


محمد أحمد العيل
-
المساهمات
308 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
28
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو محمد أحمد العيل
-
.png.cfe62bac23dc2e2336367c751c9c95b4.png) تتبنّى لغة البرمجة Go مفتوحة المصدر التي تطوّرها شركة Google، والتي يُشار إليها أحيانا بـ Golang، تتبنّى مقاربة تقليلية Minimalist في تطوير البرمجيّات تسمح بكتابة برامج سهلة، موثوقة وفعّالة. يساعدك هذا الدرس في تثبيت الإصدار 1.8 من Go (الإصدار المستقرّ الأحدث حتى الساعة) على خادوم Centos 7، وتصريف Compiling برنامج “Hello, World!” بسيط. المتطلّبات يُستحسن أولا التأكد من وجود مستخدم إداري غير المستخدم الجذر على الخادوم. تمكنك معرفة كيفية ضبط مستخدم بهذه المواصفات بقراءة هذا الدرس لتعرف كيف تنشئ مستخدما بصلاحيات sudo على Centos. الخطوة الأولى: تثبيت Go نذهب إلى الموقع الرسمي للحصول على آخر إصدار من Go. تأكّد من تنزيل حزمة لينكس الموافقة لمعمارية 64 بت. نبدأ بالانتقال إلى مجلّد تمكننا الكتابة فيه: cd /tmp نستخدم الأمر curl ونمرّر له رابط حزمة Go الذي تحصّلنا عليه من الموقع الرسمي للغة: curl -LO https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz على الرغم من أننا متأكدون من المصدر الذي نزّلنا منه الملف، إلا أنه من الجيّد التحقّق من سلامة الملفات وموثوقيّتها عند تنزيلها من الإنترنت. يوفّر موقع Go قيمة التجزئة Hash لكلّ ملف مضغوط على صفحة التنزيلات. ننفّذ الأمر التالي لحساب قيمة التجزئة الخاصّة بالملفّ الذي نزّلناه: shasum -a 256 go1.8*.tar.gz تشبه نتيجة الأمر التالي: 1862f4c3d3907e59b04a757cfda0ea7aa9ef39274af99a784f5be843c80c6772 go1.8.3.linux-amd64.tar.gz قارن قيمة التجزئة التي تحصّلت عليها مع تجزئة الملف الموجودة على صفحة تنزيلات Go. توجد قيمة تجزئة لكلّ ملف على صفحة التنزيلات، لذا تأكد من التجزئة الصحيحة. ننتقل بعد تنزيل Go والتأكد من سلامة البيانات إلى تثبيت بيئة تصريف اللغة. الخطوة الثانية: تثبيت Go يتمثّل تثبيت Go في استخراج محتويات الملفّ المضغوط وحفظها في المجلّد usr/local/. يحفظ الأمر tar محتويات الملّف بعد استخراجها على المسار المُمرَّر بعد الخيار C-. يُستخدَم الخيار x- لفك ضغط الملف، v- لإظهار مُخرجات تفصيلية لعمل الأمر ويُحدّد z- الخوارزميّة المستخدمة لضغط الملف (gzip)؛ أما الخيار f- فيحدّد الملف المضغوط الذي نستخرج محتوياته: sudo tar -C /usr/local -xvzf go1.8.3.linux-amd64.tar.gz ملحوظة: تنصح Google بوضع مجلّد Go على المسار usr/local/. لا يمنع وضع المجلّد على مسار آخر إمكانية استخدام اللغة، إلا أن المسار المُخصَّص يجب أن يُعرَّف ضمن متغيّر البيئة GOROOT. تشرح الخطوة المواليّة ضبط المسارات. سننشئ في ما يلي مجلّد عمل جديدا لـGo داخل المجلّد الشخصي للمستخدم، وننشئ فيه ثلاثة مجلدات فرعية src،bin وpkg. سيحوي المجلّد الفرعي bin البرامج التنفيذية الناتجة عن تصريف ملفات الشفرة البرمجية الموجودة في المجلّد src. لن نستخدم في هذا الدرس المجلّد pkg إلا أنه مفيد في المشاريع المتقدّمة إذ يخزّن الحزم وهي مجموعة من الشفرات البرمجية التي يمكن تشاركها بين البرامج. سنسمّي مجلّد العمل projects، إلا أن بإمكانك تسميته بالاسم الذي تريد. يؤدّي استخدام الخيار p- مع الأمر mkdir إلى إنشاء المجلّدات وفق الهرميّة الموجودة في المسار المُمرَّر للأمر. mkdir -p ~/projects/{bin,pkg,src} يصبح Go جاهزا للعمل باكتمال هذه الخطوة، إلا أن استخدامه يتطلّب ذكر مسار التثبيت كاملا في سطر الأوامر. يمكن أن نجعل الاستخدام أكثر سهولة بضبط بضعة مسارات، وهو ما سنفعله في الخطوة التالية. الخطوة الثالثة: ضبط مسارات Go سنحتاج لإدراج المسار الذي ثبّتنا عليها Go إلى متغيّر البيئة PATH$ حتى يمكننا تنفيذه بنفس طريقة تنفيذ أي أمر في الطرفية: ذكر اسم الأمر فقط، دون المسار الكامل. بما أن Go مثبَّت في مجلّد يستخدمه نظام التشغيل فسنضبُط Go ليكون متاحا لجميع المستخدمين. أنشئ سكريبت باسم path.sh على المسار etc/profile.d/ باستخدام محرّر النصوص vi: sudo vi /etc/profile.d/path.sh أضف السطر التالي إلى آخر الملف ثم احفظ الملف وأغلقه: export PATH=$PATH:/usr/local/go/bin تنبيه: عدّل المسار بما يُناسب إن كنت قد اخترت مكانا مختلفا لتثبيت Go. نعرّف أيضا قيمتيْ المتغيّريْن GOPATH وGOBINفي ملّف المستخدم bash_profile. للإشارة إلى مجلّد العمل الذي أنشأناه في الخطوة السابقة. يحدّد المتغيّر GOPATH مكان ملفات الشفرة البرمجية بينما يحدّد المتغيّر GOBIN المجلّد الذي يجب أن توضع فيه الملفات التنفيذية بعد تصريف الشفرات البرمجية. نفتح الملف bash_profile.: vi ~/.bash_profile نضيف السطريْن التاليّيْن إلى نهاية الملف: export GOBIN="$HOME/projects/bin" export GOPATH="$HOME/projects/src" تنبيه: إن كان Go مثبّتا على مسار غير المسار المنصوح به (usr/local/) فيجب أن تعرّف قيمة المتغيّر GOROOT في الملفّ bash_profile. إلى جانب المتغيّريْن GOBIN وGOPATH: export GOROOT="/path/to/go" export GOBIN="$HOME/projects/bin" export GOPATH="$HOME/projects/src" حيث path/to/go/ مسار تثبيت Go. ننفّذ الأمر source لاعتماد التغييرات على الملفات التي عدّلناها وإعادة تحميلها لجلسة الطرفية الحالية: source /etc/profile && source ~/.bash_profile يجب أن يكون كلّ شيء جاهزا الآن، وهو ما سنتأكّد منه في الخطوة التالية. الخطوة الرابعة: كتابة برنامج Go واختباره نهدف من هذه الخطوة إلى التأكد من أن بيئة Go جاهزة للعمل على جهازنا. نبدأ بإنشاء ملفّ جديد لنضع فيه أول شفرة برمجيّة نكتبها: vi ~/projects/src/hello.go تستخدم شفرة Go أدناه حزمة main، تستورد مكتبة fmt لدوالّ الإدخال والإخراج وتضبُط دالة جديدة لطباعة الجملة !Hello, World. package main import "fmt" func main() { fmt.Printf("Hello, World!\n") } احفظ الملف ثم أغلقه. ثم نصرّف الشفرة البرمجية بالأمر go install: go install $GOPATH/hello.go نحن الآن جاهزون لتشغيل البرنامج: $GOBIN/hello إن كان كل شيء على ما يُرام فستظهر رسالة Hello, World! بعد تشغيل البرنامج. نتأكد بتنفيذ برنامج Hello, World! السابق من أن بيئة Go مثبّتة وجاهزة للاستخدام. تستخدم برامج Go عادة مكتبات برمجية وحزما خارجية. راجع مقالات البرمجة بلغة Go للمزيد عن كيفية كتابة البرامج بهذه اللغة. ترجمة - بتصرّف - للمقال How To Install Go 1.7 on CentOS 7 لصاحبه Michael Lenardson.
تتبنّى لغة البرمجة Go مفتوحة المصدر التي تطوّرها شركة Google، والتي يُشار إليها أحيانا بـ Golang، تتبنّى مقاربة تقليلية Minimalist في تطوير البرمجيّات تسمح بكتابة برامج سهلة، موثوقة وفعّالة. يساعدك هذا الدرس في تثبيت الإصدار 1.8 من Go (الإصدار المستقرّ الأحدث حتى الساعة) على خادوم Centos 7، وتصريف Compiling برنامج “Hello, World!” بسيط. المتطلّبات يُستحسن أولا التأكد من وجود مستخدم إداري غير المستخدم الجذر على الخادوم. تمكنك معرفة كيفية ضبط مستخدم بهذه المواصفات بقراءة هذا الدرس لتعرف كيف تنشئ مستخدما بصلاحيات sudo على Centos. الخطوة الأولى: تثبيت Go نذهب إلى الموقع الرسمي للحصول على آخر إصدار من Go. تأكّد من تنزيل حزمة لينكس الموافقة لمعمارية 64 بت. نبدأ بالانتقال إلى مجلّد تمكننا الكتابة فيه: cd /tmp نستخدم الأمر curl ونمرّر له رابط حزمة Go الذي تحصّلنا عليه من الموقع الرسمي للغة: curl -LO https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz على الرغم من أننا متأكدون من المصدر الذي نزّلنا منه الملف، إلا أنه من الجيّد التحقّق من سلامة الملفات وموثوقيّتها عند تنزيلها من الإنترنت. يوفّر موقع Go قيمة التجزئة Hash لكلّ ملف مضغوط على صفحة التنزيلات. ننفّذ الأمر التالي لحساب قيمة التجزئة الخاصّة بالملفّ الذي نزّلناه: shasum -a 256 go1.8*.tar.gz تشبه نتيجة الأمر التالي: 1862f4c3d3907e59b04a757cfda0ea7aa9ef39274af99a784f5be843c80c6772 go1.8.3.linux-amd64.tar.gz قارن قيمة التجزئة التي تحصّلت عليها مع تجزئة الملف الموجودة على صفحة تنزيلات Go. توجد قيمة تجزئة لكلّ ملف على صفحة التنزيلات، لذا تأكد من التجزئة الصحيحة. ننتقل بعد تنزيل Go والتأكد من سلامة البيانات إلى تثبيت بيئة تصريف اللغة. الخطوة الثانية: تثبيت Go يتمثّل تثبيت Go في استخراج محتويات الملفّ المضغوط وحفظها في المجلّد usr/local/. يحفظ الأمر tar محتويات الملّف بعد استخراجها على المسار المُمرَّر بعد الخيار C-. يُستخدَم الخيار x- لفك ضغط الملف، v- لإظهار مُخرجات تفصيلية لعمل الأمر ويُحدّد z- الخوارزميّة المستخدمة لضغط الملف (gzip)؛ أما الخيار f- فيحدّد الملف المضغوط الذي نستخرج محتوياته: sudo tar -C /usr/local -xvzf go1.8.3.linux-amd64.tar.gz ملحوظة: تنصح Google بوضع مجلّد Go على المسار usr/local/. لا يمنع وضع المجلّد على مسار آخر إمكانية استخدام اللغة، إلا أن المسار المُخصَّص يجب أن يُعرَّف ضمن متغيّر البيئة GOROOT. تشرح الخطوة المواليّة ضبط المسارات. سننشئ في ما يلي مجلّد عمل جديدا لـGo داخل المجلّد الشخصي للمستخدم، وننشئ فيه ثلاثة مجلدات فرعية src،bin وpkg. سيحوي المجلّد الفرعي bin البرامج التنفيذية الناتجة عن تصريف ملفات الشفرة البرمجية الموجودة في المجلّد src. لن نستخدم في هذا الدرس المجلّد pkg إلا أنه مفيد في المشاريع المتقدّمة إذ يخزّن الحزم وهي مجموعة من الشفرات البرمجية التي يمكن تشاركها بين البرامج. سنسمّي مجلّد العمل projects، إلا أن بإمكانك تسميته بالاسم الذي تريد. يؤدّي استخدام الخيار p- مع الأمر mkdir إلى إنشاء المجلّدات وفق الهرميّة الموجودة في المسار المُمرَّر للأمر. mkdir -p ~/projects/{bin,pkg,src} يصبح Go جاهزا للعمل باكتمال هذه الخطوة، إلا أن استخدامه يتطلّب ذكر مسار التثبيت كاملا في سطر الأوامر. يمكن أن نجعل الاستخدام أكثر سهولة بضبط بضعة مسارات، وهو ما سنفعله في الخطوة التالية. الخطوة الثالثة: ضبط مسارات Go سنحتاج لإدراج المسار الذي ثبّتنا عليها Go إلى متغيّر البيئة PATH$ حتى يمكننا تنفيذه بنفس طريقة تنفيذ أي أمر في الطرفية: ذكر اسم الأمر فقط، دون المسار الكامل. بما أن Go مثبَّت في مجلّد يستخدمه نظام التشغيل فسنضبُط Go ليكون متاحا لجميع المستخدمين. أنشئ سكريبت باسم path.sh على المسار etc/profile.d/ باستخدام محرّر النصوص vi: sudo vi /etc/profile.d/path.sh أضف السطر التالي إلى آخر الملف ثم احفظ الملف وأغلقه: export PATH=$PATH:/usr/local/go/bin تنبيه: عدّل المسار بما يُناسب إن كنت قد اخترت مكانا مختلفا لتثبيت Go. نعرّف أيضا قيمتيْ المتغيّريْن GOPATH وGOBINفي ملّف المستخدم bash_profile. للإشارة إلى مجلّد العمل الذي أنشأناه في الخطوة السابقة. يحدّد المتغيّر GOPATH مكان ملفات الشفرة البرمجية بينما يحدّد المتغيّر GOBIN المجلّد الذي يجب أن توضع فيه الملفات التنفيذية بعد تصريف الشفرات البرمجية. نفتح الملف bash_profile.: vi ~/.bash_profile نضيف السطريْن التاليّيْن إلى نهاية الملف: export GOBIN="$HOME/projects/bin" export GOPATH="$HOME/projects/src" تنبيه: إن كان Go مثبّتا على مسار غير المسار المنصوح به (usr/local/) فيجب أن تعرّف قيمة المتغيّر GOROOT في الملفّ bash_profile. إلى جانب المتغيّريْن GOBIN وGOPATH: export GOROOT="/path/to/go" export GOBIN="$HOME/projects/bin" export GOPATH="$HOME/projects/src" حيث path/to/go/ مسار تثبيت Go. ننفّذ الأمر source لاعتماد التغييرات على الملفات التي عدّلناها وإعادة تحميلها لجلسة الطرفية الحالية: source /etc/profile && source ~/.bash_profile يجب أن يكون كلّ شيء جاهزا الآن، وهو ما سنتأكّد منه في الخطوة التالية. الخطوة الرابعة: كتابة برنامج Go واختباره نهدف من هذه الخطوة إلى التأكد من أن بيئة Go جاهزة للعمل على جهازنا. نبدأ بإنشاء ملفّ جديد لنضع فيه أول شفرة برمجيّة نكتبها: vi ~/projects/src/hello.go تستخدم شفرة Go أدناه حزمة main، تستورد مكتبة fmt لدوالّ الإدخال والإخراج وتضبُط دالة جديدة لطباعة الجملة !Hello, World. package main import "fmt" func main() { fmt.Printf("Hello, World!\n") } احفظ الملف ثم أغلقه. ثم نصرّف الشفرة البرمجية بالأمر go install: go install $GOPATH/hello.go نحن الآن جاهزون لتشغيل البرنامج: $GOBIN/hello إن كان كل شيء على ما يُرام فستظهر رسالة Hello, World! بعد تشغيل البرنامج. نتأكد بتنفيذ برنامج Hello, World! السابق من أن بيئة Go مثبّتة وجاهزة للاستخدام. تستخدم برامج Go عادة مكتبات برمجية وحزما خارجية. راجع مقالات البرمجة بلغة Go للمزيد عن كيفية كتابة البرامج بهذه اللغة. ترجمة - بتصرّف - للمقال How To Install Go 1.7 on CentOS 7 لصاحبه Michael Lenardson. -
.png.13b885a59b555b015d25f365fe40201d.png) بدأ تطوير لغة البرمجة Go بتجربة من مهندسين يعملون في Google لتلافي بعض التعقيدات الموجودة في لغات برمجة أخرى مع الاستفادة من نقاط قوّتها. تُطوَّر لغة Go باستمرار بمشاركة مجتمع مفتوح المصدر يزداد باضطّراد. تهدف لغة البرمجة Go إلى أن تكون سهلة، إلا أن اصطلاحات كتابة الشفرة البرمجية في Go قد تكون صعبة الاستيعاب. سأريكم في هذا الدرس كيف أبدأ جميع مشاريعي البرمجية عندما أستخدم Go، وكيفية استخدام التعابير التي توفّرها هذه اللغة. سننشئ خدمة سند خلفي Backend لتطبيق وِب. إعداد بيئة العمل الخطوة الأولى هي - بالطبع - تثبيتُ Go. يمكن تثبيت Go من المستودعات الرسمية على توزيعات لينكس؛ مثلا بالنسبة لأوبونتو: sudo apt install golang-go إصدارات Go الموجودة في المستودعات الرسمية تكون في العادة أقدم قليلا من تلك الموجودة على الموقع الرسمي، إلا أنها تؤدي الغرض؛ علاوة على سهولة التثبيت. يمكنك تثبيت إصدارات أحدث على أوبونتو (هنا) وCentos (هنا). بالنسبة لمستخدمي نظام Mac OS فيمكنهم تثبيت اللغة عن طريق Homebrew: brew install go يحوي الموقع الرسمي كذلك الملفات التنفيذية لتثبيت اللغة على أغلب أنظمة التشغيل، بما في ذلك ويندوز. تأكّد من تثبيت Go بتنفيذ الأمر التالي: go version مثال لنتيجة اﻷمر أعلاه (على توزيعة أوبونتو): go version go1.6.2 linux/amd64 – روابط للتثبيت على وندوز وإعداد المسارات – توجد الكثير من محرّرات النصوص والإضافات المتاحة لكتابة شفرات Go. أفضّل شخصيّا محرّر الشفرات Sublime Text وإضافة GoSublime؛ إلا أن طريقة كتابة Go تتيح استخدام محرّرات نصوص عاديّة بسهولة خصوصا للمشاريع الصغيرة. أعمل مع محترفين يقضون كامل اليوم في البرمجة بلغة Go باستخدام محرّر النصوص Vim، دون أي إضافة لإبراز صيغة الشفرات البرمجية Syntax highlighting. بالتأكيد لن تحتاج لأكثر من محرّر نصوص بسيط للبدء في تعلّم Go. مشروع جديد إن لم تكن أنشأت مجلّدا للعمل أثناء تثبيت Go وإعداده فالوقت مناسب لذلك. تتوقّع أدوات Go أن توجد جميع الشفرات البرمجية على المسار GOPATH/src$، وبالتالي سيكون عملنا دائما في هذا المجلّد. يمكن لمجموعة أدوات Go كذلك أن تتخاطب مع مشاريع مُضيَّفة على مواقع مثل GitHub وBitbucket إن أُعدّت لذلك. سننشئ لأغراض هذا الدرس مستودعا جديدا فارغا على GitHub ولنسمّه “hello” (أو أي اسم يناسبك). ننشئ مجلّدا ضمن مجلّد GOPATH لاستقبال ملفات المستودع (أبدل your-username باسم المستخدم الخاصّ بك على GitHub): mkdir -p $GOPATH/src/github.com/your-username cd $GOPATH/src/github.com/your-username ننسخ المستودع ضمن المجلّد الذي أنشأناه أعلاه: git clone git@github.com:your-username/hello cd hello سننشئ الآن ملفا باسم main.go ليحوي برنامجا قصيرا بلغة Go: package main func main() { println("hello!") } نفّذ الأمر go build لتصريف جميع محتويات المجلّد الحالي. سينتُج ملف تنفيذي بنفس الاسم؛ يمكنك بعدها طلب تشغيله بذكر اسمه على النحو التالي: go build ./hello النتيجة: hello! ما زلت رغم سنوات من التطوير بلغة Go أبدأ مشاريعي بنفس الطريقة: مستودع Git فارغ، ملف main.go وبضعة أوامر. يصبح أي تطبيق يتبع الطرق المتعارف عليها لتنظيم شفرة Go قابلا للتثبيت بسهولة بالأمر go get. إن أودعت على سبيل المثال الملف أعلاه ودفعته إلى مستودع Git فإن أي شخص لديه بيئة عمل Go يمكنه تنفيذ الخطوتين التاليتين لتشغيل البرنامج: go get github.com/your-username/hello $GOPATH/bin/hello إنشاء خادوم وب فلنجعل برنامجنا البسيط السابق خادوم وب: package main import "net/http" func main() { http.HandleFunc("/", hello) http.ListenAndServe(":8080", nil) } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello!")) } هناك بضعة سطور تحتاج للشرح. نحتاج أولا لاستيراد الحزمة net/httpمن المكتبة المعيارية لـGo: import "net/http" ثم نثبّت دالة معالجة Handler function في المسار الجذر لخادوم الوِب. تتعامل http.HandleFunc مع الموجّه المبدئي لطلبات Http في Go، وهو ServeMux. http.HandleFunc("/", hello) الدالة hello هي من النوع http.HandlerFunc الذي يسمح باستخدام دوال عاديّة على أنها دوال معالجة لطلبات HTTP. للدوال من النوع http.HandlerFunc توقيع Signature خاص (توقيع الدالة هو المعطيات المُمرَّرة لها وأنواع البيانات التي تُرجعها هذه الدالة) ويمكن تمريرها في معطى إلى الدالة HandleFunc التي تسجّل الدالة المُمرَّرة في المُعطى لدى الموجِّه ServeMux، وبالتالي يُنشئ خادوم الوِب، في كلّ مرة يصله فيها طلب جديد يطابق المسار الجذر، يُنشئ نسخة جديدة من الدالة hello. تستقبل الدالة hello متغيّرا من النوع http.ResponseWriter الذي تستخدمه الدالة المُعالِجة لإنشاء إجابة HTTP وبالتالي إنشاء ردّ على طلب العميل عن طريق التابع Write الذي يوفّره النوع http.ResponseWriter. بما أن التابع http.ResponseWriter.Write يأخذ معطى عامًّا من النوع []byte أو byte-slice، فنحوّل السلسة النصيّة hello إلى النوع المناسب: func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello!")) } في الأخير نشغّل خادوم وب على المنفذ 8080 عبر الدالة http.ListenAndServe التي تستقبل معطيَين، الأول هو المنفَذ Port والثاني دالة معالجة. إذا كانت قيمة المعطى الثاني هي nil فهذا يعني أننا نريد استخدام الموجّه المبدئي DefaultServeMux. هذا الاستدعاء متزامن Synchronous، أو معترِض Blocking، يبقي البرنامج قيد التشغيل إلى أن يُقطَع الاستدعاء. صرّف وشغّل البرنامج بنفس الطريقة السابقة: go build ./hello افتح سطر أوامر - طرفيّة - آخر وأرسل طلب HTTP إلى المنفذ 8080: curl http://localhost:8080 النتيجة: hello! الأمر بسيط. ليست هناك حاجة لتثبيت إطار عمل خارجي، أو تنزيل اعتماديات Dependencies أو إنشاء هياكل مشاريع. الملف التنفيذي نفسه هو شفرة أصيلة Native code بدون اعتمادات تشغيلية. علاوة على ذلك، المكتبة المعيارية لخادوم الوِب موجهة لبيئة الإنتاج مع دفاعات ضدّ الهجمات الإلكترونية الشائعة. يمكن لهذه الشفرة الإجابة على الطلبات عبر الشبكة مباشرة ودون وسائط. إضافة مسارات جديدة يمكننا فعل أمور أكثر أهمية من مجرّد قول مرحبا (hello). فليكن المُدخَل اسم مدينة نستخدمه لاستدعاء واجهة تطبيقات برمجيّة API لأحوال الطقس ونعيد توجيه الإجابة - درجة الحرارة - في الرد على الطلب. توفّر خدمة OpenWeatherMap واجهة تطبيقات برمجيّة مجانيّة وسهلة الاستخدام للحصول على توقّعات مناخية. سجّل في الموقع للحصول على مفتاح API. يمكن الاستعلام من OpenWeatherMap حسب المدن. تُرجع واجهة التطبيقات البرمجية إجابة على النحو التالي (عدّلنا قليلا على النتيجة): { "name": "Tokyo", "coord": { "lon": 139.69, "lat": 35.69 }, "weather": [ { "id": 803, "main": "Clouds", "description": "broken clouds", "icon": "04n" } ], "main": { "temp": 296.69, "pressure": 1014, "humidity": 83, "temp_min": 295.37, "temp_max": 298.15 } } المتغيّرات في Go ذات أنواع ثابتة Statical type، بمعنى أنه ينبغي التصريح بنوع البيانات التي تخزّنها المتغيّرات قبل استخدامها. لذا سيتوجّب علينا إنشاء بنية بيانات لمطابقة صيغة رد الواجهة البرمجية. لا نحتاج لحفظ جميبع المعلومات، بل يكفي أن نحتفظ بالبيانات التي نهتم بشأنها. سنكتفي الآن باسم المدينة ودرجة الحرارة المتوقّعة التي تأتي بوحدة الكيلفن Kelvin. سنعرّف بنية لتمثيل البيانات التي نحتاجها من خدمة التوقعات المناخية. type weatherData struct { Name string `json:"name"` Main struct { Kelvin float64 `json:"temp"` } `json:"main"` } تعرّف الكلمة المفتاحية type بنية بيانات جديدة نسمّيها weatherData ونصرّح بكونها من النوع struct. يحوي كلّ حقل في المتغيّرات من نوع struct اسما (مثلا Name أو Main)، نوع بيانات (string أو struct آخر مجهول الاسم) وما يُعرَف بالوسم Tag. تشبه الوسوم في Go البيانات الوصفية Metadata، وتمكّننا من استخدام الحزمة encoding/json لإعادة صفّ الإجابة التي تقدّمها خدمة OpenWeatherMap وحفظها في بنية البيانات التي أعددناها. يتطلّب الأمر كتابة شفرة برمجية أكثر ممّا عليه الحال في لغات برمجيّة ذات أنواع ديناميكية للبيانات (بمعنى أنه يمكن استخدام متغيّر فور احتياجنا له دون الحاجة للتصريح بنوع البيانات) مثل روبي وبايثون، إلا أنه يمنحنا خاصيّة الأمان في نوع البيانات. عرّفنا بنية البيانات، نحتاج الآن لطريقة تمكّننا من ملْء هذه البنية بالبيانات القادمة من واجهة التطبيقات البرمجية؛ سنكتُب دالة لهذا الغرض. func query(city string) (weatherData, error) { resp, err := http.Get("http://api.openweathermap.org/data/2.5/weather?APPID=YOUR_API_KEY&q=" + city) if err != nil { return weatherData{}, err } defer resp.Body.Close() var d weatherData if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return weatherData{}, err } return d, nil } تأخذ الدالة سلسلة محارف تمثّل المدينة وتُرجِع متغيّرا من بنية بيانات weatherData وخطأ. هذه هي الطريقة الأساسية للتعامل مع الأخطاء في Go. تغلّف الدوال سلوكا معيَّنا، ويمكن أن يخفق هذا السلوك. بالنسبة لمثالنا، يمكن أن يخفق طلب GET الذي نرسله لـOpenWeatherMap لأسباب عدّة، وقد تكون البيانات المُرجَعة غير تلك التي ننتظرها. نُرجِع في كلتا الحالتين خطأ غير فارغ Non-nil للعميل الذي يُنتظَر منه أن يتعامل مع هذا الخطأ بما يتناسب مع السياق الذي أرسل فيه الطلب. إن نجح الطلب http.Get نؤجّل طلبا لغلق متن الإجابة لننفّذه بعد الخروج من نطاق Scope الدالة (أي بعد الرجوع من دالة طلب HTTP)، وهي طريقة أنيقة لإدارة الموارد. في أثناء ذلك نحجز بنية weatherData ونستخدم json.Decoder لقراءة بيانات الإجابة وإدخالها مباشرة في بنيتنا. عندما تنجح إعادة صياغة بيانات الإجابة نعيد المتغيّر weatherData إلى المُستدعي مع خطأ فارغ للدلالة على نجاح العملية. ننتقل الآن إلى ربط تلك الدالة بالدالة المعالجة للطلب: http.HandleFunc("/weather/", func(w http.ResponseWriter, r *http.Request) { city := strings.SplitN(r.URL.Path, "/", 3)[2] data, err := query(city) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json; charset=utf-8") json.NewEncoder(w).Encode(data) }) نعرّف دالة معالجة على السطر In-line بدلا من تعريفها منفصلة. نستخدم الدالة strings.SplitN لأخذ كل ما يوجد بعد /weather/ في المسار والتعامل معه على أنه اسم مدينة. ننفّذ الطلب وإن صادفتنا أخطاء نعلم العميل بها باستخدام الدالة المساعدة http.Error، ونوقف تنفيذ الدالة للدلالة على اكتمال طلب HTTP. إن لم يوجد خطأ نخبر العميل بأننا بصدد إرسال بيانات JSON إليه ونستخدم الدالة json.NewEncode لترميز محتوى weatherData بصيغة JSON مباشرة. الشفرة لحدّ الساعة أنيقة، تعتمد أسلوبا إجرائيا Procedural ويسهل فهمها. لا مجال للخطأ في تفسيرها ولا يمكنها تجاوز الأخطاء الشائعة. إن نقلنا الدالة المعالجة لـ "hello, world" إلى المسار hello/ واستوردنا الحزم المطلوبة فسنحصُل على البرنامج المُكتمل التالي: package main import ( "encoding/json" "net/http" "strings" ) func main() { http.HandleFunc("/hello", hello) http.HandleFunc("/weather/", func(w http.ResponseWriter, r *http.Request) { city := strings.SplitN(r.URL.Path, "/", 3)[2] data, err := query(city) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json; charset=utf-8") json.NewEncoder(w).Encode(data) }) http.ListenAndServe(":8080", nil) } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello!")) } func query(city string) (weatherData, error) { resp, err := http.Get("http://api.openweathermap.org/data/2.5/weather?APPID=YOUR_API_KEY&q=" + city) if err != nil { return weatherData{}, err } defer resp.Body.Close() var d weatherData if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return weatherData{}, err } return d, nil } type weatherData struct { Name string `json:"name"` Main struct { Kelvin float64 `json:"temp"` } `json:"main"` } نصرّف البرنامج وننفّذه بنفس الطريقة التي شرحناها أعلاه: go build ./hello نفتح طرفيّة أخرى ونطلب المسار http://localhost:8080/weather/tokyo (الحرارة بمقياس كلفن): curl http://localhost:8080/weather/tokyo النتيجة: {"name":"Tokyo","main":{"temp":295.9}} الاستعلام من واجهات برمجية عدّة ربما من الممكن الحصول على درجات حرارة أكثر دقّة إن استعلمنا من خدمات طقس عدّة وحسبنا المتوسّط بينها. تتطلّب أغلب الواجهات البرمجية لخدمات الطقس التسجيل. سنضيف خدمة Weather Underground، لذا سجّل في هذه الخدمة واعثر على مفاتيح الاستيثاق الضرورية لاستخدام واجهة التطبيقات البرمجية. بما أننا نريد أن نحصُل على نفس السلوك من جميع الخدمات فسيكون من المجدي كتابة هذا السلوك في واجهة. type weatherProvider interface { temperature(city string) (float64, error) // in Kelvin, naturally } يمكننا الآن تحويل دالة الاستعلام من openWeatherMap السابقة إلى نوع بيانات يوافق الواجهة weatherProvider. بما أننا لا نحتاج لحفظ أي حالة لإجراء طلب HTTP GET فسنستخدم بنية struct فارغة، وسنضيف سطرا قصيرا في دالة الاستعلام الجديدة لتسجيل ما يحدُث عند الاتصال بالخدمات لمراجعته في ما بعد: type openWeatherMap struct{} func (w openWeatherMap) temperature(city string) (float64, error) { resp, err := http.Get("http://api.openweathermap.org/data/2.5/weather?APPID=YOUR_API_KEY&q=" + city) if err != nil { return 0, err } defer resp.Body.Close() var d struct { Main struct { Kelvin float64 `json:"temp"` } `json:"main"` } if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return 0, err } log.Printf("openWeatherMap: %s: %.2f", city, d.Main.Kelvin) return d.Main.Kelvin, nil } لا نريد سوى استخراج درجة الحرارة (بالكلفن) من الإجابة، لذا يمكننا تعريف بنية struct على السطر Inline. في ما عدا ذلك فإن الشفرة البرمجية مشابهة لدالة الاستعلام السابقة، ولكنّها معرَّفة على صيغة تابع Method لبنية openWeatherMap. تتيح لنا هذه الطريقة استخدام عيّنة Instance من openWeatherMap مكان الواجهة weatherProvider. سنفعل نفس الشيء بالنسبة لخدمة Weather Underground. الفرق الوحيد مع الخدمة السابقة هو أننا سنخزّن مفتاح الواجهة البرمجية في بنية struct ثم نستخدمه في التابع. يجدر ملاحظة أن Weather Underground لا تعالج أسماء المدن المتطابقة بنفس جودة تعامل Open WeatherMap، وهو ما ينبغي الانتباه إليه في التطبيقات الفعلية. لن نعالج هذا الأمر في مثالنا البسيط هذا. type weatherUnderground struct { apiKey string } func (w weatherUnderground) temperature(city string) (float64, error) { resp, err := http.Get("http://api.wunderground.com/api/" + w.apiKey + "/conditions/q/" + city + ".json") if err != nil { return 0, err } defer resp.Body.Close() var d struct { Observation struct { Celsius float64 `json:"temp_c"` } `json:"current_observation"` } if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return 0, err } kelvin := d.Observation.Celsius + 273.15 log.Printf("weatherUnderground: %s: %.2f", city, kelvin) return kelvin, nil } لدينا الآن مزوّدا خدمة طقس. فلنكتب دالّة تستعلم من الاثنين وتعيد متوسّط درجة الحرارة. سنكفّ - حفاظا على بساطة المثال - عن الاستعلام إذا واجهتنا مشكلة في الحصول على بيانات من الخدمتين. func temperature(city string, providers ...weatherProvider) (float64, error) { sum := 0.0 for _, provider := range providers { k, err := provider.temperature(city) if err != nil { return 0, err } sum += k } return sum / float64(len(providers)), nil } لاحظ أن تعريف الدالة قريب جدّا من تعريف التابع temperature المُعرَّف في الواجهة weatherProvider. إن جمعنا الواجهات weatherProvider في نوع بيانات ثم عرّفنا تابعا باسم temperature على هذا النوع فسيمكننا إنشاء نوع جديد يجمع الواجهات weatherProvider. type multiWeatherProvider []weatherProvider func (w multiWeatherProvider) temperature(city string) (float64, error) { sum := 0.0 for _, provider := range w { k, err := provider.temperature(city) if err != nil { return 0, err } sum += k } return sum / float64(len(w)), nil } رائع! سنتمكّن من تمرير multiWeatherProvider إلى أي دالة تقبل weatherProvider. نربُط الآن خادوم HTTP بدالة temperature للحصول على درجات الحرارة عند طلب مسار به اسم مدينة: func main() { mw := multiWeatherProvider{ openWeatherMap{}, weatherUnderground{apiKey: "your-key-here"}, } http.HandleFunc("/weather/", func(w http.ResponseWriter, r *http.Request) { begin := time.Now() city := strings.SplitN(r.URL.Path, "/", 3)[2] temp, err := mw.temperature(city) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json; charset=utf-8") json.NewEncoder(w).Encode(map[string]interface{}{ "city": city, "temp": temp, "took": time.Since(begin).String(), }) }) http.ListenAndServe(":8080", nil) } صرّف البرنامج، شغّله واطلب رابط خادوم الوب كما فعلنا سابقا. ستجد - علاوة على الإجابة بصيغة JSON في نافذة الطلب - مُخرجات قادمة من تسجيلات الخادوم التي أضفناها أعلاه في النافذة التي شغّلت منها البرنامج. ./hello 2015/01/01 13:14:15 openWeatherMap: tokyo: 295.46 2015/01/01 13:14:16 weatherUnderground: tokyo: 273.15 $ curl http://localhost:8080/weather/tokyo {"city":"tokyo","temp":284.30499999999995,"took":"821.665230ms"} جعل الاستعلامات تعمل بالتوازي نكتفي لحدّ الساعة بالاستعلام من الواجهات البرمجية بالتتالي، الواحدة تلو الأخرى. لا يوجد ما يمنعنا من الاستعلام من الواجهتيْن البرمجيّتين في نفس الوقت، وهو ما سياسهم في تقليل الوقت اللازم للإجابة. نستفيد من إمكانات Go في التشغيل المتزامن عبر وحدات Go الفرعية goroutines والقنوات Channels. سنضع كل استعلام في وحدة فرعية خاصّة به ثم نشغّلها بالتوازي. نجمع الإجابات بعد ذلك في قناة واحدة ثم نحسب المعدّلات عندما تكتمل جميع الاستعلامات. func (w multiWeatherProvider) temperature(city string) (float64, error) { // ننشئ قناتيْن، واحدة لدرجات الحرارة والأخرى للأخطاء // يُضيف كل مزوّد خدمة قيمة إلى إحدى القناتيْن فقط temps := make(chan float64, len(w)) errs := make(chan error, len(w)) // نطلق بالنسبة لكلّ مزوّد خدمة وحدة فرعية جديدة بدالة مجهولة الاسم. تستدعي الدالة مجهولة الاسم التابع temperature ثم تعيد توجيه النتيجة المتحصًّل عليها. for _, provider := range w { go func(p weatherProvider) { k, err := p.temperature(city) if err != nil { errs <- err return } temps <- k }(provider) } sum := 0.0 // نجمع درجات الحرارة - أو الأخطاء في حالة وجودها - من كل خِدمة for i := 0; i < len(w); i++ { select { case temp := <-temps: sum += temp case err := <-errs: return 0, err } } // نُرجع الحرارة كما في السابق return sum / float64(len(w)), nil } يساوي الوقت اللازم الآن لتنفيذ جميع الاستعلامات المدة الزمنية اللازمة للحصول على إجابة من أبطأ خدمة طقس؛ بدلا من مجموع المدد الزمنية لجميع الاستعلامات كما كان سابقا. كل ما احتجنا له هو تعديل سلوك multiWeatherProvider الذي ما زال مع ذلك يُرضي حاجات واجهة weatherProvider البسيطة وغير المتوازية. السهولة انتقلنا ببضع خطوات وبالاقتصار فقط على المكتبة المعيارية لـGo من مثال “hello world” إلى خادوم سند خلفي Backend server يحترم مبادئ REST. يمكن نشر الشفرة التي كتبناها على أي معمارية خواديم تقريبا. الملف التنفيذي الناتج سريع ويتضمّن جميع ما يحتاجه للعمل؛ والأهم من ذلك، الشفرة البرمجيّة واضحة لقراءتها وفهمها. كما تمكن صيانتها وتمديدها بسهولة حسب الحاجة. أنا مقتنع أن كلّ هذه الميزات هي نتيجة لتفاني Go في البساطة. ترجمة - بتصرّف - للمقال How I start Go لصاحبه Peter Bourgon.
بدأ تطوير لغة البرمجة Go بتجربة من مهندسين يعملون في Google لتلافي بعض التعقيدات الموجودة في لغات برمجة أخرى مع الاستفادة من نقاط قوّتها. تُطوَّر لغة Go باستمرار بمشاركة مجتمع مفتوح المصدر يزداد باضطّراد. تهدف لغة البرمجة Go إلى أن تكون سهلة، إلا أن اصطلاحات كتابة الشفرة البرمجية في Go قد تكون صعبة الاستيعاب. سأريكم في هذا الدرس كيف أبدأ جميع مشاريعي البرمجية عندما أستخدم Go، وكيفية استخدام التعابير التي توفّرها هذه اللغة. سننشئ خدمة سند خلفي Backend لتطبيق وِب. إعداد بيئة العمل الخطوة الأولى هي - بالطبع - تثبيتُ Go. يمكن تثبيت Go من المستودعات الرسمية على توزيعات لينكس؛ مثلا بالنسبة لأوبونتو: sudo apt install golang-go إصدارات Go الموجودة في المستودعات الرسمية تكون في العادة أقدم قليلا من تلك الموجودة على الموقع الرسمي، إلا أنها تؤدي الغرض؛ علاوة على سهولة التثبيت. يمكنك تثبيت إصدارات أحدث على أوبونتو (هنا) وCentos (هنا). بالنسبة لمستخدمي نظام Mac OS فيمكنهم تثبيت اللغة عن طريق Homebrew: brew install go يحوي الموقع الرسمي كذلك الملفات التنفيذية لتثبيت اللغة على أغلب أنظمة التشغيل، بما في ذلك ويندوز. تأكّد من تثبيت Go بتنفيذ الأمر التالي: go version مثال لنتيجة اﻷمر أعلاه (على توزيعة أوبونتو): go version go1.6.2 linux/amd64 – روابط للتثبيت على وندوز وإعداد المسارات – توجد الكثير من محرّرات النصوص والإضافات المتاحة لكتابة شفرات Go. أفضّل شخصيّا محرّر الشفرات Sublime Text وإضافة GoSublime؛ إلا أن طريقة كتابة Go تتيح استخدام محرّرات نصوص عاديّة بسهولة خصوصا للمشاريع الصغيرة. أعمل مع محترفين يقضون كامل اليوم في البرمجة بلغة Go باستخدام محرّر النصوص Vim، دون أي إضافة لإبراز صيغة الشفرات البرمجية Syntax highlighting. بالتأكيد لن تحتاج لأكثر من محرّر نصوص بسيط للبدء في تعلّم Go. مشروع جديد إن لم تكن أنشأت مجلّدا للعمل أثناء تثبيت Go وإعداده فالوقت مناسب لذلك. تتوقّع أدوات Go أن توجد جميع الشفرات البرمجية على المسار GOPATH/src$، وبالتالي سيكون عملنا دائما في هذا المجلّد. يمكن لمجموعة أدوات Go كذلك أن تتخاطب مع مشاريع مُضيَّفة على مواقع مثل GitHub وBitbucket إن أُعدّت لذلك. سننشئ لأغراض هذا الدرس مستودعا جديدا فارغا على GitHub ولنسمّه “hello” (أو أي اسم يناسبك). ننشئ مجلّدا ضمن مجلّد GOPATH لاستقبال ملفات المستودع (أبدل your-username باسم المستخدم الخاصّ بك على GitHub): mkdir -p $GOPATH/src/github.com/your-username cd $GOPATH/src/github.com/your-username ننسخ المستودع ضمن المجلّد الذي أنشأناه أعلاه: git clone git@github.com:your-username/hello cd hello سننشئ الآن ملفا باسم main.go ليحوي برنامجا قصيرا بلغة Go: package main func main() { println("hello!") } نفّذ الأمر go build لتصريف جميع محتويات المجلّد الحالي. سينتُج ملف تنفيذي بنفس الاسم؛ يمكنك بعدها طلب تشغيله بذكر اسمه على النحو التالي: go build ./hello النتيجة: hello! ما زلت رغم سنوات من التطوير بلغة Go أبدأ مشاريعي بنفس الطريقة: مستودع Git فارغ، ملف main.go وبضعة أوامر. يصبح أي تطبيق يتبع الطرق المتعارف عليها لتنظيم شفرة Go قابلا للتثبيت بسهولة بالأمر go get. إن أودعت على سبيل المثال الملف أعلاه ودفعته إلى مستودع Git فإن أي شخص لديه بيئة عمل Go يمكنه تنفيذ الخطوتين التاليتين لتشغيل البرنامج: go get github.com/your-username/hello $GOPATH/bin/hello إنشاء خادوم وب فلنجعل برنامجنا البسيط السابق خادوم وب: package main import "net/http" func main() { http.HandleFunc("/", hello) http.ListenAndServe(":8080", nil) } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello!")) } هناك بضعة سطور تحتاج للشرح. نحتاج أولا لاستيراد الحزمة net/httpمن المكتبة المعيارية لـGo: import "net/http" ثم نثبّت دالة معالجة Handler function في المسار الجذر لخادوم الوِب. تتعامل http.HandleFunc مع الموجّه المبدئي لطلبات Http في Go، وهو ServeMux. http.HandleFunc("/", hello) الدالة hello هي من النوع http.HandlerFunc الذي يسمح باستخدام دوال عاديّة على أنها دوال معالجة لطلبات HTTP. للدوال من النوع http.HandlerFunc توقيع Signature خاص (توقيع الدالة هو المعطيات المُمرَّرة لها وأنواع البيانات التي تُرجعها هذه الدالة) ويمكن تمريرها في معطى إلى الدالة HandleFunc التي تسجّل الدالة المُمرَّرة في المُعطى لدى الموجِّه ServeMux، وبالتالي يُنشئ خادوم الوِب، في كلّ مرة يصله فيها طلب جديد يطابق المسار الجذر، يُنشئ نسخة جديدة من الدالة hello. تستقبل الدالة hello متغيّرا من النوع http.ResponseWriter الذي تستخدمه الدالة المُعالِجة لإنشاء إجابة HTTP وبالتالي إنشاء ردّ على طلب العميل عن طريق التابع Write الذي يوفّره النوع http.ResponseWriter. بما أن التابع http.ResponseWriter.Write يأخذ معطى عامًّا من النوع []byte أو byte-slice، فنحوّل السلسة النصيّة hello إلى النوع المناسب: func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello!")) } في الأخير نشغّل خادوم وب على المنفذ 8080 عبر الدالة http.ListenAndServe التي تستقبل معطيَين، الأول هو المنفَذ Port والثاني دالة معالجة. إذا كانت قيمة المعطى الثاني هي nil فهذا يعني أننا نريد استخدام الموجّه المبدئي DefaultServeMux. هذا الاستدعاء متزامن Synchronous، أو معترِض Blocking، يبقي البرنامج قيد التشغيل إلى أن يُقطَع الاستدعاء. صرّف وشغّل البرنامج بنفس الطريقة السابقة: go build ./hello افتح سطر أوامر - طرفيّة - آخر وأرسل طلب HTTP إلى المنفذ 8080: curl http://localhost:8080 النتيجة: hello! الأمر بسيط. ليست هناك حاجة لتثبيت إطار عمل خارجي، أو تنزيل اعتماديات Dependencies أو إنشاء هياكل مشاريع. الملف التنفيذي نفسه هو شفرة أصيلة Native code بدون اعتمادات تشغيلية. علاوة على ذلك، المكتبة المعيارية لخادوم الوِب موجهة لبيئة الإنتاج مع دفاعات ضدّ الهجمات الإلكترونية الشائعة. يمكن لهذه الشفرة الإجابة على الطلبات عبر الشبكة مباشرة ودون وسائط. إضافة مسارات جديدة يمكننا فعل أمور أكثر أهمية من مجرّد قول مرحبا (hello). فليكن المُدخَل اسم مدينة نستخدمه لاستدعاء واجهة تطبيقات برمجيّة API لأحوال الطقس ونعيد توجيه الإجابة - درجة الحرارة - في الرد على الطلب. توفّر خدمة OpenWeatherMap واجهة تطبيقات برمجيّة مجانيّة وسهلة الاستخدام للحصول على توقّعات مناخية. سجّل في الموقع للحصول على مفتاح API. يمكن الاستعلام من OpenWeatherMap حسب المدن. تُرجع واجهة التطبيقات البرمجية إجابة على النحو التالي (عدّلنا قليلا على النتيجة): { "name": "Tokyo", "coord": { "lon": 139.69, "lat": 35.69 }, "weather": [ { "id": 803, "main": "Clouds", "description": "broken clouds", "icon": "04n" } ], "main": { "temp": 296.69, "pressure": 1014, "humidity": 83, "temp_min": 295.37, "temp_max": 298.15 } } المتغيّرات في Go ذات أنواع ثابتة Statical type، بمعنى أنه ينبغي التصريح بنوع البيانات التي تخزّنها المتغيّرات قبل استخدامها. لذا سيتوجّب علينا إنشاء بنية بيانات لمطابقة صيغة رد الواجهة البرمجية. لا نحتاج لحفظ جميبع المعلومات، بل يكفي أن نحتفظ بالبيانات التي نهتم بشأنها. سنكتفي الآن باسم المدينة ودرجة الحرارة المتوقّعة التي تأتي بوحدة الكيلفن Kelvin. سنعرّف بنية لتمثيل البيانات التي نحتاجها من خدمة التوقعات المناخية. type weatherData struct { Name string `json:"name"` Main struct { Kelvin float64 `json:"temp"` } `json:"main"` } تعرّف الكلمة المفتاحية type بنية بيانات جديدة نسمّيها weatherData ونصرّح بكونها من النوع struct. يحوي كلّ حقل في المتغيّرات من نوع struct اسما (مثلا Name أو Main)، نوع بيانات (string أو struct آخر مجهول الاسم) وما يُعرَف بالوسم Tag. تشبه الوسوم في Go البيانات الوصفية Metadata، وتمكّننا من استخدام الحزمة encoding/json لإعادة صفّ الإجابة التي تقدّمها خدمة OpenWeatherMap وحفظها في بنية البيانات التي أعددناها. يتطلّب الأمر كتابة شفرة برمجية أكثر ممّا عليه الحال في لغات برمجيّة ذات أنواع ديناميكية للبيانات (بمعنى أنه يمكن استخدام متغيّر فور احتياجنا له دون الحاجة للتصريح بنوع البيانات) مثل روبي وبايثون، إلا أنه يمنحنا خاصيّة الأمان في نوع البيانات. عرّفنا بنية البيانات، نحتاج الآن لطريقة تمكّننا من ملْء هذه البنية بالبيانات القادمة من واجهة التطبيقات البرمجية؛ سنكتُب دالة لهذا الغرض. func query(city string) (weatherData, error) { resp, err := http.Get("http://api.openweathermap.org/data/2.5/weather?APPID=YOUR_API_KEY&q=" + city) if err != nil { return weatherData{}, err } defer resp.Body.Close() var d weatherData if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return weatherData{}, err } return d, nil } تأخذ الدالة سلسلة محارف تمثّل المدينة وتُرجِع متغيّرا من بنية بيانات weatherData وخطأ. هذه هي الطريقة الأساسية للتعامل مع الأخطاء في Go. تغلّف الدوال سلوكا معيَّنا، ويمكن أن يخفق هذا السلوك. بالنسبة لمثالنا، يمكن أن يخفق طلب GET الذي نرسله لـOpenWeatherMap لأسباب عدّة، وقد تكون البيانات المُرجَعة غير تلك التي ننتظرها. نُرجِع في كلتا الحالتين خطأ غير فارغ Non-nil للعميل الذي يُنتظَر منه أن يتعامل مع هذا الخطأ بما يتناسب مع السياق الذي أرسل فيه الطلب. إن نجح الطلب http.Get نؤجّل طلبا لغلق متن الإجابة لننفّذه بعد الخروج من نطاق Scope الدالة (أي بعد الرجوع من دالة طلب HTTP)، وهي طريقة أنيقة لإدارة الموارد. في أثناء ذلك نحجز بنية weatherData ونستخدم json.Decoder لقراءة بيانات الإجابة وإدخالها مباشرة في بنيتنا. عندما تنجح إعادة صياغة بيانات الإجابة نعيد المتغيّر weatherData إلى المُستدعي مع خطأ فارغ للدلالة على نجاح العملية. ننتقل الآن إلى ربط تلك الدالة بالدالة المعالجة للطلب: http.HandleFunc("/weather/", func(w http.ResponseWriter, r *http.Request) { city := strings.SplitN(r.URL.Path, "/", 3)[2] data, err := query(city) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json; charset=utf-8") json.NewEncoder(w).Encode(data) }) نعرّف دالة معالجة على السطر In-line بدلا من تعريفها منفصلة. نستخدم الدالة strings.SplitN لأخذ كل ما يوجد بعد /weather/ في المسار والتعامل معه على أنه اسم مدينة. ننفّذ الطلب وإن صادفتنا أخطاء نعلم العميل بها باستخدام الدالة المساعدة http.Error، ونوقف تنفيذ الدالة للدلالة على اكتمال طلب HTTP. إن لم يوجد خطأ نخبر العميل بأننا بصدد إرسال بيانات JSON إليه ونستخدم الدالة json.NewEncode لترميز محتوى weatherData بصيغة JSON مباشرة. الشفرة لحدّ الساعة أنيقة، تعتمد أسلوبا إجرائيا Procedural ويسهل فهمها. لا مجال للخطأ في تفسيرها ولا يمكنها تجاوز الأخطاء الشائعة. إن نقلنا الدالة المعالجة لـ "hello, world" إلى المسار hello/ واستوردنا الحزم المطلوبة فسنحصُل على البرنامج المُكتمل التالي: package main import ( "encoding/json" "net/http" "strings" ) func main() { http.HandleFunc("/hello", hello) http.HandleFunc("/weather/", func(w http.ResponseWriter, r *http.Request) { city := strings.SplitN(r.URL.Path, "/", 3)[2] data, err := query(city) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json; charset=utf-8") json.NewEncoder(w).Encode(data) }) http.ListenAndServe(":8080", nil) } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello!")) } func query(city string) (weatherData, error) { resp, err := http.Get("http://api.openweathermap.org/data/2.5/weather?APPID=YOUR_API_KEY&q=" + city) if err != nil { return weatherData{}, err } defer resp.Body.Close() var d weatherData if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return weatherData{}, err } return d, nil } type weatherData struct { Name string `json:"name"` Main struct { Kelvin float64 `json:"temp"` } `json:"main"` } نصرّف البرنامج وننفّذه بنفس الطريقة التي شرحناها أعلاه: go build ./hello نفتح طرفيّة أخرى ونطلب المسار http://localhost:8080/weather/tokyo (الحرارة بمقياس كلفن): curl http://localhost:8080/weather/tokyo النتيجة: {"name":"Tokyo","main":{"temp":295.9}} الاستعلام من واجهات برمجية عدّة ربما من الممكن الحصول على درجات حرارة أكثر دقّة إن استعلمنا من خدمات طقس عدّة وحسبنا المتوسّط بينها. تتطلّب أغلب الواجهات البرمجية لخدمات الطقس التسجيل. سنضيف خدمة Weather Underground، لذا سجّل في هذه الخدمة واعثر على مفاتيح الاستيثاق الضرورية لاستخدام واجهة التطبيقات البرمجية. بما أننا نريد أن نحصُل على نفس السلوك من جميع الخدمات فسيكون من المجدي كتابة هذا السلوك في واجهة. type weatherProvider interface { temperature(city string) (float64, error) // in Kelvin, naturally } يمكننا الآن تحويل دالة الاستعلام من openWeatherMap السابقة إلى نوع بيانات يوافق الواجهة weatherProvider. بما أننا لا نحتاج لحفظ أي حالة لإجراء طلب HTTP GET فسنستخدم بنية struct فارغة، وسنضيف سطرا قصيرا في دالة الاستعلام الجديدة لتسجيل ما يحدُث عند الاتصال بالخدمات لمراجعته في ما بعد: type openWeatherMap struct{} func (w openWeatherMap) temperature(city string) (float64, error) { resp, err := http.Get("http://api.openweathermap.org/data/2.5/weather?APPID=YOUR_API_KEY&q=" + city) if err != nil { return 0, err } defer resp.Body.Close() var d struct { Main struct { Kelvin float64 `json:"temp"` } `json:"main"` } if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return 0, err } log.Printf("openWeatherMap: %s: %.2f", city, d.Main.Kelvin) return d.Main.Kelvin, nil } لا نريد سوى استخراج درجة الحرارة (بالكلفن) من الإجابة، لذا يمكننا تعريف بنية struct على السطر Inline. في ما عدا ذلك فإن الشفرة البرمجية مشابهة لدالة الاستعلام السابقة، ولكنّها معرَّفة على صيغة تابع Method لبنية openWeatherMap. تتيح لنا هذه الطريقة استخدام عيّنة Instance من openWeatherMap مكان الواجهة weatherProvider. سنفعل نفس الشيء بالنسبة لخدمة Weather Underground. الفرق الوحيد مع الخدمة السابقة هو أننا سنخزّن مفتاح الواجهة البرمجية في بنية struct ثم نستخدمه في التابع. يجدر ملاحظة أن Weather Underground لا تعالج أسماء المدن المتطابقة بنفس جودة تعامل Open WeatherMap، وهو ما ينبغي الانتباه إليه في التطبيقات الفعلية. لن نعالج هذا الأمر في مثالنا البسيط هذا. type weatherUnderground struct { apiKey string } func (w weatherUnderground) temperature(city string) (float64, error) { resp, err := http.Get("http://api.wunderground.com/api/" + w.apiKey + "/conditions/q/" + city + ".json") if err != nil { return 0, err } defer resp.Body.Close() var d struct { Observation struct { Celsius float64 `json:"temp_c"` } `json:"current_observation"` } if err := json.NewDecoder(resp.Body).Decode(&d); err != nil { return 0, err } kelvin := d.Observation.Celsius + 273.15 log.Printf("weatherUnderground: %s: %.2f", city, kelvin) return kelvin, nil } لدينا الآن مزوّدا خدمة طقس. فلنكتب دالّة تستعلم من الاثنين وتعيد متوسّط درجة الحرارة. سنكفّ - حفاظا على بساطة المثال - عن الاستعلام إذا واجهتنا مشكلة في الحصول على بيانات من الخدمتين. func temperature(city string, providers ...weatherProvider) (float64, error) { sum := 0.0 for _, provider := range providers { k, err := provider.temperature(city) if err != nil { return 0, err } sum += k } return sum / float64(len(providers)), nil } لاحظ أن تعريف الدالة قريب جدّا من تعريف التابع temperature المُعرَّف في الواجهة weatherProvider. إن جمعنا الواجهات weatherProvider في نوع بيانات ثم عرّفنا تابعا باسم temperature على هذا النوع فسيمكننا إنشاء نوع جديد يجمع الواجهات weatherProvider. type multiWeatherProvider []weatherProvider func (w multiWeatherProvider) temperature(city string) (float64, error) { sum := 0.0 for _, provider := range w { k, err := provider.temperature(city) if err != nil { return 0, err } sum += k } return sum / float64(len(w)), nil } رائع! سنتمكّن من تمرير multiWeatherProvider إلى أي دالة تقبل weatherProvider. نربُط الآن خادوم HTTP بدالة temperature للحصول على درجات الحرارة عند طلب مسار به اسم مدينة: func main() { mw := multiWeatherProvider{ openWeatherMap{}, weatherUnderground{apiKey: "your-key-here"}, } http.HandleFunc("/weather/", func(w http.ResponseWriter, r *http.Request) { begin := time.Now() city := strings.SplitN(r.URL.Path, "/", 3)[2] temp, err := mw.temperature(city) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json; charset=utf-8") json.NewEncoder(w).Encode(map[string]interface{}{ "city": city, "temp": temp, "took": time.Since(begin).String(), }) }) http.ListenAndServe(":8080", nil) } صرّف البرنامج، شغّله واطلب رابط خادوم الوب كما فعلنا سابقا. ستجد - علاوة على الإجابة بصيغة JSON في نافذة الطلب - مُخرجات قادمة من تسجيلات الخادوم التي أضفناها أعلاه في النافذة التي شغّلت منها البرنامج. ./hello 2015/01/01 13:14:15 openWeatherMap: tokyo: 295.46 2015/01/01 13:14:16 weatherUnderground: tokyo: 273.15 $ curl http://localhost:8080/weather/tokyo {"city":"tokyo","temp":284.30499999999995,"took":"821.665230ms"} جعل الاستعلامات تعمل بالتوازي نكتفي لحدّ الساعة بالاستعلام من الواجهات البرمجية بالتتالي، الواحدة تلو الأخرى. لا يوجد ما يمنعنا من الاستعلام من الواجهتيْن البرمجيّتين في نفس الوقت، وهو ما سياسهم في تقليل الوقت اللازم للإجابة. نستفيد من إمكانات Go في التشغيل المتزامن عبر وحدات Go الفرعية goroutines والقنوات Channels. سنضع كل استعلام في وحدة فرعية خاصّة به ثم نشغّلها بالتوازي. نجمع الإجابات بعد ذلك في قناة واحدة ثم نحسب المعدّلات عندما تكتمل جميع الاستعلامات. func (w multiWeatherProvider) temperature(city string) (float64, error) { // ننشئ قناتيْن، واحدة لدرجات الحرارة والأخرى للأخطاء // يُضيف كل مزوّد خدمة قيمة إلى إحدى القناتيْن فقط temps := make(chan float64, len(w)) errs := make(chan error, len(w)) // نطلق بالنسبة لكلّ مزوّد خدمة وحدة فرعية جديدة بدالة مجهولة الاسم. تستدعي الدالة مجهولة الاسم التابع temperature ثم تعيد توجيه النتيجة المتحصًّل عليها. for _, provider := range w { go func(p weatherProvider) { k, err := p.temperature(city) if err != nil { errs <- err return } temps <- k }(provider) } sum := 0.0 // نجمع درجات الحرارة - أو الأخطاء في حالة وجودها - من كل خِدمة for i := 0; i < len(w); i++ { select { case temp := <-temps: sum += temp case err := <-errs: return 0, err } } // نُرجع الحرارة كما في السابق return sum / float64(len(w)), nil } يساوي الوقت اللازم الآن لتنفيذ جميع الاستعلامات المدة الزمنية اللازمة للحصول على إجابة من أبطأ خدمة طقس؛ بدلا من مجموع المدد الزمنية لجميع الاستعلامات كما كان سابقا. كل ما احتجنا له هو تعديل سلوك multiWeatherProvider الذي ما زال مع ذلك يُرضي حاجات واجهة weatherProvider البسيطة وغير المتوازية. السهولة انتقلنا ببضع خطوات وبالاقتصار فقط على المكتبة المعيارية لـGo من مثال “hello world” إلى خادوم سند خلفي Backend server يحترم مبادئ REST. يمكن نشر الشفرة التي كتبناها على أي معمارية خواديم تقريبا. الملف التنفيذي الناتج سريع ويتضمّن جميع ما يحتاجه للعمل؛ والأهم من ذلك، الشفرة البرمجيّة واضحة لقراءتها وفهمها. كما تمكن صيانتها وتمديدها بسهولة حسب الحاجة. أنا مقتنع أن كلّ هذه الميزات هي نتيجة لتفاني Go في البساطة. ترجمة - بتصرّف - للمقال How I start Go لصاحبه Peter Bourgon. -
.jpg.57d84ae46728262cc08636b83650c8c0.jpg) يسألني الناس أينما ذهبت - في المؤتمرات، المحاضرات، لدى وكالات تطوير المواقع وغيرها - عن ملف composer.lock. يبدو وكأن الأمر يتعلّق بلغز يزرع الشكوك حول المعمورة! أقدّم لك هذا المقال لتوضيح ماهية هذا الملف وفكّ اللغز الذي يمثّله. يعدّ Composer أداة تدير الإصدارات الخاصة بمكتبات PHP التي يستخدمها المطوّرون في مشاريعهم البرمجية. سأفترض - لأغراض هذا المقال - أنه سبق لك استخدام Composer في مشاريع سابقة. فلنفترض أن لدينا مشروع PHP جديدا ندير اعتماديّاته Dependencies عن طريق Composer. نبدأ بملف composer.json الذي يُستخدَم لإعداد لائحة بالاعتماديّات التي نريد تثبيتها. يبدو الملف على النحو التالي: { "require": { "assassins/ezio": "1.1.0", "assassins/edward": "1.1.2", "templars/shay": "1.1.*", } } عرّفنا بوضوح الإصدارات التي نحتاجها بالنسبة للحزمتين الأولى والثانية؛ إلا أن الأمر مختلف قليلا يالنسبة للحزمة الثالثة templars/shay التي حدّدنا لها بطريقة أكثر مرونة فلم نعرّف إصدار الترقيع Patch version؛ وبالتالي سيكون أي ترقيع للإصدار 1.1 مناسبا للمشروع. تنبغي ملاحظة أن هذه الأسماء المذكورة في الشفرة أعلاه هي أسماء مفترضة لحزم وليست حزما حقيقية يمكن تثبيتها. يمكن القول إن ملف composer.json هو دليل “تقريبي” للإصدارات التي نريد تثبيتها؛ فاستخدام ماسك المكان * يجعل إصدارات عدّة متوافرة لاستخدامها. بمعنى آخر، يحدّد الملف هامشا مقبولا لهرميّة الاعتماديّات في التطبيق. لا يوجد لدينا لحدّ الساعة، أي في بداية المشروع، ملفّ composer.lock؛ إلا أنه سيظهر بعد تنفيذنا للأمر composer install. نجد مباشرة بعد تنفيذ الأمر composer install ملفّا غريبا باسم composer.lock في المجلّد الجذر للمشروع. إن ألقيت نظرة على ما بداخله فستجد أنه كبير نوعا ما. حان الوقت الآن لكشف اللّغز. في الواقع؛ الملف composer.json هو دليل تقريبي - كما قلنا - لإصدارات الاعتماديّات التي يتوجّب على Composer تثبيتها، بينما الملف composer.lock هو تسجيل دقيق بالإصدارات التي ثُبِّتت عند تنفيذ الأمر composer install. أي أنه يسجّل ما ثبّته Composer من مكتبات لمشروعك. في ما يلي مثال بسيط: "source": { "type": "git", "url": "https://github.com/templars/shay.git", "reference": "98c313c831e5d99bb393ba1844df91bab2bb5b8b" }, هل ترى سلسلة المحارف الطويلةَ تلك؟ هذا هو المعرّف الدقيق لإيداع Commit الإصدار المثبّت عندما اتّبع Composer تعليمات composer.json. يحتفظ الملف composer.lock كذلك بجميع إصدارات الاعتماديّات التي تتطلّبها اعتماديّات المشروع؛ والمكتبات التي تقوم عليها اعتماديّات اعتمديّات المشروع.. وهكذا دواليك. يعني هذا أن الملف composer.lock يحوي التسلسل الهرمي الكامل لاعتماديّات التطبيق. في ماذا يفيد وجود التسلسل الهرمي لاعتماديّات المشروع في الملف composer.lock؟ حسنا؛ يمكن أن تجرّب حذف المجلّد الذي توجد به اعتماديّات المشروع، مثلا vendor في Laravel؛ ثم تنفيذ الأمر composer install من جديد. سيجد Composer هذه المرة أن لديك ملفّ composer.lock وبدلا من البحث عن إصدارات متوافقة مع تعليمات الملف composer.jsonفسيلجأ إلى الإصدارات الدقيقة المذكورة في الملف composer.lock ويثبّتها. يعني هذا أننا سنحصُل على نفس المكتبات التي حذفناها بحذف مجلّد الاعتماديّات. سؤال آخر.. هل يجب تضمين الملف composer.lock في مستودع Git؟ يجب أن تكون الإجابة الآن واضحة. إن أردت تسجيل الإصدارات الدقيقة للاعتماديّات التي استخدمتها في المشروع فالإجابة هي نعم؛ وهذا هو الواقع في أغلب المشاريع. إن كنت تعمل ضمن فريق مطوّرين فإن جعل الملف composer.lock في المستودع يضمن أن الجميع يستخدم نفس الإصدارات؛ الأمر الذي يمكن أن يكون مفيدا في تنقيح Debugging الأخطاء التي تظهر لدى مطوّر واحد فقط من الفريق. إن كنت توزّع تطبيقك عبر Git فإن تضمين الملف composer.lock في المستودع سيضمن أن إصدارات الاعتماديّات التي استخدمتها في التطوير وأجريت عليها الاختبارات هي نفسها المستخدمة في بيئة الإنتاج. لماذا من المهم استخدام نفس إصدارات الاعتماديّات؟ فلنفترض أن Git يتجاهل وجود الملف composer.lock. تنفّذ الأمر composer install، يبحث Composer عن آخر ترقيع للإصدار 1.1 من الحزمة templars/shay فيجد الإصدار 1.1.4 ويثبّته. تعمل على المشروع باستخدام الإصدار 1.1.4، وفي هذه الأثناء يقدّم فريق الحزمة templars/shay الإصدار 1.1.5 الذي - لسوء الحظ - يتضمّن علة برمجيّة Bug حرجة. عندما تنشُر مشروعك على بيئة الإنتاج يثبّت Composer - بالاعتماد على تعليمات الملف composer.json - الإصدار 1.1.5 من الحزمة الذي يحوي علّة تمنع تطبيقك من العمل على النحو الذي تريده. يمكنك استنتاج أنه لو كان الملف composer.json في المستودع لأدّى تنفيذ الأمر composer install في بيئة الإنتاج إلى تثبيت الإصدار 1.1.4 من الحزمة templars/shay الذي سبق لك اختبار التطبيق معه. باختصار: في الأخير.. متى يتغيّر الملف composer.lock ولأي سبب؟ أرى طوال الوقت مطورين ينفّذون الأمر composer update كلّما حدّثوا الملف composer.json، للحصول على الحزم الجديدة التي أضافوها إلى الملف. في الواقع هذا الأمر خاطئ! يجب أن تستخدم الأمر composer install بدلا من ذلك، إذ أنه يثبّت الحزم الجديدة دون تحديث إصدارات الحزم الأخرى؛ هذه الطريقة آمن كثيرا. في ما يلي لائحة بإجراءات تتسبّب في تحديث الملف composer.lock: تنفيذ الأمر composer install للمرة الأولى. يُنشَأ الملف composer.lock لتسجيل الإصدارات الدقيقة للاعتماديّات المثبّتة. تنفيذ الأمر composer install بعد إضافة حزم جديدة. يُضاف الإصدار الدقيق للحزمة إلى الملف composer.lock. تنفيذ الأمر composer update. تُحدَّث إصدارات جميع الحزم إلى الترقيع الأخير بما يتوافق مع تعليمات الملف composer.json، وهو ما ينتُج عنه تحديث الإصدارات الدقيقة في الملف composer.lock. تنفيذ الأمر composer update package/name لتحديث الحزمة المذكورة إلى آخر ترقيع، بما يتوافق مع تعليمات الملف composer.json، وبالتالي يُحدَّث الملف composer.lock ليعكس التغيير الحاصل في إصدار الحزمة. يعني ما سبق أن composer install أمر “آمن”، ولن ينتُج عنه سوى إضافة حزم جديدة إلى الملف composer.lock (وليس تحديث حزم موجودة مسبقا). في حين أن الأمر composer update أمر “خطِر”، إذ أنه يتسبّب في تغيير مباشر على الإصدارات الدقيقة الموجودة في الملف composer.lock . أرجو أن يكون الملف اللغز composer.lock قد اتّضح لك بعد قراءة هذا المقال. إن كنت تعلّمت شيئا أو اثنين من هذا المقال فأرجو أن تشاركه مع أصدقائك حتى يعرفوا هم أيضا سر الملف العظيم. ترجمة - بتصرّف - للمقال PHP: The Composer Lock File لصاحبه Dayle Rees. حقوق خلفية الصورة البارزة محفوظة لـ Freepik
يسألني الناس أينما ذهبت - في المؤتمرات، المحاضرات، لدى وكالات تطوير المواقع وغيرها - عن ملف composer.lock. يبدو وكأن الأمر يتعلّق بلغز يزرع الشكوك حول المعمورة! أقدّم لك هذا المقال لتوضيح ماهية هذا الملف وفكّ اللغز الذي يمثّله. يعدّ Composer أداة تدير الإصدارات الخاصة بمكتبات PHP التي يستخدمها المطوّرون في مشاريعهم البرمجية. سأفترض - لأغراض هذا المقال - أنه سبق لك استخدام Composer في مشاريع سابقة. فلنفترض أن لدينا مشروع PHP جديدا ندير اعتماديّاته Dependencies عن طريق Composer. نبدأ بملف composer.json الذي يُستخدَم لإعداد لائحة بالاعتماديّات التي نريد تثبيتها. يبدو الملف على النحو التالي: { "require": { "assassins/ezio": "1.1.0", "assassins/edward": "1.1.2", "templars/shay": "1.1.*", } } عرّفنا بوضوح الإصدارات التي نحتاجها بالنسبة للحزمتين الأولى والثانية؛ إلا أن الأمر مختلف قليلا يالنسبة للحزمة الثالثة templars/shay التي حدّدنا لها بطريقة أكثر مرونة فلم نعرّف إصدار الترقيع Patch version؛ وبالتالي سيكون أي ترقيع للإصدار 1.1 مناسبا للمشروع. تنبغي ملاحظة أن هذه الأسماء المذكورة في الشفرة أعلاه هي أسماء مفترضة لحزم وليست حزما حقيقية يمكن تثبيتها. يمكن القول إن ملف composer.json هو دليل “تقريبي” للإصدارات التي نريد تثبيتها؛ فاستخدام ماسك المكان * يجعل إصدارات عدّة متوافرة لاستخدامها. بمعنى آخر، يحدّد الملف هامشا مقبولا لهرميّة الاعتماديّات في التطبيق. لا يوجد لدينا لحدّ الساعة، أي في بداية المشروع، ملفّ composer.lock؛ إلا أنه سيظهر بعد تنفيذنا للأمر composer install. نجد مباشرة بعد تنفيذ الأمر composer install ملفّا غريبا باسم composer.lock في المجلّد الجذر للمشروع. إن ألقيت نظرة على ما بداخله فستجد أنه كبير نوعا ما. حان الوقت الآن لكشف اللّغز. في الواقع؛ الملف composer.json هو دليل تقريبي - كما قلنا - لإصدارات الاعتماديّات التي يتوجّب على Composer تثبيتها، بينما الملف composer.lock هو تسجيل دقيق بالإصدارات التي ثُبِّتت عند تنفيذ الأمر composer install. أي أنه يسجّل ما ثبّته Composer من مكتبات لمشروعك. في ما يلي مثال بسيط: "source": { "type": "git", "url": "https://github.com/templars/shay.git", "reference": "98c313c831e5d99bb393ba1844df91bab2bb5b8b" }, هل ترى سلسلة المحارف الطويلةَ تلك؟ هذا هو المعرّف الدقيق لإيداع Commit الإصدار المثبّت عندما اتّبع Composer تعليمات composer.json. يحتفظ الملف composer.lock كذلك بجميع إصدارات الاعتماديّات التي تتطلّبها اعتماديّات المشروع؛ والمكتبات التي تقوم عليها اعتماديّات اعتمديّات المشروع.. وهكذا دواليك. يعني هذا أن الملف composer.lock يحوي التسلسل الهرمي الكامل لاعتماديّات التطبيق. في ماذا يفيد وجود التسلسل الهرمي لاعتماديّات المشروع في الملف composer.lock؟ حسنا؛ يمكن أن تجرّب حذف المجلّد الذي توجد به اعتماديّات المشروع، مثلا vendor في Laravel؛ ثم تنفيذ الأمر composer install من جديد. سيجد Composer هذه المرة أن لديك ملفّ composer.lock وبدلا من البحث عن إصدارات متوافقة مع تعليمات الملف composer.jsonفسيلجأ إلى الإصدارات الدقيقة المذكورة في الملف composer.lock ويثبّتها. يعني هذا أننا سنحصُل على نفس المكتبات التي حذفناها بحذف مجلّد الاعتماديّات. سؤال آخر.. هل يجب تضمين الملف composer.lock في مستودع Git؟ يجب أن تكون الإجابة الآن واضحة. إن أردت تسجيل الإصدارات الدقيقة للاعتماديّات التي استخدمتها في المشروع فالإجابة هي نعم؛ وهذا هو الواقع في أغلب المشاريع. إن كنت تعمل ضمن فريق مطوّرين فإن جعل الملف composer.lock في المستودع يضمن أن الجميع يستخدم نفس الإصدارات؛ الأمر الذي يمكن أن يكون مفيدا في تنقيح Debugging الأخطاء التي تظهر لدى مطوّر واحد فقط من الفريق. إن كنت توزّع تطبيقك عبر Git فإن تضمين الملف composer.lock في المستودع سيضمن أن إصدارات الاعتماديّات التي استخدمتها في التطوير وأجريت عليها الاختبارات هي نفسها المستخدمة في بيئة الإنتاج. لماذا من المهم استخدام نفس إصدارات الاعتماديّات؟ فلنفترض أن Git يتجاهل وجود الملف composer.lock. تنفّذ الأمر composer install، يبحث Composer عن آخر ترقيع للإصدار 1.1 من الحزمة templars/shay فيجد الإصدار 1.1.4 ويثبّته. تعمل على المشروع باستخدام الإصدار 1.1.4، وفي هذه الأثناء يقدّم فريق الحزمة templars/shay الإصدار 1.1.5 الذي - لسوء الحظ - يتضمّن علة برمجيّة Bug حرجة. عندما تنشُر مشروعك على بيئة الإنتاج يثبّت Composer - بالاعتماد على تعليمات الملف composer.json - الإصدار 1.1.5 من الحزمة الذي يحوي علّة تمنع تطبيقك من العمل على النحو الذي تريده. يمكنك استنتاج أنه لو كان الملف composer.json في المستودع لأدّى تنفيذ الأمر composer install في بيئة الإنتاج إلى تثبيت الإصدار 1.1.4 من الحزمة templars/shay الذي سبق لك اختبار التطبيق معه. باختصار: في الأخير.. متى يتغيّر الملف composer.lock ولأي سبب؟ أرى طوال الوقت مطورين ينفّذون الأمر composer update كلّما حدّثوا الملف composer.json، للحصول على الحزم الجديدة التي أضافوها إلى الملف. في الواقع هذا الأمر خاطئ! يجب أن تستخدم الأمر composer install بدلا من ذلك، إذ أنه يثبّت الحزم الجديدة دون تحديث إصدارات الحزم الأخرى؛ هذه الطريقة آمن كثيرا. في ما يلي لائحة بإجراءات تتسبّب في تحديث الملف composer.lock: تنفيذ الأمر composer install للمرة الأولى. يُنشَأ الملف composer.lock لتسجيل الإصدارات الدقيقة للاعتماديّات المثبّتة. تنفيذ الأمر composer install بعد إضافة حزم جديدة. يُضاف الإصدار الدقيق للحزمة إلى الملف composer.lock. تنفيذ الأمر composer update. تُحدَّث إصدارات جميع الحزم إلى الترقيع الأخير بما يتوافق مع تعليمات الملف composer.json، وهو ما ينتُج عنه تحديث الإصدارات الدقيقة في الملف composer.lock. تنفيذ الأمر composer update package/name لتحديث الحزمة المذكورة إلى آخر ترقيع، بما يتوافق مع تعليمات الملف composer.json، وبالتالي يُحدَّث الملف composer.lock ليعكس التغيير الحاصل في إصدار الحزمة. يعني ما سبق أن composer install أمر “آمن”، ولن ينتُج عنه سوى إضافة حزم جديدة إلى الملف composer.lock (وليس تحديث حزم موجودة مسبقا). في حين أن الأمر composer update أمر “خطِر”، إذ أنه يتسبّب في تغيير مباشر على الإصدارات الدقيقة الموجودة في الملف composer.lock . أرجو أن يكون الملف اللغز composer.lock قد اتّضح لك بعد قراءة هذا المقال. إن كنت تعلّمت شيئا أو اثنين من هذا المقال فأرجو أن تشاركه مع أصدقائك حتى يعرفوا هم أيضا سر الملف العظيم. ترجمة - بتصرّف - للمقال PHP: The Composer Lock File لصاحبه Dayle Rees. حقوق خلفية الصورة البارزة محفوظة لـ Freepik -
.png.7f58ab237ec5131e0b0c57dc0365fd49.png) يشيع استخدام صيغة Comma-separated values) CSV؛ قيم معزولة بفاصلة) لتخزين بيانات مُجدوَلة مثل تلك المصدَّرة من قاعدة بيانات أو ورقة حسابات. تمكن قراءة المستندات باستخدام واجهة FileReader البرمجية HTML، دون الحاجة للتخاطب مع أي خادوم Server أو سند خلفي Backend. سنرى في هذا الدّرس كيفيّة قراءة ملفات CSV في صفحة وِب باستخدام JavaScript وذلك بالاعتماد على محلّل Parser يتخاطب مع واجهة FileReader، هذا المحلّل هو Papa Parse. يتطلّب هذا الدرس معرفة جيّدة بجافاسكريبت ومكتبة jQuery. لماذا نستخدم Papa Parse يدعم محلّل Papa Parse المتصفحات الحديثة وبه الكثير من الميزات: مفتوح المصدر، مجاني وتُضاف إليه ميزات جديدة باستمرار؛ سريع، يمكنه تحليل ملايين البيانات ويدعم التشعّب التعدّدي Multi-threading؛ لا يعتمد على مكتبات خارجية؛ يدعم ترميزات Encoding مختلفة؛ يمكنه تخطّي التعليقات يتجنّب انهيار المتصفّح باستخدام التدفقات Streams للحصول على البيانات الخام. نهدف في هذا الدرس إلى قراءة البيانات من ملفّ CSV يحمّله الزائر عن طريق المتصفّح، نحلّل هذه البيانات ثم نعرضها في جدول HTML. يمكنك بعد ذلك استخدام التخزين المحلّي Local storage لديمومة البيانات أو إرسالها إلى خادوم لتخزينها في قاعدة بيانات. توجد الشفرة الكاملة لهذا الدرس في الملف المرفق. سنشرح في الفقرات الموالية أهم الخطوات. تهيئة استمارة HTML الخطوة الأولى هي كتابة شفرة HTML المسؤولة عن الاستمارة Form التي سيُحمّل المستخدم عن طريقها ملف CSV. <form class="form-inline"> <div class="form-group"> <label for="files">Upload a CSV formatted file:</label> <input type="file" id="files" class="form-control" accept=".csv" required /> </div> <div class="form-group"> <button type="submit" id="submit" class="btn btn-primary">Submit</button> </div> </form> جعلنا حقل الإدخال Input مطلوبًا كما يظهر في الشفرة أعلاه required، كما أنه لا يقبل سوى الملفات بصيغة CSV: accept=".csv" استقبال البيانات وتحليلها يُحدَّد ملف CSV في حقل الإدخال عندما ينقر المستخدم على الزّر “إرسال”. نستخدم jQuey - عند النقر على زرّ الإرسال - لتحليل الملف الذي حمّله المستخدم: $('#submit').on("click",function(e){ e.preventDefault(); $('#files').parse({ config: { delimiter: "auto", complete: buildTable, }, before: function(file, inputElem) { //console.log("Parsing file...", file); }, error: function(err, file) { //console.log("ERROR:", err, file); }, complete: function() { //console.log("Done with all files"); } }); }); الشفرة كما يظهر بسيطة. نبدأ أولا بضبط بعض المعطيات Parameters التي يحتاجها Papa parse باستخدام الكائن config. يتوفّر Papa parse أيضا على توابع لدورة حياة الملف يمكن استخدامها إن اقتضت الضرورة: before: دالة تُنفَّذ قبل بدء تحليل الملف. error: دالة تُنفَّذ عند وجود خطأ في تحليل الملف. complete: دالة تُنفَّذ بعد اكتمال تحليل الملف. لا تتلقّى هذه الدالة أية بيانات، وبالتالي يجب استخدام الدالة في المعطى complete إن كنت تريد معالجة البيانات التي تحصّل عليها المحلّل، وهو ما سنفعله. تتضمّن معطيات الكائن config المذكور أعلاه: المحرف المستخدَم للفصل بين القيم delimiter الذي ضبطناه على القيمة auto لكي يستكشف المحلّل تلقائيًا المحرف المستخدم. دالة تُنفَّذ بعد اكتمال تحليل الملف يحدّدها المعطى complete في الكائن config. أعطينا القيمة buildTable لهذا المعطى، وهو اسم دالة سنعرّفها لاحقا. تستقبل الدالة buildTable نتيجة تحليل الملف في أول معطى (results)، وهو كائن يأخذ الهيكلة التاليّة: { data: // مصفوفة بالبيانات بعد التحليل errors: // مصفوفة بالأخطاء التي قد تكون حصلت أثناء تحليل الملف meta: // كائن يتضمّن معلومات إضافية } تستقبل الدالة buildTable الكائن results وتستخدم البيانات results.data لإنشاء جدول تعرضه في صفحة الوب: function buildTable(results){ var markup = "<table class='table'>"; var data = results.data; for(i=0;i<data.length;i++){ markup+= "<tr>"; var row = data[i]; var cells = row.join(",").split(","); for(j=0;j<cells.length;j++){ markup+= "<td>"; markup+= cells[j]; markup+= "</th>"; } markup+= "</tr>"; } markup+= "</table>"; $("#app").html(markup); } ترجمة - بتصرف - للمقال Reading csv file using javascript لصاحبه Arkaprava Majumder. لتحميل الملف المرفق انقر هنا.
يشيع استخدام صيغة Comma-separated values) CSV؛ قيم معزولة بفاصلة) لتخزين بيانات مُجدوَلة مثل تلك المصدَّرة من قاعدة بيانات أو ورقة حسابات. تمكن قراءة المستندات باستخدام واجهة FileReader البرمجية HTML، دون الحاجة للتخاطب مع أي خادوم Server أو سند خلفي Backend. سنرى في هذا الدّرس كيفيّة قراءة ملفات CSV في صفحة وِب باستخدام JavaScript وذلك بالاعتماد على محلّل Parser يتخاطب مع واجهة FileReader، هذا المحلّل هو Papa Parse. يتطلّب هذا الدرس معرفة جيّدة بجافاسكريبت ومكتبة jQuery. لماذا نستخدم Papa Parse يدعم محلّل Papa Parse المتصفحات الحديثة وبه الكثير من الميزات: مفتوح المصدر، مجاني وتُضاف إليه ميزات جديدة باستمرار؛ سريع، يمكنه تحليل ملايين البيانات ويدعم التشعّب التعدّدي Multi-threading؛ لا يعتمد على مكتبات خارجية؛ يدعم ترميزات Encoding مختلفة؛ يمكنه تخطّي التعليقات يتجنّب انهيار المتصفّح باستخدام التدفقات Streams للحصول على البيانات الخام. نهدف في هذا الدرس إلى قراءة البيانات من ملفّ CSV يحمّله الزائر عن طريق المتصفّح، نحلّل هذه البيانات ثم نعرضها في جدول HTML. يمكنك بعد ذلك استخدام التخزين المحلّي Local storage لديمومة البيانات أو إرسالها إلى خادوم لتخزينها في قاعدة بيانات. توجد الشفرة الكاملة لهذا الدرس في الملف المرفق. سنشرح في الفقرات الموالية أهم الخطوات. تهيئة استمارة HTML الخطوة الأولى هي كتابة شفرة HTML المسؤولة عن الاستمارة Form التي سيُحمّل المستخدم عن طريقها ملف CSV. <form class="form-inline"> <div class="form-group"> <label for="files">Upload a CSV formatted file:</label> <input type="file" id="files" class="form-control" accept=".csv" required /> </div> <div class="form-group"> <button type="submit" id="submit" class="btn btn-primary">Submit</button> </div> </form> جعلنا حقل الإدخال Input مطلوبًا كما يظهر في الشفرة أعلاه required، كما أنه لا يقبل سوى الملفات بصيغة CSV: accept=".csv" استقبال البيانات وتحليلها يُحدَّد ملف CSV في حقل الإدخال عندما ينقر المستخدم على الزّر “إرسال”. نستخدم jQuey - عند النقر على زرّ الإرسال - لتحليل الملف الذي حمّله المستخدم: $('#submit').on("click",function(e){ e.preventDefault(); $('#files').parse({ config: { delimiter: "auto", complete: buildTable, }, before: function(file, inputElem) { //console.log("Parsing file...", file); }, error: function(err, file) { //console.log("ERROR:", err, file); }, complete: function() { //console.log("Done with all files"); } }); }); الشفرة كما يظهر بسيطة. نبدأ أولا بضبط بعض المعطيات Parameters التي يحتاجها Papa parse باستخدام الكائن config. يتوفّر Papa parse أيضا على توابع لدورة حياة الملف يمكن استخدامها إن اقتضت الضرورة: before: دالة تُنفَّذ قبل بدء تحليل الملف. error: دالة تُنفَّذ عند وجود خطأ في تحليل الملف. complete: دالة تُنفَّذ بعد اكتمال تحليل الملف. لا تتلقّى هذه الدالة أية بيانات، وبالتالي يجب استخدام الدالة في المعطى complete إن كنت تريد معالجة البيانات التي تحصّل عليها المحلّل، وهو ما سنفعله. تتضمّن معطيات الكائن config المذكور أعلاه: المحرف المستخدَم للفصل بين القيم delimiter الذي ضبطناه على القيمة auto لكي يستكشف المحلّل تلقائيًا المحرف المستخدم. دالة تُنفَّذ بعد اكتمال تحليل الملف يحدّدها المعطى complete في الكائن config. أعطينا القيمة buildTable لهذا المعطى، وهو اسم دالة سنعرّفها لاحقا. تستقبل الدالة buildTable نتيجة تحليل الملف في أول معطى (results)، وهو كائن يأخذ الهيكلة التاليّة: { data: // مصفوفة بالبيانات بعد التحليل errors: // مصفوفة بالأخطاء التي قد تكون حصلت أثناء تحليل الملف meta: // كائن يتضمّن معلومات إضافية } تستقبل الدالة buildTable الكائن results وتستخدم البيانات results.data لإنشاء جدول تعرضه في صفحة الوب: function buildTable(results){ var markup = "<table class='table'>"; var data = results.data; for(i=0;i<data.length;i++){ markup+= "<tr>"; var row = data[i]; var cells = row.join(",").split(","); for(j=0;j<cells.length;j++){ markup+= "<td>"; markup+= cells[j]; markup+= "</th>"; } markup+= "</tr>"; } markup+= "</table>"; $("#app").html(markup); } ترجمة - بتصرف - للمقال Reading csv file using javascript لصاحبه Arkaprava Majumder. لتحميل الملف المرفق انقر هنا. -
.jpg.a7e29a1aeb9e5cb296cb234ebbf929c9.jpg) توجد هذه اﻷيام الكثير من اﻷدوات لتحرير الملاحظات، الرسائل، القصص، الكتب، الشرائح التقديميّة وغيرها من أنواع المستندات على الحاسوب. يمكن لهذه الوفرة أن تكون أمرا إيجابيًّا وسلبيًّا في نفس الوقت. من جهة، تستطيع ببساطة تبديل البرنامج الذي تستخدمه إن لم يلبّ غرضك بآخر ؛ ومن جهة أخرى لا تدعم كثير من هذه الأدوات - خصوصا البرامج المغلقة - سوى صيغها الخاصّة. ينتُج عن النقطة الأخيرة أعلاه أن تخلّيك عن برنامج يصعُب كل ما زاد عدد المستندات التي كتبتها به نظرا للجهد، الوقت أو حتى المال اللازم استثمارها لجعل مستنداتك متوافقة مع البرنامج الجديد. تُسمَّى هذه الظاهرة بالارتباط ببائع Vendor lock-in. أستخدم، لهذا السبب، برامج حرّة أو مفتوحة المصدر بصيّغ مفتوحة كل ما كان ذلك ممكنا؛ حتى أزيد من احتمال توفّر برنامج لتحرير وفتح مستنداتي إن رغبتُ مستقبلا في تبديل البرنامج الذي أستخدمه حاليا. سأعرض في هذا المقال لأداتيْن تحترمان المعايير التي وضعتها لنفسي، وهما: مستندات ماركداون Markdown باستخدام Pandoc، وOrg-mode. ماركداون باستخدام Pandoc بدأ ماركداون في الأصل “أداةً موّجهة إلى كتاب الوِب لتحويل النصوص إلى HTML” حسب وصف منشِئه John Gruber. يمكن عدّ ماركداون في أيّامنا هذه لغةً ترميزيّة تركّز على البساطة. تسمح لغة ماركداون بإدارج نصوص مهيَّأة Formatted texts في المستندات. على سبيل المثال: الترويسات Headings، التركيز على أجزاء من النصّ (باستخدام خطوط ثخينة ومائلة)، روابط متشّعبة Hyperlinks، صور، قوائم، اقتباسات ومقاطع من شفرات برمجيّة. توفّر بعض إصدارات ماركداون عناصر إضافية. على سبيل المثال، يدعم إصدار ماركداون المستخدَم على GitHub الجداول، إبرازَ أساليب الصياغة الخاصّة بلغات البرمجة والترميز، قوائم المهامّ، أيقونات التعبيرية Emoji وعناصر أخرى. تتميّز المستندات المكتوبة بلغة الترميز ماركداون أنّها تُحفَظ على هيئة نصّ عاديّ، وهو ما يعني أنه يُمكن فتحُها بمحرّر نصوص بسيط مثل تلك الموجودة تقريبا على جميع الحواسب والأجهزة المحمولة. في إطار مختلف، دعنا نفترض أن لديك جهازا بمحرّر نصوص بسيط تحاول - على سبيل المثال - فتح مستند DOCX من خلاله. على الرغم من أن المستند يُمكن أن يُفتَح، إلا أن الناتج هو فوضى عارمة غير مقروءة من المحارف. يعود السبب في هذا اﻷمر إلى أنك تنظُر في صيغة ثنائية Binary format معدَّة ليقرأها برنامج؛ في هذه الحالة Microsoft Word. يقدّم ماركداون فائدة أخرى وهي فصلُ المحتوى عن أسلوب العرض. هل سبق لك أن تشتّت انتباهك عند ملاحظة أن النص لا يبدو بالطريقة التي تريد فتوقّفت في منتصف الجملة وبدأت في تعديل التنسيق؟ لن يحدُث هذا إن استخدمت Pandoc لكتابة ماركداون. عوضا عن ذلك، تكتب كل الأفكار التي تريد في الملف المصدَر، وهو ملف نصّي عادي بصيغة ماركداون، ثم بعد الانتهاء تحوّله إلى الصيغة التي ترغب فيها وتعدّل على مظهره إلى أن تصل إلى المظهر الذي تريد. قد يبدو الأمر غريبا لأول وهلة، إن كنتَ متعوّدا على مقاربة “ما تراه هو ما تحصُل عليه” WYSIWYG حيث ترى التنسيق أثناء الكتابة؛ إلا أن الأمر سيكون مختلفا بعد التعوّد، خصوصا إن كنت تعمل على مستندات كبيرة الحجم إذ أن تجربة الكتابة ستكون ألطف وأقل تشتيتا. تجد عند الانتهاء من كتابة نص ماركداون أو عندما تكون جاهزا لمعاينته الكثيرَ من الخيارات في ما يتعلّق بصيغ المستندات. يدعم Pandoc التصدير إلى صيغ كثيرة مثل PDF (عبر LaTeX)، مستندات ليبرأوفيس (DOCX، EPUB، (ODT و HTML (مع CSS). يتكامل Pandoc جيّدا مع محرّر النصوص Vim عبر الملحق vim-pandoc إلا أن بالإمكان استخدامه مستقلا عن أي محرّر نصوص. ملاحظة: احتفظ دائما بالملف المصدر (بصيغة ماركداون) حتى بعد اكتمال المستند وتصديره للصيغة التي تريد. التعديل على المصدر أسهل بكثير من التعديل على ملف مُصدَّر إلى صيغة أخرى. Org-mode برنامج Org-mode خيار جيّد آخر؛ وهو - حسب موقعه - أداة لـ“كتابة الملاحظات، قوائم المهامّ، خطط المشاريع وتأليف المستندات بطريقة سريعة وفعّالة تستخدم نظام نصوص عاديّة”. يشبه Org-mode استخدامَ ماركداون مع أداة تحويل صيّغ (كـ Pandoc). تُكتَب مستندات Org-mode بصياغة خاصّة في ملفات نصيّة عاديّة ثم تُحوَّل إلى صيغ أخرى كـ PDF (عبر LaTeX) وكذلك مستندات ODT وHTML (مع CSS). يُشكّل Org-mode جزءا من GNU Emacs لذا يجب أن يكون هذا اﻷخير مثبّتا حتى يمكنك استخدامه؛ إلا أنه بالإمكان فتح الملفات المصدرية بأي محرّر نصوص، فهي مجرّد نصوص عادية غيرمُهيَّأة. إن لم تكن تريد التعامل مع Emacs فيمكنك استخدام محلقات مثل vim-orgmode الذي يسمح باستخدام أكثر ميزات Org-mode شيوعا داخل Vim. خاتمة يوفّر كل من ماركداون (مع Pandoc) وOrg-mode ميزات تجعل الكتابة أكثر سهولة. يشترك الاثنان في إمكانيّة البدء بملف نصّي عاديّ يمكن فتحه بأي محرّر نصوص، وفصلهما بين المظهر والمحتوى ممّا يسمح بالتركيز على الأفاكار التي تريد كتابتها، كما أنهما يدعمان أدوات تحويل إلى صيغ مستندات كثيرة، مفتوحة غالبا. تتيح لك هذه الطريقة ألا تتعلّق بصيغة واحدة تحتاج لاستخدام برامج معيَّنة حتى يمكنك التعامل معها لتلبية احتياجاتك. ترجمة - بتصرّف - للمقال Command-line document conversion tools for writers لصاحبه Zsolt Szakács. حقوق الصورة البارزة محفوظة لـ Freepik
توجد هذه اﻷيام الكثير من اﻷدوات لتحرير الملاحظات، الرسائل، القصص، الكتب، الشرائح التقديميّة وغيرها من أنواع المستندات على الحاسوب. يمكن لهذه الوفرة أن تكون أمرا إيجابيًّا وسلبيًّا في نفس الوقت. من جهة، تستطيع ببساطة تبديل البرنامج الذي تستخدمه إن لم يلبّ غرضك بآخر ؛ ومن جهة أخرى لا تدعم كثير من هذه الأدوات - خصوصا البرامج المغلقة - سوى صيغها الخاصّة. ينتُج عن النقطة الأخيرة أعلاه أن تخلّيك عن برنامج يصعُب كل ما زاد عدد المستندات التي كتبتها به نظرا للجهد، الوقت أو حتى المال اللازم استثمارها لجعل مستنداتك متوافقة مع البرنامج الجديد. تُسمَّى هذه الظاهرة بالارتباط ببائع Vendor lock-in. أستخدم، لهذا السبب، برامج حرّة أو مفتوحة المصدر بصيّغ مفتوحة كل ما كان ذلك ممكنا؛ حتى أزيد من احتمال توفّر برنامج لتحرير وفتح مستنداتي إن رغبتُ مستقبلا في تبديل البرنامج الذي أستخدمه حاليا. سأعرض في هذا المقال لأداتيْن تحترمان المعايير التي وضعتها لنفسي، وهما: مستندات ماركداون Markdown باستخدام Pandoc، وOrg-mode. ماركداون باستخدام Pandoc بدأ ماركداون في الأصل “أداةً موّجهة إلى كتاب الوِب لتحويل النصوص إلى HTML” حسب وصف منشِئه John Gruber. يمكن عدّ ماركداون في أيّامنا هذه لغةً ترميزيّة تركّز على البساطة. تسمح لغة ماركداون بإدارج نصوص مهيَّأة Formatted texts في المستندات. على سبيل المثال: الترويسات Headings، التركيز على أجزاء من النصّ (باستخدام خطوط ثخينة ومائلة)، روابط متشّعبة Hyperlinks، صور، قوائم، اقتباسات ومقاطع من شفرات برمجيّة. توفّر بعض إصدارات ماركداون عناصر إضافية. على سبيل المثال، يدعم إصدار ماركداون المستخدَم على GitHub الجداول، إبرازَ أساليب الصياغة الخاصّة بلغات البرمجة والترميز، قوائم المهامّ، أيقونات التعبيرية Emoji وعناصر أخرى. تتميّز المستندات المكتوبة بلغة الترميز ماركداون أنّها تُحفَظ على هيئة نصّ عاديّ، وهو ما يعني أنه يُمكن فتحُها بمحرّر نصوص بسيط مثل تلك الموجودة تقريبا على جميع الحواسب والأجهزة المحمولة. في إطار مختلف، دعنا نفترض أن لديك جهازا بمحرّر نصوص بسيط تحاول - على سبيل المثال - فتح مستند DOCX من خلاله. على الرغم من أن المستند يُمكن أن يُفتَح، إلا أن الناتج هو فوضى عارمة غير مقروءة من المحارف. يعود السبب في هذا اﻷمر إلى أنك تنظُر في صيغة ثنائية Binary format معدَّة ليقرأها برنامج؛ في هذه الحالة Microsoft Word. يقدّم ماركداون فائدة أخرى وهي فصلُ المحتوى عن أسلوب العرض. هل سبق لك أن تشتّت انتباهك عند ملاحظة أن النص لا يبدو بالطريقة التي تريد فتوقّفت في منتصف الجملة وبدأت في تعديل التنسيق؟ لن يحدُث هذا إن استخدمت Pandoc لكتابة ماركداون. عوضا عن ذلك، تكتب كل الأفكار التي تريد في الملف المصدَر، وهو ملف نصّي عادي بصيغة ماركداون، ثم بعد الانتهاء تحوّله إلى الصيغة التي ترغب فيها وتعدّل على مظهره إلى أن تصل إلى المظهر الذي تريد. قد يبدو الأمر غريبا لأول وهلة، إن كنتَ متعوّدا على مقاربة “ما تراه هو ما تحصُل عليه” WYSIWYG حيث ترى التنسيق أثناء الكتابة؛ إلا أن الأمر سيكون مختلفا بعد التعوّد، خصوصا إن كنت تعمل على مستندات كبيرة الحجم إذ أن تجربة الكتابة ستكون ألطف وأقل تشتيتا. تجد عند الانتهاء من كتابة نص ماركداون أو عندما تكون جاهزا لمعاينته الكثيرَ من الخيارات في ما يتعلّق بصيغ المستندات. يدعم Pandoc التصدير إلى صيغ كثيرة مثل PDF (عبر LaTeX)، مستندات ليبرأوفيس (DOCX، EPUB، (ODT و HTML (مع CSS). يتكامل Pandoc جيّدا مع محرّر النصوص Vim عبر الملحق vim-pandoc إلا أن بالإمكان استخدامه مستقلا عن أي محرّر نصوص. ملاحظة: احتفظ دائما بالملف المصدر (بصيغة ماركداون) حتى بعد اكتمال المستند وتصديره للصيغة التي تريد. التعديل على المصدر أسهل بكثير من التعديل على ملف مُصدَّر إلى صيغة أخرى. Org-mode برنامج Org-mode خيار جيّد آخر؛ وهو - حسب موقعه - أداة لـ“كتابة الملاحظات، قوائم المهامّ، خطط المشاريع وتأليف المستندات بطريقة سريعة وفعّالة تستخدم نظام نصوص عاديّة”. يشبه Org-mode استخدامَ ماركداون مع أداة تحويل صيّغ (كـ Pandoc). تُكتَب مستندات Org-mode بصياغة خاصّة في ملفات نصيّة عاديّة ثم تُحوَّل إلى صيغ أخرى كـ PDF (عبر LaTeX) وكذلك مستندات ODT وHTML (مع CSS). يُشكّل Org-mode جزءا من GNU Emacs لذا يجب أن يكون هذا اﻷخير مثبّتا حتى يمكنك استخدامه؛ إلا أنه بالإمكان فتح الملفات المصدرية بأي محرّر نصوص، فهي مجرّد نصوص عادية غيرمُهيَّأة. إن لم تكن تريد التعامل مع Emacs فيمكنك استخدام محلقات مثل vim-orgmode الذي يسمح باستخدام أكثر ميزات Org-mode شيوعا داخل Vim. خاتمة يوفّر كل من ماركداون (مع Pandoc) وOrg-mode ميزات تجعل الكتابة أكثر سهولة. يشترك الاثنان في إمكانيّة البدء بملف نصّي عاديّ يمكن فتحه بأي محرّر نصوص، وفصلهما بين المظهر والمحتوى ممّا يسمح بالتركيز على الأفاكار التي تريد كتابتها، كما أنهما يدعمان أدوات تحويل إلى صيغ مستندات كثيرة، مفتوحة غالبا. تتيح لك هذه الطريقة ألا تتعلّق بصيغة واحدة تحتاج لاستخدام برامج معيَّنة حتى يمكنك التعامل معها لتلبية احتياجاتك. ترجمة - بتصرّف - للمقال Command-line document conversion tools for writers لصاحبه Zsolt Szakács. حقوق الصورة البارزة محفوظة لـ Freepik -
 مقدمة يُستخدم ميثاق (بروتوكول) الوِب TLS (اختصار لـ Transport Layer Security، أمان طبقة النقل) وسلفه SSL (اختصار لـ Secure Sockets Layer، طبقة المقابس الآمنة) لتغليف البيانات العاديّة ضمن إطار محميّ وآمن. يمكن للخواديم باستخدام هذه التقنية أن تؤمّن تبادل البيانات بينها وبين العملاء حتى ولو اعتُرِضت طريقُ الرسائل بين الخادوم والعميل. يساعد نظام الشهادات الأمنية Certificates المستخدِمين والزوار في التحقّق من أمان المواقع التي يتّصلون بها. سنقدّم في هذا الدليل الخطوات اللازمة لإعداد شهادة أمنيّة موقَّعة ذاتيًّا Self-signed certificate لاستخدامها مع خادوم الوِب Apache على أوبونتو 16.04. ملحوظة: تعمّي الشهادات الموقَّعة ذاتيًّا الاتصالات بين الخادوم والعملاء؛ لكن لن يمكنَ للعملاء استخدامُها للتحقّق من التحقّق من هويّة خادومك تلقائيًّا، إذ أنه لم تُوقّعها سلطة معترف بها. تتضمَّن المتصفّحات مثل فيرفكس وكروم قائمة بالسلطات المعترف بها والمخوَّلة إصدار شهادات TLS. يُناسب استخدام الشهادات الموقَّعة ذاتيًّا بيئات الاختبار، على الحاسوب الشخصي أو عندما لا يكون لديك نطاق Domain؛ مثلا في واجهات الوِب غير المتاحة للعموم. إن كان لديك نطاق فالأفضل أن تستخدم شهادة أمنية من سطلة معترف بها. يمكنك الحصول على شهادة مجانيّة من Let’s encrypt وإعدادها. المتطلبات ستحتاج قبل البدء بتنفيذ الخطوات الواردة في هذا الدرس إلى إعداد مستخدم إداري بامتيازات sudo غير المستخدم الجذر. راجع درس الإعداد الابتدائي لخادوم أوبونتو لمعرفة كيفية ذلك. ستحتاج أيضا لتثبيت خادوم الوِب Apache. إن رغبت في تثبيت كامل حزم LAMP (أي لينكس Linux، أباتش Apache، وMySQL وPHP) فالدرس كيف تثبت حزم MySQL ،Apache ،Linux :LAMP و PHP موجود لهذا الغرض؛ أما إن كنت ترغب في تثبيت Apache لوحده فيمكنك الاعتماد على الدرس المُشار إليه مع ترك الخطوات الخاصّة بكلّ من MySQL وPHP. تأكّد من توفّرك على المتطلّبات ثم نفّذ الخطوات المشروحة أدناه. الخطوة اﻷولى: إنشاء شهادة SSL يعمل بروتكول TLS (وسلفه SSL) باستخدام مفتاحيْن للتعميّة واحد عمومي Public وآخر خاصّ (أو سرّي) Private. يُخزَّن المفتاح السّري على الخادوم ولا يجوز أن يطّلع عليه أي عميل فهو خاصّ بالخادوم الذي يستخدمه لتعميّة المحتوى المُرسَل إلى العملاء. يُمكن لأيّ عميل الاطّلاع على شهادة TLS. تحوي هذه الشهادة المفتاح العموميّ الذي يُستخدَم لفكّ التعميّة عن المحتوى القادم من الخادوم. ملحوظة: رغم أن استخدام البروتكول SSL يقلّ يومًا بعد يوم إلا أن المصطلح “شهادة SSL” لا يزال يُستَخدَم كثيرًا، ويُقصَد به - في الغالب - TLS، الذي هو نسخة محسَّنة من SSL. تتيح مكتبة OpenSSL (مكتبة برمجيّة توفّر أدوات للتعامل مع شهادات SSL/TLS) إنشاء مفتاح تعميّة موقَّع ذاتيًّا بالأمر التالي: sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/apache-selfsigned.key -out /etc/ssl/certs/apache-selfsigned.crt ستُطرَح عليك مجموعة من الأسئلة، ولكن قبل النظر في تلك الأسئلة سنشرح الخيارات المذكورة في الأمر السابق: openssl: هذا هو الأمر الأساسي لإنشاء الشهادات، المفاتيح وبقية الملفات وإدارتها في OpenSSL. req: يحدّد هذا الأمر الفرعي المعيار X.509 لاستخدامه في البنية التحتيّة التي نريد استخدامها لإدارة المفاتيح العموميّة. يعتمد الميثاقان SSL وTLS المعيار X.509 لإدارة المفاتيح العمومية. نستخدم هذا الأمر الفرعي لطلب إنشاء شهادة تتوافق مع هذا المعيار. x.509: يغيّر هذا الخيار طريقة عمل الأمر الفرعي السابق ليخبره أننا في طور إنشاء شهادة موّقَّعة ذاتيًّا بدلا من إرسال طلب لتوقيع شهادة الذي هو السلوك المبدئي للأمر الفرعي. nodes: يطلُب هذا الخيار من openssl تجاوز خيار تأمين الشهادة بعبارة سرّ Passphrase. نريد أن يكون Apache قادرا على قراءة الشهادة بدون تدخّل من المستخدم عند بدْء تشغيل الخادوم. يمنع وجود عبارة سرّ Apache من قراءة ملفّ الشهادة وسنحتاج عند وجودها لإدخالها في كلّ مرة نعيد فيها تشغيل الخادوم. days 365: يحدّد هذا الخيار مدّة صلاحيّة الشهادة. اخترنا سنة. newkey rsa:2048: يخبر هذا الخيار الأمر openssl أننا نريد توليد شهادة ومفتاح جديد في نفس الوقت. بما أننا لم نولّد المفتاح المطلوب لتوقيع الشهادة في خطوة منفصلة فإننا نحتاج لإنشائه مع الشهادة. يحدّد الجزء rsa:2048 نوعيّة المفتاح بـ RSA وطوله بـ 2048 بت. keyout: يحدّد المسار الذي نريد حفظ المفتاح الخاصّ فيه. out: يحدّد المسار الذي نريد حفظ الشهادة فيه. ستنشئ هذه الخيارات مفاتيح التعميّة والشهادة. يطلُب الأمر كما أسلفنا الإجابة على بضعة أسئلة كما في الصورة التالية. تتعلّق الأسئلة بمعلومات عامة من قبيل الدولة والمدينة والمؤسّسة والمنظَّمة المُصدِرة للشهادة إضافة إلى معلومات عن الخادوم. يتعلّق أهمّ الأسئلة المطروحة - السطر Common Name - بالخادوم. يجب أن تجيب باسم النطاق الذي يعمل عليه الخادوم أو - وهو الأكثر شيوعا - عنوان IP العمومي للخادوم. يبدو المحثّ Prompt على النحو التالي: Country Name (2 letter code) [AU]:حرفان يمثّلان الدولة State or Province Name (full name) [Some-State]:اسم المنطقة (المحافظة أو الولاية) Locality Name (eg, city) []:اسم المدينة Organization Name (eg, company) [Internet Widgits Pty Ltd]:اسم المنظَّمة أو الشركة Organizational Unit Name (eg, section) []:اسم الفرع Common Name (e.g. server FQDN or YOUR name) []:عنوان الخادوم Email Address []:بريد المسؤول سيوضع الملفان المنشآن في مجلّدات فرعيّة من المجلّد etc/ ssl/ حسب ماهو محدَّد في الأمر. سنحتاج أيضًا - ما دمنا نتحدَّث عن OpenSSL - إلى إنشاء مجموعة Diffie-Hellman قويّة لتُستخدَم عندما يُناقش الخادوم طريقة نقل البيانات مع العملاء (خطوة من خطوات عدّة ضمن تقنيّة SSL/TLS لتأمين نقل البيانات). ينشئ اﻷمر التالي المطلوب: sudo openssl dhparam -out /etc/ssl/certs/dhparam.pem 2048 يمكن أن يستغرق الأمر بضعة دقائق، نحصُل بعدها على مجموعة Diffie-Hellman مناسبة (على المسار etc/ssl/certs/dhparam.pem/) لاستعمالها في إعداداتنا. الخطوة الثانية: إعداد Apache لاستخدام SSL أنشأنا في الخطوة السابقة ملفّيْ الشهادة والمفتاح الخاصّ. نحتاج الآن لضبط Apache للاستفادة من هذيْن الملفّيْن. سنعدّل بضعة إعدادات: سننشئ مقطعا جديدًا في إعدادات Apache لتحديد خيارات إعداد مبدئيّة آمنة لـ SSL. سنعدّل المضيف الافتراضي Virtual host الخاص بـ SSL للإشارة إلى شهادة SSL التي أنشأناها في الخطوة السابقة. سنعدّل المضيف الافتراضي غير المُعمَّى ليعيد توجيه جميع الطلبات إلى المضيف الافتراضي المُعمَّى (الخاص بـ SSL). يُنصَح بهذا الإجراء لجعل جميع الاتصالات القادمة إلى الموقع آمنة (تمرّ عبر شهادة SSL). يجدر بالإعدادات التي سنحصُل عليها بعد تنفيذ النقاط المُشار إليها أعلاه أن تكون آمنة. تحديد خيارات إعداد مبدئيّة آمنة في Apache سننشئ أولا ملفّ إعداد جديدًا في Apache نعرّف فيه بعض إعدادات SSL. سنضبُط Apache للعمل بخوارزميّات تعميّة فعّالة ونفعّل بعض الميزات المتقدّمة لمساعدتنا في إبقاء خادومنا آمنا. سيُمكن لأيّ مضيف افتراضي يفعّل SSL. أنشئ ملفّ إعداد جديد ضمن المجلَّد etc/apache2/conf-available/ (مجلَّد إعدادات Apache). سنسمّي هذا الملف بـssl-params.conf حتى يكون واضحًا أنه يتعلّق بمعطيات Parameters إعداد SSL. sudo nano /etc/apache2/conf-available/ssl-params.conf سنعتمد لضبط إعدادات Apache بطريقة آمنة على توصيّات Remy van Elst من موقع Cipherli.st. جُهِّز هذا الموقع لتوفير إعدادات تعميّة جاهزة للاستعمال في أكثر البرمجيّات شيوعًا على الخواديم. ملحوظة توفّر الإعدادات المُقترَحة مبدئيًّا في الموقع أعلاه درجة أمان عاليّة. يمكن أن تأتي هذه الدرجة من الأمان على حساب التوافق مع البرامج العميلة (المتصفّحات أو أنظمة التشغيل القديمة). إن أردت دعم إصدارات قديمة من هذه البرامج فإن الموقع يوفّر إعدادات بديلة للإعدادات المبدئيّة، يمكنك الحصول عليها بالنقر على الرابط “Yes, give me a ciphersuite that works with legacy / old software” وستلاحظ أن الإعدادات تبدّلت. يعتمد الخيار بين النسخة المبدئية من الإعدادات والنسخة البديلة على نوعيّة العملاء التي تريد دعمها. توفّر النسختان أمانًا جيّدًا. سننسخ - لأغراض هذا الدرس - الإعدادات المقترحة، مع إجراء تعديليْن عليها. سنعدّل التعليمة SSLOpenSSLConfCmd DHParameters لتشير إلى ملف Diffie-Hellman الذي أنشأناه في الخطوة الأولى. سنعدّل أيضًا تعليمات الترويسة لتغيير عمل الخاصيّة Strict-Transport-Security وذلك بحذف التعليمة preload. توفّر هذه الخاصيّة أمانًا عاليَّا جدًّا إلا أنها يمكن إن فُعِّلت بدون وعي أو بطريقة غير صحيحة - خصوصًا عند استخدام الميزة preload - أن تؤدّي إلى اختلالات كبيرة في عمل الخادوم. تأكّد عندما تفعِّل هذه الميزة أنك تدرك جيّدًا ما تفعله. # from https://cipherli.st/ # and https://raymii.org/s/tutorials/Strong_SSL_Security_On_Apache2.html SSLCipherSuite EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH SSLProtocol All -SSLv2 -SSLv3 SSLHonorCipherOrder On # تعطيل التعليمة preload في الخاصيّة Strict-Transport-Security # يمكنك إن أردت تفعيل هذه الخاصية وذلك بنزع علامة التعليق # من بداية السطر #Header always set Strict-Transport-Security "max-age=63072000; includeSubdomains; preload" # نفس التعليمة السابقة ولكن دون preload Header always set Strict-Transport-Security "max-age=63072000; includeSubdomains" Header always set X-Frame-Options DENY Header always set X-Content-Type-Options nosniff # Requires Apache >= 2.4 SSLCompression off SSLSessionTickets Off SSLUseStapling on SSLStaplingCache "shmcb:logs/stapling-cache(150000)" # أضفنا هنا المسار إلى ملفّ Diffie-Hellman SSLOpenSSLConfCmd DHParameters "/etc/ssl/certs/dhparam.pem" احفظ الملفّ ثم أغلقه عندما تكون جاهزا لذلك. تعديل ملف مضيف SSL الافتراضي المبدئي ننتقل الآن إلى الملف المبدئي Default لمضيف SSL الافتراضي الموجود على المسار etc/apache2/sites-available/default-ssl.conf/. إن كنت تستخدم مضيفا اقتراضيًّا آخر فأبدله بالمضيف الافتراضي المبدئي في الأمر أدناه. نأخذ أولًا نسخة احتياطية من الملف: sudo cp /etc/apache2/sites-available/default-ssl.conf /etc/apache2/sites-available/default-ssl.conf.bak ثم نفتح ملف المضيف الافتراضي لتحريره: sudo nano /etc/apache2/sites-available/default-ssl.conf يبدو محتوى الملف، بعد نزع أغلب التعليقات، على النحو التالي: <IfModule mod_ssl.c> <VirtualHost _default_:443> ServerAdmin webmaster@localhost DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined SSLEngine on SSLCertificateFile /etc/ssl/certs/ssl-cert-snakeoil.pem SSLCertificateKeyFile /etc/ssl/private/ssl-cert-snakeoil.key <FilesMatch "\.(cgi|shtml|phtml|php)$"> SSLOptions +StdEnvVars </FilesMatch> <Directory /usr/lib/cgi-bin> SSLOptions +StdEnvVars </Directory> # BrowserMatch "MSIE [2-6]" \ # nokeepalive ssl-unclean-shutdown \ # downgrade-1.0 force-response-1.0 </VirtualHost> </IfModule> سنعدّل قليلا على الملف بإعداد تعليمات بريد مدير الخادوم، عنوان، اسم الخادوم… إلخ. كما سنعدّل تعليمة SSL لتشير إلى مسار ملفّيْ الشهادة والمفاتيح. نختُم بنزع التعليق عن خيار يوفّر الدعم للمتصفّحات القديمة لتفعيله. يبدو الملف بعد التعديلات كالتالي: <IfModule mod_ssl.c> <VirtualHost _default_:443> # بريد مدير الخادوم ServerAdmin your_email@example.com # نطاق الخادوم أو عنوان IP الخاص به ServerName server_domain_or_IP DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined SSLEngine on SSLCertificateFile /etc/ssl/certs/apache-selfsigned.crt SSLCertificateKeyFile /etc/ssl/private/apache-selfsigned.key <FilesMatch "\.(cgi|shtml|phtml|php)$"> SSLOptions +StdEnvVars </FilesMatch> <Directory /usr/lib/cgi-bin> SSLOptions +StdEnvVars </Directory> # دعم المتصفحات القديمة BrowserMatch "MSIE [2-6]" \ nokeepalive ssl-unclean-shutdown \ downgrade-1.0 force-response-1.0 </VirtualHost> </IfModule> احفظ الملف ثم أغلقه. إعادة توجيه طلبات HTTP (غير المُعمَّاة) إلى HTTPS يجيب الخادوم بإعداداته الحاليّة على الطلبات الآمنة (HTTPS) وغير الآمنة (HTTP) على حدّ السواء. يُنصَح في أغلب الحالات من أجل أمان أعلى أن تُوجَّه طلبات HTTP تلقائيَّا إلى HTTPS. نفتح ملف المضيف الافتراضي - أو المضيف الذي تريده - لتحريره: sudo nano /etc/apache2/sites-available/000-default.conf كلّ ما نحتاجه هو إضافة تعليمة إعادة إعادة التوجيه Redirect داخل إعداد الوسم VirtualHost والإشارة إلى النسخة الآمنة من الموقع (https): <VirtualHost *:80> . . . Redirect "/" "https://your_domain_or_IP/" . . . </VirtualHost> احفظ الملف ثم أغلقه. الخطوة الثالثة: تعديل الجدار الناري إن كان جدار ufw الناري مفعّلًا، وهو ما توصي به الدروس المُشار إليها في المتطلّبات، فقد تحتاج لتعديل إعداداتِه من أجل السماح للبيانات المُؤَمَّنة (عبر SSL). يُسجّل Apache أثناء تثبيته مجموعات من المعلومات المختصرة Profiles لدى جدار ufw الناري. يمكننا عرض المجموعات المتوفّرة بالأمر التالي: sudo ufw app list تظهر مُخرجات الأمر : Available applications: Apache Apache Full Apache Secure OpenSSH يمكنك عرض الإعداد الحالي بالأمر sudo ufw status إن كان إعدادك الحالي يسمح لطلبات HTTP فقط فستبدو إعداداتك كالتالي” Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere Apache ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6) Apache (v6) ALLOW Anywhere (v6) يمكننا تفعيل المجموعة Apache Full للسماح لطلبات HTTPS وHTTP معًا، ثم حذف المجموعة Apache لأننا لم نعد بحاجة إليها، فهي متَضَمَّنة في المجموعة Apache Full : sudo ufw allow 'Apache Full' sudo ufw delete allow 'Apache' ملحوظة: يمكنك استخدام الأمر sudo ufw app info PROFILE حيث PROFILE اسم مجموعة المعلومات لمعرفة المنافذ Ports والبروتوكولات التي تسمح المجموعة للطلبات بالمرور عبرها. يجب أن تبدو حالة الجدار الناري الآن على النحو التالي: sudo ufw status المخرجات: Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere Apache Full ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6) Apache Full (v6) ALLOW Anywhere (v6) الخطوة الرابعة: اعتماد التغييرات في Apache نحن جاهزون الآن، بعد أن عدّلنا الإعدادات، لتفعيل وحدات Modules الترويسات Headers وSSL في Apache، وتفعيل المضيف الافتراضي الجاهز لاستخدام SSL ثم إعادة تشغيل Apache. يفعّل الأمران التاليّان على التوالي mod_ssl (وحدة SSL في Apache) وmod_headers (وحدة الترويسات) اللتين تحتاجهما إعداداتنا للعمل: sudo a2enmod ssl sudo a2enmod headers ثم نفعّل المضيف الافتراضي (ضع اسم المضيف مكان default-ssl إن كنت تستخدم مضيفًا غير المضيف المبدئي): sudo a2ensite default-ssl نحتاج أيضًا لتفعيل ملفّ الإعداد ssl-params الذي أنشأناه سابقا: sudo a2enconf ssl-params يجدر بالوحدات المطلوبة أن تكون الآن مفعَّلة وجاهزة للعمل، بقي لنا فقط اعتماد التغييرات. لكن قبل ذلك سنتأكّد من أنه لا توجد أخطاء صياغة في الملفات التي أعددناها وذلك بتنفيذ الأمر التالي: sudo apache2ctl configtest إن جرى كلّ شيء على ما يُرام فستظهر رسالة تشبه ما يلي: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1. Set the 'ServerName' directive globally to suppress this message Syntax OK السطر الأول ليس سوى رسالة تفيد بأنّ التعليمة ServerName غير مضبوطة لتعمل على كامل الخادوم (مثلا مضبوطة في المضيفات الافتراضية فقط). يمكنك التخلّص من هذه الرسالة - إن أردت - بضبط قيمة التعليمة ServerName على نطاق الخادوم أو عنوان IP الخاصّ به في ملف الإعدادات العام etc/apache2/apache2.conf/. هذا الإعداد اختياري، فالرسالة لا تتسبّب في أي خلل. تظهر في السطر الثاني نتيجة التحقّق من الصياغة Syntax OK وتفيد بأنه لا توجد مشكلة من هذه الناحيّة. يمكننا إذن إعادة تشغيل خادوم الوِب لاعتماد التعديلات: sudo systemctl restart apache2 الخطوة الخامسة: اختبار التعمية افتح متصفّح الوِب وأدخل العنوان //:https متبوعًا باسم نطاق الخادوم أو عنوان IP الخاصّ به: https://server_domain_or_IP بما أنّ الشهادة الأمنيّة التي أنشأناه لا تصدُر من سلطة شهادات يثق بها المتصفّح فستظهر صفحة مخيفة عند زيارة الموقع تحمل الرسالة التالية. هذا السلوك متوقَّع وطبيعي. نهتمّ في هذا الدرس بجانب التعميّة من الشهادات الأمنيّة دون جانب التحقّق من هويّة المضيف (الموقع) الذي توفّره سلطات الشهادات (وهو جانب مهمّ أيضًا لأمان التصفّح). انقر على زرّ ADVANCED ثم انقر على الرابط الذي ينقلك إلى موقعك (يوجد عادة أسفل الصفحة). ستُنقَل إلى صفحة الموقع. إن نظرت إلى شريط العناوين في المتصفّح فسترى صورة قفل عليه علامة x أمام عنوان الموقع. يعني هذا الرّمز أن المتصفّح لم يستطع التحقّق من هوية الشهادة، إلا أنه يعمّي الاتصال بينك والخادوم. إن أعددتَ إعادة توجيه طلبات HTTP إلى HTTPS فيمكنك التحقق من نجاح الأمر بالذهاب إلى العنوان http://server_domain_or_IP (بدون حرف s في http). إن ظهرت نفس الأيقونة السابقة في شريط العناوين فهذا يعني نجاح الإعداد. الخطوة السادسة: جعل إعادة التوجيه دائما إن كنت متأكّدًا من رغبتك في السماح للطلبات الآمنة فقط (القادمة عبر HTTPS)، وتحقّقت في الخطوة السابقة من عمل توجيه طلبات HTTP إلى HTTPS فيجب عليك جعل إعادة التوجيه دائمة. افتح ملف إعداد المضيف الافتراضي الذي نريد: sudo nano /etc/apache2/sites-available/000-default.conf نبحث عن سطر إعادة التوجيه الذي أضفناه في خطوة سابقة ثم نضيف إليه الكلمة المفتاحية permanent على النحو التالي: <VirtualHost *:80> . . . Redirect permanent "/" "https://your_domain_or_IP/" . . . </VirtualHost> احفظ الملف ثم أغلقه. ملحوظة: إعادة التوجيه التي أعددناها في الخطوة الثانية باستخدام التعليمة Redirect فقط هي من النوع 302. تصبح إعادة التوجيه هذه من النوع 301 (الفرق بين إعادة التوجيه 301و302) عند إضافة الكلمة المفتاحية permanent (دائم) إلى التعليمة. نتحقّق من خلو الإعدادات من أخطاء في الصياغة: sudo apache2ctl configtest ثم عندما يكون كلّ شيء على ما يرام نعيد تشغيل خادوم الوِب: sudo systemctl restart apache2 ترجمة - بتصرّف للمقال How To Create a Self-Signed SSL Certificate for Apache in Ubuntu 16.04 لصاحبه Justin Ellingwood.
مقدمة يُستخدم ميثاق (بروتوكول) الوِب TLS (اختصار لـ Transport Layer Security، أمان طبقة النقل) وسلفه SSL (اختصار لـ Secure Sockets Layer، طبقة المقابس الآمنة) لتغليف البيانات العاديّة ضمن إطار محميّ وآمن. يمكن للخواديم باستخدام هذه التقنية أن تؤمّن تبادل البيانات بينها وبين العملاء حتى ولو اعتُرِضت طريقُ الرسائل بين الخادوم والعميل. يساعد نظام الشهادات الأمنية Certificates المستخدِمين والزوار في التحقّق من أمان المواقع التي يتّصلون بها. سنقدّم في هذا الدليل الخطوات اللازمة لإعداد شهادة أمنيّة موقَّعة ذاتيًّا Self-signed certificate لاستخدامها مع خادوم الوِب Apache على أوبونتو 16.04. ملحوظة: تعمّي الشهادات الموقَّعة ذاتيًّا الاتصالات بين الخادوم والعملاء؛ لكن لن يمكنَ للعملاء استخدامُها للتحقّق من التحقّق من هويّة خادومك تلقائيًّا، إذ أنه لم تُوقّعها سلطة معترف بها. تتضمَّن المتصفّحات مثل فيرفكس وكروم قائمة بالسلطات المعترف بها والمخوَّلة إصدار شهادات TLS. يُناسب استخدام الشهادات الموقَّعة ذاتيًّا بيئات الاختبار، على الحاسوب الشخصي أو عندما لا يكون لديك نطاق Domain؛ مثلا في واجهات الوِب غير المتاحة للعموم. إن كان لديك نطاق فالأفضل أن تستخدم شهادة أمنية من سطلة معترف بها. يمكنك الحصول على شهادة مجانيّة من Let’s encrypt وإعدادها. المتطلبات ستحتاج قبل البدء بتنفيذ الخطوات الواردة في هذا الدرس إلى إعداد مستخدم إداري بامتيازات sudo غير المستخدم الجذر. راجع درس الإعداد الابتدائي لخادوم أوبونتو لمعرفة كيفية ذلك. ستحتاج أيضا لتثبيت خادوم الوِب Apache. إن رغبت في تثبيت كامل حزم LAMP (أي لينكس Linux، أباتش Apache، وMySQL وPHP) فالدرس كيف تثبت حزم MySQL ،Apache ،Linux :LAMP و PHP موجود لهذا الغرض؛ أما إن كنت ترغب في تثبيت Apache لوحده فيمكنك الاعتماد على الدرس المُشار إليه مع ترك الخطوات الخاصّة بكلّ من MySQL وPHP. تأكّد من توفّرك على المتطلّبات ثم نفّذ الخطوات المشروحة أدناه. الخطوة اﻷولى: إنشاء شهادة SSL يعمل بروتكول TLS (وسلفه SSL) باستخدام مفتاحيْن للتعميّة واحد عمومي Public وآخر خاصّ (أو سرّي) Private. يُخزَّن المفتاح السّري على الخادوم ولا يجوز أن يطّلع عليه أي عميل فهو خاصّ بالخادوم الذي يستخدمه لتعميّة المحتوى المُرسَل إلى العملاء. يُمكن لأيّ عميل الاطّلاع على شهادة TLS. تحوي هذه الشهادة المفتاح العموميّ الذي يُستخدَم لفكّ التعميّة عن المحتوى القادم من الخادوم. ملحوظة: رغم أن استخدام البروتكول SSL يقلّ يومًا بعد يوم إلا أن المصطلح “شهادة SSL” لا يزال يُستَخدَم كثيرًا، ويُقصَد به - في الغالب - TLS، الذي هو نسخة محسَّنة من SSL. تتيح مكتبة OpenSSL (مكتبة برمجيّة توفّر أدوات للتعامل مع شهادات SSL/TLS) إنشاء مفتاح تعميّة موقَّع ذاتيًّا بالأمر التالي: sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/apache-selfsigned.key -out /etc/ssl/certs/apache-selfsigned.crt ستُطرَح عليك مجموعة من الأسئلة، ولكن قبل النظر في تلك الأسئلة سنشرح الخيارات المذكورة في الأمر السابق: openssl: هذا هو الأمر الأساسي لإنشاء الشهادات، المفاتيح وبقية الملفات وإدارتها في OpenSSL. req: يحدّد هذا الأمر الفرعي المعيار X.509 لاستخدامه في البنية التحتيّة التي نريد استخدامها لإدارة المفاتيح العموميّة. يعتمد الميثاقان SSL وTLS المعيار X.509 لإدارة المفاتيح العمومية. نستخدم هذا الأمر الفرعي لطلب إنشاء شهادة تتوافق مع هذا المعيار. x.509: يغيّر هذا الخيار طريقة عمل الأمر الفرعي السابق ليخبره أننا في طور إنشاء شهادة موّقَّعة ذاتيًّا بدلا من إرسال طلب لتوقيع شهادة الذي هو السلوك المبدئي للأمر الفرعي. nodes: يطلُب هذا الخيار من openssl تجاوز خيار تأمين الشهادة بعبارة سرّ Passphrase. نريد أن يكون Apache قادرا على قراءة الشهادة بدون تدخّل من المستخدم عند بدْء تشغيل الخادوم. يمنع وجود عبارة سرّ Apache من قراءة ملفّ الشهادة وسنحتاج عند وجودها لإدخالها في كلّ مرة نعيد فيها تشغيل الخادوم. days 365: يحدّد هذا الخيار مدّة صلاحيّة الشهادة. اخترنا سنة. newkey rsa:2048: يخبر هذا الخيار الأمر openssl أننا نريد توليد شهادة ومفتاح جديد في نفس الوقت. بما أننا لم نولّد المفتاح المطلوب لتوقيع الشهادة في خطوة منفصلة فإننا نحتاج لإنشائه مع الشهادة. يحدّد الجزء rsa:2048 نوعيّة المفتاح بـ RSA وطوله بـ 2048 بت. keyout: يحدّد المسار الذي نريد حفظ المفتاح الخاصّ فيه. out: يحدّد المسار الذي نريد حفظ الشهادة فيه. ستنشئ هذه الخيارات مفاتيح التعميّة والشهادة. يطلُب الأمر كما أسلفنا الإجابة على بضعة أسئلة كما في الصورة التالية. تتعلّق الأسئلة بمعلومات عامة من قبيل الدولة والمدينة والمؤسّسة والمنظَّمة المُصدِرة للشهادة إضافة إلى معلومات عن الخادوم. يتعلّق أهمّ الأسئلة المطروحة - السطر Common Name - بالخادوم. يجب أن تجيب باسم النطاق الذي يعمل عليه الخادوم أو - وهو الأكثر شيوعا - عنوان IP العمومي للخادوم. يبدو المحثّ Prompt على النحو التالي: Country Name (2 letter code) [AU]:حرفان يمثّلان الدولة State or Province Name (full name) [Some-State]:اسم المنطقة (المحافظة أو الولاية) Locality Name (eg, city) []:اسم المدينة Organization Name (eg, company) [Internet Widgits Pty Ltd]:اسم المنظَّمة أو الشركة Organizational Unit Name (eg, section) []:اسم الفرع Common Name (e.g. server FQDN or YOUR name) []:عنوان الخادوم Email Address []:بريد المسؤول سيوضع الملفان المنشآن في مجلّدات فرعيّة من المجلّد etc/ ssl/ حسب ماهو محدَّد في الأمر. سنحتاج أيضًا - ما دمنا نتحدَّث عن OpenSSL - إلى إنشاء مجموعة Diffie-Hellman قويّة لتُستخدَم عندما يُناقش الخادوم طريقة نقل البيانات مع العملاء (خطوة من خطوات عدّة ضمن تقنيّة SSL/TLS لتأمين نقل البيانات). ينشئ اﻷمر التالي المطلوب: sudo openssl dhparam -out /etc/ssl/certs/dhparam.pem 2048 يمكن أن يستغرق الأمر بضعة دقائق، نحصُل بعدها على مجموعة Diffie-Hellman مناسبة (على المسار etc/ssl/certs/dhparam.pem/) لاستعمالها في إعداداتنا. الخطوة الثانية: إعداد Apache لاستخدام SSL أنشأنا في الخطوة السابقة ملفّيْ الشهادة والمفتاح الخاصّ. نحتاج الآن لضبط Apache للاستفادة من هذيْن الملفّيْن. سنعدّل بضعة إعدادات: سننشئ مقطعا جديدًا في إعدادات Apache لتحديد خيارات إعداد مبدئيّة آمنة لـ SSL. سنعدّل المضيف الافتراضي Virtual host الخاص بـ SSL للإشارة إلى شهادة SSL التي أنشأناها في الخطوة السابقة. سنعدّل المضيف الافتراضي غير المُعمَّى ليعيد توجيه جميع الطلبات إلى المضيف الافتراضي المُعمَّى (الخاص بـ SSL). يُنصَح بهذا الإجراء لجعل جميع الاتصالات القادمة إلى الموقع آمنة (تمرّ عبر شهادة SSL). يجدر بالإعدادات التي سنحصُل عليها بعد تنفيذ النقاط المُشار إليها أعلاه أن تكون آمنة. تحديد خيارات إعداد مبدئيّة آمنة في Apache سننشئ أولا ملفّ إعداد جديدًا في Apache نعرّف فيه بعض إعدادات SSL. سنضبُط Apache للعمل بخوارزميّات تعميّة فعّالة ونفعّل بعض الميزات المتقدّمة لمساعدتنا في إبقاء خادومنا آمنا. سيُمكن لأيّ مضيف افتراضي يفعّل SSL. أنشئ ملفّ إعداد جديد ضمن المجلَّد etc/apache2/conf-available/ (مجلَّد إعدادات Apache). سنسمّي هذا الملف بـssl-params.conf حتى يكون واضحًا أنه يتعلّق بمعطيات Parameters إعداد SSL. sudo nano /etc/apache2/conf-available/ssl-params.conf سنعتمد لضبط إعدادات Apache بطريقة آمنة على توصيّات Remy van Elst من موقع Cipherli.st. جُهِّز هذا الموقع لتوفير إعدادات تعميّة جاهزة للاستعمال في أكثر البرمجيّات شيوعًا على الخواديم. ملحوظة توفّر الإعدادات المُقترَحة مبدئيًّا في الموقع أعلاه درجة أمان عاليّة. يمكن أن تأتي هذه الدرجة من الأمان على حساب التوافق مع البرامج العميلة (المتصفّحات أو أنظمة التشغيل القديمة). إن أردت دعم إصدارات قديمة من هذه البرامج فإن الموقع يوفّر إعدادات بديلة للإعدادات المبدئيّة، يمكنك الحصول عليها بالنقر على الرابط “Yes, give me a ciphersuite that works with legacy / old software” وستلاحظ أن الإعدادات تبدّلت. يعتمد الخيار بين النسخة المبدئية من الإعدادات والنسخة البديلة على نوعيّة العملاء التي تريد دعمها. توفّر النسختان أمانًا جيّدًا. سننسخ - لأغراض هذا الدرس - الإعدادات المقترحة، مع إجراء تعديليْن عليها. سنعدّل التعليمة SSLOpenSSLConfCmd DHParameters لتشير إلى ملف Diffie-Hellman الذي أنشأناه في الخطوة الأولى. سنعدّل أيضًا تعليمات الترويسة لتغيير عمل الخاصيّة Strict-Transport-Security وذلك بحذف التعليمة preload. توفّر هذه الخاصيّة أمانًا عاليَّا جدًّا إلا أنها يمكن إن فُعِّلت بدون وعي أو بطريقة غير صحيحة - خصوصًا عند استخدام الميزة preload - أن تؤدّي إلى اختلالات كبيرة في عمل الخادوم. تأكّد عندما تفعِّل هذه الميزة أنك تدرك جيّدًا ما تفعله. # from https://cipherli.st/ # and https://raymii.org/s/tutorials/Strong_SSL_Security_On_Apache2.html SSLCipherSuite EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH SSLProtocol All -SSLv2 -SSLv3 SSLHonorCipherOrder On # تعطيل التعليمة preload في الخاصيّة Strict-Transport-Security # يمكنك إن أردت تفعيل هذه الخاصية وذلك بنزع علامة التعليق # من بداية السطر #Header always set Strict-Transport-Security "max-age=63072000; includeSubdomains; preload" # نفس التعليمة السابقة ولكن دون preload Header always set Strict-Transport-Security "max-age=63072000; includeSubdomains" Header always set X-Frame-Options DENY Header always set X-Content-Type-Options nosniff # Requires Apache >= 2.4 SSLCompression off SSLSessionTickets Off SSLUseStapling on SSLStaplingCache "shmcb:logs/stapling-cache(150000)" # أضفنا هنا المسار إلى ملفّ Diffie-Hellman SSLOpenSSLConfCmd DHParameters "/etc/ssl/certs/dhparam.pem" احفظ الملفّ ثم أغلقه عندما تكون جاهزا لذلك. تعديل ملف مضيف SSL الافتراضي المبدئي ننتقل الآن إلى الملف المبدئي Default لمضيف SSL الافتراضي الموجود على المسار etc/apache2/sites-available/default-ssl.conf/. إن كنت تستخدم مضيفا اقتراضيًّا آخر فأبدله بالمضيف الافتراضي المبدئي في الأمر أدناه. نأخذ أولًا نسخة احتياطية من الملف: sudo cp /etc/apache2/sites-available/default-ssl.conf /etc/apache2/sites-available/default-ssl.conf.bak ثم نفتح ملف المضيف الافتراضي لتحريره: sudo nano /etc/apache2/sites-available/default-ssl.conf يبدو محتوى الملف، بعد نزع أغلب التعليقات، على النحو التالي: <IfModule mod_ssl.c> <VirtualHost _default_:443> ServerAdmin webmaster@localhost DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined SSLEngine on SSLCertificateFile /etc/ssl/certs/ssl-cert-snakeoil.pem SSLCertificateKeyFile /etc/ssl/private/ssl-cert-snakeoil.key <FilesMatch "\.(cgi|shtml|phtml|php)$"> SSLOptions +StdEnvVars </FilesMatch> <Directory /usr/lib/cgi-bin> SSLOptions +StdEnvVars </Directory> # BrowserMatch "MSIE [2-6]" \ # nokeepalive ssl-unclean-shutdown \ # downgrade-1.0 force-response-1.0 </VirtualHost> </IfModule> سنعدّل قليلا على الملف بإعداد تعليمات بريد مدير الخادوم، عنوان، اسم الخادوم… إلخ. كما سنعدّل تعليمة SSL لتشير إلى مسار ملفّيْ الشهادة والمفاتيح. نختُم بنزع التعليق عن خيار يوفّر الدعم للمتصفّحات القديمة لتفعيله. يبدو الملف بعد التعديلات كالتالي: <IfModule mod_ssl.c> <VirtualHost _default_:443> # بريد مدير الخادوم ServerAdmin your_email@example.com # نطاق الخادوم أو عنوان IP الخاص به ServerName server_domain_or_IP DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined SSLEngine on SSLCertificateFile /etc/ssl/certs/apache-selfsigned.crt SSLCertificateKeyFile /etc/ssl/private/apache-selfsigned.key <FilesMatch "\.(cgi|shtml|phtml|php)$"> SSLOptions +StdEnvVars </FilesMatch> <Directory /usr/lib/cgi-bin> SSLOptions +StdEnvVars </Directory> # دعم المتصفحات القديمة BrowserMatch "MSIE [2-6]" \ nokeepalive ssl-unclean-shutdown \ downgrade-1.0 force-response-1.0 </VirtualHost> </IfModule> احفظ الملف ثم أغلقه. إعادة توجيه طلبات HTTP (غير المُعمَّاة) إلى HTTPS يجيب الخادوم بإعداداته الحاليّة على الطلبات الآمنة (HTTPS) وغير الآمنة (HTTP) على حدّ السواء. يُنصَح في أغلب الحالات من أجل أمان أعلى أن تُوجَّه طلبات HTTP تلقائيَّا إلى HTTPS. نفتح ملف المضيف الافتراضي - أو المضيف الذي تريده - لتحريره: sudo nano /etc/apache2/sites-available/000-default.conf كلّ ما نحتاجه هو إضافة تعليمة إعادة إعادة التوجيه Redirect داخل إعداد الوسم VirtualHost والإشارة إلى النسخة الآمنة من الموقع (https): <VirtualHost *:80> . . . Redirect "/" "https://your_domain_or_IP/" . . . </VirtualHost> احفظ الملف ثم أغلقه. الخطوة الثالثة: تعديل الجدار الناري إن كان جدار ufw الناري مفعّلًا، وهو ما توصي به الدروس المُشار إليها في المتطلّبات، فقد تحتاج لتعديل إعداداتِه من أجل السماح للبيانات المُؤَمَّنة (عبر SSL). يُسجّل Apache أثناء تثبيته مجموعات من المعلومات المختصرة Profiles لدى جدار ufw الناري. يمكننا عرض المجموعات المتوفّرة بالأمر التالي: sudo ufw app list تظهر مُخرجات الأمر : Available applications: Apache Apache Full Apache Secure OpenSSH يمكنك عرض الإعداد الحالي بالأمر sudo ufw status إن كان إعدادك الحالي يسمح لطلبات HTTP فقط فستبدو إعداداتك كالتالي” Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere Apache ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6) Apache (v6) ALLOW Anywhere (v6) يمكننا تفعيل المجموعة Apache Full للسماح لطلبات HTTPS وHTTP معًا، ثم حذف المجموعة Apache لأننا لم نعد بحاجة إليها، فهي متَضَمَّنة في المجموعة Apache Full : sudo ufw allow 'Apache Full' sudo ufw delete allow 'Apache' ملحوظة: يمكنك استخدام الأمر sudo ufw app info PROFILE حيث PROFILE اسم مجموعة المعلومات لمعرفة المنافذ Ports والبروتوكولات التي تسمح المجموعة للطلبات بالمرور عبرها. يجب أن تبدو حالة الجدار الناري الآن على النحو التالي: sudo ufw status المخرجات: Status: active To Action From -- ------ ---- OpenSSH ALLOW Anywhere Apache Full ALLOW Anywhere OpenSSH (v6) ALLOW Anywhere (v6) Apache Full (v6) ALLOW Anywhere (v6) الخطوة الرابعة: اعتماد التغييرات في Apache نحن جاهزون الآن، بعد أن عدّلنا الإعدادات، لتفعيل وحدات Modules الترويسات Headers وSSL في Apache، وتفعيل المضيف الافتراضي الجاهز لاستخدام SSL ثم إعادة تشغيل Apache. يفعّل الأمران التاليّان على التوالي mod_ssl (وحدة SSL في Apache) وmod_headers (وحدة الترويسات) اللتين تحتاجهما إعداداتنا للعمل: sudo a2enmod ssl sudo a2enmod headers ثم نفعّل المضيف الافتراضي (ضع اسم المضيف مكان default-ssl إن كنت تستخدم مضيفًا غير المضيف المبدئي): sudo a2ensite default-ssl نحتاج أيضًا لتفعيل ملفّ الإعداد ssl-params الذي أنشأناه سابقا: sudo a2enconf ssl-params يجدر بالوحدات المطلوبة أن تكون الآن مفعَّلة وجاهزة للعمل، بقي لنا فقط اعتماد التغييرات. لكن قبل ذلك سنتأكّد من أنه لا توجد أخطاء صياغة في الملفات التي أعددناها وذلك بتنفيذ الأمر التالي: sudo apache2ctl configtest إن جرى كلّ شيء على ما يُرام فستظهر رسالة تشبه ما يلي: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1. Set the 'ServerName' directive globally to suppress this message Syntax OK السطر الأول ليس سوى رسالة تفيد بأنّ التعليمة ServerName غير مضبوطة لتعمل على كامل الخادوم (مثلا مضبوطة في المضيفات الافتراضية فقط). يمكنك التخلّص من هذه الرسالة - إن أردت - بضبط قيمة التعليمة ServerName على نطاق الخادوم أو عنوان IP الخاصّ به في ملف الإعدادات العام etc/apache2/apache2.conf/. هذا الإعداد اختياري، فالرسالة لا تتسبّب في أي خلل. تظهر في السطر الثاني نتيجة التحقّق من الصياغة Syntax OK وتفيد بأنه لا توجد مشكلة من هذه الناحيّة. يمكننا إذن إعادة تشغيل خادوم الوِب لاعتماد التعديلات: sudo systemctl restart apache2 الخطوة الخامسة: اختبار التعمية افتح متصفّح الوِب وأدخل العنوان //:https متبوعًا باسم نطاق الخادوم أو عنوان IP الخاصّ به: https://server_domain_or_IP بما أنّ الشهادة الأمنيّة التي أنشأناه لا تصدُر من سلطة شهادات يثق بها المتصفّح فستظهر صفحة مخيفة عند زيارة الموقع تحمل الرسالة التالية. هذا السلوك متوقَّع وطبيعي. نهتمّ في هذا الدرس بجانب التعميّة من الشهادات الأمنيّة دون جانب التحقّق من هويّة المضيف (الموقع) الذي توفّره سلطات الشهادات (وهو جانب مهمّ أيضًا لأمان التصفّح). انقر على زرّ ADVANCED ثم انقر على الرابط الذي ينقلك إلى موقعك (يوجد عادة أسفل الصفحة). ستُنقَل إلى صفحة الموقع. إن نظرت إلى شريط العناوين في المتصفّح فسترى صورة قفل عليه علامة x أمام عنوان الموقع. يعني هذا الرّمز أن المتصفّح لم يستطع التحقّق من هوية الشهادة، إلا أنه يعمّي الاتصال بينك والخادوم. إن أعددتَ إعادة توجيه طلبات HTTP إلى HTTPS فيمكنك التحقق من نجاح الأمر بالذهاب إلى العنوان http://server_domain_or_IP (بدون حرف s في http). إن ظهرت نفس الأيقونة السابقة في شريط العناوين فهذا يعني نجاح الإعداد. الخطوة السادسة: جعل إعادة التوجيه دائما إن كنت متأكّدًا من رغبتك في السماح للطلبات الآمنة فقط (القادمة عبر HTTPS)، وتحقّقت في الخطوة السابقة من عمل توجيه طلبات HTTP إلى HTTPS فيجب عليك جعل إعادة التوجيه دائمة. افتح ملف إعداد المضيف الافتراضي الذي نريد: sudo nano /etc/apache2/sites-available/000-default.conf نبحث عن سطر إعادة التوجيه الذي أضفناه في خطوة سابقة ثم نضيف إليه الكلمة المفتاحية permanent على النحو التالي: <VirtualHost *:80> . . . Redirect permanent "/" "https://your_domain_or_IP/" . . . </VirtualHost> احفظ الملف ثم أغلقه. ملحوظة: إعادة التوجيه التي أعددناها في الخطوة الثانية باستخدام التعليمة Redirect فقط هي من النوع 302. تصبح إعادة التوجيه هذه من النوع 301 (الفرق بين إعادة التوجيه 301و302) عند إضافة الكلمة المفتاحية permanent (دائم) إلى التعليمة. نتحقّق من خلو الإعدادات من أخطاء في الصياغة: sudo apache2ctl configtest ثم عندما يكون كلّ شيء على ما يرام نعيد تشغيل خادوم الوِب: sudo systemctl restart apache2 ترجمة - بتصرّف للمقال How To Create a Self-Signed SSL Certificate for Apache in Ubuntu 16.04 لصاحبه Justin Ellingwood. -
 إن كنت مدير قواعد بيانات DBA فإنه من المحتمل جدًّا أن يكون سطرُ الأوامر هو وسيلتك للتخاطب مع قواعد البيانات التي تديرها. يستزف استخدام سطر الأوامر الوقت عندما تحتاج للاتّصال بقواعد بيانات عدّة تعمل على مضيفات متباعدة؛ استخدامُ واجهة رسوميّة مفيد في هذه الحالة. يمكنك بالطبع تثبيت phpMyAdmin على كلّ خادوم، إلا أنك ستحتاج إلى تسجيل الدخول إلى واجهة وِب مختلفة بالنسبة لكلّ خادوم. ماذا لو كانت لديك واجهة وحيدة للاتّصال بجميع قواعد بيانات MySQL التي تديرها؟ إن كان هذا ما تبحث عنه فأنت في المكان الصّحيح. MySQL Workbench هو واجهة رسومية موَّحدة للتعامل مع قواعد بيانات MySQL، توفّر لمعماريّي البرمجيّات Architects، المطوّرين ومديري الأنظمة آليّة فعّالة للتعامل مع قواعد بيانات متعدّدة على مضيفات متباعدة. يمكن بهذه الأداة الحصول بنظرة على معلومات عن حالة خادوم قاعدة البيانات، اتصالات العملاء ومتغيّرات الخادوم. كما تمكّنك من إدارة المستخدمين وصلاحيّاتهم، تصدير البيانات واستيرادها، تنفيذ الاستعلامات Queries، إنشاء مخطّطات Schemas جديدة وغيرها من المهامّ. يتيح MySQL Workbench أيضًا إمكانيّة تهجير Migrate البيانات من أنظمة إدارة قواعد بيانات أخرى، مثل Microsoft SQL Server وPostreSQL إلى MySQL بسهولة ويُسر. سنبيّن في هذا الدرس كيفية تثبيت الأداة على حاسوبك الشخصي وخطوات ينبغي تطبيقها جهةَ خواديم قواعد البيانات للسماح للأداة بالاتصال بهذه الخواديم. سنأخذ مثالا لتثبيت MySQL Workbench على حاسوب شخصي يعمل بالإصدار 17.04 من أوبونتو وجعله يتّصل بقاعدة بيانات على خادوم يعمل بأوبونتو 16.04. تنطبق نفس الخطوات على بقيّة توزيعات لينكس مع اختلافات تمليها طبيعة مدير الحزم الخاص بالتوزيعة. تثبيت MySQL Workbench يمكن الحصول على الأداة MySQL Workbench من صفحة التنزيل على موقع الأداة. اختر صيغة الحزمة والمعماريّة المناسبتَيْن (حزمة deb. ومعماريّة 64 بت بالنسبة لنا) ثم اطلُب تنزيل الملف (قد تحتاج لتسجيل الدخول إلى حساب أوراكل أو إنشاء حساب جديد إن لم يكن لديك واحد، الحساب والأداة مجانيّان). انتقل بعد اكتمال التنزيل إلى المُجلَّد حيثُ نزّلت الأداة (المجلّد Downloads بالنسبة لنا): cd ~/Downloads ثم استخدم الأمر dpkg لتثبيت حزمة الأداة: sudo dpkg -i mysql-workbench-community-*.deb قد تظهر رسائل خطأ تفيد بغياب حزم تعتمد عليها الأداة MySQL Workbench (رسائل الخطأ dependency problems). يمكن حلّ هذه المشاكل بتنفيذ الأمر التالي لتثبيت الحزم المفقودة: sudo apt-get install -f يحلّ الأمر السابق بتثبيت الحزم التي تطلبها الأداة MySQL Workbench. نحن الآن جاهزون لتشغيل الأداة MySQL Workbench على الحاسوب الشخصي (العميل)، ولكن قبل ذلك سنضبُط خادوم قاعدة البيانات للسماح للاتصالات البعيدة (أي التي تأتي من عملاء لا يتواجدون مع خادوم قاعدة البيانات على نفس الجهاز). إعداد خادوم MySQL للاتصالات البعيدة إن لم تضبُط خادوم MySQL لقبول اتصالات بعيدة فإن MySQL Workbench لن يمكنه الاتصال بقواعد البيانات الموجودة على هذا الخاودم. يجب أولا ضبط MySQL لقبول اتصالات قادمة من عناوين غير العنوان المحلّي 127.0.0.1. سجّل الدخول إلى الخادوم - مثلا عبر SSH - ثم افتح الملف التالي لتحريره: sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf ابحث عن السطر التالي: bind-address 127.0.0.1 وعدّله ليصبح: bind-address 0.0.0.0 احفظ الملف ثم أغلقه. أعد تشغيل خادوم MySQL بالأمر التالي: sudo systemctl restart mysql.service خادوم قاعدة البيانات جاهز الآن لتلقّي الاتصالات. الخطوة الموالية هي تحديد المستخدمين المسموح لهم بالاتصال بخادوم قاعدة البيانات ومن أي عنوان يمكنهم ذلك. يُضبَط هذا الإعداد من محثّ الأوامر command prompt في MySQL. ننفّذ الأمر التالي للانتقال إلى محثّ أوامر MySQL: mysql -u root -p ملحوظة: أبدل root باسم الحساب الإداري لديك خادوم في قاعدة البيانات. أدخل كلمة السّر عندما تُطلَب منك، ستجد بعدها أنك أمام سطر أوامر خاص بـMySQL. سنحتاج لتنفيذ أمر يعطي حساب المدير القدرة على الاتصال بخادوم قاعدة البيانات عن بعد (عبر MySQL Workbench). سنفترض أن عنوان الجهاز الذي ثبّتنا عليه MySQL Workbench هو 192.168.1.139 وأننا نريد السماح للمسخدم root بالاتصال بجميع قواعد البيانات الموجودة على الخادوم انطلاقا من العنوان السابق. ننفّذ الأمر التالي للحصول على النتيجة المذكورة: GRANT ALL ON *.* TO 'root'@'192.168.1.139' IDENTIFIED BY 'PASSWORD' WITH GRANT OPTION; حيث PASSWORD كلمة سرّ المستخدم root (أو أي مستخدم آخر تريد إعطاءه ميزة الاتصال عن بعد بالقاعدة). تأكّد من أن الأمر نُفِّذ دون أخطاء. نفّذ الأمر: exit; للخروج من سطر أوامر MySQL. يمكنك الآن الاتصال بخادوم MySQL انطلاقا من MySQL Workbench. الاتصال بقاعدة البيانات من MySQL Workbench شغّل التطبيق MySQL Workbench ثم توجّه إلى القائمة Databaseواختر Connect to database. تظهر النافذة التالية. نحدّد في هذه النافذة تفاصيل الاتصال: عنوان الخادوم، المنفذ (مبدئيّا 3306) واسم المستخدم ثم اضغط على الزرّ OK. سيُطلب منك إدخال كلمة سر المستخدم. تظهر بعد إدخال كلمة السر الصحيحة النافذة التاليّة التي يمكن من خلالها تنفيذ إجراءات مختلفة على قاعدة البيانات. تُستخدَم الطريقة السابقة لإنشاء اتصال واحد. إن كنت تعرف أنك ستتصّل بهذا الخادوم مرارا فالأفضل أن تختار Manage Connections من القائمة Database. تظهر النافذة التالية. انقر على الزّر New، حدّد التفاصيل المطلوبة للاتصال بقاعدة البيانات. تأكّد من إعطاء اسم للاتصال (خانة Connection name) ثم انقر على زرّ Test Connection لاختبار الاتصال. أدخل كلمة السر عندما تُطلَب منك ثم انقر على الزرّ OK. انقر على الزرّ OK مرة أخرى بعد نجاح اختبار الاتصال ثم Close لإغلاق نافذة الاختبار. سيُحفَظ الاتصال بعد إغلاق نافذة الاختبار. يمكنك بعدها الذهاب إلى القائمة Database واختيار Connect to Database ثم تحديد الخادوم الذي تريد الاتصال به من القائمة المنسدلة Stored Connection يمكنك بالوصول إلى هذه النقطة البدء في إنشاء قواعد البيانات وإدارتها بمساعدة أداة رسوميّة فعّالة وصديقة للمستخدم. ليس MySQL Workbench سوى أداة من بين أدوات رسومية كثيرة تساعد في جعل إدارتك لقواعد بيانات MySQL أكثر فاعليّة، جرّبها وستجد أنها ستصبح وسيلتك اليومية لإدارة قواعد بيانات MySQL. ترجمة - بتصرّف - للمقال How to Install and Use MySQL Workbench As Your Database GUI لصاحبه Jack Wallen.
إن كنت مدير قواعد بيانات DBA فإنه من المحتمل جدًّا أن يكون سطرُ الأوامر هو وسيلتك للتخاطب مع قواعد البيانات التي تديرها. يستزف استخدام سطر الأوامر الوقت عندما تحتاج للاتّصال بقواعد بيانات عدّة تعمل على مضيفات متباعدة؛ استخدامُ واجهة رسوميّة مفيد في هذه الحالة. يمكنك بالطبع تثبيت phpMyAdmin على كلّ خادوم، إلا أنك ستحتاج إلى تسجيل الدخول إلى واجهة وِب مختلفة بالنسبة لكلّ خادوم. ماذا لو كانت لديك واجهة وحيدة للاتّصال بجميع قواعد بيانات MySQL التي تديرها؟ إن كان هذا ما تبحث عنه فأنت في المكان الصّحيح. MySQL Workbench هو واجهة رسومية موَّحدة للتعامل مع قواعد بيانات MySQL، توفّر لمعماريّي البرمجيّات Architects، المطوّرين ومديري الأنظمة آليّة فعّالة للتعامل مع قواعد بيانات متعدّدة على مضيفات متباعدة. يمكن بهذه الأداة الحصول بنظرة على معلومات عن حالة خادوم قاعدة البيانات، اتصالات العملاء ومتغيّرات الخادوم. كما تمكّنك من إدارة المستخدمين وصلاحيّاتهم، تصدير البيانات واستيرادها، تنفيذ الاستعلامات Queries، إنشاء مخطّطات Schemas جديدة وغيرها من المهامّ. يتيح MySQL Workbench أيضًا إمكانيّة تهجير Migrate البيانات من أنظمة إدارة قواعد بيانات أخرى، مثل Microsoft SQL Server وPostreSQL إلى MySQL بسهولة ويُسر. سنبيّن في هذا الدرس كيفية تثبيت الأداة على حاسوبك الشخصي وخطوات ينبغي تطبيقها جهةَ خواديم قواعد البيانات للسماح للأداة بالاتصال بهذه الخواديم. سنأخذ مثالا لتثبيت MySQL Workbench على حاسوب شخصي يعمل بالإصدار 17.04 من أوبونتو وجعله يتّصل بقاعدة بيانات على خادوم يعمل بأوبونتو 16.04. تنطبق نفس الخطوات على بقيّة توزيعات لينكس مع اختلافات تمليها طبيعة مدير الحزم الخاص بالتوزيعة. تثبيت MySQL Workbench يمكن الحصول على الأداة MySQL Workbench من صفحة التنزيل على موقع الأداة. اختر صيغة الحزمة والمعماريّة المناسبتَيْن (حزمة deb. ومعماريّة 64 بت بالنسبة لنا) ثم اطلُب تنزيل الملف (قد تحتاج لتسجيل الدخول إلى حساب أوراكل أو إنشاء حساب جديد إن لم يكن لديك واحد، الحساب والأداة مجانيّان). انتقل بعد اكتمال التنزيل إلى المُجلَّد حيثُ نزّلت الأداة (المجلّد Downloads بالنسبة لنا): cd ~/Downloads ثم استخدم الأمر dpkg لتثبيت حزمة الأداة: sudo dpkg -i mysql-workbench-community-*.deb قد تظهر رسائل خطأ تفيد بغياب حزم تعتمد عليها الأداة MySQL Workbench (رسائل الخطأ dependency problems). يمكن حلّ هذه المشاكل بتنفيذ الأمر التالي لتثبيت الحزم المفقودة: sudo apt-get install -f يحلّ الأمر السابق بتثبيت الحزم التي تطلبها الأداة MySQL Workbench. نحن الآن جاهزون لتشغيل الأداة MySQL Workbench على الحاسوب الشخصي (العميل)، ولكن قبل ذلك سنضبُط خادوم قاعدة البيانات للسماح للاتصالات البعيدة (أي التي تأتي من عملاء لا يتواجدون مع خادوم قاعدة البيانات على نفس الجهاز). إعداد خادوم MySQL للاتصالات البعيدة إن لم تضبُط خادوم MySQL لقبول اتصالات بعيدة فإن MySQL Workbench لن يمكنه الاتصال بقواعد البيانات الموجودة على هذا الخاودم. يجب أولا ضبط MySQL لقبول اتصالات قادمة من عناوين غير العنوان المحلّي 127.0.0.1. سجّل الدخول إلى الخادوم - مثلا عبر SSH - ثم افتح الملف التالي لتحريره: sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf ابحث عن السطر التالي: bind-address 127.0.0.1 وعدّله ليصبح: bind-address 0.0.0.0 احفظ الملف ثم أغلقه. أعد تشغيل خادوم MySQL بالأمر التالي: sudo systemctl restart mysql.service خادوم قاعدة البيانات جاهز الآن لتلقّي الاتصالات. الخطوة الموالية هي تحديد المستخدمين المسموح لهم بالاتصال بخادوم قاعدة البيانات ومن أي عنوان يمكنهم ذلك. يُضبَط هذا الإعداد من محثّ الأوامر command prompt في MySQL. ننفّذ الأمر التالي للانتقال إلى محثّ أوامر MySQL: mysql -u root -p ملحوظة: أبدل root باسم الحساب الإداري لديك خادوم في قاعدة البيانات. أدخل كلمة السّر عندما تُطلَب منك، ستجد بعدها أنك أمام سطر أوامر خاص بـMySQL. سنحتاج لتنفيذ أمر يعطي حساب المدير القدرة على الاتصال بخادوم قاعدة البيانات عن بعد (عبر MySQL Workbench). سنفترض أن عنوان الجهاز الذي ثبّتنا عليه MySQL Workbench هو 192.168.1.139 وأننا نريد السماح للمسخدم root بالاتصال بجميع قواعد البيانات الموجودة على الخادوم انطلاقا من العنوان السابق. ننفّذ الأمر التالي للحصول على النتيجة المذكورة: GRANT ALL ON *.* TO 'root'@'192.168.1.139' IDENTIFIED BY 'PASSWORD' WITH GRANT OPTION; حيث PASSWORD كلمة سرّ المستخدم root (أو أي مستخدم آخر تريد إعطاءه ميزة الاتصال عن بعد بالقاعدة). تأكّد من أن الأمر نُفِّذ دون أخطاء. نفّذ الأمر: exit; للخروج من سطر أوامر MySQL. يمكنك الآن الاتصال بخادوم MySQL انطلاقا من MySQL Workbench. الاتصال بقاعدة البيانات من MySQL Workbench شغّل التطبيق MySQL Workbench ثم توجّه إلى القائمة Databaseواختر Connect to database. تظهر النافذة التالية. نحدّد في هذه النافذة تفاصيل الاتصال: عنوان الخادوم، المنفذ (مبدئيّا 3306) واسم المستخدم ثم اضغط على الزرّ OK. سيُطلب منك إدخال كلمة سر المستخدم. تظهر بعد إدخال كلمة السر الصحيحة النافذة التاليّة التي يمكن من خلالها تنفيذ إجراءات مختلفة على قاعدة البيانات. تُستخدَم الطريقة السابقة لإنشاء اتصال واحد. إن كنت تعرف أنك ستتصّل بهذا الخادوم مرارا فالأفضل أن تختار Manage Connections من القائمة Database. تظهر النافذة التالية. انقر على الزّر New، حدّد التفاصيل المطلوبة للاتصال بقاعدة البيانات. تأكّد من إعطاء اسم للاتصال (خانة Connection name) ثم انقر على زرّ Test Connection لاختبار الاتصال. أدخل كلمة السر عندما تُطلَب منك ثم انقر على الزرّ OK. انقر على الزرّ OK مرة أخرى بعد نجاح اختبار الاتصال ثم Close لإغلاق نافذة الاختبار. سيُحفَظ الاتصال بعد إغلاق نافذة الاختبار. يمكنك بعدها الذهاب إلى القائمة Database واختيار Connect to Database ثم تحديد الخادوم الذي تريد الاتصال به من القائمة المنسدلة Stored Connection يمكنك بالوصول إلى هذه النقطة البدء في إنشاء قواعد البيانات وإدارتها بمساعدة أداة رسوميّة فعّالة وصديقة للمستخدم. ليس MySQL Workbench سوى أداة من بين أدوات رسومية كثيرة تساعد في جعل إدارتك لقواعد بيانات MySQL أكثر فاعليّة، جرّبها وستجد أنها ستصبح وسيلتك اليومية لإدارة قواعد بيانات MySQL. ترجمة - بتصرّف - للمقال How to Install and Use MySQL Workbench As Your Database GUI لصاحبه Jack Wallen. -
 مقدّمة تتوفّر الأداة Dig على توزيعات لينكس للاستعلام من خواديم أسماء النطاقات DNS. تساعد هذه الأداة كثيرا في تشخيص مشاكل النطاقات، كما أنها مناسبة للتأكد من أن إعدادات الشبكة تعمل على النحو المتوقّع. نقدّم في هذا المقال طريقة استخدام الأمر dig للتحقّق من إعدادات أسماء النطاقات والحصول على معلومات عن كيفيّة ظهور نطاقك على شبكة الإنترنت. سنرى خلال هذا الدرس كذلك أدوات مصاحبة تكمّل عمل Dig. نفّذنا الأوامر المعروضة في هذا المقال على الإصدار 16.04 من أوبنتو، إلا أنه من المُفترَض أن تعمل بطريقة مماثلة على أغلب توزيعات لينكس الحديثة. كيف يُستخدم الأمر dig أسهل طريقة لاستخدام الأمر dig هي تمرير اسم النطاق الذي نريد الاستعلام عنه إلى الأمر: dig example.com نختبر - مثلا - محرّك البحث DuckDuckGo لنرى المعلومات التي سنحصُل عليها عنه: dig duckduckgo.com النتيجة: ; <<>> DiG 9.10.3-P4-Ubuntu <<>> duckduckgo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64718 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4000 ;; QUESTION SECTION: ;duckduckgo.com. IN A ;; ANSWER SECTION: duckduckgo.com. 176 IN A 50.18.192.251 duckduckgo.com. 176 IN A 50.18.192.250 ;; Query time: 270 msec ;; SERVER: 127.0.1.1#53(127.0.1.1) ;; WHEN: Thu Apr 20 13:28:31 GMT 2017 ;; MSG SIZE rcvd: 75 توجد الكثير من المعلومات في النتيجة أعلاه، فلنفحصها الواحدة تلو الأخرى. ; <<>> DiG 9.10.3-P4-Ubuntu <<>> duckduckgo.com ;; global options: +cmd تمثّل الأسطر أعلاه ترويسة Header الاستعلام المُرسَل. يمكن تنفيذ الأمر dig على وضع الدُّفعات Batch mode، لذا من الجيّد أن تظهر الترويسات المناسبة لكلّ وضع من أجل تسهيل تحليل النتائج وقراءتها. تأتي بعد ذلك الأسطُر التالية. ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64718 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 يُقدّم هذا المقطع ملخصًّا تقنيًّا لنتائج الاستعلام. يظهر أن الاستعلام نُفِّذ بنجاح (status: NOERROR، أي “الحالة: لا أخطاء”)، أن الأمر استخدم الخيارات qr rd raوأننا حصلنا على إجابتيْن ANSWER: 2، ومقطع معلومات إضافيّ واحد ADDITIONAL: 1. يظهر بعدها المقطع الإضافيّ الذي يحوي سجلّا من نوع OPT يشير إلى أن الخادوم يدعم معيار EDNS المطلوب لتطبيق إجراءات أمنيّة مثل DNSSEC. ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4000 ثم يأتي دور الإجابة الفعليّة التي تُظهر البيانات التي حصلنا عليها من الاستعلام. ;; QUESTION SECTION: ;duckduckgo.com. IN A ;; ANSWER SECTION: duckduckgo.com. 176 IN A 50.18.192.251 duckduckgo.com. 176 IN A 50.18.192.250 يعيد المقطع الموالي ذكر الطلب الذي أرسلناه إليه (QUESTION SECTION) ويطبع بعدها سجلّات DNS الموافقة له. يُرجع الأمر dig مبدئيّا السجلات من النوع A. تُظهر النتيجة أعلاه أن لـduckduckgo.com سجليْن من هذا النوع، يحويان عناوين IP المميّزة لاسم النطاق المطلوب. يشير العدد 176إلى المُعطى TTL أي مدة صلاحيّة المعلومة؛ وهي المدة التي سينتظرها خادوم أسماء النطاقات قبل أن يعيد النظر في الارتباط بين اسم النطاق وعنوان IP. تعني IN أن هذا السّجل من سجلات الإنترنت المعيارية. تظهر ختام تنفيذ الأمر معلومات إحصائيّة عن الاستعلام، ومن بينها المدّة التي استغرقها الخادوم للإجابة. يمكن أن تدلّ هذه المعلومة على وجود مشاكل في خادوم الأسماء (الخادوم يُطيل في الإجابة على الطلب). ;; Query time: 27 msec ;; SERVER: 127.0.1.1#53(127.0.1.1) ;; WHEN: Thu Apr 20 13:28:31 GMT 2017 ;; MSG SIZE rcvd: 75 كيف تستخدم Dig لاختبار سجلات DNS تحوي إجابة dig مبديئا معلومات عن السجلات من النوع A، إلا أنه يمكن تحديد نوع السجل المطلوب بذكره بعد اسم النطاق: dig your_domain_name.com record_type يستفسر الأمر التالي عن السجلّات من نوع MX (البريد الإلكتروني): dig duckduckgo.com MX يُظهر مقطع الإجابة السجلات التاليّة: ;; QUESTION SECTION: ;duckduckgo.com. IN MX ;; ANSWER SECTION: duckduckgo.com. 300 IN MX 60 mx2.dnsmadeeasy.com. duckduckgo.com. 300 IN MX 40 mx1.dnsmadeeasy.com. duckduckgo.com. 300 IN MX 10 in1-smtp.messagingengine.com. duckduckgo.com. 300 IN MX 20 in2-smtp.messagingengine.com. duckduckgo.com. 300 IN MX 50 mx3.dnsmadeeasy.com. نمرّر القيمة ANY مكان اسم السجل إن أردنا الحصول على معلومات عن جميع سجلات النطاق: dig duckduckgo.com ANY تتضمّن نتائج الأمر السابق جميع السجلّات التي توافق النطاق duckduckgo.com مهما كان نوعها. ملحوظة: نظرا لآليّة عمل نظام أسماء النطاقات فإن ظهور سجلّ أضيف حديثا إلى النطاق قد يأخذ وقتا. انتظر انقضاء مدّة TTL عند إضافة سجلّ جديد إلى النطاق، قبل أن تعيد الاستعلام عنه. إذا كان كلّ ما تريد البحث عنه هو عنوان (أو عناوين) IP الذي يُشير إليه النطاق فتمرير short+ مكان نوع السجل يعطيك الإجابة: dig duckduckgo.com +short النتيجة: 50.18.192.250 50.18.192.251 استعمال الأمر host بدلا من dig الأمر host هو بديل للأمر dig يشبهه في خيارات الاستخدام. يُنفَّذ الأمر host على النحو التالي: host domain_name_or_IP_address حيث domain_name_or_IP_address هو اسم نطاق أو عنوان IP. لاحظ أن الأمر host لا يحتاج لخيارات من أجل تغيير وظيفة البحث من استعلام DNS العادي إلى استعلام DNS المعكوس (معرفة اسم النطاق انطلاقا من عنوان IP)؛ إذ يختار الوظيفة المناسبة انطلاقا من المعطى المُمرَّر. يمكن تحديد نوع السجلّات التي تهمّك بتمرير الخيار t- متبوعا باسم السجّل: host -t mx duckduckgo.com النتيجة: duckduckgo.com mail is handled by 20 in2-smtp.messagingengine.com. duckduckgo.com mail is handled by 10 in1-smtp.messagingengine.com. duckduckgo.com mail is handled by 50 mx3.dnsmadeeasy.com. duckduckgo.com mail is handled by 40 mx1.dnsmadeeasy.com. duckduckgo.com mail is handled by 60 mx2.dnsmadeeasy.com. استخدم الخيار a- إن أردت معلومات عن جميع أنواع السجلات (الإجابة قد تكون طويلة): host -a duckduckgo.com يمكن أيضا استخدام الخيار v- للحصول على معلومات إضافية عن المضيف: host -v duckduckgo.com أدوات أخرى للاستعلام عن أسماء النطاقات Ping يُعدّ استخدام الأمر ping إحدى أسهل الطرق لمعرفة ما إذا كان الخادوم يميّز الأسماء بطريقة صحيحة: ping your_domain_name.com تشبه نتيجة الأمر ما يلي: PING your_domain_name.com (192.241.160.34) 56(84) bytes of data. 64 bytes from 192.241.160.34: icmp_req=1 ttl=64 time=0.026 ms 64 bytes from 192.241.160.34: icmp_req=2 ttl=64 time=0.038 ms 64 bytes from 192.241.160.34: icmp_req=3 ttl=64 time=0.037 ms . . . ستستمر مخرجات الأمر بالظهور إلى أن تضغط على زرّيْ CTRL وC معا لإيقافه. يمكنك أيضا تحديد عدد المُخرجات بالخيار c-: ping -c 3 your_domain_name.com PING your_domain_name.com (192.241.160.34) 56(84) bytes of data. 64 bytes from 192.241.160.34: icmp_req=1 ttl=64 time=0.027 ms 64 bytes from 192.241.160.34: icmp_req=2 ttl=64 time=0.059 ms 64 bytes from 192.241.160.34: icmp_req=3 ttl=64 time=0.042 ms --- your_domain_name.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 0.027/0.042/0.059/0.015 ms استخدام الأمر ping وسيلة سريعة للتأكّد من أن نتيجة تمييز اسم النطاق هي عنوان IP الذي عيّنته له. Whois يتيح ميثاق (بروتوكول) Whois معلومات عن أسماء النطاقات المسجَّلة، بما في ذلك عناوين الخواديم المعدّة للعمل عليها. على الرغم من أن أغلب المعلومات التي يُظهرها الأمر whois تتعلّق بالتسجيل Registration إلا أنها يمكن أن تكون مفيدة لمعرفة ما إذا كانت خواديم الأسماء Name servers تظهر على نجو سليم. يُستخدَم الأمر على النحو التالي: whois your_domain_name.com تظهر في نتيجة اﻷمر الكثيرُ من المعلومات التي تختلف طريقة عرضها من خادوم إلى آخر. تظهر خواديم النطاقات التي توجّه إلى عناوين IP الصحيحة عادة في أسفل النتيجة. خاتمة يمكن أن تكون الأدوات Ping، Dig وWhois على الرغم من سهولة التعامل معها مفيدة جدًّا لإجراء اختبارات أساسية على أسماء النطاقات، مما يساعدك في اقتصاد الكثير من الوقت ومعرفة مشاكل الإعدادت بسرعة. ترجمة - بتصرّف - للمقال How To Use Dig, Whois, & Ping on an Ubuntu VPS to Query DNS Data لصاحبه Justin Ellingwood.
مقدّمة تتوفّر الأداة Dig على توزيعات لينكس للاستعلام من خواديم أسماء النطاقات DNS. تساعد هذه الأداة كثيرا في تشخيص مشاكل النطاقات، كما أنها مناسبة للتأكد من أن إعدادات الشبكة تعمل على النحو المتوقّع. نقدّم في هذا المقال طريقة استخدام الأمر dig للتحقّق من إعدادات أسماء النطاقات والحصول على معلومات عن كيفيّة ظهور نطاقك على شبكة الإنترنت. سنرى خلال هذا الدرس كذلك أدوات مصاحبة تكمّل عمل Dig. نفّذنا الأوامر المعروضة في هذا المقال على الإصدار 16.04 من أوبنتو، إلا أنه من المُفترَض أن تعمل بطريقة مماثلة على أغلب توزيعات لينكس الحديثة. كيف يُستخدم الأمر dig أسهل طريقة لاستخدام الأمر dig هي تمرير اسم النطاق الذي نريد الاستعلام عنه إلى الأمر: dig example.com نختبر - مثلا - محرّك البحث DuckDuckGo لنرى المعلومات التي سنحصُل عليها عنه: dig duckduckgo.com النتيجة: ; <<>> DiG 9.10.3-P4-Ubuntu <<>> duckduckgo.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64718 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4000 ;; QUESTION SECTION: ;duckduckgo.com. IN A ;; ANSWER SECTION: duckduckgo.com. 176 IN A 50.18.192.251 duckduckgo.com. 176 IN A 50.18.192.250 ;; Query time: 270 msec ;; SERVER: 127.0.1.1#53(127.0.1.1) ;; WHEN: Thu Apr 20 13:28:31 GMT 2017 ;; MSG SIZE rcvd: 75 توجد الكثير من المعلومات في النتيجة أعلاه، فلنفحصها الواحدة تلو الأخرى. ; <<>> DiG 9.10.3-P4-Ubuntu <<>> duckduckgo.com ;; global options: +cmd تمثّل الأسطر أعلاه ترويسة Header الاستعلام المُرسَل. يمكن تنفيذ الأمر dig على وضع الدُّفعات Batch mode، لذا من الجيّد أن تظهر الترويسات المناسبة لكلّ وضع من أجل تسهيل تحليل النتائج وقراءتها. تأتي بعد ذلك الأسطُر التالية. ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 64718 ;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 يُقدّم هذا المقطع ملخصًّا تقنيًّا لنتائج الاستعلام. يظهر أن الاستعلام نُفِّذ بنجاح (status: NOERROR، أي “الحالة: لا أخطاء”)، أن الأمر استخدم الخيارات qr rd raوأننا حصلنا على إجابتيْن ANSWER: 2، ومقطع معلومات إضافيّ واحد ADDITIONAL: 1. يظهر بعدها المقطع الإضافيّ الذي يحوي سجلّا من نوع OPT يشير إلى أن الخادوم يدعم معيار EDNS المطلوب لتطبيق إجراءات أمنيّة مثل DNSSEC. ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4000 ثم يأتي دور الإجابة الفعليّة التي تُظهر البيانات التي حصلنا عليها من الاستعلام. ;; QUESTION SECTION: ;duckduckgo.com. IN A ;; ANSWER SECTION: duckduckgo.com. 176 IN A 50.18.192.251 duckduckgo.com. 176 IN A 50.18.192.250 يعيد المقطع الموالي ذكر الطلب الذي أرسلناه إليه (QUESTION SECTION) ويطبع بعدها سجلّات DNS الموافقة له. يُرجع الأمر dig مبدئيّا السجلات من النوع A. تُظهر النتيجة أعلاه أن لـduckduckgo.com سجليْن من هذا النوع، يحويان عناوين IP المميّزة لاسم النطاق المطلوب. يشير العدد 176إلى المُعطى TTL أي مدة صلاحيّة المعلومة؛ وهي المدة التي سينتظرها خادوم أسماء النطاقات قبل أن يعيد النظر في الارتباط بين اسم النطاق وعنوان IP. تعني IN أن هذا السّجل من سجلات الإنترنت المعيارية. تظهر ختام تنفيذ الأمر معلومات إحصائيّة عن الاستعلام، ومن بينها المدّة التي استغرقها الخادوم للإجابة. يمكن أن تدلّ هذه المعلومة على وجود مشاكل في خادوم الأسماء (الخادوم يُطيل في الإجابة على الطلب). ;; Query time: 27 msec ;; SERVER: 127.0.1.1#53(127.0.1.1) ;; WHEN: Thu Apr 20 13:28:31 GMT 2017 ;; MSG SIZE rcvd: 75 كيف تستخدم Dig لاختبار سجلات DNS تحوي إجابة dig مبديئا معلومات عن السجلات من النوع A، إلا أنه يمكن تحديد نوع السجل المطلوب بذكره بعد اسم النطاق: dig your_domain_name.com record_type يستفسر الأمر التالي عن السجلّات من نوع MX (البريد الإلكتروني): dig duckduckgo.com MX يُظهر مقطع الإجابة السجلات التاليّة: ;; QUESTION SECTION: ;duckduckgo.com. IN MX ;; ANSWER SECTION: duckduckgo.com. 300 IN MX 60 mx2.dnsmadeeasy.com. duckduckgo.com. 300 IN MX 40 mx1.dnsmadeeasy.com. duckduckgo.com. 300 IN MX 10 in1-smtp.messagingengine.com. duckduckgo.com. 300 IN MX 20 in2-smtp.messagingengine.com. duckduckgo.com. 300 IN MX 50 mx3.dnsmadeeasy.com. نمرّر القيمة ANY مكان اسم السجل إن أردنا الحصول على معلومات عن جميع سجلات النطاق: dig duckduckgo.com ANY تتضمّن نتائج الأمر السابق جميع السجلّات التي توافق النطاق duckduckgo.com مهما كان نوعها. ملحوظة: نظرا لآليّة عمل نظام أسماء النطاقات فإن ظهور سجلّ أضيف حديثا إلى النطاق قد يأخذ وقتا. انتظر انقضاء مدّة TTL عند إضافة سجلّ جديد إلى النطاق، قبل أن تعيد الاستعلام عنه. إذا كان كلّ ما تريد البحث عنه هو عنوان (أو عناوين) IP الذي يُشير إليه النطاق فتمرير short+ مكان نوع السجل يعطيك الإجابة: dig duckduckgo.com +short النتيجة: 50.18.192.250 50.18.192.251 استعمال الأمر host بدلا من dig الأمر host هو بديل للأمر dig يشبهه في خيارات الاستخدام. يُنفَّذ الأمر host على النحو التالي: host domain_name_or_IP_address حيث domain_name_or_IP_address هو اسم نطاق أو عنوان IP. لاحظ أن الأمر host لا يحتاج لخيارات من أجل تغيير وظيفة البحث من استعلام DNS العادي إلى استعلام DNS المعكوس (معرفة اسم النطاق انطلاقا من عنوان IP)؛ إذ يختار الوظيفة المناسبة انطلاقا من المعطى المُمرَّر. يمكن تحديد نوع السجلّات التي تهمّك بتمرير الخيار t- متبوعا باسم السجّل: host -t mx duckduckgo.com النتيجة: duckduckgo.com mail is handled by 20 in2-smtp.messagingengine.com. duckduckgo.com mail is handled by 10 in1-smtp.messagingengine.com. duckduckgo.com mail is handled by 50 mx3.dnsmadeeasy.com. duckduckgo.com mail is handled by 40 mx1.dnsmadeeasy.com. duckduckgo.com mail is handled by 60 mx2.dnsmadeeasy.com. استخدم الخيار a- إن أردت معلومات عن جميع أنواع السجلات (الإجابة قد تكون طويلة): host -a duckduckgo.com يمكن أيضا استخدام الخيار v- للحصول على معلومات إضافية عن المضيف: host -v duckduckgo.com أدوات أخرى للاستعلام عن أسماء النطاقات Ping يُعدّ استخدام الأمر ping إحدى أسهل الطرق لمعرفة ما إذا كان الخادوم يميّز الأسماء بطريقة صحيحة: ping your_domain_name.com تشبه نتيجة الأمر ما يلي: PING your_domain_name.com (192.241.160.34) 56(84) bytes of data. 64 bytes from 192.241.160.34: icmp_req=1 ttl=64 time=0.026 ms 64 bytes from 192.241.160.34: icmp_req=2 ttl=64 time=0.038 ms 64 bytes from 192.241.160.34: icmp_req=3 ttl=64 time=0.037 ms . . . ستستمر مخرجات الأمر بالظهور إلى أن تضغط على زرّيْ CTRL وC معا لإيقافه. يمكنك أيضا تحديد عدد المُخرجات بالخيار c-: ping -c 3 your_domain_name.com PING your_domain_name.com (192.241.160.34) 56(84) bytes of data. 64 bytes from 192.241.160.34: icmp_req=1 ttl=64 time=0.027 ms 64 bytes from 192.241.160.34: icmp_req=2 ttl=64 time=0.059 ms 64 bytes from 192.241.160.34: icmp_req=3 ttl=64 time=0.042 ms --- your_domain_name.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 0.027/0.042/0.059/0.015 ms استخدام الأمر ping وسيلة سريعة للتأكّد من أن نتيجة تمييز اسم النطاق هي عنوان IP الذي عيّنته له. Whois يتيح ميثاق (بروتوكول) Whois معلومات عن أسماء النطاقات المسجَّلة، بما في ذلك عناوين الخواديم المعدّة للعمل عليها. على الرغم من أن أغلب المعلومات التي يُظهرها الأمر whois تتعلّق بالتسجيل Registration إلا أنها يمكن أن تكون مفيدة لمعرفة ما إذا كانت خواديم الأسماء Name servers تظهر على نجو سليم. يُستخدَم الأمر على النحو التالي: whois your_domain_name.com تظهر في نتيجة اﻷمر الكثيرُ من المعلومات التي تختلف طريقة عرضها من خادوم إلى آخر. تظهر خواديم النطاقات التي توجّه إلى عناوين IP الصحيحة عادة في أسفل النتيجة. خاتمة يمكن أن تكون الأدوات Ping، Dig وWhois على الرغم من سهولة التعامل معها مفيدة جدًّا لإجراء اختبارات أساسية على أسماء النطاقات، مما يساعدك في اقتصاد الكثير من الوقت ومعرفة مشاكل الإعدادت بسرعة. ترجمة - بتصرّف - للمقال How To Use Dig, Whois, & Ping on an Ubuntu VPS to Query DNS Data لصاحبه Justin Ellingwood. -
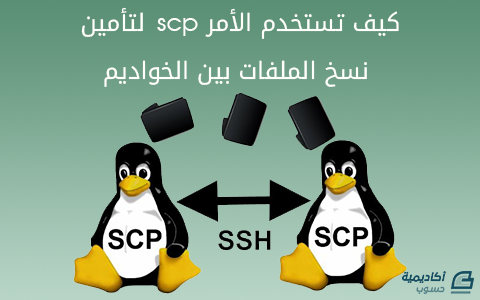 يعدّ نقل الملفات بين الحاسوب الشخصي وخادوم بعيد أو بين خادوميْن إحدى المهامّ الاعتياديّة لأي مدير أنظمة. توجد الكثير من الوسائل لإنجاز مهمة نقل الملفات هذه، إلا أنّ الأمر scp (اختصار لـ Secure copy، النسخ الآمن) يتميّز عن طرق أخرى بتعميّته (تشفيره) للملفات أثناء نقلها. تحمي التعميّةُ الملفاتِ عند النقل من أعين المتطفلين المنتشرين على الشبكة وتساعد في إبقاء محتواها خصوصيا. يعتمد الأمر scp على SSH، لذا تأكّد أنه معدّ جيّدًا. إن كان SSH معدًّا للعمل عن طريق المفاتيح العموميّة والخاصّة فلن تحتاج لإدخال كلمة السّر في كلّ مرة تنفّذ فيها الأمر scp؛ أما إن لم يكن كذلك فستُطلَب منك كلمة السرّ الخاصّة بالحساب المُستخدَم (كما سنرى بعد قليل). لا يحتاج الأمر scp، عكسَ أدوات أخرى مثل rsync، لتسجيل الدخول إلى الخادوم حتى تُنقَل الملفات. نقل ملفّ واحد من الجهاز المحلّي إلى خادوم يحتاج الأمر scp للمسار المصدَر والمسار الوِجهة لنسخ ملفّ من مكان إلى آخر. في ما يلي كيفية استخدام الأمر: scp localmachine/path_to_the_file username@server_ip:/path_to_remote_directory حيث: localmachine/path_to_the_file: المسار المصدَر (على الجهاز المحلّي). username: حساب المستخدم على الخادوم. server_ip: عنوان IP الخاصّ بالخادوم. يمكن استخدام اسم المضيف أيضا. path_to_remote_directory: المسار الوِجهة (على الخادوم). مثال على الاستخدام: scp /home/swapnil/Downloads/fedora.iso swapnil@10.0.0.75:/media/prim_5/media_server/ بالنسبة لمستخدمي Windows 10 فيمكنهم الاستعانة بـ Ubuntu bash لنسخ ملفات من حاسوب وندوز إلى خادوم لينكس: scp /mnt/c/Users/swapnil/Downloads/fedora.iso swapnil@10.0.0.75:/media/prim_5/ media_server/ نسخ مجلّد محلي إلى خادوم إن أردت نسخ مجلّد كامل، بدلا من ملفّ، إلى الخادوم فيمكنك ذلك بإضافة الخيار r- إلى الأمر؛ على النحو التالي: scp -r localmachine/path_to_the_directory username@server_ip:/path_to_remote_directory/ تأكّد من أن المسار المصدر لا يحوي شريطا مائلا / في نهايته. في نفس الوقت فإن مسار المجلَّد الوِجهة يجب - على عكس المصدر - أن يكون آخره شريطا مائلا. نسخ جميع ملفات مجلّد محلي إلى الخادوم ماذا إن أردت نسخ جميع الملفات الموجودة في مجلّد محلّي إلى مجلّد على الخادوم؟ يمكنك ذلك بإضافة شريط مائل / وعلامة * بعده إلى نهاية مسار المجلّد المصدر؛ دون أن ننسى استخدام الخيار r- مع الأمر scp: scp -r localmachine/path_to_the_directory/* username@server_ip:/path_to_remote_directory/ ملحوظة: الفرق بين هذا الأمر والأمر السابق أن الأمر الأخير ينسخ ما يحويه المجلّد من ملفّات، بينما ينسخ الأمر السابق المجلّد ومحتوياته معا. نسخ ملفّات من الخادوم إلى الجهاز المحلّي يشبه نسخ ملفات من الخادوم إلى الجهاز المحلّي عموما الطرق المشروحة سابقا، مع تبديل المعطيات - المصدر والوِجهة - المُمرَّرة إلى الأمر. نسخ ملف واحد scp username@server_ip:/path_to_remote_directory local_machine/path_to_the_file نسخ مجلّد من الخادوم scp -r username@server_ip:/path_to_remote_directory local-machine/path_to_the_directory/ تأكّد من أن المسار المصدر لا يحوي شريطا مائلا / في نهايته. في نفس الوقت فإن مسار المجلَّد الوِجهة يجب - على عكس المصدر - أن يكون آخره شريطا مائلا. نسخ جميع ملفات مجلّد من الخادوم scp -r username@server_ip:/path_to_remote_directory/* local-machine/path_to_the_directory/ النسخ الآمن للملفات من مجلّد على الخادوم إلى مجلّد آخر على الخادوم انطلاقا من الحاسوب المحلي يمكن تسجيل الدخول إلى الخادوم ثم استخدام rsync لإنجاز المهمّة، إلّا أن scp يمكنه فعل ذلك دون الحاجة لتسجيل الدخول إلى الخادوم. نسخ ملفّ واحد scp username@server_ip:/path_to_the_remote_file username@server_ip:/ path_to_destination_directory/ نسخ مجلّد scp username@server_ip:/path_to_the_remote_file username@server_ip:/ path_to_destination_directory/ ملفات من خادوم إلى خادوم آخر انطلاقا من الجهاز المحلّي تشبه هذه الحالة استخدام scp لنسخ ملفّ من مجلّد على الخادوم إلى مجلّد آخر على نفس الخادوم. الفرق هنا هو أننا نحدّد حساب المستخدم على كلا الخادوميْن وعنوانيْهما أثناء تنفيذ الأمر scp . نسخ ملف واحد scp username@server1_ip:/path_to_the_remote_file username@server2_ip:/ path_to_destination_directory/ نسخ مجلّد scp username@server1_ip:/path_to_the_remote_file username@server2_ip:/ path_to_destination_directory/ نسخ جميع ملفات مجلّد scp -r username@server1_ip:/path_to_source_directory/* username@server2_ip:/ path_to_the_destination_directory/ خاتمة تصبح الأمور سهلة كثيرًا فور فهم المبادئ العامة لعمل الأمر scp ، ويمكنك بعدها نسخ الملفات بكل سهولة وأمان. ترجمة - بتصرّف - للمقال How to Securely Transfer Files Between Servers with scp لصاحبه Swapnil Bhartiya.
يعدّ نقل الملفات بين الحاسوب الشخصي وخادوم بعيد أو بين خادوميْن إحدى المهامّ الاعتياديّة لأي مدير أنظمة. توجد الكثير من الوسائل لإنجاز مهمة نقل الملفات هذه، إلا أنّ الأمر scp (اختصار لـ Secure copy، النسخ الآمن) يتميّز عن طرق أخرى بتعميّته (تشفيره) للملفات أثناء نقلها. تحمي التعميّةُ الملفاتِ عند النقل من أعين المتطفلين المنتشرين على الشبكة وتساعد في إبقاء محتواها خصوصيا. يعتمد الأمر scp على SSH، لذا تأكّد أنه معدّ جيّدًا. إن كان SSH معدًّا للعمل عن طريق المفاتيح العموميّة والخاصّة فلن تحتاج لإدخال كلمة السّر في كلّ مرة تنفّذ فيها الأمر scp؛ أما إن لم يكن كذلك فستُطلَب منك كلمة السرّ الخاصّة بالحساب المُستخدَم (كما سنرى بعد قليل). لا يحتاج الأمر scp، عكسَ أدوات أخرى مثل rsync، لتسجيل الدخول إلى الخادوم حتى تُنقَل الملفات. نقل ملفّ واحد من الجهاز المحلّي إلى خادوم يحتاج الأمر scp للمسار المصدَر والمسار الوِجهة لنسخ ملفّ من مكان إلى آخر. في ما يلي كيفية استخدام الأمر: scp localmachine/path_to_the_file username@server_ip:/path_to_remote_directory حيث: localmachine/path_to_the_file: المسار المصدَر (على الجهاز المحلّي). username: حساب المستخدم على الخادوم. server_ip: عنوان IP الخاصّ بالخادوم. يمكن استخدام اسم المضيف أيضا. path_to_remote_directory: المسار الوِجهة (على الخادوم). مثال على الاستخدام: scp /home/swapnil/Downloads/fedora.iso swapnil@10.0.0.75:/media/prim_5/media_server/ بالنسبة لمستخدمي Windows 10 فيمكنهم الاستعانة بـ Ubuntu bash لنسخ ملفات من حاسوب وندوز إلى خادوم لينكس: scp /mnt/c/Users/swapnil/Downloads/fedora.iso swapnil@10.0.0.75:/media/prim_5/ media_server/ نسخ مجلّد محلي إلى خادوم إن أردت نسخ مجلّد كامل، بدلا من ملفّ، إلى الخادوم فيمكنك ذلك بإضافة الخيار r- إلى الأمر؛ على النحو التالي: scp -r localmachine/path_to_the_directory username@server_ip:/path_to_remote_directory/ تأكّد من أن المسار المصدر لا يحوي شريطا مائلا / في نهايته. في نفس الوقت فإن مسار المجلَّد الوِجهة يجب - على عكس المصدر - أن يكون آخره شريطا مائلا. نسخ جميع ملفات مجلّد محلي إلى الخادوم ماذا إن أردت نسخ جميع الملفات الموجودة في مجلّد محلّي إلى مجلّد على الخادوم؟ يمكنك ذلك بإضافة شريط مائل / وعلامة * بعده إلى نهاية مسار المجلّد المصدر؛ دون أن ننسى استخدام الخيار r- مع الأمر scp: scp -r localmachine/path_to_the_directory/* username@server_ip:/path_to_remote_directory/ ملحوظة: الفرق بين هذا الأمر والأمر السابق أن الأمر الأخير ينسخ ما يحويه المجلّد من ملفّات، بينما ينسخ الأمر السابق المجلّد ومحتوياته معا. نسخ ملفّات من الخادوم إلى الجهاز المحلّي يشبه نسخ ملفات من الخادوم إلى الجهاز المحلّي عموما الطرق المشروحة سابقا، مع تبديل المعطيات - المصدر والوِجهة - المُمرَّرة إلى الأمر. نسخ ملف واحد scp username@server_ip:/path_to_remote_directory local_machine/path_to_the_file نسخ مجلّد من الخادوم scp -r username@server_ip:/path_to_remote_directory local-machine/path_to_the_directory/ تأكّد من أن المسار المصدر لا يحوي شريطا مائلا / في نهايته. في نفس الوقت فإن مسار المجلَّد الوِجهة يجب - على عكس المصدر - أن يكون آخره شريطا مائلا. نسخ جميع ملفات مجلّد من الخادوم scp -r username@server_ip:/path_to_remote_directory/* local-machine/path_to_the_directory/ النسخ الآمن للملفات من مجلّد على الخادوم إلى مجلّد آخر على الخادوم انطلاقا من الحاسوب المحلي يمكن تسجيل الدخول إلى الخادوم ثم استخدام rsync لإنجاز المهمّة، إلّا أن scp يمكنه فعل ذلك دون الحاجة لتسجيل الدخول إلى الخادوم. نسخ ملفّ واحد scp username@server_ip:/path_to_the_remote_file username@server_ip:/ path_to_destination_directory/ نسخ مجلّد scp username@server_ip:/path_to_the_remote_file username@server_ip:/ path_to_destination_directory/ ملفات من خادوم إلى خادوم آخر انطلاقا من الجهاز المحلّي تشبه هذه الحالة استخدام scp لنسخ ملفّ من مجلّد على الخادوم إلى مجلّد آخر على نفس الخادوم. الفرق هنا هو أننا نحدّد حساب المستخدم على كلا الخادوميْن وعنوانيْهما أثناء تنفيذ الأمر scp . نسخ ملف واحد scp username@server1_ip:/path_to_the_remote_file username@server2_ip:/ path_to_destination_directory/ نسخ مجلّد scp username@server1_ip:/path_to_the_remote_file username@server2_ip:/ path_to_destination_directory/ نسخ جميع ملفات مجلّد scp -r username@server1_ip:/path_to_source_directory/* username@server2_ip:/ path_to_the_destination_directory/ خاتمة تصبح الأمور سهلة كثيرًا فور فهم المبادئ العامة لعمل الأمر scp ، ويمكنك بعدها نسخ الملفات بكل سهولة وأمان. ترجمة - بتصرّف - للمقال How to Securely Transfer Files Between Servers with scp لصاحبه Swapnil Bhartiya. -
 تشتهر أداة grep بكونها إحدى أدوات البحث الأكثر شهرة في الأنظمة الشبيهة بيونكس Unix-like، سواء تعلّق الأمر بالبحث عن ملفات، سطر أو أسطر عدّة ضمن ملفّ، فهي سريعة وتدعم الكثير من الخيارات مثل: البحث حسب نمط Pattern مكوَّن من سلسلة محارف String والبحث اعتمادًا على تعابير نمطية Regular expressions، بما في ذلك تعابير Perl النمطية Perl reg-ex. تتوفّر grep، نظرا لتعدّد وظائفها، على عدّة تنويعات تشمل rgrep، pgrep،fgrep، egrep وغيرها. توجد اختلافات يسيرة بين هذه التنويعات تجعل المبرمجين يستخدمون كلّ تنويعة لمهامّ محدّدة حسب رغبتهم وتفضيلهم. سنعرض في هذا المقال للاختلفات الأساسية بين التنويعات الثلاثة الأكثر شهرة، وهي egrep، grep وfgrep، ومالمتطلبات التي تجعل مستخدمي لينكس يختارون إحداها بدلا من الأخرى. سنستخدم ملفا بالمحتوى التالي ونسمّيه check_file لتطبيق الأوامر في هذا الدرس عليه. grep is a command that can be used on unix-like systems. it searches for any string in list of strings or file. It is very fast. (f|g)ile ملحوظة: لتوافق نتائج تنفيذ الأوامر لديك النتائج المعروضة في هذا الدرس، يجب أن يكون محتوى الملف مطابقا للمحتوى أعلاه: حالة الأحرف +(كبيرة أو صغيرة) وبداية الأسطر. تأكّد كذلك من تنفيذ الأوامر من المجلّد الذي يوجد به الملف، أو اكتب مسار الملف كاملا. الأمر grep يعدّ أمر grep الأمر الأساسي في الأنظمة الشبيهة بيونكس للبحث عن مجموعة محارف مهما كان نوعها ضمن سلسلة محارف، ملف، مجموعة ملفات أو ربما نتيجة تنفيذ أمر آخر. يستخدم الأمر grep التعابير النمطية القاعدية Basic Regular Expressions, BRE في البحث؛ علاوة على سلاسل المحارف الاعتيادية. تفقد المحارف الوصفية Meta characters عند استخدام التعابير النمطية القاعدية قدرتها التعبيرية، ويُتَعامل معها كأي محرف عادي؛ إلا إذا سُبِقت بمحرف تخليص Escape (وهو المحرف \). نرصُد في ما يلي أهم المحارف الوصفية بالنسبة للأمر grep. +: يعني عند تخليصه أننا نبحث عن السلاسل التي يتكرّر فيها المحرف قبله (على يساره) لمرة واحدة على الأقل. يمكن أن توافق العبارةُ a+b سلاسل المحارف ab، aabcd،aaab وaaaab، إلا أنها لا توافق العبارة bcd. ?: يشير إلى تكرار المحرف الذي قبله لمرة واحدة على الأكثر، حسب طريقة الاستخدام. (: يشير إلى بدء عبارة تناوب Alternation؛ أي موافقة أحد خيارات يفصل بينها الخط العمودي |. ): يشير إلى نهاية عبارة تناوب Alternation. |: يفصل بين الخيارات ضمن عبارة تناوب. يعني التعبير النمطي التالي (a|b)cde “الحرف a أو الحرف b تتبعه الأحرف cde بهذا الترتيب”؛ أي أن العبارتيْن acde وbcde توافقان التعبير النمطي المذكور. {: يشير هذا المحرف إلى بداية محدّدِ مجال. }: يشير هذا المحرف إلى نهاية محدّد مجال. مثلا؛ تعني العبارة التالية a{2} أننا نبحث عن الحرف a مكررا مرتيْن. راجع مقال مقدّمة في التعابير النمطية للمزيد عن هذه الدلالات واستخداماتها. ننفّذ الأمر grep بالطريقتيْن التاليتيْن: grep '(f|g)ile' check_file grep '\(f|g\)ile' check_file نلاحظ الفرق في النتيجة: يبحث الأمر الأول في الملف check_file عن سلسلة المحارف “(f|g)ile” كما كُتِبت دون أن يُفسّر المحارف (، ) و| تفسيرا خاصًّا. ينتُج عن تنفيذ الأمر إظهار الأسطُر التي تحوي سلسلة المحارف المرغوبة، مع عرض السلسلة بلون مغاير؛ حسب الإعدادات (أحمر في حالتي). تبدو النتيجة مغايرة بالنسبة للأمر الثاني الذي وضعنا فيه محرف التخليص \ أمام كل محرف نريد أن يُفسَّر بدلالته الخاصّة (محرف وصفي)، وليس كمحرف متضمَّن في الجملة التي نبحث عنها. تُصبح دلالة التعبير النمطي المُمرَّر إلى grep: “الكلمات التي يوجد بها أحد الحرفيْن f أو g متبوعا بالأحرف ile“. ملحوظة: استخدم الخيار o- إن أردتَ إظهار الكلمة التي تطابق التعبير النمطي لوحدها، دون السطر الذي توجد فيه: grep -o '(f|g)ile' check_file grep -o '\(f|g\)ile' check_file الأمر egrep يشبه اﻷمر egrep الأمرَ grep مع فرق أنه يتعامل مع المحارف الوصفية مباشرةً دون الحاجة لمحرف تخليص؛ بمعنى أنه يأخذها بدلالتها الخاصة مباشرةً. نعيد، لفهم الفكرة جيّدًا، تنفيذَ الأمريْن السابقيْن مع إحلال egrep مكان grep: egrep '(f|g)ile' check_file egrep '\(f|g\)ile' check_file يبدو الأمر هنا معكوسا: بدون تخليص المحارف الوصفية فإن الأمر egrep يحتفظ بدلالتها الخاصّة، فيبحث في الحالة الأولى عن جميع سلاسل المحارف التي تبدأ بحرف f أو g؛ أما في الحالة الثانية فيعدّ المحارف (، ) و| جزءًا من السلسلة ويبحث بالتالي عن العبارة (f|g)ile كما هي. ملحوظة: يشبه تنفيذ الأمر egrep تنفيذَ الأمر grep مع الخيار E-: grep -E '(f|g)ile' check_file grep -E '\(f|g\)ile' check_file يُفضّل كثيرون استخدام egrep بدلا من grep للبحث اعتمادًا على تعابير نمطيّة إذ أنها تزيح عن كاهلهم ضرورة تخليص المحارف الوصفية؛ خصوصا في العبارات النمطية المعقدة. الأمر fgrep لا يتعامل الأمر fgrep مع التعابير النمطية ولا المحارف الخاصّة؛ فالمعطى المُمرَّر له أولا هو سلسلة محارف ينبغي البحث عنها كما هي. يشبه استخدام fgrep استخدام الأمر grep مع فرق أن الأخير سيفسّر المحرف \ على أنه محرف تخليص، بينما لا يتعرف egrep عليه نهائيا؛ فهو بالنسبة له مجرد محرف كالبقية. fgrep '(f|g)ile' check_file fgrep '\(f|g\)ile' check_file تمكن ملاحظة أن fgrep بحث في كلتا الحالتيْن عن سلسلة المحارف كما مُرِّرت إليه. في الحالة الأولى كانت النتيجة مشابهة لتنفيذ الأمر grep بدون تخليص المحارف، وفي الثانية أضفنا محرف التخليص \؛ إلا أن fgrep لا يعدّه محرفا ذا دلالة خاصّة فيبحث عن السلسلة كما كُتبت ولا يجدها في الملف. ملحوظة: يشبه تنفيذ الأمر fgrep تنفيذَ الأمر grep مع الخيار F-: grep -F '(f|g)ile' check_file grep -F '\(f|g\)ile' check_file تعرّفنا في هذا الدرس على الفروق الأساسيّة بين ثلاث تنويعات من الأمر grep شائع الاستخدام في البحث عن سلاسل المحارف. يمكنك اختيار التنويعة التي تناسبك حسب الحاجة. ترجمة بتصرف لمقال What’s Difference Between Grep, Egrep and Fgrep in Linux? لصاحبه Gunjit Khera.
تشتهر أداة grep بكونها إحدى أدوات البحث الأكثر شهرة في الأنظمة الشبيهة بيونكس Unix-like، سواء تعلّق الأمر بالبحث عن ملفات، سطر أو أسطر عدّة ضمن ملفّ، فهي سريعة وتدعم الكثير من الخيارات مثل: البحث حسب نمط Pattern مكوَّن من سلسلة محارف String والبحث اعتمادًا على تعابير نمطية Regular expressions، بما في ذلك تعابير Perl النمطية Perl reg-ex. تتوفّر grep، نظرا لتعدّد وظائفها، على عدّة تنويعات تشمل rgrep، pgrep،fgrep، egrep وغيرها. توجد اختلافات يسيرة بين هذه التنويعات تجعل المبرمجين يستخدمون كلّ تنويعة لمهامّ محدّدة حسب رغبتهم وتفضيلهم. سنعرض في هذا المقال للاختلفات الأساسية بين التنويعات الثلاثة الأكثر شهرة، وهي egrep، grep وfgrep، ومالمتطلبات التي تجعل مستخدمي لينكس يختارون إحداها بدلا من الأخرى. سنستخدم ملفا بالمحتوى التالي ونسمّيه check_file لتطبيق الأوامر في هذا الدرس عليه. grep is a command that can be used on unix-like systems. it searches for any string in list of strings or file. It is very fast. (f|g)ile ملحوظة: لتوافق نتائج تنفيذ الأوامر لديك النتائج المعروضة في هذا الدرس، يجب أن يكون محتوى الملف مطابقا للمحتوى أعلاه: حالة الأحرف +(كبيرة أو صغيرة) وبداية الأسطر. تأكّد كذلك من تنفيذ الأوامر من المجلّد الذي يوجد به الملف، أو اكتب مسار الملف كاملا. الأمر grep يعدّ أمر grep الأمر الأساسي في الأنظمة الشبيهة بيونكس للبحث عن مجموعة محارف مهما كان نوعها ضمن سلسلة محارف، ملف، مجموعة ملفات أو ربما نتيجة تنفيذ أمر آخر. يستخدم الأمر grep التعابير النمطية القاعدية Basic Regular Expressions, BRE في البحث؛ علاوة على سلاسل المحارف الاعتيادية. تفقد المحارف الوصفية Meta characters عند استخدام التعابير النمطية القاعدية قدرتها التعبيرية، ويُتَعامل معها كأي محرف عادي؛ إلا إذا سُبِقت بمحرف تخليص Escape (وهو المحرف \). نرصُد في ما يلي أهم المحارف الوصفية بالنسبة للأمر grep. +: يعني عند تخليصه أننا نبحث عن السلاسل التي يتكرّر فيها المحرف قبله (على يساره) لمرة واحدة على الأقل. يمكن أن توافق العبارةُ a+b سلاسل المحارف ab، aabcd،aaab وaaaab، إلا أنها لا توافق العبارة bcd. ?: يشير إلى تكرار المحرف الذي قبله لمرة واحدة على الأكثر، حسب طريقة الاستخدام. (: يشير إلى بدء عبارة تناوب Alternation؛ أي موافقة أحد خيارات يفصل بينها الخط العمودي |. ): يشير إلى نهاية عبارة تناوب Alternation. |: يفصل بين الخيارات ضمن عبارة تناوب. يعني التعبير النمطي التالي (a|b)cde “الحرف a أو الحرف b تتبعه الأحرف cde بهذا الترتيب”؛ أي أن العبارتيْن acde وbcde توافقان التعبير النمطي المذكور. {: يشير هذا المحرف إلى بداية محدّدِ مجال. }: يشير هذا المحرف إلى نهاية محدّد مجال. مثلا؛ تعني العبارة التالية a{2} أننا نبحث عن الحرف a مكررا مرتيْن. راجع مقال مقدّمة في التعابير النمطية للمزيد عن هذه الدلالات واستخداماتها. ننفّذ الأمر grep بالطريقتيْن التاليتيْن: grep '(f|g)ile' check_file grep '\(f|g\)ile' check_file نلاحظ الفرق في النتيجة: يبحث الأمر الأول في الملف check_file عن سلسلة المحارف “(f|g)ile” كما كُتِبت دون أن يُفسّر المحارف (، ) و| تفسيرا خاصًّا. ينتُج عن تنفيذ الأمر إظهار الأسطُر التي تحوي سلسلة المحارف المرغوبة، مع عرض السلسلة بلون مغاير؛ حسب الإعدادات (أحمر في حالتي). تبدو النتيجة مغايرة بالنسبة للأمر الثاني الذي وضعنا فيه محرف التخليص \ أمام كل محرف نريد أن يُفسَّر بدلالته الخاصّة (محرف وصفي)، وليس كمحرف متضمَّن في الجملة التي نبحث عنها. تُصبح دلالة التعبير النمطي المُمرَّر إلى grep: “الكلمات التي يوجد بها أحد الحرفيْن f أو g متبوعا بالأحرف ile“. ملحوظة: استخدم الخيار o- إن أردتَ إظهار الكلمة التي تطابق التعبير النمطي لوحدها، دون السطر الذي توجد فيه: grep -o '(f|g)ile' check_file grep -o '\(f|g\)ile' check_file الأمر egrep يشبه اﻷمر egrep الأمرَ grep مع فرق أنه يتعامل مع المحارف الوصفية مباشرةً دون الحاجة لمحرف تخليص؛ بمعنى أنه يأخذها بدلالتها الخاصة مباشرةً. نعيد، لفهم الفكرة جيّدًا، تنفيذَ الأمريْن السابقيْن مع إحلال egrep مكان grep: egrep '(f|g)ile' check_file egrep '\(f|g\)ile' check_file يبدو الأمر هنا معكوسا: بدون تخليص المحارف الوصفية فإن الأمر egrep يحتفظ بدلالتها الخاصّة، فيبحث في الحالة الأولى عن جميع سلاسل المحارف التي تبدأ بحرف f أو g؛ أما في الحالة الثانية فيعدّ المحارف (، ) و| جزءًا من السلسلة ويبحث بالتالي عن العبارة (f|g)ile كما هي. ملحوظة: يشبه تنفيذ الأمر egrep تنفيذَ الأمر grep مع الخيار E-: grep -E '(f|g)ile' check_file grep -E '\(f|g\)ile' check_file يُفضّل كثيرون استخدام egrep بدلا من grep للبحث اعتمادًا على تعابير نمطيّة إذ أنها تزيح عن كاهلهم ضرورة تخليص المحارف الوصفية؛ خصوصا في العبارات النمطية المعقدة. الأمر fgrep لا يتعامل الأمر fgrep مع التعابير النمطية ولا المحارف الخاصّة؛ فالمعطى المُمرَّر له أولا هو سلسلة محارف ينبغي البحث عنها كما هي. يشبه استخدام fgrep استخدام الأمر grep مع فرق أن الأخير سيفسّر المحرف \ على أنه محرف تخليص، بينما لا يتعرف egrep عليه نهائيا؛ فهو بالنسبة له مجرد محرف كالبقية. fgrep '(f|g)ile' check_file fgrep '\(f|g\)ile' check_file تمكن ملاحظة أن fgrep بحث في كلتا الحالتيْن عن سلسلة المحارف كما مُرِّرت إليه. في الحالة الأولى كانت النتيجة مشابهة لتنفيذ الأمر grep بدون تخليص المحارف، وفي الثانية أضفنا محرف التخليص \؛ إلا أن fgrep لا يعدّه محرفا ذا دلالة خاصّة فيبحث عن السلسلة كما كُتبت ولا يجدها في الملف. ملحوظة: يشبه تنفيذ الأمر fgrep تنفيذَ الأمر grep مع الخيار F-: grep -F '(f|g)ile' check_file grep -F '\(f|g\)ile' check_file تعرّفنا في هذا الدرس على الفروق الأساسيّة بين ثلاث تنويعات من الأمر grep شائع الاستخدام في البحث عن سلاسل المحارف. يمكنك اختيار التنويعة التي تناسبك حسب الحاجة. ترجمة بتصرف لمقال What’s Difference Between Grep, Egrep and Fgrep in Linux? لصاحبه Gunjit Khera. -
 مقدمة يعدّ توزيع الحِمل Load balancing مكوِّنا أساسيًّا في البنى التحتية عالية التوفر Highly-available، إذ يكثر استخدامه لتحسين الأداء والثبات في مختلف الخدمات على الشبكة؛ بما في ذلك مواقع الوِب، التطبيقات، قواعد البيانات وغيرها. يقوم مبدأ توزيع الحِمل على الاعتماد على أكثر من خادوم وتوزيع العمل المطلوب إنجازه بينها. يوضّح المخطّط التالي بنية تحتية لموقع وِب بدون توزيع حِمل. يتصل الزائر في هذا المثال بخادوم الوِب مباشرة، على العنوان yourdomain.com. إن حدث خلل يجعل الخادوم المضيّف للموقع yourdomain.com غير قادر على العمل فإن الوصول إلى هذا الموقع لن يكون متاحا. علاوةً على ذلك؛ إن أراد الكثير من الزوّار الوصول إلى الموقع في نفس اللحظة ولم يستطع الخادوم التعامل معهم بالسرعة المطلوبة فإن تنزيل صفحات الموقع سيصير بطيئًا، وربما يصبح خارج الخدمة. يمثّل الخادوم في هذه الحالة نقطة إخفاق Point of failure بالنسبة للبنية التحتية، فتوقفه عن العمل يجعل البنية بجميع مكوّناتها خارج الخدمة. يمكن التخفيف من تأثير نقطة الإخفاق الوحيدة هذه بإضافة موزّع حِمل Load balancer وخادوم وِب آخر على الأقل إلى السند الخلفي Backend. تقدّم جميع الخواديم في السند الخلفي نفس المحتوى، فيحصُل الزائر بالتالي على محتوى متجانس بغضّ النظر عن خادوم الوِب الذي أجاب عن طلبه. يتصل الزائر في المخطط أعلاه أولا بموزّع الحِمل الذي يوجّه طلب الزائر إلى خادوم في السند الخلفي. يجيب الخادوم الذي وُجِّه إليه الطلبُ الزائرَ مباشرة. يصبح موزّع الحِمل في هذه الحالة هو نقطة الإخفاق، بمعنى أن توقفه عن العمل يجعل كامل البنية التحتية تتوقف عن العمل. يمكن التغلب على هذا المشكل بإدراج موزّع حِمل ثان؛ إلا أننا سنشرح - قبل أن نناقش هذه الإمكانية - كيفية عمل موزّع الحِمل. ما نوع حركة البيانات التي يمكن لموزع الحمل التعامل معها؟ يستخدم مديرو الأنظمة موزّعات الحمل لإنشاء قواعد توجيه تتعامل أساسا مع أنواع البيانات الأربعة التالية: HTTP: تُوجَّه حركة البيانات في هذه الحالة اعتمادًا على الآليات المعيارية لميثاق HTTP. يعيّن موزّع الحِمل قيم الترويسات X-Forwarded-For، X-Forwarded-Proto وX-Forwarded-Port من أجل تمرير المعلومات الأصلية عن الطلب، أي تلك القادمة من الزائر، إلى الخادوم الذي سيردّ على الطلب . HTTPS: يشبه هذا النوع النوعَ السابق، مع فرق أنه يستخدم التعميّة Encryption. تُعالَج البيانات المعمّاة بإحدى طريقتيْن: تمرير SSL +(أو SSL Passthrough)وتعتمد هذه الطريقة على الاحتفاظ بالتعميّة إلى أن تصل البيانات للخادوم الذي سيجيب على الطلب؛ أما الثانيّة فتُدعى إنهاء SSL (أو SSL Termination) ويوضَع عبء التعميّة وفكّها على موزّع الحمل، غير أن البيانات بين موزّع الحمل وخادوم الوِب تُنقَل دون تعميّة، عكس الطريقة الأولى. TCP: يمكن استخدام ميثاق TCP لتوزيع حركة البيانات بين تطبيقات لا تستخدم HTTP أو HTTPS؛ مثلا بين عنقود Cluster من خواديم قواعد البيانات. UDP: تدعم بعض موزعات الحمل الحديثة توجيه البيانات الخاصّة بمواثيق الإنترنت التي تستخدم حزم UDP مثل نظام أسماء النطاقات DNS وsyslogd. تعرّف قواعدُ التوجيه الميثاقَ والمنفَذ Port على موزّع الحمل وتربطهما بميثاق ومنفَذ موجودين على الخادوم الذي يختاره موزّع الحِمل للإجابة على طلب الزائر. كيف يختار موزّع الحمل خادوما في السند الخلفي؟ يختار موزّع الحمل الخادوم الذي سيتولّى الإجابة على الطلب بناء على عاملَيْن: أولاً؛ يتأكّد موزّع الحمل من قدرة الخادوم على الإجابة على الطلبات التي ترده، ثم يستخدم مجموعة من القواعد المضبوطة مسبقا لاختيار خادوم من بين الخواديم القادرة على الإجابة على الطلب. التحقق من قدرة الخادوم لا يجوز أن توجِّه موزعات الحِمل الطلبات إلى خادوم ليست لديه القدرة على التعامل معها. يراقب موزّع الحمل حالة الخواديم في السند الخلفي بمحاولة الاتصال بها مستخدما الميثاق والمنفَذ المعرَّفيْن في قواعد التوجيه المضبوطة عليه. إن أخفق خادوم في الإجابة على محاولات موزّع الحمل للاتصال به فإن موزع الحمل يعدّه غير قادر على معالجة الطلبات، ويحذفه بالتالي من قائمة الخواديم لديه، فلا يُوجِّه له أي طلب؛ إلى أن يجيب بطريقة مناسبة على محاولات الاتّصال اللاحقة. خوارزميّات توزيع الحِمل تحدّد خوارزميّة خادوما - من بين الخواديم الجاهزة للإجابة - لتوجيه الطلب إليه. تعدّ الخوارزميّات التالية من بين الخوارزميّات الأكثر استخداما في توزيع الحمل: الاختيار الدوري Round robin: تُختار الخواديم في هذه الخوارزميّة بالتتالي. يوجّه موزع الحمل عند استخدام هذه الخوارزمية أول طلب إلى أول خادوم في قائمته، ثم عند وصول الطلب الثاني يوجّهه إلى الخادوم الموالي، وهكذا إلى أن يصل لآخر خادوم في القائمة فيعود للأول. الأقل اتصالات Least connections: يُنصَح بهذه الخوارزميّة عندما تأخذ جلسات الاتصال Sessions آمادا طويلة. يختار الموزّع في هذه الحالة الخادوم ذا الاتصالات النشطة اﻷقل عددا. حسب المصدر Source: يختار موزّع الحمل عند استخدام هذه الخوارزميّة الخادومَ الذي سيجيب على الطلب بناءً على عنوان IP المصدَر، مثلا؛ عنوان IP الزائر. يعني استخدامُ هذه الخوارزميّة أن طلبات زائر معيَّن ستُوجَّه دوما إلى نفس الخادوم. تختلف الخوارزميّات المتاحة للاختيار بينها، حسب التقنيات المستخدمة في موزّع الحمل. كيف تتعامل موزّعات الحِمل مع الحالة State؟ تطلب بعض التطبيقات أن يواصل الزائر الاتصال بنفس الخادوم خلال جلسة الاتصال الواحدة. يمكن عند الاقتضاء استخدام خوارزميّة الاختيار حسب المصدر التي تركّز على عنوان الزائر. توجد طريقة أخرى لتلبية هذه الحاجة، وذلك بتنفيذها على مستوى تطبيق الوِب عبر الجلسات الملتصقة Sticky sessions. إذ يعيّن موزّع الحمل ملف تتبّع Cookie خاصّ بكل جلسة ثم يوجّه الطلبات التابعة لنفس الجلسة إلى نفس الخادوم، اعتمادا على ملف التتبع. تكرار موزّعات الحمل ذكرنا سابقا أن موزّع الحِمل يمكن أن يمثّل نقطة إخفاق إن كان وحيدا، وأنه يمكن تصحيح هذه الوضعية بإضافة موزّع حمل ثان. يتصل موزّع الحِمل الجديد بالأوّل لتشكيل عنقود من خادومَيْ توزيع حِمل يراقب كلّ منهما الآخر ويتأكّد من جاهزيّته لتلقي الطلبات وتوجيهها إلى الخادوم المناسب في المنتهى الخلفي. يمكن لكلٍّ من الخادوميْن في هذه الحالة اكتشاف إخفاق الآخر وعودته إلى العمل. يُحيل نظام أسماء النطاقات DNS المستخدمين إلى موزّع الحِمل الثاني في حال توقّف الأول عن العمل؛ إلا أنّ سجلات أسماء النطاقات يمكن أن تأخذ وقتا حتى يكتمل تحديثها لدى المستخدمين في جميع أنحاء العالم. يلجأ كثير من مديري الأنظمة، للتغلّب على هذا المشكل، إلى وسائل تتيح إعادة تعيين عناوين IP بمرونة، مثل عناوين IP العائمة Floating IPs. تتخلّص هذه الوسائل من مشاكل انتشار السجلات وتحديث التخبئة في سجلات DNS بتوفير عنوان IP ثابت يمكن إعادة تعيينه حسب الحاجة، وبسرعة. لا تغيّر إعادة تعيين IP من العنوان الذي تشير إليه سجلات DNS، إلا أنها تجعل من الممكن نقل عنوان IP نفسه بين خواديم مختلفة. ترجمة - بتصرف - لمقال What is Load Balancing? لصاحبته Melissa Anderson.
مقدمة يعدّ توزيع الحِمل Load balancing مكوِّنا أساسيًّا في البنى التحتية عالية التوفر Highly-available، إذ يكثر استخدامه لتحسين الأداء والثبات في مختلف الخدمات على الشبكة؛ بما في ذلك مواقع الوِب، التطبيقات، قواعد البيانات وغيرها. يقوم مبدأ توزيع الحِمل على الاعتماد على أكثر من خادوم وتوزيع العمل المطلوب إنجازه بينها. يوضّح المخطّط التالي بنية تحتية لموقع وِب بدون توزيع حِمل. يتصل الزائر في هذا المثال بخادوم الوِب مباشرة، على العنوان yourdomain.com. إن حدث خلل يجعل الخادوم المضيّف للموقع yourdomain.com غير قادر على العمل فإن الوصول إلى هذا الموقع لن يكون متاحا. علاوةً على ذلك؛ إن أراد الكثير من الزوّار الوصول إلى الموقع في نفس اللحظة ولم يستطع الخادوم التعامل معهم بالسرعة المطلوبة فإن تنزيل صفحات الموقع سيصير بطيئًا، وربما يصبح خارج الخدمة. يمثّل الخادوم في هذه الحالة نقطة إخفاق Point of failure بالنسبة للبنية التحتية، فتوقفه عن العمل يجعل البنية بجميع مكوّناتها خارج الخدمة. يمكن التخفيف من تأثير نقطة الإخفاق الوحيدة هذه بإضافة موزّع حِمل Load balancer وخادوم وِب آخر على الأقل إلى السند الخلفي Backend. تقدّم جميع الخواديم في السند الخلفي نفس المحتوى، فيحصُل الزائر بالتالي على محتوى متجانس بغضّ النظر عن خادوم الوِب الذي أجاب عن طلبه. يتصل الزائر في المخطط أعلاه أولا بموزّع الحِمل الذي يوجّه طلب الزائر إلى خادوم في السند الخلفي. يجيب الخادوم الذي وُجِّه إليه الطلبُ الزائرَ مباشرة. يصبح موزّع الحِمل في هذه الحالة هو نقطة الإخفاق، بمعنى أن توقفه عن العمل يجعل كامل البنية التحتية تتوقف عن العمل. يمكن التغلب على هذا المشكل بإدراج موزّع حِمل ثان؛ إلا أننا سنشرح - قبل أن نناقش هذه الإمكانية - كيفية عمل موزّع الحِمل. ما نوع حركة البيانات التي يمكن لموزع الحمل التعامل معها؟ يستخدم مديرو الأنظمة موزّعات الحمل لإنشاء قواعد توجيه تتعامل أساسا مع أنواع البيانات الأربعة التالية: HTTP: تُوجَّه حركة البيانات في هذه الحالة اعتمادًا على الآليات المعيارية لميثاق HTTP. يعيّن موزّع الحِمل قيم الترويسات X-Forwarded-For، X-Forwarded-Proto وX-Forwarded-Port من أجل تمرير المعلومات الأصلية عن الطلب، أي تلك القادمة من الزائر، إلى الخادوم الذي سيردّ على الطلب . HTTPS: يشبه هذا النوع النوعَ السابق، مع فرق أنه يستخدم التعميّة Encryption. تُعالَج البيانات المعمّاة بإحدى طريقتيْن: تمرير SSL +(أو SSL Passthrough)وتعتمد هذه الطريقة على الاحتفاظ بالتعميّة إلى أن تصل البيانات للخادوم الذي سيجيب على الطلب؛ أما الثانيّة فتُدعى إنهاء SSL (أو SSL Termination) ويوضَع عبء التعميّة وفكّها على موزّع الحمل، غير أن البيانات بين موزّع الحمل وخادوم الوِب تُنقَل دون تعميّة، عكس الطريقة الأولى. TCP: يمكن استخدام ميثاق TCP لتوزيع حركة البيانات بين تطبيقات لا تستخدم HTTP أو HTTPS؛ مثلا بين عنقود Cluster من خواديم قواعد البيانات. UDP: تدعم بعض موزعات الحمل الحديثة توجيه البيانات الخاصّة بمواثيق الإنترنت التي تستخدم حزم UDP مثل نظام أسماء النطاقات DNS وsyslogd. تعرّف قواعدُ التوجيه الميثاقَ والمنفَذ Port على موزّع الحمل وتربطهما بميثاق ومنفَذ موجودين على الخادوم الذي يختاره موزّع الحِمل للإجابة على طلب الزائر. كيف يختار موزّع الحمل خادوما في السند الخلفي؟ يختار موزّع الحمل الخادوم الذي سيتولّى الإجابة على الطلب بناء على عاملَيْن: أولاً؛ يتأكّد موزّع الحمل من قدرة الخادوم على الإجابة على الطلبات التي ترده، ثم يستخدم مجموعة من القواعد المضبوطة مسبقا لاختيار خادوم من بين الخواديم القادرة على الإجابة على الطلب. التحقق من قدرة الخادوم لا يجوز أن توجِّه موزعات الحِمل الطلبات إلى خادوم ليست لديه القدرة على التعامل معها. يراقب موزّع الحمل حالة الخواديم في السند الخلفي بمحاولة الاتصال بها مستخدما الميثاق والمنفَذ المعرَّفيْن في قواعد التوجيه المضبوطة عليه. إن أخفق خادوم في الإجابة على محاولات موزّع الحمل للاتصال به فإن موزع الحمل يعدّه غير قادر على معالجة الطلبات، ويحذفه بالتالي من قائمة الخواديم لديه، فلا يُوجِّه له أي طلب؛ إلى أن يجيب بطريقة مناسبة على محاولات الاتّصال اللاحقة. خوارزميّات توزيع الحِمل تحدّد خوارزميّة خادوما - من بين الخواديم الجاهزة للإجابة - لتوجيه الطلب إليه. تعدّ الخوارزميّات التالية من بين الخوارزميّات الأكثر استخداما في توزيع الحمل: الاختيار الدوري Round robin: تُختار الخواديم في هذه الخوارزميّة بالتتالي. يوجّه موزع الحمل عند استخدام هذه الخوارزمية أول طلب إلى أول خادوم في قائمته، ثم عند وصول الطلب الثاني يوجّهه إلى الخادوم الموالي، وهكذا إلى أن يصل لآخر خادوم في القائمة فيعود للأول. الأقل اتصالات Least connections: يُنصَح بهذه الخوارزميّة عندما تأخذ جلسات الاتصال Sessions آمادا طويلة. يختار الموزّع في هذه الحالة الخادوم ذا الاتصالات النشطة اﻷقل عددا. حسب المصدر Source: يختار موزّع الحمل عند استخدام هذه الخوارزميّة الخادومَ الذي سيجيب على الطلب بناءً على عنوان IP المصدَر، مثلا؛ عنوان IP الزائر. يعني استخدامُ هذه الخوارزميّة أن طلبات زائر معيَّن ستُوجَّه دوما إلى نفس الخادوم. تختلف الخوارزميّات المتاحة للاختيار بينها، حسب التقنيات المستخدمة في موزّع الحمل. كيف تتعامل موزّعات الحِمل مع الحالة State؟ تطلب بعض التطبيقات أن يواصل الزائر الاتصال بنفس الخادوم خلال جلسة الاتصال الواحدة. يمكن عند الاقتضاء استخدام خوارزميّة الاختيار حسب المصدر التي تركّز على عنوان الزائر. توجد طريقة أخرى لتلبية هذه الحاجة، وذلك بتنفيذها على مستوى تطبيق الوِب عبر الجلسات الملتصقة Sticky sessions. إذ يعيّن موزّع الحمل ملف تتبّع Cookie خاصّ بكل جلسة ثم يوجّه الطلبات التابعة لنفس الجلسة إلى نفس الخادوم، اعتمادا على ملف التتبع. تكرار موزّعات الحمل ذكرنا سابقا أن موزّع الحِمل يمكن أن يمثّل نقطة إخفاق إن كان وحيدا، وأنه يمكن تصحيح هذه الوضعية بإضافة موزّع حمل ثان. يتصل موزّع الحِمل الجديد بالأوّل لتشكيل عنقود من خادومَيْ توزيع حِمل يراقب كلّ منهما الآخر ويتأكّد من جاهزيّته لتلقي الطلبات وتوجيهها إلى الخادوم المناسب في المنتهى الخلفي. يمكن لكلٍّ من الخادوميْن في هذه الحالة اكتشاف إخفاق الآخر وعودته إلى العمل. يُحيل نظام أسماء النطاقات DNS المستخدمين إلى موزّع الحِمل الثاني في حال توقّف الأول عن العمل؛ إلا أنّ سجلات أسماء النطاقات يمكن أن تأخذ وقتا حتى يكتمل تحديثها لدى المستخدمين في جميع أنحاء العالم. يلجأ كثير من مديري الأنظمة، للتغلّب على هذا المشكل، إلى وسائل تتيح إعادة تعيين عناوين IP بمرونة، مثل عناوين IP العائمة Floating IPs. تتخلّص هذه الوسائل من مشاكل انتشار السجلات وتحديث التخبئة في سجلات DNS بتوفير عنوان IP ثابت يمكن إعادة تعيينه حسب الحاجة، وبسرعة. لا تغيّر إعادة تعيين IP من العنوان الذي تشير إليه سجلات DNS، إلا أنها تجعل من الممكن نقل عنوان IP نفسه بين خواديم مختلفة. ترجمة - بتصرف - لمقال What is Load Balancing? لصاحبته Melissa Anderson.-
- 1
-

-
- توزيع الحمل
- load balancing
- (و 2 أكثر)
-
إن كنت تقصد بالوصول الحصولَ على رابط الصورة فإن الطريقة هي نفس الطريقة المتّبعة مع القرص public؛ إلا أنه يجب إنشاء وصلة رمزية باسم storage في المجلد الجذر إلى مسار التخزين storage\app كما فعلنا عند تنفيذ الأمر php artisan storage:link، مع فرق أنه يجب إنشاء هذه الوصلة يدويا بدون الاستعانة بartisan.
-
 يتناول هذا المقال تثبيت بيئة تطوير Ruby on Rails على الإصدار 16.04 من أوبونتو. في أغلب الأحوال ستُنفَّذ الشفرة البرمجيّة التي تكتبها على خادوم لينكس، وأوبونتو هي إحدى توزيعات لينكس الأسهل استخداما وتوجد الكثير من الموارد عنها على الشبكة. تثبيت Ruby أول ما يجب علينا فعله هو تثبيت الاعتماديات Dependencies التي يحتاجها Ruby للعمل. نبدأ أولا بتحديث فهرس الحزم ثم تثبيت الاعتماديّات: sudo apt update sudo apt install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev python-software-properties libffi-dev nodejs الخطوة الموالية هي تثبيت Ruby. توجد طرق عدّة للتثبيت، سنستخدم rbenv وهي أداة خفيفة وسريعة لإدارة إصدارات Ruby. نبدأ بتثبيت rbenv : cd git clone https://github.com/rbenv/rbenv.git ~/.rbenv echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc echo 'eval "$(rbenv init -)"' >> ~/.bashrc exec $SHELL الأداة rbenv جاهزة الآن. سنثبّت ruby-build وهي إضافة تعمل مع الأداة rbenv وتتيح تثبيت إصدارات عدّة من Ruby في مجلّدات مختلفة على نفس النظام. git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc exec $SHELL ثم نثبّت الإصدار 2.4.0 من Ruby: TMPDIR=~/tmp/ rbenv install 2.4.0 rbenv global 2.4.0 يُثبّت الأمر الأول الإصدار المطلوب ضمن مجلّد العمل حيث نُفِّذ الأمر؛ في ما يضبط الأمر الثاني إصدار Ruby المبدئي، أي الإصدار الذي سيُستخدَم عند عدم تحديد إصدار. للتأكد من تثبيت Ruby والإصدار المثبّت ننفذ الأمر: ruby -v الذي يُظهر نتيجة تشبه التالي: ruby 2.4.0p0 (2016-12-24 revision 57164) [x86_64-linux] الخطوة الأخيرة هي تثبيت Bundler الذي يوفّر بيئة تطوير متجانسة لـ Ruby عبر تتبّع الاعتماديات وتثبيت الإصدارات المطلوبة منها بالضبط: gem install bundler وتنفيذ الأمر لأخذ التثبيت الجديد في الحسبان: rbenv rehash تثبيت Rails يتضمّن إطار العمل Rails الكثير من الاعتماديات، لذا سنحتاج لبيئة تنفيذ JavaScript مثل NodeJS التي ستمكّننا من استخدام مكتبات تتيح إمكانيّة جمع وضغط ملفات جافاسكريبت من أجل الحصول على بيئة تطوير أسرع. نثبّت NodeJS من المستودع الرسمي على النحو التالي: curl -sL https://deb.nodesource.com/setup_4.x | sudo -E bash - sudo apt install -y nodejs ثم نثبّت Rails: gem install rails -v 5.0.1 ثم ننفذ الأمر التالي ليمكننا استخدام Rails: rbenv rehash Rails مثبّت الآن، يمكننا التأكّد من ذلك بتنفيذ الأمر التالي الذي يُظهر رقم الإصدار المثبت: rails -v إعداد قاعدة بيانات MySQL يأتي Rails مبدئيا بقاعدة بيانات sqlite3؛ إلا أن هذا النوع من قواعد البيانات لا يناسب تطبيقات كثيرة. يمكن في هذه الحالة إعداد Rails للعمل مع قاعدة بيانات MySQL (أو PostgreSQL). نثبّت خادوم وعميل MySQL من المستودعات الرسمية لأوبونتو: sudo apt install mysql-server mysql-client libmysqlclient-dev سيُطلَب منك خلال التثبيت إنشاءُ كلمة سر خاصة بالحساب الإداري root (انتبِه إلى أنّه حساب خاص بنظام MySQL لإدارة قواعد البيانات، وليس لنظام التشغيل أوبونتو). تتضمّن الحزمة libmysqlclient-dev الملفات الضرورية لتثبيت الاعتماديّات التي يحتاجها Rails للاتصال بقاعدة بيانات MySQL. ننفّذ بعد تثبيت MySQL الأمريْن التاليّيْن لتحضير قاعدة البيانات لبيئة الإنتاج (يمكنك تجاوز هذه الخطوة إن كنت تثبّت Rails على حاسوب شخصي): sudo mysql_install_db sudo mysql_secure_installation سيُطلب منك النّظام إدخال كلمة سرّ الحساب الجذر في MySQL؛ ثمّ يسألك ما إذا كنتَ تُريد تغييرها. أدخل حرف n (دلالةً على “no” أي “لا”) إن لم تكن ترغبُ في ذلك. بالنسبة لبقية الأسئلة يمكنك قبول القيم المبدئية بالنقر على زرّ Enter. أول تطبيق Rails حان الوقت الآن لتشغيل أول تطبيق Ruby on Rails. ننشئ تطبيقا باسم myapp يستخدم قاعدة البيانات MySQL: rails new myapp -d mysql انتظر اكتمال إنشاء التطبيق الذي قد يستغرق وقتا، ثم انتقل إلى مجلد التطبيق: cd myapp عدّل الملف config/database.yml بإضافة كلمة سر الحساب الإداري لقاعدة البيانات (أعددناها أثناء تثبيت MySQL، يمكنك تركها فارغة إن لم تكن أعددتَ كلمة سر لـ MySQL): default: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: socket: /var/run/mysqld/mysqld.sock اكتب كلمة السر أمام التعليمة password ضمن المقطع السابق الموجود أعلى الملف بعد التعليقات الأولى (تبدأ التعليقات بالعلامة #)؛ ثم نفّذ الأمر التالي لإنشاء قاعدة البيانات التي سيعمل عليها التطبيق: rake db:create النتيجة: Created database 'myapp_development' Created database 'myapp_test' إن واجهك خطأ Access denied for user 'root'@'localhost' (using password: NO) فهذا يعني أنك لم تكتب كلمة السر بطريقة صحيحة. نشغل خادوم التطوير: rails server يمكنك بعد تشغيل خادوم التطوير إدخال العنوان http://localhost:3000/ في المتصفح لمعاينة صفحة التطبيق المبدئي في Rails. إعداد Git هذه الخطوة اختيارية ولكنه تفيدك إن كنت تخطّط لاستعمال Git لإدارة إصدارات المشروع وربطه بحسابك على Github. أبدل YOUR NAME وYOUR@EMAIL.com في الأوامر أدناه على التوالي باسمك والبريد الذي استخدمته للتسجيل على Github. git config --global color.ui true git config --global user.name "YOUR NAME" git config --global user.email "YOUR@EMAIL.com" ssh-keygen -t rsa -b 4096 -C "YOUR@EMAIL.com" يُولّد الأمر الأخير في الأوامر أعلاه زوج مفاتيح SSH سنستخدمها في ما بعد للاتصال بحسابنا على Github. يضع الأمر ssh-keygen مبدئيا زوج المفاتيح على المسار ssh./~. نأخذ المفتاح العمومي الذي يوجد بملف المفتاح ذي الامتداد pub، ويُسمّى مبدئيا id_rsa.pub وننسخه ضمن مفاتيح SSH على حسابنا في Github الموجودة هنا. انقر على الزّر New SSH Key، أعط للمفتاح اسما تختاره ثم ألصق في الحقل الثاني محتوى الملف ssh/id_rsa.pub/~ الذي يمكن الحصول عليه بالأمر التالي، ثم انقر على زرّ Add SSH Key لاعتماد المفتاح: cat ~/.ssh/id_rsa.pub يمكنك التأكد من نجاح العملية بتنفيذ الأمر التالي: ssh -T git@github.com يجب أن تظهر لك رسالة تشبه التالي (يُذكَر فيها اسم حسابك على Github): Hi Zeine77! You've successfully authenticated, but GitHub does not provide shell access. ترجمة - بتصرّف - للمقال Setup Ruby On Rails on Ubuntu 16.04 Xenial Xerus.
يتناول هذا المقال تثبيت بيئة تطوير Ruby on Rails على الإصدار 16.04 من أوبونتو. في أغلب الأحوال ستُنفَّذ الشفرة البرمجيّة التي تكتبها على خادوم لينكس، وأوبونتو هي إحدى توزيعات لينكس الأسهل استخداما وتوجد الكثير من الموارد عنها على الشبكة. تثبيت Ruby أول ما يجب علينا فعله هو تثبيت الاعتماديات Dependencies التي يحتاجها Ruby للعمل. نبدأ أولا بتحديث فهرس الحزم ثم تثبيت الاعتماديّات: sudo apt update sudo apt install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev python-software-properties libffi-dev nodejs الخطوة الموالية هي تثبيت Ruby. توجد طرق عدّة للتثبيت، سنستخدم rbenv وهي أداة خفيفة وسريعة لإدارة إصدارات Ruby. نبدأ بتثبيت rbenv : cd git clone https://github.com/rbenv/rbenv.git ~/.rbenv echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc echo 'eval "$(rbenv init -)"' >> ~/.bashrc exec $SHELL الأداة rbenv جاهزة الآن. سنثبّت ruby-build وهي إضافة تعمل مع الأداة rbenv وتتيح تثبيت إصدارات عدّة من Ruby في مجلّدات مختلفة على نفس النظام. git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc exec $SHELL ثم نثبّت الإصدار 2.4.0 من Ruby: TMPDIR=~/tmp/ rbenv install 2.4.0 rbenv global 2.4.0 يُثبّت الأمر الأول الإصدار المطلوب ضمن مجلّد العمل حيث نُفِّذ الأمر؛ في ما يضبط الأمر الثاني إصدار Ruby المبدئي، أي الإصدار الذي سيُستخدَم عند عدم تحديد إصدار. للتأكد من تثبيت Ruby والإصدار المثبّت ننفذ الأمر: ruby -v الذي يُظهر نتيجة تشبه التالي: ruby 2.4.0p0 (2016-12-24 revision 57164) [x86_64-linux] الخطوة الأخيرة هي تثبيت Bundler الذي يوفّر بيئة تطوير متجانسة لـ Ruby عبر تتبّع الاعتماديات وتثبيت الإصدارات المطلوبة منها بالضبط: gem install bundler وتنفيذ الأمر لأخذ التثبيت الجديد في الحسبان: rbenv rehash تثبيت Rails يتضمّن إطار العمل Rails الكثير من الاعتماديات، لذا سنحتاج لبيئة تنفيذ JavaScript مثل NodeJS التي ستمكّننا من استخدام مكتبات تتيح إمكانيّة جمع وضغط ملفات جافاسكريبت من أجل الحصول على بيئة تطوير أسرع. نثبّت NodeJS من المستودع الرسمي على النحو التالي: curl -sL https://deb.nodesource.com/setup_4.x | sudo -E bash - sudo apt install -y nodejs ثم نثبّت Rails: gem install rails -v 5.0.1 ثم ننفذ الأمر التالي ليمكننا استخدام Rails: rbenv rehash Rails مثبّت الآن، يمكننا التأكّد من ذلك بتنفيذ الأمر التالي الذي يُظهر رقم الإصدار المثبت: rails -v إعداد قاعدة بيانات MySQL يأتي Rails مبدئيا بقاعدة بيانات sqlite3؛ إلا أن هذا النوع من قواعد البيانات لا يناسب تطبيقات كثيرة. يمكن في هذه الحالة إعداد Rails للعمل مع قاعدة بيانات MySQL (أو PostgreSQL). نثبّت خادوم وعميل MySQL من المستودعات الرسمية لأوبونتو: sudo apt install mysql-server mysql-client libmysqlclient-dev سيُطلَب منك خلال التثبيت إنشاءُ كلمة سر خاصة بالحساب الإداري root (انتبِه إلى أنّه حساب خاص بنظام MySQL لإدارة قواعد البيانات، وليس لنظام التشغيل أوبونتو). تتضمّن الحزمة libmysqlclient-dev الملفات الضرورية لتثبيت الاعتماديّات التي يحتاجها Rails للاتصال بقاعدة بيانات MySQL. ننفّذ بعد تثبيت MySQL الأمريْن التاليّيْن لتحضير قاعدة البيانات لبيئة الإنتاج (يمكنك تجاوز هذه الخطوة إن كنت تثبّت Rails على حاسوب شخصي): sudo mysql_install_db sudo mysql_secure_installation سيُطلب منك النّظام إدخال كلمة سرّ الحساب الجذر في MySQL؛ ثمّ يسألك ما إذا كنتَ تُريد تغييرها. أدخل حرف n (دلالةً على “no” أي “لا”) إن لم تكن ترغبُ في ذلك. بالنسبة لبقية الأسئلة يمكنك قبول القيم المبدئية بالنقر على زرّ Enter. أول تطبيق Rails حان الوقت الآن لتشغيل أول تطبيق Ruby on Rails. ننشئ تطبيقا باسم myapp يستخدم قاعدة البيانات MySQL: rails new myapp -d mysql انتظر اكتمال إنشاء التطبيق الذي قد يستغرق وقتا، ثم انتقل إلى مجلد التطبيق: cd myapp عدّل الملف config/database.yml بإضافة كلمة سر الحساب الإداري لقاعدة البيانات (أعددناها أثناء تثبيت MySQL، يمكنك تركها فارغة إن لم تكن أعددتَ كلمة سر لـ MySQL): default: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: socket: /var/run/mysqld/mysqld.sock اكتب كلمة السر أمام التعليمة password ضمن المقطع السابق الموجود أعلى الملف بعد التعليقات الأولى (تبدأ التعليقات بالعلامة #)؛ ثم نفّذ الأمر التالي لإنشاء قاعدة البيانات التي سيعمل عليها التطبيق: rake db:create النتيجة: Created database 'myapp_development' Created database 'myapp_test' إن واجهك خطأ Access denied for user 'root'@'localhost' (using password: NO) فهذا يعني أنك لم تكتب كلمة السر بطريقة صحيحة. نشغل خادوم التطوير: rails server يمكنك بعد تشغيل خادوم التطوير إدخال العنوان http://localhost:3000/ في المتصفح لمعاينة صفحة التطبيق المبدئي في Rails. إعداد Git هذه الخطوة اختيارية ولكنه تفيدك إن كنت تخطّط لاستعمال Git لإدارة إصدارات المشروع وربطه بحسابك على Github. أبدل YOUR NAME وYOUR@EMAIL.com في الأوامر أدناه على التوالي باسمك والبريد الذي استخدمته للتسجيل على Github. git config --global color.ui true git config --global user.name "YOUR NAME" git config --global user.email "YOUR@EMAIL.com" ssh-keygen -t rsa -b 4096 -C "YOUR@EMAIL.com" يُولّد الأمر الأخير في الأوامر أعلاه زوج مفاتيح SSH سنستخدمها في ما بعد للاتصال بحسابنا على Github. يضع الأمر ssh-keygen مبدئيا زوج المفاتيح على المسار ssh./~. نأخذ المفتاح العمومي الذي يوجد بملف المفتاح ذي الامتداد pub، ويُسمّى مبدئيا id_rsa.pub وننسخه ضمن مفاتيح SSH على حسابنا في Github الموجودة هنا. انقر على الزّر New SSH Key، أعط للمفتاح اسما تختاره ثم ألصق في الحقل الثاني محتوى الملف ssh/id_rsa.pub/~ الذي يمكن الحصول عليه بالأمر التالي، ثم انقر على زرّ Add SSH Key لاعتماد المفتاح: cat ~/.ssh/id_rsa.pub يمكنك التأكد من نجاح العملية بتنفيذ الأمر التالي: ssh -T git@github.com يجب أن تظهر لك رسالة تشبه التالي (يُذكَر فيها اسم حسابك على Github): Hi Zeine77! You've successfully authenticated, but GitHub does not provide shell access. ترجمة - بتصرّف - للمقال Setup Ruby On Rails on Ubuntu 16.04 Xenial Xerus. -
 مقدّمة يعدّ Composer أحد أكثر الأدوات شيوعا بين مطّوري PHP، فهو مستخدم لإدارة الاعتمادات Dependency management إذ يُسهّل كثيرا من تثبيت وتحديث المكتبات البرمجيّة التي يحتاجها المشروع قيد التطوير. يتحقّق Composer من المكتبات التي يعتمد عليها المشروع ويثبّت الإصدار المناسب منها لمتطلّبات المشروع. يشرح هذا المقال كيفية تثبيت Composer واستخدامه على توزيعة أوبونتو 16.04. سنفترض في هذا المقال أن لديك خادوما يعمل بالإصدار المذكور، إضافة إلى مستخدم أعلى Super user. تثبيت الاعتمادات ينبغي أن نتأكّد أولا، قبل تنزيل Composer، أن حزم البرامج التي يحتاجها موجودة على نظام التشغيل لدينا. نبدأ بتحديث فهرس الحزم: sudo apt-get update ثم نثبّت الحزم المطلوبة: sudo apt install curl php-cli php-mbstring git unzip نحتاج curl لتنزيل Composer وphp-cli لتثبيته وتشغيله. ستكون الحزمة php-mbstring مطلوبة لاستخدام دوال تحتاجها مكتبة سنستخدمها لاحقا. بالنسبة لـ git فيحتاجه Composer لتنزيل اعتمادات المشاريع؛ أما unzip فيُستخدَم لاستخراج ملفات Zip. تنزيل Composer وتثبيته يوفّر Composer برنامج تثبيت مكتوبا بـ PHP. تأكّد من أنك موجود في المجلّد الشخصي للمستخدم ثم احصُل على ملف التثبيت بالأمر curl على النحو التالي: cd ~ curl -sS https://getcomposer.org/installer -o composer-setup.php ينزّل الأمر السابق ملف التثبيت ويحفظه في المجلد الشخصي باسم composer-setup.php. سنتأكّد من أن الملف الذي نزّلناه يوافق التجزئة Hash الخاصة بالملف على موقع Composer للتأكد من سلامته. افتح الصفحة التاليّة وانسخ سلسلة المحارف تحت العنوان Installer Signature (SHA-384) المكوّنة من 96 محرفا مكان SHA-384 في السكربت أدناه، بين الظفرين: php -r "if (hash_file('SHA384', 'composer-setup.php') === '**SHA-384**') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;" ينبغي أن يطبع السكربت الجملة التالية: Installer verified نثبّت Composer على النحو التالي ليكون متاحا على أي مجلّد في النظام” sudo php composer-setup.php --install-dir=/usr/local/bin --filename=composer ينزّل اﻷمر أعلاه Composer ويجعل الأمر composer متاحا على كامل النظام: All settings correct for using Composer Downloading 1.4.1... Composer successfully installed to: /usr/local/bin/composer Use it: php /usr/local/bin/composer للتحقّق من التثبيت نفّذ الأمر composer بدون تمرير معطيات. تظهر النتيجة التالية: ______ / ____/___ ____ ___ ____ ____ ________ _____ / / / __ \/ __ `__ \/ __ \/ __ \/ ___/ _ \/ ___/ / /___/ /_/ / / / / / / /_/ / /_/ (__ ) __/ / \____/\____/_/ /_/ /_/ .___/\____/____/\___/_/ /_/ Composer version 1.4.1 2017-03-10 09:29:45 Usage: command [options] [arguments] Options: -h, --help Display this help message -q, --quiet Do not output any message -V, --version Display this application version --ansi Force ANSI output --no-ansi Disable ANSI output -n, --no-interaction Do not ask any interactive question --profile Display timing and memory usage information --no-plugins Whether to disable plugins. -d, --working-dir=WORKING-DIR If specified, use the given directory as working directory. -v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug Available commands: (...) يعني هذا أن Composer ثُبِّت بنجاح على نظامك. يمكنك كذلك أن تبقي على ملفات Composer تنفيذية خاصّة بكل مشروع بدلا من أن يكون الأمر composer متاحا على كامل النظام. تفيد هذه الطريقة أيضا مفيدة إذا كان المستخدم لا يملك صلاحيات تثبيت الأداة على كامل النظام. في هذه الحالة يكون التثبيت بتنفيذ الأمر التالي بعد تنزيل ملف التثبيت والتحقق منه: php composer-setup.php سيولّد الأمر أعلاه ملف composer.phar في المجلد الذي نُفِّذ فيه الأمر. لتشغيل Composer بعد التثبيت بهذه الطريقة نفّذ الأمر من داخل مجلّد التثبيت: ./composer.phar توليد ملف composer.json ثبّتنا Composer ونحن الآن جاهزون لاستخدامه. أولّ ما يجب علينا فعله لاستغلال إمكانيّات Composer هو إنشاء ملف composer.json. دور ملف composer.json هو إخبار Composer بالمكتبات البرمجيّة التي يحتاجها المشروع الذي نعمل عليه (الاعتمادات)، مع تحديد الإصدارات المطلوبة. من المهمّ جدا تحديد الإصدارات بحيث تتناسق مع مشروعك وتتجنّب تثبيت إصدارات غير مستقرّة قد تؤثّر سلبا على ما تعمل عليه. ليس ضروريّا إنشاءُ ملف composer.json يدويّا، بل إن ذلك يجعل احتمال الأخطاء المطبعيّة في الصياغة أكبر. يولّد Composer ملف composer.json تلقائيا عند إضافة متطلّبات جديدة إلى المشروع بالأمر composer require. يمرّ استخدامُ Composer لتثبيت اعتماد جديد عادة على الخطوات التاليّة: تحديد نوع المكتبة البرمجيّة التي يحتاجها مشروعك. البحث عن مكتبة مناسبة على الموقع Packagist.org، وهو المستودع الرسمي لحزم Composer. اختيار المكتبة البرمجية التي تريد استخدامها في مشروعك. استعمال الأمر composer require لإضافة المكتبة إلى الملف composer.json. تثبيت الحزمة. سنعرض في ما يلي تطبيقا تجريبيا نطبّق من خلاله هذه الخطوات. سيكون الهدف من التطبيق تحويل جملة معيّنة إلى سلسلة محارف تصلح لتكون جزءا من رابط URL، ضمن ما يُعرَف بـ Slug. تُستخدَم هذه الطريقة كثيرا لجعل عنوان صفحة رابطا لها +(تنطبق هذه الملاحظة على المقال الذي تقرأه الآن). نبدأ بإنشاء مجلّد للمشروع نسمّيه slugify ضمن المجلّد الشخصي للمستخدم: cd ~ mkdir slugify cd slugify البحث عن حزم مكتبات على Packagist حان الآن موعد البحث عن مكتبة على Packagist.org لاستخدامها في توليد Slug في مشروعنا. إن بحثت على الموقع عن الكلمة المفتاحية slug فستجد نتائج تشبه التالي. يظهر عددان في الجانب الأيمن لكلّ حزمة في قائمة نتائج البحث. يدلّ العدد الأعلى على مرات تثبيت الحزمة، أما العدد الأسفل فيعني عدد المرات التي حصلت فيها الحزمة على نجمة على Github. يمكنك إعادة ترتيب الحزم حسب هذين العدديْن. عموما، كل ما كانت التثبيتات والنجوم أكثر كلّ ما دلّ ذلك على ثبات الحزمة؛ إلا أن من المهمّ قراءة وصف الحزمة حتى تتأكد من موافقتها لما تريد. نحتاج لمكتبة بسيطة تحوّل الجمل إلى سلسلة محارف لاستخدامها في الروابط. يبدو من أوصاف الحزم في نتائج البحث أن الحزمة cocur/slugify (لا تظهر في لقطة الشاشة أعلاه) مناسبة لنا، كما أن عدد مرات تثبيتها ونجومها مقبول، لذا سنختارها. ربما لاحظت أن أسماء الحزم على Packagist تتضمّن خانتين مفصولتين بشريط مائل. تحيل الخانة الأولى إلى الشركة أو الشخص المطوِّر للحزمة Vendor (وهو cocur في الحزمة التي اخترناها)، أما الخانة الثانيّة فهي اسم الحزمة (slugify). تشكّل الخانتان فضاء أسماء خاصًّا بالحزمة، وهو ما سنمرّره للأمر composer require عند طلب إضافة الحزمة إلى اعتمادات مشروعنا. جعل حزمة من متطلبات المشروع نعرف الآن ماهي الحزمة البرمجيّة التي نريد الاعتماد عليها في مشروعنا. الخطوة المواليّة هي إخبار Composer أن هذه الحزمة مطلوبة لمشروعنا؛ لذا سننفّذ الأمر composer require ونمرّر له فضاء الأسماء الخاصّ بالحزمة: composer require cocur/slugify تظهر مُخرجات الأمر التالية: Using version ^2.5 for cocur/slugify ./composer.json has been created Loading composer repositories with package information Updating dependencies (including require-dev) Package operations: 1 install, 0 updates, 0 removals - Installing cocur/slugify (v2.5): Downloading (100%) Writing lock file Generating autoload files يقرّر Composer تلقائيا، كما يظهر في المخرجات أعلاه، أي إصدار من الحزمة البرمجية سيُثبِّت. إن تحقّقت الآن من مجلّد المشروع فستجد ملفّيْن جديديْن هما composer.json وcomposer.lock ومجلدًّا فرعيّا جديدا باسم vendor: ls -l النتيجة: total 28 -rw-rw-r-- 1 zeine77 zeine77 59 Apr 10 15:15 composer.json -rw-rw-r-- 1 zeine77 zeine77 2901 Apr 10 15:15 composer.lock drwxrwxr-x 4 zeine77 zeine77 4096 Apr 10 15:15 vendor يُستخدَم الملفّ composer.lock لحفظ معلومات عن إصدارات المكتبات البرمجيّة المثبّتة، والتأكّد من استخدام نفس الإصدارات عندما ينسخ مطوّر آخر مشروعك للعمل عليه. تُخزَّن في المجلّد vendor ملفّات المكتبات البرمجيّة. يجب ألّا يودَع Commit المجلّد vendor في نظام إدارة النسخ، بل يُكتفى بإيداع الملفيْن composer.lock وcomposer.json. عند تثبيت مشروع يحتوي على ملفّ composer.json ستحتاج إلى تنفيذ الأمر composer install من أجل تنزيل اعتمادات المشروع. فهم القيود على إصدارات الاعتمادات فلنطبع محتوى الملف composer.json: cat composer.json تظهر النتيجة التاليّة (قد يختلف الإصدار قليلا لديك): { "require": { "cocur/slugify": "^2.5" } } ربّما لاحظت المحرف الخاصّ ^ أمام رقم الإصدار في الملفّ composer.json. يدعم Composer صيغًا وشروطا مختلفة لتحديد الإصدارات المطلوبة من الحزم والمكتبات البرمجيّة، من أجل الحفاظ على ثبات المشروع مع السماح بمرونة أكبر حسب الحاجة. يُنصَح بالعامل ^، المستخدَم عند توليد الملف composer.json تلقائيًّا، للحصول على أعلى قدر من الاستقرار. يعني استخدام ^ أن الإصدار 2.5 هو الإصدار الأدنى المتوافق مع المشروع، مع السماح بتحديث الحزمة في المستقل إلى أي إصدار يقلّ عن3.0. لن تحتاج في أغلب الحالات للتدخلّ وتحرير الملف composer.json لتعديل متطلّبات الإصدار يدويّا؛ إلا أنه توجد حالات يكون فيها هذا الأمر ضروريّا، كأن يُعلَن عن إصدار مهمّ من الحزمة يوفّر ميزات ترغب في الاستفادة منها أو عندما لا تتبع الحزمة التي تستخدمها ترقيما ذا دلالة متعارف عليه). يوضّح الجدول التالي أمثلة على تعريف القيود على الإصدارات في الملف composer.json. يظهر في العمود الأول القيدُ، وفي الثاني دلالة القيد وفي العمود الثالث أمثلة على إصدارات يسمح بها هذا القيد. Constraint Meaning Example Versions Allowed ^1.0 >= 1.0 < 2.0 1.0, 1.2.3, 1.9.9 ^1.1.0 >= 1.1.0 < 2.0 1.1.0, 1.5.6, 1.9.9 ~1.0 >= 1.0 < 2.0.0 1.0, 1.4.1, 1.9.9 ~1.0.0 >= 1.0.0 < 1.1 1.0.0, 1.0.4, 1.0.9 1.2.1 1.2.1 1.2.1 1.* >= 1.0 < 2.0 1.0.0, 1.4.5, 1.9.9 1.2.* >= 1.2 < 1.3 1.2.0, 1.2.3, 1.2.9 يحوي التوثيق الرسمي على شرح مفصّل حول طريقة طتابة القيود في الملف composer.json. تضمين سكربتات تُحمَّل تلقائيا يتيح Composer إمكانيّة التحميل التلقائي لسكربتات PHP، فيتولّى تحميل الأصناف Classes التي ترغب بتوفرها تلقائيا في تطبيقك. يجعل هذا الأمر من التعامل مع الاعتمادات وإنشاء فضاءات أسماء خاصّة بك أسهل كثيرا. كلّ ما تحتاجه لتحميل حزمة تلقائيا هو تضمين الملف vendor/autoload.php في سكربت PHP قبل استهلال Instantiation الصنف (لحظة إنشاء الكائن). نعود للتطبيق المثال slugify. سنستخدم محرر النصوص nano لإنشاء ملفّ باسم test.php داخل مجلّد المشروع الذي أنشأناه سابقا، من أجل استخدام cocur/slugify: nano test.php نضع المحتوى التالي في الملف test.php: <?php require __DIR__ . '/vendor/autoload.php'; use Cocur\Slugify\Slugify; $slugify = new Slugify(); echo $slugify->slugify('Hello World, this is a long sentence and I need to make a slug from it!'); يمكنك تشغيل السكربت من الطرفية على النحو التالي: php test.php تظهر نتيجة التنفيذ التالية: hello-world-this-is-a-long-sentence-and-i-need-to-make-a-slug-from-it تحديث اعتمادات المشروع يُستخدَم الأمر التالي لتحديث اعتمادات المشروع: composer update سيتحقّق الأمر من وجود إصدارات جديدة من المكتبات البرمجيّة المطلوبة لمشروعك، فإن وجد إصدارا جديدا يتوافق مع القيود المعرَّفة ضمن الملف composer.json فسيضعه مكان الإصدارات المثبتة. سيُحدَّث الملف composer.lock ليوافق التغييرات الجديدة. يمكنك كذلك تحديد مكتبات لتحديثها، دون أن تحدّث كامل المشروع، وذلك بتمريرها إلى الأمر composer update: composer update vendor1/package1 vendor2/package2 خاتمة أصبح استخدام Composer شائعا بين المطوّرين لدرجة أنه صار عمليًّا معيارا لتشارك المكتبات البرمجيّة واسكتشافها ممّا يعني أنه أداة ضروريّة لتكون من مجموعة الأدوات التي تعتمد عليها. ترجمة - بتصرّف - للمقال How To Install and Use Composer on Ubuntu 16.04 لصاحبه Brennen Bearnes.
مقدّمة يعدّ Composer أحد أكثر الأدوات شيوعا بين مطّوري PHP، فهو مستخدم لإدارة الاعتمادات Dependency management إذ يُسهّل كثيرا من تثبيت وتحديث المكتبات البرمجيّة التي يحتاجها المشروع قيد التطوير. يتحقّق Composer من المكتبات التي يعتمد عليها المشروع ويثبّت الإصدار المناسب منها لمتطلّبات المشروع. يشرح هذا المقال كيفية تثبيت Composer واستخدامه على توزيعة أوبونتو 16.04. سنفترض في هذا المقال أن لديك خادوما يعمل بالإصدار المذكور، إضافة إلى مستخدم أعلى Super user. تثبيت الاعتمادات ينبغي أن نتأكّد أولا، قبل تنزيل Composer، أن حزم البرامج التي يحتاجها موجودة على نظام التشغيل لدينا. نبدأ بتحديث فهرس الحزم: sudo apt-get update ثم نثبّت الحزم المطلوبة: sudo apt install curl php-cli php-mbstring git unzip نحتاج curl لتنزيل Composer وphp-cli لتثبيته وتشغيله. ستكون الحزمة php-mbstring مطلوبة لاستخدام دوال تحتاجها مكتبة سنستخدمها لاحقا. بالنسبة لـ git فيحتاجه Composer لتنزيل اعتمادات المشاريع؛ أما unzip فيُستخدَم لاستخراج ملفات Zip. تنزيل Composer وتثبيته يوفّر Composer برنامج تثبيت مكتوبا بـ PHP. تأكّد من أنك موجود في المجلّد الشخصي للمستخدم ثم احصُل على ملف التثبيت بالأمر curl على النحو التالي: cd ~ curl -sS https://getcomposer.org/installer -o composer-setup.php ينزّل الأمر السابق ملف التثبيت ويحفظه في المجلد الشخصي باسم composer-setup.php. سنتأكّد من أن الملف الذي نزّلناه يوافق التجزئة Hash الخاصة بالملف على موقع Composer للتأكد من سلامته. افتح الصفحة التاليّة وانسخ سلسلة المحارف تحت العنوان Installer Signature (SHA-384) المكوّنة من 96 محرفا مكان SHA-384 في السكربت أدناه، بين الظفرين: php -r "if (hash_file('SHA384', 'composer-setup.php') === '**SHA-384**') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;" ينبغي أن يطبع السكربت الجملة التالية: Installer verified نثبّت Composer على النحو التالي ليكون متاحا على أي مجلّد في النظام” sudo php composer-setup.php --install-dir=/usr/local/bin --filename=composer ينزّل اﻷمر أعلاه Composer ويجعل الأمر composer متاحا على كامل النظام: All settings correct for using Composer Downloading 1.4.1... Composer successfully installed to: /usr/local/bin/composer Use it: php /usr/local/bin/composer للتحقّق من التثبيت نفّذ الأمر composer بدون تمرير معطيات. تظهر النتيجة التالية: ______ / ____/___ ____ ___ ____ ____ ________ _____ / / / __ \/ __ `__ \/ __ \/ __ \/ ___/ _ \/ ___/ / /___/ /_/ / / / / / / /_/ / /_/ (__ ) __/ / \____/\____/_/ /_/ /_/ .___/\____/____/\___/_/ /_/ Composer version 1.4.1 2017-03-10 09:29:45 Usage: command [options] [arguments] Options: -h, --help Display this help message -q, --quiet Do not output any message -V, --version Display this application version --ansi Force ANSI output --no-ansi Disable ANSI output -n, --no-interaction Do not ask any interactive question --profile Display timing and memory usage information --no-plugins Whether to disable plugins. -d, --working-dir=WORKING-DIR If specified, use the given directory as working directory. -v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug Available commands: (...) يعني هذا أن Composer ثُبِّت بنجاح على نظامك. يمكنك كذلك أن تبقي على ملفات Composer تنفيذية خاصّة بكل مشروع بدلا من أن يكون الأمر composer متاحا على كامل النظام. تفيد هذه الطريقة أيضا مفيدة إذا كان المستخدم لا يملك صلاحيات تثبيت الأداة على كامل النظام. في هذه الحالة يكون التثبيت بتنفيذ الأمر التالي بعد تنزيل ملف التثبيت والتحقق منه: php composer-setup.php سيولّد الأمر أعلاه ملف composer.phar في المجلد الذي نُفِّذ فيه الأمر. لتشغيل Composer بعد التثبيت بهذه الطريقة نفّذ الأمر من داخل مجلّد التثبيت: ./composer.phar توليد ملف composer.json ثبّتنا Composer ونحن الآن جاهزون لاستخدامه. أولّ ما يجب علينا فعله لاستغلال إمكانيّات Composer هو إنشاء ملف composer.json. دور ملف composer.json هو إخبار Composer بالمكتبات البرمجيّة التي يحتاجها المشروع الذي نعمل عليه (الاعتمادات)، مع تحديد الإصدارات المطلوبة. من المهمّ جدا تحديد الإصدارات بحيث تتناسق مع مشروعك وتتجنّب تثبيت إصدارات غير مستقرّة قد تؤثّر سلبا على ما تعمل عليه. ليس ضروريّا إنشاءُ ملف composer.json يدويّا، بل إن ذلك يجعل احتمال الأخطاء المطبعيّة في الصياغة أكبر. يولّد Composer ملف composer.json تلقائيا عند إضافة متطلّبات جديدة إلى المشروع بالأمر composer require. يمرّ استخدامُ Composer لتثبيت اعتماد جديد عادة على الخطوات التاليّة: تحديد نوع المكتبة البرمجيّة التي يحتاجها مشروعك. البحث عن مكتبة مناسبة على الموقع Packagist.org، وهو المستودع الرسمي لحزم Composer. اختيار المكتبة البرمجية التي تريد استخدامها في مشروعك. استعمال الأمر composer require لإضافة المكتبة إلى الملف composer.json. تثبيت الحزمة. سنعرض في ما يلي تطبيقا تجريبيا نطبّق من خلاله هذه الخطوات. سيكون الهدف من التطبيق تحويل جملة معيّنة إلى سلسلة محارف تصلح لتكون جزءا من رابط URL، ضمن ما يُعرَف بـ Slug. تُستخدَم هذه الطريقة كثيرا لجعل عنوان صفحة رابطا لها +(تنطبق هذه الملاحظة على المقال الذي تقرأه الآن). نبدأ بإنشاء مجلّد للمشروع نسمّيه slugify ضمن المجلّد الشخصي للمستخدم: cd ~ mkdir slugify cd slugify البحث عن حزم مكتبات على Packagist حان الآن موعد البحث عن مكتبة على Packagist.org لاستخدامها في توليد Slug في مشروعنا. إن بحثت على الموقع عن الكلمة المفتاحية slug فستجد نتائج تشبه التالي. يظهر عددان في الجانب الأيمن لكلّ حزمة في قائمة نتائج البحث. يدلّ العدد الأعلى على مرات تثبيت الحزمة، أما العدد الأسفل فيعني عدد المرات التي حصلت فيها الحزمة على نجمة على Github. يمكنك إعادة ترتيب الحزم حسب هذين العدديْن. عموما، كل ما كانت التثبيتات والنجوم أكثر كلّ ما دلّ ذلك على ثبات الحزمة؛ إلا أن من المهمّ قراءة وصف الحزمة حتى تتأكد من موافقتها لما تريد. نحتاج لمكتبة بسيطة تحوّل الجمل إلى سلسلة محارف لاستخدامها في الروابط. يبدو من أوصاف الحزم في نتائج البحث أن الحزمة cocur/slugify (لا تظهر في لقطة الشاشة أعلاه) مناسبة لنا، كما أن عدد مرات تثبيتها ونجومها مقبول، لذا سنختارها. ربما لاحظت أن أسماء الحزم على Packagist تتضمّن خانتين مفصولتين بشريط مائل. تحيل الخانة الأولى إلى الشركة أو الشخص المطوِّر للحزمة Vendor (وهو cocur في الحزمة التي اخترناها)، أما الخانة الثانيّة فهي اسم الحزمة (slugify). تشكّل الخانتان فضاء أسماء خاصًّا بالحزمة، وهو ما سنمرّره للأمر composer require عند طلب إضافة الحزمة إلى اعتمادات مشروعنا. جعل حزمة من متطلبات المشروع نعرف الآن ماهي الحزمة البرمجيّة التي نريد الاعتماد عليها في مشروعنا. الخطوة المواليّة هي إخبار Composer أن هذه الحزمة مطلوبة لمشروعنا؛ لذا سننفّذ الأمر composer require ونمرّر له فضاء الأسماء الخاصّ بالحزمة: composer require cocur/slugify تظهر مُخرجات الأمر التالية: Using version ^2.5 for cocur/slugify ./composer.json has been created Loading composer repositories with package information Updating dependencies (including require-dev) Package operations: 1 install, 0 updates, 0 removals - Installing cocur/slugify (v2.5): Downloading (100%) Writing lock file Generating autoload files يقرّر Composer تلقائيا، كما يظهر في المخرجات أعلاه، أي إصدار من الحزمة البرمجية سيُثبِّت. إن تحقّقت الآن من مجلّد المشروع فستجد ملفّيْن جديديْن هما composer.json وcomposer.lock ومجلدًّا فرعيّا جديدا باسم vendor: ls -l النتيجة: total 28 -rw-rw-r-- 1 zeine77 zeine77 59 Apr 10 15:15 composer.json -rw-rw-r-- 1 zeine77 zeine77 2901 Apr 10 15:15 composer.lock drwxrwxr-x 4 zeine77 zeine77 4096 Apr 10 15:15 vendor يُستخدَم الملفّ composer.lock لحفظ معلومات عن إصدارات المكتبات البرمجيّة المثبّتة، والتأكّد من استخدام نفس الإصدارات عندما ينسخ مطوّر آخر مشروعك للعمل عليه. تُخزَّن في المجلّد vendor ملفّات المكتبات البرمجيّة. يجب ألّا يودَع Commit المجلّد vendor في نظام إدارة النسخ، بل يُكتفى بإيداع الملفيْن composer.lock وcomposer.json. عند تثبيت مشروع يحتوي على ملفّ composer.json ستحتاج إلى تنفيذ الأمر composer install من أجل تنزيل اعتمادات المشروع. فهم القيود على إصدارات الاعتمادات فلنطبع محتوى الملف composer.json: cat composer.json تظهر النتيجة التاليّة (قد يختلف الإصدار قليلا لديك): { "require": { "cocur/slugify": "^2.5" } } ربّما لاحظت المحرف الخاصّ ^ أمام رقم الإصدار في الملفّ composer.json. يدعم Composer صيغًا وشروطا مختلفة لتحديد الإصدارات المطلوبة من الحزم والمكتبات البرمجيّة، من أجل الحفاظ على ثبات المشروع مع السماح بمرونة أكبر حسب الحاجة. يُنصَح بالعامل ^، المستخدَم عند توليد الملف composer.json تلقائيًّا، للحصول على أعلى قدر من الاستقرار. يعني استخدام ^ أن الإصدار 2.5 هو الإصدار الأدنى المتوافق مع المشروع، مع السماح بتحديث الحزمة في المستقل إلى أي إصدار يقلّ عن3.0. لن تحتاج في أغلب الحالات للتدخلّ وتحرير الملف composer.json لتعديل متطلّبات الإصدار يدويّا؛ إلا أنه توجد حالات يكون فيها هذا الأمر ضروريّا، كأن يُعلَن عن إصدار مهمّ من الحزمة يوفّر ميزات ترغب في الاستفادة منها أو عندما لا تتبع الحزمة التي تستخدمها ترقيما ذا دلالة متعارف عليه). يوضّح الجدول التالي أمثلة على تعريف القيود على الإصدارات في الملف composer.json. يظهر في العمود الأول القيدُ، وفي الثاني دلالة القيد وفي العمود الثالث أمثلة على إصدارات يسمح بها هذا القيد. Constraint Meaning Example Versions Allowed ^1.0 >= 1.0 < 2.0 1.0, 1.2.3, 1.9.9 ^1.1.0 >= 1.1.0 < 2.0 1.1.0, 1.5.6, 1.9.9 ~1.0 >= 1.0 < 2.0.0 1.0, 1.4.1, 1.9.9 ~1.0.0 >= 1.0.0 < 1.1 1.0.0, 1.0.4, 1.0.9 1.2.1 1.2.1 1.2.1 1.* >= 1.0 < 2.0 1.0.0, 1.4.5, 1.9.9 1.2.* >= 1.2 < 1.3 1.2.0, 1.2.3, 1.2.9 يحوي التوثيق الرسمي على شرح مفصّل حول طريقة طتابة القيود في الملف composer.json. تضمين سكربتات تُحمَّل تلقائيا يتيح Composer إمكانيّة التحميل التلقائي لسكربتات PHP، فيتولّى تحميل الأصناف Classes التي ترغب بتوفرها تلقائيا في تطبيقك. يجعل هذا الأمر من التعامل مع الاعتمادات وإنشاء فضاءات أسماء خاصّة بك أسهل كثيرا. كلّ ما تحتاجه لتحميل حزمة تلقائيا هو تضمين الملف vendor/autoload.php في سكربت PHP قبل استهلال Instantiation الصنف (لحظة إنشاء الكائن). نعود للتطبيق المثال slugify. سنستخدم محرر النصوص nano لإنشاء ملفّ باسم test.php داخل مجلّد المشروع الذي أنشأناه سابقا، من أجل استخدام cocur/slugify: nano test.php نضع المحتوى التالي في الملف test.php: <?php require __DIR__ . '/vendor/autoload.php'; use Cocur\Slugify\Slugify; $slugify = new Slugify(); echo $slugify->slugify('Hello World, this is a long sentence and I need to make a slug from it!'); يمكنك تشغيل السكربت من الطرفية على النحو التالي: php test.php تظهر نتيجة التنفيذ التالية: hello-world-this-is-a-long-sentence-and-i-need-to-make-a-slug-from-it تحديث اعتمادات المشروع يُستخدَم الأمر التالي لتحديث اعتمادات المشروع: composer update سيتحقّق الأمر من وجود إصدارات جديدة من المكتبات البرمجيّة المطلوبة لمشروعك، فإن وجد إصدارا جديدا يتوافق مع القيود المعرَّفة ضمن الملف composer.json فسيضعه مكان الإصدارات المثبتة. سيُحدَّث الملف composer.lock ليوافق التغييرات الجديدة. يمكنك كذلك تحديد مكتبات لتحديثها، دون أن تحدّث كامل المشروع، وذلك بتمريرها إلى الأمر composer update: composer update vendor1/package1 vendor2/package2 خاتمة أصبح استخدام Composer شائعا بين المطوّرين لدرجة أنه صار عمليًّا معيارا لتشارك المكتبات البرمجيّة واسكتشافها ممّا يعني أنه أداة ضروريّة لتكون من مجموعة الأدوات التي تعتمد عليها. ترجمة - بتصرّف - للمقال How To Install and Use Composer on Ubuntu 16.04 لصاحبه Brennen Bearnes. -
 ينتشر استخدام MySQL وMariaDB كثيرا لإدارة قواعد البيانات العلاقيّة، وتستخدم الاثنتان استعلامات SQL لإدخال البيانات في القاعدة واستخراجها منها. على الرغم من أنّ استعلامات SQL في مجملها أوامر سهلة يمكن تعلّمها بيُسر، إلا أن الاستعلامات ودوالّ قواعد البيانات لا تعمل بنفس الكفاءة. تصبح كفاءة استعلامات SQL أكثر أهميّة مع ازدياد كميّة البيانات التي تخزّنها؛ وازدياد شعبيّة موقعك، في حال كنت تستخدم قاعدة البيانات في موقع ويب. يناقش هذا الدليل إجراءات بسيطة تمكّن من تسريع تنفيذ الاستعلامات في MySQL وMariaDB. سنفترض أنّ لديك قاعدة بيانات MySQL أو MariaDB مثبّتة على خادومك. مبادئ عامّة في تهيئة الجداول Tables تبدأ فعاليّة قاعدة البيانات بتصميم بنية جداول تحترم معايير مجرَّبة لتحسين الأداء. يعني هذا أنه يجب عليك التفكير في أفضل طريقة لتنظيم بياناتك قبل البدء في استخدام البرنامج. في ما يلي بضعة أسئلة تساعدك في إيجاد طريقة مثلى لتهيئة مخطّط الجداول في قاعدة البيانات. ما هو الاستخدام الأساسي للجدول؟ تُملي معرفةُ الكيفية التي ستُستغَل بها البيانات الموجودة في الجدول مستقبلا أفضلَ مقاربة لتخطيط الجداول في قاعدة البيانات. إذا كانت بعض البيانات ستُحدَّث باستمرار فإن الأفضل غالبا هو وضعها في جدول خاصّ بها. يوجد في برامج إدارة قواعد البيانات تخبئة Cache داخليّة تُحدَّث ويُعاد بناءها مع كل تغيير على الجدول، فإن كانت البيانات المُحدَّثة في جدول مستقل فإن البرنامج لن يُضطر لتحديث بقيّة البيانات في كلّ مرة وهو ما يعني جهدا أقل ووصولا أسرع. تكون عمليّات التحديث عموما أسرع بكثير عند تنفيذها على جداول صغيرة، بينما يُفضَّّل تنفيذ تحليل البيانات المعقّدة على الجداول الكبيرة، بدلا من تجميع الكثير من الجداول الصغيرة، عبر تعليمات join مثلا. ما هي أنواع البيانات المطلوبة؟ يُمكن أحيانا اقتصاد الكثير من الوقت على المدى الطويل إن استطعت تطبيق قيود سلفا على أحجام البيانات المطلوبة. إن كانت لديك، على سبيل المثال، قيم محدودة لأحد الحقول النصيّة فيمكنك استخدام نوع البيانات enum لهذا الحقل بدلا من varchar. البيانات من النوع البيانات enum ذات حجم صغير وبالتالي يُنفَّذ الاستعلام عنها بسرعة كبيرة. يصلُح النوع enum - مثلا - لحقل يُخزّن أدوار المستخدِمين في منتدى: مدير Admin، مشرف Moderator، مستخدم فعّال Poweruser أو مستخدم عادي User. ماهي الحقول التي ستستعلِم عنها؟ تساهم المعرفة القبْليّة للحقول التي ستبحث عن قيمها باستمرار في التحسين المعتبر لسرعة تنفيذ الاستعلامات، وذلك بفهرسة Indexing حقول البحث. يُضاف الفهرس على حقل على النحو التالي عند إنشاء الجدول: CREATE TABLE example_table ( id INTEGER NOT NULL AUTO_INCREMENT, name VARCHAR(50), address VARCHAR(150), username VARCHAR(16), PRIMARY KEY (id), INDEX (username) ); لاحظ التعليمة INDEX أعلاه. يفيد الفهرس على الحقل username كثيرا إذا كنا نعرف أن زوّار موقعنا سيبحثون عن المستخدمين بأسماء حساباتهم. يُنشئ الاستعلام أعلاه جدول example_table يمكن عرض خاصيّاته كالتالي: explain example_table; +----------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(50) | YES | | NULL | | | address | varchar(150) | YES | | NULL | | | username | varchar(16) | YES | MUL | NULL | | +----------+--------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) يوجد لدينا - كما يظهر - فهرسان. الأول المفتاح الرئيس Primary key ويوجد على حقل المعرِّف id، أما الثاني فهو الذي عرّفناه ويوجد على الحقل username. يعني هذا أن البحث عن المستخدمين بأسماء حساباتهم سيكون أسرع كثيرا من البحث عنهم بأحد الحقول المتبقيّة. من المهمّ جدا، من وجهة نظر التصميم البرمجي، التفكير في الحقول التي يجب أن تُفهرَس وفعل ذلك مع إنشاء الجدول؛ إلا أن بالإمكان ايضا إضافة فهارس إلى جداول موجودة سلفا على النحو التالي: CREATE INDEX index_name ON table_name(column_name); توجد طريقة أخرى للحصول على نفس النتيجة: ALTER TABLE table_name ADD INDEX ( column_name ); استخدام الدالة explain لإيجاد حقول لفهرستها إذا كان برنامجك يطلب تنفيذ استعلامات منتظمة يمكن التنبؤ بها فيجب عليك تحليل هذه الاستعلامات للتأكد من أن الاستعلامات تستخدم حقولا بها فهارس كلما كان ذلك ممكنا. تساعد الدالة explain في هذه المهمة. سنستورد قاعدة البيانات التجريبية الموجودة في المرفق employees_db.zip لتطبيق بعض الأمثلة عليها. نزّل الملف المضغوط ثم نفّذ الأمرين التاليين لفكّ ضغطه والانتقال إلى المجلّد employees_db الناتج عن فك الضغط: tar xjvf employees_db-full-1.0.6.tar.bz2 cd employees_db ثم ننفّذ اﻷمر التالي لاستيراد القاعدة إلى MySQL (ينبغي أن يكون عميل MySQL - حزمة mysql-client - مثبتا لديك): mysql -u root -p -t < employees.sql ستُطلب منك كلمة سرّ خادوم MySQL. نسجّل الدخول إلى خادوم MySQL: mysql -u root -p ننفّذ الأمر التالي داخل المحثّ Prompt الخاص بـMySQL لتحديد قاعدة البيانات التي استوردناها للتو: use employees; نحتاج أولا لإخبار MySQL ألا يستخدم تخبئته الداخليّة ليمكننا الحكم بدقّة على الوقت اللازم لتنفيذ هذه المهامّ. SET GLOBAL query_cache_size = 0; SHOW VARIABLES LIKE "query_cache_size"; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | query_cache_size | 0 | +------------------+-------+ 1 row in set (0.00 sec) يمكننا الآن تشغيل استعلام بسيط على مجموعة كبيرة من البيانات: SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000; +----------+ | count(*) | +----------+ | 588322 | +----------+ 1 row in set (0.80 sec) يطلُب الاستعلام أعلاه عدَّ الموظفين ذوي الدخل المحصور بين 60000 و70000. تُظهر النتيجة وجود 588322 موظف في هذا المجال. نستفيد الآن من الدالة explain لرؤية كيف نُفِّذ الاستعلام السابق وذلك بإضافة الكلمة EXPLAIN أمام الاستعلام الذي طبّقناه للتو: EXPLAIN SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000; +----+-------------+----------+------+---------------+------+---------+------+---------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+------+---------+------+---------+-------------+ | 1 | SIMPLE | salaries | ALL | NULL | NULL | NULL | NULL | 2844738 | Using where | +----+-------------+----------+------+---------------+------+---------+------+---------+-------------+ 1 row in set (0.00 sec) يظهر في نتيجة استخدام التعليمة EXPLAIN أن قيمة الحقل key هي NULL، ما يعني أنه لم يُستخدَم أي فهرس في الاستعلام السابق. فلنضف فهرسا على الحقل salary، ثم لنعد نفس الاستعلام ولننظر إن كان ذلك يُسرّع من تنفيذه: ALTER TABLE salaries ADD INDEX ( salary ); SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000; النتيجة: +----------+ | count(*) | +----------+ | 588322 | +----------+ 1 row in set (0.14 sec) يمكن ملاحظة أن سرعة تنفيذ الاستعلام تحسّنت كثيرا من 0.80 ثانية قبل إضافة الفهرس إلى 0.14بعد إضافته. قاعدة مهمّة أخرى عند استخدام الفهارس هي أنه ينبغي الانتباه إلى ربط الجداول (عبر التعليمة join مثلا)؛ إذ يجب أن تُنشَأ فهارس للحقول المستخدمة في الربط، كما يجب أن تشترك هذه الحقول في نوع البيانات. على سبيل المثال، إن كان لديك جدول يحوي وصفات طعام (وليكن اسمه cheeses) وآخر لمكوّنات كلّ وصفة (وليكن اسمُه ingredients) فإن ربط الجدوليْن يمكن أن يكون حسب حقل من النوع INT (عدد طبيعي) يحوي معرّف المكوّن (وليكن اسمُه ingredient_id) موجود في الجدوليْن. يمكننا بعدها إنشاء فهرس على كل من الحقليْن ingredient_id وبالتالي تسريع استعلامات join كثيرا. تحسين الاستعلامات لتسريع تنفيذها يتعلّق الجزء الثاني من معادلة تسريع الاستعلامات بتحسين الاستعلامات نفسها. تتطلّب بعض التعليمات قدرات حسابية أعلى من تعليمات أخرى، كما يمكن في أحيان كثيرة الحصول على نفس النتيجة بأكثر من طريقة، مع اختلاف في الكلفة الحسابية لكلّ طريقة. يمكن ألا تحتاج إلا إلى نتائج قليلة العدد، حسب الغرض الذي ستستخدم فيه نتيجة الاستعلام. إذا أردت على سبيل المثال معرفة ما إذا كان هناك موظَّف بدخل أقل من 40000 في قاعدة البيانات التي نزّلناها سابقا، فالاستعلام التالي يجيبك: SELECT * FROM SALARIES WHERE salary < 40000 LIMIT 1; النتيجة: +--------+--------+------------+------------+ | emp_no | salary | from_date | to_date | +--------+--------+------------+------------+ | 10022 | 39935 | 2000-09-02 | 2001-09-02 | +--------+--------+------------+------------+ 1 row in set (0.00 sec) يُنفَّّذ الاستعلام سريعا لأنه يكتفي بأول تسجيلة تحقّق الشرط المطلوب. إن كان الاستعلام - مثلا - يستخدم عامل المقارنة OR وكان عنصرا المقارنة يختبران حقولا مختلفة فإن الاستعلام قد يأخذ وقتا أكثر من اللازم. على سبيل المثال، إن أردت البحث عن جميع الموظفين الذين تبدأ أسماءهم الشخصية والعائلية بـBre فستبحث عن قيم حقليْن مختلفيْن (first_name وlast_name). يكون الاستعلام باستخدام العامل OR على النحو التالي: SELECT * FROM employees WHERE last_name like 'Bre%' OR first_name like 'Bre%'; إلا أن الاستعلام قد يكون (حسب طبيعة البيانات في الجدول) أسرع إن بحثتَ عن الأسماء الشخصيّة أولا في استعلام خاصّ ثم عن الأسماء العائلية ثانيا ودمجت الاثنين: SELECT * FROM employees WHERE first_name like 'Bre%' UNION SELECT * FROM employees WHERE last_name like 'Bre%'; خاتمة عرضنا في هذا المقال لبضعة حيّل تساعدك في البدء في تحسين الاستعلامات الموجهة لقاعدة بيانات MySQL (أو MariaDB). توجد الكثير من الحيّل الأخرى التي ستساعدك في الرفع من أداء قاعدة البيانات وبالتالي أداء تطبيقك أو موقعك. يوفّر نظاما إدارة قواعد البيانات MySQL وMariaDB توثيقا جيّدا حول كيفية تحسين استعلاماتك وإعداد قاعدة البيانات لأداء أعلى. يجب أن تتذكّر أن تحسين أداء قاعدة البيانات مرتبط ارتباطا وثيقا بطبيعة استخدامها والبيانات المخزّنة فيها، لذا كلّ ما كانت سيناريوهات الاستخدام أوضح وأكثر انتظاما كلّ ما كان تحسين الاستعلامات أسهل. ترجمة - بتصرف - للمقال How To Optimize Queries and Tables in MySQL and MariaDB on a VPS لصاحبه Justin Ellingwood.
ينتشر استخدام MySQL وMariaDB كثيرا لإدارة قواعد البيانات العلاقيّة، وتستخدم الاثنتان استعلامات SQL لإدخال البيانات في القاعدة واستخراجها منها. على الرغم من أنّ استعلامات SQL في مجملها أوامر سهلة يمكن تعلّمها بيُسر، إلا أن الاستعلامات ودوالّ قواعد البيانات لا تعمل بنفس الكفاءة. تصبح كفاءة استعلامات SQL أكثر أهميّة مع ازدياد كميّة البيانات التي تخزّنها؛ وازدياد شعبيّة موقعك، في حال كنت تستخدم قاعدة البيانات في موقع ويب. يناقش هذا الدليل إجراءات بسيطة تمكّن من تسريع تنفيذ الاستعلامات في MySQL وMariaDB. سنفترض أنّ لديك قاعدة بيانات MySQL أو MariaDB مثبّتة على خادومك. مبادئ عامّة في تهيئة الجداول Tables تبدأ فعاليّة قاعدة البيانات بتصميم بنية جداول تحترم معايير مجرَّبة لتحسين الأداء. يعني هذا أنه يجب عليك التفكير في أفضل طريقة لتنظيم بياناتك قبل البدء في استخدام البرنامج. في ما يلي بضعة أسئلة تساعدك في إيجاد طريقة مثلى لتهيئة مخطّط الجداول في قاعدة البيانات. ما هو الاستخدام الأساسي للجدول؟ تُملي معرفةُ الكيفية التي ستُستغَل بها البيانات الموجودة في الجدول مستقبلا أفضلَ مقاربة لتخطيط الجداول في قاعدة البيانات. إذا كانت بعض البيانات ستُحدَّث باستمرار فإن الأفضل غالبا هو وضعها في جدول خاصّ بها. يوجد في برامج إدارة قواعد البيانات تخبئة Cache داخليّة تُحدَّث ويُعاد بناءها مع كل تغيير على الجدول، فإن كانت البيانات المُحدَّثة في جدول مستقل فإن البرنامج لن يُضطر لتحديث بقيّة البيانات في كلّ مرة وهو ما يعني جهدا أقل ووصولا أسرع. تكون عمليّات التحديث عموما أسرع بكثير عند تنفيذها على جداول صغيرة، بينما يُفضَّّل تنفيذ تحليل البيانات المعقّدة على الجداول الكبيرة، بدلا من تجميع الكثير من الجداول الصغيرة، عبر تعليمات join مثلا. ما هي أنواع البيانات المطلوبة؟ يُمكن أحيانا اقتصاد الكثير من الوقت على المدى الطويل إن استطعت تطبيق قيود سلفا على أحجام البيانات المطلوبة. إن كانت لديك، على سبيل المثال، قيم محدودة لأحد الحقول النصيّة فيمكنك استخدام نوع البيانات enum لهذا الحقل بدلا من varchar. البيانات من النوع البيانات enum ذات حجم صغير وبالتالي يُنفَّذ الاستعلام عنها بسرعة كبيرة. يصلُح النوع enum - مثلا - لحقل يُخزّن أدوار المستخدِمين في منتدى: مدير Admin، مشرف Moderator، مستخدم فعّال Poweruser أو مستخدم عادي User. ماهي الحقول التي ستستعلِم عنها؟ تساهم المعرفة القبْليّة للحقول التي ستبحث عن قيمها باستمرار في التحسين المعتبر لسرعة تنفيذ الاستعلامات، وذلك بفهرسة Indexing حقول البحث. يُضاف الفهرس على حقل على النحو التالي عند إنشاء الجدول: CREATE TABLE example_table ( id INTEGER NOT NULL AUTO_INCREMENT, name VARCHAR(50), address VARCHAR(150), username VARCHAR(16), PRIMARY KEY (id), INDEX (username) ); لاحظ التعليمة INDEX أعلاه. يفيد الفهرس على الحقل username كثيرا إذا كنا نعرف أن زوّار موقعنا سيبحثون عن المستخدمين بأسماء حساباتهم. يُنشئ الاستعلام أعلاه جدول example_table يمكن عرض خاصيّاته كالتالي: explain example_table; +----------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(50) | YES | | NULL | | | address | varchar(150) | YES | | NULL | | | username | varchar(16) | YES | MUL | NULL | | +----------+--------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) يوجد لدينا - كما يظهر - فهرسان. الأول المفتاح الرئيس Primary key ويوجد على حقل المعرِّف id، أما الثاني فهو الذي عرّفناه ويوجد على الحقل username. يعني هذا أن البحث عن المستخدمين بأسماء حساباتهم سيكون أسرع كثيرا من البحث عنهم بأحد الحقول المتبقيّة. من المهمّ جدا، من وجهة نظر التصميم البرمجي، التفكير في الحقول التي يجب أن تُفهرَس وفعل ذلك مع إنشاء الجدول؛ إلا أن بالإمكان ايضا إضافة فهارس إلى جداول موجودة سلفا على النحو التالي: CREATE INDEX index_name ON table_name(column_name); توجد طريقة أخرى للحصول على نفس النتيجة: ALTER TABLE table_name ADD INDEX ( column_name ); استخدام الدالة explain لإيجاد حقول لفهرستها إذا كان برنامجك يطلب تنفيذ استعلامات منتظمة يمكن التنبؤ بها فيجب عليك تحليل هذه الاستعلامات للتأكد من أن الاستعلامات تستخدم حقولا بها فهارس كلما كان ذلك ممكنا. تساعد الدالة explain في هذه المهمة. سنستورد قاعدة البيانات التجريبية الموجودة في المرفق employees_db.zip لتطبيق بعض الأمثلة عليها. نزّل الملف المضغوط ثم نفّذ الأمرين التاليين لفكّ ضغطه والانتقال إلى المجلّد employees_db الناتج عن فك الضغط: tar xjvf employees_db-full-1.0.6.tar.bz2 cd employees_db ثم ننفّذ اﻷمر التالي لاستيراد القاعدة إلى MySQL (ينبغي أن يكون عميل MySQL - حزمة mysql-client - مثبتا لديك): mysql -u root -p -t < employees.sql ستُطلب منك كلمة سرّ خادوم MySQL. نسجّل الدخول إلى خادوم MySQL: mysql -u root -p ننفّذ الأمر التالي داخل المحثّ Prompt الخاص بـMySQL لتحديد قاعدة البيانات التي استوردناها للتو: use employees; نحتاج أولا لإخبار MySQL ألا يستخدم تخبئته الداخليّة ليمكننا الحكم بدقّة على الوقت اللازم لتنفيذ هذه المهامّ. SET GLOBAL query_cache_size = 0; SHOW VARIABLES LIKE "query_cache_size"; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | query_cache_size | 0 | +------------------+-------+ 1 row in set (0.00 sec) يمكننا الآن تشغيل استعلام بسيط على مجموعة كبيرة من البيانات: SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000; +----------+ | count(*) | +----------+ | 588322 | +----------+ 1 row in set (0.80 sec) يطلُب الاستعلام أعلاه عدَّ الموظفين ذوي الدخل المحصور بين 60000 و70000. تُظهر النتيجة وجود 588322 موظف في هذا المجال. نستفيد الآن من الدالة explain لرؤية كيف نُفِّذ الاستعلام السابق وذلك بإضافة الكلمة EXPLAIN أمام الاستعلام الذي طبّقناه للتو: EXPLAIN SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000; +----+-------------+----------+------+---------------+------+---------+------+---------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+----------+------+---------------+------+---------+------+---------+-------------+ | 1 | SIMPLE | salaries | ALL | NULL | NULL | NULL | NULL | 2844738 | Using where | +----+-------------+----------+------+---------------+------+---------+------+---------+-------------+ 1 row in set (0.00 sec) يظهر في نتيجة استخدام التعليمة EXPLAIN أن قيمة الحقل key هي NULL، ما يعني أنه لم يُستخدَم أي فهرس في الاستعلام السابق. فلنضف فهرسا على الحقل salary، ثم لنعد نفس الاستعلام ولننظر إن كان ذلك يُسرّع من تنفيذه: ALTER TABLE salaries ADD INDEX ( salary ); SELECT COUNT(*) FROM salaries WHERE salary BETWEEN 60000 AND 70000; النتيجة: +----------+ | count(*) | +----------+ | 588322 | +----------+ 1 row in set (0.14 sec) يمكن ملاحظة أن سرعة تنفيذ الاستعلام تحسّنت كثيرا من 0.80 ثانية قبل إضافة الفهرس إلى 0.14بعد إضافته. قاعدة مهمّة أخرى عند استخدام الفهارس هي أنه ينبغي الانتباه إلى ربط الجداول (عبر التعليمة join مثلا)؛ إذ يجب أن تُنشَأ فهارس للحقول المستخدمة في الربط، كما يجب أن تشترك هذه الحقول في نوع البيانات. على سبيل المثال، إن كان لديك جدول يحوي وصفات طعام (وليكن اسمه cheeses) وآخر لمكوّنات كلّ وصفة (وليكن اسمُه ingredients) فإن ربط الجدوليْن يمكن أن يكون حسب حقل من النوع INT (عدد طبيعي) يحوي معرّف المكوّن (وليكن اسمُه ingredient_id) موجود في الجدوليْن. يمكننا بعدها إنشاء فهرس على كل من الحقليْن ingredient_id وبالتالي تسريع استعلامات join كثيرا. تحسين الاستعلامات لتسريع تنفيذها يتعلّق الجزء الثاني من معادلة تسريع الاستعلامات بتحسين الاستعلامات نفسها. تتطلّب بعض التعليمات قدرات حسابية أعلى من تعليمات أخرى، كما يمكن في أحيان كثيرة الحصول على نفس النتيجة بأكثر من طريقة، مع اختلاف في الكلفة الحسابية لكلّ طريقة. يمكن ألا تحتاج إلا إلى نتائج قليلة العدد، حسب الغرض الذي ستستخدم فيه نتيجة الاستعلام. إذا أردت على سبيل المثال معرفة ما إذا كان هناك موظَّف بدخل أقل من 40000 في قاعدة البيانات التي نزّلناها سابقا، فالاستعلام التالي يجيبك: SELECT * FROM SALARIES WHERE salary < 40000 LIMIT 1; النتيجة: +--------+--------+------------+------------+ | emp_no | salary | from_date | to_date | +--------+--------+------------+------------+ | 10022 | 39935 | 2000-09-02 | 2001-09-02 | +--------+--------+------------+------------+ 1 row in set (0.00 sec) يُنفَّّذ الاستعلام سريعا لأنه يكتفي بأول تسجيلة تحقّق الشرط المطلوب. إن كان الاستعلام - مثلا - يستخدم عامل المقارنة OR وكان عنصرا المقارنة يختبران حقولا مختلفة فإن الاستعلام قد يأخذ وقتا أكثر من اللازم. على سبيل المثال، إن أردت البحث عن جميع الموظفين الذين تبدأ أسماءهم الشخصية والعائلية بـBre فستبحث عن قيم حقليْن مختلفيْن (first_name وlast_name). يكون الاستعلام باستخدام العامل OR على النحو التالي: SELECT * FROM employees WHERE last_name like 'Bre%' OR first_name like 'Bre%'; إلا أن الاستعلام قد يكون (حسب طبيعة البيانات في الجدول) أسرع إن بحثتَ عن الأسماء الشخصيّة أولا في استعلام خاصّ ثم عن الأسماء العائلية ثانيا ودمجت الاثنين: SELECT * FROM employees WHERE first_name like 'Bre%' UNION SELECT * FROM employees WHERE last_name like 'Bre%'; خاتمة عرضنا في هذا المقال لبضعة حيّل تساعدك في البدء في تحسين الاستعلامات الموجهة لقاعدة بيانات MySQL (أو MariaDB). توجد الكثير من الحيّل الأخرى التي ستساعدك في الرفع من أداء قاعدة البيانات وبالتالي أداء تطبيقك أو موقعك. يوفّر نظاما إدارة قواعد البيانات MySQL وMariaDB توثيقا جيّدا حول كيفية تحسين استعلاماتك وإعداد قاعدة البيانات لأداء أعلى. يجب أن تتذكّر أن تحسين أداء قاعدة البيانات مرتبط ارتباطا وثيقا بطبيعة استخدامها والبيانات المخزّنة فيها، لذا كلّ ما كانت سيناريوهات الاستخدام أوضح وأكثر انتظاما كلّ ما كان تحسين الاستعلامات أسهل. ترجمة - بتصرف - للمقال How To Optimize Queries and Tables in MySQL and MariaDB on a VPS لصاحبه Justin Ellingwood. -
 يحدُث كثيراً أن ينقسم مجتمع المطوّرين حول تقنيّات يراها بعضهم غير ذات جدوى أو على الأقل ليست بالأهميّة التي يروّج لها مؤيّدوها. تنطبق هذه الملاحظة على أطر العمل التي تعمل على ربط العلاقات بالكائنات Object relational mapping (أو ORM اختصارا)، ومن بينها Eloquent الذي يُستخدَم مبدئيًّا في Laravel؛ دون أن يعني ذلك عدم إمكانيّة استخدامه خارج Laravel كما سنرى في هذه السّلسلة. ليست أطر عمل ORM بالتقنيّة الجديدة، فهي توجد منذ سنين وأصبحت جزءًا من عمليّة التطوير بالنسبة للكثير من المبرمجين؛ كما أنها حسّنت من أدائها وتغلّبت على الكثير من النواقص مع الزمن. يتناول هذا الدّرس، الأوّل من سلسلة دروس عن الإطار Eloquent ORM، الأسباب التي أدّت إلى ظهور أطر عمل ORM والهدف من ورائها. التصوّر البرمجي Programming paradigm وإدارة البيانات العلاقيّة تُكتَب أغلب تطبيقات PHP الحديثة بأسلوب ذي تصوّر Paradigm كائنيّ التوجّه Object oriented، بينما تستخدم قواعدَ بيانات علاقيّة لإدارة البيانات وتخزينها. دور أُطُر عمل ORM هو تسهيل الانتقال بين هذيْن العالميْن أثناء تشغيل التطبيق. البرمجة كائنية التوجّه تعتمد لغات البرمجة على أفكار ونُظُم تحدّد طريقة عملها وأساليب كتابة البرامج التي تعمل بها. تُسمّى هذه الأساليب والقواعد بالتصورات البرمجيّة. يمكن للغةِ برمجة أن تُصنَّف في أكثر من تصوّر؛ إلّا أن كل لغة تركّز غالبًا على بضعة تصوّرات، ممّا يجعل كتابة برامج وفقَ هذه التصوّر ات أسهل بالنسبة لمبرمجي اللغة. تدعم لغة PHP البرمجيّة ميزات من تصوّرات برمجيّة عدّة؛ إلا أنها تُركّز على تصوّريْن: التصوّر الإجرائي Procedural الذي يمكن عدّه التصوّر الأساسي للغة منذ بداياتها. التصوّر كائنيّ التوجه Object oriented الذي اعتمده مصمّمو لغة البرمجة - فعليًّا - في الإصدار الخامس (سنة 2004). يُؤسَّس التصوّر الإجرائي على التصريح بكيفيّة إجراء العمليّات، خطوة بخطوة، واستخدام الحلقات Loops، العبارات الشرطيّة Conditions وتجميع الأوامر في سياقات محليّة Local context أو ضمن وحدات Modules يمكن استدعاءها عند الحاجة. أما التصوّر كائنيّ التوجه فيقوم على جمع البيانات والإجراءات (الدوالّ) ضمن كائن Object واحد يمكنه تطبيق الإجراءات المضمَّنة فيه على البيانات التي تخصّه. أنظمة قواعد بيانات العلاقيّة يعتمد النموذج العلاقي على نظريّة المجموعات Set theory والمنطق الرياضي من أجل تجميع البيانات ضمن جداول Tables؛ هي في الواقع علاقات Relations وفق التعريف الرياضي، ومنه التسميّة. يهدف النموذج العلاقي إلى تقديم طريقة تمكّن المستخدمين من تحديد البيانات المُعدّة للتخزين في قاعدة البيانات وتلك التي يريدون الحصول عليها من القاعدة، دون الاهتمام بالكيفيّة التي يستخدمها نظام الإدارة للإجابة على هذه الطلبات. يسمّى التصوّر البرمجي الذي يهتمّ بماهيّة المهمّة دون التركيز كثيرًا على كيفيّة أدائها بالتصوّر التقريري Declarative paradigm. يمكن عدّ لغة الاستعلام SQL تطبيقًا عمليًّا للنموذج العلاقي، وإن كانت تنحرف أحيانًا عن هذا النموذج. ربط العلاقات بالكائنات Object relational mapping تنبني شفرة التطبيقات التي تعتمد على تصوّر كائنيّ التوجه على أسس نظريّة تختلف عن تلك التي تُبنى عليها قواعد البيانات (النموذج العلاقي)؛ وهو ما يعني أنه على المطورين إيجاد طريقة للتخاطب مع قاعدة البيانات انطلاقًا من الشفرة البرمجيّة. يستخدم المبرمجون عادةً كائنًا مخصّصًا - يُسمّى كائن الوصول إلى البيانات Data access object، أو DAO اختصارا - لتخزين البيانات في القاعدة أو جلبها منها ثم تقديمها لبقيّة التطبيق بصيغة تناسبه. تُكتَب في هذا الصّنف استعلامات SQL المطلوب تنفيذها للتخاطب مع قاعدة البيانات، إما مباشرة أو عبر مكتبة وسيطة. يُساعد استخدام كائن DAO على الفصل بين أجزاء التطبيق واحترام مبادئ نمط التطوير Model-Vue-Controller (أو MVC اختصارا)؛ إلا أنّ كائنات DAO تتطلّب الكثير من الوقت، إذ يتحتّم على المطوِّر كتابة الكثير من التعليمات لتخزين البيانات في القاعدة أو جلبها منها. تأتي أطُر عمل ORM - ومن بينها Eloquent - للتخفيف من عبء هذه المهمّة. إطار العمل Eloquent ORM يسعى Laravel إلى أن يكون إطار عمل سهلَ الاستخدام يوفّر على المطوّرين الوقت ويرفع من إنتاجيّتهم؛ لذا جعل من Eloquent إطار عمل ORM الذي يستخدمه مبدئيًّا، لما يتميّز به من سهولة الاستخدام ووضوح آليّة العمل. طُوِّر Eloquent وفقا لنمط التسجيلة النشطة Active record الذي يقوم على وجود صنف Class لكلّ جدول في قاعدة البيانات، بحيث يُنشَأ كائن من هذا الصّنف لكل تسجيلة (سطر في الجدول). يعني هذا أن بيانات الكائن تحمل نسخة طبق الأصل من تسجيل الجدوَل. يُسمِّى Eloquent الصّنفَ الذي يطابق الجدول بالنموذج Model. يحوي كلّ كائن من هذا الصنف خاصيّات Attributes بعدد وأسماء توافق حقول (أعمدة) الجدول؛ وتمكّن الدوالّ التي يوفّرها من القيام بعمليّات من قبيل إدراج التسجيلة، التعديل عليها أو حذفها. إذا كان لدينا - مثلا - جدول في قاعدة البيانات باسم Address نحتفظ فيه بعناوين أشخاص، فإن إدراج عنوان جديد في قاعدة البيانات سيكافئ إنشاء كائن من الصنف (النموذج) Address وملئه بالبيانات التي نريد ثم استدعاء دالة التخزين في هذا الكائن. يضيف Eloquent وظائف مساعدة مثل التحقّق من أن الكائنات تحترم قواعد معيّنة قبل تخزينها في الجدول؛ وهو ما يعني التقليل من الأخطاء على مستوى قاعدة البيانات. قد تجد نفسك أمام حالات معقّدة لا تؤدّي فيها هذه الطريقة (تطبيق الدوالّ على الصنف المماثل لجدول قاعدة البيانات) النتيجة المطلوبة؛ يمكنك في هذه الحالة استخدام منشئ الاستعلامات Query builder وكتابة استعلامات SQL مباشرة. يُنصَح بتجنّب Eloquent عند تنفيذ سلسلة طويلة من المهامّ تلقائيًّا، دون تدخّل يدوي. يُناسب Eloquent المعاملات Transactions، وهي مجموعة إجراءات تُنفَّذ في قاعدة البيانات على أنّها وِحدة لا تتجزّأ: إما أن تُطبَّق جميع الإجراءات الموجودة في المعاملة أو لا تُطبَّق أي منها.
يحدُث كثيراً أن ينقسم مجتمع المطوّرين حول تقنيّات يراها بعضهم غير ذات جدوى أو على الأقل ليست بالأهميّة التي يروّج لها مؤيّدوها. تنطبق هذه الملاحظة على أطر العمل التي تعمل على ربط العلاقات بالكائنات Object relational mapping (أو ORM اختصارا)، ومن بينها Eloquent الذي يُستخدَم مبدئيًّا في Laravel؛ دون أن يعني ذلك عدم إمكانيّة استخدامه خارج Laravel كما سنرى في هذه السّلسلة. ليست أطر عمل ORM بالتقنيّة الجديدة، فهي توجد منذ سنين وأصبحت جزءًا من عمليّة التطوير بالنسبة للكثير من المبرمجين؛ كما أنها حسّنت من أدائها وتغلّبت على الكثير من النواقص مع الزمن. يتناول هذا الدّرس، الأوّل من سلسلة دروس عن الإطار Eloquent ORM، الأسباب التي أدّت إلى ظهور أطر عمل ORM والهدف من ورائها. التصوّر البرمجي Programming paradigm وإدارة البيانات العلاقيّة تُكتَب أغلب تطبيقات PHP الحديثة بأسلوب ذي تصوّر Paradigm كائنيّ التوجّه Object oriented، بينما تستخدم قواعدَ بيانات علاقيّة لإدارة البيانات وتخزينها. دور أُطُر عمل ORM هو تسهيل الانتقال بين هذيْن العالميْن أثناء تشغيل التطبيق. البرمجة كائنية التوجّه تعتمد لغات البرمجة على أفكار ونُظُم تحدّد طريقة عملها وأساليب كتابة البرامج التي تعمل بها. تُسمّى هذه الأساليب والقواعد بالتصورات البرمجيّة. يمكن للغةِ برمجة أن تُصنَّف في أكثر من تصوّر؛ إلّا أن كل لغة تركّز غالبًا على بضعة تصوّرات، ممّا يجعل كتابة برامج وفقَ هذه التصوّر ات أسهل بالنسبة لمبرمجي اللغة. تدعم لغة PHP البرمجيّة ميزات من تصوّرات برمجيّة عدّة؛ إلا أنها تُركّز على تصوّريْن: التصوّر الإجرائي Procedural الذي يمكن عدّه التصوّر الأساسي للغة منذ بداياتها. التصوّر كائنيّ التوجه Object oriented الذي اعتمده مصمّمو لغة البرمجة - فعليًّا - في الإصدار الخامس (سنة 2004). يُؤسَّس التصوّر الإجرائي على التصريح بكيفيّة إجراء العمليّات، خطوة بخطوة، واستخدام الحلقات Loops، العبارات الشرطيّة Conditions وتجميع الأوامر في سياقات محليّة Local context أو ضمن وحدات Modules يمكن استدعاءها عند الحاجة. أما التصوّر كائنيّ التوجه فيقوم على جمع البيانات والإجراءات (الدوالّ) ضمن كائن Object واحد يمكنه تطبيق الإجراءات المضمَّنة فيه على البيانات التي تخصّه. أنظمة قواعد بيانات العلاقيّة يعتمد النموذج العلاقي على نظريّة المجموعات Set theory والمنطق الرياضي من أجل تجميع البيانات ضمن جداول Tables؛ هي في الواقع علاقات Relations وفق التعريف الرياضي، ومنه التسميّة. يهدف النموذج العلاقي إلى تقديم طريقة تمكّن المستخدمين من تحديد البيانات المُعدّة للتخزين في قاعدة البيانات وتلك التي يريدون الحصول عليها من القاعدة، دون الاهتمام بالكيفيّة التي يستخدمها نظام الإدارة للإجابة على هذه الطلبات. يسمّى التصوّر البرمجي الذي يهتمّ بماهيّة المهمّة دون التركيز كثيرًا على كيفيّة أدائها بالتصوّر التقريري Declarative paradigm. يمكن عدّ لغة الاستعلام SQL تطبيقًا عمليًّا للنموذج العلاقي، وإن كانت تنحرف أحيانًا عن هذا النموذج. ربط العلاقات بالكائنات Object relational mapping تنبني شفرة التطبيقات التي تعتمد على تصوّر كائنيّ التوجه على أسس نظريّة تختلف عن تلك التي تُبنى عليها قواعد البيانات (النموذج العلاقي)؛ وهو ما يعني أنه على المطورين إيجاد طريقة للتخاطب مع قاعدة البيانات انطلاقًا من الشفرة البرمجيّة. يستخدم المبرمجون عادةً كائنًا مخصّصًا - يُسمّى كائن الوصول إلى البيانات Data access object، أو DAO اختصارا - لتخزين البيانات في القاعدة أو جلبها منها ثم تقديمها لبقيّة التطبيق بصيغة تناسبه. تُكتَب في هذا الصّنف استعلامات SQL المطلوب تنفيذها للتخاطب مع قاعدة البيانات، إما مباشرة أو عبر مكتبة وسيطة. يُساعد استخدام كائن DAO على الفصل بين أجزاء التطبيق واحترام مبادئ نمط التطوير Model-Vue-Controller (أو MVC اختصارا)؛ إلا أنّ كائنات DAO تتطلّب الكثير من الوقت، إذ يتحتّم على المطوِّر كتابة الكثير من التعليمات لتخزين البيانات في القاعدة أو جلبها منها. تأتي أطُر عمل ORM - ومن بينها Eloquent - للتخفيف من عبء هذه المهمّة. إطار العمل Eloquent ORM يسعى Laravel إلى أن يكون إطار عمل سهلَ الاستخدام يوفّر على المطوّرين الوقت ويرفع من إنتاجيّتهم؛ لذا جعل من Eloquent إطار عمل ORM الذي يستخدمه مبدئيًّا، لما يتميّز به من سهولة الاستخدام ووضوح آليّة العمل. طُوِّر Eloquent وفقا لنمط التسجيلة النشطة Active record الذي يقوم على وجود صنف Class لكلّ جدول في قاعدة البيانات، بحيث يُنشَأ كائن من هذا الصّنف لكل تسجيلة (سطر في الجدول). يعني هذا أن بيانات الكائن تحمل نسخة طبق الأصل من تسجيل الجدوَل. يُسمِّى Eloquent الصّنفَ الذي يطابق الجدول بالنموذج Model. يحوي كلّ كائن من هذا الصنف خاصيّات Attributes بعدد وأسماء توافق حقول (أعمدة) الجدول؛ وتمكّن الدوالّ التي يوفّرها من القيام بعمليّات من قبيل إدراج التسجيلة، التعديل عليها أو حذفها. إذا كان لدينا - مثلا - جدول في قاعدة البيانات باسم Address نحتفظ فيه بعناوين أشخاص، فإن إدراج عنوان جديد في قاعدة البيانات سيكافئ إنشاء كائن من الصنف (النموذج) Address وملئه بالبيانات التي نريد ثم استدعاء دالة التخزين في هذا الكائن. يضيف Eloquent وظائف مساعدة مثل التحقّق من أن الكائنات تحترم قواعد معيّنة قبل تخزينها في الجدول؛ وهو ما يعني التقليل من الأخطاء على مستوى قاعدة البيانات. قد تجد نفسك أمام حالات معقّدة لا تؤدّي فيها هذه الطريقة (تطبيق الدوالّ على الصنف المماثل لجدول قاعدة البيانات) النتيجة المطلوبة؛ يمكنك في هذه الحالة استخدام منشئ الاستعلامات Query builder وكتابة استعلامات SQL مباشرة. يُنصَح بتجنّب Eloquent عند تنفيذ سلسلة طويلة من المهامّ تلقائيًّا، دون تدخّل يدوي. يُناسب Eloquent المعاملات Transactions، وهي مجموعة إجراءات تُنفَّذ في قاعدة البيانات على أنّها وِحدة لا تتجزّأ: إما أن تُطبَّق جميع الإجراءات الموجودة في المعاملة أو لا تُطبَّق أي منها. -
 لطالما وفّر إطار العمل Laravel آليات سهلة للاستيثاق Authentication بالطرق التقليدية مثل استمارات Forms تسجيل الدخول في واجهة الوِب؛ إلا أن الأمر لم يكن سهلا بما فيه الكفاية بالنسبة للاستيثاق من الطلبات القادمة عبر واجهة تطبيقات برمجية. يأتي الإصدار 5.3 بحزمة جديدة، تُسمّى Passport، تهتم بتيسير استخدام Laravel لضبط خادوم Oauth وإعداده. يتناول هذا الدرس كيفية إعداد Laravel ليوفّر وظيفة خادوم Oauth اعتمادا على حزمة Passport. خادوم Oauth من المحتمل جدّا أنه سبق لك التعامل مع خادوم Oauth؛ مثلا عند استخدام حسابات على الشبكات الاجتماعية (فيس بوك، تويتر، … إلخ) للتسجيل في موقع على الشبكة. الفكرة التي تنبني عليها آلية الاستيثاق هذه هي تفويض عمليّة الاستيثاق إلى خادوم Oauth. نفترض مثلا أن لديك موقعا يستخدم هذه الآلية؛ عند تسجيل دخول الموقع عن طريق الحساب على فيس بوك فإن ما يحدُث هو التالي: يلج المستخدم إلى الموقع ويختار طريقة تسجيل الدخول (فيس بوك). يُنقَل المستخدم إلى صفحة تسجيل الدخول في فيس بوك حيثُ يُطلَب منه تسجيل الدخول إن لم يكن سبق له ذلك ثم يؤكّد سماحه لموقعك باستخدام حسابه على فيس بوك. يُعاد توجيه المستخدم إلى الموقع مع تسجيل دخوله إليه. يفترض هذا الدرس أن لديك إلماما بكيفية عمل خواديم Oauth للتصريح بالدخول. يمكن الاطّلاع على مقال مدخل إلى OAuth 2 للمزيد عن هذا الموضوع. إن كنتَ تبحث عن كيفية تسجيل الدخول إلى تطبيقك باستخدام حساب على موقع يوفّر وظيفة Oauth فراجع درس تسجيل الدخول عبر الشبكات الاجتماعية في Laravel باستخدام Socialite. إعداد خادوم Oauth على Laravel 5.3 يحتاج إعداد Passport على Laravel لتنفيذ بضعة أوامر وتحرير ملفات إعداد؛ إلا أن العملية عموما سهلة. ابدأ بتثبيت الإصدار 5.3 من Laravel: composer create-project --prefer-dist laravel/laravel laravel53oauth "5.3.*" نستخدم composer لإضافة حزمة Passport إلى متطلبات المشروع: composer require laravel/passport نسجّل مزوّد الخدمة Passport في ملفّ الإعداد config/app.php. افتح الملف ثم أضف السطر التالي إلى مصفوفة providers: Laravel\Passport\PassportServiceProvider::class, تأكّد من إعدادات قاعدة البيانات ثمّ نفّذ أمر التهجير Migration التالي: php artisan migrate ستلاحظ تنفيذ تهجيرات إضافية علاوة على تلك التي تأتي مبدئيّا مع Laravel: Migration table created successfully. Migrated: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_100000_create_password_resets_table Migrated: 2016_06_01_000001_create_oauth_auth_codes_table Migrated: 2016_06_01_000002_create_oauth_access_tokens_table Migrated: 2016_06_01_000003_create_oauth_refresh_tokens_table Migrated: 2016_06_01_000004_create_oauth_clients_table Migrated: 2016_06_01_000005_create_oauth_personal_access_clients_table يأتي مزوّد الخدمة Passport مع تهجيرات لإنشاء جداول تخزّن عملاء Client التطبيق ومعلومات رموز الوصول Access tokens. ثم ننفّذ الأمر التالي الذي سيولّد مفاتيح التعميّة Encryption keys الخاصّة بمشروع كما أنه ينشئ رموز الوصول ويخزّنها في جدول البيانات المناسب: php artisan passport:install ننتقل الآن إلى نموذج المستخدم User ونضيف إليه السّمة Trait المسمّاة HasApiTokens. يُصبح النموذج على النحو التالي (بعد نزع التعليقات للاختصار): <?php namespace App; use Illuminate\Notifications\Notifiable; use Illuminate\Foundation\Auth\User as Authenticatable; // استيراد السّمة use Laravel\Passport\HasApiTokens; class User extends Authenticatable { // استخدام السمة use HasApiTokens, Notifiable; protected $fillable = [ 'name', 'email', 'password', ]; protected $hidden = [ 'password', 'remember_token', ]; } توفّر هذه السّمة مجموعة من الدوال المساعدة التي تتيح الحصول على رموز الوصول الخاصّة بالمستخدمين ومدى الصلاحيّات Permissions scope المتاح للعميل. الخطوة المواليّة هي استدعاء الدالة Passport::routes ضمن الدالة boot الموجودة في مزوّد خدمة الاستيثاق app/Providers/AuthServiceProvider.php: public function boot() { $this->registerPolicies(); Passport::routes(); } لا تنس استدعاء الصنف Laravel\Passport\Passport في مزوّد خدمة الاستيثاق: use Laravel\Passport\Passport; يمكنك ملاحظة المسارات الجديدة التي أضافتها الدالة Passport::routes بتنفيذ أمر Artisan التالي الذي يسرُد لائحة بالمسارات الموجودة في المشروع: php artisan route:list الخطوة الأخيرة هي تعديل ملف الإعداد config/auth.php وتحديد قيمة driver في المصفوفة api لتصبح passport بدلا من token: 'api' => [ 'driver' => 'passport', 'provider' => 'users', ], يعتمد Laravel مبدئيا على رموز للاستيثاق من الطلبات القادمة عبر واجهة التطبيقات البرمجية؛ إلا أن هذه الرموز المبدئية لا تتيح إلا القليل من الخيارات، عكس ما يوفّره Passport. بهذا نكون أنهينا إعداد Laravel لأداء وظيفة خادوم Oauth. اختبار خادوم Oauth المرحلة المواليّة بعد إعداد Laravel ليعمل خادوم Oauth هي اختبار ما أعددناه. سنحتاج لعميل نجرّب عن طريقه الاستيثاق من الخادوم. نعيد النظر، قبل الانتقال للجانب التطبيقي من الاختبار، في كيفية الاستيثاق من مستخدم في خادوم Oauth. تضمّ العمليّة ثلاثة أطراف: المستخدِم، الخادوم والعميل. يريد المستخدِم تسجيل الدخول إلى العميل بالاعتماد على معلوماته الموجودة في الخادوم: ينقُل العميل المستخدِم إلى صفحة تسجيل الدخول على الخادوم. يُسجّل المستخدم الدخول إلى حسابه على الخادوم عن طريق بريده الإلكتروني وكلمة السّر. يتحقّق الخادوم من بيانات المستخدِم، ثم ينشئ - إذا كانت البيانات صحيحة - رمز وصول خاصًّا بالمستخدِم ويعيده إلى العميل. يستعمل العميل رمز الوصول الذي أرسله إليه الخادوم في طلباته المقبلة للتدليل على أن المستخدم فوّضه التعامل باسمه مع الخادوم. إنشاء مستخدمين للاختبار نبدأ بإنشاء مستخدمين لتجربة الاستيثاق. ننفذ أمر Artisan التالي لإنشاء صنف بذر Seed جديد: php artisan make:seeder UsersTableSeeder ثم نعدّل الدالة run لإنشاء مستخدمَيْن جديديْن: public function run() { $user1 = [ 'name' => 'Med Ahmed Eyil', 'email' => 'medeyil@laravel.com', 'password' => Hash::make('1234'), ]; $user2 = [ 'name' => 'Fatima Benziane', 'email' => 'fbenziane@laravel.com', 'password' => Hash::make('4567'), ]; User::create($user1); User::create($user2); } لا تنس استيراد النموذج User: use App\User; ثم نعتمد صنف البذر بتعديل الدالة run في الصنف DatabaseSeeder: public function run() { $this->call(UsersTableSeeder::class); } ثم ننفذ أمر البذر: php artisan db:seed جهّزنا الآن طرفيْن من الأطراف الثلاثة التي تحدثنا عنها، بقي العميل. إعداد العميل يوفّر Laravel بواسطة Passport مسارات من بينها المسار oauth/token/ الذي يمكّن من الحصول على رمز وصول. ينتظر المسار المعطيَات التاليّة: طريقة منح الصلاحيّة grant_type. معرّف المستخدم client_id. عبارة سر العميل client_secret. يحدّد المعطى grant_type طريقةَ توليد رموز الوصول. بما أننا نريد أن يطلُب الخادوم من المستخدم بريده الإلكتروني وكلمة السّر لكي يولّد رمز وصول للتطبيق العميل، فإن هذا المعطى سيأخذ القيمة password. يمكن لهذا المعطى أن يأخذ قيما أخرى حسب الطريقة التي تريد للتطبيقات العميلة أن تصل بها إلى موارد محميّة على خادومك. يعيّن المعطى الثاني معرّف العميل الذي نريد الاستيثاق منه؛ أما عبارة السّر فمهمتها إثبات أن العميل لديه ترخيص للاستيثاق بخادوم Oauth الذي أعددناه. سنحتاج أيضا لتمرير بريد المستخدم الإلكتروني وكلمة سره، بما أننا اخترنا طريقة password لتوليد الرموز. نعود لمشروع Laravel حيث يوجد الخادوم ثم ننفذ الأمر التالي: php artisan passport:client --password What should we name the password grant client? [Laravel Password Grant Client]: > Academy Password Client Password grant client created successfully. Client ID: 3 Client Secret: 17ZNjWn5A1I3mYOhGXZQFNACTdyt9Nwxup9jXG4M يطلُب الأمر أعلاه إنشاء تصريح لعميل للاستيثاق بخادوم Oauth ويحدّد طريقة توليد رموز الوصول بـpassword. يطلُب الأمر اسمًا للعميل ثم بعد كتابته وتأكيده يمنحنا معرّفا للعميل وعبارة سرّ. ملحوظة: رمز الوصول المولَّد فريد Unique، القيمة التي ستظهر لديك مختلفة حتما عن القيمة الظاهرة هنا. نعرّج قليلا، قبل الانتقال إلى العميل، على قاعدة البيانات وننظر في الجدول oauth_clients. لاحظ في الجدول وجود العميل الذي أنشأناه للتو، إضافة إلى عميليْن آخرين؛ أنشأهما الأمر passport:install عندما نفّذناه. تمكن ملاحظة أن قيمة العمود password_client بالنسبة للعميل الذي أنشأناه هي 1 للدلالة على أنه من نوع password. نأتي الآن للعميل، الذي يمكن أن يكون تطبيق وِب، تطبيقا للأجهزة المحمولة أو غيره. بالنسبة لي سأختار إضافة Postman على متصفح Chrome، وهي إضافة تمكّن من اختبار واجهات التطبيقات البرمجية. إرسال الطلبات نشغّل خادوم Passport بتنفيذ الأمر: php artisan serve ثم نفتح واجهة Postman ونعطيه المسار oauth/token/ ونمرّر له المعطيات التي تحدّثنا عنها سابقا. نحدّد نوع الإجراء بـ POST، ونختار تبويب Body لأننا في صدد ذكر بيانات جسم الطلب، ونختار x-www-form-urlencode للترميز. يؤدي استخدام الترميز x-www-form-urlencode إلى إرسال البيانات بنفس الطريقة التي تُرسَل بها بيانات استمارة Form على موقع وِب باستخدام الإجراء POST. إن كنتَ تُفضّل سطر الأوامر فبإمكانك تنفيذ أمر curl التالي والذي يؤدي نفس المهمّة (الخيار d- لاستخدام الترميز x-www-form-urlencode): curl -d "grant_type=password&client_id=3&client_secret=17ZNjWn5A1I3mYOhGXZQFNACTdyt9Nwxup9jXG4M&username=medeyil@laravel.com&password=1234" http://localhost:8000/oauth/token نحصُل بعد ذكر المعطيات الصحيحة وتنفيذ الطلب على الرد التالي: { "token_type": "Bearer", "expires_in": 31536000, "access_token":"رمز طويل هنا" , "refresh_token": "رمز طويل هنا" } تتضمن الإجابة أربعة حقول: نوعية الرمز token_type. يعني النوع bearer أن بإمكان الرمز منح الوصول إلى الخادوم دون الحاجة لذكر معلومات إضافية (مثل مفاتيح التعمية). مدة صلاحيّة الرمز expires_in. يحدّد مدّة صلاحيّة الرمز، بالثواني. يحدّد Laravel مبدئيا مدة طويلة (حوالي سنة)؛ إلا أنه يمكن تغيير هذه المدة. رمز الوصول access_token. رمز التحديث refresh_token. يُستخدَم لطلب رمز وصول جديد عند انتهاء مدة صلاحية رمز الوصول الحالي. حصلنا على رمز الوصول؛ سنرى الآن كيفية استخدامه للوصول إلى موارد على الخادوم. يُرسِل العميل من الآن فصاعدا رمزَ الوصول الذي حصل عليه مع كل طلب موجّه للخادوم يحتاج للاستيثاق. إن نظرت في ملفّ مسارات واجهة التطبيقات البرمجية routes/api.php فستجد أن المسار user/ محميّ بـ auth:api: Route::get('/user', function (Request $request) { return $request->user(); })->middleware('auth:api'); يعني هذا أنه يتوجّب على المستخدم تقديم بيانات الاستيثاق الخاصّة بواجهة التطبيقات، التي جعلناها تعتمد على التعريف passport، حتى يتمكن من الحصول على المورِد (الذي هو في المثال أعلاه بيانات المستخدم الذي أرسل الطلب). نعود لـPostman لطلب المسار api/user/ مع تقديم رمز الوصول الذي حصلنا عليه سابقا. ملحوظة: تنبغي إضافة api/ إلى جميع المسارات المعرّفة في الملف routes/api.php. نحدّد في خانة الترويسة Headers طبيعة المعلومات التي نريد تقديمها إلى المسار والإجراء GET المعرَّف في المسار user/ الخاص بواجهة التطبيقات. الترويسة التي نريد تحديد قيمتها هي Authorization (طلب استيثاق) وقيمتها هي: Bearer access_token حيث access_token رمز الوصول الذي حصلنا عليه في الخطوة السابقة، مسبوقا بنوع الرمز (Bearer). نحصُل على معلومات المستخدِم الذي قدّم الطلب. يمكن الحصول على نفس النتيجة بأمر curl التالي: curl -H "Authorization: Bearer access_token" http://localhost:8000/api/user يعني الخيار H- أننا نريد تضمين الترويسة التاليّة له في الطلب. نلاحظ أن الإجابات التي نحصُل عليها من خادوم Passport مهيّأة بصيغة JSON، وهو ما يجعل التعامل معها سهلا في التطبيقات العميلة على الأجهزة المحمولة والمتصفّحات. الخلاصة هي أننا استخدمنا بيانات المستخدم (البريد وكلمة السر) للحصول على رمز وصول من خادوم Passport ثم استخدمنا رمز الوصول هذا للاطلاع على موارد محميّة على الخادوم.
لطالما وفّر إطار العمل Laravel آليات سهلة للاستيثاق Authentication بالطرق التقليدية مثل استمارات Forms تسجيل الدخول في واجهة الوِب؛ إلا أن الأمر لم يكن سهلا بما فيه الكفاية بالنسبة للاستيثاق من الطلبات القادمة عبر واجهة تطبيقات برمجية. يأتي الإصدار 5.3 بحزمة جديدة، تُسمّى Passport، تهتم بتيسير استخدام Laravel لضبط خادوم Oauth وإعداده. يتناول هذا الدرس كيفية إعداد Laravel ليوفّر وظيفة خادوم Oauth اعتمادا على حزمة Passport. خادوم Oauth من المحتمل جدّا أنه سبق لك التعامل مع خادوم Oauth؛ مثلا عند استخدام حسابات على الشبكات الاجتماعية (فيس بوك، تويتر، … إلخ) للتسجيل في موقع على الشبكة. الفكرة التي تنبني عليها آلية الاستيثاق هذه هي تفويض عمليّة الاستيثاق إلى خادوم Oauth. نفترض مثلا أن لديك موقعا يستخدم هذه الآلية؛ عند تسجيل دخول الموقع عن طريق الحساب على فيس بوك فإن ما يحدُث هو التالي: يلج المستخدم إلى الموقع ويختار طريقة تسجيل الدخول (فيس بوك). يُنقَل المستخدم إلى صفحة تسجيل الدخول في فيس بوك حيثُ يُطلَب منه تسجيل الدخول إن لم يكن سبق له ذلك ثم يؤكّد سماحه لموقعك باستخدام حسابه على فيس بوك. يُعاد توجيه المستخدم إلى الموقع مع تسجيل دخوله إليه. يفترض هذا الدرس أن لديك إلماما بكيفية عمل خواديم Oauth للتصريح بالدخول. يمكن الاطّلاع على مقال مدخل إلى OAuth 2 للمزيد عن هذا الموضوع. إن كنتَ تبحث عن كيفية تسجيل الدخول إلى تطبيقك باستخدام حساب على موقع يوفّر وظيفة Oauth فراجع درس تسجيل الدخول عبر الشبكات الاجتماعية في Laravel باستخدام Socialite. إعداد خادوم Oauth على Laravel 5.3 يحتاج إعداد Passport على Laravel لتنفيذ بضعة أوامر وتحرير ملفات إعداد؛ إلا أن العملية عموما سهلة. ابدأ بتثبيت الإصدار 5.3 من Laravel: composer create-project --prefer-dist laravel/laravel laravel53oauth "5.3.*" نستخدم composer لإضافة حزمة Passport إلى متطلبات المشروع: composer require laravel/passport نسجّل مزوّد الخدمة Passport في ملفّ الإعداد config/app.php. افتح الملف ثم أضف السطر التالي إلى مصفوفة providers: Laravel\Passport\PassportServiceProvider::class, تأكّد من إعدادات قاعدة البيانات ثمّ نفّذ أمر التهجير Migration التالي: php artisan migrate ستلاحظ تنفيذ تهجيرات إضافية علاوة على تلك التي تأتي مبدئيّا مع Laravel: Migration table created successfully. Migrated: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_100000_create_password_resets_table Migrated: 2016_06_01_000001_create_oauth_auth_codes_table Migrated: 2016_06_01_000002_create_oauth_access_tokens_table Migrated: 2016_06_01_000003_create_oauth_refresh_tokens_table Migrated: 2016_06_01_000004_create_oauth_clients_table Migrated: 2016_06_01_000005_create_oauth_personal_access_clients_table يأتي مزوّد الخدمة Passport مع تهجيرات لإنشاء جداول تخزّن عملاء Client التطبيق ومعلومات رموز الوصول Access tokens. ثم ننفّذ الأمر التالي الذي سيولّد مفاتيح التعميّة Encryption keys الخاصّة بمشروع كما أنه ينشئ رموز الوصول ويخزّنها في جدول البيانات المناسب: php artisan passport:install ننتقل الآن إلى نموذج المستخدم User ونضيف إليه السّمة Trait المسمّاة HasApiTokens. يُصبح النموذج على النحو التالي (بعد نزع التعليقات للاختصار): <?php namespace App; use Illuminate\Notifications\Notifiable; use Illuminate\Foundation\Auth\User as Authenticatable; // استيراد السّمة use Laravel\Passport\HasApiTokens; class User extends Authenticatable { // استخدام السمة use HasApiTokens, Notifiable; protected $fillable = [ 'name', 'email', 'password', ]; protected $hidden = [ 'password', 'remember_token', ]; } توفّر هذه السّمة مجموعة من الدوال المساعدة التي تتيح الحصول على رموز الوصول الخاصّة بالمستخدمين ومدى الصلاحيّات Permissions scope المتاح للعميل. الخطوة المواليّة هي استدعاء الدالة Passport::routes ضمن الدالة boot الموجودة في مزوّد خدمة الاستيثاق app/Providers/AuthServiceProvider.php: public function boot() { $this->registerPolicies(); Passport::routes(); } لا تنس استدعاء الصنف Laravel\Passport\Passport في مزوّد خدمة الاستيثاق: use Laravel\Passport\Passport; يمكنك ملاحظة المسارات الجديدة التي أضافتها الدالة Passport::routes بتنفيذ أمر Artisan التالي الذي يسرُد لائحة بالمسارات الموجودة في المشروع: php artisan route:list الخطوة الأخيرة هي تعديل ملف الإعداد config/auth.php وتحديد قيمة driver في المصفوفة api لتصبح passport بدلا من token: 'api' => [ 'driver' => 'passport', 'provider' => 'users', ], يعتمد Laravel مبدئيا على رموز للاستيثاق من الطلبات القادمة عبر واجهة التطبيقات البرمجية؛ إلا أن هذه الرموز المبدئية لا تتيح إلا القليل من الخيارات، عكس ما يوفّره Passport. بهذا نكون أنهينا إعداد Laravel لأداء وظيفة خادوم Oauth. اختبار خادوم Oauth المرحلة المواليّة بعد إعداد Laravel ليعمل خادوم Oauth هي اختبار ما أعددناه. سنحتاج لعميل نجرّب عن طريقه الاستيثاق من الخادوم. نعيد النظر، قبل الانتقال للجانب التطبيقي من الاختبار، في كيفية الاستيثاق من مستخدم في خادوم Oauth. تضمّ العمليّة ثلاثة أطراف: المستخدِم، الخادوم والعميل. يريد المستخدِم تسجيل الدخول إلى العميل بالاعتماد على معلوماته الموجودة في الخادوم: ينقُل العميل المستخدِم إلى صفحة تسجيل الدخول على الخادوم. يُسجّل المستخدم الدخول إلى حسابه على الخادوم عن طريق بريده الإلكتروني وكلمة السّر. يتحقّق الخادوم من بيانات المستخدِم، ثم ينشئ - إذا كانت البيانات صحيحة - رمز وصول خاصًّا بالمستخدِم ويعيده إلى العميل. يستعمل العميل رمز الوصول الذي أرسله إليه الخادوم في طلباته المقبلة للتدليل على أن المستخدم فوّضه التعامل باسمه مع الخادوم. إنشاء مستخدمين للاختبار نبدأ بإنشاء مستخدمين لتجربة الاستيثاق. ننفذ أمر Artisan التالي لإنشاء صنف بذر Seed جديد: php artisan make:seeder UsersTableSeeder ثم نعدّل الدالة run لإنشاء مستخدمَيْن جديديْن: public function run() { $user1 = [ 'name' => 'Med Ahmed Eyil', 'email' => 'medeyil@laravel.com', 'password' => Hash::make('1234'), ]; $user2 = [ 'name' => 'Fatima Benziane', 'email' => 'fbenziane@laravel.com', 'password' => Hash::make('4567'), ]; User::create($user1); User::create($user2); } لا تنس استيراد النموذج User: use App\User; ثم نعتمد صنف البذر بتعديل الدالة run في الصنف DatabaseSeeder: public function run() { $this->call(UsersTableSeeder::class); } ثم ننفذ أمر البذر: php artisan db:seed جهّزنا الآن طرفيْن من الأطراف الثلاثة التي تحدثنا عنها، بقي العميل. إعداد العميل يوفّر Laravel بواسطة Passport مسارات من بينها المسار oauth/token/ الذي يمكّن من الحصول على رمز وصول. ينتظر المسار المعطيَات التاليّة: طريقة منح الصلاحيّة grant_type. معرّف المستخدم client_id. عبارة سر العميل client_secret. يحدّد المعطى grant_type طريقةَ توليد رموز الوصول. بما أننا نريد أن يطلُب الخادوم من المستخدم بريده الإلكتروني وكلمة السّر لكي يولّد رمز وصول للتطبيق العميل، فإن هذا المعطى سيأخذ القيمة password. يمكن لهذا المعطى أن يأخذ قيما أخرى حسب الطريقة التي تريد للتطبيقات العميلة أن تصل بها إلى موارد محميّة على خادومك. يعيّن المعطى الثاني معرّف العميل الذي نريد الاستيثاق منه؛ أما عبارة السّر فمهمتها إثبات أن العميل لديه ترخيص للاستيثاق بخادوم Oauth الذي أعددناه. سنحتاج أيضا لتمرير بريد المستخدم الإلكتروني وكلمة سره، بما أننا اخترنا طريقة password لتوليد الرموز. نعود لمشروع Laravel حيث يوجد الخادوم ثم ننفذ الأمر التالي: php artisan passport:client --password What should we name the password grant client? [Laravel Password Grant Client]: > Academy Password Client Password grant client created successfully. Client ID: 3 Client Secret: 17ZNjWn5A1I3mYOhGXZQFNACTdyt9Nwxup9jXG4M يطلُب الأمر أعلاه إنشاء تصريح لعميل للاستيثاق بخادوم Oauth ويحدّد طريقة توليد رموز الوصول بـpassword. يطلُب الأمر اسمًا للعميل ثم بعد كتابته وتأكيده يمنحنا معرّفا للعميل وعبارة سرّ. ملحوظة: رمز الوصول المولَّد فريد Unique، القيمة التي ستظهر لديك مختلفة حتما عن القيمة الظاهرة هنا. نعرّج قليلا، قبل الانتقال إلى العميل، على قاعدة البيانات وننظر في الجدول oauth_clients. لاحظ في الجدول وجود العميل الذي أنشأناه للتو، إضافة إلى عميليْن آخرين؛ أنشأهما الأمر passport:install عندما نفّذناه. تمكن ملاحظة أن قيمة العمود password_client بالنسبة للعميل الذي أنشأناه هي 1 للدلالة على أنه من نوع password. نأتي الآن للعميل، الذي يمكن أن يكون تطبيق وِب، تطبيقا للأجهزة المحمولة أو غيره. بالنسبة لي سأختار إضافة Postman على متصفح Chrome، وهي إضافة تمكّن من اختبار واجهات التطبيقات البرمجية. إرسال الطلبات نشغّل خادوم Passport بتنفيذ الأمر: php artisan serve ثم نفتح واجهة Postman ونعطيه المسار oauth/token/ ونمرّر له المعطيات التي تحدّثنا عنها سابقا. نحدّد نوع الإجراء بـ POST، ونختار تبويب Body لأننا في صدد ذكر بيانات جسم الطلب، ونختار x-www-form-urlencode للترميز. يؤدي استخدام الترميز x-www-form-urlencode إلى إرسال البيانات بنفس الطريقة التي تُرسَل بها بيانات استمارة Form على موقع وِب باستخدام الإجراء POST. إن كنتَ تُفضّل سطر الأوامر فبإمكانك تنفيذ أمر curl التالي والذي يؤدي نفس المهمّة (الخيار d- لاستخدام الترميز x-www-form-urlencode): curl -d "grant_type=password&client_id=3&client_secret=17ZNjWn5A1I3mYOhGXZQFNACTdyt9Nwxup9jXG4M&username=medeyil@laravel.com&password=1234" http://localhost:8000/oauth/token نحصُل بعد ذكر المعطيات الصحيحة وتنفيذ الطلب على الرد التالي: { "token_type": "Bearer", "expires_in": 31536000, "access_token":"رمز طويل هنا" , "refresh_token": "رمز طويل هنا" } تتضمن الإجابة أربعة حقول: نوعية الرمز token_type. يعني النوع bearer أن بإمكان الرمز منح الوصول إلى الخادوم دون الحاجة لذكر معلومات إضافية (مثل مفاتيح التعمية). مدة صلاحيّة الرمز expires_in. يحدّد مدّة صلاحيّة الرمز، بالثواني. يحدّد Laravel مبدئيا مدة طويلة (حوالي سنة)؛ إلا أنه يمكن تغيير هذه المدة. رمز الوصول access_token. رمز التحديث refresh_token. يُستخدَم لطلب رمز وصول جديد عند انتهاء مدة صلاحية رمز الوصول الحالي. حصلنا على رمز الوصول؛ سنرى الآن كيفية استخدامه للوصول إلى موارد على الخادوم. يُرسِل العميل من الآن فصاعدا رمزَ الوصول الذي حصل عليه مع كل طلب موجّه للخادوم يحتاج للاستيثاق. إن نظرت في ملفّ مسارات واجهة التطبيقات البرمجية routes/api.php فستجد أن المسار user/ محميّ بـ auth:api: Route::get('/user', function (Request $request) { return $request->user(); })->middleware('auth:api'); يعني هذا أنه يتوجّب على المستخدم تقديم بيانات الاستيثاق الخاصّة بواجهة التطبيقات، التي جعلناها تعتمد على التعريف passport، حتى يتمكن من الحصول على المورِد (الذي هو في المثال أعلاه بيانات المستخدم الذي أرسل الطلب). نعود لـPostman لطلب المسار api/user/ مع تقديم رمز الوصول الذي حصلنا عليه سابقا. ملحوظة: تنبغي إضافة api/ إلى جميع المسارات المعرّفة في الملف routes/api.php. نحدّد في خانة الترويسة Headers طبيعة المعلومات التي نريد تقديمها إلى المسار والإجراء GET المعرَّف في المسار user/ الخاص بواجهة التطبيقات. الترويسة التي نريد تحديد قيمتها هي Authorization (طلب استيثاق) وقيمتها هي: Bearer access_token حيث access_token رمز الوصول الذي حصلنا عليه في الخطوة السابقة، مسبوقا بنوع الرمز (Bearer). نحصُل على معلومات المستخدِم الذي قدّم الطلب. يمكن الحصول على نفس النتيجة بأمر curl التالي: curl -H "Authorization: Bearer access_token" http://localhost:8000/api/user يعني الخيار H- أننا نريد تضمين الترويسة التاليّة له في الطلب. نلاحظ أن الإجابات التي نحصُل عليها من خادوم Passport مهيّأة بصيغة JSON، وهو ما يجعل التعامل معها سهلا في التطبيقات العميلة على الأجهزة المحمولة والمتصفّحات. الخلاصة هي أننا استخدمنا بيانات المستخدم (البريد وكلمة السر) للحصول على رمز وصول من خادوم Passport ثم استخدمنا رمز الوصول هذا للاطلاع على موارد محميّة على الخادوم. -
 يتوفّر إطار العمل Laravel على واجهة تطبيقات برمجيّة API موّحّدة للتعامل مع الملفات. تأتي واجهة التطبيقات هذه مجهّزة مبدئيا بتعريفات Drivers تمكّن من إدارة الملفات على نظام الملفات المحلّي، خادوم FTP أو على خدمتي Amazon S3 وRackspace السّحابيتين. سنعرض في هذا الدرس لأساسيّات إدارة الملفات: رفعها Upload، تخزينها والعثور عليها في الإصدار 5.3 من إطار العمل Laravel. أقراص التخزين في Laravel تُضبَط إعدادات تخزين الملفات ضمن الملف config/filesystems.php عن طريق ما يُسمّيه Laravel الأقراص Disks. يُمثّل كل قرص تعريفا، مسارا للتخزين وإعدادات خاصّة بالقرص. يعرّف ملفّ الإعداد مبدئيا ثلاثة أقراص public، local وs3: 'disks' => [ 'local' => [ 'driver' => 'local', 'root' => storage_path('app'), ], 'public' => [ 'driver' => 'local', 'root' => storage_path('app/public'), 'visibility' => 'public', ], 's3' => [ 'driver' => 's3', 'key' => 'your-key', 'secret' => 'your-secret', 'region' => 'your-region', 'bucket' => 'your-bucket', ], ], يستخدم القرصُ local في المثال المبدئي أعلاه التعريفَ local (نظام الملفات المحلّي) ومسار التخزين storage/app. بالنسبة للقرص s3 فهو يستخدم التعريف s3 (خدمة Amazon S3) ويتطلّب قيما ضرورية للولوج إلى الخدمة. يشبه القرص public القرصَ local؛ إلا أنّ بينهما فرقًا جوهريًّا: هذا القرص مهيّأ للملفات التي نريد إتاحتها للعموم. تُخزَّن ملفات هذا القرص على المسار storage/app/public. يمكن ملاحظة أن المسار storage/app/public يوجد خارج المجلّد public الذي يحوي ملفّات المشروع المتاحة للعموم. نستخدم أمر Artisan التالي لجعل ملفات القرص public متاحة على الوِب: php artisan storage:link ينشئ الأمر وصلة رمزيّة على المسار public/storage ويجعلها تحيل إلىstorage/app/public الذي هو مسار تخزين القرص public. سنرى بعد قليل كيف نصل إلى الملفات الموجودة في هذا القرص. ملحوظة: يتطلّب استخدام التعريفيْن s3 وrackspace تثبيت الحزمتييْن التاليّتيْن على التوالي (عن طريق composer): league/flysystem-aws-s3-v3 ~1.0 league/flysystem-rackspace ~1.0 رفع ملفات وعرض روابطها في Laravel 5.3 سنهيّئ في بقيّة الدرس مشروع Laravel 5.3 للعمل عليه. سيكون هدفنا رفع صورة في المتصفّح ثم عرض هذه الصورة في صفحة الوِب. نضيف مسارين إلى ملف مسارات الوِب routes/web.php: Route::get('image-upload','ImageController@imageUpload'); Route::post('image-upload','ImageController@imageUploadPost'); يتلقّى الإجراء get طلبات عرض الصفحة، في ما نستخدم الإجراء post لتخزين الصّورة المحمَّلة في الصفحة التي سننشئها بعد قليل. الخطوة التاليّة هي إنشاء المتحكّم ImageController وكتابة الدالتين imageUpload وimageUploadPost: php artisan make:controller ImageController كلّ ما تفعله الدالة imageUpload هو استدعاء العرض image-upload: public function imageUpload() { return view('image-upload'); } بالنسبة للدالة imageUploadPost فستستقبل الصورة المحمّلة من المتصفّح، تخزّنها ثم ترسلها إلى image-upload الذي يعرضها: public function imageUploadPost(Request $request) { // TODO: return view('image-upload') ->with('message', "Image uploaded successfully") ->with('path', $imagePath); } الدالة غير مكتملة لحد الساعة، فكل ما يظهر منها هو استدعاء القالب وتمرير رسالة إليه تفيد بنجاح رفع الصورة، إضافة إلى متغيّر يمثّل رابط الصورة. استقبال الصورة، تخزينها والحصول على رابط تخزينها سيكون محلّ التعليق TODO. ننشئ القالب image-upload قبل العودة إلى الدالة imageUploadPost. ننشئ الملف image-upload.blade.php على المسار resources/views ونضع فيه المحتوى التالي: <!DOCTYPE html> <html> <head> <title>Laravel 5.3 Image Upload example</title> </head> <body> <div> @if (isset($path)) <p>{{ $message }}</p> <img src="{{ url($path) }}"> @endif <form action="{{ url('image-upload') }}" enctype="multipart/form-data" method="POST"> {{ csrf_field() }} <div> <div> <input type="file" name="image" /> </div> <div> <button type="submit">Upload</button> </div> </div> </form> </div> </body> </html> نتحقّق أولا، عن طريق الدالة isset، من وجود متغيّر باسم path في المعطيات الممرّرة إلى القالب. يمثّل المتغيّر path مسار الصورة التي نعرضها في حال وجود المتغيّر path. ثم يأتي دور استمارة الرّفع التي ترسل طلبا بإجراء POST إلى المسار image-upload. نحدّد نوع المُدخَل input الذي نريد استقبال الصورة عن طريقه بالنوع file ونحدّد اسمه بـimage. نستطيع الآن العودة إلى الدالة imageUploadPost لإكمالها: public function imageUploadPost(Request $request) { // TODO: return view('image-upload') ->with('message', "Image uploaded successfully") ->with('path', $imagePath); } نستقبل الطلب في المعطى request؛ حيث يمكننا تطبيق الدالة file للحصول على الصورة التي حمّلها المتصفّح بتحديد اسم المُدخَل input الذي استقبلها في صفحة الوٍب: $request->file('image'); نطبّق على الملف الدالة store لتخزينه: $image = $request->file('image')->store('images', 'public'); تأخذ الدالة store معطَيَيْن، الأول منهما هو اسم المجلّد حيثُ نريد تخزين الملفّ والثاني اسم القرص الذي نريد استخدامه. إن لم نحدّد اسمَ القرص فسيُستخدَم القرص المبدئي المعرّف بالتعليمة default ضمن ملف الإعداد config/filesystems (تأخذ التعليمة مبدئيا القيمة local). نريد أن تكون الصورة متاحة للعموم ضمن مجلد خاصّ بالصور اسمه images، لذا نمرّر القيمتيْن images وpublic للمعطييْن الأول والثاني على التوالي. خزّنا الآن الصورة على القرص المتاح للعموم. الخطوة التاليّة هي الحصول على مسارها من أجل إرساله إلى القالب image-upload لعرضه. نستخدم الدالة url ضمن الصنف Storage والتي يمكن تطبيقها على أقراص تستخدم أحد التعريفيْن local أو s3: $imagePath = Storage::url($image); لا ننسى استيراد الصّنف Storage: use Illuminate\Support\Facades\Storage; أصبحت دالة المتحكّم مكتملة على النحو التالي: public function imageUploadPost(Request $request) { $image = $request->file('image')->store('images','public'); $imagePath = Storage::url($image); return view('image-upload') ->with('message', "Image uploaded successfully") ->with('path', $imagePath); } لا ننسى إنشاء الوصلة الرمزية: php artisan storage:link نشغّل خادوم التطوير المضمَّن في Laravel: php artisan serve ثم نفتح المتصفّح لزيارة المسار http://localhost:8000/image-upload. نختار صورة لرفعها ثم نضغط على الزّر Upload. يخزّن Laravel الصّورة في المجلّد storage/app/public، ثم يطلُب عرض القالب image-upload مع تمرير رابط الصّورة في المتغيّر path، إضافة إلى رسالة في المتغيّر message تفيد بنجاح الرّفع. ملحوظة: يختار Laravel عند استخدام الدالة store اسما مميّزا للملف بتطبيق دالة تجزئة Hash عليه. إن أردت اختيار الاسم الذي يُخزَّن به الملف فيمكنك ذلك بالدالة storeAs: تخزين الملف في القرص المبدئي: $image = $request->file('image')->storeAs('images','fileName'); تخزين الملف مع تحديد القرص: $image = $request->file('image')->storeAs('images','fileName','public'); العمليّات على الملفات المرفوعة يوفّر Laravel الصّنفَ Storage للتعامل مع الملفات والأقراص. إضافة ملفات إلى التخزين تُستخدَم الدالة put في الصّنف Storage لتخزين ملفات على النحو التالي: Storage::put('images', $fileContents); يُمثّل المعطى الأوّل الممرَّر إلى الدالة اسمَ المجلّد الذي تريد حفظ الملفّ فيه والثاني محتوى الملفّ. تستخدم الدالة أعلاه القرص المبدئي (التعليمة default في ملف الإعداد). إن أردت استخدام قرص مغاير فيمكنك الاستعانة بالدالة disk: Storage::disk('public')->put('images', $fileContents); يُحدَّد المجلّد المُمرَّر إلى الدالة put (المعطَى الأول) اعتمادا على المسار الجذر للقرص المستخدَم؛ أي أن المقصود بالمجلّد images في المثال السابق هو المجلد storage/app/public/images؛ نظرا لكون storage/app/public هو المسار الجذر للقرص public. يُعيَّن المسار الجذر بالتعليمة root أثناء إعداد الأقراص في ملف الإعداد config/filesystems. استرجاع ملف من التخزين يتيح الصّنف Storage الدالة get لاسترجاع محتوى ملف مخزّن في القرص المبدئي: $contents = Storage::get('images/file.jpg'); يمكن تحديد القرص المستهدَف باستدعاء الدالة disk قبل تطبيق get. يتوفّر الصّنف Storage على الدالة exists التي تتيح التأكد من وجود الملفّ: $exists = Storage::disk('s3')->exists('file.jpg'); الحصول على بيانات ملفّ استخدم الدالة size على النحو التالي لمعرفة حجم ملفّ موجود في القرص المبدئي: $size = Storage::size('file1.jpg'); أو بتحديد القرص المستهدَف: $size = Storage::disk('s3')->size('file1.jpg'); يمكن على نفس المنوال معرفة تاريخ آخر تعديل على الملف على صيغة ختم زمني Timestamp: $time = Storage::lastModified('file1.jpg');
يتوفّر إطار العمل Laravel على واجهة تطبيقات برمجيّة API موّحّدة للتعامل مع الملفات. تأتي واجهة التطبيقات هذه مجهّزة مبدئيا بتعريفات Drivers تمكّن من إدارة الملفات على نظام الملفات المحلّي، خادوم FTP أو على خدمتي Amazon S3 وRackspace السّحابيتين. سنعرض في هذا الدرس لأساسيّات إدارة الملفات: رفعها Upload، تخزينها والعثور عليها في الإصدار 5.3 من إطار العمل Laravel. أقراص التخزين في Laravel تُضبَط إعدادات تخزين الملفات ضمن الملف config/filesystems.php عن طريق ما يُسمّيه Laravel الأقراص Disks. يُمثّل كل قرص تعريفا، مسارا للتخزين وإعدادات خاصّة بالقرص. يعرّف ملفّ الإعداد مبدئيا ثلاثة أقراص public، local وs3: 'disks' => [ 'local' => [ 'driver' => 'local', 'root' => storage_path('app'), ], 'public' => [ 'driver' => 'local', 'root' => storage_path('app/public'), 'visibility' => 'public', ], 's3' => [ 'driver' => 's3', 'key' => 'your-key', 'secret' => 'your-secret', 'region' => 'your-region', 'bucket' => 'your-bucket', ], ], يستخدم القرصُ local في المثال المبدئي أعلاه التعريفَ local (نظام الملفات المحلّي) ومسار التخزين storage/app. بالنسبة للقرص s3 فهو يستخدم التعريف s3 (خدمة Amazon S3) ويتطلّب قيما ضرورية للولوج إلى الخدمة. يشبه القرص public القرصَ local؛ إلا أنّ بينهما فرقًا جوهريًّا: هذا القرص مهيّأ للملفات التي نريد إتاحتها للعموم. تُخزَّن ملفات هذا القرص على المسار storage/app/public. يمكن ملاحظة أن المسار storage/app/public يوجد خارج المجلّد public الذي يحوي ملفّات المشروع المتاحة للعموم. نستخدم أمر Artisan التالي لجعل ملفات القرص public متاحة على الوِب: php artisan storage:link ينشئ الأمر وصلة رمزيّة على المسار public/storage ويجعلها تحيل إلىstorage/app/public الذي هو مسار تخزين القرص public. سنرى بعد قليل كيف نصل إلى الملفات الموجودة في هذا القرص. ملحوظة: يتطلّب استخدام التعريفيْن s3 وrackspace تثبيت الحزمتييْن التاليّتيْن على التوالي (عن طريق composer): league/flysystem-aws-s3-v3 ~1.0 league/flysystem-rackspace ~1.0 رفع ملفات وعرض روابطها في Laravel 5.3 سنهيّئ في بقيّة الدرس مشروع Laravel 5.3 للعمل عليه. سيكون هدفنا رفع صورة في المتصفّح ثم عرض هذه الصورة في صفحة الوِب. نضيف مسارين إلى ملف مسارات الوِب routes/web.php: Route::get('image-upload','ImageController@imageUpload'); Route::post('image-upload','ImageController@imageUploadPost'); يتلقّى الإجراء get طلبات عرض الصفحة، في ما نستخدم الإجراء post لتخزين الصّورة المحمَّلة في الصفحة التي سننشئها بعد قليل. الخطوة التاليّة هي إنشاء المتحكّم ImageController وكتابة الدالتين imageUpload وimageUploadPost: php artisan make:controller ImageController كلّ ما تفعله الدالة imageUpload هو استدعاء العرض image-upload: public function imageUpload() { return view('image-upload'); } بالنسبة للدالة imageUploadPost فستستقبل الصورة المحمّلة من المتصفّح، تخزّنها ثم ترسلها إلى image-upload الذي يعرضها: public function imageUploadPost(Request $request) { // TODO: return view('image-upload') ->with('message', "Image uploaded successfully") ->with('path', $imagePath); } الدالة غير مكتملة لحد الساعة، فكل ما يظهر منها هو استدعاء القالب وتمرير رسالة إليه تفيد بنجاح رفع الصورة، إضافة إلى متغيّر يمثّل رابط الصورة. استقبال الصورة، تخزينها والحصول على رابط تخزينها سيكون محلّ التعليق TODO. ننشئ القالب image-upload قبل العودة إلى الدالة imageUploadPost. ننشئ الملف image-upload.blade.php على المسار resources/views ونضع فيه المحتوى التالي: <!DOCTYPE html> <html> <head> <title>Laravel 5.3 Image Upload example</title> </head> <body> <div> @if (isset($path)) <p>{{ $message }}</p> <img src="{{ url($path) }}"> @endif <form action="{{ url('image-upload') }}" enctype="multipart/form-data" method="POST"> {{ csrf_field() }} <div> <div> <input type="file" name="image" /> </div> <div> <button type="submit">Upload</button> </div> </div> </form> </div> </body> </html> نتحقّق أولا، عن طريق الدالة isset، من وجود متغيّر باسم path في المعطيات الممرّرة إلى القالب. يمثّل المتغيّر path مسار الصورة التي نعرضها في حال وجود المتغيّر path. ثم يأتي دور استمارة الرّفع التي ترسل طلبا بإجراء POST إلى المسار image-upload. نحدّد نوع المُدخَل input الذي نريد استقبال الصورة عن طريقه بالنوع file ونحدّد اسمه بـimage. نستطيع الآن العودة إلى الدالة imageUploadPost لإكمالها: public function imageUploadPost(Request $request) { // TODO: return view('image-upload') ->with('message', "Image uploaded successfully") ->with('path', $imagePath); } نستقبل الطلب في المعطى request؛ حيث يمكننا تطبيق الدالة file للحصول على الصورة التي حمّلها المتصفّح بتحديد اسم المُدخَل input الذي استقبلها في صفحة الوٍب: $request->file('image'); نطبّق على الملف الدالة store لتخزينه: $image = $request->file('image')->store('images', 'public'); تأخذ الدالة store معطَيَيْن، الأول منهما هو اسم المجلّد حيثُ نريد تخزين الملفّ والثاني اسم القرص الذي نريد استخدامه. إن لم نحدّد اسمَ القرص فسيُستخدَم القرص المبدئي المعرّف بالتعليمة default ضمن ملف الإعداد config/filesystems (تأخذ التعليمة مبدئيا القيمة local). نريد أن تكون الصورة متاحة للعموم ضمن مجلد خاصّ بالصور اسمه images، لذا نمرّر القيمتيْن images وpublic للمعطييْن الأول والثاني على التوالي. خزّنا الآن الصورة على القرص المتاح للعموم. الخطوة التاليّة هي الحصول على مسارها من أجل إرساله إلى القالب image-upload لعرضه. نستخدم الدالة url ضمن الصنف Storage والتي يمكن تطبيقها على أقراص تستخدم أحد التعريفيْن local أو s3: $imagePath = Storage::url($image); لا ننسى استيراد الصّنف Storage: use Illuminate\Support\Facades\Storage; أصبحت دالة المتحكّم مكتملة على النحو التالي: public function imageUploadPost(Request $request) { $image = $request->file('image')->store('images','public'); $imagePath = Storage::url($image); return view('image-upload') ->with('message', "Image uploaded successfully") ->with('path', $imagePath); } لا ننسى إنشاء الوصلة الرمزية: php artisan storage:link نشغّل خادوم التطوير المضمَّن في Laravel: php artisan serve ثم نفتح المتصفّح لزيارة المسار http://localhost:8000/image-upload. نختار صورة لرفعها ثم نضغط على الزّر Upload. يخزّن Laravel الصّورة في المجلّد storage/app/public، ثم يطلُب عرض القالب image-upload مع تمرير رابط الصّورة في المتغيّر path، إضافة إلى رسالة في المتغيّر message تفيد بنجاح الرّفع. ملحوظة: يختار Laravel عند استخدام الدالة store اسما مميّزا للملف بتطبيق دالة تجزئة Hash عليه. إن أردت اختيار الاسم الذي يُخزَّن به الملف فيمكنك ذلك بالدالة storeAs: تخزين الملف في القرص المبدئي: $image = $request->file('image')->storeAs('images','fileName'); تخزين الملف مع تحديد القرص: $image = $request->file('image')->storeAs('images','fileName','public'); العمليّات على الملفات المرفوعة يوفّر Laravel الصّنفَ Storage للتعامل مع الملفات والأقراص. إضافة ملفات إلى التخزين تُستخدَم الدالة put في الصّنف Storage لتخزين ملفات على النحو التالي: Storage::put('images', $fileContents); يُمثّل المعطى الأوّل الممرَّر إلى الدالة اسمَ المجلّد الذي تريد حفظ الملفّ فيه والثاني محتوى الملفّ. تستخدم الدالة أعلاه القرص المبدئي (التعليمة default في ملف الإعداد). إن أردت استخدام قرص مغاير فيمكنك الاستعانة بالدالة disk: Storage::disk('public')->put('images', $fileContents); يُحدَّد المجلّد المُمرَّر إلى الدالة put (المعطَى الأول) اعتمادا على المسار الجذر للقرص المستخدَم؛ أي أن المقصود بالمجلّد images في المثال السابق هو المجلد storage/app/public/images؛ نظرا لكون storage/app/public هو المسار الجذر للقرص public. يُعيَّن المسار الجذر بالتعليمة root أثناء إعداد الأقراص في ملف الإعداد config/filesystems. استرجاع ملف من التخزين يتيح الصّنف Storage الدالة get لاسترجاع محتوى ملف مخزّن في القرص المبدئي: $contents = Storage::get('images/file.jpg'); يمكن تحديد القرص المستهدَف باستدعاء الدالة disk قبل تطبيق get. يتوفّر الصّنف Storage على الدالة exists التي تتيح التأكد من وجود الملفّ: $exists = Storage::disk('s3')->exists('file.jpg'); الحصول على بيانات ملفّ استخدم الدالة size على النحو التالي لمعرفة حجم ملفّ موجود في القرص المبدئي: $size = Storage::size('file1.jpg'); أو بتحديد القرص المستهدَف: $size = Storage::disk('s3')->size('file1.jpg'); يمكن على نفس المنوال معرفة تاريخ آخر تعديل على الملف على صيغة ختم زمني Timestamp: $time = Storage::lastModified('file1.jpg'); -
 يضيف الإصدار 5.3 من Laravel نظاما للإشعارات Notifications يمكن من خلاله إخطار المستخدم بحدوث شيء ما. تُستخدَم الإشعارات، التي تكون عادة على هيئة بلاغات قصيرة، لإعلام مستخدم التطبيق بوقوع أمر ما؛ على سبيل المثال “صدور فاتورة”، “تسجيل مستخدم”، “إعادة تعيين كلمة السّر” أو “نشر درس”؛ حسب طبيعة التطبيق الذي تعمل عليه. يتيح نظام الإشعارات في Laravel 5.3 وسائط عدّة (تُسمّى قنوات Channels) لتوصيل الإشعار: البريد الإلكتروني، الرسائل النصية القصيرة SMS (بالاعتماد على خدمة Nexmo) وخدمة Slack. يمكن أيضا تخزين الإشعارات في قاعدة البيانات من أجل عرضها في واجهة الوِب. سنرى في هذا الدرس كيفية عمل الإشعارات، بأخذ مثال لإشعار يُرسَل إلى بريد المستخدم عند إضافة منشور جديد. تهيئة المشروع نبدأ أولا بتهيئة المشروع الذي سنعمل عليه. أنشئ مشروع Laravel 5.3 جديدا، إن لم يكن لديك واحد جاهز واضبط إعدادات قاعدة البيانات. نستخدم نفس الإعدادات المذكورة في فقرة تهيئة بيئة التطوير من درس أساسيات التخبئة في Laravel؛ مع التعديل عليها قليلا. سنضيف صنفا لبذر المستخدمين: php artisan make:seeder UsersTableSeeder ونعدّل صنف البذر على النحو التالي لإضافة مستخدمَيْن إلى قاعدة البيانات: public function run() { $user1 = [ 'name' => 'Med Ahmed Eyil', 'email' => 'medeyil@laravel.com', 'password' => Hash::make('1234'), ]; $user2 = [ 'name' => 'Fatima Benziane', 'email' => 'fbenziane@laravel.com', 'password' => Hash::make('4567'), ]; User::create($user1); User::create($user2); } ثم ننفّذ البذر: php artisan db:seed يصبح لدينا الآن نموذجان، واحد للمستخدمين وآخر للمنشورات. ننتقل إلى ملف المسارات routes/web.php ونضيف المسار التالي: Route::get('/notify/{user_id}/{post_id}', 'PostsController@notify'); يعني هذا أنه عند زيارة الرابط notify/user_id/post_id/ (حيث user_id وpost_id معرّفا المستخدم والمنشور على التوالي) سيطلُب Laravel تنفيذ الدالة notify في المتحكم PostsController. نعدّل المتحكّم PostsController لإضافة هذه الدالة: public function notify($user_id,$post_id) { $user = User::find($user_id); $post = Post::find($post_id); // todo } سنعود لاحقا لإكمال الدالة notify التي تكتفي لحد الساعة بالعثور على المستخدم والمنشور الممررَيْن إليها في المعطيات. الإشعارات هدفنا هو التالي: يطلُب المتصفح الرابط notify/1/2/ (مثلا) فيُرسَل إشعار عبر البريد إلى المستخدم ذي المعرف 1 يخبره أن المنشور ذا المعرف 2 قد أُضيف إلى الموقع. سنحتاج لبلوغ هذا الهدف لإشعار “إضافة منشور”. ننفذ الأمر التالي لإنشاء هذا الإشعار: php artisan make:notification NewPost ستلاحظ بعد تنفيذ الأمر أعلاه ظهور مجلد جديد باسم Notifications (إن لم يكن موجودا سلفا) متفرع عن المجلد app وبداخله صنف باسم NewPost.php (نزعنا التعليقات للاختصار): <?php namespace App\Notifications; use Illuminate\Bus\Queueable; use Illuminate\Notifications\Notification; use Illuminate\Contracts\Queue\ShouldQueue; use Illuminate\Notifications\Messages\MailMessage; class NewPost extends Notification { use Queueable; public function __construct() { } public function via($notifiable) { return ['mail']; } public function toMail($notifiable) { return (new MailMessage) ->line('The introduction to the notification.') ->action('Notification Action', 'https://laravel.com') ->line('Thank you for using our application!'); } public function toArray($notifiable) { return [ ]; } } يمدّد الصنف NewPost الصنفَ Notification الذي يحوي التعليمات الضرورية للتعامل مع الإشعارات. تظهر الدالة المشيّدة Constructor وثلاث دوال أخرى: via: تعرّف القنوات التي نريد إرسال الإشعارات عبرها. توجد قناة البريد mail مبدئيا. تمكن إضافة قناة أخرى من تلك المتوفرة. يستخدم Laravel جميع القنوات المذكورة في المصفوفة المرجَعة، بمعنى؛ إن حددت مثلا القناتين mail وdatabase في المصفوفة فإن الإشعار سيُرسَل عبر البريد ويُخزَّن أيضا في قاعدة البيانات. toMail: هذه الدالة خاصّة بالتعامل مع قناة البريد الإلكتروني. تنشئ الدالة toMail كائنا من صنف MailMessage لتخصيص بريد إلكتروني. سنعود لهذا الصنف بعد قليل. toArray: إن حدّدت قناة للإشعارات في الدالة via دون أن تنشئ دالة خاصّة للتعامل معها فسيستدعي Laravel الدالة toArray. تجدر الإشارة إلى أن الدوال المخصّصة للتعامل مع قنوات الإشعارات تبدأ بـto متبوعة باسم القناة. مثلا toMail للبريد الإلكتروني (تأتي مبدئيا) وtoDatabase لتخصيص الإشعار عبر قناة قاعدة البيانات. نعدّل الصنف NewPost قليلا بحيث نمرّر للمشيّد معطى من نوع Post (نزعنا أجزاء الصنف التي لم يطرأ عليها تعديل): <?php // استدعاء الأصناف، أضفنا إليه الصنف Post use App\Post; class NewPost extends Notification { // أضفنا خاصيّة post إلى الصنف protected $post; public function __construct(Post $post) { $this->post = $post; } // بقية شفرة الصّنف } نعود إلى الدالة notify في المتحكم ونعدّلها لتصبح على النحو التالي: public function notify($user_id,$post_id) { $user = User::find($user_id); $post = Post::find($post_id); $user->notify(new NewPost($post)); } لا تنس استدعاء الصنف NewPost في المتحكم: use App\Notifications\NewPost; استدعينا الدالة notify من الكائن user$ ومررنا إليها صنفا جديدا من الإشعار NewPost. سنحتاج قبل تجربة إرسال الإشعار إلى ضبط البريد الإلكتروني في ملف النظام env.. ستجد في الملف عند فتحه الإعدادات التالية: MAIL_DRIVER=smtp MAIL_HOST=mailtrap.io MAIL_PORT=2525 MAIL_USERNAME=null MAIL_PASSWORD=null MAIL_ENCRYPTION=null يقترح Laravel مبدئيا موقع https://mailtrap.io الذي يوفر خدمة لمحاكاة إرسال بريد إلكتروني وعرضه. نحصُل بالتسجيل في الموقع على صندوق بريد للاختبار. ندخل إلى صندوق البريد (Demo inbox). ننسخ قيم Username وPassword ونضيفها إلى الإعدادات في ملف env. على النحو التالي: MAIL_DRIVER=smtp MAIL_HOST=mailtrap.io MAIL_PORT=2525 MAIL_USERNAME="be7c7d3972da27" MAIL_PASSWORD="5f445b7bdca027" MAIL_ENCRYPTION=null يمكننا الآن اختبار الإشعار بتشغيل خادوم التطبيق والذهاب إلى المسار http://localhost:8000/notify/1/2. إن نظرت في صندوق البريد على موقع mailtrap فستجد رسالة جديدة: لاحظ العنوان البريدي الذي يُوجّه إليه الإشعار medeyil@laravel.com. إن عدلت المسار الذي تطلُبه إلى التالي http://localhost:8000/notify/2/2 ونظرت في الإشعار الذي يصل إلى البريد فستجد أن المرسَل إليه To تبدّل إلى fbenziane@laravel.com الذي هو بريد المستخدم ذي المعرف 2. هل تساءلت كيف يعرف نظام الإشعارات البريد الإلكتروني الذي يجب إرسال الإشعار إليه، أي البريد الإلكتروني الخاصّ بالمستخدِم؟ تخصيص الإشعار عبر البريد الإلكتروني يمكن تطبيق الإشعارات على أي نموذج Eloquent في النظام، بشرط أن يستخدم النموذجُ السّمةَ Trait المسمّاة Notifiable. إن نظرنا إلى النموذج User الذي يأتي مبدئيا مع المشروع فسنلاحظ التالي: use Illuminate\Notifications\Notifiable; و use Notifiable; يتيح استخدام هذه السمة في النموذج إمكانية استدعاء الدالة notify: $user->notify(new NewPost($post)); التي تأخذ معطى عبارة عن كائن من صنف Notification. بالنسبة لكيفية معرفة نظام الإشعارات ببريد المستخدم فالإجابة هي أن كل قناة إشعار تتطلّب وجود خاصيّات Properties معيّنة في النموذج الذي يستدعي الدالة notify. في حالة قناة البريد الإلكتروني فإن الخاصيّة المنتظرة هي - منطقيا - عنوان البريد email. بالعودة إلى الصنف NewPost لاحظ دالة التعامل مع البريد الإلكتروني: public function toMail($notifiable) { return (new MailMessage) ->line('The introduction to the notification.') ->action('Notification Action', 'https://laravel.com') ->line('Thank you for using our application!'); } ترجع هذه الدالة كائنا من صنف MailMessage. إن تنبهت جيدا فستدرك أن العبارات الواردة في الشفرة أعلاه هي نفسها الموجودة في البريد المرسَل إلى المستخدم: الدالة line تدرج فقرة في بريد الإشعار. الدالة action تدرج زرًّا وتحدّد النص الذي يظهر على الزرّ ورابط الصفحة التي تزورها عند النقر على هذا الزرّ. توجد دوال أخرى لتخصيص الإشعار أكثر: subject لتخصيص موضوع البريد الإلكتروني. from لتحديد بريد المرسِل. attach لإضافة ملف مرفَق. priority لتحديد الأولوية (1 تعني أولوية قصوى). نخصّص في ما يلي البريد السّابق: public function toMail($notifiable) { return (new MailMessage) ->subject('New post: '. $this->post->title) ->line('Don\'t miss our new post ' .$this->post->title) ->action('View the post', 'https://laravel.com') ->line('Thank you for your visit!') ->from('hsoub@academy.com'); } نحصل بزيارة الرابط http://localhost:8000/notify/1/2 على النتيجة أدناه. بالنسبة لاسم التطبيق الذي يظهر في الإشعار فيمكن تعديله عن طريق التعليمة name في ملف الإعداد config/app.php. تأخذ التعليمة مبدئيا القيمة Laravel. إن أردت تخصيصا أكبر للبريد ومظهره فيمكنك ذلك بنشر قالب Blade الخاص بالبريد الإلكتروني للإشعار ومن ثم تخصيصه. نفذ الأمر التالي لنشر القالب: php artisan vendor:publish --tag=laravel-notifications ستجد القالب على المسار resources/views/vendor/notifications/email.blade.php؛ حيث يمكنك التعديل عليه بما تراه مناسبا.
يضيف الإصدار 5.3 من Laravel نظاما للإشعارات Notifications يمكن من خلاله إخطار المستخدم بحدوث شيء ما. تُستخدَم الإشعارات، التي تكون عادة على هيئة بلاغات قصيرة، لإعلام مستخدم التطبيق بوقوع أمر ما؛ على سبيل المثال “صدور فاتورة”، “تسجيل مستخدم”، “إعادة تعيين كلمة السّر” أو “نشر درس”؛ حسب طبيعة التطبيق الذي تعمل عليه. يتيح نظام الإشعارات في Laravel 5.3 وسائط عدّة (تُسمّى قنوات Channels) لتوصيل الإشعار: البريد الإلكتروني، الرسائل النصية القصيرة SMS (بالاعتماد على خدمة Nexmo) وخدمة Slack. يمكن أيضا تخزين الإشعارات في قاعدة البيانات من أجل عرضها في واجهة الوِب. سنرى في هذا الدرس كيفية عمل الإشعارات، بأخذ مثال لإشعار يُرسَل إلى بريد المستخدم عند إضافة منشور جديد. تهيئة المشروع نبدأ أولا بتهيئة المشروع الذي سنعمل عليه. أنشئ مشروع Laravel 5.3 جديدا، إن لم يكن لديك واحد جاهز واضبط إعدادات قاعدة البيانات. نستخدم نفس الإعدادات المذكورة في فقرة تهيئة بيئة التطوير من درس أساسيات التخبئة في Laravel؛ مع التعديل عليها قليلا. سنضيف صنفا لبذر المستخدمين: php artisan make:seeder UsersTableSeeder ونعدّل صنف البذر على النحو التالي لإضافة مستخدمَيْن إلى قاعدة البيانات: public function run() { $user1 = [ 'name' => 'Med Ahmed Eyil', 'email' => 'medeyil@laravel.com', 'password' => Hash::make('1234'), ]; $user2 = [ 'name' => 'Fatima Benziane', 'email' => 'fbenziane@laravel.com', 'password' => Hash::make('4567'), ]; User::create($user1); User::create($user2); } ثم ننفّذ البذر: php artisan db:seed يصبح لدينا الآن نموذجان، واحد للمستخدمين وآخر للمنشورات. ننتقل إلى ملف المسارات routes/web.php ونضيف المسار التالي: Route::get('/notify/{user_id}/{post_id}', 'PostsController@notify'); يعني هذا أنه عند زيارة الرابط notify/user_id/post_id/ (حيث user_id وpost_id معرّفا المستخدم والمنشور على التوالي) سيطلُب Laravel تنفيذ الدالة notify في المتحكم PostsController. نعدّل المتحكّم PostsController لإضافة هذه الدالة: public function notify($user_id,$post_id) { $user = User::find($user_id); $post = Post::find($post_id); // todo } سنعود لاحقا لإكمال الدالة notify التي تكتفي لحد الساعة بالعثور على المستخدم والمنشور الممررَيْن إليها في المعطيات. الإشعارات هدفنا هو التالي: يطلُب المتصفح الرابط notify/1/2/ (مثلا) فيُرسَل إشعار عبر البريد إلى المستخدم ذي المعرف 1 يخبره أن المنشور ذا المعرف 2 قد أُضيف إلى الموقع. سنحتاج لبلوغ هذا الهدف لإشعار “إضافة منشور”. ننفذ الأمر التالي لإنشاء هذا الإشعار: php artisan make:notification NewPost ستلاحظ بعد تنفيذ الأمر أعلاه ظهور مجلد جديد باسم Notifications (إن لم يكن موجودا سلفا) متفرع عن المجلد app وبداخله صنف باسم NewPost.php (نزعنا التعليقات للاختصار): <?php namespace App\Notifications; use Illuminate\Bus\Queueable; use Illuminate\Notifications\Notification; use Illuminate\Contracts\Queue\ShouldQueue; use Illuminate\Notifications\Messages\MailMessage; class NewPost extends Notification { use Queueable; public function __construct() { } public function via($notifiable) { return ['mail']; } public function toMail($notifiable) { return (new MailMessage) ->line('The introduction to the notification.') ->action('Notification Action', 'https://laravel.com') ->line('Thank you for using our application!'); } public function toArray($notifiable) { return [ ]; } } يمدّد الصنف NewPost الصنفَ Notification الذي يحوي التعليمات الضرورية للتعامل مع الإشعارات. تظهر الدالة المشيّدة Constructor وثلاث دوال أخرى: via: تعرّف القنوات التي نريد إرسال الإشعارات عبرها. توجد قناة البريد mail مبدئيا. تمكن إضافة قناة أخرى من تلك المتوفرة. يستخدم Laravel جميع القنوات المذكورة في المصفوفة المرجَعة، بمعنى؛ إن حددت مثلا القناتين mail وdatabase في المصفوفة فإن الإشعار سيُرسَل عبر البريد ويُخزَّن أيضا في قاعدة البيانات. toMail: هذه الدالة خاصّة بالتعامل مع قناة البريد الإلكتروني. تنشئ الدالة toMail كائنا من صنف MailMessage لتخصيص بريد إلكتروني. سنعود لهذا الصنف بعد قليل. toArray: إن حدّدت قناة للإشعارات في الدالة via دون أن تنشئ دالة خاصّة للتعامل معها فسيستدعي Laravel الدالة toArray. تجدر الإشارة إلى أن الدوال المخصّصة للتعامل مع قنوات الإشعارات تبدأ بـto متبوعة باسم القناة. مثلا toMail للبريد الإلكتروني (تأتي مبدئيا) وtoDatabase لتخصيص الإشعار عبر قناة قاعدة البيانات. نعدّل الصنف NewPost قليلا بحيث نمرّر للمشيّد معطى من نوع Post (نزعنا أجزاء الصنف التي لم يطرأ عليها تعديل): <?php // استدعاء الأصناف، أضفنا إليه الصنف Post use App\Post; class NewPost extends Notification { // أضفنا خاصيّة post إلى الصنف protected $post; public function __construct(Post $post) { $this->post = $post; } // بقية شفرة الصّنف } نعود إلى الدالة notify في المتحكم ونعدّلها لتصبح على النحو التالي: public function notify($user_id,$post_id) { $user = User::find($user_id); $post = Post::find($post_id); $user->notify(new NewPost($post)); } لا تنس استدعاء الصنف NewPost في المتحكم: use App\Notifications\NewPost; استدعينا الدالة notify من الكائن user$ ومررنا إليها صنفا جديدا من الإشعار NewPost. سنحتاج قبل تجربة إرسال الإشعار إلى ضبط البريد الإلكتروني في ملف النظام env.. ستجد في الملف عند فتحه الإعدادات التالية: MAIL_DRIVER=smtp MAIL_HOST=mailtrap.io MAIL_PORT=2525 MAIL_USERNAME=null MAIL_PASSWORD=null MAIL_ENCRYPTION=null يقترح Laravel مبدئيا موقع https://mailtrap.io الذي يوفر خدمة لمحاكاة إرسال بريد إلكتروني وعرضه. نحصُل بالتسجيل في الموقع على صندوق بريد للاختبار. ندخل إلى صندوق البريد (Demo inbox). ننسخ قيم Username وPassword ونضيفها إلى الإعدادات في ملف env. على النحو التالي: MAIL_DRIVER=smtp MAIL_HOST=mailtrap.io MAIL_PORT=2525 MAIL_USERNAME="be7c7d3972da27" MAIL_PASSWORD="5f445b7bdca027" MAIL_ENCRYPTION=null يمكننا الآن اختبار الإشعار بتشغيل خادوم التطبيق والذهاب إلى المسار http://localhost:8000/notify/1/2. إن نظرت في صندوق البريد على موقع mailtrap فستجد رسالة جديدة: لاحظ العنوان البريدي الذي يُوجّه إليه الإشعار medeyil@laravel.com. إن عدلت المسار الذي تطلُبه إلى التالي http://localhost:8000/notify/2/2 ونظرت في الإشعار الذي يصل إلى البريد فستجد أن المرسَل إليه To تبدّل إلى fbenziane@laravel.com الذي هو بريد المستخدم ذي المعرف 2. هل تساءلت كيف يعرف نظام الإشعارات البريد الإلكتروني الذي يجب إرسال الإشعار إليه، أي البريد الإلكتروني الخاصّ بالمستخدِم؟ تخصيص الإشعار عبر البريد الإلكتروني يمكن تطبيق الإشعارات على أي نموذج Eloquent في النظام، بشرط أن يستخدم النموذجُ السّمةَ Trait المسمّاة Notifiable. إن نظرنا إلى النموذج User الذي يأتي مبدئيا مع المشروع فسنلاحظ التالي: use Illuminate\Notifications\Notifiable; و use Notifiable; يتيح استخدام هذه السمة في النموذج إمكانية استدعاء الدالة notify: $user->notify(new NewPost($post)); التي تأخذ معطى عبارة عن كائن من صنف Notification. بالنسبة لكيفية معرفة نظام الإشعارات ببريد المستخدم فالإجابة هي أن كل قناة إشعار تتطلّب وجود خاصيّات Properties معيّنة في النموذج الذي يستدعي الدالة notify. في حالة قناة البريد الإلكتروني فإن الخاصيّة المنتظرة هي - منطقيا - عنوان البريد email. بالعودة إلى الصنف NewPost لاحظ دالة التعامل مع البريد الإلكتروني: public function toMail($notifiable) { return (new MailMessage) ->line('The introduction to the notification.') ->action('Notification Action', 'https://laravel.com') ->line('Thank you for using our application!'); } ترجع هذه الدالة كائنا من صنف MailMessage. إن تنبهت جيدا فستدرك أن العبارات الواردة في الشفرة أعلاه هي نفسها الموجودة في البريد المرسَل إلى المستخدم: الدالة line تدرج فقرة في بريد الإشعار. الدالة action تدرج زرًّا وتحدّد النص الذي يظهر على الزرّ ورابط الصفحة التي تزورها عند النقر على هذا الزرّ. توجد دوال أخرى لتخصيص الإشعار أكثر: subject لتخصيص موضوع البريد الإلكتروني. from لتحديد بريد المرسِل. attach لإضافة ملف مرفَق. priority لتحديد الأولوية (1 تعني أولوية قصوى). نخصّص في ما يلي البريد السّابق: public function toMail($notifiable) { return (new MailMessage) ->subject('New post: '. $this->post->title) ->line('Don\'t miss our new post ' .$this->post->title) ->action('View the post', 'https://laravel.com') ->line('Thank you for your visit!') ->from('hsoub@academy.com'); } نحصل بزيارة الرابط http://localhost:8000/notify/1/2 على النتيجة أدناه. بالنسبة لاسم التطبيق الذي يظهر في الإشعار فيمكن تعديله عن طريق التعليمة name في ملف الإعداد config/app.php. تأخذ التعليمة مبدئيا القيمة Laravel. إن أردت تخصيصا أكبر للبريد ومظهره فيمكنك ذلك بنشر قالب Blade الخاص بالبريد الإلكتروني للإشعار ومن ثم تخصيصه. نفذ الأمر التالي لنشر القالب: php artisan vendor:publish --tag=laravel-notifications ستجد القالب على المسار resources/views/vendor/notifications/email.blade.php؛ حيث يمكنك التعديل عليه بما تراه مناسبا. -
 يأتي Laravel بإطار العمل Eloquent مضمّنا مبدئيا؛ وهو ما يتيح بناء نماذج تُعالّج فيها البيانات وتُطبّق عليها القواعد التي تحكُم سير التطبيق. يُيسّر Eloquent كثيرا من الأمور على المطوِّر؛ إلا أنّه يمكن أن يكون أحيانا غير مناسب لتعقيد المشروع الذي تعمل عليه. يوفّر Laravel آلية للتعامل مع قواعد البيانات مباشرة دون الحاجة لربط كائنات التطبيق بجداول قاعدة البيانات. تُسمى هذه الآلية منشئ الاستعلامات Query builder. كانت الاستعلامات المعدّة بمنشئ الاستعلامات ترجع النتائج، في الإصدارات السابقة (قبل الإصدار 5.3) من Laravel، على هيئة مصفوفة Array؛ إلا أن الأمر تغيّر في الإصدار 5.3 وأصبحت أغلب دوالّ بناء الاستعلامات ترجع نتيجة من نوع Collection (مجموعة). سنرى في هذا المقال أمثلة تفصيلية حول هذا التغيير، ولكن قبل ذلك سنعرّج على مقارنة بين Eloquent ومنشئ الاستعلامات ومتى يكون استخدام أحدهما أنسب. أيهما أستخدم.. Eloquent أم منشئ الاستعلامات؟ يخضع تطوير البرمجيّات لإكراهات كثيرة، وهو ما يعني أن عليك أحيانا كتابة استعلامات SQL للتخاطب مع قاعدة البيانات مباشرة. يتيح Eloquent آلية أنيقة للتعامل مع قاعدة البيانات بربطها بأصناف التطبيق ممّا يقلّل كثيرا من الحاجة لتدخّل المطوّر في تفاصيل تنفيذ العمليّات. تشمل التسهيلات التي يتيحها Eloquent: التحقق المُستَتِر Dirty check: تحديث الحقول التي تغيّرت قيمتها فقط دون غيرها، عند تنفيذ استعلامات UPDATE. ربط النماذج بأحداث Events؛ مثلا لإشعار المستخدمين أو تحديث إحصائيات عند إنشاء مستخدم جديد. إدارة الحذف اللطيف Soft delete: تعليم تسجيلة على أنها محذوفة بدلا من حذفها فعلا. تنفيذ آليات التحميل الحثيث Lazy loading (طلب البيانات عند الحاجة إليها). يمكن - بالطبع - تطبيق هذه الآليات بنفسك دون الاعتماد على Eloquent؛ إلا أن ذلك سيأخذ وقتا. من الجيد أن يكون لديك سبب مقنع للوقت الذي ستمضيه في هذه المهمة بدلا من التركيز على أمور *قد* تكون أهم. سيكون مثاليّا جدا الحصولُ على كلّ هذه التسجيلات بدون دفع ثمن، إلا أن الأمور في الواقع ليست مثالية. الثمن الذي تدفعه مقابل التسهيلات التي يتضمّنها Eloquent - وأطر عمل ORM الأخرى، بغضّ النظر عن لغة البرمجة - هو سرعة تنفيذ الاستعلامات. على الجهة الأخرى، تمكّن كتابة الاستعلامات من الوصول إلى أقصى سرعة ممكنة في التنفيذ، مقابل التضحية بالجهد والوقت أثناء التطوير. لا يوجد مانع من مزج جميع الوسائل المتاحة أمامك؛ بل إن الأمر محبّذ. مثلا؛ استخدم Eloquent عندما تتعامل مع كيانات منفردة (استمارة تسجيل على موقع مثلا)، الجأ لمنشئ الاستعلامات في المهامّ التي تتطلب وقتا للتنفيذ (كيانات بالجملة Batch processing أو إعداد تقارير على سبيل المثال) واكتب استعلامات SQL مباشرة عندما تكون أمام استعلام شديد التعقيد. الجديد في Laravel 5.3 نستخدم منشئ الاستعلامات في المثال التالي للحصول على كافة المستخدمين (جدول users في قاعدة البيانات): DB::table('users')->get(); تكافئ التعليمة السابقة في نتيجتها تنفيذ الاستعلام التالي: SELECT * FROM users; كانت النتيجة، في الإصدارات السابقة من Laravel، من نوع Array (مصفوفة)؛ إلا أن هذا الأمر تغيّر في الإصدار 5.3 لتصبح النتيجة من نوع Collection (مجموعة). يعني هذا أنه للوصول إلى العنصر الأول في مجموعة المستخدمين السابقة فإننا يمكن أن نكتب: DB::table('users')->get()->first(); بدلا من: DB::table('users')->get()[0]; يجعل هذا التغيير من منشئ الاستعلامات متناسقا في نوع النتيجة مع Eloquent الذي يرجع مجموعة كائنات؛ كما أنه يمكّن من استخدام الدوال الموجودة مبدئيا للتعامل مع المجموعات؛ ومن بينها الدالة all التي ترجع مصفوفة مكافئة للمجموعة؛ مثلا ترجع التعليمة التالية مصفوفة بالمستخدمين: DB::table('users')->get()->all(); إن كان لديك تطبيق مبني على اعتبار أن منشئ الاستعلامات يُرجع النتائج على هيئة مصفوفات، فأسهل طريقة لتعديل الشفرة المصدرية للتوافق مع تغيير نوع النتيجة إلى مجموعة بدلا من مصفوفة؛ هي استخدام الدالة all. ملحوظة 1: لا ينطبق التغيير المذكور أعلاه (إرجاع مجموعة بدلا من مصفوفة) على دوال الصنف DB التي تتعامل مع استعلامات SQL مباشرة. مثلا؛ ترجع التعليمة التالية مصفوفة: DB::select('SELECT name FROM users WHERE id = ?', [1]); ملحوظة 2: انتبه عند استخدام استعلامات SQL مباشرة من ثغرات الحَقن SQL injection. استخدم ربط المتغيّرات Binding (كما في الملحوظة 1) بدلا من تمرير المتغيّر مباشرة كما في الاستعلام التالي: DB::select("SELECT name FROM users WHERE id = '$id' "]); قد يمثل الاستعلام الأخير خطرا إن لم يُتحقّق من المتغيّرid$ قبل استخدامه في الاستعلام. يتحقّق Laravel تلقائيا من المُدخلات عند ربط المتغيّرات كما في استعلام الملحوظة 1. راجع مقال استخدام Eloquent ORM للتعامل مع قاعدة البيانات في Laravel 5.
يأتي Laravel بإطار العمل Eloquent مضمّنا مبدئيا؛ وهو ما يتيح بناء نماذج تُعالّج فيها البيانات وتُطبّق عليها القواعد التي تحكُم سير التطبيق. يُيسّر Eloquent كثيرا من الأمور على المطوِّر؛ إلا أنّه يمكن أن يكون أحيانا غير مناسب لتعقيد المشروع الذي تعمل عليه. يوفّر Laravel آلية للتعامل مع قواعد البيانات مباشرة دون الحاجة لربط كائنات التطبيق بجداول قاعدة البيانات. تُسمى هذه الآلية منشئ الاستعلامات Query builder. كانت الاستعلامات المعدّة بمنشئ الاستعلامات ترجع النتائج، في الإصدارات السابقة (قبل الإصدار 5.3) من Laravel، على هيئة مصفوفة Array؛ إلا أن الأمر تغيّر في الإصدار 5.3 وأصبحت أغلب دوالّ بناء الاستعلامات ترجع نتيجة من نوع Collection (مجموعة). سنرى في هذا المقال أمثلة تفصيلية حول هذا التغيير، ولكن قبل ذلك سنعرّج على مقارنة بين Eloquent ومنشئ الاستعلامات ومتى يكون استخدام أحدهما أنسب. أيهما أستخدم.. Eloquent أم منشئ الاستعلامات؟ يخضع تطوير البرمجيّات لإكراهات كثيرة، وهو ما يعني أن عليك أحيانا كتابة استعلامات SQL للتخاطب مع قاعدة البيانات مباشرة. يتيح Eloquent آلية أنيقة للتعامل مع قاعدة البيانات بربطها بأصناف التطبيق ممّا يقلّل كثيرا من الحاجة لتدخّل المطوّر في تفاصيل تنفيذ العمليّات. تشمل التسهيلات التي يتيحها Eloquent: التحقق المُستَتِر Dirty check: تحديث الحقول التي تغيّرت قيمتها فقط دون غيرها، عند تنفيذ استعلامات UPDATE. ربط النماذج بأحداث Events؛ مثلا لإشعار المستخدمين أو تحديث إحصائيات عند إنشاء مستخدم جديد. إدارة الحذف اللطيف Soft delete: تعليم تسجيلة على أنها محذوفة بدلا من حذفها فعلا. تنفيذ آليات التحميل الحثيث Lazy loading (طلب البيانات عند الحاجة إليها). يمكن - بالطبع - تطبيق هذه الآليات بنفسك دون الاعتماد على Eloquent؛ إلا أن ذلك سيأخذ وقتا. من الجيد أن يكون لديك سبب مقنع للوقت الذي ستمضيه في هذه المهمة بدلا من التركيز على أمور *قد* تكون أهم. سيكون مثاليّا جدا الحصولُ على كلّ هذه التسجيلات بدون دفع ثمن، إلا أن الأمور في الواقع ليست مثالية. الثمن الذي تدفعه مقابل التسهيلات التي يتضمّنها Eloquent - وأطر عمل ORM الأخرى، بغضّ النظر عن لغة البرمجة - هو سرعة تنفيذ الاستعلامات. على الجهة الأخرى، تمكّن كتابة الاستعلامات من الوصول إلى أقصى سرعة ممكنة في التنفيذ، مقابل التضحية بالجهد والوقت أثناء التطوير. لا يوجد مانع من مزج جميع الوسائل المتاحة أمامك؛ بل إن الأمر محبّذ. مثلا؛ استخدم Eloquent عندما تتعامل مع كيانات منفردة (استمارة تسجيل على موقع مثلا)، الجأ لمنشئ الاستعلامات في المهامّ التي تتطلب وقتا للتنفيذ (كيانات بالجملة Batch processing أو إعداد تقارير على سبيل المثال) واكتب استعلامات SQL مباشرة عندما تكون أمام استعلام شديد التعقيد. الجديد في Laravel 5.3 نستخدم منشئ الاستعلامات في المثال التالي للحصول على كافة المستخدمين (جدول users في قاعدة البيانات): DB::table('users')->get(); تكافئ التعليمة السابقة في نتيجتها تنفيذ الاستعلام التالي: SELECT * FROM users; كانت النتيجة، في الإصدارات السابقة من Laravel، من نوع Array (مصفوفة)؛ إلا أن هذا الأمر تغيّر في الإصدار 5.3 لتصبح النتيجة من نوع Collection (مجموعة). يعني هذا أنه للوصول إلى العنصر الأول في مجموعة المستخدمين السابقة فإننا يمكن أن نكتب: DB::table('users')->get()->first(); بدلا من: DB::table('users')->get()[0]; يجعل هذا التغيير من منشئ الاستعلامات متناسقا في نوع النتيجة مع Eloquent الذي يرجع مجموعة كائنات؛ كما أنه يمكّن من استخدام الدوال الموجودة مبدئيا للتعامل مع المجموعات؛ ومن بينها الدالة all التي ترجع مصفوفة مكافئة للمجموعة؛ مثلا ترجع التعليمة التالية مصفوفة بالمستخدمين: DB::table('users')->get()->all(); إن كان لديك تطبيق مبني على اعتبار أن منشئ الاستعلامات يُرجع النتائج على هيئة مصفوفات، فأسهل طريقة لتعديل الشفرة المصدرية للتوافق مع تغيير نوع النتيجة إلى مجموعة بدلا من مصفوفة؛ هي استخدام الدالة all. ملحوظة 1: لا ينطبق التغيير المذكور أعلاه (إرجاع مجموعة بدلا من مصفوفة) على دوال الصنف DB التي تتعامل مع استعلامات SQL مباشرة. مثلا؛ ترجع التعليمة التالية مصفوفة: DB::select('SELECT name FROM users WHERE id = ?', [1]); ملحوظة 2: انتبه عند استخدام استعلامات SQL مباشرة من ثغرات الحَقن SQL injection. استخدم ربط المتغيّرات Binding (كما في الملحوظة 1) بدلا من تمرير المتغيّر مباشرة كما في الاستعلام التالي: DB::select("SELECT name FROM users WHERE id = '$id' "]); قد يمثل الاستعلام الأخير خطرا إن لم يُتحقّق من المتغيّرid$ قبل استخدامه في الاستعلام. يتحقّق Laravel تلقائيا من المُدخلات عند ربط المتغيّرات كما في استعلام الملحوظة 1. راجع مقال استخدام Eloquent ORM للتعامل مع قاعدة البيانات في Laravel 5. -
 يعدّ التصفيح Pagination (إعداد الصفحات) إحدى المهامّ الشائعة في مواقع الوِب، وهو ما دعا Laravel لتضمين هذه الوظيفة مبدئيا في إطار العمل. كانت تخصيص التصفيح في الإصدارات الأولى من Laravel بسهولة إعداد قالب Blade؛ إلا أن الأمر تغيّر في الإصدار 5.0، إذ عمل إطار العمل على تسهيل نظام التصفيح الذي يستخدمه لتمكن إعادة استخدامه في مشاريع لا تعتمد على إطار العمل Laravel. صاحب هذه العمليّة تعقيد في إمكانيّة تخصيص التصفيح. يأتي الإصدار 5.3 لتصحيح هذه الوضعية وإعادة الأمور إلى نصابها. تهيئة المشروع سنهيّئ مشروع Laravel 5.3 للعمل عليه. نبدأ بالتثبيت: composer create-project --prefer-dist laravel/laravel laravel53pagination "5.3.*" يأتي المشروع مبدئيا بنموذج للمستخدم User، سنعمل من أجل الشرح على هذا النموذج. نبدأ بإعداد مسار للمستخدمين في ملف المسارات الخاصّ بالوِب routes/web.php: Route::get('users', function () { return view('users.index') ->with('users', User::paginate(5)); }); يطلُب المسار users/ عند زيارته عرضَ القالب index.blade.php الموجود في المجلّد users ضمن مجلد القوالب resources/views. نمرّر للقالب المتغيّر users الذي يتلقّى نتيجة استدعاء الدالة paginate للحصول على المستخدمين المسجلين في قاعدة البيانات. ما يميّز هذه الدالة عن بقيّة الدوال الأخرى التي يمكن استدعاؤها في النموذج هي أنها توفّر إمكانية تطبيق الدالة links في قالب Blade من أجل إنشاء الصفحات، كما سنرى الآن. ليس لدينا لحد الساعة المجلد users ولا الملف index.blade.php، ننشئ المجلد والملف بحيث يصبح مسار ملف القالب resources/views/users/index.blade.php ثم نفتحه ونضيف إليه المحتوى التالي: <!DOCTYPE html> <html> <head> <meta charset="utf-8" > <title> Document </title> <link rel="stylesheet" href="/css/app.css"> <style type="text/css"> body { padding: 10em;}</style> </head> <body> @foreach ($users as $user) <li>{{ $user->name }}</li> @endforeach {{ $users->links() }} </body> </html> لدينا في أعلى الملف بضعة تعليمات للتنسيق، ثم تأتي في جسم المستند body التعليمة التكرارية foreach التي تمرّ على المستخدمين وتعرض أسماءهم، وفي الأخير الدالة links التي تحدثنا عنها أعلاه. يمكننا استدعاء هذه الدالة على المتغيّر users نظرا لأننا استخدمنا الدالة paginate في ملف المسارات للحصول على المستخدمين. تتكفّل الدالة links بإنشاء الصفحات عبر تقسيم المستخدمين على مجموعة من خمسة عناصر (مرّرنا المعطى 5 للدالة paginate في ملف المسارات). بقي لنا بذر جدول المستخدمين حتى يمكننا تجربة ما أنجزناه لحد الآن: php artisan make:seeder UsersTableSeeder نستعين بمكتبة Faker لتوليد مستخدمين وهميين وبذر الجدول: public function run() { User::unguard(); // نستخدم Faker لتوليد البيانات $faker = Faker\Factory::create(); // إنشاء 20 مستخدما foreach(range(1, 20) as $index) { User::create([ 'name' => $faker->name, 'email' => $faker->safeEmail, 'password' => $faker->password, ]); } User::reguard(); } لا تنس استيراد النموذج: use App\User; ثم نعدّل DatabaseSeeder لإضافة ملف البذر الذي أنشأناه للتو: $this->call(UsersTableSeeder::class); يمكننا الآن تنفيذ التهجيرات (تهجير المستخدم يأتي مبدئيا مع المشروع): php artisan migrate ثم بذر قاعدة البيانات: php artisan db:seed ثم تشغيل خادوم التطوير: php artisan serve تظهر عند زيارة الرابط http://localhost:8000/users قائمة بالمستخدمين مقسّمة على صفحات من خمسة مستخدمين. عند النقر على رقم الصّفحة ينقلك إلى مجموعة جديدة من المستخدمين. تخصيص التصفيح في Laravel يوجد القالب المبدئي لروابط الصفحات على المسار vendor/laravel/framework/src/Illuminate/Pagination/resources/views إن أردت تخصيصه فسيتوجّب عليك نشره بالأمر التالي: php artisan vendor:publish --tag=laravel-pagination وستجد بضعة قوالب على المسار ressources/views/vendor/pagination. يستخدم اثنان من هذه القوالب (bootstrap-4.blade.php وsimple-boostrap-4.blade.php) الإصدار 4 من Bootstrap والذي ما زال قيد التطوير؛ أما الآخران فأحدهما هو القالب المبدئي default.blade.php والآخر (simple-default.blade.php) نسخة مبسّطة منه لا تحوي سوى أزرار سابق ولاحق للتنقل بين الصفحات. أدناه الشفرة الخاصّة بالقالب المبدئي: @if ($paginator->hasPages()) <ul class="pagination"> {{-- Previous Page Link --}} @if ($paginator->onFirstPage()) <li class="disabled"><span>«</span></li> @else <li><a href="{{ $paginator->previousPageUrl() }}" rel="prev">«</a></li> @endif {{-- Pagination Elements --}} @foreach ($elements as $element) {{-- "Three Dots" Separator --}} @if (is_string($element)) <li class="disabled"><span>{{ $element }}</span></li> @endif {{-- Array Of Links --}} @if (is_array($element)) @foreach ($element as $page => $url) @if ($page == $paginator->currentPage()) <li class="active"><span>{{ $page }}</span></li> @else <li><a href="{{ $url }}">{{ $page }}</a></li> @endif @endforeach @endif @endforeach {{-- Next Page Link --}} @if ($paginator->hasMorePages()) <li><a href="{{ $paginator->nextPageUrl() }}" rel="next">»</a></li> @else <li class="disabled"><span>»</span></li> @endif </ul> @endif تتيح الدالة hasPages التحقق من وجود صفحات لعرضها. نتحقّق بالدالة onFirstPage من أننا على الصفحة الأولى. يمكن بالدالة hasMorePages معرفة ما إذا كان لدينا مزيد من الصفحات لعرضها. تطبع الدالتان previousPageUrl وnextPageUrlعلى التوالي رابطي الصفحة السابقة واللاحقة للصفحة الحالية التي نحصل عليها بالدالة currentPage. سنعدّل الآن القالب بحيث نضع كلمة Previous (السابق) مكان الرمز »، على ألا تظهر عندما نكون على الصفحة الأولى. نضع بنفس الطريقة كلمة Next (التالي) مكان «، على ألا تظهر عندما نكون على الصفحة الأخيرة. نحصُل على الشفرة التاليّة: @if ($paginator->hasPages()) <ul class="pagination"> {{-- Previous Page Link --}} @if (!$paginator->onFirstPage()) <li><a href="{{ $paginator->previousPageUrl() }}" rel="prev">Previous</a></li> @endif {{-- Pagination Elements --}} @foreach ($elements as $element) {{-- "Three Dots" Separator --}} @if (is_string($element)) <li class="disabled"><span>{{ $element }}</span></li> @endif {{-- Array Of Links --}} @if (is_array($element)) @foreach ($element as $page => $url) @if ($page == $paginator->currentPage()) <li class="active"><span>{{ $page }}</span></li> @else <li><a href="{{ $url }}">{{ $page }}</a></li> @endif @endforeach @endif @endforeach {{-- Next Page Link --}} @if ($paginator->hasMorePages()) <li><a href="{{ $paginator->nextPageUrl() }}" rel="next">Next</a></li> @endif </ul> @endif احفظ التعديلات ثم أعد تنزيل الصفحة للحصول على نتيجة مشابهة لتلك الظاهرة في الصورتين أعلاه.
يعدّ التصفيح Pagination (إعداد الصفحات) إحدى المهامّ الشائعة في مواقع الوِب، وهو ما دعا Laravel لتضمين هذه الوظيفة مبدئيا في إطار العمل. كانت تخصيص التصفيح في الإصدارات الأولى من Laravel بسهولة إعداد قالب Blade؛ إلا أن الأمر تغيّر في الإصدار 5.0، إذ عمل إطار العمل على تسهيل نظام التصفيح الذي يستخدمه لتمكن إعادة استخدامه في مشاريع لا تعتمد على إطار العمل Laravel. صاحب هذه العمليّة تعقيد في إمكانيّة تخصيص التصفيح. يأتي الإصدار 5.3 لتصحيح هذه الوضعية وإعادة الأمور إلى نصابها. تهيئة المشروع سنهيّئ مشروع Laravel 5.3 للعمل عليه. نبدأ بالتثبيت: composer create-project --prefer-dist laravel/laravel laravel53pagination "5.3.*" يأتي المشروع مبدئيا بنموذج للمستخدم User، سنعمل من أجل الشرح على هذا النموذج. نبدأ بإعداد مسار للمستخدمين في ملف المسارات الخاصّ بالوِب routes/web.php: Route::get('users', function () { return view('users.index') ->with('users', User::paginate(5)); }); يطلُب المسار users/ عند زيارته عرضَ القالب index.blade.php الموجود في المجلّد users ضمن مجلد القوالب resources/views. نمرّر للقالب المتغيّر users الذي يتلقّى نتيجة استدعاء الدالة paginate للحصول على المستخدمين المسجلين في قاعدة البيانات. ما يميّز هذه الدالة عن بقيّة الدوال الأخرى التي يمكن استدعاؤها في النموذج هي أنها توفّر إمكانية تطبيق الدالة links في قالب Blade من أجل إنشاء الصفحات، كما سنرى الآن. ليس لدينا لحد الساعة المجلد users ولا الملف index.blade.php، ننشئ المجلد والملف بحيث يصبح مسار ملف القالب resources/views/users/index.blade.php ثم نفتحه ونضيف إليه المحتوى التالي: <!DOCTYPE html> <html> <head> <meta charset="utf-8" > <title> Document </title> <link rel="stylesheet" href="/css/app.css"> <style type="text/css"> body { padding: 10em;}</style> </head> <body> @foreach ($users as $user) <li>{{ $user->name }}</li> @endforeach {{ $users->links() }} </body> </html> لدينا في أعلى الملف بضعة تعليمات للتنسيق، ثم تأتي في جسم المستند body التعليمة التكرارية foreach التي تمرّ على المستخدمين وتعرض أسماءهم، وفي الأخير الدالة links التي تحدثنا عنها أعلاه. يمكننا استدعاء هذه الدالة على المتغيّر users نظرا لأننا استخدمنا الدالة paginate في ملف المسارات للحصول على المستخدمين. تتكفّل الدالة links بإنشاء الصفحات عبر تقسيم المستخدمين على مجموعة من خمسة عناصر (مرّرنا المعطى 5 للدالة paginate في ملف المسارات). بقي لنا بذر جدول المستخدمين حتى يمكننا تجربة ما أنجزناه لحد الآن: php artisan make:seeder UsersTableSeeder نستعين بمكتبة Faker لتوليد مستخدمين وهميين وبذر الجدول: public function run() { User::unguard(); // نستخدم Faker لتوليد البيانات $faker = Faker\Factory::create(); // إنشاء 20 مستخدما foreach(range(1, 20) as $index) { User::create([ 'name' => $faker->name, 'email' => $faker->safeEmail, 'password' => $faker->password, ]); } User::reguard(); } لا تنس استيراد النموذج: use App\User; ثم نعدّل DatabaseSeeder لإضافة ملف البذر الذي أنشأناه للتو: $this->call(UsersTableSeeder::class); يمكننا الآن تنفيذ التهجيرات (تهجير المستخدم يأتي مبدئيا مع المشروع): php artisan migrate ثم بذر قاعدة البيانات: php artisan db:seed ثم تشغيل خادوم التطوير: php artisan serve تظهر عند زيارة الرابط http://localhost:8000/users قائمة بالمستخدمين مقسّمة على صفحات من خمسة مستخدمين. عند النقر على رقم الصّفحة ينقلك إلى مجموعة جديدة من المستخدمين. تخصيص التصفيح في Laravel يوجد القالب المبدئي لروابط الصفحات على المسار vendor/laravel/framework/src/Illuminate/Pagination/resources/views إن أردت تخصيصه فسيتوجّب عليك نشره بالأمر التالي: php artisan vendor:publish --tag=laravel-pagination وستجد بضعة قوالب على المسار ressources/views/vendor/pagination. يستخدم اثنان من هذه القوالب (bootstrap-4.blade.php وsimple-boostrap-4.blade.php) الإصدار 4 من Bootstrap والذي ما زال قيد التطوير؛ أما الآخران فأحدهما هو القالب المبدئي default.blade.php والآخر (simple-default.blade.php) نسخة مبسّطة منه لا تحوي سوى أزرار سابق ولاحق للتنقل بين الصفحات. أدناه الشفرة الخاصّة بالقالب المبدئي: @if ($paginator->hasPages()) <ul class="pagination"> {{-- Previous Page Link --}} @if ($paginator->onFirstPage()) <li class="disabled"><span>«</span></li> @else <li><a href="{{ $paginator->previousPageUrl() }}" rel="prev">«</a></li> @endif {{-- Pagination Elements --}} @foreach ($elements as $element) {{-- "Three Dots" Separator --}} @if (is_string($element)) <li class="disabled"><span>{{ $element }}</span></li> @endif {{-- Array Of Links --}} @if (is_array($element)) @foreach ($element as $page => $url) @if ($page == $paginator->currentPage()) <li class="active"><span>{{ $page }}</span></li> @else <li><a href="{{ $url }}">{{ $page }}</a></li> @endif @endforeach @endif @endforeach {{-- Next Page Link --}} @if ($paginator->hasMorePages()) <li><a href="{{ $paginator->nextPageUrl() }}" rel="next">»</a></li> @else <li class="disabled"><span>»</span></li> @endif </ul> @endif تتيح الدالة hasPages التحقق من وجود صفحات لعرضها. نتحقّق بالدالة onFirstPage من أننا على الصفحة الأولى. يمكن بالدالة hasMorePages معرفة ما إذا كان لدينا مزيد من الصفحات لعرضها. تطبع الدالتان previousPageUrl وnextPageUrlعلى التوالي رابطي الصفحة السابقة واللاحقة للصفحة الحالية التي نحصل عليها بالدالة currentPage. سنعدّل الآن القالب بحيث نضع كلمة Previous (السابق) مكان الرمز »، على ألا تظهر عندما نكون على الصفحة الأولى. نضع بنفس الطريقة كلمة Next (التالي) مكان «، على ألا تظهر عندما نكون على الصفحة الأخيرة. نحصُل على الشفرة التاليّة: @if ($paginator->hasPages()) <ul class="pagination"> {{-- Previous Page Link --}} @if (!$paginator->onFirstPage()) <li><a href="{{ $paginator->previousPageUrl() }}" rel="prev">Previous</a></li> @endif {{-- Pagination Elements --}} @foreach ($elements as $element) {{-- "Three Dots" Separator --}} @if (is_string($element)) <li class="disabled"><span>{{ $element }}</span></li> @endif {{-- Array Of Links --}} @if (is_array($element)) @foreach ($element as $page => $url) @if ($page == $paginator->currentPage()) <li class="active"><span>{{ $page }}</span></li> @else <li><a href="{{ $url }}">{{ $page }}</a></li> @endif @endforeach @endif @endforeach {{-- Next Page Link --}} @if ($paginator->hasMorePages()) <li><a href="{{ $paginator->nextPageUrl() }}" rel="next">Next</a></li> @endif </ul> @endif احفظ التعديلات ثم أعد تنزيل الصفحة للحصول على نتيجة مشابهة لتلك الظاهرة في الصورتين أعلاه. -
 يوفّر Laravel واجهة تطبيقات برمجية موّحدة للتعامل مع أنظمة تخبئة Cache مختلفة مثل Memcached وRedis. سنعرض في هذا المقال لكيفية إعداد التخبئة في Laravel ومبدأ عملها ثم نتطرق للدالة المساعدة cache التي أضيفت إلى إطار العمل بداية من الإصدار 5.3. تهيئة بيئة التطوير يُحدَّد اسم النظام المستخدَم في التعليمة CACHE_DRIVER ضمن ملف env.. تأخذ التعليمة CACHE_DRIVER مبدئيا القيمة file التي تعني أن الكائنات Objects المخبَّأة ستخزن ضمن ملف ضمن نظام التشغيل. تُضبَط إعدادات نظام التخبئة المستخدَم في الملف config/cache.php، بعد تعيينه بالتعليمة السابقة. نفترض أنك لديك مشروع Laravel بالإصدار 5.3 للتطبيق عليه. ننفذ الخطوات التالية لتهيئة مثال نعتمد عليه في ما بعد للشرح. إنشاء نموذج والتهجير المصاحب له وبذره نستخدم artisan لإنشاء نموذج Eloquent مع التهجير المصاحب له على النحو التالي: php artisan make:model Post -m نفتح ملف التهجير لضبط الحقول في جدول البيانات بإضافة حقل جديد يُسمّىtitle (العنوان): public function up() { Schema::create('posts', function (Blueprint $table) { $table->increments('id'); $table->string("title"); $table->timestamps(); }); } يمكننا الآن تنفيذ التهجير: php artisan migrate الخطوة التالية هي بذر الجدول الحصول على بيانات للتطبيق عليها. ننشئ ملف البذر: php artisan make:seeder PostsTableSeeder ثم نعدل عليه: class PostsTableSeeder extends Seeder { public function run() { Model::unguard(); // نستورد faker لبذر الجدول $faker = Faker\Factory::create(); // ننشئ 10 تسجيلات في الجدول foreach(range(1, 10) as $index) { Post::create([ 'title' => $faker->sentence(5), ]); } Model::reguard(); } } نعدّل ملف بذر قاعدة البيانات لإضافة ملف بذر الجدول posts إليه: public function run() { $this->call(PostsTableSeeder::class); } ثم ننفذ البذر: php artisan db:seed --class=PostsTableSeeder لدينا الآن جدول بيانات بـ10 تسجيلات. أكملنا إعداد النموذج الذي نريد العمل عليه، الخطوة الموالية هي إعداد المتحكم والمسارات. المتحكم والمسارات نستعين بأداة artisan لإنشاء متحكم على النحو التالي: php artisan make:controller PostsController ننشئ في المتحكم PostsController دالة باسم index نستخدمها للحصول على جميع المنشورات الموجودة في جدول البيانات posts بصيغة JSON: public function index() { $posts = Post::all(); return response()->json($posts); } لا تنس استيراد النموذج Post: use App\Post; ثم ننتقل إلى إعداد المسارات. سنضيف مسارا باسم posts/ إلى ملف مسارات واجهةالوب routes/web.php: Route::get('/posts', 'PostsController@index'); يمكننا الآن تنفيذ الأمر php artisan serve من مجلد المشروع لتشغيل الخادوم الخاص ببيئة التطوير ثم الذهاب إلى الرابط http://localhost:8000/posts لرؤية جميع المنشورات المحفوظة في الجدول. إعداد التخبئة واستخدامها تُضبَط التخبئة - كما أسلفنا - في الملفين env. وconfig/cache.php. يحوي الصنف Illuminate\Support\Facades\Cache الكثير من الدوال الثابتة Static التي تتعامل مع التخبئة. إضافة قيمة إلى التخبئة تُستخدَم الدالة Cache::put لإضافة قيمة إلى التخبئة. تأخذ الدالة ثلاثة معطيات: Cache::put('key', 'value', 10); مفتاح key يمثل اسم المتغير. لا يمكن أن تحمل قيمتان في النظام نفس المفتاح. قيمة المفتاح value. مدة زمنية معبَّر عنها بالدقائق (10 في المثال أعلاه)، وتمثل المدة التي سيحتفظ النظام فيها بقيمة المفتاح ضمن التخبئة. تمكن أتمتة إضافة المفاتيح إلى التخبئة بالدالة remember. تبحث هذه الدالة أولا عن قيمة المفتاح في التخبئة، وترجعها إن وجدته؛ فإن لم تجده تنشئ المفتاح وتعطيه القيمة التي ترجعها دالة الإغلاق Closure الممررة في المعطى الثالث. سنستخدم الدالة remember في دالة index التي أضفناها سابقا إلى المتحكم. نعدّل الدالة index على النحو التالي: public function index() { $posts = Cache::remember('posts', 5, function() { return Post::all(); }); return response()->json($posts); } لا ننسى استدعاء الصنف Cache: use Illuminate\Support\Facades\Cache; تعني الشفرة أعلاه أننا عند طلب الدالة index فإنها ستبحث عن المنشورات الموجودة في التخبئة، فإن وجدتها ترجعها وإلا فإنها تنشئها باستدعاء الدالة all من النموذج Post؛ وتحتفظ بها في التخبئة لمدة خمس دقائق؛ ثم ترجع النتيجة. بهذا تكون جميع الطلبات التي ترد إلى المسار posts/ تمر عبر التخبئة؛ سنضيف لأغراض التوضيح مسارا جديدا (ضمن routes/web.php) لنعدل عن طريقه على إحدى التسجيلات الموجودة في جدول المنشورات: Route::get('/edit/post/{id}', 'PostsController@edit'); ونعدّل المتحكم بإضافة الدالة edit التالية: public function edit($id) { $post = Post::find($id); $post->title = "New title for ".$id; $post->save(); $posts = Post::all(); return response()->json($posts); } ما يحدث هو التالي: تظهر عند زيارة الرابط posts/ المنشورات مع المرور على نظام التخبئة؛ أما عند زيارة المسار edit/post/id/ فسنعدّل على المنشور ذي المعرف id، ثم نعرض المنشورات المخزنة في الجدول مباشرة، دون البحث عنها في التخبئة. يظهر في الصورة المتحركة التالية الفرق بين استخدام التخبئة وطلب المنشورات مباشرة من الجدول: تكون التخبئة فارغة عند زيارة المسار posts/ لأول مرة. في هذه الحالة يطلب Laravel المنشورات مباشرة من جدول البيانات، يعرضها ثم يضيفها إلى التخبئة. نطلب الرابط edit/post/1/ الذي يغيّر عنوان المنشور ذي المعرف 1 ليصبح New title for 1؛ ثم يعرض المنشورات بطلبها مباشرة من جدول قاعدة البيانات. لاحظ تغير عنوان المنشور. نعود للرابط posts/ قبل انقضاء المدة المحددة في دالة التخبئة (5 دقائق)، نلاحظ أن التعديل الذي أجريناه لا يظهر في المنشورات المعروضة. ملحوظة: يجب التأكد في التطبيقات الموجهة لبيئة الإنتاج من تناسق عمليات التعديل على قاعدة البيانات والتخبئة. بمعنى أنه يجب أن ينعكس التعديل على قيمة في جدول البيانات مباشرة على القيمة المحفوظة في التخبئة. العمليات على التخبئة الحصول على قيمة من التخبئة: Cache::get('key'); يمكن إرجاع قيمة مبدئية في حال عدم وجود المفتاح في التخبئة: Cache::get('key', 'default'); تبحث الدالة أعلاه عن قيمة المفتاح key في التخبئة، فإن لم تجدها ترجع القيمة المبدئية default. التحقق من وجود مفتاح في التخبئة: if (Cache::has('key')){ Cache::get('key'); } else { Cache::put('key', $values, 10); } نتحقق في الشفرة أعلاه من وجود قيمة للمفتاح key ونرجعها إن وجدت؛ وإلا نضيف قيمة جديدة للمفتاح في التخبئة. نزع مفتاح من التخبئة: Cache::forget('key'); كما يمكن استخدام الدالة pull التي تبحث عن قيمة في التخبئة، ثم تحذفها بعد الحصول عليها: Cache::pull('key'); يشبه الأمر تنفيذ الدالتين get وforget بالتتالي. توجد طريقة أخرى لحذف محتوى التخبئة قبل انتهاء المدة المحددة له بتنفيذ أمر artisan التالي: php artisan cache:clear الدالة المساعدة cache يحتوي إطار العمل Laravel على الكثير من دوال PHP المساعدة؛ بعضها مستخدَم في وظائف إطار العمل نفسه. تعمل الدوال المساعدة Helper functions على الرفع من الإنتاجية والابتعاد عن تكرار الشفرات البرمجية بتجميع وظائف اعتيادية وإتاحة الوصول إليها حيث دعت الحاجة. يضيف الإصدار 5.3 دالة مساعدة جديدة باسم cache يمكن استخدامها في أي جزء من المشروع من أجل تسهيل التخاطب مع نظام التخبئة، بدلا من الصّنف Illuminate\Support\Facades\Cache. نحصل على قيمة المتغير key (المفتاح) باستخدام الدالة المساعدة cache على النحو التالي: cache('key'); تكافئ التعليمة أعلاه استخدام الصنف Cache على النحو التالي: Cache::get('key'); يمكن أيضا تمرير مصفوفة بالمفاتيح وقيمها إلى الدالة cache؛ ونحدّد المدة الزمنية التي نريد أن تستغرقها التخبئة: cache(['title' => 'Hsoub Academy'], 5); إن طلبنا في الخمس دقائق القادمة قيمة المفتاح title في الدالة cache فسنجد القيمة Hsoub Academy. نستخدم الدوال الموجودة في الصنف Cache في الدالة المساعدة cache بنفس الطريقة: إضافة مفتاح إلى التخبئة: cache()->put('key', 'value', 10); أو cache(['key' => 'value'],10); البحث عن قيمة المفتاح في التخبئة، وإضافته إليها إن لم يوجد بها: cache()->remember('key', 5, function() { // }); الحصول على قيمة مفتاح من التخبئة ثم حذفه منها بعد ذلك: cache()->pull('key'); حذف مفتاح من التخبئة: cache()->forget('key'); نعيد كتابة الدالة index في المتحكم PostsController بالدالة المساعدة cache بدلا من الصنف Cache: public function index() { $posts = cache()->remember('posts', 5, function() { return Post::all(); }); return response()->json($posts); } يمكن ملاحظة أنك لا تحتاج لاستيرد صنف جديد؛ فالدالة المساعدة متوفرة في جميع المشروع.
يوفّر Laravel واجهة تطبيقات برمجية موّحدة للتعامل مع أنظمة تخبئة Cache مختلفة مثل Memcached وRedis. سنعرض في هذا المقال لكيفية إعداد التخبئة في Laravel ومبدأ عملها ثم نتطرق للدالة المساعدة cache التي أضيفت إلى إطار العمل بداية من الإصدار 5.3. تهيئة بيئة التطوير يُحدَّد اسم النظام المستخدَم في التعليمة CACHE_DRIVER ضمن ملف env.. تأخذ التعليمة CACHE_DRIVER مبدئيا القيمة file التي تعني أن الكائنات Objects المخبَّأة ستخزن ضمن ملف ضمن نظام التشغيل. تُضبَط إعدادات نظام التخبئة المستخدَم في الملف config/cache.php، بعد تعيينه بالتعليمة السابقة. نفترض أنك لديك مشروع Laravel بالإصدار 5.3 للتطبيق عليه. ننفذ الخطوات التالية لتهيئة مثال نعتمد عليه في ما بعد للشرح. إنشاء نموذج والتهجير المصاحب له وبذره نستخدم artisan لإنشاء نموذج Eloquent مع التهجير المصاحب له على النحو التالي: php artisan make:model Post -m نفتح ملف التهجير لضبط الحقول في جدول البيانات بإضافة حقل جديد يُسمّىtitle (العنوان): public function up() { Schema::create('posts', function (Blueprint $table) { $table->increments('id'); $table->string("title"); $table->timestamps(); }); } يمكننا الآن تنفيذ التهجير: php artisan migrate الخطوة التالية هي بذر الجدول الحصول على بيانات للتطبيق عليها. ننشئ ملف البذر: php artisan make:seeder PostsTableSeeder ثم نعدل عليه: class PostsTableSeeder extends Seeder { public function run() { Model::unguard(); // نستورد faker لبذر الجدول $faker = Faker\Factory::create(); // ننشئ 10 تسجيلات في الجدول foreach(range(1, 10) as $index) { Post::create([ 'title' => $faker->sentence(5), ]); } Model::reguard(); } } نعدّل ملف بذر قاعدة البيانات لإضافة ملف بذر الجدول posts إليه: public function run() { $this->call(PostsTableSeeder::class); } ثم ننفذ البذر: php artisan db:seed --class=PostsTableSeeder لدينا الآن جدول بيانات بـ10 تسجيلات. أكملنا إعداد النموذج الذي نريد العمل عليه، الخطوة الموالية هي إعداد المتحكم والمسارات. المتحكم والمسارات نستعين بأداة artisan لإنشاء متحكم على النحو التالي: php artisan make:controller PostsController ننشئ في المتحكم PostsController دالة باسم index نستخدمها للحصول على جميع المنشورات الموجودة في جدول البيانات posts بصيغة JSON: public function index() { $posts = Post::all(); return response()->json($posts); } لا تنس استيراد النموذج Post: use App\Post; ثم ننتقل إلى إعداد المسارات. سنضيف مسارا باسم posts/ إلى ملف مسارات واجهةالوب routes/web.php: Route::get('/posts', 'PostsController@index'); يمكننا الآن تنفيذ الأمر php artisan serve من مجلد المشروع لتشغيل الخادوم الخاص ببيئة التطوير ثم الذهاب إلى الرابط http://localhost:8000/posts لرؤية جميع المنشورات المحفوظة في الجدول. إعداد التخبئة واستخدامها تُضبَط التخبئة - كما أسلفنا - في الملفين env. وconfig/cache.php. يحوي الصنف Illuminate\Support\Facades\Cache الكثير من الدوال الثابتة Static التي تتعامل مع التخبئة. إضافة قيمة إلى التخبئة تُستخدَم الدالة Cache::put لإضافة قيمة إلى التخبئة. تأخذ الدالة ثلاثة معطيات: Cache::put('key', 'value', 10); مفتاح key يمثل اسم المتغير. لا يمكن أن تحمل قيمتان في النظام نفس المفتاح. قيمة المفتاح value. مدة زمنية معبَّر عنها بالدقائق (10 في المثال أعلاه)، وتمثل المدة التي سيحتفظ النظام فيها بقيمة المفتاح ضمن التخبئة. تمكن أتمتة إضافة المفاتيح إلى التخبئة بالدالة remember. تبحث هذه الدالة أولا عن قيمة المفتاح في التخبئة، وترجعها إن وجدته؛ فإن لم تجده تنشئ المفتاح وتعطيه القيمة التي ترجعها دالة الإغلاق Closure الممررة في المعطى الثالث. سنستخدم الدالة remember في دالة index التي أضفناها سابقا إلى المتحكم. نعدّل الدالة index على النحو التالي: public function index() { $posts = Cache::remember('posts', 5, function() { return Post::all(); }); return response()->json($posts); } لا ننسى استدعاء الصنف Cache: use Illuminate\Support\Facades\Cache; تعني الشفرة أعلاه أننا عند طلب الدالة index فإنها ستبحث عن المنشورات الموجودة في التخبئة، فإن وجدتها ترجعها وإلا فإنها تنشئها باستدعاء الدالة all من النموذج Post؛ وتحتفظ بها في التخبئة لمدة خمس دقائق؛ ثم ترجع النتيجة. بهذا تكون جميع الطلبات التي ترد إلى المسار posts/ تمر عبر التخبئة؛ سنضيف لأغراض التوضيح مسارا جديدا (ضمن routes/web.php) لنعدل عن طريقه على إحدى التسجيلات الموجودة في جدول المنشورات: Route::get('/edit/post/{id}', 'PostsController@edit'); ونعدّل المتحكم بإضافة الدالة edit التالية: public function edit($id) { $post = Post::find($id); $post->title = "New title for ".$id; $post->save(); $posts = Post::all(); return response()->json($posts); } ما يحدث هو التالي: تظهر عند زيارة الرابط posts/ المنشورات مع المرور على نظام التخبئة؛ أما عند زيارة المسار edit/post/id/ فسنعدّل على المنشور ذي المعرف id، ثم نعرض المنشورات المخزنة في الجدول مباشرة، دون البحث عنها في التخبئة. يظهر في الصورة المتحركة التالية الفرق بين استخدام التخبئة وطلب المنشورات مباشرة من الجدول: تكون التخبئة فارغة عند زيارة المسار posts/ لأول مرة. في هذه الحالة يطلب Laravel المنشورات مباشرة من جدول البيانات، يعرضها ثم يضيفها إلى التخبئة. نطلب الرابط edit/post/1/ الذي يغيّر عنوان المنشور ذي المعرف 1 ليصبح New title for 1؛ ثم يعرض المنشورات بطلبها مباشرة من جدول قاعدة البيانات. لاحظ تغير عنوان المنشور. نعود للرابط posts/ قبل انقضاء المدة المحددة في دالة التخبئة (5 دقائق)، نلاحظ أن التعديل الذي أجريناه لا يظهر في المنشورات المعروضة. ملحوظة: يجب التأكد في التطبيقات الموجهة لبيئة الإنتاج من تناسق عمليات التعديل على قاعدة البيانات والتخبئة. بمعنى أنه يجب أن ينعكس التعديل على قيمة في جدول البيانات مباشرة على القيمة المحفوظة في التخبئة. العمليات على التخبئة الحصول على قيمة من التخبئة: Cache::get('key'); يمكن إرجاع قيمة مبدئية في حال عدم وجود المفتاح في التخبئة: Cache::get('key', 'default'); تبحث الدالة أعلاه عن قيمة المفتاح key في التخبئة، فإن لم تجدها ترجع القيمة المبدئية default. التحقق من وجود مفتاح في التخبئة: if (Cache::has('key')){ Cache::get('key'); } else { Cache::put('key', $values, 10); } نتحقق في الشفرة أعلاه من وجود قيمة للمفتاح key ونرجعها إن وجدت؛ وإلا نضيف قيمة جديدة للمفتاح في التخبئة. نزع مفتاح من التخبئة: Cache::forget('key'); كما يمكن استخدام الدالة pull التي تبحث عن قيمة في التخبئة، ثم تحذفها بعد الحصول عليها: Cache::pull('key'); يشبه الأمر تنفيذ الدالتين get وforget بالتتالي. توجد طريقة أخرى لحذف محتوى التخبئة قبل انتهاء المدة المحددة له بتنفيذ أمر artisan التالي: php artisan cache:clear الدالة المساعدة cache يحتوي إطار العمل Laravel على الكثير من دوال PHP المساعدة؛ بعضها مستخدَم في وظائف إطار العمل نفسه. تعمل الدوال المساعدة Helper functions على الرفع من الإنتاجية والابتعاد عن تكرار الشفرات البرمجية بتجميع وظائف اعتيادية وإتاحة الوصول إليها حيث دعت الحاجة. يضيف الإصدار 5.3 دالة مساعدة جديدة باسم cache يمكن استخدامها في أي جزء من المشروع من أجل تسهيل التخاطب مع نظام التخبئة، بدلا من الصّنف Illuminate\Support\Facades\Cache. نحصل على قيمة المتغير key (المفتاح) باستخدام الدالة المساعدة cache على النحو التالي: cache('key'); تكافئ التعليمة أعلاه استخدام الصنف Cache على النحو التالي: Cache::get('key'); يمكن أيضا تمرير مصفوفة بالمفاتيح وقيمها إلى الدالة cache؛ ونحدّد المدة الزمنية التي نريد أن تستغرقها التخبئة: cache(['title' => 'Hsoub Academy'], 5); إن طلبنا في الخمس دقائق القادمة قيمة المفتاح title في الدالة cache فسنجد القيمة Hsoub Academy. نستخدم الدوال الموجودة في الصنف Cache في الدالة المساعدة cache بنفس الطريقة: إضافة مفتاح إلى التخبئة: cache()->put('key', 'value', 10); أو cache(['key' => 'value'],10); البحث عن قيمة المفتاح في التخبئة، وإضافته إليها إن لم يوجد بها: cache()->remember('key', 5, function() { // }); الحصول على قيمة مفتاح من التخبئة ثم حذفه منها بعد ذلك: cache()->pull('key'); حذف مفتاح من التخبئة: cache()->forget('key'); نعيد كتابة الدالة index في المتحكم PostsController بالدالة المساعدة cache بدلا من الصنف Cache: public function index() { $posts = cache()->remember('posts', 5, function() { return Post::all(); }); return response()->json($posts); } يمكن ملاحظة أنك لا تحتاج لاستيرد صنف جديد؛ فالدالة المساعدة متوفرة في جميع المشروع. -
 سنعرض في هذا الدرس، الرابع من سلسلة دروس الحوسبة الافتراضية باستخدام KVM، كيفية إدارة الآلات الافتراضية عن طريق أدوات تعمل على سطر الأوامر؛ بدلا من واجهة virt-manager الرسومية. تفيد أدوات سطر الأوامر خصوصا في كتابة السكربتات لأتمتة Automating المهام. سنرى الأدوات التاليّة: virt-install: لإنشاء الآلات الافتراضية وضبطها. virsh: لإنشاء مجامع التخزين وإعدادها. qemu-img: لإدارة تجزئات التخزين الافتراضية. إعداد مجمع تخزين تُعد أداة virsh على سطر الأوامر واجهةً لإدارة الآلات الافتراضية وإعدادها. سنستخدم هذه الأداة في الفقرات المقبلة لإنشاء مجمع تخزين لبيئة KVM. ننفذ الأمر pool-define-as مع virsh لتعريف مجمع تخزين جديد. نمرّر للأمر اسم المجمع، نوعه ومعطيات النوع. يبلغ عدد معطيات نوع المجمع خمسة، وتختلف معطيات نوع المجمع التي يجب تمريرها إلى الأمر من نوع إلى أخر. إن أردنا - مثلا - إنشاء مجمع تخزين مماثل للمجمع SPool1 الذي أنشأناه في الدرس الماضي ، والذي هو من نوع dir فسنحتاج لذكر المعطى target (الأخير من المعطيات الخمسة، ويشير إلى مسار مجلّد على النظام المضيف) فقط ونعوّض المعطيات الأربعة المتبقية بعلامة -: $ sudo virsh pool-define-as SPool1CL dir - - - - "/mnt/spools/Spool1New" Pool SPool1CL defined تظهر بعد تنفيذ الأمر رسالة توضّح أن مجمع التخزين قد عُرِّف. ملحوظة: أسمينا مجمع التخزين SPool1CL لتمييزه عن مجمع التخزين الذي أنشأناه في الدرس السابق. يمكننا سرد جميع مجامع التخزين المتوفّرة على النظام بتمرير المعطى all-- إلى الأمر virsh pool-list: $ sudo virsh pool-list --all Name State Autostart ------------------------------------------- default active yes SPool1 active yes SPool1CL inactive no SPool2 active yes ستلاحظ ظهور مجمع التخزين SPool1CL إلى جانب مجامع التخزين التي أنشأناها في الدرس الماضي؛ لكنّه يختلف عنها في الحالة State والتفعيل التلقائي (Autostart). في الواقع، الأمر السابق يعرّف مجمع تخزين، ولكنه لا ينشئه فعليا. ننفّذ الأمر virsh pool-build لإنشاء مجمع التخزين SPool1CL المعرَّف أعلاه: $ sudo virsh pool-build SPool1CL Pool SPool1CL built تظهر بعد تنفيذ الأمر رسالة تخبرنا بإنشاء المجمع SPool1CL. يمكننا الآن تفعيل SPool1CL (تغيير الحالة من خامل inactive إلى نشِط active): $ sudo virsh pool-start SPool1CL Pool SPool1CL started إن أعدنا سرد جميع مجامع التخزين في النظام فسنلاحظ تغيّر حالة SPool1CL من inactive إلى active: $ sudo virsh pool-list --all Name State Autostart ------------------------------------------- default active yes SPool1 active yes SPool1CL active no SPool2 active yes بقي لنا تفعيل التفعيل التلقائي لـSPool1CL بتنفيذ الأمر التالي: $ sudo virsh pool-autostart SPool1CL Pool SPool1CL marked as autostarted فلنعرض معلومات مفصّلة عن مجمع التخزين الذي أكملنا إنشاءه للتو: $ sudo virsh pool-info SPool1CL Name: SPool1CL UUID: 120247f3-669c-4868-8c1e-bbd134077f55 State: running Persistent: yes Autostart: yes Capacity: 184.33 GiB Allocation: 17.90 GiB Available: 166.43 GiB مجمع التخزين SPool1CL جاهز الآن للاستخدام. يُضبَط مجمع تخزين جديد إذن على خطوات: التعريف pool-define-as، الإنشاء pool-build، التفعيل pool-start والتفعيل التلقائي pool-autostart. إعداد تجزئات تخزين افتراضية حان الآن دور التجزئات الافتراضية التي نستخدم الأداة qemu-img لإعدادها. سننشئ بهذه الأداة تجزئة افتراضية جديدة على مجمع التخزين SPool1CL. نحدّد للأداة الأمر الذي نريد تنفيذه (create بالنسبة للإنشاء)، صيغة تجزئة التخزين، مسار الملفّ الخاصّ بالتجزئة وحجمها: $ sudo qemu-img create -f raw /mnt/spools/Spool1New/SVol1.img 10G Formatting '/mnt/spools/Spool1New/SVol1.img', fmt=raw size=10737418240 لاحظ أن مسار الملفّ الخاصّ بالتجزئة mnt/spools/Spool1New/SVol1.img/ يوجد ضمن المجلّد mnt/spools/Spool1New/ الخاصّ بمجمع التخزين الذي أنشأناه أعلاه (تذكّر أننا حدّدنا النوع dir، الذي يحفظ التجزئات الافتراضية ضمن مجلد يوجد في نظام التشغيل). يمكن التحقّق من خاصيّات التجزئة بتنفيذ الأمر qemu-img info: $ sudo qemu-img info /mnt/spools/Spool1New/SVol1.img image: /mnt/spools/Spool1New/SVol1.img file format: raw virtual size: 10G (10737418240 bytes) disk size: 0 تحذير: تجنّب استخدام الأمر qemu-img للتعديل على تجزئات تستخدمها آلالات افتراضية نشطة، أو أي عمليّة Process أخرى؛ فقد يؤدي ذلك إلى إفساد التجزئة. إنشاء آلات افتراضية الخطوة الأخيرة هي إنشاء آلة افتراضية وتثبيت نظام تشغيل عليها؛ نستخدم الأداة virt-install لهذا الغرض. يتطلّب إنشاء آلة افتراضية جديدة تمرير المعطيات التاليّة إلى الأمر virt-install: اسم الآلة الافتراضية name--. مسار التجزئة التي نريد استخدامها مع الآلة الافتراضية disk path--. كيفية الاتصال بالآلة الافتراضية graphics--. تكون هذه القيمة عادة spice (اسم برمجية للتخاطب مع أسطح المكتب الافتراضية، موجودة في حزمة libvirt-bin). عدد المعالجات الافتراضية vcpu--. حجم الذاكرة العشوائية بالميغابايت ram--. مسار ملفّ ISO المستخدَم لتثبيت نظام التشغيل الضيف على الآلة الافتراضية cdrom--. واجهة الشبكة الافتراضية network--. $ sudo virt-install --name=win7 --disk path=/mnt/spools/Spool1New/SVol1.img --graphics spice --vcpu=2 --ram=4096 --cdrom=/home/zeine77/Documents/ISOs/GRMCULFRER_FR_DVD.iso --network bridge=virbr0 يبدأ بعد تنفيذ الأمر إنشاءُ الآلة الافتراضية. ثم تظهر نافذة منبثقة جديدة لبدء تثبيت نظام التشغيل الضيف. ترجمة - بتصرّف - لمقال How to Manage KVM Virtual Environment using Commandline Tools in Linux لصاحبه Mohammad Dosoukey.
سنعرض في هذا الدرس، الرابع من سلسلة دروس الحوسبة الافتراضية باستخدام KVM، كيفية إدارة الآلات الافتراضية عن طريق أدوات تعمل على سطر الأوامر؛ بدلا من واجهة virt-manager الرسومية. تفيد أدوات سطر الأوامر خصوصا في كتابة السكربتات لأتمتة Automating المهام. سنرى الأدوات التاليّة: virt-install: لإنشاء الآلات الافتراضية وضبطها. virsh: لإنشاء مجامع التخزين وإعدادها. qemu-img: لإدارة تجزئات التخزين الافتراضية. إعداد مجمع تخزين تُعد أداة virsh على سطر الأوامر واجهةً لإدارة الآلات الافتراضية وإعدادها. سنستخدم هذه الأداة في الفقرات المقبلة لإنشاء مجمع تخزين لبيئة KVM. ننفذ الأمر pool-define-as مع virsh لتعريف مجمع تخزين جديد. نمرّر للأمر اسم المجمع، نوعه ومعطيات النوع. يبلغ عدد معطيات نوع المجمع خمسة، وتختلف معطيات نوع المجمع التي يجب تمريرها إلى الأمر من نوع إلى أخر. إن أردنا - مثلا - إنشاء مجمع تخزين مماثل للمجمع SPool1 الذي أنشأناه في الدرس الماضي ، والذي هو من نوع dir فسنحتاج لذكر المعطى target (الأخير من المعطيات الخمسة، ويشير إلى مسار مجلّد على النظام المضيف) فقط ونعوّض المعطيات الأربعة المتبقية بعلامة -: $ sudo virsh pool-define-as SPool1CL dir - - - - "/mnt/spools/Spool1New" Pool SPool1CL defined تظهر بعد تنفيذ الأمر رسالة توضّح أن مجمع التخزين قد عُرِّف. ملحوظة: أسمينا مجمع التخزين SPool1CL لتمييزه عن مجمع التخزين الذي أنشأناه في الدرس السابق. يمكننا سرد جميع مجامع التخزين المتوفّرة على النظام بتمرير المعطى all-- إلى الأمر virsh pool-list: $ sudo virsh pool-list --all Name State Autostart ------------------------------------------- default active yes SPool1 active yes SPool1CL inactive no SPool2 active yes ستلاحظ ظهور مجمع التخزين SPool1CL إلى جانب مجامع التخزين التي أنشأناها في الدرس الماضي؛ لكنّه يختلف عنها في الحالة State والتفعيل التلقائي (Autostart). في الواقع، الأمر السابق يعرّف مجمع تخزين، ولكنه لا ينشئه فعليا. ننفّذ الأمر virsh pool-build لإنشاء مجمع التخزين SPool1CL المعرَّف أعلاه: $ sudo virsh pool-build SPool1CL Pool SPool1CL built تظهر بعد تنفيذ الأمر رسالة تخبرنا بإنشاء المجمع SPool1CL. يمكننا الآن تفعيل SPool1CL (تغيير الحالة من خامل inactive إلى نشِط active): $ sudo virsh pool-start SPool1CL Pool SPool1CL started إن أعدنا سرد جميع مجامع التخزين في النظام فسنلاحظ تغيّر حالة SPool1CL من inactive إلى active: $ sudo virsh pool-list --all Name State Autostart ------------------------------------------- default active yes SPool1 active yes SPool1CL active no SPool2 active yes بقي لنا تفعيل التفعيل التلقائي لـSPool1CL بتنفيذ الأمر التالي: $ sudo virsh pool-autostart SPool1CL Pool SPool1CL marked as autostarted فلنعرض معلومات مفصّلة عن مجمع التخزين الذي أكملنا إنشاءه للتو: $ sudo virsh pool-info SPool1CL Name: SPool1CL UUID: 120247f3-669c-4868-8c1e-bbd134077f55 State: running Persistent: yes Autostart: yes Capacity: 184.33 GiB Allocation: 17.90 GiB Available: 166.43 GiB مجمع التخزين SPool1CL جاهز الآن للاستخدام. يُضبَط مجمع تخزين جديد إذن على خطوات: التعريف pool-define-as، الإنشاء pool-build، التفعيل pool-start والتفعيل التلقائي pool-autostart. إعداد تجزئات تخزين افتراضية حان الآن دور التجزئات الافتراضية التي نستخدم الأداة qemu-img لإعدادها. سننشئ بهذه الأداة تجزئة افتراضية جديدة على مجمع التخزين SPool1CL. نحدّد للأداة الأمر الذي نريد تنفيذه (create بالنسبة للإنشاء)، صيغة تجزئة التخزين، مسار الملفّ الخاصّ بالتجزئة وحجمها: $ sudo qemu-img create -f raw /mnt/spools/Spool1New/SVol1.img 10G Formatting '/mnt/spools/Spool1New/SVol1.img', fmt=raw size=10737418240 لاحظ أن مسار الملفّ الخاصّ بالتجزئة mnt/spools/Spool1New/SVol1.img/ يوجد ضمن المجلّد mnt/spools/Spool1New/ الخاصّ بمجمع التخزين الذي أنشأناه أعلاه (تذكّر أننا حدّدنا النوع dir، الذي يحفظ التجزئات الافتراضية ضمن مجلد يوجد في نظام التشغيل). يمكن التحقّق من خاصيّات التجزئة بتنفيذ الأمر qemu-img info: $ sudo qemu-img info /mnt/spools/Spool1New/SVol1.img image: /mnt/spools/Spool1New/SVol1.img file format: raw virtual size: 10G (10737418240 bytes) disk size: 0 تحذير: تجنّب استخدام الأمر qemu-img للتعديل على تجزئات تستخدمها آلالات افتراضية نشطة، أو أي عمليّة Process أخرى؛ فقد يؤدي ذلك إلى إفساد التجزئة. إنشاء آلات افتراضية الخطوة الأخيرة هي إنشاء آلة افتراضية وتثبيت نظام تشغيل عليها؛ نستخدم الأداة virt-install لهذا الغرض. يتطلّب إنشاء آلة افتراضية جديدة تمرير المعطيات التاليّة إلى الأمر virt-install: اسم الآلة الافتراضية name--. مسار التجزئة التي نريد استخدامها مع الآلة الافتراضية disk path--. كيفية الاتصال بالآلة الافتراضية graphics--. تكون هذه القيمة عادة spice (اسم برمجية للتخاطب مع أسطح المكتب الافتراضية، موجودة في حزمة libvirt-bin). عدد المعالجات الافتراضية vcpu--. حجم الذاكرة العشوائية بالميغابايت ram--. مسار ملفّ ISO المستخدَم لتثبيت نظام التشغيل الضيف على الآلة الافتراضية cdrom--. واجهة الشبكة الافتراضية network--. $ sudo virt-install --name=win7 --disk path=/mnt/spools/Spool1New/SVol1.img --graphics spice --vcpu=2 --ram=4096 --cdrom=/home/zeine77/Documents/ISOs/GRMCULFRER_FR_DVD.iso --network bridge=virbr0 يبدأ بعد تنفيذ الأمر إنشاءُ الآلة الافتراضية. ثم تظهر نافذة منبثقة جديدة لبدء تثبيت نظام التشغيل الضيف. ترجمة - بتصرّف - لمقال How to Manage KVM Virtual Environment using Commandline Tools in Linux لصاحبه Mohammad Dosoukey. -
 رأينا في الدرسين السابقين من هذه السلسلة ( تثبيت KVM وإنشاء آلات افتراضية Virtual machines باستخدامه على أوبونتو و إنشاء آلات افتراضية في بيئة KVM بوسائط تثبيت شبكية) كيفية استخدام virt-manager لإنشاء آلات افتراضيّة وتثبيت أنظمة تشغيل (ضيفة) عليها، انطلاقا من وسيط تخزين محلي أو عبر الشبكة. سنتابع في هذا الدرس مع virt-manager ونرى كيفية إدارة وسائط تخزين افتراضيّة Virtual storage devices. تستخدَم أنظمة التشغيل يوميا وسائط تخزين بنظم ملفات File systems مختلفة، بعضها محلّي Local وآخر يعمل عبر الشبكة. لا توجد عموما اختلافات كبيرة بين مبادئ عمل وسائط التخزين الافتراضية وتلك الملموسة Physical. تُنشأ الأقراص الخاصّة بالآلات الافتراضية في بيئة KVM اعتمادا على أقراص التخزين الملموسة التي يتخاطب معها النظام المُضيف. يتعامل نظام التشغيل مع أقراص التخزين حسب تجزئات Partitions (أو Volumes)، ويتكوّن كل قرص صلب من تجزئة أو أكثر. بالنسبة لبيئة KVM فإنها تتعامل مع التجزئات الافتراضية ضمن مجموعات تُسمّى مجامع (أو أحواض) التخزين Storage pools. يجب أولا إنشاء مَجمع تخزين ثم ننشئ به تجزئة جديدة لقرص افتراضي. إنشاء مجامع تخزين Storage pools في بيئة KVM نبدأ أولا بعرض مجامع التخزين المتوفّرة بالنقر على قائمة Edit (تعديل) ضمن برنامج virt-manager، ثم Connection Details (تفاصيل الاتصال) ونختار تبويب Storage (تخزين). يوجد مبدئيًّا مجمع تخزين باسم default يحفظ التجزئات الافتراضية على المسار var/lib/libvirt/images/. ستلاحظ وجودَ التجزئة الخاصة بنظام التشغيل الضيف الذي أنشأناه في الدرس الأول (اخترنا عند إعداد التخزين في الخطوة 4 مساحة تخزين افتراضية موجودة سلفا). سننشئ في الخطوات التاليّة مجمع تخزين جديدا، بالنقر على زر + في الجانب السفلي الأيسر من النافذة. تظهر نافذة جديدة لإعطاء اسم لمجمع التخزين واختيار نوعه. يدعم KVM ثمانية أنواع لمجامع التخزين: dir: يحفظ التجزئات الافتراضية ضمن مجلد يوجد في نظام الملفات الذي يستخدمه نظام التشغيل . disk: يستخدم أقراصا صلبة ملموسة لحفظ التجزئات الافتراضية بداخلها. fs: يستخدم تجزئات تخزين مهيّأة سلفا لتخزين التجزئات الافتراضية. netfs: يستخدم وسائط تخزين متشاركة عبر الشبكة، مثل NFS، من أجل حفظ التجزئات الافتراضية. gluster: يحتفظ بالتجزئات الافتراضية ضمن وسيط تخزين ملموس يعمل بنظام الملفات GlusterFS. iscsi: يحفظ التجزئات الافتراضية في وسائط تخزين متوفّرة على الشبكة ببروتوكول ISCSI. scsi: يستخدم وسيط تخزين محلي يعمل بنظام SCSI. lvm: يعتمد على مدير التجزئات المنطقية لتخزين التجزئات الافتراضية. سنختار في هذه الخطوة استخدام مجمع تخزين من نوع dir (مجلد في نظام التشغيل المُضيف)؛ فهو النوع الأكثر شيوعا ولا يحتاج للتعديل على بنية نظام الملفات المحلية. لا توجد تقييدات على مكان وجود المجلد الخاص بمجمع التخزين، ولكن من المستحسَن أن يكون على تجزئة منفصلة؛ مع التأكد من الأذون والملكية الخاصة بالمجلّد حتى يمكن ل KVM التعامل معه. تأكد من أن التجزئة التي تريد إنشاء المجمع عليها فارغة، ثم ركّبها على النحو التالي: sudo mount -t ext4 /dev/sdb4 /mnt/spools/SPool1 تحذير: يمكن أن يؤدي استخدام تجزئة غير فارغة إلى مسح محتوياتها. حيث dev/sdb4/ التجزئة الملموسة وmnt/spools/SPool1/ مجلد التركيب. استخدم الأمر lsblk لعرض التجزئات المتوفرة لديك (أو الموجودة على قرص خارجي)؛ كما يمكنك استخدام الأداة الرسومية GParted لنفس الغرض. يظهر في النافذة التالية المسار الذي تريد حفظ تجزئة التخزين الافتراضية فيه. إن كنت تستخدم تجزئة منفصلة فتأكد من ذكر مسار مجلد التركيب (مثلا mnt/spools/SPool1/) هنا. يظهر مجمع التخزين SPool1 بعد إنشائه في القائمة ضمن تبويب Storage السابق. أنشأنا مجمع تخزين ويمكننا الآن إنشاء تجزئة تخزين افتراضية عليه؛ ولكن قبل ذلك سنرى نوعا آخر من أنواع مجامع التخزين، وهو fs. يشير النوع fs إلى أننا نريد استخدام تجزئة قرص ملموسة كاملة، بدلا من مجلد فقط. ستحتاج لإعداد تجزئة قرص ملموس جديدة. تأكد من اسم التجزئة الجديدة (وأنها فارغة) ثم أعدّها لاستخدام نظام الملفات ext4 (على سبيل المثال) بالأمر التالي أو ببرنامج إدارة الأقراص المفضّل لديك: sudo mkfs.ext4 /dev/sdb6 أنشئ أيضا مجلدا جديدا (مثلا SPool2) في النظام المُضيف لتركيب القرص عليه. ملحوظة: اكتف بتهيئة التجزئة وإنشاء المجلد دون تركيبها عليه. سيتولى KVM هذه المهمة. يمكننا الآن إنشاء مجمع تخزين جديد وتسميته مع تحديد نوع المجمع بـfs. حدد في الخطوة التالية من إنشاء المجمع مسار مجلد التركيب (مثلا mnt/spools/SPool2/) في الخانة Target Path (المسار المستهدَف) ومسار التجزئة التي أعددناها سابقا (dev/sdb6/ في المثال) في الخانة Source Path (المسار المصدَر). يظهر مجمع التخزين الجديد في قائمة وسائط التخزين سنناقش في الدرس الموالي إنشاء نوع آخر من مجامع التخزين (عن طريق سطر الأوامر). ننتقل الآن لإنشاء تجزئة جديدة. إضافة تجزئة تخزين افتراضية إلى مجمع تخزين في بيئة KVM توجد صيغ عدّة لتجزئات التخزين. تمكّن هذه الصّيغ من استخدام التجزئة مع مراقبين Hypervisors مختلفين: QEMU، VMware، VirtualBox أو Hyper-V. حدّد مجمع التخزين الذي تريد إضافة التجزئة إليه (SPool2 مثلا) ثم انقر على زر + الموجود تحت بيانات مجمع التخزين أمام عبارة Volumes (التجزئات) لتظهر نافذة إضافة تجزئة. حدّد اسم التجزئة الجديدة والصيغة Format التي تريد استخدامها لإنشاء التجزئة ومساحتها ثم انقر على زر Finish (إنهاء). إن كنت تنوي استخدام التجزئة على مراقب آخر غير KVM في ما بعد فتأكد من اختيار صيغة يدعمها ذلك المراقب. تظهر التجزئة الجديدة ضمن قائمة التجزئات الموجودة في مجمع التخزين SPool2. ترجمة - بتصرّف - لمقال How to Manage KVM Storage Volumes and Pools for Virtual Machines – Part 3 لصاحبه.
رأينا في الدرسين السابقين من هذه السلسلة ( تثبيت KVM وإنشاء آلات افتراضية Virtual machines باستخدامه على أوبونتو و إنشاء آلات افتراضية في بيئة KVM بوسائط تثبيت شبكية) كيفية استخدام virt-manager لإنشاء آلات افتراضيّة وتثبيت أنظمة تشغيل (ضيفة) عليها، انطلاقا من وسيط تخزين محلي أو عبر الشبكة. سنتابع في هذا الدرس مع virt-manager ونرى كيفية إدارة وسائط تخزين افتراضيّة Virtual storage devices. تستخدَم أنظمة التشغيل يوميا وسائط تخزين بنظم ملفات File systems مختلفة، بعضها محلّي Local وآخر يعمل عبر الشبكة. لا توجد عموما اختلافات كبيرة بين مبادئ عمل وسائط التخزين الافتراضية وتلك الملموسة Physical. تُنشأ الأقراص الخاصّة بالآلات الافتراضية في بيئة KVM اعتمادا على أقراص التخزين الملموسة التي يتخاطب معها النظام المُضيف. يتعامل نظام التشغيل مع أقراص التخزين حسب تجزئات Partitions (أو Volumes)، ويتكوّن كل قرص صلب من تجزئة أو أكثر. بالنسبة لبيئة KVM فإنها تتعامل مع التجزئات الافتراضية ضمن مجموعات تُسمّى مجامع (أو أحواض) التخزين Storage pools. يجب أولا إنشاء مَجمع تخزين ثم ننشئ به تجزئة جديدة لقرص افتراضي. إنشاء مجامع تخزين Storage pools في بيئة KVM نبدأ أولا بعرض مجامع التخزين المتوفّرة بالنقر على قائمة Edit (تعديل) ضمن برنامج virt-manager، ثم Connection Details (تفاصيل الاتصال) ونختار تبويب Storage (تخزين). يوجد مبدئيًّا مجمع تخزين باسم default يحفظ التجزئات الافتراضية على المسار var/lib/libvirt/images/. ستلاحظ وجودَ التجزئة الخاصة بنظام التشغيل الضيف الذي أنشأناه في الدرس الأول (اخترنا عند إعداد التخزين في الخطوة 4 مساحة تخزين افتراضية موجودة سلفا). سننشئ في الخطوات التاليّة مجمع تخزين جديدا، بالنقر على زر + في الجانب السفلي الأيسر من النافذة. تظهر نافذة جديدة لإعطاء اسم لمجمع التخزين واختيار نوعه. يدعم KVM ثمانية أنواع لمجامع التخزين: dir: يحفظ التجزئات الافتراضية ضمن مجلد يوجد في نظام الملفات الذي يستخدمه نظام التشغيل . disk: يستخدم أقراصا صلبة ملموسة لحفظ التجزئات الافتراضية بداخلها. fs: يستخدم تجزئات تخزين مهيّأة سلفا لتخزين التجزئات الافتراضية. netfs: يستخدم وسائط تخزين متشاركة عبر الشبكة، مثل NFS، من أجل حفظ التجزئات الافتراضية. gluster: يحتفظ بالتجزئات الافتراضية ضمن وسيط تخزين ملموس يعمل بنظام الملفات GlusterFS. iscsi: يحفظ التجزئات الافتراضية في وسائط تخزين متوفّرة على الشبكة ببروتوكول ISCSI. scsi: يستخدم وسيط تخزين محلي يعمل بنظام SCSI. lvm: يعتمد على مدير التجزئات المنطقية لتخزين التجزئات الافتراضية. سنختار في هذه الخطوة استخدام مجمع تخزين من نوع dir (مجلد في نظام التشغيل المُضيف)؛ فهو النوع الأكثر شيوعا ولا يحتاج للتعديل على بنية نظام الملفات المحلية. لا توجد تقييدات على مكان وجود المجلد الخاص بمجمع التخزين، ولكن من المستحسَن أن يكون على تجزئة منفصلة؛ مع التأكد من الأذون والملكية الخاصة بالمجلّد حتى يمكن ل KVM التعامل معه. تأكد من أن التجزئة التي تريد إنشاء المجمع عليها فارغة، ثم ركّبها على النحو التالي: sudo mount -t ext4 /dev/sdb4 /mnt/spools/SPool1 تحذير: يمكن أن يؤدي استخدام تجزئة غير فارغة إلى مسح محتوياتها. حيث dev/sdb4/ التجزئة الملموسة وmnt/spools/SPool1/ مجلد التركيب. استخدم الأمر lsblk لعرض التجزئات المتوفرة لديك (أو الموجودة على قرص خارجي)؛ كما يمكنك استخدام الأداة الرسومية GParted لنفس الغرض. يظهر في النافذة التالية المسار الذي تريد حفظ تجزئة التخزين الافتراضية فيه. إن كنت تستخدم تجزئة منفصلة فتأكد من ذكر مسار مجلد التركيب (مثلا mnt/spools/SPool1/) هنا. يظهر مجمع التخزين SPool1 بعد إنشائه في القائمة ضمن تبويب Storage السابق. أنشأنا مجمع تخزين ويمكننا الآن إنشاء تجزئة تخزين افتراضية عليه؛ ولكن قبل ذلك سنرى نوعا آخر من أنواع مجامع التخزين، وهو fs. يشير النوع fs إلى أننا نريد استخدام تجزئة قرص ملموسة كاملة، بدلا من مجلد فقط. ستحتاج لإعداد تجزئة قرص ملموس جديدة. تأكد من اسم التجزئة الجديدة (وأنها فارغة) ثم أعدّها لاستخدام نظام الملفات ext4 (على سبيل المثال) بالأمر التالي أو ببرنامج إدارة الأقراص المفضّل لديك: sudo mkfs.ext4 /dev/sdb6 أنشئ أيضا مجلدا جديدا (مثلا SPool2) في النظام المُضيف لتركيب القرص عليه. ملحوظة: اكتف بتهيئة التجزئة وإنشاء المجلد دون تركيبها عليه. سيتولى KVM هذه المهمة. يمكننا الآن إنشاء مجمع تخزين جديد وتسميته مع تحديد نوع المجمع بـfs. حدد في الخطوة التالية من إنشاء المجمع مسار مجلد التركيب (مثلا mnt/spools/SPool2/) في الخانة Target Path (المسار المستهدَف) ومسار التجزئة التي أعددناها سابقا (dev/sdb6/ في المثال) في الخانة Source Path (المسار المصدَر). يظهر مجمع التخزين الجديد في قائمة وسائط التخزين سنناقش في الدرس الموالي إنشاء نوع آخر من مجامع التخزين (عن طريق سطر الأوامر). ننتقل الآن لإنشاء تجزئة جديدة. إضافة تجزئة تخزين افتراضية إلى مجمع تخزين في بيئة KVM توجد صيغ عدّة لتجزئات التخزين. تمكّن هذه الصّيغ من استخدام التجزئة مع مراقبين Hypervisors مختلفين: QEMU، VMware، VirtualBox أو Hyper-V. حدّد مجمع التخزين الذي تريد إضافة التجزئة إليه (SPool2 مثلا) ثم انقر على زر + الموجود تحت بيانات مجمع التخزين أمام عبارة Volumes (التجزئات) لتظهر نافذة إضافة تجزئة. حدّد اسم التجزئة الجديدة والصيغة Format التي تريد استخدامها لإنشاء التجزئة ومساحتها ثم انقر على زر Finish (إنهاء). إن كنت تنوي استخدام التجزئة على مراقب آخر غير KVM في ما بعد فتأكد من اختيار صيغة يدعمها ذلك المراقب. تظهر التجزئة الجديدة ضمن قائمة التجزئات الموجودة في مجمع التخزين SPool2. ترجمة - بتصرّف - لمقال How to Manage KVM Storage Volumes and Pools for Virtual Machines – Part 3 لصاحبه. -
 يتناول هذا المقال، الثاني من سلسلة من أربعة أجزاء، كيفيّة توزيع آلات افتراضيّة عبر وسائط شبكة في بيئة تستخدم KVM. تأكد - قبل تنفيذ الخطوات المشروحة هنا - من تثبيت المتطلّبات المذكورة في الجزء الأول من السلسلة. تثبيت نظام تشغيل عن طريق خادوم FTP في بيئة KVM سنثبّت لأغراض هذا الدرس خادوم FTP على النظام المُضيف؛ وذلك باتباع الخطوات التالية (راجع درس كيفية تنصيب وإعداد خادوم FTP على أوبنتو لتفاصيل أكثر عن إعداد خادوم FTP). سنكتفي هنا بالأوامر الأساسية للحصول على الخادوم وتثبيت نظام ضيف على آلة افتراضية عن طريقه. للتثبيت: $ sudo apt install vsftpd ثم نعدّل ملف الإعداد etc/vsftpd.conf/ للسماح بالوصول المجهول لخادوم FTP: $ sudo nano /etc/vsftpd.conf نغيّر قيمة التعليمة anonymous_enable من NO إلى YES؛ ثم نعيد تشغيل الخادوم: $ sudo systemctl restart vsftpd.service إن أردنا مشاركة ملفات عن طريق خادوم FTP فيمكننا وضعها على المسار /srv/ftp. جهّزنا خادوم FTP لمشاركة الملفات؛ حان الآن وقت اختيار ملف ISO الخاص بنظام التشغيل الذي نريد تثبيته على الآلة الافتراضية (النظام الضّيف)؛ ونحدّد نقطة تركيب Mount point ليُركَّب عليها هذا الملف: $ sudo mount -t iso9660 -o ro ISO_FILE MOUNT_POINT تشير ISO_FILE إلى المسار الذي يوجد عليه ملف ISO وMOUNT_POINT إلى مسار مجلد التركيب. ملحوظة: تمثّل ملفات ISO نسخا خامة من أقراص صلبة ويجب تركيبها على نظام الملفات File system حتى يمكن لنظام التشغيل التعامل معها. يتعامل نظام التشغيل مع المجلَّد الذي رُكِّب عليه المحتوى كما لو كان يقرأ البيانات من قرص مًدمَج (CD أو DVD). نحدّد أثناء التركيب نظام الملفات المناسب للتعامل مع ملف ISO وهو iso9660. لا يمكن لحدّ الساعة الوصول إلى محتويات الملفّ أعلاه عن طريق FTP؛ إذ أنها لا توجد في المسار الذي يمكن لخادوم تشارك الملفات القراءة منه. ننشئ مجلدا جديدا على المسار /srv/ftp: $ sudo mkdir /srv/ftp/ubuntu-14.04 ثم ننقل إليه محتويات ملفّ ISO انطلاقا من نقطة التركيب: $ sudo cp -r /mnt/ubuntu-14.04/* /srv/ftp/ubuntu-14.04/ حيثُ mnt/ubuntu-14.04/ هي نقطة التركيب (MOUNT_POINT) السابقة. نتأكد من أن مجموعة المستخدمين ftp هي المالكة للمجلد ubuntu-14.04 الذي أنشأناه للتو حتى يمكن لخادوم FTP قراءة محتوياته: $ sudo chown -R :ftp /srv/ftp/ubuntu-14.04/ يمكننا الآن استخدام أداة virt-manager لإنشاء آلات افتراضية تستخدم وسيط التثبيت الموجود على خادوم تشارك الملفات. تظهر عند طلب إنشاء آلة افتراضية جديدة النافذة التالية. نحدّد خيار التثبيت عبر الشبكة Network Install وننتقل للخطوة الموالية. نحدّد في هذه الخطوة المسار URL الذي يوجد عليه وسيط التثبيت. بما أننا نريد الوصول إلى خادوم FTP فالمسار سيكون حسب الصيغة التالية: ftp://ip_or_host/folder حيثُ ip_or_host عنوان IP الخاص بخادوم تشارك الملفات أو اسم المضيف Host الخاص به؛ وfolder المجلّد حيث توجد ملفات نظام التشغيل الذي نريد تثبيته على الآلة الافتراضية (مجلد ubuntu-14.04 الموجود على خادوم تشارك الملفات). تذكّر أننا في الدرس السابق ثبّتنا حزمة bridge-utils وذكرنا أنها تنشئ جسرا يعمل بين الآلات الافتراضية (النظام الضّيف) والنظام المُضيف. ستلاحظ بعد تثبيت الحزمة ظهور واجهة شبكة جديدة لديك على النظام المُضيف (حيثُ ثبتتنا KVM وأدواته) باسم virbr0. يمكن للأجهزة الافتراضية التواصل مع النظام المضيف عن طريق هذه الواجهة؛ لذا سنحصُل على عنوانها بتنفيذ الأمر التالي: $ ip -4 a show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000 inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0 valid_lft forever preferred_lft forever يظهر من نتيجة الأمر أعلاه أن الواجهة vibr0 لديها العنوان 192.168.122.1 (قد يختلف العنوان لديك). يصبح عنوان المجلّد حيث توجد ملفات التثبيت على النحو التالي: ftp://192.168.122.1/ubuntu-14.04 وهو العنوان الذي أعطيناه للأداة virt-manager كما في الصورة أعلاه. تشبه الخطوات الموالية (من 3 إلى 5) الخطوات المذكورة في الجزء الأول من هذه السلسلة. تثبيت نظام تشغيل عن طريق خادوم وِب في بيئة KVM لا تقتصر إمكانيات التثبيت عبر الشبكة على الوسائط الموجودة على خواديم تشارك ملفات، بل يمكن استخدام خواديم أخرى مثل خواديم الوِب (Apache أو Nginx على سبيل المثال). سنأخذ في هذه الفقرة مثالا لإنشاء آلة افتراضية عبر الأداة virt-manager وتثبيت نظام تشغيل ضيف عن طريق وسيط تثبيت موجود على خادوم وِب. راجع درس كيف تثبت حزم MySQL ،Apache ،Linux :LAMP و PHP على أوبنتو 14.04 للمزيد عن تفاصيل تثبيت خادوم وِب Apache؛ أو مقال كيف تثبت حزم MySQL ،nginx ،Linux :LEMP وPHP على أوبنتو 14.04 إن كنت تفضّل خادوم Nginx. يمكن الاكتفاء - لأغراض هذا الدرس - بالجزء الأول من أحد المقالين المذكوريْن سابقا (تثبيت Apache أو Nginx دون بقية الحزم). لا يختلف تثبيت النظام الضّيف انطلاقا من وسيط تثبيت على خادوم وِب عن التثبيت عبر خادوم تشارك ملفات سوى في الخطوة الثانية عند تحديد العنوان. في حالة خادوم الوِب يُحدّد العنوان على النحو التالي: http://192.168.122.1/ubuntu-14.04 رأينا في هذا الدرس والدرس السابق كيفية استخدام الأداة الرسومية virt-manager لإنشاء آلات افتراضيّة في بيئة تستخدم KVM للحوسبة الافتراضية؛ سنرى في الدرس الموالي كيفية إدارة الأقراص الافتراضية في هذه البيئة. ترجمة - بتصرّف لمقال How to Deploy Multiple Virtual Machines using Network Install (HTTP, FTP and NFS) under KVM Environment – Part 2 لصاحبه Mohammad Dosoukey.
يتناول هذا المقال، الثاني من سلسلة من أربعة أجزاء، كيفيّة توزيع آلات افتراضيّة عبر وسائط شبكة في بيئة تستخدم KVM. تأكد - قبل تنفيذ الخطوات المشروحة هنا - من تثبيت المتطلّبات المذكورة في الجزء الأول من السلسلة. تثبيت نظام تشغيل عن طريق خادوم FTP في بيئة KVM سنثبّت لأغراض هذا الدرس خادوم FTP على النظام المُضيف؛ وذلك باتباع الخطوات التالية (راجع درس كيفية تنصيب وإعداد خادوم FTP على أوبنتو لتفاصيل أكثر عن إعداد خادوم FTP). سنكتفي هنا بالأوامر الأساسية للحصول على الخادوم وتثبيت نظام ضيف على آلة افتراضية عن طريقه. للتثبيت: $ sudo apt install vsftpd ثم نعدّل ملف الإعداد etc/vsftpd.conf/ للسماح بالوصول المجهول لخادوم FTP: $ sudo nano /etc/vsftpd.conf نغيّر قيمة التعليمة anonymous_enable من NO إلى YES؛ ثم نعيد تشغيل الخادوم: $ sudo systemctl restart vsftpd.service إن أردنا مشاركة ملفات عن طريق خادوم FTP فيمكننا وضعها على المسار /srv/ftp. جهّزنا خادوم FTP لمشاركة الملفات؛ حان الآن وقت اختيار ملف ISO الخاص بنظام التشغيل الذي نريد تثبيته على الآلة الافتراضية (النظام الضّيف)؛ ونحدّد نقطة تركيب Mount point ليُركَّب عليها هذا الملف: $ sudo mount -t iso9660 -o ro ISO_FILE MOUNT_POINT تشير ISO_FILE إلى المسار الذي يوجد عليه ملف ISO وMOUNT_POINT إلى مسار مجلد التركيب. ملحوظة: تمثّل ملفات ISO نسخا خامة من أقراص صلبة ويجب تركيبها على نظام الملفات File system حتى يمكن لنظام التشغيل التعامل معها. يتعامل نظام التشغيل مع المجلَّد الذي رُكِّب عليه المحتوى كما لو كان يقرأ البيانات من قرص مًدمَج (CD أو DVD). نحدّد أثناء التركيب نظام الملفات المناسب للتعامل مع ملف ISO وهو iso9660. لا يمكن لحدّ الساعة الوصول إلى محتويات الملفّ أعلاه عن طريق FTP؛ إذ أنها لا توجد في المسار الذي يمكن لخادوم تشارك الملفات القراءة منه. ننشئ مجلدا جديدا على المسار /srv/ftp: $ sudo mkdir /srv/ftp/ubuntu-14.04 ثم ننقل إليه محتويات ملفّ ISO انطلاقا من نقطة التركيب: $ sudo cp -r /mnt/ubuntu-14.04/* /srv/ftp/ubuntu-14.04/ حيثُ mnt/ubuntu-14.04/ هي نقطة التركيب (MOUNT_POINT) السابقة. نتأكد من أن مجموعة المستخدمين ftp هي المالكة للمجلد ubuntu-14.04 الذي أنشأناه للتو حتى يمكن لخادوم FTP قراءة محتوياته: $ sudo chown -R :ftp /srv/ftp/ubuntu-14.04/ يمكننا الآن استخدام أداة virt-manager لإنشاء آلات افتراضية تستخدم وسيط التثبيت الموجود على خادوم تشارك الملفات. تظهر عند طلب إنشاء آلة افتراضية جديدة النافذة التالية. نحدّد خيار التثبيت عبر الشبكة Network Install وننتقل للخطوة الموالية. نحدّد في هذه الخطوة المسار URL الذي يوجد عليه وسيط التثبيت. بما أننا نريد الوصول إلى خادوم FTP فالمسار سيكون حسب الصيغة التالية: ftp://ip_or_host/folder حيثُ ip_or_host عنوان IP الخاص بخادوم تشارك الملفات أو اسم المضيف Host الخاص به؛ وfolder المجلّد حيث توجد ملفات نظام التشغيل الذي نريد تثبيته على الآلة الافتراضية (مجلد ubuntu-14.04 الموجود على خادوم تشارك الملفات). تذكّر أننا في الدرس السابق ثبّتنا حزمة bridge-utils وذكرنا أنها تنشئ جسرا يعمل بين الآلات الافتراضية (النظام الضّيف) والنظام المُضيف. ستلاحظ بعد تثبيت الحزمة ظهور واجهة شبكة جديدة لديك على النظام المُضيف (حيثُ ثبتتنا KVM وأدواته) باسم virbr0. يمكن للأجهزة الافتراضية التواصل مع النظام المضيف عن طريق هذه الواجهة؛ لذا سنحصُل على عنوانها بتنفيذ الأمر التالي: $ ip -4 a show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 4: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000 inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0 valid_lft forever preferred_lft forever يظهر من نتيجة الأمر أعلاه أن الواجهة vibr0 لديها العنوان 192.168.122.1 (قد يختلف العنوان لديك). يصبح عنوان المجلّد حيث توجد ملفات التثبيت على النحو التالي: ftp://192.168.122.1/ubuntu-14.04 وهو العنوان الذي أعطيناه للأداة virt-manager كما في الصورة أعلاه. تشبه الخطوات الموالية (من 3 إلى 5) الخطوات المذكورة في الجزء الأول من هذه السلسلة. تثبيت نظام تشغيل عن طريق خادوم وِب في بيئة KVM لا تقتصر إمكانيات التثبيت عبر الشبكة على الوسائط الموجودة على خواديم تشارك ملفات، بل يمكن استخدام خواديم أخرى مثل خواديم الوِب (Apache أو Nginx على سبيل المثال). سنأخذ في هذه الفقرة مثالا لإنشاء آلة افتراضية عبر الأداة virt-manager وتثبيت نظام تشغيل ضيف عن طريق وسيط تثبيت موجود على خادوم وِب. راجع درس كيف تثبت حزم MySQL ،Apache ،Linux :LAMP و PHP على أوبنتو 14.04 للمزيد عن تفاصيل تثبيت خادوم وِب Apache؛ أو مقال كيف تثبت حزم MySQL ،nginx ،Linux :LEMP وPHP على أوبنتو 14.04 إن كنت تفضّل خادوم Nginx. يمكن الاكتفاء - لأغراض هذا الدرس - بالجزء الأول من أحد المقالين المذكوريْن سابقا (تثبيت Apache أو Nginx دون بقية الحزم). لا يختلف تثبيت النظام الضّيف انطلاقا من وسيط تثبيت على خادوم وِب عن التثبيت عبر خادوم تشارك ملفات سوى في الخطوة الثانية عند تحديد العنوان. في حالة خادوم الوِب يُحدّد العنوان على النحو التالي: http://192.168.122.1/ubuntu-14.04 رأينا في هذا الدرس والدرس السابق كيفية استخدام الأداة الرسومية virt-manager لإنشاء آلات افتراضيّة في بيئة تستخدم KVM للحوسبة الافتراضية؛ سنرى في الدرس الموالي كيفية إدارة الأقراص الافتراضية في هذه البيئة. ترجمة - بتصرّف لمقال How to Deploy Multiple Virtual Machines using Network Install (HTTP, FTP and NFS) under KVM Environment – Part 2 لصاحبه Mohammad Dosoukey.
