


Mustafa Suleiman
-
المساهمات
20349 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 على أرض الواقع لا يتم استخدام أحدث التقنيات في جميع المشاريع، فغالب الحال ستعمل على مشاريع تم تطويرها بالفعل منذ مدة، بالتالي ستجد أنّ JQuery مستخدمة بها بالرغم من أنّها عفا عليها الزمن ولم تعد تُستخدم بكثرة حاليًا كما كانت من قبل، وذلك بسبب تطور جافاسكريبت. بالتالي ليس شرط تعلم jQuery وتستطيع تعلم React مباشرًة وذلك يكفي، ثم تستطيع تعلم jQuery وقتما تحتاج إلى ذلك، ولو أردت رأي تعلم أساسيات jQuery ثم التطبيق على مشروع بسيط لا أكثر، وفي حال احتجتها تستطيع التعمق بها. بالنسبة لجافاسكريبت، فحاليًا قمت بإنهاء مسار الأساسيات، يجب إذن التطبيق على ما درسته، ابحث على اليوتيوب عن مشاريع جافاسكريبت للمبتدئين وقم بتنفيذ مشروعين على الأقل، ثم تستطيع متابعة دورة تطوير واجهات المستخدم.
على أرض الواقع لا يتم استخدام أحدث التقنيات في جميع المشاريع، فغالب الحال ستعمل على مشاريع تم تطويرها بالفعل منذ مدة، بالتالي ستجد أنّ JQuery مستخدمة بها بالرغم من أنّها عفا عليها الزمن ولم تعد تُستخدم بكثرة حاليًا كما كانت من قبل، وذلك بسبب تطور جافاسكريبت. بالتالي ليس شرط تعلم jQuery وتستطيع تعلم React مباشرًة وذلك يكفي، ثم تستطيع تعلم jQuery وقتما تحتاج إلى ذلك، ولو أردت رأي تعلم أساسيات jQuery ثم التطبيق على مشروع بسيط لا أكثر، وفي حال احتجتها تستطيع التعمق بها. بالنسبة لجافاسكريبت، فحاليًا قمت بإنهاء مسار الأساسيات، يجب إذن التطبيق على ما درسته، ابحث على اليوتيوب عن مشاريع جافاسكريبت للمبتدئين وقم بتنفيذ مشروعين على الأقل، ثم تستطيع متابعة دورة تطوير واجهات المستخدم.- 5 اجابة
-
- 1
-

-
في حال ستعمل على مواقع العمل الحر، فمطوري ووردبريس مطلوبين وبكثرة، لكن لا تشتت نفسك، حيث ستحتاج إلى تعلم لغة PHP من أجل تعلم ووردبريس، الأفضل التعمق في الواجهة الأمامية أولاً من خلال التقنيات التي اخترتها وهي React و Next.js واللذان يعتمدان على لغة جافاسكريبت. في حال المشاريع الموجودة على منصة العمل الحر بها مشاريع أكثر لووردبريس، فتستطيع تعلم أساسيات PHP ثم تعلم كيفية تطوير قالب لووردبريس وتخصيصه، لكن لن تكتفي بذلك ستحتاج إلى تعلم لارافل أيضًا طالما اتجهت ناحية PHP. المسار الأول من دورة PHP متاح لك بشكل مجاني تستطيع دراسته. بالنسبة لتطوير مستواك كمطور واجهة أمامية، فهناك نقطة هامة ستفيدك بشكل كبير ألا وهي تعلم أساسيات الـ UI/UX، فأنت ستعمل بمفردك على المشاريع على مواقع العمل الحر، وفي غالب الأوقات ستقوم بتصميم الواجهة وأحيانًا ستقوم بتحويل واجهة تم تصميمها من قبل مُصمم UI/UX وستعمل أنت على تحويلها إلى مشروع حي. وكذلك أثناء بناء معرض أعمالك أنت بحاجة إلى مشاريع بجودة مرتفعة، ومن غير المنطقي أن يكون التصميم الخاص بها غير جيد، وحتى لو الكود بمستوى مرتفع، فالواجهة هي مرآة للمشروع وُتعطي إنطباع فوري عنه، ستجد تفصيل هنا: وبالنسبة لطرح عروض على المشاريع بشكل جيد، ستجد تفصيل هنا:
-
من الدورات المطلوبة بالفعل، لكن في الوقت الحالي هي غير متوفرة، وقد يتم توفيرها عما قريب، حيث يتم إطلاق دورات جديدة كل فترة، تستطيع دراسة مجال الأمن السيبراني من مصادر أخرى، وبخصوص المسار البرمجي Roadmap الذي يجب أن تسير عليه لتعلم الأمن السيبراني فقد تم توضيحه هنا من قبل خبير في المجال وهو محمد عبد الباسط النوبي، بعنوان ١٠١ - دليلك فى البرمجة ومجال امن وحماية واختبار اختراق تطبيقات الويب وستجد به كل ما تحتاج معرفته. وأنصحك أيضًا بقراءة النقاش الخاص به على منصة حسوب I\O حيث أجاب به على الكثير من الأسئلة. بالنسبة لدورة العمل الحر، فذلك ليس ضمن نطاق الدورات الخاصة بالأكاديمية والتي تختص بمجال البرمجة فقط، لكن هناك دروس ومقالات متاحة لتعلم ذلك:
- 2 اجابة
-
- 1
-
-
تستطيع البدء بحل مسائل صغيرة فور تعلم أي مفهوم جديد، أي الجمع بين التعلم النظري والتطبيق عبر التمارين من خلال منصات HackerRank أو Edabit أو Codewars للمبتدئين، حيث تبدأ بالتدرج من خلال منصة سهلة نسبيًا مثل Codewars وحل الأسئلة السهلة ثم المتوسطة ثم الصعبة، ثم الإنتقال لمنصة leetcode وحل المسائل التي بها بدءًا من مستوى متوسط فما فوق. https://www.codewars.com/collections/javascript-basics-2 ولكن قبل حل المسائل البرمجية عليك تعلم أساسيات هياكل البيانات والخوارزميات أي مفاهيم بسيطة من الـ DSA مثل: Arrays وطرق التعامل معها. Strings والخوارزميات الأساسية عليها مثل عكس النصوص، البحث عن عنصر. وبعد حل أي مسألة، اقرأ حلول الآخرين لتعلم مفاهيم وطرق جديدة وخصص وقت يومي للحل حتى لو 30 دقيقة. وعند الوصول لمستوى أسئلة متوسط الصعوبة، ابدء في دراسة مفهوم Time Complexity بشكل بسيط واستيعاب الفرق بين O(n) و O(n^2).
-
الأفضل لك هو دراسة دورة الذكاء الاصطناعي، حيث يتم التركيز على تحليل البيانات بنسبة أكبر لكونه من اختصاص الدورة، بينما دورة بايثون لا يوجد تركيز على ذلك، بل مجرد شرح للأساسيات. عامًة المسارات المناسبة هي: أساسيات لغة بايثون Python تطبيقات عملية باستخدام بايثون Python تحليل البيانات أساسيات تعلم الآلة Machine Learning وبالنسبة للمهارات المطلوبة ستجد تفصيل هنا:
- 2 اجابة
-
- 1
-
-
محتوى دورة علوم الحاسوب موجه للتأسيس في البرمجة ثم بعد ذلك ستحتاج إلى دراسة مجال برمجي مطلوب في سوق العمل، ومن خلال الدورة ستتمكن من إختيار المجال الذي تريده بسبب أنك اطلعت على أغلب مجالات البرمجة خلال الدورة وأصبح لديك دراية بالمفاهيم البرمجية ووظيفة كل مجال برمجي والمهام المطلوب تنفيذها به. أي هدفها هو تعريف المتعلمين بأساسيات علوم الحاسوب وتزويدهم بالمفاهيم والأدوات اللازمة للبدء في مجال البرمجة وتطوير البرمجيات، يتم تغطية موضوعات متعددة تتضمن البرمجة، وأنظمة التشغيل، وقواعد البيانات، والشبكات والأمن والحماية. ولا يمكن اعتبار دورة علوم الحاسوب كافية للبدء بالعمل بعد انتهائها، ولكنها تزود المتعلمين بالمعرفة اللازمة للاستمرار في تعلم مجال البرمجة وتطوير مهاراتهم فيه، ومن المهم أيضًا بعد الدورة العمل على تطبيق المفاهيم والمهارات التي تم اكتسابها عبر القراءة والتدريبات العملية ومشاريع التطبيق العملية. بمعني أبسط، سيتم تأهيلك لتتمكن من دخول مجال البرمجة على أساس صحيح، ولا مشكلة إذا كانت هناك أمور تجدها غير مفهومة أو مبهمة في ذلك المسار، فالغرض هو تعريفك بالمجالات والمفاهيم. وستتمكن من استيعاب تلك الأمور لاحقًا عند إختيار المجال الذي تريد التخصص به، مثل مجال تطوير الويب. وبخصوص شرط العمل المذكورة في الدورة، فطالما أن الشرط موجود فمن حقك الحصول عليه، ولمناقشة شروط الدورة والأمور المالية، أرجو التحدث لمركز المساعدة بالأكاديمية فهي الجهة الوحيدة التي يمكنها الإجابة على ذلك.
-
يعني تحديث للغة HTML، فمقارنًة بالإصدار الرابع تم إضافة مزايا عديدة في لغة HTML 5، منها أصبح بإمكانك تضمين الفيديو والصوت مباشرة في الصفحة باستخدام وسمي <video> و <audio>، بالتالي تشغيل الوسائط أصبح أسهل وأكثر توافقًا مع جميع المتصفحات والأجهزة الحديثة. وعناصر دلالية جديدة أي وسوم جديدة تصف معنى المحتوى بشكل أفضل. بدلاً من استخدام وسم <div> لكل شيء، أصبح لدينا: <header>: للجزء العلوي من الصفحة أو القسم. <footer>: للجزء السفلي من الصفحة. <nav>: لأشرطة التنقل والروابط. <article>: لمحتوى مستقل مثل مقال أو تدوينة. <section>: لتقسيم الصفحة إلى أقسام منطقية. وتحسينات كبيرة في النماذج بإضافة أنواع جديدة من حقول الإدخال التي تسهل على المستخدم إدخال البيانات وتوفر تحققً تلقائي من صحتها، ومنها: type=email: للتأكد من أن النص المدخل بصيغة بريد إلكتروني. type=date: لعرض تقويم لاختيار التاريخ. type=number: لقبول الأرقام فقط. type=range: لإنشاء شريط تمرير. بجانب إتاحة تخزين البيانات مباشرة على جهاز المستخدم (في المتصفح) باستخدام تقنيات مثل Local Storage و Session Storage، الأمر الذي سمح بإنشاء تطبيقات ويب يمكنها العمل حتى عند انقطاع الاتصال بالإنترنت، وتحميلها بشكل أسرع. وواجهات برمجة تطبيقات متقدمة (APIs) للمبرمجين: Geolocation API: لتحديد الموقع الجغرافي للمستخدم (بعد موافقته). Drag and Drop API: لجعل سحب وإفلات العناصر في الصفحة ممكنًا. Web Workers: لتشغيل أكواد معقدة في الخلفية دون أن تتسبب في تجميد الصفحة.
- 2 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
الدورة ممنهجة على أساس دراسة المشاريع العملية التي في الدورة، بحيث يتم التوسع في شرح اللغة خلال المشاريع العملية في المسارات المختلفة، ضع في الإعتبار أنّ الدورة موجهة للجميع، لذا جزء كبير من الطلاب يُفضل التعلم من خلال مشاريع عملية، بالتالي الدورة ليس موجهة لفئة معينة بل للجميع. بالنسبة للإختبارات تستطيع السؤال أسفل كل درس أو مجموعة دروس أو في نهاية كل مسار وسيتم توفير إختبارات لك ومراجعتها.
-
توجد مكتبة لإطار لارافل للربط مع Nafath API ها هي: https://github.com/mohamad-zatar/saudi-nafath-integration/tree/v1.0 وبتفقد المكتبة يظهر عنوان الـ api هو التالي: $url = "https://$subdomain.semati.sa/nafath/api/v1/client/authorize/"; عامًة سواء من خلال PHP أو لارافل، للحصول على المفتاح ستحتاج إلى التسجيل لدى الهيئة حيث يُشترط: جهات رسمية مرخصة من قبل وزارة التجارة أو الجهات الحكومية توقيع العقد ثم الربط من خلال منصة رابط: https://www.rabet.sa/plans?service_id=86
- 1 جواب
-
- 1
-
-
أعانكم الله وسدد خطاكم، المتاح أمامك هو مواقع العمل الحر العربية، وهي مستقل وخمسات، عدا ذلك فالأمر غير حقيقي، الواقع هو أن تمتلك مهارة يحتاجها غيرك ويدفع لك من أجل القيمة التي تقدمها له. لذا كل ما عليك هو إنشاء حساب على كلاهما، وتهيئة معرض الأعمال ووصف لحسابك الشخصي، ولكن تخصص في مجال واحد فقط، لا تقم بعرض نفسك كمتخصص في أكثر من مجال دونّ وجود رابط بينهم، مثلاً في البرمجة تستطيع الجمع بين تصميم واجهة المستخدم وبين البرمجة، وفي الكتابة تستطيع الجمع ما بين التصميم والكتابة أيضًا وهكذا. أعلم أنّ الكلام سهل، لكن ما باليد حيلة سوى السعي، حاول تحسين مهاراتك في مجال مطلوب على تلك المواقع، ولو احتجت إلى أي مساعدة أخبرني.
-
في صفحتك الشخصية انزل للأسفل وستجد قسم الخبرة Experience، فاضغط على أيقونة الزائد + لإضافة خبرة: ثم اختر add position: ثم قم بإضافة أكاديمية حسوب في حقل Company or organization بكتابة Hsoub Academy وستظهر لك فاخترها، ثم في حقل Employment type اختر وظيفتك هي internship أي تدريب، وفي حقل title قم بكتابة Software Engineer Intern: وقم بملء باقي الحقول، ويجب أن تُحدد أنك ما زلت تعمل حتى الآن في Hsoub Academy من خلال حقل التاريخ، ثم اضغط على Save للحفظ. الآن توجه لأعلى صفحتك الشخصية وستجد أيقونة قلم بجانب اسمك اضغط عليها، ثم قم بتفعيل خيار Show current company in my intro أي إظهار الشركة التي تعمل بها حاليًا بجانب اسمك:

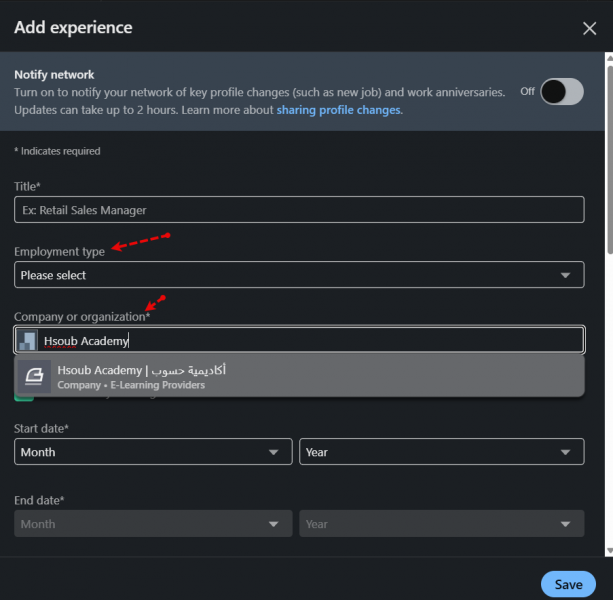

- 1 جواب
-
- 1
-
-
من المفترض أنّ Nest.js أفضل، لكن في البرمجة ذلك غير صحيح، النهج السليم هو التركيز على حل المشكلة التي تعمل عليها وليس على التقنية المستخدمة. فالمشاريع الصغيرة والمتوسطة الأنسب لها هو إطار Express.js، مثل مشاريع بناء API لمدونة شخصية أو صفحة هبوط أو متجر إلكتروني متوسط به 1000 منتج أو أقل، أو مشروع تطبيق محادثات، أو للتجارب السريعة لتطوير نماذج أولية MVPs. بينما في المشاريع الأكبر والتي يعمل عليها فريق كامل أكثر من 3 أشخاص، هنا تظهر أهمية وجود إطار قوي ذو هيكل ثابت مثل Nest.js ومعمارية متقدمة، وتعلمه ليس سهل فهو يعتمد على مباديء البرمجة كائنية التوجه وأنماط التصميم بشكل مُكثف، فهو يفرض هيكلية موحدة، بالتالي كل مبرمج سيعرف أين يجد الـ Controller وأين يكتب الـ Business Logic في الـ Service، الأمر الذي يقلل من الفوضى ويسرّع عملية انضمام المطورين الجدد في الشركات. أي الأمر بحاجة إلى وقت لتبدأ التطوير من خلاله، وللعلم ستجد أنّ من لديه خبرة في لغات برمجة قوية كائنية التوجه مثل Net. أو Java يستطيع التعامل بسهولة مع الإطار، لأنّ NestJS مستوحى من Enterprise Frameworks أي إطارات العمل الخاصة بالشركات مثل Spring Boot، وبالطبع ليس شرطًا تعلم أحد تلك اللغات، لكن للعلم بالشيء. وهو مطلوب في سوق العمل بالنسبة لمطوري الواجهة الخلفية من خلال Node.js:
-
يجب أولاً تحديد الفئة المستهدفة، وعلى أساسها تضع خطة التسويق وليس العكس، فليس جميع شرائح المستخدمين يتم التسويق لهم بنفس الآلية، وأيضًا أماكن تواجدهم على الإنترنت وطريقة التخاطب معهم مختلفة. وقبل خطة التسويق، عليك بتحديد احتياجات تلك الفئة وهل يوجد حلول متوفرة بالفعل؟ ما الدافع أو ميزة الجذب في المنتج الخاص بك؟ فهناك فئة تريد حلول متكاملة وسهلة الاستخدام وواجهة تصميم جذابة مثلاً، وفئة أخرى تريد حلول لمشاكل غير منتشرة لكن لها جمهورها، عليك بتحديد الفئة التي تحقق لك عائد أكبر والتنافسية بها قليلة قدر الإمكان، إلا لو لديك القدرة على توفير حلول تنافسية بالفعل. وبالنسبة للتسويق، فهو نتاج استكشاف ما سبق، لو وجدت أنّ الفئة المستهدفة تقوم بالبحث على جوجل، فعليك إذن استهداف SEO كخطة تسويق لتصدر النتائج في محركات البحث. أو قم بتقديم نسخة مجانية من القالب وبها ميزات مدفوعة مثلاً، لكن بشرط الإشتراك من خلال البريد الإلكتروني وكون قائمة لإعادة الاستهداف. ويجب بذل مجهود في التسويق من خلال محتوى الفيديو بغض النظر عن المنصة المستهدفة. وقم بتوفير 5 رخص مجانية لمطورين تثق بهم، مقابل مراجعة علنية ودراسة حالة.
-
جيد جدًا، لكن أنت لم تستوعب بل حفظت ما تم شرحه ثم قمت بالنقل كما بالشرح، أي عقلك لم يستوعب ما يحدث بل يتتبع الخطوات ليس أكثر. لتخطي تلك المشكلة، عليك بتعديل ما تقوم بتنفيذه أي التغيير في الأكواد والتصميم، لإجبار عقلك على الاستيعاب والتركيز.
-
وكيف قمت بتنفيذ 6 مشاريع دونّ معالجة تلك النقطة؟ هل قمت بالتطبيق العملي مع الشرح أي رؤية الخطوات ثم قمت أنت بالتنفيذ بمفردك؟ أم قمت بالتطبيق خطوة ونقل الكود من الشرح؟ الصحيح هو التدرج في التطبيق العملي من خلال تنفيذ نماذج بسيطة، ثم الإنتقال لبناء أقسام من الموقع، ثم الربط بين تلك الأقسام لإنشاء الموقع، وهناك خطوات ثابتة لتطوير موقع الويب تم توضيحها في دورة تطوير واجهات المستخدم. في حال تستطيع بناء صفحة كاملة بواسطة HTM وCSS مع استخدام Flexbox أو Grid و Media Queries دون أنّ تواجه صعوبة كبيرة، فقم بالإنتقال للتعمق في لغة جافاسكريبت. ولا مشكلة في نسيان بعض الأمور، فليس المطلوب منك حفظ جميع الأكواد، تستطيع البحث عما تريد لكن ليس كل شيء بالطبع.
-
الأمر بحاجة إلى توضيح، ما معنى "لا أتذكر إلا القليل جدًا"؟ هل لا تستطيع كتابة الأكواد من تلقاء نفسك وتضطر إلى البحث لتذكر الـ Syntax؟ وما نسبة حدوث ذلك؟
-
دورة تطوير واجهات المستخدم تُركز على الأساسيات الخاصة بتطوير الواجهة الأمامية، وهي اللغات الأساسية للويب HTML, CSS, JS بجانب المكتبات والإطارات المساعدة في عملية التطوير والمبنية على تلك اللغات. أولها مكتبة jQuery والتي تُسهل علينا كتابة المنطق البرمجي بدلاً من كتابته من الصفر بواسطة لغة جافاسكريبت، وبالطبع المكتبة تعتمد على لغة جافاسكريبت. ثم إطار عمل Bootstrap لتسهيل عملية تصميم الواجهة الأمامية بدلاً من كتابة أكواد CSS من الصفر، حيث كلاسات بوتستراب تقوم بتطبيق تنسيقات جاهزة. ما سبق هو ما سنتعلمه في تلك الدورة، أي جميع المشاريع سنستخدم بها HTML, CSS, JS بجانب jQuery وبوتستراب فقط. بينما دورة جافاسكريبت متعلقة بالتقنيات الخاصة بها وهي React وNext.js وخلافه.
-
حسب التخصص البرمجي الذي اخترته، فهناك حد أدنى للمهارات الواجب توافرها لكي تمتلك القدرة على تنفيذ المشاريع وأيضًا لكي تتفهم المطلوب من العميل وتوفر له حلول مناسبة. أعتقد أنك تقوم بدراسة الواجهة الأمامية حاليًا، والحد الأدنى هو تعلم لغات الويب الأساسية HTML, CSS, JS والتعمق بهم، ثم تعلم إطار بوتستراب أو tailwind والأفضل في رأي هو tailwind، ثم تعلم أساسيات مكتبة jQuery. ثم تعلم أساسيات التصميم الجيد لواجهة المستخدم، وستجد تفصيل هنا: وبعد ما سبق تستطيع التقدم للمشاريع التي تطلب تطوير مواقع ثابتة static، أي محتواها ثابت لا يتغير، أو يتغير لكن من خلال API خارجي وليكن جلب أخبار الطقس مثلاً، حيث لا يوجد واجهة خلفية بل ستعمل على تطوير واجهة أمامية فقط. المشكلة أنّ تلك المشاريع المنافسة عليها مرتفعة، لذا فرصة قبول عرضك منخفضة نسبيًا، لكن حاول على أي حال وستتعلم أثناء ذلك الطريقة المناسبة لطرح عرضك وخلافه، ونوعية المشاريع المطلوبة على منصة العمل الحر، والمهارات المطلوبة لذلك. وأثناء تلك الفترة، اعمل على تحسين مهاراتك بتعلم تقنيات الويب ومنها React وNext.js وأيضًا لغة Typescript. وبعدها حاول تعلم أساسيات Node.js لتصبح مطور Full-stack لتستطيع التقدم لمشاريع أفضل وتبتعد عن الزحام قدر الإمكان.
- 2 اجابة
-
- 1
-

-
سنة ونصف مدة كبيرة جدًا، لا أعتقد أنك قمت بدراسة بايثون كل تلك المدة، بل على فترات أي تنقطع ثم تعود وهكذا، لو واصلت على نفس المنوال ستمر سنوات دونّ أنّ تصل لوجهتك. يجب الإلتزام بجدول زمني واقعي والدراسة بشكل شبه يومي، حدد فترة 6 أشهر لدراسة المسار الذي تريده، و6 أشهر أخرى لتحسين مستواك به أي التعمق وتنفيذ مشاريع متقدمة، ولو انشغلت لفترة فعلى الأقل خصص ساعتين للدراسة يوميًا ولا تنقطع تمامًا، فالاستمرار في بدايات التعلم هام للغاية لتثبيت ما تعلمته وتجنب المشاكل التي مررت بها. وبالنسبة للطريقة المناسبة للدراسة، فلكل شخص طبيعة خاصة، البعض يقوم بتلخيص النقاط الهامة مع شرح مُختصر ومُركز يمكنه من المراجعة والاستيعاب عند العودة لتلك الملخصات، والبعض الآخر يُفضل الاستيعاب والتطبيق بشكل عملي ويمتلك القدرة على التذكر بشكل جيد بجانب البحث عما يريده بالنسبة للنقاط التي نسيها وذلك أمر طبيعي لكنه مستوعب لها ويستطيع توظيفها فور تذكر طريقة كتابتها أي الـ Syntax. بالنسبة لك الأفضل هي الطريقة الأولى، لأسباب منها عدم التفرغ بشكل كامل لدراسة البرمجة، وأرجو قراءة التالي: وبخصوص الحفظ فهو مهم في البداية فقط، لكن الأهم هو الاستيعاب، لذا لا تشغل بالك به واهتم بالتركيز على لماذا قمنا بالأمر بتلك الطريقة وكيف نستخدم ما تعلمناه، ثم اربط بين المفاهيم التي تعلمتها من خلال تطبيق عملي، مثلاً قم بتوظيف ما تعلمته في الدرس الحالي على تمرين سابق. وبالنسبة للإختبار فلا يتطلب منك سوى استيعاب ما قمت بدراسته والقدرة على تنفيذ مشروع كامل من خلال ما تعلمته، طالما لديك القدرة على تنفيذ مشروع بمفردك تستطيع التقدم للإختبار.
-
أحسنت في الإسراع لتوظيف ما تعلمته وتثبيته من خلال مشاريع عملية، الوقت الذي قضيته في بحث، قراءة، مشاهدة وممارسة سيعود عليك بنفع كبير، وسيجنبك الكثير من المعاناة التي تحدث نتيجة السرعة في دراسة الأساسيات وتخطي التعمق بها. المشروع به مجهود كبير بالفعل، قمت بعمل ممتاز في تطبيق المفاهيم التي تعلمتها، بدءًا من البرمجة كائنية التوجه والتعامل مع الملفات، إلى معالجة الأخطاء والتعامل مع مكتبات خارجية Selenium و openpyxl. لتحسين ما قمت به، عليك بإتباع الممارسات الجيدة الخاصة بالكود النظيف، فأسماء الدوال والمتغيرات يُفضل استخدام تسمية snake_case وهي كلمات صغيرة مع شرطة سفلية بينها، بمعنى webScraping تصبح web_scraping و all_dataBase_books تصبح all_database_books. أسماء الملفات أيضًا، الأفضل استخدام snake_case كذلك، أي Autmoations.py يصبح automations.py. وفي دالة csv_import، قمت بتحويل csv_reader إلى قائمة مرتين، في المرة الأولى، يتم استهلاك كل محتوى الملف، وفي المرة الثانية القائمة فارغة، وذلك يؤدي إلى عدم استيراد أية بيانات. عليك بقراءة الملف مرة واحدة فقط وخزن محتواه في متغير. وحاليًا، عند استيراد الكتب، قمت بجلب كل الكتب من قاعدة البيانات إلى الذاكرة، ثم تتحقق من وجود الكتاب المستورد، ولا مشكلة به هنا، لكن لو قاعدة البيانات كبيرة فالأداء سيتأثر بشكل كبير. فبدلاً من جلب كل الكتب، الأفضل أن تُنفذ استعلام بسيط على قاعدة البيانات لكل كتاب مستورد للتحقق هل هو موجود بالفعل باستخدام عنوانه ومؤلفه مثلاً، الأمر الذي يقلل من استخدام الذاكرة ويزيد من سرعة التنفيذ. وفي دالة send_email_remainders، طلبت من المستخدم إدخال كلمة المرور مباشرة في الطرفية، وبالطبع ذلك غير آمن على الإطلاق، حيث يجب عدم كتابة كلمات المرور في الكود أو إدخالها كنص عادي، استخدم متغيرات البيئة أو ملفات الإعدادات لتخزين تلك المعلومات الحساسة، الموضوع متقدم قليلاً، ولكن للعلم بالشيء. وبالنسبة للـ webScraping فالمحدد table:nth-child(13) خاص بتصميم معين للصفحة، ولو تغير التصميم قليلاً، سيتوقف الكود عن العمل، الأفضل استخدام مُحددات عامة أكثر مثل البحث عن جدول يحتوي على عنوان معين. وبالنسبة لقاعدة البيانات فدالة control ودالة fitch تقومان بالكثير من المهام بناءًا على قيمة نصية، الأفضل تطبيق مبدأ المسؤولية الواحدة Single Responsibility Principle وإنشاء دوال صغيرة ومحددة لكل مهمة، الأمر الذي يسمح لك عندما تحتاج لإضافة كتاب من أي مكان في الكود، ستستدعي دالة واضحة مثل dataBase.add_book(my_boo) بدلاً من dataBase.control('add', my_book). أيضًا ابحث عن مبدأ فصل الاهتمامات Separation of Concerns سيُفيدك.
- 1 جواب
-
- 1
-
-
تلك ليست الطريقة الصحيحة لمشاركة المشاريع في مجال البرمجة، ما يتم استخدامه هو تقنية Git والتي تعتمد عليها منصات مثل GitHub. أي الملاحظات الخاصة بك ليس لها علاقة بالتسليمات المطلوبة عند التقدم للإختبار، ما تقوم به جيد بالطبع استمر في ذلك واهتم به، حيث ستنسى بعض الأمور بعد فترة وهو ما يحدث مع الجميع، والملاحظات أو التلخيصات المركزة هي الحل، ولا تقم بتلخيص كل شيء، بل النقاط الهامة التي استوعبتها من الشرح وبشكل مُفصل بعض الشيء، بحيث تتمكن من الاستيعاب عند مراجعة تلك الملخصات فيما بعد. وبخصوص التسليمات ليس المطلوب منك تسليم كافة ما نقوم به بالدورة، بل المشاريع العملية فقط، حيث ستجد بعض الدروس بجانبها كلمة تدريب عملي، هنا يجب تسليم ما قمنا به، وليس شرطًا أن يكون التطبيق من خلال كود برمجي، فتلك دورة علوم الحاسوب وبها تطبيقات بأنواع مختلفة مثل الخوارزميات وتطبيقات سكراتش. أنشيء مجلد باسم دورة علوم الحاسوب ثم بداخله مجلد لكل خورازمية وضع به بداخل كل مجلد الملف الخاص بالخورازمية ثم ملف البرنامج الخاص بمنصة سكراتش. وبعد ذلك في المسارات الأخرى ستجد دروس باسم تطبيق عملي أو التمرين النهائي خاصة بالتدريب العملي على كتابة الأكواد البرمجية في جافاسكريبت وبايثون، حيث يتم شرح المطلوب في البداية أو الشرح بشكل نظري ثم يقوم المدرب بالتنفيذ. المطلوب منك هو الاستماع للشرح النظري والمطلوب، ثم محاولة التنفيذ بمفردك وبعد المحاولة بشكل كافي والبحث عن كيفية تنفيذ أمر على جوجل أو يوتيوب، قم بمشاهدة حل المدرب. ثم أنشيء مجلد خاص بالأكواد فقط، داخل مجلد دورة علوم الحاسوب الرئيسي واحتفظ بالكود في ملف خاص باسم المسار مثلاً أساسيات البرمجة - التمرين النهائي أي اسم المسار الخاص به ليتم مراجعته، ثم ارفع المجلد الرئيسي بالكامل على مستودع في GitHub.
-
ستحتاجين إلى التعمق في مكتبة pygame من خلال دراسة الكورسات المتاحة على اليوتيوب، ويوجد بالأكاديمية هنا دروس أيضًا: حاولي حل المشكلة، ثم توفير الكود وسيتم مساعدتك.
-
ستحتاج إلى تعلم لغات الويب الأساسية HTML, CSS, JS وذلك هو الحد الأدنى والذي من خلاله تستطيع تنفيذ ما تراه، ولو أردت تسهيل الأمر عليك يوجد مكونات جاهزة يوفرها إطار بوتستراب أو tailwind لتنفيذ نفس الواجهة، لكن لو تريد التخصص في مجال الواجهة الأمامية وإحترافه، فلا تعتمد على المكتبات وإطارات العمل في البداية، تعمق في اللغات الأساسية أولاً. والواجهة سيتم تنسيقها من خلال flex-box لذا تعمق في ذلك المفهوم عند دراسة CSS. ثم ابحث على اليوتيوب عن Build a Quiz App with HTML CSS and JavaScript أو بناء تطبيق اختبارات (كويز) باستخدام HTML CSS JavaScript وستجد مشاريع مماثلة لما تريده.
-
تقصد قسم الأسئلة الشائعة في صفحة وصف الدورة؟ أم منتدى كما في أكاديمية حسوب لطرح الأسئلة والتعليق عليها؟

