سامح أشرف
-
المساهمات
2934 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
56
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو سامح أشرف
-
يجب أن تقوم أولًا بجلب البيانات التي تريدها من قاعدة البيانات، وهذه العملية تتم داخل المتحكم Controller، كالتالي: $users = User::where('name', 'Sameh')->get(); return view('view-name', compact('users'); بهذا الشكل تم جلب البيانات من قاعدة البيانات وتم تمريرها إلى الملف view-name.blade.php يمكنك الآن أن تقوم بعمل حلقة تكرار foreach لطباعة بيانات المستخدمين في الملف view-name.blade.php، على النحو التالي: @foreach ($users as $user) <div> <span>Name: {{ $user->name }}</span> <span>Phone: {{ $user->phone }}</span> </div> @endforeach
- 2 اجابة
-
- 2
-

-
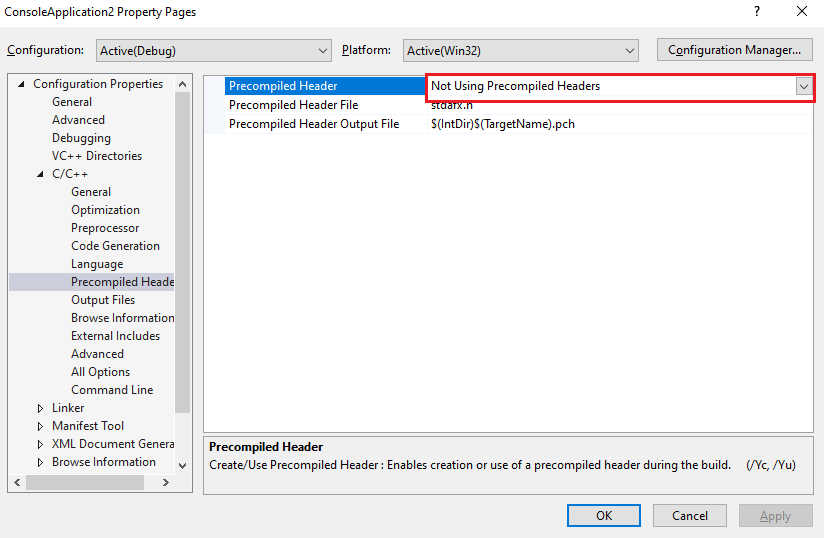
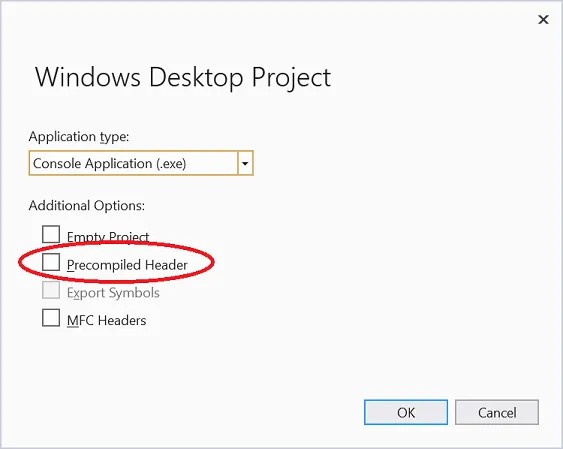
جميع مترجمي Compilers لغة ++ C لديهم مشكلة في الأداء بالنسية لعملية تصريف ملفات التروسية headers حيث أنها عملية طويلة وبطيئة، خصوصًا ملفات التروسية الخاصة بـ Windows API حيث أنها ملفات ضخمة وتستغرق الكثير من الوقت لتصريفها إلى لغة الآلة، وبالتالي كلما حاولت أن تقوم بعمل برنامج بسيط سوف يستغرق الكثير من الوقت ليتم تصريفه إلى لغة الآلة (بسبب تصريف ملفات التروسية غير المستخدمه)، ولحل هذه المشكلة ولتوفير الوقت يتم تصريف هذه الملفات بشكل مسبق Precompild ويستعملها في كل مرة، ولإستعمال هذه الملفات نستخدم الملف stdafx.h ، ويجب أن يكون هذا الملف في أول ملف يتم إستدعائه. لذلك يمكنك حل المشكلة من خلال إغلاق الخاصية Precompiled Header في بيئة التطوير الخاصة بك عبر الضغط على المشروع بزر الفأرة الأيمن وإختيار properties ثم من قائمة Precompiled Headers قم بإيقافها كما في الصورة التالية: ملاحظة في الإصدارات الأحدث من Visual Studio يتم إيقاف هذه الخاصية بشكل إفتراضي. أو يمكنك إلغاء هذه الميزة عندما تقوم بإنشاء المشروع من الأساس: أو يمكنك فقط إستدعاء هذا الملف في بداية البرنامج الخاصة بك: #include "stdafx.h"
- 1 جواب
-
- 1
-
-
يمكنك أن تقوم بالمرور على كل عناصر span الموجودة في المستند والتأكد من إحتوائه على الخاصية title، وفي حالة وجود هذه الخاصية سيتم إضافة قيمتها إلى قائمة badges: from bs4 import BeautifulSoup content = """ <span> <span title="9 gold badges"> <span class="badge1"></span> <span class="badgecount">9</span> </span> <span title="38 silver badges"> <span class="badge2"></span> <span class="badgecount">38</span> </span> <span title="56 bronze badges"> <span class="badge3"></span> <span class="badgecount">56</span> </span> </span> """ soup = BeautifulSoup(content, features='lxml') # هنا سيم تخزين كل القيم المستخرجه من عناصر span badges = [] # نقوم بتحديد كل عناصر span والمرور عليهم span_elements = soup.select('span') for span in span_elements: # في حالة وجود الخاصية title if span.has_attr('title'): badges.append(span.get('title')) print(badges) # ['9 gold badges', '38 silver badges', '56 bronze badges'] لاحظ أن كل القيم تنتهي بالكلمة "badges"، وبالتالي يمكنك أن تتأكد من صحة القيمة الموجودة في الخاصية title، على النحو التالي: for span in span_elements: if span.has_attr('title'): title = span.get('title') if title.lower().endswith('badges'): badges.append(title) print(badges) # ['9 gold badges', '38 silver badges', '56 bronze badges']
-
بدلًا من إستعمال التابع findAll و التابع find يمكنك أن تستعمل التابع select والتابع select_one للقيام بهذه المهمة، على النحو التالي: from bs4 import BeautifulSoup content = """<table cellspacing="0" cellpadding="3" border="0" id="HistoryData1" style="width:100%;border-collapse:collapse;"> <tr class="gridHeader" valign="top"> <td class="titleGridRegNoB" align="center" valign="top"><span dir=RTL>ballov</span></td> <td class="titleGridReg" align="center" valign="top">Grand</td> <td class="titleGridReg" align="center" valign="top">andera</td> <td class="titleGridReg" align="center" valign="top">colofisiaky</td> <td class="titleGridReg" align="center" valign="top">tochy</td><td class="titleGridReg" align="center" valign="top"><span dir="rtl"> (laesd)</span></td> <td class="titleGridReg" align="center" valign="top">שער נעילה מתואם</td><td class="titleGridReg" align="center" valign="top">kagt</td> </tr> <tr onmouseover="this.style.backgroundColor='#FDF1D7'" onmouseout="this.style.backgroundColor='#ffffff'"> </tr> </table> """ soup = BeautifulSoup(content, features='lxml') table = soup.select_one('table#HistoryData1') print(table) rows = table.select('tr') print(rows) لاحظ كيف تم إستعمال التابع select_one للحصول على العنصر table الذي يحمل المعرف HistoryData1 ثم تم إستعمال هذا الجدول للبحث عن كل عناصر tr التي يحتويها من خلال التابع select والذي يقوم بإرجاع قائمة من العناصر.
-
حجم كل نوع يعتمد على المصرف Compiler لديك، ويمكنك معرفة حجم كل نوع من خلال إستخدام المعامل sizeof حيث يعيد هذا المعامل حجم النوع الممر له بالبايت، كالتالي: std::cout << "int: " << sizeof(int) << " bytes\n"; // int: 4 bytes ويمكنك معرفة حجم أشهر الأنواع المستعملة في لغة ++C كالتالي: #include <iostream> int main() { std::cout << "bool:\t\t" << sizeof(bool) << " bytes\n"; std::cout << "char:\t\t" << sizeof(char) << " bytes\n"; std::cout << "wchar_t:\t" << sizeof(wchar_t) << " bytes\n"; std::cout << "char16_t:\t" << sizeof(char16_t) << " bytes\n"; std::cout << "char32_t:\t" << sizeof(char32_t) << " bytes\n"; std::cout << "short:\t\t" << sizeof(short) << " bytes\n"; std::cout << "int:\t\t" << sizeof(int) << " bytes\n"; std::cout << "long:\t\t" << sizeof(long) << " bytes\n"; std::cout << "long long:\t" << sizeof(long long) << " bytes\n"; std::cout << "float:\t\t" << sizeof(float) << " bytes\n"; std::cout << "double:\t\t" << sizeof(double) << " bytes\n"; std::cout << "long double:\t" << sizeof(long double) << " bytes\n"; return 0; } وستكون النتيجة كالتالي: bool: 1 bytes char: 1 bytes wchar_t: 2 bytes char16_t: 2 bytes char32_t: 4 bytes short: 2 bytes int: 4 bytes long: 4 bytes long long: 8 bytes float: 4 bytes double: 8 bytes long double: 8 bytes قد تجد أن الأرقام السابقة مختلفة لديك، حيث يقوم المصرّّف نفسه بتحديد حجم كل نوع، لذلك يختلف الأمر من مصرَّف لآخر.
- 1 جواب
-
- 1
-
-
أغلب الشركات تشترط أن يكون لدى المبرمج خبرة عدة عام أو عامين أو أكثر حسب الشركة، وبعض هذه الشركات قد لا تطلب أي خبرة سابقة (يسمى تدريب في بعض الأحيان ويكون بمرتب أيضًا)، لذلك قد تجد صعوبة في العمل في أحد الشركات خصوصًا إن لم يكن لديك مشاريع قد قمت بها بنفسك، لكن ليس من المستحيل أن تعمل في أحد الشركات، وهذا على عكس العمل الحر Freelancing بالطبع، حيث لا تحتاج إلى أي خبرة أو مشاريع سابقة لتعمل في أحد مواقع العمل الحر مثل مستقل (بالتأكيد وجود مشاريع في معرض أعمال سيزيد من فرصة الحصول على عمل أيضًَا). لاحظ أيضًا أنك إن لم تنهي تعلم باقي الدورة وبدأت تبحث عن عمل قبل أن تتعلم باقي أساسيات Laravel من خلال إكمال باقي مشاريع الدورة، فقد تعمل على مشاريع في أحد الشركات ولا تعلم كيفية القيام بمهمة معنية وذلك لأنك لم تكمل تعلم أساسيات Laravel وبالتالي ستضطر للتعلم أثناء العمل على مشروع مما سيجعلك تحت ضغط وقلة الوقت، وبالتالي قد يتم إنتاج المشروع بشكل غير سليم أو ربما الكود لن يكون منظم للغاية أو غير نظيف Dirty Code (عكس Clean Code) وسيأثر على عملك في المجمل. لاحظ أني لا أقصد أن هذه المشاريع التي ذكرتها في سؤالك مفيدة وسوف تستعملها بالفعل في أغلب المشاريع و المواقعالتي ستعمل عليها، ولكنها لا تكفي لعمل أي مشروع مهما كان، وهذا سبب وجود باقي الدروس والمسارات في الدورة (لتتعلم كل ما تحتاجه للعمل). لذلك نتيجة لكل ما سبق، فربما تجد صعوبة في العثور على عمل، ولكن حتى إن قمت بالعمل في أحد الشركات فستحتاج إلى إكمال التعلم وإنهاء باقي المشاريع (وفي الغالب ستتعلم وأنت تعمل على مشاريع الشركة)، لذلك من الأفضل أن تكمل الدورة للنهاية قبل البحث عن عمل في أحد الشركات.
- 4 اجابة
-
- 3
-
-
يمكنك أن تستعمل التابع select و الذي يقبل محدد CSS كمدخل له، وبالتالي تستطيع تحديد كل العناصر المحددة Selected من خلال الكود التالي: from bs4 import BeautifulSoup content="""<select> <option value="0">1999/9/5</option> <option value="1">2010/9/5</option> <option value="2">2017/9/5</option> <option value="3" selected>220/9/5</option> </select> """ soup = BeautifulSoup(content, features='lxml') # تحديد العناصر المحددة فقط selected = soup.select('option[selected]') print(selected) # [<option selected="" value="3">220/9/5</option>] يعيد هذا التابع كل العناصر التي تم إيجادها.
- 2 اجابة
-
- 1
-
-
عندما تستخدم موجهة Preprocessor Directive مثل define لتعريف قيمة ثابته مثل MAX_STUDENTS_PER_CLASS فإن هذه القيمة يتم إسبدالها في كل مكان في الملف وستكون النتيجة كالتالي: int max_students { numClassrooms * 30 }; ولكن هذه الطريقة لها العديد من المشاكل، حيث أن الـ Preprocessor لا يفهم صيغة ++C على الإطلاق ويقوم بإستبدال الثابت MAX_STUDENTS_PER_CLASS بالقيمة 30 في كل مكان يجده في الملف بغض النظر عن أي مجال Scope تكون فيه، وبالتالي قد تجد أن القيمة 30 أصبحت في أماكن غير مرغوب فيها مما يسبب بعض الأخطاء أثناء عملية التصريف Compiling. وبما أن الثابت MAX_STUDENTS_PER_CLASS يتم إستبدال قيمته قبل عملية التصريف من قِبل الـ Preprocessor فلا يمكن تتبع هذه القيمة من خلال مصحح الأخطاء debugger الموجود في بيئة التطوير لديك، وبالتالي لا يفضل أن يتم إستعمال هذه الطريقة لأنها قد تعرضك إلى أخطاء منطقية Logical Errors والتي يصعب إكتشاف سببها وحلها. أيضًا قد يتعارض تعريف القيمة من خلال Preprocessor Directive مع الكود نفسه، فعلى سبيل المثال في الكود التالي سوف يتم إزالة كل كلمات beta وإستدالها بالقيمة 3: #define beta 3 #include <iostream> int main() { int beta{ 5 }; std::cout << beta; return 0; } سوف يقوم الـ Preprocessor بتحويل الكود السابق إلى التالي: #include <iostream> int main() { int 3{ 5 }; std::cout << 3; return 0; } لاحظ كيف تم تغير اسم المتغير beta في السطر 5 إلى القيمة 3، وفي بعض الأحيان قد يتم تعريف القيمة beta في ملف آخر مما يجعل من عملية إكتشاف سبب هذه المشكلة صعبًا. وبناءً على ما سبق يفضل إستعمال const أو contexpr بدلًا من define لتفادي الأخظاء السابقة.
- 1 جواب
-
- 1
-
-
النوع الأول const عبارة عن ثابت يحمل قيمة من نوع معين، ويكتب على الصيغة التالية: // const const_name = value; cosnt age = 18; وهذا الثابت يتم جسابه وتخزين قيمته أثناء وقت التشغيل Run Time مثل المتغيرات العادية، ولكن لا يمكن تغير قيمته لاحقًا، وبالتالي إن حاولت تنفيذ الكود التالي سوف يظهر لديك خطأ: const int age{123}; age = 18; // Error: expression must be a modifiable lvalue بينما النوع الثاني constexpr هو ثابت أيضًا ولكن يتم حسابه وتخزينه أثناء عملية التصريف Compile Time ويجب أن تكون قيمته محددة بالفعل قبل تشغيل البرنامج حتى، وبالتالي يجب أن تكون قيمته معروفة من البداية، لذلك سوف يظهر لديك خطأ إن حاولت أن تقوم بتنفيذ الكود التالي: int age{}; std::cin >> age; const int myAge{ age }; int age2{}; std::cin >> age2; constexpr int myAge{ age2 }; // Error: age2 is a runtime constant, not a compile-time constant الجزء الأول من الكود سوف يعمل بدون مشكلة، بينما الجزء الثاني سوف تظهر فيه مشكلة تخبرك بأن age2 عبارة عن ثابت يتم حسابه أثناء عملية التنفيذ run time. لذلك نستنتج أنه: يجب التصريح عن أي متغير لا يمكن تعديله بعد التهيئة والذي تمت تهيئته في وقت التصريف على أنه constexpr. يجب التصريح عن أي متغير لا يمكن تعديله بعد التهيئة ومبدئه غير معروف في وقت التصريف على أنه const.
- 1 جواب
-
- 1
-
-
بالتأكيد يمكنك أن تضيف إعلانات AdSense لأي موقع على الويب طالما الموقع يستوفي شروط القبول في برنامج AdSense.
- 3 اجابة
-
- 1
-
-
يمكنك أن تقوم بإنشاء الموقع بسهولة، ولكن إعلانات AdMob هي إعلانات مخصصة لتطبيقات الهواتف الذكية فقط ولن تجد الدعم الكافي لإضافة إعلانات AdMob في موقع الويب، بينما توفر Google إعلانات AdSense لإضافة الإعلانات في الموقع. الفرق بين المواقع المخصصة لها مميزاته، والمنصات مثل Blogger و WordPress لها مميزاتها، فعلى سبيل المثال من السهل أن تبدأ مدونة Blogger في أقل من 15 دقيقة سيكون لديك مدونة كاملة ومكان تكتب فيه المقالات والعديد من القوالب الجاهزة وحماية من جوجل .. إلخ، بينما إن أردت أن تقوم بعمل موقع مدونة كاملة فسوف تحتاح إلى لغات الويب HTML و CSS و JavaScript لتصميم واجهة الموقع Frontend، وستحتاج إلى إستخدام أحد لغات تطوير الواجهات الخلفية Backend وحجز خادم ويب Web Server لتخزين ملفات وبيانات الموقع .. إلخ. هنا مقارنة بين Blogger و WordPress: بينما تمتاز المواقع المخصصة (ذات البرمجة الخاصة) بإنسيابية كبيرة في التطوير وتجهيز الموقع كما تشاء، فعلى سبيل المثال لا يمكنك أن تقوم بعمل أنواع من التدوينات (فيديو و عارض صور .. إلخ ) في Blogger كما لا يمكنك أن تقوم بتغير محرر النصوص الخاص بالمنصة، بينما في المواقع ذات البرمجة الخاصة يمكنك حرفيًا تغير أي شيء وفق رغبتك. أيضًا التكلفة تختلف بين المدونات الجاهزة والمواقع ذات البرمجة الخاصة، حيث أن مدونات Blogger قد تستعمل قوالب مجانية ولا تحتاج إلى أي إستضافة مدفوعة، وكذلك الأمر بالنسبة لووردبريس (يمكن أيضًا عمل مدونة WordPress على إستضافة خاصة)، بينما المواقع ذات البرمجة الخاصة تحتاج إلى تكلفة لتطويرها وتكلفة لإستضافة خاصة. يمكنك الإطلاع على شروط الإنضمام في Google AdSense من خلال صفحة الشروط هنا.
- 3 اجابة
-
- 1
-
-
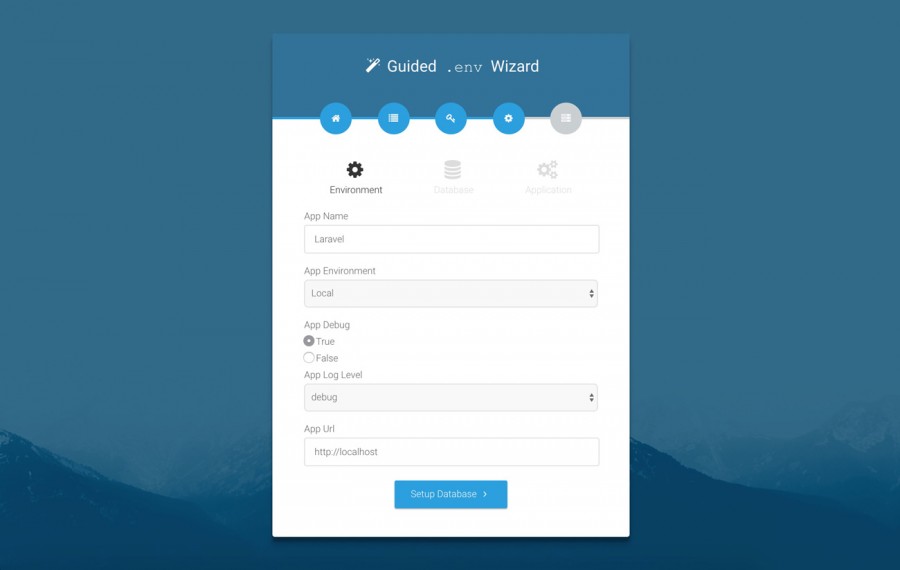
يمكنك أن تقوم بهذا الأمر لأي مشروع Laravel من خلال الحزمة rachidlaasri/laravel-installer والتي تسمح لك بإنشاء صفحات لتثبيت المشروع دون حاجة المستخدم لتعديل أي ملفات أو تثبيت أي خدمات خارجية في شكل عدد من الخطوات كما في الصورة التالية: تستطيع تثبيت الحزمة من خلال الأمر التالي: composer require rachidlaasri/laravel-installer وإذا كنت تستعمل Laravel بإصدار أقل من 5.4 فستحتاج إلى تعديل الملف config/app.php في قسم providers: 'providers' => [ RachidLaasri\LaravelInstaller\Providers\LaravelInstallerServiceProvider::class, ]; الأمر الأخير هو نشر ملفات الحزمة من خلال الأمر التالي: php artisan vendor:publish --tag=laravelinstaller سيقوم الأمر السابق بإنشاء المجلد installer في public ويمكن أن يتم بدأ تثبيت المشروع من خلال الدخول على رابط التثبيت localhost/install (مع تغير رابط الموقع إن كان هناك نطاق خاص للخادم).
- 1 جواب
-
- 1
-
-
يتم تحديد دقة الرقم عند الطباعة حسب المصرّّف نفسه، في الغالب تكون دقة الأرقم 7 أرقام فقط، ويمكن أن تستخدم معالج الإخراج output manipulator المسمى std::setprecision لتعديل دقة الأرقام، في البداية تحتاج إلى إسندعاء ملف الترويسة iomanip لكي تستطيع إستعمال معالج الإخراج std::setprecision، يقبل معالج الإخراج هذا دقة الطباعة (عدد الأرقام التي سيتم طباعتها) كمعامل له. ويمكنك أن تستعمله كالتالي: #include <iostream> #include <iomanip> int main() { std::cout << std::setprecision(10); double x{ 1.234'567'89 }; std::cout << x << '\n'; // 1.23456789 double y{ 123'456'789 }; std::cout << y << '\n'; // 123456789 return 0; } ملاحظة: يفضل أن تفصل الأرقام الكبيرة بإستخدام علامة الإقتباس المفرد ' لتسهيل القراءة فقط، وسيتم معاملة الرقم 789'456'123 على أنه الرقم 123456789 بدون مشكلة.
- 1 جواب
-
- 1
-
-
تدعم لغة ++C طباعة الأرقام بنظام ثماني وست عشري بدون مشكلة، ومع ذلك فإن طباعة الأرقام بالنظام الثماني تحتاج إلى بعض الخطوات الأضافية، تحتوي مكتبة ++C القياسية على الكائن std::bitset (موجود في ملف الترويسة header المسمى <bitset>) . في البداية يجب أن تحدد للكائن std::binset عدد الـ bits التي سيقوم بتخزينها (يجب أن يكون هذا العدد من نوع compile time constant وليس run time constant) ثم تقوم بتمرير الرقم الذي تريد تحويله إلى النظام الثنائي، كالتالي: #include <bitset> // std::bitset< حجم ال bits > variable_name { unsigned int }; std::bitset<8> bin{ 13 }; // يمكن تمرير أرقام Hex و Oct و Binary أيضًا std::bitset<8> bin2{ 0xd }; std::bitset<8> bin3{ 015 }; std::bitset<8> bin4{ 0b0000'1101 }; ملاحظة: الرقم الذي تريد تحويله إلى النظام الثنائي يجب أن يكون من نوع unsigned أي ليس له إشارة (موجب فقط)، لذلك تحتاج إلى إستخدام static_cast لتحويل نوع المتغير age عند طباعة الرقم #include <iostream> #include <bitset> int main() { std::cout << "Enter your age: "; int age{}; std::cin >> age; std::cout << "Your age in decimal is " << std::dec << age << '\n'; std::cout << "Your age in HEX is " << std::hex << age << '\n'; std::cout << "Your age in OCT is " << std::oct << age << '\n'; // تحويل المتغير إلى unsigned unsigned int unsigned_age = static_cast<unsigned int>(age); std::cout << "Your age in Binary is " << std::bitset<8>{unsigned_age} << '\n'; return 0; } وستكون النتيحة كالتالي: Enter your age: 15 Your age in decimal is 15 Your age in HEX is f Your age in OCT is 17 Your age in Binary is 00001111 يمكنك أيضًا تحويل المتغير age إلى unsinged ثم تحويله إلى كود Binary مباشرة دون تخزينه في متغير جديد: // تحويل المتغير إلى unsigned وطباعته كنظام ثنائي std::cout << "Your age in Binary is " << std::bitset<8>{static_cast<unsigned int>(age)} << '\n';
- 3 اجابة
-
- 1
-
-
يمكنك إستخدام التابع select والذي يقبل محدد CSS، وفي لغة CSS يمكن تحديد العناصر التي لها خاصية معينة من خلال وضعها داخل قوسين، كالتالي: /* تحديد عنصر div الذي له المعرف root ويحتوي على الخاصية class أيضًا */ div#root[class] from bs4 import BeautifulSoup content="""<!DOCTYPE html> <html lang="en"> <head> <title>Document</title> </head> <body> <div id="app"></div> <script src="jquery.js" data-src="jquery.min.js"></script> <script src="index.js"></script> </body> </html> """ soup = BeautifulSoup(content, features='lxml') # تحديد كل عناصر script التي تحتوي على الخاصية data-src scripts = soup.select('script[data-src]') print(scripts) # [<script data-src="jquery.min.js" src="jquery.js"></script>] كما يمكن تحديد كل عناصر script والمرور عليهم واحد تلو الآخر والتأكد من وجود خاصية معينة أم لا من خلال التابع get والذي يقوم بإعادة قيمة الخاصية في حالة تم العثور عليها أو None في حالة لم تكن موجودة: # تحديد كل عناصر script scripts = soup.select('script') for script in scripts: if script.get('data-src'): # في حالة تم العثور على الخاصية print('has data-src attribute') else: # إذا لم يحتوي العنصر على الخاصية print('has NO data-src')
-
تحتوي مكتبة BeautifulSoup على التابع select و select_one والذي يقبل كلًا منهما محدد CSS وبالتالي يمكنك أن تقوم بتحديد كل عناصر a الموجودة داخل عناصر li كالتالي: from bs4 import BeautifulSoup content="""<div> <li class="c"> <a>linkA</a> <ul> <li> <a>linkB</a> </li> </ul> </li> </div> """ soup = BeautifulSoup(content, features='lxml') anchors = soup.select('li a') print(anchors) # [<a>linkA</a>, <a>linkB</a>] التابع select يقوم بتحديد كل العناصر المطابقة لمحدد CSS، بينما التابع select_one يقوم بإرجاع أول عنصر يجده فقط.
- 2 اجابة
-
- 1
-
-
سبب المشكلة هو أن التابع std::cin يقةم بتقسيم المدخلات بالمسافات ويقوم بإستخدام أول جزء فقط (الكلمة "Mohssen") ويخزن الجزء الباقي، وعندما تستخدم std::cin مرة ثانية فإنه يجد الجزء الثاني (الكلمة "Ahmed") موجودة بالفعل، فيقوم بإستخدامها مباشرة دون إنتظار المستخدم لإدخال كلمات أخرى. لحل هذه المشكلة يمكنك أن تقوم بإدخال القيمة من خلال التابع std::getline حيث يقوم هذا التابع بإستقبال سطر كامل (إي إلى أن يصل إلى n\) ويمكنك تستخدمه كالتالي: std::cout << "Enter your full name: "; std::string name{}; std::getline(std::cin >> std::ws, name); // قراءة سطر كامل إلى المتغير name std::cout << "Enter your age: "; std::string age{}; std::getline(std::cin >> std::ws, age); // قراءة سطر كامل إلى المتغير age std::cout << "Your name is " << name << " and your age is " << age << '\n'; وستكون المدخلات كالتالي: Enter your full name: Mohssen Ahmed Enter your age: 23 Your name is Mohssen Ahmed and your age is 23 ما هو std::ws؟ الكائن std::ws هو معالج الدخل input manipulator، أي أنه يقوم بتعديل المدخلات قبل أن يتم تخزينها، والهدف منه هو أن يجعل التابع std::getline يتجاهل أي محارف فارغة في بداية النص، فعلى سبيل المثال إذا لم نقم بإستخدامه في الكود التالي: std::cout << "choose 1 or 2: "; int choice{}; std::cin >> choice; std::cout << "Enter your name: "; std::string name{}; std::getline(std::cin, name); // لاحظ أننا لم نستعمل std::ws هنا std::cout << "Hello, " << name << ", you picked " << choice << '\n'; ونتيجة الكود السابق سوف تكون: Choose 1 or 2: 2 Enter your name: Hello, , you picked 2 عندما تقوم بإدخال رقم 2 ثم تضغط على Enter (أي أنك تقوم بإدخال n\ إلى نهاية النص)، يقوم التابع std::getline بأخذ القيمة الرقمية فقط وهي 2 ويترك n\ مخزنة، وعندما تقوم بإستخدام التابع std::getline مرة أخرى فإنه يجد القيمة n\ موجودة بالفعل ويقوم بتخزينها في المتغير name، لهذا يجب أن تستخدم معالج الدخل std::ws لكي يتم تجاهل أي محارف فارغة (المسافة n\ أو t\ .. إلخ) من بداية المدخل، فيتم تجاهل وجود n\ وينتظر حتى يقوم المستخدم بإدخال اسمه. يمكنك أن تقرأ أكثر حول معالج الدخل من خلال هذه المقالة:
- 1 جواب
-
- 1
-
-
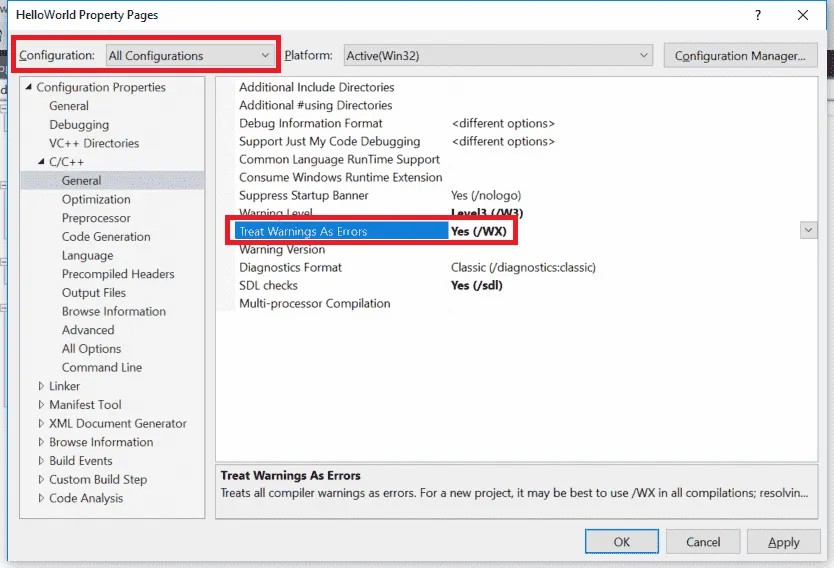
هذا تحذير warning وليس خطأ Error، ربما قمت بتفعيل "معاملة التحذيرات كأخطاء" في بيئة التطوير الخاصة بك IDE، لهذا لم يتم تصريف البرنامج. تستطيع أن تقوم بإيقاف هذا السلوك من خلال الضغط على المشروع وإختيار properties ثم قسم ++C/C قم بتغير treat warnings as errors إلى No مع العلم أنه يفضل أن تبقى على هذا السلوك لأنه يخبرك بأي مشاكل حتى ولو كانت بسيطة أثناء عملية التصريف compiling مما يقلل المشاكل التي قد تحدث في المستقبل. ويكمن سبب المشكلة في أنك تستخدم متغير من نوع float لتخزين القيمة (9.8) والتي هي عبارة عن double، ويمكنك تحديد أن الرقم عبارة عن float وليس double من خلال إضافة f إلى نهاية الرقم: // Gravitational acceleration float gravity{ 9.8f }; بهذه الطريقة يمكن أن تقوم بإخبار المصرِّف compiler بأنك تستعمل هنا قيمة literal float وليس double الإختلاف الرئيسي بين النوع float و النوع double في حجم الذاكرة المستهلك لتخزين القيمة، حيث يستخدم النوع float مساحة 4 بايت، بينما يستخدم النوع double 8 بايت
- 1 جواب
-
- 1
-
-
يمكن أيضًا إستعمال التابع extract والذي يقوم بإستخراج العنصر من المستند: from bs4 import BeautifulSoup content = """<!DOCTYPE html> <html> <head><title>html</title></head> <body> <div id="x"> <p> This is child of div with id = "x". <span>Child of "P"</span> </p> <div> Another Child of div with id = "x". </div> </div> <p> aaadas </p> </body> </html> """ soup = BeautifulSoup(content, features='lxml') e = soup.select_one('div#x') # تحديد العنصر من خلال محدد CSS # إزالة العنصر من الصفحة e.extract() # المستند بعد إزالة العنصر منه print(soup.prettify()) """ <!DOCTYPE html> <html> <head> <title> html </title> </head> <body> <p> aaadas </p> </body> </html> """ # العنصر الذي تم إزالته print(e.prettify()) """ <div id="x"> <p> This is child of div with id = "x". <span> Child of "P" </span> </p> <div> Another Child of div with id = "x". </div> </div> """
- 2 اجابة
-
- 2
-
-
حسب مرجع ++C : وهذا يعني أنه سيتم تخزين القيمة true إذا قام المستخدم بإدخال الرقم 1، بينما سيتم تخزين القيمة false إذا قام بإدخال الرقم 0، ولتغير هذا السلوك يمكنك أن تستخدم boolalpha لتخزين القيمة true عندما يدخل المستخدم النص true، وتخزين القيمة false عند يدخل النص false: bool accepted{}; std::cin >> std::boolalpha >> accepted; // يجب أن تكون المدخلات كلمة true أو false std::cout << accepted; لاحظ كيف تم إستعمال boolalpha قبل تخزين القيمة في المتغير accepted، ولإيقاف هذا السلوك يمكنك أن تستعمل noboolalpha: bool x{}; std::cin >> std::noboolalpha >> x; // يجب أن تكون المدخلات 1 أو 0 std::cout << x; ملاحظة: عند إستعمال boolalpha فسيتم معاملة كلا الرقمين 1 و 0 على أنهما قيمة false وبالتالي لا يمكن تخزين القيمة true في المتغير إلا إذا قام المستخدم بكتابة كلمة true فقط (بحروف صغيرة Lower case)
- 1 جواب
-
- 3
-
-
يمكنك أن تستخدم التابع insert والذي يقوم بإضافة جزء من (أو كل) عناصر vector إلى كائن vector آخر، ويمكنك أن تستعمله كالتالي: #include <iostream> #include <vector> int main() { std::vector<int> vector1 { 1, 2, 3, 4, 5 }; std::vector<int> vector2 { 6, 7, 8, 9, 10 }; vector1.insert(vector1.end(), vector2.begin(), vector2.end()); std::cout << "Vector1 size: " << vector1.size(); // 10 } لاحظ أن التابع insert يقبل ثلاث مدخلات، الأول هو المكان الذي سيتم إضافة العناصر فيه، وفي الكود السابق سوف يتم إضافة العناصر في نهاية الكائن vector1 والمدخل الثاني والثالث هما بداية ونهاية الجزء الذي سيتم إضافته من الكائن vector2.
- 1 جواب
-
- 1
-
-
يمكنك أن تستعمل خدمات مثل wappalyzer لفحص المواقع ومعرفة التقنيات التي تستخدمها، وستجد أن الموقع يستعمل Webpack و Angular كأدوات لإتصدير ملفات المشروع بالإضافة إلى مكتبة Bootstrap الإصدار v4.3.1 و مكتبة أيقونات font-awesome الإصدار 5.15.3 وستجد أن الموقع يستعمل خدمات أخرى مثل Google Analytics و TypeScript و ipify و recaptcha وتستطيع التأكد من كل هذه الأداوات والمكتبات من خلال تفحص الكود المصدري للموقع، حيث ستجد في الأعلى روابط لمكتبة font-awesome وملف styles الذي يحتوي على إصدار Bootstrap في داخله. وعند قراءة أي ملف JavaScript يستعمله الموقع فستجد أن كل أكواده موجودة بشكل مضغوط للغاية ولكن عند البحث عن كلمة Angular على سبيل المثال في ملف main.js (آخر ملف JavaScript مرفق في الصفحة) ستجد أن الكلمة موجودة فعلًا في أكثر من كائن مما يثبت أن الموقع يستعمل Angular كواجهة للموقع. تستطيع أن تقرأ عن التطبيقات ذات الصفحة الواحدة وتجربة إنشاء واححدة بإستخدام jQuery فقط من خلال هذه المقالة:
- 4 اجابة
-
- 1
-
-
تستطيع تحديد ما إذا كان العنصر فارغًا أم لا من خلال الخاصية contents الخاصة به، وبالتالي يمكننا المرور على كل عناصر الصفحة عبر التابع find_all والتحقق مما إذا كان العنصر فارغ أم لا: def checkEmpty(tag): return not tag.contents and not tag.name == 'br' # يقبل التابع find_all تمرير دالة له [tag.decompose() for tag in soup.find_all(checkEmpty)] لكن إن أحتوى العنصر على بعض المسافات فسوف يتم تخطيه ولن يتم حذف، لذلك يمكن أن نغير في الكود السابق ليتم حذف العناصر التي تحتوي على مسافات فقط في داخلها: from bs4 import BeautifulSoup content = """ <p> <p></p> <strong>some<br>text<br>here</strong> </p> """ soup = BeautifulSoup(content, features='lxml') def checkEmpty(tag): return (not tag.contents or len(tag.get_text(strip=True)) <= 0) and not tag.name == 'br' # إزالة كل العناصر الفارغة [tag.decompose() for tag in soup.find_all(checkEmpty)] print(soup) """ <html><body> <strong>some<br/>text<br/>here</strong> </body></html> """ لاحظ أن عنصر p لا يجوز أن يحتوي على عنصر p آخر في داخله، لذلك تقوم مكتبة BeautifulSoup بإغلاق العناصر تلقائيَا،و يتم تحويل المستند إلى هذا الشكل: <html><body><p> </p><p></p> <strong>some<br/>text<br/>here</strong> </body></html> وبالتالي سيتم حذف العنصر p الأول والثاني وسيتبقى فقط العنصر strong داخل جسم الصفحة
- 2 اجابة
-
- 1
-
-
يمكنك إستخراج البيانات بشكل بسيط ومرتب من خلال تحديد كل الكتب ثم المرور على كل كتاب وإستخراج بياناته، كالتالي: from bs4 import BeautifulSoup import pandas as pd content = open("books.xml",'r', encoding="utf-8").read() soup = BeautifulSoup(content, features='lxml') # هنا سيتم تخزين بيانات كل كتاب data = [] # نحدد كل الكتب books = soup.find_all('book') # الآن نقوم بالمرور على كل كتاب وتخزين بياناته في القائمة data for book in books: book_d = {} # بيانات الكتاب الواحد book_d['author'] = book.find('author').get_text() book_d['title'] = book.find('title').get_text() book_d['genre'] = book.find('genre').get_text() book_d['price'] = book.find('price').get_text() book_d['publish_date'] = book.find('publish_date').get_text() book_d['description'] = book.find('description').get_text() data.append(book_d) # الآن نقوم بتحويل القائمة data إلى dataFrame df = pd.DataFrame(data) # لا نحتاج إلى تحديد الأعمدة لأننا أستخدمنا قائمة من القواميس dictionaries print(df) وستكون النتيجة كالتالي: author title genre price publish_date description 0 Gambardella, Matthew XML Developer's Guide Computer 44.95 2000-10-01 An in-depth look at creating applications with... 1 Ralls, Kim Midnight Rain Fantasy 5.95 2000-12-16 A former architect battles corporate zombies, ... 2 Corets, Eva Maeve Ascendant Fantasy 5.95 2000-11-17 After the collapse of a nanotechnology society... 3 Corets, Eva Oberon's Legacy Fantasy 5.95 2001-03-10 In post-apocalypse England, the mysterious age... 4 Corets, Eva The Sundered Grail Fantasy 5.95 2001-09-10 The two daughters of Maeve, half-sisters, batt... 5 Randall, Cynthia Lover Birds Romance 4.95 2000-09-02 When Carla meets Paul at an ornithology confer... 6 Thurman, Paula Splish Splash Romance 4.95 2000-11-02 A deep sea diver finds true love twenty thousa... 7 Knorr, Stefan Creepy Crawlies Horror 4.95 2000-12-06 An anthology of horror stories about roaches,c... 8 Kress, Peter Paradox Lost Science Fiction 6.95 2000-11-02 After an inadvertant trip through a Heisenberg... 9 O'Brien, Tim Microsoft .NET: The Programming Bible Computer 36.95 2000-12-09 Microsoft's .NET initiative is explored in det... 10 O'Brien, Tim MSXML3: A Comprehensive Guide Computer 36.95 2000-12-01 The Microsoft MSXML3 parser is covered in deta... 11 Galos, Mike Visual Studio 7: A Comprehensive Guide Computer 49.95 2001-04-16 Microsoft Visual Studio 7 is explored in depth...
- 2 اجابة
-
- 2
-
-
عندما تحاول أن تقوم بطباعة أكثر من نص، لإغنه يتم تخزين هذه النصوص في ما يسمى بـ Buffer وبعد ذلك يتم عرض كل النصوص مرة واحدة على الشاشة (أو كتابتها في ملف) وتسمى هذه العملية بالصرف flushing، فعلى سبيل المثال: #include <iostream> int main() { for (char i='A'; i <= 'Z'; i++) { std::cout << i << endl; } return 0; } الكود السابق يقوم بطباعة الحروف من A إلى Z وفي كل دورة يتم عمل صرف Flushing للنص وإظهاره على الشاشة. بينما في الكود التالي: #include <iostream> int main() { for (char i='A'; i <= 'Z'; i++) { std::cout << i << "\n"; } return 0; } فإنه يتم تخزين كل الحروف الـ Buffer وبعد ذلك يتم عرض كل الحروف مرة واحدة. بالتأكيد فإن الكود الثاني أفضل من ناحية الأداء لأن الكود يقوم بعرض الحروف مرة واحدة على الشاشة، بينما الكود الأول يقوم بعمل Flushing لكل حرف في كل دورة. لذلك يفضل دائمًا أن تستعمل الرمز n\ قدر الإمكان بدلًا من إستخدام std::endl ملاحظة أخرى وهي أنه يمكن إستخدام الرمز n\ في نهاية النص كالتالي: std::cout << "Hello\n"; std::cout << "Hello" << std::endl; لاحظ أن السطر الأول يقوم بإستخدام المعامل >> مرة واحدة بينما السطر الثاني فإن يقوم بإستدعاء المعامل >> مرتين، وهذا الأمر قد يؤثر على أداء البرامج التي تعتمد على الخيوط threads بشكل أساسي. بالتوفيق، تحياتي.
- 1 جواب
-
- 4
-
-