضمّن الرسالة المطلوبة وفقًا لرقم المؤشّر المطلوب في الرابط، وفي حال عدم توفّر رسالة برقم مؤشّر موافق لذلك المطلوب، سيتحقّق الاستثناء except ونستخدمه لاكتشاف الخطأ مستخدمين استدعاء الدالة (abort(404 لإلغاء هذا الطلب الخاطئ والاستجابة له بخطأ HTTP من النوع 404 "404 Not Found". الآن ويعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، وباستخدام المتصفح سنزور الرابط الذي تسبّب بظهور رسالة الخطأ IndexError في المرة الماضية (أو أي رايط برقم مؤشّر أكبر من الرقم "2"): http://127.0.0.1:5000/messages/3 فتظهر لنا الاستجابة التالية في النتيجة: Not Found The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again. وبذلك أصبح لدينا رسالة خطأ أفضل وأوضح تشير إلى عدم تمكُّن الخادم من إيجاد الرسالة المطلوبة. أمّا فيما يلي، فسنعمل على إنشاء قالب خاص بعرض صفحة بالخطأ من النوع 404 وآخر لعرض صفحة بالخطأ من النوع 500. بدايةً سنعرّف دالة باستخدام المُزخرف الخاص ()app.errorhandler مهمتها التعامل مع الخطأ من النوع 404، لذا سنفتح الملف "app.py" لتحريره: nano app.py ونعدّل الملف ليصبح كما يلي: from flask import Flask, render_template, abort app = Flask(__name__) @app.errorhandler(404) def page_not_found(error): return render_template('404.html'), 404 @app.route('/') def index(): return render_template('index.html') @app.route('/messages/<int:idx>') def message(idx): messages = ['Message Zero', 'Message One', 'Message Two'] try: return render_template('message.html', message=messages[idx]) except IndexError: abort(404) نحفظ الملف ونغلقه. استخدمنا في الشيفرة السابقة المُزخرف ()app.errorhandler@ لتعريف الدالة ()page_not_found وتخصيصها للتعامل مع نوع خطأ بحد ذاته، إذ نمرّر لها نوع الخطأ مثل وسيط، وتكون القيمة المُعادة استدعاءً للدالة ()render_template مع القالب المُسمّى "404.html" الذي سننشئه لاحقًا وسيطًا لها؛ كما من الممكن تغيير اسم القالب بالاسم الذي نريد، لتكون بدورها القيمة المعادة من الدالة ()render_template هي الرقم الصحيح 404، وهذا يدل فلاسك على أنّ رمز الخطأ في الاستجابة يجب أن يكون "404"، وفي حال عدم تحديد أي رقم لدى استدعاء الدالة، فيستجيب فلاسك افتراضيًا بالرقم "200" الدال على نجاح الطلب. الآن، سنفتح ملف القالب المُسمّى "404.html": (env)user@localhost:$ nano templates/404.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} 404 Not Found. {% endblock %}</h1> <p>OOPS! Sammy couldn't find your page; looks like it doesn't exist.</p> <p>If you entered the URL manually, please check your spelling and try again.</p> {% endblock %} نحفظ الملف ونغلقه. في الشيفرة السابقة وكما هو الحال في جميع القوالب، وسّعنا ملف القالب "base.html" واستبدلنا محتويات كتلتي المحتوى content والعنوان title، وأضفنا أي شيفرات HTML نريدها، إذ أضفنا عنوانًا مُنسقًا وفق المستوى الأوّل من العناوين باستخدام الوسم <h1>، كما استخدمنا وسم فقرة <p> لإضافة رسالة خطأ مُخصّصة تُعلم المستخدم بكون الصفحة المطلوبة غير متوفرّة، إضافةً لرسالة تفيد أولئك المستخدمين الذين قد أدخلوا الرابط المطلوب يدويًا. كما من الممكن إضافة أي شيفرات HTML و CSS وجافا سكربت JavaScript نريدها لبناء وتنسيق صفحات الأخطاء، كما هو الحال في أي قالب آخر. الآن ويعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، سننتقل مُجدّدًا إلى الرابط: http://127.0.0.1:5000/messages/3 فتظهر الصفحة بشريط تصفُّح (الموروث من القالب الرئيسي) وبرسالة الخطأ المُخصّصة التي حددناها، وسنضيف بنفس الآلية صفحة خطأ مُخصّصة لأخطاء الخادم الداخلية "500 Internal Server Error"، لذا سنفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py سنضيف الشيفرة المسؤولة عن التعامل مع الخطأ من النوع "500" أسفل تلك المسؤولة عن التعامل مع الخطأ من النوع "404"، كما يلي: # ... @app.errorhandler(404) def page_not_found(error): return render_template('404.html'), 404 @app.errorhandler(500) def internal_error(error): return render_template('500.html'), 500 # ... اعتمدنا في الشيفرة السابقة نفس الآلية المُتبعة للتعامل مع الخطأ 404، إذ استخدمنا المُزخرف ()app.errorhandler مع الرقم "500" مثل وسيط لإنشاء دالّة باسم ()internal_error للتعامل مع هذا النوع من الأخطاء. صيّر قالبًا باسم "500.html" ليستجيب برمز الخطأ ذو الرقم "500". والآن ولبيان كيفيّة عرض رسالة الخطأ المُخصّصة، سنضيف إلى نهاية الملف app.py وجهةً تستجيبُ بخطأ HTTP من النوع "500"، والذي سيعيد خطأ "500 Internal Server Error" سواءٌ كان منقّح الأخطاء قيد التشغيل أم لا: # ... @app.route('/500') def error500(): abort(500) أنشأنا في جزء الشيفرة السابق الوجهة /500 واستخدمنا الدالة abort() لإنشاء استجابة بخطأ HTTP من النوع "500". نحفظ الملف ونغلقه. ومن ثمّ سننشئ ملف القالب المُسمّى 500.html ضمن مجلد القوالب، كما يلي: (env)user@localhost:$ nano templates/500.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} 500 Internal Server Error {% endblock %}</h1> <p>OOOOPS! Something went wrong on the server.</p> <p>Sammy is currently working on this issue. Please try again later.</p> {% endblock %} ثمّ نحفظ الملف ونغلقه. اتبعنا في الشيفرة السابقة نفس الآلية المُتبعة في القالب 404.html، إذ وسّعنا ملف القالب base.html، واستبدلنا محتويات كتلة المحتوى content بعنوان ورسالتين مُخصّصتين لإعلام المستخدم حول خطأ الخادم الداخلي الحاصل. الآن، وبعد التأكّد من كون خادم التطوير ما يزال قيد التشغيل، سننتقل إلى الوجهة الجديدة التي تستجيب بالخطأ من النوع "500" عبر الرابط: http://127.0.0.1:5000/500 فستظهر صفحتنا المُخصّصة عوضًا عن صفحة الخطأ العامّة التي تظهر افتراضيًا. ومع نهاية هذه الخطوة نكون قد تعرفنا على كيفية استخدام صفحات أخطاء مُخصّصة لأخطاء HTTP في تطبيقات فلاسك. أمّا في الخطوة التالية فسنتعرّف على كيفية استخدام السجل لتتبّع الأحداث في التطبيق، والذي من شأنه تعزيز فهمنا لآلية عمل شيفرة التطبيق ما يساعد بدوره على تطوير التطبيق واكتشاف الأخطاء وإصلاحها. الخطوة الثالثة - استخدام السجل لتتبع أحداث التطبيق سنستخدم في هذه الخطوة السجل لتتّبع الأحداث الحاصلة لدى تشغيل الخادم واستخدام التطبيق، ما يساعدنا في معرفة ما يحدث لشيفرة التطبيق أثناء تنفيذها، وهذا سيسهّل بدوره اكتشاف الأخطاء وإصلاحها. لقد سبق واطلعنا على سجل الأحداث عند كل تشغيل لخادم التطوير، والذي يبدو عادةً كما يلي: 127.0.0.1 - - [21/Sep/2021 14:36:45] "GET /messages/1 HTTP/1.1" 200 - 127.0.0.1 - - [21/Sep/2021 14:36:52] "GET /messages/2 HTTP/1.1" 200 - 127.0.0.1 - - [21/Sep/2021 14:36:54] "GET /messages/3 HTTP/1.1" 404 - إذ يتضمّن سجل الأحداث السابق المعلومات التالية: "127.0.0.1": عنوان المضيف الذي يعمل ضمنه الخادم. "[21/Sep/2021 14:36:45]": وقت وتاريخ الطلب. "GET": نوع طلب HTTP وهو في هذه الحالة من النوع "GET" المُستخدم لجلب البيانات. "messages/2/": المسار الذي طلبه المُستخدم. "HTTP/1.1": إصدار بروتوكول HTTP المُستخدَم. 200 أو 404: رمز حالة الطلب. تساعد سجلات الأحداث هذه في تشخيص الأخطاء الحاصلة في التطبيق، كما من الممكن تسجيل مزيدٍ من المعلومات في سجلات الأحداث باستخدام مُسجّل الأحداث "app.logger" الذي يوفرّه فلاسك، وذلك بغية الحصول على معلومات تفصيلية حول طلباتٍ بحد ذاتها. يمكننا مع مُسجّل الأحداث هذا استخدام عدة دوال تعيد معلومات حول الأحداث باختلاف مستوياتها، إذ يدل كل مستوًى على حدثٍ ذي درجة معيّنة من الخطورة، ومن هذه الدوال: app.logger.debug(): للحصول على معلومات تفصيلية حول الحدث. app.logger.info(): للتأكّد من كون الأمور تسير على النحو السليم. app.logger.warning(): تشير لوقوع حدث غير متوقّع، مثل انخفاض مساحة القرص الصلب التخزينية، مع بقاء التطبيق يعمل على النحو السليم. app.logger.error(): تشير لوقوع خطأ في أحد أجزاء التطبيق. app.logger.critical(): يشير لوقوع خطأ حرج يعرّض كامل التطبيق للتوقف عن العمل. ولبيان كيفيّة استخدام سجّل الأحداث في فلاسك، سنفتح الملف app.py لتحريره بغية تسجيل بعض الأحداث: (env)user@localhost:$ nano app.py سنعدّل الدالة ()message لتصبح كما يلي: # ... @app.route('/messages/<int:idx>') def message(idx): app.logger.info('Building the messages list...') messages = ['Message Zero', 'Message One', 'Message Two'] try: app.logger.debug('Get message with index: {}'.format(idx)) return render_template('message.html', message=messages[idx]) except IndexError: app.logger.error('Index {} is causing an IndexError'.format(idx)) abort(404) # ... نحفظ الملف ونغلقه. سجّلنا في الشيفرة السابقة عددًا من الأحداث من مستوياتٍ مختلفة، إذ استخدمنا الدالة ()app.logger.info لتسجيل حدث يعمل بصورةٍ سليمة (أي من مستوى المعلومات INFO)؛ كما استخدمنا الدالة ()app.logger.debug لتسجيل حدث بمعلوماتٍ تفصيلية (أي من مستوى التنقيح DEBUG) مشيرين لحصول التطبيق في هذا الحدث ضمن الطلب على رقم مؤشّر رسالة؛ ثمّ استخدمنا الدالة ()app.logger.error لتسجيل حقيقة كون الاستثناء IndexError قد تحقّق بسبب ورود رقم مؤشّر خاطئ مُسبّبًا حدوث الخلل (أي حدث من مستوى الخطأ ERROR، ذلك لأنّ خطأً ما قد حدث فعلًا). الآن وبزيارة الرابط: http://127.0.0.1:5000/messages/1 نحصل في الخرج على المعلومات التالية ضمن نافذة الطرفية التي يعمل ضمنها الخادم: [2021-09-21 15:17:02,625] INFO in app: Building the messages list... [2021-09-21 15:17:02,626] DEBUG in app: Get message with index: 1 127.0.0.1 - - [21/Sep/2021 15:17:02] "GET /messages/1 HTTP/1.1" 200 - وفيه نرى رسالة المعلومات INFO المُسجلّة من قبل الدالة ()app.logger.info، ورسالة التنقيح DEBUG المُسجّلة من قبل الدالة ()app.logger.debug والتي تبيّن رقم المؤشّر المطلوب. الآن وبزيارة رابط برقم مؤشّر خارج المجال المتوفّر، مثل: http://127.0.0.1:5000/messages/3 نحصل على الخرج التالي ضمن نافذة الطرفية: [2021-09-21 15:33:43,899] INFO in app: Building the messages list... [2021-09-21 15:33:43,899] DEBUG in app: Get message with index: 3 [2021-09-21 15:33:43,900] ERROR in app: Index 3 is causing an IndexError 127.0.0.1 - - [21/Sep/2021 15:33:43] "GET /messages/3 HTTP/1.1" 404 - وهنا نلاحظ أنّنا قد حصلنا على كل من سجلات INFO و DEBUG التي حصلنا عليها المرة الماضية ولكن مع سجل جديد لحدث خطأ ERROR بسبب طلب رسالة برقم مؤشّر غير موجود وهو الرقم "3" في مثالنا. لهذه الأحداث المُسجّلة والمعلومات التفصيلية والأخطاء المُسجلة الدور المهم في المساعدة على تحديد مكان حدوث الخطأ ما يجعل اكتشافه وإصلاحه أسهل. وبذلك ومع نهاية هذه الخطوة نكون قد تعلمنا كيفية التعامل مع مُسجّل الأحداث في فلاسك. الخاتمة تعرفنا في هذا المقال على كيفية استخدام وضع التنقيح في فلاسك، واكتشاف وإصلاح بعض الأخطاء الشائعة التي قد تواجهنا خلال تطوير تطبيق ويب باستخدام فلاسك، كما تعلمنا كيفية إنشاء صفحات أخطاء مُخصّصة لأخطاء HTTP الشائعة، ونهايةً استعرضنا كيفية استخدام مسجّل الأحداث الذي يوفرّه فلاسك لتتبع الأحداث في التطبيق ما يساعد على فحص سلوك التطبيق وفهمه. ترجمة -وبتصرف- للمقال How To Handle Errors in a Flask Application لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال السابق: كيفية استخدام القوالب في تطبيقات فلاسك Flask استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا -
 يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل. عند تطوير تطبيق ويب ما، من الضروري الفصل بين ما يدعى "منطق العمل business logic" و"منطق العرض presentation logic"؛ إذ يكون منطق العمل مسؤولاً عن التعامل مع طلبات المستخدمين، مُخاطبًا قاعدة البيانات لإنشاء الاستجابة المناسبة؛ في حين يُحدّد منطق العرض كيفيّة عرض البيانات للمستخدم، وذلك غالبًا باستخدام ملفات HTML لإنشاء الهيكل الأساسي لصفحة الويب التي تستجيب لطلبات المستخدمين، مع استخدام تنسيقات CSS لتنسيق مظهر تلك المكونات المبنية باستخدام HTML. فمثلًا في حال كان لدينا تطبيق للتواصل الاجتماعي، فيوجد عادةً حقلٌ لإدراج اسم المستخدم وحقل لإدراج كلمة المرور بحيث لا يظهران إلّا في حال كون المستخدم لم يسجل دخوله إلى التطبيق بعد، ولدى كتابة المستخدم اسم المستخدم وكلمة المرور يعمل فلاسك على تطبيق منطق العمل، إذ تُستخرج البيانات (اسم المستخدم وكلمة المرور) من الطلب ليُسجَّل دخول المستخدم إذا كانت هذه البيانات صحيحة، وإلّا ستظهر رسالة خطأ، ويجري التعامل مع كيفية ظهور رسالة الخطأ بالاعتماد على منطق العرض. يستخدم فلاسك محرّك القوالب جينجا jinja لبناء صفحات HTML ديناميكيًا باستخدام مفاهيم بايثون المألوفة، من متغيراتٍ وحلقاتٍ تكرارية وقوائم وغيرها، وبالتالي ستُستخدم هذه القوالب على أنها جزءٌ من هذا المشروع، إذ يُعرّف القالب بأنه ملف يحتوي على مكونات ثابتة وأُخرى ديناميكية، وعندما يطلب المستخدم عنصرًا من التطبيق، مثل الصفحة الرئيسية، أو صفحة تسجيل الدخول، يُمكنّنا جينجا من الاستجابة باستخدام قالب HTML، وبذلك يصبح من الممكن استخدام عددٍ كبيرٍ من الميزات غير المتوفرة أصلًا في لغة HTML المعيارية، مثل المتغيرات والعبارة الشرطية "if" والحلقات التكرارية مثل حلقة "for"، والمُرشّحات filters ومفهوم وراثة القوالب، إذ تسمح لنا هذه الخواص بكتابة صفحات HTML سهلة الإصلاح، كما تعزل جينجا شيفرات HTML تلقائيًا بهدف منع هجمات البرمجة العابرة للمواقع Cross-Site Scripting -أو اختصارًا XSS-. سنبني في هذا المقال تطبيق ويب صغير يعمل على تصييّر عدّة ملفات HTML ضمن المتصفح معًا، إذ سنستخدم المتغيرات لتمرير البيانات من الخادم إلى القوالب، كما سنطبّق مفهوم وراثة القوالب لتجنُّب التكرار في الشيفرات البرمجية. وسنستخدم كذلك التعابير المنطقية في بناء شيفرات القوالب من عبارات شرطية وحلقات، وسنطبّق المُرشّحات اللازمة لتعديل النصوص، وسنعمل من خلال إطار العمل بوتستراب bootstrap على إضافة التنسيقات على التطبيق ليبدو أكثر جاذبية بصريًا. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". توفّر إطار العمل فلاسك مُثبّت ضمن البيئة البرمجبة كما هو مُبيّن في الخطوة الأولى من المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask والإصدار الثالث من لغة بايثون. الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات routes ودوال العرض view في فلاسك، ويمكنك في هذا الصدد الاطلاع على المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask والإصدار الثالث من لغة بايثون المشار إليه أعلاه لفهم مبادئ فلاسك. فهم أساسيات لغة HTML. الخطوة الأولى - تصيير القوالب واستخدام المتغيرات بعد التأكّد من تفعيل بيئة البرمجة وتثبيت فلاسك، سنبدأ ببناء التطبيق، إذ تتمثّل الخطوة الأولى بعرض رسالة ترحيب بالزوار في الصفحة الرئيسية، وسنستخدم لهذا الغرض دالة فلاسك المساعدة ()render_template لتوفير قوالب HTML مثل استجابة ضمن الصفحة، وسنتعلّم في هذا الصدد كيفيّة تمرير المتغيرات من التطبيق إلى القوالب. بدايةً نفتح الملف "app.py" الموجود في المجلد "flask_app" لتعديله وذلك باستخدام محرّر النصوص نانو "nano" أو أي محرر آخر تفضّله: (env) user@localhost:$ nano app.py ونضيف الشيفرة التالية ضمنه: from flask import Flask, render_template app = Flask(__name__) @app.route('/') def hello(): return render_template('index.html') نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة الصنف Flask الذي سنستخدمه لإنشاء نسخة من تطبيق باسم "app"، كما استوردنا الدالة ()render_template من حزمة flask، ثمّ عرفنا دالة العرض ()hello (وهي في الواقع دالة بايثون اعتيادية تعيد استجابةً من النمط HTTP) باستخدام المُزخرف ()app.route، الذي يحوّل دوال بايثون الاعتيادية إلى دوال عرض في فلاسك، تستخدم دالة العرض هذه الدالة ()render_template لتصييّر ملف قالب HTML المُسمّى "index.html". الآن، سننشئ القالب "index.html" ضمن المجلد الفرعي "templates" من المجلد الرئيسي "flask_app"، إذ سيبحث فلاسك عن القوالب في المجلد المسمّى "templates" تحديدًا، لذا يُعدُّ الاسم مهمًا. لإنشاء هذا المجلد، نتأكد من وجودنا ضمن المجلد "flask_app" وننفذ الأمر التالي: (env) user@localhost:$ mkdir templates بعد ذلك، ننشئ ملفًا باسم "index.html" ضمن مجلد القوالب "templates" لنكتب ضمنه لاحقًا الشيفرات اللازمة، ومن الجدير بالملاحظة أنّه من غير الضروري التقيُّد باسم "index.html" على عكس اسم المجلد الرئيسي، فمن الممكن تغييّر اسم الملف ليصبح مثلًا "home.html"، أو "homepage.html"، أو أي اسم آخر تفضّله: (env) user@localhost:$ nano templates/index.html ثمّ نضيف شيفرة HTML التالية داخل الملف "index.html": <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>FlaskApp</title> </head> <body> <h1>Hello World!</h1> <h2>Welcome to FlaskApp!</h2> </body> </html> اخترنا في الشيفرة السابقة عنوانًا للصفحة، كما أضفنا الرسالة "!Hello World" لتظهر ضمن تنسيق عنوان من المستوى الأوّل H1، والرسالة "!Welcome to FlasApp" لتظهر ضمن تنسيق عنوان من المستوى الثاني H2. نحفظ الملف ونغلقه. ولتشغيل تطبيق الويب الذي أنشأناه، وبعد التأكّد من وجودنا ضمن المجلد "flask_app" مع تفعيل البيئة الافتراضية، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم app.py) باستخدام متغير بيئة فلاسك FLASK_APP، ولتشغيله بوضع التطوير، نضبط متغير بيئة فلاسك Flask_ENV على الوضع development على النحو التالي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env) user@localhost:$ export FLASK_APP=app (env) user@localhost:$ export FLASK_ENV=development بعدها سنشغل التطبيق باستخدام الأمر flask run: (env) user@localhost:$ flask run بعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نذهب إلى الرابط التالي باستخدام المتصفح: http://127.0.0.1:5000/ فتظهر العبارة "FlasApp" عنوانًا للصفحة، ويجري تصييّر الرسالتين المكتوبتين في HTML لتظهرا بالتنسيق المطلوب. تُمرّر البيانات عادةً في تطبيقات الويب من ملفات بايثون الخاصة بالتطبيق إلى قوالب HTML، ولنوضّح كيفية فعل ذلك في تطبيقنا هذا، سنمرّر متغيرًا يحتوي على التاريخ والوقت وفق التوقيت العالمي UTC إلى القالب الرئيسي، وبعدها سنعرض قيمة هذا المتغير في القالب. سنترك خادم التطوير قيد التشغيل وسنفتح الملف app.py في نافذة أسطر أوامر جديدة للتعديل عليه: (env) user@localhost:$ nano app.py سنستورد الوحدة الخاصّة بالتعامل مع الوقت والتاريخ datetime من مكتبة بايثون المعيارية وسنعدّل الدالة ()index ليبدو الملف كما يلي: import datetime from flask import Flask, render_template app = Flask(__name__) @app.route('/') def hello(): return render_template('index.html', utc_dt=datetime.datetime.utcnow()) نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة الوحدة datetime ومرّرنا المتغير المُسمّى utc_dt مع قيمة ()datetime.datetime.utcnow التي تمثّل الوقت والتاريخ الحالي وفق التوقيت العالمي إلى القالب "index.html". ولعرض قيمة هذا المتغير في الصفحة الرئيسية، سنفتح الملف index.html من أجل التعديل عليه: (env) user@localhost:$ nano templates/index.html وسنعدّل الملف كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>FlaskApp</title> </head> <body> <h1>Hello World!</h1> <h2>Welcome to FlaskApp!</h2> <h3>{{ utc_dt }}</h3> </body> </html> نحفظ الملف ونغلقه. أضفنا موضعًا لنص منسّق مثل عنوان من المستوى الثالث H3 مع استخدام المُحدّد الخاص "{{ … }}" لطباعة قيمة المتغيّر utc_dt ضمنه. الآن، بالذهاب إلى صفحة التطبيق الرئيسية ضمن المتصفح: http://127.0.0.1:5000/ ستظهر صفحة مشابهة للصورة التالية: ومع نهاية هذه الخطوة نكون قد أنشأنا صفحةً رئيسيةً ذات قالب HTML داخل تطبيق فلاسك، وصيّرنا محتويات قالب آخر، ومرّرنا وأظهرنا قيمة مُتغير، وفيما يلي سنتجنّب تكرار الشيفرات البرمجية باستخدام مفهوم وراثة القوالب. الخطوة الثانية – استخدام مفهوم وراثة القوالب سننشئ في هذه الخطوة قالبًا أساسيًا ذا محتوًى قابل للمشاركة مع القوالب الأُخرى، وسنعدّل قالب الصفحة الرئيسية index template للتطبيق ليرث من القالب الأساسي هذا، ثمّ سننشئ صفحةً جديدةً مسؤولةً عن عرض معلومات التطبيق للمستخدمين. يحتوي القالب الأساسي على أهم مكونات HTML المُستخدمة عادةً في أي قالب، مثل عنوان التطبيق وأشرطة التنقّل والتذييلات. بدايةً، سننشئ ملفًا جديدًا باسم "base.html" ضمن مجلد القوالب templates: (env) user@localhost:$ nano templates/base.html وسنكتب ضمنه الشيفرات التالية: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="#">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> نحفظ الملف ونغلقه. الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية تشمل عنوانًا وبعض التنسيقات لروابط التنقل، إضافةً إلى شريط تنقّل مع رابطين، أحدهما للوصول إلى الصفحة الرئيسية للتطبيق والآخر للوصول إلى صفحة المعلومات التي لم ننشئها بعد، إضافةً إلى عنصر الحافظة <div> ليتضمّن محتويات الصفحة. لا تعمل هذه الروابط بعد لكننا سنوضح في الخطوة التالية كيفية إنشاء الربط بين الصفحات. أمّا الأجزاء من الشيفرة الموضحّة فيما يلي فهي خاصةٌ بمحرك القوالب جينجا: {% block title %} {% endblock %}: كتلة برمجية تحجز مكانًا لعنوان الصفحة، الذي سنستخدمه لاحقًا في تحديد العنوان الخاص بكل صفحة في التطبيق دون الحاجة إلى إعادة كتابة قسم الترويسة <head> كاملًا في كل مرةٍ من أجل كل صفحة. {% block content %} {% endblock %}: كتلة برمجية أخرى ستُستبدل لاحقًا بالمحتوى الفعلي بالاعتماد على القالب الابن، أي القالب الذي يرث شيفرات القالب الرئيسي "base.html". والآن، بعد أن أصبح لديك قالبٌ رئيسي، يمكنك الاستفادة من ميزاته باستخدام فكرة الوراثة، لذلك افتح الملف "index.html": (env) user@localhost:$ nano templates/index.html ثمّ استبدل محتوياته بما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Index {% endblock %}</h1> <h1>Hello World!</h1> <h2>Welcome to FlaskApp!</h2> <h3>{{ utc_dt }}</h3> {% endblock %} استخدمنا في هذه النسخة الجديدة من القالب template.html الوسم {% extends %} للوراثة من القالب الرئيسي base.html، وذلك عن طريق استبدال الشيفرة السابقة بكتلة المحتوى content في القالب الرئيسي. تحوي كتلة المحتوى هذه على وسم <h1> وبداخله كتلة عنوان title تحتوي على العبارة "Index"، والتي بدورها تستبدل كتلة العنوان title الموجودة أصلًا في القالب الرئيسي base.html لتحتوي على العبارة "Index" وبذلك يصبح العنوان كاملًا "Index - FlaskApp"، وبهذه الطريقة نتفادى تكرار نفس النص مرتين، ذلك لأنّ هذا النص سيظهر في عنوان الصفحة وضمن الوسم <h1> أسفل شريط التصفح الموروث من القالب الرئيسي. وبذلك يصبح لدينا عدة عناوين، الأوّل بتنسيق من المستوى الأوّل <h1> يتضمّن النص "!Hello World"، والثاني بتنسيق من المستوى الثاني <h2>، والثالث بتنسيق من المستوى الثالث <h3> والذي يحتوي على قيمة متغير الوقت والتاريخ utc_dt. تمكنّنا وراثة القوالب من إعادة استخدام شيفرة HTML الموجودة في القوالب الأخرى (القالب الرئيسي base.html في حالتنا) دون الحاجة لتكراره في كل مرة. اِحفظ الملف وأغلقه، ثم حدِّث الصفحة الرئيسية index في المتصفح، فستظهر الصفحة بشريط تصفح وعنوانٍ منسقٍ كما يلي: أمّا الآن فسننشئ صفحة معلومات التطبيق، لذا سنفتح الملف "app.py" ولنضيف ضمنه وجهةً جديدةً: (env) user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهايته: # ... @app.route('/about/') def about(): return render_template('about.html') استخدمنا المزخرف ()app.route لإنشاء دالة فلاسك باسم "()about"، إذ ترجع ضمنها نتيجة استدعاء الدالة ()render_template لدى تمرير اسم ملف القالب "about.html" وسيطًا لها. نحفظ الملف ونغلقه. الآن سننشئ ملف قالب باسم "about.html" كما يلي: (env) user@localhost:$ nano templates/about.html ونضيف ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} About {% endblock %}</h1> <h3>FlaskApp is a Flask web application written in Python.</h3> {% endblock %} استخدمنا في الشيفرة السابقة الوسم extend لوراثة الشيفرات من القالب الرئيسي، كما استبدلنا كتلة المحتوى content في القالب الرئيسي بوسم من النوع <h1> الذي يعمل أيضًا بمثابة عنوان للصفحة، وأضفنا بعض المعلومات حول التطبيق ضمن وسم من النوع <h3>. نحفظ الملف ونغلقه. بعد التأكد من أنّ خادم التطوير ما يزال قيد التشغيل، ننتقل إلى الرابط التالي باستخدام المتصفح: http://127.0.0.1:5000/about فتظهر صفحةٌ مشابهة للصورة التالية: نلاحظ وراثة شريط التنقل وجزءٍ من العنوان من القالب الأساسي. ومع نهاية هذه الخطوة نكون قد أنشأنا قالبًا أساسيًا واستخدمناه في بناء صفحة التطبيق الرئيسية وصفحة معلومات التطبيق لتجنُّب تكرار الشيفرات، إلّا أنّ الروابط في شريط التنقل ما تزال غير مُفعّلة ولا تؤدي أية مهمة حتى الآن، لذا سنربط في الخطوة سنربط بين الوجهات في القوالب من خلال تعديل الروابط في شريط التنقل. الخطوة الثالثة – الربط بين الصفحات سنتعلّم في هذه الخطوة كيفيّة الربط بين الصفحات باستخدام الدالة المساعدة ()url_for، إذ سنضيف رابطين إلى شريط التنقل في القالب الأساسي، أحدهما للوصول إلى الصفحة الرئيسية والآخر للوصول إلى صفحة معلومات التطبيق. بدايةً سنفتح القالب الأساسي لتعديله: (env) user@localhost:$ nano templates/base.html ونعدّل الملف كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('hello') }}">FlaskApp</a> <a href="{{ url_for('about') }}">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> استخدمنا في الشيفرة السابقة دالة ()url_for خاصّة، والتي ستُعيد الرابط الموافق لدالة فلاسك المُمرّرة لها، إذ أنّ الرابط الأول مرتبط بالوجهة الخاصة بدالة فلاسك ()hello (وهي الصفحة الرئيسية للتطبيق)، في حين يرتبط الرابط الثاني بالوجهة الخاصة بدالة فلاسك ()about، مع ملاحظة أنّنا مرّرنا اسم دالة فلاسك وسيطًا وليس اسم الوجهة (/ أو about/). يساعد استخدام الدالة ()url_for لبناء الروابط على إدارتها على نحوٍ أفضل، فلو كتبنا الروابط بصورةٍمحددة وبتعليمات برمجية ثابتة فإنها ستفشل مع أول تعديل على الوجهات، في حين أنّه ومع استخدام الدالة ()url_for فمن الممكن التعديل على الوجهات مع ضمان محافظة الروابط على عملها الطبيعي المتوقع، ناهيك عن كون دالة ()url_for مسؤولة أيضًا عن أمور أُخرى مثل عزل المحارف الخاصة. نحفظ الملف ونغلقه. سنعود الآن إلى الصفحة الرئيسية ونجرّب الروابط الموجودة في شريط التنقل، فنجد أنها تعمل كما هو مطلوب. ومع نهاية هذه الخطوة نكون قد تعلمنا كيفية استخدام الدالة ()url_for للربط بين الوجهات في القوالب، وفيما يلي سنضيف بعض العبارات الشرطية للتحكم بما يُعرض في القوالب بناءً على الشروط التي نضعها، كما سنستخدم حلقات "for" التكرارية في قوالبنا لعرض عناصر القائمة. الخطوة الرابعة - استخدام العبارات الشرطية والحلقات التكرارية سنستخدم في هذه الخطوة العبارة الشرطية "if" في القوالب للتحكم بما سيُعرض بناءً على شروط محدّدة، كما سنستخدم حلقات "for" التكرارية للتنقّل بين عناصر قوائم بايثون وعرضها، ثمّ سنضيف صفحةً جديدةً إلى التطبيق مهمتها عرض التعليقات ضمن قائمة، بحيث تكون التعليقات ذات رقم الدليل الزوجي بخلفية زرقاء والتعليقات ذات رقم الدليل الفردي بخلفية رمادية. سننشئ بدايةً وجهةً جديدةً لصفحة التعليقات، لذا سنفتح الملف app.py للتعديل عليه: (env) user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/comments/') def comments(): comments = ['This is the first comment.', 'This is the second comment.', 'This is the third comment.', 'This is the fourth comment.' ] return render_template('comments.html', comments=comments) لدينا في الوجهة السابقة قائمة مبنية في بايثون باسم comments تحتوي على أربعة عناصر (في التطبيق العملي يمكن الحصول على هذه التعليقات من قاعدة البيانات بدلاً من كتابتها يدويًا وتثبيتها ضمن الشيفرة)، لتكون القيمة المعادة هي تصيّير لملف قالب باسم "comments.html" وذلك في السطر الأخير من الشيفرة، ممررين المتغير comments الذي يحتوي القائمة مثل وسيط إلى ملف القالب. نحفظ الملف ونغلقه. بعدها ننشئ ملف جديد باسم comments.html ضمن مجلد القوالب templates للتعديل عليه: (env) user@localhost:$ nano templates/comments.html ونضيف ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p style="font-size: 24px">{{ comment }}</p> </div> {% endfor %} </div> {% endblock %} وفيه توسعنا بالقالب الأساسي base.html واستبدلنا محتويات كتلة المحتوى content. واستخدمنا تنسيق عنوان من النمط <h1> الذي سيعمل أيضًا بمثابة عنوانٍ للصفحة. كما استخدما حلقة for التكرارية وهي من ضمن تعليمات محرّك القوالب جينجا وذلك في السطر البرمجي {% for comment in comments %} بهدف التنقل بين التعليقات في القائمة comments المُخزنة ضمن المتغير المسمّى comment، إذ سنعرض التعليقات باستخدام الوسم <p style="font-size: 24px">{{ comment }}</p>، أي بنفس الآلية التي يُعرض فيها أي متغير في جينجا، مع ملاحظة أنّ نهاية حلقة for هنا تكون باستخدام الكلمة المفتاحية {% endfor %} الأمر المختلف عن طريقة بناء حلقات for في بايثون. نحفظ الملف ونغلقه. الآن وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نفتح المتصفح وننتقل إلى صفحة التعليقات باستخدام الرابط: http://127.0.0.1:5000/comments فتظهر الصفحة بما يشبه التالي: الآن سنستخدم عبارة if الشرطية في القوالب لعرض التعليقات ذات رقم الدليل الفردي بخلفية رمادية والتعليقات ذات رقم الدليل الزوجي بخلفية زرقاء. لذا سنفتح ملف القالب comments.html: (env) user@localhost:$ nano templates/comments.html ثمّ سنعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index % 2 == 0 %} {% set bg_color = '#e6f9ff' %} {% else %} {% set bg_color = '#eee' %} {% endif %} <div style="padding: 10px; background-color: {{ bg_color }}; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment }}</p> </div> {% endfor %} </div> {% endblock %} وفي هذا التعديل أضفنا عبارة if الشرطية في السطر {% if loop.index % 2 == 0 %}، إذ أنّ المتغير loop هو متغير خاص في جينجا يمكنّنا من الوصول إلى معلومات حول الحلقة الحالية، واستخدمنا loop.index للحصول على دليل العنصر الحالي، الذي يبدأ من "1" وليس من "0" كما هو الحال في قوائم بايثون. تتحقق عبارة if ما إذا كان الدليل زوجياً باستخدام عملية باقي القسمة %، إذ تُفحص قيمة باقي قسمة الدليل على الرقم "2"، فإذا كان الباقي يساوي "0"، فهذا يعني أن الدليل زوجي، وإلّا فيكون الدليل فرديًا. استخدمنا الوسم {% set %} للتعريف عن متغير باسم bg_color ليتضمّن لون الخلفية المطلوب، فإذا كان الدليل زوجيًا، نضبط قيمة هذا المتغير إلى اللون الأزرق، وإلّا وفي حال كون الدليل فرديًا نضبطها إلى اللون الرمادي، ثم نخصّص المتغير bg_color لضبط لون الخلفية للوسم <div> الحاوي على التعليق. نستخدم loop.index في أعلى النص الخاص بالتعليق لعرض رقم الدليل الحالي ضمن وسمٍ من النوع <p>. نحفظ الملف ونغلقه. الآن بفتح المتصفح والانتقال إلى صفحة التعليقات كما يلي: http://127.0.0.1:5000/comments ستظهر صفحة التعليقات الجديدة كما في الصورة: وضّحنا فيما سبق كيفية استخدام العبارة الشرطية if، ولكن من الممكن الحصول على نفس النتيجة باستخدام الدالة الخاصّة المساعدة ()loop.cycle في جينجا، ولتوضيح هذه النقطة سنفتح الملف "comments.html": (env) user@localhost:$ nano templates/comments.html ونعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} <div style="padding: 10px; background-color: {{ loop.cycle('#EEE', '#e6f9ff') }}; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment }}</p> </div> {% endfor %} </div> {% endblock %} حذفنا في هذه الشيفرة العبارة الشرطية "if/else" واستخدمنا عوضًا عنها الدالة المساعدة ('loop.cycle('#EEE', '#e6f9ff للتنقل بين اللونين، إذ ستكون قيمة المتغيّر background-color مساويةً للقيمة "#EEE" للون الرمادي مرّةً، ثمّ تتحول إلى القيمة "#e6f9ff" للون الأزرق مرةً أُخرى، وهكذا بالتناوب. نحفظ الملف ونغلقه. لدى فتح صفحة التعليقات في المتصفح وتحديثها، ستظهر صفحةٌ مشابهةٌ لتلك التي ظهرت مع استخدام عبارة "if" الشرطية. يمكن استخدام عبارات "if" الشرطية لأغراض مختلفة، بما في ذلك التحكم بما يُعرض على الصفحة، فعلى سبيل المثال لعرض جميع التعليقات باستثناء التعليق الثاني، يمكننا استخدام عبارة if بالشرط loop.index != 2 لترشيح التعليق الثاني. لذا سنفتح قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment }}</p> </div> {% endif %} {% endfor %} </div> {% endblock %} استخدمنا العبارة الشرطية {% if loop.index != 2 %} لعرض التعليقات ذات رقم الدليل غير المساوي للرقم "2"، ما يشمل جميع التعليقات باستثناء التعليق الثاني، كما استخدمنا شيفرةً ثابتةً لتغيير لون الخلفية بدلًا من استخدام الدالة المساعدة ()loop.cycle لتسهيل الأمور، أمّا بالنسبة لبقية أجزاء الشيفرة، فلم نجري عليها أي تغييرات، وأيضًا هنا تُنهى عبارة if الشرطية باستخدام الأمر {% endif %}. نحفظ الملف ونغلقه. سنلاحظ بتحديث صفحة التعليقات عدم ظهور التعليق الثاني. سنضيف الآن رابط يسمح للمستخدم بالانتقال إلى صفحة التعليقات مباشرةً من شريط التنقل، لذا سنفتح القالب الأساسي للتعديل عليه: (env) user@localhost:$ nano templates/base.html وسنعدّل محتويات الوسم <nav> بإضافة رابط جديد <a> إليه كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('hello') }}">FlaskApp</a> <a href="{{ url_for('comments') }}">Comments</a> <a href="{{ url_for('about') }}">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> استخدمنا الدالة المساعدة ()url_for للوصول إلى دالة فلاسك ()comments نحفظ الملف ونغلقه. وبذلك أصبح شريط التنقل يحتوي على رابط جديد ينقل المستخدم إلى صفحة التعليقات مباشرةً. وبذلك نكون قد تعلمنا كيفية استخدام العبارة الشرطية "if" في القوالب للتحكّم بما يُعرَض وفقًا لشروط معينة، كما استخدمنا حلقات "for" التكرارية للتنقل بين عناصر قوائم بايثون وعرض كل منها، وتعلمنا كيفية استخدام المتغير "loop" الخاص في جينجا، وسنستخدم في الخطوة التالية مرشّحات جينجا للتحكّم بكيفية عرض بيانات المتغير. الخطوة 5 – استخدام المرشحات سنتعلّم في هذه الخطوة كيفيّة استخدام مُرشحات جينجا في القوالب، إذ سنستخدم المُرشّح upper لتحويل كامل نصوص التعليقات التي أضفناها في الخطوة السابقة (أو الواردة من قاعدة البيانات في الواقع العملي) إلى حالة أحرف كبيرة، في حين سنستخدم المرشح join لربط عدّة سلاسل نصيّة لتصبح سلسلةً واحدة، كما سنتعرّف على كيفيّة تصيّير شيفرة HTML موثوقة وآمنة دون الحاجة لعزلها باستخدام المرشح safe. بدايةً سنعمل على تحويل التعليقات في صفحة التعليقات إلى حالة الأحرف الكبيرة، لذا سنفتح القالب "comments.html" للتعديل عليه: (env) user@localhost:$ nano templates/comments.html ثمّ سنعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} </div> {% endblock %} أضفنا مرشح upper باستخدام رمز | الذي يمثل أنبوبًا pipe، والذي سيعمل على تعديل قيمة متغير comment إلى حالة الأحرف الكبيرة. نحفظ الملف ونغلقه. وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، ننتقل إلى صفحة التعليقات باستخدام المتصفح: http://127.0.0.1:5000/comments ونلاحظ أنّ جميع التعليقات أصبحت في حالة الأحرف الكبيرة بعد تطبيق المرشح، كما من الممكن تمرير وسطاء للمُرشّحات بين أقواسها. لتوضيح هذه النقطة: سنستخدم المُرشّح join لدمج جميع التعليقات الموجودة في القائمة comments ضمن سلسلة واحدة. لذا سنفتح قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدله كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} <hr> <div> <p>{{ comments | join(" | ") }}</p> </div> </div> {% endblock %} أضفنا في الشيفرة السابقة الوسم <hr> (الذي يُصيّر مثل فاصل أفقي)، والوسم <div> (الذي يُستخدم لأغراض التنسيق وتجميع العناصر)، إذ دمجنا جميع التعليقات الموجودة في القائمة comments باستخدام المُرشّح ()join. نحفظ الملف ونغلقه. وبتحديث صفحة التعليقات ستظهر كما يلي: نلاحظ عرض كافّة محتويات القائمة comments بحيث تكون التعليقات مفصولة عن بعضها برمز الشريط العمودي pipe وهي القيمة المُمررة وسيطًا إلى المُرشّح ()join. ومن المُرشّحات المهمّة الأُخرى المُرشّح safe الذي يساعد في تصيّير شيفرة HTML موثوقة في المتصفح، ولتوضيح ذلك سنضيف نصًا يحتوي على وسم HTML ما إلى قالب التعليقات (لنرى هل سيُصيّر في المُتصفّح أم سيُعامل على أنه نص عادي) باستخدام مُحدّد جينجا "{{ }}". نحصل في التطبيق العملي على هذا النص (التعليق) مثل متغير آتٍ من الخادم، ومن ثمّ سنعدّل وسيط المُرشّح ()join ليكون وسم <hr> (أي الفصل بين التعليقات بشريط أفقي) بدلًا من الشريط العمودي pipe. لذا سنفتح قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدّله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} <hr> <div> {{ "<h1>COMMENTS</h1>" }} <p>{{ comments | join(" <hr> ") }}</p> </div> </div> {% endblock %} أضفنا القيمة <h1>COMMENTS</h1> وغيرنا وسيط مُرشّح الدمج ليصبح وسم <hr>. نحفظ الملف ونغلقه. وبتحديث صفحة التعليقات تظهر صفحةٌ مشابهةٌ لما يلي: نلاحظ أنّ وسوم HTML التي أضفناها ضمن التعليقات لم تُصيَّر، وهي ميزة أمان مهمّة في جينجا، لأنّ وسوم HTML قد تكون ضارة أو خبيثة، ويمكن أن تؤدي إلى هجمات البرمجة العابرة للمواقع XSS. أمّا لتصيير وسوم HTML المُضافة السابقة نفتح ملف قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدله بإضافة المُرشّح safe، للدلالة على أنّ هذه الوسوم آمنة ونريد تصييّرها: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} <hr> <div> {{ "<h1>COMMENTS</h1>" | safe }} <p>{{ comments | join(" <hr> ") | safe }}</p> </div> </div> {% endblock %} نلاحظ أنّه من الممكن ربط المُرشّحات كما هو ظاهر في السطر: <p>{{ comments | join(" <hr> ") | safe }}</p> إذ يُطبَّق كل مُرشّح على نتيجة خرج المُرشّح السابق له. نحفظ الملف ونغلقه. وبتحديث صفحة التعليقات نجد أن وسوم HTML قد جرى تصييّرها كما هو مُتوقّع مع استخدام المُرشّح "safe": تنبيه: قد يجعل تطبيق المُرشّح "safe" لشيفرة HTML غير موثوقة المصدر تطبيقنا عرضةً لهجمات البرمجة عابرة المواقع، لذا لا يُفضّل استخدامه إلّا إذا كانت شيفرات HTML المُراد تصييّرها موثوقة المصدر. تعرّفنا في هذه الخطوة على كيفيّة استخدام المُرشّحات في قوالب جينجا لتعديل قيم المتغيرات، وفيما يلي سنستخدم حزمة بوتستراب Bootstrap لتنسيق مظهر التطبيق وجعله أكثر جاذبية بصريًا. الخطوة السادسة – استخدام بوتستراب سنتعرّف في هذه الخطوة على كيفيّة استخدام حزمة بوتستراب لتنسيق مظهر التطبيق، إذ سنضيف شريط تنقّل في القالب الأساسي بحيث يظهر في كافّة الصفحات التي ترث شيفراتها منه. يساعد إطار العمل بوتستراب bootstrap على إضافة التنسيقات على التطبيق ليبدو أكثر جاذبية بصريًا، كما سيساعدنا على تمكين ميزة الصفحات المتوافقة مع المتصفحات في تطبيق الويب، ما يضمن عمله بصورةٍ جيدة في المتصفحات الخاصة بالجوال، دون كتابة شيفرات HTML و CSS وجافا سكربت JavaScript لتحقيق هذه الغاية. وحتّى نستخدم بوتستراب سنضيفه إلى القالب الأساسي بحيث يسهل استخدامه في جميع القوالب الأُخرى. لذا سنفتح القالب الأساسي "base.html" للتعديل عليه: (env) user@localhost:$ nano templates/base.html ونعدله كما يلي: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <!-- Bootstrap CSS --> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.0/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-KyZXEAg3QhqLMpG8r+8fhAXLRk2vvoC2f3B09zVXn8CA5QIVfZOJ3BCsw2P0p/We" crossorigin="anonymous"> <title>{% block title %} {% endblock %} - FlaskApp</title> </head> <body> <nav class="navbar navbar-expand-lg navbar-light bg-light"> <div class="container-fluid"> <a class="navbar-brand" href="{{ url_for('hello') }}">FlaskApp</a> <button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item"> <a class="nav-link" href="{{ url_for('comments') }}">Comments</a> </li> <li class="nav-item"> <a class="nav-link" href="{{ url_for('about') }}">About</a> </li> </ul> </div> </div> </nav> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.0/dist/js/bootstrap.bundle.min.js" integrity="sha384-U1DAWAznBHeqEIlVSCgzq+c9gqGAJn5c/t99JyeKa9xxaYpSvHU5awsuZVVFIhvj" crossorigin="anonymous"></script> </body> </html> الجزء الأكبر من الشيفرة السابقة هو تعليمات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ضمن القسم <head> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، وفي الجزء الأخير منه يُضمِّن الوسم <script> ارتباطًا إلى شيفرة جافا سكربت اختيارية. كما تتضمّن الشيفرة أجزاءً خاصةً بمحرك القوالب جينجا والتي قد وضّحناها فيما سبق، وكذلك استخدامًا لوسوم مُحدّدة وأصناف من CSS لتحديد كيفيّة عرض كل عنصر في بوتستراب. وقد استخدمنا في الشيفرة أعلاه وسم رابط <a> من الصنف navbar-brand الخاص بإضافة رابط العلامة المميزة (شعار الشركة مثلًا) إلى شريط التصفّح وذلك ضمن الوسم <nav> (الخاص بشريط التصفّح)، وفيه نحدّد رابط العلامة المطلوب، أمّا عن الروابط الاعتيادية مثل الروابط المؤدية إلى صفحات أُخرى من التطبيق، فمن الممكن تضمينها في الوسم <"ul class="navbar-nav> الحاوي على عنصر قائمة <li> ضمن عنصر روابط <a> وبالتالي من الممكن إضافة عدّة روابط. نحفظ الملف ونغلقه. وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، ننتقل إلى الصفحة الرئيسية من التطبيق في المتصفح: http://127.0.0.1:5000/ فتظهر صفحةٌ مشابهةٌ لما يلي: وبذلك أصبح من الممكن استخدام مكونات بوتستراب لتنسيق مظهر العناصر في تطبيق فلاسك في جميع القوالب. الخاتمة تعرّفنا في هذا المقال على كيفيّة استخدام قوالب HTML في تطبيق فلاسك، إذ استخدمنا المتغيرات لتمرير البيانات من الخادم إلى القوالب مستفيدين من مفهوم وراثة القوالب لتجنُّب تكرار الشيفرات، كما استخدمنا عناصر مثل عبارات "if" الشرطية وحلقات "for" التكرارية، وربطنا بين صفحات مختلفة من صفحات التطبيق، كما تعرّفنا على كيفية تطبيق المُرشّحات لتعديل نص ما أو لعرض شيفرة HTML موثوقة، ونهايةً استخدمنا بوتستراب لتنسيق مظهر التطبيق. ترجمة -وبتصرف- للمقال How To Use Templates in a Flask Application لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال التالي: كيفية التعامل مع الأخطاء في تطبيقات فلاسك Flask المقال السابق: تعلم بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask بلغة بايثون استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا
يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل. عند تطوير تطبيق ويب ما، من الضروري الفصل بين ما يدعى "منطق العمل business logic" و"منطق العرض presentation logic"؛ إذ يكون منطق العمل مسؤولاً عن التعامل مع طلبات المستخدمين، مُخاطبًا قاعدة البيانات لإنشاء الاستجابة المناسبة؛ في حين يُحدّد منطق العرض كيفيّة عرض البيانات للمستخدم، وذلك غالبًا باستخدام ملفات HTML لإنشاء الهيكل الأساسي لصفحة الويب التي تستجيب لطلبات المستخدمين، مع استخدام تنسيقات CSS لتنسيق مظهر تلك المكونات المبنية باستخدام HTML. فمثلًا في حال كان لدينا تطبيق للتواصل الاجتماعي، فيوجد عادةً حقلٌ لإدراج اسم المستخدم وحقل لإدراج كلمة المرور بحيث لا يظهران إلّا في حال كون المستخدم لم يسجل دخوله إلى التطبيق بعد، ولدى كتابة المستخدم اسم المستخدم وكلمة المرور يعمل فلاسك على تطبيق منطق العمل، إذ تُستخرج البيانات (اسم المستخدم وكلمة المرور) من الطلب ليُسجَّل دخول المستخدم إذا كانت هذه البيانات صحيحة، وإلّا ستظهر رسالة خطأ، ويجري التعامل مع كيفية ظهور رسالة الخطأ بالاعتماد على منطق العرض. يستخدم فلاسك محرّك القوالب جينجا jinja لبناء صفحات HTML ديناميكيًا باستخدام مفاهيم بايثون المألوفة، من متغيراتٍ وحلقاتٍ تكرارية وقوائم وغيرها، وبالتالي ستُستخدم هذه القوالب على أنها جزءٌ من هذا المشروع، إذ يُعرّف القالب بأنه ملف يحتوي على مكونات ثابتة وأُخرى ديناميكية، وعندما يطلب المستخدم عنصرًا من التطبيق، مثل الصفحة الرئيسية، أو صفحة تسجيل الدخول، يُمكنّنا جينجا من الاستجابة باستخدام قالب HTML، وبذلك يصبح من الممكن استخدام عددٍ كبيرٍ من الميزات غير المتوفرة أصلًا في لغة HTML المعيارية، مثل المتغيرات والعبارة الشرطية "if" والحلقات التكرارية مثل حلقة "for"، والمُرشّحات filters ومفهوم وراثة القوالب، إذ تسمح لنا هذه الخواص بكتابة صفحات HTML سهلة الإصلاح، كما تعزل جينجا شيفرات HTML تلقائيًا بهدف منع هجمات البرمجة العابرة للمواقع Cross-Site Scripting -أو اختصارًا XSS-. سنبني في هذا المقال تطبيق ويب صغير يعمل على تصييّر عدّة ملفات HTML ضمن المتصفح معًا، إذ سنستخدم المتغيرات لتمرير البيانات من الخادم إلى القوالب، كما سنطبّق مفهوم وراثة القوالب لتجنُّب التكرار في الشيفرات البرمجية. وسنستخدم كذلك التعابير المنطقية في بناء شيفرات القوالب من عبارات شرطية وحلقات، وسنطبّق المُرشّحات اللازمة لتعديل النصوص، وسنعمل من خلال إطار العمل بوتستراب bootstrap على إضافة التنسيقات على التطبيق ليبدو أكثر جاذبية بصريًا. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". توفّر إطار العمل فلاسك مُثبّت ضمن البيئة البرمجبة كما هو مُبيّن في الخطوة الأولى من المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask والإصدار الثالث من لغة بايثون. الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات routes ودوال العرض view في فلاسك، ويمكنك في هذا الصدد الاطلاع على المقال كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask والإصدار الثالث من لغة بايثون المشار إليه أعلاه لفهم مبادئ فلاسك. فهم أساسيات لغة HTML. الخطوة الأولى - تصيير القوالب واستخدام المتغيرات بعد التأكّد من تفعيل بيئة البرمجة وتثبيت فلاسك، سنبدأ ببناء التطبيق، إذ تتمثّل الخطوة الأولى بعرض رسالة ترحيب بالزوار في الصفحة الرئيسية، وسنستخدم لهذا الغرض دالة فلاسك المساعدة ()render_template لتوفير قوالب HTML مثل استجابة ضمن الصفحة، وسنتعلّم في هذا الصدد كيفيّة تمرير المتغيرات من التطبيق إلى القوالب. بدايةً نفتح الملف "app.py" الموجود في المجلد "flask_app" لتعديله وذلك باستخدام محرّر النصوص نانو "nano" أو أي محرر آخر تفضّله: (env) user@localhost:$ nano app.py ونضيف الشيفرة التالية ضمنه: from flask import Flask, render_template app = Flask(__name__) @app.route('/') def hello(): return render_template('index.html') نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة الصنف Flask الذي سنستخدمه لإنشاء نسخة من تطبيق باسم "app"، كما استوردنا الدالة ()render_template من حزمة flask، ثمّ عرفنا دالة العرض ()hello (وهي في الواقع دالة بايثون اعتيادية تعيد استجابةً من النمط HTTP) باستخدام المُزخرف ()app.route، الذي يحوّل دوال بايثون الاعتيادية إلى دوال عرض في فلاسك، تستخدم دالة العرض هذه الدالة ()render_template لتصييّر ملف قالب HTML المُسمّى "index.html". الآن، سننشئ القالب "index.html" ضمن المجلد الفرعي "templates" من المجلد الرئيسي "flask_app"، إذ سيبحث فلاسك عن القوالب في المجلد المسمّى "templates" تحديدًا، لذا يُعدُّ الاسم مهمًا. لإنشاء هذا المجلد، نتأكد من وجودنا ضمن المجلد "flask_app" وننفذ الأمر التالي: (env) user@localhost:$ mkdir templates بعد ذلك، ننشئ ملفًا باسم "index.html" ضمن مجلد القوالب "templates" لنكتب ضمنه لاحقًا الشيفرات اللازمة، ومن الجدير بالملاحظة أنّه من غير الضروري التقيُّد باسم "index.html" على عكس اسم المجلد الرئيسي، فمن الممكن تغييّر اسم الملف ليصبح مثلًا "home.html"، أو "homepage.html"، أو أي اسم آخر تفضّله: (env) user@localhost:$ nano templates/index.html ثمّ نضيف شيفرة HTML التالية داخل الملف "index.html": <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>FlaskApp</title> </head> <body> <h1>Hello World!</h1> <h2>Welcome to FlaskApp!</h2> </body> </html> اخترنا في الشيفرة السابقة عنوانًا للصفحة، كما أضفنا الرسالة "!Hello World" لتظهر ضمن تنسيق عنوان من المستوى الأوّل H1، والرسالة "!Welcome to FlasApp" لتظهر ضمن تنسيق عنوان من المستوى الثاني H2. نحفظ الملف ونغلقه. ولتشغيل تطبيق الويب الذي أنشأناه، وبعد التأكّد من وجودنا ضمن المجلد "flask_app" مع تفعيل البيئة الافتراضية، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم app.py) باستخدام متغير بيئة فلاسك FLASK_APP، ولتشغيله بوضع التطوير، نضبط متغير بيئة فلاسك Flask_ENV على الوضع development على النحو التالي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env) user@localhost:$ export FLASK_APP=app (env) user@localhost:$ export FLASK_ENV=development بعدها سنشغل التطبيق باستخدام الأمر flask run: (env) user@localhost:$ flask run بعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نذهب إلى الرابط التالي باستخدام المتصفح: http://127.0.0.1:5000/ فتظهر العبارة "FlasApp" عنوانًا للصفحة، ويجري تصييّر الرسالتين المكتوبتين في HTML لتظهرا بالتنسيق المطلوب. تُمرّر البيانات عادةً في تطبيقات الويب من ملفات بايثون الخاصة بالتطبيق إلى قوالب HTML، ولنوضّح كيفية فعل ذلك في تطبيقنا هذا، سنمرّر متغيرًا يحتوي على التاريخ والوقت وفق التوقيت العالمي UTC إلى القالب الرئيسي، وبعدها سنعرض قيمة هذا المتغير في القالب. سنترك خادم التطوير قيد التشغيل وسنفتح الملف app.py في نافذة أسطر أوامر جديدة للتعديل عليه: (env) user@localhost:$ nano app.py سنستورد الوحدة الخاصّة بالتعامل مع الوقت والتاريخ datetime من مكتبة بايثون المعيارية وسنعدّل الدالة ()index ليبدو الملف كما يلي: import datetime from flask import Flask, render_template app = Flask(__name__) @app.route('/') def hello(): return render_template('index.html', utc_dt=datetime.datetime.utcnow()) نحفظ الملف ونغلقه. استوردنا في الشيفرة السابقة الوحدة datetime ومرّرنا المتغير المُسمّى utc_dt مع قيمة ()datetime.datetime.utcnow التي تمثّل الوقت والتاريخ الحالي وفق التوقيت العالمي إلى القالب "index.html". ولعرض قيمة هذا المتغير في الصفحة الرئيسية، سنفتح الملف index.html من أجل التعديل عليه: (env) user@localhost:$ nano templates/index.html وسنعدّل الملف كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>FlaskApp</title> </head> <body> <h1>Hello World!</h1> <h2>Welcome to FlaskApp!</h2> <h3>{{ utc_dt }}</h3> </body> </html> نحفظ الملف ونغلقه. أضفنا موضعًا لنص منسّق مثل عنوان من المستوى الثالث H3 مع استخدام المُحدّد الخاص "{{ … }}" لطباعة قيمة المتغيّر utc_dt ضمنه. الآن، بالذهاب إلى صفحة التطبيق الرئيسية ضمن المتصفح: http://127.0.0.1:5000/ ستظهر صفحة مشابهة للصورة التالية: ومع نهاية هذه الخطوة نكون قد أنشأنا صفحةً رئيسيةً ذات قالب HTML داخل تطبيق فلاسك، وصيّرنا محتويات قالب آخر، ومرّرنا وأظهرنا قيمة مُتغير، وفيما يلي سنتجنّب تكرار الشيفرات البرمجية باستخدام مفهوم وراثة القوالب. الخطوة الثانية – استخدام مفهوم وراثة القوالب سننشئ في هذه الخطوة قالبًا أساسيًا ذا محتوًى قابل للمشاركة مع القوالب الأُخرى، وسنعدّل قالب الصفحة الرئيسية index template للتطبيق ليرث من القالب الأساسي هذا، ثمّ سننشئ صفحةً جديدةً مسؤولةً عن عرض معلومات التطبيق للمستخدمين. يحتوي القالب الأساسي على أهم مكونات HTML المُستخدمة عادةً في أي قالب، مثل عنوان التطبيق وأشرطة التنقّل والتذييلات. بدايةً، سننشئ ملفًا جديدًا باسم "base.html" ضمن مجلد القوالب templates: (env) user@localhost:$ nano templates/base.html وسنكتب ضمنه الشيفرات التالية: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="#">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> نحفظ الملف ونغلقه. الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية تشمل عنوانًا وبعض التنسيقات لروابط التنقل، إضافةً إلى شريط تنقّل مع رابطين، أحدهما للوصول إلى الصفحة الرئيسية للتطبيق والآخر للوصول إلى صفحة المعلومات التي لم ننشئها بعد، إضافةً إلى عنصر الحافظة <div> ليتضمّن محتويات الصفحة. لا تعمل هذه الروابط بعد لكننا سنوضح في الخطوة التالية كيفية إنشاء الربط بين الصفحات. أمّا الأجزاء من الشيفرة الموضحّة فيما يلي فهي خاصةٌ بمحرك القوالب جينجا: {% block title %} {% endblock %}: كتلة برمجية تحجز مكانًا لعنوان الصفحة، الذي سنستخدمه لاحقًا في تحديد العنوان الخاص بكل صفحة في التطبيق دون الحاجة إلى إعادة كتابة قسم الترويسة <head> كاملًا في كل مرةٍ من أجل كل صفحة. {% block content %} {% endblock %}: كتلة برمجية أخرى ستُستبدل لاحقًا بالمحتوى الفعلي بالاعتماد على القالب الابن، أي القالب الذي يرث شيفرات القالب الرئيسي "base.html". والآن، بعد أن أصبح لديك قالبٌ رئيسي، يمكنك الاستفادة من ميزاته باستخدام فكرة الوراثة، لذلك افتح الملف "index.html": (env) user@localhost:$ nano templates/index.html ثمّ استبدل محتوياته بما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Index {% endblock %}</h1> <h1>Hello World!</h1> <h2>Welcome to FlaskApp!</h2> <h3>{{ utc_dt }}</h3> {% endblock %} استخدمنا في هذه النسخة الجديدة من القالب template.html الوسم {% extends %} للوراثة من القالب الرئيسي base.html، وذلك عن طريق استبدال الشيفرة السابقة بكتلة المحتوى content في القالب الرئيسي. تحوي كتلة المحتوى هذه على وسم <h1> وبداخله كتلة عنوان title تحتوي على العبارة "Index"، والتي بدورها تستبدل كتلة العنوان title الموجودة أصلًا في القالب الرئيسي base.html لتحتوي على العبارة "Index" وبذلك يصبح العنوان كاملًا "Index - FlaskApp"، وبهذه الطريقة نتفادى تكرار نفس النص مرتين، ذلك لأنّ هذا النص سيظهر في عنوان الصفحة وضمن الوسم <h1> أسفل شريط التصفح الموروث من القالب الرئيسي. وبذلك يصبح لدينا عدة عناوين، الأوّل بتنسيق من المستوى الأوّل <h1> يتضمّن النص "!Hello World"، والثاني بتنسيق من المستوى الثاني <h2>، والثالث بتنسيق من المستوى الثالث <h3> والذي يحتوي على قيمة متغير الوقت والتاريخ utc_dt. تمكنّنا وراثة القوالب من إعادة استخدام شيفرة HTML الموجودة في القوالب الأخرى (القالب الرئيسي base.html في حالتنا) دون الحاجة لتكراره في كل مرة. اِحفظ الملف وأغلقه، ثم حدِّث الصفحة الرئيسية index في المتصفح، فستظهر الصفحة بشريط تصفح وعنوانٍ منسقٍ كما يلي: أمّا الآن فسننشئ صفحة معلومات التطبيق، لذا سنفتح الملف "app.py" ولنضيف ضمنه وجهةً جديدةً: (env) user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهايته: # ... @app.route('/about/') def about(): return render_template('about.html') استخدمنا المزخرف ()app.route لإنشاء دالة فلاسك باسم "()about"، إذ ترجع ضمنها نتيجة استدعاء الدالة ()render_template لدى تمرير اسم ملف القالب "about.html" وسيطًا لها. نحفظ الملف ونغلقه. الآن سننشئ ملف قالب باسم "about.html" كما يلي: (env) user@localhost:$ nano templates/about.html ونضيف ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} About {% endblock %}</h1> <h3>FlaskApp is a Flask web application written in Python.</h3> {% endblock %} استخدمنا في الشيفرة السابقة الوسم extend لوراثة الشيفرات من القالب الرئيسي، كما استبدلنا كتلة المحتوى content في القالب الرئيسي بوسم من النوع <h1> الذي يعمل أيضًا بمثابة عنوان للصفحة، وأضفنا بعض المعلومات حول التطبيق ضمن وسم من النوع <h3>. نحفظ الملف ونغلقه. بعد التأكد من أنّ خادم التطوير ما يزال قيد التشغيل، ننتقل إلى الرابط التالي باستخدام المتصفح: http://127.0.0.1:5000/about فتظهر صفحةٌ مشابهة للصورة التالية: نلاحظ وراثة شريط التنقل وجزءٍ من العنوان من القالب الأساسي. ومع نهاية هذه الخطوة نكون قد أنشأنا قالبًا أساسيًا واستخدمناه في بناء صفحة التطبيق الرئيسية وصفحة معلومات التطبيق لتجنُّب تكرار الشيفرات، إلّا أنّ الروابط في شريط التنقل ما تزال غير مُفعّلة ولا تؤدي أية مهمة حتى الآن، لذا سنربط في الخطوة سنربط بين الوجهات في القوالب من خلال تعديل الروابط في شريط التنقل. الخطوة الثالثة – الربط بين الصفحات سنتعلّم في هذه الخطوة كيفيّة الربط بين الصفحات باستخدام الدالة المساعدة ()url_for، إذ سنضيف رابطين إلى شريط التنقل في القالب الأساسي، أحدهما للوصول إلى الصفحة الرئيسية والآخر للوصول إلى صفحة معلومات التطبيق. بدايةً سنفتح القالب الأساسي لتعديله: (env) user@localhost:$ nano templates/base.html ونعدّل الملف كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('hello') }}">FlaskApp</a> <a href="{{ url_for('about') }}">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> استخدمنا في الشيفرة السابقة دالة ()url_for خاصّة، والتي ستُعيد الرابط الموافق لدالة فلاسك المُمرّرة لها، إذ أنّ الرابط الأول مرتبط بالوجهة الخاصة بدالة فلاسك ()hello (وهي الصفحة الرئيسية للتطبيق)، في حين يرتبط الرابط الثاني بالوجهة الخاصة بدالة فلاسك ()about، مع ملاحظة أنّنا مرّرنا اسم دالة فلاسك وسيطًا وليس اسم الوجهة (/ أو about/). يساعد استخدام الدالة ()url_for لبناء الروابط على إدارتها على نحوٍ أفضل، فلو كتبنا الروابط بصورةٍمحددة وبتعليمات برمجية ثابتة فإنها ستفشل مع أول تعديل على الوجهات، في حين أنّه ومع استخدام الدالة ()url_for فمن الممكن التعديل على الوجهات مع ضمان محافظة الروابط على عملها الطبيعي المتوقع، ناهيك عن كون دالة ()url_for مسؤولة أيضًا عن أمور أُخرى مثل عزل المحارف الخاصة. نحفظ الملف ونغلقه. سنعود الآن إلى الصفحة الرئيسية ونجرّب الروابط الموجودة في شريط التنقل، فنجد أنها تعمل كما هو مطلوب. ومع نهاية هذه الخطوة نكون قد تعلمنا كيفية استخدام الدالة ()url_for للربط بين الوجهات في القوالب، وفيما يلي سنضيف بعض العبارات الشرطية للتحكم بما يُعرض في القوالب بناءً على الشروط التي نضعها، كما سنستخدم حلقات "for" التكرارية في قوالبنا لعرض عناصر القائمة. الخطوة الرابعة - استخدام العبارات الشرطية والحلقات التكرارية سنستخدم في هذه الخطوة العبارة الشرطية "if" في القوالب للتحكم بما سيُعرض بناءً على شروط محدّدة، كما سنستخدم حلقات "for" التكرارية للتنقّل بين عناصر قوائم بايثون وعرضها، ثمّ سنضيف صفحةً جديدةً إلى التطبيق مهمتها عرض التعليقات ضمن قائمة، بحيث تكون التعليقات ذات رقم الدليل الزوجي بخلفية زرقاء والتعليقات ذات رقم الدليل الفردي بخلفية رمادية. سننشئ بدايةً وجهةً جديدةً لصفحة التعليقات، لذا سنفتح الملف app.py للتعديل عليه: (env) user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/comments/') def comments(): comments = ['This is the first comment.', 'This is the second comment.', 'This is the third comment.', 'This is the fourth comment.' ] return render_template('comments.html', comments=comments) لدينا في الوجهة السابقة قائمة مبنية في بايثون باسم comments تحتوي على أربعة عناصر (في التطبيق العملي يمكن الحصول على هذه التعليقات من قاعدة البيانات بدلاً من كتابتها يدويًا وتثبيتها ضمن الشيفرة)، لتكون القيمة المعادة هي تصيّير لملف قالب باسم "comments.html" وذلك في السطر الأخير من الشيفرة، ممررين المتغير comments الذي يحتوي القائمة مثل وسيط إلى ملف القالب. نحفظ الملف ونغلقه. بعدها ننشئ ملف جديد باسم comments.html ضمن مجلد القوالب templates للتعديل عليه: (env) user@localhost:$ nano templates/comments.html ونضيف ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p style="font-size: 24px">{{ comment }}</p> </div> {% endfor %} </div> {% endblock %} وفيه توسعنا بالقالب الأساسي base.html واستبدلنا محتويات كتلة المحتوى content. واستخدمنا تنسيق عنوان من النمط <h1> الذي سيعمل أيضًا بمثابة عنوانٍ للصفحة. كما استخدما حلقة for التكرارية وهي من ضمن تعليمات محرّك القوالب جينجا وذلك في السطر البرمجي {% for comment in comments %} بهدف التنقل بين التعليقات في القائمة comments المُخزنة ضمن المتغير المسمّى comment، إذ سنعرض التعليقات باستخدام الوسم <p style="font-size: 24px">{{ comment }}</p>، أي بنفس الآلية التي يُعرض فيها أي متغير في جينجا، مع ملاحظة أنّ نهاية حلقة for هنا تكون باستخدام الكلمة المفتاحية {% endfor %} الأمر المختلف عن طريقة بناء حلقات for في بايثون. نحفظ الملف ونغلقه. الآن وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نفتح المتصفح وننتقل إلى صفحة التعليقات باستخدام الرابط: http://127.0.0.1:5000/comments فتظهر الصفحة بما يشبه التالي: الآن سنستخدم عبارة if الشرطية في القوالب لعرض التعليقات ذات رقم الدليل الفردي بخلفية رمادية والتعليقات ذات رقم الدليل الزوجي بخلفية زرقاء. لذا سنفتح ملف القالب comments.html: (env) user@localhost:$ nano templates/comments.html ثمّ سنعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index % 2 == 0 %} {% set bg_color = '#e6f9ff' %} {% else %} {% set bg_color = '#eee' %} {% endif %} <div style="padding: 10px; background-color: {{ bg_color }}; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment }}</p> </div> {% endfor %} </div> {% endblock %} وفي هذا التعديل أضفنا عبارة if الشرطية في السطر {% if loop.index % 2 == 0 %}، إذ أنّ المتغير loop هو متغير خاص في جينجا يمكنّنا من الوصول إلى معلومات حول الحلقة الحالية، واستخدمنا loop.index للحصول على دليل العنصر الحالي، الذي يبدأ من "1" وليس من "0" كما هو الحال في قوائم بايثون. تتحقق عبارة if ما إذا كان الدليل زوجياً باستخدام عملية باقي القسمة %، إذ تُفحص قيمة باقي قسمة الدليل على الرقم "2"، فإذا كان الباقي يساوي "0"، فهذا يعني أن الدليل زوجي، وإلّا فيكون الدليل فرديًا. استخدمنا الوسم {% set %} للتعريف عن متغير باسم bg_color ليتضمّن لون الخلفية المطلوب، فإذا كان الدليل زوجيًا، نضبط قيمة هذا المتغير إلى اللون الأزرق، وإلّا وفي حال كون الدليل فرديًا نضبطها إلى اللون الرمادي، ثم نخصّص المتغير bg_color لضبط لون الخلفية للوسم <div> الحاوي على التعليق. نستخدم loop.index في أعلى النص الخاص بالتعليق لعرض رقم الدليل الحالي ضمن وسمٍ من النوع <p>. نحفظ الملف ونغلقه. الآن بفتح المتصفح والانتقال إلى صفحة التعليقات كما يلي: http://127.0.0.1:5000/comments ستظهر صفحة التعليقات الجديدة كما في الصورة: وضّحنا فيما سبق كيفية استخدام العبارة الشرطية if، ولكن من الممكن الحصول على نفس النتيجة باستخدام الدالة الخاصّة المساعدة ()loop.cycle في جينجا، ولتوضيح هذه النقطة سنفتح الملف "comments.html": (env) user@localhost:$ nano templates/comments.html ونعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} <div style="padding: 10px; background-color: {{ loop.cycle('#EEE', '#e6f9ff') }}; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment }}</p> </div> {% endfor %} </div> {% endblock %} حذفنا في هذه الشيفرة العبارة الشرطية "if/else" واستخدمنا عوضًا عنها الدالة المساعدة ('loop.cycle('#EEE', '#e6f9ff للتنقل بين اللونين، إذ ستكون قيمة المتغيّر background-color مساويةً للقيمة "#EEE" للون الرمادي مرّةً، ثمّ تتحول إلى القيمة "#e6f9ff" للون الأزرق مرةً أُخرى، وهكذا بالتناوب. نحفظ الملف ونغلقه. لدى فتح صفحة التعليقات في المتصفح وتحديثها، ستظهر صفحةٌ مشابهةٌ لتلك التي ظهرت مع استخدام عبارة "if" الشرطية. يمكن استخدام عبارات "if" الشرطية لأغراض مختلفة، بما في ذلك التحكم بما يُعرض على الصفحة، فعلى سبيل المثال لعرض جميع التعليقات باستثناء التعليق الثاني، يمكننا استخدام عبارة if بالشرط loop.index != 2 لترشيح التعليق الثاني. لذا سنفتح قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment }}</p> </div> {% endif %} {% endfor %} </div> {% endblock %} استخدمنا العبارة الشرطية {% if loop.index != 2 %} لعرض التعليقات ذات رقم الدليل غير المساوي للرقم "2"، ما يشمل جميع التعليقات باستثناء التعليق الثاني، كما استخدمنا شيفرةً ثابتةً لتغيير لون الخلفية بدلًا من استخدام الدالة المساعدة ()loop.cycle لتسهيل الأمور، أمّا بالنسبة لبقية أجزاء الشيفرة، فلم نجري عليها أي تغييرات، وأيضًا هنا تُنهى عبارة if الشرطية باستخدام الأمر {% endif %}. نحفظ الملف ونغلقه. سنلاحظ بتحديث صفحة التعليقات عدم ظهور التعليق الثاني. سنضيف الآن رابط يسمح للمستخدم بالانتقال إلى صفحة التعليقات مباشرةً من شريط التنقل، لذا سنفتح القالب الأساسي للتعديل عليه: (env) user@localhost:$ nano templates/base.html وسنعدّل محتويات الوسم <nav> بإضافة رابط جديد <a> إليه كما يلي: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } </style> </head> <body> <nav> <a href="{{ url_for('hello') }}">FlaskApp</a> <a href="{{ url_for('comments') }}">Comments</a> <a href="{{ url_for('about') }}">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html> استخدمنا الدالة المساعدة ()url_for للوصول إلى دالة فلاسك ()comments نحفظ الملف ونغلقه. وبذلك أصبح شريط التنقل يحتوي على رابط جديد ينقل المستخدم إلى صفحة التعليقات مباشرةً. وبذلك نكون قد تعلمنا كيفية استخدام العبارة الشرطية "if" في القوالب للتحكّم بما يُعرَض وفقًا لشروط معينة، كما استخدمنا حلقات "for" التكرارية للتنقل بين عناصر قوائم بايثون وعرض كل منها، وتعلمنا كيفية استخدام المتغير "loop" الخاص في جينجا، وسنستخدم في الخطوة التالية مرشّحات جينجا للتحكّم بكيفية عرض بيانات المتغير. الخطوة 5 – استخدام المرشحات سنتعلّم في هذه الخطوة كيفيّة استخدام مُرشحات جينجا في القوالب، إذ سنستخدم المُرشّح upper لتحويل كامل نصوص التعليقات التي أضفناها في الخطوة السابقة (أو الواردة من قاعدة البيانات في الواقع العملي) إلى حالة أحرف كبيرة، في حين سنستخدم المرشح join لربط عدّة سلاسل نصيّة لتصبح سلسلةً واحدة، كما سنتعرّف على كيفيّة تصيّير شيفرة HTML موثوقة وآمنة دون الحاجة لعزلها باستخدام المرشح safe. بدايةً سنعمل على تحويل التعليقات في صفحة التعليقات إلى حالة الأحرف الكبيرة، لذا سنفتح القالب "comments.html" للتعديل عليه: (env) user@localhost:$ nano templates/comments.html ثمّ سنعدله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} </div> {% endblock %} أضفنا مرشح upper باستخدام رمز | الذي يمثل أنبوبًا pipe، والذي سيعمل على تعديل قيمة متغير comment إلى حالة الأحرف الكبيرة. نحفظ الملف ونغلقه. وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، ننتقل إلى صفحة التعليقات باستخدام المتصفح: http://127.0.0.1:5000/comments ونلاحظ أنّ جميع التعليقات أصبحت في حالة الأحرف الكبيرة بعد تطبيق المرشح، كما من الممكن تمرير وسطاء للمُرشّحات بين أقواسها. لتوضيح هذه النقطة: سنستخدم المُرشّح join لدمج جميع التعليقات الموجودة في القائمة comments ضمن سلسلة واحدة. لذا سنفتح قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدله كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} <hr> <div> <p>{{ comments | join(" | ") }}</p> </div> </div> {% endblock %} أضفنا في الشيفرة السابقة الوسم <hr> (الذي يُصيّر مثل فاصل أفقي)، والوسم <div> (الذي يُستخدم لأغراض التنسيق وتجميع العناصر)، إذ دمجنا جميع التعليقات الموجودة في القائمة comments باستخدام المُرشّح ()join. نحفظ الملف ونغلقه. وبتحديث صفحة التعليقات ستظهر كما يلي: نلاحظ عرض كافّة محتويات القائمة comments بحيث تكون التعليقات مفصولة عن بعضها برمز الشريط العمودي pipe وهي القيمة المُمررة وسيطًا إلى المُرشّح ()join. ومن المُرشّحات المهمّة الأُخرى المُرشّح safe الذي يساعد في تصيّير شيفرة HTML موثوقة في المتصفح، ولتوضيح ذلك سنضيف نصًا يحتوي على وسم HTML ما إلى قالب التعليقات (لنرى هل سيُصيّر في المُتصفّح أم سيُعامل على أنه نص عادي) باستخدام مُحدّد جينجا "{{ }}". نحصل في التطبيق العملي على هذا النص (التعليق) مثل متغير آتٍ من الخادم، ومن ثمّ سنعدّل وسيط المُرشّح ()join ليكون وسم <hr> (أي الفصل بين التعليقات بشريط أفقي) بدلًا من الشريط العمودي pipe. لذا سنفتح قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدّله ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} <hr> <div> {{ "<h1>COMMENTS</h1>" }} <p>{{ comments | join(" <hr> ") }}</p> </div> </div> {% endblock %} أضفنا القيمة <h1>COMMENTS</h1> وغيرنا وسيط مُرشّح الدمج ليصبح وسم <hr>. نحفظ الملف ونغلقه. وبتحديث صفحة التعليقات تظهر صفحةٌ مشابهةٌ لما يلي: نلاحظ أنّ وسوم HTML التي أضفناها ضمن التعليقات لم تُصيَّر، وهي ميزة أمان مهمّة في جينجا، لأنّ وسوم HTML قد تكون ضارة أو خبيثة، ويمكن أن تؤدي إلى هجمات البرمجة العابرة للمواقع XSS. أمّا لتصيير وسوم HTML المُضافة السابقة نفتح ملف قالب التعليقات: (env) user@localhost:$ nano templates/comments.html ونعدله بإضافة المُرشّح safe، للدلالة على أنّ هذه الوسوم آمنة ونريد تصييّرها: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Comments {% endblock %}</h1> <div style="width: 50%; margin: auto"> {% for comment in comments %} {% if loop.index != 2 %} <div style="padding: 10px; background-color: #EEE; margin: 20px"> <p>#{{ loop.index }}</p> <p style="font-size: 24px">{{ comment | upper }}</p> </div> {% endif %} {% endfor %} <hr> <div> {{ "<h1>COMMENTS</h1>" | safe }} <p>{{ comments | join(" <hr> ") | safe }}</p> </div> </div> {% endblock %} نلاحظ أنّه من الممكن ربط المُرشّحات كما هو ظاهر في السطر: <p>{{ comments | join(" <hr> ") | safe }}</p> إذ يُطبَّق كل مُرشّح على نتيجة خرج المُرشّح السابق له. نحفظ الملف ونغلقه. وبتحديث صفحة التعليقات نجد أن وسوم HTML قد جرى تصييّرها كما هو مُتوقّع مع استخدام المُرشّح "safe": تنبيه: قد يجعل تطبيق المُرشّح "safe" لشيفرة HTML غير موثوقة المصدر تطبيقنا عرضةً لهجمات البرمجة عابرة المواقع، لذا لا يُفضّل استخدامه إلّا إذا كانت شيفرات HTML المُراد تصييّرها موثوقة المصدر. تعرّفنا في هذه الخطوة على كيفيّة استخدام المُرشّحات في قوالب جينجا لتعديل قيم المتغيرات، وفيما يلي سنستخدم حزمة بوتستراب Bootstrap لتنسيق مظهر التطبيق وجعله أكثر جاذبية بصريًا. الخطوة السادسة – استخدام بوتستراب سنتعرّف في هذه الخطوة على كيفيّة استخدام حزمة بوتستراب لتنسيق مظهر التطبيق، إذ سنضيف شريط تنقّل في القالب الأساسي بحيث يظهر في كافّة الصفحات التي ترث شيفراتها منه. يساعد إطار العمل بوتستراب bootstrap على إضافة التنسيقات على التطبيق ليبدو أكثر جاذبية بصريًا، كما سيساعدنا على تمكين ميزة الصفحات المتوافقة مع المتصفحات في تطبيق الويب، ما يضمن عمله بصورةٍ جيدة في المتصفحات الخاصة بالجوال، دون كتابة شيفرات HTML و CSS وجافا سكربت JavaScript لتحقيق هذه الغاية. وحتّى نستخدم بوتستراب سنضيفه إلى القالب الأساسي بحيث يسهل استخدامه في جميع القوالب الأُخرى. لذا سنفتح القالب الأساسي "base.html" للتعديل عليه: (env) user@localhost:$ nano templates/base.html ونعدله كما يلي: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <!-- Bootstrap CSS --> <link href="https://cdn.jsdelivr.net/npm/bootstrap@5.1.0/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-KyZXEAg3QhqLMpG8r+8fhAXLRk2vvoC2f3B09zVXn8CA5QIVfZOJ3BCsw2P0p/We" crossorigin="anonymous"> <title>{% block title %} {% endblock %} - FlaskApp</title> </head> <body> <nav class="navbar navbar-expand-lg navbar-light bg-light"> <div class="container-fluid"> <a class="navbar-brand" href="{{ url_for('hello') }}">FlaskApp</a> <button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item"> <a class="nav-link" href="{{ url_for('comments') }}">Comments</a> </li> <li class="nav-item"> <a class="nav-link" href="{{ url_for('about') }}">About</a> </li> </ul> </div> </div> </nav> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.0/dist/js/bootstrap.bundle.min.js" integrity="sha384-U1DAWAznBHeqEIlVSCgzq+c9gqGAJn5c/t99JyeKa9xxaYpSvHU5awsuZVVFIhvj" crossorigin="anonymous"></script> </body> </html> الجزء الأكبر من الشيفرة السابقة هو تعليمات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ضمن القسم <head> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، وفي الجزء الأخير منه يُضمِّن الوسم <script> ارتباطًا إلى شيفرة جافا سكربت اختيارية. كما تتضمّن الشيفرة أجزاءً خاصةً بمحرك القوالب جينجا والتي قد وضّحناها فيما سبق، وكذلك استخدامًا لوسوم مُحدّدة وأصناف من CSS لتحديد كيفيّة عرض كل عنصر في بوتستراب. وقد استخدمنا في الشيفرة أعلاه وسم رابط <a> من الصنف navbar-brand الخاص بإضافة رابط العلامة المميزة (شعار الشركة مثلًا) إلى شريط التصفّح وذلك ضمن الوسم <nav> (الخاص بشريط التصفّح)، وفيه نحدّد رابط العلامة المطلوب، أمّا عن الروابط الاعتيادية مثل الروابط المؤدية إلى صفحات أُخرى من التطبيق، فمن الممكن تضمينها في الوسم <"ul class="navbar-nav> الحاوي على عنصر قائمة <li> ضمن عنصر روابط <a> وبالتالي من الممكن إضافة عدّة روابط. نحفظ الملف ونغلقه. وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، ننتقل إلى الصفحة الرئيسية من التطبيق في المتصفح: http://127.0.0.1:5000/ فتظهر صفحةٌ مشابهةٌ لما يلي: وبذلك أصبح من الممكن استخدام مكونات بوتستراب لتنسيق مظهر العناصر في تطبيق فلاسك في جميع القوالب. الخاتمة تعرّفنا في هذا المقال على كيفيّة استخدام قوالب HTML في تطبيق فلاسك، إذ استخدمنا المتغيرات لتمرير البيانات من الخادم إلى القوالب مستفيدين من مفهوم وراثة القوالب لتجنُّب تكرار الشيفرات، كما استخدمنا عناصر مثل عبارات "if" الشرطية وحلقات "for" التكرارية، وربطنا بين صفحات مختلفة من صفحات التطبيق، كما تعرّفنا على كيفية تطبيق المُرشّحات لتعديل نص ما أو لعرض شيفرة HTML موثوقة، ونهايةً استخدمنا بوتستراب لتنسيق مظهر التطبيق. ترجمة -وبتصرف- للمقال How To Use Templates in a Flask Application لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال التالي: كيفية التعامل مع الأخطاء في تطبيقات فلاسك Flask المقال السابق: تعلم بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask بلغة بايثون استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا -

 يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل، مانحًا المطورين مرونةً في العمل، كما أنّه أبسط للاستخدام من قِبل المطورين المبتدئين نظرًا لإمكانية إنشاء تطبيق ويب كامل بسرعة باستخدام ملفٍ وحيدٍ مكتوب بلغة بايثون. إضافةً لما سبق، يتميز فلاسك بكونه قابلًا للتوسّع والوراثة دون أن يفرض أي بنية هرمية لطريقة عرض الملفات، كما أنّه لا يتطلب أي شيفرات برمجية معقدّة استهلالية قبل البدء باستخدامه. سيمكِّننا تعلُّم فلاسك من إنشاء تطبيقات ويب بسهولة وسرعة باستخدام لغة بايثون، إذ سنستخدم مكتبات بايثون لإضفاء ميزات إضافية على تطبيق الويب، مثل تخزين البيانات في قواعد البيانات والتحقق من بيانات نماذج الإدخال في الويب. سنبني في هذا المقال تطبيق ويب صغير يعمل على تصيّير النصوص المكتوبة بلغة HTML ضمن المتصفح، إذ سنثبّت فلاسك، ثمّ سنكتب الشيفرة البرمجية الخاصّة بتطبيق فلاسك ونشغّله في وضع التطوير، وسنستخدم مفهوم التوجيه للتنقّل بين عدة صفحات ويب تؤدي وظائف مختلفة ضمن التطبيق؛ كما سنسمح للمستخدمين من خلال دوال فلاسك بالتفاعل مع التطبيق عبر وجهات routes ديناميكية، ونهايةً سنعمل على حل المشكلات الناتجة عن أي أخطاء باستخدام مُنقّح الأخطاء. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". فهم مبادئ بايثون 3، مثل أنماط البيانات والقوائم والدوال، وغيرها من المفاهيم المشابهة في بايثون 3. فهم أساسيات لغة HTML. الخطوة الأولى – تثبيت فلاسك سنفعّل في هذه الخطوة بيئة بايثون ونثبّت فلاسك باستخدام مثبِّت الحزم "pip". بدايةً، سنفعّل بيئة البرمجة في حال كانت غير مفعّلةٍ بعد كما يلي: $ source env/bin/activate بعدها نثبّت فلاسك باستخدام الأمر pip install: (env)user@localhost:$ pip install flask وحالما ينتهي التثبيت، سيظهر الخرج مُتضمنًا مجموعة الحزم المُثبّتة كما يلي: ... Installing collected packages: Werkzeug, MarkupSafe, Jinja2, itsdangerous, click, flask Successfully installed Jinja2-3.0.1 MarkupSafe-2.0.1 Werkzeug-2.0.1 click-8.0.1 flask-2.0.1 itsdangerous-2.0.1 ومنه نلاحظ أنّه أثناء تثبيت فلاسك تُثبّت أيضًا عدة حزم ومستلزمات خاصة يستخدمها فلاسك في تنفيذ العديد من الدوال المختلفة. ومع نهاية هذه الخطوة نكون قد أنشأنا مجلد للتطبيق وفعّلنا البيئة الافتراضية وثبّتنا فلاسك، وبذلك نكون مستعدين للانتقال إلى الخطوة التالية المُتمثّلة بإنشاء تطبيق بسيط. الخطوة الثانية – إنشاء تطبيق بسيط يمكننا الآن البدء باستخدام فلاسك بعدما أصبحت البيئة البرمجية جاهزة، إذ سننشئ في هذه الخطوة تطبيق ويب مُصغّر باستخدام فلاسك وذلك ضمن ملف بايثون، الذي سنكتب فيه أيضًا شيفرات HTML لإظهارها عند التشغيل ضمن المتصفح. الآن، سنفتح الملف المسمى "app.py" الموجود ضمن المجلد "flask_app" بهدف التعديل عليه وذلك باستخدام محرر النصوص نانو nano، أو أي محرّر آخر تفضّله: (env)user@localhost:$ nano app.py ونكتب الشيفرة التالية ضمن الملف app.py: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return '<h1>Hello, World!</h1>' نحفظ الملف ونغلقه. استوردنا في الجزء السابق من الشيفرة كائن فلاسك من حزمة فلاسك، ثم استخدمناه لإنشاء نسخةٍ instance فعليةٍ موجودةٍ في الذاكرة لتطبيق فلاسك Flask application instance باسم app، وليست مجرد كائن برمجي، ثمّ مررنا المتغير الخاص __name__، الذي سيخزّن اسم وحدة بايثون الحالية ليُعلم تطبيق فلاسك بمكان وجود هذه الوحدة، إذ لا بُدّ من إجراء هذه الخطوة كون فلاسك يهيّئ بعض المسارات اللازمة في الخلفية. وبمجرد إنشاء هذا التطبيق "app"، يمكنك استخدامه في معالجة طلبات الويب القادمة وإرسال الردود إلى المُستخدم. يكون المزخرف app.route@ مسؤولًا عن تعديل دوال بايثون المألوفة لتصبح دوال عرض view في فلاسك، والتي تحوّل القيمة المُعادة من قِبل الدالة إلى استجابةٍ من نوع HTTP تُعرض لدى عميل HTTP، الذي قد يكون متصفحًا مثلًا؛ فبمجرد تمرير "/" للدالة ()app.route@، سينشئ الردود على طلبات الويب الواردة إلى الرابط "/"، والذي يمثّل الرابط الرئيسي في التطبيق، وبذلك ستعيد الدالة ()hello السلسلة النصية "!Hello, World" ردًا على الطلب. وبذلك أصبح لدينا تطبيق فلاسك بسيط موجود ضمن ملف بايثون المُسمّى "app.py"، سنشغّل فيما يلي هذا التطبيق لتصيير نتيجة دالة العرض ()hello ضمن متصفح ويب. الخطوة الثالثة – تشغيل التطبيق بعد إنشائنا الملف الذي يحتوي على تطبيق فلاسك، سنشغّله باستخدام واجهة أوامر فلاسك وذلك لتشغيل خادم التطوير وتصيير شيفرة HTML ضمن المتصفح والتي كتبناها لتكون القيمة المعادة من الدالة ()hello في الخطوة السابقة. ولتشغيل تطبيق الويب الذي أنشأناه، وبعد التأكّد من وجودنا ضمن المجلد "flask_app" مع تفعيل البيئة الافتراضية، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم "app.py") وذلك باستخدام متغير بيئة فلاسك FLASK_APP على النحو التالي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_APP=app ثم نحدد وضع تشغيل التطبيق ليكون بوضع التطوير، وذلك باستخدام متغير بيئة فلاسك Flask_ENV على النحو التالي: (env)user@localhost:$ export FLASK_ENV=development وبذلك نتمكّن من استخدام المنقّح لالتقاط الأخطاء. نهايةً، نشغّل التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run حالما يعمل التطبيق، يظهر الخرج على النحو التالي: * Serving Flask app "app" (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 296-353-699 يحتوي الخرج السابق على عدة معلومات، مثل: اسم التطبيق المُشغَّل. بيئة التشغيل الحالية التي يعمل عليها التطبيق. عبارة Debug mode:on التي تشير إلى أن مُنقّح أخطاء فلاسك قيد التشغيل، وهو ذو فوائد عديدة أثناء عملية التطوير كونه يقدم رسائل خطأ مفصّلة عندما يحدث أي خلل، وهذا ما يجعل عملية تنقيح الأخطاء أسهل وأيسر. التطبيق يعمل على الحاسب المحلي وذلك على الرابط /http://127.0.0.1:5000، إذ أن "127.0.0.1" هو عنوان IP الذي يمثِّل الخادم المحلي localhost على حاسبك، و "5000:" هو رقم المنفذ. افتح المتصفح واكتب عنوان URL التالي "/http://127.0.0.1:5000"، ستظهر عبارة "!Hello, World" (ضمن تنسيق عنوان من المستوى الأوّل <h1>) استجابةً لهذا العنوان، وهذا ما يؤكد أن التطبيق يعمل بنجاح. وإذا أردنا إيقاف خادم التطوير، نضغط على "CTRL+C". تنبيه: يستخدم فلاسك خادم ويب مبسّط لاستضافة تطبيق الويب في بيئة التطوير، ما يعني أن مُنقّح أخطاء فلاسك قيد التشغيل أيضًا كي يجعل التقاط الأخطاء أسهل، ولا ينبغي استخدام خادم التطوير هذا عندما يُنقل التطبيق إلى مرحلة التشغيل الفعلي أي نشر المنتج. يمكن في هذه المرحلة الإبقاء على خادم التطوير قيد التشغيل في الطرفية terminal الخاصة به، ومن ثم فتح نافذة طرفية جديدة وتغيير المسار فيها إلى مسار مجلد المشروع حيث يتواجد ملف "hello.py"، ثم بعد ذلك تفعيل البيئة الافتراضية (السبب مبيّنٌ في الملاحظة أدناه)، وتهيّئة متغيرات البيئة FLASK_ENV و FLASK_APP، ومتابعة الخطوات التالية. (ذُكرت هذه الأوامر سابقًا في هذه الخطوة). ملاحظة: من الضروري تفعيل البيئة الافتراضية لدى فتح طرفية جديدة، أو إغلاق الطرفية الحالية التي تشغّل خادم التطوير عليها وتود إعادة تشغيله، ولا بدّ من إعداد متغيرات البيئة FLASK_ENV و FLASK_APP ليعمل الأمر flask run بصورةٍ صحيحة. كل ما عليك فعله هو تشغيل الخادم مرةً واحدةً في نافذة طرفية واحدة. لا يمكن تشغيل تطبيق فلاسك آخر باستخدام الأمر flask run نفسه خلال فترة عمل خادم تطوير تطبيقات فلاسك، كونه يستخدم المنفذ رقم 5000 افتراضيًا، وحالما يُحجَز هذا المنفذ يصبح غير متاحًا لتشغيل أي تطبيقٍ آخر، وفي حال فعلت ذلك ستظهر رسالة خطأ مشابهةٍ لما يلي: OSError: [Errno 98] Address already in use ويمكن حل لهذه المشكلة، إمّا بإيقاف الخادم العامل حاليًا عن طريق الضغط على "CTRL+C" ومن ثم تنفيذ الأمر flask run مجدّدًا، أو في حال رغبتك بتشغيل كلا التطبيقين في نفس الوقت، فمن الممكن تمرير رقم منفذٍ مختلف باستخدام الوسيط p-. سنستخدم الأمر التالي لتشغيل تطبيقٍ آخر يستخدم المنفذ "5001" مثالًا حول طريقة الحل هذه: (env)user@localhost:$ flask run -p 5001 وبذلك يصبح لدينا تطبيق أوّل يعمل على الرايط "/http://172.0.0.1:5000" وآخر يعمل على الرابط "/http://172.0.0.1:5001" إن احتجنا لذلك. وبذلك يكون قد أصبح لدينا مع نهاية هذه الخطوة تطبيق ويب صغير باستخدام فلاسك، وبعد أن شغّلنا وعرضنا المعلومات في متصفح الويب، سنتعلم فيما يلي كيفية إنشاء وجهات واستخدامها لتخديم عدّة صفحات ويب. الخطوة الرابعة – الوجهات ودوال العرض في فلاسك سنضيف في هذه الخطوة بضع وجهات للتطبيق لإظهار صفحات مختلفة اعتمادًا على الرابط المطلوب، وسنتعرف أيضًا على دوال العرض في فلاسك وكيفية استخدامها. تُعرّف الوجهة route بأنها رابطٌ يُستخدم لتحديد ما سيستقبله المستخدم لدى زيارة تطبيق الويب على متصفحه، فمثلًا يشير الرابط "/http://127.0.0.1:5000" إلى الوجهة الرئيسية التي يمكن استخدامها لعرض الصفحة الرئيسية للتطبيق، بينما يشير الرابط "http://127.0.0.1:5000/about" إلى وجهةٍ أخرى وهو صفحة المعلومات التي تعطي الزوار معلومات حول تطبيق الويب، وعلى نحوٍ مشابه يمكن إنشاء وجهة تسمح للمستخدمين بتسجيل الدخول إلى تطبيق الويب عبر الرابط "http://127.0.0.1:5000/login" مثلًا. يستخدم تطبيق فلاسك الذي أنشأناه حاليًا وجهةً واحدةً تخدّم الزوار الذين يطلبون الرابط الرئيسي "/http://127.0.0.1:5000". الآن، ولنبين كيفية إضافة صفحة ويب جديدة إلى تطبيقنا، سنعدّل ملف التطبيق لإضافة وجهةٍ جديدة تؤمن معلومات حول التطبيق عبر الرابط "http://127.0.0.1:5000/about". لذا سنفتح الملف "app.py" من أجل التعديل: (env)user@localhost:$ nano app.py ثمّ نعدّل الملف من خلال إضافة الشيفرة التالية: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return '<h1>Hello, World!</h1>' @app.route('/about/') def about(): return '<h3>This is a Flask web application.</h3>' نحفظ الملف ونغلقه. أضفنا في الشيفرة السابقة دالةً جديدةً باسم ()about، والتي صمّمناها باستخدام المًزخرف ()app.route@، الذي يحوّلها إلى دالة عرض قادرة على التعامل مع الطلبات الواردة إلى الرابط "http://127.0.0.1:5000/about". بعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نزور الرابط التالي في المتصفح: http://127.0.0.1:5000/about فيظهر النص "This is a Flask web application" مصّيرًا ضمن تنسيق عنوان من المستوى الثالث <h3> في HTML؛ كما من الممكن استخدام عدّة وجهات في دالة فلاسك الواحدة، فمثلًا من الممكن تخديم الصفحة الرئيسية للتطبيق بكل من الوجهتين "/" و "/index/"، ولتنفيذ ذلك سنفتح الملف "app.py" لتعديله: (env)user@localhost:$ nano app.py سنعدّل الملف بإضافة مُزخرف آخر إلى دالة فلاسك ()hello: from flask import Flask app = Flask(__name__) @app.route('/') @app.route('/index/') def hello(): return '<h1>Hello, World!</h1>' @app.route('/about/') def about(): return '<h3>This is a Flask web application.</h3>' نحفظ الملف ونغلقه. وبعد إضافة المُزخرف الثاني أصبح بالإمكان الوصول إلى الصفحة الرئيسية للتطبيق من خلال أي من الرابطين "/http://127.0.0.1:5000" أو "http://127.0.0.1:5000/index". تعرّفنا فيما سبق على الوجهات وكيفية استخدامها لإنشاء دوال عرض في فلاسك وكيفية إضافة وجهات جديدة إلى التطبيق. فيما يلي سنستخدم الوجهات الديناميكية المرنة للسماح للمستخدمين بالتحكم باستجابة التطبيق. الخطوة الخامسة - الوجهات الديناميكية سنستخدم في هذه الخطوة الوجهات الديناميكية لنمكّن المستخدمين من التفاعل مع التطبيق، إذ سننشئ وجهةً تجعل الكلمات المُمرّرة عبر الرابط مكتوبةً بأحرف كبيرة، كما سننشئ وجهةً تجمع رقمين مع بعضهما وتظهر النتيجة. لا يتفاعل المستخدمون عادةً مع تطبيق الويب من خلال التعديل اليدوي للرابط، بل يتفاعلون مع عناصر موجودة في الصفحة تؤدي إلى روابط مختلفة بناءً على مدخلاتهم وتصرفاتهم ضمن الصفحة، ولكن وبهدف التبسيط في هذا المقال، سنعدّل الرابط لنبيّن كيفية جعل التطبيق يستجيب بصورةٍ مختلفة بروابط مختلفة. سنفتح بدايةً الملف app.py لتعديله: (env)user@localhost:$ nano app.py مع ملاحظة انّه إذا سمحنا للمستخدم بإدخال شيءٍ ما إلى التطبيق، مثل إدخال قيمة في الرابط كما سنفعل في التعديل التالي، فيجب الانتباه إلى أنّ التطبيق يجب ألا يُظهر بيانات غير موثوقة (البيانات التي أدخلها المستخدم)، ولكي نعرض بيانات المستخدم بصورةٍ آمنة، سنستخدم الدالة "()escape" الموجودة ضمن حزمة البناء الآمن "markupsafe" المُثبتة بالتوازي مع تثبيت فلاسك. الأن، سنعدّل الملف "app.py" بإضافة السطر التالي في بدايته أعلى أمر استيراد Flask كما يلي: from markupsafe import escape from flask import Flask # ... ثمّ سنضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/capitalize/<word>/') def capitalize(word): return '<h1>{}</h1>'.format(escape(word.capitalize())) نحفظ الملف ونغلقه. تملك الوجهة الجديدة قسمًا متغيرًا مُضمّنًا في الوسم <word>، والذي يسمح لفلاسك بأخذ القيمة المُدخلة من الرابط وتمريرها إلى دالة فلاسك، إذ يُمرّر متغير الرابط <word> الكلمة مثل وسيط إلى دالة فلاسك ()capitalize. وفي حالتنا فإنّ الوسيط هذا يملك نفس اسم متغير الرابط (وهو word في حالتنا)، وبذلك يمكننا الوصول إلى الكلمة المُمررة عبر الرابط وإنشاء استجابة بنفس الكلمة المُمررة ولكن بأحرف كبيرة وذلك باستخدام دالة العرض ()capitalize العاملة أصلًا في بايثون. استخدمنا الدالة ()escape التي استوردناها سابقًا لتصيير السلسلة التي أدخلها المُستخدم والموجودة ضمن المتغير word مثل نص وليس شيفرةً للتنفيذ، وهو أمر بالغ الأهمية لتجنب هجمات البرمجة العابرة للمواقع XSS، ففي حال إدخال المستخدم شيفرة JavaScript خبيثة بدلًا من السلسلة النصية، تصيّرها الدالة ()escape على أنها نص عادي وبذلك لن ينفّذها المتصفح، ما يبقي تطبيق الويب آمنًا. ولعرض الكلمات بأحرف كبيرة ضمن تنسيق عنوان من المستوى الأوّل <h1> في HTML استخدمنا الدالة ()format من دوال بايثون. الآن وبعد التأكد من أنّ خادم التطوير ما يزال قيد التشغيل، نفتح المتصفح ونذهب إلى الروابط التالية، مع إمكانية تبديل الكلمات "hello" و "flask" و "python" التي تنتهي الروابط بها في مثالنا بأي كلمة تريد: http://127.0.0.1:5000/capitalize/hello http://127.0.0.1:5000/capitalize/flask http://127.0.0.1:5000/capitalize/python وبذلك تظهر الكلمة ضمن المتصفح بأحرف كبيرة وبتنسيق عنوان من المستوى الأول <h1>. كما يمكننا استخدام عدّة متغيرات في الوجهة، ولتوضيح ذلك سنضيف وجهةً جديدةً لجمع رقمين صحيحين ويعرض النتيجة. لذا سنفتح الملف "app.py" لتعديله: (env)user@localhost:$ nano app.py ثمّ نضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/add/<int:n1>/<int:n2>/') def add(n1, n2): return '<h1>{}</h1>'.format(n1 + n2) نحفظ الملف ونغلقه. نستخدم في هذه الوجهة المحوّل الخاص int مع المتغير الخاص بالرابط (/add/<int:n1>/<int:n2>/)؛ ومهمّة هذا المحوّل هي قبول القيم التي تُمثّل أعدادًا صحيحة موجبة فقط والتعامل معها على أنها أعداد، كونه افتراضيًا تُعدّ المتغيرات الآتية من الرابط سلاسلًا محرفية ويجري التعامل معها على هذا الأساس، وهذا أمرٌ غير مناسب لإتمام عملية الجمع العددي. الآن وبعد التأكد من أنّ خادم التطوير ما يزال قيد التشغيل، نفتح المتصفح ونذهب إلى الرابط التالي: http://127.0.0.1:5000/add/5/5/ وستكون النتيجة مجموع الرقمين (وهي "10" في حالة مثالنا هذا). تعرفنا في هذه الخطوة على كيفية استخدام الوجهات الديناميكية لعرض استجابات مُختلفة ضمن الوجهة الواحدة اعتمادًا على الرابط المطلوب، وهذا ما يعزز التجربة التفاعلية للمُستخدم. سنتعرّف في الخطوة التالية على آليات تنقيح وتصحيح الأخطاء في تطبيق فلاسك في حال حدوثها. الخطوة السادسة - تنقيح أخطاء تطبيق فلاسك خلال مراحل تطوير أي تطبيق ويب، من الطبيعي أن نمر بحالات نحصل فيها على أخطاء لدى تشغيل التطبيق عوضًا عن النتيجة المتوقعة، والتي قد تكون ناتجةً مثلًا عن خطأ إملائي بسيط في كتابة اسم أحد المتغيرات أو نتيجة نسيان التصريح عن أو استيراد إحدى الدوال؛ ولإصلاح هذه الأخطاء بسهولة يوفّر فلاسك منقّح أخطاء يعمل لدى تشغيل التطبيق في وضع التطوير، إذ سنتعلّم في هذه الخطوة آلية تصحيح أخطاء التطبيق بالاعتماد على مُنقّح الأخطاء في فلاسك. لتوضيح كيفية التعامل مع الأخطاء في حال ظهورها، سننشئ وجهةً للترحيب بمستخدم ما من قائمة أسماء مستخدمين موجودة. لذا سنفتح الملف "app.py" للتعديل عليه: (env)user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/users/<int:user_id>/') def greet_user(user_id): users = ['Ahmad', 'Mohammad', 'Adam'] return '<h2>Hi {}</h2>'.format(users[user_id]) نحفظ الملف ونغلقه. تستقبل دالة فلاسك ()greet_user في الوجهة السابقة متغير الرابط user_id مثل قيمة للوسيط user_id، إذ استخدمنا المحوّل الخاص int لقبول أعداد صحيحة موجبة فقط، حيث تتضمّن الدالة قائمةً مبنيةً في بايثون باسم users تحتوي على ثلاث سلاسل نصية تمثّل أسماء المستخدمين، وترجع دالة فلاسك السلسة الموافقة من القائمة اعتمادًا على قيمة المتغير user_id المُمرّر والذي يدل على رقم المُستخدم المراد الترحيب به بالنتيجة؛ فإذا كانت قيمة المتغير user_id تساوي "0" مثلًا، ستكون الاستجابة ظهور عبارة "Hi Ahmad" ضمن تنسيق عنوان من المستوى الثاني <h2> لأن Ahmad هو أول عنصر في القائمة المُقابل للقيمة "[user[0". الآن وبعد التأكد أن خادم التطوير ما يزال قيد التشغيل، سنفتح المتصفح لزيارة الروابط التالية: http://127.0.0.1:5000/users/0 http://127.0.0.1:5000/users/1 http://127.0.0.1:5000/users/2 فتكون النتيجة على النحو التالي: Hi Ahmad Hi Mohammad Hi Adam نلاحظ أنّ الأمور تجري على خير ما يرام حتى الآن، ولكن ماذا لو طلبنا الترحيب بمستخدم غير موجود؟ سيظهر خطأ بالتأكيد، ولتوضيح كيفية عمل مُنقّح الأخطاء في فلاسك سنزور الرابط التالي: http://127.0.0.1:5000/users/3 فتظهر صفحةٌ كما في الصورة أدناه: نلاحظ أنّ اسم الخطأ الحاصل في بايثون وهو IndexError في حالتنا يُعرض في أعلى الصفحة، ويشير هذا الخطأ إلى وقوع دليل القائمة ("3" في مثالنا) خارج المجال، إذ أن المجال في حالتنا محصورٌ بين "0" و "2" لأنّ القائمة مكونةٌ من ثلاثة عناصر، كما يظهر في مُنقح الأخطاء جميع أسطر الشيفرة التي أدّى تنفيذها إلى ظهور هذا الخطأ. وعادةً ما يتضمّن آخر سطرين من متتبّع الأخطاء مصدر الخطأ، وفي حالتنا سيبدوان على نحو مشابه لما يلي: File "/home/USER/flask_app/app.py", line 28, in greet_user return '<h2>Hi {}</h2>'.format(users[user_id]) ما يشير إلى أنّ الخطأ ناتج عن دالة الترحيب ()greet_user ضمن الملف "app.py" وتحديدًا في السطر الحاوي غلى القيمة المُعادة return، ومع معرفتنا للسطر الذي تسبّب بالخطأ يصبح تحديد المشكلة وحلها أسهل. كما يمكننا لتجنّب توقّف عمل التطبيق في حالات مشابهة لهذه الحالة استخدام العبارة "try…except" لإصلاح الخطأ، بحيث إذا احتوى الرابط المطلوب على دليل خارج مجال القائمة يتلقى المستخدم عبارة خطأ "404 Not Found"، وهو خطأ HTTP يشير للمستخدم أن الصفحة التي يطلبها غير متوفرة. لذا سنفتح الملف "app.py" للتعديل عليه: (env)user@localhost:$ nano app.py وحتى تحدث الاستجابة بخطأ من النوع HTTP 404 سنستخدم دالة فلاسك ()abort التي يمكن استخدامها لانشاء استجابات مكونة من أخطاء HTTP، لذا سنغير السطر الثاني في الملف ليصبح كما يلي: from markupsafe import escape from flask import Flask, abort ثمّ سنعدّل الدالة ()greet_user لتصبح كما يلي: # ... @app.route('/users/<int:user_id>/') def greet_user(user_id): users = ['Ahmad', 'Mohammad', 'Adam'] try: return '<h2>Hi {}</h2>'.format(users[user_id]) except IndexError: abort(404) استخدمنا try لاختبار التعبير return والتأكّد من خلوه من الأخطاء، فإذا لم يكن هناك خطأ، بمعنى أنّ قيمة المتغير user_id المُمرّرة صحيحةٌ ومن ضمن مجال قائمة users، فسيستجيب التطبيق بالترحيب المناسب، وإلّا وفي حال كون قيمة user_id خارج مجال القائمة، سيُفعَّل الاستثناء IndexError، ونستخدم الأمر except للتعامل مع الخطأ وبالتالي الاستجابة بخطأ من نوع HTTP 404 باستخدام دالة فلاسك المساعدة ()abort. الآن وبعد التأكد من كون خادم التطوير قيد التشغيل، نزور الرابط مجددًا مع تمرير القيمة 3 لرقم المُستخدم المطلوب: http://127.0.0.1:5000/users/3 فتظهر في هذه الحالة صفحة الخطأ 404 التقليدية لتشير للمستخدم أن الصفحة المطلوبة غير موجودة. ومع نهاية تطبيق الخطوات الواردة في هذا المقال، سيبدو الملف "app.py" على النحو التالي: from markupsafe import escape from flask import Flask, abort app = Flask(__name__) @app.route('/') @app.route('/index/') def hello(): return '<h1>Hello, World!</h1>' @app.route('/about/') def about(): return '<h3>This is a Flask web application.</h3>' @app.route('/capitalize/<word>/') def capitalize(word): return '<h1>{}</h1>'.format(escape(word.capitalize())) @app.route('/add/<int:n1>/<int:n2>/') def add(n1, n2): return '<h1>{}</h1>'.format(n1 + n2) @app.route('/users/<int:user_id>/') def greet_user(user_id): users = ['Ahmad', 'Mohammad', 'Adam'] try: return '<h2>Hi {}</h2>'.format(users[user_id]) except IndexError: abort(404) وبذلك أصبح لديك تصوّر عام عن كيفية استخدام مُنقّح الأخطاء في فلاسك لالتقاط الأخطاء وتحديد الآلية المُثلى لإصلاحها والتعامل معها. الخاتمة تعرفنا في هذا المقال بصورة عامة على فلاسك وكيفية تثبيته واستخدامه لإنشاء تطبيق ويب، كما تعرفنا على آلية تشغيل خادم التطوير واستخدام الوجهات ودوال فلاسك لعرض صفحات ويب مختلفة تخدّم وظائفًا محددة، كما تعلمنا كيفية استخدام الوجهات الديناميكية للسماح للمستخدم بالتفاعل مع تطبيق ويب عن طريق تعديل الرابط المطلوب، وفي النهاية تعلمنا كيفية استخدام مُنقّح الأخطاء لتحديد المشاكل. ترجمة -وبتصرف- للمقال How To Create Your First Web Application Using Flask and Python3 لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال التالي: كيفية استخدام القوالب في تطبيقات فلاسك Flask المقال السابق: تخديم تطبيقات فلاسك باستخدام خادمي الويب uWSGI و Nginx إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون بناء موقعك واستضافته باستخدام Git أساسيات تحديد التكلفة المادية الكاملة لبناء موقع ويب
يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل، مانحًا المطورين مرونةً في العمل، كما أنّه أبسط للاستخدام من قِبل المطورين المبتدئين نظرًا لإمكانية إنشاء تطبيق ويب كامل بسرعة باستخدام ملفٍ وحيدٍ مكتوب بلغة بايثون. إضافةً لما سبق، يتميز فلاسك بكونه قابلًا للتوسّع والوراثة دون أن يفرض أي بنية هرمية لطريقة عرض الملفات، كما أنّه لا يتطلب أي شيفرات برمجية معقدّة استهلالية قبل البدء باستخدامه. سيمكِّننا تعلُّم فلاسك من إنشاء تطبيقات ويب بسهولة وسرعة باستخدام لغة بايثون، إذ سنستخدم مكتبات بايثون لإضفاء ميزات إضافية على تطبيق الويب، مثل تخزين البيانات في قواعد البيانات والتحقق من بيانات نماذج الإدخال في الويب. سنبني في هذا المقال تطبيق ويب صغير يعمل على تصيّير النصوص المكتوبة بلغة HTML ضمن المتصفح، إذ سنثبّت فلاسك، ثمّ سنكتب الشيفرة البرمجية الخاصّة بتطبيق فلاسك ونشغّله في وضع التطوير، وسنستخدم مفهوم التوجيه للتنقّل بين عدة صفحات ويب تؤدي وظائف مختلفة ضمن التطبيق؛ كما سنسمح للمستخدمين من خلال دوال فلاسك بالتفاعل مع التطبيق عبر وجهات routes ديناميكية، ونهايةً سنعمل على حل المشكلات الناتجة عن أي أخطاء باستخدام مُنقّح الأخطاء. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app". فهم مبادئ بايثون 3، مثل أنماط البيانات والقوائم والدوال، وغيرها من المفاهيم المشابهة في بايثون 3. فهم أساسيات لغة HTML. الخطوة الأولى – تثبيت فلاسك سنفعّل في هذه الخطوة بيئة بايثون ونثبّت فلاسك باستخدام مثبِّت الحزم "pip". بدايةً، سنفعّل بيئة البرمجة في حال كانت غير مفعّلةٍ بعد كما يلي: $ source env/bin/activate بعدها نثبّت فلاسك باستخدام الأمر pip install: (env)user@localhost:$ pip install flask وحالما ينتهي التثبيت، سيظهر الخرج مُتضمنًا مجموعة الحزم المُثبّتة كما يلي: ... Installing collected packages: Werkzeug, MarkupSafe, Jinja2, itsdangerous, click, flask Successfully installed Jinja2-3.0.1 MarkupSafe-2.0.1 Werkzeug-2.0.1 click-8.0.1 flask-2.0.1 itsdangerous-2.0.1 ومنه نلاحظ أنّه أثناء تثبيت فلاسك تُثبّت أيضًا عدة حزم ومستلزمات خاصة يستخدمها فلاسك في تنفيذ العديد من الدوال المختلفة. ومع نهاية هذه الخطوة نكون قد أنشأنا مجلد للتطبيق وفعّلنا البيئة الافتراضية وثبّتنا فلاسك، وبذلك نكون مستعدين للانتقال إلى الخطوة التالية المُتمثّلة بإنشاء تطبيق بسيط. الخطوة الثانية – إنشاء تطبيق بسيط يمكننا الآن البدء باستخدام فلاسك بعدما أصبحت البيئة البرمجية جاهزة، إذ سننشئ في هذه الخطوة تطبيق ويب مُصغّر باستخدام فلاسك وذلك ضمن ملف بايثون، الذي سنكتب فيه أيضًا شيفرات HTML لإظهارها عند التشغيل ضمن المتصفح. الآن، سنفتح الملف المسمى "app.py" الموجود ضمن المجلد "flask_app" بهدف التعديل عليه وذلك باستخدام محرر النصوص نانو nano، أو أي محرّر آخر تفضّله: (env)user@localhost:$ nano app.py ونكتب الشيفرة التالية ضمن الملف app.py: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return '<h1>Hello, World!</h1>' نحفظ الملف ونغلقه. استوردنا في الجزء السابق من الشيفرة كائن فلاسك من حزمة فلاسك، ثم استخدمناه لإنشاء نسخةٍ instance فعليةٍ موجودةٍ في الذاكرة لتطبيق فلاسك Flask application instance باسم app، وليست مجرد كائن برمجي، ثمّ مررنا المتغير الخاص __name__، الذي سيخزّن اسم وحدة بايثون الحالية ليُعلم تطبيق فلاسك بمكان وجود هذه الوحدة، إذ لا بُدّ من إجراء هذه الخطوة كون فلاسك يهيّئ بعض المسارات اللازمة في الخلفية. وبمجرد إنشاء هذا التطبيق "app"، يمكنك استخدامه في معالجة طلبات الويب القادمة وإرسال الردود إلى المُستخدم. يكون المزخرف app.route@ مسؤولًا عن تعديل دوال بايثون المألوفة لتصبح دوال عرض view في فلاسك، والتي تحوّل القيمة المُعادة من قِبل الدالة إلى استجابةٍ من نوع HTTP تُعرض لدى عميل HTTP، الذي قد يكون متصفحًا مثلًا؛ فبمجرد تمرير "/" للدالة ()app.route@، سينشئ الردود على طلبات الويب الواردة إلى الرابط "/"، والذي يمثّل الرابط الرئيسي في التطبيق، وبذلك ستعيد الدالة ()hello السلسلة النصية "!Hello, World" ردًا على الطلب. وبذلك أصبح لدينا تطبيق فلاسك بسيط موجود ضمن ملف بايثون المُسمّى "app.py"، سنشغّل فيما يلي هذا التطبيق لتصيير نتيجة دالة العرض ()hello ضمن متصفح ويب. الخطوة الثالثة – تشغيل التطبيق بعد إنشائنا الملف الذي يحتوي على تطبيق فلاسك، سنشغّله باستخدام واجهة أوامر فلاسك وذلك لتشغيل خادم التطوير وتصيير شيفرة HTML ضمن المتصفح والتي كتبناها لتكون القيمة المعادة من الدالة ()hello في الخطوة السابقة. ولتشغيل تطبيق الويب الذي أنشأناه، وبعد التأكّد من وجودنا ضمن المجلد "flask_app" مع تفعيل البيئة الافتراضية، لا بُدّ من إرشاد فلاسك إلى موقع التطبيق (في حالتنا الملف ذو الاسم "app.py") وذلك باستخدام متغير بيئة فلاسك FLASK_APP على النحو التالي (مع ملاحظة أنّنا نستخدم الأمر set في بيئة ويندوز عوضًا عن الأمر export): (env)user@localhost:$ export FLASK_APP=app ثم نحدد وضع تشغيل التطبيق ليكون بوضع التطوير، وذلك باستخدام متغير بيئة فلاسك Flask_ENV على النحو التالي: (env)user@localhost:$ export FLASK_ENV=development وبذلك نتمكّن من استخدام المنقّح لالتقاط الأخطاء. نهايةً، نشغّل التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run حالما يعمل التطبيق، يظهر الخرج على النحو التالي: * Serving Flask app "app" (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 296-353-699 يحتوي الخرج السابق على عدة معلومات، مثل: اسم التطبيق المُشغَّل. بيئة التشغيل الحالية التي يعمل عليها التطبيق. عبارة Debug mode:on التي تشير إلى أن مُنقّح أخطاء فلاسك قيد التشغيل، وهو ذو فوائد عديدة أثناء عملية التطوير كونه يقدم رسائل خطأ مفصّلة عندما يحدث أي خلل، وهذا ما يجعل عملية تنقيح الأخطاء أسهل وأيسر. التطبيق يعمل على الحاسب المحلي وذلك على الرابط /http://127.0.0.1:5000، إذ أن "127.0.0.1" هو عنوان IP الذي يمثِّل الخادم المحلي localhost على حاسبك، و "5000:" هو رقم المنفذ. افتح المتصفح واكتب عنوان URL التالي "/http://127.0.0.1:5000"، ستظهر عبارة "!Hello, World" (ضمن تنسيق عنوان من المستوى الأوّل <h1>) استجابةً لهذا العنوان، وهذا ما يؤكد أن التطبيق يعمل بنجاح. وإذا أردنا إيقاف خادم التطوير، نضغط على "CTRL+C". تنبيه: يستخدم فلاسك خادم ويب مبسّط لاستضافة تطبيق الويب في بيئة التطوير، ما يعني أن مُنقّح أخطاء فلاسك قيد التشغيل أيضًا كي يجعل التقاط الأخطاء أسهل، ولا ينبغي استخدام خادم التطوير هذا عندما يُنقل التطبيق إلى مرحلة التشغيل الفعلي أي نشر المنتج. يمكن في هذه المرحلة الإبقاء على خادم التطوير قيد التشغيل في الطرفية terminal الخاصة به، ومن ثم فتح نافذة طرفية جديدة وتغيير المسار فيها إلى مسار مجلد المشروع حيث يتواجد ملف "hello.py"، ثم بعد ذلك تفعيل البيئة الافتراضية (السبب مبيّنٌ في الملاحظة أدناه)، وتهيّئة متغيرات البيئة FLASK_ENV و FLASK_APP، ومتابعة الخطوات التالية. (ذُكرت هذه الأوامر سابقًا في هذه الخطوة). ملاحظة: من الضروري تفعيل البيئة الافتراضية لدى فتح طرفية جديدة، أو إغلاق الطرفية الحالية التي تشغّل خادم التطوير عليها وتود إعادة تشغيله، ولا بدّ من إعداد متغيرات البيئة FLASK_ENV و FLASK_APP ليعمل الأمر flask run بصورةٍ صحيحة. كل ما عليك فعله هو تشغيل الخادم مرةً واحدةً في نافذة طرفية واحدة. لا يمكن تشغيل تطبيق فلاسك آخر باستخدام الأمر flask run نفسه خلال فترة عمل خادم تطوير تطبيقات فلاسك، كونه يستخدم المنفذ رقم 5000 افتراضيًا، وحالما يُحجَز هذا المنفذ يصبح غير متاحًا لتشغيل أي تطبيقٍ آخر، وفي حال فعلت ذلك ستظهر رسالة خطأ مشابهةٍ لما يلي: OSError: [Errno 98] Address already in use ويمكن حل لهذه المشكلة، إمّا بإيقاف الخادم العامل حاليًا عن طريق الضغط على "CTRL+C" ومن ثم تنفيذ الأمر flask run مجدّدًا، أو في حال رغبتك بتشغيل كلا التطبيقين في نفس الوقت، فمن الممكن تمرير رقم منفذٍ مختلف باستخدام الوسيط p-. سنستخدم الأمر التالي لتشغيل تطبيقٍ آخر يستخدم المنفذ "5001" مثالًا حول طريقة الحل هذه: (env)user@localhost:$ flask run -p 5001 وبذلك يصبح لدينا تطبيق أوّل يعمل على الرايط "/http://172.0.0.1:5000" وآخر يعمل على الرابط "/http://172.0.0.1:5001" إن احتجنا لذلك. وبذلك يكون قد أصبح لدينا مع نهاية هذه الخطوة تطبيق ويب صغير باستخدام فلاسك، وبعد أن شغّلنا وعرضنا المعلومات في متصفح الويب، سنتعلم فيما يلي كيفية إنشاء وجهات واستخدامها لتخديم عدّة صفحات ويب. الخطوة الرابعة – الوجهات ودوال العرض في فلاسك سنضيف في هذه الخطوة بضع وجهات للتطبيق لإظهار صفحات مختلفة اعتمادًا على الرابط المطلوب، وسنتعرف أيضًا على دوال العرض في فلاسك وكيفية استخدامها. تُعرّف الوجهة route بأنها رابطٌ يُستخدم لتحديد ما سيستقبله المستخدم لدى زيارة تطبيق الويب على متصفحه، فمثلًا يشير الرابط "/http://127.0.0.1:5000" إلى الوجهة الرئيسية التي يمكن استخدامها لعرض الصفحة الرئيسية للتطبيق، بينما يشير الرابط "http://127.0.0.1:5000/about" إلى وجهةٍ أخرى وهو صفحة المعلومات التي تعطي الزوار معلومات حول تطبيق الويب، وعلى نحوٍ مشابه يمكن إنشاء وجهة تسمح للمستخدمين بتسجيل الدخول إلى تطبيق الويب عبر الرابط "http://127.0.0.1:5000/login" مثلًا. يستخدم تطبيق فلاسك الذي أنشأناه حاليًا وجهةً واحدةً تخدّم الزوار الذين يطلبون الرابط الرئيسي "/http://127.0.0.1:5000". الآن، ولنبين كيفية إضافة صفحة ويب جديدة إلى تطبيقنا، سنعدّل ملف التطبيق لإضافة وجهةٍ جديدة تؤمن معلومات حول التطبيق عبر الرابط "http://127.0.0.1:5000/about". لذا سنفتح الملف "app.py" من أجل التعديل: (env)user@localhost:$ nano app.py ثمّ نعدّل الملف من خلال إضافة الشيفرة التالية: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return '<h1>Hello, World!</h1>' @app.route('/about/') def about(): return '<h3>This is a Flask web application.</h3>' نحفظ الملف ونغلقه. أضفنا في الشيفرة السابقة دالةً جديدةً باسم ()about، والتي صمّمناها باستخدام المًزخرف ()app.route@، الذي يحوّلها إلى دالة عرض قادرة على التعامل مع الطلبات الواردة إلى الرابط "http://127.0.0.1:5000/about". بعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نزور الرابط التالي في المتصفح: http://127.0.0.1:5000/about فيظهر النص "This is a Flask web application" مصّيرًا ضمن تنسيق عنوان من المستوى الثالث <h3> في HTML؛ كما من الممكن استخدام عدّة وجهات في دالة فلاسك الواحدة، فمثلًا من الممكن تخديم الصفحة الرئيسية للتطبيق بكل من الوجهتين "/" و "/index/"، ولتنفيذ ذلك سنفتح الملف "app.py" لتعديله: (env)user@localhost:$ nano app.py سنعدّل الملف بإضافة مُزخرف آخر إلى دالة فلاسك ()hello: from flask import Flask app = Flask(__name__) @app.route('/') @app.route('/index/') def hello(): return '<h1>Hello, World!</h1>' @app.route('/about/') def about(): return '<h3>This is a Flask web application.</h3>' نحفظ الملف ونغلقه. وبعد إضافة المُزخرف الثاني أصبح بالإمكان الوصول إلى الصفحة الرئيسية للتطبيق من خلال أي من الرابطين "/http://127.0.0.1:5000" أو "http://127.0.0.1:5000/index". تعرّفنا فيما سبق على الوجهات وكيفية استخدامها لإنشاء دوال عرض في فلاسك وكيفية إضافة وجهات جديدة إلى التطبيق. فيما يلي سنستخدم الوجهات الديناميكية المرنة للسماح للمستخدمين بالتحكم باستجابة التطبيق. الخطوة الخامسة - الوجهات الديناميكية سنستخدم في هذه الخطوة الوجهات الديناميكية لنمكّن المستخدمين من التفاعل مع التطبيق، إذ سننشئ وجهةً تجعل الكلمات المُمرّرة عبر الرابط مكتوبةً بأحرف كبيرة، كما سننشئ وجهةً تجمع رقمين مع بعضهما وتظهر النتيجة. لا يتفاعل المستخدمون عادةً مع تطبيق الويب من خلال التعديل اليدوي للرابط، بل يتفاعلون مع عناصر موجودة في الصفحة تؤدي إلى روابط مختلفة بناءً على مدخلاتهم وتصرفاتهم ضمن الصفحة، ولكن وبهدف التبسيط في هذا المقال، سنعدّل الرابط لنبيّن كيفية جعل التطبيق يستجيب بصورةٍ مختلفة بروابط مختلفة. سنفتح بدايةً الملف app.py لتعديله: (env)user@localhost:$ nano app.py مع ملاحظة انّه إذا سمحنا للمستخدم بإدخال شيءٍ ما إلى التطبيق، مثل إدخال قيمة في الرابط كما سنفعل في التعديل التالي، فيجب الانتباه إلى أنّ التطبيق يجب ألا يُظهر بيانات غير موثوقة (البيانات التي أدخلها المستخدم)، ولكي نعرض بيانات المستخدم بصورةٍ آمنة، سنستخدم الدالة "()escape" الموجودة ضمن حزمة البناء الآمن "markupsafe" المُثبتة بالتوازي مع تثبيت فلاسك. الأن، سنعدّل الملف "app.py" بإضافة السطر التالي في بدايته أعلى أمر استيراد Flask كما يلي: from markupsafe import escape from flask import Flask # ... ثمّ سنضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/capitalize/<word>/') def capitalize(word): return '<h1>{}</h1>'.format(escape(word.capitalize())) نحفظ الملف ونغلقه. تملك الوجهة الجديدة قسمًا متغيرًا مُضمّنًا في الوسم <word>، والذي يسمح لفلاسك بأخذ القيمة المُدخلة من الرابط وتمريرها إلى دالة فلاسك، إذ يُمرّر متغير الرابط <word> الكلمة مثل وسيط إلى دالة فلاسك ()capitalize. وفي حالتنا فإنّ الوسيط هذا يملك نفس اسم متغير الرابط (وهو word في حالتنا)، وبذلك يمكننا الوصول إلى الكلمة المُمررة عبر الرابط وإنشاء استجابة بنفس الكلمة المُمررة ولكن بأحرف كبيرة وذلك باستخدام دالة العرض ()capitalize العاملة أصلًا في بايثون. استخدمنا الدالة ()escape التي استوردناها سابقًا لتصيير السلسلة التي أدخلها المُستخدم والموجودة ضمن المتغير word مثل نص وليس شيفرةً للتنفيذ، وهو أمر بالغ الأهمية لتجنب هجمات البرمجة العابرة للمواقع XSS، ففي حال إدخال المستخدم شيفرة JavaScript خبيثة بدلًا من السلسلة النصية، تصيّرها الدالة ()escape على أنها نص عادي وبذلك لن ينفّذها المتصفح، ما يبقي تطبيق الويب آمنًا. ولعرض الكلمات بأحرف كبيرة ضمن تنسيق عنوان من المستوى الأوّل <h1> في HTML استخدمنا الدالة ()format من دوال بايثون. الآن وبعد التأكد من أنّ خادم التطوير ما يزال قيد التشغيل، نفتح المتصفح ونذهب إلى الروابط التالية، مع إمكانية تبديل الكلمات "hello" و "flask" و "python" التي تنتهي الروابط بها في مثالنا بأي كلمة تريد: http://127.0.0.1:5000/capitalize/hello http://127.0.0.1:5000/capitalize/flask http://127.0.0.1:5000/capitalize/python وبذلك تظهر الكلمة ضمن المتصفح بأحرف كبيرة وبتنسيق عنوان من المستوى الأول <h1>. كما يمكننا استخدام عدّة متغيرات في الوجهة، ولتوضيح ذلك سنضيف وجهةً جديدةً لجمع رقمين صحيحين ويعرض النتيجة. لذا سنفتح الملف "app.py" لتعديله: (env)user@localhost:$ nano app.py ثمّ نضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/add/<int:n1>/<int:n2>/') def add(n1, n2): return '<h1>{}</h1>'.format(n1 + n2) نحفظ الملف ونغلقه. نستخدم في هذه الوجهة المحوّل الخاص int مع المتغير الخاص بالرابط (/add/<int:n1>/<int:n2>/)؛ ومهمّة هذا المحوّل هي قبول القيم التي تُمثّل أعدادًا صحيحة موجبة فقط والتعامل معها على أنها أعداد، كونه افتراضيًا تُعدّ المتغيرات الآتية من الرابط سلاسلًا محرفية ويجري التعامل معها على هذا الأساس، وهذا أمرٌ غير مناسب لإتمام عملية الجمع العددي. الآن وبعد التأكد من أنّ خادم التطوير ما يزال قيد التشغيل، نفتح المتصفح ونذهب إلى الرابط التالي: http://127.0.0.1:5000/add/5/5/ وستكون النتيجة مجموع الرقمين (وهي "10" في حالة مثالنا هذا). تعرفنا في هذه الخطوة على كيفية استخدام الوجهات الديناميكية لعرض استجابات مُختلفة ضمن الوجهة الواحدة اعتمادًا على الرابط المطلوب، وهذا ما يعزز التجربة التفاعلية للمُستخدم. سنتعرّف في الخطوة التالية على آليات تنقيح وتصحيح الأخطاء في تطبيق فلاسك في حال حدوثها. الخطوة السادسة - تنقيح أخطاء تطبيق فلاسك خلال مراحل تطوير أي تطبيق ويب، من الطبيعي أن نمر بحالات نحصل فيها على أخطاء لدى تشغيل التطبيق عوضًا عن النتيجة المتوقعة، والتي قد تكون ناتجةً مثلًا عن خطأ إملائي بسيط في كتابة اسم أحد المتغيرات أو نتيجة نسيان التصريح عن أو استيراد إحدى الدوال؛ ولإصلاح هذه الأخطاء بسهولة يوفّر فلاسك منقّح أخطاء يعمل لدى تشغيل التطبيق في وضع التطوير، إذ سنتعلّم في هذه الخطوة آلية تصحيح أخطاء التطبيق بالاعتماد على مُنقّح الأخطاء في فلاسك. لتوضيح كيفية التعامل مع الأخطاء في حال ظهورها، سننشئ وجهةً للترحيب بمستخدم ما من قائمة أسماء مستخدمين موجودة. لذا سنفتح الملف "app.py" للتعديل عليه: (env)user@localhost:$ nano app.py ونضيف الوجهة التالية إلى نهاية الملف: # ... @app.route('/users/<int:user_id>/') def greet_user(user_id): users = ['Ahmad', 'Mohammad', 'Adam'] return '<h2>Hi {}</h2>'.format(users[user_id]) نحفظ الملف ونغلقه. تستقبل دالة فلاسك ()greet_user في الوجهة السابقة متغير الرابط user_id مثل قيمة للوسيط user_id، إذ استخدمنا المحوّل الخاص int لقبول أعداد صحيحة موجبة فقط، حيث تتضمّن الدالة قائمةً مبنيةً في بايثون باسم users تحتوي على ثلاث سلاسل نصية تمثّل أسماء المستخدمين، وترجع دالة فلاسك السلسة الموافقة من القائمة اعتمادًا على قيمة المتغير user_id المُمرّر والذي يدل على رقم المُستخدم المراد الترحيب به بالنتيجة؛ فإذا كانت قيمة المتغير user_id تساوي "0" مثلًا، ستكون الاستجابة ظهور عبارة "Hi Ahmad" ضمن تنسيق عنوان من المستوى الثاني <h2> لأن Ahmad هو أول عنصر في القائمة المُقابل للقيمة "[user[0". الآن وبعد التأكد أن خادم التطوير ما يزال قيد التشغيل، سنفتح المتصفح لزيارة الروابط التالية: http://127.0.0.1:5000/users/0 http://127.0.0.1:5000/users/1 http://127.0.0.1:5000/users/2 فتكون النتيجة على النحو التالي: Hi Ahmad Hi Mohammad Hi Adam نلاحظ أنّ الأمور تجري على خير ما يرام حتى الآن، ولكن ماذا لو طلبنا الترحيب بمستخدم غير موجود؟ سيظهر خطأ بالتأكيد، ولتوضيح كيفية عمل مُنقّح الأخطاء في فلاسك سنزور الرابط التالي: http://127.0.0.1:5000/users/3 فتظهر صفحةٌ كما في الصورة أدناه: نلاحظ أنّ اسم الخطأ الحاصل في بايثون وهو IndexError في حالتنا يُعرض في أعلى الصفحة، ويشير هذا الخطأ إلى وقوع دليل القائمة ("3" في مثالنا) خارج المجال، إذ أن المجال في حالتنا محصورٌ بين "0" و "2" لأنّ القائمة مكونةٌ من ثلاثة عناصر، كما يظهر في مُنقح الأخطاء جميع أسطر الشيفرة التي أدّى تنفيذها إلى ظهور هذا الخطأ. وعادةً ما يتضمّن آخر سطرين من متتبّع الأخطاء مصدر الخطأ، وفي حالتنا سيبدوان على نحو مشابه لما يلي: File "/home/USER/flask_app/app.py", line 28, in greet_user return '<h2>Hi {}</h2>'.format(users[user_id]) ما يشير إلى أنّ الخطأ ناتج عن دالة الترحيب ()greet_user ضمن الملف "app.py" وتحديدًا في السطر الحاوي غلى القيمة المُعادة return، ومع معرفتنا للسطر الذي تسبّب بالخطأ يصبح تحديد المشكلة وحلها أسهل. كما يمكننا لتجنّب توقّف عمل التطبيق في حالات مشابهة لهذه الحالة استخدام العبارة "try…except" لإصلاح الخطأ، بحيث إذا احتوى الرابط المطلوب على دليل خارج مجال القائمة يتلقى المستخدم عبارة خطأ "404 Not Found"، وهو خطأ HTTP يشير للمستخدم أن الصفحة التي يطلبها غير متوفرة. لذا سنفتح الملف "app.py" للتعديل عليه: (env)user@localhost:$ nano app.py وحتى تحدث الاستجابة بخطأ من النوع HTTP 404 سنستخدم دالة فلاسك ()abort التي يمكن استخدامها لانشاء استجابات مكونة من أخطاء HTTP، لذا سنغير السطر الثاني في الملف ليصبح كما يلي: from markupsafe import escape from flask import Flask, abort ثمّ سنعدّل الدالة ()greet_user لتصبح كما يلي: # ... @app.route('/users/<int:user_id>/') def greet_user(user_id): users = ['Ahmad', 'Mohammad', 'Adam'] try: return '<h2>Hi {}</h2>'.format(users[user_id]) except IndexError: abort(404) استخدمنا try لاختبار التعبير return والتأكّد من خلوه من الأخطاء، فإذا لم يكن هناك خطأ، بمعنى أنّ قيمة المتغير user_id المُمرّرة صحيحةٌ ومن ضمن مجال قائمة users، فسيستجيب التطبيق بالترحيب المناسب، وإلّا وفي حال كون قيمة user_id خارج مجال القائمة، سيُفعَّل الاستثناء IndexError، ونستخدم الأمر except للتعامل مع الخطأ وبالتالي الاستجابة بخطأ من نوع HTTP 404 باستخدام دالة فلاسك المساعدة ()abort. الآن وبعد التأكد من كون خادم التطوير قيد التشغيل، نزور الرابط مجددًا مع تمرير القيمة 3 لرقم المُستخدم المطلوب: http://127.0.0.1:5000/users/3 فتظهر في هذه الحالة صفحة الخطأ 404 التقليدية لتشير للمستخدم أن الصفحة المطلوبة غير موجودة. ومع نهاية تطبيق الخطوات الواردة في هذا المقال، سيبدو الملف "app.py" على النحو التالي: from markupsafe import escape from flask import Flask, abort app = Flask(__name__) @app.route('/') @app.route('/index/') def hello(): return '<h1>Hello, World!</h1>' @app.route('/about/') def about(): return '<h3>This is a Flask web application.</h3>' @app.route('/capitalize/<word>/') def capitalize(word): return '<h1>{}</h1>'.format(escape(word.capitalize())) @app.route('/add/<int:n1>/<int:n2>/') def add(n1, n2): return '<h1>{}</h1>'.format(n1 + n2) @app.route('/users/<int:user_id>/') def greet_user(user_id): users = ['Ahmad', 'Mohammad', 'Adam'] try: return '<h2>Hi {}</h2>'.format(users[user_id]) except IndexError: abort(404) وبذلك أصبح لديك تصوّر عام عن كيفية استخدام مُنقّح الأخطاء في فلاسك لالتقاط الأخطاء وتحديد الآلية المُثلى لإصلاحها والتعامل معها. الخاتمة تعرفنا في هذا المقال بصورة عامة على فلاسك وكيفية تثبيته واستخدامه لإنشاء تطبيق ويب، كما تعرفنا على آلية تشغيل خادم التطوير واستخدام الوجهات ودوال فلاسك لعرض صفحات ويب مختلفة تخدّم وظائفًا محددة، كما تعلمنا كيفية استخدام الوجهات الديناميكية للسماح للمستخدم بالتفاعل مع تطبيق ويب عن طريق تعديل الرابط المطلوب، وفي النهاية تعلمنا كيفية استخدام مُنقّح الأخطاء لتحديد المشاكل. ترجمة -وبتصرف- للمقال How To Create Your First Web Application Using Flask and Python3 لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال التالي: كيفية استخدام القوالب في تطبيقات فلاسك Flask المقال السابق: تخديم تطبيقات فلاسك باستخدام خادمي الويب uWSGI و Nginx إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون بناء موقعك واستضافته باستخدام Git أساسيات تحديد التكلفة المادية الكاملة لبناء موقع ويب -
 سننشئ في هذا المقال تطبيق بايثون باستخدام إطار العمل المُصغّر فلاسك Flask في الإصدار 20.04 من توزيعة أبونتو، سيتضمّن القسم الأكبر من هذا المقال معلومات حول كيفية إعداد خادم تطبيق uWSGI وكيفية الوصول إلى هذا التطبيق وآلية إعداد خادم Nginx ليعمل مثل خادم وكيل معكوس reverse proxy لدى طرف المستخدم. مستلزمات العمل قبل المتابعة في هذا المقال لا بدّ من: توفّر خادم مثبّت عليه نظام تشغيل أبونتو 20.04 ذو مستخدم عادي ليس مستخدم جذر root وبصلاحيات sudo، مع تفعيل جدار الحماية. تثبيت خادم Nginx. خادم نطاق أسماء للإشارة إلى خادم التطبيق، إذ من الممكن شراء نطاق من Namecheap أو الحصول على نطاق مجاني من Freenom، وفي مقالنا سنفترض أنّ خادم نطاق الأسماء DNS يحوي السجلات التالية: سجل من النوع A يحمل القيمة "your_domain" ويشير إلى عنوان IP العام المُخصّص لخادم التطبيق. سجل من النوع A يحمل القيمة "www.your_domain" يشير إلى عنوان IP العام المُخصّص لخادم التطبيق. إضافةً لما سبق يُفضّل وجود معرفة جيدة بالتعامل مع خادم uWSGI، ومع الخادم الذي سننشئ عليه التطبيق، والفهم الجيد لمواصفات وخصائص بروتوكول WSGI. الخطوة الأولى - تثبيت المكونات اللازمة من مستودعات أبونتو سنثبّت في هذه الخطوة كافّة المكونات التي سنحتاجها من مستودع أبونتو، إضافةً إلى مدير تثبيت حزمة بايثون "pip" لإدارة مكونات بايثون، كما سننزّل ملفات تطوير بايثون الضرورية لبناء خادم "uWSGI". بدايةً سنحدّث موقع دليل الحزمة المحلي: $ sudo apt update ثمّ سنثبّت الحزم اللازمة لبناء بيئة بايثون والتي تشمل الحزمة "python3-pip" وغيرها من الحزم وأدوات التطوير الضرورية للحصول على بيئة برمجية مستقرّة ومتينة: $ sudo apt install python3-pip python3-dev build-essential libssl-dev libffi-dev python3-setuptools الآن وبعد الانتهاء من تثبيت الحزم ننتقل إلى إنشاء البيئة الافتراضية اللازمة لمشروعنا. الخطوة الثانية – إنشاء بيئة بايثون افتراضية سنُعِد في هذه الخطوة البيئة الافتراضية اللازمة لفصل تطبيق فلاسك عن ملفات بايثون الأُخرى في النظام. سنبدأ بتثبيت الحزمة "python-venv" المسؤولة عن تحميل حزم بايثون ضمن بيئة معزولة خاصّة بكل مشروع، والتي ستتثبّت بدورها الوحدة "venv": $ sudo apt install python3-venv الآن سننشئ المجلد الرئيسي لمشروع فلاسك: $ mkdir ~/myproject ثمّ سننتقل إلى هذا المجلد كما يلي: $ cd ~/myproject وفيه سننشئ البيئة الافتراضية اللازمة لتخزين متطلبات بايثون التي سيحتاجها مشروع فلاسك، وذلك بتنفيذ الأمر التالي: $ python3.6 -m venv myprojectenv سيثبّت الأمر السابق نسخةً محليةً من بيئة بايثون ومن الحزمة "pip" في مجلد باسم "myprojectenv" ضمن المجلد الرئيسي للتطبيق. والآن، لا بدّ من تفعيل هذه البيئة الافتراضية قبل تثبيت أي تطبيقات ضمنها على النحو التالي: $ source myprojectenv/bin/activate وهنا نلاحظ تغيّر مؤشّر واجهة أسطر الأوامر ليشير إلى عملنا ضمن البيئة الافتراضية ليصبح على الشّكل: (myprojectenv)user@host:~/myproject$ الخطوة الثالثة - إعداد تطبيق فلاسك الآن، وبعد تفعيل البيئة الافتراضية والعمل ضمنها، أصبح بالإمكان تثبيت فلاسك وخادم "uWSGI" لنباشر بتصميم التطبيق. سنثبّت بدايةً المكوّن "wheel" مع استخدام مُثبّت الحزم "pip"، وبذلك نتأكّد من تثبيت وعمل الحزم بصورةٍ سليمة حتّى في حال عدم وجود "wheel". $ pip install wheel ملاحظة: بغض النظر عن إصدار بايثون المُستخدم، يجب استخدام الأمر pip وليس pip3 عندما تكون البيئة الافتراضية قيد التشغيل. سنثبّت الآن فلاسك وخادم uWSGI: (muprojectenv) $ pip install uwsgi flask وبعد انتهاء التثبيت، يمكننا البدء باستخدام فلاسك. إنشاء تطبيق بمثابة عينة للاختبار الآن، وبعدما أصبح فلاسك جاهزًا، يمكننا الشروع بإنشاء تطبيق بسيط، فكما نعلم فإن فلاسك إطار عمل مًصغّر، لا يحتوي على كثيرٍ من الأدوات مثل تلك التي يمتلكها إطار العمل كامل الميزات، إذ أن فلاسك بالأصل هو مُجرّد وحدة نستوردها إلى مشاريعنا للمساعدة في تهيئة تطبيق الويب. وطالما أنّ التطبيق ككل قد يصبح أكثر تعقيدًا لاحقًا بإضافة مكونات أُخرى عليه، سننشئ تطبيق فلاسك ضمن ملف واحد باستخدام أي محرّر نصوص تفضّله، وفي مقالنا سنستخدم محرّر نانو nano وسنسمّي الملف "myproject.py": (muprojectenv) $ nano ~/myproject/myproject.py أي ستُخزّن الشيفرة الخاصّة بالتطبيق في هذا الملف، وفيها سنستورد فلاسك وننشئ كائن فلاسك الذي سنستخدمه لتعريف الدوال التي ستعمل لدى طلب اتجاهٍ معينة من قبل المُستخدم: from flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "<h1 style='color:blue'>Hello There!</h1>" if __name__ == "__main__": app.run(host='0.0.0.0') حدّدنا في الشيفرة السابقة المحتوى الذي سيُعرض عند الدخول إلى النطاق الأساسي للتطبيق. نحفظ الملف ونغلقه بالضغط على مفتاحي "CTRL+X"، ثمّ "Y"، ثمّ "ENTER" في حال كنت تستخدم محرّر النصوص نانو. وباتباع خطوات إعداد الخادم الابتدائي سيكون جدار حماية UFW قيد التشغيل، وبالتالي لن نتمكّن من الوصول إلى لتطبيق لاختباره ما لم نسمح بالوصول إلى المنفذ 5000 كما يلي: (muprojectenv) $ sudo ufw allow 5000 سنختبر الآن تطبيق فلاسك: (muprojectenv) $ python myproject.py فيكون الخرج مُشابهًا لما يلي، والذي يتضمّن تحذيرات مهمّة ومفيدة تشير لعدم استخدام إعداد الخادم هذا (خادم التطوير) في مرحلة الاستخدام الفعلي للتطبيق (نشر المُنتج). * Serving Flask app "myproject" (lazy loading) * Environment: production WARNING: Do not use the development server in a production environment. Use a production WSGI server instead. * Debug mode: off * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) الآن وباستخدام المتصفح ننتقل إلى عنوان IP الخاص بالخادم متبوعًا برقم المنفذ الخاص بالتطبيق "5000:" على النحو التالي: http://your_server_ip:5000 فتكون النتيجة مُشابهةً لما يلي: وعند الانتهاء نضغط على "CTRL + C" في نافذة مشغّل الأوامر لإيقاف خادم تطوير فلاسك. إنشاء نقطة دخول لتطبيق WSGI في هذه الخطوة سننشئ ملفًا ليعمل مثل نقطة دخول إلى التطبيق، والتي سترشد خادم uWSGI لآلية التفاعل مع التطبيق، لذا سننشئ ملفاً باسم "wsgi.py": (muprojectenv) $ nano ~/myproject/wsgi.py سنستورد في هذا الملف نسخة فلاسك من التطبيق ونشغلها: from myproject import app if __name__ == "__main__": app.run() وبعد الانتهاء نحفظ الملف ونغلقه. الخطوة 4 – إعداد خادم uWSGI حتى الآن كتبنا شيفرة البرنامج مع إنشاء نقطة دخول، وفي هذه الخطوة سنبدأ بإعداد خادم uWSGI. اختبار خادم uWSGI بدايةً وقبل إجراء مزيدٍ من التغييرات، من المفيد اختبار ما إذا كان uWSGI قادرًا على تخديم تطبيقنا هذا، وذلك بتمرير اسم نقطة الدخول المكوّن من اسم الوحدة المُستخدمة بدون اللاحقة "py." مع اسم الاستدعاء داخل التطبيق، وبالتالي في حالتنا سيكون اسم نقطة الدخول هو "wsgi:app". كما أنّنا سنحدّد مقبس ويب للخادم ليعمل على واجهة عامّة، مُستخدمًا بروتوكول HTTP عوضًا عن بروتوكول uwsgi الثنائي، باستخدام نفس رقم المنفذ "5000" المفتوح أصلًا: (muprojectenv) $ uwsgi --socket 0.0.0.0:5000 --protocol=http -w wsgi:app وبالانتقال إلى رابط الخادم (عنوان IP الخاص به) متبوعًا برقم المنفذ "5000:" باستخدام المتصفح: http://your_server_ip:5000 يجب أن نحصل على نفس خرج التطبيق، أي: وبعد التأكد من كون الخادم يعمل كما يجب، نضغط "CTRL +C" في نافذة الطرفية لإيقاف تشغيله. وفي هذه المرحلة ومع الانتهاء من إعداد البيئة الافتراضية، أصبح من الممكن إلغاء تفعيلها: (muprojectenv) $ deactivate وبذلك فإنّ أي أوامر بلغة بايثون ستستخدم بيئة بايثون الموجودة فعليًا على النظام. إنشاء ملف ضبط uWSGI الآن وبعد ما اختبرنا وتأكدنا من قدرة uWSGI على تخديم تطبيقنا (تمكنّا من الوصول إلى خرج التطبيق من خلاله)، ولضمان عمل فعّال وموثوق للتطبيق على المدى الطويل سننشئ ملفًا ضبط uWSGI مُتضمّنًا كافّة الخيارات اللازمة لذلك. سننشئ هذا الملف ضمن مجلد التطبيق الرئيسي باسم "myproject.ini": $ nano ~/myproject/myproject.ini سنبدأ بداخله بالترويسة [uwsgi]، التي تتضمّن الإعدادات الواجب على خادم uWSGI تطبيقها، وفيها سنحدّد الوحدة المُستخدمة وهي في حالتنا "wsgi.py"، إذ نكتب اسمها دون اللاحقة، مع اسم الاستدعاء إلى uWSGI داخل التطبيق وهو "app" على النحو التالي: [uwsgi] module = wsgi:app ومن ثمّ كتبنا الأمر اللازم لتشغيل خادم uWSGI في الوضع الرئيسي Master mode مولدًّا خمس عمليات تابعة لتلك الرئيسية لتخديم الطلبات الفعليّة: [uwsgi] module = wsgi:app master = true processes = 5 ومن الجدير بالملاحظة أنّنا وفي مرحلة الاختبار فتحنا منفذًا مُباشرًا لخادم uWSGI، ولكن بما أنّنا سنستخدم خادم Nginx تاليًا للتعامل مع اتصالات العملاء (زوّار التطبيق) ليمرّر بدوره الطلبات إلى خادم uWSGI، وبما أن هذين المكونين يعملان على حاسوبٍ واحد، فمن المفضّل استخدام مقبس ويب يونكس Unix كونه أسرع وأكثر أمنًا، لذا سنستدعي المقبس "myproject.sock" لنضمّنه في مجلدنا هذا. كما سنغيّر أذونات مقبس الويب هذا بما يمنح خادم Ngnix ملكية عمليات خادم uWSGI، لذا يجب التأكّد من كون مالك المقبس لديه أذونات القراءة منه والكتابة عليه، كما سنفعّل خيار تنظيف المقبس لدى توقّف العمليات بإضافة الخيار vacuum: [uwsgi] module = wsgi:app master = true processes = 5 socket = myproject.sock chmod-socket = 660 vacuum = true ونهايةً سنضيف خيار die-on-term، وبذلك نضمن أنّه لدى كل من النظام المُهيئ وخادم uWSGI نفس الافتراضات حول معنى كل عملية، وبذلك تعمل مكونات النظامين على التوازي وصولًا إلى النتيجة المطلوب تنفيذها. [uwsgi] module = wsgi:app master = true processes = 5 socket = myproject.sock chmod-socket = 660 vacuum = true die-on-term = true نلاحظ أنّنا في هذه الخطوة لم نُحدّد بروتوكولًا كما فعلنا في نافذة أسطر الأوامر سابقًا، ذلك لأنّ خادم uWSGI يستخدم بروتوكول uwsgi افتراضيًا، وهو بروتوكول سريع يتعامل مع النظام الثنائي للعد (يستخدم كامل قيم البايت الواحد)، مُصمّم للتواصل مع الخوادم الأخرى، وخادم Nginx قادرٌ أصلًا على التخاطب معه، وبالتالي يُعد استخدام هذا البروتوكول أفضل من فرض الاتصال باستخدام بروتوكول HTTP. وعند الانتهاء نحفظ الملف ونغلقه. الخطوة الخامسة - إنشاء ملف وحدة الاتصال مع النظام سننشئ في هذه الخطوة ملف وحدة الاتصال التي ستسمح لنظام أوبنتو المُهيّأ أصلًا بتشغيل خادم uWSGI تلقائيًا ليخدّم التطبيق في كل مرة يُشغّل فيها الخادم الفعلي. سننشئ هذا الملف ضمن المسار "etc/system/system/" مع ملاحظة أنّ لاحقته هي "service." كما يلي: $ sudo nano /etc/systemd/system/myproject.service وضمن الملف نكتب الشيفرة بدءًا من القسم [Unit] الذي نحدّد من خلاله البيانات الوصفية metadata ومتطلبات العمل، وفيه نصف طبيعة الخدمة ونجعل النظام الفعلي المُهيّأ يبدأ بالعمل فقط بعد إنتهاء عمليات الربط الشبكي المطلوبة: [Unit] Description=uWSGI instance to serve myproject After=network.target بعدها نكتب القسم [Service]، وفيه نحدّد مكان تنفيذ العمليات، أي المُستخدم والمجموعة الهدف، إذ سنعطي حساب المُستخدم العادي صلاحيات المالك كونه يملك بالفعل كافّة الملفات ذات الصلة بالعمليات الجارية، كما سنعطي المجموعة www-data صلاحيات مالك المجموعة بما يضمن تخاطب سهل ما بين خادم Nginx وعمليات uWSGI الجارية، ومن الضروري في هذا المقطع استبدال اسم المُستخدم بالاسم الخاص بك، كما يلي: [Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=username Group=www-data سنحدّد الآن مجلد العمل، كما سنضبط قيمة متغير البيئة PATH بما يُعلِم النظام الفعلي المُهيّأ بأنّ ملفات تشغيل العمليات موجودةٌ ضمن البيئة الافتراضية، كما سنحدّد الأمر البرمجي المسؤول عن بدء تشغيل الخدمة، والذي يتطلّب تمرير المسار الكامل إلى ملف تشغيل uWSGI المُثبّت في البيئة الافتراضية، كما سنمرر اسم ملف الضبط ذو اللاحقة "ini." الذي أنشأناه أصلًا في مجلد المشروع. ومن المهم استبدال اسم المستخدم username ومسار المشروع بما يتوافق مع معلوماتها لديك. [Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=username Group=www-data WorkingDirectory=/home/username/myproject Environment="PATH=/home/username/myproject/myprojectenv/bin" ExecStart=/home/username/myproject/myprojectenv/bin/uwsgi --ini myproject.ini أمّا الآن فسنضيف القسم [Install]، الذي يُعلم النظام المُهيّأ بمكان ربط الخدمة التي ستبدأ فور إقلاع النظام، إذ أنّ المطلوب في حالتنا جعل الخدمة تبدأ فور إعداد وتشغيل نظام مُستخدمي التطبيق العاديين: [Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=username Group=www-data WorkingDirectory=/home/username/myproject Environment="PATH=/home/username/myproject/myprojectenv/bin" ExecStart=/home/username/myproject/myprojectenv/bin/uwsgi --ini myproject.ini [Install] WantedBy=multi-user.target وبذلك يكون ملف الخدمة الخاصّ بالنظام الفعلي المُهيّأ جاهزًا. احفظ هذا الملف واغلقه. الآن، سنشغّل خدمة uWSGI التي أنشأناها وجعلناها تبدأ فور الإقلاع: $ sudo systemctl start myproject $ sudo systemctl enable myproject ونتحقّق من حالة عملها كما يلي: $ sudo systemctl status myproject إذا كانت تعمل بصورةٍ صحيحة، فيجب أن نحصل على خرج شبيه بما يلي: ● myproject.service - uWSGI instance to serve myproject Loaded: loaded (/etc/systemd/system/myproject.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2020-05-20 13:21:39 UTC; 8h ago Main PID: 22146 (uwsgi) Tasks: 6 (limit: 2345) Memory: 25.5M CGroup: /system.slice/myproject.service ├─22146 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22161 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22162 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22163 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22164 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini └─22165 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini وفي حال وجود أي رسائل أخطاء، يجب إيجاد حلول لها قبل المتابعة في الخطوات التالية، أو يمكنك الانتقال لضبط تثبيت Nginx لتمرير الطلبات إلى مقبس "myproject.sock". الخطوة السادسة - ضبط Nginx ليعمل مثل خادم وكيل مع بداية هذه الخطوة يجب أن يكون خادم uWSGI الخاص بالتطبيق جاهزًا وقيد التشغيل، بانتظار الطلبات الواردة إلى ملف مقبس الويب المُنشأ في مجلد المشروع، وفي هذه الخطوة سنضبط خادم Nginx ليمرر طلبات الويب إلى المقبس آنف الذكر باستخدام بروتوكول "uwsgi". لذا، سننشئ ملف ضبط جديد للخادم باسم "myproject" ضمن المجلد "sites-available" الخاص بخادم Nginx: $ sudo nano /etc/nginx/sites-available/myproject وسنكتب ضمن هذا الملف الشيفرة اللازمة لجعل خادم Nginx يصغي للمنفذ الافتراضي ذو الرقم "80" بانتظار أي طلبات واردة، كما سيستخدم هذه الشيفرة أيضًا للتعامل مع طلبات الوصول عن طريق اسم مجال خادم التطبيق. server { listen 80; server_name your_domain www.your_domain; } إذ سنضيف مجموعة شيفرات متوافقة مع كل موقع مطلوب، وفيها سنضمّن الملف "uwsgi_params" المسؤول عن تحديد معاملات uWSGI الواجب ضبطها، ثمّ سنمرر الطلبات إلى ملف مقبس الويب المُعرّف أصلًا باستخدام الموجّه uwsgi_pass: server { listen 80; server_name your_domain www.your_domain; location / { include uwsgi_params; uwsgi_pass unix:/home/sammy/myproject/myproject.sock; } } نحفظ الملف ونغلقه بعد الانتهاء. ولتمكين ملف كتلة إعدادات خادم Nginx هذا، سنربطه مع المجلد "sites-enabled" كما يلي: $ sudo ln -s /etc/nginx/sites-available/myproject /etc/nginx/sites-enabled عند تثبيت مخدم Nginx، يجري إعداد ملف ضبط للمخدم اسمه "default" ضمن المجلد "sites-available"، ثم يُنشأ ارتباط رمزي بين هذا الملف والمجلد "sites-available"؛ فإذا تركت هذا الارتباط الرمزي مكانه، فسيمنع الضبط الافتراضي "default" موقعك من التحميل. يمكنك إزالة هذا الرابط باستخدام الأمر التالي: $ sudo unlink /etc/nginx/sites-enabled/default وسنتمكّن مع وجود الملف ضمن المجلد من فحص أي أخطاء في الصياغة البرمجية باستخدام الشيفرة التالية: $ sudo nginx -t وفي حال عدم ظهور أي أخطاء (أي قيمة معادة لدى تنفيذ الشيفرة السابقة)، نعيد تشغيل عملية Nginx لتتعرّف على الضبط الجديد: $ sudo systemctl restart nginx والآن أصبح من الممكن تعديل جدار الحماية مُجدّدًا، إذ أنّنا لم نعد بحاجة إلى الوصول عبر المنفذ "5000"، لذا سنحذف هذا الاستثناء: $ sudo ufw delete allow 5000 ثمّ سنسمح بالوصول إلى خادم Nginx على النحو التالي: $ sudo ufw allow 'Nginx Full' وبذلك يصبح من الممكن الوصول إلى التطبيق باستخدام اسم المجال الخاص بالخادم عبر المتصفح: http://your_domain فيظهر لنا خرج التطبيق بالشّكل التالي: أمّا إذا واجهت أي أخطاء، فعليك التحقّق منها مُستخدمًا الأوامر التالية: sudo less /var/log/nginx/error.log: للتحقّق من سجل أخطاء خادم Nginx. sudo less /var/log/nginx/access.log: للتحقّق من سجل الوصول إلى خادم Nginx. sudo journalctl -u nginx: للتحقّق من سجل عمليات خادم Nginx. sudo journalctl -u myproject: للتحقّق من سجل خادم uWSGI الخاص بتطبيق فلاسك. الخطوة السابعة - تأمين التطبيق لضمان اتصال ونقل بيانات آمن ومُشفّر من وإلى خادم التطبيق، لا بُدّ من الحصول على شهادة طبقة مقابس الويب الآمنة Secure Socket Layer -أو اختصارًا SSL-؛ وهي شهادةٌ رقميةٌ تصادق على هوية موقع الويب وتتيح اتصالاً مشفرًا، ومن الممكن الحصول على هذه الشهادة مجانًا من Let's Encypt (وهي هيئة شهادات مجانية تابعة لمجموعة أبحاث أمن الإنترنت)، أو إنشاء شهادة خاصّة بك، ناهيك عن وجود طرق عديدة للحصول على الشهادة. لذا بدايةً سنثبّت حزمة Certbot وإضافات Nginx الخاصة به باستخدام apt: $ sudo apt install certbot python3-certbot-nginx يؤمن Certbot عدة طرق مختلفة للحصول على شهادة SSL من خلال هذه الإضافات plugins، وبعد تثبيت إحداها ستعمل إضافة Nginx من تلقاء نفسها على إعادة ضبط إعدادات الخادم وإعادة تحميلها كلما دعت الحاجة لذلك، ولاستخدام هذه الإضافة سنشغّل الأمر: $ sudo certbot --nginx -d your_domain -d www.your_domain تشغّل الشيفرة السابقة certbot مع إضافة nginx–، وقد استخدمنا d- لتحديد الأسماء المتوافقة مع الشهادة. إذا كانت هذه المرة الأولى التي تشغّل فيها certbot على الخادم، سيتطلّب الأمر إدخال بريد إلكتروني والموافقة على شروط الخدمة، بعدها ستتواصل certbot مع خادم Let’s Encrypt، ثم تشغّل نظام تحقّق للتأكد من أنّك تتحكم فعلًا بالنطاق الذي تطلب الشهادة من أجله. فإذا انتهت العملية السابقة بنجاح، سيطلب منا certbot ضبط الإعدادات التي نريد لبروتوكول HTTPS: Please choose whether or not to redirect HTTP traffic to HTTPS, removing HTTP access. ------------------------------------------------------------------------------- 1: No redirect - Make no further changes to the webserver configuration. 2: Redirect - Make all requests redirect to secure HTTPS access. Choose this for new sites, or if you're confident your site works on HTTPS. You can undo this change by editing your web server's configuration. ------------------------------------------------------------------------------- Select the appropriate number [1-2] then [enter] (press 'c' to cancel): في هذه الخطوة نختار ما نريده من إعدادات ثمّ نضغط على مفتاح "ENTER" لتحديث الضبط، كما يُعاد تحميل Nginx لتطبيق الإعدادات الجديدة هذه، ونهايةً يعرض certbot رسالةً مفادها نجاح العملية وموقع تخزين الشهادة: IMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at: /etc/letsencrypt/live/your_domain/fullchain.pem Your key file has been saved at: /etc/letsencrypt/live/your_domain/privkey.pem Your cert will expire on 2020-08-18. To obtain a new or tweaked version of this certificate in the future, simply run certbot again with the "certonly" option. To non-interactively renew *all* of your certificates, run "certbot renew" - Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal. - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-le وإذا اتبعنا تعليمات تثبيت Nginx كما هو موضّح في فقرة مستلزمات العمل من هذا المقال، فلن نعود بحاجة لسماحية ملف تعريف HTTP: $ sudo ufw delete allow 'Nginx HTTP' الآن وللتحقّق من الإعدادات سننتقل مجدّدًا إلى النطاق الخاص بالتطبيق باستخدام "//:https": https://your_domain وهنا يجب أن يظهر خرج التطبيق مجدّدًا ولكن مع مؤشر الأمان الخاص بالمتصفح والذي يشير إلى أنّ الموقع آمن. الخاتمة في هذا المقال أنشأنا تطبيق فلاسك صغير آمن باستخدام بيئة بايثون افتراضية، وأنشأنا نقطة دخول إلى بروتوكول WSGI بحيث يتمكّن أي خادم تطبيق متوافق مع WSGI من التعامل معه، إذ أعددنا خادم uWSGI ليؤدي هذه المهمة، بعدها أنشأنا ملف تخديم مسؤول عن الوصول آليًا خادم التطبيق لدى إقلاع الخادم الفعلي، كما أنشأنا كتلة خادم Nginx التي تمرّر حركة مرور مستخدم الويب إلى خادم التطبيق، وبالتالي تُرحل طلبات مستخدمي التطبيق الخارجية وحركة المرور الآمنة إلى الخادم مع خادم Let's Encrypt. وبذلك نجد أنّ فلاسك إطار عمل مرن جدًا، إذ يمنح التطبيقات القدرة على العمل الفعلي دون التقيد بالهيكل والتصميم، ويمكنك استخدام ما ذُكر في هذا المقال لتخديم أي تطبيق فلاسك ترغب بتصميمه. ترجمة -وبتصرف- للمقال How To Serve Flask Applications with uWSGI and Nginx on Ubuntu 20.04 لصاحبه Mark Drake و Kathleen Juell. اقرأ أيضًا المقال التالي: تعلم بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask بلغة بايثون المقال السابق: استخدام مكتبة بايثون-ماركداون مع إطار عمل فلاسك ومحرك قواعد البيانات SQLite مدخل إلى تطوير تطبيقات الويب باستخدام إطار العمل Flask كيف تُرقِّي خادم Nginx موجود بدون قطع اتصالات العميل فهم بنية ملف إعدادات nginx وسياقات الإعدادات تنصيب، إعداد واستخدام nginx كخادوم ويب
سننشئ في هذا المقال تطبيق بايثون باستخدام إطار العمل المُصغّر فلاسك Flask في الإصدار 20.04 من توزيعة أبونتو، سيتضمّن القسم الأكبر من هذا المقال معلومات حول كيفية إعداد خادم تطبيق uWSGI وكيفية الوصول إلى هذا التطبيق وآلية إعداد خادم Nginx ليعمل مثل خادم وكيل معكوس reverse proxy لدى طرف المستخدم. مستلزمات العمل قبل المتابعة في هذا المقال لا بدّ من: توفّر خادم مثبّت عليه نظام تشغيل أبونتو 20.04 ذو مستخدم عادي ليس مستخدم جذر root وبصلاحيات sudo، مع تفعيل جدار الحماية. تثبيت خادم Nginx. خادم نطاق أسماء للإشارة إلى خادم التطبيق، إذ من الممكن شراء نطاق من Namecheap أو الحصول على نطاق مجاني من Freenom، وفي مقالنا سنفترض أنّ خادم نطاق الأسماء DNS يحوي السجلات التالية: سجل من النوع A يحمل القيمة "your_domain" ويشير إلى عنوان IP العام المُخصّص لخادم التطبيق. سجل من النوع A يحمل القيمة "www.your_domain" يشير إلى عنوان IP العام المُخصّص لخادم التطبيق. إضافةً لما سبق يُفضّل وجود معرفة جيدة بالتعامل مع خادم uWSGI، ومع الخادم الذي سننشئ عليه التطبيق، والفهم الجيد لمواصفات وخصائص بروتوكول WSGI. الخطوة الأولى - تثبيت المكونات اللازمة من مستودعات أبونتو سنثبّت في هذه الخطوة كافّة المكونات التي سنحتاجها من مستودع أبونتو، إضافةً إلى مدير تثبيت حزمة بايثون "pip" لإدارة مكونات بايثون، كما سننزّل ملفات تطوير بايثون الضرورية لبناء خادم "uWSGI". بدايةً سنحدّث موقع دليل الحزمة المحلي: $ sudo apt update ثمّ سنثبّت الحزم اللازمة لبناء بيئة بايثون والتي تشمل الحزمة "python3-pip" وغيرها من الحزم وأدوات التطوير الضرورية للحصول على بيئة برمجية مستقرّة ومتينة: $ sudo apt install python3-pip python3-dev build-essential libssl-dev libffi-dev python3-setuptools الآن وبعد الانتهاء من تثبيت الحزم ننتقل إلى إنشاء البيئة الافتراضية اللازمة لمشروعنا. الخطوة الثانية – إنشاء بيئة بايثون افتراضية سنُعِد في هذه الخطوة البيئة الافتراضية اللازمة لفصل تطبيق فلاسك عن ملفات بايثون الأُخرى في النظام. سنبدأ بتثبيت الحزمة "python-venv" المسؤولة عن تحميل حزم بايثون ضمن بيئة معزولة خاصّة بكل مشروع، والتي ستتثبّت بدورها الوحدة "venv": $ sudo apt install python3-venv الآن سننشئ المجلد الرئيسي لمشروع فلاسك: $ mkdir ~/myproject ثمّ سننتقل إلى هذا المجلد كما يلي: $ cd ~/myproject وفيه سننشئ البيئة الافتراضية اللازمة لتخزين متطلبات بايثون التي سيحتاجها مشروع فلاسك، وذلك بتنفيذ الأمر التالي: $ python3.6 -m venv myprojectenv سيثبّت الأمر السابق نسخةً محليةً من بيئة بايثون ومن الحزمة "pip" في مجلد باسم "myprojectenv" ضمن المجلد الرئيسي للتطبيق. والآن، لا بدّ من تفعيل هذه البيئة الافتراضية قبل تثبيت أي تطبيقات ضمنها على النحو التالي: $ source myprojectenv/bin/activate وهنا نلاحظ تغيّر مؤشّر واجهة أسطر الأوامر ليشير إلى عملنا ضمن البيئة الافتراضية ليصبح على الشّكل: (myprojectenv)user@host:~/myproject$ الخطوة الثالثة - إعداد تطبيق فلاسك الآن، وبعد تفعيل البيئة الافتراضية والعمل ضمنها، أصبح بالإمكان تثبيت فلاسك وخادم "uWSGI" لنباشر بتصميم التطبيق. سنثبّت بدايةً المكوّن "wheel" مع استخدام مُثبّت الحزم "pip"، وبذلك نتأكّد من تثبيت وعمل الحزم بصورةٍ سليمة حتّى في حال عدم وجود "wheel". $ pip install wheel ملاحظة: بغض النظر عن إصدار بايثون المُستخدم، يجب استخدام الأمر pip وليس pip3 عندما تكون البيئة الافتراضية قيد التشغيل. سنثبّت الآن فلاسك وخادم uWSGI: (muprojectenv) $ pip install uwsgi flask وبعد انتهاء التثبيت، يمكننا البدء باستخدام فلاسك. إنشاء تطبيق بمثابة عينة للاختبار الآن، وبعدما أصبح فلاسك جاهزًا، يمكننا الشروع بإنشاء تطبيق بسيط، فكما نعلم فإن فلاسك إطار عمل مًصغّر، لا يحتوي على كثيرٍ من الأدوات مثل تلك التي يمتلكها إطار العمل كامل الميزات، إذ أن فلاسك بالأصل هو مُجرّد وحدة نستوردها إلى مشاريعنا للمساعدة في تهيئة تطبيق الويب. وطالما أنّ التطبيق ككل قد يصبح أكثر تعقيدًا لاحقًا بإضافة مكونات أُخرى عليه، سننشئ تطبيق فلاسك ضمن ملف واحد باستخدام أي محرّر نصوص تفضّله، وفي مقالنا سنستخدم محرّر نانو nano وسنسمّي الملف "myproject.py": (muprojectenv) $ nano ~/myproject/myproject.py أي ستُخزّن الشيفرة الخاصّة بالتطبيق في هذا الملف، وفيها سنستورد فلاسك وننشئ كائن فلاسك الذي سنستخدمه لتعريف الدوال التي ستعمل لدى طلب اتجاهٍ معينة من قبل المُستخدم: from flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "<h1 style='color:blue'>Hello There!</h1>" if __name__ == "__main__": app.run(host='0.0.0.0') حدّدنا في الشيفرة السابقة المحتوى الذي سيُعرض عند الدخول إلى النطاق الأساسي للتطبيق. نحفظ الملف ونغلقه بالضغط على مفتاحي "CTRL+X"، ثمّ "Y"، ثمّ "ENTER" في حال كنت تستخدم محرّر النصوص نانو. وباتباع خطوات إعداد الخادم الابتدائي سيكون جدار حماية UFW قيد التشغيل، وبالتالي لن نتمكّن من الوصول إلى لتطبيق لاختباره ما لم نسمح بالوصول إلى المنفذ 5000 كما يلي: (muprojectenv) $ sudo ufw allow 5000 سنختبر الآن تطبيق فلاسك: (muprojectenv) $ python myproject.py فيكون الخرج مُشابهًا لما يلي، والذي يتضمّن تحذيرات مهمّة ومفيدة تشير لعدم استخدام إعداد الخادم هذا (خادم التطوير) في مرحلة الاستخدام الفعلي للتطبيق (نشر المُنتج). * Serving Flask app "myproject" (lazy loading) * Environment: production WARNING: Do not use the development server in a production environment. Use a production WSGI server instead. * Debug mode: off * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) الآن وباستخدام المتصفح ننتقل إلى عنوان IP الخاص بالخادم متبوعًا برقم المنفذ الخاص بالتطبيق "5000:" على النحو التالي: http://your_server_ip:5000 فتكون النتيجة مُشابهةً لما يلي: وعند الانتهاء نضغط على "CTRL + C" في نافذة مشغّل الأوامر لإيقاف خادم تطوير فلاسك. إنشاء نقطة دخول لتطبيق WSGI في هذه الخطوة سننشئ ملفًا ليعمل مثل نقطة دخول إلى التطبيق، والتي سترشد خادم uWSGI لآلية التفاعل مع التطبيق، لذا سننشئ ملفاً باسم "wsgi.py": (muprojectenv) $ nano ~/myproject/wsgi.py سنستورد في هذا الملف نسخة فلاسك من التطبيق ونشغلها: from myproject import app if __name__ == "__main__": app.run() وبعد الانتهاء نحفظ الملف ونغلقه. الخطوة 4 – إعداد خادم uWSGI حتى الآن كتبنا شيفرة البرنامج مع إنشاء نقطة دخول، وفي هذه الخطوة سنبدأ بإعداد خادم uWSGI. اختبار خادم uWSGI بدايةً وقبل إجراء مزيدٍ من التغييرات، من المفيد اختبار ما إذا كان uWSGI قادرًا على تخديم تطبيقنا هذا، وذلك بتمرير اسم نقطة الدخول المكوّن من اسم الوحدة المُستخدمة بدون اللاحقة "py." مع اسم الاستدعاء داخل التطبيق، وبالتالي في حالتنا سيكون اسم نقطة الدخول هو "wsgi:app". كما أنّنا سنحدّد مقبس ويب للخادم ليعمل على واجهة عامّة، مُستخدمًا بروتوكول HTTP عوضًا عن بروتوكول uwsgi الثنائي، باستخدام نفس رقم المنفذ "5000" المفتوح أصلًا: (muprojectenv) $ uwsgi --socket 0.0.0.0:5000 --protocol=http -w wsgi:app وبالانتقال إلى رابط الخادم (عنوان IP الخاص به) متبوعًا برقم المنفذ "5000:" باستخدام المتصفح: http://your_server_ip:5000 يجب أن نحصل على نفس خرج التطبيق، أي: وبعد التأكد من كون الخادم يعمل كما يجب، نضغط "CTRL +C" في نافذة الطرفية لإيقاف تشغيله. وفي هذه المرحلة ومع الانتهاء من إعداد البيئة الافتراضية، أصبح من الممكن إلغاء تفعيلها: (muprojectenv) $ deactivate وبذلك فإنّ أي أوامر بلغة بايثون ستستخدم بيئة بايثون الموجودة فعليًا على النظام. إنشاء ملف ضبط uWSGI الآن وبعد ما اختبرنا وتأكدنا من قدرة uWSGI على تخديم تطبيقنا (تمكنّا من الوصول إلى خرج التطبيق من خلاله)، ولضمان عمل فعّال وموثوق للتطبيق على المدى الطويل سننشئ ملفًا ضبط uWSGI مُتضمّنًا كافّة الخيارات اللازمة لذلك. سننشئ هذا الملف ضمن مجلد التطبيق الرئيسي باسم "myproject.ini": $ nano ~/myproject/myproject.ini سنبدأ بداخله بالترويسة [uwsgi]، التي تتضمّن الإعدادات الواجب على خادم uWSGI تطبيقها، وفيها سنحدّد الوحدة المُستخدمة وهي في حالتنا "wsgi.py"، إذ نكتب اسمها دون اللاحقة، مع اسم الاستدعاء إلى uWSGI داخل التطبيق وهو "app" على النحو التالي: [uwsgi] module = wsgi:app ومن ثمّ كتبنا الأمر اللازم لتشغيل خادم uWSGI في الوضع الرئيسي Master mode مولدًّا خمس عمليات تابعة لتلك الرئيسية لتخديم الطلبات الفعليّة: [uwsgi] module = wsgi:app master = true processes = 5 ومن الجدير بالملاحظة أنّنا وفي مرحلة الاختبار فتحنا منفذًا مُباشرًا لخادم uWSGI، ولكن بما أنّنا سنستخدم خادم Nginx تاليًا للتعامل مع اتصالات العملاء (زوّار التطبيق) ليمرّر بدوره الطلبات إلى خادم uWSGI، وبما أن هذين المكونين يعملان على حاسوبٍ واحد، فمن المفضّل استخدام مقبس ويب يونكس Unix كونه أسرع وأكثر أمنًا، لذا سنستدعي المقبس "myproject.sock" لنضمّنه في مجلدنا هذا. كما سنغيّر أذونات مقبس الويب هذا بما يمنح خادم Ngnix ملكية عمليات خادم uWSGI، لذا يجب التأكّد من كون مالك المقبس لديه أذونات القراءة منه والكتابة عليه، كما سنفعّل خيار تنظيف المقبس لدى توقّف العمليات بإضافة الخيار vacuum: [uwsgi] module = wsgi:app master = true processes = 5 socket = myproject.sock chmod-socket = 660 vacuum = true ونهايةً سنضيف خيار die-on-term، وبذلك نضمن أنّه لدى كل من النظام المُهيئ وخادم uWSGI نفس الافتراضات حول معنى كل عملية، وبذلك تعمل مكونات النظامين على التوازي وصولًا إلى النتيجة المطلوب تنفيذها. [uwsgi] module = wsgi:app master = true processes = 5 socket = myproject.sock chmod-socket = 660 vacuum = true die-on-term = true نلاحظ أنّنا في هذه الخطوة لم نُحدّد بروتوكولًا كما فعلنا في نافذة أسطر الأوامر سابقًا، ذلك لأنّ خادم uWSGI يستخدم بروتوكول uwsgi افتراضيًا، وهو بروتوكول سريع يتعامل مع النظام الثنائي للعد (يستخدم كامل قيم البايت الواحد)، مُصمّم للتواصل مع الخوادم الأخرى، وخادم Nginx قادرٌ أصلًا على التخاطب معه، وبالتالي يُعد استخدام هذا البروتوكول أفضل من فرض الاتصال باستخدام بروتوكول HTTP. وعند الانتهاء نحفظ الملف ونغلقه. الخطوة الخامسة - إنشاء ملف وحدة الاتصال مع النظام سننشئ في هذه الخطوة ملف وحدة الاتصال التي ستسمح لنظام أوبنتو المُهيّأ أصلًا بتشغيل خادم uWSGI تلقائيًا ليخدّم التطبيق في كل مرة يُشغّل فيها الخادم الفعلي. سننشئ هذا الملف ضمن المسار "etc/system/system/" مع ملاحظة أنّ لاحقته هي "service." كما يلي: $ sudo nano /etc/systemd/system/myproject.service وضمن الملف نكتب الشيفرة بدءًا من القسم [Unit] الذي نحدّد من خلاله البيانات الوصفية metadata ومتطلبات العمل، وفيه نصف طبيعة الخدمة ونجعل النظام الفعلي المُهيّأ يبدأ بالعمل فقط بعد إنتهاء عمليات الربط الشبكي المطلوبة: [Unit] Description=uWSGI instance to serve myproject After=network.target بعدها نكتب القسم [Service]، وفيه نحدّد مكان تنفيذ العمليات، أي المُستخدم والمجموعة الهدف، إذ سنعطي حساب المُستخدم العادي صلاحيات المالك كونه يملك بالفعل كافّة الملفات ذات الصلة بالعمليات الجارية، كما سنعطي المجموعة www-data صلاحيات مالك المجموعة بما يضمن تخاطب سهل ما بين خادم Nginx وعمليات uWSGI الجارية، ومن الضروري في هذا المقطع استبدال اسم المُستخدم بالاسم الخاص بك، كما يلي: [Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=username Group=www-data سنحدّد الآن مجلد العمل، كما سنضبط قيمة متغير البيئة PATH بما يُعلِم النظام الفعلي المُهيّأ بأنّ ملفات تشغيل العمليات موجودةٌ ضمن البيئة الافتراضية، كما سنحدّد الأمر البرمجي المسؤول عن بدء تشغيل الخدمة، والذي يتطلّب تمرير المسار الكامل إلى ملف تشغيل uWSGI المُثبّت في البيئة الافتراضية، كما سنمرر اسم ملف الضبط ذو اللاحقة "ini." الذي أنشأناه أصلًا في مجلد المشروع. ومن المهم استبدال اسم المستخدم username ومسار المشروع بما يتوافق مع معلوماتها لديك. [Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=username Group=www-data WorkingDirectory=/home/username/myproject Environment="PATH=/home/username/myproject/myprojectenv/bin" ExecStart=/home/username/myproject/myprojectenv/bin/uwsgi --ini myproject.ini أمّا الآن فسنضيف القسم [Install]، الذي يُعلم النظام المُهيّأ بمكان ربط الخدمة التي ستبدأ فور إقلاع النظام، إذ أنّ المطلوب في حالتنا جعل الخدمة تبدأ فور إعداد وتشغيل نظام مُستخدمي التطبيق العاديين: [Unit] Description=uWSGI instance to serve myproject After=network.target [Service] User=username Group=www-data WorkingDirectory=/home/username/myproject Environment="PATH=/home/username/myproject/myprojectenv/bin" ExecStart=/home/username/myproject/myprojectenv/bin/uwsgi --ini myproject.ini [Install] WantedBy=multi-user.target وبذلك يكون ملف الخدمة الخاصّ بالنظام الفعلي المُهيّأ جاهزًا. احفظ هذا الملف واغلقه. الآن، سنشغّل خدمة uWSGI التي أنشأناها وجعلناها تبدأ فور الإقلاع: $ sudo systemctl start myproject $ sudo systemctl enable myproject ونتحقّق من حالة عملها كما يلي: $ sudo systemctl status myproject إذا كانت تعمل بصورةٍ صحيحة، فيجب أن نحصل على خرج شبيه بما يلي: ● myproject.service - uWSGI instance to serve myproject Loaded: loaded (/etc/systemd/system/myproject.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2020-05-20 13:21:39 UTC; 8h ago Main PID: 22146 (uwsgi) Tasks: 6 (limit: 2345) Memory: 25.5M CGroup: /system.slice/myproject.service ├─22146 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22161 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22162 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22163 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini ├─22164 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini └─22165 /home/sammy/myproject/myprojectenv/bin/uwsgi --ini myproject.ini وفي حال وجود أي رسائل أخطاء، يجب إيجاد حلول لها قبل المتابعة في الخطوات التالية، أو يمكنك الانتقال لضبط تثبيت Nginx لتمرير الطلبات إلى مقبس "myproject.sock". الخطوة السادسة - ضبط Nginx ليعمل مثل خادم وكيل مع بداية هذه الخطوة يجب أن يكون خادم uWSGI الخاص بالتطبيق جاهزًا وقيد التشغيل، بانتظار الطلبات الواردة إلى ملف مقبس الويب المُنشأ في مجلد المشروع، وفي هذه الخطوة سنضبط خادم Nginx ليمرر طلبات الويب إلى المقبس آنف الذكر باستخدام بروتوكول "uwsgi". لذا، سننشئ ملف ضبط جديد للخادم باسم "myproject" ضمن المجلد "sites-available" الخاص بخادم Nginx: $ sudo nano /etc/nginx/sites-available/myproject وسنكتب ضمن هذا الملف الشيفرة اللازمة لجعل خادم Nginx يصغي للمنفذ الافتراضي ذو الرقم "80" بانتظار أي طلبات واردة، كما سيستخدم هذه الشيفرة أيضًا للتعامل مع طلبات الوصول عن طريق اسم مجال خادم التطبيق. server { listen 80; server_name your_domain www.your_domain; } إذ سنضيف مجموعة شيفرات متوافقة مع كل موقع مطلوب، وفيها سنضمّن الملف "uwsgi_params" المسؤول عن تحديد معاملات uWSGI الواجب ضبطها، ثمّ سنمرر الطلبات إلى ملف مقبس الويب المُعرّف أصلًا باستخدام الموجّه uwsgi_pass: server { listen 80; server_name your_domain www.your_domain; location / { include uwsgi_params; uwsgi_pass unix:/home/sammy/myproject/myproject.sock; } } نحفظ الملف ونغلقه بعد الانتهاء. ولتمكين ملف كتلة إعدادات خادم Nginx هذا، سنربطه مع المجلد "sites-enabled" كما يلي: $ sudo ln -s /etc/nginx/sites-available/myproject /etc/nginx/sites-enabled عند تثبيت مخدم Nginx، يجري إعداد ملف ضبط للمخدم اسمه "default" ضمن المجلد "sites-available"، ثم يُنشأ ارتباط رمزي بين هذا الملف والمجلد "sites-available"؛ فإذا تركت هذا الارتباط الرمزي مكانه، فسيمنع الضبط الافتراضي "default" موقعك من التحميل. يمكنك إزالة هذا الرابط باستخدام الأمر التالي: $ sudo unlink /etc/nginx/sites-enabled/default وسنتمكّن مع وجود الملف ضمن المجلد من فحص أي أخطاء في الصياغة البرمجية باستخدام الشيفرة التالية: $ sudo nginx -t وفي حال عدم ظهور أي أخطاء (أي قيمة معادة لدى تنفيذ الشيفرة السابقة)، نعيد تشغيل عملية Nginx لتتعرّف على الضبط الجديد: $ sudo systemctl restart nginx والآن أصبح من الممكن تعديل جدار الحماية مُجدّدًا، إذ أنّنا لم نعد بحاجة إلى الوصول عبر المنفذ "5000"، لذا سنحذف هذا الاستثناء: $ sudo ufw delete allow 5000 ثمّ سنسمح بالوصول إلى خادم Nginx على النحو التالي: $ sudo ufw allow 'Nginx Full' وبذلك يصبح من الممكن الوصول إلى التطبيق باستخدام اسم المجال الخاص بالخادم عبر المتصفح: http://your_domain فيظهر لنا خرج التطبيق بالشّكل التالي: أمّا إذا واجهت أي أخطاء، فعليك التحقّق منها مُستخدمًا الأوامر التالية: sudo less /var/log/nginx/error.log: للتحقّق من سجل أخطاء خادم Nginx. sudo less /var/log/nginx/access.log: للتحقّق من سجل الوصول إلى خادم Nginx. sudo journalctl -u nginx: للتحقّق من سجل عمليات خادم Nginx. sudo journalctl -u myproject: للتحقّق من سجل خادم uWSGI الخاص بتطبيق فلاسك. الخطوة السابعة - تأمين التطبيق لضمان اتصال ونقل بيانات آمن ومُشفّر من وإلى خادم التطبيق، لا بُدّ من الحصول على شهادة طبقة مقابس الويب الآمنة Secure Socket Layer -أو اختصارًا SSL-؛ وهي شهادةٌ رقميةٌ تصادق على هوية موقع الويب وتتيح اتصالاً مشفرًا، ومن الممكن الحصول على هذه الشهادة مجانًا من Let's Encypt (وهي هيئة شهادات مجانية تابعة لمجموعة أبحاث أمن الإنترنت)، أو إنشاء شهادة خاصّة بك، ناهيك عن وجود طرق عديدة للحصول على الشهادة. لذا بدايةً سنثبّت حزمة Certbot وإضافات Nginx الخاصة به باستخدام apt: $ sudo apt install certbot python3-certbot-nginx يؤمن Certbot عدة طرق مختلفة للحصول على شهادة SSL من خلال هذه الإضافات plugins، وبعد تثبيت إحداها ستعمل إضافة Nginx من تلقاء نفسها على إعادة ضبط إعدادات الخادم وإعادة تحميلها كلما دعت الحاجة لذلك، ولاستخدام هذه الإضافة سنشغّل الأمر: $ sudo certbot --nginx -d your_domain -d www.your_domain تشغّل الشيفرة السابقة certbot مع إضافة nginx–، وقد استخدمنا d- لتحديد الأسماء المتوافقة مع الشهادة. إذا كانت هذه المرة الأولى التي تشغّل فيها certbot على الخادم، سيتطلّب الأمر إدخال بريد إلكتروني والموافقة على شروط الخدمة، بعدها ستتواصل certbot مع خادم Let’s Encrypt، ثم تشغّل نظام تحقّق للتأكد من أنّك تتحكم فعلًا بالنطاق الذي تطلب الشهادة من أجله. فإذا انتهت العملية السابقة بنجاح، سيطلب منا certbot ضبط الإعدادات التي نريد لبروتوكول HTTPS: Please choose whether or not to redirect HTTP traffic to HTTPS, removing HTTP access. ------------------------------------------------------------------------------- 1: No redirect - Make no further changes to the webserver configuration. 2: Redirect - Make all requests redirect to secure HTTPS access. Choose this for new sites, or if you're confident your site works on HTTPS. You can undo this change by editing your web server's configuration. ------------------------------------------------------------------------------- Select the appropriate number [1-2] then [enter] (press 'c' to cancel): في هذه الخطوة نختار ما نريده من إعدادات ثمّ نضغط على مفتاح "ENTER" لتحديث الضبط، كما يُعاد تحميل Nginx لتطبيق الإعدادات الجديدة هذه، ونهايةً يعرض certbot رسالةً مفادها نجاح العملية وموقع تخزين الشهادة: IMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at: /etc/letsencrypt/live/your_domain/fullchain.pem Your key file has been saved at: /etc/letsencrypt/live/your_domain/privkey.pem Your cert will expire on 2020-08-18. To obtain a new or tweaked version of this certificate in the future, simply run certbot again with the "certonly" option. To non-interactively renew *all* of your certificates, run "certbot renew" - Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal. - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-le وإذا اتبعنا تعليمات تثبيت Nginx كما هو موضّح في فقرة مستلزمات العمل من هذا المقال، فلن نعود بحاجة لسماحية ملف تعريف HTTP: $ sudo ufw delete allow 'Nginx HTTP' الآن وللتحقّق من الإعدادات سننتقل مجدّدًا إلى النطاق الخاص بالتطبيق باستخدام "//:https": https://your_domain وهنا يجب أن يظهر خرج التطبيق مجدّدًا ولكن مع مؤشر الأمان الخاص بالمتصفح والذي يشير إلى أنّ الموقع آمن. الخاتمة في هذا المقال أنشأنا تطبيق فلاسك صغير آمن باستخدام بيئة بايثون افتراضية، وأنشأنا نقطة دخول إلى بروتوكول WSGI بحيث يتمكّن أي خادم تطبيق متوافق مع WSGI من التعامل معه، إذ أعددنا خادم uWSGI ليؤدي هذه المهمة، بعدها أنشأنا ملف تخديم مسؤول عن الوصول آليًا خادم التطبيق لدى إقلاع الخادم الفعلي، كما أنشأنا كتلة خادم Nginx التي تمرّر حركة مرور مستخدم الويب إلى خادم التطبيق، وبالتالي تُرحل طلبات مستخدمي التطبيق الخارجية وحركة المرور الآمنة إلى الخادم مع خادم Let's Encrypt. وبذلك نجد أنّ فلاسك إطار عمل مرن جدًا، إذ يمنح التطبيقات القدرة على العمل الفعلي دون التقيد بالهيكل والتصميم، ويمكنك استخدام ما ذُكر في هذا المقال لتخديم أي تطبيق فلاسك ترغب بتصميمه. ترجمة -وبتصرف- للمقال How To Serve Flask Applications with uWSGI and Nginx on Ubuntu 20.04 لصاحبه Mark Drake و Kathleen Juell. اقرأ أيضًا المقال التالي: تعلم بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask بلغة بايثون المقال السابق: استخدام مكتبة بايثون-ماركداون مع إطار عمل فلاسك ومحرك قواعد البيانات SQLite مدخل إلى تطوير تطبيقات الويب باستخدام إطار العمل Flask كيف تُرقِّي خادم Nginx موجود بدون قطع اتصالات العميل فهم بنية ملف إعدادات nginx وسياقات الإعدادات تنصيب، إعداد واستخدام nginx كخادوم ويب -
 يُعد فلاسك إطار عمل لبناء تطبيقات ويب باستخدام لغة بايثون Python، ويمكن استخدام محرّك قواعد البيانات SQLite معه لتخزين بيانات التطبيق. أمّا ماركداون Markdown فهي لغة لتوصيف تنسيق النصوص، شائعة الاستخدام لكتابة المحتوى بتنسيق سهل القراءة والتفسير من قِبل المتصفحات، إذ يمكن -باستخدام ماركداون- تنسيق النصوص الصرفة مع إضافة مميزات لها من عناوين وروابط وصور، ثمّ تحويلها إلى شيفرات HTML موافقة متضمّنةً نفس التنسيقات والمميزات. بايثون-ماركداون Python-Markdown هي مكتبة في لغة بايثون تسمح بتحويل النصوص المُنسقّة باستخدام ماركداون إلى شيفرات HTML موافقة، والتي تتبع معاييّر ماركداون نفسها مع فروق بسيطة في شكل التعليمات. سنستخدم في هذا المقال كل من إطار عمل فلاسك ومحرّك قواعد البيانات SQLite ومكتبة بايثون-ماركداون لبناء تطبيق ويب لتدوين الملاحظات، والذي يدعم تنسيق النصوص وفق ماركداون متيحًا للمستخدمين عرض وإنشاء وتنسيق الملاحظات لتتضمّن عناوينًا وروابطًا وقوائمًا وصور وغيرها من المميزات والتنسيقات، وسنستخدم حزمة بوتستراب Bootstrap لإضافة التنسيقات إلى مظهر التطبيق. مستلزمات العمل قبل المتابعة في هذا المقال لابدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_notes". يجب فهم مختلف مفاهيم فلاسك الأساسية مثل إنشاء الوجهات وتصييّر قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى – إعداد مستلزمات إنشاء التطبيق سنفعّل في هذه الخطوة بيئة بايثون، وسنثبّت كل من فلاسك ومكتبة بايثون-ماركداون باستخدام مثبّت الحزمة "pip"، ومن ثمّ سننشئ قاعدة البيانات التي سنستخدمها لتخزين الملاحظات وبعض البيانات النموذجية. سنفعّل بدايةً البيئة البرمجية في حال لم تكن مُفعلّة أصلًا، كما يلي: $ source env/bin/activate الآن وبعد تفعيل البيئة البرمجية، سنثبّت كل من فلاسك ومكتبة بايثون-ماركداون باستخدام الأمر التالي: (env)user@localhost:$ pip install flask markdown سننشئ الآن ملف تخطيط قاعدة البيانات باسم "schema.sql"، والذي سيتضمّن أوامر SQL اللازمة لإنشاء جدول الملاحظات "notes"، سننشئ هذا الملف ضمن مجلد المشروع "flask_notes": (env)user@localhost:$ nano schema.sql وسنكتب أوامر SQL التالية ضمن الملف الذي أنشأناه: DROP TABLE IF EXISTS notes; CREATE TABLE notes ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL ); يعمل أوّل أمر من أوامر SQL وهو: ;DROP TABLE IF EXISTS posts على حذف أي جداول موجودة مسبقًا باسم notes وهذا ما يجنبنا أي تضاربات قد تحصل مُستقبلًا نتيجة وجود جدولين بنفس الاسم وبأعمدة مُختلفة في قاعدة البيانات، والذي قد يؤدي لتوقف تنفيذ الشيفرة نتيجة عدم توافق الجدول الموجود مع تخطيط قاعدة البيانات، ومن الجدير بالملاحظة أنّ هذا الأمر سيحذف كل المحتويات في قاعدة البيانات في كل مرة تشغّل فيها أوامر SQL هذه، لذا لا تُدخل أي بيانات مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية؛ أمّا الأمر الثاني من أوامر SQL وهو CREATE TABLE notes فيعمل على إنشاء جدول باسم notes بالأعمدة التالية: id: وهو رقم صحيح موجب يمثّل المفتاح الأساسي للجدول، إذ سيُخصص رقم فريد لكل من مدخلات الجدول، والمدخلات في حالتنا هي الملاحظات. created: ويمثّل تاريخ إنشاء الملاحظة والذي يُملأ تلقائيًا بتاريخ ووقت إضافة الملاحظة إلى قاعدة البيانات. content: محتوى الملاحظة. احفظ الملف واغلقه. الآن سننشئ قاعدة البيانات باستخدام ملف تخطيط قاعدة البيانات "schema.sql"، لذا سنفتح ملف باسم "init_db.py" ضمن المجلد "flask_notes": (env)user@localhost:$ nano init_db.py وسنكتب ضمنه الشيفرة التالية: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO notes (content) VALUES (?)", ('# The First Note',)) cur.execute("INSERT INTO notes (content) VALUES (?)", ('_Another note_',)) cur.execute("INSERT INTO notes (content) VALUES (?)", ('Visit [this page](https://www.digitalocean.com/community/tutorials) for more tutorials.',)) connection.commit() connection.close() استوردنا في الشيفرة السابقة بدايةً وحدة sqlite3، ثمّ اتصلنا بملف اسمه "database.db"، والذي يُنشَأ تلقائيًا عند تنفيذ البرنامج، والمُمثّل لقاعدة البيانات التي ستتضمّن كافّة بيانات التطبيق، ثمّ فتحنا ملف تخطيط قاعدة البيانات "schema.sql" وشغّلناه باستخدام الدالة ()executescript المسؤولة عن تنفيذ عدّة تعليمات SQL معًا، وبالنتيجة أنشأنا جدول الملاحظات notes. ثمّ نُفّذت عدّة أوامر إدخال INSERT من أوامر SQL باستخدام كائن المؤشّر Cursor object بهدف إنشاء ثلاث ملاحظات. استخدمنا تعليمات ماركداون بحيث تكون الملاحظة الأولى بتنسيق عنوان من المستوى الأوّل <h1>، والملاحظة الثانية بخط مائل، والملاحظة الثالثة تتضمّن رابطًا، كما استخدمنا الموضع المؤقّت ? في الدالة ()execute ومرّرنا إليها السجل الحاوي على محتويات الملاحظة بما يضمن إدخال البيانات إلى القاعدة بأمان. نهايةً حفظنا التغييرات وأغلقنا الاتصال مع قاعدة البيانات. احفظ الملف واغلقه. الآن نشغّل البرنامج كما يلي: (env)user@localhost:$ python init_db.py سيظهر بعد تنفيذ البرنامج ملفٌ جديد باسم "database.db" ضمن المجلّد "flask_notes"، ومع نهاية هذه الخطوة نكون قد فعّلنا البيئة البرمجية، وثبّتنا كلًا من فلاسك ومكتبة بايثون-ماركداون، كما أنشأنا قاعدة بيانات SQLite، وسنجلب في الخطوة التالية الملاحظات من قاعدة البيانات ونحوّلها إلى ملف من نوع HTML لعرضها ضمن الصفحة الرئيسية للتطبيق. الخطوة الثانية – عرض الملاحظات في الصفحة الرئيسية للتطبيق سننشئ في هذه الخطوة تطبيق فلاسك يتصل بقاعدة البيانات ليعرض البيانات المُخزّنة فيها، إذ سنحوّل النص المُنسّق باستخدام ماركداون إلى ملف HTML والذي سيُصيّر ضمن الصفحة الرئيسية للتطبيق. بدايةً، سننشئ ملف التطبيق "app.py" ضمن المجلد "flask_notes" على النحو التالي: (env)user@localhost:$ nano app.py وسنكتب ضمنه الشيفرة التالية: import sqlite3 import markdown from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn استوردنا في بداية الشيفرة السابقة كلًا من وحدة sqlite3 وحزمة markdown ومُساعد فلاسك، إذ اتصلنا مع ملف قاعدة البيانات "database.db" بواسطة الدالة ()get_db_connection، ثمّ أسندنا القيمة sqlite3.Row للسمة row_factory، وهذا ما سيمكنّنا من الوصول إلى الجداول بأسمائها، وبالنتيجة سيعيد الاتصال مع قاعدة البيانات سجلات تسلك سلوك قواميس بايثون اعتيادية. نهايةً، ستعيد الدالة كائن الاتصال conn الذي سنستخدمه في الوصول إلى قاعدة البيانات. سنضيف بعد الدالة السابقة جزء الشيفرة التالي: #. . . app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' وبذلك نكون أنشأنا كائن تطبيق فلاسك وخصّصنا له مفتاح أمان، ما يضمن كون جلسات العمل آمنة. الآن سنضيف الشيفرة التالية: #. . . @app.route('/') def index(): conn = get_db_connection() db_notes = conn.execute('SELECT id, created, content FROM notes;').fetchall() conn.close() notes = [] for note in db_notes: note = dict(note) note['content'] = markdown.markdown(note['content']) notes.append(note) return render_template('index.html', notes=notes) دالة ()index العاملة في فلاسك هي دالةٌ مُصمّمة باستخدام المُزخرف app.route@، ويحوّل فلاسك القيمة المعادة من هذه الدالة إلى استجابة من نوع HTTP لتُعرض ضمن عميل HTTP مثل متصفح الويب. ونفتح ضمن هذه الدالة اتصالًا مع قاعدة البيانات وننفّذ تعليمة الاختيار SELECT من تعليمات SQL المسؤولة عن جلب المعرّف ID، وتاريخ الإنشاء والمحتوى لكل سجل (ملاحظة) من محتويات جدول الملاحظات notes، ونستخدم الدالة ()fetchall لجلب قائمة بجميع السجلات وحفظها ضمن المتغير db_notes، ونهايةً نغلق الاتصال. الآن، لتحويل محتوى الملاحظات من تنسيق ماركداون إلى HTML، سننشئ قائمةً جديدةً فارغةً باسم notes، لنمر على كافّة عناصر القائمة المحفوظة في المتغير db_notes ونحوّل كل ملاحظة فيها من النمط sqlite3.Row إلى قاموس بايثون عادي باستخدام دالة بايثون ()dict لتمكين عملية التحويل، ثمّ سنستخدم الدالة ()markdown.markdown لتغيير قيمة محتوى الملاحظة ['note['content إلى HTML، إذ سيعيد مثلًا استدعاء الدالة ('markdown.markdown('#Hi سيعيد السلسلة النصية '<h1>Hi</h1>' وذلك لأنّ الرمز # في ماركداون يدل على عنوان من المستوى الأوّل <h1>. الآن، وبعد تعديل محتوى ['note['content نضيف الملاحظة إلى القائمة الجديدة المُسمّاة notes، ونهايةً نصيّر قالب HTML باسم "index.html" عن طريق تمرير القائمة notes إليه. وبعد هذه التعديلات ستبدو الشيفرة على النحو التالي: import sqlite3 import markdown from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' @app.route('/') def index(): conn = get_db_connection() db_notes = conn.execute('SELECT id, created, content FROM notes;').fetchall() conn.close() notes = [] for note in db_notes: note = dict(note) note['content'] = markdown.markdown(note['content']) notes.append(note) return render_template('index.html', notes=notes) احفظ الملف واغلقه. الآن سننشئ القالب الرئيسي وملف القالب index.html، لذا سنضيف مجلدًا للقوالب باسم "templates" ضمن المجلد "flask_notes"، وفيه سنفتح ملف باسم "base.html" كما يلي: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html ونضيف الشيفرة التالية ضمن الملف "base.html"، مع ملاحظة أنّنا نستخدم بوتستراب هنا. <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskNotes</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، ويضمِّن الوسم <script> شيفرة جافا سكربت مسؤولة عن بعض ميزات بوتستراب الإضافية. يسمح الوسم <title>{% block title %} {% endblock %}</title> للقوالب الوارثة (التي ترث خصائصها من قالب HTML الرئيسي) بتعريف عناوين خاصّة بها. استخدمنا الحلقة التكرارية ()for message in get_flashed_messages لعرض الرسائل الخاطفة التحذيرية والتنبيهية؛ أما محتوى القوالب الوارثة فيُضمّن في الموضع المؤقت {% block content %} {% endblock %} الذي يوفرّه القالب الرئيسي مثل إضافة خاصّة بكل قالب يرث منه ما يجنّب تكرار التعليمات. احفظ الملف واغلقه. الآن سننشئ الملف "index.html" الذي سيرث قالب HTML الرئيسي "base.html": (env)user@localhost:$ nano templates/index.html وضمنه سنكتب الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskNotes {% endblock %}</h1> {% for note in notes %} <div class="card"> <div class="card-body"> <span class="badge badge-primary">#{{ note['id'] }}</span> <span class="badge badge-default">{{ note['created'] }}</span> <hr> <p>{{ note['content'] |safe }}</p> </div> </div> <hr> {% endfor %} {% endblock %} وبذلك نكون قد ورثنا خصائص القالب "base.html"، ثمّ عرّفنا عنوان title الملف، ومررنا باستخدام حلقة "for" التكرارية على الملاحظات لنعرض كل منها ضمن بطاقة بوتستراب Bootstrap card، بما يتضمّن معرّف وتاريخ إنشاء ومحتوى الملاحظة، والتي قد حوّلناها أصلًا إلى تنسيق HTML ضمن دالة فلاسك ()index. وقد طبقنا المُرشّح safe| من محرّك القوالب جينجا jinja على محتوى الملاحظات باستخدام | وهذا يُشبه مبدأ استدعاء دالة ما في لغة بايثون (أي أنّ الأمر safe| من أوامر جينجا يشابه بناء الأمر safe(note['content']) في لغة بايثون)، ويُمكّن المُرشّح المتصفح من تصييّر شيفرة HTML، وبدونه ستظهر تعليمات HTML ضمن الصفحة كما هي أي نص صرف، وتُعد هذه ميزة أمان تسمّى "تهريب شيفرة" HTML escaping، من شأنها منع المتصفح من تفسير شيفرات HTML الخبيثة المُسببة لثغرة أمنية خطيرة تسمّى حقن الشيفرات البرمجية cross-site scripting -أو اختصارًا XSS-، وبما أنّ مكتبة بايثون-مارك داون تعيد بالضرورة شيفرات HTML آمنة، فبإمكانك استخدام المُرشّح safe| معها ليتمكّن المتصفح من تصييّر هذه الشيفرات، ومن المهم عدم استخدام هذا المُرشّح إلّا مع شيفرات HTML الآمنة وموثوقة المصدر مثل تلك الناتجة عن مكتبة بايثون-ماركداون. احفظ الملف واغلقه. الآن سنسند القيم اللازمة لمتغيرات بيئة فلاسك، ثمّ سنشغّل التطبيق باستخدام الأوامر التالية: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run يحدّد متغير فلاسك FLASK_APP في الشيفرة السابقة التطبيق المراد تشغيله وهو في حالتنا الملف "app.py"، في حين يحدّد المتغير FLASK_ENV وضع التشغيل وهنا قد اخترنا وضع التطوير development، الذي يعني أنّ التطبيق سيعمل في وضع التطوير مع تشغيل مُنقّح الأخطاء (ومن المهم عدم اختيار هذا الوضع في مرحلة الاستخدام الفعلي للتطبيق أي مرحلة نشر المُنتج)، ونهايةً شغلنا التطبيق باستخدام الأمر flask run. الآن وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفّح سنحصل على الشكل التالي: وبذلك نجد أنّ المتصفح قد صيّر كافّة الملاحظات على أنّها مُصاغة في HTML ولم تظهر نصًا عاديًا كما هو. ومع نهاية هذه الخطوة نكون قد أنشأنا تطبيق فلاسك قادر على الاتصال مع قاعدة البيانات لجلب الملاحظات المحفوظة وتحويل محتوياتها من نص مُنسّق باستخدام ماركداون إلى ما يقابلها في HTML، ليجري تصيير شيفرات HTML هذه في الصفحة الرئيسية للتطبيق. سنضيف في الخطوة التالية اتجاه route يُمكّن المستخدمين من إضافة ملاحظات جديدة والذي بإمكانهم كتابته بتنسيق مارك داون. الخطوة الثالثة – إضافة ملاحظات جديدة سنضيف في هذه الخطوة اتجاه جديد يمكّن المستخدمين من إضافة ملاحظات جديدة مُنسقّة باستخدام مارك داون، إذ سيحفظ التطبيق هذه الملاحظات في قاعدة البيانات لعرضها لاحقًا في صفحة التطبيق الرئيسية مُنسقّة بصورةٍ صحيحة وفقًا للتنسيقات التي أضافها المستخدم، كما سنضيف زرًا في شريط التصفح لنقل المستخدم مباشرةً إلى صفحة إضافة ملاحظة جديدة. سنستخدم نموذج ويب ليُدخل المستخدم ضمنه الملاحظة الجديدة لإضافتها إلى التطبيق وحفظها في قاعدة البيانات. لذا سنفتح الملف "app.py" بهدف إضافة الاتجاه الجديد: (env)user@localhost:$ nano app.py وضمنه سنضيف الشيفرة التالية: #. . . @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() if request.method == 'POST': content = request.form['content'] if not content: flash('Content is required!') return redirect(url_for('index')) conn.execute('INSERT INTO notes (content) VALUES (?)', (content,)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('create.html') وطالما أنّنا سنستخدم هذا الاتجاه لإدخال بيانات جديدة إلى قاعدة البيانات عبر نموذج ويب فكان لا بُدّ من تمكين كلا طريقتي الطلبات GET و POST باستخدام التعليمة ('methods=('GET', 'POST في المُزخرف ()app.route، ثمّ فتحنا اتصالًا مع قاعدة البيانات باستخدام دالة فلاسك ()create. في الشيفرة السابقة: عندما يُدخل المستخدم بيانات في النموذج ويرسلها سيتحقق الشرط 'request.method == 'POST لأنّ هذا الطلب من النوع POST، وعندها نستخلص محتوى الملاحظة باستخدام ['request.form['content لنحفظه ضمن المتغير content، فإذا كان حقل المحتوى فارغًا نعرض للمستخدم رسالةً تحذيريةً تفيد بأن حقل المحتوى مطلوب "'!Content is required" ونعيد توجيهه إلى صفحة التطبيق الرئيسية، وإلّا وفي حال كون حقل المحتوى في النموذج ليس فارغًا فنستخدم تعليمة الإدخال INSERT في SQL لإضافة محتوى الملاحظة إلى جدول الملاحظات notes في قاعدة البيانات، ثمّ نحفظ التغييرات ونغلق الاتصال مع قاعدة البيانات ونعيد توجيه المستخدم إلى الصفحة الرئيسية. إذا كان الطلب من النوع GET، فهذا يعني أنّ المستخدم قد زار الصفحة فقط، وعندها نصيّر قالب HTML ذا الاسم "create.html". احفظ الملف واغلقه. نفتح الآن ملف القالب "create.html": (env)user@localhost:$ nano templates/create.html ونضيف ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Add a New Note {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="content">Note Content</label> <textarea type="text" name="content" placeholder="Note content, you can use Markdown syntax" class="form-control" value="{{ request.form['content'] }}" autofocus></textarea> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} استخدمنا في الشيفرة المضافة إلى القالب نموذجًا للإدخال ذا حقلٍ نصي يتيح للمستخدم كتابة محتوى الملاحظة، وللحفاظ على إمكانية الوصول إلى البيانات المدخلة في حال حدوث أي أخطاء (مثل حالة ترك حقل محتوى الملاحظة فارغًا)، نستخدم الكائن request.form لحفظ البيانات المدخلة في النموذج، كما أضفنا زرًا لتأكيد النموذج أسفل الحقل النصي بحيث يتيح للمستخدم تأكيد النموذج وإرساله ضمن طلب بطريقة POST. احفظ الملف واغلقه. الآن سنفتح ملف قالب HTML الرئيسي "base.html" لإضافة زر "ملاحظة جديدة "New Note" إلى شريط التصفّح: (env)user@localhost:$ nano templates/base.html ونعدّل الشيفرة في الملف لتصبح كما يلي: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskNotes</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> <li class="nav-item active"> <a class="nav-link" href="{{ url_for('create') }}">New Note</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> أضفنا في الشيفرة السابقة عنصر قائمة <li> إلى شريط التصفح واستخدمنا فيه الدالة ()url_for لتأمين الربط مع دالة فلاسك ()create، وهذا ما يضمن الوصول إلى صفحة إنشاء ملاحظة جديدة من شريط التصفح. الآن شغّل خادم التطوير إن لم يكن مُشغّلًا أصلًا باستخدام الأمر التالي: (env)user@localhost:$ flask run الآن، استخدم الرابط "http://127.0.0.1:5000/create" في المتصفّح وأضف الملاحظة التالية المُنسقّة باستخدام مارك داون: ### Flask Flask is a **web** framework for _Python_. Here is the Flask logo:  يتضمّن تنسيق مارك داون للملاحظة السابقة عنوانًا من المستوى الثالث h3 ويجعل كلمة web بخط غامق وكلمة python بخط مائل، كما يتضمّن صورة. وبتأكيد الملاحظة وإرسالها سيحوّل التطبيق التنسيقات إلى مقابلاتها في HTML لتظهر بالشكل التالي: الخاتمة أنشأنا في هذا المقال تطبيق في فلاسك لإدخال الملاحظات المُنسّقة باستخدام ماركداون، ما يسمح للمستخدمين بإضافة التنسيقات لملاحظاتهم بما يتضمّن العناوين باختلاف مستوياتها، والخطوط الغامقة والمائلة، وإضافة الصور والروابط. وربطنا التطبيق مع قاعدة بيانات SQLite لحفظ البيانات وجلبها، إذ سيفسّر التطبيق النصوص المُنسقّة باستخدام ماركداون إلى مقابلاتها من شيفرات HTML ليتمكّن المتصفح من تصييّرها بشكلها المطلوب. ترجمة -وبتصرف- للمقال How To Use Python-Markdown with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال التالي: تخديم تطبيقات فلاسك باستخدام خادمي الويب uWSGI و Nginx أهم 8 مكتبات بلغة البايثون تستخدم في المشاريع الصغيرة إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون كيف ومتى نستخدم SQLite التعامل مع قواعد البيانات SQLite في تطبيقات Flask
يُعد فلاسك إطار عمل لبناء تطبيقات ويب باستخدام لغة بايثون Python، ويمكن استخدام محرّك قواعد البيانات SQLite معه لتخزين بيانات التطبيق. أمّا ماركداون Markdown فهي لغة لتوصيف تنسيق النصوص، شائعة الاستخدام لكتابة المحتوى بتنسيق سهل القراءة والتفسير من قِبل المتصفحات، إذ يمكن -باستخدام ماركداون- تنسيق النصوص الصرفة مع إضافة مميزات لها من عناوين وروابط وصور، ثمّ تحويلها إلى شيفرات HTML موافقة متضمّنةً نفس التنسيقات والمميزات. بايثون-ماركداون Python-Markdown هي مكتبة في لغة بايثون تسمح بتحويل النصوص المُنسقّة باستخدام ماركداون إلى شيفرات HTML موافقة، والتي تتبع معاييّر ماركداون نفسها مع فروق بسيطة في شكل التعليمات. سنستخدم في هذا المقال كل من إطار عمل فلاسك ومحرّك قواعد البيانات SQLite ومكتبة بايثون-ماركداون لبناء تطبيق ويب لتدوين الملاحظات، والذي يدعم تنسيق النصوص وفق ماركداون متيحًا للمستخدمين عرض وإنشاء وتنسيق الملاحظات لتتضمّن عناوينًا وروابطًا وقوائمًا وصور وغيرها من المميزات والتنسيقات، وسنستخدم حزمة بوتستراب Bootstrap لإضافة التنسيقات إلى مظهر التطبيق. مستلزمات العمل قبل المتابعة في هذا المقال لابدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_notes". يجب فهم مختلف مفاهيم فلاسك الأساسية مثل إنشاء الوجهات وتصييّر قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى – إعداد مستلزمات إنشاء التطبيق سنفعّل في هذه الخطوة بيئة بايثون، وسنثبّت كل من فلاسك ومكتبة بايثون-ماركداون باستخدام مثبّت الحزمة "pip"، ومن ثمّ سننشئ قاعدة البيانات التي سنستخدمها لتخزين الملاحظات وبعض البيانات النموذجية. سنفعّل بدايةً البيئة البرمجية في حال لم تكن مُفعلّة أصلًا، كما يلي: $ source env/bin/activate الآن وبعد تفعيل البيئة البرمجية، سنثبّت كل من فلاسك ومكتبة بايثون-ماركداون باستخدام الأمر التالي: (env)user@localhost:$ pip install flask markdown سننشئ الآن ملف تخطيط قاعدة البيانات باسم "schema.sql"، والذي سيتضمّن أوامر SQL اللازمة لإنشاء جدول الملاحظات "notes"، سننشئ هذا الملف ضمن مجلد المشروع "flask_notes": (env)user@localhost:$ nano schema.sql وسنكتب أوامر SQL التالية ضمن الملف الذي أنشأناه: DROP TABLE IF EXISTS notes; CREATE TABLE notes ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL ); يعمل أوّل أمر من أوامر SQL وهو: ;DROP TABLE IF EXISTS posts على حذف أي جداول موجودة مسبقًا باسم notes وهذا ما يجنبنا أي تضاربات قد تحصل مُستقبلًا نتيجة وجود جدولين بنفس الاسم وبأعمدة مُختلفة في قاعدة البيانات، والذي قد يؤدي لتوقف تنفيذ الشيفرة نتيجة عدم توافق الجدول الموجود مع تخطيط قاعدة البيانات، ومن الجدير بالملاحظة أنّ هذا الأمر سيحذف كل المحتويات في قاعدة البيانات في كل مرة تشغّل فيها أوامر SQL هذه، لذا لا تُدخل أي بيانات مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية؛ أمّا الأمر الثاني من أوامر SQL وهو CREATE TABLE notes فيعمل على إنشاء جدول باسم notes بالأعمدة التالية: id: وهو رقم صحيح موجب يمثّل المفتاح الأساسي للجدول، إذ سيُخصص رقم فريد لكل من مدخلات الجدول، والمدخلات في حالتنا هي الملاحظات. created: ويمثّل تاريخ إنشاء الملاحظة والذي يُملأ تلقائيًا بتاريخ ووقت إضافة الملاحظة إلى قاعدة البيانات. content: محتوى الملاحظة. احفظ الملف واغلقه. الآن سننشئ قاعدة البيانات باستخدام ملف تخطيط قاعدة البيانات "schema.sql"، لذا سنفتح ملف باسم "init_db.py" ضمن المجلد "flask_notes": (env)user@localhost:$ nano init_db.py وسنكتب ضمنه الشيفرة التالية: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO notes (content) VALUES (?)", ('# The First Note',)) cur.execute("INSERT INTO notes (content) VALUES (?)", ('_Another note_',)) cur.execute("INSERT INTO notes (content) VALUES (?)", ('Visit [this page](https://www.digitalocean.com/community/tutorials) for more tutorials.',)) connection.commit() connection.close() استوردنا في الشيفرة السابقة بدايةً وحدة sqlite3، ثمّ اتصلنا بملف اسمه "database.db"، والذي يُنشَأ تلقائيًا عند تنفيذ البرنامج، والمُمثّل لقاعدة البيانات التي ستتضمّن كافّة بيانات التطبيق، ثمّ فتحنا ملف تخطيط قاعدة البيانات "schema.sql" وشغّلناه باستخدام الدالة ()executescript المسؤولة عن تنفيذ عدّة تعليمات SQL معًا، وبالنتيجة أنشأنا جدول الملاحظات notes. ثمّ نُفّذت عدّة أوامر إدخال INSERT من أوامر SQL باستخدام كائن المؤشّر Cursor object بهدف إنشاء ثلاث ملاحظات. استخدمنا تعليمات ماركداون بحيث تكون الملاحظة الأولى بتنسيق عنوان من المستوى الأوّل <h1>، والملاحظة الثانية بخط مائل، والملاحظة الثالثة تتضمّن رابطًا، كما استخدمنا الموضع المؤقّت ? في الدالة ()execute ومرّرنا إليها السجل الحاوي على محتويات الملاحظة بما يضمن إدخال البيانات إلى القاعدة بأمان. نهايةً حفظنا التغييرات وأغلقنا الاتصال مع قاعدة البيانات. احفظ الملف واغلقه. الآن نشغّل البرنامج كما يلي: (env)user@localhost:$ python init_db.py سيظهر بعد تنفيذ البرنامج ملفٌ جديد باسم "database.db" ضمن المجلّد "flask_notes"، ومع نهاية هذه الخطوة نكون قد فعّلنا البيئة البرمجية، وثبّتنا كلًا من فلاسك ومكتبة بايثون-ماركداون، كما أنشأنا قاعدة بيانات SQLite، وسنجلب في الخطوة التالية الملاحظات من قاعدة البيانات ونحوّلها إلى ملف من نوع HTML لعرضها ضمن الصفحة الرئيسية للتطبيق. الخطوة الثانية – عرض الملاحظات في الصفحة الرئيسية للتطبيق سننشئ في هذه الخطوة تطبيق فلاسك يتصل بقاعدة البيانات ليعرض البيانات المُخزّنة فيها، إذ سنحوّل النص المُنسّق باستخدام ماركداون إلى ملف HTML والذي سيُصيّر ضمن الصفحة الرئيسية للتطبيق. بدايةً، سننشئ ملف التطبيق "app.py" ضمن المجلد "flask_notes" على النحو التالي: (env)user@localhost:$ nano app.py وسنكتب ضمنه الشيفرة التالية: import sqlite3 import markdown from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn استوردنا في بداية الشيفرة السابقة كلًا من وحدة sqlite3 وحزمة markdown ومُساعد فلاسك، إذ اتصلنا مع ملف قاعدة البيانات "database.db" بواسطة الدالة ()get_db_connection، ثمّ أسندنا القيمة sqlite3.Row للسمة row_factory، وهذا ما سيمكنّنا من الوصول إلى الجداول بأسمائها، وبالنتيجة سيعيد الاتصال مع قاعدة البيانات سجلات تسلك سلوك قواميس بايثون اعتيادية. نهايةً، ستعيد الدالة كائن الاتصال conn الذي سنستخدمه في الوصول إلى قاعدة البيانات. سنضيف بعد الدالة السابقة جزء الشيفرة التالي: #. . . app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' وبذلك نكون أنشأنا كائن تطبيق فلاسك وخصّصنا له مفتاح أمان، ما يضمن كون جلسات العمل آمنة. الآن سنضيف الشيفرة التالية: #. . . @app.route('/') def index(): conn = get_db_connection() db_notes = conn.execute('SELECT id, created, content FROM notes;').fetchall() conn.close() notes = [] for note in db_notes: note = dict(note) note['content'] = markdown.markdown(note['content']) notes.append(note) return render_template('index.html', notes=notes) دالة ()index العاملة في فلاسك هي دالةٌ مُصمّمة باستخدام المُزخرف app.route@، ويحوّل فلاسك القيمة المعادة من هذه الدالة إلى استجابة من نوع HTTP لتُعرض ضمن عميل HTTP مثل متصفح الويب. ونفتح ضمن هذه الدالة اتصالًا مع قاعدة البيانات وننفّذ تعليمة الاختيار SELECT من تعليمات SQL المسؤولة عن جلب المعرّف ID، وتاريخ الإنشاء والمحتوى لكل سجل (ملاحظة) من محتويات جدول الملاحظات notes، ونستخدم الدالة ()fetchall لجلب قائمة بجميع السجلات وحفظها ضمن المتغير db_notes، ونهايةً نغلق الاتصال. الآن، لتحويل محتوى الملاحظات من تنسيق ماركداون إلى HTML، سننشئ قائمةً جديدةً فارغةً باسم notes، لنمر على كافّة عناصر القائمة المحفوظة في المتغير db_notes ونحوّل كل ملاحظة فيها من النمط sqlite3.Row إلى قاموس بايثون عادي باستخدام دالة بايثون ()dict لتمكين عملية التحويل، ثمّ سنستخدم الدالة ()markdown.markdown لتغيير قيمة محتوى الملاحظة ['note['content إلى HTML، إذ سيعيد مثلًا استدعاء الدالة ('markdown.markdown('#Hi سيعيد السلسلة النصية '<h1>Hi</h1>' وذلك لأنّ الرمز # في ماركداون يدل على عنوان من المستوى الأوّل <h1>. الآن، وبعد تعديل محتوى ['note['content نضيف الملاحظة إلى القائمة الجديدة المُسمّاة notes، ونهايةً نصيّر قالب HTML باسم "index.html" عن طريق تمرير القائمة notes إليه. وبعد هذه التعديلات ستبدو الشيفرة على النحو التالي: import sqlite3 import markdown from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' @app.route('/') def index(): conn = get_db_connection() db_notes = conn.execute('SELECT id, created, content FROM notes;').fetchall() conn.close() notes = [] for note in db_notes: note = dict(note) note['content'] = markdown.markdown(note['content']) notes.append(note) return render_template('index.html', notes=notes) احفظ الملف واغلقه. الآن سننشئ القالب الرئيسي وملف القالب index.html، لذا سنضيف مجلدًا للقوالب باسم "templates" ضمن المجلد "flask_notes"، وفيه سنفتح ملف باسم "base.html" كما يلي: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html ونضيف الشيفرة التالية ضمن الملف "base.html"، مع ملاحظة أنّنا نستخدم بوتستراب هنا. <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskNotes</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، ويضمِّن الوسم <script> شيفرة جافا سكربت مسؤولة عن بعض ميزات بوتستراب الإضافية. يسمح الوسم <title>{% block title %} {% endblock %}</title> للقوالب الوارثة (التي ترث خصائصها من قالب HTML الرئيسي) بتعريف عناوين خاصّة بها. استخدمنا الحلقة التكرارية ()for message in get_flashed_messages لعرض الرسائل الخاطفة التحذيرية والتنبيهية؛ أما محتوى القوالب الوارثة فيُضمّن في الموضع المؤقت {% block content %} {% endblock %} الذي يوفرّه القالب الرئيسي مثل إضافة خاصّة بكل قالب يرث منه ما يجنّب تكرار التعليمات. احفظ الملف واغلقه. الآن سننشئ الملف "index.html" الذي سيرث قالب HTML الرئيسي "base.html": (env)user@localhost:$ nano templates/index.html وضمنه سنكتب الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskNotes {% endblock %}</h1> {% for note in notes %} <div class="card"> <div class="card-body"> <span class="badge badge-primary">#{{ note['id'] }}</span> <span class="badge badge-default">{{ note['created'] }}</span> <hr> <p>{{ note['content'] |safe }}</p> </div> </div> <hr> {% endfor %} {% endblock %} وبذلك نكون قد ورثنا خصائص القالب "base.html"، ثمّ عرّفنا عنوان title الملف، ومررنا باستخدام حلقة "for" التكرارية على الملاحظات لنعرض كل منها ضمن بطاقة بوتستراب Bootstrap card، بما يتضمّن معرّف وتاريخ إنشاء ومحتوى الملاحظة، والتي قد حوّلناها أصلًا إلى تنسيق HTML ضمن دالة فلاسك ()index. وقد طبقنا المُرشّح safe| من محرّك القوالب جينجا jinja على محتوى الملاحظات باستخدام | وهذا يُشبه مبدأ استدعاء دالة ما في لغة بايثون (أي أنّ الأمر safe| من أوامر جينجا يشابه بناء الأمر safe(note['content']) في لغة بايثون)، ويُمكّن المُرشّح المتصفح من تصييّر شيفرة HTML، وبدونه ستظهر تعليمات HTML ضمن الصفحة كما هي أي نص صرف، وتُعد هذه ميزة أمان تسمّى "تهريب شيفرة" HTML escaping، من شأنها منع المتصفح من تفسير شيفرات HTML الخبيثة المُسببة لثغرة أمنية خطيرة تسمّى حقن الشيفرات البرمجية cross-site scripting -أو اختصارًا XSS-، وبما أنّ مكتبة بايثون-مارك داون تعيد بالضرورة شيفرات HTML آمنة، فبإمكانك استخدام المُرشّح safe| معها ليتمكّن المتصفح من تصييّر هذه الشيفرات، ومن المهم عدم استخدام هذا المُرشّح إلّا مع شيفرات HTML الآمنة وموثوقة المصدر مثل تلك الناتجة عن مكتبة بايثون-ماركداون. احفظ الملف واغلقه. الآن سنسند القيم اللازمة لمتغيرات بيئة فلاسك، ثمّ سنشغّل التطبيق باستخدام الأوامر التالية: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run يحدّد متغير فلاسك FLASK_APP في الشيفرة السابقة التطبيق المراد تشغيله وهو في حالتنا الملف "app.py"، في حين يحدّد المتغير FLASK_ENV وضع التشغيل وهنا قد اخترنا وضع التطوير development، الذي يعني أنّ التطبيق سيعمل في وضع التطوير مع تشغيل مُنقّح الأخطاء (ومن المهم عدم اختيار هذا الوضع في مرحلة الاستخدام الفعلي للتطبيق أي مرحلة نشر المُنتج)، ونهايةً شغلنا التطبيق باستخدام الأمر flask run. الآن وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفّح سنحصل على الشكل التالي: وبذلك نجد أنّ المتصفح قد صيّر كافّة الملاحظات على أنّها مُصاغة في HTML ولم تظهر نصًا عاديًا كما هو. ومع نهاية هذه الخطوة نكون قد أنشأنا تطبيق فلاسك قادر على الاتصال مع قاعدة البيانات لجلب الملاحظات المحفوظة وتحويل محتوياتها من نص مُنسّق باستخدام ماركداون إلى ما يقابلها في HTML، ليجري تصيير شيفرات HTML هذه في الصفحة الرئيسية للتطبيق. سنضيف في الخطوة التالية اتجاه route يُمكّن المستخدمين من إضافة ملاحظات جديدة والذي بإمكانهم كتابته بتنسيق مارك داون. الخطوة الثالثة – إضافة ملاحظات جديدة سنضيف في هذه الخطوة اتجاه جديد يمكّن المستخدمين من إضافة ملاحظات جديدة مُنسقّة باستخدام مارك داون، إذ سيحفظ التطبيق هذه الملاحظات في قاعدة البيانات لعرضها لاحقًا في صفحة التطبيق الرئيسية مُنسقّة بصورةٍ صحيحة وفقًا للتنسيقات التي أضافها المستخدم، كما سنضيف زرًا في شريط التصفح لنقل المستخدم مباشرةً إلى صفحة إضافة ملاحظة جديدة. سنستخدم نموذج ويب ليُدخل المستخدم ضمنه الملاحظة الجديدة لإضافتها إلى التطبيق وحفظها في قاعدة البيانات. لذا سنفتح الملف "app.py" بهدف إضافة الاتجاه الجديد: (env)user@localhost:$ nano app.py وضمنه سنضيف الشيفرة التالية: #. . . @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() if request.method == 'POST': content = request.form['content'] if not content: flash('Content is required!') return redirect(url_for('index')) conn.execute('INSERT INTO notes (content) VALUES (?)', (content,)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('create.html') وطالما أنّنا سنستخدم هذا الاتجاه لإدخال بيانات جديدة إلى قاعدة البيانات عبر نموذج ويب فكان لا بُدّ من تمكين كلا طريقتي الطلبات GET و POST باستخدام التعليمة ('methods=('GET', 'POST في المُزخرف ()app.route، ثمّ فتحنا اتصالًا مع قاعدة البيانات باستخدام دالة فلاسك ()create. في الشيفرة السابقة: عندما يُدخل المستخدم بيانات في النموذج ويرسلها سيتحقق الشرط 'request.method == 'POST لأنّ هذا الطلب من النوع POST، وعندها نستخلص محتوى الملاحظة باستخدام ['request.form['content لنحفظه ضمن المتغير content، فإذا كان حقل المحتوى فارغًا نعرض للمستخدم رسالةً تحذيريةً تفيد بأن حقل المحتوى مطلوب "'!Content is required" ونعيد توجيهه إلى صفحة التطبيق الرئيسية، وإلّا وفي حال كون حقل المحتوى في النموذج ليس فارغًا فنستخدم تعليمة الإدخال INSERT في SQL لإضافة محتوى الملاحظة إلى جدول الملاحظات notes في قاعدة البيانات، ثمّ نحفظ التغييرات ونغلق الاتصال مع قاعدة البيانات ونعيد توجيه المستخدم إلى الصفحة الرئيسية. إذا كان الطلب من النوع GET، فهذا يعني أنّ المستخدم قد زار الصفحة فقط، وعندها نصيّر قالب HTML ذا الاسم "create.html". احفظ الملف واغلقه. نفتح الآن ملف القالب "create.html": (env)user@localhost:$ nano templates/create.html ونضيف ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Add a New Note {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="content">Note Content</label> <textarea type="text" name="content" placeholder="Note content, you can use Markdown syntax" class="form-control" value="{{ request.form['content'] }}" autofocus></textarea> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} استخدمنا في الشيفرة المضافة إلى القالب نموذجًا للإدخال ذا حقلٍ نصي يتيح للمستخدم كتابة محتوى الملاحظة، وللحفاظ على إمكانية الوصول إلى البيانات المدخلة في حال حدوث أي أخطاء (مثل حالة ترك حقل محتوى الملاحظة فارغًا)، نستخدم الكائن request.form لحفظ البيانات المدخلة في النموذج، كما أضفنا زرًا لتأكيد النموذج أسفل الحقل النصي بحيث يتيح للمستخدم تأكيد النموذج وإرساله ضمن طلب بطريقة POST. احفظ الملف واغلقه. الآن سنفتح ملف قالب HTML الرئيسي "base.html" لإضافة زر "ملاحظة جديدة "New Note" إلى شريط التصفّح: (env)user@localhost:$ nano templates/base.html ونعدّل الشيفرة في الملف لتصبح كما يلي: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskNotes</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> <li class="nav-item active"> <a class="nav-link" href="{{ url_for('create') }}">New Note</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> أضفنا في الشيفرة السابقة عنصر قائمة <li> إلى شريط التصفح واستخدمنا فيه الدالة ()url_for لتأمين الربط مع دالة فلاسك ()create، وهذا ما يضمن الوصول إلى صفحة إنشاء ملاحظة جديدة من شريط التصفح. الآن شغّل خادم التطوير إن لم يكن مُشغّلًا أصلًا باستخدام الأمر التالي: (env)user@localhost:$ flask run الآن، استخدم الرابط "http://127.0.0.1:5000/create" في المتصفّح وأضف الملاحظة التالية المُنسقّة باستخدام مارك داون: ### Flask Flask is a **web** framework for _Python_. Here is the Flask logo:  يتضمّن تنسيق مارك داون للملاحظة السابقة عنوانًا من المستوى الثالث h3 ويجعل كلمة web بخط غامق وكلمة python بخط مائل، كما يتضمّن صورة. وبتأكيد الملاحظة وإرسالها سيحوّل التطبيق التنسيقات إلى مقابلاتها في HTML لتظهر بالشكل التالي: الخاتمة أنشأنا في هذا المقال تطبيق في فلاسك لإدخال الملاحظات المُنسّقة باستخدام ماركداون، ما يسمح للمستخدمين بإضافة التنسيقات لملاحظاتهم بما يتضمّن العناوين باختلاف مستوياتها، والخطوط الغامقة والمائلة، وإضافة الصور والروابط. وربطنا التطبيق مع قاعدة بيانات SQLite لحفظ البيانات وجلبها، إذ سيفسّر التطبيق النصوص المُنسقّة باستخدام ماركداون إلى مقابلاتها من شيفرات HTML ليتمكّن المتصفح من تصييّرها بشكلها المطلوب. ترجمة -وبتصرف- للمقال How To Use Python-Markdown with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا المقال التالي: تخديم تطبيقات فلاسك باستخدام خادمي الويب uWSGI و Nginx أهم 8 مكتبات بلغة البايثون تستخدم في المشاريع الصغيرة إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون كيف ومتى نستخدم SQLite التعامل مع قواعد البيانات SQLite في تطبيقات Flask -
 يُعد فلاسك إطار عمل لبناء تطبيقات الويب مبني باستخدام لغة بايثون، أما SQLite، فهو محرك قواعد بيانات يُستخدم مع بايثون لتخزين بيانات التطبيقات. سنبني في هذا المقال مختصِرًا للروابط URL shortener ليحوّل أي رابط إلى آخر مُختصَر وأكثر موثوقية بما يشبه مبدأ عمل موقع bit.ly. سنستخدم في بناء تطبيقنا مكتبة التعمية Hashids لتوليد سلاسل فريدة لمُعرّفات الروابط؛ إذ أن هذه المكتبة مُختصّةٌ بتوليد مُعرّفات مميزة قصيرة unique ID انطلاقًا من أرقام صحيحة، إذ تحوّل مثلاً الرقم "12" إلى سلسلة فريدة مثل "1Xcld". يمكن استخدام السلاسل الفريدة هذه لتوليد معرّفات لا يمكن التنبؤ بها سواءٌ للفيديوهات على مواقع مشاركة الفيديوهات، أو الصور في خدمة رفع الصور وغيرها. ففي حال وصول المستخدم مثلًا إلى صورةٍ ذات رابط "your_domain/image/J32Fr"، فلا يمكنه التنبؤ بمواقع الصور الأخرى، على عكس حالة استخدام معرفّات مؤلفّة من أرقام صحيحة في مختصر الروابط، فمثلاً لو كان رابط الصورة "your_domain/image/33"، فسيتمكن المستخدم من التنبؤ بمواقع الصور الأخرى بسهولة، وبالتالي يقدِّم استخدام روابط بمعرّفات غير قابلة للتنبؤ نوعًا من الخصوصية للخادم، كونها تمنع المستخدمين من اكتشاف الروابط المختصرة المُستخدمة من قِبل المستخدمين الآخرين. سنبني إذًا مختصِرًا للروابط باستخدام فلاسك وSQLite ومكتبة Hashids، بحيث يتمكّن المستخدمون من إدخال روابط وتوليد نسخٍ مختصرةٍ منها، إضافةً إلى توفير صفحة إحصاءات يمكن للمستخدمين من خلالها متابعة عدد مرات زيارة الرابط، كما سنستخدم بوتستراب bootstrap لإضافة التنسيقات للتطبيق. مستلزمات العمل قبل المتابعة في هذا المقال لا بدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو flask_shortener. فهم مبادئ فلاسك، مثل بناء الوجهات وإخراج نماذج HTML والاتصال بقواعد بيانات SQLite، ويمكنك الاطلاع على [هذا المقال](رابط المقال الأوّل بعد نشره) لمزيدٍ من المعلومات حول هذه النقاط. الخطوة الأولى- إعداد المتطلبات سنفعّل في هذه الخطوة بيئة بايثون ونثبّت فلاسك باستخدام مثبِّت الحزم pip، ثم سننشئ قاعدة بيانات سنستخدمها لتخزين الروابط، وفي حال كون بيئة البرمجة غير مفعّلة بعد، سنستخدم الأمر التالي لتفعيلها: $ source env/bin/activate وبعد تفعيل بيئة البرمجة، سنثبّت فلاسك ومكتبة Hashids باستخدام الأمر التالي: (env)user@localhost:$ pip install flask hashids ثمّ سننشئ ملف تخطيط قاعدة البيانات باسم schema.sql، ليحتوي أوامر SQL اللازمة لإنشاء جدول للعناوين باسم urls. لذا، سننشئ الملف schema.sql داخل المجلد flask_shortener كما يلي: (env)user@localhost:$ nano schema.sql ونكتب أوامر SQL التالية فيه: DROP TABLE IF EXISTS urls; CREATE TABLE urls ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, original_url TEXT NOT NULL, clicks INTEGER NOT NULL DEFAULT 0 ); أول سطرٍ من شيفرة SQL السابقة مسؤولٌ عن حذف أي جداول موجودةٍ سابقًا ضمن قاعدة البيانات urls، وبذلك لن يكون هناك أي سلوك متضارب أو عشوائي ناجمٍ عن تشابه الأسماء ضمن قاعدة البيانات، والجدير بالملاحظة أنّ تطبيق هذين الأمر سيؤدي إلى حذف كامل محتوى قاعدة البيانات الحالي، لذا لا تُدخل أي بياناتٍ مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية. بعد ذلك، سننشئ جدولًا يحتوي الأعمدة التالية: "id": ويحتوي بياناتٍ من نوع رقم صحيح ويمثِّل المعرّف الفريد لكل رابطٍ مُدخل، وسنستخدم هذا المعرّف لاحقًا في استنتاج الرابط الأصلي من سلسلة محارف عشوائية معمّاة Hash string. "created": يحتوي على تاريخ ووقت اختصار الرابط. "original_url": يحتوي على الرابط الكامل الأصلي قبل الاختصار والذي سيُعاد توجيه المستخدمين إليه. "clicks": يحتوي على عدد مرات النقر على الرابط. ستكون قيمته الابتدائية 0، وتزداد مع كل إعادة توجيه. اِحفظ الملف وأغلقه. الآن لتنفيذ ملف schema.sql المسؤول عن بناء جدول الروابط urls، سننشئ ملفًا باسم int_db.py داخل مجلد flasks_hortener: (env)user@localhost:$ nano init_db.py ونضيف الشيفرة التالية إليه: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) connection.commit() connection.close() إذ يحدث في البداية اتصالٌ مع الملف database.db المُنشأ تلقائيًا عند تنفيذ البرنامج السابق، ويمثّل هذا الملف قاعدة البيانات التي ستخزّن كامل بيانات التطبيق، ثم يُفتح بعد ذلك ملف تخطيط قاعدة البيانات schema.sql ويُشغَّل باستخدام التابع ()executscript القادر على تنفيذ عدّة تعليمات SQL معًا، وهذا ما سينشئ بالنتيجة جدول الروابط urls، وفي النهاية نؤكِّد على التغييرات ويُغلق الاتصال مع قاعدة البيانات. اِحفظ الملف وأغلقه. الآن، نشغّل البرنامج: (env)user@localhost:$ python init_db.py وبعد انتهاء تنفيذه، سيظهر ملفٌ جديدٌ باسم database.db ضمن المجلد flask_shortener. وبنهاية الخطوة الأولى، نكون قد ثبّتنا فلاسك ومكتبة Hashids، وأنشأنا مخطّط قاعدة البيانات إضافةً لقاعدة بيانات SQLite تحتوي جدولًا باسم "urls" مخصّصًا لتخزين العناوين الأصلية لتلك المُختصرة. سنستخدم فيما يلي فلاسك لإنشاء الصفحة الرئيسية index والتي سيتمكّن المستخدمون من خلالها من إدخال الروابط المطلوب اختصارها. الخطوة الثانية - إنشاء الصفحة الرئيسية لتطبيق اختصار الروابط سننشئ في هذه الخطوة الوجهة اللازم لعمل الصفحة الرئيسية index، والذي يمكّن المستخدمين من إدخال الروابط الأصلية المراد اختصارها؛ إذ ستُخزَّن هذه الروابط في قاعدة البيانات بدايةً، ويستخدم المعرّف الفريد للرابط لتوليد سلسلة محارف قصيرة معمّاة باستخدام مكتبة Hashids، ويبني الرابط المُختصر ويخرجه نتيجةً. سننشئ الآن الملف الأساسي لتطبيق فلاسك باسم app.py ضمن المجلد flask_shortener: (env)user@localhost:$ nano app.py ونضيف الشيفرة التالية ضمنه: import sqlite3 from hashids import Hashids from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn نبدأ بالشيفرة السابقة باستيراد الوحدة sqlite3، والصنف Hashids من المكتبة hashids، إضافةً للمساعد الخاص بإطار فلاسك، ثم تفتح الدالة ()get_db_connection اتصالًا مع ملف قاعدة البيانات database.db، وتعيّن قيمة السمة row_factory لتكون sqlite3.Row لنتمكّن من الوصول لأعمدة جدول قاعدة البيانات باستخدام أسمائها؛ وهذا يعني أنّ اتصال قاعدة البيانات سيعيد سجلات يمكننا التعامل معها كما هو الحال مع قواميس بايثون Dictionaries الاعتيادية (وحدات تخزين القيم المنظمّة في بايثون)، وفي النهاية تعيد الدالة كائن الاتصال conn، الذي سيُستخدم للوصول إلى قاعدة البيانات. سنضيف الآن الشيفرة التالية: . . . app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' hashids = Hashids(min_length=4, salt=app.config['SECRET_KEY']) التي تنشئ كائن تطبيق فلاسك وتحدِّد مفتاح الأمان لجعل الجلسات آمنة، وبما أنّ مفتاح الأمان هو أيضًا سلسلة محارف عشوائية وسريّة، فسنستخدمها مصدرًا لمحارف الإغفال salt لمكتبة التعمية Hashids بما يضمن كون السلاسل المعمّاة الناتجة غير قابلة للتنبؤ كونها ستتغير بتغيّر محارف الإغفال المتغيرة أصلًا باستمرار مع تغيُّر مفتاح الأمان. احرص على إبقاء محارف الإغفال سريةً حفاظًا على الأمان، ولهذا السبب ارتأينا أنّه من الأفضل استخدام مفتاح الأمان الخاص بالتطبيق على هيئة محارف إغفال. وبذلك نكون أنشأنا كائن تعمية hashids يضمن كون كل سلسلة معمّاة مؤلفّة من 4 محارف على الأقل عبر تمرير هذه القيمة إلى المعامل min_length من هذا الكائن، واستخدمنا مفتاح أمان التطبيق مثل محرف إغفال. سنضيف الآن الشيفرة التالية إلى نهاية الملف: . . . @app.route('/', methods=('GET', 'POST')) def index(): conn = get_db_connection() if request.method == 'POST': url = request.form['url'] if not url: flash('The URL is required!') return redirect(url_for('index')) url_data = conn.execute('INSERT INTO urls (original_url) VALUES (?)', (url,)) conn.commit() conn.close() url_id = url_data.lastrowid hashid = hashids.encode(url_id) short_url = request.host_url + hashid return render_template('index.html', short_url=short_url) return render_template('index.html') يعدِّل المزخرف app.route@ دوال بايثون المألوفة لتصبح دوالًا عاملةً في فلاسك مثل الدالة ()index، التي تُحوَّل القيمة المعادة منها إلى استجابةٍ من نوع HTTP تُعرض لدى عميل HTTP الذي قد يكون متصفحًا مثلًا. وضمن بناء دالة فلاسك ()index، سنمرّر السطر التالي: methods=('GET', 'POST') الحاوي على طرائق الطلبات المقبولة إلى وسيط الطرائق methods في المزخرف ()app.route، ما يضمن قبول الطلبات سواءً بطريقة GET أو POST. الآن سيُفتح اتصالٌ مع قاعدة البيانات، فإذا كان الطلب بطريقة GET، نتجاوز الشرط: if request.method == 'POST' وصولًا إلى آخر سطر في الشيفرة والمسؤول عن إخراج قالب HTML باسم index.html، الذي سيحتوي على نموذج إدخال الروابط المُراد اختصارها؛ أما في حال تحقّق الشرط السابق، فهذا يعني أنّه قد أُدخل رابطٌ من قِبل المستخدم لاختصاره، فيُخزَّن هذا الرابط ضمن المتغير url؛ أمّا في حال إرسال المستخدم النموذج دون إدخال رابط، فستظهر له رسالةً تخبره بأنّ حقل الرابط مطلوب "!The URL is required" ويُعاد توجيهه إلى الصفحة الرئيسية index مجدّدًا. وعندما يرسل المستخدم نموذجًا حاويًا على رابط، يُخزّن هذا الرابط في جدول urls من قاعدة البيانات باستخدام تعليمة INSERT INTO في SQL، كما يُضمَّن الموضع المؤقت ? (الذي سيُستبدل لاحقًا برقمٍ ما) في الدالة ()execute، ومن ثمّ يُمرّر السجل الحاوي على الرابط المطلوب اختصاره ليُحفظ في قاعدة البيانات بأمان، وفي النهاية تؤكَّد العملية ويُقطع الاتصال مع قاعدة البيانات. بعد ذلك، يُخزَّن المعرّف الخاص بالرابط المُدخل آنفًا في قاعدة البيانات ضمن متغيّر باسم url_id، و يمكننا الوصول إلى معرّف الرابط باستخدام السمة lastrowid التي تعيد معرّف آخر سجل مُدخلٍ في قاعدة البيانات. وتُبنى السلسلة المعمّاة بتمرير معرّف الرابط إلى التابع ()hashids.encode، لتخزَّن في المتغير hashid، فمثلًا ستكون القيمة المعادة لدى استدعاء التابع (hashids.encode(1 هي السلسلة المُعمّاة KJ34 وذلك اعتمادًا على محارف الإغفال المُستخدمة. ننتقل الآن إلى مرحلة بناء الرابط المُختصر باستخدام السمة request.host_url، التي يوفرّها عادةً كائن فلاسك request للوصول إلى رابط مضيف التطبيق، والذي سيكون /http://127.0.0.1:5000 في بيئة التطوير، ويصبح "your_domain" لدى نشر التطبيق؛ فمثلًا ستكون قيمة المتغير short_url مساويةً http://127.0.0.1:5000/KJ34، والتي تمثّل الرابط المختصر الذي سيعيد توجيه المُستخدم إلى الرابط الأصلي ذي المعرّف الموافق للسلسلة المعمّاة KJ34 والمحفوظ في قاعدة البيانات . نهايةً، يُخرج قالب HTML المسمّى index.html بتمرير المتغير short_url إليه. وستبدو الشيفرة كما يلي بعد الإضافات السابقة: import sqlite3 from hashids import Hashids from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' hashids = Hashids(min_length=4, salt=app.config['SECRET_KEY']) @app.route('/', methods=('GET', 'POST')) def index(): conn = get_db_connection() if request.method == 'POST': url = request.form['url'] if not url: flash('The URL is required!') return redirect(url_for('index')) url_data = conn.execute('INSERT INTO urls (original_url) VALUES (?)', (url,)) conn.commit() conn.close() url_id = url_data.lastrowid hashid = hashids.encode(url_id) short_url = request.host_url + hashid return render_template('index.html', short_url=short_url) return render_template('index.html') اِحفظ الملف وأغلقه. الآن سننشئ ملف القالب الأساسي وملف قالب HTML المسمّى index.html، لذا سنضيف مجلدًا جديدًا للقوالب باسم templates ضمن المجلد flask_shortener، وسنفتح ملفًا باسم base.html ضمنه: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html والآن سنكتب شيفرة بوتستراب bootstrap التالية ضمن الملف base.html، وإن لم تكن قوالب HTML في فلاسك مألوفةً بالنسبة لك، يمكنك قراءة الخطوة الثالثة من المقال كيفية إنشاء تطبيق ويب باستخدام إطار فلاسك في لغة بايثون 3: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskShortener</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، ويضمِّن الوسم <script> شيفرة جافاسكربت مسؤولة عن بعض ميزات بوتستراب الإضافية. يسمح الوسم التالي لكل قالب موروث بأن يُحدّد عنوانه الخاص: <title>{% block title %} {% endblock %}</title> وتُستخدم الحلقة: for message in get_flashed_messages() لعرض الرسائل الخاطفة (من تحذيرات وتنبيهات وغيرها)، في حين يُضمَّن محتوى القوالب الموروثة في الموضع المؤقت {% block content %} {% endblock %}، بما يضمن وصول كافّة القوالب إلى القالب الأساسي وهذا يمنع تكرار الشيفرات. اِحفظ الملف وأغلقه. الآن سننشئ الملف index.html، الذي سيرث الملف base.html على النحو التالي: (env)user@localhost:$ nano templates/index.html وسنكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskShortener {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="url">URL</label> <input type="text" name="url" placeholder="URL to shorten" class="form-control" value="{{ request.form['url'] }}" autofocus></input> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% if short_url %} <hr> <span>{{ short_url }}</span> {% endif %} {% endblock %} ورِث الملف index.html في الشيفرة السابقة شيفرة القالب base.html، وعرّفنا عنوانًا خاصًّا به، ثمّ أنشأنا نموذجًا ذا حقل إدخال باسم url، والذي سيسمح للمستخدمين بإدخال الروابط المُراد اختصارها، وتُخزَّن القيمة ضمن متغير الكائن ['request.form['url لتجنّب فقدان المعلومات في حال حدوث أخطاء، كأن يُرسل المستخدم النموذج دون إدخال رابط. كما يحتوي النموذج على زرٍ لتأكيد النموذج وإرساله. ثمّ يُختبر شرط كون المتحول short_url الحاوي على الرابط المختصر ليس فارغًا، ويتحقّق هذا الشرط عند إرسال النموذج وتوليد الرابط المختصر بنجاح، عندها يُعرض هذا الرابط المختصر URL أسفل نموذج الإدخال. الآن، سنضبط متغيرات البيئة التي يحتاجها فلاسك لتشغيل التطبيق كما يلي: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run يحدّد متغير البيئة FLASK_APP في الشيفرة المُبينة أعلاه التطبيق المراد تشغيله (وهو في حالتنا الملف app.py)؛ بينما يحدّد المتغير FLASK_ENV وضع التشغيل وهو وضع التطوير development في حالتنا مع تشغيل منقّح الأخطاء، ولا يجب اختيار وضع التطوير في مرحلة التشغيل الفعلي للتطبيق (نشر المُنتج)؛ أمّا الأمر flask run فهو المسؤول عن تشغيل التطبيق. الآن، نفتح المتصفح ونذهب إلى الرابط "/http://127.0.0.1:5000"، فتظهر الصفحة الرئيسية الحاوية على العبارة "Welcome to FlaskShortener" كما هو موضح في الشكل التالي: وبإدخال رابط URL ما، نحصل على الرابط المختصر كما هو موضح في الشكل التالي: وبنهاية هذه الخطوة نكون قد أنشأنا تطبيق فلاسك يستقبل روابط لاختصارها، ولكن حتى هذه اللحظة لم تفعل هذه الروابط أي شيء، لذا في الخطوة التالية سنضيف وجهة مهمتها استخلاص السلسلة المُعمّاة من الرابط المُختصَر، ليوجد الرابط الأصلي ويعيد توجيه المُستخدم إليه. الخطوة الثالثة - إنشاء وجهة لإعادة التوجيه إلى الرابط الأصلي سننشئ في هذه الخطوة وجهة مهمتها فك تشفير السلسلة المعمّاة القصيرة التي ولدّها التطبيق للرابط المختصر للحصول على القيمة العددية الصحيحة الموافقة، والتي تمثّل معرّف الرابط الأصلي في قاعدة البيانات، وبالتالي فهي تستخدم هذا المعرّف لجلب الرابط الأصلي من قاعدة البيانات واحتساب الزيادة في عدد مرات النقر على هذا الرابط clicks، أي عدد مرات طلبه. لذا، بدايةً سنفتح الملف app.py لإضافة الوجهة الجديدة: (env)user@localhost:$ nano app.py ثم سنضيف الشيفرة التالية إلى نهاية الملف: . . . @app.route('/<id>') def url_redirect(id): conn = get_db_connection() original_id = hashids.decode(id) if original_id: original_id = original_id[0] url_data = conn.execute('SELECT original_url, clicks FROM urls' ' WHERE id = (?)', (original_id,) ).fetchone() original_url = url_data['original_url'] clicks = url_data['clicks'] conn.execute('UPDATE urls SET clicks = ? WHERE id = ?', (clicks+1, original_id)) conn.commit() conn.close() return redirect(original_url) else: flash('Invalid URL') return redirect(url_for('index')) تستقبل الوجهة في الشيفرة السابقة القيمة id من الرابط ويمررها وسيطًا لدالة فلاسك ()url_redirect، فإذا كان الرابط http://127.0.0.1:5000/KJ34 مثلًا، ستُمرّر السلسلة KJ34 للمعامل id. وضمن دالة عرض فلاسك نفتح اتصالًا مع قاعدة البيانات، ثمّ نحوّل السلسلة المعمّاة إلى القيمة العددية الصحيحة الأصلية لها باستخدام التابع ()decode للكائن hashids، لتُخزّن في المتغير original_id، فإذا لم يكن هذا المتغير فارغًا، يُستخلص المعرّف ID منه. وبما أنّ التابع ()decode يُعيد سجلًا كاملًا، فسنجلب الجزء الأوّل منه، الذي يمثّل المعرّف الأصلي باستخدام التابع [original_id[0، ثمّ سنستخدم التعليمة SELECT في SQL لجلب الرابط الأصلي الذي يتوافق معرّفه في قاعدة البيانات مع المعرّف المُستخلص من السلسلة المعمّاة، إضافةً لجلب عدد الزيارات لهذا الرابط من الجدول urls؛ أما بيانات الرابط فستُجلب باستخدام التابع ()fetchone، ثم سنخزّن هذه البيانات في المتغيرين original_url و clicks. الآن وبعد زيارة هذا الرابط، سنزيد عدد الزيارات له باستخدام تعليمة UPDATE في SQL، ونهايةً نؤكّد العملية ونغلق الاتصال مع قاعدة البيانات، وسنعيد التوجيه إلى الرابط الأصلي باستخدام دالة فلاسك المُساعدة ()redirect؛ وفي حال فشل فك تشفير السلسلة المُعمّاة، ستُعرض رسالةٌ لإعلام المستخدم بأن الرابط الذي أدخله غير صالح، ثمّ يعاد توجيهه إلى الصفحة الرئيسية index. اِحفظ الملف وأغلقه. الآن، سنشغل خادم التطوير: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح، وبإدخال رابطٍ ما وزيارة الرابط المُختصَر الناتج، سيعيد التطبيق توجيه المستخدم إلى الرابط الأصلي. وبذلك نكون قد أنشأنا وجهة مهمتها إعادة توجيه مستخدم التطبيق من الرابط المُختصَر إلى الرابط الأصلي. سننشئ في الخطوة التالية صفحة إحصائيات لبيان عدد مرات زيارة كل رابط. الخطوة الرابعة - إضافة صفحة إحصائيات سننشئ في هذه الخطوة وجهة جديدة لصفحة إحصائيات مهمتها عرض عدد مرات زيارة كل رابط، كما سنضيف زرًا في شريط التصفح للوصول إلى صفحة الإحصائيات هذه، إذ تتمثّل فائدة هذه الصفحة في معرفة شعبية الروابط، الأمر المهم في مشاريع الحملات الإعلانية للشركات مثلًا، كما من الممكن عدّ هذه الصفحة ميزةً إضافية يمكن إضافتها لأي تطبيق فلاسك موجود أصلًا. لنفتح الملف app.py لإضافة الوجهة الجديدة الخاص بصفحة الإحصائيات: (env)user@localhost:$ nano app.py ونضيف الشيفرات التالية إلى نهاية الملف: . . . @app.route('/stats') def stats(): conn = get_db_connection() db_urls = conn.execute('SELECT id, created, original_url, clicks FROM urls' ).fetchall() conn.close() urls = [] for url in db_urls: url = dict(url) url['short_url'] = request.host_url + hashids.encode(url['id']) urls.append(url) return render_template('stats.html', urls=urls) سنبدأ في دالة عرض فلاسك هذه بفتح اتصالٍ مع قاعدة البيانات، ثمّ نجلب كل من معرّف الرابط وتاريخ إنشائه والرابط الأصلي وعدد مرات زيارته باستخدام التابع ()fetchall لكامل مُدخلات الجدول urls في قاعدة البيانات، وذلك من أجل تنظيم كامل هذه السجلات ضمن قائمة، لتُحفظ في المتغير db_urls، وفي النهاية نغلق الاتصال مع قاعدة البيانات. الآن ولعرض الرابط المُختصَر لكل مُدخل، لا بُدّ من بنائه وإضافته إلى كل عنصر من القائمة السابقة db_urls المجلوبة من قاعدة البيانات، لذا سننشئ قائمةً فارغةً باسم urls لنخزّن بها حقل الروابط فقط من القائمة db_urls باستخدام الحلقة التكرارية for url in db_urls. سنحوّل الكائن sqlite3.Row إلى قاموس dictionary قابل لإسناد القيم إليه باستخدام دالة بايثون ()dict، ثمّ سنضيف إليه مفتاحًا جديدًا باسم short_url ليحتوي القيمة التالية: request.host_url + hashids.encode(url['id']) المُستخدمة سابقًا في دالة عرض فلاسك ()index لبناء الروابط المُختصرة، ونهايةً سنضيف القاموس الذي يحتوي على الروابط المُختصَرة إلى القائمة urls. نهايةً سنخرج قالب HTML باسم stats.html ممررين قائمة urls إليه. اِحفظ الملف وأغلقه. سننشئ الآن ملف القالب stats.html: (env)user@localhost:$ nano templates/stats.html وسنكتب الشيفرات التالية فيه: {% extends 'base.html' %} {% block content %} <h1>{% block title %} FlaskShortener Statistics {% endblock %}</h1> <table class="table"> <thead> <tr> <th scope="col">#</th> <th scope="col">Short</th> <th scope="col">Original</th> <th scope="col">Clicks</th> <th scope="col">Creation Date</th> </tr> </thead> <tbody> {% for url in urls %} <tr> <th scope="row">{{ url['id'] }}</th> <td>{{ url['short_url'] }}</td> <td>{{ url['original_url'] }}</td> <td>{{ url['clicks'] }}</td> <td>{{ url['created'] }}</td> </tr> {% endfor %} </tbody> </table> {% endblock %} في الشفرة السابقة، ورثنا شيفرة قالب HTML الرئيسي base.html وحدّدنا عنوانًا، وعرّفنا جدولًا يضم الأعمدة التالية: #: معرّف الرابط. Short: الرابط المُختصَر. Original: الرابط الأصلي. Clicks: عدد مرات زيارة الرابط المُختصَر. Creation Date: تاريخ إنشاء الرابط المُختصَر. وجرت عملية تعبئة سجلات الجدول باستخدام حلقة for تكرارية تجلب البيانات من القائمة urls لتعرض القيم الموافقة لكل من الأعمدة السابقة لكل رابط. الآن سنشغّل خادم التطوير: (env)user@localhost:$ flask run وباستخدام المتصفح، وبالذهاب إلى الرابط "http://127.0.0.1:5000/stats" ستظهر كافّة الروابط في جدول كما في الشكل التالي: الآن سنضيف زر أوامر باسم Stats في شريط التصفّح للوصول إلى صفحة الإحصائيات، لذا سنفتح الملف base.html: (env)user@localhost:$ nano templates/base.html وسنعدّل الشيفرة فيه وفق الأسطر المُحدّدة كما يلي: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskTodo</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> <li class="nav-item active"> <a class="nav-link" href="{{ url_for('stats')}}">Stats</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> ضمنّا في الشفرة السابقة عنصر قائمة <li> في شريط التصفّح، وربطناه مع دالة فلاسك ()stats باستخدام دالة ()url_for، وبذلك يصبح بالإمكان الوصول إلى صفحة الإحصائيات من شريط التصفّح، التي ستعرض معلومات عن كل رابط، تتضمّن الرابط المُختصر المكافئ وعدد مرات زيارته. هذه الشيفرة قابلة لإعادة الاستخدام في تطبيقات أُخرى، لمراقبة عدد النقرات، وهذا يفيد مثلًا في متابعة عدد مرات الإعجاب بمنشور ما أو عدد مرات تحديثه في أحد مواقع التواصل الاجتماعي، أو عدد مرات مشاهدة صورة أو مقطع فيديو ما. نهايةً يمكنك الاطلاع على شيفرة تطبيق اختصار الروابط كاملةً. الخاتمة ستحصل مع نهاية هذا المقال وبتطبيق الخطوات الواردة فيه على تطبيق يسمح للمستخدمين بإدخال روابط طويلة لاختصارها، إذ يحوِّل الأعداد الصحيحة إلى سلاسل معمّاة قصيرة، لإعادة توجيه المستخدمين من رابطٍ لآخر، كما يمكّنك من خلاله مراقبة الروابط المُختصرة عن طريق صفحة الإحصائيات. يمكنك الاطلاع على مزيدٍ من المقالات التعليمية حول فلاسك من خلال الروابط التالية: روابط المقال الأوّل والثاني والثالث بعد النشر في الأكاديمية. كيفية إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask في لغة بايثون 3. كيفية استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite. الثالث. ترجمة -وبتصرف- للمقال How To Make a URL Shortener with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون استخدام علاقة one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite استخدام علاقة many-to-many مع فلاسك Flask ومحرك قواعد البيانات SQLite تعديل العناصر في علاقات one-to-many باستخدام فلاسك Flask ومحرك قاعدة البيانات SQLite
يُعد فلاسك إطار عمل لبناء تطبيقات الويب مبني باستخدام لغة بايثون، أما SQLite، فهو محرك قواعد بيانات يُستخدم مع بايثون لتخزين بيانات التطبيقات. سنبني في هذا المقال مختصِرًا للروابط URL shortener ليحوّل أي رابط إلى آخر مُختصَر وأكثر موثوقية بما يشبه مبدأ عمل موقع bit.ly. سنستخدم في بناء تطبيقنا مكتبة التعمية Hashids لتوليد سلاسل فريدة لمُعرّفات الروابط؛ إذ أن هذه المكتبة مُختصّةٌ بتوليد مُعرّفات مميزة قصيرة unique ID انطلاقًا من أرقام صحيحة، إذ تحوّل مثلاً الرقم "12" إلى سلسلة فريدة مثل "1Xcld". يمكن استخدام السلاسل الفريدة هذه لتوليد معرّفات لا يمكن التنبؤ بها سواءٌ للفيديوهات على مواقع مشاركة الفيديوهات، أو الصور في خدمة رفع الصور وغيرها. ففي حال وصول المستخدم مثلًا إلى صورةٍ ذات رابط "your_domain/image/J32Fr"، فلا يمكنه التنبؤ بمواقع الصور الأخرى، على عكس حالة استخدام معرفّات مؤلفّة من أرقام صحيحة في مختصر الروابط، فمثلاً لو كان رابط الصورة "your_domain/image/33"، فسيتمكن المستخدم من التنبؤ بمواقع الصور الأخرى بسهولة، وبالتالي يقدِّم استخدام روابط بمعرّفات غير قابلة للتنبؤ نوعًا من الخصوصية للخادم، كونها تمنع المستخدمين من اكتشاف الروابط المختصرة المُستخدمة من قِبل المستخدمين الآخرين. سنبني إذًا مختصِرًا للروابط باستخدام فلاسك وSQLite ومكتبة Hashids، بحيث يتمكّن المستخدمون من إدخال روابط وتوليد نسخٍ مختصرةٍ منها، إضافةً إلى توفير صفحة إحصاءات يمكن للمستخدمين من خلالها متابعة عدد مرات زيارة الرابط، كما سنستخدم بوتستراب bootstrap لإضافة التنسيقات للتطبيق. مستلزمات العمل قبل المتابعة في هذا المقال لا بدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو flask_shortener. فهم مبادئ فلاسك، مثل بناء الوجهات وإخراج نماذج HTML والاتصال بقواعد بيانات SQLite، ويمكنك الاطلاع على [هذا المقال](رابط المقال الأوّل بعد نشره) لمزيدٍ من المعلومات حول هذه النقاط. الخطوة الأولى- إعداد المتطلبات سنفعّل في هذه الخطوة بيئة بايثون ونثبّت فلاسك باستخدام مثبِّت الحزم pip، ثم سننشئ قاعدة بيانات سنستخدمها لتخزين الروابط، وفي حال كون بيئة البرمجة غير مفعّلة بعد، سنستخدم الأمر التالي لتفعيلها: $ source env/bin/activate وبعد تفعيل بيئة البرمجة، سنثبّت فلاسك ومكتبة Hashids باستخدام الأمر التالي: (env)user@localhost:$ pip install flask hashids ثمّ سننشئ ملف تخطيط قاعدة البيانات باسم schema.sql، ليحتوي أوامر SQL اللازمة لإنشاء جدول للعناوين باسم urls. لذا، سننشئ الملف schema.sql داخل المجلد flask_shortener كما يلي: (env)user@localhost:$ nano schema.sql ونكتب أوامر SQL التالية فيه: DROP TABLE IF EXISTS urls; CREATE TABLE urls ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, original_url TEXT NOT NULL, clicks INTEGER NOT NULL DEFAULT 0 ); أول سطرٍ من شيفرة SQL السابقة مسؤولٌ عن حذف أي جداول موجودةٍ سابقًا ضمن قاعدة البيانات urls، وبذلك لن يكون هناك أي سلوك متضارب أو عشوائي ناجمٍ عن تشابه الأسماء ضمن قاعدة البيانات، والجدير بالملاحظة أنّ تطبيق هذين الأمر سيؤدي إلى حذف كامل محتوى قاعدة البيانات الحالي، لذا لا تُدخل أي بياناتٍ مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية. بعد ذلك، سننشئ جدولًا يحتوي الأعمدة التالية: "id": ويحتوي بياناتٍ من نوع رقم صحيح ويمثِّل المعرّف الفريد لكل رابطٍ مُدخل، وسنستخدم هذا المعرّف لاحقًا في استنتاج الرابط الأصلي من سلسلة محارف عشوائية معمّاة Hash string. "created": يحتوي على تاريخ ووقت اختصار الرابط. "original_url": يحتوي على الرابط الكامل الأصلي قبل الاختصار والذي سيُعاد توجيه المستخدمين إليه. "clicks": يحتوي على عدد مرات النقر على الرابط. ستكون قيمته الابتدائية 0، وتزداد مع كل إعادة توجيه. اِحفظ الملف وأغلقه. الآن لتنفيذ ملف schema.sql المسؤول عن بناء جدول الروابط urls، سننشئ ملفًا باسم int_db.py داخل مجلد flasks_hortener: (env)user@localhost:$ nano init_db.py ونضيف الشيفرة التالية إليه: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) connection.commit() connection.close() إذ يحدث في البداية اتصالٌ مع الملف database.db المُنشأ تلقائيًا عند تنفيذ البرنامج السابق، ويمثّل هذا الملف قاعدة البيانات التي ستخزّن كامل بيانات التطبيق، ثم يُفتح بعد ذلك ملف تخطيط قاعدة البيانات schema.sql ويُشغَّل باستخدام التابع ()executscript القادر على تنفيذ عدّة تعليمات SQL معًا، وهذا ما سينشئ بالنتيجة جدول الروابط urls، وفي النهاية نؤكِّد على التغييرات ويُغلق الاتصال مع قاعدة البيانات. اِحفظ الملف وأغلقه. الآن، نشغّل البرنامج: (env)user@localhost:$ python init_db.py وبعد انتهاء تنفيذه، سيظهر ملفٌ جديدٌ باسم database.db ضمن المجلد flask_shortener. وبنهاية الخطوة الأولى، نكون قد ثبّتنا فلاسك ومكتبة Hashids، وأنشأنا مخطّط قاعدة البيانات إضافةً لقاعدة بيانات SQLite تحتوي جدولًا باسم "urls" مخصّصًا لتخزين العناوين الأصلية لتلك المُختصرة. سنستخدم فيما يلي فلاسك لإنشاء الصفحة الرئيسية index والتي سيتمكّن المستخدمون من خلالها من إدخال الروابط المطلوب اختصارها. الخطوة الثانية - إنشاء الصفحة الرئيسية لتطبيق اختصار الروابط سننشئ في هذه الخطوة الوجهة اللازم لعمل الصفحة الرئيسية index، والذي يمكّن المستخدمين من إدخال الروابط الأصلية المراد اختصارها؛ إذ ستُخزَّن هذه الروابط في قاعدة البيانات بدايةً، ويستخدم المعرّف الفريد للرابط لتوليد سلسلة محارف قصيرة معمّاة باستخدام مكتبة Hashids، ويبني الرابط المُختصر ويخرجه نتيجةً. سننشئ الآن الملف الأساسي لتطبيق فلاسك باسم app.py ضمن المجلد flask_shortener: (env)user@localhost:$ nano app.py ونضيف الشيفرة التالية ضمنه: import sqlite3 from hashids import Hashids from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn نبدأ بالشيفرة السابقة باستيراد الوحدة sqlite3، والصنف Hashids من المكتبة hashids، إضافةً للمساعد الخاص بإطار فلاسك، ثم تفتح الدالة ()get_db_connection اتصالًا مع ملف قاعدة البيانات database.db، وتعيّن قيمة السمة row_factory لتكون sqlite3.Row لنتمكّن من الوصول لأعمدة جدول قاعدة البيانات باستخدام أسمائها؛ وهذا يعني أنّ اتصال قاعدة البيانات سيعيد سجلات يمكننا التعامل معها كما هو الحال مع قواميس بايثون Dictionaries الاعتيادية (وحدات تخزين القيم المنظمّة في بايثون)، وفي النهاية تعيد الدالة كائن الاتصال conn، الذي سيُستخدم للوصول إلى قاعدة البيانات. سنضيف الآن الشيفرة التالية: . . . app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' hashids = Hashids(min_length=4, salt=app.config['SECRET_KEY']) التي تنشئ كائن تطبيق فلاسك وتحدِّد مفتاح الأمان لجعل الجلسات آمنة، وبما أنّ مفتاح الأمان هو أيضًا سلسلة محارف عشوائية وسريّة، فسنستخدمها مصدرًا لمحارف الإغفال salt لمكتبة التعمية Hashids بما يضمن كون السلاسل المعمّاة الناتجة غير قابلة للتنبؤ كونها ستتغير بتغيّر محارف الإغفال المتغيرة أصلًا باستمرار مع تغيُّر مفتاح الأمان. احرص على إبقاء محارف الإغفال سريةً حفاظًا على الأمان، ولهذا السبب ارتأينا أنّه من الأفضل استخدام مفتاح الأمان الخاص بالتطبيق على هيئة محارف إغفال. وبذلك نكون أنشأنا كائن تعمية hashids يضمن كون كل سلسلة معمّاة مؤلفّة من 4 محارف على الأقل عبر تمرير هذه القيمة إلى المعامل min_length من هذا الكائن، واستخدمنا مفتاح أمان التطبيق مثل محرف إغفال. سنضيف الآن الشيفرة التالية إلى نهاية الملف: . . . @app.route('/', methods=('GET', 'POST')) def index(): conn = get_db_connection() if request.method == 'POST': url = request.form['url'] if not url: flash('The URL is required!') return redirect(url_for('index')) url_data = conn.execute('INSERT INTO urls (original_url) VALUES (?)', (url,)) conn.commit() conn.close() url_id = url_data.lastrowid hashid = hashids.encode(url_id) short_url = request.host_url + hashid return render_template('index.html', short_url=short_url) return render_template('index.html') يعدِّل المزخرف app.route@ دوال بايثون المألوفة لتصبح دوالًا عاملةً في فلاسك مثل الدالة ()index، التي تُحوَّل القيمة المعادة منها إلى استجابةٍ من نوع HTTP تُعرض لدى عميل HTTP الذي قد يكون متصفحًا مثلًا. وضمن بناء دالة فلاسك ()index، سنمرّر السطر التالي: methods=('GET', 'POST') الحاوي على طرائق الطلبات المقبولة إلى وسيط الطرائق methods في المزخرف ()app.route، ما يضمن قبول الطلبات سواءً بطريقة GET أو POST. الآن سيُفتح اتصالٌ مع قاعدة البيانات، فإذا كان الطلب بطريقة GET، نتجاوز الشرط: if request.method == 'POST' وصولًا إلى آخر سطر في الشيفرة والمسؤول عن إخراج قالب HTML باسم index.html، الذي سيحتوي على نموذج إدخال الروابط المُراد اختصارها؛ أما في حال تحقّق الشرط السابق، فهذا يعني أنّه قد أُدخل رابطٌ من قِبل المستخدم لاختصاره، فيُخزَّن هذا الرابط ضمن المتغير url؛ أمّا في حال إرسال المستخدم النموذج دون إدخال رابط، فستظهر له رسالةً تخبره بأنّ حقل الرابط مطلوب "!The URL is required" ويُعاد توجيهه إلى الصفحة الرئيسية index مجدّدًا. وعندما يرسل المستخدم نموذجًا حاويًا على رابط، يُخزّن هذا الرابط في جدول urls من قاعدة البيانات باستخدام تعليمة INSERT INTO في SQL، كما يُضمَّن الموضع المؤقت ? (الذي سيُستبدل لاحقًا برقمٍ ما) في الدالة ()execute، ومن ثمّ يُمرّر السجل الحاوي على الرابط المطلوب اختصاره ليُحفظ في قاعدة البيانات بأمان، وفي النهاية تؤكَّد العملية ويُقطع الاتصال مع قاعدة البيانات. بعد ذلك، يُخزَّن المعرّف الخاص بالرابط المُدخل آنفًا في قاعدة البيانات ضمن متغيّر باسم url_id، و يمكننا الوصول إلى معرّف الرابط باستخدام السمة lastrowid التي تعيد معرّف آخر سجل مُدخلٍ في قاعدة البيانات. وتُبنى السلسلة المعمّاة بتمرير معرّف الرابط إلى التابع ()hashids.encode، لتخزَّن في المتغير hashid، فمثلًا ستكون القيمة المعادة لدى استدعاء التابع (hashids.encode(1 هي السلسلة المُعمّاة KJ34 وذلك اعتمادًا على محارف الإغفال المُستخدمة. ننتقل الآن إلى مرحلة بناء الرابط المُختصر باستخدام السمة request.host_url، التي يوفرّها عادةً كائن فلاسك request للوصول إلى رابط مضيف التطبيق، والذي سيكون /http://127.0.0.1:5000 في بيئة التطوير، ويصبح "your_domain" لدى نشر التطبيق؛ فمثلًا ستكون قيمة المتغير short_url مساويةً http://127.0.0.1:5000/KJ34، والتي تمثّل الرابط المختصر الذي سيعيد توجيه المُستخدم إلى الرابط الأصلي ذي المعرّف الموافق للسلسلة المعمّاة KJ34 والمحفوظ في قاعدة البيانات . نهايةً، يُخرج قالب HTML المسمّى index.html بتمرير المتغير short_url إليه. وستبدو الشيفرة كما يلي بعد الإضافات السابقة: import sqlite3 from hashids import Hashids from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' hashids = Hashids(min_length=4, salt=app.config['SECRET_KEY']) @app.route('/', methods=('GET', 'POST')) def index(): conn = get_db_connection() if request.method == 'POST': url = request.form['url'] if not url: flash('The URL is required!') return redirect(url_for('index')) url_data = conn.execute('INSERT INTO urls (original_url) VALUES (?)', (url,)) conn.commit() conn.close() url_id = url_data.lastrowid hashid = hashids.encode(url_id) short_url = request.host_url + hashid return render_template('index.html', short_url=short_url) return render_template('index.html') اِحفظ الملف وأغلقه. الآن سننشئ ملف القالب الأساسي وملف قالب HTML المسمّى index.html، لذا سنضيف مجلدًا جديدًا للقوالب باسم templates ضمن المجلد flask_shortener، وسنفتح ملفًا باسم base.html ضمنه: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html والآن سنكتب شيفرة بوتستراب bootstrap التالية ضمن الملف base.html، وإن لم تكن قوالب HTML في فلاسك مألوفةً بالنسبة لك، يمكنك قراءة الخطوة الثالثة من المقال كيفية إنشاء تطبيق ويب باستخدام إطار فلاسك في لغة بايثون 3: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskShortener</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، ويضمِّن الوسم <script> شيفرة جافاسكربت مسؤولة عن بعض ميزات بوتستراب الإضافية. يسمح الوسم التالي لكل قالب موروث بأن يُحدّد عنوانه الخاص: <title>{% block title %} {% endblock %}</title> وتُستخدم الحلقة: for message in get_flashed_messages() لعرض الرسائل الخاطفة (من تحذيرات وتنبيهات وغيرها)، في حين يُضمَّن محتوى القوالب الموروثة في الموضع المؤقت {% block content %} {% endblock %}، بما يضمن وصول كافّة القوالب إلى القالب الأساسي وهذا يمنع تكرار الشيفرات. اِحفظ الملف وأغلقه. الآن سننشئ الملف index.html، الذي سيرث الملف base.html على النحو التالي: (env)user@localhost:$ nano templates/index.html وسنكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskShortener {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="url">URL</label> <input type="text" name="url" placeholder="URL to shorten" class="form-control" value="{{ request.form['url'] }}" autofocus></input> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% if short_url %} <hr> <span>{{ short_url }}</span> {% endif %} {% endblock %} ورِث الملف index.html في الشيفرة السابقة شيفرة القالب base.html، وعرّفنا عنوانًا خاصًّا به، ثمّ أنشأنا نموذجًا ذا حقل إدخال باسم url، والذي سيسمح للمستخدمين بإدخال الروابط المُراد اختصارها، وتُخزَّن القيمة ضمن متغير الكائن ['request.form['url لتجنّب فقدان المعلومات في حال حدوث أخطاء، كأن يُرسل المستخدم النموذج دون إدخال رابط. كما يحتوي النموذج على زرٍ لتأكيد النموذج وإرساله. ثمّ يُختبر شرط كون المتحول short_url الحاوي على الرابط المختصر ليس فارغًا، ويتحقّق هذا الشرط عند إرسال النموذج وتوليد الرابط المختصر بنجاح، عندها يُعرض هذا الرابط المختصر URL أسفل نموذج الإدخال. الآن، سنضبط متغيرات البيئة التي يحتاجها فلاسك لتشغيل التطبيق كما يلي: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run يحدّد متغير البيئة FLASK_APP في الشيفرة المُبينة أعلاه التطبيق المراد تشغيله (وهو في حالتنا الملف app.py)؛ بينما يحدّد المتغير FLASK_ENV وضع التشغيل وهو وضع التطوير development في حالتنا مع تشغيل منقّح الأخطاء، ولا يجب اختيار وضع التطوير في مرحلة التشغيل الفعلي للتطبيق (نشر المُنتج)؛ أمّا الأمر flask run فهو المسؤول عن تشغيل التطبيق. الآن، نفتح المتصفح ونذهب إلى الرابط "/http://127.0.0.1:5000"، فتظهر الصفحة الرئيسية الحاوية على العبارة "Welcome to FlaskShortener" كما هو موضح في الشكل التالي: وبإدخال رابط URL ما، نحصل على الرابط المختصر كما هو موضح في الشكل التالي: وبنهاية هذه الخطوة نكون قد أنشأنا تطبيق فلاسك يستقبل روابط لاختصارها، ولكن حتى هذه اللحظة لم تفعل هذه الروابط أي شيء، لذا في الخطوة التالية سنضيف وجهة مهمتها استخلاص السلسلة المُعمّاة من الرابط المُختصَر، ليوجد الرابط الأصلي ويعيد توجيه المُستخدم إليه. الخطوة الثالثة - إنشاء وجهة لإعادة التوجيه إلى الرابط الأصلي سننشئ في هذه الخطوة وجهة مهمتها فك تشفير السلسلة المعمّاة القصيرة التي ولدّها التطبيق للرابط المختصر للحصول على القيمة العددية الصحيحة الموافقة، والتي تمثّل معرّف الرابط الأصلي في قاعدة البيانات، وبالتالي فهي تستخدم هذا المعرّف لجلب الرابط الأصلي من قاعدة البيانات واحتساب الزيادة في عدد مرات النقر على هذا الرابط clicks، أي عدد مرات طلبه. لذا، بدايةً سنفتح الملف app.py لإضافة الوجهة الجديدة: (env)user@localhost:$ nano app.py ثم سنضيف الشيفرة التالية إلى نهاية الملف: . . . @app.route('/<id>') def url_redirect(id): conn = get_db_connection() original_id = hashids.decode(id) if original_id: original_id = original_id[0] url_data = conn.execute('SELECT original_url, clicks FROM urls' ' WHERE id = (?)', (original_id,) ).fetchone() original_url = url_data['original_url'] clicks = url_data['clicks'] conn.execute('UPDATE urls SET clicks = ? WHERE id = ?', (clicks+1, original_id)) conn.commit() conn.close() return redirect(original_url) else: flash('Invalid URL') return redirect(url_for('index')) تستقبل الوجهة في الشيفرة السابقة القيمة id من الرابط ويمررها وسيطًا لدالة فلاسك ()url_redirect، فإذا كان الرابط http://127.0.0.1:5000/KJ34 مثلًا، ستُمرّر السلسلة KJ34 للمعامل id. وضمن دالة عرض فلاسك نفتح اتصالًا مع قاعدة البيانات، ثمّ نحوّل السلسلة المعمّاة إلى القيمة العددية الصحيحة الأصلية لها باستخدام التابع ()decode للكائن hashids، لتُخزّن في المتغير original_id، فإذا لم يكن هذا المتغير فارغًا، يُستخلص المعرّف ID منه. وبما أنّ التابع ()decode يُعيد سجلًا كاملًا، فسنجلب الجزء الأوّل منه، الذي يمثّل المعرّف الأصلي باستخدام التابع [original_id[0، ثمّ سنستخدم التعليمة SELECT في SQL لجلب الرابط الأصلي الذي يتوافق معرّفه في قاعدة البيانات مع المعرّف المُستخلص من السلسلة المعمّاة، إضافةً لجلب عدد الزيارات لهذا الرابط من الجدول urls؛ أما بيانات الرابط فستُجلب باستخدام التابع ()fetchone، ثم سنخزّن هذه البيانات في المتغيرين original_url و clicks. الآن وبعد زيارة هذا الرابط، سنزيد عدد الزيارات له باستخدام تعليمة UPDATE في SQL، ونهايةً نؤكّد العملية ونغلق الاتصال مع قاعدة البيانات، وسنعيد التوجيه إلى الرابط الأصلي باستخدام دالة فلاسك المُساعدة ()redirect؛ وفي حال فشل فك تشفير السلسلة المُعمّاة، ستُعرض رسالةٌ لإعلام المستخدم بأن الرابط الذي أدخله غير صالح، ثمّ يعاد توجيهه إلى الصفحة الرئيسية index. اِحفظ الملف وأغلقه. الآن، سنشغل خادم التطوير: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح، وبإدخال رابطٍ ما وزيارة الرابط المُختصَر الناتج، سيعيد التطبيق توجيه المستخدم إلى الرابط الأصلي. وبذلك نكون قد أنشأنا وجهة مهمتها إعادة توجيه مستخدم التطبيق من الرابط المُختصَر إلى الرابط الأصلي. سننشئ في الخطوة التالية صفحة إحصائيات لبيان عدد مرات زيارة كل رابط. الخطوة الرابعة - إضافة صفحة إحصائيات سننشئ في هذه الخطوة وجهة جديدة لصفحة إحصائيات مهمتها عرض عدد مرات زيارة كل رابط، كما سنضيف زرًا في شريط التصفح للوصول إلى صفحة الإحصائيات هذه، إذ تتمثّل فائدة هذه الصفحة في معرفة شعبية الروابط، الأمر المهم في مشاريع الحملات الإعلانية للشركات مثلًا، كما من الممكن عدّ هذه الصفحة ميزةً إضافية يمكن إضافتها لأي تطبيق فلاسك موجود أصلًا. لنفتح الملف app.py لإضافة الوجهة الجديدة الخاص بصفحة الإحصائيات: (env)user@localhost:$ nano app.py ونضيف الشيفرات التالية إلى نهاية الملف: . . . @app.route('/stats') def stats(): conn = get_db_connection() db_urls = conn.execute('SELECT id, created, original_url, clicks FROM urls' ).fetchall() conn.close() urls = [] for url in db_urls: url = dict(url) url['short_url'] = request.host_url + hashids.encode(url['id']) urls.append(url) return render_template('stats.html', urls=urls) سنبدأ في دالة عرض فلاسك هذه بفتح اتصالٍ مع قاعدة البيانات، ثمّ نجلب كل من معرّف الرابط وتاريخ إنشائه والرابط الأصلي وعدد مرات زيارته باستخدام التابع ()fetchall لكامل مُدخلات الجدول urls في قاعدة البيانات، وذلك من أجل تنظيم كامل هذه السجلات ضمن قائمة، لتُحفظ في المتغير db_urls، وفي النهاية نغلق الاتصال مع قاعدة البيانات. الآن ولعرض الرابط المُختصَر لكل مُدخل، لا بُدّ من بنائه وإضافته إلى كل عنصر من القائمة السابقة db_urls المجلوبة من قاعدة البيانات، لذا سننشئ قائمةً فارغةً باسم urls لنخزّن بها حقل الروابط فقط من القائمة db_urls باستخدام الحلقة التكرارية for url in db_urls. سنحوّل الكائن sqlite3.Row إلى قاموس dictionary قابل لإسناد القيم إليه باستخدام دالة بايثون ()dict، ثمّ سنضيف إليه مفتاحًا جديدًا باسم short_url ليحتوي القيمة التالية: request.host_url + hashids.encode(url['id']) المُستخدمة سابقًا في دالة عرض فلاسك ()index لبناء الروابط المُختصرة، ونهايةً سنضيف القاموس الذي يحتوي على الروابط المُختصَرة إلى القائمة urls. نهايةً سنخرج قالب HTML باسم stats.html ممررين قائمة urls إليه. اِحفظ الملف وأغلقه. سننشئ الآن ملف القالب stats.html: (env)user@localhost:$ nano templates/stats.html وسنكتب الشيفرات التالية فيه: {% extends 'base.html' %} {% block content %} <h1>{% block title %} FlaskShortener Statistics {% endblock %}</h1> <table class="table"> <thead> <tr> <th scope="col">#</th> <th scope="col">Short</th> <th scope="col">Original</th> <th scope="col">Clicks</th> <th scope="col">Creation Date</th> </tr> </thead> <tbody> {% for url in urls %} <tr> <th scope="row">{{ url['id'] }}</th> <td>{{ url['short_url'] }}</td> <td>{{ url['original_url'] }}</td> <td>{{ url['clicks'] }}</td> <td>{{ url['created'] }}</td> </tr> {% endfor %} </tbody> </table> {% endblock %} في الشفرة السابقة، ورثنا شيفرة قالب HTML الرئيسي base.html وحدّدنا عنوانًا، وعرّفنا جدولًا يضم الأعمدة التالية: #: معرّف الرابط. Short: الرابط المُختصَر. Original: الرابط الأصلي. Clicks: عدد مرات زيارة الرابط المُختصَر. Creation Date: تاريخ إنشاء الرابط المُختصَر. وجرت عملية تعبئة سجلات الجدول باستخدام حلقة for تكرارية تجلب البيانات من القائمة urls لتعرض القيم الموافقة لكل من الأعمدة السابقة لكل رابط. الآن سنشغّل خادم التطوير: (env)user@localhost:$ flask run وباستخدام المتصفح، وبالذهاب إلى الرابط "http://127.0.0.1:5000/stats" ستظهر كافّة الروابط في جدول كما في الشكل التالي: الآن سنضيف زر أوامر باسم Stats في شريط التصفّح للوصول إلى صفحة الإحصائيات، لذا سنفتح الملف base.html: (env)user@localhost:$ nano templates/base.html وسنعدّل الشيفرة فيه وفق الأسطر المُحدّدة كما يلي: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskTodo</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> <li class="nav-item active"> <a class="nav-link" href="{{ url_for('stats')}}">Stats</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> ضمنّا في الشفرة السابقة عنصر قائمة <li> في شريط التصفّح، وربطناه مع دالة فلاسك ()stats باستخدام دالة ()url_for، وبذلك يصبح بالإمكان الوصول إلى صفحة الإحصائيات من شريط التصفّح، التي ستعرض معلومات عن كل رابط، تتضمّن الرابط المُختصر المكافئ وعدد مرات زيارته. هذه الشيفرة قابلة لإعادة الاستخدام في تطبيقات أُخرى، لمراقبة عدد النقرات، وهذا يفيد مثلًا في متابعة عدد مرات الإعجاب بمنشور ما أو عدد مرات تحديثه في أحد مواقع التواصل الاجتماعي، أو عدد مرات مشاهدة صورة أو مقطع فيديو ما. نهايةً يمكنك الاطلاع على شيفرة تطبيق اختصار الروابط كاملةً. الخاتمة ستحصل مع نهاية هذا المقال وبتطبيق الخطوات الواردة فيه على تطبيق يسمح للمستخدمين بإدخال روابط طويلة لاختصارها، إذ يحوِّل الأعداد الصحيحة إلى سلاسل معمّاة قصيرة، لإعادة توجيه المستخدمين من رابطٍ لآخر، كما يمكّنك من خلاله مراقبة الروابط المُختصرة عن طريق صفحة الإحصائيات. يمكنك الاطلاع على مزيدٍ من المقالات التعليمية حول فلاسك من خلال الروابط التالية: روابط المقال الأوّل والثاني والثالث بعد النشر في الأكاديمية. كيفية إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask في لغة بايثون 3. كيفية استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite. الثالث. ترجمة -وبتصرف- للمقال How To Make a URL Shortener with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون استخدام علاقة one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite استخدام علاقة many-to-many مع فلاسك Flask ومحرك قواعد البيانات SQLite تعديل العناصر في علاقات one-to-many باستخدام فلاسك Flask ومحرك قاعدة البيانات SQLite -
 يُعد فلاسك إطار عمل يستخدم لغة البرمجة بايثون Python لبناء تطبيقات الويب، أما SQLite فهو محرّك قواعد بيانات يستخدم لغة البرمجة بايثون لتخزين بيانات تطبيق الويب. سنعمل في هذا المقال على تعديل تطبيق ويب مبني باستخدام فلاسك و SQLite من خلال إضافة علاقة من نوع متعدد-إلى-متعدد إليه. يمكنك البدء بقراءة هذا المقال مباشرةً، إلّا أنّه متابعةٌ للمقال السابق، لذلك من الأفضل قراءة المقال السابق بدايةً، إذ بيّنا فيه طريقة إدارة قاعدة بيانات متعدّدة الجداول ذات علاقة واحد-إلى-متعدد من خلال إنشاء تطبيق لإدارة المهام، ويمكِّن هذا التطبيق مستخدميه من إضافة عناصر مهام جديدة وتصنيفها ضمن قوائم مختلفة مع إمكانية تعديل العناصر. تُعرَّف علاقة قاعدة البيانات متعدّد-إلى-متعدّد على أنها علاقةٌ بين جدولين، إذ يمكن لأي سجلٍ من الجدولين الارتباط مع عدّة سجلات من الآخر، فمثلًا في تطبيق مدونة يمكن لجدول التدوينات posts أن يرتبط بعلاقة من نوع متعدد-إلى-متعدّد مع جدول أسماء المؤلفين (كُتَّاب التدوينات)، بمعنى أن كل تدوينة قد ترتبط بعدّة أسماء مؤلفين، وأيضًا قد يرتبط كل اسم مؤلف بعدّة تدوينات، وبالتالي فإنّ العلاقة ما بين التدوينات وأسماء المؤلفين هي علاقة متعدّد-إلى-متعدّد. أيُّ تطبيقٍ آخر من تطبيقات التواصل الاجتماعي هو مثالٌ آخر، إذ أن كل منشور قد يحتوي عدّة إشارات مرجعية، وكل إشارة مرجعية قد تتضمّن عدة منشورات. ومع اتباع الخطوات الواردة في هذا المقال، سنضيف على تطبيق إدارة المهام المُنشأ سابقًا ميزة تخصيص عناصر المهام لمستخدمين مختلفين، وسندعو المستخدمين الذين خُصَّصت لهم مهام بالمُخَصَّصين؛ فبفرض لدينا عنصر مهام من قائمة المهام المنزلية وهو "تنظيف المطبخ"، والتي من الممكن تخصيصها لشخصين مُختلفين وليكونا مثلًا أحمد ومحمّد، فكل مهمّة يمكن أن تملك عدّة مُخَصَّصين وهم في مثالنا أحمد ومحمّد، وبالمقابل يمكن تخصيص عدّة مهام للمستخدم الواحد، فمن الممكن مثلًا تخصيص عدّة مهام لأحمد، وبذلك نجد أنّ العلاقة ما بين عناصر المهام والمُخَصَّصين هي فعليًا من نوع متعدّد-إلى-متعدّد. سيُضاف إلى التطبيق مع نهاية هذا المقال وسم مُخصّص إلى Assigned to مع قائمة بأسماء المُخَصَّصين. مستلزمات العمل قبل المتابعة في هذا المقال لا بدّ من: توفُّر بيئة برمجة بايثون 3 محلية، وسنستدعي في مقالنا مجلد المشروع flask_todo المُنشأ مُسبقًا من الخطوات في المقال السابق. توفّر تطبيق إدارة المهام المُنجز في المقال السابق، وفي الخطوة الأولى من هذا المقال سيكون لديك الخيار إما باستنساخ التطبيق مُباشرةً دون إعداده من قبلك، أو اتباع الخطوات التفصيلية في المقال السابق لبناء التطبيق ومن ثمّ الإكمال في هذا المقال، كما يمكنك الحصول على الشيفرة الكاملة للتطبيق. يجب فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى - إعداد تطبيق الويب الخاص بإدارة المهام سنُعدّ في هذه الخطوة تطبيق الويب الخاص بإدارة المهام ليكون جاهزاً لإجراء التعديلات عليه، ولكن إذا كنت قد اتبعت الخطوات الواردة في المقال السابق (المذكور ضمن فقرة مستلزمات العمل من مقالنا هذا)، فستكون لديك شيفرة التطبيق إضافةً إلى البيئة الافتراضية مُفعلّةً على حاسوبك، وبإمكانك تجاوز هذه الخطوة مباشرةً. سنستخدم لشرح آلية إضافة علاقة من النوع متعدّد-إلى-متعدّد لتطبيق ويب مبني باستخدام فلاسك شيفرة تطبيق إدارة المهام الذي أنشأناه سابقًا (راجع فقرة مستلزمات العمل) والمبني باستخدام فلاسك و SQLite وإطار العمل بوتستراب Bootstrap، إذ يمكِّن هذا التطبيق مستخدميه من إنشاء مهام جديدة وتعديلها وحذفها وتمييزها على أنها "مُنجزة". بدايةً، استخدم الأمر Git لاستنساخ شيفرة تطبيق إدارة المهام المُنشأ سابقًا: $ git clone https://github.com/do-community/flask-todo بالانتقال إلى المجلد flask-todo: $ cd flask_todo سننشئ بيئة عمل افتراضية جديدة: $ python -m venv env ثمّ سنفعِّلها كما يلي: $ source env/bin/activate الآن، سنحمّل إطار فلاسك ونثبته باستخدام الأمر: $ pip install Flask ثمّ سنهيء قاعدة البيانات باستخدام البرنامج الموجود في الملف init_db.py: (env)user@localhost:$ python init_db.py بعد ذلك، سنسند القيم اللازمة إلى متغيرات بيئة فلاسك على النحو التالي: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development إذ يشير متغير البيئة FLASK_APP إلى تطبيق الويب الخاص بإدارة المهام الذي نطوّره في هذا المقال، والموجود في الملف app.py في حالتنا؛ بينما يشير المتغير FLASK_ENV إلى وضع بيئة العمل، وهنا أُسندت القيمة development للعمل بوضع تطوير التطبيق، ما يتيح تشغيل منقّح الأخطاء، ومن المهم تذكّر عدم استخدام هذا الوضع في مرحلة التشغيل الفعلي للتطبيق أي في بيئة الإنتاج. سنشغّل خادم التطوير: (env)user@localhost:$ flask run يمكننا الآن الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح للوصول إلى التطبيق. ولإيقاف خادم التطوير، نستخدم الاختصار "CTRL + C". أمّا الآن فسنطّلع على ملف تخطيط قاعدة البيانات لفهم بنية قاعدة البيانات الحالية والعلاقات ما بين الجداول فيها. إذا كنت قد اطلعت مُسبقًا من المقال السابق على الملف schema.sql وأصبح مألوفًا بالنسبة لك، فبإمكانك تجاوز هذه الخطوة. سنفتح الملف schema.sql: (env)user@localhost:$ nano schema.sql فتظهر محتويات الملف على النحو التالي: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); وفيه جدولين، الأول lists لتخزين القوائم، مثل قائمة المهام المنزلية Home أو قائمة المهام الدراسية study، والثاني items لتخزين عناصر المهام، مثل مهمّة غسل الأطباق Do the dishes أو مهمّة تعلّم فلاسك Learn Flask. ويحتوي جدول القوائم lists على الأعمدة التالية: "id": ويحتوي على معرّف ID القائمة. "created": يحتوي على تاريخ ووقت إنشاء قائمة المهام. "title": عنوان قائمة المهام. أمّا جدول عناصر المهام، فيحتوي على الأعمدة التالية: "id": يحتوي على معرّف ID العنصر. "list_id": يحتوي على معرّف القائمة التي ينتمي إليها العنصر. "created": يحتوي تاريخ إنشاء العنصر. "content": محتوى العنصر. "done": يحدّد حالة عنصر المهام من حيث الإنجاز، إذ تدل القيمة "0" على أنّ المهمّة لم تُنجز بعد، أمّا القيمة "1" فتعني أنّ المهمّة قد أُنجزت. ويتضمّن جدول العناصر items مفتاحًا أجنبيًا foreign key، إذ يشير العمود list_id إلى العمود id من جدول القوائم lists الأب، وهذا ما يمثّل علاقةً من النوع واحد-إلى-متعدّد one-to-many ما بين العناصر والقوائم، بمعنى أنّ القائمة الواحدة يمكن أن تضم عدّة عناصر في حين ينتمي كل عنصر لقائمة واحدة: FOREIGN KEY (list_id) REFERENCES lists (id) سنستخدم في الخطوة التالية العلاقة من نوع متعدّد-إلى-متعدّد للربط بين جدولين في قاعدة البيانات. الخطوة الثانية - إضافة جدول المخصصين سنستعرض في هذه الخطوة كيفية تطبيق علاقة من نوع متعدّد-إلى-متعدّد وكيفية دمج الجداول، ومن ثمّ سنضيف جدولًا جديدًا إلى قاعدة البيانات لتخزين المُخَصَّصين. العلاقة من نوع متعدّد-إلى-متعدّد هي طريقةٌ لربط جدولين، بحيث يكون لكل عنصر من أحدهما عدّة علاقات مع عدّة عناصر من الجدول الآخر. بفرض لدينا جدولٌ بسيط لعناصر المهام على النحو التالي: Items +----+-------------------+ | id | content | +----+-------------------+ | 1 | Buy eggs | | 2 | Fix lighting | | 3 | Paint the bedroom | +----+-------------------+ وجدول للمُخَصَّصين على النحو التالي: assignees +----+------+ | id | name | +----+------+ | 1 | Ahmad| | 2 | Mohammad | +----+------+ وعلى فرض أنّنا نريد تخصيص مهمّة إصلاح المصباح Fix lighting لكلٍ من أحمد ومحمّد، فمن الممكن إنجاز ذلك بإضافة صفٍ جديد لجدول العناصر كما يلي: items +----+-------------------+-----------+ | id | content | assignees | +----+-------------------+-----------+ | 1 | Buy eggs | | | 2 | Fix lighting | 1, 2 | | 3 | Paint the bedroom | | +----+-------------------+-----------+ ولكن وبما أنّ كل عمود ينبغي أن يحتوي على قيمةٍ واحدة لضمان سلاسة العمليات، نجد أنّ المنهجية أعلاه خاطئة؛ فعند إسناد قيم متعدّدة للسجل الواحد في العمود، ستغدو العمليات الأساسية البسيطة، مثل إضافة، أو تحديث البيانات معقّدةً وبطيئة، والحل يكون باستخدام جدول ثالث يحوي أعمدةً تشير إلى المفاتيح الأساسية للجداول ذات الصلة، وهو ما ندعوه عادةً جدول الدمج join table، وهو يخزّن المعرّفات لكل عنصر في كل جدول. وفيما يلي مثالٌ لجدول دمج يربط بين جدولي العناصر والمُخَصَّصين: item_assignees +----+---------+-------------+ | id | item_id | assignee_id | +----+---------+-------------+ | 1 | 2 | 1 | | 2 | 2 | 2 | +----+---------+-------------+ ففي السطر الأوّل من جدول الدمج أعلاه، يرتبط العنصّر ذو المعرّف 2، الذي يمثّل مهمّة إصلاح المصباح Fix lighting مع المُخّصَّص ذو المعرّف 1 (أحمد)، أمّا في السطر الثاني فإنّ عنصر المهام نفسه يرتبط مع المُخّصَّص ذو المعرّف 2 (محمّد)، ما يعني أنّ عنصر المهام قد خُصِّص لكل من أحمد ومحمّد، ويمكننا تخصيص عدّة عناصر مهام على نحوٍ مشابه لشخص مُخَصَّص واحد. سنعمل الآن على تعديل قاعدة بيانات تطبيق المهام لإضافة الجدول الذي يخزّن المُخَصَّصين. لذا بدايةً، سنفتح ملف تخطيط قاعدة البيانات schema.sql لإضافة جدولٍ جديد باسم assignees: (env)user@localhost:$ nano schema.sql وسنضيف سطرًا برمجيًا لحذف أي جداول موجودة أصلًا في قاعدة البيانات باسم assignees، وهذا ما يجنبنا أي تضاربات قد تحصل مُستقبلًا نتيجة وجود جدولين بنفس الاسم وبأعمدة مُختلفة في قاعدة البيانات، والذي قد يؤدي لتوقف تنفيذ الشيفرة نتيجة عدم توافق الجدول الموجود مع تخطيط قاعدة البيانات. الآن، سنضيف شيفرة SQL اللازمة للجدول الجديد: DROP TABLE IF EXISTS assignees; DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); CREATE TABLE assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL ); اِحفظ الملف وأغلقه. يحتوي جدول المُخَصَّصين assignees الجديد على الأعمدة التالية: "id": ويحتوي على معرّف ID المُخَصَّص. "name": يحتوي على اسم المُخَصَّص. الآن، سنعدّل ملف تهيئة قاعدة البيانات init_db.py بغية إضافة بعض المُخَصَّصين إلى قاعدة البيانات: (env)user@localhost:$ nano init_db.py عدّل الملف ليصبح كما يلي: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Ahmad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Mohammad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('sami',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Yousef',)) connection.commit() connection.close() اِحفظ الملف وأغلقه. استخدمنا في الشيفرة السابقة كائن المؤشّر cursor لتنفيذ تعليمة INSERT في SQL اللازمة لإدخال أربعة أسماء إلى جدول المُخّصَّصين assignees، كما استخدمنا الموضع المؤقت ? في الدالة ()execute ومرّرنا له السجل الحاوي على اسم المُخَصًّص بما يضمن إدخال البيانات في قاعدة البيانات بأمان، ثمّ حفظنا التغييرات باستخدام الدالة ()connection.commit، وأُغلق الاتصال مع قاعدة البيانات باستخدام الدالة ()connection.close. وبذلك سيُضاف أربعة مُخّصَّصين إلى قاعدة البيانات، أسماؤهم أحمد ومحمّد وسامي ويوسف. الآن سنعيد تهيئة قاعدة البيانات بتشغيل البرنامج init_db.py: (env)user@localhost:$ python init_db.py وبذلك يصبح لدينا جدول لتخزين المُخّصَّصين في قاعدة البيانات. فيما يلي سنضيف جدول الدمج بهدف إنشاء علاقةٍ من نوع متعدّد-إلى-متعدّد بين عناصر المهام والمُخّصَّصين. الخطوة الثالثة - إضافة جدول دمج ذو علاقة متعدد-إلى-متعدد سنستخدم في هذه الخطوة جدول دمج لربط عناصر المهام بالمُخَصَّصين، لذا بدايةً سنعدّل ملف تخطيط قاعدة البيانات بغية إضافة جدول دمج جديد، كما سنعدّل ملف تهيئة قاعدة البيانات لإضافة بعض التخصيصات، أي تخصيص بعض عناصر المهام لبعض المُخَصَّصين، ثمّ سنستعرض المُخَصَّصين لكل مهمّة باستخدام برنامج تجريبي لفهم التغييرات الحاصلة في قاعدة البيانات. سنفتح بدايةً ملف تخطيط قاعدة البيانات schema.sql لإضافة جدول جديد: (env)user@localhost:$ nano schema.sql وبما أنّ هذا الجدول يدمج العناصر مع المُخَصَّصين فسنسميه جدول عناصر مُخَصَّصين item_assignees، وسنضيف سطرًا برمجيًا لحذف أي جداول موجودة أصلًا في قاعدة البيانات بنفس الاسم، ومن ثمّ سنضيف شيفرة SQL اللازمة لهذا الجدول: DROP TABLE IF EXISTS assignees; DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; DROP TABLE IF EXISTS item_assignees; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); CREATE TABLE assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL ); CREATE TABLE item_assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, item_id INTEGER, assignee_id INTEGER, FOREIGN KEY(item_id) REFERENCES items(id), FOREIGN KEY(assignee_id) REFERENCES assignees(id) ); اِحفظ الملف وأغلقه. يحتوي جدول عناصر مُخَصَّصين item_assignees الجديد على الأعمدة التالية: "id": ويحتوي على معرّف ID المُدخَل والدال على العلاقة ما بين مهمّة ومُخَصَّص، إذ يمثّل كل سطر من هذا الجدول علاقةً ما بين مهمّة ومُخَصَّص. "item_id": ويحتوي على معرّف ID لعنصر المهام المُسند للمُخَصَّص ذا المعرّف "assignee_id" الموافق. "assignee_id": ويحتوي على معرّف ID للمُخَصَّص المُسند إليه عنصر المهام ذا المعرّف "item_id" الموافق. ويملك الجدول item_assignees مفتاحين أجنبيين، الأول يربط عمود معرّف العنصر item_id في هذا الجدول مع عمود المعرّف id من جدول العناصر items، والثاني يربط عمود معرّف المُخَصَّص من هذا الجدول مع عمود المعرّف id من جدول المُخَصَّصين assignees. والآن سنفتح ملف تهيئة قاعدة البيانات لإضافة بعض التخصيصات، أي إسناد مهام لمُخَصَّصين: (env)user@localhost:$ nano init_db.py وسنعدّل الملف ليصبح كما يلي: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) cur.execute("INSERT INTO assignees (name) VALUES (?)", (Ahmad,)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Mohammad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Sami',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Yousef',)) # Assign "Morning meeting" to "Ahmad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 1)) # Assign "Morning meeting" to "Mohammad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 2)) # Assign "Morning meeting" to "Yousef" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 4)) # Assign "Buy fruit" to "Ahmad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (2, 1)) connection.commit() connection.close() يُخصِّص الجزء الجديد المُضاف إلى الشيفرة السابقة عناصر مهام إلى مُخَصَّصين وذلك بإدخال كل منهما في جدول الدمج item_assignees، بحيث نُدخل معرّف قائمة المهام item_id المُراد تخصيصها (إسنادها) مع معرّف الشخص (المُخَصَّص) الموافق assignee_id. فمثلًا، أسندنا في الشيفرة أعلاه مهمّة الاجتماع الصباحي Morning meeting ذات المعرّف 1 إلى المُخَصَّص Ahmad ذو المعرّف 1، وأكملنا الأسطر التالية وفق النمط ذاته، ومجدّدًا استخدمنا الموضع المؤقت ? لتمرير القيم المراد إدخالها على هيئة مجموعة إلى التابع ()cur.execute بأمان. اِحفظ الملف وأغلقه. الآن سنعيد تهيئة قاعدة البيانات مجدّدًا بتشغيل البرنامج في الملف init_db.py كما يلي: (env)user@localhost:$ python init_db.py ثم سنشغّل البرنامج التجريبي list_example.py، الذي يعرض عناصر المهام الموجودة في قاعدة البيانات: (env)user@localhost:$ python list_example.py ويكون الخرج على النحو التالي: Home Buy fruit | id: 2 | done: 0 Cook dinner | id: 3 | done: 0 Study Learn Flask | id: 4 | done: 0 Learn SQLite | id: 5 | done: 0 Work Morning meeting | id: 1 | done: 0 نلاحظ من الخرج أنه يعرض كل عناصر المهام تحت القائمة التي يتبع لها، إضافةً لعرض معرّف وحالة كل عنصر (مُنجز / غير مُنجز)، إذ تدل القيمة 0 على عدم إنجازه بعد، أمّا القيمة 1 فتعني أنّه مُنجز. الآن، سنعمل على عرض المُخَصَّصين لكل عنصر مهام، لذلك سنفتح الملف list_example.py: (env)user@localhost:$ nano list_example.py ونعدله بحيث يعرض المُخَصَّصين لكل عنصر مهام كما يلي: from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): # Create an empty list for items items = [] # Go through each to-do item row in the groupby() grouper object for item in g: # Get the assignees of the current to-do item assignees = conn.execute('SELECT a.id, a.name FROM assignees a \ JOIN item_assignees i_a \ ON a.id = i_a.assignee_id \ WHERE i_a.item_id = ?', (item['id'],)).fetchall() # Convert the item row into a dictionary to add assignees item = dict(item) item['assignees'] = assignees items.append(item) # Build the list of dictionaries # the list's name (ex: Home/Study/Work) as the key # and a list of dictionaries of to-do items # belonging to that list as the value lists[k] = list(items) for list_, items in lists.items(): print(list_) for item in items: assignee_names = ', '.join(a['name'] for a in item['assignees']) print(' ', item['content'], '| id:', item['id'], '| done:', item['done'], '| assignees:', assignee_names) اِحفظ الملف وأغلقه. استخدمنا في الشيفرة السابقة دالة الفرز ()groupby لفرز عناصر المهام بحسب عناوين القوائم التي ينتمي لها كل عنصر (لمزيد من التفاصيل حول هذه النقطة يمكنك الاطلاع على الخطوة الثانية من مقال استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد، وخلال إجراء عملية الفرز السابقة، أنشأنا قائمةً فارغةً باسم items، وهي ستحتوي كافّة بيانات عناصر المهام، من معرّف العنصر ومحتواه والمُخَصَّص ومن ثمّ نمر ضمن حلقة for المُخصّصة للعناصر وخلال g دورة (تكرار) على كافّة عناصر المهام لجلب المُخَصَّص لكل عنصر وحفظه ضمن المتغير assignees، الذي سيخزّن نتائج الاستعلام SELECT في SQL؛ إذ يجلب هذا الاستعلام معرّف المُخَصَّص a.id واسمه a.name من جدول المُخَصَّصين assignees (وقد رمزنا لهذا الجدول بالحرف a بهدف اختصار الاستعلام)، ثمّ يدمج معرّف واسم المُخَصَّص item_assignees المرتبط بالقائمة المطلوبة في جدول الدمج (رمزه المُختصَر i_a) وذلك من خلال تحقيق شرط كون معرّف المُخَصّص المأخوذ من جدول المُخَصَّصين مساويًا للمعرّف في جدول الدمج a.id = i_a.assignee_id وذلك عند كون قيمة معرّف عنصر المهام i_a.item_id في جدول الدمج مساويةً لقيمة معرّف العنصر الحالي ['item['id'، ومن ثمّ نحصل على نتائج الاستعلام ضمن قائمة باستخدام التابع()fetchall. وبما أنّ كائن sqlite3.Row العادي لا يدعم مبدأ الإسناد، أضفنا السطر البرمجي التالي: item = dict(item) لتحويل العناصر إلى قواميس بايثون، والتي سنستخدمها لإضافة المُخَصَّصين إلى العناصر، ثمّ أضفنا مفتاحًا جديدًا وهو assignees إلى قاموس العناصر item باستخدام السطر البرمجي التالي: item['assignees'] = assignees وذلك بهدف الوصول إلى مُخَصَّصي العناصر مباشرةً من قاموس العناصر، ثمّ أضفنا العنصر المعدّل هذا إلى قائمة العناصر items، ثم بنينا قائمة القواميس المحتوية لكامل البيانات، فكل مفتاح ضمن القاموس يمثّل عنوان قائمة المهام وقيمة هذا المفتاح تضم كافّة العناصر التابعة لهذه القائمة. أما لطباعة النتائج استُخدمت الحلقة: for list_, items in lists.items() للمرور على كافّة عناوين قوائم المهام والعناصر التابعة لكل منها، بحيث يُطبَع عنوان القائمة _list، ثمّ نمر باستخدام حلقة على كافّة العناصر التابعة لها؛ كما أُضيف متغيّرٌ باسم assignee_names، بحيث تستخدم قيمته دالة الدمج ()join لدمج العناصر الناتجة عن تعليمة البناء generator expression التالية، التي تجلب اسم المُخَصَّص ['a['name: a['name'] for a in item['assignees'] مع بيانات هذا المُخَصَّص من القائمة ['item['assignees، وهذا ما يضمن إضافة أسماء المُخَصَّصين، ونهايةً تُطبع باقي بيانات عناصر المهام باستخدام الدالة ()print. نشغِّل الآن البرنامج التجريبي list_example.py: (env)user@localhost:$ python list_example.py فيكون الخرج على النحو التالي: Home Buy fruit | id: 2 | done: 0 | assignees: Ahmad Cook dinner | id: 3 | done: 0 | assignees: Study Learn Flask | id: 4 | done: 0 | assignees: Learn SQLite | id: 5 | done: 0 | assignees: Work Morning meeting | id: 1 | done: 0 | assignees: Ahmad, Mohammad, Yousef وبذلك أصبح بالإمكان عرض المُخَصَّصين لكل عنصر مهام لكامل البيانات. ومع نهاية هذه الخطوة، نكزن قد عرضنا أسماء المُخَصَّصين لكل عنصر مهام. سنستخدم هذه الشيفرة في الخطوة التالية لعرض أسماء المُخَصَّصين تحت كل عنصر مهام وذلك في الصفحة الرئيسية للتطبيق. الخطوة الرابعة - عرض المخصصين في الصفحة الرئيسية للتطبيق سنعدّل في هذه الخطوة الصفحة الرئيسية لتطبيق إدارة المهام، بحيث تعرض المُخَصَّصين لكل عنصر مهام. سنعدّل بدايةً الملف app.py، الذي يحتوي على شيفرة تطبيق فلاسك، ثمّ سنعدّل القالب index.html لعرض المُخَصَّصين تحت كل عنصر مهام في الصفحة الرئيسية. لذا، سنفتح الملف app.py لتعديل دالة فلاسك ()index: (env)user@localhost:$ nano app.py وسنعدّل الدالة لتصبح كما يلي: @app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): # Create an empty list for items items = [] # Go through each to-do item row in the groupby() grouper object for item in g: # Get the assignees of the current to-do item assignees = conn.execute('SELECT a.id, a.name FROM assignees a \ JOIN item_assignees i_a \ ON a.id = i_a.assignee_id \ WHERE i_a.item_id = ?', (item['id'],)).fetchall() # Convert the item row into a dictionary to add assignees item = dict(item) item['assignees'] = assignees items.append(item) # Build the list of dictionaries # the list's name (ex: Home/Study/Work) as the key # and a list of dictionaries of to-do items # belonging to that list as the value lists[k] = list(items) conn.close() return render_template('index.html', lists=lists) اِحفظ الملف وأغلقه. الشيفرة السابقة مماثلةٌ لتلك المُستخدمة في البرنامج التجريبي list_example.py في الخطوة الثالثة، وباستخدامنا لها سيحتوي المتغير lists على كافّة البيانات التي نحتاج بما فيها بيانات المُخَصًّصين التي سنستخدمها في القالب index.html للوصول إلى أسمائهم. لذا سنفتح الملف index.html: (env)user@localhost:$ nano templates/index.html ثم نعدّله بهدف إضافة أسماء المُخَصًّصين بعد كل عنصر ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item" {% if item['done'] %} style="text-decoration: line-through;" {% endif %} >{{ item['content'] }} {% if not item ['done'] %} {% set URL = 'do' %} {% set BUTTON = 'Do' %} {% else %} {% set URL = 'undo' %} {% set BUTTON = 'Undo' %} {% endif %} <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> <div class="col-12 col-md-3"> <form action="{{ url_for('delete', id=item['id']) }}" method="POST"> <input type="submit" value="Delete" class="btn btn-danger btn-sm"> </form> </div> </div> <hr> {% if item['assignees'] %} <span style="color: #6a6a6a">Assigned to</span> {% for assignee in item['assignees'] %} <span class="badge badge-primary"> {{ assignee['name'] }} </span> {% endfor %} {% endif %} </li> {% endfor %} </ul> </div> {% endfor %} {% endblock %} اِحفظ الملف وأغلقه. وبهذه التعديلات أعلاه نكون قد أضفنا فاصل أسطر تحت كل عنصر باستخدام وسم الفاصل الأفقي <hr>، وبالتالي في حال أُسندت مهامٌ معينة إلى مُخَصَّصين بواسطة التعليمة: if item['assignees'] ستظهر عبارة Assigned to وإلى جانبها أسماء المُخَصَّصين ['assignee['name الموافقين من القائمة ['item['assignees الآن، نشغِّل خادم التطوير: (env)user@localhost:$ flask run ونصل إلى الصفحة الرئيسية index للتطبيق من خلال الذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح. وبذلك أصبح من الممكن إسناد المهمّة الواحدة إلى عدّة مُخَصَّصين وإسناد عدّة مهام للمُخَصًّص الواحد. يمكنك الاطلاع على شيفرة التطبيق كاملةً. الخاتمة تعرفّنا في هذا المقال على علاقة قاعدة البيانات من نوع متعدّد-إلى-متعدّد، وكيفية استخدامها في تطبيق ويب مبني باستخدام فلاسك و SQLite، وكيفية دمج جدولين وفرز وتصنيف البيانات المترابطة باستخدام بايثون. ومع نهاية هذا المقال نكون قد أنجزنا تطبيق إدارة المهام كاملًا، والذي يمكّن مستخدميه من إنشاء عناصر مهام جديدة، وتمييز المُنجز منها، مع إمكانية تعديل أو حذف المهام الموجودة أصلًا، وإنشاء قوائم جديدة، بحيث من الممكن تخصيص كل عنصر مهام إلى عدّة مُخَصَّصين. ترجمة -وبتصرف- للمقال How To Use Many-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرا أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون استخدام علاقة one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite تعديل العناصر في علاقات one-to-many باستخدام فلاسك Flask ومحرك قاعدة البيانات SQLite
يُعد فلاسك إطار عمل يستخدم لغة البرمجة بايثون Python لبناء تطبيقات الويب، أما SQLite فهو محرّك قواعد بيانات يستخدم لغة البرمجة بايثون لتخزين بيانات تطبيق الويب. سنعمل في هذا المقال على تعديل تطبيق ويب مبني باستخدام فلاسك و SQLite من خلال إضافة علاقة من نوع متعدد-إلى-متعدد إليه. يمكنك البدء بقراءة هذا المقال مباشرةً، إلّا أنّه متابعةٌ للمقال السابق، لذلك من الأفضل قراءة المقال السابق بدايةً، إذ بيّنا فيه طريقة إدارة قاعدة بيانات متعدّدة الجداول ذات علاقة واحد-إلى-متعدد من خلال إنشاء تطبيق لإدارة المهام، ويمكِّن هذا التطبيق مستخدميه من إضافة عناصر مهام جديدة وتصنيفها ضمن قوائم مختلفة مع إمكانية تعديل العناصر. تُعرَّف علاقة قاعدة البيانات متعدّد-إلى-متعدّد على أنها علاقةٌ بين جدولين، إذ يمكن لأي سجلٍ من الجدولين الارتباط مع عدّة سجلات من الآخر، فمثلًا في تطبيق مدونة يمكن لجدول التدوينات posts أن يرتبط بعلاقة من نوع متعدد-إلى-متعدّد مع جدول أسماء المؤلفين (كُتَّاب التدوينات)، بمعنى أن كل تدوينة قد ترتبط بعدّة أسماء مؤلفين، وأيضًا قد يرتبط كل اسم مؤلف بعدّة تدوينات، وبالتالي فإنّ العلاقة ما بين التدوينات وأسماء المؤلفين هي علاقة متعدّد-إلى-متعدّد. أيُّ تطبيقٍ آخر من تطبيقات التواصل الاجتماعي هو مثالٌ آخر، إذ أن كل منشور قد يحتوي عدّة إشارات مرجعية، وكل إشارة مرجعية قد تتضمّن عدة منشورات. ومع اتباع الخطوات الواردة في هذا المقال، سنضيف على تطبيق إدارة المهام المُنشأ سابقًا ميزة تخصيص عناصر المهام لمستخدمين مختلفين، وسندعو المستخدمين الذين خُصَّصت لهم مهام بالمُخَصَّصين؛ فبفرض لدينا عنصر مهام من قائمة المهام المنزلية وهو "تنظيف المطبخ"، والتي من الممكن تخصيصها لشخصين مُختلفين وليكونا مثلًا أحمد ومحمّد، فكل مهمّة يمكن أن تملك عدّة مُخَصَّصين وهم في مثالنا أحمد ومحمّد، وبالمقابل يمكن تخصيص عدّة مهام للمستخدم الواحد، فمن الممكن مثلًا تخصيص عدّة مهام لأحمد، وبذلك نجد أنّ العلاقة ما بين عناصر المهام والمُخَصَّصين هي فعليًا من نوع متعدّد-إلى-متعدّد. سيُضاف إلى التطبيق مع نهاية هذا المقال وسم مُخصّص إلى Assigned to مع قائمة بأسماء المُخَصَّصين. مستلزمات العمل قبل المتابعة في هذا المقال لا بدّ من: توفُّر بيئة برمجة بايثون 3 محلية، وسنستدعي في مقالنا مجلد المشروع flask_todo المُنشأ مُسبقًا من الخطوات في المقال السابق. توفّر تطبيق إدارة المهام المُنجز في المقال السابق، وفي الخطوة الأولى من هذا المقال سيكون لديك الخيار إما باستنساخ التطبيق مُباشرةً دون إعداده من قبلك، أو اتباع الخطوات التفصيلية في المقال السابق لبناء التطبيق ومن ثمّ الإكمال في هذا المقال، كما يمكنك الحصول على الشيفرة الكاملة للتطبيق. يجب فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى - إعداد تطبيق الويب الخاص بإدارة المهام سنُعدّ في هذه الخطوة تطبيق الويب الخاص بإدارة المهام ليكون جاهزاً لإجراء التعديلات عليه، ولكن إذا كنت قد اتبعت الخطوات الواردة في المقال السابق (المذكور ضمن فقرة مستلزمات العمل من مقالنا هذا)، فستكون لديك شيفرة التطبيق إضافةً إلى البيئة الافتراضية مُفعلّةً على حاسوبك، وبإمكانك تجاوز هذه الخطوة مباشرةً. سنستخدم لشرح آلية إضافة علاقة من النوع متعدّد-إلى-متعدّد لتطبيق ويب مبني باستخدام فلاسك شيفرة تطبيق إدارة المهام الذي أنشأناه سابقًا (راجع فقرة مستلزمات العمل) والمبني باستخدام فلاسك و SQLite وإطار العمل بوتستراب Bootstrap، إذ يمكِّن هذا التطبيق مستخدميه من إنشاء مهام جديدة وتعديلها وحذفها وتمييزها على أنها "مُنجزة". بدايةً، استخدم الأمر Git لاستنساخ شيفرة تطبيق إدارة المهام المُنشأ سابقًا: $ git clone https://github.com/do-community/flask-todo بالانتقال إلى المجلد flask-todo: $ cd flask_todo سننشئ بيئة عمل افتراضية جديدة: $ python -m venv env ثمّ سنفعِّلها كما يلي: $ source env/bin/activate الآن، سنحمّل إطار فلاسك ونثبته باستخدام الأمر: $ pip install Flask ثمّ سنهيء قاعدة البيانات باستخدام البرنامج الموجود في الملف init_db.py: (env)user@localhost:$ python init_db.py بعد ذلك، سنسند القيم اللازمة إلى متغيرات بيئة فلاسك على النحو التالي: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development إذ يشير متغير البيئة FLASK_APP إلى تطبيق الويب الخاص بإدارة المهام الذي نطوّره في هذا المقال، والموجود في الملف app.py في حالتنا؛ بينما يشير المتغير FLASK_ENV إلى وضع بيئة العمل، وهنا أُسندت القيمة development للعمل بوضع تطوير التطبيق، ما يتيح تشغيل منقّح الأخطاء، ومن المهم تذكّر عدم استخدام هذا الوضع في مرحلة التشغيل الفعلي للتطبيق أي في بيئة الإنتاج. سنشغّل خادم التطوير: (env)user@localhost:$ flask run يمكننا الآن الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح للوصول إلى التطبيق. ولإيقاف خادم التطوير، نستخدم الاختصار "CTRL + C". أمّا الآن فسنطّلع على ملف تخطيط قاعدة البيانات لفهم بنية قاعدة البيانات الحالية والعلاقات ما بين الجداول فيها. إذا كنت قد اطلعت مُسبقًا من المقال السابق على الملف schema.sql وأصبح مألوفًا بالنسبة لك، فبإمكانك تجاوز هذه الخطوة. سنفتح الملف schema.sql: (env)user@localhost:$ nano schema.sql فتظهر محتويات الملف على النحو التالي: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); وفيه جدولين، الأول lists لتخزين القوائم، مثل قائمة المهام المنزلية Home أو قائمة المهام الدراسية study، والثاني items لتخزين عناصر المهام، مثل مهمّة غسل الأطباق Do the dishes أو مهمّة تعلّم فلاسك Learn Flask. ويحتوي جدول القوائم lists على الأعمدة التالية: "id": ويحتوي على معرّف ID القائمة. "created": يحتوي على تاريخ ووقت إنشاء قائمة المهام. "title": عنوان قائمة المهام. أمّا جدول عناصر المهام، فيحتوي على الأعمدة التالية: "id": يحتوي على معرّف ID العنصر. "list_id": يحتوي على معرّف القائمة التي ينتمي إليها العنصر. "created": يحتوي تاريخ إنشاء العنصر. "content": محتوى العنصر. "done": يحدّد حالة عنصر المهام من حيث الإنجاز، إذ تدل القيمة "0" على أنّ المهمّة لم تُنجز بعد، أمّا القيمة "1" فتعني أنّ المهمّة قد أُنجزت. ويتضمّن جدول العناصر items مفتاحًا أجنبيًا foreign key، إذ يشير العمود list_id إلى العمود id من جدول القوائم lists الأب، وهذا ما يمثّل علاقةً من النوع واحد-إلى-متعدّد one-to-many ما بين العناصر والقوائم، بمعنى أنّ القائمة الواحدة يمكن أن تضم عدّة عناصر في حين ينتمي كل عنصر لقائمة واحدة: FOREIGN KEY (list_id) REFERENCES lists (id) سنستخدم في الخطوة التالية العلاقة من نوع متعدّد-إلى-متعدّد للربط بين جدولين في قاعدة البيانات. الخطوة الثانية - إضافة جدول المخصصين سنستعرض في هذه الخطوة كيفية تطبيق علاقة من نوع متعدّد-إلى-متعدّد وكيفية دمج الجداول، ومن ثمّ سنضيف جدولًا جديدًا إلى قاعدة البيانات لتخزين المُخَصَّصين. العلاقة من نوع متعدّد-إلى-متعدّد هي طريقةٌ لربط جدولين، بحيث يكون لكل عنصر من أحدهما عدّة علاقات مع عدّة عناصر من الجدول الآخر. بفرض لدينا جدولٌ بسيط لعناصر المهام على النحو التالي: Items +----+-------------------+ | id | content | +----+-------------------+ | 1 | Buy eggs | | 2 | Fix lighting | | 3 | Paint the bedroom | +----+-------------------+ وجدول للمُخَصَّصين على النحو التالي: assignees +----+------+ | id | name | +----+------+ | 1 | Ahmad| | 2 | Mohammad | +----+------+ وعلى فرض أنّنا نريد تخصيص مهمّة إصلاح المصباح Fix lighting لكلٍ من أحمد ومحمّد، فمن الممكن إنجاز ذلك بإضافة صفٍ جديد لجدول العناصر كما يلي: items +----+-------------------+-----------+ | id | content | assignees | +----+-------------------+-----------+ | 1 | Buy eggs | | | 2 | Fix lighting | 1, 2 | | 3 | Paint the bedroom | | +----+-------------------+-----------+ ولكن وبما أنّ كل عمود ينبغي أن يحتوي على قيمةٍ واحدة لضمان سلاسة العمليات، نجد أنّ المنهجية أعلاه خاطئة؛ فعند إسناد قيم متعدّدة للسجل الواحد في العمود، ستغدو العمليات الأساسية البسيطة، مثل إضافة، أو تحديث البيانات معقّدةً وبطيئة، والحل يكون باستخدام جدول ثالث يحوي أعمدةً تشير إلى المفاتيح الأساسية للجداول ذات الصلة، وهو ما ندعوه عادةً جدول الدمج join table، وهو يخزّن المعرّفات لكل عنصر في كل جدول. وفيما يلي مثالٌ لجدول دمج يربط بين جدولي العناصر والمُخَصَّصين: item_assignees +----+---------+-------------+ | id | item_id | assignee_id | +----+---------+-------------+ | 1 | 2 | 1 | | 2 | 2 | 2 | +----+---------+-------------+ ففي السطر الأوّل من جدول الدمج أعلاه، يرتبط العنصّر ذو المعرّف 2، الذي يمثّل مهمّة إصلاح المصباح Fix lighting مع المُخّصَّص ذو المعرّف 1 (أحمد)، أمّا في السطر الثاني فإنّ عنصر المهام نفسه يرتبط مع المُخّصَّص ذو المعرّف 2 (محمّد)، ما يعني أنّ عنصر المهام قد خُصِّص لكل من أحمد ومحمّد، ويمكننا تخصيص عدّة عناصر مهام على نحوٍ مشابه لشخص مُخَصَّص واحد. سنعمل الآن على تعديل قاعدة بيانات تطبيق المهام لإضافة الجدول الذي يخزّن المُخَصَّصين. لذا بدايةً، سنفتح ملف تخطيط قاعدة البيانات schema.sql لإضافة جدولٍ جديد باسم assignees: (env)user@localhost:$ nano schema.sql وسنضيف سطرًا برمجيًا لحذف أي جداول موجودة أصلًا في قاعدة البيانات باسم assignees، وهذا ما يجنبنا أي تضاربات قد تحصل مُستقبلًا نتيجة وجود جدولين بنفس الاسم وبأعمدة مُختلفة في قاعدة البيانات، والذي قد يؤدي لتوقف تنفيذ الشيفرة نتيجة عدم توافق الجدول الموجود مع تخطيط قاعدة البيانات. الآن، سنضيف شيفرة SQL اللازمة للجدول الجديد: DROP TABLE IF EXISTS assignees; DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); CREATE TABLE assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL ); اِحفظ الملف وأغلقه. يحتوي جدول المُخَصَّصين assignees الجديد على الأعمدة التالية: "id": ويحتوي على معرّف ID المُخَصَّص. "name": يحتوي على اسم المُخَصَّص. الآن، سنعدّل ملف تهيئة قاعدة البيانات init_db.py بغية إضافة بعض المُخَصَّصين إلى قاعدة البيانات: (env)user@localhost:$ nano init_db.py عدّل الملف ليصبح كما يلي: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Ahmad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Mohammad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('sami',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Yousef',)) connection.commit() connection.close() اِحفظ الملف وأغلقه. استخدمنا في الشيفرة السابقة كائن المؤشّر cursor لتنفيذ تعليمة INSERT في SQL اللازمة لإدخال أربعة أسماء إلى جدول المُخّصَّصين assignees، كما استخدمنا الموضع المؤقت ? في الدالة ()execute ومرّرنا له السجل الحاوي على اسم المُخَصًّص بما يضمن إدخال البيانات في قاعدة البيانات بأمان، ثمّ حفظنا التغييرات باستخدام الدالة ()connection.commit، وأُغلق الاتصال مع قاعدة البيانات باستخدام الدالة ()connection.close. وبذلك سيُضاف أربعة مُخّصَّصين إلى قاعدة البيانات، أسماؤهم أحمد ومحمّد وسامي ويوسف. الآن سنعيد تهيئة قاعدة البيانات بتشغيل البرنامج init_db.py: (env)user@localhost:$ python init_db.py وبذلك يصبح لدينا جدول لتخزين المُخّصَّصين في قاعدة البيانات. فيما يلي سنضيف جدول الدمج بهدف إنشاء علاقةٍ من نوع متعدّد-إلى-متعدّد بين عناصر المهام والمُخّصَّصين. الخطوة الثالثة - إضافة جدول دمج ذو علاقة متعدد-إلى-متعدد سنستخدم في هذه الخطوة جدول دمج لربط عناصر المهام بالمُخَصَّصين، لذا بدايةً سنعدّل ملف تخطيط قاعدة البيانات بغية إضافة جدول دمج جديد، كما سنعدّل ملف تهيئة قاعدة البيانات لإضافة بعض التخصيصات، أي تخصيص بعض عناصر المهام لبعض المُخَصَّصين، ثمّ سنستعرض المُخَصَّصين لكل مهمّة باستخدام برنامج تجريبي لفهم التغييرات الحاصلة في قاعدة البيانات. سنفتح بدايةً ملف تخطيط قاعدة البيانات schema.sql لإضافة جدول جديد: (env)user@localhost:$ nano schema.sql وبما أنّ هذا الجدول يدمج العناصر مع المُخَصَّصين فسنسميه جدول عناصر مُخَصَّصين item_assignees، وسنضيف سطرًا برمجيًا لحذف أي جداول موجودة أصلًا في قاعدة البيانات بنفس الاسم، ومن ثمّ سنضيف شيفرة SQL اللازمة لهذا الجدول: DROP TABLE IF EXISTS assignees; DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; DROP TABLE IF EXISTS item_assignees; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); CREATE TABLE assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL ); CREATE TABLE item_assignees ( id INTEGER PRIMARY KEY AUTOINCREMENT, item_id INTEGER, assignee_id INTEGER, FOREIGN KEY(item_id) REFERENCES items(id), FOREIGN KEY(assignee_id) REFERENCES assignees(id) ); اِحفظ الملف وأغلقه. يحتوي جدول عناصر مُخَصَّصين item_assignees الجديد على الأعمدة التالية: "id": ويحتوي على معرّف ID المُدخَل والدال على العلاقة ما بين مهمّة ومُخَصَّص، إذ يمثّل كل سطر من هذا الجدول علاقةً ما بين مهمّة ومُخَصَّص. "item_id": ويحتوي على معرّف ID لعنصر المهام المُسند للمُخَصَّص ذا المعرّف "assignee_id" الموافق. "assignee_id": ويحتوي على معرّف ID للمُخَصَّص المُسند إليه عنصر المهام ذا المعرّف "item_id" الموافق. ويملك الجدول item_assignees مفتاحين أجنبيين، الأول يربط عمود معرّف العنصر item_id في هذا الجدول مع عمود المعرّف id من جدول العناصر items، والثاني يربط عمود معرّف المُخَصَّص من هذا الجدول مع عمود المعرّف id من جدول المُخَصَّصين assignees. والآن سنفتح ملف تهيئة قاعدة البيانات لإضافة بعض التخصيصات، أي إسناد مهام لمُخَصَّصين: (env)user@localhost:$ nano init_db.py وسنعدّل الملف ليصبح كما يلي: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) cur.execute("INSERT INTO assignees (name) VALUES (?)", (Ahmad,)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Mohammad',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Sami',)) cur.execute("INSERT INTO assignees (name) VALUES (?)", ('Yousef',)) # Assign "Morning meeting" to "Ahmad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 1)) # Assign "Morning meeting" to "Mohammad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 2)) # Assign "Morning meeting" to "Yousef" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (1, 4)) # Assign "Buy fruit" to "Ahmad" cur.execute("INSERT INTO item_assignees (item_id, assignee_id) VALUES (?, ?)", (2, 1)) connection.commit() connection.close() يُخصِّص الجزء الجديد المُضاف إلى الشيفرة السابقة عناصر مهام إلى مُخَصَّصين وذلك بإدخال كل منهما في جدول الدمج item_assignees، بحيث نُدخل معرّف قائمة المهام item_id المُراد تخصيصها (إسنادها) مع معرّف الشخص (المُخَصَّص) الموافق assignee_id. فمثلًا، أسندنا في الشيفرة أعلاه مهمّة الاجتماع الصباحي Morning meeting ذات المعرّف 1 إلى المُخَصَّص Ahmad ذو المعرّف 1، وأكملنا الأسطر التالية وفق النمط ذاته، ومجدّدًا استخدمنا الموضع المؤقت ? لتمرير القيم المراد إدخالها على هيئة مجموعة إلى التابع ()cur.execute بأمان. اِحفظ الملف وأغلقه. الآن سنعيد تهيئة قاعدة البيانات مجدّدًا بتشغيل البرنامج في الملف init_db.py كما يلي: (env)user@localhost:$ python init_db.py ثم سنشغّل البرنامج التجريبي list_example.py، الذي يعرض عناصر المهام الموجودة في قاعدة البيانات: (env)user@localhost:$ python list_example.py ويكون الخرج على النحو التالي: Home Buy fruit | id: 2 | done: 0 Cook dinner | id: 3 | done: 0 Study Learn Flask | id: 4 | done: 0 Learn SQLite | id: 5 | done: 0 Work Morning meeting | id: 1 | done: 0 نلاحظ من الخرج أنه يعرض كل عناصر المهام تحت القائمة التي يتبع لها، إضافةً لعرض معرّف وحالة كل عنصر (مُنجز / غير مُنجز)، إذ تدل القيمة 0 على عدم إنجازه بعد، أمّا القيمة 1 فتعني أنّه مُنجز. الآن، سنعمل على عرض المُخَصَّصين لكل عنصر مهام، لذلك سنفتح الملف list_example.py: (env)user@localhost:$ nano list_example.py ونعدله بحيث يعرض المُخَصَّصين لكل عنصر مهام كما يلي: from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): # Create an empty list for items items = [] # Go through each to-do item row in the groupby() grouper object for item in g: # Get the assignees of the current to-do item assignees = conn.execute('SELECT a.id, a.name FROM assignees a \ JOIN item_assignees i_a \ ON a.id = i_a.assignee_id \ WHERE i_a.item_id = ?', (item['id'],)).fetchall() # Convert the item row into a dictionary to add assignees item = dict(item) item['assignees'] = assignees items.append(item) # Build the list of dictionaries # the list's name (ex: Home/Study/Work) as the key # and a list of dictionaries of to-do items # belonging to that list as the value lists[k] = list(items) for list_, items in lists.items(): print(list_) for item in items: assignee_names = ', '.join(a['name'] for a in item['assignees']) print(' ', item['content'], '| id:', item['id'], '| done:', item['done'], '| assignees:', assignee_names) اِحفظ الملف وأغلقه. استخدمنا في الشيفرة السابقة دالة الفرز ()groupby لفرز عناصر المهام بحسب عناوين القوائم التي ينتمي لها كل عنصر (لمزيد من التفاصيل حول هذه النقطة يمكنك الاطلاع على الخطوة الثانية من مقال استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد، وخلال إجراء عملية الفرز السابقة، أنشأنا قائمةً فارغةً باسم items، وهي ستحتوي كافّة بيانات عناصر المهام، من معرّف العنصر ومحتواه والمُخَصَّص ومن ثمّ نمر ضمن حلقة for المُخصّصة للعناصر وخلال g دورة (تكرار) على كافّة عناصر المهام لجلب المُخَصَّص لكل عنصر وحفظه ضمن المتغير assignees، الذي سيخزّن نتائج الاستعلام SELECT في SQL؛ إذ يجلب هذا الاستعلام معرّف المُخَصَّص a.id واسمه a.name من جدول المُخَصَّصين assignees (وقد رمزنا لهذا الجدول بالحرف a بهدف اختصار الاستعلام)، ثمّ يدمج معرّف واسم المُخَصَّص item_assignees المرتبط بالقائمة المطلوبة في جدول الدمج (رمزه المُختصَر i_a) وذلك من خلال تحقيق شرط كون معرّف المُخَصّص المأخوذ من جدول المُخَصَّصين مساويًا للمعرّف في جدول الدمج a.id = i_a.assignee_id وذلك عند كون قيمة معرّف عنصر المهام i_a.item_id في جدول الدمج مساويةً لقيمة معرّف العنصر الحالي ['item['id'، ومن ثمّ نحصل على نتائج الاستعلام ضمن قائمة باستخدام التابع()fetchall. وبما أنّ كائن sqlite3.Row العادي لا يدعم مبدأ الإسناد، أضفنا السطر البرمجي التالي: item = dict(item) لتحويل العناصر إلى قواميس بايثون، والتي سنستخدمها لإضافة المُخَصَّصين إلى العناصر، ثمّ أضفنا مفتاحًا جديدًا وهو assignees إلى قاموس العناصر item باستخدام السطر البرمجي التالي: item['assignees'] = assignees وذلك بهدف الوصول إلى مُخَصَّصي العناصر مباشرةً من قاموس العناصر، ثمّ أضفنا العنصر المعدّل هذا إلى قائمة العناصر items، ثم بنينا قائمة القواميس المحتوية لكامل البيانات، فكل مفتاح ضمن القاموس يمثّل عنوان قائمة المهام وقيمة هذا المفتاح تضم كافّة العناصر التابعة لهذه القائمة. أما لطباعة النتائج استُخدمت الحلقة: for list_, items in lists.items() للمرور على كافّة عناوين قوائم المهام والعناصر التابعة لكل منها، بحيث يُطبَع عنوان القائمة _list، ثمّ نمر باستخدام حلقة على كافّة العناصر التابعة لها؛ كما أُضيف متغيّرٌ باسم assignee_names، بحيث تستخدم قيمته دالة الدمج ()join لدمج العناصر الناتجة عن تعليمة البناء generator expression التالية، التي تجلب اسم المُخَصَّص ['a['name: a['name'] for a in item['assignees'] مع بيانات هذا المُخَصَّص من القائمة ['item['assignees، وهذا ما يضمن إضافة أسماء المُخَصَّصين، ونهايةً تُطبع باقي بيانات عناصر المهام باستخدام الدالة ()print. نشغِّل الآن البرنامج التجريبي list_example.py: (env)user@localhost:$ python list_example.py فيكون الخرج على النحو التالي: Home Buy fruit | id: 2 | done: 0 | assignees: Ahmad Cook dinner | id: 3 | done: 0 | assignees: Study Learn Flask | id: 4 | done: 0 | assignees: Learn SQLite | id: 5 | done: 0 | assignees: Work Morning meeting | id: 1 | done: 0 | assignees: Ahmad, Mohammad, Yousef وبذلك أصبح بالإمكان عرض المُخَصَّصين لكل عنصر مهام لكامل البيانات. ومع نهاية هذه الخطوة، نكزن قد عرضنا أسماء المُخَصَّصين لكل عنصر مهام. سنستخدم هذه الشيفرة في الخطوة التالية لعرض أسماء المُخَصَّصين تحت كل عنصر مهام وذلك في الصفحة الرئيسية للتطبيق. الخطوة الرابعة - عرض المخصصين في الصفحة الرئيسية للتطبيق سنعدّل في هذه الخطوة الصفحة الرئيسية لتطبيق إدارة المهام، بحيث تعرض المُخَصَّصين لكل عنصر مهام. سنعدّل بدايةً الملف app.py، الذي يحتوي على شيفرة تطبيق فلاسك، ثمّ سنعدّل القالب index.html لعرض المُخَصَّصين تحت كل عنصر مهام في الصفحة الرئيسية. لذا، سنفتح الملف app.py لتعديل دالة فلاسك ()index: (env)user@localhost:$ nano app.py وسنعدّل الدالة لتصبح كما يلي: @app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): # Create an empty list for items items = [] # Go through each to-do item row in the groupby() grouper object for item in g: # Get the assignees of the current to-do item assignees = conn.execute('SELECT a.id, a.name FROM assignees a \ JOIN item_assignees i_a \ ON a.id = i_a.assignee_id \ WHERE i_a.item_id = ?', (item['id'],)).fetchall() # Convert the item row into a dictionary to add assignees item = dict(item) item['assignees'] = assignees items.append(item) # Build the list of dictionaries # the list's name (ex: Home/Study/Work) as the key # and a list of dictionaries of to-do items # belonging to that list as the value lists[k] = list(items) conn.close() return render_template('index.html', lists=lists) اِحفظ الملف وأغلقه. الشيفرة السابقة مماثلةٌ لتلك المُستخدمة في البرنامج التجريبي list_example.py في الخطوة الثالثة، وباستخدامنا لها سيحتوي المتغير lists على كافّة البيانات التي نحتاج بما فيها بيانات المُخَصًّصين التي سنستخدمها في القالب index.html للوصول إلى أسمائهم. لذا سنفتح الملف index.html: (env)user@localhost:$ nano templates/index.html ثم نعدّله بهدف إضافة أسماء المُخَصًّصين بعد كل عنصر ليصبح كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item" {% if item['done'] %} style="text-decoration: line-through;" {% endif %} >{{ item['content'] }} {% if not item ['done'] %} {% set URL = 'do' %} {% set BUTTON = 'Do' %} {% else %} {% set URL = 'undo' %} {% set BUTTON = 'Undo' %} {% endif %} <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> <div class="col-12 col-md-3"> <form action="{{ url_for('delete', id=item['id']) }}" method="POST"> <input type="submit" value="Delete" class="btn btn-danger btn-sm"> </form> </div> </div> <hr> {% if item['assignees'] %} <span style="color: #6a6a6a">Assigned to</span> {% for assignee in item['assignees'] %} <span class="badge badge-primary"> {{ assignee['name'] }} </span> {% endfor %} {% endif %} </li> {% endfor %} </ul> </div> {% endfor %} {% endblock %} اِحفظ الملف وأغلقه. وبهذه التعديلات أعلاه نكون قد أضفنا فاصل أسطر تحت كل عنصر باستخدام وسم الفاصل الأفقي <hr>، وبالتالي في حال أُسندت مهامٌ معينة إلى مُخَصَّصين بواسطة التعليمة: if item['assignees'] ستظهر عبارة Assigned to وإلى جانبها أسماء المُخَصَّصين ['assignee['name الموافقين من القائمة ['item['assignees الآن، نشغِّل خادم التطوير: (env)user@localhost:$ flask run ونصل إلى الصفحة الرئيسية index للتطبيق من خلال الذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح. وبذلك أصبح من الممكن إسناد المهمّة الواحدة إلى عدّة مُخَصَّصين وإسناد عدّة مهام للمُخَصًّص الواحد. يمكنك الاطلاع على شيفرة التطبيق كاملةً. الخاتمة تعرفّنا في هذا المقال على علاقة قاعدة البيانات من نوع متعدّد-إلى-متعدّد، وكيفية استخدامها في تطبيق ويب مبني باستخدام فلاسك و SQLite، وكيفية دمج جدولين وفرز وتصنيف البيانات المترابطة باستخدام بايثون. ومع نهاية هذا المقال نكون قد أنجزنا تطبيق إدارة المهام كاملًا، والذي يمكّن مستخدميه من إنشاء عناصر مهام جديدة، وتمييز المُنجز منها، مع إمكانية تعديل أو حذف المهام الموجودة أصلًا، وإنشاء قوائم جديدة، بحيث من الممكن تخصيص كل عنصر مهام إلى عدّة مُخَصَّصين. ترجمة -وبتصرف- للمقال How To Use Many-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرا أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون استخدام علاقة one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite تعديل العناصر في علاقات one-to-many باستخدام فلاسك Flask ومحرك قاعدة البيانات SQLite -
 يُعد فلاسك إطار عمل لبناء تطبيقات الويب مبني باستخدام لغة البرمجة بايثون Python، أمّا SQLite فيُعرَّف على أنّه محرّك قاعدة بيانات يُستخدم ضمن بايثون لتخزين بيانات التطبيقات. سنتعلّم في هذا المقال كيفية التعديل على عناصر تطبيق مبني باستخدام فلاسك و SQLite. يأتي مقالنا هذا استكمالًا للمقال السابق الذي أنشأنا فيه تطبيق ويب لإدارة المهام باستخدام فلاسك و SQLite، إذ أتاح لمستخدميه إمكانية إدارة عناصر المهام وتنظيمها ضمن قوائم، وإضافة عناصر جديدة إلى قاعدة البيانات؛ وفي مقالنا هذا سنضيف للتطبيق السابق الآليات اللازمة لإتاحة إمكانية تخصيص عناصر مهام مُنجزة، وتعديل عناصر موجودة أصلًا وحذف عناصر وإضافة قوائم جديدة إلى قاعدة البيانات، وباتبّاع الخطوات التالية سيُضاف للتطبيق السابق أزرار تحرير وحذف، إضافةً لإمكانية وضع خط متوسط لتمييّز المهام المُنجزة. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، وسنستدعي في مقالنا مجلد المشروع flask_todo المُنشأ مُسبقًا من الخطوات في المقال السابق. توفّر تطبيق إدارة المهام المُنجز في المقال السابق، وفي الخطوة الأولى من هذا المقال سيكون لديك الخيار إما باستنساخ التطبيق مُباشرةً دون إعداده من قبلك، أو باتباع الخطوات التفصيلية في المقال السابق كيفية استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite لبناء التطبيق، ومن ثمّ الإكمال في هذا المقال، كما يمكنك الحصول على الشيفرة الكاملة للتطبيق. يجب فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى - إعداد تطبيق الويب الخاص بإدارة المهام سنُعدّ في هذه الخطوة تطبيق الويب الخاص بإدارة المهام ليكون جاهزاً لإجراء التعديلات عليه، ولكن إن كنت قد اتبعت الخطوات الواردة في المقال السابق (المذكور ضمن فقرة مستلزمات العمل من مقالنا هذا)، ولديك شيفرة التطبيق إضافةً إلى البيئة الافتراضية مُفعلّةً على حاسوبك، فبإمكانك تجاوز هذه الخطوة مباشرةً. سنبدأ باستخدم الأمر Git لاستنساخ شيفرة تطبيق إدارة المهام المُنشأ سابقًا: $ git clone https://github.com/do-community/flask-todo ثم ننتقل إلى المجلّد flask-todo: $ cd flask-todo سننشئ بيئة عمل افتراضية جديدة: $ python -m venv env ومن ثمّ سنفعلها على النحو التالي: $ source env/bin/activate الآن سنحمّل إطار فلاسك ونثبته باستخدام الأمر: $ pip install Flask ثمّ سنهيء قاعدة البيانات باستخدام البرنامج الموجود في الملف init_db.py: (env)user@localhost:$ python init_db.py ثمّ سنسند القيم اللازمة إلى متغيرات بيئة فلاسك: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development إذ يشير متغير البيئة FLASK_APP إلى تطبيق الويب الخاص بإدارة المهام الذي نطوّره في هذا المقال، والموجود في الملف app.py في حالتنا؛ بينما يشير المتغير FLASK_ENV إلى وضع بيئة العمل، وهنا أُسندت القيمة development للعمل بوضع تطوير التطبيق، ما يتيح تشغيل منقّح الأخطاء، ومن المهم تذكّر عدم استخدام هذا الوضع في مرحلة التشغيل الفعلي للتطبيق أي في بيئة الإنتاج. سنشغّل خادم التطوير: (env)user@localhost:$ flask run يمكننا الآن الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح للوصول إلى التطبيق. ولإيقاف خادم التطوير، نستخدم الاختصار "CTRL + C". وسنعدّل في الخطوة التالية تطبيق إدارة المهام ليُتيح لمستخدميه إمكانية تمييز عناصر المهام المُنجزة. الخطوة الثانية - إضافة إمكانية تمييز عناصر المهام المنجزة سنضيف في هذه الخطوة زرًا يُمكّن المستخدم من وضع علامةٍ على كل عنصر مهام مُنجز لتمييزه، لذا سنضيف عمودًا جديدًا إلى جدول العناصر items في قاعدة البيانات يحتوي على علامة تميّز ما إذا كان عنصر المهام قد أُنجز أم لا، وهذا بدوره يتطلّب إنشاء وجهة جديدة ضمن ملف البرنامج app.py، إذ سيعمل على تغيير قيم العمود الجديد لكل عنصر تبعًا لنشاطات المستخدم وتفاعله مع واجهة التطبيق. وللتذكير، الأعمدة الموجودة حاليًا في الجدول items من قاعدة البيانات قبل إضافة العمود الجديد، هي: "id": يحتوي معرّف العنصر. "list_id": يحتوي معرّف القائمة التي ينتمي إليها العنصر. "created": يحوي تاريخ إنشاء العنصر. "content": محتوى العنصر. بدايةً، سنفتح ملف تخطيط قاعدة البيانات schema.sql لتعديل جدول العناصر items: (env)user@localhost:$ nano schema.sql وسنضيف عمودًا جديدًا باسم done إلى جدول العناصر items على النحو التالي: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); اِحفظ الملف وأغلقه. سيتضمّن العمود المُضاف حديثًا done إلى قاعدة بيانات التطبيق إحدى القيمتين الصحيحتين "0" أو "1"، إذ تمثّل القيمة "0" القيمة المنطقية "false للدلالة على عنصر مهام غير مُنجز، في حين تمثّل القيمة "1" القيمة المنطقية "true" للدلالة على عنصر مهام مُنجز، علمًا أن القيمة الافتراضية هي "0"، وبالتالي عند إضافة أي عنصر مهام جديد إلى قاعدة البيانات فإنّ العمود done سيشير تلقائيًا إلى القيمة "0" دلالةً على أنّ المهمّة غير مُنجزة بعد، ولن تتغير حتى يضع المستخدم علامةً على العنصر أنه مُنجز، وعندها تتغير القيمة المقابلة لهذا العنصر في العمود done من القيمة "0" إلى القيمة "1". ولتطبيق التغييرات المُنفّذة على ملف تخطيط قاعدة البيانات schema.sql، سنهيئ قاعدة البيانات مجدّدًا باستخدام برنامج init_db.py: (env)user@localhost:$ python init_db.py الآن، سنفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py ثم سنجلب كلًا من معرّف العنصر وقيمة عمود done الموافقة له إلى الدالة ()index، التي تجلب أصلًا القوائم والعناصر من قاعدة البيانات، مرسلةً إياها إلى ملف HTML المُسمّى index.html ليعمل على عرضها، لذا عدّلنا على تعليمات SQL السابقة لتصبح مثل الشيفرة التالية: @app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) conn.close() return render_template('index.html', lists=lists) اِحفظ الملف وأغلقه. وبإجراء هذه التعديلات على الشيفرة السابقة، ستُجلب معرّفات العناصر من قاعدة البيانات باستخدام التعليمة i.id، والقيمة من عمود done الموافقة باستخدام التعليمة i.done. ولفهم نتائج هذه التعديلات بوضوح، سننشئ الملف list_example.py على سبيل التجربة، وسنكتب ضمنه برنامجًا صغيرًا بهدف فهم محتويات قاعدة البيانات الجديدة: (env)user@localhost:$ nano list_example.py سنكتب ضمن هذا الملف التجريبي نفس الشيفرة السابقة مع التعديلات التي أجريناها على تعليمات SQL، ولكن سنعدّل دالة الطباعة ()print الأخيرة لتعرض كلًا من معرّف العنصر ID والقيمة الدالة على حالة إنجازه done: from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) for list_, items in lists.items(): print(list_) for item in items: print(' ', item['content'], '| id:', item['id'], '| done:', item['done']) اِحفظ الملف وأغلقه. الآن سنشغِّل هذا البرنامج التجريبي: (env)user@localhost:$ python list_example.py لنحصل على الخرج التالي: Home Buy fruit | id: 2 | done: 0 Cook dinner | id: 3 | done: 0 Study Learn Flask | id: 4 | done: 0 Learn SQLite | id: 5 | done: 0 Work Morning meeting | id: 1 | done: 0 نلاحظ من الخرج السابق أنّ قيمة العمود done هي 0 لكافّة عناصر المهام، لعدم تحديد أيٍّ منها على أنه مُنجز بعد، والآن وحتى يتمكن المستخدمون من تعديل هذه القيمة للمهام المُنجزة، سننشئ وجهة جديدة في الملف app.py. لذلك، سنفتح الملف app.py: (env)user@localhost:$ nano app.py ومن ثمّ سنضيف الشيفرة التالية إلى نهاية الملف لإضافة وجهة جديدة /do/: . . . @app.route('/<int:id>/do/', methods=('POST',)) def do(id): conn = get_db_connection() conn.execute('UPDATE items SET done = 1 WHERE id = ?', (id,)) conn.commit() conn.close() return redirect(url_for('index')) تتعامل هذه الوجهة الجديدة مع الطلبات الواردة وفق الطريقة POST فقط، إذ تستقبل دالة فلاسك ()do معرّف العنصر المراد تمييزه على أنه منجز id وسيطًا، ليفتح اتصالًا مع قاعدة البيانات، ثمّ يغيّر قيمة العمود done من 0 إلى 1 للعنصر المطلوب تمييزه على أنه مُنجزٌ باستخدام التعليمة UPDATE في SQL. وقد استخدمنا الموضع المؤقت ? في الدالة ()execute، ثم مررنا مجموعة البيانات الحاوية على معرّف العنصر ID ما يضمن إدراجًا صحيحًا وآمنًا للبيانات في قاعدة البيانات. نهايةً، أغلقنا الاتصال مع قاعدة البيانات بعد تأكيد التغييرات ليُعاد توجيه المستخدم إلى الصفحة الرئيسية index. الآن وبعد الانتهاء من إضافة الوجهة المسؤولة عن تمييز عناصر المهام على أنها مُنجزة، لا بدّ من إضافة وجهة جديدة للتراجع، بمعنى إمكانية إلغاء تمييز عنصر المهام على أنه مُنجز، لذا سنضيف الوجهة التالية إلى نهاية الملف app.py: . . . @app.route('/<int:id>/undo/', methods=('POST',)) def undo(id): conn = get_db_connection() conn.execute('UPDATE items SET done = 0 WHERE id = ?', (id,)) conn.commit() conn.close() return redirect(url_for('index')) نلاحظ أنّ شيفرة هذه الوجهة مشابهةٌ إلى حدٍ كبير لسابقتها /do/، كما أنّ دالة فلاسك ()undo تماثل الدالة ()do تمامًا بطريقة عملها ماعدا كونها تخصّص القيمة 0 للعمود done بدلًا من القيمة 1. اِحفظ الملف وأغلقه. الآن وبعد إضافة كل من الوجهتين /do/ و /undo/، سنضيف زرًا مهمّته تمييز عنصر المهام المعروض على أنه مُنجز (من خلال إضافة خط متوسّط له) أم لا اعتمادًا على حالته، أي حسب قيمة العمود done في قاعدة البيانات، لذا سنفتح ملف قالب HTML المُسمّى index.html: (env)user@localhost:$ nano templates/index.html وسنعدّل محتويات حلقة for التكرارية داخل عنصر القائمة غير المرتبة <ul> لتصبح على النحو التالي: {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item" {% if item['done'] %} style="text-decoration: line-through;" {% endif %} >{{ item['content'] }} {% if not item ['done'] %} {% set URL = 'do' %} {% set BUTTON = 'Do' %} {% else %} {% set URL = 'undo' %} {% set BUTTON = 'Undo' %} {% endif %} <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> </div> </li> {% endfor %} </ul> </div> {% endfor %} {% endblock %} أسندنا في الشيفرة السابقة وضمن الحلقة for القيمة line-through لسمة تنسيق النص text-decoration في CSS، والتي تضيف خطًّا متوسطًا للنص في حال كان عنصر القوائم مُنجزًا تبعًا لقيمة السجل الموافق للعنصر من العمود done في قاعدة البيانات، ثمّ استخدمنا تعليمة set من تعليمات محرّك القوالب جينجا Jinja لنصرّح عن متغيرين، هما URL و BUTTON؛ فإذا كان العنصر غير مُحدّدٍ على أنه مُنجز، سيأخذ المتغير BUTTON القيمة Do وسيشير المتغيّر URL إلى الوجهة /do/؛ أمّا إذا كان العنصر محّددًا على أنه مُنجَز، فسيأخذ المتغير BUTTON القيمة Undo، وسيشير المتغيّر URL إلى الوجهة /undo/. استخدمنا بعد ذلك هذين المتغيرين في نموذج إدخال يُرسل الطلب المناسب اعتمادًا على حالة عنصر المهام. نشغّل الخادم: (env)user@localhost:$ flask run الآن وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، أصبح بالإمكان تمييز عناصر المهام المُنجزة من الصفحة الرئيسية للتطبيق، في الخطوة التالية سنعمل على إضافة إمكانية تعديل عناصر المهام. الخطوة الثالثة - تعديل عناصر المهام سنضيف إلى التطبيق في هذه الخطوة صفحةً جديدةً خاصةً بتحرير عناصر المهام، ما سيتيح إمكانية تعديل محتويات كل عنصر من عناصر المهام، إضافةً لإمكانية ربط هذه العناصر مع قوائم مختلفة. الآن وضمن الملف app.py سنضيف وجهة جديدة /edit/، مهمته إخراج صفحة HTML جديدة باسم edit.html، والتي تتيح للمستخدمين إمكانية التعديل على عناصر المهام الحالية، وهنا يتوجب علينا تحديث الملف index.html لإضافة زر Edit لكل عنصر مهام. بدايةً سنفتح الملف app.py: (env)user@localhost:$ nano app.py ثم سنضيف الشيفرات الخاصّة بالوجهة الجديدة في نهاية الملف على النحو التالي: . . . @app.route('/<int:id>/edit/', methods=('GET', 'POST')) def edit(id): conn = get_db_connection() todo = conn.execute('SELECT i.id, i.list_id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id WHERE i.id = ?', (id,)).fetchone() lists = conn.execute('SELECT title FROM lists;').fetchall() if request.method == 'POST': content = request.form['content'] list_title = request.form['list'] if not content: flash('Content is required!') return redirect(url_for('edit', id=id)) list_id = conn.execute('SELECT id FROM lists WHERE title = (?);', (list_title,)).fetchone()['id'] conn.execute('UPDATE items SET content = ?, list_id = ?\ WHERE id = ?', (content, list_id, id)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('edit.html', todo=todo, lists=lists) تُستخدم القيمة id وسيطًا في دالة فلاسك الجديدة المُبيّنة في الشيفرة السابقة لجلب معرّف عنصر المهام المُراد تحريره، إضافةً إلى معرّف وعنوان القائمة التي ينتمي إليها، وقيمة السجل الموافق من العمود done، ومحتوى العنصر، وذلك باستخدام التعليمة JOIN في SQL. تُحفظ هذه البيانات في متغيرٍ باسم todo، ثمّ تُجلب كافّة قوائم المهام من قاعدة البيانات وتُخزّن في المتغير lists. في حال كان الطلب عاديًا وفق الطريقة GET، فإن الشرط التالي الدال على كون الطلب من نوع POST لن يتحقّق: if request.method == 'POST' وبالتالي سينتقل التطبيق لتنفيذ دالة إخراج القوالب ()render_template الذي سيمرِّر قيم المتغيرين todo و lists إلى الملف edit.html المُخرج. أمّا في حال تأكيد نموذج وإرساله من قبل المستخدم، عندها سيتحقّق الشرط: request.method == 'POST' ونستخلص بالتالي المحتوى والعنوان المُعدّلين المُدخلين في النموذج المُرسل؛ وفي حال عدم وجود أي محتوى، ستُعرض رسالةٌ تُخبر المستخدم بأن حقل المحتوى مطلوب "!Content is required"، ويُعاد توجيهه إلى الصفحة الرئيسية index مجدّدًا؛ وإلّا في حال وجود عنوان ومحتوى في النموذج المُرسل، يُجلب معرّف ID القائمة المُرسلة في النموذج بما يسمح للمُستخدم بنقل عنصر المهام من قائمةٍ لأُخرى. نُحدّث محتوى عنصر المهام -باستخدام التعليمة UPDATE في SQL- إلى المحتوى الجديد المُدخل من قبل المستخدم، ويحدث الأمر نفسه بالنسبة لمعرّف القائمة، إذ يُربط عنصر المهام مع القائمة الجديدة في حال تعديل المستخدم القائمة التي ينتمي إليها العنصر. نهايةً، نحفظ التغييرات ونغلق الاتصال مع قاعدة البيانات ونعيد توجيه المستخدم إلى الصفحة الرئيسية index. اِحفظ الملف وأغلقه. لاستخدام هذه الوجهة سنحتاج إلى قالب HTML جديد باسم edit.html: (env)user@localhost:$ nano templates/edit.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Edit an Item {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="content">Content</label> <input type="text" name="content" placeholder="Todo content" class="form-control" value="{{ todo['content'] or request.form['content'] }}"></input> </div> <div class="form-group"> <label for="list">List</label> <select class="form-control" name="list"> {% for list in lists %} {% if list['title'] == request.form['list'] %} <option value="{{ request.form['list'] }}" selected> {{ request.form['list'] }} </option> {% elif list['title'] == todo['title'] %} <option value="{{ todo['title'] }}" selected> {{ todo['title'] }} </option> {% else %} <option value="{{ list['title'] }}"> {{ list['title'] }} </option> {% endif %} {% endfor %} </select> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} تُستخدم التعليمة التالية: {{ todo['content'] or request.form['content'] }} في الشيفرة السابقة لتحديد محتوى عنصر المهام، والتي تبيّن أنّ هذا المحتوى إمّا أن يبقى كما هو في حال عدم إجراء تعديلات عليه، أو أن يتغير إلى ما أُدخِل من قِبل المستخدم في نموذج الإدخال المُرسل. وبالنسبة لنموذج اختيار القائمة التي ينتمي إليها العنصر، سنتبِّع الآلية السابقة ذاتها، بمعنى أننا سنمر على المتغير lists الحاوي على عنوان القائمة؛ فإذا كان هذا العنوان مطابقًا لذلك المُخزّن في الكائن request.form (من النموذج المُرسل) عندها يقع الاختيار على عنوان القائمة هذه ليصبح العنصر تابعًا لها؛ أما في حال كان عنوان القائمة في المتغير lists مطابقًا للعنوان في المتغير todo فهذا يعني أنّه لم يطرأ أي تعديل على عنوان القائمة التي ينتمي إليها العنصر ويبقى كما كان أصلًا دون تعديلات؛ وبالنسبة لباقي الخيارات فستُعرض دون وجود السمة selected بمعنى أنها غير قابلةٍ للتعديل. اِحفظ الملف وأغلقه. الآن، سنفتح الملف index.html لإضافة زر تحرير عنصر القوائم Edit: (env)user@localhost:$ nano templates/index.html سنغيّر محتويات الوسم div بالصنف "row" لإضافة عمودٍ جديد، كما هو مُوضَّح في الشيفرة التالية: . . . <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> </div> اِحفظ الملف وأغلقه. استخدمنا في الشيفرة السابقة وسم الروابط <a> الذي سيوجّه المستخدم إلى وجهة التحرير /edit/ لكل عنصرٍ من عناصر المهام. شغِّل خادم التطوير في حال لم يكن مُشغّلًا: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، نجد أنّه أصبح بالإمكان تعديل أي عنصر مهام. سنعمل في الخطوة التالية على إضافة زر حذف عناصر مهام. الخطوة الرابعة - حذف عناصر مهام سنضيف في هذه الخطوة إمكانية حذف عناصر مهام محدّدة، لذا سننشئ وجهة جديدة في الملف app.py باسم delete: (env)user@localhost:$ nano app.py ثمّ سنضيف الشيفرة التالية إلى نهاية الملف لإضافة وجهة جديدة باسم /delete/: . . . @app.route('/<int:id>/delete/', methods=('POST',)) def delete(id): conn = get_db_connection() conn.execute('DELETE FROM items WHERE id = ?', (id,)) conn.commit() conn.close() return redirect(url_for('index')) اِحفظ الملف وأغلقه. تستخدم دالة فلاسك ()delete معرّف id العنصر وسيطًا، فعند إرسال طلب HTTP من نوع POST، نستخدم تعليمة DELETE في SQL لحذف العنصر الموافق لهذا المعرّف، ثمّ نحفظ التغييرات ونغلق الاتصال مع قاعدة البيانات ونعيد توجيه المستخدم إلى الصفحة الرئيسية index. الآن، سنفتح الملف index.html الموجود في مجلد القوالب templates لإضافة زر الحذف: (env)user@localhost:$ nano templates/index.html نضيف بعد ذلك وسم <div> لإضافة زر الحذف Delete بعد الجزء الخاص بزر التحرير Edit: <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> <div class="col-12 col-md-3"> <form action="{{ url_for('delete', id=item['id']) }}" method="POST"> <input type="submit" value="Delete" class="btn btn-danger btn-sm"> </form> </div> </div> يرسل زر الحذف الجديد في الشيفرة السابقة طلبًا من نوع POST إلى وجهة route الحذف /delete/ لكل عنصرٍ مراد حذفه. اِحفظ الملف وأغلقه. الآن، نشغّل خادم التطوير: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، أصبح بالإمكان حذف أي عنصر مهام باستخدام زر الحذف Delete. سنضيف في الخطوة التالية والأخيرة إمكانية إنشاء قوائم جديدة. الخطوة الخامسة - إضافة قوائم جديدة لا يتيح تطبيقنا حتى الآن إضافة قوائم جديدة سوى في قاعدة البيانات مباشرةً، لذا في هذه الخطوة سنضيف إمكانية إنشاء قوائم جديدة لدى إضافة المستخدم عناصر جديدة بدلًا من إلزامه باختيار قائمة حصرًا من القوائم الموجودة أصلًا في قاعدة البيانات، وذلك بإضافة خيار جديد باسم قائمة جديدة New List، والذي باختياره سيتمكّن المستخدم من إدخال اسم القائمة الجديدة التي يرغب بإنشائها. لتنفيذ ذلك، سنفتح بدايةً الملف app.py: (env)user@localhost:$ nano app.py ثمّ سنعدّل دالة فلاسك ()create من خلال إضافة الشيفرات المبينة أدناه إلى الجملة الشرطية التالية: if request.method == 'POST' التي تختبر ما إذا كان الطلب مُرسلًا وفق الطريقة POST، على النحو التالي: . . . @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() if request.method == 'POST': content = request.form['content'] list_title = request.form['list'] new_list = request.form['new_list'] # If a new list title is submitted, add it to the database if list_title == 'New List' and new_list: conn.execute('INSERT INTO lists (title) VALUES (?)', (new_list,)) conn.commit() # Update list_title to refer to the newly added list list_title = new_list if not content: flash('Content is required!') return redirect(url_for('index')) list_id = conn.execute('SELECT id FROM lists WHERE title = (?);', (list_title,)).fetchone()['id'] conn.execute('INSERT INTO items (content, list_id) VALUES (?, ?)', (content, list_id)) conn.commit() conn.close() return redirect(url_for('index')) lists = conn.execute('SELECT title FROM lists;').fetchall() conn.close() return render_template('create.html', lists=lists) اِحفظ الملف وأغلقه. حفظنا في الشيفرة السابقة قيمة حقل نموذج الإدخال الجديد المُسمّى new_list ضمن متغير ليُضاف هذا الحقل لاحقًا إلى الملف create.html، ثمّ اختبرنا كون قيمة المتغير list_title تساوي New List من خلال الشرط: list_title == 'New List' and new_list والذي يعني بتحقيقه أنّ المستخدم يرغب بإنشاء قائمة جديدة، وهنا لا بدّ من التحقّق من كون قيمة المتحول new_list ليست فارغة None، فعندها سنستخدم التعليمة INSERT INTO في SQL لإضافة عنوان السلسلة الجديد المُدخل من قبل المستخدم إلى جدول القوائم lists من قاعدة البيانات. نهايةً، سنحفظ التغييرات ونحدّث قيمة متغير عنوان القائمة list_title لتصبح موافقةً لعنوان القائمة الجديدة لاستخدامه لاحقًا. بعد ذلك، سنفتح الملف create.html لإضافة وسم اختيار <option> جديد، وهذا يتيح للمستخدم إمكانية إضافة قائمة مهام جديدة: (env)user@localhost:$ nano templates/create.html وسنعدِّله ليصبح كما يلي: <div class="form-group"> <label for="list">List</label> <select class="form-control" name="list"> <option value="New List" selected>New List</option> {% for list in lists %} {% if list['title'] == request.form['list'] %} <option value="{{ request.form['list'] }}" selected> {{ request.form['list'] }} </option> {% else %} <option value="{{ list['title'] }}"> {{ list['title'] }} </option> {% endif %} {% endfor %} </select> </div> <div class="form-group"> <label for="new_list">New List</label> <input type="text" name="new_list" placeholder="New list name" class="form-control" value="{{ request.form['new_list'] }}"></input> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> اِحفظ الملف وأغلقه. أضفنا في الشيفرة السابقة وسم اختيار <option> جديد لإضافة خيار إنشاء قائمة جديدة New List، وهذا سيسمح للمستخدم بإضافة قائمة جديدة إن رغب، ثمّ أضفنا وسم <div> آخر ذو حقل إدخال باسم new_list، إذ سيُدخل فيه المستخدم عنوان القائمة الجديدة المُنشأة. الآن نشغّل خادم التطوير: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، ستبدو الصفحة الرئيسية index كما هي موضحة في الصورة التالية: وبذلك نكون قد أنشأنا تطبيق إدارة مهام بعدّة ميزات تمكّن مستخدميه من تمييز عناصر المهام المُنجزة، إضافةً لإمكانية تعديل أو حذف العناصر الموجودة أصلًا، وإمكانية إنشاء قوائم جديدة لمختلف أنواع المهام. يمكنك الاطلاع على شيفرة البرنامج كاملةً. الخاتمة من خلال اتبّاع ما شرحناه في مقالنا هذا ستحصل على تطبيق متكامل لإدارة قوائم وعناصر المهام، والذي يتمتّع بالعديد من الميزات المتمثلة بتمكين مستخدميه من تمييّز عناصر مهامهم، مثل عناصر "مُنجزة complete" أو إعادة تعيين العناصر المميزة على أنها مُنجزة مجدّدًا إلى الحالة "غير مُنجزة non-completed"، فضلًا عن توفّر إمكانية تعديل وحذف العناصر الموجودة أصلًا، وإمكانية إنشاء قوائم جديدة لمختلف أنواع المهام. يمثّل هذا المقال وسيلةً عمليةً لتعلّم كيفية استخدام فلاسك وSQLite لإدارة جداول قواعد البيانات، وتوظيف المعارف النظرية هذه في إطار عملي عن طريق تطوير تطبيق ويب قائم على فلاسك والتعديل عليه وإضافة ميزات جديدة ضمنه وتعديل عناصر قاعدة البيانات من النوع one-to-many. ترجمة -وبتصرف- للمقال How To Modify Items in a One-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون استخدام علاقة one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite
يُعد فلاسك إطار عمل لبناء تطبيقات الويب مبني باستخدام لغة البرمجة بايثون Python، أمّا SQLite فيُعرَّف على أنّه محرّك قاعدة بيانات يُستخدم ضمن بايثون لتخزين بيانات التطبيقات. سنتعلّم في هذا المقال كيفية التعديل على عناصر تطبيق مبني باستخدام فلاسك و SQLite. يأتي مقالنا هذا استكمالًا للمقال السابق الذي أنشأنا فيه تطبيق ويب لإدارة المهام باستخدام فلاسك و SQLite، إذ أتاح لمستخدميه إمكانية إدارة عناصر المهام وتنظيمها ضمن قوائم، وإضافة عناصر جديدة إلى قاعدة البيانات؛ وفي مقالنا هذا سنضيف للتطبيق السابق الآليات اللازمة لإتاحة إمكانية تخصيص عناصر مهام مُنجزة، وتعديل عناصر موجودة أصلًا وحذف عناصر وإضافة قوائم جديدة إلى قاعدة البيانات، وباتبّاع الخطوات التالية سيُضاف للتطبيق السابق أزرار تحرير وحذف، إضافةً لإمكانية وضع خط متوسط لتمييّز المهام المُنجزة. مستلزمات العمل قبل المتابعة في هذا المقال لا بُدّ من: توفُّر بيئة برمجة بايثون 3 محلية، وسنستدعي في مقالنا مجلد المشروع flask_todo المُنشأ مُسبقًا من الخطوات في المقال السابق. توفّر تطبيق إدارة المهام المُنجز في المقال السابق، وفي الخطوة الأولى من هذا المقال سيكون لديك الخيار إما باستنساخ التطبيق مُباشرةً دون إعداده من قبلك، أو باتباع الخطوات التفصيلية في المقال السابق كيفية استخدام علاقات قاعدة البيانات من نوع واحد-إلى-متعدد one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite لبناء التطبيق، ومن ثمّ الإكمال في هذا المقال، كما يمكنك الحصول على الشيفرة الكاملة للتطبيق. يجب فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى - إعداد تطبيق الويب الخاص بإدارة المهام سنُعدّ في هذه الخطوة تطبيق الويب الخاص بإدارة المهام ليكون جاهزاً لإجراء التعديلات عليه، ولكن إن كنت قد اتبعت الخطوات الواردة في المقال السابق (المذكور ضمن فقرة مستلزمات العمل من مقالنا هذا)، ولديك شيفرة التطبيق إضافةً إلى البيئة الافتراضية مُفعلّةً على حاسوبك، فبإمكانك تجاوز هذه الخطوة مباشرةً. سنبدأ باستخدم الأمر Git لاستنساخ شيفرة تطبيق إدارة المهام المُنشأ سابقًا: $ git clone https://github.com/do-community/flask-todo ثم ننتقل إلى المجلّد flask-todo: $ cd flask-todo سننشئ بيئة عمل افتراضية جديدة: $ python -m venv env ومن ثمّ سنفعلها على النحو التالي: $ source env/bin/activate الآن سنحمّل إطار فلاسك ونثبته باستخدام الأمر: $ pip install Flask ثمّ سنهيء قاعدة البيانات باستخدام البرنامج الموجود في الملف init_db.py: (env)user@localhost:$ python init_db.py ثمّ سنسند القيم اللازمة إلى متغيرات بيئة فلاسك: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development إذ يشير متغير البيئة FLASK_APP إلى تطبيق الويب الخاص بإدارة المهام الذي نطوّره في هذا المقال، والموجود في الملف app.py في حالتنا؛ بينما يشير المتغير FLASK_ENV إلى وضع بيئة العمل، وهنا أُسندت القيمة development للعمل بوضع تطوير التطبيق، ما يتيح تشغيل منقّح الأخطاء، ومن المهم تذكّر عدم استخدام هذا الوضع في مرحلة التشغيل الفعلي للتطبيق أي في بيئة الإنتاج. سنشغّل خادم التطوير: (env)user@localhost:$ flask run يمكننا الآن الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفح للوصول إلى التطبيق. ولإيقاف خادم التطوير، نستخدم الاختصار "CTRL + C". وسنعدّل في الخطوة التالية تطبيق إدارة المهام ليُتيح لمستخدميه إمكانية تمييز عناصر المهام المُنجزة. الخطوة الثانية - إضافة إمكانية تمييز عناصر المهام المنجزة سنضيف في هذه الخطوة زرًا يُمكّن المستخدم من وضع علامةٍ على كل عنصر مهام مُنجز لتمييزه، لذا سنضيف عمودًا جديدًا إلى جدول العناصر items في قاعدة البيانات يحتوي على علامة تميّز ما إذا كان عنصر المهام قد أُنجز أم لا، وهذا بدوره يتطلّب إنشاء وجهة جديدة ضمن ملف البرنامج app.py، إذ سيعمل على تغيير قيم العمود الجديد لكل عنصر تبعًا لنشاطات المستخدم وتفاعله مع واجهة التطبيق. وللتذكير، الأعمدة الموجودة حاليًا في الجدول items من قاعدة البيانات قبل إضافة العمود الجديد، هي: "id": يحتوي معرّف العنصر. "list_id": يحتوي معرّف القائمة التي ينتمي إليها العنصر. "created": يحوي تاريخ إنشاء العنصر. "content": محتوى العنصر. بدايةً، سنفتح ملف تخطيط قاعدة البيانات schema.sql لتعديل جدول العناصر items: (env)user@localhost:$ nano schema.sql وسنضيف عمودًا جديدًا باسم done إلى جدول العناصر items على النحو التالي: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, done INTEGER NOT NULL DEFAULT 0, FOREIGN KEY (list_id) REFERENCES lists (id) ); اِحفظ الملف وأغلقه. سيتضمّن العمود المُضاف حديثًا done إلى قاعدة بيانات التطبيق إحدى القيمتين الصحيحتين "0" أو "1"، إذ تمثّل القيمة "0" القيمة المنطقية "false للدلالة على عنصر مهام غير مُنجز، في حين تمثّل القيمة "1" القيمة المنطقية "true" للدلالة على عنصر مهام مُنجز، علمًا أن القيمة الافتراضية هي "0"، وبالتالي عند إضافة أي عنصر مهام جديد إلى قاعدة البيانات فإنّ العمود done سيشير تلقائيًا إلى القيمة "0" دلالةً على أنّ المهمّة غير مُنجزة بعد، ولن تتغير حتى يضع المستخدم علامةً على العنصر أنه مُنجز، وعندها تتغير القيمة المقابلة لهذا العنصر في العمود done من القيمة "0" إلى القيمة "1". ولتطبيق التغييرات المُنفّذة على ملف تخطيط قاعدة البيانات schema.sql، سنهيئ قاعدة البيانات مجدّدًا باستخدام برنامج init_db.py: (env)user@localhost:$ python init_db.py الآن، سنفتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py ثم سنجلب كلًا من معرّف العنصر وقيمة عمود done الموافقة له إلى الدالة ()index، التي تجلب أصلًا القوائم والعناصر من قاعدة البيانات، مرسلةً إياها إلى ملف HTML المُسمّى index.html ليعمل على عرضها، لذا عدّلنا على تعليمات SQL السابقة لتصبح مثل الشيفرة التالية: @app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) conn.close() return render_template('index.html', lists=lists) اِحفظ الملف وأغلقه. وبإجراء هذه التعديلات على الشيفرة السابقة، ستُجلب معرّفات العناصر من قاعدة البيانات باستخدام التعليمة i.id، والقيمة من عمود done الموافقة باستخدام التعليمة i.done. ولفهم نتائج هذه التعديلات بوضوح، سننشئ الملف list_example.py على سبيل التجربة، وسنكتب ضمنه برنامجًا صغيرًا بهدف فهم محتويات قاعدة البيانات الجديدة: (env)user@localhost:$ nano list_example.py سنكتب ضمن هذا الملف التجريبي نفس الشيفرة السابقة مع التعديلات التي أجريناها على تعليمات SQL، ولكن سنعدّل دالة الطباعة ()print الأخيرة لتعرض كلًا من معرّف العنصر ID والقيمة الدالة على حالة إنجازه done: from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) for list_, items in lists.items(): print(list_) for item in items: print(' ', item['content'], '| id:', item['id'], '| done:', item['done']) اِحفظ الملف وأغلقه. الآن سنشغِّل هذا البرنامج التجريبي: (env)user@localhost:$ python list_example.py لنحصل على الخرج التالي: Home Buy fruit | id: 2 | done: 0 Cook dinner | id: 3 | done: 0 Study Learn Flask | id: 4 | done: 0 Learn SQLite | id: 5 | done: 0 Work Morning meeting | id: 1 | done: 0 نلاحظ من الخرج السابق أنّ قيمة العمود done هي 0 لكافّة عناصر المهام، لعدم تحديد أيٍّ منها على أنه مُنجز بعد، والآن وحتى يتمكن المستخدمون من تعديل هذه القيمة للمهام المُنجزة، سننشئ وجهة جديدة في الملف app.py. لذلك، سنفتح الملف app.py: (env)user@localhost:$ nano app.py ومن ثمّ سنضيف الشيفرة التالية إلى نهاية الملف لإضافة وجهة جديدة /do/: . . . @app.route('/<int:id>/do/', methods=('POST',)) def do(id): conn = get_db_connection() conn.execute('UPDATE items SET done = 1 WHERE id = ?', (id,)) conn.commit() conn.close() return redirect(url_for('index')) تتعامل هذه الوجهة الجديدة مع الطلبات الواردة وفق الطريقة POST فقط، إذ تستقبل دالة فلاسك ()do معرّف العنصر المراد تمييزه على أنه منجز id وسيطًا، ليفتح اتصالًا مع قاعدة البيانات، ثمّ يغيّر قيمة العمود done من 0 إلى 1 للعنصر المطلوب تمييزه على أنه مُنجزٌ باستخدام التعليمة UPDATE في SQL. وقد استخدمنا الموضع المؤقت ? في الدالة ()execute، ثم مررنا مجموعة البيانات الحاوية على معرّف العنصر ID ما يضمن إدراجًا صحيحًا وآمنًا للبيانات في قاعدة البيانات. نهايةً، أغلقنا الاتصال مع قاعدة البيانات بعد تأكيد التغييرات ليُعاد توجيه المستخدم إلى الصفحة الرئيسية index. الآن وبعد الانتهاء من إضافة الوجهة المسؤولة عن تمييز عناصر المهام على أنها مُنجزة، لا بدّ من إضافة وجهة جديدة للتراجع، بمعنى إمكانية إلغاء تمييز عنصر المهام على أنه مُنجز، لذا سنضيف الوجهة التالية إلى نهاية الملف app.py: . . . @app.route('/<int:id>/undo/', methods=('POST',)) def undo(id): conn = get_db_connection() conn.execute('UPDATE items SET done = 0 WHERE id = ?', (id,)) conn.commit() conn.close() return redirect(url_for('index')) نلاحظ أنّ شيفرة هذه الوجهة مشابهةٌ إلى حدٍ كبير لسابقتها /do/، كما أنّ دالة فلاسك ()undo تماثل الدالة ()do تمامًا بطريقة عملها ماعدا كونها تخصّص القيمة 0 للعمود done بدلًا من القيمة 1. اِحفظ الملف وأغلقه. الآن وبعد إضافة كل من الوجهتين /do/ و /undo/، سنضيف زرًا مهمّته تمييز عنصر المهام المعروض على أنه مُنجز (من خلال إضافة خط متوسّط له) أم لا اعتمادًا على حالته، أي حسب قيمة العمود done في قاعدة البيانات، لذا سنفتح ملف قالب HTML المُسمّى index.html: (env)user@localhost:$ nano templates/index.html وسنعدّل محتويات حلقة for التكرارية داخل عنصر القائمة غير المرتبة <ul> لتصبح على النحو التالي: {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item" {% if item['done'] %} style="text-decoration: line-through;" {% endif %} >{{ item['content'] }} {% if not item ['done'] %} {% set URL = 'do' %} {% set BUTTON = 'Do' %} {% else %} {% set URL = 'undo' %} {% set BUTTON = 'Undo' %} {% endif %} <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> </div> </li> {% endfor %} </ul> </div> {% endfor %} {% endblock %} أسندنا في الشيفرة السابقة وضمن الحلقة for القيمة line-through لسمة تنسيق النص text-decoration في CSS، والتي تضيف خطًّا متوسطًا للنص في حال كان عنصر القوائم مُنجزًا تبعًا لقيمة السجل الموافق للعنصر من العمود done في قاعدة البيانات، ثمّ استخدمنا تعليمة set من تعليمات محرّك القوالب جينجا Jinja لنصرّح عن متغيرين، هما URL و BUTTON؛ فإذا كان العنصر غير مُحدّدٍ على أنه مُنجز، سيأخذ المتغير BUTTON القيمة Do وسيشير المتغيّر URL إلى الوجهة /do/؛ أمّا إذا كان العنصر محّددًا على أنه مُنجَز، فسيأخذ المتغير BUTTON القيمة Undo، وسيشير المتغيّر URL إلى الوجهة /undo/. استخدمنا بعد ذلك هذين المتغيرين في نموذج إدخال يُرسل الطلب المناسب اعتمادًا على حالة عنصر المهام. نشغّل الخادم: (env)user@localhost:$ flask run الآن وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، أصبح بالإمكان تمييز عناصر المهام المُنجزة من الصفحة الرئيسية للتطبيق، في الخطوة التالية سنعمل على إضافة إمكانية تعديل عناصر المهام. الخطوة الثالثة - تعديل عناصر المهام سنضيف إلى التطبيق في هذه الخطوة صفحةً جديدةً خاصةً بتحرير عناصر المهام، ما سيتيح إمكانية تعديل محتويات كل عنصر من عناصر المهام، إضافةً لإمكانية ربط هذه العناصر مع قوائم مختلفة. الآن وضمن الملف app.py سنضيف وجهة جديدة /edit/، مهمته إخراج صفحة HTML جديدة باسم edit.html، والتي تتيح للمستخدمين إمكانية التعديل على عناصر المهام الحالية، وهنا يتوجب علينا تحديث الملف index.html لإضافة زر Edit لكل عنصر مهام. بدايةً سنفتح الملف app.py: (env)user@localhost:$ nano app.py ثم سنضيف الشيفرات الخاصّة بالوجهة الجديدة في نهاية الملف على النحو التالي: . . . @app.route('/<int:id>/edit/', methods=('GET', 'POST')) def edit(id): conn = get_db_connection() todo = conn.execute('SELECT i.id, i.list_id, i.done, i.content, l.title \ FROM items i JOIN lists l \ ON i.list_id = l.id WHERE i.id = ?', (id,)).fetchone() lists = conn.execute('SELECT title FROM lists;').fetchall() if request.method == 'POST': content = request.form['content'] list_title = request.form['list'] if not content: flash('Content is required!') return redirect(url_for('edit', id=id)) list_id = conn.execute('SELECT id FROM lists WHERE title = (?);', (list_title,)).fetchone()['id'] conn.execute('UPDATE items SET content = ?, list_id = ?\ WHERE id = ?', (content, list_id, id)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('edit.html', todo=todo, lists=lists) تُستخدم القيمة id وسيطًا في دالة فلاسك الجديدة المُبيّنة في الشيفرة السابقة لجلب معرّف عنصر المهام المُراد تحريره، إضافةً إلى معرّف وعنوان القائمة التي ينتمي إليها، وقيمة السجل الموافق من العمود done، ومحتوى العنصر، وذلك باستخدام التعليمة JOIN في SQL. تُحفظ هذه البيانات في متغيرٍ باسم todo، ثمّ تُجلب كافّة قوائم المهام من قاعدة البيانات وتُخزّن في المتغير lists. في حال كان الطلب عاديًا وفق الطريقة GET، فإن الشرط التالي الدال على كون الطلب من نوع POST لن يتحقّق: if request.method == 'POST' وبالتالي سينتقل التطبيق لتنفيذ دالة إخراج القوالب ()render_template الذي سيمرِّر قيم المتغيرين todo و lists إلى الملف edit.html المُخرج. أمّا في حال تأكيد نموذج وإرساله من قبل المستخدم، عندها سيتحقّق الشرط: request.method == 'POST' ونستخلص بالتالي المحتوى والعنوان المُعدّلين المُدخلين في النموذج المُرسل؛ وفي حال عدم وجود أي محتوى، ستُعرض رسالةٌ تُخبر المستخدم بأن حقل المحتوى مطلوب "!Content is required"، ويُعاد توجيهه إلى الصفحة الرئيسية index مجدّدًا؛ وإلّا في حال وجود عنوان ومحتوى في النموذج المُرسل، يُجلب معرّف ID القائمة المُرسلة في النموذج بما يسمح للمُستخدم بنقل عنصر المهام من قائمةٍ لأُخرى. نُحدّث محتوى عنصر المهام -باستخدام التعليمة UPDATE في SQL- إلى المحتوى الجديد المُدخل من قبل المستخدم، ويحدث الأمر نفسه بالنسبة لمعرّف القائمة، إذ يُربط عنصر المهام مع القائمة الجديدة في حال تعديل المستخدم القائمة التي ينتمي إليها العنصر. نهايةً، نحفظ التغييرات ونغلق الاتصال مع قاعدة البيانات ونعيد توجيه المستخدم إلى الصفحة الرئيسية index. اِحفظ الملف وأغلقه. لاستخدام هذه الوجهة سنحتاج إلى قالب HTML جديد باسم edit.html: (env)user@localhost:$ nano templates/edit.html ونكتب ضمنه الشيفرة التالية: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Edit an Item {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="content">Content</label> <input type="text" name="content" placeholder="Todo content" class="form-control" value="{{ todo['content'] or request.form['content'] }}"></input> </div> <div class="form-group"> <label for="list">List</label> <select class="form-control" name="list"> {% for list in lists %} {% if list['title'] == request.form['list'] %} <option value="{{ request.form['list'] }}" selected> {{ request.form['list'] }} </option> {% elif list['title'] == todo['title'] %} <option value="{{ todo['title'] }}" selected> {{ todo['title'] }} </option> {% else %} <option value="{{ list['title'] }}"> {{ list['title'] }} </option> {% endif %} {% endfor %} </select> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} تُستخدم التعليمة التالية: {{ todo['content'] or request.form['content'] }} في الشيفرة السابقة لتحديد محتوى عنصر المهام، والتي تبيّن أنّ هذا المحتوى إمّا أن يبقى كما هو في حال عدم إجراء تعديلات عليه، أو أن يتغير إلى ما أُدخِل من قِبل المستخدم في نموذج الإدخال المُرسل. وبالنسبة لنموذج اختيار القائمة التي ينتمي إليها العنصر، سنتبِّع الآلية السابقة ذاتها، بمعنى أننا سنمر على المتغير lists الحاوي على عنوان القائمة؛ فإذا كان هذا العنوان مطابقًا لذلك المُخزّن في الكائن request.form (من النموذج المُرسل) عندها يقع الاختيار على عنوان القائمة هذه ليصبح العنصر تابعًا لها؛ أما في حال كان عنوان القائمة في المتغير lists مطابقًا للعنوان في المتغير todo فهذا يعني أنّه لم يطرأ أي تعديل على عنوان القائمة التي ينتمي إليها العنصر ويبقى كما كان أصلًا دون تعديلات؛ وبالنسبة لباقي الخيارات فستُعرض دون وجود السمة selected بمعنى أنها غير قابلةٍ للتعديل. اِحفظ الملف وأغلقه. الآن، سنفتح الملف index.html لإضافة زر تحرير عنصر القوائم Edit: (env)user@localhost:$ nano templates/index.html سنغيّر محتويات الوسم div بالصنف "row" لإضافة عمودٍ جديد، كما هو مُوضَّح في الشيفرة التالية: . . . <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> </div> اِحفظ الملف وأغلقه. استخدمنا في الشيفرة السابقة وسم الروابط <a> الذي سيوجّه المستخدم إلى وجهة التحرير /edit/ لكل عنصرٍ من عناصر المهام. شغِّل خادم التطوير في حال لم يكن مُشغّلًا: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، نجد أنّه أصبح بالإمكان تعديل أي عنصر مهام. سنعمل في الخطوة التالية على إضافة زر حذف عناصر مهام. الخطوة الرابعة - حذف عناصر مهام سنضيف في هذه الخطوة إمكانية حذف عناصر مهام محدّدة، لذا سننشئ وجهة جديدة في الملف app.py باسم delete: (env)user@localhost:$ nano app.py ثمّ سنضيف الشيفرة التالية إلى نهاية الملف لإضافة وجهة جديدة باسم /delete/: . . . @app.route('/<int:id>/delete/', methods=('POST',)) def delete(id): conn = get_db_connection() conn.execute('DELETE FROM items WHERE id = ?', (id,)) conn.commit() conn.close() return redirect(url_for('index')) اِحفظ الملف وأغلقه. تستخدم دالة فلاسك ()delete معرّف id العنصر وسيطًا، فعند إرسال طلب HTTP من نوع POST، نستخدم تعليمة DELETE في SQL لحذف العنصر الموافق لهذا المعرّف، ثمّ نحفظ التغييرات ونغلق الاتصال مع قاعدة البيانات ونعيد توجيه المستخدم إلى الصفحة الرئيسية index. الآن، سنفتح الملف index.html الموجود في مجلد القوالب templates لإضافة زر الحذف: (env)user@localhost:$ nano templates/index.html نضيف بعد ذلك وسم <div> لإضافة زر الحذف Delete بعد الجزء الخاص بزر التحرير Edit: <div class="row"> <div class="col-12 col-md-3"> <form action="{{ url_for(URL, id=item['id']) }}" method="POST"> <input type="submit" value="{{ BUTTON }}" class="btn btn-success btn-sm"> </form> </div> <div class="col-12 col-md-3"> <a class="btn btn-warning btn-sm" href="{{ url_for('edit', id=item['id']) }}">Edit</a> </div> <div class="col-12 col-md-3"> <form action="{{ url_for('delete', id=item['id']) }}" method="POST"> <input type="submit" value="Delete" class="btn btn-danger btn-sm"> </form> </div> </div> يرسل زر الحذف الجديد في الشيفرة السابقة طلبًا من نوع POST إلى وجهة route الحذف /delete/ لكل عنصرٍ مراد حذفه. اِحفظ الملف وأغلقه. الآن، نشغّل خادم التطوير: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، أصبح بالإمكان حذف أي عنصر مهام باستخدام زر الحذف Delete. سنضيف في الخطوة التالية والأخيرة إمكانية إنشاء قوائم جديدة. الخطوة الخامسة - إضافة قوائم جديدة لا يتيح تطبيقنا حتى الآن إضافة قوائم جديدة سوى في قاعدة البيانات مباشرةً، لذا في هذه الخطوة سنضيف إمكانية إنشاء قوائم جديدة لدى إضافة المستخدم عناصر جديدة بدلًا من إلزامه باختيار قائمة حصرًا من القوائم الموجودة أصلًا في قاعدة البيانات، وذلك بإضافة خيار جديد باسم قائمة جديدة New List، والذي باختياره سيتمكّن المستخدم من إدخال اسم القائمة الجديدة التي يرغب بإنشائها. لتنفيذ ذلك، سنفتح بدايةً الملف app.py: (env)user@localhost:$ nano app.py ثمّ سنعدّل دالة فلاسك ()create من خلال إضافة الشيفرات المبينة أدناه إلى الجملة الشرطية التالية: if request.method == 'POST' التي تختبر ما إذا كان الطلب مُرسلًا وفق الطريقة POST، على النحو التالي: . . . @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() if request.method == 'POST': content = request.form['content'] list_title = request.form['list'] new_list = request.form['new_list'] # If a new list title is submitted, add it to the database if list_title == 'New List' and new_list: conn.execute('INSERT INTO lists (title) VALUES (?)', (new_list,)) conn.commit() # Update list_title to refer to the newly added list list_title = new_list if not content: flash('Content is required!') return redirect(url_for('index')) list_id = conn.execute('SELECT id FROM lists WHERE title = (?);', (list_title,)).fetchone()['id'] conn.execute('INSERT INTO items (content, list_id) VALUES (?, ?)', (content, list_id)) conn.commit() conn.close() return redirect(url_for('index')) lists = conn.execute('SELECT title FROM lists;').fetchall() conn.close() return render_template('create.html', lists=lists) اِحفظ الملف وأغلقه. حفظنا في الشيفرة السابقة قيمة حقل نموذج الإدخال الجديد المُسمّى new_list ضمن متغير ليُضاف هذا الحقل لاحقًا إلى الملف create.html، ثمّ اختبرنا كون قيمة المتغير list_title تساوي New List من خلال الشرط: list_title == 'New List' and new_list والذي يعني بتحقيقه أنّ المستخدم يرغب بإنشاء قائمة جديدة، وهنا لا بدّ من التحقّق من كون قيمة المتحول new_list ليست فارغة None، فعندها سنستخدم التعليمة INSERT INTO في SQL لإضافة عنوان السلسلة الجديد المُدخل من قبل المستخدم إلى جدول القوائم lists من قاعدة البيانات. نهايةً، سنحفظ التغييرات ونحدّث قيمة متغير عنوان القائمة list_title لتصبح موافقةً لعنوان القائمة الجديدة لاستخدامه لاحقًا. بعد ذلك، سنفتح الملف create.html لإضافة وسم اختيار <option> جديد، وهذا يتيح للمستخدم إمكانية إضافة قائمة مهام جديدة: (env)user@localhost:$ nano templates/create.html وسنعدِّله ليصبح كما يلي: <div class="form-group"> <label for="list">List</label> <select class="form-control" name="list"> <option value="New List" selected>New List</option> {% for list in lists %} {% if list['title'] == request.form['list'] %} <option value="{{ request.form['list'] }}" selected> {{ request.form['list'] }} </option> {% else %} <option value="{{ list['title'] }}"> {{ list['title'] }} </option> {% endif %} {% endfor %} </select> </div> <div class="form-group"> <label for="new_list">New List</label> <input type="text" name="new_list" placeholder="New list name" class="form-control" value="{{ request.form['new_list'] }}"></input> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> اِحفظ الملف وأغلقه. أضفنا في الشيفرة السابقة وسم اختيار <option> جديد لإضافة خيار إنشاء قائمة جديدة New List، وهذا سيسمح للمستخدم بإضافة قائمة جديدة إن رغب، ثمّ أضفنا وسم <div> آخر ذو حقل إدخال باسم new_list، إذ سيُدخل فيه المستخدم عنوان القائمة الجديدة المُنشأة. الآن نشغّل خادم التطوير: (env)user@localhost:$ flask run وبالذهاب إلى الرابط "/http://127.0.0.1:5000" في المتصفح، ستبدو الصفحة الرئيسية index كما هي موضحة في الصورة التالية: وبذلك نكون قد أنشأنا تطبيق إدارة مهام بعدّة ميزات تمكّن مستخدميه من تمييز عناصر المهام المُنجزة، إضافةً لإمكانية تعديل أو حذف العناصر الموجودة أصلًا، وإمكانية إنشاء قوائم جديدة لمختلف أنواع المهام. يمكنك الاطلاع على شيفرة البرنامج كاملةً. الخاتمة من خلال اتبّاع ما شرحناه في مقالنا هذا ستحصل على تطبيق متكامل لإدارة قوائم وعناصر المهام، والذي يتمتّع بالعديد من الميزات المتمثلة بتمكين مستخدميه من تمييّز عناصر مهامهم، مثل عناصر "مُنجزة complete" أو إعادة تعيين العناصر المميزة على أنها مُنجزة مجدّدًا إلى الحالة "غير مُنجزة non-completed"، فضلًا عن توفّر إمكانية تعديل وحذف العناصر الموجودة أصلًا، وإمكانية إنشاء قوائم جديدة لمختلف أنواع المهام. يمثّل هذا المقال وسيلةً عمليةً لتعلّم كيفية استخدام فلاسك وSQLite لإدارة جداول قواعد البيانات، وتوظيف المعارف النظرية هذه في إطار عملي عن طريق تطوير تطبيق ويب قائم على فلاسك والتعديل عليه وإضافة ميزات جديدة ضمنه وتعديل عناصر قاعدة البيانات من النوع one-to-many. ترجمة -وبتصرف- للمقال How To Modify Items in a One-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون استخدام علاقة one-to-many مع إطار العمل فلاسك Flask ومحرك قواعد البيانات SQLite -
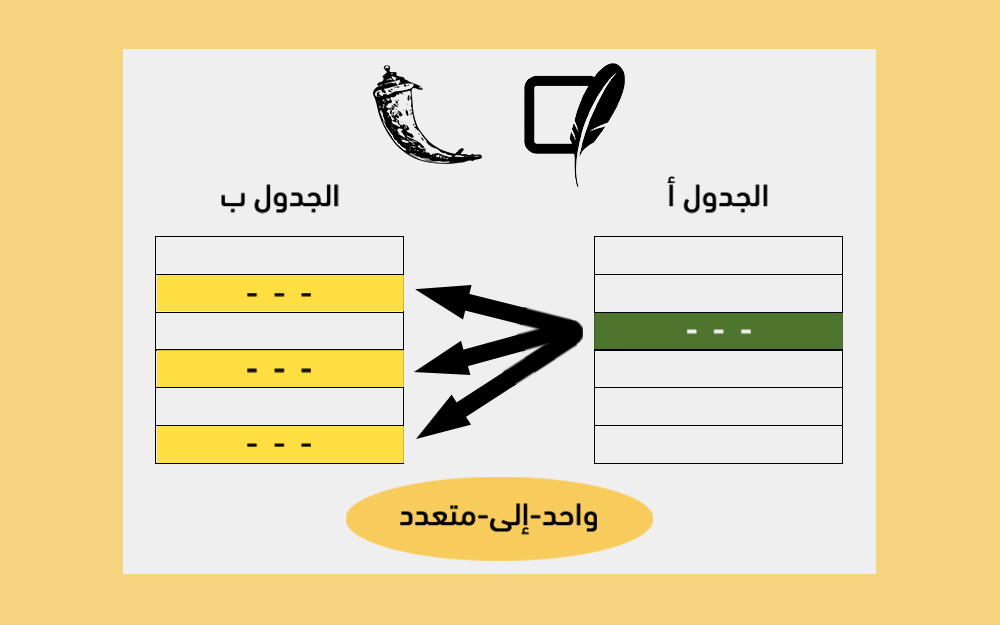 فلاسك هو إطار عمل يستخدم لغة بايثون Python لبناء تطبيقات الويب؛ أما SQLite فهو محرّك قواعد بيانات يُستخدم لتخزين بيانات تطبيق الويب. سننشئ في هذا المقال تطبيق ويب لإدارة المهام باستخدام كلٍ من إطار العمل فلاسك ومحرّك قاعدة البيانات SQLite، إذ سيتمكّن مستخدمو التطبيق من إنشاء قوائم تمثّل عناصر المهام المطلوبة. تتمثّل الفائدة العلمية والعملية من هذا المقال بتعلمّك كيفيّة استخدام SQLite مع فلاسك، بالإضافة لتعلّم كيفيّة إنشاء علاقات قاعدة البيانات من النوع واحد-إلى-متعدد. تُعرَّف علاقة قاعدة البيانات من النوع واحد-إلى-متعدد one-to-many بكونها علاقةٌ بين جدولين من قاعدة البيانات، بحيث يمكن لسجلٍ موجودٍ في أحد الجدولين الإشارة إلى عدّة سجلات من الجدول الثاني، ويشكّل تطبيق المدونة خير مثال على العلاقات في قواعد البيانات من النوع واحد-إلى-متعدد، نظرًا لارتباط الجدول الخاص بتخزين التدوينات posts مع الجدول الخاص بتخزين التعليقات comments بعلاقة من نوع واحد-إلى-متعدد؛ إذ يمكن أن يكون لكل تدوينة عدّة تعليقاتٍ مرتبطةٍ بها، وبالمقابل يرتبط كل تعليق بتدوينة واحدةٍ فقط، وبذلك فإنّ للتدوينة الواحدة علاقةٌ بالعديد من التعليقات. وفي هذه الحالة يُعد الجدول الخاص بالتدوينات "الجدول الأب parent"، في حين يُعد الجدول الخاص بالتعليقات "الجدول الابن child"؛ إذ يمكن للسجل الموجود في الجدول الأب الإشارة إلى عدّة سجلات موجودة في الجدول الابن، وهو أمرٌ أساسي لإتاحة إمكانية الوصول إلى البيانات المطلوبة في كل جدول. تتجلى إحدى دوافع استخدامنا لمحرّك قاعدة البيانات SQLite بكونه مرنًا من ناحية نقل البيانات عبر الأجهزة وبيئات التشغيل المختلفة Portable من جهة؛ وبكونه يعمل بسهولة مع لغة البرمجة بايثون دون الحاجة لتطبيق أي إعدادات إضافية من جهة أخرى؛ أمّا الدافع الآخر لاستخدامه فيتمثل بكونه مناسبًا جدًا لتصميم النماذج الأولية لتطبيقات الويب المنشئة قبل الانتقال إلى العمل على قاعدة البيانات الأكبر، مثل قاعدة بيانات MySQL، أو Postgres. مستلزمات العمل توجد مجموعةٌ من المتطلبات الواجب توفرّها وإعدادها قبل البدء في اتباع الخطوات التفصيلية المشروحة تاليًا ضمن هذا المقال، وهذه المتطلبات هي: توفُّر بيئة برمجة بايثون 3 محلية، وفي مقالنا سنسمّي مجلد المشروع بالاسم flask_todo. فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى - إنشاء قاعدة البيانات سننفّذ في هذه الخطوة مجموعةً من الخطوات الفرعية المتمثّلة بتنشيط البيئة البرمجية التي سنعمل عليها، وتثبيت فلاسك، وإنشاء قاعدة بيانات SQLite، وتعبئتها ببيانات معياريّة، وسنتعلم كذلك كيفيّة استخدام المفاتيح الأجنبية foreign keys، لإنشاء علاقة واحد-إلى-متعدّد بين القوائم والعناصر؛ إذ يمثّل المفتاح الأجنبي صلة الوصل لربط جدول من قاعدة البيانات بآخر، فهو الرابط بين الجدول الابن والجدول الأب في قاعدة البيانات هذه، والمفتاح الأساسي لجدولٍ ما هو مفتاحٌ أجنبي للجداول الأُخرى. إذا لم تنشّط البيئة البرمجية الخاصة بك بعد، فاستخدم الأمر التالي لتنشيطها بعد التأكّد من كون موجه الأوامر يشير إلى مسار مجلد المشروع flask_todo: $ source env/bin/activate وبمجرّد تنشيط البيئة البرمجية، ثبّت فلاسك باستخدام الأمر التالي: (env)user@localhost:$ pip install flask ومع اكتمال تثبيت فلاسك، أصبح بإمكانك الآن إنشاء مخطّط قاعدة البيانات المتضمِّن أوامر SQL اللازمة لإنشاء الجداول التي تحتاجها لتخزين بيانات المهام المطلوبة، إذ ستحتاج إلى جدولين، جدول يسمى lists لتخزين قوائم المهام، وجدول يسمى items لتخزين عناصر كل قائمة. الآن سننشئ ملفًا باسم schema.sql ضمن المجلد flask_todo: (env)user@localhost:$ nano schema.sql وسنكتب أوامر SQL التالية داخل هذا الملف: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, FOREIGN KEY (list_id) REFERENCES lists (id) ); اِحفظ الملف وأغلقه. أوّل سطرين من شيفرة SQL السابقة مسؤولان عن حذف أي جداول موجودة سابقًا ضمن قاعدة البيانات باسم lists أو items، وهما: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; وبذلك لن يكون هناك أي سلوكٍ متضاربٍ أو عشوائي ناجمٍ عن تشابه الأسماء ضمن قاعدة البيانات، ومن الجدير بالملاحظة أنّ تطبيق هذين الأمرين سيؤدي إلى حذف كامل محتوى قاعدة البيانات الحالي، لذا لا تُدخل أي بيانات مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية. بعد ذلك، يمكنك استخدام الأمر CREATE TABLE lists لإنشاء جدول القوائم lists، الذي سيخزن قوائم المهام المطلوبة، مثل قائمة الدراسة وقائمة العمل والقائمة الرئيسية، وما إلى ذلك، باستخدام الأعمدة التالية: "id": ويحتوي على بيانات من نوع الرقم الصحيح، ويمثّل مفتاحًا أساسيًا للجدول lists، وسيتضمّن قيم فريدة في قاعدة البيانات من أجل كل سجل، والسجل هو نوعٌ من أنواع قوائم المهام في حالتنا. "created": يحتوي على تاريخ ووقت إنشاء قائمة المهام، وتشير NOT NULL لكون هذا العمود لا يجب أن يحتوي على قيم فارغة، أما القيمة الافتراضية فهي CURRENT_TIMESTAMP، والتي تمثّل تاريخ ووقت إضافة قائمة المهام إلى قاعدة البيانات، وكما هو الحال في عمود "id" لا يتوجب عليك تحديد قيم لهذا العمود، لأن تعبئتها تلقائية. "title": عنوان قائمة المهام. وبعد إنشاء جدول القوائم lists، سننشئ الآن جدول العناصر items لتخزين عناصر المهام، إذ يحتوي هذا الجدول على معرّف "ID"، وعمود "list_id" يحوي أعدادًا صحيحة تحدّد معرّف القائمة التي ينتمي إليها العنصر، إضافةً لعمود تاريخ إنشاء العنصر، وعمود محتوى المهمّة. يمكنك استخدام مفتاح أجنبي لربط عنصرٍ ما بقائمةٍ معيّنة في قاعدة البيانات عن طريق كتابة الشيفرة التالية: FOREIGN KEY (list_id) REFERENCES lists (id) يمثّل جدول القوائم lists الجدول الأب المربوط بالجدول الآخر باستخدام المفتاح الأجنبي، وهذا يبيّن امكانية احتواء القائمة الواحدة على عدّة عناصر؛ في حين يمثّل جدول العناصر items الجدول الحاوي على المفتاح الأجنبي، وهذا يعني أن كل عنصر ينتمي إلى قائمة واحدةٍ فقط. يشير العمود list_id من جدول العناصر items الابن إلى عمود المعرِّف id من جدول القوائم lists الأب. وبذلك نجد أنّه قد حققنا فعليًا علاقة واحد-إلى-متعدّد بين جدولي lists و items، نظرًا لأنّ القائمة يمكن أن تحتوي على عدّة عناصر، وأنّ العنصر الواحد سينتمي إلى قائمةٍ واحدةٍ فقط. بعد الانتهاء من إنشاء الجداول، سنستخدم ملف schema.sql لإنشاء قاعدة البيانات. لذلك، أنشئ ملفًا باسم init_db.py ضمن المجلد flask_todo على النحو التالي: (env)user@localhost:$ nano init_db.py ثم أضِف فيه الشيفرة التالية: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) connection.commit() connection.close() اِحفظ الملف وأغلقه، وبمجرّد تنفيذ الشيفرة السابقة سيُنشأ ملفٌ باسم database.db ويُحقَّق الاتصال به، وبعدها يمكننا فتح ملف schema.sql وتشغيله باستخدام التابع ()executescript الذي ينفِّذ العديد من تعليمات SQL البرمجية في وقتٍ واحد. سيؤدي تشغيل الملف schema.sql لإنشاء جداول القوائم والعناصر، ومن ثمّ سننفّذ عددًا من تعليمات الإدخال في SQL لإنشاء ثلاث قوائم وخمسة عناصر مهام باستخدام كائن المؤشر Cursor. سنستخدم العمود "list_id" لربط كلّ عنصرٍ بقائمة عن طريق قيمة معرّف القائمة. فعلى سبيل المثال، إذا كانت القائمة المسمّاة "العمل Work" هي الإدخال الأوّل في قاعدة البيانات، فسيكون معرّفها ذو القيمة 1، وسنتمكّن باستخدامه من ربط عنصر المهام المسمّى "الاجتماع الصباحي Morning meeting" مثلًا بقائمة مهام العمل، وينطبق المبدأ نفسه على كافّة القوائم والعناصر الأُخرى. ومن ثمّ سنحفظ التغييرات ونغلق الاتصال، وسنشغّل البرنامج كما يلي: (env)user@localhost:$ python init_db.py وبعد تنفيذ هذا البرنامج سيظهر ملفٌ جديدٌ ضمن المجلد flask_todo باسم database.db، ومع انتهاء هذه الخطوة نكون قد فعّلنا البيئة البرمجية وثبتنا فلاسك، وأنشأنا قاعدة بيانات SQLite، وبذلك سنتمكن من استرجاع كل ما أُدخِل في قاعدة البيانات من قوائم وعناصر لعرضها في الصفحة الرئيسية للتطبيق الذي نحن في صدد إنشائه. الخطوة الثانية - عرض عناصر المهام سنعمل في هذه الخطوة على ربط قاعدة البيانات التي أنشأناها في الخطوة السابقة مع تطبيق فلاسك الذي سيعرض قوائم المهام والعناصر الموجودة في كلٍ منها، كما سنستخدم استعلامات قواعد البيانات المركّبة SQLite joins للاستعلام عن بيانات من الجدولين معًا، وسنعمل على تجميع عناصر المهام حسب القوائم التابعة لها. أولاً، سننشئ ملف التطبيق، لذا أنشئ ملفًا باسم app.py في المجلد flask_todo: (env)user@localhost:$ nano app.py ومن ثمّ سنضيف الشيفرة التالية إلى الملف: from itertools import groupby import sqlite3 from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' @app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.content, l.title FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) conn.close() return render_template('index.html', lists=lists) اِحفظ الملف وأغلقه. تفتح الدالة ()get_db_connection اتصالًا مع ملف قاعدة البيانات database.db، وتحدّد بعد ذلك قيمة السمة row_factory لتكون sqlite3.Row لنتمكّن من الوصول إلى الأعمدة باستخدام أسمائها، ما يعني أنّ اتصال قاعدة البيانات سيعيد سجلات يمكننا التعامل معها كما هو الحال مع قواميس بايثون Dictionaries الاعتيادية (وهي حاويات لتخزين القيم المنظمّة في بايثون)، ونهايةً تعيد الدالة كائن الاتصال conn المُستخدم للوصول إلى قاعدة البيانات. الآن سنفتح اتصالًا مع قاعدة البيانات باستخدام دالة عرض فلاسك ()index، وسننفّذ استعلام SQL التالي: SELECT i.content, l.title FROM items i JOIN lists l ON i.list_id = l.id ORDER BY l.title; وسنتمكن باستخدام الدالة ()fetchall من الحصول على نتائج الاستعلام وحفظها ضمن متغيّر todos. استخدمنا في الاستعلام السابق الأمر SELECT لجلب محتوى العنصر مع عنوان القائمة المنتمي إليها، عبر ربط كلٍ من جدولي القوائم والعناصر (إذ يشير الرمز i للعناصر، والرمز l للقوائم)، إذ سنحصل بالنتيجة على كافّة سجلات جدول العناصر ذات القيمة list_id الموافقة لقيمة المعرّف id من جدول القوائم باستخدام شرط التجميع i.list_id = l.id المكتوب بعد البادئة البرمجية ON، ومن ثمّ استخدمنا أمر الترتيب ORDER BY لفرز النتائج وفقًا لعناوين القوائم. الآن ولفهم هذا الاستعلام بوضوح، سنفتح موجه أوامر بايثون التفاعلي Python REPL في مجلد المشروع flask_todo: (env)user@localhost:$ python ومن ثمّ سنختبر محتويات المتغير todos الحاوي على نتائج الاستعلام السابق عبر تشغيل الشيفرة التالية: from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.content, l.title FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() for todo in todos: print(todo['title'], ':', todo['content']) استوردنا في الشيفرة السابقة قاعدة البيانات getdbconnection من الملف app.py، ومن ثمّ فُتِح الاتصال مع قاعدة البيانات ونُفِّذ الاستعلام (وهو استعلام SQL ذاته الموجود في الملف app.py)، وباستخدام حلقة for التكرارية طُبِع عنوان كل قائمة ومحتويات كل عنصر مهام مرتبطٍ بها، وبذلك سيظهر الخرج في حالتنا على النحو التالي: Home : Buy fruit Home : Cook dinner Study : Learn Flask Study : Learn SQLite Work : Morning meeting أغلق موجه أوامر بايثون REPL باستخدام الاختصار "CTRL+D". الآن، وبعدما فهمت آلية عمل ونتائج الاستعلامات المُجمّعة في SQL، سنعود إلى دالة فلاسك ()index الموجودة في الملف app.py، إذ سنصرّح بدايةً عن المتغير todos ومن ثمّ سنستخدم الشيفرة التالية لتجميع النتائج: lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) تبدأ الشيفرة المبينة أعلاه بالتصريح عن قاموس dictionary فارغ باسم lists، ثم تستخدم حلقة for التكرارية لتجميع النتائج الموجودة في المتغير todos وترتيبها حسب عنوان قائمة المهام باستخدام دالة الترتيب ()groupby المستوردة من المكتبة المعيارية itertools، إذ تولّد هذه الدالة مجموعةً من النتائج من أجل كل تكرار في الحلقة عبر مروره على كل عنصرٍ مخزّنٍ في المتغير todos. يمثّل متغيّر الحلقة k عناوين قوائم المهام (المنزل والدراسة والعمل في حالتنا) المُستخرجة من قاعدة البيانات عبر تمرير قيمة التابع ['lambda t: t['title وسيطًا لدالة التجميع ()groupby، التي تُعيد عنوان القائمة التي يتبع لها هذا العنصر (بنفس مبدأ الدالة ['todo['title المُستخدم في حلقة for السابقة)؛ بينما يمثّل المتغير g المجموعة الحاوية على عناصر المهام التابعة لكل عنوان قائمة. فمن أجل أول دورة في الحلقة مثلًا، سيمثّل المتغير k القائمة Home، في حين سيتكرر المتغير g ليحتوي بالنتيجة عناصر القائمة الموجودة في k وهي في حالتنا "Buy fruit" و "Cook". وهذا ما يمثّل علاقةً من نوع واحد-إلى-متعدّد بين القوائم والعناصر، بحيث يضم كل عنوان قائمة مجموعةً من عناصر المهام. وبذلك، ستظهر القوائم عند تشغيل الملف app.py وبعد انتهاء تنفيذ حلقة for على النحو التالي: {'Home': [<sqlite3.Row object at 0x7f9f58460950>, <sqlite3.Row object at 0x7f9f58460c30>], 'Study': [<sqlite3.Row object at 0x7f9f58460b70>, <sqlite3.Row object at 0x7f9f58460b50>], 'Work': [<sqlite3.Row object at 0x7f9f58460890>]} وسيحتوي كل كائن sqlite3.Row على البيانات المُسترجعة باستخدام استعلام SQL في الدالة ()index من جدول العناصر items، ولعرض هذه البيانات بوضوح أكثر، سنكتب برنامجًا يمر على محتويات الحاوية lists مستعرضًا كل قائمة وعناصرها. لكتابة هذا البرنامج، سنفتح ملفًا باسم list_example.py في المجلد flask_todo: (env)user@localhost:$ nano list_example.py ثمّ سنكتب ضمنه الشيفرات التالية: from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.content, l.title FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) for list_, items in lists.items(): print(list_) for item in items: print(' ', item['content']) اِحفظ الملف وأغلقه. الشيفرة السابقة مشابهةٌ إلى حد كبير لتلك الموجودة في الدالة ()index، وتبيّن حلقة for التكرارية فيها كيفيّة هيكلة حاوية القوائم، إذ تبدأ بالمرور على عناصر الحاوية، التي تمثّل القوائم لطباعة عناوين هذه القوائم والموجودة ضمن المتغير list_variable، ومن ثمّ المرور على كافّة عناصر المهام التابعة لكل قائمة وطباعة محتويات كل منها. وبتشغيل البرنامج list_example.py: (env)user@localhost:$ python list_example.py نحصل على الخرج التالي: Home Buy fruit Cook dinner Study Learn Flask Learn SQLite Work Morning meeting الآن وبعد فهم كل جزئية في الدالة ()index، سننشئ قالبًا رئيسي وسنعمل على إخراج الملف index.html باستخدام الأمر التالي: return render_template('index.html', lists=lists) لذا، سننشئ مجلدًا للقوالب باسم templates ضمن المجلد flask_todo وسنفتح ضمنه ملفًا باسم base.html: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html والآن سنكتب شيفرة بوتستراب Bootstap التالية ضمن الملف base.html، وإن لم تكن قوالب HTML في فلاسك مألوفةً بالنسبة لك، يمكنك قراءة الخطوة الثالثة من المقال كيفية إنشاء تطبيق ويب باستخدام إطار فلاسك في لغة بايثون 3. <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskTodo</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> اِحفظ الملف وأغلقه. الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، أما الوسم <script> فيضمِّن شيفرة جافا سكربت المسؤولة عن بعض ميزات بوتستراب الإضافية. الآن سننشئ الملف index.html الذي سيوسِّع extend شيفرة القالب الرئيسي base.html: (env)user@localhost:$ nano templates/index.html وسنكتب الشيفرة التالية في الملف index.html: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item">{{ item['content'] }}</li> {% endfor %} </ul> </div> {% endfor %} {% endblock %} استخدمنا في الشيفرة السابقة، وباتبّاع نفس القواعد المشروحة في برنامج الملف list_example.py، حلقة for تكرارية للمرور على كل عنصر ضمن الحاوية lists، لعرض عنوان كل قائمة ضمن وسم من النوع <h3>، ومن ثمّ عرض كافّة عناصر المهام التابعة لكل قائمة ضمن وسم قوائم <li>. أمّا الآن فسنعيّن قيم متغيرات البيئة التي يحتاجها فلاسك، وسنشغّل البرنامج باستخدام الأوامر التالية: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run وبمجرّد تشغيل خادم التطوير، يمكنك الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفّح، فستظهر صفحة ويب تتضمّن العبارة "Welcome to FlaskTodo" إضافةً إلى عناصر قائمتك كما هو مبين في الصورة التالية: يمكنك في هذه المرحلة إيقاف خادم التطوير باستخدام الاختصار "CTRL+C". وبذلك نكون قد أنشأنا تطبيق فلاسك لعرض قوائم المهام وعناصر كل قائمة، وفي الخطوة التالية سنتعلّم كيفية إضافة صفحة جديدة للتطبيق تمكّن المستخدم من إنشاء عناصر مهام جديدة. الخطوة الثالثة - إضافة عناصر مهام جديدة سننشئ في هذه الخطوة وجهة route جديدة لإضافة عناصر المهام، كما سنُدخل البيانات في جداول قاعدة البيانات وسنعمل على ربط كل عنصر مع القائمة التي يتبع لها. بدايةً، سنفتح الملف app.py: (env)user@localhost:$ nano app.py وفي نهايته سننشئ وجهة جديدة ليعمل مثل دالة عرض فلاسك باسم ()create: ... @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() lists = conn.execute('SELECT title FROM lists;').fetchall() conn.close() return render_template('create.html', lists=lists) اِحفظ الملف وأغلقه. وبما أنّنا سنستخدم هذه الوجهة لإدخال بيانات جديدة في قاعدة البيانات باستخدام نموذج ويب، فلا بدّ من تمكين كلا طريقتي الطلبات "GET" و "POST" باستخدام التعليمة التالية في المزخرف ()app.route: methods=('GET', 'POST') يمكنك الآن فتح اتصال ضمن دالة فلاسك ()create مع قاعدة البيانات وجلب كافّة عناوين القوائم المتوفّرة فيها، ليُغلق بعدها هذا الاتصال ويُخرَج قالب create.html يحتوي عناوين القوائم المُمرّرة. افتح إذًا ملف قالب جديد باسم create.html: (env)user@localhost:$ nano templates/create.html وأضِف شيفرة HTML التالية ضمنه: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Create a New Item {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="content">Content</label> <input type="text" name="content" placeholder="Todo content" class="form-control" value="{{ request.form['content'] }}"></input> </div> <div class="form-group"> <label for="list">List</label> <select class="form-control" name="list"> {% for list in lists %} {% if list['title'] == request.form['list'] %} <option value="{{ request.form['list'] }}" selected> {{ request.form['list'] }} </option> {% else %} <option value="{{ list['title'] }}"> {{ list['title'] }} </option> {% endif %} {% endfor %} </select> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} اِحفظ الملف وأغلقه. استخدامنا الكائن request.form لتخزين البيانات المُدخلة في النموذج والوصول إليها في حال حدوث أي أخطاء لدى إرسال وتأكيد النموذج، مثل حالة ترك حقل محتوى عنصر المهام فارغًا. وباستخدام العنصر <select>، يحدث التنقّل ما بين القوائم المُسترجعة من قاعدة البيانات باستخدام الدالة ()create، وصولًا إلى عنوان القائمة المطابق للعنوان المُخزّن في الكائن request.form؛ فإذا كان عنوان القائمة مساويًا لما هو مُخزَّن في الكائن request.form، فسيكون الخيار المحدد هو عنوان القائمة؛ وإلّا سيُعرض عنوان القائمة على نحوٍ اعتيادي ضمن وسم <option> دون أن يكون الخيار مُحدّدًا. الآن، سنشغّل تطبيق فلاسك من الطرفية terminal كما يلي: (env)user@localhost:$ flask run وبالذهاب إلى الرابط http://127.0.0.1:5000/create في المتصفح، سيظهر نموذج إنشاء عنصر مهام جديد، ولكن حتى هذه اللحظة لن يعمل هذا النموذج لعدم وجود أي شيفرة للتعامل مع الطلبات من النوع POST المُرسلة من المتصفح عند إرسال وتأكيد النموذج. لذا، سنوقف خادم التطوير حاليًا باستخدام الاختصار "CTRL+C"، ثمّ سنضيف للدالة ()create الشيفرة اللازمة لعمل النموذج بصورةٍ صحيحة عبر التعامل مع الطلبات من نوع POST. افتح الملف app.py: (env)user@localhost:$ nano app.py وسنعدّل شيفرة الدالة ()create لتصبح كما يلي: ... @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() if request.method == 'POST': content = request.form['content'] list_title = request.form['list'] if not content: flash('Content is required!') return redirect(url_for('index')) list_id = conn.execute('SELECT id FROM lists WHERE title = (?);', (list_title,)).fetchone()['id'] conn.execute('INSERT INTO items (content, list_id) VALUES (?, ?)', (content, list_id)) conn.commit() conn.close() return redirect(url_for('index')) lists = conn.execute('SELECT title FROM lists;').fetchall() conn.close() return render_template('create.html', lists=lists) اِحفظ الملف وأغلقه. يتيح الشرط 'request.method == 'POST في الشيفرة السابقة إمكانية الحصول على كلٍ من محتوى عنصر المهام وعنوان قائمة المهام من البيانات المُدخلة في النموذج؛ ففي حال ترك حقل المحتوى فارغًا، سترسِل رسالةً للمستخدم باستخدام الدالة ()flash ثمّ تُعيد التوجيه إلى الصفحة الرئيسية index؛ أما في حال كون حقل المحتوى غير فارغ، فستنفَّذ العبارة SELECT للحصول على معرّف القائمة الموافق لعنوان القائمة المُدخل في النموذج وحفظه في المتغير المُسمّى list_id، ثمّ يُنفّذ الأمر INSERT INTO لإدراج عنصر المهام الجديد في جدول العناصر items، إذ تربط قيمة المتغير list_id العنصر بالقائمة التي ينتمي إليها. وفي النهاية لا بُد من الالتزام بتأكيد العملية وإغلاق الاتصال مع قاعدة البيانات والعودة بالمستخدم إلى الصفحة الرئيسية index. سنضيف في الخطوة الأخيرة رابط إنشاء عنصر مهام جديد create/ في شريط التصفح، وعرض الرسائل أدناه، لذا سنفتح الملف base.html: (env)user@localhost:$ nano templates/base.html الآن سنعدّل الملف السابق بإضافة عنصر تنقّل <li> مرتبط بدالة فلاسك ()create، كما سنضيف حلقة for تكرارية أعلى كتلة المحتوى البرمجية لعرض الرسائل من دالة فلاسك ()get_flashed_messages على النحو التالي: <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskTodo</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="{{ url_for('create') }}">New</a> </li> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> اِحفظ الملف وأغلقه. الآن سيظهر الرابط create/ في شريط التصفح لدى تشغيل تطبيق فلاسك: (env)user@localhost:$ flask run وسننتقل بالنقر عليه إلى صفحة إنشاء عنصر مهام جديد، فإذا أُرسِل النموذج دون محتوى، ستُعرض رسالةٌ مفادها بأنّ المحتوى مطلوب !Content is required، أمّا في حال ملء النموذج، فستظهر المهمّة الجديدة المُضافة في الصفحة الرئيسية index، وبذلك نكون قد أضفنا إمكانية إنشاء عناصر مهام جديدة وحفظها في قاعدة البيانات. يمكنك الحصول على الشيفرة الكاملة للتطبيق. الخاتمة ستحصل مع نهاية هذا المقال وبتطبيق الخطوات الواردة فيه على تطبيقٍ لإدارة قوائم وعناصر المهام، إذ تضم كل قائمة عدّة عناصر مهام، وكل عنصر مهام يتبع لقائمة واحدة، ما يشكّل علاقةً من النوع واحد-إلى-متعدّد. وبذلك تكون قد تعلمّت كيفية استخدام إطار العمل فلاسك وقواعد البيانات SQLite لإدارة عدّة جداول مترابطة في قاعدة البيانات باستخدام مفهوم المفتاح الأجنبي، كما تعلمّت كيفية جلب البيانات المترابطة من جدولين وعرضها في تطبيق ويب باستخدام استعلامات SQLite المركبّة. كما تعرفّت على الدالة ()groupby المسؤولة عن فرز البيانات المستخلصة من قاعدة البيانات، وتعلمّت طريقة ربط سجلات قاعدة البيانات بالجداول التابعة لها. ترجمة -وبتصرف- للمقال How To Use One-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون الرّبط بين جدولي المقالات والمُستخدمين بعلاقة واحد للعديد One-to-Many Relationship نمذجة البيانات وأنواعها في عملية تصميم قواعد البيانات
فلاسك هو إطار عمل يستخدم لغة بايثون Python لبناء تطبيقات الويب؛ أما SQLite فهو محرّك قواعد بيانات يُستخدم لتخزين بيانات تطبيق الويب. سننشئ في هذا المقال تطبيق ويب لإدارة المهام باستخدام كلٍ من إطار العمل فلاسك ومحرّك قاعدة البيانات SQLite، إذ سيتمكّن مستخدمو التطبيق من إنشاء قوائم تمثّل عناصر المهام المطلوبة. تتمثّل الفائدة العلمية والعملية من هذا المقال بتعلمّك كيفيّة استخدام SQLite مع فلاسك، بالإضافة لتعلّم كيفيّة إنشاء علاقات قاعدة البيانات من النوع واحد-إلى-متعدد. تُعرَّف علاقة قاعدة البيانات من النوع واحد-إلى-متعدد one-to-many بكونها علاقةٌ بين جدولين من قاعدة البيانات، بحيث يمكن لسجلٍ موجودٍ في أحد الجدولين الإشارة إلى عدّة سجلات من الجدول الثاني، ويشكّل تطبيق المدونة خير مثال على العلاقات في قواعد البيانات من النوع واحد-إلى-متعدد، نظرًا لارتباط الجدول الخاص بتخزين التدوينات posts مع الجدول الخاص بتخزين التعليقات comments بعلاقة من نوع واحد-إلى-متعدد؛ إذ يمكن أن يكون لكل تدوينة عدّة تعليقاتٍ مرتبطةٍ بها، وبالمقابل يرتبط كل تعليق بتدوينة واحدةٍ فقط، وبذلك فإنّ للتدوينة الواحدة علاقةٌ بالعديد من التعليقات. وفي هذه الحالة يُعد الجدول الخاص بالتدوينات "الجدول الأب parent"، في حين يُعد الجدول الخاص بالتعليقات "الجدول الابن child"؛ إذ يمكن للسجل الموجود في الجدول الأب الإشارة إلى عدّة سجلات موجودة في الجدول الابن، وهو أمرٌ أساسي لإتاحة إمكانية الوصول إلى البيانات المطلوبة في كل جدول. تتجلى إحدى دوافع استخدامنا لمحرّك قاعدة البيانات SQLite بكونه مرنًا من ناحية نقل البيانات عبر الأجهزة وبيئات التشغيل المختلفة Portable من جهة؛ وبكونه يعمل بسهولة مع لغة البرمجة بايثون دون الحاجة لتطبيق أي إعدادات إضافية من جهة أخرى؛ أمّا الدافع الآخر لاستخدامه فيتمثل بكونه مناسبًا جدًا لتصميم النماذج الأولية لتطبيقات الويب المنشئة قبل الانتقال إلى العمل على قاعدة البيانات الأكبر، مثل قاعدة بيانات MySQL، أو Postgres. مستلزمات العمل توجد مجموعةٌ من المتطلبات الواجب توفرّها وإعدادها قبل البدء في اتباع الخطوات التفصيلية المشروحة تاليًا ضمن هذا المقال، وهذه المتطلبات هي: توفُّر بيئة برمجة بايثون 3 محلية، وفي مقالنا سنسمّي مجلد المشروع بالاسم flask_todo. فهم مختلف مفاهيم فلاسك الأساسية، مثل إنشاء الوجهات وإخراج قوالب HTML والاتصال بقاعدة بيانات SQLite. الخطوة الأولى - إنشاء قاعدة البيانات سننفّذ في هذه الخطوة مجموعةً من الخطوات الفرعية المتمثّلة بتنشيط البيئة البرمجية التي سنعمل عليها، وتثبيت فلاسك، وإنشاء قاعدة بيانات SQLite، وتعبئتها ببيانات معياريّة، وسنتعلم كذلك كيفيّة استخدام المفاتيح الأجنبية foreign keys، لإنشاء علاقة واحد-إلى-متعدّد بين القوائم والعناصر؛ إذ يمثّل المفتاح الأجنبي صلة الوصل لربط جدول من قاعدة البيانات بآخر، فهو الرابط بين الجدول الابن والجدول الأب في قاعدة البيانات هذه، والمفتاح الأساسي لجدولٍ ما هو مفتاحٌ أجنبي للجداول الأُخرى. إذا لم تنشّط البيئة البرمجية الخاصة بك بعد، فاستخدم الأمر التالي لتنشيطها بعد التأكّد من كون موجه الأوامر يشير إلى مسار مجلد المشروع flask_todo: $ source env/bin/activate وبمجرّد تنشيط البيئة البرمجية، ثبّت فلاسك باستخدام الأمر التالي: (env)user@localhost:$ pip install flask ومع اكتمال تثبيت فلاسك، أصبح بإمكانك الآن إنشاء مخطّط قاعدة البيانات المتضمِّن أوامر SQL اللازمة لإنشاء الجداول التي تحتاجها لتخزين بيانات المهام المطلوبة، إذ ستحتاج إلى جدولين، جدول يسمى lists لتخزين قوائم المهام، وجدول يسمى items لتخزين عناصر كل قائمة. الآن سننشئ ملفًا باسم schema.sql ضمن المجلد flask_todo: (env)user@localhost:$ nano schema.sql وسنكتب أوامر SQL التالية داخل هذا الملف: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; CREATE TABLE lists ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL ); CREATE TABLE items ( id INTEGER PRIMARY KEY AUTOINCREMENT, list_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, content TEXT NOT NULL, FOREIGN KEY (list_id) REFERENCES lists (id) ); اِحفظ الملف وأغلقه. أوّل سطرين من شيفرة SQL السابقة مسؤولان عن حذف أي جداول موجودة سابقًا ضمن قاعدة البيانات باسم lists أو items، وهما: DROP TABLE IF EXISTS lists; DROP TABLE IF EXISTS items; وبذلك لن يكون هناك أي سلوكٍ متضاربٍ أو عشوائي ناجمٍ عن تشابه الأسماء ضمن قاعدة البيانات، ومن الجدير بالملاحظة أنّ تطبيق هذين الأمرين سيؤدي إلى حذف كامل محتوى قاعدة البيانات الحالي، لذا لا تُدخل أي بيانات مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية. بعد ذلك، يمكنك استخدام الأمر CREATE TABLE lists لإنشاء جدول القوائم lists، الذي سيخزن قوائم المهام المطلوبة، مثل قائمة الدراسة وقائمة العمل والقائمة الرئيسية، وما إلى ذلك، باستخدام الأعمدة التالية: "id": ويحتوي على بيانات من نوع الرقم الصحيح، ويمثّل مفتاحًا أساسيًا للجدول lists، وسيتضمّن قيم فريدة في قاعدة البيانات من أجل كل سجل، والسجل هو نوعٌ من أنواع قوائم المهام في حالتنا. "created": يحتوي على تاريخ ووقت إنشاء قائمة المهام، وتشير NOT NULL لكون هذا العمود لا يجب أن يحتوي على قيم فارغة، أما القيمة الافتراضية فهي CURRENT_TIMESTAMP، والتي تمثّل تاريخ ووقت إضافة قائمة المهام إلى قاعدة البيانات، وكما هو الحال في عمود "id" لا يتوجب عليك تحديد قيم لهذا العمود، لأن تعبئتها تلقائية. "title": عنوان قائمة المهام. وبعد إنشاء جدول القوائم lists، سننشئ الآن جدول العناصر items لتخزين عناصر المهام، إذ يحتوي هذا الجدول على معرّف "ID"، وعمود "list_id" يحوي أعدادًا صحيحة تحدّد معرّف القائمة التي ينتمي إليها العنصر، إضافةً لعمود تاريخ إنشاء العنصر، وعمود محتوى المهمّة. يمكنك استخدام مفتاح أجنبي لربط عنصرٍ ما بقائمةٍ معيّنة في قاعدة البيانات عن طريق كتابة الشيفرة التالية: FOREIGN KEY (list_id) REFERENCES lists (id) يمثّل جدول القوائم lists الجدول الأب المربوط بالجدول الآخر باستخدام المفتاح الأجنبي، وهذا يبيّن امكانية احتواء القائمة الواحدة على عدّة عناصر؛ في حين يمثّل جدول العناصر items الجدول الحاوي على المفتاح الأجنبي، وهذا يعني أن كل عنصر ينتمي إلى قائمة واحدةٍ فقط. يشير العمود list_id من جدول العناصر items الابن إلى عمود المعرِّف id من جدول القوائم lists الأب. وبذلك نجد أنّه قد حققنا فعليًا علاقة واحد-إلى-متعدّد بين جدولي lists و items، نظرًا لأنّ القائمة يمكن أن تحتوي على عدّة عناصر، وأنّ العنصر الواحد سينتمي إلى قائمةٍ واحدةٍ فقط. بعد الانتهاء من إنشاء الجداول، سنستخدم ملف schema.sql لإنشاء قاعدة البيانات. لذلك، أنشئ ملفًا باسم init_db.py ضمن المجلد flask_todo على النحو التالي: (env)user@localhost:$ nano init_db.py ثم أضِف فيه الشيفرة التالية: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO lists (title) VALUES (?)", ('Work',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Home',)) cur.execute("INSERT INTO lists (title) VALUES (?)", ('Study',)) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (1, 'Morning meeting') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Buy fruit') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (2, 'Cook dinner') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn Flask') ) cur.execute("INSERT INTO items (list_id, content) VALUES (?, ?)", (3, 'Learn SQLite') ) connection.commit() connection.close() اِحفظ الملف وأغلقه، وبمجرّد تنفيذ الشيفرة السابقة سيُنشأ ملفٌ باسم database.db ويُحقَّق الاتصال به، وبعدها يمكننا فتح ملف schema.sql وتشغيله باستخدام التابع ()executescript الذي ينفِّذ العديد من تعليمات SQL البرمجية في وقتٍ واحد. سيؤدي تشغيل الملف schema.sql لإنشاء جداول القوائم والعناصر، ومن ثمّ سننفّذ عددًا من تعليمات الإدخال في SQL لإنشاء ثلاث قوائم وخمسة عناصر مهام باستخدام كائن المؤشر Cursor. سنستخدم العمود "list_id" لربط كلّ عنصرٍ بقائمة عن طريق قيمة معرّف القائمة. فعلى سبيل المثال، إذا كانت القائمة المسمّاة "العمل Work" هي الإدخال الأوّل في قاعدة البيانات، فسيكون معرّفها ذو القيمة 1، وسنتمكّن باستخدامه من ربط عنصر المهام المسمّى "الاجتماع الصباحي Morning meeting" مثلًا بقائمة مهام العمل، وينطبق المبدأ نفسه على كافّة القوائم والعناصر الأُخرى. ومن ثمّ سنحفظ التغييرات ونغلق الاتصال، وسنشغّل البرنامج كما يلي: (env)user@localhost:$ python init_db.py وبعد تنفيذ هذا البرنامج سيظهر ملفٌ جديدٌ ضمن المجلد flask_todo باسم database.db، ومع انتهاء هذه الخطوة نكون قد فعّلنا البيئة البرمجية وثبتنا فلاسك، وأنشأنا قاعدة بيانات SQLite، وبذلك سنتمكن من استرجاع كل ما أُدخِل في قاعدة البيانات من قوائم وعناصر لعرضها في الصفحة الرئيسية للتطبيق الذي نحن في صدد إنشائه. الخطوة الثانية - عرض عناصر المهام سنعمل في هذه الخطوة على ربط قاعدة البيانات التي أنشأناها في الخطوة السابقة مع تطبيق فلاسك الذي سيعرض قوائم المهام والعناصر الموجودة في كلٍ منها، كما سنستخدم استعلامات قواعد البيانات المركّبة SQLite joins للاستعلام عن بيانات من الجدولين معًا، وسنعمل على تجميع عناصر المهام حسب القوائم التابعة لها. أولاً، سننشئ ملف التطبيق، لذا أنشئ ملفًا باسم app.py في المجلد flask_todo: (env)user@localhost:$ nano app.py ومن ثمّ سنضيف الشيفرة التالية إلى الملف: from itertools import groupby import sqlite3 from flask import Flask, render_template, request, flash, redirect, url_for def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn app = Flask(__name__) app.config['SECRET_KEY'] = 'this should be a secret random string' @app.route('/') def index(): conn = get_db_connection() todos = conn.execute('SELECT i.content, l.title FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) conn.close() return render_template('index.html', lists=lists) اِحفظ الملف وأغلقه. تفتح الدالة ()get_db_connection اتصالًا مع ملف قاعدة البيانات database.db، وتحدّد بعد ذلك قيمة السمة row_factory لتكون sqlite3.Row لنتمكّن من الوصول إلى الأعمدة باستخدام أسمائها، ما يعني أنّ اتصال قاعدة البيانات سيعيد سجلات يمكننا التعامل معها كما هو الحال مع قواميس بايثون Dictionaries الاعتيادية (وهي حاويات لتخزين القيم المنظمّة في بايثون)، ونهايةً تعيد الدالة كائن الاتصال conn المُستخدم للوصول إلى قاعدة البيانات. الآن سنفتح اتصالًا مع قاعدة البيانات باستخدام دالة عرض فلاسك ()index، وسننفّذ استعلام SQL التالي: SELECT i.content, l.title FROM items i JOIN lists l ON i.list_id = l.id ORDER BY l.title; وسنتمكن باستخدام الدالة ()fetchall من الحصول على نتائج الاستعلام وحفظها ضمن متغيّر todos. استخدمنا في الاستعلام السابق الأمر SELECT لجلب محتوى العنصر مع عنوان القائمة المنتمي إليها، عبر ربط كلٍ من جدولي القوائم والعناصر (إذ يشير الرمز i للعناصر، والرمز l للقوائم)، إذ سنحصل بالنتيجة على كافّة سجلات جدول العناصر ذات القيمة list_id الموافقة لقيمة المعرّف id من جدول القوائم باستخدام شرط التجميع i.list_id = l.id المكتوب بعد البادئة البرمجية ON، ومن ثمّ استخدمنا أمر الترتيب ORDER BY لفرز النتائج وفقًا لعناوين القوائم. الآن ولفهم هذا الاستعلام بوضوح، سنفتح موجه أوامر بايثون التفاعلي Python REPL في مجلد المشروع flask_todo: (env)user@localhost:$ python ومن ثمّ سنختبر محتويات المتغير todos الحاوي على نتائج الاستعلام السابق عبر تشغيل الشيفرة التالية: from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.content, l.title FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() for todo in todos: print(todo['title'], ':', todo['content']) استوردنا في الشيفرة السابقة قاعدة البيانات getdbconnection من الملف app.py، ومن ثمّ فُتِح الاتصال مع قاعدة البيانات ونُفِّذ الاستعلام (وهو استعلام SQL ذاته الموجود في الملف app.py)، وباستخدام حلقة for التكرارية طُبِع عنوان كل قائمة ومحتويات كل عنصر مهام مرتبطٍ بها، وبذلك سيظهر الخرج في حالتنا على النحو التالي: Home : Buy fruit Home : Cook dinner Study : Learn Flask Study : Learn SQLite Work : Morning meeting أغلق موجه أوامر بايثون REPL باستخدام الاختصار "CTRL+D". الآن، وبعدما فهمت آلية عمل ونتائج الاستعلامات المُجمّعة في SQL، سنعود إلى دالة فلاسك ()index الموجودة في الملف app.py، إذ سنصرّح بدايةً عن المتغير todos ومن ثمّ سنستخدم الشيفرة التالية لتجميع النتائج: lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) تبدأ الشيفرة المبينة أعلاه بالتصريح عن قاموس dictionary فارغ باسم lists، ثم تستخدم حلقة for التكرارية لتجميع النتائج الموجودة في المتغير todos وترتيبها حسب عنوان قائمة المهام باستخدام دالة الترتيب ()groupby المستوردة من المكتبة المعيارية itertools، إذ تولّد هذه الدالة مجموعةً من النتائج من أجل كل تكرار في الحلقة عبر مروره على كل عنصرٍ مخزّنٍ في المتغير todos. يمثّل متغيّر الحلقة k عناوين قوائم المهام (المنزل والدراسة والعمل في حالتنا) المُستخرجة من قاعدة البيانات عبر تمرير قيمة التابع ['lambda t: t['title وسيطًا لدالة التجميع ()groupby، التي تُعيد عنوان القائمة التي يتبع لها هذا العنصر (بنفس مبدأ الدالة ['todo['title المُستخدم في حلقة for السابقة)؛ بينما يمثّل المتغير g المجموعة الحاوية على عناصر المهام التابعة لكل عنوان قائمة. فمن أجل أول دورة في الحلقة مثلًا، سيمثّل المتغير k القائمة Home، في حين سيتكرر المتغير g ليحتوي بالنتيجة عناصر القائمة الموجودة في k وهي في حالتنا "Buy fruit" و "Cook". وهذا ما يمثّل علاقةً من نوع واحد-إلى-متعدّد بين القوائم والعناصر، بحيث يضم كل عنوان قائمة مجموعةً من عناصر المهام. وبذلك، ستظهر القوائم عند تشغيل الملف app.py وبعد انتهاء تنفيذ حلقة for على النحو التالي: {'Home': [<sqlite3.Row object at 0x7f9f58460950>, <sqlite3.Row object at 0x7f9f58460c30>], 'Study': [<sqlite3.Row object at 0x7f9f58460b70>, <sqlite3.Row object at 0x7f9f58460b50>], 'Work': [<sqlite3.Row object at 0x7f9f58460890>]} وسيحتوي كل كائن sqlite3.Row على البيانات المُسترجعة باستخدام استعلام SQL في الدالة ()index من جدول العناصر items، ولعرض هذه البيانات بوضوح أكثر، سنكتب برنامجًا يمر على محتويات الحاوية lists مستعرضًا كل قائمة وعناصرها. لكتابة هذا البرنامج، سنفتح ملفًا باسم list_example.py في المجلد flask_todo: (env)user@localhost:$ nano list_example.py ثمّ سنكتب ضمنه الشيفرات التالية: from itertools import groupby from app import get_db_connection conn = get_db_connection() todos = conn.execute('SELECT i.content, l.title FROM items i JOIN lists l \ ON i.list_id = l.id ORDER BY l.title;').fetchall() lists = {} for k, g in groupby(todos, key=lambda t: t['title']): lists[k] = list(g) for list_, items in lists.items(): print(list_) for item in items: print(' ', item['content']) اِحفظ الملف وأغلقه. الشيفرة السابقة مشابهةٌ إلى حد كبير لتلك الموجودة في الدالة ()index، وتبيّن حلقة for التكرارية فيها كيفيّة هيكلة حاوية القوائم، إذ تبدأ بالمرور على عناصر الحاوية، التي تمثّل القوائم لطباعة عناوين هذه القوائم والموجودة ضمن المتغير list_variable، ومن ثمّ المرور على كافّة عناصر المهام التابعة لكل قائمة وطباعة محتويات كل منها. وبتشغيل البرنامج list_example.py: (env)user@localhost:$ python list_example.py نحصل على الخرج التالي: Home Buy fruit Cook dinner Study Learn Flask Learn SQLite Work Morning meeting الآن وبعد فهم كل جزئية في الدالة ()index، سننشئ قالبًا رئيسي وسنعمل على إخراج الملف index.html باستخدام الأمر التالي: return render_template('index.html', lists=lists) لذا، سننشئ مجلدًا للقوالب باسم templates ضمن المجلد flask_todo وسنفتح ضمنه ملفًا باسم base.html: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html والآن سنكتب شيفرة بوتستراب Bootstap التالية ضمن الملف base.html، وإن لم تكن قوالب HTML في فلاسك مألوفةً بالنسبة لك، يمكنك قراءة الخطوة الثالثة من المقال كيفية إنشاء تطبيق ويب باستخدام إطار فلاسك في لغة بايثون 3. <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskTodo</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> اِحفظ الملف وأغلقه. الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، أما الوسم <script> فيضمِّن شيفرة جافا سكربت المسؤولة عن بعض ميزات بوتستراب الإضافية. الآن سننشئ الملف index.html الذي سيوسِّع extend شيفرة القالب الرئيسي base.html: (env)user@localhost:$ nano templates/index.html وسنكتب الشيفرة التالية في الملف index.html: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskTodo {% endblock %}</h1> {% for list, items in lists.items() %} <div class="card" style="width: 18rem; margin-bottom: 50px;"> <div class="card-header"> <h3>{{ list }}</h3> </div> <ul class="list-group list-group-flush"> {% for item in items %} <li class="list-group-item">{{ item['content'] }}</li> {% endfor %} </ul> </div> {% endfor %} {% endblock %} استخدمنا في الشيفرة السابقة، وباتبّاع نفس القواعد المشروحة في برنامج الملف list_example.py، حلقة for تكرارية للمرور على كل عنصر ضمن الحاوية lists، لعرض عنوان كل قائمة ضمن وسم من النوع <h3>، ومن ثمّ عرض كافّة عناصر المهام التابعة لكل قائمة ضمن وسم قوائم <li>. أمّا الآن فسنعيّن قيم متغيرات البيئة التي يحتاجها فلاسك، وسنشغّل البرنامج باستخدام الأوامر التالية: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run وبمجرّد تشغيل خادم التطوير، يمكنك الذهاب إلى الرابط "/http://127.0.0.1:5000" باستخدام المتصفّح، فستظهر صفحة ويب تتضمّن العبارة "Welcome to FlaskTodo" إضافةً إلى عناصر قائمتك كما هو مبين في الصورة التالية: يمكنك في هذه المرحلة إيقاف خادم التطوير باستخدام الاختصار "CTRL+C". وبذلك نكون قد أنشأنا تطبيق فلاسك لعرض قوائم المهام وعناصر كل قائمة، وفي الخطوة التالية سنتعلّم كيفية إضافة صفحة جديدة للتطبيق تمكّن المستخدم من إنشاء عناصر مهام جديدة. الخطوة الثالثة - إضافة عناصر مهام جديدة سننشئ في هذه الخطوة وجهة route جديدة لإضافة عناصر المهام، كما سنُدخل البيانات في جداول قاعدة البيانات وسنعمل على ربط كل عنصر مع القائمة التي يتبع لها. بدايةً، سنفتح الملف app.py: (env)user@localhost:$ nano app.py وفي نهايته سننشئ وجهة جديدة ليعمل مثل دالة عرض فلاسك باسم ()create: ... @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() lists = conn.execute('SELECT title FROM lists;').fetchall() conn.close() return render_template('create.html', lists=lists) اِحفظ الملف وأغلقه. وبما أنّنا سنستخدم هذه الوجهة لإدخال بيانات جديدة في قاعدة البيانات باستخدام نموذج ويب، فلا بدّ من تمكين كلا طريقتي الطلبات "GET" و "POST" باستخدام التعليمة التالية في المزخرف ()app.route: methods=('GET', 'POST') يمكنك الآن فتح اتصال ضمن دالة فلاسك ()create مع قاعدة البيانات وجلب كافّة عناوين القوائم المتوفّرة فيها، ليُغلق بعدها هذا الاتصال ويُخرَج قالب create.html يحتوي عناوين القوائم المُمرّرة. افتح إذًا ملف قالب جديد باسم create.html: (env)user@localhost:$ nano templates/create.html وأضِف شيفرة HTML التالية ضمنه: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Create a New Item {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="content">Content</label> <input type="text" name="content" placeholder="Todo content" class="form-control" value="{{ request.form['content'] }}"></input> </div> <div class="form-group"> <label for="list">List</label> <select class="form-control" name="list"> {% for list in lists %} {% if list['title'] == request.form['list'] %} <option value="{{ request.form['list'] }}" selected> {{ request.form['list'] }} </option> {% else %} <option value="{{ list['title'] }}"> {{ list['title'] }} </option> {% endif %} {% endfor %} </select> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} اِحفظ الملف وأغلقه. استخدامنا الكائن request.form لتخزين البيانات المُدخلة في النموذج والوصول إليها في حال حدوث أي أخطاء لدى إرسال وتأكيد النموذج، مثل حالة ترك حقل محتوى عنصر المهام فارغًا. وباستخدام العنصر <select>، يحدث التنقّل ما بين القوائم المُسترجعة من قاعدة البيانات باستخدام الدالة ()create، وصولًا إلى عنوان القائمة المطابق للعنوان المُخزّن في الكائن request.form؛ فإذا كان عنوان القائمة مساويًا لما هو مُخزَّن في الكائن request.form، فسيكون الخيار المحدد هو عنوان القائمة؛ وإلّا سيُعرض عنوان القائمة على نحوٍ اعتيادي ضمن وسم <option> دون أن يكون الخيار مُحدّدًا. الآن، سنشغّل تطبيق فلاسك من الطرفية terminal كما يلي: (env)user@localhost:$ flask run وبالذهاب إلى الرابط http://127.0.0.1:5000/create في المتصفح، سيظهر نموذج إنشاء عنصر مهام جديد، ولكن حتى هذه اللحظة لن يعمل هذا النموذج لعدم وجود أي شيفرة للتعامل مع الطلبات من النوع POST المُرسلة من المتصفح عند إرسال وتأكيد النموذج. لذا، سنوقف خادم التطوير حاليًا باستخدام الاختصار "CTRL+C"، ثمّ سنضيف للدالة ()create الشيفرة اللازمة لعمل النموذج بصورةٍ صحيحة عبر التعامل مع الطلبات من نوع POST. افتح الملف app.py: (env)user@localhost:$ nano app.py وسنعدّل شيفرة الدالة ()create لتصبح كما يلي: ... @app.route('/create/', methods=('GET', 'POST')) def create(): conn = get_db_connection() if request.method == 'POST': content = request.form['content'] list_title = request.form['list'] if not content: flash('Content is required!') return redirect(url_for('index')) list_id = conn.execute('SELECT id FROM lists WHERE title = (?);', (list_title,)).fetchone()['id'] conn.execute('INSERT INTO items (content, list_id) VALUES (?, ?)', (content, list_id)) conn.commit() conn.close() return redirect(url_for('index')) lists = conn.execute('SELECT title FROM lists;').fetchall() conn.close() return render_template('create.html', lists=lists) اِحفظ الملف وأغلقه. يتيح الشرط 'request.method == 'POST في الشيفرة السابقة إمكانية الحصول على كلٍ من محتوى عنصر المهام وعنوان قائمة المهام من البيانات المُدخلة في النموذج؛ ففي حال ترك حقل المحتوى فارغًا، سترسِل رسالةً للمستخدم باستخدام الدالة ()flash ثمّ تُعيد التوجيه إلى الصفحة الرئيسية index؛ أما في حال كون حقل المحتوى غير فارغ، فستنفَّذ العبارة SELECT للحصول على معرّف القائمة الموافق لعنوان القائمة المُدخل في النموذج وحفظه في المتغير المُسمّى list_id، ثمّ يُنفّذ الأمر INSERT INTO لإدراج عنصر المهام الجديد في جدول العناصر items، إذ تربط قيمة المتغير list_id العنصر بالقائمة التي ينتمي إليها. وفي النهاية لا بُد من الالتزام بتأكيد العملية وإغلاق الاتصال مع قاعدة البيانات والعودة بالمستخدم إلى الصفحة الرئيسية index. سنضيف في الخطوة الأخيرة رابط إنشاء عنصر مهام جديد create/ في شريط التصفح، وعرض الرسائل أدناه، لذا سنفتح الملف base.html: (env)user@localhost:$ nano templates/base.html الآن سنعدّل الملف السابق بإضافة عنصر تنقّل <li> مرتبط بدالة فلاسك ()create، كما سنضيف حلقة for تكرارية أعلى كتلة المحتوى البرمجية لعرض الرسائل من دالة فلاسك ()get_flashed_messages على النحو التالي: <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskTodo</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="{{ url_for('create') }}">New</a> </li> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> اِحفظ الملف وأغلقه. الآن سيظهر الرابط create/ في شريط التصفح لدى تشغيل تطبيق فلاسك: (env)user@localhost:$ flask run وسننتقل بالنقر عليه إلى صفحة إنشاء عنصر مهام جديد، فإذا أُرسِل النموذج دون محتوى، ستُعرض رسالةٌ مفادها بأنّ المحتوى مطلوب !Content is required، أمّا في حال ملء النموذج، فستظهر المهمّة الجديدة المُضافة في الصفحة الرئيسية index، وبذلك نكون قد أضفنا إمكانية إنشاء عناصر مهام جديدة وحفظها في قاعدة البيانات. يمكنك الحصول على الشيفرة الكاملة للتطبيق. الخاتمة ستحصل مع نهاية هذا المقال وبتطبيق الخطوات الواردة فيه على تطبيقٍ لإدارة قوائم وعناصر المهام، إذ تضم كل قائمة عدّة عناصر مهام، وكل عنصر مهام يتبع لقائمة واحدة، ما يشكّل علاقةً من النوع واحد-إلى-متعدّد. وبذلك تكون قد تعلمّت كيفية استخدام إطار العمل فلاسك وقواعد البيانات SQLite لإدارة عدّة جداول مترابطة في قاعدة البيانات باستخدام مفهوم المفتاح الأجنبي، كما تعلمّت كيفية جلب البيانات المترابطة من جدولين وعرضها في تطبيق ويب باستخدام استعلامات SQLite المركبّة. كما تعرفّت على الدالة ()groupby المسؤولة عن فرز البيانات المستخلصة من قاعدة البيانات، وتعلمّت طريقة ربط سجلات قاعدة البيانات بالجداول التابعة لها. ترجمة -وبتصرف- للمقال How To Use One-to-Many Database Relationships with Flask and SQLite لصاحبه Abdelhadi Dyouri. اقرأ أيضًا إنشاء تطبيق ويب باستخدام إطار عمل فلاسك Flask من لغة بايثون الرّبط بين جدولي المقالات والمُستخدمين بعلاقة واحد للعديد One-to-Many Relationship نمذجة البيانات وأنواعها في عملية تصميم قواعد البيانات -
 يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا العديد من الأدوات والميزات التي من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل، مانحًا المطورين المرونة في العمل، كما أنّه أبسط للاستخدام من قِبل المطورين المبتدئين نظرًا لإمكانية إنشاء تطبيق ويب كامل بسرعة باستخدام ملفٍ وحيدٍ مكتوب بلغة بايثون. إضافةً لما سبق، يتميز فلاسك بكونه قابلًا للتوسّع والوراثة دون أن يفرض أي بنية هرمية لطريقة عرض الملفات، كما أنّه لا يتطلب أي شفرات برمجية معقدّة استهلالية قبل البدء باستخدامه. سنتعرّف في هذا المقال أيضًا على إطار العمل بوتستراب bootstrap لإضافة التنسيقات على التطبيق ليبدو أكثر جاذبية بصريًا، كما سيساعدنا على تمكين ميزة الصفحات المتوافقة مع المتصفحات في تطبيق الويب، ما يضمن عمله بصورةٍ جيدة في المتصفحات الخاصة بالجوال، دون كتابة شفرات HTML و CSS و JavaScript لتحقيق هذه الغاية، وبالتالي سيساعدك بوتستراب في صبِّ تركيزك على تعلُّم كيفية عمل فلاسك نفسه. يستخدم فلاسك محرّك القوالب jinja لبناء صفحات HTML ديناميكيًا باستخدام مفاهيم بايثون المألوفة، من متغيراتٍ وحلقاتٍ تكرارية وقوائم وغيرها، وبالتالي ستُستخدم هذه القوالب جزءًا من هذا المشروع. ستتمكّن في هذا المقال من بناء مدونة ويب صغيرة باستخدام إطار العمل فلاسك مع قاعدة بيانات SQLite مُستخدمًا الاصدار الثالث من بايثون، إذ سيتمكّن مستخدمو هذا التطبيق من عرض جميع التدوينات المنشورة في قاعدة بياناتك، والضغط على عنوان التدوينة لعرض محتوياتها، مع إمكانية إضافتهم لتدوينات جديدة إلى قاعدة البيانات، أو تعديل أو حذف تدوينةٍ موجودةٍ أصلًا. مستلزمات العمل قبل المتابعة في هذا المقال لابدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو flask_blog. فهم مبادئ بايثون 3 مثل أنماط البيانات والجمل الشرطية وحلقة for التكرارية والدوال، وغيرها من المفاهيم المشابهة في بايثون 3. الخطوة الأولى – تثبيت فلاسك في هذه الخطوة سنفعّل بيئة بايثون ونثبّت فلاسك باستخدام أمر تثبيت الحزم pip، وفي حال كون بيئة البرمجة غير مفعّلة بعد، سنستخدم الأمر التالي لتفعيلها بعد التأكّد من كون موجه الأوامر يشير إلى مسار مجلد المشروع flask_blog: $ source env/bin/activate وبمجرّد تفعيل بيئة البرمجة، سيُظهِر موجّه الأوامر البادئة env والتي تظهر على النحو التالي: (env)user@localhost:$ تشير هذه البادئة إلى أن بيئة العمل env فعّالةٌ حاليًا، والتي قد تكون باسمٍ آخر لديك وذلك حسب الاسم الذي اخترته لها خلال إنشائها. الآن سنثبّت حزم بايثون وسنعزل شيفرة المشروع بعيدًا عن نظام بايثون المُثبت أساسًا باستخدام أوامر pip و python. ولتثبيت فلاسك، سنشغّل الأمر التالي: (env)user@localhost:$ pip install flask وعند انتهاء التثبيت، سنشغّل الأمر التالي للتحقُّق من إتمام العملية: (env)user@localhost:$ python -c "import flask; print(flask.__version__)" وبذلك نكون قد استخدمنا واجهة سطر أوامر بايثون ذات الخيار c- لتنفّيذ شيفرة بايثون، ومن ثم استوردنا مكتبة فلاسك باستخدام الأمر import flask، ثمّ طبعنا إصدار فلاسك المُثبت باستخدام المتغير flask.__version__ variable. وسيتضمّن الخرج رقم الإصدار على النحو التالي: 1.1.2 وبذلك نكون قد أنشأنا مجلد المشروع وبيئة العمل الافتراضية، كما أنّنا ثبَّتنا فلاسك، وبذلك أصبحنا مُستعدين لإنشاء تطبيق أساسي. الخطوة الثانية – كيفية إنشاء تطبيق أساسي الآن، وبعد الانتهاء من تثبيت بيئة العمل، سنبدأ باستخدام فلاسك، إذ سننشئ في هذه الخطوة تطبيق ويب بسيط ضمن ملف بايثون وتشغيله ليبدأ الخادم بالعمل مُظهرًا بعض المعلومات في المتصفح. الآن سنفتح الملف hello.py الموجود في مجلد flask_blog للتعديل عليه باستخدام محرّر النصوص نانو nano، أو أي محرّر آخر تفضِّله: (env)user@localhost:$ nano hello.py سيشكّل ملف hello.py مثالًا مبسّطًا لكيفية التعامل مع طلبات HTTP، إذ سنستورد في هذا الملف كائن فلاسك ونكتب تابعًا لتوليد الاستجابة لطلبات بروتوكول HTTP، ولتحقيق ذلك نكتب الشيفرة التالية في الملف hello.py: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return 'Hello, World!' استوردنا في الجزء السابق من الشيفرة كائن فلاسك من حزمة فلاسك، ثم استخدمناه لإنشاء نسخةٍ فعليةٍ موجودةٍ في الذاكرة لتطبيق فلاسك Flask application instance باسم app، وليست مجرد كائن برمجي، ومن ثمّ مررنا المتغير الخاص __name__، الذي سيخزّن اسم وحدة بايثون الحالية ليُعلم تطبيق فلاسك بمكان وجود هذه الوحدة، إذ لا بُدّ من إجراء هذه الخطوة كون فلاسك يهيّئ بعض المسارات اللازمة في الخلفية. وبمجرد إنشاء هذا التطبيق app، يمكنك استخدامه في معالجة طلبات الويب القادمة وإرسال الردود إلى المُستخدم. يكون المزخرف app.route@ مسؤولًا عن تعديل دوال بايثون المألوفة لتصبح دوالًا عاملةً في فلاسك، والتي تحوّل القيمة المعادة من قِبل التابع إلى استجابةٍ من نوع HTTP تُعرض لدى عميل HTTP الذي قد يكون متصفحًا مثلًا؛ فبمجرد تمرير القيمة / وسيطًا للتابع app.route@، سينشئ الردود على طلبات الويب الواردة إلى الرابط /، والذي يمثّل الرابط الرئيسي في التطبيق، وبذلك سيعيد التابع ()hello السلسلة النصية '!Hello, World' ردًا على الطلب. الآن، اِحفظ الملف وأغلقه. ولتشغيل تطبيق الويب الذي أنشأناه، لا بُدّ من إرشاد فلاسك إلى موقعه (في حالتنا الملف ذو الاسم hello.py) باستخدام متغير بيئة فلاسك FLASK_APP على النحو التالي: (env)user@localhost:$ export FLASK_APP=hello ومن ثم تشغيله بوضع التطوير باستخدام متغير بيئة فلاسك Flask_ENV على النحو التالي: (env)user@localhost:$ export FLASK_ENV=development وفي النهاية، سنشغّل التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run وبمجرّد تشغيل التطبيق، سيكون الخرج مشابهًا لما يلي: * Serving Flask app "hello" (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 813-894-335 يحتوي الخرج السابق على عدة معلومات، مثل: اسم التطبيق المُشغَّل. بيئة التشغيل الحالية التي يعمل عليها التطبيق. عبارة Debug mode:on التي تشير إلى أن مصحّح أخطاء فلاسك قيد التشغيل، وهو ذو فوائد عديدة أثناء عملية التطوير كونه يقدم رسائل خطأ مفصّلة عندما يحدث أي خلل، ما يجعل عملية تنقيح الأخطاء أسهل وأيسر. التطبيق يعمل على الحاسب المحلي وذلك على الرابط /http://127.0.0.1:5000، إذ أن 127.0.0.1 هو عنوان IP الذي يمثِّل الخادم المحلي localhost على حاسبك، و 5000: هو رقم المنفذ. افتح المتصفح واكتب عنوان URL التالي "/http://127.0.0.1:5000"، ستظهر عبارة !Hello, World استجابةً لهذا العنوان، وهذا ما يؤكد أن التطبيق يعمل بنجاح. يستخدم فلاسك خادم ويب مبسّط لاستضافة تطبيق الويب في بيئة التطوير، ما يعني أن مصحّح أخطاء فلاسك قيد التشغيل أيضًا كي يجعل التقاط الأخطاء أسهل، ولا ينبغي استخدام خادم التطوير هذا عندما يُنقل التطبيق إلى مرحلة التشغيل الفعلي أي نشر المنتج. يمكنك في هذه المرحلة الإبقاء على خادم التطوير قيد التشغيل في الطرفية terminal الخاصة به، ومن ثم افتح نافذة طرفية جديدة وغيّر المسار فيها إلى مسار مجلد المشروع حيث يتواجد ملف hello.py، ثم فعّل البيئة الافتراضية (السبب مبيّنٌ في الملاحظة أدناه)، وهيّئ متغيرات البيئة FLASK_ENV و FLASP_APP، ومن ثم تابع الخطوات التالية. (ذُكرت هذه الأوامر سابقًا في هذه الخطوة). ملاحظة: من الضروري تفعيل البيئة الافتراضية لدى فتح طرفية جديدة، ولا بدّ من إعداد متغيرات البيئة FLASK_ENV و FLASK_APP. لا يمكن تشغيل تطبيق فلاسك آخر باستخدام الأمر flask run نفسه خلال فترة عمل خادم تطوير تطبيقات فلاسك، كونه يستخدم المنفذ رقم 5000 افتراضيًا، وحالما يُحجَز هذا المنفذ يصبح غير متاحًا لتشغيل أي تطبيقٍ آخر، وفي حال فعلت ذلك ستظهر رسالة خطأ مشابهةٍ لما يلي: OSError: [Errno 98] Address already in use ويمكن حل لهذه المشكلة، إمّا بإيقاف الخادم العامل حاليًا عن طريق الضغط على "CTRL+C" ومن ثم تنفيذ الأمر flask run مجدّدًا، أو في حال رغبتك بتشغيل كلا التطبيقين في نفس الوقت، فمن الممكن تمرير رقم منفذٍ مختلف باستخدام الوسيط p-. سنستخدم الأمر التالي لتشغيل تطبيقٍ آخر يستخدم المنفذ 5001 مثالًا حول هذه الطريقة: (env)user@localhost:$ flask run -p 5001 وبذلك أصبح لديك تطبيق ويب صغير باستخدام فلاسك، وبعد أن شغّلت وعرضت معلومات في متصفح الويب، سنستخدم فيما يلي ملفات HTML في هذا التطبيق. الخطوة الثالثة – استخدام قوالب HTML لا يعرض تطبيقك حاليًا سوى رسالةٍ صغيرة دون أي استخدامٍ للغة HTML، إذ تستخدم تطبيقات الويب عادةً HTML بصورةٍ رئيسية لعرض المعلومات لزوار الموقع أو التطبيق، لذا سنعمل فيما يلي على دمج ملفات HTML في التطبيق، والتي يمكن عرضها في متصفح الويب. يقدّم فلاسك تابعًا مساعدًا يُسمّى ()render_template، يمكنّنا من استخدام [محرّك القوالب جينجا jinja، وهذا يجعل إدارة HTML أسهل عن طريق كتابة شيفرة HTML إلى جانب الشيفرة الوظيفية المعبّرة عن غرض التطبيق وذلك في ملفات ذات امتداد "html."، وستُستخدم ملفات HTML هذه (أي القوالب) لبناء كل صفحات التطبيق، مثل الصفحة الرئيسية التي تستعرض التدوينات الحالية في المدونة، والصفحة الخاصة بكل تدوينة، والصفحة التي يتمكن المستخدم من خلالها إضافة تدوينة جديدة، وغيرها. في هذه الخطوة، سننشئ تطبيق فلاسك رئيسي في ملفٍ جديد. بدايةً استخدم محرّر النصوص نانو nano أو أي محرِّر تفضله لإنشاء الملف app.py والتعديل عليه ضمن مجلد "flask_blog"، إذ سيحتوي هذا الملف على كل الشيفرة المُستخدمة لإنشاء تطبيق التدوينات: (env)user@localhost:$ nano app.py سنستورد في هذا الملف الجديد كائن فلاسك لإنشاء نسخة تطبيق فلاسك كما فعلنا سابقًا، كما سنستورد التابع المساعد ()render_template، الذي سيمكننّا من إخراج ملفات قوالب HTML الموجودة في المجلد templates الذي سننشئه بعد قليل. سيحتوي هذا الملف الجديد على تابعٍ وحيدٍ عامل في فلاسك مسؤول عن التعامل مع الطلبات الموجهة إلى الرابط /. الآن، أضِف مايلي إلى الملف الجديد app.py: from flask import Flask, render_template app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') سيعيد التابع ()index العامل في فلاسك نتيجة استدعاء التابع ()render_template عن طريق تمرير الوسيط index.html، وهذا يخبر التابع ()render_template بالبحث عن ملف باسم index.html في مجلد القوالب المُسمّى templates. المجلد templates والملف index.html غير موجودين فعليًا حتى الآن، وستحصل على خطأ في حال شغّلت التطبيق في هذه اللحظة، ولكن ننصحك بتشغيل التطبيق الآن بهدف التعرُّف على هذا الخطأ الشائع، ومن ثم صحّحه عن طريق إنشاء الملف والمجلد اللازمين فعليًا. الآن، احفظ الملف وأغلقه، ثمّ أوقف خادم التطوير في الطرفية الأخرى التي تشغِّل التطبيق hello عن طريق الضغط على "CTRL+C"؛ ولكن قبل تشغيل التطبيق تأكد من تحديد قيمة متغير البيئة FLASK_APP على نحوٍ صحيح، نظرًا لكونك لم تعد تستخدم تطبيق hello، وذلك على النحو التالي: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ flask run سيؤدي فتح العنوان "http://127.0.0.1:5000" في المتصفح إلى ظهور صفحة تنقيح الأخطاء التي ستُعلمك بعدم العثور على القالب "index.html"، ويُميَّز سطر الشيفرة الرئيسي المسؤول عن ظهور هذا الخطأ بلونٍ واضح، وهو في هذه الحالة السطر: return render_template('index.html') وإذا نقرت عليه، سيكشف منقّح الأخطاء مزيدًا من الأسطر البرمجية، وبالتالي سيكون لديك مزيدٌ من المعلومات ذات الصلة المساعدة على حل المشكلة. كي نصحّح هذا الخطأ، سننشئ مجلدًا باسم templates ضمن المجلد flask_blog، ومن ثم سنفتح ملف index.html بداخله للتحرير كما يلي: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/index.html ثم سنضيف شيفرة HTML التالية في الملف index.html: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>FlaskBlog</title> </head> <body> <h1>Welcome to FlaskBlog</h1> </body> </html> احفظ الملف ثم استخدم المتصفح للانتقال إلى الرابط "/http://127.0.0.1:5000" مجددًّا، أو حدِّث الصفحة، وفي هذه المرة سيعرض المتصفح النص "Welcome to FlaskBlog" وذلك في صيغة وسم <h1>. تمتلك تطبيقات فلاسك عادةً مجلدًا للملفات الثابتة يسمّى static، إضافةً إلى مجلد القوالب templates، إذ يستضيف هذا المجلد ملفات، مثل CSS و JavaScript والصور التي يستخدمها التطبيق. يمكنك إنشاء ملف تنسيقات style.css لإضافة CSS إلى التطبيق من خلال البدء بإنشاء مجلدٍ باسم static داخل مجلد flask_blog الرئيسي كما يلي: (env)user@localhost:$ mkdir static ثم أضِف مجلدًا آخر باسم css داخل المجلد static لتضع به الملفات ذات اللاحقة "css."، إذ أن الهدف من هذا الإجراء هو تنظيم الملفات الثابتة في مجلدات مخصصّة حسب نوعها؛ فمثلًا نضع ملفات JavaScript في مجلد باسم js، والصور في مجلد باسم images أو img، وهكذا. ستنشئ التعليمة التالية مجلدًا باسم css داخل المجلد static: (env)user@localhost:$ mkdir static/css اِفتح الآن الملف style.css الموجود داخل المجلد css بهدف تحريره: (env)user@localhost:$ nano static/css/style.css اكتب قاعدة CSS التالية ضمن الملف style.css: h1 { border: 2px #eee solid; color: brown; text-align: center; padding: 10px; } شيفرة CSS هذه مسؤولةٌ عن إضافة حدود لكافة الوسوم من نوع <h1>، كما أنّها تغيِّر لون الخط فيها إلى البني، وتجعل محاذاة النص إلى الوسط، وتضيف هوامشًا داخليةً ضيقةً إليها. احفظ الآن الملف وأغلقه، ثم افتح ملف القالب index.html بهدف تحريره: (env)user@localhost:$ nano templates/index.html سنضيف الآن رابطًا في قسم الترويسة <head> من القالب index.html للوصول إلى الملف style.css على النحو التالي: . . . <head> <meta charset="UTF-8"> <link rel="stylesheet" href="{{ url_for('static', filename= 'css/style.css') }}"> <title>FlaskBlog</title> </head> . . . استخدمنا التابع المساعد url_for() لإنشاء المسار المناسب للملف، إذ يحدد الوسيط الأول أنّنا ننشئ ارتباطًا إلى ملفٍ ساكن، والوسيط الثاني هو مسار الملف هذا داخل مجلد الملفات الساكنة. اِحفظ الملف وأغلقه، وحالما تحدّث الصفحة index في التطبيق، ستلاحظ أن النص "Welcome to FlaskBlog" أصبح بلونٍ بني، ومحاذاته إلى الوسط، ومحاطًا بحدود. يمكنك استخدام لغة CSS لتنسيق مظهر التطبيق وجعله أكثر جاذبية بصريًا باستخدام التصميم الذي تريد؛ ولكن إن لم تكن مصمم ويب، أو لم يكن لديك الخبرة الكافية في التعامل مع CSS، فبإمكانك استخدام حزمة بوتستراب Bootstrap، التي تزودك بمكونات سهلة الاستخدام لتنسيق مظهر التطبيق، إذ سنستخدم في تطبيقنا هذا بوتستراب. وفي حال أردت إنشاء قوالب HTML أُخرى، فلن تضطر لإعادة كتابة الشيفرة التي كتبتها سابقًا في القالب index.html، فمن الممكن تفادي التكرار غير الضروري بالاستفادة من ملف القالب الرئيسي base template، والتي سترث كافّة ملفات HTML الأُخرى شيفرته. ولكي ننشئ قالب رئيسي، سننشئ بدايةً ملفًا باسم base.html في مجلد القوالب templates: (env)user@localhost:$ nano templates/base.html ثم سنكتب الشيفرة التالية في القالب base.html: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskBlog</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> اِحفظ الملف وأغلقه حالما تنتهي من تحريره. إنّ الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، ويضمِّن الوسم <script> شيفرة جافا سكربت مسؤولة عن بعض ميزات بوتستراب الإضافية. أمّا الأجزاء من الشيفرة الموضحّة فيما يلي فهي خاصةٌ بمحرك القوالب جينجا: {% block title %} {% endblock %}: كتلة برمجية تحجز مكانًا لعنوان الصفحة، والذي سنستخدمه في تحديد العنوان الخاص بكل صفحة في التطبيق دون الحاجة إلى إعادة كتابة قسم الترويسة <head> كاملًا في كل مرةٍ من أجل كل صفحة. {{ url_for('index') }}: استدعاءٌ لدالة تعيد عنوان URL إلى دالة عرض index()، والتي نمرر لها وسيطًا واحدًا فقط وهو اسم تابع فلاسك، لتنشئ ارتباطًا مع وجهة تابع فلاسك بدلًا من ملف ساكن كما كان الحال لدى استدعاء التابع ()url_for السابق الذي استخدمناه لإنشاء ارتباط مع ملف CSS الساكن. {% block content %} {% endblock %}: كتلة برمجية أخرى ستُستبدل لاحقًا بالمحتوى الفعلي بالاعتماد على القالب الابن، أي القالب الذي يرث شيفرات القالب الرئيسي base.html. والآن بعد أن أصبح لديك قالبٌ رئيسي، يمكنك الاستفادة من مميزاته باستخدام فكرة الوراثة، لذلك افتح الملف index.html: nano templates/index.html ثمّ استبدل محتوياته بما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskBlog {% endblock %}</h1> {% endblock %} استخدمنا في هذه النسخة الجديدة من القالب template.html الوسم {% extends %} لترث الشيفرات من القالب الرئيسي base.html، وذلك عن طريق استبدال الشيفرة السابقة بكتلة المحتوى content في القالب الرئيسي. تحوي كتلة المحتوى block content على وسم <h1> وبداخله كتلة عنوان title تحتوي العبارة "Welcome to FlaskBlog"، وبذلك نتفادى تكرار نفس النص مرتين، ذلك لأنّ هذا النص سيظهر في عنوان الصفحة ونص ضمن وسم <h1> أسفل شريط التصفح الموروث من القالب الرئيسي. تمكنّك وراثة القوالب من إعادة استخدام شيفرة HTML الموجودة في القوالب الأخرى (القالب الرئيسي base.html في حالتنا) دون الحاجة لتكراره في كل مرة. اِحفظ الملف وأغلقه، ثم حدِّث الصفحة الرئيسية index في المتصفح، فستظهر الصفحة بشريط تصفح وعنوانٍ منسقٍ كما يلي: وبذلك نكون قد استخدمنا قوالب HTML والملفات الساكنة في فلاسك، وكذلك استخدمنا بوتستراب لتنسيق مظهر الصفحة، واستفدنا من القالب الرئيسي لتفادي تكرار الشيفرات البرمجية. سنُعدُّ في الخطوة التالية قاعدة بيانات لتخزين بيانات التطبيق. الخطوة الرابعة – إعداد قاعدة البيانات سيكون التركيز في هذه الخطوة على إعداد قاعدة بيانات لتخزين البيانات، والتي هي تدوينات posts في حالة تطبيقنا، كما سنملأ قاعدة البيانات ببعض المدخلات التجريبية. سنستخدم ملف قاعدة بيانات من نوع SQLite لتخزين البيانات، لأن وحدة sqlite3 المُستخدمة للتعاطي مع قاعدة البيانات هذه موجودة وجاهزة افتراضيًا في مكتبة لغة بايثون. بدايةً، وبما أنّ تخزين البيانات في SQLite يكون ضمن جداول وأعمدة، وكون بيانات تطبيقنا هي تدوينات، سننشئ جدولًا باسم posts يحتوي على كافّة الأعمدة اللازمة، إذ سننشئ ملفًا بلاحقة sql. يحتوي على أوامر SQL اللازمة لإنشاء جدول posts وأعمدته اللازمة، ثم سنستخدم هذا الملف لإنشاء قاعدة البيانات. افتح الملف المُسمى schema.sql الموجود في المجلد flask_blog: (env)user@localhost:$ nano schema.sql اكتب تعليمات SQL التالية داخل هذا الملف: DROP TABLE IF EXISTS posts; CREATE TABLE posts ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL, content TEXT NOT NULL ); ثم اِحفظ الملف وأغلقه. يعمل أوّل أمر من أوامر SQL وهو: DROP TABLE IF EXISTS posts; على حذف أي جداول موجودةٍ مسبقًا باسم posts لتجنُّب أي تضاربٍ، أو نتائج عشوائية ناتجةٍ عن تشابه أسماء الجداول، ومن الجدير بالملاحظة أنّ هذا الأمر سيحذِف كل المحتويات في قاعدة البيانات في كل مرة تشغِّل فيها أوامر SQL هذه، لذلك لا تُدخل أي بيانات مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية. بينما ينشئ الأمر الثاني من أوامر SQL وهو: CREATE TABLE posts جدولًا باسم posts له الأعمدة التالية: "id": ويحتوي على بياناتٍ من نوع رقم صحيح ويمثّل مفتاحًا أساسيًا يحتوي على قيمةٍ فريدة في قاعدة البيانات من أجل كل سجل (والسجل هو التدوينة في حالتنا). "created": يحتوي على تاريخ ووقت إنشاء التدوينة، وتشير NOT NULL إلى أن هذا العمود لا يجب أن يحتوي على قيمٍ فارغة، أما القيمة الافتراضية فهي CURRENT_TIMESTAMP والتي تمثِّل تاريخ ووقت إضافة التدوينة إلى قاعدة البيانات، وكما هو الحال في عمود id، لا يتوجب عليك تحديد قيم لهذا العمود، إذ أنها تُملأ تلقائيًا. "title": عنوان التدوينة. "content": محتوى التدوينة. الآن، وبعد أن أصبح لدينا تخطيط قاعدة البيانات SQL المطلوب في ملف schema.sql، سنستخدمه لإنشاء قاعدة البيانات باستخدام ملف بايثون لإنشاء ملف قاعدة بيانات SQLite بلاحقة db.. افتح الملف المُسمّى init_db.py الموجود داخل المجلد flask_blog باستخدام محرِّر النصوص المفضل لديك: (env)user@localhost:$ nano init_db.py ثم اكتب ضمنه الشيفرة التالية: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO posts (title, content) VALUES (?, ?)", ('First Post', 'Content for the first post') ) cur.execute("INSERT INTO posts (title, content) VALUES (?, ?)", ('Second Post', 'Content for the second post') ) connection.commit() connection.close() استوردنا في الشيفرة السابقة وحدة sqlite3، ثم أنشأنا اتصالًا مع ملف قاعدة بيانات باسم database.db، والذي يُنشأ تلقائيًا فور تشغيل ملف بايثون هذا، ومن ثم استخدمنا الدالة ()open لفتح الملف schema.sql، ثم نفّذنا باستخدام التابع ()executescript محتويات هذا الملف، الذي ينفِّذ عدة عبارات SQL معًا، وهكذا يُنشأ الجدول posts. استخدمنا في الشيفرة السابقة كائن المؤشر Cursor، الذي يمكِّننا من استخدام تابعه ()execute لتنفيذ تعليمتي إدخال INSERT في SQL لإضافة تدوينتين معًا إلى جدول التدوينات posts. وفي النهاية أُرسلت هذه الأوامر إلى قاعدة البيانات وأُغلِق الاتصال المفتوح معها. اِحفظ الملف وأغلقه، ثم شغِّله من موجّه الأوامر باستخدام أمر بايثون التالي: (env)user@localhost:$ python init_db.py وحالما ينتهي التنفيذ، سيكون لديك ملفٌ جديدٌ باسم database.db ضمن مجلد flask_blog، وهذا يدل على نجاح عملية إعداد قاعدة البيانات. سنعمل في الخطوة التالية على قراءة التدوينات المُضافة إلى قاعدة البيانات وعرضها في الصفحة الرئيسية للتطبيق. الخطوة 5 – عرض كل التدوينات الآن وبعد أن أعددنا قاعدة البيانات، يمكننا تعديل دالة عرض فلاسك index() لعرض كل التدوينات الموجودة في قاعدة البيانات. لذلك، افتح الملف app.py لتنفيذ التعديلات التالية: (env)user@localhost:$ nano app.py سيكون التعديل الأوّل هو استيراد وحدة sqlite3 في بداية الملف على النحو التالي: import sqlite3 from flask import Flask, render_template . . . ثم سنبني بعد ذلك دالةً تعمل على إنشاء اتصال مع قاعدة البيانات وتعيد نتائجه. أضِف هذه الدالة مباشرةً بعد أوامر الاستيراد: . . . from flask import Flask, render_template def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn . . . تفتح الدالة get_db_connection() اتصالًا مع ملف قاعدة البيانات database.db، وتحدّد بعد ذلك قيمة السمة row_factory لتكون sqlite3.Row لنتمكّن من الوصول إلى الأعمدة باستخدام أسمائها، ما يعني أنّ اتصال قاعدة البيانات سيعيد سجلات يمكننا التعامل معها كما هو الحال مع قواميس بايثون الاعتيادية (وحدات تخزين القيم المنظمّة في بايثون)، ونهايةً يعيد التابع كائن الاتصال conn، الذي سنستخدمه للوصول إلى قاعدة البيانات. بعد أن عرّفنا الدالة get_db_connection()، سنعدّل دالة index() لتصبح كما يلي: . . . @app.route('/') def index(): conn = get_db_connection() posts = conn.execute('SELECT * FROM posts').fetchall() conn.close() return render_template('index.html', posts=posts) بعد هذا التعديل الجديد على الدالة index()، فإنّنا نفتح اتصالًا مع قاعدة البيانات باستخدام الدالة get_db_connection() التي عرفناها للتو. سننفذ بعد ذلك استعلام SQL للحصول على كل المدخلات الموجودة في الجدول posts، إذ أنّنا نستدعي التابع fetchall() لجلب كل الأسطر الناتجة عن الاستعلام، وهذا سيعيد بالنتيجة قائمةً بالتدوينات المُدخلة إلى قاعدة البيانات في الخطوة السابقة. يمكنك إغلاق الاتصال بقاعدة البيانات باستخدام التابع close() وإعادة نتيجة عرض القالب index.html، كما يمكنك تمرر الكائن posts وسيطًا، فهو الكائن الحاوي على النتائج المُستخلصة من قاعدة البيانات، ويساعدنا هذا التمرير على الوصول إلى التدوينات برمجيًا داخل قالب index.html. وبعد تنفيذ كل هذه التعديلات، احفظ الملف app.py وأغلقه. الآن وبعد أن مرّرنا كل التدوينات المُستخلصة من قاعدة البيانات إلى القالب index.html، سنستخدم حلقة for التكرارية لعرض معلومات عن كل تدوينة داخل صفحة index. افتح ملف index.html: (env)user@localhost:$ nano templates/index.html ثم عدِّله كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskBlog {% endblock %}</h1> {% for post in posts %} <a href="#"> <h2>{{ post['title'] }}</h2> </a> <span class="badge badge-primary">{{ post['created'] }}</span> <hr> {% endfor %} {% endblock %} تقابل هنا الصيغة البرمجية {% for post in posts %} حلقة for في محرّك جينجا jinja، والتي تشبه بناء حلقة for في لغة بايثون ما عدا ضرورة إغلاقها باستخدام الصيغة البرمجية {% endfor %}. الهدف من استخدام هذه الحلقة حاليًا هو المرور على كل عنصر في القائمة posts المُمررة إلى الدالة index() من خلال السطر البرمجي التالي: return render_template('index.html', posts=posts) وضمن هذه الحلقة نعرض عنوان التدوينة في وسمٍ عنوان <h2> داخل وسم الرابط <a> (لأنّنا سنستخدم هذا الوسم لاحقًا لإنشاء رابط مخصّص لعرض معلومات خاصة عن كل تدوينة). يُعرض عنوان التدوينة باستخدام محدّد المتغير المُجرد Literal variable delimiter وهو {{ ... }}. تذكّر أنّ كل عنصر post في القائمة سيكون مشابهًا لما هو عليه في قاموس بايثون، وبالتالي يمكنك الوصول إلى عنوان التدوينة من خلال post['title']؛ كما من الممكن عرض تاريخ إنشاء التدوينة بنفس الآلية. وحالما تنتهي من تعديل الملف، احفظه وأغلقه، ثم انتقل في المتصفح إلى صفحة index، وعندها ستظهر لك المشاركتان posts المُضافتان سابقًا إلى قاعدة البيانات. والآن، وبعد تعديل دالة index() المسؤولة عن عرض كل التدوينات الموجودة في قاعدة البيانات داخل الصفحة الرئيسية للتطبيق، سننتقل إلى خطوة عرض كل تدوينة في صفحة خاصة بها وذلك من خلال تمكين المستخدمين من الانتقال إلى أي تدوينة -كلٌ على حدى-. الخطوة السادسة – عرض تدوينة بحد ذاتها تهدف هذه الخطوة إلى عرض تدوينة واحدة بناءً على معرّفها ID، سننشئ وجهة route فلاسك ودالة عرض جديدة، إضافةً لقالب HTML جديد. في نهاية هذه الخطوة، سيكون الرابط "http://127.0.0.1:5000/1" مثلًا هو الصفحة التي تعرض التدوينة الأولى، لأن معرف التدوينة الأولى هو الرقم 1؛ أي سيعرض الرابط "http://127.0.0.1:5000/ID" التدوينة ذات المعرّف ID في حال وجودها في قاعدة البيانات. الآن افتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py وطالما أنّنا سنجلب التدوينات من قاعدة البيانات بناءً على معرّفها ID من مسارات متعدّدة لاحقًا عند استخدام التطبيق، سننشئ دالةً منفردة باسم get_post() تعيد معلومات التدوينة ذات المعرّف ID هذا بمجرد تمرير القيمة ID وسيطًا لها، أما في حال عدم وجود تدوينة تحمل هذا المعرّف في قاعدة البيانات، ستكون الاستجابة برسالة "غير موجود 404 Not Found"؛ ولنتمكَّن من الاستجابة برسالة الخطأ رقم 404، لا بدّ من تضمين الدالة abort() من مكتبة فلاسك Werkzeug التي يجري تنزيلها أثناء تثبيت فلاسك. ننجز الاستدعاء السابق أعلى الملف على النحو التالي: import sqlite3 from flask import Flask, render_template from werkzeug.exceptions import abort . . . ثم نضيف الدالة get_post() تمامًا بعد الدالة get_db_connection() المُعرّفة في الخطوة السابقة. . . . def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn def get_post(post_id): conn = get_db_connection() post = conn.execute('SELECT * FROM posts WHERE id = ?', (post_id,)).fetchone() conn.close() if post is None: abort(404) return post . . . تتضمّن الدالة الجديدة الوسيط post_id، الذي يحدّد التدوينة المُعادة نتيجةً لاستدعاء هذه الدالة. تُستخدم خلال تنفيذ هذه الدالة دالةٌ أخرى، هي get_db_connection() لفتح اتصال مع قاعدة البيانات وتنفيذ استعلام SQL لجلب التدوينة الموافقة لقيمة post_id الممرّرة، كما يُستخدم التابع fetchone() لجلب نتيجة الاستعلام وتخزينها في المتغير post، ومن ثمّ يُغلق الاتصال مع قاعدة البيانات؛ فإذا كانت قيمة المتغير post فارغة None، فهذا يدل على عدم العثور على نتائج في قاعدة البيانات، وعندها نستخدم الدالة abort() التي ضمّناها توًّا للرد برقم الخطأ 404 وبالتالي التوقُّف عن متابعة تنفيذ شيفرة الدالة؛ أما في حال العثور على التدوينة، تُعاد قيمة المتغير post. الآن، أضف دالة عرض فلاسك التالية في نهاية الملف app.py: . . . @app.route('/<int:post_id>') def post(post_id): post = get_post(post_id) return render_template('post.html', post=post) سنضيف في دالة عرض فلاسك الجديدة قاعدة متغيرة Variable Rule هي <int:post_id> لنحدّد أنّ الجزء بعد العلامة (/) هو رقمٌ صحيحٌ موجب، وذلك بتحويل قيمة هذا الجزء إلى النوع int، وهو ما نحتاجه للوصول إلى دالة العرض. يتعرف فلاسك على هذا الشرط ويمرّر القيمة إلى الوسيط post_id في دالة فلاسك post()، وبعد ذلك يمكننا استخدام الدالة ()get_post للحصول على التدوينة المرتبطة بالمعرّف ID المحدّد، ومن ثمّ تخزين النتيجة في المتغير post، الذي سيُمرّر في النهاية إلى القالب post.html، الذي سننشئه فيما يلي. الآن احفظ الملف app.py وافتح ملف قالب جديد post.html لتحريره: (env)user@localhost:$ nano templates/post.html اكتب الشيفرة التالية في الملف الجديد post.html، إذ تتشابه هذه الشيفرة مع تلك المُستخدمة في ملف index.html، إلّا أنّنا سنعرض معلومات عن تدوينةٍ واحدةٍ فقط، إضافةً إلى عرض محتويات هذه التدوينة: {% extends 'base.html' %} {% block content %} <h2>{% block title %} {{ post['title'] }} {% endblock %}</h2> <span class="badge badge-primary">{{ post['created'] }}</span> <p>{{ post['content'] }}</p> {% endblock %} اضفنا كتلة العنوان title المُعرفة سابقًا في القالب base.html لجعل عنوان التدوينة معروضًا باستخدام وسم من نوع عنوان <h2>، وجعله أيضًا عنوانًا للصفحة. اِحفظ الملف وأغلقه. يمكنك الآن الانتقال في المتصفح إلى الروابط التالية لاستعراض التدوينتين الموجودتين حاليًا في قاعدة البيانات، وكذلك الصفحة التي تخبر المستخدم بعدم العثور على التدوينة المطلوبة (لأنّه لا يوجد حتى الآن تدوينة برقم معرف 3): http://127.0.0.1:5000/1 http://127.0.0.1:5000/2 http://127.0.0.1:5000/3 سنعود إلى الصفحة الرئيسية لإنشاء رابط لكل عنوان تدوينة لينقلنا إلى صفحة التدوينة الخاصة به باستخدام الدالة url_for()، لذا افتح قالب index.html أولًا لتحريره: (env)user@localhost:$ nano templates/index.html ثم عدّل قيمة السمة href لتصبح {{ url_for('post', post_id=post['id']) }} بدلًا من #، بحيث تبدو حلقة for على النحو التالي: {% for post in posts %} <a href="{{ url_for('post', post_id=post['id']) }}"> <h2>{{ post['title'] }}</h2> </a> <span class="badge badge-primary">{{ post['created'] }}</span> <hr> {% endfor %} تُمرَّر القيمة post إلى الدالة url_for() التي تحتاج رقم معرّف التدوينة وسيطًا لها، وبما أنها اسم دالة العرض ()post فتُستدعى على النحو التاليpost['id' ] لتُستخدم وسيطًا للدالةurl_for() التي ستعيد بالنتيجة الرابط المناسب لكل تدوينة بناءً على معرّفها ID. اِحفظ الملف وأغلقه. ستعمل الروابط الآن في الصفحة الرئيسية على النحو المطلوب، وبذلك نكون قد انتهينا من بناء الجزء المسؤول عن عرض التدوينات الموجودة في قاعدة البيانات من تطبيق الويب، وسنضيف في الخطوات التالية إمكانية إضافة، أو تعديل، أو حذف التدوينات لهذا التطبيق. الخطوة 7 – التعديل على جدول التدوينات بعد أن أنهينا عملية استعراض التدوينات الموجودة في قاعدة البيانات داخل صفحات تطبيق الويب، سنعمل على توفير إمكانية كتابة تدوينات جديدة وحفظها في قاعدة البيانات لمستخدمي التطبيق، وكذلك إمكانية تعديل التدوينات الموجودة أصلًا أو حذف التدوينات غير اللازمة. إنشاء تدوينة جديدة لدينا حتى الآن تطبيقٌ يعرض التدوينات من قاعدة البيانات، ولكنه لا يوفر أي طريقةٍ لإضافة تدوينات جديدة، إلّا عن طريق إضافة تدوينة يدويًا عبر الاتصال بقاعدة البيانات SQLite. فيما يلي سننشئ صفحةً تمكنّنا من إضافة تدوينة جديدة عن طريق إدخال عنوانها ومحتواها مباشرةً. افتح ملف app.py لتحريره: (env)user@localhost:$ nano app.py لا بُد أولًا من استيراد التالي من إطار العمل فلاسك: الكائن request العام المسؤول عن الوصول إلى بيانات الطلب والتي ستُرسل من خلال نموذج HTML. الدالة url_for() لتوليد عناوين الروابط. الدالة flash() لعرض رسالةٍ وامضة عند انتهاء معالجة الطلب. الدالة redirect() لإعادة توجيه المستخدم إلى موقعٍ آخر في المتصفح. أضِف هذه الاستيرادات إلى الملف كما يلي: import sqlite3 from flask import Flask, render_template, request, url_for, flash, redirect from werkzeug.exceptions import abort . . . تخزّن الدالة flash() الرسائل في جلسة المتصفح لدى المستخدم، وهذا ما يتطلّب إعداد مفتاح أمان Secret Key، إذ سيُستخدم هذا المفتاح لجعل الجلسات آمنة، وبذلك يتمكّن فلاسك من الحفاظ على المعلومات عند الانتقال من طلبٍ إلى آخر، مثل حالة الانتقال من صفحة إنشاء تدوينة جديدة إلى صفحة عرض كل التدوينات، مع ملاحظة أن المستخدم يستطيع الوصول إلى المعلومات المُخزّنة في الجلسة، ولكنه لا يستطيع تعديلها إلّا إذا كان لديه مفتاح الأمان، وبالتالي لا يجب أن تسمح لأي أحدٍ بالوصول إلى مفتاح الأمان الخاص بك. ولإعداد مفتاح أمان، سنضيف ضبط SECRET_KEY إلى التطبيق من خلال الكائن app.config، الذي سنضيفه مباشرةً بعد تعريف الكائن app وقبل دالة عرض فلاسك index()، على النحو التالي: . . . app = Flask(__name__) app.config['SECRET_KEY'] = 'your secret key' @app.route('/') def index(): conn = get_db_connection() posts = conn.execute('SELECT * FROM posts').fetchall() conn.close() return render_template('index.html', posts=posts) . . . تذكّر أنّ مفتاح الأمان يجب أن يكون سلسلةً نصيةً عشوائية بطولٍ مناسب. الآن وبعد إعداد مفتاح الأمان، سننشئ دالة عرض فلاسك مسؤولة عن إخراج قالب يحتوي على نموذج إدخال يمكن للمستخدم ملؤه لإنشاء تدوينة جديدة. أضِف دالة فلاسك هذه في نهاية الملف على النحو التالي: . . . @app.route('/create', methods=('GET', 'POST')) def create(): return render_template('create.html') ستنشئ هذه الشيفرة وجهة route مهمتها قبول الطلبات سواءً بطريقة GET، أو POST، إذ أن طريقة GET هي الطريقة الافتراضية؛ ولتمكين قبول طريقة POST أيضًا المُستخدمة من قبل المتصفح عند إرسال نماذج الإدخال، سنمرر متغيرًا من نوع tuple يحتوي على طرق الطلبات المقبولة إلى وسيط الطرائق methods في المزخرف @app.route(). اِحفظ الملف وأغلقه، ثمّ لإنشاء القالب، افتح ملفًا باسم create.html داخل مجلد القوالب templates على النحو التالي: (env)user@localhost:$ nano templates/create.html أضف الشيفرة التالية داخل هذا الملف الجديد: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Create a New Post {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="title">Title</label> <input type="text" name="title" placeholder="Post title" class="form-control" value="{{ request.form['title'] }}"></input> </div> <div class="form-group"> <label for="content">Content</label> <textarea name="content" placeholder="Post content" class="form-control">{{ request.form['content'] }}</textarea> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} الجزء الأكبر من هذه الشيفرة ما هو إلّا تعليمات HTML معيارية لإظهار صندوق إدخال لاستقبال عنوان التدوينة، وصندوق كتابة لتحرير محتواها، وزرٌ لتأكيد إرسال النموذج. القيمة داخل أداة عنوان التدوينة هي {{ request.form['title'] }} والقيمة داخل أداة صندوق الكتابة هي {{ request.form['content'] }}، وقد فعلنا هذا للحفاظ على البيانات المدخلة في كل من الأداتين في حال حدوث خطأ ما؛ فمثلًا إذا كتب المستخدم محتوًى كبير للتدوينة وأرسل النموذج دون إدخال عنوان، فستظهر رسالةٌ تعلمه أنّ العنوان مطلوب دون فقدان المحتوى الذي كتبه في حقل المحتوى، لأنّ المعلومات المدخلة سيُحتفظ بها في الكائن العام request. الآن وفي حين خادم التطوير يعمل، استخدم المتصفح للانتقال إلى الوجهة /create: http://127.0.0.1:5000/create فستظهر لك صفحة إنشاء تدوينة جديدة مع أدوات لإدخال كلٍ من العنوان والمحتوى. يرسل نموذج الإدخال هذا الطلب بطريقة POST إلى دالة عرض فلاسك create()، ولكن حتى هذه اللحظة لا يوجد شيفرة مسؤولة عن معالجة هذا الطلب في الدالة، وبالتالي لن يحدث شيء في حال ملء النموذج الآن وإرساله. لذا فيما يلي ستعالج الدالة create() الطلبات الواردة بطريقة POST عند إرسال محتويات نموذج الإدخال وذلك بعد التحقق من قيمة تابع الطلب request.method؛ فإذا كانت قيمته 'POST'، تستمر بمتابعة قراءة البيانات المرسلة والتحقق منها وإدخالها في قاعدة البيانات. الآن، افتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py عدِّل شيفرة دالة عرض فلاسك create() لتصبح كما يلي: . . . @app.route('/create', methods=('GET', 'POST')) def create(): if request.method == 'POST': title = request.form['title'] content = request.form['content'] if not title: flash('Title is required!') else: conn = get_db_connection() conn.execute('INSERT INTO posts (title, content) VALUES (?, ?)', (title, content)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('create.html') تَمكَّنا باستخدام العبارة الشرطية التي توازن قيمة request.method مع القيمة POST من التحقُّق بأنّ التعليمات التالية لها لن تُنفّذ إلّا إذا كان الطلب الحالي هو فعلًا بطريقة POST، ومن ثمّ قرأنا قيم العنوان والمحتوى المرسلين من الكائن request.form الذي يمكِّننا من الوصول إلى بيانات نموذج الإدخال المُضمّنة في الطلب؛ ففي حال عدم إدخال قيمةٍ للعنوان، فسيتحقق الشرط if not title وبالتالي ستظهر رسالة للمستخدم نعلمه من خلالها بأن العنوان مطلوب؛ أمّا في حال وجود العنوان سيُفتَح الاتصال مع قاعدة البيانات باستخدام الدالة get_db_connection() لإدخال العنوان والمحتوى المرسلين إلى الجدول posts فيها. بعد تنفيذ هذه التعديلات في قاعدة البيانات وإضافة التدوينة الجديدة إليها، يُغلق الاتصال معها، ومن ثمّ نعيد توجيه الطلب إلى الصفحة الرئيسية باستخدام الدالة redirect() بتمرير الرابط الناتج عن التابع url_for() الذي قد مررنا له القيمة index وسيطًا. اِحفظ الملف وأغلقه، ثم انتقل في المتصفح إلى الوجهة /create: http://127.0.0.1:5000/create املأ النموذج بالعنوان والمحتوى الذي تريد، وسترى التدوينة الجديدة في الصفحة الرئيسية حال إرسال النموذج. الآن سنعمل على إظهار الرسائل للمستخدم وإضافة رابط في شريط التصفح في القالب base.html لتسهيل الوصول إلى هذه الصفحة الجديدة، من خلال فتح ملف القالب: (env)user@localhost:$ nano templates/base.html الآن، عدِّل الملف من خلال إضافة وسم القائمة <li> بعد الرابط About داخل وسم شريط التصفُّح <nav>، ثمّ أضف حلقة تكرارية أعلى كتلة المحتوى مباشرةً لعرض الرسائل أسفل شريط التصفح، إذ يوفّر فلاسك هذه الرسائل من خلال دالة فلاسك الخاصة get_flashed_messages(): <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskBlog</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item"> <a class="nav-link" href="#">About</a> </li> <li class="nav-item"> <a class="nav-link" href="{{url_for('create')}}">New Post</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> اِحفظ الملف وأغلقه. سيتضمن الآن شريط التصفح عنصرًا جديدًا باسم "New Post"، الذي ينقلنا إلى الوجهة /create. تعديل تدوينة منشورة لا بدّ من توفّر إمكانية التعديل على التدوينات المنشورة أصلًا في التطبيق بما يضمن إمكانية تحديثها دائمًا، لذا سنوضّح في هذا القسم من المقال كيفية إنشاء صفحة جديدة في التطبيق خاصةٍ بتعديل التدوينات. بدايةً، أضِف وجهة route جديدة إلى الملف app.py، إذ ستستقبل دالة هذه الوجهة رقم التدوينة ID المُراد تعديلها على هيئة وسيط، بحيث يكون الرابط بالشّكل /post_id/edit إذ يمثّل المتغير post_id رقم التدوينة. ولإنجاز ذلك، ابدأ بفتح الملف app.py في وضع التحرير على النحو التالي: (env)user@localhost:$ nano app.py ومن ثمّ أضف في نهاية الملف دالة edit() المشابهة للدالة create() التي أنشأناها سابقًا، لأنّ تعديل تدوينة منشورة أصلًا أمرٌ مشابهٌ من حيث المبدأ البرمجي لإنشاء تدوينة جديدة: . . . @app.route('/<int:id>/edit', methods=('GET', 'POST')) def edit(id): post = get_post(id) if request.method == 'POST': title = request.form['title'] content = request.form['content'] if not title: flash('Title is required!') else: conn = get_db_connection() conn.execute('UPDATE posts SET title = ?, content = ?' ' WHERE id = ?', (title, content, id)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('edit.html', post=post) نلاحظ من بناء الدالة السابقة تحديد التدوينة المراد تعديلها من خلال معرفة الرابط الخاص بها URL، وسيمرّر فلاسك رقم ID الخاص بها إلى دالة ()edit وسيطًا، ومن ثم نضيف هذه القيمة إلى دالة استدعاء التدوينات get_post() لاستدعاء التدوينة ذات رقم ID المحدّد من قاعدة البيانات، ومن ثم تُضاف البيانات الجديدة إليها على هيئة طلب تدوينة جديدة POST وذلك ضمن الجملة الشرطية `if request.method == 'POST. وعلى نحوٍ مشابه لحالة إنشاء تدوينة جديدة، سنبدأ باستخلاص البيانات من الكائن request.form، بحيث تُعرض رسالة تنبيهية في حال كانت قيمة العنوان فارغة، وإلّا سنؤسس الاتصال مع قاعدة البيانات، ثم نحدَّث جدول التدوينات posts بالعنوان والمحتويات الجديدة للتدوينة ذات الرقم ID الموافق للرقم الذي حصلنا عليه من رابط التدوينة المُراد تعديلها. أمّا بالنسبة للطلب GET، فسيحدث إخراجٌ لقالب edit.html المُمرر إلى المتغير post، الذي يحتوي القيمة المُعادة من الدالة get_post()، والهدف من هذا الطلب استعراض محتوى وعنوان التدوينة الحالية ضمن صفحة التعديل. احفظ الملف وأغلقه، ثمّ أنشئ قالب edit.html جديد على النحو التالي: (env)user@localhost:$ nano templates/edit.html اكتب الشيفرة البرمجية التالية في الملف الجديد: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Edit "{{ post['title'] }}" {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="title">Title</label> <input type="text" name="title" placeholder="Post title" class="form-control" value="{{ request.form['title'] or post['title'] }}"> </input> </div> <div class="form-group"> <label for="content">Content</label> <textarea name="content" placeholder="Post content" class="form-control">{{ request.form['content'] or post['content'] }}</textarea> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> <hr> {% endblock %} اِحفظ الملف وأغلقه. تتبِّع هذه الشيفرة البرمجية نفس النمط السابق ما عدا التعليمتان: {{ request.form['title'] or post['title'] }} {{ request.form['content'] or post['content'] }} اللتان تعرضان البيانات المُخزّنة ضمن طلب التعديل في حال وجودها، وإلّا ستعرضان البيانات الموجودة في المتغير post المُمرّر إلى القالب الذي يحتوي على البيانات الحالية من قاعدة البيانات. باستخدام المتصفح، اذهب الآن إلى الرابط التالي، الذي سيمكنّك من تعديل التدوينة الأولى ذات الرقم 1: http://127.0.0.1:5000/1/edit فستظهر لك صفحة تعديل "التدوينة الأولى First Post" على النحو التالي: عدّل التدوينة ثمّ أكّد النموذج وأرسله، وتأكّد من تحديث بيانات التدوينة. الآن، يجب إضافة رابط يشير إلى صفحة التعديل لكل تدوينة وذلك في صفحة المؤشر (الفهرس)، لذلك افتح ملف القالب index.html: (env)user@localhost:$ nano templates/index.html عدّل الملف ليصبح على النحو التالي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskBlog {% endblock %}</h1> {% for post in posts %} <a href="{{ url_for('post', post_id=post['id']) }}"> <h2>{{ post['title'] }}</h2> </a> <span class="badge badge-primary">{{ post['created'] }}</span> <a href="{{ url_for('edit', id=post['id']) }}"> <span class="badge badge-warning">Edit</span> </a> <hr> {% endfor %} {% endblock %} ويمكنك إضافة وسم <a> للربط مع الدالة ()edit، مرورًا بالقيمة post['id'] لربط صفحة التعديل لكلِّ تدوينة مع الرابط Edit. حذف تدوينة أحيانًا، يصبح بقاء بعض التدوينات منشورةً للعموم أمرًا غير مطلوب، ومن هنا تأتي أهمية إمكانية حذف التدوينات المنشورة أصلًا، وفيما يلي سنتعلّم كيفيّة إضافة آلية لحذف هذه التدوينات من التطبيق. بدايةً، سنضيف وجهة جديدة للحذف، هو /ID/delete يتعامل مع الطلبات من النوع POST بما يشبه الدالة edit() الذي أنشأناها سابقًا، إذ ستستقبل دالة الحذف delete() رقم معرّف التدوينة ID لحذفها من الرابط URL. الآن، افتح الملف app.py: (env)user@localhost:$ nano app.py أضِف الدالة التالية إلى نهاية الملف: # .... @app.route('/<int:id>/delete', methods=('POST',)) def delete(id): post = get_post(id) conn = get_db_connection() conn.execute('DELETE FROM posts WHERE id = ?', (id,)) conn.commit() conn.close() flash('"{}" was successfully deleted!'.format(post['title'])) return redirect(url_for('index')) تتعامل هذه الدالة فقط مع الطلبات الواردة بطريقة POST؛ وهذا يعني أنك إذا انتقلت إلى الوجهة /ID/delete في المتصفح، ستحصل على خطأ، لأن المتصفحات تستخدم طريقة GET افتراضيًا للطلبات؛ ولكن يمكنك الوصول إلى هذه الوجهة من خلال نموذج الإدخال الذي يرسل طلبًا بطريقة POST يتضمن قيمة معرّف التدوينة المُراد حذفها، لتستقبل دالة فلاسك هذه قيمة المعرّف ID وتستخدمها لجلب التدوينة من قاعدة البيانات باستخدام دالة get_post(). افتح بعد ذلك اتصالًا مع قاعدة البيانات ونفِّذ تعليمة SQL التالية لحذف التدوينة: DELETE FROM يمكنك تأكيد وإرسال التعديلات إلى قاعدة البيانات وإغلاق الاتصال أثناء إظهار رسالة وامضة تُعلم المستخدم بإتمام عملية حذف التدوينة بنجاح، ثم يُعاد توجيه المستخدم إلى الصفحة الرئيسية. لاحظ أننا هنا لا نخرج render ملف قالب، وإنمّا نضيف فقط زر أوامر "Delete" إلى صفحة تعديل التدوينة. الآن افتح ملف القالب edit.html: (env)user@localhost:$ nano templates/edit.html ثم أضف وسم النموذج <form> بعد وسم إظهار الفاصل الأفقي <hr> تماماً بعد السطر البرمجي {% endblock %} على النحو التالي: <hr> <form action="{{ url_for('delete', id=post['id']) }}" method="POST"> <input type="submit" value="Delete Post" class="btn btn-danger btn-sm" onclick="return confirm('Are you sure you want to delete this post?')"> </form> {% endblock %} إذ استخدمنا التابع confirm() لعرض رسالة تأكيد قبل إرسال الطلب. الآن انتقل إلى صفحة تعديل تدوينة في المتصفح مجددًا وجرّب حذفها: http://127.0.0.1:5000/1/edit ومع الانتهاء من هذه الخطوة، ستكون شيفرة المشروع مشابهةً لشيفرة تدوينة فلاسك على غيت هب، وبهذا سيتمكّن مستخدمو التطبيق من إنشاء تدوينات جديدة وإضافتها إلى قاعدة البيانات، وكذلك تعديل أو حذف التدوينات الموجودة أصلًا. الخاتمة قدّمنا في هذا المقال المفاهيم الأساسية لإطار عمل فلاسك في بايثون، وتعلمّت كيفيّة إنشاء تطبيق ويب بسيط وتشغيله في خادم تطوير، وآلية تمكين المستخدم من التواصل مع الخادم وتزويده ببياناتٍ مخصصة باستخدام محدِّدات الرابط URL ونماذج الادخال؛ كما اسُتخدم محرك قوالب جينجا jinja لتوفير ملفات HTML ذات المحتوى القابل لإعادة الاستخدام لكتابة منطق التطبيق فيها. ومع نهاية هذا المقال سيكون لديك مدونة ويب بكامل المميزات، والتي تتعامل مع قاعدة بيانات SQLite لإنشاء وعرض أو تعديل أو حذف التدوينات باستخدام لغة بايثون واستعلامات SQL. يمكنك أيضًا تطوير هذا التطبيق بإضافة ميزات تصريح وصول المستخدمين لتقييد عملية إنشاء وتعديل التدوينات لتكون متاحةً فقط للمستخدمين الذين لديهم حسابات، كما يمكنك مثلًا إضافة ميزة التعليقات وتضمين الكلمات المفتاحية لكل تدوينة، أو ميزة رفع الملفات التي تمكّن المستخدمين من إضافة الصور إلى محتوى التدوينة. يوجد العديد من الإضافات المطوَّرة من قبل المبرمجين لفلاسك والتي يمكنك استخدامها لتسهيل عملية التطوير، ومنها: Flask-Login: لإدارة جلسة المستخدم ومعالجة عمليات تسجيل الدخول وتسجيل الخروج وتذكّر معلومات المستخدمين الذين سجلوا الدخول سابقًا. Flask-SQLAlchemy: لتسهيل استخدام فلاسك مع مكتبة SQLAlchemy، والتي هي حزمة SQL في بايثون للتعامل مع قواعد بيانات SQL. Flask-Mail: لتنفيذ مهام إرسال رسائل البريد الإلكتروني من خلال تطبيق فلاسك. ترجمة -وبتصرف- للمقال How To Make a Web Application Using Flask in Python 3 لصاحبه Abdelhadi Dyouri. اقرأ أيضًا استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا مدخل إلى تطوير تطبيقات الويب باستخدام إطار العمل Flask
يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا العديد من الأدوات والميزات التي من شأنها جعل إنشاء تطبيقات الويب في لغة بايثون أسهل، مانحًا المطورين المرونة في العمل، كما أنّه أبسط للاستخدام من قِبل المطورين المبتدئين نظرًا لإمكانية إنشاء تطبيق ويب كامل بسرعة باستخدام ملفٍ وحيدٍ مكتوب بلغة بايثون. إضافةً لما سبق، يتميز فلاسك بكونه قابلًا للتوسّع والوراثة دون أن يفرض أي بنية هرمية لطريقة عرض الملفات، كما أنّه لا يتطلب أي شفرات برمجية معقدّة استهلالية قبل البدء باستخدامه. سنتعرّف في هذا المقال أيضًا على إطار العمل بوتستراب bootstrap لإضافة التنسيقات على التطبيق ليبدو أكثر جاذبية بصريًا، كما سيساعدنا على تمكين ميزة الصفحات المتوافقة مع المتصفحات في تطبيق الويب، ما يضمن عمله بصورةٍ جيدة في المتصفحات الخاصة بالجوال، دون كتابة شفرات HTML و CSS و JavaScript لتحقيق هذه الغاية، وبالتالي سيساعدك بوتستراب في صبِّ تركيزك على تعلُّم كيفية عمل فلاسك نفسه. يستخدم فلاسك محرّك القوالب jinja لبناء صفحات HTML ديناميكيًا باستخدام مفاهيم بايثون المألوفة، من متغيراتٍ وحلقاتٍ تكرارية وقوائم وغيرها، وبالتالي ستُستخدم هذه القوالب جزءًا من هذا المشروع. ستتمكّن في هذا المقال من بناء مدونة ويب صغيرة باستخدام إطار العمل فلاسك مع قاعدة بيانات SQLite مُستخدمًا الاصدار الثالث من بايثون، إذ سيتمكّن مستخدمو هذا التطبيق من عرض جميع التدوينات المنشورة في قاعدة بياناتك، والضغط على عنوان التدوينة لعرض محتوياتها، مع إمكانية إضافتهم لتدوينات جديدة إلى قاعدة البيانات، أو تعديل أو حذف تدوينةٍ موجودةٍ أصلًا. مستلزمات العمل قبل المتابعة في هذا المقال لابدّ من: توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو flask_blog. فهم مبادئ بايثون 3 مثل أنماط البيانات والجمل الشرطية وحلقة for التكرارية والدوال، وغيرها من المفاهيم المشابهة في بايثون 3. الخطوة الأولى – تثبيت فلاسك في هذه الخطوة سنفعّل بيئة بايثون ونثبّت فلاسك باستخدام أمر تثبيت الحزم pip، وفي حال كون بيئة البرمجة غير مفعّلة بعد، سنستخدم الأمر التالي لتفعيلها بعد التأكّد من كون موجه الأوامر يشير إلى مسار مجلد المشروع flask_blog: $ source env/bin/activate وبمجرّد تفعيل بيئة البرمجة، سيُظهِر موجّه الأوامر البادئة env والتي تظهر على النحو التالي: (env)user@localhost:$ تشير هذه البادئة إلى أن بيئة العمل env فعّالةٌ حاليًا، والتي قد تكون باسمٍ آخر لديك وذلك حسب الاسم الذي اخترته لها خلال إنشائها. الآن سنثبّت حزم بايثون وسنعزل شيفرة المشروع بعيدًا عن نظام بايثون المُثبت أساسًا باستخدام أوامر pip و python. ولتثبيت فلاسك، سنشغّل الأمر التالي: (env)user@localhost:$ pip install flask وعند انتهاء التثبيت، سنشغّل الأمر التالي للتحقُّق من إتمام العملية: (env)user@localhost:$ python -c "import flask; print(flask.__version__)" وبذلك نكون قد استخدمنا واجهة سطر أوامر بايثون ذات الخيار c- لتنفّيذ شيفرة بايثون، ومن ثم استوردنا مكتبة فلاسك باستخدام الأمر import flask، ثمّ طبعنا إصدار فلاسك المُثبت باستخدام المتغير flask.__version__ variable. وسيتضمّن الخرج رقم الإصدار على النحو التالي: 1.1.2 وبذلك نكون قد أنشأنا مجلد المشروع وبيئة العمل الافتراضية، كما أنّنا ثبَّتنا فلاسك، وبذلك أصبحنا مُستعدين لإنشاء تطبيق أساسي. الخطوة الثانية – كيفية إنشاء تطبيق أساسي الآن، وبعد الانتهاء من تثبيت بيئة العمل، سنبدأ باستخدام فلاسك، إذ سننشئ في هذه الخطوة تطبيق ويب بسيط ضمن ملف بايثون وتشغيله ليبدأ الخادم بالعمل مُظهرًا بعض المعلومات في المتصفح. الآن سنفتح الملف hello.py الموجود في مجلد flask_blog للتعديل عليه باستخدام محرّر النصوص نانو nano، أو أي محرّر آخر تفضِّله: (env)user@localhost:$ nano hello.py سيشكّل ملف hello.py مثالًا مبسّطًا لكيفية التعامل مع طلبات HTTP، إذ سنستورد في هذا الملف كائن فلاسك ونكتب تابعًا لتوليد الاستجابة لطلبات بروتوكول HTTP، ولتحقيق ذلك نكتب الشيفرة التالية في الملف hello.py: from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return 'Hello, World!' استوردنا في الجزء السابق من الشيفرة كائن فلاسك من حزمة فلاسك، ثم استخدمناه لإنشاء نسخةٍ فعليةٍ موجودةٍ في الذاكرة لتطبيق فلاسك Flask application instance باسم app، وليست مجرد كائن برمجي، ومن ثمّ مررنا المتغير الخاص __name__، الذي سيخزّن اسم وحدة بايثون الحالية ليُعلم تطبيق فلاسك بمكان وجود هذه الوحدة، إذ لا بُدّ من إجراء هذه الخطوة كون فلاسك يهيّئ بعض المسارات اللازمة في الخلفية. وبمجرد إنشاء هذا التطبيق app، يمكنك استخدامه في معالجة طلبات الويب القادمة وإرسال الردود إلى المُستخدم. يكون المزخرف app.route@ مسؤولًا عن تعديل دوال بايثون المألوفة لتصبح دوالًا عاملةً في فلاسك، والتي تحوّل القيمة المعادة من قِبل التابع إلى استجابةٍ من نوع HTTP تُعرض لدى عميل HTTP الذي قد يكون متصفحًا مثلًا؛ فبمجرد تمرير القيمة / وسيطًا للتابع app.route@، سينشئ الردود على طلبات الويب الواردة إلى الرابط /، والذي يمثّل الرابط الرئيسي في التطبيق، وبذلك سيعيد التابع ()hello السلسلة النصية '!Hello, World' ردًا على الطلب. الآن، اِحفظ الملف وأغلقه. ولتشغيل تطبيق الويب الذي أنشأناه، لا بُدّ من إرشاد فلاسك إلى موقعه (في حالتنا الملف ذو الاسم hello.py) باستخدام متغير بيئة فلاسك FLASK_APP على النحو التالي: (env)user@localhost:$ export FLASK_APP=hello ومن ثم تشغيله بوضع التطوير باستخدام متغير بيئة فلاسك Flask_ENV على النحو التالي: (env)user@localhost:$ export FLASK_ENV=development وفي النهاية، سنشغّل التطبيق باستخدام الأمر flask run: (env)user@localhost:$ flask run وبمجرّد تشغيل التطبيق، سيكون الخرج مشابهًا لما يلي: * Serving Flask app "hello" (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 813-894-335 يحتوي الخرج السابق على عدة معلومات، مثل: اسم التطبيق المُشغَّل. بيئة التشغيل الحالية التي يعمل عليها التطبيق. عبارة Debug mode:on التي تشير إلى أن مصحّح أخطاء فلاسك قيد التشغيل، وهو ذو فوائد عديدة أثناء عملية التطوير كونه يقدم رسائل خطأ مفصّلة عندما يحدث أي خلل، ما يجعل عملية تنقيح الأخطاء أسهل وأيسر. التطبيق يعمل على الحاسب المحلي وذلك على الرابط /http://127.0.0.1:5000، إذ أن 127.0.0.1 هو عنوان IP الذي يمثِّل الخادم المحلي localhost على حاسبك، و 5000: هو رقم المنفذ. افتح المتصفح واكتب عنوان URL التالي "/http://127.0.0.1:5000"، ستظهر عبارة !Hello, World استجابةً لهذا العنوان، وهذا ما يؤكد أن التطبيق يعمل بنجاح. يستخدم فلاسك خادم ويب مبسّط لاستضافة تطبيق الويب في بيئة التطوير، ما يعني أن مصحّح أخطاء فلاسك قيد التشغيل أيضًا كي يجعل التقاط الأخطاء أسهل، ولا ينبغي استخدام خادم التطوير هذا عندما يُنقل التطبيق إلى مرحلة التشغيل الفعلي أي نشر المنتج. يمكنك في هذه المرحلة الإبقاء على خادم التطوير قيد التشغيل في الطرفية terminal الخاصة به، ومن ثم افتح نافذة طرفية جديدة وغيّر المسار فيها إلى مسار مجلد المشروع حيث يتواجد ملف hello.py، ثم فعّل البيئة الافتراضية (السبب مبيّنٌ في الملاحظة أدناه)، وهيّئ متغيرات البيئة FLASK_ENV و FLASP_APP، ومن ثم تابع الخطوات التالية. (ذُكرت هذه الأوامر سابقًا في هذه الخطوة). ملاحظة: من الضروري تفعيل البيئة الافتراضية لدى فتح طرفية جديدة، ولا بدّ من إعداد متغيرات البيئة FLASK_ENV و FLASK_APP. لا يمكن تشغيل تطبيق فلاسك آخر باستخدام الأمر flask run نفسه خلال فترة عمل خادم تطوير تطبيقات فلاسك، كونه يستخدم المنفذ رقم 5000 افتراضيًا، وحالما يُحجَز هذا المنفذ يصبح غير متاحًا لتشغيل أي تطبيقٍ آخر، وفي حال فعلت ذلك ستظهر رسالة خطأ مشابهةٍ لما يلي: OSError: [Errno 98] Address already in use ويمكن حل لهذه المشكلة، إمّا بإيقاف الخادم العامل حاليًا عن طريق الضغط على "CTRL+C" ومن ثم تنفيذ الأمر flask run مجدّدًا، أو في حال رغبتك بتشغيل كلا التطبيقين في نفس الوقت، فمن الممكن تمرير رقم منفذٍ مختلف باستخدام الوسيط p-. سنستخدم الأمر التالي لتشغيل تطبيقٍ آخر يستخدم المنفذ 5001 مثالًا حول هذه الطريقة: (env)user@localhost:$ flask run -p 5001 وبذلك أصبح لديك تطبيق ويب صغير باستخدام فلاسك، وبعد أن شغّلت وعرضت معلومات في متصفح الويب، سنستخدم فيما يلي ملفات HTML في هذا التطبيق. الخطوة الثالثة – استخدام قوالب HTML لا يعرض تطبيقك حاليًا سوى رسالةٍ صغيرة دون أي استخدامٍ للغة HTML، إذ تستخدم تطبيقات الويب عادةً HTML بصورةٍ رئيسية لعرض المعلومات لزوار الموقع أو التطبيق، لذا سنعمل فيما يلي على دمج ملفات HTML في التطبيق، والتي يمكن عرضها في متصفح الويب. يقدّم فلاسك تابعًا مساعدًا يُسمّى ()render_template، يمكنّنا من استخدام [محرّك القوالب جينجا jinja، وهذا يجعل إدارة HTML أسهل عن طريق كتابة شيفرة HTML إلى جانب الشيفرة الوظيفية المعبّرة عن غرض التطبيق وذلك في ملفات ذات امتداد "html."، وستُستخدم ملفات HTML هذه (أي القوالب) لبناء كل صفحات التطبيق، مثل الصفحة الرئيسية التي تستعرض التدوينات الحالية في المدونة، والصفحة الخاصة بكل تدوينة، والصفحة التي يتمكن المستخدم من خلالها إضافة تدوينة جديدة، وغيرها. في هذه الخطوة، سننشئ تطبيق فلاسك رئيسي في ملفٍ جديد. بدايةً استخدم محرّر النصوص نانو nano أو أي محرِّر تفضله لإنشاء الملف app.py والتعديل عليه ضمن مجلد "flask_blog"، إذ سيحتوي هذا الملف على كل الشيفرة المُستخدمة لإنشاء تطبيق التدوينات: (env)user@localhost:$ nano app.py سنستورد في هذا الملف الجديد كائن فلاسك لإنشاء نسخة تطبيق فلاسك كما فعلنا سابقًا، كما سنستورد التابع المساعد ()render_template، الذي سيمكننّا من إخراج ملفات قوالب HTML الموجودة في المجلد templates الذي سننشئه بعد قليل. سيحتوي هذا الملف الجديد على تابعٍ وحيدٍ عامل في فلاسك مسؤول عن التعامل مع الطلبات الموجهة إلى الرابط /. الآن، أضِف مايلي إلى الملف الجديد app.py: from flask import Flask, render_template app = Flask(__name__) @app.route('/') def index(): return render_template('index.html') سيعيد التابع ()index العامل في فلاسك نتيجة استدعاء التابع ()render_template عن طريق تمرير الوسيط index.html، وهذا يخبر التابع ()render_template بالبحث عن ملف باسم index.html في مجلد القوالب المُسمّى templates. المجلد templates والملف index.html غير موجودين فعليًا حتى الآن، وستحصل على خطأ في حال شغّلت التطبيق في هذه اللحظة، ولكن ننصحك بتشغيل التطبيق الآن بهدف التعرُّف على هذا الخطأ الشائع، ومن ثم صحّحه عن طريق إنشاء الملف والمجلد اللازمين فعليًا. الآن، احفظ الملف وأغلقه، ثمّ أوقف خادم التطوير في الطرفية الأخرى التي تشغِّل التطبيق hello عن طريق الضغط على "CTRL+C"؛ ولكن قبل تشغيل التطبيق تأكد من تحديد قيمة متغير البيئة FLASK_APP على نحوٍ صحيح، نظرًا لكونك لم تعد تستخدم تطبيق hello، وذلك على النحو التالي: (env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ flask run سيؤدي فتح العنوان "http://127.0.0.1:5000" في المتصفح إلى ظهور صفحة تنقيح الأخطاء التي ستُعلمك بعدم العثور على القالب "index.html"، ويُميَّز سطر الشيفرة الرئيسي المسؤول عن ظهور هذا الخطأ بلونٍ واضح، وهو في هذه الحالة السطر: return render_template('index.html') وإذا نقرت عليه، سيكشف منقّح الأخطاء مزيدًا من الأسطر البرمجية، وبالتالي سيكون لديك مزيدٌ من المعلومات ذات الصلة المساعدة على حل المشكلة. كي نصحّح هذا الخطأ، سننشئ مجلدًا باسم templates ضمن المجلد flask_blog، ومن ثم سنفتح ملف index.html بداخله للتحرير كما يلي: (env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/index.html ثم سنضيف شيفرة HTML التالية في الملف index.html: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>FlaskBlog</title> </head> <body> <h1>Welcome to FlaskBlog</h1> </body> </html> احفظ الملف ثم استخدم المتصفح للانتقال إلى الرابط "/http://127.0.0.1:5000" مجددًّا، أو حدِّث الصفحة، وفي هذه المرة سيعرض المتصفح النص "Welcome to FlaskBlog" وذلك في صيغة وسم <h1>. تمتلك تطبيقات فلاسك عادةً مجلدًا للملفات الثابتة يسمّى static، إضافةً إلى مجلد القوالب templates، إذ يستضيف هذا المجلد ملفات، مثل CSS و JavaScript والصور التي يستخدمها التطبيق. يمكنك إنشاء ملف تنسيقات style.css لإضافة CSS إلى التطبيق من خلال البدء بإنشاء مجلدٍ باسم static داخل مجلد flask_blog الرئيسي كما يلي: (env)user@localhost:$ mkdir static ثم أضِف مجلدًا آخر باسم css داخل المجلد static لتضع به الملفات ذات اللاحقة "css."، إذ أن الهدف من هذا الإجراء هو تنظيم الملفات الثابتة في مجلدات مخصصّة حسب نوعها؛ فمثلًا نضع ملفات JavaScript في مجلد باسم js، والصور في مجلد باسم images أو img، وهكذا. ستنشئ التعليمة التالية مجلدًا باسم css داخل المجلد static: (env)user@localhost:$ mkdir static/css اِفتح الآن الملف style.css الموجود داخل المجلد css بهدف تحريره: (env)user@localhost:$ nano static/css/style.css اكتب قاعدة CSS التالية ضمن الملف style.css: h1 { border: 2px #eee solid; color: brown; text-align: center; padding: 10px; } شيفرة CSS هذه مسؤولةٌ عن إضافة حدود لكافة الوسوم من نوع <h1>، كما أنّها تغيِّر لون الخط فيها إلى البني، وتجعل محاذاة النص إلى الوسط، وتضيف هوامشًا داخليةً ضيقةً إليها. احفظ الآن الملف وأغلقه، ثم افتح ملف القالب index.html بهدف تحريره: (env)user@localhost:$ nano templates/index.html سنضيف الآن رابطًا في قسم الترويسة <head> من القالب index.html للوصول إلى الملف style.css على النحو التالي: . . . <head> <meta charset="UTF-8"> <link rel="stylesheet" href="{{ url_for('static', filename= 'css/style.css') }}"> <title>FlaskBlog</title> </head> . . . استخدمنا التابع المساعد url_for() لإنشاء المسار المناسب للملف، إذ يحدد الوسيط الأول أنّنا ننشئ ارتباطًا إلى ملفٍ ساكن، والوسيط الثاني هو مسار الملف هذا داخل مجلد الملفات الساكنة. اِحفظ الملف وأغلقه، وحالما تحدّث الصفحة index في التطبيق، ستلاحظ أن النص "Welcome to FlaskBlog" أصبح بلونٍ بني، ومحاذاته إلى الوسط، ومحاطًا بحدود. يمكنك استخدام لغة CSS لتنسيق مظهر التطبيق وجعله أكثر جاذبية بصريًا باستخدام التصميم الذي تريد؛ ولكن إن لم تكن مصمم ويب، أو لم يكن لديك الخبرة الكافية في التعامل مع CSS، فبإمكانك استخدام حزمة بوتستراب Bootstrap، التي تزودك بمكونات سهلة الاستخدام لتنسيق مظهر التطبيق، إذ سنستخدم في تطبيقنا هذا بوتستراب. وفي حال أردت إنشاء قوالب HTML أُخرى، فلن تضطر لإعادة كتابة الشيفرة التي كتبتها سابقًا في القالب index.html، فمن الممكن تفادي التكرار غير الضروري بالاستفادة من ملف القالب الرئيسي base template، والتي سترث كافّة ملفات HTML الأُخرى شيفرته. ولكي ننشئ قالب رئيسي، سننشئ بدايةً ملفًا باسم base.html في مجلد القوالب templates: (env)user@localhost:$ nano templates/base.html ثم سنكتب الشيفرة التالية في القالب base.html: <!doctype html> <html lang="en"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <title>{% block title %} {% endblock %}</title> </head> <body> <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskBlog</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item active"> <a class="nav-link" href="#">About</a> </li> </ul> </div> </nav> <div class="container"> {% block content %} {% endblock %} </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.3.1.slim.min.js" integrity="sha384-q8i/X+965DzO0rT7abK41JStQIAqVgRVzpbzo5smXKp4YfRvH+8abtTE1Pi6jizo" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.14.7/umd/popper.min.js" integrity="sha384-UO2eT0CpHqdSJQ6hJty5KVphtPhzWj9WO1clHTMGa3JDZwrnQq4sF86dIHNDz0W1" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/js/bootstrap.min.js" integrity="sha384-JjSmVgyd0p3pXB1rRibZUAYoIIy6OrQ6VrjIEaFf/nJGzIxFDsf4x0xIM+B07jRM" crossorigin="anonymous"></script> </body> </html> اِحفظ الملف وأغلقه حالما تنتهي من تحريره. إنّ الجزء الأكبر من الشيفرة السابقة هو تعليمات HTML معيارية وشيفرات لازمة لعمل بوتستراب، إذ تزوّد الوسوم <meta> متصفح الويب بالمعلومات، في حين ينشئ الوسم <link> ارتباطًا إلى ملفات CSS الخاصة ببوتستراب، ويضمِّن الوسم <script> شيفرة جافا سكربت مسؤولة عن بعض ميزات بوتستراب الإضافية. أمّا الأجزاء من الشيفرة الموضحّة فيما يلي فهي خاصةٌ بمحرك القوالب جينجا: {% block title %} {% endblock %}: كتلة برمجية تحجز مكانًا لعنوان الصفحة، والذي سنستخدمه في تحديد العنوان الخاص بكل صفحة في التطبيق دون الحاجة إلى إعادة كتابة قسم الترويسة <head> كاملًا في كل مرةٍ من أجل كل صفحة. {{ url_for('index') }}: استدعاءٌ لدالة تعيد عنوان URL إلى دالة عرض index()، والتي نمرر لها وسيطًا واحدًا فقط وهو اسم تابع فلاسك، لتنشئ ارتباطًا مع وجهة تابع فلاسك بدلًا من ملف ساكن كما كان الحال لدى استدعاء التابع ()url_for السابق الذي استخدمناه لإنشاء ارتباط مع ملف CSS الساكن. {% block content %} {% endblock %}: كتلة برمجية أخرى ستُستبدل لاحقًا بالمحتوى الفعلي بالاعتماد على القالب الابن، أي القالب الذي يرث شيفرات القالب الرئيسي base.html. والآن بعد أن أصبح لديك قالبٌ رئيسي، يمكنك الاستفادة من مميزاته باستخدام فكرة الوراثة، لذلك افتح الملف index.html: nano templates/index.html ثمّ استبدل محتوياته بما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskBlog {% endblock %}</h1> {% endblock %} استخدمنا في هذه النسخة الجديدة من القالب template.html الوسم {% extends %} لترث الشيفرات من القالب الرئيسي base.html، وذلك عن طريق استبدال الشيفرة السابقة بكتلة المحتوى content في القالب الرئيسي. تحوي كتلة المحتوى block content على وسم <h1> وبداخله كتلة عنوان title تحتوي العبارة "Welcome to FlaskBlog"، وبذلك نتفادى تكرار نفس النص مرتين، ذلك لأنّ هذا النص سيظهر في عنوان الصفحة ونص ضمن وسم <h1> أسفل شريط التصفح الموروث من القالب الرئيسي. تمكنّك وراثة القوالب من إعادة استخدام شيفرة HTML الموجودة في القوالب الأخرى (القالب الرئيسي base.html في حالتنا) دون الحاجة لتكراره في كل مرة. اِحفظ الملف وأغلقه، ثم حدِّث الصفحة الرئيسية index في المتصفح، فستظهر الصفحة بشريط تصفح وعنوانٍ منسقٍ كما يلي: وبذلك نكون قد استخدمنا قوالب HTML والملفات الساكنة في فلاسك، وكذلك استخدمنا بوتستراب لتنسيق مظهر الصفحة، واستفدنا من القالب الرئيسي لتفادي تكرار الشيفرات البرمجية. سنُعدُّ في الخطوة التالية قاعدة بيانات لتخزين بيانات التطبيق. الخطوة الرابعة – إعداد قاعدة البيانات سيكون التركيز في هذه الخطوة على إعداد قاعدة بيانات لتخزين البيانات، والتي هي تدوينات posts في حالة تطبيقنا، كما سنملأ قاعدة البيانات ببعض المدخلات التجريبية. سنستخدم ملف قاعدة بيانات من نوع SQLite لتخزين البيانات، لأن وحدة sqlite3 المُستخدمة للتعاطي مع قاعدة البيانات هذه موجودة وجاهزة افتراضيًا في مكتبة لغة بايثون. بدايةً، وبما أنّ تخزين البيانات في SQLite يكون ضمن جداول وأعمدة، وكون بيانات تطبيقنا هي تدوينات، سننشئ جدولًا باسم posts يحتوي على كافّة الأعمدة اللازمة، إذ سننشئ ملفًا بلاحقة sql. يحتوي على أوامر SQL اللازمة لإنشاء جدول posts وأعمدته اللازمة، ثم سنستخدم هذا الملف لإنشاء قاعدة البيانات. افتح الملف المُسمى schema.sql الموجود في المجلد flask_blog: (env)user@localhost:$ nano schema.sql اكتب تعليمات SQL التالية داخل هذا الملف: DROP TABLE IF EXISTS posts; CREATE TABLE posts ( id INTEGER PRIMARY KEY AUTOINCREMENT, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL, content TEXT NOT NULL ); ثم اِحفظ الملف وأغلقه. يعمل أوّل أمر من أوامر SQL وهو: DROP TABLE IF EXISTS posts; على حذف أي جداول موجودةٍ مسبقًا باسم posts لتجنُّب أي تضاربٍ، أو نتائج عشوائية ناتجةٍ عن تشابه أسماء الجداول، ومن الجدير بالملاحظة أنّ هذا الأمر سيحذِف كل المحتويات في قاعدة البيانات في كل مرة تشغِّل فيها أوامر SQL هذه، لذلك لا تُدخل أي بيانات مهمّة في التطبيق حتى تنتهي من كافّة الخطوات التعليميّة في المقال وتجربة نتائجه النهائية. بينما ينشئ الأمر الثاني من أوامر SQL وهو: CREATE TABLE posts جدولًا باسم posts له الأعمدة التالية: "id": ويحتوي على بياناتٍ من نوع رقم صحيح ويمثّل مفتاحًا أساسيًا يحتوي على قيمةٍ فريدة في قاعدة البيانات من أجل كل سجل (والسجل هو التدوينة في حالتنا). "created": يحتوي على تاريخ ووقت إنشاء التدوينة، وتشير NOT NULL إلى أن هذا العمود لا يجب أن يحتوي على قيمٍ فارغة، أما القيمة الافتراضية فهي CURRENT_TIMESTAMP والتي تمثِّل تاريخ ووقت إضافة التدوينة إلى قاعدة البيانات، وكما هو الحال في عمود id، لا يتوجب عليك تحديد قيم لهذا العمود، إذ أنها تُملأ تلقائيًا. "title": عنوان التدوينة. "content": محتوى التدوينة. الآن، وبعد أن أصبح لدينا تخطيط قاعدة البيانات SQL المطلوب في ملف schema.sql، سنستخدمه لإنشاء قاعدة البيانات باستخدام ملف بايثون لإنشاء ملف قاعدة بيانات SQLite بلاحقة db.. افتح الملف المُسمّى init_db.py الموجود داخل المجلد flask_blog باستخدام محرِّر النصوص المفضل لديك: (env)user@localhost:$ nano init_db.py ثم اكتب ضمنه الشيفرة التالية: import sqlite3 connection = sqlite3.connect('database.db') with open('schema.sql') as f: connection.executescript(f.read()) cur = connection.cursor() cur.execute("INSERT INTO posts (title, content) VALUES (?, ?)", ('First Post', 'Content for the first post') ) cur.execute("INSERT INTO posts (title, content) VALUES (?, ?)", ('Second Post', 'Content for the second post') ) connection.commit() connection.close() استوردنا في الشيفرة السابقة وحدة sqlite3، ثم أنشأنا اتصالًا مع ملف قاعدة بيانات باسم database.db، والذي يُنشأ تلقائيًا فور تشغيل ملف بايثون هذا، ومن ثم استخدمنا الدالة ()open لفتح الملف schema.sql، ثم نفّذنا باستخدام التابع ()executescript محتويات هذا الملف، الذي ينفِّذ عدة عبارات SQL معًا، وهكذا يُنشأ الجدول posts. استخدمنا في الشيفرة السابقة كائن المؤشر Cursor، الذي يمكِّننا من استخدام تابعه ()execute لتنفيذ تعليمتي إدخال INSERT في SQL لإضافة تدوينتين معًا إلى جدول التدوينات posts. وفي النهاية أُرسلت هذه الأوامر إلى قاعدة البيانات وأُغلِق الاتصال المفتوح معها. اِحفظ الملف وأغلقه، ثم شغِّله من موجّه الأوامر باستخدام أمر بايثون التالي: (env)user@localhost:$ python init_db.py وحالما ينتهي التنفيذ، سيكون لديك ملفٌ جديدٌ باسم database.db ضمن مجلد flask_blog، وهذا يدل على نجاح عملية إعداد قاعدة البيانات. سنعمل في الخطوة التالية على قراءة التدوينات المُضافة إلى قاعدة البيانات وعرضها في الصفحة الرئيسية للتطبيق. الخطوة 5 – عرض كل التدوينات الآن وبعد أن أعددنا قاعدة البيانات، يمكننا تعديل دالة عرض فلاسك index() لعرض كل التدوينات الموجودة في قاعدة البيانات. لذلك، افتح الملف app.py لتنفيذ التعديلات التالية: (env)user@localhost:$ nano app.py سيكون التعديل الأوّل هو استيراد وحدة sqlite3 في بداية الملف على النحو التالي: import sqlite3 from flask import Flask, render_template . . . ثم سنبني بعد ذلك دالةً تعمل على إنشاء اتصال مع قاعدة البيانات وتعيد نتائجه. أضِف هذه الدالة مباشرةً بعد أوامر الاستيراد: . . . from flask import Flask, render_template def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn . . . تفتح الدالة get_db_connection() اتصالًا مع ملف قاعدة البيانات database.db، وتحدّد بعد ذلك قيمة السمة row_factory لتكون sqlite3.Row لنتمكّن من الوصول إلى الأعمدة باستخدام أسمائها، ما يعني أنّ اتصال قاعدة البيانات سيعيد سجلات يمكننا التعامل معها كما هو الحال مع قواميس بايثون الاعتيادية (وحدات تخزين القيم المنظمّة في بايثون)، ونهايةً يعيد التابع كائن الاتصال conn، الذي سنستخدمه للوصول إلى قاعدة البيانات. بعد أن عرّفنا الدالة get_db_connection()، سنعدّل دالة index() لتصبح كما يلي: . . . @app.route('/') def index(): conn = get_db_connection() posts = conn.execute('SELECT * FROM posts').fetchall() conn.close() return render_template('index.html', posts=posts) بعد هذا التعديل الجديد على الدالة index()، فإنّنا نفتح اتصالًا مع قاعدة البيانات باستخدام الدالة get_db_connection() التي عرفناها للتو. سننفذ بعد ذلك استعلام SQL للحصول على كل المدخلات الموجودة في الجدول posts، إذ أنّنا نستدعي التابع fetchall() لجلب كل الأسطر الناتجة عن الاستعلام، وهذا سيعيد بالنتيجة قائمةً بالتدوينات المُدخلة إلى قاعدة البيانات في الخطوة السابقة. يمكنك إغلاق الاتصال بقاعدة البيانات باستخدام التابع close() وإعادة نتيجة عرض القالب index.html، كما يمكنك تمرر الكائن posts وسيطًا، فهو الكائن الحاوي على النتائج المُستخلصة من قاعدة البيانات، ويساعدنا هذا التمرير على الوصول إلى التدوينات برمجيًا داخل قالب index.html. وبعد تنفيذ كل هذه التعديلات، احفظ الملف app.py وأغلقه. الآن وبعد أن مرّرنا كل التدوينات المُستخلصة من قاعدة البيانات إلى القالب index.html، سنستخدم حلقة for التكرارية لعرض معلومات عن كل تدوينة داخل صفحة index. افتح ملف index.html: (env)user@localhost:$ nano templates/index.html ثم عدِّله كما يلي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskBlog {% endblock %}</h1> {% for post in posts %} <a href="#"> <h2>{{ post['title'] }}</h2> </a> <span class="badge badge-primary">{{ post['created'] }}</span> <hr> {% endfor %} {% endblock %} تقابل هنا الصيغة البرمجية {% for post in posts %} حلقة for في محرّك جينجا jinja، والتي تشبه بناء حلقة for في لغة بايثون ما عدا ضرورة إغلاقها باستخدام الصيغة البرمجية {% endfor %}. الهدف من استخدام هذه الحلقة حاليًا هو المرور على كل عنصر في القائمة posts المُمررة إلى الدالة index() من خلال السطر البرمجي التالي: return render_template('index.html', posts=posts) وضمن هذه الحلقة نعرض عنوان التدوينة في وسمٍ عنوان <h2> داخل وسم الرابط <a> (لأنّنا سنستخدم هذا الوسم لاحقًا لإنشاء رابط مخصّص لعرض معلومات خاصة عن كل تدوينة). يُعرض عنوان التدوينة باستخدام محدّد المتغير المُجرد Literal variable delimiter وهو {{ ... }}. تذكّر أنّ كل عنصر post في القائمة سيكون مشابهًا لما هو عليه في قاموس بايثون، وبالتالي يمكنك الوصول إلى عنوان التدوينة من خلال post['title']؛ كما من الممكن عرض تاريخ إنشاء التدوينة بنفس الآلية. وحالما تنتهي من تعديل الملف، احفظه وأغلقه، ثم انتقل في المتصفح إلى صفحة index، وعندها ستظهر لك المشاركتان posts المُضافتان سابقًا إلى قاعدة البيانات. والآن، وبعد تعديل دالة index() المسؤولة عن عرض كل التدوينات الموجودة في قاعدة البيانات داخل الصفحة الرئيسية للتطبيق، سننتقل إلى خطوة عرض كل تدوينة في صفحة خاصة بها وذلك من خلال تمكين المستخدمين من الانتقال إلى أي تدوينة -كلٌ على حدى-. الخطوة السادسة – عرض تدوينة بحد ذاتها تهدف هذه الخطوة إلى عرض تدوينة واحدة بناءً على معرّفها ID، سننشئ وجهة route فلاسك ودالة عرض جديدة، إضافةً لقالب HTML جديد. في نهاية هذه الخطوة، سيكون الرابط "http://127.0.0.1:5000/1" مثلًا هو الصفحة التي تعرض التدوينة الأولى، لأن معرف التدوينة الأولى هو الرقم 1؛ أي سيعرض الرابط "http://127.0.0.1:5000/ID" التدوينة ذات المعرّف ID في حال وجودها في قاعدة البيانات. الآن افتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py وطالما أنّنا سنجلب التدوينات من قاعدة البيانات بناءً على معرّفها ID من مسارات متعدّدة لاحقًا عند استخدام التطبيق، سننشئ دالةً منفردة باسم get_post() تعيد معلومات التدوينة ذات المعرّف ID هذا بمجرد تمرير القيمة ID وسيطًا لها، أما في حال عدم وجود تدوينة تحمل هذا المعرّف في قاعدة البيانات، ستكون الاستجابة برسالة "غير موجود 404 Not Found"؛ ولنتمكَّن من الاستجابة برسالة الخطأ رقم 404، لا بدّ من تضمين الدالة abort() من مكتبة فلاسك Werkzeug التي يجري تنزيلها أثناء تثبيت فلاسك. ننجز الاستدعاء السابق أعلى الملف على النحو التالي: import sqlite3 from flask import Flask, render_template from werkzeug.exceptions import abort . . . ثم نضيف الدالة get_post() تمامًا بعد الدالة get_db_connection() المُعرّفة في الخطوة السابقة. . . . def get_db_connection(): conn = sqlite3.connect('database.db') conn.row_factory = sqlite3.Row return conn def get_post(post_id): conn = get_db_connection() post = conn.execute('SELECT * FROM posts WHERE id = ?', (post_id,)).fetchone() conn.close() if post is None: abort(404) return post . . . تتضمّن الدالة الجديدة الوسيط post_id، الذي يحدّد التدوينة المُعادة نتيجةً لاستدعاء هذه الدالة. تُستخدم خلال تنفيذ هذه الدالة دالةٌ أخرى، هي get_db_connection() لفتح اتصال مع قاعدة البيانات وتنفيذ استعلام SQL لجلب التدوينة الموافقة لقيمة post_id الممرّرة، كما يُستخدم التابع fetchone() لجلب نتيجة الاستعلام وتخزينها في المتغير post، ومن ثمّ يُغلق الاتصال مع قاعدة البيانات؛ فإذا كانت قيمة المتغير post فارغة None، فهذا يدل على عدم العثور على نتائج في قاعدة البيانات، وعندها نستخدم الدالة abort() التي ضمّناها توًّا للرد برقم الخطأ 404 وبالتالي التوقُّف عن متابعة تنفيذ شيفرة الدالة؛ أما في حال العثور على التدوينة، تُعاد قيمة المتغير post. الآن، أضف دالة عرض فلاسك التالية في نهاية الملف app.py: . . . @app.route('/<int:post_id>') def post(post_id): post = get_post(post_id) return render_template('post.html', post=post) سنضيف في دالة عرض فلاسك الجديدة قاعدة متغيرة Variable Rule هي <int:post_id> لنحدّد أنّ الجزء بعد العلامة (/) هو رقمٌ صحيحٌ موجب، وذلك بتحويل قيمة هذا الجزء إلى النوع int، وهو ما نحتاجه للوصول إلى دالة العرض. يتعرف فلاسك على هذا الشرط ويمرّر القيمة إلى الوسيط post_id في دالة فلاسك post()، وبعد ذلك يمكننا استخدام الدالة ()get_post للحصول على التدوينة المرتبطة بالمعرّف ID المحدّد، ومن ثمّ تخزين النتيجة في المتغير post، الذي سيُمرّر في النهاية إلى القالب post.html، الذي سننشئه فيما يلي. الآن احفظ الملف app.py وافتح ملف قالب جديد post.html لتحريره: (env)user@localhost:$ nano templates/post.html اكتب الشيفرة التالية في الملف الجديد post.html، إذ تتشابه هذه الشيفرة مع تلك المُستخدمة في ملف index.html، إلّا أنّنا سنعرض معلومات عن تدوينةٍ واحدةٍ فقط، إضافةً إلى عرض محتويات هذه التدوينة: {% extends 'base.html' %} {% block content %} <h2>{% block title %} {{ post['title'] }} {% endblock %}</h2> <span class="badge badge-primary">{{ post['created'] }}</span> <p>{{ post['content'] }}</p> {% endblock %} اضفنا كتلة العنوان title المُعرفة سابقًا في القالب base.html لجعل عنوان التدوينة معروضًا باستخدام وسم من نوع عنوان <h2>، وجعله أيضًا عنوانًا للصفحة. اِحفظ الملف وأغلقه. يمكنك الآن الانتقال في المتصفح إلى الروابط التالية لاستعراض التدوينتين الموجودتين حاليًا في قاعدة البيانات، وكذلك الصفحة التي تخبر المستخدم بعدم العثور على التدوينة المطلوبة (لأنّه لا يوجد حتى الآن تدوينة برقم معرف 3): http://127.0.0.1:5000/1 http://127.0.0.1:5000/2 http://127.0.0.1:5000/3 سنعود إلى الصفحة الرئيسية لإنشاء رابط لكل عنوان تدوينة لينقلنا إلى صفحة التدوينة الخاصة به باستخدام الدالة url_for()، لذا افتح قالب index.html أولًا لتحريره: (env)user@localhost:$ nano templates/index.html ثم عدّل قيمة السمة href لتصبح {{ url_for('post', post_id=post['id']) }} بدلًا من #، بحيث تبدو حلقة for على النحو التالي: {% for post in posts %} <a href="{{ url_for('post', post_id=post['id']) }}"> <h2>{{ post['title'] }}</h2> </a> <span class="badge badge-primary">{{ post['created'] }}</span> <hr> {% endfor %} تُمرَّر القيمة post إلى الدالة url_for() التي تحتاج رقم معرّف التدوينة وسيطًا لها، وبما أنها اسم دالة العرض ()post فتُستدعى على النحو التاليpost['id' ] لتُستخدم وسيطًا للدالةurl_for() التي ستعيد بالنتيجة الرابط المناسب لكل تدوينة بناءً على معرّفها ID. اِحفظ الملف وأغلقه. ستعمل الروابط الآن في الصفحة الرئيسية على النحو المطلوب، وبذلك نكون قد انتهينا من بناء الجزء المسؤول عن عرض التدوينات الموجودة في قاعدة البيانات من تطبيق الويب، وسنضيف في الخطوات التالية إمكانية إضافة، أو تعديل، أو حذف التدوينات لهذا التطبيق. الخطوة 7 – التعديل على جدول التدوينات بعد أن أنهينا عملية استعراض التدوينات الموجودة في قاعدة البيانات داخل صفحات تطبيق الويب، سنعمل على توفير إمكانية كتابة تدوينات جديدة وحفظها في قاعدة البيانات لمستخدمي التطبيق، وكذلك إمكانية تعديل التدوينات الموجودة أصلًا أو حذف التدوينات غير اللازمة. إنشاء تدوينة جديدة لدينا حتى الآن تطبيقٌ يعرض التدوينات من قاعدة البيانات، ولكنه لا يوفر أي طريقةٍ لإضافة تدوينات جديدة، إلّا عن طريق إضافة تدوينة يدويًا عبر الاتصال بقاعدة البيانات SQLite. فيما يلي سننشئ صفحةً تمكنّنا من إضافة تدوينة جديدة عن طريق إدخال عنوانها ومحتواها مباشرةً. افتح ملف app.py لتحريره: (env)user@localhost:$ nano app.py لا بُد أولًا من استيراد التالي من إطار العمل فلاسك: الكائن request العام المسؤول عن الوصول إلى بيانات الطلب والتي ستُرسل من خلال نموذج HTML. الدالة url_for() لتوليد عناوين الروابط. الدالة flash() لعرض رسالةٍ وامضة عند انتهاء معالجة الطلب. الدالة redirect() لإعادة توجيه المستخدم إلى موقعٍ آخر في المتصفح. أضِف هذه الاستيرادات إلى الملف كما يلي: import sqlite3 from flask import Flask, render_template, request, url_for, flash, redirect from werkzeug.exceptions import abort . . . تخزّن الدالة flash() الرسائل في جلسة المتصفح لدى المستخدم، وهذا ما يتطلّب إعداد مفتاح أمان Secret Key، إذ سيُستخدم هذا المفتاح لجعل الجلسات آمنة، وبذلك يتمكّن فلاسك من الحفاظ على المعلومات عند الانتقال من طلبٍ إلى آخر، مثل حالة الانتقال من صفحة إنشاء تدوينة جديدة إلى صفحة عرض كل التدوينات، مع ملاحظة أن المستخدم يستطيع الوصول إلى المعلومات المُخزّنة في الجلسة، ولكنه لا يستطيع تعديلها إلّا إذا كان لديه مفتاح الأمان، وبالتالي لا يجب أن تسمح لأي أحدٍ بالوصول إلى مفتاح الأمان الخاص بك. ولإعداد مفتاح أمان، سنضيف ضبط SECRET_KEY إلى التطبيق من خلال الكائن app.config، الذي سنضيفه مباشرةً بعد تعريف الكائن app وقبل دالة عرض فلاسك index()، على النحو التالي: . . . app = Flask(__name__) app.config['SECRET_KEY'] = 'your secret key' @app.route('/') def index(): conn = get_db_connection() posts = conn.execute('SELECT * FROM posts').fetchall() conn.close() return render_template('index.html', posts=posts) . . . تذكّر أنّ مفتاح الأمان يجب أن يكون سلسلةً نصيةً عشوائية بطولٍ مناسب. الآن وبعد إعداد مفتاح الأمان، سننشئ دالة عرض فلاسك مسؤولة عن إخراج قالب يحتوي على نموذج إدخال يمكن للمستخدم ملؤه لإنشاء تدوينة جديدة. أضِف دالة فلاسك هذه في نهاية الملف على النحو التالي: . . . @app.route('/create', methods=('GET', 'POST')) def create(): return render_template('create.html') ستنشئ هذه الشيفرة وجهة route مهمتها قبول الطلبات سواءً بطريقة GET، أو POST، إذ أن طريقة GET هي الطريقة الافتراضية؛ ولتمكين قبول طريقة POST أيضًا المُستخدمة من قبل المتصفح عند إرسال نماذج الإدخال، سنمرر متغيرًا من نوع tuple يحتوي على طرق الطلبات المقبولة إلى وسيط الطرائق methods في المزخرف @app.route(). اِحفظ الملف وأغلقه، ثمّ لإنشاء القالب، افتح ملفًا باسم create.html داخل مجلد القوالب templates على النحو التالي: (env)user@localhost:$ nano templates/create.html أضف الشيفرة التالية داخل هذا الملف الجديد: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Create a New Post {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="title">Title</label> <input type="text" name="title" placeholder="Post title" class="form-control" value="{{ request.form['title'] }}"></input> </div> <div class="form-group"> <label for="content">Content</label> <textarea name="content" placeholder="Post content" class="form-control">{{ request.form['content'] }}</textarea> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> {% endblock %} الجزء الأكبر من هذه الشيفرة ما هو إلّا تعليمات HTML معيارية لإظهار صندوق إدخال لاستقبال عنوان التدوينة، وصندوق كتابة لتحرير محتواها، وزرٌ لتأكيد إرسال النموذج. القيمة داخل أداة عنوان التدوينة هي {{ request.form['title'] }} والقيمة داخل أداة صندوق الكتابة هي {{ request.form['content'] }}، وقد فعلنا هذا للحفاظ على البيانات المدخلة في كل من الأداتين في حال حدوث خطأ ما؛ فمثلًا إذا كتب المستخدم محتوًى كبير للتدوينة وأرسل النموذج دون إدخال عنوان، فستظهر رسالةٌ تعلمه أنّ العنوان مطلوب دون فقدان المحتوى الذي كتبه في حقل المحتوى، لأنّ المعلومات المدخلة سيُحتفظ بها في الكائن العام request. الآن وفي حين خادم التطوير يعمل، استخدم المتصفح للانتقال إلى الوجهة /create: http://127.0.0.1:5000/create فستظهر لك صفحة إنشاء تدوينة جديدة مع أدوات لإدخال كلٍ من العنوان والمحتوى. يرسل نموذج الإدخال هذا الطلب بطريقة POST إلى دالة عرض فلاسك create()، ولكن حتى هذه اللحظة لا يوجد شيفرة مسؤولة عن معالجة هذا الطلب في الدالة، وبالتالي لن يحدث شيء في حال ملء النموذج الآن وإرساله. لذا فيما يلي ستعالج الدالة create() الطلبات الواردة بطريقة POST عند إرسال محتويات نموذج الإدخال وذلك بعد التحقق من قيمة تابع الطلب request.method؛ فإذا كانت قيمته 'POST'، تستمر بمتابعة قراءة البيانات المرسلة والتحقق منها وإدخالها في قاعدة البيانات. الآن، افتح الملف app.py لتحريره: (env)user@localhost:$ nano app.py عدِّل شيفرة دالة عرض فلاسك create() لتصبح كما يلي: . . . @app.route('/create', methods=('GET', 'POST')) def create(): if request.method == 'POST': title = request.form['title'] content = request.form['content'] if not title: flash('Title is required!') else: conn = get_db_connection() conn.execute('INSERT INTO posts (title, content) VALUES (?, ?)', (title, content)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('create.html') تَمكَّنا باستخدام العبارة الشرطية التي توازن قيمة request.method مع القيمة POST من التحقُّق بأنّ التعليمات التالية لها لن تُنفّذ إلّا إذا كان الطلب الحالي هو فعلًا بطريقة POST، ومن ثمّ قرأنا قيم العنوان والمحتوى المرسلين من الكائن request.form الذي يمكِّننا من الوصول إلى بيانات نموذج الإدخال المُضمّنة في الطلب؛ ففي حال عدم إدخال قيمةٍ للعنوان، فسيتحقق الشرط if not title وبالتالي ستظهر رسالة للمستخدم نعلمه من خلالها بأن العنوان مطلوب؛ أمّا في حال وجود العنوان سيُفتَح الاتصال مع قاعدة البيانات باستخدام الدالة get_db_connection() لإدخال العنوان والمحتوى المرسلين إلى الجدول posts فيها. بعد تنفيذ هذه التعديلات في قاعدة البيانات وإضافة التدوينة الجديدة إليها، يُغلق الاتصال معها، ومن ثمّ نعيد توجيه الطلب إلى الصفحة الرئيسية باستخدام الدالة redirect() بتمرير الرابط الناتج عن التابع url_for() الذي قد مررنا له القيمة index وسيطًا. اِحفظ الملف وأغلقه، ثم انتقل في المتصفح إلى الوجهة /create: http://127.0.0.1:5000/create املأ النموذج بالعنوان والمحتوى الذي تريد، وسترى التدوينة الجديدة في الصفحة الرئيسية حال إرسال النموذج. الآن سنعمل على إظهار الرسائل للمستخدم وإضافة رابط في شريط التصفح في القالب base.html لتسهيل الوصول إلى هذه الصفحة الجديدة، من خلال فتح ملف القالب: (env)user@localhost:$ nano templates/base.html الآن، عدِّل الملف من خلال إضافة وسم القائمة <li> بعد الرابط About داخل وسم شريط التصفُّح <nav>، ثمّ أضف حلقة تكرارية أعلى كتلة المحتوى مباشرةً لعرض الرسائل أسفل شريط التصفح، إذ يوفّر فلاسك هذه الرسائل من خلال دالة فلاسك الخاصة get_flashed_messages(): <nav class="navbar navbar-expand-md navbar-light bg-light"> <a class="navbar-brand" href="{{ url_for('index')}}">FlaskBlog</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarNav" aria-controls="navbarNav" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNav"> <ul class="navbar-nav"> <li class="nav-item"> <a class="nav-link" href="#">About</a> </li> <li class="nav-item"> <a class="nav-link" href="{{url_for('create')}}">New Post</a> </li> </ul> </div> </nav> <div class="container"> {% for message in get_flashed_messages() %} <div class="alert alert-danger">{{ message }}</div> {% endfor %} {% block content %} {% endblock %} </div> اِحفظ الملف وأغلقه. سيتضمن الآن شريط التصفح عنصرًا جديدًا باسم "New Post"، الذي ينقلنا إلى الوجهة /create. تعديل تدوينة منشورة لا بدّ من توفّر إمكانية التعديل على التدوينات المنشورة أصلًا في التطبيق بما يضمن إمكانية تحديثها دائمًا، لذا سنوضّح في هذا القسم من المقال كيفية إنشاء صفحة جديدة في التطبيق خاصةٍ بتعديل التدوينات. بدايةً، أضِف وجهة route جديدة إلى الملف app.py، إذ ستستقبل دالة هذه الوجهة رقم التدوينة ID المُراد تعديلها على هيئة وسيط، بحيث يكون الرابط بالشّكل /post_id/edit إذ يمثّل المتغير post_id رقم التدوينة. ولإنجاز ذلك، ابدأ بفتح الملف app.py في وضع التحرير على النحو التالي: (env)user@localhost:$ nano app.py ومن ثمّ أضف في نهاية الملف دالة edit() المشابهة للدالة create() التي أنشأناها سابقًا، لأنّ تعديل تدوينة منشورة أصلًا أمرٌ مشابهٌ من حيث المبدأ البرمجي لإنشاء تدوينة جديدة: . . . @app.route('/<int:id>/edit', methods=('GET', 'POST')) def edit(id): post = get_post(id) if request.method == 'POST': title = request.form['title'] content = request.form['content'] if not title: flash('Title is required!') else: conn = get_db_connection() conn.execute('UPDATE posts SET title = ?, content = ?' ' WHERE id = ?', (title, content, id)) conn.commit() conn.close() return redirect(url_for('index')) return render_template('edit.html', post=post) نلاحظ من بناء الدالة السابقة تحديد التدوينة المراد تعديلها من خلال معرفة الرابط الخاص بها URL، وسيمرّر فلاسك رقم ID الخاص بها إلى دالة ()edit وسيطًا، ومن ثم نضيف هذه القيمة إلى دالة استدعاء التدوينات get_post() لاستدعاء التدوينة ذات رقم ID المحدّد من قاعدة البيانات، ومن ثم تُضاف البيانات الجديدة إليها على هيئة طلب تدوينة جديدة POST وذلك ضمن الجملة الشرطية `if request.method == 'POST. وعلى نحوٍ مشابه لحالة إنشاء تدوينة جديدة، سنبدأ باستخلاص البيانات من الكائن request.form، بحيث تُعرض رسالة تنبيهية في حال كانت قيمة العنوان فارغة، وإلّا سنؤسس الاتصال مع قاعدة البيانات، ثم نحدَّث جدول التدوينات posts بالعنوان والمحتويات الجديدة للتدوينة ذات الرقم ID الموافق للرقم الذي حصلنا عليه من رابط التدوينة المُراد تعديلها. أمّا بالنسبة للطلب GET، فسيحدث إخراجٌ لقالب edit.html المُمرر إلى المتغير post، الذي يحتوي القيمة المُعادة من الدالة get_post()، والهدف من هذا الطلب استعراض محتوى وعنوان التدوينة الحالية ضمن صفحة التعديل. احفظ الملف وأغلقه، ثمّ أنشئ قالب edit.html جديد على النحو التالي: (env)user@localhost:$ nano templates/edit.html اكتب الشيفرة البرمجية التالية في الملف الجديد: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Edit "{{ post['title'] }}" {% endblock %}</h1> <form method="post"> <div class="form-group"> <label for="title">Title</label> <input type="text" name="title" placeholder="Post title" class="form-control" value="{{ request.form['title'] or post['title'] }}"> </input> </div> <div class="form-group"> <label for="content">Content</label> <textarea name="content" placeholder="Post content" class="form-control">{{ request.form['content'] or post['content'] }}</textarea> </div> <div class="form-group"> <button type="submit" class="btn btn-primary">Submit</button> </div> </form> <hr> {% endblock %} اِحفظ الملف وأغلقه. تتبِّع هذه الشيفرة البرمجية نفس النمط السابق ما عدا التعليمتان: {{ request.form['title'] or post['title'] }} {{ request.form['content'] or post['content'] }} اللتان تعرضان البيانات المُخزّنة ضمن طلب التعديل في حال وجودها، وإلّا ستعرضان البيانات الموجودة في المتغير post المُمرّر إلى القالب الذي يحتوي على البيانات الحالية من قاعدة البيانات. باستخدام المتصفح، اذهب الآن إلى الرابط التالي، الذي سيمكنّك من تعديل التدوينة الأولى ذات الرقم 1: http://127.0.0.1:5000/1/edit فستظهر لك صفحة تعديل "التدوينة الأولى First Post" على النحو التالي: عدّل التدوينة ثمّ أكّد النموذج وأرسله، وتأكّد من تحديث بيانات التدوينة. الآن، يجب إضافة رابط يشير إلى صفحة التعديل لكل تدوينة وذلك في صفحة المؤشر (الفهرس)، لذلك افتح ملف القالب index.html: (env)user@localhost:$ nano templates/index.html عدّل الملف ليصبح على النحو التالي: {% extends 'base.html' %} {% block content %} <h1>{% block title %} Welcome to FlaskBlog {% endblock %}</h1> {% for post in posts %} <a href="{{ url_for('post', post_id=post['id']) }}"> <h2>{{ post['title'] }}</h2> </a> <span class="badge badge-primary">{{ post['created'] }}</span> <a href="{{ url_for('edit', id=post['id']) }}"> <span class="badge badge-warning">Edit</span> </a> <hr> {% endfor %} {% endblock %} ويمكنك إضافة وسم <a> للربط مع الدالة ()edit، مرورًا بالقيمة post['id'] لربط صفحة التعديل لكلِّ تدوينة مع الرابط Edit. حذف تدوينة أحيانًا، يصبح بقاء بعض التدوينات منشورةً للعموم أمرًا غير مطلوب، ومن هنا تأتي أهمية إمكانية حذف التدوينات المنشورة أصلًا، وفيما يلي سنتعلّم كيفيّة إضافة آلية لحذف هذه التدوينات من التطبيق. بدايةً، سنضيف وجهة جديدة للحذف، هو /ID/delete يتعامل مع الطلبات من النوع POST بما يشبه الدالة edit() الذي أنشأناها سابقًا، إذ ستستقبل دالة الحذف delete() رقم معرّف التدوينة ID لحذفها من الرابط URL. الآن، افتح الملف app.py: (env)user@localhost:$ nano app.py أضِف الدالة التالية إلى نهاية الملف: # .... @app.route('/<int:id>/delete', methods=('POST',)) def delete(id): post = get_post(id) conn = get_db_connection() conn.execute('DELETE FROM posts WHERE id = ?', (id,)) conn.commit() conn.close() flash('"{}" was successfully deleted!'.format(post['title'])) return redirect(url_for('index')) تتعامل هذه الدالة فقط مع الطلبات الواردة بطريقة POST؛ وهذا يعني أنك إذا انتقلت إلى الوجهة /ID/delete في المتصفح، ستحصل على خطأ، لأن المتصفحات تستخدم طريقة GET افتراضيًا للطلبات؛ ولكن يمكنك الوصول إلى هذه الوجهة من خلال نموذج الإدخال الذي يرسل طلبًا بطريقة POST يتضمن قيمة معرّف التدوينة المُراد حذفها، لتستقبل دالة فلاسك هذه قيمة المعرّف ID وتستخدمها لجلب التدوينة من قاعدة البيانات باستخدام دالة get_post(). افتح بعد ذلك اتصالًا مع قاعدة البيانات ونفِّذ تعليمة SQL التالية لحذف التدوينة: DELETE FROM يمكنك تأكيد وإرسال التعديلات إلى قاعدة البيانات وإغلاق الاتصال أثناء إظهار رسالة وامضة تُعلم المستخدم بإتمام عملية حذف التدوينة بنجاح، ثم يُعاد توجيه المستخدم إلى الصفحة الرئيسية. لاحظ أننا هنا لا نخرج render ملف قالب، وإنمّا نضيف فقط زر أوامر "Delete" إلى صفحة تعديل التدوينة. الآن افتح ملف القالب edit.html: (env)user@localhost:$ nano templates/edit.html ثم أضف وسم النموذج <form> بعد وسم إظهار الفاصل الأفقي <hr> تماماً بعد السطر البرمجي {% endblock %} على النحو التالي: <hr> <form action="{{ url_for('delete', id=post['id']) }}" method="POST"> <input type="submit" value="Delete Post" class="btn btn-danger btn-sm" onclick="return confirm('Are you sure you want to delete this post?')"> </form> {% endblock %} إذ استخدمنا التابع confirm() لعرض رسالة تأكيد قبل إرسال الطلب. الآن انتقل إلى صفحة تعديل تدوينة في المتصفح مجددًا وجرّب حذفها: http://127.0.0.1:5000/1/edit ومع الانتهاء من هذه الخطوة، ستكون شيفرة المشروع مشابهةً لشيفرة تدوينة فلاسك على غيت هب، وبهذا سيتمكّن مستخدمو التطبيق من إنشاء تدوينات جديدة وإضافتها إلى قاعدة البيانات، وكذلك تعديل أو حذف التدوينات الموجودة أصلًا. الخاتمة قدّمنا في هذا المقال المفاهيم الأساسية لإطار عمل فلاسك في بايثون، وتعلمّت كيفيّة إنشاء تطبيق ويب بسيط وتشغيله في خادم تطوير، وآلية تمكين المستخدم من التواصل مع الخادم وتزويده ببياناتٍ مخصصة باستخدام محدِّدات الرابط URL ونماذج الادخال؛ كما اسُتخدم محرك قوالب جينجا jinja لتوفير ملفات HTML ذات المحتوى القابل لإعادة الاستخدام لكتابة منطق التطبيق فيها. ومع نهاية هذا المقال سيكون لديك مدونة ويب بكامل المميزات، والتي تتعامل مع قاعدة بيانات SQLite لإنشاء وعرض أو تعديل أو حذف التدوينات باستخدام لغة بايثون واستعلامات SQL. يمكنك أيضًا تطوير هذا التطبيق بإضافة ميزات تصريح وصول المستخدمين لتقييد عملية إنشاء وتعديل التدوينات لتكون متاحةً فقط للمستخدمين الذين لديهم حسابات، كما يمكنك مثلًا إضافة ميزة التعليقات وتضمين الكلمات المفتاحية لكل تدوينة، أو ميزة رفع الملفات التي تمكّن المستخدمين من إضافة الصور إلى محتوى التدوينة. يوجد العديد من الإضافات المطوَّرة من قبل المبرمجين لفلاسك والتي يمكنك استخدامها لتسهيل عملية التطوير، ومنها: Flask-Login: لإدارة جلسة المستخدم ومعالجة عمليات تسجيل الدخول وتسجيل الخروج وتذكّر معلومات المستخدمين الذين سجلوا الدخول سابقًا. Flask-SQLAlchemy: لتسهيل استخدام فلاسك مع مكتبة SQLAlchemy، والتي هي حزمة SQL في بايثون للتعامل مع قواعد بيانات SQL. Flask-Mail: لتنفيذ مهام إرسال رسائل البريد الإلكتروني من خلال تطبيق فلاسك. ترجمة -وبتصرف- للمقال How To Make a Web Application Using Flask in Python 3 لصاحبه Abdelhadi Dyouri. اقرأ أيضًا استخدام أطر العمل في برمجة تطبيقات الويب: فلاسك نموذجا مدخل إلى تطوير تطبيقات الويب باستخدام إطار العمل Flask -
 يشير الناس عادةً لأي مجموعةٍ من مفاهيم الحوسبة المترابطة بمصطلح السحابة cloud، ولكن في الواقع السحابة هي مجموعةٌ من الأقراص والمعالجات والذواكر وغيرها من موارد عمليات المعالجة computing resources -سواءٌ كانت فيزيائية أو افتراضية- المستضافة عن بُعد remotely hosted والمُستخدمة في طرف العميل، سواء أكان هذا العميل صفحة ويب أو تطبيق للهاتف أو تطبيق سطح مكتب تقليدي، بهدف استثمار المساحات التخزينية وإمكانات الحوسبة العالية؛ ويُقصد بمصطلح الاستضافة عن بُعد remotely hosting طريقة توصيل التطبيقات وقواعد البيانات والملفات للمستخدمين من الخوادم البعيدة الموجودة خارج مراكز البيانات، إذ يمكن للمستخدم الوصول إلى التطبيق وبياناته من خلال تسجيل الدخول بأمان إلى الخادم البعيد عبر السحابة وذلك خلال متصفح الإنترنت عادةً)، وليس من السهل التفريق تمامًا بين مفهوم الحوسبة السحابية والحوسبة التقليدية القائمة على نموذج خادم/عميل؛ ولكن تتميز الحوسبة السحابية عمومًا بالقدرة على التوسُّع، أي زيادة الموارد تلقائيًا حسب الحاجة أثناء التشغيل؛ كما تتميز بآلية التصميم أيضًا، إذ تكون مصادر الحوسبة في السحابة أكثر مرونةً ومتعددة الأغراض وقابلةً للاستخدام لأي وظيفة مطلوبة على نحوٍ أكبر موارنةً بحوسبة الخوادم التقليدية. بعض الأمثلة على مفهوم السحابة لا يخلو موقع إلكتروني في أيامنا من مكون سحابي سواءٌ كان ظاهرًا لنا عند زيارته أم لا؛ أمّا بالنسبة للمستخدم العادي، فلا تمثّل السحابة سوى واجهة عرض الخدمة التي يتعامل معها، سواءٌ كانت منصة تواصل اجتماعي، أو متجرًا إلكترونيًا، أو إحدى خدمات بث الموسيقى، أو موقع حجز تذاكر طيران، أو غيرها من الخدمات المختلفة. يجب ألا ننسى أن واجهة المستخدم في موقع الويب ما هي إلا جزءٌ بسيطٌ من مجموعةٍ كبيرةٍ من العمليات الجارية في كواليس أيّ تطبيق ويب، إذ تعمل مكوناتٌ عديدة من قواعد بيانات وأدوات تسجيل الأحداث وصولًا إلى آليات التنقيب عن البيانات وأدوات الذكاء الاصطناعي وعدد من البرمجيات الموزعة الخاصة بتنفيذ المتطلبات أو الآلاف منها معًا لتشغّل خدمة ويب وتمكنَّك من استخدام أي أداة على الانترنت. وقد تتواجد المكونات المذكورة أعلاه على أي حاسوب في أي مكان، ولكن تتواجد غالبًا على السحابة. كيفية عمل السحابة صُممت مراكز البيانات لكي تحوي العديد من خوادم الأغراض العامة مع ما يلزم من إمكانات الحوسبة والتخزين، لمشاركة هذه الموارد بين التطبيقات المتعددة المُستضافة في هذه المراكز لتوفير البيانات الخاصة بها. وتُجمَّع في كثير من الحالات كافّة التطبيقات والمكتبات اللازمة لتشغيلها مع نظام التشغيل على أجهزة افتراضية virtual machines تعمل ضمن الجهاز الفيزيائي الفعلي بغض النظر عن نوع نظام تشغيله، وتدعى هذه التقنية باسم التقنية الافتراضية virtualization؛ وهي تجعل التطبيقات أكثر قابليةً للتنقل والعمل في بيئات مختلفة، شرط أن تكون قادرةً على تشغيل جهاز افتراضي ضمنها. من هنا أتى مفهوم الحوسبة المرنة elastic computing أو السحابة المرنة elastic cloud؛ فعندما يُصمّم تطبيق ليتوسع أو يتقلص حسب حجم الطلبات عليه فمن الممكن استخدام عدد أكبر أو أقل من الأجهزة الافتراضية بمرونة حسب الحالة؛ كما تعمل الأجهزة الافتراضية بمرونة أيضًا من ناحية التخزين، فمن الممكن استخدام محركات الأقراص الثابتة المتصلة بالعديد من الأجهزة الفيزيائية المختلفة والتعامل معها كما لو كانت موردًا واحدًا، مما يقلل من هدر الموارد ويسهّل عملية تطوير التطبيقات التي تتطلب كميات بيانات كبيرة جدًا. قد تكون مراكز البيانات التي تستضيف موارد الحوسبة السحابية عامّةً أو خاصّةً أو هجينة hybrid cloud؛ فمن الممكن استئجار موارد الحوسبة السحابية العامة من قبل مجموعة متنوعة من الشركات؛ وقد تقرر المؤسسة إنشاء سحابة خاصة مستضافة في مركز البيانات الخاص بها أو في جزء محجوز خصيصًا لها من مركز بيانات آخر من أجل الحصول على مستويات أعلى من الأمان والمرونة، أو حتى بهدف توفير التكاليف؛ أمّا السحب الهجينة فتتميز بقدرتها على الاستفادة من موارد السحب العامة والخاصة وذلك وفقًا لمتغيرات الطلب والأولوية. مفهوم السحابة مفتوحة المصدر إنّ أحد أهم التطورات التي حدثت مؤخرًا على أدوات وتقنيات التعامل مع السحابة هو الكم الكبير منها الذي غدا مفتوح المصدر، وقد أصبح ترخيص البرمجيات مفتوحة المصدر معيارًا لكيفية تطوير التقنيات الحديثة للتعامل مع السحابة، وفيما يلي بعض الأمثلة: OpenStack وهو مشروع مفتوح المصدر متخصص بإنشاء وإدارة البنية الأساسية للسحابة، بما يتضمن وسائط التخزين، وإمكانات الموارد الحاسوبية وإدارة الشبكات، كما يتضمّن العديد من المشاريع للمساعدة في التعامل مع كل ما يتعلّق بالسحابة بدءًا من إدارة حسابات المستخدمين وحتى استثمار قاعدة البيانات (المرحلة اللاحقة لتطويرها). حاويات Linux والتي ظهرت أصلًا بمثابة طريقة لتطوير تطبيقات السحابة، وتعتمد على الإجرائيات الخاصّة بالنواة Linux kernel مثل بديلٍ أسرع من الأجهزة الافتراضية التقليدية، كما أنّها تساعد المطورين على بناء الحاويات باستخدام مشاريع، مثل Docker و Kubernetes لتحقيق التناغم بين التطبيقات التي أُنشأت على عدّة حاويات. البيانات الضخمة و إنترنت الأشياء Internet of Things، وهما من أهم مستخدمي موارد الحوسبة السحابية، حيث تُطوَّر في كل منهما العديد من الأدوات لدعم التطبيقات لتكوت مفتوحة المصدر تمامًا. إضافةً للعديد من الأدوات الأخرى ابتداءً من حزم خوادم الويب Linux / Apache / MySQL / PHP وصولًا إلى تطبيقات التخزين السحابي ومحررات النصوص التشاركية. ترجمة -وبتصرف- للمقال what is the cloud? من موقع opensource.com. اقرأ أيضًا الانتقال إلى الحوسبة السحابيّة تعلم الحوسبة السحابيّة: المتطلبات الأساسيّة، وكيف تصبح مهندس حوسبة سحابيّة
يشير الناس عادةً لأي مجموعةٍ من مفاهيم الحوسبة المترابطة بمصطلح السحابة cloud، ولكن في الواقع السحابة هي مجموعةٌ من الأقراص والمعالجات والذواكر وغيرها من موارد عمليات المعالجة computing resources -سواءٌ كانت فيزيائية أو افتراضية- المستضافة عن بُعد remotely hosted والمُستخدمة في طرف العميل، سواء أكان هذا العميل صفحة ويب أو تطبيق للهاتف أو تطبيق سطح مكتب تقليدي، بهدف استثمار المساحات التخزينية وإمكانات الحوسبة العالية؛ ويُقصد بمصطلح الاستضافة عن بُعد remotely hosting طريقة توصيل التطبيقات وقواعد البيانات والملفات للمستخدمين من الخوادم البعيدة الموجودة خارج مراكز البيانات، إذ يمكن للمستخدم الوصول إلى التطبيق وبياناته من خلال تسجيل الدخول بأمان إلى الخادم البعيد عبر السحابة وذلك خلال متصفح الإنترنت عادةً)، وليس من السهل التفريق تمامًا بين مفهوم الحوسبة السحابية والحوسبة التقليدية القائمة على نموذج خادم/عميل؛ ولكن تتميز الحوسبة السحابية عمومًا بالقدرة على التوسُّع، أي زيادة الموارد تلقائيًا حسب الحاجة أثناء التشغيل؛ كما تتميز بآلية التصميم أيضًا، إذ تكون مصادر الحوسبة في السحابة أكثر مرونةً ومتعددة الأغراض وقابلةً للاستخدام لأي وظيفة مطلوبة على نحوٍ أكبر موارنةً بحوسبة الخوادم التقليدية. بعض الأمثلة على مفهوم السحابة لا يخلو موقع إلكتروني في أيامنا من مكون سحابي سواءٌ كان ظاهرًا لنا عند زيارته أم لا؛ أمّا بالنسبة للمستخدم العادي، فلا تمثّل السحابة سوى واجهة عرض الخدمة التي يتعامل معها، سواءٌ كانت منصة تواصل اجتماعي، أو متجرًا إلكترونيًا، أو إحدى خدمات بث الموسيقى، أو موقع حجز تذاكر طيران، أو غيرها من الخدمات المختلفة. يجب ألا ننسى أن واجهة المستخدم في موقع الويب ما هي إلا جزءٌ بسيطٌ من مجموعةٍ كبيرةٍ من العمليات الجارية في كواليس أيّ تطبيق ويب، إذ تعمل مكوناتٌ عديدة من قواعد بيانات وأدوات تسجيل الأحداث وصولًا إلى آليات التنقيب عن البيانات وأدوات الذكاء الاصطناعي وعدد من البرمجيات الموزعة الخاصة بتنفيذ المتطلبات أو الآلاف منها معًا لتشغّل خدمة ويب وتمكنَّك من استخدام أي أداة على الانترنت. وقد تتواجد المكونات المذكورة أعلاه على أي حاسوب في أي مكان، ولكن تتواجد غالبًا على السحابة. كيفية عمل السحابة صُممت مراكز البيانات لكي تحوي العديد من خوادم الأغراض العامة مع ما يلزم من إمكانات الحوسبة والتخزين، لمشاركة هذه الموارد بين التطبيقات المتعددة المُستضافة في هذه المراكز لتوفير البيانات الخاصة بها. وتُجمَّع في كثير من الحالات كافّة التطبيقات والمكتبات اللازمة لتشغيلها مع نظام التشغيل على أجهزة افتراضية virtual machines تعمل ضمن الجهاز الفيزيائي الفعلي بغض النظر عن نوع نظام تشغيله، وتدعى هذه التقنية باسم التقنية الافتراضية virtualization؛ وهي تجعل التطبيقات أكثر قابليةً للتنقل والعمل في بيئات مختلفة، شرط أن تكون قادرةً على تشغيل جهاز افتراضي ضمنها. من هنا أتى مفهوم الحوسبة المرنة elastic computing أو السحابة المرنة elastic cloud؛ فعندما يُصمّم تطبيق ليتوسع أو يتقلص حسب حجم الطلبات عليه فمن الممكن استخدام عدد أكبر أو أقل من الأجهزة الافتراضية بمرونة حسب الحالة؛ كما تعمل الأجهزة الافتراضية بمرونة أيضًا من ناحية التخزين، فمن الممكن استخدام محركات الأقراص الثابتة المتصلة بالعديد من الأجهزة الفيزيائية المختلفة والتعامل معها كما لو كانت موردًا واحدًا، مما يقلل من هدر الموارد ويسهّل عملية تطوير التطبيقات التي تتطلب كميات بيانات كبيرة جدًا. قد تكون مراكز البيانات التي تستضيف موارد الحوسبة السحابية عامّةً أو خاصّةً أو هجينة hybrid cloud؛ فمن الممكن استئجار موارد الحوسبة السحابية العامة من قبل مجموعة متنوعة من الشركات؛ وقد تقرر المؤسسة إنشاء سحابة خاصة مستضافة في مركز البيانات الخاص بها أو في جزء محجوز خصيصًا لها من مركز بيانات آخر من أجل الحصول على مستويات أعلى من الأمان والمرونة، أو حتى بهدف توفير التكاليف؛ أمّا السحب الهجينة فتتميز بقدرتها على الاستفادة من موارد السحب العامة والخاصة وذلك وفقًا لمتغيرات الطلب والأولوية. مفهوم السحابة مفتوحة المصدر إنّ أحد أهم التطورات التي حدثت مؤخرًا على أدوات وتقنيات التعامل مع السحابة هو الكم الكبير منها الذي غدا مفتوح المصدر، وقد أصبح ترخيص البرمجيات مفتوحة المصدر معيارًا لكيفية تطوير التقنيات الحديثة للتعامل مع السحابة، وفيما يلي بعض الأمثلة: OpenStack وهو مشروع مفتوح المصدر متخصص بإنشاء وإدارة البنية الأساسية للسحابة، بما يتضمن وسائط التخزين، وإمكانات الموارد الحاسوبية وإدارة الشبكات، كما يتضمّن العديد من المشاريع للمساعدة في التعامل مع كل ما يتعلّق بالسحابة بدءًا من إدارة حسابات المستخدمين وحتى استثمار قاعدة البيانات (المرحلة اللاحقة لتطويرها). حاويات Linux والتي ظهرت أصلًا بمثابة طريقة لتطوير تطبيقات السحابة، وتعتمد على الإجرائيات الخاصّة بالنواة Linux kernel مثل بديلٍ أسرع من الأجهزة الافتراضية التقليدية، كما أنّها تساعد المطورين على بناء الحاويات باستخدام مشاريع، مثل Docker و Kubernetes لتحقيق التناغم بين التطبيقات التي أُنشأت على عدّة حاويات. البيانات الضخمة و إنترنت الأشياء Internet of Things، وهما من أهم مستخدمي موارد الحوسبة السحابية، حيث تُطوَّر في كل منهما العديد من الأدوات لدعم التطبيقات لتكوت مفتوحة المصدر تمامًا. إضافةً للعديد من الأدوات الأخرى ابتداءً من حزم خوادم الويب Linux / Apache / MySQL / PHP وصولًا إلى تطبيقات التخزين السحابي ومحررات النصوص التشاركية. ترجمة -وبتصرف- للمقال what is the cloud? من موقع opensource.com. اقرأ أيضًا الانتقال إلى الحوسبة السحابيّة تعلم الحوسبة السحابيّة: المتطلبات الأساسيّة، وكيف تصبح مهندس حوسبة سحابيّة -
 علم البيانات data science هو فرع من علم الحاسوب computer science مسؤول عن تجميع ومعالجة وتحليل البيانات وصولًا إلى مخرجات جديدة ومفهومة عن الأنظمة المدروسة، إذ يتعامل علماء البيانات مع كميات كبيرة من المعلومات الواردة من مصادر متعدّدة بطرقٍ مختلفة؛ بمعنى أنّ طريقة تحليلهم للبيانات ستكون مختلفة باختلاف الحالة المدروسة، لذلك يستخدمون خوارزميات مخصصة وتقنيات الذكاء الاصطناعي AI والتعلّم الآلي ML إضافةً لوجهة نظرهم الخاصة في تحليل هذه البيانات. إذًا، علم البيانات مجالٌ واسعٌ سريع التطور في عدّة مجالات واتجاهات عملية، مثل المجال الطبي وعلم الفلك والأرصاد الجوية، والتسويق وعلم الاجتماع والمؤثرات البصرية وغيرها. ستجد في هذا المقال مقدمةً مختصرةً حول علم البيانات، هذا المجال الواسع سريع التطور في العديد من الاتجاهات العملية. أهمية علم البيانات يستند المنهج العلمي على جمع الأدلة وتفسيرها وصولًا إلى استنتاجات منطقية، وقد خدم هذا المبدأ الحضارة الإنسانية بما يكفي ليصبح من الممكن السفر جوًا عبر المحيط الأطلسي، أو الاتصال لاسلكيًا وعلاج العديد من الأمراض، وهبوط أولى المركبات على سطح المريخ وأكثر من ذلك بكثير. ويُجمع في عالمنا الحديث الكثير من البيانات متعددة المصادر لحظيًا، مثل البيانات حول العادات اليومية والعادات الغذائية، الخيارات الموسيقية، العادات الاستهلاكية، مقدار استهلاك الطاقة، معلومات الأرصاد الجوية، أنماط هجرة الكائنات، النشاط الزلزالي، مواعيد رحلات الطيران وغيرها الكثير. مع وجود الحواسيب في كل مكان فيوجد فعليًا كميةً مستمرةً من المُدخلات المضافة إلى مجموعة البيانات الضخمة. إذًا، تتوفّر لدينا في وقتنا الحاضر كمياتٌ من المعلومات عن العالم المحيط بنا ومن عينات مختلفة أكثر بكثير من أي وقتٍ مضى، وقد يقودنا تحليل مجموعات البيانات الضخمة هذه إلى استنتاجات مذهلة؛ فقد نجد أنماطًا أو ارتباطات في أماكن لم نتوقعها أو ندرسها يومًا. في الواقع، تُعد مراقبة المتغيرات البيئية وتحليلها أمرًا بالغ الأهمية في مسيرة تعلّم الإنسان وتطوره، ومع ذلك تُطبَّق كثيرٌ من تقنيات علم البيانات على مجالاتٍ سطحية أو غير أخلاقية ولكن بالمقابل يجري قدرٌ كبيرٌ من تحليل البيانات حول المواضيع المفيدة والسليمة والجديرة بالاهتمام والتي يجب أن تفخر برمجيات المصادر المفتوحة بدعمها. ومن هنا نجد أنّ البرمجيات مفتوحة المصدر أمرٌ مهمٌ للغاية في نمو وتطور علم البيانات. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن البنية الأساسية يتطلب علم البيانات بنيةً تحتيةً حاسوبيةً قوية وذلك نظرًا للكمية الهائلة من البيانات التي يحللها، فغالبًا ما تكون مجموعات البيانات أضخم من أن تُعالج على جهازٍ واحد أو حتى على مجموعةٍ صغيرة من الأجهزة، لذلك تُستخدم السحب الهجينة hybrid clouds وهي مزيجٌ من السحب العامّة والخاصة وتستفيد من مميزات كلا النوعين، لتخزين ومعالجة المعلومات وإنشاء الارتباطات بين هذه المعلومات المُحلَّلة. ولذلك تتضمّن الأدوات اللازمة لعمل عالم البيانات ما يلي: منصةً لتشغيل الخدمات المُعالجة، مثل OpenShift، وبرمجية حوسبة موزعة، مثل Hadoop، أو Spark، ونظام ملفات موزعة، مثل Ceph، أو Gluster لتوفير تخزين موثوق، وغيرها من الأدوات. وبالتالي، فإن طبيعة عمل عالم البيانات إحصائيةٌ رياضية أكثر من كونها برمجية متعلقة بهندسة الحاسوب. مهام عالم البيانات يجمِّع عالم البيانات ويُعيد توزيع البيانات ويوّحدها normalize (وهي عملية هيكلة قاعدة البيانات بهدف تقليل تكرار البيانات وتحسين تكاملها)، ومن ثم ينشئ الإجراءات اللازمة ليبدأ الحاسوب بالبحث في البيانات عن نمطٍ أو اتجاهٍ أو مجرد إنشاء تصورٍ مفيدٍ عنها؛ فمثلًا بمجرد إنشائك مخططًا بيانيًا دائريًا أو شريطيًا معبّرًا عن حقول جدول بياناتٍ ما، فستكون قد أنجزت مهمةً بسيطةً تشبه بعض مهام عالم البيانات من خلال تفسيرك لهذه البيانات وإنشاء تصوّرٍ لها يساعد الآخرين على فهمها. عندما تُحلَّل البيانات بحثًا عن أنماطٍ معينة، فلا يوجد طريقةً لجعل الحاسوب يبحث عن أمرٍ ما في هذه البيانات لأنّ الشيء الذي تريد البحث عنه ببساطة غير موجود بعد. بينما تكون تقنيات الذكاء الاصطناعي والتعلّم الآلي قادرةً على استيعاب كميةٍ كبيرةٍ من البيانات وتحليلها بحثًا عن أنماطٍ عشوائية، إلا أنّ الأمر يتطلب تدخلًا للبراعة البشرية لإيجاد القيم الغير منطقية وتفسيرها؛ وهذا يعني أنه لا بدّ من أن يكون عالم البيانات قادرًا على ما يلي: تصميم إجرائيات مخصّصة باستخدام لغات برمجة، مثل بايثون Python وR و Scala و Julia. التعامل مع المكتبات المهمّة، مثل Beautiful Soup (وهي حزمة بايثون لتحليل مستندات HTML و XML)؛ و NumPy (وهي إضافةٌ على لغة بايثون للتعامل مع المصفوفات الكبيرة والحقول متعددة المستوى)؛ و Pandas (وهي مكتبةٌ برمجيةٌ مطوّرة بلغة بايثون لمعالجة البيانات وتحليلها)، بحيث يتمكن من استخلاص البيانات Data scraping، أي استخراج البيانات التي يستطيع البشر فهمها من برنامجٍ ما مثل حالة استخراج بيانات معينة من موقع إلكتروني وحفظها بصيغةٍ أُخرى، وتنظيفها Data sanitization، أي تحقيق محوٍ آمن ودائم للبيانات الحساسة أو عالية الخصوصية لضمان عدم إمكانية استردادها من الغير، وتنظيمها Data organization، أي تصنيف البيانات وتوزيعها في فئات ليسهل استخدامها والبحث عنها. التحكم في الإصدار version-control (وهي عملية تتبع وإدارة التغييرات في الترميز البرمجي)، وضبط التكرارات في الترميز البرمجي الخاص به، ليصل بالنتيجة إلى نظرةٍ شاملة وناضجة للبيانات والعلاقات بينها. كيفية البدء بتعلم علم البيانات يمثّل علم البيانات مهنةً بحد ذاتها، فلا يمكنك تعلُّم كل ما تحتاج معرفته خلال عامٍ أو اثنين من الدراسة لتسمّي نفسك عالم بيانات، ولكن يمكنك البدء بدراستها الآن سواءً بمفردك أو باتباع تدريبٍ معتمد، ثم طبِّق الأشياء الجديدة التي تعلمتها فعليًا ومع الوقت وبتكرار العملية ستزداد معارفك في هذا المجال. ولحسن الحظ أن البرمجيات مفتوحة المصدر هي من تدير علم البيانات بصورةٍ رئيسية كما أنها برمجياتٌ متاحةٌ مجانًا للجميع، ويمكنك البدء بالخطوة الأولى في تجربة إحدى توزيعات لينوكس Linux، والتي ستمثّل منصةً جيدةً لعملك، إذ أن نظام تشغيل لينوكس مفتوح المصدر وهو مجاني ومرن جدًا مما يجعله مثاليًا للتعامل مع علم البيانات سريع التغيّر والمعروف بحاجته المستمرة للتكيُّف، كما أنّه يتوافق مع لغة بايثون الرائدة في علم البيانات، وقد صُمّمت المكتبات NumPy و Pandas خصيصًا لتحليل البيانات وتوثيقها مستنديًا بدقة عالية وتنظيم البيانات العددية number crunching، وهي عملية معالجة لكميات كبيرة من البيانات العددية وتنظيمها وإخراجها على هيئة مخططات ومبيانات graphs. تكمن إحدى أكبر صعوبات تعلُّم لغة برمجة أو مكتبة برمجية جديدة غالبًا في إيجاد طريقة لتطبيق الأدوات التي تعلمتها على حالةٍ واقعية؛ ولكن في علم البيانات وعلى عكس العديد من المجالات، لا توجد نتائج تحليل بيانات خاطئة بالمعنى الحرفي، إذ يمكنك تطبيق مبادئ علم البيانات على أي مجموعةٍ من البيانات، وفي أسوأ الأحوال ستكتشف أنه لا يوجد ارتباطٌ بين مجموعتين من البيانات، أو أنه لا يوجد نمطٌ واضحٌ في في الحدث العشوائي الذي حاولت تحليله، وهي نتائجٌ صحيحة؛ وبذلك لن تكون قد تعلمت عن علم البيانات فقط بل أثبت صحة فرضيةٍ ما من عدمها. وبفضل البرمجيات مفتوحة المصدر، أصبح من السهل إيجاد مجموعات بيانات مفتوحة ومتاحةٍ للجميع، مثل مجموعات البيانات التي توفرها Data.gov، والبنك الدولي World Bank والبيانات العامّة التي توفرها شركة غوغل Google والمتضمّنة لبياناتٍ من وكالة ناسا NASA ومن شركة GitHub وبيانات إحصاء سكان الولايات المتحدة وغيرها، والتي تمثّل مصادرًا ممتازةً يمكن استخدامها لتعلُّم كيفية استخلاص البيانات من الويب وتفريغها في صيغٍ أسهل لعمليات المعالجة وتحليلها باستخدام مكتباتٍ متخصّصة. لماذا نستخدم لغة بايثون في علم البيانات؟ من الممكن استخدام لغات برمجة مختلفة للتعامل مع علم البيانات، إلّا أنّ بايثون Python هي الأكثر شيوعًا، وعند الحديث عن تحليل البيانات فقط ستفي أي لغة برمجة بالغرض، ولكن من الممكن استثمار إمكانات بعض اللغات والمكتبات البرمجية في مجالات محدّدة صُمّمت لتنفيذها؛ إذ توفِّر المكتبة NumPy مثلًا أدواتٍ للتعامل مع المصفوفات ومعالجتها بحيث أنّك لن تضطر إلى برمجة مكتبةٍ خاصةٍ للتعامل مع المصفوفات بنفسك. تتمتّع لغة بايثون ببعض المزايا التي تتفوق بها على غيرها من اللغات، فهي مشهورة بسهولة قراءتها، فبالرغم من أنّ ترميز بايثون البرمجي قد يبدو معقدًا للمبتدئين في البرمجة، إلا أنّه أسهل في التحليل والفهم من ترميزات لغة مثل C أو ++C؛ وهذا يعني أنه من الممكن إعادة استخدام ترميزات بايثون من قبل الغير بسهولة، لأنّهم سيتمكنون من قراءة الترميز الذي كتبته وفهم الغرض منه وحتى التعديل عليه؛ كما تتضمّن بايثون عدّة مكتبات قوية ومنشأة خصيصًا للتعامل مع علوم البيانات، إذ توفر كافّة المستلزمات الضرورية لعمل علماء البيانات. إضافةً إلى ما سبق، تتمتع بايثون بمزايا أخرى، مثل نظام إدارة الحزم pip المُستخدم في تثبيت حزم البرامج وتحديثها وإدارتها، وواجهة البيئة الوهمية القوية venv؛ وهي أداةٌ لإنشاء بيئات بايثون مستقلة، والصدفة التفاعلية Interactive shell التي توفر طريقةً سريعةً لتنفيذ الأوامر وتجربة واختبار الترميز البرمجي، وغيرها من الأدوات التي جعلت بايثون رائدةً بين لغات البرمجة في مجال علم البيانات. لغة جوليا Julia وبيئة Jupyter التفاعلية لا تمثل بايثون اللغة الوحيدة القادرة على تحليل البيانات، إذ يوجد العديد من اللغات الأخرى التي قد تتفوق عليها من حيث الشعبية بين علماء البيانات مثل لغة Julia، التي تركز على الأداء وطريقة رسم تصوِّر للبيانات من خلال تمثيلها بالرسوم والمخططات التوضيحية، وقد لاحظ مطوري بيئة التطوير التفاعلية iPython شعبية لغة Julia، فارتأوا تغيير اسم هذه البيئة إلى Jupyter (جوبيتر) وهي نتيجة دمج متعمَّد لكلٍ من اللغات Julia و Python و R . ويُستخدم في هذه الأيام تطبيق الويب Jupyter notebooks للحوسبة التفاعلية، الذي يسمح لعلماء البيانات بإنشاء ومشاركة المستندات التي تدمج التعليمات البرمجية الحية والمعادلات والمخرجات الحسابية والتصورات وموارد الوسائط المتعددة الأخرى في مكانٍ واحد، ورغم كونها أداةً قويةً إلّا أنّها سهلةٌ بما يكفي لتبدأ التعلّم بها حتى لو كنت ما تزال تتعلم كتابة الترميزات البرمجية. مستقبل علم البيانات مع استمرار تطور الحواسيب تزداد كميات البيانات المتوفرة من حولنا، فإذا كنت من الأشخاص المهتمين بفهم العالم من حولهم، فعلم البيانات من أفضل الوسائل لتحقيق ذلك، ولا تنسَ مشاركة ما تفعله أو تتعلمه في علم البيانات أيًا كان لتعم الفائدة على الجميع. ترجمة -وبتصرف- للمقال What is data science? من موقع opensource.com. اقرأ أيضًا مدخل إلى البيانات وأنواعها: أنواع البيانات الأساسية المفاهيم الأساسية في قواعد البيانات وتصميمها دليلك الشامل إلى أنواع البيانات دليلك الشامل إلى قواعد البيانات DataBase
علم البيانات data science هو فرع من علم الحاسوب computer science مسؤول عن تجميع ومعالجة وتحليل البيانات وصولًا إلى مخرجات جديدة ومفهومة عن الأنظمة المدروسة، إذ يتعامل علماء البيانات مع كميات كبيرة من المعلومات الواردة من مصادر متعدّدة بطرقٍ مختلفة؛ بمعنى أنّ طريقة تحليلهم للبيانات ستكون مختلفة باختلاف الحالة المدروسة، لذلك يستخدمون خوارزميات مخصصة وتقنيات الذكاء الاصطناعي AI والتعلّم الآلي ML إضافةً لوجهة نظرهم الخاصة في تحليل هذه البيانات. إذًا، علم البيانات مجالٌ واسعٌ سريع التطور في عدّة مجالات واتجاهات عملية، مثل المجال الطبي وعلم الفلك والأرصاد الجوية، والتسويق وعلم الاجتماع والمؤثرات البصرية وغيرها. ستجد في هذا المقال مقدمةً مختصرةً حول علم البيانات، هذا المجال الواسع سريع التطور في العديد من الاتجاهات العملية. أهمية علم البيانات يستند المنهج العلمي على جمع الأدلة وتفسيرها وصولًا إلى استنتاجات منطقية، وقد خدم هذا المبدأ الحضارة الإنسانية بما يكفي ليصبح من الممكن السفر جوًا عبر المحيط الأطلسي، أو الاتصال لاسلكيًا وعلاج العديد من الأمراض، وهبوط أولى المركبات على سطح المريخ وأكثر من ذلك بكثير. ويُجمع في عالمنا الحديث الكثير من البيانات متعددة المصادر لحظيًا، مثل البيانات حول العادات اليومية والعادات الغذائية، الخيارات الموسيقية، العادات الاستهلاكية، مقدار استهلاك الطاقة، معلومات الأرصاد الجوية، أنماط هجرة الكائنات، النشاط الزلزالي، مواعيد رحلات الطيران وغيرها الكثير. مع وجود الحواسيب في كل مكان فيوجد فعليًا كميةً مستمرةً من المُدخلات المضافة إلى مجموعة البيانات الضخمة. إذًا، تتوفّر لدينا في وقتنا الحاضر كمياتٌ من المعلومات عن العالم المحيط بنا ومن عينات مختلفة أكثر بكثير من أي وقتٍ مضى، وقد يقودنا تحليل مجموعات البيانات الضخمة هذه إلى استنتاجات مذهلة؛ فقد نجد أنماطًا أو ارتباطات في أماكن لم نتوقعها أو ندرسها يومًا. في الواقع، تُعد مراقبة المتغيرات البيئية وتحليلها أمرًا بالغ الأهمية في مسيرة تعلّم الإنسان وتطوره، ومع ذلك تُطبَّق كثيرٌ من تقنيات علم البيانات على مجالاتٍ سطحية أو غير أخلاقية ولكن بالمقابل يجري قدرٌ كبيرٌ من تحليل البيانات حول المواضيع المفيدة والسليمة والجديرة بالاهتمام والتي يجب أن تفخر برمجيات المصادر المفتوحة بدعمها. ومن هنا نجد أنّ البرمجيات مفتوحة المصدر أمرٌ مهمٌ للغاية في نمو وتطور علم البيانات. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن البنية الأساسية يتطلب علم البيانات بنيةً تحتيةً حاسوبيةً قوية وذلك نظرًا للكمية الهائلة من البيانات التي يحللها، فغالبًا ما تكون مجموعات البيانات أضخم من أن تُعالج على جهازٍ واحد أو حتى على مجموعةٍ صغيرة من الأجهزة، لذلك تُستخدم السحب الهجينة hybrid clouds وهي مزيجٌ من السحب العامّة والخاصة وتستفيد من مميزات كلا النوعين، لتخزين ومعالجة المعلومات وإنشاء الارتباطات بين هذه المعلومات المُحلَّلة. ولذلك تتضمّن الأدوات اللازمة لعمل عالم البيانات ما يلي: منصةً لتشغيل الخدمات المُعالجة، مثل OpenShift، وبرمجية حوسبة موزعة، مثل Hadoop، أو Spark، ونظام ملفات موزعة، مثل Ceph، أو Gluster لتوفير تخزين موثوق، وغيرها من الأدوات. وبالتالي، فإن طبيعة عمل عالم البيانات إحصائيةٌ رياضية أكثر من كونها برمجية متعلقة بهندسة الحاسوب. مهام عالم البيانات يجمِّع عالم البيانات ويُعيد توزيع البيانات ويوّحدها normalize (وهي عملية هيكلة قاعدة البيانات بهدف تقليل تكرار البيانات وتحسين تكاملها)، ومن ثم ينشئ الإجراءات اللازمة ليبدأ الحاسوب بالبحث في البيانات عن نمطٍ أو اتجاهٍ أو مجرد إنشاء تصورٍ مفيدٍ عنها؛ فمثلًا بمجرد إنشائك مخططًا بيانيًا دائريًا أو شريطيًا معبّرًا عن حقول جدول بياناتٍ ما، فستكون قد أنجزت مهمةً بسيطةً تشبه بعض مهام عالم البيانات من خلال تفسيرك لهذه البيانات وإنشاء تصوّرٍ لها يساعد الآخرين على فهمها. عندما تُحلَّل البيانات بحثًا عن أنماطٍ معينة، فلا يوجد طريقةً لجعل الحاسوب يبحث عن أمرٍ ما في هذه البيانات لأنّ الشيء الذي تريد البحث عنه ببساطة غير موجود بعد. بينما تكون تقنيات الذكاء الاصطناعي والتعلّم الآلي قادرةً على استيعاب كميةٍ كبيرةٍ من البيانات وتحليلها بحثًا عن أنماطٍ عشوائية، إلا أنّ الأمر يتطلب تدخلًا للبراعة البشرية لإيجاد القيم الغير منطقية وتفسيرها؛ وهذا يعني أنه لا بدّ من أن يكون عالم البيانات قادرًا على ما يلي: تصميم إجرائيات مخصّصة باستخدام لغات برمجة، مثل بايثون Python وR و Scala و Julia. التعامل مع المكتبات المهمّة، مثل Beautiful Soup (وهي حزمة بايثون لتحليل مستندات HTML و XML)؛ و NumPy (وهي إضافةٌ على لغة بايثون للتعامل مع المصفوفات الكبيرة والحقول متعددة المستوى)؛ و Pandas (وهي مكتبةٌ برمجيةٌ مطوّرة بلغة بايثون لمعالجة البيانات وتحليلها)، بحيث يتمكن من استخلاص البيانات Data scraping، أي استخراج البيانات التي يستطيع البشر فهمها من برنامجٍ ما مثل حالة استخراج بيانات معينة من موقع إلكتروني وحفظها بصيغةٍ أُخرى، وتنظيفها Data sanitization، أي تحقيق محوٍ آمن ودائم للبيانات الحساسة أو عالية الخصوصية لضمان عدم إمكانية استردادها من الغير، وتنظيمها Data organization، أي تصنيف البيانات وتوزيعها في فئات ليسهل استخدامها والبحث عنها. التحكم في الإصدار version-control (وهي عملية تتبع وإدارة التغييرات في الترميز البرمجي)، وضبط التكرارات في الترميز البرمجي الخاص به، ليصل بالنتيجة إلى نظرةٍ شاملة وناضجة للبيانات والعلاقات بينها. كيفية البدء بتعلم علم البيانات يمثّل علم البيانات مهنةً بحد ذاتها، فلا يمكنك تعلُّم كل ما تحتاج معرفته خلال عامٍ أو اثنين من الدراسة لتسمّي نفسك عالم بيانات، ولكن يمكنك البدء بدراستها الآن سواءً بمفردك أو باتباع تدريبٍ معتمد، ثم طبِّق الأشياء الجديدة التي تعلمتها فعليًا ومع الوقت وبتكرار العملية ستزداد معارفك في هذا المجال. ولحسن الحظ أن البرمجيات مفتوحة المصدر هي من تدير علم البيانات بصورةٍ رئيسية كما أنها برمجياتٌ متاحةٌ مجانًا للجميع، ويمكنك البدء بالخطوة الأولى في تجربة إحدى توزيعات لينوكس Linux، والتي ستمثّل منصةً جيدةً لعملك، إذ أن نظام تشغيل لينوكس مفتوح المصدر وهو مجاني ومرن جدًا مما يجعله مثاليًا للتعامل مع علم البيانات سريع التغيّر والمعروف بحاجته المستمرة للتكيُّف، كما أنّه يتوافق مع لغة بايثون الرائدة في علم البيانات، وقد صُمّمت المكتبات NumPy و Pandas خصيصًا لتحليل البيانات وتوثيقها مستنديًا بدقة عالية وتنظيم البيانات العددية number crunching، وهي عملية معالجة لكميات كبيرة من البيانات العددية وتنظيمها وإخراجها على هيئة مخططات ومبيانات graphs. تكمن إحدى أكبر صعوبات تعلُّم لغة برمجة أو مكتبة برمجية جديدة غالبًا في إيجاد طريقة لتطبيق الأدوات التي تعلمتها على حالةٍ واقعية؛ ولكن في علم البيانات وعلى عكس العديد من المجالات، لا توجد نتائج تحليل بيانات خاطئة بالمعنى الحرفي، إذ يمكنك تطبيق مبادئ علم البيانات على أي مجموعةٍ من البيانات، وفي أسوأ الأحوال ستكتشف أنه لا يوجد ارتباطٌ بين مجموعتين من البيانات، أو أنه لا يوجد نمطٌ واضحٌ في في الحدث العشوائي الذي حاولت تحليله، وهي نتائجٌ صحيحة؛ وبذلك لن تكون قد تعلمت عن علم البيانات فقط بل أثبت صحة فرضيةٍ ما من عدمها. وبفضل البرمجيات مفتوحة المصدر، أصبح من السهل إيجاد مجموعات بيانات مفتوحة ومتاحةٍ للجميع، مثل مجموعات البيانات التي توفرها Data.gov، والبنك الدولي World Bank والبيانات العامّة التي توفرها شركة غوغل Google والمتضمّنة لبياناتٍ من وكالة ناسا NASA ومن شركة GitHub وبيانات إحصاء سكان الولايات المتحدة وغيرها، والتي تمثّل مصادرًا ممتازةً يمكن استخدامها لتعلُّم كيفية استخلاص البيانات من الويب وتفريغها في صيغٍ أسهل لعمليات المعالجة وتحليلها باستخدام مكتباتٍ متخصّصة. لماذا نستخدم لغة بايثون في علم البيانات؟ من الممكن استخدام لغات برمجة مختلفة للتعامل مع علم البيانات، إلّا أنّ بايثون Python هي الأكثر شيوعًا، وعند الحديث عن تحليل البيانات فقط ستفي أي لغة برمجة بالغرض، ولكن من الممكن استثمار إمكانات بعض اللغات والمكتبات البرمجية في مجالات محدّدة صُمّمت لتنفيذها؛ إذ توفِّر المكتبة NumPy مثلًا أدواتٍ للتعامل مع المصفوفات ومعالجتها بحيث أنّك لن تضطر إلى برمجة مكتبةٍ خاصةٍ للتعامل مع المصفوفات بنفسك. تتمتّع لغة بايثون ببعض المزايا التي تتفوق بها على غيرها من اللغات، فهي مشهورة بسهولة قراءتها، فبالرغم من أنّ ترميز بايثون البرمجي قد يبدو معقدًا للمبتدئين في البرمجة، إلا أنّه أسهل في التحليل والفهم من ترميزات لغة مثل C أو ++C؛ وهذا يعني أنه من الممكن إعادة استخدام ترميزات بايثون من قبل الغير بسهولة، لأنّهم سيتمكنون من قراءة الترميز الذي كتبته وفهم الغرض منه وحتى التعديل عليه؛ كما تتضمّن بايثون عدّة مكتبات قوية ومنشأة خصيصًا للتعامل مع علوم البيانات، إذ توفر كافّة المستلزمات الضرورية لعمل علماء البيانات. إضافةً إلى ما سبق، تتمتع بايثون بمزايا أخرى، مثل نظام إدارة الحزم pip المُستخدم في تثبيت حزم البرامج وتحديثها وإدارتها، وواجهة البيئة الوهمية القوية venv؛ وهي أداةٌ لإنشاء بيئات بايثون مستقلة، والصدفة التفاعلية Interactive shell التي توفر طريقةً سريعةً لتنفيذ الأوامر وتجربة واختبار الترميز البرمجي، وغيرها من الأدوات التي جعلت بايثون رائدةً بين لغات البرمجة في مجال علم البيانات. لغة جوليا Julia وبيئة Jupyter التفاعلية لا تمثل بايثون اللغة الوحيدة القادرة على تحليل البيانات، إذ يوجد العديد من اللغات الأخرى التي قد تتفوق عليها من حيث الشعبية بين علماء البيانات مثل لغة Julia، التي تركز على الأداء وطريقة رسم تصوِّر للبيانات من خلال تمثيلها بالرسوم والمخططات التوضيحية، وقد لاحظ مطوري بيئة التطوير التفاعلية iPython شعبية لغة Julia، فارتأوا تغيير اسم هذه البيئة إلى Jupyter (جوبيتر) وهي نتيجة دمج متعمَّد لكلٍ من اللغات Julia و Python و R . ويُستخدم في هذه الأيام تطبيق الويب Jupyter notebooks للحوسبة التفاعلية، الذي يسمح لعلماء البيانات بإنشاء ومشاركة المستندات التي تدمج التعليمات البرمجية الحية والمعادلات والمخرجات الحسابية والتصورات وموارد الوسائط المتعددة الأخرى في مكانٍ واحد، ورغم كونها أداةً قويةً إلّا أنّها سهلةٌ بما يكفي لتبدأ التعلّم بها حتى لو كنت ما تزال تتعلم كتابة الترميزات البرمجية. مستقبل علم البيانات مع استمرار تطور الحواسيب تزداد كميات البيانات المتوفرة من حولنا، فإذا كنت من الأشخاص المهتمين بفهم العالم من حولهم، فعلم البيانات من أفضل الوسائل لتحقيق ذلك، ولا تنسَ مشاركة ما تفعله أو تتعلمه في علم البيانات أيًا كان لتعم الفائدة على الجميع. ترجمة -وبتصرف- للمقال What is data science? من موقع opensource.com. اقرأ أيضًا مدخل إلى البيانات وأنواعها: أنواع البيانات الأساسية المفاهيم الأساسية في قواعد البيانات وتصميمها دليلك الشامل إلى أنواع البيانات دليلك الشامل إلى قواعد البيانات DataBase -
 أصبحت البيانات الضخمة Big Data حديث الناس في الآونة الأخيرة، ولكن ما هي البيانات الضخمة حقيقةً؟ كيف بإمكانها تغيير طريقة فهم الباحثين للعالم سواءً كانوا يعملون في الشركات، أو الهيئات غير الربحية، أو الجهات الحكومية، أو المؤسسات وغيرها من المنظمات؟ ما هي مصادر البيانات، كيف تُعالج، وكيف تُستخدم مخرجات عملية المعالجة؟ ولماذا يُعَد مفهوم المصادر المفتوحة أساسيًا في الإجابة عن التساؤلات السابقة؟ سنتعرّف في هذا المقال على كل ما يتعلّق بمفهوم البيانات الضخمة وأهميته في عالمنا المتغير. ما هي البيانات الضخمة؟ عندما نتحدث عن البيانات الضخمة فلن يحدد حجم قاعدة البيانات كونها ضخمةً أم لا، فلا يوجد قيدٌ صارمٌ ودقيق لحجم البيانات ضمن قاعدة البيانات كي نعدّها "ضخمة"، ولكن ما يحدد ذلك هو مقدار حاجتنا لاستخدام تقنياتٍ وأدواتٍ جديدة لمعالجة هذه البيانات. إذًا، للتعامل مع البيانات الضخمة، لابدّ من استخدام برامج تربط عدّة أجهزة فعلية أو افتراضية لتعمل معًا بتناغم في معالجة جميع البيانات خلال مدةٍ زمنيةٍ مقبولة. يتطلب تشغيل البرمجيات لكي تتخاطب فيما بينها بفعالية عندما تكون موزعةً على عدّة أجهزة تقنياتٍ برمجية خاصّة، بحيث تُوزَّع مهام معالجة البيانات بكفاءة، لتكون كل برمجية مسؤولةً عن قسمٍ محددٍ من البيانات لمعالجتها، وبذلك نستطيع تجميع مخرجات المعالجة من كل الأجهزة معًا بطريقةٍ نحقق من خلالها مفهوم البيانات الكبيرة. عند التفكير في تحديات التعامل مع البيانات الضخمة، لا بدّ من الأخذ في الحسبان أهمية توزيع البيانات في عناقيد clusters وكيفية ربط هذه العناقيد شبكيًا مع بعضها، وذلك نظرًا للمقارنة مع حقيقة أنّ وصول البرامج إلى البيانات المخزنة على جهاز محليًا أسرع بكثير من الوصول إليها شبكيًا. ما هي أنواع مجموعات البيانات التي تعد بيانات ضخمة؟ تتنوع استخدامات البيانات الضخمة بقدر كبر حجمها تقريبًا، وأحد أبرز الأمثلة المألوفة لمعظمنا هو كيفية تحليل شبكات التواصل الاجتماعي لبيانات مستخدميها بهدف الحصول على مزيدٍ من المعلومات عنهم، وبالتالي عرض محتوى وإعلانات ذات صلة باهتماماتهم، أو طريقة تحديد محركات البحث للعلاقة ما بين الاستعلامات والنتائج المعروضة، بحيث تقدّم إجابات أفضل على تساؤلات مستخدميها. استخدامات البيانات الضخمة أعم من ذلك بكثير، وأحد أكبر مصادر البيانات بكميات هائلة هي البيانات المالية، متضمِّنًا أسعار الأسهم والبيانات المصرفية وسجلات دفعات التجار، والمصدر الثاني هو بيانات أجهزة الاستشعار، إذ تأتي معظم هذه البيانات من ما يعرف باسم إنترنت الأشياء Internet of Things -أو اختصارًا IoT-، والتي قد تمثّل بيانات القياسات المأخوذة من قبل الروبوتات العاملة على خط إنتاج آلي في أحد مصانع السيارات، أو بيانات تحديد المواقع في شبكة اتصالات خلوي ما، أو بيانات كميات استهلاك الكهرباء اللحظية في المنازل والشركات، وصولًا إلى معلومات حركة الركاب الواردة من شركات النقل. تتمكن المؤسسات بتحليل هذه البيانات من معرفة صعود أو هبوط البيانات المسجَّلة ومعلومات الأشخاص الذين يمثّلون مصدر هذه البيانات. والآمال معقودة بأن يوفّر تحليل البيانات الضخمة خدمات أكثر تخصّصًا، وكفاءة إنتاجية أعلى في أي مجال صناعي تُجمع منه البيانات. كيفية تحليل البيانات الضخمة تُعد طريقة MapReduce إحدى أهم طرق تحويل البيانات الخام إلى معلوماتٍ مفيدة، وهي منهجية لإجراء العمليات الحسابية على البيانات من خلال عدة حواسيب وعلى التوازي؛ فهي تمثّل نموذجًا لكيفية برمجة العملية، ويُستخدم المصطلح MapReduce غالًا للإشارة إلى التطبيق الفعلي لهذا النموذج. تتألف منهجية MapReduce بصورةٍ رئيسية من جزأين، إذ يتمثَّل الأول في دالة التعيين Map function، والتي تفرز وترشِّح البيانات عبر توزيعها ضمن فئات مما يسهّل عملية تحليلها؛ أمّا الجزء الثاني فهو دالة التقليص Reduce function، التي تختصر البيانات عبر تجميعها معًا. وقد أصبح MapReduce مصطلحًا شاملًا يشير إلى نموذجٍ عام تستخدمه العديد من التقنيات، ويعود الفضل في ذلك إلى حدٍ كبير للبحث الذي أجرته جوجل Google حول هذا النموذج. ما هي الأدوات المستخدمة لتحليل البيانات الضخمة؟ تُعدّ Apache Hadoop الأداة الأكثر تأثيرًا وثباتًا في تحليل البيانات الضخمة؛ فهي إطار عملٍ واسع النطاق مفتوح المصدر يصنِّف ويعالج البيانات؛ كما يمكن لهذه الأداة أن تعمل على عتاد عادي استهلاكي commodity hardware (أو ما يُعرف باسم off-the-shelf hardware، وهي حواسيب أو أيٌ من تجهيزات تقانة المعلومات غير المكلفة وشعبية التوفّر، وتكون عادةً جدوى استبدالها بالكامل في حال حدوث أعطال أكبر من جدوى إصلاحها)، مما يجعلها فعّالة في الاستخدام مع مراكز البيانات الحالية، أو حتى لإجراء تحليل بيانات سحابي. وتُقسم Hadoop إجمالًا إلى أربعة أجزاء رئيسية: HDFS وهو مخزن بيانات يعتمد على نظام الملفات الموزعة، ومصمّمٌ للعمل مع حيز نطاق تراسلي عالٍ جدًا. منصة YARN المسؤولة عن إدارة موارد الأداة Hadoop وجدولة البرامج التي ستعمل على التجهيزات التي تستخدم هذه الأداة. نموذج إنجاز معالجة البيانات الضخمة وهو MapReduce المشروح أعلاه. مجموعة من المكتبات الشائعة الحاوية على نماذج معالجة بيانات أخرى قابلة للاستخدام. كما يوجد أدوات أخرى للتعامل مع البيانات الضخمة، إذ تُعد Apache Spark إحدى هذه الأدوات التي تحظى باهتمام بالغ؛ فهي متميزة بقدرتها على تخزين كمية كبيرة من البيانات في الذاكرة لمعالجتها. وبذلك، وعلى عكس آلية التخزين على الأقراص، تُعد Apache Spark أسرع بكثير لا سيما لبعض أنواع تحليل البيانات، ففي بعض التطبيقات سيحصل المحللون باستخدام هذه الأداة على نتائج أسرع بمئات المرات أو أكثر. ويمكن للأداة Spark استخدام نظام الملفات الموزعة HDFS أو غيره من مخازن البيانات، مثل Apache Cassandra، أو OpenStack Swift؛ كما من الممكن تشغيل Spark على جهاز محلي، مما يسهّل عمليات الاختبار والتطوير. بعض الأدوات الأخرى للتعامل مع البيانات الضخمة يوجد إجمالًا عددٌ غير محدود من الحلول مفتوحة المصدر للتعامل مع البيانات الضخمة، وقد خُصِّصت عدّة حلول منها لتوفير ميزات وأداء أمثل لمجال معين أو حتى لتجهيزات معينة ذات إعدادات خاصّة، وما سنعرضه فيما يلي لا يمثّل سوى جزءٍ من الأدوات التي تتعامل مع البيانات الضخمة. تدعم مؤسسة أباتشي Apache للبرمجيات Apache Software Foundation -أو اختصارًا ASF- عدّة مشاريع للبيانات الضخمة، ونذكر من هذه المشاريع المفيدة ما يلي: Apache Beam وهو نموذجٌ موّحدٌ لتعريف مجاري pipelines كلٍ من الدفعات batches وتدفقات البيانات المتوازية parallel، كما يسمح هذا النموذج للمطورين بكتابة الترميزات البرمجية التي تعمل على عدّة محركات معالجة. Apache Hive وهو مخزن بيانات مبني على Hadoop، ويُعد أحد مشاريع Apache عالية المستوى، إذ يسهّل قراءة وكتابة وإدارة مجموعات البيانات الكبيرة باستخدام SQL. Apache Impala وهو محرّك استعلامات في SQL يعمل مع الأداة Hadoop، وقد ضمِّن إلى حزمة Apache واشتُهر بقدرته على تحسين أداء استعلامات SQL باستخدام واجهة بسيطة مألوفة. Apache Kafka توفّر آلية تسمح للمستخدمين بالاتصال المستمر مع مصادر البيانات للحصول على البيانات باستقبال البيانات وتحديثاتها لحظيًا، وتهدف إلى تحقيق موثوقية عالية لدى استخدام أنظمة التخاطب المختلفة في نقل البيانات. Apache Lucene وهي مكتبة برمجية مختصّة بعمليات البحث وفهرسة البيانات؛ وتوفّر استعلامًا نصيًا لغويًا متقدّمًا لقواعد البيانات أو المستندات النصية full-text indexing؛ كما تستخدم أداة تصفية بيانات بالاعتماد على خوارزميات التعلم الآلي للتوصية بالعناصر الأكثر صلة لمستخدم معين recommendation engines، وتشكّل هذه المكتبة أساسًا للعديد من مشاريع البحث الأخرى مثل محركات البحث Solr وElasticsearch. Apache Pig وهي منصة لتحليل مجموعات البيانات الضخمة التي تعمل على الأداة Hadoop، وقد طورتها شركة ياهو Yahoo لإنجاز مهام MapReduce على مجموعات البيانات الضخمة، وكانت قد ساهمت ياهو في عام 2007 بها ضمن مشروع ASF. Apache Solr وهي منصة بحث متخصّصة للشركات، بُنيت اعتمادًا على مكتبة Lucene. Apache Zeppelin وهو مشروع احتضان (والاحتضان هو مرحلة وليس مكان، إذ تُحتضن المشاريع الجديدة لمدة عام أو عامين بهدف التطوير قبل الطرح). يتيح Apache Zeppelin إمكانية تحليل البيانات التفاعلية باستخدام لغة الاستعلامات SQL ولغات البرمجة الأخرى. تتضمّن الأدوات المفتوحة المصدر للتعامل مع البيانات الضخمة والتي قد ترغب بالتعرف عليها ما يلي: Elasticsearch وهو محرّك بحث آخر للمؤسسات يعتمد على مكتبة Lucene، ويمثّل جزءًا من محرك البحث المُسمى المكدس المرن Elastic stack والمعروف باسم مكدّس ELK كونه مؤلفًا من ثلاث مكونات، هي: Elasticsearch و Kibana و Logstash (محرك بحث للاستعلام النصي المتقدّم للمستندات النصية، ذو واجهة ويب HTTP يعتمد أيضًا على مكتبة Lucene). يستطيع المحرك Elasticsearch توليد نتائجٍ من البيانات سواءً كانت هذه البيانات مهيكلة أم لا. Cruise Control والتي طوِّرتها شركة لينكد إن LinkedIn لتشغيل مجموعات Apache Kafka على نطاقٍ أوسع. TensorFlow وهي مكتبة برمجية للتعلّم الآلي، تطورت هذه المكتبة سريعًا عندما جعلتها شركة غوغل Google مفتوحة المصدر في أواخر عام 2015، ولطالما أُشيد بها لسهولة استخدامها وتوفُّرها للجميع. وهكذا تستمر البيانات الضخمة بالنمو حجمًا وأهميةً، وبالتالي ستستمر الأدوات المفتوحة المصدر التي تتعامل معها بالنمو بكل تأكيد. ترجمة -وبتصرف- للمقال An introduction to big data من موقع opensource.com. اقرأ أيضًا المفاهيم الأساسية لتعلم الآلة نظرة سريعة على لغة الاستعلامات الهيكلية SQL
أصبحت البيانات الضخمة Big Data حديث الناس في الآونة الأخيرة، ولكن ما هي البيانات الضخمة حقيقةً؟ كيف بإمكانها تغيير طريقة فهم الباحثين للعالم سواءً كانوا يعملون في الشركات، أو الهيئات غير الربحية، أو الجهات الحكومية، أو المؤسسات وغيرها من المنظمات؟ ما هي مصادر البيانات، كيف تُعالج، وكيف تُستخدم مخرجات عملية المعالجة؟ ولماذا يُعَد مفهوم المصادر المفتوحة أساسيًا في الإجابة عن التساؤلات السابقة؟ سنتعرّف في هذا المقال على كل ما يتعلّق بمفهوم البيانات الضخمة وأهميته في عالمنا المتغير. ما هي البيانات الضخمة؟ عندما نتحدث عن البيانات الضخمة فلن يحدد حجم قاعدة البيانات كونها ضخمةً أم لا، فلا يوجد قيدٌ صارمٌ ودقيق لحجم البيانات ضمن قاعدة البيانات كي نعدّها "ضخمة"، ولكن ما يحدد ذلك هو مقدار حاجتنا لاستخدام تقنياتٍ وأدواتٍ جديدة لمعالجة هذه البيانات. إذًا، للتعامل مع البيانات الضخمة، لابدّ من استخدام برامج تربط عدّة أجهزة فعلية أو افتراضية لتعمل معًا بتناغم في معالجة جميع البيانات خلال مدةٍ زمنيةٍ مقبولة. يتطلب تشغيل البرمجيات لكي تتخاطب فيما بينها بفعالية عندما تكون موزعةً على عدّة أجهزة تقنياتٍ برمجية خاصّة، بحيث تُوزَّع مهام معالجة البيانات بكفاءة، لتكون كل برمجية مسؤولةً عن قسمٍ محددٍ من البيانات لمعالجتها، وبذلك نستطيع تجميع مخرجات المعالجة من كل الأجهزة معًا بطريقةٍ نحقق من خلالها مفهوم البيانات الكبيرة. عند التفكير في تحديات التعامل مع البيانات الضخمة، لا بدّ من الأخذ في الحسبان أهمية توزيع البيانات في عناقيد clusters وكيفية ربط هذه العناقيد شبكيًا مع بعضها، وذلك نظرًا للمقارنة مع حقيقة أنّ وصول البرامج إلى البيانات المخزنة على جهاز محليًا أسرع بكثير من الوصول إليها شبكيًا. ما هي أنواع مجموعات البيانات التي تعد بيانات ضخمة؟ تتنوع استخدامات البيانات الضخمة بقدر كبر حجمها تقريبًا، وأحد أبرز الأمثلة المألوفة لمعظمنا هو كيفية تحليل شبكات التواصل الاجتماعي لبيانات مستخدميها بهدف الحصول على مزيدٍ من المعلومات عنهم، وبالتالي عرض محتوى وإعلانات ذات صلة باهتماماتهم، أو طريقة تحديد محركات البحث للعلاقة ما بين الاستعلامات والنتائج المعروضة، بحيث تقدّم إجابات أفضل على تساؤلات مستخدميها. استخدامات البيانات الضخمة أعم من ذلك بكثير، وأحد أكبر مصادر البيانات بكميات هائلة هي البيانات المالية، متضمِّنًا أسعار الأسهم والبيانات المصرفية وسجلات دفعات التجار، والمصدر الثاني هو بيانات أجهزة الاستشعار، إذ تأتي معظم هذه البيانات من ما يعرف باسم إنترنت الأشياء Internet of Things -أو اختصارًا IoT-، والتي قد تمثّل بيانات القياسات المأخوذة من قبل الروبوتات العاملة على خط إنتاج آلي في أحد مصانع السيارات، أو بيانات تحديد المواقع في شبكة اتصالات خلوي ما، أو بيانات كميات استهلاك الكهرباء اللحظية في المنازل والشركات، وصولًا إلى معلومات حركة الركاب الواردة من شركات النقل. تتمكن المؤسسات بتحليل هذه البيانات من معرفة صعود أو هبوط البيانات المسجَّلة ومعلومات الأشخاص الذين يمثّلون مصدر هذه البيانات. والآمال معقودة بأن يوفّر تحليل البيانات الضخمة خدمات أكثر تخصّصًا، وكفاءة إنتاجية أعلى في أي مجال صناعي تُجمع منه البيانات. كيفية تحليل البيانات الضخمة تُعد طريقة MapReduce إحدى أهم طرق تحويل البيانات الخام إلى معلوماتٍ مفيدة، وهي منهجية لإجراء العمليات الحسابية على البيانات من خلال عدة حواسيب وعلى التوازي؛ فهي تمثّل نموذجًا لكيفية برمجة العملية، ويُستخدم المصطلح MapReduce غالًا للإشارة إلى التطبيق الفعلي لهذا النموذج. تتألف منهجية MapReduce بصورةٍ رئيسية من جزأين، إذ يتمثَّل الأول في دالة التعيين Map function، والتي تفرز وترشِّح البيانات عبر توزيعها ضمن فئات مما يسهّل عملية تحليلها؛ أمّا الجزء الثاني فهو دالة التقليص Reduce function، التي تختصر البيانات عبر تجميعها معًا. وقد أصبح MapReduce مصطلحًا شاملًا يشير إلى نموذجٍ عام تستخدمه العديد من التقنيات، ويعود الفضل في ذلك إلى حدٍ كبير للبحث الذي أجرته جوجل Google حول هذا النموذج. ما هي الأدوات المستخدمة لتحليل البيانات الضخمة؟ تُعدّ Apache Hadoop الأداة الأكثر تأثيرًا وثباتًا في تحليل البيانات الضخمة؛ فهي إطار عملٍ واسع النطاق مفتوح المصدر يصنِّف ويعالج البيانات؛ كما يمكن لهذه الأداة أن تعمل على عتاد عادي استهلاكي commodity hardware (أو ما يُعرف باسم off-the-shelf hardware، وهي حواسيب أو أيٌ من تجهيزات تقانة المعلومات غير المكلفة وشعبية التوفّر، وتكون عادةً جدوى استبدالها بالكامل في حال حدوث أعطال أكبر من جدوى إصلاحها)، مما يجعلها فعّالة في الاستخدام مع مراكز البيانات الحالية، أو حتى لإجراء تحليل بيانات سحابي. وتُقسم Hadoop إجمالًا إلى أربعة أجزاء رئيسية: HDFS وهو مخزن بيانات يعتمد على نظام الملفات الموزعة، ومصمّمٌ للعمل مع حيز نطاق تراسلي عالٍ جدًا. منصة YARN المسؤولة عن إدارة موارد الأداة Hadoop وجدولة البرامج التي ستعمل على التجهيزات التي تستخدم هذه الأداة. نموذج إنجاز معالجة البيانات الضخمة وهو MapReduce المشروح أعلاه. مجموعة من المكتبات الشائعة الحاوية على نماذج معالجة بيانات أخرى قابلة للاستخدام. كما يوجد أدوات أخرى للتعامل مع البيانات الضخمة، إذ تُعد Apache Spark إحدى هذه الأدوات التي تحظى باهتمام بالغ؛ فهي متميزة بقدرتها على تخزين كمية كبيرة من البيانات في الذاكرة لمعالجتها. وبذلك، وعلى عكس آلية التخزين على الأقراص، تُعد Apache Spark أسرع بكثير لا سيما لبعض أنواع تحليل البيانات، ففي بعض التطبيقات سيحصل المحللون باستخدام هذه الأداة على نتائج أسرع بمئات المرات أو أكثر. ويمكن للأداة Spark استخدام نظام الملفات الموزعة HDFS أو غيره من مخازن البيانات، مثل Apache Cassandra، أو OpenStack Swift؛ كما من الممكن تشغيل Spark على جهاز محلي، مما يسهّل عمليات الاختبار والتطوير. بعض الأدوات الأخرى للتعامل مع البيانات الضخمة يوجد إجمالًا عددٌ غير محدود من الحلول مفتوحة المصدر للتعامل مع البيانات الضخمة، وقد خُصِّصت عدّة حلول منها لتوفير ميزات وأداء أمثل لمجال معين أو حتى لتجهيزات معينة ذات إعدادات خاصّة، وما سنعرضه فيما يلي لا يمثّل سوى جزءٍ من الأدوات التي تتعامل مع البيانات الضخمة. تدعم مؤسسة أباتشي Apache للبرمجيات Apache Software Foundation -أو اختصارًا ASF- عدّة مشاريع للبيانات الضخمة، ونذكر من هذه المشاريع المفيدة ما يلي: Apache Beam وهو نموذجٌ موّحدٌ لتعريف مجاري pipelines كلٍ من الدفعات batches وتدفقات البيانات المتوازية parallel، كما يسمح هذا النموذج للمطورين بكتابة الترميزات البرمجية التي تعمل على عدّة محركات معالجة. Apache Hive وهو مخزن بيانات مبني على Hadoop، ويُعد أحد مشاريع Apache عالية المستوى، إذ يسهّل قراءة وكتابة وإدارة مجموعات البيانات الكبيرة باستخدام SQL. Apache Impala وهو محرّك استعلامات في SQL يعمل مع الأداة Hadoop، وقد ضمِّن إلى حزمة Apache واشتُهر بقدرته على تحسين أداء استعلامات SQL باستخدام واجهة بسيطة مألوفة. Apache Kafka توفّر آلية تسمح للمستخدمين بالاتصال المستمر مع مصادر البيانات للحصول على البيانات باستقبال البيانات وتحديثاتها لحظيًا، وتهدف إلى تحقيق موثوقية عالية لدى استخدام أنظمة التخاطب المختلفة في نقل البيانات. Apache Lucene وهي مكتبة برمجية مختصّة بعمليات البحث وفهرسة البيانات؛ وتوفّر استعلامًا نصيًا لغويًا متقدّمًا لقواعد البيانات أو المستندات النصية full-text indexing؛ كما تستخدم أداة تصفية بيانات بالاعتماد على خوارزميات التعلم الآلي للتوصية بالعناصر الأكثر صلة لمستخدم معين recommendation engines، وتشكّل هذه المكتبة أساسًا للعديد من مشاريع البحث الأخرى مثل محركات البحث Solr وElasticsearch. Apache Pig وهي منصة لتحليل مجموعات البيانات الضخمة التي تعمل على الأداة Hadoop، وقد طورتها شركة ياهو Yahoo لإنجاز مهام MapReduce على مجموعات البيانات الضخمة، وكانت قد ساهمت ياهو في عام 2007 بها ضمن مشروع ASF. Apache Solr وهي منصة بحث متخصّصة للشركات، بُنيت اعتمادًا على مكتبة Lucene. Apache Zeppelin وهو مشروع احتضان (والاحتضان هو مرحلة وليس مكان، إذ تُحتضن المشاريع الجديدة لمدة عام أو عامين بهدف التطوير قبل الطرح). يتيح Apache Zeppelin إمكانية تحليل البيانات التفاعلية باستخدام لغة الاستعلامات SQL ولغات البرمجة الأخرى. تتضمّن الأدوات المفتوحة المصدر للتعامل مع البيانات الضخمة والتي قد ترغب بالتعرف عليها ما يلي: Elasticsearch وهو محرّك بحث آخر للمؤسسات يعتمد على مكتبة Lucene، ويمثّل جزءًا من محرك البحث المُسمى المكدس المرن Elastic stack والمعروف باسم مكدّس ELK كونه مؤلفًا من ثلاث مكونات، هي: Elasticsearch و Kibana و Logstash (محرك بحث للاستعلام النصي المتقدّم للمستندات النصية، ذو واجهة ويب HTTP يعتمد أيضًا على مكتبة Lucene). يستطيع المحرك Elasticsearch توليد نتائجٍ من البيانات سواءً كانت هذه البيانات مهيكلة أم لا. Cruise Control والتي طوِّرتها شركة لينكد إن LinkedIn لتشغيل مجموعات Apache Kafka على نطاقٍ أوسع. TensorFlow وهي مكتبة برمجية للتعلّم الآلي، تطورت هذه المكتبة سريعًا عندما جعلتها شركة غوغل Google مفتوحة المصدر في أواخر عام 2015، ولطالما أُشيد بها لسهولة استخدامها وتوفُّرها للجميع. وهكذا تستمر البيانات الضخمة بالنمو حجمًا وأهميةً، وبالتالي ستستمر الأدوات المفتوحة المصدر التي تتعامل معها بالنمو بكل تأكيد. ترجمة -وبتصرف- للمقال An introduction to big data من موقع opensource.com. اقرأ أيضًا المفاهيم الأساسية لتعلم الآلة نظرة سريعة على لغة الاستعلامات الهيكلية SQL -
 راسبيري باي Raspberry Pi هو الاسم التجاري لسلسلة الحواسيب وحيدة اللوحة المُنتجة من قبل مؤسسة Raspberry Pi؛ وهي مؤسسة خيرية بريطانية غير ربحية تهدف إلى نشر ثقافة الحوسبة بين الناس وجعلها متاحةً بسهولة. أُطلقت لوحة راسبيري باي عام 2012، وأُصدرت عدة نسخٍ مكررةٍ ومطورةٍ منها منذ ذلك الحين؛ إذ كانت اللوحة الأساسية ذات وحدة معالجة مركزية CPU وحيدة النواة بسرعة 700 ميغا هرتز وذاكرة وصول عشوائي RAM بسعة 256 ميغا بايت فقط؛ أمّا الإصدار الأحدث منها فكان مع وحدة معالجة مركزية رباعية النواة بمعدّل نبضات ساعة يتجاوز 1.5 غيغا هرتز وذاكرة وصول عشوائي RAM بسعة 4 غيغا بايت، أمّا سعرها فلم يتجاوز 100$ يومًا، وهي عادةً بحدود 35$، حتى أن الإصدار "Pi Zero" كان بسعر 5$ فقط. استخدم الناس حول العالم لوحة راسبيري باي في المجالات التالية: تعلّم البرمجة. بناء مشاريع العتاد Hardware. استخدام الأتمتة في المنازل. تطبيق مجموعات Kubernetes وهو نظامٌ مفتوح المصدر لأتمتة وإدارة التطبيقات المتوضعة في الحاويات عبر عدة أجهزة والبيئات الافتراضية والمادية والسحابية والمحلية. الحوسبة الحدية Edge Computing، التي تجعل الحوسبة وتخزين البيانات أقرب إلى مصادر البيانات. التطبيقات الصناعية. إذًا، تُعَد لوحة راسبيري باي حاسوبًا قليل التكلفة يعمل بنظام تشغيل لينوكس Linux، ويوفّر مجموعةً من منافذ الإدخال والإخراج متعدّدة الأغراض GPIO، التي تسمح بالتحكم بالعناصر الإلكترونية لحالات الحوسبة الفيزيائية والعمل في مجال إنترنت الأشياء Internet of Things- أو اختصارًا IOT. إصدارات اللوحة راسبيري باي أُصدرت العديد من الأجيال للّوحة راسبيري باي ابتداءً من "Pi 1" إلى "Pi 4"، وحتّى Pi 400، كما أُصدر عمومًا نموذجين من معظم الأجيال، هما النموذج A والنموذج B؛ إذ يُعد النموذج A الأرخص وبسعة ذاكرة RAM أقل وعدد أقل من الأرجل (منافذ الـ USB ومنافذ الشبكة Ethernet). يُعَد الجيل "Pi Zero" نموذجًا مبسطًا من الجيل "Pi 1" الأصلي، ويتميز بكونه أصغر حجمًا وأقل سعرًا، ونبيِّن فيما يلي قائمةً بأجيال اللوحة: Pi 1 Model B (2012) Pi 1 Model A (2013) Pi 1 Model B+ (2014) Pi 1 Model A+ (2014) Pi 2 Model B (2015) Pi Zero (2015) Pi 3 Model B (2016) Pi Zero W (2017) Pi 3 Model B+ (2018) Pi 3 Model A+ (2019) Pi 4 Model A (2019) Pi 4 Model B (2020) Pi 400 (2021) مؤسسة راسبيري باي تسعى مؤسسة راسبيري باي لإتاحة الإمكانات الكبيرة للحوسبة والصناعة الرقمية للجميع حول العالم من خلال توفير حواسيب عالية الأداء ورخيصة الثمن ليتمكن الناس من استخدامها للتعلّم، أو حل المشاكل، أو حتى بهدف التسلية. كما أنها تسعى لتأمين طرق التواصل والتعليم اللازمة لمساعدة الناس على تعلّم الحوسبة والصناعة الرقمية، إذ أنها تطوّر مصادرًا مجانيةً لتعلّم الحوسبة وكيفية إنجاز المهام باستخدام الحواسيب، كما أنّها تدرّب أشخاصًا لتوجيه الآخرين نحو التعلُّم. ويُعد كلًا من المشروعين Code Club و CoderDojo جزءًا من مؤسسة راسبيري باي رغم كونهما منصاتٍ مستقلةً غير مرتبطة بلوحات راسبيري باي حصرًا. وتروّج مؤسسة راسبيري باي لهذه المشاريع وتسعى لتوسيع انتشارها بهدف ضمان إمكانية وصول كل طفلٍ حول العالم إلى تعلّم الحوسبة. إضافةً لذلك، يُقام الحدث Raspberry Jams لدعوة الناس من كل الفئات العمرية ليتعرفوا معًا على راسبيري باي ويتبادلون الأفكار والمشاريع. راسبيري باي والمصادر المفتوحة تعمل راسبيري باي مع الأنظمة مفتوحة المصدر؛ فهي قادرةٌ على تشغيل نظام لينوكس Linux ودعم عدّة توزيعات منه؛ كما أن نظام تشغيلها الأساسي "Pi OS" مفتوح المصدر أيضًا ويدير مجموعةً من البرامج مفتوحة المصدر. وتعد مؤسسة راسبيري باي من المساهمين في نواة لينوكس وغيرها من المشاريع مفتوحة المصدر، بالإضافة إلى إصدارها عدة برمجيات مفتوحة المصدر خاصّةً بها، ومخططات راسبيري باي دوريًا بمثابة توثيق documentation. ولكن في الواقع، لا تُعد لوحات راسبيري باي عتادً مفتوحًا (العتاد المفتوح هو العتاد المُرخص به، بحيث يمكن لأي شخص دراسته والتعديل عليه وإعادة توزيعه). تعتمد مؤسسة راسبيري باي على الأرباح من مبيعات وحدات راسبيري باي لإنجاز أعمالها الخيرية في قطاع التعليم. ما يمكنك إنجازه مع لوحة راسبيري باي يشتري بعض الناس لوحة راسبيري باي ليتعلموا كتابة الشيفرات البرمجية؛ أما الأشخاص الذين يعرفون أصلًا كتابتها فيستخدمون اللوحة لتعلّم برمجة الدارات الإلكترونية والمشاريع الفيزيائية. تفتح لوحة راسبيري باي أمامك الآفاق لإنشاء مشاريعك الخاصة، والتي من شأنها أتمتة منزلك؛ وهو أمرٌ شائعٌ في مجتمعات المصادر المفتوحة، لأنه يمنحك كافّة إمكانات السيطرة على مشروعك بدلاً من استخدام نظام مغلقٍ خاصٍ بغيرك. تبيّن القائمة التالية بعض المشاريع الممكن تنفيذها باستخدام راسبيري باي: حظر الإعلانات على شبكتك باستخدام "pi-hole". إنشاء قاعدة بيانات "PostgreSQL" في راسبيري باي. إنشاء مجيب آلي لتويتر Twitter الخاص بك باستخدام لغة بايثون Python وراسبيري باي. بناء مشاريع باستخدام الكاميرا الخاصّة بلوحة راسبيري باي وأي تجهيزات وعتاد يمكن وصلها بها. إنشاء عارض صور رقمي. القائمة السابقة هي على سبيل المثال لا الحصر إذ المشاريع التي يمكن تنفيذها براسبيري باي لا تحصى، ونترك بين يديك هذا الحاسوب الرائع لتجرب وتتعلم وتبدع. ترجمة -وبتصرف- للمقال What is Raspberry Pi? من موقع opensource.com. اقرأ أيضًا جولة في راسبيان: نظام تشغيل راسبيري باي تجميع راسبيري باي والتحضير لاستعماله إعداد Raspberry Pi للعمل بدء استخدام راسبيري باي تخصيص واجهة سطح مكتب راسبيري باي
راسبيري باي Raspberry Pi هو الاسم التجاري لسلسلة الحواسيب وحيدة اللوحة المُنتجة من قبل مؤسسة Raspberry Pi؛ وهي مؤسسة خيرية بريطانية غير ربحية تهدف إلى نشر ثقافة الحوسبة بين الناس وجعلها متاحةً بسهولة. أُطلقت لوحة راسبيري باي عام 2012، وأُصدرت عدة نسخٍ مكررةٍ ومطورةٍ منها منذ ذلك الحين؛ إذ كانت اللوحة الأساسية ذات وحدة معالجة مركزية CPU وحيدة النواة بسرعة 700 ميغا هرتز وذاكرة وصول عشوائي RAM بسعة 256 ميغا بايت فقط؛ أمّا الإصدار الأحدث منها فكان مع وحدة معالجة مركزية رباعية النواة بمعدّل نبضات ساعة يتجاوز 1.5 غيغا هرتز وذاكرة وصول عشوائي RAM بسعة 4 غيغا بايت، أمّا سعرها فلم يتجاوز 100$ يومًا، وهي عادةً بحدود 35$، حتى أن الإصدار "Pi Zero" كان بسعر 5$ فقط. استخدم الناس حول العالم لوحة راسبيري باي في المجالات التالية: تعلّم البرمجة. بناء مشاريع العتاد Hardware. استخدام الأتمتة في المنازل. تطبيق مجموعات Kubernetes وهو نظامٌ مفتوح المصدر لأتمتة وإدارة التطبيقات المتوضعة في الحاويات عبر عدة أجهزة والبيئات الافتراضية والمادية والسحابية والمحلية. الحوسبة الحدية Edge Computing، التي تجعل الحوسبة وتخزين البيانات أقرب إلى مصادر البيانات. التطبيقات الصناعية. إذًا، تُعَد لوحة راسبيري باي حاسوبًا قليل التكلفة يعمل بنظام تشغيل لينوكس Linux، ويوفّر مجموعةً من منافذ الإدخال والإخراج متعدّدة الأغراض GPIO، التي تسمح بالتحكم بالعناصر الإلكترونية لحالات الحوسبة الفيزيائية والعمل في مجال إنترنت الأشياء Internet of Things- أو اختصارًا IOT. إصدارات اللوحة راسبيري باي أُصدرت العديد من الأجيال للّوحة راسبيري باي ابتداءً من "Pi 1" إلى "Pi 4"، وحتّى Pi 400، كما أُصدر عمومًا نموذجين من معظم الأجيال، هما النموذج A والنموذج B؛ إذ يُعد النموذج A الأرخص وبسعة ذاكرة RAM أقل وعدد أقل من الأرجل (منافذ الـ USB ومنافذ الشبكة Ethernet). يُعَد الجيل "Pi Zero" نموذجًا مبسطًا من الجيل "Pi 1" الأصلي، ويتميز بكونه أصغر حجمًا وأقل سعرًا، ونبيِّن فيما يلي قائمةً بأجيال اللوحة: Pi 1 Model B (2012) Pi 1 Model A (2013) Pi 1 Model B+ (2014) Pi 1 Model A+ (2014) Pi 2 Model B (2015) Pi Zero (2015) Pi 3 Model B (2016) Pi Zero W (2017) Pi 3 Model B+ (2018) Pi 3 Model A+ (2019) Pi 4 Model A (2019) Pi 4 Model B (2020) Pi 400 (2021) مؤسسة راسبيري باي تسعى مؤسسة راسبيري باي لإتاحة الإمكانات الكبيرة للحوسبة والصناعة الرقمية للجميع حول العالم من خلال توفير حواسيب عالية الأداء ورخيصة الثمن ليتمكن الناس من استخدامها للتعلّم، أو حل المشاكل، أو حتى بهدف التسلية. كما أنها تسعى لتأمين طرق التواصل والتعليم اللازمة لمساعدة الناس على تعلّم الحوسبة والصناعة الرقمية، إذ أنها تطوّر مصادرًا مجانيةً لتعلّم الحوسبة وكيفية إنجاز المهام باستخدام الحواسيب، كما أنّها تدرّب أشخاصًا لتوجيه الآخرين نحو التعلُّم. ويُعد كلًا من المشروعين Code Club و CoderDojo جزءًا من مؤسسة راسبيري باي رغم كونهما منصاتٍ مستقلةً غير مرتبطة بلوحات راسبيري باي حصرًا. وتروّج مؤسسة راسبيري باي لهذه المشاريع وتسعى لتوسيع انتشارها بهدف ضمان إمكانية وصول كل طفلٍ حول العالم إلى تعلّم الحوسبة. إضافةً لذلك، يُقام الحدث Raspberry Jams لدعوة الناس من كل الفئات العمرية ليتعرفوا معًا على راسبيري باي ويتبادلون الأفكار والمشاريع. راسبيري باي والمصادر المفتوحة تعمل راسبيري باي مع الأنظمة مفتوحة المصدر؛ فهي قادرةٌ على تشغيل نظام لينوكس Linux ودعم عدّة توزيعات منه؛ كما أن نظام تشغيلها الأساسي "Pi OS" مفتوح المصدر أيضًا ويدير مجموعةً من البرامج مفتوحة المصدر. وتعد مؤسسة راسبيري باي من المساهمين في نواة لينوكس وغيرها من المشاريع مفتوحة المصدر، بالإضافة إلى إصدارها عدة برمجيات مفتوحة المصدر خاصّةً بها، ومخططات راسبيري باي دوريًا بمثابة توثيق documentation. ولكن في الواقع، لا تُعد لوحات راسبيري باي عتادً مفتوحًا (العتاد المفتوح هو العتاد المُرخص به، بحيث يمكن لأي شخص دراسته والتعديل عليه وإعادة توزيعه). تعتمد مؤسسة راسبيري باي على الأرباح من مبيعات وحدات راسبيري باي لإنجاز أعمالها الخيرية في قطاع التعليم. ما يمكنك إنجازه مع لوحة راسبيري باي يشتري بعض الناس لوحة راسبيري باي ليتعلموا كتابة الشيفرات البرمجية؛ أما الأشخاص الذين يعرفون أصلًا كتابتها فيستخدمون اللوحة لتعلّم برمجة الدارات الإلكترونية والمشاريع الفيزيائية. تفتح لوحة راسبيري باي أمامك الآفاق لإنشاء مشاريعك الخاصة، والتي من شأنها أتمتة منزلك؛ وهو أمرٌ شائعٌ في مجتمعات المصادر المفتوحة، لأنه يمنحك كافّة إمكانات السيطرة على مشروعك بدلاً من استخدام نظام مغلقٍ خاصٍ بغيرك. تبيّن القائمة التالية بعض المشاريع الممكن تنفيذها باستخدام راسبيري باي: حظر الإعلانات على شبكتك باستخدام "pi-hole". إنشاء قاعدة بيانات "PostgreSQL" في راسبيري باي. إنشاء مجيب آلي لتويتر Twitter الخاص بك باستخدام لغة بايثون Python وراسبيري باي. بناء مشاريع باستخدام الكاميرا الخاصّة بلوحة راسبيري باي وأي تجهيزات وعتاد يمكن وصلها بها. إنشاء عارض صور رقمي. القائمة السابقة هي على سبيل المثال لا الحصر إذ المشاريع التي يمكن تنفيذها براسبيري باي لا تحصى، ونترك بين يديك هذا الحاسوب الرائع لتجرب وتتعلم وتبدع. ترجمة -وبتصرف- للمقال What is Raspberry Pi? من موقع opensource.com. اقرأ أيضًا جولة في راسبيان: نظام تشغيل راسبيري باي تجميع راسبيري باي والتحضير لاستعماله إعداد Raspberry Pi للعمل بدء استخدام راسبيري باي تخصيص واجهة سطح مكتب راسبيري باي -
 دوكر Docker هو إطار عملٍ برمجي، يهدف إلى بناء وتشغيل وإدارة الحاويات على الخوادم والسحابة؛ وهو جزءٌ من مشروع Moby؛ ويشير عادةً المصطلح "دوكر" إلى الأدوات من أوامرٍ وبرامج خفية، أو إلى الملفات من النوع دوكر Dockerfile. إذا أردت تشغيل تطبيق ويب، جرت العادة بأن تشتري خادمًا وتنزّل عليه نظام تشغيل لينكس، وتبدأ بإعداد حزمة LAMP، ومن ثمّ تشغِّل التطبيق؛ وعند زيادة الطلب على تطبيقك، ستلجأ إلى موازنة الحمل من خلال إعداد خادمٍ ثانٍ لضمان عدم توقّف التطبيق بسبب كثرة الزيارات. أمّا في وقتنا هذا اختلف الأمر؛ فبدلًا من الاعتماد على استخدام خادماتٍ وحيدة، بُنيت شبكة الإنترنت مثلًا اعتمادًا على مصفوفةٍ ضخمة من الخوادم المترابطة ضمن نظامٍ اسمه الشائع هو "السحابة"، وبالتالي وبفضل الابتكارات، مثل نواة نطاق الأسماء و cgroups من لينكس، تحرّر مفهوم الخادم من قيود كونه عتادًا وأصبح عوضًا عن ذلك مفهومًا برمجيًا. يُطلق على الخوادم المبنية برمجيًا اسم الحاويات Containers؛ وهي مزيجٌ هجين من نظام التشغيل لينكس الذي يشغّلها، إضافةً إلى بيئة وقت تشغيل تفاعلية متوضعّة ضمن الخادم تمثّل محتويات الحاوية. التعرف على مفهوم الحاويات يمكن تصنيف تقنية الحاويات إلى ثلاثة جوانب مختلفة: البناء: إذ تُستخدم أداةٌ أو مجموعةٌ من الأدوات لبناء الحاوية، مثل أداة distrobuilder لحاويات LXC؛ وهي إحدى حاويات نظام لينكس وتمثّل بيئةً وهميةً تعمل على مستوى النظام تشغِّل عدة أنظمة لينكس معزولة على جهازٍ واحدٍ ذي نظام لينكس مضيف، وأداة Dockerfile لحاويات دوكر. التشغيل (المحرّك): إذ يُستخدم تطبيقٌ لتشغيل الحاوية، ويمثّل هذا التطبيق بالنسبة لحاويات دوكر واجهة أسطر الأوامر docker command وتطبيق دوكر الخفي dockerd daemon؛ أمّا بالنسبة للحاويات الأُخرى فهو يشير غالبًا إلى التطبيق الخفي وأوامره، مثل podman (وهي أداةٌ مفتوحة المصدر مصمّمةٌ لتسهيل العثور على التطبيقات وتشغيلها وبنائها ومشاركتها ونشرها باستخدام الحاويات المفتوحة، كما توفّر واجهة سطر أوامر مألوفةٍ لأي شخص استخدم محرّك حاويات دوكر). التناسق Orchestration: وهي التقنية المستخدمة لإدارة مجموعةٍ من الحاويات وتتضمّن أنظمة تناسق الحاويات، مثل "Kubernetes" و "OKD". توفّر الحاويات غالبًا كلًا من التطبيق والضبط اللازم لعملها، وبالتالي لن يضطر مدير النظام لقضاء وقتٍ طويل في الحصول على تطبيقٍ لتشغيل الحاوية كون هذا التطبيق موجودٌ ومثبّتٌ أصلًا. ويمثّل كل من Dockerhub و Quay.io مستودعات توفّر صورًا لاستخدامها من قِبل محركات الحاويات. ومن أهم ميزات الحاويات هي ديناميكيتها العالية؛ فهي قادرةٌ على التوقّف عن العمل والاختفاء ومن ثمّ العودة بكل مرونة، وذلك حسب حالة الحمل وبما يضمن توازنه، وتكون عملية إعادة تشغيل الحاوية سريعة ومنخفضة المتطلبات سواءً كان توقّفها ناتجٌ عن عطلٍ ما، أو ببساطة بسبب عدم الحاجة إليها عند انخفاض مستوى الحركة على الخادم، فالحاويات مصمّمةٌ لتظهر وتختفي بكل سلاسة. نظرًا لهذه الميزات وبما أنّ الحاويات سريعة الاختفاء من ناحية، وقادرة على تشغيل العديد منها عند الحاجة من ناحية أُخرى، فمن المتوقّع ألّا يجري مراقبتها وإدارتها من قِبل إنسانٍ في الوقت الفعلي، بل يحدث ذلك تلقائيًا. بدائل حاويات دوكر سهّلت حاويات لينكس إحراز تقدمٍ هائلٍ في الحوسبة عالية التوفّر، إذ يوجد العديد من مجموعات الأدوات القادرة على مساعدتك في تشغيل الخدمات، أو نظام التشغيل كاملًا في الحاويات. تشجّع مبادرة الحاوية المفتوحة OCI -وهي منظمة معايير صناعية- الابتكار بما يضمن تجنُّب مشكلة قفل العميل vendor lock-in، أي اضطرار العميل إلى الاستمرار في استخدام منتجٍ أو خدمة بغض النظر عن جودتها؛ حيث أصبح بإمكانك وبفضل هذه المبادرة اختيار مجموعة أدوات الحاويات سواءٌ كانت دوكر، CRI-O، Podman، LXC، أو غيرها. خدمات الحاويات لقد صُمّمت الحاويات بحيث تتضاعف بسرعة عند الحاجة، سواءٌ كنت تشغّل عدّة خدماتٍ مختلفةٍ معًا، أو نسخًا عديدة من خدماتٍ قليلة؛ فإذا قررت تشغيل خدمات في حاوية، فستحتاج إلى برمجية لاستضافة وإدارة هذه الحاوية، وهو ما يُسمّى بتنسيق الحاوية container orchestration، فبالرغم من كون دوكر وغيره من محركات الحاويات، مثل "Podman" و "CRI-O" أدواتٍ جيدة لتعريف الحاويات وصورها، إلّا أنّ عملها ينحصر في إنشاء وتشغيل الحاوية نفسها وليس تنظيمها وإدارتها. وتوفّر بعض المشاريع، مثل Kubernetes و OKD منظمات للحاويات لكل من دوكر و "Podman" و "CRI-O" وغيرها. قد ترغب عند استخدامك لأي من هذه المشاريع في الحصول على الدعم اللاحق عبر مشروعٍ مثل OpenShift المُعتمد أصلًا على "OKD". ما عليك معرفته حول الإصدار المشترك من دوكر جُمِّعت المكونات مفتوحة المصدر من دوكر ضمن منتجٍ يُدعى الإصدار المشترك من دوكر -أو اختصارًا docker-ce-، الذي يتضمّن محرك دوكر ومجموعةً من أوامر الطرفية لمساعدة مدراء الأنظمة على إدارة جميع الحاويات قيد الاستخدام. يمكنك تثبيت مجموعة الأدوات هذه عبر البحث عن دوكر في مدير الحزم الموزعة distribution's package manager. لماذا نستخدم دوكر ؟ تُعدّ إمكانية اختيار التقنية المستخدمة في إنجاز مهمّةٍ ما واحدةً من أهم ميزات المصادر المفتوحة. ويوفّر محرّك دوكر بيئة تجريب مفيدة للمطورين كونها بيئةً نظيفةً وخفيفة الحمولة لا تحتاج تنظيمًا معقدًا، إذ يُعد استخدام الإصدار المشترك من دوكر docker-ce أحد أفضل الطرق للبدء باستخدام الحاويات لا سيما في حال كونه متوفرًا على نظامك وكنت على درايةٍ بسلسلة أدوات دوكر. يُعد كلٌ من Dockerhub و Quay.io مستودعاتٍ تقدم صورًا لمحرك الحاوية الذي اخترته، ويُفضَّل استخدام "Podman" إذا كان الإصدار المشترك من دوكر غير متاح أو غير مدعوم. لا تزال الجهود تُبذل لتمكين المصادر المفتوحة على نحوٍ أكبر، لذا يجب أن تتماشى مشاريعك المستقبلية باستخدام الحاويات مع المصادر والمعايير المفتوحة؛ فبالرغم من كون الاضافات الاحتكارية مغلقة المصدر قد تبدو جذابة إلا أنّها تفقد مرونتها من حيث إمكانية الاختيار، كون أدواتك محصورةً في منتجٍ واحد. باختصار، ستمنحك الحاويات الحرية، طالما كانت هي حرة أصلًا. ترجمة -وبتصرف- للمقال ?What is Docker من موقع opensource.com. اقرأ أيضًا مقدّمة عن المُكوّنات المُشترَكة في Docker نظرة عامّة على إعداد الحاويّات containerization على Docker التعامل مع حاويات Docker
دوكر Docker هو إطار عملٍ برمجي، يهدف إلى بناء وتشغيل وإدارة الحاويات على الخوادم والسحابة؛ وهو جزءٌ من مشروع Moby؛ ويشير عادةً المصطلح "دوكر" إلى الأدوات من أوامرٍ وبرامج خفية، أو إلى الملفات من النوع دوكر Dockerfile. إذا أردت تشغيل تطبيق ويب، جرت العادة بأن تشتري خادمًا وتنزّل عليه نظام تشغيل لينكس، وتبدأ بإعداد حزمة LAMP، ومن ثمّ تشغِّل التطبيق؛ وعند زيادة الطلب على تطبيقك، ستلجأ إلى موازنة الحمل من خلال إعداد خادمٍ ثانٍ لضمان عدم توقّف التطبيق بسبب كثرة الزيارات. أمّا في وقتنا هذا اختلف الأمر؛ فبدلًا من الاعتماد على استخدام خادماتٍ وحيدة، بُنيت شبكة الإنترنت مثلًا اعتمادًا على مصفوفةٍ ضخمة من الخوادم المترابطة ضمن نظامٍ اسمه الشائع هو "السحابة"، وبالتالي وبفضل الابتكارات، مثل نواة نطاق الأسماء و cgroups من لينكس، تحرّر مفهوم الخادم من قيود كونه عتادًا وأصبح عوضًا عن ذلك مفهومًا برمجيًا. يُطلق على الخوادم المبنية برمجيًا اسم الحاويات Containers؛ وهي مزيجٌ هجين من نظام التشغيل لينكس الذي يشغّلها، إضافةً إلى بيئة وقت تشغيل تفاعلية متوضعّة ضمن الخادم تمثّل محتويات الحاوية. التعرف على مفهوم الحاويات يمكن تصنيف تقنية الحاويات إلى ثلاثة جوانب مختلفة: البناء: إذ تُستخدم أداةٌ أو مجموعةٌ من الأدوات لبناء الحاوية، مثل أداة distrobuilder لحاويات LXC؛ وهي إحدى حاويات نظام لينكس وتمثّل بيئةً وهميةً تعمل على مستوى النظام تشغِّل عدة أنظمة لينكس معزولة على جهازٍ واحدٍ ذي نظام لينكس مضيف، وأداة Dockerfile لحاويات دوكر. التشغيل (المحرّك): إذ يُستخدم تطبيقٌ لتشغيل الحاوية، ويمثّل هذا التطبيق بالنسبة لحاويات دوكر واجهة أسطر الأوامر docker command وتطبيق دوكر الخفي dockerd daemon؛ أمّا بالنسبة للحاويات الأُخرى فهو يشير غالبًا إلى التطبيق الخفي وأوامره، مثل podman (وهي أداةٌ مفتوحة المصدر مصمّمةٌ لتسهيل العثور على التطبيقات وتشغيلها وبنائها ومشاركتها ونشرها باستخدام الحاويات المفتوحة، كما توفّر واجهة سطر أوامر مألوفةٍ لأي شخص استخدم محرّك حاويات دوكر). التناسق Orchestration: وهي التقنية المستخدمة لإدارة مجموعةٍ من الحاويات وتتضمّن أنظمة تناسق الحاويات، مثل "Kubernetes" و "OKD". توفّر الحاويات غالبًا كلًا من التطبيق والضبط اللازم لعملها، وبالتالي لن يضطر مدير النظام لقضاء وقتٍ طويل في الحصول على تطبيقٍ لتشغيل الحاوية كون هذا التطبيق موجودٌ ومثبّتٌ أصلًا. ويمثّل كل من Dockerhub و Quay.io مستودعات توفّر صورًا لاستخدامها من قِبل محركات الحاويات. ومن أهم ميزات الحاويات هي ديناميكيتها العالية؛ فهي قادرةٌ على التوقّف عن العمل والاختفاء ومن ثمّ العودة بكل مرونة، وذلك حسب حالة الحمل وبما يضمن توازنه، وتكون عملية إعادة تشغيل الحاوية سريعة ومنخفضة المتطلبات سواءً كان توقّفها ناتجٌ عن عطلٍ ما، أو ببساطة بسبب عدم الحاجة إليها عند انخفاض مستوى الحركة على الخادم، فالحاويات مصمّمةٌ لتظهر وتختفي بكل سلاسة. نظرًا لهذه الميزات وبما أنّ الحاويات سريعة الاختفاء من ناحية، وقادرة على تشغيل العديد منها عند الحاجة من ناحية أُخرى، فمن المتوقّع ألّا يجري مراقبتها وإدارتها من قِبل إنسانٍ في الوقت الفعلي، بل يحدث ذلك تلقائيًا. بدائل حاويات دوكر سهّلت حاويات لينكس إحراز تقدمٍ هائلٍ في الحوسبة عالية التوفّر، إذ يوجد العديد من مجموعات الأدوات القادرة على مساعدتك في تشغيل الخدمات، أو نظام التشغيل كاملًا في الحاويات. تشجّع مبادرة الحاوية المفتوحة OCI -وهي منظمة معايير صناعية- الابتكار بما يضمن تجنُّب مشكلة قفل العميل vendor lock-in، أي اضطرار العميل إلى الاستمرار في استخدام منتجٍ أو خدمة بغض النظر عن جودتها؛ حيث أصبح بإمكانك وبفضل هذه المبادرة اختيار مجموعة أدوات الحاويات سواءٌ كانت دوكر، CRI-O، Podman، LXC، أو غيرها. خدمات الحاويات لقد صُمّمت الحاويات بحيث تتضاعف بسرعة عند الحاجة، سواءٌ كنت تشغّل عدّة خدماتٍ مختلفةٍ معًا، أو نسخًا عديدة من خدماتٍ قليلة؛ فإذا قررت تشغيل خدمات في حاوية، فستحتاج إلى برمجية لاستضافة وإدارة هذه الحاوية، وهو ما يُسمّى بتنسيق الحاوية container orchestration، فبالرغم من كون دوكر وغيره من محركات الحاويات، مثل "Podman" و "CRI-O" أدواتٍ جيدة لتعريف الحاويات وصورها، إلّا أنّ عملها ينحصر في إنشاء وتشغيل الحاوية نفسها وليس تنظيمها وإدارتها. وتوفّر بعض المشاريع، مثل Kubernetes و OKD منظمات للحاويات لكل من دوكر و "Podman" و "CRI-O" وغيرها. قد ترغب عند استخدامك لأي من هذه المشاريع في الحصول على الدعم اللاحق عبر مشروعٍ مثل OpenShift المُعتمد أصلًا على "OKD". ما عليك معرفته حول الإصدار المشترك من دوكر جُمِّعت المكونات مفتوحة المصدر من دوكر ضمن منتجٍ يُدعى الإصدار المشترك من دوكر -أو اختصارًا docker-ce-، الذي يتضمّن محرك دوكر ومجموعةً من أوامر الطرفية لمساعدة مدراء الأنظمة على إدارة جميع الحاويات قيد الاستخدام. يمكنك تثبيت مجموعة الأدوات هذه عبر البحث عن دوكر في مدير الحزم الموزعة distribution's package manager. لماذا نستخدم دوكر ؟ تُعدّ إمكانية اختيار التقنية المستخدمة في إنجاز مهمّةٍ ما واحدةً من أهم ميزات المصادر المفتوحة. ويوفّر محرّك دوكر بيئة تجريب مفيدة للمطورين كونها بيئةً نظيفةً وخفيفة الحمولة لا تحتاج تنظيمًا معقدًا، إذ يُعد استخدام الإصدار المشترك من دوكر docker-ce أحد أفضل الطرق للبدء باستخدام الحاويات لا سيما في حال كونه متوفرًا على نظامك وكنت على درايةٍ بسلسلة أدوات دوكر. يُعد كلٌ من Dockerhub و Quay.io مستودعاتٍ تقدم صورًا لمحرك الحاوية الذي اخترته، ويُفضَّل استخدام "Podman" إذا كان الإصدار المشترك من دوكر غير متاح أو غير مدعوم. لا تزال الجهود تُبذل لتمكين المصادر المفتوحة على نحوٍ أكبر، لذا يجب أن تتماشى مشاريعك المستقبلية باستخدام الحاويات مع المصادر والمعايير المفتوحة؛ فبالرغم من كون الاضافات الاحتكارية مغلقة المصدر قد تبدو جذابة إلا أنّها تفقد مرونتها من حيث إمكانية الاختيار، كون أدواتك محصورةً في منتجٍ واحد. باختصار، ستمنحك الحاويات الحرية، طالما كانت هي حرة أصلًا. ترجمة -وبتصرف- للمقال ?What is Docker من موقع opensource.com. اقرأ أيضًا مقدّمة عن المُكوّنات المُشترَكة في Docker نظرة عامّة على إعداد الحاويّات containerization على Docker التعامل مع حاويات Docker -
 تتعرف نواة Kernel نظام التشغيل سواءً كان Mach، أو BSD، أو لينكس Linux، أو NT على كافّة التجهيزات والعتاد المتصلة بالحاسوب عند إقلاعه باستخدام برنامج رئيسي، وتمكّنها من التواصل مع بعضها بعضًا، كما تضمن عملها على نحوٍ متناغم؛ إذ تؤدّي مجموعة التعليمات الرئيسية هذه مجموعةً من المهام، مثل إبقاء الحاسوب في حالة تشغيل وبوضعٍ آمن من خلال تشغيل مراوح التبريد دوريًا لتجنّب زيادة درجة الحرارة مثلًا، إضافةً لاستخدامها أنظمةً فرعيةً مسؤولةً عن مراقبة مساحة القرص الصلب أو التنبّه عند وصل أجهزة جديدة بالحاسوب وغيرها من العمليات. ولكن ليس هذا جلّ ما يفعله الحاسوب، وإلا كانت أهميته مثل أهمية الفرن في المنزل. أدرك علماء الحواسيب مبكرًا أهمية جعل البشر قادرين على التفاعل مع الحاسوب متى أرادوا ذلك، لذا طوروا صدفةً Shell خاصّةً بالحواسيب العاملة على نظام يونكس Unix؛ إذ تعمل هذه الصدفة خارج النواة أو حولها مثل مبدأ الصدفة في الطبيعة، وقد شكّلت هذه الصدفة تطورًا مهمًا في الوقت الذي كان الناس فيه يوجهون الأوامر للحواسيب باستخدام البطاقات المثقبّة، وتعدّ Bash واحدةً من أكثر الصدفات shells شعبيةً وأكثرها فعاليةً وسهولةً. باش Bash هو تطبيق عندما تفتح طرفيةً Terminal تُشغِّل صدفة باش، مثل GNOME Terminal، أو Konsole في نظام لينكس، أو iTerm2 في نظام ماك، أو إس macOS، فسُيرَحب بك غالبًا من خلال محث prompt؛ والذي يكون عادةً رمزًا وهو إشارة ($)، والذي يعني أن الصدفة بانتظارك لإدخال أمر. ولا بُد بالتأكيد من معرفة ما عليك كتابته من أوامر، وهذه الأوامر موضوعٌ مستقلٌ تمامًا كما سنرى. قد يكون التعبير التالي غير لطيف، إلّا أنّه يمثّل بدقة عدّة دلالاتٍ متعلقّة بمصطلح باش؛ إذ لا يميز كثيرٌ من المستخدمين الجدد بين مفهوم باش ومفهوم لينكس أو يونكس؛ فبالنسبة لهم باش هو الشاشة السوداء ذات الكتابة الخضراء التي تُكتب فيها الشيفرة اللازمة لإعطاء الأوامر للحاسوب. هذا المفهوم فيه خلطٌ ما بين صدفة باش والأوامر التي نكتبها داخل الصدفة، ومن المهم فهم أنهما مفهومان مستقلان؛ إذ أنّ باش مجرّد تطبيقٍ مهمته الرئيسية تشغيل التطبيقات الأخرى ضمن نفس النظام (من خلال أوامر). إذًا، يمكنك تعلّم باش في سياق تعلّم نظام التشغيل الذي يعمل عليه، ولكن لا يمكنك استخدامه فعليًا ما لم تتعرف على الأوامر. أوامر نظام لينكس تُخزَّن معظم الأوامر افتراضيًا في مجلدات النظام في الأنظمة المعتمدة على يونكس ولينكس (نظام BSD و macOS) في مساراتٍ، مثل "usr/bin/" و "bin/"، ولا تتعدى معرفة باش بهذه الأوامر لمعرفتك باللغة السنسكريتية، ولكن كما بإمكانك البحث وترجمة أي كلمة من اللغة السنسكريتية، يمكن لـلغة باش البحث عن الأوامر؛ فعند كتابتك لأمرٍ ما يبحث باش ضمن مسارات مجلدات محدّدة في نظامك ليرى ما إذا كان هذا الأمر موجودًا وعندها ينفذّه. تمثّل كلمة Bash بحد ذاتها أحد الأوامر، وهو الأمر الذي ينفّذ افتراضيًا عندما تفتح الطرفية أو عند دخولك إلى محرر نصوص الطرفية Console (وهو جهازٌ حقيقي أو وهمي يستقبل الرسائل والتنبيهات من النواة ويسمح بتسجيل الدخول بوضع المستخدم الوحيد). يمكنك معرفة مكان تخزين أي أمرٍ بما في ذلك الأمر Bash على نظامك باستخدام الأمر which في الطرفية على النحو التالي: $ which bash /usr/bin/bash $ which ls /usr/bin/ls تُبنى بعض الأوامر داخليًا ضمن باش نفسه، وتكون معظم الأوامر داخلية البناء خاصّةً بالبرمجة النصيّة لباش أو لإعدادات البيئة منخفضة المستوى، إلّا أنّ استخدام بعضٍ منها مفيدٌ في الوظائف العامّة، مثل الأمر cd الخاص بتغيير مسار المجلدات change directory. لا تظهر الأوامر داخلية البناء عندما تبحث عنها لأنّها غير موجودةٍ في مسار التنفيذ الاعتيادي: $ which bash which: no cd in (/usr/local/bin:/usr/bin:/bin: [...] إلّا أنّ عدم العثور عليها في البحث لا يعني عدم توفرها، فهي مبنيةٌ ضمن باش الذي تشغلِّه أصلًا. تشغيل باش توفّر معظم توزيعات لينكس ويونكس صدفة باش افتراضيًا، نظرًا لكون باش معروفٌ وشعبي جدًا، إضافةً لامتلاكه كثيرًا من الوظائف المريحة التي لا توفرّها الصدفات الأخرى؛ إلّا أنّ بعض الأنظمة توفّر حافظةً أُخرى افتراضيًا؛ ولمعرفة فيما إذا كانت الحافظة لديك من نوع باش، ما عليك سوى استخدام الأمر echo مع متغير variable خاص يُظهر اسم العملية المنفّذة حاليًا: $ echo $0 bash إذا كان باش غير متوفّر لديك ورغبت بتجربته، فمن الممكن تنزيله وتثبيته من مركز إدارة البرمجيات لديك، أو بإمكانك استخدام مدير الحزم Chocolatey إذا كان نظام التشغيل لديك ويندوز Windows؛ أو Homebrew في حال كان نظامك ماك أو إس؛ وفي حال فشل كل الطرق السابقة، فلا بُد من زيارة الصفحة الرئيسية لباش على الإنترنت للحصول على مزيدٍ من المعلومات. العمل في باش واجهة باش متوفرّةٌ في حاسوبك، فهي ليست حكرًا على مديري الخوادم أو المبرمجين، كما أنها قادرةٌ على أن تحل محل سطح مكتبك وتطبيقات تحرير النصوص والرسوميات وغيرها؛ إذ يستخدم الأشخاص باش أكثر من استخدامهم لتطبيقات سطح المكتب. يوجد المئات من التعليمات المتاحة لأنظمة لينكس ويونكس التي ستفاجئك بتنوعها؛ إذ يمكنك مثلًا باستخدام باش اقتصاص وإعادة تعيين حجم صورة دون فتح الصورة ضمن عارضٍ أو محرر صور: $ mogrify -geometry 1600^x800 \ -gravity Center \ -crop 1600x800+0+0 myphoto.jpg يمكنك تشغيل الموسيقى باستخدام أمرٍ، مثل ogg123، أو mpg321؛ أو تحويل الصوت باستخدام الأمر sox؛ أو تعديل وتحرير الفيديوهات باستخدام ffmpeg؛ أو تحرير النصوص باستخدام emacs، أو vim؛ أو التحقق من رسائل البريد الإلكتروني باستخدام pine أو mutt؛ أو تصفّح الإنترنت باستخدام elinks؛ وكذلك تصفّح الملفات باستخدام ranger أو midnightcommander، وغيرها، إذ يوفِّر باش كل هذه الإمكانات باستخدام الأوامر التي ستجدها في نظامك أو في مستودع البرمجيات الخاص بك. برمجة باش النصية أحد أهم أسباب كون باش ونظام لينكس ككل فعّالًا هو كونه قابلًا للبرمجة والتوسع إذ يمكنك كتابة تعليمات جديدة ضمن باش يدويًا، أو من خلال إنشاء قائمةٍ ضمن ملف نصي عادي وسيشغلها باش؛ فبدلًا من قضاء ساعات في كتابة وتنفيذ مئات التعليمات، يمكنك كتابة التعليمات في ملف نصي عادي وترك الأمر لحاسوبك لتنفيذها مرارًا وتكرارًا. ونظرًا لتنفيذ معظم العمليات في لينكس ضمن صدفة باش، فمن الممكن تقريبًا تنفيذ أي أمرٍ في لينكس باستخدام البرمجة النصية (سكربتات) في باش، مع وجود بعض الاستثناءات (فمثلًا قد يكون لدى تطبيقات الرسومات لغة برمجةٍ نصيةٍ خاصّةٍ بها، أو قد لا تمتلك لغة برمجة نصية أصلًا). سيفتح استخدام البرمجة النصية في نظام التشغيل الخاص أمامك آفاقًا لتنفيذ عشرات آلاف الإجراءات على حاسوبك دون تكبُّد عناء تنفيذ ذلك يدويًا. من غير الممكن إذًا تخمين التوفير في كمية العمل الذي يقدمه لينكس لمستخدميه؛ إذ أن هذا التوفير الكبير لا يأتي من فكرة أتمتة الأعمال التقليدية، وإنمّا من أتمتة أعمال لم يعتقد أحد سابقًا أنها بحاجة للأتمتة، مثل إمكانية إنشاء منهجية عمل مفصّلة خاصّة بك. عندما يقول المستخدمون المتمرسّون أنّهم يريدون تعلّم باش دون تعلّم أوامر لينكس، فهم يقصدون غالبًا أنّهم يريدون تحسين طريقة كتابة الأوامر. ينقل النص البرمجي التالي مثلًا ملفًا مؤقتًا (وهو ملف مُنشأ بعملية أخرى منفصلة) إلى مسار محدّد: #!/usr/bin/bash cp tmp.png ~/public_html/`date +%Y%m%d`.png يمكنك التحقّق من هذا الأمر من خلال نسخ السطر الأخير (الأمر الذي يبدأ بـ cp) إلى طرفية، حيث سيعمل هذا الأمر في حال وجود ملفٍ يُدعى tmp.png ومسار مجلد يُدعى ~/public_html. إذًا، يعتمد تعلُّم باش على فهم كيفية تحويل أمرٍ بسيط كهذا إلى عملية أتمتة فعلية؛ فلن يعمل النص البرمجي مثلًا في حال عدم توفّر الملف "tmp.png"؛ وعلى فرض أنّ هذا النص البرمجي مكوّنٌ أساسيٌ لمدونةٍ تتطلب صورةً جديدةً يوميًا لإنشاء صورة ترويسة مخصّصة، ففي هذه الحالة سيكون عدم تنفيذ النص البرمجي ذا تأثيرٍ كارثي على كل أجزاء المدونة. يستطيع المُستخدم الذي يعرف باش إضفاء المرونة على نصه البرمجي باستخدام بناء التعليمات في باش. #!/usr/bin/bash IMG="tmp.png" [[ -e tmp.png ]] || IMG="generic.png" cp ~/"${IMG}" ~/public_html/`date +%Y%m%d`.png يُعَد هذا مجرّد مثالٍ وحيد لعملية تعلّم كتابة النصوص البرمجية في باش، إلّا أنّه يوضّح حقيقة كون تعلّم كل من باش ولينكس مفيدًا بنفس الدرجة، وهي عملية متكاملة ولا يمكن عدُّ كلٍ منهما مهمّةً مستقلة. نقاط قوة باش تُعَد باش صدفةً فعّالةً مثل غيرها، إلّا أنها تمتاز بوجود عدة دوالٍ مريحة، مثل استخدام الأقواس المزدوجة ([[ و]]) في الترميز البرمجي، وهذه التفاصيل الخاصّة بـها هي المفضّلة لدى مستخدميها، لأنّهم يتجنبون بناء الجمل الطويل المُربك كما في الصدفات الأُخرى، مثل tcsh أو ash؛ إلّا أنّ هذه التعليمات الخاصّة بباش قد تسبّب مشاكل في التوافق عند استخدامها على الأنظمة التي لا تستخدمه، ولكن بما أنّ باش مجاني ومفتوح المصدر، فبإمكان أي مستخدمٍ تثبيته عند الحاجة لاستخدامه، وتفرض مشكلة عدم التوافق هذه فقط اعتمادًا إضافيًا على باش دون منع أي أحدٍ من استخدام البرمجة النصية. ترجمة -وبتصرف- للمقال What is Bash? من موقع opensource.com. اقرأ أيضًا إذا أردت تعلّم باش يمكنك الاطلاع على توثيقها التفصيلي في موسوعة حسوب، كما ننصحك بالإطلاع على المقالات التالية: ما هو سطر الأوامر؟ دليل ميَسَّر لكتابة سكربتات Shell سلسلة مدخل إلى كتابة سكربتات الصدفة كيفية استعمال ميزة التحكم بالوظيفة (Bash's Job Control) لإدارة عمليات الخلفية وعمليات المقدمة في لينكس
تتعرف نواة Kernel نظام التشغيل سواءً كان Mach، أو BSD، أو لينكس Linux، أو NT على كافّة التجهيزات والعتاد المتصلة بالحاسوب عند إقلاعه باستخدام برنامج رئيسي، وتمكّنها من التواصل مع بعضها بعضًا، كما تضمن عملها على نحوٍ متناغم؛ إذ تؤدّي مجموعة التعليمات الرئيسية هذه مجموعةً من المهام، مثل إبقاء الحاسوب في حالة تشغيل وبوضعٍ آمن من خلال تشغيل مراوح التبريد دوريًا لتجنّب زيادة درجة الحرارة مثلًا، إضافةً لاستخدامها أنظمةً فرعيةً مسؤولةً عن مراقبة مساحة القرص الصلب أو التنبّه عند وصل أجهزة جديدة بالحاسوب وغيرها من العمليات. ولكن ليس هذا جلّ ما يفعله الحاسوب، وإلا كانت أهميته مثل أهمية الفرن في المنزل. أدرك علماء الحواسيب مبكرًا أهمية جعل البشر قادرين على التفاعل مع الحاسوب متى أرادوا ذلك، لذا طوروا صدفةً Shell خاصّةً بالحواسيب العاملة على نظام يونكس Unix؛ إذ تعمل هذه الصدفة خارج النواة أو حولها مثل مبدأ الصدفة في الطبيعة، وقد شكّلت هذه الصدفة تطورًا مهمًا في الوقت الذي كان الناس فيه يوجهون الأوامر للحواسيب باستخدام البطاقات المثقبّة، وتعدّ Bash واحدةً من أكثر الصدفات shells شعبيةً وأكثرها فعاليةً وسهولةً. باش Bash هو تطبيق عندما تفتح طرفيةً Terminal تُشغِّل صدفة باش، مثل GNOME Terminal، أو Konsole في نظام لينكس، أو iTerm2 في نظام ماك، أو إس macOS، فسُيرَحب بك غالبًا من خلال محث prompt؛ والذي يكون عادةً رمزًا وهو إشارة ($)، والذي يعني أن الصدفة بانتظارك لإدخال أمر. ولا بُد بالتأكيد من معرفة ما عليك كتابته من أوامر، وهذه الأوامر موضوعٌ مستقلٌ تمامًا كما سنرى. قد يكون التعبير التالي غير لطيف، إلّا أنّه يمثّل بدقة عدّة دلالاتٍ متعلقّة بمصطلح باش؛ إذ لا يميز كثيرٌ من المستخدمين الجدد بين مفهوم باش ومفهوم لينكس أو يونكس؛ فبالنسبة لهم باش هو الشاشة السوداء ذات الكتابة الخضراء التي تُكتب فيها الشيفرة اللازمة لإعطاء الأوامر للحاسوب. هذا المفهوم فيه خلطٌ ما بين صدفة باش والأوامر التي نكتبها داخل الصدفة، ومن المهم فهم أنهما مفهومان مستقلان؛ إذ أنّ باش مجرّد تطبيقٍ مهمته الرئيسية تشغيل التطبيقات الأخرى ضمن نفس النظام (من خلال أوامر). إذًا، يمكنك تعلّم باش في سياق تعلّم نظام التشغيل الذي يعمل عليه، ولكن لا يمكنك استخدامه فعليًا ما لم تتعرف على الأوامر. أوامر نظام لينكس تُخزَّن معظم الأوامر افتراضيًا في مجلدات النظام في الأنظمة المعتمدة على يونكس ولينكس (نظام BSD و macOS) في مساراتٍ، مثل "usr/bin/" و "bin/"، ولا تتعدى معرفة باش بهذه الأوامر لمعرفتك باللغة السنسكريتية، ولكن كما بإمكانك البحث وترجمة أي كلمة من اللغة السنسكريتية، يمكن لـلغة باش البحث عن الأوامر؛ فعند كتابتك لأمرٍ ما يبحث باش ضمن مسارات مجلدات محدّدة في نظامك ليرى ما إذا كان هذا الأمر موجودًا وعندها ينفذّه. تمثّل كلمة Bash بحد ذاتها أحد الأوامر، وهو الأمر الذي ينفّذ افتراضيًا عندما تفتح الطرفية أو عند دخولك إلى محرر نصوص الطرفية Console (وهو جهازٌ حقيقي أو وهمي يستقبل الرسائل والتنبيهات من النواة ويسمح بتسجيل الدخول بوضع المستخدم الوحيد). يمكنك معرفة مكان تخزين أي أمرٍ بما في ذلك الأمر Bash على نظامك باستخدام الأمر which في الطرفية على النحو التالي: $ which bash /usr/bin/bash $ which ls /usr/bin/ls تُبنى بعض الأوامر داخليًا ضمن باش نفسه، وتكون معظم الأوامر داخلية البناء خاصّةً بالبرمجة النصيّة لباش أو لإعدادات البيئة منخفضة المستوى، إلّا أنّ استخدام بعضٍ منها مفيدٌ في الوظائف العامّة، مثل الأمر cd الخاص بتغيير مسار المجلدات change directory. لا تظهر الأوامر داخلية البناء عندما تبحث عنها لأنّها غير موجودةٍ في مسار التنفيذ الاعتيادي: $ which bash which: no cd in (/usr/local/bin:/usr/bin:/bin: [...] إلّا أنّ عدم العثور عليها في البحث لا يعني عدم توفرها، فهي مبنيةٌ ضمن باش الذي تشغلِّه أصلًا. تشغيل باش توفّر معظم توزيعات لينكس ويونكس صدفة باش افتراضيًا، نظرًا لكون باش معروفٌ وشعبي جدًا، إضافةً لامتلاكه كثيرًا من الوظائف المريحة التي لا توفرّها الصدفات الأخرى؛ إلّا أنّ بعض الأنظمة توفّر حافظةً أُخرى افتراضيًا؛ ولمعرفة فيما إذا كانت الحافظة لديك من نوع باش، ما عليك سوى استخدام الأمر echo مع متغير variable خاص يُظهر اسم العملية المنفّذة حاليًا: $ echo $0 bash إذا كان باش غير متوفّر لديك ورغبت بتجربته، فمن الممكن تنزيله وتثبيته من مركز إدارة البرمجيات لديك، أو بإمكانك استخدام مدير الحزم Chocolatey إذا كان نظام التشغيل لديك ويندوز Windows؛ أو Homebrew في حال كان نظامك ماك أو إس؛ وفي حال فشل كل الطرق السابقة، فلا بُد من زيارة الصفحة الرئيسية لباش على الإنترنت للحصول على مزيدٍ من المعلومات. العمل في باش واجهة باش متوفرّةٌ في حاسوبك، فهي ليست حكرًا على مديري الخوادم أو المبرمجين، كما أنها قادرةٌ على أن تحل محل سطح مكتبك وتطبيقات تحرير النصوص والرسوميات وغيرها؛ إذ يستخدم الأشخاص باش أكثر من استخدامهم لتطبيقات سطح المكتب. يوجد المئات من التعليمات المتاحة لأنظمة لينكس ويونكس التي ستفاجئك بتنوعها؛ إذ يمكنك مثلًا باستخدام باش اقتصاص وإعادة تعيين حجم صورة دون فتح الصورة ضمن عارضٍ أو محرر صور: $ mogrify -geometry 1600^x800 \ -gravity Center \ -crop 1600x800+0+0 myphoto.jpg يمكنك تشغيل الموسيقى باستخدام أمرٍ، مثل ogg123، أو mpg321؛ أو تحويل الصوت باستخدام الأمر sox؛ أو تعديل وتحرير الفيديوهات باستخدام ffmpeg؛ أو تحرير النصوص باستخدام emacs، أو vim؛ أو التحقق من رسائل البريد الإلكتروني باستخدام pine أو mutt؛ أو تصفّح الإنترنت باستخدام elinks؛ وكذلك تصفّح الملفات باستخدام ranger أو midnightcommander، وغيرها، إذ يوفِّر باش كل هذه الإمكانات باستخدام الأوامر التي ستجدها في نظامك أو في مستودع البرمجيات الخاص بك. برمجة باش النصية أحد أهم أسباب كون باش ونظام لينكس ككل فعّالًا هو كونه قابلًا للبرمجة والتوسع إذ يمكنك كتابة تعليمات جديدة ضمن باش يدويًا، أو من خلال إنشاء قائمةٍ ضمن ملف نصي عادي وسيشغلها باش؛ فبدلًا من قضاء ساعات في كتابة وتنفيذ مئات التعليمات، يمكنك كتابة التعليمات في ملف نصي عادي وترك الأمر لحاسوبك لتنفيذها مرارًا وتكرارًا. ونظرًا لتنفيذ معظم العمليات في لينكس ضمن صدفة باش، فمن الممكن تقريبًا تنفيذ أي أمرٍ في لينكس باستخدام البرمجة النصية (سكربتات) في باش، مع وجود بعض الاستثناءات (فمثلًا قد يكون لدى تطبيقات الرسومات لغة برمجةٍ نصيةٍ خاصّةٍ بها، أو قد لا تمتلك لغة برمجة نصية أصلًا). سيفتح استخدام البرمجة النصية في نظام التشغيل الخاص أمامك آفاقًا لتنفيذ عشرات آلاف الإجراءات على حاسوبك دون تكبُّد عناء تنفيذ ذلك يدويًا. من غير الممكن إذًا تخمين التوفير في كمية العمل الذي يقدمه لينكس لمستخدميه؛ إذ أن هذا التوفير الكبير لا يأتي من فكرة أتمتة الأعمال التقليدية، وإنمّا من أتمتة أعمال لم يعتقد أحد سابقًا أنها بحاجة للأتمتة، مثل إمكانية إنشاء منهجية عمل مفصّلة خاصّة بك. عندما يقول المستخدمون المتمرسّون أنّهم يريدون تعلّم باش دون تعلّم أوامر لينكس، فهم يقصدون غالبًا أنّهم يريدون تحسين طريقة كتابة الأوامر. ينقل النص البرمجي التالي مثلًا ملفًا مؤقتًا (وهو ملف مُنشأ بعملية أخرى منفصلة) إلى مسار محدّد: #!/usr/bin/bash cp tmp.png ~/public_html/`date +%Y%m%d`.png يمكنك التحقّق من هذا الأمر من خلال نسخ السطر الأخير (الأمر الذي يبدأ بـ cp) إلى طرفية، حيث سيعمل هذا الأمر في حال وجود ملفٍ يُدعى tmp.png ومسار مجلد يُدعى ~/public_html. إذًا، يعتمد تعلُّم باش على فهم كيفية تحويل أمرٍ بسيط كهذا إلى عملية أتمتة فعلية؛ فلن يعمل النص البرمجي مثلًا في حال عدم توفّر الملف "tmp.png"؛ وعلى فرض أنّ هذا النص البرمجي مكوّنٌ أساسيٌ لمدونةٍ تتطلب صورةً جديدةً يوميًا لإنشاء صورة ترويسة مخصّصة، ففي هذه الحالة سيكون عدم تنفيذ النص البرمجي ذا تأثيرٍ كارثي على كل أجزاء المدونة. يستطيع المُستخدم الذي يعرف باش إضفاء المرونة على نصه البرمجي باستخدام بناء التعليمات في باش. #!/usr/bin/bash IMG="tmp.png" [[ -e tmp.png ]] || IMG="generic.png" cp ~/"${IMG}" ~/public_html/`date +%Y%m%d`.png يُعَد هذا مجرّد مثالٍ وحيد لعملية تعلّم كتابة النصوص البرمجية في باش، إلّا أنّه يوضّح حقيقة كون تعلّم كل من باش ولينكس مفيدًا بنفس الدرجة، وهي عملية متكاملة ولا يمكن عدُّ كلٍ منهما مهمّةً مستقلة. نقاط قوة باش تُعَد باش صدفةً فعّالةً مثل غيرها، إلّا أنها تمتاز بوجود عدة دوالٍ مريحة، مثل استخدام الأقواس المزدوجة ([[ و]]) في الترميز البرمجي، وهذه التفاصيل الخاصّة بـها هي المفضّلة لدى مستخدميها، لأنّهم يتجنبون بناء الجمل الطويل المُربك كما في الصدفات الأُخرى، مثل tcsh أو ash؛ إلّا أنّ هذه التعليمات الخاصّة بباش قد تسبّب مشاكل في التوافق عند استخدامها على الأنظمة التي لا تستخدمه، ولكن بما أنّ باش مجاني ومفتوح المصدر، فبإمكان أي مستخدمٍ تثبيته عند الحاجة لاستخدامه، وتفرض مشكلة عدم التوافق هذه فقط اعتمادًا إضافيًا على باش دون منع أي أحدٍ من استخدام البرمجة النصية. ترجمة -وبتصرف- للمقال What is Bash? من موقع opensource.com. اقرأ أيضًا إذا أردت تعلّم باش يمكنك الاطلاع على توثيقها التفصيلي في موسوعة حسوب، كما ننصحك بالإطلاع على المقالات التالية: ما هو سطر الأوامر؟ دليل ميَسَّر لكتابة سكربتات Shell سلسلة مدخل إلى كتابة سكربتات الصدفة كيفية استعمال ميزة التحكم بالوظيفة (Bash's Job Control) لإدارة عمليات الخلفية وعمليات المقدمة في لينكس -
 سواء أكنت تشغّل نسخة من ووردبريس لموقع كثير الزيارات أو لمجرّد مدونة صغيرة مستخدمًا استضافة مشتركة منخفضة التكاليف، ففي كلتا الحالتين لا بدّ من تحسين أداء ووردبريس والخادم الخاص بك ليعملا بأقصى كفاءة ممكنة، يوفّر هذا المقال نظرة شاملة حول تحسين ووردبريس باستخدام منهجيات محدّدة موصى بها، إلا أنّها لا توفر شرحًا تقنيًا مفصلًا لكافة جوانب الموضوع. إن كنت تبحث عن حلول سريعة، فاذهب مباشرةً لفقرة "التخبئة" في هذا المقال، وستجد فيها أجوبة كثيرة سريعة، وفي حال رغبت بالبدء بعملية تحسين شاملة فاذهب لفقرة "كيفية تطوير الأداء في ووردبريس". كما ستجد أدناه في قسمي "العوامل المؤثّرة على الأداء" و"أدوات اختبار الأداء" نظرة شاملة حول هذا الموضوع، مع ملاحظة أنّ العديد من التقنيات التي ناقشناها في هذا المقال تطبّق أيضاً على ووردبريس متعدّد المواقع MU. العوامل المؤثرة على أداء موقع ووردبريس يوجد العديد من العوامل التي تؤثر على أداء مدونتك (أو موقعك الإلكتروني) في ووردبريس، وتتضمّن هذه العوامل على وجه الخصوص وليس التحديد كل من بيئة الاستضافة، إعدادات ووردبريس، إصدارات البرامج، وعدد المحتويات الرسومية وحجمها، وسنتناول معظم هذه العوامل. الاستضافة تعتمد تقنيات التحسين المتاحة لك على إعدادات الاستضافة. الاستضافة المُشتركة وهي النوع الأكثر شيوعًا من أنواع الاستضافة، إذ يكون موقعك الإلكتروني مستضافاً على خادم ما جنبًا إلى جنب مع العديد من المواقع الأخرى، وفي هذه الحالة تكون شركة الاستضافة هي المسؤولة عن إدارة خادم الويب، وبالتالي ستكون صلاحياتك للتحكّم بإعدادات الخادم وغيرها من الصلاحيات محدودة. وعمومًا المجالات الأكثر صلة بهذا النوع من الاستضافة هي: التخبئة Caching، أداء ووردبريس، وتحميل ملفات المحتوى خارجيًا Content Offloading. الاستضافة الوهمية والخوادم المخصصّة في هذا النوع من الاستضافة ستمتلك صلاحية التحكّم بخادمك، والذي يمكن أن يكون جهازًا مستقلًا فيزيائيًا أو واحدًا من مجموعة خوادم وهمية تتشارك نفس الموارد الفيزيائية. وأهم ما في الأمر أنّك تملك صلاحية التحكّم بالخادم، وأكثر مجالات الاهتمام بالإضافة إلى المجالات أعلاه (التخبئة وأداء ووردبريس) في هذه الحالة هي: تحسين الخادم وتحميل ملفات المحتوى خارجيًا. عدد الخوادم سيكون من الضروري استثمار عدة خوادم عند التعامل مع حالات عالية الحمل. إذا كانت تلك هي الحالة لديك، فلا بدّ من توظيف كل الأفكار والتقنيات المذكورة أعلاه. من السهل نقل قاعدة بيانات ووردبريس من خادم لآخر، ولا تتطلب عملية النقل سوى تعديلًا بسيطًا في ملف الإعدادات، ويمكن نقل الصور وجميع الملفات الثابتة بشكل مشابه إلى خوادم بديلة بسهولة (راجع القسم " تحميل ملفات المحتوى خارجيًا"). يمكن لبرنامج موازنة الحمل الديناميكي Elastic Load Balancer من أمازون أن يساعدك في توزيع الحمل على أكثر من خادم ويب إلا أنّه يتطلّب مستوى عالٍ من الخبرة. وسيوفر النوع HyperDB بديلًا فوريًا للنوع WPDB القياسي في حال كنت تستخدم عدة خوادم قواعد بيانات، والذي يستطيع التعامل مع خوادم قواعد بيانات متعدّدة سواء أكانت الهيكلية مكررة أو موزّعة. أداء التجهيزات تؤثر إمكانيات التجهيزات تأثيرًا كبيرًا على أداء موقعك الإلكتروني. ومن العوامل الهامة: عدد المعالجات وسرعتها، حجم الذاكرة المتوفرّة ومساحة القرص، إضافةً إلى نوع وسائط التخزين. وعادة ما توفر مزودات الاستضافة أداء تجهيزات أفضل مقابل تكلفة أعلى. المسافة الجغرافية من العوامل المؤثرة على الأداء أيضًا هي المسافة الفاصلة بين خادمك وزوّار موقعك الإلكتروني، وبهدف حصولهم جميعًا على أداء أمثل، من الممكن استخدام شبكة تسليم محتوى CDN التي تقوم بمزامنة وتزويد الملفات الثابتة (مثل الصور) عبر مناطق جغرافية متعدّدة. الحمل على الخادم إنّ لكمية الأحمال على خادمك وطريقة ضبطه للتعامل معها له الأثر البالغ على الأداء، فعلى سبيل المثال سيتباطأ الأداء إلى حد التوقف في حال عدم استخدامك لتقنية التخبئة، ومع وصول طلبات إضافية للصفحات؛ ستزدحم هذه الطلبات حد الاختناق مسببةً بالنتيجة تعطل خادم الويب أو قواعد البيانات الخاص بك. أما في حال ضبط إعدادات الاستضافة ضبطًا مناسبًا فسيكون الخادم قادرًا على التعامل مع كمية كبيرة من الأحمال، كما يمكن للتحميل الخارجي إلى خوادم أخرى أن يقلل من الحمل على الخادم. كما أنّ الأحمال الزائدة والهجمات الممنهجة مثل هجمات تسجيل الدخول المتكرر، والربط المكثّف مع الصور باستخدام روابط الصور لديك في عناصر صفحات ذات حمولات عالية، أو هجمات DOS جميعها يمكن أن تزيد من الحمل على خادمك، وبالتالي من المهم جدًا كشف وتحديد ومنع هذه الهجمات. إصدارات البرامج والأداء من المهم أن تتأكد أيضًا من كونك تستخدم أحدث إصدارات البرامج، كون تحديثاتها غالبًا ما تصلح الأخطاء وتحسّن الأداء، فالتأكد من كونك تستخدم أحدث إصدارات لينكس Linux (أو ويندوز)، وApache، وMySQL/MariaDB وPHP هو أمر بالغ الأهمية. إعدادات ووردبريس تؤثر القالب التي تختاره تأثيرًا كبيرًا على أداء موقعك الإلكتروني، فاختيارك لقالب سريع وخفيف سيحقق أداء وفعالية أكثر بالموازنة مع اختيار سمة مليئة بالرسومات. كما أن لعدد الإضافات وأدائها أثرًا كبيرًا على أداء موقعك الإلكتروني، فمن الممكن حذف أو إلغاء تفعيل الإضافات غير الضرورية وهي طريقة مهمة من طرق تحسين الأداء. حجم الصور والرسومات من المؤكد أن تخصيص الصور في منشوراتك بما يناسب الويب سيوفّر في الزمن وعرض الحزمة اللازم، كما أنّه سيرفع تصنيف موقعك في محركات البحث. أدوات اختبار الأداء تمثّل أداة اختبار صفحة الويب Webpagetest اختبارًا لأداء المواقع الإلكترونية بطريقة فعلية تحاكي الواقع من أماكن أو متصفحات أو سرعات اتصال مختلفة، والأداة PageSpeed Insights من Google توفّر طريقة لقياس أداء موقع ووردبريس الخاص بك معطيةً معلومات واضحة ومحددة تساعدك في إجراء التحسينات. كما تمتلك جميع أدوات التطوير المُضمّنة في المتصفحات (مثل Firefox أو Chrome) أدوات لقياس الأداء. كيفية تطوير الأداء في ووردبريس سنستعرض مجموعة من الاقتراحات والأدوات التي يمكن استخدامها بهدف تحسين أداء مواقع ووردبريس تحسين موقعك الإلكتروني في ووردبريس تصغير حجم الإضافات حتّى تحسن من أداء ووردبريس فإن أوّل وأسهل ما يمكن التفكير به هو الإضافات، عبر حذف أو إلغاء تفعيل غير الضروري منها. يمكنك استخدام تعطيل الإضافات انتقائيًا ومراقبة تأثير ذلك على أداء المخدم. فإذا كانت إحدى الإضافات تؤثر سلبًا على أداء موقعك بوضوح فعليك قراءة دليل الاستخدام الخاص بها أو أن تطلب المساعدة في أحد منتديات الدعم المناسبة الخاصة بالإضافات. تحسين ملفات المحتوى ملفات الصور هل هناك أية صور غير ضرورية (مثلًا هل من الممكن استبدال بعض الصور بنصوص؟) تأكد من تخصيص تحسين جميع ملفات الصور بطريقة مناسبة عبر اختيار الصيغة الصحيحة (JPG/PNG/GIF) مع إجراء عملية ضغط لجميع الصور. حجم/عدد الملفات الكلي هل من الممكن تقليل عدد الملفات الضرورية اللازمة للعرض الأمثل للصفحات المتتالية خلال الجلسة الواحدة على موقعك الإلكتروني؟ يوصى بدمج عدّة ملفات في ملف واحد محسّن في حال استخدامك لـ HTTP1. تصغير حجم ملفات CSS وجافاسكربت. يمكن أيضًا استخدام تحميل ملفات المحتوى خارجيًا لتحسين القالب في موقعك. ترقية التجهيزات يعد دفع مبالغ إضافية لمزوّد الاستضافة الخاص بموقعك مقابل مستويات خدمة أعلى حلًا فعالًا للغاية، فاستخدام ذاكرة وصول عشوائي RAM أكبر أو الانتقال إلى مضيف بمحرك أقراص ذو حالة ثابتة SSD مثل Digital Ocean سيحدث فرقًا مهمًا، كما سيؤثر استخدام عدد أكبر من المعالجات بسرعات أعلى تأثيرًا إيجابيًا، وإن أمكن فمن الأفضل فصل الخدمات ذات الأغراض المختلفة مثل HTTP وMySQL باستخدام إجراءات مختلفة على خوادم متعددة سواء أكانت فيزيائية أم وهمية VPS-es. تحسين البرمجيات تأكد دومًا من كونك تستخدم أحدث إصدار من نظام التشغيل مثل لينكس Linux ويندوز سيرفر Windows Server، وأحدث خادم ويب مثل ِApache أو IIS كذلك الأمر بالنسبة لقواعد البيانات مثل MySQL وPHP. يمكن أن يتعذر عليك تنفيذ واتباع الخطوات والنصائح الواردة أدناه، في هذه الحالة اطلب من مزود الاستضافة إنجاز هذه المهام، فمزود الاستضافة الجيد سيرقي حسابك أو ينقله إلى خادم محدث لتحقيق السرعة المطلوبة، وعند الضرورة يمكنك الانتقال لأحد حلول الاستضافة المدارة من شركة ووردبريس التجارية. خادم نطاق الأسماء DNS لا تشغل خادم نطاق أسماء على خادم ووردبريس بل استخدم إحدى الخدمات التجارية لخوادم نطاقات الأسماء مثل Amazon’s Route 53 أو الخدمة المجانية المقدمّة من الشركة المسجّلة للمجال الخاص بك. إنّ استخدامك لخدمة مثل خدمة أمازون سيُسهّل الانتقال بين خوادم النسخ الاحتياطي في الحالات الطارئة أو خلال أعمال الصيانة كما أنّه يوفر درجة جيدة من القدرة على استمرار العمل في حال حدوث أخطاء. إن اختيارك لاستضافة خادم DNS خارجي سيقلل حتمًا من الحمل على خادم الويب الرئيسي فبالرغم كونه إجراء بسيطًا إلا أنّه سيقلل من الحمل على وحدة المعالجة المركزية CPU عبر تحويل جزء من ضغط الشبكة إلى خارج الخادم. خادم الويب من الممكن ضبط إعدادات خادم الويب الخاص بك لتحسين الأداء من خلال استخدام تقنيات عديدة مثل التخبئة أو تعيين ترويسات المخابئ لتقليل حمل كل مستخدم. وعمومًاعليك البحث عن التحسينات الخاصة بخادم الويب الخاص بك (للحصول على المزيد من المعلومات يمكنك مثلًا البحث عن "Apache Optimization"). كما تملك بعض خوادم الويب إصدارات ذات سرعات أعلى، والتي يمكنك الحصول عليها مقابل كلفة أكبر مثل الإصدار Apache Litespeed. كما يوجد عدد من الطرق لموائمة Apache ليعطي أداءً أعلى وذلك اعتمادًا على إعدادات موقعك الإلكتروني واستضافتك مثل Memcache. PHP يتوفر العديد من مسرعات PHP القادرة على تحسين أداء ملفات PHP تحسينًا كبيرًا، وفي حال استخدمت إحداها فإن التحسين لن يشمل نسخة ووردبريس التي نصبتها فقط، وإنمّا كافّة ملفات PHP على الخادم. وللمزيد من المعلومات يمكنك البحث حول تحسينات PHP مثل APC أو OPcache. وتقدّم إضافة W3 الشاملة للتخبئة والمشروحة أدناه دعمًا متكاملًا لكل من Memcach، APC، وغيرها من أدوات التخبئة Opcode. MySQL/MariaDB لتحسينات MySQL/MariaDB أثر سحري على أداء ووردبريس، فبعض التغييرات البسيطة على إعدادات تخبئة نتائج الاستعلامات مؤقتًا ستُحدث أثرًا إيجابيًا كبيرًا، وذلك كون ووردبريس يكرر العديد من الاستعلامات في كل طلب. وفي هذه الأيام أصبح InnoDB القابل للتحسين والموائمة الدقيقة هو محرك التخزين الافتراضي لـ MySQL، لذا لا بدّ من أن تتأكد من كونك تستخدمه بالفعل، وللمزيد من المعلومات والأمثلة يمكنك البحث حول "تحسين MySQL"، "أداء mysql innodb" أو "تحسين innodb"، أمّا إذا كنت تبحث عن معلومات حول كيفية تحويل جداول MyISAM الأقدم إلى InnoDB ابحث عن "تحويل myisam إلى innodb في mysql". وطرحت Iliya Polihronov مثالًا رائعًا حول تحسين ووردبريس في WordCamp San Francisco عام 2012، إذ أنجز العديد من المهام ومن بينها تحسين الخادم الخاص بـ WordPress.com. ومن المهم ألّا تشغل خادم بريد على خادم ووردبريس الخاص بك، وكبديل له لتوفير نماذج التواصل استخدم تطبيقًا مثل Contact Form 7 والذي يوفر آلية تعامل مع البريد الإلكتروني Mailgun مجانية. التخبئة تُستخدمُ تقنية التخبئة في كلا جانبي الخادم والمستخدم، ومن شأن الإدارة الصحيحة لها أن تحسن أداء مواقع ووردبريس، فيما يلي سنستعرض أهم الإجراءات المتعلقة بالتخبئة: الإضافات الخاصّة بالتخبئة يمكنك بسهولة تنصيب إضافات خاصّة بالتخبئة مثل W3 Total Cache أو WP Super Cache والتي ستحتفظ وتخبئ منشورات وصفحات ووردبريس الخاصّة بك كملفات ثابتة، ومن ثمّ تخدم المستخدمين باستخدام هذه الملفات مما سيُقلل من حمل المعالجة على الخادم، وهذا سيُحسّن الأداء مئات المرات مع وجود بضع صفحات ثابتة. ولنتيجة أكثر فاعلية يمكن استخدام هذه الإضافة مع أداة تخبئة صفحات على مستوى النظام مثل Varnish مع ملاحظة أنّ ضبط إعدادات التخبئة سيُصبح أكثر تعقيدًا في حال احتوت منشوراتك أو صفحاتك على الكثير من المحتويات الديناميكية. الإضافة W3 TOTAL CACHE تعدّ W3 Total Cache (واختصارًا W3TC) الجيل الأحدث من إضافات الأداء في ووردبريس، والتي تستخدم أبحاث هيئات تطوير الويب لتوفير تجربة مستخدم مثالية في المواقع الإلكترونية المبنية باستخدام ووردبريس، وفيما يلي سنشرحها بالتفصيل. تتميز W3TC بقدرتها على تحسين الأداء في كلا جانبي الخادم والمستخدم، مضيفة إجراءات غير متوفّرة أصلًا. تخبئة الصفحات: يساعد استخدام W3TC على تقليل الزمن اللازم للاستجابة عبر تشكيل إصدارات HTML ثابتة للصفحات، سامحةً بذلك لخوادم الويب بتخديم هذه الصفحات دون الحاجة اللجوء إلى PHP. كما أنّها تحدث العناصر المخبئة تلقائيًا عند إضافة التعليقات أو تعديل الصفحات. تصغير الحجم Minification: وهي عملية حذف للمحارف غير ضرورية في ملفات HTML وCSS وجافاسكربت ومن ثمّ دمجها على التوالي قبل تطبيق عملية ضغط HTTP على الملفات المخبّئة. تخبئة قاعدة البيانات: وهي تخبئة نتائج الاستعلام (الكائنات) الخاصّة بقاعدة البيانات أيضًا، مما يقلل من الزمن اللازم لتوليد صفحات جديدة في العديد من المواقع الإلكترونية، وتكون فائدة هذا الإجراء ملموسة بصورة خاصة في المواقع التي تستقبل أعداد كبيرة من التعليقات. الترويسات: تدير W3TC الترويسات (entity tag, cache-control, expires) التي تتحكم بتخبئة الملفات في متصفحات الويب، مقلّلة بذلك الحمل على الخادم مما يحسّن بالنتيجة الأداء الملموس للمستخدم. شبكة تسليم المحتوى CDN: يمكنك استخدام شبكة CDN للتحميل الخارجي للموارد من حساب الاستضافة الخاص بك، إذ تنقل W3TC الطلبات على جميع الملفات الثابتة من صور وملفات CSS وجافاسكربت وغيرها إلى شبكة ذات خوادم عالية الأداء (شبكة من الخوادم عالية الأداء)، ويستخدم الخادم الأقرب للزائر لتحميل الملفات المطلوبة موفّرة بذلك أسرع تنزيلات (تحميلات) ممكنة. إنّ W3TC قادرة على تحسين ووردبريس في البيئات وحيدة أو متعدّدة الخوادم سواء أكانت الاستضافة مُشتركة أم مخصّصة. الإضافة WP SUPER CACHE وهي إضافة لتخبئة الصفحات الثابتة في ووردبريس، تولّد ملفات HTML لتُخدّم مباشرة عبر Apache دون معالجة PHP Scripts الضخمة نسبيًا وهذا ما يعطي بالنتيجة ربحًا واضحًا في سرعة مدونة ووردبريس الخاصة بك. إنّ استخدامك للإضافة WP Super Cache يمكّن خادمك من تخديم الزوار بصفحات HTML المخبّئة بنفس سرعة تخديمهم بالملفات الرسومية العادية. لذا ينصح باستخدام WP Super Cache إذا كان موقعك يخدّم بصعوبة عدد زواره اليومي، أو إن كان يظهر على أي من المواقع الإلكترونية الشهيرة مثل Digg.com وSlashdot.org. التخبئة في طرف الخادم تعدّ التخبئة في طرف الخادم أكثر تعقيدًا وهي تستخدم في المواقع عالية الحمولة، ويوجد العديد من الخيارات إلا أنّها خارج موضوع هذه المقالة. أبسط الحلول هو التخبئة محليًا في الخادم، في حين أن الأنظمة المضمّنة والأكثر تعقيدًا تستخدم عدّة خوادم تخبئة (أو ما يعرف بالخوادم الوكيلة العكسية) وذلك في الجانب الأمامي من خوادم الويب بمكان تشغيل تطبيق ووردبريس فعليًا. ومن الممكن تطوير أداء PHP بعدّة أضعاف عبر إضافة ذاكرة مخبئية من نوع opcode لتعمل كذاكرة PHP مخبئية بديلة APC. تعمل إضافة الذاكرة المخبئية التي تقدمها Varnish بالتناغم مع W3 Total Cache لتخزين الصفحات المبنية مسبقًا في الذاكرة والتخديم بها بسرعة دون الحاجة إلى تنفيذ حزمة ووردبريس، Apache أو PHP. وبذلك نجد أنّه من الممكن مساعدة Varnish من خلال عدم مطالبة زوار موقعك بتسجيل الدخول إلى ووردبريس عبر استخدام إضافة خاصة بالتعليقات مثل Disqus عوضًا عن استخدام تعليقات ووردبريس الأساسية (الأصلية/الافتراضية) وهذا ما يؤدي إلى زيادة عدد الصفحات القادر على التخديم بها من الذاكرة المخبئية. التخبئة في المتصفح تقلل التخبئة في المتصفح من الحمل على الخادم عبر تقليل عدد الطلبات لكل صفحة، على سبيل المثال يمكن للمتصفحات ومع استخدام الترويسة الصحيحة للملفات الثابتة (الصور وملفات CSS وجافاسكربت وغيرها) أن تخبئها على جهاز المستخدم، وبذلك يتحقق المتصفح فقط فيما إذا طرأ تعديل على الملفات بدلًا من طلبها بالكامل، وبالنتيجة سيتمكن خادم الويب من الإجابة بالرمز 304 يتضمّن التأكيد بأن الملف لم يتغير، بدلًا من الإجابة بالرمز 200 والذي يتطلّب إرسال الملف كاملًا. توفر W3 Total Cache الدعم المتكامل لكل من التخبئة في المتصفحات وETag وهي إحدى الآليات التي يوفرها HTTP للتحقق من ذاكرة الويب المخبئية. تحميل ملفات المحتوى خارجيًا استخدام شبكة تسليم المحتوى CDN يقلل استخدام شبكة تسليم المحتوى CDN من الحمل على موقعك الإلكتروني، فإن إجراء البحث والتسليم للصور وملفات القوالب وCSS وجافاسكربت خارجيًا إلى CDN ليس أسرع فحسب بل يخفف أيضًا الكثير من الحمل عن حزمة تطبيق ووردبريس في خادمك، ويكون استخدام شبكة تسليم المحتوى أكثر فعالية بالاشتراك مع استخدام إضافة تخبئة مثل W3TC المذكورة سابقًا. وإحدى شبكات توزيع المحتوى CDN الشائعة هي CloudFlare التي تقدّم أيضًا خدمات أمان الانترنت ISS، أسعارها تبدأ من المجاني تمامًا وتزداد الميزات المقدمّة تدريجياً مع زيادة الكلفة، فهذه الشبكات ثابتة الكلفة بمعنى أنّ الكلفة تتعلّق بالميزات المقدمّة وليس بكمية الاستخدام. تمكنّك CloudFlare من توجيه حمولات موقعك عبر شبكاتهم قبل وصولها إلى مضيفك الأصلي، أمّا الشبكة Cloudfront من أمازون فتعتمد على خدمة S3 لتوّفر آلية شبكة تسليم ملفات المحتوى تعمل على ملفاتك الثابتة. إذًا CDN هي خدمة تخبئ ملفاتك الثابتة على العديد من خوادم الويب حول العالم، موفّرة بذلك أداء تحميل أسرع لمستخدمين موقعك بغض النظر عن موقعهم الجغرافي، ويوصى باستخدام Cloudfront جنبًا لجنب مع S3 عوضًا عن استخدام S3 وحدها، والفرق في الكلفة بين الحالتين ليس بالكبير. أما خدمة MaxCDN فهي شبكة توصيل ملفات محتوى تحسب فيها التكلفة بحسب الاستخدام وليس الميزات أي بطريقة مشابهة لخدمة Cloudfront من أمازون، أما عن الاختلافات فإن MaxCDN تدعم خدمة الفيديو عند الطلب كما تدعم نسخ الملفات المتطابق (دون طلب رفعها) ولكن بإمكانك رفعها إن كنت تفضّل ذلك. ويمثّل KeyCDN مزوّد شبكة تسليم المحتوى بديل والذي يوفّر دليل دمج شبكة تسليم المحتوى مع ووردبريس خطوة بخطوة على صفحة الدعم الخاصة بالخدمة. وتعدّ كل من KeyCDN وMaxCDN من الخيارات بأسعار مقبولة وتتغلّب على أسعار المنافسين مثل أمازون، وذلك كون كل منها يمثّل قسمًا من مزوّد شبكة تسليم المحتوى أوسع. ملفات المحتوى الثابتة يمكن لأي ملف ثابت أن يحمّل خارجيًا إلى خادم آخر فمثلًا من الممكن نقل أي صورة أو ملف CSS أو جافاسكربت إلى خادم آخر، وهي تقنية شائعة الاستخدام في الأنظمة خارقة الأداء (Google, Flickr, YouTube وغيرها) إلّا أنها تبقى مفيدة للمواقع الإلكترونية الأصغر العاملة على خادم واحد، كما أنّ نقل ملفات المحتوى إلى مضيفات أسماء أخرى يمكن أن يشكّل حجر أساس للعمل على خوادم متعدّدة مستقبلًا. وحسّنت بعض خوادم الويب لتخديم الملفات الثابتة مثل lighttpd، والتي تعمل بكفاءة أعلى من خوادم الويب الأكثر تعقيدًا مثل Apache. إنّ خدمة التخزين البسيط S3 من أمازون ما هي إلّا خدمة استضافة ملفات ثابتة مخصّصة تعتمد على مبدأ حساب التكلفة وفق كمية الاستخدام دون تحديد حد أدنى لها، لذا ستكون حلًا عمليًا للمواقع الإلكترونية ذات الحمولات الأقل والتي بالكاد تصل لحالات الذروة باستخدام خادم مشترك أو خادم وحيد. مضيفات أسماء متعدّدة من الممكن تحقيق تحسين إضافي للمستخدم عبر تقسيم الملفات الثابتة على عدّة مضيفات أسماء، وبما أنّ معظم المتصفحات ترسل طلبين متزامنين إلى الخادم فقط، وعلى فرض أن الصفحة تتطلب 16 ملف عندها سيُطلب كل اثنين منها معًا، أمّا في حال وزعتها على 4 مضيفات أسماء، سيصبح من الممكن طلب كل 8 ملفات معًا، وهذا ما سيقلل زمن تحميل الصفحة للمستخدم إلّا أنّه سيزيد من الحمل على الخادم بسبب إنشاء المزيد من الطلبات المتزامنة (وهذا ما يدعى بتعدد المسارات Pipelining والذي غالبًا ما يسبب في حال فرط استخدامه إلى استهلاك كامل عرض حزمة اتصال الإنترنت الخاص بالمستخدم). كبداية فإن تحميل الصور خارجيًا هو الأسهل والأبسط، ويمكن تقسيم الصور بالتساوي على ثلاث مضيفات أسماء (مثلًا assets1.yoursite.com, assets2.yoursite.com, assets3.yoursite.com)، وفي حال زيادة الحمولة يمكن نقل مضيفات الأسماء هذه إلى خادمك الخاص. ملاحظة: تجنّب اختيار مضيف أسماء عشوائي لأن ذلك سيؤثّر سلبًا على عمليات التخبئة في المتصفح وبالنتيجة زيادة الأحمال أو حتى توليد عمليات بحث مفرطة في الـ DNS على حساب الأداء. وبشكل مشابه من الممكن تحميل أي ملف CSS أو جافاسكربت خارجيًا إلى خوادم أو مضيفات أسماء مستقلّة. الخلاصات من الممكن تحميل الخلاصات Feeds لخدمة خارجية بسهولة تامّة، وتقوم خدمات تتبع الخلاصات مثل FeedBurner من Google بذلك تلقائيًا، إذ ستتحمّل خوادم خدمة FeedBurner حمولة الخلاصات ولا تحدثها من موقعك الإلكتروني إلّا مرة كل بضع دقائق وهذا ما سيوفر أحمالًا كثيرة. كما يمكنك تحميل الخلاصات خارجيًا إلى خادم منفصل (مثل feeds.yoursite.com) ومن ثمّ يتحمّل حمولة الخلاصات من إحصائيات أو إعلانات. الضغط هنالك طرقًا عديدة لضغط الملفات والبيانات على الخادم مما يساهم بتسليم الصفحات إلى المتصفحات المستخدمين بسرعة أكبر، علمًا أنّ الإضافة W3 Total Cache المشروحة سابقًا توفّر الدعم لمعظم منهجيات الضغط الشائعة، فهي تدعم التصغير والترتيب بهدف ضغط وتجميع صفحات التنسيق وملفات جافاسكربت، كما أنّها تدعم أدوات ضغط الخرج مثل zlib. من المهم أيضًا ضغط ملفات الوسائط مثل الصور، وستساعد الإضافة WP Smushit في تحقيق ذلك. موائمة قاعدة البيانات: تنظيف قاعدة البيانات من الممكن أن تساعد الإضافة WP Optimize في تقليل الفوضى ضمن قاعدة البيانات، كما يمكن جعل ووردبريس يقلل من عدد المراجعات المحفوظة من الصفحات والمنشورات. إضافة خوادم تعد إضافة الخوادم من الطرق الفعّالة لتحسين الأداء رغم تطلبها المزيد من الخبرات، وفي هذا الصدد ينصح بشدة قراءة دليل تصميم ووردبريس القابل للتوسع في AWS والذي يوضّح كيفية بناء تنفيذ AWS ثمين وقابل للتوسّع بشدّة باستخدام مخزن البيانات العلائقية RDS من أمازون. كما يمكنك استخدام موازن الحمل الديناميكي (المرن) من أمازون لتوزيع الأحمال على عدّة خوادم ويب، أمّا بخصوص تشغيل قواعد بيانات متعدّدة أو قاعدة بيانات قابلة للتوسّع بشدّة فمن الممكن استخدام HyperDB أو RDS من أمازون. ترجمة -وبتصرف- للمقال Optimization من موقع WordPress.org اقرأ أيضًا تعلم ووردبريس الخطوات الأولى للعمل مع ووردبريس شرح مفصل لصفحات الإدارة وكيفية التحكم الكامل بموقع ووردبريس كيفية إبقاء نسخة ساكنة من موقعك أثناء بنائك لموقع ووردبريس جديد هل يؤثر استخدام إضافات كثيرة سلبا على موقع ووردبريس؟
سواء أكنت تشغّل نسخة من ووردبريس لموقع كثير الزيارات أو لمجرّد مدونة صغيرة مستخدمًا استضافة مشتركة منخفضة التكاليف، ففي كلتا الحالتين لا بدّ من تحسين أداء ووردبريس والخادم الخاص بك ليعملا بأقصى كفاءة ممكنة، يوفّر هذا المقال نظرة شاملة حول تحسين ووردبريس باستخدام منهجيات محدّدة موصى بها، إلا أنّها لا توفر شرحًا تقنيًا مفصلًا لكافة جوانب الموضوع. إن كنت تبحث عن حلول سريعة، فاذهب مباشرةً لفقرة "التخبئة" في هذا المقال، وستجد فيها أجوبة كثيرة سريعة، وفي حال رغبت بالبدء بعملية تحسين شاملة فاذهب لفقرة "كيفية تطوير الأداء في ووردبريس". كما ستجد أدناه في قسمي "العوامل المؤثّرة على الأداء" و"أدوات اختبار الأداء" نظرة شاملة حول هذا الموضوع، مع ملاحظة أنّ العديد من التقنيات التي ناقشناها في هذا المقال تطبّق أيضاً على ووردبريس متعدّد المواقع MU. العوامل المؤثرة على أداء موقع ووردبريس يوجد العديد من العوامل التي تؤثر على أداء مدونتك (أو موقعك الإلكتروني) في ووردبريس، وتتضمّن هذه العوامل على وجه الخصوص وليس التحديد كل من بيئة الاستضافة، إعدادات ووردبريس، إصدارات البرامج، وعدد المحتويات الرسومية وحجمها، وسنتناول معظم هذه العوامل. الاستضافة تعتمد تقنيات التحسين المتاحة لك على إعدادات الاستضافة. الاستضافة المُشتركة وهي النوع الأكثر شيوعًا من أنواع الاستضافة، إذ يكون موقعك الإلكتروني مستضافاً على خادم ما جنبًا إلى جنب مع العديد من المواقع الأخرى، وفي هذه الحالة تكون شركة الاستضافة هي المسؤولة عن إدارة خادم الويب، وبالتالي ستكون صلاحياتك للتحكّم بإعدادات الخادم وغيرها من الصلاحيات محدودة. وعمومًا المجالات الأكثر صلة بهذا النوع من الاستضافة هي: التخبئة Caching، أداء ووردبريس، وتحميل ملفات المحتوى خارجيًا Content Offloading. الاستضافة الوهمية والخوادم المخصصّة في هذا النوع من الاستضافة ستمتلك صلاحية التحكّم بخادمك، والذي يمكن أن يكون جهازًا مستقلًا فيزيائيًا أو واحدًا من مجموعة خوادم وهمية تتشارك نفس الموارد الفيزيائية. وأهم ما في الأمر أنّك تملك صلاحية التحكّم بالخادم، وأكثر مجالات الاهتمام بالإضافة إلى المجالات أعلاه (التخبئة وأداء ووردبريس) في هذه الحالة هي: تحسين الخادم وتحميل ملفات المحتوى خارجيًا. عدد الخوادم سيكون من الضروري استثمار عدة خوادم عند التعامل مع حالات عالية الحمل. إذا كانت تلك هي الحالة لديك، فلا بدّ من توظيف كل الأفكار والتقنيات المذكورة أعلاه. من السهل نقل قاعدة بيانات ووردبريس من خادم لآخر، ولا تتطلب عملية النقل سوى تعديلًا بسيطًا في ملف الإعدادات، ويمكن نقل الصور وجميع الملفات الثابتة بشكل مشابه إلى خوادم بديلة بسهولة (راجع القسم " تحميل ملفات المحتوى خارجيًا"). يمكن لبرنامج موازنة الحمل الديناميكي Elastic Load Balancer من أمازون أن يساعدك في توزيع الحمل على أكثر من خادم ويب إلا أنّه يتطلّب مستوى عالٍ من الخبرة. وسيوفر النوع HyperDB بديلًا فوريًا للنوع WPDB القياسي في حال كنت تستخدم عدة خوادم قواعد بيانات، والذي يستطيع التعامل مع خوادم قواعد بيانات متعدّدة سواء أكانت الهيكلية مكررة أو موزّعة. أداء التجهيزات تؤثر إمكانيات التجهيزات تأثيرًا كبيرًا على أداء موقعك الإلكتروني. ومن العوامل الهامة: عدد المعالجات وسرعتها، حجم الذاكرة المتوفرّة ومساحة القرص، إضافةً إلى نوع وسائط التخزين. وعادة ما توفر مزودات الاستضافة أداء تجهيزات أفضل مقابل تكلفة أعلى. المسافة الجغرافية من العوامل المؤثرة على الأداء أيضًا هي المسافة الفاصلة بين خادمك وزوّار موقعك الإلكتروني، وبهدف حصولهم جميعًا على أداء أمثل، من الممكن استخدام شبكة تسليم محتوى CDN التي تقوم بمزامنة وتزويد الملفات الثابتة (مثل الصور) عبر مناطق جغرافية متعدّدة. الحمل على الخادم إنّ لكمية الأحمال على خادمك وطريقة ضبطه للتعامل معها له الأثر البالغ على الأداء، فعلى سبيل المثال سيتباطأ الأداء إلى حد التوقف في حال عدم استخدامك لتقنية التخبئة، ومع وصول طلبات إضافية للصفحات؛ ستزدحم هذه الطلبات حد الاختناق مسببةً بالنتيجة تعطل خادم الويب أو قواعد البيانات الخاص بك. أما في حال ضبط إعدادات الاستضافة ضبطًا مناسبًا فسيكون الخادم قادرًا على التعامل مع كمية كبيرة من الأحمال، كما يمكن للتحميل الخارجي إلى خوادم أخرى أن يقلل من الحمل على الخادم. كما أنّ الأحمال الزائدة والهجمات الممنهجة مثل هجمات تسجيل الدخول المتكرر، والربط المكثّف مع الصور باستخدام روابط الصور لديك في عناصر صفحات ذات حمولات عالية، أو هجمات DOS جميعها يمكن أن تزيد من الحمل على خادمك، وبالتالي من المهم جدًا كشف وتحديد ومنع هذه الهجمات. إصدارات البرامج والأداء من المهم أن تتأكد أيضًا من كونك تستخدم أحدث إصدارات البرامج، كون تحديثاتها غالبًا ما تصلح الأخطاء وتحسّن الأداء، فالتأكد من كونك تستخدم أحدث إصدارات لينكس Linux (أو ويندوز)، وApache، وMySQL/MariaDB وPHP هو أمر بالغ الأهمية. إعدادات ووردبريس تؤثر القالب التي تختاره تأثيرًا كبيرًا على أداء موقعك الإلكتروني، فاختيارك لقالب سريع وخفيف سيحقق أداء وفعالية أكثر بالموازنة مع اختيار سمة مليئة بالرسومات. كما أن لعدد الإضافات وأدائها أثرًا كبيرًا على أداء موقعك الإلكتروني، فمن الممكن حذف أو إلغاء تفعيل الإضافات غير الضرورية وهي طريقة مهمة من طرق تحسين الأداء. حجم الصور والرسومات من المؤكد أن تخصيص الصور في منشوراتك بما يناسب الويب سيوفّر في الزمن وعرض الحزمة اللازم، كما أنّه سيرفع تصنيف موقعك في محركات البحث. أدوات اختبار الأداء تمثّل أداة اختبار صفحة الويب Webpagetest اختبارًا لأداء المواقع الإلكترونية بطريقة فعلية تحاكي الواقع من أماكن أو متصفحات أو سرعات اتصال مختلفة، والأداة PageSpeed Insights من Google توفّر طريقة لقياس أداء موقع ووردبريس الخاص بك معطيةً معلومات واضحة ومحددة تساعدك في إجراء التحسينات. كما تمتلك جميع أدوات التطوير المُضمّنة في المتصفحات (مثل Firefox أو Chrome) أدوات لقياس الأداء. كيفية تطوير الأداء في ووردبريس سنستعرض مجموعة من الاقتراحات والأدوات التي يمكن استخدامها بهدف تحسين أداء مواقع ووردبريس تحسين موقعك الإلكتروني في ووردبريس تصغير حجم الإضافات حتّى تحسن من أداء ووردبريس فإن أوّل وأسهل ما يمكن التفكير به هو الإضافات، عبر حذف أو إلغاء تفعيل غير الضروري منها. يمكنك استخدام تعطيل الإضافات انتقائيًا ومراقبة تأثير ذلك على أداء المخدم. فإذا كانت إحدى الإضافات تؤثر سلبًا على أداء موقعك بوضوح فعليك قراءة دليل الاستخدام الخاص بها أو أن تطلب المساعدة في أحد منتديات الدعم المناسبة الخاصة بالإضافات. تحسين ملفات المحتوى ملفات الصور هل هناك أية صور غير ضرورية (مثلًا هل من الممكن استبدال بعض الصور بنصوص؟) تأكد من تخصيص تحسين جميع ملفات الصور بطريقة مناسبة عبر اختيار الصيغة الصحيحة (JPG/PNG/GIF) مع إجراء عملية ضغط لجميع الصور. حجم/عدد الملفات الكلي هل من الممكن تقليل عدد الملفات الضرورية اللازمة للعرض الأمثل للصفحات المتتالية خلال الجلسة الواحدة على موقعك الإلكتروني؟ يوصى بدمج عدّة ملفات في ملف واحد محسّن في حال استخدامك لـ HTTP1. تصغير حجم ملفات CSS وجافاسكربت. يمكن أيضًا استخدام تحميل ملفات المحتوى خارجيًا لتحسين القالب في موقعك. ترقية التجهيزات يعد دفع مبالغ إضافية لمزوّد الاستضافة الخاص بموقعك مقابل مستويات خدمة أعلى حلًا فعالًا للغاية، فاستخدام ذاكرة وصول عشوائي RAM أكبر أو الانتقال إلى مضيف بمحرك أقراص ذو حالة ثابتة SSD مثل Digital Ocean سيحدث فرقًا مهمًا، كما سيؤثر استخدام عدد أكبر من المعالجات بسرعات أعلى تأثيرًا إيجابيًا، وإن أمكن فمن الأفضل فصل الخدمات ذات الأغراض المختلفة مثل HTTP وMySQL باستخدام إجراءات مختلفة على خوادم متعددة سواء أكانت فيزيائية أم وهمية VPS-es. تحسين البرمجيات تأكد دومًا من كونك تستخدم أحدث إصدار من نظام التشغيل مثل لينكس Linux ويندوز سيرفر Windows Server، وأحدث خادم ويب مثل ِApache أو IIS كذلك الأمر بالنسبة لقواعد البيانات مثل MySQL وPHP. يمكن أن يتعذر عليك تنفيذ واتباع الخطوات والنصائح الواردة أدناه، في هذه الحالة اطلب من مزود الاستضافة إنجاز هذه المهام، فمزود الاستضافة الجيد سيرقي حسابك أو ينقله إلى خادم محدث لتحقيق السرعة المطلوبة، وعند الضرورة يمكنك الانتقال لأحد حلول الاستضافة المدارة من شركة ووردبريس التجارية. خادم نطاق الأسماء DNS لا تشغل خادم نطاق أسماء على خادم ووردبريس بل استخدم إحدى الخدمات التجارية لخوادم نطاقات الأسماء مثل Amazon’s Route 53 أو الخدمة المجانية المقدمّة من الشركة المسجّلة للمجال الخاص بك. إنّ استخدامك لخدمة مثل خدمة أمازون سيُسهّل الانتقال بين خوادم النسخ الاحتياطي في الحالات الطارئة أو خلال أعمال الصيانة كما أنّه يوفر درجة جيدة من القدرة على استمرار العمل في حال حدوث أخطاء. إن اختيارك لاستضافة خادم DNS خارجي سيقلل حتمًا من الحمل على خادم الويب الرئيسي فبالرغم كونه إجراء بسيطًا إلا أنّه سيقلل من الحمل على وحدة المعالجة المركزية CPU عبر تحويل جزء من ضغط الشبكة إلى خارج الخادم. خادم الويب من الممكن ضبط إعدادات خادم الويب الخاص بك لتحسين الأداء من خلال استخدام تقنيات عديدة مثل التخبئة أو تعيين ترويسات المخابئ لتقليل حمل كل مستخدم. وعمومًاعليك البحث عن التحسينات الخاصة بخادم الويب الخاص بك (للحصول على المزيد من المعلومات يمكنك مثلًا البحث عن "Apache Optimization"). كما تملك بعض خوادم الويب إصدارات ذات سرعات أعلى، والتي يمكنك الحصول عليها مقابل كلفة أكبر مثل الإصدار Apache Litespeed. كما يوجد عدد من الطرق لموائمة Apache ليعطي أداءً أعلى وذلك اعتمادًا على إعدادات موقعك الإلكتروني واستضافتك مثل Memcache. PHP يتوفر العديد من مسرعات PHP القادرة على تحسين أداء ملفات PHP تحسينًا كبيرًا، وفي حال استخدمت إحداها فإن التحسين لن يشمل نسخة ووردبريس التي نصبتها فقط، وإنمّا كافّة ملفات PHP على الخادم. وللمزيد من المعلومات يمكنك البحث حول تحسينات PHP مثل APC أو OPcache. وتقدّم إضافة W3 الشاملة للتخبئة والمشروحة أدناه دعمًا متكاملًا لكل من Memcach، APC، وغيرها من أدوات التخبئة Opcode. MySQL/MariaDB لتحسينات MySQL/MariaDB أثر سحري على أداء ووردبريس، فبعض التغييرات البسيطة على إعدادات تخبئة نتائج الاستعلامات مؤقتًا ستُحدث أثرًا إيجابيًا كبيرًا، وذلك كون ووردبريس يكرر العديد من الاستعلامات في كل طلب. وفي هذه الأيام أصبح InnoDB القابل للتحسين والموائمة الدقيقة هو محرك التخزين الافتراضي لـ MySQL، لذا لا بدّ من أن تتأكد من كونك تستخدمه بالفعل، وللمزيد من المعلومات والأمثلة يمكنك البحث حول "تحسين MySQL"، "أداء mysql innodb" أو "تحسين innodb"، أمّا إذا كنت تبحث عن معلومات حول كيفية تحويل جداول MyISAM الأقدم إلى InnoDB ابحث عن "تحويل myisam إلى innodb في mysql". وطرحت Iliya Polihronov مثالًا رائعًا حول تحسين ووردبريس في WordCamp San Francisco عام 2012، إذ أنجز العديد من المهام ومن بينها تحسين الخادم الخاص بـ WordPress.com. ومن المهم ألّا تشغل خادم بريد على خادم ووردبريس الخاص بك، وكبديل له لتوفير نماذج التواصل استخدم تطبيقًا مثل Contact Form 7 والذي يوفر آلية تعامل مع البريد الإلكتروني Mailgun مجانية. التخبئة تُستخدمُ تقنية التخبئة في كلا جانبي الخادم والمستخدم، ومن شأن الإدارة الصحيحة لها أن تحسن أداء مواقع ووردبريس، فيما يلي سنستعرض أهم الإجراءات المتعلقة بالتخبئة: الإضافات الخاصّة بالتخبئة يمكنك بسهولة تنصيب إضافات خاصّة بالتخبئة مثل W3 Total Cache أو WP Super Cache والتي ستحتفظ وتخبئ منشورات وصفحات ووردبريس الخاصّة بك كملفات ثابتة، ومن ثمّ تخدم المستخدمين باستخدام هذه الملفات مما سيُقلل من حمل المعالجة على الخادم، وهذا سيُحسّن الأداء مئات المرات مع وجود بضع صفحات ثابتة. ولنتيجة أكثر فاعلية يمكن استخدام هذه الإضافة مع أداة تخبئة صفحات على مستوى النظام مثل Varnish مع ملاحظة أنّ ضبط إعدادات التخبئة سيُصبح أكثر تعقيدًا في حال احتوت منشوراتك أو صفحاتك على الكثير من المحتويات الديناميكية. الإضافة W3 TOTAL CACHE تعدّ W3 Total Cache (واختصارًا W3TC) الجيل الأحدث من إضافات الأداء في ووردبريس، والتي تستخدم أبحاث هيئات تطوير الويب لتوفير تجربة مستخدم مثالية في المواقع الإلكترونية المبنية باستخدام ووردبريس، وفيما يلي سنشرحها بالتفصيل. تتميز W3TC بقدرتها على تحسين الأداء في كلا جانبي الخادم والمستخدم، مضيفة إجراءات غير متوفّرة أصلًا. تخبئة الصفحات: يساعد استخدام W3TC على تقليل الزمن اللازم للاستجابة عبر تشكيل إصدارات HTML ثابتة للصفحات، سامحةً بذلك لخوادم الويب بتخديم هذه الصفحات دون الحاجة اللجوء إلى PHP. كما أنّها تحدث العناصر المخبئة تلقائيًا عند إضافة التعليقات أو تعديل الصفحات. تصغير الحجم Minification: وهي عملية حذف للمحارف غير ضرورية في ملفات HTML وCSS وجافاسكربت ومن ثمّ دمجها على التوالي قبل تطبيق عملية ضغط HTTP على الملفات المخبّئة. تخبئة قاعدة البيانات: وهي تخبئة نتائج الاستعلام (الكائنات) الخاصّة بقاعدة البيانات أيضًا، مما يقلل من الزمن اللازم لتوليد صفحات جديدة في العديد من المواقع الإلكترونية، وتكون فائدة هذا الإجراء ملموسة بصورة خاصة في المواقع التي تستقبل أعداد كبيرة من التعليقات. الترويسات: تدير W3TC الترويسات (entity tag, cache-control, expires) التي تتحكم بتخبئة الملفات في متصفحات الويب، مقلّلة بذلك الحمل على الخادم مما يحسّن بالنتيجة الأداء الملموس للمستخدم. شبكة تسليم المحتوى CDN: يمكنك استخدام شبكة CDN للتحميل الخارجي للموارد من حساب الاستضافة الخاص بك، إذ تنقل W3TC الطلبات على جميع الملفات الثابتة من صور وملفات CSS وجافاسكربت وغيرها إلى شبكة ذات خوادم عالية الأداء (شبكة من الخوادم عالية الأداء)، ويستخدم الخادم الأقرب للزائر لتحميل الملفات المطلوبة موفّرة بذلك أسرع تنزيلات (تحميلات) ممكنة. إنّ W3TC قادرة على تحسين ووردبريس في البيئات وحيدة أو متعدّدة الخوادم سواء أكانت الاستضافة مُشتركة أم مخصّصة. الإضافة WP SUPER CACHE وهي إضافة لتخبئة الصفحات الثابتة في ووردبريس، تولّد ملفات HTML لتُخدّم مباشرة عبر Apache دون معالجة PHP Scripts الضخمة نسبيًا وهذا ما يعطي بالنتيجة ربحًا واضحًا في سرعة مدونة ووردبريس الخاصة بك. إنّ استخدامك للإضافة WP Super Cache يمكّن خادمك من تخديم الزوار بصفحات HTML المخبّئة بنفس سرعة تخديمهم بالملفات الرسومية العادية. لذا ينصح باستخدام WP Super Cache إذا كان موقعك يخدّم بصعوبة عدد زواره اليومي، أو إن كان يظهر على أي من المواقع الإلكترونية الشهيرة مثل Digg.com وSlashdot.org. التخبئة في طرف الخادم تعدّ التخبئة في طرف الخادم أكثر تعقيدًا وهي تستخدم في المواقع عالية الحمولة، ويوجد العديد من الخيارات إلا أنّها خارج موضوع هذه المقالة. أبسط الحلول هو التخبئة محليًا في الخادم، في حين أن الأنظمة المضمّنة والأكثر تعقيدًا تستخدم عدّة خوادم تخبئة (أو ما يعرف بالخوادم الوكيلة العكسية) وذلك في الجانب الأمامي من خوادم الويب بمكان تشغيل تطبيق ووردبريس فعليًا. ومن الممكن تطوير أداء PHP بعدّة أضعاف عبر إضافة ذاكرة مخبئية من نوع opcode لتعمل كذاكرة PHP مخبئية بديلة APC. تعمل إضافة الذاكرة المخبئية التي تقدمها Varnish بالتناغم مع W3 Total Cache لتخزين الصفحات المبنية مسبقًا في الذاكرة والتخديم بها بسرعة دون الحاجة إلى تنفيذ حزمة ووردبريس، Apache أو PHP. وبذلك نجد أنّه من الممكن مساعدة Varnish من خلال عدم مطالبة زوار موقعك بتسجيل الدخول إلى ووردبريس عبر استخدام إضافة خاصة بالتعليقات مثل Disqus عوضًا عن استخدام تعليقات ووردبريس الأساسية (الأصلية/الافتراضية) وهذا ما يؤدي إلى زيادة عدد الصفحات القادر على التخديم بها من الذاكرة المخبئية. التخبئة في المتصفح تقلل التخبئة في المتصفح من الحمل على الخادم عبر تقليل عدد الطلبات لكل صفحة، على سبيل المثال يمكن للمتصفحات ومع استخدام الترويسة الصحيحة للملفات الثابتة (الصور وملفات CSS وجافاسكربت وغيرها) أن تخبئها على جهاز المستخدم، وبذلك يتحقق المتصفح فقط فيما إذا طرأ تعديل على الملفات بدلًا من طلبها بالكامل، وبالنتيجة سيتمكن خادم الويب من الإجابة بالرمز 304 يتضمّن التأكيد بأن الملف لم يتغير، بدلًا من الإجابة بالرمز 200 والذي يتطلّب إرسال الملف كاملًا. توفر W3 Total Cache الدعم المتكامل لكل من التخبئة في المتصفحات وETag وهي إحدى الآليات التي يوفرها HTTP للتحقق من ذاكرة الويب المخبئية. تحميل ملفات المحتوى خارجيًا استخدام شبكة تسليم المحتوى CDN يقلل استخدام شبكة تسليم المحتوى CDN من الحمل على موقعك الإلكتروني، فإن إجراء البحث والتسليم للصور وملفات القوالب وCSS وجافاسكربت خارجيًا إلى CDN ليس أسرع فحسب بل يخفف أيضًا الكثير من الحمل عن حزمة تطبيق ووردبريس في خادمك، ويكون استخدام شبكة تسليم المحتوى أكثر فعالية بالاشتراك مع استخدام إضافة تخبئة مثل W3TC المذكورة سابقًا. وإحدى شبكات توزيع المحتوى CDN الشائعة هي CloudFlare التي تقدّم أيضًا خدمات أمان الانترنت ISS، أسعارها تبدأ من المجاني تمامًا وتزداد الميزات المقدمّة تدريجياً مع زيادة الكلفة، فهذه الشبكات ثابتة الكلفة بمعنى أنّ الكلفة تتعلّق بالميزات المقدمّة وليس بكمية الاستخدام. تمكنّك CloudFlare من توجيه حمولات موقعك عبر شبكاتهم قبل وصولها إلى مضيفك الأصلي، أمّا الشبكة Cloudfront من أمازون فتعتمد على خدمة S3 لتوّفر آلية شبكة تسليم ملفات المحتوى تعمل على ملفاتك الثابتة. إذًا CDN هي خدمة تخبئ ملفاتك الثابتة على العديد من خوادم الويب حول العالم، موفّرة بذلك أداء تحميل أسرع لمستخدمين موقعك بغض النظر عن موقعهم الجغرافي، ويوصى باستخدام Cloudfront جنبًا لجنب مع S3 عوضًا عن استخدام S3 وحدها، والفرق في الكلفة بين الحالتين ليس بالكبير. أما خدمة MaxCDN فهي شبكة توصيل ملفات محتوى تحسب فيها التكلفة بحسب الاستخدام وليس الميزات أي بطريقة مشابهة لخدمة Cloudfront من أمازون، أما عن الاختلافات فإن MaxCDN تدعم خدمة الفيديو عند الطلب كما تدعم نسخ الملفات المتطابق (دون طلب رفعها) ولكن بإمكانك رفعها إن كنت تفضّل ذلك. ويمثّل KeyCDN مزوّد شبكة تسليم المحتوى بديل والذي يوفّر دليل دمج شبكة تسليم المحتوى مع ووردبريس خطوة بخطوة على صفحة الدعم الخاصة بالخدمة. وتعدّ كل من KeyCDN وMaxCDN من الخيارات بأسعار مقبولة وتتغلّب على أسعار المنافسين مثل أمازون، وذلك كون كل منها يمثّل قسمًا من مزوّد شبكة تسليم المحتوى أوسع. ملفات المحتوى الثابتة يمكن لأي ملف ثابت أن يحمّل خارجيًا إلى خادم آخر فمثلًا من الممكن نقل أي صورة أو ملف CSS أو جافاسكربت إلى خادم آخر، وهي تقنية شائعة الاستخدام في الأنظمة خارقة الأداء (Google, Flickr, YouTube وغيرها) إلّا أنها تبقى مفيدة للمواقع الإلكترونية الأصغر العاملة على خادم واحد، كما أنّ نقل ملفات المحتوى إلى مضيفات أسماء أخرى يمكن أن يشكّل حجر أساس للعمل على خوادم متعدّدة مستقبلًا. وحسّنت بعض خوادم الويب لتخديم الملفات الثابتة مثل lighttpd، والتي تعمل بكفاءة أعلى من خوادم الويب الأكثر تعقيدًا مثل Apache. إنّ خدمة التخزين البسيط S3 من أمازون ما هي إلّا خدمة استضافة ملفات ثابتة مخصّصة تعتمد على مبدأ حساب التكلفة وفق كمية الاستخدام دون تحديد حد أدنى لها، لذا ستكون حلًا عمليًا للمواقع الإلكترونية ذات الحمولات الأقل والتي بالكاد تصل لحالات الذروة باستخدام خادم مشترك أو خادم وحيد. مضيفات أسماء متعدّدة من الممكن تحقيق تحسين إضافي للمستخدم عبر تقسيم الملفات الثابتة على عدّة مضيفات أسماء، وبما أنّ معظم المتصفحات ترسل طلبين متزامنين إلى الخادم فقط، وعلى فرض أن الصفحة تتطلب 16 ملف عندها سيُطلب كل اثنين منها معًا، أمّا في حال وزعتها على 4 مضيفات أسماء، سيصبح من الممكن طلب كل 8 ملفات معًا، وهذا ما سيقلل زمن تحميل الصفحة للمستخدم إلّا أنّه سيزيد من الحمل على الخادم بسبب إنشاء المزيد من الطلبات المتزامنة (وهذا ما يدعى بتعدد المسارات Pipelining والذي غالبًا ما يسبب في حال فرط استخدامه إلى استهلاك كامل عرض حزمة اتصال الإنترنت الخاص بالمستخدم). كبداية فإن تحميل الصور خارجيًا هو الأسهل والأبسط، ويمكن تقسيم الصور بالتساوي على ثلاث مضيفات أسماء (مثلًا assets1.yoursite.com, assets2.yoursite.com, assets3.yoursite.com)، وفي حال زيادة الحمولة يمكن نقل مضيفات الأسماء هذه إلى خادمك الخاص. ملاحظة: تجنّب اختيار مضيف أسماء عشوائي لأن ذلك سيؤثّر سلبًا على عمليات التخبئة في المتصفح وبالنتيجة زيادة الأحمال أو حتى توليد عمليات بحث مفرطة في الـ DNS على حساب الأداء. وبشكل مشابه من الممكن تحميل أي ملف CSS أو جافاسكربت خارجيًا إلى خوادم أو مضيفات أسماء مستقلّة. الخلاصات من الممكن تحميل الخلاصات Feeds لخدمة خارجية بسهولة تامّة، وتقوم خدمات تتبع الخلاصات مثل FeedBurner من Google بذلك تلقائيًا، إذ ستتحمّل خوادم خدمة FeedBurner حمولة الخلاصات ولا تحدثها من موقعك الإلكتروني إلّا مرة كل بضع دقائق وهذا ما سيوفر أحمالًا كثيرة. كما يمكنك تحميل الخلاصات خارجيًا إلى خادم منفصل (مثل feeds.yoursite.com) ومن ثمّ يتحمّل حمولة الخلاصات من إحصائيات أو إعلانات. الضغط هنالك طرقًا عديدة لضغط الملفات والبيانات على الخادم مما يساهم بتسليم الصفحات إلى المتصفحات المستخدمين بسرعة أكبر، علمًا أنّ الإضافة W3 Total Cache المشروحة سابقًا توفّر الدعم لمعظم منهجيات الضغط الشائعة، فهي تدعم التصغير والترتيب بهدف ضغط وتجميع صفحات التنسيق وملفات جافاسكربت، كما أنّها تدعم أدوات ضغط الخرج مثل zlib. من المهم أيضًا ضغط ملفات الوسائط مثل الصور، وستساعد الإضافة WP Smushit في تحقيق ذلك. موائمة قاعدة البيانات: تنظيف قاعدة البيانات من الممكن أن تساعد الإضافة WP Optimize في تقليل الفوضى ضمن قاعدة البيانات، كما يمكن جعل ووردبريس يقلل من عدد المراجعات المحفوظة من الصفحات والمنشورات. إضافة خوادم تعد إضافة الخوادم من الطرق الفعّالة لتحسين الأداء رغم تطلبها المزيد من الخبرات، وفي هذا الصدد ينصح بشدة قراءة دليل تصميم ووردبريس القابل للتوسع في AWS والذي يوضّح كيفية بناء تنفيذ AWS ثمين وقابل للتوسّع بشدّة باستخدام مخزن البيانات العلائقية RDS من أمازون. كما يمكنك استخدام موازن الحمل الديناميكي (المرن) من أمازون لتوزيع الأحمال على عدّة خوادم ويب، أمّا بخصوص تشغيل قواعد بيانات متعدّدة أو قاعدة بيانات قابلة للتوسّع بشدّة فمن الممكن استخدام HyperDB أو RDS من أمازون. ترجمة -وبتصرف- للمقال Optimization من موقع WordPress.org اقرأ أيضًا تعلم ووردبريس الخطوات الأولى للعمل مع ووردبريس شرح مفصل لصفحات الإدارة وكيفية التحكم الكامل بموقع ووردبريس كيفية إبقاء نسخة ساكنة من موقعك أثناء بنائك لموقع ووردبريس جديد هل يؤثر استخدام إضافات كثيرة سلبا على موقع ووردبريس؟ -
.png.3f4400357390c28f4dde1f67d1264718.png) أضاف الإصدار ES6 من معايير ECMAScript الصادر عام 2015 ميزة قالب النص Template Literals إلى لغة جافاسكربت والتي تعد شكلًا جديدًا لصياغة السلاسل النصية Strings في جافاسكربت مُضيفًا العديد من الإمكانيات الجديدة الفعّالة، كإمكانية إنشاء سلاسل نصية متعدّدة السطور بطريقة سهلة، وإمكانية استخدام المواضع المؤقتة placeholder لتضمين قيم التعابير البرمجية Expressions في السلاسل النصية. إضافة لوجود ميزة متقدمة تدعى قوالب النصوص الموسومة Tagged Template Literals والتي تسمح لك بإجراء العمليات على التعابير في السلاسل النصية. تزيد كل هذه الإمكانات من خياراتك كمطور لكتابة السلاسل النصية ببراعة واحترافية، جاعلة إياك قادرًا على إنشاء سلاسل نصية ديناميكية يمكن توظيفها في عناوين الويب URLs أو في الإجراءات التي تعدّل عناصر صفحات HTML. ستتعرف في هذا المقال على الاختلافات ما بين السلاسل النصية المحصورة بين علامتي اقتباس مفردة أو مزدوجة وقوالب النصوص، كما ستتعرف على الطرق المتعدّدة للتصريح عن سلاسل نصية من أشكال مختلفة بما يتضمن السلاسل الممتدّة على أكثر من سطر والديناميكية منها التي تتغير تبعًا لقيمة متحول أو تعبير ما. ومن ثمّ ستتعلم عن قوالب النصوص الموسومة وسترى بعض الأمثلة الواقعية لمشاريع باستخدام هذه القوالب. التصريح عن السلاسل النصية سنستعرض في هذا القسم كيفية التصريح عن السلاسل النصية باستخدام علامات الاقتباس المفردة والمزدوجة، ومن ثم سننتقل لاستعراض كيفية إجراء ذلك في حالة استخدام قوالب النصوص. يمكنك كتابة سلسلة المحارف في جافاسكربت باستخدام علامات اقتباس مفردة ' ': const single = 'Every day is a good day when you paint.' كما يمكن كتابة سلسلة المحارف باستخدام علامات اقتباس مزدوجة " ": const double = "Be so very light. Be a gentle whisper." وإجمالًا لا يوجد اختلافات جوهرية ما بين استخدام علامات الاقتباس المفردة أو المزدوجة في جافاسكربت، وذلك على خلاف بعض لغات البرمجة والتي تتيح إمكانية التضمين Interpolation باستخدام إحدى الطريقتين حصرًا، والمقصود بالتضمين التعامل مع المواضع المؤقتة كجزء ديناميكي من سلسلة المحارف. ويعد استخدام علامات الاقتباس المفردة والمزدوجة خيارًا شخصيًا، كما يمكن استخدامهما معًا بشرط إغلاق أيًا منها بنفس نوع البدء: // الإغلاق هنا باستخدام علامة اقتباس مفردة لأننا بدأنا بمثلها const single = '"We don\'t make mistakes. We just have happy accidents." - Bob Ross' // الإغلاق هنا باستخدام علامة اقتباس مزدوجة لأننا بدأنا بمثلها const double = "\"We don't make mistakes. We just have happy accidents.\" - Bob Ross" console.log(single); console.log(double); وسيقوم الإجراء log( ) بالنتيجة بطباعة نفس سلسلة المحارف على الخرج: "We don't make mistakes. We just have happy accidents." - Bob Ross "We don't make mistakes. We just have happy accidents." - Bob Ross في حين أنّه تكتب قوالب النصوص عبر حصر السلسة النصية بين علامتي اقتباس مائلتين (`) : const template = `Find freedom on this canvas.` وهي لا تحتاج للإغلاق بعلامة اقتباس مفردة أو مزدوجة: const template = `"We don't make mistakes. We just have happy accidents." - Bob Ross` ولكن لا بدّ من إغلاقها بعلامة اقتباس مائلة كما بدأت: const template = `Template literals use the \` character.` وتؤدّي قوالب النصوص كافّة الوظائف التي تؤديها السلاسل النصية العادية، وبالتالي يمكنك استبدال كافّة السلاسل النصية في مشروعك بقوالب نصوص، إلّا أنّ القواعد الأساسية الشائعة في كتابة الشيفرات البرمجية تنص على استخدام قوالب النصوص فقط عند الحاجة الفعلية لها لما تقدمه من إمكانات إضافية عن السلاسل النصية العادية، وبالتالي يفضّل استخدام علامات التنصيص المفردة أو المزدوجة فقط لحصر السلاسل النصية البسيطة، وهذا ما سيجعل قراءة واختبار شيفرتك البرمجية أسهل لأي مطوّر آخر. الآن وبعد معرفتك لكيفية التصريح عن السلاسل النصية باستخدام علامات الاقتباس المفردة والمزدوجة وعلامات الاقتباس المائلة، سننتقل للتعرّف على أول فوائد قوالب النصوص وهي الكتابة على عدّة أسطر. كتابة السلاسل النصية على عدّة أسطر سنرى بدايةً كيفية التصريح عن السلاسل النصية متعددة الأسطر ما قبل ES6، ثمّ سننتقل لنلاحظ كيف سهّل استخدام قوالب النصوص من هذا الأمر. فسابقًا، وفي حال رغبت بكتابة سلسلة نصية على عدة أسطر في محرر النصوص، كان لا بدّ من استخدام عملية ربط سلاسل (+) والتي لا تمثّل دائمًا الطريقة الأفضل. فمثلًا وعلى خلاف الواقع، يبدو أنّ السلسلة النصية التالية ستظهر عند التنفيذ على عدّة أسطر: const address = 'Homer J. Simpson' + '742 Evergreen Terrace' + 'Springfield' ولكن في الواقع الإجراء السابق سيسمح لك بتقسيم السلسلة النصية إلى أجزاء أصغر وكتابتها على عدّة أسطر في محرر النصوص فقط، دون حدوث أي أثر على نتيجة الخرج، بمعنى أن السلسلة ستظهر على الخرج في سطر واحد وبدون مسافة فاصلة (رغم استخدام مسافات بادئة في بداية كل جزء من السلسلة في محرّر النصوص) بين جزء وآخر منها، ويكون ناتج تنفيذ الإجراء الإجراء log( ) عند تمرير المتغير address بالشّكل: Homer J. Simpson742 Evergreen TerraceSpringfield كما يمكنك استخدام الخط المائل العكسي \ لكتابة السلسلة النصية على عدّة أسطر في محرر النصوص كالتالي: const address = 'Homer J. Simpson\ 742 Evergreen Terrace\ Springfield' والميزة هنا أنّ المسافات البادئة ستظهر فعلًا كمسافات فارغة في السلسة النصية الناتجة، إلّا أنّها ستظهر أيضًا على سطر واحد بالشّكل : Homer J. Simpson 742 Evergreen Terrace Springfield والحل الوحيد لإنشاء سلاسل نصية على عدّة أسطر عند التنفيذ هو استخدام محرف الانتقال لسطر جديد \n أثناء كتابة الرمز، مثلًا: const address = 'Homer J. Simpson\n' + '742 Evergreen Terrace\n' + 'Springfield' وسيظهر الخرج عند التنفيذ بالشّكل: Homer J. Simpson\n 742 Evergreen Terrace\n Springfield إلّا أنّ استخدام محرف الانتقال لسطر جديد (\n) يمكن ألا يكون أمرًا بديهيًا، فيمكن أن يظن المبرمج أنّ الانتقال لسطر جديد أثناء كتابة الرمز في محرّر النصوص كافيًا لتظهر النتيجة المطلوبة في الخرج، وهذا ما توفره قوالب النصوص؛ فمع استخدامها لن تحتاج لإضافة علامة ربط السلاسل النصية أو محرف انتقال لسطر جديد ولا حتّى خط مائل عكسي، كل ما تحتاجه هو مجرّد الضغط على زر Enter وستظهر السلسلة النصية على عدّة أسطر افتراضيًا، مثلًا: const address = `Homer J. Simpson 742 Evergreen Terrace Springfield` وبذلك سيكون خرج السلسة النصية تمامًا كما كُتبت، أي في مثالنا بالشّكل: Homer J. Simpson 742 Evergreen Terrace Springfield كما أنّ استخدام قوالب النصوص سيحتفظ أثناء التنفيذ بأي مسافات بادئة وضعتها، لذا تجنّب استخدام أي مسافات إلّا في موضعها المطلوب، فمثلًا لدى كتابة الترميز التالي: const address = `Homer J. Simpson 742 Evergreen Terrace Springfield` فبالرغم من كون طريقة الكتابة السابقة أسهل وأنسب للقراءة، إلّا أنّ الخرج لن يكون كذلك، بل سيكون بالشّكل: Homer J. Simpson 742 Evergreen Terrace Springfield بعد التعرّف على السلاسل متعدّدة الأسطر، فيما يلي سنستعرض كيفية تضمين قيم التعابير البرمجية لحالات التصريح عن السلاسل النصية المختلفة. تضمين قيم التعابير البرمجية في السابق وقبل إصدار ES6 كان يستخدم علامة ربط السلاسل النصية لإنشاء سلاسل نصية ديناميكية باستخدام المتحولات أو التعابير البرمجية (سلاسل نصية ذات قيم متغيرة تبعًا لقيم هذه المتحولات أو التعابير البرمجية)، مثلًا: const method = 'concatenation' const dynamicString = 'This string is using ' + method + '.' فعند تمرير dynamicString إلى الإجراء log( )، نحصل في الخرج عند التنفيذ على النتيجة: This string is using concatenation. يمكنك تضمين التعابير البرمجية في المواضع المؤقتة مع استخدام قوالب النصوص، ويعبّر عن المواضع المؤقتة برمجيّا باستخدام الرمز ${}، فيصبح التعامل مع مضمون الأقواس على أنّه جافاسكربت وكل ما هو خارج الأقواس على أنّه سلسلة نصية، كما في المثال: const method = 'interpolation' const dynamicString = `This string is using ${method}.` وعند تمرير dynamicString إلى التابع log( )، نحصل في الخرج عند التنفيذ على النتيجة: This string is using interpolation. ويعدّ تضمين القيم في السلاسل النصية لإنشاء عناوين ويب ديناميكية Dynamic URLs من أكثر الأمثلة شيوعًا، لأنّ تنفيذ ذلك باستخدام علامات ربط السلاسل النصية لن يكون بالأمر السهل، فمثلًا الإجراء التالي يعرّف تابعًا لإنشاء السلسلة اللازمة لمنح الوصول لبروتوكول التوثيق OAuth: function createOAuthString(host, clientId, scope) { return host + '/login/oauth/authorize?client_id=' + clientId + '&scope=' + scope } createOAuthString('https://github.com', 'abc123', 'repo,user') وبتمرير هذا التابع إلى تابع log( ) نحصل في الخرج على عنوان الويب التالي: https://github.com/login/oauth/authorize?client_id=abc123&scope=repo,user ولكن ومع استخدام ميزة التضمين في السلاسل النصية التي تقدمها قوالب النصوص، لن تكون مضطرًا لاستخدام علامات الربط أو تتّبع أماكن بدء وانتهاء السلاسل، وفيما يلي نستعرض نفس المثال السابق ولكن عند بناءه باستخدام قوالب النصوص: function createOAuthString(host, clientId, scope) { return `${host}/login/oauth/authorize?client_id=${clientId}&scope=${scope}` } createOAuthString('https://github.com', 'abc123', 'repo,user') وهذا ما سيعطي نفس الخرج كما في حالة استخدام علامات ربط السلاسل النصية: https://github.com/login/oauth/authorize?client_id=abc123&scope=repo,user كما يمكنك تطبيق الإجراء trim() على أي قالب محرفي للتخلص من الفراغات في طرفي السلسلة النصية، في المثال التالي استخدامنا البناء المختصر لتابع يُنشئ عنصر قوائم في HTML برابط مخصّص: const menuItem = (url, link) => ` <li> <a href="${url}">${link}</a> </li> `.trim() menuItem('https://google.com', 'Google') ومع استخدام الإجراء trim() ستُقتص الفراغات من على جانبي القالب المحرفي مما يضمن عرض العنصر بطريقة صحيحة، كالتالي: <li> <a href="https://google.com">Google</a> </li> ولا يقتصر التضمين على المتحولات فقط، بل من الممكن تضمين أي تعبير برمجي، كما في مثال إيجاد ناتج جمع عددين التالي: const sum = (x, y) => x + y const x = 5 const y = 100 const string = `The sum of ${x} and ${y} is ${sum(x, y)}.` console.log(string) يعرّف هذا الترميز البرمجي التابع sum، والمتحولين x وy، ومن ثمّ يستخدم كلًا من التابع والمتحولين في سلسلة نصية، وتكون نتيجة التنفيذ على الخرج بالشّكل: The sum of 5 and 100 is 105. ولهذا فائدة كبيرة خاصّة عند استخدام عمليات اتخاذ قرار Ternary Operators، إذ تسمح بتضمين الشروط في السلاسل النصية، مثلًا: const age = 19 const message = `You can ${age < 21 ? 'not' : ''} view this page` console.log(message) وفي هذه الحالة ستتغير الرسالة في الخرج تبعًا لقيم المتحول age هل هو أعلى أم أقل من 21، وبما أنّ قيمة هذا المتحول في مثالنا هي 19، نحصل على الخرج التالي: You can not view this page وبذلك تكون كوّنت فكرة حول فوائد قوالب النصوص في تضمين التعابير البرمجية. وفيما يلي سنتفحّص قدرة قوالب النصوص الموسومة على التعامل مع التعابير البرمجية الممررّة إلى المواضع المؤقتة. قوالب النصوص الموسومة يعد استخدام قوالب النصوص الموسومة ميزة جيدة متطورّة لقوالب النصوص، والتي تسمّى أيضًا بالقوالب الموسومة. ويبدأ القالب الموسوم بتابع وسم يضيف الوسم للقالب المحرفي، مقدمّاً لك المزيد من التحكّم في عمليات التضمين للحصول على سلاسل نصية ديناميكية. في المثال التالي، ستُنشئ تابع وسم يعمل باستخدام القوالب الموسومة، يتضمّن هذا التابع عاملين، سميّ الأوّل string ويتضمّن السلسلة النصية المجردّة، والثاني هو عامل يستخدم مفهوم Rest Parameters والذي يمكن أن يتضمّن عددًا غير محدّدًا من الوسطاء تمثّل التعابير البرمجية المراد تضمينها في السلسلة النصية. يمكنك التحكّم بهذين العاملين والتنفيذ لرؤية ما سينتج عن تعديل كل منهما، بالشّكل: function tag(strings, ...expressions) { console.log(strings) console.log(expressions) } استخدم التابع tag كتابع القالب الموسوم ونفذ عملية التحويل على السلسلة النصية كالتالي: const string = tag`This is a string with ${true} and ${false} and ${100} interpolated inside.` وبما أنّ الترميز يتضمن إخراج كل من العاملين strings وexpressions، يكون الخرج بالشّكل: (4) ["This is a string with ", " and ", " and ", " interpolated inside." (3) [true, false, 100] العامل الأوّل strings عبارة عن شعاع يتضمّن كافّة قوالب النصوص التالية: * "This is a string with " * " and " * " and " * " interpolated inside." كما أنّ الخاصيّة raw متوفرة لهذا الوسيط من خلال استخدام strings.raw، والتي تتعامل مع السلسلة دون أخذ أي سلسلة هروب بالحسبان، فمثلًا يكون التعامل مع /n على أنّه محرف عادي ولن يفسر على أنه انتقال لسطر جديد. العامل الثاني …expressions وهو شعاع rest، ويحوي كافّة التعابير وهي: * true * false * 100 وتمرر السلاسل النصية المجرّدة والتعابير كعوامل لتابع القالب الموسوم tag، ومن الجدير بالملاحظة أنّه ليس من الضروري أن يعيد القالب الموسوم قيم من النوع سلاسل نصية حصرًا، فهو قادر على التعامل معها إلّا أنّه يعيد أي نوع من أنواع المعطيات، فعلى سبيل المثال يمكننا جعل التابع يتجاهل كل شيء ويعيد قيمة خالية null كما في التابع returnsNull التالي: function returnsNull(strings, ...expressions) { return null } const string = returnsNull`Does this work?` console.log(string) وبتمرير المتحول strings إلى الإجراء log( ) تكون القيمة المعادة في الخرج: null ويعد تغيير جانبي كل تعبير مضمّن مثالًا على الإجراءات الممكن تنفيذها في القوالب الموسومة، كما في حال رغبتك بإحاطة كل التعابير بأحد وسوم HTML. مثلًا من الممكن بناء التابع bold الذي يقوم بإضافة <strong> و</strong`> إلى جانبي كل تعبير: function bold(strings, ...expressions) { let finalString = '' //التكرار على كافّة التعابير المضمّنة في السلسة expressions.forEach((value, i) => { finalString += `${strings[i]}<strong>${value}</strong>` }) // إضافة السلسلة المجرّدة النهائية finalString += strings[strings.length - 1] return finalString } const string = bold`This is a string with ${true} and ${false} and ${100} interpolated inside.` console.log(string) يستخدم هذا الترميز الحلقة forEach للمرور على كافّة عناصر الشعاع expressions مضيفًا لكل منها عناصر جعل الخط غامقًا، ويكون الخرج الناتج بالشكل: This is a string with <strong>true</strong> and <strong>false</strong> and <strong>100</strong> interpolated inside. ولا يوجد سوى عدد قليل من الأمثلة على قوالب النصوص الموسومة في المكتبات الشائعة من جافاسكربت، فمثلَا تستخدم المكتبة graphq1-tag القالب الموسوم gq1 لتحويل السلاسل النصية من نتائج الاستعلام GraphQL إلى نمط شجرة البنية المجرّدة the abstract syntax tree (AST) وهو النمط الذي يفهمه GraphQL: import gql from 'graphql-tag' // سجل يقوم بالحصول على اسم وكنية المستخدم ذو الترتيب 5 const query = gql` { user(id: 5) { firstName lastName } } ومن المكتبات التي تستخدم توابع القوالب الموسومة أيضًا هي styled-components، والتي تمكنّك من إنشاء عناصر تفاعلية جديدة من عناصر DOM العادية عبر تطبيق تنسيقات CSS عليها: import styled from 'styled-components' const Button = styled.button` color: magenta; ` ومن الآن وصاعدًا يمكن استخدام الثابت Button كمكوّن مخصّص custom component// ولضمان عدم التعامل مع سلسلة نصية على أنّها سلسلة هروب، يمكنك استخدام الإجراء string.raw في قوالب النصوص الموسومة بالشّكل: const rawString = String.raw`I want to write /n without it being escaped.` console.log(rawString) وهذا ما سيعطي الخرج التالي: I want to write /n without it being escaped. الخلاصة راجعت في هذا المقال طريقة استخدام كل من علامات الاقتباس المفردة والمزدوجة في السلاسل النصية، كما تعلمّت عن قوالب النصوص العادية منها والموسومة، إذ تؤدي قوالب النصوص الكثير من المهام الشائعة المتعلقة بالسلاسل النصية بسهولة كبيرة عبر إمكانية تضمين التعابير البرمجية أو الكتابة على عدّة أسطر دون استخدام أي علامة ربط للسلاسل النصية أو استخدام سلاسل الهروب. كما أنّ القوالب المحرفية الموسومة تمثّل ميزة جديدة متطورة والتي قامت العديد من المكتبات الشائعة باستخدامها، مثل GraphQL و styled-components. ترجمة -وبتصرف- للمقال Understanding Template Literals in JavaScript لصاحبه Tania Rascia. اقرأ أيضًا السلاسل النصية (strings) في جافاسكربت كيفية التعامل مع النصوص في البرمجة ترميز النصوص والتعامل مع كائنات الملفات في جافاسكربت
أضاف الإصدار ES6 من معايير ECMAScript الصادر عام 2015 ميزة قالب النص Template Literals إلى لغة جافاسكربت والتي تعد شكلًا جديدًا لصياغة السلاسل النصية Strings في جافاسكربت مُضيفًا العديد من الإمكانيات الجديدة الفعّالة، كإمكانية إنشاء سلاسل نصية متعدّدة السطور بطريقة سهلة، وإمكانية استخدام المواضع المؤقتة placeholder لتضمين قيم التعابير البرمجية Expressions في السلاسل النصية. إضافة لوجود ميزة متقدمة تدعى قوالب النصوص الموسومة Tagged Template Literals والتي تسمح لك بإجراء العمليات على التعابير في السلاسل النصية. تزيد كل هذه الإمكانات من خياراتك كمطور لكتابة السلاسل النصية ببراعة واحترافية، جاعلة إياك قادرًا على إنشاء سلاسل نصية ديناميكية يمكن توظيفها في عناوين الويب URLs أو في الإجراءات التي تعدّل عناصر صفحات HTML. ستتعرف في هذا المقال على الاختلافات ما بين السلاسل النصية المحصورة بين علامتي اقتباس مفردة أو مزدوجة وقوالب النصوص، كما ستتعرف على الطرق المتعدّدة للتصريح عن سلاسل نصية من أشكال مختلفة بما يتضمن السلاسل الممتدّة على أكثر من سطر والديناميكية منها التي تتغير تبعًا لقيمة متحول أو تعبير ما. ومن ثمّ ستتعلم عن قوالب النصوص الموسومة وسترى بعض الأمثلة الواقعية لمشاريع باستخدام هذه القوالب. التصريح عن السلاسل النصية سنستعرض في هذا القسم كيفية التصريح عن السلاسل النصية باستخدام علامات الاقتباس المفردة والمزدوجة، ومن ثم سننتقل لاستعراض كيفية إجراء ذلك في حالة استخدام قوالب النصوص. يمكنك كتابة سلسلة المحارف في جافاسكربت باستخدام علامات اقتباس مفردة ' ': const single = 'Every day is a good day when you paint.' كما يمكن كتابة سلسلة المحارف باستخدام علامات اقتباس مزدوجة " ": const double = "Be so very light. Be a gentle whisper." وإجمالًا لا يوجد اختلافات جوهرية ما بين استخدام علامات الاقتباس المفردة أو المزدوجة في جافاسكربت، وذلك على خلاف بعض لغات البرمجة والتي تتيح إمكانية التضمين Interpolation باستخدام إحدى الطريقتين حصرًا، والمقصود بالتضمين التعامل مع المواضع المؤقتة كجزء ديناميكي من سلسلة المحارف. ويعد استخدام علامات الاقتباس المفردة والمزدوجة خيارًا شخصيًا، كما يمكن استخدامهما معًا بشرط إغلاق أيًا منها بنفس نوع البدء: // الإغلاق هنا باستخدام علامة اقتباس مفردة لأننا بدأنا بمثلها const single = '"We don\'t make mistakes. We just have happy accidents." - Bob Ross' // الإغلاق هنا باستخدام علامة اقتباس مزدوجة لأننا بدأنا بمثلها const double = "\"We don't make mistakes. We just have happy accidents.\" - Bob Ross" console.log(single); console.log(double); وسيقوم الإجراء log( ) بالنتيجة بطباعة نفس سلسلة المحارف على الخرج: "We don't make mistakes. We just have happy accidents." - Bob Ross "We don't make mistakes. We just have happy accidents." - Bob Ross في حين أنّه تكتب قوالب النصوص عبر حصر السلسة النصية بين علامتي اقتباس مائلتين (`) : const template = `Find freedom on this canvas.` وهي لا تحتاج للإغلاق بعلامة اقتباس مفردة أو مزدوجة: const template = `"We don't make mistakes. We just have happy accidents." - Bob Ross` ولكن لا بدّ من إغلاقها بعلامة اقتباس مائلة كما بدأت: const template = `Template literals use the \` character.` وتؤدّي قوالب النصوص كافّة الوظائف التي تؤديها السلاسل النصية العادية، وبالتالي يمكنك استبدال كافّة السلاسل النصية في مشروعك بقوالب نصوص، إلّا أنّ القواعد الأساسية الشائعة في كتابة الشيفرات البرمجية تنص على استخدام قوالب النصوص فقط عند الحاجة الفعلية لها لما تقدمه من إمكانات إضافية عن السلاسل النصية العادية، وبالتالي يفضّل استخدام علامات التنصيص المفردة أو المزدوجة فقط لحصر السلاسل النصية البسيطة، وهذا ما سيجعل قراءة واختبار شيفرتك البرمجية أسهل لأي مطوّر آخر. الآن وبعد معرفتك لكيفية التصريح عن السلاسل النصية باستخدام علامات الاقتباس المفردة والمزدوجة وعلامات الاقتباس المائلة، سننتقل للتعرّف على أول فوائد قوالب النصوص وهي الكتابة على عدّة أسطر. كتابة السلاسل النصية على عدّة أسطر سنرى بدايةً كيفية التصريح عن السلاسل النصية متعددة الأسطر ما قبل ES6، ثمّ سننتقل لنلاحظ كيف سهّل استخدام قوالب النصوص من هذا الأمر. فسابقًا، وفي حال رغبت بكتابة سلسلة نصية على عدة أسطر في محرر النصوص، كان لا بدّ من استخدام عملية ربط سلاسل (+) والتي لا تمثّل دائمًا الطريقة الأفضل. فمثلًا وعلى خلاف الواقع، يبدو أنّ السلسلة النصية التالية ستظهر عند التنفيذ على عدّة أسطر: const address = 'Homer J. Simpson' + '742 Evergreen Terrace' + 'Springfield' ولكن في الواقع الإجراء السابق سيسمح لك بتقسيم السلسلة النصية إلى أجزاء أصغر وكتابتها على عدّة أسطر في محرر النصوص فقط، دون حدوث أي أثر على نتيجة الخرج، بمعنى أن السلسلة ستظهر على الخرج في سطر واحد وبدون مسافة فاصلة (رغم استخدام مسافات بادئة في بداية كل جزء من السلسلة في محرّر النصوص) بين جزء وآخر منها، ويكون ناتج تنفيذ الإجراء الإجراء log( ) عند تمرير المتغير address بالشّكل: Homer J. Simpson742 Evergreen TerraceSpringfield كما يمكنك استخدام الخط المائل العكسي \ لكتابة السلسلة النصية على عدّة أسطر في محرر النصوص كالتالي: const address = 'Homer J. Simpson\ 742 Evergreen Terrace\ Springfield' والميزة هنا أنّ المسافات البادئة ستظهر فعلًا كمسافات فارغة في السلسة النصية الناتجة، إلّا أنّها ستظهر أيضًا على سطر واحد بالشّكل : Homer J. Simpson 742 Evergreen Terrace Springfield والحل الوحيد لإنشاء سلاسل نصية على عدّة أسطر عند التنفيذ هو استخدام محرف الانتقال لسطر جديد \n أثناء كتابة الرمز، مثلًا: const address = 'Homer J. Simpson\n' + '742 Evergreen Terrace\n' + 'Springfield' وسيظهر الخرج عند التنفيذ بالشّكل: Homer J. Simpson\n 742 Evergreen Terrace\n Springfield إلّا أنّ استخدام محرف الانتقال لسطر جديد (\n) يمكن ألا يكون أمرًا بديهيًا، فيمكن أن يظن المبرمج أنّ الانتقال لسطر جديد أثناء كتابة الرمز في محرّر النصوص كافيًا لتظهر النتيجة المطلوبة في الخرج، وهذا ما توفره قوالب النصوص؛ فمع استخدامها لن تحتاج لإضافة علامة ربط السلاسل النصية أو محرف انتقال لسطر جديد ولا حتّى خط مائل عكسي، كل ما تحتاجه هو مجرّد الضغط على زر Enter وستظهر السلسلة النصية على عدّة أسطر افتراضيًا، مثلًا: const address = `Homer J. Simpson 742 Evergreen Terrace Springfield` وبذلك سيكون خرج السلسة النصية تمامًا كما كُتبت، أي في مثالنا بالشّكل: Homer J. Simpson 742 Evergreen Terrace Springfield كما أنّ استخدام قوالب النصوص سيحتفظ أثناء التنفيذ بأي مسافات بادئة وضعتها، لذا تجنّب استخدام أي مسافات إلّا في موضعها المطلوب، فمثلًا لدى كتابة الترميز التالي: const address = `Homer J. Simpson 742 Evergreen Terrace Springfield` فبالرغم من كون طريقة الكتابة السابقة أسهل وأنسب للقراءة، إلّا أنّ الخرج لن يكون كذلك، بل سيكون بالشّكل: Homer J. Simpson 742 Evergreen Terrace Springfield بعد التعرّف على السلاسل متعدّدة الأسطر، فيما يلي سنستعرض كيفية تضمين قيم التعابير البرمجية لحالات التصريح عن السلاسل النصية المختلفة. تضمين قيم التعابير البرمجية في السابق وقبل إصدار ES6 كان يستخدم علامة ربط السلاسل النصية لإنشاء سلاسل نصية ديناميكية باستخدام المتحولات أو التعابير البرمجية (سلاسل نصية ذات قيم متغيرة تبعًا لقيم هذه المتحولات أو التعابير البرمجية)، مثلًا: const method = 'concatenation' const dynamicString = 'This string is using ' + method + '.' فعند تمرير dynamicString إلى الإجراء log( )، نحصل في الخرج عند التنفيذ على النتيجة: This string is using concatenation. يمكنك تضمين التعابير البرمجية في المواضع المؤقتة مع استخدام قوالب النصوص، ويعبّر عن المواضع المؤقتة برمجيّا باستخدام الرمز ${}، فيصبح التعامل مع مضمون الأقواس على أنّه جافاسكربت وكل ما هو خارج الأقواس على أنّه سلسلة نصية، كما في المثال: const method = 'interpolation' const dynamicString = `This string is using ${method}.` وعند تمرير dynamicString إلى التابع log( )، نحصل في الخرج عند التنفيذ على النتيجة: This string is using interpolation. ويعدّ تضمين القيم في السلاسل النصية لإنشاء عناوين ويب ديناميكية Dynamic URLs من أكثر الأمثلة شيوعًا، لأنّ تنفيذ ذلك باستخدام علامات ربط السلاسل النصية لن يكون بالأمر السهل، فمثلًا الإجراء التالي يعرّف تابعًا لإنشاء السلسلة اللازمة لمنح الوصول لبروتوكول التوثيق OAuth: function createOAuthString(host, clientId, scope) { return host + '/login/oauth/authorize?client_id=' + clientId + '&scope=' + scope } createOAuthString('https://github.com', 'abc123', 'repo,user') وبتمرير هذا التابع إلى تابع log( ) نحصل في الخرج على عنوان الويب التالي: https://github.com/login/oauth/authorize?client_id=abc123&scope=repo,user ولكن ومع استخدام ميزة التضمين في السلاسل النصية التي تقدمها قوالب النصوص، لن تكون مضطرًا لاستخدام علامات الربط أو تتّبع أماكن بدء وانتهاء السلاسل، وفيما يلي نستعرض نفس المثال السابق ولكن عند بناءه باستخدام قوالب النصوص: function createOAuthString(host, clientId, scope) { return `${host}/login/oauth/authorize?client_id=${clientId}&scope=${scope}` } createOAuthString('https://github.com', 'abc123', 'repo,user') وهذا ما سيعطي نفس الخرج كما في حالة استخدام علامات ربط السلاسل النصية: https://github.com/login/oauth/authorize?client_id=abc123&scope=repo,user كما يمكنك تطبيق الإجراء trim() على أي قالب محرفي للتخلص من الفراغات في طرفي السلسلة النصية، في المثال التالي استخدامنا البناء المختصر لتابع يُنشئ عنصر قوائم في HTML برابط مخصّص: const menuItem = (url, link) => ` <li> <a href="${url}">${link}</a> </li> `.trim() menuItem('https://google.com', 'Google') ومع استخدام الإجراء trim() ستُقتص الفراغات من على جانبي القالب المحرفي مما يضمن عرض العنصر بطريقة صحيحة، كالتالي: <li> <a href="https://google.com">Google</a> </li> ولا يقتصر التضمين على المتحولات فقط، بل من الممكن تضمين أي تعبير برمجي، كما في مثال إيجاد ناتج جمع عددين التالي: const sum = (x, y) => x + y const x = 5 const y = 100 const string = `The sum of ${x} and ${y} is ${sum(x, y)}.` console.log(string) يعرّف هذا الترميز البرمجي التابع sum، والمتحولين x وy، ومن ثمّ يستخدم كلًا من التابع والمتحولين في سلسلة نصية، وتكون نتيجة التنفيذ على الخرج بالشّكل: The sum of 5 and 100 is 105. ولهذا فائدة كبيرة خاصّة عند استخدام عمليات اتخاذ قرار Ternary Operators، إذ تسمح بتضمين الشروط في السلاسل النصية، مثلًا: const age = 19 const message = `You can ${age < 21 ? 'not' : ''} view this page` console.log(message) وفي هذه الحالة ستتغير الرسالة في الخرج تبعًا لقيم المتحول age هل هو أعلى أم أقل من 21، وبما أنّ قيمة هذا المتحول في مثالنا هي 19، نحصل على الخرج التالي: You can not view this page وبذلك تكون كوّنت فكرة حول فوائد قوالب النصوص في تضمين التعابير البرمجية. وفيما يلي سنتفحّص قدرة قوالب النصوص الموسومة على التعامل مع التعابير البرمجية الممررّة إلى المواضع المؤقتة. قوالب النصوص الموسومة يعد استخدام قوالب النصوص الموسومة ميزة جيدة متطورّة لقوالب النصوص، والتي تسمّى أيضًا بالقوالب الموسومة. ويبدأ القالب الموسوم بتابع وسم يضيف الوسم للقالب المحرفي، مقدمّاً لك المزيد من التحكّم في عمليات التضمين للحصول على سلاسل نصية ديناميكية. في المثال التالي، ستُنشئ تابع وسم يعمل باستخدام القوالب الموسومة، يتضمّن هذا التابع عاملين، سميّ الأوّل string ويتضمّن السلسلة النصية المجردّة، والثاني هو عامل يستخدم مفهوم Rest Parameters والذي يمكن أن يتضمّن عددًا غير محدّدًا من الوسطاء تمثّل التعابير البرمجية المراد تضمينها في السلسلة النصية. يمكنك التحكّم بهذين العاملين والتنفيذ لرؤية ما سينتج عن تعديل كل منهما، بالشّكل: function tag(strings, ...expressions) { console.log(strings) console.log(expressions) } استخدم التابع tag كتابع القالب الموسوم ونفذ عملية التحويل على السلسلة النصية كالتالي: const string = tag`This is a string with ${true} and ${false} and ${100} interpolated inside.` وبما أنّ الترميز يتضمن إخراج كل من العاملين strings وexpressions، يكون الخرج بالشّكل: (4) ["This is a string with ", " and ", " and ", " interpolated inside." (3) [true, false, 100] العامل الأوّل strings عبارة عن شعاع يتضمّن كافّة قوالب النصوص التالية: * "This is a string with " * " and " * " and " * " interpolated inside." كما أنّ الخاصيّة raw متوفرة لهذا الوسيط من خلال استخدام strings.raw، والتي تتعامل مع السلسلة دون أخذ أي سلسلة هروب بالحسبان، فمثلًا يكون التعامل مع /n على أنّه محرف عادي ولن يفسر على أنه انتقال لسطر جديد. العامل الثاني …expressions وهو شعاع rest، ويحوي كافّة التعابير وهي: * true * false * 100 وتمرر السلاسل النصية المجرّدة والتعابير كعوامل لتابع القالب الموسوم tag، ومن الجدير بالملاحظة أنّه ليس من الضروري أن يعيد القالب الموسوم قيم من النوع سلاسل نصية حصرًا، فهو قادر على التعامل معها إلّا أنّه يعيد أي نوع من أنواع المعطيات، فعلى سبيل المثال يمكننا جعل التابع يتجاهل كل شيء ويعيد قيمة خالية null كما في التابع returnsNull التالي: function returnsNull(strings, ...expressions) { return null } const string = returnsNull`Does this work?` console.log(string) وبتمرير المتحول strings إلى الإجراء log( ) تكون القيمة المعادة في الخرج: null ويعد تغيير جانبي كل تعبير مضمّن مثالًا على الإجراءات الممكن تنفيذها في القوالب الموسومة، كما في حال رغبتك بإحاطة كل التعابير بأحد وسوم HTML. مثلًا من الممكن بناء التابع bold الذي يقوم بإضافة <strong> و</strong`> إلى جانبي كل تعبير: function bold(strings, ...expressions) { let finalString = '' //التكرار على كافّة التعابير المضمّنة في السلسة expressions.forEach((value, i) => { finalString += `${strings[i]}<strong>${value}</strong>` }) // إضافة السلسلة المجرّدة النهائية finalString += strings[strings.length - 1] return finalString } const string = bold`This is a string with ${true} and ${false} and ${100} interpolated inside.` console.log(string) يستخدم هذا الترميز الحلقة forEach للمرور على كافّة عناصر الشعاع expressions مضيفًا لكل منها عناصر جعل الخط غامقًا، ويكون الخرج الناتج بالشكل: This is a string with <strong>true</strong> and <strong>false</strong> and <strong>100</strong> interpolated inside. ولا يوجد سوى عدد قليل من الأمثلة على قوالب النصوص الموسومة في المكتبات الشائعة من جافاسكربت، فمثلَا تستخدم المكتبة graphq1-tag القالب الموسوم gq1 لتحويل السلاسل النصية من نتائج الاستعلام GraphQL إلى نمط شجرة البنية المجرّدة the abstract syntax tree (AST) وهو النمط الذي يفهمه GraphQL: import gql from 'graphql-tag' // سجل يقوم بالحصول على اسم وكنية المستخدم ذو الترتيب 5 const query = gql` { user(id: 5) { firstName lastName } } ومن المكتبات التي تستخدم توابع القوالب الموسومة أيضًا هي styled-components، والتي تمكنّك من إنشاء عناصر تفاعلية جديدة من عناصر DOM العادية عبر تطبيق تنسيقات CSS عليها: import styled from 'styled-components' const Button = styled.button` color: magenta; ` ومن الآن وصاعدًا يمكن استخدام الثابت Button كمكوّن مخصّص custom component// ولضمان عدم التعامل مع سلسلة نصية على أنّها سلسلة هروب، يمكنك استخدام الإجراء string.raw في قوالب النصوص الموسومة بالشّكل: const rawString = String.raw`I want to write /n without it being escaped.` console.log(rawString) وهذا ما سيعطي الخرج التالي: I want to write /n without it being escaped. الخلاصة راجعت في هذا المقال طريقة استخدام كل من علامات الاقتباس المفردة والمزدوجة في السلاسل النصية، كما تعلمّت عن قوالب النصوص العادية منها والموسومة، إذ تؤدي قوالب النصوص الكثير من المهام الشائعة المتعلقة بالسلاسل النصية بسهولة كبيرة عبر إمكانية تضمين التعابير البرمجية أو الكتابة على عدّة أسطر دون استخدام أي علامة ربط للسلاسل النصية أو استخدام سلاسل الهروب. كما أنّ القوالب المحرفية الموسومة تمثّل ميزة جديدة متطورة والتي قامت العديد من المكتبات الشائعة باستخدامها، مثل GraphQL و styled-components. ترجمة -وبتصرف- للمقال Understanding Template Literals in JavaScript لصاحبه Tania Rascia. اقرأ أيضًا السلاسل النصية (strings) في جافاسكربت كيفية التعامل مع النصوص في البرمجة ترميز النصوص والتعامل مع كائنات الملفات في جافاسكربت -
 إنّ تثبيت نظام لينكس Linux ضمن بيئة وهمية ستُمكّنك من استخدام لينكس ضمن نظام ويندوز Windows، وفي هذا المقال ستتعرف على كيفية إنجاز ذلك باستخدام أحد برامج إنشاء البيئات الوهمية وهو برنامج VirtualBox. يوجد العديد من الطرق لتثبيت نظام لينكس، فبإمكانك حذف نظام التشغيل الحالي لديك واستبداله بنظام لينكس، أو أن تنصّب لينكس مع نظام ويندوز مستخدمًا وضع الإقلاع الثنائي Dual Boot وهذا ما يتيح لك إمكانية اختيار أحد النظامين لاستخدامه عند كل تشغيل للحاسوب، كما يمكنك تثبيت لينكس ضمن نظام ويندوز مستخدمًا الخيار الذي يوفّره متجر Microsoft (إلّا أنّ الإصدار الوحيد المتوفر من لينكس لهذه الطريقة هو الإصدار المُعتمد على موجه الأوامر). أمّا طريقة استخدام الأقراص الوهمية فتمثّل الخيار الأفضل والأسهل لك في حال أردت استخدام Linux استخدامًا محدودًا، والتي تتيح لك تثبيت واستخدام لينكس وكأنّه تطبيق عادي من تطبيقات ويندوز، وذلك دون القيام بأي تغييرات على نظام ويندوز المُنصّب أصلًا لديك. سنستعرض في هذا المقال كيفية تثبيت نظام لينكس ضمن نظام ويندوز باستخدام برنامج VirtualBox وهو برنامج مجاني مفتوح المصدر أصدرته Oracle، مهمّته إنشاء الأقراص الوهمية فيمكّنك من تثبيت أنظمة تشغيل مختلفة على أقراص وهمية ضمن نفس القرص الفعلي، وللحصول على أداء جيد لنظام التشغيل الوهمي، يُنصح بأن يكون لديك ذاكرة وصول عشوائي RAM بحجم 4 GB على الأقل. متطلبات تثبيت نظام لينكس ضمن بيئة وهمية اتصال إنترنت بسرعة جيدة لتحميل كل من برنامج إنشاء الأقراص الوهمية وصوة ISO من نظام لينكس، يمكنك إجراء التحميل على حاسب آخر إن أردت. نظام ويندوز يحتوي على مساحة تخزينية فارغة قدرها 12 GB على الأقل. ذاكرة RAM بحجم 4 GB (يمكن الإكمال حتى في حال كان حجم الذاكرة أقل، إلّا أنّ حاسوبك سيعاني في هذه الحالة من البطء خلال استخدامك لنظام لينكس على القرص الوهمي). يجب أن تتأكّد من تمكين ميزة التعامل مع الأقراص الوهمية virtualization في إعدادات BIOS. سنستعرض في هذا المقال خطوات تثبيت الإصدار 17.10 من توزيعة أوبنتو Ubuntu، وتبقى الخطوات نفسها من أجل أي إصدار أو توزيعة تختارها من نظام التشغيل لينكس. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن الخطوة الأولى: تحميل وتثبيت برنامج VirtualBox بدايةً نزّل أحدث إصدار من البرنامج Oracle VirtualBox وذلك من الموقع الإلكتروني الخاص به، ثمّ ثبته، وهو أمر بسيط لا يتطلّب منك سوى نقرة مزدوجة على الملف ذو اللاحقة .exe الذي حمله واتّباع التعليمات بشكلٍ مشابه لتثبيت أي برنامج عادي على نظام ويندوز. الخطوة الثانية: تحميل صورة ISO لنظام لينكس الآن يجب عليك تحميل ملف من النوع ISO لإصدار لينكس الذي ترغب بتثبيته من الموقع الإلكتروني الرسمي له، في هذا المقال سنستعرض خطوات تثبيت توزيعة أوبنتو، وبإمكانك تحميل صورة ISO لأي إصدار ترغب بتثبيته من إصدارات لينكس وذلك من موقعه الرسمي. الخطوة الثالثة: تثبيت نظام لينكس باستخدام برنامج VirtualBox الآن وبعد تحميل ملف ISO لإصدار لينكس وتثبيت برنامج VirtualBox، أصبحت جاهزًا للبدء بعملية تثبيت لينكس في VirtualBox. بدايةً افتح برنامج VirtualBox ومن ثم انقر على رمز "جديد New"، واختر اسمًا مناسبًا لنظام التشغيل الوهمي. خصص جزءًا من الذاكرة RAM لنظام التشغيل الوهمي، فمثلًا في مثالنا حجم الذاكرة 8 GB خصّصنا منها 2 GB، ويمكنك تخصيص حجم إضافي تبعًا لحجم الذاكرة في حاسوبك. أنشئ قرصًا وهميًا، والذي سيعمل كقرص صلب لنظام لينكس، أي أنّه المكان الذي ستخزن فيه ملفات نظام التشغيل الوهمي. وفي هذه المرحلة، ننصح باستخدام نمط الملفات VDI. وعند إنشاء القرص الصلب الوهمي يمكنك اختيار إمّا "مُخصّص ديناميكيًا Dynamically allocated" أو "ثابت الحجم Fixed Size". الحجم الموصى به للقرص الصلب الوهمي هو 10 GB، إلّا أنّنا ننصح بتخصيص حجم إضافي، أي حوالي 15-20 GB إن أمكن. وبعد إكمال الإجراءات السابقة، يحين وقت الإقلاع من ملف ISO وتثبيت لينكس كنظام تشغيل وهمي. إذا لم يحدد برنامج VirtualBox ملف ISO تلقائيًا، اضغط على رمز الملف واختر ملف ISO الذي حملته من مسار موقعه، كما هو موضّح في الصورة التالية: وبعد لحظات يجب أن تظهر شاشة تتضمّن خيار تثبيت لينكس، ومن هذه المرحلة تصبح الخطوات خاصّة بتوزيعة أوبنتو كونه التوزيعة التي نرغب بتثبيتها في حالتنا، وستختلف قليلًا عند اختيارك لإحدى توزيعات لينكس الأُخرى. يمكنك اختيار "تجاوز Skip" وصولًا لخيار "إكمال Continue". الآن اختر Erase disk and install Ubuntu "مسح محتويات القرص وتثبيت توزيعة أوبنتو"، ولا داعي للقلق من هذه الخطوة، فلن يحذف أي شيء لأنّك تستخدم المساحة التخزينية الخاصّة بالقرص الوهمي التي أنشأتها في الخطوات السابقة، ولن تؤثر هذه الخطوة على نظام التشغيل الأساسي ويندوز. والآن انقر على زر المتابعة Continue. وتصبح الخطوات من هذه المرحلة بمنتهى الوضوح. مجرّد متابعة للخطوات. حاول أن تختار كلمة مرور لن تنساها، وفي حال حدوث ذلك، يمكنك في أي وقت تصفير كلمة المرور الخاصّة بتوزيعة أوبنتو. الآن أوشكت على الانتهاء، سيستغرق الأمر بحدود 10-15 دقيقة لإكمال التثبيت. عند اكتمال التثبيت، أعد تشغيل النظام الوهمي. يمكنك إغلاق برنامج VirtualBox في حال تجمّده عند ظهور الشاشة المبينة في الصورة التالية: وبذلك تكون أنهيت العملية، ومن الآن فصاعدًا يمكنك استخدام نظام لينكس مباشرةً بمجرّد النقر على النظام الوهمي الذي نصّبته، ولن تحتاج لإعادة التثبيت عند كل استخدام، لذا بإمكانك حذف ملف ISO الذي حملته سابقًا. من الأمور المهمة الموصى بها أن تستخدم إصدار Guest من برنامج VirtualBox، لأنّ هذا الإصدار هو الأكثر توافق مع توزيعة أوبنتو، كما أنّه يوفّر لك حرية التعامل مع نظام ويندوز وتوزيعة أوبنتو معًا، كأن تستخدم النسخ واللصق أو السحب والإفلات بين النظامين. استكشاف المشاكل وإصلاحها في حال كانت خاصّية AMD-V معطّلة من إعدادات BIOS، فقد يظهر لك الخطأ التالي أثناء استخدامك للقرص الوهمي: Not in a hypervisor partition (HVP=0) (VERR_NEM_NOT_AVAILABLE). AMD-V is disabled in the BIOS (or by the host OS) (VERR_SVM_DISABLED). Result Code: E_FAIL (0x80004005) Component: ConsoleWrap Interface: IConsole {872da645-4a9b-1727-bee2-5585105b9eed} فهذا يعني أنّ ميزة التعامل مع الأقراص الوهمية مُعطّلة في نظامك، وكل ما عليك فعله هو تمكينها من إعدادات BIOS، ولإجراء ذلك أعد تشغيل حاسوبك، ولحظة بدء تشغيله اضغط على أحد المفاتيح F2/F10/F12 (تختلف بحسب نوع حاسوبك) للوصول إلى إعدادات BIOS، والآن ابحث عن الخيار Virtualization وفعله. وهذا كل ما تحتاجه لتثبيت نظام لينكس ضمن نظام ويندوز باستخدام برنامج VirtualBox. ترجمة -وبتصرف- للمقال Install Linux Inside Windows Using VirtualBox [Step by Step Guide] لصاحبه Abhishek Prakash. اقرأ أيضًا أساسيات إدارة الحزم في أوبنتو ودبيان - الجزء الأول كيف تضبط مزامنة الوقت في خادوم أوبنتو 16.04 الفصل الثالث: الذاكرة الوهمية (Virtual memory) في نظام التشغيل إعداد الذّاكرة الوهميّة (ملفّات التبادل) على خادوم خاص وهميّ (VPS)
إنّ تثبيت نظام لينكس Linux ضمن بيئة وهمية ستُمكّنك من استخدام لينكس ضمن نظام ويندوز Windows، وفي هذا المقال ستتعرف على كيفية إنجاز ذلك باستخدام أحد برامج إنشاء البيئات الوهمية وهو برنامج VirtualBox. يوجد العديد من الطرق لتثبيت نظام لينكس، فبإمكانك حذف نظام التشغيل الحالي لديك واستبداله بنظام لينكس، أو أن تنصّب لينكس مع نظام ويندوز مستخدمًا وضع الإقلاع الثنائي Dual Boot وهذا ما يتيح لك إمكانية اختيار أحد النظامين لاستخدامه عند كل تشغيل للحاسوب، كما يمكنك تثبيت لينكس ضمن نظام ويندوز مستخدمًا الخيار الذي يوفّره متجر Microsoft (إلّا أنّ الإصدار الوحيد المتوفر من لينكس لهذه الطريقة هو الإصدار المُعتمد على موجه الأوامر). أمّا طريقة استخدام الأقراص الوهمية فتمثّل الخيار الأفضل والأسهل لك في حال أردت استخدام Linux استخدامًا محدودًا، والتي تتيح لك تثبيت واستخدام لينكس وكأنّه تطبيق عادي من تطبيقات ويندوز، وذلك دون القيام بأي تغييرات على نظام ويندوز المُنصّب أصلًا لديك. سنستعرض في هذا المقال كيفية تثبيت نظام لينكس ضمن نظام ويندوز باستخدام برنامج VirtualBox وهو برنامج مجاني مفتوح المصدر أصدرته Oracle، مهمّته إنشاء الأقراص الوهمية فيمكّنك من تثبيت أنظمة تشغيل مختلفة على أقراص وهمية ضمن نفس القرص الفعلي، وللحصول على أداء جيد لنظام التشغيل الوهمي، يُنصح بأن يكون لديك ذاكرة وصول عشوائي RAM بحجم 4 GB على الأقل. متطلبات تثبيت نظام لينكس ضمن بيئة وهمية اتصال إنترنت بسرعة جيدة لتحميل كل من برنامج إنشاء الأقراص الوهمية وصوة ISO من نظام لينكس، يمكنك إجراء التحميل على حاسب آخر إن أردت. نظام ويندوز يحتوي على مساحة تخزينية فارغة قدرها 12 GB على الأقل. ذاكرة RAM بحجم 4 GB (يمكن الإكمال حتى في حال كان حجم الذاكرة أقل، إلّا أنّ حاسوبك سيعاني في هذه الحالة من البطء خلال استخدامك لنظام لينكس على القرص الوهمي). يجب أن تتأكّد من تمكين ميزة التعامل مع الأقراص الوهمية virtualization في إعدادات BIOS. سنستعرض في هذا المقال خطوات تثبيت الإصدار 17.10 من توزيعة أوبنتو Ubuntu، وتبقى الخطوات نفسها من أجل أي إصدار أو توزيعة تختارها من نظام التشغيل لينكس. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن الخطوة الأولى: تحميل وتثبيت برنامج VirtualBox بدايةً نزّل أحدث إصدار من البرنامج Oracle VirtualBox وذلك من الموقع الإلكتروني الخاص به، ثمّ ثبته، وهو أمر بسيط لا يتطلّب منك سوى نقرة مزدوجة على الملف ذو اللاحقة .exe الذي حمله واتّباع التعليمات بشكلٍ مشابه لتثبيت أي برنامج عادي على نظام ويندوز. الخطوة الثانية: تحميل صورة ISO لنظام لينكس الآن يجب عليك تحميل ملف من النوع ISO لإصدار لينكس الذي ترغب بتثبيته من الموقع الإلكتروني الرسمي له، في هذا المقال سنستعرض خطوات تثبيت توزيعة أوبنتو، وبإمكانك تحميل صورة ISO لأي إصدار ترغب بتثبيته من إصدارات لينكس وذلك من موقعه الرسمي. الخطوة الثالثة: تثبيت نظام لينكس باستخدام برنامج VirtualBox الآن وبعد تحميل ملف ISO لإصدار لينكس وتثبيت برنامج VirtualBox، أصبحت جاهزًا للبدء بعملية تثبيت لينكس في VirtualBox. بدايةً افتح برنامج VirtualBox ومن ثم انقر على رمز "جديد New"، واختر اسمًا مناسبًا لنظام التشغيل الوهمي. خصص جزءًا من الذاكرة RAM لنظام التشغيل الوهمي، فمثلًا في مثالنا حجم الذاكرة 8 GB خصّصنا منها 2 GB، ويمكنك تخصيص حجم إضافي تبعًا لحجم الذاكرة في حاسوبك. أنشئ قرصًا وهميًا، والذي سيعمل كقرص صلب لنظام لينكس، أي أنّه المكان الذي ستخزن فيه ملفات نظام التشغيل الوهمي. وفي هذه المرحلة، ننصح باستخدام نمط الملفات VDI. وعند إنشاء القرص الصلب الوهمي يمكنك اختيار إمّا "مُخصّص ديناميكيًا Dynamically allocated" أو "ثابت الحجم Fixed Size". الحجم الموصى به للقرص الصلب الوهمي هو 10 GB، إلّا أنّنا ننصح بتخصيص حجم إضافي، أي حوالي 15-20 GB إن أمكن. وبعد إكمال الإجراءات السابقة، يحين وقت الإقلاع من ملف ISO وتثبيت لينكس كنظام تشغيل وهمي. إذا لم يحدد برنامج VirtualBox ملف ISO تلقائيًا، اضغط على رمز الملف واختر ملف ISO الذي حملته من مسار موقعه، كما هو موضّح في الصورة التالية: وبعد لحظات يجب أن تظهر شاشة تتضمّن خيار تثبيت لينكس، ومن هذه المرحلة تصبح الخطوات خاصّة بتوزيعة أوبنتو كونه التوزيعة التي نرغب بتثبيتها في حالتنا، وستختلف قليلًا عند اختيارك لإحدى توزيعات لينكس الأُخرى. يمكنك اختيار "تجاوز Skip" وصولًا لخيار "إكمال Continue". الآن اختر Erase disk and install Ubuntu "مسح محتويات القرص وتثبيت توزيعة أوبنتو"، ولا داعي للقلق من هذه الخطوة، فلن يحذف أي شيء لأنّك تستخدم المساحة التخزينية الخاصّة بالقرص الوهمي التي أنشأتها في الخطوات السابقة، ولن تؤثر هذه الخطوة على نظام التشغيل الأساسي ويندوز. والآن انقر على زر المتابعة Continue. وتصبح الخطوات من هذه المرحلة بمنتهى الوضوح. مجرّد متابعة للخطوات. حاول أن تختار كلمة مرور لن تنساها، وفي حال حدوث ذلك، يمكنك في أي وقت تصفير كلمة المرور الخاصّة بتوزيعة أوبنتو. الآن أوشكت على الانتهاء، سيستغرق الأمر بحدود 10-15 دقيقة لإكمال التثبيت. عند اكتمال التثبيت، أعد تشغيل النظام الوهمي. يمكنك إغلاق برنامج VirtualBox في حال تجمّده عند ظهور الشاشة المبينة في الصورة التالية: وبذلك تكون أنهيت العملية، ومن الآن فصاعدًا يمكنك استخدام نظام لينكس مباشرةً بمجرّد النقر على النظام الوهمي الذي نصّبته، ولن تحتاج لإعادة التثبيت عند كل استخدام، لذا بإمكانك حذف ملف ISO الذي حملته سابقًا. من الأمور المهمة الموصى بها أن تستخدم إصدار Guest من برنامج VirtualBox، لأنّ هذا الإصدار هو الأكثر توافق مع توزيعة أوبنتو، كما أنّه يوفّر لك حرية التعامل مع نظام ويندوز وتوزيعة أوبنتو معًا، كأن تستخدم النسخ واللصق أو السحب والإفلات بين النظامين. استكشاف المشاكل وإصلاحها في حال كانت خاصّية AMD-V معطّلة من إعدادات BIOS، فقد يظهر لك الخطأ التالي أثناء استخدامك للقرص الوهمي: Not in a hypervisor partition (HVP=0) (VERR_NEM_NOT_AVAILABLE). AMD-V is disabled in the BIOS (or by the host OS) (VERR_SVM_DISABLED). Result Code: E_FAIL (0x80004005) Component: ConsoleWrap Interface: IConsole {872da645-4a9b-1727-bee2-5585105b9eed} فهذا يعني أنّ ميزة التعامل مع الأقراص الوهمية مُعطّلة في نظامك، وكل ما عليك فعله هو تمكينها من إعدادات BIOS، ولإجراء ذلك أعد تشغيل حاسوبك، ولحظة بدء تشغيله اضغط على أحد المفاتيح F2/F10/F12 (تختلف بحسب نوع حاسوبك) للوصول إلى إعدادات BIOS، والآن ابحث عن الخيار Virtualization وفعله. وهذا كل ما تحتاجه لتثبيت نظام لينكس ضمن نظام ويندوز باستخدام برنامج VirtualBox. ترجمة -وبتصرف- للمقال Install Linux Inside Windows Using VirtualBox [Step by Step Guide] لصاحبه Abhishek Prakash. اقرأ أيضًا أساسيات إدارة الحزم في أوبنتو ودبيان - الجزء الأول كيف تضبط مزامنة الوقت في خادوم أوبنتو 16.04 الفصل الثالث: الذاكرة الوهمية (Virtual memory) في نظام التشغيل إعداد الذّاكرة الوهميّة (ملفّات التبادل) على خادوم خاص وهميّ (VPS) -
 تتصدّر توزيعة أوبنتو Ubuntu من نظام لينكس Linux الخيارات عند المبتدئين الراغبين باستخدام نظام لينكس لن نتحدّث في هذا المقال عن أسباب ودوافع استخدامك لتوزيعة أوبنتو، وإنمّا سنستعرض لك كيفية تثبيته. هنالك العديد من الطرق لتثبيت توزيعة أوبنتو أو أي نظام آخر من أنظمة لينكس ومنها: تثبيت توزيعة أوبنتو ضمن جهاز وهمي في نظام ويندوز. استخدام ميزة Bash on Windows التي توفّر نظامًا فرعيًا ليعمل توزيعة أوبنتو ضمن نظام ويندوز. تثبيت كلا من توزيعة أوبنتو ونظام ويندوز، وعند الإقلاع تختار نظام التشغيل الذي تريد استخدامه بما يسمّى وضع الإقلاع المزدوج Dual Boot. يمكنك حذف نظام نظام ويندوز نهائيًا واستبداله بتوزيعة أوبنتو. والطريقة التي سنعرضها في هذا المقال هي الطريقة الرابعة، إذ سنحذف النظام بالكامل ونجعل توزيعة أوبنتو نظام التشغيل الوحيد على الحاسوب، ويمكن أن تكون هذه الطريقة هي الأسهل لتثبيت توزيعة أوبنتو. تعمل الطريقة المعروضة في هذا المقال لتثبيت توزيعة أوبنتو نفسه أو أي من التوزيعات القائمة عليه مثل Kubuntu و Xubuntu و Lubuntu و Linux Mint وغيرها، وأثناء تثبيت أي من هذه التوزيعات، ستجدُ بعض الاختلافات عن الصور التوضيحية المعروضة هنا، إلّا أنّ الخطوات الرئيسة تبقى نفسها. متطلبات تثبيت توزيعة أوبنتو من لينكس الأدوات التي تحتاجها لتثبيت توزيعة أوبنتو: قرص تخزين قابل للإزالة USB بحجم لا يقل عن 4 GB، كما يمكنك استخدام قرص DVD. اتصال انترنت (لتنزيل توزيعة أوبنتو وتنزيل أداة إعداد قرص تخزين قابل للإزالة ليصبح إقلاعيًا، ولا يلزم هذا الاتصال أثناء عملية تثبيت توزيعة أوبنتو). يمكن أن تحتاج قرص تخزين خارجي، لحفظ نسخة احتياطية من ملفاتك الهامّة الموجودة على نظام التشغيل الحالي لديك قبل البدء بالإجراء، وهو أمر اختياري. أمّا المتطلبات الدنيا للحاسوب في حال أردت تثبيت الإصدار الافتراضي أوبنتو جنوم فهي: معالج ثنائي النواة بسرعة 2 GHz. ذاكرة وصول عشوائي RAM بحجم 2 GB. مساحة خالية على القرص الصلب تعادل 25 GB على الأقل. الخطوة الأولى تنزيل توزيعة أوبنتو بدايةً وقبل أي خطوة عليك تنزيل توزيعة أوبنتو من الإنترنت، وهو متوفّر كملف من نوع ISO بحجم حوالي 2 غيغابايت، إذ أنّ ملف ISO ما هو إلّا صورة عن قرص تخزيني ولا بدّ من استخراجها على قرص تخزين قابل للإزالة أو على قرص DVD. ويمكنك تنزيل نسخة ISO من توزيعة أوبنتو من موقعه الرسمي، أمّا إذا كان اتصال الانترنت لديك بطيء أو غير مستقر، يمكنك استخدام الطرق البديلة للتنزيل المعروضة في صفحة التنزيل البديلة (حرك شريط التمرير قليلًا نحو الأسفل). الخطوة الثانية إنشاء وتجهيز قرص إقلاعي قابل للإزالة بعد تنزيل توزيعة أوبنتو من الإنترنت كملف من نوع ISO، ننتقل إلى الخطوة التالية وهي استخراج هذا الملف على قرص تخزين قابل للإزالة وتجهيزه ليصبح قرصًا إقلاعيًا متضمّنًا نظام التشغيل ليسمح لك بالإقلاع في توزيعة أوبنتو، وبذلك يمكنك اختبار توزيعة أوبنتو حتّى دون تثبيته على حاسوبك، كما سنستخدم نفس قرص التخزين لتثبيت توزيعة أوبنتو. يوجد العديد من الأدوات التي تساعدك في تجهيز قرص إقلاعي لتوزيعة أوبنتو، ومن هذه الأدوات Etcher و Rufus و Unetbootin و Universal USB installer. إذا كنت تستخدم أصلًا إحدى توزيعات لينكس، فيمكنك استخدام أداة Etcher. الخطوة الثالثة الإقلاع من القرص الإقلاعي الآن أوصِل قرص التخزين القابل للإزالة الذي أعددته ليكون إقلاعيًا ونزّلت توزيعة أوبنتو عليه إلى جهازك، وتأكّد من أنّك ضبطت إعدادات الإقلاع في BIOS ليقلع جهازك من قرص USB عوضًا عن الإقلاع من القرص الصلب، وذلك عبر جعل قرص USB هو الخيار الأوّل في ترتيب الإقلاع، ولتنفيذ ذلك أعد تشغيل جهازك، واضغط على مفتاح F2 أو F10 أو F12 لحظة ظهور شعار الشركة المصنّعة (Dell أو Acer أو Lenovo …إلخ)، وذلك للوصول إلى إعدادات BIOS، والتي تظهر لديك بطريقة مختلفة عن الصورة التالية. إذًا تتلخّص الفكرة هنا فقط بجعل القرص القابل للإزالة في بداية قائمة ترتيب خيارات الإقلاع، ومن ثمّ احفظ التغييرات واخرج من إعدادات BIOS. الخطوة الرابعة تثبيت توزيعة أوبنتو الآن وبعد ضبط إعدادات BIOS يجب أن يقلع الجهاز ضمن بيئة توزيعة أوبنتو، وستظهر لك شاشة تتضمّن خيارين، الأوّل تجربة توزيعة أوبنتو دون تثبيته، والثاني تثبيت توزيعة أوبنتو، يمكنك اختيار الخيار الأوّل. وبمرور من 10 إلى 20 ثانية أو أكثر في حال استخدامك لمنفذ من نوع USB 2، ستُسجل دخولك إلى بيئة توزيعة أوبنتو، والآن انقر على أيقونة تثبيت توزيعة أوبنتو الموجودة على سطح المكتب المسمّاة Install Ubuntu. سيطلب منك اختيار بعض الإعدادات الرئيسة مثل اللغة وتنسيق لوحة المفاتيح، اختر ما يناسبك منها. ومن ثمّ اختر التثبيت العادي normal installation، حتّى تثبت بعض البرمجيات مثل مشغّل الموسيقى، مشغل الفيديو، وبعض الألعاب. إذا كان جهازك متصلًا بالإنترنت فسيظهر لك خيار تثبيت التحديثات أثناء تثبيت توزيعة أوبنتو، يمكنك عدم اختيار ذلك لأنّه سيزيد من الزمن اللازم لإنهاء الإجراء، لاسيما إذا كان اتصال الإنترنت لديك بطيئًا، ويمكنك تحديث توزيعة أوبنتو في وقتٍ لاحق دون أن يسبب ذلك أية مشاكل. والآن نأتي إلى الخطوة الأهم الموضّحة في الصورة التالية، في حال وجود أنظمة تشغيل أخرى على جهازك، يمكنك اختيار تثبيت توزيعة أوبنتو جنبًا إلى جنب مع هذه الأنظمة في وضع الإقلاع الثنائي، أمّا إذا كان هدفك وجود نظام توزيعة أوبنتو وحده على جهازك، فاختر مسح محتويات القرص وتثبيت توزيعة أوبنتو. وبمجرّد أن تنقر على زر التثبيت الآن، ستظهر رسالة تحذيرية تنبهّك إلى أنّ كافّة البيانات على القرص ستحذف كما نوهنا سابقًا. ومن هذه اللحظة تصبح الخطوات أسهل، فهنا سيُطلب منك اختيار المنطقة الزمنية. ومن ثمّ سيُطلب منك اختيار اسمًا للمستخدم، واسمًا للحاسوب (أو ما يعرف باسم المضيف) و تعيين كلمة مرور. وما إن تنتهي من ذلك، ما عليك سوى الانتظار والمراقبة لمدة من 5 إلى 10 دقائق، وخلال هذه المدّة سترى عرضًا تقديميًا حول ميزات توزيعة أوبنتو. سيقدم عرض الشرائح المعلومات الأساسية المتعلّقة باستخدام توزيعة أوبنتو ريثما تنتهي عملية التثبيت، وعند انتهائها سيُطلب منك إعادة تشغيل الجهاز. وعند إعطاء أمر إعادة التشغيل، يمكن أن تظهر نافذة "إيقاف التشغيل" والتي تطلب منك إخراج قرص التخزين الذي استخدمته في عملية التثبيت ومن ثمّ الضغط على زر Enter. أخرج قرص التخزين القابل للإزالة، ثمّ اضغط على زر Enter، فسيقوم النظام بإعادة التشغيل ثمّ الإقلاع إلى توزيعة أوبنتو. وهذا كل ما في الأمر، أليس من السهل تثبيت توزيعة أوبنتو؟ يمكنك استخدام هذه الطريقة لاستبدال نظام ويندوز بتوزيعة أوبنتو، نرجو لك تجربة ممتعة! ترجمة -وبتصرف- للمقال How to Install Ubuntu Linux in the Simplest Possible Way لصاحبه Abhishek Prakash. اقرأ أيضًا أساسيات إدارة الحزم في أوبنتو ودبيان - الجزء الأول كيف تضبط مزامنة الوقت في خادوم أوبنتو 16.04 كيفية ضبط إعدادات الشبكات على خادوم أوبنتو أساسيات الأمن والحماية على خواديم أوبنتو: eCryptfs
تتصدّر توزيعة أوبنتو Ubuntu من نظام لينكس Linux الخيارات عند المبتدئين الراغبين باستخدام نظام لينكس لن نتحدّث في هذا المقال عن أسباب ودوافع استخدامك لتوزيعة أوبنتو، وإنمّا سنستعرض لك كيفية تثبيته. هنالك العديد من الطرق لتثبيت توزيعة أوبنتو أو أي نظام آخر من أنظمة لينكس ومنها: تثبيت توزيعة أوبنتو ضمن جهاز وهمي في نظام ويندوز. استخدام ميزة Bash on Windows التي توفّر نظامًا فرعيًا ليعمل توزيعة أوبنتو ضمن نظام ويندوز. تثبيت كلا من توزيعة أوبنتو ونظام ويندوز، وعند الإقلاع تختار نظام التشغيل الذي تريد استخدامه بما يسمّى وضع الإقلاع المزدوج Dual Boot. يمكنك حذف نظام نظام ويندوز نهائيًا واستبداله بتوزيعة أوبنتو. والطريقة التي سنعرضها في هذا المقال هي الطريقة الرابعة، إذ سنحذف النظام بالكامل ونجعل توزيعة أوبنتو نظام التشغيل الوحيد على الحاسوب، ويمكن أن تكون هذه الطريقة هي الأسهل لتثبيت توزيعة أوبنتو. تعمل الطريقة المعروضة في هذا المقال لتثبيت توزيعة أوبنتو نفسه أو أي من التوزيعات القائمة عليه مثل Kubuntu و Xubuntu و Lubuntu و Linux Mint وغيرها، وأثناء تثبيت أي من هذه التوزيعات، ستجدُ بعض الاختلافات عن الصور التوضيحية المعروضة هنا، إلّا أنّ الخطوات الرئيسة تبقى نفسها. متطلبات تثبيت توزيعة أوبنتو من لينكس الأدوات التي تحتاجها لتثبيت توزيعة أوبنتو: قرص تخزين قابل للإزالة USB بحجم لا يقل عن 4 GB، كما يمكنك استخدام قرص DVD. اتصال انترنت (لتنزيل توزيعة أوبنتو وتنزيل أداة إعداد قرص تخزين قابل للإزالة ليصبح إقلاعيًا، ولا يلزم هذا الاتصال أثناء عملية تثبيت توزيعة أوبنتو). يمكن أن تحتاج قرص تخزين خارجي، لحفظ نسخة احتياطية من ملفاتك الهامّة الموجودة على نظام التشغيل الحالي لديك قبل البدء بالإجراء، وهو أمر اختياري. أمّا المتطلبات الدنيا للحاسوب في حال أردت تثبيت الإصدار الافتراضي أوبنتو جنوم فهي: معالج ثنائي النواة بسرعة 2 GHz. ذاكرة وصول عشوائي RAM بحجم 2 GB. مساحة خالية على القرص الصلب تعادل 25 GB على الأقل. الخطوة الأولى تنزيل توزيعة أوبنتو بدايةً وقبل أي خطوة عليك تنزيل توزيعة أوبنتو من الإنترنت، وهو متوفّر كملف من نوع ISO بحجم حوالي 2 غيغابايت، إذ أنّ ملف ISO ما هو إلّا صورة عن قرص تخزيني ولا بدّ من استخراجها على قرص تخزين قابل للإزالة أو على قرص DVD. ويمكنك تنزيل نسخة ISO من توزيعة أوبنتو من موقعه الرسمي، أمّا إذا كان اتصال الانترنت لديك بطيء أو غير مستقر، يمكنك استخدام الطرق البديلة للتنزيل المعروضة في صفحة التنزيل البديلة (حرك شريط التمرير قليلًا نحو الأسفل). الخطوة الثانية إنشاء وتجهيز قرص إقلاعي قابل للإزالة بعد تنزيل توزيعة أوبنتو من الإنترنت كملف من نوع ISO، ننتقل إلى الخطوة التالية وهي استخراج هذا الملف على قرص تخزين قابل للإزالة وتجهيزه ليصبح قرصًا إقلاعيًا متضمّنًا نظام التشغيل ليسمح لك بالإقلاع في توزيعة أوبنتو، وبذلك يمكنك اختبار توزيعة أوبنتو حتّى دون تثبيته على حاسوبك، كما سنستخدم نفس قرص التخزين لتثبيت توزيعة أوبنتو. يوجد العديد من الأدوات التي تساعدك في تجهيز قرص إقلاعي لتوزيعة أوبنتو، ومن هذه الأدوات Etcher و Rufus و Unetbootin و Universal USB installer. إذا كنت تستخدم أصلًا إحدى توزيعات لينكس، فيمكنك استخدام أداة Etcher. الخطوة الثالثة الإقلاع من القرص الإقلاعي الآن أوصِل قرص التخزين القابل للإزالة الذي أعددته ليكون إقلاعيًا ونزّلت توزيعة أوبنتو عليه إلى جهازك، وتأكّد من أنّك ضبطت إعدادات الإقلاع في BIOS ليقلع جهازك من قرص USB عوضًا عن الإقلاع من القرص الصلب، وذلك عبر جعل قرص USB هو الخيار الأوّل في ترتيب الإقلاع، ولتنفيذ ذلك أعد تشغيل جهازك، واضغط على مفتاح F2 أو F10 أو F12 لحظة ظهور شعار الشركة المصنّعة (Dell أو Acer أو Lenovo …إلخ)، وذلك للوصول إلى إعدادات BIOS، والتي تظهر لديك بطريقة مختلفة عن الصورة التالية. إذًا تتلخّص الفكرة هنا فقط بجعل القرص القابل للإزالة في بداية قائمة ترتيب خيارات الإقلاع، ومن ثمّ احفظ التغييرات واخرج من إعدادات BIOS. الخطوة الرابعة تثبيت توزيعة أوبنتو الآن وبعد ضبط إعدادات BIOS يجب أن يقلع الجهاز ضمن بيئة توزيعة أوبنتو، وستظهر لك شاشة تتضمّن خيارين، الأوّل تجربة توزيعة أوبنتو دون تثبيته، والثاني تثبيت توزيعة أوبنتو، يمكنك اختيار الخيار الأوّل. وبمرور من 10 إلى 20 ثانية أو أكثر في حال استخدامك لمنفذ من نوع USB 2، ستُسجل دخولك إلى بيئة توزيعة أوبنتو، والآن انقر على أيقونة تثبيت توزيعة أوبنتو الموجودة على سطح المكتب المسمّاة Install Ubuntu. سيطلب منك اختيار بعض الإعدادات الرئيسة مثل اللغة وتنسيق لوحة المفاتيح، اختر ما يناسبك منها. ومن ثمّ اختر التثبيت العادي normal installation، حتّى تثبت بعض البرمجيات مثل مشغّل الموسيقى، مشغل الفيديو، وبعض الألعاب. إذا كان جهازك متصلًا بالإنترنت فسيظهر لك خيار تثبيت التحديثات أثناء تثبيت توزيعة أوبنتو، يمكنك عدم اختيار ذلك لأنّه سيزيد من الزمن اللازم لإنهاء الإجراء، لاسيما إذا كان اتصال الإنترنت لديك بطيئًا، ويمكنك تحديث توزيعة أوبنتو في وقتٍ لاحق دون أن يسبب ذلك أية مشاكل. والآن نأتي إلى الخطوة الأهم الموضّحة في الصورة التالية، في حال وجود أنظمة تشغيل أخرى على جهازك، يمكنك اختيار تثبيت توزيعة أوبنتو جنبًا إلى جنب مع هذه الأنظمة في وضع الإقلاع الثنائي، أمّا إذا كان هدفك وجود نظام توزيعة أوبنتو وحده على جهازك، فاختر مسح محتويات القرص وتثبيت توزيعة أوبنتو. وبمجرّد أن تنقر على زر التثبيت الآن، ستظهر رسالة تحذيرية تنبهّك إلى أنّ كافّة البيانات على القرص ستحذف كما نوهنا سابقًا. ومن هذه اللحظة تصبح الخطوات أسهل، فهنا سيُطلب منك اختيار المنطقة الزمنية. ومن ثمّ سيُطلب منك اختيار اسمًا للمستخدم، واسمًا للحاسوب (أو ما يعرف باسم المضيف) و تعيين كلمة مرور. وما إن تنتهي من ذلك، ما عليك سوى الانتظار والمراقبة لمدة من 5 إلى 10 دقائق، وخلال هذه المدّة سترى عرضًا تقديميًا حول ميزات توزيعة أوبنتو. سيقدم عرض الشرائح المعلومات الأساسية المتعلّقة باستخدام توزيعة أوبنتو ريثما تنتهي عملية التثبيت، وعند انتهائها سيُطلب منك إعادة تشغيل الجهاز. وعند إعطاء أمر إعادة التشغيل، يمكن أن تظهر نافذة "إيقاف التشغيل" والتي تطلب منك إخراج قرص التخزين الذي استخدمته في عملية التثبيت ومن ثمّ الضغط على زر Enter. أخرج قرص التخزين القابل للإزالة، ثمّ اضغط على زر Enter، فسيقوم النظام بإعادة التشغيل ثمّ الإقلاع إلى توزيعة أوبنتو. وهذا كل ما في الأمر، أليس من السهل تثبيت توزيعة أوبنتو؟ يمكنك استخدام هذه الطريقة لاستبدال نظام ويندوز بتوزيعة أوبنتو، نرجو لك تجربة ممتعة! ترجمة -وبتصرف- للمقال How to Install Ubuntu Linux in the Simplest Possible Way لصاحبه Abhishek Prakash. اقرأ أيضًا أساسيات إدارة الحزم في أوبنتو ودبيان - الجزء الأول كيف تضبط مزامنة الوقت في خادوم أوبنتو 16.04 كيفية ضبط إعدادات الشبكات على خادوم أوبنتو أساسيات الأمن والحماية على خواديم أوبنتو: eCryptfs -
.png.468f21a1f8dea86b77fd347b60354148.png) يستعرض هذا المقال كيفية إجراء إقلاع مزدوج لنظامي لينكس توزيعة أوبنتو Ubuntu وويندوز Windows 10 خطوة بخطوة، مع كافّة الصور التوضيحية اللازمة. يمثّل الإقلاع المزدوج أحد أفضل الطرق لاستخدام كلًا من نظامي التشغيل لينكس Linux وويندوز على حاسوب واحد، وباستخدام هذه الطريقة سينصبُ كلا النظامين مباشرة على القرص الفيزيائي وليس بصورة وهمية، وعند كل تشغيل لحاسوبك يمكنك اختيار النظام الذي تريده. عرضنا في مقال سابق خطوات إجراء إقلاع مزدوج لتوزيعة أوبنتو ونظام ويندوز 7، وهي الطريقة الأنسب في حال كان نمط تخزين معلومات التقسيم على القرص هو MBR، وتبقى الخطوات نفسها تقريبًا للأنظمة الأحدث المُنصّبة مع نظام ويندوز 10. سنستعرض في هذا المقال كيفية تثبيت توزيعة أوبنتو على حاسوب منصّب عليه نظام ويندوز 10 أصلًا. الإقلاع المزدوج ليس بالإجراء المعقّد إلّا أنّ تنفيذه يحتاج إلى بعض الوقت والصبر. إجراء الإقلاع المزدوج لتوزيعة أوبنتو ونظام ويندوز 10 إنّ استخدام الإجرائية المقترحة في هذا المقال مناسبة للحواسيب العاملة على نظام ويندوز 10، التي تستخدم UEFI secure boot كبرمجية إقلاع، وجدول تقسيم GPT كنمط تخزين معلومات التقسيم على القرص. التحقق من التوافق التأكد من كون نظامك يستخدم UEFI إنّ هذا المقال مناسب للتطبيق فقط على الحواسيب التي تستخدم UFEI كبرمجية إقلاع، وغالبًا ما سيستخدم حاسوبك UEFI مع نمط تخزين معلومات تجزئة القرص GPT إذا ما اشتريته خلال الخمس أو الست سنوات الماضية، وبجميع الأحوال من المستحسّن التأكّد من ذلك قبل البدء، فإذا كان حاسوبك يستخدم برمجية الإقلاع القديمة BIOS مع نمط تقسيم MBR فلن يكون هذا المقال مناسبًا لك. عملية مختلفة لحالة استخدام نمط تشفير Bitlocker إذا كان حاسوبك حديثًا ويعمل على نظام تشغيل ويندوز 10 برو، فسيكون قرصك مشفرًا بنمط Bitlocker الذي يحتاج لطريقة مختلفة لإجراء الإقلاع المزدوج. الحواسيب التي تملك كلا نوعي الأقراص HDD وSSD إذا كان لديك حاسوب مزدوج الأقراص أي يحوي كلا نوعي الأقراص HDD و SSD، ستكون العملية تقريبًا كما هي في حالتنا، ورغم ذلك من الأفضل لك اتباع مقال متخصّص لمثل هذه الحالة. المتطلبات: ما الذي ستحتاجه؟ فيما يلي قائمة تضم كل ما تحتاجه لتثبيت نظام لينكس مع نظام ويندوز بمنتهى السهولة والأمان: حاسوب مُنصّب عليه نظام التشغيل ويندوز 10 أصلًا. قرص تخزين قابل للإزالة USB خالٍ من البيانات، بحجم 4 GB على الأقل. اتصال إنترنت بهدف تحميل كل من صورة ISO من Ubuntu وأداة إنشاء الأقراص الإقلاعية، وليس من الضروري أن تجري هذه الخطوة على الحاسوب الذي ترغب بجعل إقلاعه ثنائيًا، وإنما على أي حاسوب تريده. اختياريًا يمكنك تجهيز قرص تخزين خارجي بهدف إجراء نسخ احتياطي لكافّة بياناتك الحالية قبل البدء. قرص إقلاع أو إصلاح لنظام ويندوز يمكن استخدامه لإصلاح أي مشاكل إقلاع تواجهها أثناء العملية. والآن لننتقل إلى خطوات تثبيت توزيعة أوبنتو مع نظام ويندوز 10. الخطوة الأولى (اختيارية): إنشاء نسخة احتياطية لنظام ويندوز الحالي لديك من المفضّل أن تحتفظ بنسخة احتياطية من ملفاتك حتى لا تخسرها في حال حدوث أي مشكلة أثناء إجراء تقسيم القرص، لذا ننصح بأن تنسخ ملفاتك الهامّة التي تخشى عليها من الفقدان على قرص تخزين خارجي سواء أكان من النوع HDD (أبطأ إلّا أنّه أرخص) أو SSD (أسرع لكنه أغلى سعرًا). الخطوة الثانية: تنزيل توزيعة أوبنتو (أو أي توزيعة من لينكس) من الإنترنت اذهب إلى الموقع الرسمي لأوبنتو، ونزّل الملف من النوع ISO، حجم هذا الملف حوالي 2.5 GB، كما يمكنك اختيار روابط التحميل البديلة alternative downloads إذا رغبت بتنزيل توزيعة أوبنتو مستخدمًا برنامج torrents. الخطوة الثالثة: إنشاء قرص إقلاعي يحتوي على توزيعة أوبنتو يوجد العديد من الأدوات التي تساعدك في إنشاء قرص إقلاعي يحوي توزيعة أوبنتو، وذلك بافتراض أنّك تنشئ القرص مستخدمًا نظام ويندوز، يمكنك اختيار أي من هذه الأدوات، بالنسبة لنا اخترنا الأداة Refus التي يمكنك تحميلها مجانًا من الموقع الإلكتروني الرسمي، فيتحملُ ملف بصيغة exe. الآن أوصِل قرص التخزين القابل للإزالة، وتذكّر أننا سنُهيئ هذا القرص لذا تأكّد من عدم وجود أي بيانات هامّة عليه. الآن شغّل الأداة Refus والتي ستتعرّف تلقائيًا على القرص الذي وصلته، لكن لا مانع من التأكّد منه، ثمّ حدّد مكان وجود صورة ISO التي حملتها، وتأكّد من استخدام نمط التقسيم GPT وبرمجية الإقلاع UEFI. الخطوة الرابعة: تحقق من المساحة التخزينية المتاحة على قرصك لتثبيت توزيعة أوبنتو تعرض الكثير من توزيعات لينكس خيار تخصيص مساحة من القرص أثناء تثبيت توزيعة أوبنتو، إلّا أنّ هذا لا يحدث دائمًا، لذا من المفضّل تجهيز المساحة التخزينية اللازمة قبل البدء بعملية التثبيت، ويمكنك ذلك من قائمة Windows، ابحث عن "تجزئة الأقراص disk partitions" ثم اختر "إنشاء وتهيئة أجزاء القرص الصلب Create and format hard disk partitions": ضمن أداة إدارة الأقراص، انقر نقرة بزر الفأرة الأيمن على القرص الذي تريد إنشاء القطاع فيه واختر "تقليص الحجم shrink volume". وإذا لم تملك سوى قرص واحد، فعليك تفريغ بعض المساحة ضمنه لنظام لينكس، وإذا كان لديك عدّة أقراص بأحجام جيدة، فاختر أي منها عدا القرص C لأن اختياره سيؤدي لحذف البيانات. والأمر يختلف من حاسوب لآخر، فمثلًا حجم القرص الصلب في الحاسوب الذي نعرض المثال من خلاله هو 256 غيغابايت وهو مقسّم أصلًا من الشركة الصانعة إلى عدّة أجزاء إلّا أنّ هذه الأجزاء مخصّصة لعمليات النسخ الاحتياطي وغيرها، والقطاع الرئيسي لدينا هو القرص C بحجم حوالي 220 غيغابايت ومنُصب عليه ويندوز 10. ففي حالتنا اخترنا إجراء عملية التقليص على القرص C لإتاحة المساحة التخزينية اللازمة لتثبيت لينكس. ما هو مقدار المساحة التخزينية اللازمة لنظام لينكس في حالة الإقلاع المزدوج؟ الإجابة على هذا السؤال تعتمد على مقدار حجم القرص الكلي في حاسوبك، فيمكن تثبيت توزيعة أوبنتو على مساحة تخزينية قدرها 15 أو 20 غيغابايت إلّا أنّك سرعان ما ستعاني من نفاذ المساحة. وفي هذه الأيام تأتي معظم الحواسيب مع أقراص بحجم 120 غيغابايت على الأقل، ففي هذه الحالة من الأفضل أن تخصّص 30 إلى 40 غيغابايت من القرص لنظام لينكس. أمّا إذا كان لديك قرص بحجم 250 غيغابايت خصّص مساحة تخزينية قدرها من 60 حتّى 80 غيغابايت أو أكثر. وإذا كان لديك المزيد من المساحة التخزينية على القرص، فخصص المزيد منها لنظام لينكس إن أردت. ماذا تفعل إذا كان لديك أقراص محلية مثل D أو E أو F؟ يعتقد الكثير من الناس أنّه لا يمكن تثبيت توزيعة أوبنتو إلّا على القرص C، وهذا غير صحيح. وبالنسبة لحالتنا قلصنا حجم القرص C لعدم توفّر سوى هذا القرص، أمّا إذا كان لديك أقراص D أو E أو F فبإمكانك تقليص أي منها، كما بإمكانك إن رغبت حذف الأقراص D أو E أو F ولكن إياك وحذف القرص C. الخطوة الخامسة: الإقلاع توزيعة أوبنتو من خلال القرص الإقلاعي أنشأت في الخطوة الثالثة قرصًا إقلاعيًا لتوزيعة أوبنتو، أوصل هذا القرص، ولكن وقبل أن تقلع جهاز الحاسوب من القرص، لنلقي نظرة على برمجية الإقلاع الآمن الأقل شهرة. هل من المفروض أن أقوم بتعطيل الإقلاع الآمن حتّى أتمكن من تثبيت توزيعة أوبنتو؟ قبل حوالي 6 إلى 8 سنوات، لم تكن برمجية الإقلاع الآمن UEFI مدعومة من قبل لينكس، وفي ذلك الحين كان لا بدّ من تعطيل الإقلاع الآمن حتّى تتمكن من تثبيت لينكس، ولحسن الحظ أنّه في هذه الأيام أصبح توزيعة أوبنتو وغيره من حزم لينكس تدعم الإقلاع الآمن دعمًا ممتازًا، وعمومًا ليس عليك القيام بأي إجراء بخصوص الإقلاع الآمن، إلّا إذا رفض جهازك الإقلاع من القرص الإقلاعي الذي أعدته أو في حال حدوث أي مشاكل متعلّقة بهذا الأمر، عندها يمكنك تعطيل الإقلاع الآمن في ويندوز. والآن لنرى كيف بإمكاننا الإقلاع من القرص القابل للإزالة، إذ يمكنك الوصول إلى إعدادات الإقلاع عبر الضغط على أحد الأزرار F2 أو F10 أو F12 لحظة تشغيل الحاسوب، ومنها تختار الإقلاع من القرص القابل للإزالة USB، إلّا أنّ البعض يجدون هذا الإجراء صعبًا. والطريقة الأسهل لإجراء ذلك هو الوصول إلى إعدادات الإقلاع UEFI من داخل نظام ويندوز، إلّا أنّ هذه الطريقة هي الأطول، وللوصول إليها ابحث عن UEFI ومن ثمّ اختر "تغيير خيارات البدء المتقدمة Change advanced startup options". اذهب إلى الخيار "advanced startup" ثم انقر زر إعادة التشغيل الآن. في الصفحة التالية، انقر على "Use a device": تعرّف على القرص القابل للإزالة المطلوب من خلال اسمه وحجمه، ويمكن أن يعرض اسمه بالشّكل EFI USB Device. الآن سيعاد تشغيل حاسوبك ليقلع في القرص الذي اخترته من الشاشة السابقة، وبعد بضع ثواني يجب أن تظهر نافذة كهذه: يسمح لك الخيار "تجربة توزيعة أوبنتو دون تثبيته Try Ubuntu without installing" بتجربة توزيعة أوبنتو من القرص الإقلاعي، وستجد خيار تثبيت توزيعة أوبنتو على سطح المكتب في هذه الحالة، أمّا الخيار "تثبيت Ubuntu" فيقوم بتثبيت توزيعة أوبنتو على الفور. يمكنك اختيار أي من الخيارين السابقين تبعًا لما تفضّل. الخطوة السادسة: تثبيت توزيعة أوبنتو إلى جانب نظام ويندوز الآن ابدأ بعملية التثبيت، الخطوات الأولى بسيطة جدًا تتضمّن اختيار اللغة وتنسيق لوحة المفاتيح. في الشاشة التالية، اختر "التثبيت العادي normal installation"، وما من ضرورة لتحميل التحديثات أو تثبيت برمجيات third-party حاليًا، بإمكانك إجراء ذلك بعد اكتمال التثبيت. الآن انقر على زر "متابعة continue"، يمكن أن يستغرق الانتقال إلى الصفحة التالية بعض الوقت. ملاحظة: يحاول بعض الأشخاص تحميل التحديثات وتثبيت ترميزات الوسائط أثناء التثبيت، ولكن تفيد الخبرات بأن ذلك يمكن أن يؤدي لحدوث بعض المشاكل والتي بدورها ستسببُ بفشل التثبيت، ولهذا لا ننصح بإجراء ذلك في هذه المرحلة. المنهجية 1: عند ظهور الخيار Install Ubuntu alongside Windows Boot Manager إذا ظهر "مدير إقلاع تثبيت توزيعة أوبنتو إلى جانب نظام ويندوز" في صفحة نمط التثبيت فأنت من المحظوظين، وعندها اختر هذه الطريقة ثم انقر على "إكمال". الشاشة التالية تعرض لك خيار إنشاء قطاع لتوزيعة أوبنتو عبر تحريك أداة تحديد الحجم، ففي هذه الخطوة يمكنك تخصيص المساحة المناسبة من القرص لتوزيعة أوبنتو. وستُنشئ توزيعة أوبنتو قطاع واحد فقط على كامل المساحة المخصّصة لها من القرص، وسينشئ ملف root يتضمن home وswapfile بحجم 2 غيغابايت. المنهجية الثانية: إذا لم يظهر الخيار Install Ubuntu alongside Windows Boot Manager أو كان باللون الرمادي في حال عدم ظهور خيار "مدير إقلاع تثبيت توزيعة أوبنتو إلى جانب نظام ويندوز" أو إذا ظهر باللون الرمادي، لا تقلق فما زال بالإمكان تثبيت توزيعة أوبنتو مع نظام ويندوز، ومن شاشة نمط التثبيت الحالية اختر "غير ذلك something else". وهذا ما سينقلك إلى الشاشة الخاصة بخيارات التجزئة، تذكّر أنّك أنشأت بعض المساحة التخزينية الحرة مسبقًا، والآن يمكنك اختيار تخصيص كامل المساحة الحرة لإنشاء ملف root (سيُنشأ ملفان هما home وswapfile تلقائيًا ضمن الـ root)، كما بإمكانك فصل أجزاء المستخدم الجذر root ومجلد المنزل home وذاكرة swapfile. وعمومًا يمكن اعتماد أي من الطريقتين. الصورة التالية تعرض خطوات إنشاء أجزاء مجلد النظام root، ومجلد المستخدم أو المنزل home، وقسم ذاكرة التبديل swapfile بطريقة منفصلة، ولكن بإمكانك تخصيص جزء واحد لها جميعها عبر تحديد المساحة الخالية والضغط على إشارة +. سيعرض خيار إنشاء قطاع خاص بنظام لينكس، بدايةً ستنشئ القطاع الخاص بالنظام الجذر root، وأي مساحة تخزينية تزيد عن 25 غيغابايت تكفي تمامًا لهذا القطاع، اختر الحجم المطلوب، واختر Ext 4 كنوع للملفات، واختر means root لقيمة الخيار mount point (نقطة الوصل). وبمجرد نقرك على زر موافق في الشاشة السابقة ستنتقل إلى شاشة التجزئة، في هذه المرحلة يجب إنشاء القطاع الخاص بذاكرة التبديل Swap، لذا كما في الخطوة السابقة اضغط على إشارة +، ولكن في هذه المرة اختر نوع الملفات ليكون swap area. ولا يزال اختيار الحجم المثالي لقطاع swap محط نقاش حتى الآن، ولكن إجمالًا إذا كان حجم ذاكرة الوصول العشوائي لديك 2 غيغابايت أو أقل فخصص لقطاع swap ضعف هذا الحجم، أمّا إذا كان حجم RAM من 3 إلى 6 غيغابايت عندها خصص حجمًا يساويها، أمّا إذا كان حجم لذاكرة لديك 8 غيغابايت أو أكثر، فيمكنك تخصيص مساحة تساوي نصف مساحة الذاكرة (لكن إذا كان لديك مساحة خالية (كافية على القرص الصلب، وكنت تنوي استخدام وضع الاسبات في لينكس فهنا يجب تخصيص حجم للقطاع Swap يساوي على الأقل حجم الذاكرة RAM). وتذكّر أنّه بإمكانك زيادة الحجم المخصّص للقطاع Swap في أي وقت. الآن وبطريقة مشابهة أنشئ الجزء home وخصص له أكبر مساحة تخزينية ممكنة (وهي في الواقع المساحة المتبقية بعد تخصيص كل من جزئي root و swap)، فهذا الجزء هو المتخصّص بحفظ ملفاتك من ملفات صوت وصور وملفات محمّلة. الآن وبعد انتهائك من تخصيص وتجهيز كل من الأجزاء root و home و swap انقر على زر التثبيت الآن Install now. أوشكت على الانتهاء، اختر المنطقة الزمنية. ثم سيُطلب منك إدخال اسم للمستخدم، واسمًا للمضيف (اسم الحاسوب)، وكلمة مرور. وما عليك الآن سوى الانتظار، يمكن أن يحتاج الأمر بحدود 8 إلى 10 دقائق لإكمال التثبيت وبمجرّد انتهاء التثبيت، أعد تشغيل الحاسوب. وعندها سيطلب منك إخراج القرص القابل للإزالة، ويمكنك إخراج القرص بأمان تمامًا في هذه المرحلة، وبعد ذلك إعادة التشغيل. بعد الانتهاء من العملية، لن تحتاج بعد الآن إلى القرص القابل للإزالة الذي جعلته إقلاعيًا حتّى تستخدم لينكس لأنك نصبت توزيعة أوبنتو على القرص المحلي الخاص بجهازك، وهنا يعود الخيار لك، فإن كنت ترغب بتثبيت لينكس على جهاز آخر احتفظ بالقرص القابل للإزالة كما هو، وإلّا هيئه واستخدمه لحفظ ونقل البيانات بصورة طبيعية. فإذا نفذّت جميع الخطوات تنفيذًا صحيحًا ستظهر عند تشغيل حاسوبك الشاشة التالية، وهي مخصّصة لاختيار نظام التشغيل الذي تريد الدخول إليه، اختر "Ubuntu" لتدخل على توزيعة أوبنتو، أو اختر "windows boot manager" لتدخل على نظام ويندوز. نصائح إضافية ستلاحظ وجود فرق زمني ما بين نظام ويندوز وتوزيعة أوبنتو، ويمكن حل هذه المشكلة (الفجوة الزمنية في حالة الإقلاع المزدوج) بسهولة. وستلاحظ أيضًا أنّه في شاشة الاختيار ما بين نظامي التشغيل ستكون الأولوية لتوزيعة أوبنتو، ويمكنك تعديل الترتيب جاعلًا ويندوز هو الخيار الافتراضي خاصّةً إذا كنت ستستخدمه أكثر من استخدامك لتوزيعة أوبنتو. كما يمكنك عكس الإجراء أي إزالة توزيعة أوبنتو والاحتفاظ بنظام ويندوز فقط. نرجو أن المقال كان مفيدًا لك، ولا تتردد بالسؤال في التعليقات أو طلب أي مساعدة في قسم الأسئلة والأجوبة. ترجمة -وبتصرف- للمقال How to Install Ubuntu Alongside Windows 10 لصاحبه Abhishek Prakash. اقرأ أيضًا أساسيات إدارة الحزم في أوبنتو ودبيان - الجزء الأول كيفية ضبط إعدادات الشبكات على خادوم أوبنتو كيف تضبط مزامنة الوقت في خادوم أوبنتو 16.04 كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة
يستعرض هذا المقال كيفية إجراء إقلاع مزدوج لنظامي لينكس توزيعة أوبنتو Ubuntu وويندوز Windows 10 خطوة بخطوة، مع كافّة الصور التوضيحية اللازمة. يمثّل الإقلاع المزدوج أحد أفضل الطرق لاستخدام كلًا من نظامي التشغيل لينكس Linux وويندوز على حاسوب واحد، وباستخدام هذه الطريقة سينصبُ كلا النظامين مباشرة على القرص الفيزيائي وليس بصورة وهمية، وعند كل تشغيل لحاسوبك يمكنك اختيار النظام الذي تريده. عرضنا في مقال سابق خطوات إجراء إقلاع مزدوج لتوزيعة أوبنتو ونظام ويندوز 7، وهي الطريقة الأنسب في حال كان نمط تخزين معلومات التقسيم على القرص هو MBR، وتبقى الخطوات نفسها تقريبًا للأنظمة الأحدث المُنصّبة مع نظام ويندوز 10. سنستعرض في هذا المقال كيفية تثبيت توزيعة أوبنتو على حاسوب منصّب عليه نظام ويندوز 10 أصلًا. الإقلاع المزدوج ليس بالإجراء المعقّد إلّا أنّ تنفيذه يحتاج إلى بعض الوقت والصبر. إجراء الإقلاع المزدوج لتوزيعة أوبنتو ونظام ويندوز 10 إنّ استخدام الإجرائية المقترحة في هذا المقال مناسبة للحواسيب العاملة على نظام ويندوز 10، التي تستخدم UEFI secure boot كبرمجية إقلاع، وجدول تقسيم GPT كنمط تخزين معلومات التقسيم على القرص. التحقق من التوافق التأكد من كون نظامك يستخدم UEFI إنّ هذا المقال مناسب للتطبيق فقط على الحواسيب التي تستخدم UFEI كبرمجية إقلاع، وغالبًا ما سيستخدم حاسوبك UEFI مع نمط تخزين معلومات تجزئة القرص GPT إذا ما اشتريته خلال الخمس أو الست سنوات الماضية، وبجميع الأحوال من المستحسّن التأكّد من ذلك قبل البدء، فإذا كان حاسوبك يستخدم برمجية الإقلاع القديمة BIOS مع نمط تقسيم MBR فلن يكون هذا المقال مناسبًا لك. عملية مختلفة لحالة استخدام نمط تشفير Bitlocker إذا كان حاسوبك حديثًا ويعمل على نظام تشغيل ويندوز 10 برو، فسيكون قرصك مشفرًا بنمط Bitlocker الذي يحتاج لطريقة مختلفة لإجراء الإقلاع المزدوج. الحواسيب التي تملك كلا نوعي الأقراص HDD وSSD إذا كان لديك حاسوب مزدوج الأقراص أي يحوي كلا نوعي الأقراص HDD و SSD، ستكون العملية تقريبًا كما هي في حالتنا، ورغم ذلك من الأفضل لك اتباع مقال متخصّص لمثل هذه الحالة. المتطلبات: ما الذي ستحتاجه؟ فيما يلي قائمة تضم كل ما تحتاجه لتثبيت نظام لينكس مع نظام ويندوز بمنتهى السهولة والأمان: حاسوب مُنصّب عليه نظام التشغيل ويندوز 10 أصلًا. قرص تخزين قابل للإزالة USB خالٍ من البيانات، بحجم 4 GB على الأقل. اتصال إنترنت بهدف تحميل كل من صورة ISO من Ubuntu وأداة إنشاء الأقراص الإقلاعية، وليس من الضروري أن تجري هذه الخطوة على الحاسوب الذي ترغب بجعل إقلاعه ثنائيًا، وإنما على أي حاسوب تريده. اختياريًا يمكنك تجهيز قرص تخزين خارجي بهدف إجراء نسخ احتياطي لكافّة بياناتك الحالية قبل البدء. قرص إقلاع أو إصلاح لنظام ويندوز يمكن استخدامه لإصلاح أي مشاكل إقلاع تواجهها أثناء العملية. والآن لننتقل إلى خطوات تثبيت توزيعة أوبنتو مع نظام ويندوز 10. الخطوة الأولى (اختيارية): إنشاء نسخة احتياطية لنظام ويندوز الحالي لديك من المفضّل أن تحتفظ بنسخة احتياطية من ملفاتك حتى لا تخسرها في حال حدوث أي مشكلة أثناء إجراء تقسيم القرص، لذا ننصح بأن تنسخ ملفاتك الهامّة التي تخشى عليها من الفقدان على قرص تخزين خارجي سواء أكان من النوع HDD (أبطأ إلّا أنّه أرخص) أو SSD (أسرع لكنه أغلى سعرًا). الخطوة الثانية: تنزيل توزيعة أوبنتو (أو أي توزيعة من لينكس) من الإنترنت اذهب إلى الموقع الرسمي لأوبنتو، ونزّل الملف من النوع ISO، حجم هذا الملف حوالي 2.5 GB، كما يمكنك اختيار روابط التحميل البديلة alternative downloads إذا رغبت بتنزيل توزيعة أوبنتو مستخدمًا برنامج torrents. الخطوة الثالثة: إنشاء قرص إقلاعي يحتوي على توزيعة أوبنتو يوجد العديد من الأدوات التي تساعدك في إنشاء قرص إقلاعي يحوي توزيعة أوبنتو، وذلك بافتراض أنّك تنشئ القرص مستخدمًا نظام ويندوز، يمكنك اختيار أي من هذه الأدوات، بالنسبة لنا اخترنا الأداة Refus التي يمكنك تحميلها مجانًا من الموقع الإلكتروني الرسمي، فيتحملُ ملف بصيغة exe. الآن أوصِل قرص التخزين القابل للإزالة، وتذكّر أننا سنُهيئ هذا القرص لذا تأكّد من عدم وجود أي بيانات هامّة عليه. الآن شغّل الأداة Refus والتي ستتعرّف تلقائيًا على القرص الذي وصلته، لكن لا مانع من التأكّد منه، ثمّ حدّد مكان وجود صورة ISO التي حملتها، وتأكّد من استخدام نمط التقسيم GPT وبرمجية الإقلاع UEFI. الخطوة الرابعة: تحقق من المساحة التخزينية المتاحة على قرصك لتثبيت توزيعة أوبنتو تعرض الكثير من توزيعات لينكس خيار تخصيص مساحة من القرص أثناء تثبيت توزيعة أوبنتو، إلّا أنّ هذا لا يحدث دائمًا، لذا من المفضّل تجهيز المساحة التخزينية اللازمة قبل البدء بعملية التثبيت، ويمكنك ذلك من قائمة Windows، ابحث عن "تجزئة الأقراص disk partitions" ثم اختر "إنشاء وتهيئة أجزاء القرص الصلب Create and format hard disk partitions": ضمن أداة إدارة الأقراص، انقر نقرة بزر الفأرة الأيمن على القرص الذي تريد إنشاء القطاع فيه واختر "تقليص الحجم shrink volume". وإذا لم تملك سوى قرص واحد، فعليك تفريغ بعض المساحة ضمنه لنظام لينكس، وإذا كان لديك عدّة أقراص بأحجام جيدة، فاختر أي منها عدا القرص C لأن اختياره سيؤدي لحذف البيانات. والأمر يختلف من حاسوب لآخر، فمثلًا حجم القرص الصلب في الحاسوب الذي نعرض المثال من خلاله هو 256 غيغابايت وهو مقسّم أصلًا من الشركة الصانعة إلى عدّة أجزاء إلّا أنّ هذه الأجزاء مخصّصة لعمليات النسخ الاحتياطي وغيرها، والقطاع الرئيسي لدينا هو القرص C بحجم حوالي 220 غيغابايت ومنُصب عليه ويندوز 10. ففي حالتنا اخترنا إجراء عملية التقليص على القرص C لإتاحة المساحة التخزينية اللازمة لتثبيت لينكس. ما هو مقدار المساحة التخزينية اللازمة لنظام لينكس في حالة الإقلاع المزدوج؟ الإجابة على هذا السؤال تعتمد على مقدار حجم القرص الكلي في حاسوبك، فيمكن تثبيت توزيعة أوبنتو على مساحة تخزينية قدرها 15 أو 20 غيغابايت إلّا أنّك سرعان ما ستعاني من نفاذ المساحة. وفي هذه الأيام تأتي معظم الحواسيب مع أقراص بحجم 120 غيغابايت على الأقل، ففي هذه الحالة من الأفضل أن تخصّص 30 إلى 40 غيغابايت من القرص لنظام لينكس. أمّا إذا كان لديك قرص بحجم 250 غيغابايت خصّص مساحة تخزينية قدرها من 60 حتّى 80 غيغابايت أو أكثر. وإذا كان لديك المزيد من المساحة التخزينية على القرص، فخصص المزيد منها لنظام لينكس إن أردت. ماذا تفعل إذا كان لديك أقراص محلية مثل D أو E أو F؟ يعتقد الكثير من الناس أنّه لا يمكن تثبيت توزيعة أوبنتو إلّا على القرص C، وهذا غير صحيح. وبالنسبة لحالتنا قلصنا حجم القرص C لعدم توفّر سوى هذا القرص، أمّا إذا كان لديك أقراص D أو E أو F فبإمكانك تقليص أي منها، كما بإمكانك إن رغبت حذف الأقراص D أو E أو F ولكن إياك وحذف القرص C. الخطوة الخامسة: الإقلاع توزيعة أوبنتو من خلال القرص الإقلاعي أنشأت في الخطوة الثالثة قرصًا إقلاعيًا لتوزيعة أوبنتو، أوصل هذا القرص، ولكن وقبل أن تقلع جهاز الحاسوب من القرص، لنلقي نظرة على برمجية الإقلاع الآمن الأقل شهرة. هل من المفروض أن أقوم بتعطيل الإقلاع الآمن حتّى أتمكن من تثبيت توزيعة أوبنتو؟ قبل حوالي 6 إلى 8 سنوات، لم تكن برمجية الإقلاع الآمن UEFI مدعومة من قبل لينكس، وفي ذلك الحين كان لا بدّ من تعطيل الإقلاع الآمن حتّى تتمكن من تثبيت لينكس، ولحسن الحظ أنّه في هذه الأيام أصبح توزيعة أوبنتو وغيره من حزم لينكس تدعم الإقلاع الآمن دعمًا ممتازًا، وعمومًا ليس عليك القيام بأي إجراء بخصوص الإقلاع الآمن، إلّا إذا رفض جهازك الإقلاع من القرص الإقلاعي الذي أعدته أو في حال حدوث أي مشاكل متعلّقة بهذا الأمر، عندها يمكنك تعطيل الإقلاع الآمن في ويندوز. والآن لنرى كيف بإمكاننا الإقلاع من القرص القابل للإزالة، إذ يمكنك الوصول إلى إعدادات الإقلاع عبر الضغط على أحد الأزرار F2 أو F10 أو F12 لحظة تشغيل الحاسوب، ومنها تختار الإقلاع من القرص القابل للإزالة USB، إلّا أنّ البعض يجدون هذا الإجراء صعبًا. والطريقة الأسهل لإجراء ذلك هو الوصول إلى إعدادات الإقلاع UEFI من داخل نظام ويندوز، إلّا أنّ هذه الطريقة هي الأطول، وللوصول إليها ابحث عن UEFI ومن ثمّ اختر "تغيير خيارات البدء المتقدمة Change advanced startup options". اذهب إلى الخيار "advanced startup" ثم انقر زر إعادة التشغيل الآن. في الصفحة التالية، انقر على "Use a device": تعرّف على القرص القابل للإزالة المطلوب من خلال اسمه وحجمه، ويمكن أن يعرض اسمه بالشّكل EFI USB Device. الآن سيعاد تشغيل حاسوبك ليقلع في القرص الذي اخترته من الشاشة السابقة، وبعد بضع ثواني يجب أن تظهر نافذة كهذه: يسمح لك الخيار "تجربة توزيعة أوبنتو دون تثبيته Try Ubuntu without installing" بتجربة توزيعة أوبنتو من القرص الإقلاعي، وستجد خيار تثبيت توزيعة أوبنتو على سطح المكتب في هذه الحالة، أمّا الخيار "تثبيت Ubuntu" فيقوم بتثبيت توزيعة أوبنتو على الفور. يمكنك اختيار أي من الخيارين السابقين تبعًا لما تفضّل. الخطوة السادسة: تثبيت توزيعة أوبنتو إلى جانب نظام ويندوز الآن ابدأ بعملية التثبيت، الخطوات الأولى بسيطة جدًا تتضمّن اختيار اللغة وتنسيق لوحة المفاتيح. في الشاشة التالية، اختر "التثبيت العادي normal installation"، وما من ضرورة لتحميل التحديثات أو تثبيت برمجيات third-party حاليًا، بإمكانك إجراء ذلك بعد اكتمال التثبيت. الآن انقر على زر "متابعة continue"، يمكن أن يستغرق الانتقال إلى الصفحة التالية بعض الوقت. ملاحظة: يحاول بعض الأشخاص تحميل التحديثات وتثبيت ترميزات الوسائط أثناء التثبيت، ولكن تفيد الخبرات بأن ذلك يمكن أن يؤدي لحدوث بعض المشاكل والتي بدورها ستسببُ بفشل التثبيت، ولهذا لا ننصح بإجراء ذلك في هذه المرحلة. المنهجية 1: عند ظهور الخيار Install Ubuntu alongside Windows Boot Manager إذا ظهر "مدير إقلاع تثبيت توزيعة أوبنتو إلى جانب نظام ويندوز" في صفحة نمط التثبيت فأنت من المحظوظين، وعندها اختر هذه الطريقة ثم انقر على "إكمال". الشاشة التالية تعرض لك خيار إنشاء قطاع لتوزيعة أوبنتو عبر تحريك أداة تحديد الحجم، ففي هذه الخطوة يمكنك تخصيص المساحة المناسبة من القرص لتوزيعة أوبنتو. وستُنشئ توزيعة أوبنتو قطاع واحد فقط على كامل المساحة المخصّصة لها من القرص، وسينشئ ملف root يتضمن home وswapfile بحجم 2 غيغابايت. المنهجية الثانية: إذا لم يظهر الخيار Install Ubuntu alongside Windows Boot Manager أو كان باللون الرمادي في حال عدم ظهور خيار "مدير إقلاع تثبيت توزيعة أوبنتو إلى جانب نظام ويندوز" أو إذا ظهر باللون الرمادي، لا تقلق فما زال بالإمكان تثبيت توزيعة أوبنتو مع نظام ويندوز، ومن شاشة نمط التثبيت الحالية اختر "غير ذلك something else". وهذا ما سينقلك إلى الشاشة الخاصة بخيارات التجزئة، تذكّر أنّك أنشأت بعض المساحة التخزينية الحرة مسبقًا، والآن يمكنك اختيار تخصيص كامل المساحة الحرة لإنشاء ملف root (سيُنشأ ملفان هما home وswapfile تلقائيًا ضمن الـ root)، كما بإمكانك فصل أجزاء المستخدم الجذر root ومجلد المنزل home وذاكرة swapfile. وعمومًا يمكن اعتماد أي من الطريقتين. الصورة التالية تعرض خطوات إنشاء أجزاء مجلد النظام root، ومجلد المستخدم أو المنزل home، وقسم ذاكرة التبديل swapfile بطريقة منفصلة، ولكن بإمكانك تخصيص جزء واحد لها جميعها عبر تحديد المساحة الخالية والضغط على إشارة +. سيعرض خيار إنشاء قطاع خاص بنظام لينكس، بدايةً ستنشئ القطاع الخاص بالنظام الجذر root، وأي مساحة تخزينية تزيد عن 25 غيغابايت تكفي تمامًا لهذا القطاع، اختر الحجم المطلوب، واختر Ext 4 كنوع للملفات، واختر means root لقيمة الخيار mount point (نقطة الوصل). وبمجرد نقرك على زر موافق في الشاشة السابقة ستنتقل إلى شاشة التجزئة، في هذه المرحلة يجب إنشاء القطاع الخاص بذاكرة التبديل Swap، لذا كما في الخطوة السابقة اضغط على إشارة +، ولكن في هذه المرة اختر نوع الملفات ليكون swap area. ولا يزال اختيار الحجم المثالي لقطاع swap محط نقاش حتى الآن، ولكن إجمالًا إذا كان حجم ذاكرة الوصول العشوائي لديك 2 غيغابايت أو أقل فخصص لقطاع swap ضعف هذا الحجم، أمّا إذا كان حجم RAM من 3 إلى 6 غيغابايت عندها خصص حجمًا يساويها، أمّا إذا كان حجم لذاكرة لديك 8 غيغابايت أو أكثر، فيمكنك تخصيص مساحة تساوي نصف مساحة الذاكرة (لكن إذا كان لديك مساحة خالية (كافية على القرص الصلب، وكنت تنوي استخدام وضع الاسبات في لينكس فهنا يجب تخصيص حجم للقطاع Swap يساوي على الأقل حجم الذاكرة RAM). وتذكّر أنّه بإمكانك زيادة الحجم المخصّص للقطاع Swap في أي وقت. الآن وبطريقة مشابهة أنشئ الجزء home وخصص له أكبر مساحة تخزينية ممكنة (وهي في الواقع المساحة المتبقية بعد تخصيص كل من جزئي root و swap)، فهذا الجزء هو المتخصّص بحفظ ملفاتك من ملفات صوت وصور وملفات محمّلة. الآن وبعد انتهائك من تخصيص وتجهيز كل من الأجزاء root و home و swap انقر على زر التثبيت الآن Install now. أوشكت على الانتهاء، اختر المنطقة الزمنية. ثم سيُطلب منك إدخال اسم للمستخدم، واسمًا للمضيف (اسم الحاسوب)، وكلمة مرور. وما عليك الآن سوى الانتظار، يمكن أن يحتاج الأمر بحدود 8 إلى 10 دقائق لإكمال التثبيت وبمجرّد انتهاء التثبيت، أعد تشغيل الحاسوب. وعندها سيطلب منك إخراج القرص القابل للإزالة، ويمكنك إخراج القرص بأمان تمامًا في هذه المرحلة، وبعد ذلك إعادة التشغيل. بعد الانتهاء من العملية، لن تحتاج بعد الآن إلى القرص القابل للإزالة الذي جعلته إقلاعيًا حتّى تستخدم لينكس لأنك نصبت توزيعة أوبنتو على القرص المحلي الخاص بجهازك، وهنا يعود الخيار لك، فإن كنت ترغب بتثبيت لينكس على جهاز آخر احتفظ بالقرص القابل للإزالة كما هو، وإلّا هيئه واستخدمه لحفظ ونقل البيانات بصورة طبيعية. فإذا نفذّت جميع الخطوات تنفيذًا صحيحًا ستظهر عند تشغيل حاسوبك الشاشة التالية، وهي مخصّصة لاختيار نظام التشغيل الذي تريد الدخول إليه، اختر "Ubuntu" لتدخل على توزيعة أوبنتو، أو اختر "windows boot manager" لتدخل على نظام ويندوز. نصائح إضافية ستلاحظ وجود فرق زمني ما بين نظام ويندوز وتوزيعة أوبنتو، ويمكن حل هذه المشكلة (الفجوة الزمنية في حالة الإقلاع المزدوج) بسهولة. وستلاحظ أيضًا أنّه في شاشة الاختيار ما بين نظامي التشغيل ستكون الأولوية لتوزيعة أوبنتو، ويمكنك تعديل الترتيب جاعلًا ويندوز هو الخيار الافتراضي خاصّةً إذا كنت ستستخدمه أكثر من استخدامك لتوزيعة أوبنتو. كما يمكنك عكس الإجراء أي إزالة توزيعة أوبنتو والاحتفاظ بنظام ويندوز فقط. نرجو أن المقال كان مفيدًا لك، ولا تتردد بالسؤال في التعليقات أو طلب أي مساعدة في قسم الأسئلة والأجوبة. ترجمة -وبتصرف- للمقال How to Install Ubuntu Alongside Windows 10 لصاحبه Abhishek Prakash. اقرأ أيضًا أساسيات إدارة الحزم في أوبنتو ودبيان - الجزء الأول كيفية ضبط إعدادات الشبكات على خادوم أوبنتو كيف تضبط مزامنة الوقت في خادوم أوبنتو 16.04 كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة

