Mustafa Suleiman
-
المساهمات
20355 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
ما هي المشكلة وما هو المشروع الذي تعمل عليه؟ هل تحاول رفع مشروع إلى GitHub؟ ستحتاج إلى إنشاء ملف gitignore. من أجل تجاهل مجلد البيئة الإفتراضية الذي به الحزم وعدم رفعه إلى المستودع.
-
 الحل غير صحيح، المطلوب إيجاد أكبر مجموع لـ subarray متتالي أي عناصر متجاورة في المصفوفة الأصلية بحيث، جميع عناصر الـ subarray فريدة ويُسمح بحذف أي عدد من العناصر من المصفوفة الأصلية لكن يجب أن يبقى الsubarray متتاليًا بعد الحذف. لكل قيمة فريدة في المصفوفة، تتبع الحد الأقصى لتكرار تلك القيمة، وتستطيع ببساطة تخزين القيمة الفريدة نفسها وكأنها الحد الأقصى لتكرارها، وانتبه إلى أنّ تتبع الحد الأقصى للتكرار لا يعني عد مرات الظهور بالمعنى الحرفي، بل التعامل مع كل قيمة فريدة مرة واحدة فقط، واختيار القيمة نفسها كممثل لها. ثم جمع الحدود القصوى لتكرارات كل قيمة فريدة فقط إن كانت موجبة، ولو المصفوفة تحتوي فقط على قيم سالبة أو صفر، ستقوم بإرجاع العنصر الأكبر في المصفوفة الأصلية. كالتالي: class Solution: def maxSum(self, nums): max_sum = 0 current_sum = 0 unique_elements = set() left = 0 for right in range(len(nums)): while nums[right] in unique_elements: unique_elements.remove(nums[left]) current_sum -= nums[left] left += 1 unique_elements.add(nums[right]) current_sum += nums[right] if current_sum > max_sum: max_sum = current_sum return max_sum if max_sum != 0 else max(nums) وتلك نسخة أقصر من الكود: class Solution(object): def maxSum(self, nums): ans = 0 for num in set(nums): if num > 0: ans += num return ans if ans else max(nums)
الحل غير صحيح، المطلوب إيجاد أكبر مجموع لـ subarray متتالي أي عناصر متجاورة في المصفوفة الأصلية بحيث، جميع عناصر الـ subarray فريدة ويُسمح بحذف أي عدد من العناصر من المصفوفة الأصلية لكن يجب أن يبقى الsubarray متتاليًا بعد الحذف. لكل قيمة فريدة في المصفوفة، تتبع الحد الأقصى لتكرار تلك القيمة، وتستطيع ببساطة تخزين القيمة الفريدة نفسها وكأنها الحد الأقصى لتكرارها، وانتبه إلى أنّ تتبع الحد الأقصى للتكرار لا يعني عد مرات الظهور بالمعنى الحرفي، بل التعامل مع كل قيمة فريدة مرة واحدة فقط، واختيار القيمة نفسها كممثل لها. ثم جمع الحدود القصوى لتكرارات كل قيمة فريدة فقط إن كانت موجبة، ولو المصفوفة تحتوي فقط على قيم سالبة أو صفر، ستقوم بإرجاع العنصر الأكبر في المصفوفة الأصلية. كالتالي: class Solution: def maxSum(self, nums): max_sum = 0 current_sum = 0 unique_elements = set() left = 0 for right in range(len(nums)): while nums[right] in unique_elements: unique_elements.remove(nums[left]) current_sum -= nums[left] left += 1 unique_elements.add(nums[right]) current_sum += nums[right] if current_sum > max_sum: max_sum = current_sum return max_sum if max_sum != 0 else max(nums) وتلك نسخة أقصر من الكود: class Solution(object): def maxSum(self, nums): ans = 0 for num in set(nums): if num > 0: ans += num return ans if ans else max(nums)- 5 اجابة
-
- 1
-

-
نستخدمها لمعالجة البيانات النصية وليس الصور، بالتالي لو مجموعة البيانات تحتوي على مسارات الصور images/cat1.jpg وتسمياتها "cat" في ملف CSV أو Excel، فاستخدم Pandas لقراءة القائمة. بعد ذلك، تمرر المسارات إلى tf.data أو DataLoader لتحميل الصور الفعلية ومعالجتها.
- 6 اجابة
-
- 1
-
-
تلك خوارزمية لحل مشكلة أقصى مجموع جزئي أو أكبر مجموع فرعي متجاور Maximum Subarray Problem، وذلك لإيجاد المجموع الأعظمي لتسلسل فرعي متجاور ضمن مصفوفة أحادية البعد تحتوي على أرقام قد تكون موجبة أو سالبة. تحتفظ الخوارزمية بمتغيرين max_so_far يمثل أقصى مجموع تم العثور عليه حتى الآن، و max_ending_here يمثل أقصى مجموع ينتهي عند العنصر الحالي. ثم تمر عبر عناصر المصفوفة: لكل عنصر، تضيف قيمته إلى max_ending_here. وإن أصبح max_ending_here سالبًا، تعيد تعيينه إلى الصفر لأن البدء من جديد أفضل من الاستمرار بمجموع سالب. ثم تحديث max_so_far في حال max_ending_here أكبر منه. بعد الإنتهاء تعيد max_so_far كنتيجة. وذلك مثال من خلال جافاسكريبت: let array = [-2, 1, -3, 4, -1, 2, 1, -5, 4] function maxSubArray(array) { let current_sum = array[0] let max_sum = array[0] for (let i = 1; i < array.length; i++) { current_sum = Math.max(array[i], current_sum + array[i]) if (current_sum > max_sum) { max_sum = current_sum } } return max_sum } console.log(maxSubArray(array))
- 3 اجابة
-
- 1
-
-
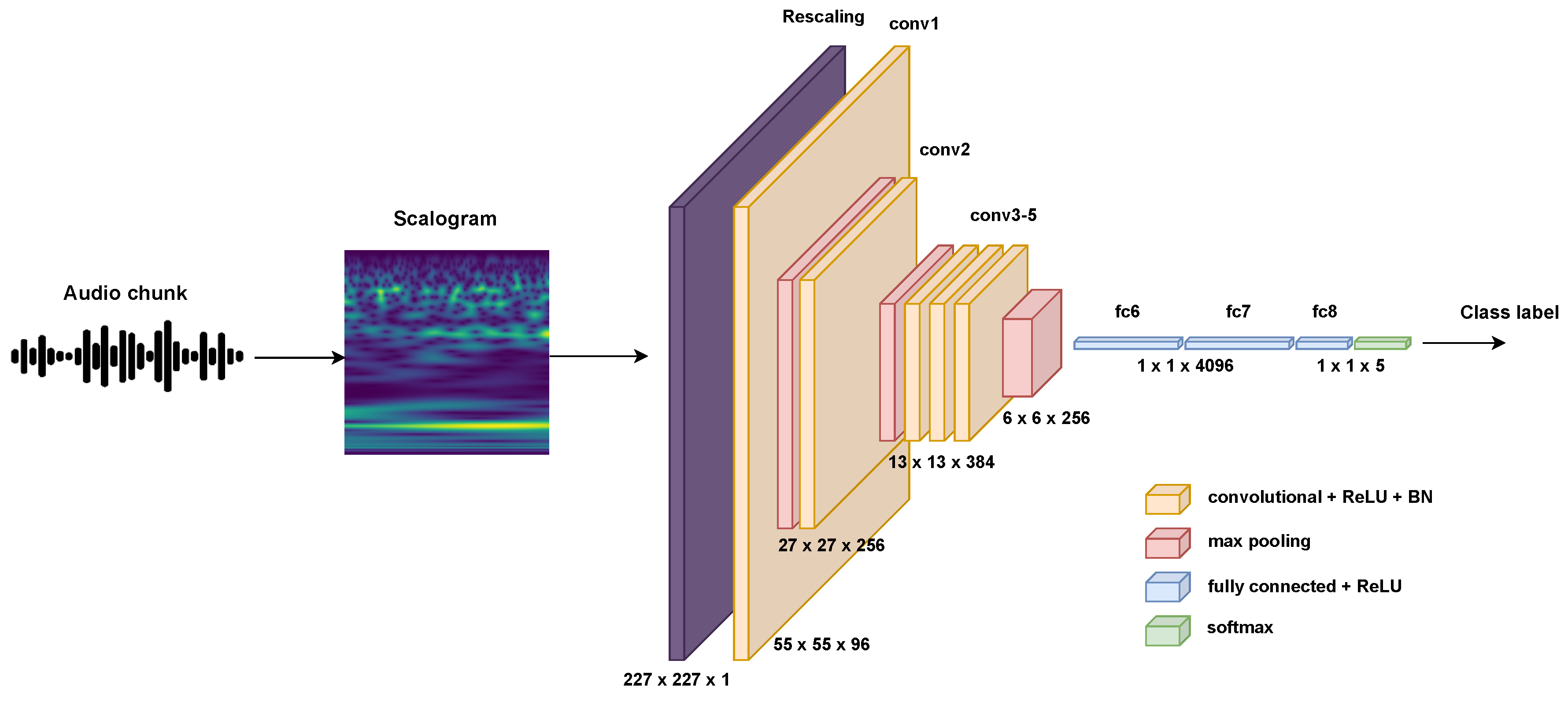
يجب أن تكون الصور في الأساس في صيغة بيانات رقمية قبل إدخالها إلى الشبكة، فالشبكة نفسها لا تقوم بتحويل الصور من شكلها الخام أي ملفات JPEG أو PNG إلى بيانات رقمية داخليًا من تلقاء نفسها، بل تعتمد على أن تكون البيانات جاهزة في شكل مناسب للمعالجة. وأنت لست بحاجة إلى القيام بذلك يدويًا، فالمكتبات المستخدمة لبناء وتدريب الشبكات العصبية وهي TensorFlow أو PyTorch تتولى تلك الخطوة تلقائيًا عند تحميل الصور. حيث أولاً تقوم بتحميل الصور باستخدام مكتبة pillow أو openCV ثم تحويلها إلى مصفوفات من خلال مكتبة numpy، بعد ذلك تهيئتها بواسطة tensorflow بضبط أبعاد الصورة لتتناسب مع مدخلات الشبكة والتهيئة Normalization بتحويل قيم البكسلات من النطاق [0, 255] إلى [0, 1] أو أي نطاق آخر، والتعامل مع القنوات للتأكد من ترتيب القنوات RGB حسب ما تتطلبه الشبكة. لكن في حال البيانات الكبيرة كآلاف الصور لن نقوم بذلك بالطريقة السابقة، فلديك مكتبة PyTorch والتي توفر أدوات لتحميل البيانات من خلال دفعات batches ومعالجتها تلقائيًا، أو من خلال tf.keras.utils.image_dataset_from_directory مع tf.data من مكتبة TensorFlow وهي الطريقة الأسهل لتحميل الصور من المجلدات وإنشاء مجموعات بيانات datasets.
- 6 اجابة
-
- 1
-
-
لعكس إتجاه الكتابة في Notepad++ اضغط على CTRL + ALT + R وسيتم عرض إتجاه النص من اليمين لليسار دون عكس النص نفسه. في حال ظهر لك تنبيه بتعطيل خاصية direct write قم بالضغط على settings بالأعلى ثم اختر MISC من على اليسار ثم تعطيل خيار direct write. لكن الكود نفسه به مشكلة، فسيظهر بشكل غير صحيح على المتصفح، بسبب <LSTag وغيرها من الأكواد، من المفترض أن يكون كالتالي: بعد تسجيل <LSTag Tooltip="CriticalHit">ضربة حرجة</LSTag>، استخدم <LSTag Type="ActionResource" Tooltip="BonusActionPoint">إجراء المكافأة</LSTag> لإجراء هجوم إضافي.
-
ليست مقتصرة فقط ذلك، بل لها تطبيقات متنوعة في مجالات أخرى أيضًا، بالطبع الاستخدام الأكثر شهرة هو معالجة الصور وتحليلها، كالتعرف على الأشياء، تصنيف الصور، واكتشاف الأنماط البصرية، بفضل قدرتها على استخلاص الميزات المكانية من البيانات ذات الأبعاد المتعددة، لكن استخداماتها تمتد إلى ما هو أبعد من ذلك. مثلاً في معالجة اللغة الطبيعية NLP لتحليل النصوص، كتصنيف المشاعر أو استخراج الميزات من التسلسلات النصية، حيث يتم التعامل مع النصوص كمصفوفات بتضمينات الكلمات، كما تُطبق في تحليل الإشارات الزمنية، مثل معالجة الصوت في التعرف على الكلام أو تحليل التسجيلات الصوتية، حيث تُعتبر الإشارات الصوتية بيانات أحادية البعد ومعالجتها باستخدام الالتفافات. وفي تحليل البيانات العلمية، كالتنبؤ بالطقس أو تحليل الصور الطبية كالأشعة السينية أو الرنين المغناطيسي، وحتى في الألعاب والروبوتات لفهم البيئة المحيطة، فكلما كانت هناك بيانات تحتوي على أنماط مكانية أو تسلسلية يمكن استخراجها، تظهر فائدة CNNs.
- 4 اجابة
-
- 1
-
-
هل اللابتوب يعمل بشكل سليم في حال قمت بنزع البطارية وتوصيله مباشرًة بالكهرباء؟ في حال ذلك إذن المشكلة من البطارية وعلى الرغم من أنها جديدة كما ذكرت فربما المشكلة من اللابتوب نفسه سواء عطل شائع في الموديل أي عيب مصنعي أو عطل في الجهاز فقط ويحتاج إلى إرساله لفني متخصص لتفقد ما المشكلة به. في حال الجهاز ما زال في فترة الضمان الأفضل صيانته في التوكيل الخاص به.
-
ذلك نقاش قديم، والبعض يتمسك برأيه بأنه لكي تتعلم البرمجة بشكل صحيح وتتأسس بشكل قوي، عليك تعلمها من خلال لغة منخفضة المستوى، ذلك صحيح لكن ليس للجميع، فشخص مبتدأ وليس لديه خلفية متعلقة بالحاسوب أو علومه سيجد صعوبة وسيصاب بالإحباط بدون داعي، فليس من الطبيعي أن يتعامل مباشرًة مع إدارة الذاكرة يدوياً باستخدام المؤشرات. لذا تستطيع تعلم البرمجة من خلال أي لغة والأسهل هي بايثون بالطبع وهي لغة قوية ومستخدمة في مجالات متقدمة، وبعد فترة من التعلم تستطيع تعلم أي لغة برمجة أخرى فالمفاهيم هي ذاتها وذلك لتعميق الفهم. ستجد هنا تفصيل بخصوص الخوارزميات وهياكل البيانات التي عليك تعلمها:
- 3 اجابة
-
- 1
-
-
ليس بشكل مباشر فلا تتوفر دالة مُضمنة في بايثون لفعل ذلك، لكن يوجد هيكل بيانات set، وهو نوع بيانات يقوم تلقائيًا بإزالة التكرارات، وبالتالي نستطيع مقارنة طوله مع طول القوائم الأصلية لمعرفة هل الأعداد فريدة أم لا. كالتالي: def are_all_unique(lst): return len(lst) == len(set(lst)) my_list1 = [1, 2, 3, 4, 5] my_list2 = [1, 2, 3, 2, 4] print(are_all_unique(my_list1)) print(are_all_unique(my_list2)) لاحظ قمت بتحويل القوائم إلى set من خلال دالة set(lst) ومقارنة الطول وإرجاع True في حال الأعداد الفريدة أو False في حال وجود أعداد غير فريدة وذلك في القائمة الثانية حيث يتكرر العدد 2
- 4 اجابة
-
- 1
-
-
استخدم سيرفر لتشغيل المشروع من خلال، وذلك من خلال تثبيت إضافة live server في محرر vscode ثم تشغيل ملف index.html من خلالها، ستجد شرح هنا: وذلك لتجنب مشكلة تشغيل ملفات HTML محلياً من خلال file:// والتي تسبب مشاكل بسبب قيود الأمان في المتصفحات الحديثةحتى بعد تفعيل Allow access to file URLs. أيضًا يجب أن تكون ملفات الترجمة صحيحة وتحتوي على أجزاء زمنية كالتالي: 1 00:00:01.000 --> 00:00:04.000 نص الترجمة الأول 2 00:00:05.000 --> 00:00:08.000 نص الترجمة الثاني. وليس به مسافات زائدة أو أخطاء في الأرقام.
- 2 اجابة
-
- 1
-
-
الوسائل المتاحة هي من خلال بطاقة إئتمانية أي من نوع Credit Card أو Debit أي بطاقة بنكية مربوطة بحساب بنكي، أو من خلال باي بال، بالطبع الدفع يكون بعملة الدولار وليس الجنيه ،لذا يجب أن تدعم البطاقة البنكية الدفع بالدولار. في حال لم تتوافر لديك طرق الدفع تلك أو يوجد مشكله بها، تستطيع الاستعانة بأحد أقرباءك أو شخص ما ليشتري لك رصيد بالأكاديمية عن طريق بطاقة الهدية ثم استخدامها لشراء الدورات.
-
محاولة جيدة وأعتقد أنك تعلمت منها بعض الأمور، عامًة في الإصدار 12 تم إتاحة Custom Community Laravel Starter Kits بمعنى Starter Kits تم تطويرها من قبل مبرمجين آخرين في مجتمع لارافل، ولم تعد الخيارات محصورة في الـ Starter Kits المقدمة من قبل لارافل فقط. مع الوقت سيتم إتاحة الكثير من الـ Starter Kits المطورة من قبل مبرمجين آخرين، وحاليًا يوجد بالفعل مجموعة بدء تدعم RTL ها هي: https://github.com/AryanpAzadeh/RTL-blade-starter-kit الشرح الموجود في المستودع بالفارسية قم بترجمته من خلال جوجل ترجمة لتفهم المميزات المتاحة
- 1 جواب
-
- 1
-

-
حاول إرجاع استجابة JSON بدلاً من إعادة التوجيه وتحديث الملف للتعامل مع الاستجابة
-
قم بحذف المستودع المحلي: rm -rf .git ثم أعد إنشائه وإعادة تنفيذ أوامر رفع المشروع git init
- 6 اجابة
-
- 1
-
-
حاول تجربة الأمر محليًا لتفقد هل المشكلة من الاستضافة أم لا، وعلى الاستضافة أيضًا تفقد الـ logs هل يوجد خطأ ظاهر؟ أحيانًا ستحتاج إلى مراسلة الدعم الفني لحل تلك المشكلة لك وتعديل الإعدادات أو عمل whitelisting للنموذج أو الكود بسبب إعدادات الأمان لديهم.
-
حاول تعطيل وضع mod_security الخاص بالحماية وتفقد هل سيحل ذلك المشكلة أم لا، وذلك بإضافة التالي لملف .htaccess ثم أعد تشغيل سيرفر apache <IfModule mod_security.c> SecFilterEngine Off SecFilterScanPOST Off </IfModule>
-
من الأفضل محاولة تنفيذه لتحقيق استفادة، من خلال Visual Studio اختاري Create a new project وابحثي عن Windows Forms App (.NET Framework) أو Windows Forms App في حال تستخدمين .NET Core ثم اختاري اختر C# كلغة البرمجة، وتسمية المشروع واضغطي على Create. ستظهر لكِ نافذة تحتوي على نموذج فارغ Form، وهو الواجهة التي سنضيف إليها الزر، ثم في نافذة Solution Explorer على الجانب الأيمن، افتحي ملف Form1.cs. وفي وضع التصميم Design View، انقر يبزر الفأرة الأيمن على النموذج واختاري Properties وبها: غيّري Text إلى Resume Button Example ليظهر كعنوان النافذة ثم Size إلى 300 عرض × 200 ارتفاع ليكون حجم النافذة مناسبًا ثم StartPosition إلى CenterScreen لجعل النافذة تظهر في المنتصف وفي في شريط الأدوات Toolbox على الجانب الأيسر، ابحثي عن Button واسحبيه إلى النموذج، ثم ضعي الزر في مكان مناسب وليكن وسط النموذج تقريبًا. بعد ذلك ستكتبي الكود، انقري بزر الفأرة الأيمن على الزر في وضع التصميم واختاري View Code، أو افتحي ملف Form1.cs مباشرة، ستجدي كود يبدأ بـ public partial class Form1 : Form. قبل أي دالة قومي بكتابة المتغيرات التالية: تخزين العرض الأصلي تخزين الإرتفاع متغير لمتابعة حجم الزر بتصغيره وتكبيره متغير خاص بوقت الـ animation كالتالي: private int originalWidth; private int originalHeight; private bool isExpanding = false; private Timer animationTimer; ثم في دالة في دالة Form1()، أضيفي كود بعد InitializeComponent() لإسناد متغيري الطول والعرض إلى button1.Width وbutton1.Height بعد ذلك عليك إعداد المؤقت timer animationTimer = new Timer(); animationTimer.Interval = 30; ثم إضافة حدث النقر Click، في في وضع التصميم، انقري مرتين على الزر، وسيُنشئ Visual Studio دالة button1_Click، اكتبي بها: MessageBox.Show("تم النقر على زر الاستئناف!"); ثم حدث تمرير المؤشر على الزر MouseEnter في نافذة Properties للزر، انقري على أيقونة البرق Events وابحثي عن MouseEnter، انقري مرتين بجانبه لإنشاء دالة واكتبي بها: isExpanding = true; animationTimer.Start(); ثم حدث مغادرة المؤشر MouseLeave بنفس الكيفية حاولي كتابة الكود الخاص به. بعد ذلك تنفيذ الرسوم المتحركة، بربط المؤقت بحدث، في Form1() بعد إعداد animationTimer.Interval، أضيفي التالي لربط المؤقت بدالة: animationTimer.Tick += AnimationTimer_Tick; ثم عليكِ كتابة تلك الدالة وهي AnimationTimer_Tick لتحريك الزر بناءًا على ما سبق. في حال واجهتي صعوبة أخبريني.
- 6 اجابة
-
- 1
-
-
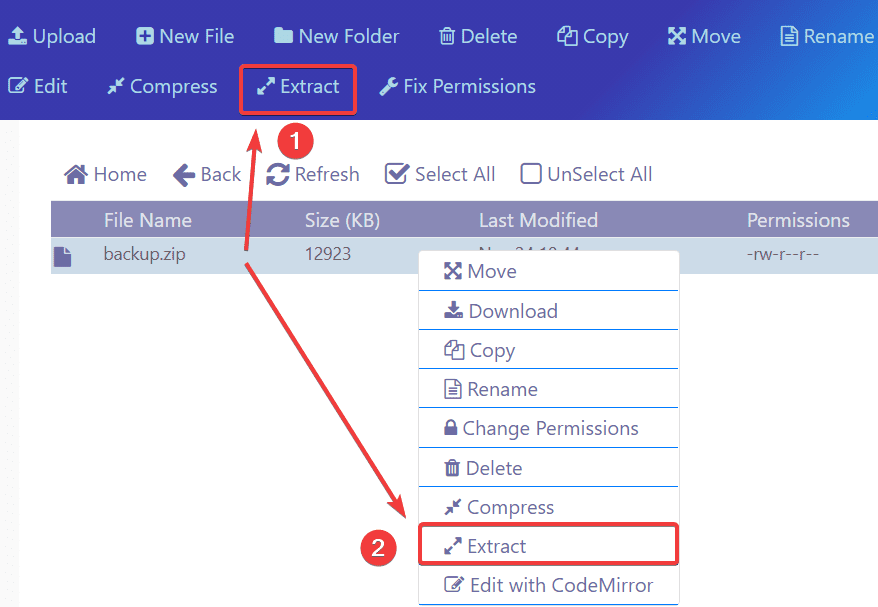
من المفترض أنه عند الضغط على الملف ثم الضغط على زر extract ثم بزر الفأرة الأيمن على الملف واختيار Extract: وسيظهر لك المسار الذي تريد فك ضغط الملف به ثم الضغط على extract وسيتم فك الضغط بدون مشكلة، ما هو الخطأ الذي يظهر لك؟
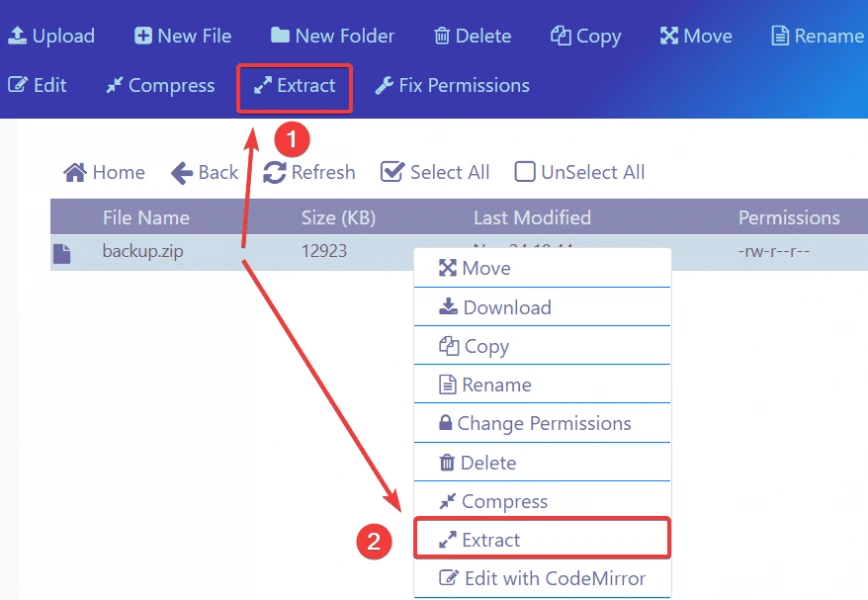
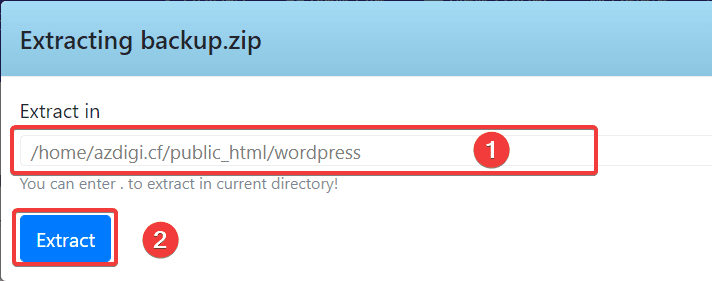
-
حاول حذف الكاش من خلال: php artisan optimize:clear وما هو المسار المستخدم في ملف routes/web.php هل يتم اسناد الطلب إلى الـ Controller الذي يحتوي على دالة store تقوم لحفظ البيانات؟ حيث أنك تستخدم {{ route('Department.index') }} كعنوان للـ action، ولكن مسار index يكون لعرض البيانات من خلال طلب GET، وليس لحفظ البيانات POST، من المفترض أن تستخدم مسار مخصص لعملية الحفظ Department.store.
- 3 اجابة
-
- 1
-
-
في المستند الرسمي لكل مكتبة أو إطار يتم شرح طريقة الاستخدام الأساسية بمعنى لو توجهنا لمستند مكتبة langchain ستجد في البداية قسم Introduction وبه تقديم للمكتبة وطريقة استخدامها بشكل بسيط جدًا. ثم يأتي ذكر قسم باسم Tutorials وبه شرح للاستخدامات المختلفة وللتفصيل يوجد قسم How-to guides. وفي قسم Tutorials يوجد شرح لبناء Chatbot بالتالي نقوم بتفقد الطريقة، وفي حال تسائلت عن أمر معين في المكتبة ستجد ذلك مُفصل في قسم API Reference. وغالب المستندات على هذا المنوال، تختلف المٌسميات أحيانًا، مثلاً تجد Quick Start أو Getting Started بدلاً من Tutorials، وتحتوي على الوظائف الأساسية الأكثر استخداماً وتقدم نظرة عامة على المكتبة وهيكلها وتشرح الاستخدامات الشائعة. و Modules بدلاً من قسم API Reference رغم أن الشائع هو API Reference، وهكذا. وابدأ تدريجيًا ولا تحاول فهم كل شيء مرة واحدة، بالمفاهيم الأساسية أولاً ثم تعمق تدريجيًا، واستخدم الأمثلة الموجودة في المستند وجرب تشغيلها وتعديلها، واستخدم خاصية البحث في الوثائق بكلمات مفتاحية تصف ما تريد تنفيذه. مع الوقت ستتمكن من التجول في المستندات بأريحية وسرعة، ولا غنى عنها، بالطبع تستطيع رؤية شرح مثلاً على اليوتيوب لكن لو واجهتك مشكلة أو تريد تعلم المزيد فالمستند الرسمي هو المكان الصحيح في أغلب الأحيان. وبمرور الوقت أيضًا سيترسخ لديك الخطوات التي تقوم بها والكود الذي تكتبه بشكل مُتكرر، ولو أردت تنفيذ أمر معين تبحث على جوجل مثلاً how to واكتب ما تريد وضع اسم المكتبة أو الإطار بجانبه مثلاً، في حال لم تجد شرح، سيتعين عليك التعمق في قراءة المستند الرسمي لتفقد هل يوجد ما تريد أم لا.
- 4 اجابة
-
- 1
-
-
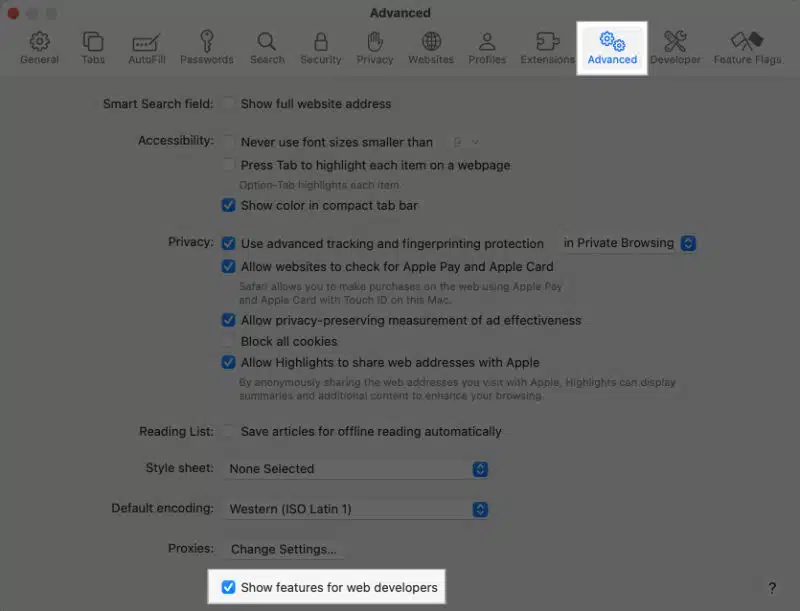
أعتقد أنك تقصد الوصول إلى الكونسول في المتصفح وذلك من خلال خيار inspect elements ، أولاً اضغط على safari ثم اختر settings أو preferences : بعد ذلك اضغط على تبويب Advanced ثم قم بتفعيل خيار Show Features for Web Developers بعد ذلك توجه للصفحة واضغط على زر الفأرة الأيمن في أي مكان وسيظهر لك خيار inspect elements
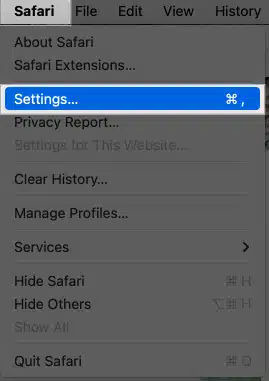
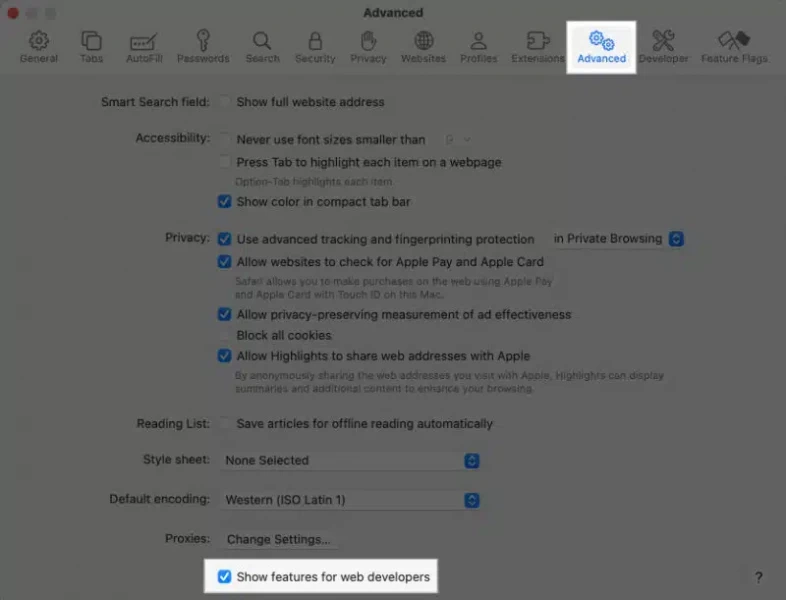
- 3 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل. في حال السؤال غير متعلق بأحد الدروس في الدورات، فتأكد من تضمين ملف التنسيقات بشكل صحيح في ملف HTML، حيث يجب أن يكون كالتالي: <link rel="stylesheet" href="style.css"> لاحظ اسم الملف style.css يجب أن يطابق نفس الملف لديك، وأيضًا المسار الخاص به، فهنا أفترض أنك وضعته بجانب ملف HTML مباشرًة.
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
- 1 جواب
-
- 1
-
-
pandas.drop() هي لإزالة صفوف أو أعمدة محددة من DataFrame حسب التسميات labels أو المواقع index وعليك أنت تحديد ذلك. import pandas as pd df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}) df.drop('A', axis=1) لاحظ يجب تحديد ما تريد حذفه وهي أسماء الأعمدة أو أرقام الصفوف باستخدام المعاملات labels وaxis، بالتالي تستطيع اختيار العناصر التي تريد إزالتها، سواء كانت تحتوي على قيم مفقودة أم لا. أما pandas.dropna() هي لإزالة الصفوف أو الأعمدة التي تحتوي على قيم مفقودة NaN تلقائيًا، أي تعتمد على وجود القيم المفقودة ولا تتطلب منك تحديد ما تريد حذفه يدويًا، فهي تبحث عن NaN وتزيل الصفوف أو الأعمدة بناءًا على معايير معينة. وتسمح لك بتحديد شروط مثل حذف الصفوف التي تحتوي على أي قيمة مفقودة، أو فقط تلك التي كل قيمها مفقودة. import pandas as pd df = pd.DataFrame({'A': [1, None, 3], 'B': [4, 5, None]}) df.dropna() وسيتم حذف أي صف به قيمة واحدة على الأقل مفقودة. أما لو تريد حذف الصفوف التي كل قيمها مفقودة فقط ستكتب التالي: df.dropna(how='all')
- 5 اجابة
-
- 1
-