لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/11/21 في كل الموقع
-
في بايثون لا يمكنك إستدعاء حزمة أكثر من مرة من أجل أداء البرنامج ، لانه مهما كان عدد مرات إستدعاء أي حزمة فإنه في الخلفية سيتم إستدعائها مرة واحدة مثل import myScript if cond: import myScript # سيتم إستدعاء الحزمة مرة واحدة فقط لهذا يجب عليك إستدعاء الحزمة خارج الحلقة ، وفي داخل الحلقة يمكنك تشغيل الدالة المراد إستخدامها كالآتي import myScript for i in range(5): myScript.func() print('imported')3 نقاط
-
اهلا بك اخي الكريم نعم لقد وجدت هذا المكاتب ولكن مع الاسف لا يوجد شروح لها في الانترنت وشرح المرفق غير واضح حقيقه قمت بتجريبه ولكن هو فقظ يقوم بحفظ البيانات بدون استدعاء وما شابه اهلا بك شاكر لك افادتك بس ياليت لو فيه شروح ل هذا الطريقه يوتيوب مثلا او شي ثاني الافاده بهم ولك جزيل الشكر2 نقاط
-
يمكنك استخدام litsql يتم تحميلها بنفس التطبيق او خفظه كملف json يتم حفظه ب SharedRefrences و عند طلب المعلومات يمكنك الأستعانة بهذا الملف أو ال litsql و استخراج البيانات منها2 نقاط
-
هناك العديد من الطرق لعمل ذلك مثل وضع شرط كعلم flag flag = False for i in range(5): if flag:break for n in range(5): if i == 4 and n ==5: flag = true print(i, n) إرسال إستثناء try: for i in range(5): for n in range(5): if i == 5: raise StopIteration print(i, n) except StopIteration: pass تفحص نفس الحالة مرةً أخرى for i in range(5): for n in range(5): if n == 5: break print(i, n) if n == 5: break إستخدام صيغة for و else for i in range(5): for n in range(5): if n == 5: break print(i, n) else: continue break وضعها في دالة def check_sth(): for i in range(5): for n in range(5): if n == 5: return print(i, n) check_sth() # تشغيل عند الحاجة2 نقاط
-
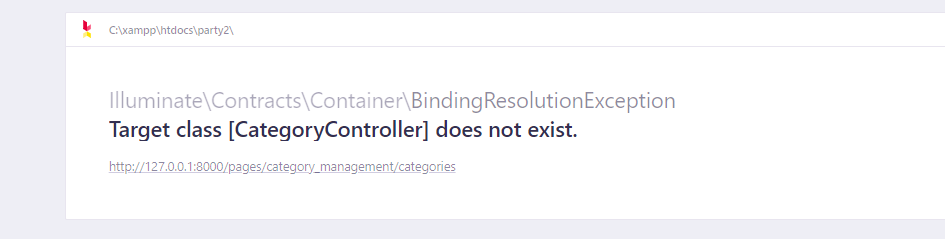
عندي مشكلة عرفت controller بس يقول مومتعرف عليه party2.rar
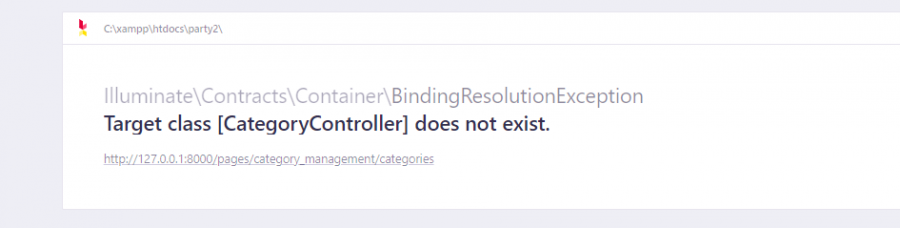 2 نقاط
2 نقاط -
عندي سوال كيف اخلي التطبيق يغير اللغة من غير لا ادخل على ملف الاعدادات بمجرد الضغط على زر بالواجهه يصير اللغة تغيرت من ملف اللغة الي عرفته في lan ياخذ القيم من الملف ويغير من خلال الزر1 نقطة
-
هل توجد طريقة لحفظ البيانات في الجهاز بعد اول تحميل؟ حتى يتم عمل البرنامج لدى المستخدم بشكل سريع وسلس مثل ما يتم استعماله لدى الصور : cached_network_image ولكن ابحث لنصوص والقوائم مثلا انا يتم حتى يتم جلب listview نحتاج بعض الوقت الذي يظهر فيه CircularProgressIndicator احاول تسريع هذا العمليه وتجنب ظهور CircularProgressIndicator كثير وان يصبح التطبيق اسرع للمستخدم1 نقطة
-
هنا مثال صغير لحفظ المعلومات داخل ال shredprefrences طبعا الحال state تكون عن طريق ال blocs , redux و كثير من مكتبات تنظيم الأحوال //هنا نقوم بحفظ الحال الى الجهاز ك file void saveToPrefs(AppState state) async { // نستدعي الshredprefrrences SharedPreferences preferences = await SharedPreferences.getInstance(); // ناخذ قيمة الحال بعد تحويلها و نقوم بتخزينها بالملف var string = json.encode(state.toJson()); writeFile(string); // و هنا نقوم بحفظ المعلومات داخل ال sharedprefrences await preferences.setString('AlbumsState', string); }1 نقطة
-
ممكن تقوم بعملية حفظ للبيانات داخل قاعدة بيانات في التطبيق و تقوم بعرض البيانات من خلال قاعدة البيانات , البيانات المرجعة من api تقوم بتخزينها في قاعدة البيانات و عند عرض البيانات على الواجهات تقوم بإرجاع البيانات من داخل قاعدة البيانات . يوجد عدة مكتبات يمكنك تصفحها من هنا أو من هنا1 نقطة
-
اواجه مشكله في تنزيل visual studio code على MacBook Air هل بإمكانكم مساعدتي ....شكرا1 نقطة
-
ربما مخفية. حاولي الضغط على F1 إن كان بوضع ملئ الشاشة اضغطي على F11 أو Ctrl + Shift + P ثم نحدد toggle menu bar1 نقطة
-
يمكنك ذلك بعدة طرق أسهلها استخدام الدالة join كالتالي: def convert(lst): return (" ".join(lst)) # اختبار التابع l = ['Hsoub', 'Mostaql'] print(convert(l)) # Output: Hsoub Mostaql حيث " " هي التي ستفصل بين الكلمات ويمكنك تغييرها. #تعديل: طريقة أخرى إذا أحببت بدون توابع جاهزة: # تابع التحويل def convert(lst): string=lst[0] # نضع أول كلمة من القائمة في السلسة for word in lst[1:]: # نضيف باقي الكلمات إلى السلسلة string +=' '+ word return string # اختبار التابع l = ['Hsoub', 'Mostaql'] print(convert(l))1 نقطة
-
لفتح مجلد ما في vs code أرجو فتح محرر أوامر cmd/terminal ثم كتابة: . code any/path> code . النقطة ضرورية، إن فتح المجلد فهذا يعني أن vs code مثبت. هذا بسبب التحديثات في البرنامج.1 نقطة
-
يتم تنزل نسخة vs code الخاصة بأجهزة mac من رابط التحميل التالي: في الجزء الأيمن خاص ب mac إن كنت تستطيع تحديد المشكلة بدقة أكثر و إرفاق صور سيكون ذلك أفضل.1 نقطة
-
تطبيق (Support Vector Regression (SVR في Sklearn ؟1 نقطة
-
ما هي المشكلة بالتحديد؟1 نقطة
-
تتميز مكتبة threading بأنها خفيفة الوزن وتتشارك الذاكرة ومسؤولة عن واجهة المستخدم وسريعة الاستجابة ويتم استخدامها بشكل جيد للتطبيقات المرتبطة بالإدخال و الإخراج, بينما مكتبة multiprocessing تستخدم مساحة ذاكرة منفصلة وأنوية متعددة لوحدة المعالجة المركزية وهي أسهل بكثير في الاستخدام, يمكنك استخدام threading إذا كان البرنامج الخاص بك يحتوي على الكثير من عمليات الادخال والاخراج أو يستخدام الشبكة ويمكنك ويمكنك استخدام multiprocessing إذا كان مرتبط بوحدة المعالجة المركزية واذا كان جهازك يحتوي على نوى متعددة1 نقطة
-
إن كنت تعمل في بيئة تفاعلية interactive interpreter حيث تحتاج لإعادة تحميل النوذج module و بسبب تعديله يمكنك استخدام الدالة reload وتمرير اسمه لها for i in range(5): reload(mySecrept) بدل التضمين العادي. بشكل عام نضمن الmodule مرة واحدة و نستدعي الدالة منه مثل إجابة الكدرب عبدالمجيد.1 نقطة
-
يمكننا إيقاف الحلقتين سوياً، بعدة طرق، استخدام Product التي تقوم على الجداء الديكارتي لقائمتين وتمر على الناتج بحلقة واحدة، هنا تعليمة break واحدة تكسر الحلقة: from itertools import product for x, y in product(range(10), range(10)): if y == : break أو نضع الحلقتين ضمن دالة و نستخدم تعليمة return: def myLoops(): for i in range(10): for j in range(10): print(...) if j == 5: return myLoops() يمكن عمل متغير بولياني Boolean يقوم بكسر الحلقة الخارجية حيث يتم اختباره بعد الخروج من الحلقة الداخلية، حيث نغير قيمته إلى Ture مثلا: myBreak = false for i in range(5): for n in range(5): if i == 5: myBreak = true break print(i, n) if myBreak : break # هنا نخرج من الحلقة الخارجية1 نقطة
-
هناك عدة لطرق لعمل ذلك ، مثل كتابة الأقواس المعكوفة مرتين x = "{{Age}}{0} ".format(23) print(x) أو يمكنك عمل ذلك بصيغة % x = " {Age}%s" print (x%(23)) أو إستخدام قوالب السلاسل النصية template string from string import Template x = Template("$open Age $close") x = x.substitute(open='{',close='}') print('{} {}'.format(x,23))1 نقطة
-
للطباعة بهذه الطريقة لا نستخدم الاشارة "\" بل نضع زوج من الأقواس المعكوفة فيكون شكل الكود كالتالي x = " {{ Age }} {0} " print(x.format(23))1 نقطة
-
أنا بستخدم firebase auth عن طريق phoneNumber ، ومشيت على الخطوات واشتغل معاي تمام، لكن استخرجت نسخة ال APK ، للأسف مش راضي يشتغل، ف هل هناك فرق بين النسخة التجريبية ونسخة ال apk أو هل في أشياء إضافية لازم أضيفها عشان تشتغل في نسخة ال apk ؟1 نقطة
-
ربما قمت بعملية توقيع التطبيق مرتين، ونتج مفتاحين مختلفين، لعرض المفتاح الذي يعمل به التطبيق يمكنك تنفيذ التعليمة: keytool -list -v -alias key -keystore android/app/key.jks ثم وضع هذه القيمة في Firebase طبعا المسار هو مكان وضع المفتاح أي ملف key.jks1 نقطة
-
يجب أن تتأكد من package name SHA1 - SHA-256 Firebase Integration1 نقطة
-
يمكنك إستخدام الطرق المذكورة مسبقاً ، ولكن هناك طريقة أسهل لعمل ذلك وهي كالآتي virtualenv venv --python=python2.7 ولكن هذه الطريقة تعمل إذا كنت مثبت ل python2.7 في مستوى النظام ، أي أن يكون المسار كالآتي /usr/bin/python2.7 أما إذا استخدمت homebrew لتثبيت بايثون أو إستخدمت أي طريقة أخرى لتثبيت بايثون ويكون المسار مختلف عن المذكور في الأعلى ، فيجب عليك تحديد المسار كالآتي virtualenv venv --python=المسار virtualenv venv --python=/usr/local/bin/python يمكنك معرفة مسار بايثون بإستخدام الأمر التالي which python أو إذا كنت تريد بايثون 3 كالآتي which python31 نقطة
-
ممكن تذهب على firebase console و من ثم الإعدادات و من ثم integration ومن ثم تأكد من SHA1 , SHA 256 و قم بإضافتهن إذا لم يكن موجودات.1 نقطة
-
نعم قمت بإضافة (SHA-1) و (SHA-256) ثواني أريك الخطأ أين يظهر بالتحديد1 نقطة
-
نعم، جربته على جهازين أو ثلاثة1 نقطة
-
قمت بإضافة الملف بشكل صحيح، والتطبيق يعمل بشكل سليم على نسخة ال debug وفعلا قمت باستخراج نسخة الapk عن طريق الأمر الذي أرفقته، وهنا ظهرت المشاكل، ماذا أفعل؟1 نقطة
-
قم بتجربة نسخة apk وليس debug طبعاً بعد التأكد من إضافة فيربيز إلى مشروعك بشكل صحيح و إضافة ملف google-services.json , ثم قم باستخراج نسخة apk عن طريق الأمر التالي flutter build apk1 نقطة
-
أقوم باستخدام Laravel Mix اعتماداً على WebPack والآن يظهر لدي الخطأ التالي: Invalid configuration object. Webpack has been initialised using a configuration object that does not match the API schema. - configuration.output.path: The provided value "public" is not an absolute path! وعندما أقوم بحذف محتويات webpack.mix.js يبقى الخطأ. كما حاولت أيضاً حذف المجلّد node_modules وإعادة تحميله من خلال npm install، ولكن لم تحل المشكلة. كيف يمكنني معالجة هذا الخطأ؟1 نقطة
-
في حالة أن ال keys أكثر من ال values يمكنك استخدام ال itertools.zip_longest حتى يمكنك استخدام ال fillvalue لتحديد قيمة لل values المتبقية كالتالي from itertools import zip_longest x =[1, 2, 3, 4, 5, 6, 7] y =[8, 9, 10] z = list(zip_longest(x, y, fillvalue ='_' )) print(z) #output #[(1, 8), (2, 9), (3, 10), (4, '-'), (5, '-'), (6, '-'), (7, '-' )]1 نقطة
-
بالطبع يمكنك تحديد الإصدار من خلال الأمر --python أو -p وذلك في حالة أنك غالباً تقوم بالتبديل بين الإصدارات ولكن يمكنك تثبيت الإصدار المستخدم من خلال ال virtualenv يمكنك عمل ذلك من خلال الملف .bashrc قم بإضافة السطر التالي له export VIRTUALENV_PYTHON=/مسار/الإصدار/الذي/تريده1 نقطة
-
حسنا استخدم حاليا firebase لايوجد مشكلة لأن أهم ميزة فيها هي real time database. التكاليف في فايربيز ترتفع مع ازدياد حجم المشروع، حاول الاشتراك بخدمة "ادفع حسب ما تستهلك" بدل الاشتراك الثابت.. بشكل عام الموضوع بحاجة لدراسة عدد المشركين و حجم المشروع والتجريب.1 نقطة
-
عند إنشاء بيئة virtualenv جديدة فقط قم بتمرير --python أو -p لتحديد أي نسخة ترغب بتشغيلها، مع تمرير مسار virtualenv. مثال: virtualenv --python=/usr/bin/python3.8 <نضع هنا مسار virtualenv> ولكن مع نسخ python3، ينصح التوثيق الرسمي بإنشاء البيئة الافتراضية من خلال الأمر التالي: python3 -m venv <envname> ولكن يجب عليك الانتباه إلى أن venv لا يسمح بإنشاء البيئة الافتراضية مع إصدارات أخرى من بايثون، لذلك يتوجب عليك أن تكون مثبّت حزمة virtualenv مسبقاً.1 نقطة
-
هي نموذج للتصنيف باستخدام الشبكات العصبونية يتم استخدامها عبر الموديول neural_network.MLPClassifier مثل أي نموذج في التعلم الألي يوجد لديه العديد من المعاملات التي تلعب دورا أساسيا في عملية تعلم الموديل عبر داتا التدريب لنقوم بالمرور على أهم المعاملات التي يأخذها هذا النموذج #استدعاء المكتبة from sklearn.neural_network import MLPClassifier في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل #الشكل العام للموديل MLPClassifierModel = MLPClassifier(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) البارمتر الأول activation مثلما نعرف يوجد في الشبكات العصبونية عدة أنواع لتوابع التنشيط أو activation ومن أهمها تابع sigmoid , relu,tanh لن أدخل في تفاصيل كل منها فأي دورة تعلم الآلة أو تعلم عميق تحوي هذه المفاهيم ولكن كنصيحه نقوم بجعل relu لجميع الطبقات ماعدا الأخيره أما الطبقة الأخيره نستخدم sigmod البارمتر الثاني solver هو طريقة الحل أو طريقة الوصول إلى أفضل قيم w,b الأوزران الخاصه بالشبكه العصبونية يوجد أكثر من طريقه مثل sgd ,adam ولكن ننصح باستخدام adam دوما البارمتر الثالث learning_rate هو معامل التعلم وهو يمثل مقدار الخطوه للوصول إلى الأوزران ويمكن تركه costant أي خطوات ثابتة أو adaptive متغيره أما ان تكون طويله أو قصيرة البارمتر الرابع early_stopping التوقف المبكر وهو يأخذ True بحال أردنا أيقاف معامل التعلم عند نقطه بحيث لا يدخل الموديل في مرحلة overfit أي الضبط الزائد وfalse عكس ذلك البارمتر الخامس alpha يمثل معامل التنعيم حيث التنعيم هو طريقة لكي يتخلص الموديل من الضبط الزائد overfit ويلعب alpha دورا مهما في ذلك البارمتر السادس hidden_layer_sizes وهو يمثل عدد الطبقات ماعدا طبقة الدخل والخرج لأنهما لا تعتبرا طبقات مخفيه وعدد الخلايا في كل طبقه حيث الأرقام تدل على عدد الخلايا في الطبقه أما موقع الرقم يدل على الطبقه وعدد المواقع يدل على عدد الطبقات المخفيه فمثلا (10,200,30,4) يوجد أربعة طبقات لأنه يوجد أربع أرقام وكل رقم منها يدل على عدد الخلايا في طبقته مثلا الطبقة الأولى تحوي 10 خلايا طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جدا فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test, y_test تسطيع كتابة الأتي لعملية التدريب MLPClassifierModel = MLPClassifier(activation='tanh', solver='adam', learning_rate='constant', early_stopping= False, alpha=0.0001 ,hidden_layer_sizes=(100, 3)) MLPClassifierModel.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لتدريب الشبكه العصبية يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي: y_pred = MLPClassifierModel.predict(X_test) حيث قمنا بالتنبؤ بقيم التصنيف لداتا الاختبار نستطيع أيضا حساب دقة الموديل أو كفاءته عن طريق التابع score ويكون وفق الشكل: print('MLPClassifierModel Test Score is : ' , MLPClassifierModel.score(X_test, y_test)) حيث قمنا بطباعة قيمتها لكي نرى كفاءة الموديل على بيانات الاختبار وهل هو يعاني من الضبط الزائد overfit أو الضبط الناقص underfit.1 نقطة
-
في الإصدارات الحديثة من تنسرفلو تم حذف هذه الدالة وأصبح بإمكانك استخدام ال generators مع الدالة Model.fit لذا لديك حلين إما أن تقوم بتثبيت إحدى الإصدارات السابقة مثل 1.15 من تنسرفلو كالتالي: pip install tensorflow==1.15 أو أن تقوم باستخدام الدالة Model.fit : # generetors الشكل العام للتابع في حالة كانت بياناتك ليست fit( x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs ) # generetors في حالة كانت بياناتك fit( data_generetors, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, **kwargs ) لكن في الحالة الثانية لن تكون قادراً على استخدام الخاصية validation_data أو validation_split والخواص الأخرى المتعلقة بهم لذا قد يكون الحل الأفضل استخدام إصدار سابق لحل مشكلتك في حال كنت تعتمد validation_generator1 نقطة
-
أصبح Model.fit_generator مهمل deprecated بداية من الإصدار 2.1 وسيتم إزالته في إصدارات قادمة وقد تم توضيح ذلك في توثيق tensorflow هنا: لذلك يمكنك أن تقوم بتمرير generator مباشرة إلى Model.fit وسيختفي هذا التحذير من الـ terminal1 نقطة
-
مرحبًا @Meezo ML، يجب عليك قبل إستدعاء الحزمة إلى مشروعك تنصيب الحزمة. ويمكنك تنصيب الحزمة من خلال مدير الحزم pip الخاص بللغة بايثون من خلال الأمر: pip install -U scikit-learn scipy matplotlib بعد تنزيل الحزمة يجب أن تعمل المكتبة دون مشاكل. أما بالنسبة لبيثون 3 فيجب عليك تثبيتها من خلال مدير الحزم pip3 من خلال الأمر: pip3 install -U scikit-learn scipy matplotlib1 نقطة
-
يبدو أنك لم تقم بتثبيت المكتبة بشكل صحيح، يمكنك تثبيتها من خلال الأمر التالي: pip3 install -U scikit-learn scipy matplotlib العلم -U يعني upgrade لتحديث المكتبة أيضًا.1 نقطة
-
الخطأ هو عدم وجود sklearn في نظامك، ولحل المشكلة يجب تثبيت مكتبة sklearn ويمكنك ذلك عن طريق: أما فتح موجه الأوامر cmd وكتابة التعليمة التالية: pip install -U scikit-learn أو من خلال الكتابة على موجه الأوامر في anconda إن كنت تستخدمها: conda install scikit-learn أو من خلال الكتابة في jupyter notebook: pip install scikit-learn1 نقطة
-
Stochastic Gradient Descent (SGD) Classifier تقوم بعمل Logistic Regression لكن باستخدام خوارزمية التحسين ال Stochastic Gradient Descent. يمكنك استخدامها عبر الموديول: linear_model.SGDClassifier sklearn.linear_model.SGDClassifier(loss='hinge', *, penalty='l2', alpha=0.0001, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, epsilon=0.1, n_jobs=None, random_state=None, learning_rate='optimal', early_stopping=False) الوسطاء: loss: هي دالة التكلفة المستخدمة، وكون المهمة هي مهمة تصنيف نستخدم الدالة الافتراضية دوماً. أي hinge. penalty: وهو نوع التنعيم المستخدم. learning_rate: وهو معامل التعلم (مقدار الخطوة). max_iter: العدد الأقصى للمحاولات. early_stopping: في حال ضبطه على True سيتم تطبيق خاصية التوقف المبكر (لمنع ال Overfitting عندما تنهار الدقة على عينة التطوير مقابل عينة الاختبار). shuffle: لخلط البيانات. verbose: ضبطه على أي قيمة غير الصفر سيعطيك التفاصيل أثناء التدريب. random_state: تتحكم بنظام العشوائية. ال attributes: coef_: الأوزان. intercept_: التقاطع مع المحور y، ضبطه على False يجبر الكلاسيفير على المرور من المبدأ 0،0 لذا يفضل ضبطه على True لإعطاء الحرية للكلاسيفير. n_iter_: عدد المحاولات التي تم تنفيضها خلال التدريب حتى الوصول لمرحلة التقارب من القيم الدنيا. الدوال: fit(X, y): لبدء التدريب على بياناتك. predict(X): لتوقع قيم الدخل اعتماداً على قيم الأوزان. score(X, y): لتقدير مدى كفاءة النموذج. مثال على مجموعة بيانات Iris Data : from sklearn.model_selection import train_test_split from sklearn.linear_model import SGDClassifier from sklearn.metrics import confusion_matrix from sklearn.datasets import load_breast_cancer import seaborn as sns import matplotlib.pyplot as plt # تحميل البيانات Data = load_breast_cancer() X = Data.data y = Data.target # تقسيم البيانات إلى عينات تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=44, shuffle =True) # SGDClassifier تطبيق SGDC = SGDClassifier(penalty='l1',loss='hinge',learning_rate='optimal',random_state=44) SGDC.fit(X_train, y_train) print('SGDC Train Score is : ' , SGDC.score(X_train, y_train)) print('SGDC Test Score is : ' , SGDC.score(X_test, y_test)) # SGDC Test Score is : 0.9414893617021277 print('SGDC loss function is : ' , SGDC.loss_function_) print('SGDC No. of iteratios is : ' , SGDC.n_iter_) # عرض مصفوفة التشتت c = confusion_matrix(y_test, SGDC.predict(X_test)) print('Confusion Matrix is : \n', c) #لرسم المصفوفة sns.heatmap(c, center = True) plt.show()1 نقطة
-
يمكنك استخدامه عبر الموديول: preprocessing.PolynomialFeatures وهو يستخدم مع التوقع الخطي لإعطاء البيانات الصفة اللاخطية، فكما تعلم أن الفرضية المستخدمة مع التوقع الخطي هي معادلة خط مستقيم من الشكل : y=wx+b وبالتالي معادلة مستقيم، وبالتالي في حال البيانات التي لها الشكل التالي لن تكون قادرة على ملاءمتها: حيث سيكون شكل ال Regressor بعد التدريب كالتالي: وبالتالي لملاءمة هكذا نوع من البيانات يجب أن تضيف لبياناتك الصفة اللاخطية وبالتالي تكون معادلة ال Regressor قادراة على ملائمة البيانات بالشكل المطلوب كالتالي: أي يجب أن تكون معادلة ال Regressor كالتالي: y=b+x1+x1^2+,,,,+x1^n للقيام بذلك باستخدام Sklearn: sklearn.preprocessing.PolynomialFeatures(degree=2, include_bias=True) degree: درجة كثير الحدود المطلوبة. include_bias: لتضمين الانحراف bias في العملية. مثال: import numpy as np from sklearn.preprocessing import PolynomialFeatures X = np.arange(4).reshape(2, 2) # تشكيل مصفوفة بقيم عشوائية print(X) ''' array([[0, 1], [2, 3]]) ''' poly = PolynomialFeatures(2) print(poly.fit_transform(X)) # للقيام بعملية التحويل نستدعي هذ التابع ''' array([[1. 0. 1. 0. 0. 1.] [1. 2. 3. 4. 6. 9.]]) '''
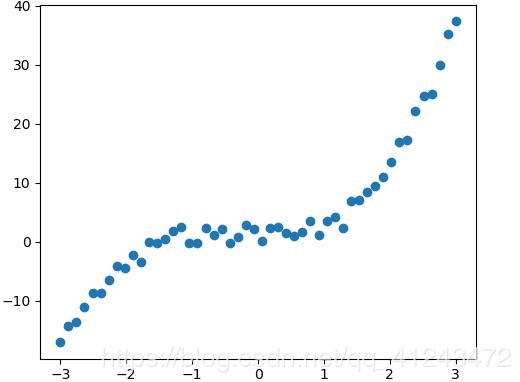
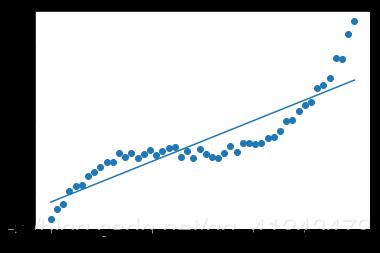
 1 نقطة
1 نقطة -
لدي المصفوفة التالية a=[3,2,3,5,6,4,7] وأريد البحث عن العدد 4 في المصفوفة باستخدام البحث الثنائي وما الفرق بينه وبين البحث الخطي ..أرجو المساعدة1 نقطة
-
يمكن تطبيق البحث الثنائي في بايثون كالتالي: نقوم بعمل دالة search ونمرر لها القائمة ومن أين يبدء البحث وأين ينتهي وكذلك العنصر الذي نبحث عنه def search (lst, l, r, x): # نتحقق من القيمة الأولية # المتغير r يجب أن يكون أكبر من l if r >= l: # نستعمل علامة القسمة المزدوجة لجلب القيمة الصحيحة فقط mid = l + (r - l)//2 # نادرًا ما يكون العنصر في وسط القائمة لكن إن وجد نقوم بإرجاعه مباشرة if lst[mid] == x: return mid # إن كان العنصر المعطى أصغر من العنصر الموجود في وسط القائمة # فإنه سيكون موجودًا في الجزء الأيسر من القائمة elif lst[mid] > x: return search(lst, l, mid-1, x) else: # العنصر موجود في الجزء الأيمن return search(lst, mid + 1, r, x) else: # إن لم يكن العنصر موجود في القائمة من البداية نقوم بإرجاع -1 return -1 myList = [ 1, 2, 3, 4, 5, 6, 7, 8 ] x = 6 result = search(myList, 0, len(myList)-1, x) if result != -1: print (f"The Element is at {result}") else: print ("The List doesn't contain the element") لاحظي أن القائمة التي نقوم بتمريرها إلى دالة search يجب أن تكون مرتبة تصاعديًا لكي تعمل الدالة بشكل سليم، ويمكن ترتيب أي قائمة من خلال التابع sort كالتالي: cars = ['Ford', 'BMW', 'Volvo'] cars.sort() print(cars) # Output: ['BMW', 'Ford', 'Volvo']1 نقطة
-
يعتبر البحث الثنائي أفضل من الخطي لأن في البحث الخطي سوف نمرر على كل عنصر لتحقق إذا كان هو أما في البحث الثنائي يتم ترتيب المصفوفه ومن ثم المقارنه مع العدد الذي في الوسط فأذا كان العدد المعطى أكبر من العدد الذي في الوسط نقوم في البحث في النصف الأعلى من المصفوفه أما إذا كان أصغر نقوم بالبحث في النصف الاسفل أما اذا كان يساويه فيكون هو العدد المنشود ويتم تكرار نفس الشي في كل مره حتى نجد العدد: a=[3,2,3,5,6,4,7] x=int(input()) a=sorted(a) start,end=0,len(a) y=-1 while(start<=end): mid=(start+end)//2 if(a[mid]==x): y=mid break if(x>a[mid]): start=mid+1 else: end=mid-1 if(y==-1): print("Number not found") else: print("Number found in index {}".format(y)) في البداية إدخال العدد المراد البحث عنه بعد ذلك ترتيب المصفوفه لأن شرط البحث الثنائي هو ان تكون المصفوفه مرتبه بعد ذلك تعيين قيمة البداية صفر وقيمة النهاية ب طول المصفوفه أعطاء y=-1 وذلك يعني أن العدد في البداية لا يعتبر موجود بعد ذلك حلقه شرط الحلقه يكون دوما البداية أصغر من النهايه بعد ذلك اسناد قيمة الاندكس الذي في الوسط إلى mid بعد ذلك عمليات المقارنه التي ذكرناها في حالة التساوي نقوم بإسناد قيمة mid إلى y في حالة x أكبر من القيمه التي في الوسط هذا يعني أنها أكبر من جميع قيم النصف الأيسر من المصفوفه بالتالي تصبح البداية الجديدة mid+1 في حالة x أصغر من القيمه التي في الوسط هذا يعني أنها أصغر من جميع قيم النصف الأيمن من المصفوفه بالتالي تصبح النهاية الجديدة mid-1 بعد اختلال الشرط نخرج من الحلقه فإذا تغيرت قيمة y هذا يعني أنه موجود ونقوم بطباعة موجود وإذا كان يساوي -1 هذا يعني أنه غير موجود1 نقطة
-
عندما تقوم بسحب البيانات من الويب فانت تحصل عليها على شكل خام ثنائي binary أو byte type وعندما تقوم بحفظها في ملف بإستخدام الدالة المخصصة لذلك تحصل على هذا الخطأ TypeError: string argument expected, got 'bytes ومعناه أن دالة الحفظ تتوقع المدخل أن يكون من نوع سلسلة نصية string لحفظها في الملف ولكن حصلت على نوع byte type لهذا يجب عليك أولاً تحويل البيانات الذي تريد حفظها من نوع byte الى نوع string وإذا أردت تحويل من نوع byte b = b"content" type(b) # <class 'bytes'> الى نوع string فيمكنك إستخدام هذا الكود bytes = b'content' bytes.decode("utf-8") او يمكنك إستخدام هذا الكود ايضاً b = b'content' str(b, 'UTF-8')1 نقطة
-
يمكنك إستخدام جملة del لحذف أي مفتاح موجود في قاموس معين، كالتالي: >>> a = {'a': 1, 'b': 3} >>> del a['a'] >>> a {'b': 3} >>> كما يمكن إستخدام التابع pop كالتالي: >>> a = {'a': 1, 'b': 3} >>> a.pop('a', None) 1 >>> a {'b': 3} >>>1 نقطة
-
عند تحديد shell=True يتوقع تمرير سلسلة نصية واحدة لعملية shell أما في حال shell=False يمكن تمرير قائمة بعدة أوامر دفعة واحدة. في حالتك تمرر أمر واحد، لذلك لا مشكلة، إنما إن أردت تمرير عدة أوامر عليك تحديد الخيار shell=False1 نقطة
-
هناك عدة طرق للقيام بالأمر: في المتحكم ProjectController عند إنشائك للمشروع في التابع store تستقبل غرض المشروع في متغير و تُنشئ مهمة عامة لهذا المشروع و بهذا الشكل يُصبح عند إنشاء أي مشروع تُنشأ له مهمة عامة: <?php public function store(Request $request) { // ... $project = Project::create($data); $project->tasks()->create(['body' => "مهمة عامة"]); // .. } في النموذج Project تُعيد تعريف الدالة boot ثم تقوم بالتسمع على حدث created بهذا الشكل: <?php protected static function boot() { parent::boot(); static::created(function (Project $project) { $project->tasks()->create(['body' => "مهمة عامة"]); }); } الآن عند إنشاء مشروع تلقائياً يتم إنشاء مهمة له و ستأخذ المهمة في الحقل body مهمة عامة. يُمكن عمل الموضوع بإستعمال المُراقبات (observers)، يُمكن أيضاً عمل الأمر بإستعمال الأحداث (events) و المُتسمعات (listeners) أدعوك للإطلاع على هاذين الأمر و عمل ما تريد القيام به بإستعمال هاتين الطريقتين للتوسع أكثر و التمرن.1 نقطة