Mustafa Suleiman
-
المساهمات
20366 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
الخطأ غير واضح، تفقد سجلات الخادم الـ Error Log هل يوجد بها خطأ ظاهر؟ أيضًا ما الغرض من السكريبت؟ هل من المفترض أن يعرض بيانات معينة في الواجهة؟ أم عليك أنت كتابة ذلك؟ حاول استخدام الكود التالي وتفقد هل يتم طباعة نتيجة أم لا، وإن تم ذلك فالسكريبت يعمل بشكل سليم: $stmt = $this->prepare("SELECT * FROM _user_groups WHERE ID = ?", true); $stmt->execute([1]); while ($row = $stmt->fetch()) { echo "Host: " . htmlspecialchars($row['db_host']) . "<br>"; echo "User: " . htmlspecialchars($row['db_user']) . "<br>"; echo "Password: " . htmlspecialchars($row['db_pass']) . "<br>"; }
-
 على حسب نوع المشكلة، ففي حالة التصنيف متعدد الفئات Multi-Class Classification، لو لديك عدد مختلف من الفئاتبين مجموعة التدريب ومجموعة التحقق، فيعني مشكلة في تقسيم البيانات، فيجب أن تكون الفئات متسقة بين المجموعتين، لكن لو مجموعة التحقق تحتوي على فئات إضافية مثل 123 فئة مقابل 5 فقط في التدريب، فيعني أن بيانات التحقق أكثر تنوعًا أوهناك خطأ في المعالجة المسبقة. وبالنسبة للتصنيف متعدد العلامات Multi-Label Classification، فمن الطبيعي أن يحتوي كل مثال على أكثر من علامة label، أي يتوافر عدد مختلف من الأعمدة بسبب أنّ مجموعة التحقق تحتوي على علامات إضافية لم تظهر في مجموعة التدريب، لكن ذلك سيؤدي إلى صعوبة في تقييم النموذج بشكل صحيح. أو ربما الفرق ناتجًا بسبب طريقة تحويل البيانات أي One-Hot Encoding أو Label Encoding، حيث إن تم تطبيق التحويل بشكل مختلف بين المجموعتين، فسينتج عن ذلك عدد أعمدة مختلف. بالتالي من الأفضل أن تتأكد من اتساق البيانات بين مجموعتي التدريب والتحقق، حيث عدد الأعمدة في train_labels وvalidation_labels متساويًا، ما لم يكن هناك سبب محدد كإضافة بيانات جديدة للتحقق فقط، ثم تفقد خطوات المعالجة للبيانات من المفترض أن تكون موحدة.
على حسب نوع المشكلة، ففي حالة التصنيف متعدد الفئات Multi-Class Classification، لو لديك عدد مختلف من الفئاتبين مجموعة التدريب ومجموعة التحقق، فيعني مشكلة في تقسيم البيانات، فيجب أن تكون الفئات متسقة بين المجموعتين، لكن لو مجموعة التحقق تحتوي على فئات إضافية مثل 123 فئة مقابل 5 فقط في التدريب، فيعني أن بيانات التحقق أكثر تنوعًا أوهناك خطأ في المعالجة المسبقة. وبالنسبة للتصنيف متعدد العلامات Multi-Label Classification، فمن الطبيعي أن يحتوي كل مثال على أكثر من علامة label، أي يتوافر عدد مختلف من الأعمدة بسبب أنّ مجموعة التحقق تحتوي على علامات إضافية لم تظهر في مجموعة التدريب، لكن ذلك سيؤدي إلى صعوبة في تقييم النموذج بشكل صحيح. أو ربما الفرق ناتجًا بسبب طريقة تحويل البيانات أي One-Hot Encoding أو Label Encoding، حيث إن تم تطبيق التحويل بشكل مختلف بين المجموعتين، فسينتج عن ذلك عدد أعمدة مختلف. بالتالي من الأفضل أن تتأكد من اتساق البيانات بين مجموعتي التدريب والتحقق، حيث عدد الأعمدة في train_labels وvalidation_labels متساويًا، ما لم يكن هناك سبب محدد كإضافة بيانات جديدة للتحقق فقط، ثم تفقد خطوات المعالجة للبيانات من المفترض أن تكون موحدة.- 5 اجابة
-
- 1
-

-
صيغة الملف لديك غير صحيحة، فلا نكتب txt. بل الصحيح هو التالي فقط .gitignore وذلك ليتم التعرف عليه من قبل مستودع git في مشروعك. ثم تنفيذ الأمر التالي لإزالة الملفات من الـ stage دون حذف التغييرات من المجلد الفعلي git restore --staged . ثم قم بإعادة تنفيذ أوامر رفع المشروع مرة أخرى أي تنفيذ git add . والأوامر الأخرى.
- 6 اجابة
-
- 1
-

-
لا يوجد خطأ ظاهر لديك، ما رسالة الخطأ التي تظهر لك؟
-
كلا الرأيين لهما وجهة نظر صحيحة لكن تختلف حسب ظروف كل شخص، أنا أميل للخيار الأول وهو تعلم الأساسيات وتخصيص أكبر وقت لها ثم الإنتقال لتعلم التقنيات، وذلك لإمتلاك أساس قوي، قدرة على التعامل مع أي مشكلة بدون الاعتماد الكلي على Laravel أو المكتبات، فهم أعمق للمفاهيم والقدرة على تعلم أي تقنية قائمة على PHP. وفي رأي لا يوجد طريق مُختصر في البرمجة، نعم تستطيع تخطي بعض الأمور ودراستها لاحقًا، لكن الأساسيات ومنها اللغة البرمجية لا أنصحك بالتهاون بها، على كل حال ستتمكن من بناء مشاريع بسيطة إلى متوسطة بدون أساس قوي، وفي المشاريع المعقدة أو المشاكل الغير بسيطة ستواجه صعوبة في فهم بعض المفاهيم العميقة أو حل المشكلات. لكن في حال ليس لديك الوقت الكافي وتريد دخول سوق العمل، أو من الأشخاص الذي يملون بسرعة وليس لديهم صبر ولا مشكلة في ذلك، فالخيار الوسط هو الأفضل لك، بمعنى تعلم القدر الكافي من اللغة وهي الأساسيات وOOP ثم الإنتقال لتعلم Laravel وبناء مشاريع من خلاله ثم العودة فيما بعد وتعلم الجزء المتقدم من لغة PHP.
- 2 اجابة
-
- 1
-
-
استخدمه في وضع البطارية وليس الشاحن، ثم تفقد هل حُلت المشكلة أم لا.
- 15 اجابة
-
- 1
-
-
تلك المشكلة متكررة بالفعل، والعديد من المستخدمين ذكروا نفس مشكلتك، حاول إعادة ضبط إعدادات الطاقة على الويندوز من خلال الأمر التالي في منفذ الأوامر: powercfg -restoredefaultschemes في حال استمرت المشكلة قم بتحديث الـ BIOS، تفقد الإصدار المتاح على موقع الشركة الرسمي لجهازك، ثم تفقد الإصدار لديك، وستجد على اليوتيوب شروحات لذلك. وإن استمرت المشكلة قم بتحديث الـ EC. وكتحذير في حال ليس لديك خبرة بكيفية فعل ذلك من الأفضل تجنب القيام بذلك بنفسك والذهاب إلى شخص مختص. عامًة ستجد شرح هنا: BIOS, EC update and EC reset
- 15 اجابة
-
- 1
-
-
في خيارات الإضافة هل قمت بالضغط على زر Sync أو مزامنة، وذلك لفحص ملفات القالب وتحديث قائمة النصوص القابلة للترجمة في Loco Translate، بعد المزامنة، حاول البحث عن النصوص التي كنت تواجه صعوبة في العثور عليها مرة أخرى. وحاول التجربة على أحد الإضافات بترجمتها وتفقد هل تعمل الإضافة أم لتفقد هل المشكلة في ترجمة القالب أم الإضافة لا تعمل من الأساس.
-
علية إذن إلى معرفة الأعمدة الموجودة فعليًا في الجدول _user_groups من خلال phpMyAdmin تستطيع تفقد الأمر يدويًا أو من خلال الاستعلام: SHOW COLUMNS FROM _user_groups; عامًة الاستعلام يحاول استخدام ID كمعرّف أساسي Primary Key لتحديد سجل معين وترتيب النتائج، فمن المرجح أن العمود الحقيقي ربما يكون بالاسم: id group_id user_group_id بمجرد تحديد العمود الصحيح لنفترض أنه group_id، تحتاج إلى تعديل الاستعلام في الكود أو تعديل قاعدة البيانات، عامًة افتح الملف الذي يولّد الاستعلام ربما يكون في class_db.php أو class_user.php، وابحث عن السطر الذي يحتوي على: $query = "SELECT * FROM _user_groups WHERE `ID` = ? ORDER BY ID ASC LIMIT 0, 1"; واستبدل ID باسم العمود الصحيح. او عليك تعديل القيمة التي يتم تمريرها للاستعلام في حال كان لا يتم كتابة الاستعلام مباشرًة.
-
ببساطة الأمر يعتمد على مدى تعقيد المشروع، ففي حال المشروع يتطلب تخصيص ومُعقد إذن إنشاء واجهة خلفية منفصلة هو الحل، بينما في أغلب الأحوال المشاريع متوسطة وتتمحور أكثر نحو الواجهة الأمامية وتستخدم الواجهة الخلفية في Next.js كما هي. فالخادم المدمج في Next.js محدود في خيارات التخصيص، ولو أردت التحكم الكامل في الـ Routing أو معالجة الطلبات أو إضافة Middleware معقدة، فستحتاج إلى Express.js أو غيره للحصول على مرونة أكبر. أو في حال وجود مشروع قائم يعتمد على Express.js بالفعل، فمن الأسهل دمج Next.js معه بدلاً من إعادة كتابة كل شيء ليتناسب مع الـ API Routes في Next.js. ستجد تفصيل هنا:
- 3 اجابة
-
- 1
-
-
plt.hist من مكتبة Matplotlib ترسم الهيستوغرام حسب البيانات التي تُمرر إليها مباشرة، ولو البيانات تحتوي على قيم inf أو -inf، فإن plt.hist ستفشل وترمي خطأ ValueError لأنها لا تستطيع التعامل مع تلك القيم غير المحدودة بشكل افتراضي، وستحتاج إلى تنظيف البيانات يدويًا قبل تمريرها من خلال استبعاد inf و-inf باستخدام numpy بواسطة np.isfinite. أما sns.histplot من مكتبة Seaborn فهي تعتمد على مكتبة Matplotlib ولكنها توفر طبقة إضافية من المعالجة التلقائية للبيانات، فبشكل افتراضي، sns.histplot تتعامل مع القيم inf و-inf عن طريق تجاهلها بمعنى أنها تستبعد القيم تلقائيًا من الرسم دون رمي خطأ، وذلك بفضل الاعتماد على مكتبة numpy وpandas في المعالجة الداخلية، بالتالي أكثر مرونة عند التعامل مع بيانات غير نظيفة مقارنة بـ plt.hist.
- 6 اجابة
-
- 1
-
-
cv2 مبنية على واجهة C++، بالتالي هي أسرع وأكثر كفاءة مقارنةً بالواجهة القديمة cv التي كانت تعتمد على C، وتوفير دعم التسريع عبر GPU من خلال CUDA لزيادة الأداء في المهام كثيفة الحسابات كمعالجة الفيديو أو التعلم العميق. والميثودز في cv2 البعض منها بأسماء مختلفة عن تلك الموجودة في cv، فمثلاً في cv يوجد cv.Canny() للكشف عن الحواف، بينما في cv2 يوجد cv2.Canny() بنفس الوظيفة ولكن مع تحسينات ومعاملات إضافية. أيضًا الواجهة cv تحتوي على دوال مثل cv.LoadImage() أو cv.CreateMat()، وهي تعتمد على هياكل بيانات قديمة مثل IplImage. بينما الواجهة الحديثة cv2 تستخدم مصفوفات NumPy مباشرة مثل cv2.imread() لتحميل صورة ولا تتطلب تحويلات معقدة بين هياكل البيانات، أيضًا متكاملة مع مكتبة SciPy. import cv2 img = cv2.imread("image.jpg") edges = cv2.Canny(img, 100, 200) أما باقي الدوال في cv2 لها أسماء مشابهة لتلك في cv ولكن مع تحسينات كدعم المزيد من المعاملات أو إرجاع قيم مختلفة. وبالطبع تم توفيز مزايا جديدة لم تكن متوفرة في CV منها cv2.bilateralFilter() لتنعيم الصور مع الحفاظ على الحواف وخوارزميات مثل SIFT وSURF للكشف عن النقاط المميزة.
- 4 اجابة
-
- 1
-
-
cv2.imwrite() خاصة بمعالجة الصور في مكتبة OpenCV، وذلك لحفظها كملفات صور بصيغ (JPG، PNG) مباشرة من مصفوفات NumPy التي تمثل الصورة، وتُركز على كفاءة حفظ الصور مع دعم ضغط اختياري، أي تستطيع تمرير صيغة JPG، للتحكم في الجودة باستخدام المعامل cv2.IMWRITE_JPEG_QUALITY وتحديد قيمة من 0 إلى 100، حيث 100 تعني أعلى جودة. أو صيغة PNG، للضغط بدون فقدان في الجودة lossless compression من خلال معامل cv2.IMWRITE_PNG_COMPRESSION. بينما plt.savefig() هي من مكتبة Matplotlib لحفظ المخططات أو الرسوم البيانية كالرسومات التخطيطية أو الصور المعروضة باستخدام plt.imshow()، أي تتعامل مع الرسومات ثنائية الأبعاد وتحويلها إلى صور أو ملفات متجهة (PDF أو SVG) تحافظ على التفاصيل عند التكبير مع خيارات تحكم في الدقة. بالتالي الاستخدام المُختلف ولا يصح المقارنة بينهم.
- 5 اجابة
-
- 1
-
-
من خلال تحويل ووردبريس إلى العربية، من خلال لوحة التحكم، اضغط على Settings ثم في القائمة المنسدلة الخاصة بـ site language اختر Arabic وستجد هنا شرح لكيفية استخدام الإضافة:
-
المشكلة تبدأ من ملفات class_user.php وclass_db.php تفقدها، فالكود يحاول جلب بيانات مستخدم أو مجموعة من خلال ID غير موجود. قبل سطر 95 أضف التالي لطباعة الاستعلام ومعرفة محتواه وإيقاف الكود قبل الوصول للسطر 95: echo $query; exit; $run = parent::prepare($query); تصفح الصفحة مرة أخرى وسيظهر لك الاستعلام الكامل مشابه لللتالي SELECT * FROM users WHERE ID = 5، ولاحظ اسم الجدول واسم العمود المستخدم. ثم اتصل بقاعدة البيانات عبر phpMyAdmin أو أي أداة إدارة قواعد بيانات متوفرة، وابحث عن الجدول المذكور في الاستعلام، وفي حال الاستعلام به ID ولكن العمود في الجدول يُسمى id فانتبه إلى حساسية الأحرف مهمة أو user_id أو أي اسم آخر، وسيكون ذلك مصدر المشكلة.
-
ليس كل ذلك، اختر واحد فقط من التالي: بيان درجات لآخر سنة دراسية / فصل دراسي بمعنى ترم أو شهادة القيد أو صورة من كارنيه الكلية (في حال لم تتمكن من استخراج بيان الدرجات بعد) بالإضافة إلى ما سبق، يجب تقديم صورة بطاقة الرقم القومي.
- 2 اجابة
-
- 1
-
-
هل قمت بتحديث apache إلى إصدار أحدث أم أنّ المشكلة حدثت فجأة وكان يعمل من قبل؟ عامًة توجه إلى المسار التالي: C:\laragon\bin\apache\httpd-2.4.54-win64-VS16\logs واحذف ملف httpd.pid ثم أعد تشغيل لاراجون والتجربة. لو استمرت المشكلة تفقد ما الذي يشغل المنفذ 80: netstat -aon | findstr :80 وأحيانًا إعادة تشغيل الحاسوب تفيد.
-
في حال السؤال خاص بأحد الدروس في الدورات، ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
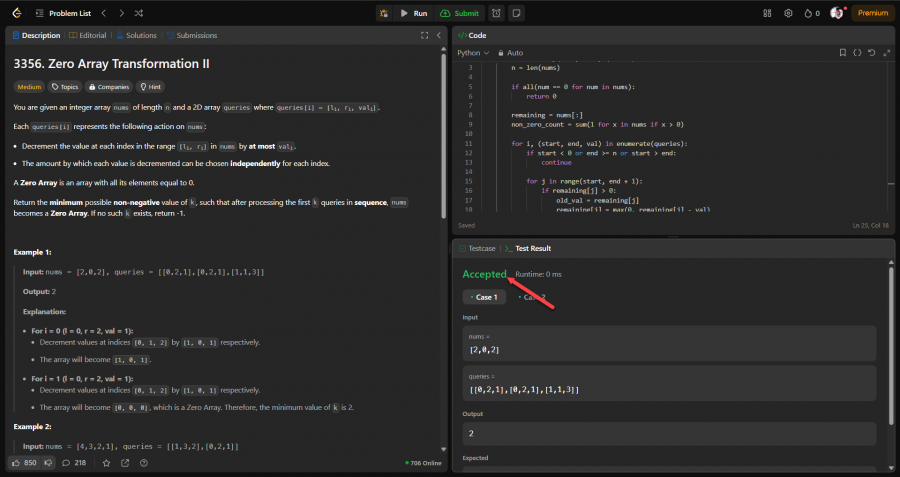
نحتاج إذن إيجاد أقل عدد ممكن من الاستعلامات الأولى التي تكفي لجعل المصفوفة كلها أصفارًا، وذلك من خلال البحث الثنائي نبدأ بتجربة عدد معين من الاستعلامات منتصف العدد الكلي، ثم نرى هل العدد كافٍ لجعل المصفوفة صفرية أم لا، في حال كافٍ، نحاول عددًا أقل، ولو العكس نجرب عدد أكبر، وتلك طريقة سريعة لإيجاد العدد الأمثل. ثم مصفوفة الفروق لتطبيق التغييرات على مدى معين من الأرقام في المصفوفة بسرعة بدلاً من تغيير كل رقم في المدى مباشرة، حيث نغير فقط أول وآخر رقم في المدى بطريقة معينة، ثم نحسب المجموع التراكمي لاحقًا لنرى التأثير على كل رقم. وبعد استخدام مصفوفة الفروق وتطبيق تأثير الاستعلامات، نحسب المجموع التراكمي للأرقام، وهو يمثل القيمة النهائية لكل رقم في المصفوفة بعد تطبيق الاستعلامات، ونتأكد هل كل القيم أصبحت صفرًا أم لا. class Solution: def minZeroArray(self, nums, queries): n = len(nums) q = len(queries) if all(x == 0 for x in nums): return 0 left, right = 0, q answer = -1 while left <= right: mid = (left + right) // 2 diff = [0] * (n + 1) for i in range(mid): l, r, val = queries[i] diff[l] += val if r + 1 < n: diff[r + 1] -= val else: pass current_sum = 0 valid = True for j in range(n): current_sum += diff[j] if current_sum < nums[j]: valid = False break if valid: answer = mid right = mid - 1 else: left = mid + 1 return answer if answer != -1 else -1
- 5 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
الحل صحيح، أين المشكلة؟
-
التعلم العميق يأتي في الدورة بعد تعلم الآلة لأنه فرع متقدم منه ويستند إلى مفاهيمه الأساسية، ولا مشكلة في تخطي مسار تعلم الآلة لكن بشرط أن دراسة جزء منه لتكوين خلفية أساسية، فالتعلم العميق يعتمد على مفاهيم كالتدرج التنازلي Gradient Descent، دوال الخسارة Loss Functions، والشبكات العصبية Neural Networks، التصنيف Classification، الانحدار Regression، ويجب الإلمام بتلك المفاهيم، لتجنب صعوبة الاستيعاب في البداية. لذا تحتاجين دراسة غالب مسار تعلم الآلة حتى قسم "تقييم نماذج التصنيف Models Evaluation" وما بعده هو اختياري وتستطيعي تجاوزهم والإنتقال للتعلم العميق، لكن عليكِ العودة ودراستهم. وفي حال الوقت ضيق لديكِ، فركزي على دراسة الأقسام التالية فقط: الانحدار لفهم التدرج التنازلي ودوال الخسارة. الانحدار اللوجيستي لفهم التنبؤ ودوال التنشيط. NumPy لكونها أداة أساسية.
- 3 اجابة
-
- 2
-
-
-
اسم المجال الذي تقصدينه هو robotics engineering والأمر ليس بتلك البساطة، برمجة عقل الروبوت تعني التركيز على الجزء البرمجي الذي يتحكم في اتخاذ القرارات، التعلم، التفاعل مع البيئة، وتنفيذ المهام، وذلك يشمل مجالات مثل الذكاء الاصطناعي AI، تعلم الآلة Machine Learning، الرؤية الحاسوبية Computer Vision، ومعالجة اللغة الطبيعية NLP، وهي كلها جزء من الدورة بالأكاديمية. حيث قمنا بدراسة ما يلي: مسار أساسيات بايثون وهي من ضمن اللغات الأساسية في تطوير الخوارزميات للروبوتات وتعلم الآلة. مسار التعامل مع البيانات والروبوتات تعتمد على البيانات مثل الحساسات لاتخاذ القرارات، بالتالي يلزم مهارات في SQL، APIs، واستخراج البيانات. تحليل البيانات (Pandas, Matplotlib, Seaborn) لفهم البيانات التي تجمعها الروبوتات وتحليل أدائها. تعلم الآلة من خلال الانحدار، التصنيف، التجميع، والترابط هي أدوات أساسية لتعليم الروبوت كيفية اتخاذ قرارات ذكية بناءًا على البيانات. الشبكات العصبية والتعلم العميق ضرورية لتطبيقات كالتعرف على الصور، معالجة اللغة، أو تحليل البيئة المحيطة بالروبوت. الرؤية الحاسوبية OpenCV و YOLO من أجل أن يرى الروبوت ويتعرف على الأشياء. نماذج اللغة الكبيرة LLMs وهندسة الموجهات لتطوير روبوتًا يتفاعل باللغة الطبيعية كالمساعدات الصوتية. نقل التعلم Transfer Learning لتدريب الروبوت بسرعة على مهام جديدة باستخدام نماذج جاهزة. وبعدها ستحتاجين إلى دراسة لغة C++ ودراسة إطار ROS لتتمكنين من برمجة الروبوتات ثم دراسة embedded systems. ستجدي هنا تفصيل بخصوص الـ Roadmap اللازمة لذلك المجال: https://github.com/h9-tect/AI-Roadmaps/blob/main/robotics-ai-roadmap.md وأيضًا ستجدي هنا roadmap لمجالات الـ AI التي تسائلتي عنها: https://github.com/h9-tect/AI-Roadmaps/tree/main
- 3 اجابة
-
- 1
-
-
لا يتم التعرف على الدالة join_paths غالبًا تلك مشكلة بسبب إصدار لارافل ربما قديم لديك أو لم يتم تثبيت الحزم بشكل صحيح، حاول تنفيذ الأمر: composer update لو استمرت المشكلة توجه إلى المسار التالي في المشروع: vendor/laravel/framework/src/Illuminate/Filesystem /functions.php واستبدل الكود الذي به بالتالي: <?php namespace Illuminate\Filesystem; if (! function_exists('Illuminate\Filesystem\join_paths')) { /** * Join the given paths together. * * @param string|null $basePath * @param string ...$paths * @return string */ function join_paths($basePath, ...$paths) { foreach ($paths as $index => $path) { if (empty($path) && $path !== '0') { unset($paths[$index]); } else { $paths[$index] = DIRECTORY_SEPARATOR.ltrim($path, DIRECTORY_SEPARATOR); } } return $basePath.implode('', $paths); } }
-
ما قمت به جيد كبداية، لكن بطيء بسبب التعقيد الزمني، حيث أنك تعيد معالجة كل عنصر في النطاق لكل استعلام، ويتحقق من المصفوفة بأكملها بعد كل خطوة، ولا حاجة لإعادة معالجة العناصر التي أصبحت 0 بالفعل، والتحقق المتكرر من المصفوفة بأكملها مكلف من حيث التعقيد الزمني. بالتالي عليك تقليل عدد العمليات لكل استعلام، وتتبع متى تصبح العناصر صفراً بطريقة أكثر كفاءة، الفكرة هي الإعتماد على مصفوفة التأثير Difference Array أو تتبع المتبقي لتجنب معالجة كل عنصر بشكل فردي في كل استعلام مع استخدام هيكل بيانات كقائمة أو مجموعة لتتبع العناصر غير الصفرية فقط. واحتفظ بنسخة من المصفوفة الأصلية لتتبع القيم المتبقية، ثم لكل استعلام قم بتطبيق التخفيض على النطاق [l,r] باستخدام قيمة val، وتتبع عدد العناصر التي أصبحت 0 بعد كل استعلام، ثم أوقف العملية بمجرد أن تصبح جميع العناصر 0. class Solution: def minZeroArray(self, nums, queries): n = len(nums) if all(num == 0 for num in nums): return 0 remaining = nums[:] non_zero_count = sum(1 for x in nums if x > 0) for i, (start, end, val) in enumerate(queries): if start < 0 or end >= n or start > end: continue for j in range(start, end + 1): if remaining[j] > 0: old_val = remaining[j] remaining[j] = max(0, remaining[j] - val) if old_val > 0 and remaining[j] == 0: non_zero_count -= 1 if non_zero_count == 0: return i + 1 return -1 لاحظ متغير non_zero_count لمعرفة عدد العناصر التي ما زالت أكبر من 0، وذلك يلغي الحاجة لاستخدام all() في كل خطوة لتقليل التعقيد.