لوحة المتصدرين



المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/19/21 في كل الموقع
-
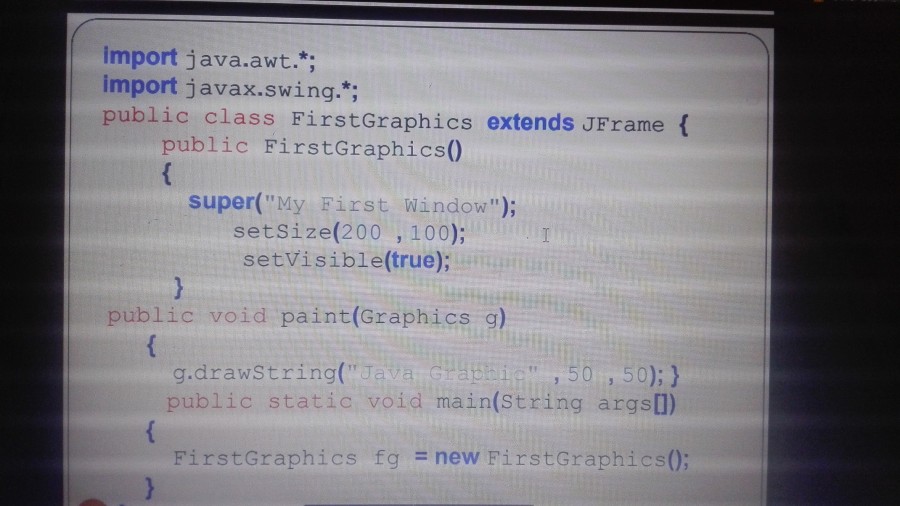
public FirstGraphics() هي الدالة البانية للصنف FirstGraphics حيث دائما، إسم الدالة البانية يطابق اسم الصنف الموافق لها. وهذه الدالة البانية هي بدون وسطاء صحيح، حيث لا يتم تمرير أي وسطاء دالخل أقواس هذه الدالة () وهي لا تقوم بإسناد قيم لخواص هذا الصنف. ولكن بما أنها ترث من الصنف JFrame، تم استدعاء الدالة super في الصنف الأب أي JFrame (دالة تستقبل نص لتعطي اسم للنافذة) وأيضا استدعاء الدوال setSize و setvisibel التي تم وراثتهم أيضا لتحديد أبعاد الإطار و الظهور ليتم عرضه. أرجو في المرة القادمة إرفاق الشيفرة بشكل نص (كود برمجي).2 نقاط
-
بداية يجب عليك معاملة أية مشاكل و صعوبات تظهر معك كأشياء طبيعية في المجال و من جانب اخر هي إمتحانات لك و لا يجب عليك التفكير في التوقف عن ما أقدمت عليه بسبب أشياء تواجهها لأنه , و بهاته الطريقة , سيكون لديك الكثير لتتوقف من أجله . كما أنه يجب عليك الإستفادة من الإجابات التي طرحها عليك الزملاء في أسئلتك السابقة : و بشكل عام فإنه يجب عليك فهم منطق هاته العمليات لا التوغل في مثال عن كود واحد و إعتباره كمعيار أو دستور للعملية . فمثلا : التشفير و فك التشفير : للتشفير : سيكون عليك تشفير سلسلة نصية معينة قبل إستعمالها , ولقراءته سنحتاج فك هذا التشفير . مثال عن الإستعمال : تشفير كلمة المرور قبل إدخالها في قاعدة البيانات في عملية تسجيل المستخدم - أ - , ثم فك تشفيرها للتحقق من مطابقتها لكلمة مرور قام المستخدم - أ - بإدخالها في عملية تسجيل دخوله لاحقا. أي : أننا نحتاج دالة تشفير و دالة فك تشفير . أو دالة و دالة معاكسة لها لعمل الفكرة , و قد تكتب خوارزميتك الخاصة للتشفير وفك التشفير أنت ذاتك فالعملية ليست حكرا على أحد لكن يقترح إستعمال المكتبات و الدوال المسبق تعريفها لأمان و سرعة أكثر . و دوال التشفير كثيرة من PHP نذكر من بينها : openssl_encrypt و الدالة المعاكسة لها : openssl_decrypt : توثيق . أمثلة : <?php $example = '@123456'; # السلسلة النصية المراد تشفيرها $cipher_algo = 'AES-128-CTR'; # خوارزمية التشفير $encryption_key = 'HsoubAcademy'; # مفتاح التشفير $options = 0; # خيارات التشفير $encryption_iv = 1234567891011121; # يعبر عن بادئة التشفير $encrypted_example = openssl_encrypt($example , $cipher_algo , $encryption_key , $options , $encryption_iv); echo $encrypted_example; // النتيجة : nLTaaXcr1A== $decrypted_example = openssl_decrypt($encrypted_example , $cipher_algo , $encryption_key , $options , $encryption_iv); echo $decrypted_example; // النتيجة : @123456 base64_encode و الدالة المعاكسة لها : base64_decode . توثيق . أمثلة : <?php $example = '@123456'; # السلسلة النصية المراد تشفيرها $encrypted_example = base64_encode($example); echo $encrypted_example; // النتيجة : QDEyMzQ1Ng== $decrypted_example = base64_decode($encrypted_example); echo $decrypted_example; // النتيجة : @123456 bin2hex و الدالة المعاكسة لها : hex2bin . توثيق و أمثلة . و غيرها الكثير .. كما يمكنك القراءة عن الموضوع أكثر هنا : رفع الصور و الملفات عن طريق الأجاكس : جافاسكربت تجعل ذلك بسيطا عن طريق إستعمال كائن يختص بنماذج البيانات و هو الكائن FormData , و لإرسال صورة أو ملف ما علينا إلا : إرسال نموذج من الكائن FormData يحمل الملف. لاحظ جيدا منطق الخطوات بالمثال التالي : $(document).ready(function(){ // 1 - إضافة حدث عن تقديم الاستمارة و رفع الملف $("#submit_file_form").click(function(){ // 2 - FormData تحضير نموذج عن الكائن var fd = new FormData(); // 3 - تحديد الملف var files = $('#my_file')[0].files; // 4 - التحقق من تحميل ملف if(files.length > 0 ){ // 5 - إضافة الملف إلى نموذج الكائن fd.append('file',files[0]); // 6 - تحضير طلب الاجاكس و إرسال نموذج الكائن $.ajax({ url: 'path/to/endpoint', type: 'POST', data: fd, contentType: false, processData: false, success: function(response){ if(response){ alert('تم رفع الملف'); }else{ alert('لم يتم رفع الملف'); } }, }); }else{ alert("قم بتحديد ملف لرفعه."); } }); }); معيارية MVC : و هي إختصار لـ Model , View , Controller و ببساطة شديدة هو نموذج معيارية Design Pattern يقضي بعزل منطق العمل عن واجهة المستخدم بهدف تحقيق إستقلالية كل منهما و تسهيل التعامل معهما في التطوير , الفحص و الصيانة . و يحقق بذلك أحد مبادئ التصميم المشهورة في علوم الحاسب : مبدأ فصل الإهتمامات separation of concerns (SoC). تقوم معيارية MVC بتقسيم التطبيق إلى ثلاث أجزاء : النموذج Model : يعبر عن المكون المركزي و الرئيسي للنمط Pattern . و يمثل بنية البيانات الخاصة بالتطبيق ، فعن طريقه تتم مباشرة إدارة بيانات وقواعد التطبيق . العرض View : و هي أي تمثيل للمعلومات مثل صفحة ويب , جداول أو نصوص . و تمثل ها هنا واجهة المستخدم . المتحكم Controller : و يقوم بإستقبال المدخلات و التحكم فيها و التحقق من إمكانية تمريرها للنموذج Model حتى يتصرف بناء عليها . هذا الفصل بين المكونات الثلاث هاته يجعلها تتفاعل فيما بينها بهاته الطريقة : النموذج Model مسؤول عن إدارة بيانات التطبيق . بحيث يتلقى مدخلات المستخدم من وحدة التحكم Controller . تستجيب وحدة التحكم Controller لإدخال المستخدم , وتتحقق من سلامتها ثم تقوم بتمرير مدخل المستخدم إلى النموذج Model , أو تقوم إستجابة لمدخل المستخدم بعرض View بتنسيق معين . و بشكل عام فإن أي فصل لهاته الثلاث مكونات , اهتمامات و وظائف هي معيارية تصميم MVC مثلها مثل أي معيارية أخرى , يتطلب التعمق فيها فهما أوسع و أعمق لأنماط ومعياريات التصميم Design Patterns . إن لم يكن لك إطلاع مسبق عنها فيمكنك أخذ فكرة عن الموضوع هنا و أيضا هنا . كما يمكنك الإطلاع عن الكود المصدري لهاته النماذج المصغرة لمعيارية MVC هنا و هنا . و بالطبع فإنه يمكنك التدرب على فصل هاته المكونات الثلاث لتطبيق الفكرة عمليا .2 نقاط
-
يمكن إجراء ذلك باستخدام الدالة concat كما في التعليق السابق، وفي حال كنت ترغب بتعديل المجموعة كاملة أي تعديل كافة المستندات الموجودة ضمن المجموعة عن طريق دمج الاسم، يمكنك إضافة الخاصية multi إلى التابع update بهذا الشكل: update( {}, [{ $set: { fullname: { $concat: [ "$firstname", " ", "$lastname" ] } } }], { multi: true } ) أما لإجراء الدمج على مستند محدد، يمكنك إضافة شرط للاستعلام من خلال الخصائص الموجودة (الاسم، الرقم المعرّف،...) وإزالة multi ليتم تطبيق التعديل على مستند واحد فقط.2 نقاط
-
يتم تطبيق selection في mongodb بدءً من طبقة المستندات. لذلك عندما نقوم بكتابة الاستعلام {"balls.color": "red"} سيتم إعادة (المستند) الذي يحقق هذا الشرط كاملاً دون تطبيق أي شروط أو فلتر على المصفوفات ضمنه. أما في حالتك فأنت ترغب أيضاً بإجراء فلتر على عناصر المصفوفة ضمن هذا المستند الذي سيتم إرجاعه. ويمكن في هذه الحالة استخدام elemMatch والذي سيعيد أول عنصر محقق لهذا الشرط فقط: find({"balls.color": "red"}, {_id: 0, balls: {$elemMatch: {color: "red"}}}); وفي حال كانت النسخة لديك أقدم من 2.2 فلن تستطيع استخدام elemMatch، يمكنك بشكل مشابه استخدام projection مع المعامل $ كالتالي: find({"balls.color": "red"}, {_id: 0, 'color.$': 1});2 نقاط
-
 فتحت الشكبة العنكبوتية المعجزة التقنية الأبرز في العصر الحديث آفاقًا جديدةً للمترجمين وأصحاب مشاريع الترجمة. وتهافتت الشركات التقنية على إنتاج البرامج والأدوات المتخصصة في مجال الترجمة لتُيسرها وتزيد من جودتها وكفاءتها، حيث ذاع صيت ما يُعرف بالترجمة بمُساعدة الحاسوب CAT tools، وتنوعت خصائصها ما بين التدقيق الإملائي والقواعدي للغة، إلى تقديم القواميس العامة والمتخصصة، وتحرير النصوص وتخزين ذاكرات للترجمة؛ وصولاً إلى إدارة مشاريع الترجمة، وتوزيع الأعمال بين فريق العمل من المترجمين. وبات الشغل الشاغل للمترجمين الارتقاء بمهاراتهم التي تزيد من فرص حصولهم على عروض ومشاريع الترجمة، وتلبيةً لمتطلبات أصحاب المشاريع التي تُلزم إتقان برنامج أو أداة من أدوات الترجمة الحديثة. تواترت البرامج والأدوات تباعًا حتى جاء برنامج Memsource ليُسطر لنفسه اسمًا ذا سمعة طيبة لاقت استحسان أصحاب المشاريع والمترجمين، وسريعًا ما كسب ثقتهم وانضم بأريحية إلى مجموعة الكات تولز التي تضم كوكبةً من البرامج والأدوات الشهيرة، والأقل شهرة، والبسيطة، أو الأكثر تعقيدًا. استكشف برنامج Memsource أنشأ ديفيد كانيك في العام 2010 برنامج Memsource وطورته شركة Memsource التشيكية وأُطلقت سحابة Memsource لاستخدام العامة عام 2011، وصُنف يضم الاسم البراق للبرنامج السحابي Memsource في مكنونه الكثير من الخصائص في قالب من البساطة والدقة المتناهية والتي منها: تُتيح العمل مع المترجمين أينما كانوا، يتميز البرنامج بتعدد الخيارات المُتاحة للمترجم بين إمكانية تنزيل مُحرر برنامج Memsource واستخدامه على جهاز الحاسوب والعمل دون اتصال بالإنترنت، أو الدخول لموقع برنامج Memsource والذي يعمل بدوره على إحدى محركات البحث المتصلة بالإنترنت والتزامن السحابي. سهولة إنشاء مشاريع الترجمة. إضافة ذاكرات الترجمة. تخزين الترجمة الجديدة في ذاكرات الترجمة. تحويل ملفات الترجمة السابقة إلى ذاكرات ترجمة جديدة. قاعدة المصطلحات للترجمة المتخصصة. برنامج Memosour والسهولة الفائقة في استخدامه تتوافر في برنامج Memsource العديد من المُميزات التي تُيسر الترجمة وإدارة المشاريع، ويظهر ذلك سريعًا عند استخدامه، فإذا كنت مُترجمًا وجرى اختيارك من قِبل مدير مشروع لمهمة ترجمة باستخدام هذا البرنامج؛ فستتلقى بريدًا إلكترونيًا بالمهمة ومعلومات مبدئية عنها؛كاسم الملف أو عدد الكلمات المُراد ترجمتها، بالإضافة لاسم المُستخدم للحساب الذي جرى إنشاؤه للمترجم أو اسم المشروع الذي سينضم للعمل فيه ورابطًا يصل من خلاله المترجم للمهمة المُسندة إليه، وعند تسجيل الدخول لحسابك على برنامج Memsource سيتسنى لك الاطلاع على المشروع والمصادر المرفقة. يجب على المترجم أولاً قبول المهمة بعد تسجيل الدخول ليتسنى له إجراء أية تغييرات على الملف؛ وذلك باختيار الملف ثم الضغط على زر خيار تغيير الحالة، كما يمكنه الاطلاع على الملف قبل الضغط على زر القبول، وبعد إتمام عملية قبول المهمة، يكون الملف جاهزًا للعمل عليه في منضدة العمل، ويصل إخطار لمدير المشروع بذلك، ويمكن للمُترجم رفض المهمة إذا لم يرغب في إنجازها. عند الضغط على اسم الملف ستُفتح صفحة أخرى على مُحرر برنامج Memsource المتصل بالإنترنت. تظهر في وسط الصفحة فقرات ملف اللغة المصدر المراد ترجمته على الجهة اليُسرى، وتظهر فقرات اللغة الهدف المُترجم إليها في الجهة اليُمنى. إذ عند فتح ملف على برنامج Memsource يتم تجزئته إلى فقرات، وتُقطع إلى جمل صحيحة، مثل: العناوين، والمحتوى، والقطع. ذاكرة الترجمة في برنامج Memsource ذاكرة الترجمة عبارة عن مصدر من المصادر للاستعانة بها أثناء عملية الترجمة، وتُبنى من أعمال سابقة للترجمة. يتمثل الهدف من ذاكرة الترجمة بالنقاط التالية: إن الهدف الرئيس من ذاكرة الترجمة توفير الوقت والجهد أثناء عملية الترجمة. توحيد ترجمة المصطلحات المستخدمة والمفردات المتكررة في النص أو الملف. زيادة الذخيرة اللغوية في ذاكرة الترجمة عند تخزين ترجمات جديدة أثناء الترجمة. فتح ملف ذاكرة الترجمة باستخدام برامج الترجمة (الكات تولز). تشمل ذاكرة الترجمة قاعدة بيانات من فقرات لترجمات سابقة من اللغة الهدف واللغة المصدر تعرضها أثناء عملية الترجمة وإعادة استخدامها وتظهر على يمين الشاشة والضغط عليها مرتين. يظهر أسفل الشاشة عرض للسياق الجاري ترجمته وتتوفر خيارات متعددة مثل كيفية عرضه والسياق الذي يضم اللغة المصدر، حيث تُتاح من قائمة "الأدوات" أعلى الشاشة إمكانية الاطلاع على الملف الأصلي في أي وقت وكذلك الوضعية المرغوب فيها، ويمكن الانتقال للملف الهدف الجاري ترجمته. توفر اللوحة الموجودة في الجهة اليمنى كافة الخيارات التي تُساعد المترجم أثناء الترجمة والانتقال من ترجمة فقرة إلى أخرى، فتظهر الخيارات بشكل تلقائي والتي تُخزنها ذاكرات الترجمة وقاعدة المصطلحات، وكل ما عليك فعله هو فتح الملف والضغط على الفقرة وترجمتها يدويًا في الجهة المُقابلة أو استخدام خيارات ذاكرة الترجمة. ضبط إعدادات الملف يمكنك ضبط إعدادات الملف عبر ما يأتي: قائمة الأدوات tools: اختر من هذه القائمة خيار "التفضيلات" preferences. خيار التفضيلات: ستجد فيها الخيارات المهمة التالية: خيارات تحديد إعدادات الانتقال بين الفقرات. عند تثبيت الترجمة وحفظها في ذاكرة الترجمة. الانتقال بين الفقرات. البحث في ذاكرة الترجمة. خيار لا يُترجم. الترجمة الآلية. يوجد في قائمة "تحرير" أعلى الشاشة خيار لإضافة المصادر التي يرغب المترجم باستخدامها وإدخالها في اللوحة يمين الشاشة وذلك بالنقر على خيار "نتائج الكات" للوحة الكات. تعكس ألوان ذاكرة الترجمة يمين الشاشة مدى تطابق النص معها، فالأخضر يعنى 100%، ويعني اللون الأصفر الموافقة والذي يرغب به مدير المشروع بينما يعني اللون الأحمر بالمنع وعدم الاستخدام. بالنسبة لعلامات التنسيق الخاصة بالملف الأصلي ذات اللون الأزرق التي قد تظهر في الفقرات، يتم إدخالها للنص المترجم عبر النقر على قائمة "تحرير" ثم اختيار "علامات" ثم النقر على خيار "إدخال علامة" أو الضغط على اختصار "F8" من لوحة المفاتيح. بعد الانتهاء من الترجمة وتثبيتها يتعين العودة إلى صفحة المشروع وإعادة تنشيطها وسيظهر اكتمال المشروع، ومن ثَم تغيير الحالة إلى اكتمال المهمة، وعندئذ لن يتسنى إجراء تعديلات على الملف إلا بإذنٍ من مدير المشروع. تُظهر قائمة "QA" يمين الشاشة أثناء الترجمة المشاكل التي يجب حلها أو تجاهلها. تتوافر أقسام عدة للمترجم على يسار الشاشة التي وصل إليها عبر الرابط المرسل إليها كقسم الوظائف والتي تضم المهام الموكلة إليه على برنامج Memsource، ويوجد قسم لذاكرات الترجمة والتي يختارها مدير المشروع وتضم قاعدة بيانات من أعمال ترجمة سابقة وقوائم بالمصطلحات، وعند إرفاقها للمشروع تقدم خيارات أثناء الترجمة. برنامج Memsource ثري بالمميزات إن وفرة المميزات الموجودة في برنامج Memsource تجعله في الصدارة، ومن أولها توفر أكثر من 500 لغة يمكن لشركات التعريب استخدامها، كما يدعم التعريب المستمر وإنشاء مهامه باستمرار، ويدعم العديد من أنواع الملفات لتصل لأكثر من 50 نوعًا والتي منها: JSON، وXML، وMarkdown، وYAML، وPO، وXLIFF، وproperties، وresx ، وcsv. كما يتميز برنامج Memsource بالتالي: تزويد المترجمين بالمحتوى ( صور الشاشة - الملاحظات - المفاتيح - الروابط ). إنشاء مشروع والعمل عليه، إمكانية التجربة المجانية لنُسخ البرنامج المدفوعة. تطبيق جوال: توّج برنامج Memsource تطوره وقدم تطبيقه الخاص للهاتف المحمول ويُعد الأول من نوعه في عالم الكات تولز، مما يمكن أداء الترجمة من أي مكان ونشرحه في مقال كامل لاحقًا. الخاتمة صنع برنامج Memsource طفرة في عالم الترجمة بمُساعدة الحاسوب وبمميزاته التي طورها لتُيسر عملية أداء مهام الترجمة التي جذبت الكثيرين لاستخدامه بثقة والحصول على نتائج مُرضية وجودة عالية دقيقة وإدارة أعمالهم عن بعد بكل تنظيم في عالمه السحابي المتطور دومًا. اقرأ أيضًا استعمال برنامج Memsource في ترجمة المحتوى. استخدام ذاكرة الترجمة وقاعدة المصطلحات في برنامج Memsource. ترجمة المحتوى وإدارة مشاريع الترجمة عن بعد مع Memsource السحابي. ترجمة المحتوى وإدارة مشاريع الترجمة من الجوال عبر تطبيق Memsource.1 نقطة
فتحت الشكبة العنكبوتية المعجزة التقنية الأبرز في العصر الحديث آفاقًا جديدةً للمترجمين وأصحاب مشاريع الترجمة. وتهافتت الشركات التقنية على إنتاج البرامج والأدوات المتخصصة في مجال الترجمة لتُيسرها وتزيد من جودتها وكفاءتها، حيث ذاع صيت ما يُعرف بالترجمة بمُساعدة الحاسوب CAT tools، وتنوعت خصائصها ما بين التدقيق الإملائي والقواعدي للغة، إلى تقديم القواميس العامة والمتخصصة، وتحرير النصوص وتخزين ذاكرات للترجمة؛ وصولاً إلى إدارة مشاريع الترجمة، وتوزيع الأعمال بين فريق العمل من المترجمين. وبات الشغل الشاغل للمترجمين الارتقاء بمهاراتهم التي تزيد من فرص حصولهم على عروض ومشاريع الترجمة، وتلبيةً لمتطلبات أصحاب المشاريع التي تُلزم إتقان برنامج أو أداة من أدوات الترجمة الحديثة. تواترت البرامج والأدوات تباعًا حتى جاء برنامج Memsource ليُسطر لنفسه اسمًا ذا سمعة طيبة لاقت استحسان أصحاب المشاريع والمترجمين، وسريعًا ما كسب ثقتهم وانضم بأريحية إلى مجموعة الكات تولز التي تضم كوكبةً من البرامج والأدوات الشهيرة، والأقل شهرة، والبسيطة، أو الأكثر تعقيدًا. استكشف برنامج Memsource أنشأ ديفيد كانيك في العام 2010 برنامج Memsource وطورته شركة Memsource التشيكية وأُطلقت سحابة Memsource لاستخدام العامة عام 2011، وصُنف يضم الاسم البراق للبرنامج السحابي Memsource في مكنونه الكثير من الخصائص في قالب من البساطة والدقة المتناهية والتي منها: تُتيح العمل مع المترجمين أينما كانوا، يتميز البرنامج بتعدد الخيارات المُتاحة للمترجم بين إمكانية تنزيل مُحرر برنامج Memsource واستخدامه على جهاز الحاسوب والعمل دون اتصال بالإنترنت، أو الدخول لموقع برنامج Memsource والذي يعمل بدوره على إحدى محركات البحث المتصلة بالإنترنت والتزامن السحابي. سهولة إنشاء مشاريع الترجمة. إضافة ذاكرات الترجمة. تخزين الترجمة الجديدة في ذاكرات الترجمة. تحويل ملفات الترجمة السابقة إلى ذاكرات ترجمة جديدة. قاعدة المصطلحات للترجمة المتخصصة. برنامج Memosour والسهولة الفائقة في استخدامه تتوافر في برنامج Memsource العديد من المُميزات التي تُيسر الترجمة وإدارة المشاريع، ويظهر ذلك سريعًا عند استخدامه، فإذا كنت مُترجمًا وجرى اختيارك من قِبل مدير مشروع لمهمة ترجمة باستخدام هذا البرنامج؛ فستتلقى بريدًا إلكترونيًا بالمهمة ومعلومات مبدئية عنها؛كاسم الملف أو عدد الكلمات المُراد ترجمتها، بالإضافة لاسم المُستخدم للحساب الذي جرى إنشاؤه للمترجم أو اسم المشروع الذي سينضم للعمل فيه ورابطًا يصل من خلاله المترجم للمهمة المُسندة إليه، وعند تسجيل الدخول لحسابك على برنامج Memsource سيتسنى لك الاطلاع على المشروع والمصادر المرفقة. يجب على المترجم أولاً قبول المهمة بعد تسجيل الدخول ليتسنى له إجراء أية تغييرات على الملف؛ وذلك باختيار الملف ثم الضغط على زر خيار تغيير الحالة، كما يمكنه الاطلاع على الملف قبل الضغط على زر القبول، وبعد إتمام عملية قبول المهمة، يكون الملف جاهزًا للعمل عليه في منضدة العمل، ويصل إخطار لمدير المشروع بذلك، ويمكن للمُترجم رفض المهمة إذا لم يرغب في إنجازها. عند الضغط على اسم الملف ستُفتح صفحة أخرى على مُحرر برنامج Memsource المتصل بالإنترنت. تظهر في وسط الصفحة فقرات ملف اللغة المصدر المراد ترجمته على الجهة اليُسرى، وتظهر فقرات اللغة الهدف المُترجم إليها في الجهة اليُمنى. إذ عند فتح ملف على برنامج Memsource يتم تجزئته إلى فقرات، وتُقطع إلى جمل صحيحة، مثل: العناوين، والمحتوى، والقطع. ذاكرة الترجمة في برنامج Memsource ذاكرة الترجمة عبارة عن مصدر من المصادر للاستعانة بها أثناء عملية الترجمة، وتُبنى من أعمال سابقة للترجمة. يتمثل الهدف من ذاكرة الترجمة بالنقاط التالية: إن الهدف الرئيس من ذاكرة الترجمة توفير الوقت والجهد أثناء عملية الترجمة. توحيد ترجمة المصطلحات المستخدمة والمفردات المتكررة في النص أو الملف. زيادة الذخيرة اللغوية في ذاكرة الترجمة عند تخزين ترجمات جديدة أثناء الترجمة. فتح ملف ذاكرة الترجمة باستخدام برامج الترجمة (الكات تولز). تشمل ذاكرة الترجمة قاعدة بيانات من فقرات لترجمات سابقة من اللغة الهدف واللغة المصدر تعرضها أثناء عملية الترجمة وإعادة استخدامها وتظهر على يمين الشاشة والضغط عليها مرتين. يظهر أسفل الشاشة عرض للسياق الجاري ترجمته وتتوفر خيارات متعددة مثل كيفية عرضه والسياق الذي يضم اللغة المصدر، حيث تُتاح من قائمة "الأدوات" أعلى الشاشة إمكانية الاطلاع على الملف الأصلي في أي وقت وكذلك الوضعية المرغوب فيها، ويمكن الانتقال للملف الهدف الجاري ترجمته. توفر اللوحة الموجودة في الجهة اليمنى كافة الخيارات التي تُساعد المترجم أثناء الترجمة والانتقال من ترجمة فقرة إلى أخرى، فتظهر الخيارات بشكل تلقائي والتي تُخزنها ذاكرات الترجمة وقاعدة المصطلحات، وكل ما عليك فعله هو فتح الملف والضغط على الفقرة وترجمتها يدويًا في الجهة المُقابلة أو استخدام خيارات ذاكرة الترجمة. ضبط إعدادات الملف يمكنك ضبط إعدادات الملف عبر ما يأتي: قائمة الأدوات tools: اختر من هذه القائمة خيار "التفضيلات" preferences. خيار التفضيلات: ستجد فيها الخيارات المهمة التالية: خيارات تحديد إعدادات الانتقال بين الفقرات. عند تثبيت الترجمة وحفظها في ذاكرة الترجمة. الانتقال بين الفقرات. البحث في ذاكرة الترجمة. خيار لا يُترجم. الترجمة الآلية. يوجد في قائمة "تحرير" أعلى الشاشة خيار لإضافة المصادر التي يرغب المترجم باستخدامها وإدخالها في اللوحة يمين الشاشة وذلك بالنقر على خيار "نتائج الكات" للوحة الكات. تعكس ألوان ذاكرة الترجمة يمين الشاشة مدى تطابق النص معها، فالأخضر يعنى 100%، ويعني اللون الأصفر الموافقة والذي يرغب به مدير المشروع بينما يعني اللون الأحمر بالمنع وعدم الاستخدام. بالنسبة لعلامات التنسيق الخاصة بالملف الأصلي ذات اللون الأزرق التي قد تظهر في الفقرات، يتم إدخالها للنص المترجم عبر النقر على قائمة "تحرير" ثم اختيار "علامات" ثم النقر على خيار "إدخال علامة" أو الضغط على اختصار "F8" من لوحة المفاتيح. بعد الانتهاء من الترجمة وتثبيتها يتعين العودة إلى صفحة المشروع وإعادة تنشيطها وسيظهر اكتمال المشروع، ومن ثَم تغيير الحالة إلى اكتمال المهمة، وعندئذ لن يتسنى إجراء تعديلات على الملف إلا بإذنٍ من مدير المشروع. تُظهر قائمة "QA" يمين الشاشة أثناء الترجمة المشاكل التي يجب حلها أو تجاهلها. تتوافر أقسام عدة للمترجم على يسار الشاشة التي وصل إليها عبر الرابط المرسل إليها كقسم الوظائف والتي تضم المهام الموكلة إليه على برنامج Memsource، ويوجد قسم لذاكرات الترجمة والتي يختارها مدير المشروع وتضم قاعدة بيانات من أعمال ترجمة سابقة وقوائم بالمصطلحات، وعند إرفاقها للمشروع تقدم خيارات أثناء الترجمة. برنامج Memsource ثري بالمميزات إن وفرة المميزات الموجودة في برنامج Memsource تجعله في الصدارة، ومن أولها توفر أكثر من 500 لغة يمكن لشركات التعريب استخدامها، كما يدعم التعريب المستمر وإنشاء مهامه باستمرار، ويدعم العديد من أنواع الملفات لتصل لأكثر من 50 نوعًا والتي منها: JSON، وXML، وMarkdown، وYAML، وPO، وXLIFF، وproperties، وresx ، وcsv. كما يتميز برنامج Memsource بالتالي: تزويد المترجمين بالمحتوى ( صور الشاشة - الملاحظات - المفاتيح - الروابط ). إنشاء مشروع والعمل عليه، إمكانية التجربة المجانية لنُسخ البرنامج المدفوعة. تطبيق جوال: توّج برنامج Memsource تطوره وقدم تطبيقه الخاص للهاتف المحمول ويُعد الأول من نوعه في عالم الكات تولز، مما يمكن أداء الترجمة من أي مكان ونشرحه في مقال كامل لاحقًا. الخاتمة صنع برنامج Memsource طفرة في عالم الترجمة بمُساعدة الحاسوب وبمميزاته التي طورها لتُيسر عملية أداء مهام الترجمة التي جذبت الكثيرين لاستخدامه بثقة والحصول على نتائج مُرضية وجودة عالية دقيقة وإدارة أعمالهم عن بعد بكل تنظيم في عالمه السحابي المتطور دومًا. اقرأ أيضًا استعمال برنامج Memsource في ترجمة المحتوى. استخدام ذاكرة الترجمة وقاعدة المصطلحات في برنامج Memsource. ترجمة المحتوى وإدارة مشاريع الترجمة عن بعد مع Memsource السحابي. ترجمة المحتوى وإدارة مشاريع الترجمة من الجوال عبر تطبيق Memsource.1 نقطة -
لدي نص كالتالي: string = "01234567890123456789" كيف يمكنني استخراج سلسلة من الأرقام، ويكون طول كل سلسلة 10 أرقام فقط، أي تكون النتيجة كالتالي: [123456789, 1234567890, 2345678901, 3456789012, 4567890123 ...]1 نقطة
-
كيف يُمكنني قراءة الملفات txt في بايثون و طباعة محتواها ؟1 نقطة
-
السلام عليكم .. ما هو ال QR code & Ban Code Screen Rider فى react native ؟؟ هل هو ال QR Scanner ؟؟ سؤال أخر .. هل لكل QR Code قيم خاصة به ؟ وكيف اقوم بجلب هذه القيم باستخدام react native ؟1 نقطة
-
حاولت إجراء تسجيل في تطبيقي باستخدام واجهة برمجة تطبيقات الصوت وأحاول الآن إعادة تشغيله ، إذا كان موجودًا. هناك كود الصوت الخاص بي. async componentDidMount() { Audio.setAudioModeAsync({ allowsRecordingIOS: true, interruptionModeAndroid: Audio.INTERRUPTION_MODE_ANDROID_DO_NOT_MIX, interruptionModeIOS: Audio.INTERRUPTION_MODE_IOS_DO_NOT_MIX, shouldDuckAndroid: true, staysActiveInBackground: true, playsInSilentModeIOS: true, }); } async startRecordingButtonPressed() { if (!recording) { recording = new Audio.Recording(); } let permissions = await Audio.requestPermissionsAsync(); if (permissions.granted) { await recording.prepareToRecordAsync(Audio.RECORDING_OPTIONS_PRESET_HIGH_QUALITY); await recording.startAsync(); this.setState({ isRecording: true }); } else { throw new Error('لا يوجد تصريح'); } } async stopRecording() { await recording.stopAndUnloadAsync(); this.setState({ isRecording: false, recordingFinished: true }); recordingURI = recording.getURI(); if (recordingURI === '' || recordingURI === null || recordingURI === undefined) { throw new Error('لا يوجد تسجيل'); } this.forceUpdate(); } async playRecording() { const result = await player.current.loadAsync({ uri: recordingURI }, {}, true); } ينتج خطأ: "undefined is not an object (evaluating player.current.loadAsync). هل يعرف أي شخص كيفية حل هذا الخطأ؟1 نقطة
-
ما الغرض من إمكانية إستعمال جملة else مع جملة for كما في الكود التالي: for i in range(10): print(i) if i == 9: print("Found 9") break; else: print("Completed successfully") لماذا لا يتم كتابة دالة print الأخيرة بعد حلقة for بشكل مباشر فقط كالتالي: for i in range(10): print(i) if i == 9: print("Found 9") break; print("Completed successfully") ألن يكون من الأسهل فعل ذلك؟ أم هل يوجد فرق بين الطريقة الأولى والثانية؟1 نقطة
-
أحاول أن أقوم بعمل دالة بديلة لدالة random.choice وتقبل الدالة قائمة العناصر وقائمة الاحتمالات كالتالي: lst= [1, 2, 3, 4] choice(lst, [0.2, 0.2, 0.4, 0.2]) وبذلك يمكن أن يكون لكل عنصر فرصة (احتمالية) مختلفة ليتم اختياره. كيف أقوم بعمل مثل هذه الدالة في بايثون؟ هل توجد دالة جاهزة تقوم بهذا الأمر؟1 نقطة
-
ما الفرق بين استعمال دالة copy من مكتبة copy كالتالي: import copy a = "deepak" b = {1: 10, 2: 20, 3: 30} a1 = copy.copy(a) b1 = copy.copy(b) print(id(a) == id(a1)) print(id(b) == id(b1)) والتي من خلالها نحصل على النتيجة التالية: True False وعندما استعمل دالة deepcopy من نفس المكتبة أحصل على نفس النتيجة import copy a = "deepak" b = {1: 10, 2: 20, 3: 30} a1 = copy.deepcopy(a) b1 = copy.deepcopy(b) print(id(a) == id(a1)) print(id(b) == id(b1)) والتي من خلالها نحصل على النتيجة التالية: True False ما الفرق بين الدالتين ومتى استعمل كلًا منهما؟1 نقطة
-
يمكن أيضًا أن تستعمل regular expression للحصول على قائمة الأرقام كالتالي: >>> import re >>> string = "01234567890123456789" >>> matches = re.finditer(r'(?=(\d{10}))', string) >>> results = [int(match.group(1)) for match in matches] >>> results [123456789, 1234567890, 2345678901, 3456789012, 4567890123, 5678901234, 6789012345, 7890123456, 8901234567, 9012345678, 123456789] لاحظ أن رقم 10 في السطر الثالث يعبر عن طول سلسلة الأرقام1 نقطة
-
الكتابة في ملفات txt قي بايثون ؟1 نقطة
-
نستخدم الدالة open التي تعيد لنا كائن من النوع file أي file object ثم في حالة القراءة لانمرر أي شيء للدالة open أما إذا أردنا التعديل (الإضافة في نهاية الملف) نمرر لها "a" وإذا أردنا الكتابة فوق الملف الموجود نمرر "w" ثم نستدعي الدالة write ونمرر لها مانريد أن يتم إضافته كالتالي: # الإضافة على الملف file = open("D:/r.txt", "a") file.write(" add line ") file.close() # نعيد فتح الملف لنتأكد من الإضافة file = open("D:/r.txt", "r") print(file.read()) # w نجرب الآن ال file = open("D:/r.txt", "w") file.write("say hi") file.close() # نعيد فتح الملف لنتأكد من الإضافة file = open("D:/r.txt", "r") print(file.read()) ولاننسى إغلاق الملف بعد الانتهاء باستخدام الدالة close.1 نقطة
-
نقوم في بايثون بفتح ملف للقراءة من خلال الدالة open، حيث نمرر الوسيط الأول مسار الملف، وفي الوسيط الثاني r للدلالة على read أي قراءة، وقمنا في المثال بتخزين مرجعية للملف المفتوح في المتغير f. ثم لقراءة محتوى الملف نطبق الدالة read على f f = open("D:\\path\to\file.txt", "r") print(f.read()) أما لقراءة الملف سطراً بسطر، يمكننا المرور عليه باستخدام حلقة: f = open("file.txt", "r") for x in f: print(x) كما يمكن استخدام الدالة readline لقراءة سطر فقط، يمكن تكرارها ضمن حلقة لقراءة عدة أسطر..1 نقطة
-
ماهي تعليمة ()public first graphics بعد وراثة صف firstGraphics الابن من الصف JFrame بلغة جافا ..اهو باني بدون وسطاء ?ام ماهو البرنامج موجود بالصورة
 1 نقطة
1 نقطة -
يمكنك إنشاء بيانات عشوائية بإستخدام دالة make_classification أو بإستخدام دالة make_blobs، كل منهما تقوم بإنشاء البيانات و إسناد بيانات موزعة طبيعياً normally distributed data لصنف محدد. الفرق أن make_blobs محكمة أكثر في توزيع البيانات، و ذلك بالأخذ في الإعتبار القيمة المركزية و الإنحراف المعياري، لكن make_classification يمكنها إضافة بيانات مختلفة عن الأصناف noisy data بإستخدام طرق مثل تكرار بعض النقاط في البيانات redundancy. لقد قام @Ali Haidar Ahmad بتغطية الجزء المتعلق بmake_classification والان يمكننا أن نلقى النظر إلى make_blobs أيضاً: from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=10, centers=3, n_features=2) بعد إستدعاء الدالة make_blobs من مكتبة sklearn.datasets الان يمكننا التعامل معها مباشرة بتحديد عدد النقاط المراد الحصول عليها n_samples و التصنيفات المراد الحصول عليها بعد إنشاء البيانات و ذلك عن طريق إعطاء قيمة للمتغير centers و أخيراً الصفات المراد الحصول عليها و هي تمثل عدد الأعمدة بالنسبة لمجموعة النقاط n_features. تطبيق المثال أعلاه ينتج مصفوفة ثنائية الأبعاد تمثل X وتحتوي على 10 صفوف و عمودين، و مصفوفة ذات بعد واحد تمثل y و تحتوي على 3 تصنيفات رئيسية ممثله ب 0,1,2.1 نقطة
-
 هذا الخطأ قد يظهر لك في أي خوارزمية أخرى قد تستخدمها. المشكلة في أنك تقوم بترميز قيم ال labels باستخدام ال One-Hot Encoding (التابع to_categorical) فتحدث المشكلة في التابع fit أي عندما يبدأ التدريب. صحيح أننا نستخدم عادةً التابع to_categorical لترميز ال labels في مسائل التصنيف المتعدد لكن في الخوارزميات المعرفة في مكتبة Sklearn لانستخدمه لأن الخوارزميات فيها لاتتعامل مع هذا الشكل من البيانات. إن شكل التابع fit في مكتبة Sklearn كالتالي: fit(X, Y) بحيث أن y هي مصفوفة من الشكل (,n_sampels) أي مصفوفة أحادية الأبعاد (1D-array). وعند استخدامك لترميز to_categorical سوف يتحول شكل البيانات إلى (n_sampels,voc) بحيث voc هي عدد ال labels الموجودة. وهذا الشكل لايتطابق مع شكل البيانات الذي تتعامل معه fit. لذا يجب أن لانقوم باستخدام هذا الترميز وأن نجعل ال labels ضمن مصفوفة 1D: حل المشكلة: import numpy as np from sklearn.naive_bayes import MultinomialNB from tensorflow.keras.utils import to_categorical from tensorflow.keras.datasets import mnist from sklearn.metrics import accuracy_score (X, Y),(Xtest, Ytest) = mnist.load_data() Y=Y.reshape(-1,) Ytest=Ytest.reshape(-1,) X = np.reshape(X, [-1, X.shape[1]*X.shape[1]]) Xtest = np.reshape(Xtest, [-1, input_size]) M =MultinomialNB() M.fit(X, Y) accuracy_score(Ytest,M.predict(Xtest)) # 0.831 نقطة
هذا الخطأ قد يظهر لك في أي خوارزمية أخرى قد تستخدمها. المشكلة في أنك تقوم بترميز قيم ال labels باستخدام ال One-Hot Encoding (التابع to_categorical) فتحدث المشكلة في التابع fit أي عندما يبدأ التدريب. صحيح أننا نستخدم عادةً التابع to_categorical لترميز ال labels في مسائل التصنيف المتعدد لكن في الخوارزميات المعرفة في مكتبة Sklearn لانستخدمه لأن الخوارزميات فيها لاتتعامل مع هذا الشكل من البيانات. إن شكل التابع fit في مكتبة Sklearn كالتالي: fit(X, Y) بحيث أن y هي مصفوفة من الشكل (,n_sampels) أي مصفوفة أحادية الأبعاد (1D-array). وعند استخدامك لترميز to_categorical سوف يتحول شكل البيانات إلى (n_sampels,voc) بحيث voc هي عدد ال labels الموجودة. وهذا الشكل لايتطابق مع شكل البيانات الذي تتعامل معه fit. لذا يجب أن لانقوم باستخدام هذا الترميز وأن نجعل ال labels ضمن مصفوفة 1D: حل المشكلة: import numpy as np from sklearn.naive_bayes import MultinomialNB from tensorflow.keras.utils import to_categorical from tensorflow.keras.datasets import mnist from sklearn.metrics import accuracy_score (X, Y),(Xtest, Ytest) = mnist.load_data() Y=Y.reshape(-1,) Ytest=Ytest.reshape(-1,) X = np.reshape(X, [-1, X.shape[1]*X.shape[1]]) Xtest = np.reshape(Xtest, [-1, input_size]) M =MultinomialNB() M.fit(X, Y) accuracy_score(Ytest,M.predict(Xtest)) # 0.831 نقطة -
خوارزمية تعتمد على التصويت بين عدة خوارزميات، بحيث تحدد لها عدة خوارزميات توقع وكل خوارزمية ستقوم بعمل fitting على البيانات ثم إجراء مايسمى "Voting" لانتخاب النتيجة الأفضل اعتماداً على الخوارزميات المستخدمة. (تشبه VotingClassifier لكن هنا لمهمة توقع). يمكنك استخادمها عبر الموديول: sklearn.ensemble.VotingRegressor(estimators, weights=None, n_jobs=None) الوسيط الأول نحدد فيه خوارزميات التوقع التي نريد استخدامها وتقبل list من ال tuble بحيث كل tuble عبارة عن قيمة أولى str تمثل اسم اختياري للخوارزمية وقيمة ثانية تمثل الكلاس (الخوارزمية) "موضحة في المثال". الوسيط weights: تحديد ماهي الأوزان في التصويت لكل خوارزمية. ويأخذ مصفوفة من الأوزان (,n_classifier,) قد تكون القيم int أو float لامشكلة. n_jobs: عدد المهام التي يتم تنفيذها على التوازي. نضع -1 لأقصى قدر ممكن(زيادة سرعة التنفيذ). ال attributes: estimators_ : معلومات عن الخوارزميات المستخدمة. التوابع: fit(data) للقيام بعملية التدريب. predict(data) للقيام بعملية توقع قيمة عينة. score(data) لإيجاد كفاءة النموذج. مثال: قمنا هنا باستخدام خوارزميتي توقع RandomForest+LinearRegression import numpy as np from sklearn.ensemble import RandomForestRegressor from sklearn.linear_model import LinearRegression from sklearn.ensemble import VotingRegressor reg1 = LinearRegression() reg2 = RandomForestRegressor(n_estimators=7, random_state=2021) # تشكيل بيانات بقيم عشوائية X = np.array([[3, 1], [32, 45], [53, 2], [5, 6]]) y = np.array([2, 6, 12, 20]) #VotingRegressor تعريف reg = VotingRegressor([('reg1', reg1), ('reg2', reg2)]) print(reg.fit(X, y).predict(X)) # [ 9.68531265 8.55106081 11.01620204 15.17599594] print(reg.score(X, y)) # 0.51189774257891011 نقطة
-
يمكنك ذلك باستخدام الموديول: sklearn.datasets.make_classification(n_samples=100, n_features=20, n_classes=2, shuffle=True, random_state=None) الوسيط الأول يحدد عدد العينات التي تريدها. افتراضياً 100 الوسيط الثاني يحدد عدد الميزات features التي تريدها. افتراضياً 20 الوسيط الثالث يحدد عدد الفئئات (Classes) التي تريدها (عدد ال labels). افاراضياً 2 الوسيط الرابع لخلط البيانات بعد إنشائها. الوسيط الأخير هو وسيط التحكم بنظام العشوائية في التقسيم. مثال: from sklearn.datasets import make_classification X, y = make_classification(n_samples=1000, n_features=4, random_state=0, shuffle=False) print(X.shape) #(1000, 4) print(y.shape,end='\n\n') # (1000,) print(X) ''' [[-1.66853167 -1.29901346 0.2746472 -0.60362044] [-2.9728827 -1.08878294 0.70885958 0.42281857] [-0.59614125 -1.37007001 -3.11685659 0.64445203] ... [ 0.91711204 1.10596645 0.86766522 -2.25625012] [ 0.10027664 1.45875846 -0.44360274 -0.67002328] [ 1.0415229 -0.01987143 0.15216419 -1.9405334 ]] '''1 نقطة
-
 يتمتع نظام تشغيل أندرويد بوسائل أمان خاصة كي تحمي مستخدميه من مخاطر سرقة البيانات أو العبث في الهاتف دون علم المستخدم، وذلك عن طريق عزل كل تطبيق داخل صندوق خاص به لا يستطيع أن يرى أو يتعامل مع الموارد الخاصة بالتطبيقات الأخرى ما لم تكن لديه الأذونات الخاصة لذلك وموافقة المستخدم عليها. بشكل افتراضي لا يملك التطبيق أي أذونات للوصول لأي شيء خارج التطبيق كاستخدام الكاميرا أو الاتصال بأحد جهات الاتصال في الهاتف ما لم يتم تضمين الأذونات الخاصة بذلك داخل التطبيق ثم موافقة المستخدم عليه. فعند تنصيب التطبيق من متجر Play يطلب من المستخدم الموافقة على أذونات محددة يحتاجها التطبيق كي يعمل وبعد الموافقة عليها يبدأ التطبيق في التحميل والتنصيب، لذا يُنصح دائمًا بقراءة هذه الأذونات بعناية والتأكد من احتياج التطبيق لها ليؤدي وظيفته المطلوبة دون الخوف من الوصول لأشياء لا يحتاجها وذلك لكثرة وجود البرمجيات الخبيثة التي تستغل موافقتك على الأذونات للعبث بموارد ومعلومات هاتفك. تطبيق 1 في هذا المثال سنتعرف على كيفية صنع تطبيق يطلب الوصول إلى أذونات معينة من المستخدم كي يؤدي وظيفته، يقوم هذا التطبيق بدور المصباح اليدوي حيث يُضيء الضوء الخاص بالكاميرا (Flashlight) بشكل برمجي عند الضغط على زر بداخله. كما نفعل دومًا نبدأ بصنع واجهة المستخدم الخاصة بالتطبيق، وتتكون من زر من النوع ImageButton -وهو زر يستطيع أن يحتوي على صورة -لتصبح الشيفرة الخاصة بملف activity_main.xml <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:gravity="center" > <ImageButton android:layout_width="wrap_content" android:layout_height="wrap_content" android:src="@drawable/power_on" android:id="@+id/btn" android:background="@null"/> </LinearLayout> بعد ذلك نقوم بالتعديل في ملف AndroidManifest.xml وإضافة الأذونات المطلوبة لكي نستطيع التحكم في ضوء الكاميرا. <uses-permission android:name="android.permission.CAMERA"/> <uses-feature android:name="android.hardware.Camera"/> باستخدام الوسم الخاص بالأذونات <uses-permissions> وتحديد الاسم الخاص به في الخاصية android:name، وأيضًا إضافة الوسم <uses-feature> لإعلام الهاتف أن التطبيق يحتاج إلى وجود كاميرا كي يعمل. ويوجد العديد من الأذونات التي تمكنك من القيام بالعديد من المهام من داخل التطبيق كالاتصال بالإنترنت أو القراءة والكتابة في الذاكرة ويمكنك التعرف عليها من هنا ويتم تعريفها داخل الملف AndroidManifest.xml كما سبق. إذا لم يتم تعريف الأذونات المستخدمة في التطبيق داخل ملف AndroidManifest.xml فإن التطبيق لن يعمل. <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="apps.noby.flashlight"> <uses-permission android:name="android.permission.CAMERA"/> <uses-feature android:name="android.hardware.Camera"/> <application android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> </application> </manifest> ننتقل الآن إلى كتابة شيفرة التحكم الخاصة بالتطبيق في ملف MainActivity.java وتنقسم إلى 1-التأكد من توفر ضوء للكاميرا في الهاتف أولًا. if(!getApplicationContext().getPackageManager().hasSystemFeature(PackageManager.FEATURE_CAMERA_FLASH)) finish(); وإذا لم يتواجد ضوء الكاميرا في الهاتف فسيتم غلق التطبيق في الحال. 2-الحصول على كائن يُمكننا من التحكم في ضوء الكاميرا وذلك عن طريق فتح الكاميرا ثم الحصول على الخصائص والمعاملات الخاصة بها وتغيير المتغير الخاص بضوء الكاميرا. camera = Camera.open(); param = camera.getParameters(); 3-برمجة الزر المتواجد في الواجهة الرئيسية لكي يُضيء ضوء الكاميرا عند الضغط عليه ويغلقه عن الضغط مرة أخرى. btn = (ImageButton) findViewById(R.id.btn); btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { if(!isTorchON){ turnONTorch(); }else turnOFFTorch(); } }); لتُصبح شيفرة التحكم الرئيسية هي package apps.noby.flashlight; import android.hardware.Camera; import android.hardware.Camera.Parameters; import android.app.Activity; import android.os.Bundle; import android.view.View; import android.widget.ImageButton; public class MainActivity extends Activity { ImageButton btn; boolean isTorchON; Camera camera; private Parameters param; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); btn = (ImageButton) findViewById(R.id.btn); btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { if(!isTorchON){ turnONTorch(); }else turnOFFTorch(); } }); } @Override protected void onStart() { super. onStart(); if(!getApplicationContext().getPackageManager().hasSystemFeature(PackageManager.FEATURE_CAMERA_FLASH)) finish(); if (camera == null) { isTorchON = false; camera = Camera.open(); param = camera.getParameters(); } } @Override protected void onPause() { super.onPause(); if (camera != null) { camera.release(); camera = null; } } } يتبقى تعريف ما هي الوظيفة الخاصة بالدالة turnONTorch() وTurnOFFTorch(). تقوم الدالة turnONTorch() بتشغيل الضوء وذلك عن طريق تمرير المعامل FLASH_MODE_TORCH كإحدى معاملات الكاميرا ثم تفعيل الكاميرا بالمعاملات الجديدة عند استدعاء startPreview(). private void turnONTorch() { param.setFlashMode(Parameters.FLASH_MODE_TORCH); camera.setParameters(param); camera.startPreview(); isTorchON = true; btn.setImageResource(R.drawable.power_off); } وبالمثل نبني turnOFFTorch() كي يتم إطفاء الضوء. private void turnOFFTorch() { param.setFlashMode(Parameters.FLASH_MODE_OFF); camera.setParameters(param); camera.stopPreview(); isTorchON = false; btn.setImageResource(R.drawable.power_on); } لتُصبح الشيفرة النهائية لملف MainActivity.java package apps.noby.flashlight; import android.content.pm.PackageManager; import android.hardware.Camera; import android.hardware.Camera.Parameters; import android.app.Activity; import android.os.Bundle; import android.view.View; import android.widget.ImageButton; public class MainActivity extends Activity { ImageButton btn; boolean isTorchON; Camera camera; private Parameters param; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); btn = (ImageButton) findViewById(R.id.btn); btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { if(!isTorchON){ turnONTorch(); }else turnOFFTorch(); } }); } private void turnONTorch() { param.setFlashMode(Parameters.FLASH_MODE_TORCH); camera.setParameters(param); camera.startPreview(); isTorchON = true; btn.setImageResource(R.drawable.power_off); } private void turnOFFTorch() { param.setFlashMode(Parameters.FLASH_MODE_OFF); camera.setParameters(param); camera.stopPreview(); isTorchON = false; btn.setImageResource(R.drawable.power_on); } @Override protected void onStart() { super. onStart(); if(! getApplicationContext().getPackageManager().hasSystemFeature(PackageManager.FEATURE_CAMERA_FLASH)) finish(); if (camera == null) { isTorchON = false; camera = Camera.open(); param = camera.getParameters(); } } @Override protected void onPause() { super.onPause(); if (camera != null) { camera.release(); camera = null; } } } بعد ذلك نقوم بتجربة التطبيق على هاتف حقيقي وليس المحاكي حيث لا يمكنه محاكاة إضاءة ضوء الكاميرا. تطبيق 2 بعد الإصدار السادس لنظام تشغيل أندرويد (Android Marshmallow) تم تعريف نموذج جديد للتعامل مع الأذونات داخل التطبيق حيث كان النموذج القديم يتطلب موافقة المستخدم على كافة الأذونات الخاصة بالتطبيق قبل تحميله على الهاتف أو رفضها وعدم تحميل التطبيق. أما الآن فأصبح بإمكان المستخدم تحميل وتنصيب التطبيق على الهاتف دون الموافقة على الأذونات إلا عند الحاجة إليها لكي تقوم بوظيفة ما، كما يمكن الموافقة على بعض الأذونات ورفض الأخرى (قد يؤدي ذلك إلى عدم عمل التطبيق بشكله الكامل) ويمكن بعد ذلك الموافقة عليها مما يعطي المستخدم القدرة على التحكم في التطبيق من داخل الإعدادات الخاصة بالتطبيق. وتنقسم الأذونات إلى قسمين: الأذونات العادية وهي التي لا تهدد خصوصية المستخدم، ويتم التعامل معها دون طلب الأذن عند الحاجة إليها يكفي فقط طلب الأذن عند التحميل من المتجر مرة واحدة. الأذونات الخطيرة وهي التي قد تصل إلى بيانات خاصة بالمستخدم وتحتاج إلى انتباه المستخدم للتطبيق وطلب الأذن منه عندما استخدامها من قبل التطبيق. سنتعامل في هذا التطبيق مع أحد هذه الأذونات الخطيرة، حيث سنقوم بصنع تطبيق يمكنه الاتصال مباشرة برقم محدد من قبل المستخدم ويُعتبر الاتصال من الأذونات الخطيرة وذلك لأنه قد يُعرض المستخدم لتكاليف خاصة بالاتصال. نبدأ أولًا بصنع واجهة المستخدم وهي تتكون من عنصر EditText كي يكتب المستخدم بداخله الرقم الذي يرغب في الاتصال به وزر للضغط عليه حتى يقوم التطبيق بالاتصال بهذا الرقم. <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="horizontal" android:layout_margin="16dp"> <EditText android:layout_width="0dp" android:layout_height="wrap_content" android:layout_weight="1" android:hint="Enter Phone Number" android:id="@+id/ph_num"/> <Button android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Call" android:id="@+id/call_btn"/> </LinearLayout> بعد ذلك نحدد الأذونات الخاصة بالتطبيق في AndroidManifest.xml وهنا هو <uses-permission android:name="android.permission.CALL_PHONE"/> ويتم تضمينه داخل الملف كما سبق. <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="apps.noby.dailer"> <uses-permission android:name="android.permission.CALL_PHONE"/> <application android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> </application> </manifest> الآن يتبقى برمجة الزر كي يقوم بالاتصال ويتم التحكم في ذلك عن طريق استخدام Intent وتمرير له ACTION_CALL لتحديد وظيفته وهي الاتصال، ثم تحديد البيانات التي نرغب في إرسالها بداخل هذا الـ Intent وهي رقم الهاتف الذي تم إدخاله من قبل المستخدم داخل EditText وتسبقه “tel:” لإعلام نظام التشغيل بأنه رقم هاتف. String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_CALL); intent.setData(Uri.parse("tel:" + num)) ; قبل القيام بعملية الاتصال يجب أولًا التأكد من حصول التطبيق على الأذونات الخاصة بالاتصال من المستخدم سواء عند التنصيب في الإصدارات القديمة أو طلبها في الإصدارات الأحدث. call_btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_CALL); intent.setData(Uri.parse("tel:" + num)) ; if (ContextCompat.checkSelfPermission(MainActivity.this, Manifest.permission.CALL_PHONE) != PackageManager.PERMISSION_GRANTED) { ActivityCompat.requestPermissions(MainActivity.this,new String[]{Manifest.permission.CALL_PHONE},CALL_PHONE_PERMISSIONS_REQUEST); } else startActivity(intent); } }); للتحقق من الأذونات نستخدم التابع checkSelfPermission() فإذا كان لم يتم الحصول عليه نطلب من المستخدم الموافقة عليه باستخدام التابع requestPermissions() غير ذلك نقوم بالاتصال. عند طلب الحصول على إذن محدد من المستخدم يظهر أمام المستخدم مربع يطلب منه الموافقة أو الرفض ويقوم بتسجيل اختيار المستخدم لذلك ثم يستدعي التابع onRequestPermissionsResult() بشكل تلقائي ونقوم بداخله من التأكد من موافقة المستخدم على الأذن وإظهار رسالة بذلك. public void onRequestPermissionsResult(int requestCode, String permissions[], int[] grantResults) { if (requestCode == CALL_PHONE_PERMISSIONS_REQUEST) { if (grantResults.length == 1 && grantResults[0] == PackageManager.PERMISSION_GRANTED) { Toast.makeText(this, "Call Phones permission granted", Toast.LENGTH_SHORT).show(); } else { Toast.makeText(this, "Call Phones permission denied", Toast.LENGTH_SHORT).show(); } } else { super.onRequestPermissionsResult(requestCode, permissions, grantResults); } } } لتُصبح الشيفرة الكاملة لهذا التطبيق في ملف MainActivity.java هي package apps.noby.dailer; import android.Manifest; import android.app.Activity; import android.content.Intent; import android.content.pm.PackageManager; import android.net.Uri; import android.os.Bundle; import android.support.v4.app.ActivityCompat; import android.support.v4.content.ContextCompat; import android.view.View; import android.widget.Button; import android.widget.EditText; import android.widget.Toast; public class MainActivity extends Activity { private static final int CALL_PHONE_PERMISSIONS_REQUEST = 3; private EditText et; private Button call_btn; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); et = (EditText) findViewById(R.id.ph_num); call_btn = (Button) findViewById(R.id.call_btn); call_btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_CALL); intent.setData(Uri.parse("tel:" + num)) ; if (ContextCompat.checkSelfPermission(MainActivity.this, Manifest.permission.CALL_PHONE) != PackageManager.PERMISSION_GRANTED) { ActivityCompat.requestPermissions(MainActivity.this,new String[]{Manifest.permission.CALL_PHONE},CALL_PHONE_PERMISSIONS_REQUEST); } else startActivity(intent); } }); } @Override public void onRequestPermissionsResult(int requestCode, String permissions[], int[] grantResults) { if (requestCode == CALL_PHONE_PERMISSIONS_REQUEST) { if (grantResults.length == 1 && grantResults[0] == PackageManager.PERMISSION_GRANTED) { Toast.makeText(this, "Call Phones permission granted", Toast.LENGTH_SHORT).show(); } else { Toast.makeText(this, "Call Phones permission denied", Toast.LENGTH_SHORT).show(); } } else { super.onRequestPermissionsResult(requestCode, permissions, grantResults); } } } لاحظ أنه إذا كان الهاتف يعمل بإصدار سابق لـ Android Marshmallow فسيتم الحصول على الموافقة على كافة الأذونات عند التحميل من المتجر كما كان يحدث سابقًا. يمكننا الآن تجربة التطبيق على المحاكي أو على هاتف حقيقي. يجب عليك مراعاة عدم إجهاد المستخدم بالعديد من الأذونات التي لا حاجة لها داخل تطبيقك حتى لا يضطر المستخدم إلى إزالة تطبيقك والتخلص منه. لذا يجب الاهتمام بتقديم تجربة استخدام جيدة، ففي العديد من الأحيان لا يكون خيار طلب الأذونات من المستخدم والقيام بالمهمة من داخل تطبيقك هو الخيار الأفضل، فقد يكون الأفضل استخدام الـ intent وطلب الوظيفة من تطبيق آخر للقيام بها. مثال على ذلك يمكننا تعديل التطبيق السابق وإزالة الأذن الخاص بالاتصال من التطبيق، وتعديل الشيفرة في MainActivty.java كي تقوم بنقل مهمة الاتصال من التطبيق نفسه إلى أحد تطبيقات الاتصال المتواجدة بالهاتف package apps.noby.dailer; import android.app.Activity; import android.content.Intent; import android.net.Uri; import android.os.Bundle; import android.view.View; import android.widget.Button; import android.widget.EditText; public class MainActivity extends Activity { private EditText et; private Button call_btn; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); et = (EditText) findViewById(R.id.ph_num); call_btn = (Button) findViewById(R.id.call_btn); call_btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_DIAL); intent.setData(Uri.parse("tel:" + num)) ; startActivity(intent); } }); } } عند تجربة التطبيق على المحاكي ينقلنا إلى تطبيق الاتصال الخاص بالهاتف مع إدخال رقم الهاتف والانتظار لاتصال المستخدم بالرقم. لا توجد طريقة أفضل من الأخرى، بل يعتمد ذلك على مدى اهتمامك بالحصول على التحكم الكامل بكافة التفاصيل لأداء المهمة عند ذلك قم بطلب الأذن من المستخدم وإذا رفض المستخدم ذلك فلن يعمل تطبيقك، أو ترك الوظيفة إلى تطبيق آخر وتكتفي فقط باستقبال أو إرسال البيانات منه أو إليه ولن تحتاج إلى الحصول على أي أذونات من المستخدم لكنك ستنقل المستخدم إلى تطبيق آخر لا تعلم عنه شيئًا قد يضر تجربة الاستخدام الخاصة بتطبيقك. بهذا نكون قد وصلنا إلى نهاية هذا الدرس، في انتظار تجربتكم وآرائكم. Icons.zip1 نقطة
يتمتع نظام تشغيل أندرويد بوسائل أمان خاصة كي تحمي مستخدميه من مخاطر سرقة البيانات أو العبث في الهاتف دون علم المستخدم، وذلك عن طريق عزل كل تطبيق داخل صندوق خاص به لا يستطيع أن يرى أو يتعامل مع الموارد الخاصة بالتطبيقات الأخرى ما لم تكن لديه الأذونات الخاصة لذلك وموافقة المستخدم عليها. بشكل افتراضي لا يملك التطبيق أي أذونات للوصول لأي شيء خارج التطبيق كاستخدام الكاميرا أو الاتصال بأحد جهات الاتصال في الهاتف ما لم يتم تضمين الأذونات الخاصة بذلك داخل التطبيق ثم موافقة المستخدم عليه. فعند تنصيب التطبيق من متجر Play يطلب من المستخدم الموافقة على أذونات محددة يحتاجها التطبيق كي يعمل وبعد الموافقة عليها يبدأ التطبيق في التحميل والتنصيب، لذا يُنصح دائمًا بقراءة هذه الأذونات بعناية والتأكد من احتياج التطبيق لها ليؤدي وظيفته المطلوبة دون الخوف من الوصول لأشياء لا يحتاجها وذلك لكثرة وجود البرمجيات الخبيثة التي تستغل موافقتك على الأذونات للعبث بموارد ومعلومات هاتفك. تطبيق 1 في هذا المثال سنتعرف على كيفية صنع تطبيق يطلب الوصول إلى أذونات معينة من المستخدم كي يؤدي وظيفته، يقوم هذا التطبيق بدور المصباح اليدوي حيث يُضيء الضوء الخاص بالكاميرا (Flashlight) بشكل برمجي عند الضغط على زر بداخله. كما نفعل دومًا نبدأ بصنع واجهة المستخدم الخاصة بالتطبيق، وتتكون من زر من النوع ImageButton -وهو زر يستطيع أن يحتوي على صورة -لتصبح الشيفرة الخاصة بملف activity_main.xml <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:gravity="center" > <ImageButton android:layout_width="wrap_content" android:layout_height="wrap_content" android:src="@drawable/power_on" android:id="@+id/btn" android:background="@null"/> </LinearLayout> بعد ذلك نقوم بالتعديل في ملف AndroidManifest.xml وإضافة الأذونات المطلوبة لكي نستطيع التحكم في ضوء الكاميرا. <uses-permission android:name="android.permission.CAMERA"/> <uses-feature android:name="android.hardware.Camera"/> باستخدام الوسم الخاص بالأذونات <uses-permissions> وتحديد الاسم الخاص به في الخاصية android:name، وأيضًا إضافة الوسم <uses-feature> لإعلام الهاتف أن التطبيق يحتاج إلى وجود كاميرا كي يعمل. ويوجد العديد من الأذونات التي تمكنك من القيام بالعديد من المهام من داخل التطبيق كالاتصال بالإنترنت أو القراءة والكتابة في الذاكرة ويمكنك التعرف عليها من هنا ويتم تعريفها داخل الملف AndroidManifest.xml كما سبق. إذا لم يتم تعريف الأذونات المستخدمة في التطبيق داخل ملف AndroidManifest.xml فإن التطبيق لن يعمل. <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="apps.noby.flashlight"> <uses-permission android:name="android.permission.CAMERA"/> <uses-feature android:name="android.hardware.Camera"/> <application android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> </application> </manifest> ننتقل الآن إلى كتابة شيفرة التحكم الخاصة بالتطبيق في ملف MainActivity.java وتنقسم إلى 1-التأكد من توفر ضوء للكاميرا في الهاتف أولًا. if(!getApplicationContext().getPackageManager().hasSystemFeature(PackageManager.FEATURE_CAMERA_FLASH)) finish(); وإذا لم يتواجد ضوء الكاميرا في الهاتف فسيتم غلق التطبيق في الحال. 2-الحصول على كائن يُمكننا من التحكم في ضوء الكاميرا وذلك عن طريق فتح الكاميرا ثم الحصول على الخصائص والمعاملات الخاصة بها وتغيير المتغير الخاص بضوء الكاميرا. camera = Camera.open(); param = camera.getParameters(); 3-برمجة الزر المتواجد في الواجهة الرئيسية لكي يُضيء ضوء الكاميرا عند الضغط عليه ويغلقه عن الضغط مرة أخرى. btn = (ImageButton) findViewById(R.id.btn); btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { if(!isTorchON){ turnONTorch(); }else turnOFFTorch(); } }); لتُصبح شيفرة التحكم الرئيسية هي package apps.noby.flashlight; import android.hardware.Camera; import android.hardware.Camera.Parameters; import android.app.Activity; import android.os.Bundle; import android.view.View; import android.widget.ImageButton; public class MainActivity extends Activity { ImageButton btn; boolean isTorchON; Camera camera; private Parameters param; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); btn = (ImageButton) findViewById(R.id.btn); btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { if(!isTorchON){ turnONTorch(); }else turnOFFTorch(); } }); } @Override protected void onStart() { super. onStart(); if(!getApplicationContext().getPackageManager().hasSystemFeature(PackageManager.FEATURE_CAMERA_FLASH)) finish(); if (camera == null) { isTorchON = false; camera = Camera.open(); param = camera.getParameters(); } } @Override protected void onPause() { super.onPause(); if (camera != null) { camera.release(); camera = null; } } } يتبقى تعريف ما هي الوظيفة الخاصة بالدالة turnONTorch() وTurnOFFTorch(). تقوم الدالة turnONTorch() بتشغيل الضوء وذلك عن طريق تمرير المعامل FLASH_MODE_TORCH كإحدى معاملات الكاميرا ثم تفعيل الكاميرا بالمعاملات الجديدة عند استدعاء startPreview(). private void turnONTorch() { param.setFlashMode(Parameters.FLASH_MODE_TORCH); camera.setParameters(param); camera.startPreview(); isTorchON = true; btn.setImageResource(R.drawable.power_off); } وبالمثل نبني turnOFFTorch() كي يتم إطفاء الضوء. private void turnOFFTorch() { param.setFlashMode(Parameters.FLASH_MODE_OFF); camera.setParameters(param); camera.stopPreview(); isTorchON = false; btn.setImageResource(R.drawable.power_on); } لتُصبح الشيفرة النهائية لملف MainActivity.java package apps.noby.flashlight; import android.content.pm.PackageManager; import android.hardware.Camera; import android.hardware.Camera.Parameters; import android.app.Activity; import android.os.Bundle; import android.view.View; import android.widget.ImageButton; public class MainActivity extends Activity { ImageButton btn; boolean isTorchON; Camera camera; private Parameters param; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); btn = (ImageButton) findViewById(R.id.btn); btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { if(!isTorchON){ turnONTorch(); }else turnOFFTorch(); } }); } private void turnONTorch() { param.setFlashMode(Parameters.FLASH_MODE_TORCH); camera.setParameters(param); camera.startPreview(); isTorchON = true; btn.setImageResource(R.drawable.power_off); } private void turnOFFTorch() { param.setFlashMode(Parameters.FLASH_MODE_OFF); camera.setParameters(param); camera.stopPreview(); isTorchON = false; btn.setImageResource(R.drawable.power_on); } @Override protected void onStart() { super. onStart(); if(! getApplicationContext().getPackageManager().hasSystemFeature(PackageManager.FEATURE_CAMERA_FLASH)) finish(); if (camera == null) { isTorchON = false; camera = Camera.open(); param = camera.getParameters(); } } @Override protected void onPause() { super.onPause(); if (camera != null) { camera.release(); camera = null; } } } بعد ذلك نقوم بتجربة التطبيق على هاتف حقيقي وليس المحاكي حيث لا يمكنه محاكاة إضاءة ضوء الكاميرا. تطبيق 2 بعد الإصدار السادس لنظام تشغيل أندرويد (Android Marshmallow) تم تعريف نموذج جديد للتعامل مع الأذونات داخل التطبيق حيث كان النموذج القديم يتطلب موافقة المستخدم على كافة الأذونات الخاصة بالتطبيق قبل تحميله على الهاتف أو رفضها وعدم تحميل التطبيق. أما الآن فأصبح بإمكان المستخدم تحميل وتنصيب التطبيق على الهاتف دون الموافقة على الأذونات إلا عند الحاجة إليها لكي تقوم بوظيفة ما، كما يمكن الموافقة على بعض الأذونات ورفض الأخرى (قد يؤدي ذلك إلى عدم عمل التطبيق بشكله الكامل) ويمكن بعد ذلك الموافقة عليها مما يعطي المستخدم القدرة على التحكم في التطبيق من داخل الإعدادات الخاصة بالتطبيق. وتنقسم الأذونات إلى قسمين: الأذونات العادية وهي التي لا تهدد خصوصية المستخدم، ويتم التعامل معها دون طلب الأذن عند الحاجة إليها يكفي فقط طلب الأذن عند التحميل من المتجر مرة واحدة. الأذونات الخطيرة وهي التي قد تصل إلى بيانات خاصة بالمستخدم وتحتاج إلى انتباه المستخدم للتطبيق وطلب الأذن منه عندما استخدامها من قبل التطبيق. سنتعامل في هذا التطبيق مع أحد هذه الأذونات الخطيرة، حيث سنقوم بصنع تطبيق يمكنه الاتصال مباشرة برقم محدد من قبل المستخدم ويُعتبر الاتصال من الأذونات الخطيرة وذلك لأنه قد يُعرض المستخدم لتكاليف خاصة بالاتصال. نبدأ أولًا بصنع واجهة المستخدم وهي تتكون من عنصر EditText كي يكتب المستخدم بداخله الرقم الذي يرغب في الاتصال به وزر للضغط عليه حتى يقوم التطبيق بالاتصال بهذا الرقم. <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="horizontal" android:layout_margin="16dp"> <EditText android:layout_width="0dp" android:layout_height="wrap_content" android:layout_weight="1" android:hint="Enter Phone Number" android:id="@+id/ph_num"/> <Button android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="Call" android:id="@+id/call_btn"/> </LinearLayout> بعد ذلك نحدد الأذونات الخاصة بالتطبيق في AndroidManifest.xml وهنا هو <uses-permission android:name="android.permission.CALL_PHONE"/> ويتم تضمينه داخل الملف كما سبق. <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="apps.noby.dailer"> <uses-permission android:name="android.permission.CALL_PHONE"/> <application android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> </application> </manifest> الآن يتبقى برمجة الزر كي يقوم بالاتصال ويتم التحكم في ذلك عن طريق استخدام Intent وتمرير له ACTION_CALL لتحديد وظيفته وهي الاتصال، ثم تحديد البيانات التي نرغب في إرسالها بداخل هذا الـ Intent وهي رقم الهاتف الذي تم إدخاله من قبل المستخدم داخل EditText وتسبقه “tel:” لإعلام نظام التشغيل بأنه رقم هاتف. String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_CALL); intent.setData(Uri.parse("tel:" + num)) ; قبل القيام بعملية الاتصال يجب أولًا التأكد من حصول التطبيق على الأذونات الخاصة بالاتصال من المستخدم سواء عند التنصيب في الإصدارات القديمة أو طلبها في الإصدارات الأحدث. call_btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_CALL); intent.setData(Uri.parse("tel:" + num)) ; if (ContextCompat.checkSelfPermission(MainActivity.this, Manifest.permission.CALL_PHONE) != PackageManager.PERMISSION_GRANTED) { ActivityCompat.requestPermissions(MainActivity.this,new String[]{Manifest.permission.CALL_PHONE},CALL_PHONE_PERMISSIONS_REQUEST); } else startActivity(intent); } }); للتحقق من الأذونات نستخدم التابع checkSelfPermission() فإذا كان لم يتم الحصول عليه نطلب من المستخدم الموافقة عليه باستخدام التابع requestPermissions() غير ذلك نقوم بالاتصال. عند طلب الحصول على إذن محدد من المستخدم يظهر أمام المستخدم مربع يطلب منه الموافقة أو الرفض ويقوم بتسجيل اختيار المستخدم لذلك ثم يستدعي التابع onRequestPermissionsResult() بشكل تلقائي ونقوم بداخله من التأكد من موافقة المستخدم على الأذن وإظهار رسالة بذلك. public void onRequestPermissionsResult(int requestCode, String permissions[], int[] grantResults) { if (requestCode == CALL_PHONE_PERMISSIONS_REQUEST) { if (grantResults.length == 1 && grantResults[0] == PackageManager.PERMISSION_GRANTED) { Toast.makeText(this, "Call Phones permission granted", Toast.LENGTH_SHORT).show(); } else { Toast.makeText(this, "Call Phones permission denied", Toast.LENGTH_SHORT).show(); } } else { super.onRequestPermissionsResult(requestCode, permissions, grantResults); } } } لتُصبح الشيفرة الكاملة لهذا التطبيق في ملف MainActivity.java هي package apps.noby.dailer; import android.Manifest; import android.app.Activity; import android.content.Intent; import android.content.pm.PackageManager; import android.net.Uri; import android.os.Bundle; import android.support.v4.app.ActivityCompat; import android.support.v4.content.ContextCompat; import android.view.View; import android.widget.Button; import android.widget.EditText; import android.widget.Toast; public class MainActivity extends Activity { private static final int CALL_PHONE_PERMISSIONS_REQUEST = 3; private EditText et; private Button call_btn; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); et = (EditText) findViewById(R.id.ph_num); call_btn = (Button) findViewById(R.id.call_btn); call_btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_CALL); intent.setData(Uri.parse("tel:" + num)) ; if (ContextCompat.checkSelfPermission(MainActivity.this, Manifest.permission.CALL_PHONE) != PackageManager.PERMISSION_GRANTED) { ActivityCompat.requestPermissions(MainActivity.this,new String[]{Manifest.permission.CALL_PHONE},CALL_PHONE_PERMISSIONS_REQUEST); } else startActivity(intent); } }); } @Override public void onRequestPermissionsResult(int requestCode, String permissions[], int[] grantResults) { if (requestCode == CALL_PHONE_PERMISSIONS_REQUEST) { if (grantResults.length == 1 && grantResults[0] == PackageManager.PERMISSION_GRANTED) { Toast.makeText(this, "Call Phones permission granted", Toast.LENGTH_SHORT).show(); } else { Toast.makeText(this, "Call Phones permission denied", Toast.LENGTH_SHORT).show(); } } else { super.onRequestPermissionsResult(requestCode, permissions, grantResults); } } } لاحظ أنه إذا كان الهاتف يعمل بإصدار سابق لـ Android Marshmallow فسيتم الحصول على الموافقة على كافة الأذونات عند التحميل من المتجر كما كان يحدث سابقًا. يمكننا الآن تجربة التطبيق على المحاكي أو على هاتف حقيقي. يجب عليك مراعاة عدم إجهاد المستخدم بالعديد من الأذونات التي لا حاجة لها داخل تطبيقك حتى لا يضطر المستخدم إلى إزالة تطبيقك والتخلص منه. لذا يجب الاهتمام بتقديم تجربة استخدام جيدة، ففي العديد من الأحيان لا يكون خيار طلب الأذونات من المستخدم والقيام بالمهمة من داخل تطبيقك هو الخيار الأفضل، فقد يكون الأفضل استخدام الـ intent وطلب الوظيفة من تطبيق آخر للقيام بها. مثال على ذلك يمكننا تعديل التطبيق السابق وإزالة الأذن الخاص بالاتصال من التطبيق، وتعديل الشيفرة في MainActivty.java كي تقوم بنقل مهمة الاتصال من التطبيق نفسه إلى أحد تطبيقات الاتصال المتواجدة بالهاتف package apps.noby.dailer; import android.app.Activity; import android.content.Intent; import android.net.Uri; import android.os.Bundle; import android.view.View; import android.widget.Button; import android.widget.EditText; public class MainActivity extends Activity { private EditText et; private Button call_btn; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); et = (EditText) findViewById(R.id.ph_num); call_btn = (Button) findViewById(R.id.call_btn); call_btn.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { String num = et.getText().toString(); Intent intent =new Intent(Intent.ACTION_DIAL); intent.setData(Uri.parse("tel:" + num)) ; startActivity(intent); } }); } } عند تجربة التطبيق على المحاكي ينقلنا إلى تطبيق الاتصال الخاص بالهاتف مع إدخال رقم الهاتف والانتظار لاتصال المستخدم بالرقم. لا توجد طريقة أفضل من الأخرى، بل يعتمد ذلك على مدى اهتمامك بالحصول على التحكم الكامل بكافة التفاصيل لأداء المهمة عند ذلك قم بطلب الأذن من المستخدم وإذا رفض المستخدم ذلك فلن يعمل تطبيقك، أو ترك الوظيفة إلى تطبيق آخر وتكتفي فقط باستقبال أو إرسال البيانات منه أو إليه ولن تحتاج إلى الحصول على أي أذونات من المستخدم لكنك ستنقل المستخدم إلى تطبيق آخر لا تعلم عنه شيئًا قد يضر تجربة الاستخدام الخاصة بتطبيقك. بهذا نكون قد وصلنا إلى نهاية هذا الدرس، في انتظار تجربتكم وآرائكم. Icons.zip1 نقطة -
يمكنك استخدامها عبر الموديول: sklearn.ensemble.AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None) base_estimator: ال estimator الأساسي الذي تبنى منه باقي المجموعة المعززة (boosted ensemble). افتراضياً None. ويفضل تركه none ليعطي أفضل النتائج في حال لم تكن لديك خبرة. n_estimators : عدد الخوارزميات أو ال estimator المستخدمة. default=50. learning_rate: مقدار معامل التعلم (حجم الخطوة)، ويأخذ فيمة من النمط float. algorithm: لتحديد الخوارزمية التي تريد تنفيذها لكي تحصل على التقارب converge وهناك خوارزميتين فقط {‘SAMME’, ‘SAMME.R’}. و SAMME.R تعتبر أسرع في الوصول للتقارب وتعطي نتيجة أفضل حقيقة (عن تجربة). افتراضياً SAMME.R. random_state: يتحكم بعملية التقسيم افتراضياً يكون None. التوابع: fit(data): للقيام بعملية التدريب. predict(data): لتوقع القيم. score(data): لتقييم كفاءة النموذج. ()get_params :لايجاد مقدار الدقة predict_proba(data) : لعمل التوقع أيضاً لكن هنا سيخرج الفيمة الاحتمالية(أي لن يتم القصر على عتبة) ال attributtes: classes_: لعرض ال labels التي وجدها. n_classes_: عدد ال labels. estimator_weights_: أوزان كل estimator تم تطبيقه. estimators_: عرض معلومات عن ال estimator التي تم تشكيلها. base_estimator_:عرض معلومات ال estimator الأساسية feature_importances_: عرض أهم الفيتشرز المؤثرة في التصنيف. مثال: from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostClassifier from sklearn.metrics import confusion_matrix from sklearn.datasets import load_breast_cancer import seaborn as sns import matplotlib.pyplot as plt # تحميل البيانات Data = load_breast_cancer() X = Data.data y = Data.target # تقسيم البيانات إلى عينات تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=44, shuffle =True) # AdaBoostClassifier تطبيق clf = AdaBoostClassifier(n_estimators=150, random_state=444) clf.fit(X_train, y_train) # النتائج print('AdaBoostClassifier Train Score is : ' , clf.score(X_train, y_train)) # AdaBoostClassifier Train Score is : 1.0 print('AdaBoostClassifier Test Score is : ' , clf.score(X_test, y_test)) # AdaBoostClassifier Test Score is : 0.9824561403508771 # عرض مصفوفة التشتت c = confusion_matrix(y_test, clf.predict(X_test)) print('Confusion Matrix is : \n', c) #لرسم المصفوفة sns.heatmap(c, center = True) plt.show()1 نقطة
-
بالإضافة للإجابة أعلاه، يمكن أيضاً للبرنامج أن ينتج خطأ في الذاكرة إذا كانت البيانات ضخمة في هذه الحالة يمكننا تبديل ترتيب الخطوات في الكود أعلاه لحل المشكلة بتطبيق تحويل نوع البيانات، و من ثم قراءة القيم منها كالتالي: enc = tfidf.fit_transform(data['tweets'].astype('U').values) # أو enc = tfidf.fit_transform(data['tweets'].astype(str).values) كما يمكننا تطبيق دالة lambda لتحويل كل تويت ل numpy string و من ثم إستدعاء الدالة fit_transform كالتالي: enc = tfidf.fit_transform(data['tweets'].apply(lambda x: np.str_(x))) وهي أكثر كفاءة في إستخدام الذاكرة من الطريقة السابقة.1 نقطة
-
بعد إضافة المستخدم إلى جدول admin، يجب إعادة إجراء الاتصال مع إضافة الخيار: --auth، ولكن يتم اتباع الخطوات التالية بالترتيب لضمان تطبيق التحقق بالشكل الصحيح: أولاً، يتم الاتصال ب mongodb دون الحاجة ل access control، من خلال الأمر التالي (مع استبدال المسار والقاعدة): mongod --path /data/db ثانياً، الاتصال من خلال تنفيذ: mongo ثالثاً، إضافة مستخدم جديد كمدير، كما يمكنك تحديد صلاحيات محددة على قواعد بيانات بالتفصيل: use dbname db.createUser( { user: "admin", pwd: "admin", roles: [ { role: "readWrite", db: "dbname" }, { role: "read", db: "another_db" } ] } ) رابعاً، إيقاف الاتصال الحالي، وإعادة تشغيله من خلال الأمر التالي (مع استبدال المسار أيضاً بالمسار الخاص بك): mongod --auth --path /data/db والآن عند تغيير القاعدة يمكنك تحديد أي مستخدم سيقوم بتنفيذ العمليات من خلال الأمر auth: use dbname db.auth("admin", "admin") ولتفعيل خاصية التحقق بالشكل افتراضي، يجب إزالة التعليق من السطر: #auth=true الموجود في الملف mongo.conf ضمن المسار: /etc/mongod.conf في مكان تنصيب mongo1 نقطة
-
لدي مجموعة من المستندات مكوّنة من البنية التالية: { "_id":ObjectId("e7c5942f08fe44c621912952"), "boxTitle": "Box1", "balls":[ { "number":"1", "color":"blue" }, { "number":"2", "color":"red" } ] }, وأحاول الحصول على المستندات التي تحقق شرط عناصر محددة من المصفوفة balls. ولكن عندما أقوم بتجربة الاستعلام التالي: find({"balls.color": "red"}, {"balls.color": 1}) يتم إرجاع هذا المستند لكن مع جميع عناصر المصفوفة balls، ولكن أنا أرغب بالحصول فقط على عنصر المصفوفة الذي يحقق الشرط أي فقط العنصر ذو اللون الأحمر، بدلاً من إرجاع العنصرين معاً. كيف يمكنني تحقيق ذلك؟1 نقطة
-
يمكن استعمال المعامل and$ الذي يقبل مصفوفة تحوي على التعابير الشرطية، لتصبح العبارة كالتالي: find( $and: [{"balls.color": "red"}, {"balls.color": 1}]) أو ربما أنت تقصد كتابة الشرط هكذا: find({"balls.color": "red", "balls.color": 1}) حيث تمرر الخاصيات و القيم جميعها بعنصر واحد.1 نقطة
-
يمكن استخدام الدالة concat لدمج عدة خاصيات سوياً: fullname: {$concat: ["$firstname", " ", "$lastname"]} حيث يتم تمرير الخاصيات المراد دمجها كعناصر مصفوفة1 نقطة
-
غالباً ماتكون البيانات المخزنة في ملفات csv من النوع object لذا عند تطبيقك ل TfidfVectorizer سيعطيك هذا الخطأ عند استدعاء التابع fit_transform. فهو يتعامل مع unicode string وليس Object، لذا لحل المشكلة نقوم بتحويل نوع البيانات dtype في ملف ال DataFrame إلى النمط unicode وذلك يتم كالتالي: enc = tfidf.fit_transform(data['tweets'].values.astype('U')) # أو enc = tfidf.fit_transform(data['tweets'].values.astype(str))1 نقطة
-
يعرف ايضاً F1 Score ب balanced F-score أو F-measure و يستخدم في حالة مشاكل تصنيف البيانات لقياس دقة و كفاءة النموذج و يعتبر أكثر شمولاً من Precision و Recall لأنهما قد يقدمان نتائج غير دقيقة، مثلاً في حالة عدم التوزيع المتساوي للأصناف Imbalanced classes وهي حالة معظم التصنفيات الحقيقية على أرض الواقع. from sklearn.metrics import f1_score #sklearn تحميل الدالة من مكتبة #تجهيز البيانات، تقسيمهاو تدريب النموذج بالإضافة بإختباره f1_score(y_true, y_pred) #تمرير القيم الناتجة من النموذج و الحقيقية للدالة يمكنك إستخدام F1 score دون تمرير parameter في حال كان التصنيف لصنفين فقط binary is the default ولكن في حال كان التصنيف يتضمن أكثر من صنفين يمكننا أن نمرر إحدى القيم لحساب المتوسط: {‘micro’, ‘macro’, ‘samples’,’ weighted’, ‘binary’} يمكنك الرجوع للمثال السابق. كما يمكننا أن نقوم بإستخدام دالة precision_recall_fscore_support والتي ترجع قيم كل من precision، recall،F1score بالإضافة لمعامل رابع يسمي support، القيمة الثالثة الراجعة من الدالة هي قيمة F1 score، راجع المثال التالي: precision_recall_fscore_support(y_true, y_pred, average='macro') لاحظ انه في هذا المثال حددنا نوع F1 score و هو عبارة عن macro. والتي تعني حساب الدقة لكل صنف على حدة و من ثم إيجاد القيمة المتوسطة لها، وهي طريقة لا تأخذ في الحسبان التوزيع غير المتساوي للأصناف. لا تنسى أن تقوم بإستدعاء الدالة عن طريق مكتبة sklearn كالتالي: from sklearn.metrics import precision_recall_fscore_support الطريقة الأخرى للحصول على قيم الF1 score هي بإستخدام دالة classification_report و التي تقوم بإستخراج نتائج الدقة للنموذج في شكل جدول متكامل و المحتوية على F1 score. راجع المثال التالي: from sklearn.metrics import classification_report print(classification_report(y_true, y_pred, labels=mylabels)) الدالة تستقبل قيم النموذج، القيم الحقيقية المتوقع التنبؤ بها، و اخيراً التصنفيات، هذه الدالة تعطي ناتج F1 score في شكل مفصل و محتوي على الدقة محسوبة بثلاث طرق macro، micro، weighted.1 نقطة
-
بدءً من الإصدار 4.4 أصبح يجب تمرير قيمة رقمية عند استخدام gt$، ولا يمكنك في الإصدارات اللاحقة استخدام gt$ مع size$. لذلك يجب عليك التأكد من إصدار mongodb لديك قبل كتابة الاستعلام. ومن بعض الطرق التي تعمل على الإصدارات المختلفة: عن طريق استخدام where: find( { $where: "this.employees.length > 5" } ); عن طريق استخدام التجميع aggregation: aggregate( [ {$project: {_id: 1, employees:1, depts:1, total_employees: {$size: "$employees"} } }, {$match: {"total_employees": {$gt: 5}}} ]) عن طريق استخدام المسارات: find({'employees.5': {$exists: true}}) وبهذه الطريقة نختبر وجود العنصر السادس من كل مصفوفة ونعيد المستندات التي تحوي عدد أكبر من 51 نقطة
-
يُمكن القيام بالأمر عن طريق إستخدام where بالشكل التالي: .find( { $where: "this.employees.length > 2" } ); كما يُمكنك أيضاً إستخدام هذه الطريقة: // ابحث عن جميع المستندات التي تحتوي على 3 عناصر على الأقل في المصفوفة .find({'employees.2': {$exists: true}})1 نقطة
-
عليك فقط عكس الشرط الأخير: find({ employees : { $gt : { $size: 5} }}) هكذا سيتم جلب أكبر مصفوفة لحجم أكبر من 5، لأنه يجب تمرير الخاصية المطلوبة للدالة gt1 نقطة
-
أفضل حل لهذه المشكلة الأمنية هو تشفير كود بايثون والتي تهدف الى تخزين شفرة المصدر الأصلية الى شكل غير قابل للقراءة بالنسبة للبشر يمكنك إستخدام Cython وهو مترجم يأخذ وحدات py ويترجمها الى ملفات C عالية الأداء وهي تدعم بايثون 2 و 3 ولا توجد طريقة لعكس الكود المترجم الى المصدر ببايثون وهناك عدة طرق أخرى تعتيم الكود Obfuscate لتقليل قابلية قراءة الكود المصدري ترجم compile ملفات py الى ملف pyc ثنائي إستخدام Pyinstaller لتحويل الكود المصدري الى ملف ثنائي قابل للتنفيذ إستخادم PyArmor لتشفير الكود إستخدام نظام التشفير المتقدم AES لتشفير ملفات py و pyc الى ملفات pye تحويل ملفات py الى ملفات c وترجمتها الى ملف مكتبة ارتباط ديناميكي dynamic link library1 نقطة
-
هذا الخطأ قد يظهر لك في أي خوارزمية أخرى في مكتبة Sklearn وليس فقط MultinomialNB، أي ممكن أن يظهر خلال استخدامك خوارزميات أخرى مثل LogisticRegression أو RandomForest. السبب هو أن التابع fit يقبل مصفوفة 2D وأنت تحاول تمرير مصفوفة 3D فيعطيك هذا الخطأ. البيانات التي تتعامل معها هي MINST Dataset وهي بيانات تمثل صور وحجم هذه الداتا 28*28*60000 أي 60 ألف عينة وكل عينة هي صورة بأبعاد 28*28. لذا لحل مشكلتك يجب أن تقوم بعمل reshape للداتاسيت حيث نقوم بجعلها 2D كما يلي: import numpy as np from tensorflow.keras.datasets import mnist from sklearn.naive_bayes import MultinomialNB from sklearn.pipeline import Pipeline from tensorflow.keras.utils import to_categorical from sklearn.metrics import f1_score,precision_score,recall_score,accuracy_score,log_loss (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train.shape image_size = x_train.shape[1] input_size = image_size * image_size input_size # نقوم بعمل إعادة تعيين للأبعاد x_train = np.reshape(x_train, [-1, input_size]) x_train = x_train.astype('float32') / 255 x_test = np.reshape(x_test, [-1, input_size]) x_test = x_test.astype('float32') / 255 # تعريف pipline t = Pipeline([('clf',MultinomialNB())]) t = text_clf.fit(x_train, y_train) accuracy_score(y_test,t.predict(x_test)) # 0.8357 ملاحظة: قمت بتقسيم كل قيمة من الداتا على 255 (أي على أكبر قيمة ممكنة للبكسل) وبالتالي تكون كل قيم البكسلات بين 0 و 1 (وهذا أمر ضروري ونسميه توحيد البيانات (Standardaization).1 نقطة
-
يمكنك استخدم سايثون لذلك ,حيث يقوم بتجميع الوحدات النمطية الخاصة بك إلى ملفات C ذات اداء عالي ، ثم بعد ذلك يمكنك تجميعها إلى مكتبات ثنائية, يمكنك قراءة المزيد عن سايثون ومعرفة كيفية استخدامه من هنا1 نقطة
-
كما أشار @محمد أبو عواد و @Wael Aljamal. أولاً أنت تعرف القائمة bar على أنها class attributes أي وكأنها static أي تتشارك القيمة مع كل الكائنات المأخوذة من الصف. ثانياً في حالة استخادم += فهذا يقابل استدعاء الدالة __iadd__ التي تقوم بتعديل القيمة الأصلية لل bar. أي أنها تغير قيمة الكائن الذي تعمل عليه. أما + فهذا يقابل استدعاء الدالة __add__ التي تقوم بإنشاء كائن جديد، أي في حالتنا سوف تنشئ نسخة من bar أي أن التعديل لن يتأثر به المتغير bar الأصلي. ويمكنك التأكد بذلك عن طريق تجربة التالي: >>> f.bar = f.bar + [4] >>> print(f.bar) # [1, 2, 3, 4] >>> print(g.bar) # [1, 2, 3] >>> foo.bar # [1, 2, 3] مع ملاحظة أن التابع الخاص __iadd__ يحاول في البداية أن يعدل القيمة الأصلية للمتغير، وإذا لم ينجح (مثلاً قد يكون متحولاً ثابتاً أي لايمكن تعديل قيمته) فإنه يقوم بإنشاء نسخة جديدة منه، أي يسلك سلوك __add__.1 نقطة
-
أولاً يجب أن تحذر فهذا المعيار يستخدم مع مهام التصنيف Classification. وهو يجمع بين المعيارين precision و recall ويحقق توازن بين قيمتهما. إن f1score هي قيمة تساوي: f1score = 2 * (precision * recall) / (precision + recall) قيمة f1 تكون بين ال 0 و 1 وكلما زادت القيمة كلما كان أداء النموذج أدق. يتم استخدامها عبر الموديول: sklearn.metrics.f1_score ويمكنك تطبيقها بالشكل التالي: from sklearn.metrics import f1_score # f1_score(y_true, y_pred,average='micro') F1Score = f1_score(y_test, y_pred, average='micro') print('F1 Score is : ', F1Score)1 نقطة
-
هناك نوعين من الخواص في بايثون هما : class attributes and instance attributes, حيث class attributes تتشارك نفس القيمة مع كل ال object يتم انشاءه من الصنف, أما ال instance attributes فهي فقط تنتمي للobject , انت هناك قمت بتعريف المتغير bar على أنه class attributes ولذلك سوف تتشارك جميع الكائنات قيمته, الحل أن نقوم بتعريف المتغير بداخل الكونستركتور كالتالي class foo: def __init__(self,x): self.bar = [] self.bar += [x] الآن لو حاولت انشاء أكثر من كائن من نفس الصنف لن تتشارك الكائنات نفس القيمة1 نقطة
-
السبب في اختلاف الدالة التي يتم استدعائها، حيث أن =+ في مثالك: >>> f.bar += [3] تقوم باستدعاء __iadd__ التي تعدل f.bar الأصلية. أما: >>> f.bar = f.bar + [4] تقوم بإنشاء قائمة جديدة ثم إسنادها للمتغير حيث أنها تستدعي الدالة __add__1 نقطة
-
يُمكن إستخدام الدالتين getattr و setattr للوصول للخاصيات: getattr(x, 'y') <=> x.y setattr(x, 'y', v) <=> x.y = v و هذا تطبيق للدالتين في مثالك: class Foo: def __init__(self): self.attr1 = True self.attr2 = False foo = Foo() x = "attr1" y = 123 setattr(foo, x, y) z = getattr(foo, x) print(z) # 1231 نقطة
-
يمكن عمل ذلك باستخدام الدالة __setattr__ كالتالي: object.__setattr__(self, name, value) أي: x = "attr1" y = 123 foo.__setattr__( x, y)1 نقطة
-
يمكننا فعل ذلك كالتالي y=20 x = True if y >= 20 else False print(x) حيث سوف يتم تخزين قيمة true في المتغير x اذا كان الشرط صحيح أما اذا كان خاطئا فسوف يتم تخزين قيمة false1 نقطة
-
نعم بالطبع تدعم بايثون هذه الطريقة مثل ternary operator لكن ترتيب الشروط فيها مختلف: a, b = 1, 2 min = a if a < b else b print(min) حيث نضع القيمة التي نريد إعادتها في حال تحقق الشرط، ثم الشرط وأخيرا القيمة الأخرى في حال لم يتحقق الشرط والشكل العام لها: [on_true] if [expression] else [on_false] كما يوجد عبارة مختصرة لكل من: a, b = 1, 2 # اختيارقيمة بناءاً على tuple # (if_test_false,if_test_true)[test] print( (b, a) [a < b] ) # أو القاموس print({True: a, False: b} [a < b]) بالنسبة لحلقة for المختصرة يوجد عدة أشكال عامة لها: for i in <collection> <loop body> _____________________ for <var> in <iterable>: <statement(s)> _____________________ مثال >>> a = [1, 2, 3] >>> for i in a: ... print(i) ... 1 2 3 حيث أدرجت مثال للمرور على قائمة بكل بساطة بدون أي تعقيدات. كما تعمل مع القواميس: >>> d = {'foo': 1, 'bar': 2, 'baz': 3} >>> for k in d: ... print(k) ... foo bar baz _____________________ >>> for k in d: ... print(d[k]) ... 1 2 3 كما يمكن المرور على قائمة من tuple : >>> i, j = (1, 2) >>> print(i, j) 1 2 >>> for i, j in [(1, 2), (3, 4), (5, 6)]: ... print(i, j) ... 1 2 3 4 5 61 نقطة
-
نعم يوجد إختصار لل if في البايثون ولكن ليس مثل javascript وهو كما في المثال التالي a,b=5,7 x = a > b and "True" or "False" #or يتم إرجاع ما بعد ال false وإذا كان and يتم إرجاع ما بعد ال true في حالة1 نقطة
-
يجب التأكد من مسار الملفات التي تم إستدعائها بإستخدام include، ويمكنك أن تستخدم دالة require لكي تظهر الخطأ (في حالة وجوده) ومعرفة السبب وراء عدم إستدعاء الملفات. أما بالنسبة للفرق بين الدوال فهو كالتالي: دالة include: تستخدم لإستدعاء ملفات php أخرى لكي يتم تنفيذها ضمن الملف الأصلي، وفي حالة عدم وجود الملف فلن يحدث خطأ وسيكمل الموقع العمل. لذلك تستخدم هذه الدالة في إستدعاء الملفات الثانوية والتي ليس لها دور رئيسي في الموقع، ويمكن إستخدام لإستدعاء نفس الملف أكثر من مرة. دالة require: لها نفس إستخدام دالة include لكن في حالة عدم وجود الملف الذي يتم إستدعائه سيحدث خطأ يوقف عمل الموقع، ولذلك تستخدم هذه الدالة في إستدعاء الملفات المهمة والرئيسية مثل ملفات الإتصال بقاعدة البيانات. دالة include_once: بها نفس إستخدام دالة include لكن إن تم إستدعاء الملف من قبل لن يتم إستدعائه مرة أخرى (أي يتم إستدعاء الملف مرة واحدة مهما كان عدد مرات إستخدام هذه الدالة لنفس الملف). دالة require_once: لها نفس إستخدام دالة require، لكن سيتم إستدعاء الملف مرة واحدة فقط مهما كان عدد مرات إستخدام الدالة لإستدعاء نفس الملف.1 نقطة