
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 04/12/25 في كل الموقع
-
اريد درس يشرح التعامل معا التاريخ في php بالتفصيل2 نقاط
-
السلام عليكم هل معني ان بستخدم الGPU او TPU ان النموذج هيتدريب في ثواني ؟2 نقاط
-
اغلب ملفات payload لاختراق الاندرويد اصبحت معروفة خاصة على اداة metasploit هل توجد طرق لاختراق الاندرويد اخرى؟ هل يمكن تشفير ملفات الاندرويد بواسطة ملف الفدية؟2 نقاط
-
السلام عليكم قمت بتحميل برنامج لارغون 6 عند الضغط علي start all ثم الضغط علي phpmyadmin يفتح لي برنامج heidisql انا اريد يفتح داخل متصفح قمت بحل مشكلة عن طريق دخول للقائمة ثم mysql ثم تحديث اصدار phpmyadmin2 نقاط
-
could you sent me the my second purchases (AI and computer science) informations, in https://support.academy.hsoub.com/conversations2 نقاط
-
ما سبب عدم ظهور النتيجة
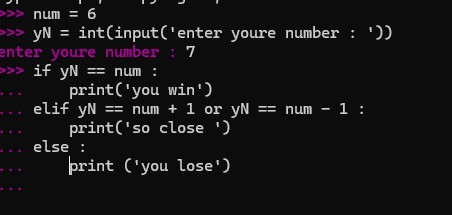 1 نقطة
1 نقطة -
محتاج اسجل ف الرواد الرقميون1 نقطة
-
وماالمشكلة حاليًا؟1 نقطة
-
ما تقصده هو أنك تريد أن يصبح برنامج phpmyadmin هو النظام الإفترضي لقاعدة البيانات، اضغط على الواجهة بزر الفأرة الأيمن ثم اختر tools ثم quick add ثم اضغط على phpmyadmin وسيتم التثبيت. ولتشغيلها اضغط على واجهة البرنامج بزر الفأرة الأيمن مرة أخرى ثم اختر mysql ومنها اختر phpmyadmin
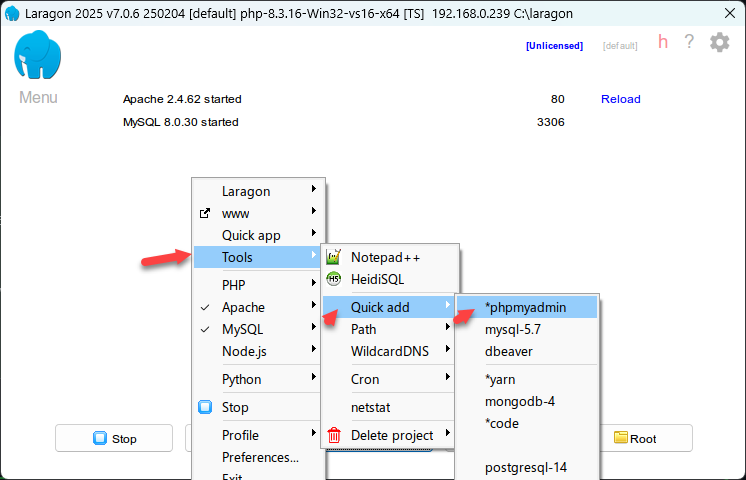 1 نقطة
1 نقطة -
فهم الخطأ DF-DFERH-01 الخطأ DF-DFERH-01 هو مشكلة شائعة تؤثر على العديد من مستخدمي متجر Play، مما يتسبب في عدم تحميل الشاشة الرئيسية بشكل صحيح.1 نقطة
-
محمد عاطف17 شكرا لك و الاخ Mustafa Suleiman لكن السؤال لك يا محمد عاطف وهو الدومين ليه اروح لمواقع لتسجيله او اريد انا املك الدومين من عندي بدون ان الجأ لموقع او هناك مفهوم اخر ما فهمت ياليت توضيح العملية وشكرا1 نقطة
-
yes I ned the informations for personal reasons1 نقطة
-
ال Stacking في NumPy هو عملية دمج عدة مصفوفات في مصفوفة واحدة جديدة، سواء بشكل أفقي أو عمودي، و تعتبر هذه العملية مفيدة عند التعامل مع بيانات متعددة الأبعاد، حيث تتيح لك تكوين هياكل بيانات أكثر تعقيدا بكفاءة، و في NumPy تنفذ هذه العملية عبر دوال مثل np.vstack() للدمج العمودي، وnp.hstack() للدمج الأفقي، بالإضافة إلى np.stack() الذي يسمح بالدمج على محور معين.1 نقطة
-
مفهوم stacking في NumPy يعني دمج عدة arrays مع بعض، لكن بطريقة معينة، تحديدا عن طريق إضافة بُعد جديد أثناء الدمج، في NumPy عندنا دوال كتير للـ stacking وأشهرها: np.stack() np.hstack() np.vstack() np.dstack() np.concatenate() و يمكن تطبيقها بهذا الشكل: import numpy as np a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) np.stack((a, b)) # الناتج: # array([[1, 2, 3], # [4, 5, 6]]) هنا أضفنا بعد جديد وأصبح a و b عبارة عن صفوف داخل مصفوفة 2D.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. الـ Stacking هو عملية دمج مصفوفات متعددة لإنشاء مصفوفة واحدة جديدة. وهذه العملية تتيح لك تجميع البيانات من مصفوفات مختلفة بطرق متنوعة، سواء كان ذلك رأسيًا أو أفقيًا أو حتى على طول أبعاد جديدة، حسب احتياجاتك. والـ Stacking مفيد في مجالات مثل معالجة البيانات وتحضيرها للتحليل أو لتدريب نماذج التعلم الآلي. فهو يسمح لك بتنظيم البيانات بطريقة مرنة ومناسبة لاحتياجاتك. وإليك بعض الأمثلة لتوضيح المفهوم import numpy as np # إنشاء مصفوفات أحادية البعد a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) # التكديس العمودي (vstack) v_stacked = np.vstack((a, b)) # النتيجة: # array([[1, 2, 3], # [4, 5, 6]]) # التكديس الأفقي (hstack) h_stacked = np.hstack((a, b)) # النتيجة: # array([1, 2, 3, 4, 5, 6]) # دالة stack مع تحديد المحور stacked_axis0 = np.stack((a, b), axis=0) # نفس نتيجة vstack stacked_axis1 = np.stack((a, b), axis=1) # النتيجة: # array([[1, 4], # [2, 5], # [3, 6]])1 نقطة
-
وعليكم السلام ورحمة الله وبركاته . كل عام وأنتم بخير وتقبل الله منا ومنكم صالح الأعمال . أولا لنشرح ماذا تفعل typescript هنا في هذه الحالة . إن في TypeScript يتم تعيين النوع any للمتغير age عند تعريفه بدون تهيئة في الكود التالي (let age;). ولكن بمجرد إسناد قيمة 20 إليه (age = 20;)، فإن TypeScript يقوم تلقائيا باستنتاج أن نوع age هو number، ولا يعود any. و هذه العملية تعرف بإسم type inference (الاستدلال التلقائي على النوع). https://www.typescriptlang.org/docs/handbook/type-inference.html ولهذا تحدث المشكلة حيث يتم التعامل مع age هكذا: في البداية، let age; لا يحتوي على قيمة، لذا يكون نوع age هو any. بعد إسناد 20 إليه (age = 20;)، يستنتج TypeScript أن age هو number، وبالتالي لم يعد any. عند استدعاء age.repeat(3)، يظهر الخطأ لأن repeat غير موجود في number بل هو دالة متاحة فقط ل string وأيضا حين المقارنة لأنه لا يمكن المقارنة ب number مع string. وإذا كنت في tsconfig.json تجعل قيمة الخاصية strict ب true فإن هذا النوع من الأخطاء يتم اكتشافه أثناء التحقق من الأنواع في وقت ال compilation وليس في وقت التشغيل. لهذا يمكنك جعلها ب false إذا لم ترد التحقق من الخطأ أثناء ال compilation. وإذا كنت تريد منع TypeScript من استنتاج النوع تلقائيا، يمكنك التصريح بأن age من النوع any: let age: any; وهذا سيحل المشكلة ولن يتم التعرف على أن age من نوع number لأنه لن يتم التعرف على النوع تلقائيا بما أننا عرفنا نوعه مقدما. ومن المفترض عند الوقوف على المتغير بعد إسناد قيمة 20 له أن يظهر بنوع number في ال IDE لديك : من الممكن أنه يوجد مشكلة لديك في vs code أو مشكلة في إصدار typescript المستعمل لديك أو يوجد مشكلة في ملف tsconfig.json حيث وضعت إعدادات تغير من تعامل vs code معه .
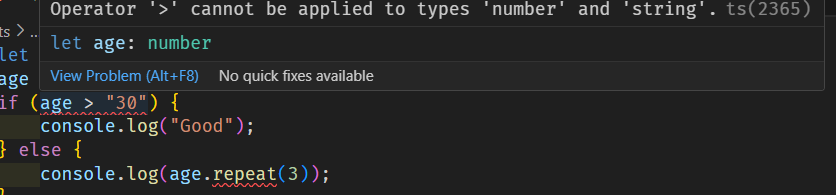
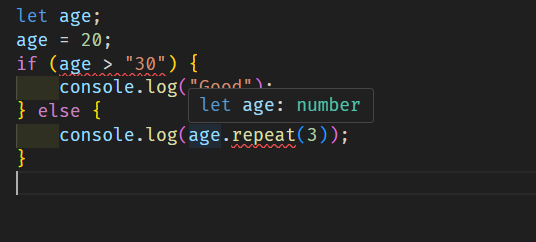 1 نقطة
1 نقطة -
 يمر أغلب مهندسي الذكاء الاصطناعي و تعلم الآلة أثناء تعلمهم للعديد من الخوارزميات الأساسية والتقليدية في تعلم الآلة بمكتبة ساي كيت ليرن Scikit Learn التي توفر هذه الخوارزميات وتوثيقًا جيدًا لها، في هذه المقالة سوف نستكشف هذه المكتبة القوية واستخداماتها ومميزاتها، وما الخوارزميات التي يوفرها، ونستعرض بعض الأمثلة العملية على حالات الاستخدام. ما هي مكتبة ساي كيت ليرن Scikit Learn تعد ساي كيت ليرن Scikit Learn أحد أشهر مكتبات أو أطر عمل لغة بايثون وأكثرها استعمالًا خاصة في مجالات علوم البيانات وتعلم الآلة، فهي توفر مجموعة من خوارزميات الذكاء الاصطناعي المبنية بكفاءة، وتتيح لنا استخدامها بسلاسة حيث تمتلك جميع خوارزميات التعلم المبنية بها طريقة شبه موحدة للتعامل معها، فاستخدام خوارزمية أخرى لنفس الغرض يتطلب ببساطة تغيير سطر واحد من الكود، وتوفر هذه المكتبة إمكانيات كبيرة عند بناء النماذج ومعالجة البيانات وتجهيزها، وحفظ النماذج في صيغة يمكن إعادة استخدامها لاحقًا. مميزات مكتبة ساي كيت ليرن Scikit Learn تسهل مكتبة ساي كيت ليرن Scikit Learn تطوير نماذج تعلم الآلة على المبتدئين والراغبين باختبار الأمور بسرعة، وتوفر لهم العديد من المميزات التي سنسردها ونتعرف عليها مثل: التوثيق الجيد: تتميز المكتبة بوجود توثيق مفصل وأمثلة استخدام كثيرة تساعدنا في البدء بتطوير واستخدام الخوارزميات المختلفة ومعرفة المعاملات التي يمكن ضبطها لتغير أداء النموذج وطريقة تدريبها القيم الافتراضية لمعاملات التحكم : لا داعي للقلق إن كنا نتعلم خوارزمية جديدة ونرغب في تجربتها دون الدخول في جميع التفاصيل وتأثيرات ضبط قيم معاملات التحكم أوالمعاملات الفائقة hyperparameters حيث تضبط المكتبة أغلب العوامل بقيم افتراضية مناسبة لأغلب الاستخدامات، لذا يمكننا التركيز على العوامل الأهم وفهمها بشكل أفضل أدوات للمفاضلة بين النماذج: مع تنوع الخوارزميات المبنية في المكتبة التي يمكنها القيام بنفس المهمة بطرق مختلفة يكون من الصعب على المبتدئ تقرير أي الخوارزميات هو الأفضل للمهمة التي يحاول إنجازها، لذلك توفر لنا المكتبة أدوات للمقارنة بين الخوارزميات المختلفة وعوامل التحكم المختلفة بسلاسة مكتبة غنية بالخوارزميات والأدوات: توفر المكتبة أغلب خوارزميات تعلم الآلة التقليدية، مما يغنينا عن عناء بناء هذه الخوارزميات من الصفر، إذ تتوفر عشرات الخوارزميات التي يمكن تطبيقها من خلال سطور معدودة من الكود، فيمكننا التركيز على تحسين معالجة البيانات وتحسين جودتها واختيار النموذج الأنسب للمشكلة التي لدينا التوافق مع المكتبات الأخرى: تعمل المكتبة بشكل سلس مع المكتبات الأخرى مثل باندا Pandas و نمباي NumPy التي توفر هياكل بيانات وعمليات تسهل اكتشاف أنماط البيانات وتحليلها ومعالجتها لتصبح جاهزة للنموذج الذي نحتاج لتدريبه معالجة البيانات باستخدام ساي كيت ليرن توفر ساي كيت ليرن Scikit Learn العديد من الأدوات الجيدة لمعالجة البيانات وتجهيزها لتدريب النماذج عليها، وكما نعرف تٌعد البيانات وجودتها العامل الأهم في تحسين دقة توقعات النماذج المستخدمة، لذلك هنالك بعض الخطوات التي نحتاج للقيام بها لمعالجة البيانات فمثلًا إذا كانت هناك قيم غير رقمية فنحن بحاجة لتحويلها إلى أرقام فنماذج تعلم الآلة هي نماذج رياضية ولن نستطيع القيام بعمليات حسابية على النصوص أو الصور بشكلها الأصلي. أمثلة على معالجة البيانات الترميز Encoding: هو عملية تبديل بعض البيانات بأرقام يسهل إجراء عمليات رياضية عليها، مع إمكانية إرجاعها لأصلها، يمكن ترميز البيانات في مكتبة Scikit Learn باستخدام الكود التالي: from sklearn.preprocessing import LabelEncoder # ترميز البيانات الوصفية city = ["القاهرة", "الرياض", "دمشق", "القاهرة"] # نعرف المٌرمز الذي يعوض عن اسمٍ برقم يعبر عنه encoder = LabelEncoder() # تقوم هذه الدالة بتجهيز المٌرمز # حيث سيمكننا أن نستخدمه أكثر من مرة بعد هذه الخطوة لترميز البيانات المدخلة له بناءً على أول بيانات أعطت له encoder.fit(city) # الآن يمكننا استخدامه على أي بيانات أخرى لترميزها city_encoded = encoder.transform(city) print(city_encoded) # Output: [1 0 2 1] print(encoder.transform(["الرياض"])) # Output: [0] # عكس الترميز print(encoder.inverse_transform(city_encoded)) # Output: ['القاهرة' 'الرياض' 'دمشق' 'القاهرة'] print(encoder.inverse_transform([2, 1, 0, 0, 1])) # Output: ['دمشق' 'القاهرة' 'الرياض' 'الرياض' 'القاهرة'](city_encoded) التعامل مع القيم المفقودة : قد تتضمن البيانات بعض القيم المفقودة ويمكن التعامل معها في مكتبة Scikit Learn بسهولة من خلال حذف الصفوف التي تحتوي قيمًا مفقودة إن كانت قليلة للغاية، أو التعويض عنها باستخدام المعلومات الإحصائية كالمتوسط الحسابي للقيم، أو بناء نموذج لتوقعها بحسب القيم الموجودة بالفعل. خوارزميات تعلم الآلة في مكتبة Scikit Learn تتضمن مكتبة Scikit Learn العديد من خوارزميات تعلم الآلة التي تساعدنا على تنفيذ مهام متنوعة، وفيما يلي نبذة عن أهم هذه الخوارزميات: أولًا: خوارزميات التعلم الخاضع للإشراف التعلم الخاضع للإشراف Supervised Learning هو نوع من التعلم الآلي يصف المهام التي تكون فيها البيانات المراد توقعها معلوم مخرجاتها الممكنة مسبقًا وتوجد بيانات تحتوي على ملاحظات سابقة تتضمن الوسوم Labels المراد تعليم النموذج توقعها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوارزميات توقع الانحدار Regression توقع الانحدار هو نوع من المهام التي يمكننا القيام بها باستخدام خوارزميات مضمنة في ساي كيت ليرن Scikit Learn، يتوقع هذا النوع من الخوارزميات الحصول على أمثلة سابقة يتعلم منها العلاقة بين المدخلات المعطاة والوسم المراد توقعه، والذي يكون قيمة عددية مستمرة continuous مثل توقع درجة الحرارة أو توقع أسعار المنازل. أمثلة على خوارزميات توقع الانحدار: توقع الانحدار الخطي Linear Regression توقع الانحدار بالدوال متعددة الحدود Polynomial Regression خوزارزميات التصنيف Classification يصنف البشر كل شيء حولهم من الحيوانات والجمادات إلى أنواع الأفلام والروايات، وتتوفر خوارزميات تستطيع محاكاة البشر وتتعلم تصنيف الأشياء المختلفة بإعطاء نماذج وملاحظات سابقة لتصنيفات قام بها البشر من قبل حتي تستطيع الآلة تعلم التصنيف، يمكن الاستفادة من التصنيف في أتمتة العديد من المهام المرجو فيها تصنيف عدد ضخم من العناصر في وقت قليل بالتالي توفير الوقت وزيادة الكفاءة، عملية التصنيف تخرج لنا قيمًا منفصلة discrete. من الأمثلة على استخدام هذه الخوارزميات توقع حالة الطقس هل هو مشمس أم غائم أم ماطر أم حار ...إلخ. وتصنيف الصور، وتوقع تقييمات الأفلام. أمثلة على خوارزميات التصنيف الانحدار اللوجستي Logistic Regression مٌصنّف الجار الأقرب Nearest Neighbors Classification شجرة القرار Decision Tree خوارزميات تجميع النماذج Models Ensemble تتيح لنا ساي كيت ليرن Scikit Learn القدرة على دمج أكثر من نموذج تعلم آلة ليشكلوا نموذجًا أقوى، يمكن تشبيه الأمر بلجنة أو فريق من الأصدقاء كل منهم خبير في مجال معين وعند جمع خبرتهم معًا يغطون على نقاط الضعف الخاصة بهم. يمكن تجميع النماذج باستخدام التصويت Voting حيث نجري تدريب لعدد من النماذج ثم نأخذ بتوقع الأغلبية في حالة كون المشكلة تصنيفية، أما أن كانت المشكلة توقع انحدار يمكن أن تأخذ متوسط التوقعات، لنلاحظ الكود التالي: from sklearn.ensemble import VotingClassifier # التصنيف اللوجيستي model1 = LogisticRegression() # شجرة القرارات model2 = tree.DecisionTreeClassifier() # مٌصنف أقرب الجيران model3 = KNeighborsClassifier(n_neighbors=3) # تجميع لتوقعات النماذج باستخدام التصويت model = VotingClassifier(estimators=[('lr', model1), ('dt', model2), ('knn', model3)], voting='hard') # تدريب النموذج # لاحظ أن مدخلات هذه الدالة هي الخواص المطلوب من النموذج تعلم الأنماط بها # بالإضافة إلى الوسم المٌراد توقعه # تمثل هذه المدخلات التجارب المٌراد للنموذج التعلم منها # يمكنك أن تستخدم هذه الدالة في تدريب أي نموذج في ساي كيت ليرن model.fit(X_train, y_train) # استخدام النموذج في التوقع # البيانات المدخلة للنموذج لم يرها من قبل # ولكنها تحتوي نفس الخواص والأعمدة التي تم تدريب النموذج عليها # نرغب في تدريب النموذج على التعميم لبيانات لم يرها من قبل y_pred = model.predict(X_test) جمعنا في الكود أعلاه عدد من النماذج الضعيفة ومحدودة المعرفة حيث يتدرب كل نموذج على جزء من البيانات، وجمعنا معرفتهم معًا للخروج بتوقع واحد مثال على هذا النوع هو خوارزمية الغابة العشوائية Random Forest وهي تجميع لنماذج من شجرة القرارات Decision Tree البسيطة. تقلل هذه الطريقة من فرص حفظ النموذج للبيانات وتمنحه مرونة أكثر لتعلم الأنماط الحقيقية التي تمكنه من توقع الإجابات الصحيحة عند تعرضه لبيانات جديدة عند تشغيل النموذج. خوارزميات التعلم غير الخاضع للإشراف التعلم غير الخاضع للإشراف Unsupervised Learning هو نوع من تعلم الآلة تكون فيه البيانات غير موسومة، ومهمة النموذج تعلم الأنماط بين البيانات ليكتشف الفروقات بينها، مثلًا إن كانت المدخلات صور فتكون المهمة معرفة أي الصور يمكن اعتبارها تابعة لنفس الشيء دون إعطاء وسم للبيانات في عملية التدريب، ما يعرفه النموذج هو الخواص المُراد للنموذج التعلم منها فقط للتميز بين الصور بناء عليها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوزارميات العنقدة أو التصنيف العنقودي Clustering لا نوفر للنموذج في هذه الحالة التصنيفات والوسوم المتوقع انتماء البيانات لها على غرار التصنيف العادي، ففي العنقدة Clustering على النموذج أن يكتشف هذا بنفسه من خلال تعلم الأنماط الموجودة بالبيانات للتمييز بينها. تستخدم خوزارميات العنقدة في أنظمة التوصية Recommendation systems لتقديم اقتراحات شخصية للمستخدمين تناسب اهتماماتهم، أو فصل عناصر الصورة Image segmentation من خلال تحديد البكسلات التي تنتمي لنفس العنصر Object في الصورة بالتالي تفريقها عن باقي العناصر. أمثلة على خوارزميات العنقدة: العنقدة حول عدد من نقاط التمركز k-means العنقدة الهرمية Hierarchical clustering خوارزميات اختزال البيانات نحتاج لاختزال البيانات Data Reduction في كثير من الحالات بسبب محدودية القدرة الحاسوبية وعدم تأثير كل هذه البيانات بشكل ملحوظ على أداء النموذج، ونجري اختزال البيانات عادة من خلال تقليل أبعادها بدمج بعض الأعمدة أو الخواص بدون خسارة المعلومات الهامة قدر الإمكان، فمثلًا يمكننا تقليل أبعاد الصورة مع الاحتفاظ بملامحها ودقتها قدر الإمكان، أو تقليل عدد الأعمدة من 100 إلى 10 مع احتفاظ الأعمدة العشرة بأغلبية المعلومات التي تؤثر على التوقعات. من أمثلة خوارزميات اختزال البيانات خوارزمية تحليل العنصر الأساسي Principal Component Analysis التي تمكننا من اختزال عدد الأعمدة أو الأبعاد بالبيانات مع الاحتفاظ بأكبر قدر ممكن من المعلومات. # تساعدنا هذه المكتبة على صنع هياكل بيانات مصفوفة # والقيام بالعديد من العمليات الحسابية import numpy as np # هذه الخوارزمية التي سنستخدمها لاختزال البيانات from sklearn.decomposition import PCA # في البداية لنصنع بيانات عشوائية لنقوم بالتجربة # يضمن لنا هذا السطر ثبات القيم العشوائية عند إعادة تشغيل هذا الكود np.random.seed(0) # نعرف مصفوفة عشوائية التوليد، تتكون من 10 صفوف و100 عمود X = np.random.rand(10, 100) # لنعرف الخوارزمية التي استوردناها pca = PCA(n_components=10) # نضع هنا عدد الأعمدة التي نرغب أن تصبح البيانات عليها # لنقم بتشغيل الخوارزمية على البيانات التي معنا x_pca = pca.fit_transform(X) # هذا السطر يقوم بتدريب الخوارزمية على اختزال البيانات وفي نفس الوقت يقوم باختزال البيانات المدخلة # لنرى النتائج print("حجم البيانات قبل الاختزال", X.shape) print("حجم البيانات بعد الاختزال", x_pca.shape) ''' المـــــــــخــرجـــــــــــــات ------------------------------------- حجم البيانات قبل الاختزال (10, 100) حجم البيانات بعد الاختزال (10, 10) ''' خوارزميات كشف الشذوذ كشف الشذوذ Anomaly Detection هو عملية ملاحظة الغير مألوف والخارج عن الأغلبية في البيانات. يستخدم في حالات عددية مثل اكتشاف المعاملات الاحتيالية في البنوك، واكتشاف الأنماط غير المعتادة في تدفق الشبكات مما قد يساعد على منع هجمات إغراق الشبكة بالطلبات، واكتشاف المنتجات المعيبة في خطوط الإنتاج واكتشاف الأنماط غير المعتادة للمؤشرات الحيوية لجسم الإنسان التي تستخدمها تطبيقات الساعات الذكية التي تجمع هذه المؤشرات. من الخوارزميات التي تطبق كشف الشذوذ خوارزمية غابة العزل Isolation Forest، وفيما يلي مثال على طريقة استخدامها: # استيراد نموذج كشف كشف الشذوذ from sklearn.ensemble import IsolationForest # سنستخدمها لتوليد بعض البيانات import numpy as np # نولد البيانات لتجربة النموذج X = np.array([[10, 10], [12, 12], [8, 8], [9, 9], [200, 200]]) # يمكنك ملاحظة أن النقطة الأخيرة شاذة عن باقي النقاط # لنقم بتعريف وتدريب النموذج clf = IsolationForest(contamination=0.2) # %يفترض هذا المعامل أن نسبة شذوذ 20 # لاحظ أن التدريب يتم بدون استخدام وسوم حيث أن هذا النموذج غير خاضع للإشراف clf.fit(X) # في حالة اكتشاف شذوذ سيتم وسمه بسالب واحد لتميزه predictions = clf.predict(X) print(predictions) # Output: [ 1 1 1 1 -1] خوارزميات التعلم الخاضع لإشراف جزئي يستخدم التعلم الخاضع لإشراف جزئي Semi-supervised Learning بيانات تتكون من خليط من البيانات الموسومة Labeled data والبيانات غير الموسومة Unlabeled data أثناء التدريب، يمكن أن يصبح هذا الأسلوب مفيدًا للغاية عندما يكون من الصعب الحصول على بيانات موسومة كافية أو يحتاج الحصول عليها إلى وقت ومجهود ضخم. يستخدم عادة في ترشيح المحتوى في أنظمة التوصية فبعض البيانات قد تكون متوفرة بشكل صريح مثل تقييمات المستخدم للمنتجات والتي يمكن الاستدلال بها لاقتراح المزيد من العناصر، ولكن يمكن أيضًا الاستفادة من المعلومات غير الموسومة والمعروفة ضمنية من خلال تفاعلات المستخدم. كما يستخدم في تدريب نماذج التعلم على الصور ومقاطع الفيديو حيث يمكن وسم بعض الصور أو العناصر فيها بشكل بشري لكن لا يمكن حصر جميع العناصر المختلفة التي قد تكون بداخل صورة ووسمها لذا سنستفيد من دمج الجزء الموسوم من البيانات مع الجزء غير الموسوم في توفير كمية أكبر من البيانات لتدريب نماذج أكثر دقة، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوراززميات التعلم الذاتي Self Training يمكننا استخدام التعلم الذاتي Self Training في ساي كيت ليرن Scikit Learn لتحويل أي نموذج تصنيف تقليدي إلى نموذج يمكنه التدريب على البيانات الموسومة وغير الموسومة معًا، شريطة أن يكون النموذج قادرًا على توقع التصنيفات كاحتمالات، ونحتاج لاستخدام نموذج يسمى SelfTrainingClassifier لتحويل النماذج العادية لنماذج خاضعة لإشراف جزئي، لاحظ الكود التالي: from sklearn.tree import DecisionTreeClassifier from sklearn.semi_supervised import SelfTrainingClassifier # نعرف أي مصنف ليكون نموذج الأساس base_classifier = DecisionTreeClassifier() # نقوم بإحاطة نموذج الأساس ليصبح قادرًا على التعلم الذاتي self_training_model = SelfTrainingClassifier(base_classifier) # نقوم بتدريب النموذج مثل أي نموذج تقليدي self_training_model.fit(X_train, y_train) ملاحظة: عند تجهيزنا لبيانات التدريب نحتاج لوسم البيانات غير الموسومة بقيمة 1- حيث أننا لا نستطيع أن نمرر البيانات خلال النموذج وهي غير موسومة. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن اختيار النموذج المناسب قد يبدو اختيار النموذج المناسب في مكتبة ساي كيت ليرن معقدًا، إذ يمكن استخدام أكثر من خوارزمية لحل نفس المشكلة. ولكل خوارزمية معاملات تحكم مختلفة، لذلك يجب علينا استخدام أدوات تساعدنا في مقارنة النماذج وقياس أدائها. فيما يلي بعض المعايير الرئيسية التي يمكن استخدامها: الدقة Accuracy: عدد التوقعات الصحيحة التي توقعها النموذج مقسومًا على إجمالي البيانات. كلما كانت النسبة أعلى، كان النموذج أفضل خطأ المتوسط التربيعي Mean Squared Error: الفرق بين القيمة الفعلية التي نريد التنبؤ بها والقيمة التي توقعها النموذج، ثم تربيع هذا الفرق. وهو يساعد في تحديد مدى دقة التوقعات بحث مصفوفة المعاملات GridSearch: يستخدم لاختبار عدد من المعاملات أو إعدادات النماذج المختلفة دفعة واحدة والعثور على أفضل مجموعة معاملات تحقق أفضل أداء. تستهلك هذه الطريقة وقتًا وموارد حاسوبية كبيرة خاصة إذا كانت المعاملات كثيرة جدًا مقارنة بين ساي كيت ليرن Scikit Learn و تنسورفلو TensorFlow يكمن الفرق الرئيسي بين تنسورفلو TensorFlow وبين ساي كيت ليرن Scikit Learn في تخصص الاستخدام، حيث أن ساي كيت ليرن مكتبة متخصصة بخوارزميات تعلم الآلة التقليدية Traditional Machine Learning بينما تنسورفلو TensorFlow إطار عمل شامل لتطوير وتشغيل نماذج التعلم العميق Deep Learning المبنية على الشبكات العصبية الاصطناعية. وعلى الرغم من إمكانية تدريب شبكات عصبية اصطناعية باستخدام ساي كيت ليرن فهي ليست محسنة لأجل هذا الغرض، إذ لا تستطيع المكتبة الاستفادة من وحدات المعالجة الرسومية GPUs التي تستطيع تسريع تدريب النماذج العميقة بشكل أفضل من وحدات المعالجة المركزية CPUs، بينما لا يقف دعم تنسورفلو TensorFlow عند استخدام GPU واحد، حيث يمكن توزيع التدريب على عدة أجهزة على التوازي وهو شيء صعب التحقيق باستخدام ساي كيت ليرن. الخلاصة تعرفنا في هذه المقالة على مكتبة الذكاء الاصطناعي الشهيرة ساي كيت ليرن Scikit Learn وأبرز مميزاتها ووضحنا بعض التطبيقات الواسعة لخوارزميات التعلم المبنية بها، وكذلك تعرفنا على الفرق بينها وبين إطار العمل تنسورفلو TensorFlow.ننصح بتعلم استخدام هذه المكتبة وتجربتها في بناء وتطبيق نماذج تعلم آلة مخصصة، فهي توفر أدوات قوية ومرنة تمكنكم من تنفيذ حلول مبتكرة في مختلف مجالات الذكاء الاصطناعي. اقرأ أيضًا الذكاء الاصطناعي: دليلك الشامل بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn العمل مع ملفات CSV وبيانات JSON باستخدام لغة بايثون استخدام التدريب الموزع ومكتبة Accelerate لتسريع تدريب نماذج الذكاء الاصطناعي1 نقطة
يمر أغلب مهندسي الذكاء الاصطناعي و تعلم الآلة أثناء تعلمهم للعديد من الخوارزميات الأساسية والتقليدية في تعلم الآلة بمكتبة ساي كيت ليرن Scikit Learn التي توفر هذه الخوارزميات وتوثيقًا جيدًا لها، في هذه المقالة سوف نستكشف هذه المكتبة القوية واستخداماتها ومميزاتها، وما الخوارزميات التي يوفرها، ونستعرض بعض الأمثلة العملية على حالات الاستخدام. ما هي مكتبة ساي كيت ليرن Scikit Learn تعد ساي كيت ليرن Scikit Learn أحد أشهر مكتبات أو أطر عمل لغة بايثون وأكثرها استعمالًا خاصة في مجالات علوم البيانات وتعلم الآلة، فهي توفر مجموعة من خوارزميات الذكاء الاصطناعي المبنية بكفاءة، وتتيح لنا استخدامها بسلاسة حيث تمتلك جميع خوارزميات التعلم المبنية بها طريقة شبه موحدة للتعامل معها، فاستخدام خوارزمية أخرى لنفس الغرض يتطلب ببساطة تغيير سطر واحد من الكود، وتوفر هذه المكتبة إمكانيات كبيرة عند بناء النماذج ومعالجة البيانات وتجهيزها، وحفظ النماذج في صيغة يمكن إعادة استخدامها لاحقًا. مميزات مكتبة ساي كيت ليرن Scikit Learn تسهل مكتبة ساي كيت ليرن Scikit Learn تطوير نماذج تعلم الآلة على المبتدئين والراغبين باختبار الأمور بسرعة، وتوفر لهم العديد من المميزات التي سنسردها ونتعرف عليها مثل: التوثيق الجيد: تتميز المكتبة بوجود توثيق مفصل وأمثلة استخدام كثيرة تساعدنا في البدء بتطوير واستخدام الخوارزميات المختلفة ومعرفة المعاملات التي يمكن ضبطها لتغير أداء النموذج وطريقة تدريبها القيم الافتراضية لمعاملات التحكم : لا داعي للقلق إن كنا نتعلم خوارزمية جديدة ونرغب في تجربتها دون الدخول في جميع التفاصيل وتأثيرات ضبط قيم معاملات التحكم أوالمعاملات الفائقة hyperparameters حيث تضبط المكتبة أغلب العوامل بقيم افتراضية مناسبة لأغلب الاستخدامات، لذا يمكننا التركيز على العوامل الأهم وفهمها بشكل أفضل أدوات للمفاضلة بين النماذج: مع تنوع الخوارزميات المبنية في المكتبة التي يمكنها القيام بنفس المهمة بطرق مختلفة يكون من الصعب على المبتدئ تقرير أي الخوارزميات هو الأفضل للمهمة التي يحاول إنجازها، لذلك توفر لنا المكتبة أدوات للمقارنة بين الخوارزميات المختلفة وعوامل التحكم المختلفة بسلاسة مكتبة غنية بالخوارزميات والأدوات: توفر المكتبة أغلب خوارزميات تعلم الآلة التقليدية، مما يغنينا عن عناء بناء هذه الخوارزميات من الصفر، إذ تتوفر عشرات الخوارزميات التي يمكن تطبيقها من خلال سطور معدودة من الكود، فيمكننا التركيز على تحسين معالجة البيانات وتحسين جودتها واختيار النموذج الأنسب للمشكلة التي لدينا التوافق مع المكتبات الأخرى: تعمل المكتبة بشكل سلس مع المكتبات الأخرى مثل باندا Pandas و نمباي NumPy التي توفر هياكل بيانات وعمليات تسهل اكتشاف أنماط البيانات وتحليلها ومعالجتها لتصبح جاهزة للنموذج الذي نحتاج لتدريبه معالجة البيانات باستخدام ساي كيت ليرن توفر ساي كيت ليرن Scikit Learn العديد من الأدوات الجيدة لمعالجة البيانات وتجهيزها لتدريب النماذج عليها، وكما نعرف تٌعد البيانات وجودتها العامل الأهم في تحسين دقة توقعات النماذج المستخدمة، لذلك هنالك بعض الخطوات التي نحتاج للقيام بها لمعالجة البيانات فمثلًا إذا كانت هناك قيم غير رقمية فنحن بحاجة لتحويلها إلى أرقام فنماذج تعلم الآلة هي نماذج رياضية ولن نستطيع القيام بعمليات حسابية على النصوص أو الصور بشكلها الأصلي. أمثلة على معالجة البيانات الترميز Encoding: هو عملية تبديل بعض البيانات بأرقام يسهل إجراء عمليات رياضية عليها، مع إمكانية إرجاعها لأصلها، يمكن ترميز البيانات في مكتبة Scikit Learn باستخدام الكود التالي: from sklearn.preprocessing import LabelEncoder # ترميز البيانات الوصفية city = ["القاهرة", "الرياض", "دمشق", "القاهرة"] # نعرف المٌرمز الذي يعوض عن اسمٍ برقم يعبر عنه encoder = LabelEncoder() # تقوم هذه الدالة بتجهيز المٌرمز # حيث سيمكننا أن نستخدمه أكثر من مرة بعد هذه الخطوة لترميز البيانات المدخلة له بناءً على أول بيانات أعطت له encoder.fit(city) # الآن يمكننا استخدامه على أي بيانات أخرى لترميزها city_encoded = encoder.transform(city) print(city_encoded) # Output: [1 0 2 1] print(encoder.transform(["الرياض"])) # Output: [0] # عكس الترميز print(encoder.inverse_transform(city_encoded)) # Output: ['القاهرة' 'الرياض' 'دمشق' 'القاهرة'] print(encoder.inverse_transform([2, 1, 0, 0, 1])) # Output: ['دمشق' 'القاهرة' 'الرياض' 'الرياض' 'القاهرة'](city_encoded) التعامل مع القيم المفقودة : قد تتضمن البيانات بعض القيم المفقودة ويمكن التعامل معها في مكتبة Scikit Learn بسهولة من خلال حذف الصفوف التي تحتوي قيمًا مفقودة إن كانت قليلة للغاية، أو التعويض عنها باستخدام المعلومات الإحصائية كالمتوسط الحسابي للقيم، أو بناء نموذج لتوقعها بحسب القيم الموجودة بالفعل. خوارزميات تعلم الآلة في مكتبة Scikit Learn تتضمن مكتبة Scikit Learn العديد من خوارزميات تعلم الآلة التي تساعدنا على تنفيذ مهام متنوعة، وفيما يلي نبذة عن أهم هذه الخوارزميات: أولًا: خوارزميات التعلم الخاضع للإشراف التعلم الخاضع للإشراف Supervised Learning هو نوع من التعلم الآلي يصف المهام التي تكون فيها البيانات المراد توقعها معلوم مخرجاتها الممكنة مسبقًا وتوجد بيانات تحتوي على ملاحظات سابقة تتضمن الوسوم Labels المراد تعليم النموذج توقعها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوارزميات توقع الانحدار Regression توقع الانحدار هو نوع من المهام التي يمكننا القيام بها باستخدام خوارزميات مضمنة في ساي كيت ليرن Scikit Learn، يتوقع هذا النوع من الخوارزميات الحصول على أمثلة سابقة يتعلم منها العلاقة بين المدخلات المعطاة والوسم المراد توقعه، والذي يكون قيمة عددية مستمرة continuous مثل توقع درجة الحرارة أو توقع أسعار المنازل. أمثلة على خوارزميات توقع الانحدار: توقع الانحدار الخطي Linear Regression توقع الانحدار بالدوال متعددة الحدود Polynomial Regression خوزارزميات التصنيف Classification يصنف البشر كل شيء حولهم من الحيوانات والجمادات إلى أنواع الأفلام والروايات، وتتوفر خوارزميات تستطيع محاكاة البشر وتتعلم تصنيف الأشياء المختلفة بإعطاء نماذج وملاحظات سابقة لتصنيفات قام بها البشر من قبل حتي تستطيع الآلة تعلم التصنيف، يمكن الاستفادة من التصنيف في أتمتة العديد من المهام المرجو فيها تصنيف عدد ضخم من العناصر في وقت قليل بالتالي توفير الوقت وزيادة الكفاءة، عملية التصنيف تخرج لنا قيمًا منفصلة discrete. من الأمثلة على استخدام هذه الخوارزميات توقع حالة الطقس هل هو مشمس أم غائم أم ماطر أم حار ...إلخ. وتصنيف الصور، وتوقع تقييمات الأفلام. أمثلة على خوارزميات التصنيف الانحدار اللوجستي Logistic Regression مٌصنّف الجار الأقرب Nearest Neighbors Classification شجرة القرار Decision Tree خوارزميات تجميع النماذج Models Ensemble تتيح لنا ساي كيت ليرن Scikit Learn القدرة على دمج أكثر من نموذج تعلم آلة ليشكلوا نموذجًا أقوى، يمكن تشبيه الأمر بلجنة أو فريق من الأصدقاء كل منهم خبير في مجال معين وعند جمع خبرتهم معًا يغطون على نقاط الضعف الخاصة بهم. يمكن تجميع النماذج باستخدام التصويت Voting حيث نجري تدريب لعدد من النماذج ثم نأخذ بتوقع الأغلبية في حالة كون المشكلة تصنيفية، أما أن كانت المشكلة توقع انحدار يمكن أن تأخذ متوسط التوقعات، لنلاحظ الكود التالي: from sklearn.ensemble import VotingClassifier # التصنيف اللوجيستي model1 = LogisticRegression() # شجرة القرارات model2 = tree.DecisionTreeClassifier() # مٌصنف أقرب الجيران model3 = KNeighborsClassifier(n_neighbors=3) # تجميع لتوقعات النماذج باستخدام التصويت model = VotingClassifier(estimators=[('lr', model1), ('dt', model2), ('knn', model3)], voting='hard') # تدريب النموذج # لاحظ أن مدخلات هذه الدالة هي الخواص المطلوب من النموذج تعلم الأنماط بها # بالإضافة إلى الوسم المٌراد توقعه # تمثل هذه المدخلات التجارب المٌراد للنموذج التعلم منها # يمكنك أن تستخدم هذه الدالة في تدريب أي نموذج في ساي كيت ليرن model.fit(X_train, y_train) # استخدام النموذج في التوقع # البيانات المدخلة للنموذج لم يرها من قبل # ولكنها تحتوي نفس الخواص والأعمدة التي تم تدريب النموذج عليها # نرغب في تدريب النموذج على التعميم لبيانات لم يرها من قبل y_pred = model.predict(X_test) جمعنا في الكود أعلاه عدد من النماذج الضعيفة ومحدودة المعرفة حيث يتدرب كل نموذج على جزء من البيانات، وجمعنا معرفتهم معًا للخروج بتوقع واحد مثال على هذا النوع هو خوارزمية الغابة العشوائية Random Forest وهي تجميع لنماذج من شجرة القرارات Decision Tree البسيطة. تقلل هذه الطريقة من فرص حفظ النموذج للبيانات وتمنحه مرونة أكثر لتعلم الأنماط الحقيقية التي تمكنه من توقع الإجابات الصحيحة عند تعرضه لبيانات جديدة عند تشغيل النموذج. خوارزميات التعلم غير الخاضع للإشراف التعلم غير الخاضع للإشراف Unsupervised Learning هو نوع من تعلم الآلة تكون فيه البيانات غير موسومة، ومهمة النموذج تعلم الأنماط بين البيانات ليكتشف الفروقات بينها، مثلًا إن كانت المدخلات صور فتكون المهمة معرفة أي الصور يمكن اعتبارها تابعة لنفس الشيء دون إعطاء وسم للبيانات في عملية التدريب، ما يعرفه النموذج هو الخواص المُراد للنموذج التعلم منها فقط للتميز بين الصور بناء عليها، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوزارميات العنقدة أو التصنيف العنقودي Clustering لا نوفر للنموذج في هذه الحالة التصنيفات والوسوم المتوقع انتماء البيانات لها على غرار التصنيف العادي، ففي العنقدة Clustering على النموذج أن يكتشف هذا بنفسه من خلال تعلم الأنماط الموجودة بالبيانات للتمييز بينها. تستخدم خوزارميات العنقدة في أنظمة التوصية Recommendation systems لتقديم اقتراحات شخصية للمستخدمين تناسب اهتماماتهم، أو فصل عناصر الصورة Image segmentation من خلال تحديد البكسلات التي تنتمي لنفس العنصر Object في الصورة بالتالي تفريقها عن باقي العناصر. أمثلة على خوارزميات العنقدة: العنقدة حول عدد من نقاط التمركز k-means العنقدة الهرمية Hierarchical clustering خوارزميات اختزال البيانات نحتاج لاختزال البيانات Data Reduction في كثير من الحالات بسبب محدودية القدرة الحاسوبية وعدم تأثير كل هذه البيانات بشكل ملحوظ على أداء النموذج، ونجري اختزال البيانات عادة من خلال تقليل أبعادها بدمج بعض الأعمدة أو الخواص بدون خسارة المعلومات الهامة قدر الإمكان، فمثلًا يمكننا تقليل أبعاد الصورة مع الاحتفاظ بملامحها ودقتها قدر الإمكان، أو تقليل عدد الأعمدة من 100 إلى 10 مع احتفاظ الأعمدة العشرة بأغلبية المعلومات التي تؤثر على التوقعات. من أمثلة خوارزميات اختزال البيانات خوارزمية تحليل العنصر الأساسي Principal Component Analysis التي تمكننا من اختزال عدد الأعمدة أو الأبعاد بالبيانات مع الاحتفاظ بأكبر قدر ممكن من المعلومات. # تساعدنا هذه المكتبة على صنع هياكل بيانات مصفوفة # والقيام بالعديد من العمليات الحسابية import numpy as np # هذه الخوارزمية التي سنستخدمها لاختزال البيانات from sklearn.decomposition import PCA # في البداية لنصنع بيانات عشوائية لنقوم بالتجربة # يضمن لنا هذا السطر ثبات القيم العشوائية عند إعادة تشغيل هذا الكود np.random.seed(0) # نعرف مصفوفة عشوائية التوليد، تتكون من 10 صفوف و100 عمود X = np.random.rand(10, 100) # لنعرف الخوارزمية التي استوردناها pca = PCA(n_components=10) # نضع هنا عدد الأعمدة التي نرغب أن تصبح البيانات عليها # لنقم بتشغيل الخوارزمية على البيانات التي معنا x_pca = pca.fit_transform(X) # هذا السطر يقوم بتدريب الخوارزمية على اختزال البيانات وفي نفس الوقت يقوم باختزال البيانات المدخلة # لنرى النتائج print("حجم البيانات قبل الاختزال", X.shape) print("حجم البيانات بعد الاختزال", x_pca.shape) ''' المـــــــــخــرجـــــــــــــات ------------------------------------- حجم البيانات قبل الاختزال (10, 100) حجم البيانات بعد الاختزال (10, 10) ''' خوارزميات كشف الشذوذ كشف الشذوذ Anomaly Detection هو عملية ملاحظة الغير مألوف والخارج عن الأغلبية في البيانات. يستخدم في حالات عددية مثل اكتشاف المعاملات الاحتيالية في البنوك، واكتشاف الأنماط غير المعتادة في تدفق الشبكات مما قد يساعد على منع هجمات إغراق الشبكة بالطلبات، واكتشاف المنتجات المعيبة في خطوط الإنتاج واكتشاف الأنماط غير المعتادة للمؤشرات الحيوية لجسم الإنسان التي تستخدمها تطبيقات الساعات الذكية التي تجمع هذه المؤشرات. من الخوارزميات التي تطبق كشف الشذوذ خوارزمية غابة العزل Isolation Forest، وفيما يلي مثال على طريقة استخدامها: # استيراد نموذج كشف كشف الشذوذ from sklearn.ensemble import IsolationForest # سنستخدمها لتوليد بعض البيانات import numpy as np # نولد البيانات لتجربة النموذج X = np.array([[10, 10], [12, 12], [8, 8], [9, 9], [200, 200]]) # يمكنك ملاحظة أن النقطة الأخيرة شاذة عن باقي النقاط # لنقم بتعريف وتدريب النموذج clf = IsolationForest(contamination=0.2) # %يفترض هذا المعامل أن نسبة شذوذ 20 # لاحظ أن التدريب يتم بدون استخدام وسوم حيث أن هذا النموذج غير خاضع للإشراف clf.fit(X) # في حالة اكتشاف شذوذ سيتم وسمه بسالب واحد لتميزه predictions = clf.predict(X) print(predictions) # Output: [ 1 1 1 1 -1] خوارزميات التعلم الخاضع لإشراف جزئي يستخدم التعلم الخاضع لإشراف جزئي Semi-supervised Learning بيانات تتكون من خليط من البيانات الموسومة Labeled data والبيانات غير الموسومة Unlabeled data أثناء التدريب، يمكن أن يصبح هذا الأسلوب مفيدًا للغاية عندما يكون من الصعب الحصول على بيانات موسومة كافية أو يحتاج الحصول عليها إلى وقت ومجهود ضخم. يستخدم عادة في ترشيح المحتوى في أنظمة التوصية فبعض البيانات قد تكون متوفرة بشكل صريح مثل تقييمات المستخدم للمنتجات والتي يمكن الاستدلال بها لاقتراح المزيد من العناصر، ولكن يمكن أيضًا الاستفادة من المعلومات غير الموسومة والمعروفة ضمنية من خلال تفاعلات المستخدم. كما يستخدم في تدريب نماذج التعلم على الصور ومقاطع الفيديو حيث يمكن وسم بعض الصور أو العناصر فيها بشكل بشري لكن لا يمكن حصر جميع العناصر المختلفة التي قد تكون بداخل صورة ووسمها لذا سنستفيد من دمج الجزء الموسوم من البيانات مع الجزء غير الموسوم في توفير كمية أكبر من البيانات لتدريب نماذج أكثر دقة، وسنوضح تاليًا أبرز الخوازرميات التي تندرج تحت هذه النوع. خوراززميات التعلم الذاتي Self Training يمكننا استخدام التعلم الذاتي Self Training في ساي كيت ليرن Scikit Learn لتحويل أي نموذج تصنيف تقليدي إلى نموذج يمكنه التدريب على البيانات الموسومة وغير الموسومة معًا، شريطة أن يكون النموذج قادرًا على توقع التصنيفات كاحتمالات، ونحتاج لاستخدام نموذج يسمى SelfTrainingClassifier لتحويل النماذج العادية لنماذج خاضعة لإشراف جزئي، لاحظ الكود التالي: from sklearn.tree import DecisionTreeClassifier from sklearn.semi_supervised import SelfTrainingClassifier # نعرف أي مصنف ليكون نموذج الأساس base_classifier = DecisionTreeClassifier() # نقوم بإحاطة نموذج الأساس ليصبح قادرًا على التعلم الذاتي self_training_model = SelfTrainingClassifier(base_classifier) # نقوم بتدريب النموذج مثل أي نموذج تقليدي self_training_model.fit(X_train, y_train) ملاحظة: عند تجهيزنا لبيانات التدريب نحتاج لوسم البيانات غير الموسومة بقيمة 1- حيث أننا لا نستطيع أن نمرر البيانات خلال النموذج وهي غير موسومة. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن اختيار النموذج المناسب قد يبدو اختيار النموذج المناسب في مكتبة ساي كيت ليرن معقدًا، إذ يمكن استخدام أكثر من خوارزمية لحل نفس المشكلة. ولكل خوارزمية معاملات تحكم مختلفة، لذلك يجب علينا استخدام أدوات تساعدنا في مقارنة النماذج وقياس أدائها. فيما يلي بعض المعايير الرئيسية التي يمكن استخدامها: الدقة Accuracy: عدد التوقعات الصحيحة التي توقعها النموذج مقسومًا على إجمالي البيانات. كلما كانت النسبة أعلى، كان النموذج أفضل خطأ المتوسط التربيعي Mean Squared Error: الفرق بين القيمة الفعلية التي نريد التنبؤ بها والقيمة التي توقعها النموذج، ثم تربيع هذا الفرق. وهو يساعد في تحديد مدى دقة التوقعات بحث مصفوفة المعاملات GridSearch: يستخدم لاختبار عدد من المعاملات أو إعدادات النماذج المختلفة دفعة واحدة والعثور على أفضل مجموعة معاملات تحقق أفضل أداء. تستهلك هذه الطريقة وقتًا وموارد حاسوبية كبيرة خاصة إذا كانت المعاملات كثيرة جدًا مقارنة بين ساي كيت ليرن Scikit Learn و تنسورفلو TensorFlow يكمن الفرق الرئيسي بين تنسورفلو TensorFlow وبين ساي كيت ليرن Scikit Learn في تخصص الاستخدام، حيث أن ساي كيت ليرن مكتبة متخصصة بخوارزميات تعلم الآلة التقليدية Traditional Machine Learning بينما تنسورفلو TensorFlow إطار عمل شامل لتطوير وتشغيل نماذج التعلم العميق Deep Learning المبنية على الشبكات العصبية الاصطناعية. وعلى الرغم من إمكانية تدريب شبكات عصبية اصطناعية باستخدام ساي كيت ليرن فهي ليست محسنة لأجل هذا الغرض، إذ لا تستطيع المكتبة الاستفادة من وحدات المعالجة الرسومية GPUs التي تستطيع تسريع تدريب النماذج العميقة بشكل أفضل من وحدات المعالجة المركزية CPUs، بينما لا يقف دعم تنسورفلو TensorFlow عند استخدام GPU واحد، حيث يمكن توزيع التدريب على عدة أجهزة على التوازي وهو شيء صعب التحقيق باستخدام ساي كيت ليرن. الخلاصة تعرفنا في هذه المقالة على مكتبة الذكاء الاصطناعي الشهيرة ساي كيت ليرن Scikit Learn وأبرز مميزاتها ووضحنا بعض التطبيقات الواسعة لخوارزميات التعلم المبنية بها، وكذلك تعرفنا على الفرق بينها وبين إطار العمل تنسورفلو TensorFlow.ننصح بتعلم استخدام هذه المكتبة وتجربتها في بناء وتطبيق نماذج تعلم آلة مخصصة، فهي توفر أدوات قوية ومرنة تمكنكم من تنفيذ حلول مبتكرة في مختلف مجالات الذكاء الاصطناعي. اقرأ أيضًا الذكاء الاصطناعي: دليلك الشامل بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn العمل مع ملفات CSV وبيانات JSON باستخدام لغة بايثون استخدام التدريب الموزع ومكتبة Accelerate لتسريع تدريب نماذج الذكاء الاصطناعي1 نقطة -
 تصميم واجهة المستخدم من أهم المهن المطلوبة حاليًا في سوق العمل، ولكن ما هي واجهة المستخدم؟ واجهة المستخدم هي ما نراه ونتفاعل معه على شاشات الحواسيب والأجهزة المحمولة، مثل موقع الإنترنت وتطبيقات الهاتف المحمول وتطبيقات الويب. لذلك فإن الشخص الذي يختار مواقع العناصر على الشاشة وتخطيط مختلف الصفحات والشاشات ومن يخطط أنماط ألوانها ورسوماتها، هو مصمم الواجهات، ويرتبط عمله مباشرة مع مطوّر الويب والتطبيقات كما يرتبط من جهة أخرى مع مصمم تجربة المستخدم. كيف يعمل مصمم واجهة المستخدم؟ من الصعب جدًّا على مصمم الرسوميات العمل على تصميم الواجهات منفردًا، لأن عمله مرتبط كليًا بالتنسيق مع مطوّر التطبيقات والويب، لذلك فإن الغالبية العظمى من مصممي الواجهات يعملون في فرق تضم مصمم رسوميات ومطوّر تطبيقات ومدير فريق الذي يجب أن يكون لديه إلمام بالتصميم والتطوير معًا، وقد يتضمن الفريق أفرادًا أكثر إن لزم الأمر مثل كاتب المحتوى وغيره. دورة تطوير واجهات المستخدم ابدأ عملك الحر بتطوير واجهات المواقع والمتاجر الإلكترونية فور انتهائك من الدورة اشترك الآن مراحل تصميم واجهة المستخدم يمر مشروع تصميم الواجهة بعدة مراحل وهي: يتلقى المدير طلبًا لتنفيذ مشروع واجهة تطبيق أو ويب ويحصل على كافة المعطيات والمعلومات اللازمة لبدء المشروع. يجتمع المدير بأعضاء الفريق ويطلعهم على المعطيات التي بين يديه ثم يوزع المهام على المصمم والمطور وعادة ما يبدأ المصممم العمل. يعمل المصمم على إنشاء رسومات نماذج أولية باستخدام القلم والورقة إلى أن يصل إلى نماذج مرضية لرؤيته الخاصة بالمشروع. ينقل المصمم هذه النماذج من الأوراق إلى الحاسوب ليرسم هذه النماذج بطريقة احترافية ومنسقة بأسلوب الإطار الشبكي Wireframe ثم يسلم هذه النماذج إلى المدير. ملاحظة: إن كان فريق العمل يعمل معًا في نفس المكتب فإنه يسلم هذه المخططات مباشرة، أو عن طريق إرسالها بالبريد الإلكتروني أو أية وسيلة اتصال أخرى، أو قد يلجأ الفريق للعمل معًا على أحد أدوات وتطبيقات سطح المكتب أو تطبيقات الويب المخصّصة لعمل الفرق في هذا المجال، حيث يتشارك الجميع الأفكار والتصاميم والنماذج ويعلّقون عليها ويتباحثون بأمرها، سنذكر بعضًا من هذه الأدوات والتطبيقات في الجزء الأخير من المقال. يتبادل المدير والمصمم الآراء والأفكار وتُنفّذ التعديلات ثم يرسل المدير النماذج إلى العميل ليبدي رأيه فيها ويطلب تعديلاته. يبدأ المصمم العمل على استخدام العناصر الرسومية والصور والألوان لإنشاء تصاميم رسومية أولية ثم يشاركها مع المدير الذي يرسلها بدوره للعميل لإبداء الرأي وطلب التعديلات. يعمل المصمم على التعديلات المطلوبة ويسلم التصاميم النهائية للمدير الذي يسلمها بدوره للمطور ليعمل على تطوير التطبيق أو الموقع ومن ثم يسلم المشروع إلى العميل. قواعد تصميم واجهة المستخدم لتصميم واجهات جيدة ومتميزة واحترافية نحتاج إلى اتباع قواعد معينة تضمن تألق وتميز التصميم كما تضمن سهولة استخدامه وقبوله من قبل المستخدمين. التناسق يجب استخدام نفس أنماط التصميم ونفس تسلسل الإجراءات للحالات المتماثلة، يتضمن ذلك الاستخدام الصحيح للألوان والطباعة والمصطلحات في الشاشات والأوامر والقوائم الفورية خلال رحلة المستخدم، حيث تسمح الواجهة المتسقة للمستخدمين بإكمال مهامهم وأهدافهم بسهولة أكبر. يجب أن يكون المستخدم مرتاحًا في استخدامه للواجهة ولا يشعر بالارتباك، مثلًا لا يجب وضع زر القائمة المنبثقة أسفل الواجهة بينما اعتاد المستخدمون على وجودها أعلى الواجهة، وكذلك لايجب أن يوضع زر شراء المنتج أعلى صفحة المنتج وفوق صورته والمعلومات حوله بينما اعتاد المستخدمون وجود هذا الزر أسفل هذه الواجهة، وهكذا. كما يُفضّل على الدوام استخدام الأشكال المألوفة والأزرار المألوفة أكثر من الأشكال الجديدة التي قد تشعر المستخدمين بالغرابة وتجعلهم يفكرون مرتين قبل استخدام العنصر أو النقر على الزر ، فهذا التردد ليس جيدًا بمقاييس تجربة المستخدم والتصميم السليم والصحيح لواجهة المستخدم. البساطة في جميع القواعد الخاصة بتصميم أي شيء تجد مبدأ البساطة دائمًا، لأن التصميم البسيط مريح أكثر للنظر ويساعد على إيصال الرسالة بسلاسة ووضوح وسهولة دون عناء وهو الهدف من التصميم، فلا أحد يحب الواجهات المزدحمة وغير المنتظمة التي تسبب الإرباك عند محاولة التعامل معها لعدم وضوح الرسالة المفروض إيصالها أو الهدف من التطبيق أو الموقع. فإضافة المزيد من العناصر المختلفة في التصميم سيقلل التركيز على العناصر المهمة والتي يجب أن يركّز عليها المصمم. لذلك يجب التخفيف من ازدحام العناصر وتأمين تصميم بسيط يتضمن أهم العناصر فقط والابتعاد عن العناصر الأقل أهمية والتي يمكن إبرازها في واجهات أخرى يمكن التنقل إليها من الواجهة الرئيسية. مثال: أهم ما يركز عليه موقعا ياهو وجوجل هو محرك البحث وعملية البحث، وبفضل التصميم البسيط والمختصر لجوجل فإن التركيز منصب على محرك البحث فحسب، بينما يسبب ازدحام العناصر المختلفة في واجهة ياهو تشتيت الانتباه عن العنصر الرئيسي الأهم وهو خانة البحث. تناسق الخطوط من المهم التمييز بين أنواع الخطوط الواجب استخدامها عند تصميم واجهات المستخدم، حيث أن هناك خطوطًا يمكن عرضها بوضوح ضمن واجهات الويب لسطح المكتب ولكنها صعبة القراءة وقليلة الوضوح عند استخدامها في الأحجام الصغيرة ضمن الشاشات الصغيرة للأجهزة المحمولة. لذلك يجب الانتباه واستخدام خطوط ثخينة نسبيًا في الواجهات المصممة للشاشات الكبيرة والخطوط النحيفة نسبيًا عند التصميم للشاشات الصغيرة. من أهم القواعد المتبعة في هذا السياق تجنب استخدام أكثر من نوعين من الخطوط ضمن أي واجهة لضمان تناسق وأناقة التصميم. مراعاة التصميم المتجاوب تساعد بعض برامج تصميم الواجهات على إنشاء تصاميم متجاوبة تتمتع بقابلية تغيير حجم العناصر والأجزاء الأساسية بحسب حجم الشاشة المعروض عليها التصميم، مثل حجم الشعار والقوائم والفقرات النصية وغيرها، بينما لا تتمتع برامج أخرى بهذه الميزة مثل برنامج الفوتوشوب والإليستريتور، لذلك يجب أن يخصص المصمم إما عناصر بأحجام متوسطة تراعي كافة الأحجام المحتملة أو يجب عليه أن ينشئ عدة نسخ من العناصر بأحجام مختلفة ليستخدمها المطور في برمجة الواجهة حتى تكون متجاوبة وقابلة للتكبير أو التصغير بحسب حجم شاشة العرض. التباين كثيرًا ما نرى واجهات لمواقع أو لتطبيقات لا تراعي مبدأ التباين على الاطلاق بحيث تكون الألوان بين العناصر المختلفة ولاسيما بين العناصر والخطوط ذات تباين متدني بحيث يكون من الصعب تمييز العناصر أو قراءة النصوص، وعلى العكس أيضًا أحيانا يكون التباين مبالغًا فيه ما يجعل النظر ومتابعة العناصر أو القراءة مزعجة للعين وغير مريحة، لذلك يجب أن يكون التباين متوسطًا ومدروسًا حتى يحقق تجربة مستخدم مريحة وجيدة. أحد أبرز أساليب تطبيق مبدأ التباين هو تصميم واجهة بلون واحد مع التدرجات القريبة وبالأخص اللون الرمادي وتدرجاته، ومع استخدام لون حيوي مميز للعنصر أو العناصر الأهم لتأمين بروزها مع تحقيق جمالية وأناقة في التصميم. الهرمية هو من المبادئ المهمة في التصميم عامة وكذلك تصميم الواجهات خاصة، نستطيع من خلاله توجيه عين المستخدم واهتمامه بطريقة تدريجية في الاتجاه الذي نريد، ويكون تطبيق هذا المبدأ عبر تعزيز خصائص مميزة إضافية تُبرز العنصر الأهم في الواجهة مع تخفيف نسبة التعزيز للعنصر التالي في الأهمية وهكذا، وبذلك يعلم تمامًا المستخدم كيفية التوجّه ضمن الواجهة. المحاذاة يجب تطبيق هذا المبدأ على جميع محاور وأطراف التصميم، وعلى عكس تصاميم أخرى حيث يطبق هذا المبدأ على محور واحد ويكون ذلك كافيًا، إلا أن ذلك غير كاف في تصميم الواجهات نظرًا لأن هذه الواجهات عادة ما تكون مكتظة بالعناصر بالموازنة مع تصاميم فنية أخرى، ما يستوجب تطبيق المحاذاة على مختلف المحاور والأطراف ليكون المنظر العام للتصميم متوازنًا ومتناسقًا. انظر للشكل التوضيحي السابق وستلاحظ مبدأ المحاذاة بكل وضوح. التقارب وهو أحد مبادئ التصميم العامة، حيث أن تطبيقه يحسّن تجربة المستخدم لأن تناثر العناصر ضمن الواجهة وتباعدها يؤدي لتجربة مزعجة للمستخدمين وغير فعّالة لذلك يجب تنظيم العناصر بقرب بعضها وبتسلسل مرتب حتى نؤمن تجربة سلسلة ومريحة للمستخدمين. الوضوح ويقصد هنا تأمين الوضوح في الخيارات والقرارات والمتطلبات التي يجب أن ينفذها المستخدم، فعلى سبيل المثال عندما تتواجد في صفحة التسجيل حقول إدخال عدة ويتطلب كل حقل نوعية إدخال مختلفة، يجب أن يكون واضحًا ومفهومًا للمستخدم ما يجب عليه إدخاله ضمن هذه الحقول وما هي الأخطاء التي ارتكبها أثناء عملية الإدخال حتى يتداركها ويصححها بطريقة سلسلة ومفهومة وواضحة. الصورة بواسطة Antonin Kus من موقع dribbble المساحة البيضاء حافظ على المساحات البيضاء قدر الإمكان وأكثر منها دون تردد، لأنها أثبتت فعاليتها في اجتذاب المستخدمين فهي تسبب الشعور بالراحة والرقي والأناقة وبها تتحقق مبادئ التناسق والبساطة بسهولة، لذلك تجنب استخدام المربعات والمستطيلات والخطوط التي تفصل بين العناصر قدر الإمكان واسمح للمساحات البيضاء بالسيطرة على مساحة التصميم العامة. مصدر الصورة أدوات تصميم واجهة المستخدم تقدم بعض هذه الأدوات والبرامج إمكانات متكاملة في تصميم الواجهات وبعضها يسمح بمشاركتها مباشرة مع باقي أعضاء الفريق لمناقشتها وتحديثها مباشرة، بينما البعض الآخر تقليدي للغاية حيث يجب أن تصمم الواجهات يدويًا من البداية ومن ثم إرسال النماذج إلى باقي أعضاء الفريق، وفي أحيان كثيرة يحتاج المصمم إلى استخدام أكثر من برنامج وتطبيق ومنصة لإتمام المهمة على أكمل وجه. أدوبي فوتوشوب أشهر برنامج للتصميم ومعالجة الصور وأكثرها شيوعًا، يمكن استخدامه لتصميم واجهات مواقع الويب أو حتى التطبيقات حيث يحتوي على أدوات الشرائح الخاصة بتقسيم وتقطيع التصميم إلى شرائح بحسب العناصر المرسومة، ومن ثم تصدّر هذه الشرائح إلى ملفات صور مستقلة لكل عنصر بتنسيق PNG لضمان خاصية الشفافية في حال تواجدها ضمن الشريحة المصدّرة، ليتمكن المطور من استخدام هذه العناصر معًا وتركيبها لإنشاء الواجهة أو التطبيق. ويمكن استخدامه لمعالجة الصور المستخدمة في التصميم أو لإنشاء عناصر أخرى كالأزرار أو الخلفيات أو أشكال القوائم وغيرها. أدوبي إليستريتور بسبب تخصصه في إنشاء الرسومات الشعاعية، فإنه البرنامج الأقوى والأنسب لإنشاء عناصر مميزة شعاعية متجاوبة التصميم لكل أجزاء وأنواع التصاميم مثل القوائم والأزرار والنماذج والرسوميات والأيقونات وغيرها. كما يمكن استخدامه لإنشاء تصاميم النماذج الأولية للمشاريع بتقنية الإطار الشبكي (Wireframe)، حيث تساعد أدواته القوية على إنشاء هذه التصاميم بسهولة وسرعة. Sketch سكتش برنامج مميز ومتخصص في إنشاء وتصميم الواجهات عالية الدقة بكل أنواعها ويعد من أقوى البرامج في هذا المجال، حيث يتضمن قوالب جاهزة للمساعدة في إنشاء هذه التصاميم، كما يتضمن إعدادات مخصصة جاهزة بحسب قياسات مختلف الأجهزة لتصميم التطبيقات والويب. لعل أبرز عيوبه هو أنه برنامج مخصص للعمل على نظام واحد فقط وهو ماكنتوش العامل على حواسيب آبل بينما لا تتوفر منه نسخ تعمل على ويندوز أو لينكس. Adobe X D يوفر أدوبي إكس دي أفضل بيئة للمشاريع الرقمية ضمن مجموعة Adobe Creative Cloud لأدوات تصميم الواجهات. لا تشبه واجهة هذا البرنامج واجهات بقية برامج أدوبي مثل الفوتوشوب والإليستريتور وغيرها، إلا أنك ستعتاد العمل عليه بسرعة لسهولة استخدامه ووفرة أدواته الخاصة بهذا النوع من التصاميم. Figma تمكنك فيجما من إنشاء واجهات وتصميمها بسرعة. حيث تفخر منصة Figma بكونها أداة تصميم تعاونية حيث يمكن لعدة مستخدمين العمل في وقت واحد على المشروع نفسه وهذا فعّال للغاية عندما يكون لديك العديد من أصحاب العلاقة في المشروع ذاته يشاركون في تشكيل النتيجة مثل المصممين والمطورين والمدراء، ولذلك هي أداة مثالية عندما تعمل على مشروع واحد بالاشتراك مع مصمم ومطور وكاتب محتوى في نفس الوقت. Balsamiq بالساميق أداة مميزة وقوية إنشاء نماذج الإطار الشبكي Wireframe حيث يمكنك تطوير البنية والتخطيطات لمشاريعك بسهولة، وتعمل عناصر السحب والإفلات على تسهيل الاستخدام ويمكنك ربط الأزرار بصفحات أخرى. هذا يعني أنه يمكنك البدء بسرعة في تخطيط واجهاتك ومن ثم مشاركتها مع فريقك أو عملائك. Zeplin مع أن زيبلن أداة جيدة لإنتاج النماذج الأولية، إلا أنه يناسب إلى حد كبير مرحلة ما بعد التصميم وما قبل التطوير جنبًا إلى جنب مع النماذج الأولية. يمكّنك تسليم التصميم والنماذج الأولية للمطورين والتأكد من تنفيذ أفكارك بطريقة جيدة. وتستطيع مشاركة ملفات سكتش Sketch و فوتوشوب Photoshop وملفات X D و فيجما Figma إلى زيبلن لاستحداث بيئة للمطورين والمصممين للعمل على المشروع معًا ومن ثم تسليمه دون الحاجة إلى إنشاء الإرشادات واستعمال وسائل التواصل المختلفة. InVision إن فيجين هو أداة تساعد في إنشاء واجهات تفاعلية جميلة مع مجموعة كبيرة من الميزات حيث يمكنك إنشاء حركات وانتقالات مخصصة من عدد من الإيماءات والتفاعلات. وبفضل هذه الأداة يمكنك التوقف عن التفكير في إنشاء العديد من النماذج لأجهزة متعددة لأنه يمكن تحقيق التصميم سريع الاستجابة داخل لوح رسم واحد. خاتمة على الرغم من أنه يجب عليك دائمًا اتخاذ قرارات قائمة على رؤيتك وخبرتك وذوقك الفني، إلا أن اتباع مجموعة من القواعد والإرشادات سيوجهك في الاتجاه الصحيح ويسمح لك باكتشاف مشاكل الاستخدام الرئيسية في وقت مبكر من عملية التصميم. تنطبق هذه القواعد على معظم واجهات المستخدم، كما تكفي مجموعة الأدوات التي ذكرناها لإنشاء تصاميم متكاملة على الرغم من وجود المزيد من التطبيقات والأدوات خارج هذه القائمة إلا أن ما ذكرناه في هذا المقال أكثر من كافٍ. والأهم هو التعاون بين أعضاء الفريق واتباع خطوات العمل لإتمام عملية التصميم وتسليم المشروع إلى العميل.1 نقطة
تصميم واجهة المستخدم من أهم المهن المطلوبة حاليًا في سوق العمل، ولكن ما هي واجهة المستخدم؟ واجهة المستخدم هي ما نراه ونتفاعل معه على شاشات الحواسيب والأجهزة المحمولة، مثل موقع الإنترنت وتطبيقات الهاتف المحمول وتطبيقات الويب. لذلك فإن الشخص الذي يختار مواقع العناصر على الشاشة وتخطيط مختلف الصفحات والشاشات ومن يخطط أنماط ألوانها ورسوماتها، هو مصمم الواجهات، ويرتبط عمله مباشرة مع مطوّر الويب والتطبيقات كما يرتبط من جهة أخرى مع مصمم تجربة المستخدم. كيف يعمل مصمم واجهة المستخدم؟ من الصعب جدًّا على مصمم الرسوميات العمل على تصميم الواجهات منفردًا، لأن عمله مرتبط كليًا بالتنسيق مع مطوّر التطبيقات والويب، لذلك فإن الغالبية العظمى من مصممي الواجهات يعملون في فرق تضم مصمم رسوميات ومطوّر تطبيقات ومدير فريق الذي يجب أن يكون لديه إلمام بالتصميم والتطوير معًا، وقد يتضمن الفريق أفرادًا أكثر إن لزم الأمر مثل كاتب المحتوى وغيره. دورة تطوير واجهات المستخدم ابدأ عملك الحر بتطوير واجهات المواقع والمتاجر الإلكترونية فور انتهائك من الدورة اشترك الآن مراحل تصميم واجهة المستخدم يمر مشروع تصميم الواجهة بعدة مراحل وهي: يتلقى المدير طلبًا لتنفيذ مشروع واجهة تطبيق أو ويب ويحصل على كافة المعطيات والمعلومات اللازمة لبدء المشروع. يجتمع المدير بأعضاء الفريق ويطلعهم على المعطيات التي بين يديه ثم يوزع المهام على المصمم والمطور وعادة ما يبدأ المصممم العمل. يعمل المصمم على إنشاء رسومات نماذج أولية باستخدام القلم والورقة إلى أن يصل إلى نماذج مرضية لرؤيته الخاصة بالمشروع. ينقل المصمم هذه النماذج من الأوراق إلى الحاسوب ليرسم هذه النماذج بطريقة احترافية ومنسقة بأسلوب الإطار الشبكي Wireframe ثم يسلم هذه النماذج إلى المدير. ملاحظة: إن كان فريق العمل يعمل معًا في نفس المكتب فإنه يسلم هذه المخططات مباشرة، أو عن طريق إرسالها بالبريد الإلكتروني أو أية وسيلة اتصال أخرى، أو قد يلجأ الفريق للعمل معًا على أحد أدوات وتطبيقات سطح المكتب أو تطبيقات الويب المخصّصة لعمل الفرق في هذا المجال، حيث يتشارك الجميع الأفكار والتصاميم والنماذج ويعلّقون عليها ويتباحثون بأمرها، سنذكر بعضًا من هذه الأدوات والتطبيقات في الجزء الأخير من المقال. يتبادل المدير والمصمم الآراء والأفكار وتُنفّذ التعديلات ثم يرسل المدير النماذج إلى العميل ليبدي رأيه فيها ويطلب تعديلاته. يبدأ المصمم العمل على استخدام العناصر الرسومية والصور والألوان لإنشاء تصاميم رسومية أولية ثم يشاركها مع المدير الذي يرسلها بدوره للعميل لإبداء الرأي وطلب التعديلات. يعمل المصمم على التعديلات المطلوبة ويسلم التصاميم النهائية للمدير الذي يسلمها بدوره للمطور ليعمل على تطوير التطبيق أو الموقع ومن ثم يسلم المشروع إلى العميل. قواعد تصميم واجهة المستخدم لتصميم واجهات جيدة ومتميزة واحترافية نحتاج إلى اتباع قواعد معينة تضمن تألق وتميز التصميم كما تضمن سهولة استخدامه وقبوله من قبل المستخدمين. التناسق يجب استخدام نفس أنماط التصميم ونفس تسلسل الإجراءات للحالات المتماثلة، يتضمن ذلك الاستخدام الصحيح للألوان والطباعة والمصطلحات في الشاشات والأوامر والقوائم الفورية خلال رحلة المستخدم، حيث تسمح الواجهة المتسقة للمستخدمين بإكمال مهامهم وأهدافهم بسهولة أكبر. يجب أن يكون المستخدم مرتاحًا في استخدامه للواجهة ولا يشعر بالارتباك، مثلًا لا يجب وضع زر القائمة المنبثقة أسفل الواجهة بينما اعتاد المستخدمون على وجودها أعلى الواجهة، وكذلك لايجب أن يوضع زر شراء المنتج أعلى صفحة المنتج وفوق صورته والمعلومات حوله بينما اعتاد المستخدمون وجود هذا الزر أسفل هذه الواجهة، وهكذا. كما يُفضّل على الدوام استخدام الأشكال المألوفة والأزرار المألوفة أكثر من الأشكال الجديدة التي قد تشعر المستخدمين بالغرابة وتجعلهم يفكرون مرتين قبل استخدام العنصر أو النقر على الزر ، فهذا التردد ليس جيدًا بمقاييس تجربة المستخدم والتصميم السليم والصحيح لواجهة المستخدم. البساطة في جميع القواعد الخاصة بتصميم أي شيء تجد مبدأ البساطة دائمًا، لأن التصميم البسيط مريح أكثر للنظر ويساعد على إيصال الرسالة بسلاسة ووضوح وسهولة دون عناء وهو الهدف من التصميم، فلا أحد يحب الواجهات المزدحمة وغير المنتظمة التي تسبب الإرباك عند محاولة التعامل معها لعدم وضوح الرسالة المفروض إيصالها أو الهدف من التطبيق أو الموقع. فإضافة المزيد من العناصر المختلفة في التصميم سيقلل التركيز على العناصر المهمة والتي يجب أن يركّز عليها المصمم. لذلك يجب التخفيف من ازدحام العناصر وتأمين تصميم بسيط يتضمن أهم العناصر فقط والابتعاد عن العناصر الأقل أهمية والتي يمكن إبرازها في واجهات أخرى يمكن التنقل إليها من الواجهة الرئيسية. مثال: أهم ما يركز عليه موقعا ياهو وجوجل هو محرك البحث وعملية البحث، وبفضل التصميم البسيط والمختصر لجوجل فإن التركيز منصب على محرك البحث فحسب، بينما يسبب ازدحام العناصر المختلفة في واجهة ياهو تشتيت الانتباه عن العنصر الرئيسي الأهم وهو خانة البحث. تناسق الخطوط من المهم التمييز بين أنواع الخطوط الواجب استخدامها عند تصميم واجهات المستخدم، حيث أن هناك خطوطًا يمكن عرضها بوضوح ضمن واجهات الويب لسطح المكتب ولكنها صعبة القراءة وقليلة الوضوح عند استخدامها في الأحجام الصغيرة ضمن الشاشات الصغيرة للأجهزة المحمولة. لذلك يجب الانتباه واستخدام خطوط ثخينة نسبيًا في الواجهات المصممة للشاشات الكبيرة والخطوط النحيفة نسبيًا عند التصميم للشاشات الصغيرة. من أهم القواعد المتبعة في هذا السياق تجنب استخدام أكثر من نوعين من الخطوط ضمن أي واجهة لضمان تناسق وأناقة التصميم. مراعاة التصميم المتجاوب تساعد بعض برامج تصميم الواجهات على إنشاء تصاميم متجاوبة تتمتع بقابلية تغيير حجم العناصر والأجزاء الأساسية بحسب حجم الشاشة المعروض عليها التصميم، مثل حجم الشعار والقوائم والفقرات النصية وغيرها، بينما لا تتمتع برامج أخرى بهذه الميزة مثل برنامج الفوتوشوب والإليستريتور، لذلك يجب أن يخصص المصمم إما عناصر بأحجام متوسطة تراعي كافة الأحجام المحتملة أو يجب عليه أن ينشئ عدة نسخ من العناصر بأحجام مختلفة ليستخدمها المطور في برمجة الواجهة حتى تكون متجاوبة وقابلة للتكبير أو التصغير بحسب حجم شاشة العرض. التباين كثيرًا ما نرى واجهات لمواقع أو لتطبيقات لا تراعي مبدأ التباين على الاطلاق بحيث تكون الألوان بين العناصر المختلفة ولاسيما بين العناصر والخطوط ذات تباين متدني بحيث يكون من الصعب تمييز العناصر أو قراءة النصوص، وعلى العكس أيضًا أحيانا يكون التباين مبالغًا فيه ما يجعل النظر ومتابعة العناصر أو القراءة مزعجة للعين وغير مريحة، لذلك يجب أن يكون التباين متوسطًا ومدروسًا حتى يحقق تجربة مستخدم مريحة وجيدة. أحد أبرز أساليب تطبيق مبدأ التباين هو تصميم واجهة بلون واحد مع التدرجات القريبة وبالأخص اللون الرمادي وتدرجاته، ومع استخدام لون حيوي مميز للعنصر أو العناصر الأهم لتأمين بروزها مع تحقيق جمالية وأناقة في التصميم. الهرمية هو من المبادئ المهمة في التصميم عامة وكذلك تصميم الواجهات خاصة، نستطيع من خلاله توجيه عين المستخدم واهتمامه بطريقة تدريجية في الاتجاه الذي نريد، ويكون تطبيق هذا المبدأ عبر تعزيز خصائص مميزة إضافية تُبرز العنصر الأهم في الواجهة مع تخفيف نسبة التعزيز للعنصر التالي في الأهمية وهكذا، وبذلك يعلم تمامًا المستخدم كيفية التوجّه ضمن الواجهة. المحاذاة يجب تطبيق هذا المبدأ على جميع محاور وأطراف التصميم، وعلى عكس تصاميم أخرى حيث يطبق هذا المبدأ على محور واحد ويكون ذلك كافيًا، إلا أن ذلك غير كاف في تصميم الواجهات نظرًا لأن هذه الواجهات عادة ما تكون مكتظة بالعناصر بالموازنة مع تصاميم فنية أخرى، ما يستوجب تطبيق المحاذاة على مختلف المحاور والأطراف ليكون المنظر العام للتصميم متوازنًا ومتناسقًا. انظر للشكل التوضيحي السابق وستلاحظ مبدأ المحاذاة بكل وضوح. التقارب وهو أحد مبادئ التصميم العامة، حيث أن تطبيقه يحسّن تجربة المستخدم لأن تناثر العناصر ضمن الواجهة وتباعدها يؤدي لتجربة مزعجة للمستخدمين وغير فعّالة لذلك يجب تنظيم العناصر بقرب بعضها وبتسلسل مرتب حتى نؤمن تجربة سلسلة ومريحة للمستخدمين. الوضوح ويقصد هنا تأمين الوضوح في الخيارات والقرارات والمتطلبات التي يجب أن ينفذها المستخدم، فعلى سبيل المثال عندما تتواجد في صفحة التسجيل حقول إدخال عدة ويتطلب كل حقل نوعية إدخال مختلفة، يجب أن يكون واضحًا ومفهومًا للمستخدم ما يجب عليه إدخاله ضمن هذه الحقول وما هي الأخطاء التي ارتكبها أثناء عملية الإدخال حتى يتداركها ويصححها بطريقة سلسلة ومفهومة وواضحة. الصورة بواسطة Antonin Kus من موقع dribbble المساحة البيضاء حافظ على المساحات البيضاء قدر الإمكان وأكثر منها دون تردد، لأنها أثبتت فعاليتها في اجتذاب المستخدمين فهي تسبب الشعور بالراحة والرقي والأناقة وبها تتحقق مبادئ التناسق والبساطة بسهولة، لذلك تجنب استخدام المربعات والمستطيلات والخطوط التي تفصل بين العناصر قدر الإمكان واسمح للمساحات البيضاء بالسيطرة على مساحة التصميم العامة. مصدر الصورة أدوات تصميم واجهة المستخدم تقدم بعض هذه الأدوات والبرامج إمكانات متكاملة في تصميم الواجهات وبعضها يسمح بمشاركتها مباشرة مع باقي أعضاء الفريق لمناقشتها وتحديثها مباشرة، بينما البعض الآخر تقليدي للغاية حيث يجب أن تصمم الواجهات يدويًا من البداية ومن ثم إرسال النماذج إلى باقي أعضاء الفريق، وفي أحيان كثيرة يحتاج المصمم إلى استخدام أكثر من برنامج وتطبيق ومنصة لإتمام المهمة على أكمل وجه. أدوبي فوتوشوب أشهر برنامج للتصميم ومعالجة الصور وأكثرها شيوعًا، يمكن استخدامه لتصميم واجهات مواقع الويب أو حتى التطبيقات حيث يحتوي على أدوات الشرائح الخاصة بتقسيم وتقطيع التصميم إلى شرائح بحسب العناصر المرسومة، ومن ثم تصدّر هذه الشرائح إلى ملفات صور مستقلة لكل عنصر بتنسيق PNG لضمان خاصية الشفافية في حال تواجدها ضمن الشريحة المصدّرة، ليتمكن المطور من استخدام هذه العناصر معًا وتركيبها لإنشاء الواجهة أو التطبيق. ويمكن استخدامه لمعالجة الصور المستخدمة في التصميم أو لإنشاء عناصر أخرى كالأزرار أو الخلفيات أو أشكال القوائم وغيرها. أدوبي إليستريتور بسبب تخصصه في إنشاء الرسومات الشعاعية، فإنه البرنامج الأقوى والأنسب لإنشاء عناصر مميزة شعاعية متجاوبة التصميم لكل أجزاء وأنواع التصاميم مثل القوائم والأزرار والنماذج والرسوميات والأيقونات وغيرها. كما يمكن استخدامه لإنشاء تصاميم النماذج الأولية للمشاريع بتقنية الإطار الشبكي (Wireframe)، حيث تساعد أدواته القوية على إنشاء هذه التصاميم بسهولة وسرعة. Sketch سكتش برنامج مميز ومتخصص في إنشاء وتصميم الواجهات عالية الدقة بكل أنواعها ويعد من أقوى البرامج في هذا المجال، حيث يتضمن قوالب جاهزة للمساعدة في إنشاء هذه التصاميم، كما يتضمن إعدادات مخصصة جاهزة بحسب قياسات مختلف الأجهزة لتصميم التطبيقات والويب. لعل أبرز عيوبه هو أنه برنامج مخصص للعمل على نظام واحد فقط وهو ماكنتوش العامل على حواسيب آبل بينما لا تتوفر منه نسخ تعمل على ويندوز أو لينكس. Adobe X D يوفر أدوبي إكس دي أفضل بيئة للمشاريع الرقمية ضمن مجموعة Adobe Creative Cloud لأدوات تصميم الواجهات. لا تشبه واجهة هذا البرنامج واجهات بقية برامج أدوبي مثل الفوتوشوب والإليستريتور وغيرها، إلا أنك ستعتاد العمل عليه بسرعة لسهولة استخدامه ووفرة أدواته الخاصة بهذا النوع من التصاميم. Figma تمكنك فيجما من إنشاء واجهات وتصميمها بسرعة. حيث تفخر منصة Figma بكونها أداة تصميم تعاونية حيث يمكن لعدة مستخدمين العمل في وقت واحد على المشروع نفسه وهذا فعّال للغاية عندما يكون لديك العديد من أصحاب العلاقة في المشروع ذاته يشاركون في تشكيل النتيجة مثل المصممين والمطورين والمدراء، ولذلك هي أداة مثالية عندما تعمل على مشروع واحد بالاشتراك مع مصمم ومطور وكاتب محتوى في نفس الوقت. Balsamiq بالساميق أداة مميزة وقوية إنشاء نماذج الإطار الشبكي Wireframe حيث يمكنك تطوير البنية والتخطيطات لمشاريعك بسهولة، وتعمل عناصر السحب والإفلات على تسهيل الاستخدام ويمكنك ربط الأزرار بصفحات أخرى. هذا يعني أنه يمكنك البدء بسرعة في تخطيط واجهاتك ومن ثم مشاركتها مع فريقك أو عملائك. Zeplin مع أن زيبلن أداة جيدة لإنتاج النماذج الأولية، إلا أنه يناسب إلى حد كبير مرحلة ما بعد التصميم وما قبل التطوير جنبًا إلى جنب مع النماذج الأولية. يمكّنك تسليم التصميم والنماذج الأولية للمطورين والتأكد من تنفيذ أفكارك بطريقة جيدة. وتستطيع مشاركة ملفات سكتش Sketch و فوتوشوب Photoshop وملفات X D و فيجما Figma إلى زيبلن لاستحداث بيئة للمطورين والمصممين للعمل على المشروع معًا ومن ثم تسليمه دون الحاجة إلى إنشاء الإرشادات واستعمال وسائل التواصل المختلفة. InVision إن فيجين هو أداة تساعد في إنشاء واجهات تفاعلية جميلة مع مجموعة كبيرة من الميزات حيث يمكنك إنشاء حركات وانتقالات مخصصة من عدد من الإيماءات والتفاعلات. وبفضل هذه الأداة يمكنك التوقف عن التفكير في إنشاء العديد من النماذج لأجهزة متعددة لأنه يمكن تحقيق التصميم سريع الاستجابة داخل لوح رسم واحد. خاتمة على الرغم من أنه يجب عليك دائمًا اتخاذ قرارات قائمة على رؤيتك وخبرتك وذوقك الفني، إلا أن اتباع مجموعة من القواعد والإرشادات سيوجهك في الاتجاه الصحيح ويسمح لك باكتشاف مشاكل الاستخدام الرئيسية في وقت مبكر من عملية التصميم. تنطبق هذه القواعد على معظم واجهات المستخدم، كما تكفي مجموعة الأدوات التي ذكرناها لإنشاء تصاميم متكاملة على الرغم من وجود المزيد من التطبيقات والأدوات خارج هذه القائمة إلا أن ما ذكرناه في هذا المقال أكثر من كافٍ. والأهم هو التعاون بين أعضاء الفريق واتباع خطوات العمل لإتمام عملية التصميم وتسليم المشروع إلى العميل.1 نقطة










