
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/25/21 في كل الموقع
-
لدي مصفوفة بالشكل التالي: x = np.array([[0, 1], # 0 [2, 3], # 1 [4, 5], # 2 [6, 7], # 3 [8, 9]]) # 4 وأريد أن أقوم بإيجاد الفهرس الخاص بكل صف في المصفوفة التالي: search_array = np.array([[0, 1], [4, 5], [8, 9] ]) من المفترض أن تكون النتيجة كالتالي: [0, 2, 4] كيف أقوم بعمل هذا الأمر باستخدام مكتبة numpy؟2 نقاط
-
لدي مجموعة من المستندات تحوي حقل معرّف ObjectID بنمط سلسلة نصيّة بدلاً من النمط Object ID المستخدم في mongodb. { .... newID: "f9e1fa551137c2c572808a5f" } هل يوجد طريقة معيّنة استطيع من خلالها أثناء عملية المقارنة التأكد من أن هذه السلسلة النصية (أي الحقل newID) هي ID صالح في mongoDB وبالتالي تحويله إلى ObjectID ؟2 نقاط
-
لقد قمت بإنشاء عدة قواعد بيانات للتجربة، ولكن هل هنالك أمر معيّن لحذف جميع قواعد البيانات الموجودة ؟ دون الحاجة لذكر جميع اسماء قواعد البيانات. من خلال التوثيق الرسمي لاحظت فقط وجود حذف قاعدة بيانات واحدة.2 نقاط
-
لدي مشروع كبير الحجم فيه عدد كبير أيضاً من المكتبات التي تم تضمينها. هل يوجد طريقة ما لإزالة المكتبات التي لا يتم استعمالها ضمن المشروع؟ أي بشكل أن يتم فقط حذف المكتبة التي ليس لها أي تضمين أو استخدام ضمن ملفات المشروع.2 نقاط
-
يظهر لي التحذير التالي في mongodb على نظام التشغيل linux: 2015-03-06T21:01:15.526-0800 I CONTROL [initandlisten] ** WARNING: /sys/kernel/mm/transparent_hugepage/defrag is 'always'. 2015-03-06T21:01:15.526-0800 I CONTROL [initandlisten] ** We suggest setting it to 'never' مامعنى هذا التحذير؟ وكيف يمكنني حل هذه المشكلة؟2 نقاط
-
عندما أستخدم التابع list.append لإضافة عنصر إلى القائمة، يتم اعتبار قيمتها False كالتالي: >>> x = [] >>> not x.append(123) True >>> ما هو سبب هذا الأمر؟ وهل يمكن تطبيقه في دوال خاصة بي أيضًا؟2 نقاط
-
تحدث المشكلة بسبب تغير طول القائمة خلال دوران الحلقة مع حذف العناصر المتكرر فعندما يقصر طول القائمة ويصبح أصغر من دليل المحرف o الأخير، لن تصل دليل الحلقة لهذا الدليل ضمن القائمة ما يمنع حذف العنصر. يمكن تطبيق نفس الشيفرة على المثال "oooo" مثلا الذي يحوي 4 محارف صوتية، ونتيجة التنفيذ أنه سيتم حذف فقط محرفين والنتيجة "oo" وعندها دليل الحلقة سيكون أكبر من طول المصفوفة و ستنتهي الحلقة قبل حذف كل المحارف. الحل بتطبيق دالة الاستبدال كما في الإجابة السابقة. أو استعمال الفلتر filter: text = "Hellooo, world! Words!" def removeVowel(text): textlist = list(text.lower()) for char in list('aeiou'): #textlist = [i for i in textlist if i != char] # ممكن هذه الطريقة أيضا textlist = list(filter(lambda a: a != char, textlist)) return "".join(textlist) print(removeVowel(text)) # hll, wrld! wrds!2 نقاط
-
المشكلة هي أنك تقوم بإستخدام دالة ()remove من أجل إزالة الحروف المتحركة فلا تقم بإستخدامها في قائمة بينما تقوم بالتكرار فيها يمكنك إستخدام دالة ()replace كما في هذا الكود للحصول على النتيجة المرغوبة text = "Hellooo, world! Words!" def anti_vowel(c): newstr = "" # الحروف المتحرك vowels = ('a', 'e', 'i', 'o', 'u') for x in c.lower(): # فحص إذا كان هناك حرف متحرك if x in vowels: # إزالة الحرف المتحرك newstr = c.replace(x, "") #إرجاع النص الجديد الخالي من الحروف المتحركة return newstr print(anti_vowel(text))2 نقاط
-
 يختلف هذا المقال قليلًا عن باقي الفصول، إذ سأدَع الحديث عن النظريات قليلًا لننشئ نحن وأنت برنامجًا سويًا، فالنظرية وإن كانت مهمة جدًا لتعلم كيفية البرمجة، إلا أنّ قراءة البرامج الحقيقية وفهم شيفراتها لا تقل أهمية، ومشروعنا في هذا المقال هو بناء روبوت ينفِذ مهمة في عالم افتراضي، وستكون تلك المهمة توصيل الطرود واستلامها. قرية المرج Meadowfield سيعمل الروبوت الخاص بنا في قرية صغيرة تُدعى قرية المرج، حيث يوجد فيها أحد عشر مكانًا بينها أربعة عشر طريقًا، ويمكن وصف القرية بالمصفوفة التالية: const roads = [ "Salma's House-Omar's House", "Salma's House-Cabin", "Salma's House-Post Office", "Omar's House-Town Hall", "Sara's House-Mostafa's House", "Sara's House-Town Hall", "Mostafa's House-Sama's House", "Sama's House-Farm", "Sama's House-Shop", "Marketplace-Farm", "Marketplace-Post Office", "Marketplace-Shop", "Marketplace-Town Hall", "Shop-Town Hall" ]; وتكوِّن شبكة الطرق في القرية مخططًا graph، وهو عبارة عن تجميعة من نقاط لتمثل الأماكن في القرية، مع خطوط تصل بينها بحيث تمثل الطرق، وسيكون هذا هو العالم الذي سيتحرك الروبوت فيه. لكن ليس من السهل التعامل مع مصفوفة السلاسل النصية السابقة، إذ لا نريد إلا الوجهات التي يمكننا الذهاب إليها من أي نقطة معطاة لنا، وعلى ذلك فسنحوِّل قائمة الطرق إلى هيكل بيانات يخبرنا بالمناطق التي نستطيع الذهاب إليها من كل نقطة أو مكان، انظركما يلي: function buildGraph(edges) { let graph = Object.create(null); function addEdge(from, to) { if (graph[from] == null) { graph[from] = [to]; } else { graph[from].push(to); } } for (let [from, to] of edges.map(r => r.split("-"))) { addEdge(from, to); addEdge(to, from); } return graph; } const roadGraph = buildGraph(roads); تُنشئ دالة buildGraph كائن خارطة map object عند إعطائها مصفوفة من الحدود edges، حيث تخزن فيها لكل عقدةٍ مصفوفةً من العقد المتصلة بها. كما تستخدِم تابع method للذهاب من سلسلة الطريق النصية التي تحمل الصيغة "Start-End" إلى مصفوفات من عنصرين تحتوي على البداية والنهاية على أساس سلسلتَين منفصلتين. المهمة سيتحرك الروبوت داخل القرية، إذ لديه طرود في أماكن مختلفة فيها، حيث يحمل كل طرد عنوانًا يجب نقله إليه؛ وسيلتقط الروبوت الطرودَ حين وصوله إليها، ثم يتركها عند وصوله إلى الوجهة المرسَل إليها، ويجب أن يقرر في كل نقطة وجهته التالية، ولا تنتهي مهمته إلا عند توصيل جميع الطرود. لكن أولًا يجب تعريف عالم افتراضي يصف هذه العملية، وذلك لنتمكّن من محاكاته، ويكون هذا النموذج قادر على إخبارنا بموقع الروبوت والطرود معًا، كما يجب تحديث هذا النموذج عندما يقرر الروبوت الذهاب إلى مكان جديد. إن كنت تفكر بأسلوب البرمجة كائنية التوجه، سيكون دافعك الأول هو البدء بتعريف كائنات للعناصر المختلفة في هذا العالم الذي أنشأناه، فصنف للروبوت، وآخر للطرد، وصنف ثالث للأماكن ربما، ثم تحمِل هذه الأصناف بعد ذلك خصائصًا تصف حالتها، كما في حالة كومة الطرود عند موقع ما، والتي يمكننا تغييرها عند إجراء تحديث لهذا العالم. لكن هذا خطأ في أغلب الحالات على الأقل، فكون شيء ما يحاكي الكائن لا يعني وجوب معاملته على أساس كائن في برنامجك؛ كما أنّ كتابة الأصناف في برنامجك دون داعي حقيقي لها، ستُنشئ تجميعةً من الكائنات المرتبطة ببعضها بعضًا لكل منها حالة داخلية متغيرة، وتكون مثل تلك البرامج صعبة الفهم وسهلة التعطل. لدينا أسلوبًا أفضل من ذلك، وهو ضغط حالة القرية إلى أقل فئة ممكنة من القيم التي تعرِّفها، فيكون لدينا الموقع الحالي للروبوت، وتجميعة الطرود غير المسلَّمة، والتي يحمل كل منها موقعه الحالي وعنوان التسليم، وحسبنا هذا! بينما نحن في ذلك، فعلينا التأكد أنه حين يتحرك الروبوت من موقعه، فعلينا حساب حالة جديدة وفق الموقف الذي يكون بعد التحرك، وذلك دون تغيير الحالة الأولى، انظر كما يلي: class VillageState { constructor(place, parcels) { this.place = place; this.parcels = parcels; } move(destination) { if (!roadGraph[this.place].includes(destination)) { return this; } else { let parcels = this.parcels.map(p => { if (p.place != this.place) return p; return {place: destination, address: p.address}; }).filter(p => p.place != p.address); return new VillageState(destination, parcels); } } } يتحقق التابع move أولًا إن كان ثمة طريق من الموقع الحالي إلى موقع الوِجهة، وإن لم يكن، فسيعيد الحالة القديمة بما أنّ هذه الخطوة غير صالحة، ثم يُنشئ حالةً جديدةً يكون فيها موقع الوِجهة هو الموقع الجديد للروبوت. لكن سيحمل هذا الروبوت معه طرودًا أخرى غير هذا الطرد، ويأخذها معه إلى موقع تسليم الطرد المسمى، ثم يتابع حملها معه بعد تسليم الطرد، ليذهب بكل منها إلى موقع تسليمه الذي يخصه، ولكي نحصل على بيانات تلك الطرود عند أي نقطة زمنية نريدها، فسنحتاج إلى إنشاء فئة set جديدة نضع فيها تلك الطرود التي يحملها إلى الموقع الجديد، ثم يترك الطرود الواجب تسليمها في موقع التسليم، أي نحذفها من فئة الطرود غير المسلَّمة. ويتكفل بعملية الانتقال استدعاء map، بينما نستدعي filter ليتولى عملية التسليم. لا تتغير كائنات الطرود عند نقلها، وإنما يعاد إنشاؤها، ويعطينا التابع move حالة جديدة للقرية مع ترك الحالة القديمة كما هي دون تغيير، انظر كما يلي: let first = new VillageState( "Post Office", [{place: "Post Office", address: "Salma's House"}] ); let next = first.move("Salma's House"); console.log(next.place); // → Salma's House console.log(next.parcels); // → [] console.log(first.place); // → Post Office تُسلَّم الطرود عند مواضع تسليمها مع حركة الروبوت بين تلك المواقع، ويُرى أثر ذلك في الحالة التالية، لكن ستظل الحالة الابتدائية تصف الموقف الذي يكون فيه الروبوت عند مكتب البريد ومعه الطرد الغير مسلَّم بعد. البيانات الثابتة Persistent Data تُسمى هياكل البيانات التي لا تتغير بالهياكل الثابتة persistent، أو غير القابلة للتغير immutable، وتحاكي السلاسل النصية والأرقام في بقائها كما هي، بدلًا من احتواء أشياء مختلفة في كل مرة. بما أن كل شيء في جافاسكربت قابل للتغير تقريبًا، فسيتطلب العمل مع كائنات أو بيانات ثابتة جهدًا، وعملًا إضافيًا، ونوعًا من التقييد، حيث لدينا دالة Object.freeze من أجل هذا، إذ تؤثر على الكائن وتجمده، وذلك لتجعله يتجاهل الكتابة على خصائصه، فتستطيع استخدام ذلك لضمان ثبات كائناتك إن أردت، لكن تذكر أن هذا التجميد يعني أن الحاسوب سيبذل مزيدًا من الجهد. نفضل إخبار العامة بترك الكائن الفلاني وشأنه وعدم العبث به، آملين تذكّرهم ذلك، بدلًا من إخبارهم بتجاهل تحديثات بعينها. let object = Object.freeze({value: 5}); object.value = 10; console.log(object.value); // → 5 لكن هنا يبرز سؤال إن كنت منتبهًا، فإن كانت اللغة نفسها تحثنا على جعل كل شيء متغيرًا وتتوقع منا ذلك، فلماذا نخرج عن هذا المسلك لنجعل بعض الكائنات ثابتةً لا تقبل التغيير؟ الإجابة بسيطة وهي أن هذا سيساعدنا في فهم برامجنا أكثر، إذ يتعلق الأمر بإدارة التعقيد لبرامجنا، فإن كانت الكائنات التي في نظامنا ثابتةً ومستقرةً، فيمكننا إجراء عمليات عليها إجراءً معزولًا -حيث سيعطينا التحرك إلى منزل سلمى مثلًا من أي حالة بدء معطاة الحالة الجديدة نفسها في كل مرة-،؛ أما إن كانت الكائنات تتغير مع الوقت، فسيضيف هذا بعدًا جديدًا من التعقيد إلى العمليات والتفكير المنطقي لحل المشكلة. وربما تقول أن مسألة توصيل الطرود، والروبوت، وهذه القرية الصغيرة، سهل أمرها ويمكن إدارتها، وربما أنت محق، لكن المعيار الذي يحدد نوع النظم الممكن بناؤها هو فهمنا نحن لتلك الأنظمة ومدى ما يمكننا فهمه مطلقًا، فأيّ شيء يسرّع فهم شيفرتك، فسيمهد لك الطريق لبناء نظم أكثر تطورًا. لكن رغم سهولة فهم النظم المبنية على هياكل بيانات ثابتة، فقد يكون من الصعب تصميم نظام مثل هذا، وخاصةً إن لم تكن لغة البرمجة التي تستخدمها مصمَّمةً لذلك، كما سنبحث عن فرص استخدام هياكل البيانات الثابتة في هذه السلسلة مع استخدامنا للهياكل المتغيرة كذلك. المحاكاة ينظر روبوت التوصيل إلى العالم، ويقرر الاتجاه الذي يريد السير فيه، وعليه فيمكننا القول أنّ الروبوت هو دالة تأخذ كائن villageState، وتعيد اسم مكان قريب. لأننا نريد الربوتات أن تكون قادرة على تذكر أشياء بعينها كي تنفِّذ الخطط الموضوعة لها من قِبلنا، فسنمرر إليها ذاكرتها، ونسمح لها بإعادة ذاكرة جديدة، ومن ثم يعيد الروبوت كائنًا يحتوي الاتجاه الذي يريد السير فيه، وقيمة ذاكرة تُعطى إليه في المرة التالية التي يُستدعى فيها. function runRobot(state, robot, memory) { for (let turn = 0;; turn++) { if (state.parcels.length == 0) { console.log(`Done in ${turn} turns`); break; } let action = robot(state, memory); state = state.move(action.direction); memory = action.memory; console.log(`Moved to ${action.direction}`); } } لننظر ما الذي يجب على الروبوت فعله كي "يحل" حالة ما: يجب عليه التقاط جميع الطرود أولًا من خلال الذهاب إلى كل موقع فيه طرد، ثم يسلِّم تلك الطرود بالذهاب إلى كل عنوان من العناوين المرسل إليها هذه الطرود، حيث لا يذهب إلى موقع التسليم إلا بعد التقاط الطرد الخاص به. تُرى ما هي أغبى خطة يمكن أن تنجح هنا؟ إنها العشوائية لا شك، حيث يتخِذ الروبوت اتجاهًا عشوائيًا عند كل منعطف، مما يعني أنه سيمر لا محالة على جميع الطرود بعد عدد من المحاولات، وسيصل كذلك إلى موقع تسليمها في مرحلة ما. انظر: function randomPick(array) { let choice = Math.floor(Math.random() * array.length); return array[choice]; } function randomRobot(state) { return {direction: randomPick(roadGraph[state.place])}; } تعيد Math.random() عددًا بين الصفر والواحد، ويكون دومًا أقل من الواحد، كما يعطينا ضرب عدد مثل هذا في طول أي مصفوفة ثم تطبيق Math.floor عليه موقعًا عشوائيًا للمصفوفة. وبما أنّ هذا الروبوت لا يحتاج إلى تذكر أي شيء، فسيَتجاهل الوسيط الثاني له ويهمل خاصية memory في كائنه المعاد؛ وتذكّر أنّه يمكن استدعاء دوال جافاسكربت بوسائط إضافية دون آثار جانبية مقلقة. نحتاج الآن إلى طريقة لإنشاء حالة جديدة بها بعض الطرود، وذلك من أجل إطلاق هذا الروبوت للعمل، والتابع الساكن -المكتوب هنا بإضافة خاصيةٍ مباشرةً للمنشئ- مكان مناسب لوضع هذه الوظيفة. VillageState.random = function(parcelCount = 5) { let parcels = []; for (let i = 0; i < parcelCount; i++) { let address = randomPick(Object.keys(roadGraph)); let place; do { place = randomPick(Object.keys(roadGraph)); } while (place == address); parcels.push({place, address}); } return new VillageState("Post Office", parcels); }; لا نريد أي طرود مرسلة من المكان نفسه الذي ترسَل إليه، ولهذا تختار حلقة do التكرارية أماكنًا جديدةً في كل مرة تحصل على مكان مطابق للعنوان. دعنا نبدأ عالمًا افتراضيًا، كما يلي: runRobot(VillageState.random(), randomRobot); // → Moved to Marketplace // → Moved to Town Hall // → … // → Done in 63 turns كما نرى من المثال، إذ غيّر الروبوت اتجاهه ثلاثًا وستين مرة، وذلك الرقم الكبير بسبب عدم التخطيط الجيد للخطوة التالية، كما سننظر في هذا قريبًا. يمكنك استخدام دالة runRobotAnimation المتاحة في البيئة البرمجية لهذا المقال، حيث ستنفِّذ المحاكاة، وستعرض لك الروبوت وهو يتحرك في خارطة القرية، بدلًا من إخراج نص فقط. runRobotAnimation(VillageState.random(), randomRobot); سندع طريقة تنفيذ runRobotAnimation مبهمةً في الوقت الحالي، حيث ستستطيع معرفة كيفية عملها بعد قراءة المقال الرابع عشر من هذه السلسلة والذي نناقش فيه تكامل جافاسكربت في المتصفحات. طريق شاحنة البريد لا شك أنّ فكرة الروبوت هذه لتوصيل البريد فكرة بدائية، وأجدر بنا تطوير هذا البرنامج قليلًا، فلم لا ننظر إلى توصيل البريد في العالم الحقيقي لنستوحي منه أفكارًا لعالمنا الصغير؟ أحد هذه الحلول هو البحث عن طريق يمر على جميع الأماكن في القرية، وحينها يأخذ الروبوت هذه الطريق مرتين. انظر مثلًا على هذا الطريق بدءًا من مكتب البريد: const mailRoute = [ "Salma's House", "Cabin", "Salma's House", "Omar's House", "Town Hall", "Sara's House", "Mostafa's House", "Sama's House", "Shop", "Sama's House", "Farm", "Marketplace", "Post Office" ]; نحتاج إلى الاستفادة من ذاكرة الروبوت إذا أردنا استخدام الروبوت المتتبع للطريق route-following، حيث يحذف الروبوت العنصر الأول عند كل منعطف ويحتفظ ببقية الطريق: function routeRobot(state, memory) { if (memory.length == 0) { memory = mailRoute; } return {direction: memory[0], memory: memory.slice(1)}; } سيكون هذا الروبوت بهذا الأسلوب الجديد أسرع من الأسلوب الأول، إذ سيكون أقصى عدد من الاتجاهات التي يسلكها أو المنعطفات التي يأخذها هو 26 -وهو ضعف عدد الأماكن في طريق القرية-، وإن كان في العادة أقل من هذا العدد، فليست جميع الأماكن بها طرود بريد في كل مرة. اكتشاف الطريق Pathfinding لنبحث في طريقة أكثر تطورًا من المرور على جميع الأماكن في القرية في كل مرة، فلا شك في أن الروبوت سيكون أكثر كفاءة إذا عدّل سلوكه ليناسب العمل الحقيقي المراد تنفيذه؛ لذا يجب امتلاكه القدرة على التحرك نحو طرد معين أو موقع تسليم بعينه، وعليه نحتاج دالة لإيجاد الطريق المناسبة. تُعَدّ مشكلة إيجاد الطريق باستخدام مخطط هي مشكلة البحث، حيث نستطيع تحديد ما إذا كان الحل المعطى -أي الطريق- مناسبًا أم لا، لكن لا نستطيع حساب الحل بالطريقة نفسها عند حساب حاصل جمع 2+2 مثلًا، وإنما يجب إنشاء حلولًا محتملةً لإيجاد واحد صالح. تتضح هنا المشكلة أكثر، إذ لا نهايةً لعدد الاحتمالات الممكنة للطرق من خلال مخطط، لكن يمكن تضييق عدد الاحتمالات إذا أردنا الطرق المؤدية من نقطة أ إلى نقطة ب مثلًا، فعندئذ لن يهمنا سوى الطرق التي تبدأ من النقطة أ، كما لا نريد الطرق التي تمر المكان نفسه مرتين، إذ لا تُعَدّ هي الطرق الأكثر كفاءة في أي مكان، ويقلل هذا عدد الطرق التي يجب اعتمادها من قِبَل دالة البحث أكثر وأكثر. نريد في الواقع أقصر طريق فقط، وعليه يجب النظر في الطرق الأقصر أولًا قبل النظر في الطرق الأطول، وأحد الأساليب لفعل ذلك هو بدء طرق من نقطة تحرك الروبوت لتُستكشف جميع الأماكن التي يمكن الوصول إليها ولم يُذهب إليها بعد، حتى تصل إحدى تلك الطرق إلى المكان المراد تسليم الطرد إليه، وهكذا نستكشف الطرق التي يحتمل أن تكون مفيدة لنا، ونتخذ أقصرها أو واحدًا من أقصر تلك الطرق. كما في الدالة التالية: function findRoute(graph, from, to) { let work = [{at: from, route: []}]; for (let i = 0; i < work.length; i++) { let {at, route} = work[i]; for (let place of graph[at]) { if (place == to) return route.concat(place); if (!work.some(w => w.at == place)) { work.push({at: place, route: route.concat(place)}); } } } } يجب أن يتم الاستكشاف بترتيب صحيح، فالأماكن التي يصل إليها أولًا يجب استكشافها أولًا، لكن انتبه إلى أن مكان س مثلًا لا يُستكشف فور الوصول إليه، إذ سيعني هذا أنه علينا استكشاف أماكن يمكن الوصول إليها من س وهكذا، رغم احتمال وجود مسارات أقصر لم تُستكشف بعد. وعلى هذا فإن الدالة تحتفظ بقائمة عمل work list، وهي مصفوفة من الأماكن التي يجب استكشافها فيما بعد مع الطرق التي توصلنا إليها، حيث تبدأ بموقع ابتدائي للبدء منه وطريق فارغة، ثم يبدأ البحث بعدها بأخذ العنصر التالي في القائمة واستكشافه، مما يعني النظر في جميع الطرق الخارجة من هذا المكان، فإن كان أحدها هو الهدف المراد، فيُعاد طريق تامة finished road، وإلا فسيضاف عنصر جديد إلى القائمة إن لم يُنظر في هذا المكان من قبل. كذلك، إن كنا قد نظرنا فيه من قبل، فقد وجدنا إما طريق أطول إلى هذا المكان أو واحدة بنفس طول الطريق الموجودة -وبما أننا نبحث عن الطرق الأقصر أولًا- ولا نحتاج إلى استكشافها عندئذ. تستطيع تخيل هذا بصريًا على أساس شبكة من الطرق المعروفة، حيث تخرج من موقع ابتدائي، وتنمو بانتظام في جميع الجوانب، لكن لا تتشابك مع بعضها أو تنعكس على نفسها؛ وبمجرد وصول خيط من تلك الشبكة إلى الموقع الهدف، فيُتتبَّع ذلك الخيط إلى نقطة البداية ليعطينا الطريق التي نريدها. لا تعالج شيفرتنا الموقف الذي لا تكون فيه عناصر عمل على قائمة العمل، وذلك لعِلمنا باتصال المخطط الخاص بنا، أي يمكن الوصول إلى كل موقع من جميع المواقع الأخرى، وسنكون قادرين دائمًا على إيجاد طريق ممتدة بين نقطتين، فلا يفشل البحث الذي نجريه. function goalOrientedRobot({place, parcels}, route) { if (route.length == 0) { let parcel = parcels[0]; if (parcel.place != place) { route = findRoute(roadGraph, place, parcel.place); } else { route = findRoute(roadGraph, place, parcel.address); } } return {direction: route[0], memory: route.slice(1)}; } يستخدِم هذا الروبوت قيمة ذاكرته على أساس قائمة من الاتجاهات ليتحرك وفقًا لها، تمامًا مثل الروبوت المتتبع للطريق الذي ذكرناه آنفًا، وعليه معرفة الخطوة التالية إذا وجد القائمة فارغة؛ كما ينظر في أول طرد غير مسلَّم في الفئة التي معه، فإن لم يكن قد التقطه، فسيرسم طريقًا إليه، وإن كان قد التقطه، فسينشئ طريقًا إلى موقع التسليم، انظر كما يلي: runRobotAnimation(VillageState.random(), goalOrientedRobot, []); ينهي هذا الروبوت مهمة تسليم خمسة طرود في نحو ستة عشر منعطفًا، وهذا أفضل بقليل من routeRobot، لكن لا زال هناك فرصة للتحسين أكثر من ذلك. تدريبات معايرة الروبوت من الصعب موازنة الروبوتات بجعلها تحل بعض السيناريوهات البسيطة، فلعل أحدها حصل على مهام سهلة دون الآخر. اكتب دالة compareRobots التي تأخذ روبوتين مع ذاكرتهما الابتدائية، وتولد مائة مهمة، ثم اجعل كل واحد من الروبوتين يحل هذه المهام كلها واحدة واحدة، ويجب أن يكون الخرج عند انتهائهما هو العدد المتوسط للخطوات التي قطعها كل واحد لكل مهمة. تأكد من إعطاء المهمة نفسها لكلا الروبوتين في تلك المهام المئة لضمان العدل والدقة في النتيجة، بدلًا من توليد مهام مختلفة لكل روبوت. تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen. function compareRobots(robot1, memory1, robot2, memory2) { // شيفرتك هنا } compareRobots(routeRobot, [], goalOrientedRobot, []); إرشادات للحل سيكون عليك كتابة صورة من دالة runRobot، بحيث تعيد عدد الخطوات التي قطعها الروبوت لإتمام المهمة، بدلًا من تسجيل الأحداث في الطرفية. عندئذ تستطيع دالة القياس توليد حالات جديدة في حلقة تكرارية، وعدّ خطوات كل روبوت؛ وحين تولد قياسات كافية، فيمكنها استخدام console.log لإخراج المتوسط لكل روبوت، والذي سيكون ناتج قسمة العدد الكلي للخطوات المقطوعة على عدد القياسات. كفاءة الروبوت هل تستطيع كتابة روبوت ينهي مهمة التوصيل أسرع من goalOrientedRobot؟ ما الأشياء التي تبدو غبيةً بوضوح؟ وكيف يمكن تطويرها؟ إن حللت التدريبات السابقة، فربما تود استخدام دالة compareRobots التي أنشأتَها قبل قليل للتحقق إن كنت قد حسّنت الروبوت أم لا. تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen. // شيفرتك هنا runRobotAnimation(VillageState.random(), yourRobot, memory); إرشادات للحل إن القيد الرئيسي لـ goalOrientedRobot هو تعاملها مع طرد واحد في كل مرة، وستمضي ذهابًا وإيابًا في القرية، وذلك لأن الطرد الذي تريده موجود على الناحية الأخرى من الخارطة، حتى لو كان في طريقها طرود أخرى أقرب. أحد الحلول الممكنة هنا هو حساب طرق جميع الطرود ثم أخذ أقصرها، ويمكن الحصول على نتائج أفضل إذا كان لدينا عدة طرق قصيرة، فسنختار حينها الطرق التي فيها التقاط طرد بدلًا من التي فيها تسليم طرد. المجموعة الثابتة ستجد أغلب هياكل البيانات الموجودة في بيئة جافاسكربت القياسية لا تناسب الاستخدام الثابت، حيث تملك المصفوفات التابعَين slice وconcat اللذَين يسمحان لنا بإنشاء مصفوفات جديدة دون تدمير القديمة، لكن Set مثلًا ليس فيه توابع لإنشاء فئة جديدة فيها عنصر مضاف إلى الفئة الأولى أو محذوف منها. اكتب صنف جديد باسم PGroup يشبه الصنف Group من المقال السادس، حيث يخزن مجموعة من القيم، وتكون له التوابع add، وdelete، وhas، كما في الصنف Group تمامًا. يعيد التابع add فيه نسخةً جديدةً من PGroup مع إضافة العضو المعطى given member وترك القديم دون المساس به، وبالمثل، فيجب على التابع delete إنشاء نسخةً جديدةً ليس فيها العضو المعطى. يجب أن يعمل هذا الصنف مع أي نوع من القيم وليس السلاسل النصية فقط، ولا تُشترط كفاءته عند استخدامه مع كميات كبيرة من القيم؛ كذلك ليس شرطًا أن يكون الباني constructor جزءًا من واجهة الصنف رغم أنك تريد استخدام ذلك داخليًا، وإنما هناك نسخة فارغة PGroup.empty يمكن استخدامها على أساس قيمة ابتدائية. لماذا تظن أننا نحتاج إلى قيمة PGroup.empty واحدة فقط بدلًا من دالة تنشئ خارطةً جديدةً وفارغةً في كل مرة؟ تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen. class PGroup { // شيفرتك هنا } let a = PGroup.empty.add("a"); let ab = a.add("b"); let b = ab.delete("a"); console.log(b.has("b")); // → true console.log(a.has("b")); // → false console.log(b.has("a")); // → false إرشادات للحل ستكون أفضل طريقة لتمثيل مجموعة من القيم الأعضاء مصفوفةً لسهولة نسخها. تستطيع إنشاء مجموعةً جديدةً حين تضاف قيمة ما إليها، وذلك بنسخ المصفوفة الأصلية التي فيها القيمة المضافة -باستخدام concat مثلًا-، وتستطيع ترشيحها من المصفوفة حين تُحذف تلك القيمة. يستطيع باني الصنف أخذ مثل هذه المصفوفة على أساس وسيط، ويخزنها على أنها الخاصية الوحيدة للنسخة، ولا تُحدَّث هذه المصفوفة بعدها. يحب إضافة الخاصية empty إلى باني غير تابع بعد تعريف الصنف، مثل وسيط عادي. تحتاج إلى نسخة empty واحدة فقط بسبب تطابق المجموعات الفارغة وعدم تغير نُسَخ الصنف، كما تستطيع إنشاء مجموعات مختلفة عديدة من هذه المجموعة الفارغة دون التأثير عليها. ترجمة -بتصرف- للفصل السابع من كتاب Elequent Javascript لصاحبه Marijn Haverbeke.2 نقاط
يختلف هذا المقال قليلًا عن باقي الفصول، إذ سأدَع الحديث عن النظريات قليلًا لننشئ نحن وأنت برنامجًا سويًا، فالنظرية وإن كانت مهمة جدًا لتعلم كيفية البرمجة، إلا أنّ قراءة البرامج الحقيقية وفهم شيفراتها لا تقل أهمية، ومشروعنا في هذا المقال هو بناء روبوت ينفِذ مهمة في عالم افتراضي، وستكون تلك المهمة توصيل الطرود واستلامها. قرية المرج Meadowfield سيعمل الروبوت الخاص بنا في قرية صغيرة تُدعى قرية المرج، حيث يوجد فيها أحد عشر مكانًا بينها أربعة عشر طريقًا، ويمكن وصف القرية بالمصفوفة التالية: const roads = [ "Salma's House-Omar's House", "Salma's House-Cabin", "Salma's House-Post Office", "Omar's House-Town Hall", "Sara's House-Mostafa's House", "Sara's House-Town Hall", "Mostafa's House-Sama's House", "Sama's House-Farm", "Sama's House-Shop", "Marketplace-Farm", "Marketplace-Post Office", "Marketplace-Shop", "Marketplace-Town Hall", "Shop-Town Hall" ]; وتكوِّن شبكة الطرق في القرية مخططًا graph، وهو عبارة عن تجميعة من نقاط لتمثل الأماكن في القرية، مع خطوط تصل بينها بحيث تمثل الطرق، وسيكون هذا هو العالم الذي سيتحرك الروبوت فيه. لكن ليس من السهل التعامل مع مصفوفة السلاسل النصية السابقة، إذ لا نريد إلا الوجهات التي يمكننا الذهاب إليها من أي نقطة معطاة لنا، وعلى ذلك فسنحوِّل قائمة الطرق إلى هيكل بيانات يخبرنا بالمناطق التي نستطيع الذهاب إليها من كل نقطة أو مكان، انظركما يلي: function buildGraph(edges) { let graph = Object.create(null); function addEdge(from, to) { if (graph[from] == null) { graph[from] = [to]; } else { graph[from].push(to); } } for (let [from, to] of edges.map(r => r.split("-"))) { addEdge(from, to); addEdge(to, from); } return graph; } const roadGraph = buildGraph(roads); تُنشئ دالة buildGraph كائن خارطة map object عند إعطائها مصفوفة من الحدود edges، حيث تخزن فيها لكل عقدةٍ مصفوفةً من العقد المتصلة بها. كما تستخدِم تابع method للذهاب من سلسلة الطريق النصية التي تحمل الصيغة "Start-End" إلى مصفوفات من عنصرين تحتوي على البداية والنهاية على أساس سلسلتَين منفصلتين. المهمة سيتحرك الروبوت داخل القرية، إذ لديه طرود في أماكن مختلفة فيها، حيث يحمل كل طرد عنوانًا يجب نقله إليه؛ وسيلتقط الروبوت الطرودَ حين وصوله إليها، ثم يتركها عند وصوله إلى الوجهة المرسَل إليها، ويجب أن يقرر في كل نقطة وجهته التالية، ولا تنتهي مهمته إلا عند توصيل جميع الطرود. لكن أولًا يجب تعريف عالم افتراضي يصف هذه العملية، وذلك لنتمكّن من محاكاته، ويكون هذا النموذج قادر على إخبارنا بموقع الروبوت والطرود معًا، كما يجب تحديث هذا النموذج عندما يقرر الروبوت الذهاب إلى مكان جديد. إن كنت تفكر بأسلوب البرمجة كائنية التوجه، سيكون دافعك الأول هو البدء بتعريف كائنات للعناصر المختلفة في هذا العالم الذي أنشأناه، فصنف للروبوت، وآخر للطرد، وصنف ثالث للأماكن ربما، ثم تحمِل هذه الأصناف بعد ذلك خصائصًا تصف حالتها، كما في حالة كومة الطرود عند موقع ما، والتي يمكننا تغييرها عند إجراء تحديث لهذا العالم. لكن هذا خطأ في أغلب الحالات على الأقل، فكون شيء ما يحاكي الكائن لا يعني وجوب معاملته على أساس كائن في برنامجك؛ كما أنّ كتابة الأصناف في برنامجك دون داعي حقيقي لها، ستُنشئ تجميعةً من الكائنات المرتبطة ببعضها بعضًا لكل منها حالة داخلية متغيرة، وتكون مثل تلك البرامج صعبة الفهم وسهلة التعطل. لدينا أسلوبًا أفضل من ذلك، وهو ضغط حالة القرية إلى أقل فئة ممكنة من القيم التي تعرِّفها، فيكون لدينا الموقع الحالي للروبوت، وتجميعة الطرود غير المسلَّمة، والتي يحمل كل منها موقعه الحالي وعنوان التسليم، وحسبنا هذا! بينما نحن في ذلك، فعلينا التأكد أنه حين يتحرك الروبوت من موقعه، فعلينا حساب حالة جديدة وفق الموقف الذي يكون بعد التحرك، وذلك دون تغيير الحالة الأولى، انظر كما يلي: class VillageState { constructor(place, parcels) { this.place = place; this.parcels = parcels; } move(destination) { if (!roadGraph[this.place].includes(destination)) { return this; } else { let parcels = this.parcels.map(p => { if (p.place != this.place) return p; return {place: destination, address: p.address}; }).filter(p => p.place != p.address); return new VillageState(destination, parcels); } } } يتحقق التابع move أولًا إن كان ثمة طريق من الموقع الحالي إلى موقع الوِجهة، وإن لم يكن، فسيعيد الحالة القديمة بما أنّ هذه الخطوة غير صالحة، ثم يُنشئ حالةً جديدةً يكون فيها موقع الوِجهة هو الموقع الجديد للروبوت. لكن سيحمل هذا الروبوت معه طرودًا أخرى غير هذا الطرد، ويأخذها معه إلى موقع تسليم الطرد المسمى، ثم يتابع حملها معه بعد تسليم الطرد، ليذهب بكل منها إلى موقع تسليمه الذي يخصه، ولكي نحصل على بيانات تلك الطرود عند أي نقطة زمنية نريدها، فسنحتاج إلى إنشاء فئة set جديدة نضع فيها تلك الطرود التي يحملها إلى الموقع الجديد، ثم يترك الطرود الواجب تسليمها في موقع التسليم، أي نحذفها من فئة الطرود غير المسلَّمة. ويتكفل بعملية الانتقال استدعاء map، بينما نستدعي filter ليتولى عملية التسليم. لا تتغير كائنات الطرود عند نقلها، وإنما يعاد إنشاؤها، ويعطينا التابع move حالة جديدة للقرية مع ترك الحالة القديمة كما هي دون تغيير، انظر كما يلي: let first = new VillageState( "Post Office", [{place: "Post Office", address: "Salma's House"}] ); let next = first.move("Salma's House"); console.log(next.place); // → Salma's House console.log(next.parcels); // → [] console.log(first.place); // → Post Office تُسلَّم الطرود عند مواضع تسليمها مع حركة الروبوت بين تلك المواقع، ويُرى أثر ذلك في الحالة التالية، لكن ستظل الحالة الابتدائية تصف الموقف الذي يكون فيه الروبوت عند مكتب البريد ومعه الطرد الغير مسلَّم بعد. البيانات الثابتة Persistent Data تُسمى هياكل البيانات التي لا تتغير بالهياكل الثابتة persistent، أو غير القابلة للتغير immutable، وتحاكي السلاسل النصية والأرقام في بقائها كما هي، بدلًا من احتواء أشياء مختلفة في كل مرة. بما أن كل شيء في جافاسكربت قابل للتغير تقريبًا، فسيتطلب العمل مع كائنات أو بيانات ثابتة جهدًا، وعملًا إضافيًا، ونوعًا من التقييد، حيث لدينا دالة Object.freeze من أجل هذا، إذ تؤثر على الكائن وتجمده، وذلك لتجعله يتجاهل الكتابة على خصائصه، فتستطيع استخدام ذلك لضمان ثبات كائناتك إن أردت، لكن تذكر أن هذا التجميد يعني أن الحاسوب سيبذل مزيدًا من الجهد. نفضل إخبار العامة بترك الكائن الفلاني وشأنه وعدم العبث به، آملين تذكّرهم ذلك، بدلًا من إخبارهم بتجاهل تحديثات بعينها. let object = Object.freeze({value: 5}); object.value = 10; console.log(object.value); // → 5 لكن هنا يبرز سؤال إن كنت منتبهًا، فإن كانت اللغة نفسها تحثنا على جعل كل شيء متغيرًا وتتوقع منا ذلك، فلماذا نخرج عن هذا المسلك لنجعل بعض الكائنات ثابتةً لا تقبل التغيير؟ الإجابة بسيطة وهي أن هذا سيساعدنا في فهم برامجنا أكثر، إذ يتعلق الأمر بإدارة التعقيد لبرامجنا، فإن كانت الكائنات التي في نظامنا ثابتةً ومستقرةً، فيمكننا إجراء عمليات عليها إجراءً معزولًا -حيث سيعطينا التحرك إلى منزل سلمى مثلًا من أي حالة بدء معطاة الحالة الجديدة نفسها في كل مرة-،؛ أما إن كانت الكائنات تتغير مع الوقت، فسيضيف هذا بعدًا جديدًا من التعقيد إلى العمليات والتفكير المنطقي لحل المشكلة. وربما تقول أن مسألة توصيل الطرود، والروبوت، وهذه القرية الصغيرة، سهل أمرها ويمكن إدارتها، وربما أنت محق، لكن المعيار الذي يحدد نوع النظم الممكن بناؤها هو فهمنا نحن لتلك الأنظمة ومدى ما يمكننا فهمه مطلقًا، فأيّ شيء يسرّع فهم شيفرتك، فسيمهد لك الطريق لبناء نظم أكثر تطورًا. لكن رغم سهولة فهم النظم المبنية على هياكل بيانات ثابتة، فقد يكون من الصعب تصميم نظام مثل هذا، وخاصةً إن لم تكن لغة البرمجة التي تستخدمها مصمَّمةً لذلك، كما سنبحث عن فرص استخدام هياكل البيانات الثابتة في هذه السلسلة مع استخدامنا للهياكل المتغيرة كذلك. المحاكاة ينظر روبوت التوصيل إلى العالم، ويقرر الاتجاه الذي يريد السير فيه، وعليه فيمكننا القول أنّ الروبوت هو دالة تأخذ كائن villageState، وتعيد اسم مكان قريب. لأننا نريد الربوتات أن تكون قادرة على تذكر أشياء بعينها كي تنفِّذ الخطط الموضوعة لها من قِبلنا، فسنمرر إليها ذاكرتها، ونسمح لها بإعادة ذاكرة جديدة، ومن ثم يعيد الروبوت كائنًا يحتوي الاتجاه الذي يريد السير فيه، وقيمة ذاكرة تُعطى إليه في المرة التالية التي يُستدعى فيها. function runRobot(state, robot, memory) { for (let turn = 0;; turn++) { if (state.parcels.length == 0) { console.log(`Done in ${turn} turns`); break; } let action = robot(state, memory); state = state.move(action.direction); memory = action.memory; console.log(`Moved to ${action.direction}`); } } لننظر ما الذي يجب على الروبوت فعله كي "يحل" حالة ما: يجب عليه التقاط جميع الطرود أولًا من خلال الذهاب إلى كل موقع فيه طرد، ثم يسلِّم تلك الطرود بالذهاب إلى كل عنوان من العناوين المرسل إليها هذه الطرود، حيث لا يذهب إلى موقع التسليم إلا بعد التقاط الطرد الخاص به. تُرى ما هي أغبى خطة يمكن أن تنجح هنا؟ إنها العشوائية لا شك، حيث يتخِذ الروبوت اتجاهًا عشوائيًا عند كل منعطف، مما يعني أنه سيمر لا محالة على جميع الطرود بعد عدد من المحاولات، وسيصل كذلك إلى موقع تسليمها في مرحلة ما. انظر: function randomPick(array) { let choice = Math.floor(Math.random() * array.length); return array[choice]; } function randomRobot(state) { return {direction: randomPick(roadGraph[state.place])}; } تعيد Math.random() عددًا بين الصفر والواحد، ويكون دومًا أقل من الواحد، كما يعطينا ضرب عدد مثل هذا في طول أي مصفوفة ثم تطبيق Math.floor عليه موقعًا عشوائيًا للمصفوفة. وبما أنّ هذا الروبوت لا يحتاج إلى تذكر أي شيء، فسيَتجاهل الوسيط الثاني له ويهمل خاصية memory في كائنه المعاد؛ وتذكّر أنّه يمكن استدعاء دوال جافاسكربت بوسائط إضافية دون آثار جانبية مقلقة. نحتاج الآن إلى طريقة لإنشاء حالة جديدة بها بعض الطرود، وذلك من أجل إطلاق هذا الروبوت للعمل، والتابع الساكن -المكتوب هنا بإضافة خاصيةٍ مباشرةً للمنشئ- مكان مناسب لوضع هذه الوظيفة. VillageState.random = function(parcelCount = 5) { let parcels = []; for (let i = 0; i < parcelCount; i++) { let address = randomPick(Object.keys(roadGraph)); let place; do { place = randomPick(Object.keys(roadGraph)); } while (place == address); parcels.push({place, address}); } return new VillageState("Post Office", parcels); }; لا نريد أي طرود مرسلة من المكان نفسه الذي ترسَل إليه، ولهذا تختار حلقة do التكرارية أماكنًا جديدةً في كل مرة تحصل على مكان مطابق للعنوان. دعنا نبدأ عالمًا افتراضيًا، كما يلي: runRobot(VillageState.random(), randomRobot); // → Moved to Marketplace // → Moved to Town Hall // → … // → Done in 63 turns كما نرى من المثال، إذ غيّر الروبوت اتجاهه ثلاثًا وستين مرة، وذلك الرقم الكبير بسبب عدم التخطيط الجيد للخطوة التالية، كما سننظر في هذا قريبًا. يمكنك استخدام دالة runRobotAnimation المتاحة في البيئة البرمجية لهذا المقال، حيث ستنفِّذ المحاكاة، وستعرض لك الروبوت وهو يتحرك في خارطة القرية، بدلًا من إخراج نص فقط. runRobotAnimation(VillageState.random(), randomRobot); سندع طريقة تنفيذ runRobotAnimation مبهمةً في الوقت الحالي، حيث ستستطيع معرفة كيفية عملها بعد قراءة المقال الرابع عشر من هذه السلسلة والذي نناقش فيه تكامل جافاسكربت في المتصفحات. طريق شاحنة البريد لا شك أنّ فكرة الروبوت هذه لتوصيل البريد فكرة بدائية، وأجدر بنا تطوير هذا البرنامج قليلًا، فلم لا ننظر إلى توصيل البريد في العالم الحقيقي لنستوحي منه أفكارًا لعالمنا الصغير؟ أحد هذه الحلول هو البحث عن طريق يمر على جميع الأماكن في القرية، وحينها يأخذ الروبوت هذه الطريق مرتين. انظر مثلًا على هذا الطريق بدءًا من مكتب البريد: const mailRoute = [ "Salma's House", "Cabin", "Salma's House", "Omar's House", "Town Hall", "Sara's House", "Mostafa's House", "Sama's House", "Shop", "Sama's House", "Farm", "Marketplace", "Post Office" ]; نحتاج إلى الاستفادة من ذاكرة الروبوت إذا أردنا استخدام الروبوت المتتبع للطريق route-following، حيث يحذف الروبوت العنصر الأول عند كل منعطف ويحتفظ ببقية الطريق: function routeRobot(state, memory) { if (memory.length == 0) { memory = mailRoute; } return {direction: memory[0], memory: memory.slice(1)}; } سيكون هذا الروبوت بهذا الأسلوب الجديد أسرع من الأسلوب الأول، إذ سيكون أقصى عدد من الاتجاهات التي يسلكها أو المنعطفات التي يأخذها هو 26 -وهو ضعف عدد الأماكن في طريق القرية-، وإن كان في العادة أقل من هذا العدد، فليست جميع الأماكن بها طرود بريد في كل مرة. اكتشاف الطريق Pathfinding لنبحث في طريقة أكثر تطورًا من المرور على جميع الأماكن في القرية في كل مرة، فلا شك في أن الروبوت سيكون أكثر كفاءة إذا عدّل سلوكه ليناسب العمل الحقيقي المراد تنفيذه؛ لذا يجب امتلاكه القدرة على التحرك نحو طرد معين أو موقع تسليم بعينه، وعليه نحتاج دالة لإيجاد الطريق المناسبة. تُعَدّ مشكلة إيجاد الطريق باستخدام مخطط هي مشكلة البحث، حيث نستطيع تحديد ما إذا كان الحل المعطى -أي الطريق- مناسبًا أم لا، لكن لا نستطيع حساب الحل بالطريقة نفسها عند حساب حاصل جمع 2+2 مثلًا، وإنما يجب إنشاء حلولًا محتملةً لإيجاد واحد صالح. تتضح هنا المشكلة أكثر، إذ لا نهايةً لعدد الاحتمالات الممكنة للطرق من خلال مخطط، لكن يمكن تضييق عدد الاحتمالات إذا أردنا الطرق المؤدية من نقطة أ إلى نقطة ب مثلًا، فعندئذ لن يهمنا سوى الطرق التي تبدأ من النقطة أ، كما لا نريد الطرق التي تمر المكان نفسه مرتين، إذ لا تُعَدّ هي الطرق الأكثر كفاءة في أي مكان، ويقلل هذا عدد الطرق التي يجب اعتمادها من قِبَل دالة البحث أكثر وأكثر. نريد في الواقع أقصر طريق فقط، وعليه يجب النظر في الطرق الأقصر أولًا قبل النظر في الطرق الأطول، وأحد الأساليب لفعل ذلك هو بدء طرق من نقطة تحرك الروبوت لتُستكشف جميع الأماكن التي يمكن الوصول إليها ولم يُذهب إليها بعد، حتى تصل إحدى تلك الطرق إلى المكان المراد تسليم الطرد إليه، وهكذا نستكشف الطرق التي يحتمل أن تكون مفيدة لنا، ونتخذ أقصرها أو واحدًا من أقصر تلك الطرق. كما في الدالة التالية: function findRoute(graph, from, to) { let work = [{at: from, route: []}]; for (let i = 0; i < work.length; i++) { let {at, route} = work[i]; for (let place of graph[at]) { if (place == to) return route.concat(place); if (!work.some(w => w.at == place)) { work.push({at: place, route: route.concat(place)}); } } } } يجب أن يتم الاستكشاف بترتيب صحيح، فالأماكن التي يصل إليها أولًا يجب استكشافها أولًا، لكن انتبه إلى أن مكان س مثلًا لا يُستكشف فور الوصول إليه، إذ سيعني هذا أنه علينا استكشاف أماكن يمكن الوصول إليها من س وهكذا، رغم احتمال وجود مسارات أقصر لم تُستكشف بعد. وعلى هذا فإن الدالة تحتفظ بقائمة عمل work list، وهي مصفوفة من الأماكن التي يجب استكشافها فيما بعد مع الطرق التي توصلنا إليها، حيث تبدأ بموقع ابتدائي للبدء منه وطريق فارغة، ثم يبدأ البحث بعدها بأخذ العنصر التالي في القائمة واستكشافه، مما يعني النظر في جميع الطرق الخارجة من هذا المكان، فإن كان أحدها هو الهدف المراد، فيُعاد طريق تامة finished road، وإلا فسيضاف عنصر جديد إلى القائمة إن لم يُنظر في هذا المكان من قبل. كذلك، إن كنا قد نظرنا فيه من قبل، فقد وجدنا إما طريق أطول إلى هذا المكان أو واحدة بنفس طول الطريق الموجودة -وبما أننا نبحث عن الطرق الأقصر أولًا- ولا نحتاج إلى استكشافها عندئذ. تستطيع تخيل هذا بصريًا على أساس شبكة من الطرق المعروفة، حيث تخرج من موقع ابتدائي، وتنمو بانتظام في جميع الجوانب، لكن لا تتشابك مع بعضها أو تنعكس على نفسها؛ وبمجرد وصول خيط من تلك الشبكة إلى الموقع الهدف، فيُتتبَّع ذلك الخيط إلى نقطة البداية ليعطينا الطريق التي نريدها. لا تعالج شيفرتنا الموقف الذي لا تكون فيه عناصر عمل على قائمة العمل، وذلك لعِلمنا باتصال المخطط الخاص بنا، أي يمكن الوصول إلى كل موقع من جميع المواقع الأخرى، وسنكون قادرين دائمًا على إيجاد طريق ممتدة بين نقطتين، فلا يفشل البحث الذي نجريه. function goalOrientedRobot({place, parcels}, route) { if (route.length == 0) { let parcel = parcels[0]; if (parcel.place != place) { route = findRoute(roadGraph, place, parcel.place); } else { route = findRoute(roadGraph, place, parcel.address); } } return {direction: route[0], memory: route.slice(1)}; } يستخدِم هذا الروبوت قيمة ذاكرته على أساس قائمة من الاتجاهات ليتحرك وفقًا لها، تمامًا مثل الروبوت المتتبع للطريق الذي ذكرناه آنفًا، وعليه معرفة الخطوة التالية إذا وجد القائمة فارغة؛ كما ينظر في أول طرد غير مسلَّم في الفئة التي معه، فإن لم يكن قد التقطه، فسيرسم طريقًا إليه، وإن كان قد التقطه، فسينشئ طريقًا إلى موقع التسليم، انظر كما يلي: runRobotAnimation(VillageState.random(), goalOrientedRobot, []); ينهي هذا الروبوت مهمة تسليم خمسة طرود في نحو ستة عشر منعطفًا، وهذا أفضل بقليل من routeRobot، لكن لا زال هناك فرصة للتحسين أكثر من ذلك. تدريبات معايرة الروبوت من الصعب موازنة الروبوتات بجعلها تحل بعض السيناريوهات البسيطة، فلعل أحدها حصل على مهام سهلة دون الآخر. اكتب دالة compareRobots التي تأخذ روبوتين مع ذاكرتهما الابتدائية، وتولد مائة مهمة، ثم اجعل كل واحد من الروبوتين يحل هذه المهام كلها واحدة واحدة، ويجب أن يكون الخرج عند انتهائهما هو العدد المتوسط للخطوات التي قطعها كل واحد لكل مهمة. تأكد من إعطاء المهمة نفسها لكلا الروبوتين في تلك المهام المئة لضمان العدل والدقة في النتيجة، بدلًا من توليد مهام مختلفة لكل روبوت. تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen. function compareRobots(robot1, memory1, robot2, memory2) { // شيفرتك هنا } compareRobots(routeRobot, [], goalOrientedRobot, []); إرشادات للحل سيكون عليك كتابة صورة من دالة runRobot، بحيث تعيد عدد الخطوات التي قطعها الروبوت لإتمام المهمة، بدلًا من تسجيل الأحداث في الطرفية. عندئذ تستطيع دالة القياس توليد حالات جديدة في حلقة تكرارية، وعدّ خطوات كل روبوت؛ وحين تولد قياسات كافية، فيمكنها استخدام console.log لإخراج المتوسط لكل روبوت، والذي سيكون ناتج قسمة العدد الكلي للخطوات المقطوعة على عدد القياسات. كفاءة الروبوت هل تستطيع كتابة روبوت ينهي مهمة التوصيل أسرع من goalOrientedRobot؟ ما الأشياء التي تبدو غبيةً بوضوح؟ وكيف يمكن تطويرها؟ إن حللت التدريبات السابقة، فربما تود استخدام دالة compareRobots التي أنشأتَها قبل قليل للتحقق إن كنت قد حسّنت الروبوت أم لا. تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen. // شيفرتك هنا runRobotAnimation(VillageState.random(), yourRobot, memory); إرشادات للحل إن القيد الرئيسي لـ goalOrientedRobot هو تعاملها مع طرد واحد في كل مرة، وستمضي ذهابًا وإيابًا في القرية، وذلك لأن الطرد الذي تريده موجود على الناحية الأخرى من الخارطة، حتى لو كان في طريقها طرود أخرى أقرب. أحد الحلول الممكنة هنا هو حساب طرق جميع الطرود ثم أخذ أقصرها، ويمكن الحصول على نتائج أفضل إذا كان لدينا عدة طرق قصيرة، فسنختار حينها الطرق التي فيها التقاط طرد بدلًا من التي فيها تسليم طرد. المجموعة الثابتة ستجد أغلب هياكل البيانات الموجودة في بيئة جافاسكربت القياسية لا تناسب الاستخدام الثابت، حيث تملك المصفوفات التابعَين slice وconcat اللذَين يسمحان لنا بإنشاء مصفوفات جديدة دون تدمير القديمة، لكن Set مثلًا ليس فيه توابع لإنشاء فئة جديدة فيها عنصر مضاف إلى الفئة الأولى أو محذوف منها. اكتب صنف جديد باسم PGroup يشبه الصنف Group من المقال السادس، حيث يخزن مجموعة من القيم، وتكون له التوابع add، وdelete، وhas، كما في الصنف Group تمامًا. يعيد التابع add فيه نسخةً جديدةً من PGroup مع إضافة العضو المعطى given member وترك القديم دون المساس به، وبالمثل، فيجب على التابع delete إنشاء نسخةً جديدةً ليس فيها العضو المعطى. يجب أن يعمل هذا الصنف مع أي نوع من القيم وليس السلاسل النصية فقط، ولا تُشترط كفاءته عند استخدامه مع كميات كبيرة من القيم؛ كذلك ليس شرطًا أن يكون الباني constructor جزءًا من واجهة الصنف رغم أنك تريد استخدام ذلك داخليًا، وإنما هناك نسخة فارغة PGroup.empty يمكن استخدامها على أساس قيمة ابتدائية. لماذا تظن أننا نحتاج إلى قيمة PGroup.empty واحدة فقط بدلًا من دالة تنشئ خارطةً جديدةً وفارغةً في كل مرة؟ تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen. class PGroup { // شيفرتك هنا } let a = PGroup.empty.add("a"); let ab = a.add("b"); let b = ab.delete("a"); console.log(b.has("b")); // → true console.log(a.has("b")); // → false console.log(b.has("a")); // → false إرشادات للحل ستكون أفضل طريقة لتمثيل مجموعة من القيم الأعضاء مصفوفةً لسهولة نسخها. تستطيع إنشاء مجموعةً جديدةً حين تضاف قيمة ما إليها، وذلك بنسخ المصفوفة الأصلية التي فيها القيمة المضافة -باستخدام concat مثلًا-، وتستطيع ترشيحها من المصفوفة حين تُحذف تلك القيمة. يستطيع باني الصنف أخذ مثل هذه المصفوفة على أساس وسيط، ويخزنها على أنها الخاصية الوحيدة للنسخة، ولا تُحدَّث هذه المصفوفة بعدها. يحب إضافة الخاصية empty إلى باني غير تابع بعد تعريف الصنف، مثل وسيط عادي. تحتاج إلى نسخة empty واحدة فقط بسبب تطابق المجموعات الفارغة وعدم تغير نُسَخ الصنف، كما تستطيع إنشاء مجموعات مختلفة عديدة من هذه المجموعة الفارغة دون التأثير عليها. ترجمة -بتصرف- للفصل السابع من كتاب Elequent Javascript لصاحبه Marijn Haverbeke.2 نقاط -

الإصدار 1.0.0
129263 تنزيل
سطع نجم لغة البرمجة بايثون في الآونة الأخيرة حتى بدأت تزاحم أقوى لغات البرمجة في الصدارة وذاك لمزايا هذه اللغة التي لا تنحصر أولها سهولة كتابة وقراءة شيفراتها حتى أصبحت الخيار الأول بين يدي المؤسسات الأكاديمية والتدريبية لتدريسها للطلاب الجدد الراغبين في الدخول إلى مجال علوم الحاسوب والبرمجة. أضف إلى ذلك أن بايثون لغةً متعدَّدة الأغراض والاستخدامات، لذا فهي دومًا الخيار الأول في شتى مجالات علوم الحاسوب الصاعدة مثل الذكاء الصنعي وتعلم الآلة وعلوم البيانات وغيرها، كما أنَّها مطلوبة بشدة في سوق العمل وتعتمدها كبرى الشركات التقنية. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن بني هذا العمل على كتاب «How to code in Python» لصاحبته ليزا تاغليفيري (Lisa Tagliaferri) وترجمه إلى العربية محمد بغات وعبد اللطيف ايمش، وحرره جميل بيلوني، ويأتي شارحًا المفاهيم البرمجية الأساسية بلغة بايثون، ونأمل في أكاديمية حسوب أن يكون إضافةً نافعةً للمكتبة العربيَّة وأن يفيد القارئ العربي في أن يكون منطلقًا للدخول إلى عالم البرمجة من أوسع أبوابه. رُبط هذا الكتاب مع توثيق لغة بايثون في موسوعة حسوب لتسهيل عملية الاطلاع على أي جزء من اللغة مباشرة وقراءة التفاصيل باللغة العربية. هذا الكتاب مرخص بموجب رخصة المشاع الإبداعي Creative Commons «نسب المُصنَّف - غير تجاري - الترخيص بالمثل 4.0». يمكنك قراءة فصول الكتاب على شكل مقالات من هذه الصفحة، «المرجع الشامل إلى تعلم لغة بايثون»، أو مباشرةً من الآتي: المقال الأول: دليل تعلم بايثون اعتبارات عملية للاختيار ما بين بايثون 2 و بايثون 3 المقال الثاني: تثبيت بايثون 3 وإعداد بيئتها البرمجية المقال الثالث: كيف تكتب أول برنامج لك المقال الرابع: كيفية استخدام سطر أوامر بايثون التفاعلي المقال الخامس: كيفية كتابة التعليقات المقال السادس: فهم أنواع البيانات المقال السابع: مدخل إلى التعامل مع السلاسل النصية المقال الثامن: كيفية تنسيق النصوص المقال التاسع: مقدمة إلى دوال التعامل مع السلاسل النصية المقال العاشر: آلية فهرسة السلاسل النصية وطريقة تقسيمها المقال الحادي عشر: كيفية التحويل بين أنواع البيانات المقال الثاني عشر: كيفية استخدام المتغيرات المقال الثالث عشر: كيفية استخدام آلية تنسيق السلاسل النصية المقال الرابع عشر: كيفية إجراء العمليات الحسابية المقال الخامس عشر: الدوال الرياضية المضمنة المقال السادس عشر: فهم العمليات المنطقية المقال السابع عشر: مدخل إلى القوائم المقال الثامن عشر: كيفية استخدام توابع القوائم المقال التاسع عشر: فهم كيفية استعمال List Comprehensions المقال العشرون: فهم نوع البيانات Tuples المقال الحادي والعشرين: فهم القواميس المقال الثاني والعشرين: كيفية استيراد الوحدات المقال الثالث والعشرين: كيفية كتابة الوحدات المقال الرابع والعشرين: كيفية كتابة التعليمات الشرطية المقال الخامس والعشرين: كيفية إنشاء حلقات تكرار while المقال السادس والعشرين: كيفية إنشاء حلقات تكرار for المقال السابع والعشرين: كيفية استخدام تعابير break وcontinue وpass عند التعامل مع حلقات التكرار المقال الثامن والعشرين: كيفية تعريف الدوال المقال التاسع والعشرين: كيفية استخدام *args و**kwargs المقال الثلاثين: كيفية إنشاء الأصناف وتعريف الكائنات المقال الحادي والثلاثين: فهم متغيرات الأصناف والنسخ المقال الثاني والثلاثين: وراثة الأصناف المقال الثالث والثلاثين: كيفية تطبيق التعددية الشكلية (Polymorphism) على الأصناف المقال الرابع والثلاثين: كيف تستخدم منقح بايثون المقال الخامس والثلاثين: كيفية تنقيح شيفرات بايثون من سطر الأوامر التفاعلي المقال السادس والثلاثين: كيف تستخدم التسجيل Logging المقال السابع والثلاثين: كيفية ترحيل شيفرة بايثون 2 إلى بايثون 31 نقطة -
أريد أن أقوم بتبديل عدد من الأسطر في ملف نصي عادي، لذلك أقوم بقراءة كل الملف (قد تحدث مشاكل إن كان الملف كبير للغاية)، وبعد ذلك أقوم بالبحث عن السطر المطلوب وتبديله، لكن المشكلة هي بمجرد إيجاد السطر المطلوب تبديله لا أعلم كيفية حذف السطر الخاص به والكتابة مكانه، هل توجد طريقة للكتابة في مكان معين في ملف نصي بدلًا من كتابة كامل محتوى الملف مرة أخرى؟ هذا هو الكود الخاص بي: f = open(file) for line in f: if line.contains('foo'): newline = line.replace('foo', 'bar') # كيفية كتابة هذا السطر الجديد مرة أخرى إلى الملف1 نقطة
-
السلام عليكم قريبا تعلمت هذه التقنيه Server Sent Events سؤالي هل اذا جربت الاكواد خاصتها مباشره هل تتسبب بالضغط على السيرفر مما يؤدي الى اغلاقه خاصه اذا كان زوار الموقع بالالاف، وهل يمكن اذا استعملناها في جلب البيانات من الداتا بيز وارسالها للمتصفح هل هذا سيؤثر ايضا على السيرفر وماهي الحلول في حال كانت الاجوبة بنعم1 نقطة
-
قمت بإنشاء الكائنات datetime64 و datetime.datetime و Timestamp كالتالي: import datetime import numpy as np import pandas as pd dt = datetime.datetime(2012, 5, 1) ts = pd.DatetimeIndex([dt])[0] dt64 = np.datetime64(dt) الآن كيف أقوم بالتحويل بين هذه الأنواع وبعضها البعض بإستخدام numpy؟1 نقطة
-
ما هي الطريقة الأكثر فاعلية لتعيين دالة map على مصفوفة numpy؟ الطريقة التي كنت أقوم بها في مشروعي الحالي هي كما يلي: import numpy as np arr = np.array([0, 1, 2, 3, 4, 5]) arr_squarer = lambda t: t ** 2 squares = np.array([arr_squarer (i) for i in arr_squarer]) لكن أعتقد أن هذه الطريقة غير عملية على الإطلاق، هل توجد طريقة أفضل للقيام بذلك من خلال مكتبة numpy فقط1 نقطة
-
لدي نقطتين كالتالي: (a, b, c) (x, y, z) وأريد أن أقوم بحساب المسافة بين النقطتين كالتالي: dist = sqrt((a-x)^2 + (b-y)^2 + (c-z)^2) كيف يمكنني حساب المسافة بين النقطتين باستخدام numpy فقط؟ import numpy point1 = numpy.array((a, b, c)) point2 = numpy.array((x, y, z))1 نقطة
-
إضافة إلى الطرق التي قدمها الأستاذ وائل. سأضيف لك طريقة هي الأسرع، حيث أنه يوجد العديد من الطرق لحسابها في بايثون و الفرق بينهم هو التعقيد الزمني. حيث يتم استخدام الدالة (Einstein’s summation)einsum كالتالي: import numpy as np point1 = numpy.array((2, 1, 2)) point2 = numpy.array((2, 1, 2)) # التابع التالي سيحسب لك المسافة من أجل نقاط أحادية وثنائية وثلاثية الأبعاد def dist(p1, p2, metric='euclidean'): p1 = np.asarray(p1) p2 = np.atleast_2d(p2) p1_dim = p1.ndim p2_dim = p2.ndim if p1_dim == 1: p1 = p1.reshape(1, 1, p1.shape[0]) if p1_dim >= 2: p1 = p1.reshape(np.prod(p1.shape[:-1]), 1, p1.shape[-1]) if p2_dim > 2: p2 = p2.reshape(np.prod(p2.shape[:-1]), p2.shape[-1]) diff = p1 - p2 dist_arr = np.einsum('ijk,ijk->ij', diff, diff) if metric[:1] == 'e': dist_arr = np.sqrt(dist_arr) dist_arr = np.squeeze(dist_arr) return dist_arr dist(point1,point2) # array(0.) لاحظ التعقيد كيف يختلف من طريقة لأخرى.
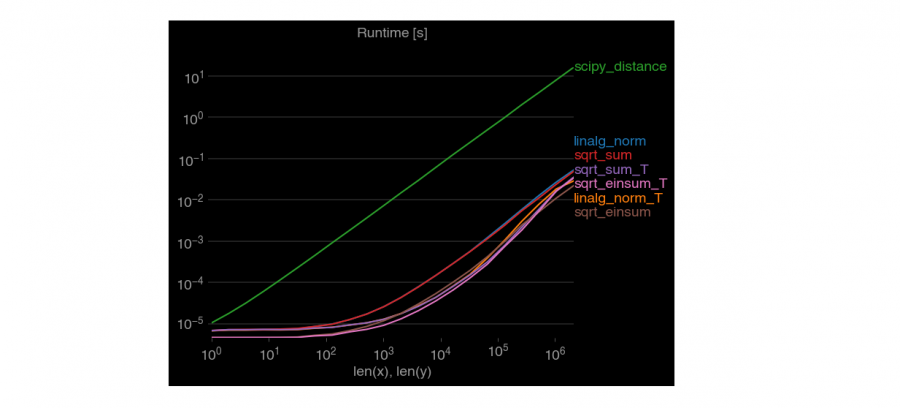 1 نقطة
1 نقطة -
هذا موقع الشخصي https://hashafai.github.io/EL-Shafeai/src/# لعرض أعمالي على GitHup عند الدخول إلى الموقع في أغلب الأحيان يتم تحمل المحتوى قبل الأيقونات اي تظهر النصوص و تنسيقات CSS لكن ايقونات fonawson تتأخر في الظهور أو حتى لا تظهر مع العلم اني أضع ملف fontawson قبل ملف التنسيقيات css و ايظا في معرض أعمالي موقع ب عنوان انطلاق تطبيق يحتوي على حركات animation عند الدخول للموقع يتم تفعيل الحركة قبل حتى تحميل الصورة اي العنصر يتحرك و الصورة لم يتم تحميلها ما هي الطريق لحل هذه المشكلة1 نقطة
-
كيف يمكنني انشاء سكربت يمكنني من ارسال رسائل الجيميل ببايثون وهل توجد مكتبة لتمكنني من القيام بذلك ؟1 نقطة
-
لدي عدد كبير من المسنتدات بالشكل التالي: { username: "Bolk777", email: "test@test.com", "phone": "44857579493", .... } وقد قمت بتعريف الحقل phone على أنه من النوع String، ولكن أريد تغيير نوع الحقل إلى Number. فهل هنالك طريقة ما لتغيير قيمة الحقل للمستندات الموجودة لدي مسبقاً ضمن المجموعة دون أن تتأثر البيانات التي بداخلها؟ وكيف يمكنني إجراء ذلك؟1 نقطة
-
لدي قاعدة بيانات mongodb وأقوم باستخدام mogoose مع node.js، وقمت مسبقاً بوضع schema معيّنة لكل مجموعة ضمن هذه القاعدة. ولكن بما تتيحه mogodb من حرية في تعديل بنية هذه المجموعات، أرى أن mongoose يفرض استخدام schema وأي حقول يتم إضافتها وهي غير موجودة مسبقاً ضمن هذه الـ schema لا يتم حفظها ضمن قاعدة البيانات. كيف يمكنني إضافة حقول جديدة ليس بالضرورة أن تكون موجودة ضمن الـ schema؟ أم هل يجب علي تجنّب استخدام mongoose في هذه الحالة؟1 نقطة
-
يمكنك استخدام بعض الأدوات مثل depcheck أو npm-check و التي ستقوم بفحص الاعتماديات الخاصة بمشروعك و إضهار قائمة لك تحتوي على الاعتماديات التي لم تستخدم و بعدها يمكنك حذفها. لتثبيت npm-check npm i npm-check و لاستخدامها، نقوم بتنفيذ الأمر التالي: npm-check1 نقطة
-
لقد أضفت العناوين الجديدة بشكلٍ صحيح1 نقطة
-
يا @علي العبسيالرمزين هذين [ ] في بايثون تسمى بقائمة وتقوم بإضافة أي عدد من العناصر داخل القائمة المهم أن تضع فاصلة , لكي تضيف عنصر جديد في القائمة الى جانب العنصر السابق وفي القائمة الخاص بك يمكنك إضافة فاصلة عند آخر عنصر موجود ومن ثم إضافة عنوان الماك الجديد كما في العناوين السابقة1 نقطة
-
الثلاث النقاط معناها بقية الكود السابق يعني هكذا mac_addresses = [ {"mac": "68:72:51:60:71:C0", "comment": "A1"}, {"mac": "68:72:51:60:74:93", "comment": "A2"}, {"mac": "68:72:51:60:72:95", "comment": "A3"}, {"mac": "68:72:51:60:72:83", "comment": "A4"}, {"mac": "68:72:51:60:71:42", "comment": "A5"}, {"mac": "68:72:51:60:73:24", "comment": "A6"}, {"mac": "68:72:51:60:71:74", "comment": "A7"}, {"mac": "78:8A:20:60:3F:97", "comment": "A10"}, {"mac": "FC:EC:DA:62:C8:E4", "comment": "A13"}, {"mac": "F4:92:BF:34:2E:1A", "comment": "A31"}, {"mac": "48:8F:5A:48:FE:D2", "comment": "LAN1"}, {"mac": "48:8F:5A:48:FE:D3", "comment": "LAN2"}, {"mac": "48:8F:5A:48:FE:D4", "comment": "LAN3"}, {"mac": "48:8F:5A:48:FE:D5", "comment": "LAN4"}, {"mac": "48:8F:5A:48:FE:D6", "comment": "LAN5"}, {"mac": "48:8F:5A:48:FE:D7", "comment": "LAN6"}, {"mac": "48:8F:5A:48:FE:D8", "comment": "LAN7"}, {"mac": "48:8F:5A:48:FE:D9", "comment": "LAN8"}, {"mac": "48:8F:5A:48:FE:DA", "comment": "LAN9"}, {"mac": "48:8F:5A:48:FE:DB", "comment": "LAN10"}, {"mac": "48:8F:5A:48:FE:DC", "comment": "LAN11"}, {"mac": "48:8F:5A:48:FE:DD", "comment": "LAN12"}, {"mac": "48:8F:5A:48:FE:DE", "comment": "LAN13"},# في الأسفل العناوين الجديد وفي الأعلى العناوين السابقة {"mac": "F4:92:BF:B0:E3:FC", "comment": "A42"}, {"mac": "F4:92:BF:F5:BA:96", "comment": "A38"}, {"mac": "F4:92:BF:F4:B8:57", "comment": "A37"}, {"mac": "F4:92:BF:F4:AB:94", "comment": "A36"}, ]1 نقطة
-
نعم كلما عليك فعله هو إضافة العنوان الجديد في الأسفل مثلما وضحت لك1 نقطة
-
هل يوجد خاصيه التسجيل بالايميل الجامعي لأخذ الكورس مجانا1 نقطة
-
لا أعتقد أنه يوجد خاصية مثل هذه في الاكاديمية ولكن يمكنك التواصل مع مركز المساعدة وسوف يجب على كل أسئلتك , يمكنك الذهاب الى مركز المساعدة من هنا1 نقطة
-
أريد استخدام learning_curve و grid_search من مكتبة Sklearn ولكن يظهر لي الخطأ التالي: from sklearn.grid_search import GridSearchCV from sklearn.learning_curve import learning_curve ImportError: No module named grid_search, learning_curve ما المشكلة؟1 نقطة
-
المشكلة تظهر لأن remove تقوم بحذف أول ظهور لأحد الحروف في القائمة، الحروف التي سيتم حذفها ستتأثر بطول القائمة و بالحروف الموجودة بها، و بما أن الحذف ينقص من عدد الحروف بالقائمة و العبارة return ترجع القائمة الجديدة فمن الأغلب أنه في بعض المرات التي ظهرت فيها بعض الحروف متتالية تم حذف إحداها و تم تمرير القائمة الجديدة مرة أخرى (inconsistency problem). يمكن حل المشكلة بإستخدام عدد من الطرق الأخرى، مثلاً list comprehension: def anti_vowel(c): vowels = ('a', 'e', 'i', 'o', 'u') return ''.join([l for l in c if l not in vowels]) anti_vowel("Hellooo, world! Woooords!") # Hll, wrld! Wrds! الناتج عبارة عن كل الحروف و علامات الترقيم ما عدا التي تم تحديدها في vowels set. يمكن أيضاً إستخدام regular expression، عن طريق إستخدام الدالة sub التي تقوم بالبحث عن واحد أو مجموعة حروف في نص محدد و إستبداله بما يتم تمريره في المدخل الثاني للدالة. import re def anti_vowel(s): return re.sub(r'[AEIOU]', '', s, flags=re.IGNORECASE) anti_vowel("Hellooo, world! Woooords!") لاحظ هنا تحديد مدخل أخير للدالة و التي يتغاضى فيها عن وجود الحروف الكبيرة أو الصغيرة (إختياري) و يبحث عن الأحرف المحددة بغض النظر عن نوعها. الطريقة الثالثة هي إستخدام translate وهي دالة تستقبل dictionary بالحروف التي سيتم إستبدالها و القيم الجديدة لها، راجع المثال التالي: dictionary = str.maketrans(dict.fromkeys('aeiouAEIOU')) "Hellooo, world! Woooords!".translate(dictionary) وفيه تم إستخدام maketrans لإنشاء mapping table من الحروف المدخلة كبيرها و صغيرها، حيث أن الحروف ستمثل المفاتيح بدون قيم values are None، و أخيراً نمرر الجدول لدالة الترجمة.1 نقطة
-
بإمكانك إستخدام التعابير النمطية لحذف كل الحروف المتحركة (aeiou): import re def removeVowel(text): result = re.sub(r'[AEIOU]', '', text, flags=re.IGNORECASE) return result text = "Hellooo, world! Words!" print(removeVowel(text)) # Hll, wrld! Wrds! أو تعكس الأمر فبدل ما تحذف تضيف تعمل حلقة للدوران على كل الحروف و إذا لم يكن الحرف ينتمي إلى الحروف aeiou تُضيفه إلى سلسلة نصية تكون مُهيئة ب "" مثال: def removeVowel(text): return ''.join([l for l in text if l not in "aeiouAEIOU"]); text = "HeElloooOOO, world! WoOrds!" print(removeVowel(text)) # Hll, wrld! Wrds!1 نقطة
-
هذا الخطأ ينتج بالطبع حسب نوع البيانات المدخلة و توزيعها، أعلم عزيزي@Meezo ML أن هذا الخطأ ناتج عن إستخدام stratify والذي يمكنك التخلص منه فقط بالمسح، راجع السطر التالي: X,X_val, y, y_val=train_test_split(data,label,test_size=0.2) لكن دعنا نفهم لماذا نتج هذا الخطأ من الأساس، stratify هو عبارة عن مدخل لدالة التقسيم والذي يمكننا إستخدامه فقط في حالة البيانات التصنيفية categorical variables و الذي يقوم بتقسيم البيانات بين التدريب و التقييم training and validation بصورة تتناسب مع توزيع البيانات الأساسية، مثلاً إذا كان لدينا صنفين في y أحدهما يمثل 25% من البيانات و الأخر 75% فإن stratify تقوم بتقسيم البيانات بين التدريب و التحقق بنفس النسبة لكل من مجموعتي البيانات. from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split iris = load_iris() X = iris.data y = iris.target X1 = pd.DataFrame(X).drop(pd.DataFrame(X).index[10:50]).drop(pd.DataFrame(X).index[70:100]).drop(pd.DataFrame(X).index[140:]) y1 = pd.DataFrame(y).drop(pd.DataFrame(y).index[10:50]).drop(pd.DataFrame(y).index[70:100]).drop(pd.DataFrame(y).index[140:]) y1.value_counts() x_train, x_test, y_train, y_test = train_test_split(X1,y1,stratify=y1) اولاً قمنا بإستدعاء الدوال لتحميل بيانات Iris وتقسيم البيانات بإستخدام train_test_split و من ثم حملنا البيانات وقسمناها إلى مدخلات و مخرجات X,y و حذفنا عدد من السطور في كل من المدخلات و المخرجات (للتأكد من تنفيذ stratify، مع العلم أنها يمكن أن تعمل حتى لو كانت الأصناف متساوية كما في حالة Iris والتي يتساوى فيها التصنيفات بعدد 50 لكل صنف) الناتج من الحذف يعطي التقسيم التالي: 2 40 1 20 0 10 بمعدل 40 عينة من الصنف الأول، 20 من الثاني و 10 من الأخير. و أخيراً عملية التقسيم تأخذ X1,y1 كمدخلات مع stratify الذي يستقبل y1 وبالتالي إن قمنا بطباعة أعداد التصنيفات في y_test سنحصل على نفس توزيع المدخلات. y_test.value_counts() 2 10 1 5 0 31 نقطة
-
بما أنك تستخدم الوسيط stratify (الطبقات)، فهذا يتطلب أن يكون عدد العينات التي تنتمي إلى كل فئة متناسب في كل من بيانات التدريب والاختبار. لكن لديك فئة من بياناتك تحتوي على عينة واحدة فقط. لذلك إما أن تكون في بيانات التدريب أو الاختبار في وقت واحد وهذا يخالف خيار التقسيم الطبقي. لذالك ينتج الخطأ. يمكنك حل المشكلة في أن تزيد عدد البيانات التي تنتمي لهذا الصنف، أو أن تلغي خاصية التقسيم الطبقي.1 نقطة
-
يتمثل مبدأ التصميم العام في Python في الوظائف (الدوال) التي تغير كائنًا في مكانه ولاتقوم بإنشاء كائن جديد ، فإن هذه الدالة تقوم بإرجاع None . وهذا أساسًا للتأكيد على عدم إرجاع كائن جديد. أي إذا كان لديك دالة تعمل على الكائن الأصلي وتقوم بتعديله في مكانه فهذه الدالة لا تقوم بإرجع أي شيء لأنه لا يوجد كائن جديد تريد إرجاعه ولهذا العديد من دوال بايثون تقوم بإرجع none ويعتبر none ك false فعلى سبيل المثال دالة ()append تقوم بتعديل الكائن الأصلي في مكانه ولا تقوم بإرجاع كائن جديد لذلك في تقوم بإرجاع none1 نقطة
-
قد يظهر هذا الخطأ في أي نموذج آخر في Sklearn بشكل مشابه تماماً. المشكلة تظهر في التابع fit ، حيث أن التابع يتوقع أبعاد X بالشكل: [n_samples,n_features] لكنك تعطيه مصفوفة من الشكل: [n_samples,] لحل المشكلة قم بإعادة تعيين الأبعاد: X=X.reshape(-1,1) lr.fit(X ,y)1 نقطة
-
أنت لديك 5 عينات، موزعة كالتالي: عينة للأصناف 2و1و3 وعينتين للصنف 4 ال "number of members in each class" يقصد بها عدد الأعضاء في كل صف أي عدد العينات من أجل كل صف. يحاول StratifiedKFold الحفاظ على نسبة معينة في كل fold من هؤلاء الأعضاء. أنت حددت 3 تقسيمات "Fold" وبالتالي في كل تقسيمة من أجل الكلاس 2 مثلاً، يجب على الأقل الحفاظ على نسبة0.33 =1/3 عضو. ومن الكلاس 1 و 3 أيضاً يجب أن تتحقق نفس النسبة (0.33 عضو). أما من أجل الكلاس 4 فيجب أن تتحقق النسبة 2/3=0.67 عضو. لكن 0.33 تعني جزء من العينة وهذا غير ممكن! يجب على الأقل أن يكون عدد الأعضاء في الكلاسات من 1 إلى 3 يساوي 3 ومن الكلاس 4 أيضاً 3 لكي يصبح 1 عضو في كل تقسيمة على الأقل. ولهذا السبب ظهر الخطأ. إذاً يجب أن يكون لديك على الأقل 3 عينات من أجل كل كلاس. لاحظ أيضاً أنك إذا وضعت 2 (أقصد تقسيمتين) سوف ينجح الأمر لكنه سيعطيك التحذير التالي: UserWarning: The least populated class in y has only 1 members, which is less than n_splits=2. % (min_groups, self.n_splits)), UserWarning) حيث أنه يعطيك خطأ إذا لم يجد أي كلاس يحقق الشرط (لأنه لن يكون لفكرة الخوارزمية معنى بعد ذلك)، بينما يعطيك تحذير إذا كان هناك كلاس واحد على الأقل يحققه.1 نقطة
-
إن timestamps في mongodb هي ثابتة ومرتبطة بشكل مباشر بتوقيت unix. أما عند التعامل معها مع الكود البرمجي مثلاً node.js يقوم المفسّر في node بأخذ قيمة التاريخ حسب timezone الجهاز الذي يقوم بالتنفيذ عليه. مثلاً في حال كانت منطقتك الزمنية UTC+2 وهكذا. لذلك قد تجد اختلاف بين القيمة التي يتم تخزينها في mongodb والقيمة التي يتم إظهارها ضمن node.js لذلك يمكن معالجة هذه المشكلة إما بالتعامل دوماً مع التوقيت حسب Unix كمرجع ثابت للتوقيت بين قاعدة البيانات وخادم الويب لديك، أو عن طريق تعديل التوقيت بالشكل المناسب لك (أخذ منطقتك الزمنية على سبيل المثال كمرجع ثابت) وحفظها أثناء إدخال البيانات إلى القاعدة. ولتحقيق ذلك تم إيجاد عدة حلول، منها مكتبة يمكنك إضافتها لتعمل مع mogoose وتدعى moment-timezone ويمكنك استخدامها كالتالي: const moment = require('moment-timezone'); const myDate = moment.tz(Date.now(), "نضع هنا المنطقة الزمنية"); ثم في ال schema نكتبها بالشكل التالي: const someSchema = new Schema( { ... anyDate: {type: Date, default: myDate}, ... } ); ولمعرفة اسماء المناطق الزمنية يمكنك التوجه إلى التوثيق الرسمي ل moment js.1 نقطة
-
إن الدالة append لاتعيد أي قيمة، نمط الإعادة لها هو NONE والتي يتم تقييمها ل false فقط في هذه الحالة لأنها ليست true وعكس true هو false .. print u.append(1) None => print not None # not None == True True هذه الدالة تعدل على القائمة الأصلية التي تم الاستدعاء عليها، ولا تعيد شيئاً.1 نقطة
-
يمكنك أن تقوم بإضافة الأرقام إلى المتغير mac_addresses، أما إن كنت تريد توليد عدد كبير من أرقام Mac Address بدلًا من إستخدام أرقام موجودة لديك مسبقًا، فيمكنك عمل دالة تقوم بذلك كالتالي: import random def genrate_mac_addresses(max = 1): addresses = [] for _ in range(max): address = {} address['mac'] = "02:00:00:%02x:%02x:%02x" % (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)) address['comment'] = "LAN4" addresses.append(address) return addresses print(genrate_mac_addresses(10)) """ Output: [ {'mac': '02:00:00:23:80:cb', 'comment': 'LAN4'}, {'mac': '02:00:00:2b:fc:16', 'comment': 'LAN4'}, {'mac': '02:00:00:1d:f5:84', 'comment': 'LAN4'}, {'mac': '02:00:00:67:62:1b', 'comment': 'LAN4'}, {'mac': '02:00:00:1f:25:01', 'comment': 'LAN4'}, {'mac': '02:00:00:56:36:b8', 'comment': 'LAN4'}, {'mac': '02:00:00:bd:56:4e', 'comment': 'LAN4'}, {'mac': '02:00:00:8c:f9:24', 'comment': 'LAN4'}, {'mac': '02:00:00:c7:1f:c8', 'comment': 'LAN4'}, {'mac': '02:00:00:b4:7f:77', 'comment': 'LAN4'} ] """ بالطبع يمكنك تعديل بنيه النص المستخدم لتوليد أرقام Mac Address معينة أو حتى تغير الـ comment وتبديله بمدخل إلى الدالة.1 نقطة
-
هذه هي القائمة الذي تحوي العناوين mac_addresses = [ {"mac": "68:72:51:60:71:C0", "comment": "A1"}, {"mac": "68:72:51:60:74:93", "comment": "A2"}, {"mac": "68:72:51:60:72:95", "comment": "A3"}, {"mac": "68:72:51:60:72:83", "comment": "A4"}, {"mac": "68:72:51:60:71:42", "comment": "A5"}, {"mac": "68:72:51:60:73:24", "comment": "A6"}, {"mac": "68:72:51:60:71:74", "comment": "A7"}, {"mac": "78:8A:20:60:3F:97", "comment": "A10"}, {"mac": "FC:EC:DA:62:C8:E4", "comment": "A13"}, {"mac": "F4:92:BF:34:2E:1A", "comment": "A31"}, {"mac": "48:8F:5A:48:FE:D2", "comment": "LAN1"}, {"mac": "48:8F:5A:48:FE:D3", "comment": "LAN2"}, {"mac": "48:8F:5A:48:FE:D4", "comment": "LAN3"}, {"mac": "48:8F:5A:48:FE:D5", "comment": "LAN4"}, {"mac": "48:8F:5A:48:FE:D6", "comment": "LAN5"}, {"mac": "48:8F:5A:48:FE:D7", "comment": "LAN6"}, {"mac": "48:8F:5A:48:FE:D8", "comment": "LAN7"}, {"mac": "48:8F:5A:48:FE:D9", "comment": "LAN8"}, {"mac": "48:8F:5A:48:FE:DA", "comment": "LAN9"}, {"mac": "48:8F:5A:48:FE:DB", "comment": "LAN10"}, {"mac": "48:8F:5A:48:FE:DC", "comment": "LAN11"}, {"mac": "48:8F:5A:48:FE:DD", "comment": "LAN12"}, {"mac": "48:8F:5A:48:FE:DE", "comment": "LAN13"}, ] والعناوين الإضافية تقوم بإضافتها في أسفل القائمة كهذا المثال [ ..., {"mac": "48:8F:5A:48:FE:ER", "comment": "LAN14"}, ] ويمكنك تكرار العملية وإضافة عناوين mac كما تشاء1 نقطة
-
تقوم على تحديد عدد معين من التقسيمات وفي كل تقسيمة يتم اختيار نسبة معينة من البيانات عشوائياً للاستخدام كعينة اختبار والباقي للتدريب. سأقوم بتطبيقه على نموذج تصنيف لكي تعرف كيفية تطبيقه بسكل عملي: from sklearn.model_selection import ShuffleSplit from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.datasets import make_blobs # إنشاء داتاسيت مزيفة ب10 عينات و3 فئات X, y = make_blobs(n_samples=10, random_state=2021) # y=array([1, 1, 2, 0, 1, 2, 0, 2, 0, 0]) # ShuffleSplit إنشاء كائن من الكلاس # حددنا عدد التقسيمات ب 5 وهو العدد الافتراضي # وحددنا حجم عينة الاحتبار ب20 في المئة cv = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0) # لتخزين النتائج من كل تقسيمة y_true, y_pred = list(), list() # عدد التقسيمات sp=cv.get_n_splits(X) # عملية التقسيم for train_ix, test_ix in cv.split(X): # تقسيم البيانات X_train, X_test = X[train_ix, :], X[test_ix, :] y_train, y_test = y[train_ix], y[test_ix] # تدريب النموذج model = RandomForestClassifier(random_state=44) model.fit(X_train, y_train) # توقع النموذج yhat = model.predict(X_test) # تخزين النتيجة for i in range(0,len(y_test)): y_true.append(y_test[i]) y_pred.append(yhat[i]) # حساب الدقة acc = accuracy_score(y_true, y_pred) print('Accuracy: %.3f' % acc)# Accuracy: 1.000 لاحظ كيف أنه قمنا بتحديد عدد معين من التقسيمات وهو 5 وحددنا نسبة مئوية للعينات التي سيتم استخدامها للاختبار في كل تقسيمة وهو 20%، ثم أدرب النموذج على بيانات التدريب وأقوم بحساب القيمة المتوقعة على عينات الاختبار وأضعها في y_pred وأضع القيم الحقيقية المقابلة لها في y_true, وهكذا بالنسبة لبقية التقسيمات حتى ننتهي وبعدها أقوم بحساب دقة النموذج.1 نقطة
-
بشكل مشابه ل LeaveOneOut لكن مع اختلاف بسيط. هذه الطريقة تقوم على تقييم النموذج على كامل العينات، بحيث في كل مرة تقوم بتدريب النموذج على كل العينات ماعدا عدد محدد من العينات تخرجها لكي تقوم باستخدامها للاختبار. المثاليين يوضحان كل شيء: قم بتشغيل الكود لترى الخرج مباشرة. import numpy as np from sklearn.model_selection import LeavePOut X = np.array([[1,4],[2,1],[3,4],[7,8]]) y = np.array([2,1,3,9]) #3 هنا حددنا عدد العينات lpo = LeavePOut(3) # لمعرفة عدد التقسيمات الممكنة print(lpo.get_n_splits(X)) # تقسيم البيانات for train_index, test_index in lpo.split(X): # للتقسيمة index عرض ال print("TRAIN:"+str(train_index)+'\n'+"TEST:"+str(test_index),end='\n\n') # تقسيم البيانات X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # عرض البيانات المقسمة print('X_train:\n '+str(X_train),end='\n\n') print('X_test:\n '+str(X_test),end='\n\n') print('y_train:\n '+str(y_train),end='\n\n') print('y_test:\n' +str(y_test),end='\n\n') في المثال التالي سوف استخدم هذا النهج في تدريب نموذج واختباره: from sklearn.model_selection import LeavePOut from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score from sklearn.datasets import make_blobs # إنشاء داتاسيت مزيفة ب10 عينات و3 فئات X, y = make_blobs(n_samples=10, random_state=2021) # y=array([1, 1, 2, 0, 1, 2, 0, 2, 0, 0]) # LeavePOut إنشاء كائن من الكلاس # تحديد عدد العينات التي نريدها للاختبار في كل مرة pout=2 cv = LeavePOut(p=pout) # لتخزين النتائج من كل تقسيمة y_true, y_pred = list(), list() # عملية التقسيم for train_ix, test_ix in cv.split(X): # تقسيم البيانات X_train, X_test = X[train_ix, :], X[test_ix, :] y_train, y_test = y[train_ix], y[test_ix] # تدريب النموذج model = RandomForestClassifier(random_state=44) model.fit(X_train, y_train) # تقييم النموذج yhat = model.predict(X_test) # تخزين النتيجة for i in range(0,pout): y_true.append(y_test[i]) y_pred.append(yhat[i]) # حساب الدقة acc = accuracy_score(y_true, y_pred) print('Accuracy: %.3f' % acc)# Accuracy: 1.000 لاحظ كيف أنه في كل مرة أقوم بأخذ عدة عينات (حددها بشكل اختياري) للاختبار والباقي للتدريب ثم أدرب النموذج عليها وأقوم بحساب القيمة المتوقعة على عينات الاختبار وأضعها في y_pred وأضع القيم الحقيقية المقابلة لها في y_true, وهكذا بالنسبة لبقية التقسيمات حتى ننتهي وبعدها أقوم بحساب دقة النموذج.1 نقطة
-
السلام عليكم أخي أولا التخصص : يجب أن تتبع التخصص الذي تحبه ووجت نفسك متفوقا فيه ثانيا النبذة التعريفية : يجب أن تتعلم المجال الذي أنت فيه وتكتسب فيه الخبرة بعد هذا تكون كتابة النبذة التعريفية سهلة ثالثا معرض الاعمال : يجي عليك البحث عن مشاريع تابعة لمجالك والعمل عليها ووضعها في معرض أعمالك رابعا العرض : إبحث في الانترنت وستجد أساليب جذب العميل خامسا فرص العمل : فرص العمل متعلقة بمدى إجتهادك في مجالك وتميز أعمالك1 نقطة
-
class MyClass: def __init__(self): self.lst = [] بايثون تقدم نوعين لل attributes هما : class attributes and instance attributes. ال class attributes تشبه كثيراً ال static attributes في جافا و c++ فهي تتشارك نفس القيمة مع كل ال object التي تؤخذ من هذا الصف، ويتم تعريف ال class attributes في بايثون تماماً كما قمت أنت بتعريف المتغير الذي سميته lst لذا فكانت القيم هي نفسها. أما ال instance attributes فهي متغير ينتمي إلى object واحد فقط أي أن كل متغير تعرفه ك instance attributes سوف تكون قيمه منفصلة في كل object تأخذه من هذا الصف ، ويتم تعريف ال instance attributes تماماً كما عرفتها لك أنا أي ضمن التابع init1 نقطة
-
# GRADED FUNCTION: forward_propagation_with_dropout def forward_propagation_with_dropout(X, parameters, keep_prob=0.5): np.random.seed(1) # retrieve parameters W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] W3 = parameters["W3"] b3 = parameters["b3"] # LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID Z1 = np.dot(W1, X) + b1 A1 = relu(Z1) ### START CODE HERE ### (approx. 4 lines) D1 = np.random.rand(A1.shape[0], A1.shape[1]) # A1 تعريف مصفوفة بقيم عشوائية بين الصفر والواحد وبنفس أبعاد المصفوفة D1 = D1 < keep_prob A1 = A1 * D1 A1 = A1 / keep_prob ### END CODE HERE ### Z2 = np.dot(W2, A1) + b2 A2 = relu(Z2) ### START CODE HERE ### (approx. 4 lines) D2 = np.random.rand(A2.shape[0], A2.shape[1]) D2 = D2 < keep_prob A2 = A2 * D2 A2 = A2 / keep_prob ### END CODE HERE ### Z3 = np.dot(W3, A2) + b3 A3 = sigmoid(Z3) cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) return A3, cache نعرف مصفوفة بقيم عشوائية بنفس أبعاد المصفوفة A ثم تحويل قيم المصفوفة D1 إلى 0 أو 1 حسب الشرط ( إذا كانت القيمة الأولى في المصفوفة D1 مثلاً 0.2 وهي أقل من العتبة (keep_prob = 0.5) أي سيكون الشرط محقق (D1<keep_porb) وسيقوم بتحويل القيمة إلى 1 , والعكس صحيح وسيقوم بتحويل القيمة إلى 0 ثم ضرب المصفوفة A1 بـ D1 بعد تعديل قيمها إلى 0,1 ثم تقسيم قيم المصفوفة A1 على العتبة....1 نقطة
-
import java.util.Scanner; public class JavaApplication16 { static void Age(int current_date, int current_month, int current_year, int birth_date, int birth_month, int birth_year) { int month[] = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 }; if (birth_date > current_date) { current_month = current_month - 1; current_date = current_date + month[birth_month - 1]; } if (birth_month > current_month) { current_year = current_year - 1; current_month = current_month + 12; } int calculated_date = current_date - birth_date; int calculated_month = current_month - birth_month; int calculated_year = current_year - birth_year; System.out.println("Present Age"); System.out.println("Years: " + calculated_year + " Months: " + calculated_month + " Days: " + calculated_date); } public static void main(String[] args) { Scanner sc=new Scanner(System.in); // إدخال التاريخ الحالي int current_date = sc.nextInt(); int current_month = sc.nextInt(); int current_year = sc.nextInt(); //إدخال تاريخ الميلاد int birth_date = sc.nextInt();; int birth_month = sc.nextInt();; int birth_year = sc.nextInt();; // استدعاء التابع الذي قمنا بتعريفه لكي يطبع لنا العمر Age(current_date, current_month, current_year, birth_date, birth_month, birth_year); } }1 نقطة
-
using namespace std; int Min(int myarray[], int n) { int res = myarray[0]; for (int i = 1; i < n; i++) res = min(res, myarray[i]); return res; } int main() { int arr[] = { 12, 1234, 45, 67, 1 }; int n = sizeof(arr) / sizeof(arr[0]); cout << "Minimum element of array: " << Min(arr, n); return 0; }1 نقطة
-
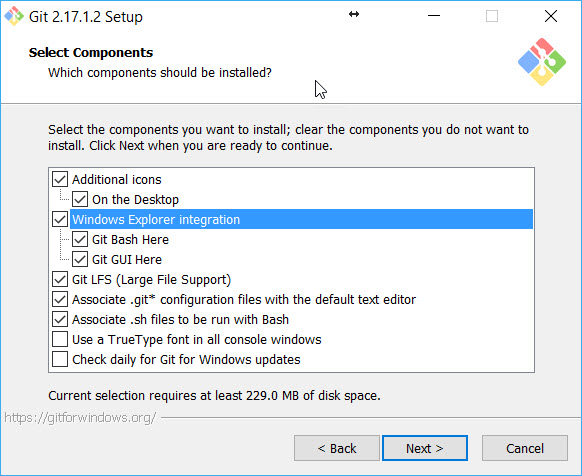
يمكنك أن تقوم بإزالة Git وتعيد تثبيت git مرة أخرى وتتأكد من تحديد خيار Windows Explorer integration (لإضافة Git إلى القائمة المختصرة) كما في الصورة التالية:
 1 نقطة
1 نقطة -
 يقسم العديد من الناس أوقات عملهم بين العديد من المهام المختلفة. قد يكون النسخ في الصباح، كتابة المحتوى فترة الظهيرة وكتابة آراء وهمية في المساء. ولكن ليس هناك مستقل جاد يفكر في تقسيم وقته بين عدة مجالات، أليس كذلك؟ بينما كان الكاتب لا يزال بعيدًا عن الاحتراف في أي مجال، وجد عملًا مناسبًا يحقق التوازن في حالة العمل المستقل في عالمين مختلفين وهو: تطوير المواقع الإلكترونية والكتابة. إنها ليست مسألة نقود (على الرغم من أنّ المزيد من المال مرحب به!) - مجرد قرار شخصي للعمل في المجالين الأكثر مناسبةً له بالطريقة الوحيدة التي يعرفها: العمل من المنزل. إذا كنت مهتمًا، تابع الشرح لكيفية مناسبة ذلك له، لماذا سيناسبك أيضًا وأسباب احتمالية عدم مناسبتها. لماذا ناسبه العمل المستقل في عدة مجالات (ويمكن أن يناسبك أيضًا!) يعمل الكاتب في هذه الأيام ككاتب ومطور مواقع إلكترونية معًا (مع الميل لاستخدام WordPress)، وهو يعمل بهذا الشكل منذ عدة سنوات. ولكن، تضمنت بداياته في العمل المستقل بعض المسارات التي فشل بها، ولا يزال يرتجف كلما تذكرها، لا سيما في كتابة مجموعة من المحتوى، نسخ ملفات صوتية يصعب فهمها مقابل مبالغ ضئيلة وملئ عدد لا نهائي من الاستبيانات. عمل صعب جدًا، ولكن المزيد من النقود تساعد إذا كنت تعيش في إحدى دول العالم الثالث. أيضًا، كان لا يزال يعمل بدوام كامل لفترة، لحين حصوله على عملاء منتظمين وثابتين. بعيدًا عن الكراهية الملحوظة تجاه المؤسسات الاستغلالية، قدمت تجربته في العمل في عدة مجالات على الإنترنت، فائدة واحدة واضحة وهي: اكتشاف حبه للكتابة. ولذلك، قرر الاستمرار بها كهواية، بينما بنى عملًا مستقلًا أكثر ثباتًا كمطور للمواقع الإلكترونية. ومع مرور الوقت، ظهرت الفائدة الثانية لخبرته المنتقاة. أعطته خبرته في تطوير المواقع الإلكترونية، أفضليةً عند التقديم لأعمال الكتابة المتعلقة بالتكنولوجيا. لم يكن على علم بالأدوات والعمليات فقط، حيث يعلم تطوير مواقع الويب كيفية الاعتماد على Google كأداة لحل المشاكل فوق كل شيء. أيضًا، تساعد مهارات البحث عند الحاجة لكتابة موثوقة حول أي موضوع يعطى لك. بطريقةٍ ما، ما كان يبدو أنه تركيبة غريبة من مجالين مختلفين أكمل العمل بهما بناءً على تفضيلاته الشخصية، أصبح خطوة جيدة للعمل. اكتسب قدرته على التعبير عن نفسه بوضوح، من خلال التعامل مع العملاء - على الرغم من أنه لا يزال يعمل على الإيجاز -، كما فتحت له مهارته في العمل على تطوير المواقع الإلكترونية عدة مجالات في عالم الكتابة. أيضًا هو فريد من نوعه وهو مستعد للرهان على أن العديد منكم يمتلك مهارات قيّمة يمكن أن تندمج معًا، وتفتح الأبوب أمام وظيفة لم تفكر بها بعد. مثلًا: إذا كنت هاوٍ في التصوير، يمكن أن يعطيك ذلك أفضلية في وظائف التصميم الجرافيكي. إذا كنت تساعد العملاء في تطوير استراتيجياتهم التسويقية على الإنترنت، ستسمح لك خبرتك في التصميم الجرافيكي على دمج الرسوم البيانية مع عروضك. إذا كنت تحب الكتابة، فأنت محظوظ؛ حيث أن الكتابة يمكن أن تندمج بشكل جيد مع أي شيء آخر. إذا لم تصل إلى هذه المرحلة بعد، يقرب الكاتب لك الأمور من خلال الكشف عن فائدتين إضافيتين للعمل المستقل في عدة مجالات: يعطي تقسيم وقتك بين مجالين طريقة للتخلص من التوتر في أحدها. يحب الكاتب العمل في الكتابة بعد الجلسات الطويلة لاستكشاف الأخطاء وحلها، وتعطيه كتابة الشيفرات الهيكل الضروري للتخلص من إجهاد العمل الزائد في الكتابة. يسمح لك الثبات في مجال واحد بأن تبدأ بمجال آخر دون القلق من سلبيات العمل المستقل (قلة عدد العملاء الأولي، خسارة الأجور المنتظمة وغيرها). لماذا قد لا يكون العمل في عدة مجالات مناسبًا لك؟ الآن، يتأمل الكاتب بأنه قد أقنعك بأنك قد تنجح في العمل كمستقل في عدة مجالات. ولكنه تحدث عن الحالة الأخرى، وهي الأسباب التي قد تجعل العمل في عدة مجالات فكرة سيئة. أولًا، يعني تقسيم وقتك للعمل في عدة مجالات، أنك ستعمل أكثر بطبيعة الحال. يتطلب العمل الأكثر وقتًا أكثر. ويتطلب التقدم في كل مجال، تطوير مهاراتك بشكل أكبر. وبصراحة، إذا كان وقتك ضيّق بالفعل، فإن دخول مجال جديد لن ينتهي بشكلٍ جيد سواء لك أو لعملائك. تتحول قلة الوقت المتاح إلى مستويات أعلى من التوتر. إذا كنت تعتقد أن محاولة العيش كمستقل فقط والتعامل مع توقعات العملاء تعد أمرًا صعبًا في السابق، عليك مضاعفة ذلك. إذا لم تكن قادرًا على التحكم بالتوتر بشكل مناسب، ستنخفض جودة عملك. وأخيرًا، من المستحيل أن تجد توازنًا، إلا إذا كنت متأكدًا من ثباتك في المجال الأول. تذكر أيامك الأولى في العمل المستقل، واسأل نفسك بصدق: هل كان بإمكانك فعلها إذا كان عليك أن توازن بين قواعد وتوقعات مجالين مختلفين مرة واحدة؟ غالبًا الإجابة هي لا، إلا إذا كنت إنسانًا آليًا. الحقيقة هي أن المفهوم الكامل للعمل في عدة مجالات في نفس الوقت، يكون مناسبًا في حالة وجود القليل من المرونة في حياتك المهنية أو تستطيع إيجادها، فقط. إذا كنت قد بدأت العمل كمستقل، يمكنك محاولة التواصل مع عملائك بطريقة سيئة؛ لأن نتيجة محاولة ذلك ستكون بنفس درجة الكارثية. الخاتمة يقرر معظم الناس أن يركزوا جهودهم المهنية في مجال واحد، لزيادة فرصهم بالنجاح وهذا قرار منطقي. ومع ذلك، يمكنك أن تصبح أفضل من خلال تقسيم جهودك. تذكر ذلك، ولنراجع ما غطيناه في هذا المنشور. إيجابيات العمل المستقل في عدة مجالات يسمح لك بمواصلة إيجاد اهتمامات جديدة بقدرات مهنية يعطي طريقة للتخلص من التوتر المميز لكل نوع من العمل قد تعطيك مهاراتك المتنوعة الأفضلية للعملاء المحتملين سلبيات العمل المستقل في عدة مجالات تأخذ وقتًا أكثر من العمل في مجال واحد بطبيعة الحال. سيتم سحبك في عدة اتجاهات. من الصعب الموازنة في العمل بين عدة مجالات إلا إذا كنت تتقدم بثبات في أحدها. هل لديك أي أسئلة حول اختيار وظيفة مستقلة ثانية؟ أو هل تريد مشاركة قصتك الخاصة؟ ضعها في قسم التعليقات أدناه! ترجمة -وبتصرف- للمقال Is It Possible to Freelance Across Multiple Fields? لكاتبه Alexander Cordova1 نقطة
يقسم العديد من الناس أوقات عملهم بين العديد من المهام المختلفة. قد يكون النسخ في الصباح، كتابة المحتوى فترة الظهيرة وكتابة آراء وهمية في المساء. ولكن ليس هناك مستقل جاد يفكر في تقسيم وقته بين عدة مجالات، أليس كذلك؟ بينما كان الكاتب لا يزال بعيدًا عن الاحتراف في أي مجال، وجد عملًا مناسبًا يحقق التوازن في حالة العمل المستقل في عالمين مختلفين وهو: تطوير المواقع الإلكترونية والكتابة. إنها ليست مسألة نقود (على الرغم من أنّ المزيد من المال مرحب به!) - مجرد قرار شخصي للعمل في المجالين الأكثر مناسبةً له بالطريقة الوحيدة التي يعرفها: العمل من المنزل. إذا كنت مهتمًا، تابع الشرح لكيفية مناسبة ذلك له، لماذا سيناسبك أيضًا وأسباب احتمالية عدم مناسبتها. لماذا ناسبه العمل المستقل في عدة مجالات (ويمكن أن يناسبك أيضًا!) يعمل الكاتب في هذه الأيام ككاتب ومطور مواقع إلكترونية معًا (مع الميل لاستخدام WordPress)، وهو يعمل بهذا الشكل منذ عدة سنوات. ولكن، تضمنت بداياته في العمل المستقل بعض المسارات التي فشل بها، ولا يزال يرتجف كلما تذكرها، لا سيما في كتابة مجموعة من المحتوى، نسخ ملفات صوتية يصعب فهمها مقابل مبالغ ضئيلة وملئ عدد لا نهائي من الاستبيانات. عمل صعب جدًا، ولكن المزيد من النقود تساعد إذا كنت تعيش في إحدى دول العالم الثالث. أيضًا، كان لا يزال يعمل بدوام كامل لفترة، لحين حصوله على عملاء منتظمين وثابتين. بعيدًا عن الكراهية الملحوظة تجاه المؤسسات الاستغلالية، قدمت تجربته في العمل في عدة مجالات على الإنترنت، فائدة واحدة واضحة وهي: اكتشاف حبه للكتابة. ولذلك، قرر الاستمرار بها كهواية، بينما بنى عملًا مستقلًا أكثر ثباتًا كمطور للمواقع الإلكترونية. ومع مرور الوقت، ظهرت الفائدة الثانية لخبرته المنتقاة. أعطته خبرته في تطوير المواقع الإلكترونية، أفضليةً عند التقديم لأعمال الكتابة المتعلقة بالتكنولوجيا. لم يكن على علم بالأدوات والعمليات فقط، حيث يعلم تطوير مواقع الويب كيفية الاعتماد على Google كأداة لحل المشاكل فوق كل شيء. أيضًا، تساعد مهارات البحث عند الحاجة لكتابة موثوقة حول أي موضوع يعطى لك. بطريقةٍ ما، ما كان يبدو أنه تركيبة غريبة من مجالين مختلفين أكمل العمل بهما بناءً على تفضيلاته الشخصية، أصبح خطوة جيدة للعمل. اكتسب قدرته على التعبير عن نفسه بوضوح، من خلال التعامل مع العملاء - على الرغم من أنه لا يزال يعمل على الإيجاز -، كما فتحت له مهارته في العمل على تطوير المواقع الإلكترونية عدة مجالات في عالم الكتابة. أيضًا هو فريد من نوعه وهو مستعد للرهان على أن العديد منكم يمتلك مهارات قيّمة يمكن أن تندمج معًا، وتفتح الأبوب أمام وظيفة لم تفكر بها بعد. مثلًا: إذا كنت هاوٍ في التصوير، يمكن أن يعطيك ذلك أفضلية في وظائف التصميم الجرافيكي. إذا كنت تساعد العملاء في تطوير استراتيجياتهم التسويقية على الإنترنت، ستسمح لك خبرتك في التصميم الجرافيكي على دمج الرسوم البيانية مع عروضك. إذا كنت تحب الكتابة، فأنت محظوظ؛ حيث أن الكتابة يمكن أن تندمج بشكل جيد مع أي شيء آخر. إذا لم تصل إلى هذه المرحلة بعد، يقرب الكاتب لك الأمور من خلال الكشف عن فائدتين إضافيتين للعمل المستقل في عدة مجالات: يعطي تقسيم وقتك بين مجالين طريقة للتخلص من التوتر في أحدها. يحب الكاتب العمل في الكتابة بعد الجلسات الطويلة لاستكشاف الأخطاء وحلها، وتعطيه كتابة الشيفرات الهيكل الضروري للتخلص من إجهاد العمل الزائد في الكتابة. يسمح لك الثبات في مجال واحد بأن تبدأ بمجال آخر دون القلق من سلبيات العمل المستقل (قلة عدد العملاء الأولي، خسارة الأجور المنتظمة وغيرها). لماذا قد لا يكون العمل في عدة مجالات مناسبًا لك؟ الآن، يتأمل الكاتب بأنه قد أقنعك بأنك قد تنجح في العمل كمستقل في عدة مجالات. ولكنه تحدث عن الحالة الأخرى، وهي الأسباب التي قد تجعل العمل في عدة مجالات فكرة سيئة. أولًا، يعني تقسيم وقتك للعمل في عدة مجالات، أنك ستعمل أكثر بطبيعة الحال. يتطلب العمل الأكثر وقتًا أكثر. ويتطلب التقدم في كل مجال، تطوير مهاراتك بشكل أكبر. وبصراحة، إذا كان وقتك ضيّق بالفعل، فإن دخول مجال جديد لن ينتهي بشكلٍ جيد سواء لك أو لعملائك. تتحول قلة الوقت المتاح إلى مستويات أعلى من التوتر. إذا كنت تعتقد أن محاولة العيش كمستقل فقط والتعامل مع توقعات العملاء تعد أمرًا صعبًا في السابق، عليك مضاعفة ذلك. إذا لم تكن قادرًا على التحكم بالتوتر بشكل مناسب، ستنخفض جودة عملك. وأخيرًا، من المستحيل أن تجد توازنًا، إلا إذا كنت متأكدًا من ثباتك في المجال الأول. تذكر أيامك الأولى في العمل المستقل، واسأل نفسك بصدق: هل كان بإمكانك فعلها إذا كان عليك أن توازن بين قواعد وتوقعات مجالين مختلفين مرة واحدة؟ غالبًا الإجابة هي لا، إلا إذا كنت إنسانًا آليًا. الحقيقة هي أن المفهوم الكامل للعمل في عدة مجالات في نفس الوقت، يكون مناسبًا في حالة وجود القليل من المرونة في حياتك المهنية أو تستطيع إيجادها، فقط. إذا كنت قد بدأت العمل كمستقل، يمكنك محاولة التواصل مع عملائك بطريقة سيئة؛ لأن نتيجة محاولة ذلك ستكون بنفس درجة الكارثية. الخاتمة يقرر معظم الناس أن يركزوا جهودهم المهنية في مجال واحد، لزيادة فرصهم بالنجاح وهذا قرار منطقي. ومع ذلك، يمكنك أن تصبح أفضل من خلال تقسيم جهودك. تذكر ذلك، ولنراجع ما غطيناه في هذا المنشور. إيجابيات العمل المستقل في عدة مجالات يسمح لك بمواصلة إيجاد اهتمامات جديدة بقدرات مهنية يعطي طريقة للتخلص من التوتر المميز لكل نوع من العمل قد تعطيك مهاراتك المتنوعة الأفضلية للعملاء المحتملين سلبيات العمل المستقل في عدة مجالات تأخذ وقتًا أكثر من العمل في مجال واحد بطبيعة الحال. سيتم سحبك في عدة اتجاهات. من الصعب الموازنة في العمل بين عدة مجالات إلا إذا كنت تتقدم بثبات في أحدها. هل لديك أي أسئلة حول اختيار وظيفة مستقلة ثانية؟ أو هل تريد مشاركة قصتك الخاصة؟ ضعها في قسم التعليقات أدناه! ترجمة -وبتصرف- للمقال Is It Possible to Freelance Across Multiple Fields? لكاتبه Alexander Cordova1 نقطة
















