لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 01/01/25 في كل الموقع
-
ريد أن أعرف ما هي الأشياء أو الدورات التي يمكنني القيام بها لمنحي الشهادة4 نقاط
-
السلام عليكم هو اي تحليل البقاء Kaplan-Meier ؟3 نقاط
-
السلام عليكم.. في البداية سنه سعيده على الجميع ان شاء الله وعسى تحقيق احلامكم واهدافكم.. في عندي سؤال كيف ترتبون وقت دراستكم للكورس وكم مره تعيدونه لضمانة الاجابه في الاختبار النهائي؟ حاليا ادرسه ساعتين ونصف يوميا وناوي اعيد الدروس مرتين... مهتم لسماعة ردودكم وسنه..2 نقاط
-
السلام عليكم ده الكود # Create a Kaplan-Meier object kaplanmeierfitter = KaplanMeierFitter() # Create a larger figure to avoid overlap plt.figure(figsize=(12, 8)) # Iterate through each unique combination of 'cyto_score', 'tbi_status', 'graft_type', and 'vent_hist' for (cyto_score, tbi_status, graft_type, vent_hist) in data_train.groupby(['cyto_score', 'tbi_status', 'graft_type', 'vent_hist']).groups: # Filter the data based on the current group group_data = data_train[(data_train['cyto_score'] == cyto_score) & (data_train['tbi_status'] == tbi_status) & (data_train['graft_type'] == graft_type) & (data_train['vent_hist'] == vent_hist)] # Fit the Kaplan-Meier model kaplanmeierfitter.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'cyto_score {cyto_score}, tbi_status {tbi_status}, graft_type {graft_type}, vent_hist {vent_hist}') # Plot the survival function with a unique color for each group kaplanmeierfitter.plot_survival_function(color=plt.cm.tab10(group_data['cyto_score'] % 10)) # Using colormap for variety # Customize the plot plt.title('Kaplan-Meier Survival Curve') plt.xlabel('Time (months)') plt.ylabel('Survival Probability') plt.legend() plt.show()2 نقاط
-
اريد صورة للاحرف والارقام والرموز بنظام اسكي2 نقاط
-
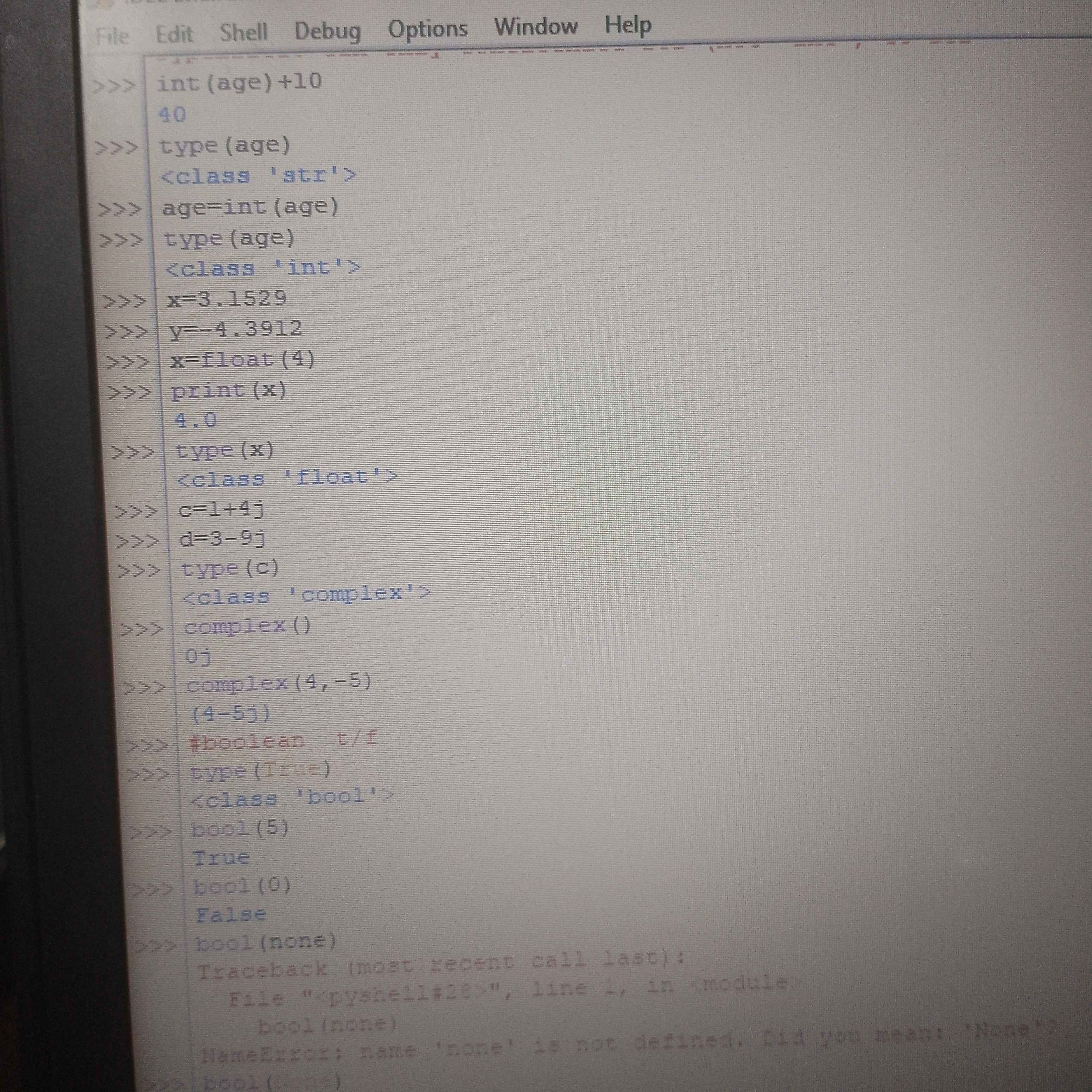
السلام عليكم ورحمة الله وبركاته عندي سؤالين الاول ليش ما يقدر اغير على كود عملتلو run? اما السؤال الثاني انا كتبت. int(age) وعادي اعتبر انو age. عبارة عن رقم وجمعلها ال10بس لما اطبع شو نوع الage بكتب انو لسا str?
 2 نقاط
2 نقاط -
السلام عليكم انا هنا مش عاوز الكود ده يشتغل الا بعد ما الحلقه ماتخلص plt.title(f'Kaplan-Meier Curve for Cyto_Score {cyto_score}') plt.xlabel('Time (months)') plt.ylabel('Survival Probability') plt.tight_layout() plt.show() ودي الحلقه إنشاء كائنات Kaplan-Meier لكل متغير kaplanmeierfitter_cyto = KaplanMeierFitter() kaplanmeierfitter_tbi = KaplanMeierFitter() kaplanmeierfitter_graft = KaplanMeierFitter() kaplanmeierfitter_vent = KaplanMeierFitter() # Iterate through each unique combination of 'cyto_score', 'tbi_status', 'graft_type', and 'vent_hist' for (cyto_score, tbi_status, graft_type, vent_hist), indices in data_train.groupby(['cyto_score', 'tbi_status', 'graft_type', 'vent_hist']).groups.items(): # Filter the data based on the current group group_data = data_train.loc[indices] # Fit the Kaplan-Meier model for each feature kaplanmeierfitter_cyto.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'Cyto_Score {cyto_score}') kaplanmeierfitter_tbi.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'tbi_status {tbi_status}') kaplanmeierfitter_graft.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'graft_type {graft_type}') kaplanmeierfitter_vent.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'vent_hist {vent_hist}') kaplanmeierfitter_cyto.plot_survival_function() هل اقدر اعمل حاجه زي كده1 نقطة
-
يمكن تحريك أمر عرض الرسم البياني خارج الحلقة وهناك طريقتان لتحقيق ذلك يمكنك تحريك أوامر plt خارج الحلقة مباشرة: for (cyto_score, tbi_status, graft_type, vent_hist), indices in data_train.groupby(['cyto_score', 'tbi_status', 'graft_type', 'vent_hist']).groups.items(): group_data = data_train.loc[indices] kaplanmeierfitter_cyto.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'Cyto_Score {cyto_score}') kaplanmeierfitter_tbi.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'tbi_status {tbi_status}') kaplanmeierfitter_graft.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'graft_type {graft_type}') kaplanmeierfitter_vent.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'vent_hist {vent_hist}') kaplanmeierfitter_cyto.plot_survival_function() plt.title('Kaplan-Meier Curves for All Cyto_Scores') plt.xlabel('Time (months)') plt.ylabel('Survival Probability') plt.tight_layout() plt.show() أو تخزين كل المنحنيات ثم عرضها مرة واحدة في النهاية: plt.figure(figsize=(10, 6)) for (cyto_score, tbi_status, graft_type, vent_hist), indices in data_train.groupby(['cyto_score', 'tbi_status', 'graft_type', 'vent_hist']).groups.items(): group_data = data_train.loc[indices] kaplanmeierfitter_cyto.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'Cyto_Score {cyto_score}') kaplanmeierfitter_cyto.plot_survival_function(ci_show=False) plt.title('Kaplan-Meier Curves for All Cyto_Scores') plt.xlabel('Time (months)') plt.ylabel('Survival Probability') plt.tight_layout() plt.show() وأرى أنّ الطريقة الثانية أفضل إذا كنت تريد عرض جميع المنحنيات في رسم بياني واحد بشكل أوضح ستحصل على رسم بياني واحد يحتوي على جميع منحنيات البقاء لمختلف قيم Cyto_Score.1 نقطة
-
وعليكم السلام ورحمة الله تعالى وبركاته، في الحقيقة لا يوجد برنامج ثابت للمراجعة يمكن تعميمه على جميع الطلبة، وهذا الأمر في الغالب لا ينجح، لأنّ الظروف اليومية تختلف من شخص إلى آخر، لذا من الأحسن عمل برنامج مرن خاص بك مثلما تفعل الآن مع التركيز مع دروس وشروحات المدرب وعمل الجوانب التطبيقية ورفع المشاريع وفي حال لم تفهم أي جزئية يمكن طرحها علينا وسنجيبك. ولا أنصح بالحفظ وما شابه ذلك، البرمجة لا تحتاج لحفظ ولا تتطلب ذلك على الإطلاق، إنما التعود على البرمجة والتدريب المستمر هو الذي يجعلك تتذكر الأكواد والمفاهيم في حال فهمتها جيدا وطبقت عليها فلن تنساها خاصة إذا كنت تخصص أوقاتا للمراجعة. https://academy.hsoub.com/questions/18294-حل-مشكلة-نسيان-دروس-البرمجة/ https://academy.hsoub.com/questions/12276-مشكل-النسيان/ https://academy.hsoub.com/questions/25392-عندي-مشكلة-في-طريقة-التعلم-وهي-أنني-أنسى-كثيرًا/1 نقطة
-
لديك استخدام غير صحيح ل groupby.groups وفلترة البيانات باستخدام الشروط أي من خلال الفلترة اليدوية للبيانات باستخدام شروط لكل مجموعة والأفضل استخدام الفهارس مباشرة: for (cyto_score, tbi_status, graft_type, vent_hist), indices in data_train.groupby(['cyto_score', 'tbi_status', 'graft_type', 'vent_hist']).groups.items(): group_data = data_train.loc[indices] كما لديك خطأ في استخدام الألوان بسبب التعامل مع سلسلة بدلا من قيمة مفردة group_data['cyto_score'] لذا يمكنك استخدام cyto_score مباشرة: color=plt.cm.tab10(cyto_score % 10) كما أنك تقوم برسم كل المنحنيات على نفس الرسم بدلا من استخدام شبكة وهذا ما تسبب في ازدحام المنحنيات في رسم واحد لذا استخدم شبكة فرعية (subplots) لكل مجموعة fig, axes = plt.subplots(2, 2, figsize=(12, 8)) kaplanmeierfitter.plot_survival_function(ax=axes[row, col]) ثم يمكنك تحديد عدد الفئات التي سيتم رسمها: if i >= len(axes): break وإضافة نطاقات الثقة عند الرسم: kaplanmeierfitter.plot_survival_function(ci_show=True)1 نقطة
-
لدي هذا المشروع اريد برمجة task5 and task7 كيف؟ numerical methods_programming project_first sem_2024_2025_part II_unlocked.pdf1 نقطة
-
يمكنك تقسيم الرسوم البيانية إلى شبكة تحتوي على 4 رسومات باستخدام مكتبة matplotlib لإنشاء شبكة من المحاور، و بهذه الطريقة يمكنك عرض الرسومات المختلفة بشكل مرتب في نافذة واحدة و يكون التعريف بهذا الشكل: from matplotlib import pyplot as plt from lifelines import KaplanMeierFitter # Create a Kaplan-Meier object kaplanmeierfitter = KaplanMeierFitter() # تحديد الشبكة (2×2) fig, axes = plt.subplots(2, 2, figsize=(15, 10)) # 2 صفوف × 2 أعمدة # تحويل الشبكة إلى قائمة لتسهيل التكرار axes = axes.flatten() # Iterate through each unique combination of 'cyto_score', 'tbi_status', 'graft_type', and 'vent_hist' groups = data_train.groupby(['cyto_score', 'tbi_status', 'graft_type', 'vent_hist']).groups for i, (group_key, group_indices) in enumerate(groups.items()): # التوقف إذا تم رسم 4 رسومات فقط if i >= 4: break # Filter the data based on the current group group_data = data_train.loc[group_indices] # Fit the Kaplan-Meier model kaplanmeierfitter.fit(group_data['efs_time'], event_observed=group_data['efs'], label=f'cyto_score {group_key[0]}, tbi_status {group_key[1]}, graft_type {group_key[2]}, vent_hist {group_key[3]}') # Plot on the corresponding subplot kaplanmeierfitter.plot_survival_function(ax=axes[i], color=plt.cm.tab10(group_data['cyto_score'] % 10)) # Customize each subplot axes[i].set_title(f'Group: cyto_score {group_key[0]}, tbi_status {group_key[1]}') axes[i].set_xlabel('Time (months)') axes[i].set_ylabel('Survival Probability') # تحسين المسافات بين الرسومات plt.tight_layout() # عرض الرسوم plt.show() هكذا يتم إنشاء شبكة من الرسومات باستخدام plt.subplots(2, 2) مما يعني 4 رسومات أي 2 صفوف × 2 أعمدة، و أيضا استخدمنا axes.flatten() لتحويل المحاور إلى قائمة لتسهيل التكرار عليها، ثم نقوم بتحديد عدد الرسومات لا يزيد عن 4 باستخدام الشرط، و كل مجموعة يتم رسمها على المحور الخاص بها باستخدام ax=axes[i].1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. أولا لنكن متفقين أن كل شخص مختلف عن الأخر في طبيعة المذاكرة والفهم فهناك من يستطيع فهم الدرس من أول مرة وهناك من يفهمه من ثاني مرة وهناك من يجب عليه التكرار اكثر من مرة ليفهم الدرس تماما . وهذا طبيعي فالجميع متفاوتون في القدرات . لهذا بالنسبة إلى تكرار الدروس فهذا يعتمد على فهمك فينبغي عليك تكرار الدرس حتي تتأكد من فهمه 100% فلو فهمته من أول مرة فلاحاجة إلى تكراره مرتين . وتأكد من التطبيق مع المدرب حيث المذاكرة فقط لن تساعدك بل ينبغي التطبيق حتي تترسخ المعلومات لديك . ويمكنك قراءة الإجابات التالية لمزيد من النصائح حول كيفية المذاكرة للدورات :1 نقطة
-
تحليل Kaplan-Meier هو تقنية إحصائية تستخدم لتقدير دالة البقاء وتحليل الوقت حتى حدوث حدث معين، مثل الوفاة أو الشفاء، و نستخدم هذا التحليل بشكل واسع في الأبحاث الطبية لدراسة بقاء المرضى بعد تشخيص مرض أو تلقي علاج، وفي مجالات أخرى مثل الهندسة لتحليل موثوقية الأنظمة، أو في الأعمال لدراسة مدة احتفاظ العملاء بالخدمات، و تعتمد الطريقة على تقسيم البيانات إلى خطوات زمنية بناء على الأوقات التي حدث فيها الحدث المدروس، مع حساب احتمال البقاء عند كل نقطة زمنية، حيث يأخذ Kaplan-Meier في الحسبان البيانات غير المكتملة مثل المرضى الذين خرجوا من الدراسة قبل حدوث الحدث، مما يجعله أداة فعالة لتحليل بيانات البقاء.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إن تحليل البقاء باستخدام مؤشر تقدير كابلان ماير هو طريقة إحصائية يتم إستخدامها لتقدير دالة البقاء (Survival Function) لمجموعة من الأفراد أو العينات التي خضعت لدراسة بمرور الوقت. والهدف من هذه الطريقة هو تقدير احتمالية البقاء (Survival Probability) على قيد الحياة حتى فترة زمنية معينة .حيث في بعض الدراسات، مثل دراسات السرطان أو الدراسات السريرية لا يعاني جميع الأفراد من التوقع المستهدف مثل الوفاة أو تدهور الحالة. ويمكنك قراءة المقال التالي لشرح ما هو تحليل البقاء survival analysis و كيف يتم إستخدام تقدير كابلان ماير :1 نقطة
-
تحليل كابلان ماير هو طريقة إحصائية تستخدم لفهم المدة الزمنية حتى حدوث حدث معين مثل المدة التي يبقى فيها العميل مشتركا في خدمة معينة أو المدة الزمنية التي يظل فيها جهاز إلكتروني يعمل قبل أن يحتاج إلى صيانة أو المدة التي يبقى فيها منتج ما في السوق قبل أن يتم إيقافه وغيرها من الأمثلة التي توضح وتحليل كابلان ماير هو جزء من تحليل البقاء وهو إحدى الطرق الأساسية المستخدمة داخل هذا المجال فتحليل البقاء (Survival Analysis) هو الإطار العام الذي يتناول دراسة الزمن حتى حدوث حدث معين (مثل إلغاء الاشتراك، حدوث خطأ تقني، انتهاء مدة منتج) ويشمل طرقا مختلفة لتحليل بيانات البقاء منها منحنيات كابلان ماير ونماذج الانحدار مثل نموذج كوكس (Cox Proportional Hazards Model) وأساليب أكثر تعقيدا تأخذ في الاعتبار تأثير عدة متغيرات وتحليل كابلان هو واحدة من الأدوات المستخدمة داخل تحليل البقاء يمكنك دراسة المزيد من هنا:1 نقطة
-
السلام عليكم لدي مشكلة لم اجد لها حل و هي عند ربط لابتوبي على شاشة مونيتور تظهر شاشة سوداء في شاشة المونيتور و لايظهر لي محتوى اللابتوب على الشاشة مع العلم اني استخدمت نفس اللابتوب و نفس الكيبل على شاشة عادية (شاشة المنزل) عرض محتوى اللابتوب عليها ممكن حلول لحل هذه المشكلة مع العلم ان شاشة تعرض محتوى اللابتوب على منفذ VGA و لكن لا تعرض على منفذ HDMI1 نقطة
-
طبيعي ما احصل رد بعد ثلاثين ساعة من التواصل؟1 نقطة
-
لدي مشكلة من ناحية شرط حفظ المشاريع, حيث انني لم اعلم بهذا الشرط الا متاخرا, لكن يوجد لدي تعليقات تثبت تطبيقي ومتابعتي وتطبيقات خارج مسار الدورة تثبت فهمي1 نقطة
-
انا طبقت كل شي بس عندي سؤال ليش كتبنا الكود على ملفين شو الفرق بينهم ؟؟
 1 نقطة
1 نقطة -
يمكن للمبرمجين الاستفادة من مهاراتهم التقنية في مجالات متعددة يمكن لشخص مثلا يدرس إدارة الأعمال أن يستخدم مهارات البرمجة لتطوير تطبيقات تساعد في تحليل البيانات أو تحسين العمليات وغيرها. بالنسبة لدراسة العلوم الشرعية فهذا الأمر يختلف في حالة ما أنك تريد دراستها في الجامعة أو في معهد خارجي أو بشكل حر، ويعتمد عليك أنت وعلى التوقيت الذي تقدمه لها، وبرنامجك الزمني، أما بالنسبة للعمل كمبرمج فهو أيضا مسألة تحتاج توضيحا إن كنت تعمل عملا حرا، أو تعمل في إطار وظيفة معينة، عمومية أو خاصة، وأنت الوحيد القادر على تحديد ما يمكنك فعله وما لا تستطيعه بناء على برنامجك. كمبرمج مستقل لو كان لي خيار دراسة العلم الشرعي لفعلت ذلك ولكن ليس في الجامعة لأني تخصصت في تخصص آخر، ولكن التخصص في تخصص تقني أو أدبي غير الشريعة لا يعني أن الطالب لن يستطيع أخذ العلوم الشرعية فالعديد من العلماء والشيوخ والدعاة هم لم يكونوا يوما خريجي مدارس وجامعات.1 نقطة
-
لا يوجد أي طريقة مضمنة مباشرة للحصول على قيمة P-value أو فترات الثقة، لكن يمكن الحصول عليها من خلال استخدام مكتبات أخرى مثل statsmodels أو عن طريق حساب هذه القيم يدويا، يمكن نقل النموذج أو البيانات إلى مكتبة مثل statsmodels للحصول على الإحصاءات المطلوبة مثل P-value، معاملات الثقة، والخطأ المعياري ثم يمكن حساب هذه القيم يدويا باستخدام مفاهيم الإحصاء (مثل الخطأ المعياري والاحتمالات التوزيعية)، أو باستخدام مكتبات مثل scipy وnumpy.1 نقطة
-
السلام عليكم كنت اتسائل عن سؤال يدور في ذهني يجب على جميع المبرمجين عند قيامهم ببرمجة مشروع موقع ان يتم تأمينه من جميع النواحي وفلتره الطلبات وغيرها الان اريد فقط مالذي احتاج اضافته في التحقق من المستخدم هل token ام الكوكيز ام uuid الخاص بـuser id او csrf وكيفية التعامل مع devise في Ruby on Rails ؟1 نقطة
-
للتحقق من المستخدم، هناك عدة استراتيجيات، منها JWT عبارة عن معيار مفتوح يستخدم لنقل البيانات بين الأطراف ككائن JSON مضغوط وآمن، بحيث تستخدم JWT لتأمين API ةيحصل المستخدم على رمز JWT بعد تسجيل الدخول، ويجب عليه إرسال هذا الرمز مع كل طلب لاحق. بعد ذلك يوجد الكوكيز هي ملفات صغيرة تُخزن على جهاز المستخدم وتُستخدم لتخزين معلومات الجلسة، وعند تسجيل الدخول، يمكن تخزين معرف الجلسة في الكوكيز، ويتم إرسال الكوكيز مع كل طلب إلى الخادم للتحقق من الجلسة. ويتوفر UUID هو معرف فريد يمكن استخدامه لتعريف المستخدمين بشكل آمن وفريد، وتُخزن UUID في قاعدة البيانات ويُستخدم لتعريف المستخدمين في التطبيقات. أما CSRF هو نوع من الهجمات التي تُجبر المستخدم على تنفيذ إجراءات غير مرغوب فيها على موقع ويب آخر يتمتع فيه المستخدم بالتصديق، والإعتماد على CSRF tokens هو آلية شائعة لمنع تلك الهجمات. وDevise هو حل كامل لمصادقة المستخدمين في تطبيقات Rails، بحيث يوفر Devise العديد من الميزات الجاهزة مثل التسجيل، تسجيل الدخول، استعادة كلمة المرور، تأكيد الحساب، وغيرها، تستطيع تثبيته كالتالي: إضافته إلى ملف gem: gem 'devise' ثم تثبيت Devise: rails generate devise:install بعد التثبيت، ستحتاج إلى اتباع التعليمات التي تظهر على الشاشة لتكوين Devise وإعداد البريد الإلكتروني لإرسال روابط تأكيد الحساب واستعادة كلمة المرور. وفي حال تقوم بإنشاء تطبيق جديد، فتستطيع إنشاء نموذج المستخدم باستخدام Devise: rails generate devise User ثم ترحيل قاعدة البيانات: rails db:migrate بعد ذلك إضافة مصادقة إلى عناصر التحكم من خلال before_action لحماية مساراتك: class ApplicationController < ActionController::Base before_action :authenticate_user! end و Rails يوفر حماية مدمجة ضد هجمات CSRF، لأنه يتم تضمين CSRF tokens تلقائيًا في النماذج والطلبات AJAX. ولو تحتاج استخدام JWT مع Devise، فهناك gem مثل devise-jwt ستوفر لك JWT مع Devise.1 نقطة
-
 يُعَدّ تحليل البقاء survival analysis أحد طرق وصف مدة بقاء شيء ما، حيث يستخدَم لدراسة عمر الإنسان غالبًا، ولكنه ينطبق أيضًا على بقاء الأجهزة الميكانيكية والإلكترونية، أو قد يدل على الفترات الزمنية التي تسبق حدثًا ما. فلربما قد رأيت سابقًا مصطلح "معدل البقاء على قيد الحياة لمدة 5 سنوات" إذا شُخِّص أحد معارفك بمرض خطير، وهو احتمال بقاء المريض على قيد الحياة لمدة 5 سنوات بعد التشخيص، علمًا أنّ هذا التقدير والإحصاءات ذات الصلة هي نتيجة لتحليل البقاء. توجد الشيفرة الخاصة بهذا المقال في الملف survival.py، في مستودع الشيفرات ThinkStats2 على GitHub. منحنيات البقاء يُعَدّ منحني البقاء survival curve الذي يرمز له بـ S(t) المفهوم الأساسي في تحليل البقاء، كما يُعَدّ دالةً تحوِّل المدة t إلى احتمال البقاء أطول من t، ويُعَدّ حساب منحني البقاء سهلًا إذا علمت توزيع المدة أو مدة الحياة، حيث يمكن حساب المنحني عندها عن طريق حساب مكمل دالة التوزيع التراكمي كما يلي: S(t)=1-CDF(t) حيث يكون CDF(t) هو احتمال أن تكون مدة البقاء على قيد الحياة أقل أو تساوي t، ونعلم مثلًا في مجموعة بيانات المسح الوطني لنمو الأسرة مدة حالات الحمل التامة التي بلغ عددها 1189 حالة، حيث يمكننا قراءة هذه البيانات وحساب دالة التوزيع التراكمي كما يلي: preg = nsfg.ReadFemPreg() complete = preg.query('outcome in [1, 3, 4]').prglngth cdf = thinkstats2.Cdf(complete, label='cdf') يدل رمز الخرج 1 على ولادة حية، ويدل رمز الخرج 3 على ولادة جنين ميت، في حين يدل رمز الخرج 4 على حالة إجهاض لا إرادية -أي غير متعمدة من قبل الأم-، كما استبعدنا حالات الإجهاض المتعمدة وحالات الحمل خارج الرحم وحالات الحمل التي كانت مستمرة أثناء مقابلة المستجيبة وذلك لأغراض هذا التحليل، كما يأخذ تابع إطار البيانات query تعبيرًا بوليانيًا ويقيّمه لكل سطر، ومن ثم يحدِّد الأسطر التي ينتج عنها قيمة True. يوضِّح الشكل السابق دالة التوزيع التراكمي ومنحني البقاء لمدة الحمل في الأعلى؛ أما في الأسفل فيوضِّح منحني الخطر hazard curve، حيث عرّفنا كائنًا يغلِّف صنف Cdf وينفذ الواجهة: class SurvivalFunction(object): def __init__(self, cdf, label=''): self.cdf = cdf self.label = label or cdf.label @property def ts(self): return self.cdf.xs @property def ss(self): return 1 - self.cdf.ps يزودنا الصنف SurvivalFunction بخاصيتين اثنتين هما ts وهي تسلسل مدد الحياة وss التي هي منحني البقاء، إذ تُعَدّ الخاصية في لغة بايثون تابعًا يمكن استدعاؤه كما لو أنه متغير، كما يمكننا استنتاج الصنف SurvivalFunction عن طريق تمرير دالة التوزيع التراكمي لمدة الحياة كما يلي: sf = SurvivalFunction(cdf) كما يزودنا الصنف SurvivalFunction بالدالتين __getitem__ وProb اللتين تقيّمان منحني البقاء. # class SurvivalFunction def __getitem__(self, t): return self.Prob(t) def Prob(self, t): return 1 - self.cdf.Prob(t) يُعَدّ sf[13] على سبيل المثال نسبة حالات الحمل التي تجاوزت الثلث الأول من الحمل: >>> sf[13] 0.86022 >>> cdf[13] 0.13978 نرى أنّ 86% من حالات الحمل تتجاوز الثلث الأول من الحمل؛ أما النسبة المتبقية 14% فهي لا تتجاوز هذه المدة، كما يزودنا الصنف SurvivalFunction بالدالة Render التي ترسم sf باستخدام الدوال الموجودة في المكتبة thinkplot: thinkplot.Plot(sf) يُظهر الشكل السابق الموجود في الأعلى النتيجة، حيث يكون المنحني مسطحًا تقريبًا بين الأسبوعين 13 و26، مما يدل على أن عدد قليل من حالات الحمل تنتهي في الثلث الثاني من الحمل، ويكون المنحني أكثر حدةً عند حوالي 39 أسبوعًا وهي أكثر فترات الحمل شيوعًا. دالة الخطر يمكننا اشتقاق دالة الخطر hazard function من منحني البقاء، حيث تُعَدّ دالة الخطر لمدة الحمل دالةً تحوِّل الزمن t إلى نسبة حالات الحمل التي تستمر حتى المدة t ومن ثم تنتهي عند t، ونقول بصورة أدق: λ(t) = S(t) − S(t+1) S(t) يُعَدّ البسط نسبة مدة الحياة التي تنتهي عند t وهي تمثِّل أيضًا دالة الكثافة الاحتمالية عند t أي PMF(t)، كما يزودنا الصنف SurvivalFunction بالدالة MakeHazard التي تحسب دالة الخطر: # class SurvivalFunction def MakeHazard(self, label=''): ss = self.ss lams = {} for i, t in enumerate(self.ts[:-1]): hazard = (ss[i] - ss[i+1]) / ss[i] lams[t] = hazard return HazardFunction(lams, label=label) حيث يُعَدّ الكائن HazardFuntion مغلِفًا لسلسلة بانداز: class HazardFunction(object): def __init__(self, d, label=''): self.series = pandas.Series(d) self.label = label قد يكون d قاموسًا أو أيّ نوع آخر قادر على استنساخ سلسلة تتضمن سلسلةً أخرى، في حين يكون label سلسلةً نصيةً مستخدَمةً لتحديد HazardFunction عند رسمه، كما يزودنا HazardFunction بالدالة __getitem__، وبالتالي يمكننا تقييمه كما يلي: >>> hf = sf.MakeHazard() >>> hf[39] 0.49689 لذا تنتهي حوالي 50% من بين جميع حالات الحمل التي تستمر حتى الأسبوع 39 في الأسبوع 39. يُظهر الشكل السابق الموجود في الأسفل دالة الخطر hazard function لمدة الحمل، كما نرى أنّ دالة الخطر بعد الأسبوع 42 تصبح غير منتظمة لأنها مبنية على عدد صغير من الحالات، لكن بخلاف ذلك يكون شكل المنحني كما هو متوقع، بحيث يبلغ ذروته عند الأسبوع 30 تقريبًا ويصبح في الثلث الأول أعلى من الثلث الثاني، كما تُعَدّ دالة الخطر مفيدةً لوحدها، لكنها أيضًا أداةً مهمةً لتقدير منحنيات البقاء كما سنرى في القسم التالي. استنتاج منحنيات البقاء إذا علمت دالة التوزيع التراكمي CDF، فمن السهل حساب دالة البقاء ودالة الخطر، لكن من الصعب في كثير من المواقف الواقعية قياس توزيع مدة الحياة مباشرةً ويجب علينا استنتاجها، فلنفترض مثلًا أنك تراقب مجموعةً من المرضى لترى المدة التي بقوا فيها على قيد الحياة بعد التشخيص، وبما أنّ التشخيص لا يكون في اليوم نفسه لكل المرضى، فسيعيش بعض المرضى فترةً أطول من غيرهم في أي فترة من الزمن، وبالطبع نعلم مدة بقاء المرضى الذين تُوفوا، إلا أننا لا نعلم مدة بقاء المرضى الذين لا زالوا على قيد الحياة وإنما لدينا حدًا أدنى لمدة البقاء. يمكننا حساب منحني البقاء إذا انتظرنا وفاة جميع المرضى، لكننا لن نستطيع الانتظار مدةً طويلةً إذا كنا بصدد تقييم فعالية دواء جديد، لذا نحتاج إلى تقدير منحنيات البقاء باستخدام معلومات غير مكتملة، وبالانتقال إلى مثال مُبهج، استخدمنا بيانات المسح الوطني لنمو الأسرة لحساب مدة بقاء المستجيبين بدون أول حالة زواج، أي المدة التي تسبق أول حالة زواج، بالطبع فإن المستجيبين هم من النساء كون الأسئلة تخص حالات الحمل، كما يتراوح مدى عمر المستجيبات بين 14 و 44 سنة، وبالتالي تزودنا مجموعة البيانات بلمحة عن النساء في مراحل مختلفة من حياتهن. تتضمن مجموعة البيانات بالنسبة للنساء المتزوجات تاريخ أول زواج بالإضافة إلى عمر المرأة عندها؛ أما بالنسبة لغير المتزوجات فنحن نعلم عمر المستجيبة أثناء المسح لكننا لا نعلم متى ستتزوج أو أنها ستتزوج حتى، ونظرًا لأننا نعلم عمر أول حالة زواج لبعض النساء، فسيبدو لنا مغريًا استبعاد بقية النساء وحساب دالة التوزيع التراكمي للبيانات المعلومة، ولكنها فكرة سيئة لأن النتيجة ستكون في هذه الحالة مضللةً جدًا لسببين اثنين هما: سينتج عن هذا مبالغة في تمثيل النساء الأكبر عمرًا، لأنه من المرجح أن تكون هذه الفئة متزوجة أثناء إجراء المسح. سينتج مبالغة في تمثيل النساء المتزوجات. سيؤدي هذا التحليل في الواقع إلى استنتاج مفاده أنّ جميع النساء يتزوجن، وهذا الأمر غير صحيح وضوحًا. تقدير كابلان ماير ليس من المفضل في هذا المثال تضمين حالات النساء غير المتزوجات وإنما هو أمر ضروري، وهو ما يقودنا إلى إحدى الخوارزميات الأساسية في تحليل البقاء والتي هي تقدير كابلان ماير Kaplan-Meier estimation. تستند الفكرة العامة على استخدام البيانات لتقدير دالة الخطر ومن ثم تحويل دالة الخطر إلى منحني البقاء، وإذا أردنا تقدير تابع الخطر، فيمكننا من أجل كل عمر الأخذ في الحسبان: (1) عدد النساء اللواتي تزوجن في هذا العمر و(2) عدد النساء "المعرضات لخطر" الزواج، وهذا يتضمن النساء اللواتي لم يتزوجن من قبل، وإليك الشيفرة الموافقة كما يلي: def EstimateHazardFunction(complete, ongoing, label=''): hist_complete = Counter(complete) hist_ongoing = Counter(ongoing) ts = list(hist_complete | hist_ongoing) ts.sort() at_risk = len(complete) + len(ongoing) lams = pandas.Series(index=ts) for t in ts: ended = hist_complete[t] censored = hist_ongoing[t] lams[t] = ended / at_risk at_risk -= ended + censored return HazardFunction(lams, label=label) تُعَدّ complete أنها الحالات الكاملة التي رُصِدَت، وتكون في مثالنا هذا أعمار المستجيبات عندما تزوجن، في حين تُعَدّ ongoing أنها الحالات غير الكاملة وهي أعمار النساء غير المتزوجات في المسح. نحسب بدايةً hist_complete، وهو دالة عدادة Counter تحوِّل العمر إلى عدد النساء المتزوجات في هذا العمر، كما نحسب hist_ongoing هو دالة عدادة Counter تحوِّل العمر إلى عدد النساء غير المتزوجات اللواتي قوبِلن في ذلك العمر؛ أما ts فهو اجتماع الأعمار التي تزوجت فيها المستجيبات والأعمار التي قوبلت فيها النساء غير المتزوجات مرتبًا ترتيبًا تصاعديًا، كما تتتبّع at_risk عدد المستجيبات المعرضات للخطر في كل عمر وهو العدد الكلي للمستجيبات، وتُخزن النتيجة في سلسلة Series بانداز Pandas والتي تحول كل عمر إلى دالة الخطر المقدَّرة في ذلك العمر. نتعامل في كل مرور على الحلقة مع عمر واحد t ونحسب عدد الأحداث التي تنتهي عند t -أي عدد المستجيبات المتزوجات عند هذا العمر- وعدد الأحداث التي أوقِفت عند t -أي عدد النساء اللواتي قوبِلن عند t ولكن تواريخ زواجهن المستقبلية موقفة censored- ويشير مصطلح "أوقف" إلى أنّ البيانات غير متاحة بسبب عملية جمع البيانات، كما تُعَدّ دالة الخطر المُقدَّرة بأنها نسبة الحالات المعرَّضة للخطر والتي تنتهي عند t، ونطرح في نهاية الحلقة من at_risk عدد الحالات التي انتهت أو أوقفت عند t، ثم نمرِّر في النهاية lams إلى الباني HazardFunction ونُعيد النتيجة. منحني الزواج علينا تنظيف البيانات وتحويلها إذا أردنا اختبار هذه الدالة، علمًا أنّ المتغيرات التي نحتاجها من المسح الوطني لنمو الأسرة هي: cmbirth: يوم ميلاد كل مستجيبة وهو معلوم في كل الحالات. cmintvw: تاريخ مقابلة كل مستجيبة وهو معلوم في كل الحالات. cmmarrhx: تاريخ أول حالة زواج للمستجيبة إذا كانت متزوجةً وكان التاريخ معلومًا. evrmarry: قيمة هذا المتغير 1 إذا كانت المستجيبة قد تزوجت قبل تاريخ المقابلة و0 بخلاف ذلك. حيث أن المتغيرات الثلاثة الأولى مرمَّزة بنظام أشهر القرن وهو العدد الصحيح للأشهر منذ شهر 12 من عام 1899، أي يكون شهر القرن 1 هو شهر 1 من عام 1900، وسنقرأ في البداية ملف المستجيبات ونستبدل قيم cmmarrhx غير الصالحة كما يلي: resp = chap01soln.ReadFemResp() resp.cmmarrhx.replace([9997, 9998, 9999], np.nan, inplace=True ثم نحسب عمر كل مستجيبة عند الزواج وعند مقابلتها: resp['agemarry'] = (resp.cmmarrhx - resp.cmbirth) / 12.0 resp['age'] = (resp.cmintvw - resp.cmbirth) / 12.0 ثم نستخرِج complete وهو عمر النساء المتزوجات عند زواجهن واللاتي لم تزلن متزوجات، وongoing وهو عمر النساء اللاتي لا يحققن ما سبق أثناء المقابلة: complete = resp[resp.evrmarry==1].agemarry ongoing = resp[resp.evrmarry==0].age سنحسب أخيرًا دالة الخطر: hf = EstimateHazardFunction(complete, ongoing) يُظهر الشكل 13.2 (الموجود في الجهة العليا) دالة الخطر المُقدَّرة، وهي منخفضة في فترة المراهقة ومرتفعة في العشرينات من العمر وتنخفض في الثلاثينات وتعود لترتفع في الأربعينات، لكن هذا ناتج عملية التقدير، حيث سينتج عن زواج عدد صغير من النساء خطرًا مقدَّرًا كبيرًا مع نقصان المستجيبات لمعرضات للخطر، لكن سيخفف منحني البقاء من هذا الضجيج. تقدير منحني البقاء يمكننا تقدير منحني البقاء عند حصولنا على دالة الخطر، حيث أنّ فرصة البقاء بعد الوقت t هو فرصة البقاء لكل الأوقات بدءًا من بداية الرصد حتى t، وهو ناتج الجداء التراكمي لدالة الخطر المكملة: [1−λ(0)] [1−λ(1)] … [1−λ(t)] يزودنا الصنف HazardFunction بالدالة MakeSurvival التي تحسب هذا الجداء: # class HazardFunction: def MakeSurvival(self): ts = self.series.index ss = (1 - self.series).cumprod() cdf = thinkstats2.Cdf(ts, 1-ss) sf = SurvivalFunction(cdf) return sf حيث أنّ ts هو تسلسل الأوقات التي قُدِّرت فيها دالة الخطر، وss هو ناتج الجداء التراكمي لدالة الخطر المكملة، وبالتالي فهو منحني البقاء، كما يتوجب علينا حساب مكمل ss ومن ثم إنشاء Cdf واستنساخ كائن SurvivalFunction وذلك بسبب الطريقة التي يُنفَّذ بها SurvivalFunction. يوضَّح الشكل السابق الموجود في الأعلى دالة الخطر لعمر أول زواج؛ أما الذي في الأسفل فيوضَّح منحني البقاء، كما يُظهر الشكل السابق الموجود في الأسفل النتيجة، حيث يكون منحني البقاء أكثر حدةً بين العمرين 25 و35، وهو المدى الذي تتزوج فيه معظم النساء؛ أما بين العمرين 35 و45 فيكون المنحني مسطحًا تقريبًا، مما يشير إلى أنه من غير المرجح زواج النساء اللواتي لم يتزوجن قبل سن الخامس والثلاثين. كان منحني ما مثل المنحني السابق أساس مقال شهير ظهر في مجلة عام 1986، فقد نُشر في مجلة نيوزويك Newsweek أن احتمال موت امرأة غير متزوجة عمرها 40 على يد قاتل أكبر من احتمال زواجها، وانتشرت هذه الإحصائيات انتشارًا واسعًا وأصبحت جزءًا من الثقافة الشعبية، لكنها كانت خاطئةً لأنها بُنيَت على تحليل خاطئ، واتضح أنهم على خطأ بسبب التغيرات الثقافية التي كانت جاريةً حينها واستمرت بعدها، لذا فقد نشرت مجلة نيوزويك Newsweek مقالًا آخرًا اعترفوا فيه بأنهم كانوا مخطئين، ونرى أنه من الأفضل قراءة المزيد عن هذا المقال والإحصائية المبنية عليه وردود الفعل لأنه سيذكِّرك بالالتزام الأخلاقي الذي يحتم عليك إجراء التحليل بعناية وتفسير النتائج بحيادية وعرضها على الجمهور بدقة وصدق. فواصل الثقة ينتج عن تحليل كابلان-ماير تقديرًا واحدًا لمنحني البقاء ولكنه مهم لحساب عدم اليقين الناتج عن التقدير، كما توجد ثلاثة مصادر محتملة للخطأ على أساس العادة وهي خطأ القياس measurement error وخطأ أخذ العينات sampling error وخطأ النمذجة modeling error، حيث يُعَدّ خطأ القياس في هذا المثال صغيرًا غالبًا، أي يعلم الأشخاص التاريخ الصحيح لولادتهم وإن كانوا قد تزوجوا بالإضافة إلى تاريخ الزواج، ويفترض أنهم قدَّموا هذه المعلومات بدقة، وإليك الشيفرة التي تحسب خطأ أخذ العينات عن طريق تطبيق إعادة أخذ العينات: def ResampleSurvival(resp, iters=101): low, high = resp.agemarry.min(), resp.agemarry.max() ts = np.arange(low, high, 1/12.0) ss_seq = [] for i in range(iters): sample = thinkstats2.ResampleRowsWeighted(resp) hf, sf = EstimateSurvival(sample) ss_seq.append(sf.Probs(ts)) low, high = thinkstats2.PercentileRows(ss_seq, [5, 95]) thinkplot.FillBetween(ts, low, high) تأخذ الدالة ResampleSurvival الوسيطَين resp وهو إطار بيانات المستجيبين وiters وهو عدد المرات التي يجب فيها إعادة أخذ العينات، ومن ثم تحسب ts وهو تسلسل الأعمار وهنا سنقيِّم منحني البقاء، كما تقوم الدالة ResampleSurvival بالخطوات التالية ضمن الحلقة: تعيد أخذ عينات المستجيبين باستخدام ResampleRowsWeighted، ورأينا هذا في قسم إعادة أخذ العينات مع الأوزان في مقال المربعات الصغرى الخطية في بايثون. تستدعي EstimateSurvival التي تستخدِم العملية الموجودة في الأقسام السابقة بهدف تقدير منحني البقاء ومنحني الخطر. ثم تقيِّم منحني البقاء في كل عمر في ts. يُعَدّ ss_seq تسلسل منحنيات البقاء المقدَّرة، كما تأخذ الدالة PercentileRows هذا التسلسل وتحسب المئين الخامس والمئين الخامس والتسعين وتعيد فاصل الثقة 90% الخاص بمنحني البقاء. يوضِّح الشكل السابق منحني البقاء للعمر عند أول زواج الممثَّل بالخط الداكن وفاصل الثقة 90% المبني على إعادة أخذ العينات مع الأوزان والممثَّل بالخط الرمادي، كما يظهر الشكل السابق النتيجة ومنحني البقاء الذي قدَّرناه في القسم السابق، ويأخذ فاصل الثقة أوزان أخذ العينات بالحسبان على عكس المنحني المقدَّر الذي لا يضع الأوزان في حسبانه، علمًا أنَّ التناقض بينهما يشير إلى التأثير الكبير لأوزان أخذ العينات على التقدير وعلينا أخذ ذلك في الحسبان. تأثيرات الفوج يُعَدّ اعتماد الأجزاء المختلفة للمنحني المقدَّر على عدة مجموعات بأنه أحد تحديات تحليل البقاء، حيث أنّ جزء المنحني عند الوقت t مبني على المستجيبات اللاتي كان عمرهن t على الأقل أثناء المقابلة، لذا يحتوي الجزء الموجود في اليسار على بيانات جميع من شارك في المسح، في حين يحتوي الجزء الموجود في اليمين على المستجيبات الأكبر سنًا. إذا لم تكن صفات المستجيبات ذات الصلة متغيرةً بمرور الوقت، فلا توجد مشكلة بالطبع، لكن يبدو في هذه الحالة أنّ أنماط الزواج متغيرة بالنسبة للنساء المولودات في أجيال مختلفة، كما يمكننا البحث في هذا التأثير عن طريق تصنيف المستجيبات إلى مجموعات بحسب عقد الميلاد، علمًا أنّ المجموعات المشابهة لهذه أي المعرفة بتاريخ ميلاد أو حدث مشابه تدعى الأفواج cohorts، في حين تدعى الفروق بين المجموعات تأثيرات الفوج cohort effects. جمعنا بيانات الدورة السادسة من 2002 المستخدَمة في هذه السلسلة وبيانات الدورة السابعة من 2006-2010 المستخدَمة في قسم التكرار في مقال اختبار الفرضيات الإحصائية وبيانات الدورة الخامسة من 1995، حيث تحوي مجموعة البيانات كلها 30769 مستجيبةً، وذلك من أجل البحث في تأثيرات الفوج في بيانات الزواج في المسح الوطني لنمو الأسرة. resp5 = ReadFemResp1995() resp6 = ReadFemResp2002() resp7 = ReadFemResp2010() resps = [resp5, resp6, resp7] استخدمنا cmbirth من أجل كل إطار بيانات resp لحساب عقد ولادة كل مستجيبة: month0 = pandas.to_datetime('1899-12-15') dates = [month0 + pandas.DateOffset(months=cm) for cm in resp.cmbirth] resp['decade'] = (pandas.DatetimeIndex(dates).year - 1900) // 10 حيث أن المتغير cmbirth مرمَّز ليدل على العدد الصحيح للأشهر التي مضت منذ شهر 12 من عام 1899، فتمثِّل month0 هذا التاريخ على أساس كائن ختم زمني Timestamp، كما نستنسخ DateOffset من أجل كل تاريخ ميلاد والذي يحتوي على أشهر القرن ونضيفه إلى month0 لتكون النتيجة تسلسلًا من الأختام الزمنية TimeStamps التي يجري تحوَّل إلى النوع DateTimeIndex، ونستخرج أخيرًا year الذي يمثِّل السنة ونحسب decades الذي يمثِّل العقد. أعدنا أخذ العينات وصّنفنا المستجيبات حسب عقد الميلاد ورسمنا منحني البقاء وذلك لكي نحرص على أخذ أوزان أخذ العينات بالحسبان وإظهار التباين الناتج عن خطأ أخذ العينات أيضًا: for i in range(iters): samples = [thinkstats2.ResampleRowsWeighted(resp) for resp in resps] sample = pandas.concat(samples, ignore_index=True) groups = sample.groupby('decade') EstimateSurvivalByDecade(groups, alpha=0.2) تستخدِم بيانات الدورات الثلاثة للمسح الوطني لنمو الأسرة أوزانًا مختلفةً، لذا أعدنا أخذ عينات كل منها على حدة ثم استخدمنا concat لدمجها لتصبح إطار بيانات واحد، علمًا أنّ المعامِل ignore_index يشير إلى concat لكي لا يطابق المستجيبين حسب الفهرس وإنما ينشئ فهرسًا جديدًا من 0 إلى 30768، كما ترسم الدالة EstimateSurvivalByDecade منحنيات بقاء كل فوج. def EstimateSurvivalByDecade(resp): for name, group in groups: hf, sf = EstimateSurvival(group) thinkplot.Plot(sf) يوضِّح الشكل السابق منحنيات بقاء المستجيبات اللواتي ولدن ضمن عقود مختلفة، كما يظهر الشكل السابق النتائج ونرى عدة أنماط فيه وهي: النساء اللواتي ولدن في الخمسينيات هم أكثر من تزوج في عمر صغير، وكذلك فإن أفراد الفوج التالي تزوجن في عمر متأخر أكثر، والفوج التالي بعد الفوج السابق وهكذا، وبقوا على الأقل حتى عمر الثلاثين تقريبًا. تملك النساء اللواتي ولدن في ستينيات القرن الماضي نمطًا غريبًا، إذ تزوجت النساء هنا في عمر 25 بمعدل أبطأ من الفوج السابق، ولكن بعد عمر 25 أصبح معدل الزواج أسرع، لكن النساء في هذا الفوج تجاوزت فوج الخمسينيات عند عمر 32، واتضح أنَّ احتمال زواج النساء في عمر 44 هو المرجَّح، لكن النساء اللواتي ولدن في الستينيات بلغن عمر 25 بين عامَي 1985 و1995، ومن المغري اعتقاد أنّ المقال الذي ذكرناه منذ قليل قد تسبب في ازدياد حالات الزواج، لكنه تفسير رديء للغاية، ومع ذلك فإنه من المحتمل أن يكون المقال وردّ الفعل عليه مؤشرَين على حالة مزاجية أثرت على سلوك هذا الفوج. يملك فوج السبعينات نمطًا مشابهًا، حيث أن النساء هنا أقل احتمالًا لأن يتزوجن قبل عمر 25 إذا وازناه مع الأفواج السابقة، لكن هذا لهذا الفوج احتمالات مشابهة للأفواج السابقة فيما يخص الزواج عند عمر 35. احتمال أن زواج فوج الثمانينيات قبل 25 هو أقل من الفوج السابق، ولكن ما يحدث بعد ذلك هو غير واضح، وإذا أردنا بيانات أكثر، فعلينا الانتظار حتى الدورة التالية من المسح الوطني لنمو الأسرة. يمكننا توليد بعض التنبؤات ريثما تصلنا البيانات. الاستقراء الخارجي Extrapolation ينتهي منحني البقاء لفوج السبعينات عند عمر 38 تقريبًا؛ أما فوج الثمانينات فينتهي منحني البقاء الخاص به عند سن 28، وبالطبع فإن بيانات فوج التسعينات نادرة جدًا، كما يمكننا استقراء هذه المنحنيات خارجيًا عن طريق استعارة بيانات من الفوج السابق، حيث يزودنا الصنف HazardFunction بالتابع Extend الذي ينسخ الذيل من HazardFunction أطول كما يلي: # class HazardFunction def Extend(self, other): last = self.series.index[-1] more = other.series[other.series.index > last] self.series = pandas.concat([self.series, more]) يحتوي HazardFunction على سلسلة تحوِّل الوقت t إلى λ(t)، ويجد التابع Extend المتغير last وهو الفهرس الأخير في self.series،ثم يختار قيم من other التي تأتي بعد last ويضيفها إلى نهاية self.series، ويمكننا الآن توسيع HazardFunction الخاص بكل فوج وذلك بالاستعانة بقيم من الفوج السابق: def PlotPredictionsByDecade(groups): hfs = [] for name, group in groups: hf, sf = EstimateSurvival(group) hfs.append(hf) thinkplot.PrePlot(len(hfs)) for i, hf in enumerate(hfs): if i > 0: hf.Extend(hfs[i-1]) sf = hf.MakeSurvival() thinkplot.Plot(sf) حيث أن groups هو كائن GroupBy فيه معلومات المستجيبات مصنفة إلى مجموعات حسب عقد الولادة، كما تحسب الحلقة الأولى HazardFunction كل مجموعة، في حين توسِّع الحلقة الثانية كل HazardFunction بقيم من الفوج السابق له والذي قد يحتوي على قيم من المجموعة التي تسبقه أيضًا (أي قد يحتوي فوج الخمسينات على قيم من فوج الأربعينات وقد يحتوي فوج الأربعينات على قيم من فوج الثلاثينات وهكذا)، ثم تحوِّل كل HazardFunction إلى SurvivalFunction وترسمه. يوضِّح الشكل السابق منحنيات البقاء الخاصة بالمستجيبات اللواتي ولدن خلال عقود مختلفة، مع تنبؤات للأفواج اللاحقة، كما يُظهر الشكل السابق النتائج، وقد حذفنا فوج الخمسينات لجعل التنبؤات أكثر وضوحًا، وتقترح هذه النتائج أنه بحلول السن الأربعين ستتقارب الأفواج الأحدث مع فوج الستينيات وستمثل المستجيبات المتزوجات نسبةً تقل عن %20 من المجموع الكلي. العمر المتبقي المتوقع إذا كان لدينا منحني بقاء، فيمكننا حساب العمر المتبقي المتوقع على أساس دالة للعمر الحالي، أي إذا كان لدينا مثلًا منحني البقاء لطول الحمل من القسم الأول من هذا المقال، فيمكننا حساب الوقت المتوقع حتى حدوث المخاض والولادة، حيث تتمثل الخطوة الأولى في استخراج دالة الكثافة الاحتمالية PMF للأعمار، كما يزودنا الصنف SurvivalFunction بالتابع الذي يقوم بالمطلوب: # class SurvivalFunction def MakePmf(self, filler=None): pmf = thinkstats2.Pmf() for val, prob in self.cdf.Items(): pmf.Set(val, prob) cutoff = self.cdf.ps[-1] if filler is not None: pmf[filler] = 1-cutoff return pmf تذكر أنّ SurvivalFunction تحتوي على Cdf للعمر، وتنسخ الحلقة القيم والاحتمالات من Cdf إلى Pmf، كما تُعَدّ cutoff هي أعلى احتمال في Cdf، وهي 1 إذا كان Cdf كاملًا وأقل من 1 بخلاف ذلك، وإذا كان Cdf غير كامل، فسنُدخل القيمة المزوَّدة إلى filter لنكملها، لكن يُعَدّ Cdf لمدة الحمل كاملًا، لذا لا داع للقلق حول هذا الأمر؛ أما الخطوة التالية هنا فهي حساب العمر المتبقي المتوقع، حيث يعني المتوقع هنا المتوسط الحسابي، كما يزودنا SurvivalFunction بدالة تقوم بهذا أيضًا: # class SurvivalFunction def RemainingLifetime(self, filler=None, func=thinkstats2.Pmf.Mean): pmf = self.MakePmf(filler=filler) d = {} for t in sorted(pmf.Values())[:-1]: pmf[t] = 0 pmf.Normalize() d[t] = func(pmf) - t return pandas.Series(d) تأخذ RemainingLifetime الوسيط filterالذي يمرَّر إلى MakePmf وfunc وهو الدالة المستخدَمة لتلخيص توزيع العمر المتبقي؛ أما pmf فهي Pmf الأعمار المتبقية المستخرَجة من SurvivalFunction، وd هو قاموس يحتوي على النتائج وهو تحويل من العمر الحالي t إلى العمر المتبقي المتوقع. تمر الحلقة مرورًا تكراريًا على القيم في Pmf، وهي تحسب التوزيع الشرطي للأعمار المتبقية لكل قيمة من t، باعتبار أنّ العمر المتبقي يتجاوز t، فإنها تنجز هذه المهمة عن طريق إزالة القيم من Pmf الواحدة تلو الأخرى ومن ثم إعادة توحيد renoramlizing القيم المتبقية، كما تستخدِم بعدها func لتلخيص التوزيع الشرطي وفي هذا المثال النتيجة هي مدة الحمل المتوسطة باعتبار أنّ المدة تتجاوز t، كما نحصل على متوسط مدة الحمل المتبقية عن طريق طرح t. يوضِّح الشكل السابق مدة الحمل المتوقعة المتبقية في الجهة اليسرى؛ أما في الجهة اليمنى فيوضِّح السنوات حتى أول زواج، كما يُظهر الشكل السابق في الجهة اليسرى طول الحمل المتبقي المتوقع على أساس دالة للمدة الحالية، أي المدة المتبقية المتوقعة في الأسبوع 0 مثلًا هي حوالي 34 أسبوع، وهي أقل من طول الحمل الكامل -أي 39 أسبوع- لأن حالات الإجهاض التي حصلت في الثلث الأول قد خفضت من المتوسط. ينخفض المنحني ببطء في الثلث الأول، وتكون المدة المتبقية المتوقعة بعد 13 أسبوع قد انخفضت 9 أسابيع لتصبح 25 أسبوع، بعد ذلك ينخفض بسرعة أكبر، وذلك بمعدل انخفاض أسبوع كامل في كل أسبوع جديد، في حين ينخفض المنحني حوالي أسبوع أو أسبوعين في الفترة ما بين الأسبوع 37 والأسبوع 42، وتكون المدة المتبقية المتوقعة في هذه الفترة ثابتةً، أي لا تصبح الوجهة أقرب مع مرور الأسابيع، وتدعى العمليات التي تحمل هذه الخاصية بعمليات بلا ذاكرة memoryless لأن ليس للماضي تأثير على التنبؤات، علمًا أنّ هذا السلوك هو الأساس الرياضي لجملة الممرضات الشهيرة التي تثير الغضب: اقترب موعد الولادة ومتوقع أن تلدي في أيّ يوم الآن. يُظهر الشكل السابق في الجهة اليمنى الوقت الوسيط المتبقي حتى أول زواج على أساس دالة للعمر، حيث يكون الوسيط هو 14 عامًا بالنسبة لفتاة عمرها 11 عامًا، ويقل المنحني حتى عمر 22 حينما يصبح الوقت المتبقي الوسيط هو حوالي 7 سنوات، ويزداد مرةً أخرى بعدها وبحلول العمر 30 يعود إلى ما كان عليه أي 14 عامًا، ويمكننا استنادًا إلى هذه البيانات استنتاج أنّ للنساء صغيرات السن أعمارًا متبقيةً متناقصةً، وتدعى المكونات الميكانيكية المرتبطة بهذه الخاصية NBUE وهي اختصار لمِن المتوقع أن يكون الجديد أفضل من المستخدَم new better than used in expectation، أي من المتوقع بقاء الجزء الجديد فترةً أطول. تملك النساء اللواتي تجاوزت أعمارهن 22 سنة وقتًا متبقيًا متزايدًا حتى أول زواج، وتدعى المكونات الميكانيكية المرتبطة بهذه الخاصية UBNE وهي اختصار لمِن المتوقع أن يكون المستخدَم أفضل من الجديد used better than new in expectation، أي من المتوقع أن يبقى الجزء المستخدَم فترةً أطول، إذ يُعَدّ الأطفال حديثو الولادة مثلًا ومرضى السرطان هم UBNE أيضًا لأن العمر المتوقع لديهم يزيد كلما طالت مدة حياتهم، فقد حسبنا الوسيط median في هذا المثال بدلًا من المتوسط mean لأن Cdf غير كامل، ويتوقع منحني البقاء أن نسبة 20% من المستجيبات لن يتزوجن قبل سن 44، وبما أن سن الزواج الأول لهؤلاء النساء غير معلوم وقد يكون غير موجود، فلن نتمكن من حساب المتوسط. استبدلنا القيم غير المعلومة هنا بالقيمة np.inf وهي قيمة خاصة تمثِّل اللانهاية، أي أنها تجعل متوسط اللانهاية لكل الاعمار، لكن يبقى الوسيط محدَّدًا تمامًا طالما أنّ أكثر من 50% من الأعمار المتبقية نهائية، وهذا صحيح حتى عمر الثلاثين؛ أما بعدها فمن الصعب تحديد عمر متبقي متوقع له، وإليك الشيفرة التي تحسب وترسم هذه الدوال: rem_life1 = sf1.RemainingLifetime() thinkplot.Plot(rem_life1) func = lambda pmf: pmf.Percentile(50) rem_life2 = sf2.RemainingLifetime(filler=np.inf, func=func) thinkplot.Plot(rem_life2) حيث أن sf1 هو منحني البقاء لطول الحمل، ويمكن في هذه الحالة استخدام القيم الافتراضية للدالة RemainingLifetime؛ أما sf2 فهو منحني البقاء للعمر عند أول زواج، وfunc هو دالة تأخذ Pmf وتحسب وسيطها -أي المئين رقم 50-. تمارين يوجد الحل الخاص بهذا التمرين في chap13soln.py في مستودع الشيفرات ThinkStats2 على GitHub (وسائر ملفات التمارين). تمرين 1 يحتوي المتغير cmdivorcx في الدورتين السادسة والسابعة من المسح الوطني لنمو الأسرة على تاريخ طلاق المستجيبين من أول حالة زواج، وهي مرمَّزة بطريقة أشهر القرن. احسب مدة حالات الزواج التي انتهت بطلاق ومدة حالات الزواج المستمرة حتى الآن، وقدِّر منحني الخطر ومنحني البقاء لمدة الزواج، ثم استخدِم طريقة إعادة أخذ العينات resampling لمراعاة أوزان أخذ العينات، ثم وضِّح خطأ أخذ العينات بصريًا عن طريق رسم البيانات الناتجة عن عدة مرات أخذ عينات، علمًا أنه من الأفضل أن تفكِّر في تقسيم المستجيبين إلى مجموعات حسب عقد الولادة وربما حسب العمر عند أول حالة زواج. ترجمة وبتصرف للمقال Chapter 13 Survival analysis analysis من كتاب Think Stats: Exploratory Data Analysis in Python. اقرأ أيضًا الانحدار الإحصائي regression ودوره في ملاءمة النماذج المختلفة مع أنواع البيانات المتاحة نمذجة التوزيعات Modelling distributions في بايثون تحليل البيانات الاستكشافية لإثبات النظريات الإحصائية div table{margin-left:inherit;margin-right:inherit;margin-bottom:2px;margin-top:2px} td p{margin:0px;} .vbar{border:none;width:2px;background-color:black;} .hbar{display: block;border:none;height:2px;width:100%;background-color:black;} .display{border-collapse:separate;border-spacing:2px;width:auto;border:none;} .dcell{white-space:nowrap;padding:0px; border:none;} .dcenter{margin:0ex auto;} .theorem{text-align:left;margin:1ex auto 1ex 0ex;} table{border-collapse:collapse;} td{padding:0;} .cellpadding0 tr td{padding:0;} .cellpadding1 tr td{padding:1px;} .center{text-align:center;margin-left:auto;margin-right:auto;}1 نقطة
يُعَدّ تحليل البقاء survival analysis أحد طرق وصف مدة بقاء شيء ما، حيث يستخدَم لدراسة عمر الإنسان غالبًا، ولكنه ينطبق أيضًا على بقاء الأجهزة الميكانيكية والإلكترونية، أو قد يدل على الفترات الزمنية التي تسبق حدثًا ما. فلربما قد رأيت سابقًا مصطلح "معدل البقاء على قيد الحياة لمدة 5 سنوات" إذا شُخِّص أحد معارفك بمرض خطير، وهو احتمال بقاء المريض على قيد الحياة لمدة 5 سنوات بعد التشخيص، علمًا أنّ هذا التقدير والإحصاءات ذات الصلة هي نتيجة لتحليل البقاء. توجد الشيفرة الخاصة بهذا المقال في الملف survival.py، في مستودع الشيفرات ThinkStats2 على GitHub. منحنيات البقاء يُعَدّ منحني البقاء survival curve الذي يرمز له بـ S(t) المفهوم الأساسي في تحليل البقاء، كما يُعَدّ دالةً تحوِّل المدة t إلى احتمال البقاء أطول من t، ويُعَدّ حساب منحني البقاء سهلًا إذا علمت توزيع المدة أو مدة الحياة، حيث يمكن حساب المنحني عندها عن طريق حساب مكمل دالة التوزيع التراكمي كما يلي: S(t)=1-CDF(t) حيث يكون CDF(t) هو احتمال أن تكون مدة البقاء على قيد الحياة أقل أو تساوي t، ونعلم مثلًا في مجموعة بيانات المسح الوطني لنمو الأسرة مدة حالات الحمل التامة التي بلغ عددها 1189 حالة، حيث يمكننا قراءة هذه البيانات وحساب دالة التوزيع التراكمي كما يلي: preg = nsfg.ReadFemPreg() complete = preg.query('outcome in [1, 3, 4]').prglngth cdf = thinkstats2.Cdf(complete, label='cdf') يدل رمز الخرج 1 على ولادة حية، ويدل رمز الخرج 3 على ولادة جنين ميت، في حين يدل رمز الخرج 4 على حالة إجهاض لا إرادية -أي غير متعمدة من قبل الأم-، كما استبعدنا حالات الإجهاض المتعمدة وحالات الحمل خارج الرحم وحالات الحمل التي كانت مستمرة أثناء مقابلة المستجيبة وذلك لأغراض هذا التحليل، كما يأخذ تابع إطار البيانات query تعبيرًا بوليانيًا ويقيّمه لكل سطر، ومن ثم يحدِّد الأسطر التي ينتج عنها قيمة True. يوضِّح الشكل السابق دالة التوزيع التراكمي ومنحني البقاء لمدة الحمل في الأعلى؛ أما في الأسفل فيوضِّح منحني الخطر hazard curve، حيث عرّفنا كائنًا يغلِّف صنف Cdf وينفذ الواجهة: class SurvivalFunction(object): def __init__(self, cdf, label=''): self.cdf = cdf self.label = label or cdf.label @property def ts(self): return self.cdf.xs @property def ss(self): return 1 - self.cdf.ps يزودنا الصنف SurvivalFunction بخاصيتين اثنتين هما ts وهي تسلسل مدد الحياة وss التي هي منحني البقاء، إذ تُعَدّ الخاصية في لغة بايثون تابعًا يمكن استدعاؤه كما لو أنه متغير، كما يمكننا استنتاج الصنف SurvivalFunction عن طريق تمرير دالة التوزيع التراكمي لمدة الحياة كما يلي: sf = SurvivalFunction(cdf) كما يزودنا الصنف SurvivalFunction بالدالتين __getitem__ وProb اللتين تقيّمان منحني البقاء. # class SurvivalFunction def __getitem__(self, t): return self.Prob(t) def Prob(self, t): return 1 - self.cdf.Prob(t) يُعَدّ sf[13] على سبيل المثال نسبة حالات الحمل التي تجاوزت الثلث الأول من الحمل: >>> sf[13] 0.86022 >>> cdf[13] 0.13978 نرى أنّ 86% من حالات الحمل تتجاوز الثلث الأول من الحمل؛ أما النسبة المتبقية 14% فهي لا تتجاوز هذه المدة، كما يزودنا الصنف SurvivalFunction بالدالة Render التي ترسم sf باستخدام الدوال الموجودة في المكتبة thinkplot: thinkplot.Plot(sf) يُظهر الشكل السابق الموجود في الأعلى النتيجة، حيث يكون المنحني مسطحًا تقريبًا بين الأسبوعين 13 و26، مما يدل على أن عدد قليل من حالات الحمل تنتهي في الثلث الثاني من الحمل، ويكون المنحني أكثر حدةً عند حوالي 39 أسبوعًا وهي أكثر فترات الحمل شيوعًا. دالة الخطر يمكننا اشتقاق دالة الخطر hazard function من منحني البقاء، حيث تُعَدّ دالة الخطر لمدة الحمل دالةً تحوِّل الزمن t إلى نسبة حالات الحمل التي تستمر حتى المدة t ومن ثم تنتهي عند t، ونقول بصورة أدق: λ(t) = S(t) − S(t+1) S(t) يُعَدّ البسط نسبة مدة الحياة التي تنتهي عند t وهي تمثِّل أيضًا دالة الكثافة الاحتمالية عند t أي PMF(t)، كما يزودنا الصنف SurvivalFunction بالدالة MakeHazard التي تحسب دالة الخطر: # class SurvivalFunction def MakeHazard(self, label=''): ss = self.ss lams = {} for i, t in enumerate(self.ts[:-1]): hazard = (ss[i] - ss[i+1]) / ss[i] lams[t] = hazard return HazardFunction(lams, label=label) حيث يُعَدّ الكائن HazardFuntion مغلِفًا لسلسلة بانداز: class HazardFunction(object): def __init__(self, d, label=''): self.series = pandas.Series(d) self.label = label قد يكون d قاموسًا أو أيّ نوع آخر قادر على استنساخ سلسلة تتضمن سلسلةً أخرى، في حين يكون label سلسلةً نصيةً مستخدَمةً لتحديد HazardFunction عند رسمه، كما يزودنا HazardFunction بالدالة __getitem__، وبالتالي يمكننا تقييمه كما يلي: >>> hf = sf.MakeHazard() >>> hf[39] 0.49689 لذا تنتهي حوالي 50% من بين جميع حالات الحمل التي تستمر حتى الأسبوع 39 في الأسبوع 39. يُظهر الشكل السابق الموجود في الأسفل دالة الخطر hazard function لمدة الحمل، كما نرى أنّ دالة الخطر بعد الأسبوع 42 تصبح غير منتظمة لأنها مبنية على عدد صغير من الحالات، لكن بخلاف ذلك يكون شكل المنحني كما هو متوقع، بحيث يبلغ ذروته عند الأسبوع 30 تقريبًا ويصبح في الثلث الأول أعلى من الثلث الثاني، كما تُعَدّ دالة الخطر مفيدةً لوحدها، لكنها أيضًا أداةً مهمةً لتقدير منحنيات البقاء كما سنرى في القسم التالي. استنتاج منحنيات البقاء إذا علمت دالة التوزيع التراكمي CDF، فمن السهل حساب دالة البقاء ودالة الخطر، لكن من الصعب في كثير من المواقف الواقعية قياس توزيع مدة الحياة مباشرةً ويجب علينا استنتاجها، فلنفترض مثلًا أنك تراقب مجموعةً من المرضى لترى المدة التي بقوا فيها على قيد الحياة بعد التشخيص، وبما أنّ التشخيص لا يكون في اليوم نفسه لكل المرضى، فسيعيش بعض المرضى فترةً أطول من غيرهم في أي فترة من الزمن، وبالطبع نعلم مدة بقاء المرضى الذين تُوفوا، إلا أننا لا نعلم مدة بقاء المرضى الذين لا زالوا على قيد الحياة وإنما لدينا حدًا أدنى لمدة البقاء. يمكننا حساب منحني البقاء إذا انتظرنا وفاة جميع المرضى، لكننا لن نستطيع الانتظار مدةً طويلةً إذا كنا بصدد تقييم فعالية دواء جديد، لذا نحتاج إلى تقدير منحنيات البقاء باستخدام معلومات غير مكتملة، وبالانتقال إلى مثال مُبهج، استخدمنا بيانات المسح الوطني لنمو الأسرة لحساب مدة بقاء المستجيبين بدون أول حالة زواج، أي المدة التي تسبق أول حالة زواج، بالطبع فإن المستجيبين هم من النساء كون الأسئلة تخص حالات الحمل، كما يتراوح مدى عمر المستجيبات بين 14 و 44 سنة، وبالتالي تزودنا مجموعة البيانات بلمحة عن النساء في مراحل مختلفة من حياتهن. تتضمن مجموعة البيانات بالنسبة للنساء المتزوجات تاريخ أول زواج بالإضافة إلى عمر المرأة عندها؛ أما بالنسبة لغير المتزوجات فنحن نعلم عمر المستجيبة أثناء المسح لكننا لا نعلم متى ستتزوج أو أنها ستتزوج حتى، ونظرًا لأننا نعلم عمر أول حالة زواج لبعض النساء، فسيبدو لنا مغريًا استبعاد بقية النساء وحساب دالة التوزيع التراكمي للبيانات المعلومة، ولكنها فكرة سيئة لأن النتيجة ستكون في هذه الحالة مضللةً جدًا لسببين اثنين هما: سينتج عن هذا مبالغة في تمثيل النساء الأكبر عمرًا، لأنه من المرجح أن تكون هذه الفئة متزوجة أثناء إجراء المسح. سينتج مبالغة في تمثيل النساء المتزوجات. سيؤدي هذا التحليل في الواقع إلى استنتاج مفاده أنّ جميع النساء يتزوجن، وهذا الأمر غير صحيح وضوحًا. تقدير كابلان ماير ليس من المفضل في هذا المثال تضمين حالات النساء غير المتزوجات وإنما هو أمر ضروري، وهو ما يقودنا إلى إحدى الخوارزميات الأساسية في تحليل البقاء والتي هي تقدير كابلان ماير Kaplan-Meier estimation. تستند الفكرة العامة على استخدام البيانات لتقدير دالة الخطر ومن ثم تحويل دالة الخطر إلى منحني البقاء، وإذا أردنا تقدير تابع الخطر، فيمكننا من أجل كل عمر الأخذ في الحسبان: (1) عدد النساء اللواتي تزوجن في هذا العمر و(2) عدد النساء "المعرضات لخطر" الزواج، وهذا يتضمن النساء اللواتي لم يتزوجن من قبل، وإليك الشيفرة الموافقة كما يلي: def EstimateHazardFunction(complete, ongoing, label=''): hist_complete = Counter(complete) hist_ongoing = Counter(ongoing) ts = list(hist_complete | hist_ongoing) ts.sort() at_risk = len(complete) + len(ongoing) lams = pandas.Series(index=ts) for t in ts: ended = hist_complete[t] censored = hist_ongoing[t] lams[t] = ended / at_risk at_risk -= ended + censored return HazardFunction(lams, label=label) تُعَدّ complete أنها الحالات الكاملة التي رُصِدَت، وتكون في مثالنا هذا أعمار المستجيبات عندما تزوجن، في حين تُعَدّ ongoing أنها الحالات غير الكاملة وهي أعمار النساء غير المتزوجات في المسح. نحسب بدايةً hist_complete، وهو دالة عدادة Counter تحوِّل العمر إلى عدد النساء المتزوجات في هذا العمر، كما نحسب hist_ongoing هو دالة عدادة Counter تحوِّل العمر إلى عدد النساء غير المتزوجات اللواتي قوبِلن في ذلك العمر؛ أما ts فهو اجتماع الأعمار التي تزوجت فيها المستجيبات والأعمار التي قوبلت فيها النساء غير المتزوجات مرتبًا ترتيبًا تصاعديًا، كما تتتبّع at_risk عدد المستجيبات المعرضات للخطر في كل عمر وهو العدد الكلي للمستجيبات، وتُخزن النتيجة في سلسلة Series بانداز Pandas والتي تحول كل عمر إلى دالة الخطر المقدَّرة في ذلك العمر. نتعامل في كل مرور على الحلقة مع عمر واحد t ونحسب عدد الأحداث التي تنتهي عند t -أي عدد المستجيبات المتزوجات عند هذا العمر- وعدد الأحداث التي أوقِفت عند t -أي عدد النساء اللواتي قوبِلن عند t ولكن تواريخ زواجهن المستقبلية موقفة censored- ويشير مصطلح "أوقف" إلى أنّ البيانات غير متاحة بسبب عملية جمع البيانات، كما تُعَدّ دالة الخطر المُقدَّرة بأنها نسبة الحالات المعرَّضة للخطر والتي تنتهي عند t، ونطرح في نهاية الحلقة من at_risk عدد الحالات التي انتهت أو أوقفت عند t، ثم نمرِّر في النهاية lams إلى الباني HazardFunction ونُعيد النتيجة. منحني الزواج علينا تنظيف البيانات وتحويلها إذا أردنا اختبار هذه الدالة، علمًا أنّ المتغيرات التي نحتاجها من المسح الوطني لنمو الأسرة هي: cmbirth: يوم ميلاد كل مستجيبة وهو معلوم في كل الحالات. cmintvw: تاريخ مقابلة كل مستجيبة وهو معلوم في كل الحالات. cmmarrhx: تاريخ أول حالة زواج للمستجيبة إذا كانت متزوجةً وكان التاريخ معلومًا. evrmarry: قيمة هذا المتغير 1 إذا كانت المستجيبة قد تزوجت قبل تاريخ المقابلة و0 بخلاف ذلك. حيث أن المتغيرات الثلاثة الأولى مرمَّزة بنظام أشهر القرن وهو العدد الصحيح للأشهر منذ شهر 12 من عام 1899، أي يكون شهر القرن 1 هو شهر 1 من عام 1900، وسنقرأ في البداية ملف المستجيبات ونستبدل قيم cmmarrhx غير الصالحة كما يلي: resp = chap01soln.ReadFemResp() resp.cmmarrhx.replace([9997, 9998, 9999], np.nan, inplace=True ثم نحسب عمر كل مستجيبة عند الزواج وعند مقابلتها: resp['agemarry'] = (resp.cmmarrhx - resp.cmbirth) / 12.0 resp['age'] = (resp.cmintvw - resp.cmbirth) / 12.0 ثم نستخرِج complete وهو عمر النساء المتزوجات عند زواجهن واللاتي لم تزلن متزوجات، وongoing وهو عمر النساء اللاتي لا يحققن ما سبق أثناء المقابلة: complete = resp[resp.evrmarry==1].agemarry ongoing = resp[resp.evrmarry==0].age سنحسب أخيرًا دالة الخطر: hf = EstimateHazardFunction(complete, ongoing) يُظهر الشكل 13.2 (الموجود في الجهة العليا) دالة الخطر المُقدَّرة، وهي منخفضة في فترة المراهقة ومرتفعة في العشرينات من العمر وتنخفض في الثلاثينات وتعود لترتفع في الأربعينات، لكن هذا ناتج عملية التقدير، حيث سينتج عن زواج عدد صغير من النساء خطرًا مقدَّرًا كبيرًا مع نقصان المستجيبات لمعرضات للخطر، لكن سيخفف منحني البقاء من هذا الضجيج. تقدير منحني البقاء يمكننا تقدير منحني البقاء عند حصولنا على دالة الخطر، حيث أنّ فرصة البقاء بعد الوقت t هو فرصة البقاء لكل الأوقات بدءًا من بداية الرصد حتى t، وهو ناتج الجداء التراكمي لدالة الخطر المكملة: [1−λ(0)] [1−λ(1)] … [1−λ(t)] يزودنا الصنف HazardFunction بالدالة MakeSurvival التي تحسب هذا الجداء: # class HazardFunction: def MakeSurvival(self): ts = self.series.index ss = (1 - self.series).cumprod() cdf = thinkstats2.Cdf(ts, 1-ss) sf = SurvivalFunction(cdf) return sf حيث أنّ ts هو تسلسل الأوقات التي قُدِّرت فيها دالة الخطر، وss هو ناتج الجداء التراكمي لدالة الخطر المكملة، وبالتالي فهو منحني البقاء، كما يتوجب علينا حساب مكمل ss ومن ثم إنشاء Cdf واستنساخ كائن SurvivalFunction وذلك بسبب الطريقة التي يُنفَّذ بها SurvivalFunction. يوضَّح الشكل السابق الموجود في الأعلى دالة الخطر لعمر أول زواج؛ أما الذي في الأسفل فيوضَّح منحني البقاء، كما يُظهر الشكل السابق الموجود في الأسفل النتيجة، حيث يكون منحني البقاء أكثر حدةً بين العمرين 25 و35، وهو المدى الذي تتزوج فيه معظم النساء؛ أما بين العمرين 35 و45 فيكون المنحني مسطحًا تقريبًا، مما يشير إلى أنه من غير المرجح زواج النساء اللواتي لم يتزوجن قبل سن الخامس والثلاثين. كان منحني ما مثل المنحني السابق أساس مقال شهير ظهر في مجلة عام 1986، فقد نُشر في مجلة نيوزويك Newsweek أن احتمال موت امرأة غير متزوجة عمرها 40 على يد قاتل أكبر من احتمال زواجها، وانتشرت هذه الإحصائيات انتشارًا واسعًا وأصبحت جزءًا من الثقافة الشعبية، لكنها كانت خاطئةً لأنها بُنيَت على تحليل خاطئ، واتضح أنهم على خطأ بسبب التغيرات الثقافية التي كانت جاريةً حينها واستمرت بعدها، لذا فقد نشرت مجلة نيوزويك Newsweek مقالًا آخرًا اعترفوا فيه بأنهم كانوا مخطئين، ونرى أنه من الأفضل قراءة المزيد عن هذا المقال والإحصائية المبنية عليه وردود الفعل لأنه سيذكِّرك بالالتزام الأخلاقي الذي يحتم عليك إجراء التحليل بعناية وتفسير النتائج بحيادية وعرضها على الجمهور بدقة وصدق. فواصل الثقة ينتج عن تحليل كابلان-ماير تقديرًا واحدًا لمنحني البقاء ولكنه مهم لحساب عدم اليقين الناتج عن التقدير، كما توجد ثلاثة مصادر محتملة للخطأ على أساس العادة وهي خطأ القياس measurement error وخطأ أخذ العينات sampling error وخطأ النمذجة modeling error، حيث يُعَدّ خطأ القياس في هذا المثال صغيرًا غالبًا، أي يعلم الأشخاص التاريخ الصحيح لولادتهم وإن كانوا قد تزوجوا بالإضافة إلى تاريخ الزواج، ويفترض أنهم قدَّموا هذه المعلومات بدقة، وإليك الشيفرة التي تحسب خطأ أخذ العينات عن طريق تطبيق إعادة أخذ العينات: def ResampleSurvival(resp, iters=101): low, high = resp.agemarry.min(), resp.agemarry.max() ts = np.arange(low, high, 1/12.0) ss_seq = [] for i in range(iters): sample = thinkstats2.ResampleRowsWeighted(resp) hf, sf = EstimateSurvival(sample) ss_seq.append(sf.Probs(ts)) low, high = thinkstats2.PercentileRows(ss_seq, [5, 95]) thinkplot.FillBetween(ts, low, high) تأخذ الدالة ResampleSurvival الوسيطَين resp وهو إطار بيانات المستجيبين وiters وهو عدد المرات التي يجب فيها إعادة أخذ العينات، ومن ثم تحسب ts وهو تسلسل الأعمار وهنا سنقيِّم منحني البقاء، كما تقوم الدالة ResampleSurvival بالخطوات التالية ضمن الحلقة: تعيد أخذ عينات المستجيبين باستخدام ResampleRowsWeighted، ورأينا هذا في قسم إعادة أخذ العينات مع الأوزان في مقال المربعات الصغرى الخطية في بايثون. تستدعي EstimateSurvival التي تستخدِم العملية الموجودة في الأقسام السابقة بهدف تقدير منحني البقاء ومنحني الخطر. ثم تقيِّم منحني البقاء في كل عمر في ts. يُعَدّ ss_seq تسلسل منحنيات البقاء المقدَّرة، كما تأخذ الدالة PercentileRows هذا التسلسل وتحسب المئين الخامس والمئين الخامس والتسعين وتعيد فاصل الثقة 90% الخاص بمنحني البقاء. يوضِّح الشكل السابق منحني البقاء للعمر عند أول زواج الممثَّل بالخط الداكن وفاصل الثقة 90% المبني على إعادة أخذ العينات مع الأوزان والممثَّل بالخط الرمادي، كما يظهر الشكل السابق النتيجة ومنحني البقاء الذي قدَّرناه في القسم السابق، ويأخذ فاصل الثقة أوزان أخذ العينات بالحسبان على عكس المنحني المقدَّر الذي لا يضع الأوزان في حسبانه، علمًا أنَّ التناقض بينهما يشير إلى التأثير الكبير لأوزان أخذ العينات على التقدير وعلينا أخذ ذلك في الحسبان. تأثيرات الفوج يُعَدّ اعتماد الأجزاء المختلفة للمنحني المقدَّر على عدة مجموعات بأنه أحد تحديات تحليل البقاء، حيث أنّ جزء المنحني عند الوقت t مبني على المستجيبات اللاتي كان عمرهن t على الأقل أثناء المقابلة، لذا يحتوي الجزء الموجود في اليسار على بيانات جميع من شارك في المسح، في حين يحتوي الجزء الموجود في اليمين على المستجيبات الأكبر سنًا. إذا لم تكن صفات المستجيبات ذات الصلة متغيرةً بمرور الوقت، فلا توجد مشكلة بالطبع، لكن يبدو في هذه الحالة أنّ أنماط الزواج متغيرة بالنسبة للنساء المولودات في أجيال مختلفة، كما يمكننا البحث في هذا التأثير عن طريق تصنيف المستجيبات إلى مجموعات بحسب عقد الميلاد، علمًا أنّ المجموعات المشابهة لهذه أي المعرفة بتاريخ ميلاد أو حدث مشابه تدعى الأفواج cohorts، في حين تدعى الفروق بين المجموعات تأثيرات الفوج cohort effects. جمعنا بيانات الدورة السادسة من 2002 المستخدَمة في هذه السلسلة وبيانات الدورة السابعة من 2006-2010 المستخدَمة في قسم التكرار في مقال اختبار الفرضيات الإحصائية وبيانات الدورة الخامسة من 1995، حيث تحوي مجموعة البيانات كلها 30769 مستجيبةً، وذلك من أجل البحث في تأثيرات الفوج في بيانات الزواج في المسح الوطني لنمو الأسرة. resp5 = ReadFemResp1995() resp6 = ReadFemResp2002() resp7 = ReadFemResp2010() resps = [resp5, resp6, resp7] استخدمنا cmbirth من أجل كل إطار بيانات resp لحساب عقد ولادة كل مستجيبة: month0 = pandas.to_datetime('1899-12-15') dates = [month0 + pandas.DateOffset(months=cm) for cm in resp.cmbirth] resp['decade'] = (pandas.DatetimeIndex(dates).year - 1900) // 10 حيث أن المتغير cmbirth مرمَّز ليدل على العدد الصحيح للأشهر التي مضت منذ شهر 12 من عام 1899، فتمثِّل month0 هذا التاريخ على أساس كائن ختم زمني Timestamp، كما نستنسخ DateOffset من أجل كل تاريخ ميلاد والذي يحتوي على أشهر القرن ونضيفه إلى month0 لتكون النتيجة تسلسلًا من الأختام الزمنية TimeStamps التي يجري تحوَّل إلى النوع DateTimeIndex، ونستخرج أخيرًا year الذي يمثِّل السنة ونحسب decades الذي يمثِّل العقد. أعدنا أخذ العينات وصّنفنا المستجيبات حسب عقد الميلاد ورسمنا منحني البقاء وذلك لكي نحرص على أخذ أوزان أخذ العينات بالحسبان وإظهار التباين الناتج عن خطأ أخذ العينات أيضًا: for i in range(iters): samples = [thinkstats2.ResampleRowsWeighted(resp) for resp in resps] sample = pandas.concat(samples, ignore_index=True) groups = sample.groupby('decade') EstimateSurvivalByDecade(groups, alpha=0.2) تستخدِم بيانات الدورات الثلاثة للمسح الوطني لنمو الأسرة أوزانًا مختلفةً، لذا أعدنا أخذ عينات كل منها على حدة ثم استخدمنا concat لدمجها لتصبح إطار بيانات واحد، علمًا أنّ المعامِل ignore_index يشير إلى concat لكي لا يطابق المستجيبين حسب الفهرس وإنما ينشئ فهرسًا جديدًا من 0 إلى 30768، كما ترسم الدالة EstimateSurvivalByDecade منحنيات بقاء كل فوج. def EstimateSurvivalByDecade(resp): for name, group in groups: hf, sf = EstimateSurvival(group) thinkplot.Plot(sf) يوضِّح الشكل السابق منحنيات بقاء المستجيبات اللواتي ولدن ضمن عقود مختلفة، كما يظهر الشكل السابق النتائج ونرى عدة أنماط فيه وهي: النساء اللواتي ولدن في الخمسينيات هم أكثر من تزوج في عمر صغير، وكذلك فإن أفراد الفوج التالي تزوجن في عمر متأخر أكثر، والفوج التالي بعد الفوج السابق وهكذا، وبقوا على الأقل حتى عمر الثلاثين تقريبًا. تملك النساء اللواتي ولدن في ستينيات القرن الماضي نمطًا غريبًا، إذ تزوجت النساء هنا في عمر 25 بمعدل أبطأ من الفوج السابق، ولكن بعد عمر 25 أصبح معدل الزواج أسرع، لكن النساء في هذا الفوج تجاوزت فوج الخمسينيات عند عمر 32، واتضح أنَّ احتمال زواج النساء في عمر 44 هو المرجَّح، لكن النساء اللواتي ولدن في الستينيات بلغن عمر 25 بين عامَي 1985 و1995، ومن المغري اعتقاد أنّ المقال الذي ذكرناه منذ قليل قد تسبب في ازدياد حالات الزواج، لكنه تفسير رديء للغاية، ومع ذلك فإنه من المحتمل أن يكون المقال وردّ الفعل عليه مؤشرَين على حالة مزاجية أثرت على سلوك هذا الفوج. يملك فوج السبعينات نمطًا مشابهًا، حيث أن النساء هنا أقل احتمالًا لأن يتزوجن قبل عمر 25 إذا وازناه مع الأفواج السابقة، لكن هذا لهذا الفوج احتمالات مشابهة للأفواج السابقة فيما يخص الزواج عند عمر 35. احتمال أن زواج فوج الثمانينيات قبل 25 هو أقل من الفوج السابق، ولكن ما يحدث بعد ذلك هو غير واضح، وإذا أردنا بيانات أكثر، فعلينا الانتظار حتى الدورة التالية من المسح الوطني لنمو الأسرة. يمكننا توليد بعض التنبؤات ريثما تصلنا البيانات. الاستقراء الخارجي Extrapolation ينتهي منحني البقاء لفوج السبعينات عند عمر 38 تقريبًا؛ أما فوج الثمانينات فينتهي منحني البقاء الخاص به عند سن 28، وبالطبع فإن بيانات فوج التسعينات نادرة جدًا، كما يمكننا استقراء هذه المنحنيات خارجيًا عن طريق استعارة بيانات من الفوج السابق، حيث يزودنا الصنف HazardFunction بالتابع Extend الذي ينسخ الذيل من HazardFunction أطول كما يلي: # class HazardFunction def Extend(self, other): last = self.series.index[-1] more = other.series[other.series.index > last] self.series = pandas.concat([self.series, more]) يحتوي HazardFunction على سلسلة تحوِّل الوقت t إلى λ(t)، ويجد التابع Extend المتغير last وهو الفهرس الأخير في self.series،ثم يختار قيم من other التي تأتي بعد last ويضيفها إلى نهاية self.series، ويمكننا الآن توسيع HazardFunction الخاص بكل فوج وذلك بالاستعانة بقيم من الفوج السابق: def PlotPredictionsByDecade(groups): hfs = [] for name, group in groups: hf, sf = EstimateSurvival(group) hfs.append(hf) thinkplot.PrePlot(len(hfs)) for i, hf in enumerate(hfs): if i > 0: hf.Extend(hfs[i-1]) sf = hf.MakeSurvival() thinkplot.Plot(sf) حيث أن groups هو كائن GroupBy فيه معلومات المستجيبات مصنفة إلى مجموعات حسب عقد الولادة، كما تحسب الحلقة الأولى HazardFunction كل مجموعة، في حين توسِّع الحلقة الثانية كل HazardFunction بقيم من الفوج السابق له والذي قد يحتوي على قيم من المجموعة التي تسبقه أيضًا (أي قد يحتوي فوج الخمسينات على قيم من فوج الأربعينات وقد يحتوي فوج الأربعينات على قيم من فوج الثلاثينات وهكذا)، ثم تحوِّل كل HazardFunction إلى SurvivalFunction وترسمه. يوضِّح الشكل السابق منحنيات البقاء الخاصة بالمستجيبات اللواتي ولدن خلال عقود مختلفة، مع تنبؤات للأفواج اللاحقة، كما يُظهر الشكل السابق النتائج، وقد حذفنا فوج الخمسينات لجعل التنبؤات أكثر وضوحًا، وتقترح هذه النتائج أنه بحلول السن الأربعين ستتقارب الأفواج الأحدث مع فوج الستينيات وستمثل المستجيبات المتزوجات نسبةً تقل عن %20 من المجموع الكلي. العمر المتبقي المتوقع إذا كان لدينا منحني بقاء، فيمكننا حساب العمر المتبقي المتوقع على أساس دالة للعمر الحالي، أي إذا كان لدينا مثلًا منحني البقاء لطول الحمل من القسم الأول من هذا المقال، فيمكننا حساب الوقت المتوقع حتى حدوث المخاض والولادة، حيث تتمثل الخطوة الأولى في استخراج دالة الكثافة الاحتمالية PMF للأعمار، كما يزودنا الصنف SurvivalFunction بالتابع الذي يقوم بالمطلوب: # class SurvivalFunction def MakePmf(self, filler=None): pmf = thinkstats2.Pmf() for val, prob in self.cdf.Items(): pmf.Set(val, prob) cutoff = self.cdf.ps[-1] if filler is not None: pmf[filler] = 1-cutoff return pmf تذكر أنّ SurvivalFunction تحتوي على Cdf للعمر، وتنسخ الحلقة القيم والاحتمالات من Cdf إلى Pmf، كما تُعَدّ cutoff هي أعلى احتمال في Cdf، وهي 1 إذا كان Cdf كاملًا وأقل من 1 بخلاف ذلك، وإذا كان Cdf غير كامل، فسنُدخل القيمة المزوَّدة إلى filter لنكملها، لكن يُعَدّ Cdf لمدة الحمل كاملًا، لذا لا داع للقلق حول هذا الأمر؛ أما الخطوة التالية هنا فهي حساب العمر المتبقي المتوقع، حيث يعني المتوقع هنا المتوسط الحسابي، كما يزودنا SurvivalFunction بدالة تقوم بهذا أيضًا: # class SurvivalFunction def RemainingLifetime(self, filler=None, func=thinkstats2.Pmf.Mean): pmf = self.MakePmf(filler=filler) d = {} for t in sorted(pmf.Values())[:-1]: pmf[t] = 0 pmf.Normalize() d[t] = func(pmf) - t return pandas.Series(d) تأخذ RemainingLifetime الوسيط filterالذي يمرَّر إلى MakePmf وfunc وهو الدالة المستخدَمة لتلخيص توزيع العمر المتبقي؛ أما pmf فهي Pmf الأعمار المتبقية المستخرَجة من SurvivalFunction، وd هو قاموس يحتوي على النتائج وهو تحويل من العمر الحالي t إلى العمر المتبقي المتوقع. تمر الحلقة مرورًا تكراريًا على القيم في Pmf، وهي تحسب التوزيع الشرطي للأعمار المتبقية لكل قيمة من t، باعتبار أنّ العمر المتبقي يتجاوز t، فإنها تنجز هذه المهمة عن طريق إزالة القيم من Pmf الواحدة تلو الأخرى ومن ثم إعادة توحيد renoramlizing القيم المتبقية، كما تستخدِم بعدها func لتلخيص التوزيع الشرطي وفي هذا المثال النتيجة هي مدة الحمل المتوسطة باعتبار أنّ المدة تتجاوز t، كما نحصل على متوسط مدة الحمل المتبقية عن طريق طرح t. يوضِّح الشكل السابق مدة الحمل المتوقعة المتبقية في الجهة اليسرى؛ أما في الجهة اليمنى فيوضِّح السنوات حتى أول زواج، كما يُظهر الشكل السابق في الجهة اليسرى طول الحمل المتبقي المتوقع على أساس دالة للمدة الحالية، أي المدة المتبقية المتوقعة في الأسبوع 0 مثلًا هي حوالي 34 أسبوع، وهي أقل من طول الحمل الكامل -أي 39 أسبوع- لأن حالات الإجهاض التي حصلت في الثلث الأول قد خفضت من المتوسط. ينخفض المنحني ببطء في الثلث الأول، وتكون المدة المتبقية المتوقعة بعد 13 أسبوع قد انخفضت 9 أسابيع لتصبح 25 أسبوع، بعد ذلك ينخفض بسرعة أكبر، وذلك بمعدل انخفاض أسبوع كامل في كل أسبوع جديد، في حين ينخفض المنحني حوالي أسبوع أو أسبوعين في الفترة ما بين الأسبوع 37 والأسبوع 42، وتكون المدة المتبقية المتوقعة في هذه الفترة ثابتةً، أي لا تصبح الوجهة أقرب مع مرور الأسابيع، وتدعى العمليات التي تحمل هذه الخاصية بعمليات بلا ذاكرة memoryless لأن ليس للماضي تأثير على التنبؤات، علمًا أنّ هذا السلوك هو الأساس الرياضي لجملة الممرضات الشهيرة التي تثير الغضب: اقترب موعد الولادة ومتوقع أن تلدي في أيّ يوم الآن. يُظهر الشكل السابق في الجهة اليمنى الوقت الوسيط المتبقي حتى أول زواج على أساس دالة للعمر، حيث يكون الوسيط هو 14 عامًا بالنسبة لفتاة عمرها 11 عامًا، ويقل المنحني حتى عمر 22 حينما يصبح الوقت المتبقي الوسيط هو حوالي 7 سنوات، ويزداد مرةً أخرى بعدها وبحلول العمر 30 يعود إلى ما كان عليه أي 14 عامًا، ويمكننا استنادًا إلى هذه البيانات استنتاج أنّ للنساء صغيرات السن أعمارًا متبقيةً متناقصةً، وتدعى المكونات الميكانيكية المرتبطة بهذه الخاصية NBUE وهي اختصار لمِن المتوقع أن يكون الجديد أفضل من المستخدَم new better than used in expectation، أي من المتوقع بقاء الجزء الجديد فترةً أطول. تملك النساء اللواتي تجاوزت أعمارهن 22 سنة وقتًا متبقيًا متزايدًا حتى أول زواج، وتدعى المكونات الميكانيكية المرتبطة بهذه الخاصية UBNE وهي اختصار لمِن المتوقع أن يكون المستخدَم أفضل من الجديد used better than new in expectation، أي من المتوقع أن يبقى الجزء المستخدَم فترةً أطول، إذ يُعَدّ الأطفال حديثو الولادة مثلًا ومرضى السرطان هم UBNE أيضًا لأن العمر المتوقع لديهم يزيد كلما طالت مدة حياتهم، فقد حسبنا الوسيط median في هذا المثال بدلًا من المتوسط mean لأن Cdf غير كامل، ويتوقع منحني البقاء أن نسبة 20% من المستجيبات لن يتزوجن قبل سن 44، وبما أن سن الزواج الأول لهؤلاء النساء غير معلوم وقد يكون غير موجود، فلن نتمكن من حساب المتوسط. استبدلنا القيم غير المعلومة هنا بالقيمة np.inf وهي قيمة خاصة تمثِّل اللانهاية، أي أنها تجعل متوسط اللانهاية لكل الاعمار، لكن يبقى الوسيط محدَّدًا تمامًا طالما أنّ أكثر من 50% من الأعمار المتبقية نهائية، وهذا صحيح حتى عمر الثلاثين؛ أما بعدها فمن الصعب تحديد عمر متبقي متوقع له، وإليك الشيفرة التي تحسب وترسم هذه الدوال: rem_life1 = sf1.RemainingLifetime() thinkplot.Plot(rem_life1) func = lambda pmf: pmf.Percentile(50) rem_life2 = sf2.RemainingLifetime(filler=np.inf, func=func) thinkplot.Plot(rem_life2) حيث أن sf1 هو منحني البقاء لطول الحمل، ويمكن في هذه الحالة استخدام القيم الافتراضية للدالة RemainingLifetime؛ أما sf2 فهو منحني البقاء للعمر عند أول زواج، وfunc هو دالة تأخذ Pmf وتحسب وسيطها -أي المئين رقم 50-. تمارين يوجد الحل الخاص بهذا التمرين في chap13soln.py في مستودع الشيفرات ThinkStats2 على GitHub (وسائر ملفات التمارين). تمرين 1 يحتوي المتغير cmdivorcx في الدورتين السادسة والسابعة من المسح الوطني لنمو الأسرة على تاريخ طلاق المستجيبين من أول حالة زواج، وهي مرمَّزة بطريقة أشهر القرن. احسب مدة حالات الزواج التي انتهت بطلاق ومدة حالات الزواج المستمرة حتى الآن، وقدِّر منحني الخطر ومنحني البقاء لمدة الزواج، ثم استخدِم طريقة إعادة أخذ العينات resampling لمراعاة أوزان أخذ العينات، ثم وضِّح خطأ أخذ العينات بصريًا عن طريق رسم البيانات الناتجة عن عدة مرات أخذ عينات، علمًا أنه من الأفضل أن تفكِّر في تقسيم المستجيبين إلى مجموعات حسب عقد الولادة وربما حسب العمر عند أول حالة زواج. ترجمة وبتصرف للمقال Chapter 13 Survival analysis analysis من كتاب Think Stats: Exploratory Data Analysis in Python. اقرأ أيضًا الانحدار الإحصائي regression ودوره في ملاءمة النماذج المختلفة مع أنواع البيانات المتاحة نمذجة التوزيعات Modelling distributions في بايثون تحليل البيانات الاستكشافية لإثبات النظريات الإحصائية div table{margin-left:inherit;margin-right:inherit;margin-bottom:2px;margin-top:2px} td p{margin:0px;} .vbar{border:none;width:2px;background-color:black;} .hbar{display: block;border:none;height:2px;width:100%;background-color:black;} .display{border-collapse:separate;border-spacing:2px;width:auto;border:none;} .dcell{white-space:nowrap;padding:0px; border:none;} .dcenter{margin:0ex auto;} .theorem{text-align:left;margin:1ex auto 1ex 0ex;} table{border-collapse:collapse;} td{padding:0;} .cellpadding0 tr td{padding:0;} .cellpadding1 tr td{padding:1px;} .center{text-align:center;margin-left:auto;margin-right:auto;}1 نقطة