

تتدرب نماذج التعلم الآلي على مجموعات من البيانات الضخمة حيث توسم نقاط الاهتمام في البيانات -أي الأجزاء المهمة في التي نريد التركيز عليها والتعلم منها- لإعطائها معنى وسياق. نتعمق في هذه المقالة في وصف طرق بناء أنظمة وسم البيانات data labeling من الصفر مركزين على تدفق البيانات في النظام وكيفية تأمينها وضمان جودتها.
ما معنى وسم البيانات
ينتج الذكاء المتأصل في الذكاء الاصطناعي من تعرضه لكميات من البيانات التي تتدرب عليها نماذج تعلم الآلة، ومع التقدم الحالي في النماذج اللغوية الضخمة مثل GPT-4 وجيمناي Gemini التي يمكنها معالجة تريليونات الوحدات اللغوية الصغيرة التي تسمى tokens، ولا تتكون هذه البيانات المستخدمة في التدريب من معلومات أولية مستخلصة من الإنترنت فقط فهي تتضمن أيضًا وسومًا حتى يكون التدريب فعالًا.
وسم البيانات data labeling هو عملية تحويل البيانات الأولية والمعلومات غير المعالجة إلى بيانات موسومة أو بيانات معنونة لإضافة سياق ومعنى واضح لها، وتحسّن هذه العملية من دقة تدريب النموذج، فأنت توضح وتشير إلى ما ترغب للنظام أن يتعرف عليه، وتتضمن الأمثلة على وسم البيانات مهام مثل تحليل المشاعر في النصوص حيث توسم النصوص في هذه الحالة بمشاعر معينة مثل إيجابي أو سلبي أو محايد، ومهام التعرف على الكائنات في الصور إذ يوسم كل كائن في الصورة بتصنيف معين. وكذلك تستخدم في تنصيص الكلام المنطوق في الملفات الصوتية، أو وسم الأفعال في مشاهد الفيديو.
تلعب جودة البيانات دورًا هائلًا في تدريب البيانات، فالمدخلات الرديئة تؤدي إلى مخرجات رديئة فلا يمكننا توقع أداء مبهر من نموذج لم يُدرّب إلا على بيانات رديئة الجودة، فالنماذج التي تتدرب على بيانات بها أخطاء وتناقض في الوسوم ستواجه صعوبة في محاولة التأقلم مع البيانات الجديدة التي لم تراها في التدريب وربما تكون متحيزة في توقعاتها مسببة أخطاء في المخرجات، ويمكن أن يؤدي تراكم البيانات الرديئة في المراحل المختلفة إلى تأثير مركب مما يؤثر على كل الخطوات والنماذج التي تعتمد عليها.
يهدف هذا المقال لتوضيح طرق تعزيز جودة البيانات واكتساب أفضلية تنافسية في كافة مراحل وسم البيانات. وللسهولة سنركز على المنصات والأدوات التي تستخدم في عملية وسم البيانات ونقارن بين مميزات ومحدوديات كل تقنية وأداة، وبعد ذلك ننتقل إلى اعتبارات أخرى لا تقل أهمية مثل تقليل التحيز، وحماية الخصوصية، وزيادة دقة وسم البيانات.
دور وسم البيانات في سير عمل تطبيقات تعلم الآلة
يقسم تدريب نماذج تعلم الآلة إلى ثلاثة تصنيفات عامة وهي التعلم الخاضع للإشراف Supervised learning والتعلم غير الخاضع لإشراف Unsupervised learning والتعلم المعزز Reinforcement learning.
يعتمد التعلم الخاضع للإشراف على البيانات الموسومة labeled training data، والتي تحتوي نقاط الاهتمام في البيانات بها على وسوم بالتوقع أو العنوان الصحيح، فيتعلم النموذج أن يربط بين خواص المدخلات والوسوم أو التسميات الصحيحة المرتبطة بها مما يعطيه القدرة على تخمين وسوم البيانات الجديدة التي لم يتدرب عليها من قبل ولا يعرف ما وسمها الحقيقي، من جهة أخرى يحلل التعلم غير الخاضع للإشراف البيانات غير الموسومة بحثًا عن الأنماط المخفية أو التجميعات الموجودة في البيانات، وأما في التعلم المعزز فتكون عملية التدريب بالتجربة والخطأ ويمكننا التدخل في مرحلة التقييم والمراجعة لتوجيه عملية التعلم.
تُدرّب معظم نماذج التعلم الآلي باستخدام أسلوب التعلم الخاضع للإشراف supervised learning. ونظرًا لأهمية البيانات عالية الجودة فينبغي اعتبارها في كل خطوة من عملية التدريب لذلك يلعب وسم البيانات دورًا حيويًا في هذه العملية.
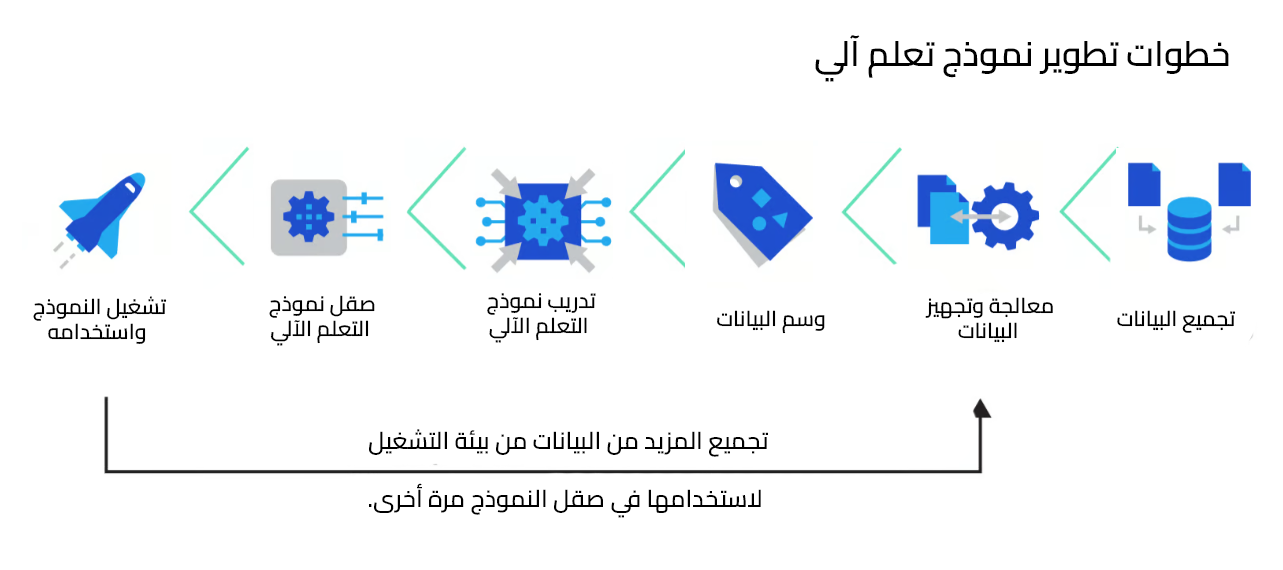
إن تحضير وجمع البيانات هي العملية التي تسبق وسم البيانات، حيث تُجمع البيانات الأولية أو الخام من مصادر متنوعة مثل المستشعرات الإلكترونية sensors، وقواعد البيانات، وسجلات العمليات logs، وواجهات برمجة التطبيقات APIs، وفي الغالب لا تخضع هذه البيانات لهيكل أو تنسيق ثابت وقد تحتوي على تناقضات وشوائب مثل قيم مفقودة أو قيم شاذة outliers أي قيما غير مألوفة وتختلف بشكل كبير عن باقي البيانات، أو قيم متكررة، لذا في عملية المعالجة تُنظّف البيانات وتُنسَّق وتُحوّل لتكون جاهزة لوسمها labeling، وتستخدم استراتيجيات عديدة للتعامل مع معالجة البيانات مثل حذف الصفوف المكررة، أو حذف الصفوف التي تحتوي على قيم مفقودة أو التعويض عن هذه القيم باستخدام نماذج تخمين إحصائية، كما يمكننا إحصائيًا اكتشاف القيم الشاذة outliers ومعالجتها.
تلي معالجة البيانات في الخطوات عملية وسم البيانات لتوفير المعلومات التي يحتاجها نموذج التعلم الآلي كي يتعلم، وتختلف استراتيجيات وسم البيانات باختلاف نوع هذه البيانات والغرض من النموذج، فوسم الصور يتطلب أساليب مختلفة عن وسم النصوص، وعلى الرغم من وجود أدوات وسم آلية ولكن التدخل البشري يحسن بشكل كبير من عملية الوسم خاصة عندما يتعلق الأمر بالدقة أو تفادي التحيز الذي قد يوجد في الأدوات الآلية، وبعد أن توسم البيانات تاتي مرحلة تأكيد الجودة والتي تضمن الدقة والتناسق واكتمال الوسوم، ويعمل فريق تأكيد الجودة على توظيف أسلوب الوسم المزدوج إذ يقوم أكثر من شخص بوسم عينة من البيانات بشكل مستقل ويقارنون نتائجهم لحل أي اختلاف في الآراء.
الخطوة التالية هي خضوع النموذج للتدريب باستخدام البيانات الموسومة ليتعلم الأنماط والعلاقات بين المدخلات والوسوم المرتبطة بها، حيث تعدل معاملات النموذج في عملية تكرارية من التخمين وتقييم الخطأ حتى تتحسن الدقة بالنسبة للوسوم المعلومة، ولتقييم فعالية النموذج يختبر على بيانات موسومة لم يرها من قبل، وتقاس صحة تخميناته وتوقعاته باستخدام معايير رقمية مثل نسبة الصواب accuracy والدقة precision والاستذكار Recall أو الحساسية sensitivity، فإذا كان أداء النموذج ضعيفًا تُعدل بعض الأشياء قبل إعادة التدريب مثل تحسين جودة بيانات التدريب بتقليل الضوضاء بالبيانات data noise أو تقليل التحيز وتحسين عملية وسم البيانات، وفي النهاية بعد إعادة التدريب وتحسين النموذج يصبح جاهزًا للتشغيل deployment ويمكنه التفاعل مع البيانات في العالم الحقيقي. وأخيرًا من المهم مراقبة أداء النموذج لكشف وتحديد أي مشكلات قد تتطلب تحديث النموذج أو إعادة تدريبه.
تحديد أنواع وطرق وسم البيانات
تَسبق عملية تحديد نوع البيانات مرحلةَ تصميم وبناء معمارية وسم البيانات، حيث توجد البيانات في تنسيقات وهياكل متنوعة تشمل النصوص والصور ومقاطع الفيديو والملفات الصوتية، وكل نوع من البيانات يأتي بمجموعة من التحديات المميزة التي تتطلب طريقة خاصة في التعامل معها لتحقيق تناسق ودقة في عملية وسم البيانات، بالإضافة لذلك فبعض البرمجيات المستخدمة في وسم البيانات تتضمن أدوات مصممة للتعامل مع أنواع معينة من البيانات، وكذلك تتخصص فرق الوسم في وسم نوع محدد من البيانات، لذلك يعتمد اختيار البرمجيات والفريق المناسب بشكلٍ كبير على المشروع.
على سبيل المثال، قد تطلب عملية وسم بيانات للرؤية الحاسوبية computer vision تصنيف الصور الرقمية ومقاطع الفيديو وإنشاء مستطيلات التحديد bounding boxes لعنونة الكائنات الموجودة داخلها. وتحتوي مجموعة بيانات وايمو المفتوحة waymo's open dataset مثلًا على مجموعة بيانات موسومة لمهام الرؤية الحاسوبية computer vision للسيارات ذاتية القيادة، وقد وُسمت هذه البيانات بجهود مجموعة من الأفراد عبر الإنترنت مع مساهمات واسمين فرديين. ومن التطبيقات الأخرى للرؤية الحاسوبية computer vision التصوير الطبي، والاستطلاع الجوي، والمراقبة، والتأمين، والواقع المعزز augmented reality.
ويمكن وسم النصوص ومعالجتها باستخدام خوارزميات معالجة اللغات الطبيعية Natural Language processing بمجموعة متنوعة من الطرق، تشمل تحليل المشاعر sentiment analysis من النصوص مثل المشاعر الإيجابية والسلبية، واستخلاص الكلمات المفتاحية مثل العبارات ذات الصلة، وكذلك التعرف على الكيانات الموجودة في النص مثل الأشخاص والأماكن والتواريخ، يمكن أيضًا تصنيف النصوص القصيرة. على سبيل المثال، يمكن تحديد فيما إذا كانت رسالة بريد إلكتروني رسالة مزعجة spam أم لا، ويمكن التعرف على لغة النص كالعربية أو الانجليزية، وتستخدم نماذج معالجة اللغات الطبيعية في تطبيقات مثل أنظمة المحادثة chatbots والمساعدات البرمجية coding assistants والمترجمات translators ومحركات البحث search engines.

كما تستخدم البيانات الصوتية في تطبيقات متنوعة تشمل تصنيف الصوتيات، والتعرف على الصوت، والتعرف على الكلام، والتحليل الصوتي، ويمكن وسم الملفات الصوتية للتعرف على كلمات معينة مثل "يا سيري" أو "Hey Siri"، وحتى تصنيف أنواع مختلفة من الأصوات، أو تحويل الكلام المنطوق إلى كلمات مكتوبة.
إن العديد من نماذج التعلم الآلي هي نماذج متعددة multimodal أي أنها نماذج قادرة على تفسير والتعامل مع البيانات من مصادر مختلفة بشكل متزامن، فيمكن للسيارات ذاتية القيادة جمع معلومات بصرية مثل إشارات المرور والمارين في الطريق وتجمع بيانات صوتية مثل صوت أبواق السيارات، مما يتطلب وسمًا متعددًا multimodal labeling حيث يقوم الواسمون البشريون بجمع ووسم أنواع مختلفة من البيانات بطريقة تراعي العلاقات والتفاعلات بين تلك الأنواع.
من المهم اختيار الطريقة الأنسب لوسم البيانات قبل الشروع في بناء النظام الخاص بنا، وقد كان الوسم البشري للبيانات سابقًا هو الطريقة المتبعة، ولكن مع التقدم الهائل في التعلم الآلي ازدادت إمكانيات الأتمتة مما جعل العملية أكثر كفاءة وأقل تكلفةً، ولكن تجدر الإشارة أنه وعلى الرغم من تحسن دقة أدوات الوسم الآلية فإنها لاتزال غير قادرة على مواكبة الدقة والاعتمادية التي يوفرها البشر.
لذا يلجأ المختصون عادة لأسلوب مختلط يتضمن مشاركة البشر والبرامج الآلية في عملية وسم البيانات، حيث تستخدم برامج آلية لتوليد الوسوم الأولية ثم تجري مراجعتها وتدقيقها وتصحيحها بواسطة الواسم البشري، وتضاف الوسوم المصححة إلى مجموعة بيانات التدريب لتحسين دقة وأداء البرنامج الآلي، وهذا يضمن الحفاظ على مستوى جيد من الدقة والتناسق وهو أكثر الاستراتيجيات شيوعًا في وسم البيانات.
اختيار مكونات نظام وسم البيانات
تبدأ عملية وسم البيانات بخطوة تجميع البيانات وتخزينها، حيث تجمع البيانات إما بشكل يدوي باستخدام أساليب مثل المقابلات الشخصية والاستبيانات واستطلاعات الرأي أو بشكل آلي مثل استخلاص البيانات من الإنترنت web scraping.
في حال عدم امتلاكك للموارد الكافية لجمع البيانات على نطاق واسع فيمكن الاعتمدا على مجموعات البيانات مفتوحة المصدر المتوفرة على منصات مثل كاجل Kaggle أو مستودع مجموعات البيانات الخاص بجامعة كاليفورنيا ايفرين UCI repository أو بحث جوجل لمجموعات البيانات Google dataset search أو جت هاب GitHub فكلها مصادر جيدة، بالإضافة لمصادر البيانات المصنعة باستخدام نماذج رياضية لتحاكي البيئات الحقيقة، ولتخزين هذه البيانات يمكنك تأجير مساحات تخزينية من مزودي خدمات سحابية مثل جوجل أو مايكروسوفت حتى تتوسع حسب احتياجاتك، فبشكل نظري يمكنهم توفير مساحة تخزين غير محدودة مع توفير ميزات مدمجة تزيد من التأمين، ولكن إذا كنت تعمل مع بيانات شديدة السرية وتحتاج للامتثال لقوانين وأنظمة معينة مثل مثل قانون حماية البيانات العامة GDPR فحلول التخزين المحلية هي الخيار المناسب.
يمكنك أن تبدأ في وسم البيانات فور أن تنتهي من تجميعها، وتعتمد عملية الوسم بشكل رئيسي على نوع البيانات، ولكن في العموم تحدد كل نقاط الاهتمام في البيانات وتصنف باستراتيجية إبقاء الإنسان مشاركًا في العملية، وتوجد العديد من المنصات المتاحة التي تبسط هذه العملية المعقدة، وبعضها مفتوح المصدر مثل Doccano و LabelStudio و CVAT ومنصات تجارية مثل scale data engine و labelbox و Supervisely.
تُراجَع الوسوم بعد إنشائها بواسطة فريق ضمان الجودة لضمان الدقة والتناسق وحل أي تناقضات موجودة في الوسوم أو اختلافات في تقرير الوسم من خلال الطرق اليدوية مثل تقرير الأغلبية أو اللجوء للمعايير أو استشارة خبراء في هذا التخصص، ويمكن تخفيف التناقضات بطرق آلية مثل استخدام نماذج إحصائية مثل Dawid-Skene لجمع الوسوم المختلفة من عدة مصادر في وسم واحد معتمد أكثر، فور الاتفاق على الوسوم بواسطة ذوي الصلة تعد الحقائق مطلقة يمكن استخدامها لتدريب نماذج التعلم الآلي، بعد التأكد من أن الوسوم دقيقة ومتسقة، تصبح هذه الوسوم حقائق ثابتة يمكن استخدامها لتدريب نماذج تعلم الآلة.
هنالك أيضًا أدوات مفتوحة المصدر وأخرى تجارية تساعدنا في مراجعة الوسوم والتحقق من الجودة وتدقيق البيانات، قد تكون الأدوات التجارية أكثر تطورًا وتوفر ميزات إضافية مثل التدقيق الآلي، ونظام إدارة المراجعات، والموافقة عليها أو رفضها وأدوات تعقب لمعايير الجودة.
مقارنة بين أدوات وسم البيانات
تُعد الأدوات مفتوحة المصدر نقطة بداية جيدة، فعلى الرغم من محدودية وظائفها وميزاتها مقارنة بالأدوات التجارية فإن غياب رسوم الترخيص يمثل ميزة مهمة للمشاريع الصغيرة، وتقدم الأدوات التجارية وسم أولي مدعوم بالذكاء الاصطناعي ويمكن تعويض هذه الميزة في الأدوات مفتوحة المصدر عن طريق دمجها مع نموذج تعلم آلي خارجي.
| الاسم | أنواع البيانات المدعومة | إدارة سير العمل | تأكيد الجودة | دعم التخزين السحابي | ملاحظات إضافية |
|---|---|---|---|---|---|
| استديو الوسم النسخة العامة Label Studio Community Edition | نصوص، صور، صوتيات، مقاطع فيديو، بيانات زمنية | نعم | لا | التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور | تحتوي النسخة المجانية على مجموعة واسعة من الميزات، ولكن النسخة المدفوعة الخاصة بالشركات أكثر احترافية |
| سي في أيه تي CVAT | صور ومقاطع فيديو | نعم | نعم | التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور | يدعم LiDAR وهو نظام لقياس المسافات ووسم المجسمات المكعبة ثلاثية الأبعاد 3D Cuboid، بالإضافة إلى وسم الأوضاع المختلفة لهيكل مبسط من نقاط مفصلية في جسد الإنسان ويمكن استخدامه لتخمين وقفته أو حركته |
| دوكانو Doccano | نصوص وصور وملفات صوتية | نعم | لا | التخزين السحابي لجوجل | مصمم لوسم النصوص |
| ڤيا VIA (VGG Image Annotator) | صور وملفات صوتية ومقاطع فيديو | لا | لا | لا | يعتمد على المتصفح |
| ميك سينس MakeSense.AI | صور | لا | لا | لا | يعتمد على المتصفح |
توفر المنصات مفتوحة المصدر العديد من الميزات المطلوبة لمشاريع وسم البيانات ولكن المشاريع المعقدة لتعلم الآلة تتطلب ميزات متقدمة مثل الأتمتة والقابلية للتوسع وتتاح هذه الميزات الإضافية في المنصات التجارية، بالإضافة لمزايا تأمينية والدعم الفني ومزايا مٌسّاعدة في عملية الوسم باستخدام نماذج التعلم الآلي وشاشة التقارير والرسومات البيانية التحليلية كل هذه الميزات تجعل المنصات التجارية تستحق الزيادة في التكلفة.
| الاسم | أنواع البيانات المدعومة | إدارة سير العمل | تأكيد الجودة | دعم التخزين السحابي | ملاحظات إضافية |
|---|---|---|---|---|---|
| Lablbox | نصوص، صور، مقاطع فيديو، ملفات صوتية، HTML | نعم | نعم | التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور | توفر المنصة فرقًا متخصصة في الوسم وفي المجالات المرتبطة بالبيانات من خلال خدمة Boost |
| Supervisely | صور، مقاطع فيديو، بيانات ثلاثية الأبعاد مجمعة من عدة مستشعرات 3D sensor fusion، الصور الطبية بصيغة DICOM | نعم | نعم | التخزين السحابي لجوجل، التخزين السحابي لميكروسوفت أزور | بيئة متكاملة مفتوحة للدمج مع مئات التطبيقات المبنية على محرك التطبيقات الخاص بهم، يدعم LiDAR و RADAR وهي أنظمة لقياس البعد واكتشاف الأجسام بالإضافة إلى الصور الطبية متعددة الشرائح أو المستويات |
| Scale AI Data Engine | النصوص، الصور، ملفات الصوت، مقاطع الفيديو، البيانات ثلاثية الأبعاد المجمعة من عدة مستشعرات 3D sensor fusion، الخرائط | نعم | نعم | التخزين السحابي لجوجل، التخزين السحابي لمايكروسوفت أزور | يوفر أدوات متخصصة في قطاعات وصناعات محددة |
| SuperAnnotate | النصوص، الصور، الملفات الصوتية، مقاطع الفيديو، PDF ،HTML | نعم | نعم | التخزين السحابي لجوجل، التخزين السحابي لميكروسوفت أزور | يوفر فرق وسم متعددة اللغات وخبراء متخصصين في مجالات مختلفة |
وإذا كنا بحاجة لميزات خاصة لا تتوفر في الأدوات المتاحة فيمكننا في هذه الحالة بناء منصة وسم محلية نقرر من خلالها ما هي البيانات التي سندعمها وما هي تنسيقاتها ونحديد أنوع الوسوم المستخدمة، كما يمكننا تصميم وبناء ميزات مثل الوسم الأولي ومراجعة الوسوم وتأكيد الجودة وأدوات لإدارة سير العمل، ولكن تكلفة بناء وتشغيل منصة تضاهي المنصات التجارية تكلفة باهظة لأغلب الشركات.
يعتمد الاختيار في النهاية على عدة عوامل، مثلًا إن لم تكن الأدوات المتاحة من خلال الأطراف الخارجية تناسب متطلبات المشروع أو إذا كانت البيانات سرية فحينها سيكون بناء منصة مخصصة محليًا هو الحل الأمثل، بينما يمكن لمشاريع أخرى أن تستفيد من نظام مختلط فالمهام الأساسية للوسم تُنفَّذ بواسطة الأدوات التجارية بينما الميزات المخصصة يمكن تطويرها محليًا ودمجها مع المنصات الخارجية.
ضمان الجودة والأمان في أنظمة وسم البيانات
يشمل نظام وسم البيانات العديد من المكونات التي تجعله معقدًا فهو يتعامل مع كميات هائلة من البيانات ومستويات مختلفة من البنية التحتية الحاسوبية وسياسات مختلفة وأنظمة سير عمل متعددة الطبقات والمستويات، كل هذا يجعل من عملية تشغيل هذه المكونات معًا بشكل سلسل مهمة مليئة بالتحديات وقد تؤثر على جودة وسم البيانات وفعاليته بالإضافة لمخاطر الأمان والخصوصية الموجودة في كل المراحل التي تمر بها العملية.
تحسين دقة وسم البيانات
تسرع الأتمتة من عملية الوسم ولكن الاعتماد المفرط على الأدوات المؤتمتة لوسم البيانات يمكن أن يقلل من دقة العملية التي تتطلب وعيًا بالسياق والمجال أو قدرة على الحكم الموضوعي وهذه قدرات لا يستطيع حاليًا أي نظامٍ برمجي تقديمها، لذا من المهم وضع توجيه لعملية الوسم بشكل بشري واكتشاف الاخطاء ومعالجتها لضمان جودة وسم البيانات.
كما يمكن تقليل الأخطاء في عملية الوسم بتوفير مجموعة من التوجيهات والإرشادات الشاملة، فمثلًا ينبغي أن تعرف كل التصنيفات الممكنة والتنسيقات المتعامل معها، وينبغي أن تكون هذه الإرشادات مفصلة خطوة بخطوة وتتضمن حلولًا للحالات المتطرفة أو الخاصة، كما ينبغي أن تتوفر مجموعة من الأمثلة التي توضح كيفية التعامل مع نقاط الاهتمام الواضحة وغير الواضحة في البيانات.
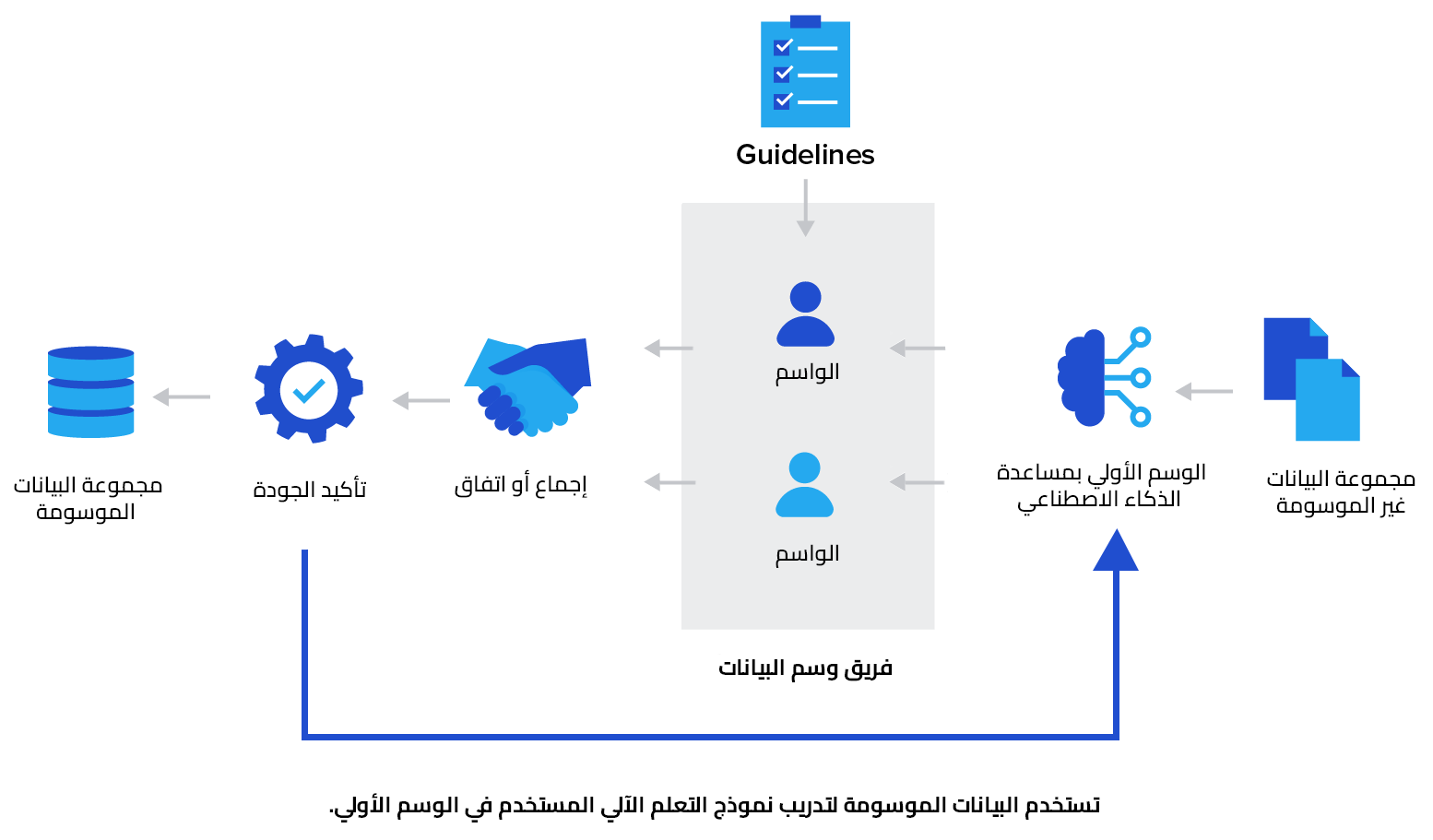
يمكننا أيضًا تجميع آراء عدد من الواسمين المستقلين عن نفس نقطة الاهتمام في البيانات ومقارنة نتائجهم فهذا من شأنه أن يؤدي إلى درجة أعلى من الدقة. فالاتفاق بين الواسمين Inter-annotator-agreement أو ما يعرف بمعيار IAA اختصارًا هو معيار مستخدم لقياس درجة الاتفاق هذه، أي أن نقطة الاهتمام في البيانات التي تحصل على أرقام منخفضة لهذا المعيار تتطلب عملية مراجعة لتقرير الوسم الأنسب لها.
كما يساهم تتبع واكتشاف الأخطاء بشكل كبير في تحسين دقة الوسوم، وكشف الأخطاء وهذا يمكن أن ينفذ آليًا باستخدام برامج مثل كلين لاب Cleanlab حيث تجري مقارنة للبيانات الموسومة باستخدام القواعد المعرفة مسبقًا لإكتشاف أي أخطاء أو اختلافات، فبالنسبة للصور يمكن اكتشاف التداخل بين مستطيلات التحديد bounding boxes آليًا، بينما في النصوص يمكن اكتشاف الوسوم المفقودة أو التنسيقات الخاطئة، وتجري مراجعة جميع الأخطاء بعد ذلك من قبل فريق ضمان الجودة، كما يمكن الاستعانة بالذكاء الاصطناعي الذي توفره العديد من المنصات التجارية لاكتشاف الأخطاء التي تحدد الأخطاء المحتملة باستخدام نماذج تعلم آلي مدربة مسبقًا على بيانات موسومة، بعد تحديد ومراجعة نقاط الاهتمام في البيانات وتقرير الوسم الأصح يضاف لبيانات التدريب الخاصة بالنموذج لتحسين دقته من خلال عملية التعلم.
يوفر تتبع الأخطاء تقييمًا في غاية الأهمية ويُحسّن عملية الوسم من خلال التعلم المستمر الذي يجري بتتبع عدة معايير مفتاحية مثل دقة الوسم ودرجة الإجماع بين الواسمين، فإن كان هناك مهام معينة تكثر فيها أخطاء الواسمين فينبغي تحديد الأسباب المؤدية لهذه الأخطاء، وتوفر العديد من المنصات التجارية أدوات مبنية بها تساعد على المراقبة والتقييم من خلال الرسومات البيانية التفاعلية التي توضح سجل الوسم وتوزيع الأخطاء، ويمكن تحسين الأداء بتعديل المعايير والإرشادات لتوضيح كيفية التعامل مع الإرشادات غير الواضحة وتحسين القواعد التي تساعد في اكتشاف الأخطاء.
التعامل مع التحيز وضمان العدالة
تعتمد عملية وسم البيانات بشكل مكثف على الحكم والتفسير الشخصي، مما يشكل تحديًا على الواسمين ليقومو بوسم البيانات بشكل عادل وغير متحيز حتى عندما تكون البيانات غير واضحة، فمثلًا عند تصنيف النصوص يمكن أن تكون بعض العبارات والمشاعر مزاحًا أو سخرية ومن السهل أن يساء فهمها، ومثالٌ آخر في تصنيف تعابير الوجه التي يمكن أن يصنفها البعض على أنه وجه حزين والبعض الآخر يراه وجه يشعر بالملل، لذا فنسبية التصنيف أو الوسم تفتح الباب أمام التحيز أو الخطأ، ويمكن أن تكون مجموعة البيانات نفسها منحازة اعتمادًا على المصدر أو التركيب السكاني أو وجهة نظر جامعها ويمكن أن تكون غير ممثلة للمجتمع، وتدريب نماذج التعلم الآلي على بيانات منحازة يمكن أن يؤدي إلى توقعات خاطئة مثل تشخيص خاطئ للمرض بسبب تحيز البيانات الطبية المستخدمة للتدريب.
لتقليل التحيز في عملية الوسم ينبغي أن يكون فريق الواسمين وفريق تأكيد الجودة من خلفيات متنوعة، فالوسم المزدوج والمتعدد يمكن أن يقلل من تأثير التحيز الناتج عن الأفراد، وعلى البيانات المستخدمة في التدريب أن تعكس العالم الحقيقي بتمثيل متوازن للتركيبة السكانية والجغرافية ويمكن جمع البيانات من مصادر واسعة التنوع وإضافة بيانات مخصوصة لمواجهة أي تحيز موجود في المصادر الأولية للبيانات، بالإضافة لذلك يمكنها أن تقلل طرق تعزيز وزيادة البيانات data augmentation مثل قلب الصور وإعادة صياغة النصوص من التحيز وتزيد تنوع البيانات بشكل مصطنع، فقلب الصورة مثلًا يُمكّن النموذج من تعلم التعرف على الكائنات بالصورة بغض النظر عن زاوية العرض مما يقلل التحيز لزاوية دوران الصورة، وإعادة صياغة النصوص تعرض النموذج لطرق أخرى للتعبير عن المعلومات مما يقلل التحيز تجاه صياغة أو كلمات معينة.
كما يمكن أن تقلل الرقابة الخارجية من التحيز الموجود في عملية الوسم، وذلك من خلال دعوة فريق خارجي من المختصين بالمجال وعلماء البيانات وخبراء تعلم الآلة لتقييم سير العمل والإشراف على مراجعة وسم البيانات، وتقديم النصائح والاقتراحات التي تساعد على تحسين عملية الوسم وتقليل التحيز.
خصوصية وأمان البيانات
تتضمن مشروعات وسم البيانات في الغالب بيانات سرية أو خاصة لذا ينبغي أن تحتوي جميع المنصات على ميزات تضمن السرية والأمان للبيانات مثل التشفير والمصادقة المتعددة للتحكم بوصول المستخدمين. فمن أجل حماية خصوصية البيانات ينبغي أن يتم حذف البيانات الشخصية أو جعلها مجهولة الهوية، بالإضافة لذلك ينبغي تدريب كل فرد في فريق الوسم على أفضل ممارسات تأمين البيانات مثل استخدام كلمات مرور قوية وتفادي مشاركة البيانات غير المقصود.
كما ينبغي أن تخضع منصات وسم البيانات للقوانين واللوائح المنظمة والتي تشمل اللائحة الشاملة لحماية البيانات GDPR وقانون كاليفورنيا لخصوصية المستخدم CCPA بالإضافة إلى قانون نقل التأمين الصحي والمساءلة HIPAA، وإخضاع المنصات التجارية للمراجعة والإشراف الخارجي والالتزام بمبادئ الثقة الخمسة وهي: الأمان والإتاحة والشفافية والموثوقية والخصوصية.
مستقبل نظام وسم البيانات
تحدث عملية وسم البيانات في الكواليس بالنسبة للمستخدم النهائي ولكنها ذات دور محوري في تطوير نماذج التعلم الآلي وأنظمة الذكاء الاصطناعي لذلك ينبغي أن يكون نظام الوسم قابلًا للتوسع ليواكب أي تغير في المتطلبات.
تُحدَّث منصات الوسم التجارية ومفتوحة المصدر بانتظام لدعم الاحتياجات النامية لوسم البيانات، لذلك ينبغي على أنظمة الوسم المطورة محليًا أن تبني بطريقة تجعل تحديثها أمرًا سلسًا، فالتصميم المعتمد على الوحدات والمكونات القابلة للتبديل بدون التأثير على باقي النظام تٌسهّل عملية التحديث والتطوير، على سبيل المثال يمكن لتوفر ميزة دمج أنظمة وسم البيانات مع مكتبات وأطر عمل مفتوحة المصدر أن تضيف نوعًا من التكييف والتأقلم، حيث يمكن تحديثها وتطويرها باستمرار مع تطور المجال.
كما توفر الحلول المبنية على خدمات الحوسبة السحابية ميزة ملحوظة للمشاريع الضخمة في وسم البيانات والتي لا يمكن أن توفرها الأنظمة المُدارة ذاتيًا، فالمنصات السحابية قابلة للتوسع آليًا في تخزينها وفي قدراتها الحاسوبية مما يقلل من الحاجة للتطويرات المكلفة في البنية التحتية.
وينبغي أيضًا توسيع قدرة فريق العمل المسؤول عن وسم البيانات مع نمو حجم مجموعات البيانات، وتدريب الواسمين الجدد بسرعة على وسم البيانات بدقة وبفعالية. والتمتع بالمرونة في سد الاحتياجات في قوة العمل باستخدام خدمات الوسم المُدارة أو التعاون مع واسمين مستقلين، وينبغي أن تكون عملية التدريب والضم للفريق قابلة للتوسع في المكان واللغة وأوقات العمل.
الخلاصة
تعرفنا في مقال اليوم على أسس وسم البيانات لنماذج تعلم الآلة ووجدنا أن المفتاح الرئيسي لتحسين أداء ودقة نموذج التعلم الآلي هو جودة البيانات الموسومة التي ندرب النموذج عليها، وتوفير الأنظمة المختلطة التي تجمع بين البشر والأدوات المؤتمتة في وسم البيانات لتتيح للذكاء الاصطناعي تحسين الطريقة التي يعمل بها والحصول على نتائج أكثر كفاءة وفعالية.
ترجمة وبتصرف لمقال Architecting Effective Data Labeling Systems for Machine Learning Pipelines لكاتبه Reza Fazeli











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.