سامح أشرف
-
المساهمات
2934 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
56
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو سامح أشرف
-
يمكنك أن تستخدم الخاصية json فقط وليس التابع ()json في الكود الخاص بك، حيث تعيد هذه الخاصية قاموس يعبر عن كود JSON الذي تم إرساله في جسم الطلب request، كالتالي: @app.route('/api/<id>', methods=['GET', 'POST']) def add_message(id): content = request.json # dictionary return content أيضًا تستطيع أن التابع ()get_json للحصول على نفس القيمة: @app.route('/api/<id>', methods=['GET', 'POST']) def add_message(id): content = request.get_json() return content لكن لاحظ أن كلا الطريقتين السابقتين تحتاج إلى إرسال نوع البيانات application/json كترويسة في الطلب header وإلا لن يعمل الكود السابق، ولكي تتخطي هذا النوع الوحصول على البيانات حتى وإن لم يتم إرسال application/json ضمن ترويسة الطلب، فعليك أن تقوم بتمرير الخاصية force بقيمة True إلى التابع get_json: @app.route('/api/<id>', methods=['GET', 'POST']) def add_message(id): content = request.get_json(force=True) return content وفي حالة ظهر لك الخطأ 400 Bad Request response فهذا يعني أن هناك مشكلة في كود JSON المرسل إلى الخادم، ويجب التحقق منه بشكل قبل إرساله إلى الخادم.، ويمكنك أن تستعمل مواقع مثل JSON validator للتحقق من صلاحية الكود أيضًا تستطيع أن تقوم بمرير الخاصية silent بقيمة True إلى التابع get_json لكي لا يظهر أي أخطاء في حالة حدوث مشكلة: @app.route('/api/<id>', methods=['GET', 'POST']) def add_message(id): content = request.get_json(force=True, silent=True) if not content: return "can't parse JSON code" return "done"
- 1 جواب
-
- 2
-

-
للقيام بهذا الأمر عليك أن تقوم بإستخدام التابع jsonify والذي سيقوم بتحويل القائمة list إلى كود JSON، لكن عليك في البداية قراءة محتوى الملف csv.txt وحفظ هذا المحتوي في قائمة، كالتالي: def parse_request(): input_file = csv.DictReader(open("csv.txt")) data = [] for line in input_file: data.append(line) ثم يمكنك أن تستعمل الدالة jsonify لتحويل هذه القائمة إلى كود JSON، على النحو التالي: import csv @app.route('/', methods=['GET']) def parse_request(): input_file = csv.DictReader(open("csv.txt")) data = [] for line in input_file: data.append(line) return flask.jsonify(data)
- 1 جواب
-
- 1
-
-
يمكنك أن تقوم بهذا الأمر من خلال حلقة for في Laravel كالتالي: <select name="card"> @for($num = 1; $num <= 30; $num++) <option value="">{{$num}}</option> @endfor </select> بهذا الشكل لن تضطر إلى إستعمال أي كوجهات غير الموجهة for فقط
- 2 اجابة
-
- 1
-
-
بما أن الملف countries.php يقوم بإرجاع مصفوفة array فيمكنك أن تقوم بإستدعائه وحفظ محتواه في متغير، كالتالي: $categories = include('countries.php'); الآن يحتوي المتغير categories على المصفوفة المرجعة من الملف countries.php ويمكنك أن تستخدمها كما تريد. وبما أن الملف countries.php موجود في مجلد resources فتستطيع الوصول إليه من خلال الدالة resource_path، على النحو التالي: $categories = include(resource_path('countries.php')); وإذا كنت تريد الوصول إلى محتوى الملف من داخل ملف عرض view فيمكنك أن تستخدم الموجهة php التالي: @php $categories = include(resource_path('countries.php')); @endphp ثم يمكنك المرور على كل عنصر في المصفوفة وإستخدام القيمة لعمل عنصر select كالتالي: <select name="nationalty" id=""> @foreach ($categories['nationalty'] as $nationalty => $value) <option value="{{$nationalty}}">{{$value}}</option> @endforeach </select>
- 3 اجابة
-
- 2
-
-
الخاصية request.data تحتوي على البيانات الممررة من خلال الطلب على شكل نص string، وللحصول على البيانات من الطلب في شكل قائمة من البيانات أو قاموس يمكنك أنت تستعمل الخاصية request.args والتي تقوم بتحويل البيانات الممررة من خلال عنوان الصفحة URL Query إلى قائمة من المفاتيح والقيم key/value: # URL : http://127.0.0.1:5000/?name=sameh @app.route('/', methods=['GET']) def parse_request(): data = flask.request.args print(data) # [('name', 'sameh')] return data كما سيتم تحويل البيانات المرجعة returned إلى كود JSON مباشرة وبشكل تلقائي (في Flask الإصدار 1.1.0 أو أحدث). تستطيع أيضًا أن تقوم بإستخدام الخاصية request.values والتي تحتوي على البيانات الموجودة في عنوان الصفحة URL Query وعلى أي بيانات ممررة من خلال نموذج Form في صفحة HTML: @app.route('/', methods=['GET']) def parse_request(): data = flask.request.values for i in data: print(i, data[i]) # name sameh return data لاحظ أنه عليك أن تستعمل حلقة for لكي تصل إلى البيانات بشكل سهل، ويمكنك أن تستعمل التابع get للحصول على قيمة معينة، على النحو التالي: @app.route('/', methods=['GET']) def parse_request(): data = flask.request.values print(data.get('name')) # sameh return data يمكنك الإطلاع على هذه المقالة للحصول على مزيد من المعلومات عن تمرير البيانات إلى تطبيق Flask:
- 1 جواب
-
- 1
-
-
std::cout جزء من لغة ++C، بينما الدالة printf جزء من لغة C ولكن على الرغم من ذلك فيمكنك أن تستعملها في ++C بدون مشكلة. ولكلٍ منهما مميزات. طريقة الكتابة الدالة printf تستخدم طريقة إستدعاء الدوال العادية، لذلك قد يكون إستعمالها أسهل بكثير من إستعمال std::cout التي تستعمل syntax مختلف كليًا عن الدالة printf، حيث يتم إستعمال المعامل >> ، لذلك قد يكون إستعمال الدالة printf أقصر في الكتابة، لكن هذا الأمر لن يكون ملاحظًا حيث أنه ليس فرق كبير، لكن الفرق يظهر بشكل أكبر عندما تحاول أن تقوم بطباعة أكثر من قيمة في مرة واحدة، حيث أن الدالة printf تسمح لك بتنسيق النص قبل طباعته (إستخدام بعض القيم مثل d% و s% وتمرير متغيرات أو قيم أخرى للتحل مكانها)، اظر مثًلا الكود التالي: printf("Message %d: %s.\n", id, content[id]); std::cout << "Message " << id << ": " << content[id] << "." << std::endl; لاحظ كيف أن الدالة printf أصبحت أقصر بكثير في الكتابة وأن النص يكون أكثر وضوحًا عند إستعمالها. أيضًا سوف يصبح الأمر أكثر تعقيدًا من هذا بكثير عندما تحاول أن تقوم بطباعة متغيرات بقيم محتلفة مثل الأرقام بنظام hex أو octa : #include <iomanip> printf("0x%05x\n", 0x3e3); std::cout << "0x" << std::hex << std::setfill('0') << std::setw(5) << 0x3e3 << std::endl; طباعة الأرقام الصحيحة integers عندما تستعمل std::cout لطباعة أرقام بقيم وأنواع مختلفة فإنه يتم تحويل هذه الأرقام بشكل تلقائي، لكن على الجانب الآخر فيجب عليك أن تستعمل syntax معين للقيام بنفس المهمة بإستخدام printf، فعلى سبيل المثال لطباعة متغير من نوع size_t بإستخدام الدالة printf فعليك أن تستعمل النص zu%، كما أن طباعة النوع int64_t ستحتاج إلى إستعمال "PRId64"% ، بينما std::cout لا تحتاج إلى أي شيء لطباعة هذه الأنواع، حيث يتم تحويلها بشكل تلقائي دون تدخل من المبرمج. الأداء Performance std::cout تستعمل iostream ليتم طباعة البيانات إلى الطرفية، ومن المعروف أن iostream بطيء للغاية مقارنة بإستعمال الدالة printf، بالطبع فرق الأداء لن يكون ملوحظًا عند طباعة نصوص صغيرة أو عند حفظها إلى ملفات، لكن عندما تريد إخراج نصوص كبيرة للغاية وفي أقل وقت ممكن فعليك أن تستعمل الدالة printf
- 2 اجابة
-
- 1
-
-
يمكنك أن تقوم بإستخدام النوع std::string مباشرة، حيث يحتوي على دالة بانية تقوم بتحويل القيمة المدخله إليها إلى النوع std::string بشكل مباشر، كالتالي: const char* s = "Hsoub"; std::string str(s); std::cout << str; تقوم هذه الدالة البانية بنسخ كل حرف من النص إلى المتغير الجديد str لاحظ أن المتغير s لا يجب أن يكون نوع nullptr وإلا سيتم تنفيذ سلوكم غير معروف undefined behavior كما يمكنك أن تحدد حجم المتغير str أيضًا من خلال تمرير رقم صحيح (عدد الحروف) كمعامل ثاني، على النحو التالي: const char* s = "Hello, World!"; std::string str(s, 5); std::cout << str; // Hello
- 2 اجابة
-
- 1
-
-
عليك أن تستعمل المعامل scope resolution operator ( :: ) والذي يقوم بتحديد مجال الدالة التي تريد إستدعائها، فعندما تستعدي الدالة execute تقوم بتنفيذ الأمر كالتالي: int main() { // namespcae::function() user::execute(); return 0; } أي أن الجزء الموجود على اليمين هو اسم الدالة والجزء الموجود على يسار المعامل هو اسم المجال namespace، وفي حالة لم يتم تحديد اسم namespace سوف يتم البحث عن الدالة في المجال العام global scope، كالتالي: void print() { std::cout << "hello, world!"; } int main() { ::print(); return 0; } بالطبع إستخدام المعامل scope resolution في الكود السابق غير ضروري ولكن في الكود الخاص بك، عليك أن تستخدمه لتشير إلى الدالة الموجودة في النطاق العام global scope: std::string user_details() { return "global"; } namespace user { std::string user_details() { return "local"; } void execute() { std::cout << ::user_details(); // global } } عند تنفيذ الدالة execute في الكود السابق سوف يتم تنفيذ الدالة الموجودة في المجال العام وسيتم طباعة كلمة global
- 1 جواب
-
- 2
-
-
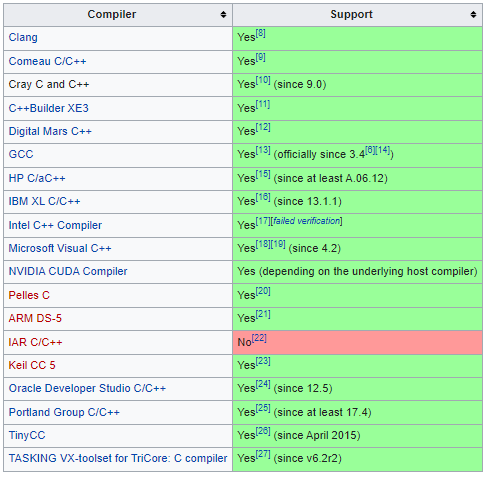
هذا الكود عبارة عن موجهة معالجة مسبق preprocessor directive ويستخدم كحارس لملفات الترويسة header guard، فبدلًا من تعريف قيمة معينة (في الغالب تكون اسم الملف بأحرف كبيرة) لكي لا يتم إستدعاء ملفات الترويسة أكثر من مرة لكي لا يحدث خطأ (function already has a body)، فيمكن أن تستخدم هذا الموجهة بشكل تلقائي في كل ملفات الترويسة لديك لكي لا يحدث هذا الخطأ. يوفر هذا الموجهة الكود والوقت لأنك لن تضطر إلى تعريف موجهة خاص لكل ملف ترويسة لديك. #pragma once struct foo { int member; }; يوجد بعض المصرفات compilers التي تقوم بتحسين أداء البرنامج عند إستعمال هذا الموجهة بدلًا من الطريقة التقليدية، حيث لن يقوم الـ preprocessor بإعادة قراءة الملفات التي تحتوي على هذا الموجهة في بدايتها مما يحسن من عملية التصريف وأداء البرنامج بشكل طفيف ملاحظة: هذا الموجهة ليس جزء من تعليمات ++C الرسمية ولكن يتم إستعماله بشكل كبير في أغلب المصرفات compilers، لذلك عليك التأكد أولًا من أن المصرَّف الذي لديك يدعم هذا الموجهة. هنا صورة توضح المصرفات التي تدعم هذا الموجهة والتي لا تدعمه: أنظر إلى خطأ function already has a body من هنا: يمكنك أن تقرأ المزيد عن هذا الموجهة من خلال هذه المقالة هنا:
- 1 جواب
-
- 1
-
-
يمكنك نقل الملفات والمجلدات عبر الأمر التالي: cp old/path/filename new/path/filename cp old/path/dirname new/path/dirname -r يجب أن تستخدم r- عندما تحاول نقل مجلد ما أيضًا، يمكنك محاولة إنشاء/نقل المشروع في مجلد downloads (في الذاكرة الداخلية) والدخول إلى المشروع عبر الأمر التالي: cd storage/downloads/my-project ثم تنفيذ أوامر composer مرة أخرى
- 9 اجابة
-
- 2
-
-
يمكنك الحصول على طول النص عبر التابع length حيث يقوم هذا التابع بإرجاع طول النص من خلال قيمة من نوع unsigned int: #include <iostream> #include <string> int main() { std::string str; std::cout << "Enter your name: "; std::getline(std::cin >> std::ws, str); std::cout << str.length() << '\n'; return 0; } ثم يمكنك المرور على كل الحروف عبر عمل حلقة for، كالتالي: #include <iostream> #include <string> int main() { std::string str; std::cout << "Enter your name: "; std::getline(std::cin >> std::ws, str); for (int i = 0; i < str.length(); ++i) std::cout << str[i] << '\n'; return 0; } لاحظ كيف تم إستخدام المتغير i للوصول إلى أحد الحروف في النص str
- 1 جواب
-
- 2
-
-
في الغالب ليس لديك صلاحيات للتعديل على مجلد المشروع، لذلك أرجو منك تنفيذ الأمر التالي: termux-setup-storage سيطلب منك صلاحيات الوصول إلى الملفات، ويجب أن تقوم بالسماح للتطبيق من خلال الضغط على "سماح allow" بعد ذلك حاول مرة أخرى تحميل المكتبة عبر composer في مجلد المشروع
- 9 اجابة
-
- 2
-
-
يتم تحميل المكتبة في المكان الحالي في سطر الأوامر، ويمكنك التأكد من هذا الأمر من خلال تنفيذ الأمر التالي: ls وستجد أنه يوجد كل الملفات والمجلدات الخاصة بـ composer (مثل composer.json و vendor .. إلخ). أما إن أردت تثبيت المكتبة (وملفات composer) في مشروع موجود، فعليك أن تذهب إلى مجلد المشروع أولًا من خلال الأمر cd، على النحو التالي: cd path/to/my-project مع تغير المسار إلى مسار المشروع الخاص بك.
- 9 اجابة
-
- 2
-
-
إن لم يكن لديك composer مسبقًا، فستحتاج أولًا إلى تثبيت composer من خلال الأمر التالي: pkg install composer ثم يمكنك أن تقوم بمحاولة تثبيت أحد الحزم كتجربة في مجلد جديد، من خلال مثل هذا الأمر: composer require monolog/monolog ثم يمكنك التأكد من أن عملية التثبيت تمت بنجاح من خلال عرض محتويات الملف composer.json، حيث سيحتوي على اسم الحزمة وإصدارها أيضًا. أما إن لم تستخدم composer من الأساس، فستحتاج إلى أن تقوم بعمل ما يقوم به composer يدويًا، مثل البحث عن المكتبات وإختيار الإصدار المناسب والمتوافق مع إصدار php لديك وكذلك الإصدار المتوافق مع باقي المكتبات المثبته بالفعل .. إلخ.
- 9 اجابة
-
- 3
-
-
يمكنك أن تقوم بعمل دالة تقارن بين رقمين مع فارق بسيط، كالتالي: #include <cmath> // epsilon عبارة عن مقدار المقبول الممكن بين المتغيرين bool isAlmostEqual(double a, double b, double epsilon) { // إذا كان المتغيرين a و b متقاربين كفاية return std::abs(a - b) <= epsilon; } ويمكن إستخدام هذه الدالة، كالتالي: double x{ 0.1 + 0.2 }; std::cout << isAlmostEqual(x, 0.3, 0.0001) << '\n'; سيتم طباعة 1 (true) إذا كان الفارق بين القيمتين أقل من أو يساوي 0.0001. كما يمكن إستخدام دالة أفضل، فبدلًا من الإعتماد على أن يكون المعامل epsilon عبارة عن الفارق بين المتغيرين، يمكن أن نستخدمه على أنه نسبة الفارق بين المتغرين: bool isAlmostEqual(double a, double b, double epsilon) { return (std::abs(a - b) <= (std::max(std::abs(a), std::abs(b)) * epsilon)); } ويمكن أن تستخدمها بنفس الطريقة السابقة أيضًا.
- 2 اجابة
-
- 1
-
-
يمكنك أن تستخدم typeid للحصول على نوع المتغير كسلسلة نصية string: #include <iostream> #include <typeinfo> int main() { int x{ 1 }; std::cout << typeid(x).name() << '\n'; // int return 0; } أما إن كنت تستعمل boost فتستطيع القيام بالتالي: #include <iostream> #include <boost/type_index.hpp> using boost::typeindex::type_id_with_cvr; int main() { int x { 1 }; std::cout << "decltype(i) is " << type_id_with_cvr<decltype(x)>().pretty_name() << '\n'; // int return 0; }
- 1 جواب
-
- 1
-
-
الملف vendor/autoload.php يتم توليده من قِبل Composer وهو عبارة عن أداة تقوم بإدارة الحزم والمكتبات الخاصة بلغة PHP في المشروع، يمكنك تحميل وتثبيت Composer من هنا لماذا تستعمل Composer؟ إذا كنت تعمل على أحد المشاريع وتستخدم العديد من الحزم والمكتبات في مشروع، فستجد أنك تقوم ببعض الخطوات الروتينية في كل مرة تريد إضافة أو تحديث مكتبة في المشروع، حيث تقوم بتحميل المكتبة من الإنترنت وتضيفها إلى المشروع حسب طريقة الإستدعاء الخاصة بها، وعليك أن تتأكد بنفسك من الإصدار الذي تريد أن تعمل عليه (وتبحث عنه في الإنترنت أيضًا)، كما يجب أن تقوم بإستخدام الدالة require و الدالة include لإستدعاء المكتبة ولن تستطيع إستخدام namespace بسهولة. وهنا يأتي دور Composer حيث يقوم بكل هذه الخطوات بصورة تلقائية، فعلى سبيل المثال لتثبيت المكتبة monolog/monolog (مكتبة خاصة بالتسجيل logging)، كل ما عليك هو تنفيذ الأمر التالي في مجلد المشروع: composer require monolog/monolog وسيقوم Composer بالبحث في موقع packagist (أكبر موقع يحتوي على مكتبات لغة PHP بشكل مجاني) إلى أن يجد المكتبة المطلوبة ويتأكد من الإصدار المستخدم في المشروع (يمكنك تحديد إصدار معين عند عملية التثبيت)، وسيقوم Composer بتحميل الإصدار الصحيح في مجلد vendor حيث سيتم عمل المجلد monolog/monolog في داخله وستجد فيه كل ملفات المكتبة، ثم سينشئ Composer ملف autoloader.php لجميع المكتبات المحمّلة وسيحمّل الاعتمادية كاملةً في المشروع الذي تعمل عليه، وبالتالي ليس عليك سوى إستدعاء هذا الملف فقط لتستطيع إستخدام كل المكتبات التي تم تثبيتها بشكل مباشر. الملفات التي يتم إنشائها تلقائيًا من خلال Composer يقوم Composer بإنشاء بعض الملفات الإضافية، وهي ملفات أساسية لكي يعمل (يتم إنشاء هذه الملفات أول مرة فقط، وبعد ذلك يتم التعديل عليها فقط عند تثبيت أي مكتبة جديدة). من ضمن تلك الملفات ستجد الملف composer.json وهو يحتوي على كل المكتبات التي تم تثبيتها في المشروع مع إصدارها الحالي. محتوى الملف composer.json: { "require": { "monolog/monolog": "^2.3" } } وستجد الملف composer.lock، وهو ملف يحتوي على كل المكتبات والحزم التي تم تثبيتها بالتفصيل (إصدار PHP المطلوب لتعمل المكتبة ومصدر المكتبة ومالك المكتبة وحقوقها .. إلخ)، وكذلك المكتبات والحزم الإضافية التي تحتاجها المكتبات. يمكنك الآن أن تستعمل المكتبة monolog/monolog كالتالي: <?php require __DIR__ . '/vendor/autoload.php'; $log = new Monolog\Logger('name'); $log->pushHandler(new Monolog\Handler\StreamHandler('app.log', Monolog\Logger::WARNING)); $log->warning('Foo'); لاحظ تم إستخدام الأصناف Monolog\Logger و Monolog\Handler\StreamHandle بشكل مباشر، وذلك لأننا إستخدمنا الملف vendor/autoload.php في بداية الملف، حيث يقوم بتجهيز وإستدعاء كل الملفات المطلوبة تلقائيًا. الكود السابق سوف ينشيء ملف باسم app.log وستم كتابة بعض البيانات فيه: [2021-12-01T19:11:32.629010+00:00] name.WARNING: Foo [] [] إدارة المكتبات من خلال Composer يمكنك أيضًا أن تقوم بتحديث المكتبات من خلال الأمر التالي: composer update عند تنفيذ هذا الأمر، فسيبحث composer عند أحدث إصدار لكل مكتبة يمكن تثبيته، ويقوم بتحديث المكتبات. أو يمكن حذف أحد المكتبات من خلال الأمر remove واسم المكتبة التالي: composer remove monolog/monolog لمزيد من المعلومات عن Composer يمكنك أن تقرأ هذه المقالات هنا:
- 9 اجابة
-
- 2
-
-
النوع * int يشير إلى مؤشر pointer إلى متغير من نوع int، ويكتب بصيغة واحدة فقط: int x{ 1 }; int * y{ &x }; std::cout << x << ' ' << y << '\n'; // 1 004FFA3C النوع الثاني هو * int const ، ويستخدم لعمل مؤشر pointer إلى ثابت من نوع int (أي أن المتغير هو الثابت وليس المؤشر)، ويكتب هذا النوع بطريقتين: const int x{ 1 }; // لاحظ أن هذا ثابت constant int const * y{ &x }; std::cout << x << ' ' << y << '\n'; // 1 004FFA3C // نفس الكود السابق const int x{ 1 }; const int * y{ &x }; // طريقة مختلفة لكتابة هذا النوع std::cout << x << ' ' << y << '\n'; // 1 004FFA3C النوع الثالث هو int * const وهو يعني عمل مؤشر ثابت لمتغير من نوع int (أي أن المؤشر pointer هو الثابت هنا): int x{ 1 }; int * const y{ &x }; std::cout << x << ' ' << y << '\n'; // 1 004FFA3C النوع الرابع وهو int const * const ويمكن أن يتم إستخدامه بطريقة أخرى وهي const int * const، تؤدي كلا الطريقتين نفس الغرض: const int x{ 1 }; int const * const y{ &x }; std::cout << x << ' ' << y << '\n'; // 1 004FFA3C // طريقة أخرى لإستعمال نفس النوع const int x{ 1 }; const int * const y{ &x }; std::cout << x << ' ' << y << '\n'; // 1 004FFA3C يمكنك ان تفهم ما يقوم به أي نوع من الأنواع السابقة من خلال قراءته من اليمين إلى اليسار، فعلى سبيل المثال النوع int * const يقرأ: int * const constant pointer to int لاحظ كيف أن إتجاه القراءة بدأ بكلمة const إلى int وبنفس الطريقة يمكن أن تقوم بقراءة باقي الأنواع: int * - pointer to int int const * - pointer to const int int * const - const pointer to int int const * const - const pointer to const int
- 1 جواب
-
- 1
-
-
يمكنك أن تستعمل الحزمة chromedriver-binary لإضافة chromedriver إلى PATH في البداية عليك تثبيت الحزمة من خلال الأمر التالي: pip install chromedriver-binary ثم يمكنك أن تستعملها بالشكل التالي: from selenium import webdriver import chromedriver_binary # عليك إستدعاء الحزمة كالتالي driver = webdriver.Chrome() driver.get("https://www.google.com")
- 2 اجابة
-
- 2
-
-
أنت تستعمل المعامل , comma operator هنا وهذا معامل موجود في لغة ++C، وهو المعامل الأقل أهمية في ترتيب التنفيذ (أي له أقل أولوية في عملية التنفيذ)، ويقوم هذا المعامل بتنفيذ الجزء الموجود على اليسار ثم يعيد الجزء الموجود على اليمين، فعلى سبيل المثال في الكود التالي سيتم زيادة قيمة x و سيتم تهيئة المتغير y بالقيمة 3 int x{ 1 }; int y{ (++x, 3) }; // تم إحاطة العملية بأقواس لكي لا يظهر خطأ too many initializer values std::cout << y; // 3 يتجنب المبرمجين إستخدام إستخدام هذا المعامل قدر الإمكان، ما عدا في حلقات for حيث يتم إستخدامه لعمل أكثر من عداد في نفس الحلقة، كما في الكود التالي: #include <iostream> int main() { for (int x{ 0 }, y{ 9 }; x < 10; ++x, --y) std::cout << x << ' ' << y << '\n'; return 0; } وستكون ابنتيجة كالتالي: 0 9 1 8 2 7 3 6 4 5 5 4 6 3 7 2 8 1 9 0 أما بالنسبة لطباعة المتغير فيمكنك ببساطة إستخدام المعامل >> مرتين أو أكثر، على النحو التالي: int x{ 1 }; int y{ 2 }; std::cout << ++x << ' ' << ++y << '\n';
- 2 اجابة
-
- 1
-
-
إن كنت تستخدم VPN فربما يؤثر على إستخدامك للموقع كـكل، لذلك من الأفضل تعطيله. أيضًا إن إشتركت في أحد الدورات للتو أو خلال اليوم فربما يتأخر تأكيد عملية الإشتراك بعض الوقت، ولكن العملية لن تستغرق أكثر من 24 ساعة على الأكثر. إن كان بإمكانك إرفاق صورة أو إضافة المزيد من التفاصيل، فسيساعد هذا الأمر على حل المشكلة أكثر. إن أستمرت المشكلة لفترة أطول يمكنك التواصل مع مركز المساعدة الخاص بالأكاديمية وسوف يساعدونك على الفور.
-
يمكنك القيام بهذا الأمر بعدة طرق، كالتالي: تحويل قيمة المتغير age إلى نص من خلال الدالة to_string: int age = 18; std::string name = "Mohammed"; std::string new_name = "Your name is " + name + " and your age is " + std::to_string(age); std::cout << new_name; // Your name is Mohammed and your age is 18 أو إن كنت تستعمل مكتبة boost فيمكنك أن تستعمل التابع int_to_string: int age = 18; std::string name = "Mohammed"; std::string new_name = "Your name is " + name + " and your age is " + boost::lexical_cast<std::string>(age); std::cout << new_name; // Your name is Mohammed and your age is 18 تستطيع أيضًا أن تستعمل stringstream، على النحو التالي: // لإستخدام stringstream #include <sstream> int age = 18; std::string name = "Mohammed"; std::stringstream ss; ss << age; std::string new_name = "Your name is " + name + " and your age is " + ss.str(); std::cout << new_name; // Your name is Mohammed and your age is 18
- 2 اجابة
-
- 1
-
-
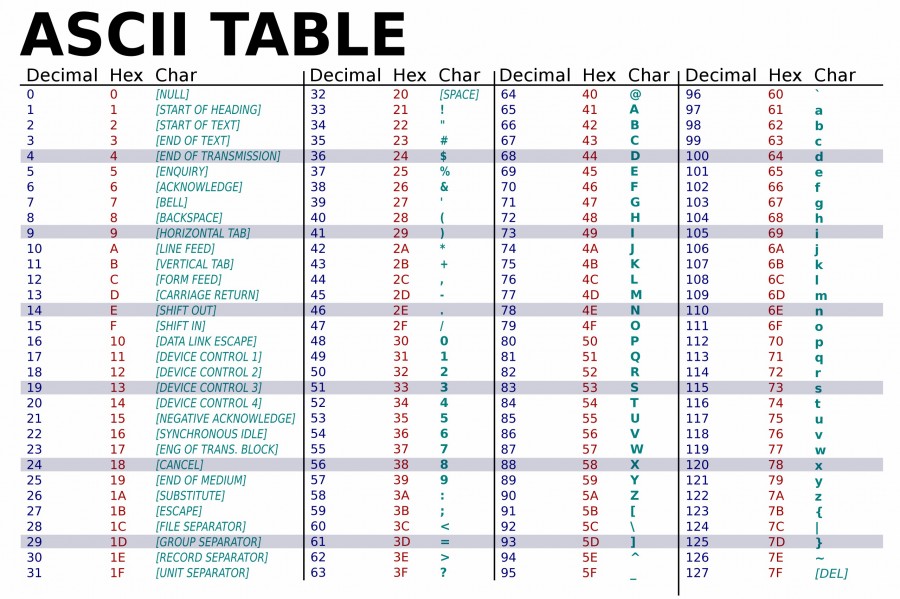
النوع char لا يستخدم فقط لتخزين حرف واحد، ويوجد منه نوعين رئيسيين: signed char unsigned char إذا كان برنامجك يعتمد على هذا النوع بشكل مباشر، فيجب أن تقوم بإستخدام أحد النوعين السابقين صراحةً، بينما في حالة أردت أن تستخدم هذا النوع للتعبير عن حرف معين فقط فيمكنك أن تستخدم char فقط بدون تحديد الجزء signed أو unsigned وعلى حسب نظام التشغيل الذي تعمل عليه سوف يتم تحديد إشارة النوع تلقائيًا. النوع char يخزن حالة واحدة من 256 قيمة بشكل إفتراضي وعلى كل المصرفات compilers (أي أنه يستغل ما مساحته 8-bit من الذاكرة) ولكن على حسب الإشارة يختلف نطاق هذه القيم، فسنجد أن النوع signed char يقوم بتخزين القيم من -128 إلى 127 (256 حالة)، بينما النوع unsigned char يقوم بتخزين القيم من 0 إلى 255 (256 حالة)، وبالتالي فإن عدد القيم هو نفسه، ولكن النطاق الذي يمكن أن تكون فيه هذه القيم مختلف بين النوعين. طبقًا لما سبق فإن النوع char يحمل قيمة رقمية وليس حرف، ويمكن التأكد من ذلك من خلال الكود التالي: char a {65}; std::cout << a; // A في هذا الكود تم تخزين القيمة 65 في المتغير a وعندما تم طباعة قيمة هذا المتغير ستجد أن الحرف A هو من تم طباعته في سطر الأوامر والسبب هو أن المصرَّف يقوم بتحويل القيمة المخزنة في المتغير من نوع char إلى حرف ASCII إختصارًا لـ American Standard Code for Information Interchange وهو جدول يعبر أن الحروف والأرقام وبعض الرموز بأرقام من بين 0 إلى 127، كالتالي: وفي هذا الجدول ستجد أن القيمة 65 تعبر عن الحرف A ولهذا السبب تم طباعة الحرف A في سطر الأوامر ملاحظة: المتغير a في الكود السابق يحمل القيمة 65 وليس '65' . سبب وجود النوع unsigned char بما النوع int يقوم بتخزين قيمة 4-byte في أغلب أنظمة التشغيل، وبما أن النوع char يخزن أرقام في الأساس كما ذكرت سابقًا، فقد تم إستخدام النوع char لتخزين الأرقام الصغيرة لتحسين أداء البرنامج والتقليل من إستهلاك الذاكرة إلى أقصى حد ممكن، وبالتالي يمكن تخزين أرقام سالبة في هذا النوع (حسب الحاجة) ، مع العلم أنه لا يجب أن تستخدم هذا النوع إلا لتخزين حرف واحد (إلا إذا كنت تعمل على تحسين إستهلاك الذاكرة بشكل كبير). لذلك يتم إستخدام النوع unsigned char في رسومات الحاسوب Computer Graphics كثيرًا، خصوصًا لتخزين الألوان، حيث يتم التعبير عن أي لون من خلال الصيغة RGB (أو RGBA في بعض الأحيان) وهي عبارة عن دمج بين الثلاثة ألوان الرئيسية (الأحمر و الأخصر والأزرق) لتكوين أي لون، وتكون قيمة كل لون من هذه الألوان الثلاثة ما بين 0 إلى 255 ويتم التعبير عن أي لون بهذا الشكل (0 ,0 ,255) (اللون الأحمر) لذلك يتم إستخدام ثلاث قيم من النوع unsigned char للتعبير عن قيمة أي لون.
- 1 جواب
-
- 2
-
-
يحتوي النوع string على التابع find والتي يقوم بإرجاع فهرس النص الذي تبحث عنه: #include <iostream> #include <string> int main() { std::string s1 = "Hello, world"; std::string s2 = "world"; // التحقق من وجود قيمة المتغير s2 داخل قيمة المتغير s1 if (s1.find(s2) != std::string::npos) { std::cout << "found '" << s2 << "' in '" << s1 << "'" << '\n'; } return 0; } في حالة وجود النص s2 داخل قيمة المتغير s1 سوف يتم طباعة الجملة found 'world' in 'Hello, world'
- 3 اجابة
-
- 2
-
-
إن أتممت تعلم اللغة نفسها، ستحتاج إلى التأكد من إتقانك للغة من خلال عمل مشاريع وبرامج بسيطة للغاية، لأنه عمل برامج بسيطة سوف يساعدك على التأكد من فهمك للغة نفسها وسيساعدك على إكتساب مهارة حل المشاكل Problem Solving، كما ستتعلم أشياء جديدة في كل مشروع تقوم به. تستطيع أن تبدأ بعمل برامج بسيطة للغاية، وتقوم هذه البرامج بحل مشكلات تواجهك أنت أو مشكلة تواجهة بعض الأشخاص بشكل عام، على سبيل المثال، تستطيع عمل برنامج بسيط يقوم بتوليد كلمات مرور عشوائية، ويمكن للمستخدم أن يقوم بإختيار ما إذا كانت كلمة السر التي سيتم توليدها تحتوي على رموز أو لا، أو يمكنك أن تقوم بعمل برنامج بسيط يعرض حالة الطقس لأيام الأسبوع المقبل .. إلخ، (يمكنك البحث عن "أفكار لبرامج بسيطة" في جوجل وسوف تجد عشرات الأفكار التي يمكنك القيام بها). بالتأكيد قد تجد نفسك لا تعرف من أين تبدأ أو كيف تقوم بعمل البرنامج ككل، وهنا يكمن جزء التعلم، حيث يجب أن تقوم بالبحث بنفسك عن كيفية حل المشاكل التي تواجهك والبحث عن معلومات أضافية في مكتبات اللغة وكيفية إستخدامها لحل مشكلة معينة، وبذلك سوف تحصل على القدرة على البحث وإكتساب مزيد من المعرفة. بعد أن تقوم بعمل الخطوات السابقة، وبعد إتمام عدد من المشاريع، يمكنك أن تقوم بالبحث عن مشاريع حقيقة تقوم بها، مثل إنشاء Backend لمدونة من خلال إطار عمل مثل Flask أو Django أو ربما تبدأ في تعلم الذكاء الإصطناعي أو مجال تحليل البيانات الضخمة .. إلخ، وهنا سوف تتعلم المزيد من الأمور قبل أن تبدأ في تعلم المجال نفسه، مما سيزيد من معرفتك وقدرتك على إنشاء المزيد من البرامج .. إلخ.
- 1 جواب
-
- 2
-