

سنتعرف في هذا الفصل إلى طريقة تتبع أداء الاستعلامات في Postgres، وذلك لمعرفة الزمن المتوقع والحقيقي للاستعلام، كما يذكر كيفية عمل قيود على استخدام الفهارس، ثم سنتطرق لفهم ذاكرة التخزين المؤقتة Cache في Postgres.
خطة التنفيذ (Execution plan)
لدى Postgres قدرة كبيرة على إظهار كيفية تنفيذ الاستعلامات خلف الكواليس، وهذا ما يُسمى بخطة التنفيذ ونستخدم لإظهار ذلك التعليمة explain، وإن فهمك لهذه المعلومات يساعدك في تحسين قاعدة بياناتك باستخدام الفهارس لرفع الكفاءة.
سننشئ جدولًا صغيرًا لنقوم عليه ببعض التجارب:
hsoubguide=# CREATE TABLE test_explain(msg varchar(20)); CREATE TABLE
جميع الاستعلامات في Postgres يكون لها خطة تنفيذ عندما يتم تنفيذها، وهناك ثلاث أشكال لتنفيذ التعليمة explain كما يلي:
-
الشكل العام: باستخدام
EXPLAIN، يقوم بعرض توقّع لما سيحدث تقريبًا، دون أن يتم التنفيذ الفعلي للتعليمة
hsoubguide=# EXPLAIN INSERT INTO test_explain(msg) VALUES('Hsoub');
QUERY PLAN
-----------------------------------------------------------
Insert on test_explain (cost=0.00..0.01 rows=1 width=58)
-> Result (cost=0.00..0.01 rows=1 width=58)
(2 rows)
hsoubguide=# SELECT * FROM test_explain ;
msg
-----
(0 rows)
-
الشكل التحليلي: باستخدام
EXPLAIN ANALYZE، يقوم بتنفيذ الاستعلام ثم يعرض شرحًا لما حدث خلال التنفيذ.
hsoubguide=# EXPLAIN ANALYZE INSERT INTO test_explain(msg) VALUES('Hsoub');
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Insert on test_explain (cost=0.00..0.01 rows=1 width=58) (actual time=0.898..0.898 rows=0 loops=1)
-> Result (cost=0.00..0.01 rows=1 width=58) (actual time=0.003..0.004 rows=1 loops=1)
Planning Time: 0.067 ms
Execution Time: 0.952 ms
(4 rows)
hsoubguide=# SELECT * FROM test_explain ;
msg
-------
Hsoub
(1 row)
-
الشكل المستفيض (verbose)، يزيد عن الشكل التحليلي بالقليل من المعلومات، وهنا يمكن استخدام
EXPLAIN VERBOSEللشرح دون التنفيذ:
hsoubguide=# EXPLAIN VERBOSE INSERT INTO test_explain(msg) VALUES('Hsoub2');
QUERY PLAN
------------------------------------------------------------------
Insert on public.test_explain (cost=0.00..0.01 rows=1 width=58)
-> Result (cost=0.00..0.01 rows=1 width=58)
Output: 'Hsoub2'::character varying(20)
(3 rows)
hsoubguide=# SELECT * FROM test_explain ; msg ------- Hsoub (1 row)
أو استخدام EXPLAIN ANALYZE VERBOSE للشرح المستفيض مع التنفيذ:
hsoubguide=# EXPLAIN ANALYZE VERBOSE INSERT INTO test_explain(msg) VALUES('Hsoub2');
QUERY PLAN
------------------------------------------------------------------------------------------------------------
Insert on public.test_explain (cost=0.00..0.01 rows=1 width=58) (actual time=0.044..0.045 rows=0 loops=1)
-> Result (cost=0.00..0.01 rows=1 width=58) (actual time=0.003..0.004 rows=1 loops=1)
Output: 'Hsoub2'::character varying(20)
Planning Time: 0.074 ms
Execution Time: 0.086 ms
(5 rows)
hsoubguide=# SELECT * FROM test_explain ; msg ------- Hsoub Hsoub2 (2 rows)
غالبًا يتم استخدام التعليمة explain مع عبارات SELECT، إلا أنه يمكن استخدامها أيضًا مع التعليمات:
-
INSERT -
UPDATE -
DELETE -
EXECUTE -
DECLARE
استخدام التعليمة Explain لشرح الاستعلامات
نستعلم في المثال التالي عن الأسماء الأخيرة للموظفين ذوي الرواتب التي تبدأ من 50000 فما فوق، كما يلي:
hsoubguide=# SELECT last_name FROM employees WHERE salary >= 50000; last_name ----------- Adams Smith (2 rows)
يمكننا تفحّص كيفية قيام Postgres بتنفيذ الاستعلام السابق كما يلي:
hsoubguide=# EXPLAIN SELECT last_name FROM employees WHERE salary >= 50000;
QUERY PLAN
-----------------------------------------------------------
Seq Scan on employees (cost=0.00..1.06 rows=2 width=128)
Filter: (salary >= 50000)
(2 rows)
كما يمكن فهم أداء تنفيذ الاستعلام الحقيقي عن طريق ANALYZE كما يلي:
hsoubguide=# EXPLAIN ANALYZE SELECT last_name FROM employees WHERE salary >= 50000;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on employees (cost=0.00..1.06 rows=2 width=128) (actual time=0.032..0.036 rows=2 loops=1)
Filter: (salary >= 50000)
Rows Removed by Filter: 3
Planning Time: 0.142 ms
Execution Time: 0.084 ms
(5 rows)
فهم خطط التنفيذ
إن نفّذنا التعليمة EXPLAIN ANALYZE على جدول مشابه للجدول السابق ولكن مع احتوائه على مليوني سطر، يمكن أن نحصل على المخرجات التالية:

تَوضّح الصورة التالية معاني هذه الأرقام المكتوبة كما يلي:

تشير الكلمة Seq Scan إلى أن عملية البحث التي تجري هي البحث التسلسلي. أما العبارة التالية:
(cost=0.00..35811.00 rows=1 width=6)
فهي التقدير التقريبي (وليس الحقيقي) لما يُتوقّع أن يستغرقه تنفيذ الاستعلام، حيث يعبر الزمن 0.00 عن الزمن اللازم لبدء الاستعلام، والزمن 35811.00 هو الزمن المتوقع لإنهاء الاستعلام، أما القيمة rows=1 هي عدد الأسطر التي يُتوقّع أن تُعطى في المخرجات، والقيمة width=6 هي الحجم التقريبي لمحتوى الأسطر التي يُتوقع أن تُعطى في المخرجات.
ولأننا قُمنا بتنفيذ التعليمة EXPLAIN ANALYZE فإننا لم نحصل فقط على التقدير المتوقع للتنفيذ، بل على الوقت الحقيقي المستغرق كذلك كما تبيّن الصورة التالية:

يُمكننا بذلك رؤية الوقت الكبير المستهلك في المسح المتتالي، وسنقارنه مع الوقت المستغرق عند إضافة فهرس واختبار النتائج:
CREATE INDEX idx_emps on employees (salary);
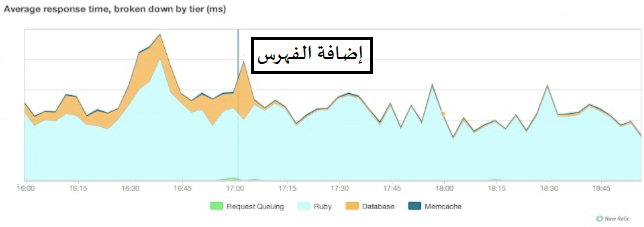
وبذلك خفضنا زمن الاستعلام من 295 ميللي ثانية إلى 1.7 ميللي ثانية فقط كما يوضح الشكل التالي:

كانت هذه مقدمة في استخدام التعليمة EXPLAIN ولا بد أن تجربها على استعلامات أكبر حجمًا لاستكشاف ما يمكنها إظهاره.
قيود شرطية على إنشاء الفهارس
قد نحتاج أحيانًا إلى وضع بعض القيود على البيانات التي نرغب بالفعل في فهرستها، فمثلًا قد لا نرغب بحذف مستخدم ما من قاعدة البيانات ولكن نريد أن نظهره على أنه محذوف بحيث يمكن إرجاع بياناته لو أراد العودة للموقع بعد شهر مثلًا، ولكن في الوقت نفسه لا نريد أن يزداد حجم البيانات التي نقوم بفهرستها، ولذلك نستخدم الفهارس الجزئية.
سنستخدم الفهارس الجزئية في المثال التالي لوضع فهرس فريد فقط للمستخدمين غير المحذوفين:
CREATE UNIQUE INDEX user_email ON users (email) WHERE deleted_at IS NULL;
ذاكرة التخزين المؤقتة (Cache)
إن معظم التطبيقات تتعامل مع جزء صغير من البيانات بشكل متكرر، ومثل العديد من الأمور الأخرى فإن البيانات يمكن أن تتبع قاعدة 80/20 حيث أن 20% من البيانات هي التي يتم قراءتها في 80% من الحالات، وأحيانا يكون هذا الرقم أكبر من ذلك.
تقوم Postgres بتتبع أنماط استخدامك للبيانات وتحاول الإبقاء على البيانات الأكثر وصولًا في ذاكرة التخزين المؤقتة.
عمومًا، سترغب في أن يكون نسبة نجاح الوصول إلى ذاكرة التخزين المؤقتة هي 99%، ويمكنك معرفة هذه النسبة باستخدام التعليمات التالية:
SELECT
sum(heap_blks_read) as heap_read,
sum(heap_blks_hit) as heap_hit,
(sum(heap_blks_hit) - sum(heap_blks_read)) / sum(heap_blks_hit) as ratio
FROM
pg_statio_user_tables;
إن وجدت أن نسبة نجاح الوصول إلى التخزين المؤقتة عندك أخفض من 99% بشكل كبير، فربما يتوجب عليك زيادة حجمها المخصص لقاعدة البيانات.
فهم استخدام الفهارس
تُعد الفهارس الطريقة الأساسية الأخرى لزيادة كفاءة قاعدة البيانات، حيث تضيف العديد من بيئات العمل الفهارس إلى المفاتيح الرئيسية في الجداول، ولكن إن كنت تُجري عمليات البحث على حقول أخرى أو تقوم بالربط بين الجداول فربما عليك إضافة الفهارس يدويًّا إلى هذه الأعمدة.
الفهارس هي الأهم في الجداول الكبيرة، فرغم أن الوصول إلى الجداول في ذاكرة التخزين المؤقتة أسرع من الوصول إليها على القرص الصلب، إلا أنه حتى البيانات فيها يمكن أن تكون بطيئة إن كان يتوجب على Postgres أن تحلل مئات آلاف الأسطر لمعرفة إن كانت تحقق شرطًا ما.
يمكنك استخدام التعليمة التالية لتوليد قائمة بالجداول مع النسبة المئوية لاستخدام الفهارس فيها:
SELECT
relname, 100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM
pg_stat_user_tables
WHERE
seq_scan + idx_scan \> 0
ORDER BY
n_live_tup DESC;
إن لم تكن قريبًا من النسبة 99% في الجداول التي تحوي 10 آلاف سطرًا فأكثر، فربما يجب عليك إضافة المزيد من الفهارس، ولكن عليك معرفة العمود المناسب الذي يجب اعتباره فهرسًا، وذلك عن طريق معرفة نوع الاستعلامات التي تتم على الجداول.
عمومًا، قد يكون من المناسب وضع الأعمدة التي تحوي المعرّفات ID أو على الأعمدة تقوم بالتصفية على أساسها غالبًا مثل created_at.
نصيحة احترافية: إن كنت تضيف فهرسًا في قاعدة بيانات قيد العمل استخدم CREATE INDEX CONCURRENTLY لتقوم ببناء الفهرس في الخلفية دون أن يتم قفل الجدول ومنع الاستعلامات عليه.
يمكن أن يستغرق الإنشاء الآني للفهارس 2-3 أضعاف الوقت المستغرق في العادة، ولا يمكن تنفيذها على دفعات، ولكن هذه المقايضة بين الوقت وتجربة المستخدم تستحق ذلك، فلا شك أنك لا تريد توقّف الموقع الخاص بك كلما قمت بإنشاء فهرس جديد في جدول كبير الحجم.
مثال باستخدام بيانات حقيقية
عند النظر إلى بيانات حقيقية من واجهة Heroku التي تم إطلاقها مؤخرًا، يمكن تنفيذ الاستعلام التالي ورؤية النتائج كما يلي:
SELECT relname,
100 * idx_scan / (seq_scan + idx_scan) percent_of_times_index_used,
n_live_tup rows_in_table
FROM pg_stat_user_tables
ORDER BY n_live_tup DESC;
relname | percent_of_times_index_used | rows_in_table
---------------------+-----------------------------+---------------
events | 0 | 669917
app_infos_user_info | 0 | 198218
app_infos | 50 | 175640
user_info | 3 | 46718
rollouts | 0 | 34078 favorites | 0 | 3059
schema_migrations | 0 | 2
authorizations | 0 | 0
delayed_jobs | 23 | 0
يمكننا أن نرى أن جدول events فيه 700 ألف سطرًا تقريبًا وليس فيه فهارس تم استخدامها، ومن هنا يمكننا التحقق ضمن تطبيقنا لنرى بعض الاستعلامات الشائعة التي تُستخدم، وأحد هذه الأمثلة هو جلب الأحداث لمدوّنة ما.
يمكنك أن ترى خطة التنفيذ باستخدام التعليمة EXPLAIN ANALYZE التي تعطيك فكرة أفضل عن الاستعلام:
EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; QUERY PLAN ------------------------------------------------------------------- Seq Scan on events (cost=0.00..63749.03 rows=38 width=688) (actual time=2.538..660.785 rows=89 loops=1) Filter: (app_info_id = 7559) Total runtime: 660.885 ms
وبما أن طريقة البحث ضمن هذا الجدول هي المسح التسلسلي، فيمكننا تحسين ذلك باستخدام فهرس، وسنضيف الفهرس الخاص بنا آنيًّا لمنع قفل الجدول، ثم سنرى كيف تتغير كفاءة الجدول:
CREATE INDEX CONCURRENTLY idx_events_app_info_id ON events(app_info_id); EXPLAIN ANALYZE SELECT * FROM events WHERE app_info_id = 7559; ---------------------------------------------------------------------- Index Scan using idx_events_app_info_id on events (cost=0.00..23.40 rows=38 width=688) (actual time=0.021..0.115 rows=89 loops=1) : Index Cond: (app_info_id = 7559) Total runtime: 0.200 ms
يتضح من التعليمة السابقة التحسن الذي أدى إليه استخدام الفهرس، ولكن يمكننا أيضًا أن نحلل النتيجة باستخدام الإضافة New Relic لنرى أننا خفّضنا بشكل كبير من الوقت المستغرق في المعالجة لقاعدة البيانات بإضافة هذا الفهرس وفهارس أخرى.
معدل نجاح الوصول إلى الفهارس في ذاكرة التخزين المؤقت
أخيرًا لدمج الأمرين معًا، فيمكنك استخدام التعليمة التالية في حال كنت ترغب بمعرفة معدل نجاح الوصول إلى الفهارس المخزنة ضمن ذاكرة التخزين المؤقت:
SELECT
sum(idx_blks_read) as idx_read,
sum(idx_blks_hit) as idx_hit,
(sum(idx_blks_hit) - sum(idx_blks_read)) / sum(idx_blks_hit) as ratio
FROM
pg_statio_user_indexes;
عمومًا يمكنك أن تتوقع أن يكون هذا المعدل بقيمة 99% بشكل مشابه لمعدل نجاح الوصول إلى الكاش المعتاد.
خلاصة
تعرفنا في هذا الفصل إلى طريقة تتبع أداء الاستعلامات في Postgres عن طريق التعليمة EXPLAIN، كما عرفنا أهمية ذاكرة التخزين المؤقتة Cache في Postgres، ويُعد هذا الفصل خطوتك الأولى في إدارة الأداء عمومًا أثناء عملك مع قواعد بيانات Postgres.
اقرأ أيضًا
- المقال التالي: أوامر متقدمة في صدفة psql
- المقال السابق: أساسيات إدارة الذاكرة في قواعد بيانات Postgres
- النسخة الكاملة من كتاب الدليل العملي إلى قواعد بيانات PostgreSQL
- كيف تنقل مجلد البيانات في PostgreSQL إلى مسار مختلف في خادم أوبنتو











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.