

الرؤية الحاسوبيّة Computer vision هي مجال فرعي من علوم الحاسوب Computer science، تهدف إلى استخراج معلومات عالية المستوى من الصور ومقاطع الفيديو. يتضمن هذا المجال مهام مثل اكتشاف الكائنات في صورة أو فيديو وتحسين واستعادة الصور (إكمال المصفوفة) وتتبع العناصر في المقاطع المتحركة. ويُغذّي هذا المجال العديد من التقنيات، بما في ذلك مرشحات الدردشة المرئية video chat filters والتعرّف على الوجه (مصادقة الوجه Face Authentication) في الأجهزة المحمولة والسيارات ذاتية القيادة.
نستخدم خلال هذه المقالة الرؤية الحاسوبيّة لإنشاء مُترجم للغة الإشارة الأمريكية واستخدامها مع كاميرا الويب الخاصة بك. نستخدم خلال هذه المقالة مكتبة الرؤية الحاسوبية الشهيرة أوبين سي في OpenCV وإطار العمل بايتورش PyTorch لبناء شبكة عصبية عميقة، والنظام البيئي أونكس ONNX لتصدير الشبكة العصبية التي سوف نبنيها. نُطبّق المفاهيم التالية أثناء إنشاء تطبيق الرؤية الحاسوبيّة خاصتنا:
- نتبع طريقة من ثلاث خطوات وهي: المعالجة المسبقة لمجموعة البيانات ثم تدريب النموذج وأخيرًا تقيّيم النموذج.
- تحسين كل خطوة من خلال استخدام تقنية زيادة أو تعزيز البيانات Data augmentation لمعالجة حالات الأيدي المدورة أو غير المتمركزة (قد تكون الأيدي في زوايا أو اتجاهات مختلفة) وتغيير جداول مُعدّل التعلّم Learning rate schedule لتحسين دقة النموذج وتصدير النماذج لزيادة سرعة الاستدلال.
- نستكشف أيضًا المفاهيم ذات الصلة بتعلّم الآلة Machine Learning.
بعد الانتهاء من هذه المقالة، سيكون لديك مُترجم لغة الإشارة الأمريكية ومعرفة أساسيّة بالتعلّم العميق Deep Learning. يمكنك أيضًا الوصول إلى الشيفرة المصدرية الكاملة لهذا المشروع هنا.
المتطلبات الأساسية
لإكمال هذه المقالة سوف تحتاج إلى ما يلي:
- بيئة تطوير محلية لبايثون Python 3 مع ذاكرة وصول عشوائي RAM لا تقل عن 1 جيجابايت. يمكنك قراءة إحدى المقالات التالية لإعداد كل ما تحتاجه حسب نظام التشغيل الذي تنوي العمل عليه: كيفية تثبيت وإعداد بيئة برمجية محلية لبايثون 3 على نظام أبونتو، كيفية تثبيت وإعداد بيئة برمجية محلية لبايثون 3 على نظام ويندوز 10.
- كاميرا ويب لاكتشاف الصور في الزمن الحقيقي Real time.
الخطوة 1 -إنشاء المشروع وتثبيت التبعيات
نُنشئ الآن مُجلّد عمل لهذا المشروع ونُثبّت التبعيات التي نحتاجها.
في توزيعات لينكس Linux، ابدأ بإعداد مُدير حزم النظام الخاص بك وثبّت حزمة virtualenv. استخدم:
$ apt-get update $ apt-get upgrade $ apt-get install python3-venv
سوف نسمي مُجلّد العمل SignLanguage:
$ mkdir ~/SignLanguage
ننتقل إلى المجلد:
$ cd ~/SignLanguage
أنشئ بيئة افتراضية جديدة للمشروع:
$ python3 -m venv signlanguage
نشّط البيئة:
$ source signlanguage/bin/activate
ثبّت بايتورش PyTorch، وهو إطار عمل للتعلم العميق في بايثون.
ثبّت بايتورش على نظام التشغيل ماك أو إس macOS باستخدام الأمر التالي:
(signlanguage) $ python -m pip install torch==1.2.0 torchvision==0.4.0
استخدم الأوامر التالية من أجل بناء النموذج على وحدة المعالجة المركزية CPU سواءًا في لينكس أو ويندوز:
(signlanguage) $ pip install torch==1.2.0+cpu torchvision==0.4.0+cpu -f https://download.pytorch.org/whl/torch_stable.html (signlanguage) $ pip install torchvision
نُثبّت الآن الحزم أوبين سي في opencv ونمباي numpy وأونكس onnx، وهي مكتبات الرؤية الحاسوبيّة والجبر الخطي وتصدير وتنفيذ نماذج الذكاء الاصطناعي على التوالي. تُقدّم opencv أدوات مساعدة مثل تدوير الصور والتقاطها والتعديل عليها، وتُقدّم numpy أدوات مساعدة للجبر الخطي مثل انعكاس وضرب المصفوفات:
(signlanguage) $ python -m pip install opencv-python==3.4.3.18 numpy==1.14.5 onnx==1.6.0 onnxruntime==1.0.0
في توزيعات لينكس، ستحتاج إلى تثبيت libSM.so:
(signlanguage) $ apt-get install libsm6 libxext6 libxrender-dev
بعد تثبيت التبعيات، دعونا نبني الإصدار الأول من مُترجم لغة الإشارة: مُصنّف لغة الإشارة.
الخطوة 2 -إعداد مجموعة بيانات تصنيف لغة الإشارة
في الأقسام الثلاثة التالية، ستبني مُصنّف لغة الإشارة باستخدام شبكة عصبية. هدفك هو إنتاج نموذج يقبل صورة اليد كمدخل ويخرج حرفًا. الخطوات الثلاث التالية مطلوبة لبناء نموذج تعلّم آلي لمهمة التصنيف التي لدينا:
- المعالجة المسبقة للبيانات: تطبيق تشفير الواحد النشط One-hot encoding على التسميات Labels وتغليف البيانات بموَتِّرات بايتورش (أو تينسرات بايتورش) PyTorch Tensors . تدريب النموذج على البيانات الإضافية من عملية الزيادة augmentation، وذلك لإعداده للإدخال غير العادي، أي عندما تكون اليد في أوضاع غير قياسيّة، مثل اليد غير المتمركزة أو المدورة.
- تحديد النموذج وتدريبه: إنشاء شبكة عصبية باستخدام بايتورش وتحديد معلمات التدريب العليا hyper-parameters -مثل مدة التدريب- وتشغيل خوارزميّة النزول الاشتقاقي العشوائي stochastic gradient descent. تتضمّن هذه المرحلة أيضًا تعديل إحدى معلمات التدريب العليا أثناء عملية التدريب، وهي قيمة مُعدّل التعلّم learning rate، وذلك من خلال جدول مُعدّل التعلّم، فكما ذكرنا سابقًا؛ هذا سوف يرفع دقة النموذج.
- التنبؤ باستخدام النموذج: تقييم الشبكة العصبية على بيانات التحقق لفهم دقتها. ثم تصدير النموذج إلى تنسيق يسمى ONNX للحصول على استدلال أسرع.
ملاحظات:
- تشفير الواحد النشط عبارة عن أشعة Vectors كل شعاع تكون جميع قيمه أصفار ماعدا بعد واحد فقط من الشعاع تكون قيمته واحد. قيمة الواحد تُشير إلى شيء معين. في جالتنا تشير إلى الصنف الذي يُعبر عن العينة المرتبطة به.
- تُشير موَتِّرات بايتورش PyTorch Tensors إلى هيكل البيانات الأساسي في بايتورش، تُشبه مصفوفات نمباي NumPy مع وظائف إضافية مُحسّنة من أجل دعم عمليات التعلّم العميق Deep Learning. تُعتبر مكونًا أساسيًا يُتيح التنفيّذ الفعّال لحسابات الشبكة العصبية.
في هذا القسم من المقالة ستنجز الخطوة الأولى التي تتضمّن تجهيز مجموعة البيانات ومعالجتها. هذا يتضمّن تنزيل البيانات وإنشاء كائن Dataset لتغليفها والتكرار عليها وتطبيق تقنية زيادة البيانات أخيرًا. في نهاية هذه الخطوة، سيكون لديك طريقة برمجية للوصول إلى الصور والتسميات الموجودة في مجموعة البيانات الخاصة بك لتغذية النموذج.
أولاً، عليك تنزيل مجموعة البيانات إلى مجلد العمل الحالي الخاص بك:
ملاحظة: في نظام التشغيل ماك، لا يتوفر wget افتراضيًا. لذلك يجب عليك تثبيت Homebrew ثم تشغيل برنامج Brew install wget.
(signlanguage) $ wget https://assets.digitalocean.com/articles/signlanguage_data/sign-language-mnist.tar.gz
فك ضغط الملف المضغوط الذي يحتوي على مجلد /data:
(signlanguage) $ tar -xzf sign-language-mnist.tar.gz
أنشئ ملفًا جديدًا باسم step_2_dataset.py:
(signlanguage) $ nano step_2_dataset.py
يجب عليك الآن استيراد الأدوات المساعدة الضرورية، ثم إنشاء الصنف الذي سيُغلّف مجموعات بيانات التدريب والاختبار ويعالجها بالشكل المناسب، وذلك من خلال تنفيذ الواجهة Dataset الخاصة ببايتورش، هذا يسمح لك بتحميل واستخدام خط معالجة (أو خط أنابيب) البيانات المدمج في بايتورش مع مجموعة بيانات تصنيف لغة الإشارة خاصتك:
from torch.utils.data import Dataset from torch.autograd import Variable import torch.nn as nn import numpy as np import torch import csv class SignLanguageMNIST(Dataset): """مجموعة بيانات تصنيف لغة الإشارة تُستخدم هذه الفئة كأداة لتحميل مجموعة بيانات لغة الإشارة في بايتورش """ pass
يُمثّل الصنف SignLanguageMNIST مجموعة بيانات تصنيف لغة الإشارة. إنها أداة مساعدة لتحميل مجموعة بيانات لغة الإشارة إلى بايتورش. مجموعة البيانات المستخدمة منشورة على موقع كاغل Kaggle في عام 2017، لمؤلف لم يُذكر اسمه الصريح، لكن اسم المستخدم هو tecperson. كل عينة عبارة عن مصفوفة من الشكل 28281*1، وكل تسمية Label هي قيمة عددية scalar.
احذف الآن العنصر النائب pass من الصنف SignLanguageMNIST. وضع مكانه تابعًا لتوليد قائمة بالتسميات المتوفرة في مجموعة البيانات اسمها mapping، وذلك لربط كل تسمية بفهرس:
@staticmethod def get_label_mapping(): """ تُعيد قائمة تربط بين تسميات مجموعة البيانات وفهارس الحروف تحويل نطاق فهارس التسميات الأصلية إلى نطاق جديد يبدأ من 0 حتى 23 """ mapping = list(range(25)) mapping.pop(9) return mapping
تحتوي التسميات الأصلية في مجموعة البيانات على قيم تتراوح من 0 إلى 25. وتتوافق كل قيمة مع حرف معين، باستثناء الحرفين J و Z المستبعدين. لذلك يوجد 24 تسمية صالحة في النطاق الأصلي (من 0 إلى 25 باستثناء 9 و25). الهدف من هذه الشيفرة هو تعديل مجال قيم التسميات إلى مجال آخر، أي تحويل نطاق فهارس التسميات الأصلية إلى نطاق جديد يبدأ من 0 ويكون متجاورًا حتى 23. وبعبارة أخرى، نطاق الفهارس الجديد هو [0، 1، 2، .. ، 23]، وذلك للتأكد من أن قيم التسمية تكون في تسلسل مضغوط متجاور. بشكل أوضح سيكون الخرج هو القائمة التالية:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]
نلاحظ أن قيم هذه القائمة تبدأ بالعدد 0 الذي يُشير للحرف A ويقابل الفهرس 0، وتنتهي مع العدد 24 والذي يشير للحرف Y ويقابل الفهرس 23. هذا يُسهل المعالجة والتفسير في خطوات المعالجة اللاحقة.
أضف بعد ذلك تابعًا لاستخراج التسميات والعينات من ملف CSV. تفترض الشيفرة التالية أن كل سطر من ملف CSV يبدأ بالتسمية (أي العمود الأول) ثم يتبعه قيم 784 بكسل (باقي الأعمدة). تُمثّل قيم 784 بكسل هذه صورة مقاسها 28 × 28، وكل بكسل تتراوح قيمته بين 0-255:
@staticmethod def read_label_samples_from_csv(path: str): """ يُمثّل التسمية وباقي القيم 2^28 هي قيم البكسلات CSV نفترض أن العمود الأول من ملف قيم البكسلات تتراوح بين 0 إلى 255 """ mapping = SignLanguageMNIST.get_label_mapping() labels, samples = [], [] with open(path) as f: _ = next(f) # skip header for line in csv.reader(f): label = int(line[0]) labels.append(mapping.index(label)) samples.append(list(map(int, line[1:]))) return labels, samples
لاحظ أن كل سطر من الكائن csv.reader القابل للتكرار عبارة عن قائمة من السلاسل. لهذا السبب نحن نستدعي الدالة int و map لتحويل جميع السلاسل إلى أعداد صحيحة.
نضع بعد هذا التابع الثابت static مباشرةً، تابعًا آخر من أجل تهيئة حامل البيانات لدينا:
def __init__(self, path: str="data/sign_mnist_train.csv", mean: List[float]=[0.485], std: List[float]=[0.229]): """ المعطيات: path: الذي يحتوي مجموعة البيانات .csv يُستخدم من أجل تحديد مسار ملف """ labels, samples = SignLanguageMNIST.read_label_samples_from_csv(path) self._samples = np.array(samples, dtype=np.uint8).reshape((-1, 28, 28, 1)) self._labels = np.array(labels, dtype=np.uint8).reshape((-1, 1)) self._mean = mean self._std = std
يبدأ هذا التابع بتحميل العينات والتسميات. ثم يُغلّف البيانات بمصفوفات نمباي. نشرح معلومات المتوسط والانحراف المعياري قريبًا، في قسم __getitem__ التالي.
ملاحظة: ملف csv. الذي يحتوي مجموعة البيانات أعمدته هي: label, pixel0, pixel1, … , pixeln
نضيف التابع __len__ بعد التابع __init__ مباشرةً. تتطلب مجموعة البيانات هذه طريقة لتحديد متى يجب إيقاف التكرار على البيانات، وهذه الطريقة هي التابع __len__ الذي يخبرها بآخر عنصر في مجموعة البيانات:
... def __len__(self): return len(self._labels)
أخيرًا، أضف التابع __getitem__ الذي يُرجع قاموسًا Dict يحتوي على العينة والتسمية:
def __getitem__(self, idx): transform = transforms.Compose([ transforms.ToPILImage(), transforms.RandomResizedCrop(28, scale=(0.8, 1.2)), transforms.ToTensor(), transforms.Normalize(mean=self._mean, std=self._std)]) return { 'image': transform(self._samples[idx]).float(), 'label': torch.from_numpy(self._labels[idx]).float() }
نحن نستخدم تقنية تُعرف باسم زيادة البيانات أثناء التدريب، حيث تخضع العينات لتغييرات لتعزيز مرونة النموذج في فهم هذه الاختلافات (مثلًا حتى لو قمنا بقلب الصورة رأسًا على عقب أو كبّرنا الصورة أو غيرنا بعض الألوان، يجب أن يفهم النموذج أن جميعها تنتمي لنفس التسمية). على وجه التحديد، نُجري عمليات تكبير الصورة عشوائيًا على مستويات ومواضع مختلفة باستخدام RandomResizeCrop. من المهم تسليط الضوء على أن عملية التكبير هذه يجب أن لا تؤثر على تسمية لغة الإشارة النهائية، أي يجب أن تظل التسمية دون تغيير. بالإضافة إلى ذلك، يمكنك تسوية أو تقييس Normalize المدخلات، مما يضمن أن قيم بكسلات الصورة تقع ضمن النطاق [0، 1] بدلاً من [0، 255]. لتحقيق ذلك، استخدم المتوسط والانحراف المعياري لمجموعة البيانات (mean_ و std_) أثناء عملية التقييس.
سيكون الصنف SignLanguageMNIST الكامل كما يلي:
from torch.utils.data import Dataset from torch.autograd import Variable import torchvision.transforms as transforms import torch.nn as nn import numpy as np import torch from typing import List import csv class SignLanguageMNIST(Dataset): """مجموعة بيانات تصنيف لغة الإشارة تُستخدم هذه الفئة كأداة لتحميل مجموعة بيانات لغة الإشارة في بايتورش """ @staticmethod def get_label_mapping(): """ تُعيد قائمة تربط بين تسميات مجموعة البيانات وفهارس الحروف تحويل نطاق فهارس التسميات الأصلية إلى نطاق جديد يبدأ من 0 حتى 23 """ mapping = list(range(25)) mapping.pop(9) return mapping @staticmethod def read_label_samples_from_csv(path: str): """ يُمثّل التسمية وباقي القيم 2^28 هي قيم البكسلات CSV نفترض أن العمود الأول من ملف قيم البكسلات تتراوح بين 0 إلى 255 """ mapping = SignLanguageMNIST.get_label_mapping() labels, samples = [], [] with open(path) as f: _ = next(f) # skip header for line in csv.reader(f): label = int(line[0]) labels.append(mapping.index(label)) samples.append(list(map(int, line[1:]))) return labels, samples def __init__(self, path: str="data/sign_mnist_train.csv", mean: List[float]=[0.485], std: List[float]=[0.229]): """ المعطيات: path: الذي يحتوي مجموعة البيانات .csv يُستخدم من أجل تحديد مسار ملف """ labels, samples = SignLanguageMNIST.read_label_samples_from_csv(path) self._samples = np.array(samples, dtype=np.uint8).reshape((-1, 28, 28, 1)) self._labels = np.array(labels, dtype=np.uint8).reshape((-1, 1)) self._mean = mean self._std = std def __len__(self): return len(self._labels) def __getitem__(self, idx): transform = transforms.Compose([ transforms.ToPILImage(), transforms.RandomResizedCrop(28, scale=(0.8, 1.2)), transforms.ToTensor(), transforms.Normalize(mean=self._mean, std=self._std)]) return { 'image': transform(self._samples[idx]).float(), 'label': torch.from_numpy(self._labels[idx]).float() }
ستتحقق الآن من توابع الأداة المساعدة لمجموعة البيانات الخاصة بنا عن طريق تحميل مجموعة بيانات SignLanguageMNIST. أضف الشيفرة التالية إلى نهاية ملفك بعد الصنف SignLanguageMNIST:
def get_train_test_loaders(batch_size=32): trainset = SignLanguageMNIST('data/sign_mnist_train.csv') trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True) testset = SignLanguageMNIST('data/sign_mnist_test.csv') testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False) return trainloader, testloader
من خلال هذه الشيفرة تجري عملية تهيئة مجموعة البيانات باستخدام الصنف SignLanguageMNIST، ثم بالنسبة لمجموعات التدريب والتحقق، تُغلّف مجموعة البيانات في DataLoader. يؤدي هذا إلى تحويل مجموعة البيانات إلى نسخة قابلة للتكرار لاستخدامها لاحقًا أثناء تدريب النموذح.
تتحقق الآن من أن الأدوات المساعدة لمجموعة البيانات تعمل، وذلك من خلال استدعاء الدالة get_train_test_loaders التي تُرجع مُحملي بيانات من الصنف DataLoader. نكتفي بواحد منهم للاختبار، ونسنده للمتغير loader، ثم نطبع السطر الأول من هذا المُحمّل. أضف ما يلي إلى نهاية ملفك:
if __name__ == '__main__': loader, _ = get_train_test_loaders(2) print(next(iter(loader)))
يمكنك التحقق من أن ملفك يطابق ملف step_2_dataset الموجود في هذا المستودع. اخرج من المحرر الخاص بك وشغّل البرنامج بما يلي:
(signlanguage) $ python step_2_dataset.py
يؤدي هذا إلى إخراج الزوج التالي من الموترات tensors. يقوم خط معالجة البيانات الخاص بنا بإخراج عينتين وتسميتين. يشير هذا إلى أن خط معالجة البيانات الخاص بنا جاهز للانطلاق:
{'image': tensor([[[[ 0.4337, 0.5022, 0.5707, ..., 0.9988, 0.9646, 0.9646], [ 0.4851, 0.5536, 0.6049, ..., 1.0502, 1.0159, 0.9988], [ 0.5364, 0.6049, 0.6392, ..., 1.0844, 1.0844, 1.0673], ..., [-0.5253, -0.4739, -0.4054, ..., 0.9474, 1.2557, 1.2385], [-0.3369, -0.3369, -0.3369, ..., 0.0569, 1.3584, 1.3242], [-0.3712, -0.3369, -0.3198, ..., 0.5364, 0.5364, 1.4783]]], [[[ 0.2111, 0.2796, 0.3481, ..., 0.2453, -0.1314, -0.2342], [ 0.2624, 0.3309, 0.3652, ..., -0.3883, -0.0629, -0.4568], [ 0.3309, 0.3823, 0.4337, ..., -0.4054, -0.0458, -1.0048], ..., [ 1.3242, 1.3584, 1.3927, ..., -0.4054, -0.4568, 0.0227], [ 1.3242, 1.3927, 1.4612, ..., -0.1657, -0.6281, -0.0287], [ 1.3242, 1.3927, 1.4440, ..., -0.4397, -0.6452, -0.2856]]]]), 'label': tensor([[24.], [11.]])}
لقد تحققت الآن من أن خط معالجة البيانات الخاص بك يعمل. بهذا تنتهي الخطوة الأولى -المعالجة المسبقة لبياناتك- والتي تتضمّن الآن تقنية زيادة البيانات لزيادة قوة النموذج. بعد ذلك سوف نبني الشبكة العصبية والمُحسّن.
الخطوة 3: بناء وتدريب مصنف لغة الإشارة باستخدام التعلم العميق
باستخدام خط معالجة بيانات فعّال، ستتمكن الآن من بناء نموذج وتدريبه على البيانات. على وجه التحديد ستبني شبكة عصبية من ست طبقات وتعرّف دالة الخسارة والمحسّن، وأخيرًا أمثلة تحسين optimize دالة الخسارة لتنبؤات الشبكة العصبية الخاصة بك. في نهاية هذه الخطوة، سيكون لديك مُصنّف لغة إشارة فعّال.
أنشئ ملفًا جديدًا يُسمى step_3_train.py:
(signlanguage) $ nano step_3_train.py
قم باستيراد الأدوات التي تحتاجها:
from torch.utils.data import Dataset from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch from step_2_dataset import get_train_test_loaders
نُعرّف الآن شبكة عصبية باستخدام بايتورش تتضمن ثلاث طبقات تلافيفية Convolutional Layers، تليها ثلاث طبقات متصلة بالكامل Fully Connected Layers. أضف الشيفرة التالية إلى نهاية البرنامج الموجود لديك:
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 6, 3) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 6, 3) self.conv3 = nn.Conv2d(6, 16, 3) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 48) self.fc3 = nn.Linear(48, 24) def forward(self, x): x = F.relu(self.conv1(x)) x = self.pool(F.relu(self.conv2(x))) x = self.pool(F.relu(self.conv3(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
نُهيّئ الآن الشبكة العصبية ونُعرّف دالة الخسارة ونحدد معلمات التحسين العليا عن طريق إضافة الشيفرة التالية إلى نهاية البرنامج:
def main(): net = Net().float() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
أخيرًا، تُدرّب النموذج على دورتين:
def main(): net = Net().float() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) trainloader, _ = get_train_test_loaders() for epoch in range(2): # loop over the dataset multiple times train(net, criterion, optimizer, trainloader, epoch) torch.save(net.state_dict(), "checkpoint.pth")
تشير دورة تدريب أو "epoch" إلى دورة واحدة كاملة عبر مجموعة البيانات التدريبية خلال مرحلة التدريب. خلال كل دورة تدريب تُعرض كل عينات البيانات الموجودة في مجموعة البيانات التدريبية مرة واحدة تمامًا على النموذج. في نهاية الدالة main تُحفظ معلمات النموذج في ملف يسمى checkpoint.pth.
أضف التعليمة البرمجية التالية إلى نهاية البرنامج الخاص بك لاستخراج الصورة والتسمية من مُحمل مجموعة البيانات ثم غلّف كل منهما في متغير بايتورش:
def train(net, criterion, optimizer, trainloader, epoch): running_loss = 0.0 for i, data in enumerate(trainloader, 0): inputs = Variable(data['image'].float()) labels = Variable(data['label'].long()) optimizer.zero_grad() # انتشار أمامي + انتشار عكسي + تحسيّن outputs = net(inputs) loss = criterion(outputs, labels[:, 0]) loss.backward() optimizer.step() # طباعة الإحصاءات running_loss += loss.item() if i % 100 == 0: print('[%d, %5d] loss: %.6f' % (epoch, i, running_loss / (i + 1)))
تُنفّذ هذا الشيفرة أيضًا عملية الانتشار الأمامي على الشبكة العصبية ثم تحسب قيمة الخسارة ثم تُنفّذ الانتشار العكسي وخطوة المُخسّن.
في نهاية الملف، أضف ما يلي لاستدعاء الدالة الرئيسية main:
if __name__ == '__main__': main()
تحقق جيدًا من تطابق ملفك مع ما يلي:
from torch.utils.data import Dataset from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch from step_2_dataset import get_train_test_loaders class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 6, 3) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 6, 3) self.conv3 = nn.Conv2d(6, 16, 3) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 48) self.fc3 = nn.Linear(48, 25) def forward(self, x): x = F.relu(self.conv1(x)) x = self.pool(F.relu(self.conv2(x))) x = self.pool(F.relu(self.conv3(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def main(): net = Net().float() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) trainloader, _ = get_train_test_loaders() for epoch in range(2): # loop over the dataset multiple times train(net, criterion, optimizer, trainloader, epoch) torch.save(net.state_dict(), "checkpoint.pth") def train(net, criterion, optimizer, trainloader, epoch): running_loss = 0.0 for i, data in enumerate(trainloader, 0): inputs = Variable(data['image'].float()) labels = Variable(data['label'].long()) optimizer.zero_grad() # انتشار أمامي + انتشار عكسي + تحسيّن outputs = net(inputs) loss = criterion(outputs, labels[:, 0]) loss.backward() optimizer.step() # طباعة الإحصاءات running_loss += loss.item() if i % 100 == 0: print('[%d, %5d] loss: %.6f' % (epoch, i, running_loss / (i + 1))) if __name__ == '__main__': main()
احفظ الملف، ثم ابدأ تجربتك الأولية عن طريق تشغيل الأمر التالي ولاحظ الخرج الناتج:
(signlanguage) $ python step_3_train.py [0, 0] loss: 3.208171 [0, 100] loss: 3.211070 [0, 200] loss: 3.192235 [0, 300] loss: 2.943867 [0, 400] loss: 2.569440 [0, 500] loss: 2.243283 [0, 600] loss: 1.986425 [0, 700] loss: 1.768090 [0, 800] loss: 1.587308 [1, 0] loss: 0.254097 [1, 100] loss: 0.208116 [1, 200] loss: 0.196270 [1, 300] loss: 0.183676 [1, 400] loss: 0.169824 [1, 500] loss: 0.157704 [1, 600] loss: 0.151408 [1, 700] loss: 0.136470 [1, 800] loss: 0.123326
للحصول على قيم خسارة أقل، يمكنك زيادة عدد الدورات إلى 5 أو 10 أو حتى 20 دورة. ومع ذلك، بعد فترة معينة من التدريب، ستتوقف قيمة الخسارة في الشبكة عن الانخفاض حتى لو زدنا عدد الدورات (نكون قد علقنا في إحدى القيم الصغرى المحليّة). لتجنب هذه المشكلة، نحتاج إلى تخفيض قيمة مُعدّل التعلّم مع ازدياد عدد دورات التدريب. يمكننا إجراء ذلك من خلال جدولة قيم مُعدّل التعلّم، بحيث نُقلل من معدل التعلم بمرور الوقت.
نُعدّل الدالة main بإضافة السطرين التاليين اللذين يتضمنان تعريف المجدول scheduler واستدعاء scheduler.step. إضافة إلى ذلك، ارفع
عدد الدورات إلى 12:
def main(): net = Net().float() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) trainloader, _ = get_train_test_loaders() for epoch in range(12): # loop over the dataset multiple times train(net, criterion, optimizer, trainloader, epoch) scheduler.step() torch.save(net.state_dict(), "checkpoint.pth")
تأكد من تطابق ملفك مع ملف الخطوة 3 الموجود في هذا المستودع. يستمر التدريب لمدة 5 دقائق تقريبًا. سيشبه الخرج الخاص بك ما يلي:
[0, 0] loss: 3.208171 [0, 100] loss: 3.211070 [0, 200] loss: 3.192235 [0, 300] loss: 2.943867 [0, 400] loss: 2.569440 [0, 500] loss: 2.243283 [0, 600] loss: 1.986425 [0, 700] loss: 1.768090 [0, 800] loss: 1.587308 ... [11, 0] loss: 0.000302 [11, 100] loss: 0.007548 [11, 200] loss: 0.009005 [11, 300] loss: 0.008193 [11, 400] loss: 0.007694 [11, 500] loss: 0.008509 [11, 600] loss: 0.008039 [11, 700] loss: 0.007524 [11, 800] loss: 0.007608
الخسارة النهائية التي حصلنا عليها هي 0.007608، وهي أصغر بثلاث مرات من قيمة الخسارة في أول دورة تدريبية 3.20. نختم بهذا الخطوة الثانية من سير العمل لدينا، حيث بنينا الشبكة العصبية ودرّبناها.
رغم أن قيمة الخسارة هذه صغيرة، إلا أنها قد لاتعطينا نظرة ثاقبة عن أداء النموذج. لذا سنحسب دقة Accuracy النموذج، وهي النسبة المئوية للصور التي صنفها النموذج بطريقة صحيحة.
الخطوة 4 -تقييم مصنف لغة الإشارة
نُقيّم الآن مصنف لغة الإشارة عن طريق حساب دقته على مجموعة التحقق، وهي مجموعة من الصور لم يراها النموذج أثناء التدريب، أي أنه لايعرفها. سيوفر هذا إحساسًا أفضل بأداء النموذج مقارنةً بقيمة الخسارة النهائية وحدها. علاوة على ذلك، سنضيف أدوات مساعدة لحفظ نموذجنا المُدرّب في نهاية التدريب وتحميل نموذجنا المدرّب مسبقًا عند إجراء الاستدلال.
أنشئ ملفًا جديد يسمى step_4_evaluate.py:
(signlanguage) $ nano step_4_evaluate.py
استيراد الأدوات التي تحتاجها:
from torch.utils.data import Dataset from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch import numpy as np import onnx import onnxruntime as ort from step_2_dataset import get_train_test_loaders from step_3_train import Net
عرّف بعد ذلك أداةً مساعدةً لتقييم أداء الشبكة العصبية. تُجري الدالة التالية مقارنةً بين الحرف المتوقع من قبل الشبكة العصبية والحرف الحقيقي لصورة واحدة مُمثّلًا بقيمته الأصلية (أي 1،2،3 … ) وليس بترميز الواحد النشط.
def evaluate(outputs: Variable, labels: Variable) -> float: """تقييم جودة توقعات النموذج، مقارنةً بالتسميات الصحيحة""" Y = labels.numpy() Yhat = np.argmax(outputs, axis=1) return float(np.sum(Yhat == Y))
المتغير outputs عبارة عن قائمة باحتمالات الصنف لكل عينة. على سبيل المثال، قد تكون مخرجات عينة واحدة هي [0.1، 0.3، 0.4، 0.2]. المتغير labels عبارة عن قائمة تحمل التسميات المقابلة للعينات. على سبيل المثال، قد تكون التسمية من أجل عينة واحدة هي 3.
يحوّل السطر ()Y = labels.numpy التسميات إلى مصفوفة نمباي. بينما يحوّل السطر الذي يليه مباشرةً القيم الاحتمالية من أجل كل عينة إلى قيمة عددية واحدة تقابل فهرس أكبر قيمة احتمالية من أجل تلك العينة. على سبيل المثال، إذا كانت قائمة الاحتمالات من أجل عينة واحدة هي [0.1، 0.3، 0.4، 0.2] فإنها يحولها إلى القيمة 2، لأن قيمة الفهرس 2 البالغة 0.4 هي أكبر قيمة.
نظرًا لأن كلا من Y و Yhat أصبحا الآن يشيران إلى صنفين، فيمكنك مقارنتهما. يتحقق Yhat == Y مما إذا كانت التسمية المتوقعة تُطابق التسمية الصحيحة، ويعيد قائمة كل عنصر فيها إما True أو False من أجل كل عينة. أخيرًا ((float(np.sum(Yhat == Y تحسب عدد حالات التطابق بين Y و Yhat (أي كم مرة حصلنا على True).
أضف الدالة الثانية batch_evaluate، والتي تُطبّق الدالة evaluate على جميع الصور:
def batch_evaluate( net: Net, dataloader: torch.utils.data.DataLoader) -> float: """تقييم الشبكة العصبية على دفعات، إذا كانت مجموعة البيانات كبيرة جدًا""" score = n = 0.0 for batch in dataloader: n += len(batch['image']) outputs = net(batch['image']) if isinstance(outputs, torch.Tensor): outputs = outputs.detach().numpy() score += evaluate(outputs, batch['label'][:, 0]) return score / n
الدفعة batch عبارة عن مجموعة من الصور المخزنة كموتر واحد. أولاً، نزيد إجمالي عدد الصور التي نُقيّمها n بعدد الصور في هذه الدفعة من خلال التعليمة
([n += len(batch['image. ثم نُنفّذ عملية الاستدلال على الشبكة العصبية باستخدام مجموعة من الصور. ونُجري عملية التحقق من النوع بالتعليمة
(if isinstance(outputs; torch.Tensor فإذا كان نوع outputs هو torch.Tensor نحول outputs إلى مصفوفة نمباي.
أخيرًا، يمكنك استخدام evaluate لحساب عدد العينات المُصنّفة بطريقة صحيحة، وفي ختام الدالة يمكنك حساب النسبة المئوية للعينات التي صنفتها بطريقة صحيحة من خلال التعليمة evaluate.
أخيرًا، أضف البرنامج التالي للاستفادة من الأدوات المساعدة السابقة:
def validate(): trainloader, testloader = get_train_test_loaders() net = Net().float() pretrained_model = torch.load("checkpoint.pth") net.load_state_dict(pretrained_model) print('=' * 10, 'PyTorch', '=' * 10) train_acc = batch_evaluate(net, trainloader) * 100. print('Training accuracy: %.1f' % train_acc) test_acc = batch_evaluate(net, testloader) * 100. print('Validation accuracy: %.1f' % test_acc) if __name__ == '__main__': validate()
من خلال هذه الشيفرة، تجري عمليّة تحميل الشبكة العصبية المُدرّبة مسبقًا وتقييم أدائها على مجموعة بيانات لغة الإشارة المتوفرة. على وجه التحديد، يطبع البرنامج دقة النموذج في توقع أصناف الصور التي المُستخدمة للتدريب، كما أنه يطبع دقة النموذج في توقع أصناف الصور التي لم يجري استخدامها أثناء عملية التدريب، وهي مجموعة منفصلة من الصور التي تضعها جانبًا لأغراض الاختبار، وتسمى مجموعة التحقق.
نُصدّر بعد ذلك نموذج بايتورش إلى ملف ONNX ثنائي. يمكن بعد ذلك استخدام هذا الملف الثنائي في الإنتاج لتنفيذ عمليات الاستدلال مع النموذج الخاص بك. والأهم من ذلك، أن الشيفرة التي تُشغّل هذا الثنائي لا تحتاج إلى نسخة من تعريف الشبكة الأصلي. في نهاية دالة validate، أضف ما يلي:
trainloader, testloader = get_train_test_loaders(1) # export to onnx fname = "signlanguage.onnx" dummy = torch.randn(1, 1, 28, 28) torch.onnx.export(net, dummy, fname, input_names=['input']) # check exported model model = onnx.load(fname) onnx.checker.check_model(model) # check model is well-formed # create runnable session with exported model ort_session = ort.InferenceSession(fname) net = lambda inp: ort_session.run(None, {'input': inp.data.numpy()})[0] print('=' * 10, 'ONNX', '=' * 10) train_acc = batch_evaluate(net, trainloader) * 100. print('Training accuracy: %.1f' % train_acc) test_acc = batch_evaluate(net, testloader) * 100. print('Validation accuracy: %.1f' % test_acc)
يؤدي هذا إلى تصدير نموذج ONNX والتحقق من النموذج الذي جرى تصديره، ثم تشغيل الاستدلال على النموذج الذي صُدّر. تحقق جيدًا من تطابق ملفك مع ملف الخطوة 4 الموجود في هذا المستودع:
from torch.utils.data import Dataset from torch.autograd import Variable import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import torch import numpy as np import onnx import onnxruntime as ort from step_2_dataset import get_train_test_loaders from step_3_train import Net def evaluate(outputs: Variable, labels: Variable) -> float: """تقييم جودة توقعات النموذج، مقارنةً بالتسميات الصحيحة""" Y = labels.numpy() Yhat = np.argmax(outputs, axis=1) return float(np.sum(Yhat == Y)) def batch_evaluate( net: Net, dataloader: torch.utils.data.DataLoader) -> float: """تقييم الشبكة العصبية على دفعات، إذا كانت مجموعة البيانات كبيرة جدًا""" score = n = 0.0 for batch in dataloader: n += len(batch['image']) outputs = net(batch['image']) if isinstance(outputs, torch.Tensor): outputs = outputs.detach().numpy() score += evaluate(outputs, batch['label'][:, 0]) return score / n def validate(): trainloader, testloader = get_train_test_loaders() net = Net().float().eval() pretrained_model = torch.load("checkpoint.pth") net.load_state_dict(pretrained_model) print('=' * 10, 'PyTorch', '=' * 10) train_acc = batch_evaluate(net, trainloader) * 100. print('Training accuracy: %.1f' % train_acc) test_acc = batch_evaluate(net, testloader) * 100. print('Validation accuracy: %.1f' % test_acc) trainloader, testloader = get_train_test_loaders(1) # export to onnx fname = "signlanguage.onnx" dummy = torch.randn(1, 1, 28, 28) torch.onnx.export(net, dummy, fname, input_names=['input']) # check exported model model = onnx.load(fname) onnx.checker.check_model(model) # check model is well-formed # create runnable session with exported model ort_session = ort.InferenceSession(fname) net = lambda inp: ort_session.run(None, {'input': inp.data.numpy()})[0] print('=' * 10, 'ONNX', '=' * 10) train_acc = batch_evaluate(net, trainloader) * 100. print('Training accuracy: %.1f' % train_acc) test_acc = batch_evaluate(net, testloader) * 100. print('Validation accuracy: %.1f' % test_acc) if __name__ == '__main__': validate()
لاستخدام نقطة التحقق checkpoint من الخطوة الأخيرة وتقييمها، شغّل ما يلي:
(signlanguage) $ python step_4_evaluate.py
سيؤدي هذا إلى الحصول على مخرجات مشابهة لما يلي، مما يؤكد أن النموذج الذي صدرته لا يعمل فحسب، بل يتوافق أيضًا مع نموذج بايتورش الأصلي الخاص
بك أيضًا:
========== PyTorch ========== Training accuracy: 99.9 Validation accuracy: 97.4 ========== ONNX ========== Training accuracy: 99.9 Validation accuracy: 97.4
حققت شبكتك العصبية دقة تصل إلى 99.9% على بيانات التدريب ودقة تبلغ 97.4% على بيانات التحقق. تُشير هذه الفجوة بين دقة التدريب والتحقق إلى أن النموذج الخاص بك أفرط في ضبط قيم معلماته على بيانات التدريب، وهذا ماندعوه بالضبط الزائد أو الإفراط في المُلائمة Overfitting. هذا يعني أنه بدلاً من تعلم الأنماط التي يمكن تعميمها على جميع الصور (بما في ذلك صور العالم الحقيقي) ، فإن النموذج الخاص بك تعلّم أنماطًا خاصة للغاية ببيانات التدريب، أي وكأنه حفظ البيانات ولم يفهمها (حافظ مش فاهم).
في هذه المرحلة، أكملنا بناء مُصنّف لغة الإشارة. يمكن لنموذجنا أن يُميّز الإشارات بطريقة صحيحة طوال الوقت تقريبًا. هذا نموذج جيد إلى حد معقول، لذلك ننتقل إلى المرحلة النهائية من تطبيقنا. سوف نستخدم مصنف لغة الإشارة هذا في تطبيق كاميرا الويب في الزمن الحقيقي.
الخطوة 5 -الربط مع الكاميرا
هدفك التالي هو ربط كاميرا الحاسوب بمصنف لغة الإشارة الخاص بك. يتضمن ذلك التقاط المُدخلات من الكاميرا ثم تصنيف لغة الإشارة المعروضة ثم عرض معنى الإشارة للمستخدم.
أنشئ الآن برنامجًا بلغة بايثون لاكتشاف الوجه. أنشئ الملف step_6_camera.py باستخدام المحرر nano أو محرر النصوص المفضل لديك:
(signlanguage) $ nano step_5_camera.py
أضف الشيفرة التالية إليه:
"""اختبار تصنيف لغة الإشارة""" import cv2 import numpy as np import onnxruntime as ort def main(): pass if __name__ == '__main__': main()
تستورد هذا الشيفرة مكتبة OpenCV المُشار إليها بالاسم cv2. تحتوي هذه المكتبة على العديد من الأدوات اللازمة لمعالجة الصور. تستورد أيضًا onnxruntime وهي كل ما تحتاجه لتشغيل الاستدلال على النموذج الخاص بك. ما تبقى من التعليمات البرمجية هو البنية المبدأية لبرنامج بايثون الذي سنكتبه.
الآن استبدل pass في الدالة main بالشيفرة التالية، التي تُهيئ مُصنف لغة الإشارة بالمعلمات التي دربنا النموذج معها مسبقًا. أربط أيضًا الفهارس بالحروف وحدد الإحصائيات المتعلقة بالمعالجة المسبقة للصور:
def main(): # الثوابت index_to_letter = list('ABCDEFGHIKLMNOPQRSTUVWXY') mean = 0.485 * 255. std = 0.229 * 255. # إنشاء جلسة قابلة للتشغيل باستخدام النموذج المُصدَّر ort_session = ort.InferenceSession("signlanguage.onnx")
ستستخدم عناصر من برنامج اختبار موجودة في وثائق OpenCV الرسمية، بالتالي ستحتاج إلى تحديث شيفرة الدالة main. ابدأ بتهيئة كائن VideoCapture الذي يلتقط البث المباشر من كاميرا حاسوبك. ضع ذلك في نهاية الدالة main:
def main(): ... # إنشاء جلسة قابلة للتشغيل باستخدام النموذج المُصدَّر ort_session = ort.InferenceSession("signlanguage.onnx") cap = cv2.VideoCapture(0)
ثم أضف حلقة while لتقرأ من الكاميرا في كل خطوة زمنية:
def main(): ... cap = cv2.VideoCapture(0) while True: # التقط إطارًا بإطار ret, frame = cap.read()
اكتب دالة مساعدة للاحتفاظ بالمنطقة الوسطى فقط مع التخلص من المناطق المحيطة من إطار الكاميرا. ضع هذه الدالة قبل الدالة main:
def center_crop(frame): h, w, _ = frame.shape start = abs(h - w) // 2 if h > w: frame = frame[start: start + w] else: frame = frame[:, start: start + h] return frame
خذ الآن المنطقة الوسطى لإطار الكاميرا، وحوّلها إلى صورة رماديّة grayscale وطبق عمليّة تقييس عليها وعدّل حجمها إلى 28 × 28. ضع هذا داخل الحلقة while داخل main:
def main(): ... while True: # التقط إطارًا بإطار ret, frame = cap.read() # معالجة البيانات frame = center_crop(frame) frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) x = cv2.resize(frame, (28, 28)) x = (frame - mean) / std
مازلنا ضمن حلقة while شغّل الاستدلال الآن باستخدام onnxruntime. وحوّل المخرجات إلى فهرس صنف، ثم إلى حرف:
... x = (frame - mean) / std x = x.reshape(1, 1, 28, 28).astype(np.float32) y = ort_session.run(None, {'input': x})[0] index = np.argmax(y, axis=1) letter = index_to_letter[int(index)]
اعرض الحرف المتوقع داخل الإطار، ثم اعرض الإطار مرة أخرى للمستخدم:
... letter = index_to_letter[int(index)] cv2.putText(frame, letter, (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (0, 255, 0), thickness=2) cv2.imshow("Sign Language Translator", frame)
في نهاية الحلقة، أضف هذه الشيفرة للتحقق مما إذا كان المستخدم قد وصل إلى الحرف q، وإذا كان الأمر كذلك، نُغلق التطبيق. نستخدم cv2.waitKey من أجل الانتظار لمدة 1 مللي ثانية. أضف ما يلي:
... cv2.imshow("Sign Language Translator", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break
أخيرًا، حرّر الكاميرا وأغلق جميع النوافذ. وضع هذا الكود خارج الحلقة while لإنهاء main:
... while True: ... if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
تحقق جيدًا من تطابق ملفك مع الشيفرة التالية أو هذا المستودع:
import cv2 import numpy as np import onnxruntime as ort def center_crop(frame): h, w, _ = frame.shape start = abs(h - w) // 2 if h > w: return frame[start: start + w] return frame[:, start: start + h] def main(): # الثوابت index_to_letter = list('ABCDEFGHIKLMNOPQRSTUVWXY') mean = 0.485 * 255. std = 0.229 * 255. # إنشاء جلسة قابلة للتشغيل باستخدام النموذج المُصدَّر ort_session = ort.InferenceSession("signlanguage.onnx") cap = cv2.VideoCapture(0) while True: # التقط إطارًا بإطار ret, frame = cap.read() # معالجة البيانات frame = center_crop(frame) frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) x = cv2.resize(frame, (28, 28)) x = (x - mean) / std x = x.reshape(1, 1, 28, 28).astype(np.float32) y = ort_session.run(None, {'input': x})[0] index = np.argmax(y, axis=1) letter = index_to_letter[int(index)] cv2.putText(frame, letter, (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.0, (0, 255, 0), thickness=2) cv2.imshow("Sign Language Translator", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() if __name__ == '__main__': main()
اخرج من الملف وشغّل البرنامج:
(signlanguage) $ python step_5_camera.py
بمجرد تشغيل البرنامج، ستظهر نافذة تحتوي على البث المباشر لكاميرا الويب الخاصة بك. يُعرض حرف لغة الإشارة المتوقع في أعلى اليسار. ارفع يدك وضع إشارتك المُفضلة لترى عمل المُصنّف الخاص بك. فيما يلي بعض النتائج النموذجية التي توضّح الحرفين L و D.

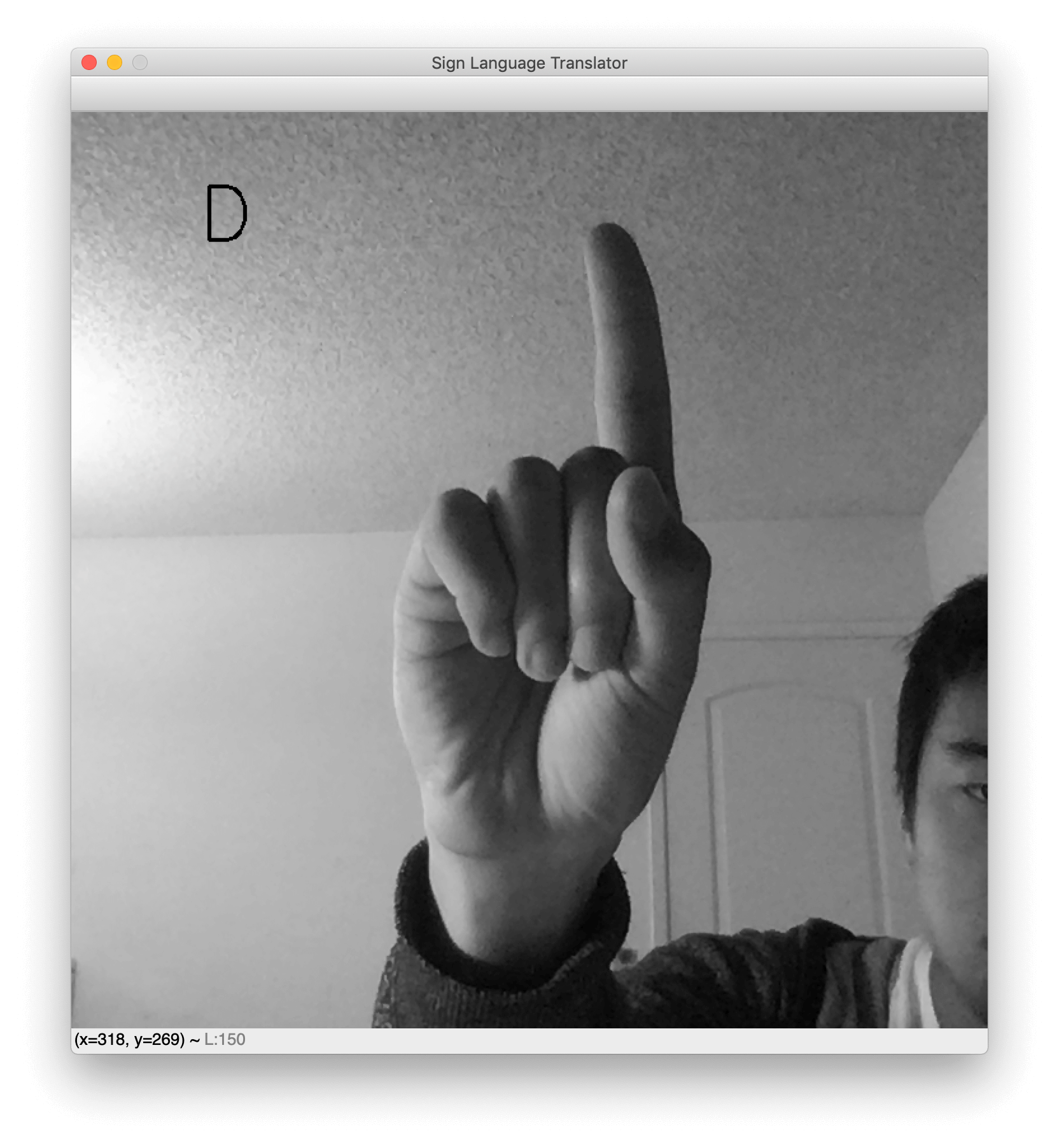
لاحظ أن الخلفية أثناء الاختبار يجب أن تكون واضحة إلى حد ما حتى يعمل هذا النموذج. سبب ذلك هو عدم التنوّع في الخلفيات الموجودة في الصور في مجموعة البيانات التي درّبنا عليها النموذج. لو كانت مجموعة البيانات تتضمن صورًا لإشارات يد ذات خلفيات متنوعة، لكانت الشبكة متينة في مواجهة الخلفيات المتنوعة التي قد تحتوي ضوضاء أو اختلافات. عمومًا، تتميز مجموعة البيانات بخلفيات فارغة وأيادي متمركزة بطريقة جيد. نتيجة لذلك، فإن أداء نموذجنا يكون مثاليًا عندما تكون يدك في المنتصف وخلفها خلفية فارغة.
وبهذا ينتهي تطبيق مُترجم لغة الإشارة.
خاتمة
لقد بنينا في مقال اليوم مُترجمًا للغة الإشارة الأمريكية باستخدام الرؤية الحاسوبية ونموذج تعلّم آلي. ورأيت جوانب جديدة لتدريب نموذج التعلّم الآلي، مثل زيادة البيانات من أجل متانة النموذج وجداول معدّل التعلّم لتقليل الخسارة وتصدير نماذج الذكاء الاصطناعي باستخدام أونكس لاستخدامها في الإنتاج. وقد توّجنا ذلك بإنشاء تطبيق رؤية حاسوبية في الزمن الحقيقي، والذي يُترجم لغة الإشارة إلى أحرف باستخدام خط معالجة أنشأناه. تجدر الإشارة إلى أن مكافحة هشاشة المُصنف النهائي يمكن معالجتها بأي من الطرق التالية أو جميعها. لمزيد من المعرفة، جرّب المواضيع التالية لتحسين هشاشة المُصنّف:
- التعميم Generalization: هذا ليس موضوعًا فرعيًا ضمن مجال الرؤية الحاسوبية، بل هو مشكلة موجودة في جميع مراحل تعلّم الآلة.
- التكيف مع المجال Domain Adaptation: لنفترض أن النموذج الخاص بك قد تدرّب في المجال A (على سبيل المثال، البيئات المشمسة). هل يمكنك تكييف النموذج مع المجال B (على سبيل المثال، البيئات الملبّدة بالغيوم) بسرعة؟
- أمثلة مخادعة Adversarial Examples: لنفترض أن الخصم يصمم صورًا عمدًا لخداع نموذجك. كيف يمكنك تصميم مثل هذه الصور؟ وكيف يمكنك مكافحتها والتعامل معها؟
ترجمة -وبتصرُّف- للمقال How To Build a Neural Network to Translate Sign Language into English لصاحبه Alvin Wan.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.