

هناك بعض البروتوكولات الضرورية للتشغيل السلس للإنترنت، ولكنها لا تتناسب تمامًا مع نموذج الطبقات الصارمة، وأحد هذه البروتوكولات هو نظام أسماء النطاقات Domain Name System -أو اختصارًا DNS-، وهو ليس تطبيقًا يستدعيه المستخدمون مباشرةً، ولكنه خدمةٌ تعتمد عليها جميع التطبيقات الأخرى تقريبًا، وذلك لاستخدام خدمة الأسماء لترجمة أسماء المضيفين إلى عناوين مضيفين؛ حيث يَسمح وجود مثل هذا التطبيق لمستخدمي التطبيقات الأخرى بالإشارة إلى المضيفين البعيدين بالاسم بدلًا من العنوان، أي تُستخدم خدمة الأسماء عادةً بواسطة تطبيقاتٍ أخرى بدلًا من البشر.
الوظيفة المهمة الثانية هي إدارة الشبكة، والتي على الرغم من أنها ليست مألوفةً للمستخدم العادي، إلا أنها تُطبَّق من قِبل الأشخاص الذين يشغلون الشبكة نيابةً عن المستخدمين غالبًا. تُعَد إدارة الشبكات على نطاقٍ واسع مشكلةً من المشاكل الصعبة للشبكات ولا تزال محور الكثير من الابتكارات. سنلقي نظرةً على بعض القضايا والأساليب لحل هذه المشكلة أدناه.
خدمة الأسماء باستخدام نظام DNS
استخدمنا في معظم هذا الكتاب العناوين لتحديد المضيفين، إلا أن العناوين ليست سهلة الاستخدام تمامًا، على الرغم من أنها مناسبة للمعالجة بواسطة الموجّهات routers، ولهذا السبب يُخصَّص أيضًا اسمٌ فريد لكل مضيفٍ في الشبكة، ولقد رأينا فعليًا في هذا القسم بروتوكولات تطبيق مثل بروتوكول HTTP تستخدم أسماءً مثل www.princeton.edu. نشرح الآن كيفية تطوير خدمة التسمية لربط أسماءٍ سهلة الاستخدام مع عناوينٍ سهلة التوجيه. تسمى خدمات الأسماء أحيانًا برمجيات وسيطة middleware لأنها تملأ الفجوة بين التطبيقات والشبكة الأساسية.
تختلف أسماء المضيفين عن عناوينهم بطريقتين مهمتين. أولهما، تكون الأسماء متغيرة الطول وذاتيةً مما يسهّل على البشر تذكرها، بينما تكون العناوين الرقمية ذات طولٍ ثابت مما يسهّل على الموجّهات معالجتها. ثانيًا، لا تحتوي الأسماء عادةً على معلوماتٍ تساعد الشبكة في تحديد موقع المضيف أو توجيه الرزم نحوه، بينما تحتوي العناوين في بعض الأحيان على معلومات توجيهٍ مضمَّنةٍ فيها، لكن العناوين المسطحة التي لا يمكن تقسيمها إلى أجزاء هي الاستثناء.
سنقدم في البداية بعض المصطلحات الأساسية قبل الدخول في تفاصيل كيفية تسمية المضيفين في الشبكة. أولًا، تحدّد مساحة الأسماء name space مجموعة الأسماء المحتملة، حيث يمكن أن تكون مساحة الأسماء إما مسطحةً flat أي أن الأسماء غير قابلة لتقسيمها إلى مكونات، أو هرميةً hierarchical مثل أسماء ملفات يونيكس. ثانيًا، يحتفظ نظام التسمية بمجموعةٍ من ارتباطات bindings الأسماء بالقيم، إذ من الممكن أن تكون القيمة أي شيءٍ نريد أن يرجعه نظام التسمية عند تقديمه مع اسم، وهي عنوانٌ في كثير من الحالات. أخيرًا، آلية التحليل resolution mechanism وهي إجراءٌ يرجع القيمة المقابلة عند استدعائه باسم. وخادم الأسماء name server هو تطبيقٌ محددٌ لآلية تحليلٍ متوفرةٍ على الشبكة ويمكن الاستعلام عنها بإرسال رسالةٍ إليها.
للإنترنت نظام تسميةٍ متطورٍ خاص نظرًا لحجمه الكبير هو نظام أسماء النطاقات Domain Name System -أو اختصارًا DNS-، لذلك نستخدم نظام DNS مثل إطار عملٍ لمناقشة مشكلة تسمية المضيفين. لاحظ أن الإنترنت لا يستخدم نظام DNS دائمًا، حيث احتفظت سلطةٌ مركزيةٌ تُسمى مركز معلومات الشبكة Network Information Center -أو اختصارًا NIC- بجدولٍ مسطحٍ لارتباطات الأسماء بالعناوين في وقتٍ مبكرٍ من تاريخ الإنترنت، عندما لم يكن هناك سوى بضع مئاتٍ من المضيفين على الإنترنت، وسُمِّي هذا الجدول HOSTS.TXT.
صدّق أو لا تصدق، أنه كان هناك أيضًا كتاب ورقي مثل دفتر الهاتف يُنشر دوريًا ويعطي قائمةً بجميع الأجهزة المتصلة بالإنترنت وجميع الأشخاص الذين لديهم حساب بريدٍ إلكتروني على الإنترنت، وكلما أراد أحد المواقع إضافة مضيفٍ جديد إلى الإنترنت، أرسل مسؤول الموقع بريدًا إلكترونيًا إلى مركز NIC الذي يعطي زوج اسم / عنوان المضيف الجديد. وكانت تُدخل هذه المعلومات يدويًا في الجدول، ويُرسَل الجدول المعدّل بالبريد إلى المواقع المختلفة كل بضعة أيام، ويثبّت مسؤول النظام في كل موقع الجدولَ على كل مضيفٍ في الموقع. طُبِّق بعد ذلك تحليل الأسماء ببساطة من خلال إجراء بحثٍ عن اسم المضيف في النسخة المحلية من الجدول وإرجاع العنوان المقابل.
لا ينبغي أن يكون مفاجئًا هنا عدم نجاح نهج التسمية عندما بدأ عدد المضيفين في الإنترنت في النمو، لذلك وُضِع نظام تسمية النطاقات في منتصف الثمانينات. يستخدم نظام DNS مساحة أسماءٍ هرميةٍ بدلًا من مساحة أسماءٍ مسطحة، ويُقسَّم "جدول" الارتباطات الذي يطبّق مساحة الأسماء هذه إلى أجزاءٍ منفصلةٍ وتُوزَّع عبر الإنترنت؛ وتوفَّر هذه الجداول الفرعية في خوادم الأسماء التي يمكن الاستعلام عنها عبر الشبكة.
ما يحدث في الإنترنت هو أن المستخدم يقدّم اسم مضيفٍ لبرنامجٍ تطبيقي قد يكون مضمَّنًا في اسمٍ مركبٍ، مثل عنوان بريدٍ إلكتروني أو محدّد URL، ويشرك هذا البرنامج نظام التسمية لترجمة هذا الاسم إلى عنوان مضيفٍ host address. يفتح التطبيق بعد ذلك اتصالًا بهذا المضيف من خلال استخدام بعض بروتوكولات النقل مثل بروتوكول TCP مع عنوان IP الخاص بالمضيف. يُوضّح الشكل التالي هذا الموقف في حالة إرسال بريدٍ إلكتروني.
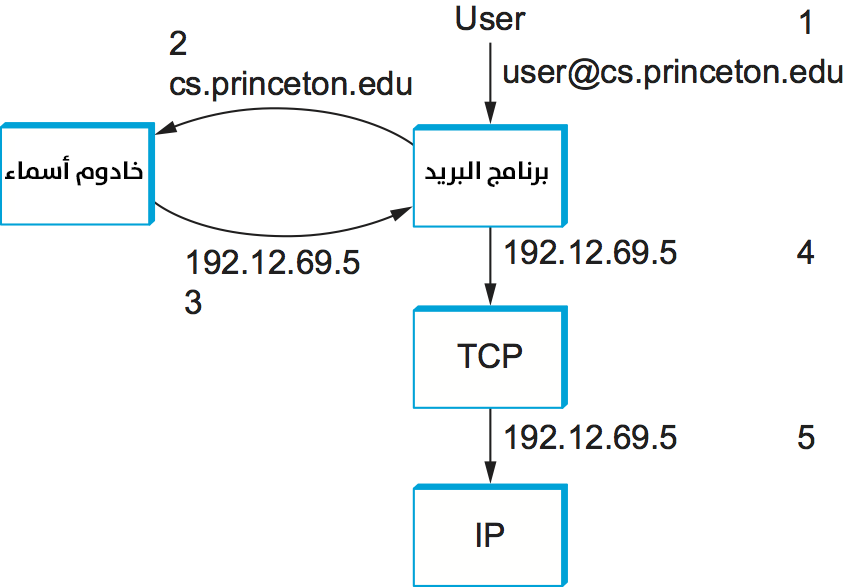
تسلسل النطاقات الهرمي
يطبّق نظام DNS مساحة أسماءٍ هرميةٍ لكائنات الإنترنت، حيث تُعالَج أسماء ملفات يونيكس Unix من اليسار إلى اليمين مع فصل مكونات التسمية بشرطةٍ مائلة slashes، بينما تُعالَج أسماء DNS من اليمين إلى اليسار وتُستخدم الفترات مثل فواصل، ولا يزال البشر يقرؤون أسماء النطاقات من اليسار إلى اليمين، على الرغم من معالجتها من اليمين إلى اليسار، فمثلًا اسم cicada.cs.princeton.edu هو اسمٍ نطاقٍ لمضيف. لاحظ أننا قلنا أن أسماء النطاقات تُستخدم لتسمية كائنات الإنترنت، وما نعنيه بهذا هو عدم استخدام نظام DNS لربط أسماء المضيفين مع عناوينهم، وإنما الأدق أن نقول أن نظام DNS يربط أسماء النطاقات مع قيم، ونفترض في الوقت الحالي أن هذه القيم هي عناوين IP.
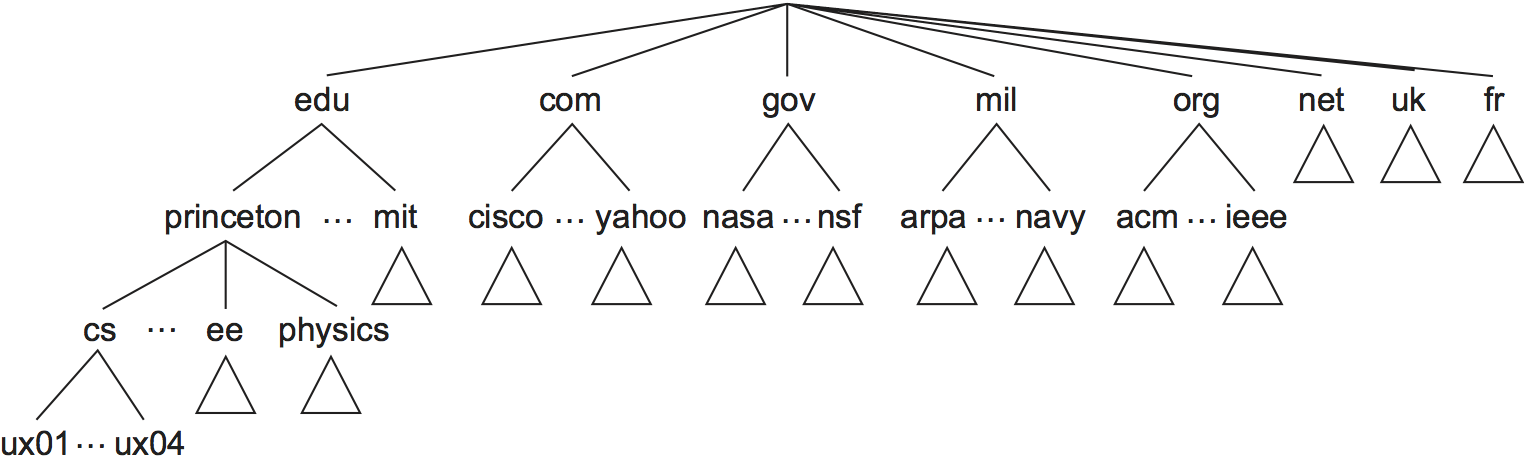
يمكن تصور التسلسل الهرمي لنظام DNS مثل شجرة بصورةٍ مشابهة لتسلسل ملفات يونيكس الهرمي، حيث تتوافق كل عقدةٍ في الشجرة مع نطاق، وتتوافق الأوراق الموجودة في الشجرة مع المضيفين الذين نسمّيهم. يوضّح الشكل السابق مثالًا عن تسلسل النطاق الهرمي، ويمكنك ملاحظة أنه لا ينبغي إسناد أي دلالاتٍ لمصطلح النطاق domain بخلاف أنه مجرد سياقٍ يمكن من خلاله تعريف أسماءٍ إضافية. يُعَد استخدام كلمة نطاق أيضًا في توجيه الإنترنت أمرًا مربكًا، حيث تعني شيئًا مختلفًا عما هو عليه في نظام DNS، فتكون مكافئةً تقريبًا لمصطلح نظامٍ مستقل autonomous system.
لقد دار نقاشٌ طويلٌ عند تطوير تسلسل أسماء النطاق الهرمي لأول مرةٍ حول الاتفاقيات التي ستحكُم الأسماء التي ستوزَّع بالقرب من قمة التسلسل الهرمي، رغم أن التسلسل الهرمي ليس واسعًا جدًا في المستوى الأول، فهناك نطاقٌ لكل بلد، بالإضافة إلى النطاقات "الستة الكبار big six"، وهي edu. وcom. وgov. وmil. وorg. وnet.، وقد كان مقر جميع هذه النطاقات الستة في الأصل في الولايات المتحدة (في مكان اختراع الإنترنت ونظام DNS)، وبالتالي يمكن فقط للمؤسسات التعليمية المعتمَدة من الولايات المتحدة تسجيل اسم نطاق edu. على سبيل المثال. وسِّع عدد نطاقات المستوى الأعلى في السنوات الأخيرة جزئيًا للتعامل مع ارتفاع الطلب على أسماء نطاقات com.، وتتضمّن نطاقات المستوى الأعلى الأحدث biz. وcoop. وinfo.، ويوجد الآن أكثر من 1200 نطاقٍ عالي المستوى.
خوادم الأسماء
سنشرح الآن كيفية تطبيق هذا التسلسل الهرمي. تتمثل الخطوة الأولى في تقسيم التسلسل الهرمي إلى أشجارٍ فرعيةٍ تُسمى مناطق zones. يوضح الشكل الآتي كيفية تقسيم التسلسل الهرمي الوارد في الشكل السابق إلى مناطق، ويمكن التفكير في كل منطقةٍ على أنها متوافقةً مع بعض السلطات الإدارية المسؤولة عن هذا الجزء من التسلسل الهرمي. يشكّل المستوى الأعلى من التسلسل الهرمي على سبيل المثال، منطقةً تديرها شركة الإنترنت للأسماء والأرقام المخصَّصة Internet Corporation for Assigned Names and Numbers -أو اختصارًا ICANN-؛ ويوجد أسفل المستوى الأعلى منطقةٌ تمثّل جامعة برينستون Princeton؛ كما توجد ضمن هذه المنطقة بعض الأقسام التي لا تتحمّل مسؤولية إدارة التسلسل الهرمي، وبالتالي تظل في المنطقة على مستوى الجامعة؛ بينما تدير أقسامٌ أخرى مثل قسم علوم الحاسوب cs المنطقةَ الخاصة بها على مستوى القسم.
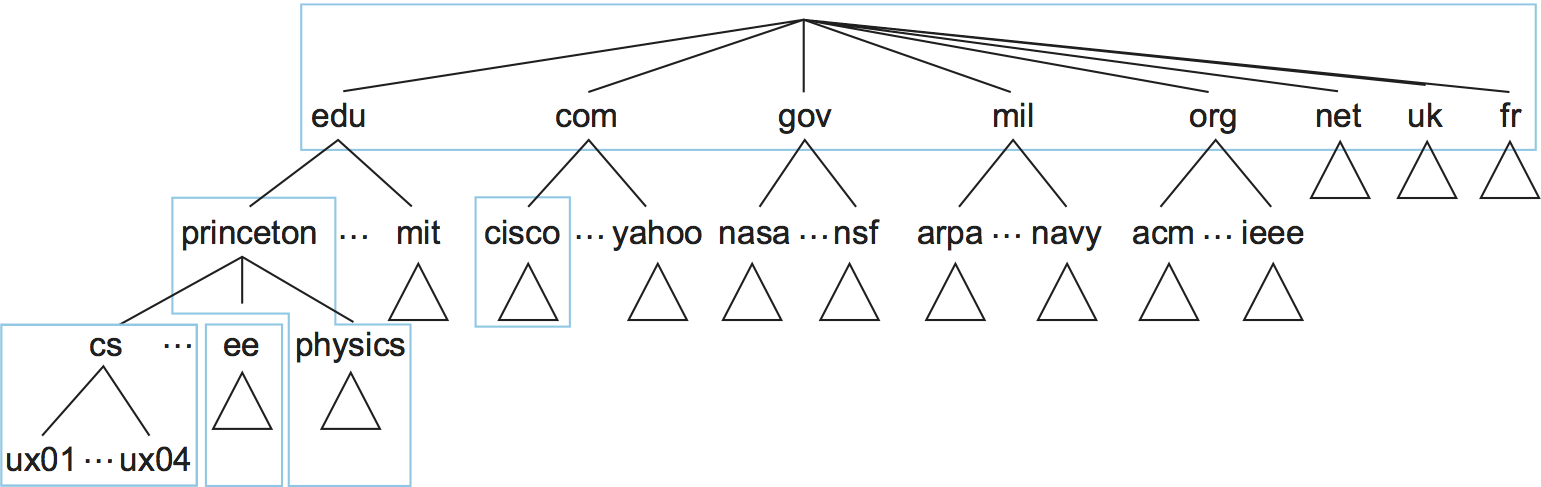
تكمن أهمية المنطقة في أنها تتوافق مع وحدة التطبيق الأساسية في نظام DNS التي هي خادم الأسماء name server، حيث تُطبَّق المعلومات الواردة في كل منطقة في اثنين أو أكثر من خوادم الأسماء، وكل خادم أسماءٍ هو برنامجٌ يمكن الوصول إليه عبر الإنترنت. يرسل العملاء استعلاماتٍ إلى خوادم الأسماء التي تستجيب بالمعلومات المطلوبة، حيث تحتوي الاستجابة أحيانًا على الإجابة النهائية التي يريدها العميل، وتحتوي أحيانًا على مؤشرٍ لخادمٍ آخر يجب على العميل الاستعلام عنه بعد ذلك، وبالتالي يجب عدّ نظام DNS على أنه ممثَّلٌ بتسلسلٍ هرمي لخوادم الأسماء بدلًا من تسلسلٍ هرمي للنطاقات كما هو موضّح في الشكل التالي.
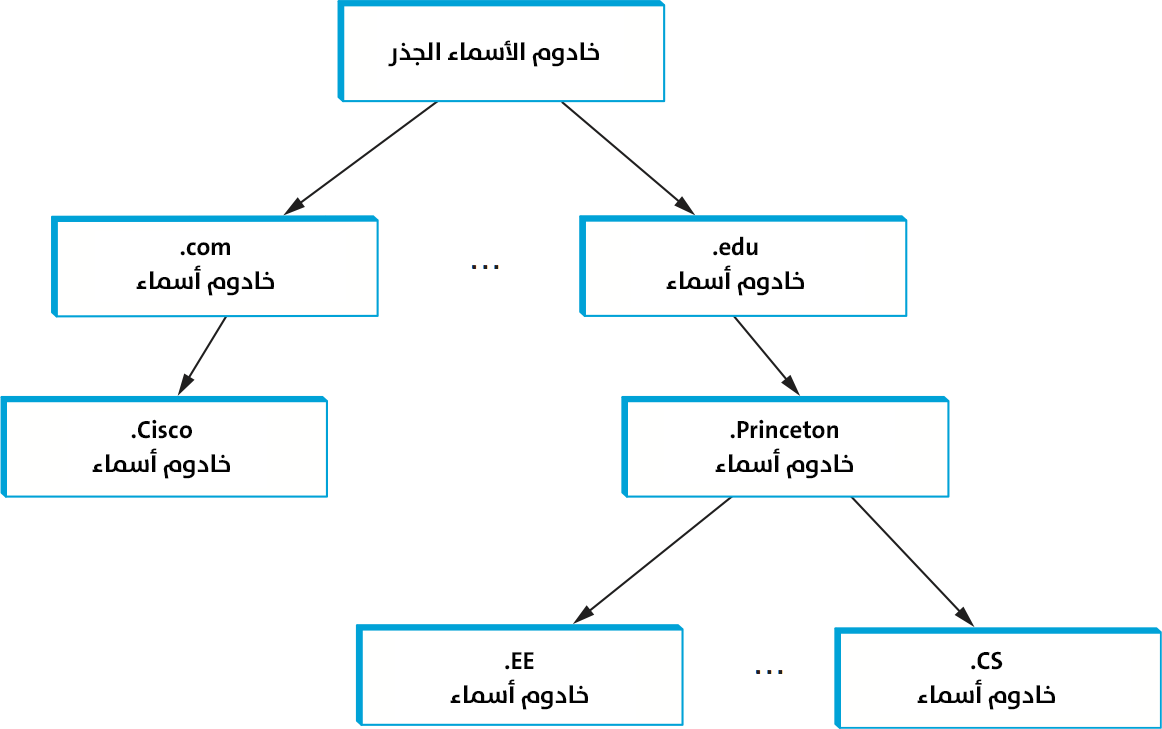
تُطبَّق كل منطقةٍ ضمن اثنين أو أكثر من خوادم الأسماء بقصد الإستفادة من التكرار، أي أن المعلومات تبقى متاحةً حتى في حالة فشل خادم أسماءٍ واحد، وعلى الجانب الآخر لدى خادم الأسماء المحدد الحرية لتطبيق أكثر من منطقةٍ واحدة. يطبّق كل خادم أسماء معلومات المنطقة بمجموعةٍ من سجلات الموارد resource records. ويُعَد سجل المورد ارتباطًا بين اسم وقيمة أو بمعنى أخر مجموعةٌ مكونةٌ من 5 قيم تحتوي على الحقول التالية:
(Name, Value, Type, Class, TTL)
يمثّل حقلا الاسم Name والقيمة Value ما تتوقعه، بينما يحدد حقل النوع Type كيفية تفسير حقل القيمة Value، حيث يشير النوع Type=A إلى أن القيمة Value هي عنوان IP، وبالتالي فإن سجلات A تطبّق ربط الاسم بالعنوان، وتشمل أنواع السجلات الأخرى ما يلي:
-
NS: يعطي حقلُ القيمةValueاسمَ النطاق لمضيفٍ يشغّل خادم أسماءٍ يعرف كيفية تحليل الأسماء داخل النطاق المحدد. -
CNAME: يعطي حقل القيمةValueالاسم المُتعارَف عليه canonical name لمضيفٍ معين والذي يُستخدَم لتحديد الأسماء المستعارة aliases. -
MX: يعطي حقل القيمةValueاسم النطاق لمضيفٍ يشغّل خادم البريد الذي يقبل رسائل نطاقٍ معيّن.
يوجد أيضًا حقل الصنف Class للسماح للكيانات التي ليست من الصنف NIC بتحديد أنواع السجلات المفيدة. يُعَد حقل الصنف Class هو الوحيد المستخدَم على نطاقٍ واسع حتى الآن هو الذي يستخدمه الإنترنت والذي يشار إليه IN. أخيرًا، يُظهر حقل مدة البقاء time-to-live أو العمر TTL مدة صلاحية سجل المورد هذا، وتستخدمه الخوادم التي تخزن مؤقتًا سجلات الموارد من الخوادم الأخرى، بحيث يتوجب على الخادم عند انتهاء مدة البقاء TTL إخراج السجل من ذاكرته المخبئية.
افترض الأمثلة التالية المستمدَّة من تسلسل النطاق الهرمي الوارد في الشكل الآتي لفهم كيفية تمثيل سجلات الموارد للمعلومات الموجودة في تسلسل النطاق الهرمي بصورةٍ أفضل، حيث سنتجاهل حقل TTL للتبسيط، ونُعطي المعلومات ذات الصلة فقط إلى أحد خوادم الأسماء المُطبّقة في كل منطقة.
أولًا، يحتوي خادم الأسماء الجذر Root name server على سجل NS لكل خادم أسماء نطاق المستوى الأعلى top-level domain -أو اختصارًا TLD-، والذي يحدّد الخادم الذي يمكنه تحليل الاستعلامات لهذا الجزء من التسلسل الهرمي لنظام أسماء النطاقات وهي edu. وcom. في هذا المثال. ويحتوي خادم الأسماء الجذر أيضًا على سجلات A التي تترجم هذه الأسماء إلى عناوين IP المقابلة. يطبّق هذان السجلان معًا بفعالية مؤشّرًا من خادم الأسماء الجذر إلى أحد خوادم TLD.
(edu, a3.nstld.com, NS, IN) (a3.nstld.com, 192.5.6.32, A, IN) (com, a.gtld-servers.net, NS, IN) (a.gtld-servers.net, 192.5.6.30, A, IN) ...
بالانتقال نزولًا إلى المستوى التالي من التسلسل الهرمي، نجد امتلاك الخادم سجلات نطاقات على النحو التالي:
(princeton.edu, dns.princeton.edu, NS, IN) (dns.princeton.edu, 128.112.129.15, A, IN) ...
نحصل على سجل NS وسجل A في هذه الحالة لخادم الأسماء المسؤول عن الجزء princeton.edu من التسلسل الهرمي، وقد يكون هذا الخادم قادرًا على تحليل بعض الاستعلامات مباشرةً مثل email.princeton.edu، بينما يمرر الاستعلامات الأخرى إلى خادمٍ في طبقة أخرى في التسلسل الهرمي، مثل الاستعلام عن penguins.cs.princeton.edu.
(email.princeton.edu, 128.112.198.35, A, IN) (penguins.cs.princeton.edu, dns1.cs.princeton.edu, NS, IN) (dns1.cs.princeton.edu, 128.112.136.10, A, IN) ...
أخيرًا، يحتوي خادم الأسماء من المستوى الثالث، مثل الخادوم الذي يديره النطاق cs.princeton.edu، على سجلات A لجميع مضيفيه، وقد يحدّد أيضًا مجموعةً من الأسماء المستعارة أي سجلات CNAME لكلٍ من هؤلاء المضيفين. تكون الأسماء المستعارة أحيانًا مجرد أسماءٍ مناسبة (كأن تكون أقصر) للأجهزة، ولكن يمكن استخدامها أيضًا لتوفير مستوىً من المراوغة indirection، فمثلًا www.cs.princeton.edu هو اسمٌ مستعارٌ للمضيف المسمى coreweb.cs.princeton.edu، وهذا ما يسمح لخادم الويب الخاص بالموقع بالانتقال إلى جهازٍ آخر دون التأثير على المستخدمين البعيدين، حيث يستمرون ببساطة في استخدام الاسم المستعار بغض النظر عن الجهاز الذي يشغّل حاليًا خادم الويب الخاص بالنطاق. تخدّم سجلات تبادل البريد MX نفس الغرض لتطبيق البريد الإلكتروني؛ فهي تسمح للمسؤول بتغيير المضيف الذي يتلقى البريد نيابةً عن النطاق دون الحاجة إلى تغيير عنوان البريد الإلكتروني للجميع.
(penguins.cs.princeton.edu, 128.112.155.166, A, IN) (www.cs.princeton.edu, coreweb.cs.princeton.edu, CNAME, IN) coreweb.cs.princeton.edu, 128.112.136.35, A, IN) (cs.princeton.edu, mail.cs.princeton.edu, MX, IN) (mail.cs.princeton.edu, 128.112.136.72, A, IN) ...
لاحظ أنه على الرغم من إمكانية تعريف سجلات الموارد لأي نوعٍ تقريبًا من الكائنات، إلا أن نظام DNS يُستخدم عادةً لتسمية المضيفين بما في ذلك الخوادم والمواقع، ولا يُستخدَم لتسمية الأفراد أو الكائنات الأخرى مثل الملفات أو الأدلة، حيث تُستخدم أنظمة التسمية الأخرى عادةً لتحديد مثل هذه الكائنات، فنظام X.500 مثلًا هو نظام تسمية ISO مصمَّمٌ لتسهيل التعرف على الأشخاص، ويسمح لك بتسمية شخصٍ من خلال إعطاء مجموعةٍ من السمات مثل الاسم والمسمّى الوظيفي ورقم الهاتف والعنوان البريدي وما إلى ذلك.
لقد أثبت نظام X.500 أنه ثقيلٌ للغاية، ولهذا انتزعته محركات البحث القوية المتاحة الآن على الويب في بعض النواحي، لكنه تطور في النهاية إلى بروتوكول الوصول إلى الدليل الخفيف Lightweight Directory Access Protocol -أو اختصارًا LDAP-، الذي يمثل مجموعةً فرعيةً من نظام X.500، والمُصمَّمٌ في الأصل على أنه واجهة حاسوبٍ أمامية لنظام X.500، ويُستخدَم اليوم على نطاقٍ واسع وغالبًا على مستوى المؤسسة مثل نظامٍ لتعلّم المعلومات حول المستخدمين.
تحليل الأسماء
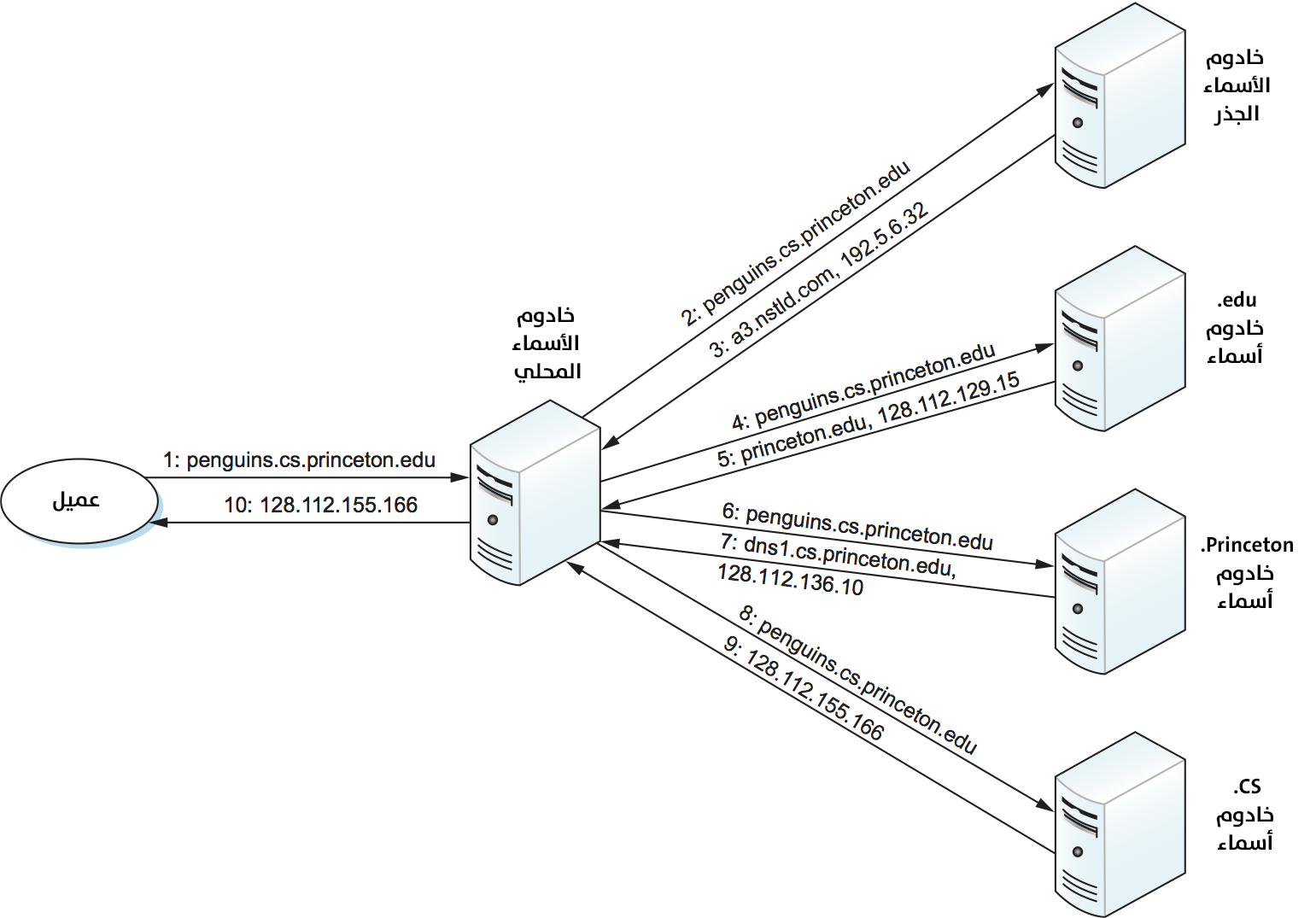
سنشرح الآن كيفية إشراك العميل هذه الخوادم لتحليل أسماء النطاقات. افترض أن العميل يريد تحليل الاسم penguins.cs.princeton.edu المتعلق بمجموعة الخوادم الواردة في القسم السابق. يمكن للعميل أولًا إرسال استعلامٍ يحتوي على هذا الاسم إلى أحد الخوادم الجذر، وكما سنرى أدناه، فمن النادر حدوث هذا عمليًا، ولكنه كافٍ لتوضيح العملية الأساسية في الوقت الحالي. الخادم الجذر غير قادرٍ على مطابقة الاسم بالكامل، لذلك يرجع أفضل تطابق لديه؛ الذي هو سجل NS للاسم edu الذي يشير إلى خادم TLD المُسمَّى a3.nstld.com، ويرجع الخادم أيضًا جميع السجلات المرتبطة بهذا السجل؛ أي يرجع في هذه الحالة السجل A للخادم a3.nstld.com، ويرسل العميل نفس الاستعلام إلى خادم الأسماء على مضيف IP ذي العنوان 192.5.6.32 إذا لم يتلقَ إجابة. لا يمكن لهذا الخادم أيضًا مطابقة الاسم بالكامل لذلك يرجع سجل NS وسجل A المقابل للنطاق princeton.edu.
يرسل العميل مرةً أخرى نفس الاستعلام السابق إلى الخادم على مضيف IP ذي العنوان 128.112.129.15، فيستعيد هذه المرة سجل NS وسجل A المقابل للنطاق cs.princeton.edu، ولكن تمّ الوصول هذه المرة إلى الخادم الذي يمكنه تحليل الاستعلام بالكامل. ينتج عن الاستعلام النهائي للخادم على 128.112.136.10 سجل A للاسم penguins.cs.princeton.edu، ويتعلم العميل أن عنوان IP المقابل هو 128.112.155.166.
لا يزال هذا المثال يترك بضعة أسئلةٍ حول عملية التحليل التي لم يُرَد عليها. يدور السؤال الأول حول كيفية تحديد العميل موقع الخادم الجذر، أو بعبارةٍ أخرى، كيف يمكنك تحليل اسم الخادم الذي يعرف كيفية تحليل الأسماء؟ هذه مشكلةٌ أساسية في أي نظام تسمية، والإجابة هي أنه يجب تمهيد bootstrapped النظام بطريقةٍ ما، فربط الاسم بالعنوان في هذه الحالة لخادمٍ جذرٍ أو أكثر معروفٌ جيدًا، أي أنه يُنشَر من خلال بعض الوسائل خارج نظام التسمية نفسه.
لا يعرف جميع العملاء خوادم الجذر عمليًا، لذلك يُهيَّأ برنامج العميل الذي يعمل على كل مضيف إنترنت بعنوان خادم أسماءٍ محلي، حيث يعرف جميع المضيفين في قسم علوم الحاسوب في جامعة برينستون الخادم الموجود على dns1.cs.princeton.edu على سبيل المثال. يحتوي خادم الأسماء المحلي على سجلات مواردٍ لخادمٍ أو أكثر من خوادم الجذر على النحو التالي:
('root', a.root-servers.net, NS, IN) (a.root-servers.net, 198.41.0.4, A, IN)
وبالتالي ينطوي تحليل الأسماء في الواقع على عميلٍ يستعلم من الخادم المحلي، الذي يعمل بدوره مثل عميلٍ يستعلم من الخوادم البعيدة نيابةً عن العميل الأصلي، فتنتج عن ذلك تفاعلات العميل / الخادم الموضحة في الشكل الآتي. إحدى مزايا هذا النموذج هي أن جميع المضيفين في الإنترنت لا يجب أن يكونوا على إطلاعٍ دائم بمكان وجود خوادم الجذر الحالية؛ أي يجب أن تعرف فقط الخوادم الجذر. تتمثل الميزة الثانية في إمكانية رؤية الخادم المحلي للإجابات العائدة من الاستعلامات التي نشرها جميع العملاء المحليين.
يضع الخادم المحلي هذه الاستجابات في الذاكرة المخبئية ويكون قادرًا في بعض الأحيان على تحليل الاستعلامات المستقبلية دون الحاجة إلى الخروج عبر الشبكة. ويشير حقل TTL في سجلات الموارد التي تُرجعها الخوادم البعيدة إلى المدة التي يمكن فيها تخزين كل سجلٍ في الذاكرة المخبئية بأمان، وهنا يمكن استخدام آلية التخبئة هذه بصورةٍ أكبر في التسلسل الهرمي، مما يقلل الحمل على الجذر وخوادم TLD.
يدور السؤال الثاني حول كيفية عمل النظام عندما يقدّم المستخدم اسمًا جزئيًا، مثل penguins بدلًا من اسم نطاقٍ كامل، مثل penguins.cs.princeton.edu. يكمن الجواب بضبط برنامج العميل بالنطاق المحلي الموجود فيه المضيف، مثل cs.princeton.edu، وإلحاق البرنامج لهذه السلسلة بأي أسماءٍ بسيطةٍ قبل إرسال استعلام.
رأينا حتى الآن ثلاثة مستوياتٍ مختلفةٍ من المعرّفات هي أسماء النطاقات وعناوين IP وعناوين الشبكة الحقيقية، ويحدث ربطٌ للمعرّفات الموجودة على مستوٍ ما بالمعرّفات الموجودة على مستوٍ آخر في نقاطٍ مختلفةٍ من معمارية الشبكة، حيث يحدد المستخدمون أولًا أسماء النطاقات عند التفاعل مع التطبيق، ثم يشرِك التطبيق نظام DNS لترجمة هذا الاسم إلى عنوان IP؛ وهو عنوان IP الذي يُوضَع في كل مخطط بيانات وليس اسم النطاق. وتتضمن عملية الترجمة هذه مخططات بيانات IP مُرسَلةً عبر الإنترنت، ولكن مخططات البيانات هذه موجّهةٌ إلى مضيفٍ يشغّل خادم أسماء، وليست موجَّهةً إلى الوجهة النهائية. بعد ذلك، يعيد بروتوكول IP التوجيه في كل موجّه، وهذا يعني غالبًا أنه يربط عنوان IP مع عنوان IP آخر؛ أي أنه يحدد عنوان الوجهة النهائية في عنوان الموجّه التالي. أخيرًا، يشرك بروتوكولُ IP بروتوكولَ تحليل العنوان Address Resolution Protocol -أو اختصارًا ARP- لترجمة عنوان IP للعقدة التوجيهية التالية إلى عنوان هذا الجهاز الحقيقي؛ فقد تكون العقدة التوجيهية التالية هي الوجهة النهائية أو قد تكون موجّهًا وسيطًا. تحتوي الإطارات المرسَلة عبر الشبكة الفيزيائية على هذه العناوين الحقيقية في ترويساتها.
إدارة الشبكة باستخدام البروتوكولين SNMP و OpenConfig
الشبكةُ نظامٌ معقدٌ من حيث عدد العقد ومجموعة البروتوكولات الممكن تشغيلها على أية عقدة، فقد تكون هناك العشرات من الموجّهات والمئات أو حتى الآلاف من المضيفين لتتبّعهم، فإذا فكرت في جميع الحالات التي يجري الاحتفاظ بها ومعالجتها في أيٍّ من هذه العقد، مثل جداول ترجمة العناوين وجداول التوجيه وحالة اتصال TCP وما إلى ذلك، فسيتراكم عليك الاضطرار إلى إدارة جميع هذه المعلومات.
من السهل تخيُّل الرغبة في معرفة حالة البروتوكولات المختلفة على العقد المختلفة، فقد ترغب مثلًا في مراقبة عدد عمليات إعادة تجميع مخطط بيانات IP المُلغاة، وذلك لتحديد إذا كنت بحاجةٍ لتعديل المهلة الزمنية لمهملات مخططات البيانات المُجمَّعة جزئيًا، وقد ترغب أيضًا على سبيل المثال في تتبع الحِمل على العقد المختلفة أي عدد الرزم المرسَلة أو المستلَمة، وذلك لتحديد ما إذا كانت هناك حاجةٌ لإضافة موجّهٍ أو روابطٍ جديدةٍ إلى الشبكة. يجب عليك أيضًا أن تكون متيقظًا للعثور على أدلةٍ عن وجود خللٍ في العتاد وسوء تصرّفٍ في البرمجيات.
ما وصفناه للتو هو مشكلة إدارة الشبكة، وهي مشكلةٌ عامةٌ في معمارية الشبكة بالكامل. وبما أن العقد التي نريد تتبّعها موزعة، فإن خيارنا الحقيقي الوحيد هو استخدام الشبكة لإدارتها؛ وهذا يعني أننا بحاجةٍ إلى بروتوكول يسمح لنا بقراءة وكتابة أجزاءٍ مختلفةٍ من معلومات الحالة على عقد الشبكة المختلفة.
بروتوكول SNMP
بروتوكول إدارة الشبكة البسيط Simple Network Management Protocol -أو اختصارًا SNMP- هو بروتوكولٌ مُستخدمٌ على نطاقٍ واسع لإدارة الشبكة، وهو في الأساس بروتوكول طلب / رد request/reply متخصص يدعم نوعين من رسائل الطلب، هما GET وSET؛ حيث تُستخدَم رسالة GET لاسترداد جزءٍ من الحالة من بعض العقد؛ وتُستخدَم رسالة SET لتخزين جزءٍ جديد من الحالة في بعض العقد. يدعم بروتوكول SNMP أيضًا عمليةً ثالثة هي GET-NEXT والتي سنوضّحها أدناه. تركز المناقشة التالية على عملية GET، نظرًا لأنها الأكثر استخدامًا.
يُستخدم SNMP بطريقةٍ واضحة، حيث يتفاعل مشغِّلٌ مع برنامج العميل الذي يعرض معلوماتٍ حول الشبكة، ويكون لهذا البرنامج عادةً واجهةٌ رسومية، ويمكنك التفكير في هذه الواجهة على أنها تلعب نفس دور متصفح الويب، فعندما يختار المشغِّل المعلومات التي يريد أن يراها، فسيستخدم برنامج العميل بروتوكول SNMP لطلب جزءٍ معينٍ من تلك المعلومات من عقدةٍ ما، وهنا سيتلقى خادم SNMP الذي يعمل على تلك العقدة الطلبَ، ويحدد موقع المعلومات المناسبة ويعيدها إلى برنامج العميل، الذي يعرضها بعد ذلك للمستخدم. يُشغَّل بروتوكول SNMP على بروتوكول UDP.
هناك تعقيدٌ واحدٌ فقط لهذا السيناريو البسيط، وهو: كيف يشير العميل بالضبط إلى أي جزءٍ من المعلومات يريد استرداده، وكيف يعرف الخادم أي متغيرٍ في الذاكرة يجب قراءته لتلبية الطلب؟ الجواب هو أن بروتوكول SNMP يعتمد على مواصفاتٍ مرافِقة تسمّى *قاعدة معلومات الإدارة management information base -أو اختصارًا MIB-؛ والتي تحدد أجزاءً معينةً من المعلومات، مثل متغيرات MIB التي يمكنك استردادها من عقدة الشبكة.
ينظّم الإصدار الحالي من قاعدة معلومات الإدارة MIB المُسمّى MIB-II المتغيرات في مجموعاتٍ مختلفة، وستدرك أن معظم هذه المجموعات تتوافق مع أحد البروتوكولات الموصوفة في هذا الكتاب. فمثلًا:
- مجموعة النظام System: تحتوي معاملات النظام (العقدة) العامة إجمالًا، بما في ذلك مكان وجود العقدة ومدة استمرار وجودها واسم النظام.
- مجموعة الواجهات Interfaces: تحتوي معلوماتٍ حول جميع واجهات الشبكة أو محوّلات الشبكة المرتبطة بهذه العقدة، مثل العنوان الحقيقي لكل واجهة وعدد الرزم المُرسَلة والمُستقبَلة على كل واجهة.
- مجموعة ترجمة العناوين Address translation: تحتوي معلوماتٍ حول بروتوكول تحليل العناوين Address Resolution Protocol، وعلى وجه الخصوص محتويات جدول ترجمة العناوين الخاص به.
- مجموعة IP: تحتوي المتغيرات المتعلقة ببروتوكول IP، بما في ذلك جدول التوجيه الخاص به، وعدد كتل البيانات التي مرّرها بنجاح، وإحصائيات حول إعادة تجميع مخطط البيانات؛ والتي تتضمن عدد المرات التي يسقِط فيها بروتوكول IP مخطط بيانات لسببٍ أو لآخر.
- مجموعة TCP: تحتوي معلوماتٍ حول اتصالات TCP، مثل عدد عمليات الفتح الخاملة والنشطة، وعدد عمليات إعادة الضبط، وعدد المُهلات الزمنية، وإعدادات المُهلات الافتراضية وغير ذلك، حيث تستمر معلومات الاتصال فقط طالما كان الاتصال موجودًا.
- مجموعة UDP: تحتوي معلوماتٍ حول حركة مرور UDP، بما في ذلك العدد الإجمالي لمخططات بيانات UDP المُرسَلة والمستلَمة.
توجد أيضًا مجموعاتٍ لبروتوكول رسائل التحكم في الإنترنت Internet Control Message Protocol -أو اختصارًا ICMP-، وبروتوكول SNMP نفسه.
بالعودة إلى مسألة العميل الذي يذكر بالضبط ما هي المعلومات التي يريد استردادها من عقدةٍ ما، فإن وجود قائمةٍ بمتغيرات MIB هو نصف المشكلة فقط، وبالتالي تبقى مشكلتان هما: 1- نحتاج إلى صياغةٍ دقيقة للعميل ليستخدمها من أجل تحديد متغيرات MIB التي يريد جلبها. 2- نحتاج إلى تمثيلٍ دقيقٍ للقيم التي يرجعها الخادم.
وتُعالَج كلتا المشكلتين باستخدام صيغة السياق المجرد الأول Abstract Syntax Notation One -أو اختصارًا ASN.1-.
لنبدأ بالمشكلة الثانية أولًا، حيث يعرّف ترميز ASN.1 وقواعد التشفير الأساسية Basic Encoding Rules -أو اختصارًا BER- تمثيلًا لأنواع البيانات المختلفة، مثل الأعداد الصحيحة integers. تحدد قاعدة MIB نوع كل متغيٍر، ثم تستخدم ترميزَ ASN.1 وقواعد BER لتشفير القيمة الموجودة في هذا المتغير أثناء نقله عبر الشبكة. يتعلق الأمر أيضًا بالمشكلة الأولى، فيحدد ترميز ASN.1 أيضًا مخطط تحديد الكائنات، وتستخدم قاعدة MIB نظام التعريف هذا لإسناد معرّفٍ فريدٍ عالميًا لكل متغير MIB.
تُقدَّم هذه المعرّفات في صيغة "نقطة dot" مثل المعرّف 1.3.6.1.2.1.4.3 الذي هو معرّف ASN.1 الفريد لمتغير MIB المتعلق بعنوان IP، والذي هو ipInReceives؛ حيث يحسب هذا المتغير عدد مخططات بيانات IP التي استلمتها هذه العقدة. تحدد البادئة 1.3.6.1.2.1 في هذا المثال قاعدة بيانات MIB، ويتوافق الرقم 4 مع مجموعة IP، ويشير رقم 3 الأخير إلى المتغير الثالث في هذه المجموعة.
تذكر أن معرفّات كائنات ASN.1 مخصصةٌ لجميع الكائنات الممكنة في العالم، وبالتالي تعمل إدارة الشبكة على النحو التالي: يضع عميل SNMP معرّف ASN.1 لمتغير MIB الذي يريده في رسالة الطلب، ويرسل هذه الرسالة إلى الخادم، يربط الخادم بعد ذلك هذا المعرّف بمتغيرٍ محلي أي موقع الذاكرة التي تُخزَّن قيمة هذا المتغير على سبيل المثال، ويسترد القيمة الحالية المحتفَظ بها في هذا المتغير، ويستخدم ترميز ASN.1 وقواعد BER لتشفير القيمة التي يرسلها مرةً أخرى إلى العميل.
العديد من متغيرات MIB هي إما جداولٌ أو بنى، حيث تشرح هذه المتغيرات المركبة سبب عملية GET-NEXT الخاصة ببروتوكول SNMP، وتُرجَع قيمة متغيرٍ ما بالإضافة إلى معرّف المتغير التالي ID، مثل العنصر التالي في الجدول أو الحقل التالي في البنية عند تطبيق هذه العملية على معرّف هذا المتغير، ويساعد هذا العميل في العبور عبر عناصر الجدول أو البنية.
بروتوكول OpenConfig
لا يزال بروتوكول SNMP مستخدمًا على نطاقٍ واسع وكان قديمًا بروتوكولَ إدارة المبدّلات والموجّهات management protocol for switches and routers، ولكن هناك اهتمامٌ متزايد مؤخرًا بطرقٍ أكثر مرونةً وقوةً لإدارة الشبكات، ومع ذلك لا يوجد اتفاقٌ كاملٌ حتى الآن على معيارٍ على مستوى الصناعة، ولكن بدأ ظهور إجماعٍ حول النهج العام، حيث يوضّح أحد الأمثلة المُسمَّى بروتوكول OpenConfig العديد من الأفكار الرئيسية.
تتمثل الإستراتيجية العامة في أتمتة إدارة الشبكة قدر الإمكان بهدف إخراج الإنسان المعرَّض للخطأ من إدارة الشبكة، ويسمى هذا أحيانًا إدارة اللمسة الصفرية zero-touch التي تشمل حدوث شيئين: أولًا، في حين استخدم المشغّلون قديمًا أدواتٍ مثل بروتوكول SNMP لمراقبة الشبكة، ولكن كان عليهم تسجيل الدخول إلى أي جهاز شبكة لا يعمل جيدًا واستخدام واجهة سطر أوامر CLI لإصلاح المشكلة، حيث تعني إدارة zero-touch أننا نحتاج أيضًا إلى ضبط الشبكة برمجيًا.
تُعَد إدارة الشبكة عبارةً عن أجزاء متساوية تقرأ معلومات الحالة وتكتب معلومات الضبط؛ فالهدف هو بناء حلقة تحكمٍ مغلقة، على الرغم من أنه ستكون هناك دائمًا سيناريوهات تحتّم تنبيه المشغّل بأن التدخل اليدوي مطلوب.
ثانيًا، توجّبَ على المشغّل قديمًا ضبط كل جهاز شبكة على حدة، لكن يجب الآن ضبط جميع الأجهزة بطريقةٍ مستقرة إذا أرادت العمل بصورةٍ صحيحةٍ مثل شبكة. ونتيجةً لذلك؛ تشير إدارة اللمسة الصفرية zero-touch أيضًا إلى أن المشغّل يجب أن يكون قادرًا على الإعلان عن نيته على مستوى الشبكة، مع وجود أداة إدارةٍ ذكيةٍ بما يكفي لإصدار توجيهات الضبط الضرورية لكل جهازٍ بطريقةٍ مستقرةٍ عالميًا.
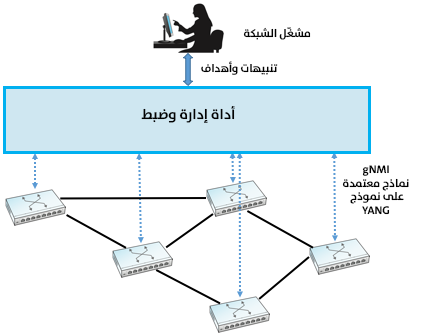
يعطي الشكل السابق وصفًا عالي المستوى لهذا النهج المثالي لإدارة الشبكة، حيث نقول "مثالي" لأن تحقيق إدارة zero-touch حقيقيةٍ لا يزال أكثر طموحًا من الواقع، ولكن يجري إحراز تقدمٍ حاليًا، حيث بدأت أدوات الإدارة الجديدة مثلًا في الاستفادة من البروتوكولات المعيارية مثل بروتوكولات HTTP لمراقبة وضبط أجهزة الشبكة. تُعَد هذه خطوةً إيجابيةً لأنها تخرجنا من إنشاء بروتوكول طلب / رد آخر، ويتيح لنا التركيز على إنشاء أدوات إدارةٍ أكثر ذكاءً، ربما من خلال الاستفادة من خوارزميات التعلم الآلي لتحديد ما إذا كان هناك شيءٌ خاطئ.
بالطريقة نفسها التي بدأ بها بروتوكول HTTP في استبدال بروتوكول SNMP للتحدث إلى أجهزة الشبكة، هناك جهدٌ موازٍ لاستبدال قاعدة MIB بمعيارٍ جديدٍ لمعلومات الحالة التي يمكن لأنواعٍ مختلفةٍ من الأجهزة الإبلاغ عنها، بالإضافة إلى معلومات الضبط التي تستطيع هذه الأجهزة نفسها الاستجابة لها. ويُعَد الاتفاق على معيارٍ واحد للضبط أمرًا صعبًا بطبيعته لأن كل بائع يدّعي أن أجهزته خاصة على عكس الأجهزة التي يبيعها منافسيهم، وهذا يعني أن التحدي ليس تقنيًا بالكامل.
تتمثل الطريقة العامة في السماح لكل مصنّع جهازٍ بنشر نموذج بياناتٍ يحدد مقابض الضبط configuration knobs وبيانات المراقبة المتاحة لمنتجه، ويحد من توحيد لغة النمذجة. المرشح الرئيسي هو نموذج YANG، الذي يرمز إلى جيلٍ جديدٍ من الجيل التالي Yet Another Next Generation، وقد اختير هذا الاسم للسخرية من عدد المرات التي يثبت فيها أن التمرين ضروري. يمكن النظر إلى نموذج YANG مثل إصدارٍ مقيَّد من لغة XSD؛ وهي لغةٌ لتعريف مخطط (نموذج) للغة XML. غير أن نموذج YANG يحدد بنية البيانات، ولكنه ليس نموذجًا خاصًا بلغة XML على عكس لغة XSD، حيث يمكن بدلًا من ذلك استخدامه مع صيغٍ مختلفةٍ للرسائل عبر الأسلاك، بما في ذلك XML وProtobufs وJSON.
المهم في هذا النهج هو أن نموذج البيانات يحدد دلالات المتغيرات المتاحة للقراءة والكتابة في نموذجٍ برمجي، أي أنه ليس مجرد نص من مواصفات المعايير. ليس هذا النهج مجانيًا للجميع، حيث يحدد كل بائعٍ نموذجًا فريدًا، نظرًا لأن مشغلي الشبكات الذين يشترون أجهزة الشبكة لديهم حافزٌ قويٌ لتكون نماذج الأجهزة المماثلة متقاربة. يؤدي نموذج YANG إلى أن تكون عملية إنشاء النماذج واستخدامها وتعديلها أكثر قابليةً للبرمجة، وبالتالي فهو قابلٌ للتكيف مع هذه العملية.
هذا هو المكان الذي يأتي فيه بروتوكول OpenConfig الذي يستخدم نموذج YANG مثل لغة نمذجة، ولكنه أنشأ أيضًا عمليةً لقيادة الصناعة نحو نماذجٍ مشتركة. يُعَد بروتوكول OpenConfig غير معروفٍ رسميًا فيما يتعلق بآلية RPC المستخدمة للتواصل مع أجهزة الشبكة، ويُسمى أحد الأساليب التي يتبّعها gNMI (واجهة إدارة شبكة gRPC). وكما قد تتخيل من اسمها، تستخدم واجهة gNMI آلية gRPC، التي تعمل على بروتوكول HTTP؛ وهذا يعني أن واجهة gNMI تتبنّى أيضًا آلية Protobufs مثل طريقةٍ تحدد بها البيانات التي تتواصل فعليًا عبر اتصال HTTP.
وبالتالي، كما هو موضحٌ في الشكل السابق، فإن الغرض من واجهة gNMI هو الحصول على واجهة إدارةٍ معيارية لأجهزة الشبكة، ولكن لم توحَّد قدرة أداة الإدارة على الأتمتة، أو الشكل الدقيق للواجهة المواجهة للمشغّل، كما لا يزال هناك مجالٌ كبيرٌ للابتكار في أدوات إدارة الشبكة مثل أي تطبيقٍ يحاول تلبية حاجة ودعم ميزاتٍ أكثر من البدائل.
نلاحظ أيضًا أن بروتوكولات NETCONF هي بروتوكولات أخرى بعد بروتوكول SNMP لتوصيل معلومات الضبط إلى أجهزة الشبكة، حيث يعمل بروتوكول OpenConfig مع بروتوكول NETCONF، لكن الواقع يشير إلى أن المستقبَل سيكون لواجهة gNMI.
نختم مناقشتنا بالتأكيد على أن عملية التغيير جارية، حيث يشير إدراج بروتوكولي SNMP وOpenConfig ضمن عنوان إدارة الشبكة إلى أنهما متكافئان، لكنهما مختلفان تمامًا، حيث يُعَد SNMP مجرد بروتوكول نقلٍ مشابهٍ لواجهة gNMI في عالم OpenConfig. وقد مكّن بروتوكول SNMP من مراقبة الأجهزة، ولكن لم يكن لديه ما يقوله تقريبًا عن ضبط الأجهزة، حيث تطلب ضبط الأجهزة تدخلًا يدويًا قديمًا؛ أما بروتوكول OpenConfig هو في الأساس محاولةٌ لتحديد مجموعةٍ مشتركةٍ من نماذج البيانات لأجهزة الشبكة، على غرار الدور الذي تلعبه قاعدة MIB في عالم SNMP، باستثناء اعتماد بروتوكول OpenConfig على نموذج YANG، وتركيزه على المراقبة والضبط بصورةٍ متساوية.
ترجمة -وبتصرّف- للقسم Infrastructure Applications من فصل Applications من كتاب Computer Networks: A Systems Approach.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.