لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 12/07/24 في كل الموقع
-
السلام عليكم هو مشارك في مسابقه علي كاغل بس هل الافضل ان اكتب الكود الاول خالص علي الجهاز وبعد ما اخلص ارفع الكود والا الافضل ان اشارك علي طوال في الnotebook kaggle ؟5 نقاط
-
السلام عليكم هي اي الاداء دي SynthCity ؟4 نقاط
-
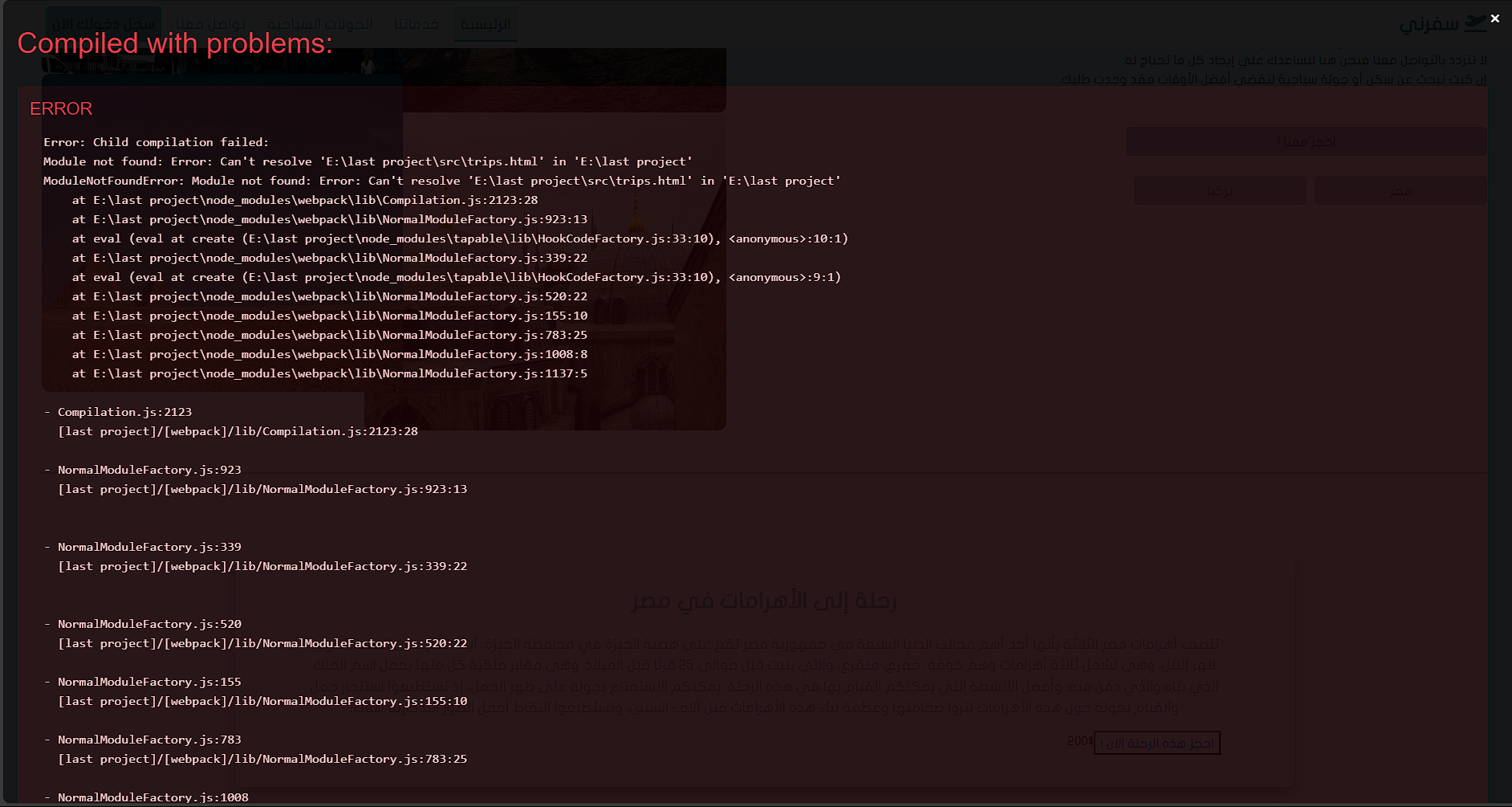
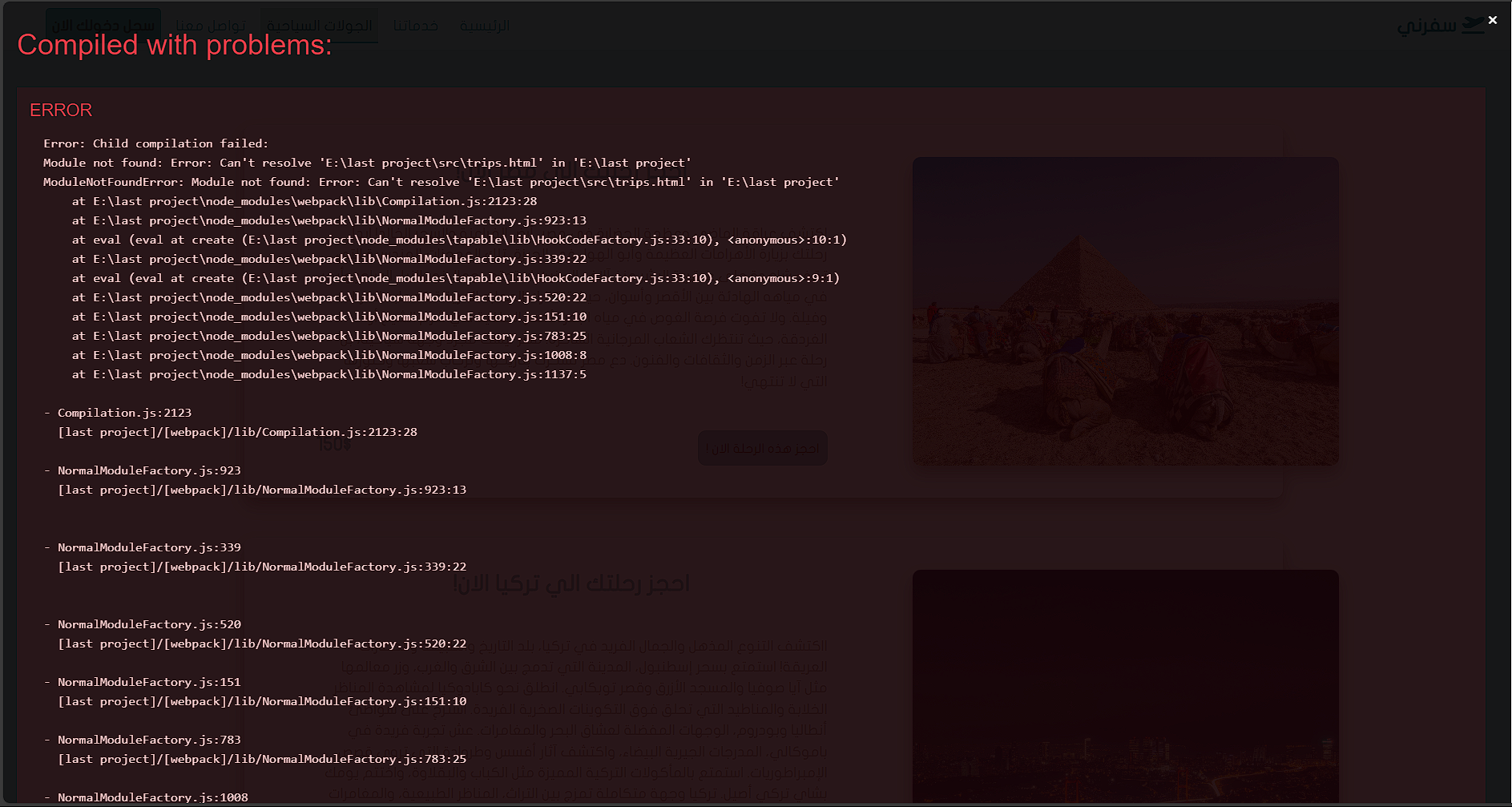
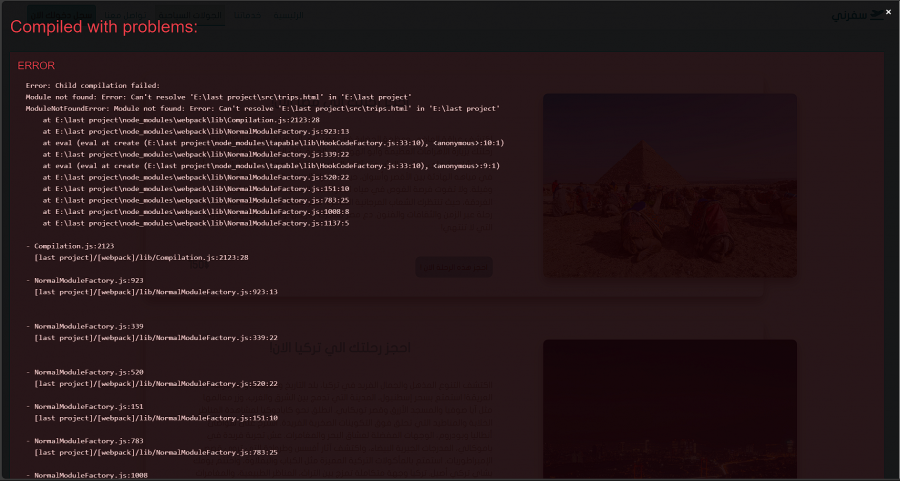
السلام عليكم ورحمة الله وبركاته قد انهيت هذه الصفحة وانهيت ال responsive الخاص بها لكن لا ادري لماذا تظهر معي مساحة فارغة في اليسار يعني scroll وانا لم اقم بتضمين اي شيء فيها حاولت استخدام كل الحلول لكن لم ينجح اي شيء last project.zip
 3 نقاط
3 نقاط -
السلام عليكم ورحمة الله وبركاته هذا الخطأ يظهر معي كثيرا وحاولت البحث عن مشكلته لم اعرفها مع اني لم اعمل كود واحد لملف بهذا الاسم يظهر لي احيانا واحيانا لا لا ادري لماذا last project (2).zip
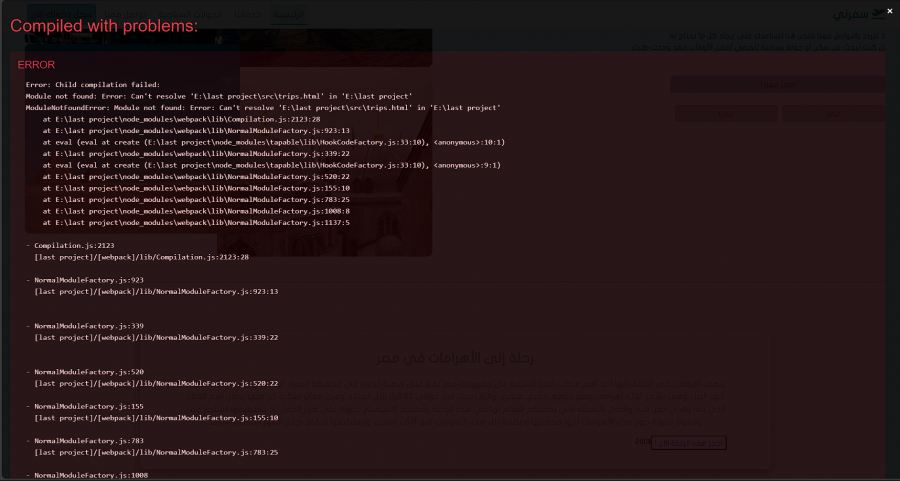 2 نقاط
2 نقاط -
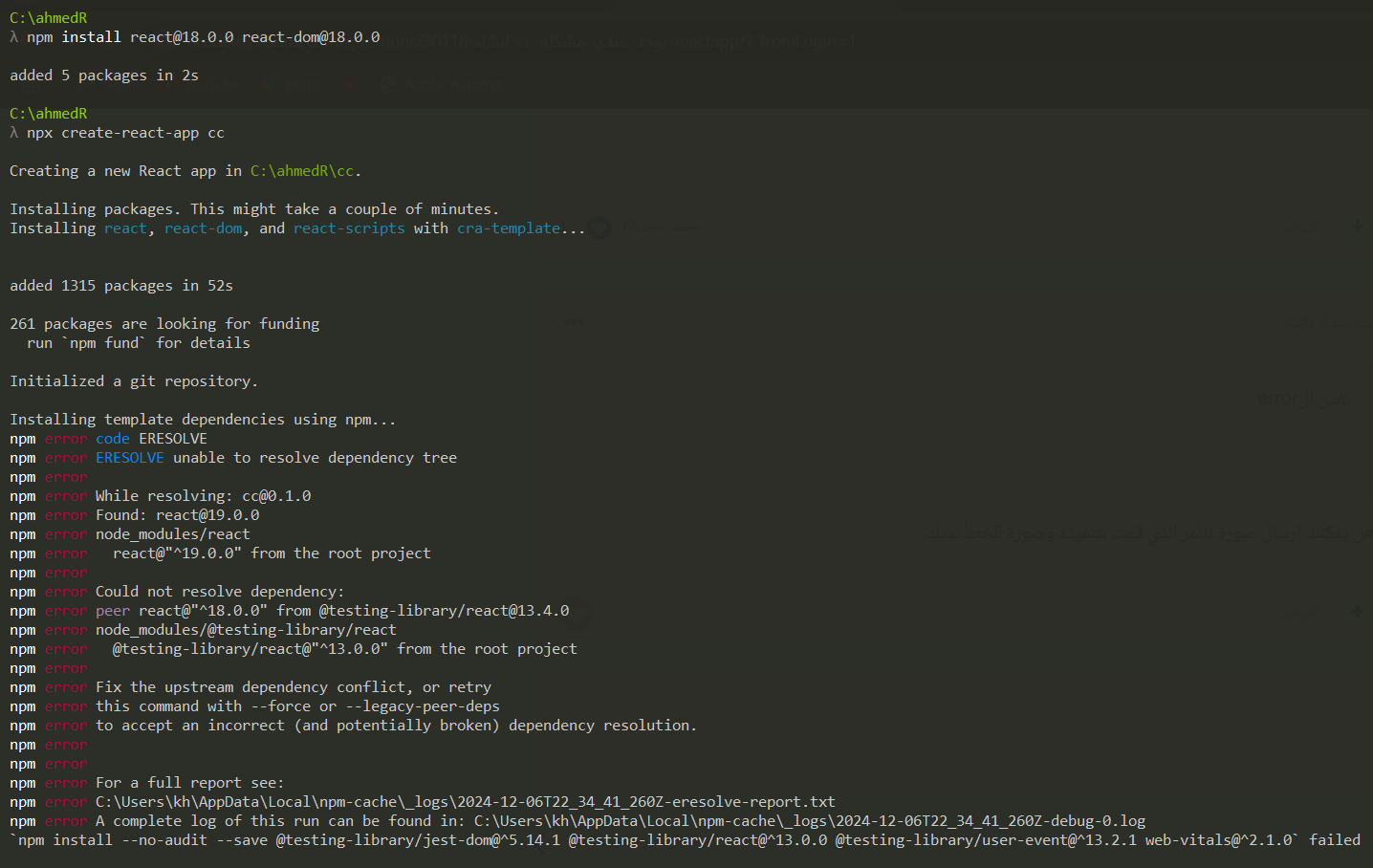
كيف ازيل كل شي له علاقه ب React بسبب تداخل الاصدارات واحمله تاني2 نقاط
-
السلام عليكم. أقوم حاليا بتنفيذ مشروع متجر إلكتروني باستخدام مكتبة React و إطار عمل Laravel حاليا أحاول تنفيذ خاصية "السلة" - Cart, كالتالي: عندما يقوم المستخدم بالضغط على زر "أضف إلى السلة" الموجود على كل منتج فإن هذا المنتج سيتم إرساله إلى السلة و سيزداد عداد السلة بواحد أريد أن أعرف ما هو المكان الأنسب لتخزين عناصر السلة قمت بإستخدام قاعدة البيانات والـ API لهذا الغرض لكن عملية إرسال المنتج إلى السلة وزيادة عداد السلة بواحد يأخذ وقتا أكثر مما ينبغي (الوقت بين إستقبال السيرفر الطلب وإرساله الإستجابة) فكرت في استخدام الكوكيز لكني علمت أن مساحة الكوكيز محدودة ولا تتجاوز 4096 بايت, فإذا قام المستخدم بإضافة الكثير من المنتجات فهذا سيسبب مشكلة حسب ما يبدو وكذلك Laravel تقوم بتشفير محتوى الكوكيز بالتالي لا أستطيع قرائته بجافاسكريبت أما بالنسبة للـ session فالمشكلة فيه أن عناصر السلة ستختفي بمجرد أن يقوم المستخدم بإنهاء الجلسة (إغلاق المتصفح وما إلى ذلك) فما هي إذن أنسب طريقة لتنفيذ هذه الخاصية؟2 نقاط
-
السلام عليكم هل استطيع انشاء تطبيق رسائل في اطار العمل Django مثل الذي في موقع اكاديمية حسوب كيف يتم ذلك مع الشرح بالتفصيل وكتابة الاكواد
 2 نقاط
2 نقاط -
2 نقاط
-
ما الفرق بين ال JavaScript وال node.js وشكراً.2 نقاط
-
بخصوص المحادثة الصوتية التي يطرح المدرب فيها أسئلة متعلقة بالدورة لمدة 30 دقيقة : هل لدى احد علم بي نوع الأسئلة في المحادثة وهل هي صعبه أم سهله ؟؟؟2 نقاط
-
حسنا هو في الحقيقة فعلا كل ما اغلق المحرر وافتحه تعلق عندي ال port وتظل مفتوحة دائما ولا تظهر عندي التيرمينال الخاصة بها او تظهر علي انها مقفولة ولكن لا استطيع ان اقفلها ابدا ولا ادري لماذا1 نقطة
-
حذفت السطر واعدت تشغيل الخادم العديد والعديد من المرات ولم تحل المشكلة ولا ادري السبب1 نقطة
-
لا فائدة ولا ادري ما العمل فهو احيانا يظهر واحيانا لا يظهر عندما اعدل علي الكود لكن عندما احدث الصفحة لا ولا ادري ما السبب
 1 نقطة
1 نقطة -
من الأفضل الإعتماد على Local Storage وسيتم تخزين البيانات على جهاز المستخدم, وتستطيع الوصول إليها من خلال جافاسكريبت، وستبقى المنتجات موجودة في السلة عند عودة المستخدم مرة أخرى. لكن للإجابة على سؤالك بشكل جيد، تحتاج إلى الإجابة على هل منتجاتك محدودة العدد؟ بمعنى، هل تحتاج إلى حجز منتج لمدة 10 دقائق حتى يتمكن المستخدم من شرائه؟ هل تريد إجراء تحليلات عليها وإرسال رسائل بريد إلكتروني لاحقًا؟ هل تريد تذكرها عبر الأجهزة بحيث تصبح متزامنة على أجهزة المستخدم؟ هل تريد من المستخدمين تسجيل الدخول أم الشراء مباشرًة؟ عملية التخزين على جانب المتصفح تعمل بشكل جيد فقط في حال كان المشروع صغير لديك، ودائمًا من الأفضل حفظ عناصر السلة في جانب الخادم1 نقطة
-
 تدخل العمليات الحسابية في العديد من سكربتات باش Bash Scripts، فقد تحتاج لحساب المساحة المتبقية من القرص الصلب مثلًا، أو حجوم الملفات أو عرض النطاق الترددي للشبكة، أو تواريخ انتهاء صلاحيات كلمات المرور، أو أعداد المضيفين hosts أو غير ذلك. وسنتعلم في مقالنا الخامس من سلسلة باش للمبتدئين طريقة استخدام معاملات باش bash operators لإجراء العمليات الحسابية داخل السكربت، وسنبدأ بجدول يتضمن المعاملات الحسابية: المعامل الوصف + الجمع - الطرح * الضرب / قسمة الأعداد الصحيحة بدون بواقي عشرية % قسمة المعاملات التي تُرجع باقي عملية القسمة فقط ** الأُس مثلًا x أُس y تنفيذ الجمع والطرح في باش لننشئ سكربت باش يدعى مثلًا addition.sh يجمع حجمي ملفين بالبايت Byte ويعطيك النتيجة، سنستعمل في السكربت وسطاء باش وقد شرحنا طريقة طريقة التعامل معها في مقال تمرير الوسطاء إلى سكربت باش، بالإضافة إلى الأمرين cut و du. يُستَخدَم الأمر du لمعرفة أحجام الملفات، ويمكن استخدام الراية أو الخيار d- بعد الأمر وهو اختصار لكلمة bytes لجعل المخرجات بالحجم الفعلي للملف بالبايتات فبدون هذا الخيار سيعرض du الحجم بالوحدة الافتراضية كيلوبايت. يُظهر هذا الأمر في النتيجة كلًا من اسم الملف وحجمه أي أنه يعطي عمودين أو مُخرَجَين، لذا سنحتاج الأمر cut لاقتطاع جزء النتيجة الذي نريده فقط وهو الحجم. وبالتالي سنستخدم أنبوب إعادة التوجيه | لتمرير خرج الأمر du إلى دخل الأمر cut. سيكون نص السكربت addition.sh كما يلي: #!/bin/bash fs1=$(du -b $1 | cut -f1) fs2=$(du -b $2 | cut -f1) echo "File size of $1 is: $fs1" echo "File size of $2 is: $fs2" total=$(($fs1 + $fs2)) echo "Total size is: $total" يحتاج السكربت السابق وسيطين، وهنا مرر له الملفين etc/passwd/ و etc/group/، ثم نفذنا السكربت وسنحصل على النتيجة التالية: kabary@handbook:~/scripts$ ./addition.sh /etc/passwd /etc/group File size of /etc/passwd is: 2795 File size of /etc/group is: 1065 Total size is: 3860 لاحظ السطر التالي الذي يتضمن عملية الجمع باستخدام المعامل +: total=$(($fs1 + $fs2)) ينبغي أن تكتب العمليات الحسابية دائمًا بين قوسين هلاليين مزدوجين (()) بالصيغة التالية: $((arithmetic-expression)) يمكنك استخدام معامل الطرح - بالطريقة نفسها، فمثلًا المتغير sub التالي سيحمل القيمة سبعة: sub=$((10-3)) تنفيذ عمليتي الضرب والقسمة في باش لننشئ سكربت بسيط اسمه giga2mega.sh مثلًا يجري عملية التحويل من جيجا بايت GB إلى ميجا بايت MB وفق التالي: #!/bin/bash GIGA=$1 MEGA=$(($GIGA * 1024)) echo "$GIGA GB is equal to $MEGA MB" لنُشغل السكربت الآن لنعرف كم تعادل 4 جيجا بايت بالميجا بايت: kabary@handbook:~/scripts$ ./giga2mega.sh 4 4 GB is equal to 4096 MB لقد استخدمنا معامل الضرب * لضرب عدد الجيجا بايت بالعدد 1024 للحصول على مكافئها بالميجا بايت: MEGA=$(($GIGA * 1024)) يمكنك تعديل السكربت نفسه ليحول الحجم من جيجا بايت إلى كيلو بايت: KILO=$(($GIGA * 1024 * 1024)) وبالطريقة نفسها حَوِّله إلى بايت. لنجرب الآن عملية القسمة باستخدام المعامل / كما يلي ونُخَزِّن النتيجة في المتغير div الذي سيحمل القيمة خمسة في مثالنا: div=$((20 / 4)) القسمة المستخدمة هنا هي قسمة الأعداد الصحيحة، وبالتالي ستكون النتيجة عددًا صحيحًا حتمًا، فلو قَسَّمتَ 5 على 2 باستخدام المعامل / فستحصل على 2 لأن هذه القسمة تهمل البواقي فهي لا تُرجع أعدادًا عشرية. kabary@handbook:~/scripts$ div=$((5 / 2)) kabary@handbook:~/scripts$ echo $div 2 إذا رغبت بالتعامل مع الأعداد العشرية فستحتاج للأمر bc، وهذا مثال على طريقة استخدامه مع القسمة الصحيحة: echo "5/2" | bc -l 2.50000000000000000000 وتبين الصورة أدناه استخدامه مع العمليات الحسابية الأخرى: استخدام الأس وباقي القسمة لننشئ سكربت اسمه power.sh يقبل وسيطين عدديين ليكونا مثلًا a و b، ويُظهر نتيجة b مرفوعًا للأُس b كما يلي: #!/bin/bash a=$1 b=$2 result=$((a**b)) echo "$1^$2=$result" إذًا فقد استخدمنا المعامل ** لحساب نتيجة a مرفوعًا للأس b، لنجرب السكربت على أعداد مختلفة كما يلي: kabary@handbook:~/scripts$ ./power.sh 2 3 2^3=8 kabary@handbook:~/scripts$ ./power.sh 3 2 3^2=9 kabary@handbook:~/scripts$ ./power.sh 5 2 5^2=25 kabary@handbook:~/scripts$ ./power.sh 4 2 4^2=16 سنتعلم الآن استخدام المعامل % أي باقي القسمة modulo، يرجع هذا المعامل باقي القسمة فقط ويكون عددًا صحيحًا، فالمتغير rem في المثال التالي سيحمل القيمة 2: rem=$((17%5)) الباقي هنا هو 2 لأننا نحصل على 17 بمضاعفة العدد 5 ثلاث مرات وإضافة 2 للنتيجة. إنشاء محول مقاييس لدرجات الحرارة باستخدام باش لنطبق مثالًا شاملًا يستخدم كل العمليات الحسابية التي تعلمناها في الفقرات السابقة، سنكتب سكربت جديد باسم c2f.sh يحول درجة الحرارة من درجة مئوية إلى فهرنهايت وفق المعادلة التالية: F = C x (9/5) + 32 الطريقة المستخدمة هنا هي إحدى الطرق المتبعة لكتابة هذا السكربت، مع العلم أنه توجد طرق أخرى تعطيك النتيجة نفسها، سنعرف بداية المتغيرات فالمتغيرCيمثل درجة الحرارة المئوية، والمتغيرFيمثل درجة الحرارة بالفهرنهايت. #!/bin/bash C=$1 F=$(echo "scale=2; $C * (9/5) + 32" | bc -l) echo "$C degrees Celsius is equal to $F degrees Fahrenheit." استخدمنا الأمر bc هنا لأننا نتعامل مع أعداد عشرية، والأمر scale=2 لإظهار خانتين فقط بعد الفاصلة العشرية. لنجري بعض الآن التحويلات باستخدام السكربت التالي الذي يقرأ درجة الحرارة المدخلة بالدرجة المئوية، وتحويلها إلى الفهرنهايت، ثم عرض النتيجة لكل قيمة مدخلة: kabary@handbook:~/scripts$ ./c2f.sh 2 2 degrees Celsius is equal to 35.60 degrees Fahrenheit. kabary@handbook:~/scripts$ ./c2f.sh -3 -3 degrees Celsius is equal to 26.60 degrees Fahrenheit. kabary@handbook:~/scripts$ ./c2f.sh 27 27 degrees Celsius is equal to 80.60 degrees Fahrenheit. الخلاصة إلى هنا نكون قد انتهينا من مقالنا الذي شرحنا فيه العمليات الحسابية الأساسية في سكربتات باش مع التطبيق العملي، نرجو أن يكون المقال قد قدم الفائدة المرجوة، وندعوك لمطالعة مقالنا التالي حول التعامل مع السلاسل النصية Strings في باش. ترجمة -وبتصرف- للمقال Using Arithmetic Operators in Bash Scripting. اقرأ أيضًا المقال السابق: استخدام المصفوفات في باش Bash قراءة وضبط متغيرات الصدفة Shell والبيئة في لينكس التوسعات في باش ميزات صدفة باش1 نقطة
تدخل العمليات الحسابية في العديد من سكربتات باش Bash Scripts، فقد تحتاج لحساب المساحة المتبقية من القرص الصلب مثلًا، أو حجوم الملفات أو عرض النطاق الترددي للشبكة، أو تواريخ انتهاء صلاحيات كلمات المرور، أو أعداد المضيفين hosts أو غير ذلك. وسنتعلم في مقالنا الخامس من سلسلة باش للمبتدئين طريقة استخدام معاملات باش bash operators لإجراء العمليات الحسابية داخل السكربت، وسنبدأ بجدول يتضمن المعاملات الحسابية: المعامل الوصف + الجمع - الطرح * الضرب / قسمة الأعداد الصحيحة بدون بواقي عشرية % قسمة المعاملات التي تُرجع باقي عملية القسمة فقط ** الأُس مثلًا x أُس y تنفيذ الجمع والطرح في باش لننشئ سكربت باش يدعى مثلًا addition.sh يجمع حجمي ملفين بالبايت Byte ويعطيك النتيجة، سنستعمل في السكربت وسطاء باش وقد شرحنا طريقة طريقة التعامل معها في مقال تمرير الوسطاء إلى سكربت باش، بالإضافة إلى الأمرين cut و du. يُستَخدَم الأمر du لمعرفة أحجام الملفات، ويمكن استخدام الراية أو الخيار d- بعد الأمر وهو اختصار لكلمة bytes لجعل المخرجات بالحجم الفعلي للملف بالبايتات فبدون هذا الخيار سيعرض du الحجم بالوحدة الافتراضية كيلوبايت. يُظهر هذا الأمر في النتيجة كلًا من اسم الملف وحجمه أي أنه يعطي عمودين أو مُخرَجَين، لذا سنحتاج الأمر cut لاقتطاع جزء النتيجة الذي نريده فقط وهو الحجم. وبالتالي سنستخدم أنبوب إعادة التوجيه | لتمرير خرج الأمر du إلى دخل الأمر cut. سيكون نص السكربت addition.sh كما يلي: #!/bin/bash fs1=$(du -b $1 | cut -f1) fs2=$(du -b $2 | cut -f1) echo "File size of $1 is: $fs1" echo "File size of $2 is: $fs2" total=$(($fs1 + $fs2)) echo "Total size is: $total" يحتاج السكربت السابق وسيطين، وهنا مرر له الملفين etc/passwd/ و etc/group/، ثم نفذنا السكربت وسنحصل على النتيجة التالية: kabary@handbook:~/scripts$ ./addition.sh /etc/passwd /etc/group File size of /etc/passwd is: 2795 File size of /etc/group is: 1065 Total size is: 3860 لاحظ السطر التالي الذي يتضمن عملية الجمع باستخدام المعامل +: total=$(($fs1 + $fs2)) ينبغي أن تكتب العمليات الحسابية دائمًا بين قوسين هلاليين مزدوجين (()) بالصيغة التالية: $((arithmetic-expression)) يمكنك استخدام معامل الطرح - بالطريقة نفسها، فمثلًا المتغير sub التالي سيحمل القيمة سبعة: sub=$((10-3)) تنفيذ عمليتي الضرب والقسمة في باش لننشئ سكربت بسيط اسمه giga2mega.sh مثلًا يجري عملية التحويل من جيجا بايت GB إلى ميجا بايت MB وفق التالي: #!/bin/bash GIGA=$1 MEGA=$(($GIGA * 1024)) echo "$GIGA GB is equal to $MEGA MB" لنُشغل السكربت الآن لنعرف كم تعادل 4 جيجا بايت بالميجا بايت: kabary@handbook:~/scripts$ ./giga2mega.sh 4 4 GB is equal to 4096 MB لقد استخدمنا معامل الضرب * لضرب عدد الجيجا بايت بالعدد 1024 للحصول على مكافئها بالميجا بايت: MEGA=$(($GIGA * 1024)) يمكنك تعديل السكربت نفسه ليحول الحجم من جيجا بايت إلى كيلو بايت: KILO=$(($GIGA * 1024 * 1024)) وبالطريقة نفسها حَوِّله إلى بايت. لنجرب الآن عملية القسمة باستخدام المعامل / كما يلي ونُخَزِّن النتيجة في المتغير div الذي سيحمل القيمة خمسة في مثالنا: div=$((20 / 4)) القسمة المستخدمة هنا هي قسمة الأعداد الصحيحة، وبالتالي ستكون النتيجة عددًا صحيحًا حتمًا، فلو قَسَّمتَ 5 على 2 باستخدام المعامل / فستحصل على 2 لأن هذه القسمة تهمل البواقي فهي لا تُرجع أعدادًا عشرية. kabary@handbook:~/scripts$ div=$((5 / 2)) kabary@handbook:~/scripts$ echo $div 2 إذا رغبت بالتعامل مع الأعداد العشرية فستحتاج للأمر bc، وهذا مثال على طريقة استخدامه مع القسمة الصحيحة: echo "5/2" | bc -l 2.50000000000000000000 وتبين الصورة أدناه استخدامه مع العمليات الحسابية الأخرى: استخدام الأس وباقي القسمة لننشئ سكربت اسمه power.sh يقبل وسيطين عدديين ليكونا مثلًا a و b، ويُظهر نتيجة b مرفوعًا للأُس b كما يلي: #!/bin/bash a=$1 b=$2 result=$((a**b)) echo "$1^$2=$result" إذًا فقد استخدمنا المعامل ** لحساب نتيجة a مرفوعًا للأس b، لنجرب السكربت على أعداد مختلفة كما يلي: kabary@handbook:~/scripts$ ./power.sh 2 3 2^3=8 kabary@handbook:~/scripts$ ./power.sh 3 2 3^2=9 kabary@handbook:~/scripts$ ./power.sh 5 2 5^2=25 kabary@handbook:~/scripts$ ./power.sh 4 2 4^2=16 سنتعلم الآن استخدام المعامل % أي باقي القسمة modulo، يرجع هذا المعامل باقي القسمة فقط ويكون عددًا صحيحًا، فالمتغير rem في المثال التالي سيحمل القيمة 2: rem=$((17%5)) الباقي هنا هو 2 لأننا نحصل على 17 بمضاعفة العدد 5 ثلاث مرات وإضافة 2 للنتيجة. إنشاء محول مقاييس لدرجات الحرارة باستخدام باش لنطبق مثالًا شاملًا يستخدم كل العمليات الحسابية التي تعلمناها في الفقرات السابقة، سنكتب سكربت جديد باسم c2f.sh يحول درجة الحرارة من درجة مئوية إلى فهرنهايت وفق المعادلة التالية: F = C x (9/5) + 32 الطريقة المستخدمة هنا هي إحدى الطرق المتبعة لكتابة هذا السكربت، مع العلم أنه توجد طرق أخرى تعطيك النتيجة نفسها، سنعرف بداية المتغيرات فالمتغيرCيمثل درجة الحرارة المئوية، والمتغيرFيمثل درجة الحرارة بالفهرنهايت. #!/bin/bash C=$1 F=$(echo "scale=2; $C * (9/5) + 32" | bc -l) echo "$C degrees Celsius is equal to $F degrees Fahrenheit." استخدمنا الأمر bc هنا لأننا نتعامل مع أعداد عشرية، والأمر scale=2 لإظهار خانتين فقط بعد الفاصلة العشرية. لنجري بعض الآن التحويلات باستخدام السكربت التالي الذي يقرأ درجة الحرارة المدخلة بالدرجة المئوية، وتحويلها إلى الفهرنهايت، ثم عرض النتيجة لكل قيمة مدخلة: kabary@handbook:~/scripts$ ./c2f.sh 2 2 degrees Celsius is equal to 35.60 degrees Fahrenheit. kabary@handbook:~/scripts$ ./c2f.sh -3 -3 degrees Celsius is equal to 26.60 degrees Fahrenheit. kabary@handbook:~/scripts$ ./c2f.sh 27 27 degrees Celsius is equal to 80.60 degrees Fahrenheit. الخلاصة إلى هنا نكون قد انتهينا من مقالنا الذي شرحنا فيه العمليات الحسابية الأساسية في سكربتات باش مع التطبيق العملي، نرجو أن يكون المقال قد قدم الفائدة المرجوة، وندعوك لمطالعة مقالنا التالي حول التعامل مع السلاسل النصية Strings في باش. ترجمة -وبتصرف- للمقال Using Arithmetic Operators in Bash Scripting. اقرأ أيضًا المقال السابق: استخدام المصفوفات في باش Bash قراءة وضبط متغيرات الصدفة Shell والبيئة في لينكس التوسعات في باش ميزات صدفة باش1 نقطة -
ستحتاج إلى استخدام Django Channels ويوجد مكتبة daphne لتسهيل إضافة ذلك للمشروع لديك. وهي ببساطة خادم ASGI (Asynchronous Server Gateway Interface) تم تطويره بواسطة فريق Django، و ASGI تلك واجهة برمجة تطبيقات API جديدة لـ Python نستخدمها لإنشاء تطبيقات ويب غير متزامنة Async. وتدعم WebSocket أيضًا لتوفير ميزات الاتصال في الوقت الفعلي Real-time. ابحث على اليوتيوب عن chat app using Django وستجد تفصيل عملي لكيفية تنفيذ الأمر.1 نقطة
-
وعليكم السلام, SynthCity هي مكتبة لمحاكاة البيانات الحقيقية حيث توفر لنا بيانات شبه حقيقية في مجال تعلم الالة فهي بيانات عالية الجودة تساعدنا بتدريب الأداة التي نريد صناعتها. SynthCity هي نقاط سحابية ملونة كاملة من 367.9 مليون نقطة اصطناعية يمكننا من خلالها محاكاة الأشياء في الحياة الواقعية كالأبنية والسيارات والأرصفة والطرق والأشجار والأعمدة وغيرها الكثير حيث أنها تتميز بالواقعية والألوان المتوفرة.1 نقطة
-
كل ما عليك في البداية هو تنفيذ المشروع على المنصة نفسها لتسهيل الأمر على نفسك، أولاً عليك إختيار مسابقة قائمة بالفعل وستجد ذلك هنا: https://www.kaggle.com/competitions ابدء بمسابقات تحت تصنيف Getting Started فهي للمبتدئين، ولا يوجد بها جوائز مالية. قم بقراءة وصف المسابقة بالكامل ثم اضغط على join competition أعلى اليمين بعد ذلك سيظهر لك زر باسم new Notebook لإنشاء Notebook على منصة Kaggle وبه كود جاهز لاستيراد الملفات الخاصة بالمشروع. بعد الإنتهاء ستجد بالجانب الملفات الناتجة من المشروع الذي تعمل عليه في مجلد kaggle/working قم بتحميلها مثلاً ملفات csv الناتجة من عملية تحليل البيانات، بعد التحميل قم بحفظ ما قمت به بالضغط على save version أعلى اليمين لحفظ العمل الخاص بك. ثم توجه لصفحة المسابقة على kaggle واضغط على submit أعلى اليمين ثم قم برفع الملف الذي قمت بتحميله وسيظهر لك النتيجة.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. هذا الأمر على عدة خيارات بالنسبة لك . حيث كتابة الكود على جهازك أولا يعطيك حرية اختيار الأدوات والمكتبات التي تفضلها حيث ستساعدك البيئة التي لديك غالبا في كتابة الأكواد بسرعة وأيضا لا تحتاج إلى الإتصال بالإنترنت أثناء كتابة الكود وأثناء تنفيذه في كل مرة وأيضا إذا كانت إمكانيات جهازك عالية ولديك معالج قوي فإن كتابة الكود أولا لديك أفضل في تلك الحالة. ولكن من عيوب تلك الطريقة أنه من الممكن أن المكتبات التي تستخدمها على جهازك غير متوافقه مع Kaggle و أيضا من الممكن أن تواجه مشكلة في تنظيم الملفات والأكواد عند رفعها. أما عند كتابة الأكواد على Kaggle Notebook مباشرة حينها يمكنك الكتابة وتنفيذ الكود مباشرة على Kaggle بدون الحاجة للانتقال بين بيئات مختلفة وهذا يسرع وقت حلك للمسابقة فإذا كانت المسابقة تعتمد على الوقت فحينها ذلك الأمر أفضل. وأيضا في Kaggle يقومون بتوفير البيئة جاهزة مسبقا لهذا لن تحتاج إلى تثبيت المكتبات أو القلق بشأن الإصدارات أو التعارضات . وإذا كان جهازك إمكانياته ليست جيدة فهنا الأفضل العمل على Kaggle مباشرة. لذلك إذا كنت مبتدئ أو تبحث عن السهولة في المشاركة فمن الأفضل أن تستخدم Kaggle Notebooks مباشرة.1 نقطة
-
عند تم اطلاق لغة JavaScript كانت تعمل فقط داخل المتصفح مما جعل استخدام اللغة محدودة جدا فهي تستعمل فقط للواجهات الأمامية في المواقع لكن عندما أتت nodejs فهي بيئة عمل أو تشغيل حيث هذه البيئة جعلت من أكواد جافاسكريبت تعمل كلغة برمجية مثلها كنظيراتها من اللغات حيث يمكننا استخدامها في حواسيبنا كما يوجد أيضا بيئات عمل أخرى كBunjs وهي نفس الفكرة حيث مكنتنا من كتابة Javascript في حواسيبنا أو بالخوادم Server مما مكننا من صناعة الواجهات الخلفية Backends فمما مكننا من تعلم لغة واحدة يمكننا صناعة فيها موقع متكامل بلغة واحدة مما يسرع عملية التعلم فلا نحتاج لتعلم لغة أخرى. بيئة عمل nodejs هي الأكثر استخداما بين بيئات العمل الأخرى للغة Javascript كما أنها مطلوبة في سوق العمل لكن بالطبع يعتمد على المكان الذي تريد العمل فيه.1 نقطة
-
بالنسبة ل JavaScript فهي لغة برمجة تعمل أساسا على المتصفح، وتم تصميمها لتطوير واجهات المستخدم على الويب، و تستخدم لإضافة تفاعلية إلى صفحات الويب، مثل التحكم في الأزرار، تعديل النصوص، عرض النوافذ المنبثقة، والتفاعل مع المستخدم. أما Node.js فهو بيئة تشغيل تتيح لك تشغيل JavaScript على جانب الخادم، و تم تطوير Node.js استنادا إلى محرك JavaScript V8 الخاص بـ Google، مما يسمح لك باستخدام JavaScript لبناء تطبيقات خادم، مثل بناء واجهات برمجية، إدارة قواعد البيانات، أو إنشاء تطبيقات تعمل في الخلفية.1 نقطة
-
الأمر يعتمد عليك و على خصائص جهازك، فالعمل على جهازك المحلي يمنحك مرونة أكبر، حيث يمكنك استخدام بيئات برمجية مختلفة بالإضافة إلى التكامل مع أدوات إضافية أو مكتبات قد تكون غير متوفرة على Kaggle، و يمكنك أيضا الاحتفاظ بنسخة محلية من الكود، كما أن هذه الطريقة تسمح لك بالعمل أوفلاين دون الحاجة إلى اتصال بالإنترنت، ولكنها تتطلب منك رفع الكود والبيانات إلى Kaggle عند الانتهاء، بالإضافة إلى تثبيت المكتبات وضبط البيئة البرمجية بنفسك، مما قد يستغرق وقتا. أما العمل مباشرة على Kaggle Notebook يوفر بيئة جاهزة مزودة بجميع المكتبات الشائعة، مما يوفر عليك وقت إعداد البيئة، كما أن Kaggle يقدم أيضا موارد مجانية مثل GPU/TPU لتسريع عملياتك، كما يمكنك مشاركة الكود بسهولة إذا كنت تعمل ضمن فريق، وتوثيق الخطوات بشكل منظم أثناء كتابة الكود. لذا إذا كان المشروع كبير أو يتطلب تخصيصا عميقا أو مكتبات خاصة، فمن الأفضل أن تبدأ على جهازك المحلي ثم ترفع الكود والنتائج إلى Kaggle لاحقا1 نقطة
-
JavaScript هي لغة برمجة تستخدم بشكل أساسي في تطوير صفحات الويب لجعلها تفاعلية، مثل إضافة تأثيرات أو التفاعل مع المستخدم. تنفذ هذه اللغة عادة في المتصفح مثل Chrome أو Firefox لتشغيل الكود على جهاز المستخدم ومن جهة أخرى Node.js هو بيئة تشغيل تسمح لنا بتشغيل أكواد JavaScript على الخوادم (Server-Side)، وليس فقط في المتصفح يعني ذلك أن Node.js يسمح بكتابة تطبيقات خوادم باستخدام JavaScript، مثل بناء سيرفرات أو التعامل مع قواعد البيانات إذا ف JavaScript هي اللغة نفسها، بينما Node.js هو الأداة التي تمكِّن من تشغيل هذه اللغة في بيئة الخادم.1 نقطة
-
SynthCity هي أداة أو مكتبة تستخدم لتوليد بيانات اصطناعية مشابهة للبيانات الحقيقية، مع الحفاظ على الخصائص والإحصائيات التي تميزها. الفائدة الأساسية من الأداة هي القدرة على توليد بيانات يمكن استخدامها لتدريب نماذج الذكاء الاصطناعي أو لاختبار الأنظمة دون الحاجة لاستخدام بيانات حقيقية قد تحتوي على معلومات حساسة أو خاصة فباستخدام SynthCity يمكن للمستخدمين إنشاء بيانات مشابهة للبيانات الأصلية، مثل البيانات المالية أو الطبية أو غيرها، لكن بشكل صناعي، مما يسمح بحماية الخصوصية أو التعامل مع حالات نقص البيانات والميزة الرئيسية هي أنه يمكن توليد بيانات تحاكي البيانات الحقيقية بشكل دقيق وتدريب نماذج الذكاء الاصطناعي عليها، مما يساعد في تحسين الأداء وتقليل المخاطر المرتبطة باستخدام البيانات الحقيقية ف SynthCity تعتمد على تقنيات حديثة مثل شبكات GAN (Generative Adversarial Networks) و Autoencoders لإنشاء هذه البيانات الاصطناعية.1 نقطة
-
SynthCity هي مكتبة مفتوحة المصدر تُستخدم لإنشاء بيانات صناعية (synthetic data) باستخدام التعلم الآلي. البيانات الصناعية يمكن إعبارها بديل آمن وفعال للبيانات الحقيقية في التطبيقات التي تتطلب الخصوصية أو عندما يكون من الصعب الحصول على بيانات حقيقية. ويمكنك زيارة مستودع الأداة على github لكيفية تثبيتها والتعامل معها : https://github.com/vanderschaarlab/synthcity1 نقطة
-
تلك مدينة افتراضية تم إنشاؤها بواسطة Google AI باستخدام تقنية الذكاء الاصطناعي، وذلك كبيئة اختبار للأنظمة المستقلة، مثل السيارات ذاتية القيادة، والروبوتات، وغيرها من التقنيات المتقدمة. أي مصممة لتكون واقعية قدر الإمكان، مع تضمينها لمعالم المدينة، مثل الطرق، والمباني، والمشاة، والمركبات، وتحتوي على كميات هائلة من البيانات، بما في ذلك بيانات الموقع، والطقس، وحركة المرور، مما يسمح بتدريب نماذج الذكاء الاصطناعي بشكل فعال. وتستطيع التحكم في جميع جوانبها، بما في ذلك الوقت من اليوم، والطقس، وحركة المرور، مما يسمح لهم باختبار سيناريوهات مختلفة. وهي مفتوحة المصدر مفتوح أي الجميع يستطيع استخدامها. https://github.com/vanderschaarlab/synthcity1 نقطة
-
و عليكم السلام، هي أداة تستعمل لتوليد بيانات واقعية جدًا، و هي تقوم بتوليد البيانات على شكل ما يدعى ب Point Cloud أي عبارة عن نقاط سحابية، و هي نقاط ثلاثية الأبعاد تشكل المشهد كله. هذه مثلًا صورة توضح النقاط السحابية: يمكنك أن تطلع أكثر على ما تقوم هذه الأداة بتوليده عن طريق الموقع التالي: https://www.synthcity.xyz/ تحياتي.
 1 نقطة
1 نقطة -
السلام عليكم، احتاج احد يساعدني في مشروع تحليل وتصميم النظم عن حجوزات الفنادق في معلومات عنه واستبداله بنظام معلوماتي محوسب أقدر يحل مشكلة الحجز بطريقة اليدوية
 1 نقطة
1 نقطة -
لا داعي للهلع والتوتر المبالغ فيه بخصوص الامتحان، فهو كسائر الامتحانات إن حضرت له جيدا وتوكلت على الله فسيوفقك بإذن الله فيه، المهم أن تركز على فهم الدروس، والتطبيق العملي وإنجاز المشاريع بالشكل المطلوب ورفعها، أما بخصوص المحادثة الصوتية فسيتم تحديد لك موعد لاجرائها في مدة 30 دقيقة أين سيطرح المدرب فيها أسئلة متعلقة بالدورة ويناقش معك ما نفذته خلالها يمكنك التعمق أكثر من هنا: الاختبار النهائي وحتى إن لم توفّق في أول محاولة، فالمحاولات القادمة يمكنك استدراك ما فاتك وتدارك ما أخطأت فيه فالمدربون سيرشدونك لتصحيح أخطائك ويوجهونك وهذا سيساعدك في اجتياز الامتحان في المرة القادمة.1 نقطة
-
تسجيل الدخول من خلال جوجل ذلك أمر مختلف تمامًا، ما قصدته هو تسجيل الحساب من خلال الـ Form بكتابة الاسم والإيميل ثم تسجيل الدخول. حيث ستحتاج إلى إنشاء حساب في https://console.cloud.google.com/ وإنشاء مشروع والحصول على API بالضغط على APIs & Services ثم Credentials. ثم استخدام مكتبة laravel/socialite لتسهيل الأمر عليك: composer require laravel/socialite وهناك المزيد من الخطوات بإعداد متغيرات البيئة، ستجد تفصيل هنا: https://laravel.com/docs/11.x/socialite1 نقطة
-
لا تقلق بخصوص الإمتحان، كل ما عليك هو الاستعداد والمراجعة وتنفيذ المشاريع على علم بما يحدث ولماذا تقوم بفعل أمر معين وهكذا وليس الكتابة وراء الشرح فقط. سيتم التركيز على الجانب العملي أكثر من الجانب النظري، لذا من الأفضل لو قمت بتنفيذ مشروع آخر بجانب ما قمت به بالدورة لقياس مدى استيعابك والمراجعة على النقاط التي تجد بها ضعف. وتستطيع إعادة الإمتحان أكثر من مرة لحين إجتيازه، لكن من الأفضل الاستعداد حفاظًا على وقتك ومجهودك.1 نقطة
-
عليك إنشاء عميل client جديد لـ Passport، وذلك نوع خاص من عملاء Passport نستخدمه لتطبيقات الويب أو الأجهزة المحمولة التي تحتاج إلى الوصول إلى موارد API محمية بواسطة Passport. من خلال الأمر: php artisan passport:client --personal وذلك يحدد العميل الشخصي على أنه شخصي، أي أنه مُصمم للاستخدام من قبل تطبيق واحد فقط. سيخبرك بكتابة اسم التطبيق قم بكتابة أي اسم تريده، ثم قم بتشغيل الخادم، وتجربة تسجيل مستخدم بإيميل مختلف.1 نقطة
-
 نشرح في مقال اليوم الخطوات الأساسية لدمج نماذج الذكاء الاصطناعي التي توفرها شركة OpenAI في تطبيق جانغو Django، ففي الآونة الأخيرة ازادت شعبية نماذج OpenAI أو ما يعرف بنماذج GPT OpenAI بشكل كبير بفضل قدرتها على توليد محتوى نصي عالي الجودة في مختلف المجالات سواء كتابة رسائل البريد الإلكتروني والقصص، أو الإجابة على استفسارات العملاء، أو ترجمة المحتوى من لغة لأخرى. تُستخدم نماذج جي بي تي GPT models من قبل المستخدمين من خلال روبوت الدردشة تشات جي بي تي ChatGPT، وهو نظام محادثة ذكي أطلقته OpenAI، لكن يمكن للمطورين الاستفادة من هذه النماذج في تطوير تطبيقاتهم الخاصة باستعمال واجهة برمجة التطبيقات API التي وفرتها OpenAI لتوفير مرونة أكبر في التعامل مع هذه النماذج. وسنوضح في الفقرات التالية خطوات إنشاء تطبيق جانغو يستخدم هذه الواجهة البرمجية، وبالتحديد الواجهة البرمجية لنموذج إكمال المحادثة ChatCompletion API من أجل توليد قصة قصيرة ونتعرف على طريقة تخصص معاملات النموذج المختلفة، وتنسيق ردوده واستجاباته. متطلبات العمل كي نتمكن من إكمال هذه المقالة، سوف تحتاج الآتي: إطار جانغو Django مثبت على بيئة افتراضية env ضمن حاسوبنا إنشاء حساب على منصة OpenAI توليد مفتاح الواجهة البرمجية OpenAI API key من لوحة تحكم الحساب في منصة OpenAI تثبيت حزمة OpenAI Package الخاصة بلغة بايثون ضمن البيئة الافتراضية كما سنشرح في الخطوة التالية تثبيت مكتبة OpenAI في جانغو لنفترض أننا ثبَّتنا جانغو في البيئة افتراضية ضمن مجلد باسم django-apps. علينا التأكد من تفعيل البيئة الافتراضية وظهور اسمها داخل قوسين() في سطر الأوامر Terminal. إذا لم تكن البيئة الافتراضية مفعّلة فيمكننا تفعيلها يدويًا بالانتقال للمجلد django-apps في سطر الأوامر وكتابة الأمر التالي: hasoub-academy@ubuntu:$ .env/bin/activate بمجرد تفعيل البيئة الافتراضية، نشغل الأمر التالي لتنزيل حزمة OpenAI Package الخاصة بلغة بايثون: (env)hasoub-academy@ubuntu:$ pip install openai نحن الآن جاهزون للبدء بتطوير تطبيق جانغو الخاص بنا كما سنوضح في الخطوات التالية. إرسال الطلبات للواجهة البرمجية OpenAI API نحتاج بداية لإضافة مفتاح الواجهة البرمجية OpenAI API key لتطبيقنا كي نتمكن من إرسال الطلبات للواجهة البرمجية ChatCompletion API. واختبار الرد الذي نحصل عليه منها. لنكتب الأمر التالي لتشغيل بايثون داخل البيئة الافتراضية: (env)hasoub-academy@ubuntu:$ python نستورد بعدها المكتبة OpenAI ونعرًف العميل client المخصص للتفاعل مع الواجهة البرمجية كما يلي: import openai client = OpenAI(api_key="your-api-key") ملاحظة: نحتاج لاستبدالyour-api-key بمفتاح الواجهة البرمجية الخاص بنا وهو شبيه للتالي sk-abdfhghlisciodfop. بعدها نرسل طلب للواجهة البرمجية ChatCompletion API باستخدم الدالة chat.completions.create: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "عد من 1 إلى 10"} ] ) حددنا في الكود السابق النموذج الذي نحتاج لاستخدامه في تطبيقنا ليكون gpt-3.5-turbo، وأضفنا كائن رسالة واحد يحتوي على الدور مستخدم user، ومرّرنا مُوجّه prompt بسيط سنرسل لاختبار الواجهة البرمجية وهو في حالتنا طلب العد من واحد إلى عشرة. ملاحظة1: عند التفاعل مع نموذج GPT سنتعامل مع ثلاثة أدوار رئيسية وهي: دور المستخدم user الذي يطرح الأسئلة أو يطلب المساعدة من النموذج، ودور النظام system الذي يتضمن القواعد والتعليمات التي توجّه للنموذج، ودور المساعد assistance الذي يمثل نموذج الذكاء الاصطناعي نفسه والذي سنستخدمة للإجابة على أسئلة المستخدم أو تنفيذ الأوامر التي يطلبها منه. ملاحظة2: من المهم دائمًا الرجوع إلى التوثيق الرسمي لمنصة OpenAI للحصول على تعليمات دقيقة وشاملة حول كيفية استخدام نماذج GPT في تطبيقاتك، فهذه النماذج تتعدل وتتغير مع مرور الوقت. لنطبع الآن الرد المستلم من الواجهة البرمجية API والذي يتضمن عرض الأعداد من واحد إلى عشرة على شكل قائمة من خلال الأمر التالي: print(response.choices[0].message.content) سنحصل على النتيجة التالية: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 بهذا نكون قد نجحنا بإرسال طلب بسيط إلى الواجهة البرمجية، واستلمنا منها الرد، وتأكدنا أن كل شيء يسير على ما يرام. نحن جاهزون الآن لاستخدام الواجهة البرمجية لإرسال مُوجّه prompt أكثر صعوبة ونطلب من النموذج كتابة محتوى قصة قصيرة. ضبط معاملات النموذج Parameters بعد أن نجنا في إرسال طلب API بسيط إلى الواجهة البرمجية لإكمال المحادثة ChatCompletion API، لنتعرف على طريقة ضبط معاملات النموذج للتحكم بسلوك هذا النموذج. فهنالك العديد من المعاملات المتاحة للتحكم في النص المولد، سنوضح ثلاثة منها. 1. درجة الحرارة Temperature يتحكم هذا المعامل في مدى عشوائية الردود المولَّدة من قبل النموذج، ويأخذ قيمة بين الصفر والواحد، فكلما ارتفعت قيمته سنحصل على تنوع وإبداع في الردود والعكس صحيح. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. سيارة 3. كتاب 4. شمس 5. شجرة لنجرب منحه قيمة قريبة من الصفر مثل 0.1 ونرى كيف ستولد الكلمات: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. فيل 3. ضوء الشمس 4. مغامرة 5. سكون نلاحظ بالتجربة أننا عندما نطلب من النموذج أن يذكر خمس كلمات عدة مرات عند ضبط البرامتر بالقيمة 0.1 فسوف نحصل على نفس الكلمات في كل مرة، أما عندما نضبط قيمته إلى 0.8 ونجرب الطلب عدة مرات فسنلاحظ تغيّر النتائج التي نحصل عليها كل مرة: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات باللغة العربية"}], temperature=0.8 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. ضوء الشمس 3. سعادة 4. صداقة 5. تقنية 2. العدد الأقصى للوحدات النصية Max Token يسمح لنا هذا المعامل بتحديد طول النص المولد، فعند ضبطع بقيمة معينة سيضمن لنا أن الردود لن تتجاوز الرقم الذي حددناه في الوحدات النصية tokens، على سبيل المثال عندما نضبط قيمة max-token إلى 10: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=10 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاحة 2. سيارة وعندما نضبط قيمة max-token إلى 20: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=20 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاح 2. سيارة 3. موسيقى 4. محيط 5. صداقة 3. التدفق Stream يحدد هذا المعامل هل نريد أن تتدفق الردود على دفعات streams أو تعود لنا دفعة واحدة، فعند ضبطه بالقيمة True، سنستلم الرد بشكل متدفق، أي على دفعات خلال عملية توليدها. هذا يفيدنا في المحادثات الطويلة وفي تطبيقات الزمن الحقيقي التفاعلية. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], stream=True ) collected_messages = [] for chunk in response: chunk_message = chunk.choices[0].delta.content if chunk_message is not None: collected_messages.append(chunk_message) print(collected_messages) المخرجــــات ['', 'قطة', '\n', 'كتاب', '\n', 'حاسوب', '\n', 'شمس', '\n', 'ماء'] سيحتفظ المتغير chunk_message بكل جزء من الرسالة المتدفقة بشكل مؤقت أثناء استلامها من الواجهة البرمجية، بعد ذلك، ستضاف هذه الأجزاء إلى القائمة collected_messages التي تُجمع فيها كل الرسائل. يجب علينا التأكد من أن الجزء المتدفق ليس None، لأن هذه القيمة تدل على انتهاء تدفق الردود وتستخدم كشرط للخروج من الحلقة التكرارية. صياغة مُوجِّه نظام System Prompt مخصص في هذه الخطوة، سنستخدم كل ما تعلمناه من مفاهيم أساسية لكتابة مُوجِّه نظام مخصص system prompt وتوفير السياق الذي يحتاجه نموذج GPT لفهم المطلوب منه ضمن تطبيق جانغو، وسنحدد القواعد التي يجب أن يتبعها النموذج لتوليد المحتوى. ننشئ بداية وحدة بايثون تحتوي على دالة تتولى المهمة المطلوبة. لذا ننشئ ملفًا جديدًا باسم story_generator.py داخل مجلد مشروع جانغو بكتابة الأمر التالي: (env)hasoub-academy@ubuntu:$ touch ~/my_blog_app/blog/blogsite/story_generator.py ثم نضيف مفتاح الواجهة البرمجية OpenAI API key إلى متغيرات البيئة environmental variables، فلا نضيفها في ملف بايثون مباشرة لحماية المفتاح: (env)hasoub-academy@ubuntu:$ export OPENAI_KEY="your-api-key" نفتح الآن الملف story_generator.py وننشئ بداخله عميل OpenAI client ونعرف دالة باسم generate_story وظيفتها توليد محتوى قصة بناءً على مجموعة من الكلمات التي يحددها المستخدم: import os from openai import OpenAI client = OpenAI(api_key=os.environ["OPENAI_KEY"]) def generate_story(words): # استدعاء واجهة برمجة التطبيقات من OpenAI لتوليد القصة response = get_short_story(words) # تنسيق الاستجابة وإرجاعها return format_response(response) لتنظيم الكود البرمجي، سنستدعي ضمن هذه الدالة البرمجية دالة منفصلة باسم get_short_story تطلب توليد القصة من الواجهة البرمجية OpenAI API، ودالة أخرى باسم format_response تنسِّق الرد المستلم من الواجهة البرمجية. لنركز الآن على دالة توليد القصة get_short_story حيث سنضيف الكود الخاص بها في نهاية الملف story_generator.py كما يلي: def get_short_story(words): # إنشاء موجه النظام system_prompt = f"""أنت مولد قصص قصيرة. اكتب قصة قصيرة باستخدام الكلمات التالية: {words}. لا تتجاوز فقرة واحدة.""" # الاتصال بواجهة برمجة التطبيقات response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{ "role": "user", "content": system_prompt }], temperature=0.8, max_tokens=1000 ) # إرجاع استجابة الواجهة البرمجية return response كما نلاحظ فقد ضبطنا هنا مُوجِّه النظام system prompt كي يخبر النموذج ما هو، وما هي المهمة التي عليه تأديتها، وحددنا في الموجّه حجم القصة المطلوبة، ثم مررنا هذا الموجّه للواجهة البرمجية ChatCompletion API. أخيرًا نكتب كود دالة التنسيق format_response في نهاية الملف story_generator.py: def format_response(response): # استخرج القصة المولدة من الاستجابة story = response.choices[0].message.content # إزالة أي نص أو تنسيقات غير مرغوبة story = story.strip() # إرجاع القصة المنسقة return story لاختبار هذه الدوال سنستدعي الدالة generate_story ونمرر لها مجموعة كلمات كمعاملات، ثم نطبع الرد الذي تعيده لنا من خلال إضافة سطر الكود التالي للملف: print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) لنحفظ الملف ونغلقه، ونشغًله من داخل سطر الأوامر كما يلي: (env) sammy@ubuntu:$ python ~/my_blog_app/blog/blogsite/story_generator.py يجب أن نحصل على قصة تشابه القصة التالية: في زاوية مريحة من غرفة مشمسة، كانت هناك قطة ذات فرو ناعم تُدعى "مشمش"، تتمدد بكسل بجانب رف كتب شاهق. بين صفوف الكتب، كان حاسوب فضولي يهمس بهدوء. بينما كانت أشعة الشمس تتسلل عبر النافذة، مُلَقيةً ضوءًا دافئًا، لاحظت "مشمش" بقعة ماء صغيرة على الرف. مدفوعةً بالفضول، دفعت القطة الكتاب الأقرب إلى البقعة، ليُفتح الكتاب ويكشف عن مكان مخفي يحتوي على عقد ماسي متلألئ. مع اكتشاف السر، بدأت "مشمش" مغامرة غير متوقعة، حيث امتزجت أشعة الشمس، والماء، وقوة المعرفة لتنسج قصة مثيرة من الغموض والاكتشاف. بعد أن تأكدنا من عمل الدالة generate_story وتوليد القصة بشكل صحيح، لنغير طريقة تنفيذ الكود وبدلاً من طباعة القصة مباشرة في سطر الأوامر، سنستدعي الدالة من خلال عرض جانغو Django view لعرض القصة على واجهة المستخدم. print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) يمكن تجربة تعديل مُوجّه النظام system prompt بما يناسبنا لتوليد محتوى أفضل. سنلاحظ بالتجربة أن بإمكاننا دائمًا تحسين النتائج بما يتناسب مع احتياجاتنا. لننتقل إلى الخطوة التالية، حيث سندمج الوحدة التي عرفناها في ملف story_generator.py مع مشروع جانغو الخاص بنا. دمج وحدة بايثون مع جانغو في الواجهة الخلفية لدمج وحدة story_generator مع مشروع جانغو في الواجهة الخلفية، علينا تنفيذ عدة خطوات بسيطة، سنبدأ أولاً بإنشاء عرض view جديد في جانغو لاستقبال الكلمات من المستخدم، ثم سنستخدم الدالة generate_story لتوليد القصة بناءً على تلك الكلمات، وفي النهاية سنعرض النتيجة للمستخدم عبر المتصفح. نفتح ملف views.py داخل مجلد مشروع جانغو، ونستورد الوحدات والحزم البرمجية اللازمة، ثم نضيف دالة عرض view باسم generate_story_from_words ونكتب ضمنها ما يلي: from django.http import JsonResponse from .story_generator import generate_story def generate_story_from_words(request): words = request.GET.get('words') # استخراج الكلمات المتوقعة من الطلب story = generate_story(words) # استدعاء دالة generate_story باستخدام الكلمات المستخرجة return JsonResponse({'story': story}) # إرجاع القصة في استجابة JSON بعدها نحتاج لربط الدالة بمسار URL في مشروع جانغو لتمكين المستخدمين من الوصول إليها عبر المتصفح. لنفتح الملف urls.py ونضيف نمط الرابط URL pattern للدالة generate_story_from_words كما يلي: urlpatterns = [ # أنماط URL الأخرى... path('generate-story/', views.generate_story_from_words, name='generate-story'), ] الآن يمكننا إرسال الطلبات من خلال نقطة الوصول التالية/generate-story/ باستخدام المتصفح، وإرسال طلب من النوع GET لها وتمرير الكلمات المتوقعة كمعاملات للطلب، نفتح سطر الأوامر ونكتب الأمر curl بالشكل التالي: (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words=قطة,كتاب,حاسوب,شمس,ماء" علينا استبدال http://your_domain بالعنوان الفعلي الذي يستضيف مشروعنا. تمثّل الكلمات الممررة عبر هذا الرابط مثل كتاب، وماء، وحاسوب ما هي الكلمات التي نريد استخدامها لتوليد محتوى القصة. يمكن بالطبع تغيير هذه الكلمات واستخدام كلمات أخرى حسب الحاجة. بعد تشغيل أمر curl يجب أن نرى ردًا من الخادم يحتوي على القصة المولدة استنادًا إلى الكلمات التي قدمناها. (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words="قطة,كتاب,حاسوب,شمس,ماء" وسنحصل على مخرجات قريبة للتالي: { "story": "كان يا مكان، في كوخ صغير مريح يقع وسط غابة كثيفة، قطة فضولية تُدعى 'مشمش' تجلس بجانب النافذة، تستمتع بأشعة الشمس الدافئة. بينما كانت 'مشمش' تحرك ذيلها بكسل، لفت نظرها كتاب مغبر ملقى على رف قريب. بدافع الفضول، قفزت بعناية إلى الرف، مما أدى إلى سقوط مجموعة من الكتب، فتح أحدها ليكشف عن مكان مخفي. داخل هذا المكان، اكتشفت 'مشمش' حاسوبًا قديمًا، بدأ شاشته يومض عندما لمست زر الطاقة. مفتونةً بالشاشة المتوهجة، انطلقت 'مشمش' في عالم من المناظر الافتراضية، حيث تجولت بحرية، تطارد الأسماك الرقمية وتوقف للإعجاب بشلالات رائعة. ضائعة في هذه المغامرة الجديدة، اكتشفت 'مشمش' عجائب العوالم الملموسة والافتراضية معًا، مدركةً أن الاستكشاف الحقيقي لا يعرف حدودًا." } الخلاصة إلى هنا نكون قد وصلنا لنهاية هذا المقال الذي وضحنا فيه الخطوات الأساسية التي نحتاجها لدمج OpenAI modes داخل تطبيق جانغو Django باستخدام الواجهة البرمجية OpenAI API، وتعلمنا طريقة إرسال الطلبات للواجهة البرمجية ChatCompletion API والتحكم بسلوك النموذج عن طريق ضبط معاملاته المختلفة. لتحسين هذا المشروع وزيادة ميزاته، يمكننا استكشاف المزيد من مميزات الواجهة البرمجية OpenAI API وتجريب مُوجِّهات نظام system prompt مختلفة، وقيم معاملات متنوعة حتى نحصل على قصة مميزة وإبداعية. ترجمة-وبتصرٌّف-للمقال How to Integrate OpenAI GPT Models in Your Django Project اقرأ أيضًا إنشاء تطبيق جانغو وتوصيله بقاعدة بيانات مدخل إلى إطار عمل الويب جانغو Django دليلك لربط واجهة OpenAI API مع Node.js استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي1 نقطة
نشرح في مقال اليوم الخطوات الأساسية لدمج نماذج الذكاء الاصطناعي التي توفرها شركة OpenAI في تطبيق جانغو Django، ففي الآونة الأخيرة ازادت شعبية نماذج OpenAI أو ما يعرف بنماذج GPT OpenAI بشكل كبير بفضل قدرتها على توليد محتوى نصي عالي الجودة في مختلف المجالات سواء كتابة رسائل البريد الإلكتروني والقصص، أو الإجابة على استفسارات العملاء، أو ترجمة المحتوى من لغة لأخرى. تُستخدم نماذج جي بي تي GPT models من قبل المستخدمين من خلال روبوت الدردشة تشات جي بي تي ChatGPT، وهو نظام محادثة ذكي أطلقته OpenAI، لكن يمكن للمطورين الاستفادة من هذه النماذج في تطوير تطبيقاتهم الخاصة باستعمال واجهة برمجة التطبيقات API التي وفرتها OpenAI لتوفير مرونة أكبر في التعامل مع هذه النماذج. وسنوضح في الفقرات التالية خطوات إنشاء تطبيق جانغو يستخدم هذه الواجهة البرمجية، وبالتحديد الواجهة البرمجية لنموذج إكمال المحادثة ChatCompletion API من أجل توليد قصة قصيرة ونتعرف على طريقة تخصص معاملات النموذج المختلفة، وتنسيق ردوده واستجاباته. متطلبات العمل كي نتمكن من إكمال هذه المقالة، سوف تحتاج الآتي: إطار جانغو Django مثبت على بيئة افتراضية env ضمن حاسوبنا إنشاء حساب على منصة OpenAI توليد مفتاح الواجهة البرمجية OpenAI API key من لوحة تحكم الحساب في منصة OpenAI تثبيت حزمة OpenAI Package الخاصة بلغة بايثون ضمن البيئة الافتراضية كما سنشرح في الخطوة التالية تثبيت مكتبة OpenAI في جانغو لنفترض أننا ثبَّتنا جانغو في البيئة افتراضية ضمن مجلد باسم django-apps. علينا التأكد من تفعيل البيئة الافتراضية وظهور اسمها داخل قوسين() في سطر الأوامر Terminal. إذا لم تكن البيئة الافتراضية مفعّلة فيمكننا تفعيلها يدويًا بالانتقال للمجلد django-apps في سطر الأوامر وكتابة الأمر التالي: hasoub-academy@ubuntu:$ .env/bin/activate بمجرد تفعيل البيئة الافتراضية، نشغل الأمر التالي لتنزيل حزمة OpenAI Package الخاصة بلغة بايثون: (env)hasoub-academy@ubuntu:$ pip install openai نحن الآن جاهزون للبدء بتطوير تطبيق جانغو الخاص بنا كما سنوضح في الخطوات التالية. إرسال الطلبات للواجهة البرمجية OpenAI API نحتاج بداية لإضافة مفتاح الواجهة البرمجية OpenAI API key لتطبيقنا كي نتمكن من إرسال الطلبات للواجهة البرمجية ChatCompletion API. واختبار الرد الذي نحصل عليه منها. لنكتب الأمر التالي لتشغيل بايثون داخل البيئة الافتراضية: (env)hasoub-academy@ubuntu:$ python نستورد بعدها المكتبة OpenAI ونعرًف العميل client المخصص للتفاعل مع الواجهة البرمجية كما يلي: import openai client = OpenAI(api_key="your-api-key") ملاحظة: نحتاج لاستبدالyour-api-key بمفتاح الواجهة البرمجية الخاص بنا وهو شبيه للتالي sk-abdfhghlisciodfop. بعدها نرسل طلب للواجهة البرمجية ChatCompletion API باستخدم الدالة chat.completions.create: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "عد من 1 إلى 10"} ] ) حددنا في الكود السابق النموذج الذي نحتاج لاستخدامه في تطبيقنا ليكون gpt-3.5-turbo، وأضفنا كائن رسالة واحد يحتوي على الدور مستخدم user، ومرّرنا مُوجّه prompt بسيط سنرسل لاختبار الواجهة البرمجية وهو في حالتنا طلب العد من واحد إلى عشرة. ملاحظة1: عند التفاعل مع نموذج GPT سنتعامل مع ثلاثة أدوار رئيسية وهي: دور المستخدم user الذي يطرح الأسئلة أو يطلب المساعدة من النموذج، ودور النظام system الذي يتضمن القواعد والتعليمات التي توجّه للنموذج، ودور المساعد assistance الذي يمثل نموذج الذكاء الاصطناعي نفسه والذي سنستخدمة للإجابة على أسئلة المستخدم أو تنفيذ الأوامر التي يطلبها منه. ملاحظة2: من المهم دائمًا الرجوع إلى التوثيق الرسمي لمنصة OpenAI للحصول على تعليمات دقيقة وشاملة حول كيفية استخدام نماذج GPT في تطبيقاتك، فهذه النماذج تتعدل وتتغير مع مرور الوقت. لنطبع الآن الرد المستلم من الواجهة البرمجية API والذي يتضمن عرض الأعداد من واحد إلى عشرة على شكل قائمة من خلال الأمر التالي: print(response.choices[0].message.content) سنحصل على النتيجة التالية: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 بهذا نكون قد نجحنا بإرسال طلب بسيط إلى الواجهة البرمجية، واستلمنا منها الرد، وتأكدنا أن كل شيء يسير على ما يرام. نحن جاهزون الآن لاستخدام الواجهة البرمجية لإرسال مُوجّه prompt أكثر صعوبة ونطلب من النموذج كتابة محتوى قصة قصيرة. ضبط معاملات النموذج Parameters بعد أن نجنا في إرسال طلب API بسيط إلى الواجهة البرمجية لإكمال المحادثة ChatCompletion API، لنتعرف على طريقة ضبط معاملات النموذج للتحكم بسلوك هذا النموذج. فهنالك العديد من المعاملات المتاحة للتحكم في النص المولد، سنوضح ثلاثة منها. 1. درجة الحرارة Temperature يتحكم هذا المعامل في مدى عشوائية الردود المولَّدة من قبل النموذج، ويأخذ قيمة بين الصفر والواحد، فكلما ارتفعت قيمته سنحصل على تنوع وإبداع في الردود والعكس صحيح. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. سيارة 3. كتاب 4. شمس 5. شجرة لنجرب منحه قيمة قريبة من الصفر مثل 0.1 ونرى كيف ستولد الكلمات: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], temperature=0.1 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. فيل 3. ضوء الشمس 4. مغامرة 5. سكون نلاحظ بالتجربة أننا عندما نطلب من النموذج أن يذكر خمس كلمات عدة مرات عند ضبط البرامتر بالقيمة 0.1 فسوف نحصل على نفس الكلمات في كل مرة، أما عندما نضبط قيمته إلى 0.8 ونجرب الطلب عدة مرات فسنلاحظ تغيّر النتائج التي نحصل عليها كل مرة: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات باللغة العربية"}], temperature=0.8 ) print(response.choices[0].message.content) المخرجــــات 1. تفاح 2. ضوء الشمس 3. سعادة 4. صداقة 5. تقنية 2. العدد الأقصى للوحدات النصية Max Token يسمح لنا هذا المعامل بتحديد طول النص المولد، فعند ضبطع بقيمة معينة سيضمن لنا أن الردود لن تتجاوز الرقم الذي حددناه في الوحدات النصية tokens، على سبيل المثال عندما نضبط قيمة max-token إلى 10: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=10 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاحة 2. سيارة وعندما نضبط قيمة max-token إلى 20: response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], max_tokens=20 ) print(response.choices[0].message.content) سنحصل على النتائج التالية: المخرجــــات 1. تفاح 2. سيارة 3. موسيقى 4. محيط 5. صداقة 3. التدفق Stream يحدد هذا المعامل هل نريد أن تتدفق الردود على دفعات streams أو تعود لنا دفعة واحدة، فعند ضبطه بالقيمة True، سنستلم الرد بشكل متدفق، أي على دفعات خلال عملية توليدها. هذا يفيدنا في المحادثات الطويلة وفي تطبيقات الزمن الحقيقي التفاعلية. response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": "اذكر خمس كلمات"}], stream=True ) collected_messages = [] for chunk in response: chunk_message = chunk.choices[0].delta.content if chunk_message is not None: collected_messages.append(chunk_message) print(collected_messages) المخرجــــات ['', 'قطة', '\n', 'كتاب', '\n', 'حاسوب', '\n', 'شمس', '\n', 'ماء'] سيحتفظ المتغير chunk_message بكل جزء من الرسالة المتدفقة بشكل مؤقت أثناء استلامها من الواجهة البرمجية، بعد ذلك، ستضاف هذه الأجزاء إلى القائمة collected_messages التي تُجمع فيها كل الرسائل. يجب علينا التأكد من أن الجزء المتدفق ليس None، لأن هذه القيمة تدل على انتهاء تدفق الردود وتستخدم كشرط للخروج من الحلقة التكرارية. صياغة مُوجِّه نظام System Prompt مخصص في هذه الخطوة، سنستخدم كل ما تعلمناه من مفاهيم أساسية لكتابة مُوجِّه نظام مخصص system prompt وتوفير السياق الذي يحتاجه نموذج GPT لفهم المطلوب منه ضمن تطبيق جانغو، وسنحدد القواعد التي يجب أن يتبعها النموذج لتوليد المحتوى. ننشئ بداية وحدة بايثون تحتوي على دالة تتولى المهمة المطلوبة. لذا ننشئ ملفًا جديدًا باسم story_generator.py داخل مجلد مشروع جانغو بكتابة الأمر التالي: (env)hasoub-academy@ubuntu:$ touch ~/my_blog_app/blog/blogsite/story_generator.py ثم نضيف مفتاح الواجهة البرمجية OpenAI API key إلى متغيرات البيئة environmental variables، فلا نضيفها في ملف بايثون مباشرة لحماية المفتاح: (env)hasoub-academy@ubuntu:$ export OPENAI_KEY="your-api-key" نفتح الآن الملف story_generator.py وننشئ بداخله عميل OpenAI client ونعرف دالة باسم generate_story وظيفتها توليد محتوى قصة بناءً على مجموعة من الكلمات التي يحددها المستخدم: import os from openai import OpenAI client = OpenAI(api_key=os.environ["OPENAI_KEY"]) def generate_story(words): # استدعاء واجهة برمجة التطبيقات من OpenAI لتوليد القصة response = get_short_story(words) # تنسيق الاستجابة وإرجاعها return format_response(response) لتنظيم الكود البرمجي، سنستدعي ضمن هذه الدالة البرمجية دالة منفصلة باسم get_short_story تطلب توليد القصة من الواجهة البرمجية OpenAI API، ودالة أخرى باسم format_response تنسِّق الرد المستلم من الواجهة البرمجية. لنركز الآن على دالة توليد القصة get_short_story حيث سنضيف الكود الخاص بها في نهاية الملف story_generator.py كما يلي: def get_short_story(words): # إنشاء موجه النظام system_prompt = f"""أنت مولد قصص قصيرة. اكتب قصة قصيرة باستخدام الكلمات التالية: {words}. لا تتجاوز فقرة واحدة.""" # الاتصال بواجهة برمجة التطبيقات response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{ "role": "user", "content": system_prompt }], temperature=0.8, max_tokens=1000 ) # إرجاع استجابة الواجهة البرمجية return response كما نلاحظ فقد ضبطنا هنا مُوجِّه النظام system prompt كي يخبر النموذج ما هو، وما هي المهمة التي عليه تأديتها، وحددنا في الموجّه حجم القصة المطلوبة، ثم مررنا هذا الموجّه للواجهة البرمجية ChatCompletion API. أخيرًا نكتب كود دالة التنسيق format_response في نهاية الملف story_generator.py: def format_response(response): # استخرج القصة المولدة من الاستجابة story = response.choices[0].message.content # إزالة أي نص أو تنسيقات غير مرغوبة story = story.strip() # إرجاع القصة المنسقة return story لاختبار هذه الدوال سنستدعي الدالة generate_story ونمرر لها مجموعة كلمات كمعاملات، ثم نطبع الرد الذي تعيده لنا من خلال إضافة سطر الكود التالي للملف: print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) لنحفظ الملف ونغلقه، ونشغًله من داخل سطر الأوامر كما يلي: (env) sammy@ubuntu:$ python ~/my_blog_app/blog/blogsite/story_generator.py يجب أن نحصل على قصة تشابه القصة التالية: في زاوية مريحة من غرفة مشمسة، كانت هناك قطة ذات فرو ناعم تُدعى "مشمش"، تتمدد بكسل بجانب رف كتب شاهق. بين صفوف الكتب، كان حاسوب فضولي يهمس بهدوء. بينما كانت أشعة الشمس تتسلل عبر النافذة، مُلَقيةً ضوءًا دافئًا، لاحظت "مشمش" بقعة ماء صغيرة على الرف. مدفوعةً بالفضول، دفعت القطة الكتاب الأقرب إلى البقعة، ليُفتح الكتاب ويكشف عن مكان مخفي يحتوي على عقد ماسي متلألئ. مع اكتشاف السر، بدأت "مشمش" مغامرة غير متوقعة، حيث امتزجت أشعة الشمس، والماء، وقوة المعرفة لتنسج قصة مثيرة من الغموض والاكتشاف. بعد أن تأكدنا من عمل الدالة generate_story وتوليد القصة بشكل صحيح، لنغير طريقة تنفيذ الكود وبدلاً من طباعة القصة مباشرة في سطر الأوامر، سنستدعي الدالة من خلال عرض جانغو Django view لعرض القصة على واجهة المستخدم. print(generate_story("قطة، كتاب، حاسوب شمس، ماء")) يمكن تجربة تعديل مُوجّه النظام system prompt بما يناسبنا لتوليد محتوى أفضل. سنلاحظ بالتجربة أن بإمكاننا دائمًا تحسين النتائج بما يتناسب مع احتياجاتنا. لننتقل إلى الخطوة التالية، حيث سندمج الوحدة التي عرفناها في ملف story_generator.py مع مشروع جانغو الخاص بنا. دمج وحدة بايثون مع جانغو في الواجهة الخلفية لدمج وحدة story_generator مع مشروع جانغو في الواجهة الخلفية، علينا تنفيذ عدة خطوات بسيطة، سنبدأ أولاً بإنشاء عرض view جديد في جانغو لاستقبال الكلمات من المستخدم، ثم سنستخدم الدالة generate_story لتوليد القصة بناءً على تلك الكلمات، وفي النهاية سنعرض النتيجة للمستخدم عبر المتصفح. نفتح ملف views.py داخل مجلد مشروع جانغو، ونستورد الوحدات والحزم البرمجية اللازمة، ثم نضيف دالة عرض view باسم generate_story_from_words ونكتب ضمنها ما يلي: from django.http import JsonResponse from .story_generator import generate_story def generate_story_from_words(request): words = request.GET.get('words') # استخراج الكلمات المتوقعة من الطلب story = generate_story(words) # استدعاء دالة generate_story باستخدام الكلمات المستخرجة return JsonResponse({'story': story}) # إرجاع القصة في استجابة JSON بعدها نحتاج لربط الدالة بمسار URL في مشروع جانغو لتمكين المستخدمين من الوصول إليها عبر المتصفح. لنفتح الملف urls.py ونضيف نمط الرابط URL pattern للدالة generate_story_from_words كما يلي: urlpatterns = [ # أنماط URL الأخرى... path('generate-story/', views.generate_story_from_words, name='generate-story'), ] الآن يمكننا إرسال الطلبات من خلال نقطة الوصول التالية/generate-story/ باستخدام المتصفح، وإرسال طلب من النوع GET لها وتمرير الكلمات المتوقعة كمعاملات للطلب، نفتح سطر الأوامر ونكتب الأمر curl بالشكل التالي: (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words=قطة,كتاب,حاسوب,شمس,ماء" علينا استبدال http://your_domain بالعنوان الفعلي الذي يستضيف مشروعنا. تمثّل الكلمات الممررة عبر هذا الرابط مثل كتاب، وماء، وحاسوب ما هي الكلمات التي نريد استخدامها لتوليد محتوى القصة. يمكن بالطبع تغيير هذه الكلمات واستخدام كلمات أخرى حسب الحاجة. بعد تشغيل أمر curl يجب أن نرى ردًا من الخادم يحتوي على القصة المولدة استنادًا إلى الكلمات التي قدمناها. (env)hasoub-academy@ubuntu:$ curl "http://your_domain/generate-story/?words="قطة,كتاب,حاسوب,شمس,ماء" وسنحصل على مخرجات قريبة للتالي: { "story": "كان يا مكان، في كوخ صغير مريح يقع وسط غابة كثيفة، قطة فضولية تُدعى 'مشمش' تجلس بجانب النافذة، تستمتع بأشعة الشمس الدافئة. بينما كانت 'مشمش' تحرك ذيلها بكسل، لفت نظرها كتاب مغبر ملقى على رف قريب. بدافع الفضول، قفزت بعناية إلى الرف، مما أدى إلى سقوط مجموعة من الكتب، فتح أحدها ليكشف عن مكان مخفي. داخل هذا المكان، اكتشفت 'مشمش' حاسوبًا قديمًا، بدأ شاشته يومض عندما لمست زر الطاقة. مفتونةً بالشاشة المتوهجة، انطلقت 'مشمش' في عالم من المناظر الافتراضية، حيث تجولت بحرية، تطارد الأسماك الرقمية وتوقف للإعجاب بشلالات رائعة. ضائعة في هذه المغامرة الجديدة، اكتشفت 'مشمش' عجائب العوالم الملموسة والافتراضية معًا، مدركةً أن الاستكشاف الحقيقي لا يعرف حدودًا." } الخلاصة إلى هنا نكون قد وصلنا لنهاية هذا المقال الذي وضحنا فيه الخطوات الأساسية التي نحتاجها لدمج OpenAI modes داخل تطبيق جانغو Django باستخدام الواجهة البرمجية OpenAI API، وتعلمنا طريقة إرسال الطلبات للواجهة البرمجية ChatCompletion API والتحكم بسلوك النموذج عن طريق ضبط معاملاته المختلفة. لتحسين هذا المشروع وزيادة ميزاته، يمكننا استكشاف المزيد من مميزات الواجهة البرمجية OpenAI API وتجريب مُوجِّهات نظام system prompt مختلفة، وقيم معاملات متنوعة حتى نحصل على قصة مميزة وإبداعية. ترجمة-وبتصرٌّف-للمقال How to Integrate OpenAI GPT Models in Your Django Project اقرأ أيضًا إنشاء تطبيق جانغو وتوصيله بقاعدة بيانات مدخل إلى إطار عمل الويب جانغو Django دليلك لربط واجهة OpenAI API مع Node.js استخدام وكلاء مكتبة المحولات Transformers Agents في الذكاء الاصطناعي التوليدي1 نقطة -
التزامن ببساطة تقنية برمجية تتيح للبرنامج تنفيذ عدة مهام في نفس الوقت، أي أن البرنامج يمكنه القيام بمهام متعددة في نفس الوقت، بدلاً من انتظار انتهاء المهام السابقة قبل البدء في المهام الجديدة. للتوضيح، ساستخدم مكتبة threading في بايثون لإنشاء خيطين Threads منفصلين، الخيط Thread الأول سيقوم بطباعة الأرقام من 1 إلى 10، والخيط الثاني سيقوم بطباعة الأحرف من A إلى J. وسيصبح البرنامج كالتالي وإليك تعليقات لتوضيح الأمر: import threading import time # دالة للخيط الأول def print_numbers(): for i in range(1, 11): print(i) time.sleep(0.5) # انتظر نصف ثانية قبل الطباعة التالية # دالة للخيط الثاني def print_letters(): for letter in 'ABCDEFGHIJ': print(letter) time.sleep(0.5) # انتظر نصف ثانية قبل الطباعة التالية # إنشاء خيطين thread1 = threading.Thread(target=print_numbers) thread2 = threading.Thread(target=print_letters) # بدء الخيطين thread1.start() thread2.start() # انتظار انتهاء الخيطين thread1.join() thread2.join() عندما تشغل البرنامج، ستلاحظ أن الأرقام والأحرف يتم طباعتها في نفس الوقت، وذلك يعني أن البرنامج يقوم بمهام متعددة في نفس الوقت، وهو ما يسمى بالتزامن. 1 A 2 B 3 C 4 D 5 E 6 F 7 G 8 H 9 I 10 J وللعلم بايثون لديها بعض القيود فيما يتعلق بالتزامن، بسبب ما يعرف بـ "Global Interpreter Lock" (GIL). ويعني أن بايثون لا يمكنه استخدام أكثر من نواة واحدة في المعالج في نفس الوقت، حتى لو كان لديك معالج متعدد النواة.1 نقطة
-
حفظ الدوال لا يعني الحفظ بالشكل التقليدي وذلك عموماً في البرمجة حيث نحتاج فقط للتطبيق كثيراً على المفاهيم التي نتعلمها والدوال كما بالسؤال وبالتالي الأهم هو أن تفهم الدالة وكيف تعمل، وتعرف متى تحتاجها. بمجرد أن تطبقها عدة مرات، ستتذكرها تلقائيًا من خلال الممارسة. ومع مرور الوقت، ستجد نفسك تستخدم بعض الدوال أكثر من غيرها، وهذه الدوال ستصبح مألوفة جدًا لك. أما الدوال التي تستخدمها نادرًا، فلا مشكلة في البحث عنها عند الحاجة والرجوع إلى مرجع مثل موسوعة حسوب1 نقطة