
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/15/21 في كل الموقع
-
هذا بسبب تمرير الدليل 0 بشكل دائم، يمكن تمرير id مثلا حسب رقم القائمة function showDetails(id) ^^^^^ var sel = document.getElementsByClassName('sedra')[id]; ^^^^^^ حيث أن getElementsByClassName تعيد مصفوفة بجميع العناصر التي لها نفس الصنف، هنا عليك تحديد من هو المقصود وتمييزه بطريقة ما إن قمت بتطبيق onclick على عنصر ما يمكنك الوصول له عن طريق this : onclick="myFunction(this)" ثم يمكنك الوصول للعناصر الأب له أو أي منهم حيث يتم استقبال العنصر بأي اسم متغير مثلا: showDetails(element) { element ... }2 نقاط
-
 بعد أن تعرّفنا على ماهية التصميم وعناصره ومبادئه، وألقينا نظرة على برامجه وتطبيقاته الأكثر شهرة، يمكننا البدء بالعمل على تصاميم مختلفة بناء على تعلمناه في المقالات السابقة في هذه السلسلة، يبقى لدينا فقط أن نعلم ما هي القواعد الأهم والمتبعة في التصميم وذلك تبعًا للمشروع الذي سنعمل عليه، دون أن ننسى استخدام العناصر بالطريقة الأمثل والالتزام بالمبادئ وإتقان استخدام برامج التصميم. وتتضمن هذه المقالة أهم القواعد الواجب اتباعها لتصميم كل من الأيقونات (الرموز) والشعارات نظرًا للتشابه الكبير من حيث المبدأ في قواعد تصميم هذين العنصرين، وسنبدأ أولًا بتعلم قواعد تصميم الأيقونات. قواعد تصميم الأيقونات الأيقونات هي الرموز المستخدمة للدلالة على أمر ما، حيث تستخدم الأيقونات كرموز للبرمجيات في أجهزة الحاسوب وأيضًا للتطبيقات في الهواتف المحمولة، فتلك الرموز المميزة لتطبيقات الهاتف المحمول ليست شعارات بل أيقونات، ولكن من الممكن أن يستخدم الشعار كأيقونة للتطبيق مثل أن نستخدم شعار أحد البنوك كأيقونة لتطبيق البنك على الهواتف المحمولة. كما نستخدم الأيقونات المصممة داخل صفحات الويب للدلالة على الخدمات أو الفئات أو الميزات أو أي شيء آخر. ومثالًا على تلك النوعية من الأيقونات تلك المستخدمة على فئات الدروس والمقالات في أكاديمية حسوب. يمكن تصميم الأيقونات بخطوط وأشكال سوداء أو بلون واحد أو بطريقة التصاميم المسطحة Flat Design (وهي تصاميم ثنائية الأبعاد تتميز بالبساطة وبدون عناصر معقدة كالظلال والقوام والتدرجات اللونية وغيرها) أو حيوية بتدرجات لونية أو حتى ثلاثية الأبعاد. وتعد أيقونات التطبيقات من أبرز وأهم أنواع الأيقونات حيث أن الأيقونة المميزة ستجذب اهتمام الناس وتدفعهم لتحميل التطبيق وتجربته، قد يكون هناك تطبيق جيد للغاية وأداؤه ممتاز ولكن أيقونته سيئة وغير مثيرة للاهتمام، بينما تطبيق آخر يؤدي نفس الغرض ولكنه سيء وأداؤه تشوبه الأخطاء والمشاكل التقنية إلا أن أيقونته مذهلة ومثيرة للاهتمام، بالتأكيد سيتم تحميل التطبيق السيء ذو الأيقونة الجيدة أكثر من الآخر إلى أن تطغى التقييمات السلبية على جمالية أيقونة التطبيق السيء، لكن ذلك سيستغرق وقتًا طويلًا كما أن العديد من الناس لا تنتبه للتقييم بل تنظر للأيقونة فحسب. فما هي أهم قواعد تصميم الأيقونات؟ سنتعرف عليها الآن. تحديد الهدف يجب أن نحدد الهدف من الأيقونة التي سنصممها، إن أيقونات التطبيقات عادة ما تكون زاهية الألوان ومفعمة بالحيوية وقد تكون ثلاثية الأبعاد أيضًا، بينما أيقونات مواقع الإنترنت عادة ما تكون مسطحة وبسيطة، إذ تستخدم للدلالة على أمور معينة فحسب. ومن هذا المنطلق يجب أن نفهم الهدف من الأيقونة ومكان استخدامها لنتمكن من تحديد الطريقة التي سنصمم بها الأيقونة. قابلية تبديل الحجم قد تستخدم الأيقونة في أكثر من موقع تمامًا مثل الشعارات، لذا يجب أن تكون إما قابلة للتكبير والتصغير ولذلك يجب أن نصممها بالرسومات الشعاعية Vector وليس النقطية حتى لا تتأثر وتتشوه بعد تغيير حجمها، أو قد نضطر إلى تصميم حزمة كاملة من الأيقونات لجميع القياسات حيث أن بعض التصاميم قد تحمل تفاصيل أكثر من اللازم وعند تصغير حجمها فإن هذه الأيقونات لن تكون واضحة أو مفهومة، فهناك أيقونات ستظهر في قوائم صغيرة الحجم أو في رموز المواقع الإلكترونية، لذلك سيتعيّن علينا أن نصمم أيقونات لمختلف القياسات بحيث نراعي وضوح فكرة الأيقونة مهما صغر حجمها. لاحظ أن الأيقونات الأصغر حجمًا هي ليست نفس الأيقونة الكبيرة، بل هي تصميم جديد مشابه ولكنه واضح ضمن الحجم الصغير. اتباع الهوية البصرية عندما نصمم أيقونة لعلامة تجارية أو أي مؤسسة لديها هوية بصرية معدة مسبقًا، فيجب أن ننتهج نهج الهوية البصرية في التصميم من حيث الأسلوب والألوان والخطوط وغيرها، فمن غير المنطقي أن تكون الأيقونة مختلفة كليًا عن باقي عناصر الهوية البصرية. لذلك عندما يطلب منك تصميم أيقونة لمؤسسة تمتلك هوية بصرية، عليك اتباع نهج تلك الهوية، واطلب منهم كتيب إرشادات الهوية البصرية، وإن لم يكن لديهم كتيب فاطلب منهم تزويدك بنسخة عن عناصر الهوية البصرية لتلقي نظرة فاحصة عليها وتتبع نهجها. لاحظ الأيقونات أسفل صفحة الويب الخاصة بشركة تويوتا للسيارات تتبع نهج الهوية البصرية للشركة. البساطة والوضوح هذا الأمر ينطبق على الأيقونات والشعارات معًا، فالهدف من الأيقونة هو التعريف والدلالة إلى شيء ما مثل تطبيق أو خدمة أو فئة أو غير ذلك، لذلك يجب أن تكون الأيقونة بسيطة وواضحة لتكون مفهومة، ويجب أن تكفي النظرة الأولى إليها لفهم ما ترمز إليه. في المثال التالي لأحد المواقع استُخدمت أيقونات دلالية إلى ميزات معينة متوفرة في خدماتهم، ولكنك ستلاحظ بسهولة أن الأيقونات غير مفهومة، بل وتسبب الارباك لمشاهدها ولو اعتمد أصحاب الموقع على النصوص فحسب لكان ذلك أفضل. بينما تبدو الأيقونات في المثال التالي واضحة وتدل بوضوح على معنى الميزة المشار إليها. اتباع الارشادات في بعض المواضع كتطبيقات سطح المكتب أو تطبيقات الهواتف المحمولة أو غيرها يكون هناك إرشادات معينة لتصميم الأيقونات بحيث يجب اتباعها للحصول على أفضل النتائج وللتوافق والتناسق مع موضع استخدام الأيقونة، لذلك يجب دائمًا البحث عن أية إرشادات متوفرة قبل البدء بالتصميم، وعلى سبيل المثال يجب اتباع الارشادات عند تصميم أيقونات تطبيقات الأندرويد وكذلك أيقونات تطبيقات أنظمة iOS. تناسق الوزن البصري في معظم الأحيان نصمم مجموعة من الأيقونات وليس أيقونة واحدة، تستخدم في مواقع الويب أو تطبيقات الهاتف المحمول أو في قوائم البرامج وغير ذلك، ولذلك يجب أن تكون جميع الأيقونات بوزن بصري واحد تقريبًا، وذلك فيما يتعلق بالخطوط والألوان والحجم، والأهم أن يكون وزنها البصري متناسقًا مع التصميم العام للهوية البصرية وواجهة الموقع وواجهة الاستخدام للتطبيق وغيرها. لاحظ أن هذه الأيقونات متطابقة في الدلالات والمعاني ولكنها تختلف من ناحية التصميم والوزن البصري. نوعية ملفات الأيقونات توجد عدة أنواع لملفات الأيقونات ولعل أشهرها هي GIF وPNG وSVG. وتُعَدّ GIF أقدم تنسيق استُخدم لتصميم الأيقونات في الماضي كما تستخدم ICO لملفات أيقونات برامج أنظمة الويندوز، واستُخدم GIF نظرًا لصغر حجمه وإمكانية إدراج الشفافية فيه عكس JPG و BMP الشائعة في ذلك الوقت، إلا أن من سلبياتها عدم إمكانية استخدام حزمة ألوان واسعة حيث تعتمد نظامًا مؤلفًا من 256 لونًا فقط، ومع مرور الوقت تطورت الأدوات والتطبيقات وأصبح بالإمكان استخدام تنسيق PNG لصناعة الأيقونات والذي يتميز بمجال طيف واسع من الألوان بالإضافة إلى إمكانية تضمين الشفافية فيه، ولكن PNG هو تنسيق للرسومات النقطية وعند محاولة تكبير التصميم من أجل بعض الواجهات و التطبيقات فسوف تظهر التشوهات والعيوب. لذلك بدأ المصممون يعتمدون أكثر على SVG الذي يعتمد الرسومات الشعاعية والتي لا تتأثر بتغيير الحجم وتحافظ على دقة التصميم إضافة إلى استخدامه طيفًا واسعًا من الألوان وتضمين الشفافية فيه، والأكثر من ذلك أن ملفاته تتميز بصغر حجمها وهو الأصغر بين بقية التنسيقات، ما جعله الخيار الأمثل لتصميم الأيقونات حاليًا. وعلى الرغم من إمكانية استخدام هذه الملفات مباشرة في بعض التصاميم إلا أن العديد من التطبيقات والواجهات لا تزال لا تدعم هذه النوعية من الملفات، لذلك يجب تحويله إلى تنسيقات أخرى مثل PNG، وبناء عليه يجب أن نحدد المقاس المطلوب بحسب التصميم الذي نعمل عليه. فالخيار الأفضل هو تصميم الأيقونة بتنسيق SVG ومن ثم تصدير جميع المقاسات والتنسيقات التي تحتاجها بتنسيقات يمكن استخدامها مثل PNG. الأيقونات والشعارات مثل أي نوع من أنواع التصاميم فإن تصميم الأيقونات جزء من فن تصميم الرسوميات (التصميم الجرافيكي) ولهذا يجب استخدام العناصر وتطبيق المبادئ الخاصة بتصميم الرسوميات لإنجاز تصاميم احترافية خالية من الأخطاء ومثيرة للاهتمام. ويتشابه تصميم الشعارات من حيث المبدأ مع تصميم الأيقونات حيث أن كليهما يجب أن يحدد الهدف والغرض من هذا العنصر (الأيقونة أو الشعار) والجمهور المستهدف ويجب أن يصمم بأحجام مختلفة بحسب موضع الاستخدام ويجب أن يكون متناسقًا ومتكاملًا مع بقية عناصر الهوية البصرية، ويجب أن يُصمم الشعار كأول عنصر من عناصر الهوية البصرية ومن ثم يتم استخراج لوحات الألوان وباقي عناصر الهوية البصرية بناءً على نموذج الشعار، كما أن تنسيق ملفات تصميم الشعار عادة ما تكون أيضًا SVG أو PNG بحسب موقع استخدامه. الشعارات ليست أيقونات، ولكن يمكن أن تشتق الأيقونات من الشعارات تمامًا مثل أيقونات تطبيقات الهاتف المحمول. ليس بالضرورة أن يكون الشعار بسيطًا بعكس الأيقونة، إلا أن البساطة في التصميم تجعل الشعار أكثر أناقة واحترافية، وأسهل للفهم والملاحظة، حيث أن الغالبية العظمى من العلامات العالمية الشهيرة اتجهت في السنوات الماضية إلى تعديل شعاراتها لجعلها أكثر بساطة وأناقة عكس شعاراتها القديمة، وهذه بعض الأمثلة بحيث نعرض الشعار القديم وآخر شعار مستخدم الآن بغض النظر عن مراحل التطور التي مر بها الشعار. قواعد تصميم الشعار ما هو الشعار؟ هو واجهة أي علامة تجارية وهو الانطباع الأول الذي يتكون لدى الجمهور بمجرد رؤيته، لذا فإن تصميمه مهم للغاية. وبما أن تصميم الشعارات والأيقونات تعتمد قواعد ومبادئ مشتركة، إذ يجب تحديد الهدف والغرض من الشعار كما يجب مراعاة قابلية التكبير والتصغير بحسب موضع الاستخدام ويفضّل الالتزام بمبدأ البساطة والوضوح في تصميمه لضمان وصول فكرته ورسالته للجمهور، وعلى عكس الأيقونات فإن الشعار هو العنصر الأول في تصميم الهوية البصرية، وتتبع الهوية البصرية تصميم الشعار في تحديد شكل وأسلوب التصميم العام، كما يفضل استخدام تنسيق SVG لملفات الشعار مع تصديرها إلى PNG بالمقاس المناسب عند الحاجة. تجنب التقليد من الطبيعي أن تتشابه الأيقونات التي تصممها مع أيقونات كثيرة متوفرة على الإنترنت نظرًا لأن مواضيعها مكررة أساسًا، ولكن من غير المقبول تكرار أو تقليد الشعارات الأخرى، فلو طُلب منك مثلًا أن تصمم شعارًا لمطعم برجر، أول ما سيخطر ببالك تصميم شكل قطعة البرجر وبعد بحث بسيط على الإنترنت ستكتشف وجود العشرات وربما المئات من الشعارات التي تشبه تصميمك وربما يكون بعضها شبه مطابق له أيضًا، الأمر الذي سيجعل العميل يعتقد أنك نسخت الشعار من مكان آخر وقدمته له ولم تبذل أي مجهود في تصميمه، حصل ذلك معي في بدايات مشواري في التصميم لذلك اعتمدت طريقة جديدة في التحضير للتصميم قبيل البدء فعليًا، وهو أن أبحث عن تصاميم متعلقة بما أنوي القيام به ثم أحاول تجنبها جميعها وأسعى إلى إيجاد فكرة جديدة تجعل تصميمي مميزًا ولا شبيه له، وهو ما سيقدّم للعميل بدوره شعارًا مذهلًا يميّزه عنه منافسيه. اكتب في بحث الصور على جوجل (شعار برجر) وستحصل على العديد من شعارات البرجر، لذا حاول تجنب إنشاء تصميم مطابق أو مشابه لأي منها، وليكن تصميمك فريدًا من نوعه. ابدأ برسم المخطط يدويًا حتى وإن لم يكن لديك موهبة في الرسم اليدوي باستخدام القلم والورق، إلا أن الرسم باستخدام الورقة وقلم الرصاص له تأثير السحر على تدفق الأفكار وتعديلها بطريقة فورية. جميع الشعارات العظيمة بدأت بخربشة بسيطة على الورق، ثم أصبحت نموذجًا أوليًا يتطور كل لحظة إلى أن يصبح فكرة مميزة ثم تُنقل هذه الفكرة إلى الحاسوب عبر رسم الخطوط الأساسية لها على برنامج التصميم ومن ثم تطويرها برسم الأشكال الأساسية ثم تتدفق الألوان على التصميم لمنحه الحيوية والهوية الخاصة به، وهكذا إلى أن تصبح الفكرة شعارًا حقيقيًا مميزًا. الصورة بوساطة rawpixel.com من موقع Freepik. الأبيض والأسود يجب علينا كمصممين أن نضع في الحسبان مسألة التصميم بالأبيض والأسود، في بعض الحالات قد يكون الشعار بطبيعة الحال بالأبيض والأسود وبالتالي لا حاجة للقلق بشأن ذلك، ولكن في معظم الأحيان يكون الشعار ملونًا ومع ذلك تضطر الشركات وخصوصًا التجارية منها إلى استخدام نسخة بالأبيض والأسود من الشعار لأجل المطبوعات والتعليب والتغليف والتطريز والنقش وغيرها، لهذا يجب أن يكون الشعار واضحًا ومفهومًا بالأبيض والأسود كما هو كذلك بالألوان في تلك الحالة. إن نظرت إلى النمط الأبيض والأسود لبعض الشعارات فإنك لن تعرف الشعار بسهولة من النظرة الأولى وأحيانًا قد لا تعرفه أبدًا بدون الألوان، ولعل السبب في أن معظم الشعارات في المثال الذي حضّرته لك لا تحتاج إلى الشعار الأبيض والأسود بطبيعة الحال، ولكنني أردت توضيح الفكرة. في الشكل التوضيحي التالي ستشاهد شعارات بالأبيض والأسود ومن ثم ستشاهد الشعارات الملونة الأصلية في الشكل التالي، لاحظ كيف من الصعب التعرف على الشعار من النظرة الأولى في الشكل الأول. لاحظ صعوبة تحديد هوية هذه الشعارات. لاحظ كيف يمكن التعرف على الشعارات بسهولة من خلال الألوان وهي شعارات MasterCard، PayPal، Tommy Hilfiger، Flickr، Microsoft وTarget. الألوان بعد دراستنا وتعرّفنا على الألوان ونماذجها ونظريتها ومخططاتها من مقال الألوان في تصميم الرسوميات ونظرية اللون فإن أكثر وأول عنصر تصميمي يطبّق عليه نظرية الألوان وكل ما يتعلق به هو الشعار. يجب التركيز على تأثير الألوان على الجمهور المستهدف، ويجب أن يكون تأثيرها إيجابيًا، وفي حال استخدام أكثر من لون فيجب تطبيق قواعد المخططات اللونية لتوفير التوازن اللوني للشعار ولا يكون نشازًا أو غير مريح للنظر. كما نستطيع استخراج لوحة الألوان للهوية البصرية للعلامة التجارية من تصميم الشعار، أو قد يحضّر المصمم لوحة الألوان مسبقًا بناءً على نهج سابق متبع من قبل العلامة التجارية أو معطيات أخرى. أحيانًا قد يكون لاسم العلامة التجارية دلالة أو تعبير يدل على الألوان التي يجب أن تتواجد في الشعار، وذلك يجعله منطقيًا ومتناسقًا مع الاسم وراسخًا أكثر في الأذهان. شعار متصفح الانترنت فاير فوكس (الثعلب الناري) بتدرجات لون النار. مراعاة نماذج الألوان من المهم أن تعلم إذا ما كان الشعار سيستخدم للشاشات فقط أم للطباعة فقط أم لكلاهما، حيث يجب أن تصمم الشعار بنموذج ألوان RGB الخاص بالشاشات وبنموذج ألوان CMYK في حالة الطباعة، وفي هذه الحالة ستلاحظ تغيرًا على الألوان بين الشعارين وهذا طبيعي نظرًا لاختلاف نظام مزج الألوان بين النموذجين. في المثال التالي قسّمت شعار إنستجرام إلى نصفين بشكل قطري (مائل) وطبّقت على كل شطر نموذجًا لونيًا مختلفًا، الاختلاف بسيط للغاية ولكنك ستلاحظه إن دققت النظر. الشعارات النصية في حال استخدام النص في الشعار أو ربما بضعة حروف أو حتى حرف واحد فمن المهم أن تكون تلك الخطوط مميزة، وقد تضطر أحيانًا إلى تحريفها للحصول على تصميم شعار نصي مميز بشكل مختلف عن النص العادي. يلجأ المصممون في بعض الأحيان إلى الخطاطين لتصميم النص أو الحروف بخطوط عربية استثنائية إلا إن امتلك المصمم القدرة على التصميم بالخط العربي (مثال: شعار قناة الجزيرة الإخبارية). وأحيانًا أخرى قد يضطر المصمم إلى تصميم خط كامل فريد من نوعه لكتابة الشعار به (مثال: شعار قناة العربية الإخبارية). ولكن في أغلب الأحيان يتخذ المصمم من أحد الخطوط المتوفرة على الحاسوب أساسًا للتصميم ويحرّفه قليلًا للوصول إلى شعار فريد ومميز. شعارات قناتي الجزيرة والعربية. مجموعة من الشعارات النصية العربية مصممة من قبل عبدالرحمن ممدوح على موقع Behance. مجموعة من الشعارات النصية العربية لمختلف المصممين العرب. مجموعة من أشهر الشعارات النصية العالمية. تنظيم عملية التصميم إذا ما نظّمت عملية التصميم من البداية إلى النهاية فإنك ستوفّر على نفسك وعلى عميلك الكثير من الوقت في محاولة معرفة ما الذي يجب أن تفعله تاليًا، الموضوع بسيط ارسم مخططًا للخطوات الواجب اتباعها وطبّقه بحذافيره وستكون على ما يرام. وليكن مخطط سير عملك كالتالي: تلقي الطلب من العميل. فهم كافة جوانب الشعار المطلوب تصميمه ابتداءً بالهدف ودراسة الجمهور المستهدف والمنطقة المستهدفة والألوان المطلوبة وهوية العميل البصرية والخطوط وغير ذلك. ليس من الضروري أن تتوافر كل هذه المعلومات من قبل العميل ولكن حاول الحصول على أكبر قدر منها لتختصر الكثير من الوقت في تعديلات كثيرة لا داعي لها عبر فهم رؤية العميل وتطلعاته. البحث عن كل ما يتعلق بالشعار من أفكار وأمثلة وشعارات مشابهة. اجلس مع نفسك وفكّر في كيفية تصميم الشعار وفي كيفية تجنب تصميم شعار مشابه لما هو موجود مسبقًا. أمسك بالورقة والقلم وابدأ برسم النماذج الأولية وطورها على الورقة إلى أن تصل لفكرة مبهرة. انقل فكرتك من الورقة إلى برنامج التصميم على الحاسوب واحرص على رسم الشعار بالرسومات الشعاعية Vector لسهولة تعديلها والتلاعب بحجمها. أرسل تصميمك إلى العميل. أجرِ جميع التعديلات المطلوبة التي سيقترحها العميل. أنهِ التصميم وسلّمه للعميل. بهذه الطريقة يمكنك أن تصمم شعارًا دون إرباك أو قلق على ما يجب أن تفعله تاليًا. خاتمة يعد تصميم الشعار المجال الأكثر انتشارًا في عالم تصميم الرسوميات حيث تجد آلافًا من الخدمات المتمثلة بتصميم الشعارات في مختلف مواقع العمل الحر، حيث يحتاج الجميع إلى شعار مثل شعار قناة يوتيوب، صفحة فيس بوك، حساب تويتر، موقع إنترنت، تطبيق هاتف محمول، متجر، مصنع، شركة، منظمة أو أي شيء تقريبًا، لذلك يجب تطوير المهارات واكتساب الخبرة اللازمة لتصميم الشعارات فهي أكثر ما يملأ مخزونك من التصاميم لوضعها في معرض أعمالك. لا يختلف تصميم الأيقونة كثيرًا عن تصميم الشعار إلا أن الاستخدامات تختلف، ويظل الشعار هو الأساس في تصميم الرسوميات حيث تتبعه تصاميم بقية العناصر وهذا ما سنكتشفه في مقال قواعد تصميم الهوية البصرية الذي سينشر لاحقًا.1 نقطة
بعد أن تعرّفنا على ماهية التصميم وعناصره ومبادئه، وألقينا نظرة على برامجه وتطبيقاته الأكثر شهرة، يمكننا البدء بالعمل على تصاميم مختلفة بناء على تعلمناه في المقالات السابقة في هذه السلسلة، يبقى لدينا فقط أن نعلم ما هي القواعد الأهم والمتبعة في التصميم وذلك تبعًا للمشروع الذي سنعمل عليه، دون أن ننسى استخدام العناصر بالطريقة الأمثل والالتزام بالمبادئ وإتقان استخدام برامج التصميم. وتتضمن هذه المقالة أهم القواعد الواجب اتباعها لتصميم كل من الأيقونات (الرموز) والشعارات نظرًا للتشابه الكبير من حيث المبدأ في قواعد تصميم هذين العنصرين، وسنبدأ أولًا بتعلم قواعد تصميم الأيقونات. قواعد تصميم الأيقونات الأيقونات هي الرموز المستخدمة للدلالة على أمر ما، حيث تستخدم الأيقونات كرموز للبرمجيات في أجهزة الحاسوب وأيضًا للتطبيقات في الهواتف المحمولة، فتلك الرموز المميزة لتطبيقات الهاتف المحمول ليست شعارات بل أيقونات، ولكن من الممكن أن يستخدم الشعار كأيقونة للتطبيق مثل أن نستخدم شعار أحد البنوك كأيقونة لتطبيق البنك على الهواتف المحمولة. كما نستخدم الأيقونات المصممة داخل صفحات الويب للدلالة على الخدمات أو الفئات أو الميزات أو أي شيء آخر. ومثالًا على تلك النوعية من الأيقونات تلك المستخدمة على فئات الدروس والمقالات في أكاديمية حسوب. يمكن تصميم الأيقونات بخطوط وأشكال سوداء أو بلون واحد أو بطريقة التصاميم المسطحة Flat Design (وهي تصاميم ثنائية الأبعاد تتميز بالبساطة وبدون عناصر معقدة كالظلال والقوام والتدرجات اللونية وغيرها) أو حيوية بتدرجات لونية أو حتى ثلاثية الأبعاد. وتعد أيقونات التطبيقات من أبرز وأهم أنواع الأيقونات حيث أن الأيقونة المميزة ستجذب اهتمام الناس وتدفعهم لتحميل التطبيق وتجربته، قد يكون هناك تطبيق جيد للغاية وأداؤه ممتاز ولكن أيقونته سيئة وغير مثيرة للاهتمام، بينما تطبيق آخر يؤدي نفس الغرض ولكنه سيء وأداؤه تشوبه الأخطاء والمشاكل التقنية إلا أن أيقونته مذهلة ومثيرة للاهتمام، بالتأكيد سيتم تحميل التطبيق السيء ذو الأيقونة الجيدة أكثر من الآخر إلى أن تطغى التقييمات السلبية على جمالية أيقونة التطبيق السيء، لكن ذلك سيستغرق وقتًا طويلًا كما أن العديد من الناس لا تنتبه للتقييم بل تنظر للأيقونة فحسب. فما هي أهم قواعد تصميم الأيقونات؟ سنتعرف عليها الآن. تحديد الهدف يجب أن نحدد الهدف من الأيقونة التي سنصممها، إن أيقونات التطبيقات عادة ما تكون زاهية الألوان ومفعمة بالحيوية وقد تكون ثلاثية الأبعاد أيضًا، بينما أيقونات مواقع الإنترنت عادة ما تكون مسطحة وبسيطة، إذ تستخدم للدلالة على أمور معينة فحسب. ومن هذا المنطلق يجب أن نفهم الهدف من الأيقونة ومكان استخدامها لنتمكن من تحديد الطريقة التي سنصمم بها الأيقونة. قابلية تبديل الحجم قد تستخدم الأيقونة في أكثر من موقع تمامًا مثل الشعارات، لذا يجب أن تكون إما قابلة للتكبير والتصغير ولذلك يجب أن نصممها بالرسومات الشعاعية Vector وليس النقطية حتى لا تتأثر وتتشوه بعد تغيير حجمها، أو قد نضطر إلى تصميم حزمة كاملة من الأيقونات لجميع القياسات حيث أن بعض التصاميم قد تحمل تفاصيل أكثر من اللازم وعند تصغير حجمها فإن هذه الأيقونات لن تكون واضحة أو مفهومة، فهناك أيقونات ستظهر في قوائم صغيرة الحجم أو في رموز المواقع الإلكترونية، لذلك سيتعيّن علينا أن نصمم أيقونات لمختلف القياسات بحيث نراعي وضوح فكرة الأيقونة مهما صغر حجمها. لاحظ أن الأيقونات الأصغر حجمًا هي ليست نفس الأيقونة الكبيرة، بل هي تصميم جديد مشابه ولكنه واضح ضمن الحجم الصغير. اتباع الهوية البصرية عندما نصمم أيقونة لعلامة تجارية أو أي مؤسسة لديها هوية بصرية معدة مسبقًا، فيجب أن ننتهج نهج الهوية البصرية في التصميم من حيث الأسلوب والألوان والخطوط وغيرها، فمن غير المنطقي أن تكون الأيقونة مختلفة كليًا عن باقي عناصر الهوية البصرية. لذلك عندما يطلب منك تصميم أيقونة لمؤسسة تمتلك هوية بصرية، عليك اتباع نهج تلك الهوية، واطلب منهم كتيب إرشادات الهوية البصرية، وإن لم يكن لديهم كتيب فاطلب منهم تزويدك بنسخة عن عناصر الهوية البصرية لتلقي نظرة فاحصة عليها وتتبع نهجها. لاحظ الأيقونات أسفل صفحة الويب الخاصة بشركة تويوتا للسيارات تتبع نهج الهوية البصرية للشركة. البساطة والوضوح هذا الأمر ينطبق على الأيقونات والشعارات معًا، فالهدف من الأيقونة هو التعريف والدلالة إلى شيء ما مثل تطبيق أو خدمة أو فئة أو غير ذلك، لذلك يجب أن تكون الأيقونة بسيطة وواضحة لتكون مفهومة، ويجب أن تكفي النظرة الأولى إليها لفهم ما ترمز إليه. في المثال التالي لأحد المواقع استُخدمت أيقونات دلالية إلى ميزات معينة متوفرة في خدماتهم، ولكنك ستلاحظ بسهولة أن الأيقونات غير مفهومة، بل وتسبب الارباك لمشاهدها ولو اعتمد أصحاب الموقع على النصوص فحسب لكان ذلك أفضل. بينما تبدو الأيقونات في المثال التالي واضحة وتدل بوضوح على معنى الميزة المشار إليها. اتباع الارشادات في بعض المواضع كتطبيقات سطح المكتب أو تطبيقات الهواتف المحمولة أو غيرها يكون هناك إرشادات معينة لتصميم الأيقونات بحيث يجب اتباعها للحصول على أفضل النتائج وللتوافق والتناسق مع موضع استخدام الأيقونة، لذلك يجب دائمًا البحث عن أية إرشادات متوفرة قبل البدء بالتصميم، وعلى سبيل المثال يجب اتباع الارشادات عند تصميم أيقونات تطبيقات الأندرويد وكذلك أيقونات تطبيقات أنظمة iOS. تناسق الوزن البصري في معظم الأحيان نصمم مجموعة من الأيقونات وليس أيقونة واحدة، تستخدم في مواقع الويب أو تطبيقات الهاتف المحمول أو في قوائم البرامج وغير ذلك، ولذلك يجب أن تكون جميع الأيقونات بوزن بصري واحد تقريبًا، وذلك فيما يتعلق بالخطوط والألوان والحجم، والأهم أن يكون وزنها البصري متناسقًا مع التصميم العام للهوية البصرية وواجهة الموقع وواجهة الاستخدام للتطبيق وغيرها. لاحظ أن هذه الأيقونات متطابقة في الدلالات والمعاني ولكنها تختلف من ناحية التصميم والوزن البصري. نوعية ملفات الأيقونات توجد عدة أنواع لملفات الأيقونات ولعل أشهرها هي GIF وPNG وSVG. وتُعَدّ GIF أقدم تنسيق استُخدم لتصميم الأيقونات في الماضي كما تستخدم ICO لملفات أيقونات برامج أنظمة الويندوز، واستُخدم GIF نظرًا لصغر حجمه وإمكانية إدراج الشفافية فيه عكس JPG و BMP الشائعة في ذلك الوقت، إلا أن من سلبياتها عدم إمكانية استخدام حزمة ألوان واسعة حيث تعتمد نظامًا مؤلفًا من 256 لونًا فقط، ومع مرور الوقت تطورت الأدوات والتطبيقات وأصبح بالإمكان استخدام تنسيق PNG لصناعة الأيقونات والذي يتميز بمجال طيف واسع من الألوان بالإضافة إلى إمكانية تضمين الشفافية فيه، ولكن PNG هو تنسيق للرسومات النقطية وعند محاولة تكبير التصميم من أجل بعض الواجهات و التطبيقات فسوف تظهر التشوهات والعيوب. لذلك بدأ المصممون يعتمدون أكثر على SVG الذي يعتمد الرسومات الشعاعية والتي لا تتأثر بتغيير الحجم وتحافظ على دقة التصميم إضافة إلى استخدامه طيفًا واسعًا من الألوان وتضمين الشفافية فيه، والأكثر من ذلك أن ملفاته تتميز بصغر حجمها وهو الأصغر بين بقية التنسيقات، ما جعله الخيار الأمثل لتصميم الأيقونات حاليًا. وعلى الرغم من إمكانية استخدام هذه الملفات مباشرة في بعض التصاميم إلا أن العديد من التطبيقات والواجهات لا تزال لا تدعم هذه النوعية من الملفات، لذلك يجب تحويله إلى تنسيقات أخرى مثل PNG، وبناء عليه يجب أن نحدد المقاس المطلوب بحسب التصميم الذي نعمل عليه. فالخيار الأفضل هو تصميم الأيقونة بتنسيق SVG ومن ثم تصدير جميع المقاسات والتنسيقات التي تحتاجها بتنسيقات يمكن استخدامها مثل PNG. الأيقونات والشعارات مثل أي نوع من أنواع التصاميم فإن تصميم الأيقونات جزء من فن تصميم الرسوميات (التصميم الجرافيكي) ولهذا يجب استخدام العناصر وتطبيق المبادئ الخاصة بتصميم الرسوميات لإنجاز تصاميم احترافية خالية من الأخطاء ومثيرة للاهتمام. ويتشابه تصميم الشعارات من حيث المبدأ مع تصميم الأيقونات حيث أن كليهما يجب أن يحدد الهدف والغرض من هذا العنصر (الأيقونة أو الشعار) والجمهور المستهدف ويجب أن يصمم بأحجام مختلفة بحسب موضع الاستخدام ويجب أن يكون متناسقًا ومتكاملًا مع بقية عناصر الهوية البصرية، ويجب أن يُصمم الشعار كأول عنصر من عناصر الهوية البصرية ومن ثم يتم استخراج لوحات الألوان وباقي عناصر الهوية البصرية بناءً على نموذج الشعار، كما أن تنسيق ملفات تصميم الشعار عادة ما تكون أيضًا SVG أو PNG بحسب موقع استخدامه. الشعارات ليست أيقونات، ولكن يمكن أن تشتق الأيقونات من الشعارات تمامًا مثل أيقونات تطبيقات الهاتف المحمول. ليس بالضرورة أن يكون الشعار بسيطًا بعكس الأيقونة، إلا أن البساطة في التصميم تجعل الشعار أكثر أناقة واحترافية، وأسهل للفهم والملاحظة، حيث أن الغالبية العظمى من العلامات العالمية الشهيرة اتجهت في السنوات الماضية إلى تعديل شعاراتها لجعلها أكثر بساطة وأناقة عكس شعاراتها القديمة، وهذه بعض الأمثلة بحيث نعرض الشعار القديم وآخر شعار مستخدم الآن بغض النظر عن مراحل التطور التي مر بها الشعار. قواعد تصميم الشعار ما هو الشعار؟ هو واجهة أي علامة تجارية وهو الانطباع الأول الذي يتكون لدى الجمهور بمجرد رؤيته، لذا فإن تصميمه مهم للغاية. وبما أن تصميم الشعارات والأيقونات تعتمد قواعد ومبادئ مشتركة، إذ يجب تحديد الهدف والغرض من الشعار كما يجب مراعاة قابلية التكبير والتصغير بحسب موضع الاستخدام ويفضّل الالتزام بمبدأ البساطة والوضوح في تصميمه لضمان وصول فكرته ورسالته للجمهور، وعلى عكس الأيقونات فإن الشعار هو العنصر الأول في تصميم الهوية البصرية، وتتبع الهوية البصرية تصميم الشعار في تحديد شكل وأسلوب التصميم العام، كما يفضل استخدام تنسيق SVG لملفات الشعار مع تصديرها إلى PNG بالمقاس المناسب عند الحاجة. تجنب التقليد من الطبيعي أن تتشابه الأيقونات التي تصممها مع أيقونات كثيرة متوفرة على الإنترنت نظرًا لأن مواضيعها مكررة أساسًا، ولكن من غير المقبول تكرار أو تقليد الشعارات الأخرى، فلو طُلب منك مثلًا أن تصمم شعارًا لمطعم برجر، أول ما سيخطر ببالك تصميم شكل قطعة البرجر وبعد بحث بسيط على الإنترنت ستكتشف وجود العشرات وربما المئات من الشعارات التي تشبه تصميمك وربما يكون بعضها شبه مطابق له أيضًا، الأمر الذي سيجعل العميل يعتقد أنك نسخت الشعار من مكان آخر وقدمته له ولم تبذل أي مجهود في تصميمه، حصل ذلك معي في بدايات مشواري في التصميم لذلك اعتمدت طريقة جديدة في التحضير للتصميم قبيل البدء فعليًا، وهو أن أبحث عن تصاميم متعلقة بما أنوي القيام به ثم أحاول تجنبها جميعها وأسعى إلى إيجاد فكرة جديدة تجعل تصميمي مميزًا ولا شبيه له، وهو ما سيقدّم للعميل بدوره شعارًا مذهلًا يميّزه عنه منافسيه. اكتب في بحث الصور على جوجل (شعار برجر) وستحصل على العديد من شعارات البرجر، لذا حاول تجنب إنشاء تصميم مطابق أو مشابه لأي منها، وليكن تصميمك فريدًا من نوعه. ابدأ برسم المخطط يدويًا حتى وإن لم يكن لديك موهبة في الرسم اليدوي باستخدام القلم والورق، إلا أن الرسم باستخدام الورقة وقلم الرصاص له تأثير السحر على تدفق الأفكار وتعديلها بطريقة فورية. جميع الشعارات العظيمة بدأت بخربشة بسيطة على الورق، ثم أصبحت نموذجًا أوليًا يتطور كل لحظة إلى أن يصبح فكرة مميزة ثم تُنقل هذه الفكرة إلى الحاسوب عبر رسم الخطوط الأساسية لها على برنامج التصميم ومن ثم تطويرها برسم الأشكال الأساسية ثم تتدفق الألوان على التصميم لمنحه الحيوية والهوية الخاصة به، وهكذا إلى أن تصبح الفكرة شعارًا حقيقيًا مميزًا. الصورة بوساطة rawpixel.com من موقع Freepik. الأبيض والأسود يجب علينا كمصممين أن نضع في الحسبان مسألة التصميم بالأبيض والأسود، في بعض الحالات قد يكون الشعار بطبيعة الحال بالأبيض والأسود وبالتالي لا حاجة للقلق بشأن ذلك، ولكن في معظم الأحيان يكون الشعار ملونًا ومع ذلك تضطر الشركات وخصوصًا التجارية منها إلى استخدام نسخة بالأبيض والأسود من الشعار لأجل المطبوعات والتعليب والتغليف والتطريز والنقش وغيرها، لهذا يجب أن يكون الشعار واضحًا ومفهومًا بالأبيض والأسود كما هو كذلك بالألوان في تلك الحالة. إن نظرت إلى النمط الأبيض والأسود لبعض الشعارات فإنك لن تعرف الشعار بسهولة من النظرة الأولى وأحيانًا قد لا تعرفه أبدًا بدون الألوان، ولعل السبب في أن معظم الشعارات في المثال الذي حضّرته لك لا تحتاج إلى الشعار الأبيض والأسود بطبيعة الحال، ولكنني أردت توضيح الفكرة. في الشكل التوضيحي التالي ستشاهد شعارات بالأبيض والأسود ومن ثم ستشاهد الشعارات الملونة الأصلية في الشكل التالي، لاحظ كيف من الصعب التعرف على الشعار من النظرة الأولى في الشكل الأول. لاحظ صعوبة تحديد هوية هذه الشعارات. لاحظ كيف يمكن التعرف على الشعارات بسهولة من خلال الألوان وهي شعارات MasterCard، PayPal، Tommy Hilfiger، Flickr، Microsoft وTarget. الألوان بعد دراستنا وتعرّفنا على الألوان ونماذجها ونظريتها ومخططاتها من مقال الألوان في تصميم الرسوميات ونظرية اللون فإن أكثر وأول عنصر تصميمي يطبّق عليه نظرية الألوان وكل ما يتعلق به هو الشعار. يجب التركيز على تأثير الألوان على الجمهور المستهدف، ويجب أن يكون تأثيرها إيجابيًا، وفي حال استخدام أكثر من لون فيجب تطبيق قواعد المخططات اللونية لتوفير التوازن اللوني للشعار ولا يكون نشازًا أو غير مريح للنظر. كما نستطيع استخراج لوحة الألوان للهوية البصرية للعلامة التجارية من تصميم الشعار، أو قد يحضّر المصمم لوحة الألوان مسبقًا بناءً على نهج سابق متبع من قبل العلامة التجارية أو معطيات أخرى. أحيانًا قد يكون لاسم العلامة التجارية دلالة أو تعبير يدل على الألوان التي يجب أن تتواجد في الشعار، وذلك يجعله منطقيًا ومتناسقًا مع الاسم وراسخًا أكثر في الأذهان. شعار متصفح الانترنت فاير فوكس (الثعلب الناري) بتدرجات لون النار. مراعاة نماذج الألوان من المهم أن تعلم إذا ما كان الشعار سيستخدم للشاشات فقط أم للطباعة فقط أم لكلاهما، حيث يجب أن تصمم الشعار بنموذج ألوان RGB الخاص بالشاشات وبنموذج ألوان CMYK في حالة الطباعة، وفي هذه الحالة ستلاحظ تغيرًا على الألوان بين الشعارين وهذا طبيعي نظرًا لاختلاف نظام مزج الألوان بين النموذجين. في المثال التالي قسّمت شعار إنستجرام إلى نصفين بشكل قطري (مائل) وطبّقت على كل شطر نموذجًا لونيًا مختلفًا، الاختلاف بسيط للغاية ولكنك ستلاحظه إن دققت النظر. الشعارات النصية في حال استخدام النص في الشعار أو ربما بضعة حروف أو حتى حرف واحد فمن المهم أن تكون تلك الخطوط مميزة، وقد تضطر أحيانًا إلى تحريفها للحصول على تصميم شعار نصي مميز بشكل مختلف عن النص العادي. يلجأ المصممون في بعض الأحيان إلى الخطاطين لتصميم النص أو الحروف بخطوط عربية استثنائية إلا إن امتلك المصمم القدرة على التصميم بالخط العربي (مثال: شعار قناة الجزيرة الإخبارية). وأحيانًا أخرى قد يضطر المصمم إلى تصميم خط كامل فريد من نوعه لكتابة الشعار به (مثال: شعار قناة العربية الإخبارية). ولكن في أغلب الأحيان يتخذ المصمم من أحد الخطوط المتوفرة على الحاسوب أساسًا للتصميم ويحرّفه قليلًا للوصول إلى شعار فريد ومميز. شعارات قناتي الجزيرة والعربية. مجموعة من الشعارات النصية العربية مصممة من قبل عبدالرحمن ممدوح على موقع Behance. مجموعة من الشعارات النصية العربية لمختلف المصممين العرب. مجموعة من أشهر الشعارات النصية العالمية. تنظيم عملية التصميم إذا ما نظّمت عملية التصميم من البداية إلى النهاية فإنك ستوفّر على نفسك وعلى عميلك الكثير من الوقت في محاولة معرفة ما الذي يجب أن تفعله تاليًا، الموضوع بسيط ارسم مخططًا للخطوات الواجب اتباعها وطبّقه بحذافيره وستكون على ما يرام. وليكن مخطط سير عملك كالتالي: تلقي الطلب من العميل. فهم كافة جوانب الشعار المطلوب تصميمه ابتداءً بالهدف ودراسة الجمهور المستهدف والمنطقة المستهدفة والألوان المطلوبة وهوية العميل البصرية والخطوط وغير ذلك. ليس من الضروري أن تتوافر كل هذه المعلومات من قبل العميل ولكن حاول الحصول على أكبر قدر منها لتختصر الكثير من الوقت في تعديلات كثيرة لا داعي لها عبر فهم رؤية العميل وتطلعاته. البحث عن كل ما يتعلق بالشعار من أفكار وأمثلة وشعارات مشابهة. اجلس مع نفسك وفكّر في كيفية تصميم الشعار وفي كيفية تجنب تصميم شعار مشابه لما هو موجود مسبقًا. أمسك بالورقة والقلم وابدأ برسم النماذج الأولية وطورها على الورقة إلى أن تصل لفكرة مبهرة. انقل فكرتك من الورقة إلى برنامج التصميم على الحاسوب واحرص على رسم الشعار بالرسومات الشعاعية Vector لسهولة تعديلها والتلاعب بحجمها. أرسل تصميمك إلى العميل. أجرِ جميع التعديلات المطلوبة التي سيقترحها العميل. أنهِ التصميم وسلّمه للعميل. بهذه الطريقة يمكنك أن تصمم شعارًا دون إرباك أو قلق على ما يجب أن تفعله تاليًا. خاتمة يعد تصميم الشعار المجال الأكثر انتشارًا في عالم تصميم الرسوميات حيث تجد آلافًا من الخدمات المتمثلة بتصميم الشعارات في مختلف مواقع العمل الحر، حيث يحتاج الجميع إلى شعار مثل شعار قناة يوتيوب، صفحة فيس بوك، حساب تويتر، موقع إنترنت، تطبيق هاتف محمول، متجر، مصنع، شركة، منظمة أو أي شيء تقريبًا، لذلك يجب تطوير المهارات واكتساب الخبرة اللازمة لتصميم الشعارات فهي أكثر ما يملأ مخزونك من التصاميم لوضعها في معرض أعمالك. لا يختلف تصميم الأيقونة كثيرًا عن تصميم الشعار إلا أن الاستخدامات تختلف، ويظل الشعار هو الأساس في تصميم الرسوميات حيث تتبعه تصاميم بقية العناصر وهذا ما سنكتشفه في مقال قواعد تصميم الهوية البصرية الذي سينشر لاحقًا.1 نقطة -
لدي شركة ناشئة صغيرة، ولكنّ المنافسين أقوياء ولهم خبرة في السوق، فهل يمكنني أن أواجههم؟1 نقطة
-

الإصدار 1.0.0
11715 تنزيل
التصميم هو مهنة العصر الحالية، هذا العصر الذي يولي أهميةً كبيرةً منقطعة النظير للعامل البصري، فيدخل مجال التصميم في كل مناحي حياتنا اليومية فكل شيء تراه حولك بدءًا من صور أغلفة المنتجات وحتى الإعلانات والملصقات والشعارات وأغلفة الكتب وكل شيء تقريبًا قد مرَّ على يدي مصمم وعولج داخل أحد تطبيقات الرسم والتصميم فسوق التصميم كبيرٌ يزداد فيه الطلب على المصممين يومًا بعد يوم. تمثلت رؤيتنا للكتاب في أن يكون المرجع الأول للمصمم العربي أو من يريد تعلم مجال التصميم الجرافيكي وذلك بجعله شاملًا لكل ما يحتاج إليه المتعلم في بداية رحلته التعليمية في هذا المجال وليتضمن العناصر الأساسية في هذا التخصص سواء كان ذلك في الأساسيات أو البرامج والتطبيقات أو أفكار التصميمات. يهدف الكتاب لإخراج أفراد متمكنين من أساسيات مجال التصميم الجرافيكي ولديهم المعلومات والخبرة الأساسية اللازمة لدخول سوق العمل وتحقيق دخل مادي عبر سوق الإنترنت الكبير وذلك من خلال تنفيذ أعمال التصميم الجرافيكي عبر منصات العمل الحر العربية مثل مستقل وخمسات. يتكون الكتاب من خمسة أقسام رئيسية: الأساسيات والمبادئ البرامج والتطبيقات مجالات التصميم الجرافيكي قواعد التصميم المسار المهني والتطوير الذاتي دخول سوق العمل هذه النقاط الخمس نعدها شاملة لما يحتاج إليه المصمم الجديد ليكون قادرًا على إنتاج تصميم وبيعه في السوق. يستهدف الكتاب جمهور المصممين المبتدئين أو من يريدون دخول هذا المجال، وعليه فإن الكتاب ليس موجهًا للمصممين المتقدمين أو المحترفين فهؤلاء في الغالب يتعلمون مباشرة من مصادر متقدمة سواءً عربية أو أجنبية ولكن قد يكون لدى البعض منهم نقص في معرفة أساسيات التصميم الفنية والأكاديمية، لذا يمكنهم آنذاك الرجوع إلى فصول بعينها من هذا الكتاب أي أنَّ فصول هذا الكتاب قد تفيد حتى من كان متقدمًا في مجال التصميم التطبيقي ولكن دون أساس أكاديمي سليم. هذا الكتاب مرخص بموجب رخصة المشاع الإبداعي Creative Commons «نسب المُصنَّف - غير تجاري - الترخيص بالمثل 4.0». يمكنك قراءة فصول الكتاب على شكل مقالات من هذه الصفحة، «أساسيات تصميم الرسوميات»، أو تجدها مسردة بالترتيب التالي: مقدمة إلى تصميم الرسوميات (التصميم الجرافيكي) عناصر تصميم الرسوميات مبادئ تصميم الرسوميات الألوان في تصميم الرسوميات ونظرية الألوان تعرف على أشهر برامج وتطبيقات تصميم الصور والرسوميات مقدمة إلى برنامج أدوبي فوتوشوب Adobe Photoshop مقدمة إلى برنامج أدوبي إليستريتور Adobe Illustrator والتعرف على واجهته مساحات وقياسات العمل التصميمي النص وأسلوب الطباعة Typography في تصميم الرسوميات قواعد التعامل مع الصور والرسوميات قواعد تصميم الأيقونات والشعارات قواعد تصميم المطبوعات والإعلانات قواعد تصميم الواجهات قواعد تصميم الرسوم البيانية قواعد تصميم الهوية البصرية دليل المسار المهني لمصمم الرسوميات مواقع العمل الحر والعمل عن بعد لتصميم الرسوميات1 نقطة -
مرحباً. هل وثيقة العمل الحر تغني عن توثيق الهوية في مستقل؟ لست مرتاحة لفكرة مشاركة بياناتي الخاصة و صورتي في الموقع1 نقطة
-
عندي مشكلة في كود مكتوب بالاصدار الخامس وبحوله الاصداء السابع السابع php7 , حولت أغلب الاوامر وتوقفت هنا , السطر الثالث $res = mysqli_query($con,$query); يطلع خطاء في con اللي هو اسم قاعدة البيانات عدلت في كل شي بس أي شيء داخل الفانكشن يطبع خطاء function show_num($qfrom,$qto) { $rem_q = array(); $query = "SELECT * FROM qna where asked = 0 AND sn >= $qfrom and sn <= $qto "; $res = mysqli_query($con,$query); $noq = mysqli_num_rows($res); $i=0; while($row = mysqli_fetch_assoc($res)) $rem_q[$i++]=$row['sn']; for($i=0;$i<$noq;$i++) {?> <input type="submit" class="qsel" name="but" value="<?php echo $rem_q[$i]; ?>" /> <?php } }1 نقطة
-
لقد أنشأت تطبيق next.js الأساسي باستخدام "npx create-next-app" وملف .eslintrc.json الذي تم إنشاؤه لإضافة قواعد eslint. ولكنه لا يعمل. كيف أضيف قواعد الفحص إلى nextjs { "env": { "browser": true, "es6": true }, "extends": [ "standard" ], "globals": { "Atomics": "readonly", "SharedArrayBuffer": "readonly", "React": "writable" }, "parserOptions": { "ecmaFeatures": { "jsx": true }, "ecmaVersion": 2018, "sourceType": "module" }, "plugins": [ "react" ], "rules": { "react/react-in-jsx-scope": "off" } }1 نقطة
-
السلام عليكم اريد تعلم البرمجة ولكن قبل ذلك اريد تعلم خوارزميات البرمجة سؤالي هو / هل هناك كتاب او ملف pdf بالعربي لتعلم خوارزميات البرمجة1 نقطة
-
ستجد في موقع حسوب ويكي صفحة كاملة خاصة بالخوارزميات, مع كل خوارزمية ستجد شرحا كتابيا و مصورا ايضا في البعض منها, مع تطبيق فعلي لكل خوارزمية باستعمال لغات متعددة مثل C , C++ , Java, Python . https://wiki.hsoub.com/Algorithms أما ان كنت تبحث عن كتاب, فيمكنك البدء بكتاب الاستاذ خالد السعداني: "البحر الشاسع لدخول الخوارزميات من بابها الواسع". الكتاب موجه للمبتدئين و الذين لا يملكون أي معرفة مسبقة بمجال الخوارزميات. يبدأ الكتاب بدروس نظرية عن الحاسوب و طريقة عمله, ثم تليه دروس عن النظام الثنائي, و بعدها تجد دروس الخوارزميات و التي تبدأ من تعريف الخوارزمية, مرورا بالمتغيرات و الدوال الشرطية وصولا الى المصفوفات. ما يميز الكتاب هو البساطة في طرح المعلومات و استعمال الاسلوب التصويري لشرح الأفكار.1 نقطة
-
نعم، لتعلم الخوارزمية انصح بمتابعة كورس او دورة من دورات تعلم البرمجة مثل التي تقدمها حسوب. اما اذا كنت تبحث عن كتاب فان مرجع مذاكره الخوارزمية والكتاب الافضل لها على الاطلاق هو : لكن هذا الكتاب بالانجليزية، ويمكنك ان تجد له ترجمة. هذه هي صورة الغلاف الخاصة به: اما بالعربية فافضل كتاب هو: وهذه هي صورة الغلاف خاصته: يمكنك شراء تلك الكتب من المكتبات او اونلاين.

 1 نقطة
1 نقطة -
لدي نظام تسجيل دخول و اريد عمل حقل يختار منه العضو اما يحفظ بيانات الدخول او لا ممكن حدا يشرح الفكرة1 نقطة
-
عرض بيانات الوزن و التاريخ في شارت في فلاتر و يكون البيانات راجعة من api كيف ممكن اعمله1 نقطة
-
انا عم حاول احترف الباك ايند بس عند كل مشكلة حدا بيسألني انو انتا دارس الخوارزميات وهياكل البيانات ف جوابي بيكون لا .. فردة الفعل بتكون غريبة انو كيف بدك تشتغل باك ايند وانتا ما درستي الخوارزميات والهياكل مابيصير ... مع انو انا عم اشتغل مشاريع وفهمان شو عم اعمل يعني بس في شوية نواقص بحسا عندي1 نقطة
-
package Java; public class Fan { final SLOW =1; final MEDIUM =2; final FAST =3; private int speed =1; private boolean on =false ; private double radius =5; String color blue; public Fan(){ } public void setSpeed(int speed){ this.speed = speed; } public void setOn(boolean on){ this.on = on; } public void setRadius(double radius){ this.radius = radius; } public void setColor(String color){ this.color = color; } public int getSpeed(){ return speed; } public boolean getOn(){ return on; } public double getRadius(){ return radius; } public String getColor(){ return color; } public String toString(){ //اذا كانت المروحة on if (.......) return "speed "+speed+"\n"+"color"+color+"\n"+"radius"+radius+"\n"; //اذا كانت المروحة not on else { return "color"+color+"\n"+"radius"+radius+"\n"; } } } كيف اكتب شرط onوnot onفي البرنامج؟ وهل هناك طريقة اخرى للحل؟1 نقطة
-
تتعلق الضريبة بعدة امور حسب الرابط الذي ارفقته مسبقا، عدد عمليات التعامل والحوالاات ثم قيمة المبلغ ضمن حدود كما في الجدول وحد أدنى و أعلى للخصم (أعتقد يتم أخد العمود حسب إما اكبر مبلغ أو أكبر عدد حوالات) حيث يتم حساب هذه العملية شهرياً ويتم خصم عمولة الخدمة من المبلغ المستوفى. كضرب النسبة المؤية بقيمة التعاملات. ربما المدرب @Adnane Kadriقد تعامل معها ويعطينا توضيحاً.1 نقطة
-
ماهي الدولة؟1 نقطة
-
إن كان لديك أكثر من قائمة منسدلة وتريد أن تقوم بالمرور عليهم جميعًا ، فيمكنك القيام بذلك من خلال حلقة for كالتالي: function showDetails() { var sels = document.getElementsByClassName('sedra'); for (var sel of sels) { var selIndex = sel.selectedIndex; // تخطي القائمة في حالة كان الإختيار هو رقم 0 if (selIndex == 0) { continue; } var option = sel.options[selIndex].value; window.open("accessories/print/print-view.php?id="+option); return; } // تم نقل الكودالشرط التالي خارج حلقة التكرار لأن في حالة وجود أكثر من قائمة منسدلة، فسيتم تحديد أحدها فقط // في حالة لم يتم اختيار أي قيمة من أي قائمة منسدلة alert("الرجاء اختيار قيمة من القائمة المنسدلة"); } الكود السابق سوف يقوم بالمرور على كل العناصر التي لديها الصنف sedra وسيقوم بجلب القيمة المختارة، وفي حالة كانت 0 سوف يتم تخطيها، إلى أن يتم العثور على قيمة معينة ثم سيتم إستخدام window.open لفتح الصفحة، وفي حالة لم يكن هناك أي اختيار في أي من القوائم فسوف يتم إظهار رسالة عبر alert.1 نقطة
-
هلقمت بمراجعة صفحة fees الخاصة ببوابة الدفع؟ لأن سؤالك أيضا غير واضح. الرابط: payment-gateway-fees1 نقطة
-
لدي جدولين في قاعدة البيانات الاول users يحتوي id ومعلومات العضو اسم وايميل وغيره الجدول الثاني chat يحوي sender_id هو نفسه ال id في جدول users كيف يمكن ربط الجدولين عند الاستعلام بحيث يتم عرض الرسالة من chat وعرض معلومات العضو من users <?php $stmt = $db->prepare('SELECT * FROM chat'); $stmt->execute(); $result = $stmt->get_result(); $count = mysqli_num_rows($result); ?> <?php if ($count > 0) : ?> <?php while ($row = $result->fetch_assoc() ): ?> <?= $row['message'] ?> "> .... .... <?php endwhile; ?> <?php endif; ?> ............................ <?php $stmt = $db->prepare('SELECT * FROM users'); $stmt->execute(); $result = $stmt->get_result(); $row_accounts = $result->fetch_assoc(); $stmt->close(); ?>1 نقطة
-
لكي تربط جدولين لديهما حقل مشترك, يمكنك استعمال JOIN او INNER JOIN. حيث يجب ان يكون الحقل من نفس النوع, $sql = "SELECT * from chat INNER JOIN users on users.id=chat.sender_id";1 نقطة
-
هل هناك طريقة بسيطة لفهرسة جميع عناصر المصفوفة باستثناء فهرس معين؟ فبفرض أني أريد أن أقوم بإستخدام كل عناصر مصفوفة معينة بإستثناء العنصر رقم 3 مثلُا، كيف يمكنني أن أقوم بذلك؟ mylist[3] # يقوم بإرجاع العنصر الموجود في الفهرس 3 # لكن هل يوجد شيء كاتاليب milist[~3] # يقوم بإرجاع كل المصفوفة ما العنصر الموجود في الفهرس 3 هل توجد طريقة في مكتبة Numpy تقوم بهذا الأمر أم علي أن أقوم بعمل مصفوفة جديدة تحتوي على كل العناصر ما عدا عنصر1 نقطة
-
سوف نقوم باستخدام inner join للربط بين الجدولين فيمكنك استخدام inner join بهذا الشكل "SELECT c.*, u.* FROM `chat` as c inner join users as u WHERE u.id = c.sender_id ORDER BY `id` DESC LIMIT 50"; ففي حالة الكود الخاص بك يتم تنفيذ هذا الاستعلام $stmt = $db->prepare("SELECT c.*, u.* FROM `chat` as c inner join users as u WHERE u.id = c.sender_id ORDER BY `ID` DESC LIMIT 50"); ومن ثم يمكنك الوصول إلى جميع الحقول بداخل الجدولين أو يمكنك تحديد مثلاً جميع حقول جدول ما و حقل من الجدول الثاني بهذا الشكل $stmt = $db->prepare("SELECT c.*, u.name FROM `chat` as c inner join users as u WHERE u.id = c.sender_id ORDER BY `ID` DESC LIMIT 50");1 نقطة
-
import {ADD_TO_FAVORITE, REMOVE_FROM_FAVORITE, CLEAR_FAVORITE} from '../types'; interface InitStateInter { myFavorite: []; } const initialState: InitStateInter = { myFavorite: [], }; const myFavorite = (state = initialState, action: any) => { switch (action.type) { case ADD_TO_FAVORITE: return { ...state, myFavorite: [...state.myFavorite, action.payload], }; case REMOVE_FROM_FAVORITE: return { ...state, myFavorite: state.myFavorite.filter( favItem => favItem !== action.payload, ), }; case CLEAR_FAVORITE: return {...initialState}; } return state; }; export default myFavorite; عندما اضيف منتج اخر للمفضلة فانه يتحقق ان كان موجود لايضيفة مرة اخرى1 نقطة
-
فلنفرض أن هناك بيانات مرجعة من api على شكل json بهذا الشكل [ { "weight": 92, "week": "2021-08-15" }, { "weight": 87, "week": "2021-08-15" }, { "weight": 80, "week": "2021-08-15" }, { "weight": 81, "week": "2021-08-15" }, { "weight": 71, "week": "2021-08-15" }, { "weight": 60, "week": "2021-08-15" }, { "weight": 58, "week": "2021-08-15" } ] فيمكننا إنشاء Class Model لهذه البيانات بهذا الشكل class UserWeightModel { UserWeightModel(this.week, this.weight); final String week; final double weight; factory UserWeightModel.fromJson(Map<String, dynamic> json) { return UserWeightModel( json['week'].toString(), json['weight'].toDouble(), ); } } ثم يمكننا عمل دالة جلب البيانات من رابط مسار api بهذا الشكل Future loadChartData2() async { var data; final url = "هنا الرابط; final response = await http.get(Uri.parse(url), headers: { 'Accept': 'application/json', 'Authorization': 'Bearer ${token}', }); if (response.statusCode == 200) { data = json.decode(response.body); final dynamic result = json.decode(response.body); for (Map<String, dynamic> i in result) { chartData.add(UserWeightModel.fromJson(i)); } } return data; } لاحظ في السطر التالي 'Authorization': 'Bearer ${token}', أننا اعتمدنا على token المخزن من عملية تسجيل الدخول للعضو , حتى نستطيع جلب الأوزارن و التاريخ الخاصة به , ثم قمنا بإسناد البيانات المرجعة من api إلى List chartData , لأننا سنستخدم هذه List في التعامل مع الشارت chartData.add(UserWeightModel.fromJson(i)); ثم الأن سنقوم باستخدام مكتبة توفر لنا شارت جاهز للتعامل معه, فقمت باختيار مكتبة syncfusion_flutter_charts: ^19.2.49 يمكنك تثبيتها في ملف pubspec.yaml من هنا , ثم تقوم بتشغيل الأمر التالي flutter pub get ليتم تضمين المكتبة إلى مشروعنا, ثم في Widget Build الخاصة بنا يمكننا عرض الشارت من خلال الكود التالي return FutureBuilder( future: loadChartData2(), builder: (context, snapshot){ if(snapshot.hasData){ return SfCartesianChart( zoomPanBehavior: _zoomPanBehavior, primaryXAxis: CategoryAxis(), title: ChartTitle(text: ""), //legend: Legend(isVisible: true), tooltipBehavior: _tooltipBehavior, series: <ChartSeries<UserWeightModel, String>>[ LineSeries<UserWeightModel, String>( dataSource: chartData, xValueMapper: (UserWeightModel user, _) => user.week.substring(5), yValueMapper: (UserWeightModel user, _) => user.weight, dataLabelSettings: DataLabelSettings(isVisible: true), enableTooltip: true, ), ], /*primaryXAxis: NumericAxis( edgeLabelPlacement: EdgeLabelPlacement.shift),*/ ); } return Center(child: CircularProgressIndicator(),); }, ), فلاحظ أنه تم استخدام FutureBuilder لأننا نتعامل مع بيانات تأخذ وقت في عملية جلبها و ايضا في future قمنا باستدعاء الدالة التي قمنا بإنشائها مسبقا وهي loadChartData2() ثم لاحظ أنه تم عرض في المحور x التاريخ xValueMapper: (UserWeightModel user, _) => user.week.substring(5), و في المحور y تم عرض الوزن yValueMapper: (UserWeightModel user, _) => user.weight, و كانت dataSource الخاصة بهذا الشارت هي List chartData dataSource: chartData,1 نقطة
-
لدي مكون يتحقق من اسم المسار ويعمل عليه: const router = useRouter(); const path = router.pathname;//props.location.pathname; const p = path.split('/').filter((s) => s !== "") let submissionId = p[0] == 's' && p[1] const submission = useQuery(SUBMISSION, { variables: { id: submissionId }, skip: submissionId === false }) يعمل هذا بشكل جيد في تطبيق react ولكن nextjs يعيد التوجيه إلى 404. هل هناك طريقة لإعداد نمط لـ nextjs لتجاهل المسارات غير الموجودة والسماح لرمز المكون بمعالجته؟1 نقطة
-
هذا يعتمد على كيفية تعامل الخادم مع الكوكيز المذكورة وكيفية البرمجة التي تمت للتعامل مع المصادقة ولكن اذا كنت تعتمد على تلك الكوكيز لابقاء المصادقة وكان هذا يتم التعامل معه من الخادم في كل مرة فنعم يعتبر هذا مصادقة تلقائية1 نقطة
-
هل يمكنك إرفاق نص المشكلة إذا كان يظهر لك , أو صورة للمشكلة ؟1 نقطة
-
اريد برمجة مكبر الصوت والتحدث و هو يجيب بالاردوينو1 نقطة
-
جربت الكود لكن هناك مشكلة <?php $uploadDir = 'uploads/'; //.............. if(!empty($_FILES["file"]["name"])) { $name = explode('.', $_FILES["file"]["name"]); $fileName = substr(md5(uniqid(rand(), true)),3,10); $end = end($name); $newName = $fileName . '.' . $end; $fileType = pathinfo($newName, PATHINFO_EXTENSION); $allowTypes = array('pdf', 'doc', 'docx', 'jpg', 'png', 'jpeg'); if(in_array($fileType, $allowTypes)) { if(move_uploaded_file($_FILES["file"]["tmp_name"], $newName)) { $uploadedFile = $fileName; } ?>1 نقطة
-
للأسف لا يمكن لأحد أن يعطيك سعرا تقريبيا للتطبيق دون معرفة تفاصيل أكثر عن هذا التطبيق, هناك عدة أسئلة يجب طرحها لمعرفة كيفية تسعير تطبيقك, ما هو مجال اختصاص التطبيق ؟ هل التطبيق مبني بطريقة احترافية و خالي من الثغرات و المشاكل البرمجية ؟ كم من الوقت و الجهد استغرق انشاء هذا التطبيق ؟ أما بالنسبة للفرق بين بيع التطبيق و بين تنزيله على حسابك الخاص في المتجر, فهذا يعتمد على الطريقة التي يتبعها تطبيقك لتحقيق المداخيل, هل التطبيق يوفر عمليات الشراء داخله ؟ ام هل يحتوي على اعلانات ؟ و هل هو موجه للمستخدمين في كل أنحاء العالم أم فقط لفئة معينة, لأن الفئة المستهدفة هي التي تحدد مدى نجاح التطبيق و تحدد حجم المداخيل الممكن توقعها.1 نقطة
-
حسناً، يمكنك استخدام الدالة argsort لفرز المصفوفة، لكنها تقوم بعملية الفرز بشكل تصاعدي: import numpy as np array = np.array([2, 9, 7, 10, 5, 3]) a = np.sort(array) a # array([ 2, 3, 5, 7, 9, 10]) لذا لجعله تنازلياً، يمكنك استخدام الدالة numpy.flip عن طريق تمرير الدالة argsort لها حيث سترد لك ال indexes للقيم مرتبة بترتيب تنازلي بعد أن يتم فرزها تصاعدياً باستخدام argsort حيث تقوم هذه الدالة بعكس ترتيب العناصر : import numpy as np a = np.array([2, 9, 7, 10, 5, 3]) n=3 ids = np.flip(np.argsort(a)) print(ids[0:n]) #[3 1 2] نفس الفكرة باستخدام np.flipud: import numpy as np a = np.array([2, 9, 7, 10, 5, 3]) n=3 ids = np.flipud(np.argsort(a)) print(ids[0:n]) #[3 1 2] أو يمكنك القيام بعكسها بإحدى الأشكال التالية: # نضرب المصفوفة بسالب وبالتالي يصبح الأصغر أكبر وبالتالي نحصل على الفهرس المطلوب np.argsort(-1*a)[:3] #- كما ويمكن استخدام المعامل # أي بشكل مشابه للطريقة السابقة (-a).argsort()[:3] # أو بالطريقة التقليدية عن طريق أخذ آخر 3 عناصر a.argsort()[::-1][:3] وكمقارنة: %timeit np.flipud(np.argsort(a))[0:3] %timeit np.flip(np.argsort(a))[0:3] %timeit np.argsort(-1*a)[:3] %timeit (-a).argsort()[:3] %timeit a.argsort()[::-1][:3] 5.14 µs ± 211 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 5.29 µs ± 337 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 4.57 µs ± 127 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 1.97 µs ± 288 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 1.86 µs ± 251 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) # الطريقة الأخيرة أفضل1 نقطة
-
حسناً دعنا نناقش كل شيء بشكل منفصل. أولاً دعني أعرفك كيف تقوم بإضافة عنصر أو عدة عناصر لمصفوفة في نمباي. أولاً لإضافة عنصر في نهاية القائمة نستخدم الدالة append كالتالي: # numpy.append(arr, values, axis=None) شكل الدالة # أول وسيط هو المصفوفة # ثاني وسيط هو القيمة # الثالث هو المحور الذي نريد إضافة العنصر له # تعيد هذه الدالة نسخة من المصفوفة تحوي العنصر أو العناصر المضافة import numpy as np a=np.array([1,2,3]) a=np.append(a,1) a # array([1, 2, 3, 1]) # لإضافة أكثر من عنصر a=np.append(a,[2,3]) a # array([1, 2, 3, 1, 2, 3]) # الآن لو جربنا إضافة مصفوفة ثنائية الأبعاد لها np.append(a,[[4, 5, 6], [7, 8, 9]]) # array([1, 2, 3, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # لاحظ كيف قام بتسطيح المصفوفة الثنائية ثم أضافها للمصفوفة وذلك لأننا لم نحدد له المحور # الآن سنحدد له المحور a # array([1, 2, 3, 1, 2, 3]) np.append(a,[[4, 5, 6], [7, 8, 9]],axis=0) # ValueError: all the input arrays must have same number of dimensions # أعطى خطأ لأن المصفوفتين يجب أن يكون لهما أبعاد متسقةأي نحن نريد أن نضيف المصفوفة الثنائية إلى المصفوفة الأصلية على المحور العمودي وبالتالي يجب أن تتطابق أبعاد الأعمدة # انظر arr=[[1, 2, 3], [4, 5, 6]] np.append([[1, 2, 3], [4, 5, 6]],[ [7, 8, 9]],axis=0) """ array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) """ الآن لو أردت إضافة عنصر في فهرس محدد من المصفوفة (أي أي مكان تريده في البداية أو النهاية أو الوسط ..) يمكنك استخدام الدالة insert: #numpy.insert(arr, obj, values, axis=None) import numpy as np #obj هو الفهرس أو الفهارس التي تريد أن تتم الإضافة عندها # تعيد نسخة أيضاً # مثلا تريد إضافة عنصر لنهاية المصفوفة a = np.asarray([1,2,3]) a=np.insert(a, 3, 1) a # array([1, 2, 3, 1]) # إذا كنت لاتعرف الفهرس الخاص بآخر عنصر a = np.asarray([1,2,3]) np.insert(a, len(a), 1) # len(a)=3 حيث ترد لك عدد العناصر في المصفوفة # array([1, 2, 3, 1]) ########################## مثال آخر ######################## a = np.array([[1, 1], [2, 2], [3, 3]]) a """ array([[1, 1], [2, 2], [3, 3]]) """ #append هنا لم نحدد له المحور وبالتالي الإضافة تكون كما في np.insert(a, 1, 5) # array([1, 5, 1, 2, 2, 3, 3]) # هنا حددنا المحور الأفقي np.insert(a, 1, 5, axis=1) """ array([[1, 5, 1], [2, 5, 2], [3, 5, 3]]) """ #brodcasting لاحظ كيف تم تنفيذ عملية نسخ وهذه عملية نسميها # الآن لاحظ حالة ثانية عندما نحدد أكثر من قيمة أي نريد أن نضيف عدة قيم في الفهرس1 على طول المحور np.insert(a, [1], [[1],[2],[3]], axis=1) """ rray([ [1, 1, 1], [2, 2, 2], [3, 3, 3]]) """ استخدام الدالة concatenate لهكذا أمر هو تكنيك غير شائع فالدالتين السابقتين ستغنينك عن أي طريثة أخرى، لكنني سأوضح لك استخدامها: # numpy.concatenate((a1, a2, ...), axis=0) # ربط سلسلة من المصفوفات على طول محور موجود # (a1, a2, ...) تسلسل من المصفوفات # يجب أن يكون للمصفوفات نفس الشكل ، إلا في البعد المقابل للمحور (الأول ، افتراضيًا) a1 = np.array([[1, 2], [3, 4]]) # shape: 2*2 """ array([[1, 2], [3, 4]]) """ a2 = np.array([[5, 6]]) # shape: 1*2 # الأبعاد متناسقة إذا أردنا إضافة المصفوفة الثانية للأولى على المحور العمودي np.concatenate((a1, a2), axis=0) """ array([[1, 2], [3, 4], [5, 6]]) """ # على المحور الأفقي الأبعاد غير متناسقة وبالتالي سيظهر خطأ لو حاولنا الإضافة لذا يجب أن نقوم بتعديل أبعاد المصفوفة وهذا سهل في حالتنا a2=a2.T # shape: 2*1 a2 """ array([[5], [6]]) """ np.concatenate((a1, a2), axis=1) """ array([[1, 2, 5], [3, 4, 6]]) """ #################################################### وأخيراً سبب الخطأ لديك أعتقد ستكون استنتجته ينفسك، فالسبب هو أنك تقوم بمحاولة ربط مصفوفة بقيمة، لكن دالة concatenate كما ذكرت لك في الكود في الأعلى تأخذ سلسلة من المصفوفات وليس القيم، وبالتالي يظهر لك الخطأ، وبالتالي لحل مشكلتك يمكنك وضع القيمة بمصفوفة وسينجح الأمر: type(a[0]) # numpy.int64 وهي ماتعتبر أبعاد صفرية وبالتالي لن ينجح في مطابقة الأبعاد وسيعطيك خطأ بأن الأبعاد غير متجانسة # لذا الحل np.concatenate((a, np.array([a[0]]))) #array([1, 2, 3, 1])1 نقطة
-
يجب عليك فهم الخطأ أولاً [0]arr ليست مصفوفة، بل هي العنصر الأول من arr وبالتالي ليس لها أي أبعاد. حاول استخدام [0:1] بدلا من ذلك ، الذي سيعيد العنصر الأول من داخل lلمصفوفة صنف واحد واستخدام .np.concatenate بشكل طبيعي np.concatenate((arr, arr[0:1])) أو يمكنك تحويل العنصر [0]arr لمصفوفة np.concatenate((arr, np.array([arr[0]])))1 نقطة
-
يمكنك استخدام ال np.argsort temp = np.random.randint(1,10, 10) temp array([5, 2, 7, 4, 4, 2, 8, 6, 4, 4]) temp[np.argsort(-temp)] لاحظ أنه هذا الحل أسرع قليلاً نتيجة أنه لا يتم ضرب المصفوفة مرتين في السالب لعكس الإتجاه وغذا كنت تهتم لأمر السرعة كثيراً فيعتبر الحل الأسرع نسبياً هو np.flip عن بقية الحلول1 نقطة
-
يمكنك استخدام الدالة numpy.insert ، انظر المثال التالي للتوضيح: a = np.array([[1, 1], [2, 2], [3, 3]]) a >>> array([[1, 1], [2, 2], [3, 3]]) np.insert(a, 1, 5) >>> array([1, 5, 1, ..., 2, 3, 3]) لاحظ ان الدالة تقوم بأخذ ثلاث قيم، اولا المصفوفة التي تريد الاضافة اليها، ثم موقع العنصر الذي تريد اضافته ، في المثال السابق مثلا كان موقع العنصر هو 1 لذا قام باضافته في المكان الثاني لانه يبدأ العد من 0، واخيرا ياخذ قيمة العنصر الذي تريد اضافته وفي المثال السابق كان 5. لاحظ انه يمكنك اضافته في اي مكان سواءكان صفا او عمود، انظر المثال التالي: a = np.array([[1, 1], [2, 2], [3, 3]]) np.insert(a, 1, 5, axis=1) array([[1, 5, 1], [2, 5, 2], [3, 5, 3]]) لاحظ ان وضع axis=1 يقوم باضفة العنصر في مكانه بالاعمدة وليس الصفوف، اما axis=0 وهي القيمه الافتراضيه يقوم باعتبار المصفوفة كانها صف ويقوم بتحديد مكان العنصر المراد اضافته على هذا الاساس1 نقطة
-
نعم يمكنك ذلك، انظر المثال التالي، دعنا ننشأ المصفوفة التاليه: array = np.array([7, 5, 3, 2, 6, 1, 4]) بعد ذلك يمكننا ترتيبها تصاعديا كالتالي: # ترتيب تصاعدي sorted_array = np.sort(array) # [1, 2, 3, 4, 5, 6, 7] او ترتيبها تنازليا كالتالي: # ترتيب تنازلي reverse_array = sorted_array[::-1] # [7, 6, 5, 4, 3, 2, 1] وبشكل عام تستخدم np.sort(array)[::-1] لترتيب المصفوفة بشكل تنازلي. طريقة اخرى مختلفه هي ان تقوم بعمل مصفوفة أخرى وتقوم باضافة العناصر المرتبه تصاعدي في المصفوفة الاولى بشكل معكوس في المصفوفة الثانية، لكن تلك الطريقة تسلتزم مجهودا اكثر وكذلك تاخذ مساحة اكبر لكنها تحافظ لنا على المصفوفة القديمة كما هي.1 نقطة
-
دعنا نقوم بانشاء مصفوفة بشكل عشوائي كالتالي: import numpy as np x = np.random.randint(0, 10, 30) print(x) output >>> [9 8 3 8 6 0 8 0 9 5 1 2 9 3 4 4 9 4 5 8 6 6 6 6 9 4 8 6 2 0] يمكننا استخدام الدالة bincount( ).argmax( ) والتي تعطينا اكثر رقم تكرر في هذة المصفوفة كالتالي: print(np.bincount(x).argmax()) output >>> 6 هنا قام بارجاع الرقم 6 لانه الاكثر تكرارا في المصفوفة التي انشأناها. كذلك يمكننا استخدام الدالة counter وذلك لاعطاءنا كل رقم في المصفوفة وعدد مرات تكراره على شكل tuple مرتبة تنازليا كالتالي: from collections import Counter b = Counter(x) print (b.most_common()) output >>> [(6, 6), (9, 5), (8, 5), (4, 4), (0, 3), (3, 2), (5, 2), (2, 2), (1, 1)] هنا قامت الدالة بارجاع كل رقم في المصفوفة وبجواره عدد مرات تكراره، فمثلا الرقم 9 تم تكراره 5 مرات وهكذا.1 نقطة
-
يمكن استخدام numpy.insert ولكنه يعيد مصفوفة جديدة لأن المصفوفات في numpy لها طول ثابت.. >>> import numpy as np >>> a = np.asarray([1,2,3]) >>> np.insert(a, 3, 1) array([ 1, 2, 3, 1]) insert يأخذ وسيطين، دليل العنصر بالمكان الذي نريد حشره ثم قيمته.. إن كنت تريد استخدام concatenate فهي تتعامل مع المصفوفات، لذلك عليك تمرير أجزاء المصوففة الثابتة و بينها العناصر الجديدة في مصفوفة خاصة np.concatenate((arr, [ arr[0] ] )) ^^^ ^^^ لاحظ إحاطة العنصر المضاف بين أقواس مصفوفة الشكل العام لها .. np.concatenate((a[:index], [value], a[index:])) إن أردت حشر العنصر في آخر المصفوفة يمكن استخدام الدالة append: import numpy as np arr = np.array([1, 2, 3]) arr = np.append(arr,1) print(arr) # [1 2 3 1]1 نقطة
-
يمكننا ضرب المصفوفة ب -1 ونرتبها تصاعدياً ثم نضرب الناتج مجدداً ب -1 لنحصل على الناتج الصحيح.. - np.sort( -a ) # مصفوفة معكوسة array([7, 7, 6, 4, 4, 4, 4, 2, 2, 2]) كما يمكن عكس اتجاه مصفوفة مرتبة مثلا باستخدام الدالة flip: np.flip(np.sort(a)) للعلم: temp[::-1].sort() # يرتب المصفوفة الأصلية في مكانها np.sort(temp)[::-1] # يقوم بإنشاء مصفوفة أخرى جديدة1 نقطة
-
إن كانت جميع القيم في المصفوفة موجبة يمكن استخدام numpy.bincounts لحساب تكرار كل عدد ثم نطبق على ناتجه الدالة argmax: arr = np.array([1,2,3,1,2,1,1,1,3,2,2,1]) myCounter = np.bincount(arr) print(np.argmax(myCounter)) كما يمكن استخدام np.histogram : np.histogram([[1, 2, 1], [1, 0, 1]], bins=[0,1,2,3]) (array([1, 4, 1]), array([0, 1, 2, 3])) bins هي العتبات التي سيتم حساب التكرار عندها، و np.histogram تعيد مصفوفة تحوي تكرار كل قيمة موافقة للعتبات bins للعنصر المقابل لها كما يمكن استخدام collections.Counter من بايثون: from collections import Counter a = [1,2,3,1,2,1,1,1,3,2,2,1] b = Counter(a) print(b.most_common(1)) حيث b يحمل تعداد التكرارات، ثم نطبيق الدالة most_common للأكثر تكرارا ونمرر الترتيب الأول لأكثر عنصر1 نقطة
-
SVR هو جزء من موديل support vector machine ويستخدم في مهام التوقع يمكنك استخدامها عبر الموديول sklearn.svm مثل أي نموذج في التعلم الآلي يوجد لديه العديد من المعاملات التي تلعب دوراً أساسيا في عملية تعلم الموديل عبر داتا التدريب لنقوم بالمرور على أهم المعاملات التي يأخذها هذا النموذج. #استدعاء المكتبة: from sklearn.svm import SVR في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل #الشكل العام للموديل: SVRModel = SVR(kernel=’rbf’, degree=3, tol=0.001,C=1.0,max_iter=-1,epsilon=0.1,cache_size=200وgamma='auto') أهم البارمتر المستخدمة: البارمتر الأول kernel نوع النواة أو المعادلة المستخدمة تكافئ فكرة تابع التنشيط في الشبكات العصبونية يوجد عدة أنواع ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ ننصح دوما باستخدام rbf لأنها الأفضل. البارمتر الثاني degree وهو في حال أردنا جعل ال regressor غير خطي أي Polynomial نضبطه بالدرجة التي نريدها(default=3). بحال استخدام الkernel=poly فيجب تحديد درجة كثير الحدود. البارمتر الثالث tol عدد يمثل نقطة إيقاف التعلم بحال تجاوز هذه القيمه فيتوقف svr. البارمتر الرابع C معامل التنعيم أفضل القيم للتجريب 0.1,0.001,10,1 البارمتر الخامس max_iter العدد الأقصى للتكرارت إذا وضعت -1 فأنه يأخذ الحد الأعلى ويفضل ذلك epsilon: ضمن هذا المقدار لن يتم تطبيق أي penalty على تابع التكلفة. أي هي هامش للسماحية بدون تطبيق penalty. افتراضياً default=0.1. cache_size: تحديد حجم ال kernel cache وافتراضياً 200 MB. gamma: معمل النواة وهي إما {‘scale’, ‘auto’}أو float وتكون افتراضياً 'default=’scale. طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جداً فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test,. y_test تسطيع كتابة الأتي لعملية التدريب: SVRM = SVR(kernel=’rbf’, degree=3, tol=0.001,C=1.0,max_iter=-1) SVRM.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لعملية التدريب يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي. #حساب القيم المتوقعة: y_pred = SVRM.predict(X_test) حيث قمنا بالتنبؤ بقيم التصنيف لداتا الاختبار نستطيع حساب دقة الموديل أو كفاءته على التدريب والاختبار عن طريق التابع score ويكون وفق الشكل #حساب الكفاءه على التدريب والاختبار: print('Train Score is : ' , SVRM.score(X_train, y_train)) print('Test Score is : ' , SVRM.score(X_test, y_test)) مثال: from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.svm import SVR # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=44) # تطبيق التابع SVRM = SVR(C = 1.0 ,epsilon=0.1,kernel = 'rbf') SVRM.fit(X_train, y_train) # عرض النتائج print('SVRM Train Score is : ' , SVRM.score(X_train, y_train)) print('SVRM Test Score is : ' , SVRM.score(X_test, y_test))1 نقطة
-
توفر Sklearn القيام بالتوقع الخطي مع التنعيم عن طريق استخدام الكلاس Ridge. يتم استخدامها عبر الموديول linear_model.Ridge كالتالي: sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None) الوسطاء: fit_intercept: لجعل المستقيم يتقاطع مع أفضل نقطة على المحور العيني y. copy_X: وسيط بولياني، في حال ضبطه على True سوف يأخذ نسخة من البيانات ، وبالتالي لاتتأثر البيانات الأصلية بالتعديل، ويفيدنا في حالة قمنا بعمل Normalize للبيانات. normalize: وسيط بولياني، في حال ضبطه على True سوف يقوم بتوحيد البيانات (تقييسها) اعتماداً على المقياس n_jobs: لتحديد عدد العمليات التي ستتم بالتوازي (Threads) أي لزيادة سرعة التنفيذ، افتراضياُ تكون قيمته None أي بدون تسريع، وبالتالي لزيادة التسريع نضع عدد صحيح وكلما زاد العدد كلما زاد التسريع (التسريع يتناسب مع قدرات جهازك)، وفي حال كان لديك GPU وأردت التدريب عليها فقم بضبطه على -1. random_state: للتحكم بآلية التقسيم. max_iter: العدد الأقصى للتكرارات. tol: مقدار التسماح في التقارب من القيم الدنيا. float, default=1e-3 solver: ال Optimezer المستخدم. solver{‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’}, default=’auto’ alpha: هو معامل التنعيم ويأخذ قيم من الصفر إلى n، و كلما زادت القيمة زاد تأثير التنعيم. default=1.0. أهم ال attributes: _coef: الأوزان التي حصلنا عليها بعد انتهاء التدريب وهي مصفوفة بأبعاد (,عدد الfeatures). intercept: التقاطع مع المحور y. أهم التوابع: fit(data, truevalue): للقيام بعملية التدريب. predict(data): دالة التوقع ونمرر لها البيانات وتعطيك التوقع لها. score(data, truevalue): لمعرفة مدي كفاءة النموذج ونمرر لها بيانات الاختبار والقيم الحقيقية لها فيقوم بعمل predict للداتا الممررة ثم يقارنها بالقيم الحقيقية ويرد الناتج حسي معيار R Squaerd. يمكن تطبيقه كما يلي: from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import Ridge # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # تطبيق التابع RidgeRegression = Ridge(alpha=0.5,random_state=20,solver='auto') RidgeRegression.fit(X_train, y_train) #Calculating Details print('Train Score is : ' , RidgeRegression.score(X_train, y_train)) print('Test Score is : ' , RidgeRegression.score(X_test, y_test)) #print('Coef is : ' , RidgeRegression.coef_) print(RidgeRegression.predict(X_test))1 نقطة
-
يمكن ذلك باستخدام مكتبة ctime في سي بلس بلس حيث يوجد الداله time تعطي الوقت بعد أعطائها القيمه 0 وبعدها نقول بتحويل الزمن لانه يكون بالثواني إلى يوم والشهر والدقائق والسنه باستخدام الداله ctime #include <iostream> #include <ctime> using namespace std; int main() { // الوقت الحالي time_t now = time(0); // تحويل الوقت الحالي إلى سترنغ char* dt = ctime(&now); cout << "The local date and time is: " << dt << endl; }1 نقطة
-
هي نموذج للتصنيف باستخدام الشبكات العصبونية يتم استخدامها عبر الموديول neural_network.MLPClassifier مثل أي نموذج في التعلم الألي يوجد لديه العديد من المعاملات التي تلعب دورا أساسيا في عملية تعلم الموديل عبر داتا التدريب لنقوم بالمرور على أهم المعاملات التي يأخذها هذا النموذج #استدعاء المكتبة from sklearn.neural_network import MLPClassifier في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل #الشكل العام للموديل MLPClassifierModel = MLPClassifier(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) البارمتر الأول activation مثلما نعرف يوجد في الشبكات العصبونية عدة أنواع لتوابع التنشيط أو activation ومن أهمها تابع sigmoid , relu,tanh لن أدخل في تفاصيل كل منها فأي دورة تعلم الآلة أو تعلم عميق تحوي هذه المفاهيم ولكن كنصيحه نقوم بجعل relu لجميع الطبقات ماعدا الأخيره أما الطبقة الأخيره نستخدم sigmod البارمتر الثاني solver هو طريقة الحل أو طريقة الوصول إلى أفضل قيم w,b الأوزران الخاصه بالشبكه العصبونية يوجد أكثر من طريقه مثل sgd ,adam ولكن ننصح باستخدام adam دوما البارمتر الثالث learning_rate هو معامل التعلم وهو يمثل مقدار الخطوه للوصول إلى الأوزران ويمكن تركه costant أي خطوات ثابتة أو adaptive متغيره أما ان تكون طويله أو قصيرة البارمتر الرابع early_stopping التوقف المبكر وهو يأخذ True بحال أردنا أيقاف معامل التعلم عند نقطه بحيث لا يدخل الموديل في مرحلة overfit أي الضبط الزائد وfalse عكس ذلك البارمتر الخامس alpha يمثل معامل التنعيم حيث التنعيم هو طريقة لكي يتخلص الموديل من الضبط الزائد overfit ويلعب alpha دورا مهما في ذلك البارمتر السادس hidden_layer_sizes وهو يمثل عدد الطبقات ماعدا طبقة الدخل والخرج لأنهما لا تعتبرا طبقات مخفيه وعدد الخلايا في كل طبقه حيث الأرقام تدل على عدد الخلايا في الطبقه أما موقع الرقم يدل على الطبقه وعدد المواقع يدل على عدد الطبقات المخفيه فمثلا (10,200,30,4) يوجد أربعة طبقات لأنه يوجد أربع أرقام وكل رقم منها يدل على عدد الخلايا في طبقته مثلا الطبقة الأولى تحوي 10 خلايا طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جدا فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test, y_test تسطيع كتابة الأتي لعملية التدريب MLPClassifierModel = MLPClassifier(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) MLPClassifierModel.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لتدريب الشبكه العصبية يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي: y_pred = MLPClassifierModel.predict(X_test) حيث قمنا بالتنبؤ بقيم التصنيف لداتا الاختبار نستطيع أيضا حساب دقة الموديل أو كفاءته عن طريق التابع score ويكون وفق الشكل: print('MLPClassifierModel Test Score is : ' , MLPClassifierModel.score(X_test, y_test)) حيث قمنا بطباعة قيمتها لكي نرى كفاءة الموديل على بيانات الاختبار وهل هو يعاني من الضبط الزائد overfit أو الضبط الناقص underfit.1 نقطة
-
في مكتبة sklearn يتطلب الأبعاد (رقم الصف,رقم العمود) ومن المؤكد أن شكل الأبعاد لديك هي (999,) وبالتالي فلن تعمل لأنه يفقد رقم العمود يكون الحل باستخدام الوظيفه reshape من المكتبة numpy لجعلها (999,1) الكود: data=data.reshape((999,1))1 نقطة
-
في الإصدارات الحديثة من تنسرفلو تم حذف هذه الدالة وأصبح بإمكانك استخدام ال generators مع الدالة Model.fit لذا لديك حلين إما أن تقوم بتثبيت إحدى الإصدارات السابقة مثل 1.15 من تنسرفلو كالتالي: pip install tensorflow==1.15 أو أن تقوم باستخدام الدالة Model.fit : # generetors الشكل العام للتابع في حالة كانت بياناتك ليست fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs ) # generetors في حالة كانت بياناتك fit( data_generetors, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs ) لكن في الحالة الثانية لن تكون قادراً على استخدام الخاصية validation_data أو validation_split والخواص الأخرى المتعلقة بهم لذا قد يكون الحل الأفضل استخدام إصدار سابق لحل مشكلتك في حال كنت تعتمد validation_generator1 نقطة
-
الخطأ هو عدم وجود sklearn في نظامك، ولحل المشكلة يجب تثبيت مكتبة sklearn ويمكنك ذلك عن طريق: أما فتح موجه الأوامر cmd وكتابة التعليمة التالية: pip install -U scikit-learn أو من خلال الكتابة على موجه الأوامر في anconda إن كنت تستخدمها: conda install scikit-learn أو من خلال الكتابة في jupyter notebook: pip install scikit-learn1 نقطة
-
Stochastic Gradient Descent (SGD) Classifier تقوم بعمل Logistic Regression لكن باستخدام خوارزمية التحسين ال Stochastic Gradient Descent. يمكنك استخدامها عبر الموديول: linear_model.SGDClassifier sklearn.linear_model.SGDClassifier(loss='hinge', *, penalty='l2', alpha=0.0001, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, epsilon=0.1, n_jobs=None, random_state=None, learning_rate='optimal', early_stopping=False) الوسطاء: loss: هي دالة التكلفة المستخدمة، وكون المهمة هي مهمة تصنيف نستخدم الدالة الافتراضية دوماً. أي hinge. penalty: وهو نوع التنعيم المستخدم. learning_rate: وهو معامل التعلم (مقدار الخطوة). max_iter: العدد الأقصى للمحاولات. early_stopping: في حال ضبطه على True سيتم تطبيق خاصية التوقف المبكر (لمنع ال Overfitting عندما تنهار الدقة على عينة التطوير مقابل عينة الاختبار). shuffle: لخلط البيانات. verbose: ضبطه على أي قيمة غير الصفر سيعطيك التفاصيل أثناء التدريب. random_state: تتحكم بنظام العشوائية. ال attributes: coef_: الأوزان. intercept_: التقاطع مع المحور y، ضبطه على False يجبر الكلاسيفير على المرور من المبدأ 0،0 لذا يفضل ضبطه على True لإعطاء الحرية للكلاسيفير. n_iter_: عدد المحاولات التي تم تنفيضها خلال التدريب حتى الوصول لمرحلة التقارب من القيم الدنيا. الدوال: fit(X, y): لبدء التدريب على بياناتك. predict(X): لتوقع قيم الدخل اعتماداً على قيم الأوزان. score(X, y): لتقدير مدى كفاءة النموذج. مثال على مجموعة بيانات Iris Data : from sklearn.model_selection import train_test_split from sklearn.linear_model import SGDClassifier from sklearn.metrics import confusion_matrix from sklearn.datasets import load_breast_cancer import seaborn as sns import matplotlib.pyplot as plt # تحميل البيانات Data = load_breast_cancer() X = Data.data y = Data.target # تقسيم البيانات إلى عينات تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=44, shuffle =True) # SGDClassifier تطبيق SGDC = SGDClassifier(penalty='l1',loss='hinge',learning_rate='optimal',random_state=44) SGDC.fit(X_train, y_train) print('SGDC Train Score is : ' , SGDC.score(X_train, y_train)) print('SGDC Test Score is : ' , SGDC.score(X_test, y_test)) # SGDC Test Score is : 0.9414893617021277 print('SGDC loss function is : ' , SGDC.loss_function_) print('SGDC No. of iteratios is : ' , SGDC.n_iter_) # عرض مصفوفة التشتت c = confusion_matrix(y_test, SGDC.predict(X_test)) print('Confusion Matrix is : \n', c) #لرسم المصفوفة sns.heatmap(c, center = True) plt.show()1 نقطة
-
يمكنك استخدامه عبر الموديول: preprocessing.PolynomialFeatures وهو يستخدم مع التوقع الخطي لإعطاء البيانات الصفة اللاخطية، فكما تعلم أن الفرضية المستخدمة مع التوقع الخطي هي معادلة خط مستقيم من الشكل : y=wx+b وبالتالي معادلة مستقيم، وبالتالي في حال البيانات التي لها الشكل التالي لن تكون قادرة على ملاءمتها: حيث سيكون شكل ال Regressor بعد التدريب كالتالي: وبالتالي لملاءمة هكذا نوع من البيانات يجب أن تضيف لبياناتك الصفة اللاخطية وبالتالي تكون معادلة ال Regressor قادراة على ملائمة البيانات بالشكل المطلوب كالتالي: أي يجب أن تكون معادلة ال Regressor كالتالي: y=b+x1+x1^2+,,,,+x1^n للقيام بذلك باستخدام Sklearn: sklearn.preprocessing.PolynomialFeatures(degree=2, include_bias=True) degree: درجة كثير الحدود المطلوبة. include_bias: لتضمين الانحراف bias في العملية. مثال: import numpy as np from sklearn.preprocessing import PolynomialFeatures X = np.arange(4).reshape(2, 2) # تشكيل مصفوفة بقيم عشوائية print(X) ''' array([[0, 1], [2, 3]]) ''' poly = PolynomialFeatures(2) print(poly.fit_transform(X)) # للقيام بعملية التحويل نستدعي هذ التابع ''' array([[1. 0. 1. 0. 0. 1.] [1. 2. 3. 4. 6. 9.]]) '''
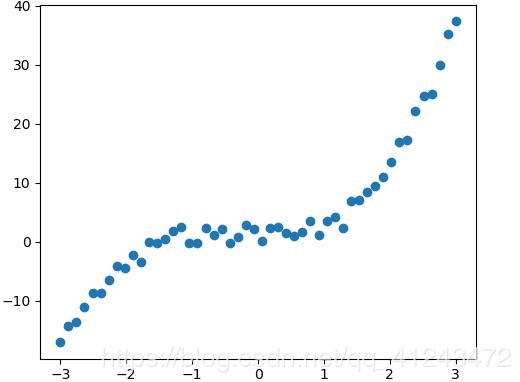
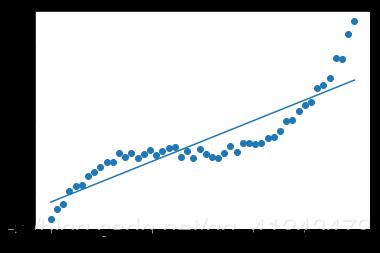
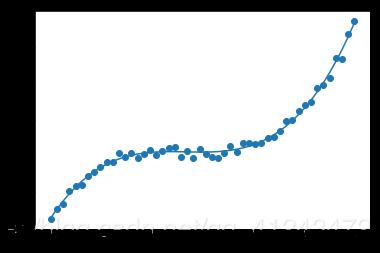 1 نقطة
1 نقطة -
يمكن ذلك باستخدام مكتبة pands في البداية نقوم باستيراد المكتبة: import pandas as pd بعد ذلك نقوم بقراءة الملف وفق الرابط url: xls = pd.ExcelFile(url) بعد ذلك نقوم بحساب عدد ال sheet في الملف من خلال تطبيق len على قائمة الأسماء sheet_names، حيث أن xls.sheet_names قائمه تحوي أسماء ال sheet في الملف: namesheet=xls.sheet_names تعريف قائمة فارغة لوضع ال sheet فيها: frames=[] مرور حلقة على عدد ال sheet وقراءة كل شيت باستخدام read_excel من pandas وإضافتها للقائمه frames: for i in range(numsheet): df1 = pd.read_excel(xls,namesheet[i]) frames.append(df1) بعد ذلك نقوم بدمج جميع ال sheet الموجودة في frames باستخدام concat: df = pd.concat(frames) أي شيئ آخر؟1 نقطة


















