


Naser Dakhel
-
المساهمات
51 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Naser Dakhel
-
 المُلكية ownership هي مجموعة من القوانين التي تحدد كيف يُدير برنامج رست استخدام الذاكرة، ويتوجب على جميع البرامج أن تُدير الطريقة التي تستخدم فيها ذاكرة الحاسوب عند تشغيلها. تلجأ بعض لغات البرمجة إلى كانس المهملات garbage collector الذي يتفقد باستمرار الذاكرة غير المُستخدمة بعد الآن أثناء عمل البرنامج، بينما تعطي لغات البرمجة الأخرى مسؤولية تحديد الذاكرة وتحريرها للمبرمج مباشرةً، إلا أن رست تسلك طريقًا آخر ثالثًا؛ ألا وهو أن الذاكرة تُدار عبر نظام ملكية يحتوي على مجموعة من القوانين التي يتفقدها المصرّف، إذ لا يُصرّف البرنامج إذا حدث خرق لأحد هذه القوانين، ولن تبطئ أي من مزايا الملكية برنامجك عند تشغيله. سيتطلب مفهوم الملكية بعض الوقت للاعتياد عليه بالنظر إلى أنه مفهوم جديد للعديد من المبرمجين، إلا أنك ستجد قوانين نظام الملكية أكثر سهولة بالممارسة وستجدها من البديهيات التي تسمح لك بكتابة شيفرة برمجية آمنة وفعّالة، لذا لا تستسلم. ستحصل على أساس قوي في فهم المزايا التي تجعل من رست لغة فريدة فور فهمك للملكية، وستتعلم في هذا المقال مفهوم الملكية بكتابة بعض الأمثلة التي تركز على هيكل بيانات data structure شائع جدًا هو السلاسل النصية strings. المكدس والكومة لا تطلب معظم لغات البرمجة منك بالتفكير بالمكدس stack والكومة heap بصورةٍ متكررة عادةً، إلا أن هذا الأمر مهم في لغات برمجة النظم مثل رست، إذ يؤثر وجود القيمة في المكدس أو الكومة على سلوك اللغة واتخاذها لبعض القرارات المعينة، وسنصف أجزاءً من نظام الملكية بما يتعلق بالكومة والمكدس لاحقًا، وسنستعرض هنا مفهومي -الكومة والمكدس- ونشرحهما للتحضير لذلك. يمثل كلًا من المكدس والكومة أجزاءً متاحةً من الذاكرة لشيفرتك البرمجية حتى تستخدمها عند وقت التشغيل runtime، إلا أنهما مُهيكلان بطريقة مختلفة؛ إذ يُخزن المكدس القيم بالترتيب الذي وردت فيه ويُزيل القيم بالترتيب المعاكس، ويُشار إلى ذلك بمصطلح الداخل آخرًا، يخرج أولًا last in, first out. يمكنك التفكير بالمكدس وكأنه كومة من الأطباق، فعندما تضيف المزيد من الأطباق، فإنك تضيفها على قمة الكومة وعندما تريد إزالة طبق فعليك إزالة واحد من القمة، ولا يُمكنك إزالة الأطباق من المنتصف أو من القاع. تُسمى عملية إضافة البيانات بالدفع إلى المكدس pushing onto the stack بينما تُدعى عملية إزالة البيانات بالإزالة من المكدس popping off the stack، ويجب على جميع البيانات المخزنة في المكدس أن تكون من حجم معروف وثابت، بينما تُخزّن البيانات ذات الحجم غير المعروف عند وقت التصريف أو ذات الحجم الممكن أن يتغير في الكومة بدلًا من ذلك. الكومة هي الأقل تنظيمًا إذ يمكنك طلب مقدار معين من المساحة عند تخزين البيانات إليها، وعندها يجد محدد المساحة memory allocator حيزًا فارغًا في الكومة يتسع للحجم المطلوب، يعلّمه على أنه حيّز قيد الاستعمال، ثم يُعيد مؤشرًا pointer يشير إلى عنوان المساحة المحجوزة، وتدعى هذه العملية بحجز مساحة الكومة allocating on the heap وتُدعى في بعض الأحيان بحجز المساحة فقط (لا تُعد عملية إضافة البيانات إلى المكدس عملية حجز مساحة). بما أن المؤشر الذي يشير إلى الكومة من حجم معروف وثابت، يمكنك تخزينه في المكدس، وعندما تريد البيانات الفعلية من الكومة يجب عليك تتبع المؤشر. فكر بالأمر وكأنه أشبه بالجلوس في مطعم، إذ تصرّح عن عدد الأشخاص في مجموعتك عند دخولك إلى المطعم، ثم يبحث كادر المطعم عن طاولة تتسع للجميع ويقودك إليها، وإذا تأخر شخص ما عن المجموعة يمكنه سؤال كادر المطعم مجددًا ليقوده إلى الطاولة. الدفع إلى المكدس أسرع من حجز الذاكرة في الكومة، لأن محدد المساحة لا يبحث عن مكان للبيانات الجديدة وموقع البيانات المخزنة، فهو دائمًا على قمة المكدس، بالمثل، يتطلب حجز المساحة في الكومة مزيدًا من العمل، إذ يجب على محدد المساحة البحث عن حيز كبير بما فيه الكفاية ليتسع البيانات ومن ثم حجزها للتحضير لعملية حجز المساحة التالية. الوصول إلى البيانات من الكومة أبطأ من الوصول إلى البيانات من المكدس وذلك لأنه عليك أن تتبع المؤشر لتصل إلى حيز الذاكرة، وتؤدي المعالجات المعاصرة عملها بصورةٍ أسرع إذا انتقلت من مكان إلى آخر ضمن الذاكرة بتواتر أقل. لنبقي على تقليد التشابيه، فكر بالأمر وكأن النادل في المطعم يأخذ الطلبات من العديد من الطاولات، وفي هذه الحالة فمن الأفضل أن يحصل النادل على جميع الطلبات في الطاولة الواحدة قبل أن ينتقل إلى الطاولة التي تليها، فأخذ الطلب من الطاولة (أ) ومن ثم أخذ الطلب من الطاولة (ب) ومن ثم العودة إلى الطاولة (أ) والطاولة (ب) مجددًا عملية أبطأ بكثير، وبالمثل فإن المعالج يستطيع إنجاز عمله بصورةٍ أفضل إذا تعامل مع البيانات القريبة من البيانات الأخرى (كما هو الحال في المكدس) بدلًا من العمل على بيانات بعيدة عن بعضها (مثل الكومة). عندما تستدعي شيفرتك البرمجية دالةً ما، يُدفع بالقيم المُمررة إليها إلى المكدس (بما فيها المؤشرات إلى البيانات الموجودة في الكومة) إضافةً إلى متغيرات الدالة المحلية، وعندما ينتهي تنفيذ الدالة، تُزال هذه القيم من المكدس. يتكفل نظام الملكية بتتبع الأجزاء التي تستخدم البيانات من الكومة ضمن شيفرتك البرمجية، وتقليل كمية البيانات المُكررة ضمن الكومة، وإزالة أي بيانات غير مُستخدمة منها حتى لا تنفد من المساحة. عندما تفهم نظام الملكية لن تحتاج للتفكير بالمكدس والكومة كثيرًا، فكل ما عليك معرفته هو أن الهدف من نظام الملكية هو إدارة بيانات الكومة، وسيساعدك هذا الأمر في فهم طريقة عمل هذا النظام. قوانين الملكية دعنا نبدأ أولًا بالنظر إلى قوانين الملكية، أبقِ هذه القوانين في ذهنك بينما تقرأ بقية المقال الذي يستعرض أمثلةً توضح هذه القوانين: لكل قيمة في رست مالك owner. يجب أن يكون لكل قيمة مالك واحد في نقطة معينة من الوقت. تُسقط القيمة عندما يخرج المالك من النطاق scope. نطاق المتغير الآن وبعد تعرفنا إلى مبادئ رست في المقالات السابقة، لن نُضمّن الشيفرة fn main() { في الأمثلة، لذا إذا كنت تتبع الأمثلة تأكد من أنك تكتب الشيفرة البرمجية داخل دالة main يدويًا، ونتيجةً لذلك ستكون أمثلتنا أقصر بعض الشيء مما سيسمح لنا بالتركيز على التفاصيل المهمة بدلًا من الشيفرة البرمجية النمطية المتكررة. سننظر إلى نطاق المتغيرات في أول مثال من أمثلة الملكية، والنطاق هو مجال ضمن البرنامج يكون فيه العنصر صالحًا. ألقِ نظرةً على المتغير التالي: let s = "hello"; يُشير المتغير s إلى السلسلة النصية المجردة، إذ أن قيمة السلسلة النصية مكتوبة بصورةٍ صريحة على أنها نص في برنامجنا، والمتغير هذا صالح من نقطة التصريح عنه إلى نهاية النطاق الحالي. توضح الشيفرة 4-1 البرنامج مع تعليقات توضح مكان صلاحية المتغير s. { // المتغير غير صالح هنا إذ لم يُصرّح عنه بعد let s = "hello"; // المتغير صالح من هذه النقطة فصاعدًا // يمكننا استخدام s في العمليات هنا } // انتهى النطاق بحلول هذه النقطة ولا يمكننا استخدام s [الشيفرة 4-1: متغير والنطاق الذي يكون فيه صالحًا] بكلمات أخرى، هناك نقطتان مهمتان حاليًا: عندما يصبح المتغير s ضمن النطاق، يصبح صالحًا. يبقى المتغير صالحًا حتى مغادرته النطاق. لحد اللحظة، العلاقة بين النطاقات والمتغيرات هي علاقة مشابهة للعلاقة التي تجدها في لغات البرمجة الأخرى، وسنبني على أساس هذا الفهم النوع String. النوع String نحتاج نوعًا أكثر تعقيدًا من الأنواع التي غطيناها سابقًا وذلك لتوضيح قوانين الملكية، إذ كانت الأنواع السابقة جميعها من أحجام معروفة ويمكن تخزينها في المكدس وإزالتها عند انتهاء نطاقها، كما أنه من الممكن نسخها بكل سهولة إلى متغير آخر جديد يمثّل نسخةً مستقلةً وذلك إذا احتاج حزءٌ ما من الشيفرة البرمجية استخدام المتغير ذاته ضمن نطاق آخر، إلا أننا بحاجة إلى النظر لأنواع البيانات المخزنة في الكومة حتى نكون قادرين على معرفة ما تفعله رست لتنظيف البيانات هذه ويمثل النوع String مثالًا رائعًا لهذا الاستخدام. سنركز على أجزاء النوع String التي ترتبط مباشرةً بالملكية، وتنطبق هذه الجوانب أيضًا على أنواع البيانات المعقدة الأخرى سواءٌ كانت هذه الأنواع موجودةً في المكتبة القياسية أو كانت مبنيةً من قبلك، وسنناقش النوع String بتعمّق أكبر لاحقًا. رأينا مسبقًا السلاسل النصية المجردة (وهي السلاسل النصية المكتوبة بين علامتي تنصيص " " بصورةٍ صريحة)، إذ تُكتب قيمة السلسلة النصية يدويًا إلى البرنامج. السلاسل النصية المجردة مفيدةٌ إلا أنها غير مناسبة لكل الحالات، مثل تلك التي نريد فيها استخدام النص ويعود السبب في ذلك إلى أنها غير قابلة للتعديل immutable، والسبب الآخر هو أنه لا يمكننا معرفة قيمة كل سلسلة نصية عندما نكتب شيفرتنا البرمجية، فعلى سبيل المثال، ماذا لو أردنا أخذ الدخل من المستخدم وتخزينه؟ تملك رست لمثل هذه الحالات نوع سلسلة نصية آخر يدعى String، ويدير هذا النوع البيانات باستخدام الكومة، وبالتالي يمكنه تخزين كمية غير معروفة من النص عند وقت التصريف. يُمكنك إنشاء String من سلسلة نصية مجردة باستخدام دالة from كما يلي: let s = String::from("hello"); يسمح لنا عامل النقطتين المزدوجتين :: بتسمية الدالة الجزئية from ضمن فضاء الأسماء namespace وأن تندرج تحت النوع String بدلًا من استخدام اسم مشابه مثل string_from، وسنناقش هذه الطريقة في الكتابة أكثر لاحقًا، بالإضافة للتكلم عن فضاءات الأسماء وإنشائها. يُمكن تعديل mutate هذا النوع من السلاسل النصية: let mut s = String::from("hello"); s.push_str(", world!"); // يُضيف ()push_str سلسلةً نصية مجردة إلى النوع String println!("{}", s); // سيطبع هذا السطر `!hello, world` إذًا، ما الفارق هنا؟ كيف يمكننا تعديل النوع String بينما لا يمكننا تعديل السلاسل النصية المجردة؟ الفارق هنا هو بكيفية تعامل كل من النوعين مع الذاكرة. الذاكرة وحجزها نعرف محتويات السلسلة النصية في حال كانت السلسلة النصية مجرّدة عند وقت التصريف، وذلك لأن النص مكتوب في الشيفرة البرمجية بصورةٍ صريحة في الملف النهائي التنفيذي، وهذا السبب في كون السلاسل النصية المجردة سريعة وفعالة، إلا أن هذه الخصائص تأتي من حقيقة أن السلاسل النصية المجردة غير قابلة للتعديل immutable، ولا يمكننا لسوء الحظ أن نضع جزءًا من الذاكرة في الملف التنفيذي الثنائي لكل قطعة من النص، وذلك إذا كان النص ذو حجم غير معلوم عند وقت التصريف كما أن حجمه قد يتغير خلال عمل البرنامج. نحتاج إلى تحديد مساحة من الذاكرة ضمن الكومة عند استخدام نوع String وذلك لدعم إمكانية تعديله وجعله سلسلةً نصيةً قابلة للزيادة والنقصان، بحيث تكون هذه المساحة التي تخزن البيانات غير معلومة الحجم عند وقت التصريف، وهذا يعني: يجب أن تُطلب الذاكرة من مُحدد الذاكرة عند وقت التشغيل. نحتاج طريقة لإعادة الذاكرة إلى محدد الذاكرة عندما ننتهي من استخدام String الخاص بنا. يُنجز المتطلّب الأول عن طريق استدعاء String::from، إذ تُطلب الذاكرة التي يحتاجها ضمنيًا، وهذا الأمر موجود في معظم لغات البرمجة. أما المتطلب الثاني فهو مختلفٌ بعض الشيء، إذ يراقب كانس المهملات -أو اختصارًا GC- الذاكرة غير المُستخدمة بعد الآن ويحررها، ولا حاجة للمبرمج بالتفكير بهذا الأمر، بينما تكون مسؤوليتنا في اللغات التي لا تحتوي على كانس المهملات هي العثور على المساحة غير المُستخدمة بعد الآن وأن نستدعي الشيفرة البرمجية بصورةٍ صريحة لتحرير تلك المساحة، كما هو الحال عندما استدعينا شيفرة برمجية لحجزها، ولطالما كانت هذه المهمة صعبة على المبرمجين، فإذا نسينا تحرير الذاكرة فنحن نهدر الذاكرة وإذا حررنا الذاكرة مبكرًا فهذا يعني أن قيمة المتغير أصبحت غير صالحة للاستخدام، بينما نحصل على خطأ إذا حررنا الذاكرة نفسها لأكثر من مرة، إذ علينا استخدام تعليمة allocate واحدة فقط مصحوبةً مع تعليمة free واحدة لكل حيز ذاكرة نستخدمه. تسلك لغة رست سلوكًا مختلفًا، إذ تُحرر الذاكرة أوتوماتيكيًا عندما يغادر المتغير الذي يملك تلك الذاكرة النطاق. إليك إصدارًا من الشيفرة 4-1 نستخدم فيه النوع String بدلًا من السلسلة النصية المجردة: { let s = String::from("hello"); // المتغير s صالح من هذه النقطة فصاعدًا // يمكننا إنجاز العمليات باستخدام المتغير s هنا } // انتهى النطاق ولم يعد المتغير s صالحًا نستعيد الذاكرة التي يستخدمها String من محدد الذاكرة عندما يخرج المتحول s من النطاق، إذ تستدعي رست دالةً مميزةً بالنيابة عنا عند خروج متحول ما من النطاق وهذه الدالة هي drop، وتُستدعى تلقائيًا عند الوصول إلى قوس الإغلاق المعقوص {. ملاحظة: يُدعى نمط تحرير الموارد في نهاية دورة حياة العنصر في لغة C++ أحيانًا "اكتساب الموارد هو تهيئتها Resource Acquisition Is Initialization" -أو اختصارًا RAII- ودالة drop في رست هي مشابهة لأنماط RAII التي قد استخدمتها سابقًا. لهذا النمط تأثير كبير في طريقة كتابة شيفرة رست البرمجية، وقد يبدو بسيطًا للوقت الحالي إلا أن سلوك الشيفرة البرمجية قد يكون غير متوقعًا في الحالات الأكثر تعقيدًا عندما يوجد عدة متغيرات تستخدم البيانات المحجوزة على الكومة، دعنا ننظر إلى بعض من هذه الحالات الآن. طرق التفاعل مع البيانات والمتغيرات: النقل يُمكن لعدة متغيرات أن تتفاعل مع نفس البيانات بطرق مختلفة في رست، دعنا ننظر إلى الشيفرة 4-2 على أنها مثال يستخدم عددًا صحيحًا. let x = 5; let y = x; [الشيفرة 4-2: إسناد قيمة العدد الصحيح إلى المتغيرين x و y] يمكنك غالبًا تخمين ما الذي تؤديه الشيفرة البرمجية السابقة: إسناد القيمة 5 إلى x ومن ثم نسخ القيمة x وإسنادها إلى القيمة y، وبالتالي لدينا متغيرين x و y وقيمة كل منهما تساوي إلى 5، وهذا ما يحدث فعلًا، لأن الأعداد الصحيحة هي قيم بسيطة بحجم معروف وثابت وبالتالي يُمكن إضافة القيمتين 5 إلى المكدس. لننظر الآن إلى إصدار String من الشيفرة السابقة: let s1 = String::from("hello"); let s2 = s1; تبدو الشيفرة البرمجية هذه شبيهة بسابقتها، وقد نفترض هنا أنها تعمل بالطريقة ذاتها، ألا وهي: ينسخ السطر الثاني القيمة المخزنة في المتغير s1 ويُسندها إلى s2 إلا أن هذا الأمر غير صحيح. انظر إلى الشكل 1 لرؤية ما الذي يحصل بدقة للنوع String، إذ يتكون هذا النوع من ثلاثة أجزاء موضحة ضمن الجدول اليساري وهي المؤشر ptr الذي يشير إلى الذاكرة التي تُخزن السلسلة النصية وطول السلسلة النصية len وسعتها capacity، وتُخزّن مجموعة المعلومات هذه في المكدس، بينما يمثّل الجدول اليميني الذاكرة في الكومة التي تخزن محتوى السلسلة النصية. [شكل 1: مخطط توضيحي لما تبدو عليه الذاكرة عند استخدام String يخزن القيمة "hello" المُسندة إلى s1] يدل الطول على كمية الذاكرة المُستهلكة بالبايت وهي الحيز الذي يشغله محتوى String، بينما تدل السعة على كمية الذاكرة المستهلكة بالكامل التي تلقّاها String من مُحدد الذاكرة، والفرق بين الطول والسعة مهم، إلا أننا سنهمل السعة لأنها غير مهمة في السياق الحالي. تُنسخ بيانات String عندما نُسند s1 إلى s2، وهذا يعني أننا ننسخ المؤشر والطول والسعة الموجودين في المكدس ولا ننسخ البيانات الموجودة في الكومة التي يشير إليها المؤشر، بكلمات أخرى، يبدو تمثيل الذاكرة بعد النسخ كما هو موضح في الشكل 2. [شكل 2: تمثيل الذاكرة للمتغير s2 الذي يحتوي على نسخة من مؤشر وطول وسعة s1] تمثيل الذاكرة غير مطابق للشكل 3 وقد ينطبق هذا التمثيل إذا نسخت رست محتويات بيانات الكومة أيضًا، وإذا فعلت رست ذلك، فستكون عملية الإسناد s2 = s1 عمليةً مكلفةً وستؤثر سلبًا على أداء وقت التشغيل إذا كانت البيانات الموجودة في الكومة كبيرة. [شكل 3: احتمال آخر لما قد تبدو عليه الذاكرة بعد عملية الإسناد s2 = s1 وذلك إذا نسخت رست محتويات الكومة أيضًا] قلنا سابقًا أن رست تستدعي الدالة drop تلقائيًا عندما يغادر متغيرٌ ما النطاق، وتحرّر الذاكرة الموجودة في الكومة لذلك المتغير، إلا أن الشكل 2 يوضح أن كلا المؤشرين يشيران إلى الموقع ذاته، ويمثّل هذا مشكلةً واضحة، إذ عندما يغادر كلًا من s1 وs2 النطاق، فهذا يعني أن الذاكرة في الكومة ستُحرّر مرتين، وهذا خطأ تحرير ذاكرة مزدوج double free error شائع، وهو خطأ من أخطاء أمان الذاكرة الذي ذكرناه سابقًا، إذ يؤدي تحرير الذاكرة نفسها مرتين إلى فساد في الذاكرة مما قد يسبب ثغرات أمنية. تنظر رست إلى s1 بكونه غير صالح بعد السطر let s2 = s1 وذلك لضمان أمان الذاكرة، وبالتالي لا يتوجب على رست تحرير أي شيء عندما يغادر المتحول s1 النطاق. انظر ما الذي يحدث عندما نحاول استخدام s1 بعد إنشاء s2 (لن تعمل الشيفرة البرمجية): let s1 = String::from("hello"); let s2 = s1; println!("{}, world!", s1); سنحصل على خطأ شبيه بالخطأ التالي لأن رست يمنعك من استخدام المرجع غير الصالح بعد الآن: $ cargo run Compiling ownership v0.1.0 (file:///projects/ownership) error[E0382]: borrow of moved value: `s1` --> src/main.rs:5:28 | 2 | let s1 = String::from("hello"); | -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait 3 | let s2 = s1; | -- value moved here 4 | 5 | println!("{}, world!", s1); | ^^ value borrowed here after move | = note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info) For more information about this error, try `rustc --explain E0382`. error: could not compile `ownership` due to previous error لعلك سمعت بمصطلح النسخ السطحي shallow copy والنسخ العميق deep copy خلال عملك على لغة برمجة أخرى؛ إذ يُشير مصطلح النسخ السطحي إلى عملية نسخ مؤشر وطول وسعة السلسلة النصية دون البيانات الموجودة في الكومة، إلا أن رست تسمّي هذه العملية بالنقل move لأنها تُزيل صلاحية المتغير الأول. في هذا المثال، نقول أن s1 نُقِلَ إلى s2، والنتيجة الحاصلة موضحة في الشكل 4. [شكل 4: تمثيل الذاكرة بعد إزالة صلاحية المتغير s1] يحلّ هذا الأمر مشكلتنا، وذلك بجعل المتغير s2 صالحًا فقط، وعند مغادرته للنطاق فإن المساحة تُحرر بناءً عليه فقط. إضافةً لما سبق، هناك خيارٌ تصميمي ملمّح إليه بواسطة هذا الحل، ألا وهو أن رست لن تُنشئ نُسَخًا عميقة من بياناتك تلقائيًا، وبالتالي لن يكون أي نسخ تلقائي مكلفًا بالنسبة لأداء وقت التشغيل. طرق التفاعل مع البيانات والمتغيرات: الاستنساخ يُمكننا استخدام تابع شائع يدعى clone إذا أردنا نسخ البيانات الموجودة في الكومة التي تعود للنوع String نسخًا عميقًا إضافةً لبيانات المكدس، وسنناقش طريقة كتابة التوابع لاحقًا، إلا أنك غالبًا ما رأيت استخدامًا للتوابع مسبقًا بالنظر إلى أنها شائعة في العديد من لغات البرمجة. إليك مثالًا عمليًا عن تابع clone: let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2); تعمل الشيفرة البرمجية بنجاح، وتولد النتيجة الموضحة في الشكل 3، إذ تُنسخ محتويات الكومة. عند رؤيتك لاستدعاء التابع clone، عليك أن تتوقع تنفيذ شيفرة برمجية إضافية وأن الشيفرة البرمجية ستكون مكلفة التنفيذ، وأن استخدام التابع هو دلالة بصرية أيضًا على حدوث شيء مختلف. نسخ بيانات المكدس فقط هناك تفصيلٌ آخر لم نتكلم بخصوصه بعد. تستخدم الشيفرة البرمجية التالية (جزء من الشيفرة 4-2) أعدادًا صحيحة، وهي شيفرة برمجية صالحة: let x = 5; let y = x; println!("x = {}, y = {}", x, y); إلا أن الشيفرة البرمجية تبدو مناقضة لما تعلمنا مسبقًا، إذ أن x صالح ولم يُنقل إلى المتغير y على الرغم من عدم استدعائنا للتابع clone. السبب في هذا هو أن الأنواع المشابهة للأعداد الصحيحة المؤلفة من حجم معروف عند وقت التصريف تُخزن كاملًا في المكدس، ولذلك يمكننا نسخها فعليًا بصورةٍ أسرع، ولا فائدة في منع x من أن يكون صالحًا في هذه الحالة بعد إنشاء المتغير y، وبكلمات أخرى ليس هناك أي فرق بين النسخ السطحي والعميق هنا، لذا لن يُغيّر استدعاء التابع clone أي شيء مقارنةً بالنسخ السطحي الاعتيادي، ولذلك يمكننا الاستغناء عنه. لدى لغة رست طريقةً مميزةً تدعى سمة trait النسخ Copy، التي تمكّننا من وضعها على الأنواع المخزنة في المكدس كما هو الحال في الأعداد الصحيحة (سنتكلم بالتفصيل عن السمات لاحقًا). إذا استخدم نوعٌ ما السمة Copy، فهذا يعني أن جميع المتغيرات التي تستخدم هذا النوع لن تُنقل وستُنسخ بدلًا من ذلك مما يجعل منها صالحة حتى بعد إسنادها إلى متغير آخر. لن تسمح لنا رست بتطبيق السمة Copy إذا كان النوع -أو أي من أجزاء النوع- يحتوي على السمة Drop، إذ أننا سنحصل على خطأ وقت التصريف إذا كان النوع بحاجة لشيء مميز للحدوث عند خروج القيمة من النطاق وأضفنا السمة Copy إلى ذلك النوع، إن أردت تعلم المزيد عن إضافة السمة Copy إلى النوع لتطبيقها، ألقِ نظرةً على الملحق (ت) قسم السمات المُشتقة derivable traits. إذًا، ما هي الأنواع التي تقبل تطبيق السمة Copy؟ يمكنك النظر إلى توثيق النوع للتأكد من ذلك، لكن تنص القاعدة العامة على أن أي مجموعةٍ من القيم البسيطة المُفردة تقبل السمة Copy، إضافةً إلى أي شيء لا يتطلب تحديد الذاكرة، أو ليس أي نوع من أنواع الموارد. إليك بعض الأنواع التي تقبل تطبيق Copy: كل أنواع الأعداد الصحيحة مثل u32. الأنواع البوليانية bool التي تحمل القيمتين true و false. جميع أنواع أعداد الفاصلة العشرية مثل f64. نوع المحرف char. الصفوف tuples إذا احتوى الصف فقط على الأنواع التي يمكن تطبيق Copy عليها، على سبيل المثال يُمكن تطبيق Copy على (i32, i32)، بينما لا يمكن تطبيق Copy على (i32, String). الملكية والدوال تشبه طريقة تمرير قيمة إلى دالة إسناد assign قيمة إلى متغير، إذ أن تمرير القيمة إلى المتغير سينقلها أو ينسخها كما هو الحال عند إسناد القيمة، توضح الشيفرة 4-3 مثالًا عن بعض الطرق التي توضح أين يخرج المتغير من النطاق. اسم الملف: src/main.rs fn main() { let s = String::from("hello"); // يدخل المتغير s إلى النطاق takes_ownership(s); // تُنقل قيمة s إلى الدالة ولا تعود صالحة للاستخدام هنا let x = 5; // يدخل المتغير x إلى النطاق makes_copy(x); // يُنقل المتغير x إلى الدالة إلا أن i32 تملك السمة Copy لذا من الممكن استخدام المتغير x بعد هذه النقطة } // يغادر المتحول x خارج النطاق ولا شيء مميز يحدث لأن قيمة s نُقِلَت fn takes_ownership(some_string: String) { // يدخل المتغير some_string إلى النطاق println!("{}", some_string); } // يُغادر المتغير some_string النطاق هنا وتُستدعى drop، وتُحرر الذاكرة الخاصة بالمتغير fn makes_copy(some_integer: i32) { // يدخل المتغير some_integer إلى النطاق println!("{}", some_integer); } // يغادر المتغير some_integer النطاق ولا يحصل أي شيء مثير للاهتمام [الشيفرة 4-3: استخدام الدوال مع الملكية والنطاق] ستعرض لنا رست خطأً عند وقت التصريف إذا حاولنا استخدام a بعد استدعاء takes_ownership، ويحمينا هذا التفقد الساكن static من بعض الأخطاء. حاول إضافة شيفرة برمجية تستخدم s و x إلى الدالة main ولاحظ أين يمكنك استخدامهما وأين تمنعك قوانين الملكية من استخدامهما. القيم المعادة والنطاق يُمكن أن تحول عملية إعادة القيمة ملكيتها أيضًا، توضح الشيفرة 4-4 مثالًا عن دالة تُعيد قيمة بصورةٍ مشابهة للشيفرة 4-3. اسم الملف: src/main.rs fn main() { let s1 = gives_ownership(); // تنقل الدالة gives_ownership قيمتها المُعادة إلى s1 let s2 = String::from("hello"); // يدخل المتغير s2 إلى النطاق let s3 = takes_and_gives_back(s2); // يُنقل المتغير s2 إلى takes_and_gives_back الذي ينقل قيمته المعادة بدوره إلى المتغير s3 } // يُغادر s3 النطاق من هنا ويُحرر من الذاكرة باستخدام drop، ولا يحصل أي شيء للمتغير s2 لأنه نُقل، بينما يغادر s1 النطاق أيضًا ويُحرر من الذاكرة باستخدام drop fn gives_ownership() -> String { // تنقل الدالة gives_ownership قيمتها المعادة إلى الدالة التي استدعتها let some_string = String::from("yours"); // يدخل المتغير some_string إلى النطاق some_string // يُعاد some_string ويُنقل إلى الدالة المُستدعاة } // تأخذ هذه الدالة سلسلة نصية وتُعيد سلسلة نصية أخرى fn takes_and_gives_back(a_string: String) -> String { // يدخل a_string إلى النطاق a_string // يُعاد a_string ويُنقل إلى الدالة المُستدعاة } [الشيفرة 4-4: تحويل ملكية القيمة المُعادة] تتبع ملكية المتغير نفس النمط في كل مرة، وهو: "إسناد قيمة إلى متغير آخر ينقلها"، وعندما يخرج متغير يتضمن على بيانات ضمن الكومة من النطاق، تُحرر قيمته باستخدام drop إلا إذا نُقلت ملكية البيانات إلى متغير آخر. على الرغم من نجاح هذه العملية، إلا أن عملية أخذ الملكية ومن ثم إعادتها عند كل دالة عملية رتيبة بعض الشيء. ماذا لو أردنا أن نسمح لدالة ما باستخدام القيمة دون الحصول على ملكيتها؟ إنه أمر مزعج جدًا أن أي شيء نمرره سيحتاج أيضًا لإعادة تمريره مجددًا إذا أردنا استخدامه من جديد، بالإضافة إلى أي بيانات نحصل عليها ضمن متن الدالة التي قد نحتاج أن نُعيدها أيضًا. تسمح لنا رست بإعادة عدّة قيم باستخدام مجموعة كما هو موضح في الشيفرة 4-5. اسم الملف: src/main.rs fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{}' is {}.", s2, len); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // يُعيد ()len طول السلسلة النصية (s, length) } [الشيفرة 4-5: إعادة الملكية إلى المعاملات] هذه العملية طويلة قليلًا وتتطلب كثيرًا من الجهد لشيء يُشاع استخدامه، ولحسن حظنا لدى رست ميزة لاستخدام القيمة دون تحويل ملكيتها وتدعى المراجع references، وسنستعرضها في المقال التالي. ترجمة -وبتصرف- لقسم من فصل Understanding Ownership من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: المراجع References والاستعارة Borrowing والشرائح Slices في لغة رست المقال السابق: التحكم بسير تنفيذ برامج راست Rust كيفية كتابة الدوال Functions والتعليقات Comments في لغة راست Rust أنواع البيانات Data Types في لغة رست Rust المتغيرات والتعديل عليها في لغة رست
المُلكية ownership هي مجموعة من القوانين التي تحدد كيف يُدير برنامج رست استخدام الذاكرة، ويتوجب على جميع البرامج أن تُدير الطريقة التي تستخدم فيها ذاكرة الحاسوب عند تشغيلها. تلجأ بعض لغات البرمجة إلى كانس المهملات garbage collector الذي يتفقد باستمرار الذاكرة غير المُستخدمة بعد الآن أثناء عمل البرنامج، بينما تعطي لغات البرمجة الأخرى مسؤولية تحديد الذاكرة وتحريرها للمبرمج مباشرةً، إلا أن رست تسلك طريقًا آخر ثالثًا؛ ألا وهو أن الذاكرة تُدار عبر نظام ملكية يحتوي على مجموعة من القوانين التي يتفقدها المصرّف، إذ لا يُصرّف البرنامج إذا حدث خرق لأحد هذه القوانين، ولن تبطئ أي من مزايا الملكية برنامجك عند تشغيله. سيتطلب مفهوم الملكية بعض الوقت للاعتياد عليه بالنظر إلى أنه مفهوم جديد للعديد من المبرمجين، إلا أنك ستجد قوانين نظام الملكية أكثر سهولة بالممارسة وستجدها من البديهيات التي تسمح لك بكتابة شيفرة برمجية آمنة وفعّالة، لذا لا تستسلم. ستحصل على أساس قوي في فهم المزايا التي تجعل من رست لغة فريدة فور فهمك للملكية، وستتعلم في هذا المقال مفهوم الملكية بكتابة بعض الأمثلة التي تركز على هيكل بيانات data structure شائع جدًا هو السلاسل النصية strings. المكدس والكومة لا تطلب معظم لغات البرمجة منك بالتفكير بالمكدس stack والكومة heap بصورةٍ متكررة عادةً، إلا أن هذا الأمر مهم في لغات برمجة النظم مثل رست، إذ يؤثر وجود القيمة في المكدس أو الكومة على سلوك اللغة واتخاذها لبعض القرارات المعينة، وسنصف أجزاءً من نظام الملكية بما يتعلق بالكومة والمكدس لاحقًا، وسنستعرض هنا مفهومي -الكومة والمكدس- ونشرحهما للتحضير لذلك. يمثل كلًا من المكدس والكومة أجزاءً متاحةً من الذاكرة لشيفرتك البرمجية حتى تستخدمها عند وقت التشغيل runtime، إلا أنهما مُهيكلان بطريقة مختلفة؛ إذ يُخزن المكدس القيم بالترتيب الذي وردت فيه ويُزيل القيم بالترتيب المعاكس، ويُشار إلى ذلك بمصطلح الداخل آخرًا، يخرج أولًا last in, first out. يمكنك التفكير بالمكدس وكأنه كومة من الأطباق، فعندما تضيف المزيد من الأطباق، فإنك تضيفها على قمة الكومة وعندما تريد إزالة طبق فعليك إزالة واحد من القمة، ولا يُمكنك إزالة الأطباق من المنتصف أو من القاع. تُسمى عملية إضافة البيانات بالدفع إلى المكدس pushing onto the stack بينما تُدعى عملية إزالة البيانات بالإزالة من المكدس popping off the stack، ويجب على جميع البيانات المخزنة في المكدس أن تكون من حجم معروف وثابت، بينما تُخزّن البيانات ذات الحجم غير المعروف عند وقت التصريف أو ذات الحجم الممكن أن يتغير في الكومة بدلًا من ذلك. الكومة هي الأقل تنظيمًا إذ يمكنك طلب مقدار معين من المساحة عند تخزين البيانات إليها، وعندها يجد محدد المساحة memory allocator حيزًا فارغًا في الكومة يتسع للحجم المطلوب، يعلّمه على أنه حيّز قيد الاستعمال، ثم يُعيد مؤشرًا pointer يشير إلى عنوان المساحة المحجوزة، وتدعى هذه العملية بحجز مساحة الكومة allocating on the heap وتُدعى في بعض الأحيان بحجز المساحة فقط (لا تُعد عملية إضافة البيانات إلى المكدس عملية حجز مساحة). بما أن المؤشر الذي يشير إلى الكومة من حجم معروف وثابت، يمكنك تخزينه في المكدس، وعندما تريد البيانات الفعلية من الكومة يجب عليك تتبع المؤشر. فكر بالأمر وكأنه أشبه بالجلوس في مطعم، إذ تصرّح عن عدد الأشخاص في مجموعتك عند دخولك إلى المطعم، ثم يبحث كادر المطعم عن طاولة تتسع للجميع ويقودك إليها، وإذا تأخر شخص ما عن المجموعة يمكنه سؤال كادر المطعم مجددًا ليقوده إلى الطاولة. الدفع إلى المكدس أسرع من حجز الذاكرة في الكومة، لأن محدد المساحة لا يبحث عن مكان للبيانات الجديدة وموقع البيانات المخزنة، فهو دائمًا على قمة المكدس، بالمثل، يتطلب حجز المساحة في الكومة مزيدًا من العمل، إذ يجب على محدد المساحة البحث عن حيز كبير بما فيه الكفاية ليتسع البيانات ومن ثم حجزها للتحضير لعملية حجز المساحة التالية. الوصول إلى البيانات من الكومة أبطأ من الوصول إلى البيانات من المكدس وذلك لأنه عليك أن تتبع المؤشر لتصل إلى حيز الذاكرة، وتؤدي المعالجات المعاصرة عملها بصورةٍ أسرع إذا انتقلت من مكان إلى آخر ضمن الذاكرة بتواتر أقل. لنبقي على تقليد التشابيه، فكر بالأمر وكأن النادل في المطعم يأخذ الطلبات من العديد من الطاولات، وفي هذه الحالة فمن الأفضل أن يحصل النادل على جميع الطلبات في الطاولة الواحدة قبل أن ينتقل إلى الطاولة التي تليها، فأخذ الطلب من الطاولة (أ) ومن ثم أخذ الطلب من الطاولة (ب) ومن ثم العودة إلى الطاولة (أ) والطاولة (ب) مجددًا عملية أبطأ بكثير، وبالمثل فإن المعالج يستطيع إنجاز عمله بصورةٍ أفضل إذا تعامل مع البيانات القريبة من البيانات الأخرى (كما هو الحال في المكدس) بدلًا من العمل على بيانات بعيدة عن بعضها (مثل الكومة). عندما تستدعي شيفرتك البرمجية دالةً ما، يُدفع بالقيم المُمررة إليها إلى المكدس (بما فيها المؤشرات إلى البيانات الموجودة في الكومة) إضافةً إلى متغيرات الدالة المحلية، وعندما ينتهي تنفيذ الدالة، تُزال هذه القيم من المكدس. يتكفل نظام الملكية بتتبع الأجزاء التي تستخدم البيانات من الكومة ضمن شيفرتك البرمجية، وتقليل كمية البيانات المُكررة ضمن الكومة، وإزالة أي بيانات غير مُستخدمة منها حتى لا تنفد من المساحة. عندما تفهم نظام الملكية لن تحتاج للتفكير بالمكدس والكومة كثيرًا، فكل ما عليك معرفته هو أن الهدف من نظام الملكية هو إدارة بيانات الكومة، وسيساعدك هذا الأمر في فهم طريقة عمل هذا النظام. قوانين الملكية دعنا نبدأ أولًا بالنظر إلى قوانين الملكية، أبقِ هذه القوانين في ذهنك بينما تقرأ بقية المقال الذي يستعرض أمثلةً توضح هذه القوانين: لكل قيمة في رست مالك owner. يجب أن يكون لكل قيمة مالك واحد في نقطة معينة من الوقت. تُسقط القيمة عندما يخرج المالك من النطاق scope. نطاق المتغير الآن وبعد تعرفنا إلى مبادئ رست في المقالات السابقة، لن نُضمّن الشيفرة fn main() { في الأمثلة، لذا إذا كنت تتبع الأمثلة تأكد من أنك تكتب الشيفرة البرمجية داخل دالة main يدويًا، ونتيجةً لذلك ستكون أمثلتنا أقصر بعض الشيء مما سيسمح لنا بالتركيز على التفاصيل المهمة بدلًا من الشيفرة البرمجية النمطية المتكررة. سننظر إلى نطاق المتغيرات في أول مثال من أمثلة الملكية، والنطاق هو مجال ضمن البرنامج يكون فيه العنصر صالحًا. ألقِ نظرةً على المتغير التالي: let s = "hello"; يُشير المتغير s إلى السلسلة النصية المجردة، إذ أن قيمة السلسلة النصية مكتوبة بصورةٍ صريحة على أنها نص في برنامجنا، والمتغير هذا صالح من نقطة التصريح عنه إلى نهاية النطاق الحالي. توضح الشيفرة 4-1 البرنامج مع تعليقات توضح مكان صلاحية المتغير s. { // المتغير غير صالح هنا إذ لم يُصرّح عنه بعد let s = "hello"; // المتغير صالح من هذه النقطة فصاعدًا // يمكننا استخدام s في العمليات هنا } // انتهى النطاق بحلول هذه النقطة ولا يمكننا استخدام s [الشيفرة 4-1: متغير والنطاق الذي يكون فيه صالحًا] بكلمات أخرى، هناك نقطتان مهمتان حاليًا: عندما يصبح المتغير s ضمن النطاق، يصبح صالحًا. يبقى المتغير صالحًا حتى مغادرته النطاق. لحد اللحظة، العلاقة بين النطاقات والمتغيرات هي علاقة مشابهة للعلاقة التي تجدها في لغات البرمجة الأخرى، وسنبني على أساس هذا الفهم النوع String. النوع String نحتاج نوعًا أكثر تعقيدًا من الأنواع التي غطيناها سابقًا وذلك لتوضيح قوانين الملكية، إذ كانت الأنواع السابقة جميعها من أحجام معروفة ويمكن تخزينها في المكدس وإزالتها عند انتهاء نطاقها، كما أنه من الممكن نسخها بكل سهولة إلى متغير آخر جديد يمثّل نسخةً مستقلةً وذلك إذا احتاج حزءٌ ما من الشيفرة البرمجية استخدام المتغير ذاته ضمن نطاق آخر، إلا أننا بحاجة إلى النظر لأنواع البيانات المخزنة في الكومة حتى نكون قادرين على معرفة ما تفعله رست لتنظيف البيانات هذه ويمثل النوع String مثالًا رائعًا لهذا الاستخدام. سنركز على أجزاء النوع String التي ترتبط مباشرةً بالملكية، وتنطبق هذه الجوانب أيضًا على أنواع البيانات المعقدة الأخرى سواءٌ كانت هذه الأنواع موجودةً في المكتبة القياسية أو كانت مبنيةً من قبلك، وسنناقش النوع String بتعمّق أكبر لاحقًا. رأينا مسبقًا السلاسل النصية المجردة (وهي السلاسل النصية المكتوبة بين علامتي تنصيص " " بصورةٍ صريحة)، إذ تُكتب قيمة السلسلة النصية يدويًا إلى البرنامج. السلاسل النصية المجردة مفيدةٌ إلا أنها غير مناسبة لكل الحالات، مثل تلك التي نريد فيها استخدام النص ويعود السبب في ذلك إلى أنها غير قابلة للتعديل immutable، والسبب الآخر هو أنه لا يمكننا معرفة قيمة كل سلسلة نصية عندما نكتب شيفرتنا البرمجية، فعلى سبيل المثال، ماذا لو أردنا أخذ الدخل من المستخدم وتخزينه؟ تملك رست لمثل هذه الحالات نوع سلسلة نصية آخر يدعى String، ويدير هذا النوع البيانات باستخدام الكومة، وبالتالي يمكنه تخزين كمية غير معروفة من النص عند وقت التصريف. يُمكنك إنشاء String من سلسلة نصية مجردة باستخدام دالة from كما يلي: let s = String::from("hello"); يسمح لنا عامل النقطتين المزدوجتين :: بتسمية الدالة الجزئية from ضمن فضاء الأسماء namespace وأن تندرج تحت النوع String بدلًا من استخدام اسم مشابه مثل string_from، وسنناقش هذه الطريقة في الكتابة أكثر لاحقًا، بالإضافة للتكلم عن فضاءات الأسماء وإنشائها. يُمكن تعديل mutate هذا النوع من السلاسل النصية: let mut s = String::from("hello"); s.push_str(", world!"); // يُضيف ()push_str سلسلةً نصية مجردة إلى النوع String println!("{}", s); // سيطبع هذا السطر `!hello, world` إذًا، ما الفارق هنا؟ كيف يمكننا تعديل النوع String بينما لا يمكننا تعديل السلاسل النصية المجردة؟ الفارق هنا هو بكيفية تعامل كل من النوعين مع الذاكرة. الذاكرة وحجزها نعرف محتويات السلسلة النصية في حال كانت السلسلة النصية مجرّدة عند وقت التصريف، وذلك لأن النص مكتوب في الشيفرة البرمجية بصورةٍ صريحة في الملف النهائي التنفيذي، وهذا السبب في كون السلاسل النصية المجردة سريعة وفعالة، إلا أن هذه الخصائص تأتي من حقيقة أن السلاسل النصية المجردة غير قابلة للتعديل immutable، ولا يمكننا لسوء الحظ أن نضع جزءًا من الذاكرة في الملف التنفيذي الثنائي لكل قطعة من النص، وذلك إذا كان النص ذو حجم غير معلوم عند وقت التصريف كما أن حجمه قد يتغير خلال عمل البرنامج. نحتاج إلى تحديد مساحة من الذاكرة ضمن الكومة عند استخدام نوع String وذلك لدعم إمكانية تعديله وجعله سلسلةً نصيةً قابلة للزيادة والنقصان، بحيث تكون هذه المساحة التي تخزن البيانات غير معلومة الحجم عند وقت التصريف، وهذا يعني: يجب أن تُطلب الذاكرة من مُحدد الذاكرة عند وقت التشغيل. نحتاج طريقة لإعادة الذاكرة إلى محدد الذاكرة عندما ننتهي من استخدام String الخاص بنا. يُنجز المتطلّب الأول عن طريق استدعاء String::from، إذ تُطلب الذاكرة التي يحتاجها ضمنيًا، وهذا الأمر موجود في معظم لغات البرمجة. أما المتطلب الثاني فهو مختلفٌ بعض الشيء، إذ يراقب كانس المهملات -أو اختصارًا GC- الذاكرة غير المُستخدمة بعد الآن ويحررها، ولا حاجة للمبرمج بالتفكير بهذا الأمر، بينما تكون مسؤوليتنا في اللغات التي لا تحتوي على كانس المهملات هي العثور على المساحة غير المُستخدمة بعد الآن وأن نستدعي الشيفرة البرمجية بصورةٍ صريحة لتحرير تلك المساحة، كما هو الحال عندما استدعينا شيفرة برمجية لحجزها، ولطالما كانت هذه المهمة صعبة على المبرمجين، فإذا نسينا تحرير الذاكرة فنحن نهدر الذاكرة وإذا حررنا الذاكرة مبكرًا فهذا يعني أن قيمة المتغير أصبحت غير صالحة للاستخدام، بينما نحصل على خطأ إذا حررنا الذاكرة نفسها لأكثر من مرة، إذ علينا استخدام تعليمة allocate واحدة فقط مصحوبةً مع تعليمة free واحدة لكل حيز ذاكرة نستخدمه. تسلك لغة رست سلوكًا مختلفًا، إذ تُحرر الذاكرة أوتوماتيكيًا عندما يغادر المتغير الذي يملك تلك الذاكرة النطاق. إليك إصدارًا من الشيفرة 4-1 نستخدم فيه النوع String بدلًا من السلسلة النصية المجردة: { let s = String::from("hello"); // المتغير s صالح من هذه النقطة فصاعدًا // يمكننا إنجاز العمليات باستخدام المتغير s هنا } // انتهى النطاق ولم يعد المتغير s صالحًا نستعيد الذاكرة التي يستخدمها String من محدد الذاكرة عندما يخرج المتحول s من النطاق، إذ تستدعي رست دالةً مميزةً بالنيابة عنا عند خروج متحول ما من النطاق وهذه الدالة هي drop، وتُستدعى تلقائيًا عند الوصول إلى قوس الإغلاق المعقوص {. ملاحظة: يُدعى نمط تحرير الموارد في نهاية دورة حياة العنصر في لغة C++ أحيانًا "اكتساب الموارد هو تهيئتها Resource Acquisition Is Initialization" -أو اختصارًا RAII- ودالة drop في رست هي مشابهة لأنماط RAII التي قد استخدمتها سابقًا. لهذا النمط تأثير كبير في طريقة كتابة شيفرة رست البرمجية، وقد يبدو بسيطًا للوقت الحالي إلا أن سلوك الشيفرة البرمجية قد يكون غير متوقعًا في الحالات الأكثر تعقيدًا عندما يوجد عدة متغيرات تستخدم البيانات المحجوزة على الكومة، دعنا ننظر إلى بعض من هذه الحالات الآن. طرق التفاعل مع البيانات والمتغيرات: النقل يُمكن لعدة متغيرات أن تتفاعل مع نفس البيانات بطرق مختلفة في رست، دعنا ننظر إلى الشيفرة 4-2 على أنها مثال يستخدم عددًا صحيحًا. let x = 5; let y = x; [الشيفرة 4-2: إسناد قيمة العدد الصحيح إلى المتغيرين x و y] يمكنك غالبًا تخمين ما الذي تؤديه الشيفرة البرمجية السابقة: إسناد القيمة 5 إلى x ومن ثم نسخ القيمة x وإسنادها إلى القيمة y، وبالتالي لدينا متغيرين x و y وقيمة كل منهما تساوي إلى 5، وهذا ما يحدث فعلًا، لأن الأعداد الصحيحة هي قيم بسيطة بحجم معروف وثابت وبالتالي يُمكن إضافة القيمتين 5 إلى المكدس. لننظر الآن إلى إصدار String من الشيفرة السابقة: let s1 = String::from("hello"); let s2 = s1; تبدو الشيفرة البرمجية هذه شبيهة بسابقتها، وقد نفترض هنا أنها تعمل بالطريقة ذاتها، ألا وهي: ينسخ السطر الثاني القيمة المخزنة في المتغير s1 ويُسندها إلى s2 إلا أن هذا الأمر غير صحيح. انظر إلى الشكل 1 لرؤية ما الذي يحصل بدقة للنوع String، إذ يتكون هذا النوع من ثلاثة أجزاء موضحة ضمن الجدول اليساري وهي المؤشر ptr الذي يشير إلى الذاكرة التي تُخزن السلسلة النصية وطول السلسلة النصية len وسعتها capacity، وتُخزّن مجموعة المعلومات هذه في المكدس، بينما يمثّل الجدول اليميني الذاكرة في الكومة التي تخزن محتوى السلسلة النصية. [شكل 1: مخطط توضيحي لما تبدو عليه الذاكرة عند استخدام String يخزن القيمة "hello" المُسندة إلى s1] يدل الطول على كمية الذاكرة المُستهلكة بالبايت وهي الحيز الذي يشغله محتوى String، بينما تدل السعة على كمية الذاكرة المستهلكة بالكامل التي تلقّاها String من مُحدد الذاكرة، والفرق بين الطول والسعة مهم، إلا أننا سنهمل السعة لأنها غير مهمة في السياق الحالي. تُنسخ بيانات String عندما نُسند s1 إلى s2، وهذا يعني أننا ننسخ المؤشر والطول والسعة الموجودين في المكدس ولا ننسخ البيانات الموجودة في الكومة التي يشير إليها المؤشر، بكلمات أخرى، يبدو تمثيل الذاكرة بعد النسخ كما هو موضح في الشكل 2. [شكل 2: تمثيل الذاكرة للمتغير s2 الذي يحتوي على نسخة من مؤشر وطول وسعة s1] تمثيل الذاكرة غير مطابق للشكل 3 وقد ينطبق هذا التمثيل إذا نسخت رست محتويات بيانات الكومة أيضًا، وإذا فعلت رست ذلك، فستكون عملية الإسناد s2 = s1 عمليةً مكلفةً وستؤثر سلبًا على أداء وقت التشغيل إذا كانت البيانات الموجودة في الكومة كبيرة. [شكل 3: احتمال آخر لما قد تبدو عليه الذاكرة بعد عملية الإسناد s2 = s1 وذلك إذا نسخت رست محتويات الكومة أيضًا] قلنا سابقًا أن رست تستدعي الدالة drop تلقائيًا عندما يغادر متغيرٌ ما النطاق، وتحرّر الذاكرة الموجودة في الكومة لذلك المتغير، إلا أن الشكل 2 يوضح أن كلا المؤشرين يشيران إلى الموقع ذاته، ويمثّل هذا مشكلةً واضحة، إذ عندما يغادر كلًا من s1 وs2 النطاق، فهذا يعني أن الذاكرة في الكومة ستُحرّر مرتين، وهذا خطأ تحرير ذاكرة مزدوج double free error شائع، وهو خطأ من أخطاء أمان الذاكرة الذي ذكرناه سابقًا، إذ يؤدي تحرير الذاكرة نفسها مرتين إلى فساد في الذاكرة مما قد يسبب ثغرات أمنية. تنظر رست إلى s1 بكونه غير صالح بعد السطر let s2 = s1 وذلك لضمان أمان الذاكرة، وبالتالي لا يتوجب على رست تحرير أي شيء عندما يغادر المتحول s1 النطاق. انظر ما الذي يحدث عندما نحاول استخدام s1 بعد إنشاء s2 (لن تعمل الشيفرة البرمجية): let s1 = String::from("hello"); let s2 = s1; println!("{}, world!", s1); سنحصل على خطأ شبيه بالخطأ التالي لأن رست يمنعك من استخدام المرجع غير الصالح بعد الآن: $ cargo run Compiling ownership v0.1.0 (file:///projects/ownership) error[E0382]: borrow of moved value: `s1` --> src/main.rs:5:28 | 2 | let s1 = String::from("hello"); | -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait 3 | let s2 = s1; | -- value moved here 4 | 5 | println!("{}, world!", s1); | ^^ value borrowed here after move | = note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info) For more information about this error, try `rustc --explain E0382`. error: could not compile `ownership` due to previous error لعلك سمعت بمصطلح النسخ السطحي shallow copy والنسخ العميق deep copy خلال عملك على لغة برمجة أخرى؛ إذ يُشير مصطلح النسخ السطحي إلى عملية نسخ مؤشر وطول وسعة السلسلة النصية دون البيانات الموجودة في الكومة، إلا أن رست تسمّي هذه العملية بالنقل move لأنها تُزيل صلاحية المتغير الأول. في هذا المثال، نقول أن s1 نُقِلَ إلى s2، والنتيجة الحاصلة موضحة في الشكل 4. [شكل 4: تمثيل الذاكرة بعد إزالة صلاحية المتغير s1] يحلّ هذا الأمر مشكلتنا، وذلك بجعل المتغير s2 صالحًا فقط، وعند مغادرته للنطاق فإن المساحة تُحرر بناءً عليه فقط. إضافةً لما سبق، هناك خيارٌ تصميمي ملمّح إليه بواسطة هذا الحل، ألا وهو أن رست لن تُنشئ نُسَخًا عميقة من بياناتك تلقائيًا، وبالتالي لن يكون أي نسخ تلقائي مكلفًا بالنسبة لأداء وقت التشغيل. طرق التفاعل مع البيانات والمتغيرات: الاستنساخ يُمكننا استخدام تابع شائع يدعى clone إذا أردنا نسخ البيانات الموجودة في الكومة التي تعود للنوع String نسخًا عميقًا إضافةً لبيانات المكدس، وسنناقش طريقة كتابة التوابع لاحقًا، إلا أنك غالبًا ما رأيت استخدامًا للتوابع مسبقًا بالنظر إلى أنها شائعة في العديد من لغات البرمجة. إليك مثالًا عمليًا عن تابع clone: let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2); تعمل الشيفرة البرمجية بنجاح، وتولد النتيجة الموضحة في الشكل 3، إذ تُنسخ محتويات الكومة. عند رؤيتك لاستدعاء التابع clone، عليك أن تتوقع تنفيذ شيفرة برمجية إضافية وأن الشيفرة البرمجية ستكون مكلفة التنفيذ، وأن استخدام التابع هو دلالة بصرية أيضًا على حدوث شيء مختلف. نسخ بيانات المكدس فقط هناك تفصيلٌ آخر لم نتكلم بخصوصه بعد. تستخدم الشيفرة البرمجية التالية (جزء من الشيفرة 4-2) أعدادًا صحيحة، وهي شيفرة برمجية صالحة: let x = 5; let y = x; println!("x = {}, y = {}", x, y); إلا أن الشيفرة البرمجية تبدو مناقضة لما تعلمنا مسبقًا، إذ أن x صالح ولم يُنقل إلى المتغير y على الرغم من عدم استدعائنا للتابع clone. السبب في هذا هو أن الأنواع المشابهة للأعداد الصحيحة المؤلفة من حجم معروف عند وقت التصريف تُخزن كاملًا في المكدس، ولذلك يمكننا نسخها فعليًا بصورةٍ أسرع، ولا فائدة في منع x من أن يكون صالحًا في هذه الحالة بعد إنشاء المتغير y، وبكلمات أخرى ليس هناك أي فرق بين النسخ السطحي والعميق هنا، لذا لن يُغيّر استدعاء التابع clone أي شيء مقارنةً بالنسخ السطحي الاعتيادي، ولذلك يمكننا الاستغناء عنه. لدى لغة رست طريقةً مميزةً تدعى سمة trait النسخ Copy، التي تمكّننا من وضعها على الأنواع المخزنة في المكدس كما هو الحال في الأعداد الصحيحة (سنتكلم بالتفصيل عن السمات لاحقًا). إذا استخدم نوعٌ ما السمة Copy، فهذا يعني أن جميع المتغيرات التي تستخدم هذا النوع لن تُنقل وستُنسخ بدلًا من ذلك مما يجعل منها صالحة حتى بعد إسنادها إلى متغير آخر. لن تسمح لنا رست بتطبيق السمة Copy إذا كان النوع -أو أي من أجزاء النوع- يحتوي على السمة Drop، إذ أننا سنحصل على خطأ وقت التصريف إذا كان النوع بحاجة لشيء مميز للحدوث عند خروج القيمة من النطاق وأضفنا السمة Copy إلى ذلك النوع، إن أردت تعلم المزيد عن إضافة السمة Copy إلى النوع لتطبيقها، ألقِ نظرةً على الملحق (ت) قسم السمات المُشتقة derivable traits. إذًا، ما هي الأنواع التي تقبل تطبيق السمة Copy؟ يمكنك النظر إلى توثيق النوع للتأكد من ذلك، لكن تنص القاعدة العامة على أن أي مجموعةٍ من القيم البسيطة المُفردة تقبل السمة Copy، إضافةً إلى أي شيء لا يتطلب تحديد الذاكرة، أو ليس أي نوع من أنواع الموارد. إليك بعض الأنواع التي تقبل تطبيق Copy: كل أنواع الأعداد الصحيحة مثل u32. الأنواع البوليانية bool التي تحمل القيمتين true و false. جميع أنواع أعداد الفاصلة العشرية مثل f64. نوع المحرف char. الصفوف tuples إذا احتوى الصف فقط على الأنواع التي يمكن تطبيق Copy عليها، على سبيل المثال يُمكن تطبيق Copy على (i32, i32)، بينما لا يمكن تطبيق Copy على (i32, String). الملكية والدوال تشبه طريقة تمرير قيمة إلى دالة إسناد assign قيمة إلى متغير، إذ أن تمرير القيمة إلى المتغير سينقلها أو ينسخها كما هو الحال عند إسناد القيمة، توضح الشيفرة 4-3 مثالًا عن بعض الطرق التي توضح أين يخرج المتغير من النطاق. اسم الملف: src/main.rs fn main() { let s = String::from("hello"); // يدخل المتغير s إلى النطاق takes_ownership(s); // تُنقل قيمة s إلى الدالة ولا تعود صالحة للاستخدام هنا let x = 5; // يدخل المتغير x إلى النطاق makes_copy(x); // يُنقل المتغير x إلى الدالة إلا أن i32 تملك السمة Copy لذا من الممكن استخدام المتغير x بعد هذه النقطة } // يغادر المتحول x خارج النطاق ولا شيء مميز يحدث لأن قيمة s نُقِلَت fn takes_ownership(some_string: String) { // يدخل المتغير some_string إلى النطاق println!("{}", some_string); } // يُغادر المتغير some_string النطاق هنا وتُستدعى drop، وتُحرر الذاكرة الخاصة بالمتغير fn makes_copy(some_integer: i32) { // يدخل المتغير some_integer إلى النطاق println!("{}", some_integer); } // يغادر المتغير some_integer النطاق ولا يحصل أي شيء مثير للاهتمام [الشيفرة 4-3: استخدام الدوال مع الملكية والنطاق] ستعرض لنا رست خطأً عند وقت التصريف إذا حاولنا استخدام a بعد استدعاء takes_ownership، ويحمينا هذا التفقد الساكن static من بعض الأخطاء. حاول إضافة شيفرة برمجية تستخدم s و x إلى الدالة main ولاحظ أين يمكنك استخدامهما وأين تمنعك قوانين الملكية من استخدامهما. القيم المعادة والنطاق يُمكن أن تحول عملية إعادة القيمة ملكيتها أيضًا، توضح الشيفرة 4-4 مثالًا عن دالة تُعيد قيمة بصورةٍ مشابهة للشيفرة 4-3. اسم الملف: src/main.rs fn main() { let s1 = gives_ownership(); // تنقل الدالة gives_ownership قيمتها المُعادة إلى s1 let s2 = String::from("hello"); // يدخل المتغير s2 إلى النطاق let s3 = takes_and_gives_back(s2); // يُنقل المتغير s2 إلى takes_and_gives_back الذي ينقل قيمته المعادة بدوره إلى المتغير s3 } // يُغادر s3 النطاق من هنا ويُحرر من الذاكرة باستخدام drop، ولا يحصل أي شيء للمتغير s2 لأنه نُقل، بينما يغادر s1 النطاق أيضًا ويُحرر من الذاكرة باستخدام drop fn gives_ownership() -> String { // تنقل الدالة gives_ownership قيمتها المعادة إلى الدالة التي استدعتها let some_string = String::from("yours"); // يدخل المتغير some_string إلى النطاق some_string // يُعاد some_string ويُنقل إلى الدالة المُستدعاة } // تأخذ هذه الدالة سلسلة نصية وتُعيد سلسلة نصية أخرى fn takes_and_gives_back(a_string: String) -> String { // يدخل a_string إلى النطاق a_string // يُعاد a_string ويُنقل إلى الدالة المُستدعاة } [الشيفرة 4-4: تحويل ملكية القيمة المُعادة] تتبع ملكية المتغير نفس النمط في كل مرة، وهو: "إسناد قيمة إلى متغير آخر ينقلها"، وعندما يخرج متغير يتضمن على بيانات ضمن الكومة من النطاق، تُحرر قيمته باستخدام drop إلا إذا نُقلت ملكية البيانات إلى متغير آخر. على الرغم من نجاح هذه العملية، إلا أن عملية أخذ الملكية ومن ثم إعادتها عند كل دالة عملية رتيبة بعض الشيء. ماذا لو أردنا أن نسمح لدالة ما باستخدام القيمة دون الحصول على ملكيتها؟ إنه أمر مزعج جدًا أن أي شيء نمرره سيحتاج أيضًا لإعادة تمريره مجددًا إذا أردنا استخدامه من جديد، بالإضافة إلى أي بيانات نحصل عليها ضمن متن الدالة التي قد نحتاج أن نُعيدها أيضًا. تسمح لنا رست بإعادة عدّة قيم باستخدام مجموعة كما هو موضح في الشيفرة 4-5. اسم الملف: src/main.rs fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{}' is {}.", s2, len); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // يُعيد ()len طول السلسلة النصية (s, length) } [الشيفرة 4-5: إعادة الملكية إلى المعاملات] هذه العملية طويلة قليلًا وتتطلب كثيرًا من الجهد لشيء يُشاع استخدامه، ولحسن حظنا لدى رست ميزة لاستخدام القيمة دون تحويل ملكيتها وتدعى المراجع references، وسنستعرضها في المقال التالي. ترجمة -وبتصرف- لقسم من فصل Understanding Ownership من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: المراجع References والاستعارة Borrowing والشرائح Slices في لغة رست المقال السابق: التحكم بسير تنفيذ برامج راست Rust كيفية كتابة الدوال Functions والتعليقات Comments في لغة راست Rust أنواع البيانات Data Types في لغة رست Rust المتغيرات والتعديل عليها في لغة رست -
 نتطرق في هذا المقال إلى كل من ملفات الترويسة الخاصة بالقيم الحدّية Limits والدوال الرياضية في لغة C، كما نقدّم شرحًا موجزًا عن الأسماء المعرفة بداخل كل من الملفات، ويمكنك الاحتفاظ بهذا القسم كمرجع سريع بخصوص هذا الأمر. القيم الحدية يعرّف ملفا الترويسة <float.h> و <limits.h> عدة قيم حدية معرفة حسب التطبيق. ملف الترويسة <limits.h> يوضح الجدول 1 الأسماء المُصرح عنها في هذا الملف وقيمها المسموحة، إضافةً إلى وصف موجز عن وظيفتها، إذ يوضح وصف SHRT_MIN مثلًا أن قيمة الاسم في بعض التطبيقات يجب أن تكون أقل من أو تساوي القيمة -32767، وهذا يعني أن البرنامج لا يستطيع الاعتماد على متغيرات صغيرة short لتخزين قيم سالبة تتعدى 32767- إذا أردنا قابلية نقل أكبر للبرنامج. قد يدعم التطبيق في بعض الأحيان القيم السالبة الأكبر إلا أن الحد الأدنى الذي يجب أن يدعمه التطبيق هو 32767-. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الاسم القيم المسموحة الوصف CHAR_BIT (≥8) بتات في قيمة من نوع char CHAR_MAX اقرأ الملاحظة القيمة العظمى لنوع char CHAR_MIN اقرأ الملاحظة القيمة الدنيا لنوع char INT_MAX (≥+32767) القيمة العظمى لنوع int INT_MIN (≤−32767) القيمة الدنيا لنوع int LONG_MAX (≥+2147483647) القيمة العظمى لنوع long LONG_MIN (≤−2147483647) القيمة الدنيا لنوع long MB_LEN_MAX (≥1) عدد البتات الأعظمي في محرف متعدد البتات multibyte character SCHAR_MAX (≥+127) القيمة العظمى لنوع signed char SCHAR_MIN (≤−127) القيمة الدنيا لنوع signed char SHRT_MAX (≥+32767) القيمة العظمى لنوع short SHRT_MIN (≤−32767) القيمة الدنيا لنوع short UCHAR_MAX (≥255U) القيمة العظمى لنوع unsigned char UINT_MAX (≥65535U) القيمة الدنيا لنوع unsigned int ULONG_MAX (≥4294967295U) القيمة العظمى لنوع unsigned long USHRT_MAX (≥65535U) القيمة الدنيا لنوع unsigned short [جدول 1 أسماء ملف الترويسة <limits.h>] ملاحظة: إذا كان التطبيق يعامل char على أنه من نوع ذو إشارة فقيمة CHAR_MAX وCHAR_MIN مماثلة لقيمة SCHAR الموافق لها، وإلا فقيمة CHAR_MIN هي صفر وقيمة CHAR_MAX هي مساوية لقيمة UCHAR_MAX. ملف الترويسة <float.h> يتضمن ملف الترويسة <float.h> قيمًا دنيا للأرقام ذات الفاصلة العائمة floating point بصورةٍ مشابهة لما سبق، ويمكن الافتراض عند عدم وجود قيمة دنيا لنوع ما أن هذا النوع لا يمتلك قيمة دنيا أو أن القيمة مرتبطة بقيمة أخرى. الاسم القيم المسموحة الوصف FLT_RADIX (≥2) تمثيل أساس الأس DBL_DIG (≥10) عدد خانات الدقة في نوع double DBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 DBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع double DBL_MAX (≥1E+37) القيمة العظمى لنوع double DBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع double DBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع double DBL_MIN (≤1E−37) القيمة الدنيا للنوع double DBL_MIN_10_EXP (≤37) القيمة الدنيا لأس (أساسه 10) من نوع double DBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع double FLT_DIG (≥6) عدد خانات الدقة في نوع float FLT_EPSILON (≤1E−5) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 FLT_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع float FLT_MAX (≥1E+37) القيمة العظمى للنوع float FLT_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع float FLT_MAX_EXP (—) القيمة العظمة لأس (أساسه FLT_RADIX) من نوع float FLT_MIN (≤1E−37) القيمة الدنيا للنوع float FLT_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع float FLT_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع float FLT_ROUNDS (0) يحدد التقريب للفاصلة العائمة، غير مُحدّد لقيمة 1-، تقريب باتجاه الصفر لقيمة 0، تقريب للقيمة الأقرب لقيمة 1، تقريب إلى اللا نهاية الموجبة لقيمة 2، تقريب إلى اللا نهاية السالبة لقيمة 3. أي قيمة أخرى تكون محددة بحسب التطبيق LDBL_DIG (≥10) عدد خانات الدقة في نوع long double LDBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 LDBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع long double LDBL_MAX (≥1E+37) القيمة العظمى للنوع long double LDBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع long double LDBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع long double LDBL_MIN (≤1E−37) القيمة الدنيا للنوع long double LDBL_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع long double LDBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع long double [جدول 2 أسماء ملف الترويسة <float.h>] الدوال الرياضية إذا كنت تكتب برامجًا رياضيّة تجري عمليات على الفاصلة العائمة وما شابه، فهذا يعني أنك تحتاج الوصول إلى مكتبات الدوال الرياضية دون أدنى شك، ويأخذ هذا النوع من الدوال وسطاءً من النوع double ويعيد نتيجةً من النوع ذاته أيضًا. تُعرَّف الدوال والماكرو المرتبطة بها في ملف الترويسة <math.h>. يُستبدل الماكرو HUGE_VAL المُعرف إلى تعبير ذي قيمة موجبة من نوع عدد عشري مضاعف الدقة "double"، ولا يمكن تمثيله بالضرورة باستخدام النوع float. نحصل على خطأ نطاق domain error في جميع الدوال إذا كانت قيمة الوسيط المُدخل خارج النطاق المُعرّف للدالة، مثل محاولة الحصول على جذر تربيعي لعدد سالب، وإذا حصل هذا الخطأ يُضبط errno إلى الثابت EDOM، وتُعيد الدالة قيمة معرّفة بحسب التطبيق. نحصل على خطأ مجال range error إذا لم يكن من الممكن تمثيل نتيجة الدالة بقيمة عدد عشري مضاعف الدقة، تُعيد الدالة القيمة ±HUGE_VAL إذا كانت قيمة النتيجة كبيرة جدًا (الإشارة موافقة للقيمة) وتُضبط errno إلى ERANGE إذا كانت القيمة صغيرة جدًا وتُعاد القيمة 0.0 وتُعتمد قيمة errno على تعريف التطبيق. تصف اللائحة التالية كلًا من الدوال المتاحة باختصار: الدالة double acos(double x);: تُعيد القيمة الرئيسة Principal value لقوس جيب التمام Arc cosine للوسيط x في النطاق من 0 إلى π راديان، ونحصل على الخطأ EDOM إذا كان x خارج النطاق -1 إلى 1. الدالة double asin(double x);: تُعيد القيمة الرئيسة لقوس الجيب Arc sin للوسيط x في النطاق من -π/2 إلى +π/2 راديان، ونحصل على الخطأ EDOM إذا كان xخارج النطاق -1 إلى 1. الدالة double atan(double x);: تُعيد القيمة الرئيسة لقوس الظل Arc tan للوسيط x في النطاق من -π/2 إلى +π/2 راديان. الدالة double atan2(double y, double x);: تُعيد القيمة الرئيسة لقوس الظل للقيمة y/x في النطاق من -π إلى +π راديان، وتستخدم إشارتي الوسيطين x و y لتحديد الربع الذي تقع فيه قيمة الإجابة، ونحصل على الخطأ EDOM في حال كان x و y مساويين إلى الصفر. الدالة double cos(double x);: تُعيد جيب تمام قيمة الوسيط x (تُقاس x بالراديان). الدالة double sin(double x);: تُعيد جيب قيمة الوسيط x (تُقاس x بالراديان). الدالة double tan(double x);: تُعيد ظل قيمة الوسيط x (تُقاس x بالراديان)، وتكون إشارة HUGE_VAL غير مضمونة الصحّة إذا حدث خطأ مجال. الدالة double cosh(double x);: تُعيد جيب التمام القطعي Hyperbolic للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا جدًا. الدالة double sinh(double x);: تُعيد الجيب القطعي للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا للغاية. الدالة double tanh(double x);: تُعيد الظل القطعي للقيمة x. الدالة double exp(double x);: دالة أسية للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار xكبيرًا جدًا. الدالة double frexp(double value, int *exp);: تجزئة عدد ذو فاصلة عائمة إلى كسر طبيعي وأُس عدد صحيح من الأساس 2، ويخزن هذا العدد الصحيح في الغرض المُشار إليه بواسطة المؤشر exp. الدالة double ldexp(double x, int exp);: ضرب x بمقدار 2 إلى الأُس exp، وقد نحصل على الخطأ ERANGE. الدالة double log(double x);: اللوغاريتم الطبيعي للقيمة x، وقد نحصل على الخطأ EDOM إذا كانت القيمة x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double log10(double x);: اللوغاريتم ذو الأساس 10 للقيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double modf(double value, double *iptr);: تجزئة قيمة الوسيط value إلى جزء عدد صحيح وجزء كسري، ويحمل كل جزء إشارة الوسيط ذاتها، وتُخزن قيمة العدد الصحيح على أنها قيمة من نوع double في الكائن المُشار إليه بواسطة المؤشر iptr وتُعيد الدالة الجزء الكسري. الدالة double pow(double x, double y);: تحسب x إلى الأس y، ونحصل على الخطأ EDOM إذا كانت القيمة x سالبة و y عدد غير صحيح، أو ERANGE إذا لم يكن من الممكن تمثيل النتيجة في حال كانت x تساوي إلى الصفر و y موجبة أو تساوي الصفر. الدالة double sqrt(double x);: تحسب مربع القيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة. الدالة double ceil(double x);: أصغر عدد صحيح لا يكون أصغر من x. الدالة double fabs(double x);: القيمة المطلقة للوسيط x. الدالة double floor(double x);: أكبر عدد صحيح لا يكون أكبر من x. الدالة double fmod(double x, double y);: الباقي العشري من عملية القسمة x/y، ويعتمد الأمر على تعريف التطبيق فيما إذا كانت fmod تُعيد صفرًا أو خطأ نطاق في حال كانت y تساوي إلى الصفر. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: تعلم لغة سي التعامل مع المكتبات في لغة سي C المقال السابق: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C
نتطرق في هذا المقال إلى كل من ملفات الترويسة الخاصة بالقيم الحدّية Limits والدوال الرياضية في لغة C، كما نقدّم شرحًا موجزًا عن الأسماء المعرفة بداخل كل من الملفات، ويمكنك الاحتفاظ بهذا القسم كمرجع سريع بخصوص هذا الأمر. القيم الحدية يعرّف ملفا الترويسة <float.h> و <limits.h> عدة قيم حدية معرفة حسب التطبيق. ملف الترويسة <limits.h> يوضح الجدول 1 الأسماء المُصرح عنها في هذا الملف وقيمها المسموحة، إضافةً إلى وصف موجز عن وظيفتها، إذ يوضح وصف SHRT_MIN مثلًا أن قيمة الاسم في بعض التطبيقات يجب أن تكون أقل من أو تساوي القيمة -32767، وهذا يعني أن البرنامج لا يستطيع الاعتماد على متغيرات صغيرة short لتخزين قيم سالبة تتعدى 32767- إذا أردنا قابلية نقل أكبر للبرنامج. قد يدعم التطبيق في بعض الأحيان القيم السالبة الأكبر إلا أن الحد الأدنى الذي يجب أن يدعمه التطبيق هو 32767-. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الاسم القيم المسموحة الوصف CHAR_BIT (≥8) بتات في قيمة من نوع char CHAR_MAX اقرأ الملاحظة القيمة العظمى لنوع char CHAR_MIN اقرأ الملاحظة القيمة الدنيا لنوع char INT_MAX (≥+32767) القيمة العظمى لنوع int INT_MIN (≤−32767) القيمة الدنيا لنوع int LONG_MAX (≥+2147483647) القيمة العظمى لنوع long LONG_MIN (≤−2147483647) القيمة الدنيا لنوع long MB_LEN_MAX (≥1) عدد البتات الأعظمي في محرف متعدد البتات multibyte character SCHAR_MAX (≥+127) القيمة العظمى لنوع signed char SCHAR_MIN (≤−127) القيمة الدنيا لنوع signed char SHRT_MAX (≥+32767) القيمة العظمى لنوع short SHRT_MIN (≤−32767) القيمة الدنيا لنوع short UCHAR_MAX (≥255U) القيمة العظمى لنوع unsigned char UINT_MAX (≥65535U) القيمة الدنيا لنوع unsigned int ULONG_MAX (≥4294967295U) القيمة العظمى لنوع unsigned long USHRT_MAX (≥65535U) القيمة الدنيا لنوع unsigned short [جدول 1 أسماء ملف الترويسة <limits.h>] ملاحظة: إذا كان التطبيق يعامل char على أنه من نوع ذو إشارة فقيمة CHAR_MAX وCHAR_MIN مماثلة لقيمة SCHAR الموافق لها، وإلا فقيمة CHAR_MIN هي صفر وقيمة CHAR_MAX هي مساوية لقيمة UCHAR_MAX. ملف الترويسة <float.h> يتضمن ملف الترويسة <float.h> قيمًا دنيا للأرقام ذات الفاصلة العائمة floating point بصورةٍ مشابهة لما سبق، ويمكن الافتراض عند عدم وجود قيمة دنيا لنوع ما أن هذا النوع لا يمتلك قيمة دنيا أو أن القيمة مرتبطة بقيمة أخرى. الاسم القيم المسموحة الوصف FLT_RADIX (≥2) تمثيل أساس الأس DBL_DIG (≥10) عدد خانات الدقة في نوع double DBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 DBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع double DBL_MAX (≥1E+37) القيمة العظمى لنوع double DBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع double DBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع double DBL_MIN (≤1E−37) القيمة الدنيا للنوع double DBL_MIN_10_EXP (≤37) القيمة الدنيا لأس (أساسه 10) من نوع double DBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع double FLT_DIG (≥6) عدد خانات الدقة في نوع float FLT_EPSILON (≤1E−5) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 FLT_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع float FLT_MAX (≥1E+37) القيمة العظمى للنوع float FLT_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع float FLT_MAX_EXP (—) القيمة العظمة لأس (أساسه FLT_RADIX) من نوع float FLT_MIN (≤1E−37) القيمة الدنيا للنوع float FLT_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع float FLT_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع float FLT_ROUNDS (0) يحدد التقريب للفاصلة العائمة، غير مُحدّد لقيمة 1-، تقريب باتجاه الصفر لقيمة 0، تقريب للقيمة الأقرب لقيمة 1، تقريب إلى اللا نهاية الموجبة لقيمة 2، تقريب إلى اللا نهاية السالبة لقيمة 3. أي قيمة أخرى تكون محددة بحسب التطبيق LDBL_DIG (≥10) عدد خانات الدقة في نوع long double LDBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 LDBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع long double LDBL_MAX (≥1E+37) القيمة العظمى للنوع long double LDBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع long double LDBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع long double LDBL_MIN (≤1E−37) القيمة الدنيا للنوع long double LDBL_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع long double LDBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع long double [جدول 2 أسماء ملف الترويسة <float.h>] الدوال الرياضية إذا كنت تكتب برامجًا رياضيّة تجري عمليات على الفاصلة العائمة وما شابه، فهذا يعني أنك تحتاج الوصول إلى مكتبات الدوال الرياضية دون أدنى شك، ويأخذ هذا النوع من الدوال وسطاءً من النوع double ويعيد نتيجةً من النوع ذاته أيضًا. تُعرَّف الدوال والماكرو المرتبطة بها في ملف الترويسة <math.h>. يُستبدل الماكرو HUGE_VAL المُعرف إلى تعبير ذي قيمة موجبة من نوع عدد عشري مضاعف الدقة "double"، ولا يمكن تمثيله بالضرورة باستخدام النوع float. نحصل على خطأ نطاق domain error في جميع الدوال إذا كانت قيمة الوسيط المُدخل خارج النطاق المُعرّف للدالة، مثل محاولة الحصول على جذر تربيعي لعدد سالب، وإذا حصل هذا الخطأ يُضبط errno إلى الثابت EDOM، وتُعيد الدالة قيمة معرّفة بحسب التطبيق. نحصل على خطأ مجال range error إذا لم يكن من الممكن تمثيل نتيجة الدالة بقيمة عدد عشري مضاعف الدقة، تُعيد الدالة القيمة ±HUGE_VAL إذا كانت قيمة النتيجة كبيرة جدًا (الإشارة موافقة للقيمة) وتُضبط errno إلى ERANGE إذا كانت القيمة صغيرة جدًا وتُعاد القيمة 0.0 وتُعتمد قيمة errno على تعريف التطبيق. تصف اللائحة التالية كلًا من الدوال المتاحة باختصار: الدالة double acos(double x);: تُعيد القيمة الرئيسة Principal value لقوس جيب التمام Arc cosine للوسيط x في النطاق من 0 إلى π راديان، ونحصل على الخطأ EDOM إذا كان x خارج النطاق -1 إلى 1. الدالة double asin(double x);: تُعيد القيمة الرئيسة لقوس الجيب Arc sin للوسيط x في النطاق من -π/2 إلى +π/2 راديان، ونحصل على الخطأ EDOM إذا كان xخارج النطاق -1 إلى 1. الدالة double atan(double x);: تُعيد القيمة الرئيسة لقوس الظل Arc tan للوسيط x في النطاق من -π/2 إلى +π/2 راديان. الدالة double atan2(double y, double x);: تُعيد القيمة الرئيسة لقوس الظل للقيمة y/x في النطاق من -π إلى +π راديان، وتستخدم إشارتي الوسيطين x و y لتحديد الربع الذي تقع فيه قيمة الإجابة، ونحصل على الخطأ EDOM في حال كان x و y مساويين إلى الصفر. الدالة double cos(double x);: تُعيد جيب تمام قيمة الوسيط x (تُقاس x بالراديان). الدالة double sin(double x);: تُعيد جيب قيمة الوسيط x (تُقاس x بالراديان). الدالة double tan(double x);: تُعيد ظل قيمة الوسيط x (تُقاس x بالراديان)، وتكون إشارة HUGE_VAL غير مضمونة الصحّة إذا حدث خطأ مجال. الدالة double cosh(double x);: تُعيد جيب التمام القطعي Hyperbolic للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا جدًا. الدالة double sinh(double x);: تُعيد الجيب القطعي للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا للغاية. الدالة double tanh(double x);: تُعيد الظل القطعي للقيمة x. الدالة double exp(double x);: دالة أسية للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار xكبيرًا جدًا. الدالة double frexp(double value, int *exp);: تجزئة عدد ذو فاصلة عائمة إلى كسر طبيعي وأُس عدد صحيح من الأساس 2، ويخزن هذا العدد الصحيح في الغرض المُشار إليه بواسطة المؤشر exp. الدالة double ldexp(double x, int exp);: ضرب x بمقدار 2 إلى الأُس exp، وقد نحصل على الخطأ ERANGE. الدالة double log(double x);: اللوغاريتم الطبيعي للقيمة x، وقد نحصل على الخطأ EDOM إذا كانت القيمة x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double log10(double x);: اللوغاريتم ذو الأساس 10 للقيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double modf(double value, double *iptr);: تجزئة قيمة الوسيط value إلى جزء عدد صحيح وجزء كسري، ويحمل كل جزء إشارة الوسيط ذاتها، وتُخزن قيمة العدد الصحيح على أنها قيمة من نوع double في الكائن المُشار إليه بواسطة المؤشر iptr وتُعيد الدالة الجزء الكسري. الدالة double pow(double x, double y);: تحسب x إلى الأس y، ونحصل على الخطأ EDOM إذا كانت القيمة x سالبة و y عدد غير صحيح، أو ERANGE إذا لم يكن من الممكن تمثيل النتيجة في حال كانت x تساوي إلى الصفر و y موجبة أو تساوي الصفر. الدالة double sqrt(double x);: تحسب مربع القيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة. الدالة double ceil(double x);: أصغر عدد صحيح لا يكون أصغر من x. الدالة double fabs(double x);: القيمة المطلقة للوسيط x. الدالة double floor(double x);: أكبر عدد صحيح لا يكون أكبر من x. الدالة double fmod(double x, double y);: الباقي العشري من عملية القسمة x/y، ويعتمد الأمر على تعريف التطبيق فيما إذا كانت fmod تُعيد صفرًا أو خطأ نطاق في حال كانت y تساوي إلى الصفر. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: تعلم لغة سي التعامل مع المكتبات في لغة سي C المقال السابق: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C -
 تُعد القدرة على تشغيل جزء من الشيفرة البرمجية إذا تحقق شرط ما، أو تشغيل جزء ما باستمرار بينما الشرط محقق من الكتل الأساسية في بناء أي لغة برمجة، كما تُعد تعابير if والحلقات التكرارية أكثر اللبنات التي تسمح لك بالتحكم بسير تنفيذ البرنامج flow control في البرامج المكتوبة بلغة راست. تعابير if الشرطية يسمح لك تعبير if بتفرعة branch شيفرتك البرمجية بحسب الشروط، ويُمكنك كتابة الشرط بحيث "إذا تحقق هذا الشرط فنفذ هذا الجزء من الشيفرة البرمجية، وإلا فلا تنفّذه". أنشئ مشروعًا جديدًا باسم "branches" في المجلد "projects"، إذ سنستخدم هذا المشروع للتعرف على تعابير if. عدّل الملف "src/main.rs" ليحتوي على الشيفرة التالية: اسم الملف: src/main.rs fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } } تبدأ جميع تعابير if بالكلمة المفتاحية if متبوعةً بالشرط، ويتحقق الشرط في مثالنا السابق فيما إذا كانت قيمة المتغير number أصغر من 5، ونضع شيفرة برمجية مباشرةً بعد الشرط داخل أقواس معقوصة تُنفّذ إذا كان الشرط المذكور محققًا، تُدعى الشيفرة البرمجية المُرتبطة بالشرط في تعابير if بالأذرع arms في بعض الأحيان، وهي تشبه أذرع تعابير match التي تكلمنا عنها سابقًا. يُمكننا أيضًا تضمين تعبير else اختياريًا وهو ما فعلناه في هذا المثال، وذلك لإعطاء البرنامج كتلة بديلة للتنفيذ إذا كان الشرط في تعليمة if السابقة غير مُحقّق. يتخطى البرنامج كتلة تعليمة if ببساطة وينفذ بقية البرنامج في حال عدم وجود تعبير else. نحصل على الخرج التالي في حال تجربتنا لتنفيذ الشيفرة البرمجية: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/branches` condition was true دعنا نُغيّر قيمة number إلى قيمة أخرى تجعل قيمة الشرط false ونرى ما الذي سيحدث: let number = 7; نفّذ البرنامج مجددًا، وانظر إلى الخرج: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/branches` condition was false من الجدير بالذكر أيضًا أن الشرط في هذه الشيفرة البرمجية يجب أن يكون من النوع bool وإذا لم يكن كذلك فسنحصل على خطأ، جرّب تنفيذ الشيفرة البرمجية التالية على سبيل المثال: اسم الملف: src/main.rs fn main() { let number = 3; if number { println!("number was three"); } } يُقيَّم شرط if إلى القيمة 3 هذه المرة، ويعرض لنا راست الخطأ التالي: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) error[E0308]: mismatched types --> src/main.rs:4:8 | 4 | if number { | ^^^^^^ expected `bool`, found integer For more information about this error, try `rustc --explain E0308`. error: could not compile `branches` due to previous error يُشير الخطأ إلى أن راست توقّع تلقي قيمة من نوع bool إلا أنه حصل على قيمة عدد صحيح integer. لا تُحوّل راست الأنواع غير البوليانية إلى أنواع بوليانية بعكس لغات البرمجة الأخرى، مثل روبي وجافا سكريبت، إذ عليك أن تكون دقيقًا بكتابة شرط تعليمة if ليكون تعبيرًا يُقيَّم إلى قيمة بوليانية، على سبيل المثال إن أردنا لكتلة تعليمة if أن تعمل فقط في حالة كان الرقم لا يساوي الصفر فيمكننا تغيير التعبير كما يلي: اسم الملف: src/main.rs fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } } سيطبع تشغيل الشيفرة البرمجية السابقة "number was something other than zero". التعامل مع عدة شروط باستخدام else if يُمكنك استخدام عدة شروط باستخدام if و else في تعابير else if، على سبيل المثال: اسم الملف: src/main.rs fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } } لهذا البرنامج أربعة مسارات مختلفة ممكنة التنفيذ، ومن المُفترض أن تحصل على الخرج التالي بعد تشغيله: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/branches` number is divisible by 3 يتحقَّق البرنامج عند تنفيذه من كل تعبير if فيما إذا كان مُحقًًقًا ويُنفّذ أول متن شرط يُحقّق، لاحظ أنه على الرغم من قابلية قسمة 6 على 2 إلا أننا لم نرى الخرج number is divisible by 2، أو الخرج number is not divisible by 4, 3, or 2 من كتلة التعليمة else، وذلك لأن راست تُنفّذ الكتلة الأولى التي تحقق الشرط فقط وحالما تجد هذه الكتلة، فإنها لا تتفقّد تحقق الشروط الأخرى التي تلي تلك الكتلة. قد يسبب استخدام الكثير من تعابير else if الفوضى في شيفرتك البرمجية، لذا إذا كان لديك أكثر من تعبير واحد، تأكد من إعادة النظر إلى شيفرتك البرمجية ومحاولة تحسينها، وسنناقش لاحقًا هيكل تفرعي branching construct في راست يُدعى match وقد صُمّم لهذه الحالات خصيصًا. استخدام if في تعليمة let يُمكننا استخدام if في الجانب الأيمن من تعليمة let بالنظر إلى أنها تعبير وإسناد النتيجة إلى متغير كما توضح الشيفرة 3-2. اسم الملف: src/main.rs fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); } [الشيفرة 3-2: إسناد نتيجة تعبير if إلى متغير] يُسند المتغير number إلى قيمة بناءً على نتيجة تعبير if، نفّذ الشيفرة البرمجية السابقة ولاحظ النتيجة: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.30s Running `target/debug/branches` The value of number is: 5 تذكر أن كُتل الشيفرات البرمجية تُقيّم إلى قيمة آخر تعبير موجود داخلها والأرقام بحد ذاتها هي تعابير أيضًا، في هذه الحالة تعتمد قيمة تعبير if بالكامل على أي كتلة برمجية تُنفَّذ، وهذا يعني أنه يجب أن تكون القيم المُحتمل أن تكون نتيجة تعبير if من النوع ذاته. نجد في الشيفرة 2 نتيجة كل من ذراع if و else، إذ تُمثّل القيمة النوع الصحيح i32. نحصل على خطأ إذا كانت الأنواع غير متوافقة كما هو الحال في المثال التالي: اسم الملف: src/main.rs fn main() { let condition = true; let number = if condition { 5 } else { "six" }; println!("The value of number is: {number}"); } عندما نحاول تصريف الشيفرة البرمجية السابقة سنحصل على خطأ، إذ يوجد لذراعي if و else قيمتين من أنواع غير متوافقة، ويدلّنا راست على مكان المشكلة في البرنامج بالضبط عن طريق الرسالة: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) error[E0308]: `if` and `else` have incompatible types --> src/main.rs:4:44 | 4 | let number = if condition { 5 } else { "six" }; | - ^^^^^ expected integer, found `&str` | | | expected because of this For more information about this error, try `rustc --explain E0308`. error: could not compile `branches` due to previous error يُقيَّم التعبير الموجود في كتلة if إلى عدد صحيح، بينما يُقيَّم التعبير الموجود في كتلة else إلى سلسلة نصية، وذلك لن يعمل لأنه يجب على المتغيرات أن تكون من النوع ذاته وذلك حتى تعرف راست نوع المتغير number وقت التصريف بصورةٍ نهائية ومؤكدة، إذ تسمح معرفة نوع number للمصرف بالتحقق من أن النوع المُستخدم صالح الاستخدام في كل مكان نستخدم فيه المتغير number، ولن تكون راست قادرةً على التحقق من هذا الأمر إذا كان نوع المتغير number يُحدّد عند وقت التشغيل runtime فقط، إذ سيُصبح المصرف مُشوَّشًا ولن يُقدم الضمانات ذاتها في الشيفرة البرمجية إذا كان عليه تتبع عدة أنواع افتراضية لأي متغير. التكرار باستخدام الحلقات نحتاج غالبًا لتنفيذ جزء محدد من الشيفرة البرمجية أكثر من مرة واحدة، ولتحقيق ذلك تزوّدنا راست بالحلقات التي تُنفّذ الشيفرة البرمجية داخل متن الحلقة من البداية إلى النهاية ومن ثم إلى البداية مجددًا، وللتعرّف إلى الحلقات دعنا نُنشئ مشروعًا جديدًا باسم "loops". لراست ثلاثة أنواع من الحلقات، هي: loop و while و for، دعنا نجرّب كل منها. تكرار الشيفرة البرمجية باستخدام loop تُعلِم الكلمة المفتاحية loop راست بوجوب تنفيذ جزء من الشيفرة البرمجية على نحوٍ متكرر إلى الأبد أو لحين تحديد التوقف بصورةٍ صريحة. على سبيل المثال، عدّل محتويات الملف "src/main.rs" في مجلد مشروعنا الجديد "loops" ليحتوي على الشيفرة البرمجية التالية: اسم الملف: src/main.rs fn main() { loop { println!("again!"); } } عندما نُشغّل البرنامج السابق سنجد النص "again!" مطبوعًا مرةً بعد الأخرى باستمرار إلى أن نوقف البرنامج يدويًا، ونستطيع إيقافه باستخدام اختصار لوحة المفاتيح "ctrl-c"، إذ تدعم معظم الطرفيات هذا الاختصار لإيقاف البرنامج في حال تكرار حلقة للأبد. جرّب الأمر: $ cargo run Compiling loops v0.1.0 (file:///projects/loops) Finished dev [unoptimized + debuginfo] target(s) in 0.29s Running `target/debug/loops` again! again! again! again! ^Cagain! يُمثل الرمز ^C الموضع الذي ضغطت فيه على الاختصار "ctrl-c"، وقد تجد الكلمة again! مطبوعةً بعد ^C أو قد لا تجدها بحسب مكان التنفيذ ضمن الشيفرة البرمجية عند ضغطك على إشارة المقاطعة interrupt signal. تُزوّدنا راست أيضًا لحسن الحظ بطريقة أخرى للخروج قسريًا من حلقة تكرارية باستخدام شيفرة برمجية، إذ يمكننا استخدام الكلمة المفتاحية break داخل الحلقة التكرارية لإخبار البرنامج بأننا نريد إيقاف تنفيذ الحلقة. تذكر أننا فعلنا ذلك عند كتابتنا شيفرة برنامج لعبة التخمين سابقًا وذلك للخروج من البرنامج عندما يفوز اللاعب بتخمين الرقم الصحيح. كما أننا استخدمنا أيضًا الكلمة المفتاحية continue في لعبة التخمين، وهي كلمة تُخبر البرنامج بتخطي أي شيفرة برمجية متبقية داخل الحلقة في التكرار الحالي والذهاب إلى التكرار اللاحق. إعادة قيم من الحلقات واحدة من استخدامات loop هي إعادة تنفيذ عملية قد تفشل، مثل التحقق إذا أنهى خيط thread ما العمل، وقد تحتاج أيضًا إلى تمرير نتيجة هذه العملية خارج الحلقة إلى باقي الشيفرة البرمجية؛ ولتحقيق ذلك يمكنك إضافة القيمة التي تُريد إعادتها بعد تعبير break، إذ سيتوقف عندها تنفيذ الحلقة وستُعاد القيمة خارج الحلقة حتى يتسنى لك استخدامها كما هو موضح: fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); } نُصرّح عن متغير باسم counter ونُهيّئه بالقيمة "0" قبل الحلقة التكرارية، ثم نصرح عن متغير باسم result لتخزين القيمة المُعادة من الحلقة. نُضيف 1 إلى المتغير counter عند كل تكرار للحلقة ومن ثم نتحقق فيما إذا كان المتغير counter مساويًا إلى القيمة 10، وعندما يتحقق هذا الشرط نستخدم الكلمة المفتاحية break مع القيمة counter * 2، ونستخدم بعد الحلقة فاصلة منقوطة لإنهاء التعليمة التي تُسند القيمة إلى result، وأخيرًا نطبع القيمة result التي تكون في هذه الحالة مساويةً إلى 20. تسمية الحلقات للتفريق بين عدة حلقات تُطبّق break و continue في حال وجود حلقة داخل حلقة على الحلقة الداخلية الموجود بها الكلمة المفتاحية، ويمكنك تحديد تسمية الحلقة loop label اختياريًا عند إنشاء حلقة حتى يُمكنك استخدام break أو continue مع تحديد تسمية الحلقة بدلًا من تنفيذ عملها على الحلقة الداخلية. يجب أن تبدأ تسمية الحلقة بعلامة تنصيص واحدة، ويوضح المثال التالي استخدام حلقتين متداخلتين: fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); } للحلقة الخارجية التسمية 'counting_up وستعدّ من 0 إلى 2، بينما تعدّ الحلقة الداخلية عديمة التسمية من 10 إلى 9. لا تُحدد break الأولى أي تسمية لذلك ستغادر الحلقة الداخلية فقط، بينما ستغادر تعليمة break 'counting_up الحلقة الخارجية، وتطبع الشيفرة البرمجية السابقة ما يلي: $ cargo run Compiling loops v0.1.0 (file:///projects/loops) Finished dev [unoptimized + debuginfo] target(s) in 0.58s Running `target/debug/loops` count = 0 remaining = 10 remaining = 9 count = 1 remaining = 10 remaining = 9 count = 2 remaining = 10 End count = 2 الحلقات الشرطية باستخدام while سيحتاج البرنامج غالبًا إلى تقييم شرط داخل حلقة، بحيث يستمر تنفيذ الحلقة إذا كان الشرط محققًا وإلا فسيتوقف تنفيذها عن طريق استدعاء break وإيقاف الحلقة ومن الممكن تطبيق شيء مماثل باستخدام مزيج من loop و if و else و break، ويمكنك تجربة الأمر الآن داخل برنامج إذا أردت ذلك. يُعد هذا النمط شائعًا جدًا وهذا هو السبب وراء وجود بنية مُضمَّنة في راست لهذا الاستخدام تُدعى حلقة while. نستخدم في الشيفرة 3-3 التالية الحلقة while لتكرار الحلقة ثلاث مرات بالعدّ تنازليًا في كل مرة وعند الخروج من الحلقة نطبع رسالة ونُنهي البرنامج. اسم الملف: src/main.rs fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); } [الشيفرة 3-3: استخدام حلقة while لتنفيذ شيفرة برمجية عند تحقق شرط ما] يُغنينا استخدام هذه البنية عناء استخدام الكثير من التداخلات بواسطة loop و if و else و break كما أنه أكثر وضوحًا، إذ طالما يكون الشرط محققًا ستُنفّذ الحلقة وإلا فسيغادر الحلقة. استخدام for مع تجميعة Collection يمكنك اختيار البنية while للانتقال بين عناصر التجميعة مثل المصفوفات. توضح الشيفرة 3-4 ذلك الاستخدام بطباعة كل عنصر في المصفوفة a. اسم الملف: src/main.rs fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } } [الشيفرة 4: الانتقال بين عناصر التجميعة باستخدام حلقة while] إليك الشيفرة البرمجية التي تنتقل بين عناصر المصفوفة، إذ تبدأ من الدليل "0" وتنتقل إلى ما يليه لحد الوصول إلى الدليل الأخير في المصفوفة (أي عندما يكون index < 5 غير محقق). سيطبع تنفيذ الشيفرة السابقة عناصر المصفوفة كما يلي: $ cargo run Compiling loops v0.1.0 (file:///projects/loops) Finished dev [unoptimized + debuginfo] target(s) in 0.32s Running `target/debug/loops` the value is: 10 the value is: 20 the value is: 30 the value is: 40 the value is: 50 تظهر جميع قيم عناصر المصفوفة الخمسة ضمن الطرفية كما هو متوقع. على الرغم من أن index سيصل إلى القيمة 5 في مرحلة ما إلا أن تنفيذ الحلقة يتوقف قبل محاولة طباعة العنصر السادس من المصفوفة. سلوك البرنامج معرض للخطأ، فقد يهلع البرنامج إذا كانت قيمة الدليل أو الشرط الذي يُفحص خاطئة، على سبيل المثال إذا استبدلنا تعريف المصفوفة a ليكون لها أربعة عناصر ولكننا نسينا تحديث الشرط إلى while index < 4، ستهلع الشيفرة البرمجية، كما أن هذا السلوك بطيء لأن المصرف يُضيف شيفرة برمجية عند وقت التشغيل لإنجاز التحقق من الشرط فيما إذا كان الدليل خارج حدود المصفوفة عند كل تكرار ضمن الحلقة. بدلًا من ذلك، يمكننا استخدام حلقة for وتنفيذ شيفرة برمجية لكل عنصر في التجميعة، وتبدو الحلقة بالشكل الموضح في الشيفرة 3-5. اسم الملف: src/main.rs fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } } [الشيفرة 3-5: الانتقال بين عناصر التجميعة باستخدام حلقة for] ستجد الخرج ذاته للشيفرة 3-4 عند تنفيذ الشيفرة السابقة، والأهم هنا أننا زدنا من أمان شيفرتنا البرمجية وأزلنا أي فرص للأخطاء الناجمة عن الذهاب إلى ما بعد حدود المصفوفة، أو عدم الذهاب إلى نهايتها وبالتالي عدم طباعة جميع العناصر. لست مضطرًا لتغيير أي شيفرة برمجية باستخدام حلقة for إذا عدلت رقم العناصر في المصفوفة، الأمر الذي ستضطر لفعله في حال استخدامك للشيفرة 3-4. تُستخدم حلقات for كثيرًا نظرًا للأمان والإيجاز التي تقدمه مقارنةً ببُنى الحلقات الأخرى الموجودة في راست، حتى أن معظم مبرمجين لغة راست يفضلون استخدام الحلقة for عند تنفيذ شيفرة برمجية يُفترض تنفيذها عدد معين من المرات كما هو الحال في مثال العد التنازلي الذي أنجزناه باستخدام حلقة while في الشيفرة 3-3، ويُنجز ذلك الأمر باستخدام Range المُضمَّن في المكتبة القياسية، والذي يولّد بدوره جميع الأرقام في السلسلة بدءًا من رقم معين وانتهاءً برقم آخر. إليك ما سيبدو عليه برنامج العد التنازلي باستخدام حلقة for وتابع آخر لم نتكلم عنه بعد وهو rev، المُستخدم في عكس المجال: اسم الملف: src/main.rs fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); } تبدو هذه الشيفرة البرمجية أفضل، أليس كذلك؟ ترجمة -وبتصرف- للقسم Control Flow من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: الملكية Ownership في لغة رست المقال السابق: كيفية كتابة الدوال Functions والتعليقات Comments في لغة راست Rust أنواع البيانات Data Types في لغة رست Rust المتغيرات والتعديل عليها في لغة رست
تُعد القدرة على تشغيل جزء من الشيفرة البرمجية إذا تحقق شرط ما، أو تشغيل جزء ما باستمرار بينما الشرط محقق من الكتل الأساسية في بناء أي لغة برمجة، كما تُعد تعابير if والحلقات التكرارية أكثر اللبنات التي تسمح لك بالتحكم بسير تنفيذ البرنامج flow control في البرامج المكتوبة بلغة راست. تعابير if الشرطية يسمح لك تعبير if بتفرعة branch شيفرتك البرمجية بحسب الشروط، ويُمكنك كتابة الشرط بحيث "إذا تحقق هذا الشرط فنفذ هذا الجزء من الشيفرة البرمجية، وإلا فلا تنفّذه". أنشئ مشروعًا جديدًا باسم "branches" في المجلد "projects"، إذ سنستخدم هذا المشروع للتعرف على تعابير if. عدّل الملف "src/main.rs" ليحتوي على الشيفرة التالية: اسم الملف: src/main.rs fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } } تبدأ جميع تعابير if بالكلمة المفتاحية if متبوعةً بالشرط، ويتحقق الشرط في مثالنا السابق فيما إذا كانت قيمة المتغير number أصغر من 5، ونضع شيفرة برمجية مباشرةً بعد الشرط داخل أقواس معقوصة تُنفّذ إذا كان الشرط المذكور محققًا، تُدعى الشيفرة البرمجية المُرتبطة بالشرط في تعابير if بالأذرع arms في بعض الأحيان، وهي تشبه أذرع تعابير match التي تكلمنا عنها سابقًا. يُمكننا أيضًا تضمين تعبير else اختياريًا وهو ما فعلناه في هذا المثال، وذلك لإعطاء البرنامج كتلة بديلة للتنفيذ إذا كان الشرط في تعليمة if السابقة غير مُحقّق. يتخطى البرنامج كتلة تعليمة if ببساطة وينفذ بقية البرنامج في حال عدم وجود تعبير else. نحصل على الخرج التالي في حال تجربتنا لتنفيذ الشيفرة البرمجية: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/branches` condition was true دعنا نُغيّر قيمة number إلى قيمة أخرى تجعل قيمة الشرط false ونرى ما الذي سيحدث: let number = 7; نفّذ البرنامج مجددًا، وانظر إلى الخرج: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/branches` condition was false من الجدير بالذكر أيضًا أن الشرط في هذه الشيفرة البرمجية يجب أن يكون من النوع bool وإذا لم يكن كذلك فسنحصل على خطأ، جرّب تنفيذ الشيفرة البرمجية التالية على سبيل المثال: اسم الملف: src/main.rs fn main() { let number = 3; if number { println!("number was three"); } } يُقيَّم شرط if إلى القيمة 3 هذه المرة، ويعرض لنا راست الخطأ التالي: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) error[E0308]: mismatched types --> src/main.rs:4:8 | 4 | if number { | ^^^^^^ expected `bool`, found integer For more information about this error, try `rustc --explain E0308`. error: could not compile `branches` due to previous error يُشير الخطأ إلى أن راست توقّع تلقي قيمة من نوع bool إلا أنه حصل على قيمة عدد صحيح integer. لا تُحوّل راست الأنواع غير البوليانية إلى أنواع بوليانية بعكس لغات البرمجة الأخرى، مثل روبي وجافا سكريبت، إذ عليك أن تكون دقيقًا بكتابة شرط تعليمة if ليكون تعبيرًا يُقيَّم إلى قيمة بوليانية، على سبيل المثال إن أردنا لكتلة تعليمة if أن تعمل فقط في حالة كان الرقم لا يساوي الصفر فيمكننا تغيير التعبير كما يلي: اسم الملف: src/main.rs fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } } سيطبع تشغيل الشيفرة البرمجية السابقة "number was something other than zero". التعامل مع عدة شروط باستخدام else if يُمكنك استخدام عدة شروط باستخدام if و else في تعابير else if، على سبيل المثال: اسم الملف: src/main.rs fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } } لهذا البرنامج أربعة مسارات مختلفة ممكنة التنفيذ، ومن المُفترض أن تحصل على الخرج التالي بعد تشغيله: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/branches` number is divisible by 3 يتحقَّق البرنامج عند تنفيذه من كل تعبير if فيما إذا كان مُحقًًقًا ويُنفّذ أول متن شرط يُحقّق، لاحظ أنه على الرغم من قابلية قسمة 6 على 2 إلا أننا لم نرى الخرج number is divisible by 2، أو الخرج number is not divisible by 4, 3, or 2 من كتلة التعليمة else، وذلك لأن راست تُنفّذ الكتلة الأولى التي تحقق الشرط فقط وحالما تجد هذه الكتلة، فإنها لا تتفقّد تحقق الشروط الأخرى التي تلي تلك الكتلة. قد يسبب استخدام الكثير من تعابير else if الفوضى في شيفرتك البرمجية، لذا إذا كان لديك أكثر من تعبير واحد، تأكد من إعادة النظر إلى شيفرتك البرمجية ومحاولة تحسينها، وسنناقش لاحقًا هيكل تفرعي branching construct في راست يُدعى match وقد صُمّم لهذه الحالات خصيصًا. استخدام if في تعليمة let يُمكننا استخدام if في الجانب الأيمن من تعليمة let بالنظر إلى أنها تعبير وإسناد النتيجة إلى متغير كما توضح الشيفرة 3-2. اسم الملف: src/main.rs fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); } [الشيفرة 3-2: إسناد نتيجة تعبير if إلى متغير] يُسند المتغير number إلى قيمة بناءً على نتيجة تعبير if، نفّذ الشيفرة البرمجية السابقة ولاحظ النتيجة: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) Finished dev [unoptimized + debuginfo] target(s) in 0.30s Running `target/debug/branches` The value of number is: 5 تذكر أن كُتل الشيفرات البرمجية تُقيّم إلى قيمة آخر تعبير موجود داخلها والأرقام بحد ذاتها هي تعابير أيضًا، في هذه الحالة تعتمد قيمة تعبير if بالكامل على أي كتلة برمجية تُنفَّذ، وهذا يعني أنه يجب أن تكون القيم المُحتمل أن تكون نتيجة تعبير if من النوع ذاته. نجد في الشيفرة 2 نتيجة كل من ذراع if و else، إذ تُمثّل القيمة النوع الصحيح i32. نحصل على خطأ إذا كانت الأنواع غير متوافقة كما هو الحال في المثال التالي: اسم الملف: src/main.rs fn main() { let condition = true; let number = if condition { 5 } else { "six" }; println!("The value of number is: {number}"); } عندما نحاول تصريف الشيفرة البرمجية السابقة سنحصل على خطأ، إذ يوجد لذراعي if و else قيمتين من أنواع غير متوافقة، ويدلّنا راست على مكان المشكلة في البرنامج بالضبط عن طريق الرسالة: $ cargo run Compiling branches v0.1.0 (file:///projects/branches) error[E0308]: `if` and `else` have incompatible types --> src/main.rs:4:44 | 4 | let number = if condition { 5 } else { "six" }; | - ^^^^^ expected integer, found `&str` | | | expected because of this For more information about this error, try `rustc --explain E0308`. error: could not compile `branches` due to previous error يُقيَّم التعبير الموجود في كتلة if إلى عدد صحيح، بينما يُقيَّم التعبير الموجود في كتلة else إلى سلسلة نصية، وذلك لن يعمل لأنه يجب على المتغيرات أن تكون من النوع ذاته وذلك حتى تعرف راست نوع المتغير number وقت التصريف بصورةٍ نهائية ومؤكدة، إذ تسمح معرفة نوع number للمصرف بالتحقق من أن النوع المُستخدم صالح الاستخدام في كل مكان نستخدم فيه المتغير number، ولن تكون راست قادرةً على التحقق من هذا الأمر إذا كان نوع المتغير number يُحدّد عند وقت التشغيل runtime فقط، إذ سيُصبح المصرف مُشوَّشًا ولن يُقدم الضمانات ذاتها في الشيفرة البرمجية إذا كان عليه تتبع عدة أنواع افتراضية لأي متغير. التكرار باستخدام الحلقات نحتاج غالبًا لتنفيذ جزء محدد من الشيفرة البرمجية أكثر من مرة واحدة، ولتحقيق ذلك تزوّدنا راست بالحلقات التي تُنفّذ الشيفرة البرمجية داخل متن الحلقة من البداية إلى النهاية ومن ثم إلى البداية مجددًا، وللتعرّف إلى الحلقات دعنا نُنشئ مشروعًا جديدًا باسم "loops". لراست ثلاثة أنواع من الحلقات، هي: loop و while و for، دعنا نجرّب كل منها. تكرار الشيفرة البرمجية باستخدام loop تُعلِم الكلمة المفتاحية loop راست بوجوب تنفيذ جزء من الشيفرة البرمجية على نحوٍ متكرر إلى الأبد أو لحين تحديد التوقف بصورةٍ صريحة. على سبيل المثال، عدّل محتويات الملف "src/main.rs" في مجلد مشروعنا الجديد "loops" ليحتوي على الشيفرة البرمجية التالية: اسم الملف: src/main.rs fn main() { loop { println!("again!"); } } عندما نُشغّل البرنامج السابق سنجد النص "again!" مطبوعًا مرةً بعد الأخرى باستمرار إلى أن نوقف البرنامج يدويًا، ونستطيع إيقافه باستخدام اختصار لوحة المفاتيح "ctrl-c"، إذ تدعم معظم الطرفيات هذا الاختصار لإيقاف البرنامج في حال تكرار حلقة للأبد. جرّب الأمر: $ cargo run Compiling loops v0.1.0 (file:///projects/loops) Finished dev [unoptimized + debuginfo] target(s) in 0.29s Running `target/debug/loops` again! again! again! again! ^Cagain! يُمثل الرمز ^C الموضع الذي ضغطت فيه على الاختصار "ctrl-c"، وقد تجد الكلمة again! مطبوعةً بعد ^C أو قد لا تجدها بحسب مكان التنفيذ ضمن الشيفرة البرمجية عند ضغطك على إشارة المقاطعة interrupt signal. تُزوّدنا راست أيضًا لحسن الحظ بطريقة أخرى للخروج قسريًا من حلقة تكرارية باستخدام شيفرة برمجية، إذ يمكننا استخدام الكلمة المفتاحية break داخل الحلقة التكرارية لإخبار البرنامج بأننا نريد إيقاف تنفيذ الحلقة. تذكر أننا فعلنا ذلك عند كتابتنا شيفرة برنامج لعبة التخمين سابقًا وذلك للخروج من البرنامج عندما يفوز اللاعب بتخمين الرقم الصحيح. كما أننا استخدمنا أيضًا الكلمة المفتاحية continue في لعبة التخمين، وهي كلمة تُخبر البرنامج بتخطي أي شيفرة برمجية متبقية داخل الحلقة في التكرار الحالي والذهاب إلى التكرار اللاحق. إعادة قيم من الحلقات واحدة من استخدامات loop هي إعادة تنفيذ عملية قد تفشل، مثل التحقق إذا أنهى خيط thread ما العمل، وقد تحتاج أيضًا إلى تمرير نتيجة هذه العملية خارج الحلقة إلى باقي الشيفرة البرمجية؛ ولتحقيق ذلك يمكنك إضافة القيمة التي تُريد إعادتها بعد تعبير break، إذ سيتوقف عندها تنفيذ الحلقة وستُعاد القيمة خارج الحلقة حتى يتسنى لك استخدامها كما هو موضح: fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); } نُصرّح عن متغير باسم counter ونُهيّئه بالقيمة "0" قبل الحلقة التكرارية، ثم نصرح عن متغير باسم result لتخزين القيمة المُعادة من الحلقة. نُضيف 1 إلى المتغير counter عند كل تكرار للحلقة ومن ثم نتحقق فيما إذا كان المتغير counter مساويًا إلى القيمة 10، وعندما يتحقق هذا الشرط نستخدم الكلمة المفتاحية break مع القيمة counter * 2، ونستخدم بعد الحلقة فاصلة منقوطة لإنهاء التعليمة التي تُسند القيمة إلى result، وأخيرًا نطبع القيمة result التي تكون في هذه الحالة مساويةً إلى 20. تسمية الحلقات للتفريق بين عدة حلقات تُطبّق break و continue في حال وجود حلقة داخل حلقة على الحلقة الداخلية الموجود بها الكلمة المفتاحية، ويمكنك تحديد تسمية الحلقة loop label اختياريًا عند إنشاء حلقة حتى يُمكنك استخدام break أو continue مع تحديد تسمية الحلقة بدلًا من تنفيذ عملها على الحلقة الداخلية. يجب أن تبدأ تسمية الحلقة بعلامة تنصيص واحدة، ويوضح المثال التالي استخدام حلقتين متداخلتين: fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); } للحلقة الخارجية التسمية 'counting_up وستعدّ من 0 إلى 2، بينما تعدّ الحلقة الداخلية عديمة التسمية من 10 إلى 9. لا تُحدد break الأولى أي تسمية لذلك ستغادر الحلقة الداخلية فقط، بينما ستغادر تعليمة break 'counting_up الحلقة الخارجية، وتطبع الشيفرة البرمجية السابقة ما يلي: $ cargo run Compiling loops v0.1.0 (file:///projects/loops) Finished dev [unoptimized + debuginfo] target(s) in 0.58s Running `target/debug/loops` count = 0 remaining = 10 remaining = 9 count = 1 remaining = 10 remaining = 9 count = 2 remaining = 10 End count = 2 الحلقات الشرطية باستخدام while سيحتاج البرنامج غالبًا إلى تقييم شرط داخل حلقة، بحيث يستمر تنفيذ الحلقة إذا كان الشرط محققًا وإلا فسيتوقف تنفيذها عن طريق استدعاء break وإيقاف الحلقة ومن الممكن تطبيق شيء مماثل باستخدام مزيج من loop و if و else و break، ويمكنك تجربة الأمر الآن داخل برنامج إذا أردت ذلك. يُعد هذا النمط شائعًا جدًا وهذا هو السبب وراء وجود بنية مُضمَّنة في راست لهذا الاستخدام تُدعى حلقة while. نستخدم في الشيفرة 3-3 التالية الحلقة while لتكرار الحلقة ثلاث مرات بالعدّ تنازليًا في كل مرة وعند الخروج من الحلقة نطبع رسالة ونُنهي البرنامج. اسم الملف: src/main.rs fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); } [الشيفرة 3-3: استخدام حلقة while لتنفيذ شيفرة برمجية عند تحقق شرط ما] يُغنينا استخدام هذه البنية عناء استخدام الكثير من التداخلات بواسطة loop و if و else و break كما أنه أكثر وضوحًا، إذ طالما يكون الشرط محققًا ستُنفّذ الحلقة وإلا فسيغادر الحلقة. استخدام for مع تجميعة Collection يمكنك اختيار البنية while للانتقال بين عناصر التجميعة مثل المصفوفات. توضح الشيفرة 3-4 ذلك الاستخدام بطباعة كل عنصر في المصفوفة a. اسم الملف: src/main.rs fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } } [الشيفرة 4: الانتقال بين عناصر التجميعة باستخدام حلقة while] إليك الشيفرة البرمجية التي تنتقل بين عناصر المصفوفة، إذ تبدأ من الدليل "0" وتنتقل إلى ما يليه لحد الوصول إلى الدليل الأخير في المصفوفة (أي عندما يكون index < 5 غير محقق). سيطبع تنفيذ الشيفرة السابقة عناصر المصفوفة كما يلي: $ cargo run Compiling loops v0.1.0 (file:///projects/loops) Finished dev [unoptimized + debuginfo] target(s) in 0.32s Running `target/debug/loops` the value is: 10 the value is: 20 the value is: 30 the value is: 40 the value is: 50 تظهر جميع قيم عناصر المصفوفة الخمسة ضمن الطرفية كما هو متوقع. على الرغم من أن index سيصل إلى القيمة 5 في مرحلة ما إلا أن تنفيذ الحلقة يتوقف قبل محاولة طباعة العنصر السادس من المصفوفة. سلوك البرنامج معرض للخطأ، فقد يهلع البرنامج إذا كانت قيمة الدليل أو الشرط الذي يُفحص خاطئة، على سبيل المثال إذا استبدلنا تعريف المصفوفة a ليكون لها أربعة عناصر ولكننا نسينا تحديث الشرط إلى while index < 4، ستهلع الشيفرة البرمجية، كما أن هذا السلوك بطيء لأن المصرف يُضيف شيفرة برمجية عند وقت التشغيل لإنجاز التحقق من الشرط فيما إذا كان الدليل خارج حدود المصفوفة عند كل تكرار ضمن الحلقة. بدلًا من ذلك، يمكننا استخدام حلقة for وتنفيذ شيفرة برمجية لكل عنصر في التجميعة، وتبدو الحلقة بالشكل الموضح في الشيفرة 3-5. اسم الملف: src/main.rs fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } } [الشيفرة 3-5: الانتقال بين عناصر التجميعة باستخدام حلقة for] ستجد الخرج ذاته للشيفرة 3-4 عند تنفيذ الشيفرة السابقة، والأهم هنا أننا زدنا من أمان شيفرتنا البرمجية وأزلنا أي فرص للأخطاء الناجمة عن الذهاب إلى ما بعد حدود المصفوفة، أو عدم الذهاب إلى نهايتها وبالتالي عدم طباعة جميع العناصر. لست مضطرًا لتغيير أي شيفرة برمجية باستخدام حلقة for إذا عدلت رقم العناصر في المصفوفة، الأمر الذي ستضطر لفعله في حال استخدامك للشيفرة 3-4. تُستخدم حلقات for كثيرًا نظرًا للأمان والإيجاز التي تقدمه مقارنةً ببُنى الحلقات الأخرى الموجودة في راست، حتى أن معظم مبرمجين لغة راست يفضلون استخدام الحلقة for عند تنفيذ شيفرة برمجية يُفترض تنفيذها عدد معين من المرات كما هو الحال في مثال العد التنازلي الذي أنجزناه باستخدام حلقة while في الشيفرة 3-3، ويُنجز ذلك الأمر باستخدام Range المُضمَّن في المكتبة القياسية، والذي يولّد بدوره جميع الأرقام في السلسلة بدءًا من رقم معين وانتهاءً برقم آخر. إليك ما سيبدو عليه برنامج العد التنازلي باستخدام حلقة for وتابع آخر لم نتكلم عنه بعد وهو rev، المُستخدم في عكس المجال: اسم الملف: src/main.rs fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); } تبدو هذه الشيفرة البرمجية أفضل، أليس كذلك؟ ترجمة -وبتصرف- للقسم Control Flow من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: الملكية Ownership في لغة رست المقال السابق: كيفية كتابة الدوال Functions والتعليقات Comments في لغة راست Rust أنواع البيانات Data Types في لغة رست Rust المتغيرات والتعديل عليها في لغة رست -

 تنتشر الدوال في معظم شيفرات راست البرمجية، وقد رأيت سابقًا واحدةً من أهم الدوال في اللغة ألا وهي دالة main وهي نقطة البداية للكثير من البرامج، كما أنك رأيت أيضًا الكلمة المفتاحية fn التي تسمح لك بالتصريح عن دالةٍ جديدة. تستخدم شيفرة راست البرمجية نمط الثعبان snake case نمطًا اصطلاحيًا لأسماء الدوال والمتغيرات، إذ تكون الأحرف في هذا النمط جميعها أحرف صغيرة ويفصل ما بين الكلمة والأخرى شرطة سفلية. إليك برنامجًا يحتوي على مثال لتعريف دالة: اسم الملف: src/main.rs fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); } نعرّف الدالة في راست بإدخال الكلمة fn متبوعةً باسم الدالة يليها قوسين هلاليّين parentheses ()، بينما تُخبر الأقواس المعقوفة curly brackets {} المصرف بموضع بداية وانتهاء متن الدالة. يُمكننا استدعاء أي دالة عرفناها سابقًا بإدخال اسمها متبوعًا بقوسين هلاليّين، وبما أن الدالة another_function مُعرفةٌ في البرنامج، يمكننا استدعائها من داخل الدالة main. لاحظ أننا عرفنا another_function بعد دالة main في الشيفرة البرمجية إلا أنه يمكننا تعريفها قبلها أيضًا، إذ لا تُبالي راست بموضع تعريف الدوال طالما يوجد التعريف داخل النطاق scope الذي استدعيت الدالة منه. دعنا نبدأ مشروعًا ثنائيًا binary project جديدًا باسم "functions" للنظر إلى الدوال بتعمّق أكبر، وضع مثال "another_function" السابق في ملف "src/main.rs" ونفّذه. يجب أن يظهر لك الخرج التالي: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 0.28s Running `target/debug/functions` Hello, world! Another function. تُنفّذ هذه السطور البرمجية بالترتيب التي ظهرت فيه في الدالة main، أي تُطبع الرسالة "Hello, world!" أولًا، ثم تُستدعى الدالة another_function وتُطبع رسالتها. المعاملات يُمكننا تعريف الدوال بحيث تحتوي على معاملات parameters، وهي متغيرات خاصة تنتمي إلى بصمة الدالة function's signature، ويُمكنك استخدام قيم فعلية لهذه الدالة عند احتوائها على معاملات، وتُدعى هذه القيم بالوسطاء arguments إلا أنه غالبًا ما يُستخدم المصطلحان معامل ووسيط بصورةٍ تبادلية interchangeably لأي من المتغيرات في تعريف الدالة أو القيم الفعلية المُمرّرة للدالة عند استدعائها. نُضيف معاملًا في هذا الإصدار من الدالة another_function: اسم الملف: src/main.rs fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); } يجب أن تحصل على الخرج التالي عند تجربتك لتشغيل البرنامج: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 1.21s Running `target/debug/functions` The value of x is: 5 يحتوي تصريح الدالة another_function على معامل واحد باسم x وهو من النوع i32، بالتالي يضع الماكرو !println القيمة 5 عند تمريرها إلى الدالة مثل قيمة للمعامل x في تنسيق السلسلة النصية. يجب التصريح عن نوع كل معامل في بصمة الدالة، وهذا أمر متعمد في تصميم لغة راست؛ إذ يعني تحديد أنواع المعاملات في تعريف الدالة أن المُصرّف لن يحتاج منك استخدامها في مكان آخر ضمن الشيفرة البرمجية لمعرفة النوع الذي قصدته، وبالتالي يستطيع المصرف إعطاء رسائل خطأ ذات معنًى ومضمون مُساعد أكثر إذا كان يعلم نوع المعاملات التي تأخذها الدالة. يجب فصل المعاملات بالفاصلة عند تعريف أكثر من معامل واحد كما هو موضح: اسم الملف: src/main.rs fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); } يُنشئ هذا المثال دالةً باسم print_labeled_measurment بمعاملَين، إذ يسمى المعامل الأول value وهو من النوع i32، بينما يسمى النوع الثاني unit_label وهو من النوع char، وتطبع الدالة نصًّا يحتوي على كل من value و unit_label. دعنا نجرّب تشغيل الشيفرة البرمجية السابقة، وذلك باستبدال البرنامج الموجود حاليًا في ملف "src/main.rs" لمشروع "function" بالشيفرة البرمجية السابقة، وتشغيل البرنامج باستخدام cargo run: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/functions` The measurement is: 5h نحصل على الخرج السابق طالما استُدعيت الدالة بالقيمة "5" للمعامل value والقيمة 'h' للمعامل unit_label. التعابير والتعليمات يتألف متن الدالة من مجموعة من التعليمات التي تنتهي -اختياريًا- بتعبير expression، والدوال التي غطيناها حتى الآن لم تتضمن تعبيرًا في نهاية التعليمة، إلا أننا قد رأينا تعبيرًا بمثابة جزء من تعليمة. من المهم أن نميّز بين المصطلحين، وذلك لأن راست لغة مبنية على التعابير وذلك الأمر لا ينطبق على بقية اللغات، لذا دعنا ننظر إلى ماهية التعليمات والتعابير وما هو الفرق فيما بينهما وكيف يؤثر كل منهما على متن الدالة. التعليمات هي توجيهات تُجري عمليات ما ولا تُعيد قيمةً، بينما تُقيّم التعابير إلى قيمة ناتجة. دعنا ننظر إلى بعض الأمثلة. استخدمنا في الحقيقة سابقًا كلًا من التعابير والتعليمات، وذلك بإنشاء متغير وإسناد قيمة إليه باستخدام الكلمة المفتاحية let، نجد في الشيفرة 3-1 التعليمة let y = 6;. اسم الملف: src/main.rs fn main() { let y = 6; } [الشيفرة 3-1: تعريف دالة main يحتوي على تعليمة واحدة] تُعدّ تعاريف الدوال تعليمات أيضًا، فالمثال السابق هو تعليمة واحدة بذات نفسه. لا تُعيد التعليمات أي قيمة، لذلك لا يُمكنك إسناد تعليمة let إلى متغير آخر كما نحاول في المثال التالي، إذ ستحصل على خطأ: اسم الملف: src/main.rs fn main() { let x = (let y = 6); } ستحصل على الخطأ التالي عند محاولتك لتشغيل البرنامج السابق: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) error: expected expression, found statement (`let`) --> src/main.rs:2:14 | 2 | let x = (let y = 6); | ^^^^^^^^^ | = note: variable declaration using `let` is a statement error[E0658]: `let` expressions in this position are unstable --> src/main.rs:2:14 | 2 | let x = (let y = 6); | ^^^^^^^^^ | = note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information warning: unnecessary parentheses around assigned value --> src/main.rs:2:13 | 2 | let x = (let y = 6); | ^ ^ | = note: `#[warn(unused_parens)]` on by default help: remove these parentheses | 2 - let x = (let y = 6); 2 + let x = let y = 6; | For more information about this error, try `rustc --explain E0658`. warning: `functions` (bin "functions") generated 1 warning error: could not compile `functions` due to 2 previous errors; 1 warning emitted لا تُعيد التعليمة let y = 6 أي قيمة، لذا لا يوجد هناك أي قيمة لإسنادها إلى x، وهذا الأمر مختلفٌ عن باقي لغات البرمجة مثل سي C وروبي Ruby إذ تُعيد عملية الإسناد في هذه اللغات قيمة الإسناد، وبالتالي يمكنك كتابة التعليمة x = y = 6 بحيث تُسند القيمة 6 إلى كل من x و y إلا أن هذا الأمر لا ينطبق في راست. تُقيِّم وتركّب التعابير معظم الشيفرة البرمجية التي ستكتبها في راست، خُذ على سبيل المثال تعبير العملية الحسابية 5 + 6، التي تُقيّم إلى القيمة 11. يمكن أن تكون التعابير جزءًا من التعليمات، ففي الشيفرة 3-1 تُمثّل 6 في التعليمة let y = 6; تعبيرًا يُقيّم إلى القيمة 6. يُعد كل من استدعاء الدالة واستدعاء الماكرو وإنشاء نطاق جديد باستخدام الأقواس المعقوفة تعبيرًا، على سبيل المثال: اسم الملف: src/main.rs fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); } التعبير التالي هو جزءٌ يُقيم إلى القيمة 4: { let x = 3; x + 1 } تُسند القيمة فيما بعد إلى y كجزء من تعليمة let، لاحظ أن السطر x + 1 لا يحتوي على فاصلة منقوطة في نهايته مثل معظم الأسطر التي كتبناها لحد اللحظة، وذلك لأن التعابير لا تحتوي على فاصلة منقوطة في النهاية، وإذا أضفت الفاصلة المنقوطة فسيتحول التعبير إلى تعليمة ولن يكون هناك أي قيمة مُعادة حينها. تذكّر ما سبق بينما نتكلم عن القيم المُعادة من الدوال والتعابير لاحقًا. الدوال التي تعيد قيمة يُمكن للدوال أن تُعيد قيمًا إلى الشيفرة البرمجية التي استدعتها، ولا نُسمّي القيم المُعادة هذه إلا أنه يجب التصريح عن نوعها باستخدام السهم <-. القيمة المُعادة من الدالة في راست هي مرادف لقيمة التعبير الأخير في متن الدالة، ويُمكنك إعادة قيمة مبكرًا من الدالة باستخدام الكلمة المفتاحية return وتحديد القيمة بعدها، إلا أن معظم الدوال تُعيد قيمة التعبير الأخير ضمنيًا. إليك مثالًا عن دالة تُعيد قيمة: اسم الملف: src/main.rs fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); } لا يوجد في الدالة five أي استدعاءات، أو ماكرو، أو حتى تعليمة let، بل فقط الرقم 5، وتلك دالة صالحة في لغة راست. لاحظ أن نوع القيمة المُعادة من الدالة مُحدّد أيضًا بكتابة -> i32. يجب أن تحصل على الخرج التالي إذا جرّبت تشغيل الشيفرة البرمجية: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 0.30s Running `target/debug/functions` The value of x is: 5 تُمثّل القيمة 5 في الدالة five القيمة المُعادة من الدالة، وهذا السبب في تحديدنا لنوع القيمة المعادة بالنوع i32، لكن دعنا ننظر إلى الدالة بتعمُّق أكبر، إذ يوجد جزآن مُهمّان، هما: أولًا، يوضح السطر let x = five(); أننا نستخدم القيمة المُعادة من الدالة لإسنادها مثل قيمة أولية للمتغير وبما أن الدالة تُعيد القيمة 5، فهذا الأمر موافق لكتابة السطر البرمجي التالي تمامًا: let x = 5; ثانيًا، لا تحتوي الدالة five أي معاملات وتُعرِّف نوع القيمة المعادة، إلا أن متن الدالة يحتوي على القيمة 5 بصورةٍ منفردة دون فاصلة منقوطة وذلك لأنه تعبير نُريد قيمته على أنها قيمة الدالة المُعادة. دعنا ننظر إلى مثال آخر: اسم الملف: src/main.rs fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 } سيطبع تنفيذ الشيفرة البرمجية السابقة The value of x is: 6، إلا أننا سنحصل على خطأ إذا استبدلنا الفاصلة المنقوطة في نهاية السطر x + 1 مما يُغيّر السطر من تعبير إلى تعليمة. اسم الملف: src/main.rs fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1; } تصريف الشيفرة البرمجية السابقة سيتسبب بخطأ كما هو موضح: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) error[E0308]: mismatched types --> src/main.rs:7:24 | 7 | fn plus_one(x: i32) -> i32 { | -------- ^^^ expected `i32`, found `()` | | | implicitly returns `()` as its body has no tail or `return` expression 8 | x + 1; | - help: remove this semicolon For more information about this error, try `rustc --explain E0308`. error: could not compile `functions` due to previous error تُشير الرسالة الأساسية إلى أن سبب الخطأ هو بسبب "أنواع غير متوافقة mismatched types". يدل تعريف الدالة plus_one على أنها تُعيد قيمةً من النوع i32 إلا أن التعبير لا يُقيَّم إلى قيمة، وهو الشيء المُعبّر بالقوسين () نوع الوحدة unit type، وبالتالي لا يوجد هناك أي قيمة لإعادتها مما يتناقض مع تعريف الدالة ويتسبب بخطأ. توفّر راست في رسالة الخطأ رسالةً لمساعدتك في حل هذه المشكلة إذ تقترح إزالة الفاصلة المنقوطة مما سيحلّ المشكلة بدوره. التعليقات يسعى جميع المبرمجين لجعل شيفرتهم البرمجية سهلة الفهم، إلا أن الشرح الإضافي في بعض الأحيان لازم، وهنا تأتي أهمية التعليقات في الشيفرة المصدرية التي يتجاهلها المُصرّف إلا أنها مفيدة بحقّ للناس الذين يقرؤون شيفرتك المصدرية. إليك تعليقًا بسيطًا: // hello, world يبدأ التعليق في لغة راست بشرطتين مائلتين ويستمر التعليق إلى نهاية السطر، وإذا أردت استخدام التعليق ليشمل عدّة أسطر فعليك استخدام // في كل سطر كما يلي: // So we’re doing something complicated here, long enough that we need // multiple lines of comments to do it! Whew! Hopefully, this comment will // explain what’s going on. يُمكن إضافة التعليقات في نهاية الأسطر البرمجية: اسم الملف: src/main.rs fn main() { let lucky_number = 7; // I’m feeling lucky today } إلا أنك غالبًا ما سترى التعليقات بالتنسيق التالي على سطر منفصل عن بقية الشيفرة البرمجية التي تشرحها: اسم الملف: src/main.rs fn main() { // I’m feeling lucky today let lucky_number = 7; } يوجد طريقة أخرى لكتابة التعليقات ألا وهي التعليقات التوثيقية documentation comments التي سنناقشها لاحقًا. ترجمة -وبتصرف- للقسم Functions والقسم Comments من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: التحكم بسير تنفيذ برامج رست Rust المقال السابق: أنواع البيانات Data Types في لغة رست Rust تعلم لغة رست Rust: البدايات برمجة لعبة تخمين الأرقام بلغة رست Rust
تنتشر الدوال في معظم شيفرات راست البرمجية، وقد رأيت سابقًا واحدةً من أهم الدوال في اللغة ألا وهي دالة main وهي نقطة البداية للكثير من البرامج، كما أنك رأيت أيضًا الكلمة المفتاحية fn التي تسمح لك بالتصريح عن دالةٍ جديدة. تستخدم شيفرة راست البرمجية نمط الثعبان snake case نمطًا اصطلاحيًا لأسماء الدوال والمتغيرات، إذ تكون الأحرف في هذا النمط جميعها أحرف صغيرة ويفصل ما بين الكلمة والأخرى شرطة سفلية. إليك برنامجًا يحتوي على مثال لتعريف دالة: اسم الملف: src/main.rs fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); } نعرّف الدالة في راست بإدخال الكلمة fn متبوعةً باسم الدالة يليها قوسين هلاليّين parentheses ()، بينما تُخبر الأقواس المعقوفة curly brackets {} المصرف بموضع بداية وانتهاء متن الدالة. يُمكننا استدعاء أي دالة عرفناها سابقًا بإدخال اسمها متبوعًا بقوسين هلاليّين، وبما أن الدالة another_function مُعرفةٌ في البرنامج، يمكننا استدعائها من داخل الدالة main. لاحظ أننا عرفنا another_function بعد دالة main في الشيفرة البرمجية إلا أنه يمكننا تعريفها قبلها أيضًا، إذ لا تُبالي راست بموضع تعريف الدوال طالما يوجد التعريف داخل النطاق scope الذي استدعيت الدالة منه. دعنا نبدأ مشروعًا ثنائيًا binary project جديدًا باسم "functions" للنظر إلى الدوال بتعمّق أكبر، وضع مثال "another_function" السابق في ملف "src/main.rs" ونفّذه. يجب أن يظهر لك الخرج التالي: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 0.28s Running `target/debug/functions` Hello, world! Another function. تُنفّذ هذه السطور البرمجية بالترتيب التي ظهرت فيه في الدالة main، أي تُطبع الرسالة "Hello, world!" أولًا، ثم تُستدعى الدالة another_function وتُطبع رسالتها. المعاملات يُمكننا تعريف الدوال بحيث تحتوي على معاملات parameters، وهي متغيرات خاصة تنتمي إلى بصمة الدالة function's signature، ويُمكنك استخدام قيم فعلية لهذه الدالة عند احتوائها على معاملات، وتُدعى هذه القيم بالوسطاء arguments إلا أنه غالبًا ما يُستخدم المصطلحان معامل ووسيط بصورةٍ تبادلية interchangeably لأي من المتغيرات في تعريف الدالة أو القيم الفعلية المُمرّرة للدالة عند استدعائها. نُضيف معاملًا في هذا الإصدار من الدالة another_function: اسم الملف: src/main.rs fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); } يجب أن تحصل على الخرج التالي عند تجربتك لتشغيل البرنامج: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 1.21s Running `target/debug/functions` The value of x is: 5 يحتوي تصريح الدالة another_function على معامل واحد باسم x وهو من النوع i32، بالتالي يضع الماكرو !println القيمة 5 عند تمريرها إلى الدالة مثل قيمة للمعامل x في تنسيق السلسلة النصية. يجب التصريح عن نوع كل معامل في بصمة الدالة، وهذا أمر متعمد في تصميم لغة راست؛ إذ يعني تحديد أنواع المعاملات في تعريف الدالة أن المُصرّف لن يحتاج منك استخدامها في مكان آخر ضمن الشيفرة البرمجية لمعرفة النوع الذي قصدته، وبالتالي يستطيع المصرف إعطاء رسائل خطأ ذات معنًى ومضمون مُساعد أكثر إذا كان يعلم نوع المعاملات التي تأخذها الدالة. يجب فصل المعاملات بالفاصلة عند تعريف أكثر من معامل واحد كما هو موضح: اسم الملف: src/main.rs fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); } يُنشئ هذا المثال دالةً باسم print_labeled_measurment بمعاملَين، إذ يسمى المعامل الأول value وهو من النوع i32، بينما يسمى النوع الثاني unit_label وهو من النوع char، وتطبع الدالة نصًّا يحتوي على كل من value و unit_label. دعنا نجرّب تشغيل الشيفرة البرمجية السابقة، وذلك باستبدال البرنامج الموجود حاليًا في ملف "src/main.rs" لمشروع "function" بالشيفرة البرمجية السابقة، وتشغيل البرنامج باستخدام cargo run: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/functions` The measurement is: 5h نحصل على الخرج السابق طالما استُدعيت الدالة بالقيمة "5" للمعامل value والقيمة 'h' للمعامل unit_label. التعابير والتعليمات يتألف متن الدالة من مجموعة من التعليمات التي تنتهي -اختياريًا- بتعبير expression، والدوال التي غطيناها حتى الآن لم تتضمن تعبيرًا في نهاية التعليمة، إلا أننا قد رأينا تعبيرًا بمثابة جزء من تعليمة. من المهم أن نميّز بين المصطلحين، وذلك لأن راست لغة مبنية على التعابير وذلك الأمر لا ينطبق على بقية اللغات، لذا دعنا ننظر إلى ماهية التعليمات والتعابير وما هو الفرق فيما بينهما وكيف يؤثر كل منهما على متن الدالة. التعليمات هي توجيهات تُجري عمليات ما ولا تُعيد قيمةً، بينما تُقيّم التعابير إلى قيمة ناتجة. دعنا ننظر إلى بعض الأمثلة. استخدمنا في الحقيقة سابقًا كلًا من التعابير والتعليمات، وذلك بإنشاء متغير وإسناد قيمة إليه باستخدام الكلمة المفتاحية let، نجد في الشيفرة 3-1 التعليمة let y = 6;. اسم الملف: src/main.rs fn main() { let y = 6; } [الشيفرة 3-1: تعريف دالة main يحتوي على تعليمة واحدة] تُعدّ تعاريف الدوال تعليمات أيضًا، فالمثال السابق هو تعليمة واحدة بذات نفسه. لا تُعيد التعليمات أي قيمة، لذلك لا يُمكنك إسناد تعليمة let إلى متغير آخر كما نحاول في المثال التالي، إذ ستحصل على خطأ: اسم الملف: src/main.rs fn main() { let x = (let y = 6); } ستحصل على الخطأ التالي عند محاولتك لتشغيل البرنامج السابق: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) error: expected expression, found statement (`let`) --> src/main.rs:2:14 | 2 | let x = (let y = 6); | ^^^^^^^^^ | = note: variable declaration using `let` is a statement error[E0658]: `let` expressions in this position are unstable --> src/main.rs:2:14 | 2 | let x = (let y = 6); | ^^^^^^^^^ | = note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information warning: unnecessary parentheses around assigned value --> src/main.rs:2:13 | 2 | let x = (let y = 6); | ^ ^ | = note: `#[warn(unused_parens)]` on by default help: remove these parentheses | 2 - let x = (let y = 6); 2 + let x = let y = 6; | For more information about this error, try `rustc --explain E0658`. warning: `functions` (bin "functions") generated 1 warning error: could not compile `functions` due to 2 previous errors; 1 warning emitted لا تُعيد التعليمة let y = 6 أي قيمة، لذا لا يوجد هناك أي قيمة لإسنادها إلى x، وهذا الأمر مختلفٌ عن باقي لغات البرمجة مثل سي C وروبي Ruby إذ تُعيد عملية الإسناد في هذه اللغات قيمة الإسناد، وبالتالي يمكنك كتابة التعليمة x = y = 6 بحيث تُسند القيمة 6 إلى كل من x و y إلا أن هذا الأمر لا ينطبق في راست. تُقيِّم وتركّب التعابير معظم الشيفرة البرمجية التي ستكتبها في راست، خُذ على سبيل المثال تعبير العملية الحسابية 5 + 6، التي تُقيّم إلى القيمة 11. يمكن أن تكون التعابير جزءًا من التعليمات، ففي الشيفرة 3-1 تُمثّل 6 في التعليمة let y = 6; تعبيرًا يُقيّم إلى القيمة 6. يُعد كل من استدعاء الدالة واستدعاء الماكرو وإنشاء نطاق جديد باستخدام الأقواس المعقوفة تعبيرًا، على سبيل المثال: اسم الملف: src/main.rs fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); } التعبير التالي هو جزءٌ يُقيم إلى القيمة 4: { let x = 3; x + 1 } تُسند القيمة فيما بعد إلى y كجزء من تعليمة let، لاحظ أن السطر x + 1 لا يحتوي على فاصلة منقوطة في نهايته مثل معظم الأسطر التي كتبناها لحد اللحظة، وذلك لأن التعابير لا تحتوي على فاصلة منقوطة في النهاية، وإذا أضفت الفاصلة المنقوطة فسيتحول التعبير إلى تعليمة ولن يكون هناك أي قيمة مُعادة حينها. تذكّر ما سبق بينما نتكلم عن القيم المُعادة من الدوال والتعابير لاحقًا. الدوال التي تعيد قيمة يُمكن للدوال أن تُعيد قيمًا إلى الشيفرة البرمجية التي استدعتها، ولا نُسمّي القيم المُعادة هذه إلا أنه يجب التصريح عن نوعها باستخدام السهم <-. القيمة المُعادة من الدالة في راست هي مرادف لقيمة التعبير الأخير في متن الدالة، ويُمكنك إعادة قيمة مبكرًا من الدالة باستخدام الكلمة المفتاحية return وتحديد القيمة بعدها، إلا أن معظم الدوال تُعيد قيمة التعبير الأخير ضمنيًا. إليك مثالًا عن دالة تُعيد قيمة: اسم الملف: src/main.rs fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); } لا يوجد في الدالة five أي استدعاءات، أو ماكرو، أو حتى تعليمة let، بل فقط الرقم 5، وتلك دالة صالحة في لغة راست. لاحظ أن نوع القيمة المُعادة من الدالة مُحدّد أيضًا بكتابة -> i32. يجب أن تحصل على الخرج التالي إذا جرّبت تشغيل الشيفرة البرمجية: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) Finished dev [unoptimized + debuginfo] target(s) in 0.30s Running `target/debug/functions` The value of x is: 5 تُمثّل القيمة 5 في الدالة five القيمة المُعادة من الدالة، وهذا السبب في تحديدنا لنوع القيمة المعادة بالنوع i32، لكن دعنا ننظر إلى الدالة بتعمُّق أكبر، إذ يوجد جزآن مُهمّان، هما: أولًا، يوضح السطر let x = five(); أننا نستخدم القيمة المُعادة من الدالة لإسنادها مثل قيمة أولية للمتغير وبما أن الدالة تُعيد القيمة 5، فهذا الأمر موافق لكتابة السطر البرمجي التالي تمامًا: let x = 5; ثانيًا، لا تحتوي الدالة five أي معاملات وتُعرِّف نوع القيمة المعادة، إلا أن متن الدالة يحتوي على القيمة 5 بصورةٍ منفردة دون فاصلة منقوطة وذلك لأنه تعبير نُريد قيمته على أنها قيمة الدالة المُعادة. دعنا ننظر إلى مثال آخر: اسم الملف: src/main.rs fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 } سيطبع تنفيذ الشيفرة البرمجية السابقة The value of x is: 6، إلا أننا سنحصل على خطأ إذا استبدلنا الفاصلة المنقوطة في نهاية السطر x + 1 مما يُغيّر السطر من تعبير إلى تعليمة. اسم الملف: src/main.rs fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1; } تصريف الشيفرة البرمجية السابقة سيتسبب بخطأ كما هو موضح: $ cargo run Compiling functions v0.1.0 (file:///projects/functions) error[E0308]: mismatched types --> src/main.rs:7:24 | 7 | fn plus_one(x: i32) -> i32 { | -------- ^^^ expected `i32`, found `()` | | | implicitly returns `()` as its body has no tail or `return` expression 8 | x + 1; | - help: remove this semicolon For more information about this error, try `rustc --explain E0308`. error: could not compile `functions` due to previous error تُشير الرسالة الأساسية إلى أن سبب الخطأ هو بسبب "أنواع غير متوافقة mismatched types". يدل تعريف الدالة plus_one على أنها تُعيد قيمةً من النوع i32 إلا أن التعبير لا يُقيَّم إلى قيمة، وهو الشيء المُعبّر بالقوسين () نوع الوحدة unit type، وبالتالي لا يوجد هناك أي قيمة لإعادتها مما يتناقض مع تعريف الدالة ويتسبب بخطأ. توفّر راست في رسالة الخطأ رسالةً لمساعدتك في حل هذه المشكلة إذ تقترح إزالة الفاصلة المنقوطة مما سيحلّ المشكلة بدوره. التعليقات يسعى جميع المبرمجين لجعل شيفرتهم البرمجية سهلة الفهم، إلا أن الشرح الإضافي في بعض الأحيان لازم، وهنا تأتي أهمية التعليقات في الشيفرة المصدرية التي يتجاهلها المُصرّف إلا أنها مفيدة بحقّ للناس الذين يقرؤون شيفرتك المصدرية. إليك تعليقًا بسيطًا: // hello, world يبدأ التعليق في لغة راست بشرطتين مائلتين ويستمر التعليق إلى نهاية السطر، وإذا أردت استخدام التعليق ليشمل عدّة أسطر فعليك استخدام // في كل سطر كما يلي: // So we’re doing something complicated here, long enough that we need // multiple lines of comments to do it! Whew! Hopefully, this comment will // explain what’s going on. يُمكن إضافة التعليقات في نهاية الأسطر البرمجية: اسم الملف: src/main.rs fn main() { let lucky_number = 7; // I’m feeling lucky today } إلا أنك غالبًا ما سترى التعليقات بالتنسيق التالي على سطر منفصل عن بقية الشيفرة البرمجية التي تشرحها: اسم الملف: src/main.rs fn main() { // I’m feeling lucky today let lucky_number = 7; } يوجد طريقة أخرى لكتابة التعليقات ألا وهي التعليقات التوثيقية documentation comments التي سنناقشها لاحقًا. ترجمة -وبتصرف- للقسم Functions والقسم Comments من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: التحكم بسير تنفيذ برامج رست Rust المقال السابق: أنواع البيانات Data Types في لغة رست Rust تعلم لغة رست Rust: البدايات برمجة لعبة تخمين الأرقام بلغة رست Rust -
 نستعرض في هذا المقال كيفية التعامل مع المحارف في لغة سي باستخدام دوال المكتبات القياسية، إضافةً إلى التوطين وإعدادات اللغة المحلية locale. التعامل مع المحارف هناك مجموعةٌ متنوعةٌ من الدوال تهدف لفحص وربط mapping المحارف، إذ تسمح لك دوال الفحص test functions -التي سنناقشها أولًا- بفحص فيما إذا كان المحرف من نوع معين، مثل حرف أبجدي، أو حرف صغير أم كبير، أو محرف رقمي، أو محرف تحكّم control character، أو إشارة ترقيم، أو محرف قابل للطباعة أو لا، وهكذا. تُعيد دوال فحص المحرف قيمة عدد صحيح integer تساوي الصفر إذا لم يكن المحرف المُحدّد منتميًا إلى التصنيف المذكور، أو قيمة غير صفرية عدا ذلك، ويأخذ هذا النوع من الدوال وسيطًا ذا قيمة عدد صحيح تُمثّل قيمته من نوع "unsigned char"، أو عدد صحيح ثابت قيمته "EOF" مثل تلك القيمة المُعادة من دوال مشابهة، مثل getchar()، ونحصل على سلوك غير معرّف خارج هذه الحالات. تعتمد هذه الدوال على إعدادات البرنامج المحلية: محرف الطباعة printing character هو عضو من مجموعة المحارف المعرّفة بحسب التطبيق، ويشغل كل محرف طباعة موقع طباعة واحد، ومحرف التحكم control character هو عضو من مجموعة المحارف المعرفة بحسب التطبيق أيضًا إلا أن كل محرف منها ليس بمحرف طباعة. إذا استخدمنا مجموعة محارف معيار ASCII 7-bit، ستكون محارف الطباعة بين الفراغ (0x20) وتيلدا tilde (0x7e)، بينما تكون محارف التحكم بين NUL (0x0) و US (0x1f) والمحرف DEL (0x7f). تجد أدناه ملخصًا يحتوي على جميع دوال فحص المحرف، ويجب تضمين ملف الترويسة <ctype.h> قبل استخدام أيّ منها. دالة isalnum(int c): تُعيد القيمة "True" إذا كان c محرفًا أبجديًا أو رقمًا؛ أي (isalpha(c)||isdigit(c)). دالة isalpha(int c): تُعيد القيمة "True" إذا كان هذا الشرط (isupper(c)||islower(c)) محققًا، كما أنها تُعيد القيمة True لمجموعة المحارف المُعرفة بحسب التطبيق التي لا تعيد القيمة True عند تمريرها على الدالة iscntrl أو isdigit أو ispunct أو isspace وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة iscntrl(int c): تُعيد القيمة True إذا كان المحرف محرف تحكم. دالة isdigit(int c): تُعيدالقيمة True إذا كان المحرف رقمًا عشريًا decimal. دالة isgraph(int c): تُعيد القيمة True إذا كان المحرف هو محرف طباعة عدا محرف المسافة الفارغة. دالة islower(int c): تُعيد القيمة True إذا كان المحرف محرفًا أبجديًا صغيرًا lower case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في C المحلية. دالة isprint(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة (متضمّنًا محرف المسافة الفارغة). دالة ispunct(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة عدا محرف المسافة الفارغة أو المحارف التي تُعيد القيمة True في دالة isalnum. دالة isspace(int c): تُعيد القيمة True إذا كان المحرف محرف مسافة بيضاء (المحرف ' ' أو \f أو \n أو \r أو \t أو \v) دالة isupper(int c): تُعيد القيمة True إذا كان المحرف محرف أبجديًا كبيرًا upper case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة isxdigit(int c): تُعيد القيمة True إذا كان المحرف رقم ستّ عشري صالح. هناك دالتان إضافيتان تربطان المحارف من مجموعةٍ إلى أخرى، إذ تُعيد الدالة tolower محرفًا صغيرًا موافقًا لمحرف كبير مُرِّر لها، على سبيل المثال: tolower('A') == 'a' تُعيد الدالة tolower المحرف ذاته، إذا تلقّت أي محرف مُغاير للمحارف الأبجدية الكبيرة. تربط الدالة toupper المعاكسة للدالة السابقة في عملها المحرف المُمرّر لها إلى مكافئه الكبير. تُجرى عملية الربط في الدالتين السابقتين فقط في حال وجود محرف موافق للمحرف المُمرّر لها، إذ لا تمتلك بعض اللغات محرفًا كبيرًا موافق لمحرف صغير والعكس صحيح. التوطين Localization نستطيع التحكم بالإعدادات المحليّة للبرنامج من هنا، ويصرح ملف الترويسة <locale.h> دوال setlocale و localeconv وعددًا من الماكرو: LC_ALL LC_COLLATE LC_CTYPE LC_MONETARY LC_NUMERIC LC_TIME تُستبدل جميع الماكرو بتعبير ثابت ذي قيمة عدد صحيح وتُستخدم القيمة الناتجة عن التعبير مكان الوسيط category في الدالة setlocale (يمكن تعريف أسماء أخرى أيضًا، ويجب أن يبدأ كل منها بـ LC_X، إذ يمثّل X المحرف الأبجدي الكبير)، ويُستخدم النوع struct lconv لتخزين المعلومات المتعلقة بتنسيق القيم الرقمية، ويُستخدَم CHAR_MAX للأعضاء من النوع char للدلالة على أن القيمة غير متوافرة في الإعدادات المحلية الحالية. يحتوي lconv على عضو واحد على الأقل من الأعضاء التالية: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } العضو الاستخدام تمثيله في إصدارات سي المحلية ملاحظات إضافية char *decimal_point يُستخدم المحرف للفاصلة العشرية في القيم المنسقة غير المالية. "." --- char *thousands_sep يُستخدم المحرف لفصل مجموعات من الخانات الواقعة على يسار الفاصلة العشرية في القيم المنسقة غير المالية. "" --- char *grouping يعرّف عدد الخانات في كل مجموعة في القيم المنسقة غير المالية، وتحدد القيمة CHAR_MAX أنه لا يوجد أي تجميع إضافي مطلوب، بينما تحدد القيمة 0 أنه يجب تكرار العنصر السابق للخانات الرقمية المتبقية، وإذا استُخدمت أي قيمة أخرى فهي تمثل قيمة العدد الصحيح المُمثل لعدد الخانات التي تتألف منها المجموعة الحالية (المحرف اللاحق في السلسلة النصية يُفسَّر قبل التجميع). "" يحدد "\3" أن الخانات يجب أن تجمع كل ثلاثة في مجموعة ويشير محرف الإنهاء الفارغ terminating null في السلسلة النصية إلى تكرار \3. char *int_curr_symbol تُستخدم المحارف الأولى الثلاث لتخزين رمز العملة العالمي الأبجدي لإصدار سي المحلي، بينما يُستخدم المحرف الرابع للفصل بين رمز العملة العالمي والكمية النقدية. "" --- char *currency_symbol يمثل رمز العملة للإصدار المحلي الحالي. "" --- char *mon_decimal_point المحرف المُستخدم مثل فاصلة عشرية عند تنسيق القيم النقدية. "" --- char *mon_thousands_sep يمثل فاصل مجموعات خانات الأرقام ذات القيم المنسقة بتنسيق نقدي. "" --- char *mon_grouping يعرف عدد الخانات في كل مجموعة عند تنسيق قيم نقدية، وتُفسّر عناصره على أنها جزء من التجميع "" --- char *positive_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية غير سالبة. "" --- char *negative_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية سالبة. "" --- char int_frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية منسقة عالميًا. CHAR_MAX --- char frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية غير منسقة عالميًا. CHAR_MAX --- char p_cs_precedes قيمة 1 تدل على وجوب إتباع currency_symbol بالقيمة عند تنسيق قيمة غير سالبة نقدية، بينما تدل القيمة 0 على إسباق currency_symbol بالقيمة. CHAR_MAX --- char p_sep_by_space قيمة 1 تدل على تفريق رمز العملة من القيمة بمسافة فارغة عند تنسيق قيمة غير سالبة نقدية، بينما تدل قيمة 0 على عدم وجود أي مسافة فارغة. CHAR_MAX --- char n_cs_precedes تشابه p_cs_precedes ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sep_by_space تشابه p_sep_by_space ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sign_posn يشابه p_sign_posn ولكن للقيم النقدية السالبة. CHAR_MAX --- char p_sign_posn يمثل موقع positive_sign للقيم النقدية المنسقة غير السالبة. CHAR_MAX يتبع الشروط التالية: تُحيط الأقواس القيمة النقدية وcurrency_symbol. تسبق السلسلة النصية كل من القيمة النقدية و currency_symbol. تتبع السلسلة النصية القيمة النقدية و currency_symbol. تسبق السلسلة النصية القيمة currency_symbol. تتبع السلسلة النصية القيمة currency_symbol دالة setlocale لضبط الإعدادات المحلية يكون تعريف دالة setlocale على النحو التالي: #include <locale.h> char *setlocale(int category, const char *locale); تسمح هذه الدالة بضبط إعدادات البرنامج المحلية، ويمكن ضبط جميع أجزاء الإصدار المحلي باختيار القيم المناسبة لوسيط التصنيف category كما يلي: القيمة LC_ALL: تضبط كامل الإصدار المحلي. القيمة LC_COLLATE: تعديل سلوك strcoll و strxfrm. القيمة LC_CTYPE: تعديل سلوك دوال التعامل مع المحارف character-handling. القيمة LC_MONETARY: تعديل تنسيق القيم النقدية المُعادة من دالة localeconv. القيمة LC_NUMERIC: تعديل محرف الفاصلة العشرية لتنسيق الدخل والخرج وبرامج تحويل السلاسل النصية. القيمة LC_TIME: تعديل سلوك strftime. يمكن ضبط قيم الإعدادات المحلية إلى: "C" تحديد البيئة ذات المتطلبات الدنيا لترجمة سي C "" تحديد البيئة الأصيلة المعرفة حسب التطبيق قيمة معرفة بحسب التنفيذ تحديد البيئة الموافقة لهذه القيمة البيئة الافتراضية عند بداية البرنامج موافقة للبيئة التي نحصل عليها عند تنفيذ التعليمة التالية: setlocale(LC_ALL, "C"); يمكن فحص السلسلة النصية الحالية المترافقة مع تصنيف ما بتمرير مؤشر فارغ null قيمةً للوسيط locale؛ نحصل على السلسلة النصية المترافقة مع التصنيف category المحدد للتوطين الجديد إذا كان من الممكن حصول التصنيف المحدد، وتُستخدم هذه السلسلة النصية في استدعاء لاحق للدالة setlocale مع تصنيفها المترافق لاستعادة الجزء الموافق من إعدادات البرنامج المحلية، وإذا كان التحديد غير ممكن الحصول نحصل على مؤشر فراغ دون تغيير الإعدادات المحلية. دالة localeconv يكون تصريح الدالة على النحو التالي: #include <locale.h> struct lconv *localeconv(void); تُعيد هذه الدالة مؤشرًا يشير إلى هيكل من النوع struct lconv، ويُضبط هذا المؤشر طبقًا للإعدادات المحلية الحالية ويمكن تغييره باستدعاء لاحق للدالة localconv أو setlocale، ويجب ألّا يكون الهيكل قابلًا للتعديل بأي طريقة أخرى. على سبيل المثال، إذا كانت إعدادات القيم النقدية المحلية الحالية مُمثّلةً حسب الإعدادات التالية: IR£1,234.56 تنسيق القيم الموجبة (IR£1,234.56) تنسيق القيم السالبة IRP 1,234.56 التنسيق العالمي يجب أن تحمل الأعضاء التي تمثّل القيم النقدية في lconv القيم التالية: int_curr_symbol "IRP " currency_symbol "IR£" mon_decimal_point "." mon_thousands_sep "," mon_grouping "\3" postive_sign "" negative_sign "" int_frac_digits 2 frac_digits 2 p_cs_precedes 1 p_sep_by_space 0 n_cs_precedes 1` n_sep_by_space 0 p_sign_posn CHAR_MAX n_sign_posn 0 ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: القيم الحدية والدوال الرياضية في لغة سي C المقال السابق: مقدمة إلى مكتبات لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C مدخل إلى المصفوفات في لغة سي C
نستعرض في هذا المقال كيفية التعامل مع المحارف في لغة سي باستخدام دوال المكتبات القياسية، إضافةً إلى التوطين وإعدادات اللغة المحلية locale. التعامل مع المحارف هناك مجموعةٌ متنوعةٌ من الدوال تهدف لفحص وربط mapping المحارف، إذ تسمح لك دوال الفحص test functions -التي سنناقشها أولًا- بفحص فيما إذا كان المحرف من نوع معين، مثل حرف أبجدي، أو حرف صغير أم كبير، أو محرف رقمي، أو محرف تحكّم control character، أو إشارة ترقيم، أو محرف قابل للطباعة أو لا، وهكذا. تُعيد دوال فحص المحرف قيمة عدد صحيح integer تساوي الصفر إذا لم يكن المحرف المُحدّد منتميًا إلى التصنيف المذكور، أو قيمة غير صفرية عدا ذلك، ويأخذ هذا النوع من الدوال وسيطًا ذا قيمة عدد صحيح تُمثّل قيمته من نوع "unsigned char"، أو عدد صحيح ثابت قيمته "EOF" مثل تلك القيمة المُعادة من دوال مشابهة، مثل getchar()، ونحصل على سلوك غير معرّف خارج هذه الحالات. تعتمد هذه الدوال على إعدادات البرنامج المحلية: محرف الطباعة printing character هو عضو من مجموعة المحارف المعرّفة بحسب التطبيق، ويشغل كل محرف طباعة موقع طباعة واحد، ومحرف التحكم control character هو عضو من مجموعة المحارف المعرفة بحسب التطبيق أيضًا إلا أن كل محرف منها ليس بمحرف طباعة. إذا استخدمنا مجموعة محارف معيار ASCII 7-bit، ستكون محارف الطباعة بين الفراغ (0x20) وتيلدا tilde (0x7e)، بينما تكون محارف التحكم بين NUL (0x0) و US (0x1f) والمحرف DEL (0x7f). تجد أدناه ملخصًا يحتوي على جميع دوال فحص المحرف، ويجب تضمين ملف الترويسة <ctype.h> قبل استخدام أيّ منها. دالة isalnum(int c): تُعيد القيمة "True" إذا كان c محرفًا أبجديًا أو رقمًا؛ أي (isalpha(c)||isdigit(c)). دالة isalpha(int c): تُعيد القيمة "True" إذا كان هذا الشرط (isupper(c)||islower(c)) محققًا، كما أنها تُعيد القيمة True لمجموعة المحارف المُعرفة بحسب التطبيق التي لا تعيد القيمة True عند تمريرها على الدالة iscntrl أو isdigit أو ispunct أو isspace وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة iscntrl(int c): تُعيد القيمة True إذا كان المحرف محرف تحكم. دالة isdigit(int c): تُعيدالقيمة True إذا كان المحرف رقمًا عشريًا decimal. دالة isgraph(int c): تُعيد القيمة True إذا كان المحرف هو محرف طباعة عدا محرف المسافة الفارغة. دالة islower(int c): تُعيد القيمة True إذا كان المحرف محرفًا أبجديًا صغيرًا lower case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في C المحلية. دالة isprint(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة (متضمّنًا محرف المسافة الفارغة). دالة ispunct(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة عدا محرف المسافة الفارغة أو المحارف التي تُعيد القيمة True في دالة isalnum. دالة isspace(int c): تُعيد القيمة True إذا كان المحرف محرف مسافة بيضاء (المحرف ' ' أو \f أو \n أو \r أو \t أو \v) دالة isupper(int c): تُعيد القيمة True إذا كان المحرف محرف أبجديًا كبيرًا upper case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة isxdigit(int c): تُعيد القيمة True إذا كان المحرف رقم ستّ عشري صالح. هناك دالتان إضافيتان تربطان المحارف من مجموعةٍ إلى أخرى، إذ تُعيد الدالة tolower محرفًا صغيرًا موافقًا لمحرف كبير مُرِّر لها، على سبيل المثال: tolower('A') == 'a' تُعيد الدالة tolower المحرف ذاته، إذا تلقّت أي محرف مُغاير للمحارف الأبجدية الكبيرة. تربط الدالة toupper المعاكسة للدالة السابقة في عملها المحرف المُمرّر لها إلى مكافئه الكبير. تُجرى عملية الربط في الدالتين السابقتين فقط في حال وجود محرف موافق للمحرف المُمرّر لها، إذ لا تمتلك بعض اللغات محرفًا كبيرًا موافق لمحرف صغير والعكس صحيح. التوطين Localization نستطيع التحكم بالإعدادات المحليّة للبرنامج من هنا، ويصرح ملف الترويسة <locale.h> دوال setlocale و localeconv وعددًا من الماكرو: LC_ALL LC_COLLATE LC_CTYPE LC_MONETARY LC_NUMERIC LC_TIME تُستبدل جميع الماكرو بتعبير ثابت ذي قيمة عدد صحيح وتُستخدم القيمة الناتجة عن التعبير مكان الوسيط category في الدالة setlocale (يمكن تعريف أسماء أخرى أيضًا، ويجب أن يبدأ كل منها بـ LC_X، إذ يمثّل X المحرف الأبجدي الكبير)، ويُستخدم النوع struct lconv لتخزين المعلومات المتعلقة بتنسيق القيم الرقمية، ويُستخدَم CHAR_MAX للأعضاء من النوع char للدلالة على أن القيمة غير متوافرة في الإعدادات المحلية الحالية. يحتوي lconv على عضو واحد على الأقل من الأعضاء التالية: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } العضو الاستخدام تمثيله في إصدارات سي المحلية ملاحظات إضافية char *decimal_point يُستخدم المحرف للفاصلة العشرية في القيم المنسقة غير المالية. "." --- char *thousands_sep يُستخدم المحرف لفصل مجموعات من الخانات الواقعة على يسار الفاصلة العشرية في القيم المنسقة غير المالية. "" --- char *grouping يعرّف عدد الخانات في كل مجموعة في القيم المنسقة غير المالية، وتحدد القيمة CHAR_MAX أنه لا يوجد أي تجميع إضافي مطلوب، بينما تحدد القيمة 0 أنه يجب تكرار العنصر السابق للخانات الرقمية المتبقية، وإذا استُخدمت أي قيمة أخرى فهي تمثل قيمة العدد الصحيح المُمثل لعدد الخانات التي تتألف منها المجموعة الحالية (المحرف اللاحق في السلسلة النصية يُفسَّر قبل التجميع). "" يحدد "\3" أن الخانات يجب أن تجمع كل ثلاثة في مجموعة ويشير محرف الإنهاء الفارغ terminating null في السلسلة النصية إلى تكرار \3. char *int_curr_symbol تُستخدم المحارف الأولى الثلاث لتخزين رمز العملة العالمي الأبجدي لإصدار سي المحلي، بينما يُستخدم المحرف الرابع للفصل بين رمز العملة العالمي والكمية النقدية. "" --- char *currency_symbol يمثل رمز العملة للإصدار المحلي الحالي. "" --- char *mon_decimal_point المحرف المُستخدم مثل فاصلة عشرية عند تنسيق القيم النقدية. "" --- char *mon_thousands_sep يمثل فاصل مجموعات خانات الأرقام ذات القيم المنسقة بتنسيق نقدي. "" --- char *mon_grouping يعرف عدد الخانات في كل مجموعة عند تنسيق قيم نقدية، وتُفسّر عناصره على أنها جزء من التجميع "" --- char *positive_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية غير سالبة. "" --- char *negative_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية سالبة. "" --- char int_frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية منسقة عالميًا. CHAR_MAX --- char frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية غير منسقة عالميًا. CHAR_MAX --- char p_cs_precedes قيمة 1 تدل على وجوب إتباع currency_symbol بالقيمة عند تنسيق قيمة غير سالبة نقدية، بينما تدل القيمة 0 على إسباق currency_symbol بالقيمة. CHAR_MAX --- char p_sep_by_space قيمة 1 تدل على تفريق رمز العملة من القيمة بمسافة فارغة عند تنسيق قيمة غير سالبة نقدية، بينما تدل قيمة 0 على عدم وجود أي مسافة فارغة. CHAR_MAX --- char n_cs_precedes تشابه p_cs_precedes ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sep_by_space تشابه p_sep_by_space ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sign_posn يشابه p_sign_posn ولكن للقيم النقدية السالبة. CHAR_MAX --- char p_sign_posn يمثل موقع positive_sign للقيم النقدية المنسقة غير السالبة. CHAR_MAX يتبع الشروط التالية: تُحيط الأقواس القيمة النقدية وcurrency_symbol. تسبق السلسلة النصية كل من القيمة النقدية و currency_symbol. تتبع السلسلة النصية القيمة النقدية و currency_symbol. تسبق السلسلة النصية القيمة currency_symbol. تتبع السلسلة النصية القيمة currency_symbol دالة setlocale لضبط الإعدادات المحلية يكون تعريف دالة setlocale على النحو التالي: #include <locale.h> char *setlocale(int category, const char *locale); تسمح هذه الدالة بضبط إعدادات البرنامج المحلية، ويمكن ضبط جميع أجزاء الإصدار المحلي باختيار القيم المناسبة لوسيط التصنيف category كما يلي: القيمة LC_ALL: تضبط كامل الإصدار المحلي. القيمة LC_COLLATE: تعديل سلوك strcoll و strxfrm. القيمة LC_CTYPE: تعديل سلوك دوال التعامل مع المحارف character-handling. القيمة LC_MONETARY: تعديل تنسيق القيم النقدية المُعادة من دالة localeconv. القيمة LC_NUMERIC: تعديل محرف الفاصلة العشرية لتنسيق الدخل والخرج وبرامج تحويل السلاسل النصية. القيمة LC_TIME: تعديل سلوك strftime. يمكن ضبط قيم الإعدادات المحلية إلى: "C" تحديد البيئة ذات المتطلبات الدنيا لترجمة سي C "" تحديد البيئة الأصيلة المعرفة حسب التطبيق قيمة معرفة بحسب التنفيذ تحديد البيئة الموافقة لهذه القيمة البيئة الافتراضية عند بداية البرنامج موافقة للبيئة التي نحصل عليها عند تنفيذ التعليمة التالية: setlocale(LC_ALL, "C"); يمكن فحص السلسلة النصية الحالية المترافقة مع تصنيف ما بتمرير مؤشر فارغ null قيمةً للوسيط locale؛ نحصل على السلسلة النصية المترافقة مع التصنيف category المحدد للتوطين الجديد إذا كان من الممكن حصول التصنيف المحدد، وتُستخدم هذه السلسلة النصية في استدعاء لاحق للدالة setlocale مع تصنيفها المترافق لاستعادة الجزء الموافق من إعدادات البرنامج المحلية، وإذا كان التحديد غير ممكن الحصول نحصل على مؤشر فراغ دون تغيير الإعدادات المحلية. دالة localeconv يكون تصريح الدالة على النحو التالي: #include <locale.h> struct lconv *localeconv(void); تُعيد هذه الدالة مؤشرًا يشير إلى هيكل من النوع struct lconv، ويُضبط هذا المؤشر طبقًا للإعدادات المحلية الحالية ويمكن تغييره باستدعاء لاحق للدالة localconv أو setlocale، ويجب ألّا يكون الهيكل قابلًا للتعديل بأي طريقة أخرى. على سبيل المثال، إذا كانت إعدادات القيم النقدية المحلية الحالية مُمثّلةً حسب الإعدادات التالية: IR£1,234.56 تنسيق القيم الموجبة (IR£1,234.56) تنسيق القيم السالبة IRP 1,234.56 التنسيق العالمي يجب أن تحمل الأعضاء التي تمثّل القيم النقدية في lconv القيم التالية: int_curr_symbol "IRP " currency_symbol "IR£" mon_decimal_point "." mon_thousands_sep "," mon_grouping "\3" postive_sign "" negative_sign "" int_frac_digits 2 frac_digits 2 p_cs_precedes 1 p_sep_by_space 0 n_cs_precedes 1` n_sep_by_space 0 p_sign_posn CHAR_MAX n_sign_posn 0 ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: القيم الحدية والدوال الرياضية في لغة سي C المقال السابق: مقدمة إلى مكتبات لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C مدخل إلى المصفوفات في لغة سي C -
 شاع في السنوات الماضية مع تطوّر التقنية في حياتنا ودخولها لكل جوانبها مصطلح الأمن السيبراني Cybersecurity، كما أن الطلب تزايد عليه بالنظر إلى أنّ أي مؤسسة تستخدم تقنيات الحاسوب بحاجة لحماية بنيتها التحتية ضدّ الهجمات الخبيثة والمخترقين. تُشير بعض الإحصاءات التي أجرتها الجمعية الدولية للضمان الاجتماعي ISSA عام 2021 آنذاك إلى أن 57 بالمئة من المؤسسات تعاني من نقص بخصوص مختصّي الأمن السيبراني، وإن دلّت هذه الأرقام على شيء فهي تدلّ على نموّ هذا المجال وتزايد الطلب عليه. فما هو اختصاص الأمن السيبراني؟ وما هي مهام مختص الأمن السيبراني؟ وكيف يمكنك البدء بتعلم هذا المجال؟ هذا ما سنناقشه ضمن هذا المقال. تاريخ الأمن السيبراني كانت الحاجة للأمن السيبراني واضحة منذ ظهور شبكة الإنترنت وانتشارها في ثمانينيات القرن الماضي، إذ شهدنا ظهور مصطلحات متعلقة بهذا المجال مثل الفايروس Virus ومضاد الفيروسات Anti-virus وغيرها، إلا أن التهديدات السيبرانية لم تكن بالتعقيد والصعوبة التي هي عليه الآن. أولى ظهور لبرمجية خبيثة malware كان في عام 1971 باسم كريبر Creeper إذ كان برنامجًا تجريبيًا كُتب بواسطة بوب توماس في شركة BBN، تلاه بعد ذلك ظهور أول مضاد فيروسات في عام 1972 باسم ريبر Reaper الذي أنشئ بواسطة راي توملنسون بهدف القضاء على البرمجية الخبيثة كريبر. مع وصول شبكة الإنترنت إلى كافة بقاع العالم ومع التحول الرقمي الحاصل في كافة قطاعات الحياة اليوم أهمها قطاعات البنى التحتية المدنية من أنظمة تحكم وأنظمة الطاقة والاتصالات والمياه وقطاع الصحة والقطاعات المالية والمصرفية وقطاع النقل والطيران وغيرها، بدأت الهجمات السيبرانية تأخذ بعدًا آخر، فتخيل ماذا سيحصل إن حصل هجوم سيبراني على أحد تلك الخدمات المهمة المفصلية أو تخيل حصول هجوم سيبراني على أحد أنظمة إدارة السدود أو الطاقة في بلد ما، هذا لا يقاس مع حصول هجمات على أفراد التي تكون دائرة الضرر فيها صغيرة جدًا، إذ ممكن أن تؤدي إلى شلل في الحياة وهنالك الكثير من أمثلة تلك الهجمات لا يسع المقال لذكرها هنا. أذكر مرة أنه حصل خلل في التراسل الشبكي في أنظمة إحدى المباني الخدمية مما أوقف العمل بشكل كامل في ذلك المبنى لتتراكم أعداد الناس وتشكل طوابير طويلة منتظرين عودة النظام للعمل أو ستتوقف معاملاتهم بالكامل، وأذكر مرة حصل خلل في نظام شبكة محطات الوقود لتخرج مجموعة كبيرة من المحطات عن العمل في المدينة وتصطف طوابير من السيارات منتظرة عودة الخدمة للعمل، وهذان مثالان عن عطل غير مقصود فما بالك لو كان مقصودًا وناجمًا عن هجوم سيبراني منظم؟ تخيل ماذا سيحصل، لذا كانت أهمية الأمن السيبراني بأهمية الحاجة إليه والضرر الحاصل دونه. ما هو الأمن السيبراني؟ يُعرف الأمن السيبراني Cybersecurity بأنه عملية تأمين وحماية الأنظمة الرقمية والشبكات الإلكترونية وكل ما يتعلق بالأجهزة الرقمية وتكنولوجيا المعلومات الرقمية ضدّ أي هجمات رقمية أو تسمى هجمات سيبرانية Cyber Attacks. تستهدف الهجمات السيبرانية تخريب أو تعطيل أو سرقة شبكة أو نظام حاسوبي، أو دخولًا غير مصرّح به إليهما، وقد يكون الهدف من هذه الهجمات الوصول إلى بيانات ما لتعديلها أو تخريبها، أو ابتزاز الفرد أو المؤسسة مقابل هذه البيانات، أو أن تكون ذات هدف تخريبي تهدف لإيقاف عمل المؤسسة. تأتي هنا مهمّة الأمن السيبراني ألا وهي وقف هذه الهجمات السيبرانية عن طريق الكشف عن الفيروسات الرقمية وتعطيلها وتأمين وسائل اتصال مشفّرة وآمنة تضمن تبادل البيانات الحساسة دون خطر تسريبها أو قدرة الوصول إليها من المخترقين. يستخدم مختصّ الأمن السيبراني لتحقيق ذلك مجموعة من الأدوات والتقنيات مثل جدران الحماية (النارية) Firewalls وأنظمة كشف التسلل Intrusion Detection Systems أو اختصارًا IDS، بالإضافة إلى إجراء اختبارات الأمان وتعريف حدود واضحة (صلاحيات المستخدم، أماكن تخزين البيانات الحساسة، …إلخ). فوائد الأمن السيبراني يستند الأمن السيبراني على ثلاث مبادئ وهي الخصوصية Confidentiality والسلامة Integrity والتوفر Availability، ويرمز إلى هذه المبادئ بشكل كامل بالاختصار CIA: الخصوصية: ضمان الوصول إلى الأنظمة والبيانات فقط للأشخاص المُصرَّح بهم، بإجراء عمليات التعديل البيانات واستعادتها والاطّلاع عليها. السلامة: ويُقصد بها سلامة البيانات وهي ضمان أن البيانات يمكن الاعتماد عليها بشكل دقيق وصحيح، دون أن تُغيَّر من قبل أطراف أخرى غير مصرّح لها بالتغيير (وهو ما يضمنه المبدأ السابق). التوفر: ضمان أن الأطراف المُصرّح لها بالوصول إلى البيانات تستطيع الوصول إليها بأي وقت دون مشاكل وبشكل مستمرّ، وهذا يتطلب المحافظة على سلامة التجهيزات (العتاد الصلب) وسلامة البنية التحتية والنظام الذي يحتوي على البيانات ويعرضها. التطبيق الصحيح للمبادئ الثلاث السابقة يضمن لنا حماية بياناتنا الشخصية ويوفّر بيئة عمل مريحة وآمنة في المؤسسات التي تعتمد على التقنيات والأنظمة الحاسوبية، مما ينعكس بالإيجاب على سمعة المؤسسة وأدائها. أضِف إلى ذلك تفادي الخسارات في حال وقوع هجوم سيبراني على المؤسسة، سواءً أكانت ماديّة (تعطّل بنى تحتية أو سرقة بيانات أو ابتزاز) أو معنويّة (خسارة المؤسسة سمعتها وثقة جمهورها). إذ تُشير إحصاءات أجرتها مجلة Cybercrime المختصة بمجال الأمن السيبراني في عام 2021 إلى أن الجرائم السيبرانية تسببت بخسائر قيمتها 6 تريليون دولار أمريكي، دعونا نقارن هذا الرقم لفهم ضخامته، إذ أنه سيأتي ثالثًا إذا أردنا وضعه ضمن الناتج المحلي الإجمالي لدول العالم بعد الولايات المتحدة الأمريكية والصين! ومن المقدّر أن تزداد الخسائر باستمرار بحلول عام 2025 إلى 10.5 تريليون دولار أمريكي. دعنا لا ننسى أيضًا مهمة مميزة للأمن السيبراني ألا وهي استرداد البيانات واسترجاعها إن حصلت عملية اختراق أو تخريب، إذ تُعدّ مهمة استعادة البيانات بسرعة من أهم مهام مختص الأمن السيبراني. وجود فريق أمن سيبراني مختص لصدّ الهجمات والتعرّف عليها أمر لا غنى عنه، خصوصًا في القطاعات الحساسة مثل المؤسسات الحكومية والبنوك وشركات الطيران. لكن هل تحتاج جميع المؤسسات إلى الأمن السيبراني بقدر متساوٍ من الأهمية؟ في الحقيقة لا، فأهمية الأمن السيبراني بالنسبة لمدوّنة أو موقع شخصي ليست بقدرٍ مساوٍ لشركة طيران أو مؤسسة مصرفيّة. ألا أن هنالك قواعد عامّة يجب اتّباعها بغض النظر عن غرض المؤسسة وطبيعة نشاطها كإدارة البيانات الحساسة وحمايتها مثل كلمات المرور والمحافظة على آخر إصدار مستقر من العتاد البرمجي المُستخدم وأخذ نُسخ احتياطية من البيانات بشكل دوري. ما هو الفرق بين أمن المعلومات والأمن السيبراني؟ قد تتساءل ما الفرق بين أمن المعلومات والأمن السيبراني؟ إذ كثيرًا ما يُطرح هذا السؤال وهو ما سنجيب عليه في هذه الفقرة. يهتمّ الأمن السيبراني كما ذكرنا سابقًا بحماية الأنظمة والأجهزة الحاسوبيّة، ويتضمن ذلك أمن الشبكات والتطبيقات والسحابة cloud والبنية التحتية، وذلك بمنع الوصول غير المصرّح له لهذه الأنظمة بهدف التحكم بها أو الحصول على البيانات التي تحتويها. يركّز مجال أمن المعلومات على المعلومات بذات نفسها وكيفية حمايتها بغض النظر عن الوسيط الذي يحتويها بخلاف الأمن السيبراني (النظام أو العتاد الصلب)، ويُعدّ مجال أمن المعلومات خط الدفاع الثاني في حال التعرض لهجوم سيبراني واختراقه بحيث لا يستفيد المخترق من البيانات حتى وإن كانت بحوزته (إذ أن خط الدفاع الأول هنا هو الأمن السيبراني). مصطلحات شائعة في مجال الأمن السيبراني نذكر هنا بعض أكثر المصطلحات شيوعًا في مجال الأمن السيبراني ومعناها بشرح مقتضب: الجريمة السيبرانية Cybercrime: هي أي هجوم يقوم بها شخص أو مجموعة من الأشخاص ويكون الهدف فيها نظام حاسوبي بهدف التحكم به أو الحصول على بيانات بشكل غير مُصرَّح به، إما بهدف التخريب أو الابتزاز. شبكة روبوتات Robot Network: تُعرف اختصارًا باسم Botnet وهي شبكة تتكون من آلاف أو ملايين الأجهزة المتصلة مع بعضها البعض والمصابة ببرمجية خبيثة malware، ويستخدم المخترقون هذه الشبكة لتنفيذ هجماتهم مثل هجمات الحرمان من الخدمة الموزّع DDoS attacks أو إرسال الرسائل المزعجة Spam. ** خرق بيانات Data Breach**: هي الحادثة التي يحصل بها المخترق على بيانات ما بعد نجاح هجمة سيبرانية، وعادةً ما تكون هذه البيانات بيانات شخصية حساسة مثل كلمات المرور أو بيانات مصرفية وغيرها. المخترق ذو القبعة البيضاء White hat وذو القبعة السوداء Black hat: يُقصد بهذين المصطلحين نيّة كل مخترق من عملية الاختراق إذ أن للمخترق ذو القبعة السوداء نيّة سيئة باستخدام البيانات التي يحصل عليها أو الثغرات الأمنية بالابتزاز المالي أو التخريب بينما يكون هدف المخترق ذو القبعة البيضاء الكشف عن هذه الثغرات وسدّها لحماية النظام بشكل أكبر وغالبًا ما تُدعى هذه الفئة من المخترقين بالمخترقين الأخلاقيين Ethical Hackers. أنواع تهديدات الأمن السيبراني على الرغم من تطوّر الهجمات السيبرانية مع مرور الوقت وزيادة تعقيدها إلا أن هناك العديد من أنواع التهديدات الشائعة التي يجب أن يكون مختصّ الأمن السيبراني ملمًّا بها وبطريقة تحصين النظام ضدها. نذكر من أشهر أنواع تهديدات الأمن السيبراني ما يلي: التصيّد الاحتيالي Phishing: هي محاولة المخترق لخداع الضحية الهدف باتخاذ إجراءات غير آمنة وخاطئة، مثل إرسال رابط لصفحة دخول إلى موقع معيّن ومطالبتهم بتسجيل الدخول بحساباتهم في هذا الموقع، إلا أن الصفحة مُستنسخة وعملية التسجيل مزيّفة مما يسمح للمخترق بالحصول على بيانات حساب الضحية. هجمات الحرمان من الخدمة الموزّعة Distributed Denial of Service: تُعرَف اختصارًا بهجمات DDoS، وهي هجمات تتمّ عن طريق إغراق خادم النظام بسيل من المعلومات غير اللازمة باستخدام مجموعة من الأجهزة Botnet وذلك بهدف تعطيل الخدمة أو إبطائها، مما يتسبب بحرمان استخدام الخدمة للمستخدم أو حجبها. البرمجيات الخبيثة malware: هي برمجية يزرعها المهاجم في النظام الضحية بحيث تُنفّذ مجموعة من الأوامر والمهام غير المصرّح بها على جهاز الضحية، نذكر من هذه البرمجيات برمجيات الفدية ransomware التي تشفّر بيانات جهاز الضحية وتمنعه من الدخول إليها بهدف الحصول على مبلغ مالي، وبرمجيات التجسس spyware التي تراقب نشاط المستخدم على حاسبه بشكل سرّي وتسرق بيانات حساسة مثل كلمات السر. هجمات كلمة المرور password attacks: هجوم يحاول فيه المخترق تخمين كلمة المرور لملفات أو نظام، وتتم عملية التخمين عادةً بمساعدة أدوات مخصصة وليس يدويًا. لذا يُنصح على الدوام بالابتعاد عن كلمات السر القصيرة والمُستخدمة بكثرة مثل password123 أو qwerty، والكلمات الموجودة في القاموس دون إضافة رموز وأرقام بينها (لأن هذه الأدوات تجرّب الكلمات الموجودة في القواميس). هجوم الوسيط man-in-the-middle attack: هجوم يستطيع المخترق عن طريقه الوصول إلى البيانات المُرسلة بين المُرسل والمُستقبل عن طريق التنصّت إلى الاتصال ما بينهما، وتتضمّن معظم بروتوكولات نقل البيانات نوعًا من التشفير والمصادقة للحماية من هذا النوع من الهجمات مثل شهادة SSL في بروتوكول HTTPS. أنواع الأمن السيبراني ينقسم مجال الأمن السيبراني إلى عدّة مجالات فرعية أخرى، إذ يختص كل مجال بعيّن بجانب من الفضاء السيبراني. نذكر من هذه المجالات ما يلي: أمن الشبكات Network Security: يُعنى هذا المجال بحماية شبكات الحاسوب ويُحقَّق ذلك عن طريق بعض التقنيات مثل منع فقدان البيانات Data Loss Prevention اختصارًا DLP وإدارة الوصول إلى الهوية Identitiy Access Managment اختصارًا IAM وغيرها من التقنيات التي تجعل من الشبكات فضاءً آمنًا لمشاركة البيانات. أمن الهواتف المحمولة Mobile Security: عادةً ما يكون لهواتف موظّفي المؤسسة أو طاقمها وصول كامل لنظام المؤسسة وبياناتها، وبالنظر إلى أن الهواتف المحمولة هي الجهاز الأكثر استخدامًا عادةً لكل فرد فهذا يُضيف أهميّة زائدة على هذا المجال، إذ يجب تأمين هذه الأجهزة ضد الهجمات الخبيثة باستخدام مختلف التطبيقات (مثل تطبيقات المراسلة وغيرها). أمن السحابة Cloud Security: بدأت كافة المؤسسات بتبني تقنيات السحابة مؤخرًا، مما جعل أمن السحابة مجالًا مهمًا. تتضمن عملية حماية السحابة شروط التحكم بها والوصول إليها وكيفية توزيع بياناتها وهيكلة البنية التحتية ويندرج كل ذلك فيما يدعى باستراتيجية أمن السحابة cloud security strategy. أمن إنترنت الأشياء IoT Security: يُقصد بإنترنت الأشياء مجموعة الأجهزة التي تتواصل مع بعضها البعض وتراقب بيئتها المحيطة باستخدام الحساسات بالإضافة إلى إمكانية التحكم بها عبر الإنترنت. يحمي أمن إنترنت الأشياء هذه الأجهزة من استغلالها من طرف المخترقين عن طريق استخدام ثغرات في الأجهزة بذات نفسها أو وسيط الاتصال فيما بينها. أمن التطبيقات Application Security: التطبيقات التي تستخدم اتصال الإنترنت معرّضة لخطر الاختراق كأي نظام آخر يستخدم شبكات الإنترنت. يعمل أمن التطبيقات على حمايتها عن طريق منع التفاعلات الخبيثة مع التطبيقات الأخرى أو الواجهات البرمجية API. مجالات الأمن السيبراني يحتوي مجال الأمن السيبراني على عدّة مسميات وظيفية فرعيّة مخصصة عنه، ولكل من هذه المسميات مهامها المحدّدة ومتطلباتها، نذكر منها أهم مجالات الأمن السيبراني مع شرح بسيط لكل منها. كبير موظفي أمن المعلومات كبير موظفي أمن المعلومات Chief Information Security Officer اختصارًا CISO هو موظف ذو خبرة كبيرة مسؤول عن أمان المعلومات ضمن المؤسسة بشكل كامل، وتضمن مهامه تطوير طرق حماية البيانات وصيانتها وإدارة برامج المخاطرة، وعادةً ما يشغل هذا المنصب شخصٌ له باعٌ طويل في مجال أمن المعلومات وعمل في واحدة أو أكثر من وظائف أمن المعلومات بحيث يمتلك على خبرة كافية تمكّنه من قيادة فريق الأمن السيبراني في المؤسسة. مهندس الأمن تتضمّن مهام مهندس الأمن Security Architect تصميم نظم الأمان المُستخدمة في الدفاع عن المؤسسة من هجمات البرمجيات الخبيثة، إذ يُجري مهندس الأمن اختبارات لكشف الثغرات ونقاط الضعف في النظام بالإضافة لتزويد المعلومات المهمة إلى أعضاء الفريق الأمني الآخرين. يتطلّب هذا العمل خبرة في مجال هندسة المعلومات والشبكات وإدارة المخاطر بالإضافة إلى بروتوكولات الأمن وتشفير المعلومات. مهندس الأمن السيبراني يعمل مهندس الأمن السيبراني Cybersecurity Engineer على الإجراءات اللازمة التي تمنع نجاح هجوم سيبراني على أنظمة المؤسسة من شبكات وأجهزة، إذ يعمل على تطوير أنظمة دفاع سيبرانية ويعمل بشكل وثيق مع باقي أقسام المؤسسة للحفاظ على أمنها العام. يتطلّب هذا المنصب فهمًا جيدًا لكيفية عمل الشبكات وإدارة نظم التشغيل وهيكلتها بالإضافة إلى إتقان لغة البرمجة C (لأن لغة C تتعامل مع الحاسوب بمستوى منخفض مما يمنحك أريحية التعامل مع نظام التشغيل ومكوناته مقارنةً بلغات البرمجة عالية المستوى الأخرى مثل جافاسكربت وبايثون). محلل البرمجيات الخبيثة يعمل محلل البرمجيات الخبيثة Malware Analyst على فحص وتحليل التهديدات السيبرانية مثل الفيروسات وأحصنة طروادة Trojan horses والروبوتات bots لفهم طبيعتها وتطوير أدوات حماية للمدافعة ضدها، بالإضافة إلى توثيق طرق الحماية ضد البرمجيات الخبيثة وتجنبها. يتطلب هذا المنصب فهمًا لكل من نظام ويندوز ولينكس بالإضافة إلى معرفة بلغة البرمجة C/C++، واستخدام بعض الأدوات مثل IDA Pro وRegShot وTCP View. مختبر الاختراق أو المخترق الأخلاقي يُعرف مختبر الاختراق Penetration Tester بالمخترق الأخلاقي Ethical Hacker أيضًا، وهو مستشار أمني تتمثل مهامه باستغلال الثغرات الأمنية ونقاط الضعف في النظام بطريقة مماثلة لما سيفعله المخترق ذو النية السيئة التخريبية، إلا أن مختبر الاختراق يُطلِع فريق الأمان السيبراني في المؤسسة على الثغرات لتصحيحها، كما أنه يصمّم أدوات الاختراق ويوثّق نتائج الاختبار. المحلل الجنائي الرقمي يعمل المحلل الجنائي الرقمي Computer Forensics Analyst بعد حدوث هجوم سيبراني، إذ يجمع الأدلة الرقمية ويحاول استعادة البيانات المحذوفة أو المُعدَّل عليها أو المسروقة. يتطلّب هذا العمل معرفة بالشبكات والأمن السيبراني وفهم لقوانين الجرائم السيبرانية بالإضافة إلى مهارات تحليلية والانتباه للتفاصيل الدقيقة. كيف أبدأ بتعلم تخصص الأمن السيبراني؟ إن أردت البدء بتعلم الأمن السيبراني، فهذا يعني أنه عليك أن تبدأ بتعلم بعض المفاهيم والأدوات الأساسية في هذا المجال ألا وهي: تعلم أساسيات البرمجة، وذلك باختيار لغة برمجة معيّنة (يُفضّل البدء بلغة C أو C++ إن أردت دخول مجال الأمن السيبراني لأن اللغتين تتعامل مع الحاسوب على مستوى منخفض مما يمنحك أريحية التحكم بنظام التشغيل وأجزاء النظام الأخرى). فهم كيفية عمل أنظمة التشغيل وبنيتها، ننصحُك هنا بقراءة كتاب أنظمة التشغيل للمبرمجين كيفية عمل قواعد البيانات التي تخزّن بيانات أي نظام حاسوبي وعمليّة تصميمها، يمكنك الاطّلاع على كتاب تصميم قواعد البيانات للحصول على فهم أوّلي حول هذا الموضوع. إتقان التعامل مع سطر الأوامر command line بمختلف أوامره البسيطة والمتقدمة. فهم كيفية عمل الشبكات وكيف تتواصل الأجهزة مع بعضها البعض وتتبادل البيانات باستخدام بروتوكولات الاتصال المختلفة. التعامل مع أحد توزيعات لينكس الموجهة للأمن السيبراني والاختراقات بتمرّس، ونذكر منها توزيعة ريدهات Redhat لإدارة الخوادم (التي ستمكنك من الحصول على شهادة RHCSA وشهادة RHCE) ولينكس كالي Kali Linux، إذ تحتوي هذه التوزيعات على أدوات أساسية للتعامل مع الشبكات ومهام الأمن السيبراني. ماذا بعد؟ اختر مجالًا لتركّز عليه من المجالات السابقة التي ذكرناها، إذ أنّ مسار التعلم الخاص بك سيختلف بحسب توجهك، وهناك بعض الشهادات التي يجب أن تمتلكها لتزيد من فرصك في الحصول على عمل بحسب المجال الذي تختاره. على سبيل المثال تُعدّ شهادة CEH هامة لمختبر الاختراق -أو المخترق الأخلاقي- وشهادة CHFI هامة للمحلل الجنائي الرقمي. نرشّح لك أيضًا كتاب دليل الأمان الرقمي للاستزادة وتعلّم المزيد بخصوص الأمن السيبراني والاختراق. المصادر: What is Cybersecurity? Everything You Need to Know | TechTarget Top 20 Cybersecurity Terms You Need to Know (simplilearn.com) What Is Cybersecurity | Types and Threats Defined | Cybersecurity | CompTIA How To Learn Cybersecurity on Your Own A Basic Guide On Cyber Security For Beginners 2022 Edition | Simplilearn The Life and Times of Cybersecurity Professionals 2021 - Volume V - ISSA اقرأ أيضًا الهجمات الأمنية Security Attacks في الشبكات الحاسوبية تأمين الشبكات اللاسلكية كيف نخفف من هجمات DDoS ضد موقعنا باستخدام CloudFlare 7 تدابير أمنية لحماية خواديمك
شاع في السنوات الماضية مع تطوّر التقنية في حياتنا ودخولها لكل جوانبها مصطلح الأمن السيبراني Cybersecurity، كما أن الطلب تزايد عليه بالنظر إلى أنّ أي مؤسسة تستخدم تقنيات الحاسوب بحاجة لحماية بنيتها التحتية ضدّ الهجمات الخبيثة والمخترقين. تُشير بعض الإحصاءات التي أجرتها الجمعية الدولية للضمان الاجتماعي ISSA عام 2021 آنذاك إلى أن 57 بالمئة من المؤسسات تعاني من نقص بخصوص مختصّي الأمن السيبراني، وإن دلّت هذه الأرقام على شيء فهي تدلّ على نموّ هذا المجال وتزايد الطلب عليه. فما هو اختصاص الأمن السيبراني؟ وما هي مهام مختص الأمن السيبراني؟ وكيف يمكنك البدء بتعلم هذا المجال؟ هذا ما سنناقشه ضمن هذا المقال. تاريخ الأمن السيبراني كانت الحاجة للأمن السيبراني واضحة منذ ظهور شبكة الإنترنت وانتشارها في ثمانينيات القرن الماضي، إذ شهدنا ظهور مصطلحات متعلقة بهذا المجال مثل الفايروس Virus ومضاد الفيروسات Anti-virus وغيرها، إلا أن التهديدات السيبرانية لم تكن بالتعقيد والصعوبة التي هي عليه الآن. أولى ظهور لبرمجية خبيثة malware كان في عام 1971 باسم كريبر Creeper إذ كان برنامجًا تجريبيًا كُتب بواسطة بوب توماس في شركة BBN، تلاه بعد ذلك ظهور أول مضاد فيروسات في عام 1972 باسم ريبر Reaper الذي أنشئ بواسطة راي توملنسون بهدف القضاء على البرمجية الخبيثة كريبر. مع وصول شبكة الإنترنت إلى كافة بقاع العالم ومع التحول الرقمي الحاصل في كافة قطاعات الحياة اليوم أهمها قطاعات البنى التحتية المدنية من أنظمة تحكم وأنظمة الطاقة والاتصالات والمياه وقطاع الصحة والقطاعات المالية والمصرفية وقطاع النقل والطيران وغيرها، بدأت الهجمات السيبرانية تأخذ بعدًا آخر، فتخيل ماذا سيحصل إن حصل هجوم سيبراني على أحد تلك الخدمات المهمة المفصلية أو تخيل حصول هجوم سيبراني على أحد أنظمة إدارة السدود أو الطاقة في بلد ما، هذا لا يقاس مع حصول هجمات على أفراد التي تكون دائرة الضرر فيها صغيرة جدًا، إذ ممكن أن تؤدي إلى شلل في الحياة وهنالك الكثير من أمثلة تلك الهجمات لا يسع المقال لذكرها هنا. أذكر مرة أنه حصل خلل في التراسل الشبكي في أنظمة إحدى المباني الخدمية مما أوقف العمل بشكل كامل في ذلك المبنى لتتراكم أعداد الناس وتشكل طوابير طويلة منتظرين عودة النظام للعمل أو ستتوقف معاملاتهم بالكامل، وأذكر مرة حصل خلل في نظام شبكة محطات الوقود لتخرج مجموعة كبيرة من المحطات عن العمل في المدينة وتصطف طوابير من السيارات منتظرة عودة الخدمة للعمل، وهذان مثالان عن عطل غير مقصود فما بالك لو كان مقصودًا وناجمًا عن هجوم سيبراني منظم؟ تخيل ماذا سيحصل، لذا كانت أهمية الأمن السيبراني بأهمية الحاجة إليه والضرر الحاصل دونه. ما هو الأمن السيبراني؟ يُعرف الأمن السيبراني Cybersecurity بأنه عملية تأمين وحماية الأنظمة الرقمية والشبكات الإلكترونية وكل ما يتعلق بالأجهزة الرقمية وتكنولوجيا المعلومات الرقمية ضدّ أي هجمات رقمية أو تسمى هجمات سيبرانية Cyber Attacks. تستهدف الهجمات السيبرانية تخريب أو تعطيل أو سرقة شبكة أو نظام حاسوبي، أو دخولًا غير مصرّح به إليهما، وقد يكون الهدف من هذه الهجمات الوصول إلى بيانات ما لتعديلها أو تخريبها، أو ابتزاز الفرد أو المؤسسة مقابل هذه البيانات، أو أن تكون ذات هدف تخريبي تهدف لإيقاف عمل المؤسسة. تأتي هنا مهمّة الأمن السيبراني ألا وهي وقف هذه الهجمات السيبرانية عن طريق الكشف عن الفيروسات الرقمية وتعطيلها وتأمين وسائل اتصال مشفّرة وآمنة تضمن تبادل البيانات الحساسة دون خطر تسريبها أو قدرة الوصول إليها من المخترقين. يستخدم مختصّ الأمن السيبراني لتحقيق ذلك مجموعة من الأدوات والتقنيات مثل جدران الحماية (النارية) Firewalls وأنظمة كشف التسلل Intrusion Detection Systems أو اختصارًا IDS، بالإضافة إلى إجراء اختبارات الأمان وتعريف حدود واضحة (صلاحيات المستخدم، أماكن تخزين البيانات الحساسة، …إلخ). فوائد الأمن السيبراني يستند الأمن السيبراني على ثلاث مبادئ وهي الخصوصية Confidentiality والسلامة Integrity والتوفر Availability، ويرمز إلى هذه المبادئ بشكل كامل بالاختصار CIA: الخصوصية: ضمان الوصول إلى الأنظمة والبيانات فقط للأشخاص المُصرَّح بهم، بإجراء عمليات التعديل البيانات واستعادتها والاطّلاع عليها. السلامة: ويُقصد بها سلامة البيانات وهي ضمان أن البيانات يمكن الاعتماد عليها بشكل دقيق وصحيح، دون أن تُغيَّر من قبل أطراف أخرى غير مصرّح لها بالتغيير (وهو ما يضمنه المبدأ السابق). التوفر: ضمان أن الأطراف المُصرّح لها بالوصول إلى البيانات تستطيع الوصول إليها بأي وقت دون مشاكل وبشكل مستمرّ، وهذا يتطلب المحافظة على سلامة التجهيزات (العتاد الصلب) وسلامة البنية التحتية والنظام الذي يحتوي على البيانات ويعرضها. التطبيق الصحيح للمبادئ الثلاث السابقة يضمن لنا حماية بياناتنا الشخصية ويوفّر بيئة عمل مريحة وآمنة في المؤسسات التي تعتمد على التقنيات والأنظمة الحاسوبية، مما ينعكس بالإيجاب على سمعة المؤسسة وأدائها. أضِف إلى ذلك تفادي الخسارات في حال وقوع هجوم سيبراني على المؤسسة، سواءً أكانت ماديّة (تعطّل بنى تحتية أو سرقة بيانات أو ابتزاز) أو معنويّة (خسارة المؤسسة سمعتها وثقة جمهورها). إذ تُشير إحصاءات أجرتها مجلة Cybercrime المختصة بمجال الأمن السيبراني في عام 2021 إلى أن الجرائم السيبرانية تسببت بخسائر قيمتها 6 تريليون دولار أمريكي، دعونا نقارن هذا الرقم لفهم ضخامته، إذ أنه سيأتي ثالثًا إذا أردنا وضعه ضمن الناتج المحلي الإجمالي لدول العالم بعد الولايات المتحدة الأمريكية والصين! ومن المقدّر أن تزداد الخسائر باستمرار بحلول عام 2025 إلى 10.5 تريليون دولار أمريكي. دعنا لا ننسى أيضًا مهمة مميزة للأمن السيبراني ألا وهي استرداد البيانات واسترجاعها إن حصلت عملية اختراق أو تخريب، إذ تُعدّ مهمة استعادة البيانات بسرعة من أهم مهام مختص الأمن السيبراني. وجود فريق أمن سيبراني مختص لصدّ الهجمات والتعرّف عليها أمر لا غنى عنه، خصوصًا في القطاعات الحساسة مثل المؤسسات الحكومية والبنوك وشركات الطيران. لكن هل تحتاج جميع المؤسسات إلى الأمن السيبراني بقدر متساوٍ من الأهمية؟ في الحقيقة لا، فأهمية الأمن السيبراني بالنسبة لمدوّنة أو موقع شخصي ليست بقدرٍ مساوٍ لشركة طيران أو مؤسسة مصرفيّة. ألا أن هنالك قواعد عامّة يجب اتّباعها بغض النظر عن غرض المؤسسة وطبيعة نشاطها كإدارة البيانات الحساسة وحمايتها مثل كلمات المرور والمحافظة على آخر إصدار مستقر من العتاد البرمجي المُستخدم وأخذ نُسخ احتياطية من البيانات بشكل دوري. ما هو الفرق بين أمن المعلومات والأمن السيبراني؟ قد تتساءل ما الفرق بين أمن المعلومات والأمن السيبراني؟ إذ كثيرًا ما يُطرح هذا السؤال وهو ما سنجيب عليه في هذه الفقرة. يهتمّ الأمن السيبراني كما ذكرنا سابقًا بحماية الأنظمة والأجهزة الحاسوبيّة، ويتضمن ذلك أمن الشبكات والتطبيقات والسحابة cloud والبنية التحتية، وذلك بمنع الوصول غير المصرّح له لهذه الأنظمة بهدف التحكم بها أو الحصول على البيانات التي تحتويها. يركّز مجال أمن المعلومات على المعلومات بذات نفسها وكيفية حمايتها بغض النظر عن الوسيط الذي يحتويها بخلاف الأمن السيبراني (النظام أو العتاد الصلب)، ويُعدّ مجال أمن المعلومات خط الدفاع الثاني في حال التعرض لهجوم سيبراني واختراقه بحيث لا يستفيد المخترق من البيانات حتى وإن كانت بحوزته (إذ أن خط الدفاع الأول هنا هو الأمن السيبراني). مصطلحات شائعة في مجال الأمن السيبراني نذكر هنا بعض أكثر المصطلحات شيوعًا في مجال الأمن السيبراني ومعناها بشرح مقتضب: الجريمة السيبرانية Cybercrime: هي أي هجوم يقوم بها شخص أو مجموعة من الأشخاص ويكون الهدف فيها نظام حاسوبي بهدف التحكم به أو الحصول على بيانات بشكل غير مُصرَّح به، إما بهدف التخريب أو الابتزاز. شبكة روبوتات Robot Network: تُعرف اختصارًا باسم Botnet وهي شبكة تتكون من آلاف أو ملايين الأجهزة المتصلة مع بعضها البعض والمصابة ببرمجية خبيثة malware، ويستخدم المخترقون هذه الشبكة لتنفيذ هجماتهم مثل هجمات الحرمان من الخدمة الموزّع DDoS attacks أو إرسال الرسائل المزعجة Spam. ** خرق بيانات Data Breach**: هي الحادثة التي يحصل بها المخترق على بيانات ما بعد نجاح هجمة سيبرانية، وعادةً ما تكون هذه البيانات بيانات شخصية حساسة مثل كلمات المرور أو بيانات مصرفية وغيرها. المخترق ذو القبعة البيضاء White hat وذو القبعة السوداء Black hat: يُقصد بهذين المصطلحين نيّة كل مخترق من عملية الاختراق إذ أن للمخترق ذو القبعة السوداء نيّة سيئة باستخدام البيانات التي يحصل عليها أو الثغرات الأمنية بالابتزاز المالي أو التخريب بينما يكون هدف المخترق ذو القبعة البيضاء الكشف عن هذه الثغرات وسدّها لحماية النظام بشكل أكبر وغالبًا ما تُدعى هذه الفئة من المخترقين بالمخترقين الأخلاقيين Ethical Hackers. أنواع تهديدات الأمن السيبراني على الرغم من تطوّر الهجمات السيبرانية مع مرور الوقت وزيادة تعقيدها إلا أن هناك العديد من أنواع التهديدات الشائعة التي يجب أن يكون مختصّ الأمن السيبراني ملمًّا بها وبطريقة تحصين النظام ضدها. نذكر من أشهر أنواع تهديدات الأمن السيبراني ما يلي: التصيّد الاحتيالي Phishing: هي محاولة المخترق لخداع الضحية الهدف باتخاذ إجراءات غير آمنة وخاطئة، مثل إرسال رابط لصفحة دخول إلى موقع معيّن ومطالبتهم بتسجيل الدخول بحساباتهم في هذا الموقع، إلا أن الصفحة مُستنسخة وعملية التسجيل مزيّفة مما يسمح للمخترق بالحصول على بيانات حساب الضحية. هجمات الحرمان من الخدمة الموزّعة Distributed Denial of Service: تُعرَف اختصارًا بهجمات DDoS، وهي هجمات تتمّ عن طريق إغراق خادم النظام بسيل من المعلومات غير اللازمة باستخدام مجموعة من الأجهزة Botnet وذلك بهدف تعطيل الخدمة أو إبطائها، مما يتسبب بحرمان استخدام الخدمة للمستخدم أو حجبها. البرمجيات الخبيثة malware: هي برمجية يزرعها المهاجم في النظام الضحية بحيث تُنفّذ مجموعة من الأوامر والمهام غير المصرّح بها على جهاز الضحية، نذكر من هذه البرمجيات برمجيات الفدية ransomware التي تشفّر بيانات جهاز الضحية وتمنعه من الدخول إليها بهدف الحصول على مبلغ مالي، وبرمجيات التجسس spyware التي تراقب نشاط المستخدم على حاسبه بشكل سرّي وتسرق بيانات حساسة مثل كلمات السر. هجمات كلمة المرور password attacks: هجوم يحاول فيه المخترق تخمين كلمة المرور لملفات أو نظام، وتتم عملية التخمين عادةً بمساعدة أدوات مخصصة وليس يدويًا. لذا يُنصح على الدوام بالابتعاد عن كلمات السر القصيرة والمُستخدمة بكثرة مثل password123 أو qwerty، والكلمات الموجودة في القاموس دون إضافة رموز وأرقام بينها (لأن هذه الأدوات تجرّب الكلمات الموجودة في القواميس). هجوم الوسيط man-in-the-middle attack: هجوم يستطيع المخترق عن طريقه الوصول إلى البيانات المُرسلة بين المُرسل والمُستقبل عن طريق التنصّت إلى الاتصال ما بينهما، وتتضمّن معظم بروتوكولات نقل البيانات نوعًا من التشفير والمصادقة للحماية من هذا النوع من الهجمات مثل شهادة SSL في بروتوكول HTTPS. أنواع الأمن السيبراني ينقسم مجال الأمن السيبراني إلى عدّة مجالات فرعية أخرى، إذ يختص كل مجال بعيّن بجانب من الفضاء السيبراني. نذكر من هذه المجالات ما يلي: أمن الشبكات Network Security: يُعنى هذا المجال بحماية شبكات الحاسوب ويُحقَّق ذلك عن طريق بعض التقنيات مثل منع فقدان البيانات Data Loss Prevention اختصارًا DLP وإدارة الوصول إلى الهوية Identitiy Access Managment اختصارًا IAM وغيرها من التقنيات التي تجعل من الشبكات فضاءً آمنًا لمشاركة البيانات. أمن الهواتف المحمولة Mobile Security: عادةً ما يكون لهواتف موظّفي المؤسسة أو طاقمها وصول كامل لنظام المؤسسة وبياناتها، وبالنظر إلى أن الهواتف المحمولة هي الجهاز الأكثر استخدامًا عادةً لكل فرد فهذا يُضيف أهميّة زائدة على هذا المجال، إذ يجب تأمين هذه الأجهزة ضد الهجمات الخبيثة باستخدام مختلف التطبيقات (مثل تطبيقات المراسلة وغيرها). أمن السحابة Cloud Security: بدأت كافة المؤسسات بتبني تقنيات السحابة مؤخرًا، مما جعل أمن السحابة مجالًا مهمًا. تتضمن عملية حماية السحابة شروط التحكم بها والوصول إليها وكيفية توزيع بياناتها وهيكلة البنية التحتية ويندرج كل ذلك فيما يدعى باستراتيجية أمن السحابة cloud security strategy. أمن إنترنت الأشياء IoT Security: يُقصد بإنترنت الأشياء مجموعة الأجهزة التي تتواصل مع بعضها البعض وتراقب بيئتها المحيطة باستخدام الحساسات بالإضافة إلى إمكانية التحكم بها عبر الإنترنت. يحمي أمن إنترنت الأشياء هذه الأجهزة من استغلالها من طرف المخترقين عن طريق استخدام ثغرات في الأجهزة بذات نفسها أو وسيط الاتصال فيما بينها. أمن التطبيقات Application Security: التطبيقات التي تستخدم اتصال الإنترنت معرّضة لخطر الاختراق كأي نظام آخر يستخدم شبكات الإنترنت. يعمل أمن التطبيقات على حمايتها عن طريق منع التفاعلات الخبيثة مع التطبيقات الأخرى أو الواجهات البرمجية API. مجالات الأمن السيبراني يحتوي مجال الأمن السيبراني على عدّة مسميات وظيفية فرعيّة مخصصة عنه، ولكل من هذه المسميات مهامها المحدّدة ومتطلباتها، نذكر منها أهم مجالات الأمن السيبراني مع شرح بسيط لكل منها. كبير موظفي أمن المعلومات كبير موظفي أمن المعلومات Chief Information Security Officer اختصارًا CISO هو موظف ذو خبرة كبيرة مسؤول عن أمان المعلومات ضمن المؤسسة بشكل كامل، وتضمن مهامه تطوير طرق حماية البيانات وصيانتها وإدارة برامج المخاطرة، وعادةً ما يشغل هذا المنصب شخصٌ له باعٌ طويل في مجال أمن المعلومات وعمل في واحدة أو أكثر من وظائف أمن المعلومات بحيث يمتلك على خبرة كافية تمكّنه من قيادة فريق الأمن السيبراني في المؤسسة. مهندس الأمن تتضمّن مهام مهندس الأمن Security Architect تصميم نظم الأمان المُستخدمة في الدفاع عن المؤسسة من هجمات البرمجيات الخبيثة، إذ يُجري مهندس الأمن اختبارات لكشف الثغرات ونقاط الضعف في النظام بالإضافة لتزويد المعلومات المهمة إلى أعضاء الفريق الأمني الآخرين. يتطلّب هذا العمل خبرة في مجال هندسة المعلومات والشبكات وإدارة المخاطر بالإضافة إلى بروتوكولات الأمن وتشفير المعلومات. مهندس الأمن السيبراني يعمل مهندس الأمن السيبراني Cybersecurity Engineer على الإجراءات اللازمة التي تمنع نجاح هجوم سيبراني على أنظمة المؤسسة من شبكات وأجهزة، إذ يعمل على تطوير أنظمة دفاع سيبرانية ويعمل بشكل وثيق مع باقي أقسام المؤسسة للحفاظ على أمنها العام. يتطلّب هذا المنصب فهمًا جيدًا لكيفية عمل الشبكات وإدارة نظم التشغيل وهيكلتها بالإضافة إلى إتقان لغة البرمجة C (لأن لغة C تتعامل مع الحاسوب بمستوى منخفض مما يمنحك أريحية التعامل مع نظام التشغيل ومكوناته مقارنةً بلغات البرمجة عالية المستوى الأخرى مثل جافاسكربت وبايثون). محلل البرمجيات الخبيثة يعمل محلل البرمجيات الخبيثة Malware Analyst على فحص وتحليل التهديدات السيبرانية مثل الفيروسات وأحصنة طروادة Trojan horses والروبوتات bots لفهم طبيعتها وتطوير أدوات حماية للمدافعة ضدها، بالإضافة إلى توثيق طرق الحماية ضد البرمجيات الخبيثة وتجنبها. يتطلب هذا المنصب فهمًا لكل من نظام ويندوز ولينكس بالإضافة إلى معرفة بلغة البرمجة C/C++، واستخدام بعض الأدوات مثل IDA Pro وRegShot وTCP View. مختبر الاختراق أو المخترق الأخلاقي يُعرف مختبر الاختراق Penetration Tester بالمخترق الأخلاقي Ethical Hacker أيضًا، وهو مستشار أمني تتمثل مهامه باستغلال الثغرات الأمنية ونقاط الضعف في النظام بطريقة مماثلة لما سيفعله المخترق ذو النية السيئة التخريبية، إلا أن مختبر الاختراق يُطلِع فريق الأمان السيبراني في المؤسسة على الثغرات لتصحيحها، كما أنه يصمّم أدوات الاختراق ويوثّق نتائج الاختبار. المحلل الجنائي الرقمي يعمل المحلل الجنائي الرقمي Computer Forensics Analyst بعد حدوث هجوم سيبراني، إذ يجمع الأدلة الرقمية ويحاول استعادة البيانات المحذوفة أو المُعدَّل عليها أو المسروقة. يتطلّب هذا العمل معرفة بالشبكات والأمن السيبراني وفهم لقوانين الجرائم السيبرانية بالإضافة إلى مهارات تحليلية والانتباه للتفاصيل الدقيقة. كيف أبدأ بتعلم تخصص الأمن السيبراني؟ إن أردت البدء بتعلم الأمن السيبراني، فهذا يعني أنه عليك أن تبدأ بتعلم بعض المفاهيم والأدوات الأساسية في هذا المجال ألا وهي: تعلم أساسيات البرمجة، وذلك باختيار لغة برمجة معيّنة (يُفضّل البدء بلغة C أو C++ إن أردت دخول مجال الأمن السيبراني لأن اللغتين تتعامل مع الحاسوب على مستوى منخفض مما يمنحك أريحية التحكم بنظام التشغيل وأجزاء النظام الأخرى). فهم كيفية عمل أنظمة التشغيل وبنيتها، ننصحُك هنا بقراءة كتاب أنظمة التشغيل للمبرمجين كيفية عمل قواعد البيانات التي تخزّن بيانات أي نظام حاسوبي وعمليّة تصميمها، يمكنك الاطّلاع على كتاب تصميم قواعد البيانات للحصول على فهم أوّلي حول هذا الموضوع. إتقان التعامل مع سطر الأوامر command line بمختلف أوامره البسيطة والمتقدمة. فهم كيفية عمل الشبكات وكيف تتواصل الأجهزة مع بعضها البعض وتتبادل البيانات باستخدام بروتوكولات الاتصال المختلفة. التعامل مع أحد توزيعات لينكس الموجهة للأمن السيبراني والاختراقات بتمرّس، ونذكر منها توزيعة ريدهات Redhat لإدارة الخوادم (التي ستمكنك من الحصول على شهادة RHCSA وشهادة RHCE) ولينكس كالي Kali Linux، إذ تحتوي هذه التوزيعات على أدوات أساسية للتعامل مع الشبكات ومهام الأمن السيبراني. ماذا بعد؟ اختر مجالًا لتركّز عليه من المجالات السابقة التي ذكرناها، إذ أنّ مسار التعلم الخاص بك سيختلف بحسب توجهك، وهناك بعض الشهادات التي يجب أن تمتلكها لتزيد من فرصك في الحصول على عمل بحسب المجال الذي تختاره. على سبيل المثال تُعدّ شهادة CEH هامة لمختبر الاختراق -أو المخترق الأخلاقي- وشهادة CHFI هامة للمحلل الجنائي الرقمي. نرشّح لك أيضًا كتاب دليل الأمان الرقمي للاستزادة وتعلّم المزيد بخصوص الأمن السيبراني والاختراق. المصادر: What is Cybersecurity? Everything You Need to Know | TechTarget Top 20 Cybersecurity Terms You Need to Know (simplilearn.com) What Is Cybersecurity | Types and Threats Defined | Cybersecurity | CompTIA How To Learn Cybersecurity on Your Own A Basic Guide On Cyber Security For Beginners 2022 Edition | Simplilearn The Life and Times of Cybersecurity Professionals 2021 - Volume V - ISSA اقرأ أيضًا الهجمات الأمنية Security Attacks في الشبكات الحاسوبية تأمين الشبكات اللاسلكية كيف نخفف من هجمات DDoS ضد موقعنا باستخدام CloudFlare 7 تدابير أمنية لحماية خواديمك- 1 تعليق
-
- 3
-

-
 تنتمي كل قيمة في لغة رست إلى نوع بيانات معيّن، ويُساعد ذلك لغة رست بمعرفة نوع البيانات التي تدلّ عليها هذه القيمة وكيفية التعامل معها، وسننظر إلى مجموعتين من أنواع البيانات، هي: القيم المُفردة scalar والقيم المركّبة compound. تذكر أن لغة رست لغة برمجة متقيدة بأنواع البيانات statically typed، أي أنه يجب أن تعرف أنواع البيانات جميعها عند وقت التصريف، ويستطيع المصرّف عادةً استنتاج نوع المتغيرات بناءً على القيمة وكيفية استخدامها ضمن الشيفرة البرمجية، إلا أننا يجب أن نحدّد الأنواع في بعض الحالات، مثل التحويل من String إلى نوع عددي باستخدام parse كما رأينا في مقالنا السابق فقرة مقارنة التخمين إلى الرقم السري: let guess: u32 = "42".parse().expect("Not a number!"); نحصل على الخطأ التالي إن لم نُضف النوع u32 : كما هو موضح أعلاه، ويدل الخطأ على أن المصرّف يحتاج المزيد من المعلومات حول النوع الذي نريد استخدامه: $ cargo build Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations) error[E0282]: type annotations needed --> src/main.rs:2:9 | 2 | let guess = "42".parse().expect("Not a number!"); | ^^^^^ consider giving `guess` a type For more information about this error, try `rustc --explain E0282`. error: could not compile `no_type_annotations` due to previous error ستجد ترميزًا مختلفًا لكل من أنواع البيانات الأخرى. الأنواع المفردة يمثّل النوع المفرد scalar type قيمة فردية، ولدى لغة رست أربع أنواع مُفردة أولية هي: الأعداد الصحيحة integers والأعداد ذات الفاصلة العشرية floating-point numbers والقيم البوليانية booleans والمحارف characters، وقد تتعرف على بعضها من لغة برمجة أخرى تعاملت معها سابقًا. دعنا نتحدّث عن كيفية استعمال هذه الأنواع في لغة رست. أنواع الأعداد الصحيحة العدد الصحيح integer هو عدد لا يحتوي على جزء كسري، وسبق لنا استخدام نوع من أنواع الأعداد الصحيحة سابقًا وهو u32، ويحدد التصريح عن هذا النوع أن القيمة المُسندة إلى المتغير ستكون عدد صحيح عديم الإشارة unsigned integer (تبدأ الأعداد الصحيحة ذات الإشارة بالحرف i بدلًا من u)، ويأخذ مساحة 32 بت. يوضّح الجدول 3-1 أنواع الأعداد الصحيحة المُضمّنة في لغة رست، ويمكننا استخدام أي من هذه المتغايرات variants للتصريح عن نوع قيمة العدد الصحيح. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الطول ذو إشارة عديم الإشارة 8-بت i8 u8 16-بت i16 u16 32-بت i32 u32 64-بت i64 u64 128-بت i128 u128 يعتمد على معمارية الحاسب isize usize [جدول 3-1: أنواع الأعداد الصحيحة في راست] يُمكن أن يكون كل متغاير ذو إشارة أو عديم إشارة وذو طول محدّد، إذ تُشير كلمة ذو إشارة signed وعديم الإشارة unsigned إلى إمكانية كون العدد سالبًا أم لا، وبتعبير آخر، هل يحتاج العدد إلى إشارةٍ معه (ذو إشارة signed) أم أنه سيكون موجبًا فقط وسيُمثّل بالتالي دون أي إشارة (عديم الإشارة unsigned). الأمر مماثل لكتابة الأعداد على ورقة، فعندما نحتاج لاستخدام الإشارة يُوضّح العدد وبجانبه إشارة (سواءً موجبة أو سالبة)، وفي حال كان الافتراض أن جميع الأعداد موجبة، فلا نضع أي إشارة بجانب الأعداد، وتُخزّن الأعداد ذات الإشارة باستخدام تمثيل المتمّم الثنائي two's complement. يُمكن أن يخزِّن كل متغاير ذي إشارة القيم المنتمية إلى المجال من 2n-1- إلى 2n-1 - 1، إذ تمثّل "n" عدد البتات التي يستخدمها المتغاير، وبالتالي يمكن للنوع i8 تخزين القيم التي تنتمي إلى المجال من 27- إلى 1- 27 الذي يساوي من -128 إلى 127، بينما يمكن للمتغايرات عديمة الإشارة تخزين القيم ضمن المجال من 0 إلى 2n-1، وبالتالي يمكن للنوع u8 أن يخزن الأعداد من 0 إلى 28-1 وهو ما يساوي المجال من 0 إلى 255. إضافةً لما سبق، يعتمد النوعان isize وusize على معمارية الحاسب الذي يعمل عليه برنامجك، وهو بطول 64 بت إذا كان من معمارية 64 بت وبطول 32 بت إذا كان من معمارية 32 بت. يُمكنك كتابة الأعداد الصحيحة المُجرّدة integer literals بأي من التنسيقات الموضحة في الجدول 3-2، لاحظ أن لغة رست توفر صياغة لكتابة الأعداد بطريقة تدل على نوعها لتمثيل عدة أنواع عددية إذ تسمح بوجود لاحقة للنوع type suffix مثل "57u8" لتحديد نوعه، ويُمكن أن تستخدم صياغة الأعداد تلك أيضًا الرمز _ بمثابة فاصل بصري لجعل الأعداد أسهل للقراءة مثل "1_000" الذي يحمل القيمة "1000" ذاتها. العدد المجرد مثال عشري 98_222 ست عشري 0xff ثُماني 0o77 ثُنائي 0b1111_0000 بايت (فقط بحجم u8) b'A' [جدول 3-2: الأعداد الصحيحة المجردة في لغة رست] إذًا، كيف يمكنك معرفة أي أنواع الأعداد الصحيحة التي يجب عليك استخدامها؟ أنواع لغة رست الافتراضية هي الخيار الأمثل إذا لم تكُن متأكدًا بخصوص هذا الأمر، نوع العدد الصحيح الافتراضي هو i32، والحالة التي قد تستخدم فيها أحد النوعين isize أوusize هي عندما تستخدم قيمة المتغير دليلًا index ما ضمن مجموعة collection. طفحان الأعداد الصحيحة بفرض أن هناك متغير من النوع u8 الذي يمكنه تخزين القيم من 0 إلى 255. إذا حاولت إسناد قيمة إلى ذلك المتغير خارج النطاق المذكور -مثل القيمة 256- فسيتسبب ذلك بحدوث ما يسمى طفحان الأعداد الصحيحة integer overflow الذي قد يتسبب بحدوث نتيجة من اثنتان. تتفقد لغة رست عند تصريف البرنامج في نمط تنقيح الأخطاء debug mode حالات طفحان الأعداد الصحيحة التي ستتسبب بهلع panic برنامجك عند تشغيله، ويستخدم مبرمجو لغة رست مصطلح هلع panic عندما يتوقف البرنامج بسبب خطأ ما، وسنناقش هذا الأمر بتعمق أكبر لاحقًا. لا تتحقق لغة رست من حالات طفحان الأعداد الصحيحة التي تتسبب بهلع البرنامج عند تصريفه باستخدام نمط الإطلاق release mode باستخدام الراية flag --release، وتجري راست بدلًا من ذلك عمليةً تُعرف بانتقال المتمم الثنائي two's complement wrapping إذا حدث أي طفحان. باختصار، تنتقل القيمة التي تحتوي على قيمة أكبر من القيمة العظمى الممكن للنوع تخزينها إلى أصغر قيمة يمكن للمتغير تخزينها، فعلى سبيل المثال تصبح القيمة 256 في النوع u8 مساويةً إلى الصفر والقيمة 257 إلى 1 وهكذا، لن يهلع البرنامج في هذه الحالة، بل سيحمل المتغير قيمةً مختلفة، ويُعدّ الاعتماد على عملية الانتقال wrapping في طفحان الأعداد الصحيحة خطأً. يُمكنك استخدام أحد الطرق التالية للتعامل على نحوٍ صريح مع حالات الطفحان وهي طرق مُضمنّة في المكتبة القياسية للأنواع العددية الأولية: تمكين الانتقال في جميع أنماط بناء البرنامج باستخدام توابع wrapping_* مثل wrapping_add. إعادة القيمة None إذا لم يكن هناك أي طفحان باستخدام التوابع checked_*. إعادة القيمة والقيمة البوليانية التي تشير إلى حدوث طفحان باستخدام توابع overflowing_*. إشباع saturate القيم العُظمى والدُنيا للقيمة باستخدام توابع saturating_*. أنواع أعداد الفاصلة العشرية لدى لغة راست نوعَين من أنواع أعداد الفاصلة العشرية floating-point numbers وهي الأعداد التي تحتوي على فواصل عشرية، وهما f32 و f64، وبحجم 32 بت و64 بت، والنوع الافتراضي هو f64، لأنها تكون بنفس سرعة المُعالجات الحديثة f32 ولكنها أكثر دقة، وجميع أنواع أعداد الفاصلة العشرية ذات إشارة. إليك مثالًا يوضح أعداد الفاصلة العشرية عمليًا: اسم الملف: src/main.rs fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 } تُمثّل أعداد الفاصلة العشرية بحسب معيار IEEE-754. للنوع f32 دقة وحيدة single-precision، بينما للنوع f64 دقة مضاعفة double precision. العمليات على الأنواع العددية تدعم لغة راست العمليات الرياضية الأساسية التي تتوقع إجرائها على الأنواع العددية، وهي الجمع والطرح والضرب والقسمة وباقي القسمة. يُقرّب ناتج قسمة الأعداد الصحيحة إلى أقرب عدد صحيح، وتوضح الشيفرة البرمجية التالية كيفية إجراء كل من العمليات باستخدام تعليمة let: اسم الملف src/main.rs fn main() { // الجمع let sum = 5 + 10; // الطرح let difference = 95.5 - 4.3; // الضرب let product = 4 * 30; // القسمة let quotient = 56.7 / 32.2; let floored = 2 / 3; // Results in 0 // باقي القسمة let remainder = 43 % 5; } يستخدم كل تعبير من التعابير السابقة عاملًا رياضيًا ويُقيّم الناتج إلى قيمة واحدة، ثم تُسند هذه القيمة إلى المتغير. النوع البولياني للنوع البولياني boolean type في لغة رست -كما هو الحال في معظم لغات البرمجة الأخرى- قيمتان: true و false، ويبلغ حجم النوع هذا بتًا واحدًا، ويُحدّد النوع البولياني في لغة راست باستخدام الكلمة bool كما يوضح المثال التالي: اسم الملف: src/main.rs fn main() { let t = true; let f: bool = false; // تحديد النوع بوضوح } الاستخدام الأساسي للقيم البوليانية هو في التعابير الشرطية conditionals مثل تعابير if، وسنغطّي تعابير if وكيفية عملها في لغة رست لاحقًا. نوع المحرف نوع char في لغة رست هو أكثر أنواع القيم الأبجدية بدائية، إليك بعض الأمثلة عن تصريح قيم char: اسم الملف: src/main.rs fn main() { let c = 'z'; let z: char = 'ℤ'; // تحديد النوع بوضوح let heart_eyed_cat = '?'; } لاحظ أننا حددنا النوع char المجرد باستخدام علامتَي تنصيص فردية، بعكس نوع السلسلة النصية string المجرّد الذي يستخدم علامتَي تنصيص مزدوجة، ويبلغ حجم النوع char في لغة راست أربعة بايتات وتمثل القيمة قيمة يونيكود Unicode عددية التي يُمكن أن تمثل قيمًا أكثر ممّا تستطيع الآسكي ASCII تمثيله. تتضمن لغة راست كذلك الأحرف المُعلّمة accented letters وكل من المحارف الصينية واليابانية والكورية، إضافةً إلى الرموز التعبيرية emoji والمسافات الفارغة ذات العرض الصفري zero-width space، إذ تُعد جميع القيم السابقة المذكورة قيمًا صالحة ويُمكن تخزينها في متغير من نوع char. تتراوح قيم يونيكود العددية من "U+0000" إلى "U+D7FF" ومن "U+E000" إلى "U+10FFFF"، إلا أن مصطلح المحرف character غير موجود في نظام اليونيكود، وبالتالي يمكن ألا يتطابق فهمك كإنسان لماهية المحرف مع تعريف النوع char في لغة راست، وسنناقش هذا الموضوع بالتفصيل لاحقًا. الأنواع المركبة يُمكن للأنواع المركبة compound types أن تجمع عدّة قيم في نوع واحد، وللغة رست نوعان من الأنواع المركبة وهي المجموعات tuples والمصفوفات arrays. نوع المجموعة المجموعة هي طريقة عامة لجمع عدّة قيم من أنواع مختلفة إلى نوع مُركب واحد، وللمجموعات حجم مُحدّد إذ لا يُمكن أن يكبر أو يصغر الحجم بعد التصريح عنه. نستطيع إنشاء مجموعة عن طريق كتابة لائحة من العناصر يُفصل ما بينها بالفاصلة داخل قوسين، وكل موضع داخل هذه اللائحة يمثل قيمةً بنوع مُعيّن، ويمكن أن تختلف هذه الأنواع فيما بينها. أضفنا أنواع عناصر اللائحة في مثالنا التالي ولكن هذه الخطوة اختيارية: اسم الملف: src/main.rs fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); } يُسند المتغير tup إلى كامل المجموعة، لأن المجموعة تمثّل عنصرًا مركبًا واحدًا، وللحصول على القيم الفردية داخل المجموعة يمكننا استخدام مطابقة الأنماط pattern matching لتفكيك destructure قيمة المجموعة كما هو موضح: اسم الملف: src/main.rs fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); } يُنشئ هذا البرنامج مجموعة ويُسندها إلى المتغير tup، ومن ثم يستخدم نمطًا مع let لأخذ المتغير tup وتحويله إلى ثلاث قيم منفصلة وهي x و y و z، ويدعى هذا بالتفكيك destructuring لأنه يُفكك المجموعة الواحدة إلى ثلاث أجزاء، ويطبع البرنامج أخيرًا قيمة y المساوية إلى "6.4". يمكننا أيضًا الوصول إلى عناصر المجموعة مباشرةً باستخدام النقطة (.) متبوعةً بدليل القيمة التي نريد الوصول إليها، كما هو موضح في المثال التالي: اسم الملف: src/main.rs fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; } يُنشئ هذا البرنامج مجموعةً باسم x، ثم يستخدم قيمة كل من عناصرها باستخدام دليل كل منها، ويبدأ الدليل الأول بالرقم 0 كما هو الحال في معظم لغات البرمجة. للمجموعة اسم مميّز إذا كانت فارغة ألا وهو الوحدة unit، وتُكتب قيمتها وقيمة أنواعها بالشكل ()، اللتان تُمثّلان قيمة فارغة أو قيمة إعادة فارغة empty return type، تُعيد التعابير ضمنيًا قيمة الوحدة إذا لم يكن التعبير يُعيد أي قيمة أخرى. نوع المصفوفة المصفوفة هي نوع من الأنواع الأخرى التي تحتوي على مجموعة من قيم متعددة، ويجب أن تكون جميع هذه القيم من النوع ذاته على عكس المجموعة، وللمصفوفات حجم ثابت بعكس بعض لغات البرمجة الأخرى. نكتب القيم في المصفوفة مثل لائحة من القيم مفصول ما بينها بفاصلة داخل أقواس معقوفة square brackets: اسم الملف: src/main.rs fn main() { let a = [1, 2, 3, 4, 5]; } يُمكن للمصفوفات أن تكون مفيدةً عندما تريد من بياناتك أن تكون موجودةً على المكدّس stack بدلًا من الكومة heap (سنناقش المكدس والكومة لاحقًا) أو عندما تريد أن تتأكد أن هناك مجموعة ثابتة العدد من العناصر. المصفوفة ليست نوعًا مرنًا مثل نوع الشعاع vector، فالشعاع هو نوع مماثل يحتوي على مجموعة وهو مُضمّن في المكتبة القياسية ويمكن أن يتغير حجمه بالزيادة أو النقصان، وإن لم تكُن متأكدًا أيُّهما تستخدم، فذلك يعني أنك غالبًا بحاجة استخدام الشعاع، وسنناقش هذا الأمر بالتفصيل لاحقًا. تبرز أهمية المصفوفات عندما تعرف عدد العناصر التي تحتاجها، على سبيل المثال إذا كنت تستخدم أسماء الأشهر في برنامج فمن الأفضل في هذه الحالة استخدام المصفوفة بدلًا من الشعاع لأنك تعلم أنك بحاجة 12 عنصر فقط: let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; يُكتب نوع المصفوفة باستخدام الأقواس المعقوفة مع نوع العناصر ومن ثم فاصلة منقوطة وعدد العناصر ضمن المصفوفة كما هو موضح: let a: [i32; 5] = [1, 2, 3, 4, 5]; يمثل النوع i32 في مثالنا هذا نوع عناصر المصفوفة، بينما يمثل العدد "5" الذي يقع بعد الفاصلة المنقوطة عدد عناصر المصفوفة الخمس. يمكنك تهيئة المصفوفة بحيث تحمل القيمة ذاتها لكافة العناصر عن طريق تحديد القيمة الابتدائية initial value متبوعةً بفاصلة منقوطة ومن ثم طول المصفوفة ضمن أقواس معقوفة، كما هو موضح: let a = [3; 5]; ستحتوي المصفوفة a على 5 عناصر وستكون قيم العناصر جميعها مساوية إلى 3 مبدئيًا، وهذا الأمر مماثل لكتابة السطر البرمجي let a = [3, 3, 3 ,3 ,3]; إلا أن هذه الطريقة مختصرة. الوصول إلى عناصر المصفوفة تُمثل المصفوفة جزءًا واحدًا معلوم الحجم من الذاكرة، والذي يُمكن تخزينه في المكدس، ويمكنك الوصول إلى عناصر المصفوفة باستخدام الدليل كما هو موضح: اسم الملف: src/main.rs fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; } في مثالنا السابق، سيُسند إلى المتغير first القيمة الابتدائية 1 لأنها القيمة الموجودة في الدليل [0] ضمن المصفوفة، بينما سيُسند إلى المتغير second القيمة 2 لأنها القيمة الموجودة في الدليل[1] ضمن المصفوفة. محاولة الوصول الخاطئ إلى عناصر المصفوفة دعنا نرى ما الذي سيحدث إذا حاولت الوصول إلى عنصر من عناصر المصفوفة إذا كان ذلك العنصر يقع خارج المصفوفة بعد نهايتها، ولنقل أننا سننفّذ الشيفرة البرمجية التالية المشابهة للعبة التخمين في المقال السابق بالحصول على دليل المصفوفة من المستخدم: اسم الملف: src/main.rs use std::io; fn main() { let a = [1, 2, 3, 4, 5]; println!("Please enter an array index."); let mut index = String::new(); io::stdin() .read_line(&mut index) .expect("Failed to read line"); let index: usize = index .trim() .parse() .expect("Index entered was not a number"); let element = a[index]; println!("The value of the element at index {index} is: {element}"); } ستُصرّف الشيفرة البرمجية بنجاح، وإذا شغلت البرنامج باستخدام cargo run وأدخلت القيم 0 أو 1 أو 2 أو 3 أو 4، فسيطبع البرنامج القيمة الموافقة لهذا الدليل ضمن المصفوفة، إلا أنك ستحصل على الخرج التالي إذا حاولت إدخال قيمة أكبر من حجم المصفوفة (مثل 10): thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 10', src/main.rs:19:19 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace تسبب البرنامج بخطأ عند التشغيل runtime error عند إدخال قيمة خاطئة إلى عملية الوصول للعناصر بالدليل، وانتهى البرنامج برسالة خطأ ولم يُنفّذ تعليمة !println الأخيرة. تتفقد لغة راست الدليل الذي حدّدته عند محاولتك الوصول إليه فيما إذا كان أصغر من حجم المصفوفة، وإذا كان الدليل أكبر أو يساوي حجم المصفوفة فسيهلع panic البرنامج، وتحدث عملية التفقد هذه عند وقت التشغيل خصوصًا في هذه الحالة وذلك لأن المصرف ربما لن يعرف القيمة التي سيدخلها المستخدم عند تشغيل الشيفرة بعد ذلك. كان هذا مثالًا لمبادئ أمان ذاكرة رست بصورةٍ عملية، وتفتقر معظم لغات البرمجة منخفضة المستوى هذا النوع من التحقق، إذ يُمكن الوصول إلى ذاكرة خاطئة عندما تُعطي دليلًا خاطئًا في هذه اللغات. تحميك لغة رست من هذا النوع من الأخطاء بالخروج من البرنامج فورًا عوضًا عن السماح بالوصول إلى ذاكرة خاطئة والاستمرار بالبرنامج، وسنناقش لاحقًا كيفية تعامل لغة رست مع الأخطاء وكيف يُمكنك كتابة شيفرة برمجية سهلة القراءة وآمنة بحيث لا يهلع البرنامج عند تنفيذها أو تسمح بالوصول إلى ذاكرة خاطئة. ترجمة -وبتصرف- للقسم Data Types من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: كيفية كتابة الدوال Functions والتعليقات Comments في لغة رست Rust المقال السابق: المتغيرات والتعديل عليها في لغة رست تعلم لغة رست Rust: البدايات برمجة لعبة تخمين الأرقام بلغة رست Rust
تنتمي كل قيمة في لغة رست إلى نوع بيانات معيّن، ويُساعد ذلك لغة رست بمعرفة نوع البيانات التي تدلّ عليها هذه القيمة وكيفية التعامل معها، وسننظر إلى مجموعتين من أنواع البيانات، هي: القيم المُفردة scalar والقيم المركّبة compound. تذكر أن لغة رست لغة برمجة متقيدة بأنواع البيانات statically typed، أي أنه يجب أن تعرف أنواع البيانات جميعها عند وقت التصريف، ويستطيع المصرّف عادةً استنتاج نوع المتغيرات بناءً على القيمة وكيفية استخدامها ضمن الشيفرة البرمجية، إلا أننا يجب أن نحدّد الأنواع في بعض الحالات، مثل التحويل من String إلى نوع عددي باستخدام parse كما رأينا في مقالنا السابق فقرة مقارنة التخمين إلى الرقم السري: let guess: u32 = "42".parse().expect("Not a number!"); نحصل على الخطأ التالي إن لم نُضف النوع u32 : كما هو موضح أعلاه، ويدل الخطأ على أن المصرّف يحتاج المزيد من المعلومات حول النوع الذي نريد استخدامه: $ cargo build Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations) error[E0282]: type annotations needed --> src/main.rs:2:9 | 2 | let guess = "42".parse().expect("Not a number!"); | ^^^^^ consider giving `guess` a type For more information about this error, try `rustc --explain E0282`. error: could not compile `no_type_annotations` due to previous error ستجد ترميزًا مختلفًا لكل من أنواع البيانات الأخرى. الأنواع المفردة يمثّل النوع المفرد scalar type قيمة فردية، ولدى لغة رست أربع أنواع مُفردة أولية هي: الأعداد الصحيحة integers والأعداد ذات الفاصلة العشرية floating-point numbers والقيم البوليانية booleans والمحارف characters، وقد تتعرف على بعضها من لغة برمجة أخرى تعاملت معها سابقًا. دعنا نتحدّث عن كيفية استعمال هذه الأنواع في لغة رست. أنواع الأعداد الصحيحة العدد الصحيح integer هو عدد لا يحتوي على جزء كسري، وسبق لنا استخدام نوع من أنواع الأعداد الصحيحة سابقًا وهو u32، ويحدد التصريح عن هذا النوع أن القيمة المُسندة إلى المتغير ستكون عدد صحيح عديم الإشارة unsigned integer (تبدأ الأعداد الصحيحة ذات الإشارة بالحرف i بدلًا من u)، ويأخذ مساحة 32 بت. يوضّح الجدول 3-1 أنواع الأعداد الصحيحة المُضمّنة في لغة رست، ويمكننا استخدام أي من هذه المتغايرات variants للتصريح عن نوع قيمة العدد الصحيح. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الطول ذو إشارة عديم الإشارة 8-بت i8 u8 16-بت i16 u16 32-بت i32 u32 64-بت i64 u64 128-بت i128 u128 يعتمد على معمارية الحاسب isize usize [جدول 3-1: أنواع الأعداد الصحيحة في راست] يُمكن أن يكون كل متغاير ذو إشارة أو عديم إشارة وذو طول محدّد، إذ تُشير كلمة ذو إشارة signed وعديم الإشارة unsigned إلى إمكانية كون العدد سالبًا أم لا، وبتعبير آخر، هل يحتاج العدد إلى إشارةٍ معه (ذو إشارة signed) أم أنه سيكون موجبًا فقط وسيُمثّل بالتالي دون أي إشارة (عديم الإشارة unsigned). الأمر مماثل لكتابة الأعداد على ورقة، فعندما نحتاج لاستخدام الإشارة يُوضّح العدد وبجانبه إشارة (سواءً موجبة أو سالبة)، وفي حال كان الافتراض أن جميع الأعداد موجبة، فلا نضع أي إشارة بجانب الأعداد، وتُخزّن الأعداد ذات الإشارة باستخدام تمثيل المتمّم الثنائي two's complement. يُمكن أن يخزِّن كل متغاير ذي إشارة القيم المنتمية إلى المجال من 2n-1- إلى 2n-1 - 1، إذ تمثّل "n" عدد البتات التي يستخدمها المتغاير، وبالتالي يمكن للنوع i8 تخزين القيم التي تنتمي إلى المجال من 27- إلى 1- 27 الذي يساوي من -128 إلى 127، بينما يمكن للمتغايرات عديمة الإشارة تخزين القيم ضمن المجال من 0 إلى 2n-1، وبالتالي يمكن للنوع u8 أن يخزن الأعداد من 0 إلى 28-1 وهو ما يساوي المجال من 0 إلى 255. إضافةً لما سبق، يعتمد النوعان isize وusize على معمارية الحاسب الذي يعمل عليه برنامجك، وهو بطول 64 بت إذا كان من معمارية 64 بت وبطول 32 بت إذا كان من معمارية 32 بت. يُمكنك كتابة الأعداد الصحيحة المُجرّدة integer literals بأي من التنسيقات الموضحة في الجدول 3-2، لاحظ أن لغة رست توفر صياغة لكتابة الأعداد بطريقة تدل على نوعها لتمثيل عدة أنواع عددية إذ تسمح بوجود لاحقة للنوع type suffix مثل "57u8" لتحديد نوعه، ويُمكن أن تستخدم صياغة الأعداد تلك أيضًا الرمز _ بمثابة فاصل بصري لجعل الأعداد أسهل للقراءة مثل "1_000" الذي يحمل القيمة "1000" ذاتها. العدد المجرد مثال عشري 98_222 ست عشري 0xff ثُماني 0o77 ثُنائي 0b1111_0000 بايت (فقط بحجم u8) b'A' [جدول 3-2: الأعداد الصحيحة المجردة في لغة رست] إذًا، كيف يمكنك معرفة أي أنواع الأعداد الصحيحة التي يجب عليك استخدامها؟ أنواع لغة رست الافتراضية هي الخيار الأمثل إذا لم تكُن متأكدًا بخصوص هذا الأمر، نوع العدد الصحيح الافتراضي هو i32، والحالة التي قد تستخدم فيها أحد النوعين isize أوusize هي عندما تستخدم قيمة المتغير دليلًا index ما ضمن مجموعة collection. طفحان الأعداد الصحيحة بفرض أن هناك متغير من النوع u8 الذي يمكنه تخزين القيم من 0 إلى 255. إذا حاولت إسناد قيمة إلى ذلك المتغير خارج النطاق المذكور -مثل القيمة 256- فسيتسبب ذلك بحدوث ما يسمى طفحان الأعداد الصحيحة integer overflow الذي قد يتسبب بحدوث نتيجة من اثنتان. تتفقد لغة رست عند تصريف البرنامج في نمط تنقيح الأخطاء debug mode حالات طفحان الأعداد الصحيحة التي ستتسبب بهلع panic برنامجك عند تشغيله، ويستخدم مبرمجو لغة رست مصطلح هلع panic عندما يتوقف البرنامج بسبب خطأ ما، وسنناقش هذا الأمر بتعمق أكبر لاحقًا. لا تتحقق لغة رست من حالات طفحان الأعداد الصحيحة التي تتسبب بهلع البرنامج عند تصريفه باستخدام نمط الإطلاق release mode باستخدام الراية flag --release، وتجري راست بدلًا من ذلك عمليةً تُعرف بانتقال المتمم الثنائي two's complement wrapping إذا حدث أي طفحان. باختصار، تنتقل القيمة التي تحتوي على قيمة أكبر من القيمة العظمى الممكن للنوع تخزينها إلى أصغر قيمة يمكن للمتغير تخزينها، فعلى سبيل المثال تصبح القيمة 256 في النوع u8 مساويةً إلى الصفر والقيمة 257 إلى 1 وهكذا، لن يهلع البرنامج في هذه الحالة، بل سيحمل المتغير قيمةً مختلفة، ويُعدّ الاعتماد على عملية الانتقال wrapping في طفحان الأعداد الصحيحة خطأً. يُمكنك استخدام أحد الطرق التالية للتعامل على نحوٍ صريح مع حالات الطفحان وهي طرق مُضمنّة في المكتبة القياسية للأنواع العددية الأولية: تمكين الانتقال في جميع أنماط بناء البرنامج باستخدام توابع wrapping_* مثل wrapping_add. إعادة القيمة None إذا لم يكن هناك أي طفحان باستخدام التوابع checked_*. إعادة القيمة والقيمة البوليانية التي تشير إلى حدوث طفحان باستخدام توابع overflowing_*. إشباع saturate القيم العُظمى والدُنيا للقيمة باستخدام توابع saturating_*. أنواع أعداد الفاصلة العشرية لدى لغة راست نوعَين من أنواع أعداد الفاصلة العشرية floating-point numbers وهي الأعداد التي تحتوي على فواصل عشرية، وهما f32 و f64، وبحجم 32 بت و64 بت، والنوع الافتراضي هو f64، لأنها تكون بنفس سرعة المُعالجات الحديثة f32 ولكنها أكثر دقة، وجميع أنواع أعداد الفاصلة العشرية ذات إشارة. إليك مثالًا يوضح أعداد الفاصلة العشرية عمليًا: اسم الملف: src/main.rs fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 } تُمثّل أعداد الفاصلة العشرية بحسب معيار IEEE-754. للنوع f32 دقة وحيدة single-precision، بينما للنوع f64 دقة مضاعفة double precision. العمليات على الأنواع العددية تدعم لغة راست العمليات الرياضية الأساسية التي تتوقع إجرائها على الأنواع العددية، وهي الجمع والطرح والضرب والقسمة وباقي القسمة. يُقرّب ناتج قسمة الأعداد الصحيحة إلى أقرب عدد صحيح، وتوضح الشيفرة البرمجية التالية كيفية إجراء كل من العمليات باستخدام تعليمة let: اسم الملف src/main.rs fn main() { // الجمع let sum = 5 + 10; // الطرح let difference = 95.5 - 4.3; // الضرب let product = 4 * 30; // القسمة let quotient = 56.7 / 32.2; let floored = 2 / 3; // Results in 0 // باقي القسمة let remainder = 43 % 5; } يستخدم كل تعبير من التعابير السابقة عاملًا رياضيًا ويُقيّم الناتج إلى قيمة واحدة، ثم تُسند هذه القيمة إلى المتغير. النوع البولياني للنوع البولياني boolean type في لغة رست -كما هو الحال في معظم لغات البرمجة الأخرى- قيمتان: true و false، ويبلغ حجم النوع هذا بتًا واحدًا، ويُحدّد النوع البولياني في لغة راست باستخدام الكلمة bool كما يوضح المثال التالي: اسم الملف: src/main.rs fn main() { let t = true; let f: bool = false; // تحديد النوع بوضوح } الاستخدام الأساسي للقيم البوليانية هو في التعابير الشرطية conditionals مثل تعابير if، وسنغطّي تعابير if وكيفية عملها في لغة رست لاحقًا. نوع المحرف نوع char في لغة رست هو أكثر أنواع القيم الأبجدية بدائية، إليك بعض الأمثلة عن تصريح قيم char: اسم الملف: src/main.rs fn main() { let c = 'z'; let z: char = 'ℤ'; // تحديد النوع بوضوح let heart_eyed_cat = '?'; } لاحظ أننا حددنا النوع char المجرد باستخدام علامتَي تنصيص فردية، بعكس نوع السلسلة النصية string المجرّد الذي يستخدم علامتَي تنصيص مزدوجة، ويبلغ حجم النوع char في لغة راست أربعة بايتات وتمثل القيمة قيمة يونيكود Unicode عددية التي يُمكن أن تمثل قيمًا أكثر ممّا تستطيع الآسكي ASCII تمثيله. تتضمن لغة راست كذلك الأحرف المُعلّمة accented letters وكل من المحارف الصينية واليابانية والكورية، إضافةً إلى الرموز التعبيرية emoji والمسافات الفارغة ذات العرض الصفري zero-width space، إذ تُعد جميع القيم السابقة المذكورة قيمًا صالحة ويُمكن تخزينها في متغير من نوع char. تتراوح قيم يونيكود العددية من "U+0000" إلى "U+D7FF" ومن "U+E000" إلى "U+10FFFF"، إلا أن مصطلح المحرف character غير موجود في نظام اليونيكود، وبالتالي يمكن ألا يتطابق فهمك كإنسان لماهية المحرف مع تعريف النوع char في لغة راست، وسنناقش هذا الموضوع بالتفصيل لاحقًا. الأنواع المركبة يُمكن للأنواع المركبة compound types أن تجمع عدّة قيم في نوع واحد، وللغة رست نوعان من الأنواع المركبة وهي المجموعات tuples والمصفوفات arrays. نوع المجموعة المجموعة هي طريقة عامة لجمع عدّة قيم من أنواع مختلفة إلى نوع مُركب واحد، وللمجموعات حجم مُحدّد إذ لا يُمكن أن يكبر أو يصغر الحجم بعد التصريح عنه. نستطيع إنشاء مجموعة عن طريق كتابة لائحة من العناصر يُفصل ما بينها بالفاصلة داخل قوسين، وكل موضع داخل هذه اللائحة يمثل قيمةً بنوع مُعيّن، ويمكن أن تختلف هذه الأنواع فيما بينها. أضفنا أنواع عناصر اللائحة في مثالنا التالي ولكن هذه الخطوة اختيارية: اسم الملف: src/main.rs fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); } يُسند المتغير tup إلى كامل المجموعة، لأن المجموعة تمثّل عنصرًا مركبًا واحدًا، وللحصول على القيم الفردية داخل المجموعة يمكننا استخدام مطابقة الأنماط pattern matching لتفكيك destructure قيمة المجموعة كما هو موضح: اسم الملف: src/main.rs fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); } يُنشئ هذا البرنامج مجموعة ويُسندها إلى المتغير tup، ومن ثم يستخدم نمطًا مع let لأخذ المتغير tup وتحويله إلى ثلاث قيم منفصلة وهي x و y و z، ويدعى هذا بالتفكيك destructuring لأنه يُفكك المجموعة الواحدة إلى ثلاث أجزاء، ويطبع البرنامج أخيرًا قيمة y المساوية إلى "6.4". يمكننا أيضًا الوصول إلى عناصر المجموعة مباشرةً باستخدام النقطة (.) متبوعةً بدليل القيمة التي نريد الوصول إليها، كما هو موضح في المثال التالي: اسم الملف: src/main.rs fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; } يُنشئ هذا البرنامج مجموعةً باسم x، ثم يستخدم قيمة كل من عناصرها باستخدام دليل كل منها، ويبدأ الدليل الأول بالرقم 0 كما هو الحال في معظم لغات البرمجة. للمجموعة اسم مميّز إذا كانت فارغة ألا وهو الوحدة unit، وتُكتب قيمتها وقيمة أنواعها بالشكل ()، اللتان تُمثّلان قيمة فارغة أو قيمة إعادة فارغة empty return type، تُعيد التعابير ضمنيًا قيمة الوحدة إذا لم يكن التعبير يُعيد أي قيمة أخرى. نوع المصفوفة المصفوفة هي نوع من الأنواع الأخرى التي تحتوي على مجموعة من قيم متعددة، ويجب أن تكون جميع هذه القيم من النوع ذاته على عكس المجموعة، وللمصفوفات حجم ثابت بعكس بعض لغات البرمجة الأخرى. نكتب القيم في المصفوفة مثل لائحة من القيم مفصول ما بينها بفاصلة داخل أقواس معقوفة square brackets: اسم الملف: src/main.rs fn main() { let a = [1, 2, 3, 4, 5]; } يُمكن للمصفوفات أن تكون مفيدةً عندما تريد من بياناتك أن تكون موجودةً على المكدّس stack بدلًا من الكومة heap (سنناقش المكدس والكومة لاحقًا) أو عندما تريد أن تتأكد أن هناك مجموعة ثابتة العدد من العناصر. المصفوفة ليست نوعًا مرنًا مثل نوع الشعاع vector، فالشعاع هو نوع مماثل يحتوي على مجموعة وهو مُضمّن في المكتبة القياسية ويمكن أن يتغير حجمه بالزيادة أو النقصان، وإن لم تكُن متأكدًا أيُّهما تستخدم، فذلك يعني أنك غالبًا بحاجة استخدام الشعاع، وسنناقش هذا الأمر بالتفصيل لاحقًا. تبرز أهمية المصفوفات عندما تعرف عدد العناصر التي تحتاجها، على سبيل المثال إذا كنت تستخدم أسماء الأشهر في برنامج فمن الأفضل في هذه الحالة استخدام المصفوفة بدلًا من الشعاع لأنك تعلم أنك بحاجة 12 عنصر فقط: let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; يُكتب نوع المصفوفة باستخدام الأقواس المعقوفة مع نوع العناصر ومن ثم فاصلة منقوطة وعدد العناصر ضمن المصفوفة كما هو موضح: let a: [i32; 5] = [1, 2, 3, 4, 5]; يمثل النوع i32 في مثالنا هذا نوع عناصر المصفوفة، بينما يمثل العدد "5" الذي يقع بعد الفاصلة المنقوطة عدد عناصر المصفوفة الخمس. يمكنك تهيئة المصفوفة بحيث تحمل القيمة ذاتها لكافة العناصر عن طريق تحديد القيمة الابتدائية initial value متبوعةً بفاصلة منقوطة ومن ثم طول المصفوفة ضمن أقواس معقوفة، كما هو موضح: let a = [3; 5]; ستحتوي المصفوفة a على 5 عناصر وستكون قيم العناصر جميعها مساوية إلى 3 مبدئيًا، وهذا الأمر مماثل لكتابة السطر البرمجي let a = [3, 3, 3 ,3 ,3]; إلا أن هذه الطريقة مختصرة. الوصول إلى عناصر المصفوفة تُمثل المصفوفة جزءًا واحدًا معلوم الحجم من الذاكرة، والذي يُمكن تخزينه في المكدس، ويمكنك الوصول إلى عناصر المصفوفة باستخدام الدليل كما هو موضح: اسم الملف: src/main.rs fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; } في مثالنا السابق، سيُسند إلى المتغير first القيمة الابتدائية 1 لأنها القيمة الموجودة في الدليل [0] ضمن المصفوفة، بينما سيُسند إلى المتغير second القيمة 2 لأنها القيمة الموجودة في الدليل[1] ضمن المصفوفة. محاولة الوصول الخاطئ إلى عناصر المصفوفة دعنا نرى ما الذي سيحدث إذا حاولت الوصول إلى عنصر من عناصر المصفوفة إذا كان ذلك العنصر يقع خارج المصفوفة بعد نهايتها، ولنقل أننا سننفّذ الشيفرة البرمجية التالية المشابهة للعبة التخمين في المقال السابق بالحصول على دليل المصفوفة من المستخدم: اسم الملف: src/main.rs use std::io; fn main() { let a = [1, 2, 3, 4, 5]; println!("Please enter an array index."); let mut index = String::new(); io::stdin() .read_line(&mut index) .expect("Failed to read line"); let index: usize = index .trim() .parse() .expect("Index entered was not a number"); let element = a[index]; println!("The value of the element at index {index} is: {element}"); } ستُصرّف الشيفرة البرمجية بنجاح، وإذا شغلت البرنامج باستخدام cargo run وأدخلت القيم 0 أو 1 أو 2 أو 3 أو 4، فسيطبع البرنامج القيمة الموافقة لهذا الدليل ضمن المصفوفة، إلا أنك ستحصل على الخرج التالي إذا حاولت إدخال قيمة أكبر من حجم المصفوفة (مثل 10): thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 10', src/main.rs:19:19 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace تسبب البرنامج بخطأ عند التشغيل runtime error عند إدخال قيمة خاطئة إلى عملية الوصول للعناصر بالدليل، وانتهى البرنامج برسالة خطأ ولم يُنفّذ تعليمة !println الأخيرة. تتفقد لغة راست الدليل الذي حدّدته عند محاولتك الوصول إليه فيما إذا كان أصغر من حجم المصفوفة، وإذا كان الدليل أكبر أو يساوي حجم المصفوفة فسيهلع panic البرنامج، وتحدث عملية التفقد هذه عند وقت التشغيل خصوصًا في هذه الحالة وذلك لأن المصرف ربما لن يعرف القيمة التي سيدخلها المستخدم عند تشغيل الشيفرة بعد ذلك. كان هذا مثالًا لمبادئ أمان ذاكرة رست بصورةٍ عملية، وتفتقر معظم لغات البرمجة منخفضة المستوى هذا النوع من التحقق، إذ يُمكن الوصول إلى ذاكرة خاطئة عندما تُعطي دليلًا خاطئًا في هذه اللغات. تحميك لغة رست من هذا النوع من الأخطاء بالخروج من البرنامج فورًا عوضًا عن السماح بالوصول إلى ذاكرة خاطئة والاستمرار بالبرنامج، وسنناقش لاحقًا كيفية تعامل لغة رست مع الأخطاء وكيف يُمكنك كتابة شيفرة برمجية سهلة القراءة وآمنة بحيث لا يهلع البرنامج عند تنفيذها أو تسمح بالوصول إلى ذاكرة خاطئة. ترجمة -وبتصرف- للقسم Data Types من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: كيفية كتابة الدوال Functions والتعليقات Comments في لغة رست Rust المقال السابق: المتغيرات والتعديل عليها في لغة رست تعلم لغة رست Rust: البدايات برمجة لعبة تخمين الأرقام بلغة رست Rust -
 سيساهم قرار لجنة لغة سي المعيارية بتعريف إجراءات Routines عدد من المكتبات بما يعود بالنفع الكبير لجميع مستخدمي لغة سي دون أي شك، إذ لم يكن هناك أي معيار مُتّفق عليه يعرف إجراءات المكتبات ويقدم دعمًا للغة، وانعكس ذلك سلبًا على قابلية نقل البرامج Portability كثيرًا. ليس من المطلوب أن تتواجد إجراءات المكتبة داخل البرنامج، إذ تتواجد فقط في البيئات المُستضافة Hosted environment وتنطبق هذه الحالة غالبًا على مبرمجي التطبيقات، بينما لن تكون المكتبات موجودةً في حالة مبرمجي النظم المُدمجة ومبرمجي البيئات المُستضافة؛ إذ يستخدم هذا النوع من المبرمجين لغة سي لوحدها ضمن بيئة مستقلة Freestanding environment، وبالتالي لن يكون هذا المقال مهمًّا لهم. لن تكون المواضيع التي ستتبع هذه المقدمة مكتوبةً بهدف قراءتها بالتسلسل، ويمكنك قراءتها أجزاء منفصلة، إذ نهدف هنا إلى توفير محتوى يُستخدم كمرجع بسيط للمعلومات وليس درس تعليمي شامل، وإلا فسيتطلب الأمر كتابًا مخصصًا لنستطيع تغطية جميع المكتبات. ملفات الترويسات والأنواع القياسية تُستخدم عدّة أنواع types وماكرو macro على نحوٍ واسع في دوال المكتبات، وتُعرّف في ملف #include الموافق للدالة. كما سيصرِّح ملف الترويسة Header عن الأنواع والنماذج الأولية المناسبة لدوالّ المكتبة، وعلينا أن نذكر عدّة نقاط مهمة بهذا الخصوص: تُحجز جميع المعرّفات الخارجية External identifiers وأسماء الماكرو المُصرّح عنها في أي ملف ترويسة لمكتبة، بحيث لا يُمكن استخدامها أو إعادة تعريفها لأي استعمال آخر. قد تحمل الأسماء في بعض الأحيان أثرًا "سحريًّا" عندما تكون معروفةً للمصرف ويتسبب ذلك باستخدام بعض الأساليب الخاصة لتطبيقها. جميع المعرفات التي تبدأ بمحرف الشرطة السفلية underscore _ محجوزة. يمكن تضمين ملفات الترويسة بأي ترتيب كان ولأكثر من مرة، إلا أن تضمينها يجب أن يحدث خارج أي تصريح داخلي أو تعريف وقبل أي استخدام للدوال والماكرو المعرّفة بداخلها. نحصل على سلوك غير معرّف إن مرّرنا قيمة غير صالحة لدالة، مثل مؤشر فارغ، أو قيمة خارج نطاق القيم التي تقبلها الدالة. لا يُحدّد المعيار النوع ذاته من القيود الموضحة أعلاه بخصوص المعرّفات، وقد يتبادر إلى ذهنك المغامرة والاستفادة من هذه الثغرات، إلا أننا ننصحك بالالتزام بالطرق الآمنة. ملفات الترويسة المعيارية هي: <assert.h> <locale.h> <stddef.h> <ctype.h> <math.h> <stdio.h> <errno.h> <setjmp.h> <stdlib.h> <float.h> <signal.h> <string.h> <limits.h> <stdarg.h> <time.h> معلومة عامّة أخيرة: تُنفّذ العديد من إجراءات المكتبات على أنها ماكرو في عملها، شرط ألا يتسبب ذلك في أي مشاكل ناتجة عن الآثار الجانبية لهذا الاستخدام (كما وضّح الفصل السابع). يضمن المعيار وجود دالة اعتيادية إذا كان هناك دالة تُستخدم عادةً مثل ماكرو موافقة لها، بحيث تُنجز الدالتان العمل ذاته، وحتى تستخدم الدالة الاعتيادية عليك أن تُلغي تعريف الماكرو باستخدام التوجيه #undef، أو أن تكتب اسم الماكرو داخل قوسين، مما يضمن أنه لن يُعامل معاملة الماكرو: some function("Might be a macro\n"); //قد يمثل هذا ماكرو (some function)("Can't be a macro\n"); //من غير الممكن أن يكون هذا ماكرو مجموعات المحارف والاختلافات اللغوية قدّمت لجنة المعيار بعض المزايا الموجهة لاستخدام سي في البيئات التي لا تستخدم مجموعة محارف معيار US ASCII، والاختلافات اللغوية الأخرى التي تستخدم الفاصلة أو النقطة للدلالة على الفاصلة العشرية. قُدّمت التسهيلات (ألقِ نظرةً على القسم) بفكرة برنامج يتحكم بسلوك دوال المكتبات ليوافق الاختلافات اللغوية. تُعد مهمة تقديم دعم متكامل لمختلف اللغات والتقاليد مهمّة صعبة، وغالبًا ما يُساء فهمها، والتسهيلات المُزوّدة بمكتبات لغة سي هي الخطوة الأولى في هذا المشوار الطويل للوصول إلى الحل الكامل. الحل الوحيد المُعرّف من المعيار هو ما يدعى بلغة C المحلية locale، ويقدّم هذا دعمًا فعالًا على نحوٍ مشابه لعمل لغة سي القديمة، بينما تقدم الإعدادات المحلية الأخرى سلوكًا مختلفًا بحسب تعريف التطبيق. ملف ترويسة <stddef.h> هناك عددٌ صغير من الأنواع والماكرو الموجودة في <stddef.h> والمُستخدمة كثيرًا في ملفات الترويسة الأخرى، الذين سنتكلم عنها لاحقًا. تعطينا عملية طرح مؤشر من آخر نتيجةً من نوع مختلف بحسب التطبيق، وللسماح بالاستخدام الآمن في حال الاختلاف، يعرّف ملف الترويسة <stddef.h> النوع ptrdiff_t، كما يمكنك استخدام النوع size_t لتخزين نتيجة العامل sizeof بصورةٍ مشابهة. لأسباب لا تزال مخفية عنّا للوقت الحالي، هناك "مؤشر ثابت فارغ معرّف بحسب التنفيذ" معرّف في <stddef.h> باسم NULL، قد يبدو ذلك غير ضروريًا بالنظر إلى أن لغة سي تعرّف ثابت الرقم الصحيح 0 إلى القيمة التي يمكن إسنادها إلى مؤشر فارغ ومقارنتها معه، إلا أن الممارسة التالية شائعة جدًا وسط مبرمجي لغة سي المتمرسين: #include <stdio.h> #include <stddef.h> FILE *fp; if((fp = fopen("somefile", "r")) != NULL){ /* وهلمّ جرًّا */ هناك ماكرو باسم offsetof مهمته إيجاد مقدار الإزاحة offset بالبايت لعضو هيكل ما؛ إذ أن مقدار الإزاحة هو المسافة بين العضو وبداية الهيكل، إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> #include <stddef.h> main(){ size_t distance; struct x{ int a, b, c; }s_tr; distance = offsetof(s_tr, c); printf("Offset of x.c is %lu bytes\n", (unsigned long)distance); exit(EXIT_SUCCESS); } [مثال 1] يجب أن يكون التعبير s_tr.c قادرًا على التقييم مثل عنوانٍ لثابت (انظر مقال هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C)، فإذا كان العضو الذي تبحث عن مقدار إزاحته هو حقل بتات bitfield فستحصل على سلوك غير معرّف في هذه الحالة. لاحظ طريقة تحويل الأنواع في size_t التي نحوّل فيها لأطول نوع ممكن عديم الإشارة للتأكد من أن وسيط printf هو من النوع المناسب (%ul هو رمز التنسيق الخاص بطباعة النوع unsigned long) مع المحافظة على دقة القيمة، وهذا بسبب أن نوع size_t مجهول للمبرمج. العنصر الأخير المُصرّح عنه في <stddef.h> هو wchar_t وهو قيمة عدد صحيح كبيرة يُمكن تخزين محرف عريض wide character فيها ينتمي إلى أي مجموعة محارف موسّعة extended character set. ملف الترويسة يعرّف ملف الترويسة ما يُدعى errno الذي يُستبدل بتعبير ثابت ذو قيمة صحيحة لا تساوي الصفر، ويُضمن أن يكون هذا التعبير مقبولًا في موجّهات #if، ويعرّف أيضًا الماكرو EDOM والماكرو ERANGE اللذان يُستخدمان في الدوال الرياضية للدلالة على نوع الخطأ الحاصل وسنشرحهما بتوسعٍ أكبر لاحقًا. يُستخدم errno للدلالة على خطأ مُكتشف من دوال المكتبات، وهو ليس متغير خارجي بالضرورة -كما كان سابقًا- بل هو قيمةٌ متغيرةٌ من نوع int، إذ تُسند القيمة صفر إليه عند بداية تشغيل البرنامج، ولا يُعاد ضبط قيمته من تلك النقطة فصاعدًا إلا إذا جرى ذلك مباشرةً؛ أي بكلمات أخرى، لا تحاول إجراءات المكتبات إعادة ضبطه إطلاقًا، وإذا حدث أي خطأ في إجراء المكتبة فإن قيمة errno تتغير إلى قيمة معينة تشير إلى نوع الخطأ الحاصل ويُعيد الإجراء هذه القيمة (غالبًا -1) للدلالة على الخطأ، إليك تطبيقًا عمليًا عن ذلك: #include <stdio.h> #include <stddef.h> #include <errno.h> errno = 0; if(some_library_function(arguments) < 0){ // خطأ في معالجة الشيفرة المصدرية // قد يستخدم قيمة errno مباشرةً تطبيق errno غير معروف بالنسبة للمبرمج، فلا تحاول فعل أي شيء على هذه القيمة عدا إعادة ضبطها أو فحصها، فعلى سبيل المثال، من غير المضمون أن يكون لهذه القيمة عنوانًا على الذاكرة. يجب أن تتفقّد قيمة errno فقط في حال كانت دالة المكتبة المُستخدمة توثّق تأثيرها على errno، إذ يمكن لدوال المكتبات الأخرى أن تضبطها إلى قيمة عشوائية بعد استدعائها إلا إذا كان وصف الدالة يحدد ما الذي تفعله الدالة بالقيمة بصورةٍ صريحة. تشخيص الأخطاء من المفيد عندما تبحث عن الأخطاء في برنامجك أن تكون قادرًا على فحص قيمة تعبير ما والتأكد من أن قيمته هي ما تتوقّعها فعلًا، وهذا ما تقدمه لك دالة assert. يجب عليك أن تُضمّن ملف الترويسة <assert.h> أولًا حتى تتمكن من استخدام الدالة assert، وهذه الدالة معرفةٌ على النحو التالي: #include <assert.h> void assert(int expression) إذا كانت قيمة التعبير صفر (أي "خطأ false")، فستطبع الدالة assert رسالةً تدل على التعبير الفاشل، وتتضمن الرسالة اسم ملف الشيفرة المصدرية والسطر الذي يحتوي على التوكيد assertion والتعبير، ومن ثم تُستدعى دالة abort التي تقطع عمل البرنامج. assert(1 == 2); /* قد يتسبب ما سبق بالتالي */ Assertion failed: 1 == 2, file silly.c, line 15 في حقيقة الأمر الكلمة Assert معرّفة مثل ماكرو، وليس مثل دالة حقيقية. لتعطيل التوكيدات في برنامج يستوفي شروط عمله دون مشاكل، نعرّف الاسم NDEBUG قبل تضمين <assert.h>، وسيعطّل هذا جميع التوكيدات الموجودة في كامل البرنامج. عليك أن تعرف الآثار الجانبية التي يتسبب بها هذا للتعبير، فلن يُقيّم التعبير تعطيل التوكيدات باستخدام NDEBUG، وبذلك سيسلك المثال التالي سلوكًا غير مُتوقع عند إلغاء التوكيدات باستخدام #define NDEBUG. #define NDEBUG #include <assert.h> void func(void) { int c; assert((c = getchar()) != EOF); putchar(c); } [مثال 2] لاحظ أن الدالة assert لا تُعيد أي قيمة. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C المقال السابق: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة سي C بنية برنامج لغة سي C المحارف المستخدمة في لغة سي C مدخل إلى المصفوفات في لغة سي C
سيساهم قرار لجنة لغة سي المعيارية بتعريف إجراءات Routines عدد من المكتبات بما يعود بالنفع الكبير لجميع مستخدمي لغة سي دون أي شك، إذ لم يكن هناك أي معيار مُتّفق عليه يعرف إجراءات المكتبات ويقدم دعمًا للغة، وانعكس ذلك سلبًا على قابلية نقل البرامج Portability كثيرًا. ليس من المطلوب أن تتواجد إجراءات المكتبة داخل البرنامج، إذ تتواجد فقط في البيئات المُستضافة Hosted environment وتنطبق هذه الحالة غالبًا على مبرمجي التطبيقات، بينما لن تكون المكتبات موجودةً في حالة مبرمجي النظم المُدمجة ومبرمجي البيئات المُستضافة؛ إذ يستخدم هذا النوع من المبرمجين لغة سي لوحدها ضمن بيئة مستقلة Freestanding environment، وبالتالي لن يكون هذا المقال مهمًّا لهم. لن تكون المواضيع التي ستتبع هذه المقدمة مكتوبةً بهدف قراءتها بالتسلسل، ويمكنك قراءتها أجزاء منفصلة، إذ نهدف هنا إلى توفير محتوى يُستخدم كمرجع بسيط للمعلومات وليس درس تعليمي شامل، وإلا فسيتطلب الأمر كتابًا مخصصًا لنستطيع تغطية جميع المكتبات. ملفات الترويسات والأنواع القياسية تُستخدم عدّة أنواع types وماكرو macro على نحوٍ واسع في دوال المكتبات، وتُعرّف في ملف #include الموافق للدالة. كما سيصرِّح ملف الترويسة Header عن الأنواع والنماذج الأولية المناسبة لدوالّ المكتبة، وعلينا أن نذكر عدّة نقاط مهمة بهذا الخصوص: تُحجز جميع المعرّفات الخارجية External identifiers وأسماء الماكرو المُصرّح عنها في أي ملف ترويسة لمكتبة، بحيث لا يُمكن استخدامها أو إعادة تعريفها لأي استعمال آخر. قد تحمل الأسماء في بعض الأحيان أثرًا "سحريًّا" عندما تكون معروفةً للمصرف ويتسبب ذلك باستخدام بعض الأساليب الخاصة لتطبيقها. جميع المعرفات التي تبدأ بمحرف الشرطة السفلية underscore _ محجوزة. يمكن تضمين ملفات الترويسة بأي ترتيب كان ولأكثر من مرة، إلا أن تضمينها يجب أن يحدث خارج أي تصريح داخلي أو تعريف وقبل أي استخدام للدوال والماكرو المعرّفة بداخلها. نحصل على سلوك غير معرّف إن مرّرنا قيمة غير صالحة لدالة، مثل مؤشر فارغ، أو قيمة خارج نطاق القيم التي تقبلها الدالة. لا يُحدّد المعيار النوع ذاته من القيود الموضحة أعلاه بخصوص المعرّفات، وقد يتبادر إلى ذهنك المغامرة والاستفادة من هذه الثغرات، إلا أننا ننصحك بالالتزام بالطرق الآمنة. ملفات الترويسة المعيارية هي: <assert.h> <locale.h> <stddef.h> <ctype.h> <math.h> <stdio.h> <errno.h> <setjmp.h> <stdlib.h> <float.h> <signal.h> <string.h> <limits.h> <stdarg.h> <time.h> معلومة عامّة أخيرة: تُنفّذ العديد من إجراءات المكتبات على أنها ماكرو في عملها، شرط ألا يتسبب ذلك في أي مشاكل ناتجة عن الآثار الجانبية لهذا الاستخدام (كما وضّح الفصل السابع). يضمن المعيار وجود دالة اعتيادية إذا كان هناك دالة تُستخدم عادةً مثل ماكرو موافقة لها، بحيث تُنجز الدالتان العمل ذاته، وحتى تستخدم الدالة الاعتيادية عليك أن تُلغي تعريف الماكرو باستخدام التوجيه #undef، أو أن تكتب اسم الماكرو داخل قوسين، مما يضمن أنه لن يُعامل معاملة الماكرو: some function("Might be a macro\n"); //قد يمثل هذا ماكرو (some function)("Can't be a macro\n"); //من غير الممكن أن يكون هذا ماكرو مجموعات المحارف والاختلافات اللغوية قدّمت لجنة المعيار بعض المزايا الموجهة لاستخدام سي في البيئات التي لا تستخدم مجموعة محارف معيار US ASCII، والاختلافات اللغوية الأخرى التي تستخدم الفاصلة أو النقطة للدلالة على الفاصلة العشرية. قُدّمت التسهيلات (ألقِ نظرةً على القسم) بفكرة برنامج يتحكم بسلوك دوال المكتبات ليوافق الاختلافات اللغوية. تُعد مهمة تقديم دعم متكامل لمختلف اللغات والتقاليد مهمّة صعبة، وغالبًا ما يُساء فهمها، والتسهيلات المُزوّدة بمكتبات لغة سي هي الخطوة الأولى في هذا المشوار الطويل للوصول إلى الحل الكامل. الحل الوحيد المُعرّف من المعيار هو ما يدعى بلغة C المحلية locale، ويقدّم هذا دعمًا فعالًا على نحوٍ مشابه لعمل لغة سي القديمة، بينما تقدم الإعدادات المحلية الأخرى سلوكًا مختلفًا بحسب تعريف التطبيق. ملف ترويسة <stddef.h> هناك عددٌ صغير من الأنواع والماكرو الموجودة في <stddef.h> والمُستخدمة كثيرًا في ملفات الترويسة الأخرى، الذين سنتكلم عنها لاحقًا. تعطينا عملية طرح مؤشر من آخر نتيجةً من نوع مختلف بحسب التطبيق، وللسماح بالاستخدام الآمن في حال الاختلاف، يعرّف ملف الترويسة <stddef.h> النوع ptrdiff_t، كما يمكنك استخدام النوع size_t لتخزين نتيجة العامل sizeof بصورةٍ مشابهة. لأسباب لا تزال مخفية عنّا للوقت الحالي، هناك "مؤشر ثابت فارغ معرّف بحسب التنفيذ" معرّف في <stddef.h> باسم NULL، قد يبدو ذلك غير ضروريًا بالنظر إلى أن لغة سي تعرّف ثابت الرقم الصحيح 0 إلى القيمة التي يمكن إسنادها إلى مؤشر فارغ ومقارنتها معه، إلا أن الممارسة التالية شائعة جدًا وسط مبرمجي لغة سي المتمرسين: #include <stdio.h> #include <stddef.h> FILE *fp; if((fp = fopen("somefile", "r")) != NULL){ /* وهلمّ جرًّا */ هناك ماكرو باسم offsetof مهمته إيجاد مقدار الإزاحة offset بالبايت لعضو هيكل ما؛ إذ أن مقدار الإزاحة هو المسافة بين العضو وبداية الهيكل، إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> #include <stddef.h> main(){ size_t distance; struct x{ int a, b, c; }s_tr; distance = offsetof(s_tr, c); printf("Offset of x.c is %lu bytes\n", (unsigned long)distance); exit(EXIT_SUCCESS); } [مثال 1] يجب أن يكون التعبير s_tr.c قادرًا على التقييم مثل عنوانٍ لثابت (انظر مقال هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C)، فإذا كان العضو الذي تبحث عن مقدار إزاحته هو حقل بتات bitfield فستحصل على سلوك غير معرّف في هذه الحالة. لاحظ طريقة تحويل الأنواع في size_t التي نحوّل فيها لأطول نوع ممكن عديم الإشارة للتأكد من أن وسيط printf هو من النوع المناسب (%ul هو رمز التنسيق الخاص بطباعة النوع unsigned long) مع المحافظة على دقة القيمة، وهذا بسبب أن نوع size_t مجهول للمبرمج. العنصر الأخير المُصرّح عنه في <stddef.h> هو wchar_t وهو قيمة عدد صحيح كبيرة يُمكن تخزين محرف عريض wide character فيها ينتمي إلى أي مجموعة محارف موسّعة extended character set. ملف الترويسة يعرّف ملف الترويسة ما يُدعى errno الذي يُستبدل بتعبير ثابت ذو قيمة صحيحة لا تساوي الصفر، ويُضمن أن يكون هذا التعبير مقبولًا في موجّهات #if، ويعرّف أيضًا الماكرو EDOM والماكرو ERANGE اللذان يُستخدمان في الدوال الرياضية للدلالة على نوع الخطأ الحاصل وسنشرحهما بتوسعٍ أكبر لاحقًا. يُستخدم errno للدلالة على خطأ مُكتشف من دوال المكتبات، وهو ليس متغير خارجي بالضرورة -كما كان سابقًا- بل هو قيمةٌ متغيرةٌ من نوع int، إذ تُسند القيمة صفر إليه عند بداية تشغيل البرنامج، ولا يُعاد ضبط قيمته من تلك النقطة فصاعدًا إلا إذا جرى ذلك مباشرةً؛ أي بكلمات أخرى، لا تحاول إجراءات المكتبات إعادة ضبطه إطلاقًا، وإذا حدث أي خطأ في إجراء المكتبة فإن قيمة errno تتغير إلى قيمة معينة تشير إلى نوع الخطأ الحاصل ويُعيد الإجراء هذه القيمة (غالبًا -1) للدلالة على الخطأ، إليك تطبيقًا عمليًا عن ذلك: #include <stdio.h> #include <stddef.h> #include <errno.h> errno = 0; if(some_library_function(arguments) < 0){ // خطأ في معالجة الشيفرة المصدرية // قد يستخدم قيمة errno مباشرةً تطبيق errno غير معروف بالنسبة للمبرمج، فلا تحاول فعل أي شيء على هذه القيمة عدا إعادة ضبطها أو فحصها، فعلى سبيل المثال، من غير المضمون أن يكون لهذه القيمة عنوانًا على الذاكرة. يجب أن تتفقّد قيمة errno فقط في حال كانت دالة المكتبة المُستخدمة توثّق تأثيرها على errno، إذ يمكن لدوال المكتبات الأخرى أن تضبطها إلى قيمة عشوائية بعد استدعائها إلا إذا كان وصف الدالة يحدد ما الذي تفعله الدالة بالقيمة بصورةٍ صريحة. تشخيص الأخطاء من المفيد عندما تبحث عن الأخطاء في برنامجك أن تكون قادرًا على فحص قيمة تعبير ما والتأكد من أن قيمته هي ما تتوقّعها فعلًا، وهذا ما تقدمه لك دالة assert. يجب عليك أن تُضمّن ملف الترويسة <assert.h> أولًا حتى تتمكن من استخدام الدالة assert، وهذه الدالة معرفةٌ على النحو التالي: #include <assert.h> void assert(int expression) إذا كانت قيمة التعبير صفر (أي "خطأ false")، فستطبع الدالة assert رسالةً تدل على التعبير الفاشل، وتتضمن الرسالة اسم ملف الشيفرة المصدرية والسطر الذي يحتوي على التوكيد assertion والتعبير، ومن ثم تُستدعى دالة abort التي تقطع عمل البرنامج. assert(1 == 2); /* قد يتسبب ما سبق بالتالي */ Assertion failed: 1 == 2, file silly.c, line 15 في حقيقة الأمر الكلمة Assert معرّفة مثل ماكرو، وليس مثل دالة حقيقية. لتعطيل التوكيدات في برنامج يستوفي شروط عمله دون مشاكل، نعرّف الاسم NDEBUG قبل تضمين <assert.h>، وسيعطّل هذا جميع التوكيدات الموجودة في كامل البرنامج. عليك أن تعرف الآثار الجانبية التي يتسبب بها هذا للتعبير، فلن يُقيّم التعبير تعطيل التوكيدات باستخدام NDEBUG، وبذلك سيسلك المثال التالي سلوكًا غير مُتوقع عند إلغاء التوكيدات باستخدام #define NDEBUG. #define NDEBUG #include <assert.h> void func(void) { int c; assert((c = getchar()) != EOF); putchar(c); } [مثال 2] لاحظ أن الدالة assert لا تُعيد أي قيمة. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C المقال السابق: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة سي C بنية برنامج لغة سي C المحارف المستخدمة في لغة سي C مدخل إلى المصفوفات في لغة سي C -
 المتغيرات في رست غير قابلة للتعديل افتراضيًا كما ذكرنا في السابق، وهذه ميزة من ميزات لغة راست التي تهدف إلى جعل شيفرتك البرمجية المكتوبة آمنة وسهلة التزامن concurrency قدر الإمكان، إلا أنها تمنحك خيار التعديل mutable على المتغيرات إذا أردت ذلك. دعنا نرى لماذا تفضّل لغة راست جعل المتغيرات غير قابلة للتعديل في المقام الأول وما هي الحالات التي قد تريد التعديل عليها. قابلية التعديل على المتغيرات عندما تُسند أي قيمة إلى اسم متغيرٍ ما للمرة الأولى فهي غير قابلة للتغيير. لتوضيح ذلك دعنا نولّد مشروعًا جديدًا باسم "variables" في مجلد "projects" باستخدام الأمر cargo new variables. بعد ذلك، افتح افتح الملف "src/main.rs" في المجلد "variables" الجديد، واستبدل الشيفرة البرمجية الموجودة داخله بالشيفرة التالية. لن تُصرّف الشيفرة البرمجية هذه بعد، وسنفحص أولًا خطأ عدم قابلية التعديل immutability error. اسم الملف: src/main.rs fn main() { let x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); } احفظ وشغّل البرنامج باستخدام الأمر cargo run، إذ يجب أن تتلقى رسالة خطأ كما هو موضّح في الخرج التالي: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) error[E0384]: cannot assign twice to immutable variable `x` --> src/main.rs:4:5 | 2 | let x = 5; | - | | | first assignment to `x` | help: consider making this binding mutable: `mut x` 3 | println!("The value of x is: {x}"); 4 | x = 6; | ^^^^^ cannot assign twice to immutable variable For more information about this error, try `rustc --explain E0384`. error: could not compile `variables` due to previous error يوضح المثال أن المُصرّف يُساعدك لإيجاد الأخطاء ضمن البرنامج، ويمكن لأخطاء المصرّف أن تكون مُحبِطة ولكنها تعني أن برنامجك لا بفعل ما تريد فعله بأمان، وهذا لا يعني أنك مبرمج سيّء، إذ يحصل مستخدمو لغة راست المتمرسون على أخطاء تصريفيّة أيضًا. تُشير رسالة الخطأ "cannot assign twice immutable variablex" إلى أنك لا تستطيع إعادة إسناد قيمة أخرى إلى المتغير غير القابل للتعديل x. من المهم الحصول على أخطاء عند تصريف الشيفرة البرمجية عندما نحاول تعديل قيمة من المُفترض أن تكون غير قابلة للتعديل، فقد يؤدي هذا السلوك إلى أخطاء داخل البرنامج، ومن الممكن أن تتوقف بعض أجزاء البرنامج عن العمل بصورةٍ صحيحة إذا كان جزء من أجزاء برنامجك يعمل وفق الافتراض أن القيمة لن تتغير أبدًا وغيّر جزءٌ آخر هذه القيمة، وهذا النوع من الأخطاء صعب التعقّب عادةً بالأخص عندما يكون الجزء الثاني من البرنامج يُغيّر القيمة فقط في بعض الحالات. يضمن لك مصرّف لغة راست أن القيمة لن تتغيّر إذا حدّدتَ أنها لن تتغير، لذا لن يكون عليك تعقّب هذا النوع من الأخطاء بنفسك، وستكون شيفرتك البرمجية سهلة الفهم. قد تكون قابلية التعديل مفيدة جدًا في بعض الحالات، وقد تجعل من شيفرتك البرمجية أسهل للكتابة، ويمكنك جعل المتغيرات قابلة للتعديل عكس حالتها الافتراضية باستخدام الكلمة mut أمام اسم المتغير، كما يُبرز استخدام الكلمة المفتاحية هذه أيضًا لقارئ الشيفرة البرمجية أن هذه القيمة ستتغير ضمن جزء ما من أجزاء البرنامج إلى قيمة جديدة. على سبيل المثال، دعنا نغير محتويات الملف "src/main.rs" إلى التالي: fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); } عند تشغيل البرنامج، نحصل على التالي: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) Finished dev [unoptimized + debuginfo] target(s) in 0.30s Running `target/debug/variables` The value of x is: 5 The value of x is: 6 سُمح لنا الآن بتغيير قيمة x من 5 إلى 6 عند استخدام mut. يعتمد استخدام -أو عدم استخدام- قابلية التعديل على الشيء الأكثر وضوحًا في كل حالة بنظرك. الثوابت الثوابت constants هي قيم مُسندة إلى اسم ما ولا يُمكن تغييرها كما هو الحال في المتغيرات غير القابلة للتعديل، إلا أن هناك بعض الفروقات بين الثوابت والمتغيرات. أولًا، ليس من المسموح استخدام mut مع الثوابت، إذ أنها غير قابلة للتعديل افتراضيًا وهي الحالة الدائمة لها، نصرّح ثابتًا باستخدام الكلمة المفتاحية const بدلًا من let ويجب تحديد نوع القيمة عندها. سنغطّي أنواع البيانات لاحقًا، لذا لا تقلق بخصوص التفاصيل الآن، فكل ما يجب معرفته هو أنه يجب علينا تحديد النوع دائمًا مع الثوابت. ثانيًا، يُمكن التصريح عن الثوابت ضمن أي نطاق بما فيه النطاق العام global scope الذي يجعل منها قيمًا يمكن الاستفادة منها لأجزاء مختلفة من البرنامج. ثالثًا، يمكن أن تُسند الثوابت فقط إلى تعابير ثابتة وليس إلى قيمة تُحسب عند تشغيل البرنامج. إليك مثالًا عن تصريح ثابت ما: const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3; اسم الثابت هو "THREE_HOURS_IN_SECONDS" وتُسند قيمته إلى ناتج ضرب 60 (الثواني في الدقيقة) مع 60 (الدقائق في الساعة) مع 3 (عدد الساعات التي نريد حسابها في هذا البرنامج)، تُسمّى الثوابت في لغة رست اصطلاحًا باستخدام أحرف كبيرة وشرطة سفلية underscore بين كل كلمة وأخرى. يستطيع المصرّف في هذه الحالة تقييم ناتج العمليات عند تصريف البرنامج، مما يسمح لنا بكتابة القيمة بطريقة أكثر بساطة وأسهل فهمًا للقارئ من كتابة القيمة 10,800 فورًا. الثوابت صالحة للاستخدام طوال فترة تشغيل البرنامج وضمن النطاق التي صُرّحت فيه، مما يجعل من الثوابت أمرًا مفيدًا في تطبيقك الذي تتطلب أجزاء مختلفة منه معرفة قيمة معينة في الوقت ذاته، مثل عدد النقاط الأعظمي المسموح الحصول عليها من قبِل كل لاعب في لعبة أو سرعة الضوء. تٌفيدك عملية تسمية القيم المُستخدمة ضمن برنامجك مثل ثوابت في معرفة معنى القيمة لكل من يقرأ شيفرتك البرمجية، كما تُساعد في وجود القيمة في مكان واحد ضمن برنامجك بحيث يسهل عليك تعديلها مرةً واحدةً إذا أردت في المستقبل. التظليل يُمكنك التصريح عن متغير جديد يحمل اسمًا مماثلًا لمتغير آخر سابق كما رأينا في المقال السابق الذي ناقش كيفية برمجة لعبة تخمين، ويقول مبرمجو اللغة عادةً أن المتغير الأوّل تظلّل shadowed بالثاني، مما يعني أن المتغير الثاني هو ما سيجده المُصرّف عندما تستخدم اسم المتغير من النقطة تلك فصاعدًا. بالمثل، فالمتغير الثاني ظَلّل overshadow الأول آخذًا استخدامات اسم المتغير لنفسه حتى يُظلّل المتغير الثاني بنفسه أو ينتهي النطاق الذي ينتمي إليه. يمكننا تظليل متغير ما باستخدام اسم المتغير ذاته وإعادة استخدامه مع الكلمة المفتاحية let كما هو موضح: اسم الملف: src/main.rs fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); } يُسند البرنامج أولًا المتغير x إلى القيمة 5، ثم يُنشئ متغيرًا جديدًا x بتكرار let x = آخذًا القيمة الأصلية ومُضيفًا إليها 1، وبالتالي تصبح قيمة x مساويةً إلى 6، ثم تُظلّل تعليمة let الثالثة ضمن النطاق الداخلي المحتوى داخل الأقواس المعقوصة curly brackets المتغير x وتنشئ متغير x مجددًا وتضرب قيمته السابقة بالرقم 2، فتصبح قيمة المتغير 12، وعند نهاية النطاق ينتهي التظليل الداخلي ويعود المتغير x إلى قيمته السابقة 6. نحصل على الخرج التالي عند تشغيل البرنامج: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/variables` The value of x in the inner scope is: 12 The value of x is: 6 التظليل مختلف عن استخدام الكلمة المفتاحية mut لأنك ستحصل على خطأ تصريفي compile-time error إذا حاولت إعادة إسناد قيمة إلى هذا المتغير عن طريق الخطأ دون استخدام الكلمة المفتاحية let. يمكننا إجراء عدة تغييرات على قيمة ما باستخدام let وجعل المتغير غير قابل للتعديل بعد هذه استكمال هذه التغييرات. الفارق الآخر بين mut والتظليل هو أنه يمكننا تغيير نوع القيمة باستخدام الاسم ذاته عندما نُعيد إنشاء متغير جديد عمليًا باستخدام الكلمة المفتاحية let. على سبيل المثال، لنقل أن برنامجنا يسأل المستخدم بأن يُدخل عدد المسافات الفارغة التي يُريدها بين نص معين بإدخال محرف المسافة الفارغة ومن ثمّ يجب أن نُخزّن هذا الدخل على أنه رقم: fn main() { let spaces = " "; let spaces = spaces.len(); } متغير spaces الأول من نوع سلسلة نصية string بينما المتغير spaces الآخر من نوع عددي، إذًا، يوفّر علينا التظليل هنا عناء إنشاء متغير باسم جديد، مثل spaces_str و spaces_num، ويمكننا بدلًا من ذلك إعادة استخدام الاسم "spaces"، إلا أننا سنحصل على خطأ تصريفي إذا حاولنا استخدام mut في هذه الحالة: fn main() { let mut spaces = " "; spaces = spaces.len(); } يُشير الخطأ إلى أنه من غير المسموح التعديل على نوع المتغير: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) error[E0308]: mismatched types --> src/main.rs:3:14 | 2 | let mut spaces = " "; | ----- expected due to this value 3 | spaces = spaces.len(); | ^^^^^^^^^^^^ expected `&str`, found `usize` For more information about this error, try `rustc --explain E0308`. error: could not compile `variables` due to previous error الآن وبعد رؤيتنا لكيفية عمل المتغيرات، سننظر إلى أنواع البيانات الأخرى التي يمكننا استخدامها. ترجمة -وبتصرف- للقسم Variables and Mutability من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: أنواع البيانات Data Types في لغة رست Rust المقال السابق: برمجة لعبة تخمين الأرقام بلغة رست Rust برمجة لعبة تخمين الأرقام بلغة رست Rust
المتغيرات في رست غير قابلة للتعديل افتراضيًا كما ذكرنا في السابق، وهذه ميزة من ميزات لغة راست التي تهدف إلى جعل شيفرتك البرمجية المكتوبة آمنة وسهلة التزامن concurrency قدر الإمكان، إلا أنها تمنحك خيار التعديل mutable على المتغيرات إذا أردت ذلك. دعنا نرى لماذا تفضّل لغة راست جعل المتغيرات غير قابلة للتعديل في المقام الأول وما هي الحالات التي قد تريد التعديل عليها. قابلية التعديل على المتغيرات عندما تُسند أي قيمة إلى اسم متغيرٍ ما للمرة الأولى فهي غير قابلة للتغيير. لتوضيح ذلك دعنا نولّد مشروعًا جديدًا باسم "variables" في مجلد "projects" باستخدام الأمر cargo new variables. بعد ذلك، افتح افتح الملف "src/main.rs" في المجلد "variables" الجديد، واستبدل الشيفرة البرمجية الموجودة داخله بالشيفرة التالية. لن تُصرّف الشيفرة البرمجية هذه بعد، وسنفحص أولًا خطأ عدم قابلية التعديل immutability error. اسم الملف: src/main.rs fn main() { let x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); } احفظ وشغّل البرنامج باستخدام الأمر cargo run، إذ يجب أن تتلقى رسالة خطأ كما هو موضّح في الخرج التالي: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) error[E0384]: cannot assign twice to immutable variable `x` --> src/main.rs:4:5 | 2 | let x = 5; | - | | | first assignment to `x` | help: consider making this binding mutable: `mut x` 3 | println!("The value of x is: {x}"); 4 | x = 6; | ^^^^^ cannot assign twice to immutable variable For more information about this error, try `rustc --explain E0384`. error: could not compile `variables` due to previous error يوضح المثال أن المُصرّف يُساعدك لإيجاد الأخطاء ضمن البرنامج، ويمكن لأخطاء المصرّف أن تكون مُحبِطة ولكنها تعني أن برنامجك لا بفعل ما تريد فعله بأمان، وهذا لا يعني أنك مبرمج سيّء، إذ يحصل مستخدمو لغة راست المتمرسون على أخطاء تصريفيّة أيضًا. تُشير رسالة الخطأ "cannot assign twice immutable variablex" إلى أنك لا تستطيع إعادة إسناد قيمة أخرى إلى المتغير غير القابل للتعديل x. من المهم الحصول على أخطاء عند تصريف الشيفرة البرمجية عندما نحاول تعديل قيمة من المُفترض أن تكون غير قابلة للتعديل، فقد يؤدي هذا السلوك إلى أخطاء داخل البرنامج، ومن الممكن أن تتوقف بعض أجزاء البرنامج عن العمل بصورةٍ صحيحة إذا كان جزء من أجزاء برنامجك يعمل وفق الافتراض أن القيمة لن تتغير أبدًا وغيّر جزءٌ آخر هذه القيمة، وهذا النوع من الأخطاء صعب التعقّب عادةً بالأخص عندما يكون الجزء الثاني من البرنامج يُغيّر القيمة فقط في بعض الحالات. يضمن لك مصرّف لغة راست أن القيمة لن تتغيّر إذا حدّدتَ أنها لن تتغير، لذا لن يكون عليك تعقّب هذا النوع من الأخطاء بنفسك، وستكون شيفرتك البرمجية سهلة الفهم. قد تكون قابلية التعديل مفيدة جدًا في بعض الحالات، وقد تجعل من شيفرتك البرمجية أسهل للكتابة، ويمكنك جعل المتغيرات قابلة للتعديل عكس حالتها الافتراضية باستخدام الكلمة mut أمام اسم المتغير، كما يُبرز استخدام الكلمة المفتاحية هذه أيضًا لقارئ الشيفرة البرمجية أن هذه القيمة ستتغير ضمن جزء ما من أجزاء البرنامج إلى قيمة جديدة. على سبيل المثال، دعنا نغير محتويات الملف "src/main.rs" إلى التالي: fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); } عند تشغيل البرنامج، نحصل على التالي: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) Finished dev [unoptimized + debuginfo] target(s) in 0.30s Running `target/debug/variables` The value of x is: 5 The value of x is: 6 سُمح لنا الآن بتغيير قيمة x من 5 إلى 6 عند استخدام mut. يعتمد استخدام -أو عدم استخدام- قابلية التعديل على الشيء الأكثر وضوحًا في كل حالة بنظرك. الثوابت الثوابت constants هي قيم مُسندة إلى اسم ما ولا يُمكن تغييرها كما هو الحال في المتغيرات غير القابلة للتعديل، إلا أن هناك بعض الفروقات بين الثوابت والمتغيرات. أولًا، ليس من المسموح استخدام mut مع الثوابت، إذ أنها غير قابلة للتعديل افتراضيًا وهي الحالة الدائمة لها، نصرّح ثابتًا باستخدام الكلمة المفتاحية const بدلًا من let ويجب تحديد نوع القيمة عندها. سنغطّي أنواع البيانات لاحقًا، لذا لا تقلق بخصوص التفاصيل الآن، فكل ما يجب معرفته هو أنه يجب علينا تحديد النوع دائمًا مع الثوابت. ثانيًا، يُمكن التصريح عن الثوابت ضمن أي نطاق بما فيه النطاق العام global scope الذي يجعل منها قيمًا يمكن الاستفادة منها لأجزاء مختلفة من البرنامج. ثالثًا، يمكن أن تُسند الثوابت فقط إلى تعابير ثابتة وليس إلى قيمة تُحسب عند تشغيل البرنامج. إليك مثالًا عن تصريح ثابت ما: const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3; اسم الثابت هو "THREE_HOURS_IN_SECONDS" وتُسند قيمته إلى ناتج ضرب 60 (الثواني في الدقيقة) مع 60 (الدقائق في الساعة) مع 3 (عدد الساعات التي نريد حسابها في هذا البرنامج)، تُسمّى الثوابت في لغة رست اصطلاحًا باستخدام أحرف كبيرة وشرطة سفلية underscore بين كل كلمة وأخرى. يستطيع المصرّف في هذه الحالة تقييم ناتج العمليات عند تصريف البرنامج، مما يسمح لنا بكتابة القيمة بطريقة أكثر بساطة وأسهل فهمًا للقارئ من كتابة القيمة 10,800 فورًا. الثوابت صالحة للاستخدام طوال فترة تشغيل البرنامج وضمن النطاق التي صُرّحت فيه، مما يجعل من الثوابت أمرًا مفيدًا في تطبيقك الذي تتطلب أجزاء مختلفة منه معرفة قيمة معينة في الوقت ذاته، مثل عدد النقاط الأعظمي المسموح الحصول عليها من قبِل كل لاعب في لعبة أو سرعة الضوء. تٌفيدك عملية تسمية القيم المُستخدمة ضمن برنامجك مثل ثوابت في معرفة معنى القيمة لكل من يقرأ شيفرتك البرمجية، كما تُساعد في وجود القيمة في مكان واحد ضمن برنامجك بحيث يسهل عليك تعديلها مرةً واحدةً إذا أردت في المستقبل. التظليل يُمكنك التصريح عن متغير جديد يحمل اسمًا مماثلًا لمتغير آخر سابق كما رأينا في المقال السابق الذي ناقش كيفية برمجة لعبة تخمين، ويقول مبرمجو اللغة عادةً أن المتغير الأوّل تظلّل shadowed بالثاني، مما يعني أن المتغير الثاني هو ما سيجده المُصرّف عندما تستخدم اسم المتغير من النقطة تلك فصاعدًا. بالمثل، فالمتغير الثاني ظَلّل overshadow الأول آخذًا استخدامات اسم المتغير لنفسه حتى يُظلّل المتغير الثاني بنفسه أو ينتهي النطاق الذي ينتمي إليه. يمكننا تظليل متغير ما باستخدام اسم المتغير ذاته وإعادة استخدامه مع الكلمة المفتاحية let كما هو موضح: اسم الملف: src/main.rs fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); } يُسند البرنامج أولًا المتغير x إلى القيمة 5، ثم يُنشئ متغيرًا جديدًا x بتكرار let x = آخذًا القيمة الأصلية ومُضيفًا إليها 1، وبالتالي تصبح قيمة x مساويةً إلى 6، ثم تُظلّل تعليمة let الثالثة ضمن النطاق الداخلي المحتوى داخل الأقواس المعقوصة curly brackets المتغير x وتنشئ متغير x مجددًا وتضرب قيمته السابقة بالرقم 2، فتصبح قيمة المتغير 12، وعند نهاية النطاق ينتهي التظليل الداخلي ويعود المتغير x إلى قيمته السابقة 6. نحصل على الخرج التالي عند تشغيل البرنامج: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) Finished dev [unoptimized + debuginfo] target(s) in 0.31s Running `target/debug/variables` The value of x in the inner scope is: 12 The value of x is: 6 التظليل مختلف عن استخدام الكلمة المفتاحية mut لأنك ستحصل على خطأ تصريفي compile-time error إذا حاولت إعادة إسناد قيمة إلى هذا المتغير عن طريق الخطأ دون استخدام الكلمة المفتاحية let. يمكننا إجراء عدة تغييرات على قيمة ما باستخدام let وجعل المتغير غير قابل للتعديل بعد هذه استكمال هذه التغييرات. الفارق الآخر بين mut والتظليل هو أنه يمكننا تغيير نوع القيمة باستخدام الاسم ذاته عندما نُعيد إنشاء متغير جديد عمليًا باستخدام الكلمة المفتاحية let. على سبيل المثال، لنقل أن برنامجنا يسأل المستخدم بأن يُدخل عدد المسافات الفارغة التي يُريدها بين نص معين بإدخال محرف المسافة الفارغة ومن ثمّ يجب أن نُخزّن هذا الدخل على أنه رقم: fn main() { let spaces = " "; let spaces = spaces.len(); } متغير spaces الأول من نوع سلسلة نصية string بينما المتغير spaces الآخر من نوع عددي، إذًا، يوفّر علينا التظليل هنا عناء إنشاء متغير باسم جديد، مثل spaces_str و spaces_num، ويمكننا بدلًا من ذلك إعادة استخدام الاسم "spaces"، إلا أننا سنحصل على خطأ تصريفي إذا حاولنا استخدام mut في هذه الحالة: fn main() { let mut spaces = " "; spaces = spaces.len(); } يُشير الخطأ إلى أنه من غير المسموح التعديل على نوع المتغير: $ cargo run Compiling variables v0.1.0 (file:///projects/variables) error[E0308]: mismatched types --> src/main.rs:3:14 | 2 | let mut spaces = " "; | ----- expected due to this value 3 | spaces = spaces.len(); | ^^^^^^^^^^^^ expected `&str`, found `usize` For more information about this error, try `rustc --explain E0308`. error: could not compile `variables` due to previous error الآن وبعد رؤيتنا لكيفية عمل المتغيرات، سننظر إلى أنواع البيانات الأخرى التي يمكننا استخدامها. ترجمة -وبتصرف- للقسم Variables and Mutability من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: أنواع البيانات Data Types في لغة رست Rust المقال السابق: برمجة لعبة تخمين الأرقام بلغة رست Rust برمجة لعبة تخمين الأرقام بلغة رست Rust -
 استعرضنا في المقالات السابقة مبادئ اللغة وغطّينا معظم الجوانب المعرّفة من المعيار تقريبًا، إلا أن هناك بعض التفاصيل المتفرقة التي لا تنطوي تحت أي عنوان محدد، وتأتي هذه المقالة لجمع هذه التفاصيل المتفرقة العويصة من لغة C. استعدّ لما هو قادم ولا تتردد بتدوين الملاحظات التي تعتقد أنها ستهمّك، واقرأها من وقت إلى وقت آخر، فالأمر الذي تجده للمرة الأولى غير مثير للاهتمام وصعب الفهم سيصبح ضروريًّا ومفيدًا لك بعد أن تكتسب الخبرة الكافية لتوظيفه. معرف النوع typedef يسود الاعتقاد بأن معرّف النوع هو صنف تخزين، إلا أن هذا الاعتقاد خاطئ، إذ يسمح لك هذا المعرّف باختيار مرادفات لأنواع أخرى، والتي من الممكن أن يُصرّح عنها بطريقة مختلفة، ويصبح الاسم الجديد المرادف مكافئًا للنوع الذي تريده، كما سيوضح المثال التالي: typedef int aaa, bbb, ccc; typedef int ar[15], arr[9][6]; typedef char c, *cp, carr[100]; /* صرّح عن بعض الكائنات */ /* جميع الأعداد الصحيحة */ aaa int1; bbb int2; ccc int3; ar yyy; /* مصفوفة من 15 عدد صحيح */ arr xxx; /* مصفوفة من 9×6 عدد صحيح */ c ch; /* محرف */ cp pnt; /* مؤشر يشير لمحرف */ carr chry; /* مصفوفة من 100 محرف */ تنص القاعدة العامة في استخدام معرف النوع على كتابة التصريح وكأنك تصرح عن متغيرات من الأنواع التي تريدها، فعندما يتضمن التصريح الاسم مع نوعه المحدد، فإن إسباق ذلك بمعرّف النوع يعني أنك تصرح عن اسم جديد لنوع ما بدلًا من التصريح عن متغيرات، ويمكن بعدها استخدام أسماء النوع الجديد مثل سابقة prefix لتصريح متغير من النوع الجديد. لا يُعد استخدام الكلمة المفتاحية typedef شائعًا في معظم البرامج، ويُستخدم غالبًا في ملفات الترويسة ومن النادر أن تجده في الممارسة اليومية الاعتيادية. تُعرَّف الأنواع الجديدة للمتغيرات الأساسية في البرامج التي تتطلب قابلية نقل كبيرة غالبًا، وتُستخدم تعليمات typedef المناسبة لكتابة البرنامج بصورة مُخصصة للآلة الهدف، إلا أن استخدامها الزائد قد يتسبب ببعض اللبس لمبرمجي اللغة إذا كانوا يستخدمون بيئة مغايرة، يوضح المثال التالي ما نقصده: // ملف 'mytype.h' typedef short SMALLINT /* النطاق *******30000 */ typedef int BIGINT // النطاق ******* 2E9 /* البرنامج*/ #include "mytype.h" SMALLINT i; BIGINT loop_count; لا يتسع نطاق العدد الصحيح في BIGINT في بعض الآلات، ونتيجةً لذلك يجب إعادة تعريف النوع ليصبح long. لإعادة استخدام الاسم المُصرّح مثل تعريف نوع typedef، يجب أن يحتوي تصريحه محدد نوع واحد على الأقل، وهذا من شأنه أن يبعد أي لبس: typedef int new_thing; func(new_thing x){ float new_thing; new_thing = x; } نحذّر هنا أن الكلمة المفتاحية typedef يمكن استخدامها فقط للتصريح عن نوع القيمة المُعادة من دالة وليس نوع الدالة الكامل، ونقصد بنوع الدالة الكامل معلومات حول معاملات الدالة ونوع القيمة المُعادة أيضًا. /* صرّح عن func باستخدام typedef لتكون من النوع الذي يأخذ وسيطين من نوع عدد صحيح ويعيد قيمة عدد صحيح */ typedef int func(int, int); /* خطأ */ func func_name{ /*....*/ } // مثال صالح، يعيد مؤشر إلى النوع func func *func_name(){ /*....*/ } /* مثال صالح إذا كانت الدوال تعيد دوالًا، لكن هذا غير ممكن في لغة سي */ func func_name(){ /*....*/ } لا يمكن استخدام معرّف مثل معامل صوري في دالة إذا كان ذلك المعرّف مرتبطًا بمعرف نوع typedef معين ضمن النطاق، إذ سيسبب التصريح من الشكل التالي بمشكلة: typedef int i1_t, i2_t, i3_t, i4_t; int f(i1_t, i2_t, i3_t, i4_t) //هنا النقطة X يصل المصرف إلى النقطة "X" عند قراءة تصريح الدالة، ولا يعرف فيما إذا كان يقرأ تصريحًا عن دالة، وهذه الحالة مشابهة إلى: int f(int, int, int, int) /* نموذج أولي */ أو int f(a, b, c, d) /* ليس نموذجًا أوليًا */ يمكن حل المشكلة السابقة (في أسوأ الحالات) بالنظر إلى ما يتبع النقطة "X"؛ فإذا كانت فاصلة منقوطة فهذا تصريح؛ أما إذا كان } فهذا تعريف. تعني القاعدة التي تمنع أسماء تعريف النوع من أن تكون لمعامل صوري أن المصرف يمكنه دائمًا أن يخبر فيما إذا كان يعالج تصريحًا أو تعريفًا بالنظر إلى المعرف الأول الذي يتبع اسم الدالة. استخدام معرف النوع مفيد عندما تريد التصريح عن أشياء ذات صياغة معقدة، مثل "مصفوفة مؤلفة من عشرة مؤشرات تشير إلى مصفوفة تتألف من خمسة أعداد صحيحة"، وهي صيغة معقدة للكتابة حتى لأمهر المبرمجين. يمكنك كتابتها لمرة واحدة فقط باستخدام معرف النوع أو تجزئتها إلى قطع مقبولة التعقيد: typedef int (*a10ptoa5i[10])[5]; /* أو */ typedef int a5i[5]; typedef a5i *atenptoa5i[10]; جرّبها بنفسك. المؤهلان const و volatile تُعد المؤهلات qualifiers من الأشياء الجديدة التي أتت مع لغة سي C المعيارية، على الرغم من أن فكرة const كانت من لغة ++C أصلًا. دعنا أولًا نوضح لك شيئًا، وهو أن مفهومي const و volatile مستقلان كليًا عن بعضهما بعضًا، إذ يسود الاعتقاد الخاطئ أن const تؤدي عكس غرض volatile، إلا أن المفهومين غير مرتبطين ويجب أن تبقي ذلك ببالك. بما أن تصاريح const هي الأبسط فسنبدأ بها، إلا أننا سنستعرض الحالات التي تُستخدم فيها كلا النوعين من المؤهلات. إليك لائحةً بالكلمات المفتاحية المرتبطة بهذا الشأن: char long float volatile short signed double void int unsigned const يمثل كل من const و volatile في اللائحة السابقة أنواع مؤهلات، والكلمات المفتاحية المتبقية هي محددات نوع type specifiers، ويُسمح باستخدام عدة محددات أنواع بالشكل التالي: char, signed char, unsigned char int, signed int, unsigned int short int, signed short int, unsigned short int long int, signed long int, unsigned long int float double long double هناك بعض النقاط التي يجب أن ننوه إليها، وهي أن جميع التصاريح التي تحتوي على int ستكون ذات إشارة signed افتراضيًا، وبذلك فالكلمة المفتاحية signed هي تكرار لا لزوم له في هذا السياق، ويمكن التخلص من int إذا وُجد أي محدد نوع أو مؤهل لأن int هو النوع الافتراضي. يمكن تطبيق الكلمتين المفتاحيتين const و volatile لأي تصريح، متضمّنًا تصريح الهياكل والاتحادات وأنواع المعدّدات أو أسماء typedef، ونقول عن تصريح يحتوي هذه الكلمتين المفتاحيتين بأنه مؤهّل، وهذا السبب في تسمية const و volatile بالمؤهّلات عوضًا عن تسميتهما بمحددات النوع، إليك بعض الأمثلة: volatile i; volatile int j; const long q; const volatile unsigned long int rt_clk; struct{ const long int li; signed char sc; }volatile vs; لا تشعر بالضيق من الأمثلة السابقة، فبعضها معقّد وسنشرح معناها لاحقًا، لكن تذكر أنه من الممكن زيادة التعقيد باستخدام محددات صنف التخزين أيضًا، ويوضح المثال التالي استخدامًا واقعيًا ضمن بعض أنوية نظام تشغيل في الوقت الحقيقي: extern const volatile unsigned long int rt_clk; المؤهل const لنلقي نظرةً على كيفية استخدام المؤهل const، والأمر بسيطٌ جدًا، إذ تعني const أن الشيء ليس قابلًا للتعديل، فإذا صُرّح عن كائن بيانات باستخدام الكلمة المفتاحية const مثل جزءٍ من توصيف نوعه فهذا يعني أنه من غير الممكن إسناد أي قيمة إليه خلال تشغيل البرنامج، ويحتوي التصريح عن الكائن غالبًا على قيمة أولية (وإلا فمتى سيحصل على قيمة إن لم يكن الإسناد إليه مسموحًا؟) إلا أنها ليست الحالة دائمًا؛ فعلى سبيل المثال، إذا أردت الوصول إلى منفذ port للعتاد الصلب ضمن عنوان ذاكرة محدد واحتجت للقراءة منه فقط، فسيُصرّح عنه أنه مؤهل const لكنه لن يُهيأ. يُعدّ أخذُ عنوان كائن بيانات ذي نوع ليس const ووضعه في مؤشر يشير إلى إصدار مؤهل باستخدام const للنوع نفسه طريقةً آمنةً ومسموحة، إذ سيمكنك ذلك من استخدام المؤشر للنظر إلى الكائن دون إمكانية التعديل عليه، بينما يُعدّ وضع عنوان نوع ثابت إلى مؤشر يشير إلى النوع غير المؤهل طريقةً خطرةً وبالتالي فهي محظورة، إلا أنه يمكنك تجاوز ذلك باستخدام تحويل الأنواع cast. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ int i; const int ci = 123; /* تصريح عن مؤشر يشير إلى ثابت */ const int *cpi; /* مؤشر اعتيادي يشير إلى كائن غير ثابت */ int *ncpi; cpi = &ci; ncpi = &i; /* التعليمة التالية صالحة */ cpi = ncpi; /* يتطلب الأمر في هذه الحالة تحويل للأنواع لأنه خطأ كبير، انظر لما يلي لمعرفة السماحيات */ ncpi = (int *)cpi; /* عدّل على ثابت من خلال المؤشر للحصول على سلوك غير محدد */ *ncpi = 0; exit(EXIT_SUCCESS); } [مثال 1] كما يوضح المثال السابق، فمن الممكن أخذ عنوان كائن ثابت وإنشاء مؤشر يشير إلى كائن غير ثابت ومن ثم استخدام المؤشر، وسيولد ذلك خطأً في برنامجك ويؤدي إلى سلوك غير محدد. الهدف الرئيسي من استخدام الكائنات الثابتة هو وضعها في حالة قراءة فقط، والسماح للمصرف بإجراء بعض التفقد الإضافي لها ضمن البرنامج، وسيكون المصرف قادرًا على التحقق من أن كائنات const لم تُعدّل قسريًا من قبل المستخدم إلا إذا كنت قادرًا على تجاوز ذلك باستخدام المؤشرات. إليك ميزةً إضافية. ما الذي يعنيه التالي؟ char c; char *const cp = &c; الأمر بسيط جدًا، إذ أن cp مؤشر يشير إلى char وهي الحالة الاعتيادية إن لم تتواجد الكلمة المفتاحية const، وتعني الكلمة المفتاحية const أن cp لا يمكن التعديل عليه، إلا أنه من الممكن تعديل الشيء المُشار إليه بواسطة المؤشر، فالمؤشر هو الثابت وليس الشيء الذي يشير إليه. المثال المُعاكس لما سبق هو: const char *cp; الذي يعني أن cp هو مؤشر اعتيادي يمكن التعديل عليه، إلا أن الشيء الذي يشير إليه يجب عدم تعديله، إذًا من الممكن اختيار كون المؤشر أو الشيء الذي يشير إليه قابلًا للتعديل أو لا باستخدام التصريح المناسب بحسب التطبيق الذي تحتاجه. المؤهل volatile ننتقل إلى volatile بعد تحدثنا عن const. يعود السبب في استخدامنا لهذا النوع من المؤهلات إلى معالجة المشاكل الناتجة عند وقت التشغيل أو الأنظمة المُدمجة المُبرمجة باستخدام لغة سي. تخيّل كتابة شيفرة برمجية تتحكم بجهاز عتاد صلب بوضع قيم مناسبة في مسجّلات الجهاز في عناوين معروفة، ودعنا نتخيل أيضًا أن للجهاز مسجّلين، كل مسجل بطول 16 بت، بعنوان ذاكرة تصاعدي، والمسجل الأول هو مسجل التحكم والحالة control and status register -أو اختصارًا csr-، والمسجل الثاني هو منفذ البيانات، ونستطيع الوصول إلى جهاز مماثل بالطريقة التالية: // مثال بلغة C المعيارية دون استخدام const أو volatile /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs *dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 2] تُعد الطريقة المتبعة في استخدام تصريح الهيكل لوصف تخطيط مسجل الجهاز واسمه ممارسةً شائعة، لاحظ أنه لا يوجد أي كائنات معرفة من هذا النوع، إذ يحدّد التصريح ببساطة الهيكل دون استخدام أي مساحة. نستخدم تحويل أنواع ثابت للوصول إلى مسجلات الجهاز وكأنها تشير إلى هيكل، إلا أنها تشير في هذه الحالة إلى عنوان الذاكرة بدلًا من ذلك. إلا أن هناك مشكلةً كبيرةً في مصرّفات لغة سي السابقة، وهي متعلقة بحلقة while التكرارية التي تختبر المسجل الأول (مسجل الحالة) وتنتظر البت ERROR أو READY ليظهر، وسيلاحظ أي مصرّف جيد أن الحلقة تفحص عنوان ذاكرة مماثل بصورةٍ متكررة، وسيحاول المصرف أن يشير إلى الذاكرة مرةً واحدةً وأن ينسخ القيمة إلى المسجل لتسريع العملية؛ وهذا ما لا نريده، إذ أن هذه الحالة من الحالات التي يجب علينا التحقق من المكان الذي يشير إليه المؤشر كل دورة ضمن الحلقة. نتيجةً للمشكلة السابقة، لم تكن معظم مصرفات لغة سي قادرةً سابقًا على تحسين أداء البرنامج، وللتخلص من هذه المشكلة (ومشاكل أخرى مشابهة مرتبطة بمتى يمكن الكتابة على شيء يشير إليه المؤشر) قُدِّمت الكلمة المفتاحية volatile، التي تخبر المصرف أن الكائن عرضةٌ للتغير المفاجئ بسبب أسباب لا يمكن التنبؤ بها من خلال النظر إلى البرنامج ذات نفسه، وتُجبر كل مرجع refernece للكائن بأن يصبح مرجعًا فعليًّا (وليس عن طريق مؤشر). إليك البرنامج السابق (مثال 2) مكتوبًا باستخدام volatile و const. /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short volatile csr; unsigned short const volatile data; }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs * const dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 3] تطابق القوانين الخاصة بمزج volatile والأنواع الاعتيادية تلك الخاصة بالمؤهل const، إذ من الممكن إسناد مؤشر يشير إلى كائن مؤهّل بالمؤهّل volatile إلى عنوان كائن اعتيادي بأمان دون أي مشاكل، إلا أنه من الخطر (ويجب استخدام تحويل الأنواع في هذه الحالة) أخذ عنوان الكائن المؤهل بالمؤهل volatile ووضعه في مؤشر يشير إلى كائن اعتيادي، واستخدام مؤشر من هذا النوع سيتسبب بسلوك غير معرّف. إذا صُرّح عن مصفوفة أو هيكل باستخدام إحدى المؤهلين const أو volatile، فمن الممكن لجميع الأعضاء أن تمتلك هذا المؤهل أيضًا، وهذا الأمر المنطقي إذا فكرت به للحظة، فكيف لعضو من هيكل مؤهل بالمؤهل const أن يكون قابلًا للتعديل؟ هذا يعني أن أي محاولة لإعادة كتابة المثال السابق ممكنة، فعوضًا عن تصريح مسجلات الجهاز بكونها volatile في الهيكل، من الممكن للمؤشر أي يُصرّح بأن يشير إلى هيكل volatile عوضًا عن ذلك، على النحو التالي: struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; volatile struct devregs *const dvp=DEVADDR+devno; بما أن dvp يشير إلى كائن volatile، فمن غير المسموح تحسين المراجع عن طريق المؤشرات، وعلى الرغم من أن ما سبق يعمل، إلا أنه ممارسةٌ سيئة، إذ ينتمي تصريح volatile إلى الهيكل، ومسجلات الجهاز هي volatile وهذا المكان الذي يجب أن يبقى فيه التصريح، لتسهيل قراءة الشيفرة البرمجية. إذًا، مؤهل النوع volatile مهم جدًا لأي كائن سيتعرض لتغييرات، سواءٌ كانت التغييرات بواسطة العتاد الصلب أو برامج خدمات المقاطعة الغير المتزامنة asynchronous interrupt service routines. وما إن اعتقدت أنّك فهمت كلّ ما سبق بصورة مثالية، حتى يأتي التصريح التالي الذي سيغير من رأيك: volatile struct devregs{ /* محتوى */ }v_decl; الذي يصرح عن النوع struct devregs إضافةً إلى كائن مؤهل باستخدام volatile من ذلك النوع باسم v_decl. ويتبعه التصريح التالي: struct devregs nv_decl; الذي يصرح عن nv_decl وهو ليس مؤهّلًا باستخدام volatile؛ فالتأهيل ليس جزءًا من النوع struct devregs وإنما ينطبق فقط على تصريح v_decl. لننظر للأمر من زاوية أخرى لعلّ الأمر يتضح لك بعض الشيء (التصريحان متماثلان في نتيجتهما): struct devregs{ /* محتوى */ }volatile v_decl; إذا أردت الطريقة المختصرة لإرفاق مؤهل إلى نوع آخر، فيمكنك استخدام typedef لتحقيق الآتي: struct x{ int a; }; typedef const struct x csx; csx const_sx; struct x non_const_sx = {1}; const_sx = non_const_sx; /* التعديل على ثابت بتسبب بخطأ */ العمليات غير القابلة للتجزئة سيفهم الذي يتعاملون مع تقنيات مقاطعات العتاد الصلب والجوانب الأخرى للوقت الحقيقي في البرمجة أهمية أنواع volatile، وهناك ضرورةٌ في هذا المجال للتأكد من أن الوصول إلى كائنات البيانات متواصل، إلا أن مناقشة هذا الأمر سيأخذنا في رحلة بعيدة عن موضوعنا هنا، لكن دعنا نتكلم عن بعض المشكلات بخصوص هذا الأمر على الأقل. لا تخطئ الاعتقاد وتفترض أن جميع العمليات المكتوبة في لغة سي متواصلة، فعلى سبيل المثال قد يكون التصريح التالي عدّادًا يُحدّث عن طريق مقاطعة برنامج ساعة: extern const volatile unsigned long realtimeclock; من المهم هنا أن يتضمن التصريح على المؤهل volatile بسبب التغييرات اللامتزامنة التي تحصل له، ويحتوي على المؤهل const لأنه من غير الممكن التعديل على قيمته سوى عن طريق برنامج المقاطعة، وإن سُمح للبرنامج الوصول إليه بالطريقة التالية سنحصل على مشكلة: unsigned long int time_of_day; time_of_day = real_time_clock; ماذا لو استغرقت عملية نسخ long إلى long آخر عدّة تعليمات آلة لنسخ الكلمتين real_time_clock و time_of_day؟ من الممكن حدوث مقاطعة خلال عملية الإسناد وستكون أسوأ حالة لهذه المقاطعة هي عندما تكون الكلمة الأقل ترتيبًا لـreal_time_clock تساوي 0xffff والكلمة مرتفعة الترتيب تساوي 0x0000، وبهذا ستكون قيمة الكلمة منخفضة الترتيب مساوية إلى 0xffff. تعمل المقاطعة عملها وتزيد الكلمة منخفضة الترتيب لـreal_time_clock إلى 0x0 والكلمة مرتفعة الترتيب إلى 0x1 ومن ثم تعيد القيمة، ويُستكمل ما تبقى من الإسناد فيما بعد وينتهي الأمر باحتواء time_of_day على القيمة 0x0001ffff و real_time_clock على القيمة الصائبة 0x00010000. تعدّ المشكلات المسابقة لما سبق منطقةً خطرة، ويعلم جميع من يعمل في البيئات غير المتزامنة هذا الأمر جيّدًا، ولا تأخذ لغة سي المعيارية أي إجراءات احترازية لتفادي هذا النوع من المشكلات، ويجب تطبيق الطريقة الاعتيادية. يُصرّح ملف الترويسة signal.h عن نوع باسم sig_atomic_t ومن المضمون إمكانية تعديل هذا النوع بأمان عند التعامل مع الأحداث غير المتزامنة، وهذا يعني أنه من الممكن تعديله عن طريق إسناد قيمة إليه أو زيادة قيمته أو إنقاصها أو أي شيء آخر يعطي قيمة جديدة بحسب القيمة السابقة، وهو ليس آمنًا. نقاط التسلسل ترتبط نقاط التسلسل sequence points بمشكلات برمجة الوقت الحقيقي، إلا أنها مختلفة عن المشكلات التي ناقشناها، وتعدّ بمثابة محاولة للمعيار في تعريف الحالات التي تسمح -أو لا تسمح- بها طرق معينة من التحسين، على سبيل المثال، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> int i_var; void func(void); main(){ while(i_var != 10000){ func(); i_var++; } exit(EXIT_SUCCESS); } void func(void){ printf("in func, i_var is %d\n", i_var); } [مثال 4] قد يحاول المصرّف تحسين الأداء في الحلقة التكرارية بحيث يخزّن i_var في مسجّل الآلة لزيادة السرعة، إلا أن الدالة تحتاج وصولًا إلى القيمة الصحيحة من i_var حتى يمكنها طباعة القيمة الصحيحة، وهذا يعني أن المسجّل يجب أن يعيد تخزين قيمة i_var عند كل استدعاءٍ للدالة على الأقل، ويصف المعيار الشروط التي تحدد متى وأين يحصل ذلك. تُستكمل التأثيرات الجانبية لكل تعبير في نقطة التسلسل التي سبقتها، وهذا السبب في عدم قدرتنا على الاعتماد على تعابير مشابهة لهذه: a[i] = i++; وذلك بسبب عدم وجود أي نقطة تسلسلية مُحدّدة ضمن الإسناد أو عوامل الزيادة والنقصان، ولا يمكننا معرفة متى سيؤثر عامل الزيادة على i تحديدًا. يعرّف المعيار نقاط التسلسل على النحو التالي: نقطة استدعاء دالة، بعد تقييم وسطائها. نهاية المعامل الأول للعامل &&. نهاية المعامل الأول للعامل ||. نهاية المعامل الأول للعامل الشرطي :?. نهاية كل من معاملات عامل الفاصلة ,. نهاية تقييم تعبير كامل، على النحو التالي: تقييم القيمة الأولية لكائن auto. تعبير اعتيادي، أي متبوع بفاصلة منقوطة. تعابير التحكم في تعليمات do أو while أو if أو switch أو for. التعبيران الآخران في تعليمة حلقة for. التعبير في تعليمة return. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: مقدمة إلى مكتبات لغة سي C المقال السابق: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C
استعرضنا في المقالات السابقة مبادئ اللغة وغطّينا معظم الجوانب المعرّفة من المعيار تقريبًا، إلا أن هناك بعض التفاصيل المتفرقة التي لا تنطوي تحت أي عنوان محدد، وتأتي هذه المقالة لجمع هذه التفاصيل المتفرقة العويصة من لغة C. استعدّ لما هو قادم ولا تتردد بتدوين الملاحظات التي تعتقد أنها ستهمّك، واقرأها من وقت إلى وقت آخر، فالأمر الذي تجده للمرة الأولى غير مثير للاهتمام وصعب الفهم سيصبح ضروريًّا ومفيدًا لك بعد أن تكتسب الخبرة الكافية لتوظيفه. معرف النوع typedef يسود الاعتقاد بأن معرّف النوع هو صنف تخزين، إلا أن هذا الاعتقاد خاطئ، إذ يسمح لك هذا المعرّف باختيار مرادفات لأنواع أخرى، والتي من الممكن أن يُصرّح عنها بطريقة مختلفة، ويصبح الاسم الجديد المرادف مكافئًا للنوع الذي تريده، كما سيوضح المثال التالي: typedef int aaa, bbb, ccc; typedef int ar[15], arr[9][6]; typedef char c, *cp, carr[100]; /* صرّح عن بعض الكائنات */ /* جميع الأعداد الصحيحة */ aaa int1; bbb int2; ccc int3; ar yyy; /* مصفوفة من 15 عدد صحيح */ arr xxx; /* مصفوفة من 9×6 عدد صحيح */ c ch; /* محرف */ cp pnt; /* مؤشر يشير لمحرف */ carr chry; /* مصفوفة من 100 محرف */ تنص القاعدة العامة في استخدام معرف النوع على كتابة التصريح وكأنك تصرح عن متغيرات من الأنواع التي تريدها، فعندما يتضمن التصريح الاسم مع نوعه المحدد، فإن إسباق ذلك بمعرّف النوع يعني أنك تصرح عن اسم جديد لنوع ما بدلًا من التصريح عن متغيرات، ويمكن بعدها استخدام أسماء النوع الجديد مثل سابقة prefix لتصريح متغير من النوع الجديد. لا يُعد استخدام الكلمة المفتاحية typedef شائعًا في معظم البرامج، ويُستخدم غالبًا في ملفات الترويسة ومن النادر أن تجده في الممارسة اليومية الاعتيادية. تُعرَّف الأنواع الجديدة للمتغيرات الأساسية في البرامج التي تتطلب قابلية نقل كبيرة غالبًا، وتُستخدم تعليمات typedef المناسبة لكتابة البرنامج بصورة مُخصصة للآلة الهدف، إلا أن استخدامها الزائد قد يتسبب ببعض اللبس لمبرمجي اللغة إذا كانوا يستخدمون بيئة مغايرة، يوضح المثال التالي ما نقصده: // ملف 'mytype.h' typedef short SMALLINT /* النطاق *******30000 */ typedef int BIGINT // النطاق ******* 2E9 /* البرنامج*/ #include "mytype.h" SMALLINT i; BIGINT loop_count; لا يتسع نطاق العدد الصحيح في BIGINT في بعض الآلات، ونتيجةً لذلك يجب إعادة تعريف النوع ليصبح long. لإعادة استخدام الاسم المُصرّح مثل تعريف نوع typedef، يجب أن يحتوي تصريحه محدد نوع واحد على الأقل، وهذا من شأنه أن يبعد أي لبس: typedef int new_thing; func(new_thing x){ float new_thing; new_thing = x; } نحذّر هنا أن الكلمة المفتاحية typedef يمكن استخدامها فقط للتصريح عن نوع القيمة المُعادة من دالة وليس نوع الدالة الكامل، ونقصد بنوع الدالة الكامل معلومات حول معاملات الدالة ونوع القيمة المُعادة أيضًا. /* صرّح عن func باستخدام typedef لتكون من النوع الذي يأخذ وسيطين من نوع عدد صحيح ويعيد قيمة عدد صحيح */ typedef int func(int, int); /* خطأ */ func func_name{ /*....*/ } // مثال صالح، يعيد مؤشر إلى النوع func func *func_name(){ /*....*/ } /* مثال صالح إذا كانت الدوال تعيد دوالًا، لكن هذا غير ممكن في لغة سي */ func func_name(){ /*....*/ } لا يمكن استخدام معرّف مثل معامل صوري في دالة إذا كان ذلك المعرّف مرتبطًا بمعرف نوع typedef معين ضمن النطاق، إذ سيسبب التصريح من الشكل التالي بمشكلة: typedef int i1_t, i2_t, i3_t, i4_t; int f(i1_t, i2_t, i3_t, i4_t) //هنا النقطة X يصل المصرف إلى النقطة "X" عند قراءة تصريح الدالة، ولا يعرف فيما إذا كان يقرأ تصريحًا عن دالة، وهذه الحالة مشابهة إلى: int f(int, int, int, int) /* نموذج أولي */ أو int f(a, b, c, d) /* ليس نموذجًا أوليًا */ يمكن حل المشكلة السابقة (في أسوأ الحالات) بالنظر إلى ما يتبع النقطة "X"؛ فإذا كانت فاصلة منقوطة فهذا تصريح؛ أما إذا كان } فهذا تعريف. تعني القاعدة التي تمنع أسماء تعريف النوع من أن تكون لمعامل صوري أن المصرف يمكنه دائمًا أن يخبر فيما إذا كان يعالج تصريحًا أو تعريفًا بالنظر إلى المعرف الأول الذي يتبع اسم الدالة. استخدام معرف النوع مفيد عندما تريد التصريح عن أشياء ذات صياغة معقدة، مثل "مصفوفة مؤلفة من عشرة مؤشرات تشير إلى مصفوفة تتألف من خمسة أعداد صحيحة"، وهي صيغة معقدة للكتابة حتى لأمهر المبرمجين. يمكنك كتابتها لمرة واحدة فقط باستخدام معرف النوع أو تجزئتها إلى قطع مقبولة التعقيد: typedef int (*a10ptoa5i[10])[5]; /* أو */ typedef int a5i[5]; typedef a5i *atenptoa5i[10]; جرّبها بنفسك. المؤهلان const و volatile تُعد المؤهلات qualifiers من الأشياء الجديدة التي أتت مع لغة سي C المعيارية، على الرغم من أن فكرة const كانت من لغة ++C أصلًا. دعنا أولًا نوضح لك شيئًا، وهو أن مفهومي const و volatile مستقلان كليًا عن بعضهما بعضًا، إذ يسود الاعتقاد الخاطئ أن const تؤدي عكس غرض volatile، إلا أن المفهومين غير مرتبطين ويجب أن تبقي ذلك ببالك. بما أن تصاريح const هي الأبسط فسنبدأ بها، إلا أننا سنستعرض الحالات التي تُستخدم فيها كلا النوعين من المؤهلات. إليك لائحةً بالكلمات المفتاحية المرتبطة بهذا الشأن: char long float volatile short signed double void int unsigned const يمثل كل من const و volatile في اللائحة السابقة أنواع مؤهلات، والكلمات المفتاحية المتبقية هي محددات نوع type specifiers، ويُسمح باستخدام عدة محددات أنواع بالشكل التالي: char, signed char, unsigned char int, signed int, unsigned int short int, signed short int, unsigned short int long int, signed long int, unsigned long int float double long double هناك بعض النقاط التي يجب أن ننوه إليها، وهي أن جميع التصاريح التي تحتوي على int ستكون ذات إشارة signed افتراضيًا، وبذلك فالكلمة المفتاحية signed هي تكرار لا لزوم له في هذا السياق، ويمكن التخلص من int إذا وُجد أي محدد نوع أو مؤهل لأن int هو النوع الافتراضي. يمكن تطبيق الكلمتين المفتاحيتين const و volatile لأي تصريح، متضمّنًا تصريح الهياكل والاتحادات وأنواع المعدّدات أو أسماء typedef، ونقول عن تصريح يحتوي هذه الكلمتين المفتاحيتين بأنه مؤهّل، وهذا السبب في تسمية const و volatile بالمؤهّلات عوضًا عن تسميتهما بمحددات النوع، إليك بعض الأمثلة: volatile i; volatile int j; const long q; const volatile unsigned long int rt_clk; struct{ const long int li; signed char sc; }volatile vs; لا تشعر بالضيق من الأمثلة السابقة، فبعضها معقّد وسنشرح معناها لاحقًا، لكن تذكر أنه من الممكن زيادة التعقيد باستخدام محددات صنف التخزين أيضًا، ويوضح المثال التالي استخدامًا واقعيًا ضمن بعض أنوية نظام تشغيل في الوقت الحقيقي: extern const volatile unsigned long int rt_clk; المؤهل const لنلقي نظرةً على كيفية استخدام المؤهل const، والأمر بسيطٌ جدًا، إذ تعني const أن الشيء ليس قابلًا للتعديل، فإذا صُرّح عن كائن بيانات باستخدام الكلمة المفتاحية const مثل جزءٍ من توصيف نوعه فهذا يعني أنه من غير الممكن إسناد أي قيمة إليه خلال تشغيل البرنامج، ويحتوي التصريح عن الكائن غالبًا على قيمة أولية (وإلا فمتى سيحصل على قيمة إن لم يكن الإسناد إليه مسموحًا؟) إلا أنها ليست الحالة دائمًا؛ فعلى سبيل المثال، إذا أردت الوصول إلى منفذ port للعتاد الصلب ضمن عنوان ذاكرة محدد واحتجت للقراءة منه فقط، فسيُصرّح عنه أنه مؤهل const لكنه لن يُهيأ. يُعدّ أخذُ عنوان كائن بيانات ذي نوع ليس const ووضعه في مؤشر يشير إلى إصدار مؤهل باستخدام const للنوع نفسه طريقةً آمنةً ومسموحة، إذ سيمكنك ذلك من استخدام المؤشر للنظر إلى الكائن دون إمكانية التعديل عليه، بينما يُعدّ وضع عنوان نوع ثابت إلى مؤشر يشير إلى النوع غير المؤهل طريقةً خطرةً وبالتالي فهي محظورة، إلا أنه يمكنك تجاوز ذلك باستخدام تحويل الأنواع cast. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ int i; const int ci = 123; /* تصريح عن مؤشر يشير إلى ثابت */ const int *cpi; /* مؤشر اعتيادي يشير إلى كائن غير ثابت */ int *ncpi; cpi = &ci; ncpi = &i; /* التعليمة التالية صالحة */ cpi = ncpi; /* يتطلب الأمر في هذه الحالة تحويل للأنواع لأنه خطأ كبير، انظر لما يلي لمعرفة السماحيات */ ncpi = (int *)cpi; /* عدّل على ثابت من خلال المؤشر للحصول على سلوك غير محدد */ *ncpi = 0; exit(EXIT_SUCCESS); } [مثال 1] كما يوضح المثال السابق، فمن الممكن أخذ عنوان كائن ثابت وإنشاء مؤشر يشير إلى كائن غير ثابت ومن ثم استخدام المؤشر، وسيولد ذلك خطأً في برنامجك ويؤدي إلى سلوك غير محدد. الهدف الرئيسي من استخدام الكائنات الثابتة هو وضعها في حالة قراءة فقط، والسماح للمصرف بإجراء بعض التفقد الإضافي لها ضمن البرنامج، وسيكون المصرف قادرًا على التحقق من أن كائنات const لم تُعدّل قسريًا من قبل المستخدم إلا إذا كنت قادرًا على تجاوز ذلك باستخدام المؤشرات. إليك ميزةً إضافية. ما الذي يعنيه التالي؟ char c; char *const cp = &c; الأمر بسيط جدًا، إذ أن cp مؤشر يشير إلى char وهي الحالة الاعتيادية إن لم تتواجد الكلمة المفتاحية const، وتعني الكلمة المفتاحية const أن cp لا يمكن التعديل عليه، إلا أنه من الممكن تعديل الشيء المُشار إليه بواسطة المؤشر، فالمؤشر هو الثابت وليس الشيء الذي يشير إليه. المثال المُعاكس لما سبق هو: const char *cp; الذي يعني أن cp هو مؤشر اعتيادي يمكن التعديل عليه، إلا أن الشيء الذي يشير إليه يجب عدم تعديله، إذًا من الممكن اختيار كون المؤشر أو الشيء الذي يشير إليه قابلًا للتعديل أو لا باستخدام التصريح المناسب بحسب التطبيق الذي تحتاجه. المؤهل volatile ننتقل إلى volatile بعد تحدثنا عن const. يعود السبب في استخدامنا لهذا النوع من المؤهلات إلى معالجة المشاكل الناتجة عند وقت التشغيل أو الأنظمة المُدمجة المُبرمجة باستخدام لغة سي. تخيّل كتابة شيفرة برمجية تتحكم بجهاز عتاد صلب بوضع قيم مناسبة في مسجّلات الجهاز في عناوين معروفة، ودعنا نتخيل أيضًا أن للجهاز مسجّلين، كل مسجل بطول 16 بت، بعنوان ذاكرة تصاعدي، والمسجل الأول هو مسجل التحكم والحالة control and status register -أو اختصارًا csr-، والمسجل الثاني هو منفذ البيانات، ونستطيع الوصول إلى جهاز مماثل بالطريقة التالية: // مثال بلغة C المعيارية دون استخدام const أو volatile /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs *dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 2] تُعد الطريقة المتبعة في استخدام تصريح الهيكل لوصف تخطيط مسجل الجهاز واسمه ممارسةً شائعة، لاحظ أنه لا يوجد أي كائنات معرفة من هذا النوع، إذ يحدّد التصريح ببساطة الهيكل دون استخدام أي مساحة. نستخدم تحويل أنواع ثابت للوصول إلى مسجلات الجهاز وكأنها تشير إلى هيكل، إلا أنها تشير في هذه الحالة إلى عنوان الذاكرة بدلًا من ذلك. إلا أن هناك مشكلةً كبيرةً في مصرّفات لغة سي السابقة، وهي متعلقة بحلقة while التكرارية التي تختبر المسجل الأول (مسجل الحالة) وتنتظر البت ERROR أو READY ليظهر، وسيلاحظ أي مصرّف جيد أن الحلقة تفحص عنوان ذاكرة مماثل بصورةٍ متكررة، وسيحاول المصرف أن يشير إلى الذاكرة مرةً واحدةً وأن ينسخ القيمة إلى المسجل لتسريع العملية؛ وهذا ما لا نريده، إذ أن هذه الحالة من الحالات التي يجب علينا التحقق من المكان الذي يشير إليه المؤشر كل دورة ضمن الحلقة. نتيجةً للمشكلة السابقة، لم تكن معظم مصرفات لغة سي قادرةً سابقًا على تحسين أداء البرنامج، وللتخلص من هذه المشكلة (ومشاكل أخرى مشابهة مرتبطة بمتى يمكن الكتابة على شيء يشير إليه المؤشر) قُدِّمت الكلمة المفتاحية volatile، التي تخبر المصرف أن الكائن عرضةٌ للتغير المفاجئ بسبب أسباب لا يمكن التنبؤ بها من خلال النظر إلى البرنامج ذات نفسه، وتُجبر كل مرجع refernece للكائن بأن يصبح مرجعًا فعليًّا (وليس عن طريق مؤشر). إليك البرنامج السابق (مثال 2) مكتوبًا باستخدام volatile و const. /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short volatile csr; unsigned short const volatile data; }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs * const dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 3] تطابق القوانين الخاصة بمزج volatile والأنواع الاعتيادية تلك الخاصة بالمؤهل const، إذ من الممكن إسناد مؤشر يشير إلى كائن مؤهّل بالمؤهّل volatile إلى عنوان كائن اعتيادي بأمان دون أي مشاكل، إلا أنه من الخطر (ويجب استخدام تحويل الأنواع في هذه الحالة) أخذ عنوان الكائن المؤهل بالمؤهل volatile ووضعه في مؤشر يشير إلى كائن اعتيادي، واستخدام مؤشر من هذا النوع سيتسبب بسلوك غير معرّف. إذا صُرّح عن مصفوفة أو هيكل باستخدام إحدى المؤهلين const أو volatile، فمن الممكن لجميع الأعضاء أن تمتلك هذا المؤهل أيضًا، وهذا الأمر المنطقي إذا فكرت به للحظة، فكيف لعضو من هيكل مؤهل بالمؤهل const أن يكون قابلًا للتعديل؟ هذا يعني أن أي محاولة لإعادة كتابة المثال السابق ممكنة، فعوضًا عن تصريح مسجلات الجهاز بكونها volatile في الهيكل، من الممكن للمؤشر أي يُصرّح بأن يشير إلى هيكل volatile عوضًا عن ذلك، على النحو التالي: struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; volatile struct devregs *const dvp=DEVADDR+devno; بما أن dvp يشير إلى كائن volatile، فمن غير المسموح تحسين المراجع عن طريق المؤشرات، وعلى الرغم من أن ما سبق يعمل، إلا أنه ممارسةٌ سيئة، إذ ينتمي تصريح volatile إلى الهيكل، ومسجلات الجهاز هي volatile وهذا المكان الذي يجب أن يبقى فيه التصريح، لتسهيل قراءة الشيفرة البرمجية. إذًا، مؤهل النوع volatile مهم جدًا لأي كائن سيتعرض لتغييرات، سواءٌ كانت التغييرات بواسطة العتاد الصلب أو برامج خدمات المقاطعة الغير المتزامنة asynchronous interrupt service routines. وما إن اعتقدت أنّك فهمت كلّ ما سبق بصورة مثالية، حتى يأتي التصريح التالي الذي سيغير من رأيك: volatile struct devregs{ /* محتوى */ }v_decl; الذي يصرح عن النوع struct devregs إضافةً إلى كائن مؤهل باستخدام volatile من ذلك النوع باسم v_decl. ويتبعه التصريح التالي: struct devregs nv_decl; الذي يصرح عن nv_decl وهو ليس مؤهّلًا باستخدام volatile؛ فالتأهيل ليس جزءًا من النوع struct devregs وإنما ينطبق فقط على تصريح v_decl. لننظر للأمر من زاوية أخرى لعلّ الأمر يتضح لك بعض الشيء (التصريحان متماثلان في نتيجتهما): struct devregs{ /* محتوى */ }volatile v_decl; إذا أردت الطريقة المختصرة لإرفاق مؤهل إلى نوع آخر، فيمكنك استخدام typedef لتحقيق الآتي: struct x{ int a; }; typedef const struct x csx; csx const_sx; struct x non_const_sx = {1}; const_sx = non_const_sx; /* التعديل على ثابت بتسبب بخطأ */ العمليات غير القابلة للتجزئة سيفهم الذي يتعاملون مع تقنيات مقاطعات العتاد الصلب والجوانب الأخرى للوقت الحقيقي في البرمجة أهمية أنواع volatile، وهناك ضرورةٌ في هذا المجال للتأكد من أن الوصول إلى كائنات البيانات متواصل، إلا أن مناقشة هذا الأمر سيأخذنا في رحلة بعيدة عن موضوعنا هنا، لكن دعنا نتكلم عن بعض المشكلات بخصوص هذا الأمر على الأقل. لا تخطئ الاعتقاد وتفترض أن جميع العمليات المكتوبة في لغة سي متواصلة، فعلى سبيل المثال قد يكون التصريح التالي عدّادًا يُحدّث عن طريق مقاطعة برنامج ساعة: extern const volatile unsigned long realtimeclock; من المهم هنا أن يتضمن التصريح على المؤهل volatile بسبب التغييرات اللامتزامنة التي تحصل له، ويحتوي على المؤهل const لأنه من غير الممكن التعديل على قيمته سوى عن طريق برنامج المقاطعة، وإن سُمح للبرنامج الوصول إليه بالطريقة التالية سنحصل على مشكلة: unsigned long int time_of_day; time_of_day = real_time_clock; ماذا لو استغرقت عملية نسخ long إلى long آخر عدّة تعليمات آلة لنسخ الكلمتين real_time_clock و time_of_day؟ من الممكن حدوث مقاطعة خلال عملية الإسناد وستكون أسوأ حالة لهذه المقاطعة هي عندما تكون الكلمة الأقل ترتيبًا لـreal_time_clock تساوي 0xffff والكلمة مرتفعة الترتيب تساوي 0x0000، وبهذا ستكون قيمة الكلمة منخفضة الترتيب مساوية إلى 0xffff. تعمل المقاطعة عملها وتزيد الكلمة منخفضة الترتيب لـreal_time_clock إلى 0x0 والكلمة مرتفعة الترتيب إلى 0x1 ومن ثم تعيد القيمة، ويُستكمل ما تبقى من الإسناد فيما بعد وينتهي الأمر باحتواء time_of_day على القيمة 0x0001ffff و real_time_clock على القيمة الصائبة 0x00010000. تعدّ المشكلات المسابقة لما سبق منطقةً خطرة، ويعلم جميع من يعمل في البيئات غير المتزامنة هذا الأمر جيّدًا، ولا تأخذ لغة سي المعيارية أي إجراءات احترازية لتفادي هذا النوع من المشكلات، ويجب تطبيق الطريقة الاعتيادية. يُصرّح ملف الترويسة signal.h عن نوع باسم sig_atomic_t ومن المضمون إمكانية تعديل هذا النوع بأمان عند التعامل مع الأحداث غير المتزامنة، وهذا يعني أنه من الممكن تعديله عن طريق إسناد قيمة إليه أو زيادة قيمته أو إنقاصها أو أي شيء آخر يعطي قيمة جديدة بحسب القيمة السابقة، وهو ليس آمنًا. نقاط التسلسل ترتبط نقاط التسلسل sequence points بمشكلات برمجة الوقت الحقيقي، إلا أنها مختلفة عن المشكلات التي ناقشناها، وتعدّ بمثابة محاولة للمعيار في تعريف الحالات التي تسمح -أو لا تسمح- بها طرق معينة من التحسين، على سبيل المثال، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> int i_var; void func(void); main(){ while(i_var != 10000){ func(); i_var++; } exit(EXIT_SUCCESS); } void func(void){ printf("in func, i_var is %d\n", i_var); } [مثال 4] قد يحاول المصرّف تحسين الأداء في الحلقة التكرارية بحيث يخزّن i_var في مسجّل الآلة لزيادة السرعة، إلا أن الدالة تحتاج وصولًا إلى القيمة الصحيحة من i_var حتى يمكنها طباعة القيمة الصحيحة، وهذا يعني أن المسجّل يجب أن يعيد تخزين قيمة i_var عند كل استدعاءٍ للدالة على الأقل، ويصف المعيار الشروط التي تحدد متى وأين يحصل ذلك. تُستكمل التأثيرات الجانبية لكل تعبير في نقطة التسلسل التي سبقتها، وهذا السبب في عدم قدرتنا على الاعتماد على تعابير مشابهة لهذه: a[i] = i++; وذلك بسبب عدم وجود أي نقطة تسلسلية مُحدّدة ضمن الإسناد أو عوامل الزيادة والنقصان، ولا يمكننا معرفة متى سيؤثر عامل الزيادة على i تحديدًا. يعرّف المعيار نقاط التسلسل على النحو التالي: نقطة استدعاء دالة، بعد تقييم وسطائها. نهاية المعامل الأول للعامل &&. نهاية المعامل الأول للعامل ||. نهاية المعامل الأول للعامل الشرطي :?. نهاية كل من معاملات عامل الفاصلة ,. نهاية تقييم تعبير كامل، على النحو التالي: تقييم القيمة الأولية لكائن auto. تعبير اعتيادي، أي متبوع بفاصلة منقوطة. تعابير التحكم في تعليمات do أو while أو if أو switch أو for. التعبيران الآخران في تعليمة حلقة for. التعبير في تعليمة return. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: مقدمة إلى مكتبات لغة سي C المقال السابق: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C -
 دعنا نتعرّف إلى رست بالعمل على مشروع عملي سويًّا، إذ سيقدم هذا المقال بعض المفاهيم الشائعة في رست وكيفية استخدامها في برامج حقيقية، وسنتعلم كل من let و match والتوابع methods والدوال المترابطة associated functions واستخدام صناديق crates خارجية والمزيد، وسنناقش هذه التفاصيل بتعمق أكبر في مقالات لاحقة، إلا أننا سنتدرب على الأساسيات في هذا المقال. سنعمل على برنامج بسيط وشائع للمبتدئين ألا وهو لعبة تخمين. إليك كيف سيعمل البرنامج: سيولّد البرنامج رقمًا صحيحًا عشوائيًا بين 1 و100، ثمّ سينتظر من اللاعب إدخال التخمين، ثم سيجيب البرنامج فيما إذا كان التخمين أكبر أو أصغر من الإجابة، وفي حال كان التخمين صحيحًا، سيطبع البرنامج رسالة تهنئة وينتهي البرنامج. إعداد المشروع الجديد اذهب إلى مجلد "directory" الذي أنشأناه في المقال السابق لإعداد المشروع الجديد باستخدام أداة كارجو Cargo كما يلي: $ cargo new guessing_game $ cd guessing_game يأخذ الأمر الأول cargo new اسم المشروع، وهو في حالتنا "guessing_game" مقل وسيطٍ أول، بينما ينتقل الأمر الثاني إلى مجلد المشروع. ألقِ نظرةً إلى محتويات الملف "Cargo.toml" الناتج: [package] name = "guessing_game" version = "0.1.0" edition = "2021" # يمكنك رؤية المزيد من المفاتيح من الرابط https://doc.rust-lang.org/cargo/reference/manifest.html [dependencies] كما رأينا في المقال السابق، يولّد الأمر cargo new برنامج "!Hello, world" لك. ألقِ نظرةً على محتويات ملف "src/main.rs": fn main() { println!("Hello, world!"); } دعنا الآن نصرّف هذا البرنامج ونشغله باتباع نفس الخطوة وباستخدام أمر cargo run: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 1.50s Running `target/debug/guessing_game` Hello, world! تبرز أهمية الأمر run عندما تريد أن تفحص التغييرات في مشروعك تباعًا وأن تفحص البرنامج بسرعة بعد كل إضافة قبل المضيّ قدمًا للإضافة التالية وهذا ما سنفعله بالضبط في لعبتنا هذه. أعِد الآن فتح الملف "src/main.rs"، إذ سنكتب الشيفرة البرمجية لمشروعنا فيه. معالجة التخمين الجزء الأول من برنامج لعبة التخمين هو سؤال المستخدم ليدخل التخمين، ومن ثم معالجة هذا الدخل والتحقق من أنه بتنسيق مناسب. دعنا بدايةً نسمح المستخدم بإدخال تخمين. اكتب الشيفرة التالية في الملف "src/main.rs": use std::io; fn main() { println!("Guess the number!"); println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); println!("You guessed: {guess}"); } [شيفرة 2-1: شيفرة برمجية تأخذ التخمين من المستخدم في الدخل وتطبعه] تحتوي الشيفرة البرمجية السابقة على كثيرٍ من المعلومات الجديدة، لذلك دعنا نراجعها سطرًا بسطر. علينا أن نستخدم المكتبة io وأن نضيفها إلى نطاق scope المشروع للحصول على دخل المستخدم ومن ثم طباعة نتيجة الدخل في الخرج؛ إذ تأتي مكتبة io مع المكتبة القياسية، التي تُعرف باسم std: use std::io; تحتوي رست افتراضيًا على مجموعةٍ معرفةٍ من العناصر ضمن المكتبة القياسية التي تُضاف إلى نطاق أي برنامج، وتُسمى هذه العناصر باسم المقدمة prelude ويمكنك رؤية جميع محتوياتها في توثيق المكتبة القياسية. إذا أردت استخدام نوع محدد غير متواجد في المقدمة، فعليك إضافته إلى النطاق عن طريق استخدام تعليمة use. تتيح لك مكتبة std::io استخدام عدد من المزايا المفيدة منها القدرة على تلقّي دخل المستخدم. دالة main هي النقطة التي يبدأ منها البرنامج كما رأينا في المقال السابق: fn main() { تصرّح الصيغة fn عن دالة جديدة وتُشير الأقواس () إلى أن الدالة لا تأخذ أي معاملات، ويُشير القوس المعقوص } إلى بداية متن الدالة. تشير println! إلى ماكرو كما تطرقنا إلى ذلك في المقال السابق ويطبع هذا الماكرو السلسلة النصية إلى الشاشة: println!("Guess the number!"); println!("Please input your guess."); تطبع الشيفرة السابقة جملةً تدلّ المستخدم على ماهية اللعبة ومن ثم جملة تطلب منه إدخالًا. تخزين القيم والمتغيرات نُنشئ الآن متغيرًا لتخزين دخل المستخدم كما يلي: let mut guess = String::new(); أصبح الآن برنامجنا أكثر إثارةً للاهتمام؛ فهناك الكثير من الأشياء التي تحدث عند تنفيذ هذا السطر القصير، إذ نستخدم تعليمة let لإنشاء متغير، إليك مثالًا آخر عن إنشاء متغير: let apples = 5; يُنشئ هذا السطر متغيرًا جديدًا باسم apples ويُسنده إليه القيمة 5. المتغيرات في لغة رست ثابتة immutable افتراضيًا، وهذا يعني أن المتغير سيحافظ على قيمته الأولية التي أُسندت إليه ولن تُغيّر وسنتحدث في هذا الموضوع بتوسع أكثر لاحقًا. لجعل المتغير قابلًا للتغيير mutable نستخدم الكلمة المفتاحية mut قبل اسم المتغير: let apples = 5; // ثابت let mut bananas = 5; // متغيّر لاحظ أن // تتسبب ببدء تعليق سطري ينتهي بنهاية السطر وتتجاهل رست كل ما ورد ضمن التعليق، وسنناقش التعليقات لاحقًا بتوسع أكبر. بالعودة إلى برنامج لعبة التخمين، فأنت تعلم الآن أن let mut guess سيُضيف متغيرًا يقبل التغيير باسم guess، وتُخبر إشارة المساواة = رست أنّنا نريد إسناد قيمة ما إلى المتغير، يقع على يمين إشارة المساواة القيمة التي نريد إسنادها إلى guess وهي قيمةٌ ناتجةٌ عن استدعاء الدالة String::new وهي دالة تُعيد نُسخةً instance من النوع "String"؛ وهو نوع من أنواع السلاسل النصية الموجود في المكتبة القياسية وهو نص بترميز UTF-8 وقابل للزيادة. تُشير :: في السطر new:: إلى أن new مرتبطةٌ بدالة من نوع String؛ والدالة المرتبطة associated function هي دالة تُطبّق على نوع ما -وفي هذه الحالة هو String- وتُنشئ الدالة new هذه سلسلةً نصيةً جديدةً وفارغة، وستجد دالة new هذه في العديد من الأنواع لأنه اسم شائع لدالة تُنشئ قيمةً جديدةً من نوعٍ ما. إذا نظرنا إلى السطر let mut guess = String::new(); كاملًا، فهو سطرٌ لإنشاء متغير قابل للتغيير مُسندٌ إلى نُسخة جديدة وفارغة من النوع String. تلقي دخل المستخدم تذكر أننا ضمّننا إمكانية تلقي الدخل وعرض الخرج عن طريق use std::io; من المكتبة القياسية في السطر الأول من البرنامج. دعنا الآن نستدعي دالة stdin من وحدة io التي ستسمح لنا بالتعامل مع دخل المستخدم: io::stdin() .read_line(&mut guess) يمكننا استخدام استدعاء الدالة السابقة حتى لو لم نستورد مكتبة io بكتابتنا use std::io في بداية البرنامج ولكن الاستدعاء حينها سيكون بالشكل std::io::stdin. تُعيد الدالة stdin نسخة من النوع std::io::Stdin وهو نوع يُمثّل مُعالجًا للدخل القياسي من الطرفية. يستدعي السطر .read_line(&mut guess) تابع read_line ضمن معالج الدخل القياسي للحصول على دخل المستخدم، كما أننا نمرّر &mut guess مثل وسيط إلى read_line للدلالة على السلسلة النصية التي سيُخزّن بها دخل المستخدم. تتمثّل وظيفة read_line بأخذ ما يكتبه المستخدم إلى الدخل القياسي وإلحاقه append بالسلسلة النصية (دون الكتابة فوق overwriting محتوياته)، ولذا فنحن نمرّر هنا السلسلة النصية وسيطًا، ويجب أن يكون الوسيط قابلًا للتغيير حتى يكون التابع قادرًا على تغيير محتويات السلسلة النصية. يُشير الرمز & إلى أن هذا الوسيط يمثل مرجعًا، وهي طريقةٌ تسمح لأجزاء مختلفة من شيفرتك البرمجية بالوصول إلى الجزء ذاته من البيانات دون الحاجة إلى نسخ البيانات إلى الذاكرة عدة مرات. تُعد ميزة المراجع ميزةً معقّدةً وأكبر ميزات رست هو مستوى الأمان العالي وسهولة استخدام المراجع. لا تحتاج لمعرفة المزيد من هذه التفاصيل حتى تُنهي كتابة هذا البرنامج، إذ يكفي للآن أن تعرف أن المراجع غير قابلة للتغيير افتراضيًا -كما هو الحال في المتغيرات- وبالتالي يجب عليك كتابة &mut guess بدلًا من &guess إذا أردت جعلها قابلة للتغيير (سنشرح لاحقًا المراجع باستفاضة). التعامل مع الأخطاء الممكنة باستخدام نوع النتيجة Result ما زلنا نعمل على السطر البرمجي ذاته، ونناقش الآن السطر الثالث من النص، إلا أنه يجب الملاحظة أنه يمثل جزءًا من السطر البرمجي المنطقي ذاته. يمثل الجزء الثالث التابع: .expect("Failed to read line"); كان بإمكانك كتابة السطر البرمجي على النحو التالي: io::stdin().read_line(&mut guess).expect("Failed to read line"); إلا أن قراءة سطر طويل عملية صعبةٌ ومن الأفضل تقسيمه لأجزاء، لذلك من المحبّذ استخدام سطور جديدة ومسافات فارغة أخرى لتجزئة السطور الطويلة عندما تستدعي تابعًا على النحو التالي: .method_name(). دعنا الآن نناقش عمل السطر هذا. تضع الدالة read_line كل ما يكتبه المستخدم إلى السلسلة النصية التي نمررها لها كما ذكرنا سابقًا، إلا أنها تُعيد أيضًا قيمة Result وهي مُعدّد enumeration وغالبًا ما يُختصر بكتابة enum؛ وهو نوع يُمكن أن يأخذ عدّة حالات ونسمّي كل حالة ممكنة له بمتغاير variant. سنغطّي المعددات بتفصيل أكبر لاحقًا، إلا أن الهدف من أنواع Result هو لترميز معلومات التعامل مع الأخطاء. متغايرات Result هي Ok و Err؛ إذ يشير مغاير Ok إلى نجاح العملية ويحتوي بداخله على قيمة النجاح المولّدة؛ بينما يشير المتغاير Err إلى فشل العملية ويحتوي بداخله على معلومات حول سبب أو كيفية فشلها. لقيم النوع Result توابع معرفة لهم مثل أي قيم من نوع أخر، وتحتوي نسخةُ من النوع Result على التابع expect الذي يمكنك استدعاءه؛ فإذا كانت نسخة Result هذه لها قيمة Err فهذا يعني أن التابع expect سيتسبب بتوقف البرنامج وعرض الرسالة التي مرّرتها وسيطًا إلى التابع expect؛ وإذا أعاد التابع read_line قيمة Err، فهذا يعني أن الخطأ الناجم مرتبط بنظام التشغيل؛ وإذا كانت نسخة Result تحتوي على القيمة Ok، فسيأخذ التابع expect القيمة المُعادة التي تخزنها Ok ويُعيد القيمة إليك فقط كي تستخدمها، وتمثل القيمة في هذه الحالة عدد البايتات التي أدخلها المستخدم. إذا لم تستدعي التابع expect، سيُصرّف البرنامج بصورةٍ طبيعية، ولكنك ستحصل على التحذير التالي: $ cargo build Compiling guessing_game v0.1.0 (file:///projects/guessing_game) warning: unused `Result` that must be used --> src/main.rs:10:5 | 10 | io::stdin().read_line(&mut guess); | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ | = note: `#[warn(unused_must_use)]` on by default = note: this `Result` may be an `Err` variant, which should be handled warning: `guessing_game` (bin "guessing_game") generated 1 warning Finished dev [unoptimized + debuginfo] target(s) in 0.59s يحذرك رست هنا أنك لم تستخدم قيمة Result المُعادة من التابع read_line، مما يعني أن البرنامج لن يستطيع التعامل مع الأخطاء ممكنة الحدوث. الطريقة الصحيحة في تجنُّب التحذيرات هي بتطبيق طريقة معينة للتعامل مع أخطاء، إلا أننا نريد من البرنامج أن يتوقف في حالتنا هذه، لذا فيمكننا استخدام expect. ستتعلم ما يخص التعافي من الأخطاء (متابعة عمل البرنامج بعد ارتكاب الأخطاء) لاحقًا. طباعة القيم باستخدام مواضع println! المؤقتة هناك سطر واحد متبقي لمناقشته -بتجاهل الأقواس المعقوصة- ألا وهو: println!("You guessed: {guess}"); يطبع هذا السطر السلسلة النصية التي تحتوي دخل المستخدم، وتمثل مجموعة الأقواس المعقوصة {} مواضع مؤقتة placeholders. فكّر بالأمر وكأن {} كماشة سلطعون تُمسك القيمة في مكانها، ويمكنك طباعة أكثر من قيمة واحدة باستخدام الأقواس المعقوصة، إذ يدل أول قوسين على أول قيمة موجودة في لائحة بعد السلسلة النصية المُنسقّة، ويدل ثاني قوسين على القيمة الثاني في اللائحة وهلم جرًّا. إذا أردنا طباعة عدة قيم باستخدام استدعاء واحد للماكرو println! فسيبدو على النحو التالي: let x = 5; let y = 10; println!("x = {} and y = {}", x, y); سنحصل بعد تنفيذ الشيفرة السابقة على الخرج x = 5 and y = 10. التأكد من عمل الجزء الأول دعنا نتأكد من عمل الجزء الأول من لعبة التخمين، لذلك شغّل الشيفرة البرمجية باستخدام الأمر cargo run: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 6.44s Running `target/debug/guessing_game` Guess the number! Please input your guess. 6 You guessed: 6 وبهذا تكون قد أنجزت الجزء الأول من اللعبة، والبرنامج الآن قادر على استقبال الدخل من لوحة المفاتيح وطباعته. توليد الرقم السري الآن، علينا أن نولد الرقم السري الذي سيخمنه المستخدم، إذ يجب أن يكون هذا الرفم مختلفًا في كل مرة حتى تكون اللعبة أكثر متعةً للعب في كل مرة تحاول التخمين. سنستخدم رقمًا عشوائيًا بين 1 و100 حتى لا تكون اللعبة صعبةً جدًا. لا تتضمّن المكتبة القياسية الخاصة برست على مولّد عشوائي للأرقام، إلا أن فريق تطوير رست يقدم صندوق rand بهذه الوظيفة. استخدام صندوق ما للحصول على إمكانيات أكبر تذكر أن الصندوق هو مجموعة من ملفات رست المصدرية، إذ يمثّل المشروع الذي نبنيه الآن صندوقًا ثنائيًا binary crate أي أنه ملف تنفيذي، بينما يمثل صندوق rand صندوق مكتبة library crate، أي أنه يحتوي شيفرة مصدرية مكتوبة لتُستخدم في برامج أخرى ولا يمكن تشغيلها بصورةٍ مستقلة. تبرز أداة كارجو عند تنسيقها للصناديق الخارجية. قبل كتابة الشيفرة البرمجية التي تستخدم rand، علينا تعديل الملف "Cargo.toml" لتضمين صندوق rand مثل اعتمادية. افتح الملف وأضِف السطر التالي إلى نهاية الملف أسفل ترويسة القسم [dependencies] التي أنشأه لك كارجو مسبقًا، وتأكد من تحديد rand بدقة باستخدام رقم الإصدار وإلا فإن الشيفرة البرمجية الموجودة في المقال قد لا تعمل. اسم الملف: Cargo.toml rand = "0.8.3" كُل ما يتبع ترويسة القسم في ملف "Cargo.toml" هو جزءٌ من قسم ما يستمر حتى بداية القسم الآخر، وفي القسم [dependencies] أنت تُعلم كارجو بالصناديق الخارجية التي يعتمد مشروعك عليها وأي إصدار منها يتطلّب، ونحدّد في حالتنا هذه الصندوق rand ذو الإصدار "0.8.3"، ويفهم كارجو الإدارة الدلالية لنسخ البرمجيات Semantic Versioning -أو اختصارًا SemVer- وهي صيغة قياسية لكتابة أرقام الإصدارات، وفي الحقيقة فإن الرقم "0.8.3" هو اختصارٌ للرقم "^0.8.3"، وهو يعني أن أي إصدار مسموح هو "0.8.3" على الأقل و"0.9.0" على الأكثر. يضع كارجو في الحسبان أن هذه الإصدارات تحتوي على واجهات برمجية عامة public APIs متوافقة مع الإصدار "0.8.3" ويضمن ذلك التحديد أنك ستحصل على آخر الإصدارات المتوافقة مع الشيفرة البرمجية في هذا المقال، إذ من غير المضمون أن تكون الإصدارات المساوية إلى "0.9.0" أو أعلى تحتوي على ذات الواجهة البرمجية التي نتبعها في الأمثلة هنا. الآن ومن دون تغيير في الشيفرة البرمجية، دعنا نبني المشروع كما هو موضح في الشيفرة 2-2. $ cargo build Updating crates.io index Downloaded rand v0.8.3 Downloaded libc v0.2.86 Downloaded getrandom v0.2.2 Downloaded cfg-if v1.0.0 Downloaded ppv-lite86 v0.2.10 Downloaded rand_chacha v0.3.0 Downloaded rand_core v0.6.2 Compiling rand_core v0.6.2 Compiling libc v0.2.86 Compiling getrandom v0.2.2 Compiling cfg-if v1.0.0 Compiling ppv-lite86 v0.2.10 Compiling rand_chacha v0.3.0 Compiling rand v0.8.3 Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 2.53s [شيفرة 2-2: الخرج الناتج من تنفيذ الأمر cargo build بعد إضافة صندوق rand مثل اعتمادية] قد تجد اختلافًا في أرقام الإصدارات (إلا أنها ستكون متوافقة مع الشيفرة البرمجية والشكر إلى SemVer) وسطورًا مختلفة (بحسب نظام التشغيل الذي تستخدمه) وقد تكون السطور مكتوبةً بترتيب مختلف. يبحث كارجو عن آخر الإصدارات التي تحتاجها اعتمادية خارجية عند تضمينها وذلك من المسجل registry وهي نسخة من البيانات من Crates.io، وهو موقع ينشر فيه الناس مشاريع رست مفتوحة المصدر حتى يتسنى للآخرين استخدامها. يتفقد كارجو قسم [dependencies] بعد تحديث المسجل ويحمّل أي صندوق موجود لم يُحمّل بعد. في حالتنا هذه وعلى الرغم من أننا أضفنا rand فقط مثل اعتمادية، فقد أضاف كارجو أيضًا صناديق أخرى يعتمد rand عليها حتى يعمل، وبعد تحميل الصناديق يُصرّفها رست ويصرّف المشروع باستخدام الاعتماديات المتاحة. إذا نفذت الأمر cargo build مجددًا دون أي تغيير فلن تحصل على أي خرج إضافي عن السطر Finished، إذ يعرف كارجو أنه حمّل وصرّف الاعتماديات وأنك لم تغيّر أي شيء بخصوصهم في ملف "Cargo.toml"، كما يعرف كارجو أنك لم تغيّر أي شيء على شيفرتك البرمجية ولهذا فهو لا يُعيد تصريفها أيضًا، وفي هذه الحالة لا يوجد أي شيء ليفعله ويغادر مباشرةً. إذا فتحت الملف "src/main.rs" وعدّلت تعديلًا بسيطًا ومن ثمّ حفظته وحاولت إعادة بناء المشروع، فستجد السطرين التاليين فقط في الخرج: $ cargo build Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 2.53 secs توضح السطور السابقة أن كارجو حدّث وبنى التغييرات الطفيفة إلى الملف "src/main.rs"، ويعلم كارجو أنه يستطيع إعادة استخدام الاعتماديات التي حمّلها سابقًا وصرّفها بما أنك لم تعدل عليها. التأكد من أن المشاريع يمكن إعادة إنتاجها باستخدام ملف Cargo.lock لدى كارجو آلية تتحقق من أنك تستطيع إعادة بناء الأداة كل مرة تبني أنت أو شخص آخر شيفرتك البرمجية، يستخدم كارجو فقط إصدارات الاعتماديات التي حددتها إلا إذا حددت عكس ذلك. على سبيل المثال، لنقل أن إصدار 0.8.4 من صندوق rand سيُطلق الأسبوع القادم، ويتضمن هذا الإصدار تصحيحًا مهمًا لمشكلة ما إلا أنه يحتوي أيضًا على تراجع regression، وسيتسبب هذا بتعطل شيفرتك البرمجية؛ تُنشئ رست في هذه الحالة ملفًا يدعى "Cargo.lock" عند أول تنفيذ للأمر cargo build ويقع هذا الملف في مجلد "guessing_game". يوجِد كارجو جميع إصدارات الاعتماديات التي تلائم مشروعك عندما تبنيه للمرة الأولى، ومن ثم يكتب الإصدارات إلى ملف "Cargo.lock"، وبالتالي سيجد كارجو عندما تبني مشروعك في المستقبل أن الملف "Cargo.lock" موجود وسيستخدم عندها الإصدارات المحددة في ذلك الملف بدلًا من إيجاد الإصدارات المناسبة مجددًا، ويسمح لك هذا بالحصول على نسخة من المشروع قابلة لإعادة الإنتاج تلقائيًا، وبكلمات أخرى، سيظلّ مشروعك معتمدًا على الإصدار "0.8.3" حتى تقرّر التحديث إلى إصدار آخر بصورةٍ صريحة، ويعود الشكر إلى ملف "Cargo.lock" في ذلك. بما أن ملف "Cargo.lock" مهم للحصول على نسخ قابلة لإعادة الإنتاج، فمن الشائع أن يُضاف إلى نظام التحكم بالإصدارات version control مع باقي الشيفرة المصدرية في مشروعك. تحديث صندوق للحصول على إصدار جديد يقدم لك كارجو إمكانية تحديث صندوق ما باستخدام الأمر update، الذي سيتجاهل بدوره الملف "Cargo.lock" وسيبحث عن آخر الإصدارات التي تلائم متطلباتك في ملف "Cargo.toml"، إذ يكتب كارجو هذه الإصدارات إلى "Cargo.lock"، وإلا فسيبحث كارجو افتراضيًا عن إصدارات أحدث من "0.8.3" وأقدم من "0.9.0". إذا كان للصندوق rand إصداران جديدان هما "0.8.4" و"0.9.0" فستجد ما يلي عند تشغيل cargo update: $ cargo update Updating crates.io index Updating rand v0.8.3 -> v0.8.4 يتجاهل كارجو الإصدار "0.9.0"، وستلاحظ أيضًا بحلول هذه النقطة أن ملف "Cargo.lock" يُشير إلى أن الإصدار الحالي من صندوق rand هو "0.8.4"؛ ولاستخدام الإصدار "0.9.0" من rand أو أي إصدار آخر من السلسلة "x.0.9"K عليك تحديث ملف "Cargo.toml" ليبدو على النحو التالي: [dependencies] rand = "0.9.0" سيحدّث كارجو في المرة القادمة التي تنفذ فيها الأمر cargo build مسجّل الصناديق المتاحة ويُعيد تقييم متطلبات rand حسب الإصدار الجديد الذي حدّدته. هناك الكثير من الأشياء التي يمكننا الحديث عنها بخصوص كارجو ونظامه، وهذا ما سنفعله لاحقًا، إلا أن ما ذكرناه الآن كافي مبدئيًا. يجعل كارجو عملية إعادة استخدام المكتبات عملية أكثر سهولة، ويمكّن مستخدمي لغة رست من كتابة مشاريع صغيرة تعتمد على عدد من الحزم. توليد الرقم العشوائي دعنا نبدأ باستخدام rand لتوليد الرقم العشوائي، إذ تكمن خطوتنا التالية في التعديل على محتويات الملف "src/main.rs" كما هو موضح في الشيفرة 2-3. use std::io; use rand::Rng; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); println!("You guessed: {guess}"); } [شيفرة 2-3: إضافة شيفرة برمجية لتوليد الرقم العشوائي] نُضيف أولًا السطر use rand::Rng، إذ تُعرّف السمة Rng التوابع التي تستخدمها مولّدات الأرقام العشوائية، ويجب أن تكون هذه السمة ضمن النطاق حتى نستطيع استخدام هذه التوابع. سنناقش السمات بتفصيل أكبر لاحقًا. ثم نُضيف سطرين في وسط البرنامج، إذ نستدعي في السطر الأول الدالة rand::thread_rng التي تُعطينا مولّد رقم عشوائي معيّن سنستخدمه وهو مولد محلي لخيط التنفيذ الحالي ويُبذر seeded بواسطة نظام التشغيل، ونستدعي بعدها التابع gen_range على مولد الأرقام العشوائية، التابع السابق معرّف بالسمة Rng التي أضفناها إلى النطاق باستخدام التعليمة use rand::Rng. يأخذ التابع gen_rang تعبير مجال range expression مثل وسيط، ويولّد رقمًا ينتمي إلى ذلك المجال، إذ نستخدم تعبير المجال من النوع ذو التنسيق start..=end، ويتضمن المجال الحد الأعلى والأدنى داخله، لذا بكتابتنا للمجال "1..=100" فنحن نحدّد الأعداد بين 1 و100. ملاحظة: لن تعرف أي السمات وأي التوابع والدوال التي يجب أن تستدعيها من الصندوق من تلقاء نفسك، لذا يتضمن كل صندوق توثيق مرفقًا بتوجيهات لكيفية استخدام الصندوق. ميزة أخرى لطيفة من كارجو هي أن تنفيذ الأمر cargo doc --open سيتسبب ببناء التوثيق المزوّد بواسطة جميع الاعتماديات المحلية وفتحها في متصفحك، وإن كنت مهتمًا على سبيل المثال بالاستخدامات الأخرى الموجودة في الصندوق rand فكل ما عليك فعله هو تنفيذ الأمر cargo doc --open والنقر على rand في الشريط الجانبي على الجانب الأيسر. يطبع السطر الجديد الثاني الرقم السري، وهذا مفيد بينما تُطوّر البرنامج حتى تكون قادرًا على تجربته، إلا أننا سنحذفه من الإصدار الأخير في نهاية المطاف، فاللعبة عديمة الفائدة إذا كانت تطبع الإجابة فور تشغيلها. جرّب تنفيذ البرنامج عدة مرات: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 2.53s Running `target/debug/guessing_game` Guess the number! The secret number is: 7 Please input your guess. 4 You guessed: 4 $ cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.02s Running `target/debug/guessing_game` Guess the number! The secret number is: 83 Please input your guess. 5 You guessed: 5 يجب أن تحصل على رقم مختلف في كل مرة ويجب أن تكون الأرقام بين 1 و100، وإذا حدث ذلك فأحسنت. مقارنة التخمين مع الرقم السري يمكننا الآن مقارنة التخمين الذي أدخله المستخدم مع الرقم السري العشوائي، وتوضّح الشيفرة 2-4 هذه الخطوة، لاحظ أن الشيفرة البرمجية لن تُصرّف بنجاح بعد كما سنوضح لاحقًا. اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { // --snip-- println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => println!("You win!"), } } [شيفرة 2-4: التعامل مع الحالات المُمكنة ضمن عملية المقارنة] نُضيف أولًا تعليمة use أخرى تقدّم لنا نوعًا جديدًا يدعى std::cmp::Ordering إلى النطاق من المكتبة القياسية، والنوع Ordering هو مُعدّد enum آخر يحتوي على المتغايرات Less و Greater و Equal، وهي النتائج الثلاث الممكنة عندما تُقارن ما بين قيمتين. نُضيف بعدها خمسة أسطر في النهاية، وتستخدم هذه الأسطر بدورها النوع Ordering، ويُقارن التابع cmp بين قيمتين ويُمكن استدعاؤه على أي شيء يمكن مقارنته، ويتطلب الأمر استخدام المرجع للشيء الذي تريد مقارنته، وفي حالتنا هذه فهو يقارن guess مع secret_number، ثم يُعيد متغايرًا من متغايرات المعدّد Ordering الذي أضفناه سابقًا إلى النطاق باستخدام تعليمة use، ونستخدم هنا تعبير match لتحديد ما الذي سنفعله لاحقًا بناءً على متغاير Ordering المُعاد من استدعاء cmp باستخدام القيمتين guess و secret_number. يتألف تعبير match من أذرع arms، ويتألف كل ذراع من نمط يُستخدم في عملية المقارنة والشيفرة البرمجية التي يجب أن تعمل في حال كانت القيمة المُعطاة إلى match توافق نمط الذراع. تأخذ رست القيمة المُعطاة إلى match وتنظر إلى كلّ نمط ذراع. تُعدّ الأذرع وبنية match من أبرز مزايا رست، إذ تسمح لك بالتعبير عن عدّة حالات قد تحدث ضمن شيفرتك البرمجية وأن تتأكد من معالجتها جميعًا، وسنغطّي هذه المزايا بتعمُّق أكبر لاحقًا. دعنا نوضح مثالًا عن تعبير match نستخدمه هنا؛ لنقُل أن المستخدم قد خمّن القيمة 50 وأن الرقم العشوائي السري المولّد كان 38، تُقارن شيفرتنا البرمجية القيمة 50 إلى 38 ويُعيد التابع cmp في هذه الحالة القيمة Ordering::Greater لأن 50 أكبر من 38، ويتلقّى التعبير match القيمة Ordering::Greater ويبدأ بتفقد كل نمط ذراع، إذ يُنظر إلى نمط الذراع الأولى وهو Ordering::Less وهي قيمةٌ لا توافق القيمة Ordering::Greater وبالتالي يجري تجاهل الشيفرة البرمجية ضمن الذراع وينتقل إلى نمط الذراع الأخرى وهو Ordering::Greater الذي يُطابق !Ordering::Greater، وبالتالي تُنفّذ الشيفرة البرمجية الموجود ضمن الذراع ويُطبع النص "Too big!" إلى الشاشة. ينتهي التعبير match بعد أول مطابقة ناجحة، لذا لن تجري المطابقة مع نمط الذراع الثالثة في هذه الحالة. إلا أن الشيفرة 2-4 لن تُصرّف، دعنا نجرّب ذلك: $ cargo build Compiling libc v0.2.86 Compiling getrandom v0.2.2 Compiling cfg-if v1.0.0 Compiling ppv-lite86 v0.2.10 Compiling rand_core v0.6.2 Compiling rand_chacha v0.3.0 Compiling rand v0.8.3 Compiling guessing_game v0.1.0 (file:///projects/guessing_game) error[E0308]: mismatched types --> src/main.rs:22:21 | 22 | match guess.cmp(&secret_number) { | ^^^^^^^^^^^^^^ expected struct `String`, found integer | = note: expected reference `&String` found reference `&{integer}` For more information about this error, try `rustc --explain E0308`. error: could not compile `guessing_game` due to previous error تتلخّص المشكلة الأساسية بوجود أنواع غير متوافقة mismatched types. لدى رست نظام نوع ساكن static type قوي، إلا أنها تحتوي أيضًا على واجهة نوع type interface، وبالتالي استنتجت رست عند كتابتنا للتعليمة let mut guess = String::new() بأن guess يجب أن تكون String ولم تُجبرنا على كتابة النوع، بينما secret_number على الجانب الآخر هو من نوع عددي وهناك عدد من أنواع رست الرقمية التي يمكن أن تحتوي على القيم بين 1 و100، مثل i32 وهو عدد بطول 32 بت، و u32 وهو عدد عديم الإشارة unsigned بطول 32 بت، وi64 وهو عدد بطول 64 بت، إضافةً إلى أنواع أخرى، ويستخدم رست النوع i32 افتراضيًا إن لم يُحدد النوع وهو نوع secret_number في هذه الحالة، والسبب في حدوث المشكلة هو عدم قدرة رست على المقارنة بين نوع عددي وسلسلة نصية. إذًا، علينا أن نحوّل النوع String الذي يقرأه البرنامج في الدخل إلى نوع عددي، وذلك كي يتسنّى لنا مقارنته مقارنةً عدديّةً مع الرقم السري، ونُنجز ذلك عن طريق إضافة السطر الجديد التالي إلى متن الدالة main: اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); println!("Please input your guess."); // --snip-- let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = guess.trim().parse().expect("Please type a number!"); println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => println!("You win!"), } } السطر الجديد هو: let guess: u32 = guess.trim().parse().expect("Please type a number!"); نُنشئ متغيرًا باسم "guess"، ولكن مهلًا ألا يوجد متغير باسم "guess" في برنامجنا مسبقًا؟ نعم، ولكن رست تسمح لنا بتظليل shadow القيمة السابقة للمتغير guess بقيمة أخرى جديدة، ويسمح لنا التظليل بإعادة استخدام اسم المتحول guessبدلًا من إجبارنا على إنشاء متغير جديد، بحيث يصبح لدينا مثلًا guess_str و guess، وسنغطّي هذا الأمر بتفصيلٍ أكبر لاحقًا، ويكفي الآن أن تعرف بوجود هذه الميزة وأن استخدامها شائع عندما نريد تحويل قيمة من نوع إلى آخر. نُسند المتغير الجديد إلى التعبير guess.trim().parse()، إذ تشير guess ضمن التعبير إلى المتغير guess الأصلي الذي يحتوي على الدخل (سلسلة نصية string). يحذف التابع trim عند استخدامه ضمن نسخة من النوع String أي مسافات فارغة whitespaces في بداية ونهاية السلسلة النصية، وهو أمر لازم الحدوث قبل أن نحوّل السلسلة النصية إلى النوع u32 الذي يمكن أن يحتوي فقط على قيمة عددية، وذلك لأن المستخدم يضغط على زرّ الإدخال enter لإنهاء عمل التابع read_line بعد إدخال تخمينه مما يُضيف محرف سطر جديد إلى السلسلة النصية؛ فعلى سبيل المثال، إذا أدخل المستخدم 5 وضغط على زر الإدخال، فستأخذ السلسلة النصية guess القيمة "5\n"، إذ يمثل المحرف "\n" محرف سطر جديد (يتسبب الضغط على زر الإدخال في أنظمة ويندوز برجوع السطر وإضافة سطر جديد "\r\n") ويُزيل التابع trim المحرف "\n" أو "\r\n" ونحصل بالتالي على "5" فقط. يحول التابع parse السلاسل النصية إلى نوع آخر، ونستخدمه هنا لتحويل السلسلة النصية إلى عدد، وعلينا إخبار رست بتحديد النوع الذي نريد التحويل إليه باستخدام let guess: u32، إذ تُشير النقطتان ":" الموجودتان بعد guess إلى أننا سنحدد نوع المتغير بعدها. تحتوي رست على عدد من الأنواع العددية المُضمّنة built-in منها u32 الذي استخدمناه هنا وهو نوع عدد صحيح عديم الإشارة بطول 32-بت وهو خيار افتراضي جيّد للقيم الموجبة الصغيرة، وستتعلّم لاحقًا عن الأنواع العددية الأخرى. إضافةً إلى ما سبق، تعني u32 في مثالنا والمقارنة مع secret_number أن رست سيستنتج أن secret_number يجب أن تكون من النوع u32 أيضًا، لذا أصبحت المقارنة الآن بين قيمتين من النوع ذاته. يعمل التابع parse فقط على المحارف التي يمكن أن تُحوَّل منطقيًا إلى أعداد، لذلك من الشائع أن يتسبّب بأخطاء؛ فعلى سبيل المثال لن يستطيع التابع التحويل السلسلة النصية إلى نوع عددي إذا كانت تحتوي على القيمة "A?%" ولهذا السبب فإن التابع parse يُعيد أيضًا النوع Result بصورةٍ مماثلة للتابع read_line، الذي ناقشناه سابقًا في فقرة "التعامل مع الأخطاء الممكنة باستخدام النوع Result"، وسنتعامل مع النوع Result هذا بطريقة مماثلة باستخدام تابع expect مجددًا. إذا أعاد التابع parse متغاير Result المتمثل بالقيمة Err فهذا يعني أنه لم يستطع التحويل إلى نوع عددي من السلسلة النصية، وفي هذه الحالة، سيوقف استدعاء expect اللعبة وستُطبع الرسالة التي نمررها له، بينما يُعيد متغاير Result ذو القيمة Ok إذا استطاع تحويل القيمة بنجاح من نوع سلسلة نصية إلى نوع عددي، وتُعيد عندها expect العدد الذي نريده من قيمة Ok. دعنا نشغّل البرنامج الآن. $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 0.43s Running `target/debug/guessing_game` Guess the number! The secret number is: 58 Please input your guess. 76 You guessed: 76 Too big! رائع، فعلى الرغم من أننا أضفنا مسافات فارغة قبل التخمين، إلا أن البرنامج توصّل إلى أن تخمين المستخدم هو 67. شغّل البرنامج عدّة مرات أخرى لتتأكد من السلوك المختلف لحالات مختلفة من الإدخال: خمّن العدد بصورةٍ صحيحة، خمّن عددًا أكبر من الإجابة، خمّن عددًا أصغر من الإجابة. تعمل اللعبة لدينا الآن جيدًا، إلا أن المستخدم يمكنه التخمين مرةً واحدةً فقط، دعنا نغيّر من ذلك بإضافة حلقة تكرارية loop. السماح بعدة تخمينات باستخدام الحلقات التكرارية تُنشئ الكلمة المفتاحية loop حلقةً تكراريةً لا نهائية، وسنستخدم الحلقة هنا بهدف منح المستخدم فرصًا أكبر في تخمين العدد: اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); // --snip-- println!("The secret number is: {secret_number}"); loop { println!("Please input your guess."); // --snip-- let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = guess.trim().parse().expect("Please type a number!"); println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => println!("You win!"), } } } نقلنا محتوى البرنامج من تلقي الدخل guess إلى ما بعده لداخل الحلقة. تأكد من محاذاة السطور الموجودة داخل الحلقة التكرارية بمقدار أربع مسافات فارغة، وشغّل البرنامج مجددًا. سيسألك البرنامج الآن عن تخمين جديد إلى ما لا نهاية وهذه مشكلةٌ جديدة، إذ لن يستطيع المستخدم الخروج من البرنامج في هذه الحالة. يمكن للمستخدم إيقاف البرنامج قسريًا عن طريق استخدام اختصار لوحة المفاتيح "ctrl-c"، إلا أن هناك طريقة أخرى للهروب من هذا البرنامج الذي لا يشبع، إذ يمكن للمستخدم أن يُدخل قيمة غير عددية كما ذكرنا في القسم "مقارنة التخمين إلى الرقم السري" الذي يناقش استخدام parse ويتسبب ذلك بتوقف البرنامج، ويمكننا الاستفادة من ذلك الأمر بالسماح لمستخدمنا بمغادرة البرنامج كما هو موضح هنا: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 1.50s Running `target/debug/guessing_game` Guess the number! The secret number is: 59 Please input your guess. 45 You guessed: 45 Too small! Please input your guess. 60 You guessed: 60 Too big! Please input your guess. 59 You guessed: 59 You win! Please input your guess. quit thread 'main' panicked at 'Please type a number!: ParseIntError { kind: InvalidDigit }', src/main.rs:28:47 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace نستطيع الآن مغادرة اللعبة بكتابة quit، إلا أنك ستلاحظ أن إدخال أي قيمة غير عددية سيتسبب بذلك أيضًا، ولكن مشاكلنا لم تنتهي بعد، فما زلنا نريد أن نغادر اللعبة بعد أن نحصل على التخمين الصحيح. مغادرة اللعبة بعد إدخال التخمين الصحيح دعنا نبرمج اللعبة بحيث نُغادر منها عند فوز المستخدم بإضافة تعليمة break: اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); loop { println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = guess.trim().parse().expect("Please type a number!"); println!("You guessed: {guess}"); // --snip-- match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => { println!("You win!"); break; } } } } عند إضافة السطر break بعد "You win!"، يخرج البرنامج من الحلقة عندما يكون تخمين المستخدم مساويًا إلى الرقم السري، ويعني الخروج من الحلقة أيضًا الخروج من البرنامج لأن الحلقة هي آخر جزء من الدالة main. التعامل مع الدخل غير الصالح دعنا نجعل البرنامج يتجاهل دخل المستخدم عندما يكون ذو قيمة غير عددية بدلًا من إيقافه لتحسين اللعبة أكثر، وذلك ليتسنّى للمستخدم إعادة إدخال التخمين بصورةٍ صحيحة. يمكننا تحقيق ما سبق عن طريق تغيير السطر الذي يحتوي على تحويل guess من String إلى u32 كما توضح الشيفرة 2-5. اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); loop { println!("Please input your guess."); let mut guess = String::new(); // --snip-- io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; println!("You guessed: {guess}"); // --snip-- match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => { println!("You win!"); break; } } } } [شيفرة 2-5: تجاهل تخمين غير عددي وسؤال المستخدم عن تخمين آخر بدلًا من إيقاف البرنامج] بدّلنا استدعاء التابع expect بتعبير match لتفادي إيقاف البرنامج والتعامل مع الخطأ. تذكر أن parse تُعيد قيمةً من نوع Result ويمثّل Result معدّدًا يحتوي على المغايرين Ok و Err. نستخدم هنا تعبير match بصورةٍ مماثلة لما فعلناه عند استخدام نتيجة Ordering في تابع cmp. إذا نجح التابع parse بتحويل السلسلة النصية إلى عدد، فسيعيد القيمة Ok التي تحتوي على العدد الناتج، وستطابق قيمة Ok نمط الذراع الأول وبذلك سيعيد تعبير match قيمة num التي أنتجها التابع parse ووضعها داخل قيمة Ok، وسينتهي المطاف بهذا الرقم حيث نريده في متغير guess الجديد الذي أنشأناه. إذا لم يكن التابع parse قادرًا على تحويل السلسلة النصية إلى عدد، فسيعيد قيمةً من النوع Err التي تحتوي بدورها على معلومات حول الخطأ، لا تُطابق قيمة Err نمط Ok(num) في ذراع match الأولى إلا أنها تطابق النمط Err(_) في الذراع الثانية، وترمز الشرطة السفلية _ إلى الحصول على جميع القيم الممكنة، وفي مثالنا هذا فنحن نقول أننا نريد أن نطابق جميع قيم Err الممكنة بغض النظر عن المعلومات الموجودة داخلها، وبالتالي سينفذ البرنامج الذراع الثانية التي تتضمن على continue التي تخبر البرنامج بالذهاب إلى الدورة الثانية من الحلقة loop وأن تسأل المستخدم عن تخمينٍ آخر، لذا أصبح برنامجنا يتجاهل جميع أخطاء parse الممكنة بنجاح. يجب أن تعمل جميع أجزاء البرنامج كما هو متوقّع، لنجرّبه: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 4.45s Running `target/debug/guessing_game` Guess the number! The secret number is: 61 Please input your guess. 10 You guessed: 10 Too small! Please input your guess. 99 You guessed: 99 Too big! Please input your guess. foo Please input your guess. 61 You guessed: 61 You win! عظيم، استطعنا إنهاء كامل لعبة التخمين عن طريق تعديل بسيط، إلا أنه يجب أن تتذكر أن برنامجنا ما زال يطبع المرقم السري، وذلك ساعدنا جدًا خلال تجربتنا للبرنامج وفحصه إلا أنه يُفسد لعبتنا، لذا لنحذف السطر println! الذي يطبع الرقم السري على الشاشة. توضح الشيفرة 2-6 محتوى البرنامج النهائي. اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); loop { println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => { println!("You win!"); break; } } } } [شيفرة 2-6: الشيفرة البرمجية للعبة التخمين كاملةً] ملخص أنهينا بالوصول إلى هذه النقطة لعبة التخمين كاملةً، تهانينا. كان هذا المشروع بمثابة تطبيق عملي وطريقة للتعرف على مفاهيم رست الجديدة، مثل let و match والدوال واستخدام الصناديق الخارجية وغيرها. ستتعلم المزيد عن هذه المفاهيم بالتفصيل فيما يتبع، إذ سنتكلم عن المفاهيم الموجودة في معظم لغات البرمجة، مثل المتغيرات وأنواع البيانات والدوال وسنستعرض كيفية استخدامها في لغة رست، ثم سنتوجه لمناقشة مفهوم الملكية ownership وهي ميزة تجعل من لغة رست مميّزة دونًا عن لغات البرمجة الأخرى، ومن ثمّ سنناقش صيغة syntax التابع والهياكل structs، ومن ثمّ سنشرح كيفية عمل المعدّدات enums. ترجمة -وبتصرف- لفصل Programming a Guessing Game من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: المتغيرات والتعديل عليها في لغة رست المقال السابق: تعلم لغة رست Rust: البدايات تعلم البرمجة دليلك الشامل إلى لغات البرمجة تعرف على أشهر لغات برمجة الألعاب
دعنا نتعرّف إلى رست بالعمل على مشروع عملي سويًّا، إذ سيقدم هذا المقال بعض المفاهيم الشائعة في رست وكيفية استخدامها في برامج حقيقية، وسنتعلم كل من let و match والتوابع methods والدوال المترابطة associated functions واستخدام صناديق crates خارجية والمزيد، وسنناقش هذه التفاصيل بتعمق أكبر في مقالات لاحقة، إلا أننا سنتدرب على الأساسيات في هذا المقال. سنعمل على برنامج بسيط وشائع للمبتدئين ألا وهو لعبة تخمين. إليك كيف سيعمل البرنامج: سيولّد البرنامج رقمًا صحيحًا عشوائيًا بين 1 و100، ثمّ سينتظر من اللاعب إدخال التخمين، ثم سيجيب البرنامج فيما إذا كان التخمين أكبر أو أصغر من الإجابة، وفي حال كان التخمين صحيحًا، سيطبع البرنامج رسالة تهنئة وينتهي البرنامج. إعداد المشروع الجديد اذهب إلى مجلد "directory" الذي أنشأناه في المقال السابق لإعداد المشروع الجديد باستخدام أداة كارجو Cargo كما يلي: $ cargo new guessing_game $ cd guessing_game يأخذ الأمر الأول cargo new اسم المشروع، وهو في حالتنا "guessing_game" مقل وسيطٍ أول، بينما ينتقل الأمر الثاني إلى مجلد المشروع. ألقِ نظرةً إلى محتويات الملف "Cargo.toml" الناتج: [package] name = "guessing_game" version = "0.1.0" edition = "2021" # يمكنك رؤية المزيد من المفاتيح من الرابط https://doc.rust-lang.org/cargo/reference/manifest.html [dependencies] كما رأينا في المقال السابق، يولّد الأمر cargo new برنامج "!Hello, world" لك. ألقِ نظرةً على محتويات ملف "src/main.rs": fn main() { println!("Hello, world!"); } دعنا الآن نصرّف هذا البرنامج ونشغله باتباع نفس الخطوة وباستخدام أمر cargo run: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 1.50s Running `target/debug/guessing_game` Hello, world! تبرز أهمية الأمر run عندما تريد أن تفحص التغييرات في مشروعك تباعًا وأن تفحص البرنامج بسرعة بعد كل إضافة قبل المضيّ قدمًا للإضافة التالية وهذا ما سنفعله بالضبط في لعبتنا هذه. أعِد الآن فتح الملف "src/main.rs"، إذ سنكتب الشيفرة البرمجية لمشروعنا فيه. معالجة التخمين الجزء الأول من برنامج لعبة التخمين هو سؤال المستخدم ليدخل التخمين، ومن ثم معالجة هذا الدخل والتحقق من أنه بتنسيق مناسب. دعنا بدايةً نسمح المستخدم بإدخال تخمين. اكتب الشيفرة التالية في الملف "src/main.rs": use std::io; fn main() { println!("Guess the number!"); println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); println!("You guessed: {guess}"); } [شيفرة 2-1: شيفرة برمجية تأخذ التخمين من المستخدم في الدخل وتطبعه] تحتوي الشيفرة البرمجية السابقة على كثيرٍ من المعلومات الجديدة، لذلك دعنا نراجعها سطرًا بسطر. علينا أن نستخدم المكتبة io وأن نضيفها إلى نطاق scope المشروع للحصول على دخل المستخدم ومن ثم طباعة نتيجة الدخل في الخرج؛ إذ تأتي مكتبة io مع المكتبة القياسية، التي تُعرف باسم std: use std::io; تحتوي رست افتراضيًا على مجموعةٍ معرفةٍ من العناصر ضمن المكتبة القياسية التي تُضاف إلى نطاق أي برنامج، وتُسمى هذه العناصر باسم المقدمة prelude ويمكنك رؤية جميع محتوياتها في توثيق المكتبة القياسية. إذا أردت استخدام نوع محدد غير متواجد في المقدمة، فعليك إضافته إلى النطاق عن طريق استخدام تعليمة use. تتيح لك مكتبة std::io استخدام عدد من المزايا المفيدة منها القدرة على تلقّي دخل المستخدم. دالة main هي النقطة التي يبدأ منها البرنامج كما رأينا في المقال السابق: fn main() { تصرّح الصيغة fn عن دالة جديدة وتُشير الأقواس () إلى أن الدالة لا تأخذ أي معاملات، ويُشير القوس المعقوص } إلى بداية متن الدالة. تشير println! إلى ماكرو كما تطرقنا إلى ذلك في المقال السابق ويطبع هذا الماكرو السلسلة النصية إلى الشاشة: println!("Guess the number!"); println!("Please input your guess."); تطبع الشيفرة السابقة جملةً تدلّ المستخدم على ماهية اللعبة ومن ثم جملة تطلب منه إدخالًا. تخزين القيم والمتغيرات نُنشئ الآن متغيرًا لتخزين دخل المستخدم كما يلي: let mut guess = String::new(); أصبح الآن برنامجنا أكثر إثارةً للاهتمام؛ فهناك الكثير من الأشياء التي تحدث عند تنفيذ هذا السطر القصير، إذ نستخدم تعليمة let لإنشاء متغير، إليك مثالًا آخر عن إنشاء متغير: let apples = 5; يُنشئ هذا السطر متغيرًا جديدًا باسم apples ويُسنده إليه القيمة 5. المتغيرات في لغة رست ثابتة immutable افتراضيًا، وهذا يعني أن المتغير سيحافظ على قيمته الأولية التي أُسندت إليه ولن تُغيّر وسنتحدث في هذا الموضوع بتوسع أكثر لاحقًا. لجعل المتغير قابلًا للتغيير mutable نستخدم الكلمة المفتاحية mut قبل اسم المتغير: let apples = 5; // ثابت let mut bananas = 5; // متغيّر لاحظ أن // تتسبب ببدء تعليق سطري ينتهي بنهاية السطر وتتجاهل رست كل ما ورد ضمن التعليق، وسنناقش التعليقات لاحقًا بتوسع أكبر. بالعودة إلى برنامج لعبة التخمين، فأنت تعلم الآن أن let mut guess سيُضيف متغيرًا يقبل التغيير باسم guess، وتُخبر إشارة المساواة = رست أنّنا نريد إسناد قيمة ما إلى المتغير، يقع على يمين إشارة المساواة القيمة التي نريد إسنادها إلى guess وهي قيمةٌ ناتجةٌ عن استدعاء الدالة String::new وهي دالة تُعيد نُسخةً instance من النوع "String"؛ وهو نوع من أنواع السلاسل النصية الموجود في المكتبة القياسية وهو نص بترميز UTF-8 وقابل للزيادة. تُشير :: في السطر new:: إلى أن new مرتبطةٌ بدالة من نوع String؛ والدالة المرتبطة associated function هي دالة تُطبّق على نوع ما -وفي هذه الحالة هو String- وتُنشئ الدالة new هذه سلسلةً نصيةً جديدةً وفارغة، وستجد دالة new هذه في العديد من الأنواع لأنه اسم شائع لدالة تُنشئ قيمةً جديدةً من نوعٍ ما. إذا نظرنا إلى السطر let mut guess = String::new(); كاملًا، فهو سطرٌ لإنشاء متغير قابل للتغيير مُسندٌ إلى نُسخة جديدة وفارغة من النوع String. تلقي دخل المستخدم تذكر أننا ضمّننا إمكانية تلقي الدخل وعرض الخرج عن طريق use std::io; من المكتبة القياسية في السطر الأول من البرنامج. دعنا الآن نستدعي دالة stdin من وحدة io التي ستسمح لنا بالتعامل مع دخل المستخدم: io::stdin() .read_line(&mut guess) يمكننا استخدام استدعاء الدالة السابقة حتى لو لم نستورد مكتبة io بكتابتنا use std::io في بداية البرنامج ولكن الاستدعاء حينها سيكون بالشكل std::io::stdin. تُعيد الدالة stdin نسخة من النوع std::io::Stdin وهو نوع يُمثّل مُعالجًا للدخل القياسي من الطرفية. يستدعي السطر .read_line(&mut guess) تابع read_line ضمن معالج الدخل القياسي للحصول على دخل المستخدم، كما أننا نمرّر &mut guess مثل وسيط إلى read_line للدلالة على السلسلة النصية التي سيُخزّن بها دخل المستخدم. تتمثّل وظيفة read_line بأخذ ما يكتبه المستخدم إلى الدخل القياسي وإلحاقه append بالسلسلة النصية (دون الكتابة فوق overwriting محتوياته)، ولذا فنحن نمرّر هنا السلسلة النصية وسيطًا، ويجب أن يكون الوسيط قابلًا للتغيير حتى يكون التابع قادرًا على تغيير محتويات السلسلة النصية. يُشير الرمز & إلى أن هذا الوسيط يمثل مرجعًا، وهي طريقةٌ تسمح لأجزاء مختلفة من شيفرتك البرمجية بالوصول إلى الجزء ذاته من البيانات دون الحاجة إلى نسخ البيانات إلى الذاكرة عدة مرات. تُعد ميزة المراجع ميزةً معقّدةً وأكبر ميزات رست هو مستوى الأمان العالي وسهولة استخدام المراجع. لا تحتاج لمعرفة المزيد من هذه التفاصيل حتى تُنهي كتابة هذا البرنامج، إذ يكفي للآن أن تعرف أن المراجع غير قابلة للتغيير افتراضيًا -كما هو الحال في المتغيرات- وبالتالي يجب عليك كتابة &mut guess بدلًا من &guess إذا أردت جعلها قابلة للتغيير (سنشرح لاحقًا المراجع باستفاضة). التعامل مع الأخطاء الممكنة باستخدام نوع النتيجة Result ما زلنا نعمل على السطر البرمجي ذاته، ونناقش الآن السطر الثالث من النص، إلا أنه يجب الملاحظة أنه يمثل جزءًا من السطر البرمجي المنطقي ذاته. يمثل الجزء الثالث التابع: .expect("Failed to read line"); كان بإمكانك كتابة السطر البرمجي على النحو التالي: io::stdin().read_line(&mut guess).expect("Failed to read line"); إلا أن قراءة سطر طويل عملية صعبةٌ ومن الأفضل تقسيمه لأجزاء، لذلك من المحبّذ استخدام سطور جديدة ومسافات فارغة أخرى لتجزئة السطور الطويلة عندما تستدعي تابعًا على النحو التالي: .method_name(). دعنا الآن نناقش عمل السطر هذا. تضع الدالة read_line كل ما يكتبه المستخدم إلى السلسلة النصية التي نمررها لها كما ذكرنا سابقًا، إلا أنها تُعيد أيضًا قيمة Result وهي مُعدّد enumeration وغالبًا ما يُختصر بكتابة enum؛ وهو نوع يُمكن أن يأخذ عدّة حالات ونسمّي كل حالة ممكنة له بمتغاير variant. سنغطّي المعددات بتفصيل أكبر لاحقًا، إلا أن الهدف من أنواع Result هو لترميز معلومات التعامل مع الأخطاء. متغايرات Result هي Ok و Err؛ إذ يشير مغاير Ok إلى نجاح العملية ويحتوي بداخله على قيمة النجاح المولّدة؛ بينما يشير المتغاير Err إلى فشل العملية ويحتوي بداخله على معلومات حول سبب أو كيفية فشلها. لقيم النوع Result توابع معرفة لهم مثل أي قيم من نوع أخر، وتحتوي نسخةُ من النوع Result على التابع expect الذي يمكنك استدعاءه؛ فإذا كانت نسخة Result هذه لها قيمة Err فهذا يعني أن التابع expect سيتسبب بتوقف البرنامج وعرض الرسالة التي مرّرتها وسيطًا إلى التابع expect؛ وإذا أعاد التابع read_line قيمة Err، فهذا يعني أن الخطأ الناجم مرتبط بنظام التشغيل؛ وإذا كانت نسخة Result تحتوي على القيمة Ok، فسيأخذ التابع expect القيمة المُعادة التي تخزنها Ok ويُعيد القيمة إليك فقط كي تستخدمها، وتمثل القيمة في هذه الحالة عدد البايتات التي أدخلها المستخدم. إذا لم تستدعي التابع expect، سيُصرّف البرنامج بصورةٍ طبيعية، ولكنك ستحصل على التحذير التالي: $ cargo build Compiling guessing_game v0.1.0 (file:///projects/guessing_game) warning: unused `Result` that must be used --> src/main.rs:10:5 | 10 | io::stdin().read_line(&mut guess); | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ | = note: `#[warn(unused_must_use)]` on by default = note: this `Result` may be an `Err` variant, which should be handled warning: `guessing_game` (bin "guessing_game") generated 1 warning Finished dev [unoptimized + debuginfo] target(s) in 0.59s يحذرك رست هنا أنك لم تستخدم قيمة Result المُعادة من التابع read_line، مما يعني أن البرنامج لن يستطيع التعامل مع الأخطاء ممكنة الحدوث. الطريقة الصحيحة في تجنُّب التحذيرات هي بتطبيق طريقة معينة للتعامل مع أخطاء، إلا أننا نريد من البرنامج أن يتوقف في حالتنا هذه، لذا فيمكننا استخدام expect. ستتعلم ما يخص التعافي من الأخطاء (متابعة عمل البرنامج بعد ارتكاب الأخطاء) لاحقًا. طباعة القيم باستخدام مواضع println! المؤقتة هناك سطر واحد متبقي لمناقشته -بتجاهل الأقواس المعقوصة- ألا وهو: println!("You guessed: {guess}"); يطبع هذا السطر السلسلة النصية التي تحتوي دخل المستخدم، وتمثل مجموعة الأقواس المعقوصة {} مواضع مؤقتة placeholders. فكّر بالأمر وكأن {} كماشة سلطعون تُمسك القيمة في مكانها، ويمكنك طباعة أكثر من قيمة واحدة باستخدام الأقواس المعقوصة، إذ يدل أول قوسين على أول قيمة موجودة في لائحة بعد السلسلة النصية المُنسقّة، ويدل ثاني قوسين على القيمة الثاني في اللائحة وهلم جرًّا. إذا أردنا طباعة عدة قيم باستخدام استدعاء واحد للماكرو println! فسيبدو على النحو التالي: let x = 5; let y = 10; println!("x = {} and y = {}", x, y); سنحصل بعد تنفيذ الشيفرة السابقة على الخرج x = 5 and y = 10. التأكد من عمل الجزء الأول دعنا نتأكد من عمل الجزء الأول من لعبة التخمين، لذلك شغّل الشيفرة البرمجية باستخدام الأمر cargo run: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 6.44s Running `target/debug/guessing_game` Guess the number! Please input your guess. 6 You guessed: 6 وبهذا تكون قد أنجزت الجزء الأول من اللعبة، والبرنامج الآن قادر على استقبال الدخل من لوحة المفاتيح وطباعته. توليد الرقم السري الآن، علينا أن نولد الرقم السري الذي سيخمنه المستخدم، إذ يجب أن يكون هذا الرفم مختلفًا في كل مرة حتى تكون اللعبة أكثر متعةً للعب في كل مرة تحاول التخمين. سنستخدم رقمًا عشوائيًا بين 1 و100 حتى لا تكون اللعبة صعبةً جدًا. لا تتضمّن المكتبة القياسية الخاصة برست على مولّد عشوائي للأرقام، إلا أن فريق تطوير رست يقدم صندوق rand بهذه الوظيفة. استخدام صندوق ما للحصول على إمكانيات أكبر تذكر أن الصندوق هو مجموعة من ملفات رست المصدرية، إذ يمثّل المشروع الذي نبنيه الآن صندوقًا ثنائيًا binary crate أي أنه ملف تنفيذي، بينما يمثل صندوق rand صندوق مكتبة library crate، أي أنه يحتوي شيفرة مصدرية مكتوبة لتُستخدم في برامج أخرى ولا يمكن تشغيلها بصورةٍ مستقلة. تبرز أداة كارجو عند تنسيقها للصناديق الخارجية. قبل كتابة الشيفرة البرمجية التي تستخدم rand، علينا تعديل الملف "Cargo.toml" لتضمين صندوق rand مثل اعتمادية. افتح الملف وأضِف السطر التالي إلى نهاية الملف أسفل ترويسة القسم [dependencies] التي أنشأه لك كارجو مسبقًا، وتأكد من تحديد rand بدقة باستخدام رقم الإصدار وإلا فإن الشيفرة البرمجية الموجودة في المقال قد لا تعمل. اسم الملف: Cargo.toml rand = "0.8.3" كُل ما يتبع ترويسة القسم في ملف "Cargo.toml" هو جزءٌ من قسم ما يستمر حتى بداية القسم الآخر، وفي القسم [dependencies] أنت تُعلم كارجو بالصناديق الخارجية التي يعتمد مشروعك عليها وأي إصدار منها يتطلّب، ونحدّد في حالتنا هذه الصندوق rand ذو الإصدار "0.8.3"، ويفهم كارجو الإدارة الدلالية لنسخ البرمجيات Semantic Versioning -أو اختصارًا SemVer- وهي صيغة قياسية لكتابة أرقام الإصدارات، وفي الحقيقة فإن الرقم "0.8.3" هو اختصارٌ للرقم "^0.8.3"، وهو يعني أن أي إصدار مسموح هو "0.8.3" على الأقل و"0.9.0" على الأكثر. يضع كارجو في الحسبان أن هذه الإصدارات تحتوي على واجهات برمجية عامة public APIs متوافقة مع الإصدار "0.8.3" ويضمن ذلك التحديد أنك ستحصل على آخر الإصدارات المتوافقة مع الشيفرة البرمجية في هذا المقال، إذ من غير المضمون أن تكون الإصدارات المساوية إلى "0.9.0" أو أعلى تحتوي على ذات الواجهة البرمجية التي نتبعها في الأمثلة هنا. الآن ومن دون تغيير في الشيفرة البرمجية، دعنا نبني المشروع كما هو موضح في الشيفرة 2-2. $ cargo build Updating crates.io index Downloaded rand v0.8.3 Downloaded libc v0.2.86 Downloaded getrandom v0.2.2 Downloaded cfg-if v1.0.0 Downloaded ppv-lite86 v0.2.10 Downloaded rand_chacha v0.3.0 Downloaded rand_core v0.6.2 Compiling rand_core v0.6.2 Compiling libc v0.2.86 Compiling getrandom v0.2.2 Compiling cfg-if v1.0.0 Compiling ppv-lite86 v0.2.10 Compiling rand_chacha v0.3.0 Compiling rand v0.8.3 Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 2.53s [شيفرة 2-2: الخرج الناتج من تنفيذ الأمر cargo build بعد إضافة صندوق rand مثل اعتمادية] قد تجد اختلافًا في أرقام الإصدارات (إلا أنها ستكون متوافقة مع الشيفرة البرمجية والشكر إلى SemVer) وسطورًا مختلفة (بحسب نظام التشغيل الذي تستخدمه) وقد تكون السطور مكتوبةً بترتيب مختلف. يبحث كارجو عن آخر الإصدارات التي تحتاجها اعتمادية خارجية عند تضمينها وذلك من المسجل registry وهي نسخة من البيانات من Crates.io، وهو موقع ينشر فيه الناس مشاريع رست مفتوحة المصدر حتى يتسنى للآخرين استخدامها. يتفقد كارجو قسم [dependencies] بعد تحديث المسجل ويحمّل أي صندوق موجود لم يُحمّل بعد. في حالتنا هذه وعلى الرغم من أننا أضفنا rand فقط مثل اعتمادية، فقد أضاف كارجو أيضًا صناديق أخرى يعتمد rand عليها حتى يعمل، وبعد تحميل الصناديق يُصرّفها رست ويصرّف المشروع باستخدام الاعتماديات المتاحة. إذا نفذت الأمر cargo build مجددًا دون أي تغيير فلن تحصل على أي خرج إضافي عن السطر Finished، إذ يعرف كارجو أنه حمّل وصرّف الاعتماديات وأنك لم تغيّر أي شيء بخصوصهم في ملف "Cargo.toml"، كما يعرف كارجو أنك لم تغيّر أي شيء على شيفرتك البرمجية ولهذا فهو لا يُعيد تصريفها أيضًا، وفي هذه الحالة لا يوجد أي شيء ليفعله ويغادر مباشرةً. إذا فتحت الملف "src/main.rs" وعدّلت تعديلًا بسيطًا ومن ثمّ حفظته وحاولت إعادة بناء المشروع، فستجد السطرين التاليين فقط في الخرج: $ cargo build Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 2.53 secs توضح السطور السابقة أن كارجو حدّث وبنى التغييرات الطفيفة إلى الملف "src/main.rs"، ويعلم كارجو أنه يستطيع إعادة استخدام الاعتماديات التي حمّلها سابقًا وصرّفها بما أنك لم تعدل عليها. التأكد من أن المشاريع يمكن إعادة إنتاجها باستخدام ملف Cargo.lock لدى كارجو آلية تتحقق من أنك تستطيع إعادة بناء الأداة كل مرة تبني أنت أو شخص آخر شيفرتك البرمجية، يستخدم كارجو فقط إصدارات الاعتماديات التي حددتها إلا إذا حددت عكس ذلك. على سبيل المثال، لنقل أن إصدار 0.8.4 من صندوق rand سيُطلق الأسبوع القادم، ويتضمن هذا الإصدار تصحيحًا مهمًا لمشكلة ما إلا أنه يحتوي أيضًا على تراجع regression، وسيتسبب هذا بتعطل شيفرتك البرمجية؛ تُنشئ رست في هذه الحالة ملفًا يدعى "Cargo.lock" عند أول تنفيذ للأمر cargo build ويقع هذا الملف في مجلد "guessing_game". يوجِد كارجو جميع إصدارات الاعتماديات التي تلائم مشروعك عندما تبنيه للمرة الأولى، ومن ثم يكتب الإصدارات إلى ملف "Cargo.lock"، وبالتالي سيجد كارجو عندما تبني مشروعك في المستقبل أن الملف "Cargo.lock" موجود وسيستخدم عندها الإصدارات المحددة في ذلك الملف بدلًا من إيجاد الإصدارات المناسبة مجددًا، ويسمح لك هذا بالحصول على نسخة من المشروع قابلة لإعادة الإنتاج تلقائيًا، وبكلمات أخرى، سيظلّ مشروعك معتمدًا على الإصدار "0.8.3" حتى تقرّر التحديث إلى إصدار آخر بصورةٍ صريحة، ويعود الشكر إلى ملف "Cargo.lock" في ذلك. بما أن ملف "Cargo.lock" مهم للحصول على نسخ قابلة لإعادة الإنتاج، فمن الشائع أن يُضاف إلى نظام التحكم بالإصدارات version control مع باقي الشيفرة المصدرية في مشروعك. تحديث صندوق للحصول على إصدار جديد يقدم لك كارجو إمكانية تحديث صندوق ما باستخدام الأمر update، الذي سيتجاهل بدوره الملف "Cargo.lock" وسيبحث عن آخر الإصدارات التي تلائم متطلباتك في ملف "Cargo.toml"، إذ يكتب كارجو هذه الإصدارات إلى "Cargo.lock"، وإلا فسيبحث كارجو افتراضيًا عن إصدارات أحدث من "0.8.3" وأقدم من "0.9.0". إذا كان للصندوق rand إصداران جديدان هما "0.8.4" و"0.9.0" فستجد ما يلي عند تشغيل cargo update: $ cargo update Updating crates.io index Updating rand v0.8.3 -> v0.8.4 يتجاهل كارجو الإصدار "0.9.0"، وستلاحظ أيضًا بحلول هذه النقطة أن ملف "Cargo.lock" يُشير إلى أن الإصدار الحالي من صندوق rand هو "0.8.4"؛ ولاستخدام الإصدار "0.9.0" من rand أو أي إصدار آخر من السلسلة "x.0.9"K عليك تحديث ملف "Cargo.toml" ليبدو على النحو التالي: [dependencies] rand = "0.9.0" سيحدّث كارجو في المرة القادمة التي تنفذ فيها الأمر cargo build مسجّل الصناديق المتاحة ويُعيد تقييم متطلبات rand حسب الإصدار الجديد الذي حدّدته. هناك الكثير من الأشياء التي يمكننا الحديث عنها بخصوص كارجو ونظامه، وهذا ما سنفعله لاحقًا، إلا أن ما ذكرناه الآن كافي مبدئيًا. يجعل كارجو عملية إعادة استخدام المكتبات عملية أكثر سهولة، ويمكّن مستخدمي لغة رست من كتابة مشاريع صغيرة تعتمد على عدد من الحزم. توليد الرقم العشوائي دعنا نبدأ باستخدام rand لتوليد الرقم العشوائي، إذ تكمن خطوتنا التالية في التعديل على محتويات الملف "src/main.rs" كما هو موضح في الشيفرة 2-3. use std::io; use rand::Rng; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); println!("You guessed: {guess}"); } [شيفرة 2-3: إضافة شيفرة برمجية لتوليد الرقم العشوائي] نُضيف أولًا السطر use rand::Rng، إذ تُعرّف السمة Rng التوابع التي تستخدمها مولّدات الأرقام العشوائية، ويجب أن تكون هذه السمة ضمن النطاق حتى نستطيع استخدام هذه التوابع. سنناقش السمات بتفصيل أكبر لاحقًا. ثم نُضيف سطرين في وسط البرنامج، إذ نستدعي في السطر الأول الدالة rand::thread_rng التي تُعطينا مولّد رقم عشوائي معيّن سنستخدمه وهو مولد محلي لخيط التنفيذ الحالي ويُبذر seeded بواسطة نظام التشغيل، ونستدعي بعدها التابع gen_range على مولد الأرقام العشوائية، التابع السابق معرّف بالسمة Rng التي أضفناها إلى النطاق باستخدام التعليمة use rand::Rng. يأخذ التابع gen_rang تعبير مجال range expression مثل وسيط، ويولّد رقمًا ينتمي إلى ذلك المجال، إذ نستخدم تعبير المجال من النوع ذو التنسيق start..=end، ويتضمن المجال الحد الأعلى والأدنى داخله، لذا بكتابتنا للمجال "1..=100" فنحن نحدّد الأعداد بين 1 و100. ملاحظة: لن تعرف أي السمات وأي التوابع والدوال التي يجب أن تستدعيها من الصندوق من تلقاء نفسك، لذا يتضمن كل صندوق توثيق مرفقًا بتوجيهات لكيفية استخدام الصندوق. ميزة أخرى لطيفة من كارجو هي أن تنفيذ الأمر cargo doc --open سيتسبب ببناء التوثيق المزوّد بواسطة جميع الاعتماديات المحلية وفتحها في متصفحك، وإن كنت مهتمًا على سبيل المثال بالاستخدامات الأخرى الموجودة في الصندوق rand فكل ما عليك فعله هو تنفيذ الأمر cargo doc --open والنقر على rand في الشريط الجانبي على الجانب الأيسر. يطبع السطر الجديد الثاني الرقم السري، وهذا مفيد بينما تُطوّر البرنامج حتى تكون قادرًا على تجربته، إلا أننا سنحذفه من الإصدار الأخير في نهاية المطاف، فاللعبة عديمة الفائدة إذا كانت تطبع الإجابة فور تشغيلها. جرّب تنفيذ البرنامج عدة مرات: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 2.53s Running `target/debug/guessing_game` Guess the number! The secret number is: 7 Please input your guess. 4 You guessed: 4 $ cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.02s Running `target/debug/guessing_game` Guess the number! The secret number is: 83 Please input your guess. 5 You guessed: 5 يجب أن تحصل على رقم مختلف في كل مرة ويجب أن تكون الأرقام بين 1 و100، وإذا حدث ذلك فأحسنت. مقارنة التخمين مع الرقم السري يمكننا الآن مقارنة التخمين الذي أدخله المستخدم مع الرقم السري العشوائي، وتوضّح الشيفرة 2-4 هذه الخطوة، لاحظ أن الشيفرة البرمجية لن تُصرّف بنجاح بعد كما سنوضح لاحقًا. اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { // --snip-- println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => println!("You win!"), } } [شيفرة 2-4: التعامل مع الحالات المُمكنة ضمن عملية المقارنة] نُضيف أولًا تعليمة use أخرى تقدّم لنا نوعًا جديدًا يدعى std::cmp::Ordering إلى النطاق من المكتبة القياسية، والنوع Ordering هو مُعدّد enum آخر يحتوي على المتغايرات Less و Greater و Equal، وهي النتائج الثلاث الممكنة عندما تُقارن ما بين قيمتين. نُضيف بعدها خمسة أسطر في النهاية، وتستخدم هذه الأسطر بدورها النوع Ordering، ويُقارن التابع cmp بين قيمتين ويُمكن استدعاؤه على أي شيء يمكن مقارنته، ويتطلب الأمر استخدام المرجع للشيء الذي تريد مقارنته، وفي حالتنا هذه فهو يقارن guess مع secret_number، ثم يُعيد متغايرًا من متغايرات المعدّد Ordering الذي أضفناه سابقًا إلى النطاق باستخدام تعليمة use، ونستخدم هنا تعبير match لتحديد ما الذي سنفعله لاحقًا بناءً على متغاير Ordering المُعاد من استدعاء cmp باستخدام القيمتين guess و secret_number. يتألف تعبير match من أذرع arms، ويتألف كل ذراع من نمط يُستخدم في عملية المقارنة والشيفرة البرمجية التي يجب أن تعمل في حال كانت القيمة المُعطاة إلى match توافق نمط الذراع. تأخذ رست القيمة المُعطاة إلى match وتنظر إلى كلّ نمط ذراع. تُعدّ الأذرع وبنية match من أبرز مزايا رست، إذ تسمح لك بالتعبير عن عدّة حالات قد تحدث ضمن شيفرتك البرمجية وأن تتأكد من معالجتها جميعًا، وسنغطّي هذه المزايا بتعمُّق أكبر لاحقًا. دعنا نوضح مثالًا عن تعبير match نستخدمه هنا؛ لنقُل أن المستخدم قد خمّن القيمة 50 وأن الرقم العشوائي السري المولّد كان 38، تُقارن شيفرتنا البرمجية القيمة 50 إلى 38 ويُعيد التابع cmp في هذه الحالة القيمة Ordering::Greater لأن 50 أكبر من 38، ويتلقّى التعبير match القيمة Ordering::Greater ويبدأ بتفقد كل نمط ذراع، إذ يُنظر إلى نمط الذراع الأولى وهو Ordering::Less وهي قيمةٌ لا توافق القيمة Ordering::Greater وبالتالي يجري تجاهل الشيفرة البرمجية ضمن الذراع وينتقل إلى نمط الذراع الأخرى وهو Ordering::Greater الذي يُطابق !Ordering::Greater، وبالتالي تُنفّذ الشيفرة البرمجية الموجود ضمن الذراع ويُطبع النص "Too big!" إلى الشاشة. ينتهي التعبير match بعد أول مطابقة ناجحة، لذا لن تجري المطابقة مع نمط الذراع الثالثة في هذه الحالة. إلا أن الشيفرة 2-4 لن تُصرّف، دعنا نجرّب ذلك: $ cargo build Compiling libc v0.2.86 Compiling getrandom v0.2.2 Compiling cfg-if v1.0.0 Compiling ppv-lite86 v0.2.10 Compiling rand_core v0.6.2 Compiling rand_chacha v0.3.0 Compiling rand v0.8.3 Compiling guessing_game v0.1.0 (file:///projects/guessing_game) error[E0308]: mismatched types --> src/main.rs:22:21 | 22 | match guess.cmp(&secret_number) { | ^^^^^^^^^^^^^^ expected struct `String`, found integer | = note: expected reference `&String` found reference `&{integer}` For more information about this error, try `rustc --explain E0308`. error: could not compile `guessing_game` due to previous error تتلخّص المشكلة الأساسية بوجود أنواع غير متوافقة mismatched types. لدى رست نظام نوع ساكن static type قوي، إلا أنها تحتوي أيضًا على واجهة نوع type interface، وبالتالي استنتجت رست عند كتابتنا للتعليمة let mut guess = String::new() بأن guess يجب أن تكون String ولم تُجبرنا على كتابة النوع، بينما secret_number على الجانب الآخر هو من نوع عددي وهناك عدد من أنواع رست الرقمية التي يمكن أن تحتوي على القيم بين 1 و100، مثل i32 وهو عدد بطول 32 بت، و u32 وهو عدد عديم الإشارة unsigned بطول 32 بت، وi64 وهو عدد بطول 64 بت، إضافةً إلى أنواع أخرى، ويستخدم رست النوع i32 افتراضيًا إن لم يُحدد النوع وهو نوع secret_number في هذه الحالة، والسبب في حدوث المشكلة هو عدم قدرة رست على المقارنة بين نوع عددي وسلسلة نصية. إذًا، علينا أن نحوّل النوع String الذي يقرأه البرنامج في الدخل إلى نوع عددي، وذلك كي يتسنّى لنا مقارنته مقارنةً عدديّةً مع الرقم السري، ونُنجز ذلك عن طريق إضافة السطر الجديد التالي إلى متن الدالة main: اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); println!("Please input your guess."); // --snip-- let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = guess.trim().parse().expect("Please type a number!"); println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => println!("You win!"), } } السطر الجديد هو: let guess: u32 = guess.trim().parse().expect("Please type a number!"); نُنشئ متغيرًا باسم "guess"، ولكن مهلًا ألا يوجد متغير باسم "guess" في برنامجنا مسبقًا؟ نعم، ولكن رست تسمح لنا بتظليل shadow القيمة السابقة للمتغير guess بقيمة أخرى جديدة، ويسمح لنا التظليل بإعادة استخدام اسم المتحول guessبدلًا من إجبارنا على إنشاء متغير جديد، بحيث يصبح لدينا مثلًا guess_str و guess، وسنغطّي هذا الأمر بتفصيلٍ أكبر لاحقًا، ويكفي الآن أن تعرف بوجود هذه الميزة وأن استخدامها شائع عندما نريد تحويل قيمة من نوع إلى آخر. نُسند المتغير الجديد إلى التعبير guess.trim().parse()، إذ تشير guess ضمن التعبير إلى المتغير guess الأصلي الذي يحتوي على الدخل (سلسلة نصية string). يحذف التابع trim عند استخدامه ضمن نسخة من النوع String أي مسافات فارغة whitespaces في بداية ونهاية السلسلة النصية، وهو أمر لازم الحدوث قبل أن نحوّل السلسلة النصية إلى النوع u32 الذي يمكن أن يحتوي فقط على قيمة عددية، وذلك لأن المستخدم يضغط على زرّ الإدخال enter لإنهاء عمل التابع read_line بعد إدخال تخمينه مما يُضيف محرف سطر جديد إلى السلسلة النصية؛ فعلى سبيل المثال، إذا أدخل المستخدم 5 وضغط على زر الإدخال، فستأخذ السلسلة النصية guess القيمة "5\n"، إذ يمثل المحرف "\n" محرف سطر جديد (يتسبب الضغط على زر الإدخال في أنظمة ويندوز برجوع السطر وإضافة سطر جديد "\r\n") ويُزيل التابع trim المحرف "\n" أو "\r\n" ونحصل بالتالي على "5" فقط. يحول التابع parse السلاسل النصية إلى نوع آخر، ونستخدمه هنا لتحويل السلسلة النصية إلى عدد، وعلينا إخبار رست بتحديد النوع الذي نريد التحويل إليه باستخدام let guess: u32، إذ تُشير النقطتان ":" الموجودتان بعد guess إلى أننا سنحدد نوع المتغير بعدها. تحتوي رست على عدد من الأنواع العددية المُضمّنة built-in منها u32 الذي استخدمناه هنا وهو نوع عدد صحيح عديم الإشارة بطول 32-بت وهو خيار افتراضي جيّد للقيم الموجبة الصغيرة، وستتعلّم لاحقًا عن الأنواع العددية الأخرى. إضافةً إلى ما سبق، تعني u32 في مثالنا والمقارنة مع secret_number أن رست سيستنتج أن secret_number يجب أن تكون من النوع u32 أيضًا، لذا أصبحت المقارنة الآن بين قيمتين من النوع ذاته. يعمل التابع parse فقط على المحارف التي يمكن أن تُحوَّل منطقيًا إلى أعداد، لذلك من الشائع أن يتسبّب بأخطاء؛ فعلى سبيل المثال لن يستطيع التابع التحويل السلسلة النصية إلى نوع عددي إذا كانت تحتوي على القيمة "A?%" ولهذا السبب فإن التابع parse يُعيد أيضًا النوع Result بصورةٍ مماثلة للتابع read_line، الذي ناقشناه سابقًا في فقرة "التعامل مع الأخطاء الممكنة باستخدام النوع Result"، وسنتعامل مع النوع Result هذا بطريقة مماثلة باستخدام تابع expect مجددًا. إذا أعاد التابع parse متغاير Result المتمثل بالقيمة Err فهذا يعني أنه لم يستطع التحويل إلى نوع عددي من السلسلة النصية، وفي هذه الحالة، سيوقف استدعاء expect اللعبة وستُطبع الرسالة التي نمررها له، بينما يُعيد متغاير Result ذو القيمة Ok إذا استطاع تحويل القيمة بنجاح من نوع سلسلة نصية إلى نوع عددي، وتُعيد عندها expect العدد الذي نريده من قيمة Ok. دعنا نشغّل البرنامج الآن. $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 0.43s Running `target/debug/guessing_game` Guess the number! The secret number is: 58 Please input your guess. 76 You guessed: 76 Too big! رائع، فعلى الرغم من أننا أضفنا مسافات فارغة قبل التخمين، إلا أن البرنامج توصّل إلى أن تخمين المستخدم هو 67. شغّل البرنامج عدّة مرات أخرى لتتأكد من السلوك المختلف لحالات مختلفة من الإدخال: خمّن العدد بصورةٍ صحيحة، خمّن عددًا أكبر من الإجابة، خمّن عددًا أصغر من الإجابة. تعمل اللعبة لدينا الآن جيدًا، إلا أن المستخدم يمكنه التخمين مرةً واحدةً فقط، دعنا نغيّر من ذلك بإضافة حلقة تكرارية loop. السماح بعدة تخمينات باستخدام الحلقات التكرارية تُنشئ الكلمة المفتاحية loop حلقةً تكراريةً لا نهائية، وسنستخدم الحلقة هنا بهدف منح المستخدم فرصًا أكبر في تخمين العدد: اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); // --snip-- println!("The secret number is: {secret_number}"); loop { println!("Please input your guess."); // --snip-- let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = guess.trim().parse().expect("Please type a number!"); println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => println!("You win!"), } } } نقلنا محتوى البرنامج من تلقي الدخل guess إلى ما بعده لداخل الحلقة. تأكد من محاذاة السطور الموجودة داخل الحلقة التكرارية بمقدار أربع مسافات فارغة، وشغّل البرنامج مجددًا. سيسألك البرنامج الآن عن تخمين جديد إلى ما لا نهاية وهذه مشكلةٌ جديدة، إذ لن يستطيع المستخدم الخروج من البرنامج في هذه الحالة. يمكن للمستخدم إيقاف البرنامج قسريًا عن طريق استخدام اختصار لوحة المفاتيح "ctrl-c"، إلا أن هناك طريقة أخرى للهروب من هذا البرنامج الذي لا يشبع، إذ يمكن للمستخدم أن يُدخل قيمة غير عددية كما ذكرنا في القسم "مقارنة التخمين إلى الرقم السري" الذي يناقش استخدام parse ويتسبب ذلك بتوقف البرنامج، ويمكننا الاستفادة من ذلك الأمر بالسماح لمستخدمنا بمغادرة البرنامج كما هو موضح هنا: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 1.50s Running `target/debug/guessing_game` Guess the number! The secret number is: 59 Please input your guess. 45 You guessed: 45 Too small! Please input your guess. 60 You guessed: 60 Too big! Please input your guess. 59 You guessed: 59 You win! Please input your guess. quit thread 'main' panicked at 'Please type a number!: ParseIntError { kind: InvalidDigit }', src/main.rs:28:47 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace نستطيع الآن مغادرة اللعبة بكتابة quit، إلا أنك ستلاحظ أن إدخال أي قيمة غير عددية سيتسبب بذلك أيضًا، ولكن مشاكلنا لم تنتهي بعد، فما زلنا نريد أن نغادر اللعبة بعد أن نحصل على التخمين الصحيح. مغادرة اللعبة بعد إدخال التخمين الصحيح دعنا نبرمج اللعبة بحيث نُغادر منها عند فوز المستخدم بإضافة تعليمة break: اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); loop { println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = guess.trim().parse().expect("Please type a number!"); println!("You guessed: {guess}"); // --snip-- match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => { println!("You win!"); break; } } } } عند إضافة السطر break بعد "You win!"، يخرج البرنامج من الحلقة عندما يكون تخمين المستخدم مساويًا إلى الرقم السري، ويعني الخروج من الحلقة أيضًا الخروج من البرنامج لأن الحلقة هي آخر جزء من الدالة main. التعامل مع الدخل غير الصالح دعنا نجعل البرنامج يتجاهل دخل المستخدم عندما يكون ذو قيمة غير عددية بدلًا من إيقافه لتحسين اللعبة أكثر، وذلك ليتسنّى للمستخدم إعادة إدخال التخمين بصورةٍ صحيحة. يمكننا تحقيق ما سبق عن طريق تغيير السطر الذي يحتوي على تحويل guess من String إلى u32 كما توضح الشيفرة 2-5. اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); println!("The secret number is: {secret_number}"); loop { println!("Please input your guess."); let mut guess = String::new(); // --snip-- io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; println!("You guessed: {guess}"); // --snip-- match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => { println!("You win!"); break; } } } } [شيفرة 2-5: تجاهل تخمين غير عددي وسؤال المستخدم عن تخمين آخر بدلًا من إيقاف البرنامج] بدّلنا استدعاء التابع expect بتعبير match لتفادي إيقاف البرنامج والتعامل مع الخطأ. تذكر أن parse تُعيد قيمةً من نوع Result ويمثّل Result معدّدًا يحتوي على المغايرين Ok و Err. نستخدم هنا تعبير match بصورةٍ مماثلة لما فعلناه عند استخدام نتيجة Ordering في تابع cmp. إذا نجح التابع parse بتحويل السلسلة النصية إلى عدد، فسيعيد القيمة Ok التي تحتوي على العدد الناتج، وستطابق قيمة Ok نمط الذراع الأول وبذلك سيعيد تعبير match قيمة num التي أنتجها التابع parse ووضعها داخل قيمة Ok، وسينتهي المطاف بهذا الرقم حيث نريده في متغير guess الجديد الذي أنشأناه. إذا لم يكن التابع parse قادرًا على تحويل السلسلة النصية إلى عدد، فسيعيد قيمةً من النوع Err التي تحتوي بدورها على معلومات حول الخطأ، لا تُطابق قيمة Err نمط Ok(num) في ذراع match الأولى إلا أنها تطابق النمط Err(_) في الذراع الثانية، وترمز الشرطة السفلية _ إلى الحصول على جميع القيم الممكنة، وفي مثالنا هذا فنحن نقول أننا نريد أن نطابق جميع قيم Err الممكنة بغض النظر عن المعلومات الموجودة داخلها، وبالتالي سينفذ البرنامج الذراع الثانية التي تتضمن على continue التي تخبر البرنامج بالذهاب إلى الدورة الثانية من الحلقة loop وأن تسأل المستخدم عن تخمينٍ آخر، لذا أصبح برنامجنا يتجاهل جميع أخطاء parse الممكنة بنجاح. يجب أن تعمل جميع أجزاء البرنامج كما هو متوقّع، لنجرّبه: $ cargo run Compiling guessing_game v0.1.0 (file:///projects/guessing_game) Finished dev [unoptimized + debuginfo] target(s) in 4.45s Running `target/debug/guessing_game` Guess the number! The secret number is: 61 Please input your guess. 10 You guessed: 10 Too small! Please input your guess. 99 You guessed: 99 Too big! Please input your guess. foo Please input your guess. 61 You guessed: 61 You win! عظيم، استطعنا إنهاء كامل لعبة التخمين عن طريق تعديل بسيط، إلا أنه يجب أن تتذكر أن برنامجنا ما زال يطبع المرقم السري، وذلك ساعدنا جدًا خلال تجربتنا للبرنامج وفحصه إلا أنه يُفسد لعبتنا، لذا لنحذف السطر println! الذي يطبع الرقم السري على الشاشة. توضح الشيفرة 2-6 محتوى البرنامج النهائي. اسم الملف: src/main.rs use rand::Rng; use std::cmp::Ordering; use std::io; fn main() { println!("Guess the number!"); let secret_number = rand::thread_rng().gen_range(1..=100); loop { println!("Please input your guess."); let mut guess = String::new(); io::stdin() .read_line(&mut guess) .expect("Failed to read line"); let guess: u32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; println!("You guessed: {guess}"); match guess.cmp(&secret_number) { Ordering::Less => println!("Too small!"), Ordering::Greater => println!("Too big!"), Ordering::Equal => { println!("You win!"); break; } } } } [شيفرة 2-6: الشيفرة البرمجية للعبة التخمين كاملةً] ملخص أنهينا بالوصول إلى هذه النقطة لعبة التخمين كاملةً، تهانينا. كان هذا المشروع بمثابة تطبيق عملي وطريقة للتعرف على مفاهيم رست الجديدة، مثل let و match والدوال واستخدام الصناديق الخارجية وغيرها. ستتعلم المزيد عن هذه المفاهيم بالتفصيل فيما يتبع، إذ سنتكلم عن المفاهيم الموجودة في معظم لغات البرمجة، مثل المتغيرات وأنواع البيانات والدوال وسنستعرض كيفية استخدامها في لغة رست، ثم سنتوجه لمناقشة مفهوم الملكية ownership وهي ميزة تجعل من لغة رست مميّزة دونًا عن لغات البرمجة الأخرى، ومن ثمّ سنناقش صيغة syntax التابع والهياكل structs، ومن ثمّ سنشرح كيفية عمل المعدّدات enums. ترجمة -وبتصرف- لفصل Programming a Guessing Game من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: المتغيرات والتعديل عليها في لغة رست المقال السابق: تعلم لغة رست Rust: البدايات تعلم البرمجة دليلك الشامل إلى لغات البرمجة تعرف على أشهر لغات برمجة الألعاب -
 قدمنا سابقًا مفهوم النطاق scope والربط linkage، ووضحنا كيف يمكن استخدامهما سويًّا للتحكم بقابلية الوصول لأجزاء معينة ضمن البرنامج، وعمدنا إلى إعطاء وصف غامض لما يحدّد التعريف Definition لأن شرح ذلك سيتسبب بتشويشك في تلك المرحلة ولن يكون مثمرًا لرحلة تعلمك، إلا أنه علينا تحديد هذا الأمر في مرحلة من المراحل وهذا ما سنفعله في هذ الجزئية من السلسلة، كما سنتكلم عن صنف التخزين Storage class لجعل الأمر أكثر إثارة للاهتمام. لعلك ستجد مزج هذه المفاهيم واستخدامها سويًّا معقدًا ومربكًا، وهذا مبرّر، إلا أننا سنحاول إزالة الغموض بالتكلم عن بعض القوانين المفيدة لاحقًا، لكنك بحاجة لقراءة بعض التفاصيل قبل ذلك على الأقل مرةً واحدةً لتفهم هذه القوانين. حتى تفهم القوانين جيدًا، عليك أن تفهم ثلاثة مفاهيم مختلفة -ولكن مرتبطة- وهي كما يدعوها المعيار: المدة الزمنية duration. النطاق scope. الربط linkage. ويشرح المعيار هذه المصطلحات، كما أننا ناقشنا النطاق والربط في المقالة سابقة الذكر لكننا سنعيد ذكرهما بصورةٍ مقتضبة. محددات صنف التخزين تندرج خمس كلمات مفتاحية تحت تصنيف محدّدات صنف التخزين storage class specifiers، أحدها هو typedef، وبالرغم من أنه أشبه باختصار عن شبهه بخاصيّة، إلا أننا سنناقش هذه الكلمة المفتاحية بالتفصيل لاحقًا. يتبقى لدينا الكلمات المفتاحية auto و extern و register و static. تساعدك محددات صنف التخزين على تحديد نوع التخزين المستخدم لكائنات البيانات، وهناك صنف تخزين واحد مسموح به عند التصريح، وهذا الأمر منطقي لأن هناك طريقةً واحدةً لتخزين الأشياء. يُطبق المحدّد الافتراضي على عملية التصريح إذا أُهمل محدد صف التخزين، ويعتمد اختيار المحدد الافتراضي على نوع التصريح إذا كان خارج دالة (تصريح خارجي) أو داخل الدالة (تصريح داخلي)، إذ أن محدد التخزين الافتراضي للتصريح الخارجي هو extern بينما auto هو محدد التخزين الافتراضي للتصريح الداخلي، والاستثناء الوحيد لهذه القاعدة هو تصريح الدوال، إذ إن قيمة المحدد الافتراضي لها هو extern دائمًا. يمكن أن يؤثر مكان التصريح ومحددات صنف التخزين المستخدمة (أو الافتراضية في حال عدم وجودها) على ربط الاسم، بالإضافة إلى تصريحات الاسم ذاته التي تلي التصريح الأولي، ولحسن الحظ فإن ذلك لا يؤثر على النطاق أو المدة الزمنية. سنستعرض المفاهيم الأسهل أوّلًا. المدة الزمنية تصف المدة الزمنية لكائن ما طبيعة تخزينه، وذلك إذا كان حجز المساحة يصبح مرةً واحدةً عند تشغيل البرنامج أو أنه من طبيعة عابرة بمعنى أن مساحته تُحجز وتحرّر عند الضرورة. هناك نوعان فقط من المدة الزمنية، هما: المدة الساكنة static duration والمدة التلقائية automatic duration؛ إذ تعني المدة الساكنة أن مساحة التخزين المحجوزة للكائن دائمة؛ بينما تعني المدة التلقائية أن مساحة التخزين المحجوزة للكائن تُحرّر وتُحجز عند الضرورة، ومن السهل معرفة أي من المدتين ستحصل عليهما، لأنك ستحصل على المدة التلقائية فقط في حالة: إذا كان التصريح داخل دالة، ولم يكن التصريح يحتوي على أي من الكلمتين المفتاحيتين static أو extern. وليس التصريح تصريحًا لدالة. ستجد أن معاملات الدالة الصورية تطابق هذه القوانين الثلاث دائمًا، وبذلك فهي ذات مدة تلقائية. مع أن تواجد الكلمة المفتاحية static ضمن التصريح يعني أن الكائن ذو مدة ساكنة دون أي شك، إلا أنها ليست الطريقة الوحيدة لإنجاز ذلك، ويسبب هذا بعض اللبس لدى الكثير، وعلينا تقبُّل هذا الأمر. تُمنح كائنات البيانات المصرحة داخل الدوال محدد صنف التخزين الافتراضي auto، إلا إذا استُخدم محدد آخر لصنف التخزين. لن تحتاج الوصول إلى هذه الكائنات من خارج الدالة في معظم الحالات، لذا ستريد أن تكون عديمة الربط no linkage، وفي هذه الحالة نستخدم الحالة الافتراضية auto أو محدّد صنف التخزين register storage، إذ سيعطينا هذا كائنًا عديم الربط وذا مدة تلقائية. لا يمكن تطبيق الكلمة المفتاحية auto أو register ضمن تصريح يقع خارج دالةٍ ما. يُعد صنف التخزين register مثيرًا للاهتمام، فعلى الرغم من قلة استخدامه هذه الأيام إلا أنه يقترح على المصرف تخزين الكائن في مسجل register واحد أو أكثر في الذاكرة والذي ينعكس بالإيجاب على سرعة التنفيذ. لا ينفذ المصرف الأوامر بناءً على هذا الأمر إلا أن متغيرات register لا تمتلك أي عنوان ( يُمنع استخدام العامل & معها) لتسهيل الأمر وذلك لأن بعض الحواسيب لا تدعم المسجلات ذات العناوين. قد يتسبب التصريح عن عدة كائنات register بتأثير عكسي فيبطئ البرنامج بدلًا من تسريعه، وذلك لأن المصرف سوف يضطر إلى حجز مزيدٍ من المسجلات عند الدخول إلى (تنفيذ) الدالة وهي عملية بطيئة، أو لن يكون هناك العدد الكافي من المسجلات المتبقية لتُستخدم في العمليات الحسابية الوسيطة. يعود الاختيار في استخدام المسجلات إلى الآلة المُستخدمة، ويجب استخدام هذه الطريقة فقط عندما توضح الحسابات أن هذا النوع ضروري لتسريع تنفيذ دالة ما بعينها، وعندها يتوجب عليك فحص البرنامج وتجربته. يجب ألّا تصرح عن متغيرات المسجلات أبدًا خلال عملية تطوير البرنامج برأينا، بل تأكد من أن البرنامج يعمل ومن ثم أجرِ بعض القياسات، وعندها قرّر استخدام هذا النوع من المتغيرات حسب النتائج فيما إذا كان يتسبب استخدامها بتحسن ملحوظ في الأداء، ولكن عليك تكرار العملية ذاتها إذا اتبعت هذه الطريقة في كل نوع من المعالجات المسبقة التي تنقل برنامجك إليها، إذ يحتوي كل نوع من المعالجات المسبقة على خصائص مختلفة. ملاحظة أخيرة بخصوص متغيرات register: يُعد محدد صنف التخزين هذا المحدد الوحيد الممكن استخدامه ضمن نموذج دالة أولي function prototype أو تعريف دالة، ويجري تجاهل محدد صنف التخزين في حالة نموذج الدالة الأولي، بينما يشير تعريف الدالة على أن المعامل الفعلي مخزّن في مسجّل إذا كان الأمر ممكنًا. إليك مثالًا يوضح كيفية يمكن توظيف ذلك: #include <stdio.h> #include <stdlib.h> void func(register int arg1, double arg2); main(){ func(5, 2); exit(EXIT_SUCCESS); } /* توضح الدالة أنه يمكن التصريح عن المعاملات الصورية باستخدام صنف تخزين مسجّل */ void func(register int arg1, double arg2){ /* هذا الاستخدام لأهداف توضيحية، فلا أحد يكتب ذلك في هذا السياق لا يمكن أخذ عنوان arg1 حتى لو أردت ذلك */ double *fp = &arg2; while(arg1){ printf("res = %f\n", arg1 * (*fp)); arg1--; } } [مثال 1] تعتمد إذًا المدة الزمنية لكائن على محدد صنف التخزين المستخدَم -بغض النظر عن كون الكائن كائن بيانات أو دالة-، كما تعتمد على مكان التصريح (في كتلة داخلية أو على كامل نطاق الملف؟). يعتمد الربط أيضًا على محدد صنف التخزين، إضافةً إلى نوع الكائن ونطاق التصريح عنه. يوضح الجدول 1 والجدول 2 التاليين مدة التخزين الناتجة والربط لكل من الحالات الممكنة عند استخدام محددات صنف التخزين الممكنة، وموضع التصريح. يُعد ربط الكائنات باستخدام المدة الساكنة أكثر تعقيدًا، لذا ننصحك باستخدام هذه الجداول لتوجيهك في الحالات البسيطة وانتظر قليلًا حتى نصل إلى الجزء الذي نتكلم فيه عن التعريفات. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية static أحدهما داخلي ساكنة extern أحدهما خارجي غالبًا ساكنة لا يوجد دالة خارجي غالبًا ساكنة لا يوجد كائن بيانات خارجي ساكنة أهملنا في الجدول السابق المحددين register و auto لأنه من غير المسموح استخدامهما على نطاق التصريحات الخارجية (على نطاق الملف). محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية register كائن بيانات فقط لا يوجد تلقائية auto كائن بيانات فقط لا يوجد تلقائية static كائن بيانات فقط لا يوجد ساكنة extern كلاهما خارجي غالبًا ساكنة لا يوجد none كائن بيانات لا يوجد تلقائية لا يوجد none دالة خارجي غالبًا ساكنة تحتفظ المتغيرات الساكنة static الداخلية بقيمها بين استدعاءات الدوال التي تحتويها، وهذا شيءٌ مفيدٌ جدًا في بعض الحالات. النطاق علينا الآن إلقاء نظرة على نطاق أسماء الكائنات مجددًا، والذي يعرف أين ومتى يكون لاسمٍ ما معنًى محدد. هناك أنواعٌ مختلفة للنطاق هي: نطاق دالة. نطاق ملف. نطاق كتلة. نطاق نموذج دالة أولي. النطاق الأسهل هو نطاق الدالة، إذ ينطبق ذلك على عناوين labels الأسماء المرئية ضمن دالة ما صُرّح عنها بداخلها، ولا يمكن لعنوانين داخل نفس الدالة أن يمتلكان الاسم ذاته، لكن يمكن للعنوان استخدام الاسم ذاته إذا كان ضمن أي دالةٍ أخرى بحكم أن النطاق هو نطاق دالة. ليست العناوين كائنات فهي لا تمتلك أي مساحة تخزينية ولا يعني مفهوم الربط والمدة الزمنية أي معنًى في عالمها. يمتلك أي اسم مُصرّح عنه خارج الدالة نطاق ملف، وهذا يعني أن الاسم قابلٌ للاستخدام ضمن أي نقطة من البرنامج من لحظة التصريح عنه إلى نهاية ملف الشيفرة المصدرية الذي يحتوي ذلك التصريح، ومن الممكن طبعًا لهذه الأسماء أن تصبح مخفية مؤقتًا باستخدام تصريحات ضمن تعليمات مركبة، لأنه كما نعلم، ينبغي على تعريفات الدالة أن تكون خارج الدوال الأخرى حتى يكون اسم الدالة في التعريف ذو نطاق ملف. يمتلك الاسم المُصرّح عنه بداخل تعليمة مركبة أو معامل دالة صوري نطاق كتلة ومن الممكن استخدامه ضمن الكتلة حتى الوصول للقوس { الذي يغلِق التعليمة المركبة، ويُخفي أي تصريح لاسم ضمن تعليمة مركبة أي تصريح خارجي آخر للاسم ذاته حتى نهاية التعليمة المركبة. يعدّ نطاق النموذج الأولي للدالة مثالًا مميزًا وبسيطًا من النطاقات، إذ يمتد تصريح الاسم حتى نهاية النموذج الأولي للدالة فقط، وهذا يعني أن ما يلي خاطئ (باستخدام نفس الاسم مرتين): void func(int i, int i); وهذا هو الاستعمال الصحيح: void func(int i, int j); وتختفي الأسماء المُصرّح عنها بداخل الأقواس خارجها. نطاق الاسم مستقل تمامًا عن أي محدد صنف تخزين مُستخدم في التصريح. الربط سنذكّر بمصطلح الربط Linkage بصورةٍ مقتضبة هنا أيضًا، إذ يُستخدم الربط لتحديد ما الذي يجعل الاسم المُعلن عنه في نطاقات مختلفة يشير إلى الشيء ذاته، إذ يمتلك الكائن اسمًا واحدًا فقط، ولكننا في بعض الحالات نحتاج للإشارة إلى هذا الكائن على مستوى نطاقات مختلفة، ويُعدّ استدعاء الدالة printf من أماكن متعددة ضمن البرنامج أبسط الأمثلة، حتى لو كانت هذه الأماكن المذكورة لا تنتمي إلى ملف الشيفرة المصدرية ذاته. يحذّر المعيار أنه يجب على التصاريح التي تشير إلى الشيء ذاته أن تكون من نوع متوافق، وإلا فسنحصل على برنامج ذي سلوك غير محدد، وسنتكلم عن الأنواع المتوافقة بالتفصيل لاحقًا، وسنكتفي حاليًا بقول أن التصاريح يجب أن تكون متطابقةً باستثناء استخدام محددات صنف محدد التخزين، وتحقيق هذا من مسؤوليات المبرمج، إلا أن هناك بعض الأدوات لتساعدك في تحقيق هذا غالبًا. هناك ثلاثة أنواع مختلفة من الربط: الربط الخارجي. الربط الداخلي. عديم الربط. إذا كان اسم الكائن ذو ربط خارجي فهذا يعني أن جميع النسخ instances الموجودة في البرنامج -الذي قد يكون مؤلفًا من عدد من ملفات الشيفرة المصدرية والمكتبات- تعود إلى الكائن ذاته، ويعني الربط الداخلي لكائن ما أن نُسخ هذا الكائن الموجودة في ملف الشيفرة المصدرية نفسه فقط تُشير إلى الشيء ذاته، بينما يعني الكائن عديم الربط أن كل كائن ذي اسم مماثل له هو كائنٌ منفصلٌ عنه. الربط والتعاريف يجب لكل كائن بيانات أو دالة مُستخدمة في برنامج (عدا معاملات عامل sizeof) أن تمتلك تعريفًا واحدًا فقط، ومع أننا لم نتطرق إلى هذا بعد، إلا أن هذا الأمر مهمٌ جدًا؛ ويعود السبب بعدم تطرقنا لهذا الأمر إلى استخدام جميع أمثلتنا كائنات بيانات ذات مدة تلقائية فقط وكون تصاريحها تعاريفًا، أو دوالًا كنا قد عرّفناها من خلال كتابة متنها. تعني القاعدة السابقة أنه يجب للكائنات ذات الربط الخارجي أن تحتوي على تعريفٍ واحد فقط ضمن كامل البرنامج، ويجب للكائنات ذات الربط الداخلي (المقيدة داخل ملف شيفرة مصدرية واحد) أن يُعرّف عنها لمرة واحدة فقط ضمن الملف المُصرّح فيه عنها، كما أن للكائنات عديمة الربط تعريفٌ واحد فقط، إذ أن التصريح عنها هو تعريفٌ أيضًا. لجمع النقاط الآنف ذكرها، نسأل الأسئلة التالية: كيف أستطيع الحصول على نوع الربط الذي أريده؟ ما الشيء الذي يحدد التعريف؟ علينا أن ننظر إلى الربط أولًا ومن ثم التعريف. إذّا، كيف نحصل على التعريف المناسب لاسمٍ ما؟ القوانين معقدة بعض الشيء. ينتج التصريح خارج دالة (نطاق ملف) تحتوي على محدد صنف تخزين ساكن ربطًا داخليًا لهذا الاسم، ويحدد المعيار وجوب وجود تصاريح الدالة التي تحتوي على الكلمة المفتاحية static على مستوى الملف وخارج أي كتلة برمجية. إذا احتوى التصريح على محدد صنف التخزين extern، أو إذا كان تصريح الدالة لا يحتوي على محدد صنف التخزين، أو كلا الحالتين، فهذا يعني: إذا وجِد تصريح للمعرف ذاته بنطاق ملف، فهذا يعني أن الربط الناتج مماثلٌ لهذا التصريح السابق المرئي. وإلا، فالنتيجة هي ربط خارجي. إذا لم يكن التصريح ذو نطاق الملف تصريحًا لدالة أو لم يحتوي على محدد صنف تخزين واضح، فالنتيجة هي ربط خارجي. أي شكل آخر من التصاريح سيكون عديم الربط. إذا وجِد معرف ذو ربط داخلي وخارجي في ذات الوقت ضمن ملف شيفرة مصدرية ما، فالنتيجة غير محددة. استُخدمت القوانين السابقة لكتابة جدول الربط السابق (جدول 2) دون تطبيق كامل للقاعدة 2، وهذا السبب في استخدامنا الكلمة "خارجي غالبًا"، وتسمح لك القاعدة 2 بتحديد الربط بدقة في هذه الحالات. ما الذي يجعل التصريح تعريفًا؟ التصاريح التي تعطينا كائنات عديمة الربط هي تعاريف أيضًا. التصاريح التي تتضمن قيمةً أولية هي تعاريف دائمًا، وهذا يتضمن تهيئة دالة ما بكتابة متن الدالة، ويمكن للتصاريح ذات نطاق الكتلة أن تحتوي على قيم أولية فقط في حال كانت عديمة الربط. وإلا، فالتصريح عن الاسم على نطاق ملف بدون محدد صنف التخزين أو مع محدد صنف التخزين static هو تعريف مبدئي tentative definition، وإذا احتوى ملف شيفرة مصدرية على تعريف مبدئي واحد أو أكثر لكائن ما وكان الملف لا يحتوي على أي تعاريف فعلية، يصبح للكائن تعريفٌ افتراضيٌ وهو مشابه لحالة إسناد القيمة الأولية "0" إليه (تُهيّأ عناصر المصفوفات والهياكل جميعها إلى قيمة "0")، ولا يوجد للدوال تعريفٌ مبدئي. طبقًا لما سبق، لا تتسبب التصريحات التي تحتوي على محدد صنف تخزين خارجي extern بتعريف، إلا إذا ضمّنت قيمةً أوليةً للتصريح. الاستخدام العملي لكل من الربط والتعاريف تبدو القوانين التي تحدد كل من الربط والتعريف المرتبطة بالتصاريح معقدةً بعض الشيء، إلا أن استخدام هذه القوانين عمليًّا ليس بالأمر الصعب، دعونا نناقش بعض الحالات الاعتيادية. أنواع إمكانية أو قابلية الوصول الثلاث التي ستريدها لكائنات البيانات أو الدوال هي: على كامل نطاق البرنامج. مقيّد بنطاق ملف شيفرة مصدرية واحد. مقيّد بنطاق دالة واحدة، أو تعليمة مركبة واحدة. ستحتاج إلى ربط خارجي وربط داخلي وربط عديم لكل من الحالات الثلاث السابقة بالترتيب، ومن الممارسات المُحبذة بالنسبة للحالة الأولى والثانية هي التصريح عن الأسماء ضمن ملف الشيفرة المصدرية الموافق لها قبل أن تعرّف أي دالة، ويوضح الشكل 1 هيكل ملف الشيفرة المصدرية بهذا الخصوص. [شكل 1 هيكل ملف الشيفرة المصدرية] يمكن أن تُسبق تصاريح الربط الخارجية بالكلمة المفتاحية extern وتصاريح الربط الداخلية بالكلمة المفتاحية static. إليك مثالًا عن ذلك: /* مثال عن هيكل ملف الشيفرة المصدرية */ #include <stdio.h> /* يمكن الوصول للأشياء ذات الربط الخارجي عبر البرنامج ما يلي هو تصاريح وليس تعاريف، لذا نفترض أن التعاريف في مكان ما آخر */ extern int important_variable; extern int library_func(double, int); /* تعاريف ذات ربط خارجي */ extern int ext_int_def = 0; /* تعريف صريح */ int tent_ext_int_def; /* تعريف مبدئي */ /* * يمكن الوصول للأشياء ذات الربط الداخلي فقط من داخل الملف * يعني استخدام المحدد الساكن أن التعريفات هي تعريفات مبدئية */ static int less_important_variable; static struct{ int member_1; int member_2; }local_struct; /* ذات ربط داخلي لكنها ليست بتعريف مبدئي لأنها دالة */ static void lf(void); /* * التعريف مع الربط الداخلي */ static float int_link_f_def = 5.3; /* وأحيرًا إليك تعاريف الدوال ضمن هذا الملف */ /* للدالة التالية ربط خارجي ويمكن استدعاؤها من أي مكان ضمن البرنامج */ void f1(int a){} /* يمكن استخدام الدالتين التاليتين باسمهما ضمن هذا الملف */ static int local_function(int a1, int a2){ return(a1 * a2); } static void lf(void){ /* متغير ساكن عديم الربط، لذا يمكن استخدامه فقط ضمن هذه الدالة، وهو تعريف بحكم أنه عديم الربط */ static int count; /* متغير تلقائي عديم الربط ولكنه ذو مُهيّأ بقيمة أولية */ int i = 1; printf("lf called for time no %d\n", ++count); } /* ضُمّنت التعاريف الفعلية لجميع التعاريف المبدئية المتبقية في نهاية الملف */ [مثال 2] نقترح عليك قراءة الفقرات السابقة مجددًا لملاحظة القوانين التي طُبّقت في المثال 2. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة C المقال السابق: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C
قدمنا سابقًا مفهوم النطاق scope والربط linkage، ووضحنا كيف يمكن استخدامهما سويًّا للتحكم بقابلية الوصول لأجزاء معينة ضمن البرنامج، وعمدنا إلى إعطاء وصف غامض لما يحدّد التعريف Definition لأن شرح ذلك سيتسبب بتشويشك في تلك المرحلة ولن يكون مثمرًا لرحلة تعلمك، إلا أنه علينا تحديد هذا الأمر في مرحلة من المراحل وهذا ما سنفعله في هذ الجزئية من السلسلة، كما سنتكلم عن صنف التخزين Storage class لجعل الأمر أكثر إثارة للاهتمام. لعلك ستجد مزج هذه المفاهيم واستخدامها سويًّا معقدًا ومربكًا، وهذا مبرّر، إلا أننا سنحاول إزالة الغموض بالتكلم عن بعض القوانين المفيدة لاحقًا، لكنك بحاجة لقراءة بعض التفاصيل قبل ذلك على الأقل مرةً واحدةً لتفهم هذه القوانين. حتى تفهم القوانين جيدًا، عليك أن تفهم ثلاثة مفاهيم مختلفة -ولكن مرتبطة- وهي كما يدعوها المعيار: المدة الزمنية duration. النطاق scope. الربط linkage. ويشرح المعيار هذه المصطلحات، كما أننا ناقشنا النطاق والربط في المقالة سابقة الذكر لكننا سنعيد ذكرهما بصورةٍ مقتضبة. محددات صنف التخزين تندرج خمس كلمات مفتاحية تحت تصنيف محدّدات صنف التخزين storage class specifiers، أحدها هو typedef، وبالرغم من أنه أشبه باختصار عن شبهه بخاصيّة، إلا أننا سنناقش هذه الكلمة المفتاحية بالتفصيل لاحقًا. يتبقى لدينا الكلمات المفتاحية auto و extern و register و static. تساعدك محددات صنف التخزين على تحديد نوع التخزين المستخدم لكائنات البيانات، وهناك صنف تخزين واحد مسموح به عند التصريح، وهذا الأمر منطقي لأن هناك طريقةً واحدةً لتخزين الأشياء. يُطبق المحدّد الافتراضي على عملية التصريح إذا أُهمل محدد صف التخزين، ويعتمد اختيار المحدد الافتراضي على نوع التصريح إذا كان خارج دالة (تصريح خارجي) أو داخل الدالة (تصريح داخلي)، إذ أن محدد التخزين الافتراضي للتصريح الخارجي هو extern بينما auto هو محدد التخزين الافتراضي للتصريح الداخلي، والاستثناء الوحيد لهذه القاعدة هو تصريح الدوال، إذ إن قيمة المحدد الافتراضي لها هو extern دائمًا. يمكن أن يؤثر مكان التصريح ومحددات صنف التخزين المستخدمة (أو الافتراضية في حال عدم وجودها) على ربط الاسم، بالإضافة إلى تصريحات الاسم ذاته التي تلي التصريح الأولي، ولحسن الحظ فإن ذلك لا يؤثر على النطاق أو المدة الزمنية. سنستعرض المفاهيم الأسهل أوّلًا. المدة الزمنية تصف المدة الزمنية لكائن ما طبيعة تخزينه، وذلك إذا كان حجز المساحة يصبح مرةً واحدةً عند تشغيل البرنامج أو أنه من طبيعة عابرة بمعنى أن مساحته تُحجز وتحرّر عند الضرورة. هناك نوعان فقط من المدة الزمنية، هما: المدة الساكنة static duration والمدة التلقائية automatic duration؛ إذ تعني المدة الساكنة أن مساحة التخزين المحجوزة للكائن دائمة؛ بينما تعني المدة التلقائية أن مساحة التخزين المحجوزة للكائن تُحرّر وتُحجز عند الضرورة، ومن السهل معرفة أي من المدتين ستحصل عليهما، لأنك ستحصل على المدة التلقائية فقط في حالة: إذا كان التصريح داخل دالة، ولم يكن التصريح يحتوي على أي من الكلمتين المفتاحيتين static أو extern. وليس التصريح تصريحًا لدالة. ستجد أن معاملات الدالة الصورية تطابق هذه القوانين الثلاث دائمًا، وبذلك فهي ذات مدة تلقائية. مع أن تواجد الكلمة المفتاحية static ضمن التصريح يعني أن الكائن ذو مدة ساكنة دون أي شك، إلا أنها ليست الطريقة الوحيدة لإنجاز ذلك، ويسبب هذا بعض اللبس لدى الكثير، وعلينا تقبُّل هذا الأمر. تُمنح كائنات البيانات المصرحة داخل الدوال محدد صنف التخزين الافتراضي auto، إلا إذا استُخدم محدد آخر لصنف التخزين. لن تحتاج الوصول إلى هذه الكائنات من خارج الدالة في معظم الحالات، لذا ستريد أن تكون عديمة الربط no linkage، وفي هذه الحالة نستخدم الحالة الافتراضية auto أو محدّد صنف التخزين register storage، إذ سيعطينا هذا كائنًا عديم الربط وذا مدة تلقائية. لا يمكن تطبيق الكلمة المفتاحية auto أو register ضمن تصريح يقع خارج دالةٍ ما. يُعد صنف التخزين register مثيرًا للاهتمام، فعلى الرغم من قلة استخدامه هذه الأيام إلا أنه يقترح على المصرف تخزين الكائن في مسجل register واحد أو أكثر في الذاكرة والذي ينعكس بالإيجاب على سرعة التنفيذ. لا ينفذ المصرف الأوامر بناءً على هذا الأمر إلا أن متغيرات register لا تمتلك أي عنوان ( يُمنع استخدام العامل & معها) لتسهيل الأمر وذلك لأن بعض الحواسيب لا تدعم المسجلات ذات العناوين. قد يتسبب التصريح عن عدة كائنات register بتأثير عكسي فيبطئ البرنامج بدلًا من تسريعه، وذلك لأن المصرف سوف يضطر إلى حجز مزيدٍ من المسجلات عند الدخول إلى (تنفيذ) الدالة وهي عملية بطيئة، أو لن يكون هناك العدد الكافي من المسجلات المتبقية لتُستخدم في العمليات الحسابية الوسيطة. يعود الاختيار في استخدام المسجلات إلى الآلة المُستخدمة، ويجب استخدام هذه الطريقة فقط عندما توضح الحسابات أن هذا النوع ضروري لتسريع تنفيذ دالة ما بعينها، وعندها يتوجب عليك فحص البرنامج وتجربته. يجب ألّا تصرح عن متغيرات المسجلات أبدًا خلال عملية تطوير البرنامج برأينا، بل تأكد من أن البرنامج يعمل ومن ثم أجرِ بعض القياسات، وعندها قرّر استخدام هذا النوع من المتغيرات حسب النتائج فيما إذا كان يتسبب استخدامها بتحسن ملحوظ في الأداء، ولكن عليك تكرار العملية ذاتها إذا اتبعت هذه الطريقة في كل نوع من المعالجات المسبقة التي تنقل برنامجك إليها، إذ يحتوي كل نوع من المعالجات المسبقة على خصائص مختلفة. ملاحظة أخيرة بخصوص متغيرات register: يُعد محدد صنف التخزين هذا المحدد الوحيد الممكن استخدامه ضمن نموذج دالة أولي function prototype أو تعريف دالة، ويجري تجاهل محدد صنف التخزين في حالة نموذج الدالة الأولي، بينما يشير تعريف الدالة على أن المعامل الفعلي مخزّن في مسجّل إذا كان الأمر ممكنًا. إليك مثالًا يوضح كيفية يمكن توظيف ذلك: #include <stdio.h> #include <stdlib.h> void func(register int arg1, double arg2); main(){ func(5, 2); exit(EXIT_SUCCESS); } /* توضح الدالة أنه يمكن التصريح عن المعاملات الصورية باستخدام صنف تخزين مسجّل */ void func(register int arg1, double arg2){ /* هذا الاستخدام لأهداف توضيحية، فلا أحد يكتب ذلك في هذا السياق لا يمكن أخذ عنوان arg1 حتى لو أردت ذلك */ double *fp = &arg2; while(arg1){ printf("res = %f\n", arg1 * (*fp)); arg1--; } } [مثال 1] تعتمد إذًا المدة الزمنية لكائن على محدد صنف التخزين المستخدَم -بغض النظر عن كون الكائن كائن بيانات أو دالة-، كما تعتمد على مكان التصريح (في كتلة داخلية أو على كامل نطاق الملف؟). يعتمد الربط أيضًا على محدد صنف التخزين، إضافةً إلى نوع الكائن ونطاق التصريح عنه. يوضح الجدول 1 والجدول 2 التاليين مدة التخزين الناتجة والربط لكل من الحالات الممكنة عند استخدام محددات صنف التخزين الممكنة، وموضع التصريح. يُعد ربط الكائنات باستخدام المدة الساكنة أكثر تعقيدًا، لذا ننصحك باستخدام هذه الجداول لتوجيهك في الحالات البسيطة وانتظر قليلًا حتى نصل إلى الجزء الذي نتكلم فيه عن التعريفات. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية static أحدهما داخلي ساكنة extern أحدهما خارجي غالبًا ساكنة لا يوجد دالة خارجي غالبًا ساكنة لا يوجد كائن بيانات خارجي ساكنة أهملنا في الجدول السابق المحددين register و auto لأنه من غير المسموح استخدامهما على نطاق التصريحات الخارجية (على نطاق الملف). محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية register كائن بيانات فقط لا يوجد تلقائية auto كائن بيانات فقط لا يوجد تلقائية static كائن بيانات فقط لا يوجد ساكنة extern كلاهما خارجي غالبًا ساكنة لا يوجد none كائن بيانات لا يوجد تلقائية لا يوجد none دالة خارجي غالبًا ساكنة تحتفظ المتغيرات الساكنة static الداخلية بقيمها بين استدعاءات الدوال التي تحتويها، وهذا شيءٌ مفيدٌ جدًا في بعض الحالات. النطاق علينا الآن إلقاء نظرة على نطاق أسماء الكائنات مجددًا، والذي يعرف أين ومتى يكون لاسمٍ ما معنًى محدد. هناك أنواعٌ مختلفة للنطاق هي: نطاق دالة. نطاق ملف. نطاق كتلة. نطاق نموذج دالة أولي. النطاق الأسهل هو نطاق الدالة، إذ ينطبق ذلك على عناوين labels الأسماء المرئية ضمن دالة ما صُرّح عنها بداخلها، ولا يمكن لعنوانين داخل نفس الدالة أن يمتلكان الاسم ذاته، لكن يمكن للعنوان استخدام الاسم ذاته إذا كان ضمن أي دالةٍ أخرى بحكم أن النطاق هو نطاق دالة. ليست العناوين كائنات فهي لا تمتلك أي مساحة تخزينية ولا يعني مفهوم الربط والمدة الزمنية أي معنًى في عالمها. يمتلك أي اسم مُصرّح عنه خارج الدالة نطاق ملف، وهذا يعني أن الاسم قابلٌ للاستخدام ضمن أي نقطة من البرنامج من لحظة التصريح عنه إلى نهاية ملف الشيفرة المصدرية الذي يحتوي ذلك التصريح، ومن الممكن طبعًا لهذه الأسماء أن تصبح مخفية مؤقتًا باستخدام تصريحات ضمن تعليمات مركبة، لأنه كما نعلم، ينبغي على تعريفات الدالة أن تكون خارج الدوال الأخرى حتى يكون اسم الدالة في التعريف ذو نطاق ملف. يمتلك الاسم المُصرّح عنه بداخل تعليمة مركبة أو معامل دالة صوري نطاق كتلة ومن الممكن استخدامه ضمن الكتلة حتى الوصول للقوس { الذي يغلِق التعليمة المركبة، ويُخفي أي تصريح لاسم ضمن تعليمة مركبة أي تصريح خارجي آخر للاسم ذاته حتى نهاية التعليمة المركبة. يعدّ نطاق النموذج الأولي للدالة مثالًا مميزًا وبسيطًا من النطاقات، إذ يمتد تصريح الاسم حتى نهاية النموذج الأولي للدالة فقط، وهذا يعني أن ما يلي خاطئ (باستخدام نفس الاسم مرتين): void func(int i, int i); وهذا هو الاستعمال الصحيح: void func(int i, int j); وتختفي الأسماء المُصرّح عنها بداخل الأقواس خارجها. نطاق الاسم مستقل تمامًا عن أي محدد صنف تخزين مُستخدم في التصريح. الربط سنذكّر بمصطلح الربط Linkage بصورةٍ مقتضبة هنا أيضًا، إذ يُستخدم الربط لتحديد ما الذي يجعل الاسم المُعلن عنه في نطاقات مختلفة يشير إلى الشيء ذاته، إذ يمتلك الكائن اسمًا واحدًا فقط، ولكننا في بعض الحالات نحتاج للإشارة إلى هذا الكائن على مستوى نطاقات مختلفة، ويُعدّ استدعاء الدالة printf من أماكن متعددة ضمن البرنامج أبسط الأمثلة، حتى لو كانت هذه الأماكن المذكورة لا تنتمي إلى ملف الشيفرة المصدرية ذاته. يحذّر المعيار أنه يجب على التصاريح التي تشير إلى الشيء ذاته أن تكون من نوع متوافق، وإلا فسنحصل على برنامج ذي سلوك غير محدد، وسنتكلم عن الأنواع المتوافقة بالتفصيل لاحقًا، وسنكتفي حاليًا بقول أن التصاريح يجب أن تكون متطابقةً باستثناء استخدام محددات صنف محدد التخزين، وتحقيق هذا من مسؤوليات المبرمج، إلا أن هناك بعض الأدوات لتساعدك في تحقيق هذا غالبًا. هناك ثلاثة أنواع مختلفة من الربط: الربط الخارجي. الربط الداخلي. عديم الربط. إذا كان اسم الكائن ذو ربط خارجي فهذا يعني أن جميع النسخ instances الموجودة في البرنامج -الذي قد يكون مؤلفًا من عدد من ملفات الشيفرة المصدرية والمكتبات- تعود إلى الكائن ذاته، ويعني الربط الداخلي لكائن ما أن نُسخ هذا الكائن الموجودة في ملف الشيفرة المصدرية نفسه فقط تُشير إلى الشيء ذاته، بينما يعني الكائن عديم الربط أن كل كائن ذي اسم مماثل له هو كائنٌ منفصلٌ عنه. الربط والتعاريف يجب لكل كائن بيانات أو دالة مُستخدمة في برنامج (عدا معاملات عامل sizeof) أن تمتلك تعريفًا واحدًا فقط، ومع أننا لم نتطرق إلى هذا بعد، إلا أن هذا الأمر مهمٌ جدًا؛ ويعود السبب بعدم تطرقنا لهذا الأمر إلى استخدام جميع أمثلتنا كائنات بيانات ذات مدة تلقائية فقط وكون تصاريحها تعاريفًا، أو دوالًا كنا قد عرّفناها من خلال كتابة متنها. تعني القاعدة السابقة أنه يجب للكائنات ذات الربط الخارجي أن تحتوي على تعريفٍ واحد فقط ضمن كامل البرنامج، ويجب للكائنات ذات الربط الداخلي (المقيدة داخل ملف شيفرة مصدرية واحد) أن يُعرّف عنها لمرة واحدة فقط ضمن الملف المُصرّح فيه عنها، كما أن للكائنات عديمة الربط تعريفٌ واحد فقط، إذ أن التصريح عنها هو تعريفٌ أيضًا. لجمع النقاط الآنف ذكرها، نسأل الأسئلة التالية: كيف أستطيع الحصول على نوع الربط الذي أريده؟ ما الشيء الذي يحدد التعريف؟ علينا أن ننظر إلى الربط أولًا ومن ثم التعريف. إذّا، كيف نحصل على التعريف المناسب لاسمٍ ما؟ القوانين معقدة بعض الشيء. ينتج التصريح خارج دالة (نطاق ملف) تحتوي على محدد صنف تخزين ساكن ربطًا داخليًا لهذا الاسم، ويحدد المعيار وجوب وجود تصاريح الدالة التي تحتوي على الكلمة المفتاحية static على مستوى الملف وخارج أي كتلة برمجية. إذا احتوى التصريح على محدد صنف التخزين extern، أو إذا كان تصريح الدالة لا يحتوي على محدد صنف التخزين، أو كلا الحالتين، فهذا يعني: إذا وجِد تصريح للمعرف ذاته بنطاق ملف، فهذا يعني أن الربط الناتج مماثلٌ لهذا التصريح السابق المرئي. وإلا، فالنتيجة هي ربط خارجي. إذا لم يكن التصريح ذو نطاق الملف تصريحًا لدالة أو لم يحتوي على محدد صنف تخزين واضح، فالنتيجة هي ربط خارجي. أي شكل آخر من التصاريح سيكون عديم الربط. إذا وجِد معرف ذو ربط داخلي وخارجي في ذات الوقت ضمن ملف شيفرة مصدرية ما، فالنتيجة غير محددة. استُخدمت القوانين السابقة لكتابة جدول الربط السابق (جدول 2) دون تطبيق كامل للقاعدة 2، وهذا السبب في استخدامنا الكلمة "خارجي غالبًا"، وتسمح لك القاعدة 2 بتحديد الربط بدقة في هذه الحالات. ما الذي يجعل التصريح تعريفًا؟ التصاريح التي تعطينا كائنات عديمة الربط هي تعاريف أيضًا. التصاريح التي تتضمن قيمةً أولية هي تعاريف دائمًا، وهذا يتضمن تهيئة دالة ما بكتابة متن الدالة، ويمكن للتصاريح ذات نطاق الكتلة أن تحتوي على قيم أولية فقط في حال كانت عديمة الربط. وإلا، فالتصريح عن الاسم على نطاق ملف بدون محدد صنف التخزين أو مع محدد صنف التخزين static هو تعريف مبدئي tentative definition، وإذا احتوى ملف شيفرة مصدرية على تعريف مبدئي واحد أو أكثر لكائن ما وكان الملف لا يحتوي على أي تعاريف فعلية، يصبح للكائن تعريفٌ افتراضيٌ وهو مشابه لحالة إسناد القيمة الأولية "0" إليه (تُهيّأ عناصر المصفوفات والهياكل جميعها إلى قيمة "0")، ولا يوجد للدوال تعريفٌ مبدئي. طبقًا لما سبق، لا تتسبب التصريحات التي تحتوي على محدد صنف تخزين خارجي extern بتعريف، إلا إذا ضمّنت قيمةً أوليةً للتصريح. الاستخدام العملي لكل من الربط والتعاريف تبدو القوانين التي تحدد كل من الربط والتعريف المرتبطة بالتصاريح معقدةً بعض الشيء، إلا أن استخدام هذه القوانين عمليًّا ليس بالأمر الصعب، دعونا نناقش بعض الحالات الاعتيادية. أنواع إمكانية أو قابلية الوصول الثلاث التي ستريدها لكائنات البيانات أو الدوال هي: على كامل نطاق البرنامج. مقيّد بنطاق ملف شيفرة مصدرية واحد. مقيّد بنطاق دالة واحدة، أو تعليمة مركبة واحدة. ستحتاج إلى ربط خارجي وربط داخلي وربط عديم لكل من الحالات الثلاث السابقة بالترتيب، ومن الممارسات المُحبذة بالنسبة للحالة الأولى والثانية هي التصريح عن الأسماء ضمن ملف الشيفرة المصدرية الموافق لها قبل أن تعرّف أي دالة، ويوضح الشكل 1 هيكل ملف الشيفرة المصدرية بهذا الخصوص. [شكل 1 هيكل ملف الشيفرة المصدرية] يمكن أن تُسبق تصاريح الربط الخارجية بالكلمة المفتاحية extern وتصاريح الربط الداخلية بالكلمة المفتاحية static. إليك مثالًا عن ذلك: /* مثال عن هيكل ملف الشيفرة المصدرية */ #include <stdio.h> /* يمكن الوصول للأشياء ذات الربط الخارجي عبر البرنامج ما يلي هو تصاريح وليس تعاريف، لذا نفترض أن التعاريف في مكان ما آخر */ extern int important_variable; extern int library_func(double, int); /* تعاريف ذات ربط خارجي */ extern int ext_int_def = 0; /* تعريف صريح */ int tent_ext_int_def; /* تعريف مبدئي */ /* * يمكن الوصول للأشياء ذات الربط الداخلي فقط من داخل الملف * يعني استخدام المحدد الساكن أن التعريفات هي تعريفات مبدئية */ static int less_important_variable; static struct{ int member_1; int member_2; }local_struct; /* ذات ربط داخلي لكنها ليست بتعريف مبدئي لأنها دالة */ static void lf(void); /* * التعريف مع الربط الداخلي */ static float int_link_f_def = 5.3; /* وأحيرًا إليك تعاريف الدوال ضمن هذا الملف */ /* للدالة التالية ربط خارجي ويمكن استدعاؤها من أي مكان ضمن البرنامج */ void f1(int a){} /* يمكن استخدام الدالتين التاليتين باسمهما ضمن هذا الملف */ static int local_function(int a1, int a2){ return(a1 * a2); } static void lf(void){ /* متغير ساكن عديم الربط، لذا يمكن استخدامه فقط ضمن هذه الدالة، وهو تعريف بحكم أنه عديم الربط */ static int count; /* متغير تلقائي عديم الربط ولكنه ذو مُهيّأ بقيمة أولية */ int i = 1; printf("lf called for time no %d\n", ++count); } /* ضُمّنت التعاريف الفعلية لجميع التعاريف المبدئية المتبقية في نهاية الملف */ [مثال 2] نقترح عليك قراءة الفقرات السابقة مجددًا لملاحظة القوانين التي طُبّقت في المثال 2. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة C المقال السابق: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C -
 ادعنا نبدأ رحلتنا مع لغة رست، إذ هناك الكثير لنتعلمه، وعلى كل رحلة أن تبدأ في مكان ما. سنناقش في هذا المقال كلًا من التالي: تثبيت لغة رست على لينكس Linux وماك أو إس macOS وويندوز Windows. كتابة برنامج يطبع العبارة "Hello, world!". استخدام أداة كارجو cargo، مدير حزم لغة رست package manager ونظام بنائها build system. تثبيت لغة رست أولى خطواتنا هنا هي تثبيت لغة رست هي بتنزيل رست عن طريق أداة سطر الأوامر rustup، التي تدير إصدارات رست والأدوات المرتبطة بها، وستحتاج لاتصال بالإنترنت لهذه الخطوة. ملاحظة: إذا كنت لا تفضل استخدام rustup لسبب ما، اطّلع على هذه الصفحة للمزيد من الخيارات لتثبيت لغة رست. تثبّت الخطوات التالية آخر إصدارات لغة رست المستقرة، ويضمن لك ثبات رست تصريف جميع الأمثلة الموجودة في هذه السلسلة حتى مع الإصدارات القادمة الجديدة، إلا أنه قد يختلف الخرج قليلًا بين الإصدارات، وذلك بسبب تطوير لغة راست على رسائل الخطأ والتحذيرات. بكلمات أخرى: سيعمل أي إصدار جديد ومستقر من لغة رست تثبّته باتباع الخطوات التالية كما هو متوقع منه ضمن محتوى هذه السلسلة. الإشارة إلى سطر الأوامر سنستعرض بعض الأوامر المُستخدمة في الطرفية terminal ضمن هذا المقال والسلسلة ككُل، إذ تبدأ الأسطر التي يجب أن تُدخلها بالرمز "$"، وليس عليك هنا أن تكتب الرمز "$"، الذي يدل على بداية أمر جديد، وعادةً ما تعرض الأسطر التي لا تبدأ بهذا الرمز الخرج لأمر سابق. إضافةً لما سبق، تستخدم الأمثلة التي تعتمد على صدفة Shell PowerShell خصوصًا الرمز "<" بدلًا من "$". تثبيت أداة سطر الأوامر rustup على لينكس أو ماك أو إس إذا كنت تستخدم نظام لينكس أو ماك أو إس، افتح الطرفية لإدخال الأمر التالي: $ curl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh سينزّل الأمر السابق سكريبتًا script ويبدأ بتثبيت أداة rustup التي ستثبّت بدورها آخر إصدارات لغة رست المستقرة، وقد يُطلب منك كلمة المرور لحسابك. إذا انتهت عملية التثبيت بنجاح، ستجد السطر التالي: Rust is installed now. Great! ستحتاج أيضًا إلى رابط linker، وهو برنامج يستخدمه رست لضمّ الخرج المُصرَّف إلى ملف واحد، وسيكون موجودًا غالبًا لديك. يجب عليك تثبيت مصرف سي C الذي يتضمن عادةً على رابط، إذا حصلت على أخطاء رابط، كما أن مصرف سي مفيد أيضًا لاعتماد بعض حزم لغة راست الشائعة على شيفرة لغة سي. يمكنك الحصول على مصرف سي على نظام ماك أو إس بكتابة الأمر التالي: $ xcode-select --install يجب أن يثبت مستخدمو نظام لينكس GCC أو Clang اعتمادًا على توثيق التوزيعة distribution؛ فإذا كنت تستخدم مثلًا توزيعة أوبنتو Ubuntu، فيمكنك تثبيت حزمة build-essential. تثبيت أداة سطر الأوامر rustup على ويندوز إن كنت تستخدم نظام ويندوز، اذهب إلى www.rust-lang.org/tools/install، واتبّع التعليمات لتثبيت لغة رست، إذ ستستلم في مرحلة ما من مراحل التثبيت رسالةً مفادها أنك ستحتاج إلى أدوات بناء C++ الخاصة ببرنامج فيجوال ستوديو Visual Studio إصدار 2013 أو ما بعده، والطريقة الأسهل في الحصول على أدوات البناء هذه هي بتثبيتها مباشرةً من Visual Studio 2022، وتأكد من اختيار "C++ build tools" عند سؤالك عن أي الإصدارات التي تريد تثبيتها وتأكد أيضًا من تضمين حزمة Windows 10 SDK وحزمة اللغة الإنجليزية إلى جانب أي حزمة لغة أخرى من اختيارك. يستخدم باقي الكتاب أوامر تعمل في كلٍّ من "cmd.exe" وصدفة PowerShell، وإذا كانت هناك أي فروقات معينة سنشرح أيهما يجب أن تستخدم. التحديث والتثبيت في لغة رست تُعد عملية التحديث بعد تثبيت لغة رست باستخدام rustup عمليةً سهلة، فكل ما يجب عليك فعله هو تنفيذ سكريبت التحديث من الصدفة: $ rustup update لإزالة تثبيت لغة رست وأداة rustup، نفذ سكريبت إزالة التثبيت من الصدفة: $ rustup self uninstall استكشاف الأخطاء وإصلاحها في لغة رست للتأكد من أنك أنهيت عملية تثبيت لغة رست بنجاح، افتح الصدفة وأدخل السطر التالي: $ rustc --version من المفترض أن تجد رقم الإصدار وقيمة الإيداع المُعمّاة commit hash وتاريخ الإيداع لآخر إصدار مستقر جرى إطلاقه بالتنسيق التالي: rustc x.y.z (abcabcabc yyyy-mm-dd) إذا ظهر لك السطر السابق، فهذا يعني أنك ثبّتتَ لغة رست بنجاح؛ وإذا لم تجد هذه المعلومات وكنت تستخدم نظام ويندوز، فتأكد أن راست موجود في متغير النظام system variable المسمى %PATH%كما يلي: إذا كنت تستخدم نظام تشغيل ويندوز، اكتب في واجهة سطر أوامر CMD ما يلي: > echo %PATH% أما في صدفة PowerShell، استخدم السطر التالي: > echo $env:Path وفي نظام تشغيل لينكس وماك أو إس، استخدم: $ echo $PATH إذا كان كل شيء صحيحًا، ورست لا يعمل فهناك عددٌ من الأماكن التي تستطيع الحصول منها على مساعدة، إذ يمكنك مثلًا طرح مشكلتك في قسم الأسئلة والأجوبة في أكاديمية حسوب أو إن أردت يمكنك التواصل مع فريق لغة رست مباشرة عبر صفحة التواصل. التوثيق المحلي للغة رست يتضمن تثبيت لغة رست أيضًا نسخةً محليةً من التوثيق documentation لتتمكّن من قراءتها دون اتصال بالإنترنت، ولفتح النسخة ضمن المتصفح، نفذ الأمر rustup doc. استخدم توثيق الواجهة البرمجية في كل مرة تصادف نوعًا أو دالةً في المكتبة القياسية ولست متأكدًا ممّا تفعل أو كيف تستخدمها. كتابة أول برنامج بلغة رست الآن، وبعد الانتهاء من تثبيت لغة رست، يمكنك كتابة أول برنامج. من المتعارف عليه عند تعلم لغة برمجة جديدة هو كتابة برنامج بسيط يطبع السلسلة النصية "Hello, world!" على الشاشة، لذا دعنا ننجز ذلك. ملاحظة: يفترض هذا الكتاب معرفتك بأساسيات سطر الأوامر، ولا تتطلب لغة رست طريقةً معينةً لكيفية تعديلك أو استخدامك للأدوات أو مكان وجود شيفرتك البرمجية، لذا يمكنك استخدام بيئة برمجية متكاملة integrated development environment -أو اختصارًا IDE- إذا أردت، ولك الحرية في اختيار ما هو مفضّل لك. هناك العديد من البيئات البرمجية المتكاملة التي تقدم دعمًا للغة راست، ويمكنك تفقّد توثيق البيئة البرمجية المتكاملة التي اخترتها لمزيدٍ من التفاصيل. يحاول فريق تطوير لغة رست مؤخرًا توجيه جهودهم نحو تمكين دعم جيد للبيئات البرمجية المتكاملة عن طريق rust-analyzer. إنشاء مجلد لمشروع بلفة رست ستبدأ بإنشاء مجلد لتخزين شيفرة لغة رست البرمجية، ولا يهمّ المكان الذي ستخزن الشيفرة فيه، إلا أننا نقترح إنشاء مجلد "projects" للتمارين والمشاريع الموجودة في هذا الكتاب ضمن المجلد الرئيس home. افتح الطرفية وأدخِل الأوامر التالية لإنشاء مجلد "projects" ومجلد لمشروع "Hello, world!" ضمن المجلد "projects". لمستخدمي نظام لينكس وماك أو إس وصدفة PowerShell على نظام ويندوز، أدخل التالي: $ mkdir ~/projects $ cd ~/projects $ mkdir hello_world $ cd hello_world ولطرفية ويندوز CMD، أدخل التالي: > mkdir "%USERPROFILE%\projects" > cd /d "%USERPROFILE%\projects" > mkdir hello_world > cd hello_world كتابة وتشغيل برنامج بلغة رست أنشئ ملفًا مصدريًا جديدًا وسمّه باسم "main.rs"، إذ يجب أن تنتهي ملفات شيفرة لغة رست بالامتداد ".rs" دائمًا، وإذا كنت تستخدم أكثر من كلمة واحدة في اسم الملف، فاستخدم الشرطة السفلية underscore للفصل ما بين الكلمات، فعلى سبيل المثال استخدم الاسم "hello_world.rs" بدلًا من "helloworld.rs". الآن افتح ملف "main.rs" الذي أنشأته لتوك وأدخِل الشيفرة التالية: fn main() { println!("Hello, world!"); } [شيفرة 1: برنامج يطبع "Hello, world!"] احفظ الملف واذهب مجددًا إلى نافذة الطرفية. أدخل الأوامر التالية لتصريف وتشغيل الملف إذا كنت تستخدم نظام لينكس أو ماك أو إس: $ rustc main.rs $ ./main Hello, world! إذا كنت تستخدم نظام ويندوز أدخل الأمر .\main.exe بدلًا من ./main: > rustc main.rs > .\main.exe Hello, world! يجب أن تحصل على السلسلة النصية "Hello,world!" مطبوعةً على الطرفية بغض النظر عن نظام تشغيلك، وإن لم يظهر الخرج، فعُد إلى فقرة استكشاف الأخطاء وإصلاحها لطرق الحصول على مساعدة. إذا حصلت على السلسلة النصية "Hello, world!"، تهانينا، فقد كتبت رسميًا أولى برامج لغة رست، مما يجعلك مبرمج لغة رست، أهلًا بك. أجزاء برنامج لغة رست دعنا نطّلع بالتفصيل على الأشياء التي تحدث في برنامج "Hello, world!"، إليك أول الأجزاء: fn main() { } تعرّف هذه السطور دالةً في لغة رست، ودالة main هي دالة مميزة؛ إذ أنها نقطة تشغيل الشيفرة البرمجية الأولية في أي برنامج رست تنفيذي. يصرح السطر الأول عن دالة تدعى main لا تمتلك أي معاملات ولا تُعيد أي قيمة، وإذا أردنا تحديد أي معاملات، نستطيع فعل ذلك عن طريق وضعها داخل قوسين "()". لاحظ أيضًا أن متن الدالة محتوًى داخل أقواس معقوصة "{}"، إذ تتطلب لغة رست وجود هذه الأقواس حول متن أي دالة، ويُعد وضع القوس المعقوص الأول على سطر تصريح الدالة ذاته مع ترك مسافة فارغة بينهما تنسيقًا مُحبّذًا. ملاحظة: إذا أردت الالتزام بتنسيق موحّد ضمن جميع مشاريع رست الخاصة بك، يمكنك استخدام أداة تنسيق تلقائية تدعى rustfmt لتنسيق الشيفرة البرمجية بأسلوب معين، وقد ضمّن فريق تطوير لغة رست هذه الأداة مع توزيعة لغة رست القياسية، مثل rustc، لذا من المفترض أن تكون مثبتة مسبقًا على جهازك. نجد داخل دالة main الشيفرة البرمجية التالية: println!("Hello, world!"); يفعل السطر السابق كامل العمل الذي يهدف إليه برنامجنا البسيط، ألا وهو طباعة النص إلى الشاشة وهناك أربع نقاط مهمة بهذا الخصوص يجب ملاحظتها هنا، هي: أولًا، أسلوب لغة رست في التنسيق هو محاذاة السطر indent باستخدام أربع مسافات فارغة وليس مسافة جدولة tab. ثانيًا، تستدعي println! ماكرو رست، وإذا أردنا استدعاء دالة بدلًا من ذلك، فسنستخدم println (أي الاستغناء عن !)، وسنتناقش بخصوص الماكرو في لغة رست بمزيد من التفاصيل في جزئية لاحقة من هذه السلسلة وكل ما عليك معرفته الآن هو أن استخدام ! يعني أننا نستدعي ماكرو بدلًا من الدالة الاعتيادية، وأن الماكرو لا يتبع القوانين ذاتها التي تتبعها الدوال. ثالثًا، السلسلة النصية "Hello, world!" تُمرّر وسيطًا argument للماكرو !println، ثمّ تُطبع السلسلة النصية على الشاشة. رابعًا، نُنهي السطر بالفاصلة المنقوطة (;) وذلك يُشير إلى انتهاء ذلك التعبير expression وأن التعبير التالي سيبدأ من بعده، وتنتهي معظم أسطر شيفرة لغة رست بالفاصلة المنقوطة. تصريف البرنامج وتشغيله في لغة رست لقد شغّلت لتوّك برنامجًا جديد الإنشاء، دعنا ننظر إلى كل خطوة من هذه العملية بتمعّن. قبل تشغيل برنامج رست، يجب عليك تصريفه باستخدام مصرف لغة رست بإدخال الأمر rustc وتمرير اسم الملف المصدري كما يلي: $ rustc main.rs إذا كان لديك معرفة سابقة بلغة C أو C++، فستلاحظ أن هذا مماثل لاستخدام الأمر gcc أو clang. بعد التصريف بنجاح، يُخرج رست ملفًا ثنائيًا تنفيذيًا binary executable. يمكنك رؤية الملف التنفيذي على نظام لينكس أو ماك أو إس أو صدفة PowerShell على ويندوز عبر تنفيذ الأمر ls، وستجد في نظامَي لينكس وماك أو إس ملفين، بينما ستجد ثلاث ملفات إذا كنت تستخدم صدفة PowerShell وهي الملفات ذاتها التي ستجدها عند استخدامك طرفية CMD على ويندوز. $ ls main main.rs أدخل في طرفية CMD على ويندوز ما يلي (يعني الخيار /B أننا نريد فقط عرض أسماء الملفات): > dir /B main.exe main.pdb main.rs يعرض ما سبق شيفرة الملف المصدر بامتداد ".rs"، إضافةً إلى الملف التنفيذي (المسمى main.exe على ويندوز و main على بقية المنصات)، وعند استخدام ويندوز هناك ملف يحتوي على معلومات لتصحيح الأخطاء بامتداد ".pdb"، ويمكنك تشغيل الملف التنفيذي "main" أو "main.exe" على النحو التالي: $ ./main # أو .\main.exe على ويندوز إذا كان "main.rs" هو برنامج "Hello, world!" فسيطبع السطر السابق "Hello, world!" على طرفيتك. قد لا تكون معتادًا على كون جزء التصريف خطوة مستقلة إذا كنت تألف لغة ديناميكية، مثل روبي Ruby، أو بايثون Python، أو جافاسكربت JavaScript. تعدّ لغة رست لغة مُصرّفة سابقة للوقت ahead-of-time compiled language، مما يعني أن البرنامج يُصرّف وينتج عن ذلك ملف تنفيذي يُمنح لأحد آخر، بحيث يمكن له تشغيله دون وجود لغة رست عنده، وعلى النقيض تمامًا إذا أعطيت أحدًا ما ملفًا بامتداد ".rb" أو ".py" أو ".js" فلن يستطيع تشغيله إن لم يتواجد تطبيق روبي أو بايثون أو جافاسكربت مثبتًا عنده، والفارق هنا هو أنه عليك استخدام أمرٍ واحد فقط لتصريف وتشغيل البرنامج. تصميم لغات البرمجة مبني على المقايضات. يُعد تصريف البرنامج باستخدام rustc فقط كافيًا للبرامج البسيطة، إلا أنك ستحتاج لإدارة جميع الخيارات مع زيادة حجم برنامجك وجعل مشاركة شيفرتك البرمجية مع الغير عملية أسهل، ولذلك سنقدّم لك في الفقرة التالية أداة كارجو Cargo التي ستساعدكَ في كتابة برامج لغة رست لها تطبيقات فعلية في الحياة الواقعية. نظام بناء لغة رست "مرحبا كارجو" كارجو هو نظام بناء لغة رست ومدير حزم، إذ يعتمد معظم مستخدمي لغة رست على هذه الأداة لإدارة مشاريع رست لأنها تتكفل بإنجاز الكثير من المهام نيابةً عنك، مثل بناء شيفرتك البرمجية وتنزيل المكتبات التي تعتمد شيفرتك عليها وبناء هذه المكتبات (ندعو المكتبات التي تحتاجها شيفرتك البرمجية لتعمل بالاعتماديات dependencies). لا تحتاج برامج رست البسيطة -مثل البرنامج الذي كتبناه سابقًا- إلى أي اعتماديات، لذا إذا أردنا بناء مشروع "Hello, world!" باستخدام كارجو، فسيستخدم فقط الجزء الذي يتكفل ببناء الشيفرة البرمجية ضمن كارجو لا غير. ستُضيف بعض الاعتماديات عند كتابتك لبرامج أكثر تعقيدًا، وإذا كنت تستخدم كارجو حينها، فستكون إضافة تلك الاعتماديات سهلةً جدًا. يفترض هذا الكتاب بأنك تستخدم كارجو بما أن معظم مشاريع لغة رست تستخدمه؛ إذ يُثبَّت كارجو تلقائيًا مع رست إذا استخدمت البرنامج الرسمي لتثبيته والذي ناقشناه في فقرة التثبيت، وإذا ثبتت رست باستخدام طرق أخرى، تأكد من وجود كارجو بإدخال الأمر التالي إلى الطرفية: $ cargo --version إذا ظهر لك رقم الإصدار، فهذا يعني أنه موجود. إذا ظهرت رسالة خطأ مثل "command not found"، ألقِ نظرةً على توثيق طريقة التثبيت التي اتبعتها لمعرفة طريقة تثبيت كارجو بصورةٍ منفصلة. إنشاء مشروع للغة رست باستخدام كارجو دعنا نُنشئ مشروعًا جديدًا باستخدام كارجو ونُقارن بين هذه الطريقة وطريقتنا السابقة في إنشاء مشروع "Hello, world!". انتقل إلى مجلد "projects" (أو أي اسم مغاير اخترته لتخزّن فيه شيفرتك البرمجية)، ثم نفذ الأوامر التالية (بغض النظر عن نظام تشغيلك): $ cargo new hello_cargo $ cd hello_cargo يُنشئ الأمر الأول مجلدًا جديدًا باسم "hello_cargo" -إذ أننا اخترنا تسمية "hello_cargo" لمشروعنا- ومن ثم يُنشئ كارجو ملفاته في المجلد الذي اخترناه بذات الاسم. اذهب إلى المجلد "hello_cargo" واعرض الملفات الموجودة فيه، ستجد أن كارجو قد أنشأ ملفين ومجلدًا واحدًا داخله، هم: ملف باسم "cargo.toml"، ومجلد "src"، وملف "main.rs"؛ كما أنه هيأ مستودع غيت Git جديد مع ملف ".gitignore". لن تُوَلّد ملفات غيت إذا استخدمت الأمر cargo new ضمن مستودع جيت موجود مسبقًا، ويمكنك تجاوز ذلك السلوك عن طريق استخدام الأمر cargo new --vcs=git. ملاحظة: غيت هو نظام شائع للتحكم بالإصدارات، ويمكنك تغيير نظام التحكم بالإصدارات عند تنفيذ الأمر cargo new بإضافة الراية --vcs. يمكنك تنفيذ الأمر cargo new --help إذا أردت رؤية الخيارات المتاحة. افتح الملف "Cargo.toml" باستخدام محرر النصوص المفضل لديك، يجب أن تكون الشيفرة البرمجية بداخله مشابهة للشيفرة 1-2. [package] name = "hello_cargo" version = "0.1.0" edition = "2021" [dependencies] [الشيفرة 1-2: محتوى ملف Cargo.toml الناتج عن تنفيذ الأمر cargo new] يمكنك الاطلاع على مزيدٍ من المفاتيح وتعريفاتها على الرابط. هذا الملف مكتوب بتنسيق لغة TOML (اختصارًا للغة توم المُختصرة الواضحة Tom's Obvious, Minimal Langaug)، وهي لغة تنسيق كارجو. يمثل السطر الأول [package] قسم ترويسة الذي يشير إلى أن ما يليه هي معلومات لإعداد الحزمة. نُضيف المزيد من الأقسام إذا أردنا إضافة المزيد من المعلومات إلى هذا الملف. تُعدّ الأسطر الثلاث التالية المعلومات التي يحتاجها كارجو لتصريف برنامجك ألا وهي: اسم المشروع وإصدار لغة رست المُستخدم، وسنتحدث عن مفتاح edition لاحقًا. السطر الأخير [dependencies] هو بداية جزء جديد يحتوي على أي اعتماديات يعتمد عليها مشروعك لعمله. يُشار إلى حزم الشيفرات البرمجية في لغة رست باسم الصناديق crates، ولا نحتاج هنا أي صناديق أخرى لهذا المشروع، ولكننا سنحتاج إلى صناديق إضافية في مشاريع لاحقة وعندها سنستخدم هذا القسم. أما الآن فافتح الملف "main.rs" الموجود داخل المجلد "src" وألقِ نظرةً على ما داخله: fn main() { println!("Hello, world!"); } قد ولّد كارجو برنامج "!Hello, world" لك على نحوٍ مماثل للبرنامج الذي كتبناه سابقًا في الشيفرة 1-1، والاختلاف الوحيد حتى اللحظة بين مشروعنا السابق ومشروع كارجو هو أن كارجو أضاف الشيفرة البرمجية داخل مجلد "src" وأنه لدينا ملف الإعداد "Cargo.toml" في المجلد الرئيسي. يتوقع كارجو بأن تتواجد ملفاتك المصدرية داخل المجلد "src"، وأن يكون المجلد الرئيسي للمشروع فقط للملفات التوضيحية README files والمعلومات عن رخصة البرنامج license information وملفات الضبط configuration files وأي ملفات أخرى غير مرتبطة بشيفرتك المصدرية مباشرةً. يساعدك استخدام كارجو في تنظيم ملفاتك إذ أن هناك مكان لكل شيء وكلّ شيء يُخزّن في مكانه. يمكنك تحويل مشروعك إلى مشروع يستخدم كارجو إذا أنشأت مشروعًا جديدًا دون استخدام كارجو على نحوٍ مماثل لما فعلناه في مشروع "!Hello, world"، فكل ما عليك فعله هو نقل الشيفرة المصدرية الخاصة بالمشروع إلى مجلد "src" وإنشاء ملف "Cargo.toml" موافق لتفاصيل المشروع. بناء وتشغيل مشروع كارجو دعنا ننظر الآن إلى ما هو مختلف عندما نشغّل برنامج "!Hello, world" باستخدام كارجو. أنشئ مشروعك بإدخال الأمر التالي داخل المجلد "hello_cargo": $ cargo build Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo) Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs يُنشئ الأمر السابق ملف تنفيذي ضمن المجلد "target/debug/hello_cargo" (أو "target\debug\hello_cargo.exe" على ويندوز) بدلًا عن مجلدك الحالي، ويمكنك تشغيل الملف التنفيذي باستخدام الأمر التالي: $ ./target/debug/hello_cargo # أو .\target\debug\hello_cargo.exe على ويندوز Hello, world! إذا مر كل ما سبق بنجاح فستُطبع "Hello, world!" على الطرفية. يتسبب تنفيذ الأمر cargo build للمرة الأولى بإنشاء كارجو لملف جديد في المجلد الرئيسي باسم "Cargo.lock" وهذا الملف يتابع إصدارات الاعتماديات المستخدمة في مشروعك، وبما أن هذا المشروع لا يحتوي على أي اعتماديات، فلن يكون هذا الملف ذا أهمية كبيرة، إلا أن هذا يعني أنه لا يوجد أي حاجة لتغيير محتويات هذا الملف يدويًا بل يتكفل كارجو بمحتوياته بدلًا عنك. بنينا لتوّنا مشروعًا باستخدام cargo build وشغّلناه باستخدام الأمر ./target/debug/hello_cargo، إلا أنه يمكننا استخدام الأمر cargo run أيضًا لتصريف الشيفرة البرمجية وتشغيلها مما ينتج عن تشغيل الملف التنفيذ باستخدام أمر واحد فقط: $ cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs Running `target/debug/hello_cargo` Hello, world! يستخدم معظم المطورين cargo run لأنه أكثر ملاءمةً من تذكُّر تشغيل cargo build ثم استخدام المسار الكامل وصولًا للملف الثنائي (التنفيذي). لاحظ أننا لم نرى هذه المرة أي خرج يشير إلى أن كارجو يصرّف "hello_cargo"، وذلك لأن كارجو لاحظ أن الملف لم يتغير وبالتالي فقد شغّل مباشرةً الملف الثنائي، وإلّا في حالة تعديل الشيفرة المصدرية سيعيد كارجو بناء المشروع قبل تشغيله وستجد خرجًا مشابهًا لما يلي: $ cargo run Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo) Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs Running `target/debug/hello_cargo` Hello, world! يحتوي كارجو أيضًا على أمر آخر وهو cargo check، ويتحقق هذا الأمر من شيفرتك البرمجية للتأكد من أنها ستُصرّف بنجاح ولكنه لا يولّد أي ملف تنفيذي: $ cargo check Checking hello_cargo v0.1.0 (file:///projects/hello_cargo) Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs لكن في أيّ الحالات لن تحتاج إلى ملف تنفيذي؟ يكون الأمر cargo check أسرع غالبًا في تنفيذه من الأمر cargo build لأنه يتخطى مرحلة توليد الملف التنفيذي، وبالتالي إذا أردت التحقق باستمرار من صحة شيفرتك البرمجية خلال كتابتها فاستخدام cargo check سيُسرّع العملية بصورةٍ ملحوظة. ينفّذ معظم مستخدمي لغة رست الأمر cargo check دوريًا عادةً للتأكد من صحة شيفرتهم البرمجية ومن أنها ستُصرّف دون مشاكل، ثمّ ينفذون الأمر cargo build عندما يحين الوقت لتوليد ملف تنفيذي واستخدامه. دعنا نلخّص ما تعلمناه لحد اللحظة بخصوص كارجو: نُنشئ المشاريع باستخدام الأمر cargo new. نبني المشروع باستخدام الأمر cargo build. نستطيع بناء المشروع وتشغيله بأمر واحد وهو cargo run. يمكننا بناء المشروع دون توليد ملف تنفيذي ثنائي بهدف التحقق من الأخطاء في الشيفرة البرمجية باستخدام الأمر cargo check. يخزن كارجو ناتج عملية البناء في المجلد "target/debug" عوضًا عن تخزينها في مجلد الشيفرة البرمجية ذاتها. الميزة الإضافية في كارجو هي أن الأوامر هي نفسها ضمن جميع أنظمة التشغيل التي تعمل عليها، وبالتالي ومن هذه النقطة فصاعدًا لن نزوّدك بنظام التشغيل بالتحديد (لينكس أو ماك أو إس أو ويندوز) لكل توجيه. بناء المشروع لإطلاقه يمكنك استخدام الأمر cargo build --release عندما يصل مشروعك إلى مرحلة الإطلاق لتصريفه بصورةٍ مُحسّنة، وسيولّد هذا الأمر ملفًا تنفيذيًا في المجلد "target/release" بدلًا من المجلد "target/debug"، ويزيد التحسين من سرعة تنفيذ شيفرتك البرمجية إلا أن عملية تصريفه ستستغرق وقتًا أطول، وهذا السبب في تواجد خيارين لبناء المشروع: أحدهما هو بهدف التطوير عندما تحتاج لبناء المشروع بسرعة وبصورةٍ دورية والآخر لبناء النسخة النهائية من البرنامج التي ستعطيها إلى المستخدم وفي هذه الحالة لن تُصرّف البرنامج دوريًا وسيكون البرنامج الناتج أسرع ما يمكن. إذا أردت قياس الوقت الذي تستغرقه شيفرتك البرمجية لتُنفّذ، استخدم الأمر cargo build --release وقِس الوقت باستخدام الملف التنفيذي الموجود في المجلد "target/release". أداة كارجو مثل أداة عرض لن يقدّم لك كارجو في المشاريع البسيطة الكثير من الإيجابيات مقارنةً باستخدام الأمر rustc، إلا أن الفارق سيتضح أكثر حالما تعمل على برنامج معقدة تتألف من عدّة صناديق crates، وعندما تنمو البرامج لعدة ملفات أو تحتاج إلى اعتماديات، فمن الأسهل في هذه الحالة استخدام كارجو لتنسيق عملية بناء المشروع. على الرغم من بساطة مشروع "hello_cargo" السابق إلا أنه يستخدم الآن الأدوات الواقعية والعملية التي ستستخدمها طوال مسيرتك مع لغة رست، وحتى تستطيع العمل على أي مشروع موجود مسبقًا، يمكنك استخدام الأوامر التالية للتحقق من الشيفرة البرمجية باستخدام غيت، ثمّ انتقل إلى مجلد المشروع وابنه: $ git clone example.org/someproject $ cd someproject $ cargo build لمزيدٍ من المعلومات حول كارجو، انظر إلى التوثيق. ملخص لقد قطعتَ شوطًا كبيرًا ضمن رحلتك مع لغة رست في هذا المقال، إذ تعلمنا ما يلي: تثبيت آخر إصدارات لغة رست المستقرة باستخدام rustup. تحديث إصدار لغة رست الموجود إلى آخر جديد. فتح التوثيق المحلي (دون اتصال بالإنترنت). كتابة وتشغيل برنامج "!Hello, world" باستخدام rustc مباشرةً. إنشاء وتشغيل برنامج جديد باستخدام أداة كارجو. حان الوقت المناسب لبناء برنامج أكثر واقعية للاعتياد على قراءة وكتابة شيفرة رست. لذا، سنبني في المقالة التالية برنامج لعبة تخمين، لكن إذا أردت تعلم أساسيات البرمجة في لغة رست، انتقل إلى المقالة التي تليها مباشرةً. ترجمة -وبتصرف- لفصل Getting Started من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: برمجة لعبة تخمين الأرقام بلغة رست Rust تعلم البرمجة دليلك الشامل إلى لغات البرمجة
ادعنا نبدأ رحلتنا مع لغة رست، إذ هناك الكثير لنتعلمه، وعلى كل رحلة أن تبدأ في مكان ما. سنناقش في هذا المقال كلًا من التالي: تثبيت لغة رست على لينكس Linux وماك أو إس macOS وويندوز Windows. كتابة برنامج يطبع العبارة "Hello, world!". استخدام أداة كارجو cargo، مدير حزم لغة رست package manager ونظام بنائها build system. تثبيت لغة رست أولى خطواتنا هنا هي تثبيت لغة رست هي بتنزيل رست عن طريق أداة سطر الأوامر rustup، التي تدير إصدارات رست والأدوات المرتبطة بها، وستحتاج لاتصال بالإنترنت لهذه الخطوة. ملاحظة: إذا كنت لا تفضل استخدام rustup لسبب ما، اطّلع على هذه الصفحة للمزيد من الخيارات لتثبيت لغة رست. تثبّت الخطوات التالية آخر إصدارات لغة رست المستقرة، ويضمن لك ثبات رست تصريف جميع الأمثلة الموجودة في هذه السلسلة حتى مع الإصدارات القادمة الجديدة، إلا أنه قد يختلف الخرج قليلًا بين الإصدارات، وذلك بسبب تطوير لغة راست على رسائل الخطأ والتحذيرات. بكلمات أخرى: سيعمل أي إصدار جديد ومستقر من لغة رست تثبّته باتباع الخطوات التالية كما هو متوقع منه ضمن محتوى هذه السلسلة. الإشارة إلى سطر الأوامر سنستعرض بعض الأوامر المُستخدمة في الطرفية terminal ضمن هذا المقال والسلسلة ككُل، إذ تبدأ الأسطر التي يجب أن تُدخلها بالرمز "$"، وليس عليك هنا أن تكتب الرمز "$"، الذي يدل على بداية أمر جديد، وعادةً ما تعرض الأسطر التي لا تبدأ بهذا الرمز الخرج لأمر سابق. إضافةً لما سبق، تستخدم الأمثلة التي تعتمد على صدفة Shell PowerShell خصوصًا الرمز "<" بدلًا من "$". تثبيت أداة سطر الأوامر rustup على لينكس أو ماك أو إس إذا كنت تستخدم نظام لينكس أو ماك أو إس، افتح الطرفية لإدخال الأمر التالي: $ curl --proto '=https' --tlsv1.3 https://sh.rustup.rs -sSf | sh سينزّل الأمر السابق سكريبتًا script ويبدأ بتثبيت أداة rustup التي ستثبّت بدورها آخر إصدارات لغة رست المستقرة، وقد يُطلب منك كلمة المرور لحسابك. إذا انتهت عملية التثبيت بنجاح، ستجد السطر التالي: Rust is installed now. Great! ستحتاج أيضًا إلى رابط linker، وهو برنامج يستخدمه رست لضمّ الخرج المُصرَّف إلى ملف واحد، وسيكون موجودًا غالبًا لديك. يجب عليك تثبيت مصرف سي C الذي يتضمن عادةً على رابط، إذا حصلت على أخطاء رابط، كما أن مصرف سي مفيد أيضًا لاعتماد بعض حزم لغة راست الشائعة على شيفرة لغة سي. يمكنك الحصول على مصرف سي على نظام ماك أو إس بكتابة الأمر التالي: $ xcode-select --install يجب أن يثبت مستخدمو نظام لينكس GCC أو Clang اعتمادًا على توثيق التوزيعة distribution؛ فإذا كنت تستخدم مثلًا توزيعة أوبنتو Ubuntu، فيمكنك تثبيت حزمة build-essential. تثبيت أداة سطر الأوامر rustup على ويندوز إن كنت تستخدم نظام ويندوز، اذهب إلى www.rust-lang.org/tools/install، واتبّع التعليمات لتثبيت لغة رست، إذ ستستلم في مرحلة ما من مراحل التثبيت رسالةً مفادها أنك ستحتاج إلى أدوات بناء C++ الخاصة ببرنامج فيجوال ستوديو Visual Studio إصدار 2013 أو ما بعده، والطريقة الأسهل في الحصول على أدوات البناء هذه هي بتثبيتها مباشرةً من Visual Studio 2022، وتأكد من اختيار "C++ build tools" عند سؤالك عن أي الإصدارات التي تريد تثبيتها وتأكد أيضًا من تضمين حزمة Windows 10 SDK وحزمة اللغة الإنجليزية إلى جانب أي حزمة لغة أخرى من اختيارك. يستخدم باقي الكتاب أوامر تعمل في كلٍّ من "cmd.exe" وصدفة PowerShell، وإذا كانت هناك أي فروقات معينة سنشرح أيهما يجب أن تستخدم. التحديث والتثبيت في لغة رست تُعد عملية التحديث بعد تثبيت لغة رست باستخدام rustup عمليةً سهلة، فكل ما يجب عليك فعله هو تنفيذ سكريبت التحديث من الصدفة: $ rustup update لإزالة تثبيت لغة رست وأداة rustup، نفذ سكريبت إزالة التثبيت من الصدفة: $ rustup self uninstall استكشاف الأخطاء وإصلاحها في لغة رست للتأكد من أنك أنهيت عملية تثبيت لغة رست بنجاح، افتح الصدفة وأدخل السطر التالي: $ rustc --version من المفترض أن تجد رقم الإصدار وقيمة الإيداع المُعمّاة commit hash وتاريخ الإيداع لآخر إصدار مستقر جرى إطلاقه بالتنسيق التالي: rustc x.y.z (abcabcabc yyyy-mm-dd) إذا ظهر لك السطر السابق، فهذا يعني أنك ثبّتتَ لغة رست بنجاح؛ وإذا لم تجد هذه المعلومات وكنت تستخدم نظام ويندوز، فتأكد أن راست موجود في متغير النظام system variable المسمى %PATH%كما يلي: إذا كنت تستخدم نظام تشغيل ويندوز، اكتب في واجهة سطر أوامر CMD ما يلي: > echo %PATH% أما في صدفة PowerShell، استخدم السطر التالي: > echo $env:Path وفي نظام تشغيل لينكس وماك أو إس، استخدم: $ echo $PATH إذا كان كل شيء صحيحًا، ورست لا يعمل فهناك عددٌ من الأماكن التي تستطيع الحصول منها على مساعدة، إذ يمكنك مثلًا طرح مشكلتك في قسم الأسئلة والأجوبة في أكاديمية حسوب أو إن أردت يمكنك التواصل مع فريق لغة رست مباشرة عبر صفحة التواصل. التوثيق المحلي للغة رست يتضمن تثبيت لغة رست أيضًا نسخةً محليةً من التوثيق documentation لتتمكّن من قراءتها دون اتصال بالإنترنت، ولفتح النسخة ضمن المتصفح، نفذ الأمر rustup doc. استخدم توثيق الواجهة البرمجية في كل مرة تصادف نوعًا أو دالةً في المكتبة القياسية ولست متأكدًا ممّا تفعل أو كيف تستخدمها. كتابة أول برنامج بلغة رست الآن، وبعد الانتهاء من تثبيت لغة رست، يمكنك كتابة أول برنامج. من المتعارف عليه عند تعلم لغة برمجة جديدة هو كتابة برنامج بسيط يطبع السلسلة النصية "Hello, world!" على الشاشة، لذا دعنا ننجز ذلك. ملاحظة: يفترض هذا الكتاب معرفتك بأساسيات سطر الأوامر، ولا تتطلب لغة رست طريقةً معينةً لكيفية تعديلك أو استخدامك للأدوات أو مكان وجود شيفرتك البرمجية، لذا يمكنك استخدام بيئة برمجية متكاملة integrated development environment -أو اختصارًا IDE- إذا أردت، ولك الحرية في اختيار ما هو مفضّل لك. هناك العديد من البيئات البرمجية المتكاملة التي تقدم دعمًا للغة راست، ويمكنك تفقّد توثيق البيئة البرمجية المتكاملة التي اخترتها لمزيدٍ من التفاصيل. يحاول فريق تطوير لغة رست مؤخرًا توجيه جهودهم نحو تمكين دعم جيد للبيئات البرمجية المتكاملة عن طريق rust-analyzer. إنشاء مجلد لمشروع بلفة رست ستبدأ بإنشاء مجلد لتخزين شيفرة لغة رست البرمجية، ولا يهمّ المكان الذي ستخزن الشيفرة فيه، إلا أننا نقترح إنشاء مجلد "projects" للتمارين والمشاريع الموجودة في هذا الكتاب ضمن المجلد الرئيس home. افتح الطرفية وأدخِل الأوامر التالية لإنشاء مجلد "projects" ومجلد لمشروع "Hello, world!" ضمن المجلد "projects". لمستخدمي نظام لينكس وماك أو إس وصدفة PowerShell على نظام ويندوز، أدخل التالي: $ mkdir ~/projects $ cd ~/projects $ mkdir hello_world $ cd hello_world ولطرفية ويندوز CMD، أدخل التالي: > mkdir "%USERPROFILE%\projects" > cd /d "%USERPROFILE%\projects" > mkdir hello_world > cd hello_world كتابة وتشغيل برنامج بلغة رست أنشئ ملفًا مصدريًا جديدًا وسمّه باسم "main.rs"، إذ يجب أن تنتهي ملفات شيفرة لغة رست بالامتداد ".rs" دائمًا، وإذا كنت تستخدم أكثر من كلمة واحدة في اسم الملف، فاستخدم الشرطة السفلية underscore للفصل ما بين الكلمات، فعلى سبيل المثال استخدم الاسم "hello_world.rs" بدلًا من "helloworld.rs". الآن افتح ملف "main.rs" الذي أنشأته لتوك وأدخِل الشيفرة التالية: fn main() { println!("Hello, world!"); } [شيفرة 1: برنامج يطبع "Hello, world!"] احفظ الملف واذهب مجددًا إلى نافذة الطرفية. أدخل الأوامر التالية لتصريف وتشغيل الملف إذا كنت تستخدم نظام لينكس أو ماك أو إس: $ rustc main.rs $ ./main Hello, world! إذا كنت تستخدم نظام ويندوز أدخل الأمر .\main.exe بدلًا من ./main: > rustc main.rs > .\main.exe Hello, world! يجب أن تحصل على السلسلة النصية "Hello,world!" مطبوعةً على الطرفية بغض النظر عن نظام تشغيلك، وإن لم يظهر الخرج، فعُد إلى فقرة استكشاف الأخطاء وإصلاحها لطرق الحصول على مساعدة. إذا حصلت على السلسلة النصية "Hello, world!"، تهانينا، فقد كتبت رسميًا أولى برامج لغة رست، مما يجعلك مبرمج لغة رست، أهلًا بك. أجزاء برنامج لغة رست دعنا نطّلع بالتفصيل على الأشياء التي تحدث في برنامج "Hello, world!"، إليك أول الأجزاء: fn main() { } تعرّف هذه السطور دالةً في لغة رست، ودالة main هي دالة مميزة؛ إذ أنها نقطة تشغيل الشيفرة البرمجية الأولية في أي برنامج رست تنفيذي. يصرح السطر الأول عن دالة تدعى main لا تمتلك أي معاملات ولا تُعيد أي قيمة، وإذا أردنا تحديد أي معاملات، نستطيع فعل ذلك عن طريق وضعها داخل قوسين "()". لاحظ أيضًا أن متن الدالة محتوًى داخل أقواس معقوصة "{}"، إذ تتطلب لغة رست وجود هذه الأقواس حول متن أي دالة، ويُعد وضع القوس المعقوص الأول على سطر تصريح الدالة ذاته مع ترك مسافة فارغة بينهما تنسيقًا مُحبّذًا. ملاحظة: إذا أردت الالتزام بتنسيق موحّد ضمن جميع مشاريع رست الخاصة بك، يمكنك استخدام أداة تنسيق تلقائية تدعى rustfmt لتنسيق الشيفرة البرمجية بأسلوب معين، وقد ضمّن فريق تطوير لغة رست هذه الأداة مع توزيعة لغة رست القياسية، مثل rustc، لذا من المفترض أن تكون مثبتة مسبقًا على جهازك. نجد داخل دالة main الشيفرة البرمجية التالية: println!("Hello, world!"); يفعل السطر السابق كامل العمل الذي يهدف إليه برنامجنا البسيط، ألا وهو طباعة النص إلى الشاشة وهناك أربع نقاط مهمة بهذا الخصوص يجب ملاحظتها هنا، هي: أولًا، أسلوب لغة رست في التنسيق هو محاذاة السطر indent باستخدام أربع مسافات فارغة وليس مسافة جدولة tab. ثانيًا، تستدعي println! ماكرو رست، وإذا أردنا استدعاء دالة بدلًا من ذلك، فسنستخدم println (أي الاستغناء عن !)، وسنتناقش بخصوص الماكرو في لغة رست بمزيد من التفاصيل في جزئية لاحقة من هذه السلسلة وكل ما عليك معرفته الآن هو أن استخدام ! يعني أننا نستدعي ماكرو بدلًا من الدالة الاعتيادية، وأن الماكرو لا يتبع القوانين ذاتها التي تتبعها الدوال. ثالثًا، السلسلة النصية "Hello, world!" تُمرّر وسيطًا argument للماكرو !println، ثمّ تُطبع السلسلة النصية على الشاشة. رابعًا، نُنهي السطر بالفاصلة المنقوطة (;) وذلك يُشير إلى انتهاء ذلك التعبير expression وأن التعبير التالي سيبدأ من بعده، وتنتهي معظم أسطر شيفرة لغة رست بالفاصلة المنقوطة. تصريف البرنامج وتشغيله في لغة رست لقد شغّلت لتوّك برنامجًا جديد الإنشاء، دعنا ننظر إلى كل خطوة من هذه العملية بتمعّن. قبل تشغيل برنامج رست، يجب عليك تصريفه باستخدام مصرف لغة رست بإدخال الأمر rustc وتمرير اسم الملف المصدري كما يلي: $ rustc main.rs إذا كان لديك معرفة سابقة بلغة C أو C++، فستلاحظ أن هذا مماثل لاستخدام الأمر gcc أو clang. بعد التصريف بنجاح، يُخرج رست ملفًا ثنائيًا تنفيذيًا binary executable. يمكنك رؤية الملف التنفيذي على نظام لينكس أو ماك أو إس أو صدفة PowerShell على ويندوز عبر تنفيذ الأمر ls، وستجد في نظامَي لينكس وماك أو إس ملفين، بينما ستجد ثلاث ملفات إذا كنت تستخدم صدفة PowerShell وهي الملفات ذاتها التي ستجدها عند استخدامك طرفية CMD على ويندوز. $ ls main main.rs أدخل في طرفية CMD على ويندوز ما يلي (يعني الخيار /B أننا نريد فقط عرض أسماء الملفات): > dir /B main.exe main.pdb main.rs يعرض ما سبق شيفرة الملف المصدر بامتداد ".rs"، إضافةً إلى الملف التنفيذي (المسمى main.exe على ويندوز و main على بقية المنصات)، وعند استخدام ويندوز هناك ملف يحتوي على معلومات لتصحيح الأخطاء بامتداد ".pdb"، ويمكنك تشغيل الملف التنفيذي "main" أو "main.exe" على النحو التالي: $ ./main # أو .\main.exe على ويندوز إذا كان "main.rs" هو برنامج "Hello, world!" فسيطبع السطر السابق "Hello, world!" على طرفيتك. قد لا تكون معتادًا على كون جزء التصريف خطوة مستقلة إذا كنت تألف لغة ديناميكية، مثل روبي Ruby، أو بايثون Python، أو جافاسكربت JavaScript. تعدّ لغة رست لغة مُصرّفة سابقة للوقت ahead-of-time compiled language، مما يعني أن البرنامج يُصرّف وينتج عن ذلك ملف تنفيذي يُمنح لأحد آخر، بحيث يمكن له تشغيله دون وجود لغة رست عنده، وعلى النقيض تمامًا إذا أعطيت أحدًا ما ملفًا بامتداد ".rb" أو ".py" أو ".js" فلن يستطيع تشغيله إن لم يتواجد تطبيق روبي أو بايثون أو جافاسكربت مثبتًا عنده، والفارق هنا هو أنه عليك استخدام أمرٍ واحد فقط لتصريف وتشغيل البرنامج. تصميم لغات البرمجة مبني على المقايضات. يُعد تصريف البرنامج باستخدام rustc فقط كافيًا للبرامج البسيطة، إلا أنك ستحتاج لإدارة جميع الخيارات مع زيادة حجم برنامجك وجعل مشاركة شيفرتك البرمجية مع الغير عملية أسهل، ولذلك سنقدّم لك في الفقرة التالية أداة كارجو Cargo التي ستساعدكَ في كتابة برامج لغة رست لها تطبيقات فعلية في الحياة الواقعية. نظام بناء لغة رست "مرحبا كارجو" كارجو هو نظام بناء لغة رست ومدير حزم، إذ يعتمد معظم مستخدمي لغة رست على هذه الأداة لإدارة مشاريع رست لأنها تتكفل بإنجاز الكثير من المهام نيابةً عنك، مثل بناء شيفرتك البرمجية وتنزيل المكتبات التي تعتمد شيفرتك عليها وبناء هذه المكتبات (ندعو المكتبات التي تحتاجها شيفرتك البرمجية لتعمل بالاعتماديات dependencies). لا تحتاج برامج رست البسيطة -مثل البرنامج الذي كتبناه سابقًا- إلى أي اعتماديات، لذا إذا أردنا بناء مشروع "Hello, world!" باستخدام كارجو، فسيستخدم فقط الجزء الذي يتكفل ببناء الشيفرة البرمجية ضمن كارجو لا غير. ستُضيف بعض الاعتماديات عند كتابتك لبرامج أكثر تعقيدًا، وإذا كنت تستخدم كارجو حينها، فستكون إضافة تلك الاعتماديات سهلةً جدًا. يفترض هذا الكتاب بأنك تستخدم كارجو بما أن معظم مشاريع لغة رست تستخدمه؛ إذ يُثبَّت كارجو تلقائيًا مع رست إذا استخدمت البرنامج الرسمي لتثبيته والذي ناقشناه في فقرة التثبيت، وإذا ثبتت رست باستخدام طرق أخرى، تأكد من وجود كارجو بإدخال الأمر التالي إلى الطرفية: $ cargo --version إذا ظهر لك رقم الإصدار، فهذا يعني أنه موجود. إذا ظهرت رسالة خطأ مثل "command not found"، ألقِ نظرةً على توثيق طريقة التثبيت التي اتبعتها لمعرفة طريقة تثبيت كارجو بصورةٍ منفصلة. إنشاء مشروع للغة رست باستخدام كارجو دعنا نُنشئ مشروعًا جديدًا باستخدام كارجو ونُقارن بين هذه الطريقة وطريقتنا السابقة في إنشاء مشروع "Hello, world!". انتقل إلى مجلد "projects" (أو أي اسم مغاير اخترته لتخزّن فيه شيفرتك البرمجية)، ثم نفذ الأوامر التالية (بغض النظر عن نظام تشغيلك): $ cargo new hello_cargo $ cd hello_cargo يُنشئ الأمر الأول مجلدًا جديدًا باسم "hello_cargo" -إذ أننا اخترنا تسمية "hello_cargo" لمشروعنا- ومن ثم يُنشئ كارجو ملفاته في المجلد الذي اخترناه بذات الاسم. اذهب إلى المجلد "hello_cargo" واعرض الملفات الموجودة فيه، ستجد أن كارجو قد أنشأ ملفين ومجلدًا واحدًا داخله، هم: ملف باسم "cargo.toml"، ومجلد "src"، وملف "main.rs"؛ كما أنه هيأ مستودع غيت Git جديد مع ملف ".gitignore". لن تُوَلّد ملفات غيت إذا استخدمت الأمر cargo new ضمن مستودع جيت موجود مسبقًا، ويمكنك تجاوز ذلك السلوك عن طريق استخدام الأمر cargo new --vcs=git. ملاحظة: غيت هو نظام شائع للتحكم بالإصدارات، ويمكنك تغيير نظام التحكم بالإصدارات عند تنفيذ الأمر cargo new بإضافة الراية --vcs. يمكنك تنفيذ الأمر cargo new --help إذا أردت رؤية الخيارات المتاحة. افتح الملف "Cargo.toml" باستخدام محرر النصوص المفضل لديك، يجب أن تكون الشيفرة البرمجية بداخله مشابهة للشيفرة 1-2. [package] name = "hello_cargo" version = "0.1.0" edition = "2021" [dependencies] [الشيفرة 1-2: محتوى ملف Cargo.toml الناتج عن تنفيذ الأمر cargo new] يمكنك الاطلاع على مزيدٍ من المفاتيح وتعريفاتها على الرابط. هذا الملف مكتوب بتنسيق لغة TOML (اختصارًا للغة توم المُختصرة الواضحة Tom's Obvious, Minimal Langaug)، وهي لغة تنسيق كارجو. يمثل السطر الأول [package] قسم ترويسة الذي يشير إلى أن ما يليه هي معلومات لإعداد الحزمة. نُضيف المزيد من الأقسام إذا أردنا إضافة المزيد من المعلومات إلى هذا الملف. تُعدّ الأسطر الثلاث التالية المعلومات التي يحتاجها كارجو لتصريف برنامجك ألا وهي: اسم المشروع وإصدار لغة رست المُستخدم، وسنتحدث عن مفتاح edition لاحقًا. السطر الأخير [dependencies] هو بداية جزء جديد يحتوي على أي اعتماديات يعتمد عليها مشروعك لعمله. يُشار إلى حزم الشيفرات البرمجية في لغة رست باسم الصناديق crates، ولا نحتاج هنا أي صناديق أخرى لهذا المشروع، ولكننا سنحتاج إلى صناديق إضافية في مشاريع لاحقة وعندها سنستخدم هذا القسم. أما الآن فافتح الملف "main.rs" الموجود داخل المجلد "src" وألقِ نظرةً على ما داخله: fn main() { println!("Hello, world!"); } قد ولّد كارجو برنامج "!Hello, world" لك على نحوٍ مماثل للبرنامج الذي كتبناه سابقًا في الشيفرة 1-1، والاختلاف الوحيد حتى اللحظة بين مشروعنا السابق ومشروع كارجو هو أن كارجو أضاف الشيفرة البرمجية داخل مجلد "src" وأنه لدينا ملف الإعداد "Cargo.toml" في المجلد الرئيسي. يتوقع كارجو بأن تتواجد ملفاتك المصدرية داخل المجلد "src"، وأن يكون المجلد الرئيسي للمشروع فقط للملفات التوضيحية README files والمعلومات عن رخصة البرنامج license information وملفات الضبط configuration files وأي ملفات أخرى غير مرتبطة بشيفرتك المصدرية مباشرةً. يساعدك استخدام كارجو في تنظيم ملفاتك إذ أن هناك مكان لكل شيء وكلّ شيء يُخزّن في مكانه. يمكنك تحويل مشروعك إلى مشروع يستخدم كارجو إذا أنشأت مشروعًا جديدًا دون استخدام كارجو على نحوٍ مماثل لما فعلناه في مشروع "!Hello, world"، فكل ما عليك فعله هو نقل الشيفرة المصدرية الخاصة بالمشروع إلى مجلد "src" وإنشاء ملف "Cargo.toml" موافق لتفاصيل المشروع. بناء وتشغيل مشروع كارجو دعنا ننظر الآن إلى ما هو مختلف عندما نشغّل برنامج "!Hello, world" باستخدام كارجو. أنشئ مشروعك بإدخال الأمر التالي داخل المجلد "hello_cargo": $ cargo build Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo) Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs يُنشئ الأمر السابق ملف تنفيذي ضمن المجلد "target/debug/hello_cargo" (أو "target\debug\hello_cargo.exe" على ويندوز) بدلًا عن مجلدك الحالي، ويمكنك تشغيل الملف التنفيذي باستخدام الأمر التالي: $ ./target/debug/hello_cargo # أو .\target\debug\hello_cargo.exe على ويندوز Hello, world! إذا مر كل ما سبق بنجاح فستُطبع "Hello, world!" على الطرفية. يتسبب تنفيذ الأمر cargo build للمرة الأولى بإنشاء كارجو لملف جديد في المجلد الرئيسي باسم "Cargo.lock" وهذا الملف يتابع إصدارات الاعتماديات المستخدمة في مشروعك، وبما أن هذا المشروع لا يحتوي على أي اعتماديات، فلن يكون هذا الملف ذا أهمية كبيرة، إلا أن هذا يعني أنه لا يوجد أي حاجة لتغيير محتويات هذا الملف يدويًا بل يتكفل كارجو بمحتوياته بدلًا عنك. بنينا لتوّنا مشروعًا باستخدام cargo build وشغّلناه باستخدام الأمر ./target/debug/hello_cargo، إلا أنه يمكننا استخدام الأمر cargo run أيضًا لتصريف الشيفرة البرمجية وتشغيلها مما ينتج عن تشغيل الملف التنفيذ باستخدام أمر واحد فقط: $ cargo run Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs Running `target/debug/hello_cargo` Hello, world! يستخدم معظم المطورين cargo run لأنه أكثر ملاءمةً من تذكُّر تشغيل cargo build ثم استخدام المسار الكامل وصولًا للملف الثنائي (التنفيذي). لاحظ أننا لم نرى هذه المرة أي خرج يشير إلى أن كارجو يصرّف "hello_cargo"، وذلك لأن كارجو لاحظ أن الملف لم يتغير وبالتالي فقد شغّل مباشرةً الملف الثنائي، وإلّا في حالة تعديل الشيفرة المصدرية سيعيد كارجو بناء المشروع قبل تشغيله وستجد خرجًا مشابهًا لما يلي: $ cargo run Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo) Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs Running `target/debug/hello_cargo` Hello, world! يحتوي كارجو أيضًا على أمر آخر وهو cargo check، ويتحقق هذا الأمر من شيفرتك البرمجية للتأكد من أنها ستُصرّف بنجاح ولكنه لا يولّد أي ملف تنفيذي: $ cargo check Checking hello_cargo v0.1.0 (file:///projects/hello_cargo) Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs لكن في أيّ الحالات لن تحتاج إلى ملف تنفيذي؟ يكون الأمر cargo check أسرع غالبًا في تنفيذه من الأمر cargo build لأنه يتخطى مرحلة توليد الملف التنفيذي، وبالتالي إذا أردت التحقق باستمرار من صحة شيفرتك البرمجية خلال كتابتها فاستخدام cargo check سيُسرّع العملية بصورةٍ ملحوظة. ينفّذ معظم مستخدمي لغة رست الأمر cargo check دوريًا عادةً للتأكد من صحة شيفرتهم البرمجية ومن أنها ستُصرّف دون مشاكل، ثمّ ينفذون الأمر cargo build عندما يحين الوقت لتوليد ملف تنفيذي واستخدامه. دعنا نلخّص ما تعلمناه لحد اللحظة بخصوص كارجو: نُنشئ المشاريع باستخدام الأمر cargo new. نبني المشروع باستخدام الأمر cargo build. نستطيع بناء المشروع وتشغيله بأمر واحد وهو cargo run. يمكننا بناء المشروع دون توليد ملف تنفيذي ثنائي بهدف التحقق من الأخطاء في الشيفرة البرمجية باستخدام الأمر cargo check. يخزن كارجو ناتج عملية البناء في المجلد "target/debug" عوضًا عن تخزينها في مجلد الشيفرة البرمجية ذاتها. الميزة الإضافية في كارجو هي أن الأوامر هي نفسها ضمن جميع أنظمة التشغيل التي تعمل عليها، وبالتالي ومن هذه النقطة فصاعدًا لن نزوّدك بنظام التشغيل بالتحديد (لينكس أو ماك أو إس أو ويندوز) لكل توجيه. بناء المشروع لإطلاقه يمكنك استخدام الأمر cargo build --release عندما يصل مشروعك إلى مرحلة الإطلاق لتصريفه بصورةٍ مُحسّنة، وسيولّد هذا الأمر ملفًا تنفيذيًا في المجلد "target/release" بدلًا من المجلد "target/debug"، ويزيد التحسين من سرعة تنفيذ شيفرتك البرمجية إلا أن عملية تصريفه ستستغرق وقتًا أطول، وهذا السبب في تواجد خيارين لبناء المشروع: أحدهما هو بهدف التطوير عندما تحتاج لبناء المشروع بسرعة وبصورةٍ دورية والآخر لبناء النسخة النهائية من البرنامج التي ستعطيها إلى المستخدم وفي هذه الحالة لن تُصرّف البرنامج دوريًا وسيكون البرنامج الناتج أسرع ما يمكن. إذا أردت قياس الوقت الذي تستغرقه شيفرتك البرمجية لتُنفّذ، استخدم الأمر cargo build --release وقِس الوقت باستخدام الملف التنفيذي الموجود في المجلد "target/release". أداة كارجو مثل أداة عرض لن يقدّم لك كارجو في المشاريع البسيطة الكثير من الإيجابيات مقارنةً باستخدام الأمر rustc، إلا أن الفارق سيتضح أكثر حالما تعمل على برنامج معقدة تتألف من عدّة صناديق crates، وعندما تنمو البرامج لعدة ملفات أو تحتاج إلى اعتماديات، فمن الأسهل في هذه الحالة استخدام كارجو لتنسيق عملية بناء المشروع. على الرغم من بساطة مشروع "hello_cargo" السابق إلا أنه يستخدم الآن الأدوات الواقعية والعملية التي ستستخدمها طوال مسيرتك مع لغة رست، وحتى تستطيع العمل على أي مشروع موجود مسبقًا، يمكنك استخدام الأوامر التالية للتحقق من الشيفرة البرمجية باستخدام غيت، ثمّ انتقل إلى مجلد المشروع وابنه: $ git clone example.org/someproject $ cd someproject $ cargo build لمزيدٍ من المعلومات حول كارجو، انظر إلى التوثيق. ملخص لقد قطعتَ شوطًا كبيرًا ضمن رحلتك مع لغة رست في هذا المقال، إذ تعلمنا ما يلي: تثبيت آخر إصدارات لغة رست المستقرة باستخدام rustup. تحديث إصدار لغة رست الموجود إلى آخر جديد. فتح التوثيق المحلي (دون اتصال بالإنترنت). كتابة وتشغيل برنامج "!Hello, world" باستخدام rustc مباشرةً. إنشاء وتشغيل برنامج جديد باستخدام أداة كارجو. حان الوقت المناسب لبناء برنامج أكثر واقعية للاعتياد على قراءة وكتابة شيفرة رست. لذا، سنبني في المقالة التالية برنامج لعبة تخمين، لكن إذا أردت تعلم أساسيات البرمجة في لغة رست، انتقل إلى المقالة التي تليها مباشرةً. ترجمة -وبتصرف- لفصل Getting Started من كتاب The Rust Programming Language. اقرأ أيضًا المقال التالي: برمجة لعبة تخمين الأرقام بلغة رست Rust تعلم البرمجة دليلك الشامل إلى لغات البرمجة -
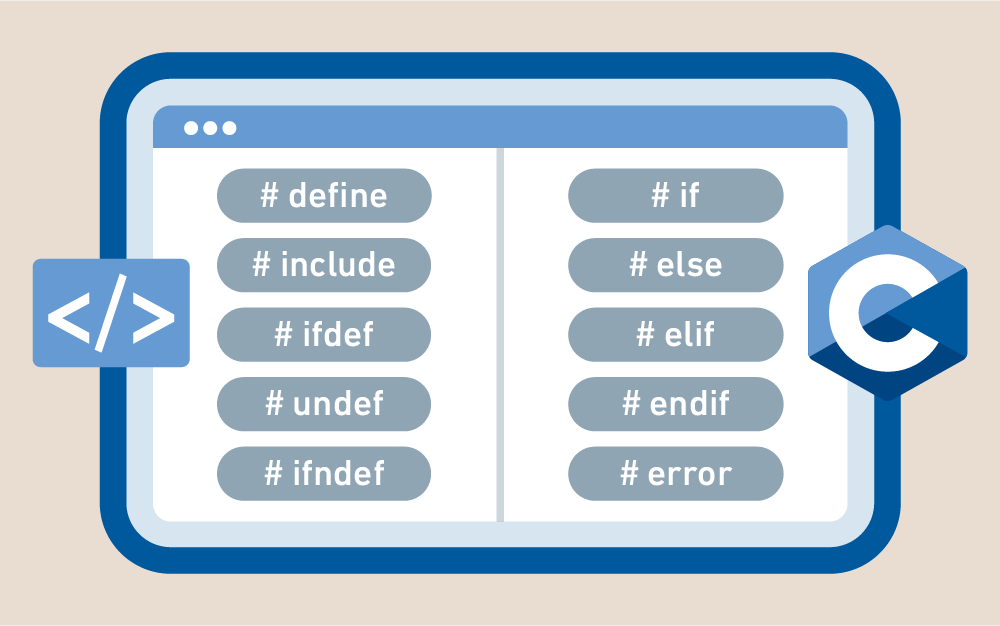 يتناول المقال مرحلة المعالجة المسبقة للشيفرة المصدرية بما فيها مراحل استبدال الماكرو ومختلف موجهات المعالج المسبق الأخرى. أثر المعيار ستشعر أن المعالج المُسبق Preprocessor لا ينتمي إلى لغة سي عمومًا، إذ لا يسمح لك وجوده بالتعامل بصورةٍ متكاملة مع اللغة كما أنك لا تستطيع الاستغناء عنه في ذات الوقت، وفي الحقيقة، كان استخدام المعالج المُسبق في أيام سي الأولى اختياريًا واعتاد الناس على كتابة برامج لغة سي C بدونه، ويمكننا أن ننظر إلى كونه جزءًا من لغة سي حاليًا صدفةً إلى حدٍ ما، إذ كان يعالج بعضًا من أوجه القصور في اللغة، مثل تعريف الثوابت وتضمين التعريفات القياسية، وأصبح نتيجةً لذلك جزءًا ضمن حزمة لغة سي ككُل. لم يكن هناك في تلك الفترة معيارٌ رسميٌ متفقٌ عليه يوحّد ما يفعله المعالج المسبق، وكانت إصدارات مختلفة منه مُطبّقة بصورةٍ مختلف على عدة أنظمة، وأصبحت عملية نقل البرنامج وتصديره إلى أنظمة أخرى مشكلةً كبيرة إذا استخدم ما يزيد عن الخصائص الأساسية للمعالج. كانت وظيفة المعيار الأساسية هنا هي تعريف سلوك المعالج المُسبق بما يتوافق مع الممارسات الشائعة، وقد سبق حصول ذلك مع لغة سي القديمة، إلا أن المعيار اتخذ إجراءات إضافية وسط الخلاف وحدد مجموعةً من الخصائص الإضافية التي قُدمت مع إصدارات المعالج المُسبق الأكثر شعبية، وعلى الرغم من فائدة هذه الخصائص إلا أن الخلاف كان بخصوص الاتفاق على طريقة تطبيقها. لم يكترث المعيار لمشكلة القابلية مع البرامج القديمة بالنظر إلى أن هذه البرامج تستخدم طرقًا غير قابلة للنقل في المقام الأول، وسيحسِّن تواجد هذه الخصائص المتقدمة ضمن المعيار سهولة نقل برامج لغة سي مستقبلًا بصورةٍ ملحوظة. يعدّ استخدام المعالج المسبق سهلًا إذا استُخدم لمهمته الأساسية البسيطة في جعل البرامج سهلة القراءة والصيانة، ولكن يُفضّل ترك خصائصه المتقدمة لاستخدام الخبراء. بحكم تجربتنا، يُعد استخدام #define ومجموعة تعليمات التصريف الشرطي conditional compilation (أوامر #if) مناسبًا للمبتدئين، وإذا ما زلت مبتدئً في لغة سي، فاقرأ هذه المقالة مرةً واحدة لمعرفة إمكانيات المعالج المُسبق واستخدم التمارين للتأكد من فهمك، وإلا فنحن ننصح بخبرة لا تقل عن ستة أشهر في لغة سي حتى تستطيع فهم إمكانيات المعالج المسبق كاملةً، لذا لن نركز على منحك مقدمة سهلة هنا بل سنركز على التفاصيل الدقيقة فورًا. كيف يعمل المعالج المسبق؟ بالرغم من أن المعالج المسبق الموضح في الشكل التالي سينتهي به المطاف غالبًا بكونه جزءًا هامًا من مصرف لغة سي المعيارية، إلا أنه يمكننا التفكير به على أنه برنامجٌ منفصلٌ يحول شيفرة سي المصدرية التي تحتوي على موجهات المعالج المسبق إلى شيفرة مصدرية لا تحتوي على هذه الموجهات. شكل 1: المعالج المسبق في لغة سي من المهم هنا أن نتذكر أن المعالج المسبق لا يعمل متبعًا القوانين الخاصة بشيفرة لغة سي ذاتها، وإنما يعمل على أساس كل سطرٍ بسطره، وهذا يعني أن نهاية السطر حدثٌ مميز وليس كما تنظر لغة سي إلى نهاية السطر بكونه مشابهًا لمحرف مسافة أو مسافة جدولة. لا يعي المعالج المسبق قوانين لغة سي الخاصة بالنطاق Scope، إذ تأخذ موجهات المعالج المسبق (مثل #define) تأثيرها فور رؤيتها ويبقى تأثيرها موجودًا حتى الوصول إلى نهاية الملف الذي يحتوي هذه الموجهات، ولا ينطبق هنا هيكل البرنامج المتعلق بالكتل البرمجية. من المحبّذ إذًا استخدام موجهات المعالج المسبق بأقل ما أمكن، فكلما قلّ عدد الأجزاء التي لا تتبع قوانين النطاق "الاعتيادية" كلّما قلت إمكانية ارتكاب الأخطاء، وهذا ما نقصده عندما نقول أن تكامل المعالج المسبق ولغة سي C محدودٌ فيما بينهما. يصف المعيار بعض القوانين المعقدة بخصوص كتابة موجهات المعالج المسبق، وبالأخص بالنسبة للمفاتيح Tokens، ويجب عليك معرفة القوانين كلها إذا أردت فهم موجهات المعالج المسبق، فالنص الذي يُعالج لا يعدّ سلسلةً من المحارف بل هو مُجزّأٌ إلى مفاتيح ومن ثم معلومات معالجة مُجزأة. من الأفضل اللجوء إلى المعيار إذا أردت تعريفًا كاملًا بالعملية، إلا أننا سنتطرق إلى شرح بسيط؛ إذ سنشرح كل جزء موجود في القائمة التالية لاحقًا. اسم ملف الترويسة > يمكن استخدام أي محرف هنا (باستثناء) <. مفتاح المعالج المسبق اسم ملف الترويسة كما ذُكر سابقًا لكن فقط في حالة ذكره ضمن #include أو معرّف identifier مثل معرف لغة C أو كلمة مفتاحية أو ثابت وهو أي عدد صحيح أو طبيعي ثابت أو سلسلة نصية وهو سلسلة نصية سي اعتيادية أو عامل وهو من أحد عوامل لغة سي أو واحد من علامات الترقيم [ ] ( ) { } * , : = ; ... # أو أي محرف غير فارغ (محرف فارغ مثل محرف المسافة) غير مذكور في اللائحة أعلاه نقصد أي محرف (باستثناء) أي باستثناء المحرفين < أو محرف السطر الجديد. الموجهات Directives تبدأ موجّهات المعالج المسبق بالمحرف "#" دائمًا، وتُتبع بمحرف مسافة فارغة اختياريًا إلا أن هذا الاستخدام غير شائع، ويوضح الجدول التالي الموجهات المعرّفة في المعيار. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الموجّه المعنى # include تضمين ملف مصدري # define تعريف ماكرو # undef التراجع عن تعريف ماكرو # if تصريف شرطي # ifdef تصريف شرطي # ifndef تصريف شرطي # elif تصريف شرطي # else تصريف شرطي # endif تصريف شرطي # line التحكم بتقارير الأخطاء # error عرض رسالة خطأ قسرية # pragma تُستخدم للتحكم المعتمد على التنفيذ # موجّه فارغ؛ دون تأثير جدول 1 موجّهات المعالج المُسبق سنشرح كل من معنى واستخدام الموجّهات بالتفصيل في الفقرات التالية. لاحظ أن المحرف # والكلمة المفتاحية التي تليه عنصرين مستقلين منفصلين، ويمكن إضافة مسافةٍ بيضاء بينهما. الموجه الفارغ هذا الموجّه بسيط، إذ ليس لإشارة # بمفردها على السطر أي تأثير. موجه تعريف الماكرو define هناك طريقتان لتعريف الماكرو، أولهما تبدو مثل تابع والأخرى على النقيض، إليك مثالًا باستخدام الطريقتين: #define FMAC(a,b) a here, then b #define NONFMAC some text here يعرّف التصريحان السابقان ماكرو ونصًا بديلًا له، إذ سيستخدم ليُستبدل بالماكرو المذكور ضمن كامل البرنامج، ويمكن استخدامهما بعد التصريح عنهما على النحو التالي مع ملاحظة أثر استبدال الماكرو الموضح في التعليقات: NONFMAC /* النص هنا */ FMAC(first text, some more) /* النص الأول، ومزيدٌ من النص */ يُستبدل اسم الماكرو في الحالة التي لا يبدو فيها مثل دالة بالنص البديل ببساطة، وكذلك الأمر بالنسبة لماكرو من نوع دالة، وفي حال كان النص البديل يحتوي على معرّف يطابق اسم معامل من معاملات الماكرو، يُستخدم النص الموجود وسيطًا بدلًا من المعرِّف في النص البديل. يُحدَّد نطاق الأسماء المذكورة في وسطاء الماكرو بالكتلة التي تحتوي الموجه #define. تُهمل أي مسافات فارغة بعد أو قبل النص البديل ضمن تعريف الماكرو، وذلك لكلا الطريقتين على حد سواء. يتبادر إلى البعض السؤال الفضولي التالي: كيف يمكنني تعريف ماكرو بسيط بحيث يكون النص البديل الخاص به ينتهي بالقوس المفتوح ")"؟ الإجابة بسيطة، إذا احتوى تعريف الماكرو على مسافة أمام القوس ")"، فلن يحتسب الماكرو من نوع ماكرو دالة، بل نص بديل لماكرو بسيط فحسب، إلا أنه لا يوجد قيد مماثل عندما تستخدم الماكرو الشبيه بالدالة. يسمح المعيار للماكرو بغض النظر عن نوع أن يُعاد تعريفه في أي لحظة باستخدام موجّه # define آخر، وذلك بفرض عدم تغيير نوع الماكرو وأن تكون المفاتيح التي تشكل التعريف الأساسي وإعادة التعريف متماثلة بالعدد والترتيب والكتابة بما فيها استخدام المسافة الفارغة، وتُعد المسافات الفارغة في هذا السياق متساوية، وطبقًا لذلك فالتالي صحيح: # define XXX abc/*تعليق*/def hij # define XXX abc def hij وذلك لأن التعليق شكلٌ من أشكال المسافات الفارغة، وسلسلة المفاتيح للحالتين السابقتين هي: # w-s define w-s XXX w-s abc w-s def w-s hij w-s إذ تعني w-s مفتاح مسافة بيضاء. استبدال الماكرو أين سيتسبب اسم الماكرو باستبدال النص بالنص البديل؟ يحدث الاستبدال عمليًا في أي مكان يحدث التعرف فيه على المعرّف identifier مثل مفتاح منفصل ضمن البرنامج، عدا المعرف المتبوع بالمحرف "#" الخاص بموجّه المعالج المُسبق. يمكنك كتابة التالي: #define define XXX #define YYY ZZZ ومن المتوقع أن يتسبب استبدال سطر #define الثاني بالسطر #xxx بخطأ. يُستبدل المعرف المرتبط بماكرو بسيط عندما يُرى بمفتاح الماكرو البديل، ومن ثم يُعاد مسحه rescanned (سنتكلم عن ذلك لاحقًا) للعثور على أي استبدالات أخرى. يمكن استخدام ماكرو الدالة مثل أي دالة أخرى اعتيادية، وذلك بوضع مساحات فارغة حول اسم الماكرو ولائحة الوسطاء وغيره، كما قد يحتوي على محرف سطر جديد: #define FMAC(a, b) printf("%s %s\n", a, b) FMAC ("hello", "sailor" ); /* ينتج ما سبق بالتالي */ printf("%s %s\n", "hello", "sailor") يمكن أن تأخذ وسطاء الماكرو من نوع دالة أي تسلسل عشوائي للمفتاح، وتُستخدم الفاصلة "," لفصل الوسطاء عن بعضهم بعضًا، ولكن يمكن إخفاؤها بوضعها داخل أقواس "( )". توازن الأزواج المتطابقة من الأقواس داخل الوسيط بعضها بعضًا، وبالتالي ينهي القوس "(" استدعاء الماكرو إذا كان القوس ")" هو الذي بدأ باستدعائه. #define CALL(a, b) a b CALL(printf, ("%d %d %s\n",1, 24, "urgh")); /* results in */ printf ("%d %d %s\n",1, 24, "urgh"); لاحظ كيف حافظنا على الأقواس حول الوسيط الثاني للدالة CALL عند الاستبدال، ولم تُزال من النص. إذا أردت استخدام ماكرو مثل printt، لن يساعدك المعيار بهذا الخصوص عندما تختار عدد متغير من الوسطاء، فذلك غير مدعوم. نحصل على سلوك غير معرف إذا لم يحتوي أحد الوسطاء على مفتاح معالج مسبق، والأمر مماثل إذا احتوت سلسلة مفاتيح المعالج المسبق التي تشكل الوسيط على موجّه معالج مسبق مغاير: #define CALL(a, b) a b /* كل حالة تنتج عن سلوك غير محدد */ CALL(,hello) CALL(xyz, #define abc def) إلا أننا نعتقد برأينا أن الاستخدام الثاني الخاطئ للدالة CALL يجب أن ينتج بسلوك معرف، إذ أن أي أحد قادر على كتابة ذلك سيستفيد من انتباه المصرّف. تتبع معالجة ماكرو الدالة الخطوات التالية: جميع وسطائها معرفة. إن كان أي من المفاتيح ضمن الوسيط مرشح لاستبدال بواسطة ماكرو، فسيُستبدل حتى الوصول للنقطة التي لا يمكن فيها إجراء المزيد من الاستبدالات، باستثناء الحالات المذكورة في البند الثالث التالي. لا يوجد هناك أي خطر بخصوص امتلاك الماكرو لعدد مختلف من الوسطاء بعد إضافة فاصلة إلى قائمة الوسطاء الأساسية، إذ يُحدد الوسطاء في الخطوة السابقة فقط. تُستبدل المعرفات التي تسمّي وسيط الماكرو في نص الاستبدال بسلسلة مفتاح مثل وسيطٍ فعلي، ويُهمل الاستبدال إذا كان المعرف مسبوقًا بإشارة "#" أو اثنتين "##" أو متبوعًا بالإشارتين "##". التنصيص هناك طريقةٌ خاصة لمعالجة الأماكن التي يسبق فيها وسيط الماكرو الإشارة "#" في نص الماكرو البديل، إذ تًهمل أي مسافة فارغة تسبق أو تلي قائمة الوسطاء الفعلية للمفتاح، ومن ثم تُحوّل قائمة المفتاح والإشارة # إلى سلسلة نصية واحدة، وتُعامل المسافات بين المفاتيح كأنها محارف مسافة في سلسلة نصية؛ ولمنع حدوث أي نتائج مفاجئة، يُسبق أي محرف " أو \ في السلسلة النصية الجديدة بالمحرف \. إليك المثال التالي الذي يوضح الخاصية المذكورة: #define MESSAGE(x) printf("Message: %s\n", #x) MESSAGE (Text with "quotes"); /* * النتيجة هي * printf("Message: %s\n", "Text with \"quotes\""); */ لصق المفتاح Token pasting قد نجد العامل ## في أي مكان ضمن النص البديل للماكرو باستثناء نهايته أو بدايته، وتُستخدم سلسلة مفتاح وسيط الماكرو لاستبدال النص البديل إذا ورد في اسم الوسيط لماكرو دالة مسبوقًا أو متبوعًا بأحد هذه العوامل، وتُدمج المفاتيح المحيطة بالعامل ## سويًا سواءٌ كانت ضمن ماكرو دالة أو ماكرو بسيط، ونحصل على سلوك غير معرف إذا شكّل ذلك مفتاح غير صالح، ويُجرى إعادة مسح بعدها. إليك عملية تحصل على عدة مراحل يُستخدم فيها إعادة المسح لتوضيح لصق المفتاح: #define REPLACE some replacement text #define JOIN(a, b) a ## b JOIN(REP, LACE) becomes, after token pasting, REPLACE becomes, after rescanning some replacement text إعادة المسح يُمسح النص البديل مضافًا إلى مفاتيح الملف المصدري مجددًا حالما تحصل العملية الموضحة في الفقرة السابقة، وذلك للبحث عن أسماء ماكرو أخرى لاستبدالها، مع استثناء أن اسم الماكرو داخل النص البديل لا يُستبدل. من الممكن أن نضيف ماكرو متداخلة Nested macros وبالتالي يمكن لعدد من الماكرو أن تُعالج لاستبدالها في أي نقطة دفعةً واحدة، ولا يوجد في هذه الحالة أي اسم مرشح لاستبداله ضمن المستوى الداخلي لهذا التداخل، وهذا يسمح لنا بإعادة تعريف الدوال الموجودة سابقًا مثل ماكرو: #define exit(x) exit((x)+1) تصبح أسماء الماكرو التي لم تُستبدل مفاتيحٌ محمية من الاستبدال مستقبلًا، حتى لو وردت أي عمليات تالية لتبديلها، وهذا يدرأ الخطر عن حدوث التعادوية recursion اللانهائية في المعالج المسبق، وتنطبق هذه الحماية فقط في حالة نتج اسم الماكرو عن النص البديل، وليس النص المصدري ضمن البرنامج، إليك ما الذي نقصده: #define m(x) m((x)+1) /* هذا */ m(abc); /* ينتج عن هذا بعد الاستبدال */ m((abc)+1); /* * على الرغم من أن النتيجة السابقة تبدو مثل ماكرو * إلا أن القواعد تنص على لزوم عدم استبداله */ m(m(abc)); /* * تبدأ m( الخارجية باستدعاء الماكرو, * لكن تُستبدل الداخلية أولًا * لتصبح بالشكل m((abc)+1) * وتُستخدم مثل وسيط، مما يعطينا */ m(m((abc+1)); /* * ويصبح بعد الاستبدال على النحو التالي */ m((m((abc+1))+1); إذا لم يؤلمك دماغك بقراءة ما سبق، فاذهب واقرأ ما الذي يقوله المعيار عن هذا ونضمن لك أنه سيؤلمك. ملاحظات هناك مشكلة غير واضحة تحدث عند استخدام وسطاء ماكرو الدالة. /* تحذير: هناك مشكلة في هذا البرنامج */ #define SQR(x) ( x * x ) /* * عند ورود المعاملات الصورية في النص البديل، تُستبدل بالمعاملات الفعلية للماكرو */ printf("sqr of %d is %d\n", 2, SQR(2)); المعامل الصوري formal parameter للماكرو SQR هو x، والمعامل الفعلي actual argument هو 2، وبالتالي سينتج النص البديل عن: printf("sqr of %d is %d\n", 2, ( 2 * 2 )); لاحظ استخدام الأقواس، فالمثال التالي قد يتسبب بمشكلة: /* مثال سيء */ #define DOUBLE(y) y+y printf("twice %d is %d\n", 2, DOUBLE(2)); printf("six times %d is %d\n", 2, 3*DOUBLE(2)); تكمن المشكلة في أن التعبير الأخير في استدعاء الدالة printf الثاني يُستبدل بالتالي: 3*2+2 وهذا ينتج عن 8 وليس 12. تنص القاعدة على أنه يجب عليك الحرص بخصوص الأقواس فهي ضرورية في حالة استخدام الماكرو لبناء تعابير. إليك مثالًا آخر: SQR(3+4) /* تصبح بالشكل التالي بعد الاستبدال */ ( 3+4 * 3+4 ) /* للأسف، ما زالت خاطئة! */ لذا، يجب عليك النظر بحرص إلى الوسطاء الصورية عندما ترِد ضمن نصل بديل. إليك الأمثلة الصحيحة عن الدالتين SQR و DOUBLE: #define SQR(x) ((x)*(x)) #define DOUBLE(x) ((x)+(x)) في جعبة الماكرو حيلةٌ صغيرة بعد لمفاجئتك، كما سيوضح لك المثال التالي: #include <stdio.h> #include <stdlib.h> #define DOUBLE(x) ((x)+(x)) main(){ int a[20], *ip; ip = a; a[0] = 1; a[1] = 2; printf("%d\n", DOUBLE(*ip++)); exit(EXIT_SUCCESS); } مثال 1 لمَ يتسبب المثال السابق بمشاكل؟ لأن نص ماكرو البديل يشير إلى *ip++ مرتين، مما يتسبب بزيادة ip مرتين، لا يجب للماكرو أن يُستخدم مع التعابير التي لها آثار جانبية، إلا إذا تحققت بحرص من أمانها. بغض النظر عن هذه التحذيرات التي تخص الماكرو، إلا أنها تقدم خصائص مفيدة، وستُستخدم هذه الخصائص كثيرًا من الآن فصاعدًا. موجه التراجع عن تعريف ماكرو undef يُمكن أن يُهمل (يُنتسى) أي معرّف يعود لموجه #define بكتابة: #undef NAME إذ لا يولد #undef خطأً إن لم يكن الاسم NAME معرفًا مسبقًا. سنستفيد من هذا الموجه كثيرًا عمّا قريب، وسنتكلم لاحقًا عن بعض دوال المكتبات التي هي في الحقيقة ماكرو وليس دالة، وستصبح قادرًا على الوصول إلى الدالة الفعلية عن طريق التراجع عن تعريفها. موجه تضمين ملف مصدري include يمكن كتابة هذا الموجه بشكلين: #include <filename> #include "filename" ينجم عن استخدام أحد الطريقتين قراءة ملف جديد عند نقطة ذكر الموجّه، وكأننا استبدالنا سطر الموجه بمحتويات الملف المذكور، وإذا احتوى هذا الملف على بعض التعليمات الخاطئة ستظهر لك الأخطاء مع إشارتها إلى الملف التي نجمت عنه مصحوبةً برقم السطر، وهذه مهمة مطوّر المصرف، وينص المعيار على أنه يجب للمصرف دعم ثمانية طبقات من موجّهات # include المتداخلة على الأقل. يمكن الاختلاف بين استخدام <> و " " حول اسم الملف بالمكان الذي سيُبحث فيه عن الملف؛ إذ يتسبب استخدام الأقواس في البحث في عددٍ من الأماكن المعرّفة بحسب التطبيق؛ بينما يتسبب استخدام علامتي التنصيص بحثًا في المكان المرتبط بمكان ملف الشيفرة المصدرية، وستُعلمك ملاحظات تطبيقك بما هو المقصود بكلمة "المكان" والتفاصيل المرتبطة بها، إذا لم تعود عملية البحث عن الملف باستخدام علامتي التنصيص بأي نتيجة، تُعاود عملية البحث من جديد وكأنك استخدمت القوسين. تُستخدم الأقواس عمومًا عندما تريد تحديد ملفات ترويسة لمكتبة قياسية Standard library، بينما تُستخدم علامتي التنصيص لملفات الترويسة الخاصة بك، التي تكون مخصصة غالبًا لبرنامج واحد. لا يحدد المعيار كيفية تسمية ملف بصورةٍ صالحة، إلا أنه يحدد وجوب وجود طريقة فريدة معرفة بحسب التطبيق لترجمة اسم الملفات من الشكل xxx.x (يمثّل كل x حرفًا)، إلى أسماء ملفات الشيفرة المصدرية، ويمكن تجاهل الفرق بين الأحرف الكبيرة والصغيرة من قِبل التطبيق، ويمكن أن يختار التطبيق أيضًا ستة محارف ذات أهمية فقط بعد محرف النقطة .. يمكنك أيضًا الكتابة بالشكل التالي: # define NAME <stdio.h> # include NAME للحصول على نتيجة مماثلة لهذا: # include <stdio.h> إلا أن هذه الطريقة تعقيدٌ لا داعي له، وهي معرضةٌ لبعض الأخطاء طبقًا للقواعد المعرفة بحسب التطبيق إذ تحدد هذه القواعد كيف سيُعالج النص بين القوسين < >. من الأبسط أن يكون النص البديل للماكرو NAME سلسلةً نصية، على سبيل المثال: #define NAME "stdio.h" #include NAME لا يوجد في حالتنا السابقة أي فرصة للأخطاء الناتجة عن التصرف المعرف بحسب التطبيق، إلا أن مسارات البحث مختلفة كما وضحنا سابقًا. سلسلة المفتاح في حالتنا الأولى التي تستبدِل NAME هي على النحو التالي (بحسب القوانين التي ناقشناها سابقًا): < stdio . h > أما في الحالة الثانية فهي من الشكل: "stdio.h" الحالة الثانية سهلة الفهم، لأنه يوجد لدينا فقط سلسلة نصية وهي مفتاح تقليدي لموجّه # include، بينما الحالة الثانية معرفةٌ بحسب التطبيق، وبالتالي يعتمد تشكيل سلسلة المفاتيح لاسم ترويسة صالح على التطبيق. أخيرًا، المحرف الأخير من الملف المُضمّن داخل موجه include يجب أن يكون سطرًا جديدًا، وإلا سنحصل على خطأ. الأسماء مسبقة التعريف الأسماء التالية هي أسماء مسبقة التعريف predefined names داخل المعالج المُسبق: الاسم __LINE__: ثابت عدد صحيح بالنظام العشري، ويشير إلى السطر الحالي ضمن ملف الشيفرة المصدرية. الاسم __FILE__: اسم ملف الشيفرة المصدرية الحالي، وهو سلسلة نصية. الاسم __DATE__: التاريخ الحالي، وهو سلسلة نصية من الشكل: Apr 21 1990 إذ يظهر اسم الشهر كما هو معرّف في الدالة المكتبية asctime وأول خانة من التاريخ مسافة فارغة إذان كان التاريخ أقل من 10. الاسم __TIME__: وقت ترجمة الملف، وهو سلسلة نصية موافقة للشكل السابق باستخدام الدالة asctime، أي من الشكل "hh:mm:ss". الاسم __STDC__: عدد صحيح ثابت بقيمة 1، ويُستخدم لاختبار اتباع المصرّف لضوابط المعيار، إذ يمتلك هذا العدد قيمًا مختلفة لإصدارات مختلفة من المعيار. الطريقة الشائعة في استخدام هذه الأسماء المعرفة مسبقًا هي على النحو التالي: #define TEST(x) if(!(x))\ printf("test failed, line %d file %s\n",\ __LINE__, __FILE__) /**/ TEST(a != 23); /**/ مثال 2 إذا كانت نتيجة TEST في المثال السابق خطأ، فستُطبع الرسالة متضمنةً اسم الملف ورقم السطر في الرسالة. إلا أن استخدام تعليمة if في هذه الحالات قد يتسبب ببعض من اللبس، كما يوضح المثال التالي: if(expression) TEST(expr2); else statement_n; إذ سترتبط تعليمة else بتعليمة if المخفية التي ستُستبدل باستخدام الماكرو TEST، وعلى الرغم من أن حدوث هذا الشيء عند الممارسة مستبعد إلا أنه سيكون خطأً لعينًا صعب الحل والتشخيص إذا حدث لك، ولتفادي ذلك، يُحبّذ استخدام الأقواس وجعل محتوى كل تعليمة تحكم بتدفق البرنامج مثل تعليمة مركّبة بغض النظر عن طولها. لا يمكننا استعمال أي من الأسماء __LINE__ أو __FILE__ أو __DATE__ أو __TIME__ أو __STDC__ أو أي من الأسماء المعرفة الأخرى ضمن موجه #define أو #undef. ينص المعيار على أن أي اسم محجوز يجب أن يبدأ بشرطةٍ سفلية underscore وحرفٍ كبير، أو شرطتان، وبالتالي يمكنك استخدام أي اسم لاستخدامك الخاص، لكن انتبه من استخدام الأسماء المحجوزة في ملفات الترويسة التي ضمّنتها في برنامجك. موجه التحكم بتقارير الأخطاء line يُستخدم هذا الموجه في ضبط القيمة التي يحملها كل من __LINE__ و __FILE__، لكن ما المُستفاد من ذلك؟ توّلد العديد من الأدوات في الوقت الحالي شيفرةً بلغة سي C خرجًا لها، ويسمح هذا الموجه لهذه الأدوات بالتحكم برقم السطر الحالي إلا أن استخدامه محدودٌ لمبرمج لغة سي الاعتيادية. يأتي الموجه بالشكل التالي: # line number optional-string-literal newline يضبط الرقم number قيمة __LINE__ وتضبط السلسلة النصية الاختيارية إن وُجدت قيمة __FILE__. في الحقيقة، ستُوسّع سلسلة المفاتيح التي تتبع الموجه #line باستخدام ماكرو، ومن المفترض أن تشكّل موجهًا صالحًا بعد التوسعة. التصريف الشرطي يتحكم بالتصريف الشرطي عدد من الموجهات، إذ تسمح هذه الموجهات بتصريف أجزاء معينة من البرنامج اختياريًا أو تجاهلها حسب الشروط، وهذه الشروط هي: #if و #ifdef و #ifndef و #elif و #else و #endif إضافةً إلى عامل المُعالج المسبق الأحادي. يمكننا استخدام الموجهات على النحو التالي: #ifdef NAME /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif #ifndef NAME /* صرّف هذا القسم إذا كان الاسم غير معرّفًا */ #else /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif يُستخدم كل من #ifdef و #endif لاختبار تعريف اسم الماكرو، ويمكن استخدام #else طبعًا مع #ifdef (و #if أو #elif أيضًا)، لا يوجد التباس حول استخدام #else، لأن استخدام #endif يحدّد نطاق الموجّه مما يبعد أي مجال للشبهات. ينص المعيار على وجوب دعم ثمان طبقات من الموجهات الشرطية المتداخلة، إلا أنه من المستبعد وجود أي حدّ عمليًّا. تُستخدم هذه الموجهات لتحديد فقرات صغيرة من برامج سي التي تعتمد على الآلة التي تعمل عليها (عندما لا يكون بالإمكان جعل كامل البرنامج ذا أداء مستقل غير مرتبط بطبيعة الآلة التي يعمل عليها)، أو لتحديد خوارزميات مختلفة تعتمد على بعض المقايضات لتنفيذها. تأخذ بنية #if و #elif تعبيرًا ثابتًا وحيدًا ذا قيمةٍ صحيحة، وقيم المعالج المسبق هذه مماثلةٌ للقيم الاعتيادية باستثناء أنها يجب أن تخلو من عوامل تحويل الأنواع casts. تخضع سلسلة المفتاح التي تشكّل التعبير الثابت لعملية استبدال بالماكرو، عدا الأسماء المسبوقة بموجه التعريف فلا تُستبدل. بالاعتماد على ما سبق ذكره، فالتعبير defined NAME أو defined ( NAME ) يُقيّمان إلى القيمة 1 إذا كان NAME معرّفًا، وإلى القيمة 0 إن لم يكن معرّفًا، وتُستبدل جميع المعرفات ضمن التعبير -بما فيها كلمات لغة سي المفتاحية- بالقيمة 0، ومن ثم يُقيّم التعبير. يُقصد بالاستبدال (بما فيه استبدال الكلمات المفتاحية) أن sizeof لا يمكن استخدامه في هذه التعابير للحصول على القيمة التي تحصل عليها في الحالة الاعتيادية. تُستخدم القيمة الصفر -كما هو الحال في تعليمات سي الشرطية- للدلالة على القيمة "خطأ false"، وتدل أي قيمة أخرى على القيمة "صواب true". يجب استخدام المعالج المسبق العمليات الحسابية وفق النطاقات المحددة في ملف الترويسة <limits.h>، وأن تُعامل التعابير ذات قيمة العدد الصحيح مثل عدد صحيح طويل والعدد الصحيح عديم الإشارة مثل عدد صحيح طويل عديم الإشارة، بينما لا يتوجب على المحارف أن تكون مساوية إلى القيمة ذاتها عند وقت التنفيذ، لذا من الأفضل في البرامج القابلة للنقل أن نتجنب استخدامها في تعابير المعالج المُسبق. تعني القوانين السابقة عمومًا أنه بإمكاننا أن نحصل على نتائج حسابية من المعالج المسبق التي قد تكون مختلفة عن النتائج التي نحصل عليها عند وقت التنفيذ، وذلك بفرض إجراء الترجمة والتنفيذ على آلات مختلفة. إليك مثالًا: #include <limits.h> #if ULONG_MAX+1 != 0 printf("Preprocessor: ULONG_MAX+1 != 0\n"); #endif if(ULONG_MAX+1 != 0) printf("Runtime: ULONG_MAX+1 != 0\n"); مثال 3 من الممكن أن يُجري المعالج المسبق بعض العمليات الحسابية بنطاق أكبر من النطاق المُستخدم في البيئة المُستهدفة، ويمكن في هذه الحالة ألّا يطفح تعبير المعالج المسبق ULONG MAX+1 ليعطي النتيجة 0، بينما يجب أن يحدث لك في بيئة التنفيذ. يوضح المثال التالي استخدام الثوابت المذكور آنفًا، وتعليمة "وإلّا else" الشرطية #elif. #define NAME 100 #if ((NAME > 50) && (defined __STDC__)) /* افعل شيئًا */ #elif NAME > 25 /* افعل شيئًا آخر */ #elif NAME > 10 /* افعل شيئًا آخر */ #else /* الاحتمال الأخير */ #endif يتوجب التنويه هنا على أن موجهات التصريف الشرطية لا تتبع لقوانين النطاق الخاصة بلغة سي، ولهذا فيجب استخدامها بحرص، إلا إذا أردت أن يصبح برنامجك صعب القراءة، إذ من الصعب أن تقرأ برنامج سي C مع وجود هذه الأشياء كل بضعة أسطر، وسيتملكك الغضب تجاه كاتب البرنامج إذا صادفت شيفرة مشابهة لهذه دون أي موجه #if واضح بالقرب منها: #else } #endif لذلك يجب أن تعامل هذه الموجهات معاملة الصلصة الحارّة، استخدامها ضروري في بعض الأحيان، إلا أن الاستخدام الزائد لها سيعقّد الأمور. موجه التحكم المعتمد على التنفيذ pragma كان هذا الموجه بمثابة محاولة للجنة المعيار بإضافة طريقة للولوج للباب الخلفي، إذ يسمح هذا الموجه بتنفيذ بعض الأشياء المعرفة بحسب التطبيق. إذا لم يعرف التطبيق ما الذي سيفعله بهذا الموجه (أي لم يتعرف على وظيفته) فيستجاهله ببساطة، إليك مثالًا عن استخدامه: #pragma byte_align يُستخدم الموجه السابق لإعلام التطبيق بضرورة محاذاة جميع أعضاء الهياكل بالنسبة لعنوان البايت الخاص بهم، إذ يمكن لبعض معماريات المعالجات أن تتعامل مع أعضاء الهياكل بطول الكلمة بمحاذاة عنوان البايت، ولكن مع خسارة السرعة في الوصول إليها. يمكن أن يُفسّر هذا الأمر بحسب تفسير التطبيق له طبعًا، وإن لم يكن للتطبيق أي تفسير خاص به، فلن يأخذ الموجه أي تأثير، ولن يُعد خطأً، ومن المثير للاهتمام رؤية بعض الاستخدامات الخاصة لهذا النوع من الموجهات. موجه عرض رسالة خطأ قسرية error يُتبع هذا الموجه بمفتاح أو أكثر في نهاية السطر الخاص به، وتُشكّل رسالة تشخيصية من قبل المصرف تحتوي على هذه المفاتيح، ولا توجد مزيدٌ من التفاصيل عن ذلك في المعيار. يُمكن استخدام هذا الموجه لإيقاف عملية التصريف على آلة ذات عتاد صلب غير مناسب لتنفيذ البرنامج: #include <limits.h> #if CHAR_MIN > -128 #error character range smaller than required #endif سيتسبب ذلك ببعض الأخطاء المتوقعة عند مرحلة التصريف إذا نُفّذ الموجه وعُرضت الرسالة. الخاتمة على الرغم من الخصائص القوية والمرنة التي يوفرها المعالج المسبق، إلا أنها شديدة التعقيد، وهناك عددٌ قليل من الجوانب المتعلقة به ضرورية الفهم، مثل القدرة على تعريف الماكرو ودوال الماكرو، والمستخدمة بكثرة في أي برنامج سي تقريبًا عدا البرامج البسيطة، كما أن تضمين ملفات الترويسة مهمّ أيضًا طبعًا. للتصريف الشرطي استخدامان مهمان، أولهما هو القدرة على تصريف البرنامج بوجود أو بعدم وجود تعليمات الاكتشاف عن الأخطاء Debugging ضمن البرنامج، وثانيهما هو القدرة على تحديد تعليمات معينة يعتمد تنفيذها على طبيعة التطبيق أو الآلة التي يعمل عليها البرنامج. باستثناء ما ذكرنا سابقًا، من الممكن نسيان المزايا الأخرى التي ذُكرت في المقال، إذ لن يتسبب التخلي عنها بفقدان كثيرٍ من الخصائص، ولعلّ الحل الأمثل هو تواجد فرد واحد متخصّص في المعالج المسبق ضمن الفريق البرمجي لتطوير الماكرو التي تفيد مشروعًا ما بعينه باستخدام بعض المزايا الغريبة، مثل التنصيص ولصق المفاتيح. سيستفيد معظم مستخدمي لغة سي C أكثر إذا وجّهوا جهدهم بدلًا من ذلك نحو تعلم بعض الأجزاء الأخرى من لغة سي، أو تقنيات التحكم بجودة البرمجيات إذا أتقنوا اللغة. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C المقال السابق: تهيئة المتغيرات وأنواع البيانات في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C
يتناول المقال مرحلة المعالجة المسبقة للشيفرة المصدرية بما فيها مراحل استبدال الماكرو ومختلف موجهات المعالج المسبق الأخرى. أثر المعيار ستشعر أن المعالج المُسبق Preprocessor لا ينتمي إلى لغة سي عمومًا، إذ لا يسمح لك وجوده بالتعامل بصورةٍ متكاملة مع اللغة كما أنك لا تستطيع الاستغناء عنه في ذات الوقت، وفي الحقيقة، كان استخدام المعالج المُسبق في أيام سي الأولى اختياريًا واعتاد الناس على كتابة برامج لغة سي C بدونه، ويمكننا أن ننظر إلى كونه جزءًا من لغة سي حاليًا صدفةً إلى حدٍ ما، إذ كان يعالج بعضًا من أوجه القصور في اللغة، مثل تعريف الثوابت وتضمين التعريفات القياسية، وأصبح نتيجةً لذلك جزءًا ضمن حزمة لغة سي ككُل. لم يكن هناك في تلك الفترة معيارٌ رسميٌ متفقٌ عليه يوحّد ما يفعله المعالج المسبق، وكانت إصدارات مختلفة منه مُطبّقة بصورةٍ مختلف على عدة أنظمة، وأصبحت عملية نقل البرنامج وتصديره إلى أنظمة أخرى مشكلةً كبيرة إذا استخدم ما يزيد عن الخصائص الأساسية للمعالج. كانت وظيفة المعيار الأساسية هنا هي تعريف سلوك المعالج المُسبق بما يتوافق مع الممارسات الشائعة، وقد سبق حصول ذلك مع لغة سي القديمة، إلا أن المعيار اتخذ إجراءات إضافية وسط الخلاف وحدد مجموعةً من الخصائص الإضافية التي قُدمت مع إصدارات المعالج المُسبق الأكثر شعبية، وعلى الرغم من فائدة هذه الخصائص إلا أن الخلاف كان بخصوص الاتفاق على طريقة تطبيقها. لم يكترث المعيار لمشكلة القابلية مع البرامج القديمة بالنظر إلى أن هذه البرامج تستخدم طرقًا غير قابلة للنقل في المقام الأول، وسيحسِّن تواجد هذه الخصائص المتقدمة ضمن المعيار سهولة نقل برامج لغة سي مستقبلًا بصورةٍ ملحوظة. يعدّ استخدام المعالج المسبق سهلًا إذا استُخدم لمهمته الأساسية البسيطة في جعل البرامج سهلة القراءة والصيانة، ولكن يُفضّل ترك خصائصه المتقدمة لاستخدام الخبراء. بحكم تجربتنا، يُعد استخدام #define ومجموعة تعليمات التصريف الشرطي conditional compilation (أوامر #if) مناسبًا للمبتدئين، وإذا ما زلت مبتدئً في لغة سي، فاقرأ هذه المقالة مرةً واحدة لمعرفة إمكانيات المعالج المُسبق واستخدم التمارين للتأكد من فهمك، وإلا فنحن ننصح بخبرة لا تقل عن ستة أشهر في لغة سي حتى تستطيع فهم إمكانيات المعالج المسبق كاملةً، لذا لن نركز على منحك مقدمة سهلة هنا بل سنركز على التفاصيل الدقيقة فورًا. كيف يعمل المعالج المسبق؟ بالرغم من أن المعالج المسبق الموضح في الشكل التالي سينتهي به المطاف غالبًا بكونه جزءًا هامًا من مصرف لغة سي المعيارية، إلا أنه يمكننا التفكير به على أنه برنامجٌ منفصلٌ يحول شيفرة سي المصدرية التي تحتوي على موجهات المعالج المسبق إلى شيفرة مصدرية لا تحتوي على هذه الموجهات. شكل 1: المعالج المسبق في لغة سي من المهم هنا أن نتذكر أن المعالج المسبق لا يعمل متبعًا القوانين الخاصة بشيفرة لغة سي ذاتها، وإنما يعمل على أساس كل سطرٍ بسطره، وهذا يعني أن نهاية السطر حدثٌ مميز وليس كما تنظر لغة سي إلى نهاية السطر بكونه مشابهًا لمحرف مسافة أو مسافة جدولة. لا يعي المعالج المسبق قوانين لغة سي الخاصة بالنطاق Scope، إذ تأخذ موجهات المعالج المسبق (مثل #define) تأثيرها فور رؤيتها ويبقى تأثيرها موجودًا حتى الوصول إلى نهاية الملف الذي يحتوي هذه الموجهات، ولا ينطبق هنا هيكل البرنامج المتعلق بالكتل البرمجية. من المحبّذ إذًا استخدام موجهات المعالج المسبق بأقل ما أمكن، فكلما قلّ عدد الأجزاء التي لا تتبع قوانين النطاق "الاعتيادية" كلّما قلت إمكانية ارتكاب الأخطاء، وهذا ما نقصده عندما نقول أن تكامل المعالج المسبق ولغة سي C محدودٌ فيما بينهما. يصف المعيار بعض القوانين المعقدة بخصوص كتابة موجهات المعالج المسبق، وبالأخص بالنسبة للمفاتيح Tokens، ويجب عليك معرفة القوانين كلها إذا أردت فهم موجهات المعالج المسبق، فالنص الذي يُعالج لا يعدّ سلسلةً من المحارف بل هو مُجزّأٌ إلى مفاتيح ومن ثم معلومات معالجة مُجزأة. من الأفضل اللجوء إلى المعيار إذا أردت تعريفًا كاملًا بالعملية، إلا أننا سنتطرق إلى شرح بسيط؛ إذ سنشرح كل جزء موجود في القائمة التالية لاحقًا. اسم ملف الترويسة > يمكن استخدام أي محرف هنا (باستثناء) <. مفتاح المعالج المسبق اسم ملف الترويسة كما ذُكر سابقًا لكن فقط في حالة ذكره ضمن #include أو معرّف identifier مثل معرف لغة C أو كلمة مفتاحية أو ثابت وهو أي عدد صحيح أو طبيعي ثابت أو سلسلة نصية وهو سلسلة نصية سي اعتيادية أو عامل وهو من أحد عوامل لغة سي أو واحد من علامات الترقيم [ ] ( ) { } * , : = ; ... # أو أي محرف غير فارغ (محرف فارغ مثل محرف المسافة) غير مذكور في اللائحة أعلاه نقصد أي محرف (باستثناء) أي باستثناء المحرفين < أو محرف السطر الجديد. الموجهات Directives تبدأ موجّهات المعالج المسبق بالمحرف "#" دائمًا، وتُتبع بمحرف مسافة فارغة اختياريًا إلا أن هذا الاستخدام غير شائع، ويوضح الجدول التالي الموجهات المعرّفة في المعيار. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الموجّه المعنى # include تضمين ملف مصدري # define تعريف ماكرو # undef التراجع عن تعريف ماكرو # if تصريف شرطي # ifdef تصريف شرطي # ifndef تصريف شرطي # elif تصريف شرطي # else تصريف شرطي # endif تصريف شرطي # line التحكم بتقارير الأخطاء # error عرض رسالة خطأ قسرية # pragma تُستخدم للتحكم المعتمد على التنفيذ # موجّه فارغ؛ دون تأثير جدول 1 موجّهات المعالج المُسبق سنشرح كل من معنى واستخدام الموجّهات بالتفصيل في الفقرات التالية. لاحظ أن المحرف # والكلمة المفتاحية التي تليه عنصرين مستقلين منفصلين، ويمكن إضافة مسافةٍ بيضاء بينهما. الموجه الفارغ هذا الموجّه بسيط، إذ ليس لإشارة # بمفردها على السطر أي تأثير. موجه تعريف الماكرو define هناك طريقتان لتعريف الماكرو، أولهما تبدو مثل تابع والأخرى على النقيض، إليك مثالًا باستخدام الطريقتين: #define FMAC(a,b) a here, then b #define NONFMAC some text here يعرّف التصريحان السابقان ماكرو ونصًا بديلًا له، إذ سيستخدم ليُستبدل بالماكرو المذكور ضمن كامل البرنامج، ويمكن استخدامهما بعد التصريح عنهما على النحو التالي مع ملاحظة أثر استبدال الماكرو الموضح في التعليقات: NONFMAC /* النص هنا */ FMAC(first text, some more) /* النص الأول، ومزيدٌ من النص */ يُستبدل اسم الماكرو في الحالة التي لا يبدو فيها مثل دالة بالنص البديل ببساطة، وكذلك الأمر بالنسبة لماكرو من نوع دالة، وفي حال كان النص البديل يحتوي على معرّف يطابق اسم معامل من معاملات الماكرو، يُستخدم النص الموجود وسيطًا بدلًا من المعرِّف في النص البديل. يُحدَّد نطاق الأسماء المذكورة في وسطاء الماكرو بالكتلة التي تحتوي الموجه #define. تُهمل أي مسافات فارغة بعد أو قبل النص البديل ضمن تعريف الماكرو، وذلك لكلا الطريقتين على حد سواء. يتبادر إلى البعض السؤال الفضولي التالي: كيف يمكنني تعريف ماكرو بسيط بحيث يكون النص البديل الخاص به ينتهي بالقوس المفتوح ")"؟ الإجابة بسيطة، إذا احتوى تعريف الماكرو على مسافة أمام القوس ")"، فلن يحتسب الماكرو من نوع ماكرو دالة، بل نص بديل لماكرو بسيط فحسب، إلا أنه لا يوجد قيد مماثل عندما تستخدم الماكرو الشبيه بالدالة. يسمح المعيار للماكرو بغض النظر عن نوع أن يُعاد تعريفه في أي لحظة باستخدام موجّه # define آخر، وذلك بفرض عدم تغيير نوع الماكرو وأن تكون المفاتيح التي تشكل التعريف الأساسي وإعادة التعريف متماثلة بالعدد والترتيب والكتابة بما فيها استخدام المسافة الفارغة، وتُعد المسافات الفارغة في هذا السياق متساوية، وطبقًا لذلك فالتالي صحيح: # define XXX abc/*تعليق*/def hij # define XXX abc def hij وذلك لأن التعليق شكلٌ من أشكال المسافات الفارغة، وسلسلة المفاتيح للحالتين السابقتين هي: # w-s define w-s XXX w-s abc w-s def w-s hij w-s إذ تعني w-s مفتاح مسافة بيضاء. استبدال الماكرو أين سيتسبب اسم الماكرو باستبدال النص بالنص البديل؟ يحدث الاستبدال عمليًا في أي مكان يحدث التعرف فيه على المعرّف identifier مثل مفتاح منفصل ضمن البرنامج، عدا المعرف المتبوع بالمحرف "#" الخاص بموجّه المعالج المُسبق. يمكنك كتابة التالي: #define define XXX #define YYY ZZZ ومن المتوقع أن يتسبب استبدال سطر #define الثاني بالسطر #xxx بخطأ. يُستبدل المعرف المرتبط بماكرو بسيط عندما يُرى بمفتاح الماكرو البديل، ومن ثم يُعاد مسحه rescanned (سنتكلم عن ذلك لاحقًا) للعثور على أي استبدالات أخرى. يمكن استخدام ماكرو الدالة مثل أي دالة أخرى اعتيادية، وذلك بوضع مساحات فارغة حول اسم الماكرو ولائحة الوسطاء وغيره، كما قد يحتوي على محرف سطر جديد: #define FMAC(a, b) printf("%s %s\n", a, b) FMAC ("hello", "sailor" ); /* ينتج ما سبق بالتالي */ printf("%s %s\n", "hello", "sailor") يمكن أن تأخذ وسطاء الماكرو من نوع دالة أي تسلسل عشوائي للمفتاح، وتُستخدم الفاصلة "," لفصل الوسطاء عن بعضهم بعضًا، ولكن يمكن إخفاؤها بوضعها داخل أقواس "( )". توازن الأزواج المتطابقة من الأقواس داخل الوسيط بعضها بعضًا، وبالتالي ينهي القوس "(" استدعاء الماكرو إذا كان القوس ")" هو الذي بدأ باستدعائه. #define CALL(a, b) a b CALL(printf, ("%d %d %s\n",1, 24, "urgh")); /* results in */ printf ("%d %d %s\n",1, 24, "urgh"); لاحظ كيف حافظنا على الأقواس حول الوسيط الثاني للدالة CALL عند الاستبدال، ولم تُزال من النص. إذا أردت استخدام ماكرو مثل printt، لن يساعدك المعيار بهذا الخصوص عندما تختار عدد متغير من الوسطاء، فذلك غير مدعوم. نحصل على سلوك غير معرف إذا لم يحتوي أحد الوسطاء على مفتاح معالج مسبق، والأمر مماثل إذا احتوت سلسلة مفاتيح المعالج المسبق التي تشكل الوسيط على موجّه معالج مسبق مغاير: #define CALL(a, b) a b /* كل حالة تنتج عن سلوك غير محدد */ CALL(,hello) CALL(xyz, #define abc def) إلا أننا نعتقد برأينا أن الاستخدام الثاني الخاطئ للدالة CALL يجب أن ينتج بسلوك معرف، إذ أن أي أحد قادر على كتابة ذلك سيستفيد من انتباه المصرّف. تتبع معالجة ماكرو الدالة الخطوات التالية: جميع وسطائها معرفة. إن كان أي من المفاتيح ضمن الوسيط مرشح لاستبدال بواسطة ماكرو، فسيُستبدل حتى الوصول للنقطة التي لا يمكن فيها إجراء المزيد من الاستبدالات، باستثناء الحالات المذكورة في البند الثالث التالي. لا يوجد هناك أي خطر بخصوص امتلاك الماكرو لعدد مختلف من الوسطاء بعد إضافة فاصلة إلى قائمة الوسطاء الأساسية، إذ يُحدد الوسطاء في الخطوة السابقة فقط. تُستبدل المعرفات التي تسمّي وسيط الماكرو في نص الاستبدال بسلسلة مفتاح مثل وسيطٍ فعلي، ويُهمل الاستبدال إذا كان المعرف مسبوقًا بإشارة "#" أو اثنتين "##" أو متبوعًا بالإشارتين "##". التنصيص هناك طريقةٌ خاصة لمعالجة الأماكن التي يسبق فيها وسيط الماكرو الإشارة "#" في نص الماكرو البديل، إذ تًهمل أي مسافة فارغة تسبق أو تلي قائمة الوسطاء الفعلية للمفتاح، ومن ثم تُحوّل قائمة المفتاح والإشارة # إلى سلسلة نصية واحدة، وتُعامل المسافات بين المفاتيح كأنها محارف مسافة في سلسلة نصية؛ ولمنع حدوث أي نتائج مفاجئة، يُسبق أي محرف " أو \ في السلسلة النصية الجديدة بالمحرف \. إليك المثال التالي الذي يوضح الخاصية المذكورة: #define MESSAGE(x) printf("Message: %s\n", #x) MESSAGE (Text with "quotes"); /* * النتيجة هي * printf("Message: %s\n", "Text with \"quotes\""); */ لصق المفتاح Token pasting قد نجد العامل ## في أي مكان ضمن النص البديل للماكرو باستثناء نهايته أو بدايته، وتُستخدم سلسلة مفتاح وسيط الماكرو لاستبدال النص البديل إذا ورد في اسم الوسيط لماكرو دالة مسبوقًا أو متبوعًا بأحد هذه العوامل، وتُدمج المفاتيح المحيطة بالعامل ## سويًا سواءٌ كانت ضمن ماكرو دالة أو ماكرو بسيط، ونحصل على سلوك غير معرف إذا شكّل ذلك مفتاح غير صالح، ويُجرى إعادة مسح بعدها. إليك عملية تحصل على عدة مراحل يُستخدم فيها إعادة المسح لتوضيح لصق المفتاح: #define REPLACE some replacement text #define JOIN(a, b) a ## b JOIN(REP, LACE) becomes, after token pasting, REPLACE becomes, after rescanning some replacement text إعادة المسح يُمسح النص البديل مضافًا إلى مفاتيح الملف المصدري مجددًا حالما تحصل العملية الموضحة في الفقرة السابقة، وذلك للبحث عن أسماء ماكرو أخرى لاستبدالها، مع استثناء أن اسم الماكرو داخل النص البديل لا يُستبدل. من الممكن أن نضيف ماكرو متداخلة Nested macros وبالتالي يمكن لعدد من الماكرو أن تُعالج لاستبدالها في أي نقطة دفعةً واحدة، ولا يوجد في هذه الحالة أي اسم مرشح لاستبداله ضمن المستوى الداخلي لهذا التداخل، وهذا يسمح لنا بإعادة تعريف الدوال الموجودة سابقًا مثل ماكرو: #define exit(x) exit((x)+1) تصبح أسماء الماكرو التي لم تُستبدل مفاتيحٌ محمية من الاستبدال مستقبلًا، حتى لو وردت أي عمليات تالية لتبديلها، وهذا يدرأ الخطر عن حدوث التعادوية recursion اللانهائية في المعالج المسبق، وتنطبق هذه الحماية فقط في حالة نتج اسم الماكرو عن النص البديل، وليس النص المصدري ضمن البرنامج، إليك ما الذي نقصده: #define m(x) m((x)+1) /* هذا */ m(abc); /* ينتج عن هذا بعد الاستبدال */ m((abc)+1); /* * على الرغم من أن النتيجة السابقة تبدو مثل ماكرو * إلا أن القواعد تنص على لزوم عدم استبداله */ m(m(abc)); /* * تبدأ m( الخارجية باستدعاء الماكرو, * لكن تُستبدل الداخلية أولًا * لتصبح بالشكل m((abc)+1) * وتُستخدم مثل وسيط، مما يعطينا */ m(m((abc+1)); /* * ويصبح بعد الاستبدال على النحو التالي */ m((m((abc+1))+1); إذا لم يؤلمك دماغك بقراءة ما سبق، فاذهب واقرأ ما الذي يقوله المعيار عن هذا ونضمن لك أنه سيؤلمك. ملاحظات هناك مشكلة غير واضحة تحدث عند استخدام وسطاء ماكرو الدالة. /* تحذير: هناك مشكلة في هذا البرنامج */ #define SQR(x) ( x * x ) /* * عند ورود المعاملات الصورية في النص البديل، تُستبدل بالمعاملات الفعلية للماكرو */ printf("sqr of %d is %d\n", 2, SQR(2)); المعامل الصوري formal parameter للماكرو SQR هو x، والمعامل الفعلي actual argument هو 2، وبالتالي سينتج النص البديل عن: printf("sqr of %d is %d\n", 2, ( 2 * 2 )); لاحظ استخدام الأقواس، فالمثال التالي قد يتسبب بمشكلة: /* مثال سيء */ #define DOUBLE(y) y+y printf("twice %d is %d\n", 2, DOUBLE(2)); printf("six times %d is %d\n", 2, 3*DOUBLE(2)); تكمن المشكلة في أن التعبير الأخير في استدعاء الدالة printf الثاني يُستبدل بالتالي: 3*2+2 وهذا ينتج عن 8 وليس 12. تنص القاعدة على أنه يجب عليك الحرص بخصوص الأقواس فهي ضرورية في حالة استخدام الماكرو لبناء تعابير. إليك مثالًا آخر: SQR(3+4) /* تصبح بالشكل التالي بعد الاستبدال */ ( 3+4 * 3+4 ) /* للأسف، ما زالت خاطئة! */ لذا، يجب عليك النظر بحرص إلى الوسطاء الصورية عندما ترِد ضمن نصل بديل. إليك الأمثلة الصحيحة عن الدالتين SQR و DOUBLE: #define SQR(x) ((x)*(x)) #define DOUBLE(x) ((x)+(x)) في جعبة الماكرو حيلةٌ صغيرة بعد لمفاجئتك، كما سيوضح لك المثال التالي: #include <stdio.h> #include <stdlib.h> #define DOUBLE(x) ((x)+(x)) main(){ int a[20], *ip; ip = a; a[0] = 1; a[1] = 2; printf("%d\n", DOUBLE(*ip++)); exit(EXIT_SUCCESS); } مثال 1 لمَ يتسبب المثال السابق بمشاكل؟ لأن نص ماكرو البديل يشير إلى *ip++ مرتين، مما يتسبب بزيادة ip مرتين، لا يجب للماكرو أن يُستخدم مع التعابير التي لها آثار جانبية، إلا إذا تحققت بحرص من أمانها. بغض النظر عن هذه التحذيرات التي تخص الماكرو، إلا أنها تقدم خصائص مفيدة، وستُستخدم هذه الخصائص كثيرًا من الآن فصاعدًا. موجه التراجع عن تعريف ماكرو undef يُمكن أن يُهمل (يُنتسى) أي معرّف يعود لموجه #define بكتابة: #undef NAME إذ لا يولد #undef خطأً إن لم يكن الاسم NAME معرفًا مسبقًا. سنستفيد من هذا الموجه كثيرًا عمّا قريب، وسنتكلم لاحقًا عن بعض دوال المكتبات التي هي في الحقيقة ماكرو وليس دالة، وستصبح قادرًا على الوصول إلى الدالة الفعلية عن طريق التراجع عن تعريفها. موجه تضمين ملف مصدري include يمكن كتابة هذا الموجه بشكلين: #include <filename> #include "filename" ينجم عن استخدام أحد الطريقتين قراءة ملف جديد عند نقطة ذكر الموجّه، وكأننا استبدالنا سطر الموجه بمحتويات الملف المذكور، وإذا احتوى هذا الملف على بعض التعليمات الخاطئة ستظهر لك الأخطاء مع إشارتها إلى الملف التي نجمت عنه مصحوبةً برقم السطر، وهذه مهمة مطوّر المصرف، وينص المعيار على أنه يجب للمصرف دعم ثمانية طبقات من موجّهات # include المتداخلة على الأقل. يمكن الاختلاف بين استخدام <> و " " حول اسم الملف بالمكان الذي سيُبحث فيه عن الملف؛ إذ يتسبب استخدام الأقواس في البحث في عددٍ من الأماكن المعرّفة بحسب التطبيق؛ بينما يتسبب استخدام علامتي التنصيص بحثًا في المكان المرتبط بمكان ملف الشيفرة المصدرية، وستُعلمك ملاحظات تطبيقك بما هو المقصود بكلمة "المكان" والتفاصيل المرتبطة بها، إذا لم تعود عملية البحث عن الملف باستخدام علامتي التنصيص بأي نتيجة، تُعاود عملية البحث من جديد وكأنك استخدمت القوسين. تُستخدم الأقواس عمومًا عندما تريد تحديد ملفات ترويسة لمكتبة قياسية Standard library، بينما تُستخدم علامتي التنصيص لملفات الترويسة الخاصة بك، التي تكون مخصصة غالبًا لبرنامج واحد. لا يحدد المعيار كيفية تسمية ملف بصورةٍ صالحة، إلا أنه يحدد وجوب وجود طريقة فريدة معرفة بحسب التطبيق لترجمة اسم الملفات من الشكل xxx.x (يمثّل كل x حرفًا)، إلى أسماء ملفات الشيفرة المصدرية، ويمكن تجاهل الفرق بين الأحرف الكبيرة والصغيرة من قِبل التطبيق، ويمكن أن يختار التطبيق أيضًا ستة محارف ذات أهمية فقط بعد محرف النقطة .. يمكنك أيضًا الكتابة بالشكل التالي: # define NAME <stdio.h> # include NAME للحصول على نتيجة مماثلة لهذا: # include <stdio.h> إلا أن هذه الطريقة تعقيدٌ لا داعي له، وهي معرضةٌ لبعض الأخطاء طبقًا للقواعد المعرفة بحسب التطبيق إذ تحدد هذه القواعد كيف سيُعالج النص بين القوسين < >. من الأبسط أن يكون النص البديل للماكرو NAME سلسلةً نصية، على سبيل المثال: #define NAME "stdio.h" #include NAME لا يوجد في حالتنا السابقة أي فرصة للأخطاء الناتجة عن التصرف المعرف بحسب التطبيق، إلا أن مسارات البحث مختلفة كما وضحنا سابقًا. سلسلة المفتاح في حالتنا الأولى التي تستبدِل NAME هي على النحو التالي (بحسب القوانين التي ناقشناها سابقًا): < stdio . h > أما في الحالة الثانية فهي من الشكل: "stdio.h" الحالة الثانية سهلة الفهم، لأنه يوجد لدينا فقط سلسلة نصية وهي مفتاح تقليدي لموجّه # include، بينما الحالة الثانية معرفةٌ بحسب التطبيق، وبالتالي يعتمد تشكيل سلسلة المفاتيح لاسم ترويسة صالح على التطبيق. أخيرًا، المحرف الأخير من الملف المُضمّن داخل موجه include يجب أن يكون سطرًا جديدًا، وإلا سنحصل على خطأ. الأسماء مسبقة التعريف الأسماء التالية هي أسماء مسبقة التعريف predefined names داخل المعالج المُسبق: الاسم __LINE__: ثابت عدد صحيح بالنظام العشري، ويشير إلى السطر الحالي ضمن ملف الشيفرة المصدرية. الاسم __FILE__: اسم ملف الشيفرة المصدرية الحالي، وهو سلسلة نصية. الاسم __DATE__: التاريخ الحالي، وهو سلسلة نصية من الشكل: Apr 21 1990 إذ يظهر اسم الشهر كما هو معرّف في الدالة المكتبية asctime وأول خانة من التاريخ مسافة فارغة إذان كان التاريخ أقل من 10. الاسم __TIME__: وقت ترجمة الملف، وهو سلسلة نصية موافقة للشكل السابق باستخدام الدالة asctime، أي من الشكل "hh:mm:ss". الاسم __STDC__: عدد صحيح ثابت بقيمة 1، ويُستخدم لاختبار اتباع المصرّف لضوابط المعيار، إذ يمتلك هذا العدد قيمًا مختلفة لإصدارات مختلفة من المعيار. الطريقة الشائعة في استخدام هذه الأسماء المعرفة مسبقًا هي على النحو التالي: #define TEST(x) if(!(x))\ printf("test failed, line %d file %s\n",\ __LINE__, __FILE__) /**/ TEST(a != 23); /**/ مثال 2 إذا كانت نتيجة TEST في المثال السابق خطأ، فستُطبع الرسالة متضمنةً اسم الملف ورقم السطر في الرسالة. إلا أن استخدام تعليمة if في هذه الحالات قد يتسبب ببعض من اللبس، كما يوضح المثال التالي: if(expression) TEST(expr2); else statement_n; إذ سترتبط تعليمة else بتعليمة if المخفية التي ستُستبدل باستخدام الماكرو TEST، وعلى الرغم من أن حدوث هذا الشيء عند الممارسة مستبعد إلا أنه سيكون خطأً لعينًا صعب الحل والتشخيص إذا حدث لك، ولتفادي ذلك، يُحبّذ استخدام الأقواس وجعل محتوى كل تعليمة تحكم بتدفق البرنامج مثل تعليمة مركّبة بغض النظر عن طولها. لا يمكننا استعمال أي من الأسماء __LINE__ أو __FILE__ أو __DATE__ أو __TIME__ أو __STDC__ أو أي من الأسماء المعرفة الأخرى ضمن موجه #define أو #undef. ينص المعيار على أن أي اسم محجوز يجب أن يبدأ بشرطةٍ سفلية underscore وحرفٍ كبير، أو شرطتان، وبالتالي يمكنك استخدام أي اسم لاستخدامك الخاص، لكن انتبه من استخدام الأسماء المحجوزة في ملفات الترويسة التي ضمّنتها في برنامجك. موجه التحكم بتقارير الأخطاء line يُستخدم هذا الموجه في ضبط القيمة التي يحملها كل من __LINE__ و __FILE__، لكن ما المُستفاد من ذلك؟ توّلد العديد من الأدوات في الوقت الحالي شيفرةً بلغة سي C خرجًا لها، ويسمح هذا الموجه لهذه الأدوات بالتحكم برقم السطر الحالي إلا أن استخدامه محدودٌ لمبرمج لغة سي الاعتيادية. يأتي الموجه بالشكل التالي: # line number optional-string-literal newline يضبط الرقم number قيمة __LINE__ وتضبط السلسلة النصية الاختيارية إن وُجدت قيمة __FILE__. في الحقيقة، ستُوسّع سلسلة المفاتيح التي تتبع الموجه #line باستخدام ماكرو، ومن المفترض أن تشكّل موجهًا صالحًا بعد التوسعة. التصريف الشرطي يتحكم بالتصريف الشرطي عدد من الموجهات، إذ تسمح هذه الموجهات بتصريف أجزاء معينة من البرنامج اختياريًا أو تجاهلها حسب الشروط، وهذه الشروط هي: #if و #ifdef و #ifndef و #elif و #else و #endif إضافةً إلى عامل المُعالج المسبق الأحادي. يمكننا استخدام الموجهات على النحو التالي: #ifdef NAME /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif #ifndef NAME /* صرّف هذا القسم إذا كان الاسم غير معرّفًا */ #else /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif يُستخدم كل من #ifdef و #endif لاختبار تعريف اسم الماكرو، ويمكن استخدام #else طبعًا مع #ifdef (و #if أو #elif أيضًا)، لا يوجد التباس حول استخدام #else، لأن استخدام #endif يحدّد نطاق الموجّه مما يبعد أي مجال للشبهات. ينص المعيار على وجوب دعم ثمان طبقات من الموجهات الشرطية المتداخلة، إلا أنه من المستبعد وجود أي حدّ عمليًّا. تُستخدم هذه الموجهات لتحديد فقرات صغيرة من برامج سي التي تعتمد على الآلة التي تعمل عليها (عندما لا يكون بالإمكان جعل كامل البرنامج ذا أداء مستقل غير مرتبط بطبيعة الآلة التي يعمل عليها)، أو لتحديد خوارزميات مختلفة تعتمد على بعض المقايضات لتنفيذها. تأخذ بنية #if و #elif تعبيرًا ثابتًا وحيدًا ذا قيمةٍ صحيحة، وقيم المعالج المسبق هذه مماثلةٌ للقيم الاعتيادية باستثناء أنها يجب أن تخلو من عوامل تحويل الأنواع casts. تخضع سلسلة المفتاح التي تشكّل التعبير الثابت لعملية استبدال بالماكرو، عدا الأسماء المسبوقة بموجه التعريف فلا تُستبدل. بالاعتماد على ما سبق ذكره، فالتعبير defined NAME أو defined ( NAME ) يُقيّمان إلى القيمة 1 إذا كان NAME معرّفًا، وإلى القيمة 0 إن لم يكن معرّفًا، وتُستبدل جميع المعرفات ضمن التعبير -بما فيها كلمات لغة سي المفتاحية- بالقيمة 0، ومن ثم يُقيّم التعبير. يُقصد بالاستبدال (بما فيه استبدال الكلمات المفتاحية) أن sizeof لا يمكن استخدامه في هذه التعابير للحصول على القيمة التي تحصل عليها في الحالة الاعتيادية. تُستخدم القيمة الصفر -كما هو الحال في تعليمات سي الشرطية- للدلالة على القيمة "خطأ false"، وتدل أي قيمة أخرى على القيمة "صواب true". يجب استخدام المعالج المسبق العمليات الحسابية وفق النطاقات المحددة في ملف الترويسة <limits.h>، وأن تُعامل التعابير ذات قيمة العدد الصحيح مثل عدد صحيح طويل والعدد الصحيح عديم الإشارة مثل عدد صحيح طويل عديم الإشارة، بينما لا يتوجب على المحارف أن تكون مساوية إلى القيمة ذاتها عند وقت التنفيذ، لذا من الأفضل في البرامج القابلة للنقل أن نتجنب استخدامها في تعابير المعالج المُسبق. تعني القوانين السابقة عمومًا أنه بإمكاننا أن نحصل على نتائج حسابية من المعالج المسبق التي قد تكون مختلفة عن النتائج التي نحصل عليها عند وقت التنفيذ، وذلك بفرض إجراء الترجمة والتنفيذ على آلات مختلفة. إليك مثالًا: #include <limits.h> #if ULONG_MAX+1 != 0 printf("Preprocessor: ULONG_MAX+1 != 0\n"); #endif if(ULONG_MAX+1 != 0) printf("Runtime: ULONG_MAX+1 != 0\n"); مثال 3 من الممكن أن يُجري المعالج المسبق بعض العمليات الحسابية بنطاق أكبر من النطاق المُستخدم في البيئة المُستهدفة، ويمكن في هذه الحالة ألّا يطفح تعبير المعالج المسبق ULONG MAX+1 ليعطي النتيجة 0، بينما يجب أن يحدث لك في بيئة التنفيذ. يوضح المثال التالي استخدام الثوابت المذكور آنفًا، وتعليمة "وإلّا else" الشرطية #elif. #define NAME 100 #if ((NAME > 50) && (defined __STDC__)) /* افعل شيئًا */ #elif NAME > 25 /* افعل شيئًا آخر */ #elif NAME > 10 /* افعل شيئًا آخر */ #else /* الاحتمال الأخير */ #endif يتوجب التنويه هنا على أن موجهات التصريف الشرطية لا تتبع لقوانين النطاق الخاصة بلغة سي، ولهذا فيجب استخدامها بحرص، إلا إذا أردت أن يصبح برنامجك صعب القراءة، إذ من الصعب أن تقرأ برنامج سي C مع وجود هذه الأشياء كل بضعة أسطر، وسيتملكك الغضب تجاه كاتب البرنامج إذا صادفت شيفرة مشابهة لهذه دون أي موجه #if واضح بالقرب منها: #else } #endif لذلك يجب أن تعامل هذه الموجهات معاملة الصلصة الحارّة، استخدامها ضروري في بعض الأحيان، إلا أن الاستخدام الزائد لها سيعقّد الأمور. موجه التحكم المعتمد على التنفيذ pragma كان هذا الموجه بمثابة محاولة للجنة المعيار بإضافة طريقة للولوج للباب الخلفي، إذ يسمح هذا الموجه بتنفيذ بعض الأشياء المعرفة بحسب التطبيق. إذا لم يعرف التطبيق ما الذي سيفعله بهذا الموجه (أي لم يتعرف على وظيفته) فيستجاهله ببساطة، إليك مثالًا عن استخدامه: #pragma byte_align يُستخدم الموجه السابق لإعلام التطبيق بضرورة محاذاة جميع أعضاء الهياكل بالنسبة لعنوان البايت الخاص بهم، إذ يمكن لبعض معماريات المعالجات أن تتعامل مع أعضاء الهياكل بطول الكلمة بمحاذاة عنوان البايت، ولكن مع خسارة السرعة في الوصول إليها. يمكن أن يُفسّر هذا الأمر بحسب تفسير التطبيق له طبعًا، وإن لم يكن للتطبيق أي تفسير خاص به، فلن يأخذ الموجه أي تأثير، ولن يُعد خطأً، ومن المثير للاهتمام رؤية بعض الاستخدامات الخاصة لهذا النوع من الموجهات. موجه عرض رسالة خطأ قسرية error يُتبع هذا الموجه بمفتاح أو أكثر في نهاية السطر الخاص به، وتُشكّل رسالة تشخيصية من قبل المصرف تحتوي على هذه المفاتيح، ولا توجد مزيدٌ من التفاصيل عن ذلك في المعيار. يُمكن استخدام هذا الموجه لإيقاف عملية التصريف على آلة ذات عتاد صلب غير مناسب لتنفيذ البرنامج: #include <limits.h> #if CHAR_MIN > -128 #error character range smaller than required #endif سيتسبب ذلك ببعض الأخطاء المتوقعة عند مرحلة التصريف إذا نُفّذ الموجه وعُرضت الرسالة. الخاتمة على الرغم من الخصائص القوية والمرنة التي يوفرها المعالج المسبق، إلا أنها شديدة التعقيد، وهناك عددٌ قليل من الجوانب المتعلقة به ضرورية الفهم، مثل القدرة على تعريف الماكرو ودوال الماكرو، والمستخدمة بكثرة في أي برنامج سي تقريبًا عدا البرامج البسيطة، كما أن تضمين ملفات الترويسة مهمّ أيضًا طبعًا. للتصريف الشرطي استخدامان مهمان، أولهما هو القدرة على تصريف البرنامج بوجود أو بعدم وجود تعليمات الاكتشاف عن الأخطاء Debugging ضمن البرنامج، وثانيهما هو القدرة على تحديد تعليمات معينة يعتمد تنفيذها على طبيعة التطبيق أو الآلة التي يعمل عليها البرنامج. باستثناء ما ذكرنا سابقًا، من الممكن نسيان المزايا الأخرى التي ذُكرت في المقال، إذ لن يتسبب التخلي عنها بفقدان كثيرٍ من الخصائص، ولعلّ الحل الأمثل هو تواجد فرد واحد متخصّص في المعالج المسبق ضمن الفريق البرمجي لتطوير الماكرو التي تفيد مشروعًا ما بعينه باستخدام بعض المزايا الغريبة، مثل التنصيص ولصق المفاتيح. سيستفيد معظم مستخدمي لغة سي C أكثر إذا وجّهوا جهدهم بدلًا من ذلك نحو تعلم بعض الأجزاء الأخرى من لغة سي، أو تقنيات التحكم بجودة البرمجيات إذا أتقنوا اللغة. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C المقال السابق: تهيئة المتغيرات وأنواع البيانات في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C -
 تشير فيكي ساندرز، رائدةُ أعمالٍ ورأسماليةٌ مُخاطِرة إلى حلم العديد من النساء ببدء مشاريع تجارية خاصة بهنّ، ولكنّ تحقيق ذلك يحتاجُ إلى استثمارٍ فاعلٍ للوقت، وتفانٍ، وإبداعٍ، ومالٍ -أيضًا- إذ تفشلُ أفضلُ الأفكار ما لم تحظَ بدعمٍ ماليٍّ، وبإدارةٍ مالية فاعلَين، وليس لدى أغلبِ الشركاتِ الناشئةِ منصبُ (كبير الموظفين الماليِّين) فضلًا عن أنها لا تمتلك مبالغَ مالية كبيرة لتمويل المشاريع التجارية التي تُعَدُّ حُلُمًا لمالكيها. ووفقًا لتقريرٍ حديث، هناك أكثرُ من 11 مليون مشروعٍ تجاريٍّ تملكها نساء في الولايات المتحدة الأمريكية، وتوظِّف لديها ما يقارب 9 ملايين شخص، وتولِّدُ عائداتٍ تصلُ إلى أكثرَ مِن 1.6 تريليون دولار، وقدِ ازدادتِ عائداتُ تلك المشاريع التجارية بنسبةٍ تتجاوز 35% على مدى العقد الماضي موازنةً بنسبة 27% بالنسبة لجميع الشركات في الولايات المتحدة، ومع تلك الإحصاءاتِ المُبهِرة، إلا أنَّ أقلَّ من 4% من تمويل رأس المال المُخاطِر Venture Capital فقط يذهب لصالح مجموعة روَّاد الأعمال المُشار إليها، وتلك هي الطريقةُ التي انخرطَت فيها فيكي ساندرز Vicky Saunders، وشركتُها الناشئةُ ذات رأس المال المُخاطِر المسماة شي إي أو SheEo، في المشهد. تصفُ ساندرز نفسها بأنها رائدة أعمال، وقد سبق لها أن شاركت في تأسيس أربعة مشاريع تجارية مختلفة، وإدارتها، وتعتقد بأنَّه يجب تحديدُ مجال التمويل بالنسبة لرائدات الأعمال من النساء، وتعرضُ خطَّتها عبر شركتها شي إي أو SheEO، وهي منصَّةٌ تسعى إلى توفير "العوامل المُنشِّطة" للنساء لاستثمار المال بهدف إنشاء رأسمالٍ يجري توزيعُه لاختيار المشاريع التجارية المملوكة لنساء، وذلك في صورة قروض بفائدة 0% تُسدَّدُ خلال خمس سنواتٍ، ولا تقتصر تلك العوامل المُنشِّطة على المستثمرين، بأيِّ حال، وتتصور ساندرز تلك النساءَ بوصفهن جزءًا أساسًا من الشركات التي يستثمرن فيها، وذلك عبر توفير الدعم العملياتي والموارد لكل من المُورِّدين والبائعين، وفرصة اتصال شبكي لكل شيءٍ، بدءًا بالدعم القانوني، وصولًا إلى الحصول على زبائن جُدُد، وفي إحدى الحملات الأخيرة التي سُمِّيَت راديكال جينروسيتي Radical Generosity، جُمِعَ مبلغ 1,000 دولارمن كل 500 امرأةٍ، ثم قُسِّمَ المبلغ المجموع- وهو500,000 دولار- بين المشاريع التجارية الخمسة التي تملكها وتديرها نساء. وفي السنة الثالثة لمشروع التمويل ذاك، أي في العام 2017، مَوَّلَت شركةُ شي إي أو SheEO عددًا من الشركات بلغ 15 شركة، واستثمرت 1.5 مليون دولار، كما موَّلت شركة شي إي أو روّادَ أعمالٍ يعملون على مشاريع تجارية متنوعة، ومنها مشاريع ذكاء صناعي، ومشاريع أجهزةٍ للأشخاص من ذوي القدرات الخاصة، ومشاريع طعام، وتعليم، وتعملُ شركةُ شي إي أو حاليًا في أربع مناطق، هي: كندا Canada، ولوس أنجلوس Los Angeles، وسان فرانسيسكو San Francisco، وكولورادو Colorado؛ وتتصف أهدافها في تمويل المشاريع التجارية التي تقودها نساء بالسموّ، وتأملُ ساندرز أن تحظى- بحلول العام 2020- بملايين المستثمرين وبمليار دولارٍ لتمويل 10,000 رائد أعمال، ولكنَّ هدفها الأساس يتمثل في تغيير الثقافة التي تحكُم الكيفيةَ التي يدعم فيها المستثمرون الشركاتِ- كلّ الشركات، وبحسب قولِ ساندرز، إنَّ تنشيط دور النساء نيابة عن نساءٍ أُخريات سيغيرُ العالم. وفي ظل الاقتصاد العالمي السائد اليوم؛ الذي يسير بوتيرةٍ سريعة، باتت إدارةُ الأمور المالية للشركة أكثر تعقيدًا من أي وقتٍ مضى، وبالنسبة للمديرين الماليين، ليس التوجيهُ المتأني والمدروسُ للأنشطة المالية التقليدية- التخطيط المالي، واستثمار الأموال، وجمعُها- سوى جزءٍ من ذلك العمل، فالمديرون الماليون ليسوا مجرد متعاملين مع الأرقام؛ وبوصفهم جزءًا من الإدارة العليا للشركة، يحتاج المديرون الماليون التنفيذيون Chief Financial Officers إلى استيعابٍ واسع للشركة التي يعملون لصالحها، وللمجال الذي تمارس فيه نشاطها، إلى جانب الابتكار والقدرة على القيادة، وعليهم ألا يحيدوا عن النظرة الأساسية التي تمثل هدفَ المدير المالي، وهي: زيادة قيمة الشركة لصالح مالكيها. تُصنَّفُ الإدارةُ المالية -وهي جمعُ مالِ الشركة وإنفاقُه- على أنها علمٌ وفنٌّ في آنٍ واحدٍ معًا؛ إذ يتعلق الجزءُ العلميُّ منها بتحليل الأرقامِ وتدفُّقاتِ النقد عبر الشركة، أما الجزءُ الفنّيُّ من الإدارة المالية، فيُعنى بالإجابة عن أسئلة مثل: هل تستخدمُ الشركةُ مواردَها المالية الاستخدام الأمثل؟ وبعيدًا عنِ التكاليف. لِمَ نختارُ نوعًا محددًا من التمويل؟ وما مدى خطورة كل خيارٍ من الخيارات المطروحة؟ ومن الهواجس الأخرى المهمة بالنسبة لكل من المديرين التجاريين والمستثمرين، فَهمُ أساساتِ أسواق الأوراق المالية والأوراق المالية المتداوَلة فيها، وهو فهمٌ يؤثر في كل من الخطط المؤسسية والموارد المالية للمستثمرين، وهناك حاليًا حوالي 52% من البالغين في الولايات المتحدة الذين يملكون أسهُمًا، في حين كانت تلك النسبة 25% فقط في العام 1981. يُركِّزُ هذا المقال على الإدارة المالية للشركة، وعلى أسواق الأوراق المالية التي تجمع فيها الشركاتُ المالَ، وسنبدأ بنظرة عامة حول الدور الذي يلعبهُ التمويل والمدير المالي في الاستراتيجية التجارية العامة للشركة، ثم ننتقل بعد ذلك للحديث عن استخدامات الأموال القصيرة، والطويلة، الأمد، وبعدها سنبحث في المصادر الرئيسة للتمويل القصير، والطويل، الأجل، ثم سنراجع وظيفة أسواق الأوراق المالية، وتنظيمَها، وعمليّاتِها، وأخيرًا، سنطَّلعُ على التوجهات الحديثة الرئيسة التي تؤثر في الإدارة المالية وأسواق الأوراق المالية. دور التمويل والمدير المالي تحتاجُ أيُّ شركةٍ كانت إلى المال لتعمل، سواءٌ أكانت شركةَ جنرال موتورز General Motors؟ أو مخبزًا في بلدةٍ صغيرة، وكي تكسب الشركةُ المالَ؛ عليها أن تُنفِقَه أولًا- على المخزون ومستلزمات الإنتاج، والتجهيزات والمرافق، وعلى رواتب الموظفين وأجورهم، ولذلك، يُعَدُّ التمويلُ عاملًا أساسًا لنجاح جميع الشركات، ومع أنَّ إدارة تمويل الشركة قد لا تكون مرئيةً مثل: التسويق أوِ الإنتاج، إلا أنها لا تقل عنهما أهمية لتحقيق النجاح للشركة. فالإدارةُ المالية Financial Management- التي تُعرَّف بأنها فنُّ وعِلمُ إدارةِ أموال الشركة لتحقيق أهدافها- ليست مسؤولية القسم المالي فقط، فجميع القرارات التي تتخذها الشركة لها نتائج مالية، وعلى المديرين في الأقسامِ كافة العمل عن كثب مع الفريق المالي في الشركة، فمثلًا: لو كنتَ تعمل مندوبَ مبيعاتٍ، فستؤثر سياساتُ التحصيل والائتمان التي تنتهجها الشركة في قدرتك على تحقيق مبيعات، وسيكون على رئيس قسم تقنية المعلومات في الشركة، تبريرُ أي طلباتٍ يقدِّمُها للحصول على أنظمةٍ حاسوبية جديدة، أو أجهزة حاسوب محمولة، للموظفين. يجب أن تمثِّلَ عائداتُ مبيعاتِ منتجاتِ الشركة المصدرَ الرئيسَ للتمويل، ولكنَّ ذلك المال الناتج عن المبيعات لا يتوفر دائمًا عندما تظهر الحاجة إليه لدفع الفواتير، وعلى المديرين الماليين تَعقُّبُ كيفية تدفُّقِ المال إلى داخل الشركة وخروجه منها (انظر الصورة 16.2)، إذ يعملُ أولئك المديرون مع أقسام الشركة الأخرى لتحديد كيفية استخدام الأموال المتوفرة، وكم من المال ستحتاج الشركة، ثم يختارون أفضلَ المصادر للحصول على التمويل المطلوب. فعلى سبيل المثال: يتعقَّبُ المديرُ المالي بياناتِ العمليات اليومية مثل: وارِدات الصندوق (أو المقبوضات النقدية Cash Collection، والدفعات المالية (النفقات) Disbursements لضمان كفاية كمية النقد الموجودة لدى الشركة، ومدى تمكِّنُها من الوفاء بالتزاماتها. وعلى المدى الطويل، سيدرسُ المدير المالي بتأنٍّ ما إذا كان على الشركة افتتاحُ منشأةِ تصنيعٍ جديدة، وتوقيتَ ذلك؛ كما سيقترح ذلك المديرُ الطريقةَ الأنسب لتمويل المشروع، وجمع الأموال، وبعد ذلك مراقبة تنفيذ المشروع وتشغيله. هذا وترتبط الإدارة المالية بالمحاسبة ارتباطًا وثيقًا، وفي معظم الشركات، تكون هاتان الوظيفتان من مسؤولية نائب رئيس الشؤون المالية Vice) President of Finance)، أو المدير المالي التنفيذي CFO؛ أما الوظيفة الرئيسة للمحاسب، فهي جمعُ البيانات المالية وعَرضُها، هذا ويستخدم المديرون الماليون البياناتِ المالية، وغيرها من المعلومات التي يُعِدُّها المحاسبون، بهدف اتخاذ القرارات المالية، ويركز المديرون الماليون على التدفقات النقدية Cash Flows- ويُقصَد بها النقود الداخلة إلى الشركة والخارجة منها Inflows and Outflows of Cash- فيتولى أولئك المديرون تخطيط تدفقاتِ الشركةِ النقدية ومراقبتها، لضمان توفر النقد عند الحاجة. مسؤوليات المدير المالي وأنشطته على المديرين الماليين عملٌ مُعقَّدٌ وصعب، فهُم يحللون البياناتِ المالية التي يُعِدُّها المحاسبون، ويراقبون الحالة المالية للشركة، كما يُعدُّونَ الخططَ المالية ويطبقونها، وقد ينخرطون في أحد الأيام في تطوير طريقةٍ أفضل لأتمتةِ المقبوضات النقدية (واردات الصندوق)؛ أما في يوم آخر، فقد تراهم يحللون مسألة استحواذٍ مقترحةً، وتتضمن الأنشطةُ الرئيسة للمدير المالي كلًا مما يأتي: التخطيط المالي: ويتضمن إعدادَ الخطة المالية، وعائداتِ المشاريع، والمصروفات، واحتياجات التمويل، على مدى فترة زمنية محددة. الاستثمار (إنفاق المال): أي إنفاق أموال الشركة في الأوراق المالية، والمشاريع، التي تولِّدُ عائداتٍ عالية بالنسبة لمخاطرها. التمويل (جمع الأموال): أي الحصول على التمويل اللازم لعمليات الشركة واستثماراتها، والسعي لتحقيق أفضل توازن بين الدَّين (أي المال المُقتَرَض) وبين حقوق الملكية، أي الأموال التي تُجمَع من بيع الملكية في الشركة أو المشروع التجاري. هدف المدير المالي كيف يمكن للمديرين الماليين اتخاذُ قراراتِ تخطيطٍ، واستثمارٍ، وتمويلٍ، حكيمة؟ يتمثل الهدف الرئيس للمدير المالي في زيادة قيمة الشركة لصالح مالكيها، وتُقاس قيمةُ شركةٍ مملوكةٍ ملكية عامة بسعر سهمها؛ أما قيمة الشركة المملوكة ملكية خاصة، فهي السعر الذي يمكن أن تُباع مقابله. ولزيادة قيمة الشركة، فعلى المدير المالي أن يأخذ بالحسبان النتائج القصيرة، والطويلة الأمد، لأعمال الشركة، وتُعَدُّ زيادةُ الأرباح أحدَ الأساليب المُتَّبَعة لتحقيق ذلك، ولكنها يجب ألا تكون الأسلوبَ الوحيد، لأنّ منهجَ زيادة الأرباح ذاك يفضِّلُ تحقيقَ مكاسب قصيرة الأمد على تحقيق أهدافٍ طويلة الأمد، فماذا لو أنَّ شركة تعمل في مجالِ تقنيةٍ عالية التطوُّر- يشهد منافسةً شديدة- لم تُجرِ أي أبحاث، أو لم تقم بأي تطوير؟ فعلى المدى القصير، ستحقق تلك الشركةُ أرباحًا عالية نتيجة توفيرها مصاريفَ إجراء تلك الأبحاث، والتطويرات، التي تكلف كثيرًا من المال؛ أما على المدى الطويل، فقد تخسرُ قدرتها على المنافسة بسبب افتقارها إلى منتجاتٍ جديدة. الصورة 16.2: كيفية تدفُّقِ النقد عبر الشركة: (حقوق الصورة محفوظة لجامعة رايس "Rice"، أوبن ستاك "OpenStax"). ويصحُّ ذلك بصرف النظر عن حجم الشركة، وعن النقطة التي وصلت إليها خلال دورة حياتها، ففي شركة كورنينغ Corning للتقنية -وهي شركة أُسِّسَت منذ أكثر من 160 عامًا- تتبنى الإدارةُ النظرةَ المستقبليةَ الطويلة الأمد، وليس فقط بهدف الحصول على مكاسبَ ربعِ سنوية تلبَّيَ بها توقُّعاتِ وول ستريت Wall Street؛ فشركةُ كورنينغ- التي ارتبط اسمُها -سابقًا- بالنسبة للمستهلكين بمنتجات المطبخ، مثل: أواني المطبخ كوريل Corelle، وأواني الطهي الزجاجية المقاوِمة للحرارة بايركس Pyrex- هي اليوم شركةُ تقنية تُصنِّعُ منتجاتِ سيراميك وزجاج متخصصة، وهي من المورِّدين الرائدين لزجاج يسمى زجاج غوريلا Gorilla Glass، الذي يُعَد نوعًا خاصًا من الزجاج يُستخدَم لشاشات الأجهزة المحمولة، ومن بينها آيفون iPhone، وآيباد iPad، والأجهزة العاملة على نظام التشغيل التابع لشركة غوغل Google، كما أنّها مخترعة ألياف ضوئية، ناقلات (كابلات) ألياف ضوئية، في قطاع الاتصالات، وتتطلبُ خطوطُ المنتجات تلك استثمارتٍ ضخمةً خلال دورات البحث والتطوير الطويلة الخاصة بها، إلى جانب الاستثمارات التي تحتاجها المصانع والمعدّات فور البدء بإنتاجها. وقد يكون ذلك خطيرًا على المدى القصير، ولكن متابعةَ السير في تلك المهمة قد تأتي بنتائج إيجابية؛ فقد أعلنت شركةُ كورنينغ مؤخرًا عن خططٍ لتطوير قسمٍ منفصل لديها مُكرَّسٍ لزجاج غوريلا Gorilla Glass، الذي تستحوذ فيه اليوم على 20% من سوق الهواتف المحمولة بمبيعاتٍ تخطَّت 200 مليون جهاز، وبالإضافة إلى ما سبق، فقد عادت تجارة ناقلات (كابلات) الألياف الضوئية الخاصة بشركة كورنينغ إلى الرواج والانتعاش، بالتوازي مع زيادة الشركات المُزوِّدة بخدمة تلك الناقلات (الكابلات) -مثل: شركة فيرايزون Verizon- تطويرَ شبكة ناقلات الألياف الضوئية على امتداد أراضي الولايات المتحدة الأمريكية، ومع بداية العام 2017، ساعد التزامُ شركة كورنينغ- المتمثل بإعادة تحديدها الهدف من بعض التقنيات الخاصة بها، وتطويرِ منتجاتٍ جديدة- في زيادة دخلها الصافي، فزادت عائداتُها الربع سنوية مؤخرًا بنسبةٍ تجاوزت 16%. ومثلما يُظهِرُ وضعُ شركة كورنينغ، يطمح المديرون الماليون دائمًا إلى تحقيق توازنٍ بين فرصة تحقيق ربحٍ، واحتماليةِ تكبُّدِ خسائر، وفي المجال المالي، تُسمى فرصةُ تحقيق الربح: العائد Return؛ أما احتماليةُ الخسارة -أو إمكانية ألا يحقق أحدُ الاستثماراتِ مستوى العائدِ المرجوَّ منه- فتسمى المُخاطرة Risk. ومن المبادئ الرئيسة في المجال المالي أنه كلما ازدادتِ المخاطرُ، ارتفعَ العائدُ المتوقع أو الذي تطلبه الجهةُ المُخاطِرة، ويُسمّى هذا المبدأُ المقبول على نطاقٍ واسع: نسبة/ مفاضلة العائد إلى المخاطرة Risk-Return Trade-Off، إذ يأخذِ المديرون الماليون بالحسبان العديدَ من عوامل المخاطرة والعائد عند اتخاذهم قراراتِ استثمارٍ وتمويل، ومن بين تلك العوامل: الأنماطُ المتغيرة للطلب في السوق، ومعدلات الفائدة، والظروف الاقتصادية العامة، وظروف السوق، والمسائل الاجتماعية، مثل: تأثيرات البيئة وسياسات فرص التوظيف المتساوية. كيفية استخدام المؤسسات للأموال على الشركة الاستمرار في استثمار المال في عملياتها بهدف تحقيق النمو والازدهار، ويحدد المديرُ الماليُّ الطريقةَ الأمثل لاستخدام أموال الشركة، إذ تدعم النفقاتُ القصيرة الأجل العملياتِ اليومية للشركة، فمثلًا: تُنفِق شركةُ تصنيع الملابس الرياضية، نايكي Nike، المال لشراء مواد خام مثل: الجلد والقماش، ولدفع رواتب موظفيها؛ أما النفقات الطويلة الأجل، فتُخصَّصُ -عادة- للأصول الثابتة؛ إذ تتضمن تلك النفقاتُ بالنسبة لشركة نايكي- مثلًا- نفقاتٍ مخصصة لشراء مصنعٍ جديد، أو شراء معداتِ تصنيعٍ مؤتمَتة، أو للاستحواذ على مصنعِ ألبسةٍ رياضيةٍ صغير. النفقات القصيرة الأجل النفقات القصيرة الأجل Short-term Expenses- التي تُسمّى غالبًا: النفقات التشغيلية Operating Expenses- هي التي تُستخدَم لدعم أنشطة الإنتاج والبيع الحالية في الشركة، وينتج عنها عادةً أصولٌ حاليّة Current Assets تتضمن نقودًا، وأيَّ أصولٍ أخرى (حسابات مستحقة القبض ومخزون) يمكن تحويلها إلى نقود خلال سنة واحدة، وهدفُ المدير المالي هو إدارة الأصول الحالية بحيث يكون لدى الشركة نقدٌ كافٍ لدفع فواتيرها، ورفدِ حساباتها مستحقة القبض، ومخزونها. إدارة النقد: ضمان توفر السيولة يُعَدُّ النقدُ شريانَ الحياة بالنسبة للشركة، فبدونه لا يمكن لها أن تعمل، ومن الواجبات المهمة التي يقوم بها المدير المالي؛ إدارةُ النَّقد Cash Management، أي ضمانُ وجودِ ما يكفي من نقدٍ في متناول اليد لدفع الفواتير عندَ استحقاقها، ولتغطية النفقات غير المتوقعة. تضعُ الشركاتُ توقُّعاتٍ حول احتياجاتها من النقد لفترةٍ محددة، إذ تحتفظُ العديد منها بحدٍّ أدنى من الرصيد النقدي لتغطية النفقات غير المتوقعة، أوِ استعدادًا للتغيرات المفاجِئة في التدفقاتِ النقدية المخطط لها، كما يضعُ المديرون الماليون ترتيباتٍ للقروضِ بهدف تغطية أي عُجُوزات؛ فإذا كانت كمية التدفقات النقدية الواردة إلى داخل الشركة Cash Inflows، وتوقيتها، مُطابِقَين بصورة قريبة لكمية التدفقات النقدية الخارجة منها Cash Outflows، ولتوقيتها، فلا تحتاجُ الشركةُ سوى إلى الاحتفاظ بكمية قليلة من النقد في متناول اليد، فالشركةُ ذاتُ المبيعات والإيرادات المتوقَّعَة والمُنتظَمة خلال السنة، تحتاجُ إلى نقدٍ أقلَّ مما تحتاج شركةٌ ذاتُ أنماط فصلية متباينة من المبيعات والإيرادات، فشركةُ دُمى (ألعاب) مثلًا- والتي تشهد ذروةَ المبيعات في فصل الخريف- تنفق مبلغًا كبيرًا من النقد خلال فصلَي الربيع والصيف لتملأَ مخزوناتِها، إذ يكون لديها فائضٌ نقديٌّ خلال الشتاء وأوائل الربيع، بفضل ما تجمعه من مال من المبيعات التي تحققها في الفصل الذي يشهد ذروة المبيعات بالنسبة لها. ولأنَّ الفائدة الناتجة عن النقد الموجود في صورة حسابات جارية تكون منخفضة -إن وُجِدَت- يحاولُ المديرُ المالي إبقاء أرصدة النقد منخفضة، واستثمارَ النقد الفائض، وتُستثمَرُ المبالغُ الفائضة بصورة مؤقتة في الأوراق المالية القابلة للتداول Marketable Securities، وهي استثماراتٌ نقدية قصيرة الأجل يمكن تحويلُها بسهولةٍ إلى نقد، كما يبحثُ المديرُ الماليُّ عن استثماراتٍ منخفضة المخاطر تولِّدُ عائداتٍ مرتفعة، وتتضمن ثلاثةَ أنواعٍ من أكثر الأوراق النقدية القابلة للتداول شيوعًا وهي: أُذونات الخزينة Treasury Bills، وشهادات الإيداع Certificates of Deposit، والأوراق التجارية Commercial Papers. و(تُعرَّفُ الأوراق التجارية "Commercial Papers" بأنها دَينٌ قصيرُ الأجل غيرُ مضمون، تُصدِرُه شركةٌ مالية ذات وضعٍ ماليٍّ قوي)، ولدى المديرين الماليين في يومنا هذا أدواتٌ جديدة لمساعدتهم في العثور على أفضل الاستثمارات القصيرة الأجَل، مثل: منصات التجارة الإلكترونية التي توفِّرُ الوقتَ وتتيح الوصول إلى أنواعٍ أكثر من الاستثمارات، ويُعَدُّ ذلك مفيدًا بصورة خاصة بالنسبة للشركات الصغيرة التي لا تملك فِرَق موظفين ماليين كبيرة. وتواجه الشركاتُ التي تمارس عملياتها خارج حدود الدولة التي يوجد فيها مقرها الرئيس؛ صعوباتٍ أكبر متعلقة بإدارة النقد، فتطويرُ الأنظمة الخاصة بإدارة النقد على المستوى الدولي قد يبدو -نظريًّا- أمرًا بسيطًا، ولكنه مُعقَّدٌ جدًا من الناحية العملية، فبالإضافة إلى تعامُلِ أُمَناء الخزينة مع عدد من العملات الأجنبية، عليهم استيعابُ الممارسات المصرفية والمستلزمات أو الشروط التنظيمية والضريبية في كل بلد، واتِّباعُها، فقد تُعيقُ تلك الأنظمةُ المختلفة قدرتَهم على تحويل الأموال بحُرّيةٍ عَبْرَ حدود الدول؛ هذا فضلًا عن أنَّ إصدار مجموعةٍ نموذجية من الإجراءات لكل مكتب قد لا يجدي نفعًا، بسبب اختلاف الممارسات التجارية المحلية من بلد لآخر، وبالإضافة إلى ما سبق، فقد يُعارِضُ المديرون المحليون التحوُّلَ إلى هيكليةٍ مركزية؛ لأنهم لا يريدون التخلّيَ عن تحكُّمِهِم في النقد الذي تُنتِجُه الوحداتُ التابعة لهم، وعلى المديرين الماليين للشركات أن يكونوا على دراية بالأعراف المحلية، وأن يتعاملوا معها بدقة وتأنٍّ، وأن يتكيفوا مع استراتيجية المركزية Centralization Strategy وفقًا لذلك. وإلى جانب سعي المدير المالي إلى تحقيق توازنٍ سليم بينَ النقد والأوراق المالية القابلة للتداول؛ فإنه يحاول تقصيرَ الوقت الممتد بين شراء الخدمات أو محتويات المخازن (التدفقات النقدية الخارجة من الشركة) وبين جمع النقد من المبيعات (التدفقات النقدية الداخلة إلى الشركة). وتتضمن الاستراتيجياتُ الثلاث الرئيسة: جمعَ المال المُستَحَق للشركة (الحسابات مستحقة القبض) بالسرعة الممكنة، ودفع المال المشغولةُ به ذمة الشركات لصالح أطرافٍ أخرى (الحسابات مستحقة الدفع) خلال أطول مدة ممكنة، دون أن يمس ذلك بسمعة الشركة الائتمانية، وتقليلَ الأموال المُكرَّسة للمخزون. إدارة الحسابات مستحقة القبض تُمثِّلُ الحساباتُ مُستَحَقةُ القبض Accounts Receivable المبيعاتِ التي لَمّا يُدفَع ثمنُها للشركة، ولأن المنتَج يكون قد بيعَ بدون أن تكون الشركةُ قد قبضت ثمنه، فترقى الحساباتُ مستحقة القبض إلى مرتبة أحد استخدامات النقد، وتمثل الحساباتُ مستحقةُ القبض بالنسبة لشركة تصنيعٍ عادية ما بين 15- 20% من أصولها الإجمالية. إنَّ هدفَ المدير المالي هو جمعُ المال المُستحَقّ للشركة بأسرع وقتٍ ممكن، وذلك بالتوازي مع توفير شروطٍ ائتمانية للزبائن جذّابة بما يكفي لزيادة المبيعات، وتتضمن إدارةُ الحسابات مستحقة الدفع وضعَ سياساتٍ ائتمانية، ومبادئ توجيهيةً حول توفير الائتمان، والشروط الائتمانية، وشروطًا محددة لإعادة الدفع، بما في ذلك المدة التي على الزبائن خلالها دفعُ الفواتير المُستحقة في ذممهم، وما إذا كانت ستُمنَحُ تخفيضاتٌ للزبائن الذين يدفعون تلك الفواتير بصورة أسرع، ومن الجوانب الأخرى لإدارة الحسابات مستحقة الدفع؛ تقريرُ سياساتِ تحصيل الأموال، وإجراءاتِ تحصيل الحسابات المتأخر دفعُها. إن وضعَ سياساتِ الائتمان وتحصيل الأموال هو عملٌ يحقق التوازن، ويضطلع به المديرون الماليون، فمن جهة، ينتج عن السياساتِ الائتمانية المُيَسَّرة، أوِ الشروط الائتمانية السَّخيّة (يُقصَد بها فترة إعادة دفع طويلة أو حسومات نقدية كبيرة) زيادةٌ في المبيعات، ومن جهةٍ أخرى، على الشركة تمويلُ مزيدٍ من الحسابات المستحقة القبض، وتزدادُ -أيضًا- مخاطرُ وجود حساباتٍ مستحقة القبض غيرِ قابلةٍ للتحصيل Uncollectible Accounts Receivable. وأثناء وضعِ الشركاتِ سياساتها الائتمانية، وتلك الخاصةَ بتحصيل أموالها، فإنها تأخذ بالحسبان تأثيرَها على المبيعات، وتوقيتَ التدفُقِ النقديّ، وتجربتها مع الديون المعدومة Bad Debt، ومواصفات الزبون Customer Profile، والمعايير السائدة في القطاع الذي تنشط فيه تلك الشركات. إنَّ الشركاتِ التي تريد تسريعَ عمليات التحصيل، تتولى بنشاطٍ إدارةَ حساباتِها مستحقة القبض، وذلك بدلًا مِن ترك الأمر للزبائن ليدفعوا متى يشاؤون، ووفقًا لإحصاءاتٍ حديثة؛ فإنّ أكثر من 90% من الشركات تعاني من تأخُّرٍ في الدفع من قبل زبائنها، وهناك شركاتٌ تشطب نسبةً من الديون المعدومة، وهي نسبة قد تكون مرتفعة. تلعبُ التقنية دورًا مهمًا في مساعدة الشركات على تطوير أدائها الخاص بالائتمان وتحصيل الأموال، فمثلًا: تستخدمُ العديدُ من الشركاتِ أحدَ أنواع عملياتِ اتخاذ القرار المؤتمَتة، سواءٌ الذي يأتي منها بصيغة نظام تخطيط موارد المؤسسة ERP System، أو بصورةِ مزيجٍ من البرمجيات والنماذج التكميلية التي تساعد الشركاتِ على اتخاذ قراراتٍ واعية، تتعلق بعملياتِ الائتمان وتحصيل الأموال. وتُفضِّلُ بعضُ الشركاتِ تعهيدَ العمليات المالية والمحاسبية التجارية (أي الاستعانة على أدائها بمصادر خارجية) مُستعينةً باختصاصيين، بدلًا من إنشاء أنظمتها الخاصة بالتعامل مع تلك العمليات. إنَّ توفُّرَ التقنية عالية التطوُّر، والمنصّاتِ الإلكترونية المتخصصة، التي سيكون صعبًا ومُكلِفًا توفيرُها داخل الشركة، سيُقنِع الشركاتِ من الأحجام كافة بقبول الاستعانة بها، ولكن، ليس سهلًا على المديرين الماليين قبول التخلي عن التحكُّم بالأمور المالية لأطرافٍ خارجية، إذ تزدادُ المخاطرُ لدى تحويل البيانات المالية للشركة، وسواها من بيانات مهمة، إلى نظامٍ حاسوبيٍّ خارجي؛ إذ يتمثل ذلك الخطر في احتمالية تسريب تلك البيانات أو فقدانها، أو قد تتعرض للسرقة من قبل المنافسين، كما إنَّ مراقبةَ جهةٍ مُزوِّدةٍ خارجية يكون أصعبَ من مراقبة موظفي الشركة، وتُعَدُّ التجارةُ الدولية أحدَ المجالات التي تجذب العديدَ من الزبائن، والتي تحكمها أنظمةٌ وترتيباتٌ تختلف من بلدٍ لآخر، وتتطلب قَدْرًا كبيرًا منَ التوثيق، حيث يمكن للمُزوِّدين -بفضل أنظمةِ تقنية المعلومات المتخصصة- أن يتتبّعوا -ليس فقط- الموقعَ الحقيقي الذي توجد فيه السِّلع، بل وحتى الأعمالَ الورقيَّةَ المرتبطة بعمليات شحنِها، حيث تبلغ نفقاتُ معالجةِ السلع المُشتراة في الخارج، حوالي ضعفَي تلك النفقات بالنسبة للسلع المحلية، وهذا ما يجعل من الأنظمة الأكثر كفاءة أكثرَ تحقيقًا للفائدة. المخزون يُعَدُّ شراءُ المخزون الذي تحتاج إليه الشركةُ أحدَ الاستخدامات الأخرى للأموال، إذ يمثِّلُ المخزونُ بالنسبة لشركة عادية حوالي 20% من أصولها الإجمالية، ولا تقتصرُ النفقاتُ المرتبطةُ به على سعر شرائه، بل تتعداه لتشملَ نفقات طلب الحصول عليه، والتعاملِ معه، وتخزينِه، والفائدة المترتبة عليه، وتأمينِه. ولدى كلٍّ من مديري الإنتاج، والتسويق، والمديرين الماليين، وجهاتُ نظرٍ مختلفة حول المخزون، فمديرو الإنتاج يريدون كمياتٍ كبيرة من المواد الخام في متناول اليد ضمن المخازن، لتجنُّبِ التأخير في عملياتِ الإنتاج، أما مديرو التسويق، فيفضِّلون وجود كثيرٍ منَ السِلَع النهائية الجاهزة لتلبية طلبات الزبائن بأسرع وقت، وبالمقابل، يفضِّلُ المديرون الماليون وجودَ أقلِّ كمّيةٍ ممكنة من المخزون، دون أن يؤدّيَ ذلك إلى الإضرار بالمبيعات أو بجودة الإنتاج، وعلى المديرين الماليين العملُ عن كثب مع أقرانهم؛ مديري التسويق، والإنتاج، لتحقيق التوازن بين تلك الأهداف المتعارضة، وتتمثلُ الأساليبُ المُتَّبَعة لتخفيض الاستثماراتِ التي تُنفَقُ على المخزون في إدارة المخزون Inventory Management، واتّباع نظام الوقت المناسب Just-in-Time System، وتخطيط متطلبات المواد Materials Requirement Planning. وفي شركات البيع بالتجزئة، تعد إدارة المخزون أساسيةً بالنسبة للمديرين الماليين الذين يراقبون عن كثب معدلَ دوران المخزون Inventory Turnover بفضل المبيعات، إذ يُظهِرُ هذا المعدَّلُ سرعةَ تحرُّكِ المخزون عبر الشركة، وتحوُّلِهِ إلى مبيعات، فإذا كان رقمُ المخزون مرتفعًا جدًا، فإنه يؤثِّر عادةً في كميةِ رأس المال العامل Working Capital الذي تمتلكه الشركة في متناول يدها، مُجبِرًا إياها على اقتراض المال لتغطية نفقات المخزون الفائض؛ أما إذا كان رقمُ معدلِ دورانِ المخزون منخفضًا جدًا، فيعني ذلك أنه ليسَ لدى الشركة ما يكفي من مخزون منتجاتٍ في متناول يدها لتلبية احتياجات الزبائن، مما قد يدفعهم إلى البحث عما يحتاجون إليه من منتجاتٍ لدى شركات أخرى. المصروفات الطويلة الأجل تستثمر الشركاتُ أموالها -أيضًا- في الأصول المادية مثل: الأرض، والمباني، والتجهيزات، والمعدات، وأنظمة المعلومات، وتسمى هذه المصروفات النفقات الرأسمالية Capital Expenditures، فخلافًا للمصروفات التشغيلية Operating Expenses التي تُنتِجُ فوائدَ خلال سنة واحدة، تتجاوز فوائدُ المصروفاتِ التشغيلية تلك المدةَ، فشراءُ آلةِ طباعةٍ قابلةٍ للاستخدام لمدة سبعِ سنواتٍ يُعَدُّ من المصروفاتِ الرأسمالية التي تُسجَّل في الميزانية العمومية للشركة؛ بوصفها من الأصول الثابتة Fixed Assets، ولكن الحبر، والورق، وغيرَها من المستلزمات، تُعد من المصاريف التشغيلية وليس الرأسمالية؛ أما عملياتُ الاندماج Mergers، والاستحواذ Acquisitions، فتعد من المصاريف الرأسمالية. تُنفِقُ الشركاتُ مصاريفَ رأسمالية لأسباب عديدة، أبرزُها توسيعُ الأصول الثابتة، واستبدالها، وتجديدها، وتصنيعُ منتجاتٍ جديدة، ولدى معظم شركات التصنيع استثماراتٌ كبرى مخصصة للمصروفات الرأسمالية، المتمثلة باقتناء أصولٍ ثابتةٍ طويلة الأجَل، فشركة صناعة الطائرات بوينغ Boeing مثلًا، تنفق ملياراتِ الدولارات سنويًا على منشآتِ تصنيع الطائرات، ولأنّ المصروفاتِ الرأسمالية باهظة التكلفة، ولها تأثيرٌ كبير على مستقبل الشركة، فيستخدمُ المديرون الماليون عمليةً تُدعى الميزانية الرأسمالية Capital Budgeting لتحليل المشاريع طويلة الأجَل، واختيار تلك التي توفر أفضل العائدات، بالتوازي مع رفع قيمة الشركة، وتتسم القراراتُ المتعلقةُ بتصنيعِ منتجاتٍ جديدة، وتلك الخاصة بالاستحواذ على شركاتٍ أخرى، بأهميةٍ خاصة؛ حيث يأخذ المديرون تكاليفَ المشروع بالحُسبان، ويتنبؤون بالمزايا المستقبلية التي سيقدِّمُها المشروعُ بهدف حساب العائد على الاستثمار Return on Investment المتوقع الخاص بالشركة ذات الصلة. ترجمة -وبتصرف- للفصل Understanding Financial Management and Securities Markets من كتاب introduction to business اقرا أيضًا المقال السابق: الخدمات المصرفية العالمية وأهم التوجهات الحديثة لدى المؤسسات المالية نظام الاحتياطي الفيدرالي لإدارة العرض النقدي نظرة عامة حول التمويل الريادي واستراتيجيات المحاسبة
تشير فيكي ساندرز، رائدةُ أعمالٍ ورأسماليةٌ مُخاطِرة إلى حلم العديد من النساء ببدء مشاريع تجارية خاصة بهنّ، ولكنّ تحقيق ذلك يحتاجُ إلى استثمارٍ فاعلٍ للوقت، وتفانٍ، وإبداعٍ، ومالٍ -أيضًا- إذ تفشلُ أفضلُ الأفكار ما لم تحظَ بدعمٍ ماليٍّ، وبإدارةٍ مالية فاعلَين، وليس لدى أغلبِ الشركاتِ الناشئةِ منصبُ (كبير الموظفين الماليِّين) فضلًا عن أنها لا تمتلك مبالغَ مالية كبيرة لتمويل المشاريع التجارية التي تُعَدُّ حُلُمًا لمالكيها. ووفقًا لتقريرٍ حديث، هناك أكثرُ من 11 مليون مشروعٍ تجاريٍّ تملكها نساء في الولايات المتحدة الأمريكية، وتوظِّف لديها ما يقارب 9 ملايين شخص، وتولِّدُ عائداتٍ تصلُ إلى أكثرَ مِن 1.6 تريليون دولار، وقدِ ازدادتِ عائداتُ تلك المشاريع التجارية بنسبةٍ تتجاوز 35% على مدى العقد الماضي موازنةً بنسبة 27% بالنسبة لجميع الشركات في الولايات المتحدة، ومع تلك الإحصاءاتِ المُبهِرة، إلا أنَّ أقلَّ من 4% من تمويل رأس المال المُخاطِر Venture Capital فقط يذهب لصالح مجموعة روَّاد الأعمال المُشار إليها، وتلك هي الطريقةُ التي انخرطَت فيها فيكي ساندرز Vicky Saunders، وشركتُها الناشئةُ ذات رأس المال المُخاطِر المسماة شي إي أو SheEo، في المشهد. تصفُ ساندرز نفسها بأنها رائدة أعمال، وقد سبق لها أن شاركت في تأسيس أربعة مشاريع تجارية مختلفة، وإدارتها، وتعتقد بأنَّه يجب تحديدُ مجال التمويل بالنسبة لرائدات الأعمال من النساء، وتعرضُ خطَّتها عبر شركتها شي إي أو SheEO، وهي منصَّةٌ تسعى إلى توفير "العوامل المُنشِّطة" للنساء لاستثمار المال بهدف إنشاء رأسمالٍ يجري توزيعُه لاختيار المشاريع التجارية المملوكة لنساء، وذلك في صورة قروض بفائدة 0% تُسدَّدُ خلال خمس سنواتٍ، ولا تقتصر تلك العوامل المُنشِّطة على المستثمرين، بأيِّ حال، وتتصور ساندرز تلك النساءَ بوصفهن جزءًا أساسًا من الشركات التي يستثمرن فيها، وذلك عبر توفير الدعم العملياتي والموارد لكل من المُورِّدين والبائعين، وفرصة اتصال شبكي لكل شيءٍ، بدءًا بالدعم القانوني، وصولًا إلى الحصول على زبائن جُدُد، وفي إحدى الحملات الأخيرة التي سُمِّيَت راديكال جينروسيتي Radical Generosity، جُمِعَ مبلغ 1,000 دولارمن كل 500 امرأةٍ، ثم قُسِّمَ المبلغ المجموع- وهو500,000 دولار- بين المشاريع التجارية الخمسة التي تملكها وتديرها نساء. وفي السنة الثالثة لمشروع التمويل ذاك، أي في العام 2017، مَوَّلَت شركةُ شي إي أو SheEO عددًا من الشركات بلغ 15 شركة، واستثمرت 1.5 مليون دولار، كما موَّلت شركة شي إي أو روّادَ أعمالٍ يعملون على مشاريع تجارية متنوعة، ومنها مشاريع ذكاء صناعي، ومشاريع أجهزةٍ للأشخاص من ذوي القدرات الخاصة، ومشاريع طعام، وتعليم، وتعملُ شركةُ شي إي أو حاليًا في أربع مناطق، هي: كندا Canada، ولوس أنجلوس Los Angeles، وسان فرانسيسكو San Francisco، وكولورادو Colorado؛ وتتصف أهدافها في تمويل المشاريع التجارية التي تقودها نساء بالسموّ، وتأملُ ساندرز أن تحظى- بحلول العام 2020- بملايين المستثمرين وبمليار دولارٍ لتمويل 10,000 رائد أعمال، ولكنَّ هدفها الأساس يتمثل في تغيير الثقافة التي تحكُم الكيفيةَ التي يدعم فيها المستثمرون الشركاتِ- كلّ الشركات، وبحسب قولِ ساندرز، إنَّ تنشيط دور النساء نيابة عن نساءٍ أُخريات سيغيرُ العالم. وفي ظل الاقتصاد العالمي السائد اليوم؛ الذي يسير بوتيرةٍ سريعة، باتت إدارةُ الأمور المالية للشركة أكثر تعقيدًا من أي وقتٍ مضى، وبالنسبة للمديرين الماليين، ليس التوجيهُ المتأني والمدروسُ للأنشطة المالية التقليدية- التخطيط المالي، واستثمار الأموال، وجمعُها- سوى جزءٍ من ذلك العمل، فالمديرون الماليون ليسوا مجرد متعاملين مع الأرقام؛ وبوصفهم جزءًا من الإدارة العليا للشركة، يحتاج المديرون الماليون التنفيذيون Chief Financial Officers إلى استيعابٍ واسع للشركة التي يعملون لصالحها، وللمجال الذي تمارس فيه نشاطها، إلى جانب الابتكار والقدرة على القيادة، وعليهم ألا يحيدوا عن النظرة الأساسية التي تمثل هدفَ المدير المالي، وهي: زيادة قيمة الشركة لصالح مالكيها. تُصنَّفُ الإدارةُ المالية -وهي جمعُ مالِ الشركة وإنفاقُه- على أنها علمٌ وفنٌّ في آنٍ واحدٍ معًا؛ إذ يتعلق الجزءُ العلميُّ منها بتحليل الأرقامِ وتدفُّقاتِ النقد عبر الشركة، أما الجزءُ الفنّيُّ من الإدارة المالية، فيُعنى بالإجابة عن أسئلة مثل: هل تستخدمُ الشركةُ مواردَها المالية الاستخدام الأمثل؟ وبعيدًا عنِ التكاليف. لِمَ نختارُ نوعًا محددًا من التمويل؟ وما مدى خطورة كل خيارٍ من الخيارات المطروحة؟ ومن الهواجس الأخرى المهمة بالنسبة لكل من المديرين التجاريين والمستثمرين، فَهمُ أساساتِ أسواق الأوراق المالية والأوراق المالية المتداوَلة فيها، وهو فهمٌ يؤثر في كل من الخطط المؤسسية والموارد المالية للمستثمرين، وهناك حاليًا حوالي 52% من البالغين في الولايات المتحدة الذين يملكون أسهُمًا، في حين كانت تلك النسبة 25% فقط في العام 1981. يُركِّزُ هذا المقال على الإدارة المالية للشركة، وعلى أسواق الأوراق المالية التي تجمع فيها الشركاتُ المالَ، وسنبدأ بنظرة عامة حول الدور الذي يلعبهُ التمويل والمدير المالي في الاستراتيجية التجارية العامة للشركة، ثم ننتقل بعد ذلك للحديث عن استخدامات الأموال القصيرة، والطويلة، الأمد، وبعدها سنبحث في المصادر الرئيسة للتمويل القصير، والطويل، الأجل، ثم سنراجع وظيفة أسواق الأوراق المالية، وتنظيمَها، وعمليّاتِها، وأخيرًا، سنطَّلعُ على التوجهات الحديثة الرئيسة التي تؤثر في الإدارة المالية وأسواق الأوراق المالية. دور التمويل والمدير المالي تحتاجُ أيُّ شركةٍ كانت إلى المال لتعمل، سواءٌ أكانت شركةَ جنرال موتورز General Motors؟ أو مخبزًا في بلدةٍ صغيرة، وكي تكسب الشركةُ المالَ؛ عليها أن تُنفِقَه أولًا- على المخزون ومستلزمات الإنتاج، والتجهيزات والمرافق، وعلى رواتب الموظفين وأجورهم، ولذلك، يُعَدُّ التمويلُ عاملًا أساسًا لنجاح جميع الشركات، ومع أنَّ إدارة تمويل الشركة قد لا تكون مرئيةً مثل: التسويق أوِ الإنتاج، إلا أنها لا تقل عنهما أهمية لتحقيق النجاح للشركة. فالإدارةُ المالية Financial Management- التي تُعرَّف بأنها فنُّ وعِلمُ إدارةِ أموال الشركة لتحقيق أهدافها- ليست مسؤولية القسم المالي فقط، فجميع القرارات التي تتخذها الشركة لها نتائج مالية، وعلى المديرين في الأقسامِ كافة العمل عن كثب مع الفريق المالي في الشركة، فمثلًا: لو كنتَ تعمل مندوبَ مبيعاتٍ، فستؤثر سياساتُ التحصيل والائتمان التي تنتهجها الشركة في قدرتك على تحقيق مبيعات، وسيكون على رئيس قسم تقنية المعلومات في الشركة، تبريرُ أي طلباتٍ يقدِّمُها للحصول على أنظمةٍ حاسوبية جديدة، أو أجهزة حاسوب محمولة، للموظفين. يجب أن تمثِّلَ عائداتُ مبيعاتِ منتجاتِ الشركة المصدرَ الرئيسَ للتمويل، ولكنَّ ذلك المال الناتج عن المبيعات لا يتوفر دائمًا عندما تظهر الحاجة إليه لدفع الفواتير، وعلى المديرين الماليين تَعقُّبُ كيفية تدفُّقِ المال إلى داخل الشركة وخروجه منها (انظر الصورة 16.2)، إذ يعملُ أولئك المديرون مع أقسام الشركة الأخرى لتحديد كيفية استخدام الأموال المتوفرة، وكم من المال ستحتاج الشركة، ثم يختارون أفضلَ المصادر للحصول على التمويل المطلوب. فعلى سبيل المثال: يتعقَّبُ المديرُ المالي بياناتِ العمليات اليومية مثل: وارِدات الصندوق (أو المقبوضات النقدية Cash Collection، والدفعات المالية (النفقات) Disbursements لضمان كفاية كمية النقد الموجودة لدى الشركة، ومدى تمكِّنُها من الوفاء بالتزاماتها. وعلى المدى الطويل، سيدرسُ المدير المالي بتأنٍّ ما إذا كان على الشركة افتتاحُ منشأةِ تصنيعٍ جديدة، وتوقيتَ ذلك؛ كما سيقترح ذلك المديرُ الطريقةَ الأنسب لتمويل المشروع، وجمع الأموال، وبعد ذلك مراقبة تنفيذ المشروع وتشغيله. هذا وترتبط الإدارة المالية بالمحاسبة ارتباطًا وثيقًا، وفي معظم الشركات، تكون هاتان الوظيفتان من مسؤولية نائب رئيس الشؤون المالية Vice) President of Finance)، أو المدير المالي التنفيذي CFO؛ أما الوظيفة الرئيسة للمحاسب، فهي جمعُ البيانات المالية وعَرضُها، هذا ويستخدم المديرون الماليون البياناتِ المالية، وغيرها من المعلومات التي يُعِدُّها المحاسبون، بهدف اتخاذ القرارات المالية، ويركز المديرون الماليون على التدفقات النقدية Cash Flows- ويُقصَد بها النقود الداخلة إلى الشركة والخارجة منها Inflows and Outflows of Cash- فيتولى أولئك المديرون تخطيط تدفقاتِ الشركةِ النقدية ومراقبتها، لضمان توفر النقد عند الحاجة. مسؤوليات المدير المالي وأنشطته على المديرين الماليين عملٌ مُعقَّدٌ وصعب، فهُم يحللون البياناتِ المالية التي يُعِدُّها المحاسبون، ويراقبون الحالة المالية للشركة، كما يُعدُّونَ الخططَ المالية ويطبقونها، وقد ينخرطون في أحد الأيام في تطوير طريقةٍ أفضل لأتمتةِ المقبوضات النقدية (واردات الصندوق)؛ أما في يوم آخر، فقد تراهم يحللون مسألة استحواذٍ مقترحةً، وتتضمن الأنشطةُ الرئيسة للمدير المالي كلًا مما يأتي: التخطيط المالي: ويتضمن إعدادَ الخطة المالية، وعائداتِ المشاريع، والمصروفات، واحتياجات التمويل، على مدى فترة زمنية محددة. الاستثمار (إنفاق المال): أي إنفاق أموال الشركة في الأوراق المالية، والمشاريع، التي تولِّدُ عائداتٍ عالية بالنسبة لمخاطرها. التمويل (جمع الأموال): أي الحصول على التمويل اللازم لعمليات الشركة واستثماراتها، والسعي لتحقيق أفضل توازن بين الدَّين (أي المال المُقتَرَض) وبين حقوق الملكية، أي الأموال التي تُجمَع من بيع الملكية في الشركة أو المشروع التجاري. هدف المدير المالي كيف يمكن للمديرين الماليين اتخاذُ قراراتِ تخطيطٍ، واستثمارٍ، وتمويلٍ، حكيمة؟ يتمثل الهدف الرئيس للمدير المالي في زيادة قيمة الشركة لصالح مالكيها، وتُقاس قيمةُ شركةٍ مملوكةٍ ملكية عامة بسعر سهمها؛ أما قيمة الشركة المملوكة ملكية خاصة، فهي السعر الذي يمكن أن تُباع مقابله. ولزيادة قيمة الشركة، فعلى المدير المالي أن يأخذ بالحسبان النتائج القصيرة، والطويلة الأمد، لأعمال الشركة، وتُعَدُّ زيادةُ الأرباح أحدَ الأساليب المُتَّبَعة لتحقيق ذلك، ولكنها يجب ألا تكون الأسلوبَ الوحيد، لأنّ منهجَ زيادة الأرباح ذاك يفضِّلُ تحقيقَ مكاسب قصيرة الأمد على تحقيق أهدافٍ طويلة الأمد، فماذا لو أنَّ شركة تعمل في مجالِ تقنيةٍ عالية التطوُّر- يشهد منافسةً شديدة- لم تُجرِ أي أبحاث، أو لم تقم بأي تطوير؟ فعلى المدى القصير، ستحقق تلك الشركةُ أرباحًا عالية نتيجة توفيرها مصاريفَ إجراء تلك الأبحاث، والتطويرات، التي تكلف كثيرًا من المال؛ أما على المدى الطويل، فقد تخسرُ قدرتها على المنافسة بسبب افتقارها إلى منتجاتٍ جديدة. الصورة 16.2: كيفية تدفُّقِ النقد عبر الشركة: (حقوق الصورة محفوظة لجامعة رايس "Rice"، أوبن ستاك "OpenStax"). ويصحُّ ذلك بصرف النظر عن حجم الشركة، وعن النقطة التي وصلت إليها خلال دورة حياتها، ففي شركة كورنينغ Corning للتقنية -وهي شركة أُسِّسَت منذ أكثر من 160 عامًا- تتبنى الإدارةُ النظرةَ المستقبليةَ الطويلة الأمد، وليس فقط بهدف الحصول على مكاسبَ ربعِ سنوية تلبَّيَ بها توقُّعاتِ وول ستريت Wall Street؛ فشركةُ كورنينغ- التي ارتبط اسمُها -سابقًا- بالنسبة للمستهلكين بمنتجات المطبخ، مثل: أواني المطبخ كوريل Corelle، وأواني الطهي الزجاجية المقاوِمة للحرارة بايركس Pyrex- هي اليوم شركةُ تقنية تُصنِّعُ منتجاتِ سيراميك وزجاج متخصصة، وهي من المورِّدين الرائدين لزجاج يسمى زجاج غوريلا Gorilla Glass، الذي يُعَد نوعًا خاصًا من الزجاج يُستخدَم لشاشات الأجهزة المحمولة، ومن بينها آيفون iPhone، وآيباد iPad، والأجهزة العاملة على نظام التشغيل التابع لشركة غوغل Google، كما أنّها مخترعة ألياف ضوئية، ناقلات (كابلات) ألياف ضوئية، في قطاع الاتصالات، وتتطلبُ خطوطُ المنتجات تلك استثمارتٍ ضخمةً خلال دورات البحث والتطوير الطويلة الخاصة بها، إلى جانب الاستثمارات التي تحتاجها المصانع والمعدّات فور البدء بإنتاجها. وقد يكون ذلك خطيرًا على المدى القصير، ولكن متابعةَ السير في تلك المهمة قد تأتي بنتائج إيجابية؛ فقد أعلنت شركةُ كورنينغ مؤخرًا عن خططٍ لتطوير قسمٍ منفصل لديها مُكرَّسٍ لزجاج غوريلا Gorilla Glass، الذي تستحوذ فيه اليوم على 20% من سوق الهواتف المحمولة بمبيعاتٍ تخطَّت 200 مليون جهاز، وبالإضافة إلى ما سبق، فقد عادت تجارة ناقلات (كابلات) الألياف الضوئية الخاصة بشركة كورنينغ إلى الرواج والانتعاش، بالتوازي مع زيادة الشركات المُزوِّدة بخدمة تلك الناقلات (الكابلات) -مثل: شركة فيرايزون Verizon- تطويرَ شبكة ناقلات الألياف الضوئية على امتداد أراضي الولايات المتحدة الأمريكية، ومع بداية العام 2017، ساعد التزامُ شركة كورنينغ- المتمثل بإعادة تحديدها الهدف من بعض التقنيات الخاصة بها، وتطويرِ منتجاتٍ جديدة- في زيادة دخلها الصافي، فزادت عائداتُها الربع سنوية مؤخرًا بنسبةٍ تجاوزت 16%. ومثلما يُظهِرُ وضعُ شركة كورنينغ، يطمح المديرون الماليون دائمًا إلى تحقيق توازنٍ بين فرصة تحقيق ربحٍ، واحتماليةِ تكبُّدِ خسائر، وفي المجال المالي، تُسمى فرصةُ تحقيق الربح: العائد Return؛ أما احتماليةُ الخسارة -أو إمكانية ألا يحقق أحدُ الاستثماراتِ مستوى العائدِ المرجوَّ منه- فتسمى المُخاطرة Risk. ومن المبادئ الرئيسة في المجال المالي أنه كلما ازدادتِ المخاطرُ، ارتفعَ العائدُ المتوقع أو الذي تطلبه الجهةُ المُخاطِرة، ويُسمّى هذا المبدأُ المقبول على نطاقٍ واسع: نسبة/ مفاضلة العائد إلى المخاطرة Risk-Return Trade-Off، إذ يأخذِ المديرون الماليون بالحسبان العديدَ من عوامل المخاطرة والعائد عند اتخاذهم قراراتِ استثمارٍ وتمويل، ومن بين تلك العوامل: الأنماطُ المتغيرة للطلب في السوق، ومعدلات الفائدة، والظروف الاقتصادية العامة، وظروف السوق، والمسائل الاجتماعية، مثل: تأثيرات البيئة وسياسات فرص التوظيف المتساوية. كيفية استخدام المؤسسات للأموال على الشركة الاستمرار في استثمار المال في عملياتها بهدف تحقيق النمو والازدهار، ويحدد المديرُ الماليُّ الطريقةَ الأمثل لاستخدام أموال الشركة، إذ تدعم النفقاتُ القصيرة الأجل العملياتِ اليومية للشركة، فمثلًا: تُنفِق شركةُ تصنيع الملابس الرياضية، نايكي Nike، المال لشراء مواد خام مثل: الجلد والقماش، ولدفع رواتب موظفيها؛ أما النفقات الطويلة الأجل، فتُخصَّصُ -عادة- للأصول الثابتة؛ إذ تتضمن تلك النفقاتُ بالنسبة لشركة نايكي- مثلًا- نفقاتٍ مخصصة لشراء مصنعٍ جديد، أو شراء معداتِ تصنيعٍ مؤتمَتة، أو للاستحواذ على مصنعِ ألبسةٍ رياضيةٍ صغير. النفقات القصيرة الأجل النفقات القصيرة الأجل Short-term Expenses- التي تُسمّى غالبًا: النفقات التشغيلية Operating Expenses- هي التي تُستخدَم لدعم أنشطة الإنتاج والبيع الحالية في الشركة، وينتج عنها عادةً أصولٌ حاليّة Current Assets تتضمن نقودًا، وأيَّ أصولٍ أخرى (حسابات مستحقة القبض ومخزون) يمكن تحويلها إلى نقود خلال سنة واحدة، وهدفُ المدير المالي هو إدارة الأصول الحالية بحيث يكون لدى الشركة نقدٌ كافٍ لدفع فواتيرها، ورفدِ حساباتها مستحقة القبض، ومخزونها. إدارة النقد: ضمان توفر السيولة يُعَدُّ النقدُ شريانَ الحياة بالنسبة للشركة، فبدونه لا يمكن لها أن تعمل، ومن الواجبات المهمة التي يقوم بها المدير المالي؛ إدارةُ النَّقد Cash Management، أي ضمانُ وجودِ ما يكفي من نقدٍ في متناول اليد لدفع الفواتير عندَ استحقاقها، ولتغطية النفقات غير المتوقعة. تضعُ الشركاتُ توقُّعاتٍ حول احتياجاتها من النقد لفترةٍ محددة، إذ تحتفظُ العديد منها بحدٍّ أدنى من الرصيد النقدي لتغطية النفقات غير المتوقعة، أوِ استعدادًا للتغيرات المفاجِئة في التدفقاتِ النقدية المخطط لها، كما يضعُ المديرون الماليون ترتيباتٍ للقروضِ بهدف تغطية أي عُجُوزات؛ فإذا كانت كمية التدفقات النقدية الواردة إلى داخل الشركة Cash Inflows، وتوقيتها، مُطابِقَين بصورة قريبة لكمية التدفقات النقدية الخارجة منها Cash Outflows، ولتوقيتها، فلا تحتاجُ الشركةُ سوى إلى الاحتفاظ بكمية قليلة من النقد في متناول اليد، فالشركةُ ذاتُ المبيعات والإيرادات المتوقَّعَة والمُنتظَمة خلال السنة، تحتاجُ إلى نقدٍ أقلَّ مما تحتاج شركةٌ ذاتُ أنماط فصلية متباينة من المبيعات والإيرادات، فشركةُ دُمى (ألعاب) مثلًا- والتي تشهد ذروةَ المبيعات في فصل الخريف- تنفق مبلغًا كبيرًا من النقد خلال فصلَي الربيع والصيف لتملأَ مخزوناتِها، إذ يكون لديها فائضٌ نقديٌّ خلال الشتاء وأوائل الربيع، بفضل ما تجمعه من مال من المبيعات التي تحققها في الفصل الذي يشهد ذروة المبيعات بالنسبة لها. ولأنَّ الفائدة الناتجة عن النقد الموجود في صورة حسابات جارية تكون منخفضة -إن وُجِدَت- يحاولُ المديرُ المالي إبقاء أرصدة النقد منخفضة، واستثمارَ النقد الفائض، وتُستثمَرُ المبالغُ الفائضة بصورة مؤقتة في الأوراق المالية القابلة للتداول Marketable Securities، وهي استثماراتٌ نقدية قصيرة الأجل يمكن تحويلُها بسهولةٍ إلى نقد، كما يبحثُ المديرُ الماليُّ عن استثماراتٍ منخفضة المخاطر تولِّدُ عائداتٍ مرتفعة، وتتضمن ثلاثةَ أنواعٍ من أكثر الأوراق النقدية القابلة للتداول شيوعًا وهي: أُذونات الخزينة Treasury Bills، وشهادات الإيداع Certificates of Deposit، والأوراق التجارية Commercial Papers. و(تُعرَّفُ الأوراق التجارية "Commercial Papers" بأنها دَينٌ قصيرُ الأجل غيرُ مضمون، تُصدِرُه شركةٌ مالية ذات وضعٍ ماليٍّ قوي)، ولدى المديرين الماليين في يومنا هذا أدواتٌ جديدة لمساعدتهم في العثور على أفضل الاستثمارات القصيرة الأجَل، مثل: منصات التجارة الإلكترونية التي توفِّرُ الوقتَ وتتيح الوصول إلى أنواعٍ أكثر من الاستثمارات، ويُعَدُّ ذلك مفيدًا بصورة خاصة بالنسبة للشركات الصغيرة التي لا تملك فِرَق موظفين ماليين كبيرة. وتواجه الشركاتُ التي تمارس عملياتها خارج حدود الدولة التي يوجد فيها مقرها الرئيس؛ صعوباتٍ أكبر متعلقة بإدارة النقد، فتطويرُ الأنظمة الخاصة بإدارة النقد على المستوى الدولي قد يبدو -نظريًّا- أمرًا بسيطًا، ولكنه مُعقَّدٌ جدًا من الناحية العملية، فبالإضافة إلى تعامُلِ أُمَناء الخزينة مع عدد من العملات الأجنبية، عليهم استيعابُ الممارسات المصرفية والمستلزمات أو الشروط التنظيمية والضريبية في كل بلد، واتِّباعُها، فقد تُعيقُ تلك الأنظمةُ المختلفة قدرتَهم على تحويل الأموال بحُرّيةٍ عَبْرَ حدود الدول؛ هذا فضلًا عن أنَّ إصدار مجموعةٍ نموذجية من الإجراءات لكل مكتب قد لا يجدي نفعًا، بسبب اختلاف الممارسات التجارية المحلية من بلد لآخر، وبالإضافة إلى ما سبق، فقد يُعارِضُ المديرون المحليون التحوُّلَ إلى هيكليةٍ مركزية؛ لأنهم لا يريدون التخلّيَ عن تحكُّمِهِم في النقد الذي تُنتِجُه الوحداتُ التابعة لهم، وعلى المديرين الماليين للشركات أن يكونوا على دراية بالأعراف المحلية، وأن يتعاملوا معها بدقة وتأنٍّ، وأن يتكيفوا مع استراتيجية المركزية Centralization Strategy وفقًا لذلك. وإلى جانب سعي المدير المالي إلى تحقيق توازنٍ سليم بينَ النقد والأوراق المالية القابلة للتداول؛ فإنه يحاول تقصيرَ الوقت الممتد بين شراء الخدمات أو محتويات المخازن (التدفقات النقدية الخارجة من الشركة) وبين جمع النقد من المبيعات (التدفقات النقدية الداخلة إلى الشركة). وتتضمن الاستراتيجياتُ الثلاث الرئيسة: جمعَ المال المُستَحَق للشركة (الحسابات مستحقة القبض) بالسرعة الممكنة، ودفع المال المشغولةُ به ذمة الشركات لصالح أطرافٍ أخرى (الحسابات مستحقة الدفع) خلال أطول مدة ممكنة، دون أن يمس ذلك بسمعة الشركة الائتمانية، وتقليلَ الأموال المُكرَّسة للمخزون. إدارة الحسابات مستحقة القبض تُمثِّلُ الحساباتُ مُستَحَقةُ القبض Accounts Receivable المبيعاتِ التي لَمّا يُدفَع ثمنُها للشركة، ولأن المنتَج يكون قد بيعَ بدون أن تكون الشركةُ قد قبضت ثمنه، فترقى الحساباتُ مستحقة القبض إلى مرتبة أحد استخدامات النقد، وتمثل الحساباتُ مستحقةُ القبض بالنسبة لشركة تصنيعٍ عادية ما بين 15- 20% من أصولها الإجمالية. إنَّ هدفَ المدير المالي هو جمعُ المال المُستحَقّ للشركة بأسرع وقتٍ ممكن، وذلك بالتوازي مع توفير شروطٍ ائتمانية للزبائن جذّابة بما يكفي لزيادة المبيعات، وتتضمن إدارةُ الحسابات مستحقة الدفع وضعَ سياساتٍ ائتمانية، ومبادئ توجيهيةً حول توفير الائتمان، والشروط الائتمانية، وشروطًا محددة لإعادة الدفع، بما في ذلك المدة التي على الزبائن خلالها دفعُ الفواتير المُستحقة في ذممهم، وما إذا كانت ستُمنَحُ تخفيضاتٌ للزبائن الذين يدفعون تلك الفواتير بصورة أسرع، ومن الجوانب الأخرى لإدارة الحسابات مستحقة الدفع؛ تقريرُ سياساتِ تحصيل الأموال، وإجراءاتِ تحصيل الحسابات المتأخر دفعُها. إن وضعَ سياساتِ الائتمان وتحصيل الأموال هو عملٌ يحقق التوازن، ويضطلع به المديرون الماليون، فمن جهة، ينتج عن السياساتِ الائتمانية المُيَسَّرة، أوِ الشروط الائتمانية السَّخيّة (يُقصَد بها فترة إعادة دفع طويلة أو حسومات نقدية كبيرة) زيادةٌ في المبيعات، ومن جهةٍ أخرى، على الشركة تمويلُ مزيدٍ من الحسابات المستحقة القبض، وتزدادُ -أيضًا- مخاطرُ وجود حساباتٍ مستحقة القبض غيرِ قابلةٍ للتحصيل Uncollectible Accounts Receivable. وأثناء وضعِ الشركاتِ سياساتها الائتمانية، وتلك الخاصةَ بتحصيل أموالها، فإنها تأخذ بالحسبان تأثيرَها على المبيعات، وتوقيتَ التدفُقِ النقديّ، وتجربتها مع الديون المعدومة Bad Debt، ومواصفات الزبون Customer Profile، والمعايير السائدة في القطاع الذي تنشط فيه تلك الشركات. إنَّ الشركاتِ التي تريد تسريعَ عمليات التحصيل، تتولى بنشاطٍ إدارةَ حساباتِها مستحقة القبض، وذلك بدلًا مِن ترك الأمر للزبائن ليدفعوا متى يشاؤون، ووفقًا لإحصاءاتٍ حديثة؛ فإنّ أكثر من 90% من الشركات تعاني من تأخُّرٍ في الدفع من قبل زبائنها، وهناك شركاتٌ تشطب نسبةً من الديون المعدومة، وهي نسبة قد تكون مرتفعة. تلعبُ التقنية دورًا مهمًا في مساعدة الشركات على تطوير أدائها الخاص بالائتمان وتحصيل الأموال، فمثلًا: تستخدمُ العديدُ من الشركاتِ أحدَ أنواع عملياتِ اتخاذ القرار المؤتمَتة، سواءٌ الذي يأتي منها بصيغة نظام تخطيط موارد المؤسسة ERP System، أو بصورةِ مزيجٍ من البرمجيات والنماذج التكميلية التي تساعد الشركاتِ على اتخاذ قراراتٍ واعية، تتعلق بعملياتِ الائتمان وتحصيل الأموال. وتُفضِّلُ بعضُ الشركاتِ تعهيدَ العمليات المالية والمحاسبية التجارية (أي الاستعانة على أدائها بمصادر خارجية) مُستعينةً باختصاصيين، بدلًا من إنشاء أنظمتها الخاصة بالتعامل مع تلك العمليات. إنَّ توفُّرَ التقنية عالية التطوُّر، والمنصّاتِ الإلكترونية المتخصصة، التي سيكون صعبًا ومُكلِفًا توفيرُها داخل الشركة، سيُقنِع الشركاتِ من الأحجام كافة بقبول الاستعانة بها، ولكن، ليس سهلًا على المديرين الماليين قبول التخلي عن التحكُّم بالأمور المالية لأطرافٍ خارجية، إذ تزدادُ المخاطرُ لدى تحويل البيانات المالية للشركة، وسواها من بيانات مهمة، إلى نظامٍ حاسوبيٍّ خارجي؛ إذ يتمثل ذلك الخطر في احتمالية تسريب تلك البيانات أو فقدانها، أو قد تتعرض للسرقة من قبل المنافسين، كما إنَّ مراقبةَ جهةٍ مُزوِّدةٍ خارجية يكون أصعبَ من مراقبة موظفي الشركة، وتُعَدُّ التجارةُ الدولية أحدَ المجالات التي تجذب العديدَ من الزبائن، والتي تحكمها أنظمةٌ وترتيباتٌ تختلف من بلدٍ لآخر، وتتطلب قَدْرًا كبيرًا منَ التوثيق، حيث يمكن للمُزوِّدين -بفضل أنظمةِ تقنية المعلومات المتخصصة- أن يتتبّعوا -ليس فقط- الموقعَ الحقيقي الذي توجد فيه السِّلع، بل وحتى الأعمالَ الورقيَّةَ المرتبطة بعمليات شحنِها، حيث تبلغ نفقاتُ معالجةِ السلع المُشتراة في الخارج، حوالي ضعفَي تلك النفقات بالنسبة للسلع المحلية، وهذا ما يجعل من الأنظمة الأكثر كفاءة أكثرَ تحقيقًا للفائدة. المخزون يُعَدُّ شراءُ المخزون الذي تحتاج إليه الشركةُ أحدَ الاستخدامات الأخرى للأموال، إذ يمثِّلُ المخزونُ بالنسبة لشركة عادية حوالي 20% من أصولها الإجمالية، ولا تقتصرُ النفقاتُ المرتبطةُ به على سعر شرائه، بل تتعداه لتشملَ نفقات طلب الحصول عليه، والتعاملِ معه، وتخزينِه، والفائدة المترتبة عليه، وتأمينِه. ولدى كلٍّ من مديري الإنتاج، والتسويق، والمديرين الماليين، وجهاتُ نظرٍ مختلفة حول المخزون، فمديرو الإنتاج يريدون كمياتٍ كبيرة من المواد الخام في متناول اليد ضمن المخازن، لتجنُّبِ التأخير في عملياتِ الإنتاج، أما مديرو التسويق، فيفضِّلون وجود كثيرٍ منَ السِلَع النهائية الجاهزة لتلبية طلبات الزبائن بأسرع وقت، وبالمقابل، يفضِّلُ المديرون الماليون وجودَ أقلِّ كمّيةٍ ممكنة من المخزون، دون أن يؤدّيَ ذلك إلى الإضرار بالمبيعات أو بجودة الإنتاج، وعلى المديرين الماليين العملُ عن كثب مع أقرانهم؛ مديري التسويق، والإنتاج، لتحقيق التوازن بين تلك الأهداف المتعارضة، وتتمثلُ الأساليبُ المُتَّبَعة لتخفيض الاستثماراتِ التي تُنفَقُ على المخزون في إدارة المخزون Inventory Management، واتّباع نظام الوقت المناسب Just-in-Time System، وتخطيط متطلبات المواد Materials Requirement Planning. وفي شركات البيع بالتجزئة، تعد إدارة المخزون أساسيةً بالنسبة للمديرين الماليين الذين يراقبون عن كثب معدلَ دوران المخزون Inventory Turnover بفضل المبيعات، إذ يُظهِرُ هذا المعدَّلُ سرعةَ تحرُّكِ المخزون عبر الشركة، وتحوُّلِهِ إلى مبيعات، فإذا كان رقمُ المخزون مرتفعًا جدًا، فإنه يؤثِّر عادةً في كميةِ رأس المال العامل Working Capital الذي تمتلكه الشركة في متناول يدها، مُجبِرًا إياها على اقتراض المال لتغطية نفقات المخزون الفائض؛ أما إذا كان رقمُ معدلِ دورانِ المخزون منخفضًا جدًا، فيعني ذلك أنه ليسَ لدى الشركة ما يكفي من مخزون منتجاتٍ في متناول يدها لتلبية احتياجات الزبائن، مما قد يدفعهم إلى البحث عما يحتاجون إليه من منتجاتٍ لدى شركات أخرى. المصروفات الطويلة الأجل تستثمر الشركاتُ أموالها -أيضًا- في الأصول المادية مثل: الأرض، والمباني، والتجهيزات، والمعدات، وأنظمة المعلومات، وتسمى هذه المصروفات النفقات الرأسمالية Capital Expenditures، فخلافًا للمصروفات التشغيلية Operating Expenses التي تُنتِجُ فوائدَ خلال سنة واحدة، تتجاوز فوائدُ المصروفاتِ التشغيلية تلك المدةَ، فشراءُ آلةِ طباعةٍ قابلةٍ للاستخدام لمدة سبعِ سنواتٍ يُعَدُّ من المصروفاتِ الرأسمالية التي تُسجَّل في الميزانية العمومية للشركة؛ بوصفها من الأصول الثابتة Fixed Assets، ولكن الحبر، والورق، وغيرَها من المستلزمات، تُعد من المصاريف التشغيلية وليس الرأسمالية؛ أما عملياتُ الاندماج Mergers، والاستحواذ Acquisitions، فتعد من المصاريف الرأسمالية. تُنفِقُ الشركاتُ مصاريفَ رأسمالية لأسباب عديدة، أبرزُها توسيعُ الأصول الثابتة، واستبدالها، وتجديدها، وتصنيعُ منتجاتٍ جديدة، ولدى معظم شركات التصنيع استثماراتٌ كبرى مخصصة للمصروفات الرأسمالية، المتمثلة باقتناء أصولٍ ثابتةٍ طويلة الأجَل، فشركة صناعة الطائرات بوينغ Boeing مثلًا، تنفق ملياراتِ الدولارات سنويًا على منشآتِ تصنيع الطائرات، ولأنّ المصروفاتِ الرأسمالية باهظة التكلفة، ولها تأثيرٌ كبير على مستقبل الشركة، فيستخدمُ المديرون الماليون عمليةً تُدعى الميزانية الرأسمالية Capital Budgeting لتحليل المشاريع طويلة الأجَل، واختيار تلك التي توفر أفضل العائدات، بالتوازي مع رفع قيمة الشركة، وتتسم القراراتُ المتعلقةُ بتصنيعِ منتجاتٍ جديدة، وتلك الخاصة بالاستحواذ على شركاتٍ أخرى، بأهميةٍ خاصة؛ حيث يأخذ المديرون تكاليفَ المشروع بالحُسبان، ويتنبؤون بالمزايا المستقبلية التي سيقدِّمُها المشروعُ بهدف حساب العائد على الاستثمار Return on Investment المتوقع الخاص بالشركة ذات الصلة. ترجمة -وبتصرف- للفصل Understanding Financial Management and Securities Markets من كتاب introduction to business اقرا أيضًا المقال السابق: الخدمات المصرفية العالمية وأهم التوجهات الحديثة لدى المؤسسات المالية نظام الاحتياطي الفيدرالي لإدارة العرض النقدي نظرة عامة حول التمويل الريادي واستراتيجيات المحاسبة -
 حان الوقت للتكلم عن التهيئة Initialization في لغة سي بعد أن تكلمنا عن جميع أنواع البيانات المدعومة في اللغة، إذ تسمح لغة سي للمتغيرات الاعتيادية والهياكل والاتحادات والمصفوفات بأن تحمل قيمةً أوليةً عند التعريف عنها، وكان للغة سي القديمة بعض القوانين الغريبة بهذا الخصوص التي تعكس تقاعس مبرمجي مصرّفات سي عن إنجاز بعض العمل الإضافي، وأتت لغة C المعيارية لحل هذه المشكلات وأصبح من الممكن الآن تهيئة الأشياء عندما تريد وكيفما تريد. أنواع التهيئة في لغة سي هناك نوعان من التهيئة؛ تهيئة عند وقت التصريف compile time وتهيئة عند وقت التشغيل run time، ويعتمد النوع الذي ستحصل عليه على مدة التخزين storage duration للشيء الذي يُهيّأ. يُصرح عن الكائنات ذات المدة الساكنة static duration إما خارج الدوال، أو داخلها باستخدام الكلمة المفتاحية extern أو static على أنها جزءٌ من التصريح، ويُهيّأ هذا النوع عند وقت التصريف فقط. لجميع الكائنات الأخرى مدةٌ تلقائية automatic duration، يمكن تهيئتها فقط عند وقت التشغيل، إذ أن التصنيفين حصريان فيما بينهما. على الرغم من ارتباط مدة التخزين بالربط (انظر مقال الربط) إلا أنهما مختلفان ويجب عدم الخلط فيما بينهما. يمكن استخدام التهيئة عند وقت التصريف فقط في حال استخدام التعابير الثابتة constant expressions، بينما يمكن استخدام التهيئة عند وقت التشغيل لأي تعبير كان، وقد أُلغي قيد لغة سي القديمة الذي ينص على إمكانية تهيئة المتغيرات البسيطة وحدها عند وقت التشغيل، وليس المصفوفات، أو الهياكل، أو الاتحادات. التعابير الثابتة هناك بعض الاستخدامات الضرورية للتعابير الثابتة، ويُعد تعريف التعبير الثابت بسيط الفهم، إذ يُقيّم التعبير الثابت constant expression عند وقت التصريف وليس عند وقت التشغيل، ويمكن استخدام هذا النوع من التعابير في أي مكان يسمح باستخدام قيمة ثابتة. يُشترط على التعبير الثابت ألا يحتوي على أي عامل إسناد أو زيادة أو نقصان أو استدعاء لدالة ما أو عامل الفاصلة، إلا إذا كان التعبير جزءًا من معامل sizeof، وقد يبدو هذا الشرط غريبًا بعض الشيء، إلا أنه بسبب أن العامل sizeof يُقيّم نوع التعبير وليس قيمته. يؤكد المعيار على وجوب تقييم الأعداد الحقيقية عند وقت التصريف بدقة ونطاق مماثلين لحالة تقييمهم في وقت التشغيل. يوجد هناك طريقةٌ محدودة أكثر تدعى تعابير الأعداد الصحيحة الثابتة integral constant expressions، ولهذه التعابير نوع عدد صحيح وتحتوي على معاملات operands من نوع عدد صحيح ثابت أو معدّدات ثابتة enumeration constants، أو محارف ثابتة، بالإضافة إلى تعابير sizeof والأعداد الحقيقية الثابتة التي تكون معاملات لتحويل الأنواع casts، ويسمح لعوامل تحويل الأنواع بتحويل الأنواع الحسابية إلى أنواع صحيحة فقط. لا تُطبّق أي قيود على محتويات تعابير sizeof طبقًا لما سبق قوله (يُقيّم نوع التعبير وليس قيمته). يُشابه التعبير الحسابي الثابت arithmetic constant expression التعبير الصحيح الثابت، ولكنه يسمح باستخدام الأعداد الصحيحة الثابتة، ويحدّ من استخدام تحويل الأنواع بالتحويل من نوع حسابي إلى آخر. العنوان الثابت address constant هو مؤشر يشير إلى كائن ذي مدة تخزين ساكنة أو إلى مؤشر يشير إلى دالةٍ ما، ويمكنك الحصول على هذه العناوين باستخدام العامل "&" أو باستخدام التحويلات الاعتيادية للمصفوفات وأسماء الدوال إلى مؤشرات عندما تُستخدم ضمن تعبير، ويمكن استخدام كلٍ من العوامل "[]" و "." و "<-" و "&" و "*" ضمن التعبير طالما لا يتضمن ذلك الاستخدام محاولة للوصول لقيمة أي كائن. استكمال عن التهيئة يُسمح لأنواع الثوابت المختلفة بالتواجد في العديد من الأماكن، إلا أن تعابير الأعداد الصحيحة الثابتة شديدة الأهمية على وجه الخصوص لأنها من النوع الوحيد الذي قد يُستخدم لتحديد حجم المصفوفة وقيم ما يسبق تعليمة case. تتميز أنواع الثوابت المسموح باستخدامها مثل قيمة أولية لتهيئة التعابير بأنها أقل محدودية، إذ من المسموح لك باستخدام تعابير حسابية ثابتة، أو مؤشر فراغ، أو عنوان ثابت، أو عنوان ثابت لكائن زائد أو ناقص تعبير صحيح ثابت، ويعتمد الأمر طبعًا على نوع الشيء الذي يجري تهيئته سواءٌ كان نوع تعبير ثابت محدد مناسبًا أم لا. إليك مثالًا يحتوي على تهيئة لعدة متغيرات: #include <stdio.h> #include <stdlib.h> #define NMONTHS 12 int month = 0; short month_days[] = {31,28,31,30,31,30,31,31,30,31,30,31}; char *mnames[] ={ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; main(){ int day_count = month; for(day_count = month; day_count < NMONTHS; day_count++){ printf("%d days in %s\n", month_days[day_count], mnames[day_count]); } exit(EXIT_SUCCESS); } مثال 1 تهيئة المتغيرات الاعتيادية بسيطة، فعليك فقط إضافة = expression بعد اسم المتغير في التصريح، والتي تدل expression على التعبير الذي ستُسند قيمته إلى المتغير، وسيُهيّأ المتغير بهذه القيمة، ويعتمد استخدام مجمل التعابير أو استخدام التعابير الثابتة حصرًا على مدة التخزين، وهذا ينطبق على جميع الكائنات. تهيئة المصفوفات أحادية البعد بسيطةٌ أيضًا، إذ عليك فقط كتابة قائمة بالقيم التي تريدها وتفصل كل قيمة بفاصلة داخل أقواس معقوصة؛ ويوضّح المثال التالي طريقة تهيئة المصفوفة، ويُحدّد حجم المصفوفة طبقًا للقيم الأولية الموجودة إن لم تحدد حجم المصفوفة على نحوٍ صريح، أما إذا حددت الحجم صراحةً، فيجب أن يكون عدد القيم الأولية التي تزودها يساوي أو أصغر من الحجم، إذ يسبب إضافة قيم أكبر من حجم المصفوفة خطئًا، بينما ستهيّئ القيم الموجودة -وإن كانت قليلة- العناصر الأولى من المصفوفة. يمكنك بناء سلسلة نصية يدويًا بالطريقة: char str[] = {'h', 'e', 'l', 'l', 'o', 0}; يمكن أيضًا استخدام سلسلة نصية ضمن علامتي تنصيص لتهيئة مصفوفة من المحارف: char str[] = "hello"; سيُضمّن المحرف الفارغ في نهاية المصفوفة في حالتنا السابقة تلقائيًا إذا كانت هناك مساحةٌ كافية، أو إذا لم يُحدد حجم المصفوفة، إليك المثال التالي: /* لا يوجد مكان للمحرف الفارغ */ char str[5] = "hello"; /* يوجد مكان للمحرف الفارغ */ char str[6] = "hello"; استخدم البرنامج في مثال 1 السلاسل النصية لأهداف مختلفة، إذ كان استخدامهم بهدف تهيئة مصفوفة من مؤشرات تشير إلى محارف، وهذا استخدام مختلفٌ تمامًا. يمكن استخدام تعبير من نوع مناسب لتهيئة هياكل من نوع مدة تلقائية، وإلا فيجب استخدام قائمة تحتوي على تعابير ثابتة بين قوسين على النحو التالي: #include <stdio.h> #include <stdlib.h> struct s{ int a; char b; char *cp; }ex_s = { 1, 'a', "hello" }; main(){ struct s first = ex_s; struct s second = { 2, 'b', "byebye" }; exit(EXIT_SUCCESS); } مثال 2 يمكن تهيئة العنصر الأول فقط من الاتحاد. يحدث تجاهلٌ للأعضاء عديمة الاسم ضمن الهيكل أو الاتحاد خلال عملية التهيئة، سواءٌ كانت حقول بتات bitfields، أو مسافات فارغة لمحاذاة عنوان التخزين، فمن غير المطلوب أخذهم بالحسبان عندما تختار القيم الأولية لأعضاء الهيكل الحقيقية (ذات الاسم). هناك طريقتان لكتابة القيم الأولية لكائنات تحتوي على كائنات فرعية بداخلها، فيمكن كتابة قيمة أولية لكل عضو بالطريقة: struct s{ int a; struct ss{ int c; char d; }e; }x[] = { 1, 2, 'a', 3, 4, 'b' }; مثال 3 سيُسنِد ما سبق القيمة 1 إلى x[0].a و 2 إلى x[0].e.c و a إلى x[0].e.d و 3 إلى x[1].a وهكذا. استخدام الأقواس الداخلية أكثر أمانًا للتعبير عن القيم التي تقصدها، إذ تسبّب قيمةٌ خاطئةٌ واحدة فوضى عارمة. struct s{ int a; struct ss{ int c; char d; }e; }x[] = { {1, {2, 'a'}}, {3, {4, 'b'}} }; مثال 4 استخدم الأقواس دائمًا، لأن هذه الطريقة آمنة، والأمر مماثل بالنسبة للمصفوفات بكونها هياكل: float y[4][3] = { {1, 3, 5}, /* y[0][0], y[0][1], y[0][2] */ {2, 4, 6}, /* y[1][0], y[1][1], y[1][2] */ {3, 5, 7} /* y[2][0], y[2][1], y[2][2] */ }; مثال 5 تُهيّأ قيم الأسطر الثلاث الأولى كاملةً من y، ويبقى السطر الرابع y[3] غير مُهيّأ. تُسند لجميع الكائنات ذات المدة الساكنة قيمٌ أولية ضمنية تلقائية إذا لم يوجد أي قيمة أولية لها، ويكون أثر القيمة الأولية التلقائية الضمنية مماثلًا لأثر إسناد القيمة 0 الثابتة، وهذا الأمر شائع الاستخدام، وتفترض معظم برامج لغة سي نتيجةً لذلك أن الكائنات الخارجية والكائنات الساكنة الداخلية تبدأ بالقيمة صفر. تُضمن عملية التهيئة للكائنات ذات المدة التلقائية فقط في حالة وجود تعليمتها المركبة "في الأعلى"، إذ قد يتسبب الانتقال إلى أحد الكائنات فورًا بعدم حصول عملية التهيئة وهذا الأمر غير مستحب ويجب تجنبه. يشير المعيار بصراحة إلى أن وجود القيم الأولية في التصريح ضمن تعليمات switch لن يكون مفيدًا، لأن التصريح لا يُصنف بكونه تعليمة، ويمكن عنونة label التعليمة فقط، ونتيجةً لذلك فلا يمكن للقيم الأولية في تعليمات switch أن تُنفّذ لأن كتلة الشيفرة البرمجية التي تحتويها يجب أن تلي ذكر التصاريح. يمكن أن يُستخدم التصريح داخل دالة ما (نطاق مرتبط بكتلة الدالة) للإشارة إلى كائن ذي ربطٍ خارجي External linkage أو ربط داخلي Internal linkage باستخدام عدّة طرق تطرقنا إليها في مقال الربط والنطاق وهناك مزيدٌ من الطرق التي سنتطرق إليها لاحقًا. إذا اتبعت الطرق السابقة (التي من المستبعد أن تتحقق من قبيل الصدفة)، فلا يمكنك تهيئة الكائن على أنه جزء من التصريح، وإليك الطريقة الوحيدة التي تستطيع تحقيق ذلك بها: int x; /* ربط خارجي */ main(){ extern int x = 5; /* استخدام ممنوع */ } لم يكشف مصرّفنا التهيئة الممنوعة في هذا المثال أيضًا. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C المقال السابق: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C
حان الوقت للتكلم عن التهيئة Initialization في لغة سي بعد أن تكلمنا عن جميع أنواع البيانات المدعومة في اللغة، إذ تسمح لغة سي للمتغيرات الاعتيادية والهياكل والاتحادات والمصفوفات بأن تحمل قيمةً أوليةً عند التعريف عنها، وكان للغة سي القديمة بعض القوانين الغريبة بهذا الخصوص التي تعكس تقاعس مبرمجي مصرّفات سي عن إنجاز بعض العمل الإضافي، وأتت لغة C المعيارية لحل هذه المشكلات وأصبح من الممكن الآن تهيئة الأشياء عندما تريد وكيفما تريد. أنواع التهيئة في لغة سي هناك نوعان من التهيئة؛ تهيئة عند وقت التصريف compile time وتهيئة عند وقت التشغيل run time، ويعتمد النوع الذي ستحصل عليه على مدة التخزين storage duration للشيء الذي يُهيّأ. يُصرح عن الكائنات ذات المدة الساكنة static duration إما خارج الدوال، أو داخلها باستخدام الكلمة المفتاحية extern أو static على أنها جزءٌ من التصريح، ويُهيّأ هذا النوع عند وقت التصريف فقط. لجميع الكائنات الأخرى مدةٌ تلقائية automatic duration، يمكن تهيئتها فقط عند وقت التشغيل، إذ أن التصنيفين حصريان فيما بينهما. على الرغم من ارتباط مدة التخزين بالربط (انظر مقال الربط) إلا أنهما مختلفان ويجب عدم الخلط فيما بينهما. يمكن استخدام التهيئة عند وقت التصريف فقط في حال استخدام التعابير الثابتة constant expressions، بينما يمكن استخدام التهيئة عند وقت التشغيل لأي تعبير كان، وقد أُلغي قيد لغة سي القديمة الذي ينص على إمكانية تهيئة المتغيرات البسيطة وحدها عند وقت التشغيل، وليس المصفوفات، أو الهياكل، أو الاتحادات. التعابير الثابتة هناك بعض الاستخدامات الضرورية للتعابير الثابتة، ويُعد تعريف التعبير الثابت بسيط الفهم، إذ يُقيّم التعبير الثابت constant expression عند وقت التصريف وليس عند وقت التشغيل، ويمكن استخدام هذا النوع من التعابير في أي مكان يسمح باستخدام قيمة ثابتة. يُشترط على التعبير الثابت ألا يحتوي على أي عامل إسناد أو زيادة أو نقصان أو استدعاء لدالة ما أو عامل الفاصلة، إلا إذا كان التعبير جزءًا من معامل sizeof، وقد يبدو هذا الشرط غريبًا بعض الشيء، إلا أنه بسبب أن العامل sizeof يُقيّم نوع التعبير وليس قيمته. يؤكد المعيار على وجوب تقييم الأعداد الحقيقية عند وقت التصريف بدقة ونطاق مماثلين لحالة تقييمهم في وقت التشغيل. يوجد هناك طريقةٌ محدودة أكثر تدعى تعابير الأعداد الصحيحة الثابتة integral constant expressions، ولهذه التعابير نوع عدد صحيح وتحتوي على معاملات operands من نوع عدد صحيح ثابت أو معدّدات ثابتة enumeration constants، أو محارف ثابتة، بالإضافة إلى تعابير sizeof والأعداد الحقيقية الثابتة التي تكون معاملات لتحويل الأنواع casts، ويسمح لعوامل تحويل الأنواع بتحويل الأنواع الحسابية إلى أنواع صحيحة فقط. لا تُطبّق أي قيود على محتويات تعابير sizeof طبقًا لما سبق قوله (يُقيّم نوع التعبير وليس قيمته). يُشابه التعبير الحسابي الثابت arithmetic constant expression التعبير الصحيح الثابت، ولكنه يسمح باستخدام الأعداد الصحيحة الثابتة، ويحدّ من استخدام تحويل الأنواع بالتحويل من نوع حسابي إلى آخر. العنوان الثابت address constant هو مؤشر يشير إلى كائن ذي مدة تخزين ساكنة أو إلى مؤشر يشير إلى دالةٍ ما، ويمكنك الحصول على هذه العناوين باستخدام العامل "&" أو باستخدام التحويلات الاعتيادية للمصفوفات وأسماء الدوال إلى مؤشرات عندما تُستخدم ضمن تعبير، ويمكن استخدام كلٍ من العوامل "[]" و "." و "<-" و "&" و "*" ضمن التعبير طالما لا يتضمن ذلك الاستخدام محاولة للوصول لقيمة أي كائن. استكمال عن التهيئة يُسمح لأنواع الثوابت المختلفة بالتواجد في العديد من الأماكن، إلا أن تعابير الأعداد الصحيحة الثابتة شديدة الأهمية على وجه الخصوص لأنها من النوع الوحيد الذي قد يُستخدم لتحديد حجم المصفوفة وقيم ما يسبق تعليمة case. تتميز أنواع الثوابت المسموح باستخدامها مثل قيمة أولية لتهيئة التعابير بأنها أقل محدودية، إذ من المسموح لك باستخدام تعابير حسابية ثابتة، أو مؤشر فراغ، أو عنوان ثابت، أو عنوان ثابت لكائن زائد أو ناقص تعبير صحيح ثابت، ويعتمد الأمر طبعًا على نوع الشيء الذي يجري تهيئته سواءٌ كان نوع تعبير ثابت محدد مناسبًا أم لا. إليك مثالًا يحتوي على تهيئة لعدة متغيرات: #include <stdio.h> #include <stdlib.h> #define NMONTHS 12 int month = 0; short month_days[] = {31,28,31,30,31,30,31,31,30,31,30,31}; char *mnames[] ={ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; main(){ int day_count = month; for(day_count = month; day_count < NMONTHS; day_count++){ printf("%d days in %s\n", month_days[day_count], mnames[day_count]); } exit(EXIT_SUCCESS); } مثال 1 تهيئة المتغيرات الاعتيادية بسيطة، فعليك فقط إضافة = expression بعد اسم المتغير في التصريح، والتي تدل expression على التعبير الذي ستُسند قيمته إلى المتغير، وسيُهيّأ المتغير بهذه القيمة، ويعتمد استخدام مجمل التعابير أو استخدام التعابير الثابتة حصرًا على مدة التخزين، وهذا ينطبق على جميع الكائنات. تهيئة المصفوفات أحادية البعد بسيطةٌ أيضًا، إذ عليك فقط كتابة قائمة بالقيم التي تريدها وتفصل كل قيمة بفاصلة داخل أقواس معقوصة؛ ويوضّح المثال التالي طريقة تهيئة المصفوفة، ويُحدّد حجم المصفوفة طبقًا للقيم الأولية الموجودة إن لم تحدد حجم المصفوفة على نحوٍ صريح، أما إذا حددت الحجم صراحةً، فيجب أن يكون عدد القيم الأولية التي تزودها يساوي أو أصغر من الحجم، إذ يسبب إضافة قيم أكبر من حجم المصفوفة خطئًا، بينما ستهيّئ القيم الموجودة -وإن كانت قليلة- العناصر الأولى من المصفوفة. يمكنك بناء سلسلة نصية يدويًا بالطريقة: char str[] = {'h', 'e', 'l', 'l', 'o', 0}; يمكن أيضًا استخدام سلسلة نصية ضمن علامتي تنصيص لتهيئة مصفوفة من المحارف: char str[] = "hello"; سيُضمّن المحرف الفارغ في نهاية المصفوفة في حالتنا السابقة تلقائيًا إذا كانت هناك مساحةٌ كافية، أو إذا لم يُحدد حجم المصفوفة، إليك المثال التالي: /* لا يوجد مكان للمحرف الفارغ */ char str[5] = "hello"; /* يوجد مكان للمحرف الفارغ */ char str[6] = "hello"; استخدم البرنامج في مثال 1 السلاسل النصية لأهداف مختلفة، إذ كان استخدامهم بهدف تهيئة مصفوفة من مؤشرات تشير إلى محارف، وهذا استخدام مختلفٌ تمامًا. يمكن استخدام تعبير من نوع مناسب لتهيئة هياكل من نوع مدة تلقائية، وإلا فيجب استخدام قائمة تحتوي على تعابير ثابتة بين قوسين على النحو التالي: #include <stdio.h> #include <stdlib.h> struct s{ int a; char b; char *cp; }ex_s = { 1, 'a', "hello" }; main(){ struct s first = ex_s; struct s second = { 2, 'b', "byebye" }; exit(EXIT_SUCCESS); } مثال 2 يمكن تهيئة العنصر الأول فقط من الاتحاد. يحدث تجاهلٌ للأعضاء عديمة الاسم ضمن الهيكل أو الاتحاد خلال عملية التهيئة، سواءٌ كانت حقول بتات bitfields، أو مسافات فارغة لمحاذاة عنوان التخزين، فمن غير المطلوب أخذهم بالحسبان عندما تختار القيم الأولية لأعضاء الهيكل الحقيقية (ذات الاسم). هناك طريقتان لكتابة القيم الأولية لكائنات تحتوي على كائنات فرعية بداخلها، فيمكن كتابة قيمة أولية لكل عضو بالطريقة: struct s{ int a; struct ss{ int c; char d; }e; }x[] = { 1, 2, 'a', 3, 4, 'b' }; مثال 3 سيُسنِد ما سبق القيمة 1 إلى x[0].a و 2 إلى x[0].e.c و a إلى x[0].e.d و 3 إلى x[1].a وهكذا. استخدام الأقواس الداخلية أكثر أمانًا للتعبير عن القيم التي تقصدها، إذ تسبّب قيمةٌ خاطئةٌ واحدة فوضى عارمة. struct s{ int a; struct ss{ int c; char d; }e; }x[] = { {1, {2, 'a'}}, {3, {4, 'b'}} }; مثال 4 استخدم الأقواس دائمًا، لأن هذه الطريقة آمنة، والأمر مماثل بالنسبة للمصفوفات بكونها هياكل: float y[4][3] = { {1, 3, 5}, /* y[0][0], y[0][1], y[0][2] */ {2, 4, 6}, /* y[1][0], y[1][1], y[1][2] */ {3, 5, 7} /* y[2][0], y[2][1], y[2][2] */ }; مثال 5 تُهيّأ قيم الأسطر الثلاث الأولى كاملةً من y، ويبقى السطر الرابع y[3] غير مُهيّأ. تُسند لجميع الكائنات ذات المدة الساكنة قيمٌ أولية ضمنية تلقائية إذا لم يوجد أي قيمة أولية لها، ويكون أثر القيمة الأولية التلقائية الضمنية مماثلًا لأثر إسناد القيمة 0 الثابتة، وهذا الأمر شائع الاستخدام، وتفترض معظم برامج لغة سي نتيجةً لذلك أن الكائنات الخارجية والكائنات الساكنة الداخلية تبدأ بالقيمة صفر. تُضمن عملية التهيئة للكائنات ذات المدة التلقائية فقط في حالة وجود تعليمتها المركبة "في الأعلى"، إذ قد يتسبب الانتقال إلى أحد الكائنات فورًا بعدم حصول عملية التهيئة وهذا الأمر غير مستحب ويجب تجنبه. يشير المعيار بصراحة إلى أن وجود القيم الأولية في التصريح ضمن تعليمات switch لن يكون مفيدًا، لأن التصريح لا يُصنف بكونه تعليمة، ويمكن عنونة label التعليمة فقط، ونتيجةً لذلك فلا يمكن للقيم الأولية في تعليمات switch أن تُنفّذ لأن كتلة الشيفرة البرمجية التي تحتويها يجب أن تلي ذكر التصاريح. يمكن أن يُستخدم التصريح داخل دالة ما (نطاق مرتبط بكتلة الدالة) للإشارة إلى كائن ذي ربطٍ خارجي External linkage أو ربط داخلي Internal linkage باستخدام عدّة طرق تطرقنا إليها في مقال الربط والنطاق وهناك مزيدٌ من الطرق التي سنتطرق إليها لاحقًا. إذا اتبعت الطرق السابقة (التي من المستبعد أن تتحقق من قبيل الصدفة)، فلا يمكنك تهيئة الكائن على أنه جزء من التصريح، وإليك الطريقة الوحيدة التي تستطيع تحقيق ذلك بها: int x; /* ربط خارجي */ main(){ extern int x = 5; /* استخدام ممنوع */ } لم يكشف مصرّفنا التهيئة الممنوعة في هذا المثال أيضًا. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C المقال السابق: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C -
 تطرقنا في المقال السابق إلى الهياكل وبعض الهياكل الشائعة، مثل الأشجار والقوائم المرتبطة، وننتقل الآن إلى الاتحادات وحقول البتات والمعددات ونتكلم عن استعمال وخصائص كل منها. الاتحادات Unions لن تستغرق الاتحادات Unions وقتًا طويلًا لشرحها، فهي تشابه الهياكل بفرق أنك لا تستخدم الكلمة المفتاحية struct بل تستخدم union، وتعمل الاتحادات بالطريقة ذاتها التي تعمل بها الهياكل structures بفرق أن أعضائها مُخزنون على كتلة تخزينية واحدة بعكس أعضاء الهياكل التي تُخزن على كتل تخزينية متفرقة متعاقبة، ولكن ما الذي يفيدنا هذا الأمر؟ تدفعنا الحاجة في بعض الأحيان إلى استخدام الهياكل بهدف تخزين قيم مختلفة بأنواع مختلفة وبأوقاتٍ مختلفة مع المحافظة قدر الإمكان على مساحة التخزين وعدم هدر الموارد؛ في حين يمكننا باستخدام الاتحادات تحديد النوع الذي ندخله إليها والتأكد من استرجاع القيمة بنوعها المناسب فيما بعد. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ union { float u_f; int u_i; }var; var.u_f = 23.5; printf("value is %f\n", var.u_f); var.u_i = 5; printf("value is %d\n", var.u_i); exit(EXIT_SUCCESS); } مثال 1 إذا أضفنا قيمةً من نوع float إلى الاتحاد في مثالنا السابق، ثم استعدناه على أنه قيمةٌ من نوع int، فسنحصل على قيمة غير معروفة، لأن النوعان يُخزنان على نحوٍ مختلف وأضف على ذلك أنهما من أطوالٍ مختلفة؛ فالقيمة من نوع int ستكون غالبًا تمثيل الآلة (الحاسوب) لبتات float منخفضة الترتيب، ولربما ستشكل جزءًا من قيمة float العشرية (ما بعد الفاصلة). ينص المعيار على اعتماد النتيجة في هذه الحالة على تعريف التطبيق (وليست سلوكًا غير معرفًا)، والنتيجة معرفةٌ من المعيار في حالة واحدة، ألا وهي أن يكون لبعض أعضاء الاتحاد هياكل ذات "سلسلة مبدئية مشتركة common initial sequence"، أي أن لأول عضو من كل هيكل نوع متوافق compatible type، أو من الطول ذاته في حالة حقول البتات bitfields، ويوافق اتحادنا الشروط التي ذكرناها، وبالتالي يمكننا استخدام السلسلة المبدئية المشتركة على نحوٍ تبادلي، يا لحظنا الرائع. يعمل مصرّف لغة سي على حجز المساحة اللازمة لأكبر عضو ضمن الاتحاد لا أكثر (بعنوان مناسب إن أمكن)، أي لا يوجد هناك أي تفقد للتأكد من أن استخدام الأعضاء صائب فهذه مهمتك، وستكتشف عاجلًا أم آجلًا إذا فشلت في تحقيق هذه المهمة. تبدأ أعضاء الاتحاد من عنوان التخزين ذاته (من المضمون أنه لا يوجد هناك أي فراغات بين أيٍ من الأعضاء). يُعد تضمين الاتحاد في هيكل من أكثر الطرق شيوعًا لتذكر طريقة عمل الاتحاد، وذلك باستخدام عضو آخر من الهيكل ذاته ليدل على نوع الشيء الموجود في الاتحاد. إليك مثالًا عمّا سيبدو ذلك: #include <stdio.h> #include <stdlib.h> /* شيفرة للأنواع في الاتحاد */ #define FLOAT_TYPE 1 #define CHAR_TYPE 2 #define INT_TYPE 3 struct var_type{ int type_in_union; union{ float un_float; char un_char; int un_int; }vt_un; }var_type; void print_vt(void){ switch(var_type.type_in_union){ default: printf("Unknown type in union\n"); break; case FLOAT_TYPE: printf("%f\n", var_type.vt_un.un_float); break; case CHAR_TYPE: printf("%c\n", var_type.vt_un.un_char); break; case INT_TYPE: printf("%d\n", var_type.vt_un.un_int); break; } } main(){ var_type.type_in_union = FLOAT_TYPE; var_type.vt_un.un_float = 3.5; print_vt(); var_type.type_in_union = CHAR_TYPE; var_type.vt_un.un_char = 'a'; print_vt(); exit(EXIT_SUCCESS); } مثال 2 يوضح المثال السابق أيضًا استخدام عامل النقطة للوصول إلى ما داخل الهياكل أو الاتحادات التي تحتوي على هياكل أو اتحادات أخرى بدورها، تسمح لك بعض مصرفات لغة سي الحالية بإهمال بعض الأجزاء من أسماء الكائنات المُدمجة شرط ألا يتسبب ذلك بجعل الاسم غامض، فعلى سبيل المثال يسمح استخدام الاسم الواضح var_type.un_int للمصرف بمعرفة ما تقصده، إلا أن هذا غير مسموح في المعيار. لا يمكن مقارنة الهياكل بحثًا عن المساواة فيما بينها ويقع اللوم على الاتحادات، إذ أن احتمالية احتواء هيكل ما على اتحاد يجعل من مهمة المقارنة مهمةً صعبة، إذ لا يمكن للمصرّف أن يعرف ما الذي يحويه الاتحاد في الوقت الحالي مما لا يسمح له بإجراء عملية المقارنة. قد يبدو الكلام السابق صعب الفهم وغير دقيق بنسبة 100%، إذ أن معظم الهياكل لا تحتوي على اتحادات، ولكن هناك مشكلة فلسفية بخصوص القصد من كلمة "مساواة" عندما نُسقطها على الهياكل. بغض النظر، تمنح الاتحادات عذرًا مناسبًا للمعيار بتجنبه لأي مشاكل بواسطة عدم دعمه لمقارنة الهياكل. حقول البتات Bitfields دعنا نلقي نظرةً على حقول البتات بما أننا نتكلم عن موضوع هياكل البيانات، إذ يمكن تعريفها فقط بداخل هيكل أو اتحاد، وتسمح لك حقول البتات بتحديد بعض الكائنات الصغيرة بحسب طول بتات محدد، إلا أن فائدتها محدودةٌ ولا تُستخدم إلا في حالات نادرة، ولكننا سنتطرق إلى الموضوع بغض النظر عن ذلك. يوضح لك المثال استخدام حقول البتات: struct { /* كل حقل بسعة 4 بتات */ unsigned field1 :4; /* * حقل بسعة 3 بتات دون اسم * تسمح الحقول عديمة الاسم بالفراغات بين عناوين الذاكرة */ unsigned :3; /* * حقل بسعة بت واحد * تكون قيمته 0 أو 1- في نظام المتمم الثنائي */ signed field2 :1; /* محاذاة الحقل التالي مع وحدة التخزين */ unsigned :0; unsigned field3 :6; }full_of_fields; مثال 3 يمكن التلاعب والوصول إلى كل حقل بصورةٍ منفردة وكأنه عضو اعتيادي من هيكل ما، وتعني الكلمتان المفتاحيتان signed وunsigned ما هو متوقع، إلا أنه يجدر بالذكر أن حقلًا بحجم 1 بت ذا إشارة سيأخذ واحدةً من القيمتين 0 أو -1 وذلك في آلة تعمل بنظام المتمم الثنائي، ويُسمح للتصريحات بأن تحتوي المؤهلين const أو volatile. تُستخدم حقول البتات بشكل رئيس إما للسماح بتحزيم مجموعة من البيانات بأقل مساحة، أو لتحديد الحقول ضمن ملفات بيانات خارجية. لا تقدم لغة سي أي ضمانات بخصوص ترتيب الحقول بكلمات الآلة التي تعمل عليها، لذا إذا كنت تريد استخدام حقول البتات للهدف الثاني، فسيصبح برنامجك غير قابل للتنقل ومعتمدًا على المصرّف الذي يصرف البرنامج أيضًا. ينص المعيار على أن الحقول مُحزّمة بما يدعى "وحدات تخزين"، التي تكون عادةً كلمات آلة. يُحدّد ترتيب التحزيم وفيما إذا كان سيتجاوز حقل البتات حاجز التخزين أم لا بحسب تعريف التطبيق، ونستخدم حقلًا بعرض صفر قبل الحقل الذي تريد تطبيق الحد عنده لإجبار الحقل على البقاء ضمن حدود وحدة التخزين. كن حذرًا عند استخدام حقول البتات، إذ يتطلب الأمر شيفرة وقت تشغيل run-time طويلة للتلاعب بهذه الأشياء، وقد ينتج ذلك بتوفير الكثير من المساحة (أكثر من حاجتك). ليس لحقول البتات أي عناوين، وبالتالي لا يمكنك استخدام المؤشرات أو المصفوفات معها. المعددات enums تقع المُعدّدات enums تحت تصنيف "منجزة جزئيًا"، إذ ليست بأنواع مُعددة بصورٍ كاملة مثل لغة باسكال، ومهمتها الوحيدة هي مساعدتك في التخفيف من عدد تعليمات #define في برنامجك، إليك ما تبدو عليه: enum e_tag{ a, b, c, d=20, e, f, g=20, h }var; يمثل e_tag الوسم بصورةٍ مشابهة لما تكلمنا عنه في الهياكل والاتحادات، ويمثل var تعريفًا للمتغير. الأسماء المُعلنة بداخل المُعدد ثوابت من نوع int، إليك قيمها: a == 0 b == 1 c == 2 d == 20 e == 21 f == 22 g == 20 h == 21 تلاحظ أنه بغياب أي قيمة مُسندة للمتغيرات، تبدأ القيم من الصفر تصاعديًا، ويمكنك إسناد قيمة مخصصة إنذا أردت في البداية، إلا أن القيم التي ستتزايد بعدها ستكون من نوع عدد صحيح ثابت integral constant (كما سنرى لاحقًا)، وتُمثّل هذه القيمة بنوع int ومن الممكن أن تحمل عدة أسماء القيمة ذاتها. تُستخدم المُعدّدات للحصول على إصدار ملائم للنطاق Scope بدلًا من استخدام #define على النحو التالي: #define a 0 #define b 1 /* وهكذا دواليك */ إذ يتبع استخدام المعددات لقوانين نطاق لغة سي C، بينما تشمل تعليمات #define كامل نطاق الملف. قد لا تهمك هذه المعلومة، ولكن المعيار ينص على أن أنواع المعددات من نوع متوافق مع أنواع الأعداد الصحيحة بحسب تعريف التطبيق، لكن ما الذي يعنيه ذلك؟ لاحظ المثال التالي: enum ee{a,b,c}e_var, *ep; تسلك الأسماء a و b و c سلوك الأعداد الصحيحة الثابتة int عندما تستخدمها، و e_var من نوع enum ee و ep مؤشر يشير إلى المعدد ee. تعني متطلبات التوافقية بين الأنواع (بالإضافة لمشكلات أخرى) أن هناك نوع عدد صحيح ذو عنوان يمكن إسناده إلى ep من غير خرق أي من متطلبات التوافقية بين الأنواع للمؤشرات. المؤهلات والأنواع المشتقة تعد المصفوفات والهياكل والاتحادات "مشتقةٌ من derived from" (أي تحتوي) أنواعٍ أخرى، ولا يمكن لأي ممّا سبق أن تُشتق من أنواع غير مكتملة incomplete types، وهذا يعني أنه من غير الممكن للهيكل أو الاتحاد أن يحتوي مثالًا من نفسه، لأن نوعه غير مكتمل حتى ينتهي التصريح عنه، وبما أن المؤشر الذي يشير إلى نوع غير مكتمل ليس بنوع غير مكتمل بذات نفسه فمن الممكن استخدامه باشتقاق المصفوفات والهياكل والاتحادات. لا ينتقل التأهيل إلى النوع المُشتق إن كان أي من الأنواع التي اشتُق منها تحتوي على مؤهلات مثل const أو volatile، وهذا يعني أن الهيكل الذي يحتوي على كائن ذو مؤهل ثابت const لا يجعل من الهيكل بنفسه مؤهلًا بهذا المؤهل، ويمكن لأي عضو غير ثابت أن يُعدّل عليه بداخل الهيكل، وهذا ما هو متوقع، إلا أن المعيار ينص على أن أي نوع مشتق يحتوي على نوع مؤهل باستخدام const (أو أي نوع داخلي تعاودي) لا يمكن التعديل عليه، فالهيكل الذي يحتوي الثابت لا يمكن وضعه على الطرف الأيسر من عامل الإسناد. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: تهيئة المتغيرات وأنواع البيانات في لغة سي C المقال السابق: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C
تطرقنا في المقال السابق إلى الهياكل وبعض الهياكل الشائعة، مثل الأشجار والقوائم المرتبطة، وننتقل الآن إلى الاتحادات وحقول البتات والمعددات ونتكلم عن استعمال وخصائص كل منها. الاتحادات Unions لن تستغرق الاتحادات Unions وقتًا طويلًا لشرحها، فهي تشابه الهياكل بفرق أنك لا تستخدم الكلمة المفتاحية struct بل تستخدم union، وتعمل الاتحادات بالطريقة ذاتها التي تعمل بها الهياكل structures بفرق أن أعضائها مُخزنون على كتلة تخزينية واحدة بعكس أعضاء الهياكل التي تُخزن على كتل تخزينية متفرقة متعاقبة، ولكن ما الذي يفيدنا هذا الأمر؟ تدفعنا الحاجة في بعض الأحيان إلى استخدام الهياكل بهدف تخزين قيم مختلفة بأنواع مختلفة وبأوقاتٍ مختلفة مع المحافظة قدر الإمكان على مساحة التخزين وعدم هدر الموارد؛ في حين يمكننا باستخدام الاتحادات تحديد النوع الذي ندخله إليها والتأكد من استرجاع القيمة بنوعها المناسب فيما بعد. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ union { float u_f; int u_i; }var; var.u_f = 23.5; printf("value is %f\n", var.u_f); var.u_i = 5; printf("value is %d\n", var.u_i); exit(EXIT_SUCCESS); } مثال 1 إذا أضفنا قيمةً من نوع float إلى الاتحاد في مثالنا السابق، ثم استعدناه على أنه قيمةٌ من نوع int، فسنحصل على قيمة غير معروفة، لأن النوعان يُخزنان على نحوٍ مختلف وأضف على ذلك أنهما من أطوالٍ مختلفة؛ فالقيمة من نوع int ستكون غالبًا تمثيل الآلة (الحاسوب) لبتات float منخفضة الترتيب، ولربما ستشكل جزءًا من قيمة float العشرية (ما بعد الفاصلة). ينص المعيار على اعتماد النتيجة في هذه الحالة على تعريف التطبيق (وليست سلوكًا غير معرفًا)، والنتيجة معرفةٌ من المعيار في حالة واحدة، ألا وهي أن يكون لبعض أعضاء الاتحاد هياكل ذات "سلسلة مبدئية مشتركة common initial sequence"، أي أن لأول عضو من كل هيكل نوع متوافق compatible type، أو من الطول ذاته في حالة حقول البتات bitfields، ويوافق اتحادنا الشروط التي ذكرناها، وبالتالي يمكننا استخدام السلسلة المبدئية المشتركة على نحوٍ تبادلي، يا لحظنا الرائع. يعمل مصرّف لغة سي على حجز المساحة اللازمة لأكبر عضو ضمن الاتحاد لا أكثر (بعنوان مناسب إن أمكن)، أي لا يوجد هناك أي تفقد للتأكد من أن استخدام الأعضاء صائب فهذه مهمتك، وستكتشف عاجلًا أم آجلًا إذا فشلت في تحقيق هذه المهمة. تبدأ أعضاء الاتحاد من عنوان التخزين ذاته (من المضمون أنه لا يوجد هناك أي فراغات بين أيٍ من الأعضاء). يُعد تضمين الاتحاد في هيكل من أكثر الطرق شيوعًا لتذكر طريقة عمل الاتحاد، وذلك باستخدام عضو آخر من الهيكل ذاته ليدل على نوع الشيء الموجود في الاتحاد. إليك مثالًا عمّا سيبدو ذلك: #include <stdio.h> #include <stdlib.h> /* شيفرة للأنواع في الاتحاد */ #define FLOAT_TYPE 1 #define CHAR_TYPE 2 #define INT_TYPE 3 struct var_type{ int type_in_union; union{ float un_float; char un_char; int un_int; }vt_un; }var_type; void print_vt(void){ switch(var_type.type_in_union){ default: printf("Unknown type in union\n"); break; case FLOAT_TYPE: printf("%f\n", var_type.vt_un.un_float); break; case CHAR_TYPE: printf("%c\n", var_type.vt_un.un_char); break; case INT_TYPE: printf("%d\n", var_type.vt_un.un_int); break; } } main(){ var_type.type_in_union = FLOAT_TYPE; var_type.vt_un.un_float = 3.5; print_vt(); var_type.type_in_union = CHAR_TYPE; var_type.vt_un.un_char = 'a'; print_vt(); exit(EXIT_SUCCESS); } مثال 2 يوضح المثال السابق أيضًا استخدام عامل النقطة للوصول إلى ما داخل الهياكل أو الاتحادات التي تحتوي على هياكل أو اتحادات أخرى بدورها، تسمح لك بعض مصرفات لغة سي الحالية بإهمال بعض الأجزاء من أسماء الكائنات المُدمجة شرط ألا يتسبب ذلك بجعل الاسم غامض، فعلى سبيل المثال يسمح استخدام الاسم الواضح var_type.un_int للمصرف بمعرفة ما تقصده، إلا أن هذا غير مسموح في المعيار. لا يمكن مقارنة الهياكل بحثًا عن المساواة فيما بينها ويقع اللوم على الاتحادات، إذ أن احتمالية احتواء هيكل ما على اتحاد يجعل من مهمة المقارنة مهمةً صعبة، إذ لا يمكن للمصرّف أن يعرف ما الذي يحويه الاتحاد في الوقت الحالي مما لا يسمح له بإجراء عملية المقارنة. قد يبدو الكلام السابق صعب الفهم وغير دقيق بنسبة 100%، إذ أن معظم الهياكل لا تحتوي على اتحادات، ولكن هناك مشكلة فلسفية بخصوص القصد من كلمة "مساواة" عندما نُسقطها على الهياكل. بغض النظر، تمنح الاتحادات عذرًا مناسبًا للمعيار بتجنبه لأي مشاكل بواسطة عدم دعمه لمقارنة الهياكل. حقول البتات Bitfields دعنا نلقي نظرةً على حقول البتات بما أننا نتكلم عن موضوع هياكل البيانات، إذ يمكن تعريفها فقط بداخل هيكل أو اتحاد، وتسمح لك حقول البتات بتحديد بعض الكائنات الصغيرة بحسب طول بتات محدد، إلا أن فائدتها محدودةٌ ولا تُستخدم إلا في حالات نادرة، ولكننا سنتطرق إلى الموضوع بغض النظر عن ذلك. يوضح لك المثال استخدام حقول البتات: struct { /* كل حقل بسعة 4 بتات */ unsigned field1 :4; /* * حقل بسعة 3 بتات دون اسم * تسمح الحقول عديمة الاسم بالفراغات بين عناوين الذاكرة */ unsigned :3; /* * حقل بسعة بت واحد * تكون قيمته 0 أو 1- في نظام المتمم الثنائي */ signed field2 :1; /* محاذاة الحقل التالي مع وحدة التخزين */ unsigned :0; unsigned field3 :6; }full_of_fields; مثال 3 يمكن التلاعب والوصول إلى كل حقل بصورةٍ منفردة وكأنه عضو اعتيادي من هيكل ما، وتعني الكلمتان المفتاحيتان signed وunsigned ما هو متوقع، إلا أنه يجدر بالذكر أن حقلًا بحجم 1 بت ذا إشارة سيأخذ واحدةً من القيمتين 0 أو -1 وذلك في آلة تعمل بنظام المتمم الثنائي، ويُسمح للتصريحات بأن تحتوي المؤهلين const أو volatile. تُستخدم حقول البتات بشكل رئيس إما للسماح بتحزيم مجموعة من البيانات بأقل مساحة، أو لتحديد الحقول ضمن ملفات بيانات خارجية. لا تقدم لغة سي أي ضمانات بخصوص ترتيب الحقول بكلمات الآلة التي تعمل عليها، لذا إذا كنت تريد استخدام حقول البتات للهدف الثاني، فسيصبح برنامجك غير قابل للتنقل ومعتمدًا على المصرّف الذي يصرف البرنامج أيضًا. ينص المعيار على أن الحقول مُحزّمة بما يدعى "وحدات تخزين"، التي تكون عادةً كلمات آلة. يُحدّد ترتيب التحزيم وفيما إذا كان سيتجاوز حقل البتات حاجز التخزين أم لا بحسب تعريف التطبيق، ونستخدم حقلًا بعرض صفر قبل الحقل الذي تريد تطبيق الحد عنده لإجبار الحقل على البقاء ضمن حدود وحدة التخزين. كن حذرًا عند استخدام حقول البتات، إذ يتطلب الأمر شيفرة وقت تشغيل run-time طويلة للتلاعب بهذه الأشياء، وقد ينتج ذلك بتوفير الكثير من المساحة (أكثر من حاجتك). ليس لحقول البتات أي عناوين، وبالتالي لا يمكنك استخدام المؤشرات أو المصفوفات معها. المعددات enums تقع المُعدّدات enums تحت تصنيف "منجزة جزئيًا"، إذ ليست بأنواع مُعددة بصورٍ كاملة مثل لغة باسكال، ومهمتها الوحيدة هي مساعدتك في التخفيف من عدد تعليمات #define في برنامجك، إليك ما تبدو عليه: enum e_tag{ a, b, c, d=20, e, f, g=20, h }var; يمثل e_tag الوسم بصورةٍ مشابهة لما تكلمنا عنه في الهياكل والاتحادات، ويمثل var تعريفًا للمتغير. الأسماء المُعلنة بداخل المُعدد ثوابت من نوع int، إليك قيمها: a == 0 b == 1 c == 2 d == 20 e == 21 f == 22 g == 20 h == 21 تلاحظ أنه بغياب أي قيمة مُسندة للمتغيرات، تبدأ القيم من الصفر تصاعديًا، ويمكنك إسناد قيمة مخصصة إنذا أردت في البداية، إلا أن القيم التي ستتزايد بعدها ستكون من نوع عدد صحيح ثابت integral constant (كما سنرى لاحقًا)، وتُمثّل هذه القيمة بنوع int ومن الممكن أن تحمل عدة أسماء القيمة ذاتها. تُستخدم المُعدّدات للحصول على إصدار ملائم للنطاق Scope بدلًا من استخدام #define على النحو التالي: #define a 0 #define b 1 /* وهكذا دواليك */ إذ يتبع استخدام المعددات لقوانين نطاق لغة سي C، بينما تشمل تعليمات #define كامل نطاق الملف. قد لا تهمك هذه المعلومة، ولكن المعيار ينص على أن أنواع المعددات من نوع متوافق مع أنواع الأعداد الصحيحة بحسب تعريف التطبيق، لكن ما الذي يعنيه ذلك؟ لاحظ المثال التالي: enum ee{a,b,c}e_var, *ep; تسلك الأسماء a و b و c سلوك الأعداد الصحيحة الثابتة int عندما تستخدمها، و e_var من نوع enum ee و ep مؤشر يشير إلى المعدد ee. تعني متطلبات التوافقية بين الأنواع (بالإضافة لمشكلات أخرى) أن هناك نوع عدد صحيح ذو عنوان يمكن إسناده إلى ep من غير خرق أي من متطلبات التوافقية بين الأنواع للمؤشرات. المؤهلات والأنواع المشتقة تعد المصفوفات والهياكل والاتحادات "مشتقةٌ من derived from" (أي تحتوي) أنواعٍ أخرى، ولا يمكن لأي ممّا سبق أن تُشتق من أنواع غير مكتملة incomplete types، وهذا يعني أنه من غير الممكن للهيكل أو الاتحاد أن يحتوي مثالًا من نفسه، لأن نوعه غير مكتمل حتى ينتهي التصريح عنه، وبما أن المؤشر الذي يشير إلى نوع غير مكتمل ليس بنوع غير مكتمل بذات نفسه فمن الممكن استخدامه باشتقاق المصفوفات والهياكل والاتحادات. لا ينتقل التأهيل إلى النوع المُشتق إن كان أي من الأنواع التي اشتُق منها تحتوي على مؤهلات مثل const أو volatile، وهذا يعني أن الهيكل الذي يحتوي على كائن ذو مؤهل ثابت const لا يجعل من الهيكل بنفسه مؤهلًا بهذا المؤهل، ويمكن لأي عضو غير ثابت أن يُعدّل عليه بداخل الهيكل، وهذا ما هو متوقع، إلا أن المعيار ينص على أن أي نوع مشتق يحتوي على نوع مؤهل باستخدام const (أو أي نوع داخلي تعاودي) لا يمكن التعديل عليه، فالهيكل الذي يحتوي الثابت لا يمكن وضعه على الطرف الأيسر من عامل الإسناد. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: تهيئة المتغيرات وأنواع البيانات في لغة سي C المقال السابق: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C- 1 تعليق
-
- 1
-
-
 اتجه تطوير لغات الحاسوب سابقًا في اتجاهٍ من اتجاهين، إذ سلكت كوبول COBOL سلوكًا ركز على استخدام هياكل البيانات بعيدًا عن العمليات الحسابية والخوارزميات، بينما سلكت لغات مثل فورتران FORTRAN وألغول Algol سلوكًا معاكسًا. أراد العلماء وقتها إجراء العمليات الحسابية باستخدام بيانات غير مُهيكلة نسبيًا، إلا أنه سرعان ما لاحظ الجميع أن استخدام المصفوفات لا غنى عنه؛ بينما أراد المستخدمون الاعتياديون طريقةً لإجراء العمليات الحسابية البسيطة فقط، إلا أن طريقة هيكلة البيانات كانت عائقًا أمام تحقيق ذلك. أثر كلا السلوكين في تصميم لغة سي، إذ أنها تحتوي تحكمًا هيكليًا لتدفق البرنامج مناسب للغة من هذا العمر، كما أنها جعلت من مفهوم هياكل البيانات شائعًا. ركزنا على جانب الخوارزميات من اللغة حتى اللحظة، ولم نولي الكثير من الانتباه بخصوص تخزين البيانات، ومع أننا تطرقنا إلى المصفوفات التي تُعدّ هيكل بيانات إلا أنها شائعة الاستخدام وبسيطة ولا تستحق فصلًا مخصصًا لها، واكتفينا إلى الآن بالنظر إلى اللغة انطلاقًا من بينة هيكلية شبيهة بلغة فورتران. كان استخدام كلٍ من البيانات والخوارزميات هو التوجه الأكثر رواجًا في أواخر ثمانينيات وبداية تسعينيات القرن الماضي، وفق ما يُدعى بالبرمجة كائنية التوجه Object-Oriented Programming. لا يوجد أي دعم لهذه الطريقة في لغة سي، إلا أن لغة C++ قدمت دعمًا لها (وهي لغةٌ مبنيةٌ على لغة سي)، ولكن هذا النقاش خارج موضوعنا حاليًا. تأخذ البيانات الانتباه الأكبر لمعظم مشاكل الحوسبة المتقدمة وليس الخوارزميات، فستكون مهمتك بسيطةً ببرمجة البرنامج إن استطعت تصميم هياكل بيانات صحيحة ومناسبة، إلا أنك تحتاج إلى دعمٍ من اللغة في هذه الحالة، فمهمتك ستصبح أقل سهولة ومعرضةً أكثر للأخطاء إن لم يكن هناك أي دعم لأنواع هياكل البيانات المختلفة عن المصفوفات. تقع هذه المهمة على كاهل لغة البرمجة، فليس كافيًا أن تسمح لك اللغة بفعل ما تريد، بل يجب أن تساعدك في فعل ما تريد. تقدم لك لغة سي سعيًا منها بتقديم هياكل بيانات مناسبة كلًا من المصفوفات Arrays والهياكل Structures والاتحادات Unions، وقد برهنت على أنها كافيةٌ لمعظم المستخدمين الاعتياديين وبالتالي لم يُضِف المعيار أي جديد بشأنها. الهياكل Structures تسمح لك المصفوفات بتخزين مجموعة من الكائنات المتماثلة تحت اسم معين، وهذا مفيدٌ لعدد من المهام، ولكنه ليس مرن التعامل، إذ تحتوي معظم كائنات البيانات ذات التطبيقات الواقعية على هيكل معيّن معقد لا يمكن استخدامه مع طريقة تخزين المصفوفة للبيانات. لنوضح ما سبق بالمثال التالي: لنفرض أننا نريد تمثيل سلسلةٍ نصية ذات خصائص معينة، بجانب محتواها. هناك نوع الخط وحجمه، وهما سمتان لا تؤثران في محتوى السلسلة، لكنهما تحددان الطريقة التي تُعرض فيها السلسلة على الشاشة سواءٌ كان النص مكتوبًا بخط غامق أو مائل، والأمر ذاته ينطبق على حجم الخط. كيف نستطيع تمثيل السلسلة النصية بكائن واحد ضمن مصفوفة إذا كان يحتوي على ثلاث سمات مختلفة؟ يمكننا تحقيق ذلك في لغة سي C بسهولة، حاول أولًا تمثيل السمات الثلاث باستخدام الأنواع الأساسية، فعلى فرض أنه يمكننا تخزين كل محرف باستخدام النوع char، يمكننا الإشارة إلى نوع الخط المستخدم باستخدام النوع short (نستخدم "1" للإشارة إلى الخط الاعتيادي و"2" للخط المائل و"3" للخط الغامق، وهكذا)، كما يمكننا تخزين حجم الخط باستخدام النوع short، وتُعد جميع الفرضيات السابقة معقولةً عمليًا، إذ تدعم معظم الأنظمة عددًا قليلًا من الخطوط مهما كانت هذه الأنظمة معقدة، ويتراوح حجم الخط بين 6 ومرتبة المئات القليلة، فأي خط أصغر من 6 هو صعب القراءة، والخط الأكبر من 50 هو خط أكبر من خطوط عناوين الجرائد. إذًا، لدينا الآن محرف وعددين صغيرين وتُعامل هذه البيانات معاملة كائن واحد، إليك كيف نصرّح عن ذلك في لغة سي: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }; يصرح ما سبق عن نوع جديد من الكائنات يمكنك استخدامه ضمن البرنامج، ويعتمد الأمر بصورةٍ رئيسية على ذكر الكلمة المفتاحية struct، المتبوعة بمعرّف identifier اختياري هو الوسم wp_char في هذه الحالة، ويسمح لنا هذا الوسم بتسمية النوع للإشارة إليه فيما بعد. يمكننا أيضًا استخدام الوسم بالطريقة التالية بعد التصريح عنه: struct wp_char x, y; يُعرّف ما سبق متغيرين باسم x و y، بالطريقة ذاتها للتعريف التالي: int x, y; لكن المتغيرات في المثال الأول من نوع struct wp_char عوضًا عن int في المثال الثاني، ويمثّل الوسم اسمًا للنوع الذي صرحنا عنه سابقًا. نذّكر هنا أنه من الممكن استخدام اسم وسم الهيكل مثل أي معرّف اعتيادي بصورةٍ آمنة، ويدل الاسم على معنًى مختلف عندما يُسبق بالكلمة المفتاحية struct فقط، ومن الشائع أن يُعرّف كائن مُهيكل باسم مماثل لوسم الهيكل الخاص به. struct wp_char wp_char; يُعرّف السطر السابق متغيرًا باسم wp_char من النوع struct wp_char، ويمكننا فعل ذلك لأن لوسوم الهياكل "فضاء اسماء name space" خاصة بها ولا تتعارض مع الأسماء الأخرى، وسنتكلم أكثر عن الوسوم عندما نناقش "الأنواع غير المكتملة incomplete types". يمكن التعريف عن المتغيرات على الفور عقب التصريح عن هيكل ما: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }v1; struct wp_char v2; لدينا في هذه الحالة متغيرين، أحدهما باسم v1 والآخر باسم v2، وإذا استخدمنا الطريقة السابقة في التعريف عن v1، يصبح الوسم غير ضروري ويُتخلّى عنه غالبًا إلا في حال احتجنا إلى الوسم لاستخدامه مع عامل sizeof والتحويل بين الأنواع casts. يُعد المتغيران السابقان كائنات مُهيكلة، ويحتوي كل منهما على ثلاثة أعضاء members مستقلين عن بعضهم باسم wp_cval و wp_font و wp_psize، ونستخدم عامل النقطة . للوصول إلى كلّ من الأعضاء السابقة على النحو التالي: v1.wp_cval = 'x'; v1.wp_font = 1; v1.wp_psize = 10; v2 = v1; تُضبط أعضاء المتغير v1 في المثال السابق إلى قيمها المناسبة، ومن ثم تُنسخ قيم v1 إلى v2 باستخدام عملية الإسناد. في الحقيقة، العملية الوحيدة المسموحة في الهياكل بكاملها هي الإسناد؛ إذ يمكن إسناد الهياكل إلى بعضها بعضًا أو تمريرها مثل وسطاء للدوال أو قيمةٍ تُعيدها دالةٌ ما، إلا أن نسخ الهياكل عمليةٌ غير فعالة وتتفاداها معظم البرامج عن طريق التلاعب بالمؤشرات التي تشير إلى الهياكل عوضًا عن ذلك، إذ من الأسرع عمومًا نسخ المؤشرات عوضًا عن الهياكل. تسمح اللغة بمقارنة الهياكل بحثًا عن المساواة فيما بينها، وهي سهوة مفاجئة ولا يوجد سبب مقنع لسماحها بذلك كما سنذكر قريبًا. إليك مثالًا يستخدم مصفوفةً من الهياكل، وهو الهيكل ذاته الذي تكلمنا عنه سابقًا، إذ تُستخدم دالةٌ لقراءة المحارف من دخل البرنامج القياسي وتُعيد هيكلًا مهيّأً بقيمٍ مناسبة مقابله، ومن ثم تُرتّب الهياكل بحسب قيمة كل محرف وتُطبع وذلك عندما يُقرأ محرف سطر جديد، أو عندما تمتلئ المصفوفة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; /* نوع دخل الدالة الذي كان من الممكن التصريح عنه سابقًا، وتعيد الدالة هيكلًا ولا تأخذ أي وسطاء */ struct wp_char infun(void); main(){ int icount, lo_indx, hi_indx; for(icount = 0; icount < ARSIZE; icount++){ ar[icount] = infun(); if(ar[icount].wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة icount * مع تجاهل \n */ break; } } /* نجري الآن عملية الترتيب */ for(lo_indx = 0; lo_indx <= icount-2; lo_indx++) for(hi_indx = lo_indx+1; hi_indx <= icount-1; hi_indx++){ if(ar[lo_indx].wp_cval > ar[hi_indx].wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = ar[lo_indx]; ar[lo_indx] = ar[hi_indx]; ar[hi_indx] = wp_tmp; } } /* طباعة القيم */ for(lo_indx = 0; lo_indx < icount; lo_indx++){ printf("%c %d %d\n", ar[lo_indx].wp_cval, ar[lo_indx].wp_font, ar[lo_indx].wp_psize); } exit(EXIT_SUCCESS); } struct wp_char infun(void){ struct wp_char wp_char; wp_char.wp_cval = getchar(); wp_char.wp_font = 2; wp_char.wp_psize = 10; return(wp_char); } مثال 1 من الطبيعي أن نلجأ إلى التصريح عن مصفوفات من الهياكل حالما نستطيع ونتعلم كيفية التصريح عنها، وأن نستخدم هذه الهياكل عناصرًا لهياكل أخرى وما إلى ذلك، والقيد الوحيد هنا هو أنه لا يمكن للهيكل أن يحتوي مثالًا لنفسه على أنه عضو داخله (يصبح حينها حجمها موضع جدل مثير للفلاسفة، ولكنه غير مفيد لأي مبرمج سي C). المؤشرات والهياكل ذكرنا سابقًا أنه من الشائع استخدام المؤشرات في الهياكل بدلًا من استخدام الهياكل مباشرةً، لنتعلم كيفية تحقيق ذلك إذَا. يُعد التصريح عن المؤشرات سهلًا، ونعتقد أنك أتقنته: struct wp_char *wp_p; يمنحنا التصريح السابق مؤشرًا مباشرةً، ولكن كيف يمكننا الوصول إلى أعضاء الهيكل؟ تتمثل إحدى الطرق باستخدام المؤشر الذي يشير إلى الهيكل، ثم اختيار العضو على النحو التالي: /* نحصل على الهيكل ومن ثم نحدد العضو*/ (*wp_p).wp_cval نستخدم الأقواس لأن أسبقية عامل النقطة . أعلى من *، إلا أن الطريقة السابقة غير سهلة التعامل وقدمت لغة سي نتيجة لذلك عاملًا جديدًا لجعل التعليمة أنيقة ويُعرف باسم العامل "المُشير إلى pointing-to"، إليك مثالًا عن استخدامه: // العضو الذي يشير إليه المؤشر wp_p في الهيكل wp_cval wp_p->wp_cval = 'x'; ومع أن مظهره غير مثالي، إلا أنه مفيد جدًا في حال احتواء هيكل ما على المؤشرات، مثل القوائم المترابطة Linked list، إذ أن استخدام الطريقة السابقة أسهل بكثير إن أردت تتبع مرحلة أو مرحلتين من الروابط ضمن قائمة مترابطة. إذا لم تصادف القوائم المترابطة بعد، فلا تقلق، إذ سنتطرق إليها لاحقًا. إذا كان الكائن على يسار العامل . أو <- نوعًا مؤهّلًا qualified type (باستخدام الكلمة المفتاحية const أو volatile)، فستكون النتيجة أيضًا معرفةً حسب هذه المؤهلات qualifiers. إليك مثالًا عن ذلك باستخدام المؤشرات؛ فعندما يشير المؤشر إلى نوع مؤهل، تكون النتيجة من نوع مؤهل أيضًا. #include <stdio.h> #include <stdlib.h> struct somestruct{ int i; }; main(){ struct somestruct *ssp, s_item; const struct somestruct *cssp; s_item.i = 1; /* مسموح */ ssp = &s_item; ssp->i += 2; /* مسموح */ cssp = &s_item; cssp->i = 0; /*يشير إلى كائن ثابت cssp غير مسموح لأن المؤشر */ exit(EXIT_SUCCESS); } يبدو أن بعض مبرمجي المصرّفات نسوا هذا المتطلب، إذ استخدمنا مصرفًا لتجربة المثال السابق ولم يحذرنا بخصوص الإسناد الأخير الذي خرق القيد. إليك المثال 1 مكتوبًا باستخدام المؤشرات، وبتغيير دالة الدخل infun بحيث تقبل مؤشرًا يشير إلى هيكل بدلًا من إعادة مؤشر، وهذا ما ستراه على الأغلب عندما تنظر إلى بعض البرامج العملية. نتخلى عن نسخ الهياكل في البرامج إن أردنا زيادة فاعلية تنفيذها ونستخدم بدلًا من ذلك مصفوفات تحتوي على مؤشرات؛ إذ تُستخدم هذه المؤشرات للحصول على البيانات المخزنة، إلا أن هذه الطريقة ستزيد من تعقيد الأمور، ولا تستحق العناء في التطبيقات البسيطة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; void infun(struct wp_char *); main(){ struct wp_char wp_tmp, *lo_indx, *hi_indx, *in_p; for(in_p = ar; in_p < &ar[ARSIZE]; in_p++){ infun(in_p); if(in_p->wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة in_p * مع تجاهل \n */ break; } } /* * نبدأ بترتيب القيم * علينا الحرص هنا وتجنب حالة طفحان * لذا نتفقد دائمًا وجود قيمتين لترتيبهما */ if(in_p-ar > 1) for(lo_indx = ar; lo_indx <= in_p-2; lo_indx++){ for(hi_indx = lo_indx+1; hi_indx <= in_p-1; hi_indx++){ if(lo_indx->wp_cval > hi_indx->wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = *lo_indx; *lo_indx = *hi_indx; *hi_indx = wp_tmp; } } } /* طباعة القيم */ for(lo_indx = ar; lo_indx < in_p; lo_indx++){ printf("%c %d %d\n", lo_indx->wp_cval, lo_indx->wp_font, lo_indx->wp_psize); } exit(EXIT_SUCCESS); } void infun( struct wp_char *inp){ inp->wp_cval = getchar(); inp->wp_font = 2; inp->wp_psize = 10; return; } مثال 2 هناك مشكلةٌ أخرى يجب النظر إليها، ألا وهي كيف سيبدو الهيكل عند تخزينه في الذاكرة؟ إلا أننا لن نقلق بهذا الخصوص كثيرًا في الوقت الحالي، ولكن من المفيد أن تستخدم في بعض الأحيان هياكل لغة سي C مكتوبة بواسطة برامج أخرى. تُحجز المساحة للهيكل wp_char كما هو موضح على النحو التالي: شكل 1 مخطط تخزين الهيكل يفترض الشكل بعض الأشياء مسبقًا: يأخذ المتغير من نوع char بايتًا واحدًا من الذاكرة، بينما يأخذ short 2 بايت من الذاكرة، وأن لجميع المتغيرات من نوع short عنوانًا زوجيًا على هذه المعمارية، ونتيجةً لما سبق يبقى عضو واحد بحجم 1 بايت ضمن الهيكل دون تسمية مُدخل من المصرف وذلك لأغراض تتعلق بمعمارية الذاكرة. القيود السابقة شائعة الوجود وتتسبب غالبًا بما يسمى هياكل ذات "ثقوب holes". تضمن لغة سي المعيارية بعض الأمور بخصوص تنسيق الهياكل والاتحادات: تُحجز الذاكرة لكلٍ من أعضاء الهياكل بحسب الترتيب التي ظهرت بها هذه الأعضاء ضمن التصريح عن الهيكل وبترتيبٍ تصاعدي للعناوين. لا يجب أن يكون هناك أي حشو padding في الذاكرة أمام العضو الأول. يماثل عنوان الهيكل عنوان العضو الأول له، وذلك بفرض استخدام تحويل الأنواع casting المناسب، وبالنظر إلى التصريح السابق للهيكل wp_char فإن التالي محقق: (char *)item == &item.wp_cval. ليس لحقول البتات bit fields (سنذكرها لاحقًا) أي عناوين، فهي محزّمةٌ تقنيًا إلى وحدات units وتنطبق عليها القوانين السابقة. القوائم المترابطة وهياكل أخرى يفتح استخدام الهياكل مع المؤشرات الباب لكثيرٍ من الإمكانات. لسنا بصدد تقديم شرح مفصل ومعقد عن هياكل البيانات المترابطة هنا، ولكننا سنشرح مثالين شائعين جدًا من هذه الطبيعة، ألا وهما القوائم المترابطة Linked lists والأشجار Trees، ويجمع بين الهيكلين السابقين استخدام المؤشرات بداخلهما تشير إلى هياكل أخرى، وتكون الهياكل الأخرى عادةً من النوع ذاته. يوضح الشكل 2 طبيعة القائمة المترابطة. شكل 2 قائمة مترابطة باستخدام المؤشرات نحتاج للحصول على ما سبق إلى لتصريح عنه بما يوافق التالي: struct list_ele{ int data; /* تستطيع تسمية العضو بأي اسم*/ struct list_ele *ele_p; }; يبدو للوهلة الأولى أن الهيكل يحتوي نفسه (وهو ممنوع) ولكن يحتوي الهيكل في حقيقة الأمر مؤشرًا يشير إلى نفسه فقط، لكن لمَ يُعد التصريح عن المؤشر بالشكل السابق مسموحًا؟ يعلم المصرف بحلول وصوله إلى تلك النقطة بوجود struct list_ele، ولهذا السبب يكون التصريح مسموح، ومن الممكن أيضًا كتابة تصريح غير مكتمل للهيكل على النحو التالي قبل التصريح الكامل: struct list_ele; يصرح التصريح السابق عن نوع غير مكتمل incomplete type، سيسمح بالتصريح عن المؤشرات قبل التصريح الكامل، يفيد ذلك أيضًا في حال وجود حالة للإشارة إلى هياكل فيما بينها التي يجب أن تحتوي مؤشرًا لكل منها كما هو موضح في المثال. struct s_1; /* نوع غير مكتمل */ struct s_2{ int something; struct s_1 *sp; }; struct s_1{ /* التصريح الكامل */ float something; struct s_2 *sp; }; مثال 3 يوضح المثال السابق حاجتنا للأنواع غير المكتملة، كما يوضح خاصيةً مهمةً لأسماء أعضاء الهيكل إذ يشكّل كل هيكل فضاء أسماء name space خاصٍ به، ويمكن بذلك أن تتماثل أسماء عناصر من هياكل مختلفة دون أي مشاكل. تُستخدم الأنواع غير المكتملة فقط في حال لم نكن بحاجة استخدام حجم الهيكل، وإلا فيجب التصريح كاملًا عن الهيكل قبل استخدام حجمه، ولا يجب أن يكون هذا التصريح بداخل كتلة برمجية داخلية وإلا سيصبح تصريحًا جديدًا لهيكل مختلف. struct x; /* نوع غير مكتمل */ /* استخدام مسموح للوسوم */ struct x *p, func(void); void f1(void){ struct x{int i;}; /* إعادة تصريح */ } /* التصريح الكامل */ struct x{ float f; }s_x; void f2(void){ /* تعليمات صالحة */ p = &s_x; *p = func(); s_x = func(); } struct x func(void){ struct x tmp; tmp.f = 0; return (tmp); } مثال 4 يجدر الانتباه إلى أنك تحصل على هيكل من نوع غير مكتمل فقط عن طريق ذكر اسمه، وبناءً على ما سبق، تعمل الشيفرة التالية دون مشاكل: struct abc{ struct xyz *p;}; /* struct xyz تصريح النوع غير المكتمل */ struct xyz{ struct abc *p;}; /* أصبح النوع غير المكتمل مكتملًا */ هناك خطرٌ كبير في المثال السابق، كما هو موضح هنا: struct xyz{float x;} var1; main(){ struct abc{ struct xyz *p;} var2; /* struct xyz إعادة تصريح للهيكل */ struct xyz{ struct abc *p;} var3; } نتيجةً لما سبق، يمكن للمتغير var2.p أن يخزن عنوان var1، وليس عنوان var3 قطعًا الذي هو من نوع مختلف. يمكن تصحيح ما سبق (بفرض أنك لم تتعمد فعله) على النحو التالي: struct xyz{float x;} var1; main(){ struct xyz; /* نوع جديد غير مكتمل */ struct abc{ struct xyz *p;} var2; struct xyz{ struct abc *p;} var3; } يُستكمل نوع الهيكل أو الاتحاد عند الوصول إلى قوس الإغلاق {، ويجب أن يحتوي عضوًا واحدًا على الأقل أو نحصل على سلوك غير محدد. نستطيع الحصول على أنواع غير مكتملة عن طريق تصريح مصفوفة دون تحديد حجمها، ويصنف النوع على أنه غير مكتمل حتى يقدم تصريحًا آخرًا حجمها: int ar[]; /* نوع غير مكتمل */ int ar[5]; /* نكمل النوع هنا */ سيعمل المثال السابق إن جربته فقط في حال كانت التصريحات خارج أي كتلة برمجية (تصريحات خارجية)، إلا أن السبب في ذلك ليس متعلقًا بموضوعنا. بالعودة إلى مثال القوائم المترابطة، كان لدينا ثلاث عناصر مترابطة في القائمة، التي يمكن بناؤها على النحو التالي: struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ return(0); } مثال 5 يمكننا طباعة محتويات القائمة بطريقتين، إما بالمرور على المصفوفة بحسب دليلها index، أو باستخدام المؤشرات كما سنوضح في المثال التالي: #include <stdio.h> #include <stdlib.h> struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ struct list_ele *lp; ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ /* اتباع المؤشرات */ lp = ar; while(lp){ printf("contents %d\n", lp->data); lp = lp->pointer; } exit(EXIT_SUCCESS); } مثال 6 الطريقة التي تُستخدم فيها المؤشرات في المثال السابق مثيرةٌ للاهتمام، لاحظ كيف أن المؤشر الذي يشير إلى عنصر ما يُستخدم للإشارة إلى العنصر الذي يليه حتى إيجاد المؤشر ذو القيمة 0، مما يتسبب بتوقف حلقة while التكرارية. يمكن ترتيب المؤشرات بأي طريقة وهذا ما يجعل القائمة هيكلًا مرن التعامل. إليك دالةً يمكن تضمينها مثل جزء من برنامجنا السابق بهدف ترتيب القائمة المترابطة بحسب قيمة بياناتها العددية، وذلك عن طريق إعادة ترتيب المؤشرات حتى الوصول إلى عناصر القائمة عند المرور عليها بالترتيب. من المهم أن نشير هنا إلى أن البيانات لا تُنسخ، إذ تعيد الدالة مؤشرًا إلى بداية القائمة لأن بدايتها لا تساوي إلى التعبير ar[0] بالضرورة. struct list_ele * sortfun( struct list_ele *list ) { int exchange; struct list_ele *nextp, *thisp, dummy; /* * الخوارزمية على النحو التالي: * البحث عبر القائمة بصورةٍ متكررة * إذا وجد عنصرين خارج الترتيب * اِربطهما بصورةٍ معاكسة * توقف عند المرور بجميع عناصر القائمة * دون أي تبديل مطلوب * يحدث الخلط عند العمل على العنصر خلف العنصر الأول المثير للاهتمام * وهذا بسبب الآليات البسيطة المتعلقة بربط العناصر وإلغاء ربطها */ dummy.pointer = list; do{ exchange = 0; thisp = &dummy; while( (nextp = thisp->pointer) && nextp->pointer){ if(nextp->data < nextp->pointer->data){ /* exchange */ exchange = 1; thisp->pointer = nextp->pointer; nextp->pointer = thisp->pointer->pointer; thisp->pointer->pointer = nextp; } thisp = thisp->pointer; } }while(exchange); return(dummy.pointer); } مثال 7 ستلاحظ استخدام تعابير مشابهة للتعبير thisp->pointer->pointer عند التعامل مع القوائم، وبالتالي يجب أن تفهم هذه التعابير، وهي بسيطة إذ يدل شكلها على الروابط المتبعة. الأشجار تُعد الأشجار هيكل بيانات شائع أيضًا، وهي في حقيقة الأمر قائمةٌ مترابطةٌ ذات فروع، والنوع الأكثر شيوعًا هو الشجرة الثنائية binary tree، التي تحتوي على عناصر تُدعى العقد "nodes" كما يلي: struct tree_node{ int data; struct tree_node *left_p, *right_p; }; تعمل الأشجار في علوم الحاسوب من الأعلى إلى الأسفل (لأسباب تاريخية لن نناقشها)، إذ توجد عقدة الجذر root أعلى الشجرة وتتفرع فروع هذه الشجرة في الأسفل. تُستبدل بيانات أعضاء الهيكل الخاصة بالعقد بقيمها في الشكل التالي والتي سنستخدمها لاحقًا. شكل 3 شجرة لن تجذب الأشجار انتباهك إذا كان اهتمامك الرئيس هو التعامل مع المحارف والتلاعب بها، ولكنها مهمة جدًا بالنسبة لمصمّمي كل من قواعد البيانات والمصرّفات والأدوات المعقدة الأخرى. تتميز الأشجار بميزة خاصة جدًا ألا وهي أنها مرتبة، فيمكن أن تدعم بكل سهولة خوارزميات البحث الثنائي، ومن الممكن دائمًا إضافة مزيدٍ من العقد الجديدة إلى الشجرة في الأماكن المناسبة، فالشجرة هيكل بيانات مفيدٌ ومرن. بالنظر إلى الشكل السابق، نلاحظ أن الشجرة مبنيّةٌ بحرص حتى تكون مهمة البحث عن قيمة ما في حقول البيانات من العقد مهمةً سهلةً، وإن فرضنا أننا نريد أن نعرف فيما إذا كانت القيمة x موجودةً في الشجرة عبر البحث عنها، نتبع الخوارزمية التالية: نبدأ بعقدة جذر الشجرة: إذا كانت الشجرة فارغة (لا تحتوي على عقد) إعادة القيمة "فشل البحث" إذا كانت القيمة التي نبحث عنها مساويةً إلى قيمة العقدة الحالية إعادة القيمة "نجاح البحث" إذا كانت القيمة في العقدة الحالية أكبر من القيمة التي نبحث عنها ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيسر فيما عدا ذلك، ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيمن إليك الخوارزمية بلغة سي: #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }tree[7]; /* * خوارزمية البحث ضمن الشجرة * تبحث عن القيمةفي الشجرة v * تُعيد مؤشر يشير إلى أول عقدة تحوي النتيجة * أو تُعيد القيمة 0 */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* لا يوجد أي شجرة متبقية ولم يُعثر على القيمة */ return(0); } main(){ /* بناء الشجرة يدويًا */ struct tree_node *tp, *root_p; int i; for(i = 0; i < 7; i++){ int j; j = i+1; tree[i].data = j; if(j == 2 || j == 6){ tree[i].left_p = &tree[i-1]; tree[i].right_p = &tree[i+1]; } } /* الجذر */ root_p = &tree[3]; root_p->left_p = &tree[1]; root_p->right_p = &tree[5]; /* حاول أن تبحث */ tp = t_search(root_p, 9); if(tp) printf("found at position %d\n", tp-tree); else printf("value not found\n"); exit(EXIT_SUCCESS); } مثال 8 يعمل المثال السابق بنجاح دون أخطاء، ومن الجدير بالذكر أنه يمكننا استخدام ذلك في جعل أي قيمة مدخلة إلى الشجرة تُخزن في مكانها الصحيح باستخدام خوارزمية البحث ذاتها، أي بإضافة شيفرة برمجية إضافية تحجز مساحة لقيمة جديدة باستخدام دالة malloc عندما لا تجد الخوارزمية القيمة، وتُضاف العقدة الجديدة في مكان مؤشر الفراغ null pointer الأول. من المعقد تحقيق ما سبق، وذلك بسبب مشكلة التعامل مع مؤشر العقدة الجذر، ونلجأ في هذه الحالة إلى مؤشر يشير إلى مؤشر آخر. اقرأ المثال التالي بانتباه، إذ أنه أحد أكثر الأمثلة تعقيدًا حتى اللحظة، وإذا استطعت فهمه فهذا يعني أنك تستطيع فهم الأغلبية الساحقة من برامج سي. #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }; /* * خوارزمية البحث ضمن شجرة * ابحث عن القيمة v ضمن الشجرة * أعد مؤشرًا إلى أول عقدة تحتوي على القيمة هذه * أعد القيمة 0 إن لم تجد نتيجة */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ printf("looking for %d, looking at %d\n", v, root->data); if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* value not found, no tree left */ return(0); } /* * أدخل عقدة ضمن شجرة * أعد 0 عند نجاح العملية أو * أعد 1 إن كانت القيمة موجودة في الشجرة * أعد 2 إن حصل خطأ في عملية حجز الذاكرة malloc error */ int t_insert(struct tree_node **root, int v){ while(*root){ if((*root)->data == v) return(1); if((*root)->data > v) root = &((*root)->left_p); else root = &((*root)->right_p); } /* value not found, no tree left */ if((*root = (struct tree_node *) malloc(sizeof (struct tree_node))) == 0) return(2); (*root)->data = v; (*root)->left_p = 0; (*root)->right_p = 0; return(0); } main(){ /* construct tree by hand */ struct tree_node *tp, *root_p = 0; int i; /* we ingore the return value of t_insert */ t_insert(&root_p, 4); t_insert(&root_p, 2); t_insert(&root_p, 6); t_insert(&root_p, 1); t_insert(&root_p, 3); t_insert(&root_p, 5); t_insert(&root_p, 7); /* try the search */ for(i = 1; i < 9; i++){ tp = t_search(root_p, i); if(tp) printf("%d found\n", i); else printf("%d not found\n", i); } exit(EXIT_SUCCESS); } مثال 9 تسمح لك الخوارزمية التالية بالمرور على الشجرة وزيارة جميع العُقد بالترتيب باستخدام التعاودية recursion، وهي أحد أكثر الأمثلة أناقةً، انظر إليها وحاول فهمها. void t_walk(struct tree_node *root_p){ if(root_p == 0) return; t_walk(root_p->left_p); printf("%d\n", root_p->data); t_walk(root_p->right_p); } مثال 10 ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C المقال السابق: التعامل مع المؤشرات Pointers في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى
اتجه تطوير لغات الحاسوب سابقًا في اتجاهٍ من اتجاهين، إذ سلكت كوبول COBOL سلوكًا ركز على استخدام هياكل البيانات بعيدًا عن العمليات الحسابية والخوارزميات، بينما سلكت لغات مثل فورتران FORTRAN وألغول Algol سلوكًا معاكسًا. أراد العلماء وقتها إجراء العمليات الحسابية باستخدام بيانات غير مُهيكلة نسبيًا، إلا أنه سرعان ما لاحظ الجميع أن استخدام المصفوفات لا غنى عنه؛ بينما أراد المستخدمون الاعتياديون طريقةً لإجراء العمليات الحسابية البسيطة فقط، إلا أن طريقة هيكلة البيانات كانت عائقًا أمام تحقيق ذلك. أثر كلا السلوكين في تصميم لغة سي، إذ أنها تحتوي تحكمًا هيكليًا لتدفق البرنامج مناسب للغة من هذا العمر، كما أنها جعلت من مفهوم هياكل البيانات شائعًا. ركزنا على جانب الخوارزميات من اللغة حتى اللحظة، ولم نولي الكثير من الانتباه بخصوص تخزين البيانات، ومع أننا تطرقنا إلى المصفوفات التي تُعدّ هيكل بيانات إلا أنها شائعة الاستخدام وبسيطة ولا تستحق فصلًا مخصصًا لها، واكتفينا إلى الآن بالنظر إلى اللغة انطلاقًا من بينة هيكلية شبيهة بلغة فورتران. كان استخدام كلٍ من البيانات والخوارزميات هو التوجه الأكثر رواجًا في أواخر ثمانينيات وبداية تسعينيات القرن الماضي، وفق ما يُدعى بالبرمجة كائنية التوجه Object-Oriented Programming. لا يوجد أي دعم لهذه الطريقة في لغة سي، إلا أن لغة C++ قدمت دعمًا لها (وهي لغةٌ مبنيةٌ على لغة سي)، ولكن هذا النقاش خارج موضوعنا حاليًا. تأخذ البيانات الانتباه الأكبر لمعظم مشاكل الحوسبة المتقدمة وليس الخوارزميات، فستكون مهمتك بسيطةً ببرمجة البرنامج إن استطعت تصميم هياكل بيانات صحيحة ومناسبة، إلا أنك تحتاج إلى دعمٍ من اللغة في هذه الحالة، فمهمتك ستصبح أقل سهولة ومعرضةً أكثر للأخطاء إن لم يكن هناك أي دعم لأنواع هياكل البيانات المختلفة عن المصفوفات. تقع هذه المهمة على كاهل لغة البرمجة، فليس كافيًا أن تسمح لك اللغة بفعل ما تريد، بل يجب أن تساعدك في فعل ما تريد. تقدم لك لغة سي سعيًا منها بتقديم هياكل بيانات مناسبة كلًا من المصفوفات Arrays والهياكل Structures والاتحادات Unions، وقد برهنت على أنها كافيةٌ لمعظم المستخدمين الاعتياديين وبالتالي لم يُضِف المعيار أي جديد بشأنها. الهياكل Structures تسمح لك المصفوفات بتخزين مجموعة من الكائنات المتماثلة تحت اسم معين، وهذا مفيدٌ لعدد من المهام، ولكنه ليس مرن التعامل، إذ تحتوي معظم كائنات البيانات ذات التطبيقات الواقعية على هيكل معيّن معقد لا يمكن استخدامه مع طريقة تخزين المصفوفة للبيانات. لنوضح ما سبق بالمثال التالي: لنفرض أننا نريد تمثيل سلسلةٍ نصية ذات خصائص معينة، بجانب محتواها. هناك نوع الخط وحجمه، وهما سمتان لا تؤثران في محتوى السلسلة، لكنهما تحددان الطريقة التي تُعرض فيها السلسلة على الشاشة سواءٌ كان النص مكتوبًا بخط غامق أو مائل، والأمر ذاته ينطبق على حجم الخط. كيف نستطيع تمثيل السلسلة النصية بكائن واحد ضمن مصفوفة إذا كان يحتوي على ثلاث سمات مختلفة؟ يمكننا تحقيق ذلك في لغة سي C بسهولة، حاول أولًا تمثيل السمات الثلاث باستخدام الأنواع الأساسية، فعلى فرض أنه يمكننا تخزين كل محرف باستخدام النوع char، يمكننا الإشارة إلى نوع الخط المستخدم باستخدام النوع short (نستخدم "1" للإشارة إلى الخط الاعتيادي و"2" للخط المائل و"3" للخط الغامق، وهكذا)، كما يمكننا تخزين حجم الخط باستخدام النوع short، وتُعد جميع الفرضيات السابقة معقولةً عمليًا، إذ تدعم معظم الأنظمة عددًا قليلًا من الخطوط مهما كانت هذه الأنظمة معقدة، ويتراوح حجم الخط بين 6 ومرتبة المئات القليلة، فأي خط أصغر من 6 هو صعب القراءة، والخط الأكبر من 50 هو خط أكبر من خطوط عناوين الجرائد. إذًا، لدينا الآن محرف وعددين صغيرين وتُعامل هذه البيانات معاملة كائن واحد، إليك كيف نصرّح عن ذلك في لغة سي: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }; يصرح ما سبق عن نوع جديد من الكائنات يمكنك استخدامه ضمن البرنامج، ويعتمد الأمر بصورةٍ رئيسية على ذكر الكلمة المفتاحية struct، المتبوعة بمعرّف identifier اختياري هو الوسم wp_char في هذه الحالة، ويسمح لنا هذا الوسم بتسمية النوع للإشارة إليه فيما بعد. يمكننا أيضًا استخدام الوسم بالطريقة التالية بعد التصريح عنه: struct wp_char x, y; يُعرّف ما سبق متغيرين باسم x و y، بالطريقة ذاتها للتعريف التالي: int x, y; لكن المتغيرات في المثال الأول من نوع struct wp_char عوضًا عن int في المثال الثاني، ويمثّل الوسم اسمًا للنوع الذي صرحنا عنه سابقًا. نذّكر هنا أنه من الممكن استخدام اسم وسم الهيكل مثل أي معرّف اعتيادي بصورةٍ آمنة، ويدل الاسم على معنًى مختلف عندما يُسبق بالكلمة المفتاحية struct فقط، ومن الشائع أن يُعرّف كائن مُهيكل باسم مماثل لوسم الهيكل الخاص به. struct wp_char wp_char; يُعرّف السطر السابق متغيرًا باسم wp_char من النوع struct wp_char، ويمكننا فعل ذلك لأن لوسوم الهياكل "فضاء اسماء name space" خاصة بها ولا تتعارض مع الأسماء الأخرى، وسنتكلم أكثر عن الوسوم عندما نناقش "الأنواع غير المكتملة incomplete types". يمكن التعريف عن المتغيرات على الفور عقب التصريح عن هيكل ما: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }v1; struct wp_char v2; لدينا في هذه الحالة متغيرين، أحدهما باسم v1 والآخر باسم v2، وإذا استخدمنا الطريقة السابقة في التعريف عن v1، يصبح الوسم غير ضروري ويُتخلّى عنه غالبًا إلا في حال احتجنا إلى الوسم لاستخدامه مع عامل sizeof والتحويل بين الأنواع casts. يُعد المتغيران السابقان كائنات مُهيكلة، ويحتوي كل منهما على ثلاثة أعضاء members مستقلين عن بعضهم باسم wp_cval و wp_font و wp_psize، ونستخدم عامل النقطة . للوصول إلى كلّ من الأعضاء السابقة على النحو التالي: v1.wp_cval = 'x'; v1.wp_font = 1; v1.wp_psize = 10; v2 = v1; تُضبط أعضاء المتغير v1 في المثال السابق إلى قيمها المناسبة، ومن ثم تُنسخ قيم v1 إلى v2 باستخدام عملية الإسناد. في الحقيقة، العملية الوحيدة المسموحة في الهياكل بكاملها هي الإسناد؛ إذ يمكن إسناد الهياكل إلى بعضها بعضًا أو تمريرها مثل وسطاء للدوال أو قيمةٍ تُعيدها دالةٌ ما، إلا أن نسخ الهياكل عمليةٌ غير فعالة وتتفاداها معظم البرامج عن طريق التلاعب بالمؤشرات التي تشير إلى الهياكل عوضًا عن ذلك، إذ من الأسرع عمومًا نسخ المؤشرات عوضًا عن الهياكل. تسمح اللغة بمقارنة الهياكل بحثًا عن المساواة فيما بينها، وهي سهوة مفاجئة ولا يوجد سبب مقنع لسماحها بذلك كما سنذكر قريبًا. إليك مثالًا يستخدم مصفوفةً من الهياكل، وهو الهيكل ذاته الذي تكلمنا عنه سابقًا، إذ تُستخدم دالةٌ لقراءة المحارف من دخل البرنامج القياسي وتُعيد هيكلًا مهيّأً بقيمٍ مناسبة مقابله، ومن ثم تُرتّب الهياكل بحسب قيمة كل محرف وتُطبع وذلك عندما يُقرأ محرف سطر جديد، أو عندما تمتلئ المصفوفة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; /* نوع دخل الدالة الذي كان من الممكن التصريح عنه سابقًا، وتعيد الدالة هيكلًا ولا تأخذ أي وسطاء */ struct wp_char infun(void); main(){ int icount, lo_indx, hi_indx; for(icount = 0; icount < ARSIZE; icount++){ ar[icount] = infun(); if(ar[icount].wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة icount * مع تجاهل \n */ break; } } /* نجري الآن عملية الترتيب */ for(lo_indx = 0; lo_indx <= icount-2; lo_indx++) for(hi_indx = lo_indx+1; hi_indx <= icount-1; hi_indx++){ if(ar[lo_indx].wp_cval > ar[hi_indx].wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = ar[lo_indx]; ar[lo_indx] = ar[hi_indx]; ar[hi_indx] = wp_tmp; } } /* طباعة القيم */ for(lo_indx = 0; lo_indx < icount; lo_indx++){ printf("%c %d %d\n", ar[lo_indx].wp_cval, ar[lo_indx].wp_font, ar[lo_indx].wp_psize); } exit(EXIT_SUCCESS); } struct wp_char infun(void){ struct wp_char wp_char; wp_char.wp_cval = getchar(); wp_char.wp_font = 2; wp_char.wp_psize = 10; return(wp_char); } مثال 1 من الطبيعي أن نلجأ إلى التصريح عن مصفوفات من الهياكل حالما نستطيع ونتعلم كيفية التصريح عنها، وأن نستخدم هذه الهياكل عناصرًا لهياكل أخرى وما إلى ذلك، والقيد الوحيد هنا هو أنه لا يمكن للهيكل أن يحتوي مثالًا لنفسه على أنه عضو داخله (يصبح حينها حجمها موضع جدل مثير للفلاسفة، ولكنه غير مفيد لأي مبرمج سي C). المؤشرات والهياكل ذكرنا سابقًا أنه من الشائع استخدام المؤشرات في الهياكل بدلًا من استخدام الهياكل مباشرةً، لنتعلم كيفية تحقيق ذلك إذَا. يُعد التصريح عن المؤشرات سهلًا، ونعتقد أنك أتقنته: struct wp_char *wp_p; يمنحنا التصريح السابق مؤشرًا مباشرةً، ولكن كيف يمكننا الوصول إلى أعضاء الهيكل؟ تتمثل إحدى الطرق باستخدام المؤشر الذي يشير إلى الهيكل، ثم اختيار العضو على النحو التالي: /* نحصل على الهيكل ومن ثم نحدد العضو*/ (*wp_p).wp_cval نستخدم الأقواس لأن أسبقية عامل النقطة . أعلى من *، إلا أن الطريقة السابقة غير سهلة التعامل وقدمت لغة سي نتيجة لذلك عاملًا جديدًا لجعل التعليمة أنيقة ويُعرف باسم العامل "المُشير إلى pointing-to"، إليك مثالًا عن استخدامه: // العضو الذي يشير إليه المؤشر wp_p في الهيكل wp_cval wp_p->wp_cval = 'x'; ومع أن مظهره غير مثالي، إلا أنه مفيد جدًا في حال احتواء هيكل ما على المؤشرات، مثل القوائم المترابطة Linked list، إذ أن استخدام الطريقة السابقة أسهل بكثير إن أردت تتبع مرحلة أو مرحلتين من الروابط ضمن قائمة مترابطة. إذا لم تصادف القوائم المترابطة بعد، فلا تقلق، إذ سنتطرق إليها لاحقًا. إذا كان الكائن على يسار العامل . أو <- نوعًا مؤهّلًا qualified type (باستخدام الكلمة المفتاحية const أو volatile)، فستكون النتيجة أيضًا معرفةً حسب هذه المؤهلات qualifiers. إليك مثالًا عن ذلك باستخدام المؤشرات؛ فعندما يشير المؤشر إلى نوع مؤهل، تكون النتيجة من نوع مؤهل أيضًا. #include <stdio.h> #include <stdlib.h> struct somestruct{ int i; }; main(){ struct somestruct *ssp, s_item; const struct somestruct *cssp; s_item.i = 1; /* مسموح */ ssp = &s_item; ssp->i += 2; /* مسموح */ cssp = &s_item; cssp->i = 0; /*يشير إلى كائن ثابت cssp غير مسموح لأن المؤشر */ exit(EXIT_SUCCESS); } يبدو أن بعض مبرمجي المصرّفات نسوا هذا المتطلب، إذ استخدمنا مصرفًا لتجربة المثال السابق ولم يحذرنا بخصوص الإسناد الأخير الذي خرق القيد. إليك المثال 1 مكتوبًا باستخدام المؤشرات، وبتغيير دالة الدخل infun بحيث تقبل مؤشرًا يشير إلى هيكل بدلًا من إعادة مؤشر، وهذا ما ستراه على الأغلب عندما تنظر إلى بعض البرامج العملية. نتخلى عن نسخ الهياكل في البرامج إن أردنا زيادة فاعلية تنفيذها ونستخدم بدلًا من ذلك مصفوفات تحتوي على مؤشرات؛ إذ تُستخدم هذه المؤشرات للحصول على البيانات المخزنة، إلا أن هذه الطريقة ستزيد من تعقيد الأمور، ولا تستحق العناء في التطبيقات البسيطة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; void infun(struct wp_char *); main(){ struct wp_char wp_tmp, *lo_indx, *hi_indx, *in_p; for(in_p = ar; in_p < &ar[ARSIZE]; in_p++){ infun(in_p); if(in_p->wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة in_p * مع تجاهل \n */ break; } } /* * نبدأ بترتيب القيم * علينا الحرص هنا وتجنب حالة طفحان * لذا نتفقد دائمًا وجود قيمتين لترتيبهما */ if(in_p-ar > 1) for(lo_indx = ar; lo_indx <= in_p-2; lo_indx++){ for(hi_indx = lo_indx+1; hi_indx <= in_p-1; hi_indx++){ if(lo_indx->wp_cval > hi_indx->wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = *lo_indx; *lo_indx = *hi_indx; *hi_indx = wp_tmp; } } } /* طباعة القيم */ for(lo_indx = ar; lo_indx < in_p; lo_indx++){ printf("%c %d %d\n", lo_indx->wp_cval, lo_indx->wp_font, lo_indx->wp_psize); } exit(EXIT_SUCCESS); } void infun( struct wp_char *inp){ inp->wp_cval = getchar(); inp->wp_font = 2; inp->wp_psize = 10; return; } مثال 2 هناك مشكلةٌ أخرى يجب النظر إليها، ألا وهي كيف سيبدو الهيكل عند تخزينه في الذاكرة؟ إلا أننا لن نقلق بهذا الخصوص كثيرًا في الوقت الحالي، ولكن من المفيد أن تستخدم في بعض الأحيان هياكل لغة سي C مكتوبة بواسطة برامج أخرى. تُحجز المساحة للهيكل wp_char كما هو موضح على النحو التالي: شكل 1 مخطط تخزين الهيكل يفترض الشكل بعض الأشياء مسبقًا: يأخذ المتغير من نوع char بايتًا واحدًا من الذاكرة، بينما يأخذ short 2 بايت من الذاكرة، وأن لجميع المتغيرات من نوع short عنوانًا زوجيًا على هذه المعمارية، ونتيجةً لما سبق يبقى عضو واحد بحجم 1 بايت ضمن الهيكل دون تسمية مُدخل من المصرف وذلك لأغراض تتعلق بمعمارية الذاكرة. القيود السابقة شائعة الوجود وتتسبب غالبًا بما يسمى هياكل ذات "ثقوب holes". تضمن لغة سي المعيارية بعض الأمور بخصوص تنسيق الهياكل والاتحادات: تُحجز الذاكرة لكلٍ من أعضاء الهياكل بحسب الترتيب التي ظهرت بها هذه الأعضاء ضمن التصريح عن الهيكل وبترتيبٍ تصاعدي للعناوين. لا يجب أن يكون هناك أي حشو padding في الذاكرة أمام العضو الأول. يماثل عنوان الهيكل عنوان العضو الأول له، وذلك بفرض استخدام تحويل الأنواع casting المناسب، وبالنظر إلى التصريح السابق للهيكل wp_char فإن التالي محقق: (char *)item == &item.wp_cval. ليس لحقول البتات bit fields (سنذكرها لاحقًا) أي عناوين، فهي محزّمةٌ تقنيًا إلى وحدات units وتنطبق عليها القوانين السابقة. القوائم المترابطة وهياكل أخرى يفتح استخدام الهياكل مع المؤشرات الباب لكثيرٍ من الإمكانات. لسنا بصدد تقديم شرح مفصل ومعقد عن هياكل البيانات المترابطة هنا، ولكننا سنشرح مثالين شائعين جدًا من هذه الطبيعة، ألا وهما القوائم المترابطة Linked lists والأشجار Trees، ويجمع بين الهيكلين السابقين استخدام المؤشرات بداخلهما تشير إلى هياكل أخرى، وتكون الهياكل الأخرى عادةً من النوع ذاته. يوضح الشكل 2 طبيعة القائمة المترابطة. شكل 2 قائمة مترابطة باستخدام المؤشرات نحتاج للحصول على ما سبق إلى لتصريح عنه بما يوافق التالي: struct list_ele{ int data; /* تستطيع تسمية العضو بأي اسم*/ struct list_ele *ele_p; }; يبدو للوهلة الأولى أن الهيكل يحتوي نفسه (وهو ممنوع) ولكن يحتوي الهيكل في حقيقة الأمر مؤشرًا يشير إلى نفسه فقط، لكن لمَ يُعد التصريح عن المؤشر بالشكل السابق مسموحًا؟ يعلم المصرف بحلول وصوله إلى تلك النقطة بوجود struct list_ele، ولهذا السبب يكون التصريح مسموح، ومن الممكن أيضًا كتابة تصريح غير مكتمل للهيكل على النحو التالي قبل التصريح الكامل: struct list_ele; يصرح التصريح السابق عن نوع غير مكتمل incomplete type، سيسمح بالتصريح عن المؤشرات قبل التصريح الكامل، يفيد ذلك أيضًا في حال وجود حالة للإشارة إلى هياكل فيما بينها التي يجب أن تحتوي مؤشرًا لكل منها كما هو موضح في المثال. struct s_1; /* نوع غير مكتمل */ struct s_2{ int something; struct s_1 *sp; }; struct s_1{ /* التصريح الكامل */ float something; struct s_2 *sp; }; مثال 3 يوضح المثال السابق حاجتنا للأنواع غير المكتملة، كما يوضح خاصيةً مهمةً لأسماء أعضاء الهيكل إذ يشكّل كل هيكل فضاء أسماء name space خاصٍ به، ويمكن بذلك أن تتماثل أسماء عناصر من هياكل مختلفة دون أي مشاكل. تُستخدم الأنواع غير المكتملة فقط في حال لم نكن بحاجة استخدام حجم الهيكل، وإلا فيجب التصريح كاملًا عن الهيكل قبل استخدام حجمه، ولا يجب أن يكون هذا التصريح بداخل كتلة برمجية داخلية وإلا سيصبح تصريحًا جديدًا لهيكل مختلف. struct x; /* نوع غير مكتمل */ /* استخدام مسموح للوسوم */ struct x *p, func(void); void f1(void){ struct x{int i;}; /* إعادة تصريح */ } /* التصريح الكامل */ struct x{ float f; }s_x; void f2(void){ /* تعليمات صالحة */ p = &s_x; *p = func(); s_x = func(); } struct x func(void){ struct x tmp; tmp.f = 0; return (tmp); } مثال 4 يجدر الانتباه إلى أنك تحصل على هيكل من نوع غير مكتمل فقط عن طريق ذكر اسمه، وبناءً على ما سبق، تعمل الشيفرة التالية دون مشاكل: struct abc{ struct xyz *p;}; /* struct xyz تصريح النوع غير المكتمل */ struct xyz{ struct abc *p;}; /* أصبح النوع غير المكتمل مكتملًا */ هناك خطرٌ كبير في المثال السابق، كما هو موضح هنا: struct xyz{float x;} var1; main(){ struct abc{ struct xyz *p;} var2; /* struct xyz إعادة تصريح للهيكل */ struct xyz{ struct abc *p;} var3; } نتيجةً لما سبق، يمكن للمتغير var2.p أن يخزن عنوان var1، وليس عنوان var3 قطعًا الذي هو من نوع مختلف. يمكن تصحيح ما سبق (بفرض أنك لم تتعمد فعله) على النحو التالي: struct xyz{float x;} var1; main(){ struct xyz; /* نوع جديد غير مكتمل */ struct abc{ struct xyz *p;} var2; struct xyz{ struct abc *p;} var3; } يُستكمل نوع الهيكل أو الاتحاد عند الوصول إلى قوس الإغلاق {، ويجب أن يحتوي عضوًا واحدًا على الأقل أو نحصل على سلوك غير محدد. نستطيع الحصول على أنواع غير مكتملة عن طريق تصريح مصفوفة دون تحديد حجمها، ويصنف النوع على أنه غير مكتمل حتى يقدم تصريحًا آخرًا حجمها: int ar[]; /* نوع غير مكتمل */ int ar[5]; /* نكمل النوع هنا */ سيعمل المثال السابق إن جربته فقط في حال كانت التصريحات خارج أي كتلة برمجية (تصريحات خارجية)، إلا أن السبب في ذلك ليس متعلقًا بموضوعنا. بالعودة إلى مثال القوائم المترابطة، كان لدينا ثلاث عناصر مترابطة في القائمة، التي يمكن بناؤها على النحو التالي: struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ return(0); } مثال 5 يمكننا طباعة محتويات القائمة بطريقتين، إما بالمرور على المصفوفة بحسب دليلها index، أو باستخدام المؤشرات كما سنوضح في المثال التالي: #include <stdio.h> #include <stdlib.h> struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ struct list_ele *lp; ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ /* اتباع المؤشرات */ lp = ar; while(lp){ printf("contents %d\n", lp->data); lp = lp->pointer; } exit(EXIT_SUCCESS); } مثال 6 الطريقة التي تُستخدم فيها المؤشرات في المثال السابق مثيرةٌ للاهتمام، لاحظ كيف أن المؤشر الذي يشير إلى عنصر ما يُستخدم للإشارة إلى العنصر الذي يليه حتى إيجاد المؤشر ذو القيمة 0، مما يتسبب بتوقف حلقة while التكرارية. يمكن ترتيب المؤشرات بأي طريقة وهذا ما يجعل القائمة هيكلًا مرن التعامل. إليك دالةً يمكن تضمينها مثل جزء من برنامجنا السابق بهدف ترتيب القائمة المترابطة بحسب قيمة بياناتها العددية، وذلك عن طريق إعادة ترتيب المؤشرات حتى الوصول إلى عناصر القائمة عند المرور عليها بالترتيب. من المهم أن نشير هنا إلى أن البيانات لا تُنسخ، إذ تعيد الدالة مؤشرًا إلى بداية القائمة لأن بدايتها لا تساوي إلى التعبير ar[0] بالضرورة. struct list_ele * sortfun( struct list_ele *list ) { int exchange; struct list_ele *nextp, *thisp, dummy; /* * الخوارزمية على النحو التالي: * البحث عبر القائمة بصورةٍ متكررة * إذا وجد عنصرين خارج الترتيب * اِربطهما بصورةٍ معاكسة * توقف عند المرور بجميع عناصر القائمة * دون أي تبديل مطلوب * يحدث الخلط عند العمل على العنصر خلف العنصر الأول المثير للاهتمام * وهذا بسبب الآليات البسيطة المتعلقة بربط العناصر وإلغاء ربطها */ dummy.pointer = list; do{ exchange = 0; thisp = &dummy; while( (nextp = thisp->pointer) && nextp->pointer){ if(nextp->data < nextp->pointer->data){ /* exchange */ exchange = 1; thisp->pointer = nextp->pointer; nextp->pointer = thisp->pointer->pointer; thisp->pointer->pointer = nextp; } thisp = thisp->pointer; } }while(exchange); return(dummy.pointer); } مثال 7 ستلاحظ استخدام تعابير مشابهة للتعبير thisp->pointer->pointer عند التعامل مع القوائم، وبالتالي يجب أن تفهم هذه التعابير، وهي بسيطة إذ يدل شكلها على الروابط المتبعة. الأشجار تُعد الأشجار هيكل بيانات شائع أيضًا، وهي في حقيقة الأمر قائمةٌ مترابطةٌ ذات فروع، والنوع الأكثر شيوعًا هو الشجرة الثنائية binary tree، التي تحتوي على عناصر تُدعى العقد "nodes" كما يلي: struct tree_node{ int data; struct tree_node *left_p, *right_p; }; تعمل الأشجار في علوم الحاسوب من الأعلى إلى الأسفل (لأسباب تاريخية لن نناقشها)، إذ توجد عقدة الجذر root أعلى الشجرة وتتفرع فروع هذه الشجرة في الأسفل. تُستبدل بيانات أعضاء الهيكل الخاصة بالعقد بقيمها في الشكل التالي والتي سنستخدمها لاحقًا. شكل 3 شجرة لن تجذب الأشجار انتباهك إذا كان اهتمامك الرئيس هو التعامل مع المحارف والتلاعب بها، ولكنها مهمة جدًا بالنسبة لمصمّمي كل من قواعد البيانات والمصرّفات والأدوات المعقدة الأخرى. تتميز الأشجار بميزة خاصة جدًا ألا وهي أنها مرتبة، فيمكن أن تدعم بكل سهولة خوارزميات البحث الثنائي، ومن الممكن دائمًا إضافة مزيدٍ من العقد الجديدة إلى الشجرة في الأماكن المناسبة، فالشجرة هيكل بيانات مفيدٌ ومرن. بالنظر إلى الشكل السابق، نلاحظ أن الشجرة مبنيّةٌ بحرص حتى تكون مهمة البحث عن قيمة ما في حقول البيانات من العقد مهمةً سهلةً، وإن فرضنا أننا نريد أن نعرف فيما إذا كانت القيمة x موجودةً في الشجرة عبر البحث عنها، نتبع الخوارزمية التالية: نبدأ بعقدة جذر الشجرة: إذا كانت الشجرة فارغة (لا تحتوي على عقد) إعادة القيمة "فشل البحث" إذا كانت القيمة التي نبحث عنها مساويةً إلى قيمة العقدة الحالية إعادة القيمة "نجاح البحث" إذا كانت القيمة في العقدة الحالية أكبر من القيمة التي نبحث عنها ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيسر فيما عدا ذلك، ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيمن إليك الخوارزمية بلغة سي: #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }tree[7]; /* * خوارزمية البحث ضمن الشجرة * تبحث عن القيمةفي الشجرة v * تُعيد مؤشر يشير إلى أول عقدة تحوي النتيجة * أو تُعيد القيمة 0 */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* لا يوجد أي شجرة متبقية ولم يُعثر على القيمة */ return(0); } main(){ /* بناء الشجرة يدويًا */ struct tree_node *tp, *root_p; int i; for(i = 0; i < 7; i++){ int j; j = i+1; tree[i].data = j; if(j == 2 || j == 6){ tree[i].left_p = &tree[i-1]; tree[i].right_p = &tree[i+1]; } } /* الجذر */ root_p = &tree[3]; root_p->left_p = &tree[1]; root_p->right_p = &tree[5]; /* حاول أن تبحث */ tp = t_search(root_p, 9); if(tp) printf("found at position %d\n", tp-tree); else printf("value not found\n"); exit(EXIT_SUCCESS); } مثال 8 يعمل المثال السابق بنجاح دون أخطاء، ومن الجدير بالذكر أنه يمكننا استخدام ذلك في جعل أي قيمة مدخلة إلى الشجرة تُخزن في مكانها الصحيح باستخدام خوارزمية البحث ذاتها، أي بإضافة شيفرة برمجية إضافية تحجز مساحة لقيمة جديدة باستخدام دالة malloc عندما لا تجد الخوارزمية القيمة، وتُضاف العقدة الجديدة في مكان مؤشر الفراغ null pointer الأول. من المعقد تحقيق ما سبق، وذلك بسبب مشكلة التعامل مع مؤشر العقدة الجذر، ونلجأ في هذه الحالة إلى مؤشر يشير إلى مؤشر آخر. اقرأ المثال التالي بانتباه، إذ أنه أحد أكثر الأمثلة تعقيدًا حتى اللحظة، وإذا استطعت فهمه فهذا يعني أنك تستطيع فهم الأغلبية الساحقة من برامج سي. #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }; /* * خوارزمية البحث ضمن شجرة * ابحث عن القيمة v ضمن الشجرة * أعد مؤشرًا إلى أول عقدة تحتوي على القيمة هذه * أعد القيمة 0 إن لم تجد نتيجة */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ printf("looking for %d, looking at %d\n", v, root->data); if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* value not found, no tree left */ return(0); } /* * أدخل عقدة ضمن شجرة * أعد 0 عند نجاح العملية أو * أعد 1 إن كانت القيمة موجودة في الشجرة * أعد 2 إن حصل خطأ في عملية حجز الذاكرة malloc error */ int t_insert(struct tree_node **root, int v){ while(*root){ if((*root)->data == v) return(1); if((*root)->data > v) root = &((*root)->left_p); else root = &((*root)->right_p); } /* value not found, no tree left */ if((*root = (struct tree_node *) malloc(sizeof (struct tree_node))) == 0) return(2); (*root)->data = v; (*root)->left_p = 0; (*root)->right_p = 0; return(0); } main(){ /* construct tree by hand */ struct tree_node *tp, *root_p = 0; int i; /* we ingore the return value of t_insert */ t_insert(&root_p, 4); t_insert(&root_p, 2); t_insert(&root_p, 6); t_insert(&root_p, 1); t_insert(&root_p, 3); t_insert(&root_p, 5); t_insert(&root_p, 7); /* try the search */ for(i = 1; i < 9; i++){ tp = t_search(root_p, i); if(tp) printf("%d found\n", i); else printf("%d not found\n", i); } exit(EXIT_SUCCESS); } مثال 9 تسمح لك الخوارزمية التالية بالمرور على الشجرة وزيارة جميع العُقد بالترتيب باستخدام التعاودية recursion، وهي أحد أكثر الأمثلة أناقةً، انظر إليها وحاول فهمها. void t_walk(struct tree_node *root_p){ if(root_p == 0) return; t_walk(root_p->left_p); printf("%d\n", root_p->data); t_walk(root_p->right_p); } مثال 10 ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C المقال السابق: التعامل مع المؤشرات Pointers في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى -
 تحدثنا في مقال سابق عن المؤشرات Pointers في لغة سي C وتعرفنا عليها بوصفها موضوعًا مهمًا للغاية في لغة سي، وسنكمل في هذا المقال الحديث عنها وكيفية التعامل معها مثل استخدامها ضمن التعابير التي تحوي عوامل الإسناد والزيادة والنقصان بالإضافة لأمثلة عملية، فإن لم تطلع على الفصل المذكور، فارجع له أولًا لارتباط المقالين مع بعضهما. مؤشرات الدوال من المفيد أن يكون لدينا إمكانية استخدام المؤشرات على الدوال، كما أن التصريح عن هذا النوع من المؤشرات سهلٌ عن طريق كتابته وكأنك تصرّح عن دالة على النحو التالي: int func(int a, float b); ومن ثم إضافة قوسين حول اسم الدالة والرمز * أمامه، مما يدل على أن هذا التصريح يعود لمؤشر. لاحظ أن التخلي عن القوسين يتسبب بالتصريح عن دالة تُعيد مؤشرًا حسب قوانين الأسبقية: /* int دالةٌ تعيد مؤشرًا إلى قيمة صحيحة */ int *func(int a, float b); /* مؤشر إلى دالة تعيد قيمة صحيحة int*/ int (*func)(int a, float b); حالما تحصل على المؤشر تستطيع إسناد العنوان إلى النوع المحدد للدالة باستخدام اسمها، إذ يُحوَّل اسم الدالة إلى عنوان في أي تعبير تحتويه بصورةٍ مشابهة لاسم المصفوفة، ويمكنك استدعاء الدالة في هذه الحالة باستخدام إحدى الطريقتين: (*func)(1,2); /* or */ func(1,2); تفضّل لغة سي المعيارية الطريقة الثانية، إليك مثالًا بسيطًا عنها: #include <stdio.h> #include <stdlib.h> void func(int); main(){ void (*fp)(int); fp = func; (*fp)(1); fp(2); exit(EXIT_SUCCESS); } void func(int arg){ printf("%d\n", arg); } [مثال 1] يمكنك توظيف مصفوفة من المؤشرات التي تشير إلى مصفوفات مختلفة إذا أردت كتابة آلةً محدودة الحالات finite state machine، وسيبدو التصريح عنها مماثلًا لما يلي: void (*fparr[])(int, float) = { /* المهيئات initializers*/ }; /* استدعاء أحد القيم */ fparr[5](1, 3.4); [مثال 17.5] ولكننا لن نتكلم عن هذه الطريقة. المؤشرات في التعابير بعد إدخال الأنواع المؤهّلة qualified types ومفهوم الأنواع غير المُكتملة incomplete types مع استخدام مؤشر الفراغ * void، أصبح هناك بعض القواعد المعقدة عن مزج المؤشرات وما هو مسموحٌ لك فعليًا في العمليات الحسابية معها. قد تستطيع تجاوز هذه القواعد دون أي مشكلات، لأن معظمها "بديهي" ولكننا سنتكلم عنها بغض النظر عن ذلك، ولا شكّ أنك سترغب بقراءة معيار لغة سي لتحرّي الدقة، لأن ما سيأتي هو تفسير بلغة بسيطة لما ورد في المعيار. لعلك لا تعلم بدقة ما الذي يقصده المعيار عندما يذكر مصطلحي الكائنات objects والأنواع غير المُكتملة incomplete types، فقد استخدمنا هذه المصطلحات حتى الآن بتهاون. يُعد الكائن جزءًا من البيانات المخزنة التي يمكن تفسير محتوياتها إلى قيمة، وبناءً على ذلك فالدالة ليست كائنًا؛ بينما يُعرف النوع غير المكتمل بكونه نوعًا معروفًا ذا اسم معروف لكن دون حجم محدّد بعد، ويمكنك الحصول على هذا النوع عن طريق وسيلتين، هما: التصريح عن مصفوفة دون تحديد حجمها: int x[]; ويجب توفير المزيد من المعلومات بخصوص هذه المصفوفة في التعريف لاحقًا، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. التصريح عن هيكل Structure أو اتحاد Union دون التعريف عن محتوياته، ويجب التعريف عن محتوياته لاحقًا في هذه الحالة، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. سنناقش المزيد عن الأنواع غير المكتملة لاحقًا. التحويلات يمكن تحويل المؤشرات التي تشير إلى void إلى مؤشرات تشير إلى أي كائن أو نوع غير مكتمل، وتحصل على قيمةٍ مساوية لقيمة المؤشر الأصل بعد تحويل مؤشر يشير إلى كائن أو نوع غير مكتمل إلى مؤشر من نوع * void: int i; int *ip; void *vp; ip = &i; vp = ip; ip = vp; if(ip != &i) printf("Compiler error\n"); يمكن تحويل مؤشر من نوع غير مؤهّل unqualified إلى مؤشر من نوع مؤهل، ولكن العكس غير ممكن، وستكون قيمة المؤشرين متكافئتين: int i; int *ip; const int *cpi; ip = &i; cpi = ip; /* مسموح*/ if(cpi != ip) printf("Compiler error\n"); ip = cpi; /* ممنوع */ لا يساوي مؤشر ثابت فارغ null pointer constant (سنتكلم عن هذا النوع لاحقًا) أيّ مؤشر يشير لأي كائن أو دالة. العمليات الحسابية يمكن للتعابير Expressions أن تجمع (أو تطرح، وهو ما يكافئ جمع قيم سالبة) أعدادًا صحيحةً إلى قيمة المؤشرات بغض النظر عن نوع الكائن الذي تشير إليه، وتكون النتيجة مماثلةً لنوع المؤشر؛ وفي حالة إضافة القيمة n، فسيشير المؤشر إلى العنصر الذي يلي العنصر السابق ضمن المصفوفة بمقدار n، والاستخدام الأكثر شيوعًا لهذه الميزة هي بإضافة 1 إلى المؤشر لتمريره على المصفوفة من بدايتها إلى نهايتها، إلا أن استخدام قيم مغايرة للقيمة 1 والطرح بدلًا من الجمع ممكن. نحصل على حالة طفحان overflow أو طفحان تجاوز الحد الأدنى underflow إذا كان المؤشر الناتج عن عملية الجمع يشير إلى ما يسبق المصفوفة أو ما يلي العنصر المعدوم الأخير للمصفوفة، وهذا يعني أن النتيجة غير مُعرّفة. يملك العنصر الأخير الزائد في المصفوفة عنوانًا صالحًا، ويؤكد المعيار لنا ذلك، إلا أنه ليس من المفترض أن تحاول الوصول إلى ذلك العنصر، وعنوانه موجودٌ للتأكد من وجوده لتجنُّب الوقوع في حالة طفحان. تعمّدنا استخدام الكلمة "تعبير" عوضًا عن قولنا "إضافة قيمة إلى المؤشر بنفسه"، إلا أنه يمكنك فعل ذلك شرط ألا يكون المؤشر مؤهلًا بالكلمة المفتاحية "const"، ويكافئ طبعًا استخدام عامل الزيادة "++" وعامل النقصان "--" جمع أو طرح واحد. يمكن طرح مؤشرين من أنواع متوافقة compatible types أو غير مؤهلة من بعضهما بعضًا، وتكون النتيجة من النوع "ptrdiff_t"، المعرّف في ملف الترويسة stddef.h، إلا أنه يجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها، أو على الأقل أن يشير واحدًا منها إلى ما بعد أو قبل المصفوفة، وإلا سنحصل على سلوك غير محدد، وتكون نتيجة عملية الطرح هي عدد العناصر التي تفصل المؤشرين ضمن المصفوفة. إليك المثال التالي: int x[100]; int *pi, *cpi = &x[99]; /* x إلى العنصر الأخير من ال cpi يشير*/ pi = x; if((cpi - pi) != 99) printf("Error\n"); pi = cpi; pi++; /* increment past end of x */ if((pi - cpi) != 1) printf("Error\n"); التعابير العلاقية تسمح لنا التعابير العلاقية بالمقارنة بين المؤشرات، لكن يمكنك فقط مقارنة: المؤشرات التي تشير لكائنات ذات أنواع متوافقة مع بعضها الآخر. المؤشرات التي تشير لأنواع غير مكتملة متوافقة مع بعضها الآخر. ولا يهم إذا كانت الأنواع المُشارة إليها مؤهلة أو غير مؤهلة. إذا تساوت قيم مؤشرين، فهذا يعني أن المؤشرين يشيران إلى الشيء ذاته، سواءٌ كان هذا الشيء كائنًا أو عنصرًا غير موجودًا خارج مصفوفة ما (راجع فقرة العمليات الحسابية أعلاه). تقدِّم العوامل العلاقية ">" و "=>" وغيرها النتيجة التي تتوقعها عند استخدامها مع المؤشرات ضمن نفس المصفوفة، وإذا كانت قيمة أحد المؤشرات أقل مقارنةً مع الآخر، فهذا يعني أنه يشير لقيمةٍ أقرب لمقدمة المصفوفة (العنصر ذو الدليل index الأقل). يمكن إسناد مؤشر فارغ ثابت إلى مؤشر آخر، وسيكون متساوي مع مؤشر فارغ ثابت آخر إذا فحصناهما باستخدام عامل المقارنة، بينما لن يتساوى مؤشر فارغ ثابت أو غير ثابت عند مقارنتهما مع أي مؤشر آخر يشير لشيءٍ ما. الإسناد يمكنك استخدام المؤشرات مع عوامل الإسناد، شرط أن يستوفي الاستخدام الشروط التالية: يجب أن يكون الجانب الأيسر من عامل الإسناد مؤشرًا، وأن يكون الجانب الأيمن منه مؤشرًا فارغًا ثابتًا. يجب أن يكون مُعاملٌ من المعاملات مؤشرًا يشير إلى كائن أو نوع غير مُكتمل، والمعامل الآخر مؤشرًا إلى الفراغ "void"، سواءٌ كان مؤهلًا أو لا. يُعدّ المُعاملان مؤشرين لأنواع متوافقة سواءٌ كانت مؤهلةً أم لا. يجب أن يكون للنوع المُشار إليه في الحالتين الأخيرتين على الجانب الأيسر من عامل الإسناد النوع ذاته من المؤهلات على الأقل، والموافق لمؤهل النوع الواقع على الجانب الأيمن من عامل الإسناد، أو أكثر من مؤهل مماثل. يمكنك إذًا إسناد مؤشر يشير إلى قيمة صحيحة "int" إلى مؤشر يشير إلى قيمة من نوع عدد صحيح ثابت "const int" (مؤهلات النوع الأيسر تزيد عن مؤهلات النوع الأيمن) ولكن لا يمكنك إسناد مؤشر يشير إلى "const int" إلى مؤشر يشير إلى "int"، والأمر منطقي جدًا إذا أخذت لحظةً للتفكير به. يمكن استخدام العاملين "=+" و "=-" مع المؤشرات طالما أن الجانب الأيسر من العامل مؤشر يشير إلى كائن، والجانب الأيمن من العامل تعبير ينتج قيمةً صحيحة integral، وتوضح قوانين العمليات الحسابية في الفقرات السابقة ما سيحصل في هذه الحالة. العامل الشرطي وضّحنا سابقًا سلوك العامل الشرطي conditional operator عند استخدامه مع المؤشرات. المصفوفات وعامل & والدوال ذكرنا عدّة مرات أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول، وقلنا أن الاستثناء الوحيد هو عند استخدام اسم المصفوفة مع عامل "sizeof"، وهو عاملٌ مهمٌ إذا أردت استخدام الدالة "malloc"، إلا أن هناك استثناءً آخر، ألا وهو عندما يكون اسم المصفوفة مُعاملًا لعامل "&" (عنوان العامل)، إذ يُحوّل اسم المصفوفة هنا إلى عنوان كامل المصفوفة بدلًا من عنوان عنصرها الأول عادةً، لكن ما الفرق؟ لعلك تعتقد أن العنوانين متماثلان، إلا أن الفرق هو نوعهما، فبالنسبة لمصفوفةٍ تحتوي "n" عنصر بنوع "T"، يكون عنوان عنصرها الأول من نوع "مؤشر إلى T"، بينما يكون عنوان كامل المصفوفة من نوع " مؤشر إلى مصفوفة من n عنصر من نوع T"، وهو مختلف جدًا. إليك مثالًا عن ذلك: int ar[10]; int *ip; int (*ar10i)[10]; /* مؤشر لمصفوفة من 10 عناصر صحيحة */ ip = ar; /* عنوان العنصر الأول */ ip = &ar[0]; /* عنوان العنصر الأول */ ar10i = &ar; /* عنوان كامل المصفوفة */ أين تُستخدم المؤشرات إلى المصفوفات؟ في الحقيقة ليس غالبًا، إلا أننا نعلم أن التصريح عن مصفوفة متعددة الأبعاد هو في الحقيقة تصريح عن مصفوفة مصفوفات. إليك مثالًا يستخدم هذا المفهوم (إلا أن فهم ما يفعل يقع على عاتقك)، وليس من الشائع استخدام هذه الطريقة: int ar2d[5][4]; int (*ar4i)[4]; /* مؤشر إلى مصفوفة من 4 أعداد صحيحة */ for(ar4i= ar2d; ar4i < &(ar2d[5]); ar4i++) (*ar4i)[2] = 0; /* ar2d[n][2] = 0 */ ما قد يثير اهتمامك أكثر من عناوين المصفوفات هو ما الذي قد يحدث عندما نصرِّح عن دالة تأخذ مصفوفةً في أحد وسطائها. بالنظر إلى أن المصفوفة تحوّل إلى عنوان عنصرها الأول فحتى لو حاولت تمرير مصفوفة إلى دالة باستخدام اسم المصفوفة وسيطًا، فسينتهي بك الأمر بتمرير مؤشر إلى عنصر المصفوفة الأول. لكن ماذا لو صرّحت عن الدالة بكونها تأخذ وسيطًا من نوع "مصفوفة من نوع ما" على النحو التالي: void f(int ar[10]); ما الذي يحدث في هذه الحالة؟ قد تفاجئك الإجابة هنا، إذ أن المصرّف ينظر إلى السطر السابق ويقول لنفسه "سيكون هذا مؤشرًا لهذه المصفوفة" ويعيد كتابة الوسيط على أنه من نوع مؤشر، ووفقًا لذلك نجد أن التصريحات الثلاثة التالية متكافئة: void f(int ar[10]); void f(int *ar); void f(int ar[]); /* !حجم المصفوفة هنا لا علاقة له */ قد تضع يدك على رأسك بعد هذه المعلومة، لكن تمهّل! إليك بعض الأسئلة للتهدئة من غضبك وإحباطك: لم كانت المعلومة السابقة منطقية؟ لماذا تعمل التعابير بالصياغة [ar[5 أو أي صياغةٍ أخرى ضمن التصريح عن دالة، ثم داخل الدالة كما هو متوقعٌ منها؟ فكّر في الأسئلة السابقة، وستفهم استخدام المؤشرات مع المصفوفات بصورةٍ ممتازة عندما تتوصل لإجابة ترضيك. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C المقال السابق: عامل sizeof وحجز مساحات التخزين في لغة سي C المؤشرات Pointers في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C
تحدثنا في مقال سابق عن المؤشرات Pointers في لغة سي C وتعرفنا عليها بوصفها موضوعًا مهمًا للغاية في لغة سي، وسنكمل في هذا المقال الحديث عنها وكيفية التعامل معها مثل استخدامها ضمن التعابير التي تحوي عوامل الإسناد والزيادة والنقصان بالإضافة لأمثلة عملية، فإن لم تطلع على الفصل المذكور، فارجع له أولًا لارتباط المقالين مع بعضهما. مؤشرات الدوال من المفيد أن يكون لدينا إمكانية استخدام المؤشرات على الدوال، كما أن التصريح عن هذا النوع من المؤشرات سهلٌ عن طريق كتابته وكأنك تصرّح عن دالة على النحو التالي: int func(int a, float b); ومن ثم إضافة قوسين حول اسم الدالة والرمز * أمامه، مما يدل على أن هذا التصريح يعود لمؤشر. لاحظ أن التخلي عن القوسين يتسبب بالتصريح عن دالة تُعيد مؤشرًا حسب قوانين الأسبقية: /* int دالةٌ تعيد مؤشرًا إلى قيمة صحيحة */ int *func(int a, float b); /* مؤشر إلى دالة تعيد قيمة صحيحة int*/ int (*func)(int a, float b); حالما تحصل على المؤشر تستطيع إسناد العنوان إلى النوع المحدد للدالة باستخدام اسمها، إذ يُحوَّل اسم الدالة إلى عنوان في أي تعبير تحتويه بصورةٍ مشابهة لاسم المصفوفة، ويمكنك استدعاء الدالة في هذه الحالة باستخدام إحدى الطريقتين: (*func)(1,2); /* or */ func(1,2); تفضّل لغة سي المعيارية الطريقة الثانية، إليك مثالًا بسيطًا عنها: #include <stdio.h> #include <stdlib.h> void func(int); main(){ void (*fp)(int); fp = func; (*fp)(1); fp(2); exit(EXIT_SUCCESS); } void func(int arg){ printf("%d\n", arg); } [مثال 1] يمكنك توظيف مصفوفة من المؤشرات التي تشير إلى مصفوفات مختلفة إذا أردت كتابة آلةً محدودة الحالات finite state machine، وسيبدو التصريح عنها مماثلًا لما يلي: void (*fparr[])(int, float) = { /* المهيئات initializers*/ }; /* استدعاء أحد القيم */ fparr[5](1, 3.4); [مثال 17.5] ولكننا لن نتكلم عن هذه الطريقة. المؤشرات في التعابير بعد إدخال الأنواع المؤهّلة qualified types ومفهوم الأنواع غير المُكتملة incomplete types مع استخدام مؤشر الفراغ * void، أصبح هناك بعض القواعد المعقدة عن مزج المؤشرات وما هو مسموحٌ لك فعليًا في العمليات الحسابية معها. قد تستطيع تجاوز هذه القواعد دون أي مشكلات، لأن معظمها "بديهي" ولكننا سنتكلم عنها بغض النظر عن ذلك، ولا شكّ أنك سترغب بقراءة معيار لغة سي لتحرّي الدقة، لأن ما سيأتي هو تفسير بلغة بسيطة لما ورد في المعيار. لعلك لا تعلم بدقة ما الذي يقصده المعيار عندما يذكر مصطلحي الكائنات objects والأنواع غير المُكتملة incomplete types، فقد استخدمنا هذه المصطلحات حتى الآن بتهاون. يُعد الكائن جزءًا من البيانات المخزنة التي يمكن تفسير محتوياتها إلى قيمة، وبناءً على ذلك فالدالة ليست كائنًا؛ بينما يُعرف النوع غير المكتمل بكونه نوعًا معروفًا ذا اسم معروف لكن دون حجم محدّد بعد، ويمكنك الحصول على هذا النوع عن طريق وسيلتين، هما: التصريح عن مصفوفة دون تحديد حجمها: int x[]; ويجب توفير المزيد من المعلومات بخصوص هذه المصفوفة في التعريف لاحقًا، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. التصريح عن هيكل Structure أو اتحاد Union دون التعريف عن محتوياته، ويجب التعريف عن محتوياته لاحقًا في هذه الحالة، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. سنناقش المزيد عن الأنواع غير المكتملة لاحقًا. التحويلات يمكن تحويل المؤشرات التي تشير إلى void إلى مؤشرات تشير إلى أي كائن أو نوع غير مكتمل، وتحصل على قيمةٍ مساوية لقيمة المؤشر الأصل بعد تحويل مؤشر يشير إلى كائن أو نوع غير مكتمل إلى مؤشر من نوع * void: int i; int *ip; void *vp; ip = &i; vp = ip; ip = vp; if(ip != &i) printf("Compiler error\n"); يمكن تحويل مؤشر من نوع غير مؤهّل unqualified إلى مؤشر من نوع مؤهل، ولكن العكس غير ممكن، وستكون قيمة المؤشرين متكافئتين: int i; int *ip; const int *cpi; ip = &i; cpi = ip; /* مسموح*/ if(cpi != ip) printf("Compiler error\n"); ip = cpi; /* ممنوع */ لا يساوي مؤشر ثابت فارغ null pointer constant (سنتكلم عن هذا النوع لاحقًا) أيّ مؤشر يشير لأي كائن أو دالة. العمليات الحسابية يمكن للتعابير Expressions أن تجمع (أو تطرح، وهو ما يكافئ جمع قيم سالبة) أعدادًا صحيحةً إلى قيمة المؤشرات بغض النظر عن نوع الكائن الذي تشير إليه، وتكون النتيجة مماثلةً لنوع المؤشر؛ وفي حالة إضافة القيمة n، فسيشير المؤشر إلى العنصر الذي يلي العنصر السابق ضمن المصفوفة بمقدار n، والاستخدام الأكثر شيوعًا لهذه الميزة هي بإضافة 1 إلى المؤشر لتمريره على المصفوفة من بدايتها إلى نهايتها، إلا أن استخدام قيم مغايرة للقيمة 1 والطرح بدلًا من الجمع ممكن. نحصل على حالة طفحان overflow أو طفحان تجاوز الحد الأدنى underflow إذا كان المؤشر الناتج عن عملية الجمع يشير إلى ما يسبق المصفوفة أو ما يلي العنصر المعدوم الأخير للمصفوفة، وهذا يعني أن النتيجة غير مُعرّفة. يملك العنصر الأخير الزائد في المصفوفة عنوانًا صالحًا، ويؤكد المعيار لنا ذلك، إلا أنه ليس من المفترض أن تحاول الوصول إلى ذلك العنصر، وعنوانه موجودٌ للتأكد من وجوده لتجنُّب الوقوع في حالة طفحان. تعمّدنا استخدام الكلمة "تعبير" عوضًا عن قولنا "إضافة قيمة إلى المؤشر بنفسه"، إلا أنه يمكنك فعل ذلك شرط ألا يكون المؤشر مؤهلًا بالكلمة المفتاحية "const"، ويكافئ طبعًا استخدام عامل الزيادة "++" وعامل النقصان "--" جمع أو طرح واحد. يمكن طرح مؤشرين من أنواع متوافقة compatible types أو غير مؤهلة من بعضهما بعضًا، وتكون النتيجة من النوع "ptrdiff_t"، المعرّف في ملف الترويسة stddef.h، إلا أنه يجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها، أو على الأقل أن يشير واحدًا منها إلى ما بعد أو قبل المصفوفة، وإلا سنحصل على سلوك غير محدد، وتكون نتيجة عملية الطرح هي عدد العناصر التي تفصل المؤشرين ضمن المصفوفة. إليك المثال التالي: int x[100]; int *pi, *cpi = &x[99]; /* x إلى العنصر الأخير من ال cpi يشير*/ pi = x; if((cpi - pi) != 99) printf("Error\n"); pi = cpi; pi++; /* increment past end of x */ if((pi - cpi) != 1) printf("Error\n"); التعابير العلاقية تسمح لنا التعابير العلاقية بالمقارنة بين المؤشرات، لكن يمكنك فقط مقارنة: المؤشرات التي تشير لكائنات ذات أنواع متوافقة مع بعضها الآخر. المؤشرات التي تشير لأنواع غير مكتملة متوافقة مع بعضها الآخر. ولا يهم إذا كانت الأنواع المُشارة إليها مؤهلة أو غير مؤهلة. إذا تساوت قيم مؤشرين، فهذا يعني أن المؤشرين يشيران إلى الشيء ذاته، سواءٌ كان هذا الشيء كائنًا أو عنصرًا غير موجودًا خارج مصفوفة ما (راجع فقرة العمليات الحسابية أعلاه). تقدِّم العوامل العلاقية ">" و "=>" وغيرها النتيجة التي تتوقعها عند استخدامها مع المؤشرات ضمن نفس المصفوفة، وإذا كانت قيمة أحد المؤشرات أقل مقارنةً مع الآخر، فهذا يعني أنه يشير لقيمةٍ أقرب لمقدمة المصفوفة (العنصر ذو الدليل index الأقل). يمكن إسناد مؤشر فارغ ثابت إلى مؤشر آخر، وسيكون متساوي مع مؤشر فارغ ثابت آخر إذا فحصناهما باستخدام عامل المقارنة، بينما لن يتساوى مؤشر فارغ ثابت أو غير ثابت عند مقارنتهما مع أي مؤشر آخر يشير لشيءٍ ما. الإسناد يمكنك استخدام المؤشرات مع عوامل الإسناد، شرط أن يستوفي الاستخدام الشروط التالية: يجب أن يكون الجانب الأيسر من عامل الإسناد مؤشرًا، وأن يكون الجانب الأيمن منه مؤشرًا فارغًا ثابتًا. يجب أن يكون مُعاملٌ من المعاملات مؤشرًا يشير إلى كائن أو نوع غير مُكتمل، والمعامل الآخر مؤشرًا إلى الفراغ "void"، سواءٌ كان مؤهلًا أو لا. يُعدّ المُعاملان مؤشرين لأنواع متوافقة سواءٌ كانت مؤهلةً أم لا. يجب أن يكون للنوع المُشار إليه في الحالتين الأخيرتين على الجانب الأيسر من عامل الإسناد النوع ذاته من المؤهلات على الأقل، والموافق لمؤهل النوع الواقع على الجانب الأيمن من عامل الإسناد، أو أكثر من مؤهل مماثل. يمكنك إذًا إسناد مؤشر يشير إلى قيمة صحيحة "int" إلى مؤشر يشير إلى قيمة من نوع عدد صحيح ثابت "const int" (مؤهلات النوع الأيسر تزيد عن مؤهلات النوع الأيمن) ولكن لا يمكنك إسناد مؤشر يشير إلى "const int" إلى مؤشر يشير إلى "int"، والأمر منطقي جدًا إذا أخذت لحظةً للتفكير به. يمكن استخدام العاملين "=+" و "=-" مع المؤشرات طالما أن الجانب الأيسر من العامل مؤشر يشير إلى كائن، والجانب الأيمن من العامل تعبير ينتج قيمةً صحيحة integral، وتوضح قوانين العمليات الحسابية في الفقرات السابقة ما سيحصل في هذه الحالة. العامل الشرطي وضّحنا سابقًا سلوك العامل الشرطي conditional operator عند استخدامه مع المؤشرات. المصفوفات وعامل & والدوال ذكرنا عدّة مرات أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول، وقلنا أن الاستثناء الوحيد هو عند استخدام اسم المصفوفة مع عامل "sizeof"، وهو عاملٌ مهمٌ إذا أردت استخدام الدالة "malloc"، إلا أن هناك استثناءً آخر، ألا وهو عندما يكون اسم المصفوفة مُعاملًا لعامل "&" (عنوان العامل)، إذ يُحوّل اسم المصفوفة هنا إلى عنوان كامل المصفوفة بدلًا من عنوان عنصرها الأول عادةً، لكن ما الفرق؟ لعلك تعتقد أن العنوانين متماثلان، إلا أن الفرق هو نوعهما، فبالنسبة لمصفوفةٍ تحتوي "n" عنصر بنوع "T"، يكون عنوان عنصرها الأول من نوع "مؤشر إلى T"، بينما يكون عنوان كامل المصفوفة من نوع " مؤشر إلى مصفوفة من n عنصر من نوع T"، وهو مختلف جدًا. إليك مثالًا عن ذلك: int ar[10]; int *ip; int (*ar10i)[10]; /* مؤشر لمصفوفة من 10 عناصر صحيحة */ ip = ar; /* عنوان العنصر الأول */ ip = &ar[0]; /* عنوان العنصر الأول */ ar10i = &ar; /* عنوان كامل المصفوفة */ أين تُستخدم المؤشرات إلى المصفوفات؟ في الحقيقة ليس غالبًا، إلا أننا نعلم أن التصريح عن مصفوفة متعددة الأبعاد هو في الحقيقة تصريح عن مصفوفة مصفوفات. إليك مثالًا يستخدم هذا المفهوم (إلا أن فهم ما يفعل يقع على عاتقك)، وليس من الشائع استخدام هذه الطريقة: int ar2d[5][4]; int (*ar4i)[4]; /* مؤشر إلى مصفوفة من 4 أعداد صحيحة */ for(ar4i= ar2d; ar4i < &(ar2d[5]); ar4i++) (*ar4i)[2] = 0; /* ar2d[n][2] = 0 */ ما قد يثير اهتمامك أكثر من عناوين المصفوفات هو ما الذي قد يحدث عندما نصرِّح عن دالة تأخذ مصفوفةً في أحد وسطائها. بالنظر إلى أن المصفوفة تحوّل إلى عنوان عنصرها الأول فحتى لو حاولت تمرير مصفوفة إلى دالة باستخدام اسم المصفوفة وسيطًا، فسينتهي بك الأمر بتمرير مؤشر إلى عنصر المصفوفة الأول. لكن ماذا لو صرّحت عن الدالة بكونها تأخذ وسيطًا من نوع "مصفوفة من نوع ما" على النحو التالي: void f(int ar[10]); ما الذي يحدث في هذه الحالة؟ قد تفاجئك الإجابة هنا، إذ أن المصرّف ينظر إلى السطر السابق ويقول لنفسه "سيكون هذا مؤشرًا لهذه المصفوفة" ويعيد كتابة الوسيط على أنه من نوع مؤشر، ووفقًا لذلك نجد أن التصريحات الثلاثة التالية متكافئة: void f(int ar[10]); void f(int *ar); void f(int ar[]); /* !حجم المصفوفة هنا لا علاقة له */ قد تضع يدك على رأسك بعد هذه المعلومة، لكن تمهّل! إليك بعض الأسئلة للتهدئة من غضبك وإحباطك: لم كانت المعلومة السابقة منطقية؟ لماذا تعمل التعابير بالصياغة [ar[5 أو أي صياغةٍ أخرى ضمن التصريح عن دالة، ثم داخل الدالة كما هو متوقعٌ منها؟ فكّر في الأسئلة السابقة، وستفهم استخدام المؤشرات مع المصفوفات بصورةٍ ممتازة عندما تتوصل لإجابة ترضيك. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C المقال السابق: عامل sizeof وحجز مساحات التخزين في لغة سي C المؤشرات Pointers في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C -
 يُعيد العامل "sizeof" حجم المُعامل operator بالبايتات، وتعتمد نتيجة العامل "sizeof" بكونها عددًا صحيحًا عديم الإشارة "unsigned int" أو عددًا كبيرًا عديم الإشارة "unsigned long" على التطبيق implementation، وهذا هو السبب في تفادينا لأي مشكلات في المثال السابق (المقال السابق) عند التصريح عن دالة malloc على الرغم من عدم تزويد التصريح بأي تفاصيل عن معاملاتها؛ إذ يجب استخدام ملف الترويسة stdlib.h عوضًا عن ذلك عادةً للتصريح عن malloc على النحو الصحيح. إليك المثال ذاته ولكن بتركيز على جعله قابلًا للتنقل portable عبر مختلف الأجهزة: #include <stdlib.h> /* malloc() يتضمن ملف الترويسة تصريحًا عن */ float *fp; fp = (float *)malloc(sizeof(float)); يجب أن يُكتب معامل sizeof داخل قوسين إذا كان فقط اسمًا لنوع بيانات (وهي الحالة في مثالنا السابق)، بينما يمكنك التخلي عن القوسين إذا كنت تستخدم اسم كائن بيانات عوضًا عن ذلك، ولكن هذه الحالة نادرة الحدوث. #include <stdlib.h> int *ip, ar[100]; ip = (int *)malloc(sizeof ar); لدينا في المثال السابق مصفوفة باسم ar مكونةٌ من 100 عنصر من نوع عدد صحيح int، ويشير ip إلى مساحة التخزين الخاصة بهذه المصفوفة (مساحةٌ لمئة قيمة من نوع int) بعد استدعاء malloc (بفرض أن الاستدعاء كان ناجحًا). تعدّ char (محرف وهي اختصارٌ إلى character) وحدة القياس الأساسية للتخزين في لغة سي، وتساوي بايتًا واحدًا، جرّب نتيجة التعليمة الآتية: sizeof(char) وبناءً على ذلك، يمكنك حجز مساحة لعشرة قيم من نوع char على النحو التالي: malloc(10) ولحجز مساحة لمصفوفة بحجم عشرة قيم من نوع int، نكتب: malloc(sizeof(int[10])) تُعيد الدالة malloc مؤشرًا إلى الفراغ null pointer في حال لم تتوفر المساحة الكافية للإشارة إلى خطأ ما. يحتوي ملف الترويسة stdio.h ثابتًا معرّفًا باسم NULL، والذي يُستخدم عادةً للتحقق من القيمة المُعادة من الدالة malloc ودوال أخرى من المكتبة القياسية، وتُعد القيمة 0 أو (void *)0 مساويةً لهذا الثابت ويمكن استخدامها. إليك المثال التالي لتوضيح استخدام الدالة malloc، إذ يقرأ البرنامج في المثال سلاسلًا نصيةً بعدد MAXSTRING من الدخل، ثمّ يرتب السلاسل النصية أبجديًّا باستخدام الدالة strcmp. يُشار إلى نهاية السلسلة النصية بمحرف الهروب escape character التالي n\، وتُرتَّب السلاسل باستخدام مصفوفة من المؤشرات تُشير إلى السلسلة النصية وتبديل مواضع المؤشرات حتى الوصول إلى الترتيب الصحيح، مما يجنُّبنا عناء نسخ السلاسل النصية ويحسّن من سرعة تنفيذ البرنامج ويحد من هدر الموارد إلى حدٍّ ما. استخدمنا في الإصدار الأول من المثال مصفوفةً ثابتة الحجم، ثم استخدمنا في الإصدار الثاني حجز المساحة باستخدام malloc لكل سلسلة نصية عند وقت التشغيل run-time، بينما بقيت مصفوفة المؤشرات -لسوء الحظ- ثابتة الحجم، إلا أنه يمكننا تطبيق حلّ أفضل باستخدام قائمة مترابطة Linked list، أو أي هيكل بيانات مشابه لتخزين المؤشرات دون الحاجة لاستخدام المصفوفات ثابتة الحجم إطلاقًا، ولكننا لم نتكلم عن هياكل البيانات بعد. إليك ما يبدو عليه هيكل برنامجنا: while(number of strings read < MAXSTRING && input still remains){ read next string; } sort array of pointers; print array of pointers; exit; سنستخدم بعض الدوال في برنامجنا أيضًا: char *next_string(char *destination) تقرأ الدالة السابقة سطرًا من المحارف بحيث ينتهي السطر بالمحرف n\ من دخل البرنامج، وتُسند المحارف البالغ عددها MAXLEN-1 إلى المصفوفة المُشار إليها بالمصفوفة الهدف destination، إذ يمثّل MAXLEN قيمةً ثابتةً لطول السلسلة النصية العظمى. إذا كان المحرف الأول المقروء هو EOF (أي نهاية الملف)، أعِد مؤشرًا إلى الفراغ، وفيما عدا ذلك أعِد عنوان بداية السلسلة النصية (الهدف destination)، بحيث تحتوي السلسلة النصية الهدف دائمًا على المحرف n\، الذي يشير إلى نهاية السلسلة. void sort_arr(const char *p_array[]) تمثل المصفوفة p_array[] مصفوفة المؤشرات التي تشير للمحارف، ويمكن أن تكون المصفوفة كبيرة الحجم ولكن يُشار إلى نهايتها بأول عنصر يحتوي على مؤشر فراغ null pointer. ترتّب الدالة sort_arr المؤشرات بحيث تُشير إلى السلاسل النصية المرتبة أبجديًا عند اجتياز مصفوفة المؤشرات بناءً على دليل index المؤشر. void print_arr(const char *p_array[]) تُشابه دالة print_arr الدالة sort_arr ولكنها تطبع السلاسل النصية حسب ترتيبها الأبجدي. تذكّر أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول في أي تعبير يحتوي على اسمها، ومن شأن ذلك أن يساعدك في فهم الأمثلة على نحوٍ أفضل؛ والأمر مماثلٌ بالنسبة لمصفوفة ثنائية البعد، مثل مصفوفة strings في المثال التالي، فنوع التعبير strings[1][2] هو char، ولكن للعنصر strings[1] نوع "مصفوفة من char"، ولذلك يُحوَّل اسم المصفوفة إلى عنوان العنصر الأول ونحصل على &strings[1][0]. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(char *destination); main(){ /* نصرح عن المصفوفة مع إضافة عنصر فارغ في نهايتها */ char *p_array[MAXSTRING+1]; /* مصفوفة تخزين السلاسل النصية */ char strings[MAXSTRING][MAXLEN]; /* عدد السلاسل النصية المقروءة */ int nstrings; nstrings = 0; while(nstrings < MAXSTRING && next_string(strings[nstrings]) != 0){ p_array[nstrings] = strings[nstrings]; nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(char *destination){ char *cp; int c; cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); return(destination); } [مثال 1] إعادة الدالة next_string لمؤشر ليس من قبيل المصادفة، إذ أصبح بإمكاننا الآن الاستغناء عن استخدام مصفوفة السلاسل النصية واستخدام next_string لحجز مساحة التخزين الموافقة لها. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(void); main(){ char *p_array[MAXSTRING+1]; int nstrings; nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 2] وأخيرًا إليك المثال كاملًا مع استخدام مصفوفة p_array للدالة malloc، ولاحظ إعادة كتابة معظم أدلة المصفوفة لتستخدم ترميز المؤشرات. إذا كنت تشعر بالإرهاق من جميع المعلومات التي قرأتها فتجاوز المثال التالي، فهو صعبٌ بعض الشيء. شرح المثال: تعني char **p مؤشرًا يشير إلى المؤشر الذي يشير إلى محرف، ويجد معظم مبرمجو لغة سي هذه الطريقة في استخدام المؤشرات صعبة الفهم. #include <stdio.h> #include <stdlib.hi> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /*الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char **p_array); void sort_arr(const char **p_array); char *next_string(void); main(){ char **p_array; int nstrings; /* عدد السلاسل النصية المقروءة */ p_array = (char **)malloc( sizeof(char *[MAXSTRING+1])); if(p_array == 0){ printf("No memory\n"); exit(EXIT_FAILURE); } nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char **p_array){ while(*p_array) printf("%s\n", *p_array++); } void sort_arr(const char **p_array){ const char **lo_p, **hi_p, *tmp; for(lo_p = p_array; *lo_p != 0 && *(lo_p+1) != 0; lo_p++){ for(hi_p = lo_p+1; *hi_p != 0; hi_p++){ if(strcmp(*hi_p, *lo_p) >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = *hi_p; *hi_p = *lo_p; *lo_p = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 3] سنستعرض مثالًا آخر لتوضيح استخدام دالة malloc وإمكاناتها في التعامل مع السلاسل النصية الطويلة؛ إذ يقرأ المثال السلاسل النصية من الدخل ويبحث عن محرف سطر جديد لتحديد نهاية السلسلة النصية (أي n\)، ثم يطبع السلسلة النصية إلى الخرج، ويتوقف البرنامج عن العمل عندما يصادف محرف نهاية الملف EOF. تُسنَد المحارف إلى مصفوفة، ويُدلّ على نهاية المصفوفة -كما هو معتاد- بالقيمة صفر، مع ملاحظة أن محرف السطر الجديد لا يُخزَّن بالمصفوفة بل يُستخدم فقط لتحديد سطر الدخل الواجب طباعته للخرج. لا يعلم البرنامج طول السلسلة النصية تحديدًا، ولذلك يبدأ بفحص كل عشرة محارف وحجز المساحة الخاصة بهم (الثابت GROW_BY). تُستدعى الدالة malloc في حال كانت السلسلة النصية أطول من عشرة محارف لحجز المساحة للسلسلة النصية وإضافة عشرة محارف أخرى، ثم تُنسخ المحارف الحالية للمساحة الجديدة وتُستخدم من البرنامج وتُحرّر المساحة القديمة. تُستخدم الدالة free لتحرير المساحة القديمة المحجوزة من malloc مسبقًا، إذ يجب عليك تحرير المساحة غير المُستخدمة بعد الآن دوريًا قبل أن تتراكم، واستخدام free يحرّر المساحة ويسمح بإعادة استخدامها لاحقًا. يستخدم البرنامج الدالة fprintf لعرض أي أخطاء، وهي دالةٌ مشابهة للدالة printf التي اعتدنا على رؤيتها، والفرق الوحيد بينهما هو أن الدالة fprintf تأخذ وسيطًا إضافيًّا يدل على وسيط الخرج الذي سيُطبع إليه، وهناك ثابتان لهذا الغرض معرّفان في ملف الترويسة stdio.h؛ إذ أن استخدام الثابت الأول stdout يعني استخدام خرج البرنامج القياسي، بينما يشير استخدام الثابت الثاني stderr إلى مجرى أخطاء البرنامج القياسي standard error stream، وقد يكون وسيطا الخرج متماثلين في بعض الأنظمة إلا أن بعض الأنظمة الأخرى تفصل بين الاثنين. #include <stdio.h> #include <stdlib.h> #include <string.h> #define GROW_BY 10 /* يزداد حجم السلسلة النصية كل مرة بمقدار 10 */ main(){ char *str_p, *next_p, *tmp_p; int ch, need, chars_read; if(GROW_BY < 2){ fprintf(stderr, "Growth constant too small\n"); exit(EXIT_FAILURE); } str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; chars_read = 0; while((ch = getchar()) != EOF){ /* (*) */ if(ch == '\n'){ /* الإشارة إلى نهاية السطر */ *next_p = 0; printf("%s\n", str_p); free(str_p); chars_read = 0; str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; continue; } /* * التحقق من وصولنا إلى نهاية المساحة المحجوزة */ if(chars_read == GROW_BY-1){ *next_p = 0; /* للدلالة على نهاية السلسلة النصية */ /* نستخدم الطرح بين المؤشرات لإيجاد طول السلسلة النصية الحالية*/ need = next_p - str_p +1; tmp_p = (char *)malloc(need+GROW_BY); if(tmp_p == NULL){ fprintf(stderr,"No more store\n"); exit(EXIT_FAILURE); } /* ننسخ السلسلة النصية باستخدام دالة المكتبة */ strcpy(tmp_p, str_p); free(str_p); str_p = tmp_p; /* * next_p إعادة ضبط */ next_p = str_p + need-1; chars_read = 0; } /* * إسناد المحرف إلى نهاية السلسلة النصية */ *next_p++ = ch; chars_read++; } /* * عند وصولنا إلى نهاية الملف * هل توجد محارف غير مطبوعة؟ */ if(str_p - next_p){ *next_p = 0; fprintf(stderr,"Incomplete last line\n"); printf("%s\n", str_p); } exit(EXIT_SUCCESS); } [مثال 4] (*) تُعاد الحلقة في الموضع المذكور عند كل سطر، وهناك مساحةٌ للعنصر صفر في نهاية السلسلة النصية دائمًا، لأننا نتحقق من أصغر من 2 وهو ما تحققنا منه سابقًا GROW_BY ذلك في الشرط التالي إلا في حال كان. قد لا يكون برنامجنا السابق مثالًا واقعيًا عن التعامل مع السلاسل النصية الطويلة، إذ يتطلب حجم التخزين الأعظمي ضعف الحجم المطلوب لأطول سلسلة نصية، ولكنه برنامج يعمل صحيحًا بغض النظر، إلا أنه يكلفنا الكثير بخصوص الموارد بنسخ السلاسل النصية ويمكن حل المشكلتين عن طريق استخدام دالة realloc. نستطيع استخدام القوائم المترابطة لطريقة أكثر تعقيدًا، مع استخدام الهياكل Structures التي سنتكلم عنها لاحقًا، إلا أن هذه الطريقة تأتي أيضًا ببعض المشكلات لأن دوال المكتبة القياسية لن تعمل عند استخدام طريقة مغايرة لتخزين السلاسل النصية. ما الأشياء التي لا يستطيع العامل sizeof فعلها؟ يرتكب المبتدئون غالبًا الخطأ التالي عند استخدام العامل sizeof: #include <stdio.h> #include <stdlib.h> const char arr[] = "hello"; const char *cp = arr; main(){ printf("Size of arr %lu\n", (unsigned long) sizeof(arr)); printf("Size of *cp %lu\n", (unsigned long) sizeof(*cp)); exit(EXIT_SUCCESS); } [مثال 5] لن تكون الأرقام ذاتها عند الطباعة، إذ سيعرف أولًا حجم arr بكونها 6 بصورةٍ صحيحة (خمسة محارف متبوعةٍ بمحرف الفراغ null)، بينما ستطبع التعليمة الثانية -على جميع الأنظمة- القيمة 1، لأن المؤشر cp* من نوع const char ذو الحجم 1 بايت، بينما arr مختلفةٌ فهي مصفوفةٌ من نوع const char. تسبب هذه المشكلة مصدرًا للحيرة، إذ أن هذه الحالة الوحيدة التي لا يجري فيها تحويل المصفوفة إلى مؤشر أولًا، فمن المستحيل استخدام sizeof لإيجاد طول مصفوفة باستخدام مؤشر يشير إليها، ويجب عليك استخدام اسم المصفوفة حصرًا. نوع قيمة sizeof لعلك تتساءل الآن عن نتيجة التالي: sizeof ( sizeof (anything legal) ) فما هو نوع نتيجة عامل sizeof؟ الإجابة على هذا السؤال معرّفة بحسب التطبيق، وقد تكون unsigned long أو unsigned int بحسب تطبيقك، إلا أن هناك شيئان يمكن فعلهما للتأكد من أنك تستخدم القيمة بصورة صحيحة، وهما: يمكنك استخدام تحويل الأنواع cast وتحويل القيمة إلى unsigned long قسريًا (كما فعلنا في المثال السابق). يمكنك استخدام النوع المُعرّف size_t الموجود في ملف الترويسة stddef.h كما يوضح المثال التالي: #include <stddef.h> #include <stdio.h> #include <stdlib.h> main(){ size_t sz; sz = sizeof(sz); printf("size of sizeof is %lu\n", (unsigned long)sz); exit(EXIT_SUCCESS); } [مثال 6] ترجمة -وبتصرف- لقسم Sizeof and storage allocation من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المؤشرات Pointers في لغة سي C المقال السابق: التعامل مع المحارف والسلاسل النصية في لغة سي C الذاكرة الوهمية (Virtual memory) في نظام التشغيل فهم الملفات Files وأنظمة الملفات file systems
يُعيد العامل "sizeof" حجم المُعامل operator بالبايتات، وتعتمد نتيجة العامل "sizeof" بكونها عددًا صحيحًا عديم الإشارة "unsigned int" أو عددًا كبيرًا عديم الإشارة "unsigned long" على التطبيق implementation، وهذا هو السبب في تفادينا لأي مشكلات في المثال السابق (المقال السابق) عند التصريح عن دالة malloc على الرغم من عدم تزويد التصريح بأي تفاصيل عن معاملاتها؛ إذ يجب استخدام ملف الترويسة stdlib.h عوضًا عن ذلك عادةً للتصريح عن malloc على النحو الصحيح. إليك المثال ذاته ولكن بتركيز على جعله قابلًا للتنقل portable عبر مختلف الأجهزة: #include <stdlib.h> /* malloc() يتضمن ملف الترويسة تصريحًا عن */ float *fp; fp = (float *)malloc(sizeof(float)); يجب أن يُكتب معامل sizeof داخل قوسين إذا كان فقط اسمًا لنوع بيانات (وهي الحالة في مثالنا السابق)، بينما يمكنك التخلي عن القوسين إذا كنت تستخدم اسم كائن بيانات عوضًا عن ذلك، ولكن هذه الحالة نادرة الحدوث. #include <stdlib.h> int *ip, ar[100]; ip = (int *)malloc(sizeof ar); لدينا في المثال السابق مصفوفة باسم ar مكونةٌ من 100 عنصر من نوع عدد صحيح int، ويشير ip إلى مساحة التخزين الخاصة بهذه المصفوفة (مساحةٌ لمئة قيمة من نوع int) بعد استدعاء malloc (بفرض أن الاستدعاء كان ناجحًا). تعدّ char (محرف وهي اختصارٌ إلى character) وحدة القياس الأساسية للتخزين في لغة سي، وتساوي بايتًا واحدًا، جرّب نتيجة التعليمة الآتية: sizeof(char) وبناءً على ذلك، يمكنك حجز مساحة لعشرة قيم من نوع char على النحو التالي: malloc(10) ولحجز مساحة لمصفوفة بحجم عشرة قيم من نوع int، نكتب: malloc(sizeof(int[10])) تُعيد الدالة malloc مؤشرًا إلى الفراغ null pointer في حال لم تتوفر المساحة الكافية للإشارة إلى خطأ ما. يحتوي ملف الترويسة stdio.h ثابتًا معرّفًا باسم NULL، والذي يُستخدم عادةً للتحقق من القيمة المُعادة من الدالة malloc ودوال أخرى من المكتبة القياسية، وتُعد القيمة 0 أو (void *)0 مساويةً لهذا الثابت ويمكن استخدامها. إليك المثال التالي لتوضيح استخدام الدالة malloc، إذ يقرأ البرنامج في المثال سلاسلًا نصيةً بعدد MAXSTRING من الدخل، ثمّ يرتب السلاسل النصية أبجديًّا باستخدام الدالة strcmp. يُشار إلى نهاية السلسلة النصية بمحرف الهروب escape character التالي n\، وتُرتَّب السلاسل باستخدام مصفوفة من المؤشرات تُشير إلى السلسلة النصية وتبديل مواضع المؤشرات حتى الوصول إلى الترتيب الصحيح، مما يجنُّبنا عناء نسخ السلاسل النصية ويحسّن من سرعة تنفيذ البرنامج ويحد من هدر الموارد إلى حدٍّ ما. استخدمنا في الإصدار الأول من المثال مصفوفةً ثابتة الحجم، ثم استخدمنا في الإصدار الثاني حجز المساحة باستخدام malloc لكل سلسلة نصية عند وقت التشغيل run-time، بينما بقيت مصفوفة المؤشرات -لسوء الحظ- ثابتة الحجم، إلا أنه يمكننا تطبيق حلّ أفضل باستخدام قائمة مترابطة Linked list، أو أي هيكل بيانات مشابه لتخزين المؤشرات دون الحاجة لاستخدام المصفوفات ثابتة الحجم إطلاقًا، ولكننا لم نتكلم عن هياكل البيانات بعد. إليك ما يبدو عليه هيكل برنامجنا: while(number of strings read < MAXSTRING && input still remains){ read next string; } sort array of pointers; print array of pointers; exit; سنستخدم بعض الدوال في برنامجنا أيضًا: char *next_string(char *destination) تقرأ الدالة السابقة سطرًا من المحارف بحيث ينتهي السطر بالمحرف n\ من دخل البرنامج، وتُسند المحارف البالغ عددها MAXLEN-1 إلى المصفوفة المُشار إليها بالمصفوفة الهدف destination، إذ يمثّل MAXLEN قيمةً ثابتةً لطول السلسلة النصية العظمى. إذا كان المحرف الأول المقروء هو EOF (أي نهاية الملف)، أعِد مؤشرًا إلى الفراغ، وفيما عدا ذلك أعِد عنوان بداية السلسلة النصية (الهدف destination)، بحيث تحتوي السلسلة النصية الهدف دائمًا على المحرف n\، الذي يشير إلى نهاية السلسلة. void sort_arr(const char *p_array[]) تمثل المصفوفة p_array[] مصفوفة المؤشرات التي تشير للمحارف، ويمكن أن تكون المصفوفة كبيرة الحجم ولكن يُشار إلى نهايتها بأول عنصر يحتوي على مؤشر فراغ null pointer. ترتّب الدالة sort_arr المؤشرات بحيث تُشير إلى السلاسل النصية المرتبة أبجديًا عند اجتياز مصفوفة المؤشرات بناءً على دليل index المؤشر. void print_arr(const char *p_array[]) تُشابه دالة print_arr الدالة sort_arr ولكنها تطبع السلاسل النصية حسب ترتيبها الأبجدي. تذكّر أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول في أي تعبير يحتوي على اسمها، ومن شأن ذلك أن يساعدك في فهم الأمثلة على نحوٍ أفضل؛ والأمر مماثلٌ بالنسبة لمصفوفة ثنائية البعد، مثل مصفوفة strings في المثال التالي، فنوع التعبير strings[1][2] هو char، ولكن للعنصر strings[1] نوع "مصفوفة من char"، ولذلك يُحوَّل اسم المصفوفة إلى عنوان العنصر الأول ونحصل على &strings[1][0]. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(char *destination); main(){ /* نصرح عن المصفوفة مع إضافة عنصر فارغ في نهايتها */ char *p_array[MAXSTRING+1]; /* مصفوفة تخزين السلاسل النصية */ char strings[MAXSTRING][MAXLEN]; /* عدد السلاسل النصية المقروءة */ int nstrings; nstrings = 0; while(nstrings < MAXSTRING && next_string(strings[nstrings]) != 0){ p_array[nstrings] = strings[nstrings]; nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(char *destination){ char *cp; int c; cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); return(destination); } [مثال 1] إعادة الدالة next_string لمؤشر ليس من قبيل المصادفة، إذ أصبح بإمكاننا الآن الاستغناء عن استخدام مصفوفة السلاسل النصية واستخدام next_string لحجز مساحة التخزين الموافقة لها. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(void); main(){ char *p_array[MAXSTRING+1]; int nstrings; nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 2] وأخيرًا إليك المثال كاملًا مع استخدام مصفوفة p_array للدالة malloc، ولاحظ إعادة كتابة معظم أدلة المصفوفة لتستخدم ترميز المؤشرات. إذا كنت تشعر بالإرهاق من جميع المعلومات التي قرأتها فتجاوز المثال التالي، فهو صعبٌ بعض الشيء. شرح المثال: تعني char **p مؤشرًا يشير إلى المؤشر الذي يشير إلى محرف، ويجد معظم مبرمجو لغة سي هذه الطريقة في استخدام المؤشرات صعبة الفهم. #include <stdio.h> #include <stdlib.hi> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /*الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char **p_array); void sort_arr(const char **p_array); char *next_string(void); main(){ char **p_array; int nstrings; /* عدد السلاسل النصية المقروءة */ p_array = (char **)malloc( sizeof(char *[MAXSTRING+1])); if(p_array == 0){ printf("No memory\n"); exit(EXIT_FAILURE); } nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char **p_array){ while(*p_array) printf("%s\n", *p_array++); } void sort_arr(const char **p_array){ const char **lo_p, **hi_p, *tmp; for(lo_p = p_array; *lo_p != 0 && *(lo_p+1) != 0; lo_p++){ for(hi_p = lo_p+1; *hi_p != 0; hi_p++){ if(strcmp(*hi_p, *lo_p) >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = *hi_p; *hi_p = *lo_p; *lo_p = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 3] سنستعرض مثالًا آخر لتوضيح استخدام دالة malloc وإمكاناتها في التعامل مع السلاسل النصية الطويلة؛ إذ يقرأ المثال السلاسل النصية من الدخل ويبحث عن محرف سطر جديد لتحديد نهاية السلسلة النصية (أي n\)، ثم يطبع السلسلة النصية إلى الخرج، ويتوقف البرنامج عن العمل عندما يصادف محرف نهاية الملف EOF. تُسنَد المحارف إلى مصفوفة، ويُدلّ على نهاية المصفوفة -كما هو معتاد- بالقيمة صفر، مع ملاحظة أن محرف السطر الجديد لا يُخزَّن بالمصفوفة بل يُستخدم فقط لتحديد سطر الدخل الواجب طباعته للخرج. لا يعلم البرنامج طول السلسلة النصية تحديدًا، ولذلك يبدأ بفحص كل عشرة محارف وحجز المساحة الخاصة بهم (الثابت GROW_BY). تُستدعى الدالة malloc في حال كانت السلسلة النصية أطول من عشرة محارف لحجز المساحة للسلسلة النصية وإضافة عشرة محارف أخرى، ثم تُنسخ المحارف الحالية للمساحة الجديدة وتُستخدم من البرنامج وتُحرّر المساحة القديمة. تُستخدم الدالة free لتحرير المساحة القديمة المحجوزة من malloc مسبقًا، إذ يجب عليك تحرير المساحة غير المُستخدمة بعد الآن دوريًا قبل أن تتراكم، واستخدام free يحرّر المساحة ويسمح بإعادة استخدامها لاحقًا. يستخدم البرنامج الدالة fprintf لعرض أي أخطاء، وهي دالةٌ مشابهة للدالة printf التي اعتدنا على رؤيتها، والفرق الوحيد بينهما هو أن الدالة fprintf تأخذ وسيطًا إضافيًّا يدل على وسيط الخرج الذي سيُطبع إليه، وهناك ثابتان لهذا الغرض معرّفان في ملف الترويسة stdio.h؛ إذ أن استخدام الثابت الأول stdout يعني استخدام خرج البرنامج القياسي، بينما يشير استخدام الثابت الثاني stderr إلى مجرى أخطاء البرنامج القياسي standard error stream، وقد يكون وسيطا الخرج متماثلين في بعض الأنظمة إلا أن بعض الأنظمة الأخرى تفصل بين الاثنين. #include <stdio.h> #include <stdlib.h> #include <string.h> #define GROW_BY 10 /* يزداد حجم السلسلة النصية كل مرة بمقدار 10 */ main(){ char *str_p, *next_p, *tmp_p; int ch, need, chars_read; if(GROW_BY < 2){ fprintf(stderr, "Growth constant too small\n"); exit(EXIT_FAILURE); } str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; chars_read = 0; while((ch = getchar()) != EOF){ /* (*) */ if(ch == '\n'){ /* الإشارة إلى نهاية السطر */ *next_p = 0; printf("%s\n", str_p); free(str_p); chars_read = 0; str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; continue; } /* * التحقق من وصولنا إلى نهاية المساحة المحجوزة */ if(chars_read == GROW_BY-1){ *next_p = 0; /* للدلالة على نهاية السلسلة النصية */ /* نستخدم الطرح بين المؤشرات لإيجاد طول السلسلة النصية الحالية*/ need = next_p - str_p +1; tmp_p = (char *)malloc(need+GROW_BY); if(tmp_p == NULL){ fprintf(stderr,"No more store\n"); exit(EXIT_FAILURE); } /* ننسخ السلسلة النصية باستخدام دالة المكتبة */ strcpy(tmp_p, str_p); free(str_p); str_p = tmp_p; /* * next_p إعادة ضبط */ next_p = str_p + need-1; chars_read = 0; } /* * إسناد المحرف إلى نهاية السلسلة النصية */ *next_p++ = ch; chars_read++; } /* * عند وصولنا إلى نهاية الملف * هل توجد محارف غير مطبوعة؟ */ if(str_p - next_p){ *next_p = 0; fprintf(stderr,"Incomplete last line\n"); printf("%s\n", str_p); } exit(EXIT_SUCCESS); } [مثال 4] (*) تُعاد الحلقة في الموضع المذكور عند كل سطر، وهناك مساحةٌ للعنصر صفر في نهاية السلسلة النصية دائمًا، لأننا نتحقق من أصغر من 2 وهو ما تحققنا منه سابقًا GROW_BY ذلك في الشرط التالي إلا في حال كان. قد لا يكون برنامجنا السابق مثالًا واقعيًا عن التعامل مع السلاسل النصية الطويلة، إذ يتطلب حجم التخزين الأعظمي ضعف الحجم المطلوب لأطول سلسلة نصية، ولكنه برنامج يعمل صحيحًا بغض النظر، إلا أنه يكلفنا الكثير بخصوص الموارد بنسخ السلاسل النصية ويمكن حل المشكلتين عن طريق استخدام دالة realloc. نستطيع استخدام القوائم المترابطة لطريقة أكثر تعقيدًا، مع استخدام الهياكل Structures التي سنتكلم عنها لاحقًا، إلا أن هذه الطريقة تأتي أيضًا ببعض المشكلات لأن دوال المكتبة القياسية لن تعمل عند استخدام طريقة مغايرة لتخزين السلاسل النصية. ما الأشياء التي لا يستطيع العامل sizeof فعلها؟ يرتكب المبتدئون غالبًا الخطأ التالي عند استخدام العامل sizeof: #include <stdio.h> #include <stdlib.h> const char arr[] = "hello"; const char *cp = arr; main(){ printf("Size of arr %lu\n", (unsigned long) sizeof(arr)); printf("Size of *cp %lu\n", (unsigned long) sizeof(*cp)); exit(EXIT_SUCCESS); } [مثال 5] لن تكون الأرقام ذاتها عند الطباعة، إذ سيعرف أولًا حجم arr بكونها 6 بصورةٍ صحيحة (خمسة محارف متبوعةٍ بمحرف الفراغ null)، بينما ستطبع التعليمة الثانية -على جميع الأنظمة- القيمة 1، لأن المؤشر cp* من نوع const char ذو الحجم 1 بايت، بينما arr مختلفةٌ فهي مصفوفةٌ من نوع const char. تسبب هذه المشكلة مصدرًا للحيرة، إذ أن هذه الحالة الوحيدة التي لا يجري فيها تحويل المصفوفة إلى مؤشر أولًا، فمن المستحيل استخدام sizeof لإيجاد طول مصفوفة باستخدام مؤشر يشير إليها، ويجب عليك استخدام اسم المصفوفة حصرًا. نوع قيمة sizeof لعلك تتساءل الآن عن نتيجة التالي: sizeof ( sizeof (anything legal) ) فما هو نوع نتيجة عامل sizeof؟ الإجابة على هذا السؤال معرّفة بحسب التطبيق، وقد تكون unsigned long أو unsigned int بحسب تطبيقك، إلا أن هناك شيئان يمكن فعلهما للتأكد من أنك تستخدم القيمة بصورة صحيحة، وهما: يمكنك استخدام تحويل الأنواع cast وتحويل القيمة إلى unsigned long قسريًا (كما فعلنا في المثال السابق). يمكنك استخدام النوع المُعرّف size_t الموجود في ملف الترويسة stddef.h كما يوضح المثال التالي: #include <stddef.h> #include <stdio.h> #include <stdlib.h> main(){ size_t sz; sz = sizeof(sz); printf("size of sizeof is %lu\n", (unsigned long)sz); exit(EXIT_SUCCESS); } [مثال 6] ترجمة -وبتصرف- لقسم Sizeof and storage allocation من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المؤشرات Pointers في لغة سي C المقال السابق: التعامل مع المحارف والسلاسل النصية في لغة سي C الذاكرة الوهمية (Virtual memory) في نظام التشغيل فهم الملفات Files وأنظمة الملفات file systems -
 تُستخدم لغة سي على نطاق واسع في تطبيقات المعالجة والتعامل بالمحارف characters والسلاسل النصية strings، وهذا الأمر غريب بعض الشيء لأن اللغة لا تحتوي على مزايا موجهة لهذا الغرض بالتحديد،؛ وإذا كنت معتادًا على لغات البرمجة التي تحتوي على مزايا موجهة للتعامل مع المحارف والسلاسل النصية، فستجد التعامل مع لغة سي بهذا الخصوص مضجرًا على أقل تقدير. تحتوي المكتبة القياسية على العديد من الدوال التي تساعدك في التعامل مع السلاسل النصية، إلا أن الأمر يبقى صعبًا بعض الشيء مقارنةً بلغاتٍ أخرى. على سبيل المثال، عليك استدعاء دالة مخصصة للمقارنة ما بين سلسلتين نصيتين بدلًا من استخدام عامل المساواة "="، ولكن هناك جانبٌ مشرقٌ لهذا الأمر، إذ يعني ذلك أن اللغة غير مُثقلة بطرق دعم معالجة السلاسل النصية مما يساعد بالمحافظة على برامج أصغر وأقل تشعّبًا، وحالما تكتب برنامجًا لمعالجة السلاسل النصية بلغة سي بنجاح أخيرًا، ستكون قادرًا على تشغيله بسرعة أكبر مقارنةً باللغات الأخرى. التعامل مع المحارف يجري التعامل مع محارف السلسلة النصية في لغة سي عن طريق التصريح عن مصفوفات، أو حجزهم ديناميكيًا، والتعامل مع المحارف وتحريكها "يدويًّا". إليك مثالًا عن برنامج يقرأ نصًّا سطرًا بسطر من دخل البرنامج القياسي، ويتوقف البرنامج عن القراءة إذا كان السطر مكوّنًا من السلسلة النصية "stop"، ويُطبع طول السطر فيما عدا ذلك. يعتمد البرنامج على تقنية تُستخدم في معظم برامج سي ألا وهي: يقرأ البرنامج المحارف ويحوّلها إلى مصفوفة ويحدّد نهاية المصفوفة بمحرفٍ إضافي له القيمة صفر؛ كما يستخدم هذا المثال دالة strcmp للمقارنة بين سلسلتين نصيتين من خلال تضمين المكتبة string.h. #include <stdio.h> #include <stdlib.h> #include <string.h> #define LINELNG 100 /* الطول الأعظمي لسطر الدخل الواحد */ main(){ char in_line[LINELNG]; char *cp; int c; cp = in_line; while((c = getc(stdin)) != EOF){ if(cp == &in_line[LINELNG-1] || c == '\n'){ /*إدخال ما يدل على نهاية السطر*/ *cp = 0; if(strcmp(in_line, "stop") == 0 ) exit(EXIT_SUCCESS); else printf("line was %d characters long\n", (int)(cp-in_line)); cp = in_line; } else *cp++ = c; } exit(EXIT_SUCCESS); } [مثال 1] يوضح لنا هذا المثال مزيدًا من مزايا وطرق لغة سي المُستخدمة في برامجها، وأهمها هو طريقة تمثيل السلاسل النصية ومعالجتها. إليك تطبيقًا عمليًّا عن الدالة strcmp التي تقارن بين سلسلتين نصيتين وتعيد القيمة صفر إن تساوت قيمتهما، وللدالة هذه في الحقيقة تطبيقات أكثر ولكننا سنتجاهل المعلومات التي قد تزيد من تعقيد شرحنا. لاحظ استخدام الكلمة المفتاحية const في التصريح عن الوسطاء، والذي يوضِّح أن الدالة لن تعدل على محتويات السلسلة النصية بل ستفحص قيم محتوياتها فقط، ونلاحظ استخدام هذه الطريقة في التعريف عن العديد من دوال المكتبة القياسية. /* * برنامج يختبر مساواة سلسلتين نصيتين * يُعيد القيمة "خطأ" إذا تساوت السلسلتين */ int str_eq(const char *s1, const char *s2){ while(*s1 == *s2){ /* * إعادة 0 عند نهاية السلسلة النصية */ if(*s1 == 0) return(0); s1++; s2++; } /* عُثر على فرق بين السلسلتين */ return(1); } [مثال 2] السلاسل النصية يعرف كل مبرمجٍ للغة سي معنى السلسلة النصية، فهي مصفوفةٌ من متغيرات من نوع "char"، ويكون المحرف الأخير لهذه السلسلة النصية متبوعًا بمحرف فراغ null. ربما تصرخ الآن وتقول "ولكنني اعتقدت أن السلسلة النصية هي نصٌ محتوًى داخل إشارتي تنصيص!" أنت محقّ، إذ تُعد السلسلة التالية في لغة سي مصفوفةً من المحارف: "a string" وهذا الشيء الوحيد الذي يمكنك التصريح عنه لحظة استخدامه، أي دون التصريح عن مصفوفة المحارف وتحديد حجمها. احذر: كانت السلاسل النصية في لغة سي القديمة تُخزّن مثل أي سلسلة محارف اعتيادية، وكانت قابلةً للتعديل. إلا أن المعيار ينص على أن محاولة التعديل على سلسلة نصية سيتسبب بسلوك غير محدد على الرغم من كون السلاسل النصية مصفوفةً من نوع "char" وليس "const char". لاستخدام السلسلة النصية داخل علامتي تنصيص أثران: أولهما أن السلسلة النصية تحلّ محل تصريح وبديل عن الاسم، كما أنها تمثِّل تصريحًا خفيًّا لمصفوفة من المحارف، وتُهيّأ قيمة هذه المصفوفة إلى قيم المحارف الموجودة في السلسلة النصية متبوعةً بمحرف قيمته صفر، ولا يوجد لهذه المصفوفة أي اسم، لذا باستثناء الاسم، يكون الوضع مشابهًا للتالي: char secret[9]; secret[0] = 'a'; secret[1] = ' '; secret[2] = 's'; secret[3] = 't'; secret[4] = 'r'; secret[5] = 'i'; secret[6] = 'n'; secret[7] = 'g'; secret[8] = 0; وهي مصفوفةٌ من المحارف متبوعةٌ بقيمة صفر، وتحتوي جميع قيم المحارف بداخلها، لكنها عديمة الاسم إذا صُرِّح عنها باستخدام طريقة السلسلة النصية المحاطة بعلامتي تنصيص، فكيف نستطيع استخدامها؟ يكون وجود السلسلة النصية بمثابة اسمٍ مخفي لها حالما تراها لغة سي محاطةً بعلامتي تنصيص، إذ أن وجود السلسلة النصية بهذا الشكل لا يؤدي إلى تصريح ضمني فقط، بل يؤدي إلى إعطاء اسمٍ لمصفوفة موافقة. نتذكر جميعنا أن اسم المصفوفة مساوٍ لعنوان عنصرها الأول (تفقد مقالة المؤشرات) فما نوع السلسلة التالية؟ "a string" النوع مؤشر طبعًا، إذ أن السلسلة النصية المكتوبة بالشكل السابق تكافئ مؤشرًا إلى أول عناصر المصفوفة الخفية عديمة الاسم، وهي مصفوفةٌ من نوع char، فالمؤشر من نوع "مؤشر إلى char"، ويوضح الشكل 1 هذه الحالة. شكل 1 أثر استخدام السلسلة النصية للبرهان على السابق، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> main(){ int i; char *cp; cp = "a string"; while(*cp != 0){ putchar(*cp); cp++; } putchar('\n'); for(i = 0; i < 8; i++) putchar("a string"[i]); putchar('\n'); exit(EXIT_SUCCESS); } [مثال 3] تضبط الحلقة الأولى مؤشرًا يشير إلى بداية المصفوفة، ويُمرّر المؤشر على المصفوفة إلى أن يصل المؤشر إلى القيمة صفر في النهاية، بينما "تَعرف" الحلقة الثانية طول السلسلة النصية وهي أقل فائدة مقارنةً بسابقتها. لاحظ أن الحلقة الأولى غير معتمدة على طول السلسلة النصية بل على وصولها لنهايتها وهو الشيء الأهم الذي ينبغي عليك تذكره من هذا المثال. يجري التعامل مع السلاسل النصية في لغة سي بطريقة ثابتة دون أي استثناءات وهي الطريقة التي تتوقعها جميع دوال التعامل مع السلاسل النصية، فيسمح الصفر في نهاية السلسلة النصية للدوال بمعرفة نهاية السلسلة النصية. عُد للمثال السابق الخاص بدالة str_eq، إذ تأخذ الدالة مؤشرين يشيران لمحرفين مثل وسطاء (تُقبل السلسلة النصية ذاتها بكونها واحدًا من الوسيطين أو كلاهما) وتُقارن السلسلة النصية بالتحقق من كل محرف واحدًا تلو الآخر، وإذا تساوى المحرفين فتتحقّق من أن المؤشر لم يصل إلى نهاية السلسلة عن طريق الجملة الشرطية التالية: if(*s1 == 0): وإذا وصل المؤشر للنهاية فإنها تُعيد 0 للدلالة على أن السلسلتين متساويتين، يمكن إجراء الاختبار ذاته باستخدام المؤشر s2* دون أي فارق؛ أما في حالة الفرق بين المحرفين تُعاد القيمة 1 للدلالة على فشل المساواة. تُستدعى الدالة strcmp في المثال باستخدام وسيطين مختلفين عن بعضهما، إذ أن الوسيط الأول هو مصفوفة محارف والثاني سلسلة نصية، لكنهما في الحقيقة يمثلان الشيء ذاته؛ فمصفوفة المحارف التي تنتهي بالعنصر صفر (يسند برنامجنا القيمة صفر إلى أول عنصر فارغ في مصفوفة in_line) والسلسلة النصية بين قوسين (التي تُمثّل بدورها أيضًا مصفوفة محارف تنتهي بصفر) من نفس الطبيعة، واستخدامهما مثل وسيطين للدالة strcmp ينتج بتمرير مؤشرَي محارف (وقد شرحنا السبب بذلك بإفاضة سابقًا). المؤشرات وعامل الزيادة ذكرنا سابقًا التعبير التالي، وقلنا أنّنا ستعيد النظر فيه لاحقًا: (*p)++; حان الوقت الآن للكلام عن ذلك؛ إذ تُستخدم المؤشرات بكثرة مع المصفوفات والتمرير بينها، لذلك من الطبيعي استخدام العاملين -- و ++ معها. يوضح المثال التالي إسناد القيمة صفر إلى مصفوفة باستخدام المؤشر وعامل الزيادة: #define ARLEN 10 int ar[ARLEN], *ip; ip = ar; while(ip < &ar[ARLEN]) *(ip++) = 0; [مثال 4] يُضبط المؤشر ip ليبدأ من بداية المصفوفة، وعلى الرغم من إشارة المؤشر إلى داخل المصفوفة إلا أن القيمة التي يشير إليها تساوي الصفر، وعند وصولنا للحركة التكرارية ينجز عامل الزيادة ما هو متوقع ويُنقل المؤشر للعنصر الذي يليه داخل المصفوفة، وبالتالي استخدام العامل ++ عامل إلحاق postfix مفيدٌ في هذه الحالة. معظم الأشياء التي ناقشناها شائعة الوجود، وستجدها في معظم البرامج (استخدام عامل الزيادة والمؤشرات بالشكل الموضح في المثال السابق) ليس مرةً واحدةً أو مرتين بل تقريبًا كل عدّة أسطر ضمن الشيفرة البرمجية، وستعتقد أنك تراها بصورةٍ أكثر إذا كنت تجد استخدامها صعب الفهم. لكن ما هي التشكيلات التي يمكننا الحصول عليها؟ بالنظر إلى أن * تعني التأشير و ++ تعني الزيادة و -- تعني النقصان، كما أنه لدينا خياري وضع العاملين السابقين مثل عامل إلحاق postfix أو عامل إسباق prefix، نحصل على الاحتمالات التالية (بغض النظر عن عامل الزيادة أو النقصان) مع التركيز على موضع الأقواس: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } (p*)++ زيادة سابقة للشيء الذي يشير إليه المؤشر ++(p*) زيادة لاحقة للشيء الذي يشير إليه المؤشر (++p)* زيادة لاحقة على المؤشر *(p++)* زيادة سابقة على المؤشر [جدول 1 معاني المؤشرات] اقرأ الجدول السابق بحرص وتأكد أنك تفهم جميع التركيبات التي ذُكرت. يمكن فهم محتوى الجدول السابق بعد تفكير بسيط، ولكن هل يمكنك توقع ما الذي سيحدث عند إزالة الأقواس بالنظر إلى أن الأسبقية للعوامل الثلاث * و -- و ++ متساوية؟ تتوقع حدوث أخطاء كارثية، أليس كذلك؟ يوضّح الجدول 1 أن هناك حالةٌ واحدةٌ يجب أن تحافظ فيها على الأقواس. مع أقواس دون أقواس إن أمكن (p*)++ p*++ ++(p*) ++(p*) (++p)* ++p* (p++)* p++* [جدول 2 المزيد من معاني المؤشرات] لعلّ الأشكال المثيرة للتشويش في الجدول السابق ستدفعك لاستخدام الأقواس بغض النظر عن أهمية استعمالها في أي حالة سعيًا منك لتحسين قابلية قراءة الشيفرة البرمجية وفهمها، لكن يتخلى معظم مبرمجي لغة سي عن استخدام الأقواس بعد تعلُّم قوانين الأسبقية ونادرًا ما يستخدمون الأقواس في تعابيرهم، لذا عليك الاعتياد على قراءة الأمثلة التالية سواءٌ كانت مع أقواس أو بدونها، فالاعتياد على هذا الأمر سيساعدك بحقّ في تعلمك. المؤشرات عديمة النوع من المهم في بعض الأحيان تحويل نوعٍ من المؤشرات إلى نوع آخر بمساعدة التحويل بين الأنواع مثل التعبير التالي: (type *) expression يُحوَّل التعبير expression في المثال السابق إلى مؤشر من نوع "مؤشر إلى نوع type" بغض النظر عن نوع التعبير السابق، إلا أنه يجب تفادي هذه الطريقة إلا في حال كنت مدركًا تمامًا لما تفعله، فمن غير المحبّذ استخدامها إلا إذا كنت مبرمجًا خبيرًا. لا تفترض أن التحويل بين الأنواع يلغي أي حسابات أخرى بخصوص "الأنواع غير المتوافقة مع بعضها" التي تقع على عاتق المصرّف، إذ من المهم إعادة حساب القيم الجديدة للمؤشر بعد تغيير نوعه على العديد من معماريات الحاسوب. هناك بعض الحالات التي ستحتاج فيها لاستخدام مؤشر "معمّم generic"، وأبرز مثال على ذلك هو تطبيق لدالة المكتبة القياسية malloc التي تُستخدم لحجز المساحة على الذاكرة للكائن الذي لم يصرّح عنه بعد، ويجري تزويد الحجم المراد حجزه عن طريق تزويد مثل وسيطٍ سواءٌ كان الكائن متغيرًا من نوع float أو مصفوفة من نوع int أو أي شيء آخر. تعيد الدالة مؤشرًا إلى عنوان التخزين المحجوز التي تختاره بطريقتها الخاصة (والتي لن نتطرق إليها) من مجموعةٍ من عناوين الذاكرة الفارغة، ومن ثم يُحوَّل المؤشر إلى النوع المناسب. على سبيل المثال، تحتاج القيمة من نوع float إلى 4 بايتات من الذاكرة، وبالتالي نكتب ما يلي لحجز مساحة للقيمة: float *fp; fp = (float *)malloc(4); تعثر الدالة malloc على 4 بايتات من الذاكرة الفارغة، ويُحوَّل عنوان الذاكرة إلى مؤشر من نوع "مؤشر إلى float"، ثم تُسند القيمة إلى المؤشر (fp في حالة مثالنا السابق). لكن ما هو نوع المؤشر الذي ستُسند قيمة malloc إليه؟ نحن بحاجة نوع يمكن أن يحتوي جميع أنواع المؤشرات فنحن لا نعلم نوع المؤشر الذي ستعيده الدالة malloc. الحل هو باستخدام نوع المؤشر * void الذي تكلمنا عنه سابقًا، إليك المثال السابق مع إضافة تصريح للدالة malloc: void *malloc(); float *fp; fp = (float *)malloc(4); لا حاجة لاستخدام تحويل الأنواع على القيمة المُعادة من الدالة malloc حسب قوانين الإسناد للمؤشرات، ولكن استُخدم تحويل الأنواع لممارسة الأمر لا أكثر. لا بد من طريقة لمعرفة قيمة وسيط malloc الدقيقة في نهاية المطاف، ولكن القيمة ستكون مختلفةً على أجهزة بمعماريات مختلفة، لذا لا يمكنك الاكتفاء باستخدام القيمة الثابتة 4 فقط، بل يجب علينا استخدام عامل sizeof. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: عامل sizeof وحجز مساحات التخزين في لغة سي C المقال السابق: المؤشرات Pointers في لغة سي C المحارف المستخدمة في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى البنية النصية لبرامج سي C
تُستخدم لغة سي على نطاق واسع في تطبيقات المعالجة والتعامل بالمحارف characters والسلاسل النصية strings، وهذا الأمر غريب بعض الشيء لأن اللغة لا تحتوي على مزايا موجهة لهذا الغرض بالتحديد،؛ وإذا كنت معتادًا على لغات البرمجة التي تحتوي على مزايا موجهة للتعامل مع المحارف والسلاسل النصية، فستجد التعامل مع لغة سي بهذا الخصوص مضجرًا على أقل تقدير. تحتوي المكتبة القياسية على العديد من الدوال التي تساعدك في التعامل مع السلاسل النصية، إلا أن الأمر يبقى صعبًا بعض الشيء مقارنةً بلغاتٍ أخرى. على سبيل المثال، عليك استدعاء دالة مخصصة للمقارنة ما بين سلسلتين نصيتين بدلًا من استخدام عامل المساواة "="، ولكن هناك جانبٌ مشرقٌ لهذا الأمر، إذ يعني ذلك أن اللغة غير مُثقلة بطرق دعم معالجة السلاسل النصية مما يساعد بالمحافظة على برامج أصغر وأقل تشعّبًا، وحالما تكتب برنامجًا لمعالجة السلاسل النصية بلغة سي بنجاح أخيرًا، ستكون قادرًا على تشغيله بسرعة أكبر مقارنةً باللغات الأخرى. التعامل مع المحارف يجري التعامل مع محارف السلسلة النصية في لغة سي عن طريق التصريح عن مصفوفات، أو حجزهم ديناميكيًا، والتعامل مع المحارف وتحريكها "يدويًّا". إليك مثالًا عن برنامج يقرأ نصًّا سطرًا بسطر من دخل البرنامج القياسي، ويتوقف البرنامج عن القراءة إذا كان السطر مكوّنًا من السلسلة النصية "stop"، ويُطبع طول السطر فيما عدا ذلك. يعتمد البرنامج على تقنية تُستخدم في معظم برامج سي ألا وهي: يقرأ البرنامج المحارف ويحوّلها إلى مصفوفة ويحدّد نهاية المصفوفة بمحرفٍ إضافي له القيمة صفر؛ كما يستخدم هذا المثال دالة strcmp للمقارنة بين سلسلتين نصيتين من خلال تضمين المكتبة string.h. #include <stdio.h> #include <stdlib.h> #include <string.h> #define LINELNG 100 /* الطول الأعظمي لسطر الدخل الواحد */ main(){ char in_line[LINELNG]; char *cp; int c; cp = in_line; while((c = getc(stdin)) != EOF){ if(cp == &in_line[LINELNG-1] || c == '\n'){ /*إدخال ما يدل على نهاية السطر*/ *cp = 0; if(strcmp(in_line, "stop") == 0 ) exit(EXIT_SUCCESS); else printf("line was %d characters long\n", (int)(cp-in_line)); cp = in_line; } else *cp++ = c; } exit(EXIT_SUCCESS); } [مثال 1] يوضح لنا هذا المثال مزيدًا من مزايا وطرق لغة سي المُستخدمة في برامجها، وأهمها هو طريقة تمثيل السلاسل النصية ومعالجتها. إليك تطبيقًا عمليًّا عن الدالة strcmp التي تقارن بين سلسلتين نصيتين وتعيد القيمة صفر إن تساوت قيمتهما، وللدالة هذه في الحقيقة تطبيقات أكثر ولكننا سنتجاهل المعلومات التي قد تزيد من تعقيد شرحنا. لاحظ استخدام الكلمة المفتاحية const في التصريح عن الوسطاء، والذي يوضِّح أن الدالة لن تعدل على محتويات السلسلة النصية بل ستفحص قيم محتوياتها فقط، ونلاحظ استخدام هذه الطريقة في التعريف عن العديد من دوال المكتبة القياسية. /* * برنامج يختبر مساواة سلسلتين نصيتين * يُعيد القيمة "خطأ" إذا تساوت السلسلتين */ int str_eq(const char *s1, const char *s2){ while(*s1 == *s2){ /* * إعادة 0 عند نهاية السلسلة النصية */ if(*s1 == 0) return(0); s1++; s2++; } /* عُثر على فرق بين السلسلتين */ return(1); } [مثال 2] السلاسل النصية يعرف كل مبرمجٍ للغة سي معنى السلسلة النصية، فهي مصفوفةٌ من متغيرات من نوع "char"، ويكون المحرف الأخير لهذه السلسلة النصية متبوعًا بمحرف فراغ null. ربما تصرخ الآن وتقول "ولكنني اعتقدت أن السلسلة النصية هي نصٌ محتوًى داخل إشارتي تنصيص!" أنت محقّ، إذ تُعد السلسلة التالية في لغة سي مصفوفةً من المحارف: "a string" وهذا الشيء الوحيد الذي يمكنك التصريح عنه لحظة استخدامه، أي دون التصريح عن مصفوفة المحارف وتحديد حجمها. احذر: كانت السلاسل النصية في لغة سي القديمة تُخزّن مثل أي سلسلة محارف اعتيادية، وكانت قابلةً للتعديل. إلا أن المعيار ينص على أن محاولة التعديل على سلسلة نصية سيتسبب بسلوك غير محدد على الرغم من كون السلاسل النصية مصفوفةً من نوع "char" وليس "const char". لاستخدام السلسلة النصية داخل علامتي تنصيص أثران: أولهما أن السلسلة النصية تحلّ محل تصريح وبديل عن الاسم، كما أنها تمثِّل تصريحًا خفيًّا لمصفوفة من المحارف، وتُهيّأ قيمة هذه المصفوفة إلى قيم المحارف الموجودة في السلسلة النصية متبوعةً بمحرف قيمته صفر، ولا يوجد لهذه المصفوفة أي اسم، لذا باستثناء الاسم، يكون الوضع مشابهًا للتالي: char secret[9]; secret[0] = 'a'; secret[1] = ' '; secret[2] = 's'; secret[3] = 't'; secret[4] = 'r'; secret[5] = 'i'; secret[6] = 'n'; secret[7] = 'g'; secret[8] = 0; وهي مصفوفةٌ من المحارف متبوعةٌ بقيمة صفر، وتحتوي جميع قيم المحارف بداخلها، لكنها عديمة الاسم إذا صُرِّح عنها باستخدام طريقة السلسلة النصية المحاطة بعلامتي تنصيص، فكيف نستطيع استخدامها؟ يكون وجود السلسلة النصية بمثابة اسمٍ مخفي لها حالما تراها لغة سي محاطةً بعلامتي تنصيص، إذ أن وجود السلسلة النصية بهذا الشكل لا يؤدي إلى تصريح ضمني فقط، بل يؤدي إلى إعطاء اسمٍ لمصفوفة موافقة. نتذكر جميعنا أن اسم المصفوفة مساوٍ لعنوان عنصرها الأول (تفقد مقالة المؤشرات) فما نوع السلسلة التالية؟ "a string" النوع مؤشر طبعًا، إذ أن السلسلة النصية المكتوبة بالشكل السابق تكافئ مؤشرًا إلى أول عناصر المصفوفة الخفية عديمة الاسم، وهي مصفوفةٌ من نوع char، فالمؤشر من نوع "مؤشر إلى char"، ويوضح الشكل 1 هذه الحالة. شكل 1 أثر استخدام السلسلة النصية للبرهان على السابق، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> main(){ int i; char *cp; cp = "a string"; while(*cp != 0){ putchar(*cp); cp++; } putchar('\n'); for(i = 0; i < 8; i++) putchar("a string"[i]); putchar('\n'); exit(EXIT_SUCCESS); } [مثال 3] تضبط الحلقة الأولى مؤشرًا يشير إلى بداية المصفوفة، ويُمرّر المؤشر على المصفوفة إلى أن يصل المؤشر إلى القيمة صفر في النهاية، بينما "تَعرف" الحلقة الثانية طول السلسلة النصية وهي أقل فائدة مقارنةً بسابقتها. لاحظ أن الحلقة الأولى غير معتمدة على طول السلسلة النصية بل على وصولها لنهايتها وهو الشيء الأهم الذي ينبغي عليك تذكره من هذا المثال. يجري التعامل مع السلاسل النصية في لغة سي بطريقة ثابتة دون أي استثناءات وهي الطريقة التي تتوقعها جميع دوال التعامل مع السلاسل النصية، فيسمح الصفر في نهاية السلسلة النصية للدوال بمعرفة نهاية السلسلة النصية. عُد للمثال السابق الخاص بدالة str_eq، إذ تأخذ الدالة مؤشرين يشيران لمحرفين مثل وسطاء (تُقبل السلسلة النصية ذاتها بكونها واحدًا من الوسيطين أو كلاهما) وتُقارن السلسلة النصية بالتحقق من كل محرف واحدًا تلو الآخر، وإذا تساوى المحرفين فتتحقّق من أن المؤشر لم يصل إلى نهاية السلسلة عن طريق الجملة الشرطية التالية: if(*s1 == 0): وإذا وصل المؤشر للنهاية فإنها تُعيد 0 للدلالة على أن السلسلتين متساويتين، يمكن إجراء الاختبار ذاته باستخدام المؤشر s2* دون أي فارق؛ أما في حالة الفرق بين المحرفين تُعاد القيمة 1 للدلالة على فشل المساواة. تُستدعى الدالة strcmp في المثال باستخدام وسيطين مختلفين عن بعضهما، إذ أن الوسيط الأول هو مصفوفة محارف والثاني سلسلة نصية، لكنهما في الحقيقة يمثلان الشيء ذاته؛ فمصفوفة المحارف التي تنتهي بالعنصر صفر (يسند برنامجنا القيمة صفر إلى أول عنصر فارغ في مصفوفة in_line) والسلسلة النصية بين قوسين (التي تُمثّل بدورها أيضًا مصفوفة محارف تنتهي بصفر) من نفس الطبيعة، واستخدامهما مثل وسيطين للدالة strcmp ينتج بتمرير مؤشرَي محارف (وقد شرحنا السبب بذلك بإفاضة سابقًا). المؤشرات وعامل الزيادة ذكرنا سابقًا التعبير التالي، وقلنا أنّنا ستعيد النظر فيه لاحقًا: (*p)++; حان الوقت الآن للكلام عن ذلك؛ إذ تُستخدم المؤشرات بكثرة مع المصفوفات والتمرير بينها، لذلك من الطبيعي استخدام العاملين -- و ++ معها. يوضح المثال التالي إسناد القيمة صفر إلى مصفوفة باستخدام المؤشر وعامل الزيادة: #define ARLEN 10 int ar[ARLEN], *ip; ip = ar; while(ip < &ar[ARLEN]) *(ip++) = 0; [مثال 4] يُضبط المؤشر ip ليبدأ من بداية المصفوفة، وعلى الرغم من إشارة المؤشر إلى داخل المصفوفة إلا أن القيمة التي يشير إليها تساوي الصفر، وعند وصولنا للحركة التكرارية ينجز عامل الزيادة ما هو متوقع ويُنقل المؤشر للعنصر الذي يليه داخل المصفوفة، وبالتالي استخدام العامل ++ عامل إلحاق postfix مفيدٌ في هذه الحالة. معظم الأشياء التي ناقشناها شائعة الوجود، وستجدها في معظم البرامج (استخدام عامل الزيادة والمؤشرات بالشكل الموضح في المثال السابق) ليس مرةً واحدةً أو مرتين بل تقريبًا كل عدّة أسطر ضمن الشيفرة البرمجية، وستعتقد أنك تراها بصورةٍ أكثر إذا كنت تجد استخدامها صعب الفهم. لكن ما هي التشكيلات التي يمكننا الحصول عليها؟ بالنظر إلى أن * تعني التأشير و ++ تعني الزيادة و -- تعني النقصان، كما أنه لدينا خياري وضع العاملين السابقين مثل عامل إلحاق postfix أو عامل إسباق prefix، نحصل على الاحتمالات التالية (بغض النظر عن عامل الزيادة أو النقصان) مع التركيز على موضع الأقواس: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } (p*)++ زيادة سابقة للشيء الذي يشير إليه المؤشر ++(p*) زيادة لاحقة للشيء الذي يشير إليه المؤشر (++p)* زيادة لاحقة على المؤشر *(p++)* زيادة سابقة على المؤشر [جدول 1 معاني المؤشرات] اقرأ الجدول السابق بحرص وتأكد أنك تفهم جميع التركيبات التي ذُكرت. يمكن فهم محتوى الجدول السابق بعد تفكير بسيط، ولكن هل يمكنك توقع ما الذي سيحدث عند إزالة الأقواس بالنظر إلى أن الأسبقية للعوامل الثلاث * و -- و ++ متساوية؟ تتوقع حدوث أخطاء كارثية، أليس كذلك؟ يوضّح الجدول 1 أن هناك حالةٌ واحدةٌ يجب أن تحافظ فيها على الأقواس. مع أقواس دون أقواس إن أمكن (p*)++ p*++ ++(p*) ++(p*) (++p)* ++p* (p++)* p++* [جدول 2 المزيد من معاني المؤشرات] لعلّ الأشكال المثيرة للتشويش في الجدول السابق ستدفعك لاستخدام الأقواس بغض النظر عن أهمية استعمالها في أي حالة سعيًا منك لتحسين قابلية قراءة الشيفرة البرمجية وفهمها، لكن يتخلى معظم مبرمجي لغة سي عن استخدام الأقواس بعد تعلُّم قوانين الأسبقية ونادرًا ما يستخدمون الأقواس في تعابيرهم، لذا عليك الاعتياد على قراءة الأمثلة التالية سواءٌ كانت مع أقواس أو بدونها، فالاعتياد على هذا الأمر سيساعدك بحقّ في تعلمك. المؤشرات عديمة النوع من المهم في بعض الأحيان تحويل نوعٍ من المؤشرات إلى نوع آخر بمساعدة التحويل بين الأنواع مثل التعبير التالي: (type *) expression يُحوَّل التعبير expression في المثال السابق إلى مؤشر من نوع "مؤشر إلى نوع type" بغض النظر عن نوع التعبير السابق، إلا أنه يجب تفادي هذه الطريقة إلا في حال كنت مدركًا تمامًا لما تفعله، فمن غير المحبّذ استخدامها إلا إذا كنت مبرمجًا خبيرًا. لا تفترض أن التحويل بين الأنواع يلغي أي حسابات أخرى بخصوص "الأنواع غير المتوافقة مع بعضها" التي تقع على عاتق المصرّف، إذ من المهم إعادة حساب القيم الجديدة للمؤشر بعد تغيير نوعه على العديد من معماريات الحاسوب. هناك بعض الحالات التي ستحتاج فيها لاستخدام مؤشر "معمّم generic"، وأبرز مثال على ذلك هو تطبيق لدالة المكتبة القياسية malloc التي تُستخدم لحجز المساحة على الذاكرة للكائن الذي لم يصرّح عنه بعد، ويجري تزويد الحجم المراد حجزه عن طريق تزويد مثل وسيطٍ سواءٌ كان الكائن متغيرًا من نوع float أو مصفوفة من نوع int أو أي شيء آخر. تعيد الدالة مؤشرًا إلى عنوان التخزين المحجوز التي تختاره بطريقتها الخاصة (والتي لن نتطرق إليها) من مجموعةٍ من عناوين الذاكرة الفارغة، ومن ثم يُحوَّل المؤشر إلى النوع المناسب. على سبيل المثال، تحتاج القيمة من نوع float إلى 4 بايتات من الذاكرة، وبالتالي نكتب ما يلي لحجز مساحة للقيمة: float *fp; fp = (float *)malloc(4); تعثر الدالة malloc على 4 بايتات من الذاكرة الفارغة، ويُحوَّل عنوان الذاكرة إلى مؤشر من نوع "مؤشر إلى float"، ثم تُسند القيمة إلى المؤشر (fp في حالة مثالنا السابق). لكن ما هو نوع المؤشر الذي ستُسند قيمة malloc إليه؟ نحن بحاجة نوع يمكن أن يحتوي جميع أنواع المؤشرات فنحن لا نعلم نوع المؤشر الذي ستعيده الدالة malloc. الحل هو باستخدام نوع المؤشر * void الذي تكلمنا عنه سابقًا، إليك المثال السابق مع إضافة تصريح للدالة malloc: void *malloc(); float *fp; fp = (float *)malloc(4); لا حاجة لاستخدام تحويل الأنواع على القيمة المُعادة من الدالة malloc حسب قوانين الإسناد للمؤشرات، ولكن استُخدم تحويل الأنواع لممارسة الأمر لا أكثر. لا بد من طريقة لمعرفة قيمة وسيط malloc الدقيقة في نهاية المطاف، ولكن القيمة ستكون مختلفةً على أجهزة بمعماريات مختلفة، لذا لا يمكنك الاكتفاء باستخدام القيمة الثابتة 4 فقط، بل يجب علينا استخدام عامل sizeof. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: عامل sizeof وحجز مساحات التخزين في لغة سي C المقال السابق: المؤشرات Pointers في لغة سي C المحارف المستخدمة في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى البنية النصية لبرامج سي C -
 يشابه استخدام المؤشرات Pointers في لغة سي عملية تعلُّم قيادة الدراجة الهوائية، فعندما تصل إلى النقطة التي تعتقد أنك لن تتعلمها أبدًا، تبدأ بإتقانها، وبعد أن تتعلمها سيكون من الصعب نسيانها. لا يوجد هناك أي شيء مميّز بخصوص المؤشرات، ونعتقد أن معظم القرّاء يعرفون عنها مسبقًا، وفي الحقيقة، واحدةٌ من ميزات لغة سي هي اعتمادها الكبير على استخدام المؤشرات مقارنةً باللغات الأخرى، إضافةً إلى الأشياء الأخرى الممكن إنجازها بواسطة المؤشرات بسهولة ودون قيود إلى حدٍّ ما. التصريح عن المؤشرات ينبغي التصريح عن المؤشرات قبل استخدامها بصورةٍ مماثلة لأي متغير آخر تعاملنا معه مسبقًا. يتشابه التصريح عن المؤشر مع أي تصريح آخر، ولكن هناك نقطة مهمّة، إذ تدلّ الكلمة المفتاحية عند التصريح عن المؤشر في البداية، مثل int أوchar وغيرها عن نوع المتغير الذي سيشير المؤشر إليه، وليس نوع المؤشر بذات نفسه، ويشير المؤشّر على قيمة واحدة كل مرة من ذلك النوع وليس جميع القيم من النوع ذاته. إليك مثالًا يوضح التصريح عن مصفوفة ومؤشر: int ar[5], *ip; يصبح لدينا بعد التصريح مصفوفة ومؤشر، كما يوضح الشكل 1: شكل 1 مصفوفة ومؤشر يوضح الرمز * الموجود أمام ip أن هذا مؤشر، وليس متغيرًا اعتياديًا، وهو مؤشرٌ من النوع pointer to int، أي يشير إلى قيمة من نوع int فقط، لكن لم تُسند له قيمة أوليّة بعد، ولا يمكننا استخدامه في هذه الحالة قبل أن نجعله يؤشّر على قيمةٍ ما. لاحظ أنه لا يمكنك تعيين قيمةٍ من نوع int فورًا، لأن القيم الصحيحة لها النوع int ونحن نريد هنا قيمةً من نوع "مؤشر إلى نوع صحيح pointer to int". لكن، ما الذي سيشير إليه ip في هذه الحالة إذا كانت التعليمة التالية صحيحة ؟ ip = 6; قد تختلف الإجابة هنا، ولا يوجد إجابةً واحدةً عمّا قد يشير إليه ip، ولكن خلاصة الأمر أن هذا النوع من الإسناد غير صحيح في لغة سي. إليك الطريقة الصحيحة لإسناد قيمة أولية لمؤشر ما: int ar[5], *ip; ip = &ar[3]; يؤشّر المؤشر في هذا المثال إلى عنصرٍ من المصفوفة ar بدليل 3، أي العنصر الرابع من المصفوفة. تحذير هام: يمكنك إسناد القيم إلى المؤشرات كما في أي متغير اعتدت عليه، ولكن تكمن الأهمية في نوع هذه القيمة وما الذي تعنيه. يدل الشكل 2 على قيم المتغيرات الموجودة بعد التصريح، ويدل ?? على كون المتغير غير مُسند لقيمة أولية أي غير مهيَّأ. شكل 2 مصفوفة ومؤشر مهيّأ نلاحظ أن قيمة المتغير ip مساوية لقيمة التعبير &ar[3]، ويشير السهم إلى أن المؤشر ip يشير إلى المتغير [ar[3. لكن ما الذي يعنيه العامل الأحادي &؟ يُشار إلى هذا العامل بكونه عامل "عنوان المتغير"، إذ أن المؤشرات تخزّن عنوان المتغير الذي تؤشّر عليه في معظم الأنظمة. ربّما ستواجه صعوبةً بخصوص هذا الأمر إذا كنت تفهم ما نعني هنا بالعنوان مقارنةً بالأشخاص الذين لا يفهمون هذا الأمر، إذ أن التفكير بالمؤشرات كونها عناوينًا يؤدي إلى كثيرٍ من المشاكل في الفهم. قد تكون عملية التلاعب بعناوين معالج "أ" مستحيلةً على متحكّم آلة غسيل من نوع "ب" يستخدم عناوينًا بسعة 17-بِت عندما تكون في طور الغسيل، ويقلب ترتيب البِتات الزوجية والفردية عندما ينفد من مسحوق الغسيل. من المستبعد لأي أحد أن يستخدم لغة سي بمعمارية مشابهة لمثالنا السابق، ولكن هناك بعض الحالات الأخرى والأقل شدّة التي قد يمكن تشغيل لغة سي على معماريتها. لكننا سنتابع استخدام الكلمة "عنوان المتغير"، لأن استخدام مصطلح أو كلمة مغايرة لذلك سيتسبب بمزيدٍ من المشكلات. يعيد تطبيق العامل & لمعامل ما مؤشّرًا لهذا المعامل: int i; float f; /* مؤشر إلى عدد صحيح '&i' */ /* مؤشر إلى عدد حقيقي '&f'*/ وسيشير المؤشر في كل حالة إلى الكائن الذي يوافق اسمه اسم المستخدم في التعبير. المؤشر مفيدٌ فقط في حال وجود طريقة للوصول إلى الشيء الذي يشير إليه، وتستخدم لغة سي العامل الأحادي * لتحقيق ذلك؛ فإذا كان p من نوع "مؤشر إلى نوعٍ ما pointer to something"، فيشير التعبير *p إلى الشيء الذي يشير إليه ذلك المؤشر. على سبيل المثال، نتبع مايلي للوصول إلى المتغير x باستخدام المؤشر p: #include <stdio.h> #include <stdlib.h> main(){ int x, *p; p = &x; //تهيئة المؤشر *p = 0; // x إسناد القيمة 0 إلى المتغير printf("x is %d\n", x); printf("*p is %d\n", *p); *p += 1; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); (*p)++; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); exit(EXIT_SUCCESS); } [مثال 1] من الجدير بالذكر معرفة أن استخدام التركيب المؤلف من & و * بالشكل &* يلغي تأثير كلٍّ منهما، لأن & تعيد عنوان الكائن أي قيمة مؤشّره، و* تعني "القيمة التي يشير إليها المؤشر". لكن انتبه، فليس لبعض الأشياء مثل الثوابت أي عنوان، وبذلك لا يمكن تطبيق العامل & عليها، والتعبير 1.5& ليسَ مؤشّرًا بل تعبيرًا خاطئًا. من المثير للانتباه أيضًا إلى أن لغة سي من اللغات القليلة التي تسمح بوجود تعبير على الجانب الأيسر من عامل الإسناد. انظر مجدّدًا إلى المثال؛ إذ نصادف التعبير p* مرتين، ومن ثم التعليمة (*p)++; المثيرة للاهتمام، وستثير هذه التساؤلات من معظم المبتدئين حتى لو استطعت فهم أن التعليمة p = 0* تسند القيمة 0 إلى المتغير المُشار إليه بواسطة المؤشر p، وأن التعليمة p += 1* تضيف واحدًا إلى المتغير المُشار إليه بالمؤشر p، فاستخدام العامل ++ مع p* يبدو صعب الفهم قليلًا. تستحق أسبقية التعبير ++(p*) النظر إليها بدقة، وسنناقش مزيدًا من التفاصيل بهذا الخصوص، ولكن دعونا نركّز عمّا يحدث في هذا المثال تحديدًا. تُستخدم الأقواس للتأكد بأن * تُطبَّق على p فقط، ومن ثم تحدث زيادةً بمقدار واحد على الشيء المُشار إليه بالمؤشر p، وبالنظر إلى جدول الأسبقية في مقال العوامل في لغة سي C نلاحظ أن للعاملين ++ و* الأسبقية ذاتها، ولكن العاملين يرتبطان من اليمين إلى اليسار، وبمعنى آخر تصبح العملية بالتخلص من الأقواس مكافئةً للعملية (++p)*، وبغض النظر عن معنى هذه العملية (التي سنتكلم عن معناها لاحقًا)، لا بُدّ من الحفاظ على الأقواس في هذه الحالة والانتباه إلى مواضعها الصحيحة. لذا، وبما أن المؤشر يعطي عنوان الشيء الذي يشير إليه، فاستخدام pointer* (إذ أن pointer هو أيضًا مؤشر) يعيد الشيء بذاته مباشرةً، ولكن ما الذي نستفيد من ذلك؟ أول الأمور التي نستفيد منها هي تجاوز قيد الاستدعاء بالقيمة call-by-value عند استخدام الدوال؛ فعلى سبيل المثال تخيل دالةً تعيد قيمتين ممثلتين بأعداد صحيحة تمثّل الشهر واليوم لهذا الشهر، وأن لهذه الدالة طريقةً (غير محددة) لتحديد هذه القيم، والتحدي هنا هو إعادة قيمتين منفصلتين بنفس الوقت. إليك طريقةً لتجاوز هذه العقبة بالمثال: #include <stdio.h> #include <stdlib.h> void date(int *, int *); /* التصريح عن الدالة */ main(){ int month, day; date (&day, &month); printf("day is %d, month is %d\n", day, month); exit(EXIT_SUCCESS); } void date(int *day_p, int *month_p){ int day_ret, month_ret; /*حساب قيمة day و month في day_ret و month_ret*/ *day_p = day_ret; *month_p = month_ret; } [مثال 2] لاحظ طريقة التصريح عن date المتقدمة، التي توضح أنها دالةٌ تأخذ وسيطين من نوع "مؤشر إلى قيمة من نوع int"، وتعيد void لأن القيم التي تُمرّر بواسطة المؤشرات ليست من نوع قيمة اعتيادية. تمرِّر الدالة main المؤشرات إلى الدالة date على أنها وسطاء باستخدام المتغيرات الداخلية day_ret و month_ret، ومن ثم تأخذ قيمتهما وتسندها إلى الأماكن التي تشير إليها وسطاء الدالة (المؤشرات). يوضح الشكل 3 ما الذي يحدث عند استدعاء الدالة date: شكل 3 عند استدعاء الدالة date تُمرَّر الوسطاء إلى date، ولكن المتغيرين day و month غير مهيّأين بقيمةٍ أولية ضمن الدالة main. يوضح الشكل 4 ما الذي يحدث عندما تصل الدالة date إلى تعليمة return، بفرض أن قيمة day هي "12" وقيمة month هي "5". شكل 4 عندما تصل الدالة date إلى تعليمة return واحدةٌ من المزايا الرائعة التي قدّمتها لغة سي المعيارية هي السماح بالتصريح عن أنواع وسطاء دالة date مسبقًا، إذ كان نسيان أن الدالة تقبل مؤشرات وسطاءً لها وتمرير نوع آخر أمرًا شائع الحدوث. تخيل استدعاء الدالة date دون أي تصريح واضح مُسبقٍ لها على النحو التالي: date(day, month); لن يعرف المصرّف هنا أن الدالة تقبل المؤشرات وسطاءً لها وستُمرر قيمًا من نوع int افتراضيًا لكل من day و month، وبما أن تمرير المؤشرات والأعداد الصحيحة يجري على معظم الحواسيب بالطريقة نفسها، لذا ستُنفَّذ الدالة في هذه الحالة، ثم تعيد القيم في النهاية وتسندها إلى المكان الذي يشير إليه كلًا من day و month، إذا كانا مؤشرين. لن يعطي ذلك أي نتيجة بل وربما يتسبب بضرر مفاجئ للبيانات في مكان آخر بذاكرة الحاسوب، وتعقُّب هذا النوع من الأخطاء صعبٌ جدًا. لحسن الحظ، يمكن أن يعرف المصرّف المعلومات الكافية عن date بالتصريح عن الدالة مسبقًا، وذلك من شأنه أن يحذره بخصوص أي أخطاء مرتكبة. قد يفاجئك سماع أن المؤشرات لا تستخدم كثيرًا لتمكين طريقة الاستدعاء بالإشارة call-by-reference، إذ يُعدّ استخدام الاستدعاء بالقيمة call-by-value وإعادة قيمة واحدة باستخدام return كافٍ في معظم الحالات، والاستخدام الأكثر شيوعًا للمؤشرات هو الانتقال ما بين المصفوفات. المصفوفات والمؤشرات تملك عناصر المصفوفة عناوينًا مثل أي متغير اعتيادي آخر. int ar[20], *ip; ip = &ar[5]; *ip = 0; // يكافئ التعبير ar[5] = 0; في المثال السابق، يُخزَّن عنوان العنصر ar[5] في المؤشر ip، ثم تُسند القيمة صفر إلى موضع المؤشر في السطر الذي يليه. هذا الشيء غير مثير للإعجاب بحد ذاته، بل إن طريقة عمل العمليات الحسابية والمؤشر سويًّا هي التي تستدعي الاهتمام، فعلى الرغم من بساطة هذا الأمر، إلا أنه يُعد واحدًا من أساسات لغة سي المميزة. نحصل على مؤشر إذا أضفنا قيمة عدد صحيح إلى مؤشر ما، ويكون للمؤشر الذي حصلنا عليه نفس نوع المؤشر الأصلي؛ فبإضافة العدد "n" إلى مؤشر ما يشير إلى عنصر في مصفوفة، سنحصل على عنصر يشير إلى العنصر الذي يلي العنصر السابق بمقدار "n" داخل المصفوفة ذاتها، ويمكن تطبيق حالة الطرح بما أن العدد "n" يمكن أن يكون سالبًا. بالرجوع إلى المثال السابق، ينتج عن التعبير التالي: *(ip+1) = 0; تغيير قيمة ar[6] إلى صفر، وهكذا. لا تعدّ هذه الطريقة تحسينًا على طرق الوصول إلى عناصر المصفوفة الاعتيادية، إليك مثالًا عن ذلك بدلًا من السابق: int ar[20], *ip; for(ip = &ar[0]; ip < &ar[20]; ip++) *ip = 0; يوضّح المثال السابق ميزةً كلاسيكيةً للغة سي، إذ يشير المؤشر إلى بداية المصفوفة، وبينما يشير المؤشر إلى المصفوفة يمكن الوصول إلى عناصر المصفوفة واحدًا تلو الآخر بزيادة المؤشر بمقدار واحد كلّ مرة. يدعم معيار سي بعض الممارسات الموجودة وذلك بالسماح لاستخدام عنوان العنصر ar[20] على الرغم من عدم وجود هذا العنصر، ويسمح لك هذا باستخدام المؤشرات لاختبار حدود المصفوفة ضمن الحلقات التكرارية كما هو الحال في المثال السابق، إذ أن ضمان عمله يمتد لعنصر واحد فقط خارج نهاية المصفوفة وليس أكثر من ذلك. لكن ما المميز في هذه الطريقة مقارنةً باستخدام دليل المصفوفة للوصول إلى العنصر بالطريقة الاعتيادية؟ يمكن الوصول إلى عناصر المصفوفات في معظم الحالات بالتعاقب، واستعرضت القليل من الأمثلة البرمجية السابقة خيار الوصول إلى العناصر "عشوائيًا". إذا أردت الوصول إلى عناصر المصفوفة بالتعاقب فسيقدّم استخدام المؤشرات تنفيذًا أسرع، إذ يتطلب الأمر على معظم معماريات الحاسوب عملية ضرب وجمع واحدةً للوصول إلى عنصر ضمن مصفوفة أحادية البعد باستخدام دليله، بينما لا يتطلب الأمر باستخدام المؤشرات إجراء أي عمليات حسابية إطلاقًا، إذ يخزن المؤشر العنوان الدقيق للكائن (عنصر المصفوفة في هذه الحالة). العملية الحسابية الوحيدة المُجراة في المثال السابق هي ضمن حلقة for التكرارية، إذ تحدث عملية إضافة ومقارنة كل دورة داخل الحلقة. إذا أردنا استخدام طريقة الوصول لعناصر المصفوفة باستخدام الأدلة، نكتب: int ar[20], i; for(i = 0; i < 20; i++) ar[i] = 0; تحدث العمليات الحسابية ذاتها في الحلقة التكرارية كما في المثال السابق، لكن بإضافة حسابات العنوان المُجراة كل دورة في الحلقة. لا تعدّ نقطة توفير الوقت والفاعلية مشكلةً كبيرةً في معظم الأحيان، إلا أن الأمر مهمٌ هنا في حالة الحلقات التكرارية، إذ تتكرر الحلقات عددًا كبيرًا من المرات وكل جزء من الثانية يمكن توفيره في كل دورة له تأثير، ولا يستطيع المصرّف مهما كان ذكيًّا التعرُّف على جميع الحالات التي يمكن له استخدام المؤشرات بدلًا من طريقة دليل المصفوفة ضمنيًا. إذا استوعبت جميع ما قرأته حتى الآن فتابع معنا، وإلّا فتجاوز هذا القسم واذهب للمقال التالي، فعلى الرغم من المعلومات المثيرة للاهتمام في الأقسام التالية إلا أنها غير ضرورية وتُعرَف برهبتها لمبرمجي لغة سي المتمرسين حتى. في حقيقة الأمر، لا "تفهم" لغة سي مبدأ الوصول لعناصر المصفوفة باستخدام أدلتها (باستثناء نقطة التصريح عن المصفوفة)، فالتعبير x[n] يُترجم بالنسبة للمصرّف على النحو التالي: (x+n)*، إذ يُحوَّل اسم المصفوفة إلى مؤشر يشير إلى العنصر الأول للمصفوفة وذلك أينما وجد اسم المصفوفة ضمن تعبير ما. يُعد هذا سببٌ من ضمن أسباب أخرى لبدء عناصر المصفوفة بالرقم صفر؛ فإذا كان x اسم المصفوفة، سيكون التعبير &x[0] مساوٍ للمصفوفة x، أي مؤشر إلى العنصر الأول من المصفوفة. نستطيع الوصول إلى x[0] باستخدام المؤشرات باستخدام التعبير *(&x[0])، مما يعني أن *(&x[0] + 5) مساوٍ للتعبير *(x + 5) وهو ذات التعبير [x[5. يفتح ذلك الأمر سيلًا من التساؤلات عن الإمكانيات الناتجة، فإذا كان التعبير x[5] يُترجم إلى *(x + 5) والتعبير x + 5 يعطي النتيجة ذاتها للتعبير: 5 + x فالتعبير 5[x] مساوٍ للتعبير x[5]. إليك برنامجًا يُصرّف وينفذ دون أي أخطاء إن لم تصدق هذا الأمر: #include <stdio.h> #include <stdlib.h> #define ARSZ 20 main(){ int ar[ARSZ], i; for(i = 0; i < ARSZ; i++){ ar[i] = i; i[ar]++; printf("ar[%d] now = %d\n", i, ar[i]); } printf("15[ar] = %d\n", 15[ar]); exit(EXIT_SUCCESS); } [مثال 3] لتلخيص ما سبق: تبدأ العناصر في أي مصفوفة من الدليل ذي الرقم صفر. ليس هناك أي وجود للمصفوفات متعددة الأبعاد، بل هي في حقيقة الأمر مصفوفاتٌ تحتوي على مصفوفات. تُشير المؤشرات إلى أشياء، والمؤشرات التي تشير إلى أشياء من أنواع مختلفة هي بدورها من أنواع مختلفة أيضًا ولا يوجد أي تشابه بين الأنواع المختلفة في لغة سي وأي تحويل ضمني تلقائي بينهما. يمكن استخدام المؤشرات لمحاكاة استخدام الاستدعاء بالإشارة ضمن الدوال، ولكن الأمر يستغرق بعضًا من الجهد لتحقيقه. تُستخدم زيادة أو نقصان قيمة مؤشر ما للتنقل بين عناصر المصفوفة. يضمن المعيار أن محاولة الوصول إلى العنصر ذي الدليل "n" في مصفوفة ذات حجم "n" محاولةٌ صالحة على الرغم من عدم وجود هذا العنصر وذلك لتسهيل أمر التنقل داخل المصفوفة بزيادة قيمة المؤشر، ويكون مجال قيم مصفوفة مصرّح عنها على النحو int ar[N] هو &ar[0] وصولًا إلى &ar[N] ولكن يجب عليك تفادي الوصول إلى قيمة العنصر الأخير الزائف. الأنواع المؤهلة Qualified تابع قراءة الفقرات التالية إن كنت واثقًا من فهمك لأساسيات عملية التصريح عن المؤشرات واستخدامها، وإلا فمن المهم العودة إلى الفقرات السابقة ومحاولة فهمها جيّدًا قبل قراءة الفقرات التالية، إذ أن المعلومات المذكورة في الفقرات التالية أكثر تعقيدًا، ولا داعِ لجعل الأمر أسوأ بعدم تحضيرك وفهمك لما سبق. قدم المعيار شيئان باسم مؤهلات النوع type qualifiers، إذ لم يكونا في لغة سي القديمة مسبقًا، ويمكن تطبيقهما لأي نوع مصرّحٌ عنه للتعديل من تصرفه، ومن هنا أتى اسمهما. سنتجاهل إحداهما (المدعو باسم "volatile") إلا أنه لا يمكننا تجاهل الآخر "const". إذا سبقت الكلمة المفتاحية "const" أي تصريح، فهذا يعني أن الشيء الذي صُرّح عنه هو ثابت، ويجب عليك تجنب محاولة التغيير على قيمة الكائنات الثابتة "const" وإلا فستحصل على سلوك غير محدّد undefined behaviour، وسيحذّرك المصرّف عادةً بمنعك من هذه المحاولة إلا إذا تجاوزت هذا القيد بحيلةٍ ما. هناك فائدتان مرجوتان من تصريح كائن ما بكونه ثابتًا "const": يشير استخدام الكلمة المفتاحية "const" إلى أن القيمة غير قابلة للتغيير، مما يجبر المصرّف على التحقق من أي تغييرات طرأت على هذه القيمة ضمن الشيفرة البرمجية، وهذا الأمر باعث للطمأنينة في حال أردت استخدام قيمٍ ثابتة، مثل المؤشرات التي تُستخدم وسطاءً في بعض الدوال. إذا احتوى التصريح عن الدالة مؤشرات تشير إلى كائنات ثابتة على أنها وسطاء، فهذا يعني أن الدالة لن تشير إلى أي كائن آخر. عندما يعلم المصرّف بأن الأشياء هي كائنات ثابتة، ينعكس ذلك إيجابيًا على قدرته برفع فاعلية الشيفرة البرمجية وسرعتها. الثوابت عديمة الفائدة في حال لم تسند إليها أي قيمة، لن نتطرق بالتفصيل بخصوص تهيئة الثوابت (سنناقش الأمر لاحقًا)، كل ما عليك تذكره الآن هو أنه من الممكن لأي تصريح إسناد القيمة لتعبيرٍ ثابت. إليك بعض الأمثلة عن التصريح عن ثوابت: const int x = 1; /* ثابت x */ const float f = 3.5; /* ثابت f*/ const char y[10]; /* y مصفوفة من 10 عناصر ذات قيم صحيحة ثابتة */ /* لا تفكر بخصوص تهيئة قيمها بعد */ ما يثير الاهتمام هو كون هذا المؤهل ممكن التطبيق على المؤشرات بطريقتين: إما بجعل الشيء الذي يشير إليه المؤشر ثابتًا، بحيث يصبح نوع المؤشر "مؤشر إلى ثابت"، أو بجعل المؤشر بذات نفسه ثابتًا (مؤشرًا ثابتًا)، إليك مثالًا عن ذلك: int i; /* عدد صحيح اعتيادي i */ const int ci = 1; /* عدد صحيح ثابت ci */ int *pi; /* مؤشر إلى عدد صحيح pi */ const int *pci; /* مؤشر إلى عدد صحيح ثابت pci */ /* بالانتقال إلى الأمثلة الأكثر تعقيدًا */ // مؤشر ثابت يشير إلى قيمة عدد صحيح cpi int *const cpi = &i; // مؤشر ثابت يشير إلى قيمة عدد صحيح ثابتة cpci const int *const cpci = &ci; التصريح الأول (للمتغير i) اعتيادي، ولكن تصريح ci يوضح أنه عدد صحيح ثابت وبذلك لا يمكن التعديل على قيمته، وسيكون بلا فائدة إن لم يُهيّأ (إسناد قيمة أولية له). ليس من الصعب فهم الغرض من مؤشر لعدد صحيح، ومؤشر لعدد صحيح ثابت، ولكن يجب الانتباه إلى أنواع المؤشرات المختلفة، إذ لا يجوز الخلط بينهم. يمكنك تغيير قيمة كل من pi و pci بجعلهما يشيران إلى أشياء أخرى، كما يمكنك تغيير قيمة الشيء الذي يشير إليه المؤشر pi بالنظر إلى كونه عدد صحيح غير ثابت، ولكن لا يمكنك إلّا الوصول إلى قيمة الشيء الذي يشير إليه المؤشر pci دون التعديل عليه نظرًا لكونه ثابتًا. يُعد التصريحان الأخيران أكثر التصريحات تعقيدًا ضمن المثال؛ فإذا كانت المؤشرات بذات نفسها ثابتةً، فمن غير المسموح تغيير المكان الذي تشير إليه، وبالتالي يجب تهيأتهما بقيمة أولية مثل ci. يمكن للشيء المُشار إليه بالمؤشر أن يكون ثابتًا أو غير ثابت بغض النظر عن كون المؤشر ثابتًا بدوره أم لا، وهذا يملي بعض القيود على استخدام الكائن المُشار إليه. أخيرًا للتوضيح: ما الذي يملي وجود نوع مؤهّل؟ كان ci في المثال السابق نوعًا مؤهلًا بكل وضوح، ولكن pci لم تنطبق عليه هذه الحالة بما أن المؤشر ليس من نوع مؤهّل بل الشيء الذي يشير إليه. الأشياء الوحيدة الذي كانت ذات أنواع مؤهلة في المثال هي: ci و cpi و cpci. سيتطلب منك الأمر بعض الوقت للاعتياد على هذا النوع من التصريحات، ولكن استخدامها سيكون تلقائيًّا وطبيعيًا بعد فترة فلا تقلق، إلا أن التعقيدات تبدأ بالظهور لاحقًا عندما يتوجب عليك الإجابة على السؤال: "هل من المسموح لي -على سبيل المثال- مقارنة مؤشر اعتيادي مع مؤشر ثابت؟ وإذا كان الجواب نعم، ما الذي تعنيه المقارنة؟". معظم القوانين واضحة بهذا الخصوص، ولكن يجب ذكرها وتوضيحها بغض النظر عن سهولتها. سنتكلم عن أنواع البيانات المؤهلة بتوسعٍ أكبر لاحقًا. عمليات المؤشرات الحسابية سنتكلم بالتفصيل لاحقًا عن عمليات المؤشرات الحسابية، ولكننا سنكتفي الآن بإصدار مختصرٍ يفي بالغرض. يمكنك الطرح أو المقارنة بين مؤشرين من النوع نفسه بالإضافة إلى إضافة قيمة عددية صحيحة إلى المؤشر، ويجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها وإلا حصلنا على سلوك غير محدد. نتيجة طرح مؤشرين هي قيمة العناصر التي تفصل بينهما في المصفوفة، ونوع النتيجة معرفٌ بحسب التطبيق وسيكون إما "short" أو "int" أو "long"، ويوضح المثال القادم مثالًا على حساب الفرق بين مؤشرين واستخدام النتيجة، ولكن قبل أن ننتقل إلى المثال يجب أن تعرف معلومةً مهمة. يُحوَّل اسم المصفوفة في أي تعبير إلى مؤشر يشير إلى العنصر الأول ضمن هذه المصفوفة، والحالة الوحيدة الاستثنائية هي عند استخدام اسم المصفوفة مع الكلمة المفتاحية "sizeof"، أو عند استخدام سلسلة نصية لتهيئة قيمة مصفوفة ما، أو عندما يكون اسم المصفوفة مرتبطًا بعامل "عنوان الكائن" (العامل الأحادي "&")، لكننا لم نتطرق إلى أيّ من الحالات السابقة بعد، وسنناقشها لاحقًا. إليك المثال: #include <stdio.h> #include <stdlib.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %d\n", (int)(fp2-fp1)); fp2++; } exit(EXIT_SUCCESS); } [مثال 4] يشير المؤشر fp2 إلى عناصر المصفوفة، ويُطبع الفرق بين قيمته الحالية وقيمته الأصلية، وللتأكد من عدم تمرير النوع الخاطئ للوسيط للدالة printf تُحوَّل القيمة الناتجة عن فرق المؤشرين قسريًّا إلى int باستخدام تحويل الأنواع (int)، وهذا يجنّبنا من الأخطاء على الحواسيب التي تعيد قيمة long لهذا النوع من العمليات. قد يعود إلينا المثال السابق بإجابات خاطئة إذا كان الفرق بين القيمتين من نوع long وكانت المصفوفة كبيرة الحجم، ونلاحظ في المثال التالي إصدارًا آمنًا من المثال السابق، إذ يُستخدم تحويل الأنواع قسريًا للسماح بوجود قيم long: #include <stdio.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %ld\n", (long)(fp2-fp1)); fp2++; } return(0); } [مثال 5] مؤشرات void و null والمؤشرات الإشكالية لغة سي حريصة بشأن أنواع المؤشرات، ولن تسمح لك عمومًا باستخدام مؤشرات ذات أنوع مختلفة ضمن التعبير ذاته. يختلف مؤشر إلى نوع "char" عن مؤشر إلى نوع "int" ولا يمكنك -على سبيل المثال- إسناد قيمة أحدهما إلى الآخر أو المقارنة فيما بينهما أو طرحهما من بعضهما واستخدام النتيجة مثل وسيط في دالة ما، كما يمكن أيضًا تخزين النوعين في الذاكرة بصورةٍ مختلفة وأن يكونا بأطوال مختلفة. لكن نريد في بعض الحالات تجاوز هذه القيود، فكيف نفعل ذلك؟ يكمن الحل هنا باستخدام أنواع خاصة، وقد قدمنا واحدًا من هذه الأنواع سابقًا ألا وهو "مؤشر إلى void"، وقُدّمت هذه الميزة مع سي المعيارية إذ افتُرض سابقًا أن المؤشر من نوع "مؤشر إلى char" كافٍ لهذه المهمة، وكان الافتراض صحيحًا إلى حدٍّ ما إلا أنه كان حلًّا غير منظّمًا، بينما قدّم الحل الجديد طريقةً أكثر أمانًا وأقل تشويشًا. لا يوجد أي استخدام للمؤشر هذا، لأن "* void" لا يشير إلى أي قيمة، لذا يحسّن هذا الأمر من سهولة قراءة الشيفرة البرمجية. يمكن أن يخزن المؤشر من النوع "* void" أي قيمة من أي مؤشر آخر، ويمكن إسناده إلى مؤشر آخر من أي نوع أيضًا، إلا أنه يجب استخدام هذا النوع من المؤشرات بحذر لأنه قد ينتهي الأمر بك ببعض الأخطاء الوخيمة، وسنناقش استخدامه الآمن مع دالة "malloc" لاحقًا. قد تحتاج أيضًا في بعض الحالات إلى مؤشر مضمون أنه لا يشير إلى أي كائن والذي يُدعى مؤشر من نوع "null" أو مؤشر الفراغ null pointer. من الشائع في لغة سي كتابة بعض الإجراءات routines التي تعيد مؤشرات، بحيث يمكن الدلالة على فشل ذلك الإجراء بعدم قدرته على إعادة مؤشر صالح عن طريق إعادة مؤشر الفراغ. ومن الأمثلة على ذلك إجراء فحصٍ لقيم موجودة في جدول ما بحثًا عن قيمة معينة ويعيد مؤشرًا على الكائن المُطابق إن وُجدت النتيجة أو مؤشر الفراغ إن لم تُوجد أي نتيجةٍ مطابقة. لكن كيف يمكن كتابة مؤشر فراغ؟ هناك طريقتان لفعل ذلك وكلا الطريقتين متماثلتين في النتيجة، إما باستخدام رقم صحيح ثابت بقيمة "0" أو تحويل القيمة إلى نوع "* void" باستخدام التحويل بين الأنواع، وتدعى نتيجة الطريقتين بمؤشر الفراغ الثابت null pointer constant. إذا أسندت مؤشر فراغ إلى أي مؤشر آخر أو قارنت بين مؤشر الفراغ ومؤشر آخر فسيُحوَّل مؤشر الفراغ إلى نوع المؤشر الآخر تلقائيًّا، مما سيحلّ أي مشكلة بخصوص توافقية الأنواع، ولن تُساوي القيمة التي يشير إليها ذلك المؤشر -مؤشر الفراغ- أي قيمة كائن آخر يشير إليها أي مؤشر داخل البرنامج (أي سيشير إلى قيمة فريدة). القيم الوحيدة الممكن إسنادها للمؤشرات باستثناء القيمة "0" هي قيم المؤشرات الأخرى من نفس النوع، إلا أن الأمر الذي يجعل من لغة سي مميزة وبديلًا مفيدًا للغة التجميعية هو سماحها لك بفعل بعض الأشياء التي لا تسمح لك بها معظم لغات البرمجة الأخرى، جرّب التالي: int *ip; ip = (int *)6; *ip = 0xFF; ما نتيجة السابق؟ تُهيأ قيمة المؤشر إلى 6 (لاحظ تحويل نوع 6 من int إلى مؤشر)، وهذه عملية تُجرى على مستوى الآلة غالبًا ويكون تمثيل قيمة المؤشر بالبتات غير مشابه لما قد يكون تمثيل الرقم 6، كما تُسند القيمة الست عشرية FF بعد التهيئة إلى الكائن الذي يشير إليه المؤشر. تُكتب القيمة 0xFF على الرقم الصحيح ذو الموضع 6، إذ يعتمد الموضع 6 على تفسير الآلة له على الذاكرة. قد تحتاج لهذا النوع من الأشياء وقد لا تحتاج إليها إطلاقًا، ولكن لغة سي تعطيك الخيار، ومن الواجب معرفتها إذ أنه من الممكن كتابتها على نحوٍ خاطئ غير مقصود مما سيتسبب بنتائج مفاجئة جدًا. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف والسلاسل النصية في لغة سي C المقال السابق: مدخل إلى المصفوفات في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C البنية النصية لبرامج سي C
يشابه استخدام المؤشرات Pointers في لغة سي عملية تعلُّم قيادة الدراجة الهوائية، فعندما تصل إلى النقطة التي تعتقد أنك لن تتعلمها أبدًا، تبدأ بإتقانها، وبعد أن تتعلمها سيكون من الصعب نسيانها. لا يوجد هناك أي شيء مميّز بخصوص المؤشرات، ونعتقد أن معظم القرّاء يعرفون عنها مسبقًا، وفي الحقيقة، واحدةٌ من ميزات لغة سي هي اعتمادها الكبير على استخدام المؤشرات مقارنةً باللغات الأخرى، إضافةً إلى الأشياء الأخرى الممكن إنجازها بواسطة المؤشرات بسهولة ودون قيود إلى حدٍّ ما. التصريح عن المؤشرات ينبغي التصريح عن المؤشرات قبل استخدامها بصورةٍ مماثلة لأي متغير آخر تعاملنا معه مسبقًا. يتشابه التصريح عن المؤشر مع أي تصريح آخر، ولكن هناك نقطة مهمّة، إذ تدلّ الكلمة المفتاحية عند التصريح عن المؤشر في البداية، مثل int أوchar وغيرها عن نوع المتغير الذي سيشير المؤشر إليه، وليس نوع المؤشر بذات نفسه، ويشير المؤشّر على قيمة واحدة كل مرة من ذلك النوع وليس جميع القيم من النوع ذاته. إليك مثالًا يوضح التصريح عن مصفوفة ومؤشر: int ar[5], *ip; يصبح لدينا بعد التصريح مصفوفة ومؤشر، كما يوضح الشكل 1: شكل 1 مصفوفة ومؤشر يوضح الرمز * الموجود أمام ip أن هذا مؤشر، وليس متغيرًا اعتياديًا، وهو مؤشرٌ من النوع pointer to int، أي يشير إلى قيمة من نوع int فقط، لكن لم تُسند له قيمة أوليّة بعد، ولا يمكننا استخدامه في هذه الحالة قبل أن نجعله يؤشّر على قيمةٍ ما. لاحظ أنه لا يمكنك تعيين قيمةٍ من نوع int فورًا، لأن القيم الصحيحة لها النوع int ونحن نريد هنا قيمةً من نوع "مؤشر إلى نوع صحيح pointer to int". لكن، ما الذي سيشير إليه ip في هذه الحالة إذا كانت التعليمة التالية صحيحة ؟ ip = 6; قد تختلف الإجابة هنا، ولا يوجد إجابةً واحدةً عمّا قد يشير إليه ip، ولكن خلاصة الأمر أن هذا النوع من الإسناد غير صحيح في لغة سي. إليك الطريقة الصحيحة لإسناد قيمة أولية لمؤشر ما: int ar[5], *ip; ip = &ar[3]; يؤشّر المؤشر في هذا المثال إلى عنصرٍ من المصفوفة ar بدليل 3، أي العنصر الرابع من المصفوفة. تحذير هام: يمكنك إسناد القيم إلى المؤشرات كما في أي متغير اعتدت عليه، ولكن تكمن الأهمية في نوع هذه القيمة وما الذي تعنيه. يدل الشكل 2 على قيم المتغيرات الموجودة بعد التصريح، ويدل ?? على كون المتغير غير مُسند لقيمة أولية أي غير مهيَّأ. شكل 2 مصفوفة ومؤشر مهيّأ نلاحظ أن قيمة المتغير ip مساوية لقيمة التعبير &ar[3]، ويشير السهم إلى أن المؤشر ip يشير إلى المتغير [ar[3. لكن ما الذي يعنيه العامل الأحادي &؟ يُشار إلى هذا العامل بكونه عامل "عنوان المتغير"، إذ أن المؤشرات تخزّن عنوان المتغير الذي تؤشّر عليه في معظم الأنظمة. ربّما ستواجه صعوبةً بخصوص هذا الأمر إذا كنت تفهم ما نعني هنا بالعنوان مقارنةً بالأشخاص الذين لا يفهمون هذا الأمر، إذ أن التفكير بالمؤشرات كونها عناوينًا يؤدي إلى كثيرٍ من المشاكل في الفهم. قد تكون عملية التلاعب بعناوين معالج "أ" مستحيلةً على متحكّم آلة غسيل من نوع "ب" يستخدم عناوينًا بسعة 17-بِت عندما تكون في طور الغسيل، ويقلب ترتيب البِتات الزوجية والفردية عندما ينفد من مسحوق الغسيل. من المستبعد لأي أحد أن يستخدم لغة سي بمعمارية مشابهة لمثالنا السابق، ولكن هناك بعض الحالات الأخرى والأقل شدّة التي قد يمكن تشغيل لغة سي على معماريتها. لكننا سنتابع استخدام الكلمة "عنوان المتغير"، لأن استخدام مصطلح أو كلمة مغايرة لذلك سيتسبب بمزيدٍ من المشكلات. يعيد تطبيق العامل & لمعامل ما مؤشّرًا لهذا المعامل: int i; float f; /* مؤشر إلى عدد صحيح '&i' */ /* مؤشر إلى عدد حقيقي '&f'*/ وسيشير المؤشر في كل حالة إلى الكائن الذي يوافق اسمه اسم المستخدم في التعبير. المؤشر مفيدٌ فقط في حال وجود طريقة للوصول إلى الشيء الذي يشير إليه، وتستخدم لغة سي العامل الأحادي * لتحقيق ذلك؛ فإذا كان p من نوع "مؤشر إلى نوعٍ ما pointer to something"، فيشير التعبير *p إلى الشيء الذي يشير إليه ذلك المؤشر. على سبيل المثال، نتبع مايلي للوصول إلى المتغير x باستخدام المؤشر p: #include <stdio.h> #include <stdlib.h> main(){ int x, *p; p = &x; //تهيئة المؤشر *p = 0; // x إسناد القيمة 0 إلى المتغير printf("x is %d\n", x); printf("*p is %d\n", *p); *p += 1; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); (*p)++; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); exit(EXIT_SUCCESS); } [مثال 1] من الجدير بالذكر معرفة أن استخدام التركيب المؤلف من & و * بالشكل &* يلغي تأثير كلٍّ منهما، لأن & تعيد عنوان الكائن أي قيمة مؤشّره، و* تعني "القيمة التي يشير إليها المؤشر". لكن انتبه، فليس لبعض الأشياء مثل الثوابت أي عنوان، وبذلك لا يمكن تطبيق العامل & عليها، والتعبير 1.5& ليسَ مؤشّرًا بل تعبيرًا خاطئًا. من المثير للانتباه أيضًا إلى أن لغة سي من اللغات القليلة التي تسمح بوجود تعبير على الجانب الأيسر من عامل الإسناد. انظر مجدّدًا إلى المثال؛ إذ نصادف التعبير p* مرتين، ومن ثم التعليمة (*p)++; المثيرة للاهتمام، وستثير هذه التساؤلات من معظم المبتدئين حتى لو استطعت فهم أن التعليمة p = 0* تسند القيمة 0 إلى المتغير المُشار إليه بواسطة المؤشر p، وأن التعليمة p += 1* تضيف واحدًا إلى المتغير المُشار إليه بالمؤشر p، فاستخدام العامل ++ مع p* يبدو صعب الفهم قليلًا. تستحق أسبقية التعبير ++(p*) النظر إليها بدقة، وسنناقش مزيدًا من التفاصيل بهذا الخصوص، ولكن دعونا نركّز عمّا يحدث في هذا المثال تحديدًا. تُستخدم الأقواس للتأكد بأن * تُطبَّق على p فقط، ومن ثم تحدث زيادةً بمقدار واحد على الشيء المُشار إليه بالمؤشر p، وبالنظر إلى جدول الأسبقية في مقال العوامل في لغة سي C نلاحظ أن للعاملين ++ و* الأسبقية ذاتها، ولكن العاملين يرتبطان من اليمين إلى اليسار، وبمعنى آخر تصبح العملية بالتخلص من الأقواس مكافئةً للعملية (++p)*، وبغض النظر عن معنى هذه العملية (التي سنتكلم عن معناها لاحقًا)، لا بُدّ من الحفاظ على الأقواس في هذه الحالة والانتباه إلى مواضعها الصحيحة. لذا، وبما أن المؤشر يعطي عنوان الشيء الذي يشير إليه، فاستخدام pointer* (إذ أن pointer هو أيضًا مؤشر) يعيد الشيء بذاته مباشرةً، ولكن ما الذي نستفيد من ذلك؟ أول الأمور التي نستفيد منها هي تجاوز قيد الاستدعاء بالقيمة call-by-value عند استخدام الدوال؛ فعلى سبيل المثال تخيل دالةً تعيد قيمتين ممثلتين بأعداد صحيحة تمثّل الشهر واليوم لهذا الشهر، وأن لهذه الدالة طريقةً (غير محددة) لتحديد هذه القيم، والتحدي هنا هو إعادة قيمتين منفصلتين بنفس الوقت. إليك طريقةً لتجاوز هذه العقبة بالمثال: #include <stdio.h> #include <stdlib.h> void date(int *, int *); /* التصريح عن الدالة */ main(){ int month, day; date (&day, &month); printf("day is %d, month is %d\n", day, month); exit(EXIT_SUCCESS); } void date(int *day_p, int *month_p){ int day_ret, month_ret; /*حساب قيمة day و month في day_ret و month_ret*/ *day_p = day_ret; *month_p = month_ret; } [مثال 2] لاحظ طريقة التصريح عن date المتقدمة، التي توضح أنها دالةٌ تأخذ وسيطين من نوع "مؤشر إلى قيمة من نوع int"، وتعيد void لأن القيم التي تُمرّر بواسطة المؤشرات ليست من نوع قيمة اعتيادية. تمرِّر الدالة main المؤشرات إلى الدالة date على أنها وسطاء باستخدام المتغيرات الداخلية day_ret و month_ret، ومن ثم تأخذ قيمتهما وتسندها إلى الأماكن التي تشير إليها وسطاء الدالة (المؤشرات). يوضح الشكل 3 ما الذي يحدث عند استدعاء الدالة date: شكل 3 عند استدعاء الدالة date تُمرَّر الوسطاء إلى date، ولكن المتغيرين day و month غير مهيّأين بقيمةٍ أولية ضمن الدالة main. يوضح الشكل 4 ما الذي يحدث عندما تصل الدالة date إلى تعليمة return، بفرض أن قيمة day هي "12" وقيمة month هي "5". شكل 4 عندما تصل الدالة date إلى تعليمة return واحدةٌ من المزايا الرائعة التي قدّمتها لغة سي المعيارية هي السماح بالتصريح عن أنواع وسطاء دالة date مسبقًا، إذ كان نسيان أن الدالة تقبل مؤشرات وسطاءً لها وتمرير نوع آخر أمرًا شائع الحدوث. تخيل استدعاء الدالة date دون أي تصريح واضح مُسبقٍ لها على النحو التالي: date(day, month); لن يعرف المصرّف هنا أن الدالة تقبل المؤشرات وسطاءً لها وستُمرر قيمًا من نوع int افتراضيًا لكل من day و month، وبما أن تمرير المؤشرات والأعداد الصحيحة يجري على معظم الحواسيب بالطريقة نفسها، لذا ستُنفَّذ الدالة في هذه الحالة، ثم تعيد القيم في النهاية وتسندها إلى المكان الذي يشير إليه كلًا من day و month، إذا كانا مؤشرين. لن يعطي ذلك أي نتيجة بل وربما يتسبب بضرر مفاجئ للبيانات في مكان آخر بذاكرة الحاسوب، وتعقُّب هذا النوع من الأخطاء صعبٌ جدًا. لحسن الحظ، يمكن أن يعرف المصرّف المعلومات الكافية عن date بالتصريح عن الدالة مسبقًا، وذلك من شأنه أن يحذره بخصوص أي أخطاء مرتكبة. قد يفاجئك سماع أن المؤشرات لا تستخدم كثيرًا لتمكين طريقة الاستدعاء بالإشارة call-by-reference، إذ يُعدّ استخدام الاستدعاء بالقيمة call-by-value وإعادة قيمة واحدة باستخدام return كافٍ في معظم الحالات، والاستخدام الأكثر شيوعًا للمؤشرات هو الانتقال ما بين المصفوفات. المصفوفات والمؤشرات تملك عناصر المصفوفة عناوينًا مثل أي متغير اعتيادي آخر. int ar[20], *ip; ip = &ar[5]; *ip = 0; // يكافئ التعبير ar[5] = 0; في المثال السابق، يُخزَّن عنوان العنصر ar[5] في المؤشر ip، ثم تُسند القيمة صفر إلى موضع المؤشر في السطر الذي يليه. هذا الشيء غير مثير للإعجاب بحد ذاته، بل إن طريقة عمل العمليات الحسابية والمؤشر سويًّا هي التي تستدعي الاهتمام، فعلى الرغم من بساطة هذا الأمر، إلا أنه يُعد واحدًا من أساسات لغة سي المميزة. نحصل على مؤشر إذا أضفنا قيمة عدد صحيح إلى مؤشر ما، ويكون للمؤشر الذي حصلنا عليه نفس نوع المؤشر الأصلي؛ فبإضافة العدد "n" إلى مؤشر ما يشير إلى عنصر في مصفوفة، سنحصل على عنصر يشير إلى العنصر الذي يلي العنصر السابق بمقدار "n" داخل المصفوفة ذاتها، ويمكن تطبيق حالة الطرح بما أن العدد "n" يمكن أن يكون سالبًا. بالرجوع إلى المثال السابق، ينتج عن التعبير التالي: *(ip+1) = 0; تغيير قيمة ar[6] إلى صفر، وهكذا. لا تعدّ هذه الطريقة تحسينًا على طرق الوصول إلى عناصر المصفوفة الاعتيادية، إليك مثالًا عن ذلك بدلًا من السابق: int ar[20], *ip; for(ip = &ar[0]; ip < &ar[20]; ip++) *ip = 0; يوضّح المثال السابق ميزةً كلاسيكيةً للغة سي، إذ يشير المؤشر إلى بداية المصفوفة، وبينما يشير المؤشر إلى المصفوفة يمكن الوصول إلى عناصر المصفوفة واحدًا تلو الآخر بزيادة المؤشر بمقدار واحد كلّ مرة. يدعم معيار سي بعض الممارسات الموجودة وذلك بالسماح لاستخدام عنوان العنصر ar[20] على الرغم من عدم وجود هذا العنصر، ويسمح لك هذا باستخدام المؤشرات لاختبار حدود المصفوفة ضمن الحلقات التكرارية كما هو الحال في المثال السابق، إذ أن ضمان عمله يمتد لعنصر واحد فقط خارج نهاية المصفوفة وليس أكثر من ذلك. لكن ما المميز في هذه الطريقة مقارنةً باستخدام دليل المصفوفة للوصول إلى العنصر بالطريقة الاعتيادية؟ يمكن الوصول إلى عناصر المصفوفات في معظم الحالات بالتعاقب، واستعرضت القليل من الأمثلة البرمجية السابقة خيار الوصول إلى العناصر "عشوائيًا". إذا أردت الوصول إلى عناصر المصفوفة بالتعاقب فسيقدّم استخدام المؤشرات تنفيذًا أسرع، إذ يتطلب الأمر على معظم معماريات الحاسوب عملية ضرب وجمع واحدةً للوصول إلى عنصر ضمن مصفوفة أحادية البعد باستخدام دليله، بينما لا يتطلب الأمر باستخدام المؤشرات إجراء أي عمليات حسابية إطلاقًا، إذ يخزن المؤشر العنوان الدقيق للكائن (عنصر المصفوفة في هذه الحالة). العملية الحسابية الوحيدة المُجراة في المثال السابق هي ضمن حلقة for التكرارية، إذ تحدث عملية إضافة ومقارنة كل دورة داخل الحلقة. إذا أردنا استخدام طريقة الوصول لعناصر المصفوفة باستخدام الأدلة، نكتب: int ar[20], i; for(i = 0; i < 20; i++) ar[i] = 0; تحدث العمليات الحسابية ذاتها في الحلقة التكرارية كما في المثال السابق، لكن بإضافة حسابات العنوان المُجراة كل دورة في الحلقة. لا تعدّ نقطة توفير الوقت والفاعلية مشكلةً كبيرةً في معظم الأحيان، إلا أن الأمر مهمٌ هنا في حالة الحلقات التكرارية، إذ تتكرر الحلقات عددًا كبيرًا من المرات وكل جزء من الثانية يمكن توفيره في كل دورة له تأثير، ولا يستطيع المصرّف مهما كان ذكيًّا التعرُّف على جميع الحالات التي يمكن له استخدام المؤشرات بدلًا من طريقة دليل المصفوفة ضمنيًا. إذا استوعبت جميع ما قرأته حتى الآن فتابع معنا، وإلّا فتجاوز هذا القسم واذهب للمقال التالي، فعلى الرغم من المعلومات المثيرة للاهتمام في الأقسام التالية إلا أنها غير ضرورية وتُعرَف برهبتها لمبرمجي لغة سي المتمرسين حتى. في حقيقة الأمر، لا "تفهم" لغة سي مبدأ الوصول لعناصر المصفوفة باستخدام أدلتها (باستثناء نقطة التصريح عن المصفوفة)، فالتعبير x[n] يُترجم بالنسبة للمصرّف على النحو التالي: (x+n)*، إذ يُحوَّل اسم المصفوفة إلى مؤشر يشير إلى العنصر الأول للمصفوفة وذلك أينما وجد اسم المصفوفة ضمن تعبير ما. يُعد هذا سببٌ من ضمن أسباب أخرى لبدء عناصر المصفوفة بالرقم صفر؛ فإذا كان x اسم المصفوفة، سيكون التعبير &x[0] مساوٍ للمصفوفة x، أي مؤشر إلى العنصر الأول من المصفوفة. نستطيع الوصول إلى x[0] باستخدام المؤشرات باستخدام التعبير *(&x[0])، مما يعني أن *(&x[0] + 5) مساوٍ للتعبير *(x + 5) وهو ذات التعبير [x[5. يفتح ذلك الأمر سيلًا من التساؤلات عن الإمكانيات الناتجة، فإذا كان التعبير x[5] يُترجم إلى *(x + 5) والتعبير x + 5 يعطي النتيجة ذاتها للتعبير: 5 + x فالتعبير 5[x] مساوٍ للتعبير x[5]. إليك برنامجًا يُصرّف وينفذ دون أي أخطاء إن لم تصدق هذا الأمر: #include <stdio.h> #include <stdlib.h> #define ARSZ 20 main(){ int ar[ARSZ], i; for(i = 0; i < ARSZ; i++){ ar[i] = i; i[ar]++; printf("ar[%d] now = %d\n", i, ar[i]); } printf("15[ar] = %d\n", 15[ar]); exit(EXIT_SUCCESS); } [مثال 3] لتلخيص ما سبق: تبدأ العناصر في أي مصفوفة من الدليل ذي الرقم صفر. ليس هناك أي وجود للمصفوفات متعددة الأبعاد، بل هي في حقيقة الأمر مصفوفاتٌ تحتوي على مصفوفات. تُشير المؤشرات إلى أشياء، والمؤشرات التي تشير إلى أشياء من أنواع مختلفة هي بدورها من أنواع مختلفة أيضًا ولا يوجد أي تشابه بين الأنواع المختلفة في لغة سي وأي تحويل ضمني تلقائي بينهما. يمكن استخدام المؤشرات لمحاكاة استخدام الاستدعاء بالإشارة ضمن الدوال، ولكن الأمر يستغرق بعضًا من الجهد لتحقيقه. تُستخدم زيادة أو نقصان قيمة مؤشر ما للتنقل بين عناصر المصفوفة. يضمن المعيار أن محاولة الوصول إلى العنصر ذي الدليل "n" في مصفوفة ذات حجم "n" محاولةٌ صالحة على الرغم من عدم وجود هذا العنصر وذلك لتسهيل أمر التنقل داخل المصفوفة بزيادة قيمة المؤشر، ويكون مجال قيم مصفوفة مصرّح عنها على النحو int ar[N] هو &ar[0] وصولًا إلى &ar[N] ولكن يجب عليك تفادي الوصول إلى قيمة العنصر الأخير الزائف. الأنواع المؤهلة Qualified تابع قراءة الفقرات التالية إن كنت واثقًا من فهمك لأساسيات عملية التصريح عن المؤشرات واستخدامها، وإلا فمن المهم العودة إلى الفقرات السابقة ومحاولة فهمها جيّدًا قبل قراءة الفقرات التالية، إذ أن المعلومات المذكورة في الفقرات التالية أكثر تعقيدًا، ولا داعِ لجعل الأمر أسوأ بعدم تحضيرك وفهمك لما سبق. قدم المعيار شيئان باسم مؤهلات النوع type qualifiers، إذ لم يكونا في لغة سي القديمة مسبقًا، ويمكن تطبيقهما لأي نوع مصرّحٌ عنه للتعديل من تصرفه، ومن هنا أتى اسمهما. سنتجاهل إحداهما (المدعو باسم "volatile") إلا أنه لا يمكننا تجاهل الآخر "const". إذا سبقت الكلمة المفتاحية "const" أي تصريح، فهذا يعني أن الشيء الذي صُرّح عنه هو ثابت، ويجب عليك تجنب محاولة التغيير على قيمة الكائنات الثابتة "const" وإلا فستحصل على سلوك غير محدّد undefined behaviour، وسيحذّرك المصرّف عادةً بمنعك من هذه المحاولة إلا إذا تجاوزت هذا القيد بحيلةٍ ما. هناك فائدتان مرجوتان من تصريح كائن ما بكونه ثابتًا "const": يشير استخدام الكلمة المفتاحية "const" إلى أن القيمة غير قابلة للتغيير، مما يجبر المصرّف على التحقق من أي تغييرات طرأت على هذه القيمة ضمن الشيفرة البرمجية، وهذا الأمر باعث للطمأنينة في حال أردت استخدام قيمٍ ثابتة، مثل المؤشرات التي تُستخدم وسطاءً في بعض الدوال. إذا احتوى التصريح عن الدالة مؤشرات تشير إلى كائنات ثابتة على أنها وسطاء، فهذا يعني أن الدالة لن تشير إلى أي كائن آخر. عندما يعلم المصرّف بأن الأشياء هي كائنات ثابتة، ينعكس ذلك إيجابيًا على قدرته برفع فاعلية الشيفرة البرمجية وسرعتها. الثوابت عديمة الفائدة في حال لم تسند إليها أي قيمة، لن نتطرق بالتفصيل بخصوص تهيئة الثوابت (سنناقش الأمر لاحقًا)، كل ما عليك تذكره الآن هو أنه من الممكن لأي تصريح إسناد القيمة لتعبيرٍ ثابت. إليك بعض الأمثلة عن التصريح عن ثوابت: const int x = 1; /* ثابت x */ const float f = 3.5; /* ثابت f*/ const char y[10]; /* y مصفوفة من 10 عناصر ذات قيم صحيحة ثابتة */ /* لا تفكر بخصوص تهيئة قيمها بعد */ ما يثير الاهتمام هو كون هذا المؤهل ممكن التطبيق على المؤشرات بطريقتين: إما بجعل الشيء الذي يشير إليه المؤشر ثابتًا، بحيث يصبح نوع المؤشر "مؤشر إلى ثابت"، أو بجعل المؤشر بذات نفسه ثابتًا (مؤشرًا ثابتًا)، إليك مثالًا عن ذلك: int i; /* عدد صحيح اعتيادي i */ const int ci = 1; /* عدد صحيح ثابت ci */ int *pi; /* مؤشر إلى عدد صحيح pi */ const int *pci; /* مؤشر إلى عدد صحيح ثابت pci */ /* بالانتقال إلى الأمثلة الأكثر تعقيدًا */ // مؤشر ثابت يشير إلى قيمة عدد صحيح cpi int *const cpi = &i; // مؤشر ثابت يشير إلى قيمة عدد صحيح ثابتة cpci const int *const cpci = &ci; التصريح الأول (للمتغير i) اعتيادي، ولكن تصريح ci يوضح أنه عدد صحيح ثابت وبذلك لا يمكن التعديل على قيمته، وسيكون بلا فائدة إن لم يُهيّأ (إسناد قيمة أولية له). ليس من الصعب فهم الغرض من مؤشر لعدد صحيح، ومؤشر لعدد صحيح ثابت، ولكن يجب الانتباه إلى أنواع المؤشرات المختلفة، إذ لا يجوز الخلط بينهم. يمكنك تغيير قيمة كل من pi و pci بجعلهما يشيران إلى أشياء أخرى، كما يمكنك تغيير قيمة الشيء الذي يشير إليه المؤشر pi بالنظر إلى كونه عدد صحيح غير ثابت، ولكن لا يمكنك إلّا الوصول إلى قيمة الشيء الذي يشير إليه المؤشر pci دون التعديل عليه نظرًا لكونه ثابتًا. يُعد التصريحان الأخيران أكثر التصريحات تعقيدًا ضمن المثال؛ فإذا كانت المؤشرات بذات نفسها ثابتةً، فمن غير المسموح تغيير المكان الذي تشير إليه، وبالتالي يجب تهيأتهما بقيمة أولية مثل ci. يمكن للشيء المُشار إليه بالمؤشر أن يكون ثابتًا أو غير ثابت بغض النظر عن كون المؤشر ثابتًا بدوره أم لا، وهذا يملي بعض القيود على استخدام الكائن المُشار إليه. أخيرًا للتوضيح: ما الذي يملي وجود نوع مؤهّل؟ كان ci في المثال السابق نوعًا مؤهلًا بكل وضوح، ولكن pci لم تنطبق عليه هذه الحالة بما أن المؤشر ليس من نوع مؤهّل بل الشيء الذي يشير إليه. الأشياء الوحيدة الذي كانت ذات أنواع مؤهلة في المثال هي: ci و cpi و cpci. سيتطلب منك الأمر بعض الوقت للاعتياد على هذا النوع من التصريحات، ولكن استخدامها سيكون تلقائيًّا وطبيعيًا بعد فترة فلا تقلق، إلا أن التعقيدات تبدأ بالظهور لاحقًا عندما يتوجب عليك الإجابة على السؤال: "هل من المسموح لي -على سبيل المثال- مقارنة مؤشر اعتيادي مع مؤشر ثابت؟ وإذا كان الجواب نعم، ما الذي تعنيه المقارنة؟". معظم القوانين واضحة بهذا الخصوص، ولكن يجب ذكرها وتوضيحها بغض النظر عن سهولتها. سنتكلم عن أنواع البيانات المؤهلة بتوسعٍ أكبر لاحقًا. عمليات المؤشرات الحسابية سنتكلم بالتفصيل لاحقًا عن عمليات المؤشرات الحسابية، ولكننا سنكتفي الآن بإصدار مختصرٍ يفي بالغرض. يمكنك الطرح أو المقارنة بين مؤشرين من النوع نفسه بالإضافة إلى إضافة قيمة عددية صحيحة إلى المؤشر، ويجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها وإلا حصلنا على سلوك غير محدد. نتيجة طرح مؤشرين هي قيمة العناصر التي تفصل بينهما في المصفوفة، ونوع النتيجة معرفٌ بحسب التطبيق وسيكون إما "short" أو "int" أو "long"، ويوضح المثال القادم مثالًا على حساب الفرق بين مؤشرين واستخدام النتيجة، ولكن قبل أن ننتقل إلى المثال يجب أن تعرف معلومةً مهمة. يُحوَّل اسم المصفوفة في أي تعبير إلى مؤشر يشير إلى العنصر الأول ضمن هذه المصفوفة، والحالة الوحيدة الاستثنائية هي عند استخدام اسم المصفوفة مع الكلمة المفتاحية "sizeof"، أو عند استخدام سلسلة نصية لتهيئة قيمة مصفوفة ما، أو عندما يكون اسم المصفوفة مرتبطًا بعامل "عنوان الكائن" (العامل الأحادي "&")، لكننا لم نتطرق إلى أيّ من الحالات السابقة بعد، وسنناقشها لاحقًا. إليك المثال: #include <stdio.h> #include <stdlib.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %d\n", (int)(fp2-fp1)); fp2++; } exit(EXIT_SUCCESS); } [مثال 4] يشير المؤشر fp2 إلى عناصر المصفوفة، ويُطبع الفرق بين قيمته الحالية وقيمته الأصلية، وللتأكد من عدم تمرير النوع الخاطئ للوسيط للدالة printf تُحوَّل القيمة الناتجة عن فرق المؤشرين قسريًّا إلى int باستخدام تحويل الأنواع (int)، وهذا يجنّبنا من الأخطاء على الحواسيب التي تعيد قيمة long لهذا النوع من العمليات. قد يعود إلينا المثال السابق بإجابات خاطئة إذا كان الفرق بين القيمتين من نوع long وكانت المصفوفة كبيرة الحجم، ونلاحظ في المثال التالي إصدارًا آمنًا من المثال السابق، إذ يُستخدم تحويل الأنواع قسريًا للسماح بوجود قيم long: #include <stdio.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %ld\n", (long)(fp2-fp1)); fp2++; } return(0); } [مثال 5] مؤشرات void و null والمؤشرات الإشكالية لغة سي حريصة بشأن أنواع المؤشرات، ولن تسمح لك عمومًا باستخدام مؤشرات ذات أنوع مختلفة ضمن التعبير ذاته. يختلف مؤشر إلى نوع "char" عن مؤشر إلى نوع "int" ولا يمكنك -على سبيل المثال- إسناد قيمة أحدهما إلى الآخر أو المقارنة فيما بينهما أو طرحهما من بعضهما واستخدام النتيجة مثل وسيط في دالة ما، كما يمكن أيضًا تخزين النوعين في الذاكرة بصورةٍ مختلفة وأن يكونا بأطوال مختلفة. لكن نريد في بعض الحالات تجاوز هذه القيود، فكيف نفعل ذلك؟ يكمن الحل هنا باستخدام أنواع خاصة، وقد قدمنا واحدًا من هذه الأنواع سابقًا ألا وهو "مؤشر إلى void"، وقُدّمت هذه الميزة مع سي المعيارية إذ افتُرض سابقًا أن المؤشر من نوع "مؤشر إلى char" كافٍ لهذه المهمة، وكان الافتراض صحيحًا إلى حدٍّ ما إلا أنه كان حلًّا غير منظّمًا، بينما قدّم الحل الجديد طريقةً أكثر أمانًا وأقل تشويشًا. لا يوجد أي استخدام للمؤشر هذا، لأن "* void" لا يشير إلى أي قيمة، لذا يحسّن هذا الأمر من سهولة قراءة الشيفرة البرمجية. يمكن أن يخزن المؤشر من النوع "* void" أي قيمة من أي مؤشر آخر، ويمكن إسناده إلى مؤشر آخر من أي نوع أيضًا، إلا أنه يجب استخدام هذا النوع من المؤشرات بحذر لأنه قد ينتهي الأمر بك ببعض الأخطاء الوخيمة، وسنناقش استخدامه الآمن مع دالة "malloc" لاحقًا. قد تحتاج أيضًا في بعض الحالات إلى مؤشر مضمون أنه لا يشير إلى أي كائن والذي يُدعى مؤشر من نوع "null" أو مؤشر الفراغ null pointer. من الشائع في لغة سي كتابة بعض الإجراءات routines التي تعيد مؤشرات، بحيث يمكن الدلالة على فشل ذلك الإجراء بعدم قدرته على إعادة مؤشر صالح عن طريق إعادة مؤشر الفراغ. ومن الأمثلة على ذلك إجراء فحصٍ لقيم موجودة في جدول ما بحثًا عن قيمة معينة ويعيد مؤشرًا على الكائن المُطابق إن وُجدت النتيجة أو مؤشر الفراغ إن لم تُوجد أي نتيجةٍ مطابقة. لكن كيف يمكن كتابة مؤشر فراغ؟ هناك طريقتان لفعل ذلك وكلا الطريقتين متماثلتين في النتيجة، إما باستخدام رقم صحيح ثابت بقيمة "0" أو تحويل القيمة إلى نوع "* void" باستخدام التحويل بين الأنواع، وتدعى نتيجة الطريقتين بمؤشر الفراغ الثابت null pointer constant. إذا أسندت مؤشر فراغ إلى أي مؤشر آخر أو قارنت بين مؤشر الفراغ ومؤشر آخر فسيُحوَّل مؤشر الفراغ إلى نوع المؤشر الآخر تلقائيًّا، مما سيحلّ أي مشكلة بخصوص توافقية الأنواع، ولن تُساوي القيمة التي يشير إليها ذلك المؤشر -مؤشر الفراغ- أي قيمة كائن آخر يشير إليها أي مؤشر داخل البرنامج (أي سيشير إلى قيمة فريدة). القيم الوحيدة الممكن إسنادها للمؤشرات باستثناء القيمة "0" هي قيم المؤشرات الأخرى من نفس النوع، إلا أن الأمر الذي يجعل من لغة سي مميزة وبديلًا مفيدًا للغة التجميعية هو سماحها لك بفعل بعض الأشياء التي لا تسمح لك بها معظم لغات البرمجة الأخرى، جرّب التالي: int *ip; ip = (int *)6; *ip = 0xFF; ما نتيجة السابق؟ تُهيأ قيمة المؤشر إلى 6 (لاحظ تحويل نوع 6 من int إلى مؤشر)، وهذه عملية تُجرى على مستوى الآلة غالبًا ويكون تمثيل قيمة المؤشر بالبتات غير مشابه لما قد يكون تمثيل الرقم 6، كما تُسند القيمة الست عشرية FF بعد التهيئة إلى الكائن الذي يشير إليه المؤشر. تُكتب القيمة 0xFF على الرقم الصحيح ذو الموضع 6، إذ يعتمد الموضع 6 على تفسير الآلة له على الذاكرة. قد تحتاج لهذا النوع من الأشياء وقد لا تحتاج إليها إطلاقًا، ولكن لغة سي تعطيك الخيار، ومن الواجب معرفتها إذ أنه من الممكن كتابتها على نحوٍ خاطئ غير مقصود مما سيتسبب بنتائج مفاجئة جدًا. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف والسلاسل النصية في لغة سي C المقال السابق: مدخل إلى المصفوفات في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C البنية النصية لبرامج سي C -
 تستخدم لغة سي المصفوفات Arrays مثل سائر اللغات الأخرى لتمثيل مجموعة من متغيرات ذات خصائص متماثلة، إذ يكون لهذه المجموعة اسمًا واحدًا وتُحدّد عناصرها عن طريق دليل Index. إليك مثالًا للتصريح عن مصفوفةٍ ما: double ar[100]; في هذا المثال اسم المصفوفة هو ar ويمكن الوصول لعناصر المصفوفة عن طريق دليل كلٍّ منها كما يلي: ar[0] وصولًا إلى ar[99] لا غير، كما يوضح الشكل 1: شكل 1 مصفوفة ذات 100 عنصر يمثّل كلّ عنصر من عناصر المصفوفة المئة متغيّرًا منفصلًا من نوع double، ويُرمز لكل عنصر من أي مصفوفة في لغة سي بدءًا من الدليل 0 وصولًا إلى الدليل الذي يساوي حجم المصفوفة المُصرّح عنه ناقص واحد، ويعدّ البدء بالترقيم من 0 مفاجئًا لبعض المبتدئين فركّز على هذه النقطة. عليك أن تنتبه أيضًا إلى أن المصفوفات لا تقبل حجمًا متغيّرًا عند التصريح عنها، إذ يجب أن يكون الرقم تعبيرًا ثابتًا يمكن معرفة قيمته الثابتة وقت تصريف البرنامج compile time وليس وقت التشغيل run time. يوضح المثال التالي طريقة خاطئة للتصريح عن مصفوفة باستخدام الوسيط x: f(int x){ char var_sized_array[x]; /* هذه الطريقة ممنوعة*/ } وهذا ممنوع لأن قيمة x غير معروفة عند تصريف البرنامج، فهي قيمة تُعرف عند تشغيل البرنامج وليس عند تصريفه. من الأسهل لو كان مسموحًا استخدام المتغيرات لتحديد حجم المصفوفات وبالأخص البعد الأوّل لها، ولكن هذا الأمر لم تسمح به سي القديمة أو سي المعيارية، إلا أن هناك مصرّف قديم جدًا للغة سي اعتاد السماح بهذا. المصفوفات متعددة الأبعاد يمكن التصريح عن المصفوفات متعددة الأبعاد Multidimensional arrays على النحو التالي: int three_dee[5][4][2]; int t_d[2][3] تُستخدم الأقواس المعقوفة بعد كلٍّ من المصفوفات السابقة، وإذا نظرت إلى جدول الأسبقية في مقال العوامل في لغة سي C، فستلاحظ أن قراءة القوسين [] تكون من اليسار إلى اليمين وبذلك تكون نتيجة التصريح مصفوفةً تحتوي على خمس عناصر باسم three_dee، ويحتوي كل عنصر من عناصر هذه المصفوفة بدوره على مصفوفة بحجم أربعة عناصر وكل عنصر من هذه المصفوفة الأخيرة يحتوي على مصفوفة من عنصرين، وجميع العناصر من نوع int، وبهذه الحالة فنحن صرحنا عن مصفوفة مصفوفات، ويوضح الشكل 2 مثالًا على مصفوفة ثنائية البعد باسم t_d في مثال التصريح. شكل 2 هيكل مصفوفة ثنائية البعد ستلاحظ في الشكل السابق أن t_d[0] عنصرٌ واحدٌ متبوعٌ بعنصر t_d[1] دون أي فواصل، وكلا العنصرين يمثّلان مصفوفةً بحدّ ذاتهما بسعة ثلاث أعداد صحيحة. يأتي العنصر t_d[1][0] مباشرةً بعد العنصر t_d[0][2]، ومن الممكن الوصول إلى t_d[1][0] بالاستفادة من عدم وجود أي طريقة للتحقق من حدود المصفوفة باستخدام التعبير t_d[0][3] إلا أن هذا غير محبّذ أبدًا، لأن النتائج ستكون غير متوقعة إذا تغيّرت تفاصيل التصريح عن المصفوفة t_d. حسنًا، لكن هل هذا الأمر يؤثر على سلوك البرنامج عمليًّا؟ في الحقيقة لا، إلا أنه من الجدير بالذكر أن موقع تخزين العنصر الواقع على أقصى اليمين ضمن المصفوفة "يتغير بسرعة"، ويؤثر ذلك على المصفوفات عند استخدام المؤشرات معها، ولكن يمكن استخدامها بشكلها الطبيعي عدا عن تلك الحالة، مثل التعابير التالية: three_dee[1][3][1] = 0; three_dee[4][3][1] += 2; التعبير الأخير مثيرٌ للاهتمام لسببين، أولهما أنه يصل إلى قيمة العنصر الأخير من المصفوفة والمصرّح أنها بحجم [2][4][5]، والدليل الذي نستطيع استخدامه هو أقل بواحد دائمًا من العدد الذي صرّحنا عنه، أما ثانيًا، فنلاحظ أهمية وسهولة استخدام عامل الإسناد المُركّب في هذه الحالة. يفضّل مبرمجو لغة سي المتمرسون هذه الطريقة المختصرة، إليك كيف سيبدو الأمر لو كان التعبير مكتوبًا بلغة أخرى لا تسمح باستخدام هذا العامل: three_dee[4][3][1] = three_dee[4][3][1] + 2; ففي هذه الحالة يجب أن يتحقق القارئ أن العنصر على يمين عامل الإسناد هو ذات العنصر على يسار عامل الإسناد، كما أن الطريقة المُختصرة أفضل عند تصريفها، إذ يُحسب دليل العنصر وقيمته مرةً واحدة، مما ينتج شيفرةً برمجيةً أقصر وأسرع. قد ينتبه بعض المصرّفات طبعًا إلى أن العنصرين على طرفَي عامل الإسناد متساويين ولن تلجأ للوصول للقيمة مرتين، ولكن هذه الحالة لا تنطبق على جميع المصرّفات، وهناك العديد من الحالات أيضًا التي لا تستطيع فيها المصرفات الذكية هذه باختصار الخطوات. على الرغم من تقديم لغة سي دعمًا للمصفوفات متعددة الأبعاد، إلا أنه من النادر أن تجدها مُستخدمةً عمليًّا، إذ تُستخدم المصفوفات أحادية البعد أكثر في معظم البرامج، وأبسط هذه الأسباب هو أن السلسلة النصية String تُمثّل بمصفوفة أحادية البعد، وقد تلاحظ استخدام المصفوفات ثنائية البعد في بعض الحالات، ولكن استخدام المصفوفات ذات أبعاد أكثر من ذلك نادرة الحدوث، وذلك لكون المصفوفة هيكل بيانات غير مرن بالتعامل، كما أن سهولة عملية إنشاء ومعالجة هياكل البيانات وأنواعها في لغة سي تعني إمكانية استبدال المصفوفات في معظم البرامج متقدمة المستوى، وسننظر إلى هذه الطرق عندما ننظر إلى المؤشرات. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: المؤشرات Pointers في لغة سي C المقال السابق: مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C الدوال في لغة C البنية النصية لبرامج سي C
تستخدم لغة سي المصفوفات Arrays مثل سائر اللغات الأخرى لتمثيل مجموعة من متغيرات ذات خصائص متماثلة، إذ يكون لهذه المجموعة اسمًا واحدًا وتُحدّد عناصرها عن طريق دليل Index. إليك مثالًا للتصريح عن مصفوفةٍ ما: double ar[100]; في هذا المثال اسم المصفوفة هو ar ويمكن الوصول لعناصر المصفوفة عن طريق دليل كلٍّ منها كما يلي: ar[0] وصولًا إلى ar[99] لا غير، كما يوضح الشكل 1: شكل 1 مصفوفة ذات 100 عنصر يمثّل كلّ عنصر من عناصر المصفوفة المئة متغيّرًا منفصلًا من نوع double، ويُرمز لكل عنصر من أي مصفوفة في لغة سي بدءًا من الدليل 0 وصولًا إلى الدليل الذي يساوي حجم المصفوفة المُصرّح عنه ناقص واحد، ويعدّ البدء بالترقيم من 0 مفاجئًا لبعض المبتدئين فركّز على هذه النقطة. عليك أن تنتبه أيضًا إلى أن المصفوفات لا تقبل حجمًا متغيّرًا عند التصريح عنها، إذ يجب أن يكون الرقم تعبيرًا ثابتًا يمكن معرفة قيمته الثابتة وقت تصريف البرنامج compile time وليس وقت التشغيل run time. يوضح المثال التالي طريقة خاطئة للتصريح عن مصفوفة باستخدام الوسيط x: f(int x){ char var_sized_array[x]; /* هذه الطريقة ممنوعة*/ } وهذا ممنوع لأن قيمة x غير معروفة عند تصريف البرنامج، فهي قيمة تُعرف عند تشغيل البرنامج وليس عند تصريفه. من الأسهل لو كان مسموحًا استخدام المتغيرات لتحديد حجم المصفوفات وبالأخص البعد الأوّل لها، ولكن هذا الأمر لم تسمح به سي القديمة أو سي المعيارية، إلا أن هناك مصرّف قديم جدًا للغة سي اعتاد السماح بهذا. المصفوفات متعددة الأبعاد يمكن التصريح عن المصفوفات متعددة الأبعاد Multidimensional arrays على النحو التالي: int three_dee[5][4][2]; int t_d[2][3] تُستخدم الأقواس المعقوفة بعد كلٍّ من المصفوفات السابقة، وإذا نظرت إلى جدول الأسبقية في مقال العوامل في لغة سي C، فستلاحظ أن قراءة القوسين [] تكون من اليسار إلى اليمين وبذلك تكون نتيجة التصريح مصفوفةً تحتوي على خمس عناصر باسم three_dee، ويحتوي كل عنصر من عناصر هذه المصفوفة بدوره على مصفوفة بحجم أربعة عناصر وكل عنصر من هذه المصفوفة الأخيرة يحتوي على مصفوفة من عنصرين، وجميع العناصر من نوع int، وبهذه الحالة فنحن صرحنا عن مصفوفة مصفوفات، ويوضح الشكل 2 مثالًا على مصفوفة ثنائية البعد باسم t_d في مثال التصريح. شكل 2 هيكل مصفوفة ثنائية البعد ستلاحظ في الشكل السابق أن t_d[0] عنصرٌ واحدٌ متبوعٌ بعنصر t_d[1] دون أي فواصل، وكلا العنصرين يمثّلان مصفوفةً بحدّ ذاتهما بسعة ثلاث أعداد صحيحة. يأتي العنصر t_d[1][0] مباشرةً بعد العنصر t_d[0][2]، ومن الممكن الوصول إلى t_d[1][0] بالاستفادة من عدم وجود أي طريقة للتحقق من حدود المصفوفة باستخدام التعبير t_d[0][3] إلا أن هذا غير محبّذ أبدًا، لأن النتائج ستكون غير متوقعة إذا تغيّرت تفاصيل التصريح عن المصفوفة t_d. حسنًا، لكن هل هذا الأمر يؤثر على سلوك البرنامج عمليًّا؟ في الحقيقة لا، إلا أنه من الجدير بالذكر أن موقع تخزين العنصر الواقع على أقصى اليمين ضمن المصفوفة "يتغير بسرعة"، ويؤثر ذلك على المصفوفات عند استخدام المؤشرات معها، ولكن يمكن استخدامها بشكلها الطبيعي عدا عن تلك الحالة، مثل التعابير التالية: three_dee[1][3][1] = 0; three_dee[4][3][1] += 2; التعبير الأخير مثيرٌ للاهتمام لسببين، أولهما أنه يصل إلى قيمة العنصر الأخير من المصفوفة والمصرّح أنها بحجم [2][4][5]، والدليل الذي نستطيع استخدامه هو أقل بواحد دائمًا من العدد الذي صرّحنا عنه، أما ثانيًا، فنلاحظ أهمية وسهولة استخدام عامل الإسناد المُركّب في هذه الحالة. يفضّل مبرمجو لغة سي المتمرسون هذه الطريقة المختصرة، إليك كيف سيبدو الأمر لو كان التعبير مكتوبًا بلغة أخرى لا تسمح باستخدام هذا العامل: three_dee[4][3][1] = three_dee[4][3][1] + 2; ففي هذه الحالة يجب أن يتحقق القارئ أن العنصر على يمين عامل الإسناد هو ذات العنصر على يسار عامل الإسناد، كما أن الطريقة المُختصرة أفضل عند تصريفها، إذ يُحسب دليل العنصر وقيمته مرةً واحدة، مما ينتج شيفرةً برمجيةً أقصر وأسرع. قد ينتبه بعض المصرّفات طبعًا إلى أن العنصرين على طرفَي عامل الإسناد متساويين ولن تلجأ للوصول للقيمة مرتين، ولكن هذه الحالة لا تنطبق على جميع المصرّفات، وهناك العديد من الحالات أيضًا التي لا تستطيع فيها المصرفات الذكية هذه باختصار الخطوات. على الرغم من تقديم لغة سي دعمًا للمصفوفات متعددة الأبعاد، إلا أنه من النادر أن تجدها مُستخدمةً عمليًّا، إذ تُستخدم المصفوفات أحادية البعد أكثر في معظم البرامج، وأبسط هذه الأسباب هو أن السلسلة النصية String تُمثّل بمصفوفة أحادية البعد، وقد تلاحظ استخدام المصفوفات ثنائية البعد في بعض الحالات، ولكن استخدام المصفوفات ذات أبعاد أكثر من ذلك نادرة الحدوث، وذلك لكون المصفوفة هيكل بيانات غير مرن بالتعامل، كما أن سهولة عملية إنشاء ومعالجة هياكل البيانات وأنواعها في لغة سي تعني إمكانية استبدال المصفوفات في معظم البرامج متقدمة المستوى، وسننظر إلى هذه الطرق عندما ننظر إلى المؤشرات. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: المؤشرات Pointers في لغة سي C المقال السابق: مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C الدوال في لغة C البنية النصية لبرامج سي C -
 على الرغم من تفادينا لموضوعَي النطاق Scope والربط Linkage في أمثلتنا البسيطة سابقًا، إلا أن الوقت قد حان لشرح هذين المفهومين وأثرهما على قابلية الوصول للكائنات المختلفة في برنامج سي C، ولكن لمَ علينا الاكتراث بذلك على أي حال؟ لأن البرامج العملية التي نستخدمها تُبنى من عدّة ملفات ومكتبات، وبالتالي من المهم للدوال في ملف ما أن تكون قادرةً على الإشارة إلى دوال، أو كائنات في ملفات أو مكتبات أخرى، وهناك عدّة قوانين ومفاهيم تجعل من ذلك ممكنًا. عُد لاحقًا إلى هذه الجزئية إن كنت جديدًا على لغة سي، لأن هناك بعض المفاهيم الأهم التي يجب عليك معرفتها أوّلًا. الربط Linkage هناك نوعان أساسيان من الكائنات في لغة سي C، هما: الكائنات الخارجية والكائنات الداخلية، والفرق بين الاثنين مُعتمدٌ على الدوال؛ إذ أن أيّ شيء يُصرّح عنه خارج الدالة فهو خارجي؛ وأي شيء يُصرّح عنه داخل الدالة بما فيه مُعاملات الدالة فهو داخلي. بما أننا لا نستطيع تعريف دالة ما داخل دالة أخرى، فهذا يعني أن الدوال هي كائنات خارجية دائمًا، وإذا نظرنا إلى بنية برنامج سي على المستوى الخارجي، سنلاحظ أنه يمثّل مجموعةً من الكائنات الخارجية External objects. يمكن للكائنات الخارجية فقط أن تُشارك في هذا الاتصال عبر الملفات والمكتبات، وتُعرف قابلية الوصول للكائنات هذه من ملف إلى آخر أو ضمن الملف نفسه وفقًا للمعيار باسم الربط Linkage، وهناك ثلاثة أنواع للربط، هي: الربط الخارجي External linkage والربط الداخلي Internal Linkage وعديم الربط No linkage. يكون أي شيء داخلي في الدالة سواءٌ كان وسطاء الدالة أو متغيراتها عديم الربط دائمًا ويمكن الوصول إليه من داخل الدالة فقط، ويمكنك التصريح عن الشيء الذي تريده داخل الدالة مسبوقًا بالكلمة المفتاحية extern لتجاوز هذا القيد، وهذا سيدل على أن الكائن ليس داخليًّا، وليس عليك القلق بهذا الشأن في الوقت الحالي. تكون الكائنات ذات الربط الخارجي موجودةً على المستوى الخارجي لبنية البرنامج، وهذا هو نوع الربط الافتراضي للدوال ولأي شيء آخر يُصرَّح عنه خارج الدوال، وتُشير جميع الأسماء المماثلة لاسم الكائن ذو الربط الخارجي إلى الكائن نفسه. ستحصل على سلوك غير محدد من البرنامج، إذا صرحت عن كائن بنفس الاسم مرتين أو أكثر بربط خارجي وبأنواع غير متوافقة. المثال الذي يأتي إلى بالنا مباشرةً بخصوص الربط الخارجي هو الدالة printf والمُصرّح عنها في ملف الترويسة <stdio.h> على النحو التالي: int printf(const char *, ...); يمكننا فورًا بالنظر إلى التصريح السابق معرفة أن الدالة printf تُعيد قيمةً من نوع int باستخدام النموذج الأولي الموضّح، كما نعرف أن للدالة ربطًا خارجيًّا لأنها كائن خارجي (تذكّر، كل دالة هي كائن خارجي افتراضيًا)، وبالتالي فنحن نقصد هذه الدالة تحديدًا عندما نكتب الاسم printf في أي مكان ضمن البرنامج، إذا استخدمنا الربط الخارجي. ستحتاج في بعض الأحيان لطريقة تمكّنك من التصريح عن الدوال والكائنات الأخرى في ملفٍ واحد بحيث تسمح لهم بالإشارة إلى بعضهم البعض دون القدرة على الوصول إلى تلك الكائنات والدوال من خارج الملف. نحتاج هذه الطريقة غالبًا في الوحدات modules التي تدعم دوال المكتبات، إذ من الأفضل في هذه الحالة إخفاء بعض الكائنات التي تجعل استخدام هذه الدالة ضمن المكتبة ممكنًا، فهي ليست ضرورية المعرفة لمستخدم المكتبة وستكون سببًا للإزعاج لا غير، ونستطيع تحقيق ذلك الأمر عن طريق استخدام الربط الداخلي. تُشير الأسماء ذات الربط الداخلي للكائن ذاته ضمن ملف الشيفرة المصدرية الواحد، ويمكنك التصريح عن كائن ذي ربط داخلي عن طريق بدء التصريح بالكلمة المفتاحية "static" التي ستغيّر ربط الكائن من ربط خارجي (افتراضي) إلى ربط داخلي، كما يمكنك التصريح عن كائنات داخلية باستخدام "static" بهدف استخدامٍ آخر ولكننا لن نتطرق لهذا الاستخدام حاليًا. من المُربك استخدام المصطلحين "داخلي" و"خارجي" لوصف نوع الربط ونوع الكائن، ولكن يعود ذلك لأسباب تاريخية، إذ سيتذكر مبرمجو لغة سي القدماء كون الاستخدامين متساويين، وأن استخدام أحدهما يتضمن تحقّق الآخر، ولكن تغيّر ذلك الأمر للأسف حديثًا وأصبح معنى الاستخدامين مختلف، ولنلخّص الفرق فيما يلي: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } نوع الربط نوع الكائن قابلية الوصول خارجي خارجي يمكن الوصول إليه من أي مكان ضمن البرنامج داخلي خارجي يمكن الوصول إليه عبر ملف واحد فقط لا يوجد ربط داخلي محلّي لدالة واحدة [جدول 1 الربط وقابلية الوصول] أخيرًا وقبل أن ننتقل إلى مثالٍ آخر، علينا أن نعرف أن لجميع الكائنات ذات الربط الخارجي تعريفٌ واحدٌ فقط، مع أنه بالإمكان أن يوجد عدة تصريحات متوافقة حسب حاجتك. إليك المثال: /* الملف الأول */ int i; /* تعريف*/ main () { void f_in_other_place (void); /* تصريح*/ i = 0 } /* نهاية الملف الأول */ /* بداية الملف الثاني */ extern int i; /* تصريح*/ void f_in_other_place (void){ /* تعريف*/ i++; } /* نهاية الملف الثاني */ [مثال 1] على الرغم من تعقيد القوانين الكاملة التي تحدد الفرق بين التعريف والتصريح إلا أن هناك طريقةً بسيطةً وسهلة، هي: التصريح عن الدالة دون تضمين متن الدالة هو تصريحٌ لا غير. التصريح عن الدالة مرفقًا بمتن الدالة هو تعريف. عمومًا، التصريح عن كائن على المستوى الخارجي للبرنامج (مثل المتغير i في المثال السابق) هو تعريف، إلا إذا سُبق بالكلمة المفتاحية extern وعندها يصبح تصريحًا فقط. وسنتكلم لاحقًا عن التعريف والتصريح بصورةٍ أعمق لا تبقي مجالًا للشك. من الواضح في مثالنا السابق أنه من السهل الوصول من أي ملف للكائنات المعرفة في ملفات أخرى باستخدام أسمائها فقط، وسيدلك المثال على كيفية بناء برامج ذات ملفات ودوال ومتغيرات متعددة سواءٌ كانت مُعرّفةً أو مصرّحٌ عنها وفق ما يناسب كل حالة. إليك مثالًا آخر يوضح استخدام "static" لتقييد قابلية الوصول إلى الدوال والأشياء الأخرى. /* مثال عن وحدة في مكتبة */ /* الدالة callable هي الدالة الوحيدة المرئية على المستوى الخارجي */ static buf [100]; static length; static void fillup(void); int callable (){ if (length ==0){ fillup (); } return (buf [length--]); } static void fillup (void){ while (length <100){ buf [length++] = 0; } } [مثال 2] يمكن للمستخدم -بفرض استخدام المثال السابق وحدةً مستقلّة- إعادة استخدام الأسماء "length" و "buf" و "fillup" بأمان دون أي تأثيرات جانبية أو أخطاء غير متوقعة، ونستثني من ذلك الاسم "callable"، إذ إنه قابل الوصول خارج الملف (الوحدة المستقلة). تكون قيمة الكائن الخارجي الذي يمتلك مُهيّئًا initializer واحدًا مساوية للصفر قبل بدء البرنامج (لم نتكلم عن أي مُهيّئات عدا الدوال حتى الآن)، وتعتمد الكثير من البرامج على ذلك، بما فيها المثال السابق لقيمة length الابتدائية. تأثير النطاق لا تقتصر عملية مشاركة الأسماء وقابلية الوصول إليها على الربط ببساطة، فالربط يسمح لك باستخدام عدة أسماء والوصول إليها سويًّا ضمن البرنامج أو ضمن الملف، ولكن النطاق Scope يحدد رؤية الأسماء، وقواعد النطاق لحسن الحظ مستقلةٌ عن مبدأ الربط، لذا ليس عليك حفظ أي قواعد مركبة بين المفهومين. تزيد الكلمة المفتاحية "extern" من تعقيد البرنامج، فعلى الرغم من وضوح استخدامها وتأثيرها إلا أنها تغيّر من بنية برنامج لغة سي الكُتلية التي اعتدنا عليها، وسنناقش المشاكل الناتجة عن استخدامها الخاطئ وغير المسؤول لاحقًا، وقد نظرنا إلى استخدامها مُسبقًا للتأكد من أن التصريح لشيء ما ضمن المستوى الخارجي للبرنامج هو تصريحٌ وليس تعريف. ملاحظة: يمكنك تجاوز الكلمة المفتاحية "extern" عن طريق مُهيّئ للكائن. التصريح عن أي كائن بيانات (ليس بدالة) ضمن المستوى الخارجي للبرنامج هو تعريفٌ، إلا إذا سبق التصريح الكلمة المفتاحية "extern"، راجع المثال 9.4 من أجل ملاحظة هذه النقطة عمليًّا. تحتوي تصريحات الدوال الكلمة المفتاحية "extern" ضمنيًّا سواءٌ كانت مكتوبةً أم لا، والطريقتان التاليتان للتصريح عن الدالة some_function متكافئتان، وتُعدان تصريحًا وليس تعريفًا: void some_function(void); extern void some_function(void); الشيء الوحيد الذي يفصل التصريحات السابقة عن كونها تعريفات هو متن الدالة، الذي يُعد مُهيِّئًا للدالة، لذلك عند إضافة المُهيّئ يتحول التصريح إلى تعريف، لا توجد أي مشكلة بخصوص ذلك. لكن ما الذي يحدث في المثال التالي؟ void some_function(void){ int i_var; extern float e_f_var; } void another_func(void){ int i; i = e_f_var; /* مشكلة تتعلق بالنطاق */ } ما الهدف من المثال السابق؟ من المفيد في بعض الأحيان أن تستخدم كائنًا خارجيًّا ضمن دالة ما، وإن اتبعت الطريقة الاعتيادية بالتصريح عن الكائن في بداية ملف الشيفرة المصدرية، فسيكون صعبًا على القارئ معرفة أي من الدوال تستخدم ذلك الكائن؛ بدلًا من ذلك، يمكنك تقييد نطاق الكائن وقابلية الوصول إليه في المكان الذي تريد الوصول إليه، ممّا سيسهّل على القارئ معرفة أن الاسم سيُستخدم فقط في هذا المكان المحدود وليس على كامل نطاق ملف الشيفرة المصدرية. يجدر الانتباه إلى أن معظم طرق إدارة الوسطاء في هذه الحالة عمليةٌ صعبةٌ بعض الشيء. سنناقش المزيد من القواعد عن الطريقة الأمثل لإنشاء برنامج ذو ملفات متعددة، وما الممكن حدوثه عند المزج بين التصريحات الداخلية والخارجية والكلمات المفتاحية "extern" و "static". لن تكون عملية قراءة هذه القواعد ممتعةً، لكنها ستكون إجابةً لأسئلة من نوع "ماذا لو؟". الكائنات الداخلية الساكنة يمكنك التصريح عن كائنات داخلية على أنها كائنات داخلية ساكنة باستخدام الكلمة المفتاحية "static"، وتكتسب المتغيرات الداخلية بعضًا من الخصائص باستخدامها هذه الكلمة المفتاحية ألا وهي: تُهيّأ قيمتها إلى الصفر عند بداية البرنامج. تحافظ على قيمتها من بداية التعليمة التي تضم تصريحها إلى نهايتها. يوجد نسخةٌ واحدةٌ من كل متغيّر داخلي ساكن تتشاركه الاستدعاءات التعاودية للدوال التي تحوي هذه المتغيرات. يمكن أن تُستخدم المتغيرات الداخلية الساكنة لعدة أمور، أحدها هو عدّ مرات استدعاء دالةٍ ما، إذ تحافظ المتغيرات الداخلية الساكنة على قيمتها بعد الخروج من الدالة بعكس المتغيرات الداخلية الاعتيادية. إليك دالةً تُعيد عددًا بين 0 و15، ولكنها تُبقي عدد المرات التي استُدعيت بها: int small_val (void) { static unsigned count; count ++; return (count % 16); } [مثال 3] يمكن أن نستخدم هذه الطريقة للكشف عن الاستدعاءات التعاودية مفرطة الحدوث: void r_func (void){ static int depth; depth++; if (depth > 200) { printf ("excessive recursion\n"); exit (1); } else { /* .r_func() نفّذ بعض الأوامر الاعتيادية. قد تتسبب النتائج باستدعاء آخر لدالة التعاود */ x_func(); } depth--; } [مثال 4] ترجمة -وبتصرف- لقسم من الفصل Functions من كتاب The C Book اقرأ أيضًا المقال التالي: مدخل إلى المصفوفات في لغة سي C المقال السابق: مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C الدوال في لغة C البنية النصية لبرامج سي C العوامل في لغة سي C
على الرغم من تفادينا لموضوعَي النطاق Scope والربط Linkage في أمثلتنا البسيطة سابقًا، إلا أن الوقت قد حان لشرح هذين المفهومين وأثرهما على قابلية الوصول للكائنات المختلفة في برنامج سي C، ولكن لمَ علينا الاكتراث بذلك على أي حال؟ لأن البرامج العملية التي نستخدمها تُبنى من عدّة ملفات ومكتبات، وبالتالي من المهم للدوال في ملف ما أن تكون قادرةً على الإشارة إلى دوال، أو كائنات في ملفات أو مكتبات أخرى، وهناك عدّة قوانين ومفاهيم تجعل من ذلك ممكنًا. عُد لاحقًا إلى هذه الجزئية إن كنت جديدًا على لغة سي، لأن هناك بعض المفاهيم الأهم التي يجب عليك معرفتها أوّلًا. الربط Linkage هناك نوعان أساسيان من الكائنات في لغة سي C، هما: الكائنات الخارجية والكائنات الداخلية، والفرق بين الاثنين مُعتمدٌ على الدوال؛ إذ أن أيّ شيء يُصرّح عنه خارج الدالة فهو خارجي؛ وأي شيء يُصرّح عنه داخل الدالة بما فيه مُعاملات الدالة فهو داخلي. بما أننا لا نستطيع تعريف دالة ما داخل دالة أخرى، فهذا يعني أن الدوال هي كائنات خارجية دائمًا، وإذا نظرنا إلى بنية برنامج سي على المستوى الخارجي، سنلاحظ أنه يمثّل مجموعةً من الكائنات الخارجية External objects. يمكن للكائنات الخارجية فقط أن تُشارك في هذا الاتصال عبر الملفات والمكتبات، وتُعرف قابلية الوصول للكائنات هذه من ملف إلى آخر أو ضمن الملف نفسه وفقًا للمعيار باسم الربط Linkage، وهناك ثلاثة أنواع للربط، هي: الربط الخارجي External linkage والربط الداخلي Internal Linkage وعديم الربط No linkage. يكون أي شيء داخلي في الدالة سواءٌ كان وسطاء الدالة أو متغيراتها عديم الربط دائمًا ويمكن الوصول إليه من داخل الدالة فقط، ويمكنك التصريح عن الشيء الذي تريده داخل الدالة مسبوقًا بالكلمة المفتاحية extern لتجاوز هذا القيد، وهذا سيدل على أن الكائن ليس داخليًّا، وليس عليك القلق بهذا الشأن في الوقت الحالي. تكون الكائنات ذات الربط الخارجي موجودةً على المستوى الخارجي لبنية البرنامج، وهذا هو نوع الربط الافتراضي للدوال ولأي شيء آخر يُصرَّح عنه خارج الدوال، وتُشير جميع الأسماء المماثلة لاسم الكائن ذو الربط الخارجي إلى الكائن نفسه. ستحصل على سلوك غير محدد من البرنامج، إذا صرحت عن كائن بنفس الاسم مرتين أو أكثر بربط خارجي وبأنواع غير متوافقة. المثال الذي يأتي إلى بالنا مباشرةً بخصوص الربط الخارجي هو الدالة printf والمُصرّح عنها في ملف الترويسة <stdio.h> على النحو التالي: int printf(const char *, ...); يمكننا فورًا بالنظر إلى التصريح السابق معرفة أن الدالة printf تُعيد قيمةً من نوع int باستخدام النموذج الأولي الموضّح، كما نعرف أن للدالة ربطًا خارجيًّا لأنها كائن خارجي (تذكّر، كل دالة هي كائن خارجي افتراضيًا)، وبالتالي فنحن نقصد هذه الدالة تحديدًا عندما نكتب الاسم printf في أي مكان ضمن البرنامج، إذا استخدمنا الربط الخارجي. ستحتاج في بعض الأحيان لطريقة تمكّنك من التصريح عن الدوال والكائنات الأخرى في ملفٍ واحد بحيث تسمح لهم بالإشارة إلى بعضهم البعض دون القدرة على الوصول إلى تلك الكائنات والدوال من خارج الملف. نحتاج هذه الطريقة غالبًا في الوحدات modules التي تدعم دوال المكتبات، إذ من الأفضل في هذه الحالة إخفاء بعض الكائنات التي تجعل استخدام هذه الدالة ضمن المكتبة ممكنًا، فهي ليست ضرورية المعرفة لمستخدم المكتبة وستكون سببًا للإزعاج لا غير، ونستطيع تحقيق ذلك الأمر عن طريق استخدام الربط الداخلي. تُشير الأسماء ذات الربط الداخلي للكائن ذاته ضمن ملف الشيفرة المصدرية الواحد، ويمكنك التصريح عن كائن ذي ربط داخلي عن طريق بدء التصريح بالكلمة المفتاحية "static" التي ستغيّر ربط الكائن من ربط خارجي (افتراضي) إلى ربط داخلي، كما يمكنك التصريح عن كائنات داخلية باستخدام "static" بهدف استخدامٍ آخر ولكننا لن نتطرق لهذا الاستخدام حاليًا. من المُربك استخدام المصطلحين "داخلي" و"خارجي" لوصف نوع الربط ونوع الكائن، ولكن يعود ذلك لأسباب تاريخية، إذ سيتذكر مبرمجو لغة سي القدماء كون الاستخدامين متساويين، وأن استخدام أحدهما يتضمن تحقّق الآخر، ولكن تغيّر ذلك الأمر للأسف حديثًا وأصبح معنى الاستخدامين مختلف، ولنلخّص الفرق فيما يلي: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } نوع الربط نوع الكائن قابلية الوصول خارجي خارجي يمكن الوصول إليه من أي مكان ضمن البرنامج داخلي خارجي يمكن الوصول إليه عبر ملف واحد فقط لا يوجد ربط داخلي محلّي لدالة واحدة [جدول 1 الربط وقابلية الوصول] أخيرًا وقبل أن ننتقل إلى مثالٍ آخر، علينا أن نعرف أن لجميع الكائنات ذات الربط الخارجي تعريفٌ واحدٌ فقط، مع أنه بالإمكان أن يوجد عدة تصريحات متوافقة حسب حاجتك. إليك المثال: /* الملف الأول */ int i; /* تعريف*/ main () { void f_in_other_place (void); /* تصريح*/ i = 0 } /* نهاية الملف الأول */ /* بداية الملف الثاني */ extern int i; /* تصريح*/ void f_in_other_place (void){ /* تعريف*/ i++; } /* نهاية الملف الثاني */ [مثال 1] على الرغم من تعقيد القوانين الكاملة التي تحدد الفرق بين التعريف والتصريح إلا أن هناك طريقةً بسيطةً وسهلة، هي: التصريح عن الدالة دون تضمين متن الدالة هو تصريحٌ لا غير. التصريح عن الدالة مرفقًا بمتن الدالة هو تعريف. عمومًا، التصريح عن كائن على المستوى الخارجي للبرنامج (مثل المتغير i في المثال السابق) هو تعريف، إلا إذا سُبق بالكلمة المفتاحية extern وعندها يصبح تصريحًا فقط. وسنتكلم لاحقًا عن التعريف والتصريح بصورةٍ أعمق لا تبقي مجالًا للشك. من الواضح في مثالنا السابق أنه من السهل الوصول من أي ملف للكائنات المعرفة في ملفات أخرى باستخدام أسمائها فقط، وسيدلك المثال على كيفية بناء برامج ذات ملفات ودوال ومتغيرات متعددة سواءٌ كانت مُعرّفةً أو مصرّحٌ عنها وفق ما يناسب كل حالة. إليك مثالًا آخر يوضح استخدام "static" لتقييد قابلية الوصول إلى الدوال والأشياء الأخرى. /* مثال عن وحدة في مكتبة */ /* الدالة callable هي الدالة الوحيدة المرئية على المستوى الخارجي */ static buf [100]; static length; static void fillup(void); int callable (){ if (length ==0){ fillup (); } return (buf [length--]); } static void fillup (void){ while (length <100){ buf [length++] = 0; } } [مثال 2] يمكن للمستخدم -بفرض استخدام المثال السابق وحدةً مستقلّة- إعادة استخدام الأسماء "length" و "buf" و "fillup" بأمان دون أي تأثيرات جانبية أو أخطاء غير متوقعة، ونستثني من ذلك الاسم "callable"، إذ إنه قابل الوصول خارج الملف (الوحدة المستقلة). تكون قيمة الكائن الخارجي الذي يمتلك مُهيّئًا initializer واحدًا مساوية للصفر قبل بدء البرنامج (لم نتكلم عن أي مُهيّئات عدا الدوال حتى الآن)، وتعتمد الكثير من البرامج على ذلك، بما فيها المثال السابق لقيمة length الابتدائية. تأثير النطاق لا تقتصر عملية مشاركة الأسماء وقابلية الوصول إليها على الربط ببساطة، فالربط يسمح لك باستخدام عدة أسماء والوصول إليها سويًّا ضمن البرنامج أو ضمن الملف، ولكن النطاق Scope يحدد رؤية الأسماء، وقواعد النطاق لحسن الحظ مستقلةٌ عن مبدأ الربط، لذا ليس عليك حفظ أي قواعد مركبة بين المفهومين. تزيد الكلمة المفتاحية "extern" من تعقيد البرنامج، فعلى الرغم من وضوح استخدامها وتأثيرها إلا أنها تغيّر من بنية برنامج لغة سي الكُتلية التي اعتدنا عليها، وسنناقش المشاكل الناتجة عن استخدامها الخاطئ وغير المسؤول لاحقًا، وقد نظرنا إلى استخدامها مُسبقًا للتأكد من أن التصريح لشيء ما ضمن المستوى الخارجي للبرنامج هو تصريحٌ وليس تعريف. ملاحظة: يمكنك تجاوز الكلمة المفتاحية "extern" عن طريق مُهيّئ للكائن. التصريح عن أي كائن بيانات (ليس بدالة) ضمن المستوى الخارجي للبرنامج هو تعريفٌ، إلا إذا سبق التصريح الكلمة المفتاحية "extern"، راجع المثال 9.4 من أجل ملاحظة هذه النقطة عمليًّا. تحتوي تصريحات الدوال الكلمة المفتاحية "extern" ضمنيًّا سواءٌ كانت مكتوبةً أم لا، والطريقتان التاليتان للتصريح عن الدالة some_function متكافئتان، وتُعدان تصريحًا وليس تعريفًا: void some_function(void); extern void some_function(void); الشيء الوحيد الذي يفصل التصريحات السابقة عن كونها تعريفات هو متن الدالة، الذي يُعد مُهيِّئًا للدالة، لذلك عند إضافة المُهيّئ يتحول التصريح إلى تعريف، لا توجد أي مشكلة بخصوص ذلك. لكن ما الذي يحدث في المثال التالي؟ void some_function(void){ int i_var; extern float e_f_var; } void another_func(void){ int i; i = e_f_var; /* مشكلة تتعلق بالنطاق */ } ما الهدف من المثال السابق؟ من المفيد في بعض الأحيان أن تستخدم كائنًا خارجيًّا ضمن دالة ما، وإن اتبعت الطريقة الاعتيادية بالتصريح عن الكائن في بداية ملف الشيفرة المصدرية، فسيكون صعبًا على القارئ معرفة أي من الدوال تستخدم ذلك الكائن؛ بدلًا من ذلك، يمكنك تقييد نطاق الكائن وقابلية الوصول إليه في المكان الذي تريد الوصول إليه، ممّا سيسهّل على القارئ معرفة أن الاسم سيُستخدم فقط في هذا المكان المحدود وليس على كامل نطاق ملف الشيفرة المصدرية. يجدر الانتباه إلى أن معظم طرق إدارة الوسطاء في هذه الحالة عمليةٌ صعبةٌ بعض الشيء. سنناقش المزيد من القواعد عن الطريقة الأمثل لإنشاء برنامج ذو ملفات متعددة، وما الممكن حدوثه عند المزج بين التصريحات الداخلية والخارجية والكلمات المفتاحية "extern" و "static". لن تكون عملية قراءة هذه القواعد ممتعةً، لكنها ستكون إجابةً لأسئلة من نوع "ماذا لو؟". الكائنات الداخلية الساكنة يمكنك التصريح عن كائنات داخلية على أنها كائنات داخلية ساكنة باستخدام الكلمة المفتاحية "static"، وتكتسب المتغيرات الداخلية بعضًا من الخصائص باستخدامها هذه الكلمة المفتاحية ألا وهي: تُهيّأ قيمتها إلى الصفر عند بداية البرنامج. تحافظ على قيمتها من بداية التعليمة التي تضم تصريحها إلى نهايتها. يوجد نسخةٌ واحدةٌ من كل متغيّر داخلي ساكن تتشاركه الاستدعاءات التعاودية للدوال التي تحوي هذه المتغيرات. يمكن أن تُستخدم المتغيرات الداخلية الساكنة لعدة أمور، أحدها هو عدّ مرات استدعاء دالةٍ ما، إذ تحافظ المتغيرات الداخلية الساكنة على قيمتها بعد الخروج من الدالة بعكس المتغيرات الداخلية الاعتيادية. إليك دالةً تُعيد عددًا بين 0 و15، ولكنها تُبقي عدد المرات التي استُدعيت بها: int small_val (void) { static unsigned count; count ++; return (count % 16); } [مثال 3] يمكن أن نستخدم هذه الطريقة للكشف عن الاستدعاءات التعاودية مفرطة الحدوث: void r_func (void){ static int depth; depth++; if (depth > 200) { printf ("excessive recursion\n"); exit (1); } else { /* .r_func() نفّذ بعض الأوامر الاعتيادية. قد تتسبب النتائج باستدعاء آخر لدالة التعاود */ x_func(); } depth--; } [مثال 4] ترجمة -وبتصرف- لقسم من الفصل Functions من كتاب The C Book اقرأ أيضًا المقال التالي: مدخل إلى المصفوفات في لغة سي C المقال السابق: مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C الدوال في لغة C البنية النصية لبرامج سي C العوامل في لغة سي C -
 نظرنا سابقًا إلى كيفية تعيين نوع للدالة Funtion type (كيفية التصريح عن القيمة المُعادة ونوع أيّ وسيط argument تأخذه الدالة)، وأن تعريف definition الدالة يمثّل متنها أو جسمها body، ولننظر الآن إلى استخدامات الوسطاء. استدعاء الوسيط بقيمته call by value تُعامل لغة سي C وسطاء الدالة بطريقة بسيطة وثابتة دون أي استثناءات فردية؛ إذ تُعامل وسطاء الدالة عندما تُستدعى الدالة مثل أي تعبير اعتيادي، وتُحوّل قيم هذه التعابير وتُستخدم فيما بعد لتهيئة القيمة الأولية لمعاملات الدالة المُستدعاة الموافقة، التي تتصرف بدورها مثل أيّ متغير محلي داخل الدالة، كما هو موضح في المثال: void called_func(int, float); main(){ called_func(1, 2*3.5); exit(EXIT_SUCCESS); } void called_func(int iarg, float farg){ float tmp; tmp = iarg * farg; } [مثال 1] يوجد للدالة called_func تعبيران يحلّان محل الوسطاء في دالة main، وتُقيّم قيمتهما ويُستخدمان في إسناد قيمة مبدئية للمعاملين irag و frag في الدالة called_func، ويملك المعاملان الخصائص ذاتها التي يملكها أي متغير داخلي مصرّحٌ عنه في الدالة called_func دون أي تفريق، مثل tmp. تُعد عملية إسناد القيمة المبدئية للمعاملات الفعلية التواصل الأخير بين مستدعي الدالة والدالة المُستدعاة، إذا استثنينا القيمة المُعادة. يجب أن ينسى من اعتاد البرمجة باستخدام فورتران FORTRAN وباسكال Pascal طريقة استخدام وسطاء من نوع var، والتي يمكن للدالة أن تغير من قيم وسطائها؛ إذ لا يمكنك في لغة سي أن تؤثر على قيم وسطاء الدالة بأي شكل من الأشكال، إليك مثالًا نوضّح فيه المقصود. #include <stdio.h> #include <stdlib.h> main(){ void changer(int); int i; i = 5; printf("before i=%d\n", i); changer(i); printf("after i=%d\n", i); exit(EXIT_SUCCESS); } void changer(int x){ while(x){ printf("changer: x=%d\n", x); x--; } } [مثال 2] ستكون نتيجة المثال السابق على النحو التالي: before i=5 changer: x=5 changer: x=4 changer: x=3 changer: x=2 changer: x=1 after i=5 تَستخدم الدالة changer معاملها الفعلي x بمثابة متغير اعتيادي (وهو فعلًا متغير اعتيادي)، ورغم أن قيمة x تغيرت إلا أن المتغير i في الدالة main لم يتأثر بالتغيير، وهذه هي النقطة التي نريد توضيحها لك بمثالنا، إذ تُمرَّر الوسطاء في سي C إلى الدالة باستخدام قيمها فقط ولا تُمرر أي تغييرات من الدالة بالمقابل. استدعاء الوسيط بمرجعه call by reference من الممكن كتابة دوال تأخذ المؤشرات pointers على أنها وسطاء، مما يعطينا شكلًا من أشكال الاستدعاء بالمرجع. سنناقش هذا لاحقًا، إذ ستسمح هذه الطريقة للدالة بتغيير قيم المتغيرات التي استدعتها. التعاود Recursion بعد أن تكلمنا عن كيفية تمرير الوسطاء بأمان، حان الوقت للتكلم على التعاود Recursion، إذ يثير هذا الموضوع جدلًا طويلًا غير مثمرٍ بين المبرمجين، فالبعض يعدّه رائعًا ويستخدمه متى ما أتيحت له الفرصة، بينما يتجنَّب الطرف الآخر استخدامه بأي ثمن، لكن دعنا نوضّح أنك ستضطرّ لاستخدامه في بعض الحالات دون أي مفرّ. لا يتطلب دعم التعاود أيّ جهد إضافي لتضمينه في أي لغة برمجة، وبذلك -وكما توقّعت- تدعم لغة سي C التعاود. يمكن لأي دالة أن تستدعي نفسها من داخلها أو من داخل أي دالة أخرى في لغة سي، ويتسبب كل استدعاء للدالة بحجز متغيراتٍ جديدة مصرّح عنها داخل الدالة، وفي الحقيقة، كانت تفتقر التصريحات التي استخدمناها حتى اللحظة إلى شيءٍ ما، ألا وهو الكلمة المفتاحية auto التي تعني "الحجز التلقائي". /* مثال عن الحجز التلقائي */ main(){ auto int var_name; . . . } تُحجز وتُحرّر مساحة التخزين للمتغيرات التلقائية تلقائيًا عند البدء بتنفيذ الدالة وعند إعادتها للقيمة، أي الخروج منها، وبذلك سيحتاج البرنامج فقط لحجز مساحة لمصفوفتين مثلًا، في حال صرَّحت دالتين عن مصفوفتين تلقائيتين automatic ونُفِّذت الدالتان في الوقت نفسه. على الرغم من كون "auto" كلمةً مفتاحية في لغة سي، لكنها لا تُستخدم عمليًا لأنها الحالة الافتراضية لعمليات التصريح عن المتغيرات الداخلية وغير صالحة في حال استخدامها مع عمليات التصريح عن المتغيرات الخارجية. تكون قيمة المتغير التلقائي غير معروفةٍ عند التصريح عنه إذا لم تُسند أي قيمة ابتدائية إليه، وسيتسبب استخدام قيمة المتغير في هذه الحالة في ظهور سلوكٍ غير محدد. يجب علينا انتقاء الأمثلة التي سنشرح عن طريقها مفهوم التعاود، إذ لا توضّح الأمثلة البسيطة مفهوم التعاود على النحو المناسب، والأمثلة التي توضح المفهوم كاملًا صعبة الفهم على المبتدئين، الذين يواجهون بعض الصعوبة في التمييز بين التصريح والتعريف على سبيل المثال، وسنتكلم لاحقًا عن مفهوم التعاود وفائدته باستخدام بعض الأمثلة عندما نتكلم عن هياكل البيانات. يوضح المثال التالي برنامجًا يحتوي دالةً تعاوديةً تتحقق من التعابير المُدخلة إليها بما فيها الأرقام (0-9) والعوامل "*" و "%" و "/" و "+" و "-"، إضافةً إلى الأقواس، بالطريقة نفسها التي تستخدمها لغة سي، كما استخدم ستروستروب Stroustrup في كتابه عن لغة ++C المثال ذاته لتوضيح مفهوم التعاود، وهذا من قبيل الصدفة لا غير. يُقيّم التعبير في المثال التالي، ثُم تُطبع قيمته إن صادف محرفًا غير موجودًا في لغته (المحارف التي ذكرناها سابقًا)، ولغرض البساطة لن يكون في المثال أي طريقة للتحقق من الأخطاء. يعتمد المثال كثيرًا على الدالة ungetc التي تسمح للمحرف الأخير الذي قُرأ بواسطة الدالة getchar أن يُعيّن على أنه "غير مقروء" للسماح بقراءته مرةً أخرى، والمُعامل الثاني المُستخدم في المثال مُصرّحٌ عنه في stdio.h. سيرغب من يفهم صيغة باكوس نور BNF بمعرفة أن التعبير سيُفهم عن طريق استخدام الصيغة التالية: <primary> ::= digit | (<exp>) <unary> ::= <primary> | -<unary> | +<unary> <mult> ::= <unary> | <mult> * <unary> | <mult> / <unary> | <mult> % <unary> <exp> ::= <exp> + <mult> | <exp> - <mult> | <mult> يكمن التعاود في مثالنا ضمن مكانين أساسيين، هما: الدالة unary_exp التي تستدعي نفسها، والدالة primary التي تستدعي الدالة الموجودة على المستوى العلوي للبرنامج (نقصد دالة expr) لتقييم التعابير المكتوبة بين قوسين. حاول تشغيل البرنامج باستخدام كل من الأمثلة التالية إذا لم تفهم عمله، وتتبَّع عمله يدويًّا على المُدخلات، كما يلي: 1 1+2 1+2 * 3+4 1+--4 1+(2*3)+4 سيستغرق هذا بعض الوقت منك. /* * برنامج يتحقق من تعابير لغة سي على نحوٍ تعاودي * لم يُشدّد على حالات الإدخال الخاطئة من المستخدم */ #include <stdio.h> #include <stdlib.h> int expr(void); int mul_exp(void); int unary_exp(void); int primary(void); main(){ int val; for(;;){ printf("expression: "); val = expr(); if(getchar() != '\n'){ printf("error\n"); while(getchar() != '\n') /* فارغ */; } else{ printf("result is %d\n", val); } } exit(EXIT_SUCCESS); } int expr(void){ int val, ch_in; val = mul_exp(); for(;;){ switch(ch_in = getchar()){ default: ungetc(ch_in,stdin); return(val); case '+': val = val + mul_exp(); break; case '-': val = val - mul_exp(); break; } } } int mul_exp(void){ int val, ch_in; val = unary_exp(); for(;;){ switch(ch_in = getchar()){ default: ungetc(ch_in, stdin); return(val); case '*': val = val * unary_exp(); break; case '/': val = val / unary_exp(); break; case '%': val = val % unary_exp(); break; } } } int unary_exp(void){ int val, ch_in; switch(ch_in = getchar()){ default: ungetc(ch_in, stdin); val = primary(); break; case '+': val = unary_exp(); break; case '-': val = -unary_exp(); break; } return(val); } int primary(void){ int val, ch_in; ch_in = getchar(); if(ch_in >= '0' && ch_in <= '9'){ val = ch_in - '0'; goto out; } if(ch_in == '('){ val = expr(); getchar(); /* “')” تخطي قوس الإغلاق */ goto out; } printf("error: primary read %d\n", ch_in); exit(EXIT_FAILURE); out: return(val); } [مثال 3] ترجمة -وبتصرف- لقسم من الفصل Functions من كتاب The C Book اقرأ أيضًا المقال التالي: مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C المقال السابق: الدوال في لغة C البنية النصية لبرامج سي C العوامل في لغة سي C
نظرنا سابقًا إلى كيفية تعيين نوع للدالة Funtion type (كيفية التصريح عن القيمة المُعادة ونوع أيّ وسيط argument تأخذه الدالة)، وأن تعريف definition الدالة يمثّل متنها أو جسمها body، ولننظر الآن إلى استخدامات الوسطاء. استدعاء الوسيط بقيمته call by value تُعامل لغة سي C وسطاء الدالة بطريقة بسيطة وثابتة دون أي استثناءات فردية؛ إذ تُعامل وسطاء الدالة عندما تُستدعى الدالة مثل أي تعبير اعتيادي، وتُحوّل قيم هذه التعابير وتُستخدم فيما بعد لتهيئة القيمة الأولية لمعاملات الدالة المُستدعاة الموافقة، التي تتصرف بدورها مثل أيّ متغير محلي داخل الدالة، كما هو موضح في المثال: void called_func(int, float); main(){ called_func(1, 2*3.5); exit(EXIT_SUCCESS); } void called_func(int iarg, float farg){ float tmp; tmp = iarg * farg; } [مثال 1] يوجد للدالة called_func تعبيران يحلّان محل الوسطاء في دالة main، وتُقيّم قيمتهما ويُستخدمان في إسناد قيمة مبدئية للمعاملين irag و frag في الدالة called_func، ويملك المعاملان الخصائص ذاتها التي يملكها أي متغير داخلي مصرّحٌ عنه في الدالة called_func دون أي تفريق، مثل tmp. تُعد عملية إسناد القيمة المبدئية للمعاملات الفعلية التواصل الأخير بين مستدعي الدالة والدالة المُستدعاة، إذا استثنينا القيمة المُعادة. يجب أن ينسى من اعتاد البرمجة باستخدام فورتران FORTRAN وباسكال Pascal طريقة استخدام وسطاء من نوع var، والتي يمكن للدالة أن تغير من قيم وسطائها؛ إذ لا يمكنك في لغة سي أن تؤثر على قيم وسطاء الدالة بأي شكل من الأشكال، إليك مثالًا نوضّح فيه المقصود. #include <stdio.h> #include <stdlib.h> main(){ void changer(int); int i; i = 5; printf("before i=%d\n", i); changer(i); printf("after i=%d\n", i); exit(EXIT_SUCCESS); } void changer(int x){ while(x){ printf("changer: x=%d\n", x); x--; } } [مثال 2] ستكون نتيجة المثال السابق على النحو التالي: before i=5 changer: x=5 changer: x=4 changer: x=3 changer: x=2 changer: x=1 after i=5 تَستخدم الدالة changer معاملها الفعلي x بمثابة متغير اعتيادي (وهو فعلًا متغير اعتيادي)، ورغم أن قيمة x تغيرت إلا أن المتغير i في الدالة main لم يتأثر بالتغيير، وهذه هي النقطة التي نريد توضيحها لك بمثالنا، إذ تُمرَّر الوسطاء في سي C إلى الدالة باستخدام قيمها فقط ولا تُمرر أي تغييرات من الدالة بالمقابل. استدعاء الوسيط بمرجعه call by reference من الممكن كتابة دوال تأخذ المؤشرات pointers على أنها وسطاء، مما يعطينا شكلًا من أشكال الاستدعاء بالمرجع. سنناقش هذا لاحقًا، إذ ستسمح هذه الطريقة للدالة بتغيير قيم المتغيرات التي استدعتها. التعاود Recursion بعد أن تكلمنا عن كيفية تمرير الوسطاء بأمان، حان الوقت للتكلم على التعاود Recursion، إذ يثير هذا الموضوع جدلًا طويلًا غير مثمرٍ بين المبرمجين، فالبعض يعدّه رائعًا ويستخدمه متى ما أتيحت له الفرصة، بينما يتجنَّب الطرف الآخر استخدامه بأي ثمن، لكن دعنا نوضّح أنك ستضطرّ لاستخدامه في بعض الحالات دون أي مفرّ. لا يتطلب دعم التعاود أيّ جهد إضافي لتضمينه في أي لغة برمجة، وبذلك -وكما توقّعت- تدعم لغة سي C التعاود. يمكن لأي دالة أن تستدعي نفسها من داخلها أو من داخل أي دالة أخرى في لغة سي، ويتسبب كل استدعاء للدالة بحجز متغيراتٍ جديدة مصرّح عنها داخل الدالة، وفي الحقيقة، كانت تفتقر التصريحات التي استخدمناها حتى اللحظة إلى شيءٍ ما، ألا وهو الكلمة المفتاحية auto التي تعني "الحجز التلقائي". /* مثال عن الحجز التلقائي */ main(){ auto int var_name; . . . } تُحجز وتُحرّر مساحة التخزين للمتغيرات التلقائية تلقائيًا عند البدء بتنفيذ الدالة وعند إعادتها للقيمة، أي الخروج منها، وبذلك سيحتاج البرنامج فقط لحجز مساحة لمصفوفتين مثلًا، في حال صرَّحت دالتين عن مصفوفتين تلقائيتين automatic ونُفِّذت الدالتان في الوقت نفسه. على الرغم من كون "auto" كلمةً مفتاحية في لغة سي، لكنها لا تُستخدم عمليًا لأنها الحالة الافتراضية لعمليات التصريح عن المتغيرات الداخلية وغير صالحة في حال استخدامها مع عمليات التصريح عن المتغيرات الخارجية. تكون قيمة المتغير التلقائي غير معروفةٍ عند التصريح عنه إذا لم تُسند أي قيمة ابتدائية إليه، وسيتسبب استخدام قيمة المتغير في هذه الحالة في ظهور سلوكٍ غير محدد. يجب علينا انتقاء الأمثلة التي سنشرح عن طريقها مفهوم التعاود، إذ لا توضّح الأمثلة البسيطة مفهوم التعاود على النحو المناسب، والأمثلة التي توضح المفهوم كاملًا صعبة الفهم على المبتدئين، الذين يواجهون بعض الصعوبة في التمييز بين التصريح والتعريف على سبيل المثال، وسنتكلم لاحقًا عن مفهوم التعاود وفائدته باستخدام بعض الأمثلة عندما نتكلم عن هياكل البيانات. يوضح المثال التالي برنامجًا يحتوي دالةً تعاوديةً تتحقق من التعابير المُدخلة إليها بما فيها الأرقام (0-9) والعوامل "*" و "%" و "/" و "+" و "-"، إضافةً إلى الأقواس، بالطريقة نفسها التي تستخدمها لغة سي، كما استخدم ستروستروب Stroustrup في كتابه عن لغة ++C المثال ذاته لتوضيح مفهوم التعاود، وهذا من قبيل الصدفة لا غير. يُقيّم التعبير في المثال التالي، ثُم تُطبع قيمته إن صادف محرفًا غير موجودًا في لغته (المحارف التي ذكرناها سابقًا)، ولغرض البساطة لن يكون في المثال أي طريقة للتحقق من الأخطاء. يعتمد المثال كثيرًا على الدالة ungetc التي تسمح للمحرف الأخير الذي قُرأ بواسطة الدالة getchar أن يُعيّن على أنه "غير مقروء" للسماح بقراءته مرةً أخرى، والمُعامل الثاني المُستخدم في المثال مُصرّحٌ عنه في stdio.h. سيرغب من يفهم صيغة باكوس نور BNF بمعرفة أن التعبير سيُفهم عن طريق استخدام الصيغة التالية: <primary> ::= digit | (<exp>) <unary> ::= <primary> | -<unary> | +<unary> <mult> ::= <unary> | <mult> * <unary> | <mult> / <unary> | <mult> % <unary> <exp> ::= <exp> + <mult> | <exp> - <mult> | <mult> يكمن التعاود في مثالنا ضمن مكانين أساسيين، هما: الدالة unary_exp التي تستدعي نفسها، والدالة primary التي تستدعي الدالة الموجودة على المستوى العلوي للبرنامج (نقصد دالة expr) لتقييم التعابير المكتوبة بين قوسين. حاول تشغيل البرنامج باستخدام كل من الأمثلة التالية إذا لم تفهم عمله، وتتبَّع عمله يدويًّا على المُدخلات، كما يلي: 1 1+2 1+2 * 3+4 1+--4 1+(2*3)+4 سيستغرق هذا بعض الوقت منك. /* * برنامج يتحقق من تعابير لغة سي على نحوٍ تعاودي * لم يُشدّد على حالات الإدخال الخاطئة من المستخدم */ #include <stdio.h> #include <stdlib.h> int expr(void); int mul_exp(void); int unary_exp(void); int primary(void); main(){ int val; for(;;){ printf("expression: "); val = expr(); if(getchar() != '\n'){ printf("error\n"); while(getchar() != '\n') /* فارغ */; } else{ printf("result is %d\n", val); } } exit(EXIT_SUCCESS); } int expr(void){ int val, ch_in; val = mul_exp(); for(;;){ switch(ch_in = getchar()){ default: ungetc(ch_in,stdin); return(val); case '+': val = val + mul_exp(); break; case '-': val = val - mul_exp(); break; } } } int mul_exp(void){ int val, ch_in; val = unary_exp(); for(;;){ switch(ch_in = getchar()){ default: ungetc(ch_in, stdin); return(val); case '*': val = val * unary_exp(); break; case '/': val = val / unary_exp(); break; case '%': val = val % unary_exp(); break; } } } int unary_exp(void){ int val, ch_in; switch(ch_in = getchar()){ default: ungetc(ch_in, stdin); val = primary(); break; case '+': val = unary_exp(); break; case '-': val = -unary_exp(); break; } return(val); } int primary(void){ int val, ch_in; ch_in = getchar(); if(ch_in >= '0' && ch_in <= '9'){ val = ch_in - '0'; goto out; } if(ch_in == '('){ val = expr(); getchar(); /* “')” تخطي قوس الإغلاق */ goto out; } printf("error: primary read %d\n", ch_in); exit(EXIT_FAILURE); out: return(val); } [مثال 3] ترجمة -وبتصرف- لقسم من الفصل Functions من كتاب The C Book اقرأ أيضًا المقال التالي: مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C المقال السابق: الدوال في لغة C البنية النصية لبرامج سي C العوامل في لغة سي C