
البحث في الموقع
المحتوى عن 'الخوارزميات'.
تم العثور على 13 نتائج
-
 نشأ الذكاء الصناعي في الخمسينيات من القرن الماضي عندما بدأ بعض الباحثين في مجال علوم الحاسب بالتساؤل عما إذا كان من الممكن جعل أجهزة الحاسب "تفكر" -وهو سؤال ما زلنا نستكشف تداعياته حتى اليوم. إن التعريف المختصر لمجال الذكاء الصناعي على النحو التالي: هو الجهد المبذول لأتمتة المهام الفكرية التي يؤديها البشر عادة. تشكل خوارزميات الذكاء الصناعي أساس الأنظمة الذكية الحديثة، حيث تمكّن الآلات من التعلم والاستنتاج واتخاذ القرارات باستقلالية. أحدثت هذه الخوارزميات ثورة في مختلف المجالات، بدءًا من الرؤية الحاسوبية ومعالجة اللغة الطبيعية إلى الروبوتات وأنظمة التوصية. يعد فهم المفاهيم والأنواع الأساسية لخوارزميات الذكاء الصناعي أمرًا بالغ الأهمية لفهم تعقيدات الذكاء الصناعي وتطبيقاته الواسعة. لقد حققت خوارزميات الذكاء الصناعي في السنوات الأخيرة تقدمًا كبيرًا، وذلك بفضل توفر كميات هائلة من البيانات وزيادة القدرة الحسابية وتحقيق اختراقات في البحث الخوارزمي. تتمتع هذه الخوارزميات بالقدرة على معالجة مجموعات البيانات الضخمة وتحليلها واكتشاف الأنماط المخفية واستخلاص رؤى قيّمة من البيانات. لقد أصبحوا فعّالين في حل المشكلات المعقدة التي كانت تعتبر ذات يوم تتجاوز قدرات الآلات. يشمل مجال الذكاء الاصطناعي العديد من مناهج الخوارزميات، كل منها مصمم لمعالجة مهام ومجالات مشكلة محددة، ويمكن فرز أنواع هذه الخوارزميات بطرق عديدة: حسب طريقة التدريب أو نوع البيانات التي تتعامل معها أو حجم البيانات التي يمكن أن تستفيد منها، لكن التصنيف الأشيع يكون وفقًا للمهمة التي يمكن أن تؤديها. بينما توفر خوارزميات الذكاء الاصطناعي إمكانات هائلة، فإنها تطرح أيضًا تحديات واعتبارات أخلاقية. يجب معالجة قضايا مثل تحيز البيانات وقابلية التفسير والإنصاف والخصوصية لضمان النشر المسؤول والأخلاقي لأنظمة الذكاء الاصطناعي. علاوة على ذلك، يستمر مجال الذكاء الاصطناعي في التطور بسرعة، مع استمرار البحث والتقدم في تقنيات الخوارزميات. تعد مواكبة أحدث التطورات وفهم نقاط القوة والقيود الخاصة بالخوارزميات المختلفة أمرًا ضروريًا للممارسين والباحثين وصناع السياسات. سوف نستكشف في هذا المقال الأنواع الرئيسية لخوارزميات الذكاء الاصطناعي وفقًا للمهمة التي تؤديها ونناقش خصائصها وكيفية تطبيقها ونفحص التحديات التي تطرحها هذه الخوارزميات. من خلال اكتساب فهم شامل لخوارزميات الذكاء الاصطناعي، يمكننا تقدير أهميتها في قيادة الابتكار وحل المشكلات المعقدة وتشكيل مستقبل الذكاء الاصطناعي والحياة. تمهيد إلى خوارزميات الذكاء الاصطناعي لابد من التنويه لبعض النقاط المهمة لكي نضمن لك قراءةً مستنيرة خلال هذه المقالة. المتطلبات لتكون على بينةٍ أثناء قراءة هذه المقالة، لابد وأن يكون لديك: معرفة مسبقة بالذكاء الصناعي وفروعه وأساسياته، سيكون من الأفضل أن تقرأ المقالة الأولى في هذه السلسلة على الأقل. معرفة بمجالات الذكاء الصناعي. يمكنك قراءة مقالة مجالات الذكاء الاصطناعي. (اختياري) أن يكون لديك اطلاع على تعلم الآلة. يمكنك قراءة مقالة تعلم الآلة. هل يجب أن أعرف جميع أنواع خوارزميات الذكاء الاصطناعي؟ لكي تصبح مبرمجًا للذكاء الاصطناعي، ليس من الضروري معرفة جميع أنواع خوارزميات الذكاء الاصطناعي. مجال الذكاء الاصطناعي واسع ويشمل مجموعة واسعة من الخوارزميات والتقنيات. بصفتك مبرمجًا للذكاء الاصطناعي، يمكنك اختيار التخصص في مجالات أو خوارزميات محددة بناءً على اهتماماتك وأهدافك المهنية ومتطلبات المشاريع التي تعمل عليها. ومع ذلك فإن وجود فهم عام للمفاهيم الأساسية والخوارزميات شائعة الاستخدام في الذكاء الاصطناعي أمر مفيد. يتضمن ذلك معرفة خوارزميات التعلم الآلي مثل التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف والتعلم المعزز. إضافةً إلى ذلك يمكن أن يكون الإلمام بالشبكات العصبية وتقنيات التعلم العميق مفيدًا للغاية، حيث يتم استخدامها على نطاق واسع في تطبيقات الذكاء الاصطناعي المختلفة. خلال قراءتك للمقالة سترى مراجعة شاملة للمناهج والخوارزميات وسياق تطورها، لكن ليس من الضروري أن تتعرّف عن قرب عن جميعها أو حتى نصفها، فكما ذكرت؛ هذا يعتمد على المجال الذي ستختص فيه. مثلًا إن كان اهتمامك في معالجة اللغات الطبيعية أو الرؤية الحاسوبية، فلن تحتاج إلى الخوارزميات التطورية أو التعلم المعزز كقاعدة عامة. ما الفرق بين خوارزميتن الذكاء الاصطناعي ونموذج الذكاء الاصطناعي خوارزمية الذكاء الاصطناعي هي مجموعة التعليمات التي تحدد كيفية تنفيذ مهمة حسابية، بينما نموذج الذكاء الاصطناعي هو التمثيل المكتسب الناتج عن تطبيق الخوارزمية على بيانات التدريب. لتوضيح الفرق ضع في اعتبارك السيناريو التالي: تريد إنشاء نموذج لتصنيف صور القطط والكلاب. يمكن أن تكون الخوارزمية التي تختارها عبارة عن شبكة عصبية تلافيفية CNN، والتي تحدد بنية الشبكة وعملية التدريب عليها. النموذج في هذه الحالة سيكون CNN المُدرّبة أي بعد أن تعلّمت من مجموعة البيانات. يمكن بعد ذلك استخدام النموذج لتصنيف الصور الجديدة غير المرئية كقطط أو كلاب. باختصار النموذج هو ناتج الخوارزمية، أي يمكن القول أن النموذج هو خوارزمية مُدرّبة جاهزة للاستخدام والتطبيق الفعلي. تجدر الإشارة إلى أنهما مصطلحان يُستخدمان غالبًا بالتبادل، لكن يجب معرفة الفرق بينهما. ما المقصود بالأنماط تشير الأنماط في سياق الذكاء الاصطناعي إلى الهياكل أو العلاقات المتكررة في البيانات التي يمكن تحديدها واستخدامها لعمل تنبؤات أو استخلاص رؤى. من خلال تحليل كميات كبيرة من البيانات، يمكن لخوارزميات الذكاء الاصطناعي تحديد الأنماط والتعلم منها لتحسين الأداء أو اتخاذ قرارات ذكية. يمكن أن تظهر الأنماط في أشكال مختلفة، مثل السلاسل الرقمية أو السلاسل النص أو الصور أو الإشارات الصوتية. صُمّمت خوارزميات الذكاء الاصطناعي للتعرف على الأنماط داخل أنواع البيانات هذه واستخراج الخصائص ذات الصلة التي تساعد في حل مهام محددة. على سبيل المثال، في التعرف على الصور، تتعلم خوارزميات الذكاء الاصطناعي أنماطًا من قيم البكسل تتوافق مع كائنات أو ميزات مختلفة. في معالجة اللغة الطبيعية، تتعلم نماذج الذكاء الاصطناعي أنماطًا في تراكيب اللغة والسياق لفهم وإنشاء نص يشبه الإنسان. باختصار، النمط هو شكل معيّن تتكرر فيه المعلومات، وهي صفات وخصائص تُميّز الأشياء، وهو مصطلح أساسي في تعلّم الآلة. مثلًا: كل التفاحات لها شكل شبه كروي (نمط)، العرب ينطقون لغة خاصة هي اللغة العربية (نمط)، يمكن تمييز الطبيب في المستشفى من لباسه (نمط). تطور خوارزميات الذكاء الاصطناعي: من الأنظمة المعتمدة على القواعد إلى أعجوبة التعلم العميق شهدت خوارزميات الذكاء الصناعي تطورًا ملحوظًا على مر السنين، مما دفع مجال الذكاء الصناعي إلى آفاق جديدة للابتكار والتطبيق. من البدايات المتواضعة إلى أحدث التطورات، تُظهر رحلة خوارزميات الذكاء الصناعي التقدم الملحوظ الذي تم إحرازه في تطوير الأنظمة الذكية. يستكشف هذا القسم من المقالة تطور خوارزميات الذكاء الصناعي وتتبع أسسها والمعالم الرئيسية والاتجاهات الناشئة التي تشكل مستقبل الذكاء الصناعي. الأيام الأولى: الذكاء الاصطناعي المعتمد على القواعد والأنظمة الخبيرة يمكن إرجاع جذور خوارزميات الذكاء الاصطناعي إلى الأيام الأولى من المجال عندما ركز الباحثون على الذكاء الصناعي المعتمد على القواعد والأنظمة الخبيرة. تضمنت هذه الأساليب تمثيل المعرفة البشرية في أنظمة قائمة على القواعد، وتمكين أجهزة الحاسب من محاكاة التفكير البشري وحل مشكلات محددة ضمن مجالات محددة مسبقًا. كان التطور الملحوظ خلال هذه الفترة هو إنشاء أنظمة خبيرة يمكن أن تحاكي قدرات صنع القرار للخبراء البشريين في المجالات المتخصصة. ثورة التعلم الآلي: الانتقال من القواعد الصريحة إلى التعلم من البيانات كان ظهور التعلم الآلي بمثابة تحول كبير في خوارزميات الذكاء الاصطناعي، والانتقال من البرمجة الصريحة القائمة على القواعد إلى الخوارزميات التي تتعلم من البيانات. اكتسبت المناهج الإحصائية بدايةً مكانة بارزة، مما سمح للآلات بالتعرف على الأنماط وإجراء التنبؤات بناءً على الأمثلة المرصودة. شهد لاحقًا هذا العصر ظهور خوارزميات مثل الانحدار الخطي والانحدار اللوجستي وأشجار القرار، مما مكّن الآلات من التعلم من البيانات المصنفة واتخاذ قرارات مستنيرة. كما أدى تطوير الشبكات العصبية وخوارزمية الانتشار العكسي في هذه الفترة إلى دفع المجال بشكل أكبر من خلال تقديم مفهوم تدريب الشبكات العميقة. التعلم المعزز: التعلم من خلال التفاعل مع البيئة اكتسبت خوارزميات التعلم المعزز مكانة بارزة من خلال تمكين الآلات من التعلم من خلال التفاعلات مع البيئة، وهي مستوحاة من علم النفس السلوكي. تعمل هذه الخوارزميات على تحسين عمليات اتخاذ القرار من خلال تعظيم المكافآت والعقوبات وبشكل تراكمي. تشمل المعالم الرئيسية لهذه المرحلة تطوير خوارزمية Q-Learning وتمهيد الطريق للتعلم المعزز الحديث والتطورات اللاحقة مثل شبكات كيو العميقة DQN وغيرهم. حقق التعلم المعزز نجاحًا ملحوظًا في مجالات مثل لعب الألعاب والروبوتات، حيث أُظهرت قوة التعلّم من خلال التجربة والخطأ. الخوارزميات التطورية: التحسين والبحث تستمد الخوارزميات التطورية الإلهام من التطور الطبيعي والمبادئ الجينية لتحسين المشكلات المعقدة والبحث عن الحلول المثلى. تعد الخوارزميات الجينية وخوارزميات أسراب الطيور وخوازميات مستعمرات النمل -أمثلة على الخوارزميات التطورية التي أثبتت فعاليتها في حل بعض مشكلات التحسين المعقدة. وجدت هذه الخوارزميات تطبيقات في مجالات مثل التصميم الهندسي والجدولة واستخراج البيانات. التعلم العميق: إطلاق العنان لقوة الشبكات العصبية ظهرت خوارزميات التعلم العميق كقوة مهيمنة في الذكاء الصناعي، تغذيها التطورات في القوة الحسابية وتوافر كميات هائلة من البيانات. من خلال الاستفادة من فكرة الطبقات المتعددة للشبكات العصبية، تفوقت خوارزميات التعلم العميق على خوارزميات التعلّم الآلي الأخرى في جميع المهام الحسية والإدراكية. أحدثت الشبكات العصبية التلافيفية CNNs ثورة في مهام الرؤية الحاسوبية، بينما أظهرت الشبكات العصبية المتكررة RNNs أداءً استثنائيًا في تحليل البيانات النصية والزمنية. يتيح عمق وتعقيد هذه الشبكات استخراج معلومات عالية الدقة من البيانات، وإطلاق العنان لإمكانيات جديدة في مجالات مثل التعرف على الصور ومعالجة اللغة الطبيعية والتعرّف على الكلام. ظهور النهج الهجين مع استمرار تطور خوارزميات الذكاء الاصطناعي، اكتسبت الأساليب الهجينة التي تجمع بين تقنيات متعددة مكانة بارزة. مثلًا أدى دمج التعلم العميق مع التعلم المعزز إلى حدوث تطورات في مجالات مثل القيادة المستقلة ولعب الألعاب. أتاح اندماج الخوارزميات التطورية مع تقنيات التعلم الآلي إنشاء استراتيجيات تحسين أكثر قوة. تستفيد المناهج الهجينة من نقاط القوة في النماذج الحسابية المختلفة لمواجهة تحديات العالم الحقيقي المعقدة. يعد تطوّر خوارزميات الذكاء الصناعي عملية مستمرة، مع العديد من الاتجاهات الناشئة التي تشكل مستقبل المجال. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن أنواع خوارزميات الذكاء الاصطناعي وفقًا لنواع المهمة هناك عدة أنواع من خوارزميات الذكاء الصناعي وفقًا لنوع المهمة، وهي تندرج عمومّا تحت 6 أنواع هي: الانحدار والتصنيف والعنقدة والتجميع والتوليد والتفاعل. خوارزميات الانحدار أو التوقع Regression يُعد هذا النوع من الخوارزميات من خوارزميات تعلم الآلة الخاضعة للإشراف، وتستخدم لعمل تنبؤات. يتضمن التطبيق الرئيسي لخوارزميات الانحدار التنبؤ بسعر سوق الأسهم والتنبؤ بالطقس، وما إلى ذلك. هناك أنواع مختلفة من الانحدار مثل الانحدار الخطي والانحدار متعدد الحدود وما إلى ذلك. الخوارزميات الأكثر شيوعًا في هذا القسم هي خوارزمية الانحدار الخطي Linear Regression. تُستخدم خوارزمية الانحدار الخطي لتحليل العلاقة بين متغيرين: متغير إدخال (غالبًا ما يسمى المتغير المستقل) ومتغير الإخراج (غالبًا ما يسمى المتغير التابع). يهدف إلى العثور على علاقة خطية أو اتجاه يناسب نقاط البيانات بشكل أفضل. تعمل الخوارزمية من خلال إيجاد معادلة مستقيم تساهم في تقليل الفرق بين القيم المتوقعة والقيم الحقيقية لمتغير الإخراج. يمكن استخدام هذه المعادلة لاحقًا لعمل تنبؤات لقيم الإدخال الجديدة بناءً على العلاقة التي تم تعلمها. غالبًا ما يستخدم الانحدار الخطي في مهام مثل التنبؤ بأسعار المنازل بناءً على عوامل مثل الحجم والموقع ، أو تقدير المبيعات بناءً على نفقات الإعلان ، أو تحليل تأثير المتغيرات على نتيجة معينة. يوفر طريقة بسيطة وقابلة للتفسير لفهم العلاقة بين المتغيرات وعمل تنبؤات بناءً على تلك العلاقة. خوارزميات التصنيف Classification خوارزميات تُستخدم لتصنيف البيانات إلى فئتين أو أكثر، وتعتبر خوارزميات التصنيف جزءًا من التعلم الخاضع للإشراف. على سبيل المثال، يمكن استخدام خوارزميات التصنيف لتصنيف رسائل البريد الإلكتروني كرسائل عادية أو عشوائية Spam. هناك نوعان أساسيان من التصنيف: تصنيف الثنائي Binary classification: هنا يكون لدينا فئتين. مثلًا في مهمة تصنيف المرضى المصابين بكوفيد 19، يجب على الخوارزمية أن تحدد فيما إذا كان الشخص مريضًا أو غير مريض. تصنيف متعدد الفئات Multiclass classification: هنا يكون لدينا أكثر من فئة. مثلًا في مهمة تصنيف مراجعات الأفلام. يجب على الخوارزمية أن تحدد فيما إذا كان الشخص معجبًا بالفيلم أو غير معجب أو محايد. من أشهر خوارزميات التصنيف خوارزمية الانحدار اللوجستي Logistic regression والغابات العشوائية Random Forest و SVM إضافةً إلى الشبكات العصبية والتعلم العميق. غالبًا ما يستخدم الانحدار اللوجستي لمشاكل التصنيف الثنائي، بينما تُعرف الغابات العشوائية و SVM بقدرتهما على التعامل مع مهام التصنيف الثنائية ومتعددة الفئات. اكتسبت الشبكات العصبية، بما في ذلك نماذج التعلم العميق، شعبية هائلة بسبب قدرتها على تعلم الأنماط المعقدة في البيانات، مما يجعلها مناسبة لمجموعة واسعة من مشاكل التصنيف. توفر هذه الخوارزميات أدوات قوية للباحثين والممارسين لتحليل البيانات وتصنيفها، مما يتيح التقدم في مجالات مثل التعرف على الصور ومعالجة اللغة الطبيعية والتشخيص الطبي ..إلخ. خوارزميات العنقدة Clustering تُستخدم لتجميع العناصر المتشابهة بغية فرزها أو تصنيفها أو اختزالها. تعتمد هذه الخوارزميات على تقسيم البيانات إلى مجموعات مميزة من العناصر المتشابهة. خذ مثلًا عملية تحميل الصور على أحد مواقع التواصل الاجتماعي كمثال. هنا قد يرغب الموقع في تجميع الصور التي تُظهر الشخص نفسه مع بعضها بغية تنظيم صورك. إلا أن الموقع لا يعرف من يظهر في الصور ولا يعرف عدد الأشخاص المختلفين الذين يظهرون في مجموعة الصور خاصتك. تتمثل الطريقة المعقولة لحل المشكلة في استخراج كل الوجوه وتقسيمها إلى مجموعات من الوجوه المتشابهة، ومن أجل كل صورة جديدة تحملها يضعها في المجموعة الأكثر شبهًا لها. هذا مايُسمّى بالعنقدة. أبرز أمثلتها هي الخوارزمية التصنيفية K-Means. خوارزميات التعلم الجماعي Ensemble learning يشير التعلم الجماعي إلى الخوارزميات التي تجمع التنبؤات من نموذجين أو أكثر. على الرغم من وجود عدد غير محدود تقريبًا من الطرق التي يمكن من خلالها تحقيق ذلك، ربما توجد ثلاث فئات من تقنيات التعلم الجماعي التي تتم مناقشتها بشكل شائع واستخدامها في الممارسة العملية: التعبئة Bagging: يعتمد على استخدام عدة نماذج لإنشاء التوقعات، ثم أخذ قرار الغالبية. أي مثلًا كان هناك 3 نماذج تتوقع أن الشخص مريض ونموذج واحد يتوقع أنه غير مريض، فتكون النتيجة أنه غير مريض بتصويت الغالبية. التكديس Stacking: هنا يُستخدم نموذج آخر لمعرفة أفضل طريقة للجمع بين تنبؤات النماذج. التعزيز Boosting: هنا يكون لدينا عدة نماذج وكل منها يُصحح أخطاء الآخر على التسلسل، وصولًا إلى نموذج نهائي قوي (هذا هو النوع الأنجح والأكثر استخدامًا). أبرز الأمثلة على هذه الخوارزميات هي خوارزمية تعزيز التدرج الشديد XGBoost، وتعتبر من خوارزميات التعلم الآلي المستخدمة في مهام التصنيف أو الانحدار، وتندرج تحت مفهوم أساليب التعلم الجماعي التي تجمع بين العديد من النماذج الأضعف (غالبًا أشجار القرار) لإنشاء نموذج تنبؤي قوي. تعزيز التدرج هو مصطلح عام يشير إلى فئة من الخوارزميات حيث يركز كل نموذج لاحق في المجموعة على تصحيح الأخطاء التي ارتكبتها النماذج السابقة. إنه يعمل عن طريق إضافة نماذج جديدة باستمرار، مع تدريب كل نموذج جديد لتقليل الأخطاء التي ارتكبتها النماذج السابقة. الخوارزميات التوليدية Generative هي فئة من خوارزميات الذكاء الاصطناعي التي تهدف إلى إنشاء عينات بيانات جديدة تشبه مجموعة بيانات تدريب معينة. تتعلم هذه النماذج التوزيع الأساسي لبيانات التدريب وتستخدمها لتوليد عينات جديدة تظهر خصائص متشابهة. تُستخدم النماذج التوليدية على نطاق واسع في العديد من التطبيقات، بما في ذلك إنشاء الصور وتوليد النصوص (مثل ChatGPT) وتوليف البيانات. فيما يلي بعض الأنواع الشائعة من النماذج التوليدية: شبكات الخصومة التوليدية GANs: تتكون شبكات GAN من مكونين رئيسيين: شبكة المولدات وشبكة التمييز. يهدف المولد إلى إنتاج عينات بيانات واقعيّة، بينما يحاول المميّز التمييز بين العينات الحقيقية والمولدة، ومن خلال عملية التدريب تتعلم شبكات GAN إنشاء عينات بيانات واقعية. أحد أمثلتها هو توليد صور أشخاص غير حقيقيين. النماذج التوليدية لمعالجة اللغة الطبيعية: يمكن لنماذج مثل شبكات الخصومة التوليدية والشبكات العصبية المتكررة RNN ونماذج المحولات Transformers إنشاء نصوص بيانات واقعية (مثل ChatGPT). تحتوي النماذج التوليدية على مجموعة واسعة من التطبيقات، بما في ذلك تركيب الصور وزيادة حجم مجموعات البيانات وإنشاء النصوص واكتشاف الشذوذ. إنها ذات قيمة في السيناريوهات التي يكون الهدف فيها هو إنشاء عينات بيانات جديدة تلتقط خصائص بيانات التدريب وتوزيعها. خوارزميات التفاعل أو التعلم المعزز RL خوارزميات التعلم المعزز هي فئة من خوارزميات الذكاء الاصطناعي التي تمكّن الوكيل Agents (يمكنك اعتباره الآلة) من تعلم كيفية اتخاذ القرارات أو اتخاذ الإجراءات في بيئة ما لزيادة المكافأة التراكمية. تتعلم خوارزميات RL من خلال التجربة والخطأ، حيث يتفاعل الوكيل مع البيئة ويتلقى تعليقات في شكل مكافآت أو عقوبات بناءًا على صحة الإجراء المُتخذ أو عدم صحته، ويقوم بتعديل سلوكه لتحقيق أعلى مكافأة ممكنة. هناك العديد من المكونات الرئيسية في خوارزميات RL. أولاً، هناك وكيل يتخذ إجراءات في البيئة. هدف الوكيل هو تعلم "سياسة Policy"، وهي رسم خرائط بين الحالات التي يمكن أن يمر بها الوكيل في البيئة والإجراءات التي يمكن أن يقوم بها عند كل حالة، والتي تزيد من المكافأة المتوقعة على المدى الطويل. البيئة هي النظام الخارجي الذي يتفاعل معه الوكيل، والتي تُقدّم ملاحظات للوكيل من خلال المكافآت. تستخدم خوارزميات RL عادةً دالة قيمة أو دالة Q لتقدير المكافأة التراكمية المتوقعة لزوج معين من إجراءات الحالة (مثلا إذا كنت في الحالة S5 واتخذت الإجراء A1 ستحصل على مكافأة 10+). تمثل دالة القيمة المكافأة طويلة الأجل التي يمكن أن يتوقعها الوكيل من كونه في حالة معينة واتباع سياسة معينة. تقدر دالة Q المكافأة التراكمية المتوقعة على وجه التحديد لأزواج (إجراء، حالة). تستخدم خوارزميات RL تقديرات القيمة هذه لتوجيه عملية اتخاذ القرار لدى الوكيل. هناك خوارزميات RL مختلفة مثل Q-Learning وتدرجات السياسة Policy gradients ..إلخ، ولكل منها نهجها الخاص في التعلم والتحسين. تم تطبيق خوارزميات التعلم المعزز بنجاح في مجالات مختلفة، مثل الروبوتات والأنظمة المستقلة ولعب الألعاب وأنظمة التحكم. إنها تمكن الوكلاء من التعلم من التجربة والتكيف مع البيئات المتغيرة واكتشاف الاستراتيجيات المثلى لحل المشكلات المعقدة. تطبيق خوارزميات الذكاء الاصطناعي في الذكاء الصناعي عمومًا ومجال تعلم الآلة خصوصًا، يختلف نهج الخوارزمية عن الخوارزمية التقليدية. السبب هو أن الخطوة الأولى هي معالجة البيانات -وبعد ذلك، سيبدأ الحاسوب في التعلّم. أي عند الحديث عن الخوارزميات في سياق الذكاء الصناعي وتعلم الآلة نتحدث عن الإجراءات والعمليات التي تُطبّق على البيانات لاستكشاف وفهم الأنماط Patterns والعلاقات السائدة في البيانات والتعلّم منها، ويكون نتاج هذه الخوارزميات هو نماذج Models يمكن تطبيقها على أرض الواقع. ملاحظة 1: النموذج هو ناتج الخوارزمية، أي يمكن القول أن النموذج هو خوارزمية مُدرّبة جاهزة للاستخدام والتطبيق الفعلي. تجدر الإشارة إلى أنهما مصطلحان يُستخدمان غالبًا بالتبادل (لافرق في أن تقول نموذج أو خوارزمية)، لكن وجب التنويه للفرق بينهما. ملاحظة 2: النمط هو شكل معيّن تتكرر فيه المعلومات، وهي صفات وخصائص تُميّز الأشياء، وهو مصطلح أساسي في تعلّم الآلة. مثلًا: كل التفاحات لها شكل شبه كروي (نمط)، العرب ينطقون لغة خاصة هي اللغة العربية (نمط)، يمكن تمييز الطبيب في المستشفى من لباسه (نمط). من السهل بناء وتطبيق بعض الخوارزميات، إلا أن بعضها الآخر يتطلّب خطوات برمجية ورياضيات معقدة. الخبر السار هو أنه لا يتعين عليك في معظم الأوقات أن تبني هذه الخوارزميات من الصفر، لأن هناك مجموعة متنوعة من اللغات البرمجية مثل Python و R والعديد من أطر العمل كتنسرفلو Tensorflow وكيراس Keras وباي تورش Pytorch وسكايت ليرن Sklearn التي تجعل العملية سهلة ومباشرة. هناك المئات من خوارزميات تعلم الآلة المتاحة، إلا أنّه يمكن تقسيمها فعليًا إلى أربع فئات رئيسية: التعلم الخاضع للإشراف supervised learning، والتعلم غير الخاضع للإشراف unsupervised learning، والتعلم المعزز reinforcement learning، والتعلم شبه الخاضع للإشراف semi-supervised learning، وقد ألقينا نظرة عن هذه الأنواع في مقالة تعلم الآلة. خطوات تدريب خوارزميات الذكاء الاصطناعي إن الهدف من عملية تدريب الخوارزمية هو إنشاء نموذج يعتمد على تلك الخوارزمية لإعطاء قرارات في أرض الواقع. بالتالي لتحقيق النجاح في تطبيق خوارزميات الذكاء الصناعي على مشكلة ما، من المهم اتباع نهج منظّم، وإلا قد تكون النتائج بعيدة عن المتوقع. إذًا يجب أن نختار خوارزمية مناسبة وأن ندربها بأفضل شكل ممكن لكي نحصل على قرارات مثالية قدر الإمكان. بدايةً تحتاج إلى إجراء عمليات معالجة البيانات، ثم من الجيد (إن أمكن) إجراء تمثيل مرئي لهذه البيانات، حيث يفيدنا التمثيل المرئي في الإجابة على أسئلة مثل: هل هناك بعض الأنماط؟ إذا كانت الإجابة بنعم، فقد تكون البيانات سهلة التعلّم وواضحة للخوارزمية. الخطوة 1: تحديد المشكلة وجمع البيانات: بدايةً يجب أن تحدد المشكلة التي تعمل عليها، وهذا يتضمن الإجابة على أسئلة مثل: ماذا ستكون البيانات التي تعطيها للخوارزمية (أي ما هو الدخل)؟ ما هي المشكلة التي تحاول حلها (أي ماهو الخرج)؟ لا يمكنك الانتقال إلى المرحلة التالية حتى تعرف ما هي المدخلات والمخرجات، والبيانات التي ستستخدمها. تتضمن هذه المرحلة أيضًا فحص البيانات التي تم جمعها وتنظيفها وإصلاح أية مشاكل فيها. الخطوة 2: اختيار الخوارزمية المناسبة: تحتاج الآن إلى تحديد خوارزمية مناسبة لحل هذه المشكلة، وسيكون الأمر أشبه بالتخمين المستنير، أي يجب أن تستفيد من النظريات وتجارب الآخرين، وهذا سيتضمن عملية تجربة وخطأ (قد تجرب عدة خورازميات). الخطوة 3: تحضير البيانات للتدريب: بمجرد أن تعرف ما الذي تريد أن تُدرّب الخوارزمية عليه، تكون جاهزًا تقريبًا لبدء نماذج التدريب. إن تحضير البيانات يعني تنسيقها بطريقة يمكن إدخالها في خوارزمية التعلّم. الخطوة 4: تدريب النموذج: سيتم استخدام حوالي 70% من البيانات المتاحة من أجل تدريب الخوارزمية وإنتاج النموذج. افترض أنك تبني نظامًا للتعلم الآلي للتنبؤ بقيمة السيارة المستعملة. ستشمل البيانات عوامل مثل: سنة التصنيع والطراز والمسافة المقطوعة والحالة. من خلال معالجة بيانات التدريب هذه، ستحسب الخوارزمية أوزان كل من هذه العوامل (وزن تأثيرها في قيمة السيارة) لتعطي نموذجًا يتوقع القيمة بناءًا على هذه العوامل. الخطوة 5: تقييم أداء النموذج: سيتم استخدام حوالي 30% من البيانات المتاحة من أجل تقييم أداء النموذج. في هذه المرحلة يمكنك معرفة ما إذا كان النموذج دقيقًا في قراراته. في مثالنا على السيارات المستعملة، سيكون السؤال: هل تتوافق توقعات النموذج مع قيم السوق في أرض الواقع؟ الخطوة 6: تحسين أداء النموذج: من خلال إضافة بيانات جديدة أو التلاعب بالخوارزمية ومعاملاتها أو حتى تغيير الخورازمية. في القسم التالي سنتحدث عن أنواع خوارزميات الذكاء الاصطناعي. هذه الأنواع تتضمن خوارزميات مختلفة وكلها تندرج تحت الفئات الرئيسية الأربعة سالفة الذكر. خوارزميات الذكاء الاصطناعي والمجتمع تسلط هذه الفقرة الضوء على الأهمية المتزايدة للاعتبارات الأخلاقية والتفسير والإنصاف في خوارزميات الذكاء الصناعي، حيث يستمر تأثير الذكاء الاصطناعي على المجتمع في التوسع. دعونا نتعمق في كل جانب! الاعتبارات الأخلاقية تشمل الاعتبارات الأخلاقية في الذكاء الصناعي معالجة الآثار الأخلاقية والتأثير المجتمعي المحتمل لأنظمة الذكاء الصناعي. نظرًا لأن خوارزميات الذكاء الاصطناعي أصبحت أكثر تكاملًا في جوانب مختلفة من حياتنا، فمن المهم ضمان تطويرها ونشرها بطريقة أخلاقية. يتضمن ذلك اعتبارات مثل حماية الخصوصية وأمن البيانات والتحيّز الخوارزمي والشفافية والمساءلة. تظهر المخاوف الأخلاقية عندما تتخذ خوارزميات الذكاء الصناعي قرارات قد يكون لها عواقب وخيمة على الأفراد أو المجموعات، ومن المهم وضع مبادئ توجيهية وأطر لتقليل الضرر المحتمل وضمان ممارسات الذكاء الاصطناعي الأخلاقية. قابلية التفسير يشير التفسير إلى القدرة على فهم وشرح القرارات أو التنبؤات التي تتخذها خوارزميات الذكاء الصناعي. نظرًا لأن الذكاء الصناعي يصبح أكثر تعقيدًا مع خوارزميات مثل شبكات التعلم العميق، يصبح تفسير النتائج التي تعطيها أصعب. من الضروري تطوير أساليب وتقنيات تمكّن البشر من فهم الأسباب الكامنة وراء قرارات خوارزميات الذكاء الاصطناعي من أجل الثقة بها. يساعد التفسير في تحديد التحيزات المحتملة وضمان المساءلة وبناء ثقة المستخدم. بالإضافة إلى ذلك تسمح القابلية للتفسير لخبراء المجال بالتحقق من صحة نماذج الذكاء الاصطناعي وتحسينها، مما يجعلها أكثر موثوقية وفعالية. الإنصاف يشير الإنصاف في خوارزميات الذكاء الصناعي إلى المعاملة غير المنحازة للأفراد أو المجموعات، بغض النظر عن سماتهم الشخصية مثل الجنس أو العرق أو الحالة الاجتماعية والاقتصادية. يمكن أن يظهر التحيّز عن غير قصد في أنظمة الذكاء الاصطناعي بسبب بيانات التدريب المتحيزة أو الافتراضات الأساسية. يعد تعزيز العدالة في خوارزميات الذكاء الاصطناعي أمرًا بالغ الأهمية لتجنب استمرار عدم المساواة الاجتماعية وضمان تكافؤ الفرص للجميع. تنبع الأهمية المتزايدة لهذه الجوانب من الاعتراف بأن أنظمة الذكاء الاصطناعي لديها القدرة على التأثير بشكل كبير على الأفراد والمجتمعات والمجتمعات ككل. تتم معالجة هذه الاعتبارات بنشاط من قبل الباحثين وصانعي السياسات والمتخصصين في الصناعة لوضع مبادئ توجيهية أخلاقية وتطوير مقاييس الإنصاف وتعزيز الشفافية في خوارزميات الذكاء الاصطناعي. من خلال دمج هذه الاعتبارات في عمليات التطوير والنشر، يمكننا أن نسعى جاهدين من أجل بناء بيئة للذكاء الاصطناعي أكثر أخلاقية وشمولية، ليعود بالنفع على المجتمع ككل. خاتمة خوارزميات الذكاء الاصطناعي مجال واسع يتكون من خوارزميات التعلم الآلي وخوارزميات التعلم العميق وغيرها من الخورازميات. تمنح خوارزميات الذكاء الصناعي الآلات القدرة على اتخاذ القرارات والتعرّف على الأنماط واستخلاص استنتاجات مفيدة والتي تعني أساسًا تقليد الذكاء البشري. في المقالة السابقة ناقشنا تطوّر هذه الخوارزميات منذ ولادة هذا المجال وكيفية تصنيف هذه الخوارزميات إلى 6 فئات. هي: الانحدار والتصنيف والعنقدة والتجميع والتوليد والتفاعل. تعرّفنا على كيفية تطبيق هذه الخوارزميات والخطوات العامة لذلك. لضمان النشر المسؤول والمفيد للذكاء الاصطناعي، تحدثنا عن ضرورة مراعاة الآثار الأخلاقية وضمان القابلية للتفسير من أجل الشفافية والمساءلة والسعي لتحقيق العدالة لتجنب التمييز والتحيز. إن تطوّر خوارزميات الذكاء الصناعي مثير للاهتمام ومحفّز للتفكير. لقد كان لها نصيب من الإخفاقات والاختراقات الهائلة. مع تطبيقات مثل ChatGPT و Dalle.E وغيرهما، نكون قد خدشنا سطح التطبيقات الممكنة للذكاء الصناعي. هناك تحديات أيضًا، وهناك بالتأكيد المزيد في المستقبل. اقرأ أيضًا أنواع الذكاء الاصطناعي الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تطبيقات الذكاء الاصطناعي أهمية الذكاء الاصطناعي المرجع الشامل إلى تعلم الخوارزميات للمبتدئين
نشأ الذكاء الصناعي في الخمسينيات من القرن الماضي عندما بدأ بعض الباحثين في مجال علوم الحاسب بالتساؤل عما إذا كان من الممكن جعل أجهزة الحاسب "تفكر" -وهو سؤال ما زلنا نستكشف تداعياته حتى اليوم. إن التعريف المختصر لمجال الذكاء الصناعي على النحو التالي: هو الجهد المبذول لأتمتة المهام الفكرية التي يؤديها البشر عادة. تشكل خوارزميات الذكاء الصناعي أساس الأنظمة الذكية الحديثة، حيث تمكّن الآلات من التعلم والاستنتاج واتخاذ القرارات باستقلالية. أحدثت هذه الخوارزميات ثورة في مختلف المجالات، بدءًا من الرؤية الحاسوبية ومعالجة اللغة الطبيعية إلى الروبوتات وأنظمة التوصية. يعد فهم المفاهيم والأنواع الأساسية لخوارزميات الذكاء الصناعي أمرًا بالغ الأهمية لفهم تعقيدات الذكاء الصناعي وتطبيقاته الواسعة. لقد حققت خوارزميات الذكاء الصناعي في السنوات الأخيرة تقدمًا كبيرًا، وذلك بفضل توفر كميات هائلة من البيانات وزيادة القدرة الحسابية وتحقيق اختراقات في البحث الخوارزمي. تتمتع هذه الخوارزميات بالقدرة على معالجة مجموعات البيانات الضخمة وتحليلها واكتشاف الأنماط المخفية واستخلاص رؤى قيّمة من البيانات. لقد أصبحوا فعّالين في حل المشكلات المعقدة التي كانت تعتبر ذات يوم تتجاوز قدرات الآلات. يشمل مجال الذكاء الاصطناعي العديد من مناهج الخوارزميات، كل منها مصمم لمعالجة مهام ومجالات مشكلة محددة، ويمكن فرز أنواع هذه الخوارزميات بطرق عديدة: حسب طريقة التدريب أو نوع البيانات التي تتعامل معها أو حجم البيانات التي يمكن أن تستفيد منها، لكن التصنيف الأشيع يكون وفقًا للمهمة التي يمكن أن تؤديها. بينما توفر خوارزميات الذكاء الاصطناعي إمكانات هائلة، فإنها تطرح أيضًا تحديات واعتبارات أخلاقية. يجب معالجة قضايا مثل تحيز البيانات وقابلية التفسير والإنصاف والخصوصية لضمان النشر المسؤول والأخلاقي لأنظمة الذكاء الاصطناعي. علاوة على ذلك، يستمر مجال الذكاء الاصطناعي في التطور بسرعة، مع استمرار البحث والتقدم في تقنيات الخوارزميات. تعد مواكبة أحدث التطورات وفهم نقاط القوة والقيود الخاصة بالخوارزميات المختلفة أمرًا ضروريًا للممارسين والباحثين وصناع السياسات. سوف نستكشف في هذا المقال الأنواع الرئيسية لخوارزميات الذكاء الاصطناعي وفقًا للمهمة التي تؤديها ونناقش خصائصها وكيفية تطبيقها ونفحص التحديات التي تطرحها هذه الخوارزميات. من خلال اكتساب فهم شامل لخوارزميات الذكاء الاصطناعي، يمكننا تقدير أهميتها في قيادة الابتكار وحل المشكلات المعقدة وتشكيل مستقبل الذكاء الاصطناعي والحياة. تمهيد إلى خوارزميات الذكاء الاصطناعي لابد من التنويه لبعض النقاط المهمة لكي نضمن لك قراءةً مستنيرة خلال هذه المقالة. المتطلبات لتكون على بينةٍ أثناء قراءة هذه المقالة، لابد وأن يكون لديك: معرفة مسبقة بالذكاء الصناعي وفروعه وأساسياته، سيكون من الأفضل أن تقرأ المقالة الأولى في هذه السلسلة على الأقل. معرفة بمجالات الذكاء الصناعي. يمكنك قراءة مقالة مجالات الذكاء الاصطناعي. (اختياري) أن يكون لديك اطلاع على تعلم الآلة. يمكنك قراءة مقالة تعلم الآلة. هل يجب أن أعرف جميع أنواع خوارزميات الذكاء الاصطناعي؟ لكي تصبح مبرمجًا للذكاء الاصطناعي، ليس من الضروري معرفة جميع أنواع خوارزميات الذكاء الاصطناعي. مجال الذكاء الاصطناعي واسع ويشمل مجموعة واسعة من الخوارزميات والتقنيات. بصفتك مبرمجًا للذكاء الاصطناعي، يمكنك اختيار التخصص في مجالات أو خوارزميات محددة بناءً على اهتماماتك وأهدافك المهنية ومتطلبات المشاريع التي تعمل عليها. ومع ذلك فإن وجود فهم عام للمفاهيم الأساسية والخوارزميات شائعة الاستخدام في الذكاء الاصطناعي أمر مفيد. يتضمن ذلك معرفة خوارزميات التعلم الآلي مثل التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف والتعلم المعزز. إضافةً إلى ذلك يمكن أن يكون الإلمام بالشبكات العصبية وتقنيات التعلم العميق مفيدًا للغاية، حيث يتم استخدامها على نطاق واسع في تطبيقات الذكاء الاصطناعي المختلفة. خلال قراءتك للمقالة سترى مراجعة شاملة للمناهج والخوارزميات وسياق تطورها، لكن ليس من الضروري أن تتعرّف عن قرب عن جميعها أو حتى نصفها، فكما ذكرت؛ هذا يعتمد على المجال الذي ستختص فيه. مثلًا إن كان اهتمامك في معالجة اللغات الطبيعية أو الرؤية الحاسوبية، فلن تحتاج إلى الخوارزميات التطورية أو التعلم المعزز كقاعدة عامة. ما الفرق بين خوارزميتن الذكاء الاصطناعي ونموذج الذكاء الاصطناعي خوارزمية الذكاء الاصطناعي هي مجموعة التعليمات التي تحدد كيفية تنفيذ مهمة حسابية، بينما نموذج الذكاء الاصطناعي هو التمثيل المكتسب الناتج عن تطبيق الخوارزمية على بيانات التدريب. لتوضيح الفرق ضع في اعتبارك السيناريو التالي: تريد إنشاء نموذج لتصنيف صور القطط والكلاب. يمكن أن تكون الخوارزمية التي تختارها عبارة عن شبكة عصبية تلافيفية CNN، والتي تحدد بنية الشبكة وعملية التدريب عليها. النموذج في هذه الحالة سيكون CNN المُدرّبة أي بعد أن تعلّمت من مجموعة البيانات. يمكن بعد ذلك استخدام النموذج لتصنيف الصور الجديدة غير المرئية كقطط أو كلاب. باختصار النموذج هو ناتج الخوارزمية، أي يمكن القول أن النموذج هو خوارزمية مُدرّبة جاهزة للاستخدام والتطبيق الفعلي. تجدر الإشارة إلى أنهما مصطلحان يُستخدمان غالبًا بالتبادل، لكن يجب معرفة الفرق بينهما. ما المقصود بالأنماط تشير الأنماط في سياق الذكاء الاصطناعي إلى الهياكل أو العلاقات المتكررة في البيانات التي يمكن تحديدها واستخدامها لعمل تنبؤات أو استخلاص رؤى. من خلال تحليل كميات كبيرة من البيانات، يمكن لخوارزميات الذكاء الاصطناعي تحديد الأنماط والتعلم منها لتحسين الأداء أو اتخاذ قرارات ذكية. يمكن أن تظهر الأنماط في أشكال مختلفة، مثل السلاسل الرقمية أو السلاسل النص أو الصور أو الإشارات الصوتية. صُمّمت خوارزميات الذكاء الاصطناعي للتعرف على الأنماط داخل أنواع البيانات هذه واستخراج الخصائص ذات الصلة التي تساعد في حل مهام محددة. على سبيل المثال، في التعرف على الصور، تتعلم خوارزميات الذكاء الاصطناعي أنماطًا من قيم البكسل تتوافق مع كائنات أو ميزات مختلفة. في معالجة اللغة الطبيعية، تتعلم نماذج الذكاء الاصطناعي أنماطًا في تراكيب اللغة والسياق لفهم وإنشاء نص يشبه الإنسان. باختصار، النمط هو شكل معيّن تتكرر فيه المعلومات، وهي صفات وخصائص تُميّز الأشياء، وهو مصطلح أساسي في تعلّم الآلة. مثلًا: كل التفاحات لها شكل شبه كروي (نمط)، العرب ينطقون لغة خاصة هي اللغة العربية (نمط)، يمكن تمييز الطبيب في المستشفى من لباسه (نمط). تطور خوارزميات الذكاء الاصطناعي: من الأنظمة المعتمدة على القواعد إلى أعجوبة التعلم العميق شهدت خوارزميات الذكاء الصناعي تطورًا ملحوظًا على مر السنين، مما دفع مجال الذكاء الصناعي إلى آفاق جديدة للابتكار والتطبيق. من البدايات المتواضعة إلى أحدث التطورات، تُظهر رحلة خوارزميات الذكاء الصناعي التقدم الملحوظ الذي تم إحرازه في تطوير الأنظمة الذكية. يستكشف هذا القسم من المقالة تطور خوارزميات الذكاء الصناعي وتتبع أسسها والمعالم الرئيسية والاتجاهات الناشئة التي تشكل مستقبل الذكاء الصناعي. الأيام الأولى: الذكاء الاصطناعي المعتمد على القواعد والأنظمة الخبيرة يمكن إرجاع جذور خوارزميات الذكاء الاصطناعي إلى الأيام الأولى من المجال عندما ركز الباحثون على الذكاء الصناعي المعتمد على القواعد والأنظمة الخبيرة. تضمنت هذه الأساليب تمثيل المعرفة البشرية في أنظمة قائمة على القواعد، وتمكين أجهزة الحاسب من محاكاة التفكير البشري وحل مشكلات محددة ضمن مجالات محددة مسبقًا. كان التطور الملحوظ خلال هذه الفترة هو إنشاء أنظمة خبيرة يمكن أن تحاكي قدرات صنع القرار للخبراء البشريين في المجالات المتخصصة. ثورة التعلم الآلي: الانتقال من القواعد الصريحة إلى التعلم من البيانات كان ظهور التعلم الآلي بمثابة تحول كبير في خوارزميات الذكاء الاصطناعي، والانتقال من البرمجة الصريحة القائمة على القواعد إلى الخوارزميات التي تتعلم من البيانات. اكتسبت المناهج الإحصائية بدايةً مكانة بارزة، مما سمح للآلات بالتعرف على الأنماط وإجراء التنبؤات بناءً على الأمثلة المرصودة. شهد لاحقًا هذا العصر ظهور خوارزميات مثل الانحدار الخطي والانحدار اللوجستي وأشجار القرار، مما مكّن الآلات من التعلم من البيانات المصنفة واتخاذ قرارات مستنيرة. كما أدى تطوير الشبكات العصبية وخوارزمية الانتشار العكسي في هذه الفترة إلى دفع المجال بشكل أكبر من خلال تقديم مفهوم تدريب الشبكات العميقة. التعلم المعزز: التعلم من خلال التفاعل مع البيئة اكتسبت خوارزميات التعلم المعزز مكانة بارزة من خلال تمكين الآلات من التعلم من خلال التفاعلات مع البيئة، وهي مستوحاة من علم النفس السلوكي. تعمل هذه الخوارزميات على تحسين عمليات اتخاذ القرار من خلال تعظيم المكافآت والعقوبات وبشكل تراكمي. تشمل المعالم الرئيسية لهذه المرحلة تطوير خوارزمية Q-Learning وتمهيد الطريق للتعلم المعزز الحديث والتطورات اللاحقة مثل شبكات كيو العميقة DQN وغيرهم. حقق التعلم المعزز نجاحًا ملحوظًا في مجالات مثل لعب الألعاب والروبوتات، حيث أُظهرت قوة التعلّم من خلال التجربة والخطأ. الخوارزميات التطورية: التحسين والبحث تستمد الخوارزميات التطورية الإلهام من التطور الطبيعي والمبادئ الجينية لتحسين المشكلات المعقدة والبحث عن الحلول المثلى. تعد الخوارزميات الجينية وخوارزميات أسراب الطيور وخوازميات مستعمرات النمل -أمثلة على الخوارزميات التطورية التي أثبتت فعاليتها في حل بعض مشكلات التحسين المعقدة. وجدت هذه الخوارزميات تطبيقات في مجالات مثل التصميم الهندسي والجدولة واستخراج البيانات. التعلم العميق: إطلاق العنان لقوة الشبكات العصبية ظهرت خوارزميات التعلم العميق كقوة مهيمنة في الذكاء الصناعي، تغذيها التطورات في القوة الحسابية وتوافر كميات هائلة من البيانات. من خلال الاستفادة من فكرة الطبقات المتعددة للشبكات العصبية، تفوقت خوارزميات التعلم العميق على خوارزميات التعلّم الآلي الأخرى في جميع المهام الحسية والإدراكية. أحدثت الشبكات العصبية التلافيفية CNNs ثورة في مهام الرؤية الحاسوبية، بينما أظهرت الشبكات العصبية المتكررة RNNs أداءً استثنائيًا في تحليل البيانات النصية والزمنية. يتيح عمق وتعقيد هذه الشبكات استخراج معلومات عالية الدقة من البيانات، وإطلاق العنان لإمكانيات جديدة في مجالات مثل التعرف على الصور ومعالجة اللغة الطبيعية والتعرّف على الكلام. ظهور النهج الهجين مع استمرار تطور خوارزميات الذكاء الاصطناعي، اكتسبت الأساليب الهجينة التي تجمع بين تقنيات متعددة مكانة بارزة. مثلًا أدى دمج التعلم العميق مع التعلم المعزز إلى حدوث تطورات في مجالات مثل القيادة المستقلة ولعب الألعاب. أتاح اندماج الخوارزميات التطورية مع تقنيات التعلم الآلي إنشاء استراتيجيات تحسين أكثر قوة. تستفيد المناهج الهجينة من نقاط القوة في النماذج الحسابية المختلفة لمواجهة تحديات العالم الحقيقي المعقدة. يعد تطوّر خوارزميات الذكاء الصناعي عملية مستمرة، مع العديد من الاتجاهات الناشئة التي تشكل مستقبل المجال. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن أنواع خوارزميات الذكاء الاصطناعي وفقًا لنواع المهمة هناك عدة أنواع من خوارزميات الذكاء الصناعي وفقًا لنوع المهمة، وهي تندرج عمومّا تحت 6 أنواع هي: الانحدار والتصنيف والعنقدة والتجميع والتوليد والتفاعل. خوارزميات الانحدار أو التوقع Regression يُعد هذا النوع من الخوارزميات من خوارزميات تعلم الآلة الخاضعة للإشراف، وتستخدم لعمل تنبؤات. يتضمن التطبيق الرئيسي لخوارزميات الانحدار التنبؤ بسعر سوق الأسهم والتنبؤ بالطقس، وما إلى ذلك. هناك أنواع مختلفة من الانحدار مثل الانحدار الخطي والانحدار متعدد الحدود وما إلى ذلك. الخوارزميات الأكثر شيوعًا في هذا القسم هي خوارزمية الانحدار الخطي Linear Regression. تُستخدم خوارزمية الانحدار الخطي لتحليل العلاقة بين متغيرين: متغير إدخال (غالبًا ما يسمى المتغير المستقل) ومتغير الإخراج (غالبًا ما يسمى المتغير التابع). يهدف إلى العثور على علاقة خطية أو اتجاه يناسب نقاط البيانات بشكل أفضل. تعمل الخوارزمية من خلال إيجاد معادلة مستقيم تساهم في تقليل الفرق بين القيم المتوقعة والقيم الحقيقية لمتغير الإخراج. يمكن استخدام هذه المعادلة لاحقًا لعمل تنبؤات لقيم الإدخال الجديدة بناءً على العلاقة التي تم تعلمها. غالبًا ما يستخدم الانحدار الخطي في مهام مثل التنبؤ بأسعار المنازل بناءً على عوامل مثل الحجم والموقع ، أو تقدير المبيعات بناءً على نفقات الإعلان ، أو تحليل تأثير المتغيرات على نتيجة معينة. يوفر طريقة بسيطة وقابلة للتفسير لفهم العلاقة بين المتغيرات وعمل تنبؤات بناءً على تلك العلاقة. خوارزميات التصنيف Classification خوارزميات تُستخدم لتصنيف البيانات إلى فئتين أو أكثر، وتعتبر خوارزميات التصنيف جزءًا من التعلم الخاضع للإشراف. على سبيل المثال، يمكن استخدام خوارزميات التصنيف لتصنيف رسائل البريد الإلكتروني كرسائل عادية أو عشوائية Spam. هناك نوعان أساسيان من التصنيف: تصنيف الثنائي Binary classification: هنا يكون لدينا فئتين. مثلًا في مهمة تصنيف المرضى المصابين بكوفيد 19، يجب على الخوارزمية أن تحدد فيما إذا كان الشخص مريضًا أو غير مريض. تصنيف متعدد الفئات Multiclass classification: هنا يكون لدينا أكثر من فئة. مثلًا في مهمة تصنيف مراجعات الأفلام. يجب على الخوارزمية أن تحدد فيما إذا كان الشخص معجبًا بالفيلم أو غير معجب أو محايد. من أشهر خوارزميات التصنيف خوارزمية الانحدار اللوجستي Logistic regression والغابات العشوائية Random Forest و SVM إضافةً إلى الشبكات العصبية والتعلم العميق. غالبًا ما يستخدم الانحدار اللوجستي لمشاكل التصنيف الثنائي، بينما تُعرف الغابات العشوائية و SVM بقدرتهما على التعامل مع مهام التصنيف الثنائية ومتعددة الفئات. اكتسبت الشبكات العصبية، بما في ذلك نماذج التعلم العميق، شعبية هائلة بسبب قدرتها على تعلم الأنماط المعقدة في البيانات، مما يجعلها مناسبة لمجموعة واسعة من مشاكل التصنيف. توفر هذه الخوارزميات أدوات قوية للباحثين والممارسين لتحليل البيانات وتصنيفها، مما يتيح التقدم في مجالات مثل التعرف على الصور ومعالجة اللغة الطبيعية والتشخيص الطبي ..إلخ. خوارزميات العنقدة Clustering تُستخدم لتجميع العناصر المتشابهة بغية فرزها أو تصنيفها أو اختزالها. تعتمد هذه الخوارزميات على تقسيم البيانات إلى مجموعات مميزة من العناصر المتشابهة. خذ مثلًا عملية تحميل الصور على أحد مواقع التواصل الاجتماعي كمثال. هنا قد يرغب الموقع في تجميع الصور التي تُظهر الشخص نفسه مع بعضها بغية تنظيم صورك. إلا أن الموقع لا يعرف من يظهر في الصور ولا يعرف عدد الأشخاص المختلفين الذين يظهرون في مجموعة الصور خاصتك. تتمثل الطريقة المعقولة لحل المشكلة في استخراج كل الوجوه وتقسيمها إلى مجموعات من الوجوه المتشابهة، ومن أجل كل صورة جديدة تحملها يضعها في المجموعة الأكثر شبهًا لها. هذا مايُسمّى بالعنقدة. أبرز أمثلتها هي الخوارزمية التصنيفية K-Means. خوارزميات التعلم الجماعي Ensemble learning يشير التعلم الجماعي إلى الخوارزميات التي تجمع التنبؤات من نموذجين أو أكثر. على الرغم من وجود عدد غير محدود تقريبًا من الطرق التي يمكن من خلالها تحقيق ذلك، ربما توجد ثلاث فئات من تقنيات التعلم الجماعي التي تتم مناقشتها بشكل شائع واستخدامها في الممارسة العملية: التعبئة Bagging: يعتمد على استخدام عدة نماذج لإنشاء التوقعات، ثم أخذ قرار الغالبية. أي مثلًا كان هناك 3 نماذج تتوقع أن الشخص مريض ونموذج واحد يتوقع أنه غير مريض، فتكون النتيجة أنه غير مريض بتصويت الغالبية. التكديس Stacking: هنا يُستخدم نموذج آخر لمعرفة أفضل طريقة للجمع بين تنبؤات النماذج. التعزيز Boosting: هنا يكون لدينا عدة نماذج وكل منها يُصحح أخطاء الآخر على التسلسل، وصولًا إلى نموذج نهائي قوي (هذا هو النوع الأنجح والأكثر استخدامًا). أبرز الأمثلة على هذه الخوارزميات هي خوارزمية تعزيز التدرج الشديد XGBoost، وتعتبر من خوارزميات التعلم الآلي المستخدمة في مهام التصنيف أو الانحدار، وتندرج تحت مفهوم أساليب التعلم الجماعي التي تجمع بين العديد من النماذج الأضعف (غالبًا أشجار القرار) لإنشاء نموذج تنبؤي قوي. تعزيز التدرج هو مصطلح عام يشير إلى فئة من الخوارزميات حيث يركز كل نموذج لاحق في المجموعة على تصحيح الأخطاء التي ارتكبتها النماذج السابقة. إنه يعمل عن طريق إضافة نماذج جديدة باستمرار، مع تدريب كل نموذج جديد لتقليل الأخطاء التي ارتكبتها النماذج السابقة. الخوارزميات التوليدية Generative هي فئة من خوارزميات الذكاء الاصطناعي التي تهدف إلى إنشاء عينات بيانات جديدة تشبه مجموعة بيانات تدريب معينة. تتعلم هذه النماذج التوزيع الأساسي لبيانات التدريب وتستخدمها لتوليد عينات جديدة تظهر خصائص متشابهة. تُستخدم النماذج التوليدية على نطاق واسع في العديد من التطبيقات، بما في ذلك إنشاء الصور وتوليد النصوص (مثل ChatGPT) وتوليف البيانات. فيما يلي بعض الأنواع الشائعة من النماذج التوليدية: شبكات الخصومة التوليدية GANs: تتكون شبكات GAN من مكونين رئيسيين: شبكة المولدات وشبكة التمييز. يهدف المولد إلى إنتاج عينات بيانات واقعيّة، بينما يحاول المميّز التمييز بين العينات الحقيقية والمولدة، ومن خلال عملية التدريب تتعلم شبكات GAN إنشاء عينات بيانات واقعية. أحد أمثلتها هو توليد صور أشخاص غير حقيقيين. النماذج التوليدية لمعالجة اللغة الطبيعية: يمكن لنماذج مثل شبكات الخصومة التوليدية والشبكات العصبية المتكررة RNN ونماذج المحولات Transformers إنشاء نصوص بيانات واقعية (مثل ChatGPT). تحتوي النماذج التوليدية على مجموعة واسعة من التطبيقات، بما في ذلك تركيب الصور وزيادة حجم مجموعات البيانات وإنشاء النصوص واكتشاف الشذوذ. إنها ذات قيمة في السيناريوهات التي يكون الهدف فيها هو إنشاء عينات بيانات جديدة تلتقط خصائص بيانات التدريب وتوزيعها. خوارزميات التفاعل أو التعلم المعزز RL خوارزميات التعلم المعزز هي فئة من خوارزميات الذكاء الاصطناعي التي تمكّن الوكيل Agents (يمكنك اعتباره الآلة) من تعلم كيفية اتخاذ القرارات أو اتخاذ الإجراءات في بيئة ما لزيادة المكافأة التراكمية. تتعلم خوارزميات RL من خلال التجربة والخطأ، حيث يتفاعل الوكيل مع البيئة ويتلقى تعليقات في شكل مكافآت أو عقوبات بناءًا على صحة الإجراء المُتخذ أو عدم صحته، ويقوم بتعديل سلوكه لتحقيق أعلى مكافأة ممكنة. هناك العديد من المكونات الرئيسية في خوارزميات RL. أولاً، هناك وكيل يتخذ إجراءات في البيئة. هدف الوكيل هو تعلم "سياسة Policy"، وهي رسم خرائط بين الحالات التي يمكن أن يمر بها الوكيل في البيئة والإجراءات التي يمكن أن يقوم بها عند كل حالة، والتي تزيد من المكافأة المتوقعة على المدى الطويل. البيئة هي النظام الخارجي الذي يتفاعل معه الوكيل، والتي تُقدّم ملاحظات للوكيل من خلال المكافآت. تستخدم خوارزميات RL عادةً دالة قيمة أو دالة Q لتقدير المكافأة التراكمية المتوقعة لزوج معين من إجراءات الحالة (مثلا إذا كنت في الحالة S5 واتخذت الإجراء A1 ستحصل على مكافأة 10+). تمثل دالة القيمة المكافأة طويلة الأجل التي يمكن أن يتوقعها الوكيل من كونه في حالة معينة واتباع سياسة معينة. تقدر دالة Q المكافأة التراكمية المتوقعة على وجه التحديد لأزواج (إجراء، حالة). تستخدم خوارزميات RL تقديرات القيمة هذه لتوجيه عملية اتخاذ القرار لدى الوكيل. هناك خوارزميات RL مختلفة مثل Q-Learning وتدرجات السياسة Policy gradients ..إلخ، ولكل منها نهجها الخاص في التعلم والتحسين. تم تطبيق خوارزميات التعلم المعزز بنجاح في مجالات مختلفة، مثل الروبوتات والأنظمة المستقلة ولعب الألعاب وأنظمة التحكم. إنها تمكن الوكلاء من التعلم من التجربة والتكيف مع البيئات المتغيرة واكتشاف الاستراتيجيات المثلى لحل المشكلات المعقدة. تطبيق خوارزميات الذكاء الاصطناعي في الذكاء الصناعي عمومًا ومجال تعلم الآلة خصوصًا، يختلف نهج الخوارزمية عن الخوارزمية التقليدية. السبب هو أن الخطوة الأولى هي معالجة البيانات -وبعد ذلك، سيبدأ الحاسوب في التعلّم. أي عند الحديث عن الخوارزميات في سياق الذكاء الصناعي وتعلم الآلة نتحدث عن الإجراءات والعمليات التي تُطبّق على البيانات لاستكشاف وفهم الأنماط Patterns والعلاقات السائدة في البيانات والتعلّم منها، ويكون نتاج هذه الخوارزميات هو نماذج Models يمكن تطبيقها على أرض الواقع. ملاحظة 1: النموذج هو ناتج الخوارزمية، أي يمكن القول أن النموذج هو خوارزمية مُدرّبة جاهزة للاستخدام والتطبيق الفعلي. تجدر الإشارة إلى أنهما مصطلحان يُستخدمان غالبًا بالتبادل (لافرق في أن تقول نموذج أو خوارزمية)، لكن وجب التنويه للفرق بينهما. ملاحظة 2: النمط هو شكل معيّن تتكرر فيه المعلومات، وهي صفات وخصائص تُميّز الأشياء، وهو مصطلح أساسي في تعلّم الآلة. مثلًا: كل التفاحات لها شكل شبه كروي (نمط)، العرب ينطقون لغة خاصة هي اللغة العربية (نمط)، يمكن تمييز الطبيب في المستشفى من لباسه (نمط). من السهل بناء وتطبيق بعض الخوارزميات، إلا أن بعضها الآخر يتطلّب خطوات برمجية ورياضيات معقدة. الخبر السار هو أنه لا يتعين عليك في معظم الأوقات أن تبني هذه الخوارزميات من الصفر، لأن هناك مجموعة متنوعة من اللغات البرمجية مثل Python و R والعديد من أطر العمل كتنسرفلو Tensorflow وكيراس Keras وباي تورش Pytorch وسكايت ليرن Sklearn التي تجعل العملية سهلة ومباشرة. هناك المئات من خوارزميات تعلم الآلة المتاحة، إلا أنّه يمكن تقسيمها فعليًا إلى أربع فئات رئيسية: التعلم الخاضع للإشراف supervised learning، والتعلم غير الخاضع للإشراف unsupervised learning، والتعلم المعزز reinforcement learning، والتعلم شبه الخاضع للإشراف semi-supervised learning، وقد ألقينا نظرة عن هذه الأنواع في مقالة تعلم الآلة. خطوات تدريب خوارزميات الذكاء الاصطناعي إن الهدف من عملية تدريب الخوارزمية هو إنشاء نموذج يعتمد على تلك الخوارزمية لإعطاء قرارات في أرض الواقع. بالتالي لتحقيق النجاح في تطبيق خوارزميات الذكاء الصناعي على مشكلة ما، من المهم اتباع نهج منظّم، وإلا قد تكون النتائج بعيدة عن المتوقع. إذًا يجب أن نختار خوارزمية مناسبة وأن ندربها بأفضل شكل ممكن لكي نحصل على قرارات مثالية قدر الإمكان. بدايةً تحتاج إلى إجراء عمليات معالجة البيانات، ثم من الجيد (إن أمكن) إجراء تمثيل مرئي لهذه البيانات، حيث يفيدنا التمثيل المرئي في الإجابة على أسئلة مثل: هل هناك بعض الأنماط؟ إذا كانت الإجابة بنعم، فقد تكون البيانات سهلة التعلّم وواضحة للخوارزمية. الخطوة 1: تحديد المشكلة وجمع البيانات: بدايةً يجب أن تحدد المشكلة التي تعمل عليها، وهذا يتضمن الإجابة على أسئلة مثل: ماذا ستكون البيانات التي تعطيها للخوارزمية (أي ما هو الدخل)؟ ما هي المشكلة التي تحاول حلها (أي ماهو الخرج)؟ لا يمكنك الانتقال إلى المرحلة التالية حتى تعرف ما هي المدخلات والمخرجات، والبيانات التي ستستخدمها. تتضمن هذه المرحلة أيضًا فحص البيانات التي تم جمعها وتنظيفها وإصلاح أية مشاكل فيها. الخطوة 2: اختيار الخوارزمية المناسبة: تحتاج الآن إلى تحديد خوارزمية مناسبة لحل هذه المشكلة، وسيكون الأمر أشبه بالتخمين المستنير، أي يجب أن تستفيد من النظريات وتجارب الآخرين، وهذا سيتضمن عملية تجربة وخطأ (قد تجرب عدة خورازميات). الخطوة 3: تحضير البيانات للتدريب: بمجرد أن تعرف ما الذي تريد أن تُدرّب الخوارزمية عليه، تكون جاهزًا تقريبًا لبدء نماذج التدريب. إن تحضير البيانات يعني تنسيقها بطريقة يمكن إدخالها في خوارزمية التعلّم. الخطوة 4: تدريب النموذج: سيتم استخدام حوالي 70% من البيانات المتاحة من أجل تدريب الخوارزمية وإنتاج النموذج. افترض أنك تبني نظامًا للتعلم الآلي للتنبؤ بقيمة السيارة المستعملة. ستشمل البيانات عوامل مثل: سنة التصنيع والطراز والمسافة المقطوعة والحالة. من خلال معالجة بيانات التدريب هذه، ستحسب الخوارزمية أوزان كل من هذه العوامل (وزن تأثيرها في قيمة السيارة) لتعطي نموذجًا يتوقع القيمة بناءًا على هذه العوامل. الخطوة 5: تقييم أداء النموذج: سيتم استخدام حوالي 30% من البيانات المتاحة من أجل تقييم أداء النموذج. في هذه المرحلة يمكنك معرفة ما إذا كان النموذج دقيقًا في قراراته. في مثالنا على السيارات المستعملة، سيكون السؤال: هل تتوافق توقعات النموذج مع قيم السوق في أرض الواقع؟ الخطوة 6: تحسين أداء النموذج: من خلال إضافة بيانات جديدة أو التلاعب بالخوارزمية ومعاملاتها أو حتى تغيير الخورازمية. في القسم التالي سنتحدث عن أنواع خوارزميات الذكاء الاصطناعي. هذه الأنواع تتضمن خوارزميات مختلفة وكلها تندرج تحت الفئات الرئيسية الأربعة سالفة الذكر. خوارزميات الذكاء الاصطناعي والمجتمع تسلط هذه الفقرة الضوء على الأهمية المتزايدة للاعتبارات الأخلاقية والتفسير والإنصاف في خوارزميات الذكاء الصناعي، حيث يستمر تأثير الذكاء الاصطناعي على المجتمع في التوسع. دعونا نتعمق في كل جانب! الاعتبارات الأخلاقية تشمل الاعتبارات الأخلاقية في الذكاء الصناعي معالجة الآثار الأخلاقية والتأثير المجتمعي المحتمل لأنظمة الذكاء الصناعي. نظرًا لأن خوارزميات الذكاء الاصطناعي أصبحت أكثر تكاملًا في جوانب مختلفة من حياتنا، فمن المهم ضمان تطويرها ونشرها بطريقة أخلاقية. يتضمن ذلك اعتبارات مثل حماية الخصوصية وأمن البيانات والتحيّز الخوارزمي والشفافية والمساءلة. تظهر المخاوف الأخلاقية عندما تتخذ خوارزميات الذكاء الصناعي قرارات قد يكون لها عواقب وخيمة على الأفراد أو المجموعات، ومن المهم وضع مبادئ توجيهية وأطر لتقليل الضرر المحتمل وضمان ممارسات الذكاء الاصطناعي الأخلاقية. قابلية التفسير يشير التفسير إلى القدرة على فهم وشرح القرارات أو التنبؤات التي تتخذها خوارزميات الذكاء الصناعي. نظرًا لأن الذكاء الصناعي يصبح أكثر تعقيدًا مع خوارزميات مثل شبكات التعلم العميق، يصبح تفسير النتائج التي تعطيها أصعب. من الضروري تطوير أساليب وتقنيات تمكّن البشر من فهم الأسباب الكامنة وراء قرارات خوارزميات الذكاء الاصطناعي من أجل الثقة بها. يساعد التفسير في تحديد التحيزات المحتملة وضمان المساءلة وبناء ثقة المستخدم. بالإضافة إلى ذلك تسمح القابلية للتفسير لخبراء المجال بالتحقق من صحة نماذج الذكاء الاصطناعي وتحسينها، مما يجعلها أكثر موثوقية وفعالية. الإنصاف يشير الإنصاف في خوارزميات الذكاء الصناعي إلى المعاملة غير المنحازة للأفراد أو المجموعات، بغض النظر عن سماتهم الشخصية مثل الجنس أو العرق أو الحالة الاجتماعية والاقتصادية. يمكن أن يظهر التحيّز عن غير قصد في أنظمة الذكاء الاصطناعي بسبب بيانات التدريب المتحيزة أو الافتراضات الأساسية. يعد تعزيز العدالة في خوارزميات الذكاء الاصطناعي أمرًا بالغ الأهمية لتجنب استمرار عدم المساواة الاجتماعية وضمان تكافؤ الفرص للجميع. تنبع الأهمية المتزايدة لهذه الجوانب من الاعتراف بأن أنظمة الذكاء الاصطناعي لديها القدرة على التأثير بشكل كبير على الأفراد والمجتمعات والمجتمعات ككل. تتم معالجة هذه الاعتبارات بنشاط من قبل الباحثين وصانعي السياسات والمتخصصين في الصناعة لوضع مبادئ توجيهية أخلاقية وتطوير مقاييس الإنصاف وتعزيز الشفافية في خوارزميات الذكاء الاصطناعي. من خلال دمج هذه الاعتبارات في عمليات التطوير والنشر، يمكننا أن نسعى جاهدين من أجل بناء بيئة للذكاء الاصطناعي أكثر أخلاقية وشمولية، ليعود بالنفع على المجتمع ككل. خاتمة خوارزميات الذكاء الاصطناعي مجال واسع يتكون من خوارزميات التعلم الآلي وخوارزميات التعلم العميق وغيرها من الخورازميات. تمنح خوارزميات الذكاء الصناعي الآلات القدرة على اتخاذ القرارات والتعرّف على الأنماط واستخلاص استنتاجات مفيدة والتي تعني أساسًا تقليد الذكاء البشري. في المقالة السابقة ناقشنا تطوّر هذه الخوارزميات منذ ولادة هذا المجال وكيفية تصنيف هذه الخوارزميات إلى 6 فئات. هي: الانحدار والتصنيف والعنقدة والتجميع والتوليد والتفاعل. تعرّفنا على كيفية تطبيق هذه الخوارزميات والخطوات العامة لذلك. لضمان النشر المسؤول والمفيد للذكاء الاصطناعي، تحدثنا عن ضرورة مراعاة الآثار الأخلاقية وضمان القابلية للتفسير من أجل الشفافية والمساءلة والسعي لتحقيق العدالة لتجنب التمييز والتحيز. إن تطوّر خوارزميات الذكاء الصناعي مثير للاهتمام ومحفّز للتفكير. لقد كان لها نصيب من الإخفاقات والاختراقات الهائلة. مع تطبيقات مثل ChatGPT و Dalle.E وغيرهما، نكون قد خدشنا سطح التطبيقات الممكنة للذكاء الصناعي. هناك تحديات أيضًا، وهناك بالتأكيد المزيد في المستقبل. اقرأ أيضًا أنواع الذكاء الاصطناعي الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تطبيقات الذكاء الاصطناعي أهمية الذكاء الاصطناعي المرجع الشامل إلى تعلم الخوارزميات للمبتدئين -

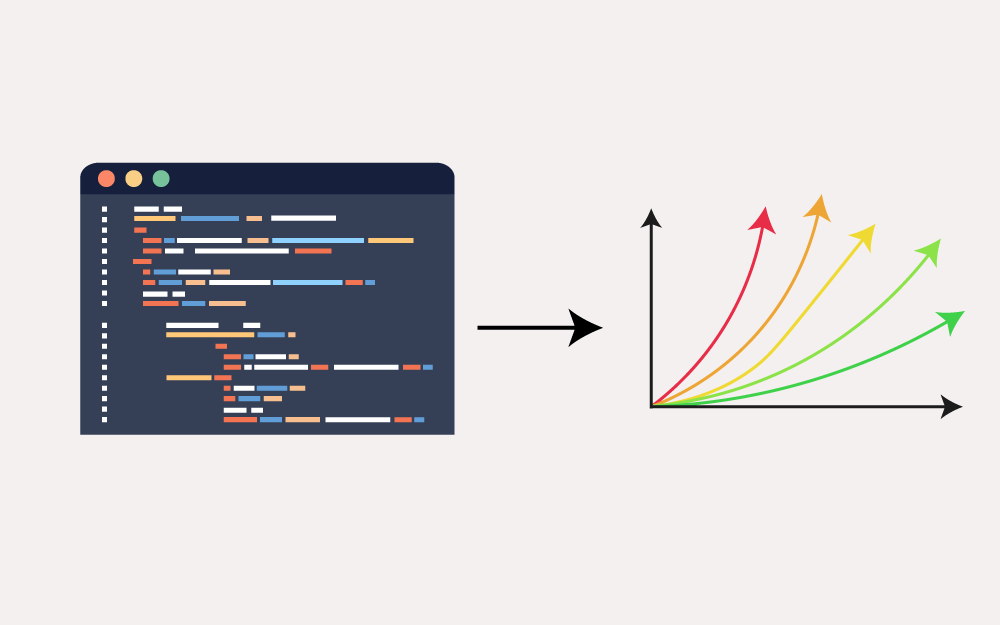 بعد أن تعلمنا كيفية قياس سرعة البرامج في المقال السابق قياس أداء وسرعة تنفيذ شيفرة بايثون، سنتعلم كيفية قياس الزيادات النظرية theoretical increases في وقت التنفيذ runtime مع نمو حجم البيانات الخاصة بالبرنامج، ويُطلق على ذلك في علوم الحاسوب ترميز O الكبير big O notation. ربما يشعر مطورو البرامج الذين ليس لديهم خلفية في علوم الحاسوب التقليدية بوجود نقص في معارفهم، على الرغم من كون المعرفة في علوم الحاسوب مفيدة، لكنه ليس مرتبط مباشرةً مع تطوير البرمجيات. تُعدّ Big O نوعًا من خوارزميات التحليل التي تصف تعقيد الشيفرة مع زيادة عدد العناصر التي تعمل عليها. تصنف الشيفرة في مرتبة تصف عمومًا الوقت الذي تستغرقه الشيفرة لتُنفّذ، وكلما زادت تزيد كمية العمل الواجب إنجازه. يصف مطور لغة بايثون Python نيد باتشلدر Ned Batchelder خوارزمية big O بكونها تحليلًا لكيفية "تباطؤ الشيفرة كلما زادت البيانات" وهو عنوان حديثه في معرض PyCon 2018. لننظر إلى المثال التالي: لنفترض أنه لديك كميةٌ معينةٌ من العمل الذي يستغرق ساعةً ليكتمل، فإذا تضاعفت كمية العمل، كم سيستغرق من الوقت؟ ربما تعتقد أنه سيستغرق ضعف المدة ولكن الجواب الصحيح هو: يعتمد الأمر على نوع العمل المُنجز. إذا استغرقت ساعةً لقراءة كتاب قصير، فستستغرق أكثر أو أقل من ساعتين لقراءة كتابين قصيرين، وإذا كان بإمكانك ترتيب 500 كتاب أبجديًا، سيستغرق ترتيب 1000 كتاب أكثر من ساعتين لأنك ستبحث عن المكان المناسب لكل كتاب في مجموعة أكبر من الكتب. من ناحية أخرى، إذا أردت التأكد أن رف الكتب فارغ أو لا، لا يهم إذا كان هناك 0 أو 10 أو 1000 كتاب على الرف، فنظرةٌ واحدةٌ كافية لتعرف الجواب، إذ سيبقى وقت التنفيذ على حاله بغض النظر عن عدد الكتب الموجودة. يمكن أن يكون بعض الناس أسرع أو أبطأ في قراءة أو ترتيب الكتب أبجديًا ولكن تبقى هذه التوجهات العامة نفسها. تصف خوارزمية big O هذه التوجهات، إذ يمكن أن تُنفذ الخوارزمية على حاسوب سريع أو بطيء ولكننا نستطيع استخدام big O لوصف كيفية عمل الخوارزمية عمومًا، بغض النظر عن العتاد الذي ينفذ هذه الخوارزمية. لا تستخدم big O وحدات معينة مثل الثواني أو دورات المعالج لوصف وقت تنفيذ الخوارزمية لأنها تختلف بين أجهزة الحاسوب ولغات البرمجة. مراتب Big O يُعرّف ترميز Big O عادةً المراتب التالية، التي تتراوح من المنخفضة -التي تصف الشيفرة التي لا تتباطأ كثيرًا كلما زادت البيانات- إلى المراتب العليا -التي تصف الشيفرة الأكثر تباطؤًا: O(1) وقت ثابت (أدنى مرتبة) O(log n) وقت لوغاريتمي O(n) وقت خطي O(n log n) وقت N-Log-N O(n2) وقت متعدد الحدود O(2n) وقت أسي O(n!) وقت عاملي (أعلى مرتبة) لاحظ أن big O تستخدم حرف O كبير متبوعًا بقوسين يحتويان وصف المرتبة، إذ يمثّل حرف O الكبير المرتبة وتمثل n حجم دخل البيانات التي تعمل عليها الشيفرة. نلفظها "big oh of n" أو "big oh n". لا تحتاج لفهم المعنى الدقيق لكلمات مثل لوغاريتمي أو حدودي لاستخدام صيغة big O، إذ سنصِف كل نوع بالتفصيل في الفقرة التالية ولكن هذا تبسيط لهم: خوارزميات O(1) و O(log n) سريعة خوارزميات O(n) و O(n log n) ليست سيئة خوارزميات O(n2) و O(2n) بطيئة يمكن طبعًا مناقشة العكس في بعض الحالات ولكن هذه التوصيفات هي قواعد جيدة عمومًا، فهناك مراتب أكثر من big O المذكورة هنا ولكن هذه هي الأعم. دعنا نتحدث عن أنواع المهام التي يصفها كل نوع من هذه المهام. اصطلاح رف الكتب Bookshelf لمراتب Big O سنستمر في المثال التالي لمراتب big O باستخدام مصطلح رف الكتب، إذ تمثّل n عدد الكتب في الرف ويصف ترميز Big O كيف أن المهام المختلفة تستغرق وقتًا أطول كلما زاد عدد الكتب. تعقيد O(1): وقت ثابت معرفة "هل رف الكتب فارغ؟" هي عملية ذات وقت ثابت، إذ لا يهم عدد الكتب في الرف، فنظرةٌ واحدةٌ ستخبرنا ما إذا كان رف الكتب فارغ أم لا. يمكن أن يختلف عدد الكتب ولكن وقت التنفيذ يبقى ثابتًا، لأنه طالما رأينا كتابًا واحدًا على الرف يمكننا إيقاف البحث. القيمة n غير مهمة لسرعة تنفيذ المهمة لذا لا يوجد n في O(1). يمكنك أيضًا رؤية الوقت الثابت مكتوبًا (O(c أحيانًا . تعقيد O(log n): لوغاريتمي اللوغاريتم هو عكس الأس، الأس 24 أو 2×2×2×2 يساوي 16 ولكن اللوغاريتم log2(16) (تلفظ لوغاريتم أساس 2 للعدد 16) يساوي 4. نفترض في البرمجة قيمة الأساس 2 ولذلك نكتب O(log n) بدلًا من O(log2 n). البحث عن كتاب في رف كتب مرتب أبجديًا هي عملية لوغاريتمية الوقت؛ فمن أجل إيجاد كتاب واحد، يمكن التحقق من الكتاب في منتصف الرف، وإذا كان هو الكتاب المطلوب تكون قد انتهيت، وإذا لم يكن كذلك، يمكن تحديد إذا كان الكتاب قبل أو بعد الكتاب الذي في المنتصف. يقلل ذلك مجال البحث إلى النصف، ويمكنك تكرار هذه العملية مجددًا من خلال فحص الكتاب الذي في منتصف النصف الذي تتوقع فيه إيجاد الكتاب. نسمي ذلك خوارزمية بحث ثنائية binary search وهناك مثال على ذلك في "أمثلة عن ترميز Big O" لاحقًا. عدد المرات التي تستطيع قسم مجموعة n كتاب للنصف هي log2 n، في رف فيه 16 كتاب ستحتاج إلى 4 خطوات على الأكثر لإيجاد الكتاب الصحيح، لأن كل خطوة تقلل عدد الكتب التي يجب البحث فيها إلى النصف. يحتاج رف الكتب الذي فيه ضعف عدد الكتب فقط إلى خطوة إضافية واحدة للبحث عنه. إذا كان هناك 4.2 مليار كتاب في رف كتب مرتبة أبجديًا ستحتاج فقط إلى 32 خطوة لإيجاد كتاب معين. تتضمن خوارزميات Log n عادةً خطوة فرّق تسد divide and conquer وتنطوي على اختيار نصف دخل n للعمل عليه وبعدها نصف آخر من ذلك النصف وهكذا دواليك. تتدرج عمليات log n جيدًا، إذ يمكن أن يزداد العمل n إلى الضعف ولكن سيزداد وقت التنفيذ خطوةً واحدةً فقط. تعقيد O(n): وقت خطي تستغرق عملية قراءة كل الكتب على الرف وقتًا خطيًا؛ فإذا كانت الكتب بنفس الطول تقريبًا وضاعفت عدد الكتب على الرف، فسيستغرق ضعف الوقت تقريبًا لقراءة كل الكتب، ويزداد وقت التنفيذ بالتناسب مع عدد الكتب n. تعقيد O(n log n): وقت N-Log-N ترتيب الكتب أبجديًا هي عملية تستغرق وقت n-log-n. هذه المرتبة هي ناتج ضرب وقتي التنفيذ O(n) و O(log n) ببعضهما. يمكن القول أن مهمة O(n log n) هي مهمة O(log n) مع تنفيذها n مرة. فيما يلي تفسير بسيط حول ذلك. ابدأ بمجموعة كتب يجب ترتيبها أبجديًا ورف كتب فارغ، واتبع الخطوات في خوارزمية البحث الثنائي كما موضح في الفقرة السابقة "تعقيد O(log n): زمن لوغاريتمي" لمعرفة مكان كل كتاب على الرف. هذه عملية O(log n)، ومن أجل ترتيب n كتاب أبجديًا وكان كل كتاب بحاجة إلى log n خطوة لترتيبه أبجديًا، ستحتاج n×log n أو n log n خطوة لترتيب كل مجموعة الكتب أبجديًا. إذا تضاعف عدد الكتب سيستغرق أكثر من ضعف الوقت لترتيبهم أبجديًا، لذا تتدرج خوارزميات n log n جيدًا. خوارزميات الترتيب ذات الكفاءة، هي: O(n log n)، مثل ترتيب الدمج merge sort والترتيب السريع quicksort وترتيب الكومة heapsort وترتيب تيم Timsort (من اختراع تيم بيترز Tim Peters وهي الخوارزمية التي يستخدمها تابع sort() الخاص ببايثون). تعقيد O(n2): وقت متعدد الحدود التحقق من الكتب المكررة في رف كتب غير مرتب هي عملية تستغرق وقت حدودي polynomial time operation؛ فإذا كان هناك 100 كتاب يمكنك أن تبدأ بالكتاب الأول وتقارنه مع التسعة وتسعون الكتاب الباقين لمعرفة التشابه، ثم نأخذ ثاني كتاب ونتحقق بنفس الطريقة مثل باقي بقية الكتب التسعة وتسعون. خطوات التحقق من التكرار لكتاب واحد هي 99 (سنقرّب هذا الرقم إلى 100 الذي هو n في هذا المثال). يجب علينا فعل ذلك 100 مرة، مرةً لكل كتاب، لذا عدد خطوات التحقق لكل كتاب على الرف هو تقريبًا n×n أو n2. (يبقى هذا التقريب n2 صالحًا حتى لو كنا أذكياء ولم نكرر المقارنات). يزداد وقت التنفيذ بازدياد عدد الكتب تربيعيًا. سيأخذ التحقق من التكرار لمئة كتاب 100×100 أو 10,000 خطوة، ولكن التحقق من ضعف هذه القيمة أي 200 كتاب سيكون 200×200 أو 40,000 خطوة، أي أربع مرات عمل أكثر. وجد بعض الخبراء في كتابة الشيفرات الواقعية للعالم الحقيقي أن معظم استخدامات تحليل big O هي لتفادي كتابة خوارزمية O(n2) عن طريق الخطأ، عند وجود خوارزمية O(n log n) أو O(n). مرتبة O(n2) هي عندما تبدأ الخوارزميات بالتباطؤ كثيرًا، لذا معرفة أن الشيفرة الخاصة بك في مرتبة O(n2) أو أعلى يجب أن يجعلك تتوقف. ربما توجد خوارزمية مختلفة يمكنها حل المشكلة بصورةٍ أسرع، ويمكن في هذه الحالة أن يكون الإطلاع على قسم هيكلة البيانات والخوارزميات Data Structure and Algorithms -أو اختصارًا DSA- إما على أكاديمية حسوب مفيدًا. نسمي أيضًا O(n2) وقتًا تربيعيًا، ويمكن أن يكون لخوارزميات O(n3) وقتًا تكعيبيًا وهو أبطأ من O(n2) أو وقتًا رباعيًا O(n4) الذي هو أبطأ من O(n3) أو غيره من الأوقات الزمنية متعددة الحدود. تعقيد O(2n): وقت أسي أخذ صور لرف الكتب مع كل مجموعة ممكنة من الكتب هو عملية تستغرق وقتًا أُسّيًا. انظر لهذا الأمر بهذه الطريقة، كل كتاب على الرف يمكن أن يكون في الصورة أو لا يكون. يبين الشكل 1 كل مجموعة ممكنة، إذ تكون n هي 1 أو 2 أو 3. إذا كانت n هي 1 هناك طريقين للتجميع، إذا كانت n هي 2 هناك أربعة صور ممكنة، الكتابان على الرف، أو الكتابان ليسا على الرف، أو الكتاب الأول موجود والثاني ليس موجودًا، أو الكتاب الأول ليس موجودًا والثاني موجود. إذا أضفنا كتابًا ثالثًا، نكون قد ضاعفنا مرةً ثانية العمل المُراد فعله، لذا يجب عليك النظر إلى كل مجموعة فرعية لكتابين التي تضم الكتاب الثالث (أربعة صور) وكل مجموعة فرعية لكتابين دون الكتاب الثالث (أربعة صور أُخرى أي 23 أو 8 صور). يضاعف كل كتاب إضافي كمية العمل، فمن أجل n كتاب سيكون عدد الصور التي يجب أخذها (أي العمل الواجب فعله) هو 2n. [الشكل 1: مجموعة الكتب الممكنة على رف كتب من أجل كتاب واحد أو اثنين أو ثلاث كتب] يزداد وقت التنفيذ للمهام الأُسية بسرعة كبيرة. تحتاج ستة كتب إلى 26 أو 32 صورة، ولكن 32 كتاب يحتاج 232 أو أكثر من 4.2 مليار صورة. مرتبة O(22) أو O(23) أو O(24) وما بعدها هي مراتب مختلفة ولكنها كلها تحتوي تعقيدات وقت أُسّي. تعقيد O(n!): وقت عاملي أخذ صورةٍ لكل ترتيب معين هي عملية تستغرق وقتًا عاملي. نطلق على كل ترتيب ممكن اسم التبديل permutation من أجل n كتاب. النتيجة هي ترتيب n! أو n عاملي، فمثلًا 3! هي 3×2×1 أو 6. يبين الشكل 2 كل التبديلات الممكنة لثلاثة كتب. [الشكل 2: كل تبديلات !3 (أي 6) لثلاثة كتب على رف كتب] لحساب ذلك بنفسك، فكر بكل التبديلات الممكنة بالنسبة إلى n كتاب. لديك n خيار ممكن للكتاب الأول وبعدها n-1 خيار ممكن للكتاب الثاني (أي كل كتاب ما عدا المكان الذي اخترته للكتاب الأول) وبعدها n-2 خيار ممكن للكتاب الثالث وهكذا دواليك. مع 6 كتب تكون نتيجة !6 هي 6×5×4×3×2×1 أو 720 صورة. إضافة كتاب واحد آخر يجعل عدد الصور المطلوبة !7 أو 5.040. حتى من أجل قيم n صغيرة، تصبح خوارزميات الوقت العاملي مستحيلة الإنجاز في وقت منطقي، فإذا كان لديك 20 كتاب ويمكنك ترتيبهم وأخذ صورة كل ثانية، فستحتاج إلى وقت أكثر من عمر الكون للانتهاء من كل تبديل. واحدة من مشاكل O(n!) المعروفة هي معضلة مندوب المبيعات المسافر، إذ يجب على مندوب المبيعات أن يزور n مدينة ويريد حساب المسافة المقطوعة لكل مراتب n! الممكنة والتي يمكنه زيارتها، إذ يستطيع من تلك الحالات إيجاد أقصر طريق، ومن أجل منطقة بعدد كبير من المدن تصبح هذه المهمة مستحيلة الإنجاز في وقت منطقي. لحسن الحظ هناك خوارزميات مُحسنة لإيجاد طريق قصير (ولكن ليس من المضمون أن يكون الأقصر) بطريقة أسرع من O(n!). يحسب ترميز Big O الحالات الأسوأ يحسب Big O أسوأ حالة ممكنة لأي مهمة، إذ يحتاج إيجاد كتاب معين في رف كتب غير مُنظم مثلًا أن تبدأ من أحد الأطراف وتتحقق من الكتب حتى تجد الكتاب المطلوب. يمكن أن تكون محظوظًا ويكون الكتاب المطلوب هو أول كتاب تتحقق منه، ولكن ربما تكون سيء الحظ ويكون الكتاب الذي تريده هو آخر كتاب تتحقق منه، أو قد لا يكون موجودًا على الرف إطلاقًا. لذلك، في أفضل الحالات لا يهم إذا كان هناك مليارات الكتب التي يجب البحث فيها لأنك ستجد الكتاب الذي تريده مباشرةً، لكن هذا التفاؤل ليس مفيدًا في خوارزميات التحليل. تصف Big O ماذا يحصل في الحالات الأسوأ حظًا، أي إذا كان لديك n كتاب يجب عليك البحث في كل الكتب، ففي هذا المثال يزداد وقت التنفيذ بنفس معدل ازدياد عدد الكتب. يستخدم بعض المبرمجين ترميز big Omega لوصف الحالة الأفضل للخوارزمية، فمثلًا تعمل خوارزمية Ω(n) بكفاءة خطية في أفضل حالاتها وفي الحالة الأسوأ ربما تستغرق وقتًا أطول. تواجه بعض الخوارزميات حالات محظوظة جدًا، يحيث لا تعمل أي شيء، مثل إيجاد مسار الطريق لمكان أنت أصلًا فيه. يصف ترميز Big Theta الخوارزميات التي لها الترتيب نفسه في أسوأ وأفضل الحالات، فمثلًا تصف Θ(n) خوارزميةً لديها كفاءة خطية في أحسن وأسوأ الحالات، أي أنها خوارزمية O(n) وكذلك Ω(n). لا يُستخدم هذين الترميزين كثيرًا مثل استخدام big O ولكن تجدر معرفتهما. يُعد سماع الناس يتحدثون عن "big O الحالة الوسطية" عندما يعنون big Theta أو "big O الحالة الفُضلى" عندما يعنون big Omega أمرًا شائعًا رغم أنه متناقض؛ إذ تصف big O الحالة الأسوأ لوقت تنفيذ الخوارزمية تحديدًا، ولكن حتى لو كانت كلماتهم خاطئة لا تزال تفهم المعنى بغض النظر. العمليات الرياضية الكافية للتعامل مع Big O إذا كان علم الجبر لديك ضعيفًا فمعرفة العمليات الرياضية التالية أكثر من كافي عند التعامل مع big O: الضرب: تكرار الإضافة أي 2×4=8 هو مثل 2+2+2+2=8، وفي حال المتغيرات يكون n+n+n هو 3×n. ترميز الضرب: يهمل ترميز الجبر عادةً إشارة ×، لذا 2×n تُكتب 2n ومع الأرقام 3×2 تُكتب (3)2 أو ببساطة 6. خاصية الضرب بالعدد 1: ضرب أي عدد بالرقم 1 يُنتج الرقم نفسه أي 5=x15 و42 =x142 أو عمومًا n×1=n توزيع الضرب على الجمع: (3×2) + (3×2) = (4+3)2x كل طرف من المعادلة يساوي 14 أي عمومًا a(b+c) = ab+ac الأس: تكرار الضرب 16= 24 (تُلفظ "2 مرفوعة للقوة الرابعة تساوي 16") مثل 2×2×2×2= 16 هنا تكون 2 هي الأساس و 4 هي الأس. باستخدام المتغيرات n×n×n×n هي n4. يُستخدم في بايثون المعامل ** على سبيل المثال 2**4 تساوي 16. الأس الأول يساوي الأساس: 2= 21 و 9999=99991 وبصورةٍ عامة n1=n الأس 0 يساوي 1: 1= 20 و 1=99990 وبصورةٍ عامة n0=1 المعاملات: عوامل الضرب في 3n2+4n+5 المعاملات هي 3 و4 و5. يمكنك معرفة أن 5 هي معامل لأن 5 يمكن أن يُعاد كتابتها بالشكل (1)5 وأيضًا يمكن إعادة كتابتها 5n0. اللوغاريتمات: عكس الأس. لأن 16=24 نعرف أن log2(16)=4. نفول لوغاريتم الأساس 2 للعدد 16 هو 4. نستخدم في بايثون دالة math.log() إذ math.log(16, 2) تساوي إلى 4.0. يتطلب حساب big O تبسيط العمليات عن طريق جمع الحدود المتشابهة؛ والحد هو مجموعة من الأرقام والمتغيرات مضروبة مع بعضها، ففي 3n2+4n+5 تكون الحدود هي 3n2 و4n و5، إذ أن الحدود المتشابهة لديها نفس المتغير مرفوعًا لنفس القوة. في التعبير 3n2+4n+6n+5 الحدان 4n و6n هما متشابهان بإمكاننا التبسيط وإعادة الكتابة كالتالي 3n2+10n+5. خذ بالحسبان أنه يمكن كتابة 3n2+5n+4 على النحو التالي 3n2+5n+4(1)، إذ تطابق الحدود في هذا التعبير مرتبات big O التالية O(n2) و O(n) و O(1). سيفيد هذا لاحقًا عندما نُسقط المعاملات في حسابات big O. ستفيد هذه التذكرة عندما تحاول معرفة big O لقطعة من الشيفرة، ولكن لن تحتاجها بعد أن تنتهي من "تحليل Big O بنظرة سريعة" في المقال التالي. مفهوم big O بسيط ويمكن أن يفيد حتى لو لم تتبع القواعد الرياضية بصرامة. الخلاصة يُعد ترميز Big O من أكثر المفاهيم انتشارًا في علم الحواسيب للمبرمجين، وهو بحاجة لبعض المفاهيم في الرياضيات لفهمه، ولكن يمكن للمفهوم الأساسي، ألا وهو معرفة أن الشيفرة ستبطأ كلما زادت البيانات، أن يصف الخوارزميات دون الحاجة إلى أرقام كبيرة لحسابها. هناك سبع مراتب لترميز big O، وهي: O(1) أو الوقت الثابت، الذي يصف الشيفرة التي لا تتغير مع زيادة البيانات؛ و O(log n) أو الوقت اللوغاريتمي الذي يصف الشيفرة التي تزداد بخطوة كلما تضاعف عدد البيانات بمقدار n؛ و O(n) أو الوقت الخطي، الذي يصف الشيفرة التي تتباطأ يتناسب مع زيادة حجم البيانات بمقدار n؛ و O(n log n) أو وقت n-log-n، الذي يصف الشيفرة التي هي أبطأ من O(n) والعديد من خوارزميات الترتيب لديها هذه المرتبة. المراتب الأعلى هي أبطأ لأن وقت تنفيذها يزداد بصورةٍ أسرع من زيادة حجم دخل البيانات. يصف الوقت الحدودي O(n2) الشيفرة التي يزداد وقت تنفيذها بتربيع الدخل n. ليست المراتب O(2n) أو الوقت الأسّي، و O(n!) أو الوقت العاملي شائعة جدًا، ولكنها تأتي مع المجموعات والتبديلات على الترتيب. ترجمة -وبتصرف- لقسم من الفصل Measuring Performance And Big O Algorithm Analysis من كتاب Beyond the Basic Stuff with Python. اقرأ أيضًا المقال السابق: قياس أداء وسرعة تنفيذ شيفرة بايثون -تحليل الخوارزميات تعقيد الخوارزميات Algorithms Complexity دليل شامل عن تحليل تعقيد الخوارزمية
بعد أن تعلمنا كيفية قياس سرعة البرامج في المقال السابق قياس أداء وسرعة تنفيذ شيفرة بايثون، سنتعلم كيفية قياس الزيادات النظرية theoretical increases في وقت التنفيذ runtime مع نمو حجم البيانات الخاصة بالبرنامج، ويُطلق على ذلك في علوم الحاسوب ترميز O الكبير big O notation. ربما يشعر مطورو البرامج الذين ليس لديهم خلفية في علوم الحاسوب التقليدية بوجود نقص في معارفهم، على الرغم من كون المعرفة في علوم الحاسوب مفيدة، لكنه ليس مرتبط مباشرةً مع تطوير البرمجيات. تُعدّ Big O نوعًا من خوارزميات التحليل التي تصف تعقيد الشيفرة مع زيادة عدد العناصر التي تعمل عليها. تصنف الشيفرة في مرتبة تصف عمومًا الوقت الذي تستغرقه الشيفرة لتُنفّذ، وكلما زادت تزيد كمية العمل الواجب إنجازه. يصف مطور لغة بايثون Python نيد باتشلدر Ned Batchelder خوارزمية big O بكونها تحليلًا لكيفية "تباطؤ الشيفرة كلما زادت البيانات" وهو عنوان حديثه في معرض PyCon 2018. لننظر إلى المثال التالي: لنفترض أنه لديك كميةٌ معينةٌ من العمل الذي يستغرق ساعةً ليكتمل، فإذا تضاعفت كمية العمل، كم سيستغرق من الوقت؟ ربما تعتقد أنه سيستغرق ضعف المدة ولكن الجواب الصحيح هو: يعتمد الأمر على نوع العمل المُنجز. إذا استغرقت ساعةً لقراءة كتاب قصير، فستستغرق أكثر أو أقل من ساعتين لقراءة كتابين قصيرين، وإذا كان بإمكانك ترتيب 500 كتاب أبجديًا، سيستغرق ترتيب 1000 كتاب أكثر من ساعتين لأنك ستبحث عن المكان المناسب لكل كتاب في مجموعة أكبر من الكتب. من ناحية أخرى، إذا أردت التأكد أن رف الكتب فارغ أو لا، لا يهم إذا كان هناك 0 أو 10 أو 1000 كتاب على الرف، فنظرةٌ واحدةٌ كافية لتعرف الجواب، إذ سيبقى وقت التنفيذ على حاله بغض النظر عن عدد الكتب الموجودة. يمكن أن يكون بعض الناس أسرع أو أبطأ في قراءة أو ترتيب الكتب أبجديًا ولكن تبقى هذه التوجهات العامة نفسها. تصف خوارزمية big O هذه التوجهات، إذ يمكن أن تُنفذ الخوارزمية على حاسوب سريع أو بطيء ولكننا نستطيع استخدام big O لوصف كيفية عمل الخوارزمية عمومًا، بغض النظر عن العتاد الذي ينفذ هذه الخوارزمية. لا تستخدم big O وحدات معينة مثل الثواني أو دورات المعالج لوصف وقت تنفيذ الخوارزمية لأنها تختلف بين أجهزة الحاسوب ولغات البرمجة. مراتب Big O يُعرّف ترميز Big O عادةً المراتب التالية، التي تتراوح من المنخفضة -التي تصف الشيفرة التي لا تتباطأ كثيرًا كلما زادت البيانات- إلى المراتب العليا -التي تصف الشيفرة الأكثر تباطؤًا: O(1) وقت ثابت (أدنى مرتبة) O(log n) وقت لوغاريتمي O(n) وقت خطي O(n log n) وقت N-Log-N O(n2) وقت متعدد الحدود O(2n) وقت أسي O(n!) وقت عاملي (أعلى مرتبة) لاحظ أن big O تستخدم حرف O كبير متبوعًا بقوسين يحتويان وصف المرتبة، إذ يمثّل حرف O الكبير المرتبة وتمثل n حجم دخل البيانات التي تعمل عليها الشيفرة. نلفظها "big oh of n" أو "big oh n". لا تحتاج لفهم المعنى الدقيق لكلمات مثل لوغاريتمي أو حدودي لاستخدام صيغة big O، إذ سنصِف كل نوع بالتفصيل في الفقرة التالية ولكن هذا تبسيط لهم: خوارزميات O(1) و O(log n) سريعة خوارزميات O(n) و O(n log n) ليست سيئة خوارزميات O(n2) و O(2n) بطيئة يمكن طبعًا مناقشة العكس في بعض الحالات ولكن هذه التوصيفات هي قواعد جيدة عمومًا، فهناك مراتب أكثر من big O المذكورة هنا ولكن هذه هي الأعم. دعنا نتحدث عن أنواع المهام التي يصفها كل نوع من هذه المهام. اصطلاح رف الكتب Bookshelf لمراتب Big O سنستمر في المثال التالي لمراتب big O باستخدام مصطلح رف الكتب، إذ تمثّل n عدد الكتب في الرف ويصف ترميز Big O كيف أن المهام المختلفة تستغرق وقتًا أطول كلما زاد عدد الكتب. تعقيد O(1): وقت ثابت معرفة "هل رف الكتب فارغ؟" هي عملية ذات وقت ثابت، إذ لا يهم عدد الكتب في الرف، فنظرةٌ واحدةٌ ستخبرنا ما إذا كان رف الكتب فارغ أم لا. يمكن أن يختلف عدد الكتب ولكن وقت التنفيذ يبقى ثابتًا، لأنه طالما رأينا كتابًا واحدًا على الرف يمكننا إيقاف البحث. القيمة n غير مهمة لسرعة تنفيذ المهمة لذا لا يوجد n في O(1). يمكنك أيضًا رؤية الوقت الثابت مكتوبًا (O(c أحيانًا . تعقيد O(log n): لوغاريتمي اللوغاريتم هو عكس الأس، الأس 24 أو 2×2×2×2 يساوي 16 ولكن اللوغاريتم log2(16) (تلفظ لوغاريتم أساس 2 للعدد 16) يساوي 4. نفترض في البرمجة قيمة الأساس 2 ولذلك نكتب O(log n) بدلًا من O(log2 n). البحث عن كتاب في رف كتب مرتب أبجديًا هي عملية لوغاريتمية الوقت؛ فمن أجل إيجاد كتاب واحد، يمكن التحقق من الكتاب في منتصف الرف، وإذا كان هو الكتاب المطلوب تكون قد انتهيت، وإذا لم يكن كذلك، يمكن تحديد إذا كان الكتاب قبل أو بعد الكتاب الذي في المنتصف. يقلل ذلك مجال البحث إلى النصف، ويمكنك تكرار هذه العملية مجددًا من خلال فحص الكتاب الذي في منتصف النصف الذي تتوقع فيه إيجاد الكتاب. نسمي ذلك خوارزمية بحث ثنائية binary search وهناك مثال على ذلك في "أمثلة عن ترميز Big O" لاحقًا. عدد المرات التي تستطيع قسم مجموعة n كتاب للنصف هي log2 n، في رف فيه 16 كتاب ستحتاج إلى 4 خطوات على الأكثر لإيجاد الكتاب الصحيح، لأن كل خطوة تقلل عدد الكتب التي يجب البحث فيها إلى النصف. يحتاج رف الكتب الذي فيه ضعف عدد الكتب فقط إلى خطوة إضافية واحدة للبحث عنه. إذا كان هناك 4.2 مليار كتاب في رف كتب مرتبة أبجديًا ستحتاج فقط إلى 32 خطوة لإيجاد كتاب معين. تتضمن خوارزميات Log n عادةً خطوة فرّق تسد divide and conquer وتنطوي على اختيار نصف دخل n للعمل عليه وبعدها نصف آخر من ذلك النصف وهكذا دواليك. تتدرج عمليات log n جيدًا، إذ يمكن أن يزداد العمل n إلى الضعف ولكن سيزداد وقت التنفيذ خطوةً واحدةً فقط. تعقيد O(n): وقت خطي تستغرق عملية قراءة كل الكتب على الرف وقتًا خطيًا؛ فإذا كانت الكتب بنفس الطول تقريبًا وضاعفت عدد الكتب على الرف، فسيستغرق ضعف الوقت تقريبًا لقراءة كل الكتب، ويزداد وقت التنفيذ بالتناسب مع عدد الكتب n. تعقيد O(n log n): وقت N-Log-N ترتيب الكتب أبجديًا هي عملية تستغرق وقت n-log-n. هذه المرتبة هي ناتج ضرب وقتي التنفيذ O(n) و O(log n) ببعضهما. يمكن القول أن مهمة O(n log n) هي مهمة O(log n) مع تنفيذها n مرة. فيما يلي تفسير بسيط حول ذلك. ابدأ بمجموعة كتب يجب ترتيبها أبجديًا ورف كتب فارغ، واتبع الخطوات في خوارزمية البحث الثنائي كما موضح في الفقرة السابقة "تعقيد O(log n): زمن لوغاريتمي" لمعرفة مكان كل كتاب على الرف. هذه عملية O(log n)، ومن أجل ترتيب n كتاب أبجديًا وكان كل كتاب بحاجة إلى log n خطوة لترتيبه أبجديًا، ستحتاج n×log n أو n log n خطوة لترتيب كل مجموعة الكتب أبجديًا. إذا تضاعف عدد الكتب سيستغرق أكثر من ضعف الوقت لترتيبهم أبجديًا، لذا تتدرج خوارزميات n log n جيدًا. خوارزميات الترتيب ذات الكفاءة، هي: O(n log n)، مثل ترتيب الدمج merge sort والترتيب السريع quicksort وترتيب الكومة heapsort وترتيب تيم Timsort (من اختراع تيم بيترز Tim Peters وهي الخوارزمية التي يستخدمها تابع sort() الخاص ببايثون). تعقيد O(n2): وقت متعدد الحدود التحقق من الكتب المكررة في رف كتب غير مرتب هي عملية تستغرق وقت حدودي polynomial time operation؛ فإذا كان هناك 100 كتاب يمكنك أن تبدأ بالكتاب الأول وتقارنه مع التسعة وتسعون الكتاب الباقين لمعرفة التشابه، ثم نأخذ ثاني كتاب ونتحقق بنفس الطريقة مثل باقي بقية الكتب التسعة وتسعون. خطوات التحقق من التكرار لكتاب واحد هي 99 (سنقرّب هذا الرقم إلى 100 الذي هو n في هذا المثال). يجب علينا فعل ذلك 100 مرة، مرةً لكل كتاب، لذا عدد خطوات التحقق لكل كتاب على الرف هو تقريبًا n×n أو n2. (يبقى هذا التقريب n2 صالحًا حتى لو كنا أذكياء ولم نكرر المقارنات). يزداد وقت التنفيذ بازدياد عدد الكتب تربيعيًا. سيأخذ التحقق من التكرار لمئة كتاب 100×100 أو 10,000 خطوة، ولكن التحقق من ضعف هذه القيمة أي 200 كتاب سيكون 200×200 أو 40,000 خطوة، أي أربع مرات عمل أكثر. وجد بعض الخبراء في كتابة الشيفرات الواقعية للعالم الحقيقي أن معظم استخدامات تحليل big O هي لتفادي كتابة خوارزمية O(n2) عن طريق الخطأ، عند وجود خوارزمية O(n log n) أو O(n). مرتبة O(n2) هي عندما تبدأ الخوارزميات بالتباطؤ كثيرًا، لذا معرفة أن الشيفرة الخاصة بك في مرتبة O(n2) أو أعلى يجب أن يجعلك تتوقف. ربما توجد خوارزمية مختلفة يمكنها حل المشكلة بصورةٍ أسرع، ويمكن في هذه الحالة أن يكون الإطلاع على قسم هيكلة البيانات والخوارزميات Data Structure and Algorithms -أو اختصارًا DSA- إما على أكاديمية حسوب مفيدًا. نسمي أيضًا O(n2) وقتًا تربيعيًا، ويمكن أن يكون لخوارزميات O(n3) وقتًا تكعيبيًا وهو أبطأ من O(n2) أو وقتًا رباعيًا O(n4) الذي هو أبطأ من O(n3) أو غيره من الأوقات الزمنية متعددة الحدود. تعقيد O(2n): وقت أسي أخذ صور لرف الكتب مع كل مجموعة ممكنة من الكتب هو عملية تستغرق وقتًا أُسّيًا. انظر لهذا الأمر بهذه الطريقة، كل كتاب على الرف يمكن أن يكون في الصورة أو لا يكون. يبين الشكل 1 كل مجموعة ممكنة، إذ تكون n هي 1 أو 2 أو 3. إذا كانت n هي 1 هناك طريقين للتجميع، إذا كانت n هي 2 هناك أربعة صور ممكنة، الكتابان على الرف، أو الكتابان ليسا على الرف، أو الكتاب الأول موجود والثاني ليس موجودًا، أو الكتاب الأول ليس موجودًا والثاني موجود. إذا أضفنا كتابًا ثالثًا، نكون قد ضاعفنا مرةً ثانية العمل المُراد فعله، لذا يجب عليك النظر إلى كل مجموعة فرعية لكتابين التي تضم الكتاب الثالث (أربعة صور) وكل مجموعة فرعية لكتابين دون الكتاب الثالث (أربعة صور أُخرى أي 23 أو 8 صور). يضاعف كل كتاب إضافي كمية العمل، فمن أجل n كتاب سيكون عدد الصور التي يجب أخذها (أي العمل الواجب فعله) هو 2n. [الشكل 1: مجموعة الكتب الممكنة على رف كتب من أجل كتاب واحد أو اثنين أو ثلاث كتب] يزداد وقت التنفيذ للمهام الأُسية بسرعة كبيرة. تحتاج ستة كتب إلى 26 أو 32 صورة، ولكن 32 كتاب يحتاج 232 أو أكثر من 4.2 مليار صورة. مرتبة O(22) أو O(23) أو O(24) وما بعدها هي مراتب مختلفة ولكنها كلها تحتوي تعقيدات وقت أُسّي. تعقيد O(n!): وقت عاملي أخذ صورةٍ لكل ترتيب معين هي عملية تستغرق وقتًا عاملي. نطلق على كل ترتيب ممكن اسم التبديل permutation من أجل n كتاب. النتيجة هي ترتيب n! أو n عاملي، فمثلًا 3! هي 3×2×1 أو 6. يبين الشكل 2 كل التبديلات الممكنة لثلاثة كتب. [الشكل 2: كل تبديلات !3 (أي 6) لثلاثة كتب على رف كتب] لحساب ذلك بنفسك، فكر بكل التبديلات الممكنة بالنسبة إلى n كتاب. لديك n خيار ممكن للكتاب الأول وبعدها n-1 خيار ممكن للكتاب الثاني (أي كل كتاب ما عدا المكان الذي اخترته للكتاب الأول) وبعدها n-2 خيار ممكن للكتاب الثالث وهكذا دواليك. مع 6 كتب تكون نتيجة !6 هي 6×5×4×3×2×1 أو 720 صورة. إضافة كتاب واحد آخر يجعل عدد الصور المطلوبة !7 أو 5.040. حتى من أجل قيم n صغيرة، تصبح خوارزميات الوقت العاملي مستحيلة الإنجاز في وقت منطقي، فإذا كان لديك 20 كتاب ويمكنك ترتيبهم وأخذ صورة كل ثانية، فستحتاج إلى وقت أكثر من عمر الكون للانتهاء من كل تبديل. واحدة من مشاكل O(n!) المعروفة هي معضلة مندوب المبيعات المسافر، إذ يجب على مندوب المبيعات أن يزور n مدينة ويريد حساب المسافة المقطوعة لكل مراتب n! الممكنة والتي يمكنه زيارتها، إذ يستطيع من تلك الحالات إيجاد أقصر طريق، ومن أجل منطقة بعدد كبير من المدن تصبح هذه المهمة مستحيلة الإنجاز في وقت منطقي. لحسن الحظ هناك خوارزميات مُحسنة لإيجاد طريق قصير (ولكن ليس من المضمون أن يكون الأقصر) بطريقة أسرع من O(n!). يحسب ترميز Big O الحالات الأسوأ يحسب Big O أسوأ حالة ممكنة لأي مهمة، إذ يحتاج إيجاد كتاب معين في رف كتب غير مُنظم مثلًا أن تبدأ من أحد الأطراف وتتحقق من الكتب حتى تجد الكتاب المطلوب. يمكن أن تكون محظوظًا ويكون الكتاب المطلوب هو أول كتاب تتحقق منه، ولكن ربما تكون سيء الحظ ويكون الكتاب الذي تريده هو آخر كتاب تتحقق منه، أو قد لا يكون موجودًا على الرف إطلاقًا. لذلك، في أفضل الحالات لا يهم إذا كان هناك مليارات الكتب التي يجب البحث فيها لأنك ستجد الكتاب الذي تريده مباشرةً، لكن هذا التفاؤل ليس مفيدًا في خوارزميات التحليل. تصف Big O ماذا يحصل في الحالات الأسوأ حظًا، أي إذا كان لديك n كتاب يجب عليك البحث في كل الكتب، ففي هذا المثال يزداد وقت التنفيذ بنفس معدل ازدياد عدد الكتب. يستخدم بعض المبرمجين ترميز big Omega لوصف الحالة الأفضل للخوارزمية، فمثلًا تعمل خوارزمية Ω(n) بكفاءة خطية في أفضل حالاتها وفي الحالة الأسوأ ربما تستغرق وقتًا أطول. تواجه بعض الخوارزميات حالات محظوظة جدًا، يحيث لا تعمل أي شيء، مثل إيجاد مسار الطريق لمكان أنت أصلًا فيه. يصف ترميز Big Theta الخوارزميات التي لها الترتيب نفسه في أسوأ وأفضل الحالات، فمثلًا تصف Θ(n) خوارزميةً لديها كفاءة خطية في أحسن وأسوأ الحالات، أي أنها خوارزمية O(n) وكذلك Ω(n). لا يُستخدم هذين الترميزين كثيرًا مثل استخدام big O ولكن تجدر معرفتهما. يُعد سماع الناس يتحدثون عن "big O الحالة الوسطية" عندما يعنون big Theta أو "big O الحالة الفُضلى" عندما يعنون big Omega أمرًا شائعًا رغم أنه متناقض؛ إذ تصف big O الحالة الأسوأ لوقت تنفيذ الخوارزمية تحديدًا، ولكن حتى لو كانت كلماتهم خاطئة لا تزال تفهم المعنى بغض النظر. العمليات الرياضية الكافية للتعامل مع Big O إذا كان علم الجبر لديك ضعيفًا فمعرفة العمليات الرياضية التالية أكثر من كافي عند التعامل مع big O: الضرب: تكرار الإضافة أي 2×4=8 هو مثل 2+2+2+2=8، وفي حال المتغيرات يكون n+n+n هو 3×n. ترميز الضرب: يهمل ترميز الجبر عادةً إشارة ×، لذا 2×n تُكتب 2n ومع الأرقام 3×2 تُكتب (3)2 أو ببساطة 6. خاصية الضرب بالعدد 1: ضرب أي عدد بالرقم 1 يُنتج الرقم نفسه أي 5=x15 و42 =x142 أو عمومًا n×1=n توزيع الضرب على الجمع: (3×2) + (3×2) = (4+3)2x كل طرف من المعادلة يساوي 14 أي عمومًا a(b+c) = ab+ac الأس: تكرار الضرب 16= 24 (تُلفظ "2 مرفوعة للقوة الرابعة تساوي 16") مثل 2×2×2×2= 16 هنا تكون 2 هي الأساس و 4 هي الأس. باستخدام المتغيرات n×n×n×n هي n4. يُستخدم في بايثون المعامل ** على سبيل المثال 2**4 تساوي 16. الأس الأول يساوي الأساس: 2= 21 و 9999=99991 وبصورةٍ عامة n1=n الأس 0 يساوي 1: 1= 20 و 1=99990 وبصورةٍ عامة n0=1 المعاملات: عوامل الضرب في 3n2+4n+5 المعاملات هي 3 و4 و5. يمكنك معرفة أن 5 هي معامل لأن 5 يمكن أن يُعاد كتابتها بالشكل (1)5 وأيضًا يمكن إعادة كتابتها 5n0. اللوغاريتمات: عكس الأس. لأن 16=24 نعرف أن log2(16)=4. نفول لوغاريتم الأساس 2 للعدد 16 هو 4. نستخدم في بايثون دالة math.log() إذ math.log(16, 2) تساوي إلى 4.0. يتطلب حساب big O تبسيط العمليات عن طريق جمع الحدود المتشابهة؛ والحد هو مجموعة من الأرقام والمتغيرات مضروبة مع بعضها، ففي 3n2+4n+5 تكون الحدود هي 3n2 و4n و5، إذ أن الحدود المتشابهة لديها نفس المتغير مرفوعًا لنفس القوة. في التعبير 3n2+4n+6n+5 الحدان 4n و6n هما متشابهان بإمكاننا التبسيط وإعادة الكتابة كالتالي 3n2+10n+5. خذ بالحسبان أنه يمكن كتابة 3n2+5n+4 على النحو التالي 3n2+5n+4(1)، إذ تطابق الحدود في هذا التعبير مرتبات big O التالية O(n2) و O(n) و O(1). سيفيد هذا لاحقًا عندما نُسقط المعاملات في حسابات big O. ستفيد هذه التذكرة عندما تحاول معرفة big O لقطعة من الشيفرة، ولكن لن تحتاجها بعد أن تنتهي من "تحليل Big O بنظرة سريعة" في المقال التالي. مفهوم big O بسيط ويمكن أن يفيد حتى لو لم تتبع القواعد الرياضية بصرامة. الخلاصة يُعد ترميز Big O من أكثر المفاهيم انتشارًا في علم الحواسيب للمبرمجين، وهو بحاجة لبعض المفاهيم في الرياضيات لفهمه، ولكن يمكن للمفهوم الأساسي، ألا وهو معرفة أن الشيفرة ستبطأ كلما زادت البيانات، أن يصف الخوارزميات دون الحاجة إلى أرقام كبيرة لحسابها. هناك سبع مراتب لترميز big O، وهي: O(1) أو الوقت الثابت، الذي يصف الشيفرة التي لا تتغير مع زيادة البيانات؛ و O(log n) أو الوقت اللوغاريتمي الذي يصف الشيفرة التي تزداد بخطوة كلما تضاعف عدد البيانات بمقدار n؛ و O(n) أو الوقت الخطي، الذي يصف الشيفرة التي تتباطأ يتناسب مع زيادة حجم البيانات بمقدار n؛ و O(n log n) أو وقت n-log-n، الذي يصف الشيفرة التي هي أبطأ من O(n) والعديد من خوارزميات الترتيب لديها هذه المرتبة. المراتب الأعلى هي أبطأ لأن وقت تنفيذها يزداد بصورةٍ أسرع من زيادة حجم دخل البيانات. يصف الوقت الحدودي O(n2) الشيفرة التي يزداد وقت تنفيذها بتربيع الدخل n. ليست المراتب O(2n) أو الوقت الأسّي، و O(n!) أو الوقت العاملي شائعة جدًا، ولكنها تأتي مع المجموعات والتبديلات على الترتيب. ترجمة -وبتصرف- لقسم من الفصل Measuring Performance And Big O Algorithm Analysis من كتاب Beyond the Basic Stuff with Python. اقرأ أيضًا المقال السابق: قياس أداء وسرعة تنفيذ شيفرة بايثون -تحليل الخوارزميات تعقيد الخوارزميات Algorithms Complexity دليل شامل عن تحليل تعقيد الخوارزمية -
 لا يملك الكثير من المبرمجين الذين يصنعون أروع البرامج وأكثرها فائدةً اليوم -مثل العديد من الأشياء التي نراها على الإنترنت أو نستخدمها يوميًا- خلفيةً نظريةً في علوم الحاسوب، لكنهم لا يزالون مبرمجين رائعين ومبدعين ونقدِّر ما يبنونه، حيث تملك علوم الحاسوب النظرية استخداماتها وتطبيقاتها، ويمكن أن تكون عمليةً تمامًا. يستهدف هذا المقال المبرمجين الذين يعرفون عملهم جيدًا ولكنهم لا يملكون خلفيةً نظريةً في علوم الحاسوب، وذلك من خلال واحدة من أكثر أدوات علوم الحاسوب واقعيةً، وهي: صيغة O الكبير Big O notation، وتحليل تعقيد الخوارزمية algorithm complexity. تُعَدّ هذه الأداة واحدةً من الأدوات المفيدة عمليًا للأشخاص العاملين في المجال الأكاديمي لعلوم الحاسوب، وفي إنشاء برامج على مستوى الإنتاج في الصناعة، لذلك نأمل أن تتمكن من تطبيقها في الشيفرة الخاصة بك لتحسينها بعد قراءة هذا المقال، كما يُفتَرض أن تكون قادرًا على فهم جميع المصطلحات الشائعة التي يستخدمها المختصون في علوم الحاسوب، مثل مصطلحات: التعقيد "Big O"، و"السلوك المقارب asymptotic behavior"، و"تحليل الحالة الأسوأ worst-case analysis" بعد قراءة هذا المقال. يستهدف هذا المقال أيضًا طلاب المدارس الإعدادية والثانوية في أي مكان في العالم، والذين يتنافسون دوليًا في الأولمبياد الدولي للمعلوماتية، أو مسابقة الخوارزميات الطلابية، أو مسابقات أخرى مماثلة. لا يحتوي هذا المقال على أي متطلبات رياضية مسبقَة، كما سيمنحك الخلفية التي ستحتاجها لمواصلة دراسة الخوارزميات مع فهمٍ أقوى للنظرية الكامنة وراءها، وننصح الأشخاص الذين يشاركون في هذه المسابقات الطلابية بشدة بقراءة هذا المقال التمهيدي بأكمله ومحاولة فهمه تمامًا، لأنه سيكون ضروريًا أثناء دراسة الخوارزميات وتعلُّم المزيد من التقنيات المتقدِّمة. سيكون هذا المقال مفيدًا للمبرمجين الصناعيين الذين ليس لديهم خبرة كبيرة في علوم الحاسوب النظرية، ونظرًا لتخصيص هذا المقال للطلاب، فقد يبدو في بعض الأحيان مثل كتاب مدرسي، حيث قد ترى بعض الموضوعات شديدة الوضوح لأنك رأيتها خلال سنوات دراستك على سبيل المثال، لذلك يمكنك تخطيها إذا شعرت أنك تفهمها. تصبح الأقسام الأخرى أقل عمقًا ونظريًا، حيث يحتاج الطلاب المشاركون في هذه المسابقات إلى معرفة المزيد عن الخوارزميات النظرية أكثر من ممارس المهنة العادي، ولا تزال معرفة هذه الأشياء أمرًا جيدًا بما أنها ليست صعبةً كثيرًا، لذا يستحق ذلك الأمر إعطاءه بعضًا من وقتك. لا تحتاج إلى خلفية رياضية لأن النص الأصلي لهذا المقال قد استهدف طلاب المدارس الثانوية، لذلك سيكون أي شخصٍ لديه بعض الخبرة في البرمجة -أي إن عرف ما هي العَودية recursion على سبيل المثال- قادرًا على المتابعة دون أي مشكلة. ستجد خلال هذا المقال العديد من الروابط التي تنقلك للاطلاع على مواد مهمة خارج نطاق موضوع المقال، إذ يُحتمل درايتك بمعظم هذه المفاهيم إذا كنت مبرمجًا صناعيًا؛ أما إذا كنت طالبًا مشاركًا في المسابقات، فسيعطيك اتباع هذه الروابط أفكارًا حول مجالات أخرى من علوم الحاسوب أو هندسة البرمجيات التي ربما لم تستكشفها بعد، والتي يمكنك الاطلاع عليها لتوسيع اهتماماتك. يصعب على الكثير من المبرمجين والطلاب فهم تحليل تعقيد الخوارزمية وصيغة Big O، أو يخافون منه، أو يتجنبونه تمامًا ويعدّونه عديم الفائدة، لكنه ليس صعبًا أو نظريًا كما قد يبدو للوهلة الأولى. يُعَدّ تعقيد الخوارزمية طريقةً لقياس سرعة تشغيل برنامج ما أو خوارزمية ما، لذلك يُعَد أمرًا عمليًا. الدافع Motivation يوجد أدوات لقياس مدى سرعة تشغيل البرنامج، فهناك برامج تسمى المشخِّصات profilers، حيث تقيس وقت التشغيل بالميلي ثانية ويمكنها مساعدتنا في تحسين الشيفرة الخاصة بنا عن طريق تحديد الاختناقات bottlenecks، وعلى الرغم من فائدة هذه الأداة إلا أنها ليست ذات صلة فعلية بتعقيد الخوارزمية، فتعقيد الخوارزمية مصمَّمٌ لمقارنة خوارزميتين ضمن المستوى المثالي، أي تجاهل التفاصيل منخفضة المستوى، مثل: لغة برمجة التطبيق، أو العتاد الذي تعمل عليه الخوارزمية، أو مجموعة تعليمات وحدة المعالجة المركزية CPU. عندما نريد مقارنة الخوارزميات من حيث ماهيتها -أي الأفكار التي تُعرّفنا كيفية حساب شيءٍ ما-، فلن يساعدنا العد بالميلي ثانية في ذلك، إذ يُحتمَل أن تعمل الخوارزمية السيئة والمكتوبة بلغة برمجة منخفضة المستوى مثل لغة التجميع Assembly، بصورة أسرع بكثير من خوارزمية جيدة مكتوبة بلغة برمجة عالية المستوى مثل بايثون، أو روبي، لذلك يجب تحديد معنى "الخوارزمية الأفضل". بما أن الخوارزميات هي برامج تجري عمليات حسابية فقط، ولا تجري أشياءً أخرى تقوم بها الحواسيب، مثل: مهام الشبكات، أو دخل المستخدم، وخرجه؛ فسيسمح لنا ذلك بتحليل التعقيد بقياس مدى سرعة البرنامج عند إجراء العمليات الحسابية. تتضمن أمثلة العمليات الحسابية البحتة العمليات العشرية العددية numerical floating-point operations، مثل: الجمع والضرب، أو البحث داخل قاعدة بيانات متناسبة مع الذاكرة العشوائية RAM عن قيمة معينة، أو تحديد المسار الذي ستمر به شخصية ذكاء اصطناعي في لعبة فيديو، بحيث يتعين عليها فقط السير مسافةً قصيرةً داخل عالمها الافتراضي (كما في الشكل الآتي)، أو تشغيل تطابق نمط تعبير نمطي regular expressions مع سلسلة، فالعمليات الحسابية موجودة في كل مكان في البرامج الحاسوبية. تستخدم شخصيات الذكاء الاصطناعي في ألعاب الفيديو الخوارزميات لتجنب العقبات عند تنقّلها في العالم الافتراضي يُعَدّ تحليل التعقيد أداةً لشرح كيفية تصرّف الخوارزمية مع زيادة حجم الدخل. وهنا نتساءل، إذا زدنا الدخل، فكيف ستتصرّف الخوارزمية؟ أي إذا كانت الخوارزمية الخاصة بنا تستغرق ثانيةً واحدةً للتشغيل بالنسبة إلى دخلٍ بحجم 1000، فكيف ستتصرف الخوارزمية إذا ضاعفنا حجم الدخل؟ هل ستعمل بالسرعة نفسها، أم بنصف السرعة، أم أبطأ بأربع مرات؟ يُعَدّ هذا مهمًا في البرمجة العملية لأنه سيسمح لنا بالتنبؤ بسلوك الخوارزمية عندما تصبح بيانات الدخل أكبر؛ فمثلًا، إذا أنشأنا خوارزميةً لتطبيق ويب يعمل جيدًا مع 1000 مستخدِم، وقِسنا وقت تشغيله باستخدام تحليل تعقيد الخوارزمية، فيمكننا توقُّع ما سيحدث بمجرد حصولنا على 2000 مستخدِم بدلًا من ذلك. يمنحنا تحليل التعقيد في مسابقات الخوارزميات رؤيةً عن المدة التي سيستغرقها تشغيل الشيفرة لأكبر حالات الاختبار التي تُستخدَم لاختبار صحة البرنامج، لذلك إذا قِسنا سلوك برنامجنا مع دخل صغير، فسنعرف سلوكه مع الدخل الأكبر. لنبدأ بمثال بسيط هو إيجاد العنصر الأكبر في مصفوفة. عد التعليمات سنستخدم لغات برمجة مختلفة لأمثلة هذا المقال، لكن لا تيأس إن لم تعرف لغة برمجة معينة، وبما أنك تعرف البرمجة، فيجب أن تكون قادرًا على قراءة الأمثلة دون أي مشكلة حتى إن لم تكن على دراية بلغة البرمجة المختارة، لأنها ستكون بسيطةً ولن نستخدم أية ميزات خاصة بلغة معينة. إذا كنت طالبًا منافسًا في مسابقات الخوارزميات، فيُرجَّح استخدمك لغة C++، لذلك لن تواجه مشكلة، وبالتالي نوصي في هذه الحالة التدرّب باستخدام لغة C++. يمكن البحث عن العنصر الأكبر في مصفوفة باستخدام شيفرة لغة جافا سكريبت التالية، بافتراض أن مصفوفة الدخل هي A، وحجمها n: var M = A[ 0 ]; for ( var i = 0; i < n; ++i ) { if ( A[ i ] >= M ) { M = A[ i ]; } } أول شيء سنفعله هو حساب عدد التعليمات الأساسية التي ينفذها هذا الجزء من الشيفرة، حيث سنفعل هذا مرةً واحدةً فقط، ولن يكون ضروريًا لاحقًا، لذلك تحمَّل لبضع لحظات. نقسّم الشيفرة إلى تعليماتٍ بسيطة عندما نحللها، فهذه التعليمات البسيطة هي ذات التعليمات، أو قريبة منها، والتي يمكن لوحدة المعالجة المركزية من تنفيذها مباشرةً، كما سنفترض أن معالجنا يمكنه تنفيذ العمليات التالية على أساس تعليمة واحدة لكل منها: إسناد قيمة لمتغير. البحث عن قيمة عنصر معين في مصفوفة. مقارنة قيمتين. زيادة قيمة. العمليات الحسابية الأساسية، مثل: الجمع، والضرب. سنفترض أن التفرع -أي الاختيار بين جزئي if وelse بعد تقييم شرط if- سيحدث على الفور ولن يحسب هذه التعليمات. السطر الأول من الشيفرة السابقة هو: var M = A[ 0 ]; يتطلب هذا السطر تعليمتين: إحداهما للبحث عن العنصر A[ 0 ]، والأخرى لإسناد قيمته إلى M، حيث سنفترض أن قيمة n تساوي 1 على الأقل دائمًا، كما تتطلّب الخوارزمية هاتين التعليمتين دائمًا، بغض النظر عن قيمة n، ويجب أيضًا تشغيل شيفرة تهيئة حلقة for دائمًا، ويعطينا هذا تعليمتين أخريين، هما: الإسناد assignment، والمقارنة comparison: i = 0; i < n; ستشغَّل هاتان التعليمتان قبل أول تكرار من حلقة for، كما نحتاج إلى تعليمتين إضافيتين للتشغيل بعد كل تكرار لحلقة for، وهما: زيادة المتغير i، ومقارنة للتحقق من أننا ما زلنا ضمن الحلقة، أي كما يلي: ++i; i < n; إذا تجاهلنا جسم الحلقة، فسيكون عدد التعليمات التي تحتاجها هذه الخوارزمية هو 4 + 2n، أي 4 تعليمات في بداية حلقة for، وتعليمتين في نهاية كل تكرار من n تكرار. يمكننا الآن تحديد دالة رياضية f( n )، حيث تعطينا عدد التعليمات التي تحتاجها الخوارزمية عند إعطاء n، أي لدينا f( n ) = 4 + 2n عندما يكون جسم حلقة for فارغًا. تحليل الحالة الأسوأ Worst-case analysis لدينا بالنظر إلى جسم حلقة for عملية بحث في مصفوفة، وعملية مقارنة تحدث دائمًا، كما يلي: if ( A[ i ] >= M ) { … أي يوجد تعليمتان، ولكن اعتمادًا على قيم المصفوفة، فقد يعمل جسم تعليمة if وقد لا يعمل. فإذا تحقق A[ i ] >= M، فسنشغّل هاتين التعليمتين الإضافيتين -أي البحث في مصفوفة والإسناد-، كما يلي: M = A[ i ] لكن لا يمكننا الآن تحديد الدالة f( n ) بسهولة، وذلك لعدم اعتماد عدد التعليمات على n فقط، وإنما على الدخل أيضًا، فإذا كان الدخل A = [ 1, 2, 3, 4 ] مثلًا، فستحتاج الخوارزمية إلى تعليمات أكثر مما إذا كان الدخل A = [ 4, 3, 2, 1 ]. نفكر عند تحليل الخوارزميات في أسوأ سيناريو غالبًا، فما هو أسوأ شيء يمكن حدوثه لخوارزميتنا؟ ومتى تحتاج الخوارزمية إلى معظم التعليمات لإكمالها؟ في هذه الحالة، يحدث ذلك عندما يكون لدينا مصفوفة بترتيب تصاعدي مثل A = [ 1, 2, 3, 4 ]، حيث يجب استبدال المتغير M في كل مرة، وبالتالي، سينتج عن ذلك تنفيذ معظم التعليمات، ويُطلَق على هذه الحالة اسم تحليل الحالة الأسوأ Worst-case analysis؛ وهذا ليس أكثر من مجرد التفكير في الحالة التي تحدث عندما نكون الأقل حظًا. لدينا في أسوأ الحالات 4 تعليمات للتشغيل داخل جسم حلقة for، لذلك لدينا f( n ) = 4 + 2n + 4n = 6n + 4، حيث تعطينا الدالة f عدد التعليمات التي قد تكون مطلوبةً في الحالة الأسوأ بالاعتماد على حجم المشكلة n. السلوك المقارب Asymptotic behavior تمنحنا الدالة السابقة فكرةً جيدةً عن مدى سرعة الخوارزمية، ولكن كما وعدناك، فلن تحتاج إلى القيام بالمهمة الشاقة المتمثلة في عد التعليمات في البرنامج. يعتمد عدد تعليمات وحدة المعالجة المركزية الفعلية اللازمة لكل عبارة لغة برمجة، على مُصرِّف compiler لغة البرمجة، وكذا على مجموعة تعليمات وحدة المعالجة المركزية المتاحة، سواءً كان معالج AMD أو Intel Pentium على حاسوبك، أو كان معالج MIPS على Playstation 2 الخاصة بك، وسنتجاهل ذلك أيضًا كما ذكرنا سابقًا. سنشغّل الآن الدالة "f" الخاصة بنا من خلال "مرشِّح filter" ليساعدنا في التخلص من التفاصيل الصغيرة التي يفضّل المتخصصون في علوم الحاسوب تجاهلها. يوجد قسمان في الدالة f التي تساوي 6n + 4، وهما: 6n، و4، كما لا نهتم في تحليل التعقيد إلا بما يحدث لدالة عد التعليمات عندما يكبر دخل البرنامج (n)، ويتماشى هذا مع الأفكار السابقة لسلوك "السيناريو الأسوأ" الذي ينص على الاهتمام بكيفية تصرّف الخوارزمية عند معالجتها بصورة سيئة، أي عندما تفعل هذه الخوارزمية شيئًا صعبًا، وهذا مفيد حقًا عند مقارنة الخوارزميات. إذا تغلبت خوارزمية على خوارزمية أخرى عند استخدام دخل كبير، فيُرجَّح أن الخوارزمية الأسرع ستبقى أسرع عند إعطاء دخلٍ أسهل وأصغر. سنحذف الأقسام التي تنمو ببطء ونبقي فقط الأقسام التي تنمو بسرعة عندما تصبح n أكبر، ومن الواضح أن 4 ستبقى 4 لأن n تنمو بصورة أكبر؛ أما 6n فتنمو بصورةٍ أكبر وأكبر، لذلك تميل إلى كونها أهم بالنسبة للمشكلات الأكبر، وبالتالي، أول شيء سنفعله هو حذف 4 والاحتفاظ بالدالة على صورة f( n ) = 6n. يُعَدّ ما سبق منطقيًا، وذلك لأنّ الرقم 4 هو "ثابت التهيئة initialization constant" ببساطة، وقد تتطلب لغات البرمجة المختلفة وقتًا مختلفًا لعملية الإعداد، فمثلًا، تحتاج لغة جافا إلى بعض الوقت لتهيئة آلتها الافتراضية virtual machine، وبما أننا نتجاهل الاختلافات في لغات البرمجة، فمن المنطقي تجاهل هذه القيمة فقط. الشيء الثاني الذي سنتجاهله هو معامل الضرب الثابت أمام n، وبالتالي ستصبح الدالة f( n ) = n، مما يجعل الأمور أكثر بساطةً. يُعَدّ إهمال معامل الضرب أمرًا منطقيًا إذا فكرنا في كيفية تصريف لغات البرمجة المختلفة، فقد تُصرَّف عبارة "البحث في المصفوفة" في إحدى لغات البرمجة إلى تعليمات مختلفة عن لغات برمجةٍ مختلفة، كما لا يتضمّن الإجراء A[ i ] التحقق من عدم تجاوز المتغير i لحجم المصفوفة المُصرَّح عنها في لغة سي C على سبيل المثال، ولكنه يتضمّن ذلك في لغة باسكال Pascal؛ إذًا فالشيفرة التالية المكتوبة بلغة باسكال: M := A[ i ] تكافئ الشيفرة التالية المكتوبة بلغة سي: if ( i >= 0 && i < n ) { M = A[ i ]; } لذلك نتوقّع أن لغات البرمجة المختلفة ستنتج عوامِلًا مختلفةً عندما نعُد تعليماتها. تستخدِم لغة باسكال مصرِّفًا غبيًا يغفَل عن التحسينات الممكنة في هذا المثال، كما تتطلب ثلاث تعليمات لكل وصول إلى مصفوفة، في حين تتطلب لغة سي تعليمةً واحدةً. يُطبَّق إهمال هذا العامل على جميع الاختلافات بين لغات البرمجة والمصرِّفات أيضًا، وبالتالي، تُحلَّل فكرة الخوارزمية فقط. يُسمَّى المرشِّح المتمثِّل بعمليتَي "إهمال جميع العوامل"، و"الإبقاء على القسم الذي يكبر أكثر" كما هو موصوف أعلاه بالسلوك المقارب asymptotic behavior، ولذلك نمثِّل السلوك المقارب للدالة f( n ) = 2n + 8 من خلال الدالة f( n ) = n. نهتم رياضيًا بنهاية الدالة f لأن n يميل إلى اللانهاية؛ ولكن إن لم تفهم ما تعنيه هذه العبارة، فلا تقلق لأنّ هذا كل ما تحتاج إلى معرفته، كما لن نستطيع إهمال الثوابت في النهاية في إطار رياضي صارم، ولكننا نفعل ذلك لأغراض علوم الحاسوب وللأسباب الموضَّحة أعلاه. سنحل بعض الأمثلة لفهم الفكرة أكثر، فمثلًا، لنجد السلوك المقارب لدوال المثال التالي بإهمال العوامِل الثابتة، والحفاظ على الأقسام التي تكبر بسرعة: تعطي الدالة f( n ) = 5n + 12 الدالة f( n ) = n باستخدام الاستنتاج نفسه بالضبط كما هو مذكور أعلاه. تعطي الدالة f (n) = 109 الدالة f( n ) = 1، حيث سنهمل معامل الضرب 109 * 1، لكن لا يزال يتعين علينا وضع 1 هنا للإشارة إلى أنّ لهذه الدالة قيمة غير صفرية. تعطي الدالة f( n ) =n2 + 3n + 112 الدالة f( n ) = n2، حيث تكبرn2 أكثر من 3n بالنسبة لقيمة n كبيرة بدرجة كافية، لذلك نحتفظ بها. تعطي الدالة f( n ) = n3 + 1999n + 1337 الدالة f( n ) = n3، فعلى الرغم من أنّ العامل الموجود أمام n كبير جدًا، لكن لا يزال بإمكاننا العثور على قيمة n كبيرة بما يكفي، بحيث يكون n3 أكبر من 1999n، وبما أننا مهتمون بسلوك قيم n الكبيرة جدًا، فسنبقي على n3 فقط، أي تصبح الدالة n3 المرسومة باللون الأزرق في الشكل التالي أكبر من الدالة 1999n المرسومة باللون الأحمر بعد القيمة n = 45، كما تبقى هي الأكبر بعد هذه النقطة إلى الأبد. تعطي الدالة f( n ) = n +√n الدالة f (n) = n، وذلك لأنّ n تنمو أسرع من √n كلما زادتn ويمكنك تجربة الأمثلة الآتية بنفسك. تمرين 1 f( n ) = n6 + 3n f( n ) = 2n + 12 f( n ) = 3n + 2n f( n ) = nn + n (اكتب نتائجك، وسترى الحل أدناه). إذا واجهتك مشكلة مع أحد العناصر المذكورة أعلاه، فجرِّب بعض قيم n الكبيرة لمعرفة القسم الأكبر، وهذا بسيط جدًا، أليس كذلك؟ التعقيد Complexity بما أنه يمكننا إهمال كل هذه الثوابت "الشكلية"، فمن السهل جدًا معرفة السلوك المقارب لدالة عدّ تعليمات البرنامج، حيث يملك البرنامج الذي لا يحتوي على حلقات، الدالة f( n ) = 1، لأن عدد التعليمات التي يحتاجها هو مجرد عددٍ ثابت -إلا في حالة استخدامه العودية كما سنرى لاحقًا-. يملك البرنامج الذي يحتوي حلقةً واحدةً تمتد من 1 إلى n، الدالة f( n ) = n، حيث سينفِّذ عددًا ثابتًا من التعليمات قبل الحلقة، وعددًا ثابتًا من التعليمات بعد الحلقة، وعددًا ثابتًا من التعليمات داخل الحلقة التي تُشغَّل جميعًا n مرة. يجب أن يكون هذا أكثر سهولةً وأقل مللًا من عدّ التعليمات الفردية، لذلك لنلقِ نظرةً على بعض الأمثلة لفهم ذلك أكثر. يتحقق البرنامج التالي المكتوب بلغة PHP من وجود قيمة معيَّنة داخل مصفوفة A لها الحجم n: <?php $exists = false; for ( $i = 0; $i < n; ++$i ) { if ( $A[ $i ] == $value ) { $exists = true; break; } } ?> تسمَّى هذه الطريقة للبحث عن قيمة داخل مصفوفة البحث الخطي linear search، وهذا اسم معقول لاحتواء هذا البرنامج على الدالة f( n ) = n، كما سنحدد بالضبط ما تعنيه كلمة "خطي" في القسم التالي. لاحظ وجود عبارة "break" هنا، والتي قد تؤدّي إلى إنهاء البرنامج في وقت قريب، وربما بعد تكرارٍ واحد؛ لكن تذكّر اهتمامنا بالسيناريو الأسوأ، وهو بالنسبة لهذا البرنامج عدم احتواء المصفوفة A على القيمة التي نبحث عنها، لذلك لا يزال لدينا الدالة f( n ) = n. تمرين 2 حلّل عدد التعليمات التي يحتاجها برنامج PHP أعلاه بالنسبة إلى n في الحالة الأسوأ للعثور على الدالة ( f( n، وذلك على غرار الطريقة التي حلّلنا بها البرنامج الأول المكتوب بلغة جافا سكريبت، ثم تحقق من أنه لدينا f( n ) = n بصورةٍ مقاربة. لنلقِ نظرةً على البرنامج المكتوب بلغة بايثون Python، والذي يجمع عنصرين من مصفوفة معًا لينتج مجموع يُخزَّن في متغير آخر: v = a[ 0 ] + a[ 1 ] لدينا هنا عددٌ ثابت من التعليمات، لذلك f (n) = 1. يتحقق البرنامج التالي المكتوب بلغة C++ من احتواء متّجه -مصفوفة مختارة أو جزء من مصفوفة- يُسمَّى A، وذو حجم n على قيمتين متماثلتين في أي مكان ضمنه: bool duplicate = false; for ( int i = 0; i < n; ++i ) { for ( int j = 0; j < n; ++j ) { if ( i != j && A[ i ] == A[ j ] ) { duplicate = true; break; } } if ( duplicate ) { break; } } بما أنه توجد هنا حلقتان متداخلتان داخل بعضهما البعض، فسيكون لدينا سلوكًا مقاربًا موصوفًا بالدالة f( n ) = n2. إذا استدعى برنامج دالةً داخل حلقة وعرفنا عدد التعليمات التي تجريها الدالة المستدعاة، فمن السهل تحديد عدد تعليمات البرنامج بأكمله. لنلقِ نظرةً على المثال التالي المكتوب بلغة ? int i; for ( i = 0; i < n; ++i ) { f( n ); } إذا علمنا أن f( n ) هي دالة تنفِّذ n تعليمة بالضبط، فيمكننا حينئذٍ معرفة أن عدد تعليمات البرنامج بأكمله هو n2 بصورةٍ مقاربة، حيث تُستدعى الدالة n مرة تمامًا. ننتقل الآن إلى الصيغة التخيُّلية التي يستخدمها علماء الحاسوب للسلوك المقارب، حيث سنقول أن برنامجنا هو Θ ( f( n )) عندما نحدِّد الدالة f بصورة مقاربة، فمثلًا، البرامج المذكورة أعلاه هي Θ (1) وΘ( n2 ) وΘ( n2 ) على التوالي، حيث تُقرَأ Θ( n ) "ثيتا بالنسبة إلى n". نقول أحيانًا أنّ f( n ) -وهي الدالة الأصلية التي تحسب عدد التعليمات بما في ذلك الثوابت- هي شيء ما Θ، حيث نقول مثلًا أنّ f( n ) = 2n هي دالة Θ( n )، كما يمكننا كتابة 2n ∈ Θ (n) أيضًا، والتي تُنطَق "2n هي ثيتا بالنسبة إلى n". لا ترتبك بشأن هذا الصيغة، فكل ما تنص عليه هو أنه إذا حسبنا عدد التعليمات التي يحتاجها البرنامج وهي 2n، فسيُوصَف السلوك المقارب للخوارزمية بـ n والذي نتج بإهمال الثوابت. فيما يلي بعض العبارات الرياضية الصحيحة باستخدام هذا الصيغة: n6 + 3n ∈ Θ( n6 ) 2n + 12 ∈ Θ( 2n ) 3n + 2n ∈ Θ( 3n ) nn + n ∈ Θ( nn ) بالمناسبة، إذا حللت التمرين 1 السابق، فهذه هي بالضبط الإجابات التي يجب أن تصل إليها. نسمّي ما نضعه ( هنا )Θ التعقيد الزمني time complexity، أو تعقيد complexity الخوارزمية، لذلك فللخوارزمية التي تحتوي على الصيغة Θ( n ) تعقيدٌ هو n. لدينا أيضًا أسماءً خاصةً للصيغ التالية: Θ( 1 )، وΘ( n )، وΘ( n2 ) وΘ( log( n ) )، وذلك لكثرة ظهورها، حيث نقول أنّ خوارزمية Θ( 1 ) هي خوارزمية ذات وقت ثابت constant-time algorithm، والخوارزمية Θ( n ) خطية linear، وΘ( n2 ) تربيعية quadratic؛ أما الخوارمية Θ( log( n ) ) فهي لوغاريتمية logarithmic. لا تقلق إن لم تعرف ما هي اللوغاريتمات حتى الآن، سنشرح ذلك لاحقًا. صيغة O الكبير Big-O notation قد تكون معرفة سلوك الخوارزمية بهذه الطريقة كما فعلنا أعلاه أمرًا صعبًا، خاصةً بالنسبة للأمثلة الأعقد، ولكن يمكننا القول بأن سلوك خوارزميتنا لن يتجاوز أبدًا حدًا معينًا، وبالتالي لن نضطر إلى تحديد السرعة التي تعمل بها الخوارزمية، وذلك حتى عند تجاهل الثوابت بالطريقة التي طبّقناها سابقًا، فكل ما علينا فعله هو إيجاد حدٍ معين، حيث سنشرح ذلك بمثال. مشكلة الفرز (sorting problem) هي إحدى المشكلات الشهيرة التي يستخدمها علماء الحاسوب لتدريس الخوارزميات، حيث تُعطَى مصفوفة A بحجم n في مشكلة الفرز، ويُطلَب منا كتابة برنامج لفرز أو ترتيب هذه المصفوفة، وتُعَدّ هذه المشكلة مشكلةً مهمةً كونها مشكلةً واقعيةً في الأنظمة الحقيقية، إذ يحتاج مستكشف الملفات إلى فرز الملفات التي يعرضها حسب الاسم حتى يتمكن المستخدِم من التنقل بينها بسهولة، أو قد تحتاج لعبة فيديو إلى فرز الكائنات ثلاثية الأبعاد المعروضة في العالم بناءً على بعدها عن عين اللاعب داخل العالم الافتراضي من أجل تحديد ما هو مرئي وما هو غير مرئي، وهو ما يسمى مشكلة الرؤية Visibility Problem، فالكائنات التي تكون أقرب للاعب هي المرئية، في حين أنّ الكائنات البعيدة قد تخفيها الكائنات الموجودة أمامها، ويوضّح الشكل الآتي هذه المشكلة، إذ لن يرى اللاعب الموجود في النقطة الصفراء المناطق المظلَّلة، كما يُعَدّ تقسيم العالم إلى أجزاء صغيرة وفرزها حسب المسافة التي تفصلها عن اللاعب إحدى طرق حل مشكلة الرؤية. يُعَدّ الفرز أيضًا مهمًا بسبب وجود العديد من الخوارزميات لحله، كما يكون بعضها أسوأ من البعض الآخر، وهي أيضًا مشكلة سهلة التحديد والشرح، لذلك لنكتب جزءًا من شيفرة تفرز مصفوفة. الطريقة التالية هي طريقة غير فعالة لفرز مصفوفة في لغة روبي Ruby، حيث تدعم لغة روبي فرز المصفوفات باستخدام دوال مبنيّة مسبقًا يجب استخدامها بدلًا من ذلك، وهي بالتأكيد أسرع مما سنراه هنا، ولكن ما سنستخدمه هنا هي شيفرة بغرض التوضيح فقط: b = [] n.times do m = a[ 0 ] mi = 0 a.each_with_index do |element, i| if element < m m = element mi = i end end a.delete_at( mi ) b << m end تسمى هذه الطريقة الفرز الانتقائي Selection sort، حيث تجد هذه الخوارزمية الحد الأدنى من المصفوفة -يُرمَز إلى المصفوفة بالمتغير a في الشيفرة السابقة، بينما يُرمَز إلى الحد الأدنى بالمتغير m، والمتغير mi هو دليله في المصفوفة-، وتضعه في نهاية مصفوفة جديدة -أي المصفوفة b في حالتنا-، ثم تزيله من المصفوفة الأصلية، وبعدها تجد الحد الأدنى بين القيم المتبقية للمصفوفة الأصلية، وتلحِقه بالمصفوفة الجديدة التي تحتوي على عنصرين الآن، ثم تزيله من المصفوفة الأصلية؛ وتستمر هذه العملية إلى حين إزالة جميع العناصر من المصفوفة الأصلية وإدخالها في المصفوفة الجديدة، مما يعني فرز المصفوفة. نلاحظ وجود حلقتين متداخلتين في الشيفرة السابقة، حيث تعمل الحلقة الخارجية n مرة، وتعمل الحلقة الداخلية مرةً واحدةً لكل عنصر من عناصر المصفوفة a. تحتوي المصفوفة a في البداية على n عنصر، ونزيل عنصر مصفوفة واحد في كل تكرار، لذلك تتكرر الحلقة الداخلية n مرة خلال التكرار الأول للحلقة الخارجية، ثم n - 1 مرة، وبعدها n - 2 مرة، وهكذا دواليك حتى التكرار الأخير للحلقة الخارجية التي تعمل خلالها مرةً واحدةً فقط. من الصعب قليلًا تقييم تعقيد هذا البرنامج، حيث يجب معرفة المجموع 1 + 2 + … +(n+(n-1، ولكن يمكننا بالتأكيد إيجاد "الحد الأعلى" لهذا المجموع، وهذا يعني أنه يمكننا تغيير برنامجنا - أي يمكنك فعل ذلك في عقلك، وليس في الشيفرة الفعلية- لجعله أسوأ مما هو عليه، ومن ثم إيجاد تعقيد هذا البرنامج الجديد، فإذا تمكّنا من العثور على تعقيد البرنامج الأسوأ الذي أنشأناه، فسنعلم أنّ برنامجنا الأصلي أسوأ أو ربما أفضل. بالتالي إذا أوجدنا تعقيدًا جيدًا لبرنامجنا المعدَّل الذي هو أسوأ من برنامجنا الأصلي، فيمكننا معرفة أنه سيكون لبرنامجنا الأصلي تعقيدًا جيدًا جدًا أيضًا، أي إما جيدًا بمستوى برنامجنا المعدَّل أو أفضل منه. لنفكّر في طريقة تعديل هذا البرنامج لتسهيل معرفة تعقيده، ولكن ضع في بالك أنه لا يمكننا سوى جعل الأمر أسوأ هكذا، إذ سيأخذ البرنامج مزيدًا من التعليمات، وبالتالي سيكون تقديرنا مفيدًا لبرنامجنا الأصلي. يمكن تغيير الحلقة الداخلية للبرنامج بجعلها تتكرر n مرة دائمًا بدلًا من تكرارها عددًا متغيرًا من المرات، كما ستكون بعض هذه التكرارات عديمة الفائدة، لكنها ستساعدنا في تحليل تعقيد الخوارزمية الناتجة؛ وإذا أجرينا هذا التغيير البسيط، فمن الواضح أن الخوارزمية الجديدة التي أنشأناها هي Θ( n2 ) وذلك لوجود حلقتين متداخلتين بحيث يتكرر كل منهما n مرة بالضبط، وبالتالي، يمكننا القول أنّ الخوارزمية الأصلية هي O( n2 ). تُنطَق O( n2 ) "أوه كبيرة لمربع n، أي big oh of n squared"، وهذا يقودنا للقول بأن برنامجنا ليس أسوأ من n2 بصورةٍ مقاربة، فقد يكون أفضل من ذلك أو مثله. إذا كان برنامجنا هو بالفعل Θ( n2 ) فلا يزال بإمكاننا القول أنه O( n2 ) أي تخيل تغيير البرنامج الأصلي بطريقة لا تغيره كثيرًا، لكنها لا تزال تجعله أسوأ قليلًا مثل إضافة تعليمات لا معنى لها في بداية البرنامج، بحيث سيؤدي فعل ذلك إلى تغيير دالة عدّ التعليمات بواسطة ثابت بسيط، والذي سنتجاهله عندما يتعلق الأمر بالسلوك المقارب، وبالتالي فالبرنامج Θ( n2 ) هو O( n2 ) أيضًا. قد لايكون البرنامج O( n2 ) هو Θ( n2 ) أيضًا، فأيّ برنامج Θ( n ) مثلًا هو O( n2 ) وO( n ) كذلك، وإذا تخيلنا أن برنامج Θ( n ) هو عبارة عن حلقة for بسيطة تتكرر n مرة، فيمكن جعلها أسوأ بتغليفها ضمن حلقة for أخرى تتكرر n مرة أيضًا، وبالتالي ينتج برنامج له دالة f( n ) = n2، كما يمكن تعميم ذلك بالقول أنّ أي برنامج Θ( a ) هو O( b ) عندما يكون b أسوأ من a. لا يحتاج التغيير الذي أجريناه على البرنامج إلى إعطائنا برنامجًا له معنى أو مكافئًا لبرنامجنا الأصلي، حيث يحتاج فقط إلى تنفيذ تعليمات أكثر من التعليمات الأصلية بالنسبة إلى قيمة n معينة، أي نستخدم هذا التغيير من أجل حساب عدد التعليمات فقط وليس لحل مشكلتنا. لذا يمكن القول بأن برنامجنا هو O( n2 ) بطريقةٍ آمنة، وذلك لأننا حلّلنا خوارزميتنا، ووجدناها ليست أسوأ من n2، ولكنها في الواقع قد تساوي n2، وبالتالي يمكننا تقدير سرعة تشغيل برنامجنا. لنستعرض بعض الأمثلة لتساعدك على التعرف على هذه الصيغة الجديدة. تمرين 3 أيٌّ مما يلي صحيح؟ خوارزمية Θ( n ) هي O( n ) خوارزمية Θ( n ) هي O( n2 ) خوارزمية Θ( n2 ) هي O( n3 ) خوارزمية Θ( n ) هي O( 1 ) خوارزمية O( 1 ) هي Θ( 1 ) خوارزمية O( n ) هي Θ( 1 ) الحل هذا صحيح لأنّ برنامجنا الأصلي كان Θ( n )، ويمكننا تحقيق O( n ) دون تغيير برنامجنا على الإطلاق. هذا صحيح لأنّ n2 أسوأ من n. هذا صحيح لأنّ n3 أسوأ من n2. هذا خطأ لأنّ 1 ليس أسوأ من n، فإذا أخذ البرنامج n تعليمةً بصورةٍ مقاربة -أي عددًا خطيًا من التعليمات-، فلا يمكننا جعله أسوأ ولا يمكن جعله يأخذ تعليمةً واحدةً بصورةٍ مقاربة -أي عددًا ثابتًا من التعليمات-. هذا صحيح لأنّ التعقيدان متماثلان. قد يكون هذا صحيحًا أو غير صحيح وذلك اعتمادًا على الخوارزمية، لكنه خاطئ في الحالة العامة، فإذا كانت الخوارزمية Θ( 1 )، فمن المؤكد أنها O( n )؛ أما إذا كانت O( n ) فقد لا تكون Θ( 1 )، فمثلًا، خوارزمية Θ( n ) هي O ( n ) وليست Θ( 1 ). تمرين 4 استخدم متتالية الجمع الحسابية arithmetic progression sum لإثبات أنّ البرنامج أعلاه ليس O( n2 ) فقط، وإنما Θ( n2 ) أيضًا، ويمكنك البحث عن معنى المتتالية الحسابية في ويكيبيديا في حالة عدم معرفتك بها. يعطي التعقيد O-complexity لخوارزمية ما حدًا أعلى لتعقيد الخوارزمية الفعلي - أي الوقت الأكبر الذي قد تستغرقه الخوارزمية-، بينما تعطي الصيغة Θ تعقيد الخوارزمية الفعلي، حيث نقول أحيانًا أن الصيغة Θ تعطينا حدًا تامًا، وإذا علمت أننا وجدنا حد تعقيدٍ غير تام، فيمكنك استخدام الحرف الصغير o للإشارة إلى ذلك، فمثلًا، إذا كان للخوارزمية التعقيد Θ( n )، فسيكون تعقيدها التام n، وبالتالي سيكون لهذه الخوارزمية O( n ) و O( n2 ) معًا. بما أن الخوارزمية هي Θ( n )، فسيكون حد O( n ) هو الحد التام؛ أما حد O( n2 ) فليس تامًا، ولذلك يمكننا كتابة أن الخوارزمية هي o( n2 ) والتي تُنطق "o الصغير بالنسبة إلى مربع n"، وذلك لتوضيح أن الحد ليس تامًا. كما يُفضَّل إيجاد حدود تامة للخوارزميات لأنها تعطينا مزيدًا من المعلومات حول سلوكها، ولكنه ليس أمرًا سهلًا دائمًا. تمرين 5 حدّد أيًا من الحدود التالية هي حدودًا تامةً وأيها لا، ثم تحقق من صحتها أو خطئها، ويجب عليك استخدام الصيغة o لتحديد الحدود غير التامة: خوارزمية Θ (n) التي لها الحد الأعلى O (n). خوارزمية Θ (n2) التي لها الحد الأعلى O (n3). خوارزمية Θ(1) التي لها الحد الأعلى O (n). خوارزمية Θ (n) التي لها الحد الأعلى O (1). خوارزمية Θ (n) التي لها الحد الأعلى O (2n). الحل الحد تام لأنّ تعقيد Θ وتعقيد O متماثلان في هذه الحالة. الحد غير تام لأنّ تعقيد O أكبر من تعقيد Θ، وقد يكون حد O( n2 ) تامًا، لذلك يمكننا كتابة أن الخوارزمية هي o( n3). الحد غير تام، لأنّ تعقيد O أكبر من تعقيد Θ، وقد يكون حد O( 1 ) تامًا، لذلك يمكننا الإشارة بأنّ الحد O( n ) ليس تامًا من خلال كتابته بالشكل o( n ). الحد خاطئ، فقد اُرتكِب خطأ في حسابه، فلا يمكن أن يكون لخوارزمية Θ( n ) حد أعلى من O( 1 )، وذلك لأنّ التعقيد n أكبر من التعقيد 1 -تذكر أنّ O تعطي حدًا أعلى. الحد تام، فقد يبدو مثل حد غير تام، لكن هذا ليس صحيحًا في الواقع، -تذكر أنّ سلوك 2n وn المقارب هو نفسه، وأنّ الصيغتَين O وΘ تهتمان بالسلوك المقارب؛ إذًا لدينا O( 2n ) = O( n )، وبالتالي، فهذا الحد تام لأن التعقيد هو نفس Θ. قد تجد نفسك تائهًا قليلًا في هذه الصيغة الجديدة، ولكن سنقدم صيغتين آخرين بسيطتين بالنسبة للصيغ Θ، وO، وo قبل انتقالنا إلى بعض الأمثلة، ويُستحسَن أن تعرف هاتين الصيغتَين الآن، حيث لن نستخدمهما كثيرًا في هذا المقال لاحقًا. عدّلنا برنامجنا في المثال أعلاه ليصبح أسوأ -أي أخذ المزيد من التعليمات، وبالتالي المزيد من الوقت- وأنشأنا الصيغة O، حيث تُعَدّ الصيغة O ذا مغزىً لأنها تخبرنا بأن برنامجنا لن يكون أبدًا أبطأ من حدٍ معين، ولهذا فهي توفر معلومات قيّمةً تمكننا من القول بأن برنامجنا جيد بما فيه الكفاية، وإذا فعلنا العكس وعدّلنا برنامجنا ليصبح أفضل، ثم أوجدنا تعقيد البرنامج الناتج، فنستخدم الصيغة Ω التي تعطينا تعقيدًا يخبرنا بأن برنامجنا لن يكون أفضل، وهذا مفيد إذا أردنا إثبات أن البرنامج يعمل ببطء أو أن الخوارزمية سيئة، وقد يكون هذا مفيدًا للقول بأن الخوارزمية بطيئة جدًا عند استخدامها في حالة معينة، فمثلًا، خوارزمية Ω( n3 ) ليست أفضل من n3. قد تكون الصيغة Θ( n3 ) سيئًة مثل Θ (n4) أو أسوأ منها، لكننا نعلم أنها سيئة إلى حد ما على الأقل. إذًا تعطينا الصيغة Ω حدًا أدنى لتعقيد خوارزمية، كما يمكننا كتابة الصيغة ω على غرار الصيغة ο عندما يكون الحد ليس تامًا، فمثلًا، خوارزمية Θ ( n3 ) هي ο( n4 ) وω( n2 ) وتُقرَأ Ω( n ) "أوميغا كبيرة بالنسبة إلى n"، بينما تُقرَأ ω( n ) "أوميغا صغيرة بالنسبة إلى n". تمرين 6 اكتب حد O تام وآخر غير تام، وحد Ω تام وآخر غير تام من اختيارك للتعقيدات التالية، ولكن بشرط وجودهما طبعًا: Θ( 1 ) Θ(√n) Θ( n ) Θ( n2 ) Θ( n3 ) الحل هذا هو تطبيق مباشر للتعاريف أعلاه: الحدود التامة هي O( 1 ) وΩ( 1 )، كما يكون حد O غير التام هو O( n ) -تذكّر أن O تعطينا حدًا أعلى-، وبما أن n أكبر من 1، فسيمثِّل حدًا غير تام يمكننا كتابته بالشكل o( n ) أيضًا، كما لا يمكننا إيجاد حد غير تام للصيغة Ω لعدم تمكننا من الحصول على أقل من 1 لهذه الدوال، إذًا يجب تعاملنا مع الحد التام فقط. يجب أن تكون للحدود التامة تعقيد Θ نفسه، لذا فهي O(√n) وΩ(√n) على التوالي؛ أما الحدود غير التامة فقد تكون O( n )، حيث تُعَدّ n أكبر من √n وبالتالي فهي حد أعلى لها. وبما أننا نعلم أن هذا حدًا أعلى غير تام، فيمكننا أيضًا كتابته بالصورة o( n )؛ أما الحد الأدنى غير التام، فيمكننا ببساطة استخدام Ω( 1 )، وبما أننا نعلم أن هذا الحد ليس تامًا، فيمكننا كتابته بالصورة ω( 1. 3 ). الحدود التامة هي O( n ) وΩ( n ). قد يكون الحدان الغير تامين هما ω( 1 ) وo( n3 ) وهي في الواقع حدودٌ سيئة للغاية، لأنها بعيدة كل البعد عن التعقيدات الأصلية، إلا أنها لا تزال صالحة باستخدام التعاريف. الحدود التامة هي O( n2 ) وΩ( n2 ) ويمكننا استخدام ω( 1 ) وo( n3 ) بالنسبة للحدود غير التامة كما في المثال السابق. الحدود التامة هي O( n3 ) وΩ( n3 ) على التوالي، وقد يكون الحدان غير التامَين هما ω(n2 √n) وω(n3 √n)، وعلى الرغم من أنّ هذه الحدود ليست تامة، إلا أنها أفضل من تلك الموجودة في جواب رقم 3 و4 من هذا التمرين أعلاه. قد تعطي الصيغتان O وΩ أيضًا حدودًا تامة، وسبب استخدامنا لهما بدلًا من الصيغة Θ هو أننا قد لا نكون قادرين على معرفة ما إذا كان الحد الذي أوجدناه تامًا أم لا، أو ربما لا نرغب في متابعة العملية باستخدام الصيغة Θ التي تحتاج تدقيقًا عميقًا. إذا لم تتذكر تمامًا جميع الرموز المختلفة واستخداماتها، فلا تقلق بشأنها كثيرًا الآن، حيث يمكنك دائمًا العودة والبحث عنها، وأهم الرموز هي O وΘ. لاحظ أيضًا أنه على الرغم من كون الصيغة Ω تعطينا سلوكًا ذو حدٍ منخفض للدالة -أي تحسّن برنامجنا وأصبح ينفّذ تعليماتٍ أقل-، إلا أننا ما زلنا نشير إليها بتحليل "الحالة الأسوأ"، لأننا نزوّد برنامجنا بأسوأ دخلٍ ممكن من n ونحلّل سلوكه في ظل هذا الافتراض. يوضح الجدول التالي الرموز التي قدمناها للتو وتوافقاتها مع الرموز الرياضية المعتادة للمقارنات التي نستخدمها مع الأعداد، كما يعود السبب في عدم استخدامنا للرموز المعتادة هنا واستخدام الأحرف الإغريقية بدلًا منها، إلى الإشارة إلى إجراء مقارنة سلوك مقارب وليس مقارنة بسيطة: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } عامل المقارنة المقارب Asymptotic comparison operator عامل المقارنة العددي Numeric comparison operator الخوارزمية هي ( شيء ما )o يوجد عدد < هذا الشيء الخوارزمية هي ( شيء ما )O يوجد عدد ≤ هذا الشيء الخوارزمية هي ( شيء ما )Θ يوجد عدد = هذا الشيء الخوارزمية هي ( شيء ما )Ω يوجد عدد ≥ هذا الشيء الخوارزمية هي ( شيء ما )ω يوجد عدد > هذا الشيء اللوغاريتمات Logarithms هل تعرف ما هي اللوغاريتمات؟ إن كانت إجابتك نعم، فلا تتردد في تخطي هذا القسم، فهذا القسم هو مقدمة لمن ليس على دراية باللوغاريتمات، أو لمن لم يستخدمها كثيرًا مؤخرًا، فهو موجَّهٌ للطلاب الأصغر سنًا، والذين لم يروا اللوغاريتمات في المدرسة بعد. تُعَدّ اللوغاريتمات مهمة بسبب ظهورها بكثرة عند تحليل التعقيد، ويُعَدّ اللوغاريتم عمليةً تُطبَّق على رقم ما ليصبح أصغر، حيث تشبه هذه العملية الجذر التربيعي لرقم إلى حد كبير؛ لذلك إذا كان هناك شيء واحد تريد تذكره حول اللوغاريتمات، فهو أنها تأخذ رقمًا وتجعله أصغر بكثير من الأصل. يوضِّح الشكل الآتي مقارنةً بين الدوال n، و√n، وlog( n )، إذ تنمو الدالة n -أو كما تُسمَّى الدالة الخطية linear function- المرسومة باللون الأخضر في أعلى الشكل، أسرع بكثير من دالة الجذر التربيعي المرسومة باللون الأحمر في المنتصف، والتي بدورها تنمو أسرع بكثير من الدالة log( n ) المرسومة باللون الأزرق في الجزء السفلي من هذا الرسم البياني، ويكون الفرق واضحًا تمامًا حتى بالنسبة إلى n صغيرة مثل n = 100. تُعَدّ اللوغاريتمات عمليةً عكسيةً لرفع شيءٍ ما إلى أس مثل الجذور التربيعية التي هي عملية عكسية لتربيع شيءٍ ما، وسنشرح ذلك بمثال. ضع في بالك المعادلة التالية: 2x = 1024 نريد حل هذه المعادلة لإيجاد قيمة x، لذلك لنسأل أنفسنا: ما هو الرقم الذي يجب رفع الأساس 2 إليه حتى نحصل على 1024؟ هذا الرقم هو 10. بالفعل لدينا 210 = 1024، وهو أمر سهل التحقق منه؛ كما تساعدنا اللوغاريتمات من خلال الإشارة إلى هذه المشكلة باستخدام صيغة جديدة، فالرقم 10 في هذه الحالة هو لوغاريتم 1024 ونكتبه بالصورة ( log( 1024 ونقرأه "لوغاريتم 1024". بما أننا نستخدم العدد 2 أساسًا، فتسمى هذه اللوغاريتمات لوغاريتمات الأساس 2، كما توجد لوغاريتمات لها أساسات أخرى، ولكننا سنستخدم فقط لوغاريتمات الأساس 2 في هذا المقال، وإذا كنت طالبًا منافسًا في مسابقات دولية ولا تعرف شيئًا عن اللوغاريتمات، فنوصيك بشِدة بالتدرّب على اللوغاريتمات بعد الانتهاء من هذا المقال. تُعَدّ لوغاريتمات الأساس 2 أكثر أنواع اللوغاريتمات شيوعًا في علوم الحاسوب لأنه غالبًا ما يكون لدينا كيانان مختلفان فقط هما: 0 و1، كما نميل أيضًا إلى تقسيم مشكلة كبيرة واحدة إلى نصفين، لذلك ما عليك سوى معرفة لوغاريتمات الأساس 2 لمتابعة هذا المقال. تمرين 7 حُلّ المعادلات أدناه، وأوجد اللوغاريتم في كل حالة باستخدام اللوغاريتمات ذات الأساس 2 فقط: 2x = 64 (22)x= 64 4x = 4 2x = 1 2x + 2x = 32 (2x) * (2x) = 64 الحل لا يتضمن الحل أكثر من تطبيق الأفكار المُعرَّفة أعلاه: يمكننا باستخدام طريقة التجربة والخطأ إيجاد أن x = 6، وبالتالي، log( 64 ) = 6. يمكن كتابة (22)x بالصورة 22x من خلال تطبيق خصائص الأس، إذًا لدينا 2x = 6 لأن log( 64 ) = 6 من النتيجة السابقة، وبالتالي، x = 3. يمكننا كتابة 4 بالشكل 22 باستخدام معرفتنا من المعادلة السابقة، وبهذا تصبح المعادلة (22)x= 4 وهي 22x = 4 نفسها، ونلاحظ أن log( 4 ) = 2 لأن 22 = 4، وبالتالي، لدينا أن 2x = 2، وعليه فـ x = 1؛ كما يمكن ملاحظة ذلك بسهولة من المعادلة الأصلية، حيث أن ناتج الرفع للأس 1 هو الأساس نفسه. تذكر أن ناتج الرفع للأس 0 هو 1، لذلك لدينا log( 1 ) = 0، بما أنّ 20= 1، وبالتالي، x = 0. لا يمكننا أخذ اللوغاريتم مباشرةً بسبب وجود المجموع، ولكن يمكن ملاحظة أنّ 2x+ 2x هي 2 * (2x) نفسها، حيث ضربنا هنا بالعدد 2 أي لهما الأساس نفسه، وبالتالي، ينتج 2x + 1، والآن كل ما علينا فعله هو حل المعادلة 2x + 1= 32، حيث نجد أنّ log( 32 ) = 5، وهكذا x + 1 = 5، وبالتالي، x = 4. نضرب هنا قوتين للعدد 2 معًا، ولذلك يمكننا ضمهما من خلال ملاحظة أن (2x) * (2x) هي 22x نفسها، وبالتالي كل ما علينا فعله هو حل المعادلة 22x= 64 التي حللناها بالفعل أعلاه، حيث x = 3. التعقيد العودي Recursive complexity لنلقِ نظرةً على دالة عودية recursive function، فالدالة العودية هي دالة تستدعي نفسها. هل يمكننا تحليل تعقيدها؟ توجِد الدالة الآتية والمكتوبة بلغة بايثون، حيث تُقيِّم مضروب factorial عددٍ معين، إذ يمكن إيجاد مضروب عدد صحيح موجب بضربه بجميع الأعداد الصحيحة السابقة معًا، فمثلًا، مضروب العدد 5 هو 5 * 4 * 3 * 2 * 1؛ كما نعبِّر عن ذلك بالصورة "!5" ونقرؤها "مضروب العدد خمسة five factorial"، ويفضِّل بعض الناس نُطقها بصوت عالٍ مثل "خمسة !!!". def factorial( n ): if n == 1: return 1 return n * factorial( n - 1 ) لنحلّل تعقيد هذه الدالة، فعلى الرغم من عدم احتواء هذه الدالة على أية حلقات، إلا أنّ تعقيدها ليس ثابتًا constant، حيث يجب علينا متابعة عد التعليمات مرةً أخرى لمعرفة تعقيدها، فإذا مرّرنا المتغير n إلى هذه الدالة، فستنفّذ n مرة؛ وإذا لم تكن متأكدًا من ذلك، فشغّل هذه الدالة "يدويًا" الآن من أجل n = 5 للتحقق منها. ستنفَّذ هذه الدالة مثلًا 5 مرات من أجل n = 5، بحيث ستستمر في إنقاص قيمة n بمقدار 1 في كل استدعاء، وبالتالي، يكون تعقيد هذه الدالة هو ( Θ( n. إذا لم تكن متأكدًا من هذه الحقيقة، فتذكر أنه يمكنك دائمًا العثور على التعقيد الدقيق عن طريق حساب عدد التعليمات، وإذا رغبت في ذلك، فيمكنك محاولة حساب عدد التعليمات الفعلية التي تطبّقها هذه الدالة لإيجاد الدالة f( n )، والوصول إلى نتيجة أنها خطية بالفعل، مع العلم أنّ خطية تعني Θ( n ). يحتوي الشكل التالي على رسم بياني لمساعدتك على فهم مفهوم العودية المُطبَّقة عند استدعاء الدالة factorial( 5 )، ويجب على هذا الشكل توضيح لماذا تعقيد هذه الدالة هو تعقيد خطي: العودية (معاوة الاستدعاء) التي تطبّقها الدالة factorial التعقيد اللوغاريتمي Logarithmic complexity إحدى المشكلات الشهيرة في علوم الحاسوب هي البحث عن قيمة داخل مصفوفة، ولقد حلّلنا هذه المشكلة سابقًا من خلال الحالة العامة، كما تصبح هذه المشكلة ممتعةً إذا كان لدينا مصفوفة مرتَّبة ونريد إيجاد قيمة معينة بداخلها، حيث تُسمَّى إحدى طرق القيام بذلك البحث الثنائي binary search. ننظر إلى العنصر الأوسط في المصفوفة، وإذا وجدنا العنصر هناك، فقد انتهينا؛ وإلّا فإذا كانت القيمة التي وجدناها أكبر من القيمة التي نبحث عنها، فسنعلم أن العنصر سيكون في الجزء الأيسر من المصفوفة؛ وإلّا فإننا نعلم أنه سيكون في الجزء الأيمن من المصفوفة، كما يمكننا الاستمرار في تقسيم هذه المصفوفات الصغيرة إلى نصفين حتى يتبقّى عنصر واحد فقط، وتوضّح الشيفرة الوهمية التالية هذه الفكرة: def binarySearch( A, n, value ): if n = 1: if A[ 0 ] = value: return true else: return false if value < A[ n / 2 ]: return binarySearch( A[ 0...( n / 2 - 1 ) ], n / 2 - 1, value ) else if value > A[ n / 2 ]: return binarySearch( A[ ( n / 2 + 1 )...n ], n / 2 - 1, value ) else: return true تُعَدّ هذه الشيفرة الوهمية تبسيطًا للتطبيق الفعلي، كما يُعَدّ وصفها أسهل من تطبيقها عمليًا، حيث يحتاج المبرمج إلى الاهتمام ببعض مشاكل التطبيق. يجب تطبيق الدالة floor() أو ceil() بسبب وجود أخطاء بفارق الواحد off-by-one، وقد لا ينتج عن القسمة على العدد 2 قيمةً صحيحةً، فالجزء الصحيح أو المتمم الصحيح الأسفل floor لعدد حقيقي ما x، هو أكبر عدد صحيح ليس أكبر من x، فصحيح العدد 2.6 هو 2، أي أنّ أكبر عدد صحيح ليس أكبر من 2.6. بينما السقف أو المتمم الصحيح الأعلى ceil لعدد حقيقي x، فهو أصغر عدد صحيح ولكنه ليس أصغر من x، لأن سقف العدد 2.15 هو 3، أي أنّ أصغر عدد صحيح ليس أصغر من 2.15. لكن يمكننا افتراض أن هذه الطريقة ستنجح دائمًا، وسنفترض أنّ تطبيقنا الفعلي يهتم بأخطاء الفراق الواحد off-by-one، وذلك لأننا نريد تحليل تعقيد هذه الطريقة فقط. إذا لم تطبّق البحث الثنائي مطلقًا، فقد ترغب في فعل ذلك باستخدام لغة البرمجة المفضلة لديك. يوضّح الشكل الآتي لصاحبه لوك فرانكل Luke Francl طريقة عمل البحث الثنائي باستخدام العودية، حيث يُميَّز الوسيط A لكل استدعاء باللون الأسود، وتستمر العودية حتى تصبح المصفوفة مكوّنةً من عنصر واحد فقط. إذا لم تكن متأكدًا من عمل هذه الطريقة، فشغّلها يدويًا باستخدام مثال بسيط واقنع نفسك بأنها تعمل بالفعل. لنحاول تحليل هذه الخوارزمية العودية، حيث سنفترض -من أجل التبسيط- أن المصفوفة تُقسَم دائمًا إلى نصفين تمامًا، متجاهلين الجزأين 1+ و 1- من الاستدعاء العودي. كما يجب اقتناعك بعدم تأثير إجراء تغيير بسيط على نتائج التعقيد مثل تجاهل الجزأين 1+ و1-، وهذه حقيقة يجب عادةً إثباتها إذا أردنا أن نكون حريصين من وجهة نظر رياضية، لكنها بديهية عمليًا. سنفترض للتبسيط أن حجم المصفوفة هو بالضبط قوة للعدد 2. بحيث لا يغير هذا الافتراض النتائج النهائية لتعقيدنا الذي سنصل إليه، وسيحدث السيناريو الأسوأ لهذه المشكلة عند عدم ظهور القيمة التي نبحث عنها في مصفوفتنا على الإطلاق، كما سنبدأ في هذه الحالة بمصفوفة ذات حجم n في الاستدعاء الأول للعودية، ثم سنحصل على مصفوفة بحجم n / 2 في الاستدعاء التالي. وبعدها سنحصل على مصفوفة بحجم n / 4 في الاستدعاء العودي التالي، ثم مصفوفة بحجم n / 8، وهكذا؛ حيث تقسَم المصفوفة إلى نصفين في كل استدعاء، حتى نصل إلى عنصر واحد فقط، لذلك لنكتب عدد العناصر في المصفوفة الخاصة بنا لكل استدعاء كما يلي: 0th iteration: n 1st iteration: n / 2 2nd iteration: n / 4 3rd iteration: n / 8 … ith iteration: n / 2i last iteration: 1 لاحظ احتواء المصفوفة على n / 2i عنصر في التكرار i بسبب تقسيم المصفوفة في كل تكرار إلى نصفين، مما يعني أننا نقسم عدد عناصرها على 2، أي نضرب المقام بـ 2؛ وإذا فعلنا ذلك i مرة، فسنحصل على n / 2i، إذ يستمر هذا الإجراء ونحصل على عدد أصغر من العناصر مع كل قيمة أكبر للمتغير i، حتى نصل إلى التكرار الأخير الذي يتبقى فيه عنصر واحد فقط، وإذا رغبنا في معرفة التكرار i الذي يتبقى فيه عنصرٌ واحد فقط، فعلينا حل المعادلة التالية: 1 = n / 2i سيكون هذا صحيحًا فقط عندما نصل إلى الاستدعاء النهائي للدالة ()binarySearch، وليس في الحالة العامة، لذلك فإيجاد قيمة i هنا سيساعدنا في العثور على التكرار الذي ستنتهي فيه العودية. وإذا ضربنا كلا الطرفين بـ 2i فسنحصل على: 2i= n يجب أن تبدو هذه المعادلة مألوفة إذا قرأت قسم اللوغاريتمات أعلاه، وبالتالي ينتج: i = log( n ) يخبرنا هذا أن عدد التكرارات المطلوبة لإجراء بحث ثنائي هو log( n )، حيث n هي عدد عناصر المصفوفة الأصلية، ويُعَدّ ذلك أمرًا منطقيًا. بافتراض أنّ n = 32 فسيكون لدينا مصفوفة مؤلفة من 32 عنصرًا، فكم مرةً يجب تقسيم هذه المصفوفة إلى نصفين للحصول على عنصر واحد فقط؟ سنحتاج إلى تقسيمها خمس مرات للحصول إلى عنصر واحد، أي بالترتيب التالي: 32 ← 16 ← 8 ← 4 ← 2 ← 1، والعدد 5 هو لوغاريتم 32، لذلك يكون تعقيد البحث الثنائي هو Θ( log( n ) ). تسمح لنا هذه النتيجة الأخيرة بمقارنة البحث الثنائي والبحث الخطي، وبما أن ( log( n أصغر بكثير من n، فيمكن استنتاج أن البحث الثنائي أسرع بكثير من البحث الخطي للبحث داخل مصفوفة، لذلك يُستحسَن إبقاء المصفوفات مرتبةً عند العمل على عدة عمليات بحث فيها. الفرز الأمثل Optimal sorting تهانينا! لقد بتّ الآن تعرف كلًا من تحليل تعقيد الخوارزميات، وسلوك الدوال المقارب، وصيغة big-O؛ بالإضافة إلى كيفية إيجاد تعقيد الخوارزمية ليكون O( 1 )، وO( log( n ) )، وO( n )، وO( n2 ) وما إلى ذلك بديهيًا، كما أصبحت تعرف الرموز o، وO، وω، وΩ، وΘ، وماذا يعني تحليل الحالة الأسوأ أيضًا. يُعَدّ هذا القسم الأخير من المقال أعقد قليلًا، لذا لا تتردد في أخذ راحة إذا تعبت، حيث سيتطلب منك التركيز وقضاء بعض الوقت في حل التمارين، لكنه سيوفر لك طريقةً مفيدةً للغاية في تحليل تعقيد الخوارزمية وهذا أمرٌ مهم، لذلك فهو بالتأكيد يستحق الفهم. يُدعى الفرز الذي طبقناه سابقًا بالفرز الانتقائي، حيث ذكرنا أنه ليس الفرز الأمثل؛ والخوارزمية المثلى هي الخوارزمية التي تحل المشكلة بأفضل طريقة ممكنة، مما يعني عدم وجود خوارزميات أفضل منها، وهذا يعني أن لدى جميع الخوارزميات الأخرى الموجهة لحل المشكلة تعقيدًا أسوأً أو مساويًا لتلك الخوارزمية المثلى، كما قد يكون هناك العديد من الخوارزميات المثلى لمشكلةٍ ما بحيث تشترك جميعها في التعقيد نفسه، ويمكن حل مشكلة الفرز على النحو الأمثل بطرق مختلفة، كما يمكن استخدام فكرة البحث الثنائي نفسها من أجل الفرز بسرعة، وتسمى طريقة الفرز المثلى هذه الفرز بالدمج mergesort. سنحتاج أولًا في إجراء فرز الدمج، إلى إنشاء دالة مساعدة والتي سنستخدمها بعد ذلك لإجراء الفرز الفعلي، حيث تأخذ دالة الدمج merge مصفوفتين مرتّبتَين سابقًا، ثم تدمجهما معًا في مصفوفة كبيرة مرتبة، ويمكن القيام بذلك بسهولة كما يلي: def merge( A, B ): if empty( A ): return B if empty( B ): return A if A[ 0 ] < B[ 0 ]: return concat( A[ 0 ], merge( A[ 1...A_n ], B ) ) else: return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) ) تأخذ الدالة concat عنصرًا يُسمى "الرأس head" ومصفوفة تُسمى "الذيل tail"، ثم تبني وتعيد مصفوفةً جديدةً تحتوي على عنصر "الرأس" الذي يمثِّل العنصر الأول في المصفوفة الجديدة، وعلى عنصر "الذيل" الذي يمثِّل بقية العناصر الموجودة في المصفوفة، حيث تعيد الدالة concat( 3, [ 4, 5, 6 ] ) مثلًا، ما يلي: [ 3, 4, 5, 6 ]. ونستخدم المتغيرين An وBn للإشارة إلى أحجام المصفوفتين A وB على التوالي. تمرين 8 تحقق من إجراء الدالة المذكورة أعلاه لعملية الدمج، ثم أعد كتابتها بلغة البرمجة المفضلة لديك بطريقة تكرارية -أي باستخدام حلقات for- بدلًا من استخدام العودية. يكشف تحليل هذه الخوارزمية أن وقت تشغيلها Θ( n )، حيث يمثِّل n طول المصفوفة الناتجة أي n = A_n + B_n. تمرين 9 تحقق من أن وقت تشغيل الدالة merge هو Θ( n ). يمكننا بناء خوارزمية فرز أفضل باستخدام هذه الدالة، حيث نقسم المصفوفة إلى قسمين، ونرتِّب كل جزء من الجزأين عوديًا، ثم ندمج المصفوفتين المرتبتين في مصفوفة واحدة كبيرة، وذلك كما يلي: def mergeSort( A, n ): if n = 1: return A # it is already sorted middle = floor( n / 2 ) leftHalf = A[ 1...middle ] rightHalf = A[ ( middle + 1 )...n ] return merge( mergeSort( leftHalf, middle ), mergeSort( rightHalf, n - middle ) ) يُعَدّ فهم هذه الدالة أصعب مما مررنا به سابقًا، لذلك قد يأخذ منك التمرين التالي بضع دقائق. تمرين 10 تحقق من صحة الدالة mergeSort، وذلك من خلال التحقق من تمكّن الدالة mergeSort من فرز المصفوفة المعطاة بصورة صحيحة، وإذا واجهتك مشكلة في فهم سبب نجاحها في ذلك، فجرّبها باستخدام مصفوفة صغيرة على أساس مثال ثم شغّلها "يدويًا"، وتأكد عند تشغيل هذه الدالة يدويًا من حصولك على النصف الأيسر leftHalf والنصف الأيمن rightHalf. وإذا قسّمت المصفوفة في المنتصف تقريبًا، فليس من الضروري قسم المصفوفة في المنتصف تمامًا إذا احتوت على عدد فردي من العناصر وهذا الهدف من استخدام الدالة floor أعلاه. لنحلل الآن تعقيد الدالة mergeSort، حيث سنقسم المصفوفة إلى نصفين متساويين في الحجم على غرار دالة البحث الثنائي binarySearch في كل خطوة من خطوات الدالة mergeSort، ولكننا سنحافظ في هذه الحالة على كلا النصفين طوال فترة التنفيذ، ثم نطبّق الخوارزمية عوديًا في كل نصف، كما نطبّق عملية الدمج merge على النتيجة التي تستغرق وقتًا مقداره Θ( n ) بعد أن تعيد الخوارزمية العودية. لبهذا نكون قد قسمنا المصفوفة الأصلية إلى مصفوفتين بحجم n / 2 لكل منهما، ثم دمجنا هذه المصفوفات، وهي عملية لدمج n عنصرًا وبالتالي تستغرق وقتًا (Θ (n، كما يوضح الشكل التالي هذه العملية العودية: شجرة العودية لطريقة الفرز بالدمج merge sort تمثِّل كل دائرة استدعاءً للدالة mergeSort كما يشير الرقم المكتوب في الدائرة إلى حجم المصفوفة التي يجري فرزها، إذ تكون الدائرة الزرقاء العلوية الاستدعاء الأصلي للدالة mergeSort، بحيث نحصل على فرز مصفوفة بالحجم n، كما تشير الأسهم إلى الاستدعاءات المتكررة التي تجريها الدوال فيما بينها. يعمل الاستدعاء الأصلي للدالة mergeSort على استدعائها مرتين في مصفوفتين وحجم كل منهما n / 2، حيث يشار إلى ذلك بواسطة السهمين الموجودين في الأعلى، ثم يجري كل من هذين الاستدعائَين بدورهما استدعائين خاصين بهما لدمج مصفوفتين بحجم n / 4 لكل منهما، وهكذا دواليك حتى نصل إلى مصفوفات ذات حجم 1؛ ويسمَّى هذا الرسم البياني بالشجرة العودية recursion tree، لأنه يوضح كيفية حدوث العودية ويظهر مثل شجرة، لكن الجذر root في الأعلى والأوراق في الأسفل، لذلك يظهر مثل شجرة مقلوبة. لاحظ أن العدد الإجمالي للعناصر هو n في كل مستوى من الرسم البياني أعلاه، حيث يحتوي المستوى الأول على استدعاء واحد فقط للدالة mergeSort مع مصفوفة بحجم n أي العدد الإجمالي للعناصر هو n، كما يحتوي المستوى الثاني على استدعائين للدالة mergeSort وكل منهما بحجم n / 2. لكن n / 2 + n / 2 = n وهكذا يكون العدد الإجمالي للعناصر هو n في هذا المستوى، كما توجد 4 استدعاءات في المستوى الثالث، بحيث يُطبَّق كل استدعاء على مصفوفة بحجم n / 4، أي سيساوي عدد العناصر الإجمالي n / 4 + n / 4 + n / 4 + n / 4 = 4n / 4 = n، وبالتالي نحصل على n عنصر. يجب على المستدعي في كل مستوى من هذا الرسم البياني إجراء عملية دمج merge على العناصر التي يعيدها المستدعَى، إذ يجب على الدائرة المشار إليها باللون الأحمر مثلًا، ترتيب عدد n / 2 من العناصر، وذلك بتقسيم المصفوفة ذات الحجم n / 2 إلى مصفوفتين بحجم n / 4، ثم تُستدعَى الدالة mergeSort عوديًا لفرز تلك المصفوفة، ثم تُدمَجان معًا، ويُشار إلى هذه الاستدعاءات بالدوائر ذات اللون الأخضر. تحتاج عملية الدمج إلى دمج n / 2 عنصر في كل مستوى من الشجرة، ويكون العدد الإجمالي للعناصر المدموجة هو n. حيث تدمج الدالة في ذلك المستوى n / 2 عنصر، ويجب على الدالة الموجودة على يمينها -ذات اللون الأزرق- دمج n / 2 عنصرأيضًا، وبالتالي ينتج عدد العناصر الإجمالي التي يجب دمجها في هذا المستوى . تعقيد كل مستوى هو Θ( n )، كما يكون عدد المستويات في هذا الرسم البياني، والذي يُطلق عليه أيضًا عمق depth شجرة العودية مساويًا لـ log( n )، وسبب ذلك هو السبب ذاته تمامًا الذي استخدمناه عند تحليل تعقيد البحث الثنائي. لدينا log( n ) مستوى وتعقيد كل مستوى هو Θ( n )، وبالتالي، يكون تعقيد الدالة mergeSort هو Θ(n * log( n ))، وهذا أفضل بكثير من Θ( n2 ) الذي هو تعقيد خوارزمية الفرز الانتقائي -تذكر أنّ log( n ) أصغر بكثير من n، وبالتالي يكون n * log (n) أصغر بكثير من n * n = n2-، وإذا وجدت ذلك معقدًا، فلا تقلق لأن الأمر ليس سهلًا في المرة الأولى. يسمح لنا تحليل التعقيد بمقارنة الخوارزميات لمعرفة أيها أفضل كما رأيت في هذا المثال الأخير، ويمكننا الآن أن نكون على يقينٍ تام من تفوّق خوارزمية الفرز بالدمج على خوارزمية الفرز الانتقائي للمصفوفات الكبيرة، كما سيكون استخلاص هذا الاستنتاج صعبًا إذا لم تملك الخلفية النظرية لتحليل الخوارزمية. تُستخدَم خوارزميات الفرز التي لها وقت تشغيل Θ( n * log( n ) )عمليًا، إذ تستخدم نواة نظام لينكس مثلًا، خوارزمية فرز تسمى heapsort، والتي لها وقت تشغيل مماثل لخوارزمية الفرز بالدمج mergesort الذي أوجدناه للتو، والذي هو Θ( n log( n ) )، لذلك فهو الأمثل. لاحظ أننا لم نثبت أن خوارزميات الفرز هذه هي الأمثل، لأن ذلك يتطلب معرفةً رياضيةً أكبر، لكن كن مطمئنًا أنه لا يمكن لهذه الخوارزميات المثلى التحسن أكثر من ذلك من وجهة نظر التعقيد. يجب الآن بعد قراءة هذا المقال أن يكون حدسك الذي طورته لتحليل تعقيد الخوارزمية قادرًا على مساعدتك في تصميم برامج أسرع، ويجب عليك تركيز جهودك المثلى على الأشياء المهمة حقًا بدلًا من الأشياء الصغيرة التي لا تهمك، مما يتيح لك العمل بصورةٍ أكثر إنتاجية. كما يجب أن تكون اللغة الرياضية والتمثيل الذي طُوِّر في هذا المقال مثل صيغة Big-O مفيدَين أيضًا في التواصل مع مهندسي البرمجيات الآخرين عندما تنقاشهم بموضوع وقت تشغيل الخوارزميات. ترجمة -وبتصرف- للمقال A Gentle Introduction to Algorithm Complexity Analysis لصاحبه Dionysis "dionyziz" Zindros. اقرأ أيضًا المرجع الشامل إلى تعلم الخوارزميات للمبتدئين تعقيد الخوارزميات Algorithms Complexity ترميز Big-O في الخوارزميات خوارزمية ديكسترا Dijkstra’s Algorithm
لا يملك الكثير من المبرمجين الذين يصنعون أروع البرامج وأكثرها فائدةً اليوم -مثل العديد من الأشياء التي نراها على الإنترنت أو نستخدمها يوميًا- خلفيةً نظريةً في علوم الحاسوب، لكنهم لا يزالون مبرمجين رائعين ومبدعين ونقدِّر ما يبنونه، حيث تملك علوم الحاسوب النظرية استخداماتها وتطبيقاتها، ويمكن أن تكون عمليةً تمامًا. يستهدف هذا المقال المبرمجين الذين يعرفون عملهم جيدًا ولكنهم لا يملكون خلفيةً نظريةً في علوم الحاسوب، وذلك من خلال واحدة من أكثر أدوات علوم الحاسوب واقعيةً، وهي: صيغة O الكبير Big O notation، وتحليل تعقيد الخوارزمية algorithm complexity. تُعَدّ هذه الأداة واحدةً من الأدوات المفيدة عمليًا للأشخاص العاملين في المجال الأكاديمي لعلوم الحاسوب، وفي إنشاء برامج على مستوى الإنتاج في الصناعة، لذلك نأمل أن تتمكن من تطبيقها في الشيفرة الخاصة بك لتحسينها بعد قراءة هذا المقال، كما يُفتَرض أن تكون قادرًا على فهم جميع المصطلحات الشائعة التي يستخدمها المختصون في علوم الحاسوب، مثل مصطلحات: التعقيد "Big O"، و"السلوك المقارب asymptotic behavior"، و"تحليل الحالة الأسوأ worst-case analysis" بعد قراءة هذا المقال. يستهدف هذا المقال أيضًا طلاب المدارس الإعدادية والثانوية في أي مكان في العالم، والذين يتنافسون دوليًا في الأولمبياد الدولي للمعلوماتية، أو مسابقة الخوارزميات الطلابية، أو مسابقات أخرى مماثلة. لا يحتوي هذا المقال على أي متطلبات رياضية مسبقَة، كما سيمنحك الخلفية التي ستحتاجها لمواصلة دراسة الخوارزميات مع فهمٍ أقوى للنظرية الكامنة وراءها، وننصح الأشخاص الذين يشاركون في هذه المسابقات الطلابية بشدة بقراءة هذا المقال التمهيدي بأكمله ومحاولة فهمه تمامًا، لأنه سيكون ضروريًا أثناء دراسة الخوارزميات وتعلُّم المزيد من التقنيات المتقدِّمة. سيكون هذا المقال مفيدًا للمبرمجين الصناعيين الذين ليس لديهم خبرة كبيرة في علوم الحاسوب النظرية، ونظرًا لتخصيص هذا المقال للطلاب، فقد يبدو في بعض الأحيان مثل كتاب مدرسي، حيث قد ترى بعض الموضوعات شديدة الوضوح لأنك رأيتها خلال سنوات دراستك على سبيل المثال، لذلك يمكنك تخطيها إذا شعرت أنك تفهمها. تصبح الأقسام الأخرى أقل عمقًا ونظريًا، حيث يحتاج الطلاب المشاركون في هذه المسابقات إلى معرفة المزيد عن الخوارزميات النظرية أكثر من ممارس المهنة العادي، ولا تزال معرفة هذه الأشياء أمرًا جيدًا بما أنها ليست صعبةً كثيرًا، لذا يستحق ذلك الأمر إعطاءه بعضًا من وقتك. لا تحتاج إلى خلفية رياضية لأن النص الأصلي لهذا المقال قد استهدف طلاب المدارس الثانوية، لذلك سيكون أي شخصٍ لديه بعض الخبرة في البرمجة -أي إن عرف ما هي العَودية recursion على سبيل المثال- قادرًا على المتابعة دون أي مشكلة. ستجد خلال هذا المقال العديد من الروابط التي تنقلك للاطلاع على مواد مهمة خارج نطاق موضوع المقال، إذ يُحتمل درايتك بمعظم هذه المفاهيم إذا كنت مبرمجًا صناعيًا؛ أما إذا كنت طالبًا مشاركًا في المسابقات، فسيعطيك اتباع هذه الروابط أفكارًا حول مجالات أخرى من علوم الحاسوب أو هندسة البرمجيات التي ربما لم تستكشفها بعد، والتي يمكنك الاطلاع عليها لتوسيع اهتماماتك. يصعب على الكثير من المبرمجين والطلاب فهم تحليل تعقيد الخوارزمية وصيغة Big O، أو يخافون منه، أو يتجنبونه تمامًا ويعدّونه عديم الفائدة، لكنه ليس صعبًا أو نظريًا كما قد يبدو للوهلة الأولى. يُعَدّ تعقيد الخوارزمية طريقةً لقياس سرعة تشغيل برنامج ما أو خوارزمية ما، لذلك يُعَد أمرًا عمليًا. الدافع Motivation يوجد أدوات لقياس مدى سرعة تشغيل البرنامج، فهناك برامج تسمى المشخِّصات profilers، حيث تقيس وقت التشغيل بالميلي ثانية ويمكنها مساعدتنا في تحسين الشيفرة الخاصة بنا عن طريق تحديد الاختناقات bottlenecks، وعلى الرغم من فائدة هذه الأداة إلا أنها ليست ذات صلة فعلية بتعقيد الخوارزمية، فتعقيد الخوارزمية مصمَّمٌ لمقارنة خوارزميتين ضمن المستوى المثالي، أي تجاهل التفاصيل منخفضة المستوى، مثل: لغة برمجة التطبيق، أو العتاد الذي تعمل عليه الخوارزمية، أو مجموعة تعليمات وحدة المعالجة المركزية CPU. عندما نريد مقارنة الخوارزميات من حيث ماهيتها -أي الأفكار التي تُعرّفنا كيفية حساب شيءٍ ما-، فلن يساعدنا العد بالميلي ثانية في ذلك، إذ يُحتمَل أن تعمل الخوارزمية السيئة والمكتوبة بلغة برمجة منخفضة المستوى مثل لغة التجميع Assembly، بصورة أسرع بكثير من خوارزمية جيدة مكتوبة بلغة برمجة عالية المستوى مثل بايثون، أو روبي، لذلك يجب تحديد معنى "الخوارزمية الأفضل". بما أن الخوارزميات هي برامج تجري عمليات حسابية فقط، ولا تجري أشياءً أخرى تقوم بها الحواسيب، مثل: مهام الشبكات، أو دخل المستخدم، وخرجه؛ فسيسمح لنا ذلك بتحليل التعقيد بقياس مدى سرعة البرنامج عند إجراء العمليات الحسابية. تتضمن أمثلة العمليات الحسابية البحتة العمليات العشرية العددية numerical floating-point operations، مثل: الجمع والضرب، أو البحث داخل قاعدة بيانات متناسبة مع الذاكرة العشوائية RAM عن قيمة معينة، أو تحديد المسار الذي ستمر به شخصية ذكاء اصطناعي في لعبة فيديو، بحيث يتعين عليها فقط السير مسافةً قصيرةً داخل عالمها الافتراضي (كما في الشكل الآتي)، أو تشغيل تطابق نمط تعبير نمطي regular expressions مع سلسلة، فالعمليات الحسابية موجودة في كل مكان في البرامج الحاسوبية. تستخدم شخصيات الذكاء الاصطناعي في ألعاب الفيديو الخوارزميات لتجنب العقبات عند تنقّلها في العالم الافتراضي يُعَدّ تحليل التعقيد أداةً لشرح كيفية تصرّف الخوارزمية مع زيادة حجم الدخل. وهنا نتساءل، إذا زدنا الدخل، فكيف ستتصرّف الخوارزمية؟ أي إذا كانت الخوارزمية الخاصة بنا تستغرق ثانيةً واحدةً للتشغيل بالنسبة إلى دخلٍ بحجم 1000، فكيف ستتصرف الخوارزمية إذا ضاعفنا حجم الدخل؟ هل ستعمل بالسرعة نفسها، أم بنصف السرعة، أم أبطأ بأربع مرات؟ يُعَدّ هذا مهمًا في البرمجة العملية لأنه سيسمح لنا بالتنبؤ بسلوك الخوارزمية عندما تصبح بيانات الدخل أكبر؛ فمثلًا، إذا أنشأنا خوارزميةً لتطبيق ويب يعمل جيدًا مع 1000 مستخدِم، وقِسنا وقت تشغيله باستخدام تحليل تعقيد الخوارزمية، فيمكننا توقُّع ما سيحدث بمجرد حصولنا على 2000 مستخدِم بدلًا من ذلك. يمنحنا تحليل التعقيد في مسابقات الخوارزميات رؤيةً عن المدة التي سيستغرقها تشغيل الشيفرة لأكبر حالات الاختبار التي تُستخدَم لاختبار صحة البرنامج، لذلك إذا قِسنا سلوك برنامجنا مع دخل صغير، فسنعرف سلوكه مع الدخل الأكبر. لنبدأ بمثال بسيط هو إيجاد العنصر الأكبر في مصفوفة. عد التعليمات سنستخدم لغات برمجة مختلفة لأمثلة هذا المقال، لكن لا تيأس إن لم تعرف لغة برمجة معينة، وبما أنك تعرف البرمجة، فيجب أن تكون قادرًا على قراءة الأمثلة دون أي مشكلة حتى إن لم تكن على دراية بلغة البرمجة المختارة، لأنها ستكون بسيطةً ولن نستخدم أية ميزات خاصة بلغة معينة. إذا كنت طالبًا منافسًا في مسابقات الخوارزميات، فيُرجَّح استخدمك لغة C++، لذلك لن تواجه مشكلة، وبالتالي نوصي في هذه الحالة التدرّب باستخدام لغة C++. يمكن البحث عن العنصر الأكبر في مصفوفة باستخدام شيفرة لغة جافا سكريبت التالية، بافتراض أن مصفوفة الدخل هي A، وحجمها n: var M = A[ 0 ]; for ( var i = 0; i < n; ++i ) { if ( A[ i ] >= M ) { M = A[ i ]; } } أول شيء سنفعله هو حساب عدد التعليمات الأساسية التي ينفذها هذا الجزء من الشيفرة، حيث سنفعل هذا مرةً واحدةً فقط، ولن يكون ضروريًا لاحقًا، لذلك تحمَّل لبضع لحظات. نقسّم الشيفرة إلى تعليماتٍ بسيطة عندما نحللها، فهذه التعليمات البسيطة هي ذات التعليمات، أو قريبة منها، والتي يمكن لوحدة المعالجة المركزية من تنفيذها مباشرةً، كما سنفترض أن معالجنا يمكنه تنفيذ العمليات التالية على أساس تعليمة واحدة لكل منها: إسناد قيمة لمتغير. البحث عن قيمة عنصر معين في مصفوفة. مقارنة قيمتين. زيادة قيمة. العمليات الحسابية الأساسية، مثل: الجمع، والضرب. سنفترض أن التفرع -أي الاختيار بين جزئي if وelse بعد تقييم شرط if- سيحدث على الفور ولن يحسب هذه التعليمات. السطر الأول من الشيفرة السابقة هو: var M = A[ 0 ]; يتطلب هذا السطر تعليمتين: إحداهما للبحث عن العنصر A[ 0 ]، والأخرى لإسناد قيمته إلى M، حيث سنفترض أن قيمة n تساوي 1 على الأقل دائمًا، كما تتطلّب الخوارزمية هاتين التعليمتين دائمًا، بغض النظر عن قيمة n، ويجب أيضًا تشغيل شيفرة تهيئة حلقة for دائمًا، ويعطينا هذا تعليمتين أخريين، هما: الإسناد assignment، والمقارنة comparison: i = 0; i < n; ستشغَّل هاتان التعليمتان قبل أول تكرار من حلقة for، كما نحتاج إلى تعليمتين إضافيتين للتشغيل بعد كل تكرار لحلقة for، وهما: زيادة المتغير i، ومقارنة للتحقق من أننا ما زلنا ضمن الحلقة، أي كما يلي: ++i; i < n; إذا تجاهلنا جسم الحلقة، فسيكون عدد التعليمات التي تحتاجها هذه الخوارزمية هو 4 + 2n، أي 4 تعليمات في بداية حلقة for، وتعليمتين في نهاية كل تكرار من n تكرار. يمكننا الآن تحديد دالة رياضية f( n )، حيث تعطينا عدد التعليمات التي تحتاجها الخوارزمية عند إعطاء n، أي لدينا f( n ) = 4 + 2n عندما يكون جسم حلقة for فارغًا. تحليل الحالة الأسوأ Worst-case analysis لدينا بالنظر إلى جسم حلقة for عملية بحث في مصفوفة، وعملية مقارنة تحدث دائمًا، كما يلي: if ( A[ i ] >= M ) { … أي يوجد تعليمتان، ولكن اعتمادًا على قيم المصفوفة، فقد يعمل جسم تعليمة if وقد لا يعمل. فإذا تحقق A[ i ] >= M، فسنشغّل هاتين التعليمتين الإضافيتين -أي البحث في مصفوفة والإسناد-، كما يلي: M = A[ i ] لكن لا يمكننا الآن تحديد الدالة f( n ) بسهولة، وذلك لعدم اعتماد عدد التعليمات على n فقط، وإنما على الدخل أيضًا، فإذا كان الدخل A = [ 1, 2, 3, 4 ] مثلًا، فستحتاج الخوارزمية إلى تعليمات أكثر مما إذا كان الدخل A = [ 4, 3, 2, 1 ]. نفكر عند تحليل الخوارزميات في أسوأ سيناريو غالبًا، فما هو أسوأ شيء يمكن حدوثه لخوارزميتنا؟ ومتى تحتاج الخوارزمية إلى معظم التعليمات لإكمالها؟ في هذه الحالة، يحدث ذلك عندما يكون لدينا مصفوفة بترتيب تصاعدي مثل A = [ 1, 2, 3, 4 ]، حيث يجب استبدال المتغير M في كل مرة، وبالتالي، سينتج عن ذلك تنفيذ معظم التعليمات، ويُطلَق على هذه الحالة اسم تحليل الحالة الأسوأ Worst-case analysis؛ وهذا ليس أكثر من مجرد التفكير في الحالة التي تحدث عندما نكون الأقل حظًا. لدينا في أسوأ الحالات 4 تعليمات للتشغيل داخل جسم حلقة for، لذلك لدينا f( n ) = 4 + 2n + 4n = 6n + 4، حيث تعطينا الدالة f عدد التعليمات التي قد تكون مطلوبةً في الحالة الأسوأ بالاعتماد على حجم المشكلة n. السلوك المقارب Asymptotic behavior تمنحنا الدالة السابقة فكرةً جيدةً عن مدى سرعة الخوارزمية، ولكن كما وعدناك، فلن تحتاج إلى القيام بالمهمة الشاقة المتمثلة في عد التعليمات في البرنامج. يعتمد عدد تعليمات وحدة المعالجة المركزية الفعلية اللازمة لكل عبارة لغة برمجة، على مُصرِّف compiler لغة البرمجة، وكذا على مجموعة تعليمات وحدة المعالجة المركزية المتاحة، سواءً كان معالج AMD أو Intel Pentium على حاسوبك، أو كان معالج MIPS على Playstation 2 الخاصة بك، وسنتجاهل ذلك أيضًا كما ذكرنا سابقًا. سنشغّل الآن الدالة "f" الخاصة بنا من خلال "مرشِّح filter" ليساعدنا في التخلص من التفاصيل الصغيرة التي يفضّل المتخصصون في علوم الحاسوب تجاهلها. يوجد قسمان في الدالة f التي تساوي 6n + 4، وهما: 6n، و4، كما لا نهتم في تحليل التعقيد إلا بما يحدث لدالة عد التعليمات عندما يكبر دخل البرنامج (n)، ويتماشى هذا مع الأفكار السابقة لسلوك "السيناريو الأسوأ" الذي ينص على الاهتمام بكيفية تصرّف الخوارزمية عند معالجتها بصورة سيئة، أي عندما تفعل هذه الخوارزمية شيئًا صعبًا، وهذا مفيد حقًا عند مقارنة الخوارزميات. إذا تغلبت خوارزمية على خوارزمية أخرى عند استخدام دخل كبير، فيُرجَّح أن الخوارزمية الأسرع ستبقى أسرع عند إعطاء دخلٍ أسهل وأصغر. سنحذف الأقسام التي تنمو ببطء ونبقي فقط الأقسام التي تنمو بسرعة عندما تصبح n أكبر، ومن الواضح أن 4 ستبقى 4 لأن n تنمو بصورة أكبر؛ أما 6n فتنمو بصورةٍ أكبر وأكبر، لذلك تميل إلى كونها أهم بالنسبة للمشكلات الأكبر، وبالتالي، أول شيء سنفعله هو حذف 4 والاحتفاظ بالدالة على صورة f( n ) = 6n. يُعَدّ ما سبق منطقيًا، وذلك لأنّ الرقم 4 هو "ثابت التهيئة initialization constant" ببساطة، وقد تتطلب لغات البرمجة المختلفة وقتًا مختلفًا لعملية الإعداد، فمثلًا، تحتاج لغة جافا إلى بعض الوقت لتهيئة آلتها الافتراضية virtual machine، وبما أننا نتجاهل الاختلافات في لغات البرمجة، فمن المنطقي تجاهل هذه القيمة فقط. الشيء الثاني الذي سنتجاهله هو معامل الضرب الثابت أمام n، وبالتالي ستصبح الدالة f( n ) = n، مما يجعل الأمور أكثر بساطةً. يُعَدّ إهمال معامل الضرب أمرًا منطقيًا إذا فكرنا في كيفية تصريف لغات البرمجة المختلفة، فقد تُصرَّف عبارة "البحث في المصفوفة" في إحدى لغات البرمجة إلى تعليمات مختلفة عن لغات برمجةٍ مختلفة، كما لا يتضمّن الإجراء A[ i ] التحقق من عدم تجاوز المتغير i لحجم المصفوفة المُصرَّح عنها في لغة سي C على سبيل المثال، ولكنه يتضمّن ذلك في لغة باسكال Pascal؛ إذًا فالشيفرة التالية المكتوبة بلغة باسكال: M := A[ i ] تكافئ الشيفرة التالية المكتوبة بلغة سي: if ( i >= 0 && i < n ) { M = A[ i ]; } لذلك نتوقّع أن لغات البرمجة المختلفة ستنتج عوامِلًا مختلفةً عندما نعُد تعليماتها. تستخدِم لغة باسكال مصرِّفًا غبيًا يغفَل عن التحسينات الممكنة في هذا المثال، كما تتطلب ثلاث تعليمات لكل وصول إلى مصفوفة، في حين تتطلب لغة سي تعليمةً واحدةً. يُطبَّق إهمال هذا العامل على جميع الاختلافات بين لغات البرمجة والمصرِّفات أيضًا، وبالتالي، تُحلَّل فكرة الخوارزمية فقط. يُسمَّى المرشِّح المتمثِّل بعمليتَي "إهمال جميع العوامل"، و"الإبقاء على القسم الذي يكبر أكثر" كما هو موصوف أعلاه بالسلوك المقارب asymptotic behavior، ولذلك نمثِّل السلوك المقارب للدالة f( n ) = 2n + 8 من خلال الدالة f( n ) = n. نهتم رياضيًا بنهاية الدالة f لأن n يميل إلى اللانهاية؛ ولكن إن لم تفهم ما تعنيه هذه العبارة، فلا تقلق لأنّ هذا كل ما تحتاج إلى معرفته، كما لن نستطيع إهمال الثوابت في النهاية في إطار رياضي صارم، ولكننا نفعل ذلك لأغراض علوم الحاسوب وللأسباب الموضَّحة أعلاه. سنحل بعض الأمثلة لفهم الفكرة أكثر، فمثلًا، لنجد السلوك المقارب لدوال المثال التالي بإهمال العوامِل الثابتة، والحفاظ على الأقسام التي تكبر بسرعة: تعطي الدالة f( n ) = 5n + 12 الدالة f( n ) = n باستخدام الاستنتاج نفسه بالضبط كما هو مذكور أعلاه. تعطي الدالة f (n) = 109 الدالة f( n ) = 1، حيث سنهمل معامل الضرب 109 * 1، لكن لا يزال يتعين علينا وضع 1 هنا للإشارة إلى أنّ لهذه الدالة قيمة غير صفرية. تعطي الدالة f( n ) =n2 + 3n + 112 الدالة f( n ) = n2، حيث تكبرn2 أكثر من 3n بالنسبة لقيمة n كبيرة بدرجة كافية، لذلك نحتفظ بها. تعطي الدالة f( n ) = n3 + 1999n + 1337 الدالة f( n ) = n3، فعلى الرغم من أنّ العامل الموجود أمام n كبير جدًا، لكن لا يزال بإمكاننا العثور على قيمة n كبيرة بما يكفي، بحيث يكون n3 أكبر من 1999n، وبما أننا مهتمون بسلوك قيم n الكبيرة جدًا، فسنبقي على n3 فقط، أي تصبح الدالة n3 المرسومة باللون الأزرق في الشكل التالي أكبر من الدالة 1999n المرسومة باللون الأحمر بعد القيمة n = 45، كما تبقى هي الأكبر بعد هذه النقطة إلى الأبد. تعطي الدالة f( n ) = n +√n الدالة f (n) = n، وذلك لأنّ n تنمو أسرع من √n كلما زادتn ويمكنك تجربة الأمثلة الآتية بنفسك. تمرين 1 f( n ) = n6 + 3n f( n ) = 2n + 12 f( n ) = 3n + 2n f( n ) = nn + n (اكتب نتائجك، وسترى الحل أدناه). إذا واجهتك مشكلة مع أحد العناصر المذكورة أعلاه، فجرِّب بعض قيم n الكبيرة لمعرفة القسم الأكبر، وهذا بسيط جدًا، أليس كذلك؟ التعقيد Complexity بما أنه يمكننا إهمال كل هذه الثوابت "الشكلية"، فمن السهل جدًا معرفة السلوك المقارب لدالة عدّ تعليمات البرنامج، حيث يملك البرنامج الذي لا يحتوي على حلقات، الدالة f( n ) = 1، لأن عدد التعليمات التي يحتاجها هو مجرد عددٍ ثابت -إلا في حالة استخدامه العودية كما سنرى لاحقًا-. يملك البرنامج الذي يحتوي حلقةً واحدةً تمتد من 1 إلى n، الدالة f( n ) = n، حيث سينفِّذ عددًا ثابتًا من التعليمات قبل الحلقة، وعددًا ثابتًا من التعليمات بعد الحلقة، وعددًا ثابتًا من التعليمات داخل الحلقة التي تُشغَّل جميعًا n مرة. يجب أن يكون هذا أكثر سهولةً وأقل مللًا من عدّ التعليمات الفردية، لذلك لنلقِ نظرةً على بعض الأمثلة لفهم ذلك أكثر. يتحقق البرنامج التالي المكتوب بلغة PHP من وجود قيمة معيَّنة داخل مصفوفة A لها الحجم n: <?php $exists = false; for ( $i = 0; $i < n; ++$i ) { if ( $A[ $i ] == $value ) { $exists = true; break; } } ?> تسمَّى هذه الطريقة للبحث عن قيمة داخل مصفوفة البحث الخطي linear search، وهذا اسم معقول لاحتواء هذا البرنامج على الدالة f( n ) = n، كما سنحدد بالضبط ما تعنيه كلمة "خطي" في القسم التالي. لاحظ وجود عبارة "break" هنا، والتي قد تؤدّي إلى إنهاء البرنامج في وقت قريب، وربما بعد تكرارٍ واحد؛ لكن تذكّر اهتمامنا بالسيناريو الأسوأ، وهو بالنسبة لهذا البرنامج عدم احتواء المصفوفة A على القيمة التي نبحث عنها، لذلك لا يزال لدينا الدالة f( n ) = n. تمرين 2 حلّل عدد التعليمات التي يحتاجها برنامج PHP أعلاه بالنسبة إلى n في الحالة الأسوأ للعثور على الدالة ( f( n، وذلك على غرار الطريقة التي حلّلنا بها البرنامج الأول المكتوب بلغة جافا سكريبت، ثم تحقق من أنه لدينا f( n ) = n بصورةٍ مقاربة. لنلقِ نظرةً على البرنامج المكتوب بلغة بايثون Python، والذي يجمع عنصرين من مصفوفة معًا لينتج مجموع يُخزَّن في متغير آخر: v = a[ 0 ] + a[ 1 ] لدينا هنا عددٌ ثابت من التعليمات، لذلك f (n) = 1. يتحقق البرنامج التالي المكتوب بلغة C++ من احتواء متّجه -مصفوفة مختارة أو جزء من مصفوفة- يُسمَّى A، وذو حجم n على قيمتين متماثلتين في أي مكان ضمنه: bool duplicate = false; for ( int i = 0; i < n; ++i ) { for ( int j = 0; j < n; ++j ) { if ( i != j && A[ i ] == A[ j ] ) { duplicate = true; break; } } if ( duplicate ) { break; } } بما أنه توجد هنا حلقتان متداخلتان داخل بعضهما البعض، فسيكون لدينا سلوكًا مقاربًا موصوفًا بالدالة f( n ) = n2. إذا استدعى برنامج دالةً داخل حلقة وعرفنا عدد التعليمات التي تجريها الدالة المستدعاة، فمن السهل تحديد عدد تعليمات البرنامج بأكمله. لنلقِ نظرةً على المثال التالي المكتوب بلغة ? int i; for ( i = 0; i < n; ++i ) { f( n ); } إذا علمنا أن f( n ) هي دالة تنفِّذ n تعليمة بالضبط، فيمكننا حينئذٍ معرفة أن عدد تعليمات البرنامج بأكمله هو n2 بصورةٍ مقاربة، حيث تُستدعى الدالة n مرة تمامًا. ننتقل الآن إلى الصيغة التخيُّلية التي يستخدمها علماء الحاسوب للسلوك المقارب، حيث سنقول أن برنامجنا هو Θ ( f( n )) عندما نحدِّد الدالة f بصورة مقاربة، فمثلًا، البرامج المذكورة أعلاه هي Θ (1) وΘ( n2 ) وΘ( n2 ) على التوالي، حيث تُقرَأ Θ( n ) "ثيتا بالنسبة إلى n". نقول أحيانًا أنّ f( n ) -وهي الدالة الأصلية التي تحسب عدد التعليمات بما في ذلك الثوابت- هي شيء ما Θ، حيث نقول مثلًا أنّ f( n ) = 2n هي دالة Θ( n )، كما يمكننا كتابة 2n ∈ Θ (n) أيضًا، والتي تُنطَق "2n هي ثيتا بالنسبة إلى n". لا ترتبك بشأن هذا الصيغة، فكل ما تنص عليه هو أنه إذا حسبنا عدد التعليمات التي يحتاجها البرنامج وهي 2n، فسيُوصَف السلوك المقارب للخوارزمية بـ n والذي نتج بإهمال الثوابت. فيما يلي بعض العبارات الرياضية الصحيحة باستخدام هذا الصيغة: n6 + 3n ∈ Θ( n6 ) 2n + 12 ∈ Θ( 2n ) 3n + 2n ∈ Θ( 3n ) nn + n ∈ Θ( nn ) بالمناسبة، إذا حللت التمرين 1 السابق، فهذه هي بالضبط الإجابات التي يجب أن تصل إليها. نسمّي ما نضعه ( هنا )Θ التعقيد الزمني time complexity، أو تعقيد complexity الخوارزمية، لذلك فللخوارزمية التي تحتوي على الصيغة Θ( n ) تعقيدٌ هو n. لدينا أيضًا أسماءً خاصةً للصيغ التالية: Θ( 1 )، وΘ( n )، وΘ( n2 ) وΘ( log( n ) )، وذلك لكثرة ظهورها، حيث نقول أنّ خوارزمية Θ( 1 ) هي خوارزمية ذات وقت ثابت constant-time algorithm، والخوارزمية Θ( n ) خطية linear، وΘ( n2 ) تربيعية quadratic؛ أما الخوارمية Θ( log( n ) ) فهي لوغاريتمية logarithmic. لا تقلق إن لم تعرف ما هي اللوغاريتمات حتى الآن، سنشرح ذلك لاحقًا. صيغة O الكبير Big-O notation قد تكون معرفة سلوك الخوارزمية بهذه الطريقة كما فعلنا أعلاه أمرًا صعبًا، خاصةً بالنسبة للأمثلة الأعقد، ولكن يمكننا القول بأن سلوك خوارزميتنا لن يتجاوز أبدًا حدًا معينًا، وبالتالي لن نضطر إلى تحديد السرعة التي تعمل بها الخوارزمية، وذلك حتى عند تجاهل الثوابت بالطريقة التي طبّقناها سابقًا، فكل ما علينا فعله هو إيجاد حدٍ معين، حيث سنشرح ذلك بمثال. مشكلة الفرز (sorting problem) هي إحدى المشكلات الشهيرة التي يستخدمها علماء الحاسوب لتدريس الخوارزميات، حيث تُعطَى مصفوفة A بحجم n في مشكلة الفرز، ويُطلَب منا كتابة برنامج لفرز أو ترتيب هذه المصفوفة، وتُعَدّ هذه المشكلة مشكلةً مهمةً كونها مشكلةً واقعيةً في الأنظمة الحقيقية، إذ يحتاج مستكشف الملفات إلى فرز الملفات التي يعرضها حسب الاسم حتى يتمكن المستخدِم من التنقل بينها بسهولة، أو قد تحتاج لعبة فيديو إلى فرز الكائنات ثلاثية الأبعاد المعروضة في العالم بناءً على بعدها عن عين اللاعب داخل العالم الافتراضي من أجل تحديد ما هو مرئي وما هو غير مرئي، وهو ما يسمى مشكلة الرؤية Visibility Problem، فالكائنات التي تكون أقرب للاعب هي المرئية، في حين أنّ الكائنات البعيدة قد تخفيها الكائنات الموجودة أمامها، ويوضّح الشكل الآتي هذه المشكلة، إذ لن يرى اللاعب الموجود في النقطة الصفراء المناطق المظلَّلة، كما يُعَدّ تقسيم العالم إلى أجزاء صغيرة وفرزها حسب المسافة التي تفصلها عن اللاعب إحدى طرق حل مشكلة الرؤية. يُعَدّ الفرز أيضًا مهمًا بسبب وجود العديد من الخوارزميات لحله، كما يكون بعضها أسوأ من البعض الآخر، وهي أيضًا مشكلة سهلة التحديد والشرح، لذلك لنكتب جزءًا من شيفرة تفرز مصفوفة. الطريقة التالية هي طريقة غير فعالة لفرز مصفوفة في لغة روبي Ruby، حيث تدعم لغة روبي فرز المصفوفات باستخدام دوال مبنيّة مسبقًا يجب استخدامها بدلًا من ذلك، وهي بالتأكيد أسرع مما سنراه هنا، ولكن ما سنستخدمه هنا هي شيفرة بغرض التوضيح فقط: b = [] n.times do m = a[ 0 ] mi = 0 a.each_with_index do |element, i| if element < m m = element mi = i end end a.delete_at( mi ) b << m end تسمى هذه الطريقة الفرز الانتقائي Selection sort، حيث تجد هذه الخوارزمية الحد الأدنى من المصفوفة -يُرمَز إلى المصفوفة بالمتغير a في الشيفرة السابقة، بينما يُرمَز إلى الحد الأدنى بالمتغير m، والمتغير mi هو دليله في المصفوفة-، وتضعه في نهاية مصفوفة جديدة -أي المصفوفة b في حالتنا-، ثم تزيله من المصفوفة الأصلية، وبعدها تجد الحد الأدنى بين القيم المتبقية للمصفوفة الأصلية، وتلحِقه بالمصفوفة الجديدة التي تحتوي على عنصرين الآن، ثم تزيله من المصفوفة الأصلية؛ وتستمر هذه العملية إلى حين إزالة جميع العناصر من المصفوفة الأصلية وإدخالها في المصفوفة الجديدة، مما يعني فرز المصفوفة. نلاحظ وجود حلقتين متداخلتين في الشيفرة السابقة، حيث تعمل الحلقة الخارجية n مرة، وتعمل الحلقة الداخلية مرةً واحدةً لكل عنصر من عناصر المصفوفة a. تحتوي المصفوفة a في البداية على n عنصر، ونزيل عنصر مصفوفة واحد في كل تكرار، لذلك تتكرر الحلقة الداخلية n مرة خلال التكرار الأول للحلقة الخارجية، ثم n - 1 مرة، وبعدها n - 2 مرة، وهكذا دواليك حتى التكرار الأخير للحلقة الخارجية التي تعمل خلالها مرةً واحدةً فقط. من الصعب قليلًا تقييم تعقيد هذا البرنامج، حيث يجب معرفة المجموع 1 + 2 + … +(n+(n-1، ولكن يمكننا بالتأكيد إيجاد "الحد الأعلى" لهذا المجموع، وهذا يعني أنه يمكننا تغيير برنامجنا - أي يمكنك فعل ذلك في عقلك، وليس في الشيفرة الفعلية- لجعله أسوأ مما هو عليه، ومن ثم إيجاد تعقيد هذا البرنامج الجديد، فإذا تمكّنا من العثور على تعقيد البرنامج الأسوأ الذي أنشأناه، فسنعلم أنّ برنامجنا الأصلي أسوأ أو ربما أفضل. بالتالي إذا أوجدنا تعقيدًا جيدًا لبرنامجنا المعدَّل الذي هو أسوأ من برنامجنا الأصلي، فيمكننا معرفة أنه سيكون لبرنامجنا الأصلي تعقيدًا جيدًا جدًا أيضًا، أي إما جيدًا بمستوى برنامجنا المعدَّل أو أفضل منه. لنفكّر في طريقة تعديل هذا البرنامج لتسهيل معرفة تعقيده، ولكن ضع في بالك أنه لا يمكننا سوى جعل الأمر أسوأ هكذا، إذ سيأخذ البرنامج مزيدًا من التعليمات، وبالتالي سيكون تقديرنا مفيدًا لبرنامجنا الأصلي. يمكن تغيير الحلقة الداخلية للبرنامج بجعلها تتكرر n مرة دائمًا بدلًا من تكرارها عددًا متغيرًا من المرات، كما ستكون بعض هذه التكرارات عديمة الفائدة، لكنها ستساعدنا في تحليل تعقيد الخوارزمية الناتجة؛ وإذا أجرينا هذا التغيير البسيط، فمن الواضح أن الخوارزمية الجديدة التي أنشأناها هي Θ( n2 ) وذلك لوجود حلقتين متداخلتين بحيث يتكرر كل منهما n مرة بالضبط، وبالتالي، يمكننا القول أنّ الخوارزمية الأصلية هي O( n2 ). تُنطَق O( n2 ) "أوه كبيرة لمربع n، أي big oh of n squared"، وهذا يقودنا للقول بأن برنامجنا ليس أسوأ من n2 بصورةٍ مقاربة، فقد يكون أفضل من ذلك أو مثله. إذا كان برنامجنا هو بالفعل Θ( n2 ) فلا يزال بإمكاننا القول أنه O( n2 ) أي تخيل تغيير البرنامج الأصلي بطريقة لا تغيره كثيرًا، لكنها لا تزال تجعله أسوأ قليلًا مثل إضافة تعليمات لا معنى لها في بداية البرنامج، بحيث سيؤدي فعل ذلك إلى تغيير دالة عدّ التعليمات بواسطة ثابت بسيط، والذي سنتجاهله عندما يتعلق الأمر بالسلوك المقارب، وبالتالي فالبرنامج Θ( n2 ) هو O( n2 ) أيضًا. قد لايكون البرنامج O( n2 ) هو Θ( n2 ) أيضًا، فأيّ برنامج Θ( n ) مثلًا هو O( n2 ) وO( n ) كذلك، وإذا تخيلنا أن برنامج Θ( n ) هو عبارة عن حلقة for بسيطة تتكرر n مرة، فيمكن جعلها أسوأ بتغليفها ضمن حلقة for أخرى تتكرر n مرة أيضًا، وبالتالي ينتج برنامج له دالة f( n ) = n2، كما يمكن تعميم ذلك بالقول أنّ أي برنامج Θ( a ) هو O( b ) عندما يكون b أسوأ من a. لا يحتاج التغيير الذي أجريناه على البرنامج إلى إعطائنا برنامجًا له معنى أو مكافئًا لبرنامجنا الأصلي، حيث يحتاج فقط إلى تنفيذ تعليمات أكثر من التعليمات الأصلية بالنسبة إلى قيمة n معينة، أي نستخدم هذا التغيير من أجل حساب عدد التعليمات فقط وليس لحل مشكلتنا. لذا يمكن القول بأن برنامجنا هو O( n2 ) بطريقةٍ آمنة، وذلك لأننا حلّلنا خوارزميتنا، ووجدناها ليست أسوأ من n2، ولكنها في الواقع قد تساوي n2، وبالتالي يمكننا تقدير سرعة تشغيل برنامجنا. لنستعرض بعض الأمثلة لتساعدك على التعرف على هذه الصيغة الجديدة. تمرين 3 أيٌّ مما يلي صحيح؟ خوارزمية Θ( n ) هي O( n ) خوارزمية Θ( n ) هي O( n2 ) خوارزمية Θ( n2 ) هي O( n3 ) خوارزمية Θ( n ) هي O( 1 ) خوارزمية O( 1 ) هي Θ( 1 ) خوارزمية O( n ) هي Θ( 1 ) الحل هذا صحيح لأنّ برنامجنا الأصلي كان Θ( n )، ويمكننا تحقيق O( n ) دون تغيير برنامجنا على الإطلاق. هذا صحيح لأنّ n2 أسوأ من n. هذا صحيح لأنّ n3 أسوأ من n2. هذا خطأ لأنّ 1 ليس أسوأ من n، فإذا أخذ البرنامج n تعليمةً بصورةٍ مقاربة -أي عددًا خطيًا من التعليمات-، فلا يمكننا جعله أسوأ ولا يمكن جعله يأخذ تعليمةً واحدةً بصورةٍ مقاربة -أي عددًا ثابتًا من التعليمات-. هذا صحيح لأنّ التعقيدان متماثلان. قد يكون هذا صحيحًا أو غير صحيح وذلك اعتمادًا على الخوارزمية، لكنه خاطئ في الحالة العامة، فإذا كانت الخوارزمية Θ( 1 )، فمن المؤكد أنها O( n )؛ أما إذا كانت O( n ) فقد لا تكون Θ( 1 )، فمثلًا، خوارزمية Θ( n ) هي O ( n ) وليست Θ( 1 ). تمرين 4 استخدم متتالية الجمع الحسابية arithmetic progression sum لإثبات أنّ البرنامج أعلاه ليس O( n2 ) فقط، وإنما Θ( n2 ) أيضًا، ويمكنك البحث عن معنى المتتالية الحسابية في ويكيبيديا في حالة عدم معرفتك بها. يعطي التعقيد O-complexity لخوارزمية ما حدًا أعلى لتعقيد الخوارزمية الفعلي - أي الوقت الأكبر الذي قد تستغرقه الخوارزمية-، بينما تعطي الصيغة Θ تعقيد الخوارزمية الفعلي، حيث نقول أحيانًا أن الصيغة Θ تعطينا حدًا تامًا، وإذا علمت أننا وجدنا حد تعقيدٍ غير تام، فيمكنك استخدام الحرف الصغير o للإشارة إلى ذلك، فمثلًا، إذا كان للخوارزمية التعقيد Θ( n )، فسيكون تعقيدها التام n، وبالتالي سيكون لهذه الخوارزمية O( n ) و O( n2 ) معًا. بما أن الخوارزمية هي Θ( n )، فسيكون حد O( n ) هو الحد التام؛ أما حد O( n2 ) فليس تامًا، ولذلك يمكننا كتابة أن الخوارزمية هي o( n2 ) والتي تُنطق "o الصغير بالنسبة إلى مربع n"، وذلك لتوضيح أن الحد ليس تامًا. كما يُفضَّل إيجاد حدود تامة للخوارزميات لأنها تعطينا مزيدًا من المعلومات حول سلوكها، ولكنه ليس أمرًا سهلًا دائمًا. تمرين 5 حدّد أيًا من الحدود التالية هي حدودًا تامةً وأيها لا، ثم تحقق من صحتها أو خطئها، ويجب عليك استخدام الصيغة o لتحديد الحدود غير التامة: خوارزمية Θ (n) التي لها الحد الأعلى O (n). خوارزمية Θ (n2) التي لها الحد الأعلى O (n3). خوارزمية Θ(1) التي لها الحد الأعلى O (n). خوارزمية Θ (n) التي لها الحد الأعلى O (1). خوارزمية Θ (n) التي لها الحد الأعلى O (2n). الحل الحد تام لأنّ تعقيد Θ وتعقيد O متماثلان في هذه الحالة. الحد غير تام لأنّ تعقيد O أكبر من تعقيد Θ، وقد يكون حد O( n2 ) تامًا، لذلك يمكننا كتابة أن الخوارزمية هي o( n3). الحد غير تام، لأنّ تعقيد O أكبر من تعقيد Θ، وقد يكون حد O( 1 ) تامًا، لذلك يمكننا الإشارة بأنّ الحد O( n ) ليس تامًا من خلال كتابته بالشكل o( n ). الحد خاطئ، فقد اُرتكِب خطأ في حسابه، فلا يمكن أن يكون لخوارزمية Θ( n ) حد أعلى من O( 1 )، وذلك لأنّ التعقيد n أكبر من التعقيد 1 -تذكر أنّ O تعطي حدًا أعلى. الحد تام، فقد يبدو مثل حد غير تام، لكن هذا ليس صحيحًا في الواقع، -تذكر أنّ سلوك 2n وn المقارب هو نفسه، وأنّ الصيغتَين O وΘ تهتمان بالسلوك المقارب؛ إذًا لدينا O( 2n ) = O( n )، وبالتالي، فهذا الحد تام لأن التعقيد هو نفس Θ. قد تجد نفسك تائهًا قليلًا في هذه الصيغة الجديدة، ولكن سنقدم صيغتين آخرين بسيطتين بالنسبة للصيغ Θ، وO، وo قبل انتقالنا إلى بعض الأمثلة، ويُستحسَن أن تعرف هاتين الصيغتَين الآن، حيث لن نستخدمهما كثيرًا في هذا المقال لاحقًا. عدّلنا برنامجنا في المثال أعلاه ليصبح أسوأ -أي أخذ المزيد من التعليمات، وبالتالي المزيد من الوقت- وأنشأنا الصيغة O، حيث تُعَدّ الصيغة O ذا مغزىً لأنها تخبرنا بأن برنامجنا لن يكون أبدًا أبطأ من حدٍ معين، ولهذا فهي توفر معلومات قيّمةً تمكننا من القول بأن برنامجنا جيد بما فيه الكفاية، وإذا فعلنا العكس وعدّلنا برنامجنا ليصبح أفضل، ثم أوجدنا تعقيد البرنامج الناتج، فنستخدم الصيغة Ω التي تعطينا تعقيدًا يخبرنا بأن برنامجنا لن يكون أفضل، وهذا مفيد إذا أردنا إثبات أن البرنامج يعمل ببطء أو أن الخوارزمية سيئة، وقد يكون هذا مفيدًا للقول بأن الخوارزمية بطيئة جدًا عند استخدامها في حالة معينة، فمثلًا، خوارزمية Ω( n3 ) ليست أفضل من n3. قد تكون الصيغة Θ( n3 ) سيئًة مثل Θ (n4) أو أسوأ منها، لكننا نعلم أنها سيئة إلى حد ما على الأقل. إذًا تعطينا الصيغة Ω حدًا أدنى لتعقيد خوارزمية، كما يمكننا كتابة الصيغة ω على غرار الصيغة ο عندما يكون الحد ليس تامًا، فمثلًا، خوارزمية Θ ( n3 ) هي ο( n4 ) وω( n2 ) وتُقرَأ Ω( n ) "أوميغا كبيرة بالنسبة إلى n"، بينما تُقرَأ ω( n ) "أوميغا صغيرة بالنسبة إلى n". تمرين 6 اكتب حد O تام وآخر غير تام، وحد Ω تام وآخر غير تام من اختيارك للتعقيدات التالية، ولكن بشرط وجودهما طبعًا: Θ( 1 ) Θ(√n) Θ( n ) Θ( n2 ) Θ( n3 ) الحل هذا هو تطبيق مباشر للتعاريف أعلاه: الحدود التامة هي O( 1 ) وΩ( 1 )، كما يكون حد O غير التام هو O( n ) -تذكّر أن O تعطينا حدًا أعلى-، وبما أن n أكبر من 1، فسيمثِّل حدًا غير تام يمكننا كتابته بالشكل o( n ) أيضًا، كما لا يمكننا إيجاد حد غير تام للصيغة Ω لعدم تمكننا من الحصول على أقل من 1 لهذه الدوال، إذًا يجب تعاملنا مع الحد التام فقط. يجب أن تكون للحدود التامة تعقيد Θ نفسه، لذا فهي O(√n) وΩ(√n) على التوالي؛ أما الحدود غير التامة فقد تكون O( n )، حيث تُعَدّ n أكبر من √n وبالتالي فهي حد أعلى لها. وبما أننا نعلم أن هذا حدًا أعلى غير تام، فيمكننا أيضًا كتابته بالصورة o( n )؛ أما الحد الأدنى غير التام، فيمكننا ببساطة استخدام Ω( 1 )، وبما أننا نعلم أن هذا الحد ليس تامًا، فيمكننا كتابته بالصورة ω( 1. 3 ). الحدود التامة هي O( n ) وΩ( n ). قد يكون الحدان الغير تامين هما ω( 1 ) وo( n3 ) وهي في الواقع حدودٌ سيئة للغاية، لأنها بعيدة كل البعد عن التعقيدات الأصلية، إلا أنها لا تزال صالحة باستخدام التعاريف. الحدود التامة هي O( n2 ) وΩ( n2 ) ويمكننا استخدام ω( 1 ) وo( n3 ) بالنسبة للحدود غير التامة كما في المثال السابق. الحدود التامة هي O( n3 ) وΩ( n3 ) على التوالي، وقد يكون الحدان غير التامَين هما ω(n2 √n) وω(n3 √n)، وعلى الرغم من أنّ هذه الحدود ليست تامة، إلا أنها أفضل من تلك الموجودة في جواب رقم 3 و4 من هذا التمرين أعلاه. قد تعطي الصيغتان O وΩ أيضًا حدودًا تامة، وسبب استخدامنا لهما بدلًا من الصيغة Θ هو أننا قد لا نكون قادرين على معرفة ما إذا كان الحد الذي أوجدناه تامًا أم لا، أو ربما لا نرغب في متابعة العملية باستخدام الصيغة Θ التي تحتاج تدقيقًا عميقًا. إذا لم تتذكر تمامًا جميع الرموز المختلفة واستخداماتها، فلا تقلق بشأنها كثيرًا الآن، حيث يمكنك دائمًا العودة والبحث عنها، وأهم الرموز هي O وΘ. لاحظ أيضًا أنه على الرغم من كون الصيغة Ω تعطينا سلوكًا ذو حدٍ منخفض للدالة -أي تحسّن برنامجنا وأصبح ينفّذ تعليماتٍ أقل-، إلا أننا ما زلنا نشير إليها بتحليل "الحالة الأسوأ"، لأننا نزوّد برنامجنا بأسوأ دخلٍ ممكن من n ونحلّل سلوكه في ظل هذا الافتراض. يوضح الجدول التالي الرموز التي قدمناها للتو وتوافقاتها مع الرموز الرياضية المعتادة للمقارنات التي نستخدمها مع الأعداد، كما يعود السبب في عدم استخدامنا للرموز المعتادة هنا واستخدام الأحرف الإغريقية بدلًا منها، إلى الإشارة إلى إجراء مقارنة سلوك مقارب وليس مقارنة بسيطة: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } عامل المقارنة المقارب Asymptotic comparison operator عامل المقارنة العددي Numeric comparison operator الخوارزمية هي ( شيء ما )o يوجد عدد < هذا الشيء الخوارزمية هي ( شيء ما )O يوجد عدد ≤ هذا الشيء الخوارزمية هي ( شيء ما )Θ يوجد عدد = هذا الشيء الخوارزمية هي ( شيء ما )Ω يوجد عدد ≥ هذا الشيء الخوارزمية هي ( شيء ما )ω يوجد عدد > هذا الشيء اللوغاريتمات Logarithms هل تعرف ما هي اللوغاريتمات؟ إن كانت إجابتك نعم، فلا تتردد في تخطي هذا القسم، فهذا القسم هو مقدمة لمن ليس على دراية باللوغاريتمات، أو لمن لم يستخدمها كثيرًا مؤخرًا، فهو موجَّهٌ للطلاب الأصغر سنًا، والذين لم يروا اللوغاريتمات في المدرسة بعد. تُعَدّ اللوغاريتمات مهمة بسبب ظهورها بكثرة عند تحليل التعقيد، ويُعَدّ اللوغاريتم عمليةً تُطبَّق على رقم ما ليصبح أصغر، حيث تشبه هذه العملية الجذر التربيعي لرقم إلى حد كبير؛ لذلك إذا كان هناك شيء واحد تريد تذكره حول اللوغاريتمات، فهو أنها تأخذ رقمًا وتجعله أصغر بكثير من الأصل. يوضِّح الشكل الآتي مقارنةً بين الدوال n، و√n، وlog( n )، إذ تنمو الدالة n -أو كما تُسمَّى الدالة الخطية linear function- المرسومة باللون الأخضر في أعلى الشكل، أسرع بكثير من دالة الجذر التربيعي المرسومة باللون الأحمر في المنتصف، والتي بدورها تنمو أسرع بكثير من الدالة log( n ) المرسومة باللون الأزرق في الجزء السفلي من هذا الرسم البياني، ويكون الفرق واضحًا تمامًا حتى بالنسبة إلى n صغيرة مثل n = 100. تُعَدّ اللوغاريتمات عمليةً عكسيةً لرفع شيءٍ ما إلى أس مثل الجذور التربيعية التي هي عملية عكسية لتربيع شيءٍ ما، وسنشرح ذلك بمثال. ضع في بالك المعادلة التالية: 2x = 1024 نريد حل هذه المعادلة لإيجاد قيمة x، لذلك لنسأل أنفسنا: ما هو الرقم الذي يجب رفع الأساس 2 إليه حتى نحصل على 1024؟ هذا الرقم هو 10. بالفعل لدينا 210 = 1024، وهو أمر سهل التحقق منه؛ كما تساعدنا اللوغاريتمات من خلال الإشارة إلى هذه المشكلة باستخدام صيغة جديدة، فالرقم 10 في هذه الحالة هو لوغاريتم 1024 ونكتبه بالصورة ( log( 1024 ونقرأه "لوغاريتم 1024". بما أننا نستخدم العدد 2 أساسًا، فتسمى هذه اللوغاريتمات لوغاريتمات الأساس 2، كما توجد لوغاريتمات لها أساسات أخرى، ولكننا سنستخدم فقط لوغاريتمات الأساس 2 في هذا المقال، وإذا كنت طالبًا منافسًا في مسابقات دولية ولا تعرف شيئًا عن اللوغاريتمات، فنوصيك بشِدة بالتدرّب على اللوغاريتمات بعد الانتهاء من هذا المقال. تُعَدّ لوغاريتمات الأساس 2 أكثر أنواع اللوغاريتمات شيوعًا في علوم الحاسوب لأنه غالبًا ما يكون لدينا كيانان مختلفان فقط هما: 0 و1، كما نميل أيضًا إلى تقسيم مشكلة كبيرة واحدة إلى نصفين، لذلك ما عليك سوى معرفة لوغاريتمات الأساس 2 لمتابعة هذا المقال. تمرين 7 حُلّ المعادلات أدناه، وأوجد اللوغاريتم في كل حالة باستخدام اللوغاريتمات ذات الأساس 2 فقط: 2x = 64 (22)x= 64 4x = 4 2x = 1 2x + 2x = 32 (2x) * (2x) = 64 الحل لا يتضمن الحل أكثر من تطبيق الأفكار المُعرَّفة أعلاه: يمكننا باستخدام طريقة التجربة والخطأ إيجاد أن x = 6، وبالتالي، log( 64 ) = 6. يمكن كتابة (22)x بالصورة 22x من خلال تطبيق خصائص الأس، إذًا لدينا 2x = 6 لأن log( 64 ) = 6 من النتيجة السابقة، وبالتالي، x = 3. يمكننا كتابة 4 بالشكل 22 باستخدام معرفتنا من المعادلة السابقة، وبهذا تصبح المعادلة (22)x= 4 وهي 22x = 4 نفسها، ونلاحظ أن log( 4 ) = 2 لأن 22 = 4، وبالتالي، لدينا أن 2x = 2، وعليه فـ x = 1؛ كما يمكن ملاحظة ذلك بسهولة من المعادلة الأصلية، حيث أن ناتج الرفع للأس 1 هو الأساس نفسه. تذكر أن ناتج الرفع للأس 0 هو 1، لذلك لدينا log( 1 ) = 0، بما أنّ 20= 1، وبالتالي، x = 0. لا يمكننا أخذ اللوغاريتم مباشرةً بسبب وجود المجموع، ولكن يمكن ملاحظة أنّ 2x+ 2x هي 2 * (2x) نفسها، حيث ضربنا هنا بالعدد 2 أي لهما الأساس نفسه، وبالتالي، ينتج 2x + 1، والآن كل ما علينا فعله هو حل المعادلة 2x + 1= 32، حيث نجد أنّ log( 32 ) = 5، وهكذا x + 1 = 5، وبالتالي، x = 4. نضرب هنا قوتين للعدد 2 معًا، ولذلك يمكننا ضمهما من خلال ملاحظة أن (2x) * (2x) هي 22x نفسها، وبالتالي كل ما علينا فعله هو حل المعادلة 22x= 64 التي حللناها بالفعل أعلاه، حيث x = 3. التعقيد العودي Recursive complexity لنلقِ نظرةً على دالة عودية recursive function، فالدالة العودية هي دالة تستدعي نفسها. هل يمكننا تحليل تعقيدها؟ توجِد الدالة الآتية والمكتوبة بلغة بايثون، حيث تُقيِّم مضروب factorial عددٍ معين، إذ يمكن إيجاد مضروب عدد صحيح موجب بضربه بجميع الأعداد الصحيحة السابقة معًا، فمثلًا، مضروب العدد 5 هو 5 * 4 * 3 * 2 * 1؛ كما نعبِّر عن ذلك بالصورة "!5" ونقرؤها "مضروب العدد خمسة five factorial"، ويفضِّل بعض الناس نُطقها بصوت عالٍ مثل "خمسة !!!". def factorial( n ): if n == 1: return 1 return n * factorial( n - 1 ) لنحلّل تعقيد هذه الدالة، فعلى الرغم من عدم احتواء هذه الدالة على أية حلقات، إلا أنّ تعقيدها ليس ثابتًا constant، حيث يجب علينا متابعة عد التعليمات مرةً أخرى لمعرفة تعقيدها، فإذا مرّرنا المتغير n إلى هذه الدالة، فستنفّذ n مرة؛ وإذا لم تكن متأكدًا من ذلك، فشغّل هذه الدالة "يدويًا" الآن من أجل n = 5 للتحقق منها. ستنفَّذ هذه الدالة مثلًا 5 مرات من أجل n = 5، بحيث ستستمر في إنقاص قيمة n بمقدار 1 في كل استدعاء، وبالتالي، يكون تعقيد هذه الدالة هو ( Θ( n. إذا لم تكن متأكدًا من هذه الحقيقة، فتذكر أنه يمكنك دائمًا العثور على التعقيد الدقيق عن طريق حساب عدد التعليمات، وإذا رغبت في ذلك، فيمكنك محاولة حساب عدد التعليمات الفعلية التي تطبّقها هذه الدالة لإيجاد الدالة f( n )، والوصول إلى نتيجة أنها خطية بالفعل، مع العلم أنّ خطية تعني Θ( n ). يحتوي الشكل التالي على رسم بياني لمساعدتك على فهم مفهوم العودية المُطبَّقة عند استدعاء الدالة factorial( 5 )، ويجب على هذا الشكل توضيح لماذا تعقيد هذه الدالة هو تعقيد خطي: العودية (معاوة الاستدعاء) التي تطبّقها الدالة factorial التعقيد اللوغاريتمي Logarithmic complexity إحدى المشكلات الشهيرة في علوم الحاسوب هي البحث عن قيمة داخل مصفوفة، ولقد حلّلنا هذه المشكلة سابقًا من خلال الحالة العامة، كما تصبح هذه المشكلة ممتعةً إذا كان لدينا مصفوفة مرتَّبة ونريد إيجاد قيمة معينة بداخلها، حيث تُسمَّى إحدى طرق القيام بذلك البحث الثنائي binary search. ننظر إلى العنصر الأوسط في المصفوفة، وإذا وجدنا العنصر هناك، فقد انتهينا؛ وإلّا فإذا كانت القيمة التي وجدناها أكبر من القيمة التي نبحث عنها، فسنعلم أن العنصر سيكون في الجزء الأيسر من المصفوفة؛ وإلّا فإننا نعلم أنه سيكون في الجزء الأيمن من المصفوفة، كما يمكننا الاستمرار في تقسيم هذه المصفوفات الصغيرة إلى نصفين حتى يتبقّى عنصر واحد فقط، وتوضّح الشيفرة الوهمية التالية هذه الفكرة: def binarySearch( A, n, value ): if n = 1: if A[ 0 ] = value: return true else: return false if value < A[ n / 2 ]: return binarySearch( A[ 0...( n / 2 - 1 ) ], n / 2 - 1, value ) else if value > A[ n / 2 ]: return binarySearch( A[ ( n / 2 + 1 )...n ], n / 2 - 1, value ) else: return true تُعَدّ هذه الشيفرة الوهمية تبسيطًا للتطبيق الفعلي، كما يُعَدّ وصفها أسهل من تطبيقها عمليًا، حيث يحتاج المبرمج إلى الاهتمام ببعض مشاكل التطبيق. يجب تطبيق الدالة floor() أو ceil() بسبب وجود أخطاء بفارق الواحد off-by-one، وقد لا ينتج عن القسمة على العدد 2 قيمةً صحيحةً، فالجزء الصحيح أو المتمم الصحيح الأسفل floor لعدد حقيقي ما x، هو أكبر عدد صحيح ليس أكبر من x، فصحيح العدد 2.6 هو 2، أي أنّ أكبر عدد صحيح ليس أكبر من 2.6. بينما السقف أو المتمم الصحيح الأعلى ceil لعدد حقيقي x، فهو أصغر عدد صحيح ولكنه ليس أصغر من x، لأن سقف العدد 2.15 هو 3، أي أنّ أصغر عدد صحيح ليس أصغر من 2.15. لكن يمكننا افتراض أن هذه الطريقة ستنجح دائمًا، وسنفترض أنّ تطبيقنا الفعلي يهتم بأخطاء الفراق الواحد off-by-one، وذلك لأننا نريد تحليل تعقيد هذه الطريقة فقط. إذا لم تطبّق البحث الثنائي مطلقًا، فقد ترغب في فعل ذلك باستخدام لغة البرمجة المفضلة لديك. يوضّح الشكل الآتي لصاحبه لوك فرانكل Luke Francl طريقة عمل البحث الثنائي باستخدام العودية، حيث يُميَّز الوسيط A لكل استدعاء باللون الأسود، وتستمر العودية حتى تصبح المصفوفة مكوّنةً من عنصر واحد فقط. إذا لم تكن متأكدًا من عمل هذه الطريقة، فشغّلها يدويًا باستخدام مثال بسيط واقنع نفسك بأنها تعمل بالفعل. لنحاول تحليل هذه الخوارزمية العودية، حيث سنفترض -من أجل التبسيط- أن المصفوفة تُقسَم دائمًا إلى نصفين تمامًا، متجاهلين الجزأين 1+ و 1- من الاستدعاء العودي. كما يجب اقتناعك بعدم تأثير إجراء تغيير بسيط على نتائج التعقيد مثل تجاهل الجزأين 1+ و1-، وهذه حقيقة يجب عادةً إثباتها إذا أردنا أن نكون حريصين من وجهة نظر رياضية، لكنها بديهية عمليًا. سنفترض للتبسيط أن حجم المصفوفة هو بالضبط قوة للعدد 2. بحيث لا يغير هذا الافتراض النتائج النهائية لتعقيدنا الذي سنصل إليه، وسيحدث السيناريو الأسوأ لهذه المشكلة عند عدم ظهور القيمة التي نبحث عنها في مصفوفتنا على الإطلاق، كما سنبدأ في هذه الحالة بمصفوفة ذات حجم n في الاستدعاء الأول للعودية، ثم سنحصل على مصفوفة بحجم n / 2 في الاستدعاء التالي. وبعدها سنحصل على مصفوفة بحجم n / 4 في الاستدعاء العودي التالي، ثم مصفوفة بحجم n / 8، وهكذا؛ حيث تقسَم المصفوفة إلى نصفين في كل استدعاء، حتى نصل إلى عنصر واحد فقط، لذلك لنكتب عدد العناصر في المصفوفة الخاصة بنا لكل استدعاء كما يلي: 0th iteration: n 1st iteration: n / 2 2nd iteration: n / 4 3rd iteration: n / 8 … ith iteration: n / 2i last iteration: 1 لاحظ احتواء المصفوفة على n / 2i عنصر في التكرار i بسبب تقسيم المصفوفة في كل تكرار إلى نصفين، مما يعني أننا نقسم عدد عناصرها على 2، أي نضرب المقام بـ 2؛ وإذا فعلنا ذلك i مرة، فسنحصل على n / 2i، إذ يستمر هذا الإجراء ونحصل على عدد أصغر من العناصر مع كل قيمة أكبر للمتغير i، حتى نصل إلى التكرار الأخير الذي يتبقى فيه عنصر واحد فقط، وإذا رغبنا في معرفة التكرار i الذي يتبقى فيه عنصرٌ واحد فقط، فعلينا حل المعادلة التالية: 1 = n / 2i سيكون هذا صحيحًا فقط عندما نصل إلى الاستدعاء النهائي للدالة ()binarySearch، وليس في الحالة العامة، لذلك فإيجاد قيمة i هنا سيساعدنا في العثور على التكرار الذي ستنتهي فيه العودية. وإذا ضربنا كلا الطرفين بـ 2i فسنحصل على: 2i= n يجب أن تبدو هذه المعادلة مألوفة إذا قرأت قسم اللوغاريتمات أعلاه، وبالتالي ينتج: i = log( n ) يخبرنا هذا أن عدد التكرارات المطلوبة لإجراء بحث ثنائي هو log( n )، حيث n هي عدد عناصر المصفوفة الأصلية، ويُعَدّ ذلك أمرًا منطقيًا. بافتراض أنّ n = 32 فسيكون لدينا مصفوفة مؤلفة من 32 عنصرًا، فكم مرةً يجب تقسيم هذه المصفوفة إلى نصفين للحصول على عنصر واحد فقط؟ سنحتاج إلى تقسيمها خمس مرات للحصول إلى عنصر واحد، أي بالترتيب التالي: 32 ← 16 ← 8 ← 4 ← 2 ← 1، والعدد 5 هو لوغاريتم 32، لذلك يكون تعقيد البحث الثنائي هو Θ( log( n ) ). تسمح لنا هذه النتيجة الأخيرة بمقارنة البحث الثنائي والبحث الخطي، وبما أن ( log( n أصغر بكثير من n، فيمكن استنتاج أن البحث الثنائي أسرع بكثير من البحث الخطي للبحث داخل مصفوفة، لذلك يُستحسَن إبقاء المصفوفات مرتبةً عند العمل على عدة عمليات بحث فيها. الفرز الأمثل Optimal sorting تهانينا! لقد بتّ الآن تعرف كلًا من تحليل تعقيد الخوارزميات، وسلوك الدوال المقارب، وصيغة big-O؛ بالإضافة إلى كيفية إيجاد تعقيد الخوارزمية ليكون O( 1 )، وO( log( n ) )، وO( n )، وO( n2 ) وما إلى ذلك بديهيًا، كما أصبحت تعرف الرموز o، وO، وω، وΩ، وΘ، وماذا يعني تحليل الحالة الأسوأ أيضًا. يُعَدّ هذا القسم الأخير من المقال أعقد قليلًا، لذا لا تتردد في أخذ راحة إذا تعبت، حيث سيتطلب منك التركيز وقضاء بعض الوقت في حل التمارين، لكنه سيوفر لك طريقةً مفيدةً للغاية في تحليل تعقيد الخوارزمية وهذا أمرٌ مهم، لذلك فهو بالتأكيد يستحق الفهم. يُدعى الفرز الذي طبقناه سابقًا بالفرز الانتقائي، حيث ذكرنا أنه ليس الفرز الأمثل؛ والخوارزمية المثلى هي الخوارزمية التي تحل المشكلة بأفضل طريقة ممكنة، مما يعني عدم وجود خوارزميات أفضل منها، وهذا يعني أن لدى جميع الخوارزميات الأخرى الموجهة لحل المشكلة تعقيدًا أسوأً أو مساويًا لتلك الخوارزمية المثلى، كما قد يكون هناك العديد من الخوارزميات المثلى لمشكلةٍ ما بحيث تشترك جميعها في التعقيد نفسه، ويمكن حل مشكلة الفرز على النحو الأمثل بطرق مختلفة، كما يمكن استخدام فكرة البحث الثنائي نفسها من أجل الفرز بسرعة، وتسمى طريقة الفرز المثلى هذه الفرز بالدمج mergesort. سنحتاج أولًا في إجراء فرز الدمج، إلى إنشاء دالة مساعدة والتي سنستخدمها بعد ذلك لإجراء الفرز الفعلي، حيث تأخذ دالة الدمج merge مصفوفتين مرتّبتَين سابقًا، ثم تدمجهما معًا في مصفوفة كبيرة مرتبة، ويمكن القيام بذلك بسهولة كما يلي: def merge( A, B ): if empty( A ): return B if empty( B ): return A if A[ 0 ] < B[ 0 ]: return concat( A[ 0 ], merge( A[ 1...A_n ], B ) ) else: return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) ) تأخذ الدالة concat عنصرًا يُسمى "الرأس head" ومصفوفة تُسمى "الذيل tail"، ثم تبني وتعيد مصفوفةً جديدةً تحتوي على عنصر "الرأس" الذي يمثِّل العنصر الأول في المصفوفة الجديدة، وعلى عنصر "الذيل" الذي يمثِّل بقية العناصر الموجودة في المصفوفة، حيث تعيد الدالة concat( 3, [ 4, 5, 6 ] ) مثلًا، ما يلي: [ 3, 4, 5, 6 ]. ونستخدم المتغيرين An وBn للإشارة إلى أحجام المصفوفتين A وB على التوالي. تمرين 8 تحقق من إجراء الدالة المذكورة أعلاه لعملية الدمج، ثم أعد كتابتها بلغة البرمجة المفضلة لديك بطريقة تكرارية -أي باستخدام حلقات for- بدلًا من استخدام العودية. يكشف تحليل هذه الخوارزمية أن وقت تشغيلها Θ( n )، حيث يمثِّل n طول المصفوفة الناتجة أي n = A_n + B_n. تمرين 9 تحقق من أن وقت تشغيل الدالة merge هو Θ( n ). يمكننا بناء خوارزمية فرز أفضل باستخدام هذه الدالة، حيث نقسم المصفوفة إلى قسمين، ونرتِّب كل جزء من الجزأين عوديًا، ثم ندمج المصفوفتين المرتبتين في مصفوفة واحدة كبيرة، وذلك كما يلي: def mergeSort( A, n ): if n = 1: return A # it is already sorted middle = floor( n / 2 ) leftHalf = A[ 1...middle ] rightHalf = A[ ( middle + 1 )...n ] return merge( mergeSort( leftHalf, middle ), mergeSort( rightHalf, n - middle ) ) يُعَدّ فهم هذه الدالة أصعب مما مررنا به سابقًا، لذلك قد يأخذ منك التمرين التالي بضع دقائق. تمرين 10 تحقق من صحة الدالة mergeSort، وذلك من خلال التحقق من تمكّن الدالة mergeSort من فرز المصفوفة المعطاة بصورة صحيحة، وإذا واجهتك مشكلة في فهم سبب نجاحها في ذلك، فجرّبها باستخدام مصفوفة صغيرة على أساس مثال ثم شغّلها "يدويًا"، وتأكد عند تشغيل هذه الدالة يدويًا من حصولك على النصف الأيسر leftHalf والنصف الأيمن rightHalf. وإذا قسّمت المصفوفة في المنتصف تقريبًا، فليس من الضروري قسم المصفوفة في المنتصف تمامًا إذا احتوت على عدد فردي من العناصر وهذا الهدف من استخدام الدالة floor أعلاه. لنحلل الآن تعقيد الدالة mergeSort، حيث سنقسم المصفوفة إلى نصفين متساويين في الحجم على غرار دالة البحث الثنائي binarySearch في كل خطوة من خطوات الدالة mergeSort، ولكننا سنحافظ في هذه الحالة على كلا النصفين طوال فترة التنفيذ، ثم نطبّق الخوارزمية عوديًا في كل نصف، كما نطبّق عملية الدمج merge على النتيجة التي تستغرق وقتًا مقداره Θ( n ) بعد أن تعيد الخوارزمية العودية. لبهذا نكون قد قسمنا المصفوفة الأصلية إلى مصفوفتين بحجم n / 2 لكل منهما، ثم دمجنا هذه المصفوفات، وهي عملية لدمج n عنصرًا وبالتالي تستغرق وقتًا (Θ (n، كما يوضح الشكل التالي هذه العملية العودية: شجرة العودية لطريقة الفرز بالدمج merge sort تمثِّل كل دائرة استدعاءً للدالة mergeSort كما يشير الرقم المكتوب في الدائرة إلى حجم المصفوفة التي يجري فرزها، إذ تكون الدائرة الزرقاء العلوية الاستدعاء الأصلي للدالة mergeSort، بحيث نحصل على فرز مصفوفة بالحجم n، كما تشير الأسهم إلى الاستدعاءات المتكررة التي تجريها الدوال فيما بينها. يعمل الاستدعاء الأصلي للدالة mergeSort على استدعائها مرتين في مصفوفتين وحجم كل منهما n / 2، حيث يشار إلى ذلك بواسطة السهمين الموجودين في الأعلى، ثم يجري كل من هذين الاستدعائَين بدورهما استدعائين خاصين بهما لدمج مصفوفتين بحجم n / 4 لكل منهما، وهكذا دواليك حتى نصل إلى مصفوفات ذات حجم 1؛ ويسمَّى هذا الرسم البياني بالشجرة العودية recursion tree، لأنه يوضح كيفية حدوث العودية ويظهر مثل شجرة، لكن الجذر root في الأعلى والأوراق في الأسفل، لذلك يظهر مثل شجرة مقلوبة. لاحظ أن العدد الإجمالي للعناصر هو n في كل مستوى من الرسم البياني أعلاه، حيث يحتوي المستوى الأول على استدعاء واحد فقط للدالة mergeSort مع مصفوفة بحجم n أي العدد الإجمالي للعناصر هو n، كما يحتوي المستوى الثاني على استدعائين للدالة mergeSort وكل منهما بحجم n / 2. لكن n / 2 + n / 2 = n وهكذا يكون العدد الإجمالي للعناصر هو n في هذا المستوى، كما توجد 4 استدعاءات في المستوى الثالث، بحيث يُطبَّق كل استدعاء على مصفوفة بحجم n / 4، أي سيساوي عدد العناصر الإجمالي n / 4 + n / 4 + n / 4 + n / 4 = 4n / 4 = n، وبالتالي نحصل على n عنصر. يجب على المستدعي في كل مستوى من هذا الرسم البياني إجراء عملية دمج merge على العناصر التي يعيدها المستدعَى، إذ يجب على الدائرة المشار إليها باللون الأحمر مثلًا، ترتيب عدد n / 2 من العناصر، وذلك بتقسيم المصفوفة ذات الحجم n / 2 إلى مصفوفتين بحجم n / 4، ثم تُستدعَى الدالة mergeSort عوديًا لفرز تلك المصفوفة، ثم تُدمَجان معًا، ويُشار إلى هذه الاستدعاءات بالدوائر ذات اللون الأخضر. تحتاج عملية الدمج إلى دمج n / 2 عنصر في كل مستوى من الشجرة، ويكون العدد الإجمالي للعناصر المدموجة هو n. حيث تدمج الدالة في ذلك المستوى n / 2 عنصر، ويجب على الدالة الموجودة على يمينها -ذات اللون الأزرق- دمج n / 2 عنصرأيضًا، وبالتالي ينتج عدد العناصر الإجمالي التي يجب دمجها في هذا المستوى . تعقيد كل مستوى هو Θ( n )، كما يكون عدد المستويات في هذا الرسم البياني، والذي يُطلق عليه أيضًا عمق depth شجرة العودية مساويًا لـ log( n )، وسبب ذلك هو السبب ذاته تمامًا الذي استخدمناه عند تحليل تعقيد البحث الثنائي. لدينا log( n ) مستوى وتعقيد كل مستوى هو Θ( n )، وبالتالي، يكون تعقيد الدالة mergeSort هو Θ(n * log( n ))، وهذا أفضل بكثير من Θ( n2 ) الذي هو تعقيد خوارزمية الفرز الانتقائي -تذكر أنّ log( n ) أصغر بكثير من n، وبالتالي يكون n * log (n) أصغر بكثير من n * n = n2-، وإذا وجدت ذلك معقدًا، فلا تقلق لأن الأمر ليس سهلًا في المرة الأولى. يسمح لنا تحليل التعقيد بمقارنة الخوارزميات لمعرفة أيها أفضل كما رأيت في هذا المثال الأخير، ويمكننا الآن أن نكون على يقينٍ تام من تفوّق خوارزمية الفرز بالدمج على خوارزمية الفرز الانتقائي للمصفوفات الكبيرة، كما سيكون استخلاص هذا الاستنتاج صعبًا إذا لم تملك الخلفية النظرية لتحليل الخوارزمية. تُستخدَم خوارزميات الفرز التي لها وقت تشغيل Θ( n * log( n ) )عمليًا، إذ تستخدم نواة نظام لينكس مثلًا، خوارزمية فرز تسمى heapsort، والتي لها وقت تشغيل مماثل لخوارزمية الفرز بالدمج mergesort الذي أوجدناه للتو، والذي هو Θ( n log( n ) )، لذلك فهو الأمثل. لاحظ أننا لم نثبت أن خوارزميات الفرز هذه هي الأمثل، لأن ذلك يتطلب معرفةً رياضيةً أكبر، لكن كن مطمئنًا أنه لا يمكن لهذه الخوارزميات المثلى التحسن أكثر من ذلك من وجهة نظر التعقيد. يجب الآن بعد قراءة هذا المقال أن يكون حدسك الذي طورته لتحليل تعقيد الخوارزمية قادرًا على مساعدتك في تصميم برامج أسرع، ويجب عليك تركيز جهودك المثلى على الأشياء المهمة حقًا بدلًا من الأشياء الصغيرة التي لا تهمك، مما يتيح لك العمل بصورةٍ أكثر إنتاجية. كما يجب أن تكون اللغة الرياضية والتمثيل الذي طُوِّر في هذا المقال مثل صيغة Big-O مفيدَين أيضًا في التواصل مع مهندسي البرمجيات الآخرين عندما تنقاشهم بموضوع وقت تشغيل الخوارزميات. ترجمة -وبتصرف- للمقال A Gentle Introduction to Algorithm Complexity Analysis لصاحبه Dionysis "dionyziz" Zindros. اقرأ أيضًا المرجع الشامل إلى تعلم الخوارزميات للمبتدئين تعقيد الخوارزميات Algorithms Complexity ترميز Big-O في الخوارزميات خوارزمية ديكسترا Dijkstra’s Algorithm -
 نستعرض في هذا المقال بعض أشهر الخوارزميات المستخدمة لتحليل المسارات في الأشجار، مثل خوارزمية بْرِم Prim وخوارزمية فلويد-وورشال Floyd-Warshall وخوارِزمية بلمان-فورد Bellman-Ford. خوارزمية برم Prim's Algorithm لنفترض أنّ لدينا 8 منازل، ونريد إعداد خطوط هاتفية بينها بأقل تكلفة ممكنة. لأجل ذلك سننشئ شجرةً حروفها تمثل المنازل، وأضلَاعها تمثّل تكلفة توصيل الخط الهاتفي بين منزلين. سنحاول وصل الخطوط بين جميع المنازل بأقل كلفة ممكنة، ولتحقيق ذلك سنستخدم خوارزمية برم Prim، وهي خوارزمية شرهة تبحث عن أصغر شجرة ممتدة spanning tree في مخطط موزون غير موجّه undirected weighted graph. وهذا يعني أنها تبحث عن مجموعة من الأضلاع التي تشكل شجرة تتضمّن كل العقد، بحيث يكون الوزن الإجمالي لجميع أضلاع الشجرة أقل ما يمكن. طُوِّرت هذه الخوارزمية عام 1930 من قبل عالم الرياضيات التشيكي Vojtěch Jarník، ثم أعاد عالم الحوسبة روبرت كلاي بْرِم اكتشافها ونشرها في عام 1957، وكذلك إيدجر ديكسترا في عام 1959. تُعرف أيضًا باسم خوارزمية DJP وخوارزمية Jarnik وخوارزمية Prim-Jarnik وخوارزمية Prim-Dijsktra. إذا كانت G مخططًا غير موجّه، فنقول أنّ المخطط S هو مخطط فرعي subgraph من G إذا كانت جميع حروفه وأضلَاعه تنتمي إلى G. ونقول أنّ S شجرة ممتدة فقط إذا كانت: تحتوي جميع عقد G. وكانت شجرة، أي أنّها لا تحتوي أيّ دورة cycle، وجميع عقدها متصلة. تحتوى (n-1) ضلعًا، حيث n يمثّل عدد العقد في G. يمكن أن يكون لمخطط ما أكثر من شجرة ممتدة واحدة، والشجرة الممتدة الصغرى لمخطط موزون غير موجّه هي شجرة مجموع أوزان أضلاعها أقل ما يمكن. سنستخدم خوارزمية Prim لإيجاد الشجرة الممتدة الصغرى، وسيساعدنا هذا على حل مشكلة الخطوط الهاتفية في المثال أعلاه. أولاً، سنختار عقدةً ما لتكون العقدة المصدرية source node، ولتكن العقدة 1 مثلًا. سنضيف الآن الضلع الذي ينطلق من 1 وله أقل كلفة إلى المخطط الفرعي، ونلوّن الأضلاع التي أضفناها إلى المخطط الفرعي باللون الأزرق. وسيكون الضلع 1-5 في مثالنا هو الضلع الذي له أقل كلفة. الآن، سنأخذ الضلع الأقل كلفة من بين جميع الأضلاع المُنطلِقة من العقدة 1 أو العقدة 5. وبما أنّنا لوّنّا 1-5 سلفًا، فالضلع المرشّح الثاني هو الضلع 1-2. نأخذ هذه المرة الضلع الأقل كلفةً من بين جميع الأضلاع (غير المُلوّنة) المُنطلقة من العقدة 1 أو العقدة 2 أو العقدة 5، والذي هو في حالتنا 5-4. تحتاج الخطوة التالية إلى تركيز، وفيها سنحاول أن نفعل ما فعلناه سابقا، ونختار من بين جميع الأضلاع (غير المُلوّنة) التي تنطلق من العقدة 1 أو 2 أو 5 أو 4 الضلع الذي له أقل كلفة، وهو 2-4. ولكن انتبه إلى أنّه في حال اختيار هذا الضلع، فسنخلُق دورةً cycle في المخطط الفرعي، ذلك أنّ العقدتين 2 و4 موجودتان سلفًا فيه، لذا فإنّ أخذ الضلع 2-4 ليس الخيار الصحيح. وبدلًا من ذلك سنختار الضلع 4-8. إذا واصلنا على هذا النحو فسنختَار الأضلاع 8-6 و6-7 و4-3، وسيبدو المخطط الفرعي النهائي هكذا: إذا أزلنا الأضلاع التي لم نَخترها (غير المُلوّنة)، فسنحصل على: هذه هي الشجرة الممتدة الصغرى MST التي نبحث عنها، ونستنتج منها أنّ تكلفة إعداد خطوط الهاتف هي: 4 + 2 + 5 + 11 + 9 + 2 + 1 = 34. يمكن أن تكون هناك عدة أشجار ممتدة صغرى للمخطط نفسه بحسب العقدة المصدرية التي اخترناها. انظر شيفرة توضيحية لهذه الخوارزمية، حيث تمثل Graph مخططًا فارغًا متصلًا غير موزون، وتمثل Vnew مخططًا فرعيًا جديدًا عقدته المصدرية هي x: Procedure PrimsMST(Graph): Vnew[] = {x} Enew[] = {} while Vnew is not equal to V u -> a node from Vnew v -> a node that is not in Vnew such that edge u-v has the minimum cost // إذا كان لعقدتين الوزن نفسه، فاختر أيًّا منهما add v to Vnew add edge (u, v) to Enew end while Return Vnew and Enew التعقيد التعقيد الزمني للمنظور البسيط أعلاه هو ( O (V 2، يمكننا تقليل التعقيد باستخدام طابور أولويات priority queue، فإذا أضفنا عقدةً جديدةً إلى المخطط الفرعي الجديد Vnew، فيمكننا إضافة أضلاعها المجاورة إلى رتل الأولويات، ثم إخراج الضلع الموزون ذو الكلفة الأدنى منه. وحينئذ يصبح التعقيد مساويًا للقيمة O (ElogE)، حيث يمثّل E عدد الأضلاع. يمكنك أيضًا إنشاء كَومة ثنائية Binary Heap لتخفيض التعقيد إلى O (ElogV). هذه شيفرة توضيحية تستخدم طابور الأولويات: Procedure MSTPrim(Graph, source): for each u in V key[u] := inf parent[u] := NULL end for key[source] := 0 Q = Priority_Queue() Q = V while Q is not empty u -> Q.pop for each v adjacent to i if v belongs to Q and Edge(u,v) < key[v] // edge(u, v) كلفة Edge(u, v) تمثل parent[v] := u key[v] := Edge(u, v) end if end for end while تخزّن key[] الكلفة الأقل لعبور العقدة v، فيما تُستخدم parent[] لتخزين العقدة الأصلية parent node، وهذا مفيد لتسلّق الشجرة وطباعتها. فيما يلي برنامج بسيط بلغة Java: import java.util.*; public class Graph { private static int infinite = 9999999; int[][] LinkCost; int NNodes; Graph(int[][] mat) { int i, j; NNodes = mat.length; LinkCost = new int[NNodes][NNodes]; for ( i=0; i < NNodes; i++) { for ( j=0; j < NNodes; j++) { LinkCost[i][j] = mat[i][j]; if ( LinkCost[i][j] == 0 ) LinkCost[i][j] = infinite; } } for ( i=0; i < NNodes; i++) { for ( j=0; j < NNodes; j++) if ( LinkCost[i][j] < infinite ) System.out.print( " " + LinkCost[i][j] + " " ); else System.out.print(" * " ); System.out.println(); } } public int unReached(boolean[] r) { boolean done = true; for ( int i = 0; i < r.length; i++ ) if ( r[i] == false ) return i; return -1; } public void Prim( ) { int i, j, k, x, y; boolean[] Reached = new boolean[NNodes]; int[] predNode = new int[NNodes]; Reached[0] = true; for ( k = 1; k < NNodes; k++ ) { Reached[k] = false; } predNode[0] = 0; printReachSet( Reached ); for (k = 1; k < NNodes; k++) { x = y = 0; for ( i = 0; i < NNodes; i++ ) for ( j = 0; j < NNodes; j++ ) { if ( Reached[i] && !Reached[j] && LinkCost[i][j] < LinkCost[x][y] ) { x = i; y = j; } } System.out.println("Min cost edge: (" + + x + "," + + y + ")" + "cost = " + LinkCost[x][y]); predNode[y] = x; Reached[y] = true; printReachSet( Reached ); System.out.println(); } int[] a= predNode; for ( i = 0; i < NNodes; i++ ) System.out.println( a[i] + " --> " + i ); } void printReachSet(boolean[] Reached ) { System.out.print("ReachSet = "); for (int i = 0; i < Reached.length; i++ ) if ( Reached[i] ) System.out.print( i + " "); //System.out.println(); } public static void main(String[] args) { int[][] conn = {{0,3,0,2,0,0,0,0,4}, // 0 {3,0,0,0,0,0,0,4,0}, // 1 {0,0,0,6,0,1,0,2,0}, // 2 {2,0,6,0,1,0,0,0,0}, // 3 {0,0,0,1,0,0,0,0,8}, // 4 {0,0,1,0,0,0,8,0,0}, // 5 {0,0,0,0,0,8,0,0,0}, // 6 {0,4,2,0,0,0,0,0,0}, // 7 {4,0,0,0,8,0,0,0,0} // 8 }; Graph G = new Graph(conn); G.Prim(); } } صرّف الشيفرة أعلاه باستخدام التعليمة javac Graph.java، وسيكون الخرج الناتج كما يلي: $ java Graph * 3 * 2 * * * * 4 3 * * * * * * 4 * * * * 6 * 1 * 2 * 2 * 6 * 1 * * * * * * * 1 * * * * 8 * * 1 * * * 8 * * * * * * * 8 * * * * 4 2 * * * * * * 4 * * * 8 * * * * ReachSet = 0 Min cost edge: (0,3)cost = 2 ReachSet = 0 3 Min cost edge: (3,4)cost = 1 ReachSet = 0 3 4 Min cost edge: (0,1)cost = 3 ReachSet = 0 1 3 4 Min cost edge: (0,8)cost = 4 ReachSet = 0 1 3 4 8 Min cost edge: (1,7)cost = 4 ReachSet = 0 1 3 4 7 8 Min cost edge: (7,2)cost = 2 ReachSet = 0 1 2 3 4 7 8 Min cost edge: (2,5)cost = 1 ReachSet = 0 1 2 3 4 5 7 8 Min cost edge: (5,6)cost = 8 ReachSet = 0 1 2 3 4 5 6 7 8 0 --> 0 0 --> 1 7 --> 2 0 --> 3 3 --> 4 2 --> 5 5 --> 6 1 --> 7 0 --> 8 خوارزمية بلمان- فورد Bellman–Ford خوارزمية بِلمان - فورد Bellman–Ford هي خوارزمية تحاول حساب أقصر المسارات من رأس مصدري source vertex إلى جميع الحروف الأخرى في مخطط موجّه موزون، ورغم أنّ هذه الخوارزمية أبطأ من خوارزمية Dijkstra، إلا أنها تعمل في الحالات التي تكون فيها أوزان الأضلاع سالبة، كما أنّها قادرة على العثور على الدورات ذات الوزن السالب في المخطط، على خلاف خوارزمية Dijkstra التي لا تعمل في حال كانت هناك دورة سالبة، إذ ستستمر في المرور عبر الدورة مرارًا وتكرارًا، وتستمر أيضًا في تقليل المسافة بين الرأسيْن. تتمثل فكرة هذه الخوارزمية في المرور عبر جميع أضلاع المخطط واحدًا تلو الآخر بترتيب عشوائي، شرط أن يحقق الترتيب المعادلة التالية: بعد تحديد الترتيب، سنخفّف الضلع -تخفيف الضلع هو تخفيض تكلفة الوصول إلى رأس معيّن عبر استخدام رأس آخر وسيط- وفقًا لصيغة التخفيف التالية. لكل ضلع u-v من u إلى v: if distance[u] + cost[u][v] < d[v] d[v] = d[u] + cost[u][v] بمعنى أنّه إذا كانت المسافة من المصدر إلى أيّ رأس u + وزن الضلع u-v < المسافة من المصدر إلى رأس ٍآخر v، فسنحدّث المسافة من المصدر إلى v. نحتاج إلى تخفيف الأضلاع (V-1) مرّة على الأكثر، حيث V هو عدد الأضلاع في المخطط. سنشرح لاحقًا لماذا اخترنا العدد (V-1)، ونخزّن أيضًا الرأس الأب parent vertex الخاص بكل الرأس، ونكتب ما يلي في كل مرّة نخفّف ضلعًا: parent[v] = u هذا يعني أننا وجدنا مسارًا آخر أقصر للوصول إلى v عبر u. سنحتاج أيضًا هذه القيمة المُخزّنة لاحقًا لطباعة أقصر مسار من المصدر إلى الرأس المنشود. انظر المثال التالي: لقد اخترنا 1 ليكون الرأس المصدري، والآن نريد العثور على أقصر مسار من هذا المصدر إلى جميع الحروف الأخرى. نكتب في البداية d[1] = 0، لأنّ 1 هو المصدر؛ أما البقيّة فستساوي اللانهاية لأنّنا لا نعرف مسافاتها بعد. سنخفّف الأضلاع في هذا التسلسل: +--------+--------+--------+--------+--------+--------+--------+ | التسلسل | 1 | 2 | 3 | 4 | 5 | 6 | +--------+--------+--------+--------+--------+--------+--------+ | الضلع | 4->5 | 3->4 | 1->3 | 1->4 | 4->6 | 2->3 | +--------+--------+--------+--------+--------+--------+--------+ يمكنك أن تختار أيّ تسلسل تريد، إذا خفّفنا الأضلاع مرّةً واحدة، فسنحصل على المسافات من المصدر إلى جميع الرؤوس الأخرى للمسار الذي يستخدم ضلعًا واحدًا على الأكثر. لنخفّف الآن الأضلاع ونحدث قيم d[]: d[4] + cost[4][5] = infinity + 7 = infinity. لا يمكننا تحديث هذا. d[2] + cost[3][4] = infinity. لا يمكننا تحديث هذا. d[1] + cost[1][3] = 0 + 2 = 2 < d[2] إذًا d[3] = 2 و parent[1] = 1. d[1] + cost[1][4] = 4. إذن d[4] = 4 < d[4]. parent[4] = 1. d[4] + cost[4][6] = 9. d[6] = 9 < d[6]. parent[6] = 4. d[2] + cost[2][3] = infinity لا يمكننا تحديث هذا. تعذّر تحديث بعض الرؤوس نتيجة عدم تحقّق الشرط d[u] + cost[u][v] < d[v]. وكما قلنا سابقًا، فقد حصلنا على المسارات من المصدر إلى العقد الأخرى باستخدام ضلع واحد على الأكثر. سيزوّدنا التكرار الثاني بمسار يستخدم عقدتين: d[4] + cost[4][5] = 12 < d[5]. d[5] = 12. parent[5] = 4. d[3] + cost[3][4] = 1 < d[4]. d[4] = 1. parent[4] = 3 d[3] تبقى بلا تغيير. d[4] تبقى بلا تغيير d[4] + cost[4][6] = 6 < d[6]. d[6] = 6. parent[6] = 4. d[3] تبقى بلا تغيير. هكذا سيبدو المخطط: التكرار الثالث سيحدّث الرأس 5 فقط، حيث سيضع القيمة 8 في d[5]. وسيبدو المخطط هكذا: بعد هذا، ستبقى المسافة كما هي مهما زِدنا من التكرارات، لذلك سنخزّن راية flag للتحقق من وقوع أيّ تحديث أم لا، فإذا لم يقع أيّ تحديث، أوقفنا حلقة التكرار. هذه شيفرة توضيحية: Procedure Bellman-Ford(Graph, source): n := number of vertices in Graph for i from 1 to n d[i] := infinity parent[i] := NULL end for d[source] := 0 for i from 1 to n-1 flag := false for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] d[v] := d[u] + cost[u][v] parent[v] := u flag := true end if end for if flag == false break end for Return d لتتبع الدورات السالبة، سنعدّل الشيفرة كما يلي: Procedure Bellman-Ford-With-Negative-Cycle-Detection(Graph, source): n := number of vertices in Graph for i from 1 to n d[i] := infinity parent[i] := NULL end for d[source] := 0 for i from 1 to n-1 flag := false for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] d[v] := d[u] + cost[u][v] parent[v] := u flag := true end if end for if flag == false break end for for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] Return "Negative Cycle Detected" end if end for Return d لأجل طباعة أقصر مسار إلى رأس معين، سنكّرر خلفيًا إلى الأب parent إلى أن نعثر على القيمة المعدومة NULL، ثمّ نطبع الحروف. انظر الشيفرة التوضيحية التالية: Procedure PathPrinting(u) v := parent[u] if v == NULL return PathPrinting(v) print -> u سيساوي التعقيد الزمني لهذه الخوارزمية O (V * E) إن استخدمنا قائمة تجاور adjacency list بما أننا سنحتاج إلى تخفيف الأضلاع بحد أقصى (V-1) مرة، حيث تشير E إلى عدد الأضلاع؛ أما إن استخدمنا مصفوفة تجاور لتمثيل المخطط، فسيكون التعقيد الزمني O (V ^ 3)، ذلك أننا سنستطيع التكرار على جميع الأضلاع عند استخدام قائمة التجاور خلال زمن قدره O(E)، بينما نستغرق زمنًا قدره O (V ^ 2) إن استخدمنا مصفوفة التجاور. رصد الدورات السالبة في المخططات نستطيع رصد أي دورة سالبة في المخطط باستخدام خوارزمية بِلمَن-فورد Bellman-Ford. ونحن نعرف أنه يجب تخفيف جميع أضلاع المخطط عدد (V-1) مرة من أجل العثور على أقصر مسار، حيث تمثل V عدد الرؤوس في المخطط، وقد رأينا أنه لا يمكن تحديث d[] مهما كان عدد التكرارات التي أجريناها. إذا كانت هناك دورة سالبة في المخطط، فسيمكننا تحديث d[] حتى بعد التكرار (V-1)، ذلك أن كل تكرار، سيقلل العبور خلال دورة سالبة تكلفةَ المسار الأقصر، وهذا سبب أن خوارزمية بِلمَن فورد تحد عدد التكرارات بـ (V-1) مرة، لأننا سنعلق داخل حلقة أبدية لا تنتهي إن استخدمنا خوارزمية ديكسترا. سنركز الآن على كيفية إيجاد دورة سالبة، انظر المخطط التالي: لنختر الرأس1 ليكون المصدر، بعد تطبيق خوارزمية بلمان-فورد لأقصر مسار ذي مصدر وحيد على المخطط، سنجد المسافات التي تفصل المصدر عن جميع الرؤوس الأخرى. انظر: هكذا سيبدو المخطط بعد (V-1) = 3 تكرار، وينبغي أن تكون هذه هي النتيجة الصحيحة، لأنّنا سنحتاج 3 تكرارات على الأكثر للعثور على أقصر مسار ما دامت هناك 4 أضلاع في المخطط، لذا إمّا أنّ هذه هي الإجابة الصحيحة، وإمّا أنّ هناك دورة ذات وزن سالب في المخطط. ولنعرف ذلك، سنضيف تكرارًا جديدًا بعد التكرار (V-1)، فإذا استمرت المسافة في الانخفاض، فذلك يعني أنّ هناك دورة سالبة في المخطط. ولهذا المثال فإنه بالنسبة للضلع 2-3، تكون نتيجة d[2] + cost [2] [3] مساوية لـ 1، وهو أقل من d[3]، لذا يمكننا أن نستنتج أنّ هناك دورةً سالبةً في المخطط. والسؤال الآن هو كيف نجد هذه الدورة السالبة؟ سنجري تعديلًا بسيطًا على خوارزمية Bellman-Ford للعثور على الدورة السالبة: Procedure NegativeCycleDetector(Graph, source): n := number of vertices in Graph for i from 1 to n d[i] := infinity end for d[source] := 0 for i from 1 to n-1 flag := false for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] d[v] := d[u] + cost[u][v] flag := true end if end for if flag == false break end for for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] Return "Negative Cycle Detected" end if end for Return "No Negative Cycle" بهذه الطريقة نستطيع التحقق مما إذا كانت هناك أيّ دورة سالبة في المخطط، كذلك نستطيع تعديل خوارزمية Bellman-Ford لتخزين الدورات السالبة وحفظ سجل لها. لماذا نحتاج إلى تخفيف جميع الأضلاع بحد أقصى (V-1) مرة نحتاج إلى تخفيف جميع أضلاع المخطط في خوارزمية Bellman-Ford للعثور على أقصر مسار، وتُكرّر هذه العملية (V-1) مرّةً بحد أقصى، حيث يمثل V عدد الرؤوس في المخطط. ويعتمد عدد التكرارات اللازمة للعثور على أقصر مسار من المصدر إلى جميع الرؤوس الأخرى على الترتيب الذي اخترناه لتخفيف الأضلاع. انظر المثال التالي: لقد اخترنا الرأس 1 ليكون المصدر، سنبحث عن أقصر مسافة تفصل بين المصدر وجميع الحروف الأخرى. ونستطيع رؤية أننا سنحتاج في أسوأ الأحوال إلى (V-1) ضلع للوصول إلى الرأس 4، ووفقًا للترتيب الذي اكتُشفت من خلاله الأضلاع، فقد نحتاج إلى (V-1) مرة. للتوضيح، سنستخدم خوارزمية Bellman-Ford في مثال توضيحي للعثور على أقصر مسار. انظر التسلسل التالي: +--------+--------+--------+------+ | التسلسل | 1 | 2 | 3 | +--------+--------+--------+------+ | الضلع | 3->4 | 2->3 | 1->2 | +--------+--------+--------+------+ في التكرار الأول: d[3] + cost[3][4] = infinity لن يحدث أيّ تغيير. d[2] + cost[2][3] = infinity لن يحدث أيّ تغيير. d[1] + cost[1][2] = 2 < d[2]. d[2] = 2. parent[2] = 1. لاحظ أنّ عملية التخفيف لم تغيّر إلا قيمة d[2] فقط. سيبدو المخطط خاصتنا هكذا: التكرار الثاني: d[3] + cost[3][4] = infinity لن يحدث أيّ تغيير. d[2] + cost[2][3] = 5 < d[3]. d[3] = 5. parent[3] = 2. لن يحدث أيّ تغيير. غيّرت عمليةُ التخفيف قيمةَ d[3] في هذه المرّة. وسيبدو المخطط هكذا: التكرار الثالث: d[3] + cost[3][4] = 7 < d[4] . d[4] = 7 . parent[4] = 3 . لن يحدث أيّ تغيير. لن يحدث أيّ تغيير. وجدنا في التكرار الثالث أقصر مسار إلى 4 من المصدر 1، حيث سيبدو المخطط هكذا: احتجنا إلى 3 تكرارات للعثور على أقصر مسار. ستظل قيمة d[] كما هي بعد ذلك مهما حاولنا تخفيف الأضلاع. إليك تسلسلًا آخر: +--------+--------+--------+------+ | التسلسل | 1 | 2 | 3 | +--------+--------+--------+------+ | الضلع | 1->2 | 2->3 | 3->4 | +--------+--------+--------+------+ سنحصل على: d[1] + cost[1][2] = 2 < d[2] . d[2] = 2 . d[2] + cost[2][3] = 5 < d[3]. d[3] = 5. d[3] + cost[3][4] = 7 < d[4]. d[4] = 5. وجدنا أقصر مسار من المصدر إلى جميع العقد الأخرى منذ التكرار الأول، يمكننا إجراء التسلسلات الإضافية 1-> 2 و3-> 4 و 2-> 3، والتي ستعطينا أقصر مسار بعد تكرارين. يقودنا هذا إلى استنتاج أنه مهما كان ترتيب التسلسل، فلن نحتاج أكثر من 3 تكرارات للعثور على أقصر مسار من المصدر. نستنتج أيضًا أننا قد لا نحتاج في بعض الحالات إلّا إلى تكرار واحد فقط للعثور على أقصر مسار من المصدر. وسنحتاج في أسوأ الحالات إلى (V-1) تكرار. أرجو أن تكون قد فهمت الآن لماذا ينبغي أن نكرّر عملية التخفيف (V-1) مرّة. خوارزمية فلويد وورشال Floyd-Warshall تُستخدم خوارزمية فلويد وورشال Floyd-Warsha ll لإيجاد أقصر المسارات في مخطط موزون قد تكون أوزان أضلاعه موجبة أو سالبة. عند تنفيذ الخوارزمية مرّةً واحدة، سنحصل على أطوال -مجاميع أوزان- أقصر المسارات بين كل أزواج الرؤوس، ويمكنها -بقليل من التعديل- طباعة أقصر مسار، كما يمكنها رصد الدورات السالبة في المخطط. وخوارزمية Floyd- Warshall هي من خوارزميات البرمجة الديناميكية. لنطبق هذه الخوارزمية على المخطط التالي: أول شيء نفعله هو أخذ مصفوفتين ثنائيتَي الأبعاد لتكونا مصفُوفتي تجاور adjacency matrices يساوي حجماهما العدد الإجمالي للرؤوس. وفي مثالنا، سنأخذ مصفوفتين من الحجم 4*4، الأولى هي مصفوفة المسافات Distance Matrix، وسنخزّن فيها أقصر مسافة عثرنا عليها حتى الآن بين رأسين. بدايةً، إذا كان هناك ضلع بين u-v وكانت المسافة / الوزن = w، فإننا نضع distance[u][v] = w، وسنضع قيمة ما لا نهاية للأضلاغ غير الموجودة. المصفوفة الثانية هي مصفوفة المسارات Path Matrix، ونستخدمها لتوليد أقصر مسار بين رأسين، لذا إذا كان هناك مسار بين u وv، فسنضع path[u][v] = u، وهذا يعني أنّ أفضل طريقة للوصول إلى الرأس v انطلاقًا من u هو باستخدام الضلع الذي يربط v بـ u، وإذا لم يكن هناك مسار بين الرأسين، فسنعطيه القيمة N كناية على عدم وجود مسار متاح حاليًا. سيبدو جدولا المخطط كما يلي: +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | | 1 | 2 | 3 | 4 | | | 1 | 2 | 3 | 4 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 1 | 0 | 3 | 6 | 15 | | 1 | N | 1 | 1 | 1 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 2 | inf | 0 | -2 | inf | | 2 | N | N | 2 | N | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 3 | inf | inf | 0 | 2 | | 3 | N | N | N | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 4 | 1 | inf | inf | 0 | | 4 | 4 | N | N | N | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ المسار المسافة وقد وضعنا الرأس N في المواضع القطرية diagonals في مصفوفة المسارات نظرًا لعدم وجود حلقة loop، ولما كانت المسافة من كل رأس إلى نفسه تساوي 0، فقد وضعنا القيمة 0 في المواضع القطرية في مصفوفة المسافات. سنختار رأسًا وسطيًا k لأجل تطبيق خوارزمية Floyd-Warshall، وسنتحق بعد ذلك لكلّ رأس i مما إن كنا نستطيع الانتقال من i إلى k ثم من k إلى j، حيث j يمثّل رأسًا آخر، لتقليل تكلفة الانتقال من i إلى j. إذا كانت المسافة distance [j] أكبر من المسافة distance [k] + distance[k] [j]، فسنحدّث قيمة distance [j]، ونضع فيها مجموع هاتين المسافتين، كما سنحدّث path [j] ونعطيها القيمة path[k] [j]، لأنّ الانتقال من i إلى k، ثم من k إلى j أفضل. كما ستٌختار جميع الرؤوس بنفس طريقة اختيار k. وهكذا نحصل على 3 حلقات متداخلة: k من 1 إلى 4. i من 1 إلى 4. j من 1 إلى 4. هذه شيفرة توضيحية لذلك: if distance[i][j] > distance[i][k] + distance[k][j] distance[i][j] := distance[i][k] + distance[k][j] path[i][j] := path[k][j] end if السؤال الآن هو: لكل زوج u,v من الرؤوس، هل يوجد رأس يمكن أن نمرّ عبره لتقصير المسافة بين u وv؟ سيكون العدد الإجمالي لعمليات المخطط هو 4 * 4 * 4 = 64. وهذا يعني أنّنا سنجري هذا الاختبار 64 مرة، لنلقي نظرةً على بعض هذه الحالات: إذا كانت k = 1 وi = 2 وj = 3، فإن [distance [j ستساوي -2، وهي ليست أكبر من distance [k] + distance[k] [j] = -2 + 0 = -2، لذلك ستبقى دون تغيير. ومرةً أخرى، إذا كانت k = 1 وi = 4 وj = 2، فستكون distance [j] = infinity، وهي أكبر من distance [k] + distance[k] [j] = 1 + 3 = 4، لذا نضع distance [j] = 4، وpath [j] = path[k] [j] = 1. وهذا يعني أنّه للانتقال من الرأس 4 إلى 2، فإنّ المسار 4-> 1-> 2 يكون أقصر من المسار الحالي. انظر هذا الرابط الأجنبي للاطلاع على حسابات كل خطوة، وستبدو مصفوفتنا كما يلي بعد إجراء التعديلات اللازمة. بعد إجراء التغييرات اللازمة، ستبدو المصفوفتان كما يلي: +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | | 1 | 2 | 3 | 4 | | | 1 | 2 | 3 | 4 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 1 | 0 | 3 | 1 | 3 | | 1 | N | 1 | 2 | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 2 | 1 | 0 | -2 | 0 | | 2 | 4 | N | 2 | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 3 | 3 | 6 | 0 | 2 | | 3 | 4 | 1 | N | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 4 | 1 | 4 | 2 | 0 | | 4 | 4 | 1 | 2 | N | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ المسار المسافة وهكذا نكون قد حصلنا على مصفوفةِ أقصر المسافات، فمثلًا، تكون أقصر مسافة من 1 إلى 4 هي 3، وأقصر مسافة من 4 إلى 3 هي 2. انظر إلى الشيفرة التوضيحية التالية، حيث تمثل V عدد الرؤوس: Procedure Floyd-Warshall(Graph): for k from 1 to V for i from 1 to V for j from 1 to V if distance[i][j] > distance[i][k] + distance[k][j] distance[i][j] := distance[i][k] + distance[k][j] path[i][j] := path[k][j] end if end for end for end for سنتحقق من مصفوفة المسارات Path من أجل طباعة المسار، ولطباعة المسار من u إلى v، سنبدأ من path[u] [v]. ثمّ نستمر في تغيير v = path[u] [v] إلى أن نحصل على path[u] [v] = u، وندفع كل قيم path[u] [v] إلى مكدّس. بعد العثور على الرأس u، سنطبع u ونبدأ بإخراج العناصر من المكدّس وطباعتها. هذا الأمر ممكن لأنّ مصفوفة المسارات تخزّن قيمة الرأس الذي يشارك في أقصر مسار إلى v انطلاقًا من أيّ عقدة أخرى. انظر إلى الشيفرة التوضيحية لذلك: Procedure PrintPath(source, destination): s = Stack() S.push(destination) while Path[source][destination] is not equal to source S.push(Path[source][destination]) destination := Path[source][destination] end while print -> source while S is not empty print -> S.pop end while من أجل التحقق من وجود دورة سالبة، سيكون علينا التحقق من القطر diagonal الرئيسي لمصفوفة المسافات، وإذا كانت أيٌّ من القيم القطرية diagonal سالبة، فهذا يعني وجود دورة سالبة في المخطط. إن تعقيد خوارزمية فلويد-وورشال Floyd-Warshall هو O (V3)، وتعقيد المساحة هو: O (V2). ترجمة -بتصرّف- للفصول 19 و20 و22 من كتاب Algorithms Notes for Professionals. اقرأ أيضًا المقال السابق: تطبيقات الخوارزميات الشرهة المرجع الشامل إلى تعلم الخوارزميات للمبتدئين دليل شامل عن تحليل تعقيد الخوارزمية مدخل إلى الخوارزميات خوارزمية تحديد المسار النجمية A* Pathfinding خوارزمية ديكسترا Dijkstra’s Algorithm
نستعرض في هذا المقال بعض أشهر الخوارزميات المستخدمة لتحليل المسارات في الأشجار، مثل خوارزمية بْرِم Prim وخوارزمية فلويد-وورشال Floyd-Warshall وخوارِزمية بلمان-فورد Bellman-Ford. خوارزمية برم Prim's Algorithm لنفترض أنّ لدينا 8 منازل، ونريد إعداد خطوط هاتفية بينها بأقل تكلفة ممكنة. لأجل ذلك سننشئ شجرةً حروفها تمثل المنازل، وأضلَاعها تمثّل تكلفة توصيل الخط الهاتفي بين منزلين. سنحاول وصل الخطوط بين جميع المنازل بأقل كلفة ممكنة، ولتحقيق ذلك سنستخدم خوارزمية برم Prim، وهي خوارزمية شرهة تبحث عن أصغر شجرة ممتدة spanning tree في مخطط موزون غير موجّه undirected weighted graph. وهذا يعني أنها تبحث عن مجموعة من الأضلاع التي تشكل شجرة تتضمّن كل العقد، بحيث يكون الوزن الإجمالي لجميع أضلاع الشجرة أقل ما يمكن. طُوِّرت هذه الخوارزمية عام 1930 من قبل عالم الرياضيات التشيكي Vojtěch Jarník، ثم أعاد عالم الحوسبة روبرت كلاي بْرِم اكتشافها ونشرها في عام 1957، وكذلك إيدجر ديكسترا في عام 1959. تُعرف أيضًا باسم خوارزمية DJP وخوارزمية Jarnik وخوارزمية Prim-Jarnik وخوارزمية Prim-Dijsktra. إذا كانت G مخططًا غير موجّه، فنقول أنّ المخطط S هو مخطط فرعي subgraph من G إذا كانت جميع حروفه وأضلَاعه تنتمي إلى G. ونقول أنّ S شجرة ممتدة فقط إذا كانت: تحتوي جميع عقد G. وكانت شجرة، أي أنّها لا تحتوي أيّ دورة cycle، وجميع عقدها متصلة. تحتوى (n-1) ضلعًا، حيث n يمثّل عدد العقد في G. يمكن أن يكون لمخطط ما أكثر من شجرة ممتدة واحدة، والشجرة الممتدة الصغرى لمخطط موزون غير موجّه هي شجرة مجموع أوزان أضلاعها أقل ما يمكن. سنستخدم خوارزمية Prim لإيجاد الشجرة الممتدة الصغرى، وسيساعدنا هذا على حل مشكلة الخطوط الهاتفية في المثال أعلاه. أولاً، سنختار عقدةً ما لتكون العقدة المصدرية source node، ولتكن العقدة 1 مثلًا. سنضيف الآن الضلع الذي ينطلق من 1 وله أقل كلفة إلى المخطط الفرعي، ونلوّن الأضلاع التي أضفناها إلى المخطط الفرعي باللون الأزرق. وسيكون الضلع 1-5 في مثالنا هو الضلع الذي له أقل كلفة. الآن، سنأخذ الضلع الأقل كلفة من بين جميع الأضلاع المُنطلِقة من العقدة 1 أو العقدة 5. وبما أنّنا لوّنّا 1-5 سلفًا، فالضلع المرشّح الثاني هو الضلع 1-2. نأخذ هذه المرة الضلع الأقل كلفةً من بين جميع الأضلاع (غير المُلوّنة) المُنطلقة من العقدة 1 أو العقدة 2 أو العقدة 5، والذي هو في حالتنا 5-4. تحتاج الخطوة التالية إلى تركيز، وفيها سنحاول أن نفعل ما فعلناه سابقا، ونختار من بين جميع الأضلاع (غير المُلوّنة) التي تنطلق من العقدة 1 أو 2 أو 5 أو 4 الضلع الذي له أقل كلفة، وهو 2-4. ولكن انتبه إلى أنّه في حال اختيار هذا الضلع، فسنخلُق دورةً cycle في المخطط الفرعي، ذلك أنّ العقدتين 2 و4 موجودتان سلفًا فيه، لذا فإنّ أخذ الضلع 2-4 ليس الخيار الصحيح. وبدلًا من ذلك سنختار الضلع 4-8. إذا واصلنا على هذا النحو فسنختَار الأضلاع 8-6 و6-7 و4-3، وسيبدو المخطط الفرعي النهائي هكذا: إذا أزلنا الأضلاع التي لم نَخترها (غير المُلوّنة)، فسنحصل على: هذه هي الشجرة الممتدة الصغرى MST التي نبحث عنها، ونستنتج منها أنّ تكلفة إعداد خطوط الهاتف هي: 4 + 2 + 5 + 11 + 9 + 2 + 1 = 34. يمكن أن تكون هناك عدة أشجار ممتدة صغرى للمخطط نفسه بحسب العقدة المصدرية التي اخترناها. انظر شيفرة توضيحية لهذه الخوارزمية، حيث تمثل Graph مخططًا فارغًا متصلًا غير موزون، وتمثل Vnew مخططًا فرعيًا جديدًا عقدته المصدرية هي x: Procedure PrimsMST(Graph): Vnew[] = {x} Enew[] = {} while Vnew is not equal to V u -> a node from Vnew v -> a node that is not in Vnew such that edge u-v has the minimum cost // إذا كان لعقدتين الوزن نفسه، فاختر أيًّا منهما add v to Vnew add edge (u, v) to Enew end while Return Vnew and Enew التعقيد التعقيد الزمني للمنظور البسيط أعلاه هو ( O (V 2، يمكننا تقليل التعقيد باستخدام طابور أولويات priority queue، فإذا أضفنا عقدةً جديدةً إلى المخطط الفرعي الجديد Vnew، فيمكننا إضافة أضلاعها المجاورة إلى رتل الأولويات، ثم إخراج الضلع الموزون ذو الكلفة الأدنى منه. وحينئذ يصبح التعقيد مساويًا للقيمة O (ElogE)، حيث يمثّل E عدد الأضلاع. يمكنك أيضًا إنشاء كَومة ثنائية Binary Heap لتخفيض التعقيد إلى O (ElogV). هذه شيفرة توضيحية تستخدم طابور الأولويات: Procedure MSTPrim(Graph, source): for each u in V key[u] := inf parent[u] := NULL end for key[source] := 0 Q = Priority_Queue() Q = V while Q is not empty u -> Q.pop for each v adjacent to i if v belongs to Q and Edge(u,v) < key[v] // edge(u, v) كلفة Edge(u, v) تمثل parent[v] := u key[v] := Edge(u, v) end if end for end while تخزّن key[] الكلفة الأقل لعبور العقدة v، فيما تُستخدم parent[] لتخزين العقدة الأصلية parent node، وهذا مفيد لتسلّق الشجرة وطباعتها. فيما يلي برنامج بسيط بلغة Java: import java.util.*; public class Graph { private static int infinite = 9999999; int[][] LinkCost; int NNodes; Graph(int[][] mat) { int i, j; NNodes = mat.length; LinkCost = new int[NNodes][NNodes]; for ( i=0; i < NNodes; i++) { for ( j=0; j < NNodes; j++) { LinkCost[i][j] = mat[i][j]; if ( LinkCost[i][j] == 0 ) LinkCost[i][j] = infinite; } } for ( i=0; i < NNodes; i++) { for ( j=0; j < NNodes; j++) if ( LinkCost[i][j] < infinite ) System.out.print( " " + LinkCost[i][j] + " " ); else System.out.print(" * " ); System.out.println(); } } public int unReached(boolean[] r) { boolean done = true; for ( int i = 0; i < r.length; i++ ) if ( r[i] == false ) return i; return -1; } public void Prim( ) { int i, j, k, x, y; boolean[] Reached = new boolean[NNodes]; int[] predNode = new int[NNodes]; Reached[0] = true; for ( k = 1; k < NNodes; k++ ) { Reached[k] = false; } predNode[0] = 0; printReachSet( Reached ); for (k = 1; k < NNodes; k++) { x = y = 0; for ( i = 0; i < NNodes; i++ ) for ( j = 0; j < NNodes; j++ ) { if ( Reached[i] && !Reached[j] && LinkCost[i][j] < LinkCost[x][y] ) { x = i; y = j; } } System.out.println("Min cost edge: (" + + x + "," + + y + ")" + "cost = " + LinkCost[x][y]); predNode[y] = x; Reached[y] = true; printReachSet( Reached ); System.out.println(); } int[] a= predNode; for ( i = 0; i < NNodes; i++ ) System.out.println( a[i] + " --> " + i ); } void printReachSet(boolean[] Reached ) { System.out.print("ReachSet = "); for (int i = 0; i < Reached.length; i++ ) if ( Reached[i] ) System.out.print( i + " "); //System.out.println(); } public static void main(String[] args) { int[][] conn = {{0,3,0,2,0,0,0,0,4}, // 0 {3,0,0,0,0,0,0,4,0}, // 1 {0,0,0,6,0,1,0,2,0}, // 2 {2,0,6,0,1,0,0,0,0}, // 3 {0,0,0,1,0,0,0,0,8}, // 4 {0,0,1,0,0,0,8,0,0}, // 5 {0,0,0,0,0,8,0,0,0}, // 6 {0,4,2,0,0,0,0,0,0}, // 7 {4,0,0,0,8,0,0,0,0} // 8 }; Graph G = new Graph(conn); G.Prim(); } } صرّف الشيفرة أعلاه باستخدام التعليمة javac Graph.java، وسيكون الخرج الناتج كما يلي: $ java Graph * 3 * 2 * * * * 4 3 * * * * * * 4 * * * * 6 * 1 * 2 * 2 * 6 * 1 * * * * * * * 1 * * * * 8 * * 1 * * * 8 * * * * * * * 8 * * * * 4 2 * * * * * * 4 * * * 8 * * * * ReachSet = 0 Min cost edge: (0,3)cost = 2 ReachSet = 0 3 Min cost edge: (3,4)cost = 1 ReachSet = 0 3 4 Min cost edge: (0,1)cost = 3 ReachSet = 0 1 3 4 Min cost edge: (0,8)cost = 4 ReachSet = 0 1 3 4 8 Min cost edge: (1,7)cost = 4 ReachSet = 0 1 3 4 7 8 Min cost edge: (7,2)cost = 2 ReachSet = 0 1 2 3 4 7 8 Min cost edge: (2,5)cost = 1 ReachSet = 0 1 2 3 4 5 7 8 Min cost edge: (5,6)cost = 8 ReachSet = 0 1 2 3 4 5 6 7 8 0 --> 0 0 --> 1 7 --> 2 0 --> 3 3 --> 4 2 --> 5 5 --> 6 1 --> 7 0 --> 8 خوارزمية بلمان- فورد Bellman–Ford خوارزمية بِلمان - فورد Bellman–Ford هي خوارزمية تحاول حساب أقصر المسارات من رأس مصدري source vertex إلى جميع الحروف الأخرى في مخطط موجّه موزون، ورغم أنّ هذه الخوارزمية أبطأ من خوارزمية Dijkstra، إلا أنها تعمل في الحالات التي تكون فيها أوزان الأضلاع سالبة، كما أنّها قادرة على العثور على الدورات ذات الوزن السالب في المخطط، على خلاف خوارزمية Dijkstra التي لا تعمل في حال كانت هناك دورة سالبة، إذ ستستمر في المرور عبر الدورة مرارًا وتكرارًا، وتستمر أيضًا في تقليل المسافة بين الرأسيْن. تتمثل فكرة هذه الخوارزمية في المرور عبر جميع أضلاع المخطط واحدًا تلو الآخر بترتيب عشوائي، شرط أن يحقق الترتيب المعادلة التالية: بعد تحديد الترتيب، سنخفّف الضلع -تخفيف الضلع هو تخفيض تكلفة الوصول إلى رأس معيّن عبر استخدام رأس آخر وسيط- وفقًا لصيغة التخفيف التالية. لكل ضلع u-v من u إلى v: if distance[u] + cost[u][v] < d[v] d[v] = d[u] + cost[u][v] بمعنى أنّه إذا كانت المسافة من المصدر إلى أيّ رأس u + وزن الضلع u-v < المسافة من المصدر إلى رأس ٍآخر v، فسنحدّث المسافة من المصدر إلى v. نحتاج إلى تخفيف الأضلاع (V-1) مرّة على الأكثر، حيث V هو عدد الأضلاع في المخطط. سنشرح لاحقًا لماذا اخترنا العدد (V-1)، ونخزّن أيضًا الرأس الأب parent vertex الخاص بكل الرأس، ونكتب ما يلي في كل مرّة نخفّف ضلعًا: parent[v] = u هذا يعني أننا وجدنا مسارًا آخر أقصر للوصول إلى v عبر u. سنحتاج أيضًا هذه القيمة المُخزّنة لاحقًا لطباعة أقصر مسار من المصدر إلى الرأس المنشود. انظر المثال التالي: لقد اخترنا 1 ليكون الرأس المصدري، والآن نريد العثور على أقصر مسار من هذا المصدر إلى جميع الحروف الأخرى. نكتب في البداية d[1] = 0، لأنّ 1 هو المصدر؛ أما البقيّة فستساوي اللانهاية لأنّنا لا نعرف مسافاتها بعد. سنخفّف الأضلاع في هذا التسلسل: +--------+--------+--------+--------+--------+--------+--------+ | التسلسل | 1 | 2 | 3 | 4 | 5 | 6 | +--------+--------+--------+--------+--------+--------+--------+ | الضلع | 4->5 | 3->4 | 1->3 | 1->4 | 4->6 | 2->3 | +--------+--------+--------+--------+--------+--------+--------+ يمكنك أن تختار أيّ تسلسل تريد، إذا خفّفنا الأضلاع مرّةً واحدة، فسنحصل على المسافات من المصدر إلى جميع الرؤوس الأخرى للمسار الذي يستخدم ضلعًا واحدًا على الأكثر. لنخفّف الآن الأضلاع ونحدث قيم d[]: d[4] + cost[4][5] = infinity + 7 = infinity. لا يمكننا تحديث هذا. d[2] + cost[3][4] = infinity. لا يمكننا تحديث هذا. d[1] + cost[1][3] = 0 + 2 = 2 < d[2] إذًا d[3] = 2 و parent[1] = 1. d[1] + cost[1][4] = 4. إذن d[4] = 4 < d[4]. parent[4] = 1. d[4] + cost[4][6] = 9. d[6] = 9 < d[6]. parent[6] = 4. d[2] + cost[2][3] = infinity لا يمكننا تحديث هذا. تعذّر تحديث بعض الرؤوس نتيجة عدم تحقّق الشرط d[u] + cost[u][v] < d[v]. وكما قلنا سابقًا، فقد حصلنا على المسارات من المصدر إلى العقد الأخرى باستخدام ضلع واحد على الأكثر. سيزوّدنا التكرار الثاني بمسار يستخدم عقدتين: d[4] + cost[4][5] = 12 < d[5]. d[5] = 12. parent[5] = 4. d[3] + cost[3][4] = 1 < d[4]. d[4] = 1. parent[4] = 3 d[3] تبقى بلا تغيير. d[4] تبقى بلا تغيير d[4] + cost[4][6] = 6 < d[6]. d[6] = 6. parent[6] = 4. d[3] تبقى بلا تغيير. هكذا سيبدو المخطط: التكرار الثالث سيحدّث الرأس 5 فقط، حيث سيضع القيمة 8 في d[5]. وسيبدو المخطط هكذا: بعد هذا، ستبقى المسافة كما هي مهما زِدنا من التكرارات، لذلك سنخزّن راية flag للتحقق من وقوع أيّ تحديث أم لا، فإذا لم يقع أيّ تحديث، أوقفنا حلقة التكرار. هذه شيفرة توضيحية: Procedure Bellman-Ford(Graph, source): n := number of vertices in Graph for i from 1 to n d[i] := infinity parent[i] := NULL end for d[source] := 0 for i from 1 to n-1 flag := false for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] d[v] := d[u] + cost[u][v] parent[v] := u flag := true end if end for if flag == false break end for Return d لتتبع الدورات السالبة، سنعدّل الشيفرة كما يلي: Procedure Bellman-Ford-With-Negative-Cycle-Detection(Graph, source): n := number of vertices in Graph for i from 1 to n d[i] := infinity parent[i] := NULL end for d[source] := 0 for i from 1 to n-1 flag := false for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] d[v] := d[u] + cost[u][v] parent[v] := u flag := true end if end for if flag == false break end for for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] Return "Negative Cycle Detected" end if end for Return d لأجل طباعة أقصر مسار إلى رأس معين، سنكّرر خلفيًا إلى الأب parent إلى أن نعثر على القيمة المعدومة NULL، ثمّ نطبع الحروف. انظر الشيفرة التوضيحية التالية: Procedure PathPrinting(u) v := parent[u] if v == NULL return PathPrinting(v) print -> u سيساوي التعقيد الزمني لهذه الخوارزمية O (V * E) إن استخدمنا قائمة تجاور adjacency list بما أننا سنحتاج إلى تخفيف الأضلاع بحد أقصى (V-1) مرة، حيث تشير E إلى عدد الأضلاع؛ أما إن استخدمنا مصفوفة تجاور لتمثيل المخطط، فسيكون التعقيد الزمني O (V ^ 3)، ذلك أننا سنستطيع التكرار على جميع الأضلاع عند استخدام قائمة التجاور خلال زمن قدره O(E)، بينما نستغرق زمنًا قدره O (V ^ 2) إن استخدمنا مصفوفة التجاور. رصد الدورات السالبة في المخططات نستطيع رصد أي دورة سالبة في المخطط باستخدام خوارزمية بِلمَن-فورد Bellman-Ford. ونحن نعرف أنه يجب تخفيف جميع أضلاع المخطط عدد (V-1) مرة من أجل العثور على أقصر مسار، حيث تمثل V عدد الرؤوس في المخطط، وقد رأينا أنه لا يمكن تحديث d[] مهما كان عدد التكرارات التي أجريناها. إذا كانت هناك دورة سالبة في المخطط، فسيمكننا تحديث d[] حتى بعد التكرار (V-1)، ذلك أن كل تكرار، سيقلل العبور خلال دورة سالبة تكلفةَ المسار الأقصر، وهذا سبب أن خوارزمية بِلمَن فورد تحد عدد التكرارات بـ (V-1) مرة، لأننا سنعلق داخل حلقة أبدية لا تنتهي إن استخدمنا خوارزمية ديكسترا. سنركز الآن على كيفية إيجاد دورة سالبة، انظر المخطط التالي: لنختر الرأس1 ليكون المصدر، بعد تطبيق خوارزمية بلمان-فورد لأقصر مسار ذي مصدر وحيد على المخطط، سنجد المسافات التي تفصل المصدر عن جميع الرؤوس الأخرى. انظر: هكذا سيبدو المخطط بعد (V-1) = 3 تكرار، وينبغي أن تكون هذه هي النتيجة الصحيحة، لأنّنا سنحتاج 3 تكرارات على الأكثر للعثور على أقصر مسار ما دامت هناك 4 أضلاع في المخطط، لذا إمّا أنّ هذه هي الإجابة الصحيحة، وإمّا أنّ هناك دورة ذات وزن سالب في المخطط. ولنعرف ذلك، سنضيف تكرارًا جديدًا بعد التكرار (V-1)، فإذا استمرت المسافة في الانخفاض، فذلك يعني أنّ هناك دورة سالبة في المخطط. ولهذا المثال فإنه بالنسبة للضلع 2-3، تكون نتيجة d[2] + cost [2] [3] مساوية لـ 1، وهو أقل من d[3]، لذا يمكننا أن نستنتج أنّ هناك دورةً سالبةً في المخطط. والسؤال الآن هو كيف نجد هذه الدورة السالبة؟ سنجري تعديلًا بسيطًا على خوارزمية Bellman-Ford للعثور على الدورة السالبة: Procedure NegativeCycleDetector(Graph, source): n := number of vertices in Graph for i from 1 to n d[i] := infinity end for d[source] := 0 for i from 1 to n-1 flag := false for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] d[v] := d[u] + cost[u][v] flag := true end if end for if flag == false break end for for all edges from (u,v) in Graph if d[u] + cost[u][v] < d[v] Return "Negative Cycle Detected" end if end for Return "No Negative Cycle" بهذه الطريقة نستطيع التحقق مما إذا كانت هناك أيّ دورة سالبة في المخطط، كذلك نستطيع تعديل خوارزمية Bellman-Ford لتخزين الدورات السالبة وحفظ سجل لها. لماذا نحتاج إلى تخفيف جميع الأضلاع بحد أقصى (V-1) مرة نحتاج إلى تخفيف جميع أضلاع المخطط في خوارزمية Bellman-Ford للعثور على أقصر مسار، وتُكرّر هذه العملية (V-1) مرّةً بحد أقصى، حيث يمثل V عدد الرؤوس في المخطط. ويعتمد عدد التكرارات اللازمة للعثور على أقصر مسار من المصدر إلى جميع الرؤوس الأخرى على الترتيب الذي اخترناه لتخفيف الأضلاع. انظر المثال التالي: لقد اخترنا الرأس 1 ليكون المصدر، سنبحث عن أقصر مسافة تفصل بين المصدر وجميع الحروف الأخرى. ونستطيع رؤية أننا سنحتاج في أسوأ الأحوال إلى (V-1) ضلع للوصول إلى الرأس 4، ووفقًا للترتيب الذي اكتُشفت من خلاله الأضلاع، فقد نحتاج إلى (V-1) مرة. للتوضيح، سنستخدم خوارزمية Bellman-Ford في مثال توضيحي للعثور على أقصر مسار. انظر التسلسل التالي: +--------+--------+--------+------+ | التسلسل | 1 | 2 | 3 | +--------+--------+--------+------+ | الضلع | 3->4 | 2->3 | 1->2 | +--------+--------+--------+------+ في التكرار الأول: d[3] + cost[3][4] = infinity لن يحدث أيّ تغيير. d[2] + cost[2][3] = infinity لن يحدث أيّ تغيير. d[1] + cost[1][2] = 2 < d[2]. d[2] = 2. parent[2] = 1. لاحظ أنّ عملية التخفيف لم تغيّر إلا قيمة d[2] فقط. سيبدو المخطط خاصتنا هكذا: التكرار الثاني: d[3] + cost[3][4] = infinity لن يحدث أيّ تغيير. d[2] + cost[2][3] = 5 < d[3]. d[3] = 5. parent[3] = 2. لن يحدث أيّ تغيير. غيّرت عمليةُ التخفيف قيمةَ d[3] في هذه المرّة. وسيبدو المخطط هكذا: التكرار الثالث: d[3] + cost[3][4] = 7 < d[4] . d[4] = 7 . parent[4] = 3 . لن يحدث أيّ تغيير. لن يحدث أيّ تغيير. وجدنا في التكرار الثالث أقصر مسار إلى 4 من المصدر 1، حيث سيبدو المخطط هكذا: احتجنا إلى 3 تكرارات للعثور على أقصر مسار. ستظل قيمة d[] كما هي بعد ذلك مهما حاولنا تخفيف الأضلاع. إليك تسلسلًا آخر: +--------+--------+--------+------+ | التسلسل | 1 | 2 | 3 | +--------+--------+--------+------+ | الضلع | 1->2 | 2->3 | 3->4 | +--------+--------+--------+------+ سنحصل على: d[1] + cost[1][2] = 2 < d[2] . d[2] = 2 . d[2] + cost[2][3] = 5 < d[3]. d[3] = 5. d[3] + cost[3][4] = 7 < d[4]. d[4] = 5. وجدنا أقصر مسار من المصدر إلى جميع العقد الأخرى منذ التكرار الأول، يمكننا إجراء التسلسلات الإضافية 1-> 2 و3-> 4 و 2-> 3، والتي ستعطينا أقصر مسار بعد تكرارين. يقودنا هذا إلى استنتاج أنه مهما كان ترتيب التسلسل، فلن نحتاج أكثر من 3 تكرارات للعثور على أقصر مسار من المصدر. نستنتج أيضًا أننا قد لا نحتاج في بعض الحالات إلّا إلى تكرار واحد فقط للعثور على أقصر مسار من المصدر. وسنحتاج في أسوأ الحالات إلى (V-1) تكرار. أرجو أن تكون قد فهمت الآن لماذا ينبغي أن نكرّر عملية التخفيف (V-1) مرّة. خوارزمية فلويد وورشال Floyd-Warshall تُستخدم خوارزمية فلويد وورشال Floyd-Warsha ll لإيجاد أقصر المسارات في مخطط موزون قد تكون أوزان أضلاعه موجبة أو سالبة. عند تنفيذ الخوارزمية مرّةً واحدة، سنحصل على أطوال -مجاميع أوزان- أقصر المسارات بين كل أزواج الرؤوس، ويمكنها -بقليل من التعديل- طباعة أقصر مسار، كما يمكنها رصد الدورات السالبة في المخطط. وخوارزمية Floyd- Warshall هي من خوارزميات البرمجة الديناميكية. لنطبق هذه الخوارزمية على المخطط التالي: أول شيء نفعله هو أخذ مصفوفتين ثنائيتَي الأبعاد لتكونا مصفُوفتي تجاور adjacency matrices يساوي حجماهما العدد الإجمالي للرؤوس. وفي مثالنا، سنأخذ مصفوفتين من الحجم 4*4، الأولى هي مصفوفة المسافات Distance Matrix، وسنخزّن فيها أقصر مسافة عثرنا عليها حتى الآن بين رأسين. بدايةً، إذا كان هناك ضلع بين u-v وكانت المسافة / الوزن = w، فإننا نضع distance[u][v] = w، وسنضع قيمة ما لا نهاية للأضلاغ غير الموجودة. المصفوفة الثانية هي مصفوفة المسارات Path Matrix، ونستخدمها لتوليد أقصر مسار بين رأسين، لذا إذا كان هناك مسار بين u وv، فسنضع path[u][v] = u، وهذا يعني أنّ أفضل طريقة للوصول إلى الرأس v انطلاقًا من u هو باستخدام الضلع الذي يربط v بـ u، وإذا لم يكن هناك مسار بين الرأسين، فسنعطيه القيمة N كناية على عدم وجود مسار متاح حاليًا. سيبدو جدولا المخطط كما يلي: +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | | 1 | 2 | 3 | 4 | | | 1 | 2 | 3 | 4 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 1 | 0 | 3 | 6 | 15 | | 1 | N | 1 | 1 | 1 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 2 | inf | 0 | -2 | inf | | 2 | N | N | 2 | N | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 3 | inf | inf | 0 | 2 | | 3 | N | N | N | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 4 | 1 | inf | inf | 0 | | 4 | 4 | N | N | N | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ المسار المسافة وقد وضعنا الرأس N في المواضع القطرية diagonals في مصفوفة المسارات نظرًا لعدم وجود حلقة loop، ولما كانت المسافة من كل رأس إلى نفسه تساوي 0، فقد وضعنا القيمة 0 في المواضع القطرية في مصفوفة المسافات. سنختار رأسًا وسطيًا k لأجل تطبيق خوارزمية Floyd-Warshall، وسنتحق بعد ذلك لكلّ رأس i مما إن كنا نستطيع الانتقال من i إلى k ثم من k إلى j، حيث j يمثّل رأسًا آخر، لتقليل تكلفة الانتقال من i إلى j. إذا كانت المسافة distance [j] أكبر من المسافة distance [k] + distance[k] [j]، فسنحدّث قيمة distance [j]، ونضع فيها مجموع هاتين المسافتين، كما سنحدّث path [j] ونعطيها القيمة path[k] [j]، لأنّ الانتقال من i إلى k، ثم من k إلى j أفضل. كما ستٌختار جميع الرؤوس بنفس طريقة اختيار k. وهكذا نحصل على 3 حلقات متداخلة: k من 1 إلى 4. i من 1 إلى 4. j من 1 إلى 4. هذه شيفرة توضيحية لذلك: if distance[i][j] > distance[i][k] + distance[k][j] distance[i][j] := distance[i][k] + distance[k][j] path[i][j] := path[k][j] end if السؤال الآن هو: لكل زوج u,v من الرؤوس، هل يوجد رأس يمكن أن نمرّ عبره لتقصير المسافة بين u وv؟ سيكون العدد الإجمالي لعمليات المخطط هو 4 * 4 * 4 = 64. وهذا يعني أنّنا سنجري هذا الاختبار 64 مرة، لنلقي نظرةً على بعض هذه الحالات: إذا كانت k = 1 وi = 2 وj = 3، فإن [distance [j ستساوي -2، وهي ليست أكبر من distance [k] + distance[k] [j] = -2 + 0 = -2، لذلك ستبقى دون تغيير. ومرةً أخرى، إذا كانت k = 1 وi = 4 وj = 2، فستكون distance [j] = infinity، وهي أكبر من distance [k] + distance[k] [j] = 1 + 3 = 4، لذا نضع distance [j] = 4، وpath [j] = path[k] [j] = 1. وهذا يعني أنّه للانتقال من الرأس 4 إلى 2، فإنّ المسار 4-> 1-> 2 يكون أقصر من المسار الحالي. انظر هذا الرابط الأجنبي للاطلاع على حسابات كل خطوة، وستبدو مصفوفتنا كما يلي بعد إجراء التعديلات اللازمة. بعد إجراء التغييرات اللازمة، ستبدو المصفوفتان كما يلي: +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | | 1 | 2 | 3 | 4 | | | 1 | 2 | 3 | 4 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 1 | 0 | 3 | 1 | 3 | | 1 | N | 1 | 2 | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 2 | 1 | 0 | -2 | 0 | | 2 | 4 | N | 2 | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 3 | 3 | 6 | 0 | 2 | | 3 | 4 | 1 | N | 3 | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ | 4 | 1 | 4 | 2 | 0 | | 4 | 4 | 1 | 2 | N | +-----+-----+-----+-----+-----+ +-----+-----+-----+-----+-----+ المسار المسافة وهكذا نكون قد حصلنا على مصفوفةِ أقصر المسافات، فمثلًا، تكون أقصر مسافة من 1 إلى 4 هي 3، وأقصر مسافة من 4 إلى 3 هي 2. انظر إلى الشيفرة التوضيحية التالية، حيث تمثل V عدد الرؤوس: Procedure Floyd-Warshall(Graph): for k from 1 to V for i from 1 to V for j from 1 to V if distance[i][j] > distance[i][k] + distance[k][j] distance[i][j] := distance[i][k] + distance[k][j] path[i][j] := path[k][j] end if end for end for end for سنتحقق من مصفوفة المسارات Path من أجل طباعة المسار، ولطباعة المسار من u إلى v، سنبدأ من path[u] [v]. ثمّ نستمر في تغيير v = path[u] [v] إلى أن نحصل على path[u] [v] = u، وندفع كل قيم path[u] [v] إلى مكدّس. بعد العثور على الرأس u، سنطبع u ونبدأ بإخراج العناصر من المكدّس وطباعتها. هذا الأمر ممكن لأنّ مصفوفة المسارات تخزّن قيمة الرأس الذي يشارك في أقصر مسار إلى v انطلاقًا من أيّ عقدة أخرى. انظر إلى الشيفرة التوضيحية لذلك: Procedure PrintPath(source, destination): s = Stack() S.push(destination) while Path[source][destination] is not equal to source S.push(Path[source][destination]) destination := Path[source][destination] end while print -> source while S is not empty print -> S.pop end while من أجل التحقق من وجود دورة سالبة، سيكون علينا التحقق من القطر diagonal الرئيسي لمصفوفة المسافات، وإذا كانت أيٌّ من القيم القطرية diagonal سالبة، فهذا يعني وجود دورة سالبة في المخطط. إن تعقيد خوارزمية فلويد-وورشال Floyd-Warshall هو O (V3)، وتعقيد المساحة هو: O (V2). ترجمة -بتصرّف- للفصول 19 و20 و22 من كتاب Algorithms Notes for Professionals. اقرأ أيضًا المقال السابق: تطبيقات الخوارزميات الشرهة المرجع الشامل إلى تعلم الخوارزميات للمبتدئين دليل شامل عن تحليل تعقيد الخوارزمية مدخل إلى الخوارزميات خوارزمية تحديد المسار النجمية A* Pathfinding خوارزمية ديكسترا Dijkstra’s Algorithm -
.png.603fdf87571e0cdfaa8f60e5abf75744.png) الرسم التخطيطي أو المخطط هو مجموعة من النقاط والخطوط التي ترتبط ببعضها (يمكن أن تكون فارغة)، وتسمى نقاط المخطط رؤوسًا vertices أو عقدًا nodes، بينما تسمى الخطوط التي تربط رؤوس المخطط أضلاعًا edges أو أقواسًا أو خطوطًا. يعرَّف مخطط G مثلًا كزوْج (V، E)، حيث تمثّل V مجموعة من الحروف، وتمثّل E مجموعة الأضلاع التي تربط تلك الحروف، انظر: E ⊆ {(u,v) | u, v ∈ V} تخزين المخططات هناك طريقتان شائعتان لتخزين المخططات، وهما: مصفوفة التجاور Adjacency Matrix. قائمة التجاور. مصفوفة التجاور مصفوفة التجاور هي مصفوفة تُستخدم لتمثيل مخطط محدود finite graph، وتشير عناصر المصفوفة إلى ما إذا كانت أزواج الرؤوس متجاورة (مترابطة) في المخطط أم لا. وفي نظرية المخططات، نقول أنّ العقدة B مجاورة للعقدة A إذا كنا نستطيع الذهاب من العقدة A إلى العقدة B، وسنتعلم الآن كيفية تخزين العُقد المتجاورة عبر مصفوفة التجاور Adjacency Matrix ثنائية الأبعاد، هذا يعني أننا سنمثل العقد التي تتشارك الأضلاع فيما بينها. نرى في الشكل الموضح أعلاه جدولًا إلى جانب المخطط، ويمثّل هذا الجدول مصفوفة التجاور الخاصة بالمخطط المجاور له، وتمثل Matrix[i][j] = 1 هنا وجود ضلع بين i و j. بالمقابل، سنكتب Matrix[i][j] = 0 إذا لم يكن هناك أيّ ضلع يربطهما. نستطيع وزن تلك الأضلاع، أي إلحاق رقم بكل ضلع -قد يمثل هذا الرقم المسافة بين مدينتين مثلًا-، وهنا نضع الوزن في الموضع Matrix[i][j] بدلًا من 1. والمخطط الموضح أعلاه ثنائي الاتجاه Bidirectional، أو غير موجّه Undirected، أي أنّه إذا كان بإمكاننا الانتقال من العقدة 2 إلى العقدة 1 فيمكننا أيضًا الانتقال من العقدة 1 إلى العقدة 2. إن لم تتحقّق هذه الخاصية نقول أنّ المخطط موجّه Directed. وتوضع أسهم بدل الخطوط إذا كان المخطط موجَّهًا، كما يمكن استخدام مصفوفات التجاور لتمثيل هذا النوع من المخططات. لكن على خلاف المخططات غير الموجّهة، فإن العقد التي لا تشترك في أيّ ضلع تُمثَّل باللانهاية inf في المخططات الموجّهة كما يبيّن الرسم أعلاه. هناك أمر آخر ينبغي الانتباه له، وهو أنّ مصفوفة التجاور الخاصة بمخطط غير موجّه تكون دائما غير متماثلة. انظر الشيفرة التوضيحية pseudo-code التالية لإنشاء مصفوفة التجاور، حيث يمثل N عدد العُقد: Procedure AdjacencyMatrix(N): Matrix[N][N] for i from 1 to N for j from 1 to N Take input -> Matrix[i][j] endfor endfor فيما يلي طريقة أخرى لتعبئة المصفوفة، يمثل N فيها عدد العُقَد بينما يمثل E عدد الأضلاع: Procedure AdjacencyMatrix(N, E): Matrix[N][E] for i from 1 to E input -> n1, n2, cost Matrix[n1][n2] = cost Matrix[n2][n1] = cost endfor يمكنك إزالة السطر Matrix[n2][n1] = cost من الشيفرة في المخططات الموجّهة. عيوب استخدام مصفوفة التجاور إحدى المشاكل التي تنجم عن استخدام مصفوفات التجاور هو أنّها تستهلك مقدارا كبيرًا من الذاكرة، فمهما كان عدد أضلاع المخطط، سنحتاج دائمًا إلى مصفوفة بحجم N*N، حيث يمثّل N عدد العُقد. أما إذا كانت هناك 10000 عقدة في المخطط فسنحتاج مصفوفة بحجم 4 * 10000 * 10000، أي حوالي 381 ميغابايت، وهذا مضيعة للذاكرة، علمًا أنّ الكثير من المخططات لا تحتوي إلا القليل من الأضلاع. وبفرض أنّنا نريد أن نعرف العقد التي يمكننا الوصول إليها انطلاقًا من العقدة u، فسنحتاج إلى التحقق من الصفّ الخاص بـ u في المصفوفة بالكامل، وهذا سيكلفنا الكثير من الوقت. والفائدة الوحيدة لمصفوفة التجاور هي أنها تمكّننا من العثور بسهولة على مسار بين عقدتين مثل u-v، وكذلك تكلفة cost ذلك المسار، أي مجموع أوزان الأضلاع التي تؤلف المسار. شيفرة جافا التالية تطبق الشيفرة العامّة أعلاه: import java.util.Scanner; public class Represent_Graph_Adjacency_Matrix { private final int vertices; private int[][] adjacency_matrix; public Represent_Graph_Adjacency_Matrix(int v) { vertices = v; adjacency_matrix = new int[vertices + 1][vertices + 1]; } public void makeEdge(int to, int from, int edge) { try { adjacency_matrix[to][from] = edge; } catch (ArrayIndexOutOfBoundsException index) { System.out.println("The vertices does not exists"); } } public int getEdge(int to, int from) { try { return adjacency_matrix[to][from]; } catch (ArrayIndexOutOfBoundsException index) { System.out.println("The vertices does not exists"); } return -1; } public static void main(String args[]) { int v, e, count = 1, to = 0, from = 0; Scanner sc = new Scanner(System.in); Represent_Graph_Adjacency_Matrix graph; try { System.out.println("Enter the number of vertices: "); v = sc.nextInt(); System.out.println("Enter the number of edges: "); e = sc.nextInt(); graph = new Represent_Graph_Adjacency_Matrix(v); System.out.println("Enter the edges: <to> <from>"); while (count <= e) { to = sc.nextInt(); from = sc.nextInt(); graph.makeEdge(to, from, 1); count++; } System.out.println("The adjacency matrix for the given graph is: "); System.out.print(" "); for (int i = 1; i <= v; i++) System.out.print(i + " "); System.out.println(); for (int i = 1; i <= v; i++) { System.out.print(i + " "); for (int j = 1; j <= v; j++) System.out.print(graph.getEdge(i, j) + " "); System.out.println(); } } catch (Exception E) { System.out.println("Something went wrong"); } sc.close(); } } لتشغيل الشيفرة أعلاه، احفظ الملف، ثم صرّف compile الشيفرة باستخدام التعليمة الآتية: javac Represent_Graph_Adjacency_Matrix.java انظر المثال التالي الذي يوضح هذا: $ java Represent_Graph_Adjacency_Matrix Enter the number of vertices: 4 Enter the number of edges: 6 Enter the edges: 1 1 3 4 2 3 1 4 2 4 1 2 The adjacency matrix for the given graph is: 1 2 3 4 1 1 1 0 1 2 0 0 1 1 3 0 0 0 1 4 0 0 0 0 تخزين المخططات (قوائم التجاور) قائمة التجاور هي مجموعة من القوائم غير المرتبة تُستخدم لتمثيل المخططات المحدودة finite graphs، وتصف كل قائمة في المجموعة جيرانَ كلّ حرف من حروف المخطط. وميزة قوائم التجاور أنّها تحتاج مساحة ذاكرة أقل لتخزين المخططات. انظر المثال التالي عن مخططٍ ومصفوفة التجاور الخاصة به: وهذه قائمة التجاور الخاصة بالمخطط أعلاه: تسمى هذه القائمة قائمةَ التجاور adjacency list، وتوضّح الروابط بين العقد. نستطيع إن شئنا تخزين هذه المعلومات باستخدام مصفوفة ثنائية الأبعاد، لكن هذا سيكلفنا نفس مقدار الذاكرة الذي يتطلّبه تخزين مصفوفة التجاور. بدلاً من ذلك، سنستخدم الذاكرة المخصّصة ديناميكيًا لتخزين هذه القيم. تدعم العديد من لغات البرمجة نوعي البيانات المتجهات Vector والقوائم List ، والتي يمكننا استخدامها لتخزين قائمة التجاور، وهكذا لن يكون علينا تحديد حجم القائمة إذ يكفي أن نحدّد الحد الأقصى لعدد العقد. انظر الشيفرة العامة لذلك، حيث يمثل maxN الحد الأقصى للعُقد، بينما يمثل E عدد الأضلاع، ويشير التعبير x, y إلى وجود ضلع يربط بين x وy: Procedure Adjacency-List(maxN, E): edge[maxN] = Vector() for i from 1 to E input -> x, y edge[x].push(y) edge[y].push(x) end for Return edge وبما أنّ هذا المخطط غير موجّه فإنّ وجود ضلع من x إلى y يستلزم وجود ضلع معاكس، أي ضلعٍ من y إلى x، ولن تتحقق هذه الخاصية في المخططات غير الموجّهة. أما بالنسبة للمخططات الموزونة فسنحتاج إلى تخزين التكلفة (الوزن) أيضًا، من خلال إنشاء متجه أو قائمة أخرى باسم cost[] لتخزينها، انظر الشيفرة العامة لذلك: Procedure Adjacency-List(maxN, E): edge[maxN] = Vector() cost[maxN] = Vector() for i from 1 to E input -> x, y, w edge[x].push(y) cost[x].push(w) end for Return edge, cost يمكننا الآن أن نعثر بسهولة على العقد المتصلة بعقدة ما وعددها أيضًا، وسنحتاج وقتًا أقل مقارنة بمصفوفة التجاور. بالمقابل، ستكون مصفوفة التجاور أكثر كفاءة إن احتجنا إلى معرفة ما إذا كان هناك ضلع بين u وv. مقدمة إلى نظرية الرسوم التخطيطية نظرية المخططات أو الرسوم التخطيطية Graph Theory هي فرع من فروع الرياضيات يهتم بدراسة الرسوم التخطيطية، وهي كائنات رياضية تُستخدم لنمذجة العلاقات الزوجية بين الكائنات. طُوِّرت نظرية المخططات من قبل اختراع الحاسوب، إذ كتب ليونهارت أويلر Leonhard Euler ورقة حول جسور كونيجسبرج السبعة Seven Bridges of Königsberg والتي تُعدّ أوّل ورقة علمية عن نظرية المخططات، وأدرك الناس منذ ذلك الحين أنه إذا أمكننا تحويل المشاكل إلى مسائل من نوع مدينة-طريق City-Road، فيمكننا حلها بسهولة باستخدام نظرية المخططات. وهناك تطبيقات عديدة لهذه النظرية، لعل أشهرها هو العثور على أقصر مسافة بين مدينتين. فمثلا، ينبغي أن تمرّ عبر العديد من المُوجّهات routers عندما تدخل موقعًا إلكترونيا، انطلاقًا من الخادم، لكي تصل محتويات الموقع إلى حاسوبك. تساهم نظرية المخططات هنا في العثور على الموجّهات التي ينبغي المرور عبرها للوصول إلى حاسوبك في أسرع وقت. كما تُستخدم خلال الحروب لتحديد الطريق الذي يجب قصفه لقطع العاصمة عن المدن الأخرى. وسنتعلم فيما يلي بعض الأساسيات لهذه النظرية. إليك تعاريف من المهم الاطلاع عليها ومعرفتها: المخططات: لنقل أنّ لدينا 6 مدن، نرقّم هذه المدن من 1 إلى 6. سننشئ الآن مخططًا يمثّل هذه المدن، حيث تمثل الرؤوسُ المدن، مع ربط المدن التي تربطها طرق فيما بينها بأضلاع. هذا مخطط بسيط لتمثيل المدن والطرق الرابطة بينها، ونسمي هذه المدن في نظرية المخططات عقدًا Nodes أو حروفًا Vertex فيما نسمّي الطرق أضلاعًا Edge. يمكن أن تمثل العقدة أشياءً كثيرة، إذ قد تمثّل مدنًا أو مطارات أو مربّعات على رقعة الشطرنج. بالمقابل، تمثل الأضلاع العلاقات بين تلك العقد. مثلًا، يمكن أن تمثّل هذه العلاقات الوقت اللازم للانتقال من مطار إلى آخر، أو نقلة الفارس من مربّع إلى المربعات الأخرى على رقعة الشطرنج، وغير ذلك. تمثيل لمسار الفارس على رقعة الشطرنج وببساطة، تمثّل العقدة أيّ نوع من الكائنات، وتمثّل الأضلاع العلاقات بين تلك الكائنات. العقدة المتجاورة Adjacent Node: تكون B مجاورة لـ A إذا اشتركت عقدة A مع عقدة أخرى B في ضلع واحد، أي نقول أنّ العقدتين متجاورتان إذا اتصلت عقدتان اتصالًا مباشرًا، ويمكن لكل عقدة أن يكون لها عدة عقد مجاورة. المخططات الموجّهة وغير الموجّهة Directed and Undirected Graph: توضع علامات توجيهية (مثل الأسهم) على الأضلاع في المخططات الموجّهة للدلالة على أنّ الضلع أحادي الاتجاه. من ناحية أخرى، تحتوي أضلاع المخططات غير الموجّهة على علامات اتجاه على كلا الجانبين، للدلالة على أنها ثنائية الاتجاه. لكن تُحذف علامات التوجيه تلك في الغالب من المخططات غير الموجّهة، وتمثّل حينها الأضلاع كخطوط وحسب. وإذا افترضنا وجود حفلٍ في مكان ما، فسنمثّل الأشخاص الحاضرين بالعُقد، وسنرسم خطًا بين شخصين إذا تصافحا. لا شك أن هذه المخططات غير موجّهة هنا، لأنّه إذا صافح عمرو زيدًا فهذا يعني أنّ زيدًا صافح عَمرًا كذلك، فهي عملية ثنائية. بالمقابل، إذا رسمنا ضلعًا من عمرو إلى زيد إن كان زيد يقدّر عَمرًا ويحترمه فإنّ هذه المخططات ستكون موجّهة، ذلك أن الإعجاب لا يشترط أن يكون متبادلًا. يُطلق على النوع الأول مخططات غير موجّهة undirected graphs، وتسمّى الأضلاع أضلاعًا غير موجّهة undirected edges، بالمقابل، يسمّى النوع الثاني مخططات موجّهة directed graph وتسمّى الأضلاع أضلاعًا موجّهة directed edges. المخططات الموزونة وغير الموزونة Weighted and Unweighted Graph: المخطط الموزون هو مخطط يكون لكلّ ضلع من أضلاعه رقم (وزن)، يمكن أن تمثّل هذه الأوزان التكاليف أو الأطوال أو السعات وغير ذلك، وذلك اعتمادًا على المشكلة المطروحة. بالمقابل، المخططات غير الموزونة هي مخططات نفترض أنّ أوزان جميع أضلاعها متساوية (تساوي1 افتراضيًا ). المسارات: يمثّل المسار طريقًا للانتقال من عقدة إلى أخرى ويتألّف من سلسلة من الأضلاع، ولا شيء يمنع وجود عدة مسارات بين عقدتين. في المثال أعلاه، هناك مساران من A إلى D، الأول هو A-> B ،B-> C ،C-> D ، وكلفته (مجموع أوزان الأضلاع التي تؤلّفه) هي 3 + 4 + 2 = 9، أما المسار الآخر فهو A-> D، وكلفته 10. يقال أن المسار الذي يكلّف أدنى قدر هو المسار الأقصر. الدرجة degree: درجة الحرف degree of a vertex هي عدد الأضلاع المرتبطة به، فإذا كان هناك ضلع يرتبط بالحرف في كلا الطرفين (حلقة loop)، فسيُحسب مرتين. يكون للعُقد في المخططات الموجّهة نوعان مختلفان من الدرجات: الدرجة الداخلية In-degree: عدد الأضلاع التي تشير إلى العقدة. الدرجة الخارجية Out-degree: عدد الأضلاع التي تنطلق من العقدة الحالية وتشير إلى العقد الأخرى. بالنسبة للمخططات غير الموجّهة، يكون هناك نوع واحد طبعا، ويُسمّى درجة الحرف. بعض الخوارزميات المتعلقة بنظرية المخططات: خوارزمية بلمان فورد Bellman–Ford خوارزمية ديكسترا Dijkstra خوارزمية فورد فولكرسون Ford–Fulkerson خوارزمية كروسكال Kruskal. خوارزمية الجار الأقرب Nearest neighbour algorithm. خوارزمية بْرِم Prim. خوارزمية البحث العميق أولا Depth-first search. خوارزمية البحث العريض أولًا Breadth-first search. سوف نستعرضُ بعض هذه الخوارزميات لاحقًا. الترتيب الطوبولوجي Topological Sort يرتّب الترتيب الطوبولوجي حروف مخطط موجّه ترتيبًا خطيًا، إذ يضعها في قائمة مُرتّبة حسب الأضلاع الموجّهة التي تربط تلك الحروف. وليكون هذا الترتيب ممكنا، يجب ألّا يحتوي المخطط على دورة موجّهة directed cycle، فإن كان لدينا مخطط G = (V, E)، فالترتيب الخطي رياضيًا هو ترتيب متوافق مع المخطط، أي يحقّق ما يلي: إن كانت G تحتوي الضلع (u, v) ∈ E الذي ينتمي إلى E وينطلق من الحرف u إلى v، فستكون u أصغر من v وفق هذا الترتيب. وهنا من المهم ملاحظة أنّ كلّ مخطط موجّه غير دوري directed acyclic graph، أو DAG اختصارًا له ترتيب طوبولوجي واحد على الأقل، وهناك عدد من الخوارزميات التي تمكّننا من إنشاء ترتيب طوبولوجي لمخطط موجّه غير دوري في وقتٍ خطي، هذا مثال عام على إحداها: استدع دالة depth_first_search(G) لحساب أوقات الإنتهاء finishing times بـ v.f لكل حرف v عقب الانتهاء من حرف ما، أدرِجه في مقدّمة قائمة مرتبطة linked list. يُحدَّد الترتيب الطوبولوجي بقائمة الحروف المرتبطة التي نتجت من الخطوتين السابقتين. يمكن إجراء ترتيب طوبولوجي في مدة V + E، لأنّ "خوارزمية البحث العميق أولًا depth-first search" تستغرق مدّة (V + E) ـ كما ستستغرق Ω(1) (وقت ثابت) لإدراج كل الحروف |V| في مقدمة القائمة المرتبطة. تستخدم العديدُ من التطبيقات المخططاتَ الموجّهة الدورية directed acyclic graphs لتمثيل الأسبقية بين الأحداث، إذ يُستخدم الترتيب الطوبولوجي للحصول على الترتيب الصحيح لمعالجة كل حرف من حروف المخطط. وقد تمثّل حروف المخططُ المهامَ التي يتعيّن إنجازها، فيما تمثل الأضلاع أسبقية تنفيذ تلك المهام، وهكذا يمثّل الترتيب الطوبولوجي التسلسل المناسب لأداء مجموعة المهام الموضّحة في V. مثال ليكن v حرفًا يمثّل مهمّة Task(hours_to_complete: int)، بحيث يمثّل الوسيط hours_to_complete الوقت المُستغرَق لتنفيذ المهمة. فمثلًا، تمثّل Task(4) مهمّة تستغرق 4 ساعات لإكمالها. من جهة أخرى، يمثّل ضلع e قيمة Cooldown(hours: int)، والتي تمثّل المدة الزمنية التي تنقضي قبل استئناف المهمة التالية (أي التي يشير إليها الضلع) بعد الانتهاء من المهمة الحالية (التي ينطلق منها الضلع). فإن كان هناك ضلع Cooldown(3) يربط بين مهمّتين أ و ب، فذلك يعني أنه بعد الانتهاء من المهمة أ، ستحتاج أن تنتظر 3 ساعات حتى تستطيع تنفيذ المهمة ب (مثلا ليبرد المحرّك). فيما يلي، المخطط غير الدوري والموجّه dag يحتوي 5 رؤوس: A <- dag.add_vertex(Task(4)); B <- dag.add_vertex(Task(5)); C <- dag.add_vertex(Task(3)); D <- dag.add_vertex(Task(2)); E <- dag.add_vertex(Task(7)); نربط الحروف عبر أضلاع موجّهة بحيث يكون المخططات غير دوري، انظر: // A ---> C -----+ // | | | // v v v // B ---> D ---> E dag.add_edge(A, B, Cooldown(2)); dag.add_edge(A, C, Cooldown(2)); dag.add_edge(B, D, Cooldown(1)); dag.add_edge(C, D, Cooldown(1)); dag.add_edge(C, E, Cooldown(1)); dag.add_edge(D, E, Cooldown(3)); ستكون هناك ثلاثة تراتيب طوبولوجية ممكنة بين A وE: A -> B -> D -> E A -> C -> D -> E A -> C -> E رصد الدورات في المخططات الموجهة باستخدام الاجتياز العميق أولا Depth First Traversal إذا نتج عن الاجتياز العميق أولًا ضلعٌ خلفي back edge، فذلك يعني أنّ المخطط الموجّه يحتوي دورة cycle. والضلع الخلفي هو ضلع ينطلق من عقدة ويعود إليها أو إلى إحدى أسلافها في شجرة بحث عميق أولًا Depth-first search اختصارًا DFS. بالنسبة لمخطط غير متصل disconnected graph، سنحصل على غابة بحث عميق أولا أو غابة DFS وهي اختصار لـ DFS forest، لذلك سيكون عليك التكرار على جميع الحروف في المخطط لإيجاد أشجار البحث العميق أولًا والمنفصلة disjoint DFS trees. فيما يلي تنفيذ بلغة C++: #include <iostream> #include <list> using namespace std; #define NUM_V 4 bool helper(list<int> *graph, int u, bool* visited, bool* recStack) { visited[u]=true; recStack[u]=true; list<int>::iterator i; for(i = graph[u].begin();i!=graph[u].end();++i) { if(recStack[*i]) شرح السطر السابق في الشيفرة: عند إيجاد حرف v في مكدس التكرارية الخاص باجتياز DFS، أعِد true، تابع المثال الآتي: return true; else if(*i==u) // في حال كان هناك ضلع من الحرف إلى نفسه return true; else if(!visited[*i]) { if(helper(graph, *i, visited, recStack)) return true; } } recStack[u]=false; return false; } هنا تستدعي دالة التغليف الدالةَ helper على كل حرف لم يُزَر بعد، وتعيد دالة helper القيمة true عند رصد ضلع خلفي في الشجيرة، وإلا فإنها تعيد false، تابع المثال الآتي: bool isCyclic(list<int> *graph, int V) { bool visited[V]; // مصفوفة لتتبع الأحرف المُزارة سلفا bool recStack[V]; // مصفوفة لتتبع الأحرف في المكدس التكراري للاجتياز for(int i = 0;i<V;i++) visited[i]=false, recStack[i]=false; // تهيئة جميع الأحرف على أنها غير مُزارة تكراريًا for(int u = 0; u < V; u++) // التحقق اليدوي مما إذا كانت كل الأحرف مُزارة { if(visited[u]==false) { if(helper(graph, u, visited, recStack)) // التحقق مما إذا كانت شجرةُ “بحثٍ عميقٍ أولًا” تحتوي دورة. return true; } } return false; } /* Driver function */ int main() { list<int>* graph = new list<int>[NUM_V]; graph[0].push_back(1); graph[0].push_back(2); graph[1].push_back(2); graph[2].push_back(0); graph[2].push_back(3); graph[3].push_back(3); bool res = isCyclic(graph, NUM_V); cout<<res<<endl; } تكون النتيجة كما هو موضّح أدناه، أن هناك ثلاثة أضلاع خلفية في المخططات، واحد بين الحرفين 0 و 2؛ وآخر بين الحروف 0 و1 و2؛ والحرف 3. والتعقيد الزمني للبحث يساوي O (V + E)، حيث يمثّل V عدد الحروف، وE يمثّل عدد الأضلاع. خوارزمية Thorup كيف يمكن العثور على أقصر مسار من حرف (مصدر) معيّن إلى أيّ حرف آخر في مخطط غير موجّهة؟ قدّم "ميكيل توغوب Mikkel Thorup" -نُطْقُ اسمه من الدانماركية- أول خوارزمية تحل هذه المشكلة. يساوي التعقيد الزمني لهذه الخوارزمية O (m). وفيما يلي الأفكارُ الأساسية التي تعتمد عليها الخوارزمية: هناك عدّة طرق للعثور على الشجرة المتفرّعة spanning tree في مدة O (m) (لن نذكر هذه الطرق هنا)، سيكون عليك إنشاء الشجرة المتفرّعة من الضلع الأقصر إلى الأطول، وسينتج عن ذلك غابة (مجموعة من الأشجار غير المتصلة بالضرورة) تحتوي العديد من المكوّنات المتصلة قبل أن تنمو كاملةً. اختر عددًا صحيحًا b (b> = 2)، ولا تأخذ بالحسبان إلّا الغابات المتفرّعة ذات الطول الأقصى b ^ k، ثم ادمج المكونات المتشابهة في كل شيء ولكن تختلف في قيمة k. سنسمّى أصغر قيم k مستوى المكوّن level of the component. ثم ضع المكوّنات بعد هذا في الشجرة في المكان المناسب بحيث يكون الحرف u أبًا للحرف v إذ كان u هي أصغر مكوّن مختلف عن v ويحتوي v بشكل كامل. الجذر سيكون المخطط بأكمله، أمّا الأوراق فهي الحروف المفردة single vertices في المخطط الأصلي (مستواها يساوي سالب ما لا نهاية). ستحتوي الشجرة على O (n) عقدة. حافظ على المسافة بين كل مكوّن وبين المصدر كما هو الحال في خوارزمية Dijkstra، تساوي مسافة مكوّن يحتوي أكثر من حرفٍ المسافةَ الأقل بين أبنائها غير الموسَّعين unexpanded children. اجعل مسافة الحرف الأصلي source vertex على 0، ثمّ حدّث الأسلاف وفقًا لذلك. احسب المسافات بنظام العدّ من الأساس b أو base b، وعند زيارة عقدة في المستوى k للمرة الأولى، ضع أبناءها في مجموعات أو سلَّات buckets مشتركة بين جميع العقد من المستوى k. وخذ بالحسبان أوّل b سلّة وحسب في كل مرة تزور فيها عقدة، وَزُر كلّ واحدة منها ثمّ أزلها، ثمّ حدّث مسافة العقدة الحالية، وَأعِد ربط العقدة الحالية بأصلها باستخدام المسافة الجديدة وانتظر الزيارة القادمة للسلات التالية. عند زيارة ورقة leaf، تكون المسافة الحالية هي المسافة النهائية للحرف. وسِّع جميع الأضلاع المنطلقة منه في المخطط الأصلي، ثمّ حدّث المسافات وفقًا لذلك. زر العقدة الجذرية (المخطط كاملًا) بشكل متكرر إلى أن تصل إلى الوجهة المقصودة. تعتمد هذه الخوارزمية على حقيقة أنّه لا يمكن أن يوجد ضلع ذا طول أقل من l بين مكوّنيْن متصليْن في غابة متفرّعة ذات حدّ طولي يساوي length limitation، لذلك، يمكنك حصر تركيزك على مكوّن واحد متصل بدءًا من مسافة x إلى أن تصل إلى المسافة x + l. ستزور بعض الحروف في الطريق قبل زيارة جميع الحروف ذات المسافة الأقصر، لكن ذلك لا يهم بما أنّنا نعلم أنّه لن يكون هناك مسار أقصر إلى هنا من تلك الحروف. اجتياز المخططات Graph Traversals هناك العديد من الخوارزميات للبحث في المخططات، سنستعرض إحداها فيما يلي، وهي خوارزمية البحث العميق أولا. تنفذ الشيفرة التالية هذه الخوارزمية، إذ تنشئ دالة تأخذ فهرس العقدة الحالي كوسيط، وقائمة التجاور (مخزّنة في متجهة من المتجهات)، ومتجهة منطقية vector of boolean لتعقّب العقدة التي تمت زيارتها، انظر: void dfs(int node, vector<vector<int>>* graph, vector<bool>* visited) { // التحقّق مما إذا كانت العقدة مُزارة سلفا if((*visited)[node]) return; // set as visited to avoid visiting the same node twice (*visited)[node] = true; // نفّذ بعض الإجراءات هنا cout << node; // اجتياز العقد المتجاورة عبر البحث العميق أولا for(int i = 0; i < (*graph)[node].size(); ++i) dfs((*graph)[node][i], graph, visited); } ترجمة -بتصرّف- للفصلين 9 و10 من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: الأشجار Trees في الخوازرميات مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية النسخة الكاملة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة
الرسم التخطيطي أو المخطط هو مجموعة من النقاط والخطوط التي ترتبط ببعضها (يمكن أن تكون فارغة)، وتسمى نقاط المخطط رؤوسًا vertices أو عقدًا nodes، بينما تسمى الخطوط التي تربط رؤوس المخطط أضلاعًا edges أو أقواسًا أو خطوطًا. يعرَّف مخطط G مثلًا كزوْج (V، E)، حيث تمثّل V مجموعة من الحروف، وتمثّل E مجموعة الأضلاع التي تربط تلك الحروف، انظر: E ⊆ {(u,v) | u, v ∈ V} تخزين المخططات هناك طريقتان شائعتان لتخزين المخططات، وهما: مصفوفة التجاور Adjacency Matrix. قائمة التجاور. مصفوفة التجاور مصفوفة التجاور هي مصفوفة تُستخدم لتمثيل مخطط محدود finite graph، وتشير عناصر المصفوفة إلى ما إذا كانت أزواج الرؤوس متجاورة (مترابطة) في المخطط أم لا. وفي نظرية المخططات، نقول أنّ العقدة B مجاورة للعقدة A إذا كنا نستطيع الذهاب من العقدة A إلى العقدة B، وسنتعلم الآن كيفية تخزين العُقد المتجاورة عبر مصفوفة التجاور Adjacency Matrix ثنائية الأبعاد، هذا يعني أننا سنمثل العقد التي تتشارك الأضلاع فيما بينها. نرى في الشكل الموضح أعلاه جدولًا إلى جانب المخطط، ويمثّل هذا الجدول مصفوفة التجاور الخاصة بالمخطط المجاور له، وتمثل Matrix[i][j] = 1 هنا وجود ضلع بين i و j. بالمقابل، سنكتب Matrix[i][j] = 0 إذا لم يكن هناك أيّ ضلع يربطهما. نستطيع وزن تلك الأضلاع، أي إلحاق رقم بكل ضلع -قد يمثل هذا الرقم المسافة بين مدينتين مثلًا-، وهنا نضع الوزن في الموضع Matrix[i][j] بدلًا من 1. والمخطط الموضح أعلاه ثنائي الاتجاه Bidirectional، أو غير موجّه Undirected، أي أنّه إذا كان بإمكاننا الانتقال من العقدة 2 إلى العقدة 1 فيمكننا أيضًا الانتقال من العقدة 1 إلى العقدة 2. إن لم تتحقّق هذه الخاصية نقول أنّ المخطط موجّه Directed. وتوضع أسهم بدل الخطوط إذا كان المخطط موجَّهًا، كما يمكن استخدام مصفوفات التجاور لتمثيل هذا النوع من المخططات. لكن على خلاف المخططات غير الموجّهة، فإن العقد التي لا تشترك في أيّ ضلع تُمثَّل باللانهاية inf في المخططات الموجّهة كما يبيّن الرسم أعلاه. هناك أمر آخر ينبغي الانتباه له، وهو أنّ مصفوفة التجاور الخاصة بمخطط غير موجّه تكون دائما غير متماثلة. انظر الشيفرة التوضيحية pseudo-code التالية لإنشاء مصفوفة التجاور، حيث يمثل N عدد العُقد: Procedure AdjacencyMatrix(N): Matrix[N][N] for i from 1 to N for j from 1 to N Take input -> Matrix[i][j] endfor endfor فيما يلي طريقة أخرى لتعبئة المصفوفة، يمثل N فيها عدد العُقَد بينما يمثل E عدد الأضلاع: Procedure AdjacencyMatrix(N, E): Matrix[N][E] for i from 1 to E input -> n1, n2, cost Matrix[n1][n2] = cost Matrix[n2][n1] = cost endfor يمكنك إزالة السطر Matrix[n2][n1] = cost من الشيفرة في المخططات الموجّهة. عيوب استخدام مصفوفة التجاور إحدى المشاكل التي تنجم عن استخدام مصفوفات التجاور هو أنّها تستهلك مقدارا كبيرًا من الذاكرة، فمهما كان عدد أضلاع المخطط، سنحتاج دائمًا إلى مصفوفة بحجم N*N، حيث يمثّل N عدد العُقد. أما إذا كانت هناك 10000 عقدة في المخطط فسنحتاج مصفوفة بحجم 4 * 10000 * 10000، أي حوالي 381 ميغابايت، وهذا مضيعة للذاكرة، علمًا أنّ الكثير من المخططات لا تحتوي إلا القليل من الأضلاع. وبفرض أنّنا نريد أن نعرف العقد التي يمكننا الوصول إليها انطلاقًا من العقدة u، فسنحتاج إلى التحقق من الصفّ الخاص بـ u في المصفوفة بالكامل، وهذا سيكلفنا الكثير من الوقت. والفائدة الوحيدة لمصفوفة التجاور هي أنها تمكّننا من العثور بسهولة على مسار بين عقدتين مثل u-v، وكذلك تكلفة cost ذلك المسار، أي مجموع أوزان الأضلاع التي تؤلف المسار. شيفرة جافا التالية تطبق الشيفرة العامّة أعلاه: import java.util.Scanner; public class Represent_Graph_Adjacency_Matrix { private final int vertices; private int[][] adjacency_matrix; public Represent_Graph_Adjacency_Matrix(int v) { vertices = v; adjacency_matrix = new int[vertices + 1][vertices + 1]; } public void makeEdge(int to, int from, int edge) { try { adjacency_matrix[to][from] = edge; } catch (ArrayIndexOutOfBoundsException index) { System.out.println("The vertices does not exists"); } } public int getEdge(int to, int from) { try { return adjacency_matrix[to][from]; } catch (ArrayIndexOutOfBoundsException index) { System.out.println("The vertices does not exists"); } return -1; } public static void main(String args[]) { int v, e, count = 1, to = 0, from = 0; Scanner sc = new Scanner(System.in); Represent_Graph_Adjacency_Matrix graph; try { System.out.println("Enter the number of vertices: "); v = sc.nextInt(); System.out.println("Enter the number of edges: "); e = sc.nextInt(); graph = new Represent_Graph_Adjacency_Matrix(v); System.out.println("Enter the edges: <to> <from>"); while (count <= e) { to = sc.nextInt(); from = sc.nextInt(); graph.makeEdge(to, from, 1); count++; } System.out.println("The adjacency matrix for the given graph is: "); System.out.print(" "); for (int i = 1; i <= v; i++) System.out.print(i + " "); System.out.println(); for (int i = 1; i <= v; i++) { System.out.print(i + " "); for (int j = 1; j <= v; j++) System.out.print(graph.getEdge(i, j) + " "); System.out.println(); } } catch (Exception E) { System.out.println("Something went wrong"); } sc.close(); } } لتشغيل الشيفرة أعلاه، احفظ الملف، ثم صرّف compile الشيفرة باستخدام التعليمة الآتية: javac Represent_Graph_Adjacency_Matrix.java انظر المثال التالي الذي يوضح هذا: $ java Represent_Graph_Adjacency_Matrix Enter the number of vertices: 4 Enter the number of edges: 6 Enter the edges: 1 1 3 4 2 3 1 4 2 4 1 2 The adjacency matrix for the given graph is: 1 2 3 4 1 1 1 0 1 2 0 0 1 1 3 0 0 0 1 4 0 0 0 0 تخزين المخططات (قوائم التجاور) قائمة التجاور هي مجموعة من القوائم غير المرتبة تُستخدم لتمثيل المخططات المحدودة finite graphs، وتصف كل قائمة في المجموعة جيرانَ كلّ حرف من حروف المخطط. وميزة قوائم التجاور أنّها تحتاج مساحة ذاكرة أقل لتخزين المخططات. انظر المثال التالي عن مخططٍ ومصفوفة التجاور الخاصة به: وهذه قائمة التجاور الخاصة بالمخطط أعلاه: تسمى هذه القائمة قائمةَ التجاور adjacency list، وتوضّح الروابط بين العقد. نستطيع إن شئنا تخزين هذه المعلومات باستخدام مصفوفة ثنائية الأبعاد، لكن هذا سيكلفنا نفس مقدار الذاكرة الذي يتطلّبه تخزين مصفوفة التجاور. بدلاً من ذلك، سنستخدم الذاكرة المخصّصة ديناميكيًا لتخزين هذه القيم. تدعم العديد من لغات البرمجة نوعي البيانات المتجهات Vector والقوائم List ، والتي يمكننا استخدامها لتخزين قائمة التجاور، وهكذا لن يكون علينا تحديد حجم القائمة إذ يكفي أن نحدّد الحد الأقصى لعدد العقد. انظر الشيفرة العامة لذلك، حيث يمثل maxN الحد الأقصى للعُقد، بينما يمثل E عدد الأضلاع، ويشير التعبير x, y إلى وجود ضلع يربط بين x وy: Procedure Adjacency-List(maxN, E): edge[maxN] = Vector() for i from 1 to E input -> x, y edge[x].push(y) edge[y].push(x) end for Return edge وبما أنّ هذا المخطط غير موجّه فإنّ وجود ضلع من x إلى y يستلزم وجود ضلع معاكس، أي ضلعٍ من y إلى x، ولن تتحقق هذه الخاصية في المخططات غير الموجّهة. أما بالنسبة للمخططات الموزونة فسنحتاج إلى تخزين التكلفة (الوزن) أيضًا، من خلال إنشاء متجه أو قائمة أخرى باسم cost[] لتخزينها، انظر الشيفرة العامة لذلك: Procedure Adjacency-List(maxN, E): edge[maxN] = Vector() cost[maxN] = Vector() for i from 1 to E input -> x, y, w edge[x].push(y) cost[x].push(w) end for Return edge, cost يمكننا الآن أن نعثر بسهولة على العقد المتصلة بعقدة ما وعددها أيضًا، وسنحتاج وقتًا أقل مقارنة بمصفوفة التجاور. بالمقابل، ستكون مصفوفة التجاور أكثر كفاءة إن احتجنا إلى معرفة ما إذا كان هناك ضلع بين u وv. مقدمة إلى نظرية الرسوم التخطيطية نظرية المخططات أو الرسوم التخطيطية Graph Theory هي فرع من فروع الرياضيات يهتم بدراسة الرسوم التخطيطية، وهي كائنات رياضية تُستخدم لنمذجة العلاقات الزوجية بين الكائنات. طُوِّرت نظرية المخططات من قبل اختراع الحاسوب، إذ كتب ليونهارت أويلر Leonhard Euler ورقة حول جسور كونيجسبرج السبعة Seven Bridges of Königsberg والتي تُعدّ أوّل ورقة علمية عن نظرية المخططات، وأدرك الناس منذ ذلك الحين أنه إذا أمكننا تحويل المشاكل إلى مسائل من نوع مدينة-طريق City-Road، فيمكننا حلها بسهولة باستخدام نظرية المخططات. وهناك تطبيقات عديدة لهذه النظرية، لعل أشهرها هو العثور على أقصر مسافة بين مدينتين. فمثلا، ينبغي أن تمرّ عبر العديد من المُوجّهات routers عندما تدخل موقعًا إلكترونيا، انطلاقًا من الخادم، لكي تصل محتويات الموقع إلى حاسوبك. تساهم نظرية المخططات هنا في العثور على الموجّهات التي ينبغي المرور عبرها للوصول إلى حاسوبك في أسرع وقت. كما تُستخدم خلال الحروب لتحديد الطريق الذي يجب قصفه لقطع العاصمة عن المدن الأخرى. وسنتعلم فيما يلي بعض الأساسيات لهذه النظرية. إليك تعاريف من المهم الاطلاع عليها ومعرفتها: المخططات: لنقل أنّ لدينا 6 مدن، نرقّم هذه المدن من 1 إلى 6. سننشئ الآن مخططًا يمثّل هذه المدن، حيث تمثل الرؤوسُ المدن، مع ربط المدن التي تربطها طرق فيما بينها بأضلاع. هذا مخطط بسيط لتمثيل المدن والطرق الرابطة بينها، ونسمي هذه المدن في نظرية المخططات عقدًا Nodes أو حروفًا Vertex فيما نسمّي الطرق أضلاعًا Edge. يمكن أن تمثل العقدة أشياءً كثيرة، إذ قد تمثّل مدنًا أو مطارات أو مربّعات على رقعة الشطرنج. بالمقابل، تمثل الأضلاع العلاقات بين تلك العقد. مثلًا، يمكن أن تمثّل هذه العلاقات الوقت اللازم للانتقال من مطار إلى آخر، أو نقلة الفارس من مربّع إلى المربعات الأخرى على رقعة الشطرنج، وغير ذلك. تمثيل لمسار الفارس على رقعة الشطرنج وببساطة، تمثّل العقدة أيّ نوع من الكائنات، وتمثّل الأضلاع العلاقات بين تلك الكائنات. العقدة المتجاورة Adjacent Node: تكون B مجاورة لـ A إذا اشتركت عقدة A مع عقدة أخرى B في ضلع واحد، أي نقول أنّ العقدتين متجاورتان إذا اتصلت عقدتان اتصالًا مباشرًا، ويمكن لكل عقدة أن يكون لها عدة عقد مجاورة. المخططات الموجّهة وغير الموجّهة Directed and Undirected Graph: توضع علامات توجيهية (مثل الأسهم) على الأضلاع في المخططات الموجّهة للدلالة على أنّ الضلع أحادي الاتجاه. من ناحية أخرى، تحتوي أضلاع المخططات غير الموجّهة على علامات اتجاه على كلا الجانبين، للدلالة على أنها ثنائية الاتجاه. لكن تُحذف علامات التوجيه تلك في الغالب من المخططات غير الموجّهة، وتمثّل حينها الأضلاع كخطوط وحسب. وإذا افترضنا وجود حفلٍ في مكان ما، فسنمثّل الأشخاص الحاضرين بالعُقد، وسنرسم خطًا بين شخصين إذا تصافحا. لا شك أن هذه المخططات غير موجّهة هنا، لأنّه إذا صافح عمرو زيدًا فهذا يعني أنّ زيدًا صافح عَمرًا كذلك، فهي عملية ثنائية. بالمقابل، إذا رسمنا ضلعًا من عمرو إلى زيد إن كان زيد يقدّر عَمرًا ويحترمه فإنّ هذه المخططات ستكون موجّهة، ذلك أن الإعجاب لا يشترط أن يكون متبادلًا. يُطلق على النوع الأول مخططات غير موجّهة undirected graphs، وتسمّى الأضلاع أضلاعًا غير موجّهة undirected edges، بالمقابل، يسمّى النوع الثاني مخططات موجّهة directed graph وتسمّى الأضلاع أضلاعًا موجّهة directed edges. المخططات الموزونة وغير الموزونة Weighted and Unweighted Graph: المخطط الموزون هو مخطط يكون لكلّ ضلع من أضلاعه رقم (وزن)، يمكن أن تمثّل هذه الأوزان التكاليف أو الأطوال أو السعات وغير ذلك، وذلك اعتمادًا على المشكلة المطروحة. بالمقابل، المخططات غير الموزونة هي مخططات نفترض أنّ أوزان جميع أضلاعها متساوية (تساوي1 افتراضيًا ). المسارات: يمثّل المسار طريقًا للانتقال من عقدة إلى أخرى ويتألّف من سلسلة من الأضلاع، ولا شيء يمنع وجود عدة مسارات بين عقدتين. في المثال أعلاه، هناك مساران من A إلى D، الأول هو A-> B ،B-> C ،C-> D ، وكلفته (مجموع أوزان الأضلاع التي تؤلّفه) هي 3 + 4 + 2 = 9، أما المسار الآخر فهو A-> D، وكلفته 10. يقال أن المسار الذي يكلّف أدنى قدر هو المسار الأقصر. الدرجة degree: درجة الحرف degree of a vertex هي عدد الأضلاع المرتبطة به، فإذا كان هناك ضلع يرتبط بالحرف في كلا الطرفين (حلقة loop)، فسيُحسب مرتين. يكون للعُقد في المخططات الموجّهة نوعان مختلفان من الدرجات: الدرجة الداخلية In-degree: عدد الأضلاع التي تشير إلى العقدة. الدرجة الخارجية Out-degree: عدد الأضلاع التي تنطلق من العقدة الحالية وتشير إلى العقد الأخرى. بالنسبة للمخططات غير الموجّهة، يكون هناك نوع واحد طبعا، ويُسمّى درجة الحرف. بعض الخوارزميات المتعلقة بنظرية المخططات: خوارزمية بلمان فورد Bellman–Ford خوارزمية ديكسترا Dijkstra خوارزمية فورد فولكرسون Ford–Fulkerson خوارزمية كروسكال Kruskal. خوارزمية الجار الأقرب Nearest neighbour algorithm. خوارزمية بْرِم Prim. خوارزمية البحث العميق أولا Depth-first search. خوارزمية البحث العريض أولًا Breadth-first search. سوف نستعرضُ بعض هذه الخوارزميات لاحقًا. الترتيب الطوبولوجي Topological Sort يرتّب الترتيب الطوبولوجي حروف مخطط موجّه ترتيبًا خطيًا، إذ يضعها في قائمة مُرتّبة حسب الأضلاع الموجّهة التي تربط تلك الحروف. وليكون هذا الترتيب ممكنا، يجب ألّا يحتوي المخطط على دورة موجّهة directed cycle، فإن كان لدينا مخطط G = (V, E)، فالترتيب الخطي رياضيًا هو ترتيب متوافق مع المخطط، أي يحقّق ما يلي: إن كانت G تحتوي الضلع (u, v) ∈ E الذي ينتمي إلى E وينطلق من الحرف u إلى v، فستكون u أصغر من v وفق هذا الترتيب. وهنا من المهم ملاحظة أنّ كلّ مخطط موجّه غير دوري directed acyclic graph، أو DAG اختصارًا له ترتيب طوبولوجي واحد على الأقل، وهناك عدد من الخوارزميات التي تمكّننا من إنشاء ترتيب طوبولوجي لمخطط موجّه غير دوري في وقتٍ خطي، هذا مثال عام على إحداها: استدع دالة depth_first_search(G) لحساب أوقات الإنتهاء finishing times بـ v.f لكل حرف v عقب الانتهاء من حرف ما، أدرِجه في مقدّمة قائمة مرتبطة linked list. يُحدَّد الترتيب الطوبولوجي بقائمة الحروف المرتبطة التي نتجت من الخطوتين السابقتين. يمكن إجراء ترتيب طوبولوجي في مدة V + E، لأنّ "خوارزمية البحث العميق أولًا depth-first search" تستغرق مدّة (V + E) ـ كما ستستغرق Ω(1) (وقت ثابت) لإدراج كل الحروف |V| في مقدمة القائمة المرتبطة. تستخدم العديدُ من التطبيقات المخططاتَ الموجّهة الدورية directed acyclic graphs لتمثيل الأسبقية بين الأحداث، إذ يُستخدم الترتيب الطوبولوجي للحصول على الترتيب الصحيح لمعالجة كل حرف من حروف المخطط. وقد تمثّل حروف المخططُ المهامَ التي يتعيّن إنجازها، فيما تمثل الأضلاع أسبقية تنفيذ تلك المهام، وهكذا يمثّل الترتيب الطوبولوجي التسلسل المناسب لأداء مجموعة المهام الموضّحة في V. مثال ليكن v حرفًا يمثّل مهمّة Task(hours_to_complete: int)، بحيث يمثّل الوسيط hours_to_complete الوقت المُستغرَق لتنفيذ المهمة. فمثلًا، تمثّل Task(4) مهمّة تستغرق 4 ساعات لإكمالها. من جهة أخرى، يمثّل ضلع e قيمة Cooldown(hours: int)، والتي تمثّل المدة الزمنية التي تنقضي قبل استئناف المهمة التالية (أي التي يشير إليها الضلع) بعد الانتهاء من المهمة الحالية (التي ينطلق منها الضلع). فإن كان هناك ضلع Cooldown(3) يربط بين مهمّتين أ و ب، فذلك يعني أنه بعد الانتهاء من المهمة أ، ستحتاج أن تنتظر 3 ساعات حتى تستطيع تنفيذ المهمة ب (مثلا ليبرد المحرّك). فيما يلي، المخطط غير الدوري والموجّه dag يحتوي 5 رؤوس: A <- dag.add_vertex(Task(4)); B <- dag.add_vertex(Task(5)); C <- dag.add_vertex(Task(3)); D <- dag.add_vertex(Task(2)); E <- dag.add_vertex(Task(7)); نربط الحروف عبر أضلاع موجّهة بحيث يكون المخططات غير دوري، انظر: // A ---> C -----+ // | | | // v v v // B ---> D ---> E dag.add_edge(A, B, Cooldown(2)); dag.add_edge(A, C, Cooldown(2)); dag.add_edge(B, D, Cooldown(1)); dag.add_edge(C, D, Cooldown(1)); dag.add_edge(C, E, Cooldown(1)); dag.add_edge(D, E, Cooldown(3)); ستكون هناك ثلاثة تراتيب طوبولوجية ممكنة بين A وE: A -> B -> D -> E A -> C -> D -> E A -> C -> E رصد الدورات في المخططات الموجهة باستخدام الاجتياز العميق أولا Depth First Traversal إذا نتج عن الاجتياز العميق أولًا ضلعٌ خلفي back edge، فذلك يعني أنّ المخطط الموجّه يحتوي دورة cycle. والضلع الخلفي هو ضلع ينطلق من عقدة ويعود إليها أو إلى إحدى أسلافها في شجرة بحث عميق أولًا Depth-first search اختصارًا DFS. بالنسبة لمخطط غير متصل disconnected graph، سنحصل على غابة بحث عميق أولا أو غابة DFS وهي اختصار لـ DFS forest، لذلك سيكون عليك التكرار على جميع الحروف في المخطط لإيجاد أشجار البحث العميق أولًا والمنفصلة disjoint DFS trees. فيما يلي تنفيذ بلغة C++: #include <iostream> #include <list> using namespace std; #define NUM_V 4 bool helper(list<int> *graph, int u, bool* visited, bool* recStack) { visited[u]=true; recStack[u]=true; list<int>::iterator i; for(i = graph[u].begin();i!=graph[u].end();++i) { if(recStack[*i]) شرح السطر السابق في الشيفرة: عند إيجاد حرف v في مكدس التكرارية الخاص باجتياز DFS، أعِد true، تابع المثال الآتي: return true; else if(*i==u) // في حال كان هناك ضلع من الحرف إلى نفسه return true; else if(!visited[*i]) { if(helper(graph, *i, visited, recStack)) return true; } } recStack[u]=false; return false; } هنا تستدعي دالة التغليف الدالةَ helper على كل حرف لم يُزَر بعد، وتعيد دالة helper القيمة true عند رصد ضلع خلفي في الشجيرة، وإلا فإنها تعيد false، تابع المثال الآتي: bool isCyclic(list<int> *graph, int V) { bool visited[V]; // مصفوفة لتتبع الأحرف المُزارة سلفا bool recStack[V]; // مصفوفة لتتبع الأحرف في المكدس التكراري للاجتياز for(int i = 0;i<V;i++) visited[i]=false, recStack[i]=false; // تهيئة جميع الأحرف على أنها غير مُزارة تكراريًا for(int u = 0; u < V; u++) // التحقق اليدوي مما إذا كانت كل الأحرف مُزارة { if(visited[u]==false) { if(helper(graph, u, visited, recStack)) // التحقق مما إذا كانت شجرةُ “بحثٍ عميقٍ أولًا” تحتوي دورة. return true; } } return false; } /* Driver function */ int main() { list<int>* graph = new list<int>[NUM_V]; graph[0].push_back(1); graph[0].push_back(2); graph[1].push_back(2); graph[2].push_back(0); graph[2].push_back(3); graph[3].push_back(3); bool res = isCyclic(graph, NUM_V); cout<<res<<endl; } تكون النتيجة كما هو موضّح أدناه، أن هناك ثلاثة أضلاع خلفية في المخططات، واحد بين الحرفين 0 و 2؛ وآخر بين الحروف 0 و1 و2؛ والحرف 3. والتعقيد الزمني للبحث يساوي O (V + E)، حيث يمثّل V عدد الحروف، وE يمثّل عدد الأضلاع. خوارزمية Thorup كيف يمكن العثور على أقصر مسار من حرف (مصدر) معيّن إلى أيّ حرف آخر في مخطط غير موجّهة؟ قدّم "ميكيل توغوب Mikkel Thorup" -نُطْقُ اسمه من الدانماركية- أول خوارزمية تحل هذه المشكلة. يساوي التعقيد الزمني لهذه الخوارزمية O (m). وفيما يلي الأفكارُ الأساسية التي تعتمد عليها الخوارزمية: هناك عدّة طرق للعثور على الشجرة المتفرّعة spanning tree في مدة O (m) (لن نذكر هذه الطرق هنا)، سيكون عليك إنشاء الشجرة المتفرّعة من الضلع الأقصر إلى الأطول، وسينتج عن ذلك غابة (مجموعة من الأشجار غير المتصلة بالضرورة) تحتوي العديد من المكوّنات المتصلة قبل أن تنمو كاملةً. اختر عددًا صحيحًا b (b> = 2)، ولا تأخذ بالحسبان إلّا الغابات المتفرّعة ذات الطول الأقصى b ^ k، ثم ادمج المكونات المتشابهة في كل شيء ولكن تختلف في قيمة k. سنسمّى أصغر قيم k مستوى المكوّن level of the component. ثم ضع المكوّنات بعد هذا في الشجرة في المكان المناسب بحيث يكون الحرف u أبًا للحرف v إذ كان u هي أصغر مكوّن مختلف عن v ويحتوي v بشكل كامل. الجذر سيكون المخطط بأكمله، أمّا الأوراق فهي الحروف المفردة single vertices في المخطط الأصلي (مستواها يساوي سالب ما لا نهاية). ستحتوي الشجرة على O (n) عقدة. حافظ على المسافة بين كل مكوّن وبين المصدر كما هو الحال في خوارزمية Dijkstra، تساوي مسافة مكوّن يحتوي أكثر من حرفٍ المسافةَ الأقل بين أبنائها غير الموسَّعين unexpanded children. اجعل مسافة الحرف الأصلي source vertex على 0، ثمّ حدّث الأسلاف وفقًا لذلك. احسب المسافات بنظام العدّ من الأساس b أو base b، وعند زيارة عقدة في المستوى k للمرة الأولى، ضع أبناءها في مجموعات أو سلَّات buckets مشتركة بين جميع العقد من المستوى k. وخذ بالحسبان أوّل b سلّة وحسب في كل مرة تزور فيها عقدة، وَزُر كلّ واحدة منها ثمّ أزلها، ثمّ حدّث مسافة العقدة الحالية، وَأعِد ربط العقدة الحالية بأصلها باستخدام المسافة الجديدة وانتظر الزيارة القادمة للسلات التالية. عند زيارة ورقة leaf، تكون المسافة الحالية هي المسافة النهائية للحرف. وسِّع جميع الأضلاع المنطلقة منه في المخطط الأصلي، ثمّ حدّث المسافات وفقًا لذلك. زر العقدة الجذرية (المخطط كاملًا) بشكل متكرر إلى أن تصل إلى الوجهة المقصودة. تعتمد هذه الخوارزمية على حقيقة أنّه لا يمكن أن يوجد ضلع ذا طول أقل من l بين مكوّنيْن متصليْن في غابة متفرّعة ذات حدّ طولي يساوي length limitation، لذلك، يمكنك حصر تركيزك على مكوّن واحد متصل بدءًا من مسافة x إلى أن تصل إلى المسافة x + l. ستزور بعض الحروف في الطريق قبل زيارة جميع الحروف ذات المسافة الأقصر، لكن ذلك لا يهم بما أنّنا نعلم أنّه لن يكون هناك مسار أقصر إلى هنا من تلك الحروف. اجتياز المخططات Graph Traversals هناك العديد من الخوارزميات للبحث في المخططات، سنستعرض إحداها فيما يلي، وهي خوارزمية البحث العميق أولا. تنفذ الشيفرة التالية هذه الخوارزمية، إذ تنشئ دالة تأخذ فهرس العقدة الحالي كوسيط، وقائمة التجاور (مخزّنة في متجهة من المتجهات)، ومتجهة منطقية vector of boolean لتعقّب العقدة التي تمت زيارتها، انظر: void dfs(int node, vector<vector<int>>* graph, vector<bool>* visited) { // التحقّق مما إذا كانت العقدة مُزارة سلفا if((*visited)[node]) return; // set as visited to avoid visiting the same node twice (*visited)[node] = true; // نفّذ بعض الإجراءات هنا cout << node; // اجتياز العقد المتجاورة عبر البحث العميق أولا for(int i = 0; i < (*graph)[node].size(); ++i) dfs((*graph)[node][i], graph, visited); } ترجمة -بتصرّف- للفصلين 9 و10 من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: الأشجار Trees في الخوازرميات مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية النسخة الكاملة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة -
.png.21e980e7365805c52d0c8a59ad7dac74.png) تمثل الأشجار نوعًا فرعيًا لهيكل أعم من هياكل البياناتٍ التخطيطية التفرعية Node-Edge Graph Data Structure كالآتي: والشجرة هي مخطط يحقق الشرطين التاليين: غير حلقي acyclic: أي لا يحتوي أيّ دورات cycles أو حلقات loops. متصل: أي يمكن الوصول إلى كل عقدة من عقد المخطط عبر مسار معيّن. وهيكل الشجرة شائع جدًا في علوم الحاسوب، إذ يُستخدم لنمذجة العديد من هياكل البيانات الخوارزمية المختلفة، مثل الأشجار الثنائية العادية والأشجار الحمراء-السوداء red-black trees، وأشجار B وأشجار AB وأشجار 23 وأشجار الكومة Heap وكذلك أشجار Trie. وتكون الشجرة جِذريةً Rooted Tree في حال: اختيار خلية واحدة لتكون جذرًا للشجرة. صباغة Painting الجذر في أعلى الشجرة. إنشاء طبقة سفلية lower layer لكل خلية في المخطط تبعًا للمسافة بينها وبين الجذر، فكلما كانت المسافة أكبر، كانت الخلية أسفل كما في الصورة التوضيحية أعلاه. ويرمز عادةً للأشجار بالرمز T. الأشجار اللانهائية anary tree نُمثّل الأشجار اللانهائية -أي الأشجار التي يمكن أن يتفرّع عدد لانهائي من الفروع من عقدها- على هيئة أشجار ثنائية binary tree، وهي أشجار يتفرع عن كل عقدة منها فرعان فقط، ويُعَد الفرع الثاني منهما شقيقًا Sibling، لاحظ أنه إذا كانت الشجرة ثنائيةً، فسينشئ التمثيل عُقدًا إضافية. ثم نكرر بعد ذلك على الأشقاء، ومن ثم على الفروع، وبما أن أغلب الأشجار ضحلة (أي لها مستويات تفرع هرمي قليلة، رغم إمكانية كثرة الفروع للمستوى الواحد)، فإن هذا ينتج عنه شيفرة ذات كفاءة عالية، لاحظ أن هذا عكس هرمية البشر، إذ يكون لنا مستويات كثيرة جدًا في هرمية الآباء وأولاد قليلون لكل مستوى موازنةً بأولئك الآباء. من الممكن حفظ المؤشرات الخلفية للسماح للشجرة أن ترتقي، لكن تلك المؤشرات صعبة في معالجتها وصيانتها. لاحظ أنه عادةً ما يكون لدينا دالة واحدة للاستدعاء على الجذر، ودالة تكرارية recursive مع معامِلات إضافية، وفي هذا المثال فهي عمق الشجرة، انظر: struct node { struct node *next; struct node *child; std::string data; } void printtree_r(struct node *node, int depth) { int i; while(node) { if(node->child) { for(i=0;i<depth*3;i++) printf(" "); printf("{\n"): printtree_r(node->child, depth +1); for(i=0;i<depth*3;i++) printf(" "); printf("{\n"): for(i=0;i<depth*3;i++) printf(" "); printf("%s\n", node->data.c_str()); node = node->next; } } } void printtree(node *root) { printree_r(root, 0); } التحقق من تساوي شجرتين ثنائيتين انظر الشجرتين التاليتين: هاتان الشجرتين متساويتان، على خلاف الشجرتين التاليتين: وفيما يلي شيفرة عامة زائفة pseudo code للتحقق من تساوي شجرتين: boolean sameTree(node root1, node root2){ if(root1 == NULL && root2 == NULL) return true; if(root1 == NULL || root2 == NULL) return false; if(root1->data == root2->data && sameTree(root1->left,root2->left) && sameTree(root1->right, root2->right)) return true; } أشجار البحث الثنائية Binary Search Trees الأشجار الثنائية هي الأشجار التي يتفرّع عن كلّ عقدة منها ابنان على الأكثر، وشجرة البحث الثنائية Binary search tree أو BST اختصارًا هي شجرة ثنائية عناصرها مُرتّبة ترتيبًا خاصًا، إذ تكون جميع القيم الموجودة في الشجيرة أو الفرع sub tree الأيسر أصغر من القيم في الشجَيرة اليمنى. إدراج عنصر في شجرة بحث ثنائية Python رسم يوضح كيفية إدراج عنصر في الشجرة هذا تنفيذ بسيط لكيفية إدراج عنصر في شجرة بحث ثنائية مكتوب بلغة Python. class Node: def __init__(self, val): self.l_child = None self.r_child = None self.data = val def insert(root, node): if root is None: root = node else: if root.data > node.data: if root.l_child is None: root.l_child = node else: insert(root.l_child, node) else: if root.r_child is None: root.r_child = node else: insert(root.r_child, node) def in_order_print(root): if not root: return in_order_print(root.l_child) print root.data in_order_print(root.r_child) def pre_order_print(root): if not root: return print root.data pre_order_print(root.l_child) pre_order_print(root.r_child) حذف عنصر من شجرة بحث ثنائية C++ قبل أن نبدأ، نريد أن التذكير بمفهوم شجرة البحث الثنائية BST، وهي التي يتفرّع عن كل عقدة منها عقدتان كحد أقصى (ابن أيمن وأيسر)، حيث تحتوي الشجيرة اليسرى المتفرّعة عن عقدة ما على مفتاح قيمته أصغر من أو تساوي مفتاحَ العقدة الأصلية. وتحتوي الشجيرة اليمنى للعقدة على مفتاح أكبر من مفتاح العقدة الأصلية. سنناقش في هذه الفقرة كيفية حذف عقدة من شجرة بحث ثنائية مع الحفاظ على الخاصية أعلاه. هناك ثلاث حالات يجب مراعاتها عند حذف العقدة، هي الآتية: الحالة 1: العقدة المراد حذفها هي ورقة أو عقدة طرفية leaf node، مثل العقدة ذات القيمة 22. الحالة 2: العقدة المراد حذفها لها ابن واحد، مثل العقدة ذات القيمة 26. الحالة 3: العقدة المراد حذفها لها ابنان، مثل العقدة ذات القيمة 49. شرح الحالات عندما تكون العقدة المراد حذفها ورقةً، فما عليك سوى حذف العقدة وتعيين المؤشر الفارغ nullptr إلى العقدة الأصلية. عندما تحتوي العقدة المراد حذفها على ابن واحد فقط، انسخ قيمة الابن إلى قيمة العقدة ثمّ احذف الابن (ستُحوّل إلى الحالة 1). عندما يكون للعقدة المراد حذفها ابنان، فيمكن نسخ القيمة الأصغر من شجيرتها اليمنى إلى العقدة، بعدها يمكن حذف القيمة الدنيا من الشجيرة اليمنى للعقدة، حيث ستُحوَّل إلى الحالة 2. انظر المثال التالي على حذف عنصر من شجرة بحث ثنائية: struct node { int data; node *left, *right; }; node* delete_node(node *root, int data) { if(root == nullptr) return root; else if(data < root->data) root->left = delete_node(root->left, data); else if(data > root->data) root->right = delete_node(root->right, data); else { if(root->left == nullptr && root->right == nullptr) // الحالة 1 { free(root); root = nullptr; } else if(root->left == nullptr) // الحالة 2 { node* temp = root; root= root->right; free(temp); } else if(root->right == nullptr) // الحالة 2 { node* temp = root; root = root->left; free(temp); } else // الحالة 3 { node* temp = root->right; while(temp->left != nullptr) temp = temp->left; root->data = temp->data; root->right = delete_node(root->right, temp->data); } } return root; } التعقيد الزمني للشيفرة أعلاه هو O(h)، حيث تمثّل h ارتفاع الشجرة. أدنى سلف مشترك في شجرة بحث ثنائية انظر شجرة البحث الثنائية التالية: أدنى سلف مشترك Lowest common ancestor لـ 22 و26 هو 24. أدنى سلف مشترك لـ 26 و49 هو 46. أدنى سلف مشترك لـ 22 و24 هو 24. تُستغل الخاصية المميّزة لأشجار البحث الثنائية للعثور على السلف الأدنى للعقد، فيما يلي شيفرة عامة للعثور على السلف المشترك الأدنى: lowestCommonAncestor(root,node1, node2){ if(root == NULL) return NULL; else if(node1->data == root->data || node2->data== root->data) return root; else if((node1->data <= root->data && node2->data > root->data) || (node2->data <= root->data && node1->data > root->data)){ return root; } else if(root->data > max(node1->data,node2->data)){ return lowestCommonAncestor(root->left, node1, node2); } else { return lowestCommonAncestor(root->right, node1, node2); } } شجرة البحث الثنائية Python انظر إلى شيفرة البايثون التالية: class Node(object): def __init__(self, val): self.l_child = None self.r_child = None self.val = val class BinarySearchTree(object): def insert(self, root, node): if root is None: return node if root.val < node.val: root.r_child = self.insert(root.r_child, node) else: root.l_child = self.insert(root.l_child, node) return root def in_order_place(self, root): if not root: return None else: self.in_order_place(root.l_child) print root.val self.in_order_place(root.r_child) def pre_order_place(self, root): if not root: return None else: print root.val self.pre_order_place(root.l_child) self.pre_order_place(root.r_child) def post_order_place(self, root): if not root: return None else: self.post_order_place(root.l_child) self.post_order_place(root.r_child) print root.val هذه شيفرة لإنشاء عقدة جديدة وإدراج البيانات فيها: r = Node(3) node = BinarySearchTree() nodeList = [1, 8, 5, 12, 14, 6, 15, 7, 16, 8] for nd in nodeList: node.insert(r, Node(nd)) print "------In order ---------" print (node.in_order_place(r)) print "------Pre order ---------" print (node.pre_order_place(r)) print "------Post order ---------" print (node.post_order_place(r)) التحقق مما إذا كانت الشجرة شجرة بحث ثنائية أم لا تكون شجرةٌ ثنائيةٌ ما "شجرةَ بحث ثنائية" إذا كانت تستوفي أيًّا من الشروط التالية: إن كانت فارغة. لا تتفرع منها أيّ شجيرات. لكلّ عقدة x في الشجرة، يجب أن تكون جميع المفاتيح (إن وجدت) في الشجيرة اليسرى أصغر من مفتاح x، أي key(x)، ويتعيّن أن تكون جميع المفاتيح (إذا وجدت) في الشجيرة اليمنى أكبر من key(x). الخوارزمية التكرارية التالية تتحقق من الشروط أعلاه: is_BST(root): if root == NULL: return true تحقق من القيم في الشجيرة اليسرى: if root->left != NULL: max_key_in_left = find_max_key(root->left) if max_key_in_left > root->key: return false تحقق من القيم في الشجيرة اليمنى: if root->right != NULL: min_key_in_right = find_min_key(root->right) if min_key_in_right < root->key: return false return is_BST(root->left) && is_BST(root->right) رغم صحة الخوارزمية أعلاه إلا أنها تفتقر إلى الكفاءة، لأنّها تمر على كلّ عقدة عدّة مرات، ولتقليل عدد مرّات زيارة كل عقدة يجب أن نتذكر القيم الدنيا والقصوى الممكنة للمفاتيح في الشجيرة التي نزورها. سنستخدم هذه الفكرة لتطوير خوازمية أكثر فعالية. ولفعل هذا، نرمز للقيمة الدنيا الممكنة لأيّ مفتاح K_MIN، والقيمة القصوى بالرمز K_MAX. فإن بدأتَ من جذر الشجرة يكون نطاق قيم الشجرة هو [ K_MIN ،K_MAX]. وإذا كان x هو مفتاح عقدة الجذر فسيكون نطاق القيم في الشجيرة اليسرى هو [K_MIN,x)، ونطاق القيم في الشجيرة اليمنى هو (x,K_MAX]. s_BST(root, min, max): if root == NULL: return true // هل مفتاح العقدة الحالية خارج النطاق؟ if root->key < min || root->key > max: return false // التحقق مما إذا كانت الشجيرتان اليسرى واليمنى أشجارَ بحث ثنائية return is_BST(root->left,min,root->key-1) && is_BST(root->right,root->key+1,max) وستُستَدعى في البداية على النحو التالي: is_BST(my_tree_root,KEY_MIN,KEY_MAX) هناك منظور آخر لحل الأمر، وهو الاجتياز المُرتّب inorder traversal للشجرة الثنائية -انظر أدناه-، فإذا نتج عن ذلك الاجتياز المُرتب تسلسلٌ مرتّب من المفاتيح، فستكون الشجرة شجرة بحث ثنائية. وللتحقق ممّا إذا كان التسلسل الناتج مُرتّبًا أم لا، فعليك تخزين قيمة العقدة المُزارة سابقًا، ثمّ موازنتها بالعقدة الحالية. النظر في ما إن كانت شجرة ما تحقق شرط أشجار البحث الثنائية انظر المثال التالي: إن كانت المدخلات كما يلي: فإن الخرج سيكون خاطئًا false، وعليه لا تكون هذه شجرة بحث ثنائية، ذلك أنّ 4 في الشجيرة اليسرى أكبر من قيمة الجذر 3. انظر الآن مثالًا على شجرة أخرى: النتيجة ستكون صحيحة وتكون شجرة بحث ثنائية. اجتيازات الأشجار الثنائية Binary Tree traversals زيارة عقدة لشجرة ثنائية بترتيب معيّن يُسمّى اجتيازَا أو عبورًا traversal، وهناك عدة أنواع من الاجتياز سنستعرض في هذه الفقرة بعضها. الاجتياز بالمستويات: التطبيق انظر الشجرة التالية: يكون الاجتياز بالمستويات على الترتيب التالي: 1 2 3 4 5 6 7 مع طبع بيانات العُقَد مستوىً بمستوى، انظر: include<iostream> #include<queue> #include<malloc.h> using namespace std; struct node{ int data; node *left; node *right; }; void levelOrder(struct node *root){ if(root == NULL) return; queue<node *> Q; Q.push(root); while(!Q.empty()){ struct node* curr = Q.front(); cout<< curr->data <<" "; if(curr->left != NULL) Q.push(curr-> left); if(curr->right != NULL) Q.push(curr-> right); Q.pop(); } } struct node* newNode(int data) { struct node* node = (struct node*) malloc(sizeof(struct node)); node->data = data; node->left = NULL; node->right = NULL; return(node); } int main(){ struct node *root = newNode(1); root->left = newNode(2); root->right = newNode(3); root->left->left = newNode(4); root->left->right = newNode(5); root->right->left = newNode(6); root->right->right = newNode(7); printf("Level Order traversal of binary tree is \n"); levelOrder(root); return 0; } تُستخدم الصفوف Queues -وهو نوع من البيانات- لتحقيق الهدف أعلاه. الاجتياز التنازلي والتصاعدي والمرتب انظر الشجرة الثنائية التالية: الاجتياز التنازلي Pre-order traversal: يبدأ هذا النوع باجتياز العقدة، ثم الشجيرة اليسرى للعقدة، ثمّ الشجيرة اليمنى لها. ويكون الاجتياز التنازلي بالترتيب التالي: 1 2 4 5 3 6 7 الاجتياز المُرتّب In-order traversal: هو اجتياز الشجيرة اليسرى للعقدة، ثمّ العقدة نفسها، ثم الشجيرة اليمنى للعقدة. يكون الاجتياز المُرتّب بالترتيب التالي: 4 2 5 1 6 3 7 الاجتياز التصاعدي Post-order traversal: هو اجتياز الشجيرة اليسرى للعقدة، ثم الشجيرة اليمنى، ثمّ العقدة، ويكون الاجتياز التصاعدي بالترتيب التالي: 4 5 2 6 7 3 1 العثور على أدنَى سلف مشترك لشجرة ثنائية السلف المشترك الأدنى للعقدتين n1 وn2 هو أدنى عقدة في الشجرة يكون كلّ من n1 وn2 أحفادًا لها. انظر الشجرة التالية: أدنى سلف مشترك للعقدتين ذواتي القيمتين 1 و4 هو 2. أدنى سلف مشترك للعقدتين ذواتي القيمتين 1 و5 هو 3. أدنى سلف مشترك للعقدتين ذواتي القيمتين 2 و4 هو 4. أدنى سلف مشترك للعقدتين ذواتي القيمتين 1 و2 هو 2. ترجمة -بتصرّف- للفصول من 4 إلى 8 من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: ترميز Big-O المرجع الشامل إلى: تعلم الخوارزميات للمبتدئين تعقيد الخوارزميات Algorithms Complexity مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية النسخة الكاملة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة
تمثل الأشجار نوعًا فرعيًا لهيكل أعم من هياكل البياناتٍ التخطيطية التفرعية Node-Edge Graph Data Structure كالآتي: والشجرة هي مخطط يحقق الشرطين التاليين: غير حلقي acyclic: أي لا يحتوي أيّ دورات cycles أو حلقات loops. متصل: أي يمكن الوصول إلى كل عقدة من عقد المخطط عبر مسار معيّن. وهيكل الشجرة شائع جدًا في علوم الحاسوب، إذ يُستخدم لنمذجة العديد من هياكل البيانات الخوارزمية المختلفة، مثل الأشجار الثنائية العادية والأشجار الحمراء-السوداء red-black trees، وأشجار B وأشجار AB وأشجار 23 وأشجار الكومة Heap وكذلك أشجار Trie. وتكون الشجرة جِذريةً Rooted Tree في حال: اختيار خلية واحدة لتكون جذرًا للشجرة. صباغة Painting الجذر في أعلى الشجرة. إنشاء طبقة سفلية lower layer لكل خلية في المخطط تبعًا للمسافة بينها وبين الجذر، فكلما كانت المسافة أكبر، كانت الخلية أسفل كما في الصورة التوضيحية أعلاه. ويرمز عادةً للأشجار بالرمز T. الأشجار اللانهائية anary tree نُمثّل الأشجار اللانهائية -أي الأشجار التي يمكن أن يتفرّع عدد لانهائي من الفروع من عقدها- على هيئة أشجار ثنائية binary tree، وهي أشجار يتفرع عن كل عقدة منها فرعان فقط، ويُعَد الفرع الثاني منهما شقيقًا Sibling، لاحظ أنه إذا كانت الشجرة ثنائيةً، فسينشئ التمثيل عُقدًا إضافية. ثم نكرر بعد ذلك على الأشقاء، ومن ثم على الفروع، وبما أن أغلب الأشجار ضحلة (أي لها مستويات تفرع هرمي قليلة، رغم إمكانية كثرة الفروع للمستوى الواحد)، فإن هذا ينتج عنه شيفرة ذات كفاءة عالية، لاحظ أن هذا عكس هرمية البشر، إذ يكون لنا مستويات كثيرة جدًا في هرمية الآباء وأولاد قليلون لكل مستوى موازنةً بأولئك الآباء. من الممكن حفظ المؤشرات الخلفية للسماح للشجرة أن ترتقي، لكن تلك المؤشرات صعبة في معالجتها وصيانتها. لاحظ أنه عادةً ما يكون لدينا دالة واحدة للاستدعاء على الجذر، ودالة تكرارية recursive مع معامِلات إضافية، وفي هذا المثال فهي عمق الشجرة، انظر: struct node { struct node *next; struct node *child; std::string data; } void printtree_r(struct node *node, int depth) { int i; while(node) { if(node->child) { for(i=0;i<depth*3;i++) printf(" "); printf("{\n"): printtree_r(node->child, depth +1); for(i=0;i<depth*3;i++) printf(" "); printf("{\n"): for(i=0;i<depth*3;i++) printf(" "); printf("%s\n", node->data.c_str()); node = node->next; } } } void printtree(node *root) { printree_r(root, 0); } التحقق من تساوي شجرتين ثنائيتين انظر الشجرتين التاليتين: هاتان الشجرتين متساويتان، على خلاف الشجرتين التاليتين: وفيما يلي شيفرة عامة زائفة pseudo code للتحقق من تساوي شجرتين: boolean sameTree(node root1, node root2){ if(root1 == NULL && root2 == NULL) return true; if(root1 == NULL || root2 == NULL) return false; if(root1->data == root2->data && sameTree(root1->left,root2->left) && sameTree(root1->right, root2->right)) return true; } أشجار البحث الثنائية Binary Search Trees الأشجار الثنائية هي الأشجار التي يتفرّع عن كلّ عقدة منها ابنان على الأكثر، وشجرة البحث الثنائية Binary search tree أو BST اختصارًا هي شجرة ثنائية عناصرها مُرتّبة ترتيبًا خاصًا، إذ تكون جميع القيم الموجودة في الشجيرة أو الفرع sub tree الأيسر أصغر من القيم في الشجَيرة اليمنى. إدراج عنصر في شجرة بحث ثنائية Python رسم يوضح كيفية إدراج عنصر في الشجرة هذا تنفيذ بسيط لكيفية إدراج عنصر في شجرة بحث ثنائية مكتوب بلغة Python. class Node: def __init__(self, val): self.l_child = None self.r_child = None self.data = val def insert(root, node): if root is None: root = node else: if root.data > node.data: if root.l_child is None: root.l_child = node else: insert(root.l_child, node) else: if root.r_child is None: root.r_child = node else: insert(root.r_child, node) def in_order_print(root): if not root: return in_order_print(root.l_child) print root.data in_order_print(root.r_child) def pre_order_print(root): if not root: return print root.data pre_order_print(root.l_child) pre_order_print(root.r_child) حذف عنصر من شجرة بحث ثنائية C++ قبل أن نبدأ، نريد أن التذكير بمفهوم شجرة البحث الثنائية BST، وهي التي يتفرّع عن كل عقدة منها عقدتان كحد أقصى (ابن أيمن وأيسر)، حيث تحتوي الشجيرة اليسرى المتفرّعة عن عقدة ما على مفتاح قيمته أصغر من أو تساوي مفتاحَ العقدة الأصلية. وتحتوي الشجيرة اليمنى للعقدة على مفتاح أكبر من مفتاح العقدة الأصلية. سنناقش في هذه الفقرة كيفية حذف عقدة من شجرة بحث ثنائية مع الحفاظ على الخاصية أعلاه. هناك ثلاث حالات يجب مراعاتها عند حذف العقدة، هي الآتية: الحالة 1: العقدة المراد حذفها هي ورقة أو عقدة طرفية leaf node، مثل العقدة ذات القيمة 22. الحالة 2: العقدة المراد حذفها لها ابن واحد، مثل العقدة ذات القيمة 26. الحالة 3: العقدة المراد حذفها لها ابنان، مثل العقدة ذات القيمة 49. شرح الحالات عندما تكون العقدة المراد حذفها ورقةً، فما عليك سوى حذف العقدة وتعيين المؤشر الفارغ nullptr إلى العقدة الأصلية. عندما تحتوي العقدة المراد حذفها على ابن واحد فقط، انسخ قيمة الابن إلى قيمة العقدة ثمّ احذف الابن (ستُحوّل إلى الحالة 1). عندما يكون للعقدة المراد حذفها ابنان، فيمكن نسخ القيمة الأصغر من شجيرتها اليمنى إلى العقدة، بعدها يمكن حذف القيمة الدنيا من الشجيرة اليمنى للعقدة، حيث ستُحوَّل إلى الحالة 2. انظر المثال التالي على حذف عنصر من شجرة بحث ثنائية: struct node { int data; node *left, *right; }; node* delete_node(node *root, int data) { if(root == nullptr) return root; else if(data < root->data) root->left = delete_node(root->left, data); else if(data > root->data) root->right = delete_node(root->right, data); else { if(root->left == nullptr && root->right == nullptr) // الحالة 1 { free(root); root = nullptr; } else if(root->left == nullptr) // الحالة 2 { node* temp = root; root= root->right; free(temp); } else if(root->right == nullptr) // الحالة 2 { node* temp = root; root = root->left; free(temp); } else // الحالة 3 { node* temp = root->right; while(temp->left != nullptr) temp = temp->left; root->data = temp->data; root->right = delete_node(root->right, temp->data); } } return root; } التعقيد الزمني للشيفرة أعلاه هو O(h)، حيث تمثّل h ارتفاع الشجرة. أدنى سلف مشترك في شجرة بحث ثنائية انظر شجرة البحث الثنائية التالية: أدنى سلف مشترك Lowest common ancestor لـ 22 و26 هو 24. أدنى سلف مشترك لـ 26 و49 هو 46. أدنى سلف مشترك لـ 22 و24 هو 24. تُستغل الخاصية المميّزة لأشجار البحث الثنائية للعثور على السلف الأدنى للعقد، فيما يلي شيفرة عامة للعثور على السلف المشترك الأدنى: lowestCommonAncestor(root,node1, node2){ if(root == NULL) return NULL; else if(node1->data == root->data || node2->data== root->data) return root; else if((node1->data <= root->data && node2->data > root->data) || (node2->data <= root->data && node1->data > root->data)){ return root; } else if(root->data > max(node1->data,node2->data)){ return lowestCommonAncestor(root->left, node1, node2); } else { return lowestCommonAncestor(root->right, node1, node2); } } شجرة البحث الثنائية Python انظر إلى شيفرة البايثون التالية: class Node(object): def __init__(self, val): self.l_child = None self.r_child = None self.val = val class BinarySearchTree(object): def insert(self, root, node): if root is None: return node if root.val < node.val: root.r_child = self.insert(root.r_child, node) else: root.l_child = self.insert(root.l_child, node) return root def in_order_place(self, root): if not root: return None else: self.in_order_place(root.l_child) print root.val self.in_order_place(root.r_child) def pre_order_place(self, root): if not root: return None else: print root.val self.pre_order_place(root.l_child) self.pre_order_place(root.r_child) def post_order_place(self, root): if not root: return None else: self.post_order_place(root.l_child) self.post_order_place(root.r_child) print root.val هذه شيفرة لإنشاء عقدة جديدة وإدراج البيانات فيها: r = Node(3) node = BinarySearchTree() nodeList = [1, 8, 5, 12, 14, 6, 15, 7, 16, 8] for nd in nodeList: node.insert(r, Node(nd)) print "------In order ---------" print (node.in_order_place(r)) print "------Pre order ---------" print (node.pre_order_place(r)) print "------Post order ---------" print (node.post_order_place(r)) التحقق مما إذا كانت الشجرة شجرة بحث ثنائية أم لا تكون شجرةٌ ثنائيةٌ ما "شجرةَ بحث ثنائية" إذا كانت تستوفي أيًّا من الشروط التالية: إن كانت فارغة. لا تتفرع منها أيّ شجيرات. لكلّ عقدة x في الشجرة، يجب أن تكون جميع المفاتيح (إن وجدت) في الشجيرة اليسرى أصغر من مفتاح x، أي key(x)، ويتعيّن أن تكون جميع المفاتيح (إذا وجدت) في الشجيرة اليمنى أكبر من key(x). الخوارزمية التكرارية التالية تتحقق من الشروط أعلاه: is_BST(root): if root == NULL: return true تحقق من القيم في الشجيرة اليسرى: if root->left != NULL: max_key_in_left = find_max_key(root->left) if max_key_in_left > root->key: return false تحقق من القيم في الشجيرة اليمنى: if root->right != NULL: min_key_in_right = find_min_key(root->right) if min_key_in_right < root->key: return false return is_BST(root->left) && is_BST(root->right) رغم صحة الخوارزمية أعلاه إلا أنها تفتقر إلى الكفاءة، لأنّها تمر على كلّ عقدة عدّة مرات، ولتقليل عدد مرّات زيارة كل عقدة يجب أن نتذكر القيم الدنيا والقصوى الممكنة للمفاتيح في الشجيرة التي نزورها. سنستخدم هذه الفكرة لتطوير خوازمية أكثر فعالية. ولفعل هذا، نرمز للقيمة الدنيا الممكنة لأيّ مفتاح K_MIN، والقيمة القصوى بالرمز K_MAX. فإن بدأتَ من جذر الشجرة يكون نطاق قيم الشجرة هو [ K_MIN ،K_MAX]. وإذا كان x هو مفتاح عقدة الجذر فسيكون نطاق القيم في الشجيرة اليسرى هو [K_MIN,x)، ونطاق القيم في الشجيرة اليمنى هو (x,K_MAX]. s_BST(root, min, max): if root == NULL: return true // هل مفتاح العقدة الحالية خارج النطاق؟ if root->key < min || root->key > max: return false // التحقق مما إذا كانت الشجيرتان اليسرى واليمنى أشجارَ بحث ثنائية return is_BST(root->left,min,root->key-1) && is_BST(root->right,root->key+1,max) وستُستَدعى في البداية على النحو التالي: is_BST(my_tree_root,KEY_MIN,KEY_MAX) هناك منظور آخر لحل الأمر، وهو الاجتياز المُرتّب inorder traversal للشجرة الثنائية -انظر أدناه-، فإذا نتج عن ذلك الاجتياز المُرتب تسلسلٌ مرتّب من المفاتيح، فستكون الشجرة شجرة بحث ثنائية. وللتحقق ممّا إذا كان التسلسل الناتج مُرتّبًا أم لا، فعليك تخزين قيمة العقدة المُزارة سابقًا، ثمّ موازنتها بالعقدة الحالية. النظر في ما إن كانت شجرة ما تحقق شرط أشجار البحث الثنائية انظر المثال التالي: إن كانت المدخلات كما يلي: فإن الخرج سيكون خاطئًا false، وعليه لا تكون هذه شجرة بحث ثنائية، ذلك أنّ 4 في الشجيرة اليسرى أكبر من قيمة الجذر 3. انظر الآن مثالًا على شجرة أخرى: النتيجة ستكون صحيحة وتكون شجرة بحث ثنائية. اجتيازات الأشجار الثنائية Binary Tree traversals زيارة عقدة لشجرة ثنائية بترتيب معيّن يُسمّى اجتيازَا أو عبورًا traversal، وهناك عدة أنواع من الاجتياز سنستعرض في هذه الفقرة بعضها. الاجتياز بالمستويات: التطبيق انظر الشجرة التالية: يكون الاجتياز بالمستويات على الترتيب التالي: 1 2 3 4 5 6 7 مع طبع بيانات العُقَد مستوىً بمستوى، انظر: include<iostream> #include<queue> #include<malloc.h> using namespace std; struct node{ int data; node *left; node *right; }; void levelOrder(struct node *root){ if(root == NULL) return; queue<node *> Q; Q.push(root); while(!Q.empty()){ struct node* curr = Q.front(); cout<< curr->data <<" "; if(curr->left != NULL) Q.push(curr-> left); if(curr->right != NULL) Q.push(curr-> right); Q.pop(); } } struct node* newNode(int data) { struct node* node = (struct node*) malloc(sizeof(struct node)); node->data = data; node->left = NULL; node->right = NULL; return(node); } int main(){ struct node *root = newNode(1); root->left = newNode(2); root->right = newNode(3); root->left->left = newNode(4); root->left->right = newNode(5); root->right->left = newNode(6); root->right->right = newNode(7); printf("Level Order traversal of binary tree is \n"); levelOrder(root); return 0; } تُستخدم الصفوف Queues -وهو نوع من البيانات- لتحقيق الهدف أعلاه. الاجتياز التنازلي والتصاعدي والمرتب انظر الشجرة الثنائية التالية: الاجتياز التنازلي Pre-order traversal: يبدأ هذا النوع باجتياز العقدة، ثم الشجيرة اليسرى للعقدة، ثمّ الشجيرة اليمنى لها. ويكون الاجتياز التنازلي بالترتيب التالي: 1 2 4 5 3 6 7 الاجتياز المُرتّب In-order traversal: هو اجتياز الشجيرة اليسرى للعقدة، ثمّ العقدة نفسها، ثم الشجيرة اليمنى للعقدة. يكون الاجتياز المُرتّب بالترتيب التالي: 4 2 5 1 6 3 7 الاجتياز التصاعدي Post-order traversal: هو اجتياز الشجيرة اليسرى للعقدة، ثم الشجيرة اليمنى، ثمّ العقدة، ويكون الاجتياز التصاعدي بالترتيب التالي: 4 5 2 6 7 3 1 العثور على أدنَى سلف مشترك لشجرة ثنائية السلف المشترك الأدنى للعقدتين n1 وn2 هو أدنى عقدة في الشجرة يكون كلّ من n1 وn2 أحفادًا لها. انظر الشجرة التالية: أدنى سلف مشترك للعقدتين ذواتي القيمتين 1 و4 هو 2. أدنى سلف مشترك للعقدتين ذواتي القيمتين 1 و5 هو 3. أدنى سلف مشترك للعقدتين ذواتي القيمتين 2 و4 هو 4. أدنى سلف مشترك للعقدتين ذواتي القيمتين 1 و2 هو 2. ترجمة -بتصرّف- للفصول من 4 إلى 8 من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: ترميز Big-O المرجع الشامل إلى: تعلم الخوارزميات للمبتدئين تعقيد الخوارزميات Algorithms Complexity مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية النسخة الكاملة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة-
- 1
-

-
- الخوارزميات
- الأشجار
- (و 1 أكثر)
-
.png.2f79fb79a8286f96f5ac77cfadf23d4c.png) ترميز Big-O هو ترميز رياضي في الأساس يُستخدم لموازنة معدّلات تقارب الدوال، وسنستعرض في هذا المقال استخدامات هذا الترميز في تحليل الخوارزميات وتصنيفها كما يلي. إذا كانت n -> f(n) وn -> g(n) دالتين مُعرّفتين على الأعداد الطبيعية، فسنقول أنّ f = O(g) فقط إذا كانت f(n)/g(n) محصورة bounded عندما يؤول n إلى اللا نهاية. أي أن f = O(g) فقط إذا كان هناك ثابت A، بحيث يكون f(n)/g(n) <= A لكل n. وفي الواقع فإن نطاق استخدام ترميز Big-O أوسع قليلاً في الرياضيات، لكن سنضيّقه في النطاق المُستخدَم في تحليل الخوارزميات للتبسيط، أي الدوال المُعرَّفة على الأعداد الطبيعية والتي ليست لها قيم صفرية أو جذور zero values عندما يؤول n إلى اللانهاية. شرح لنأخذ حالة هاتين الدالتين: f(n) = 100n^2 + 10n + 1 7 والدالة g(n) = n^2 من الواضح تمامًا أنهما تؤولان إلى اللانهاية عندما يؤول n إلى اللانهاية. لكن قد لا يكفي أحيانًا أن نعرف النهاية limit، فقد نرغب أيضًا في معرفة السرعة التي تقترب بها الدوال من نهايتها، وهنا يأتي دور ترميز Big-O إذ يساعد على تصنيف الدوال بحسَب سرعة تقاربها. فعندئذ نطبّق التعريف للتحقق ممّا إذا كانت f = O(g) حيث لدينا: f(n)/g(n) = 100 + 10/n + 1/n^2 وبما أن 10/n يساوي القيمة 10 عندما يكون n=1 ويتناقص مع تزايد قيمة n، وبما أنّ 1/n^2 تساوي 1 عندما يساوي n القيمة 1 وهو أيضًا يتناقص مع تزايد قيمة n، فنحصل على المتراجحة f(n)/g(n) <= 100 +10 + 1 = 111 وقد تحقّق شرط التعريف هنا لأنّنا وجدنا حدًّا bound للتعبير f(n)/g(n) - وهو 111-، ونكون بهذا قد أثبتنا أنّf = O(g)، ونقول أنّ f هي Big-O لـ n^2. هذا يعني أنّ f تؤول إلى اللانهاية بنفس سرعة g تقريبًا. قد يبدو هذا غريبًا في البداية لأنّنا وجدنا أنّ f أكبر بـ 111 مرة من g، أو بعبارة أخرى، عندما تنمو g بمقدار 1، فإن f تنمو بمقدار 111 على أقصى حد. والحقيقة أنّ ترميز Big-O ليس دقيقًا في تصنيف سرعات تقارب الدوال، لهذا نَستخدم علاقة التكافؤ equivalence relationship في الرياضيات عندما نريد تقديرًا دقيقًا للسرعة. لكن إن أردت تصنيف الخوارزميات إلى أصناف عامّة بحسب السرعات، فإنّ Big-O كافية، إذ لن نحتاج إلى التمييز بين دالتين تنمو إحداهما أسرع من الأخرى بعدد محدد من المرات، بل المهم هو التمييز بين الدوال التي تنمو لانهائيًا أسرع من بعضها البعض. على سبيل المثال، في حالة h(n) = n^2*log(n) نلاحظ أنّ h(n)/g(n) = log(n) تؤول إلى ما لانهاية عندما يؤول n إلى ما لا نهاية، لذا فإنّ h ليست من الصنف O (n ^ 2)، لأنّ h تنمو لانهائيًا أسرع من n ^ 2. وفي مجال تحليل تعقيد الخوارزميات، نكتب f = O(g) للدلالة على أنّ: f = O(g) و g = O(f) والتي يمكن تأويلها على أنّ g هي أصغر دالة من الصنف Big-O لــ f؛ أما في الرياضيات فنقول أنّ هاتين الدالتين Big-Theta لبعضها البعض. كيفية الاستخدام أول شيء عليك حسابه عند موازنة أداء الخوارزميات هو عدد العمليات التي تجريها الخوارزمية، وهو ما يُسمّى وقت التعقيد time complexity. ونفترض في هذا النموذج أنّ كل عملية أساسية (الجمع والضرب والمقارنة والتعيين وما إلى ذلك) تستغرق مقدارًا ثابتًا من الوقت، ونحسب عدد هذه العمليات. ونعبر في الغالب عن هذا العدد كدالة لحجم الدخل -الذي نصطلح على تسميته n-، ويؤول هذا العدد (الدالة) في الغالب إلى ما لا نهاية عندما يؤول n إلى ما لا نهاية، أما خلاف ذلك، فنقول أنّ الخوارزمية من النوع O (1). ونحن نصنّف الخوارزميات إلى أصناف بحسب سرعات الدوال ونمثّلها بالترميز Big-O: فمثلًا إن قلنا أنّ خوارزميةً ما من النوع الآتي: O (n ^ 2) فإنّنا نقصد أنّ عدد العمليات التي تنفّذها الخوارزمية -معبَّرًا عنها كدالة لـ n- هو O (n ^ 2). وهو ما يعني أنّ سرعة الخوارزمية تقارب سرعة خوارزمية تجري عددًا من العمليات يساوي مرّبع حجم الدخل أو أسرع. لاحظ لفظة أو أسرع، لقد وضعناها لأنّنا استخدمنا Big-O بدلاً عن Big-Theta، ذلك أنّه من الشائع أن ترى الناس تكتب Big-O، رغم أنّهم يعنون Big-Theta. ونحن نأخذ الحالة الأسوأ في حسابنا عادة عند عدّ العمليات، فإن كانت حلقة تكرارية تُنفَّذ n مرّةً على الأكثر وكانت تحتوي على 5 عمليات، فإنّ عدد العمليات المُقدَّر سيكون 5n. كذلك من الممكن مراعاة متوسط تعقيد الحالة. يمكن أن نأخذ مساحة التخزين بالحسبان كذلك، وهو ما يُسمّى تعقيد المساحة space complexity للخوارزمية، ذلك أن الوقت ليس المورد الوحيد المهم، وفي هذه الحالة نحسُب عدد البايتات التي تشغلها الخوارزمية في الذاكرة كدالة لحجم الدخل، ونستخدم Big-O كما في حالة تعقيد الوقت. مثال عن حلقة بسيطة Simple Loop الدالة التالية تبحث عن أكبر عنصر في المصفوفة: int find_max(const int *array, size_t len) { int max = INT_MIN; for (size_t i = 0; i < len; i++) { if (max < array[i]) { max = array[i]; } } return max; } حجم الدخل هو حجم المصفوفة، والذي سمّيناه len في الشيفرة أعلاه. دعنا الآن نَعُد العمليات. int max = INT_MIN; size_t i = 0; تُنفَّذ هاتان العمليتان مرةً واحدة، لذا فلدينا عمليتان هنا. والآن نعدّ عمليات الحلقة: if (max < array[i]) i++; max = array[i] لمّا كانت هناك 3 عمليات في الحلقة، وكانت الحلقة تُنفَّذ n مرة، فسنضيف 3n إلى 2 (العمليتان اللتان حسبناهما من قبل)، ليبلغ الإجمالي 3n + 2. تجري دالتنا إذن عددًا من العمليات مقداره 3n + 2 عملية للعثور على أكبر عنصر في المصفوفة (تعقيدها يساوي 3n + 2). وهذا يعرف بتعددية الحدود polynomial، وأسرع عواملها نموّا هو العامل n، لذا يساوي تعقيدها O (n). لعلّك لاحظت أنّ طريقة عدّ العمليات ليست دقيقة، فقد قلنا مثلًا أنّ (max < array) هي عملية واحدة، ولكن اعتمادًا على هندسة الحاسوب فقد تنطوي هذه العبارة على تعليمتين مثلاً، الأولى لقراءة الذاكرة والثانية للمقارنة. وقد اعتبرنا كذلك أنّ جميع العمليات متشابهة رغم أنّ العمليات التي تخصّ الذاكرة على سبيل المثال تكون أبطأ من العمليات الأخرى، كما يختلف أداؤها اختلافًا كبيرًا بسبب تأثيرات التخزين المؤقت cache. كذلك تجاهلنا أيضًا تعليمة الإعادة return وحقيقةَ إنشاء إطار frame خاص بالدالة، وما إلى ذلك من الأمور الجانبية. لكنّ هذا لن يؤثّر في النهاية على تحليل التعقيد، ذلك أنّه مهما كانت طريقة عدّ العمليات، فلن يؤثّر إلا على معامل العامل n وكذلك لن يؤثر على الثابت، لذا ستظل النتيجة O (n). ويُظهر التعقيد كيف تتطوّر الخوارزمية مع تطوّر حجم الدخل، بيْد أنّها ليست الجانب الوحيد الذي يمثّل الأداء. مثال عن الحلقات المتشعبة Nested Loops تتحقق الدالة التالية ممّا إذا كانت المصفوفة تحتوي أيّ تكرارات، وذلك عبر المرور على كل عنصر على حدة، ثم المرور مجدّدا على المصفوفة للتحقّق ممّا إذا كان هناك عنصر آخر يساويه. _Bool contains_duplicates(const int *array, size_t len) { for (int i = 0; i < len - 1; i++) { for (int j = 0; j < len; j++) { if (i != j && array[i] == array[j]) { return 1; } } } return 0; } تنفّذ الحلقة الداخلية عند كل تكرار عددًا ثابتًا من العمليات (بغضّ النظر عن قيمة n)، كما تنفّذ الحلقة الخارجية أيضًا بعض العمليات الثابتة علاوة على تنفيذ الحلقة الداخلية عدد n مرّة. أيضًا، تنفَّذ الحلقةُ الخارجية نفسها n مرّة، وعليه تُنفّذ العمليات داخل الحلقة الداخلية n^2 مرّة بينما تُنفّذ عمليات الحلقة الخارجية n مرّة، أمّا عملية التعيين إلى i فتُتفّذ مرّة واحدة. وهكذا يمكن التعبير عن التعقيد بمعادلة مثل an^2 + bn + c، ولمّا كان المعامل الأعلى هو n^2، فإنّ ترميز O سيساوي O(n^2). لعلك لاحظت أن هناك فرصة لتحسين الخوارزمية أكثر، إذ يمكن مثلًا تجنّب إجراء نفس المقارنات أكثرة من مرّة. يمكننا أن نبدأ من i + 1 في الحلقة الداخلية نظرًا لأنّ جميع العناصر التي تسبقه قد تم التحقق منها سلفًا وقورنت مع جميع عناصر المصفوفة، بما في ذلك العنصر الموجود عند الفهرس i + 1. هذا يسمح لنا بحذف الاختبار i == j. _Bool faster_contains_duplicates(const int *array, size_t len) { for (int i = 0; i < len - 1; i++) { for (int j = i + 1; j < len; j++) { if (array[i] == array[j]) { return 1; } } } return 0; } كما ترى فإنّ هذا الإصدار أفضل لأنّه يُجري عمليات أقل، لكن كيف نترجم هذا في ترميز Big-O؟ حسنًا، في الإصدار الجديد، يُنفّذ مَتن الحلقة الداخلية المرات 1 + 2 + ... + n - 1 = n(n-1)/2 لا يزال هذا التعبير كثير الحدود من الدرجة الثانية، لذا سيظلّ التعقيد مساويا لـ O(n^2). وقد قلّلنا التعقيد إذ خفّضنا عدد العمليات إلى النصف تقريبًا، بيْد أنّنا ما زلنا في نفس صنف التعقيد من Big-O. ونحتاج إلى تقسيم عدد العمليات على مقدار يؤول إلى اللا نهاية مع n من أجل تقليل التعقيد إلى صنف أدنى. الخوارزميات اللوغاريتمية لنفترض أنّ لدينا مشكلة ذات حجم n، ولنفترض أنّ حجم مشكلتنا الأصلية ينخفض إلى النصف (n / 2) بعد كل خطوة من خطوات الخوارزمية. أي أنّه في كل خطوة جديدة يصير حجم المشكلة نصف ما كانت عليه في الخطوة التي قبلها: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الخطوة المشكلة 1 n/2 2 n/4 3 n/8 4 n/16 تكون المشكلة محلولة حين يتعذر تقليل حجمها أكثر بعد الخروج من شرط التحقق، أي عندما تكون n مساوية للقيمة 1. لنفترض الآن أنّ حجم المشكلة يساوي n، نريد أن نحسب عدد الخطوات اللازمة لحل الخوارزمية، سنرمز لهذا العدد بالحرف k: عند الخطوة k، سيساوي حجم المشكلة 1 (أي أنّ المشكلة ستكون قد حُلَّت). من جهة أخرى، نعلم أنّه عند الخطوة k، ينبغي أن يساوي حجم المشكلة العدد (n/2^k). من 1، 2، إذًا n = 2k. طبّق دالة اللوغاريتم على كلا الجانبين: log n = k * loge_2 → k = loge n / loge 2 باستخدام المعادلة التالية: logx (m) / logx (n) = logn (m) حيث يرمز التعبير logt إلى اللوغاريتم ذي الأساس t، وتصبح النتيجة k = log2 (n) أو k = log n ببساطة. انظر المثال التوضيحي التالي: for(int i=1; i<=n; i=i*2) { // إجراء بعض العمليات } إن كان n يساوي 256، فكم تتوقّع أن يكون عدد الخطوات التي ستنفّذها الحلقة أو أي خوارزمية أخرى ينخفض حجم مشكلتها إلى النصف بعد كل خطوة؟ سنرمز للعدد الذي نبحث عنه بالرمز k، ونحسبه على النحو الآتي: k = log2 (256). k = log2 (2^8) ( نعلم أنّ log(a^a) = 1 لكل عدد a). k = 8. هذا مثال آخر لتوضيح هذا النوع من الخوارزميات. وهي خوارزمية البحث الثنائي Binary Search Algorithm. int bSearch(int arr[],int size,int item){ int low=0; int high=size-1; while(low<=high){ mid=low+(high-low)/2; if(arr[mid]==item) return mid; else if(arr[mid]<item) low=mid+1; else high=mid-1; } return –1;// لا يوجد } مثال على خوارزمية من الصنف O (log n) انظر المشكلة التالية: L قائمة مرتّبة تحتوي n عددًا صحيحًا نسبيًا (n كبيرة جدا)، على سبيل المثال [-5, -2, -1, 0، 1، 2، 4] (هنا، n تساوي 7). إذا كانت L تحتوي العدد الصحيح 0، فكيف يمكنك العثور على فهرس 0؟ المقاربة البسيطة أول ما يتبادر إلى الذهن هو قراءة كل فهرس إلى حين العثور على 0، وفي أسوأ الحالات سيكون علينا إجراء n عملية، وعليه فإنّ التعقيد سيساوي O (n). لا مشكلة في هذا مع القيم الصغيرة لـ n، ولكن هل هناك طريقة أفضل؟ مبدأ الحصار Dichotomy انظر الخوارزمية التالية Python3: a = 0 b = n-1 while True: h = (a+b) // (*) if L[h] == 0: return h elif L[h] > 0: b = h elif L[h] < 0: a = h وفي أسوأ الحالات، علينا الانتظار حتى يتساوى a وb، لكن كم عدد العمليات التي يتطلبها ذلك؟ قطعًا ليس n لأننا نقسم المسافة بين a وb على 2 في كل مرة ندخل إلى الحلقة، لذا فالتعقيد يساوي O (log n). إذا صادفت خوارزمية يُقسم حجمها على عدد معيّن (2 أو 3 أو أيّ عدد) بعد كل خطوة، فإنّ تعقيدها سيكون لوغاريتميًا. ترجمة -بتصرّف- للفصل الثالث من كتاب Algorithms Notes for Professionals. اقرأ أيضًا المقالة السابقة: تعقيد الخوارزميات مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية مدخل إلى الذكاء الاصطناعي وتعلم الآلة
ترميز Big-O هو ترميز رياضي في الأساس يُستخدم لموازنة معدّلات تقارب الدوال، وسنستعرض في هذا المقال استخدامات هذا الترميز في تحليل الخوارزميات وتصنيفها كما يلي. إذا كانت n -> f(n) وn -> g(n) دالتين مُعرّفتين على الأعداد الطبيعية، فسنقول أنّ f = O(g) فقط إذا كانت f(n)/g(n) محصورة bounded عندما يؤول n إلى اللا نهاية. أي أن f = O(g) فقط إذا كان هناك ثابت A، بحيث يكون f(n)/g(n) <= A لكل n. وفي الواقع فإن نطاق استخدام ترميز Big-O أوسع قليلاً في الرياضيات، لكن سنضيّقه في النطاق المُستخدَم في تحليل الخوارزميات للتبسيط، أي الدوال المُعرَّفة على الأعداد الطبيعية والتي ليست لها قيم صفرية أو جذور zero values عندما يؤول n إلى اللانهاية. شرح لنأخذ حالة هاتين الدالتين: f(n) = 100n^2 + 10n + 1 7 والدالة g(n) = n^2 من الواضح تمامًا أنهما تؤولان إلى اللانهاية عندما يؤول n إلى اللانهاية. لكن قد لا يكفي أحيانًا أن نعرف النهاية limit، فقد نرغب أيضًا في معرفة السرعة التي تقترب بها الدوال من نهايتها، وهنا يأتي دور ترميز Big-O إذ يساعد على تصنيف الدوال بحسَب سرعة تقاربها. فعندئذ نطبّق التعريف للتحقق ممّا إذا كانت f = O(g) حيث لدينا: f(n)/g(n) = 100 + 10/n + 1/n^2 وبما أن 10/n يساوي القيمة 10 عندما يكون n=1 ويتناقص مع تزايد قيمة n، وبما أنّ 1/n^2 تساوي 1 عندما يساوي n القيمة 1 وهو أيضًا يتناقص مع تزايد قيمة n، فنحصل على المتراجحة f(n)/g(n) <= 100 +10 + 1 = 111 وقد تحقّق شرط التعريف هنا لأنّنا وجدنا حدًّا bound للتعبير f(n)/g(n) - وهو 111-، ونكون بهذا قد أثبتنا أنّf = O(g)، ونقول أنّ f هي Big-O لـ n^2. هذا يعني أنّ f تؤول إلى اللانهاية بنفس سرعة g تقريبًا. قد يبدو هذا غريبًا في البداية لأنّنا وجدنا أنّ f أكبر بـ 111 مرة من g، أو بعبارة أخرى، عندما تنمو g بمقدار 1، فإن f تنمو بمقدار 111 على أقصى حد. والحقيقة أنّ ترميز Big-O ليس دقيقًا في تصنيف سرعات تقارب الدوال، لهذا نَستخدم علاقة التكافؤ equivalence relationship في الرياضيات عندما نريد تقديرًا دقيقًا للسرعة. لكن إن أردت تصنيف الخوارزميات إلى أصناف عامّة بحسب السرعات، فإنّ Big-O كافية، إذ لن نحتاج إلى التمييز بين دالتين تنمو إحداهما أسرع من الأخرى بعدد محدد من المرات، بل المهم هو التمييز بين الدوال التي تنمو لانهائيًا أسرع من بعضها البعض. على سبيل المثال، في حالة h(n) = n^2*log(n) نلاحظ أنّ h(n)/g(n) = log(n) تؤول إلى ما لانهاية عندما يؤول n إلى ما لا نهاية، لذا فإنّ h ليست من الصنف O (n ^ 2)، لأنّ h تنمو لانهائيًا أسرع من n ^ 2. وفي مجال تحليل تعقيد الخوارزميات، نكتب f = O(g) للدلالة على أنّ: f = O(g) و g = O(f) والتي يمكن تأويلها على أنّ g هي أصغر دالة من الصنف Big-O لــ f؛ أما في الرياضيات فنقول أنّ هاتين الدالتين Big-Theta لبعضها البعض. كيفية الاستخدام أول شيء عليك حسابه عند موازنة أداء الخوارزميات هو عدد العمليات التي تجريها الخوارزمية، وهو ما يُسمّى وقت التعقيد time complexity. ونفترض في هذا النموذج أنّ كل عملية أساسية (الجمع والضرب والمقارنة والتعيين وما إلى ذلك) تستغرق مقدارًا ثابتًا من الوقت، ونحسب عدد هذه العمليات. ونعبر في الغالب عن هذا العدد كدالة لحجم الدخل -الذي نصطلح على تسميته n-، ويؤول هذا العدد (الدالة) في الغالب إلى ما لا نهاية عندما يؤول n إلى ما لا نهاية، أما خلاف ذلك، فنقول أنّ الخوارزمية من النوع O (1). ونحن نصنّف الخوارزميات إلى أصناف بحسب سرعات الدوال ونمثّلها بالترميز Big-O: فمثلًا إن قلنا أنّ خوارزميةً ما من النوع الآتي: O (n ^ 2) فإنّنا نقصد أنّ عدد العمليات التي تنفّذها الخوارزمية -معبَّرًا عنها كدالة لـ n- هو O (n ^ 2). وهو ما يعني أنّ سرعة الخوارزمية تقارب سرعة خوارزمية تجري عددًا من العمليات يساوي مرّبع حجم الدخل أو أسرع. لاحظ لفظة أو أسرع، لقد وضعناها لأنّنا استخدمنا Big-O بدلاً عن Big-Theta، ذلك أنّه من الشائع أن ترى الناس تكتب Big-O، رغم أنّهم يعنون Big-Theta. ونحن نأخذ الحالة الأسوأ في حسابنا عادة عند عدّ العمليات، فإن كانت حلقة تكرارية تُنفَّذ n مرّةً على الأكثر وكانت تحتوي على 5 عمليات، فإنّ عدد العمليات المُقدَّر سيكون 5n. كذلك من الممكن مراعاة متوسط تعقيد الحالة. يمكن أن نأخذ مساحة التخزين بالحسبان كذلك، وهو ما يُسمّى تعقيد المساحة space complexity للخوارزمية، ذلك أن الوقت ليس المورد الوحيد المهم، وفي هذه الحالة نحسُب عدد البايتات التي تشغلها الخوارزمية في الذاكرة كدالة لحجم الدخل، ونستخدم Big-O كما في حالة تعقيد الوقت. مثال عن حلقة بسيطة Simple Loop الدالة التالية تبحث عن أكبر عنصر في المصفوفة: int find_max(const int *array, size_t len) { int max = INT_MIN; for (size_t i = 0; i < len; i++) { if (max < array[i]) { max = array[i]; } } return max; } حجم الدخل هو حجم المصفوفة، والذي سمّيناه len في الشيفرة أعلاه. دعنا الآن نَعُد العمليات. int max = INT_MIN; size_t i = 0; تُنفَّذ هاتان العمليتان مرةً واحدة، لذا فلدينا عمليتان هنا. والآن نعدّ عمليات الحلقة: if (max < array[i]) i++; max = array[i] لمّا كانت هناك 3 عمليات في الحلقة، وكانت الحلقة تُنفَّذ n مرة، فسنضيف 3n إلى 2 (العمليتان اللتان حسبناهما من قبل)، ليبلغ الإجمالي 3n + 2. تجري دالتنا إذن عددًا من العمليات مقداره 3n + 2 عملية للعثور على أكبر عنصر في المصفوفة (تعقيدها يساوي 3n + 2). وهذا يعرف بتعددية الحدود polynomial، وأسرع عواملها نموّا هو العامل n، لذا يساوي تعقيدها O (n). لعلّك لاحظت أنّ طريقة عدّ العمليات ليست دقيقة، فقد قلنا مثلًا أنّ (max < array) هي عملية واحدة، ولكن اعتمادًا على هندسة الحاسوب فقد تنطوي هذه العبارة على تعليمتين مثلاً، الأولى لقراءة الذاكرة والثانية للمقارنة. وقد اعتبرنا كذلك أنّ جميع العمليات متشابهة رغم أنّ العمليات التي تخصّ الذاكرة على سبيل المثال تكون أبطأ من العمليات الأخرى، كما يختلف أداؤها اختلافًا كبيرًا بسبب تأثيرات التخزين المؤقت cache. كذلك تجاهلنا أيضًا تعليمة الإعادة return وحقيقةَ إنشاء إطار frame خاص بالدالة، وما إلى ذلك من الأمور الجانبية. لكنّ هذا لن يؤثّر في النهاية على تحليل التعقيد، ذلك أنّه مهما كانت طريقة عدّ العمليات، فلن يؤثّر إلا على معامل العامل n وكذلك لن يؤثر على الثابت، لذا ستظل النتيجة O (n). ويُظهر التعقيد كيف تتطوّر الخوارزمية مع تطوّر حجم الدخل، بيْد أنّها ليست الجانب الوحيد الذي يمثّل الأداء. مثال عن الحلقات المتشعبة Nested Loops تتحقق الدالة التالية ممّا إذا كانت المصفوفة تحتوي أيّ تكرارات، وذلك عبر المرور على كل عنصر على حدة، ثم المرور مجدّدا على المصفوفة للتحقّق ممّا إذا كان هناك عنصر آخر يساويه. _Bool contains_duplicates(const int *array, size_t len) { for (int i = 0; i < len - 1; i++) { for (int j = 0; j < len; j++) { if (i != j && array[i] == array[j]) { return 1; } } } return 0; } تنفّذ الحلقة الداخلية عند كل تكرار عددًا ثابتًا من العمليات (بغضّ النظر عن قيمة n)، كما تنفّذ الحلقة الخارجية أيضًا بعض العمليات الثابتة علاوة على تنفيذ الحلقة الداخلية عدد n مرّة. أيضًا، تنفَّذ الحلقةُ الخارجية نفسها n مرّة، وعليه تُنفّذ العمليات داخل الحلقة الداخلية n^2 مرّة بينما تُنفّذ عمليات الحلقة الخارجية n مرّة، أمّا عملية التعيين إلى i فتُتفّذ مرّة واحدة. وهكذا يمكن التعبير عن التعقيد بمعادلة مثل an^2 + bn + c، ولمّا كان المعامل الأعلى هو n^2، فإنّ ترميز O سيساوي O(n^2). لعلك لاحظت أن هناك فرصة لتحسين الخوارزمية أكثر، إذ يمكن مثلًا تجنّب إجراء نفس المقارنات أكثرة من مرّة. يمكننا أن نبدأ من i + 1 في الحلقة الداخلية نظرًا لأنّ جميع العناصر التي تسبقه قد تم التحقق منها سلفًا وقورنت مع جميع عناصر المصفوفة، بما في ذلك العنصر الموجود عند الفهرس i + 1. هذا يسمح لنا بحذف الاختبار i == j. _Bool faster_contains_duplicates(const int *array, size_t len) { for (int i = 0; i < len - 1; i++) { for (int j = i + 1; j < len; j++) { if (array[i] == array[j]) { return 1; } } } return 0; } كما ترى فإنّ هذا الإصدار أفضل لأنّه يُجري عمليات أقل، لكن كيف نترجم هذا في ترميز Big-O؟ حسنًا، في الإصدار الجديد، يُنفّذ مَتن الحلقة الداخلية المرات 1 + 2 + ... + n - 1 = n(n-1)/2 لا يزال هذا التعبير كثير الحدود من الدرجة الثانية، لذا سيظلّ التعقيد مساويا لـ O(n^2). وقد قلّلنا التعقيد إذ خفّضنا عدد العمليات إلى النصف تقريبًا، بيْد أنّنا ما زلنا في نفس صنف التعقيد من Big-O. ونحتاج إلى تقسيم عدد العمليات على مقدار يؤول إلى اللا نهاية مع n من أجل تقليل التعقيد إلى صنف أدنى. الخوارزميات اللوغاريتمية لنفترض أنّ لدينا مشكلة ذات حجم n، ولنفترض أنّ حجم مشكلتنا الأصلية ينخفض إلى النصف (n / 2) بعد كل خطوة من خطوات الخوارزمية. أي أنّه في كل خطوة جديدة يصير حجم المشكلة نصف ما كانت عليه في الخطوة التي قبلها: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الخطوة المشكلة 1 n/2 2 n/4 3 n/8 4 n/16 تكون المشكلة محلولة حين يتعذر تقليل حجمها أكثر بعد الخروج من شرط التحقق، أي عندما تكون n مساوية للقيمة 1. لنفترض الآن أنّ حجم المشكلة يساوي n، نريد أن نحسب عدد الخطوات اللازمة لحل الخوارزمية، سنرمز لهذا العدد بالحرف k: عند الخطوة k، سيساوي حجم المشكلة 1 (أي أنّ المشكلة ستكون قد حُلَّت). من جهة أخرى، نعلم أنّه عند الخطوة k، ينبغي أن يساوي حجم المشكلة العدد (n/2^k). من 1، 2، إذًا n = 2k. طبّق دالة اللوغاريتم على كلا الجانبين: log n = k * loge_2 → k = loge n / loge 2 باستخدام المعادلة التالية: logx (m) / logx (n) = logn (m) حيث يرمز التعبير logt إلى اللوغاريتم ذي الأساس t، وتصبح النتيجة k = log2 (n) أو k = log n ببساطة. انظر المثال التوضيحي التالي: for(int i=1; i<=n; i=i*2) { // إجراء بعض العمليات } إن كان n يساوي 256، فكم تتوقّع أن يكون عدد الخطوات التي ستنفّذها الحلقة أو أي خوارزمية أخرى ينخفض حجم مشكلتها إلى النصف بعد كل خطوة؟ سنرمز للعدد الذي نبحث عنه بالرمز k، ونحسبه على النحو الآتي: k = log2 (256). k = log2 (2^8) ( نعلم أنّ log(a^a) = 1 لكل عدد a). k = 8. هذا مثال آخر لتوضيح هذا النوع من الخوارزميات. وهي خوارزمية البحث الثنائي Binary Search Algorithm. int bSearch(int arr[],int size,int item){ int low=0; int high=size-1; while(low<=high){ mid=low+(high-low)/2; if(arr[mid]==item) return mid; else if(arr[mid]<item) low=mid+1; else high=mid-1; } return –1;// لا يوجد } مثال على خوارزمية من الصنف O (log n) انظر المشكلة التالية: L قائمة مرتّبة تحتوي n عددًا صحيحًا نسبيًا (n كبيرة جدا)، على سبيل المثال [-5, -2, -1, 0، 1، 2، 4] (هنا، n تساوي 7). إذا كانت L تحتوي العدد الصحيح 0، فكيف يمكنك العثور على فهرس 0؟ المقاربة البسيطة أول ما يتبادر إلى الذهن هو قراءة كل فهرس إلى حين العثور على 0، وفي أسوأ الحالات سيكون علينا إجراء n عملية، وعليه فإنّ التعقيد سيساوي O (n). لا مشكلة في هذا مع القيم الصغيرة لـ n، ولكن هل هناك طريقة أفضل؟ مبدأ الحصار Dichotomy انظر الخوارزمية التالية Python3: a = 0 b = n-1 while True: h = (a+b) // (*) if L[h] == 0: return h elif L[h] > 0: b = h elif L[h] < 0: a = h وفي أسوأ الحالات، علينا الانتظار حتى يتساوى a وb، لكن كم عدد العمليات التي يتطلبها ذلك؟ قطعًا ليس n لأننا نقسم المسافة بين a وb على 2 في كل مرة ندخل إلى الحلقة، لذا فالتعقيد يساوي O (log n). إذا صادفت خوارزمية يُقسم حجمها على عدد معيّن (2 أو 3 أو أيّ عدد) بعد كل خطوة، فإنّ تعقيدها سيكون لوغاريتميًا. ترجمة -بتصرّف- للفصل الثالث من كتاب Algorithms Notes for Professionals. اقرأ أيضًا المقالة السابقة: تعقيد الخوارزميات مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية مدخل إلى الذكاء الاصطناعي وتعلم الآلة -
.png.e952a3b3fe7eb2058bb2ae1fd279bebc.png) تستعرض هذه المقالة مفهوم التعقيد Complexity، وهو أحد المفاهيم الأساسية في علم الخوارزميات، مع ذكر بعض أهم أصناف التعقيد وبعض الترميزات المستخدمة في ذلك. ترميز Big-Omega تُستخدم ترميز Ω -notation لتمثيل المقارِب الأدنى asymptotic lower bound. التعريف الرسمي لتكن fn) و g(n) دالتين مُعرّفتين على مجموعة الأعداد الحقيقية الموجبة، فنقول أنّ f(n) = Ω(g(n)) في حال وُجِدت ثابتان موجبان c و n0 يحققان الآتي لكل n أكبر من أو تساوي n0: 0 ≤ c g(n) ≤ f(n) نظرية بالنسبة لدالتين f(n) و g(n)، نقول أنّ f(n) = Ө(g(n)) فقط إذا كان الآتي محققًا: f(n) = O(g(n)). f(n) = Ω(g(n)). يمكن تمثيل ترميز Ω بيانيًا على النحو التالي: على سبيل المثال، إذا كانت f(n) = 3n^2 + 5n - 4 فستكون f(n) = Ω(n^2)، كما ستكون f(n) = Ω(n) أو حتى f(n) = Ω(1) صحيحة. لدينا مثال آخر يحل خوارزمية التطابق التام matching algorithm، حيث إذا كان عدد الرؤوس vertices فرديًا، فسنحصل على الخرج "No Matching Matching"، وإلا فينبغي تجربة جميع التطابقات الممكنة. وكنا نودّ القول أنّ الخوارزمية تتطلب وقتًا أسيًا exponential time، لكن الواقع أنه لا يمكنك إثبات وجود حدّ أدنى Ω(n^2) باستخدام التعريف المعتاد لـ Ω نظرًا لأنّ الخوارزمية تُجرى في وقت خطي linear time لقيم n الفردية. وبدلًا من هذا فيجب علينا تعريف f(n)=Ω(g(n)) على نحو أنه بالنسبة لثابت c قيمته أكبر من الصفر، فهناك عدد لا نهائي من قيم n التي تحقّق الآتي: f(n)≥ c g(n) يوفّق هذا التعريف بين الحدّين الأعلى والأدنى إذ يحقّق التكافؤ الآتي: f(n)=Ω(g(n)) فقط إن كان f(n) != o(g(n)) ترميز Big-Theta على خلاف ترميز Big-O الذي يمثل الحد الأعلى upper bound فقط من وقت تشغيل الخوارزميات، فإنّ ترميز Big-Theta هو رابط محصور Tight bound يشمل الحدّ العلوي والسفلي معًا، وهو أكثر دقة لكنه صعب الحساب. وترميز Big-Theta متماثلة، أي تحقق المعادلة: f(x) = Ө(g(x)) <=> g(x) = Ө(f(x)) ولتفهم ذلك بسهولة، اعلم أن المعادلة الآتية f(x) = Ө(g(x)) <=> g(x) = Ө(f(x))f(x) = Ө(g(x)) تعني أنّ الرسمين البيانيين للدالتين f و g ينمُوان بنفس المعدّل، أو أنّ الرسمين البيانيين "يتصرّفان" بشكل متماثل عند قيم x الكبيرة. والتعبير الرياضي الكامل لترميز Big-Theta هو كما يلي: Ө(f(x)) = {g: N0 -> R and c1, c2, n0 > 0} حيث تكون c1 < abs(g(n) / f(n)) لكل n أكبر من n0، وتمثل abs القيمة المطلقة. ﻣﺜــــﺎل إذا كانت الخوارزمية تأخذ العدد الآتي عمليةً للانتهاء مقابل مُدخل n، فنقول أنّ تعقيدها يساوي O(n^2) ، كما يساوي أيضًا O(n^3) وO(n^100). 42n^2 + 25n + 4 أمّا في حال ترميز Big-Theta، فنقول أنّ التعقيد يساوي Ө(n^2)، لكن لا يساوي Ө(n^3) أو Ө(n^4)، إلخ… . كذلك، فإن كانت الخوارزمية من نوع Ө(f(n))، فستكون أيضًا من النوع O(f(n))، ولكن ليس العكس. التعريف الرياضي تُعرّف Ө(g(x)) على أنها مجموعة من الدوال، أما تعريفها الرياضي الرسمي Formal mathematical definition فهو: Ө(g(x)) = f(x)} وإذا كانت هناك ثوابت موجبة N وc1 و c2، بحيث يكون 0 <= c1*g(x) <= f(x) <= c2g*(x) لكل x أكبر من N}. وهذا يعني أنّ Ө(g(x)) هي مجموعةٌ تحتوي كلّ دالة f مُحاصَرة من قبل الدالة g، بمعنى أنّه توجد 3 ثوابت موجبة هي c1 و c2 وN، بحيث يكون لدينا: 0 <= c1*g(x) <= f(x) <= c2*g(x) لكل عدد x أكبر من N. وبما أن Ө(g(x)) مجموعةً فيمكننا كتابة الآتي للإشارة إلى أنّ f(x) تنتمي إلى Ө(g(x)). f(x) ∈ Ө(g(x)) غير أن الشائع هو كتابة الآتي للتعبير عن نفس الترميز: f(x) = Ө(g(x)) ويمكن تفسير Ө(g(x)) عندما تظهر في ترميز ما على أنّها كناية عن دالة مجهولة لا تهمّنا تسميتها، فمثلًا، المعادلة الآتية: T(n) = T(n/2) + Ө(n) تكافئ T(n) = T(n/2) + f(n) حيث تمثّل f(n) دالةً ما من المجموعة Ө(n)ا وإن كانت f و g دالتين مُعرَّفتين على نفس النطاق من مجموعة الأعداد الحقيقية real numbers، فإننا نكتب الآتي: f(x) = Ө(g(x)) عندما تؤول x إلى ما لا نهاية x->infinity، وذلك فقط في حالة وجود ثابتْين موجبيْن K و L وعدد حقيقي x0 يحققون K|g(x)| <= f(x) <= L|g(x)| لكل x أكبر من أو تساوي x0. يكون التعريف مكافئًا للعبارة التالية: f(x) = O(g(x)) والعبارة: f(x) = Ω(g(x)) استخدام مفهوم النهايات limits إذا كان لدينا limit(x->infinity) f(x)/g(x) = c ∈ ( 0,∞) أي أنّ النهاية موجودة وموجبة، أي: f(x) = Ө(g(x)) وفيما يلي بعض أصناف التعقيد الشائعة: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الاسم الترميز n = 10 n = 100 Constant - ثابت Ө(1) 1 1 Logarithmic - لوغارتمي Ө(log(n)) 3 7 Linear - خطي Ө(n) 10 100 Linearithmic - لوغارتمي-خطي Ө(n*log(n)) 30 700 Quadratic - تربيعي Ө(n^2) 100 10000 Exponential - أسّي Ө(2^n) 1024 1.267650e+ 30 Factorial - مُعاملي Ө(n!) 3 628 800 9.332622e+157 موازنة الصيغ المقاربة asymptotic notations لتكن f(n) و g(n) دالتين مُعرّفتين على مجموعة الأعداد الحقيقية الموجبة، ولتكن c, c1, c2, n0 ثوابت حقيقية موجبة. يوضّح الجدول التالي الفروق بين مختلف الصيغ: الترميز f(n) = O(g(n)) f(n) = Ω(g(n)) f(n) = Θ(g(n)) f(n) = o(g(n)) f(n) = ω(g(n)) التعريف الرسمي ∃ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ f(n) ≤ c g(n) ∃ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ c g(n) ≤ f(n) ∃ c1, c2 > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ c1 g(n) ≤ f(n) ≤ c2 g(n) ∀ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ f(n) < c g(n) ∀ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ c g(n) < f(n) التشابه مع الموازنة بين عددين a وb a ≤ b a ≥ b a = b a < b a > b أمثلة 7n + 10 = O(n^2 + n - 9) n^3 - 34 = Ω(10n^2 - 7n + 1) 1/2 n^2 - 7n = Θ(n^2) 5n^2 = o(n^3) 7n^2 = ω(n) الرسوم البيانية يمكن تمثيل الصيغ المُقارِبة بواسطة مخطّط فِن كما يلي: ترجمة -بتصرّف- للفصل الثاني من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة بايثون باستخدام مكتبة Scikit-Learn النسخة الكامة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة
تستعرض هذه المقالة مفهوم التعقيد Complexity، وهو أحد المفاهيم الأساسية في علم الخوارزميات، مع ذكر بعض أهم أصناف التعقيد وبعض الترميزات المستخدمة في ذلك. ترميز Big-Omega تُستخدم ترميز Ω -notation لتمثيل المقارِب الأدنى asymptotic lower bound. التعريف الرسمي لتكن fn) و g(n) دالتين مُعرّفتين على مجموعة الأعداد الحقيقية الموجبة، فنقول أنّ f(n) = Ω(g(n)) في حال وُجِدت ثابتان موجبان c و n0 يحققان الآتي لكل n أكبر من أو تساوي n0: 0 ≤ c g(n) ≤ f(n) نظرية بالنسبة لدالتين f(n) و g(n)، نقول أنّ f(n) = Ө(g(n)) فقط إذا كان الآتي محققًا: f(n) = O(g(n)). f(n) = Ω(g(n)). يمكن تمثيل ترميز Ω بيانيًا على النحو التالي: على سبيل المثال، إذا كانت f(n) = 3n^2 + 5n - 4 فستكون f(n) = Ω(n^2)، كما ستكون f(n) = Ω(n) أو حتى f(n) = Ω(1) صحيحة. لدينا مثال آخر يحل خوارزمية التطابق التام matching algorithm، حيث إذا كان عدد الرؤوس vertices فرديًا، فسنحصل على الخرج "No Matching Matching"، وإلا فينبغي تجربة جميع التطابقات الممكنة. وكنا نودّ القول أنّ الخوارزمية تتطلب وقتًا أسيًا exponential time، لكن الواقع أنه لا يمكنك إثبات وجود حدّ أدنى Ω(n^2) باستخدام التعريف المعتاد لـ Ω نظرًا لأنّ الخوارزمية تُجرى في وقت خطي linear time لقيم n الفردية. وبدلًا من هذا فيجب علينا تعريف f(n)=Ω(g(n)) على نحو أنه بالنسبة لثابت c قيمته أكبر من الصفر، فهناك عدد لا نهائي من قيم n التي تحقّق الآتي: f(n)≥ c g(n) يوفّق هذا التعريف بين الحدّين الأعلى والأدنى إذ يحقّق التكافؤ الآتي: f(n)=Ω(g(n)) فقط إن كان f(n) != o(g(n)) ترميز Big-Theta على خلاف ترميز Big-O الذي يمثل الحد الأعلى upper bound فقط من وقت تشغيل الخوارزميات، فإنّ ترميز Big-Theta هو رابط محصور Tight bound يشمل الحدّ العلوي والسفلي معًا، وهو أكثر دقة لكنه صعب الحساب. وترميز Big-Theta متماثلة، أي تحقق المعادلة: f(x) = Ө(g(x)) <=> g(x) = Ө(f(x)) ولتفهم ذلك بسهولة، اعلم أن المعادلة الآتية f(x) = Ө(g(x)) <=> g(x) = Ө(f(x))f(x) = Ө(g(x)) تعني أنّ الرسمين البيانيين للدالتين f و g ينمُوان بنفس المعدّل، أو أنّ الرسمين البيانيين "يتصرّفان" بشكل متماثل عند قيم x الكبيرة. والتعبير الرياضي الكامل لترميز Big-Theta هو كما يلي: Ө(f(x)) = {g: N0 -> R and c1, c2, n0 > 0} حيث تكون c1 < abs(g(n) / f(n)) لكل n أكبر من n0، وتمثل abs القيمة المطلقة. ﻣﺜــــﺎل إذا كانت الخوارزمية تأخذ العدد الآتي عمليةً للانتهاء مقابل مُدخل n، فنقول أنّ تعقيدها يساوي O(n^2) ، كما يساوي أيضًا O(n^3) وO(n^100). 42n^2 + 25n + 4 أمّا في حال ترميز Big-Theta، فنقول أنّ التعقيد يساوي Ө(n^2)، لكن لا يساوي Ө(n^3) أو Ө(n^4)، إلخ… . كذلك، فإن كانت الخوارزمية من نوع Ө(f(n))، فستكون أيضًا من النوع O(f(n))، ولكن ليس العكس. التعريف الرياضي تُعرّف Ө(g(x)) على أنها مجموعة من الدوال، أما تعريفها الرياضي الرسمي Formal mathematical definition فهو: Ө(g(x)) = f(x)} وإذا كانت هناك ثوابت موجبة N وc1 و c2، بحيث يكون 0 <= c1*g(x) <= f(x) <= c2g*(x) لكل x أكبر من N}. وهذا يعني أنّ Ө(g(x)) هي مجموعةٌ تحتوي كلّ دالة f مُحاصَرة من قبل الدالة g، بمعنى أنّه توجد 3 ثوابت موجبة هي c1 و c2 وN، بحيث يكون لدينا: 0 <= c1*g(x) <= f(x) <= c2*g(x) لكل عدد x أكبر من N. وبما أن Ө(g(x)) مجموعةً فيمكننا كتابة الآتي للإشارة إلى أنّ f(x) تنتمي إلى Ө(g(x)). f(x) ∈ Ө(g(x)) غير أن الشائع هو كتابة الآتي للتعبير عن نفس الترميز: f(x) = Ө(g(x)) ويمكن تفسير Ө(g(x)) عندما تظهر في ترميز ما على أنّها كناية عن دالة مجهولة لا تهمّنا تسميتها، فمثلًا، المعادلة الآتية: T(n) = T(n/2) + Ө(n) تكافئ T(n) = T(n/2) + f(n) حيث تمثّل f(n) دالةً ما من المجموعة Ө(n)ا وإن كانت f و g دالتين مُعرَّفتين على نفس النطاق من مجموعة الأعداد الحقيقية real numbers، فإننا نكتب الآتي: f(x) = Ө(g(x)) عندما تؤول x إلى ما لا نهاية x->infinity، وذلك فقط في حالة وجود ثابتْين موجبيْن K و L وعدد حقيقي x0 يحققون K|g(x)| <= f(x) <= L|g(x)| لكل x أكبر من أو تساوي x0. يكون التعريف مكافئًا للعبارة التالية: f(x) = O(g(x)) والعبارة: f(x) = Ω(g(x)) استخدام مفهوم النهايات limits إذا كان لدينا limit(x->infinity) f(x)/g(x) = c ∈ ( 0,∞) أي أنّ النهاية موجودة وموجبة، أي: f(x) = Ө(g(x)) وفيما يلي بعض أصناف التعقيد الشائعة: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الاسم الترميز n = 10 n = 100 Constant - ثابت Ө(1) 1 1 Logarithmic - لوغارتمي Ө(log(n)) 3 7 Linear - خطي Ө(n) 10 100 Linearithmic - لوغارتمي-خطي Ө(n*log(n)) 30 700 Quadratic - تربيعي Ө(n^2) 100 10000 Exponential - أسّي Ө(2^n) 1024 1.267650e+ 30 Factorial - مُعاملي Ө(n!) 3 628 800 9.332622e+157 موازنة الصيغ المقاربة asymptotic notations لتكن f(n) و g(n) دالتين مُعرّفتين على مجموعة الأعداد الحقيقية الموجبة، ولتكن c, c1, c2, n0 ثوابت حقيقية موجبة. يوضّح الجدول التالي الفروق بين مختلف الصيغ: الترميز f(n) = O(g(n)) f(n) = Ω(g(n)) f(n) = Θ(g(n)) f(n) = o(g(n)) f(n) = ω(g(n)) التعريف الرسمي ∃ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ f(n) ≤ c g(n) ∃ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ c g(n) ≤ f(n) ∃ c1, c2 > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ c1 g(n) ≤ f(n) ≤ c2 g(n) ∀ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ f(n) < c g(n) ∀ c > 0, ∃ n0 > 0 : ∀ n ≥ n0, 0 ≤ c g(n) < f(n) التشابه مع الموازنة بين عددين a وb a ≤ b a ≥ b a = b a < b a > b أمثلة 7n + 10 = O(n^2 + n - 9) n^3 - 34 = Ω(10n^2 - 7n + 1) 1/2 n^2 - 7n = Θ(n^2) 5n^2 = o(n^3) 7n^2 = ω(n) الرسوم البيانية يمكن تمثيل الصيغ المُقارِبة بواسطة مخطّط فِن كما يلي: ترجمة -بتصرّف- للفصل الثاني من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة بايثون باستخدام مكتبة Scikit-Learn النسخة الكامة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة -
 تُعرف خوارزمية ديكسترا بخوارزمية أقصر مسار أحادي المصدر single-source shortest path algorithm، وتُستخدم للعثور على أقصر المسارات بين العقد في مخطط، وقد ابتُكرت هذه الخوارزمية على يد إدجستر ديكسترا Edsger W. Dijkstra -النطق من الهولندية- عام 1956، ونُشِرت بعدها بثلاث سنوات. يمكننا العثور على أقصر مسار باستخدام خوارزمية البحث بالوُسع أو العرض أولًا Breadth First Search اختصارًا BFS. وتعمل هذه الخوارزمية جيدًا لكنّها محدودة، إذ تفترض أنّ تكلفة cost اجتياز كل مسار لا تتغيّر، أي أنّ أوزان جميع الأضلاع متساوية. تساعدنا خوارزمية ديكسترا على العثور على أقصر مسار حتى لو كانت تكاليف المسارات مختلفة. سنتعلّم في البداية كيفية تعديل خوارزمية BFS لكتابة خوارزمية Dijkstra، ثم سنضيف طابور الأولويات priority queue لجعلها خوارزمية Dijkstra كاملة. لنفترض أنّ المسافة بين كل عقدة وبين المصدر مُخزّنة في مصفوفة d[]، حيث تمثّل d[3] مثلًا الوقت اللازم للوصول إلى العقدة 3 من المصدر، وإذا لم نعرف المسافة فسنضع قيمة ما لا نهاية infinity في d[3]. لنفترض أن cost مصفوفة تخزّن التكاليف، بحيث تحتوي cost[u][v] على كلفة مجموع أوزان الأضلاع التي تؤلف المسار u-v، أي أنّ الانتقال من العقدة u إلى العقدة v يتطلب تكلفة cost[u][v]. قبل أن نواصل، سنوضّح مفهوم تخفيف الضلع Edge Relaxation. لنفترض أنّك تحتاج 10 دقائق للانتقال من منزلك (المصدر) إلى المكان A، بينما يستغرق الانتقال إلى المكان B حوالي 25 دقيقة. سيكون لدينا إذًا الآتي: d[A] = 10 d[B] = 25 لنفترض الآن أنّك تحتاج 7 دقائق للانتقال من A إلى B، هذا يعني أنّ: cost[A][B] = 7 يمكننا الذهاب إلى B عبر الانتقال من المصدر (منزلك) إلى A، ثمّ من A إلى B، وسيستغرق هذا 10 + 7 = 17 دقيقة بدلًا من 25 دقيقة: d[A] + cost[A][B] < d[B] نحدّث الجدول على النحو التالي: d[B] = d[A] + cost[A][B] يسمّى هذا تخفيفًا relaxation، إذ نذهب من u إلى v، فإذا وجدنا أنّ < d[u] + cost[u][v] < d[v]، فسنحدّث المصفوفة بالقيمة d[v] = d[u] + cost[u][v]. لم نكن بحاجة إلى زيارة أيّ عقدة مرتين في خوارزمية البحث بالوُسع أولًا BFS، فقد اكتفينا بالتحقّق ممّا إذا تمّت زيارة العقدة أم لا، فإن لم تُزَر، فسنضع العقدة في الطابور ثمّ نحددها على أنّها "تمت زيارتها"، بعدها نزيد المسافة بمقدار 1؛ أما في خوارزمية Dijkstra، فإننا نضع العقدة في الطابور، لكن بدلًا من تحديثها وتحديدها على أنّها مُزارة، فسنخفّف الضلع الجديد relax أو نحدّثه. انظر المثال التالي: لنفترض أنّ العقدة 1 هي المصدر، إذًا: d[1] = 0 d[2] = d[3] = d[4] = infinity (or a large value) لقد عيّنا قيم d [2] وd [3] وd [4] إلى ما لا نهاية لأنّنا لا نعرف المسافة بعد، أمّا مسافة المصدر فتُساوي 0 بالطبع. سننتقل الآن إلى العُقد الأخرى انطلاقًا من المصدر، وإذا كانت هناك حاجة لتحديثها فسنضيفها إلى الطابور. لنقل على سبيل المثال أنّنا سنجتاز الضلع 1-2، وبما أن d[1] + 2 < d[2]، فسنضع d[2] = 2، وبالمثل نجتاز الضلع 1-3، وتبعًا لذلك نكتب d [3] = 5. يمكن أن ترى بوضوح أنّ 5 ليست أقصر مسافة يمكننا عبورها للذهاب إلى العقدة 3، لذا فإنّ اجتياز العقدة مرّةً واحدةً فقط كما في خوارزمية BFS، ليس صالحًا هنا. ويمكننا إضافة التحديث d [3] = d [2] + 1 = 3 إذا انتقلنا من العقدة 2 إلى العقدة 3 باستخدام الضلع 2-3. وكما ترى، فمن الممكن تحديث العقدة الواحدة عدّة مرات. قد تسأل عن عدد المرات التي يمكن أن نفعل فيها ذلك، والإجابة هنا هي أن الحد الأقصى لعدد مرات تحديث العقدة هو الدرجة الداخلية in-degree لتلك العقدة. فيما يلي شيفرة عامّة لزيارة أيّ عقدة عدّة مرات، هذه الشيفرة هي تعديل لخوارزمية BFS: procedure BFSmodified(G, source): Q = queue() distance[] = infinity Q.enqueue(source) distance[source]=0 while Q is not empty u <- Q.pop() for all edges from u to v in G.adjacentEdges(v) do if distance[u] + cost[u][v] < distance[v] distance[v] = distance[u] + cost[u][v] end if end for end while Return distance يمكن استخدام هذا للعثور على أقصر مسار إلى جميع العقدة انطلاقًا من المصدر، ولا يُعد تعقيد هذه الشيفرة جيدًا، ذلك أننا في خوارزمية BFS نتبّع طريقة أوّل من يأتي هو أوّل من يُخدم "first come, first serve" عندما تنتقل من العقدة 1 إلى أي عقدة أخرى. فمثلًا، نحن ذهبنا إلى العقدة 3 من المصدر قبل معالجة العقدة 2، وعليه سنحدّث العقدة 4 إذا ذهبنا إلى العقدة 3 من المصدر، وذلك لأنّ 5 + 3 = 8. وعندما نحدّث العقدة 3 مرّةً أخرى من العقدة 2، فسيكون علينا تحديث العقدة 4 بالقيمة 3 + 3 = 6 مرّةً أخرى، وعليه تكون العقدة 4 قد حُدِّثَت مرتين. وقد اقترح Dijkstra طريقة أخرى بدلًا من طريقة أوّل من يأتي أوّل من يُخدَم، فإذا حدّثنا العُقَد الأقرب أولًا سنستطيع إجراء عدد أقل من التحديثات، وإذا كنا قد عالجنا العقدة 2 من قبل، فإنّ العقدة 3 ستكون قد حُدِّثت كذلك من قبل، وسنحصل على أقصر مسافة بسهولة بعد تحديث العقدة 4 وفقًا لذلك. الفكرة هنا هي أن نختار أقرب عقدة إلى المصدر من الطابور، لذلك سنستخدم طابور أولويات Priority Queue، وعندما ننزع عنصرًا من الطابور، سنحصل على أقرب عقدة u من المصدر عبر التحقق من قيمة d[u]. انظر الشيفرة التوضيحية التالية: procedure dijkstra(G, source): Q = priority_queue() distance[] = infinity Q.enqueue(source) distance[source] = 0 while Q is not empty u <- nodes in Q with minimum distance[] remove u from the Q for all edges from u to v in G.adjacentEdges(v) do if distance[u] + cost[u][v] < distance[v] distance[v] = distance[u] + cost[u][v] Q.enqueue(v) end if end for end while Return distance تعيد الشيفرة التوضيحية مسافةَ جميعِ العقد الأخرى من المصدر، فإذا أردنا معرفة مسافة عقدة v، فيمكننا ببساطة إعادة القيمة الناتجة عن أخذ v من الطابور. السؤال الآن هو: هل تعمل خوارزمية ديكسترا حال وجود ضلع سالب negative edge؟ إذا كانت هناك دورة سالبة فستحدث حلقة لا نهائية، وذلك لأنها ستستمر في تخفيض التكلفة إلى الأبد، ولن تعمل خوارزمية ديكسترا حتى لو كان لدينا ضلع سالب إلا إذا عدنا مباشرةً بعد أخذ الهدف من الطابور، لكن لن تكون الخوارزمية حينئذ خوارزميةَ Dijkstra، وسنحتاج إلى خوارزمية بيلمن فورد Bellman-Ford لمعالجة الأضلاع أو الدورات السالبة. يتساوى تعقيد خوارزمية BFS مع O(log(V+E))، حيث يمثّل V عدد العقد، ويمثّل E عدد الأضلاع، والتعقيد مقارب لهذه القيمة فيما يخصّ خوارزمية Dijkstra، لكنّ ترتيب طابور الأولويات يأخذ O (logV)، لذا فإنّ التعقيد الكلي يساوي: O (V log (V) + E). المثال أدناه هو تطبيق بلغة جافا لخوارزمية Dijkstra باستخدام مصفوفة التجاور: import java.util.*; import java.lang.*; import java.io.*; class ShortestPath { static final int V=9; int minDistance(int dist[], Boolean sptSet[]) { int min = Integer.MAX_VALUE, min_index=-1; for (int v = 0; v < V; v++) if (sptSet[v] == false && dist[v] <= min) { min = dist[v]; min_index = v; } return min_index; } void printSolution(int dist[], int n) { System.out.println("Vertex Distance from Source"); for (int i = 0; i < V; i++) System.out.println(i+" \t\t "+dist[i]); } void dijkstra(int graph[][], int src) { Boolean sptSet[] = new Boolean[V]; for (int i = 0; i < V; i++) { dist[i] = Integer.MAX_VALUE; sptSet[i] = false; } dist[src] = 0; for (int count = 0; count < V-1; count++) { int u = minDistance(dist, sptSet); sptSet[u] = true; for (int v = 0; v < V; v++) if (!sptSet[v] && graph[u][v]!=0 && dist[u] != Integer.MAX_VALUE && dist[u]+graph[u][v] < dist[v]) dist[v] = dist[u] + graph[u][v]; } printSolution(dist, V); } public static void main (String[] args) { int graph[][] = new int[][]{{0, 4, 0, 0, 0, 0, 0, 8, 0}, {4, 0, 8, 0, 0, 0, 0, 11, 0}, {0, 8, 0, 7, 0, 4, 0, 0, 2}, {0, 0, 7, 0, 9, 14, 0, 0, 0}, {0, 0, 0, 9, 0, 10, 0, 0, 0}, {0, 0, 4, 14, 10, 0, 2, 0, 0}, {0, 0, 0, 0, 0, 2, 0, 1, 6}, {8, 11, 0, 0, 0, 0, 1, 0, 7}, {0, 0, 2, 0, 0, 0, 6, 7, 0} }; ShortestPath t = new ShortestPath(); t.dijkstra(graph, 0); } } هذا هو الخرج المتوقّع: Vertex Distance from Source 0 0 1 4 2 12 3 19 4 21 5 11 6 9 7 8 8 14 ترجمة -بتصرّف- للفصل 11 من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: الرسوم التخطيطية Graphs في الخوارزميات المرجع الشامل إلى تعلم الخوارزميات للمبتدئين مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية مدخل إلى الذكاء الاصطناعي وتعلم الآلة
تُعرف خوارزمية ديكسترا بخوارزمية أقصر مسار أحادي المصدر single-source shortest path algorithm، وتُستخدم للعثور على أقصر المسارات بين العقد في مخطط، وقد ابتُكرت هذه الخوارزمية على يد إدجستر ديكسترا Edsger W. Dijkstra -النطق من الهولندية- عام 1956، ونُشِرت بعدها بثلاث سنوات. يمكننا العثور على أقصر مسار باستخدام خوارزمية البحث بالوُسع أو العرض أولًا Breadth First Search اختصارًا BFS. وتعمل هذه الخوارزمية جيدًا لكنّها محدودة، إذ تفترض أنّ تكلفة cost اجتياز كل مسار لا تتغيّر، أي أنّ أوزان جميع الأضلاع متساوية. تساعدنا خوارزمية ديكسترا على العثور على أقصر مسار حتى لو كانت تكاليف المسارات مختلفة. سنتعلّم في البداية كيفية تعديل خوارزمية BFS لكتابة خوارزمية Dijkstra، ثم سنضيف طابور الأولويات priority queue لجعلها خوارزمية Dijkstra كاملة. لنفترض أنّ المسافة بين كل عقدة وبين المصدر مُخزّنة في مصفوفة d[]، حيث تمثّل d[3] مثلًا الوقت اللازم للوصول إلى العقدة 3 من المصدر، وإذا لم نعرف المسافة فسنضع قيمة ما لا نهاية infinity في d[3]. لنفترض أن cost مصفوفة تخزّن التكاليف، بحيث تحتوي cost[u][v] على كلفة مجموع أوزان الأضلاع التي تؤلف المسار u-v، أي أنّ الانتقال من العقدة u إلى العقدة v يتطلب تكلفة cost[u][v]. قبل أن نواصل، سنوضّح مفهوم تخفيف الضلع Edge Relaxation. لنفترض أنّك تحتاج 10 دقائق للانتقال من منزلك (المصدر) إلى المكان A، بينما يستغرق الانتقال إلى المكان B حوالي 25 دقيقة. سيكون لدينا إذًا الآتي: d[A] = 10 d[B] = 25 لنفترض الآن أنّك تحتاج 7 دقائق للانتقال من A إلى B، هذا يعني أنّ: cost[A][B] = 7 يمكننا الذهاب إلى B عبر الانتقال من المصدر (منزلك) إلى A، ثمّ من A إلى B، وسيستغرق هذا 10 + 7 = 17 دقيقة بدلًا من 25 دقيقة: d[A] + cost[A][B] < d[B] نحدّث الجدول على النحو التالي: d[B] = d[A] + cost[A][B] يسمّى هذا تخفيفًا relaxation، إذ نذهب من u إلى v، فإذا وجدنا أنّ < d[u] + cost[u][v] < d[v]، فسنحدّث المصفوفة بالقيمة d[v] = d[u] + cost[u][v]. لم نكن بحاجة إلى زيارة أيّ عقدة مرتين في خوارزمية البحث بالوُسع أولًا BFS، فقد اكتفينا بالتحقّق ممّا إذا تمّت زيارة العقدة أم لا، فإن لم تُزَر، فسنضع العقدة في الطابور ثمّ نحددها على أنّها "تمت زيارتها"، بعدها نزيد المسافة بمقدار 1؛ أما في خوارزمية Dijkstra، فإننا نضع العقدة في الطابور، لكن بدلًا من تحديثها وتحديدها على أنّها مُزارة، فسنخفّف الضلع الجديد relax أو نحدّثه. انظر المثال التالي: لنفترض أنّ العقدة 1 هي المصدر، إذًا: d[1] = 0 d[2] = d[3] = d[4] = infinity (or a large value) لقد عيّنا قيم d [2] وd [3] وd [4] إلى ما لا نهاية لأنّنا لا نعرف المسافة بعد، أمّا مسافة المصدر فتُساوي 0 بالطبع. سننتقل الآن إلى العُقد الأخرى انطلاقًا من المصدر، وإذا كانت هناك حاجة لتحديثها فسنضيفها إلى الطابور. لنقل على سبيل المثال أنّنا سنجتاز الضلع 1-2، وبما أن d[1] + 2 < d[2]، فسنضع d[2] = 2، وبالمثل نجتاز الضلع 1-3، وتبعًا لذلك نكتب d [3] = 5. يمكن أن ترى بوضوح أنّ 5 ليست أقصر مسافة يمكننا عبورها للذهاب إلى العقدة 3، لذا فإنّ اجتياز العقدة مرّةً واحدةً فقط كما في خوارزمية BFS، ليس صالحًا هنا. ويمكننا إضافة التحديث d [3] = d [2] + 1 = 3 إذا انتقلنا من العقدة 2 إلى العقدة 3 باستخدام الضلع 2-3. وكما ترى، فمن الممكن تحديث العقدة الواحدة عدّة مرات. قد تسأل عن عدد المرات التي يمكن أن نفعل فيها ذلك، والإجابة هنا هي أن الحد الأقصى لعدد مرات تحديث العقدة هو الدرجة الداخلية in-degree لتلك العقدة. فيما يلي شيفرة عامّة لزيارة أيّ عقدة عدّة مرات، هذه الشيفرة هي تعديل لخوارزمية BFS: procedure BFSmodified(G, source): Q = queue() distance[] = infinity Q.enqueue(source) distance[source]=0 while Q is not empty u <- Q.pop() for all edges from u to v in G.adjacentEdges(v) do if distance[u] + cost[u][v] < distance[v] distance[v] = distance[u] + cost[u][v] end if end for end while Return distance يمكن استخدام هذا للعثور على أقصر مسار إلى جميع العقدة انطلاقًا من المصدر، ولا يُعد تعقيد هذه الشيفرة جيدًا، ذلك أننا في خوارزمية BFS نتبّع طريقة أوّل من يأتي هو أوّل من يُخدم "first come, first serve" عندما تنتقل من العقدة 1 إلى أي عقدة أخرى. فمثلًا، نحن ذهبنا إلى العقدة 3 من المصدر قبل معالجة العقدة 2، وعليه سنحدّث العقدة 4 إذا ذهبنا إلى العقدة 3 من المصدر، وذلك لأنّ 5 + 3 = 8. وعندما نحدّث العقدة 3 مرّةً أخرى من العقدة 2، فسيكون علينا تحديث العقدة 4 بالقيمة 3 + 3 = 6 مرّةً أخرى، وعليه تكون العقدة 4 قد حُدِّثَت مرتين. وقد اقترح Dijkstra طريقة أخرى بدلًا من طريقة أوّل من يأتي أوّل من يُخدَم، فإذا حدّثنا العُقَد الأقرب أولًا سنستطيع إجراء عدد أقل من التحديثات، وإذا كنا قد عالجنا العقدة 2 من قبل، فإنّ العقدة 3 ستكون قد حُدِّثت كذلك من قبل، وسنحصل على أقصر مسافة بسهولة بعد تحديث العقدة 4 وفقًا لذلك. الفكرة هنا هي أن نختار أقرب عقدة إلى المصدر من الطابور، لذلك سنستخدم طابور أولويات Priority Queue، وعندما ننزع عنصرًا من الطابور، سنحصل على أقرب عقدة u من المصدر عبر التحقق من قيمة d[u]. انظر الشيفرة التوضيحية التالية: procedure dijkstra(G, source): Q = priority_queue() distance[] = infinity Q.enqueue(source) distance[source] = 0 while Q is not empty u <- nodes in Q with minimum distance[] remove u from the Q for all edges from u to v in G.adjacentEdges(v) do if distance[u] + cost[u][v] < distance[v] distance[v] = distance[u] + cost[u][v] Q.enqueue(v) end if end for end while Return distance تعيد الشيفرة التوضيحية مسافةَ جميعِ العقد الأخرى من المصدر، فإذا أردنا معرفة مسافة عقدة v، فيمكننا ببساطة إعادة القيمة الناتجة عن أخذ v من الطابور. السؤال الآن هو: هل تعمل خوارزمية ديكسترا حال وجود ضلع سالب negative edge؟ إذا كانت هناك دورة سالبة فستحدث حلقة لا نهائية، وذلك لأنها ستستمر في تخفيض التكلفة إلى الأبد، ولن تعمل خوارزمية ديكسترا حتى لو كان لدينا ضلع سالب إلا إذا عدنا مباشرةً بعد أخذ الهدف من الطابور، لكن لن تكون الخوارزمية حينئذ خوارزميةَ Dijkstra، وسنحتاج إلى خوارزمية بيلمن فورد Bellman-Ford لمعالجة الأضلاع أو الدورات السالبة. يتساوى تعقيد خوارزمية BFS مع O(log(V+E))، حيث يمثّل V عدد العقد، ويمثّل E عدد الأضلاع، والتعقيد مقارب لهذه القيمة فيما يخصّ خوارزمية Dijkstra، لكنّ ترتيب طابور الأولويات يأخذ O (logV)، لذا فإنّ التعقيد الكلي يساوي: O (V log (V) + E). المثال أدناه هو تطبيق بلغة جافا لخوارزمية Dijkstra باستخدام مصفوفة التجاور: import java.util.*; import java.lang.*; import java.io.*; class ShortestPath { static final int V=9; int minDistance(int dist[], Boolean sptSet[]) { int min = Integer.MAX_VALUE, min_index=-1; for (int v = 0; v < V; v++) if (sptSet[v] == false && dist[v] <= min) { min = dist[v]; min_index = v; } return min_index; } void printSolution(int dist[], int n) { System.out.println("Vertex Distance from Source"); for (int i = 0; i < V; i++) System.out.println(i+" \t\t "+dist[i]); } void dijkstra(int graph[][], int src) { Boolean sptSet[] = new Boolean[V]; for (int i = 0; i < V; i++) { dist[i] = Integer.MAX_VALUE; sptSet[i] = false; } dist[src] = 0; for (int count = 0; count < V-1; count++) { int u = minDistance(dist, sptSet); sptSet[u] = true; for (int v = 0; v < V; v++) if (!sptSet[v] && graph[u][v]!=0 && dist[u] != Integer.MAX_VALUE && dist[u]+graph[u][v] < dist[v]) dist[v] = dist[u] + graph[u][v]; } printSolution(dist, V); } public static void main (String[] args) { int graph[][] = new int[][]{{0, 4, 0, 0, 0, 0, 0, 8, 0}, {4, 0, 8, 0, 0, 0, 0, 11, 0}, {0, 8, 0, 7, 0, 4, 0, 0, 2}, {0, 0, 7, 0, 9, 14, 0, 0, 0}, {0, 0, 0, 9, 0, 10, 0, 0, 0}, {0, 0, 4, 14, 10, 0, 2, 0, 0}, {0, 0, 0, 0, 0, 2, 0, 1, 6}, {8, 11, 0, 0, 0, 0, 1, 0, 7}, {0, 0, 2, 0, 0, 0, 6, 7, 0} }; ShortestPath t = new ShortestPath(); t.dijkstra(graph, 0); } } هذا هو الخرج المتوقّع: Vertex Distance from Source 0 0 1 4 2 12 3 19 4 21 5 11 6 9 7 8 8 14 ترجمة -بتصرّف- للفصل 11 من كتاب Algorithms Notes for Professionals اقرأ أيضًا المقالة السابقة: الرسوم التخطيطية Graphs في الخوارزميات المرجع الشامل إلى تعلم الخوارزميات للمبتدئين مدخل إلى الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية مدخل إلى الذكاء الاصطناعي وتعلم الآلة -
 هذه المقالة هي تتمة للمقالة السابقة، وفيها تجد عددًا من التطبيقات الحقيقية للخوارزميات الشَرِهَة لحل بعض المشاكل، مثل تقليل التأخير وجدولة الوظائف وإدارة ذاكرة التخزين المؤقت. التخزين المؤقت غير المتصل Offline Caching تنشأ مشكلة التخزين المؤقت caching بسبب محدودية مساحة التخزين، فمثلًا لنفرض أن ذاكرةَ تخزينٍ مؤقتة ولتكن C، تحتوي على عدد k من الصفحات، ونريد معالجة سلسلة من العناصر عددها m عنصر، هنا يجب تخزين هذه العناصر في الذاكرة المؤقتة قبل معالجتها. لا شك أنه لن توجد مشكلة إن كانت m<=k، إذ سنضع جميع العناصر في ذاكرة التخزين المؤقت، ولكن في العادة تكون m>>k. نقول أنّ طلبيّةً ما مقبولة في ذاكرة التخزين المؤقت cache hit إذا كان العنصر موجودًا في ذاكرة التخزين المؤقت فعليًا، وإلا سنقول أنّها مُفوَّتة عن ذاكرة التخزين المؤقت cache miss. سيكون علينا في مثل هذه الحالة إحضار العنصر المطلوب إلى ذاكرة التخزين المؤقت وإخراج عنصر آخر، وذلك بفرض أنّ ذاكرة التخزين المؤقت ممتلئة، وهدفنا هو تصميم جدول إخلاء eviction schedule يقلّل قدر الإمكان من عدد عمليات الإخلاء الضرورية. هناك عدة استراتيجيات شَرِهَة لحلّ هذه المشكلة، من بينها: أول داخل، أول خارج First in, first out أو FIFO: تُخلى أقدم صفحة. آخر داخل، أوّل خارج Last in, first out أو LIFO: تُخلى أحدث صفحة. خروج الأبكر وصولًا Last recent out أو اختصارا LRU: إخلاء الصفحة التي تمّ الدخول إليها في أبكر وقت. الأقل طلبًا Least frequently requested أو LFU: إخلاء الصفحة التي طُلِبت أقل عدد من المرات. أطول مسافة أمامية Longest forward distance أو LFD: إخلاء الصفحة التي ستُطلَب في أبعد مسافة في المستقبل. مثال FIFO لنفترض أنّ حجم ذاكرة التخزين المؤقت هو k=3، وأنّ ذاكرة التخزين المؤقت الأولية تحتوي a,b,c، وأنّ هناك قائمةً من الطلبيات هي على النحو الآتي: a,a,d,e,b,b,a,c,f,d,e,a,f,b,e,c table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الطلب a a d e b b a c f d e a f b e c المخزن المؤقت 1 a a d d d d a a a d d d f f f c المخزن المؤقت 2 b b b e e e e c c c e e e b b b المخزن المؤقت 3 c c c c b b b b f f f a a a e e الحالات المفوَّتة x x x x x x x x x x x x x فوّتنا ثلاثة عشرة عنصرًا من ذاكرة التخزين المؤقت من بين ستة عشر طلبية، وهو أمر لا يبدو جيدًا، لذلك من الأحسن أن نجرّب استراتيجيةً أخرى. مثال LFD لنفترض أنّ حجم ذاكرة التخزين المؤقت هو k=3، وأنّ ذاكرة التخزين المؤقت الأولية تحتوي a,b,c؛ أما الطلبيات فهي: الطلب a a d e b b a c f d e a f b e c المخزن المؤقت 1 a a d e e e e e e e e e e e e c المخزن المؤقت 2 b b b b b b a a a a a a f f f f المخزن المؤقت 3 c c c c c c c c f d d d d b b b الحالات المفوَّتة x x x x x x x x فوّتنا ثمانيةً هذه المرة، وهذا أفضل بكثير. تمرين جرّب استراتيجيات LIFO وLFU وRFU على المثال، وانظر إلى ما يحدث. يتكون البرنامج التوضيحي التالي (مكتوب بلغة C++) من جزأين، حيث أن الأول هو هيكل البرنامج، ويحلّ المشكلة اعتمادًا على استراتيجية الشَرِههَ المختارة: #include <iostream> #include <memory> using namespace std; const int cacheSize = 3; const int requestLength = 16; const char request[] = {'a','a','d','e','b','b','a','c','f','d','e','a','f','b','e','c'}; char cache[] = {'a','b','c'}; // for reset char originalCache[] = {'a','b','c'}; class Strategy { public: Strategy(std::string name) : strategyName(name) {} virtual ~Strategy() = default; // احسب موضع التخزين المؤقت الذي ينبغي أن يُستخدم virtual int apply(int requestIndex) = 0; // حدّث المعلومات التي تحتاجها الاستراتيجية virtual void update(int cachePlace, int requestIndex, bool cacheMiss) = 0; const std::string strategyName; }; bool updateCache(int requestIndex, Strategy* strategy) { // حدد مكان وضع الطلب int cachePlace = strategy->apply(requestIndex); // تحقق مما إذا قُبِل التخزين المؤقت أم لا bool isMiss = request[requestIndex] != cache[cachePlace]; // تحديث الاستراتيجية - مثلا: إعادة حساب المسافات strategy->update(cachePlace, requestIndex, isMiss); //الكتابة في ذاكرة التخزين المؤقت cache[cachePlace] = request[requestIndex]; return isMiss; } int main() { Strategy* selectedStrategy[] = { new FIFO, new LIFO, new LRU, new LFU, new LFD }; for (int strat=0; strat < 5; ++strat) { //إعادة تعيين المخزن المؤقت for (int i=0; i < cacheSize; ++i) cache[i] = originalCache[i]; cout <<"\nStrategy: " << selectedStrategy[strat]->strategyName << endl; cout << "\nCache initial: ("; for (int i=0; i < cacheSize-1; ++i) cout << cache[i] << ","; cout << cache[cacheSize-1] << ")\n\n"; cout << "Request\t"; for (int i=0; i < cacheSize; ++i) cout << "cache " << i << "\t"; cout << "cache miss" << endl; int cntMisses = 0; for(int i=0; i<requestLength; ++i) { bool isMiss = updateCache(i, selectedStrategy[strat]); if (isMiss) ++cntMisses; cout << " " << request[i] << "\t"; for (int l=0; l < cacheSize; ++l) cout << " " << cache[l] << "\t"; cout << (isMiss ? "x" : "") << endl; } cout<< "\nTotal cache misses: " << cntMisses << endl; } for(int i=0; i<5; ++i) delete selectedStrategy[i]; } الفكرة الأساسية بسيطة، حيث نستدعي الاستراتيجية مرتين لكل طلب: التطبيق apply: يجب أن تخبر الاستراتيجية المستدعي بالصفحة التي يجب استخدامها. التحديث update: بعد أن يستخدم المستدعي المساحة، يخبر الإستراتيجية ما إذا تمّ تفويته أم لا. ثمّ تستطيع الاستراتيجية حينها تحديث بياناتها الداخلية. فمثلًا، على الاستراتيجية LFU تحديث تردّد القبول hit frequency لصفحات ذاكرة التخزين المؤقت، بينما تعيد استراتيجية LFD حساب مسافات صفحات ذاكرة التخزين المؤقت. نقدّم الآن تطبيقات للاستراتيجيات الخمس: FIFO class FIFO : public Strategy { public: FIFO() : Strategy("FIFO") { for (int i=0; i<cacheSize; ++i) age[i] = 0; } int apply(int requestIndex) override { int oldest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(age[i] > age[oldest]) oldest = i; } return oldest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { // لم يتغير أي شيء، لسنا بحاجة إلى تحديث الصفحات if(!cacheMiss) return; // كل الصفحات القديمة تُصبح أقدم، والجديدة تحصل على القيمة 0 for(int i=0; i<cacheSize; ++i) { if(i != cachePos) age[i]++; else age[i] = 0; } } private: int age[cacheSize]; }; لا تحتاج FIFO إلا إلى المعلومات المتعلقة بطول الصفحة في ذاكرة التخزين المؤقت (نسبة إلى الصفحات الأخرى)، لذا فهي تكتفي بانتظار حدوث فوات miss، ثم تجعل الصفحات التي لم تُخلى أقدم. بالنسبة للمثال أعلاه، فسيكون الحل كالتالي: Strategy: FIFO Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d d b c x e d e c x b d e b x b d e b a a e b x c a c b x f a c f x d d c f x e d e f x a d e a x f f e a x b f b a x e f b e x c c b e x Total cache misses: 13 العدد الإجمالي للفوات وهذا يكافئ الحل أعلاه. LIFO class LIFO : public Strategy { public: LIFO() : Strategy("LIFO") { for (int i=0; i<cacheSize; ++i) age[i] = 0; } int apply(int requestIndex) override { int newest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(age[i] < age[newest]) newest = i; } return newest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { // لم يتغير شيء، لا نحتاج إلى تحديث الصفحات if(!cacheMiss) return; // كل الصفحات القديمة تُصبح أقدم، والصفحة الجديدة تحصل على القيمة 0 for(int i=0; i<cacheSize; ++i) { if(i != cachePos) age[i]++; else age[i] = 0; } } private: int age[cacheSize]; }; تقديم LIFO مشابه إلى حد ما لتقديم FIFO، بيْد أنّنا نخلي الصفحة الأحدث وليس الأقدم. ستكون نتائج البرنامج كالتالي: Strategy: LIFO Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d d b c x e e b c x b e b c b e b c a a b c x c a b c f f b c x d d b c x e e b c x a a b c x f f b c x b f b c e e b c x c e b c Total cache misses: 9 العدد الإجمالي لحالات الفوات LRU، سنستخدم كلمة oldest في المثال أدناه للإشارة إلى طول فترة "عدم" الاستخدام. class LRU : public Strategy { public: LRU() : Strategy("LRU") { for (int i=0; i<cacheSize; ++i) age[i] = 0; } int apply(int requestIndex) override { int oldest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(age[i] > age[oldest]) oldest = i; } return oldest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { // الصفحات القديمة تصبح أقدم، والصفحة الجديدة تأخذ القيمة 0 for(int i=0; i<cacheSize; ++i) { if(i != cachePos) age[i]++; else age[i] = 0; } } private: int age[cacheSize]; }; في حالة LRU، فإن الاستراتيجية مستقلة عن صفحة ذاكرة التخزين المؤقت، إذ أنّ تركيزها ينصبّ على الصفحة الأخيرة فقط. نتائج البرنامج هي: Strategy: LRU Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d a d c x e a d e x b b d e x b b d e a b a e x c b a c x f f a c x d f d c x e f d e x a a d e x f a f e x b a f b x e e f b x c e c b x Total cache misses: 13 العدد الإجمالي لحالات الفوات LFU: class LFU : public Strategy { public: LFU() : Strategy("LFU") { for (int i=0; i<cacheSize; ++i) requestFrequency[i] = 0; } int apply(int requestIndex) override { int least = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(requestFrequency[i] < requestFrequency[least]) least = i; } return least; } void update(int cachePos, int requestIndex, bool cacheMiss) override { if(cacheMiss) requestFrequency[cachePos] = 1; else ++requestFrequency[cachePos]; } private: // ما هو تردد استخدام الصفحة int requestFrequency[cacheSize]; }; تُخلي LFU الصفحة الأقل استخدامًا، لذا تعتمد استراتيجية التحديث على عدد مرّات الوصول إلى الصفحات. وبالطبع، يُصفَّر العدّاد بعد الإخلاء، وهذه نتائج البرنامج: Strategy: LFU Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d a d c x e a d e x b a b e x b a b e a a b e c a b c x f a b f x d a b d x e a b e x a a b e f a b f x b a b f e a b e x c a b c x Total cache misses: 10 LFD: class LFD : public Strategy { public: LFD() : Strategy("LFD") { // الحساب المُسبق للاستخدام اللاحق قبل تلبية الطلبات for (int i=0; i<cacheSize; ++i) nextUse[i] = calcNextUse(-1, cache[i]); } int apply(int requestIndex) override { int latest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(nextUse[i] > nextUse[latest]) latest = i; } return latest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { nextUse[cachePos] = calcNextUse(requestIndex, cache[cachePos]); } private: int calcNextUse(int requestPosition, char pageItem) { for(int i = requestPosition+1; i < requestLength; ++i) { if (request[i] == pageItem) return i; } return requestLength + 1; } // الاستخدام اللاحق للصفحة int nextUse[cacheSize]; }; تختلف استراتيجية LFD عن جميع ما قبلها، فهي الاستراتيجية الوحيدة التي تستخدم الطلبات المستقبلية لاتخاذ القرار بخصوص الصفحة التي ينبغي أن تُخلى. يَستخدم التطبيق دالة calcNextUse للحصول على الصفحة التي يكون استخدَامها التالي هو الأبعد في المستقبل. الحل الذي يعطيه البرنامج يساوي الحل اليدوي الذي وجدناه أعلاه: Strategy: LFD Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d a b d x e a b e x b a b e b a b e a a b e c a c e x f a f e x d a d e x e a d e a a d e f f d e x b b d e x e b d e c c d e x Total cache misses: 8 استراتيجية LFD الشَرِهَة هي الاستراتيجية المثلى من بين الاستراتيجيات الخمس المقدمة، لكن هناك مشكلة كبيرة، فهي حل مثالي غير متصل optimal offline solution، أي أنّها تتطلب قراءة جميع عناصر الطابور مرّةً واحدة؛ لكن عند التطبيق، سيكون التخزين المؤقت غالبًا مشكلة متصلة online، أي لا يمكنك أن تعرف من العناصر غير السابقة وحدها، وهذا يعني أنّ هذه الاستراتيجية غير مجدية لأننا لا نستطيع معرفة الموعد القادم الذي سنحتاج فيه إلى عنصر معيّن؛ أما الاستراتيجيات الأربع الأخرى فهي متصلة أيضًا. وبالنسبة للمشاكل المتصلة online، سنحتاج إلى منظور مختلف. جهاز التذاكر لنفترض أنّ لدينا جهاز تذاكر يصرّف المبالغ بقطع نقدية تحمل القيم 1 و2 و5 و10 و20. يمكن النظر إلى عملية الصرف مثل سلسلة من القطع النقدية التي تتساقط حتى يُستوفى المبلغ الصحيح، ونقول أنّ الصرف مثالي حين يكون عدد القطع النقدية أقل ما يمكن بالنسبة إلى قيمته. وإذا كانت M توجد بين [1,50] وتمثّل سعر التذكرة T، و العدد P الموجود بين [1,50] يمثل المبلغ المالي المدفوع مقابل التذكرة T، حيث P >= M؛ فإننا نكتب D=P-M، ونعرّف الفائدة benefit لخطوة معيّنة على أنّها الفرق بين D وD-c، حيث تمثّلc القطعة النقدية التي أضافها الجهاز في هذه الخطوة. انظر إلى الخوارزمية الشَرِهَة التوضيحية لإجراء عملية الصرف: الخطوة 1: إذا كانت D > 20، أضف القطعة 20، وعيّن D = D - 20. الخطوة 2: إذا كانت D > 10، أضف القطعة 10 وعيّن D = D - 10. الخطوة 3: إذا كانت D > 5، أضف القطعة 5 وعيّن D = D - 5. الخطوة 4: إذا كانت D > 2، أضف القطعة 2 وعيّن D = D - 2. الخطوة 5: إذا كانت D > 1، أضف القطعة 1 وعيّن D = D - 1. بعد ذلك سيكون مجموع جميع العملات مساويًا القيمة D. هذه الخوارزمية شَرِهَة لأنّها تبحث بعد كل خطوة وبعد كل تكرار عن تعظيم الفائدة. والآن، لنكتب برنامج التذكرة بلغة C++: #include <iostream> #include <vector> #include <string> #include <algorithm> using namespace std; // اقرأ قيم بعض القطع النقدية، ورتّبها تنازليا // احذف النسخ مع ضمان أن تكون القطعة 1 موجودة بينها std::vector<unsigned int> readInCoinValues(); int main() { std::vector<unsigned int> coinValues; // مصفوفة القطع النقدية تنازليا int ticketPrice; // في المثال M int paidMoney; // في المثال P // ولِّد قيم القطع النقدية coinValues = readInCoinValues(); cout << "ticket price: "; cin >> ticketPrice; cout << "money paid: "; cin >> paidMoney; if(paidMoney <= ticketPrice) { cout << "No exchange money" << endl; return 1; } int diffValue = paidMoney - ticketPrice; // هنا تبدأ الخوارزمية الشَرِهَة. // نحفظ عدد القطع النقدية التي علينا إعطاؤها std::vector<unsigned int> coinCount; for(auto coinValue = coinValues.begin(); coinValue != coinValues.end(); ++coinValue) { int countCoins = 0; while (diffValue >= *coinValue) { diffValue -= *coinValue; countCoins++; } coinCount.push_back(countCoins); } // اطبع النتائج cout << "the difference " << paidMoney - ticketPrice << " is paid with: " << endl; for(unsigned int i=0; i < coinValues.size(); ++i) { if(coinCount[i] > 0) cout << coinCount[i] << " coins with value " << coinValues[i] << endl; } return 0; } std::vector<unsigned int> readInCoinValues() { // قيم القطع النقدية std::vector<unsigned int> coinValues; // تحقق من أنّ 1 موجود في المتجهة coinValues.push_back(1); // اقرأ قيم القطع النقدية، لاحظ أن خطأ المعالجة يهمَل. while(true) { int coinValue; cout << "Coin value (<1 to stop): "; cin >> coinValue; if(coinValue > 0) coinValues.push_back(coinValue); else break; } // رتب القيم sort(coinValues.begin(), coinValues.end(), std::greater<int>()); // امح النسخ التي لها القيمة نفسها auto last = std::unique(coinValues.begin(), coinValues.end()); coinValues.erase(last, coinValues.end()); // اطبع المصفوفة cout << "Coin values: "; for(auto i : coinValues) cout << i << " "; cout << endl; return coinValues; } لاحظ أننا لم نضع أيّ فحص للمدخلات من أجل إبقاء المثال بسيطًا، وهنا سيكون خرج المثال كما يلي: Coin value (<1 to stop): 2 Coin value (<1 to stop): 4 Coin value (<1 to stop): 7 Coin value (<1 to stop): 9 Coin value (<1 to stop): 14 Coin value (<1 to stop): 4 Coin value (<1 to stop): 0 Coin values: 14 9 7 4 2 1 ticket price: 34 money paid: 67 the difference 33 is paid with: 2 coins with value 14 1 coins with value 4 1 coins with value 1 إن كانت قيمة القطعة النقدية تساوي 1، فستنتهي الخوارزمية، لأن: D تنخفض مع كل خطوة. لا يمكن أن تكون D موجبةً وأصغر من أصغر عملة (1) في نفس الوقت. هذه الخوارزمية فيها ثغرتان: إذا كانت C هي أكبر قطعة نقدية، فسيكون وقت التشغيل كثير الحدود polynomial طالما أنّ D/C كثيرة الحدود أيضًا، ذلك أن تمثيل D يستخدم بتَّات log D وحسب؛ أمّا وقت التشغيل، فهو على الأقل خطيٌ في D/C تختار خوَارزميتنا الخيار المحلي الأمثل في كل خطوة، لكنّ هذا لا يعني أنّ الحل الذي تقدمه الخوارزمية هو الحل الأمثل العام. انظر إلى المثال التوضيحي التالي: لنفترض أنّ القطع النقدية هي 1,3,4، وأنّ D=6. من الواضح أنّ الحل الأمثل هو قطعتان نقديتان من فئة 3، ولكنّ الخوارزمية الشَرِهَة ستختار 4 في الخطوة الأولى، لذا سيكون عليها أن تختار 1 في الخطوتين الثانية والثالثة، وعليه فهي لا تعطينا الحل الأمثل. قد يكون استخدام البرمجة الديناميكية لإيجاد الحل الأمثل هو الأفضل في هذه الحالة. جدولة الوظائف لنفترض أنّ لدينا مجموعةً من الوظائف J={a,b,c,d,e,f,g}. إذا كانت j التي تنتمي إلى J هي وظيفة تبدأ عند sj وتنتهي عند fj، فسنقول عندئذ أنّ وظيفتين متوافقتان إذا لم تتدَاخلا overlap. انظر الصورة التالية: والهدف هنا هو العثور على أكبر مجموعة من الوظائف المتوافقة مع بعضها بعضًا، وهناك عدة أوجه شَرِهَة لحل هذه المشكلة: أبكر وقت بداية: خذ الوظائف وفق ترتيب تصاعدي لقيم sj. أبكر وقت انتهاء: خذ الوظائف وفق ترتيب تصاعدي لـ fj. أقصر مدة: خذ الوظائف وفق ترتيب تصاعدي لـ fj-sj. أقل تعارض: لكل وظيفة j، احسب عدد الوظائف المتعارضة معها (cj). السؤال الآن هو: أيّ وجه أفضل؟ من الواضح أنّ منظور أبكر وقت بداية غير صالح كما يوضّح المثال المضاد التالي: كذلك فإن منظور أقصر مدة ليس مثاليًا: وقد يبدو أنّ منظور أقل تعارض هو الأمثل، غير أن المثال المضاد التالي ينفي ذلك: إذًا الحل المتبقي هو أبكر وقت انتهاء. انظر شيفرته التوضيحية: رتّب الوظائف بحسب وقت الانتهاء f1<=f2<=...<=fn. لتكن A مجموعةً فارغة. من j=1 إلى n، إذا كان j متوافقًا مع جميع الوظائف في A، ضع A=A+{j}. ستكون A هي أكبر مجموعة تضمّ وظائفًا متوافقة. أو نفس الأمر مكتوبًا في برنامج بلغة C++: #include <iostream> #include <utility> #include <tuple> #include <vector> #include <algorithm> const int jobCnt = 10; // أوقات بداية الوظائف const int startTimes[] = { 2, 3, 1, 4, 3, 2, 6, 7, 8, 9}; // أوقات انتهاء الوظائف const int endTimes[] = { 4, 4, 3, 5, 5, 5, 8, 9, 9, 10}; using namespace std; int main() { vector<pair<int,int>> jobs; for(int i=0; i<jobCnt; ++i) jobs.push_back(make_pair(startTimes[i], endTimes[i])); // المرحلة الأولى: الترتيب sort(jobs.begin(), jobs.end(),[](pair<int,int> p1, pair<int,int> p2) { return p1.second < p2.second; }); // A المرحلة الثانية: المجموعة الفارغة vector<int> A; // المرحلة الثالثة for(int i=0; i<jobCnt; ++i) { auto job = jobs[i]; bool isCompatible = true; for(auto jobIndex : A) { // A تحقق مما إذا كانت الوظيفة الحالية غير متوافقة مع الوظيفة من if(job.second >= jobs[jobIndex].first && job.first <= jobs[jobIndex].second) { isCompatible = false; break; } } if(isCompatible) A.push_back(i); } // A المرحلة الرابعة: طباعة cout << "Compatible: "; for(auto i : A) cout << "(" << jobs[i].first << "," << jobs[i].second << ") "; cout << endl; return 0; } خرج هذا المثال سيكون: Compatible: (1,3) (4,5) (6,8) (9,10) تعقيد هذا التطبيق يساوي Θ (n ^ 2)، لكن هناك تطبيق آخر من التعقيد Θ (n log n) (انظر مثال جافا أدناه). أصبحت لدينا الآن خوارزمية شَرِهَة لحل مشكلة الجدولة الزمنية، ولكن أهي مُثلى؟ لنفترض أنّ هذه الخوارزمية الشَرِهَة ليست مثلى، وأن i1,i2,...,ik تشير إلى مجموعة من الوظائف التي اختارتها الخوارزمية الشَرِهَة، ولتكن j1,j2,...,jm تشير إلى مجموعة الوظائف في الحل الأمثل، وليكن r هو العدد الأكبر الذي يحقق i1=j1,i2=j2,...,ir=jr. الوظيفة i(r+1) موجودة وتنتهي قبل الوظيفة j(r+1) (أبكر وقت انتهاء)، لكن هذا يعني أنّ الوظيفة الآتية ستكون أيضًا حلًّا أمثلَ، ولكلّ k من المجال [1,(r+1)]، سيكون لدينا jk=ik، مما يناقض فرضية أنّ r هو العدد الأكبر. وهذا يُتمّ البرهان. j1,j2,...,jr,i(r+1),j(r+2),...,jm يوضّح المثال التالي أنّ هناك العديد من الاستراتيجيات الشَرِهَة الممكنة في الغالب، ولكن ليست كلها تجد الحل الأمثل العام، بل قد لا تجده أي منها. فيما يلي برنامج Java تعقيده Θ (n log n) . import java.util.Arrays; import java.util.Comparator; class Job { int start, finish, profit; Job(int start, int finish, int profit) { this.start = start; this.finish = finish; this.profit = profit; } } class JobComparator implements Comparator<Job> { public int compare(Job a, Job b) { return a.finish < b.finish ? -1 : a.finish == b.finish ? 0 : 1; } } public class WeightedIntervalScheduling { static public int binarySearch(Job jobs[], int index) { int lo = 0, hi = index - 1; while (lo <= hi) { int mid = (lo + hi) / 2; if (jobs[mid].finish <= jobs[index].start) { if (jobs[mid + 1].finish <= jobs[index].start) lo = mid + 1; else return mid; } else hi = mid - 1; } return -1; } static public int schedule(Job jobs[]) { Arrays.sort(jobs, new JobComparator()); int n = jobs.length; int table[] = new int[n]; table[0] = jobs[0].profit; for (int i=1; i<n; i++) { int inclProf = jobs[i].profit; int l = binarySearch(jobs, i); if (l != -1) inclProf += table[l]; table[i] = Math.max(inclProf, table[i-1]); } return table[n-1]; } public static void main(String[] args) { Job jobs[] = {new Job(1, 2, 50), new Job(3, 5, 20), new Job(6, 19, 100), new Job(2, 100, 200)}; System.out.println("Optimal profit is " + schedule(jobs)); } } الخرج المتوقع هو: Optimal profit is 250 تقليل التأخير Minimizing Lateness هناك العديد من المشاكل التي تقلل التأخير، ولنفترض هنا أنّ لدينا مصدرًا وحيدًا يمكنه معالجة مهمّة واحدة فقط في كل مرّة، والوظيفة j تتطلب tj وحدة وقت من زمن المعالجة، وتبدأ عند التوقيت dj، فإن بدأت j في الوقت sj، فستنتهي عند الوقت fj = sj + tj. نعرّف التأخير lateness بالصيغة التالية: L=max{ 0 ,fj-dh}، لكل وظيفة j، والهدف هو تقليل أقصى تأخير لـ L. 1 2 3 4 5 6 tj 3 2 1 4 3 2 dj 6 8 9 9 10 11 الوظيفة 3 2 2 5 5 5 4 4 4 4 1 1 1 6 6 الوقت 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Lj 8- 5- 4- 1 7 4 من الواضح أنّ الحل L=7 ليس الأمثل. لهذا من الأفضل أن نلقي نظرةً على بعض الاستراتيجيات الشَرِهَة: أقصر وقت معالجة أولاً: نُجدول المهام وفق ترتيب تصاعدي لوقت المعالجة j`. أبكر موعد نهائي أولًا: جدولة المهام وفق ترتيب تصاعدي للمواعيد النهائية dj. أقصر مُهلة Smallest slack: جدولة المهام وفق ترتيب تصاعدي للمهلة dj-tj. من الواضح أنّ منظور أقصر وقت معالجة أولًا ليس الأمثل، هذا المثال المضاد يبيّن ذلك: 1 2 tj 1 5 dj 10 5 كذلك فإن منظور أقصر مهلة لديه مشاكل مشابهة كما يبيّن المثال التالي: 1 2 tj 1 5 dj 3 5 والإستراتيجية الأخيرة تبدو صالحة، انظر هذه الشيفرة التوضيحية لها: رتّب n وظيفةً بحسب المواعيد النهائية، بحيث تكون d1<=d2<=...<=dn. عيّن t=0. من j=1 إلى n: عيّن المهمة j للفاصل الزمني [t,t+tj]. عيّن sj=t وfj=t+tj. عيّن t=t+tj. أعِد المجالات [s1,f1],[s2,f2],...,[sn,fn]. هذا تطبيق بلغة C++: #include <iostream> #include <utility> #include <tuple> #include <vector> #include <algorithm> const int jobCnt = 10; // أوقات بداية الوظائف const int processTimes[] = { 2, 3, 1, 4, 3, 2, 3, 5, 2, 1}; // أوقات انتهاء الوظائف const int dueTimes[] = { 4, 7, 9, 13, 8, 17, 9, 11, 22, 25}; using namespace std; int main() { vector<pair<int,int>> jobs; for(int i=0; i<jobCnt; ++i) jobs.push_back(make_pair(processTimes[i], dueTimes[i])); // المرحلة الأولى: الترتيب sort(jobs.begin(), jobs.end(),[](pair<int,int> p1, pair<int,int> p2) { return p1.second < p2.second; }); // t=0 المرحلة الثانية: تعيين int t = 0; // المرحلة الثالثة vector<pair<int,int>> jobIntervals; for(int i=0; i<jobCnt; ++i) { jobIntervals.push_back(make_pair(t,t+jobs[i].first)); t += jobs[i].first; } // المرحلة الرابعة: طباعة المجالات cout << "Intervals:\n" << endl; int lateness = 0; for(int i=0; i<jobCnt; ++i) { auto pair = jobIntervals[i]; lateness = max(lateness, pair.second-jobs[i].second); cout << "(" << pair.first << "," << pair.second << ") " << "Lateness: " << pair.second-jobs[i].second << std::endl; } cout << "\nmaximal lateness is " << lateness << endl; return 0; } والخرج الناتج لهذا البرنامج هو: Intervals: (0,2) Lateness:-2 (2,5) Lateness:-2 (5,8) Lateness: 0 (8,9) Lateness: 0 (9,12) Lateness: 3 (12,17) Lateness: 6 (17,21) Lateness: 8 (21,23) Lateness: 6 (23,25) Lateness: 3 (25,26) Lateness: 1 maximal lateness is 8 الظاهر هنا أنّ وقت تشغيل هذه الخوارزمية هو Θ(n log n)، لأنّ الترتيب هو العملية الغالبة في هذه الخوارزمية. سنحاول الآن إثبات أنّ هذه الخوارزمية مُثلى، وهذا يستلزم ألا يكون في الجدول الزمني وقت خامل idle time أو غير مُستخدم. وهو أمر يتحقق في منظور أبكر موعد نهائي أولًا. لنفترض أنّ الوظائف مُرقّمة بحيث تكون d1<=d2<=...<=dn. نقول أن تقليبات جدول ما inversion of a schedule هي أزواج من الوظائف i وj، بحيث تكون i<j، وتكون j مُجدولةً قبل i. من الواضح أنّ منظور أبكر وقت نهائي أولًا ليس لها تقليبات، وإن كان الجدول يحتوي تقليبة، فهذا يعني أنّه يحتوي زوجًا من الوظائف المقلوبة والمُجدولة بالتتابع. إذا كانت L هي قيمة التأخير قبل التبديل، وM هو التأخير بعد التبديل، فستكون Lk=Mk لكل k != i,j.، نظرًا لأنّ تبديل وظيفتين متجاورتين لا ينقل الوظائف الأخرى من مواقعها. من الواضح أنّ Mi<=Li لأنّ الوظيفة i جُدوِلَت في وقت أبكر، أما إذا تأخرت الوظيفة j فيمكن أن نستنتج من التعريف أنّ: Mj = fi-dj من التعريف <= fi-di ( j و i لأنّه يمكن مبادلة) <= Li هذا يعني أنّ التأخير بعد المبادلة سيكون أقل أو يساوي التأخير قبل المبادلة، وهذا يُتمّ البرهان. لنفترض أنّ S* هو الجدول الأمثل وأنّ له أقل عدد ممكن من التقليبات. يمكن أن نفترض أنّ S* ليس فيه وقت شاغر، إذ لو كانت لـ S* أي تقليبات، فسيكون لدينا S=S*، وهذا يتمّ البرهان؛ أمّا إن احتوى S* على تقلِيبة فستكون له تقلِيبة مجاورة adjacent inversion. الخاصية الأخيرة تنصّ على أنّنا نستطيع تبديل التقليبات المتجاورة وتقليل عدد التقليبات دون زيادة التأخير، وهذا يتناقض مع تعريف S*. هناك الكثير من التطبيقات لمشكلة تقليل التأخير ومشكلة الحد الأدنى المشابهة لها minimum makespan problem، وهي المشكلة التي تحاول تقليل وقت انتهاء الوظائف. والمعتاد أنه لا تكون لديك آلة واحدة فقط، بل العديد من الآلات التي يمكنها القيام بالمهام نفسها بمعدّلات مختلفة. يمكن أن تتحول هذه المشكلة بسرعة إلى مشكلة من الصنف NP-complete. يظهر هنا سؤال مثير للاهتمام إن نظرنا إلى المشكلة المتصلة online، حيث تكون لدينا كل المهام والبيانات، لكن في صورة متصلة online، حيث تظهر المهام أثناء التنفيذ. ترجمة -بتصرّف- للفصل 18 من كتاب Algorithms Notes for Professionals. اقرأ أيضًا دليل شامل عن تحليل تعقيد الخوارزمية المرجع الشامل إلى تعلم الخوارزميات للمبتدئين مدخل إلى الخوارزميات خوارزمية تحديد المسار النجمية A* Pathfinding خوارزمية ديكسترا Dijkstra’s Algorithm
هذه المقالة هي تتمة للمقالة السابقة، وفيها تجد عددًا من التطبيقات الحقيقية للخوارزميات الشَرِهَة لحل بعض المشاكل، مثل تقليل التأخير وجدولة الوظائف وإدارة ذاكرة التخزين المؤقت. التخزين المؤقت غير المتصل Offline Caching تنشأ مشكلة التخزين المؤقت caching بسبب محدودية مساحة التخزين، فمثلًا لنفرض أن ذاكرةَ تخزينٍ مؤقتة ولتكن C، تحتوي على عدد k من الصفحات، ونريد معالجة سلسلة من العناصر عددها m عنصر، هنا يجب تخزين هذه العناصر في الذاكرة المؤقتة قبل معالجتها. لا شك أنه لن توجد مشكلة إن كانت m<=k، إذ سنضع جميع العناصر في ذاكرة التخزين المؤقت، ولكن في العادة تكون m>>k. نقول أنّ طلبيّةً ما مقبولة في ذاكرة التخزين المؤقت cache hit إذا كان العنصر موجودًا في ذاكرة التخزين المؤقت فعليًا، وإلا سنقول أنّها مُفوَّتة عن ذاكرة التخزين المؤقت cache miss. سيكون علينا في مثل هذه الحالة إحضار العنصر المطلوب إلى ذاكرة التخزين المؤقت وإخراج عنصر آخر، وذلك بفرض أنّ ذاكرة التخزين المؤقت ممتلئة، وهدفنا هو تصميم جدول إخلاء eviction schedule يقلّل قدر الإمكان من عدد عمليات الإخلاء الضرورية. هناك عدة استراتيجيات شَرِهَة لحلّ هذه المشكلة، من بينها: أول داخل، أول خارج First in, first out أو FIFO: تُخلى أقدم صفحة. آخر داخل، أوّل خارج Last in, first out أو LIFO: تُخلى أحدث صفحة. خروج الأبكر وصولًا Last recent out أو اختصارا LRU: إخلاء الصفحة التي تمّ الدخول إليها في أبكر وقت. الأقل طلبًا Least frequently requested أو LFU: إخلاء الصفحة التي طُلِبت أقل عدد من المرات. أطول مسافة أمامية Longest forward distance أو LFD: إخلاء الصفحة التي ستُطلَب في أبعد مسافة في المستقبل. مثال FIFO لنفترض أنّ حجم ذاكرة التخزين المؤقت هو k=3، وأنّ ذاكرة التخزين المؤقت الأولية تحتوي a,b,c، وأنّ هناك قائمةً من الطلبيات هي على النحو الآتي: a,a,d,e,b,b,a,c,f,d,e,a,f,b,e,c table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الطلب a a d e b b a c f d e a f b e c المخزن المؤقت 1 a a d d d d a a a d d d f f f c المخزن المؤقت 2 b b b e e e e c c c e e e b b b المخزن المؤقت 3 c c c c b b b b f f f a a a e e الحالات المفوَّتة x x x x x x x x x x x x x فوّتنا ثلاثة عشرة عنصرًا من ذاكرة التخزين المؤقت من بين ستة عشر طلبية، وهو أمر لا يبدو جيدًا، لذلك من الأحسن أن نجرّب استراتيجيةً أخرى. مثال LFD لنفترض أنّ حجم ذاكرة التخزين المؤقت هو k=3، وأنّ ذاكرة التخزين المؤقت الأولية تحتوي a,b,c؛ أما الطلبيات فهي: الطلب a a d e b b a c f d e a f b e c المخزن المؤقت 1 a a d e e e e e e e e e e e e c المخزن المؤقت 2 b b b b b b a a a a a a f f f f المخزن المؤقت 3 c c c c c c c c f d d d d b b b الحالات المفوَّتة x x x x x x x x فوّتنا ثمانيةً هذه المرة، وهذا أفضل بكثير. تمرين جرّب استراتيجيات LIFO وLFU وRFU على المثال، وانظر إلى ما يحدث. يتكون البرنامج التوضيحي التالي (مكتوب بلغة C++) من جزأين، حيث أن الأول هو هيكل البرنامج، ويحلّ المشكلة اعتمادًا على استراتيجية الشَرِههَ المختارة: #include <iostream> #include <memory> using namespace std; const int cacheSize = 3; const int requestLength = 16; const char request[] = {'a','a','d','e','b','b','a','c','f','d','e','a','f','b','e','c'}; char cache[] = {'a','b','c'}; // for reset char originalCache[] = {'a','b','c'}; class Strategy { public: Strategy(std::string name) : strategyName(name) {} virtual ~Strategy() = default; // احسب موضع التخزين المؤقت الذي ينبغي أن يُستخدم virtual int apply(int requestIndex) = 0; // حدّث المعلومات التي تحتاجها الاستراتيجية virtual void update(int cachePlace, int requestIndex, bool cacheMiss) = 0; const std::string strategyName; }; bool updateCache(int requestIndex, Strategy* strategy) { // حدد مكان وضع الطلب int cachePlace = strategy->apply(requestIndex); // تحقق مما إذا قُبِل التخزين المؤقت أم لا bool isMiss = request[requestIndex] != cache[cachePlace]; // تحديث الاستراتيجية - مثلا: إعادة حساب المسافات strategy->update(cachePlace, requestIndex, isMiss); //الكتابة في ذاكرة التخزين المؤقت cache[cachePlace] = request[requestIndex]; return isMiss; } int main() { Strategy* selectedStrategy[] = { new FIFO, new LIFO, new LRU, new LFU, new LFD }; for (int strat=0; strat < 5; ++strat) { //إعادة تعيين المخزن المؤقت for (int i=0; i < cacheSize; ++i) cache[i] = originalCache[i]; cout <<"\nStrategy: " << selectedStrategy[strat]->strategyName << endl; cout << "\nCache initial: ("; for (int i=0; i < cacheSize-1; ++i) cout << cache[i] << ","; cout << cache[cacheSize-1] << ")\n\n"; cout << "Request\t"; for (int i=0; i < cacheSize; ++i) cout << "cache " << i << "\t"; cout << "cache miss" << endl; int cntMisses = 0; for(int i=0; i<requestLength; ++i) { bool isMiss = updateCache(i, selectedStrategy[strat]); if (isMiss) ++cntMisses; cout << " " << request[i] << "\t"; for (int l=0; l < cacheSize; ++l) cout << " " << cache[l] << "\t"; cout << (isMiss ? "x" : "") << endl; } cout<< "\nTotal cache misses: " << cntMisses << endl; } for(int i=0; i<5; ++i) delete selectedStrategy[i]; } الفكرة الأساسية بسيطة، حيث نستدعي الاستراتيجية مرتين لكل طلب: التطبيق apply: يجب أن تخبر الاستراتيجية المستدعي بالصفحة التي يجب استخدامها. التحديث update: بعد أن يستخدم المستدعي المساحة، يخبر الإستراتيجية ما إذا تمّ تفويته أم لا. ثمّ تستطيع الاستراتيجية حينها تحديث بياناتها الداخلية. فمثلًا، على الاستراتيجية LFU تحديث تردّد القبول hit frequency لصفحات ذاكرة التخزين المؤقت، بينما تعيد استراتيجية LFD حساب مسافات صفحات ذاكرة التخزين المؤقت. نقدّم الآن تطبيقات للاستراتيجيات الخمس: FIFO class FIFO : public Strategy { public: FIFO() : Strategy("FIFO") { for (int i=0; i<cacheSize; ++i) age[i] = 0; } int apply(int requestIndex) override { int oldest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(age[i] > age[oldest]) oldest = i; } return oldest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { // لم يتغير أي شيء، لسنا بحاجة إلى تحديث الصفحات if(!cacheMiss) return; // كل الصفحات القديمة تُصبح أقدم، والجديدة تحصل على القيمة 0 for(int i=0; i<cacheSize; ++i) { if(i != cachePos) age[i]++; else age[i] = 0; } } private: int age[cacheSize]; }; لا تحتاج FIFO إلا إلى المعلومات المتعلقة بطول الصفحة في ذاكرة التخزين المؤقت (نسبة إلى الصفحات الأخرى)، لذا فهي تكتفي بانتظار حدوث فوات miss، ثم تجعل الصفحات التي لم تُخلى أقدم. بالنسبة للمثال أعلاه، فسيكون الحل كالتالي: Strategy: FIFO Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d d b c x e d e c x b d e b x b d e b a a e b x c a c b x f a c f x d d c f x e d e f x a d e a x f f e a x b f b a x e f b e x c c b e x Total cache misses: 13 العدد الإجمالي للفوات وهذا يكافئ الحل أعلاه. LIFO class LIFO : public Strategy { public: LIFO() : Strategy("LIFO") { for (int i=0; i<cacheSize; ++i) age[i] = 0; } int apply(int requestIndex) override { int newest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(age[i] < age[newest]) newest = i; } return newest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { // لم يتغير شيء، لا نحتاج إلى تحديث الصفحات if(!cacheMiss) return; // كل الصفحات القديمة تُصبح أقدم، والصفحة الجديدة تحصل على القيمة 0 for(int i=0; i<cacheSize; ++i) { if(i != cachePos) age[i]++; else age[i] = 0; } } private: int age[cacheSize]; }; تقديم LIFO مشابه إلى حد ما لتقديم FIFO، بيْد أنّنا نخلي الصفحة الأحدث وليس الأقدم. ستكون نتائج البرنامج كالتالي: Strategy: LIFO Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d d b c x e e b c x b e b c b e b c a a b c x c a b c f f b c x d d b c x e e b c x a a b c x f f b c x b f b c e e b c x c e b c Total cache misses: 9 العدد الإجمالي لحالات الفوات LRU، سنستخدم كلمة oldest في المثال أدناه للإشارة إلى طول فترة "عدم" الاستخدام. class LRU : public Strategy { public: LRU() : Strategy("LRU") { for (int i=0; i<cacheSize; ++i) age[i] = 0; } int apply(int requestIndex) override { int oldest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(age[i] > age[oldest]) oldest = i; } return oldest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { // الصفحات القديمة تصبح أقدم، والصفحة الجديدة تأخذ القيمة 0 for(int i=0; i<cacheSize; ++i) { if(i != cachePos) age[i]++; else age[i] = 0; } } private: int age[cacheSize]; }; في حالة LRU، فإن الاستراتيجية مستقلة عن صفحة ذاكرة التخزين المؤقت، إذ أنّ تركيزها ينصبّ على الصفحة الأخيرة فقط. نتائج البرنامج هي: Strategy: LRU Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d a d c x e a d e x b b d e x b b d e a b a e x c b a c x f f a c x d f d c x e f d e x a a d e x f a f e x b a f b x e e f b x c e c b x Total cache misses: 13 العدد الإجمالي لحالات الفوات LFU: class LFU : public Strategy { public: LFU() : Strategy("LFU") { for (int i=0; i<cacheSize; ++i) requestFrequency[i] = 0; } int apply(int requestIndex) override { int least = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(requestFrequency[i] < requestFrequency[least]) least = i; } return least; } void update(int cachePos, int requestIndex, bool cacheMiss) override { if(cacheMiss) requestFrequency[cachePos] = 1; else ++requestFrequency[cachePos]; } private: // ما هو تردد استخدام الصفحة int requestFrequency[cacheSize]; }; تُخلي LFU الصفحة الأقل استخدامًا، لذا تعتمد استراتيجية التحديث على عدد مرّات الوصول إلى الصفحات. وبالطبع، يُصفَّر العدّاد بعد الإخلاء، وهذه نتائج البرنامج: Strategy: LFU Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d a d c x e a d e x b a b e x b a b e a a b e c a b c x f a b f x d a b d x e a b e x a a b e f a b f x b a b f e a b e x c a b c x Total cache misses: 10 LFD: class LFD : public Strategy { public: LFD() : Strategy("LFD") { // الحساب المُسبق للاستخدام اللاحق قبل تلبية الطلبات for (int i=0; i<cacheSize; ++i) nextUse[i] = calcNextUse(-1, cache[i]); } int apply(int requestIndex) override { int latest = 0; for(int i=0; i<cacheSize; ++i) { if(cache[i] == request[requestIndex]) return i; else if(nextUse[i] > nextUse[latest]) latest = i; } return latest; } void update(int cachePos, int requestIndex, bool cacheMiss) override { nextUse[cachePos] = calcNextUse(requestIndex, cache[cachePos]); } private: int calcNextUse(int requestPosition, char pageItem) { for(int i = requestPosition+1; i < requestLength; ++i) { if (request[i] == pageItem) return i; } return requestLength + 1; } // الاستخدام اللاحق للصفحة int nextUse[cacheSize]; }; تختلف استراتيجية LFD عن جميع ما قبلها، فهي الاستراتيجية الوحيدة التي تستخدم الطلبات المستقبلية لاتخاذ القرار بخصوص الصفحة التي ينبغي أن تُخلى. يَستخدم التطبيق دالة calcNextUse للحصول على الصفحة التي يكون استخدَامها التالي هو الأبعد في المستقبل. الحل الذي يعطيه البرنامج يساوي الحل اليدوي الذي وجدناه أعلاه: Strategy: LFD Cache initial: (a,b,c) Request cache 0 cache 1 cache 2 cache miss a a b c a a b c d a b d x e a b e x b a b e b a b e a a b e c a c e x f a f e x d a d e x e a d e a a d e f f d e x b b d e x e b d e c c d e x Total cache misses: 8 استراتيجية LFD الشَرِهَة هي الاستراتيجية المثلى من بين الاستراتيجيات الخمس المقدمة، لكن هناك مشكلة كبيرة، فهي حل مثالي غير متصل optimal offline solution، أي أنّها تتطلب قراءة جميع عناصر الطابور مرّةً واحدة؛ لكن عند التطبيق، سيكون التخزين المؤقت غالبًا مشكلة متصلة online، أي لا يمكنك أن تعرف من العناصر غير السابقة وحدها، وهذا يعني أنّ هذه الاستراتيجية غير مجدية لأننا لا نستطيع معرفة الموعد القادم الذي سنحتاج فيه إلى عنصر معيّن؛ أما الاستراتيجيات الأربع الأخرى فهي متصلة أيضًا. وبالنسبة للمشاكل المتصلة online، سنحتاج إلى منظور مختلف. جهاز التذاكر لنفترض أنّ لدينا جهاز تذاكر يصرّف المبالغ بقطع نقدية تحمل القيم 1 و2 و5 و10 و20. يمكن النظر إلى عملية الصرف مثل سلسلة من القطع النقدية التي تتساقط حتى يُستوفى المبلغ الصحيح، ونقول أنّ الصرف مثالي حين يكون عدد القطع النقدية أقل ما يمكن بالنسبة إلى قيمته. وإذا كانت M توجد بين [1,50] وتمثّل سعر التذكرة T، و العدد P الموجود بين [1,50] يمثل المبلغ المالي المدفوع مقابل التذكرة T، حيث P >= M؛ فإننا نكتب D=P-M، ونعرّف الفائدة benefit لخطوة معيّنة على أنّها الفرق بين D وD-c، حيث تمثّلc القطعة النقدية التي أضافها الجهاز في هذه الخطوة. انظر إلى الخوارزمية الشَرِهَة التوضيحية لإجراء عملية الصرف: الخطوة 1: إذا كانت D > 20، أضف القطعة 20، وعيّن D = D - 20. الخطوة 2: إذا كانت D > 10، أضف القطعة 10 وعيّن D = D - 10. الخطوة 3: إذا كانت D > 5، أضف القطعة 5 وعيّن D = D - 5. الخطوة 4: إذا كانت D > 2، أضف القطعة 2 وعيّن D = D - 2. الخطوة 5: إذا كانت D > 1، أضف القطعة 1 وعيّن D = D - 1. بعد ذلك سيكون مجموع جميع العملات مساويًا القيمة D. هذه الخوارزمية شَرِهَة لأنّها تبحث بعد كل خطوة وبعد كل تكرار عن تعظيم الفائدة. والآن، لنكتب برنامج التذكرة بلغة C++: #include <iostream> #include <vector> #include <string> #include <algorithm> using namespace std; // اقرأ قيم بعض القطع النقدية، ورتّبها تنازليا // احذف النسخ مع ضمان أن تكون القطعة 1 موجودة بينها std::vector<unsigned int> readInCoinValues(); int main() { std::vector<unsigned int> coinValues; // مصفوفة القطع النقدية تنازليا int ticketPrice; // في المثال M int paidMoney; // في المثال P // ولِّد قيم القطع النقدية coinValues = readInCoinValues(); cout << "ticket price: "; cin >> ticketPrice; cout << "money paid: "; cin >> paidMoney; if(paidMoney <= ticketPrice) { cout << "No exchange money" << endl; return 1; } int diffValue = paidMoney - ticketPrice; // هنا تبدأ الخوارزمية الشَرِهَة. // نحفظ عدد القطع النقدية التي علينا إعطاؤها std::vector<unsigned int> coinCount; for(auto coinValue = coinValues.begin(); coinValue != coinValues.end(); ++coinValue) { int countCoins = 0; while (diffValue >= *coinValue) { diffValue -= *coinValue; countCoins++; } coinCount.push_back(countCoins); } // اطبع النتائج cout << "the difference " << paidMoney - ticketPrice << " is paid with: " << endl; for(unsigned int i=0; i < coinValues.size(); ++i) { if(coinCount[i] > 0) cout << coinCount[i] << " coins with value " << coinValues[i] << endl; } return 0; } std::vector<unsigned int> readInCoinValues() { // قيم القطع النقدية std::vector<unsigned int> coinValues; // تحقق من أنّ 1 موجود في المتجهة coinValues.push_back(1); // اقرأ قيم القطع النقدية، لاحظ أن خطأ المعالجة يهمَل. while(true) { int coinValue; cout << "Coin value (<1 to stop): "; cin >> coinValue; if(coinValue > 0) coinValues.push_back(coinValue); else break; } // رتب القيم sort(coinValues.begin(), coinValues.end(), std::greater<int>()); // امح النسخ التي لها القيمة نفسها auto last = std::unique(coinValues.begin(), coinValues.end()); coinValues.erase(last, coinValues.end()); // اطبع المصفوفة cout << "Coin values: "; for(auto i : coinValues) cout << i << " "; cout << endl; return coinValues; } لاحظ أننا لم نضع أيّ فحص للمدخلات من أجل إبقاء المثال بسيطًا، وهنا سيكون خرج المثال كما يلي: Coin value (<1 to stop): 2 Coin value (<1 to stop): 4 Coin value (<1 to stop): 7 Coin value (<1 to stop): 9 Coin value (<1 to stop): 14 Coin value (<1 to stop): 4 Coin value (<1 to stop): 0 Coin values: 14 9 7 4 2 1 ticket price: 34 money paid: 67 the difference 33 is paid with: 2 coins with value 14 1 coins with value 4 1 coins with value 1 إن كانت قيمة القطعة النقدية تساوي 1، فستنتهي الخوارزمية، لأن: D تنخفض مع كل خطوة. لا يمكن أن تكون D موجبةً وأصغر من أصغر عملة (1) في نفس الوقت. هذه الخوارزمية فيها ثغرتان: إذا كانت C هي أكبر قطعة نقدية، فسيكون وقت التشغيل كثير الحدود polynomial طالما أنّ D/C كثيرة الحدود أيضًا، ذلك أن تمثيل D يستخدم بتَّات log D وحسب؛ أمّا وقت التشغيل، فهو على الأقل خطيٌ في D/C تختار خوَارزميتنا الخيار المحلي الأمثل في كل خطوة، لكنّ هذا لا يعني أنّ الحل الذي تقدمه الخوارزمية هو الحل الأمثل العام. انظر إلى المثال التوضيحي التالي: لنفترض أنّ القطع النقدية هي 1,3,4، وأنّ D=6. من الواضح أنّ الحل الأمثل هو قطعتان نقديتان من فئة 3، ولكنّ الخوارزمية الشَرِهَة ستختار 4 في الخطوة الأولى، لذا سيكون عليها أن تختار 1 في الخطوتين الثانية والثالثة، وعليه فهي لا تعطينا الحل الأمثل. قد يكون استخدام البرمجة الديناميكية لإيجاد الحل الأمثل هو الأفضل في هذه الحالة. جدولة الوظائف لنفترض أنّ لدينا مجموعةً من الوظائف J={a,b,c,d,e,f,g}. إذا كانت j التي تنتمي إلى J هي وظيفة تبدأ عند sj وتنتهي عند fj، فسنقول عندئذ أنّ وظيفتين متوافقتان إذا لم تتدَاخلا overlap. انظر الصورة التالية: والهدف هنا هو العثور على أكبر مجموعة من الوظائف المتوافقة مع بعضها بعضًا، وهناك عدة أوجه شَرِهَة لحل هذه المشكلة: أبكر وقت بداية: خذ الوظائف وفق ترتيب تصاعدي لقيم sj. أبكر وقت انتهاء: خذ الوظائف وفق ترتيب تصاعدي لـ fj. أقصر مدة: خذ الوظائف وفق ترتيب تصاعدي لـ fj-sj. أقل تعارض: لكل وظيفة j، احسب عدد الوظائف المتعارضة معها (cj). السؤال الآن هو: أيّ وجه أفضل؟ من الواضح أنّ منظور أبكر وقت بداية غير صالح كما يوضّح المثال المضاد التالي: كذلك فإن منظور أقصر مدة ليس مثاليًا: وقد يبدو أنّ منظور أقل تعارض هو الأمثل، غير أن المثال المضاد التالي ينفي ذلك: إذًا الحل المتبقي هو أبكر وقت انتهاء. انظر شيفرته التوضيحية: رتّب الوظائف بحسب وقت الانتهاء f1<=f2<=...<=fn. لتكن A مجموعةً فارغة. من j=1 إلى n، إذا كان j متوافقًا مع جميع الوظائف في A، ضع A=A+{j}. ستكون A هي أكبر مجموعة تضمّ وظائفًا متوافقة. أو نفس الأمر مكتوبًا في برنامج بلغة C++: #include <iostream> #include <utility> #include <tuple> #include <vector> #include <algorithm> const int jobCnt = 10; // أوقات بداية الوظائف const int startTimes[] = { 2, 3, 1, 4, 3, 2, 6, 7, 8, 9}; // أوقات انتهاء الوظائف const int endTimes[] = { 4, 4, 3, 5, 5, 5, 8, 9, 9, 10}; using namespace std; int main() { vector<pair<int,int>> jobs; for(int i=0; i<jobCnt; ++i) jobs.push_back(make_pair(startTimes[i], endTimes[i])); // المرحلة الأولى: الترتيب sort(jobs.begin(), jobs.end(),[](pair<int,int> p1, pair<int,int> p2) { return p1.second < p2.second; }); // A المرحلة الثانية: المجموعة الفارغة vector<int> A; // المرحلة الثالثة for(int i=0; i<jobCnt; ++i) { auto job = jobs[i]; bool isCompatible = true; for(auto jobIndex : A) { // A تحقق مما إذا كانت الوظيفة الحالية غير متوافقة مع الوظيفة من if(job.second >= jobs[jobIndex].first && job.first <= jobs[jobIndex].second) { isCompatible = false; break; } } if(isCompatible) A.push_back(i); } // A المرحلة الرابعة: طباعة cout << "Compatible: "; for(auto i : A) cout << "(" << jobs[i].first << "," << jobs[i].second << ") "; cout << endl; return 0; } خرج هذا المثال سيكون: Compatible: (1,3) (4,5) (6,8) (9,10) تعقيد هذا التطبيق يساوي Θ (n ^ 2)، لكن هناك تطبيق آخر من التعقيد Θ (n log n) (انظر مثال جافا أدناه). أصبحت لدينا الآن خوارزمية شَرِهَة لحل مشكلة الجدولة الزمنية، ولكن أهي مُثلى؟ لنفترض أنّ هذه الخوارزمية الشَرِهَة ليست مثلى، وأن i1,i2,...,ik تشير إلى مجموعة من الوظائف التي اختارتها الخوارزمية الشَرِهَة، ولتكن j1,j2,...,jm تشير إلى مجموعة الوظائف في الحل الأمثل، وليكن r هو العدد الأكبر الذي يحقق i1=j1,i2=j2,...,ir=jr. الوظيفة i(r+1) موجودة وتنتهي قبل الوظيفة j(r+1) (أبكر وقت انتهاء)، لكن هذا يعني أنّ الوظيفة الآتية ستكون أيضًا حلًّا أمثلَ، ولكلّ k من المجال [1,(r+1)]، سيكون لدينا jk=ik، مما يناقض فرضية أنّ r هو العدد الأكبر. وهذا يُتمّ البرهان. j1,j2,...,jr,i(r+1),j(r+2),...,jm يوضّح المثال التالي أنّ هناك العديد من الاستراتيجيات الشَرِهَة الممكنة في الغالب، ولكن ليست كلها تجد الحل الأمثل العام، بل قد لا تجده أي منها. فيما يلي برنامج Java تعقيده Θ (n log n) . import java.util.Arrays; import java.util.Comparator; class Job { int start, finish, profit; Job(int start, int finish, int profit) { this.start = start; this.finish = finish; this.profit = profit; } } class JobComparator implements Comparator<Job> { public int compare(Job a, Job b) { return a.finish < b.finish ? -1 : a.finish == b.finish ? 0 : 1; } } public class WeightedIntervalScheduling { static public int binarySearch(Job jobs[], int index) { int lo = 0, hi = index - 1; while (lo <= hi) { int mid = (lo + hi) / 2; if (jobs[mid].finish <= jobs[index].start) { if (jobs[mid + 1].finish <= jobs[index].start) lo = mid + 1; else return mid; } else hi = mid - 1; } return -1; } static public int schedule(Job jobs[]) { Arrays.sort(jobs, new JobComparator()); int n = jobs.length; int table[] = new int[n]; table[0] = jobs[0].profit; for (int i=1; i<n; i++) { int inclProf = jobs[i].profit; int l = binarySearch(jobs, i); if (l != -1) inclProf += table[l]; table[i] = Math.max(inclProf, table[i-1]); } return table[n-1]; } public static void main(String[] args) { Job jobs[] = {new Job(1, 2, 50), new Job(3, 5, 20), new Job(6, 19, 100), new Job(2, 100, 200)}; System.out.println("Optimal profit is " + schedule(jobs)); } } الخرج المتوقع هو: Optimal profit is 250 تقليل التأخير Minimizing Lateness هناك العديد من المشاكل التي تقلل التأخير، ولنفترض هنا أنّ لدينا مصدرًا وحيدًا يمكنه معالجة مهمّة واحدة فقط في كل مرّة، والوظيفة j تتطلب tj وحدة وقت من زمن المعالجة، وتبدأ عند التوقيت dj، فإن بدأت j في الوقت sj، فستنتهي عند الوقت fj = sj + tj. نعرّف التأخير lateness بالصيغة التالية: L=max{ 0 ,fj-dh}، لكل وظيفة j، والهدف هو تقليل أقصى تأخير لـ L. 1 2 3 4 5 6 tj 3 2 1 4 3 2 dj 6 8 9 9 10 11 الوظيفة 3 2 2 5 5 5 4 4 4 4 1 1 1 6 6 الوقت 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Lj 8- 5- 4- 1 7 4 من الواضح أنّ الحل L=7 ليس الأمثل. لهذا من الأفضل أن نلقي نظرةً على بعض الاستراتيجيات الشَرِهَة: أقصر وقت معالجة أولاً: نُجدول المهام وفق ترتيب تصاعدي لوقت المعالجة j`. أبكر موعد نهائي أولًا: جدولة المهام وفق ترتيب تصاعدي للمواعيد النهائية dj. أقصر مُهلة Smallest slack: جدولة المهام وفق ترتيب تصاعدي للمهلة dj-tj. من الواضح أنّ منظور أقصر وقت معالجة أولًا ليس الأمثل، هذا المثال المضاد يبيّن ذلك: 1 2 tj 1 5 dj 10 5 كذلك فإن منظور أقصر مهلة لديه مشاكل مشابهة كما يبيّن المثال التالي: 1 2 tj 1 5 dj 3 5 والإستراتيجية الأخيرة تبدو صالحة، انظر هذه الشيفرة التوضيحية لها: رتّب n وظيفةً بحسب المواعيد النهائية، بحيث تكون d1<=d2<=...<=dn. عيّن t=0. من j=1 إلى n: عيّن المهمة j للفاصل الزمني [t,t+tj]. عيّن sj=t وfj=t+tj. عيّن t=t+tj. أعِد المجالات [s1,f1],[s2,f2],...,[sn,fn]. هذا تطبيق بلغة C++: #include <iostream> #include <utility> #include <tuple> #include <vector> #include <algorithm> const int jobCnt = 10; // أوقات بداية الوظائف const int processTimes[] = { 2, 3, 1, 4, 3, 2, 3, 5, 2, 1}; // أوقات انتهاء الوظائف const int dueTimes[] = { 4, 7, 9, 13, 8, 17, 9, 11, 22, 25}; using namespace std; int main() { vector<pair<int,int>> jobs; for(int i=0; i<jobCnt; ++i) jobs.push_back(make_pair(processTimes[i], dueTimes[i])); // المرحلة الأولى: الترتيب sort(jobs.begin(), jobs.end(),[](pair<int,int> p1, pair<int,int> p2) { return p1.second < p2.second; }); // t=0 المرحلة الثانية: تعيين int t = 0; // المرحلة الثالثة vector<pair<int,int>> jobIntervals; for(int i=0; i<jobCnt; ++i) { jobIntervals.push_back(make_pair(t,t+jobs[i].first)); t += jobs[i].first; } // المرحلة الرابعة: طباعة المجالات cout << "Intervals:\n" << endl; int lateness = 0; for(int i=0; i<jobCnt; ++i) { auto pair = jobIntervals[i]; lateness = max(lateness, pair.second-jobs[i].second); cout << "(" << pair.first << "," << pair.second << ") " << "Lateness: " << pair.second-jobs[i].second << std::endl; } cout << "\nmaximal lateness is " << lateness << endl; return 0; } والخرج الناتج لهذا البرنامج هو: Intervals: (0,2) Lateness:-2 (2,5) Lateness:-2 (5,8) Lateness: 0 (8,9) Lateness: 0 (9,12) Lateness: 3 (12,17) Lateness: 6 (17,21) Lateness: 8 (21,23) Lateness: 6 (23,25) Lateness: 3 (25,26) Lateness: 1 maximal lateness is 8 الظاهر هنا أنّ وقت تشغيل هذه الخوارزمية هو Θ(n log n)، لأنّ الترتيب هو العملية الغالبة في هذه الخوارزمية. سنحاول الآن إثبات أنّ هذه الخوارزمية مُثلى، وهذا يستلزم ألا يكون في الجدول الزمني وقت خامل idle time أو غير مُستخدم. وهو أمر يتحقق في منظور أبكر موعد نهائي أولًا. لنفترض أنّ الوظائف مُرقّمة بحيث تكون d1<=d2<=...<=dn. نقول أن تقليبات جدول ما inversion of a schedule هي أزواج من الوظائف i وj، بحيث تكون i<j، وتكون j مُجدولةً قبل i. من الواضح أنّ منظور أبكر وقت نهائي أولًا ليس لها تقليبات، وإن كان الجدول يحتوي تقليبة، فهذا يعني أنّه يحتوي زوجًا من الوظائف المقلوبة والمُجدولة بالتتابع. إذا كانت L هي قيمة التأخير قبل التبديل، وM هو التأخير بعد التبديل، فستكون Lk=Mk لكل k != i,j.، نظرًا لأنّ تبديل وظيفتين متجاورتين لا ينقل الوظائف الأخرى من مواقعها. من الواضح أنّ Mi<=Li لأنّ الوظيفة i جُدوِلَت في وقت أبكر، أما إذا تأخرت الوظيفة j فيمكن أن نستنتج من التعريف أنّ: Mj = fi-dj من التعريف <= fi-di ( j و i لأنّه يمكن مبادلة) <= Li هذا يعني أنّ التأخير بعد المبادلة سيكون أقل أو يساوي التأخير قبل المبادلة، وهذا يُتمّ البرهان. لنفترض أنّ S* هو الجدول الأمثل وأنّ له أقل عدد ممكن من التقليبات. يمكن أن نفترض أنّ S* ليس فيه وقت شاغر، إذ لو كانت لـ S* أي تقليبات، فسيكون لدينا S=S*، وهذا يتمّ البرهان؛ أمّا إن احتوى S* على تقلِيبة فستكون له تقلِيبة مجاورة adjacent inversion. الخاصية الأخيرة تنصّ على أنّنا نستطيع تبديل التقليبات المتجاورة وتقليل عدد التقليبات دون زيادة التأخير، وهذا يتناقض مع تعريف S*. هناك الكثير من التطبيقات لمشكلة تقليل التأخير ومشكلة الحد الأدنى المشابهة لها minimum makespan problem، وهي المشكلة التي تحاول تقليل وقت انتهاء الوظائف. والمعتاد أنه لا تكون لديك آلة واحدة فقط، بل العديد من الآلات التي يمكنها القيام بالمهام نفسها بمعدّلات مختلفة. يمكن أن تتحول هذه المشكلة بسرعة إلى مشكلة من الصنف NP-complete. يظهر هنا سؤال مثير للاهتمام إن نظرنا إلى المشكلة المتصلة online، حيث تكون لدينا كل المهام والبيانات، لكن في صورة متصلة online، حيث تظهر المهام أثناء التنفيذ. ترجمة -بتصرّف- للفصل 18 من كتاب Algorithms Notes for Professionals. اقرأ أيضًا دليل شامل عن تحليل تعقيد الخوارزمية المرجع الشامل إلى تعلم الخوارزميات للمبتدئين مدخل إلى الخوارزميات خوارزمية تحديد المسار النجمية A* Pathfinding خوارزمية ديكسترا Dijkstra’s Algorithm -
 كما رأينا في مقالة طريقة عمل الواجهات بلغة جافا، تُوفِّر جافا تنفيذين implementations للواجهة List، هما ArrayList وLinkedList، حيث يكون النوع LinkedList أسرع بالنسبة لبعض التطبيقات، بينما يكون النوع ArrayList أسرع بالنسبة لتطبيقاتٍ أخرى. وإذا أردنا أن نُحدِّد أيهما أفضل للاستخدام في تطبيق معين، فيمكننا تجربة كلٍّ منهما على حدةٍ لنرى الزمن الذي سيَستغرِقه. يُطلَق على هذا الأسلوب اسم التشخيص profiling، ولكنّ له بعض الإشكاليّات: أننا سنضطّر إلى تنفيذ الخوارزميتين كلتيهما لكي نتمكَّن من الموازنة بينهما. قد تعتمد النتائج على نوع الحاسوب المُستخدَم، فقد تعمل خوارزمية معينة بكفاءةٍ عالية على حاسوب معين، في حين قد تَعمَل خوارزميةٌ أخرى بكفاءةٍ عاليةٍ على حاسوب مختلف. قد تعتمد النتائج على حجم المشكلة أو البيانات المُدْخَلة. يُمكِننا معالجة بعض هذه النقاط المُشكلةِ بالاستعانة بما يُعرَف باسم تحليل الخوارزميات، الذي يُمكِّننا من الموازنة بين عدة خوارزمياتٍ دون الحاجة إلى تنفيذها فعليًا، ولكننا سنضطّر عندئذٍ لوضع بعض الافتراضات: فلكي نتجنَّب التفاصيل المتعلقة بعتاد الحاسوب، سنُحدِّد العمليات الأساسية التي تتألف منها أي خوارزميةٍ مثل الجمع والضرب وموازنة عددين، ثم نَحسِب عدد العمليات التي تتطلّبها كل خوارزمية. ولكي نتجنَّب التفاصيل المتعلقة بالبيانات المُدْخَلة، فإن الخيار الأفضل هو تحليل متوسط الأداء للمُدْخَلات التي نتوقع التعامل معها. فإذا لم يَكُن ذلك متاحًا، فسيكون تحليل الحالة الأسوأ هو الخيار البديل الأكثر شيوعًا. أخيرًا، سيتعيّن علينا التعامل مع احتمالية أن يكون أداء خوارزميةٍ معينةٍ فعّالًا عند التعامل مع مشكلات صغيرة وأن يكون أداء خوارزميةٍ أخرى فعّالًا عند التعامل مع مشكلاتٍ كبيرة. وفي تلك الحالة، عادةً ما نُركِّز على المشكلات الكبيرة، لأن الاختلاف في الأداء لا يكون كبيرًا مع المشكلات الصغيرة، ولكنه يكون كذلك مع المشكلات الكبيرة. يقودنا هذا النوع من التحليل إلى تصنيف بسيط للخوارزميات. على سبيل المثال، إذا كان زمن تشغيل خوارزمية A يتناسب مع حجم المدخلات n، وكان زمن تشغيل خوارزمية أخرى B يتناسب مع n2، فيُمكِننا أن نقول إن الخوارزمية A أسرع من الخوارزمية B لقيم n الكبيرة على الأقل. يُمكِن تصنيف غالبية الخوارزميات البسيطة إلى إحدى التصنيفات التالية: ذات زمن ثابت: تكون الخوارزمية ثابتة الزمن إذا لم يعتمد زمن تشغيلها على حجم المدخلات. على سبيل المثال، إذا كان لدينا مصفوفةٌ مكوَّنةٌ من عدد n من العناصر، واستخدمنا العامل [] لقراءة أيٍّ من عناصرها، فإن ذلك يتطلَّب نفس عدد العمليات بغضّ النظر عن حجم المصفوفة. ذات زمن خطّي: تكون الخوارزمية خطيّةً إذا تناسب زمن تشغيلها مع حجم المدخلات. فإذا كنا نحسب حاصل مجموع العناصر الموجودة ضمن مصفوفة مثلًا، فعلينا أن نسترجع قيمة عدد n من العناصر، وأن نُنفِّذ عدد n-1 من عمليات الجمع، وبالتالي يكون العدد الكليّ للعمليات (الاسترجاع والجمع) هو 2*n-1، وهو عددٌ يتناسب مع n. ذات زمن تربيعي: تكون الخوارزمية خطيةً إذا تناسب زمن تشغيلها مع n2. على سبيل المثال، إذا كنا نريد أن نفحص ما إذا كان هنالك أيُّ عنصرٍ ضمن قائمةٍ معينةٍ مُكرَّرًا، فإن بإمكان خوارزميةٍ بسيطةٍ أن توازن كل عنصرٍ ضمن القائمة بجميع العناصر الأخرى، وذلك نظرًا لوجود عدد n من العناصر، والتي لا بُدّ من موازنة كُلٍّ منها مع عدد n-1 من العناصر الأخرى، يكون العدد الكليّ لعمليات الموازنة هو n2-n، وهو عددٌ يتناسب مع n2. الترتيب الانتقائي Selection sort تُنفِّذ الشيفرة المثال التالية خوارزميةً بسيطةً تُعرَف باسم الترتيب الانتقائي: public class SelectionSort { /** * بدل العنصرين الموجودين بالفهرس i والفهرس j */ public static void swapElements(int[] array, int i, int j) { int temp = array[i]; array[i] = array[j]; array[j] = temp; } /** * اعثر على فهرس أصغر عنصر بدءًا من الفهرس المُمرَّر * عبر المعامل index وحتى نهاية المصفوفة */ public static int indexLowest(int[] array, int start) { int lowIndex = start; for (int i = start; i < array.length; i++) { if (array[i] < array[lowIndex]) { lowIndex = i; } } return lowIndex; } /** * رتب المصفوفة باستخدام خوارزمية الترتيب الانتقائي */ public static void selectionSort(int[] array) { for (int i = 0; i < array.length; i++) { int j = indexLowest(array, i); swapElements(array, i, j); } } } يُبدِّل التابع الأول swapElements عنصرين ضمن المصفوفة، وتَستغرِق عمليتا قراءة العناصر وكتابتها زمنًا ثابتًا؛ لأننا لو عَرَفنا حجم العناصر وموضع العنصر الأول ضمن المصفوفة، فسيكون بإمكاننا حساب موضع أي عنصرٍ آخرَ باستخدام عمليتي ضربٍ وجمعٍ فقط، وكلتاهما من العمليات التي تَستغرِق زمنًا ثابتًا. ولمّا كانت جميع العمليات ضمن التابع swapElements تَستغرِق زمنًا ثابتًا، فإن التابع بالكامل يَستغرِق بدوره زمنًا ثابتًا. يبحثُ التابع الثاني indexLowest عن فهرسِ index أصغرِ عنصرٍ في المصفوفة بدءًا من فهرسٍ معينٍ يُخصِّصه المعامل start، ويقرأ كل تكرارٍ ضمن الحلقة التكراريّة عنصرين من المصفوفة ويُوازن بينهما، ونظرًا لأن كل تلك العمليات تستغرِق زمنًا ثابتًا، فلا يَهُمّ أيُها نَعُدّ. ونحن هنا بهدف التبسيط سنحسب عدد عمليات الموازنة: إذا كان start يُساوِي الصفر، فسيَمُرّ التابع indexLowest عبر المصفوفة بالكامل، وبالتالي يكون عدد عمليات الموازنة المُجراة مُساويًا لعدد عناصر المصفوفة، وليكن n. إذا كان start يُساوِي 1، فإن عدد عمليات الموازنة يُساوِي n-1. في العموم، يكون عدد عمليات الموازنة مساويًا لقيمة n-start، وبالتالي، يَستغرِق التابع indexLowest زمنًا خطّيًا. يُرتِّب التابع الثالث selectionSort المصفوفة. ويُنفِّذ التابع حلقة تكرار من 0 إلى n-1، أي يُنفذِّ الحلقة عدد n من المرات. وفي كل مرة يَستدعِي خلالها التابع indexLowest، ثم يُنفِّذ العملية swapElements التي تَستغرِق زمنًا ثابتًا. عند استدعاء التابع indexLowest لأوّلِ مرة، فإنه يُنفِّذ عددًا من عمليات الموازنة مقداره n، وعند استدعائه للمرة الثانية، فإنه يُنفِّذ عددًا من عمليات الموازنة مقداره n-1، وهكذا. وبالتالي سيكون العدد الإجمالي لعمليات الموازنة هو: n + n-1 + n-2 + ... + 1 + 0 يبلُغ مجموع تلك السلسلة مقدارًا يُساوِي n(n+1)/2، وهو مقدارٌ يتناسب مع n2، مما يَعنِي أن التابع selectionSort يقع تحت التصنيف التربيعي. يُمكِننا الوصول إلى نفس النتيجة بطريقة أخرى، وهي أن ننظر للتابع indexLowest كما لو كان حلقة تكرارٍ متداخلةً nested، ففي كل مرة نَستدعِي خلالها التابع indexLowest، فإنه يُنفِّذ مجموعةً من العمليات يكون عددها متناسبًا مع n، ونظرًا لأننا نَستدعيه عددًا من المرات مقداره n، فإن العدد الكليّ للعمليات يكون متناسبًا مع n2. ترميز Big O تنتمي جميع الخوارزميات التي تَستغرِق زمنًا ثابتًا إلى مجموعةٍ يُطلَق عليها اسم O(1)، فإذا قلنا إن خوارزميةً معينةً تنتمي إلى المجموعة O(1)، فهذا يعني ضمنيًّا أنها تستغرِق زمنًا ثابتًا. وعلى نفس المنوال، تنتمي جميع الخوارزميات الخطيّة -التي تستغرِق زمنًا خطيًا- إلى المجموعة O(n)، بينما تنتمي جميع الخوارزميات التربيعية إلى المجموعة O(n2). تطلَق على تصنيف الخوارزميات بهذا الأسلوب تسمية ترميز Big O. يُوفِّر هذا الترميز أسلوبًا سهلًا لكتابة القواعد العامة التي تسلُكها الخوارزميات في العموم. فلو نفَّذنا خوارزميةً خطيةً وتبعناها بخوارزميةٍ ثابتة الزمن على سبيل المثال، ، فإن زمن التشغيل الإجمالي يكون خطيًا. وننبّه هنا إلى أنّ ∈ تَعنِي "ينتمي إلى": If f ∈ O(n) and g ∈ O(1), f+g ∈ O(n) إذا أجرينا عمليتين خطيتين، فسيكون المجموع الإجمالي خطيًا: If f ∈ O(n) and g ∈ O(n), f+g ∈ O(n) في الحقيقة، إذا أجرينا عمليةً خطيّةً أي عددٍ من المرات، وليكن k، فإن المجموع الإجمالي سيبقى خطيًا طالما أن k قيمة ثابتة لا تعتمد على n: If f ∈ O(n) and k is constant, kf ∈ O(n) في المقابل، إذا أجرينا عمليةً خطيةً عدد n من المرات، فستكون النتيجة تربيعيةً: If f ∈ O(n), nf ∈ O(n^2) وفي العموم، ما يهمنا هو أكبر أسٍّ للأساس n، فإذا كان العدد الكليّ للعمليات يُساوِي 2n+1، فإنه إجمالًا ينتمي إلى O(n)، ولا أهمية للثابت 2 ولا للقيمة المضافة 1 في هذا النوع من تحليل الخوارزميات. وبالمثل، ينتمي n2+100n+1000 إلى O( n2). ولا أهمّية للأرقام الكبيرة التي تراها. يُعدّ ترتيب النمو Order of growth طريقةً أخرى للتعبير عن نفس الفكرة، ويشير ترتيبُ نموٍّ معين إلى مجموعة الخوارزميات التي ينتمي زمن تشغيلها إلى نفس تصنيف ترميز big O، حيث تنتمي جميع الخوارزميات الخطية مثلًا إلى نفس ترتيب النمو؛ وذلك لأن زمن تشغيلها ينتمي إلى المجموعة O(n). ويُقصَد بكلمة "ترتيب" ضمن هذا السياق "مجموعة"، مثل اِستخدَامنا لتلك الكلمة في عبارةٍ مثل "ترتيب فرسان المائدة المستديرة". ويُقصَد بهذا أنهم مجموعة من الفرسان، وليس طريقة صفّهم أو ترتيبهم، أي يُمكِنك أن تنظر إلى ترتيب الخوارزميات الخطية وكأنها مجموعة من الخوارزميات التي تتمتّع بكفاءةٍ عالية. تمرين 2 يشتمل التمرين التالي على تنفيذ الواجهة List باستخدام مصفوفةٍ لتخزين عناصر القائمة. ستجد الملفات التالية في مستودع الشيفرة الخاص بالكتاب -انظر القسم 0.1-: MyArrayList.java : يحتوي على تنفيذ جزئي للواجهة List، فهناك أربعةُ توابعَ غير مكتملة عليك أن تكمل كتابة شيفرتها. MyArrayListTest.java: يحتوي على مجموعة من اختبارات JUnit، والتي يُمكِنك أن تَستخدِمها للتحقق من صحة عملك. كما ستجد الملف build.xml. يُمكِنك أن تُنفِّذ الأمر ant MyArrayList؛ لكي تتمكَّن من تشغيل الصنف MyArrayList.java وأنت ما تزال في المجلد code الذي يحتوي على عدة اختباراتٍ بسيطة. ويُمكِنك بدلًا من ذلك أن تُنفِّذ الأمر ant MyArrayListTest لكي تُشغِّل اختباراتِ JUnit. عندما تُشغِّل تلك الاختبارات فسيفشل بعضها، والسبب هو وجود توابع ينبغي عليك إكمالها. إذا نظرت إلى الشيفرة، فستجد 4 تعليقات TODO تشير إلى هذه موضع كل من هذه التوابع. ولكن قبل أن تبدأ في إكمال تلك التوابع، دعنا نلق نظرةً سريعةً على بعض أجزاء الشيفرة. تحتوي الشيفرة التالية على تعريف الصنف ومتغيراتِ النُّسَخ instance variables وباني الصنف constructor: public class MyArrayList<E> implements List<E> { int size; // احتفظ بعدد العناصر private E[] array; // خزِّن العناصر public MyArrayList() { array = (E[]) new Object[10]; size = 0; } } يحتفظ المتغير size -كما يُوضِّح التعليق- بعدد العناصر التي يَحمِلها كائنٌ من النوع MyArrayList، بينما يُمثِل المتغير array المصفوفة التي تحتوي على تلك العناصر ذاتها. يُنشِئ الباني مصفوفةً مكوَّنةً من عشرة عناصر تَحمِل مبدئيًّا القيمة الفارغة null، كما يَضبُط قيمة المتغير size إلى 0. غالبًا ما يكون طول المصفوفة أكبر من قيمة المتغير size، مما يَعنِي وجود أماكنَ غير مُستخدَمةٍ في المصفوفة. array = new E[10]; لكي تتمكَّن من تخطِي تلك العقبة، عليك أن تُنشِئ مصفوفةً من النوع Object، ثم تُحوِّل نوعها typecast. يُمكِنك قراءة المزيد عن ذلك في ما المقصود بالأنواع المعمّمة (باللغة الإنجليزية). ولنُلقِ نظرةً الآن على التابع المسؤول عن إضافة العناصر إلى القائمة: public boolean add(E element) { if (size >= array.length) { // أنشئ مصفوفة أكبر وانسخ إليها العناصر E[] bigger = (E[]) new Object[array.length * 2]; System.arraycopy(array, 0, bigger, 0, array.length); array = bigger; } array[size] = element; size++; return true; } في حالة عدم وجود المزيد من الأماكن الشاغرة في المصفوفة، سنضطّر إلى إنشاء مصفوفةٍ أكبر نَنسَخ إليها العناصر الموجودة سابقًا، وعندئذٍ سنتمكَّن من إضافة العنصر الجديد إلى تلك المصفوفة، مع زيادة قيمة المتغير size. يعيد ذلك التابع قيمةً من النوع boolean. قد لا يكون سبب ذلك واضحًا، فلربما تظن أنه سيعيد القيمة true دائمًا. قد لا تتضح لنا الكيفية التي ينبغي أن نُحلِّل أداء التابع على أساسها. في الأحوال العاديّة يستغرق التابع زمنًا ثابتًا، ولكنه في الحالات التي نضطّر خلالها إلى إعادة ضبط حجم المصفوفة سيستغرِق زمنًا خطيًا. وسنتطرّق إلى كيفية معالجة ذلك في جزئية لاحقة من هذه السلسلة. في الأخير، لنُلقِ نظرةً على التابع get، وبعدها يُمكِنك البدء في حل التمرين: public T get(int index) { if (index < 0 || index >= size) { throw new IndexOutOfBoundsException(); } return array[index]; } كما نرى، فالتابع get بسيطٌ للغاية ويعمل كما يلي: إذا كان الفهرس المطلوب خارج نطاق المصفوفة، فسيُبلِّغ التابع عن اعتراض exception؛ أما إذا ضمن نطاق المصفوفة، فإن التابع يسترجع عنصر المصفوفة ويعيده. لاحِظ أن التابع يَفحَص ما إذا كانت قيمة الفهرس أقل من قيمة size لا قيمة array.length، وبالتالي لا يعيد التابع قيم عناصر المصفوفة غير المُستخدَمة. ستجد التابع set في الملف MyArrayList.java على النحو التالي: public T set(int index, T element) { // TODO: fill in this method. return null; } اقرأ توثيق set باللغة الإنجليزية، ثم أكمل متن التابع. لا بُدّ أن ينجح الاختبار testSet عندما تُشغِّل MyArrayListTest مرةً أخرى. الخطوة التالية هي إكمال التابع indexOf. وقد وفَّرنا لك أيضًا التابع المساعد equals للموازنة بين قيمة عنصر ضمن المصفوفة وبين قيمة معينة أخرى. يعيد ذلك التابع القيمة true إذا كانت القيمتان متساويتين كما يُعالِج القيمة الفارغة null بشكل سليم. لاحِظ أن هذا التابع مُعرَّف باستخدام المُعدِّل private؛ لأنه ليس جزءًا من الواجهة List، ويُستخدَم فقط داخل الصنف. شغِّل الاختبار MyArrayListTest مرة أخرى عندما تنتهي، والآن ينبغي أن ينجح الاختبار testIndexOf وكذلك الاختبارات الأخرى التي تعتمد عليه. ما يزال هناك تابعان آخران عليك إكمالهما لكي تنتهي من التمرين، حيث أن التابع الأول هو عبارة عن بصمة أخرى من التابع add. تَستقبِل تلك البصمة فهرسًا وتُخزِّن فيه قيمةً جديدة. قد تضطّر أثناء ذلك إلى تحريك العناصر الأخرى لكي تُوفِّر مكانًا للعنصر الجديد. مثلما سبق، اقرأ التوثيق باللغة الإنجليزية أولًا ثم نفِّذ التابع، بعدها شغِّل الاختبارات لكي تتأكّد من أنك تنفيذك سليم. لننتقل الآن إلى التابع الأخير. أكمل متن التابع remove وعندما تنتهي من إكمال هذا التابع، فالمتوقع أن تنجح جميع الاختبارات. وبعد أن تُنهِي جميع التوابع وتتأكَّد من أنها تَعمَل بكفاءة، يُمكِنك الاطلاع على الشيفرة. ترجمة -بتصرّف- للفصل Chapter 2: Analysis of Algorithms من كتاب Think Data Structures: Algorithms and Information Retrieval in Java. اقرأ أيضًا المقال التالي: تحليل زمن تشغيل القوائم المنفذة باستخدام مصفوفة المقال السابق: طريقة عمل الواجهات في لغة جافا تحليل الخوارزميات في جافا الرسوم التخطيطية Graphs في الخوارزميات تعقيد الخوارزميات Algorithms Complexity الأشجار Trees في الخوارزميات
كما رأينا في مقالة طريقة عمل الواجهات بلغة جافا، تُوفِّر جافا تنفيذين implementations للواجهة List، هما ArrayList وLinkedList، حيث يكون النوع LinkedList أسرع بالنسبة لبعض التطبيقات، بينما يكون النوع ArrayList أسرع بالنسبة لتطبيقاتٍ أخرى. وإذا أردنا أن نُحدِّد أيهما أفضل للاستخدام في تطبيق معين، فيمكننا تجربة كلٍّ منهما على حدةٍ لنرى الزمن الذي سيَستغرِقه. يُطلَق على هذا الأسلوب اسم التشخيص profiling، ولكنّ له بعض الإشكاليّات: أننا سنضطّر إلى تنفيذ الخوارزميتين كلتيهما لكي نتمكَّن من الموازنة بينهما. قد تعتمد النتائج على نوع الحاسوب المُستخدَم، فقد تعمل خوارزمية معينة بكفاءةٍ عالية على حاسوب معين، في حين قد تَعمَل خوارزميةٌ أخرى بكفاءةٍ عاليةٍ على حاسوب مختلف. قد تعتمد النتائج على حجم المشكلة أو البيانات المُدْخَلة. يُمكِننا معالجة بعض هذه النقاط المُشكلةِ بالاستعانة بما يُعرَف باسم تحليل الخوارزميات، الذي يُمكِّننا من الموازنة بين عدة خوارزمياتٍ دون الحاجة إلى تنفيذها فعليًا، ولكننا سنضطّر عندئذٍ لوضع بعض الافتراضات: فلكي نتجنَّب التفاصيل المتعلقة بعتاد الحاسوب، سنُحدِّد العمليات الأساسية التي تتألف منها أي خوارزميةٍ مثل الجمع والضرب وموازنة عددين، ثم نَحسِب عدد العمليات التي تتطلّبها كل خوارزمية. ولكي نتجنَّب التفاصيل المتعلقة بالبيانات المُدْخَلة، فإن الخيار الأفضل هو تحليل متوسط الأداء للمُدْخَلات التي نتوقع التعامل معها. فإذا لم يَكُن ذلك متاحًا، فسيكون تحليل الحالة الأسوأ هو الخيار البديل الأكثر شيوعًا. أخيرًا، سيتعيّن علينا التعامل مع احتمالية أن يكون أداء خوارزميةٍ معينةٍ فعّالًا عند التعامل مع مشكلات صغيرة وأن يكون أداء خوارزميةٍ أخرى فعّالًا عند التعامل مع مشكلاتٍ كبيرة. وفي تلك الحالة، عادةً ما نُركِّز على المشكلات الكبيرة، لأن الاختلاف في الأداء لا يكون كبيرًا مع المشكلات الصغيرة، ولكنه يكون كذلك مع المشكلات الكبيرة. يقودنا هذا النوع من التحليل إلى تصنيف بسيط للخوارزميات. على سبيل المثال، إذا كان زمن تشغيل خوارزمية A يتناسب مع حجم المدخلات n، وكان زمن تشغيل خوارزمية أخرى B يتناسب مع n2، فيُمكِننا أن نقول إن الخوارزمية A أسرع من الخوارزمية B لقيم n الكبيرة على الأقل. يُمكِن تصنيف غالبية الخوارزميات البسيطة إلى إحدى التصنيفات التالية: ذات زمن ثابت: تكون الخوارزمية ثابتة الزمن إذا لم يعتمد زمن تشغيلها على حجم المدخلات. على سبيل المثال، إذا كان لدينا مصفوفةٌ مكوَّنةٌ من عدد n من العناصر، واستخدمنا العامل [] لقراءة أيٍّ من عناصرها، فإن ذلك يتطلَّب نفس عدد العمليات بغضّ النظر عن حجم المصفوفة. ذات زمن خطّي: تكون الخوارزمية خطيّةً إذا تناسب زمن تشغيلها مع حجم المدخلات. فإذا كنا نحسب حاصل مجموع العناصر الموجودة ضمن مصفوفة مثلًا، فعلينا أن نسترجع قيمة عدد n من العناصر، وأن نُنفِّذ عدد n-1 من عمليات الجمع، وبالتالي يكون العدد الكليّ للعمليات (الاسترجاع والجمع) هو 2*n-1، وهو عددٌ يتناسب مع n. ذات زمن تربيعي: تكون الخوارزمية خطيةً إذا تناسب زمن تشغيلها مع n2. على سبيل المثال، إذا كنا نريد أن نفحص ما إذا كان هنالك أيُّ عنصرٍ ضمن قائمةٍ معينةٍ مُكرَّرًا، فإن بإمكان خوارزميةٍ بسيطةٍ أن توازن كل عنصرٍ ضمن القائمة بجميع العناصر الأخرى، وذلك نظرًا لوجود عدد n من العناصر، والتي لا بُدّ من موازنة كُلٍّ منها مع عدد n-1 من العناصر الأخرى، يكون العدد الكليّ لعمليات الموازنة هو n2-n، وهو عددٌ يتناسب مع n2. الترتيب الانتقائي Selection sort تُنفِّذ الشيفرة المثال التالية خوارزميةً بسيطةً تُعرَف باسم الترتيب الانتقائي: public class SelectionSort { /** * بدل العنصرين الموجودين بالفهرس i والفهرس j */ public static void swapElements(int[] array, int i, int j) { int temp = array[i]; array[i] = array[j]; array[j] = temp; } /** * اعثر على فهرس أصغر عنصر بدءًا من الفهرس المُمرَّر * عبر المعامل index وحتى نهاية المصفوفة */ public static int indexLowest(int[] array, int start) { int lowIndex = start; for (int i = start; i < array.length; i++) { if (array[i] < array[lowIndex]) { lowIndex = i; } } return lowIndex; } /** * رتب المصفوفة باستخدام خوارزمية الترتيب الانتقائي */ public static void selectionSort(int[] array) { for (int i = 0; i < array.length; i++) { int j = indexLowest(array, i); swapElements(array, i, j); } } } يُبدِّل التابع الأول swapElements عنصرين ضمن المصفوفة، وتَستغرِق عمليتا قراءة العناصر وكتابتها زمنًا ثابتًا؛ لأننا لو عَرَفنا حجم العناصر وموضع العنصر الأول ضمن المصفوفة، فسيكون بإمكاننا حساب موضع أي عنصرٍ آخرَ باستخدام عمليتي ضربٍ وجمعٍ فقط، وكلتاهما من العمليات التي تَستغرِق زمنًا ثابتًا. ولمّا كانت جميع العمليات ضمن التابع swapElements تَستغرِق زمنًا ثابتًا، فإن التابع بالكامل يَستغرِق بدوره زمنًا ثابتًا. يبحثُ التابع الثاني indexLowest عن فهرسِ index أصغرِ عنصرٍ في المصفوفة بدءًا من فهرسٍ معينٍ يُخصِّصه المعامل start، ويقرأ كل تكرارٍ ضمن الحلقة التكراريّة عنصرين من المصفوفة ويُوازن بينهما، ونظرًا لأن كل تلك العمليات تستغرِق زمنًا ثابتًا، فلا يَهُمّ أيُها نَعُدّ. ونحن هنا بهدف التبسيط سنحسب عدد عمليات الموازنة: إذا كان start يُساوِي الصفر، فسيَمُرّ التابع indexLowest عبر المصفوفة بالكامل، وبالتالي يكون عدد عمليات الموازنة المُجراة مُساويًا لعدد عناصر المصفوفة، وليكن n. إذا كان start يُساوِي 1، فإن عدد عمليات الموازنة يُساوِي n-1. في العموم، يكون عدد عمليات الموازنة مساويًا لقيمة n-start، وبالتالي، يَستغرِق التابع indexLowest زمنًا خطّيًا. يُرتِّب التابع الثالث selectionSort المصفوفة. ويُنفِّذ التابع حلقة تكرار من 0 إلى n-1، أي يُنفذِّ الحلقة عدد n من المرات. وفي كل مرة يَستدعِي خلالها التابع indexLowest، ثم يُنفِّذ العملية swapElements التي تَستغرِق زمنًا ثابتًا. عند استدعاء التابع indexLowest لأوّلِ مرة، فإنه يُنفِّذ عددًا من عمليات الموازنة مقداره n، وعند استدعائه للمرة الثانية، فإنه يُنفِّذ عددًا من عمليات الموازنة مقداره n-1، وهكذا. وبالتالي سيكون العدد الإجمالي لعمليات الموازنة هو: n + n-1 + n-2 + ... + 1 + 0 يبلُغ مجموع تلك السلسلة مقدارًا يُساوِي n(n+1)/2، وهو مقدارٌ يتناسب مع n2، مما يَعنِي أن التابع selectionSort يقع تحت التصنيف التربيعي. يُمكِننا الوصول إلى نفس النتيجة بطريقة أخرى، وهي أن ننظر للتابع indexLowest كما لو كان حلقة تكرارٍ متداخلةً nested، ففي كل مرة نَستدعِي خلالها التابع indexLowest، فإنه يُنفِّذ مجموعةً من العمليات يكون عددها متناسبًا مع n، ونظرًا لأننا نَستدعيه عددًا من المرات مقداره n، فإن العدد الكليّ للعمليات يكون متناسبًا مع n2. ترميز Big O تنتمي جميع الخوارزميات التي تَستغرِق زمنًا ثابتًا إلى مجموعةٍ يُطلَق عليها اسم O(1)، فإذا قلنا إن خوارزميةً معينةً تنتمي إلى المجموعة O(1)، فهذا يعني ضمنيًّا أنها تستغرِق زمنًا ثابتًا. وعلى نفس المنوال، تنتمي جميع الخوارزميات الخطيّة -التي تستغرِق زمنًا خطيًا- إلى المجموعة O(n)، بينما تنتمي جميع الخوارزميات التربيعية إلى المجموعة O(n2). تطلَق على تصنيف الخوارزميات بهذا الأسلوب تسمية ترميز Big O. يُوفِّر هذا الترميز أسلوبًا سهلًا لكتابة القواعد العامة التي تسلُكها الخوارزميات في العموم. فلو نفَّذنا خوارزميةً خطيةً وتبعناها بخوارزميةٍ ثابتة الزمن على سبيل المثال، ، فإن زمن التشغيل الإجمالي يكون خطيًا. وننبّه هنا إلى أنّ ∈ تَعنِي "ينتمي إلى": If f ∈ O(n) and g ∈ O(1), f+g ∈ O(n) إذا أجرينا عمليتين خطيتين، فسيكون المجموع الإجمالي خطيًا: If f ∈ O(n) and g ∈ O(n), f+g ∈ O(n) في الحقيقة، إذا أجرينا عمليةً خطيّةً أي عددٍ من المرات، وليكن k، فإن المجموع الإجمالي سيبقى خطيًا طالما أن k قيمة ثابتة لا تعتمد على n: If f ∈ O(n) and k is constant, kf ∈ O(n) في المقابل، إذا أجرينا عمليةً خطيةً عدد n من المرات، فستكون النتيجة تربيعيةً: If f ∈ O(n), nf ∈ O(n^2) وفي العموم، ما يهمنا هو أكبر أسٍّ للأساس n، فإذا كان العدد الكليّ للعمليات يُساوِي 2n+1، فإنه إجمالًا ينتمي إلى O(n)، ولا أهمية للثابت 2 ولا للقيمة المضافة 1 في هذا النوع من تحليل الخوارزميات. وبالمثل، ينتمي n2+100n+1000 إلى O( n2). ولا أهمّية للأرقام الكبيرة التي تراها. يُعدّ ترتيب النمو Order of growth طريقةً أخرى للتعبير عن نفس الفكرة، ويشير ترتيبُ نموٍّ معين إلى مجموعة الخوارزميات التي ينتمي زمن تشغيلها إلى نفس تصنيف ترميز big O، حيث تنتمي جميع الخوارزميات الخطية مثلًا إلى نفس ترتيب النمو؛ وذلك لأن زمن تشغيلها ينتمي إلى المجموعة O(n). ويُقصَد بكلمة "ترتيب" ضمن هذا السياق "مجموعة"، مثل اِستخدَامنا لتلك الكلمة في عبارةٍ مثل "ترتيب فرسان المائدة المستديرة". ويُقصَد بهذا أنهم مجموعة من الفرسان، وليس طريقة صفّهم أو ترتيبهم، أي يُمكِنك أن تنظر إلى ترتيب الخوارزميات الخطية وكأنها مجموعة من الخوارزميات التي تتمتّع بكفاءةٍ عالية. تمرين 2 يشتمل التمرين التالي على تنفيذ الواجهة List باستخدام مصفوفةٍ لتخزين عناصر القائمة. ستجد الملفات التالية في مستودع الشيفرة الخاص بالكتاب -انظر القسم 0.1-: MyArrayList.java : يحتوي على تنفيذ جزئي للواجهة List، فهناك أربعةُ توابعَ غير مكتملة عليك أن تكمل كتابة شيفرتها. MyArrayListTest.java: يحتوي على مجموعة من اختبارات JUnit، والتي يُمكِنك أن تَستخدِمها للتحقق من صحة عملك. كما ستجد الملف build.xml. يُمكِنك أن تُنفِّذ الأمر ant MyArrayList؛ لكي تتمكَّن من تشغيل الصنف MyArrayList.java وأنت ما تزال في المجلد code الذي يحتوي على عدة اختباراتٍ بسيطة. ويُمكِنك بدلًا من ذلك أن تُنفِّذ الأمر ant MyArrayListTest لكي تُشغِّل اختباراتِ JUnit. عندما تُشغِّل تلك الاختبارات فسيفشل بعضها، والسبب هو وجود توابع ينبغي عليك إكمالها. إذا نظرت إلى الشيفرة، فستجد 4 تعليقات TODO تشير إلى هذه موضع كل من هذه التوابع. ولكن قبل أن تبدأ في إكمال تلك التوابع، دعنا نلق نظرةً سريعةً على بعض أجزاء الشيفرة. تحتوي الشيفرة التالية على تعريف الصنف ومتغيراتِ النُّسَخ instance variables وباني الصنف constructor: public class MyArrayList<E> implements List<E> { int size; // احتفظ بعدد العناصر private E[] array; // خزِّن العناصر public MyArrayList() { array = (E[]) new Object[10]; size = 0; } } يحتفظ المتغير size -كما يُوضِّح التعليق- بعدد العناصر التي يَحمِلها كائنٌ من النوع MyArrayList، بينما يُمثِل المتغير array المصفوفة التي تحتوي على تلك العناصر ذاتها. يُنشِئ الباني مصفوفةً مكوَّنةً من عشرة عناصر تَحمِل مبدئيًّا القيمة الفارغة null، كما يَضبُط قيمة المتغير size إلى 0. غالبًا ما يكون طول المصفوفة أكبر من قيمة المتغير size، مما يَعنِي وجود أماكنَ غير مُستخدَمةٍ في المصفوفة. array = new E[10]; لكي تتمكَّن من تخطِي تلك العقبة، عليك أن تُنشِئ مصفوفةً من النوع Object، ثم تُحوِّل نوعها typecast. يُمكِنك قراءة المزيد عن ذلك في ما المقصود بالأنواع المعمّمة (باللغة الإنجليزية). ولنُلقِ نظرةً الآن على التابع المسؤول عن إضافة العناصر إلى القائمة: public boolean add(E element) { if (size >= array.length) { // أنشئ مصفوفة أكبر وانسخ إليها العناصر E[] bigger = (E[]) new Object[array.length * 2]; System.arraycopy(array, 0, bigger, 0, array.length); array = bigger; } array[size] = element; size++; return true; } في حالة عدم وجود المزيد من الأماكن الشاغرة في المصفوفة، سنضطّر إلى إنشاء مصفوفةٍ أكبر نَنسَخ إليها العناصر الموجودة سابقًا، وعندئذٍ سنتمكَّن من إضافة العنصر الجديد إلى تلك المصفوفة، مع زيادة قيمة المتغير size. يعيد ذلك التابع قيمةً من النوع boolean. قد لا يكون سبب ذلك واضحًا، فلربما تظن أنه سيعيد القيمة true دائمًا. قد لا تتضح لنا الكيفية التي ينبغي أن نُحلِّل أداء التابع على أساسها. في الأحوال العاديّة يستغرق التابع زمنًا ثابتًا، ولكنه في الحالات التي نضطّر خلالها إلى إعادة ضبط حجم المصفوفة سيستغرِق زمنًا خطيًا. وسنتطرّق إلى كيفية معالجة ذلك في جزئية لاحقة من هذه السلسلة. في الأخير، لنُلقِ نظرةً على التابع get، وبعدها يُمكِنك البدء في حل التمرين: public T get(int index) { if (index < 0 || index >= size) { throw new IndexOutOfBoundsException(); } return array[index]; } كما نرى، فالتابع get بسيطٌ للغاية ويعمل كما يلي: إذا كان الفهرس المطلوب خارج نطاق المصفوفة، فسيُبلِّغ التابع عن اعتراض exception؛ أما إذا ضمن نطاق المصفوفة، فإن التابع يسترجع عنصر المصفوفة ويعيده. لاحِظ أن التابع يَفحَص ما إذا كانت قيمة الفهرس أقل من قيمة size لا قيمة array.length، وبالتالي لا يعيد التابع قيم عناصر المصفوفة غير المُستخدَمة. ستجد التابع set في الملف MyArrayList.java على النحو التالي: public T set(int index, T element) { // TODO: fill in this method. return null; } اقرأ توثيق set باللغة الإنجليزية، ثم أكمل متن التابع. لا بُدّ أن ينجح الاختبار testSet عندما تُشغِّل MyArrayListTest مرةً أخرى. الخطوة التالية هي إكمال التابع indexOf. وقد وفَّرنا لك أيضًا التابع المساعد equals للموازنة بين قيمة عنصر ضمن المصفوفة وبين قيمة معينة أخرى. يعيد ذلك التابع القيمة true إذا كانت القيمتان متساويتين كما يُعالِج القيمة الفارغة null بشكل سليم. لاحِظ أن هذا التابع مُعرَّف باستخدام المُعدِّل private؛ لأنه ليس جزءًا من الواجهة List، ويُستخدَم فقط داخل الصنف. شغِّل الاختبار MyArrayListTest مرة أخرى عندما تنتهي، والآن ينبغي أن ينجح الاختبار testIndexOf وكذلك الاختبارات الأخرى التي تعتمد عليه. ما يزال هناك تابعان آخران عليك إكمالهما لكي تنتهي من التمرين، حيث أن التابع الأول هو عبارة عن بصمة أخرى من التابع add. تَستقبِل تلك البصمة فهرسًا وتُخزِّن فيه قيمةً جديدة. قد تضطّر أثناء ذلك إلى تحريك العناصر الأخرى لكي تُوفِّر مكانًا للعنصر الجديد. مثلما سبق، اقرأ التوثيق باللغة الإنجليزية أولًا ثم نفِّذ التابع، بعدها شغِّل الاختبارات لكي تتأكّد من أنك تنفيذك سليم. لننتقل الآن إلى التابع الأخير. أكمل متن التابع remove وعندما تنتهي من إكمال هذا التابع، فالمتوقع أن تنجح جميع الاختبارات. وبعد أن تُنهِي جميع التوابع وتتأكَّد من أنها تَعمَل بكفاءة، يُمكِنك الاطلاع على الشيفرة. ترجمة -بتصرّف- للفصل Chapter 2: Analysis of Algorithms من كتاب Think Data Structures: Algorithms and Information Retrieval in Java. اقرأ أيضًا المقال التالي: تحليل زمن تشغيل القوائم المنفذة باستخدام مصفوفة المقال السابق: طريقة عمل الواجهات في لغة جافا تحليل الخوارزميات في جافا الرسوم التخطيطية Graphs في الخوارزميات تعقيد الخوارزميات Algorithms Complexity الأشجار Trees في الخوارزميات -
 ركّزنا في المقالات السابقة من هذه السلسلة على صحة البرامج، وإلى جانب ذلك، تُعَد مشكلة الكفاءة efficiency من المشاكل المهمة كذلك، فعندما نحلِّل كفاءة برنامجٍ ما، فعادةً ما تُطرح أسئلةٌ مثل كم من الوقت سيستغرقه البرنامج؟ وهل هناك طريقةٌ أخرى للحصول على نفس الإجابة ولكن بطريقةٍ أسرع؟ وعمومًا دائمًا ما ستكون كفاءة البرنامج أقلّ أهميةً من صحته؛ فإذا لم تهتم بصحة البرنامج، فيمكنك إذًا أن تشغّله بسرعةٍ، ولكن قلّما سيهتم به أحدٌ. كذلك لا توجد أي فائدةٍ من برنامجٍ يستغرق عشرات الآلاف من السنين ليعطيك إجابةً صحيحةً. يشير مصطلح الكفاءة عمومًا إلى الاستخدام الأمثل لأي مورِد resource بما في ذلك الوقت وذاكرة الحاسوب ونطاق التردد الشبكي، وسنركّز في هذا المقال على الوقت، والسؤال الأهم الذي نريد الإجابة عليه هو ما الوقت الذي يستغرقه البرنامج ليُنجز المَهمّة الموكلة إليه؟ في الواقع، ليس هناك أي معنىً من تصنيف البرامج على أنها تعمل بكفاءةٍ أم لا، وإنما يكون من الأنسب أن نوازن بين برنامجين صحيحين ينفّذان نفس المهمة لنعرف أيًا منهما أكثر كفاءةً من الآخر، بمعنى أيهما ينجز مهمّته بصورةٍ أسرع، إلا أن تحديد ذلك ليس بالأمر السهل لأن زمن تشغيل البرنامج غير معرَّف؛ فقد يختلف حسب عدد معالجات الحاسوب وسرعتها، كما قد يعتمد على تصميم آلة جافا الافتراضية Java Virtual Machine (في حالة برامج جافا) المفسِّرة للبرنامج؛ وقد يعتمد كذلك على المصرّف المستخدَم لتصريف البرنامج إلى لغة الآلة، كما يعتمد زمن تشغيل أي برنامجٍ على حجم المشكلة التي ينبغي للبرنامج أن يحلّها، فمثلًا سيستغرق برنامج ترتيب sorting وقتًا أطول لترتيب 10000 عنصر مما سيستغرقه لترتيب 100 عنصر؛ وعندما نوازن بين زمنيْ تشغيل برنامجين، سنجد أن برنامج A يحلّ المشاكل الصغيرة أسرع بكثيرٍ من برنامج B بينما يحلّ البرنامج B المشاكل الكبيرة أسرع من البرنامج A، فلا يوجد برنامجٌ معينٌ هو الأسرع دائمًا في جميع الحالات. عمومًا، هناك حقلٌ ضِمن علوم الحاسوب يُكرّس لتحليل كفاءة البرامج، ويعرف باسم تحليل الخوارزميات Analysis of Algorithms، حيث يركِّز على الخوارزميات نفسها لا البرامج؛ لتجنُّب التعامل مع التنفيذات implementations المختلفة لنفس الخوارزمية باستخدام لغاتٍ برمجيةٍ مختلفةٍ ومصرّفةٍ بأدواتٍ مختلفةٍ وتعمل على حواسيب مختلفةٍ؛ وعمومًا يُعَد مجال تحليل الخوارزميات مجالًا رياضيًا مجرّدًا عن كل تلك التفاصيل الصغيرة، فعلى الرغم من أنه حقلٌ نظريٌ في المقام الأول، إلا أنه يلزَم كلّ مبرمجٍ أن يطّلع على بعضٍ من تقنياته ومفاهيمه الأساسية، ولهذا سيَتناول هذا المقال مقدمةً مختصرةً جدًا عن بعضٍ من تلك الأساسيات والمفاهيم، ولأن هذه السلسلة ليست ذات اتجاه رياضي، فستكون المناقشة عامةً نوعًا ما. يُعَد التحليل المُقارِب asymptotic analysis أحد أهم تقنيات ذلك المجال، ويُقصد بالمُقارِب asymptotic ما يميل إليه على المدى البعيد بازدياد حجم المشكلة، حيث يجيب التحليل المُقارِب لزمن تشغيل run time خوارزميةٍ عن أسئلةٍ مثل، كيف يؤثر حجم المشكلة problem size على زمن التشغيل؟ ويُعَد التحليل مُقارِبًا؛ لأنه يهتم بما سيحدث لزمن التشغيل عند زيادة حجم المشكلة بدون أي قيودٍ، أما ما سيحدث للأحجام الصغيرة من المشاكل فهي أمورٌ لا تعنيه؛ فإذا أظهر التحليل المُقارِب لخوارزمية A أنها أسرع من خوارزمية B، فلا يعني ذلك بالضرورة أن الخوارزمية A ستكون أسرع من B عندما يكون حجم المشكلة صغيرًا مثل 10 أو 1000 أو حتى 1000000، وإنما يعني أنه بزيادة حجم المشكلة، ستصل حتمًا إلى نقطةٍ تكون عندها خوارزمية A أسرع من خوارزمية B. يرتبط مفهوم التحليل المُقارِب بـمصطلح ترميز O الكبير Big-Oh notation، حيث يمكّننا هذا الترميز من قوْل أن زمن تشغيل خوارزميةٍ معينةٍ هو O(n2) أو O(n) أو O(log(n))، وعمومًا يُشار إليه بـ O(f(n))، حيث f(n) عِبارةٌ عن دالة تُسند عددًا حقيقيًا موجبًا لكلّ عددٍ صحيحٍ موجبٍ n، بينما يشير n ضِمن هذا الترميز إلى حجم المشكلة، ولذلك يلزَمك أن تحدّد حجم المشكلة قبل أن تبدأ في تحليلها، وهو ليس أمرًا معقدًا على أية حال؛ فمثلًا، إذا كانت المشكلة هي ترتيب قائمةٍ من العناصر، فإن حجم تلك المشكلة يمكنه أن يكون عدد العناصر ضِمن القائمة، وهذا مثالٌ آخرٌ، عندما يكون مُدخَل الخوارزمية عِبارةٌ عن عددٍ صحيحٍ (لفحْص إذا ما كان ذلك العدد عددًا أوليًا prime أم لا) يكون حجم المشكلة في تلك الحالة هو عدد البتات bits الموجودة ضِمن ذلك العدد المُدخَل لا العدد ذاته؛ وعمومًا يُعَد عدد البتات bits الموجودة في قيمة المُدخَل قياسًا جيدًا لحجم المشكلة. إذا كان زمن تشغيل خوارزميةٍ معينةٍ هو O(f(n))، فذلك يعني أنه بالنسبة للقيم الكبيرة من حجم المشكلة، لن يتعدى الزمن حاصل ضرْب قيمةٍ ثابتةٍ معينةٍ في f(n)، أي أن هناك عدد C وعددٌ صحيحٌ آخرٌ موجبٌ M، وعندما تصبح n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أقلّ من أو يساوي C×f(n)؛ حيث يأخذ الثابت C في حسبانه تفاصيلًا مثل سرعة الحاسوب المستخدَم في تشغيل الخوارزمية، وإذا كان ذلك الحاسوب أبطأ، فقد تستخدم قيمة أكبر للثابت، إلا أن تغييره لن يغيّر من حقيقة أن زمن تشغيل الخوارزمية هو O(f(n)؛ وبفضل ذلك الثابت، لن يكون من الضروري تحديد إذا ما كنا نقيس الزمن بالثواني أو السنوات أو أي وحدة قياسٍ أخرى؛ لأن التحويل من وحدةٍ معينةٍ إلى أخرى يتمثَّل بعملية ضربٍ في قيمة ثابتة، بالإضافة إلى ما سبق، لا تَعتمد O(f(n)) نهائيًا على ما يحدُث في الأحجام الأصغر من المشكلة، وإنما على ما يحدُث على المدى الطويل بينما يزيد حجم المشكلة دون أي قيودٍ. سنفحص مثالًا بسيطًا عِبارةً عن حساب حاصل مجموع العناصر الموجودة ضِمن مصفوفةٍ، وفي هذه الحالة، يكون حجم المشكلة n هو طول تلك المصفوفة، فإذا كان A هو اسم المصفوفة، ستُكتب الخوارزمية بلغة جافا كالتالي: total = 0; for (int i = 0; i < n; i++) total = total + A[i]; تنفِّذ الخوارزمية عملية total = total + A[i] عدد n من المرات، أي أن الزمن الكلي المُستغرق أثناء تلك العملية يساوي a×n، حيث a هو زمن تنفيذ العملية مرةٍ واحدةٍ؛ إلى جانب ذلك، تزيد الخوارزمية قيمة المتغيّر i وتوازنه مع قيمة n في كلّ مرةٍ تنفِّذ فيها مَتْن الحلقة loop، الأمر الذي يؤدي إلى زيادة زمن التشغيل بمقدار يساوي b×n حيث b عِبارةٌ عن ثابتٍ، وبالإضافة إلى ما سبق، يُهيئ كلًا من i وtotal إلى الصفر مبدئيًا مما يزيد من زمن التشغيل بمقدار ثابتٍ معينٍ وليكن c، وبالتالي، يساوي زمن تشغيل الخوارزمية للقيمة (a+b)×n+c، حيث a وb وc عِبارةٌ عن ثوابتٍ تعتمد على عوامل مثل كيفية تصريف compile الشيفرة ونوع الحاسوب المستخدَم، وبالاعتماد على حقيقة أن c دائمًا ما تكون أقلّ من أو تساوي c×n لأي عددٍ صحيحٍ موجبٍ n، يمكننا إذًا أن نقول أن زمن التشغيل أقلّ من أو يساوي (a+b+c)×n، أي أنه أقلّ من أو يساوي حاصل ضرْب ثابتٍ في n، أي يكون زمن تشغيل الخوارزمية هو O(n). إذا استشكل عليك أن تفهم ما سبق، فإنه يعني أنه لأي قيم n كبيرة، فإن الثابت c في المعادلة (a+b)×n+c غير مهمٍ إذا ووزِن مع (a+b)×n، ونصيغ ذلك بأن نقول إن c تعبّر عن عنصرٍ ذات رتبةٍ أقل lower order، وعادةً ما نتجاهل تلك العناصر في سياق التحليل المُقارِب؛ ويمكن لتحليلٍ مُقارِب آخرٍ أكثر حدَّة أن يستنتج ما يلي: "يَستغرق كلّ تكرار iteration ضِمن حلقة for مقدارًا ثابتًا من الوقت، ولأن الخوارزمية تتضمّن عدد n من التكرارات، فإن زمن التشغيل الكلي هو حاصل ضرْب ثابتٍ في n مضافًا إليه عناصر ذات رتبة أقلّ للتهيئة المبدئية، وإذا تجاهلنا تلك العناصر، سنجد أن زمن التشغيل يساوي O(n). يفيد أحيانًا أن نخصِّص حدًا أدنىً lower limit لزمن التشغيل، حيث سيمكّننا ذلك من أن نقول أن زمن تشغيل خوارزميةٍ معينةٍ أكبر من أو يساوي حاصل ضرْب قيمةٍ ثابتةٍ في f(n)، وهو ما يعرّفه ترميزٌ آخرٌ هو Ω(f(n))، ويُقرأ أوميجا لدالة f أو ترميز أوميجا الكبير لدالة f (أوميجا Omega هو حرفٌ أبجديٌ يونانيٌ ويمثِّل الترميز Ω حالته الكبيرة)؛ وإذا شئنا الدقة، عندما نقول أن زمن تشغيل خوارزمية هو Ω(f(n))، فإن المقصود هو وجود عددٍ موجبٍ C وعددٍ صحيحٍ آخرٍ موجبٍ M، وعندما تكون قيمة n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أكبر من أو يساوي حاصل ضرْب C في f(n)، ونستخلّص مما سبق أن O(f(n)) يوفّر معلومةً عن الحد الأقصى للزمن الذي قد تنتظره حتى تنتهي الخوارزمية من العمل، بينما يوفّر Ω(f(n)) معلومةً عن الحد الأدنى للزمن. سنفْحص الآن خوارزميةً أخرى: public static void simpleBubbleSort( int[] A, int n ) { for (int i = 0; i < n; i++) { // Do n passes through the array... for (int j = 0; j < n-1; j++) { if ( A[j] > A[j+1] ) { // A[j] و A[j+1] رتِّب int temp = A[j]; A[j] = A[j+1]; A[j+1] = temp; } } } } يمثِّل المعامِل n في المثال السابق حجم المشكلة، حيث ينفِّذ الحاسوب حلقة for الخارجية عدد n من المرات، وفي كلّ مرة ينفِّذ فيها تلك الحلقة، فإنه ينفِّذ أيضًا حلقة for داخليةً عدد n-1 من المرات، إذًا سينفّذ الحاسوب تعليمة if عدد n×(n-1) من المرات، أي يساوي n2-n، ولأن العناصر ذات الرتبة الأقل غير مهمّةٍ في التحليل المُقارِب، سنكتفي بأن نقول أن تعليمة if تنفَّذ عدد n2 مرةٍ؛ وعلى وجهٍ أكثر تحديدًا، ينفِّذ الحاسوب الاختبار A[j] > A[j+1] عدد n2 من المرات، ويكون زمن تشغيل الخوارزمية هو Ω( n2)، أي يساوي حاصل ضرْب قيمةٍ ثابتةٍ في n2 على الأقل، وإذا فحصنا العمليات الأخرى (تعليمات الإسناد assignment وزيادة i وj بمقدار الواحد..إلخ)، فإننا لن نجد أي عمليةً منها تنفَّذ أكثر من عدد n2 مرة؛ ونستنتج من ذلك أن زمن التشغيل هو O(n2) أيضًا، أي أنه لن يتجاوز حاصل ضرْب قيمةٍ ثابتةٍ في n2، ونظرًا لأن زمن التشغيل يساوي كلًا من Ω( n2) و O( n2)، فإنه أيضًا يساوي Θ( n2). لقد أوضحنا حتى الآن أن زمن التشغيل يعتمد على حجم المشكلة، ولكننا تجاهلنا تفصيلةٍ مهمةٍ أخرى، وهي أنه لا يعتمد فقط على حجم المشكلة، وإنما كثيرًا ما يعتمد على نوعية البيانات المطلوب معالجتها، فمثلًا قد يعتمد زمن تشغيل خوارزمية ترتيب على الترتيب الأولي للعناصر المطلوب ترتيبها، وليس فقط على عددها. لكي نأخذ تلك الاعتمادية في الحسبان، سنُجري تحليلًا لزمن التشغيل على كلًا من الحالة الأسوأ the worst case analysis والحالة الوسطى average case analysis، بالنسبة لتحليل زمن تشغيل الحالة الأسوأ، سنفحص جميع المشاكل المحتملة لحجم يساوي n وسنحدّد أطول زمن تشغيل من بينها جميعًا، بالمِثل بالنسبة للحالة الوسطى، سنفحص جميع المشاكل المحتملة لحجم يساوي n ونحسب قيمة متوسط زمن تشغيلها جميعًا، وعمومًا سيَفترض تحليل زمن التشغيل للحالة الوسطى أن جميع المشاكل بحجم n لها نفس احتمالية الحدوث على الرغم من عدم واقعية ذلك في بعض الأحيان، أو حتى إمكانية حدوثه وذلك في حالة وجود عددٍ لا نهائيٍ من المشاكل المختلفة لحجمٍ معينٍ. عادةً ما يتساوى زمن تشغيل الحالة الأسوأ والوسطى ضِمن مُضاعفٍ ثابتٍ، وذلك يعني أنهما متساويان بقدر اهتمام التحليل المُقارِب، أي أن زمن تشغيل الحالة الوسطى والحالة الأسوأ هو O(f(n)) أو Θ(f(n))، إلا أن هنالك بعض الحالات القليلة التي يختلف فيها التحليل المُقارِب للحالة الأسوأ عن الحالة الوسطى كما سنرى لاحقًا. بالإضافة إلى ما سبق، يمكن مناقشة تحليل زمن تشغيل الحالة المُثلى best case، والذي سيفحص أقصر زمن تشغيلٍ ممكنٍ لجميع المُدخَلات من حجمٍ معينٍ، وعمومًا يُعَد أقلهم فائدةً. حسنًا، ما الذي ينبغي أن تعرفه حقًا عن تحليل الخوارزميات لتستكمل قراءة ما هو متبقّيٍ من هذه السلسلة؟ في الواقع، لن نقدِم على أي تحليلٍ رياضيٍ حقيقيٍ، ولكن ينبغي أن تفهَم بعض المناقشات العامة عن حالاتٍ بسيطةٍ مثل الأمثلة التي رأيناها في هذا المقال، والأهم من ذلك هو أن تفهم ما يعنيه بالضبط قوْل أن وقت تشغيل خوارزميةٍ معينةٍ هو O(f(n)) أو Θ(f(n)) لبعض الدوال الشائعة f(n)، كما أن النقطة المُهمّة هي أن تلك الترميزات لا تُخبرك أي شيءٍ عن القيمة العددية الفعلية لزمن تشغيل الخوارزمية لأي حالةٍ معينةٍ كما أنها لا تخبرك بأي شيءٍ عن زمن تشغيل الخوارزمية للقيم الصغيرة من n، وإنما ستخبرك بمعدل زيادة زمن التشغيل بزيادة حجم المشكلة. سنفترض أننا نوازن بين خوارزميتين لحل نفس المشكلة، وزمن تشغيل إحداها هو Θ( n2) بينما زمن تشغيل الأخرى هو Θ(n3)، فما الذي يعنيه ذلك؟ إذا كنت تريد معرفة أي خوارزميةٍ منهما هي الأسرع لمشكلةٍ حجمها 100 مثلًا، فالأمر غير مؤكدٍ، فوِفقًا للتحليل المُقارِب يمكن أن تكون أي خوارزميةٍ منهما هي الأسرع في هذه الحالة؛ أما بالنسبة للمشاكل الأكبر حجمًا، سيصل حجم المشكلة n إلى نقطةٍ تكون معها خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)؛ وعلاوةً على ذلك، يزداد تميز خوارزمية Θ( n2) عن خوارزمية Θ(n3) بزيادة حجم المشكلة أكثر فأكثر، وعمومًا ستكون هناك قيمٌ لحجم المشكلة n تكون معها خوارزمية Θ( n2) أسرع ألف مرةٍ أو مليون مرةٍ أو حتى بليون مرةٍ وهكذا؛ وذلك لأن دالة a×n3 تنمو أسرع بكثيرٍ من دالة b×n2 لأي ثابتين موجبين a وb، وذلك يعني أنه بالنسبة للمشاكل الكبيرة، ستكون خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)، ونحن لا نعرف بالضبط إلى أي درجةٍ بالضبط ينبغي أن تكون المشكلة كبيرةٌ، وعمليًا، يُحتمل لخوارزمية Θ( n2) أن تكون أسرع حتى للقيم الصغيرة من حجم المشكلة n؛ وعمومًا تُفضّل خوارزمية Θ( n2) عن خوارزمية Θ(n3). لكي تفهم وتطبّق التحليل المُقارِب، لابدّ أن يكون لديك فكرةً عن معدّل نمو بعض الدوال الشائعة، وبالنسبة للدوال الأسية (power) n, n2, n3, n4, …,، كلما كان الأس أكبر، ازداد معدّل نمو الدالة؛ أما بالنسبة للدوال الأسية exponential من النوع 2n و 10n حيث n هو الأس، يكون معدّل نموها أسرع بكثيرٍ من أي دالةٍ أسيةٍ عاديةٍ power، وعمومًا تنمو الدوال الأسية بسرعةٍ جدًا لدرجة تجعل الخوارزميات التي ينمو زمن تشغيلها بذلك المعدّل غير عمليةٍ عمومًا حتى للقيم الصغيرة من n لأن زمن التشغيل طويلٌ جدًا، وإلى جانب ذلك، تُستخدم دالة اللوغاريتم log(n) بكثرةٍ في التحليل المُقارِب، فإذا كان هناك عددٌ كبيرٌ من دوال اللوغاريتم، ولكن تلك التي أساسها يساوي 2 هي الأكثر استخدامًا في علوم الحاسوب، وتُكتب عادة كالتالي log2(n)، حيث تنمو دالة اللوغاريتم ببطئٍ إلى درجةٍ أبطأ من معدّل نمو n، وينبغي أن يساعدك الجدول التالي على فهم الفروق بين معدّلات النمو للدوال المختلفة: يرجع السبب وراء استخدام log(n) بكثرةٍ إلى ارتباطها بالضرب والقسمة على 2، سنفْترض أنك بدأت بعدد n ثم قسَمته على 2 ثم قسَمته على 2 مرةٍ أخرى، وهكذا إلى أن وصَلت إلى عددٍ أقل من أو يساوي 1، سيساوي عدد مرات القسمة (مقربًا لأقرب عدد صحيح) لقيمة log(n). فمثلًا انظر إلى خوارزمية البحث الثنائي binary search في مقال البحث والترتيب في المصفوفات Array في جافا، حيث تبحث تلك الخوارزمية عن عنصرٍ ضِمن مصفوفةٍ مرتّبةٍ، وسنستخدم طول المصفوفة مثل حجمٍ للمشكلة n، إذ يُقسَم عدد عناصر المصفوفة على 2 في كلّ خطوةٍ ضِمن خوارزمية البحث الثنائي، بحيث تتوقّف عندما يصبح عدد عناصرها أقلّ من أو يساوي 1، وذلك يعني أن عدد خطوات الخوارزمية لمصفوفة طولها n يساوي log(n) للحدّ الأقصى؛ ونستنتج من ذلك أن زمن تشغيل الحالة الأسوأ لخوارزمية البحث الثنائي هو Θ(log(n)) كما أنه هو نفسه زمن تشغيل الحالة الوسطى، في المقابل، يساوي زمن تشغيل خوارزمية البحث الخطي الذي تعرّضنا له في مقال السابق ذكره أعلاه حول البحث والترتيب في المصفوفات Array في جافا لقيمة Θ(n)، حيث يمنحك ترميز Θ طريقةً كميّةً quantitative لتعبّر عن حقيقة كون البحث الثنائي أسرع بكثيرٍ من البحث الخطي linear search. تَقسِم كلّ خطوةٍ في خوارزمية البحث الثنائي حجم المسألة على 2، وعمومًا يحدُث كثيرًا أن تُقسَم عمليةٌ معينةٌ ضِمن خوارزمية حجم المشكلة n على 2، وعندما يحدث ذلك ستظهر دالة اللوغاريتم في التحليل المُقارِب لزمن تشغيل الخوارزمية. يُعَد موضوع تحليل الخوارزميات algorithms analysis حقلًا ضخمًا ورائعًا، ناقشنا هنا جزءًا صغيرًا فقط من مفاهيمه الأساسية التي تفيد لفهم واستيعاب الاختلافات بين الخوارزميات المختلفة. ترجمة -بتصرّف- للقسم Section 5: Analysis of Algorithms من فصل Chapter 8: Correctness, Robustness, Efficiency من كتاب Introduction to Programming Using Java. اقرأ أيضًا المقال السابق: التوكيد assertion والتوصيف annotation في لغة جافا مدخل إلى الخوارزميات ترميز Big-O في الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية تعقيد الخوارزميات Algorithms Complexity النسخة الكاملة لكتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة
ركّزنا في المقالات السابقة من هذه السلسلة على صحة البرامج، وإلى جانب ذلك، تُعَد مشكلة الكفاءة efficiency من المشاكل المهمة كذلك، فعندما نحلِّل كفاءة برنامجٍ ما، فعادةً ما تُطرح أسئلةٌ مثل كم من الوقت سيستغرقه البرنامج؟ وهل هناك طريقةٌ أخرى للحصول على نفس الإجابة ولكن بطريقةٍ أسرع؟ وعمومًا دائمًا ما ستكون كفاءة البرنامج أقلّ أهميةً من صحته؛ فإذا لم تهتم بصحة البرنامج، فيمكنك إذًا أن تشغّله بسرعةٍ، ولكن قلّما سيهتم به أحدٌ. كذلك لا توجد أي فائدةٍ من برنامجٍ يستغرق عشرات الآلاف من السنين ليعطيك إجابةً صحيحةً. يشير مصطلح الكفاءة عمومًا إلى الاستخدام الأمثل لأي مورِد resource بما في ذلك الوقت وذاكرة الحاسوب ونطاق التردد الشبكي، وسنركّز في هذا المقال على الوقت، والسؤال الأهم الذي نريد الإجابة عليه هو ما الوقت الذي يستغرقه البرنامج ليُنجز المَهمّة الموكلة إليه؟ في الواقع، ليس هناك أي معنىً من تصنيف البرامج على أنها تعمل بكفاءةٍ أم لا، وإنما يكون من الأنسب أن نوازن بين برنامجين صحيحين ينفّذان نفس المهمة لنعرف أيًا منهما أكثر كفاءةً من الآخر، بمعنى أيهما ينجز مهمّته بصورةٍ أسرع، إلا أن تحديد ذلك ليس بالأمر السهل لأن زمن تشغيل البرنامج غير معرَّف؛ فقد يختلف حسب عدد معالجات الحاسوب وسرعتها، كما قد يعتمد على تصميم آلة جافا الافتراضية Java Virtual Machine (في حالة برامج جافا) المفسِّرة للبرنامج؛ وقد يعتمد كذلك على المصرّف المستخدَم لتصريف البرنامج إلى لغة الآلة، كما يعتمد زمن تشغيل أي برنامجٍ على حجم المشكلة التي ينبغي للبرنامج أن يحلّها، فمثلًا سيستغرق برنامج ترتيب sorting وقتًا أطول لترتيب 10000 عنصر مما سيستغرقه لترتيب 100 عنصر؛ وعندما نوازن بين زمنيْ تشغيل برنامجين، سنجد أن برنامج A يحلّ المشاكل الصغيرة أسرع بكثيرٍ من برنامج B بينما يحلّ البرنامج B المشاكل الكبيرة أسرع من البرنامج A، فلا يوجد برنامجٌ معينٌ هو الأسرع دائمًا في جميع الحالات. عمومًا، هناك حقلٌ ضِمن علوم الحاسوب يُكرّس لتحليل كفاءة البرامج، ويعرف باسم تحليل الخوارزميات Analysis of Algorithms، حيث يركِّز على الخوارزميات نفسها لا البرامج؛ لتجنُّب التعامل مع التنفيذات implementations المختلفة لنفس الخوارزمية باستخدام لغاتٍ برمجيةٍ مختلفةٍ ومصرّفةٍ بأدواتٍ مختلفةٍ وتعمل على حواسيب مختلفةٍ؛ وعمومًا يُعَد مجال تحليل الخوارزميات مجالًا رياضيًا مجرّدًا عن كل تلك التفاصيل الصغيرة، فعلى الرغم من أنه حقلٌ نظريٌ في المقام الأول، إلا أنه يلزَم كلّ مبرمجٍ أن يطّلع على بعضٍ من تقنياته ومفاهيمه الأساسية، ولهذا سيَتناول هذا المقال مقدمةً مختصرةً جدًا عن بعضٍ من تلك الأساسيات والمفاهيم، ولأن هذه السلسلة ليست ذات اتجاه رياضي، فستكون المناقشة عامةً نوعًا ما. يُعَد التحليل المُقارِب asymptotic analysis أحد أهم تقنيات ذلك المجال، ويُقصد بالمُقارِب asymptotic ما يميل إليه على المدى البعيد بازدياد حجم المشكلة، حيث يجيب التحليل المُقارِب لزمن تشغيل run time خوارزميةٍ عن أسئلةٍ مثل، كيف يؤثر حجم المشكلة problem size على زمن التشغيل؟ ويُعَد التحليل مُقارِبًا؛ لأنه يهتم بما سيحدث لزمن التشغيل عند زيادة حجم المشكلة بدون أي قيودٍ، أما ما سيحدث للأحجام الصغيرة من المشاكل فهي أمورٌ لا تعنيه؛ فإذا أظهر التحليل المُقارِب لخوارزمية A أنها أسرع من خوارزمية B، فلا يعني ذلك بالضرورة أن الخوارزمية A ستكون أسرع من B عندما يكون حجم المشكلة صغيرًا مثل 10 أو 1000 أو حتى 1000000، وإنما يعني أنه بزيادة حجم المشكلة، ستصل حتمًا إلى نقطةٍ تكون عندها خوارزمية A أسرع من خوارزمية B. يرتبط مفهوم التحليل المُقارِب بـمصطلح ترميز O الكبير Big-Oh notation، حيث يمكّننا هذا الترميز من قوْل أن زمن تشغيل خوارزميةٍ معينةٍ هو O(n2) أو O(n) أو O(log(n))، وعمومًا يُشار إليه بـ O(f(n))، حيث f(n) عِبارةٌ عن دالة تُسند عددًا حقيقيًا موجبًا لكلّ عددٍ صحيحٍ موجبٍ n، بينما يشير n ضِمن هذا الترميز إلى حجم المشكلة، ولذلك يلزَمك أن تحدّد حجم المشكلة قبل أن تبدأ في تحليلها، وهو ليس أمرًا معقدًا على أية حال؛ فمثلًا، إذا كانت المشكلة هي ترتيب قائمةٍ من العناصر، فإن حجم تلك المشكلة يمكنه أن يكون عدد العناصر ضِمن القائمة، وهذا مثالٌ آخرٌ، عندما يكون مُدخَل الخوارزمية عِبارةٌ عن عددٍ صحيحٍ (لفحْص إذا ما كان ذلك العدد عددًا أوليًا prime أم لا) يكون حجم المشكلة في تلك الحالة هو عدد البتات bits الموجودة ضِمن ذلك العدد المُدخَل لا العدد ذاته؛ وعمومًا يُعَد عدد البتات bits الموجودة في قيمة المُدخَل قياسًا جيدًا لحجم المشكلة. إذا كان زمن تشغيل خوارزميةٍ معينةٍ هو O(f(n))، فذلك يعني أنه بالنسبة للقيم الكبيرة من حجم المشكلة، لن يتعدى الزمن حاصل ضرْب قيمةٍ ثابتةٍ معينةٍ في f(n)، أي أن هناك عدد C وعددٌ صحيحٌ آخرٌ موجبٌ M، وعندما تصبح n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أقلّ من أو يساوي C×f(n)؛ حيث يأخذ الثابت C في حسبانه تفاصيلًا مثل سرعة الحاسوب المستخدَم في تشغيل الخوارزمية، وإذا كان ذلك الحاسوب أبطأ، فقد تستخدم قيمة أكبر للثابت، إلا أن تغييره لن يغيّر من حقيقة أن زمن تشغيل الخوارزمية هو O(f(n)؛ وبفضل ذلك الثابت، لن يكون من الضروري تحديد إذا ما كنا نقيس الزمن بالثواني أو السنوات أو أي وحدة قياسٍ أخرى؛ لأن التحويل من وحدةٍ معينةٍ إلى أخرى يتمثَّل بعملية ضربٍ في قيمة ثابتة، بالإضافة إلى ما سبق، لا تَعتمد O(f(n)) نهائيًا على ما يحدُث في الأحجام الأصغر من المشكلة، وإنما على ما يحدُث على المدى الطويل بينما يزيد حجم المشكلة دون أي قيودٍ. سنفحص مثالًا بسيطًا عِبارةً عن حساب حاصل مجموع العناصر الموجودة ضِمن مصفوفةٍ، وفي هذه الحالة، يكون حجم المشكلة n هو طول تلك المصفوفة، فإذا كان A هو اسم المصفوفة، ستُكتب الخوارزمية بلغة جافا كالتالي: total = 0; for (int i = 0; i < n; i++) total = total + A[i]; تنفِّذ الخوارزمية عملية total = total + A[i] عدد n من المرات، أي أن الزمن الكلي المُستغرق أثناء تلك العملية يساوي a×n، حيث a هو زمن تنفيذ العملية مرةٍ واحدةٍ؛ إلى جانب ذلك، تزيد الخوارزمية قيمة المتغيّر i وتوازنه مع قيمة n في كلّ مرةٍ تنفِّذ فيها مَتْن الحلقة loop، الأمر الذي يؤدي إلى زيادة زمن التشغيل بمقدار يساوي b×n حيث b عِبارةٌ عن ثابتٍ، وبالإضافة إلى ما سبق، يُهيئ كلًا من i وtotal إلى الصفر مبدئيًا مما يزيد من زمن التشغيل بمقدار ثابتٍ معينٍ وليكن c، وبالتالي، يساوي زمن تشغيل الخوارزمية للقيمة (a+b)×n+c، حيث a وb وc عِبارةٌ عن ثوابتٍ تعتمد على عوامل مثل كيفية تصريف compile الشيفرة ونوع الحاسوب المستخدَم، وبالاعتماد على حقيقة أن c دائمًا ما تكون أقلّ من أو تساوي c×n لأي عددٍ صحيحٍ موجبٍ n، يمكننا إذًا أن نقول أن زمن التشغيل أقلّ من أو يساوي (a+b+c)×n، أي أنه أقلّ من أو يساوي حاصل ضرْب ثابتٍ في n، أي يكون زمن تشغيل الخوارزمية هو O(n). إذا استشكل عليك أن تفهم ما سبق، فإنه يعني أنه لأي قيم n كبيرة، فإن الثابت c في المعادلة (a+b)×n+c غير مهمٍ إذا ووزِن مع (a+b)×n، ونصيغ ذلك بأن نقول إن c تعبّر عن عنصرٍ ذات رتبةٍ أقل lower order، وعادةً ما نتجاهل تلك العناصر في سياق التحليل المُقارِب؛ ويمكن لتحليلٍ مُقارِب آخرٍ أكثر حدَّة أن يستنتج ما يلي: "يَستغرق كلّ تكرار iteration ضِمن حلقة for مقدارًا ثابتًا من الوقت، ولأن الخوارزمية تتضمّن عدد n من التكرارات، فإن زمن التشغيل الكلي هو حاصل ضرْب ثابتٍ في n مضافًا إليه عناصر ذات رتبة أقلّ للتهيئة المبدئية، وإذا تجاهلنا تلك العناصر، سنجد أن زمن التشغيل يساوي O(n). يفيد أحيانًا أن نخصِّص حدًا أدنىً lower limit لزمن التشغيل، حيث سيمكّننا ذلك من أن نقول أن زمن تشغيل خوارزميةٍ معينةٍ أكبر من أو يساوي حاصل ضرْب قيمةٍ ثابتةٍ في f(n)، وهو ما يعرّفه ترميزٌ آخرٌ هو Ω(f(n))، ويُقرأ أوميجا لدالة f أو ترميز أوميجا الكبير لدالة f (أوميجا Omega هو حرفٌ أبجديٌ يونانيٌ ويمثِّل الترميز Ω حالته الكبيرة)؛ وإذا شئنا الدقة، عندما نقول أن زمن تشغيل خوارزمية هو Ω(f(n))، فإن المقصود هو وجود عددٍ موجبٍ C وعددٍ صحيحٍ آخرٍ موجبٍ M، وعندما تكون قيمة n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أكبر من أو يساوي حاصل ضرْب C في f(n)، ونستخلّص مما سبق أن O(f(n)) يوفّر معلومةً عن الحد الأقصى للزمن الذي قد تنتظره حتى تنتهي الخوارزمية من العمل، بينما يوفّر Ω(f(n)) معلومةً عن الحد الأدنى للزمن. سنفْحص الآن خوارزميةً أخرى: public static void simpleBubbleSort( int[] A, int n ) { for (int i = 0; i < n; i++) { // Do n passes through the array... for (int j = 0; j < n-1; j++) { if ( A[j] > A[j+1] ) { // A[j] و A[j+1] رتِّب int temp = A[j]; A[j] = A[j+1]; A[j+1] = temp; } } } } يمثِّل المعامِل n في المثال السابق حجم المشكلة، حيث ينفِّذ الحاسوب حلقة for الخارجية عدد n من المرات، وفي كلّ مرة ينفِّذ فيها تلك الحلقة، فإنه ينفِّذ أيضًا حلقة for داخليةً عدد n-1 من المرات، إذًا سينفّذ الحاسوب تعليمة if عدد n×(n-1) من المرات، أي يساوي n2-n، ولأن العناصر ذات الرتبة الأقل غير مهمّةٍ في التحليل المُقارِب، سنكتفي بأن نقول أن تعليمة if تنفَّذ عدد n2 مرةٍ؛ وعلى وجهٍ أكثر تحديدًا، ينفِّذ الحاسوب الاختبار A[j] > A[j+1] عدد n2 من المرات، ويكون زمن تشغيل الخوارزمية هو Ω( n2)، أي يساوي حاصل ضرْب قيمةٍ ثابتةٍ في n2 على الأقل، وإذا فحصنا العمليات الأخرى (تعليمات الإسناد assignment وزيادة i وj بمقدار الواحد..إلخ)، فإننا لن نجد أي عمليةً منها تنفَّذ أكثر من عدد n2 مرة؛ ونستنتج من ذلك أن زمن التشغيل هو O(n2) أيضًا، أي أنه لن يتجاوز حاصل ضرْب قيمةٍ ثابتةٍ في n2، ونظرًا لأن زمن التشغيل يساوي كلًا من Ω( n2) و O( n2)، فإنه أيضًا يساوي Θ( n2). لقد أوضحنا حتى الآن أن زمن التشغيل يعتمد على حجم المشكلة، ولكننا تجاهلنا تفصيلةٍ مهمةٍ أخرى، وهي أنه لا يعتمد فقط على حجم المشكلة، وإنما كثيرًا ما يعتمد على نوعية البيانات المطلوب معالجتها، فمثلًا قد يعتمد زمن تشغيل خوارزمية ترتيب على الترتيب الأولي للعناصر المطلوب ترتيبها، وليس فقط على عددها. لكي نأخذ تلك الاعتمادية في الحسبان، سنُجري تحليلًا لزمن التشغيل على كلًا من الحالة الأسوأ the worst case analysis والحالة الوسطى average case analysis، بالنسبة لتحليل زمن تشغيل الحالة الأسوأ، سنفحص جميع المشاكل المحتملة لحجم يساوي n وسنحدّد أطول زمن تشغيل من بينها جميعًا، بالمِثل بالنسبة للحالة الوسطى، سنفحص جميع المشاكل المحتملة لحجم يساوي n ونحسب قيمة متوسط زمن تشغيلها جميعًا، وعمومًا سيَفترض تحليل زمن التشغيل للحالة الوسطى أن جميع المشاكل بحجم n لها نفس احتمالية الحدوث على الرغم من عدم واقعية ذلك في بعض الأحيان، أو حتى إمكانية حدوثه وذلك في حالة وجود عددٍ لا نهائيٍ من المشاكل المختلفة لحجمٍ معينٍ. عادةً ما يتساوى زمن تشغيل الحالة الأسوأ والوسطى ضِمن مُضاعفٍ ثابتٍ، وذلك يعني أنهما متساويان بقدر اهتمام التحليل المُقارِب، أي أن زمن تشغيل الحالة الوسطى والحالة الأسوأ هو O(f(n)) أو Θ(f(n))، إلا أن هنالك بعض الحالات القليلة التي يختلف فيها التحليل المُقارِب للحالة الأسوأ عن الحالة الوسطى كما سنرى لاحقًا. بالإضافة إلى ما سبق، يمكن مناقشة تحليل زمن تشغيل الحالة المُثلى best case، والذي سيفحص أقصر زمن تشغيلٍ ممكنٍ لجميع المُدخَلات من حجمٍ معينٍ، وعمومًا يُعَد أقلهم فائدةً. حسنًا، ما الذي ينبغي أن تعرفه حقًا عن تحليل الخوارزميات لتستكمل قراءة ما هو متبقّيٍ من هذه السلسلة؟ في الواقع، لن نقدِم على أي تحليلٍ رياضيٍ حقيقيٍ، ولكن ينبغي أن تفهَم بعض المناقشات العامة عن حالاتٍ بسيطةٍ مثل الأمثلة التي رأيناها في هذا المقال، والأهم من ذلك هو أن تفهم ما يعنيه بالضبط قوْل أن وقت تشغيل خوارزميةٍ معينةٍ هو O(f(n)) أو Θ(f(n)) لبعض الدوال الشائعة f(n)، كما أن النقطة المُهمّة هي أن تلك الترميزات لا تُخبرك أي شيءٍ عن القيمة العددية الفعلية لزمن تشغيل الخوارزمية لأي حالةٍ معينةٍ كما أنها لا تخبرك بأي شيءٍ عن زمن تشغيل الخوارزمية للقيم الصغيرة من n، وإنما ستخبرك بمعدل زيادة زمن التشغيل بزيادة حجم المشكلة. سنفترض أننا نوازن بين خوارزميتين لحل نفس المشكلة، وزمن تشغيل إحداها هو Θ( n2) بينما زمن تشغيل الأخرى هو Θ(n3)، فما الذي يعنيه ذلك؟ إذا كنت تريد معرفة أي خوارزميةٍ منهما هي الأسرع لمشكلةٍ حجمها 100 مثلًا، فالأمر غير مؤكدٍ، فوِفقًا للتحليل المُقارِب يمكن أن تكون أي خوارزميةٍ منهما هي الأسرع في هذه الحالة؛ أما بالنسبة للمشاكل الأكبر حجمًا، سيصل حجم المشكلة n إلى نقطةٍ تكون معها خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)؛ وعلاوةً على ذلك، يزداد تميز خوارزمية Θ( n2) عن خوارزمية Θ(n3) بزيادة حجم المشكلة أكثر فأكثر، وعمومًا ستكون هناك قيمٌ لحجم المشكلة n تكون معها خوارزمية Θ( n2) أسرع ألف مرةٍ أو مليون مرةٍ أو حتى بليون مرةٍ وهكذا؛ وذلك لأن دالة a×n3 تنمو أسرع بكثيرٍ من دالة b×n2 لأي ثابتين موجبين a وb، وذلك يعني أنه بالنسبة للمشاكل الكبيرة، ستكون خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)، ونحن لا نعرف بالضبط إلى أي درجةٍ بالضبط ينبغي أن تكون المشكلة كبيرةٌ، وعمليًا، يُحتمل لخوارزمية Θ( n2) أن تكون أسرع حتى للقيم الصغيرة من حجم المشكلة n؛ وعمومًا تُفضّل خوارزمية Θ( n2) عن خوارزمية Θ(n3). لكي تفهم وتطبّق التحليل المُقارِب، لابدّ أن يكون لديك فكرةً عن معدّل نمو بعض الدوال الشائعة، وبالنسبة للدوال الأسية (power) n, n2, n3, n4, …,، كلما كان الأس أكبر، ازداد معدّل نمو الدالة؛ أما بالنسبة للدوال الأسية exponential من النوع 2n و 10n حيث n هو الأس، يكون معدّل نموها أسرع بكثيرٍ من أي دالةٍ أسيةٍ عاديةٍ power، وعمومًا تنمو الدوال الأسية بسرعةٍ جدًا لدرجة تجعل الخوارزميات التي ينمو زمن تشغيلها بذلك المعدّل غير عمليةٍ عمومًا حتى للقيم الصغيرة من n لأن زمن التشغيل طويلٌ جدًا، وإلى جانب ذلك، تُستخدم دالة اللوغاريتم log(n) بكثرةٍ في التحليل المُقارِب، فإذا كان هناك عددٌ كبيرٌ من دوال اللوغاريتم، ولكن تلك التي أساسها يساوي 2 هي الأكثر استخدامًا في علوم الحاسوب، وتُكتب عادة كالتالي log2(n)، حيث تنمو دالة اللوغاريتم ببطئٍ إلى درجةٍ أبطأ من معدّل نمو n، وينبغي أن يساعدك الجدول التالي على فهم الفروق بين معدّلات النمو للدوال المختلفة: يرجع السبب وراء استخدام log(n) بكثرةٍ إلى ارتباطها بالضرب والقسمة على 2، سنفْترض أنك بدأت بعدد n ثم قسَمته على 2 ثم قسَمته على 2 مرةٍ أخرى، وهكذا إلى أن وصَلت إلى عددٍ أقل من أو يساوي 1، سيساوي عدد مرات القسمة (مقربًا لأقرب عدد صحيح) لقيمة log(n). فمثلًا انظر إلى خوارزمية البحث الثنائي binary search في مقال البحث والترتيب في المصفوفات Array في جافا، حيث تبحث تلك الخوارزمية عن عنصرٍ ضِمن مصفوفةٍ مرتّبةٍ، وسنستخدم طول المصفوفة مثل حجمٍ للمشكلة n، إذ يُقسَم عدد عناصر المصفوفة على 2 في كلّ خطوةٍ ضِمن خوارزمية البحث الثنائي، بحيث تتوقّف عندما يصبح عدد عناصرها أقلّ من أو يساوي 1، وذلك يعني أن عدد خطوات الخوارزمية لمصفوفة طولها n يساوي log(n) للحدّ الأقصى؛ ونستنتج من ذلك أن زمن تشغيل الحالة الأسوأ لخوارزمية البحث الثنائي هو Θ(log(n)) كما أنه هو نفسه زمن تشغيل الحالة الوسطى، في المقابل، يساوي زمن تشغيل خوارزمية البحث الخطي الذي تعرّضنا له في مقال السابق ذكره أعلاه حول البحث والترتيب في المصفوفات Array في جافا لقيمة Θ(n)، حيث يمنحك ترميز Θ طريقةً كميّةً quantitative لتعبّر عن حقيقة كون البحث الثنائي أسرع بكثيرٍ من البحث الخطي linear search. تَقسِم كلّ خطوةٍ في خوارزمية البحث الثنائي حجم المسألة على 2، وعمومًا يحدُث كثيرًا أن تُقسَم عمليةٌ معينةٌ ضِمن خوارزمية حجم المشكلة n على 2، وعندما يحدث ذلك ستظهر دالة اللوغاريتم في التحليل المُقارِب لزمن تشغيل الخوارزمية. يُعَد موضوع تحليل الخوارزميات algorithms analysis حقلًا ضخمًا ورائعًا، ناقشنا هنا جزءًا صغيرًا فقط من مفاهيمه الأساسية التي تفيد لفهم واستيعاب الاختلافات بين الخوارزميات المختلفة. ترجمة -بتصرّف- للقسم Section 5: Analysis of Algorithms من فصل Chapter 8: Correctness, Robustness, Efficiency من كتاب Introduction to Programming Using Java. اقرأ أيضًا المقال السابق: التوكيد assertion والتوصيف annotation في لغة جافا مدخل إلى الخوارزميات ترميز Big-O في الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية تعقيد الخوارزميات Algorithms Complexity النسخة الكاملة لكتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة -
 هل تتساءل ماذا تعني البرمجة وتريد دخول سوق عمل البرمجة وترغب بالتعرف على مجالات عمل المبرمج؟ هذا الفيديو سيجيبك عن استفساراتك ويبين لك معنى الخوارزميات والتفكير المنطقي المستعمل في تعلم البرمجة.
هل تتساءل ماذا تعني البرمجة وتريد دخول سوق عمل البرمجة وترغب بالتعرف على مجالات عمل المبرمج؟ هذا الفيديو سيجيبك عن استفساراتك ويبين لك معنى الخوارزميات والتفكير المنطقي المستعمل في تعلم البرمجة.-
- 3
-
-
- البرمجة
- تطوير التطبيقات
- (و 1 أكثر)




