

عند تشغيل خدمات وتطبيقات متعددة على عنقود Kubernetes، يمكن أن يساعدك مكدس سجلات مركزي على مستوى العنقود على فرز الحجم الكبير لبيانات السجلات التي تنتجها كائنات Pod، وتحليل تلك السجلّات بسرعة. أحد حلول التسجيل المركزية الشائعة هو مكدس EFK الذي يضم التطبيقات الثلاث Elasticsearch، وFluentd وKibana.
Elasticsearch هو محرك بحث فوري ومُوزّع وقابل للتحجيم يسمح بالبحث في النصوص والبيانات المنظَّمة وكذلك التحليلات. يُستخدم Elasticsearch عادةً لفهرسة كميات كبيرة من بيانات السجلّات والبحث فيها، ولكن يمكن استخدامه أيضًا للبحث في العديد من أنواع المستندات المختلفة.
يُنشَر Elasticsearch عادة جنبًا إلى جنب مع Kibana، وهي واجهة أمامية ولوحة تحكم فعّالة لعرض البيانات. تتيح Kibana استكشاف بيانات سجل Elasticsearch الخاص بك من خلال واجهة ويب، وإنشاء لوحات تحكم واستعلامات للإجابة بسرعة على الأسئلة والحصول على نظرة مفصَّلة عن تطبيقات Kubernetes.
سنستخدم في هذا الدرس Fluentd لجمع بيانات السجل وتحويلها وشحنها إلى سند Elasticsearch الخلفي. Fluentd هو مُجمِّع بيانات شائع الاستخدام، ومفتوح المصدر، سنعدّه على عُقد Kubernetes لتتبّع ملفات سجلّات الحاوية، وتصفية وتحويل بيانات السجل، وتسليمها إلى عنقود Elasticsearch، حيث تُفهرَس وتُخزَّن.
سنبدأ بإعداد وتشغيل عنقود Elasticearch قابل للتحجيم، ثم ننشئ خدمة Kibana وعمليّة النشر الخاصّة بها على Kubernetes. في الختام، سنعدّ Fluentd بصيغة متحكّم DaemonSet حتى يُشغَّل على كل عقدة عاملة على Kubernetes.
المتطلبات الأساسية
قبل أن تبدأ بهذا الدليل، تأكد من توفر ما يلي لك:
-
عنقود Kubernetes، الإصدار 1.10 فما فوق، مع تفعيل التحكّم في الوصول اعتمادًا على الدور (Role-Based Accedd Control, RBAC).
- تأكّد أن العنقود لديه موارد كافية لتشغيل مكدس EFK، وإن لم يكن، زد حجم العنقود بإضافة عقَد عاملة جديدة. سننشر Elasticsearch على ثلاث كائنات Pod (يمكنك تقليل العدد إلى 1 إنْ لزم الأمر)، بالإضافة إلى كائن Pod واحد لبيئة Kibana. ستشغّل كل عقدة عاملة كائن Pod لتطبيق Fluentd. يتكون العنقود في هذا الدليل من ثلاث عقد عاملة ومستوى تحكم مُدبَّر (Managed control plane) واحد.
-
أداة سطر الأوامر
kubectlمُثبّتة على جهازك المحلي، مُعدَّة للاتصال بالعنقود. يمكنك قراءة المزيد حول تثبيتkubectlفي التوثيق الرسمي.
بمجرد الانتهاء من إعداد هذه المكونات، تكون جاهزًا للبدء بهذا الدليل.
الخطوة الأولى: إنشاء فضاء أسماء (Namespace)
قبل إطلاق عنقود Elasticsearch، سنُنشئ أولاً فضاء أسماء نثبّت فيه جميع أدوات التسجيل الخاصة بنا. يتيح لك Kubernetes فصل الكائنات التي تعمل في العنقود باستخدام تجريد ينشئ "عنقودَا افتراضيًّا" يُسمّى فضاء الأسماء. سننشئ في هذا الدليل فضاء أسماء نطلق عليه kube-logging نثبّت فيه مكونات مكدس EFK. علاوةً على ذلك، سيسمح لنا فضاء الأسماء هذا بتنظيف مكدس EFK وإزالته بسرعة دون فقدان وظائف أخرى في عنقود Kubernetes.
للبدء، تَحقَّق أولاً من فضاءات الأسماء الموجودة في العنقود باستخدام kubectl:
$ kubectl get namespaces
يجب أن ترى فضاءات الأسماء الثلاثة المبدئية التالية، والتي تأتي مُثبَّتة مسبقًا مع عنقود Kubernetes:
NAME STATUS AGE default Active 5m kube-system Active 5m kube-public Active 5m
يحتوي فضاء الأسماء default على كائنات أنشئت بدون تحديد فضاء أسماء لها. يحتوي فضاء الأسماء kube-system على كائنات أنشأها واستخدمها نظام Kubernetes، مثلkube-dns، kube-proxy، وkubernetes-dashboard. من الجيد الحفاظ على نظافة فضاءات الأسماء هذه وعدم تلويثها بأحمال عمل التطبيقات والأدوات الأخرى.
فضاء الأسماء kube-public هو الآخرأنشئ تلقائيًا ويمكن استخدامه لتخزين الكائنات التي تريد لها أن تكون قابلة للقراءة ويمكن الوصول إليها عبر العنقود بأكمله، حتى للمستخدمين الذين لم تستوثق منهم (Unauthenticated users).
لإنشاء فضاء الأسماء kube-logging، أولًا افتح ملفًّا يُسمى kube-logging.yaml باستخدام المحرر المفضل لديك، مثل nano:
$ nano kube-logging.yaml
داخل المحرر، الصق كائن فضاء الأسماء التالي المكتوب بصيغة YAML:
kind: Namespace apiVersion: v1 metadata: name: kube-logging
ثم احفظ الملف وأغلقه.
هنا، نحدد نوع كائن Kubernetes بأنه فضاء أسماء. لمعرفة المزيد حول كائنات فضاء الأسماء، راجع إرشادات فاضاءات الأسماء في توثيق Kubernetes. نحدد أيضًا إصدار واجهة تطبيقات Kubernetes المستخدم لإنشاء الكائن (v1)، ونعيّن قيمة الحقل name (الاسم) لتكون kube-logging.
أنشئ فضاء أسماء باستخدام الأمر kubectl create مع خيار اسم الملف f-، مباشرة بعد تحرير ملف كائن فضاء الأسماء kube-logging.yaml، وذلك على النحو التالي:
$kubectl create -f kube-logging.yaml
تظهر المُخرجات كالتالي:
namespace/kube-logging created
يمكنك بعد ذلك التأكد من إنشاء فضاء الأسماء بنجاح:
$ kubectl get namespaces
عند هذه النقطة، من المُفترض أن ترى فضاء الأسماء الجديد kube-logging :
NAME STATUS AGE default Active 23m kube-logging Active 1m kube-public Active 23m kube-system Active 23m
يمكننا الآن نشر عنقود Elasticsearch في فضاء الأسماء المعزول الخاص بالتسجيل.
الخطوة 2 - إنشاء Elasticsearch StatefulSet
الآن بعد أن أنشأنا فضاء أسماء لاستيعاب مكدس السجلّات، يمكننا البدء في طرح مكوناته المختلفة. سنبدأ أولاً بنشر عنقود Elasticsearch من ثلاث عُقد.
في هذا الدليل نستخدم ثلاث كائنات Pod ليعمل عليها عنقود Elasticsearch، والهدف هو تجنب مشكلة "الدماغ المنصدع" (Split-brain)، التي قد تحدث في العنقود متعدّد العقد. تحدث مشكلة "الدماغ المنصدع" عندما يتعذر على عُقدة (أو عدة عقد) التواصل مع العقد الأخرى، فتُختار عدة عقد لتلعب دور القبطان (Master). مع ثلاث عقد، إذا انفصلت عقدة عن العنقود يمكن للعقدتين الأخريين انتخاب قبطان جديد ويمكن للعنقود أن يستمر في العمل بينما تحاول العقدة الضائعة الالتحاق.
راجع المقالين A new era for cluster coordination in Elasticsearch وVoting configurations لمعرفة المزيد عن المشكلة المذكورة.
إنشاء خدمة مجهولة العنوان (Headless Service)
للبدء، سننشئ خدمة Kubernetes مجهولة العنوان تسمى elasticsearch تعرّف اسم نطاق لكائنات Pod الثلاثة الموجودة في عنقود Elasticsearch. لا توازن الخدمة مجهولة العنوان الحمل وليس لديها عنوان IP ثابت. راجع توثيق Kubernetes للمزيد عن هذه الخدمات.
افتح الملف elasticsearch_svc.yaml بمحرّر النصوص المفضل لديك:
$ nano elasticsearch_svc.yaml
الصق فيه خدمة Kubernetes التالية (بصيغة YAML):
elasticsearch_svc.yaml
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
ثم احفظ الملف وأغلقه.
نعيّن خدمة (service) تسمى elasticearch في فضاء الأسماء kube-logging ، ونعطيها اللصيقة app: elasticsearch. ثم نعيّن القيمة app: elasticsearch للحقل spec.selector. لكي تختار لخدمة كائن Pod عن طريق اللصيقة app: elasticsearch. عندما نربط متحكّم StatefulSet في عنقود Elasticsearch الخاص بنا مع هذه الخدمة، سترجع الخدمة سجل DNS من النوع A يشير إلى كائنات Pod ذات اللصيقة app: elasticsearch في عنقود Elasticsearch.
ثم نعيّن الحقل clusterIP لتكون قيمته None، ممّا يجعل الخدمة مجهولة العنوان. أخيرًا، نُحدد المنافذ 9200 و9300 التي تُستخدَم على التوالي للتفاعل مع واجهة التطبيقات من النوع، وللتواصل الداخلي بين العقد.
أنشئ الخدمة باستخدام kubectl:
$ kubectl create -f elasticsearch_svc.yaml
يجدر أن تظهر مُخرجات كالتالي:
service/elasticsearch created
أخيرًا، تحقق جيدًا من إنشاء الخدمة بنجاح باستخدام kubectl get:
kubectl get services --namespace=kube-logging
يجب أن ترى ما يلي:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 26s
الآن بعد أن أعددنا خدمتنا المستقرة مجهولة العنوان والنطاق elasticsearch.kube-logging.svc.cluster.local. لكائنات Pod الخاصة بنا، يمكننا المضي قدمًا وإنشاء متحكّم المجموعة ذات الحالة (StatefulSet).
إنشاء مجموعة ذات حالة (StatefulSet) من كائنات Pod
يسمح لك كائن StatefulSet في Kubernetes بتعيين هوية ثابتة لكائنات Pod ومنحها تخزينًا مستقرًّا ودائما. يحتاج Elasticsearch لتخزين مستقر لضمان ديمومة البيانات عند إعادة جدولة كائنات Pod وإعادة تشغيلها. راجع التوثيق الرسمي للمزيد حول كائنات StatefulSet.
افتح الملف المُسمّى elasticsearch_statefulset.yaml في المُحرر المفضل لديك:
$ nano elasticsearch_statefulset.yaml
سنمرّ خطوة خطوة على تعريف كائن StatefulSet من خلال لصق أجزاء من التعريف في الملف المذكور.
نبدأ بنسخ ثم لصق الجزء التالي:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
نعرّف في الجزء أعلاه كائن StatefulSet باسم es-cluster في فضاء الأسماء kube-logging. ثم نربطه بخدمة elasticsearch التي أنشئت مسبقًا باستخدام حقل serviceName، ممّا يضمن إمكانية الوصول إلى كل كائن Pod في المجموعة باستخدام النطاق التالي: es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local، حيث [0,1,2] يُشير إلى العدد الترتيبي لكائن Pod.
نحدد ثلاث نسخ متطابقة (كائنات Pod) بتعيين القيمة 3 للحقل replicas، ونعيّن القيمة app: elasticseach للمُحدِّد matchLabels، ونكرّر الأمر مع الحقل spec.template.metadata.. يجب أن تتطابق قيمتا الحقلين .spec.selector.matchLabels و .spec.template.metadata.labels.
يمكننا الآن الانتقال إلى مواصفات الكائن. ألصق الجزء التعريفي التالي، المكتوب بصيغة YAML، أسفل الجزء السابق:
. . .
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
هنا نحدد كائنات Pod في المجموعة ذات الحالة (StatefulSet). نسمّي الحاويات elasticsearch ونختار صورة Docker من الرابط docker.elastic.co/elasticsearch/elasticsearch:7.2.0. في هذه المرحلة، يمكنك تعديل وسم الصورة هذا ليتوافق مع صورة Elasticsearch الداخلية الخاصة بك، أو مع إصدار مختلف. لاحظ أنه لأغراض هذا الدليل، اقتصر الااختبارعلى الإصدار 7.2.0 من Elasticsearch.
ثم نستخدم الحقل resources لتحديد أن الحاوية تحتاج على الأقل لضمان 10% من وحدة المعالجة المركزية الافتراضية ( 0.1vCPU)، ويمكن أن يزيد الاستخدام ليصل إلى وحدة معالجة كاملة (1vCPU)، أي أننا نعيّن الحد الأقصى لاستهلاك المورد في حالات مثل استقبال كائن Pod لكمية أولية كبيرة من البيانات أو في أوقات الذروة). يجب تعديل هذه القيم اعتمادًا على الحمل المتوقع والموارد المتاحة. راجع توثيق Kubernetes للمزيد عن الطلبات على الموارد وحدوها.
ثم نفتح المنفذين 9200 و 9300، مع تسميتهما، بغرض الاتصال بواجهة تطبيقات REST والاتصال الداخلي، على التوالي. نحدد نقطة لتركيب تجزئات التخزين (الحقل volumeMount) ونسمّيها data. وظيفة نقطة التركيب تلك هي تحميل التجزئة المستقرّة (كائن من النوع PersistentVolume) المُسماة data الموجودة ضمن الحاوية على المسار usr/share/elasticsearch/data/. سنحدد مطالب الحجم (VolumeClaims) لهذه المجموعة في جزء لاحق من التعريف.
أخيرًا، نعيّن بعض متغيرات البيئة في الحاوية:
-
cluster.name: اسم عنقود Elasticsearch، والذي في هذا الدليل هوk8s-logs. -
node.name: اسم العقدة، الذي عيّناه للحقلmetadata.name.باستخدامvalueFrom. ستُترجم هذه القيمة إلى[es-cluster-[0,1,2، اعتمادًا على العدد الترتيبي المعيّن للعقدة. -
discovery.seed_hosts: يعين هذا الحقل قائمة بالعقد المؤهلة لتؤدّي دور القبطان في العنقود الذي سيؤسس لعملية استكشاف العقد. في هذا الدليل، وبفضل الخدمة مجهولة العنوان التي أعددناها سابقًا، تأخذ كائنات Pod نطاقات بالصيغةes-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local، لذلك عيّنا هذا المتغير وفقًا لذلك. يمكننا تقصير النطاق إلىes-cluster-[0,1,2].elasticsearchباستخدام ترجمة أسماء النطاقات الداخلية في Kubernetes. راجع توثيق Elasticsearch للمزيد عن الاستكشاف في Elasticsearch. -
cluster.initial_master_nodes: يحدد هذا الحقل أيضًا قائمة عقد مؤهلة لتؤدّي دور القبطان في العنقود ستشارك في عملية انتخاب القبطان. لاحظ أنه في هذا الحقل، يجب تحديد العقد من خلالnode.nameوليس أسماء المضيفين. -
ES_JAVA_OPTS: ضبطنا المتغيّر على القيمXms512m -Xmx512m-لإخبار آلة جافا الافتراضية (JVM) برغبتنا في استخدام 512 ميجابايت لتكون الحد الأدنى والحد الأقصى لحجم كومة الذاكرة المؤقتة. يجب ضبط هذه المعاملات بناءً على توفر الموارد للعنقود واحتياجاته. راجع المقال التالي للمزيد من التفاصيل.
يظهر الجزء الموالي من التعريف على النحو التالي:
. . .
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
في هذه الجزء، نحدد العديد من الحاويات الأولية التي تُشغَّب قبل حاوية تطبيق elasticearch الرئيسية. تُشغَّل هذه الحاويات الأولية (Init Containers) حتى إكمال عملها بالترتيب المحدد. راجع التوثيق الرسمي لمعرفة المزيد عن الحاويات الأولية.
تنفّذ الحاوية الأولى، المُسمّاة fix-permissions، أمر chown لتغيير الحساب والمجموعة المالكيْن لمجلّد بيانات دليل Elasticsearch ليصبحا 1000: 1000، وهما معرّفا (UID) مستخدم ومجموعة Elasticsearch. يركّب Kubernetes مجلّد البيانات بالحساب الجذر (root)، مما يجعل وصول Elasticsearch إليه غير ممكن. راجع توثيق Elasticsearch لمزيد من المعلومات حول هذه الخطوة.
تنفّذ الحاوية الثانية، المسمّاة increase-fd-ulimit، أمرًا لزيادة حدود استدعاءات mmap التي يمكن لنظام التشغيل إجراؤها، والتي قد يكون عددها افتراضيًا منخفضًا جدًا، مما ينتج عنه أخطاء في الذاكرة. راجع توثيق Elasticsearch لمزيد من المعلومات حول هذه الخطوة.
الحاوية الأوليّة التالية هي increase-fd-ulimit والتي تنفّذ الأمر ulimit لزيادة الحد الأقصى لعدد واصفات الملفات المفتوحة (File descriptor). راجع توثيق Elasticsearch لمزيد من المعلومات حول هذه الخطوة.
اقتباسملاحظة: ينصح توثيق Elasticsearch الرسمي كذلك بتعطيل مساحة التبادل (Swap) لأسباب تتعلق بالأداء. قد تكون مساحة التبادل هذه معطّلة فعلًا، حسب تثبيت Kubernetes لديك أو حسب المزوِّد (Provider). للتحقق من ذلك، نفّذ الأمر
execفي حاوية قيد التشغيل ونفّذ الأمرcat/proc/swapلسرد أجهزة التبادل النشطة. إذا لم تر أي شيء هناك، فهذا يعني أن مساحة التبادل معطّلة.
الآن بعد أن حددنا حاوية التطبيق الرئيسية والحاويات الأوليّة التي تُشغَّل قبلها لضبط نظام تشغيل الحاوية، يمكننا إضافة الجزء الأخير إلى ملف تعريف كائن StatefulSet، وهو الجزء المتعلّق بقوالب مطالب الحجم (volumeClaimTemplates).
ألصق الجزء التالي المتعلّق بتعريف volumeClaimTemplate:
. . .
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
في هذا الجزء، نحدد المجلد VolumeClaimTemplates الخاص بكائن StatefulSet. سيستخدم Kubernetes هذا المجلّد لإنشاء تجزئات دائمة (PersistentVolumes) لكائنات Pod. في التعريف أعلاه، نسميها data (وهو الاسم الذي نشير إليه في وحدة التخزين التي تم تعريفها سابقًا)، ونعطيها نفس اللصيقة (app: elasticsearch) اللتي أعطيناها لكائن StatefulSet سابقا.
ثم نحدد وضع الوصول إلى التجزئات ليكون ReadWriteOnce، مما يعني أنه لا تمكن القراءة والكتابة منها إلّا بواسطة عُقدة واحدة. نحدد الصنف do-block-storage ليكون صنف التخزين إذ أننا نستخدم عنقود Kubernetes من DigitalOcean لأغراض الشرح. يجب تغيير هذه القيمة اعتمادًا على أين تشغّل عنقود Kubernetes الخاص بك. راجع توثيق Kubernetes للمزيد عن التخزين الدائم.
أخيرًا، نحدد حجم كل مجلد دائم (PersistentVolume) ليكون 100 غيغابايت. يجب تعديل هذه القيمة حسب احتياجات بيئة الإنتاج الخاصة بك.
تبدو المواصفات الكاملة لكائن StatefulSet كالتالي:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
احفظ الملف ثم أغلقه بعد التأكد من محتواه.
الآن، انشر ملف StatefulSet باستخدام kubectl:
$ kubectl create -f elasticsearch_statefulset.yaml
يجب أن تشاهد المُخرجات التالية:
statefulset.apps/es-cluster created
يمكنك مراقبة حالة StatefulSet أثناء إطلاقه باستخدام kubectl rollout status:
$ kubectl rollout status sts/es-cluster --namespace=kube-logging
يجب أن ترى المخرجات التالية أثناء إطلاق العنقود:
Waiting for 3 pods to be ready... Waiting for 2 pods to be ready... Waiting for 1 pods to be ready... partitioned roll out complete: 3 new pods have been updated...
بمجرد نشر كل كائنات Pod، يمكنك التحقق من أن عنقود Elasticsearch الخاص بك يعمل من خلال إرسال طلب إلى واجهة تطبيقات REST. لذا، أعد توجيه المنفذ المحلي 9200 إلى المنفذ 9200 على إحدى عُقد Elasticsearch وهي (es-cluster-0)، باستخدام kubectl port-forward:
$ kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
ثم، في نافذة طرفية منفصلة، نفذ طلب curl باتجاه واجهة REST:
$ curl http://localhost:9200/_cluster/state?pretty
يجب أن تظهر المخرجات التالية:
{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 348,
"cluster_uuid" : "QD06dK7CQgids-GQZooNVw",
"version" : 3,
"state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg",
"master_node" : "IdM5B7cUQWqFgIHXBp0JDg",
"blocks" : { },
"nodes" : {
"u7DoTpMmSCixOoictzHItA" : {
"name" : "es-cluster-1",
"ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg",
"transport_address" : "10.244.8.2:9300",
"attributes" : { }
},
"IdM5B7cUQWqFgIHXBp0JDg" : {
"name" : "es-cluster-0",
"ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ",
"transport_address" : "10.244.44.3:9300",
"attributes" : { }
},
"R8E7xcSUSbGbgrhAdyAKmQ" : {
"name" : "es-cluster-2",
"ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA",
"transport_address" : "10.244.40.4:9300",
"attributes" : { }
}
},
...
تشير المخرجات إلى أنّ العنقود k8s-logs المكوَّن من ثلاث عقد ( es-cluster-1، es-cluster-0 وes-cluster-2.) قد أنشئ بنجاح. العقدة التي تؤدي دور القبطان هي حاليًّا es-cluster-0.
الآن بعد أن أصبح عنقود Elasticsearch جاهزًا يمكنك الانتقال إلى إعداد واجهة Kibana الأمامية.
الخطوة 3: إنشاء خدمة ونشر كيبانا
لإطلاق Kibana على Kubernetes، سننشئ خدمة تسمى kibana، وننشئ أيضًا عملية نشر (Deployment) تتكوّن من كائن Pod واحد. يمكنك تحديد عدد النسخ التي تحتاجها بناءً على احتياجات بيئة الإنتاج الخاصة بك، وتحديد النوع LoadBalancer لتوزيع عبء بين كائنات Pod.
هذه المرة ، سننشئ الخدمة والنشر في الملف نفسه. افتح ملفًا يسمى kibana.yaml في محررك المفضل:
$ nano kibana.yaml
ألصق المواصفات التالية للخدمة:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
ثم احفظ الملف وأغلقه.
في هذه المواصفات، حددنا خدمة تسمى kibana في فضاء الأسماء kube-logging، وأعطيناها اللصيقة app: kibana. حددنا أيضًا أنه يجب الوصول إليها على المنفذ 5601 واستخدمنا اللصيقة app: kibana لتحديد كائنات Pod المُستهدَفة بالخدمة.
في مواصفات النشر Deployment، نحدد عملية نشر تُسمى kibana ونحدد أننا نريد كائن Pod واحدا. نستخدم صورة Kibana من الرابط docker.elastic.co/kibana/kibana:7.2.0. عند هذه النقطة يمكنك وضع صورة كيبانا الخاصة أو العامة التي تودّ استخدامها.
نحدد أن الحاوية تحتاج على الأقل لضمان 10% من وحدة المعالجة المركزية الافتراضية ( 0.1vCPU)، ويمكن أن يزيد الاستخدام ليصل إلى وحدة معالجة كاملة (1vCPU)، أي أننا نعيّن الحد الأقصى لاستهلاك المورد. يمكنك تغيير هذه المعاملات اعتمادًا على الحمل المتوقع والموارد المتاحة.
بعد ذلك ، نستخدم متغير البيئة ELASTICSEARCH_URL لتعيين نقطة النهاية والمنفذ لعنقود Elasticsearch. باستخدام نطاقات Kubernetes نجد أن نقطة النهاية تتوافق مع اسم الخدمة الخاص بها elasticsearch. سيُترجم اسم النطاق إلى قائمة عناوين IP الخاصة بكائنات Pod الثلاث. راجع توثيق Kubernetes للمزيد عن إدارة أسماء النطاقات في Kubernetes.
أخيرًا، عيّنا 5601 ليكون منفذ حاويات Kibana، حيث ستعيد خدمة Kibana توجيه الطلبات إليه.
يمكنك - بعد التأكّد من إعدادات Kibana - إطلاق الخدمة وتشغيل عملية النشر باستخدام kubectl:
$ kubectl create -f kibana.yaml
يجب أن تشاهد المخرجات التالية:
service/kibana created deployment.apps/kibana created
يمكنك التحقق من نجاح إطلاق الخدمة عن طريق تشغيل الأمر التالي:
$ kubectl rollout status deployment/kibana --namespace=kube-logging
يجب أن تشاهد المخرجات التالية:
deployment "kibana" successfully rolled out
للوصول إلى واجهة Kibana، سنعيد توجيه منفذ محلي مرة أخرى إلى عُقدة Kubernetes التي تشغّل Kibana. احصل على تفاصيل كائن Pod الخاص بعقدة Kibana باستخدام kubectl get:
$ kubectl get pods --namespace=kube-logging
المخرجات:
NAME READY STATUS RESTARTS AGE es-cluster-0 1/1 Running 0 55m es-cluster-1 1/1 Running 0 54m es-cluster-2 1/1 Running 0 54m kibana-6c9fb4b5b7-plbg2 1/1 Running 0 4m27s
هنا نلاحظ أن كائن Pod الخاص بعقدة Kibana يُسمّى kibana-6c9fb4b5b7-plbg2.
أعد توجيه المنفذ المحلي 5601 إلى المنفذ 5601 على ذلك الكائن:
$ kubectl port-forward kibana-6c9fb4b5b7-plbg2 5601:5601 --namespace=kube-logging
يجب أن تظهر المخرجات التالية:
Forwarding from 127.0.0.1:5601 -> 5601 Forwarding from [::1]:5601 -> 5601
الآن، زر رابط URL التالي:
http://localhost:5601
إذا رأيت صفحة ترحيب Kibana التالية، فقد نجحت في نشر Kibana في عنقود Kubernetes:
يمكنك الآن الانتقال إلى إطلاق المكون النهائي لمكدس EFK وهو مُجمِّع السجلات Fluentd.
الخطوة 4: إنشاء Fluentd DaemonSet
في هذا الدليل، سنعدّ Fluentd بصيغة DaemonSet، وهو نوع من أعباء العمل في Kubernetes يشغّل نسخة من كائن Pod على كل عقدة في عنقود Kubernetes. باستخدام وحدة تحكم DaemonSet هذه، سنطلق وكيل تسجيل Fluentd عبارة عن كائن Pod على كل عقدة من العنقود. راجع هذا المقال من توثيق Kubernetes الرسمي لمعرفة المزيد حول بنية التسجيل هذه.
تُلتَقط سجّلات المُخرجات والأخطاء المعيارية (stdout و stderr على التوالي) للتطبيقات العاملة ضمن حاويّات ويُعاد توجيهها إلى ملفات JSON على العقد. سيتتبّع وكيل Fluentd ملفّات السجلّات تلك، ويفرز الأحداث الموجودة فيها، ويحوّل بيانات السجلّات وفي الأخير يشحنها إلى السند الخلفي لحفظ السجلّات على Elasticsearch الذي نشرناه في الخطوة الثانية من هذا الدليل.
بالإضافة إلى سجلات الحاوية، يتتبّع وكيل Fluentd سجلات مكونات نظام Kubernetes مثل سجلات kubelet وkube-proxy وDocker. راجع ملف kubernetes.conf المستخدم لإعداد وكيل التسجيل للاطلاع على قائمة كاملة بالمصادر التي يتتبعها وكيل تسجيل Fluentd. راجع توثيق Kubernetes لمعرفة المزيد حول تسجيل الأحداث على مستوى عقد Kubernetes.
ابدأ بفتح الملف fluentd.yaml في محرر النصوص المفضل لديك:
$ nano fluentd.yaml
مرة أخرى ، سنلصق تعريفات الكائن جزءًا جزءًا، مع شرح سياق التعريفات في كل جزء. نستند في هذا الدليل على مواصفات متحكّم Fluentd DaemonSet التي يوفرها فريق صيانة Fluentd. مورد مفيد آخر يقدمه مشرفو Fluentd هو مقالات Flunetd ضمن توثيق Kuberentes.
أولاً، الصق في تعريف ServiceAccount التالي:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
هنا، قمنا بإنشاء حساب خدمة باسم flentd ستستخدمه كائنات Pod التابعة لخدمة Fluentd في الوصول إلى واجهة تطبيقات Kubernetes. ننشئ الحساب في فضاء الأسماء kube-logging ونعطيه مرة أخرى اللصيقة app: fluentd. راجع توثيق Kubernetes للمزيد عن حسابات الخدمة في Kubernetes.
بعد ذلك، الصق الجزء التالي الذي يعرّف الكائن ClusterRole :
. . .
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
هنا نحدد ClusterRole يسمى fluentd نمنحه صلاحيات get،وlist و watch على كائنات Pod وفضاءات الأسماء. تسمح الكائنات من النوع ClusterRoles بمنح الوصول إلى موارد Kubernetes في نطاق العنقود مثل العقَد. راجع [فصل استخدام تراخيص RBAC]() ضمن توثيق Kubernetes، للمزيد عن التحكم في الوصول المعتمد على الأدوار (RBAC).
الآن، الصق الجزء التعريفي التالي المتعلق بكائن ClusterRoleBinding:
. . . --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: kube-logging
نعرّف كائنًا من النوع ClusterRoleBinding ونسمّيهfluentd. وظيفة هذا الكائن هي الربط بين الكائن من النوع ClusterRole وحساب خدمة fluentd، ممّا يمنح الخدمة الصلاحيّات المدرجة في الكائن من النوع ClusterRole الذي أسميناهfluentd .
عند هذه النقطة يمكننا البدء بلصق التعريفات ضمن المواصفات الفعليّة لمتحكّم DaemonSet:
. . .
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
هنا، نحدد متحكّم DaemonSet يُسمى fluentd في فضاء أسماء kube-logging ونعطيها اللصيقة app: fluentd.
بعد ذلك، الصق الجزء التعريفي التالي:
. . .
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
هنا، نطابق اللصيقة app: fluentd المُعرَّفة في metadata.labels.، ثم نعيّن متحكّم DaemonSet لحساب خدمة fluentd. نختار أيضًا كائنات Pod التي تطابق المحدّد app: fluentd ليتولّى المتحكّم DaemonSet إدارتها.
بعد ذلك، نحدد تسهيلاً بلا جدول زمني (NoSchedule toleration) لمطابقة الشائبة (Taint) المكافئة على عقد Kubernetes الرئيسية (القبطان). نضمن بذلك أنّ المتحكّم DaemonSet سيُطلَق أيضًا على العقد الرئيسيى في على سادة Kubernetes. أزل هذا التسهيل إذا كنت لا ترغب في تشغيل كائن Pod لتطبيق Fluentd على العقد الرئيسية الخاصة بك. راجع هذا الفصل في توثيق Kubernetes للمزيد عن التسهيلات والشوائب. بعد ذلك، نبدأ في تحديد حاوية كائن Pod، والتي نسميها fluentd.
يستخدم هذا الدليل صورة رسمية من توزيعة دبيان يوفّرها فريق صيانة Fluentd. عدّل وسم image في مواصفات الحاوية إذا كنت ترغب في استخدام صورة Fluentd خاصة أو عامة، أو استخدام صورة بإصدار مختلف. يتوفر ملف Dockerfile ومحتويات هذه الصورة في مستودع fluentd-kubernetes-daemonset على Github.
بعد ذلك، نضبط Fluentd باستخدام بعض متغيرات البيئة:
-
FLUENT_ELASTICSEARCH_HOST: نعيّن قيمة هذا المتغيّر لتكون اسم نطاق خدمة Elasticsearch مجهولة العنوان المُحدَّد سابقًاelasticsearch.kube-logging.svc.cluster.local. يُترجم اسم النطاق هذا إلى قائمة عناوين IP لكائنات Pod الثلاث الخاصة بتطبيق Elasticsearch. من المُرجَّح أن يكون عنوان مضيف Elasticsearch الحالي هو عنوان IP الأول في القائمة المُرجَعة. لتوزيع السجلات على العنقود، ستحتاج إلى تعديل إعدادات مُلحَق Fluentd الخاص بمُخرجات Elasticsearch. راجع توثيق Fluentd للمزيد حول هذا الملحق. -
FLUENT_ELASTICSEARCH_PORT: نحدّد قيمة المتغيّر لتكون المنفذ الذي عيّناه سابقًا،9200. -
FLUENT_ELASTICSEARCH_SCHEME: نعيّن القيمةhttp. -
FLUENTD_SYSTEMD_CONF: نعيّن القيمةdisableلحذف مُخرجاتsystemdغير المضبوطة في الحاوية.
أخيرًا، نلصق الجزء التالي من التعريف:
. . .
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
هنا نحدد القيمة 512 ميجابايت لتكون الحد الأقصى للذاكرة على كائن Pod الخاص بتطبيق Fluentd الذي نضمن له 0.1 من المعالج الافتراضي (0.1vCPU) و 200 ميجابايت من الذاكرة. يمكنك تدقيق حدود الموارد والطلبات بناءً على حجم السجلّات المتوقعة والموارد المتاحة.
بعد ذلك، نقوم نركّب مسارات المضيف var/log/ و var/lib/docker/containers/ في الحاوية باستخدام نقطتيْ التركيب (volumeMounts) المذكورتيْن varlog و varlibdockercontainers . تُعرَّف التجزئات (volumes) في نهاية الجزء السابق.
الوسيط الأخير الذي نعرّفه هو terminationGracePeriodSeconds، والذي يمنح 30 ثانية لإيقاف Fluentd بأمان عند استقبال إشارة SIGTERM. بعد 30 ثانية، تُرسَل إلى الحاويات إشارة SIGKILL. القيمة الافتراضية للوسيط terminationGracePeriodSeconds هي 30 ثانية، لذلك في معظم الحالات يمكن إغفال هذا الوسيط. راجع هذا المقال من غوغل عن أفضل الممارسات لإيقاف أعباء العمل على Kubernetes.
يجب أن تبدو المواصفات الكاملة لتطبيق Fluentd كما يلي:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
احفظ الملف وأغلقه بعد ضبط إعداد المتحكّم DaemonSet لتطبيق Fluentd.
الآن، أطلق DaemonSet باستخدام kubectl:
$ kubectl create -f fluentd.yaml
يجب أن تشاهد الناتج التالي:
serviceaccount/fluentd created clusterrole.rbac.authorization.k8s.io/fluentd created clusterrolebinding.rbac.authorization.k8s.io/fluentd created daemonset.extensions/fluentd created
تحقق من نجاح إطلاق DaemonSet باستخدام kubectl:
$ kubectl get ds --namespace=kube-logging
يجب أن ترى الحالة الظاهرة في المُخرجات التالية:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE fluentd 3 3 3 3 3 <none> 58s
تشير النتيجة أعلاه إلى وجود ثلاث كائنات Pod قيد التشغيل ويعمل عليها المتحكّم fluentd. يتوافق هذا العدد مع عقد Kubernetes.
يمكننا الآن النظر في Kibana للتحقق من أن بيانات السجلّات تُجمَع وتُشحَن كما نريد إلى Elasticsearch.
استخدم المتصفّح لفتح العنوان التالي http://localhost:5601، مع استمرار تنفيذ الأمرkubectl port-forward.
اضغط على زر Discover (اكتشف) في قائمة التنقل اليسرى:
يجب أن تظهر نافذة الإعدادات التالية:

تتيح لك هذه النافذة تحديد مؤشرات Elasticsearch التي ترغب في استكشافها في Kibana. لمعرفة المزيد، راجع المقال التالي في توثيق Kibana للمزيد عن أنماط الفهرسة في Kibana. في الوقت الحالي، سنستخدم نمط محارف البدل logstash-* لالتقاط جميع بيانات السجلّات في عنقود Elasticsearch الخاص بنا. اكتبlogstash-* في مربع النص ثم انقر على Next (التالي).
ستنتقل بعد ذلك إلى الصفحة التالية.
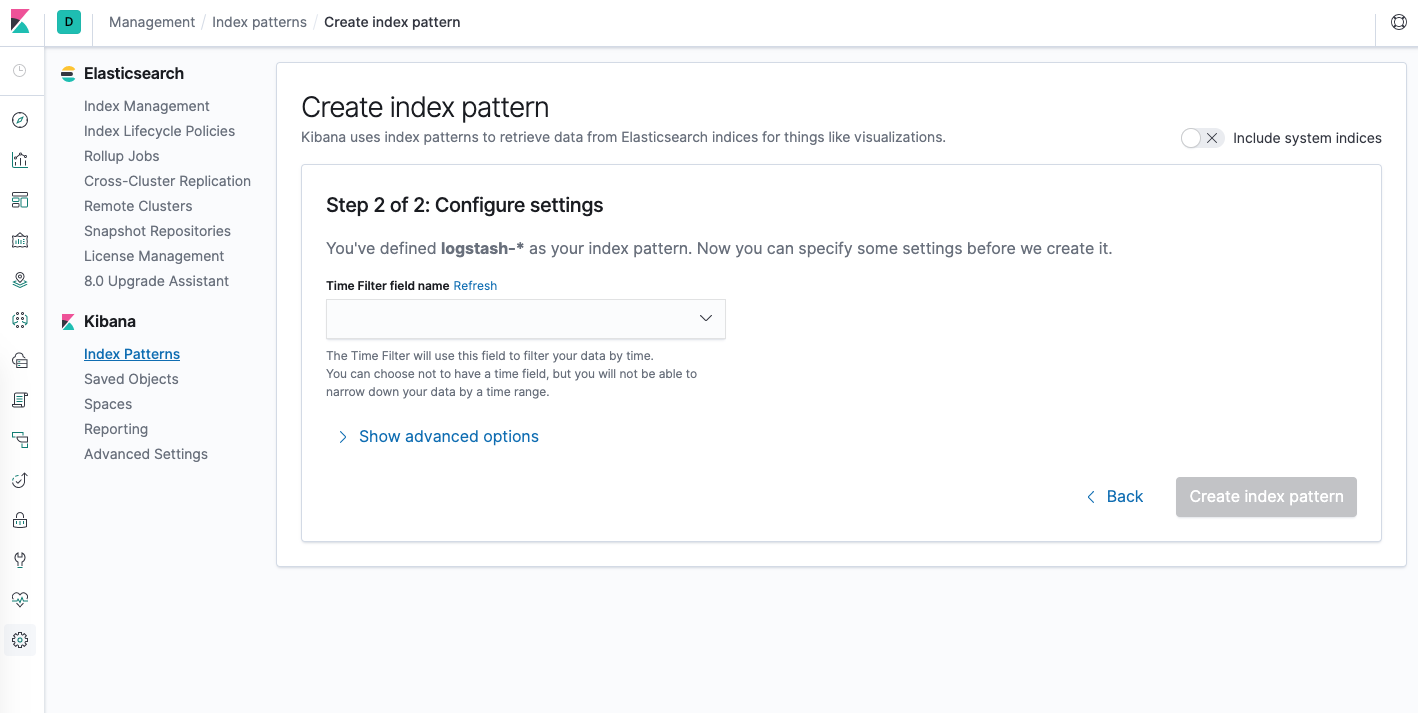
تسمح هذه النفاذة بإعداد الحقل الذي سيستخدمه Kibana لتصفية بيانات السجل حسب الوقت. في القائمة المنسدلة، حدد حقلtimestamp@، واضغط على Create index pattern (إنشاء نمط فهرس).
الآن، اضغط على Discover (اكتشف) في قائمة التنقل اليسرى.
يجب أن تشاهد مخطّطًا بيانيّا وبعض المُدخلات الأخيرة في السجلّات.

بالوصول إلى هذه النقطة تكون قد نجحت في إعداد حزمة EFK وإطلاقها على عنقود Kubernetes. راجع دليل مستخدم Kibana لمعرفة كيفية استخدام Kibana لتحليل بيانات السجل.
في القسم الاختياري التالي، سننشر كائن Pod لعدّاد بسيط يطبع أعدادًا على وحدة الإخراج المعيارية (stdout)، ونعثر على سجلاته في Kibana.
الخطوة 5 (اختياري) - اختبار تسجيل الحاويات
لتوضيح حالة بسيطة لاستخدام Kibana لاستكشاف أحدث السجلات على كائن Pod معيّن، سننشر كائن Pod محدود الإمكانيّات يطبع أعدادًا متسلسلة على وحدة stdout.
لنبدأ بإنشاء كائن Pod. افتح ملفًا يسمى counter.yaml في محررك المفضل:
$ nano counter.yaml
ثم الصق مواصفات التالية لكائن Pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
احفظ الملف ثم أغلقه.
تعرّف المواصفات كائن Pod محدود يُسمى counter ينفّذ حلقة while تكرارية تطبع أعدادًا تسلسلية.
ننشر counter باستخدامkubectl:
$ kubectl create -f counter.yaml
بمجرد إنشاء كائن Pod وتشغيله، انتقل مرة أخرى إلى لوحة معلومات Kibana.
أدخل العبارة kubernetes.pod_name: counter في شريط البحث ضمن صفحة Discover (اكتشف). تصفّي العبارة السابقة بيانات السجلّات لعرض البيانات القادمة من كائن Pod المسمَّىcounter دون غيره.
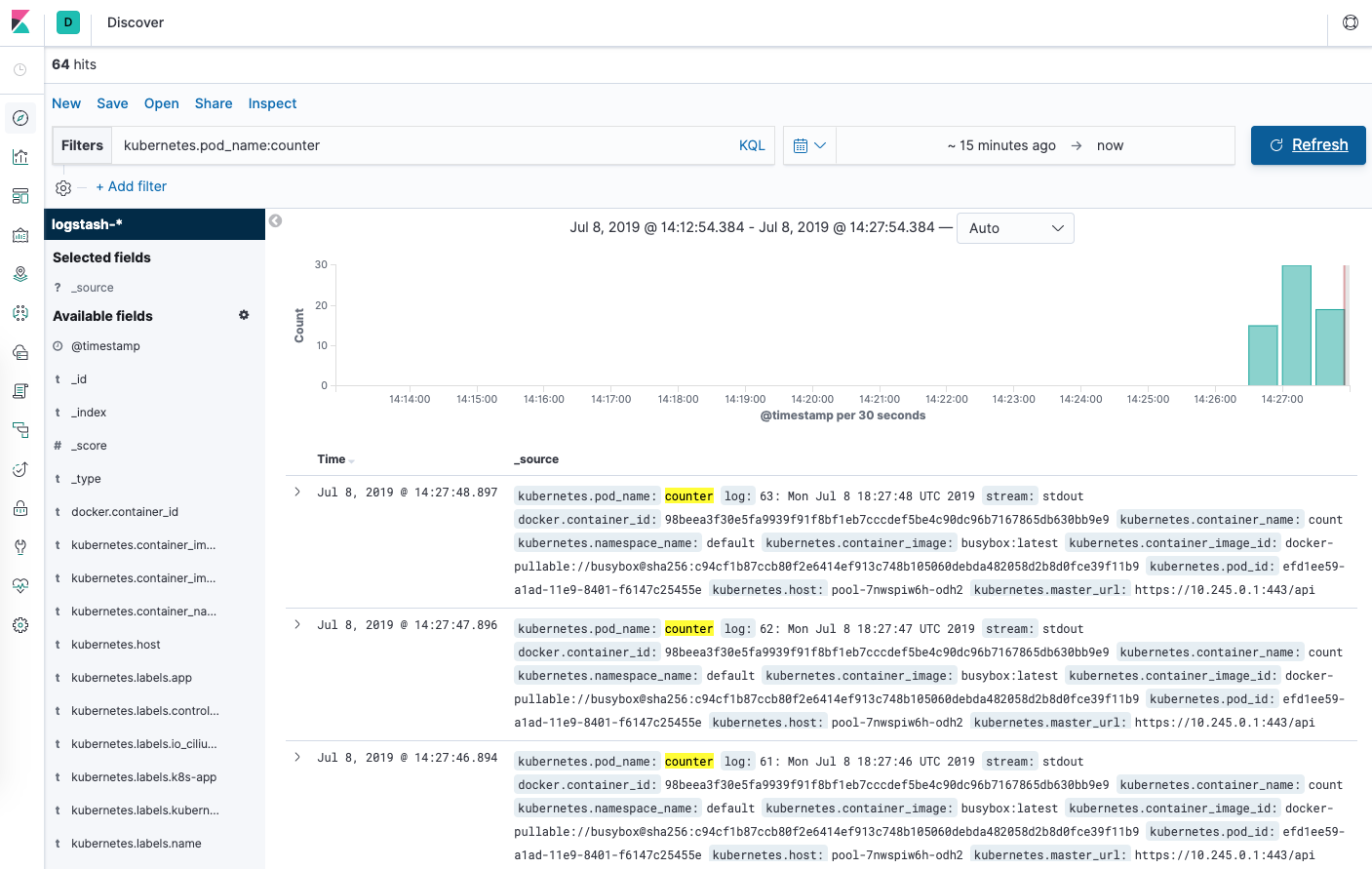
يمكنك النقر على أي من مُدخلات السجل لعرض بيانات وصفية إضافية مثل اسم الحاوية، وعقدة Kubernetes، وفضاء الأسماء، والمزيد.
خاتمة
أوضحنا في هذا الدليل كيفية إعداد وتهيئة Elasticsearch و Fluentd و Kibana على عنقود Kubernetes. استخدمنا الحد الأدنى لإنشاء بنية تسجيل تتكون من وكيل تسجيل واحد يعمل على كل عقدة Kubernetes عاملة.
قبل نشر مكدس التسجيل هذا على عنقود Kubernetes ضمن بيئة إنتاج، من الأفضل ضبط متطلبات الموارد وحدودها كما هو موضح في هذا الدليل. قد تحتاج أيضًا إلى إعدادX-Pacl لتمكين ميزات المراقبة والأمان المضمنة.
تتكون بنية التسجيل التي استخدمناها هنا من ثلاث كائنات Pod لتطبيق Elasticsearch، وكائن Pod واحد لتطبيق Kibana (بدون موازنة الحِمل)، ومجموعة من كائنات Pod لتطبيق Fluentd تُشغَّل على أنها متحكّمات DaemonSet. قد ترغب في تحجيم هذا الإعداد وفقًا لحالة استخدام بيئة الإنتاج الخاصة بك. راجع هذا المقال للمزيد عن حجيم Elasticsearch و Kibana.
يسمح Kubernetes أيضًا ببُنى أكثر تغقيدًا لوكلاء التسجيل ممّا قد يتناسب أكثر مع استخداماتك. راجع هذا المقال على توثيق Kubernetes للمزيد عن بنية السجلّات في Kubernetes.
ترجمة - وبتصرّف - للمقال How To Set Up an Elasticsearch, Fluentd and Kibana (EFK) Logging Stack on Kubernetes لصاحبه Hanif Jetha.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.